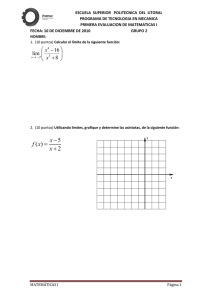
Tema 2 : Conceptes bàsics de la teoria de la
informació
Dept. Enginyeria de la Informació i de les Comunicacions
Escola d’Enginyeria, UAB
Informació i Seguretat, 2017-2018
dEIC. 2017-2018. cb ea
1 / 32
Contingut
Mesura de la Informació.
Model de Shannon de font discreta sense memòria.
Entropia d’una variable aleatòria discreta.
Informació mútua entre dues v.a. discretes. Capacitat d’un canal.
dEIC. 2017-2018. cb ea
2 / 32
Mesura de la informació
Considerem la incertesa com la falta de certesa davant d’una
determinada situació o un experiment,
I
que no s’ha realitzat anteriorment, o
I
amb resultats de caràcter aleatori.
La quantitat d’informació que obtenim després de realitzar
l’experiment és igual a la quantitat d’incertesa abans de
realitzar-ho.
Quin resultat dóna més informació?
I
I
5 a un dau (perfecte) o + a una moneda (perfecta)?
Més possibilitats → més informació.
c o + a una moneda amb p(c) = 0.9 i p(+) = 0.1?
Més improbable → més informació.
dEIC. 2017-2018. cb ea
3 / 32
La funció incertesa/informació
Diem I(n) a la incertesa sobre n resultats possibles i equiprobables.
Requisits per a la funció d’incertesa:
1. I(1) = 0, i I(n) < I(n + 1), ∀n ∈ N,
2. I(nm) = I(n) + I(m), ∀n, m ∈ N,
3. I(nk ) = k · I(n), ∀n, k ∈ N.
dEIC. 2017-2018. cb ea
4 / 32
Mesura de Hartley
L’any 1928, Hartley va proposar I(n) = log n, que compleix els
requisits anteriors.
I(n)
2
I(n) = log n
1
1
2
3
4
5
n
Problema: No es tenen en compte les probabilitats de cada
resultat!
dEIC. 2017-2018. cb ea
5 / 32
Mesura de Hartley -> Mesura de Shannon
Els esdeveniments menys probables donen més informació, per
tant, la informació ha de créixer respecte a la inversa de les
1
probabilitats, és a dir, I(A) = f ( p(A)
) on f és una funció creixent
i A un esdeveniment amb probabilitat p(A).
L’any 1948, C.E. Shannon proposa com a mesura de la
incertesa/informació d’un esdeveniment A amb probabilitat p(A):
1
I(A) = log p(A)
= − log p(A)
dEIC. 2017-2018. cb ea
6 / 32
Mesura de Shannon
I(A)
1
I(A) = log p(A)
1
1
p(A)
Aquesta definició compleix els requisits per a una mesura de la
incertesa i coincideix amb la mesura de Hartley si els
esdeveniments són equiprobables.
dEIC. 2017-2018. cb ea
7 / 32
Informació d’una font
Si una font d’informació (computador, imatge, texte,...) produeix
símbols a1 , a2 , . . . , an , amb probabilitats p(a1 ), p(a2 ), . . . , p(an ),
les informacions associades a aquests símbols dependran de la seva
probabilitat.
La informació de la font serà la mitjana ponderada (esperança
matemàtica) de la informació de tots els símbols:
n
X
p(ai )I(ai ) =
i=1
n
X
p(ai ) log
i=1
1
.
p(ai )
També és la incertesa mitjana que tenim sobre el resultat.
dEIC. 2017-2018. cb ea
8 / 32
Exemple
S = {c, +} amb p(c) = 0.9 i p(+) = 0.1.
I(c) = − log2 0.9 = 0.15 i I(+) = − log2 0.1 = 3.32.
