Clase05-02
Anuncio

Universidad Nacional de Ingenierı́a - Facultad de Ingenierı́a Mecánica
Departamento Académico de Ingenierı́a Aplicada
CONTROL MODERNO Y ÓPTIMO (MT 227C)
Clase05-02
Elizabeth Villota Cerna
29/09/2010
Semestre 2010II - UNI
En lo que sigue discutiremos métodos para el diseño de controladores por realimentación para el caso
de sistemas lineales. El proceso de diseño involucra tres pasos. En el primer paso asumimos que todos los
estados están disponibles y procedemos con el diseño de leyes de control por realimentación de estados.
Luego procedemos con el segundo paso; que corresponde al diseño del estimador, también denominado como
el observador del vector de estados. El último paso consiste en combinar los dos pasos anteriores tal que la
ley de control, diseñada en el primer paso, usa el estimador de estados en vez de el vector de estados real. El
resultado de este paso es un compensador combinado controlador-estimador. A continuación discutiremos el
controlador por realimentación de estados.
5.2.
Control por realimentación de estados
El estado de un sistema dinámico es una colección de variables que permiten la predicción del desarrollo
de un sistema a futuro. A continuación exploraremos la idea de diseñar la dinámica de un sistema a través
de realimentación de estados. La ley de control por realimentación será desarrollada paso a paso usando una
única idea: la ubicación de los autovalores del sistema en lazo cerrado en posiciones deseadas.
5.2.1.
Estructura del controlador
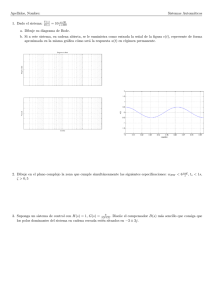
La Fig. 1 muestra un diagrama de un sistema de control por realimentación de estados tı́pico. El sistema
completo consiste del proceso dinámico (planta), que es considerado lineal, los elementos del controlador K
y kr , la entrada de referencia (o señal de comando) r y procesos de disturbio d. El objetivo del controlador
por realimentación es regular la salida del sistema z tal que rastree la señal de referencia aún en la presencia
de disturbios y también incerteza en el proceso.
Figura 1: Sistema de control por realimentación de estados. El controlador usa el estado del sistema x y la
entrada de referencia r para comandar el proceso (planta) a través de su entrada u. El disturbio es modelado
a través de una entrada aditiva d.
Un elemento importante del diseño de control es la especificación de desempeño. La especificación más
simple de desempeño es la de estabilidad: en la ausencia de disturbios, nuestro objetivo es hacer que el
punto de equilibrio del sistema sea asintóticamente estable. A menudo, especificaciones de desempeño más
sofisticadas dotan de propiedades deseadas a una respuesta al escalón o a la respuesta en frecuencia del
sistema, tales como tiempo de levantamiento, sobreimpulso y tiempo de establecimiento de la respuesta al
escalón. Adicionalmente, una preocupación frecuente es que el sistema posea propiedades de atenuación de
disturbios. Considerando un sistema descrito por la ecuación diferencial lineal:
ẋ(t) = Ax(t) + Bu(t), x(0) = xo
z(t) = Cx(t) + Du(t),
,
y(t) = In x(t)
donde hemos ignorado el disturbio d por ahora. Nuestro objetivo es llevar la salida z a una referencia deseada
r y mantenerla alli.
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
5.2.2.
Estabilización por realimentación de estados
Asumiendo que todos los componentes del vector de estados pueden ser medidos. Dado que el estado en
el tiempo t contiene toda la información necesaria para predecir el comportamiento futuro del sistema, la
ley de control invariante en el tiempo más general es una función del estado y de la entrada de referencia:
u = α(x, r).
Si la ley de control por realimentación de estados es asumida lineal, entonces la realimentación se puede
escribir como una combinación lineal de todas las variables de estado, incluyendo la referencia:
u = −Kx + kr r,
donde K ∈ Rm×n es una matriz constante y r es el valor de referencia, asumido por ahora constante. El
sistema en lazo cerrado es entonces:
ẋ = Ax + B(−Kx + kr r), x(0) = xo
ẋ = (A − BK)x + Bkr r, x(0) = xo
Los polos del sistema en lazo cerrado son las raices de la ecuación caracterı́stica:
det(sIn − A + BK) = 0.
