Ampliación de Matemáticas
Grado en Ingeniería Informática
Grado en Estadística.
Doble grado en Informática y Estadística.
Índice
1 Series
1.1 Series de números reales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.1.1 Algunas propiedades de las series. . . . . . . . . . . . . . . . . . . . . . . .
1.1.2 Series de términos positivos. . . . . . . . . . . . . . . . . . . . . . . . . . .
1.1.3 Series alternadas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.1.4 Convergencia condicional y absoluta. . . . . . . . . . . . . . . . . . . . . .
1.2 Series de potencias. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.2.1 Representación de funciones en series de potencias. . . . . . . . . . . . . .
1.3 Series de Fourier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3.1 Desarrollos de Fourier con sólo cosenos o sólo senos. . . . . . . . . . . . .
1.3.2 Series de Fourier en un intervalo general [a,b]. . . . . . . . . . . . . . . . .
1
1
3
4
6
7
8
10
14
16
18
2 Interpolación Polinómica
2.1 Polinomio interpolador de Lagrange . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 Forma de Newton del polinomio interpolador de Lagrange. . . . . . . . . . . . . .
2.3 Interpolación de Hermite. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4 Interpolación polinómica segmentaria. . . . . . . . . . . . . . . . . . . . . . . . .
2.5 Splines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
19
19
22
24
26
27
3 Producto interior. Ajuste
3.1 Producto interior. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2 Normas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3 Ángulo y Ortogonalidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4 Proyección y componente ortogonal. . . . . . . . . . . . . . . . . . . . . . . . . .
3.5 Expresión de la proyección en una base arbitraria. . . . . . . . . . . . . . . . . .
3.6 Ecuaciones normales en IRn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.7 Aplicaciones de la proyección. Ajuste Discreto. . . . . . . . . . . . . . . . . . . .
3.7.1 Recta de ajuste. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.7.2 Caso general discreto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
29
30
31
35
37
39
40
40
41
4 Resolución Numérica de Sistemas
4.1 Errores de redondeo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
4.1.1 Situaciones que merecen atención. . . . . . . . . . . . . . . . . . . . . . .
4.2 Aspectos computacionales de la eliminación gaussiana. . . . . . . . . . . . . . . .
4.2.1 Necesidad computacional de pivotaje. . . . . . . . . . . . . . . . . . . . .
4.2.2 Número de operaciones de la eliminación gaussiana. . . . . . . . . . . . .
4.2.3 Implementación práctica. . . . . . . . . . . . . . . . . . . . . . . . . . . .
4.3 Normas matriciales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
43
44
44
45
45
46
50
50
i
ii
4.4
4.5
Análisis del problema del acondicionamiento. . . . . . . . . . . . . . . . . . . . .
Métodos iterativos para la resolución de sistemas lineales. . . . . . . . . . . . . .
4.5.1 Métodos de Jacobi y Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . .
52
53
56
5 Cálculo diferencial en varias variables
5.1 Funciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.1.1 Representación gráfica. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2 Límites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.3 Continuidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.4 Diferenciabilidad. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.5 Extremos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.5.1 Formas Cuadráticas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.5.2 Polinomio de Taylor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.5.3 Extremos relativos condicionados. . . . . . . . . . . . . . . . . . . . . . . .
57
57
58
59
64
65
72
74
76
78
6 Programación Lineal
6.1 Un primer ejemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.2 Definiciones y Terminología. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.3 Solución gráfica de problemas en IR2 . . . . . . . . . . . . . . . . . . . . . . . . .
83
83
85
86
Tema 1
Series
1.1
Series de números reales.
Definición 1.1 Llamaremos serie de números reales a una sucesión {sn }∞
n=1 definida a partir
de otra sucesión de números reales, {an }∞
,
de
la
forma
n=1
sn =
n
X
ai = a1 + · · · + an
(1.1)
i=1
Los términos de la sucesión {sn }∞
n=1 de la definición anterior reciben el nombre de sumas parciales
y an recibe el nombre de término general de la serie.
¿Qué utilidad o interés tiene una sucesión como la de la definición anterior? La respuesta
está en el significado de su límite. Puesto que sn es la suma de n números reales (a1 , a2 , . . . , an ),
sn+1 es la suma de los anteriores y an+1 y así sucesivamente, el
s = lim sn
n→∞
(1.2)
en caso de que exista, será la definición matemática de una suma con infinitos sumandos.
Si el límite s en (1.2) existe y es finito diremos que la serie es convergente, si es infinito, divergente y si no existe diremos que la serie es oscilante. A la condición convergente, divergente
u oscilante de una serie se le llama carácter de la misma.
El límite s en (1.2) recibe el nombre de suma de la serie y se denota
∞
X
ai
(1.3)
i=1
Esta notación puede resultar confusa porque
P(1.3) se emplea tanto para denotar la propia serie
como su límite, así, una afirmación del tipo ∞
i=1 ai es convergente, divergente u oscilante lo que
significa es que la sucesión {sn }∞
lo
es.
n=1
Otra manera de representar la idea de sumar infinitas cantidades ai es escribir
a1 + a2 + · · · + an + · · ·
donde los últimos puntos suspensivos son los "más importantes" porque son los que conllevan
precisamente la idea de continuar sumando (hasta infinito). Nótese que a1 + a2 + · · · + an no es
una suma de infinitos términos; es sólo una suma de n términos.
2 Series
Ampliación de Matemáticas.
Ejercicio 1.1 Completa lo que consideres necesario en la tabla siguiente (puede haber resultados
que todavía no sean conocidos):
an
1
1
5
a1 + a2 + · · · + an + · · ·
1 + 1 + ··· + 1 + ···
1
1
1
5 + 5 + ··· + 5 + ···
∞
X
ai
i=1
∞
X
1
5
i=1
−3
n
−3 − 3 − · · · − 3 − · · ·
1 + 2 + ··· + n + ···
sn =
1
i=1
∞
X
∞
X
sn =
sn =
2n
1
n
2 + 2 2 + · · · + 2n + · · ·
sn =
i
1 + 21 + · · · + n1 + · · ·
i=1
i=1
n
X
i=
i=1
2i
i=1
∞
X
i=1
n
X
i=1
i=1
∞
X
ai
s = lim sn
1=n
s = lim n = +∞
n
1
=
5
5
s = lim
n→∞
i=1
n
X
n
X
sn =
(−3) = −3n
−3
i=1
∞
X
n
X
sn =
n
X
i=1
1
i
sn =
(n + 1)n
2
n→∞
n
= +∞
n→∞ 5
s = lim −3n = −∞
n→∞
s = lim
n→∞
n(n + 1)
= +∞
2
2i = 2n+1 − 2 s = lim (2n+1 − 2) = +∞
n→∞
n
X
1
i=1
i
=?
s = lim sn = +∞
n→∞
(−1)n
(−1)n + 1
Ejemplo 1.1 Consideremos la serie
∞
X
q i , llamada serie geométrica. Para estudiar su carác-
i=0
ter debemos hallar el límite de la sucesión {sn }∞
n=1 .
sn =
n−1
X
(
i
q =
i=0
q n −1
q−1
n
si
si
q 6= 1
q=1
(1.4)
(Obsérvese que sn es, para esta serie, la suma de los n primeros términos de una progresión
geométrica de razón q).
qn − 1
lim
=
n→∞ q − 1
(1 − q)−1
∞
si
si
|q| < 1
q>1
(1.5)
El límite anterior no existe si q ≤ −1. Concluimos entonces que este tipo de series son convergentes cuando |q| < 1, divergentes si q ≥ 1 y oscilantes para q ≤ −1.
Ampliación de Matemáticas.
1.1.1
Series 3
Algunas propiedades de las series.
1. El carácter de una serie
∞
X
ai se mantiene si se suprimen o modifican los k primeros
i=1
términos de la sucesión {an }∞
n=1 .
2. Las series
∞
X
ai y
i=1
∞
X
cai , siendo c cualquier número real no nulo, tienen el mismo
i=1
carácter. Si son convergentes se verifica la relación
∞
X
cai = c
i=1
3. Si
∞
X
ai y
i=1
∞
X
∞
X
ai
(1.6)
i=1
bi son convergentes, también lo es
i=1
∞
X
(ai + bi ) y se verifica
i=1
∞
∞
∞
X
X
X
(ai + bi ) =
ai +
bi
i=1
i=1
(1.7)
i=1
Estas tres propiedades pueden demostrarse sin más que tener en cuenta lo que significa el carácter
de una serie y aplicar algunas propiedades de los límites.
