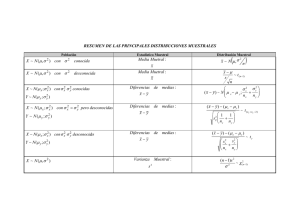
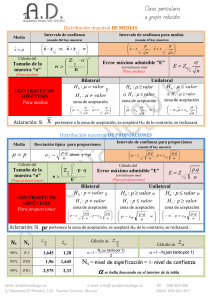
Uno de los propositos de la estadistica es extraer conclusiones
Anuncio

MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM ESTADÍSTICA INFERENCIAL PARAMÉTRICA INTRODUCCIÓN En este bloque temático lo primero que haremos será repasar de manera general la estadística inferencial ya estudiada en Estadística I. Luego desarrollaremos los temas centrales de esta unidad. El primero de ellos será distribución del estadístico proporción muestral para luego estimar el parámetro proporción poblacional (proporción de individuos con una característica particular) y realizar pruebas de hipótesis. Luego continuaremos con el tema de comparación de medias de dos poblaciones. Y finalmente estudiaremos la diferencia de proporciones de dos poblaciones. 1.1) ESTADÍSTICA INFERENCIAL Como vimos anteriormente uno de los propósitos centrales de la estadística inferencial es obtener conclusiones acerca de características de una población. Como las poblaciones son grandes y no pueden ser estudiadas en su totalidad, generalmente el estudio se basa en el examen de solo una parte de esta. Esto nos permite estimar dichos parámetros poblacionales desconocidas, examinando la información obtenida de una muestra. Esta muestra debe ser lo más representativa posible de la población y el muestreo debe ser probabilístico preferentemente. En este marco es importante mencionar que primero repasaremos nuevamente la teoría del muestreo que estudia las relaciones que existen entre la distribución de un carácter en una población y la distribución del mismo carácter en todas las muestras que tomemos de la misma. El muestreo más importante es el muestreo aleatorio, en el que todos los elementos de la población tienen la misma probabilidad de ser extraídos e incluidos en la muestra. Existen otros tipos de muestreo como el muestreo por conglomerados, sistemático y estratificado. Cuando contamos con una muestra, la aplicación de los principios de la estadística inferencial puede hacerse en forma sistemática, dividiendo el estudio en tres partes. Estas tres aéreas de la Estadística Inferencial son las distribuciones muestrales, la estimación y el contraste de hipótesis. Este apunte está organizado de manera que para cada caso, sean tratados los tres aspectos estadísticos. 1.2) Distribuciones muestrales Si las muestras obtenidas de una población son aleatorias, no se espera que dos muestras aleatorias del mismo tamaño y tomadas de la misma población sean completamente parecidas; puede esperarse que cualquier estadístico, como por ejemplo la media muestral, calculado a partir de las medias en una muestra aleatoria, cambie su valor de una muestra a otra. Por ello, lo que se busca es estudiar la distribución de todos los valores posibles de un estadístico. Es decir, como los valores de un estadístico, tal como x, varían de una muestra aleatoria a otra, se le puede considerar como una variable aleatoria con su correspondiente distribución de frecuencias. La distribución de frecuencias de un estadístico muestral se denomina distribución muestral. En general, la distribución muestral de un estadístico es la de todos sus valores posibles calculados a partir de muestras del mismo tamaño. Las distribuciones muestrales pueden construirse experimentalmente a partir de poblaciones finitas y discretas de la siguiente manera: 1 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM 1. De una población finita de tamaño N, se extraen de manera aleatoria todas las muestras posibles de tamaño n. 2. Se calcula la estadística de interés para cada muestra (media muestral, desvío estándar muestral, proporción muestral, entre otras) . 3. Se lista en una columna los distintos valores de la estadística, y en otra columna las frecuencias correspondientes de cada valor observado. Así, si se calcula la media muestral para cada muestra; la colección de todas estas medias muestrales recibe el nombre de distribución muestral de medias. Si hacemos lo mismo con las desviaciones estándares, la colección de todas estas desviaciones estándar muestrales se llama distribución muestral de la desviación estándar. Normalmente, para una distribución muestral, se tiene interés en conocer tres cosas: media, varianza y forma funcional (apariencia gráfica). 1.3) Estimación El objetivo principal de la estadística inferencial es la estimación, esto es que mediante el estudio de una muestra de una población se quiere generalizar las conclusiones al total de la misma. Existen dos tipos de estimaciones para parámetros; puntuales y por intervalo. Una estimación puntual es un único valor estadístico y se usa para estimar un parámetro. El estadístico usado se denomina estimador. Una estimación por intervalo es un rango, generalmente de ancho finito, que se espera que contenga el parámetro. Estimación Puntual La inferencia estadística está casi siempre concentrada en obtener algún tipo de conclusión acerca de uno o más parámetros (características poblacionales). Para ello se requiere datos muestrales de cada una de las poblaciones en estudio. De esta manera, las conclusiones pueden estar basadas en los valores calculados de varias cantidades muestrales. Por ejemplo, si deseamos conocer el verdadero valor de la media poblacional para un cierto carácter , se puede tomar muestras de la población y usando las medias muestrales X estimar la media poblacional. De forma similar, si 2 es la varianza de la distribución de del parámetro en la población, el valor de la varianza muestral s2 se podría utilizar para inferir algo acerca de 2. Una estimación puntual de un parámetro es un sólo número que se puede considerar como el valor más razonable de . La estimación puntual se obtiene al seleccionar una estadística apropiada y calcular su valor a partir de datos de la muestra dada. La estadística seleccionada se llama estimador puntual de . Estimación por Intervalos Debido a la variabilidad de la muestra, nunca se tendrá el caso de que = . El estimador puntual nada dice sobre lo cercano que esta de . Una alternativa para obtener un solo valor del parámetro que se esté estimando es calcular e informar todo un intervalo de valores factibles, un estimado de intervalo o intervalo de confianza (IC), en el que pueda precisarse, con una cierta probabilidad, que el verdadero valor del parámetro se encuentre dentro de esos límites. Elegiremos probabilidades cercanas a la unidad, que se representan por 1-α y cuyos valores más frecuentes suelen ser 0'90, 0'95 y 0'99. Tendremos que obtener dos estadísticos que nos darán los valores extremos del intervalo, tales que Al valor 1-α se le llama coeficiente de confianza, y al valor 100 (1-α) % se le llama nivel de confianza. 2 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Se denomina estimación confidencial o intervalo de confianza para un nivel de confianza 1α dado, a un intervalo que ha sido construido de tal manera que con frecuencia 1-α realmente contiene el parámetro Un intervalo de confianza se calcula siempre seleccionando primero un nivel de confianza, que es una medida del grado de fiabilidad en el intervalo. La probabilidad de error (no contener el parámetro) es α y la probabilidad de acierto (contener el parámetro) es 1-α. Un intervalo de confianza con un nivel de confianza de 95% podría tener un límite inferior de 9162.5 y uno superior de 9482.9. Entonces, en un nivel de confianza de 95%, es posible tener cualquier valor de entre 9162.5 y 9482.9. Un nivel de confianza de 95% (1-α= 0.95) implica que 95% de todas las muestras daría lugar a un intervalo que incluye o cualquier otro parámetro que se esté estimando, y sólo 5% (α = 0,05) de las muestras producirá un intervalo erróneo. Cuanto mayor sea el nivel de confianza podremos creer que el valor del parámetro que se estima está dentro del intervalo. Se denomina coeficiente de confianza a la probabilidad de que un estimador por intervalos cubra el verdadero valor del parámetro que se pretende estimar, se lo representa por 1-α. 1.4) Prueba de hipótesis Otra rama de la estadística inferencial recibe el nombre de Contraste de Hipótesis. En la práctica, muchas veces nos encontramos con casos en los que existe una teoría preconcebida relativa a la característica de la población en estudio. El Contraste de Hipótesis, en toda investigación, implica la existencia de dos teorías o hipótesis implícitas, que reflejan esta idea a priori que tenemos y que pretendemos contrastar con la realidad.. Este es uno de los aspectos más útiles de la inferencia estadística, puesto que muchos tipos de problemas de toma de decisiones, pruebas o experimentos en el mundo de la ingeniería, pueden formularse como problemas de prueba de hipótesis. Una hipótesis estadística es una proposición o supuesto sobre los parámetros de una o más poblaciones. Un contraste o test de hipótesis es una técnica de Inferencia Estadística que permite comprobar si la información que proporciona una muestra observada concuerda (o no) con la hipótesis estadística formulada sobre el modelo de probabilidad en estudio y, por tanto, se puede aceptar (o no) la hipótesis formulada. Una hipótesis estadística puede ser: Paramétrica: es una afirmación sobre los valores de los parámetros poblacionales desconocidos. Las hipótesis paramétricas se clasifican en: Simple: si la hipótesis asigna valores únicos a los parámetros ( = 1'5, = 10, X = Y ,...). Compuesta: si la hipótesis asigna un rango de valores a los parámetros poblacionales desconocidos ( > 1'5, 5 < < 10, X < Y ,...). No Paramétrica: es una afirmación sobre alguna característica estadística de la población en estudio. Por ejemplo, las observaciones son independientes, la distribución de la variable en estudio es normal, la distribución es simétrica,... En el contraste de hipótesis estadísticas siempre se acepta, provisionalmente, una hipótesis como verdadera, que es la hipótesis nula H0, y que es sometida a comprobación experimental frente a otra hipótesis complementaria que llamaremos hipótesis alternativa H1. Como 3 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM consecuencia de la comprobación experimental, la hipótesis nula H0 podrá seguir siendo aceptada como verdadera o, por el contrario, tendremos que rechazarla y aceptar como verdadera la hipótesis alternativa H1. Las hipótesis deben ser formuladas de tal manera que sean mutuamente excluyentes y complementarias. La especificación apropiada de la hipótesis nula y alternativa depende de la naturaleza propia del problema en cuestión. Las formas básicas de establecer las hipótesis sobre el parámetro θ son las siguientes: I H o : 0 H1 : 0 II H o : 0 H1 : 0 III H o : 0 H1 : 0 IV H o : 1 2 H1 : 1 ó >2 Es importante recordar que las hipótesis siempre son proposiciones sobre la población o distribución bajo estudio, no proposiciones sobre la muestra. Por lo general, el valor del parámetro de la población especificado en la hipótesis nula se determina en una de tres maneras diferentes: 1. Puede ser resultado de la experiencia pasada o del conocimiento del proceso, entonces el objetivo de la prueba de hipótesis usualmente es determinar si ha cambiado el valor del parámetro. 