Informació de la font:
p(c)I(c) + p(+)I(+) = −p(c) log2 p(c) − p(+) log2 p(+) =
−0.9 · (−0.15) − 0.1 · (−3.32) = 0.47
La incertesa mitjana (a priori) és igual a la informacio promig (a
posteriori).
dEIC. 2017-2018. cb ea
9 / 32
Unitats de mesura de la informació
I
La unitat d’informació més petita, que anomenarem bit, serà
la informació associada a dos esdeveniment equiprobables
a1 , a2 (p(a1 ) = p(a2 ) = 12 ):
1 = p(a1 ) logx
1
1
1
+ p(a2 ) logx
= 2 logx 2
p(a1 )
p(a2 )
2
logx 2 = 1 =⇒ x = 2.
Quan volem la informació mesurada en bits, fem servir log2 ().
I
I
Si la base és 10. La unitat s’anomena dit (o Hartley) i és el
grau d’incertesa corresponent a 10 esdeveniments possibles i
equiprobables.
Si la base és el número e (cas continu), la unitat de mesura
s’anomena nat.
dEIC. 2017-2018. cb ea
10 / 32
Font discreta sense memòria
Seguint el model de Shannon, podem pensar en una font discreta
sense memòria com un espai mostral i una variable aleatòria
discreta que assigna a cada missatge la seva informació.
Emissor
X
{I(a1 ), I(a2 ), . . . , I(an )}
Exemple
I
I
Una moneda amb p(c) = 0.6. Aleshores, S = {c, +},
X(c) = I(c) = − log2 (0.6) i X(+) = I(+) = − log2 (0.4).
Tenim tres ciutats, S = {A, B, C}, amb probabilitat de
trobar-nos a cada ciutat { 12 , 14 , 14 }. Aleshores X(A) = 1,
X(B) = X(C) = 2.
dEIC. 2017-2018. cb ea
11 / 32
Incertesa de la font
La incertesa o informació mitjana que ens dóna la font serà la
mitjana de les informacions, o sigui, l’esperança matemàtica de la
variable aleatòria X.
Exemple 1
Quina informació ens dóna un dau perfecte?
S = {1, 2, 3, 4, 5, 6}, amb pi = 16 , ∀i. Aleshores la informació que
P
ens dóna un dau és E[X] = 6i=1 16 log2 (6) = log2 (6) = 2.58 bits.
Si no es diu el contrari, la informació sempre es dóna en bits i, per
tant, la base del logaritme és 2.
dEIC. 2017-2018. cb ea
12 / 32
Incertesa de la font 2
Exemple 2
Quina informació ens dóna una moneda amb p(+) = 0.3?
S = {c, +} i la informació de la moneda és
E[X] = −0.3 log 0.3 − 0.7 log 0.7 = 0.88 bits.
dEIC. 2017-2018. cb ea
13 / 32
Definició d’entropia d’una v.a. discreta
Definició
Sigui X una v.a. discreta
Pnamb distribució de probabilitats
{p1 , . . . , pn }, (pi > 0, i=1 pi = 1). Aleshores, l’entropia de X és
H(X) = −
i=1 pi log pi
Pn
(mesurada en bits/resultat o bits/missatge, prenent els logaritmes
en base 2). Si admetèssim probabilitats nul·les, hauríem d’acceptar
“0 · log 0 = 0”.
Notació
H(X) = H(S) = H(p1 , . . . , pn ).
dEIC. 2017-2018. cb ea
14 / 32
Exemples d’entropia
L’entropia pot mesurar diferents aspectes d’X: incertesa,
informació i aleatorietat.
Exemples
1. Sigui S = {a1 , a2 , a3 } amb probabilitats p1 = 12 , p2 = p3 = 14 .
Quant val l’entropia?
2. Tenim dues monedes X, Y , aparentment iguals. Sabem que
H(X) = 1 i H(Y ) = 0.88. Què podem assegurar sobre la
qualitat de les dues monedes?
3. Estem en una ciutat A amb probabilitat 12 , en una ciutat B
amb probabilitat 14 i en una ciutat C amb probabilitat 14 .