Ejercicio 1.2 Extender la tercera de las propiedades anteriores, si es posible, al caso en que
∞
∞
X
X
ai ,
bi o ambas sean divergentes u oscilantes.
i=1
i=1
Si una serie resulta convergente parece razonable que las cantidades que se van añadiendo
(los ai ) tiendan a cero. Así ocurre, en efecto, como puede verse en el siguiente teorema.
Teorema 1.1 Si
∞
X
ai es convergente entonces
i=1
lim an = 0.
n→∞
(1.8)
Demostración. Sea s la suma de la serie. Se verifica entonces
limn→∞ sn = s
así como
limn→∞ sn−1 = s,
por tanto
limn→∞ an = limn→∞ (sn − sn−1 ) = s − s = 0.
La condición dada en el teorema anterior es necesaria pero no suficiente para la convergencia.
Por ejemplo la serie
1 1 1 1 1 1 1 1 1
1 + + + + + + + + + + ···
2 2 3 3 3 4 4 4 4
es divergente con an →P
0.
Para que una serie ∞
i=1 ai sea convergente no basta, según se ha dicho, con que la sucesión
∞
{a
Pn∞}n=1 tienda a cero sino que además habrá de hacerlo "suficientemente rápido".
P∞ La 2serie
(1/n),
denominada
serie
armónica,
es
divergente
mientras
que
la
serie
n=1
n=1 (1/n ) es
convergente. La demostración de su carácter se verá en la siguiente sección. Ambas cumplen
que el límite de la sucesión {an }∞
n=1 es cero.
4 Series
1.1.2
Ampliación de Matemáticas.
Series de términos positivos.
En este apartado veremos algunos resultados útiles para determinar el carácter de series de
términos positivos.
Ejercicio 1.3 ¿Puede una serie de términos positivos ser oscilante?
Teorema 1.2 (Primer criterio de comparación ) Sean
minos positivos tales que ai ≤ bi ∀i ∈ IN. Entonces
P∞
P
1. Si ∞
i=1 ai también lo es.
i=1 bi es convergente,
P
P∞
2. Si ∞
i=1 ai es divergente,
i=1 bi también lo es.
P∞
Teorema 1.3 (Segundo criterio de comparación ) Sean
términos positivos tales que existe
an
lim
n→∞ bn
i=1 ai y
P∞
P∞
y
i=1 ai
i=1 bi dos series de tér-
P∞
i=1 bi
dos series de
(1.9)
Entonces
1. Si el límite es finito y distinto de cero, ambas series tienen el mismo carácter
2. Si el límite es nulo se verifica
P∞
P
(a) Si ∞
i=1 ai también lo es.
i=1 bi es convergente,
P∞
P∞
(b) Si i=1 ai es divergente, i=1 bi también lo es.
3. Si el límite es infinito se verifica
P∞
P
(a) Si ∞
i=1 ai también lo es.
i=1 bi es divergente,
P∞
P∞
(b) Si i=1 ai es convergente, i=1 bi también lo es.
Ejercicio 1.4 Demostrar los dos teoremas anteriores.
En los dos teoremas anteriores el carácter de la serie se obtenía por comparación con el de
otra. En los resultados que siguen el carácter se obtendrá a partir de la serie objeto de estudio
únicamente.
Teorema 1.4 (Criterio del cociente ) Sea
lim
n→∞
P∞
i=1 ai una serie de términos positivos tal que
an+1
=c
an
Entonces
1. Si c < 1 la serie es convergente.
2. Si c > 1 o c = +∞ la serie es divergente.
Si c = 1 no se puede asegurar nada sobre el carácter de la serie.
(1.10)
Ampliación de Matemáticas.
Series 5
Teorema 1.5 (Criterio de la raíz ) Sea
P∞
i=1 ai una serie de términos positivos tal que
√
n
lim
n→∞
an = c.
(1.11)
Entonces
1. Si c < 1 la serie es convergente.
2. Si c > 1 o c = +∞ la serie es divergente.
Si c = 1 no se puede asegurar nada sobre el carácter de la serie.
Teorema 1.6 (Criterio de la Integral ) Sea f : [1, ∞) −→ IR decreciente y positiva. Sea
an = f (n) ∀n ∈ IN. Entonces la serie
∞
X
an
(1.12)
n=1
y la integral
Z ∞
f (t)dt
(1.13)
1
tienen el mismo carácter.
Ejercicio 1.5 Estudiar el carácter de las series de la forma
∞
X
1
n=1
nc
(1.14)
para cualquier c ∈ IR.
La idea del primer criterio de comparación suele ser la simplificación de una serie eliminando
partes poco significativas para de esta manera poder compararla con otra más simple. En el
segundo criterio de comparación, necesitamos "intuir cómo va" el término general de la serie por
lo que tienen mucha importancia los infinitésimos equivalentes estudiados en Fundamentos de
Matemáticas. El criterio del cociente suele ser adecuado con términos generales que se simplifican
mucho al hacer el correspondiente cociente. El criterio de la raíz es adecuado para términos
generales que se simplifican al tomar raíces n-ésimas; este criterio es más fuerte que el criterio
del cociente, pues si el del cociente funciona, también lo hará el de la raíz (en virtud del criterio
de Cauchy para el cálculo de límites de sucesiones).
Los resultados de esta sección son también aprovechables para el estudio del carácter de series
de términos negativos. Basta tener en cuenta que la multiplicación por constantes no altera el
carácter. En particular, una serie y su opuesta tienen el mismo carácter, y si la de partida era
de términos negativos, su opuesta será de términos positivos.
6 Series
Ampliación de Matemáticas.
Ejercicio 1.6 Averigua el carácter de las series siguientes indicando el criterio empleado:
serie
∞
X
n=1
∞
X
2n
criterio
1
√
sen
n=1
carácter (razonado)
n
1
n
∞
X
1
n=1
n!
∞ X
2n + 1 n
n=1
3n + 2
∞
X
1
n=1
1.1.3
n2
Series alternadas.
De no estar ante una serie de términos positivos (o negativos) que es la situación más deseable
en lo que al estudio del carácter se refiere, lo más que se puede pedir es conocer los cambios de
signo de la sucesión {an }∞
n=1 . Esto es lo que sucede con las series alternadas.
Definición 1.2 Llamaremos serie alternada a la de la forma
∞
X
(−1)n an con an ≥ 0
n=1
IN.
Ejercicio 1.7 Razona si las siguientes series son alternadas o no:
serie
∞
X
−1
√
n n
2
n=1
∞
X
(−1)n
n=1
∞
X
n=1
2n
(−1)n
(−2)n
∞
X
(−1)(n+1)
n=1
∞
X
−5n
cos(π n)
2n
n=1
∞
X
sen n
n=1
Alternada (SI/NO/?) (razonado)
∀n ∈
Ampliación de Matemáticas.
Series 7
Por supuesto no todas las series que no son de términos positivos o negativos son alternadas.
Para las series alternadas se dispone del siguiente resultado bastante útil a la hora de estudiar
su carácter.
∞
X
Teorema 1.7 (Criterio de Leibnitz) Sea
(−1)n an una serie alternada tal que
n=1
a1 ≥ a2 ≥ · · · ≥ an ≥ . . .
con
lim an = 0.
n→∞
Entonces la serie es convergente y, si sn es su suma parcial n-ésima y s su suma, se tiene que
|sn − s| ≤ an+1
Ejercicio 1.8 Estudiar el carácter de la serie armónica alternada
∞
X
(−1)n
n=1
1.1.4
1
n
Convergencia condicional y absoluta.
Cuando se quiere estudiar el carácter de una serie cuyos términos cambian de signo una solución
puede ser pasar a considerar la serie de los valores absolutos.
Definición 1.3 Diremos que la serie
∞
X
an es absolutamente convergente si la serie
n=1
es convergente.
∞
X
|an |
n=1
Teorema 1.8 Las series absolutamente convergentes son convergentes.