2. Puede obtenerse a partir de alguna teoría o modelo que se relaciona con el proceso bajo estudio. En este caso, el objetivo de la prueba de hipótesis es verificar la teoría o modelo. 3. Cuando el valor del parámetro proviene de consideraciones externas, tales como las especificaciones de diseño o ingeniería, o de obligaciones contractuales. En esta situación, el objetivo usual de la prueba de hipótesis es probar el cumplimiento de las especificaciones. Un procedimiento que conduce a una decisión sobre una hipótesis en particular recibe el nombre de prueba de hipótesis. Los procedimientos de prueba de hipótesis dependen del empleo de la información contenida en la muestra aleatoria de la población de interés. Si esta información es consistente con la hipótesis, se concluye que ésta es verdadera; sin embargo si esta información es inconsistente con la hipótesis, se concluye que esta es falsa. Debe hacerse hincapié en que la verdad o falsedad de una hipótesis en particular nunca puede conocerse con certidumbre, a menos que pueda examinarse a toda la población. Usualmente esto es imposible en muchas situaciones prácticas. Por tanto, es necesario desarrollar un procedimiento de prueba de hipótesis teniendo en cuenta la probabilidad de llegar a una conclusión equivocada. La hipótesis nula, representada por Ho, es la afirmación sobre una o más características de poblaciones que al inicio se supone cierta (es decir, la "creencia a priori"). La hipótesis alternativa, representada por H1, es la afirmación contradictoria a Ho, y ésta es la hipótesis del investigador. La hipótesis nula se rechaza en favor de la hipótesis alternativa, sólo si la evidencia muestral sugiere que Ho es falsa. Si la muestra no contradice decididamente a Ho, se continúa 4 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM creyendo en la validez de la hipótesis nula. Entonces, las dos conclusiones posibles de un análisis por prueba de hipótesis son rechazar Ho o no rechazar Ho. Región crítica y región de aceptación La región crítica está constituida por el conjunto de muestras para las cuales se rechaza la hipótesis nula H0. La región de aceptación está constituida por el conjunto de muestras para las cuales se acepta la hipótesis nula H0. El valor o valores que separan la región crítica de la región de aceptación reciben el nombre de valor o valores críticos. Cuando el contraste es de la forma I o IV, o sea, bilateral, estas regiones serán del tipo de las indicadas en el siguiente gráfico: Región crítica (Rechazar H 0 ) Región de aceptación (Aceptar H 0 ) Región crítica (Rechazar H 0 ) C C C |-----------------------|-----------------------------------------------------|-----------------------| ↑ ↑ |----- - - - - --Valores críticos---------------| Si el contraste es de forma II, es decir, unilateral a la izquierda, estas regiones serán del tipo de las indicadas en el siguiente gráfico: Región crítica (Rechazar H 0 ) Región de aceptación (Aceptar H 0 ) C C ← |-------------------------------------|-------------------------------------------------------| → ↑ Valor crítico Análogamente, si el contraste es de forma III, es decir, unilateral a la derecha, entonces las regiones son del tipo a las indicadas en el gráfico siguiente: Región de aceptación (Aceptar H 0 ) C Región crítica (Rechazar H 0 ) C ←|-----------------------------------------------------------------|---------------------------------|→ ↑ Valor crítico Errores de Tipo I y de Tipo II En todo problema de decisión, cuando tenemos que elegir entre varias alternativas o decisiones existe la posibilidad o riesgo de equivocarnos cometiendo los correspondientes errores. Así pues, en el contraste de hipótesis, basándonos en la información proporcionada por la muestra, tenemos que decidir si aceptamos la hipótesis nula H 0 o si la rechazamos. La decisión siempre la hacemos sobre la hipótesis nula, existiendo un riesgo de equivocarnos que nos llevará a los errores de tipo I y de tipo II. 5 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM El error tipo I se define como el rechazo de la hipótesis nula Ho cuando ésta es verdadera. También es conocido como ó nivel de significancia. Si tuviéramos un nivel de confianza del 95% entonces el nivel de significancia sería del 5%. Análogamente si se tiene un nivel de confianza del 90% entonces el nivel de significancia sería del 10%. El error tipo II ó error se define como la aceptación de la hipótesis nula cuando ésta es falsa. Existen cuatro resultados posibles de nuestra decisión sobre la hipótesis nula, dos de ellos no nos llevan a ningún tipo de error y los otros dos dan lugar a los errores de tipo I y de tipo II. En efecto, la tabla siguiente nos muestra los cuatro posibles resultados: Decisión Aceptamos H 0 Rechazamos H 0 H 0 es verdadera H 0 es falsa Decisión correcta No hay error 1- Nivel de confianza Error de tipo II Error de tipo I Decisión correcta No hay error 1- Si la hipótesis nula H0 es verdadera, podemos aceptar H0 o rechazar H0 basándonos en la información proporcionada por la muestra. Si aceptamos H0 cuando es verdadera, la decisión es correcta y no hay error. Si rechazamos H0 cuando es verdadera, hemos cometido un error, que se llama error de tipo I. Si la hipótesis nula H0 es falsa, podemos aceptar H0 o rechazar H0 basándonos en la información muestral. Si aceptamos H0 cuando es falsa, hemos cometido un error, que se llama error de tipo II. Si rechazamos la hipótesis nula H0 cuando es falsa, la decisión es correcta y no hay error. Es necesario dar una medida de la posibilidad o del riesgo de cometer estos dos tipos de errores. Estas medidas son probabilidades y las notaremos por α y β, siendo: = Riesgo de error de tipo I = P (Error de tipo I) = P (Rechazar H 0 / H 0 es cierta). = Riesgo de error de tipo II = P (Error de tipo II)= P (Aceptar H 0 / H 0 es falsa) Los errores tipo I y tipo II están relacionados. Una disminución en la probabilidad de uno por lo general tiene como resultado un aumento en la probabilidad del otro. El tamaño de la región crítica, y por tanto la probabilidad de cometer un error tipo I, siempre se puede reducir al ajustar el o los valores críticos. Un aumento en el tamaño muestral n reducirá la probabilidad de error. Si los errores de tipo I y de tipo II son nulos, α=β=0, entonces decimos que el test o contraste es ideal. Cuando estudiamos los intervalos de confianza, decimos que 1-α es el nivel de confianza, y ahora podemos decir que representa el complemento de la P (error de tipo I), siempre y cuando el test sea bilateral, es decir: Nivel de confianza = 1-α =1-P(error de tipo I)= P(aceptar H 0 / H 0 es cierta) Se denomina nivel de significación de un contraste a la probabilidad de cometer un error tipo I. Fijar el nivel de significación equivale a decidir de antemano la probabilidad máxima que se está dispuesto a asumir de rechazar la hipótesis nula cuando es cierta. El nivel de 6 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM significación lo elige el experimentador y tiene por ello la ventaja de tomarlo tan pequeño como desee (normalmente se toma = 0'05, 0'01 o 0'001). La selección de un nivel de significación conduce a dividir en dos regiones el conjunto de posibles valores del estadístico de contraste: La región de Rechazo, con probabilidad α, bajo H0. La región de Aceptación, con probabilidad 1 - α, bajo H0. Según la forma de la región de rechazo, un contraste de hipótesis, paramétrico o no, se denomina: Contraste unilateral o contraste de una cola: es el contraste de hipótesis cuya región de rechazo está formada por una cola de la distribución del estadístico de contraste, bajo H0. Contraste bilateral o contraste de dos colas: es el contraste de hipótesis cuya región de rechazo está formada por las dos colas de la distribución del estadístico de contraste, bajo H0. Es decir, la región de rechazo se divide en dos lados o colas de la distribución de la estadística de prueba. Estadística de prueba: La estadística de prueba es alguna estadística que se puede calcular a partir de los datos de la muestra. Sirve como un productor de decisiones, ya que la decisión de rechazar o no la hipótesis nula depende de la magnitud de la estadística de prueba. La fórmula para la estadística de prueba que se aplica en muchas de las pruebas de hipótesis es: Estadística de prueba = estadística relevante – parámetro supuesto / error estándar La clave para la inferencia estadística es la distribución muestral. Es necesario recordar esto en los casos en los que se deba especificar la distribución de probabilidad de la estadística de prueba. Para repasar o comprender mejor te sugerimos este link : http://www.ditutor.com/inferencia_estadistica/estadistica_inferencial.html A continuación, se analizaran las distribuciones muestrales, estimación y prueba de hipótesis para: la media, una proporción, la diferencia de medias y la diferencia de proporciones. Se recomienda hacer un estudio completo de cada tema, y al final de cada uno hacer un resumen integratorio. 