La ley de control por realimentación de estados consiste en seleccionar ganancias:
kij ,
i = 1, 2, ..., m, j = 1, 2, .., n,
tal que las raices de la ecuación caracterı́stica del sistema en lazo cerrado:
det(sIn − A + BK) = 0,
esten en las ubicaciones deseadas en el plano complejo. Si asumimos que el diseñador ha hecho una selección de
los polos deseados del sistema en lazo cerrado, y ellos son: p1 , p2 , ..., pn . Los polos (del sistema en lazo cerrado)
deseados pueden ser reales o complejos. Si son complejos, ellos deben estar en pares complejos conjugados.
Esto es debido al uso de ganancias reales kij . Una vez que definimos los polos deseados, podemos formar el
polinomio caracterı́stico en lazo cerrado deseado,
αc (s) = (s − p1 )(s − p2 )...(s − pn )
αc (s) = sn + αn−1 sn−1 + ... + α1 s + αo .
Nuestro objetivo es seleccionar una matriz de realimentación K tal que:
det(sIn − A + BK) = sn + αn−1 sn−1 + ... + α1 s + αo .
El problema arriba presentado es también llamado problema de ubicación de polos o problema de asignación
de autovalores. Primero discutiremos el problema de ubicación de polos para una planta con una entrada.
Ubicación de polos para sistemas de una entrada
En este caso, K = k ∈ R1×n . La solución de este problema se obtiene fácilmente si el
Ax(t) + bu(t) ya está en la forma canónica controlable. En tal caso tenemos:
0
1
0
...
0
0
0
0
1
...
0
0
.
..
..
A − bk =
.
0
0
0
...
0
1
−ao − k1 −a1 − k2 −a2 − k3 ... −an−2 − kn−1 −an−1 − kn
Entonces, las ganancias deseadas son:
k1
k2
= αo − ao ,
= α1 − a1 ,
..
.
kn
= αn−1 − an−1
Clase05-02, pág. 8
.
sistema ẋ(t) =
.
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
Si el sistema ẋ(t) = Ax(t)+bu(t) no está en la forma canónica controlable, primero transformamos el sistema
en la forma canónica y luego calculamos el vector de ganancias k̃ tal que:
det(sIn − Ã + b̃k̃) = sn + αn−1 sn−1 + ... + α1 s + αo .
Entonces,
k̃ =
Luego:
αo − ao
α1 − a1
...
αn−1 − an−1
k = k̃T,
.
donde T es la transformación que lleva al sistema ẋ(t) = Ax(t) + bu(t) a la forma canónica controlable.
Podemos representar la fórmula de arriba para la matriz de ganancias en una forma alternativa. Para
esto, nótese que:
q1
q1 A
k̃T = αo − ao α1 − a1 ... αn−1 − an−1
.
..
.
n−1
q1 A
k̃T = q1 (αo In + α1 A + ... + αn−1 An−1 ) − q1 (ao In + a1 A + ... + an−1 An−1 ).
Por el teorema de Cayley-Hamilton, tenemos:
An = −(ao In + a1 A + ... + an−1 An−1 ).
Entonces:
k = q1 αc (A).
La expresión para el vector fila de ganancias fue propuesto por Ackerman en 1972 y ahora se conoce como
Fórmula de Ackerman para ubicación de polos.
Ejemplo, sistema de una entrada
Para el sistema dinámico lineal:
ẋ =
1 −1
1 −2
x+
2
1
u,
usaremos la fórmula de Ackerman para diseñar el controlador por realimentación de estados, u = −Kx, tal
que los polos en lazo cerrado esten localizados en {−1, −2}.
Para usar la fórmula de Ackerman, primero formamos la matriz de controlabilidad del sistema ẋ(t) =
Ax(t) + bu(t) y luego encontramos la última fila de su inversa, denotada por q1 . La matriz de controlabilidad
es:
2 1
b Ab =
.
1 0
La inversa de la matriz arriba es:
Entonces, q1 =
0 1
1 −2
.
1 −2 . El polinomio caracterı́stico del sistema en lazo cerrado deseado es:
αc (s) = (s + 1)(s + 2) = s2 + 3s + 2.