Ejercicio 1.9 Determinar el carácter de
Serie
∞
X
sen n
2n
n=1
∞
X
(sen n)n
√
n
n
n=1
∞
X (1 − n)n
n=1
Carácter
Explicación
(n2 + 1)n
La convergencia absoluta es una condición suficiente para la convergencia pero no necesaria.
La serie armónica alternada proporciona el contraejemplo puesto que es convergente pero no
absolutamente convergente.
Definición 1.4 Las series convergentes pero no absolutamente convergentes se denominan condicionalmente convergentes.
P∞
Definición
P∞ 1.5 Dada la serie n=1 an llamaremos reordenación suya a cualquier serie de la
forma n=1 aσ(n) donde σ : IN −→ IN es una biyección cualquiera.
8 Series
Ampliación de Matemáticas.
Las series absoluta y condicionalmente convergentes tienen comportamientos muy diferentes
con respecto a la reordenación de sus términos como puede verse en el siguiente teorema.
Teorema 1.9 Si una serie es absolutamente convergente cualquier reordenación suya también
lo es y la suma de cualquier reordenación coincide con la de la serie de partida.
Si una serie es condicionalmente convergente entonces dado un valor real arbitrario, se puede
reordenar la serie de modo que la suma sea ese valor. Es también posible reordenar la serie de
modo que resulte divergente.
El teorema anterior implica que no se tiene la propiedad conmutativa en general a la hora de
sumar infinitos términos.
1.2
Series de potencias.
Así como en una serie numérica sus términos son números reales, se puede encontrar una serie
donde sus términos sean funciones. Cuando todas las funciones dependen de la variable x, se
∞
X
tiene una serie de la forma
fn (x) llamada serie de funciones.
n=0
Las series pueden verse como sumas con infinitos sumandos. En el caso numérico la serie
generaliza las sumas finitas de números, en el de series de funciones, se generalizan las funciones
definidas mediante un número finito de sumas. Entre estas funciones, sin duda, las más conocidas
son los polinomios. Cuando el número de sumandos de un polinomio se aumenta hacia infinito
aparecen las series de potencias.
Definición 1.6 Llamaremos serie de potencias centrada en c a toda serie de funciones de la
forma
∞
X
an (x − c)n
(1.15)
n=0
Cuando en una serie de funciones se toma un valor particular de x, x0 , y las funciones se
evalúan en ese punto, la serie se convierte en una serie numérica. La convergencia de la serie
de funciones estará relacionada con la convergencia de la serie numérica que se obtiene para un
determinado valor. Las series de potencias tienen un comportamiento muy específico en lo que
a convergencia se refiere como puede verse en el siguiente teorema.
P
n
Teorema 1.10 Sea ∞
n=0 an (x − c) una serie de potencias que converge para un cierto x0 6= c.
Sea δ ∈ IR tal que 0 < δ < |x0 − c|. Entonces la serie
∞
X
an (x − c)n
n=0
converge absolutamente en [c − δ, c + δ].
Del resultado anterior se concluye que si una serie de potencias centrada en c converge para
un cierto x0 , también lo hace para los x que estén a menos distancia de c. Al conjunto formado
por los números reales para los cuales una serie de potencias es convergente se le denomina
Ampliación de Matemáticas.
Series 9
campo de convergencia de la serie. Si el conjunto anterior está acotado llamaremos radio de
convergencia R al siguiente número
∞
X
R = sup{ |x − c| /
an (x − c)n
converge }
(1.16)
n=0
Si el campo de convergencia no está acotado, diremos que el radio de convergencia es ∞. Si
la serie sólo converge cuando x = c, diremos que el radio de convergencia es 0.
Obsérvese que si el radio de convergencia es R > 0, el teorema 1.10 nos dice que la serie
de potencias converge en (c − R, c + R) y no converge en (−∞, c − R) y (c + R, ∞). En los
extremos del intervalo x = c − R y x = c + R puede ocurrir cualquier cosa. Es decir, el campo de
convergencia ha de ser necesariamente uno de estos cuatro conjuntos: (c−R, c+R), [c−R, c+R),
(c − R, c + R] o [c − R, c + R].
Para determinar el radio de convergencia resulta útil el siguiente teorema.
Teorema 1.11 Sea
P∞
n=0 an (x − c)
n una serie de potencias tal que
lim
n→∞
p
n
|an | = l
(1.17)
Entonces R = 1/l si l 6= 0. Si el límite es 0, el radio de convergencia es infinito y si el límite es
infinito, R = 0.
El límite que aparece en el teorema anterior se calcula con frecuencia utilizando el criterio de
Cauchy. Veamos algunos ejemplos en los que se determina el radio y campo de convergencia de
una serie de potencias.
∞
X
Ejemplo 1.2 Consideremos la serie
22n xn .
n=0
lim
n→∞
√
p
n
n
|an | = lim 22n = 4
n→∞
(1.18)
Entonces R = 1/4. Veamos qué sucede en c − R y c + R, que en nuestro caso son −1/4 y 1/4.
En x = 1/4 la serie es
n X
∞
∞
X
1
22n
=
1
(1.19)
4
n=0
n=0
y por tanto divergente. En x = −1/4 la serie es
∞
X
n=0
2n
2
−1
4
n
=
∞
X
(−1)n
n=0
de carácter oscilante.
Entonces el campo de convergencia se reduce al intervalo (−1/4, 1/4).
(1.20)
10 Series
Ampliación de Matemáticas.
Ejemplo 1.3 Consideremos la serie
∞
X
xn
n=0
n!
.
p
1
n
|an | = lim √
n→∞
n→∞ n n!
(1.21)
n!
1
= lim
lim √
=0
n
n→∞
(n
+
1)!
n!
(1.22)
lim
Aplicando el criterio de Cauchy
n→∞
Entonces R = ∞ y por tanto el campo de convergencia es IR.
1.2.1
Representación de funciones en series de potencias.
∞
X
Teorema 1.12 Sea s(x) =
an (x − c)n una serie de potencias con radio de convergencia
n=0
R > 0. Entonces, para cada x ∈ (c − R, c + R), existe s0 (x) y se verifica
0
s (x) =
∞
X
n an (x − c)n−1
n=1
Por lo tanto, s0 (x) vuelve a ser una serie de potencias y en (c − R, c + R), la derivada de la
serie (suma infinita) es la suma (infinita) de las derivadas, pues
!
∞
X
n
d
an (x − c)
s0 (x) = dx
n=0
d a + a (x − c) + a (x − c)2 + · · · + a (x − c)n + · · · = dx
0
1
2
n
n−1
= a1 + 2 · a2 · (x − c) + · · · + n · an · (x − c)
+ ···
∞
X
=
n an (x − c)n−1
n=1
Nota: Esta propiedad (la derivada de una suma finita de funciones derivables es la suma de sus
derivadas) no siempre es cierta para una suma infinita. Es otro ejemplo de propiedad (véase
la conmutatividad en series numéricas condicionalmente convergentes) que se pierde cuando se
pasa del caso finito al infinito.
Si volvemos a aplicar el teorema 1.12 a la serie s0 (x) obtenemos
s00 (x) =
∞
X
n(n − 1)an (x − c)n−2
∀x ∈ (c − R, c + R)
(1.23)
n=2
y así sucesivamente. Podemos afirmar entonces que para la función s(x), suma de la serie de
partida, se verifica que es C ∞ (de clase infinito o indefinidamente derivable) y
k)
s (x) =
∞
X
n(n − 1) . . . (n − k + 1)an (x − c)n−k
∀x ∈ (c − R, c + R),
k ∈ IN
(1.24)
n=k
Si evaluamos las series dadas en (1.24) en x = c se obtiene
sk) (c) = k!ak
k = 1, 2, . . .
(1.25)
Ampliación de Matemáticas.
Series 11
y por tanto
s(x) =
∞
X
n
an (x − c) =
n=0
∞ n)
X
s (c)
n=0
n!
(x − c)n
(1.26)
Hemos visto así que las series de potencias son siempre series de Taylor (límites de polinomios
de Taylor) de su función suma.
Cabe ahora preguntarse si, dada una función f indefinidamente derivable y su serie de
Taylor
∞
X
f n) (c)
(x − c)n
(1.27)
n!
n=0
esta serie tiene siempre una función suma que resulte ser la propia f . En contra de lo que podría
esperarse la respuesta es negativa, es decir, es posible que se verifique
f (x) 6=
∞
X
f n) (c)
n=0
n!