1.5) Distribución Muestral de Medias El conocimiento y comprensión de las distribuciones muestrales son necesarios para entender los conceptos de la estadística inferencial. Una de las distribuciones muestrales más importantes es la distribución de la media de la muestra. La aplicación mas sencilla de la distribución muestral de la media de la muestra es el cálculo de la probabilidad de obtener 7 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM una muestra con una media de alguna magnitud especifica. Este es un ejemplo de cómo elaborar esta distribución. Se tiene una población de tamaño N=5, la cual se compone de las edades de cinco niños que son pacientes externos de una clínica de salud mental. Las edades son las siguientes: x1=6, x2=8, x3=10, x4=12, x5=14. La media para esta población es igual a x / N =(6+8+10+12+14)/5 = 10. La varianza es x = 2 2 = N 40 =8 5 Otra medida de dispersión que se puede calcular es: x 2 2 S= N 1 = 40 =10 4 Esta cantidad se utilizara en el los temas de inferencia estadística. Siguiendo con el ejemplo, a partir de esta población se extraen todas las muestras posibles de tamaño n=2. Se observa que cuando el muestreo se efectúa con reemplazos, hay 25 muestras posibles, cada una con sus respectivas medias muestrales. Para elaborar una distribución muestral para x se listan los diferentes valores de x en una columna y sus frecuencias de ocurrencia en otra. Como dijimos anteriormente, para una distribución muestral se tiene interés en la forma funcional de la distribución, su media y su varianza. Para el cálculo de la media muestral se suman las 25 medias de las muestras y se divide entre el número de muestras. Es interesante destacar que la media de la distribución muestral para x tiene el mismo valor que la media para la población original. El cálculo de la varianza se calcula de la siguiente manera: 2 x= x x 2 i Nn = 100 8 2 =4= = 25 2 n Se puede advertir que la varianza de la distribución muestral no es igual a la varianza de la población. Sin embargo, la varianza de la distribución muestral es igual a la varianza de la población dividida por el tamaño de la muestra utilizada para obtener la distribución muestral. La raíz cuadrada de la varianza de la distribución muestral se llama error estándar y es igual a / n. Se puede distinguir dos situaciones: muestreo a partir de una población que sigue una distribución normal y muestreo a partir de una que no sigue una distribución normal. Si la población es normal se cumplen las propiedades enunciadas anteriormente. Si la población no es normal, se utiliza un teorema conocido como el teorema del límite central. Teorema del límite central Si se seleccionan muestras aleatorias de una población con media y desviación estándar , entonces, cuando n es grande, la distribución maestral de medias tendrá aproximadamente una distribución normal con una media igual a y una desviación estándar de / n . La aproximación será cada vez más exacta a medida de que n sea cada vez mayor. Aplicando este teorema, cuando el 8 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM tamaño de la muestra es grande, el muestro de x tendrá una distribución aproximadamente normal. Si la población de la que se extraen las muestras es normal, la distribución muestral de medias será normal sin importar el tamaño de la muestra. Si la población de donde se extraen las muestras no es normal, entonces el tamaño de la muestra debe ser mayor o igual a 30, para que la distribución muestral tenga una forma acampanada. Mientras mayor sea el tamaño de la muestra, más cerca estará la distribución muestral de ser normal. Para muchos propósitos, la aproximación normal se considera buena si se cumple n=30 Cuando el muestreo se realiza sin reemplazos, la varianza de la distribución muestral no es igual a la varianza poblacional dividida entre el tamaño de la muestra. Sin embargo existe una relación que se obtiene al multiplicar: / n . (N-n)/(N-1) Esta es la varianza de la distribución maestral de x cuando el muestreo es sin reemplazos. El factor (N-n)/(N-1) se llama corrección por población finita y se puede omitir cuando el tamaño de la muestra es pequeño en comparación con el tamaño de la población. Es decir, la corrección de población finita generalmente se ignora cuando n/N 0.5 La distribución normal es una distribución continua, en forma de campana en donde la media, la mediana y la moda tienen un mismo valor. Con esta distribución podíamos calcular la probabilidad de algún evento relacionado con la variable aleatoria, mediante la siguiente fórmula: z= x Sabemos que cuando se extraen muestras de tamaño mayor a 30 o bien de cualquier tamaño de una población normal, la distribución muestral de medias tiene un comportamiento aproximadamente normal. Teniendo en cuanta esto y sabiendo que la desviación estándar es / n , se hacen los reemplazos correspondientes. Así la formula para calcular la probabilidad del comportamiento del estadístico, en este caso la media de la muestra, quedaría de la siguiente manera: y para poblaciones finitas y muestro con reemplazo: Ejemplo 1: Si la media y la desviación estándar de la concentración en suero en hombres sanos es de 120 15mg por cada 100 ml, respectivamente, ¿Cuál es la probabilidad de que una muestra aleatoria de 50 hombres normales tenga una media entre 115 y 125mg/100ml? Solución: No se especifica la forma funcional de la población de valores de las concentraciones de hierro en el suero, pero como el tamaño de la muestra es mayor a 30, se puede utilizar el teorema del limite central para transformar la distribución muestral de x en aproximadamente normal con media de 120 y una desviación estándar de 15/ 50 =2.12. La probabilidad buscada es: 9 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM 125 120 115 120 z 2.12 2.12 =P (-2.36 z 2.36 P (115 x 125) = P = 0.9909 – 0.0091 =0.9818 Ejemplo 2: Las estaturas de 1000 estudiantes están distribuidas aproximadamente en forma normal con una media de 174.5 centímetros y una desviación estándar de 6.9 centímetros. Si se extraen 200 muestras aleatorias de tamaño 25 sin reemplazo de esta población, determine: a. El número de las medias muestrales que caen entre 172.5 y 175.8 centímetros. b. El número de medias muestrales que caen por debajo de 172 centímetros. Solución: Como se puede observar en este ejercicio se cuenta con una población finita y un muestreo sin reemplazo, por lo que se tendrá que agregar el factor de corrección. Se procederá a calcular el denominador de Z para sólo sustituirlo en cada inciso. Primero vamos a calcular el erro estándar para una población finita a. Ahora con esta probabilidad calculamos la cantidad de muestras: (0.7607)(200)=152 medias muestrales b. (0.0336)(200)= 7 medias muestrales Estimación para la Media Supongamos que un grupo de investigadores quiere estimar la media de una población que sigue una distribución normal y que, para ello, extraen una muestra aleatoria de tamaño n de la población y calculan el valor de x , el cual utilizan como una estimación puntual de . Aunque este estimador posee todas las cualidades de un buen estimador, no se puede 10 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM esperar que x sea igual a . Por lo tanto, es mucho más significativo estimar mediante un intervalo que de alguna forma muestre el valor de . Para realizar esa estimación por intervalos, aprovechamos las distribuciones muestrales. En este caso, como el interés está en la media de la muestra como estimador de la media de una población, es necesario tener en cuenta la distribución muestral de la media. En base a la distribución muestral de medias, la fórmula para el cálculo de probabilidad es la siguiente: . Cuando se desconoce el valor de la media poblacional lo podemos estimar por medio de la media de la muestra, para ello sólo se despejará de la formula anterior, quedando lo siguiente: Tomamos un intervalo que contenga una masa de probabilidad de1- . La cantidad 1- se conoce como coeficiente de confianza y designa el área total dentro del intervalo en el que puede hallarse el valor real de . Este intervalo lo queremos tan pequeño como sea posible. Por ello lo mejor es tomarlo simétrico con respecto a la media (0), ya que allí es donde se acumula más masa. Así las dos colas de la distribución (zonas más alejadas de la media) se repartirán a partes iguales el resto de la masa de probabilidad, . El intervalo de confianza al nivel de1- para la esperanza de una normal de varianza conocida es el comprendido entre los valores La forma habitual de escribir este intervalo es: 11 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM De esta fórmula se puede observar que tanto el tamaño de la muestra como el valor de z se conocerán. Z se puede obtener de la tabla de la distribución normal a partir del nivel de confianza establecido. Este valor de Z se conoce como coeficiente de confiabilidad, que indica en cuantos errores estándar están aproximadamente el 95% de los valores posibles de x (siempre que 1- =0.95). El otro componente conocido es el error estándar o desviación estándar de la distribución muestral de x . Cuando 1- = 0.95, el intervalo recibe el nombre de confianza del 95% para . Se dice que se tiene el 95 por ciento de confianza de que la media de la población esté dentro del intervalo calculado. Como vemos, conociendo la ley de distribución, la media muestral y la varianza, podemos estimar el valor de la media poblacional. Ejemplo: Un fisioterapista desea estimar, con el 99% de confianza, la media de fuerza máxima de un músculo particular en cierto grupo de individuos. Se inclina a suponer que los valores de dicha fuerza muestran una distribución aproximadamente normal con una varianza de 144. Una muestra de 15 individuos que participaron en el experimento proporcionó una media de 94.3. Solución: En la tabla de distribución normal, el valor de Z que corresponde a un coeficiente de confianza de .99 es de 2.58. Este es el coeficiente de confiabilidad. El error estándar es de x=12/ 15 = 3.10. Por lo tanto el intervalo de confianza del 99% para es: 84.3 2.58(3.10) = 84.3 8.0 entonces I.C.