Quin es el nombre de preguntes (amb resposta SI/NO) que
hem de fer, de mitjana, per saber on estem?
dEIC. 2017-2018. cb ea
15 / 32
Teorema fonamental de l’entropia
Proposició
Sigui X una v.a. discreta amb distribució de probabilitats
{p1 , . . . , pn }, aleshores
1. H(X) ≥ 0,
2. H(X) = 0 si i només si existeix un i tal que pi = 1.
Teorema fonamental de l’entropia
Sigui X una v.a. discreta amb distribució de probabilitats
{p1 , . . . , pn } aleshores
1. H(X) ≤ log n,
2. H(X) = log n si i només si pi = n1 , ∀i.
H(p1 , . . . , pn ) ≤ H n1 , . . . , n1 . L’entropia d’una v.a. és màxima
quan la distribució de probabilitats és equiprobable.
dEIC. 2017-2018. cb ea
16 / 32
Entropia binària
És especialment interessant el cas de l’entropia binària; per
exemple, l’entropia d’una font que emet zeros i uns.
S = {a1 , a2 }, p(a1 ) = p, p(a2 ) = 1 − p.
H(X) = H(p, 1 − p) = −p log p − (1 − p) log(1 − p)
Es pot veure com una funció d’una variable:
H(p)
1
1
p
1
H(p) = p log p1 + (1 − p) log
1−p
Mínim i màxim: H(1, 0) = H(0, 1) = 0; H
dEIC. 2017-2018. cb ea
1 1
2, 2
= log 2 = 1.
17 / 32
Canal discret sense memòria
Soroll
Font
Emissor
Canal
Receptor
Missatge
Destí
Missatge
En un esquema d’un sistema comunicació on tenim un canal amb
soroll, el missatge de sortida del canal no sempre coincideix amb el
missatge d’entrada.
X
x1
x2
..
.
xn
dEIC. 2017-2018. cb ea
Canal
Y
y1
y2
..
.
ym
18 / 32
Exemple de canal amb soroll
BSC: Canal binari i simètric
X
0•
Y
•0
1−p
p
X = {x0 = 0, x1 = 1}
Y = {y0 = 0, y1 = 1}
p
1•
1−p
•1
p és la probabilitat d’error al bit (0 ≤ p ≤ 12 ).
Les probabilitats condicionades, p(y0 |x0 ) = p(y1 |x1 ) = 1 − p i
p(y1 |x0 ) = p(y0 |x1 ) = p, determinen la matriu del canal,
p(yj |xi )
x0
x1
y0
1−p
p
dEIC. 2017-2018. cb ea
y1
p
1−p
19 / 32
Entropia conjunta entre dues v.a. discretes
Suposem que X i Y son v.a. discretes que representen l’entrada i
la sortida d’un canal i poden prendre valors a S = {x1 , . . . , xn } i
R = {y1 , . . . , ym }, respectivament.
(X, Y ) es una v.a. bidimensional que pot prendre valors a
S × R = {(xi , yj )|i = 1, . . . , n; j = 1, . . . , m},
amb distribució de probabilitats
{p(xi , yj )|i = 1, . . . , n; j = 1, . . . , m},
on p(xi , yj ) = p(X = xi ∩ Y = yj ). Aleshores,
H(X, Y ) = −
n X
m
X
p(xi , yj ) log p(xi , yj ).
i=1 j=1
dEIC. 2017-2018. cb ea
20 / 32
Entropia condicionada d’X donat Y = y
Fixant un valor yj de la v.a. Y , (X|Y = yj ) és una v.a. que pot
prendre valors a S amb distribució de probabilitats
{p(xi |yj )|i = 1, . . . , n}. Aleshores,
H(X|Y = yj ) = −
n
X
p(xi |yj ) log p(xi |yj ).
i=1
Similarment,
H(Y |X = xi ) = −
m
X
p(yj |xi ) log p(yj |xi ).
j=1
Ens interessa calcular la mitjana de H(X|Y = yj ), per a tots els
yj .
dEIC. 2017-2018. cb ea
21 / 32
Exemple d’entropia condicionada d’Y donat X = x
Considerem un canal BSC amb probabilitat d’error p.