(x − c)n
(1.28)
como se ve en el siguiente ejemplo.
1
Ejemplo 1.4 Sea f (x) = e− x2 si x 6= 0 y f (0) = 0. La función anterior cumple que
f n) (0) = 0
∀n ∈ IN
(1.29)
por lo que su serie de McLaurin (es decir, la serie de Taylor centrada en c = 0) resulta idénticamente nula y su suma no coincide con f para ningún x 6= 0.
¿Cómo saber entonces si la serie de Taylor de una función tiene por suma la propia función?
Los siguientes ejemplos muestran algunas formas de conseguir averiguarlo.
P
xn
Ejemplo 1.5 Sea f (x) = ex . Su serie de McLaurin es ∞
n=0 n! . Se vio en el ejemplo 1.3 que
esta serie convergía para todo x real. ¿Es su suma ex ?. Como para series de Taylor la suma
n-ésima sn (x) es el polinomio de Taylor de grado n de la función,
f (x) − sn (x) =
f n+1) (ξx ) n+1
eξx
x
=
xn+1 ,
(n + 1)!
(n + 1)!
Entonces
|f (x) − sn (x)| ≤
ξx ∈ (min(0, x), max(0, x))
max(1, ex )
|x|n+1
(n + 1)!
(1.30)
(1.31)
y
|x|n+1
=0
n→∞ (n + 1)!
por tratarse del término general de una serie convergente.
lim
Ejemplo 1.6 La serie de McLaurin de la función f (x) = (1 + x)−1 es
de una serie geométrica converge para x ∈ (−1, 1) y su suma es
∞
X
(−x)n =
n=0
(1.32)
P∞
1
1 − (−x)
En este caso por tanto la convergencia de la serie hacia f es inmediata.
n
n=0 (−x) . Al tratarse
(1.33)
12 Series
Ampliación de Matemáticas.
Ejemplo 1.7 Como se ha visto en el ejemplo anterior que ∀x ∈ (−1, 1) se tiene que f (x) =
∞
∞
X
X
1
n
0
=
(−x) , aplicando el teorema 1.12 de derivación, obtenemos que f (x) =
(−1) ·
1+x
n=0
n=1
n · (−x)n−1 , es decir,
∞
X
−1
0
=
f
(x)
=
(−1)n · n · xn−1
(1 + x)2
∀x ∈ (−1, 1)
n=1
Y una nueva aplicación de dicho teorema daría
∞
X
2
00
=
f
(x)
=
(−1)n · n · (n − 1) · xn−2
(1 + x)3
∀x ∈ (−1, 1)
n=2
Nota: Estos resultados nos permiten obtener la suma de algunas series numéricas concretas, por
ejemplo:
∞
X
5n
n=0
∞
X
n=1
∞
X
n!
(−1)n
n!
(−1)n
n=2
n(n − 1)
3n−2
= e5
Desarrollo de ex en x = 5
= e−1 − 1
Desarrollo de ex en x = −1
=
27
32
Desarrollo de
2
en x = 1/3
(1 + x)3
Un resultado análogo a la derivación de una serie de potencias se verifica para la integración.
Teorema 1.13 Si el intervalo [a, b] está contenido en el campo de convergencia de la serie de
∞
X
potencias
an (x − c)n , entonces se tiene
n=0
Z b
∞
X
a
n=0
!
an (x − c)
n
Z b
∞ X
n
dx =
an
(x − c) dx
n=0
a
∞
Ejemplo 1.8 Como ∀x ∈ (−1, 1) se tiene que f (x) =
X
1
=
(−x)n , aplicando el teorema
1+x
n=0
anterior para a = c = 0,
Z b
∞ Z b
∞
X
X
1
(−1)n bn+1
n
dx = ln(1 + b) =
(−x) dx =
n+1
0 1+x
0
n=0
n=0
∞
X
(−1)n bn+1
, ∀b ∈ (−1, 1), que llevado a la forma más habitual (x
n+1
n=0
en lugar de b) nos conduce a otra función representada por su serie de Taylor en (−1, 1)
Es decir que ln(1 + b) =
ln(1 + x) =
∞
X
(−1)n xn+1
n=0
n+1
, ∀x ∈ (−1, 1)
Ampliación de Matemáticas.
Series 13
Las funciones representables por su serie de Taylor (también llamadas funciones analíticas)
pueden ser aproximadas (en principio, en cualquier proceso donde intervengan) por polinomios
truncando su serie de Taylor. Esta aproximación será "muyRbuena" si nos quedamos con un
6 2
número suficientemente elevado de términos. Por ejemplo, 0 ex dx no posee una expresión
2
sencilla en términos de funciones elementales pues, es sabido que una primitiva de ex no puede
conseguirse así. Pero como
e
x2
=
∞
X
x2n
n=0
n!
Z 6
⇒
x2
e dx ≈
0
m Z 6
X
x2n
n=0 0
n!
dx
A continuación ponemos una tabla con algunas de estas aproximaciones (nota:
3.644831077 × 1014 )
m
m Z 6
X
x2n
n=0 0
1
5
10
20
40
80
100
n!
R 6 x2
0 e dx ≈
dx
78
3.290229974 × 105
4.088873580 × 108
1.799203394 × 1012
2.997050140 × 1014
3.644831077 × 1014
3.644831077 × 1014
Algunas funciones analíticas (funciones representables por su serie de Taylor) de uso habitual
son:
1)
ex
=
∞
X
xn
n=0
2)
sen x
=
∞
X
(−1)n x2n+1
n=0
3)
cos x
=
(2n + 1)!
∞
X
(−1)n x2n
(2n)!
n=0
4)
1
1−x
=
5) ln(1 + x) =
, ∀ x ∈ IR
n!
∞
X
xn
, ∀ x ∈ IR
, ∀ x ∈ IR
, ∀x ∈ (−1, 1)
n=0
∞
X
(−1)n xn+1
n=0
n+1
, ∀x ∈ (−1, 1)
14 Series
1.3
Ampliación de Matemáticas.
Series de Fourier
En el apartado anterior se ha visto que algunas funciones pueden representarse mediante su
serie de Taylor. Esto significa que pueden ser aproximadas por polinomios, consiguiéndose una
precisión tan alta como se desee. El hecho de que se puedan utilizar polinomios, no significa
que sea la mejor elección posible para el aproximante (la función por aproximar puede tener
propiedades, como son la periodicidad o la acotación, que los polinomios no poseen). En esta
sección se considerarán nuevos aproximantes inicialmente aptos para funciones periódicas. Estos
aproximantes serán combinaciones lineales de las funciones sen(nx) y cos(nx).
Definición 1.7 Llamaremos serie trigonométrica a cualquier serie de funciones de la forma
∞
a0 X
+
(an cos(nx) + bn sen(nx))
2
(1.34)
n=1
Las constantes a0 , an y bn reciben el nombre de coeficientes de la serie trigonométrica.
Definición 1.8 Sea f (x) una función integrable en [−π.π]. Se define la serie de Fourier
de f(x) como la serie trigonométrica (1.34) cuyos coeficientes vienen dados por las siguientes
expresiones:
Z
1 π
f (x)dx
(1.35)
a0 =
π −π
Z
1 π
an =
f (x) cos(nx)dx ∀n ∈ IN
(1.36)
π −π
Z
1 π
f (x) sen(nx)dx ∀n ∈ IN
(1.37)
bn =
π −π
Denotemos s(x) a la suma de la serie de Fouier de una función f (x), es decir
∞
s(x) =
a0 X
+
(an cos(nx) + bn sen(nx))
2
(1.38)
n=1
en los puntos en los que la serie converja. Lo deseable es que s(x) = f (x) pues en este caso las
sumas parciales de la serie serían aproximaciones a f (x) con límite la propia f (x). No es difícil
ver que las sumas parciales de las series trigonométricas son 2π-periódicas, por tanto s(x) será
también una función 2π-periódica. En general f (x) no lo es. Dado que sólo se han utilizado los
valores de f (x) en [−π, π] para determinar los coeficientes de su serie de Fourier, sólo podemos
esperar que f (x) = s(x) en [−π, π]. Fuera de este intervalo la suma de la serie de Fourier
convergerá a una "repetición 2π-periódica" de la función f (x). El siguiente teorema concreta
estas afirmaciones.