= (76.3 ; 92.3) Se dice que se tiene el 99% de confianza de que la media de la población esta entre 76.3 y 92.3 ya que, al repetir el muestreo, el 99% de todos los intervalos que podrían ser construidos de esta forma, incluirían a la media de la población. Este procedimiento para obtener un intervalo de confianza para la media de la población, requiere el conocimiento de la varianza de la población de la que se extrae la muestra. Sin embrago, la situación más común es aquella en donde no se conoce el valor de la media ni el valor de la varianza. Esto impide que podamos utilizar el estadístico Z para la construcción de intervalos. Aunque la estadística Z tiene una distribución normal cuando la población es normal o aproximadamente normal cuando n es muy grande, no se puede utilizar porque se desconoce . En estos casos se puede utilizar una estimación puntual de la desviación estándar, es decir igualar la desviación estándar de la muestra a la de la población (s= ). Sin embargo, en estadística inferencial, los estadísticos para medir la dispersión más convenientes son los insesgados como la cuasivarianza típica. Según el caso se utilizará la cuasivarianza típica o la desviación típica. Por ejemplo si tomamos una muestra de tamaño 25 y desviación típica igual a 10, la cuasivarianza típica será: En los casos en los que se desconoce pero la población de donde provienen los datos es normal, lo correcto es utilizar otra distribución llamada "t" de student, que no depende de (desconocido) sino de su estimación puntual insesgada, es decir la cuasivarianza típica. Esta distribución se aplicara siempre que no sean conocidos la media y varianza de la población. El calculo de la media y el intervalo de confianza al nivel 1- cuando los parámetros son desconocidos es: 12 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Y se tomara como intervalo de confianza aquella región en la que En este caso se usa la notación: El procedimiento es básicamente el mismo, lo que es diferente es el origen del coeficiente de confiabilidad. Este se obtiene a partir de la tabla de distribución t. Ejemplo: Se desea estimar la concentración media de amilasa en suero de una población sana. Las mediciones se efectuaron en una muestra de 15 individuos aparentemente saludables. La muestra proporcionó una media de 96 unidades/100ml y una desviación estándar de 35 unidades/100ml. La varianza se desconoce. Solución: Podemos utilizar la media de la muestra 96 como una estimación puntual de la media de la población. Pero al no conocer la desviación estándar, podemos suponer que la población sigue una distribución aproximadamente normal antes de construir un intervalo de confianza para . Si suponemos que esta hipótesis es razonable, podemos buscar un intervalo de confianza del 95%. Se tiene el estimador x y el error estándar es s/ n = 35 / 15 = 9.04. Buscamos el coeficiente de confiabilidad, es decir, el valor de t asociado a un coeficiente de confianza de .95 y n – 1 =14 grados de libertad. Se encuentra que el valor de t, que es el coeficiente de confiabilidad, es de 2.1448. Ahora se construye el intervalo de confianza al 95 por ciento: 96 2.1448(9.04) = 96 19 entonces el I.C = ( 77 ; 15 ) Este intervalo se puede interpretar desde dos puntos de vista, probabilístico y práctico. Se dice que se tiene el 95% de confianza de que la media real de la población está entre 77 y 115 ya que con muestreos repetidos, el 95% de los intervalos construidos de una forma semejante incluyen a . Contrastes para la media Los contrastes para la media son muy importantes. Cuando analizamos un carácter dentro de una población, una de las primeras cosas que hacemos es calcular la media para dicho carácter. Muchas veces tenemos un valor a priori de la media poblacional y es necesario determinar si coincide o se aproxima al valor real en la población. Los contrastes de hipótesis para la media nos permiten comprobar si el valor fijado a priori de la media coincide con el de la población. Cuando el muestreo se realiza a partir de una población normal y se conoce la varianza de la población, la estadística de prueba para H0 : = 0 es: 13 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Contrastes sobre la media de una población N(μ,σ) con σ conocida: Este contraste se aplica cuando tenemos una población que se distribuye normalmente N(μ,σ), en donde la varianza 2 es conocida, y mediante una muestra aleatoria simple de tamaño n, ( x1 , x2 , x3 ,..., xn ) , y un nivel de significación α dado, queremos realizar los siguientes contrastes: H 0 : 0 2. H1 : 0 1. H 0 : 0 H1 : 0 H 0 : 0 3. H1 : 0 La técnica para hacer el contraste consiste en suponer que H0 es cierta, y averiguar con los datos muestrales si es verdaderamente cierta o no. Para dar una forma homogénea a todos los contrastes de hipótesis es costumbre denominar al valor del estadístico del contraste calculado sobre la muestra como valor experimental y a los extremos de la región crítica, como valores teóricos. Definiendo entonces para cada caso un valor teórico y uno experimental. H 0 : 0 De dos colas H1 : 0 1. Contraste de Sabemos que la población se distribuye normalmente, por lo que El valor teórico se obtiene de la tabla de distribución normal. Si H0 es cierta, entonces esperamos que el valor zexp obtenido sobre la muestra esté cercano a cero con una gran probabilidad. La regla de decisión será: - Rechazamos H 0 si: zexp x 0 < z / 2 n - Aceptamos H 0 si: ó zexp x 0 > z / 2 n z / 2 zexp z / 2 La regla de decisión también la podemos formular en función de la región crítica o de la región de aceptación, así pues, si calculamos la media x (media muestral) correspondiente a la muestra aleatoria de tamaño n, entonces: Si x 0 z / 2 , 0 z / 2 aceptamos H 0 . n n Si x 0 z / 2 , 0 z / 2 rechazamos H 0 . n n 14 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Por lo tanto, se rechaza la hipótesis nula si el valor calculado de la estadística de prueba cae en la región de rechazo y no se rechaza si cae en la región de aceptación. H 0 : 0 De una cola H1 : 0 2. Contraste de Bajo la hipótesis nula la distribución de la media muestral es y como región crítica consideraremos aquella formada por los valores extremadamente bajos de Zexp, con probabilidad , es decir Entonces la región de aceptación, o de modo más correcto, de no rechazo de la hipótesis nula es: . La regla de decisión será: - Rechazamos H 0 si: zexp x 0 <- z / 2 n - Aceptamos H 0 si: zexp x 0 - z / 2 n Se rechaza la hipótesis nula, cuando uno de los estadístico Z o sombreada de sus gráficas respectivas. toma un valor en la zona H 0 : 0 H1 : 0 3. Contraste de 15 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Si observamos el caso anterior, podemos ver que aquí tomamos como hipótesis alternativa su contraria. Por simetría con respecto al caso anterior, la región donde no se rechaza la hipótesis nula es La regla de decisión será: - Rechazamos H 0 si: zexp x 0 > z / 2 n - Aceptamos H 0 si: zexp x 0 z / 2 n Regiones de aceptación y rechazo para el test unilateral contrario Ejemplo: Supóngase que un investigador está estudiando el nivel promedio de alguna enzima en cierta población de seres humanos. El investigador toma una muestra de 10 individuos, determina el nivel de la enzima en cada uno de ellos y calcula la media muestral igual a 22. La variable de interés sigue una distribución aproximadamente normal con una varianza de 45. Con estos datos y los procedimientos de prueba de hipótesis, ¿es posible concluir que el nivel medio de la enzima en esta población es diferente de 25? Solución: H0: = 25 H1: ≠ 25 Primero, es necesario especificar las regiones de rechazo y aceptación. Para ello definimos un nivel de significación , que es la probabilidad de cometer un error de tipo I. Supongamos que queremos que la probabilidad de rechazar una hipótesis nula verdadera es =0.05. Al estar la región de rechazo formada por dos partes (contraste bilateral), parece lógico que se pueda dividir a en partes iguales siendo /2=0.025. La región de aceptación será 1- /2= 0.975. Este valor nos ayudara a encontrar el valor de z en la tabla de distribución normal. El valor z para 1- /2=0.975 es 1.96. Como el contraste es bilateral, la región de rechazo consiste en todos los valores de la estadística de prueba mayores o iguales que 1.96 o menores o iguales que -1.96. Entonces, se rechaza H0 si el valor calculado es ≥1.96 o ≤-1.96. De otra manera no se rechaza. El valor de y la regla de decisión deben ser establecidos antes de reunir los datos, lo cual evita que los resultados de la muestra influyan en la decisión. 16 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Calculo de la estadística de prueba: zexp= 22 25 3 -1.41 = 45 / 10 2.1213 = Como -1.41 no está en la región de rechazo, no se puede rechazar la hipótesis nula. Se puede concluir que puede ser igual a 25 y que las acciones del administrador o medico deben estar de acuerdo con esta conclusión. También se puede llegar a esta misma conclusión mediante el uso de un intervalo confianza del 10(1- ) por ciento. El intervalo de confianza de 95% para es: 22 1.96 45 / 10 = 22 1.96 (2.1213) = 22 4.16 I.C= (17.84 ; 26.16) Dado que este intervalo incluye a 25, se dice que 25 es un candidato para la media y por lo tanto, puede ser igual a 25. H0 no se rechaza. Contrastes sobre la media de una población N (μ,σ) con σ desconocida Este contraste es aplicable cuando se tiene una muestra aleatoria simple ( x1 , x2 , x3 ,..., xn ) procedente de una población N (μ,σ), en donde ni la media ni la varianza 2 son conocidos y, con un nivel de significación α dado, queremos realizar los siguientes contrastes: H 0 : 0 2. H1 : 0 1. H 0 : 0 H1 : 0 3. H 0 : 0 H1 : 0 Es decir nuevamente queremos ver si el valor fijado a priori de la media poblacional es o no el real. Utilizando el estadístico de prueba: texp x 0 s n Se tendrán los siguientes contrastes. H 0 : 0 o Test de dos colas H1 : 0 1. Contraste de Al no conocer 2 va a ser necesario estimarlo a partir de su estimador insesgado: la cuasivarianza muestral, Ŝ 2. Por ello la distribución del estimador del contraste será una t de Student, que ha perdido un grado de libertad, y según la definición de la distribución de Student: 17 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Definimos al valor del estadístico del contraste calculado sobre la muestra como valor