X
0•
1−p
Y
•0
X = {x0 = 0, x1 = 1}
Y = {y0 = 0, y1 = 1}
•1
Matriu
del canal:
1−p
p
.
p
1−p
p
p
1•
1−p
H(Y |X = 0) = −p(y0 |x0 ) log p(y0 |x0 ) − p(y1 |x0 ) log p(y1 |x0 ) =
= −(1 − p) log(1 − p) − p log p = H(p).
De la mateixa manera, H(Y |X = 1) = H(p).
dEIC. 2017-2018. cb ea
22 / 32
Entropia condicionada d’X donat Y
La incertesa que tenim respecte a l’entrada sabent la sortida serà
(entropia condicionada d’X, donat Y ):
H(X|Y ) =
m
X
n X
m
X
p(yj )H(X|Y = yj ) = −
p(xi , yj ) log p(xi |yj ).
j=1
i=1 j=1
Similarment, la incertesa respecte a la sortida sabent l’entrada és
(entropia condicionada d’Y , donat X):
H(Y |X) =
n
X
n X
m
X
p(xi )H(Y |X = xi ) = −
p(yj , xi ) log p(yj |xi ).
i=1
i=1 j=1
Nota: (X|Y ) (similarment (Y |X)) no és una v.a.
dEIC. 2017-2018. cb ea
23 / 32
Exemple d’entropia condicionada d’Y donat X
Considerem un canal BSC amb probabilitat d’error p.
X
0•
1−p
Y
•0
X = {x0 = 0, x1 = 1}
Y = {y0 = 0, y1 = 1}
•1
Matriu
del canal:
1−p
p
.
p
1−p
p
p
1•
1−p
Suposem que p(x0 ) = α i p(x1 ) = 1 − α. Aleshores,
H(Y |X) = p(x0 )H(Y |X = x0 ) + p(x1 )H(Y |X = x1 ) =
= αH(p) + (1 − α)H(p) = H(p).
dEIC. 2017-2018. cb ea
24 / 32
Propietats de l’entropia condicionada
Proposició
Siguin X i Y dues v.a. discretes. Aleshores
1. H(X, Y ) = H(X) + H(Y |X) = H(Y ) + H(X|Y ).
2. H(X, Y ) ≤ H(X) + H(Y ), amb igualtat si i només si X i Y
són independents.
3. H(X|Y ) ≤ H(X), H(Y |X) ≤ H(Y ); amb igualtat si i només
si X i Y són independents.
4. H(X) − H(X|Y ) = H(Y ) − H(Y |X).
Definició
La informació mútua entre dues v.a. discretes X i Y és
I(X, Y ) = H(X) − H(X|Y ) = H(Y ) − H(Y |X).
dEIC. 2017-2018. cb ea
25 / 32
Propietats de la informació mútua
Proposició
I(X, Y ) ≥ 0. I(X, Y ) = 0 si i només X i Y són independents.
Exemple
Tenim dues monedes, una d’elles amb dues cares. En triem
aleatòriament una i la llencem dos cops. Quina informació ens
dóna el resultat respecte a la moneda triada?
dEIC. 2017-2018. cb ea
26 / 32
Canals discrets sense memòria
Un canal discret i sense memòria queda definit per:
1. Un conjunt d’entrades, A = {A1 , . . . , An }, amb {p(Ai )}ni=1
(distribució inicial),
2. un conjunt de sortides, B = {B1 , . . . , Bm }, amb {p(Bj )}m
j=1
(distribució final), i
3. un conjunt de probabilitats condicionades:
{p(Bj |Ai )|i = 1, . . . , n; j = 1, . . . , m}.
Matriu del canal:
Els valors p(Bj |Ai ) són con
stants que depenen del canal
p(B1 |A1 ) · · · p(Bm |A1 )
..
..
(de fet, del soroll del canal). El
.