Teorema 1.14 Sea f˜ 2π-periódica, monótona a trozos y acotada en (−π, π]. Entonces su serie
de Fourier converge en (−π, π]. En los puntos de continuidad de f˜, la suma es f˜. En los puntos
de discontinuidad, la suma es la media de los límites laterales, es decir, si c es un punto de
discontinuidad de f˜ y s es la función suma
s(c) =
limx→c+ f˜(x) + limx→c− f˜(x)
2
Ampliación de Matemáticas.
Series 15
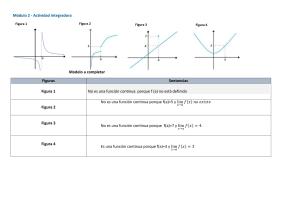
Ejemplo 1.9 Sea f una función con la siguiente definición en (−π, π].
0 si −π < x ≤ 0
f (x) =
x
si 0 < x ≤ π
Denotemos f˜(x) la prolongación 2π-periódica de f (x) . Las siguientes gráficas corresponden
a estas dos funciones. Nótese que todos los puntos de discontinuidad de f˜(x) tienen imagen π
f (x)
-π
π
π
*
π
f˜(x)
*
o
o
-π
π
*
o
2π
3π
4π
El teorema 1.14 nos permite trazar la gráfica de la suma de la serie de Fourier s(x) sin
conocer explícitamente su expresión. Su gráfica es la siguiente:
o
π
o
s(x)
o
*
*
*
o
o
o
-π
π
2π
3π
4π
Basta observar la gráfica de s(x) para obtener evaluaciones de s(x). Las siguientes líneas
muestran algunas de estas evaluaciones:
• s(−1) = f˜(−1) = f (1) = 0 porque x = −1 es un punto de continuidad de f˜(x), perteneciente
al intervalos (−π, π] donde f y f˜ coinciden.
• s(7) = f˜(7) = f˜(7 − 2π) = f (7 − 2π) = 7 − 2π porque estamos de nuevo en un punto de
continuidad de f˜(x) que es una función 2π-periódica y 7 − 2π ∈ (−π, π] donde f (x) y f˜(x)
coinciden.
limx→π+ f˜(x)+limx→p− f˜(x)
2
0 + f (π)
0+π
=
. Obsérvese
2
2
que en los puntos de discontinuidad de f˜(x) el valor de la suma de la serie de Fourier
es siempre el punto medio del salto. Si prolongamos la definición de f (x) a x = 0 con
(π)
continuidad, podemos expresar el punto medio del salto como f (0)+f
.
2
• s(3π) = s(3π − 2π) = s(π) =
=
Con independencia de todo lo anterior, podemos obtener la expresión explícita de la serie de
Fourier de f (x). Los coeficientes de esta serie son:
Z
1 π
π
a0 =
xdx =
π 0
2
Z
2
1 π
− 2 si n impar
an =
x cos(nx)dx =
πn
π 0
0
si n par
16 Series
Ampliación de Matemáticas.
1
bn =
π
Z π
0
1
n
x sen(nx)dx =
1
−
n
si n impar
si n par
Entonces la serie de Fourier es
∞ π X
s(x) = −
4
n=1
(−1)n
2
cos((2n − 1)x) +
sen(nx)
π(2n − 1)2
n
(1.39)
A continuación se muestra la gráfica de la función f junto con la suma parcial de su serie de
Fourier correspondiente a n = 4:
Nótese que la suma parcial aproxima en realidad a la prolongación de f (x), f˜(x). Obsérvese
tambien que la aproximación se vuelve menos precisa (se aleja más de la gráfica de f˜(x)) a
medida que nos acercamos a los puntos de discontinuidad de f˜(x).
Veamos para finalizar este ejemplo cómo utilizar series de Fourier para conseguir el valor de
la suma de series numéricas.
∞
X
1
(2n − 1)2
n=1
Observemos que las expresiones que queremos sumar aparecen en 1.39, en concreto en los
coeficientes de los cosenos. Si evaluamos 1.39 en x = 0 para que desaparezcan los términos del
seno, tenemos
Supongamos que queremos hallar la suma de la serie
∞
s(0) =
π
2X
1
−
4 π
(2n − 1)2
(1.40)
n=1
Sabemos también que s(0) = f (0) = 0 puesto que x = 0 es un punto de continuidad de f˜(x).
Entonces
∞
0=
π
2X
1
−
4 π
(2n − 1)2
n=1
1.3.1
⇒
∞
X
n=1
1
π2
=
(2n − 1)2
8
Desarrollos de Fourier con sólo cosenos o sólo senos.
Recordemos que se dice que una función g(x) es par si g(x) = g(−x) (simétrica respecto al eje
vertical, por ejemplo x2 + 1, cos x, cos(5x), ...) y que es impar si g(x) = −g(−x) (por ejemplo
x3 − x, sen x, sen(4x), ...). Para estas funciones se tienen las propiedades:
1. El producto de dos funciones pares es una nueva función par.
2. El producto de dos funciones impares es una nueva función par.
Ampliación de Matemáticas.
Series 17
3. El producto de una función par por una función impar es una nueva función impar.
4. Si g es una función impar,
Z a
g(x)dx = 0 ∀a ∈ IR
(1.41)
−a
y si g es una función par,
Z a
Z a
g(x)dx ∀a ∈ IR
g(x)dx = 2
−a
(1.42)
0
Como consecuencia de las propiedades anteriores y de las fórmulas para hallar los coeficientes
de la serie de Fourier de una función f (x) se tiene que los cálculos pueden reducirse a la mitad
en los siguientes casos:
• Si f (x) es par, su serie de Fourier tendrá sólo cosenos.
• Si f (x) es impar, su serie de Fourier tendrá sólo senos.
Si tenemos una función f (x) definida en el intervalo [0, π] podemos prolongarla o extenderla
al intervalo [−π, π] simetrizándola respecto al eje vertical (es decir, llevarla a una función par)
mediante la definición
fp (x) =
f (x)
si 0 ≤ x ≤ π
f (−x) si − π ≤ x ≤ 0
Así, fp (x) es una función par que coincide con f (x) en [0, π], por lo que su serie de Fourier
(que contendrá sólo cosenos) aproxima a los valores de f (x) en [0, π]. Obviamente, algo similar
puede hacerse respecto a prolongaciones impares, definiendo
fi (x) =
f (x)
si 0 ≤ x ≤ π
−f (−x) si − π ≤ x ≤ 0
Así se obtendrían aproximaciones a los valores de f (x) en [0, π] mediante una serie trigonométrica que contendría sólo senos.
18 Series
Ampliación de Matemáticas.
Observación: Ya hemos comentado que la continuidad favorece la bondad de las aproximaciones.
La prolongación par, mantiene la continuidad en x = 0 y x = π; pero la impar no, si f (0) 6= 0 o
bien f (π) 6= 0.
Las prolongaciones pares e impares que acaban de presentarse para el intervalo [0, π] pueden
hacerse de forma absolutamente análoga para cualquier intervalo [0, c].
1.3.2
Series de Fourier en un intervalo general [a,b].
Si f (x) es una función definida en un intervalo [a, b], podemos trasladarla al intervalo [−π, π]
l
b−a
mediante el cambio de variable x = t+c, donde para abreviar la escritura se definen l =
π
2
a+b
y c=
. Así cuando t recorre el intervalo [−π, π], la variable x va recorriendo el intervalo
2
[a, b], pero los valores funcionales (las alturas) son idénticos. Gráficamente:
Si ahora aproximamos la función g(t) = f
l
t + c , t ∈ [−π, π] por su serie de Fourier
π
∞
X
a0
+
(an cos(nt) + bn sen(nt))
g(t) ≈
2
n=1
donde, debido al cambio de variable t = πl (x − c), los coeficientes son
1
an =
π
Z π
1
g(t) cos(nt) dt =
l
−π
Z b
1
π
Z π
Z b
bn =
g(t) sen(nt) dt =
−π
1
l
f (x) cos
a
f (x) sen
a
nπ
l
nπ
l
(x − c) dx , n = 0, 1, 2, . . .