experimental y a los extremos de la región crítica, como valores teóricos: Entonces: - Se rechaza H 0 si: texp t / 2 ó texp t / 2 - Se acepta H 0 si: t / 2 texp t / 2 Región crítica para el contraste bilateral de una media Ejemplo: Conocemos que las alturas X de los individuos de una ciudad, se distribuyen de modo gaussiano. Deseamos contrastar con un nivel de significación de =0.05 si la altura media es diferente de 174 cm. Para ello nos basamos en un estudio en el que con una muestra de n=25 personas se obtuvo: Solución: El contraste que se plantea es: H0: = 174cm H1: ≠ 174cm La técnica a utilizar consiste en suponer que H0 es cierta y ver si el valor que toma el estadístico es ``razonable" o no bajo esta hipótesis, para el nivel de significación dado. Aceptaremos la hipótesis alternativa (y en consecuencia se rechazará la hipótesis nula) si Para ello procedemos al cálculo de Texp: 18 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Luego, aunque podamos pensar que ciertamente el verdadero valor de no es 174, no hay una evidencia suficiente para rechazar esta hipótesis al nivel de confianza del 95%. Es decir, no se rechaza H0. H 0 : 0 Tests de una cola H1 : 0 2. Contraste de Por analogía con el contraste bilateral, definiremos Entonces: - Se rechaza H 0 si: texp t - Se acepta H 0 si: texp t Región crítica para uno de los contrastes unilaterales de una media. H 0 : 0 H1 : 0 3. Contraste de En este caso también definimos Texp y Tteo 19 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM - Se rechaza H 0 si: texp t - Se acepta H 0 si: texp t Región crítica para el contraste unilateral de una media contrario al anterior. Ejemplo: Consideramos el mismo ejemplo de antes. Visto que no hemos podido rechazar el que la altura media de la población sea igual a 174 cm, deseamos realizar el contraste sobre si la altura media es menor de 174 cm. Solución: Ahora el contraste es H0: ≥ 174cm H1: < 174cm Para realizar este contraste, consideramos el caso límite y observamos si la hipótesis nula debe ser rechazada o no. Este es: De nuevo la técnica a utilizar consiste en suponer que H0' es cierta y ver si el valor que toma el estadístico es aceptable bajo esta hipótesis, con un nivel de confianza del 95%. Se aceptará la hipótesis alternativa (y en consecuencia se rechazará la hipótesis nula) si 20 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM El valor de Texp obtenido fue de Texp= -1.959< t24,0.05= -t24,0.95 = -1.71 Por ello hemos de aceptar la hipótesis alternativa Mientras que en el ejemplo anterior no existía una evidencia significativa para decir que 174 cm, el ``simple hecho" de plantearnos un contraste que parece el mismo pero en versión unilateral nos conduce a rechazar de modo significativo que =174 y aceptamos que <174 cm. Es por ello que podemos decir que no sólo H0' es rechazada, sino también H0. Es en este sentido en el que los tests con H0 y H0' los consideramos equivalentes: 2) DISTRIBUCIÓN MUESTRAL DE PROPORCIONES Existen ocasiones en las cuales no estamos interesados en la media de la muestra, sino que queremos investigar la proporción de artículos defectuosos o la proporción de alumnos reprobados en la muestra. La distribución muestral de proporciones es la adecuada para dar respuesta a estas situaciones. Esta distribución se genera de igual manera que la distribución muestral de medias, a excepción de que al extraer las muestras de la población se calcula el estadístico proporción (p=x/n en donde "x" es el número de éxitos u observaciones de interés y "n" el tamaño de la muestra) en lugar del estadístico media. Una población binomial está estrechamente relacionada con la distribución muestral de proporciones; una población binomial es una colección de éxitos y fracasos, mientras que una distribución muestral de proporciones contiene las posibilidades o proporciones de todos los números posibles de éxitos en un experimento binomial, y como consecuencia de esta relación, las afirmaciones probabilísticas referentes a la proporción muestral pueden evaluarse usando la aproximación normal a la binomial, siempre que np 5 y n(1-p) 5. Cualquier evento se puede convertir en una proporción si se divide el número obtenido entre el número de intentos. La distribución muestral de proporciones se puede obtener experimentalmente. A partir de la población, que se supone es finita, se toman todas las muestras posibles de un tamaño dado, y para cada muestra se calcula la proporción de la muestra p̂ . Después, se elabora una distribución de frecuencias de p̂ , numerando los distintos valores de p̂ junto con sus 21 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM frecuencias de ocurrencias. Esta distribución de frecuencias constituye la distribución muestral de p̂ . La media de la distribución muestral de proporciones es el promedio de todas las proporciones posibles de la muestra y es igual a la proporción en la población de un cierto evento p: p̂ = p La varianza de la distribución binomial es 2= npq, por lo que la varianza de la distribución muestral de proporciones es: p̂ = pq = n 2 p̂ = pq n La fórmula que se utilizará para el cálculo de probabilidad en una distribución muestral de proporciones está basada en la aproximación de la distribución normal a la binomial. Esta fórmula nos servirá para calcular la probabilidad del comportamiento de la proporción en la muestra. z= pˆ p pq n Ejemplo 1: Supóngase que en una población de seres humanos, el 0.8 son daltónicos. Si se eligen aleatoriamente 150 individuos de esta población, ¿Cuál es la probabilidad de que una proporción de individuos daltónicos tenga un tamaño del 0.15? Solución: Si la proporción de la población se designa como p, se puede decir que p=0.8. Como np y n(1-p) son mayores que 5 (150x0.8=12 y 150x0.92=138), se puede decir que, en este caso p sigue una distribución aproximadamente normal, con una media p̂ = p= 0.8 y una varianza igual a p(1-p)/n = (0.8).(0.92)/150=0.00049. La probabilidad buscada es el área bajo la curva de p̂ a la derecha de 0.15. Esta área es igual al área bajo la curva normal estándar a la derecha de: z= pˆ p pq n = 0.15 0.8 0.00049 = 0.07 =3.15 0.0222 Al utilizar la tabla de distribución normal estándar se tiene que el área a la derecha de z=3.15 es 1-0.9992=0.0008. Se puede decir que la probabilidad de observar p̂ 0.15 en una muestra aleatoria de tamaño n=150 de una población en la que p=0.08 es 0.0008. Si se extrajera una muestra de este tipo, seria un evento muy extraño. Ejemplo 2: Un medicamento para malestar estomacal tiene la advertencia de que algunos usuarios pueden presentar una reacción adversa a él, más aún, se piensa que alrededor del 3% de los usuarios tienen tal reacción. Si una muestra aleatoria de 150 personas con malestar estomacal usa el medicamento, encuentre la probabilidad de que la proporción de la muestra de los usuarios que realmente presentan una reacción adversa, exceda el 4%. a. Resolverlo mediante la aproximación de la normal a la binomial 22 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM b. Resolverlo con la distribución muestral de proporciones a. Aproximación de la distribución normal a la binomial: Datos: n=150 personas x= (0.04)(150) = 6 personas Media = np= (150)(0.03)= 4.5 p=0.03 p(x>6) = ? p(x>6) = 0.1685. Este valor significa que existe una probabilidad del 17% de que al extraer una muestra de 150 personas, más de 6 presentarán una reacción adversa. b. Distribución Muestral de Proporciones Datos: n=150 personas P=0.03 p(p>0.04) = ? Observe que este valor es igual al obtenido y la interpretación es: existe una probabilidad del 17% de que al tomar una muestra de 150 personas se tenga una proporción mayor de 0.04 presentando una reacción adversa. Estimación de una Proporción LINK RECOMENDADO: http://www.youtube.com/watch?v=ttoyw4UgqkE Muchas preguntas de interés para los profesionales tienen relación con las proporciones de la población. Por ejemplo ¿Qué proporción de alguna población tienen cierta enfermedad? o ¿Qué proporción es inmune a cierta enfermedad? Para estimar la proporción de una población se procede de la misma manera que cuando se estima la media de una población. Se extrae una muestra de la población de interés y se calcula la proporción p̂ . Esta se utiliza como el estimador puntual para la proporción de la población. Un estimador puntual de la proporción P en un experimento binomial está dado por la estadística P =X/N, donde x representa el número de éxitos en n pruebas. Por tanto, la proporción de la muestra p =x/n se utilizará como estimador puntual del parámetro P. Como vimos anteriormente, cuando np y n(1-p) son mayores que 5, se puede considerar que la distribución muestral de p̂ se aproxima bastante a una distribución normal. En estos casos, el coeficiente de confiabilidad es algún valor de Z de la distribución normal estándar. El error 23 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM estándar es igual pˆ (1 pˆ ) / n . Como P es el parámetro que se tarta de calcular, se se debe utilizar como estimación. p̂ desconoce, Podemos establecer un intervalo de confianza para P al considerar la distribución muestral de proporciones. Al despejar P de esta ecuación nos queda: En este despeje podemos observar que se necesita el valor del parámetro P y es precisamente lo que queremos estimar, por lo que lo sustituiremos por la proporción de la muestra p siempre y cuando el tamaño de muestra no sea pequeño. Cuando n es pequeña y la proporción desconocida P se considera cercana a 0 ó a 1, el procedimiento del intervalo de confianza que se establece aquí no es confiable, por tanto, no se debe utilizar. El error de estimación será la diferencia absoluta entre p y P. Para encontrar el intervalo de confianza al nivel de significación para p se considera el intervalo que hace que la distribución de Z~N(0,1) deje la probabilidad fuera del mismo. Es decir, se considera el intervalo cuyos extremos son los cuantiles 2 y 1- 2 . Así se puede afirmar con una confianza de 1- que: Ejemplo: Se llevo a cabo una encuesta para estudiar los hábitos y actitud hacia la salud mental de cierta población urbana de adultos. De los 300 entrevistados, 123 de ellos dijeron que