Formulario. Estadística Administrativa
Módulo 1. Introducción al análisis estadístico
Histogramas
El número de intervalos de clase, k, se elige de tal forma que el valor
2k sea menor (pero el valor más aproximado) al número de
observaciones.
Criterio de Sturges: k= 1+3.3log(n)
Ancho de clase =
Media aritmética (media
muestral)
Media aritmética
(muestral) para datos
agrupados
fi = frecuencia absoluta de la clase i
mi= es el punto medio de la clase i
k = # Intervalos de clase
Si n es impar,
Mediana (muestral)
Si n es par,
es la observación ordenada
es el promedio las observaciones ordenadas
y
Moda (muestral)
Es el valor que más se repite
Varianza muestral
Varianza muestral para
datos agrupados
Desviación estándar
muestral
Coeficiente de variación
muestral
fi = frecuencia absoluta de la clase i
mi= es el punto medio de la clase i
k = # Intervalos de clase
Es la media muestral
agrupada
Percentil P
0< P < 100
Diagrama de caja
Es la observación ordenada
1.
2.
3.
4.
5.
Observación mínima no considerada extrema = Q1 - 1.5*fs
Primer cuartil (Percentil 25, Q1)
Mediana (Percentil 50, Q2)
Tercer cuartil (Percentil 75, Q3)
Observación máxima no considerada extrema = Q3 + 1.5*fs
Rango intercuartílico = fs= Q3 – Q1
Puntos extremos del lado izquierdo < Q1 - 1.5*fs
Puntos extremos del lado derecho > Q3 + 1.5*fs
Módulo 2. Teoría de Probabilidad
Probabilidad marginal
Regla del complemento
Probabilidad conjunta
Regla de la adición para eventos mutuamente
excluyentes
Regla de la adición para eventos con elementos
en común
Regla de la multiplicación para eventos
independientes
Regla de la multiplicación para eventos
dependientes
Probabilidad condicional para eventos
independientes
Probabilidad condicional para eventos
dependientes
Regla de producto para pares ordenados
Regla de producto para arreglos ordenados de
k elementos
Permutaciones
P(A)
P(Ac) = 1 – P(A)
P(A ∩ B)
P(A
B)= P(A) + P(B)
P(A
B) = P(A) + P(B) – P(A ∩ B)
P(A ∩ B) = P(A)P(B)
P(A ∩ B) = P(A/B)P(B)
P(A ∩ B) = P(B/A)P(A)
P(A/B) = P(A)
P(A/B) =
T = n1*n2
Tk = n1*n2*……*nk
En la selección: Importa el orden y la selección
es sin reemplazo.
Combinaciones
En la selección: No importa el orden y la
selección es sin reemplazo.
;
n
Cx
;
P(B/A) = P(B)
; P(B/A) =
Módulo 3. Modelación de mediciones aleatorias
Distribución de probabilidad de una variable
aleatoria discreta
Distribución de probabilidad acumulada de
una variable aleatoria discreta
Valor esperado de una variable aleatoria
discreta
para todos los valores de X
para todos los valores de X
donde,
Varianza de una variables aleatoria discreta
Distribución de probabilidad Binomial
X = # de éxitos en n pruebas idénticas
Valor esperado y varianza de una variable
aleatoria Binomial
Distribución de probabilidad Poisson
X = # de éxitos en un intervalo de tiempo
Valor esperado y varianza de una variable
aleatoria Poisson
Función de densidad de probabilidad
P(X = x) = nCx
Para x = 0,1,2,3,...,n
µ = E(X) = np
σ 2 = V(X) = np(1-p)
P(X = x) =
x = 0,1,2,3,………
E(X) = µ
V(X) = µ
f(x) para variables aleatorias continuas
Distribución de probabilidad acumulada de