Luego,
k
= q1 αc (A)
2
= q1 (A
+ 3A + 2I2 )
1 0
1 −1
1 −1
1 −1
+2
+3
= q1
0 1
1 −2 1 −2
1 −2 0 1
3 −3
2 0
+
+
= q1
−1 3
3 −6
0 2
5 −2
= 1 −2
2 −1
= 1 0
Clase05-02, pág. 9
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
Ubicación de polos para sistemas de múltiples entrada
Si el sistema ẋ(t) = Ax(t) + Bu(t) ya se encuentra en la forma canónica controlable, procedemos como
a continuación. Primero representamos la matriz B como:
0 0 ... 0 0
0 0 ... 0 0
0 0 ... 0 0 0 0 ... 0 0
.. ..
..
..
.
.
.
.
1 x x x x 1 0 0 0 0
0 0 ... 0 0 0 0 ... 0 0 1 x x x x
0 0 ... 0 0 0 0 ... 0 0 0 1 x x x
..
.. ..
..
.. = B̂Γ
..
..
= .
.
.
.
B=
.
.
.
0 1 x x x 0 1 0 0 0
0 0 ... 1 x
.
.
..
..
..
.
0 0 0 0 1
.
.
.
0 0 ... 0 0 0 0 ... 0 0
0 0 ... 0 0 0 0 ... 0 0
.
.
..
..
.
..
.
.
.
0
0
0
0
1
0
0
0
0 1
donde la matriz Γ es no singular y cuadrada que consiste de filas de B diferentes de cero. Luego, sea:
K̂ = ΓK.
Nótese que:
0
0
..
.
k̂
11
0
0
.
B̂ K̂ = ..
k̂21
.
.
.
0
0
..
.
k̂m1
0
0
...
...
0
0
0
0
..
.
k̂12
0
0
...
...
...
k̂1n−1
0
0
k̂1n
0
0
..
.
k̂22
...
k̂2n−1
0
0
...
...
0
0
k̂2n
..
.
0
0
..
.
k̂m2
... k̂mn−1
k̂mn
;
esto es, las filas no ceros en el producto B̂ K̂ coinciden con las filas no ceros de la matriz A en su forma
canónica controlable. Si seleccionamos, por ejemplo, las ganancias kij , i = 1, 2, ..., m y j = 1, 2, ..., n, tal que:
0
1
0 ...
0
0
0
0
1 ...
0
0
..
.. ;
A − BK = A − B̂ K̂ = .
.
0
0
0 ...
0
1
−αo −α1 α2 ... αn−2 αn−1
donde:
K = Γ−1 K̂.
Si el sistema ẋ(t) = Ax(t) + Bu(t) no está en la forma canónica controlable, primero lo llevaremos a esa
forma y luego calcularemos la matriz de ganancias que ubica los polos del sistema en lazo cerrado en las
posiciones deseada para el sistema ẋ(t) = Ax(t) + Bu(t) en la forma canónica controlable. la matriz de
ganancias que ubica los polos del sistema en lazo cerrado en las posiciones pre-especificadas para el sistema
ẋ(t) = Ax(t) + Bu(t) en sus coordinadas originales es entonces dado por:
K = Γ−1 K̂T.
Clase05-02, pág. 10
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
donde T es la matriz de transformación que lleva al sistema ẋ(t) = Ax(t) + Bu(t) a la forma canónica
controlable.
Ejemplo, múltiples entradas
Para el sistema dinámico lineal:
0
1
ẋ =
0
0
0
0
1
0
1
2
3
−21
0
0
x +
0
5
0
0
u,
0
1
1
0
0
0
usaremos su forma canónica controlable para encontrar la matriz K ∈ R2×4 tal que los polos en lazo cerrado
esten ubicados en:
−2, −3 + −3 + i, −3 − i, −4.
Primero transformamos ẋ(t) = Ax(t) + Bu(t) a la forma canónica controlable.
de controlabilidad:
1 0 0 0 0
0 0 1 0 0
b1 b2 Ab1 Ab2 A2 b1 ... =
0 0 0 0 1
0 1 0 5 0
Para eso, formamos la matriz
...
...
.
...
...
Entonces seleccionamos, procediendo de izquierda a derecha, las primeras cuatro columnas linealmente independientes de la matriz de controlabilidad. Obtenemos:
b1 b2 Ab1 A2 b1 .
Entonces, los ı́ndices de controlabilidad son d1 = 3 y d2 = 1. Rearreglamos las columnas y formamos la
matriz L de la forma:
L = b1 Ab1 A2 b1 b2 = I4 = L−1 .
Las últimas filas que necesitamos para la construcción de la matriz de transformación son:
q1 = 0 0 1 0 and q2 = 0 0 0 1 .