se sometían regularmente a una revisión dental dos veces por año. Se desea construir un intervalo de confianza de 95% para la proporción de individuos de la población muestreada que se somete a la revisión dental dos veces al año. Solución: La mejor estimación puntual de la proporción de la población es p̂ =123/300 = 0.41. El tamaño de la muestra y la estimación de p son suficientes como para justificar el uso de la distribución normal estándar para construir el intervalo de confianza. El coeficiente de confiabilidad que corresponde a un nivel de confianza de .95 es de 1.96 y la estimación del error estándar p̂ es pˆ (1 pˆ ) / n = 0.41(0.59) / 300 =0.28. El intervalo de confianza del 95% para p, con base en estos datos, es 0.41 1.96(0.28) 0.41 0.05 (0.36 ; 0.46) 24 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Se puede decir que se tiene el 95% de confianza de que la proporción real p está entre 0.36 y 0.46 ya que, al repetir el muestreo, el 95% de los intervalos construidos de esta forma incluyen a la proporción p real. Contrastes de una proporción LINK RECOMENTADADO : http://www.youtube.com/watch?v=AN1tIWEo8qw Este test se utiliza para contrastar la igualdad o desigualdad de proporciones que han sido estimadas y las proporciones reales. Supongamos que tenemos una sucesión de observaciones independientes, de modo que cada una de ellas se comporta como una distribución de Bernoulli de parámetro p. La v.a. X, definida como el número de éxitos obtenidos en una muestra de tamaño n es por definición una v.a. de distribución binomial: La proporción muestral (estimador del verdadero parámetro p a partir de la muestra) es: Nuestro contraste de significación es: frente a otras hipótesis alternativas. Para ello nos basamos en un estadístico (de contraste) que ya fue considerado anteriormente en la construcción de intervalos de confianza para proporciones y que sigue una distribución aproximadamente normal para tamaños muestrales suficientemente grandes: Entonces, si la hipótesis H0 es cierta se tiene Se pueden hacer pruebas unilaterales y bilaterales para rechazar o no la hipótesis nula. H 0 : p p0 Contraste bilateral H1 : p p0 1. Contraste de Extraemos una muestra y observamos el valor X=x = p̂ = x . n Entonces se define 25 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Se acepta H 0 si: z / 2 zexp z / 2 Siendo el criterio de aceptación o rechazo de la hipótesis nula el que refleja la figura para el contraste bilateral de una proporción H 0 : p p0 Contrastes unilaterales H1 : p p0 2. Contraste de: El criterio de aceptación o rechazo a seguir es: Se acepta H 0 si: Siendo z zexp z P Z z ó P Z z 1 Entonces para un contraste unilateral cuando H0: p p0 26 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM H 0 : p p0 H1 : p p0 3. Contraste de: Este es el test unilateral contrario, se tiene la expresión simétrica Se acepta H 0 si: zexp z Contraste unilateral cuando se tiene H0: p p0 Ejemplo: Suponer que hay interés por saber que proporción de la población de conductores de automóviles utilizan con regularidad el cinturón de seguridad del asiento. En una encuesta de 300 conductores adultos de automóviles, 123 de ello dijeron que regularmente utilizaban el cinturón de seguridad. ¿Es posible concluir a partir de estos datos que, en la población muestreada, la proporción de quienes utilizan regularmente el cinturón de seguridad no es del 50? Solución: H0: p = 0.5 H1: p ≠ 0.5 A partir de los datos se tiene que p̂ =0.41 y el error estándar es (0.5)(0.5) / 300 . El cálculo de la estadística de prueba es: 27 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Z= 0.41 0.5 (0.5)(0.5) 300 = 0.9 = - 3.11 0.0289 Si =0.05, los valores críticos son ± 1.96. Se rechaza H0 a menos que 1.96<zcalculada<1.96. Como -3.11< -1.96 se rechaza la hipótesis nula. Se concluye que la proporción de la población que usa regularmente el cinturón de seguridad no es de 0.5. 2) DISTRIBUCIÓN MUESTRAL DE DIFERENCIA DE MEDIAS Con frecuencia, el interés se centra en dos poblaciones. Puede ser que un investigador desee saber algo acerca de las diferencias entre las medias de dos poblaciones. Para este y otros casos, el conocimiento acerca de la distribución muestral de la diferencia entre dos medias es muy útil. Se tienen dos poblaciones distintas, la primera con media 1 y desviación estándar 1, y la segunda con media 2 y desviación estándar 2. Se elige una muestra aleatoria de tamaño n1 de la primera población y una muestra independiente aleatoria de tamaño n2 de la segunda población; se calcula la media muestral para cada muestra y la diferencia entre dichas medias. La colección de todas esas diferencias junto con sus frecuencias, se llama distribución muestral de las diferencias entre medias o la distribución muestral del estadístico La distribución es aproximadamente normal para n1 30 y n2 30. Si las poblaciones son normales, entonces la distribución muestral de medias es normal sin importar los tamaños de las muestras. Sabemos que cuando n es grande, la distribución muestral de medias tendrá aproximadamente una distribución normal con una media igual a (la media de la población) y una desviación estándar de / n . Con esto podemos deducir que la media para esta distribución muestral de diferencia de medias es igual a las diferencia entre las medias reales de las poblaciones 1- 2. La varianza es igual a ( 21/n1) + ( 22/n2). Y el error estándar de la diferencia entre las medias muestrales es: . La fórmula que se utilizará para el cálculo de probabilidad del estadístico de diferencia de medias es: Este procedimiento es válido incluso cuando el tamaño de las muestras es diferente y cuando las varianzas tienen valores diferentes. Ejemplo: En un estudio para comparar los pesos promedio de niños y niñas de sexto grado en una escuela primaria se usará una muestra aleatoria de 20 niños y otra de 25 niñas. Se sabe que tanto para niños como para niñas los pesos siguen una distribución normal. El promedio de los pesos de todos los niños de sexto grado de esa escuela es de 100 libras y su desviación estándar es de 14.142, mientras que el promedio de los pesos de todas las niñas 28 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM del sexto grado de esa escuela es de 85 libras y su desviación estándar es de 12.247 libras. Si representa el promedio de los pesos de 20 niños y es el promedio de los pesos de una muestra de 25 niñas, encuentre la probabilidad de que el promedio de los pesos de los 20 niños sea al menos 20 libras más grande que el de las 25 niñas. Solución: Datos: 1 = 100 libras 2 = 85 libras 1 = 14.142 libras 2 = 12.247 libras n1 = 20 niños n2 = 25 niñas =? Por lo tanto, la probabilidad de que el promedio de los pesos de la muestra de niños sea al menos 20 libras más grande que el de la muestra de las niñas es 0.1056. Estimación de la Diferencia entre dos Medias En ciertos casos, se desea estimar la diferencia entre las medias de dos poblaciones. Teniendo dos poblaciones donde el carácter que estudiamos en ambas (X1 y X2) son v.a. distribuidas según leyes gaussianas, podemos realizar una estimación de la diferencia entre dos medias. A partir de cada población se extrae una muestra aleatoria independiente y de los datos de cada una se calculan las medias muestrales x 1 y x 2. Sabemos que el estimador x 1- x 2 proporciona una estimación insesgada de 1 - 2, que es la diferencia entre las medias de las poblaciones. La varianza del estimador es ( 12/n1) + ( 22/n2). Por tanto, para obtener una estimación puntual de 1- 2, se seleccionan dos muestras aleatorias independientes que no tienen por qué ser necesariamente del mismo tamaño, una de cada población, de tamaño n1 y n2, se calcula la diferencia , de las medias muestrales. Intervalo para la diferencia de medias cuando se conoce la varianza: Recordando a la distribución muestral de diferencia de medias: 29 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Al despejar de esta ecuación 1 - 2 se tiene: En el caso en que se desconozcan las varianzas de la población y los tamaños de muestra sean mayores a 30 se podrá utilizar la varianza de la muestra como una estimación puntual. Ejemplo: A un equipo de investigación le interesa conocer la diferencia entre las concentraciones de acido úrico en pacientes con y sin mongolismo. En una hospital para el tratamiento del retardo mental, una muestra de 12 individuos con mongolismo proporciona una media de x 1= 4.5mg/100ml. En un hospital general se encontró que una muestra de 15 individuos normales de la misma edad y sexo presenta un nivel medio de x 2= 3.4. Si suponemos que las dos poblaciones de valores muestran una distribución normal y sus varianzas son iguales a 1, calcular el intervalo de confianza del 95% para 1- 2. Solución: Para una estimación puntual de 1- 2 se utiliza = 4.5 - 3.4=1.1. El coeficiente de confiabilidad correspondiente al .95, que se halla en la tabla normal, es 1.96. El error estándar es: 1 1 = 0.39 12 15 Por lo tanto el intervalo de confianza del 95% es: 1.1 1.96 (0.39) 1.1 0.8 (0.3 ; 1.9) Se dice que se tiene una confianza del 95% de que la diferencia real 1- 2, está entre 0.3 y 1.9 debido a que en muestreos repetidos el 95% de los intervalos construidos de esa manera incluiría la diferencia entre las medias reales. Intervalo para la diferencia de medias cuando se desconoce la varianza Cuando se desconocen las varianzas de la población y se requiere estimar la diferencia entre las medias de dos poblaciones con un intervalo de confianza, se puede utilizar la distribución t para extraer el factor de confiabilidad, siempre que las poblaciones sean normales o supongamos que lo son. 1. Intervalo para la diferencia de medias homocedáticas: Si suponemos que las varianzas de dos poblaciones son iguales, las dos varianzas de las muestras calculadas a partir de las muestras independientes pueden construirse como 30 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM estimaciones de una sola cosa, la varianza común. Esta varianza se obtiene calculando el promedio ponderado de las dos varianzas de las muestras. Cada varianza de las muestras es ponderada en base a sus grados de libertad. La estimación conjunta se