Modelos lineales: ANOVA Y ANCOVA
Leonel Villacrés
Carlos Dota
Análisis de Regresión y Análisis de Anova.
El análisis de regresión se usa para explicar o modelar la relación entre una variable
continua Y, llamada variable respuesta o variable dependiente, y una o más variables
continuas X1,.....,Xp, llamadas variables explicativas o independientes. Cuando p = 1, se
denomina regresión simple y cuando p > 1 se denomina regresión múltiple. Cuando hay más
de una variable respuesta Y, entonces el análisis se denomina regresión múltiple
multivariada. Cuando las Y son totalmente independientes entre sí, entonces hacer una
regresión múltiple multivariada sería el equivalente a realizar tantas regresiones múltiples
invariadas como Y’s haya.
Si la(s) variable(s) explicativas son categóricas en vez de continuas entonces nos
enfrentamos ante un caso típico de análisis de la varianza o ANOVA (ADEVA en español). Al
igual que antes, si p = 1, el análisis se denomina ANOVA unifactorial, mientras que si p > 1
el análisis se denomina ANOVA multifactorial. Si en vez de una variable respuesta continua
tenemos dos o más Y, entonces el análisis se denomina ANOVA multivariado (MANOVA) de
uno o varios factores. Este tipo de análisis también queda fuera del ámbito de esta sesión.
Por ´ultimo, es posible que en el mismo análisis aparezcan tanto variables explicativas
continuas como categóricas, y en este caso el análisis pasaría a denominarse análisis de la
covarianza o ANCOVA. Aquí ya no haríamos distinción entre ´único o múltiple ya que este
análisis se compone siempre de, al menos, dos variables explicativas (una continua y una
categórica).
A pesar de la abundancia de terminología, todos estos modelos caen dentro de la categoría
de modelos lineales.
Aplicación de Modelos Lineales.
Aplicación de
modelos lineales
ANOVA
La(s) variable(s) independiente(s)
es/son categórica(s)
Regresión
La(s) variable(s) es/son
continua(s)
ANCOVA
Las variables independientes son
categóricas y continuas
ANOVA.
El análisis de la varianza (o ANOVA por sus siglas en inglés, Analysis of Variance) es una
técnica estadística que señala si dos variables (una independiente y otra dependiente) están
relacionadas en base a si las medias de la variable dependiente son diferentes en las
categorías o grupos de la variable independiente. Es decir, señala si las medias entre dos o
más grupos son similares o diferentes.
𝑯𝒐: 𝜇1 = 𝜇2 = 𝜇3 = 𝜇4 =. . . 𝜇𝑛
𝑯𝟏: 𝜇1 ≠ 𝜇2 = 𝜇3 = 𝜇4 =. . . 𝜇𝑛 Por lo menos una de ellas es diferente
Este contraste es fundamental en el análisis de resultados experimentales, en los que
interesa comparar los resultados de K 'tratamientos' o 'factores' con respecto a la variable
dependiente o de interés.
El Anova requiere el cumplimiento los siguientes supuestos:
Las poblaciones (distribuciones de probabilidad de la variable dependiente
correspondiente a cada factor) son normales.
Para evaluar la normalidad de un conjunto de datos tenemos los siguientes test:
Test de Kolmogorov-Smirnow
Test de Shapiro-\Wilks
El método de Anderson Darling o Ryan Joiner
Las K muestras sobre las que se aplican los tratamientos son independientes.
Las poblaciones tienen la misma varianza (homocedasticidad).
El test de Levene se usa para contrastar si k muestras tienen la misma varianza,
es decir, la homogeneidad de varianzas. Otros contrastes, como por ejemplo el
análisis de la varianza, suponen que las varianzas son iguales para todos los
grupos. De ahí la importancia de verificar con el test de Levene esa hipótesis.
Objetivo.
Comprobar si el factor X influye sobre el valor medio de Y o no, es decir,
Comprobar si se puede aceptar que:
o
H0: μ1 = μ2 = μ3 =... (es decir X no influye sobre Y), contra
o
H1: no son todas iguales (es decir, X sí influye sobre Y)
¿Cuándo usamos ANOVA?
Hay varios subtipos de ANOVA. Hoy nos centramos en ANOVA de un factor. Se le denomina
ANOVA de un factor porque a la variable independiente se le conoce como factor. Usamos
ANOVA de un factor cuando queremos saber si las medias de una variable son diferentes
entre los niveles o grupos de otra variable.
Tabla de ANOVA.
¿Cómo se interpreta el test de F y la significación?
Hemos de analizar e interpretar al aplicar ANOVA de un factor:
Significación: si es menor de 0,05 es que las dos variables están relacionadas y por
tanto que hay diferencias significativas entre los grupos
Valor de F: cuanto más alto sea F, más están relacionadas las variables, lo que
significa que las medias de la variable dependiente difieren o varían mucho entre
los grupos de la variable independiente.