···
.
conjunt de probabilitats és una
p(B1 |An ) · · · p(Bm |An )
característica del canal.
dEIC. 2017-2018. cb ea
27 / 32
Recordem que la informació mútua entre la entrada i la sortida del
canal és
I(A, B) = H(A) − H(A|B) = H(B) − H(B|A),
que representa la mitjana d’informació rebuda sobre l’entrada, un
cop coneguda la sortida, on
H(A)
=
−
n
X
p(Ai ) log p(Ai );
H(B) = −
i=1
H(B|A)
=
−
n X
m
X
m
X
p(Bj ) log p(Bj )
j=1
p(Ai , Bj ) log(p(Bj |Ai ))
i=1 j=1
H(A|B)
=
−
n X
m
X
p(Ai , Bj ) log(p(Ai |Bj ))
i=1 j=1
p(Ai , Bj )
p(Bj )
=
=
p(Ai )p(Bj |Ai );
n
X
p(Ai |Bj ) =
p(Ai )p(Bj |Ai )
;
p(Bj )
p(Bj |Ai )p(Ai ).
i=1
dEIC. 2017-2018. cb ea
28 / 32
Capacitat d’un canal
{p(Bj |Ai )|i = 1, . . . , n; j = 1, . . . , m} és una característica del
canal i, per tant, I(A, B) només depèn de la distribució inicial
{p(Ai )}ni=1 .
Podem modificar la distribució inicial per adaptar la font al canal
per tal de maximitzar el rendiment del canal, és a dir, que la
informació mútua I(A, B) sigui màxima.
Diem I(p1 , . . . , pn ) = I(A, B), on pi = p(Ai ).
La capacitat del canal és: C = max{pi ,i=1,...,n} I(p1 , ..., pn ), on
1. 0 ≤ pi ≤ 1, ∀i = 1, . . . , n, i
Pn
2.
i=1 pi = 1.
dEIC. 2017-2018. cb ea
29 / 32
Exemple de càlcul de la capacitat d’un canal
Considerem un canal BSC amb probabilitat d’error p.
X
0•
Y
•0
1−p
p
p
1•
1−p
•1
X = {x0 = 0, x1 = 1}
Y = {y0 = 0, y1 = 1}
Matriu
del canal:
1−p
p
,
p
1−p
p(x0 ) = α, p(x1 ) = 1 − α.
Sabem que H(Y |X) = H(p)
dEIC. 2017-2018. cb ea
30 / 32
Exemple de càlcul de la capacitat d’un canal (cont.)
I(X, Y ) = H(Y ) − H(Y |X) = H(Y ) − H(p).
H(Y ) = −p(y0 ) log p(y0 ) − p(y1 ) log p(y1 ) ≤ 1.
C = maxα I(X, Y ) = maxα H(Y ) − H(p) ≤ 1 − H(p).
p(y0 ) = p(x0 )p(y0 |x0 ) + p(x1 )p(y0 |x1 ) = (1 − p)α + p(1 − α),
p(y1 ) = p(x0 )p(y1 |x0 ) + p(x1 )p(y1 |x1 ) = pα + (1 − p)(1 − α).
Si α =
1
2
aleshores p(y0 ) = p(y1 ) =
dEIC. 2017-2018. cb ea
1
2
i C = 1 − H(p).
31 / 32
Interpretació de la capacitat d’un canal
I
I
I
La capacitat indica la quantitat màxima d’informació que pot
passar per símbol d’entrada. Igual que l’entropia i la
informació mútua, la unitat seran els bits/símbol o
bits/entrada.
Si un canal, físicament, deixa passar k símbols/segon, llavors
la velocitat màxima de transmissió d’informació pel canal és
kC bits/segon.
Per a un canal gaussià, la velocitat màxima, en bits
d’informació per segon, és C = W log(1 + S/N ), on W és
l’amplada de banda, S és la potència del senyal i N és la
potència del soroll (variança). S/N s’anomena la relació
senyal-soroll (SNR) i 10 log10 (S/N ) és la mateixa relació
expressada en dB.
dEIC. 2017-2018. cbe a
32 / 32