La matriz de transformación es:
T =
q1
q1 A q1 A2
0
0
q2 =
1
0
Y el sistema ẋ(t) = Ax(t) + Bu(t) en el nuevo sistema
0
1 0 0
0
0
1 0
à = T AT −1 =
1
2 3 0
−21 0 0 5
0 1
1 3
3 11
0 0
0
0
.
0
1
coordenado tiene la forma:
0 0
0 0
and B̃ = T B =
1 0
0 1
El polinomio caracterı́stico del sistema en lazo cerrado es:
.
αc (s) = (s + 2)(s + 3 − i)(s + 3 + i)(s + 4) = s4 + 12s3 + 54s2 + 108s + 80.
Una posible elección de la matriz de ganancias K̃, dentro de tantas, que funciona para el caso es K̃ tal que:
0
1
0
0
0
0
1
0
.
à − B̃ K̃ =
0
0
0
1
−80 −108 −54 −12
Nótese que Γ = I2 . Entonces:
K̃ =
1
59
2
108
3
54
−1
17
Clase05-02, pág. 11
,
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
y luego:
K = K̃T =
3
54
11
270
40
977
−1
17
.
El algoritmo aqui presentado para ubicación de polos para sistemas de múltiples entradas presenta más
un valor teórico antes que práctico. EL algoritmo presenta problemas de implementación numérica porque la
transformación del sistema ẋ(t) = Ax(t)+Bu(t) a la forma canónica controlable sufre de propiedades numéricas pobres. Existen otros algoritmos más robustos, como los implementados en MATLAB, especificamente
en la función place.
La solución del problema de ubicación de polos para un sistema de múltiples entradas no es única.
Entonces, los grados de libertad restantes pueden ser usados para alcanzar objetivos secundarios. En la
semanas siguientes discutiremos un método para construir una ley de control lineal por realimentación de
estados que ubica los polos del sistema en lazo cerrado en posiciones pre-especificadas y al mismo tiempo
minimiza un ı́ndice de desempeño cuadrático.
Como resultado de la discusión en esta parte, enunciaremos un teorema fundamental de sistemas lineales:
Teorema El problema de ubicación de polos tiene solución para todas las elecciones de los n polos en
lazo cerrado, simétricos con respecto al eje real, si y sólo si el sistema ẋ(t) = Ax(t) + Bu(t) es controlable. ⋄
5.2.3.
Desempeño. Control para la solución en estado estacionario
Nótese que kr no afecta la estabilidad del sistema (que es determinado por los autovalores de A − BK)
pero si afecta la solución en estado estacionario. En particular, el punto de equilibrio y la salida del sistema
en lazo cerrado estan dados por:
ẋe = 0 = (A − BK)xe + Bkr r,
xe
ze
= −(A − BK)−1 Bkr r,
= Cxe + Due
entonces kr debe ser elegido tal que ze = r (el valor deseado de la salida). Asumiendo que D = 0 (el caso
más común), entonces:
ze = r = −C(A − BK)−1 Bkr r,
luego para cuando kr sea un escalar (sistema de una entrada y una salida) tenemos:
kr = −1/(C(A − BK)−1 B).
Nótese que kr es exactamente la inversa de la ganancia en la frecuencia cero del sistema en lazo cerrado.
5.2.4.
Especificaciones del diseño del control por realimentación de estados
La ubicación de los autovalores determina el comportamiento de la dinámica en lazo cerrado, y como
consecuencia, la decisión más importante es donde ubicaremos los autovalores. Como en todos los casos
de diseño de sistemas de control, existe una concesión mutua entre la magnitud de la entrada de control,
la robustez del sistema a las perturbaciones y el desempeño del sistema en lazo cerrado. En esta sección
revisaremos brevemente estas concesiones mutuas con el caso especial de sistemas de segunda orden.
Sistema de segunda orden
El sistema de segunda orden es una clase de sistema que ocurre frecuentemente en el análisis y diseño de
sistemas de relimentación.
Un sistema de segunda orden se puede escribir como:
q̈ + 2ζωo q̇ + ωo2 q = kωo2 u,
En la forma de espacio de estados, el sistema se escribe como:
dx
0
ωo
0
=
x+
u,
−ωo −2ζωo
kωo
dt
Clase05-02, pág. 12
y = q.
y=
1 0
x.