(x − c) dx , n = 1, 2, 3, . . .
se tiene que la aproximación, ya en la variable x tras deshacer el cambio en la fórmula anterior
para aproximar g(t), es
f (x) ≈
∞ nπ
nπ
X
a0
+
an cos
(x − c) + bn sen
(x − c)
, ∀x ∈ [a, b]
2
l
l
n=1
Si f (x) está definida en [a, b] podemos prolongarla a un intervalo de doble longitud de forma
par o de forma impar respecto del centro del intervalo final. Entonces la serie de la fórmula anterior tendría sólo cosenos o sólo senos (respectivamente) como sucedía cuando tratamos funciones
definidas en el intervalo [−π, π].
Tema 2
Interpolación Polinómica
La utilización de un polinomio en sustitución de una función en algún proceso matemático trae
consigo casi siempre una simplificación del problema, y la introducción de un error. En conjunto
la sustitución suele ser ventajosa, sobre todo si se elige adecuadamente el polinomio, y por tanto
muy frecuente.
¿Por qué se eligen los polinomios como sustitutos cuando se quiere simplificar un problema? Se pueden citar como razones su sencillez de evaluación (sólo se necesita un número finito
de sumas y productos), la obtención inmediata de sus primitivas y derivadas o la facilidad para
modificarlos manteniéndonos en la clase de los polinomios (obsérvese que si P (x) es un polinomio
de grado menor o igual que n, P (ax + b) también lo es).
A las razones anteriores hay que añadir que los polinomios son buenos aproximantes para
funciones de una clase tan amplia como la de las funciones continuas, como se deduce del siguiente
teorema debido a Weierstrass.
Teorema 2.1 Sea f : [a, b] −→ IR continua. Entonces dado > 0 existe un polinomio P (x) tal
que
|f (x) − P (x)| < ∀x ∈ [a, b]
(2.1)
2.1
Polinomio interpolador de Lagrange
Consideremos el siguiente problema: de una función f (x) se conoce su valor en n + 1 nodos
distintos x0 , x1 , . . . , xn . ¿Es posible encontrar un polinomio Pn (x) de grado menor o igual que n
que coincida con f en los mencionados nodos? Responderemos a esta pregunta construyendo el
polinomio.
Para cada i = 0, 1, 2, . . . , n, sea Li (x) un polinomio de grado menor o igual que n que se anula
sobre todos los nodos excepto xi y tal que Li (xi ) = 1. Obsérvese que las condiciones impuestas
sobre el grado y las raíces de Li (x) determinan que sea de la forma
Li (x) = ci (x − x0 )(x − x1 ) . . . (x − xi−1 )(x − xi+1 ) . . . (x − xn )
y la condición Li (xi ) = 1 proporciona el valor de ci :
−1
n
Y
ci =
(xi − xj )
j=0
j 6= i
(2.2)
(2.3)
20 Interpolación Polinómica
Ampliación de Matemáticas.
Entonces
Li (x) =
n
Y
j=0
j 6= i
(x − xj )
(xi − xj )
(2.4)
La obtención del polinomio interpolante es inmediata utilizando estos polinomios.
Pn (x) =
n
X
f (xi )Li (x)
(2.5)
i=0
Ejercicio 2.1 Demostrar que el polinomio interpolante que se acaba de obtener es único.
π
,
4
interpolador que se obtiene con los datos anteriores es:
Ejemplo 2.1 Sea f (x) = sen x, x0 = 0,
x1 =
x2 =
3π
y x3 = 2π. El polinomio
4
P3 (x) = f (x0 )L0 (x) + f (x1 )L1 (x) + f (x2 )L2 (x) + f (x3 )L3 (x)
Dado que tanto f (x0 ) como f (x3 ) son nulos, el polinomio se reduce a:
√
√
2 x(x − 3π
2 x(x − π4 )(x − 2π)
4 )(x − 2π)
P3 (x) =
+
π
3π
π 3π
2 π4 ( π4 − 3π
2 3π
4 )( 4 − 2π)
4 ( 4 − 4 )( 4 − 2π)
Su representación gráfica junto con la de f (x) es la siguiente:
P3 (x)
f (x)
Como puede verse en la gráfica anterior, la aproximación que proporciona el polinomio interpolante es mejor en unas "zonas" que en otras. (Obsérvese por ejemplo la diferencia entre f (x)
y P3 (x) en x = π2 y x = 3π
2 )
El siguiente resultado proporciona, bajo ciertas condiciones, una expresión de la diferencia
f (x) − Pn (x) que permitirá en ocasiones acotar el error que se comete al sustituir la función por
el polinomio.
Teorema 2.2 Sea f : [a.b] −→ IR con f ∈ C (n) ([a, b]) y tal que existe la derivada n + 1 en
(a,b). Sean x0 , x1 , . . . , xn ∈ [a, b], n + 1 nodos distintos y Pn (x) el polinomio de grado menor
o igual que n tal que f (xi ) = Pn (xi ) para i = 0, 1, . . . , n. Entonces para cada x ∈ [a, b] existe
ξx ∈ (min(x0 , x1 , . . . , xn , x), max(x0 , x1 , . . . , xn , x)) tal que
f (x) − Pn (x) =
f n+1) (ξx )
(x − x0 )(x − x1 ) . . . (x − xn )
(n + 1)!
(2.6)
Ampliación de Matemáticas.
Interpolación Polinómica 21
Al igual que sucede con la expresión del error en el polinomio de Taylor, su acotación dependerá del conocimiento de una cota de la derivada en un intervalo adecuado.
Ejemplo 2.2 Utilizando la expresión del error que proporciona el teorema 2.2, vamos a acotar
el error que se comete al utilizar el polinomio del ejemplo 2.1 en los siguientes casos:
1. x =
π
,
2
x=
3π
2
y
x=−
π
4
2. x ∈ [0, π]
π π
3. x ∈ [− , ]
2 2
(Obsérvese que la función sen x satisface en los tres casos las hipótesis del teorema)
Según el teorema 2.2 se dispone de la siguiente expresión para el error:
π
3π
f iv) (ξx )
x x−
x−
(x − 2π)
f (x) − P (x) =
4!
4
4
Dado que f iv) (x) = sen x y que ξx ∈ [0,2π] o un intervalo mayor, la única cota disponible
para el módulo de la derivada que aparece en (2.6) es 1:
1
3π
π
|f (x) − P (x)| ≤
x−
(x − 2π)
x x−
4!
4
4
Si llamamos φ(x) al polinomio del segundo miembro y particularizamos la acotación anterior
a los puntos que nos interesan tenemos:
π
π
1
π
|f
−P
| ≤ |φ
| = 0.190252
2
2
4!
2
3π
π
1
3π
|f
−P 3
| ≤ |φ
| = 2.85378
2
2
4!
2
π
−π
1
−π
|f −
−P
| ≤ |φ
| = 1.14151
4
4
4!
4
En la gráfica de la función y el interpolante puede apreciarse lo exagerado de esta acotación
para el segundo de los puntos.
Para los dos casos que quedan el objetivo es encontrar una cota de |f (x) − P (x)| válida en
un intervalo. Puesto que la derivada que aparece en la expresión del error está acotada por uno,
vamos a hallar
maxx∈[0,π] |φ(x)| y maxx∈[− π2 , π2 ] |φ(x)|
Las raíces de φ0 (x) expresadas con seis cifras significativas son:
r1 = 0.342278
r2 = 1.68440
r3 = 5.04189
Como |φ(x)| es una función continua y los intervalos son cerrados, los máximos buscados
se alcanzarán en un punto del intervalo abierto que necesariamente será una raíz de φ0 (x) o un
extremo del intervalo. (Obsérvese que en los puntos en los que |φ(x)| no sea derivable no se
22 Interpolación Polinómica
Ampliación de Matemáticas.
puede alcanzar el máximo buscado porque el módulo de un polinomio sólo puede ser no derivable
en una raíz de éste.) Entonces:
maxx∈[0,π] |φ(x)| = max{|φ(r1 )|, |φ(r2 )|, |φ(0)|, |φ(π)|} = |φ(π)|
π
π
π
maxx∈[− π2 , π2 ] |φ(x)| = max{|φ(r1 )|, |φ(− )|}, |φ( )|} = |φ(− )|
2
2
2
Llegamos así a la siguiente acotación para el error:
maxx∈[0,π] |f (x) − P (x)| ≤
|φ(π)|
= 0.761008
4!
maxx∈[− π2 , π2 ] |f (x) − P (x)| ≤
|φ(− π2 ))|
= 4.75630
4!