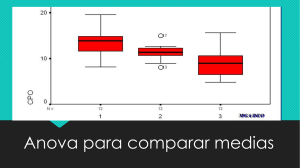
Interpretación de la Gráfica en ANOVA (Gráfica de Caja).
Una gráfica de caja proporciona un resumen gráfico de la distribución de cada muestra. La
gráfica de caja permite comparar fácilmente la forma, tendencia central y variabilidad de las
muestras.
Interpretación. Utilice una gráfica de caja para examinar la dispersión de los datos
y para identificar cualquier posible valor atípico. Las gráficas de caja funcionan
mejor cuando el tamaño de la muestra es mayor que 20.
Conclusiones.
P < Nivel de significancia Rechazar Ho
Cuando F < FTable
o
Se acepta la Ho y se rechaza la H1
Ejemplo utilizando Python 3.
1. Existen tres grupos de estudiantes (A, B y C), ¿existe diferencia
estadísticamente significativa en el promedio de edad entre los tres grupos?
Nota: Cuando se tiene más de dos grupos se debe aplicar la prueba de ANOVA.
Datos.
A
37
33
37
57
26
59
20
54
52
44
61
35
62
17
55
16
53
46
37
20
25
57
17
25
53
B
40
19
23
15
11
30
39
27
26
12
32
31
29
10
39
40
32
49
48
35
35
28
19
18
35
C
19
25
52
59
65
15
47
31
48
29
20
52
44
37
65
52
51
22
16
22
22
51
36
32
63
Resultados.
Librerías: Statsmodels y Pandas
Pandas. pandas es un paquete de Python que proporciona estructuras de datos
rápidas, flexibles y expresivas, diseñadas para que el trabajo con datos
"relacionales" o "etiquetados" sea fácil e intuitivo. Pretende ser el bloque de
construcción fundamental de alto nivel para realizar análisis de datos prácticos y
del mundo real en Python.
Statsmodels. Gráficos estadísticos.
Python.
Excel.
Hipótesis Nula: El promedio de edad en los tres grupos es igual, con un 95% de
confiabilidad
Hipótesis Alterna: en al menos un grupo, el promedio de edad es distinto, con 95%
de confiabilidad (no tenemos la suficiente evidencia para rechazar la hipótesis nula)
¿Qué grupo o que grupos son los que están haciendo la diferencia?
Se utiliza técnicas de “comparación múltiple” también llamadas, en ciertos ámbitos, pruebas
“Post hoc”, tratan de elegir una de esas muchas posibles afirmaciones que, de hecho, están
comprimidas dentro de la Hipótesis alternativa, dentro de H1.
Con estas técnicas dibujamos, perfilamos, concretamos, la forma de la H1, lo que
específicamente podemos afirmar en ella. Existen diversas técnicas de Comparaciones
múltiples:
LSD de Fisher
Bonferroni
HSD de Tuckey
Duncan
Newman-Keuls
Scheffé
Análisis de la Covarianza (ANCOVA)
El análisis de la covarianza (ANCOVA) se trata de dos o más variantes medidas y donde
cualquier variable independiente mesurable no se encuentra a niveles predeterminados.
La ANCOVA hace uso de conceptos tanto del análisis de varianza como de la regresión.
Para medir la relación entre dos variables.
Uso de análisis de covarianza
Para controlar el error y aumentar la precisión.
Ajustar medias de tratamientos de la variable dependiente a las diferencias en
conjuntos de valores de variables independientes correspondientes.
Interpretación de la naturaleza de los efectos de los tratamientos.
Dividir una covarianza total o suma de productos cruzados en componentes
La covarianza indica el sentido de la correlación entre las variables; si es positivo nos dice
que se relacionarían de forma directa y si es negativa de forma inversa.
Dónde la y con el acento es la media de la variable Y, y la x con el acento es la media de la
variable X. “i” es la posición de la observación y “n” el número total de observaciones.
Uso de Ancova
Uno de los métodos que usa la covarianza (aunque Pandas lo va a hacer solo) es el
coeficiente de correlación lineal de Pearson. Cuanto más se acerque a 1 o -1 más
correlacionadas están las variables. Su uso en Pandas es muy similar a la covarianza.
Coeficiente de correlación lineal de Pearson.
Siendo:
Cov (x;y): la covarianza entre el valor “x” e “y”.
σ(x): desviación típica de “x”.
σ(y): desviación típica de “y”
Recta de regresión lineal
Usando las funciones de varianza, media y covarianza Pandas no es muy complicado hacer
una recta de regresión
 0
0