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
Los autovalores del sistema están dados por:
λ = −ζωo ±
p
ωo2 (ζ 2 − 1),
y observamos que el origen es un punto de equilibrio estable si ωo > 0 y ζ > 0. Nótese que los autovalores
son complejos si ζ < 1 y reales en caso contrario.
La forma de la solución depende del valor de ζ, el cual se denomina factor de amortiguamiento del sistema.
Si ζ > 1, decimos que el sistema es sobreamortiguado, y la respuesta natural (u = 0) del sistema está dado
por:
βx1o + x2o −αt αx1o + x2o −βt
y(t) =
e
−
e ,
β−α
β−α
p
p
donde α = ωo (ζ + ζ 2 − 1) y β = ωo (ζ − ζ 2 − 1). Vemos que la respuesta consiste en la suma de dos
señales que decaen exponencialmente. Si ζ = 1, entonces el sistema es criticamente amortiguado y la solución
resulta:
y(t) = e−ζωo t (x1o + (x2o + ζωo x1o )t).
Nótese que la respuesta es aún asintóticamente estable mientras que ωo > 0, a pesar que el segundo término
en la solución este creciendo con el tiempo (pero más lento que el término exponencial decayente que lo
multiplica).
Finalmente, si 0 < ζ < 1, entonces la solución es oscilatoria y se dice que el sistema es subamortiguado.
El parámetro ωo es conocido como la frecuencia natural del sistema. La respuesta natural del sistema esta
dado por:
1
ζωo
−ζωo t
x1o +
x2o sin ωd t),
y(t) = e
(x1o cos ωd t +
ωd
ωd
p
donde ωd = ωo 1 − ζ 2 es llamada la frecuencia amortiguada.
Debido a la forma simple de un sistema de segunda orden, es posible resolver el sistema en forma analı́tica
para una entrada del tipo escalón. Para este caso, la solución depende de ζ:
!
ζ
−ζωo t
−ζωo t
y(t) = k 1 − e
cos ωd t + p
e
sin ωd t , ζ < 1
1 − ζ2
y(t) = k 1 − e−ζωo t (1 + ωo t) , ζ = 1
√ 2
√ 2
1
1
ζ
ζ
+ 1)e−ζωo t(ζ− ζ −1) + ( p
− 1)e−ζωo t(ζ+ ζ −1)
y(t) = k 1 − ( p
2
2
1 − ζ2
1 − ζ2
!
, ζ > 1,
donde hemos tomado x(0) = 0.
La Fig. 2 muestra respuestas de un sistema de 2da orden a una entrada del tipo escalón con k = 1 y
para diferentes valores de ζ. La forma de la respuesta es determinado por ζ, y la velocidad de la respuesta
es determinada por ωo : la respuesta es más rápida si ωo es grande.
2
Im
ζ = 0.4
ζ = 0.7
ζ =1
ζ = 1.2
ζ =0
1.5
Re
y
1
0.5
0
0
(a) Eigenvalues
ζ
5
10
Normalized time ω0 t
15
(b) Step responses
Figure 6.8: Step response for a second-order system. Normalized step responses h for the
Figura 2: Respuestas de un sistema de 2da orden a una entrada del tipo escalón unitario
Clase05-02, pág. 13
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
Adicionalmente también podemos calcular las propiedades de la respuesta al escalón. Por ejemplo, para
un sistema subamortiguado:
!
ζ
y(t) = k 1 − p
e−ζωo t sin(ωd t + ϕ) ,
1 − ζ2
donde ϕ = arccosζ. El sobreimpulso máximo ocurrirá por primera vez cuando la derivada de y sea cero, que
se puede mostrar que es:
√ 2
Mp = eπζ/ 1−ζ .
De la misma forma se pueden calcular otras caracterı́sticas de la respuesta al escalón, Cuadro 3.
Property
Value
Steady-state value
k
ϕ/ tan ϕ
Rise time
Tr = 1/ω0 · e
√
2
M p = e−π ζ / 1−ζ
Overshoot
Settling time (2%)
Ts ≈ 4/ζ ω0
ζ = 0.5
√
ζ = 1/ 2
ζ =1
k
k
k
1.8/ω0
2.2/ω0
2.7/ω0
16%
4%
0%
8.0/ω0
5.9/ω0
5.8/ω0
Figura 3: Propiedades de la respuesta al escalón para un sistema de 2do orden con 0 < ζ < 1.