obtiene con la formula: Donde se ha definido a como la cuasivarianza muestral ponderada de Ŝ 21 y Ŝ 22. Las varianzas se desconocen, el intervalo se distribuye entonces como una de Student con n1+n2-2 grados de libertad Si 1- es el nivel de significación con el que deseamos establecer el intervalo para la diferencia de las dos medias, calculamos el valor t n1+n2-1,1- /2 que deja por encima de si /2 de la masa de probabilidad de Tn1+n2-2. El intervalo de confianza al nivel 1- para la diferencia de esperanzas de dos poblaciones con la misma varianza (aunque esta sea desconocida) es: Ejemplo: Se efectuaron estudios sobre la concentración media de amilasa en suero de una población sana. Las mediciones se efectuaron en una muestra de 15 individuos aparentemente saludables. La muestra proporcionó una media de 96 unidades/100ml y una desviación estándar de 35 unidades/100ml. Se hicieron también las determinaciones de amilasa en el suero de 22 individuos hospitalizados que forman una muestra independiente. La media y la desviación estándar de esta muestra son 120 y 40 unidades/ml, respectivamente. La estimación puntual de 1- 2 es de 120 – 96 =24. Se desea construir un intervalo de confianza para la diferencia entre las concentraciones medias de amilasa del suero en individuos aparentemente sanos y la media para los pacientes hospitalizados. Solución: Suponemos que las dos poblaciones en estudio tienen una distribución normal y que sus varianzas son iguales. Primero, buscamos la estimación conjunta de la varianza común como sigue: Ŝ 2 = 14(35)2 + 21(40)2 / 15 + 22 – 2 = 1450 El intervalo de confianza del 95% para 1- 2 es: (120-96) 2.0301 1450 1450 15 22 24 (2.0301)(12.75) 24 26 I.C = (-2 ; 50) Se dice que se tiene un 95% de confianza de que la diferencia real 1- 2 esta entre -2 y 50 ya que, al muestrear varias veces, el 95% de los intervalos así construidos incluyen a 1- 2. Ejemplo: Queremos estudiar la influencia que puede tener el tabaco con el peso de los niños al nacer. Para ello se consideran dos grupos de mujeres embarazadas (unas que fuman un paquete al día y otras que no) y se obtienen los siguientes datos sobre el peso X, de sus hijos: 31 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM En ambos grupos los pesos de los recién nacidos provienen de sendas distribuciones normales de medias desconocidas, y con varianzas que si bien son desconocidas, podemos suponer que son las mismas. Calcular en cuanto influye el que la madre sea fumadora en el peso de su hijo. Solución: Si queremos estimar en cuanto influye el que la madre sea fumadora en el peso de su hijo, podemos estimar un intervalo de confianza para 1- 2, lo que nos dará la diferencia de peso esperado entre un niño del primer grupo y otro del segundo. El estadístico que se ha de aplicar para esta cuestión es: donde Consideramos un nivel de significación que nos parezca aceptable, por ejemplo =0.05, y el intervalo buscado se obtiene a partir de 95% Con lo cual se puede decir que un intervalo de confianza para el peso esperado en que supera un hijo de madre no fumadora al de otro de madre fumadora está comprendido con un nivel de confianza del 95% entre los 0,068 Kg y los 0,731 Kg. 32 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Contrastes para la diferencia de medias apareadas En el análisis de la diferencia de medias de dos poblaciones, se supone que las muestras son independientes. Un método que se utiliza con frecuencia para averiguar la efectividad de un tratamiento o procedimiento experimental es aquel que hace uso de observaciones relacionadas que resultan de muestras no independientes. Una prueba de hipótesis que se basa en este tipo de datos se conoce como prueba de comparaciones por parejas o para muestras apareadas. Las muestras apareadas aparecen como distintas observaciones realizadas sobre los mismos individuos. Un ejemplo de observaciones apareadas consiste en considerar a un conjunto de n personas a las que se le aplica un tratamiento médico y se mide por ejemplo el nivel de insulina en la sangre antes (X) y después del mismo (Y). No es posible considerar a X e Y como variables independientes ya que va a existir una dependencia clara entre las dos variables. Si queremos contrastar el que los pacientes han experimentado o no una mejoría con el tratamiento, llamemos di a la diferencia entre las observaciones antes y después del tratamiento di = xi-yi El objetivo de la prueba de comparaciones por pares es eliminar al máximo las fuentes de variación por medio de la formación de parejas similares respecto a tantas variables como sea posible. En estos casos, en lugar de llevar a cabo el análisis con observaciones individuales, se puede utilizar como variable de interés la diferencia entre los pares individuales de observación. Supongamos que la v.a. que define la diferencia entre el antes y después del tratamiento es una v.a. d que se distribuye normalmente, pero cuyas media y varianza son desconocidas. Si queremos contrastar la hipótesis de que el tratamiento ha producido cierto efecto En el caso en que H0 fuese cierta tendríamos que el estadístico de contraste que nos conviene es: Donde es la media muestral de las diferencias di y Ŝ d es la cuasivarianza muestral de las mismas. El tipo de contraste sería entonces del mismo tipo que el realizado para la media con varianza desconocida. Cuando H0 es verdadera la estadística de prueba sigue una distribución t de Student con n-1 grados de libertad. 1. Contraste bilateral: Consideramos el contraste de tipo Entonces se define 33 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM y se rechaza la hipótesis nula cuando: ó . 2. Contrastes unilaterales: En los dos tipos de contrastes unilaterales o de una cola se utiliza el mismo estadístico: Si el contraste es entonces: Se rechaza H0 si: . Para el test contrario Se rechaza H0 si: Texp > t n-1 ,1- . Si el contraste se realiza cuando 2 d es conocida, entonces el estadístico del contraste es: y el tratamiento es análogo en los tres casos. Contrastes de diferencia entre medias poblacionales independientes Este tipo de contraste también es aplicado para diferencia de medias, pero en los casos en los que se comparan medias poblacionales para un carácter determinado en dos poblaciones distintas. Sean dos poblaciones normales N x , x y N y , y con x y y conocidas, de las cuales se extraen dos muestras aleatorias e independientes de tamaño nx y ny respectivamente. Con un nivel de significación α dado, queremos realizar los siguientes contrastes: 34 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM H 0 : x y d0 H 0 : x y d0 H 0 : x y d0 2. 3. H1 : x y d 0 H1 : x y d 0 H1 : x y d 0 1. El caso más frecuente es cuando d0=0. Sin embrago, es posible probar la hipótesis de que la diferencia es igual que, mayor o igual que, menor o igual que algún valor distinto de cero. Utilizando el estadístico zexp x y d0 x2 nx y2 se tienen los siguientes contrastes. ny Contraste de medias con varianzas conocidas: De manera similar al caso del contraste para una media, queremos en esta ocasión contrastar la hipótesis de que las dos poblaciones (cuyas varianzas suponemos conocidas) sólo difieren en una cantidad . frente a hipótesis alternativas que darán lugar a contrastes unilaterales o bilaterales. Para ello nos basamos en la distribución del siguiente estadístico de contraste: 1. Contraste bilateral o de dos colas: Se define entonces Se acepta H 0 si: z / 2 zexp z / 2 35 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM y el test consiste en: 2. Contrastes unilaterales o de una cola Se utiliza en ambos caso el mismo estadístico utilizado para el contraste bilateral: Para el test Se acepta H 0 si: zexp z y para el contraste de significación contrario: Se acepta H 0 si: zexp z Ejemplo: Un equipo de investigadores desea saber si los datos que han recolectado proporcionan la evidencia suficiente para indicar una diferencia entre las concentraciones medias de ácido úrico en el suero de individuos normales e individuos con síndrome de Down. Los datos presentan las concentraciones de acido úrico en el suero de 12 individuos con síndrome de Down y 15 individuos sanos. Las medias son x 1=4.5mg/100ml y x 2=3.4mg/100ml. Solución: El contraste es H0: 1- 2 = 0 o 1= 2 H1: 1- 2 ≠ 0 o 1≠ 2 36 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Si =0.05, los valores críticos de z son ± 1.96. Se rechaza H0 a menos que 1.96<zcalculada<1.96. Cálculo de la estadística de prueba: Z= (4.5 3.4) 0 1 / 12 1 / 15 = 1.1 =2.82 0.39 Como 2.82 es mayor que 1.96 se rechaza la hipótesis nula. Se concluye que, de acuerdo con estos datos, hay indicios de que las medias de las poblaciones son diferentes. Contraste de medias homocedáticas Aplicable al caso en el que deseamos contrastar la diferencia de medias de dos poblaciones independientes cuando sólo conocemos que las varianzas de ambas poblaciones son iguales, pero desconocidas. El problema a contrastar es: El estadístico que usaremos para el contraste ya lo hemos visto. Si suponemos que H0 es cierta se tiene Donde es la cuasivarianza muestral ponderada de Ŝ 21 y Ŝ 22. Se han perdido dos grados de libertad a causa de la estimación de 2 1= 2 2 mediante Ŝ 21 y Ŝ 22. 