una variable aleatoria continua
Valores esperados para variables aleatorias
continuas
donde,
Varianza de una variable aleatoria continua
Propiedades del valor esperado
Propiedad de la varianza
Función de densidad de probabilidad normal
E(aX + b) = aE(X) + b
V(aX + b) = a2V(X)
Si X ~ Normal con E(X) = µ y V(X) = σ 2
Entonces
~ Normal Estándar con
E(Z) = 0 y V(Z) = 1
Función de densidad de probabilidad de una
variable aleatoria exponencial
Función de distribución acumulada de una
variable aleatoria exponencial
para
Módulo 4. Distribuciones de muestreo y estimación de parámetros
Distribuciones de muestreo
Escenario
Estadístico Distribución
Población normal
Normal
Parámetros
y
Población desconocida
Aproximadamente
Normal
y
Aproximadamente
normal
y
Intervalos de confianza estimados de 100*(1-α)%
Escenario
Intervalo
Caso 1. Intervalo para µ
σ
x ± zα 2
Distribución poblacional de X normal
n
Varianza conocida, σ2
Caso 2. Intervalo para µ con muestras pequeñas
Distribución poblacional de X normal
Varianza desconocida
Caso 3. Intervalo para σ 2
Distribución poblacional de X normal
LIC
LSC
Caso 4. Intervalo para p
;
(Nivel de confianza aproximado)
;
Tamaños de muestra
Para estimar un intervalo para µ para el Caso 1
(Población infinita)
E = Error máximo permisible
Para estimar un intervalo para µ para el Caso 1
(Población finita)
N= Tamaño de la población
D=
Para estimar un intervalo para P para el Caso 5
E = Error máximo permisible
Módulo 5. Pruebas de hipótesis paramétricas y no paramétricas
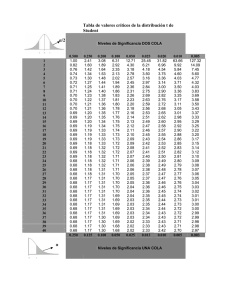
Pruebas de hipótesis con un nivel de significancia de α para una población
Escenario
Hipótesis
Estadístico
Regiones de rechazo
Caso 1. Prueba para µ
Distribución de X normal
Varianza conocida, σ2
H0 : µ = µ0
Ha : µ > µ0
Ha : µ < µ0
Ha : µ ≠ µ0
Z
z
zα
z - zα
- zα/2 ó z
zα/2
H0 : µ = µ0
Caso 2. Prueba para µ
Distribución de X normal
Varianza desconocida
Ha : µ > µ0
t
tα,n-1
Ha : µ < µ0
t
- tα, n-1
Ha : µ ≠ µ0
Caso 3. Prueba para σ 2
Distribución de X normal
Caso 4. Prueba para p
(nivel de significancia aproximado)
;
;
t
- tα/2, n-1 ó
t
tα/2, n-1
H 0 : σ2 = σ2 0
H a : σ2 > σ2 0
χ2
H a : σ2 < σ2 0
H a : σ 2 ≠ σ2 0
χ2
χ2
χ2α, n-1
χ21-α, n-1
χ21-α/2, n-1 ó χ2 >= χ2α/2, n-1
H0: p = p0
Ha: p > p0
z
zα
Ha: p < p0
z
- zα
Ha: p ≠ p0
z
- zα/2 ó
z
Pruebas de hipótesis con un nivel de significancia de α para dos poblaciones
zα/2
Escenario
Caso 1. Prueba para
µ1 − µ2
Distribuciones normales.
Varianzas conocidas (σ12,σ22)
Muestras independientes.
Hipótesis
Estadístico
Regiones de
rechazo
H0: µ1 − µ2 = Δ0
Ha: µ1 − µ2 > Δ0
Ha: µ1 − µ2 < Δ0
z
z
zα
- zα
z - zα/2 ó
z zα/2
Ha: µ1 − µ2 ≠ Δ0
Ha: µ1 − µ2 > Δ0
z
zα
Ha: µ1 − µ2 < Δ0
z
- zα
z
Ha: µ1 − µ2 ≠ Δ0
- zα/2 ó
z zα/2
Caso 2. Prueba para µ 1 − µ 2
H0: µ1 − µ2 = Δ0
Escenario 1
Distribuciones normales.
Muestras independientes.
Ha: µ1 − µ2 > Δ0
t
tα, (n + n2) -2
Ha: µ1 − µ2 < Δ0
t
- tα, (n1+ n2) -2
Varianzas desconocidas, pero
asumidas iguales.
σ1 2 = σ2 2
Escenario 2
Distribuciones normales.
Muestras independientes.
Varianzas desconocidas, pero
asumidas diferentes.