Como puede verse la utilización del polinomio en un intervalo exterior al determinado por los
nodos (extrapolación) puede aumentar considerablemente la cota del error. Además, la gráfica
del ejemplo 2.1, induce a pensar que no estamos ante un problema de cota de error exagerada
sino de mala aproximación. Si se desea aproximar en [− π2 , π2 ] sería más conveniente otra elección
de nodos.
Ejercicio 2.2 Sea f (x) = sen x, x0 = − π4 , x1 = 0, y x2 = π4 . Hallar el polinomio interpolador que, para la función sen x, determinan los nodos anteriores. Acotar el error que se
comete al utilizar ese polinomio para aproximar la función sen x en [− π4 , π4 ].
2.2
Forma de Newton del polinomio interpolador de Lagrange.
La expresión del polinomio interpolador obtenida en la sección anterior, conocida con el nombre
de Lagrange, tiene algunas desventajas desde el punto de vista de su utilización práctica:
1. El número de operaciones necesarias para la evaluación de un polinomio interpolador de
grado n escrito en la forma de Lagrange es muy superior al que requeriría la evaluación del
mismo polinomio escrito en potencias de x.
2. Si se desea aumentar el grado del polinomio interpolador añadiendo un nodo más, hay que
volver a construir el polinomio desde el principio.
La forma de Newton del polinomio interpolador consiste en expresar dicho polinomio como
P (x) = f [x0 ] + f [x0 , x1 ](x − x0 ) + · · · + f [x0 , x1 , . . . , xn ](x − x0 )(x − x1 ) . . . (x − xn−1 ) (2.7)
donde f [x0 ], . . . , f [x0 , x1 , ..., xn ] son valores numéricos que llamaremos coeficientes del polinomio
interpolador expresado en forma de Newton. Puede probarse que dichos coeficientes verifican las
siguientes propiedades:
1. f [x0 , x1 , . . . xi ] = f [xσ(0) , xσ(1) , . . . xσ(i) ], para cualquier permutación σ de los índices.
2. f [x0 ] = f (x0 )
Ampliación de Matemáticas.
Interpolación Polinómica 23
3. Se verifica la siguiente relación
f [x0 , x1 , . . . xi ] =
f [x1 , . . . xi ] − f [x0 , . . . xi−1 ]
xi − x0
i = 1, 2, . . . n
(2.8)
Los coeficientes f [x0 , x1 , . . . xi ] serán llamados en adelante diferencias divididas. La última
de las propiedades anteriores justifica el nombre y permite obtener los coeficientes necesarios para
el polinomio interpolador de grado n a partir de una tabla. Para cuatro nodos, por ejemplo, la
tabla sería como sigue:
x0 f [x0 ]
f [x0 , x1 ]
x1 f [x1 ]
f [x0 , x1 , x2 ]
f [x1 , x2 ]
x2 f [x2 ]
f [x0 , x1 , x2 , x3 ]
(2.9)
f [x1 , x2 , x3 ]
f [x2 , x3 ]
x3 f [x3 ]
y el polinomio
P3 (x) = f [x0 ] + f [x0 , x1 ](x − x0 ) + f [x0 , x1 , x2 ](x − x0 )(x − x1 )
+ f [x0 , x1 , x2 , x3 ](x − x0 )(x − x1 )(x − x2 ).
(2.10)
Obsérvese que si se quiere obtener P4 basta añadir un elemento en la parte inferior de cada
columna de la tabla para hallar f [x0 , x1 , x2 , x3 , x4 ].
Ejemplo 2.3 Obtengamos la forma de Newton del polinomio interpolante del ejemplo 2.1:
0
π
4
0
√
√
2 2
π
2
2
√
8 2
− 2
3π
0
3π
4
2π
√
2
2
√
2 2
−
5π
√
8 2
−
35π 2
√
128 2
105π 3
0
√
√ √ 2 2
8 2
π
128 2
π
3π
P3 (x) = 0 +
x−− 2 x x−
+
x x−
x−
π
3π
4
105π 3
4
4
24 Interpolación Polinómica
2.3
Ampliación de Matemáticas.
Interpolación de Hermite.
El polinomio de Taylor de una función se obtuvo imponiendo la coincidencia de las derivadas
en un punto; el polinomio interpolador de Lagrange se consiguió imponiendo la coincidencia
de imágenes en un conjunto de puntos. Plantearemos ahora un problema general del que las
situaciones anteriores son casos particulares.
De una función f (x) se conoce su valor en n + 1 nodos distintos x0 , x1 , . . . , xn . En cada
uno de los nodos anteriores se conocen los valores de derivadas sucesivas de la función hasta un
determinado orden (en general distinto para cada nodo). ¿Es posible encontrar un polinomio que
tenga en común con la función las imágenes y derivadas mencionadas? De existir este polinomio
tendría que verificar:
f 0 (x0 ) = P 0 (x0 ) . . .
f 0 (x1 ) = P 0 (x1 ) . . .
..
.
f m0 ) (x0 ) = P m0 ) (x0 )
f m1 ) (x1 ) = P m1 ) (x1 )
..
.
f (xn ) = P (xn ) f 0 (xn ) = P 0 (xn ) . . .
f mn ) (xn ) = P mn ) (xn )
f (x0 ) = P (x0 )
f (x1 ) = P (x1 )
..
.
(2.11)
Para simplificar la notación, si hacemos N = n+m0 +· · ·+mn , tendremos con las ecuaciones
anteriores N + 1 condiciones o igualdades que cumplir. Así que sería deseable que el polinomio
buscado tuviera grado menor o igual que N , pues entonces el número de sus coeficientes es igual
al de condiciones que tenemos.
Puede probarse que tal polinomio, que denotamos por PN (x), existe y es único. Llamaremos
al polinomio obtenido polinomio de Hermite y a este tipo de interpolación interpolación de
Hermite.
Aunque los coeficientes de PN (x) pueden obtenerse resolviendo un sistema de ecuaciones
lineales al imponer las condiciones dadas en (2.11), es más eficiente construirlo mediante una
tabla similar a la tabla de diferencias divididas empleada para la obtención de la forma de Newton
del polinomio interpolador.
Para ello es necesario ampliar la definición de diferencia dividida en el siguiente sentido: si
x0 , x1 , . . . , xs verifican xi ≤ xi+1 i = 0, 1, . . . s y xi , xi+1 , . . . , xj es un subconjunto suyo con
índices consecutivos se define
f [xi , xi+1 , . . . xj ] =
f [xi+1 , . . . xj ] − f [xi , . . . xj−1 ]
xj − xi
f [xi , xi+1 , . . . xj ] =
f j−i) (xi )
(j − i)!
si xi 6= xj
si xi = xj
(2.12)
(2.13)
Para obtener el polinomio de Hermite del problema (2.11) basta con hacer una tabla de
diferencias divididas de este tipo en la que los nodos estén en orden creciente y cada xi se repita
mi + 1 veces (tantas como datos se conocen de él).
Ampliación de Matemáticas.
Interpolación Polinómica 25
Ejemplo 2.4 Obtengamos el polinomio de Hermite de la función f (x) = ln x que cumple P (1) =
f (1), P 0 (1) = f 0 (1), P 00 (1) = f 00 (1), P (2) = f (2) y P 0 (2) = f 0 (2).
1 0.000000
1.000000
−0.500000
1 0.000000
1.000000
0.193147
−0.306853
1 0.000000
0.693147
−0.079441
0.113706
−0.193147
2 0.693147
0.500000
2 0.693147
El polinomio será pues
P (x) = 0 + 1(x − 1) − 0.5(x − 1)2 + 0.193147(x − 1)3 − 0.079441(x − 1)3 (x − 2)
Podemos ampliar la definición de diferencias divididas de la siguiente manera: si xi , xi+1 , . . . , xj
es un conjunto de nodos (repetidos o no), definimos
f [xi , xi+1 , . . . , xj ] = f [xσ(i) , xσ(i+1) , . . . , xσ(j) ]
(2.14)
con xσ(i) ≤ xσ(i+1) ≤ · · · ≤ xσ(j) .