1. Contraste bilateral Para el contraste de significación Se tiene como en casos anteriores que el contraste adecuado consiste en definir Y rechazar o admitir la hipótesis nula siguiendo el criterio 37 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM 2. Contrastes unilaterales Cuando el contraste es unilateral del modo El contraste se realiza siguiendo el mismo proceso que en otros realizados anteriormente y utilizando el mismo estadístico, lo que nos lleva a Y cuando el contraste de significación es el contrario Del mismo modo Ejemplo: Un grupo de investigadores colecto datos acerca de las concentraciones de amilasa en el suero de muestras de individuos sanos y de individuos hospitalizados. Desean saber si es posible concluir que las medias de las poblaciones son distintas. Los datos son las mediciones de amilasa en suero de n2= 15 individuos sanos y n1= 22 individuos hospitalizados. Las medias muestrales y sus desviaciones estándar son las siguientes: s1=40 unidades/ml x 1=120 unidades/ml x 2=96 unidades/ml s2=35 unidades/ml Solución: El contraste es: H0: 1- 2 = 0 H1: 1- 2 ≠ 0 Si definimos a =0.05, los valores críticos de t son ± 2.0301. Se rechaza H0 a menos que 2.0301<tcalculada<2.0301. El cálculo de la estadística de prueba es: Ŝ 2= t= 21(1600) 14(1225) =1450 21 14 (120 96) 0 1450 1450 15 22 = 24 =1.88 12.75 38 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM No es posible rechazar H0 porque -2.0301<1.88<2.0301. Es decir, 1.88 cae dentro de la región de aceptación. Con base a estos datos no es posible concluir que las dos medias de la población son diferentes. Contraste de medias no homocedáticas Es un tipo de contraste que se aplica en el caso más problemático, es decir cuando sólo conocemos de las dos poblaciones que su distribución es normal, y que sus varianzas no son conocidas y significativamente diferentes. El contraste es: En este caso el estadístico de contraste tendrá una ley de distribución muy particular. Consistirá en una distribución t de Student, con un número de grados de libertad que en lugar de depender de modo determinista de la muestra (a través de su tamaño), depende de un modo aleatorio mediante las varianzas muestrales. Concretamente, el estadístico que nos interesa es donde f es el número de grados de libertad que se calcula mediante la fórmula de Welch No desarrollamos en detalle los cálculos a realizar, pues la técnica para efectuar los contrastes es análoga a las vistas anteriormente cuando las varianzas son desconocidas e iguales. Nota Si lo que pretendemos contrastar es si las medias poblacionales de dos muestras independientes obtenidas de poblaciones normales son idénticas, esto se reduce a los casos anteriores tomando , es decir, realizando el contraste: 3) DISTRIBUCIÓN MUESTRAL DE DIFERENCIA DE PROPORCIONES Muchas aplicaciones involucran poblaciones de datos cualitativos que deben compararse utilizando proporciones o porcentajes. Cuando el muestreo 39 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM procede de dos poblaciones binomiales y se trabaja con dos proporciones muestrales, la distribución muestral de diferencia de proporciones es aproximadamente normal para tamaños de muestra grande (n1p1 5, n1q1 5, n2p2 5 y n2q2 5). Entonces p1 y p2 tienen distribuciones muestrales aproximadamente normales, así que su diferencia p1-p2 también tiene una distribución muestral aproximadamente normal. Cuando se estudió la distribución muestral de proporciones se comprobó que p̂ = p y que p̂ = pq n por lo que se puede deducir que: p̂ 1 - p̂ 2 = p1-p2 y que . Si tenemos dos poblaciones suficientemente pequeñas, podemos extraer de la población 1 todas las muestras aleatorias posibles de tamaño n1 y calcular a partir de cada conjunto de datos de la muestra la proporción de la muestra p̂ 1. Lo mismo podemos hacer con la población 2. Luego es posible calcular las diferencias entre todos los pares posibles de proporciones muestrales, donde un miembro de cada par tiene un valor p̂ 1 y el otro un valor p̂ 2. La distribución muestral de la diferencia ente las dos porciones de las muestras consiste en todas las diferencias existentes acompañadas de sus frecuencias de ocurrencias. La fórmula que se utilizará para el cálculo de probabilidad del estadístico de diferencia de proporciones es: Ejemplo: Los hombres y mujeres adultos de una ciudad grande en sus opiniones sobre la promulgación de la pena de muerte para personas culpables de asesinato. Se cree que el 12% de los hombres adultos están a favor de la pena de muerte, mientras que sólo 10% de las mujeres adultas lo están. Si se pregunta a dos muestras aleatorias de 100 hombres y 100 mujeres su opinión sobre la promulgación de la pena de muerte, determine la probabilidad de que el porcentaje de hombres a favor sea al menos 3% mayor que el de las mujeres. Solución: Datos: PH = 0.12 PM = 0.10 nH = 100 nM = 100 p(pH-pM 0.03) = ? Hay que tener en cuanta que debe incluirse el factor de corrección de 0.5 por ser una distribución binomial y que se está utilizando la distribución normal. 40 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Se concluye que la probabilidad de que el porcentaje de hombres a favor de la pena de muerte, al menos 3% mayor que el de mujeres es de 0.4562. Estimación de la Diferencia de dos Proporciones Muchas veces se tiene interés en conocer la magnitud de la diferencia entre dos poblaciones, podemos comparar por ejemplo, entre hombres y mujeres, dos grupos de edades, dos grupos socioeconómicos. Un estimador puntual insesgado de la diferencia de proporciones de las poblaciones se obtiene al calcular las diferencias de las proporciones de las muestras p̂ 1 - p̂ 2. Cuando n1 y n2 son de gran tamaño y las proporciones de la población no están muy cerca de 0 o de 1, es posible aplicar el teorema del límite central y utilizar la teoría de la distribución normal para obtener los intervalos de confianza. Vamos a considerar que tenemos dos poblaciones de modo que en cada una de ellas estudiamos una v.a. dicotómica (Bernoulli) de parámetros respectivos p1 y p2. De cada población vamos a extraer muestras de tamaño n1 y n2 Si las muestras son suficientemente grandes ocurre que Anteriormente, se vio el tema de la generación de las distribuciones muestrales, en donde se tenía el valor de los parámetros, se seleccionaban dos muestras y podíamos calcular la probabilidad del comportamiento de los estadísticos. Para este caso en particular se utilizará la distribución muestral de diferencia de proporciones para la estimación de la misma. Recordando la formula: Despejando P1-P2 de esta ecuación obtenemos un intervalo de confianza del 100(1 - ) para P1-P2 : Donde Z se obtiene de la tabla de distribución normal al nivel 1-α/2. Aquí se tiene el mismo caso que en la estimación de una proporción, ya que al hacer el despeje nos queda las dos proporciones poblacionales y es precisamente lo que queremos estimar, por lo que se utilizarán las proporciones de la muestra como estimadores puntuales: 41 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM Ejemplo: Un artículo relacionado con la salud, reporta los siguientes datos sobre la incidencia de disfunciones importantes entre recién nacidos con madres fumadoras de marihuana y de madres que no la fumaban: Usuaria No Usuaria Tamaño Muestral 1246 11178 Número de disfunciones 42 294 Proporción muestral 0.0337 0.0263 Encuentre el intervalo de confianza del 99% para la diferencia de proporciones. Solución: Representemos P1 la proporción de nacimientos donde aparecen disfunciones entre todas las madres que fuman marihuana y definamos P2, de manera similar, para las no fumadoras. El valor de z para un 99% de confianza es de 2.58. -0.0064<P1-P2<0.0212 Este intervalo es bastante angosto, lo cual sugiere que P1-P2 ha sido estimado de manera precisa. Contrastes sobre la diferencia de proporciones Supongamos que tenemos dos muestras independientes tomadas sobre dos poblaciones, en la que estudiamos una variable de tipo dicotómico (Bernoulli): Si X1 y X2 contabilizan en cada caso el número de éxitos en cada muestra se tiene que cada una de ellas se distribuye como una variable aleatoria binomial, de modo que los estimadores de las proporciones en cada población tienen distribuciones que de un modo aproximado son normales (cuando n1 y n2 son bastante grandes) 42 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM El contraste que nos interesa realizar es el de si la diferencia entre las proporciones en cada población es una cantidad conocida Si H0 fuese cierta se tendría que: Desafortunadamente ni p1 ni p2 son conocidos de antemano y utilizamos sus estimadores, lo que da lugar a un error que es pequeño cuando los tamaños muestrales son importantes: La prueba que se utiliza con más frecuencia con relación a la diferencia entre las proporciones de dos poblaciones es aquella en la que su diferencia es cero. Sin embargo, es posible probar que dicha diferencia es igual a algún otro valor. Se pueden hacer pruebas unilaterales y bilaterales. Siempre que la hipótesis nula sea p1-p2=0, se supone que las proporciones de las dos poblaciones son iguales. Esto permite combinar los resultados de las dos muestras y obtener una estimación ponderada de la proporción común supuesta: p = x1+x2 / n1+n2 Donde x1 y x2 son el número de la primera y segunda muestra que poseen la característica de interés. Esta estimación ponderada se utiliza para calcular el error estándar estimado para el estimador como sigue: ˆ p(1 p) p(1 p) n n El estadístico de contraste se convierte en: Z= ( pˆ pˆ ) ( p p) ̂ 1. Contraste bilateral El contraste bilateral sobre la diferencia de proporciones es Entonces se define 43 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM y se rechaza la hipótesis nula si Zexp<-z1- /2 o si Zexp>-z1- /2 2. Contrastes unilaterales En el contraste Se rechazará H0 si Zexp< -z1- . Para el test contrario Se rechaza H0 si Zexp> -z 1- . Ejemplo: En un estudio para comparar un nuevo tratamiento para la migraña con el tratamiento habitual, 78 de los 100 individuos que recibieron el tratamiento habitual respondieron favorablemente. De los 100 individuos que recibieron el nuevo tratamiento, 90 respondieron satisfactoriamente. ¿Proporcionan estos datos la evidencia suficiente para afirmar que el nuevo tratamiento es más efectivo que el habitual? Solución: Se calculan: p̂ 1= 78/100=0.78 p= p̂ 2=90/100=0.90 90 78 =0.84 100 100 Las hipótesis son: H0=p2-p1 0 H1= p2-p1>0 Sea =0.05. El valor crítico de z es 1.645. Se rechaza H0 si el valor de z es mayor que 1.645. El cálculo del estadístico de prueba es: z= (0.90 0.78) (0.84)(0.16) (0.84)(0.16) 100 100 0.12 =2.32 0.0518 Como 2.32>1-645, se rechaza H0. Estos datos sugieren que el tratamiento es más efectivo que el habitual 44 MATERIAL DE CÁTEDRA TEMA 1 : ESTADÍSTICA INFERENCIAL- ESTADISTICA II –UNaM BIBLIOGRAFÍA Bioestadística De Daniel, Wayne Estadística para administradores ,William Mendenhall Estadística , Murray R. Spiegel Link recomendados http://www.ditutor.com/inferencia_estadistica/estadistica_inferencial.html http://intranet.catie.ac.cr/intranet/posgrado/Herramientas_Estadisticas/Manual.p df 45