La respuesta en la frecuencia también puede ser calculada explı́citamente y está dada por:
M eiθ =
kωo2
kωo2
=
(iω)2 + 2ζωo (iω) + ωo2
ωo2 + 2iζωo ω + −ω 2
Una ilustración gráfica de la respuesta en frecuencia está dada en la Fig. 4. Nótese que el pico de la resonancia
aumenta a medida que crece ζ.
2
10
Im ζ ≈ 0
Gain
ζ = 0.08
ζ = 0.2
ζ = 0.5
ζ
0
10
−2
ζ =1
10
Phase [deg]
Re
0
ζ
−90
−180 −1
10
(a) Eigenvalues
0
10
Normalized frequency ω/ω0
10
1
(b) Frequency responses
Figura 4: Respuesta en frecuencia de un sistema de 2do orden.
Sistema de orden alto
Para sistemas de orden alto, la ubicación de polos es considerablemente más dificil, especialmente cuando
tratamos de considerar las múltiples concesiones mutuas presentes en el diseño de control por realimentación.
Una de las razones por las que los sistemas de segundo orden son tan importantes en los sistemas
de realimentación es que aún para sistemas complicados la respuesta es a menudo caracterizada por los
autovalores dominantes. Para definir los autovalores dominantes, consideremos el sistema con autovalores λj
j = 1, ..., n. Definimos el factor de amortiguamiento para el autovalor complejo como:
ζ=
−Reλ
.
kλk
Decimos que el par de autovalores complejos conjugados λ, λ∗ es un par dominante si tiene el menor factor
de amortiguamiento comparado con los otros autovalores del sistema. Por consiguiente, se puede decir que el
Clase05-02, pág. 14
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
par dominante de autovalores será el factor principal en la respuesta del sistema después que los transientes
debido a otros términos (autovalores) hayan desaparecido. A pesar de que esto último no siempre se cumple,
a menudo el caso de los autovalores dominantes determinana la respuesta (al escalón) del sistema.
El único requerimiento formal en la asignación de autovalores es que el sistema sea controlable. En la
práctia existen otras restricciones porque la selección de autovalores tiene un gran efecto en la magnitud
y la variación del cambio de la señal de control. Autovalores grandes requerirán por lo general grandes
señales de actuación ası́ como también rápidos cambios de estas señales. La capacidad de los actuadores
impondrá restricciones en la posible ubicación de los autovalores del sistema en lazo cerrado.
A continuación, usaremos las ganancias K y kr para diseñar la dinámica del sistema en lazo cerrado
y satisfacer nuestro objetivo. Los ejemplos a seguir pretender ilustrar y proveer mayor intuición en como
construir tal ley de control por realimentación de estados.
5.2.5.
Ejemplo, sistema de balance
Considerando el sistema de la Fig. 5, recordemos que este sistema es un modelo para una clase de sistemas
en los que el centro de masa es balanceado sobre un punto pivote.
MODELO DEL SISTEMA - puede ser NO LINEAL
Las ecuaciones (no lineales) de movimiento del sistema estan dados por:
p̈
F
(M + m) −ml cos θ
cṗ + ml sin θθ̇2
=
.
+
0
−ml cos θ (J + ml2 )
θ̈
γ θ̇ − mgl sin θ
Por simplicidad tomamos c = γ = 0.
PUNTO DE EQUILIBRIO PARA LINEALIZACIÓN - LINEALIZACIÓN
Linealizando en torno al punto de equilibrio xe
son:
0
0
0
0
A=
0 m2 l2 g/µ
0 Mt mgl/µ
= (p, 0, 0, 0), la matriz
0
1 0
0
0 1
, B =
Jt /µ
0 0
lm/µ
0 0
donde µ = Mt Jt − m2 l2 , Mt = M + m y Jt = J + ml2 .
dinámica y la matriz de control
,
ANÁLISIS DE SISTEMA
Controlabilidad:
La matriz de controlabilidad es:
Wc =
B
AB
A2 B
0
0
A3 B =
Jt /µ
lm/µ
Jt /µ
0
lm/µ
0
0
gl3 m3 g/µ2
2 2 2
0
g l m (M + m)/µ2
El determinante de la matriz es:
det(Wc ) =
gl3 m3 /µ2
gl2 m2 (M + m)/µ2
.