σ1 2 ≠ σ2 2
1
t - tα/2, (n1+ n2) -2
ó t tα/2,( n1+ n2) -2
Ha: µ1 − µ2 ≠ Δ0
H0: µ1 − µ2 = Δ0
Ha: µ1 − µ2 > Δ0
T
tα, ν
Ha: µ1 − µ2 < Δ0
T
- tα, ν
t - tα/2, ν
ó t tα/2,
Ha: µ1 − µ2 ≠ Δ0
Caso 3. Prueba para σ 12/σ 22
H0: σ12/σ22 = 1
Distribuciones normales
Ha: σ12/σ22 > 1
ν
ν1=n1-1
ν2=n2-1
F
Fα,ν1,ν2
Muestras independientes
Ha: σ12/σ22 < 1
F
F
Ha: σ12/σ22 ≠ 1
Donde,
Caso 4. Prueba para p1 − p 2
F1-α,ν1,ν2
F1-α/2,ν1,ν2 ó
F fα/2,ν1,ν2
y
H0: p1 − p 2 = 0
(nivel de significancia aproximado)
Escenario 1
Muestras independientes
Δ0 = 0
y
Ha: p1 − p 2 > 0
z
zα
Ha: p1 − p 2 < 0
z
- zα
Ha: p1 − p 2 ≠ 0
;
z
- zα/2 ó
z zα/2
i = 1, 2
H0: p1 − p 2 = 0
Escenario 2
Muestras independientes
Δ0 ≠ 0
y
;
Ha: p1 − p 2 > 0
z
zα
Ha: p1 − p 2 < 0
z
- zα
Ha: p1 − p 2 ≠ 0
i = 1, 2
z
- zα/2 ó
z zα/2
Valor P para una prueba Z
Valor P = 1 – P(Z < z calculada)
para una prueba de cola superior
Valor P = P(Z < - z calculada)
para una prueba de cola inferior
Valor P = 2*[1 - P(Z < |z calculada|)]
para una prueba de dos colas
Si,
Valor P
Valor P
Rechazar H0 al nivel α
No rechazar H0 al nivel α
Análisis de Varianza, ANOVA, de un factor
Hipótesis
Supuestos
Región de rechazo
H0 = µ1 = µ2 = …= µi = ... = µk
Ha = al menos dos de las µi son diferentes
Las poblaciones tienen distribuciones normales
Las poblaciones tienen desviaciones estándar poblacionales iguales.
Las muestras se seleccionan de manera independiente
Rechazar H0 si
F >= Fα, k – 1, n – k
Tabla ANOVA
Fuente de
Variación
Suma de Cuadrados
G. de L.
Entre
tratamientos
Cuadrados Medios
Estadístico
k-1
Dentro de
tratamientos
SCE = SC(Total) - SCT
Total
n-k
n-1
Donde,
Ti
ni
Es la suma total de los valores x en la muestra i
Es el número de observaciones en la muestra i
Es la suma de los valores de x en todas las muestras
Son los valores de x en todas las muestras elevados al cuadrado y luego sumados
N
K
es el número total de observaciones n = n1 + n2 + ….+ ni + … + nk
El número de niveles (poblaciones o tratamientos) del factor
Aplicaciones:
Pruebas de la bondad de ajuste
Hipótesis
Estadístico
Frecuencias esperadas
iguales o diferentes
H0: las frecuencias observadas
son iguales a las esperadas
Normalidad
Ha: Son diferentes
H0: las variables categóricas
son independientes
Tablas de contingencia
Ha: Son dependientes
k = clases o celdas
ei = n*pi
r = # renglones
c = # columnas
Regiones de
rechazo
Niveles de confianza más utilizados para estimar intervalos que involucran Z
α
α/2
1-α
z α/2
0.90
0.1
0.05
z 0.05 = 1.645
0.95
0.05
0.025
z 0.025 = 1.96
0.98
0.02
0.01
z 0.01 = 2.33
0.99
0.01
0.005
z 0.005 = 2.575
Regiones de rechazo más utilizadas para pruebas Z con un nivel de significancia de α
Prueba de cola inferior
α
z
- zα
Prueba de cola superior
z
zα
Prueba de dos colas
z
- zα ó
z
zα
0.1
-z 0.1 = -1.282
z 0.1 = 1.282
-z0.05 = -1.645 ó
z0.05 = 1.645
0.05
-z 0.05 = -1.645
z 0.05 = 1.645
-z0.025 = -1.96 ó
z0.025 = 1.96
0.02
-z 0.02 = -2.054
z 0.02 = 2.054
0.01
-z 0.01 = -2.326
z 0.01 = 2.326
-z0.01 = -2.33 ó
z0.01 = 2.33
-z0.005 = -2.575 ó z0.005 = 2.575
 0
0



![( ) ( )2 ( )[ ] ( )ξ ( ) PQ](http://s2.studylib.es/store/data/006099496_1-61f82d8b006ba0985f60bbb263d08047-300x300.png)