0
0
g 2 l 4 m4
6= 0,
µ4
y concluimos que el sistema es controlable. Esto significa que podemos mover el sistema desde una condición
inicial hasta un estado fina y, en particular, que siempre podemos encontrar una entrada que lleve el sistema
desde una condición inicial hasta el punto de equilibrio.
Clase05-02, pág. 15
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
m
θ
l
F
M
p
(a) Segway
(b) Cart-pendulum system
Figura 5: Sistema de balance.
Polos en lazo abierto:
Usando los siguiente parámetos para el sistema (correspondiente, a groso modo, a un humano siendo
balanceado por un carro de estabilización): M = 10 kg, m = 80kg, c = 0,1N/m/s, γ = 0,01N/rad/sec,
l = 1m y J = 100kgm2 , g = 9,8m/m2 .
Los autovalores de la dinámica del sistema en lazo abierto están dados por λ={0, 2.6842, 2.6851,-0.0011}.
DISEÑO DEL CONTROL
Polos en lazo cerrado:
Para decidir donde ubicar los autovalores del sistema en lazo cerrado, primero notamos que, a groso modo,
la dinámica del sistema en lazo cerrado tendrá dos componentes: la dinámica rápida que estabiliza el péndulo
en la posición invertida y la dinámica lenta que controla la posición del carrito.pPara la dinámica rápida, la
dinámica natural del péndulo (cuando cuelga hacia abajo) esta dada por ωo = mgl/(J + ml2 ) ∼ 2,1rad/s.
Para proveer una respuesta rápida escogemos un factor de amortiguamiento de ζ = 0,5, luego tratamos de
ubicar
el primer par de autovalores en λ1,2 ∼ −ζωo ± ωo ∼ −1 ± 2i, donde hemos usado la aproximación
p
ζ 2 − 1 ∼ 1. Para la dinámica lenta, escogemos una factor de amortiguamiento igual a 0.5 para obtener un
tiempo de subida de aproximadamente 5s. Esto resulta en autovalores λ3,4 = −0,35 ± 0,35i.
Luego el polinomio caracterı́stico del sistema en lazo cerrado serı́a:
αc (s) = (s + 1 − 2i)(s + 1 + 2i)(s + 0,35 − 0,35i)(s + 0,35 + 0,35i)
Estabilización por realimentación de estados:
Cálculando la inversa de la matriz de controlabilidad para encontrar q1 . Luego, usando la fórmula de
Ackerman:
K = q1 αc (A),
obtenemos:
K=
−15,3 1731,3 −49,9 422,8
.
Esta matriz de ganancias K también se puede obtener usando la función place en MATLAB.
Controlador por alimentación directa:
La ganancia por alimentación directa kr es:
kr = −1/(C(A − BK)−1 B) =
Clase05-02, pág. 16
−15,29
0
CONTROL POR REALIMENTACIÓN DE ESTADOS/DISEÑO DE CONTROLADORES
SIMULACIONES
La respuesta a una entrada escalón para el controlador aplicado en el sistema linealizado está dado en
la Fig. 6 (parte izquierda). Observamos que la fuerza de entrada es excesivamente grande, casi tres veces la
fuerza de gravedad en su pico.
Para proveer una fuerza más realista rediseñamos el controlador para que presenta una dinámica controlada un poco más lenta. Para la dinámica del péndulo variamos la frecuencia natural por un factor de tres
y mantenemos el factor de amortiguamiento. La dinámica del carrito también la desaceleramos, el factor de
amortiguamiento permanece en 0.7 pero la frecuencia natural cambia a 1 (correspondiente a un tiempo de
subida de 10s). Luego, los polos deseados resultan:
λ = {−0,33 ± 0,66i, −0,18 ± 0,18i}.
El desempeño del controlador es mostrado en la Fig. 6.
2
Position p [m]
1
0
0
5
10
15
30
Input force F [N]
Input force F [N]
Position p [m]
2
20
10
0
−10
0
5
10
Time t [s]
15
1
0
0
10
20
30
40
10
20
Time t [s]
30
40
30
20
10
0
−10
0
(a) λ1,2 = −1 ± 2i
(b) λ1,2 = −0.33 ± 0.66i
Figura 6: Control por realimentación de estados para un sistema de balance.
Fuente: Capı́tulo 3 del libro Systems and Control de Stanislaw H. Zak (2002).
Fuente: Capı́tulo 6 del libro Feedback Systems: An Introduction for Scientists and Engineers, de Karl J.
Åström y Richard M. Murray.
Clase05-02, pág. 17