Utilizando esta definición, el polinomio de Hermite puede obtenerse colocando los nodos en la
tabla en un orden arbitrario aunque, desde un punto de vista práctico, resulta más conveniente
agrupar los nodos repetidos.
Teorema 2.3 Sea f : [a, b] −→ IR con f ∈ C (N ) ([a, b]) y tal que existe la derivada N + 1 en
(a,b). Sean x0 , x1 , . . . , xn ∈ [a, b], n + 1 nodos distintos y PN (x) el polinomio de Hermite que
j)
satisface f j) (xi ) = PN (xi ), j = 0, 1, . . . mi , i = 0, 1, . . . , n con m0 + m1 + · · · + mn + n = N .
Entonces para cada x ∈ [a, b] existe ξx ∈ (min(x0 , x1 , . . . , xn , x), max(x0 , x1 , . . . , xn , x)) tal que
f (x) − PN (x) =
f N +1) (ξx )
(x − x0 )m0 +1 . . . (x − xn )mn +1
(N + 1)!
(2.15)
Obsérvese que cuando m0 = · · · = mn = 0 (no hay derivadas) tenemos la interpolación de
Lagrange y que si n = 0 (sólo un nodo, el x0 ) tenemos el polinomio de Taylor centrado en x0 .
Por otra parte, el polinomio de Hermite obtenido para m0 = m1 = . . . mn = 1 es el más usual
y recibe el nombre de interpolación osculatoria.
26 Interpolación Polinómica
2.4
Ampliación de Matemáticas.
Interpolación polinómica segmentaria.
Utilizando la forma de Newton del polinomio interpolante, es sencillo aumentar el grado del
polinomio. ¿Es ésta una buena medida para mejorar la aproximación? El teorema de Weierstrass
puede inducir a pensar que sí, pero en general no es cierto. Runge demostró que los polinomios
interpolantes de la función
1
f (x) =
(2.16)
1 + x2
en el intervalo [−10, 10], construídos utilizando nodos equidistantes (diremos que los nodos
son equidistantes cuando la diferencia entre dos consecutivos sea una cantidad constante h > 0
que llamaremos tamaño de paso), sólo convergen a f (x) en la parte central del intervalo. Las
siguientes gráficas muestran la función f (x) junto con sus polinomios
interpolantes de grado 6
(izquierda) y 12 (derecha),
construídos a partir de nodos equidistantes. Obsérvese
cómo las oscilaciones de los
polinomios interpolantes en
las proximidades de los extremos del intervalo aumentan con el grado.
P12 (x)
P6 (x)
Una elección más adecuada de los nodos puede conseguir mejorar la aproximación, pero esta
elección varía con la función, y el grado a que se puede llegar hace que el camino no sea rentable.
Una solución mejor puede ser dividir el intervalo en el que se desea un polinomio interpolador y
considerar en cada subintervalo un polinomio interpolador distinto. A esta forma de interpolación
polinómica se le llama segmentaria o interpolación a trozos. Normalmente los polinomios
utilizados en cada subintervalo son del mismo tipo y el grado suele ser menor o igual que 3. Por
ejemplo, son habituales la interpolación lineal a trozos, con polinomios de grado menor o
igual que 1, o la interpolación cuadrática a trozos, con polinomios de grado menor o igual
que 2.
La interpolación segmentaria tiene el inconveniente de que la función aproximante que se
obtiene, en general no es derivable en los puntos comunes a dos intervalos consecutivos de la
partición considerada.
Una interpolación segmentaria en la que desaparece el problema comentado de la no existencia
de derivada en los nodos comunes es la conocida como interpolación cúbica de Hermite. En
esta interpolación las condiciones que se se imponen para cada nodo de los que determinan los
subintervalos de la partición son dos: coincidencia en imagen y en primera derivada. Así, en cada
trozo [xi−1 , xi ] se tendrá un polinomio de Hermite de grado 3 diferente y el interpolante global
será de clase 1. A este interpolante (que ya no es un polinomio , si no varios trozos "pegados")
se le llama interpolante cúbico de Hermite o trazador cubico de Hermite.
El error en la interpolación segmentaria depende del grado de los polinomios utilizados y de
la proximidad de los nodos. Veamos un ejemplo:
Ampliación de Matemáticas.
Interpolación Polinómica 27
Ejemplo 2.5 En el intervalo [a,b] se utiliza interpolación lineal a trozos con nodos equidistantes.
Sea h la distancia entre dos nodos consecutivos. Cualquier punto de [a, b] se hallará entre dos
nodos consecutivos xi−1 y xi . El error de interpolación para ese x será entonces
f (x) − P1 (x) =
f 00 (ξx )
(x − xi )(x − xi−1 ).
2!
(2.17)
Supongamos que se conoce una cota M del módulo de la derivada segunda de f en [a, b]. Como
el valor máximo de |(x − xi )(x − xi−1 )| en [xi−1 , xi ] es h2 /4 (¿por qué?) tenemos
|f (x) − P1 (x)| ≤
M h2
2! 4
∀x ∈ [a, b]
(2.18)
Obsérvese que en una situación como la descrita la acotación (2.18) asegura que los interpolantes
lineales a trozos convergen a la función cuando h tiende a 0.
2.5
Splines.
La interpolación segmentaria utilizando polinomios de Hermite no es la única forma de utilizar
polinomios diferentes para conseguir aproximantes globales que satisfagan ciertas condiciones
de regularidad. Los splines son otra alternativa. Trataremos únicamente el caso de los splines
cúbicos.
En un intervalo [a, b] se tiene la partición a = x0 < x1 < · · · < xn = b y se desea un
interpolante, en cada subintervalo determinado por la partición, de grado menor o igual que tres
que coincida con la función en los nodos y de forma que el aproximante final sea de clase 2 en
todo el intervalo. Denominaremos a este aproximante spline cúbico.
Analicemos si las condiciones que se le imponen a un spline cúbico son razonables. En cada
subintervalo [xi−1 , xi ] tenemos que determinar un polinomio
Pi (x) = ai (x − xi−1 )3 + bi (x − xi−1 )2 + ci (x − xi−1 ) + di
(2.19)
lo que supone 4n coeficientes para determinar. Estos polinomios han de verificar:
Pi (xi−1 ) = f (xi−1 ) i = 1, 2, . . . n
(2.20)
Pi (xi ) = f (xi ) i = 1, 2, . . . n
(2.21)
0
Pi0 (xi ) = Pi+1
(xi ) i = 1, 2, . . . n − 1
(2.22)
00
Pi00 (xi ) = Pi+1
(xi ) i = 1, 2, . . . n − 1
(2.23)
lo que significa que se tienen 2n + 2n − 2 condiciones, dos menos por tanto que el número
de coeficientes que hay que determinar. La expresión de los polinomios Pi (x) en potencias de
(x − xi−1 ) resulta ventajosa a la hora de buscar relaciones entre los coeficientes de los polinomios,
que faciliten la resolución del sistema. Puede probarse que el sistema planteado tiene solución
que por supuesto no es única. Para igualar el número de condiciones y el de coeficientes se suelen
imponer condiciones suplementarias. Las dos más usuales son: derivada segunda nula en a y b
(spline natural) o fijar los valores de la derivada primera en a y b (spline sujeto).
28 Interpolación Polinómica
Ampliación de Matemáticas.
Una ventaja de la interpolación segmentaria de Hermite frente a los splines cúbicos les que
permite ir logrando aproximaciones en cada subintervalo de manera independiente de los demás.
Así, si deseamos modificar el perfil del trazador en un tramo podemos cambiar allí sus valores
que esto no afectará a los trozos donde los valores se mantengan. En los splines sin embargo, la
modificación de cualquier dato afecta al interpolante obtenido en todos los subintervalos de la
partición.
Ventajas del spline son que el interpolante final es de clase 2 (tiene dos derivadas continuas)
mientras con la cúbica de Hermite a trozos sólo conseguimos primera derivada continua, y que
podemos obtener el aproximante sin necesidad de conocer el valor de la derivada en los nodos.
La elección de una interpolación cúbica de Hermite o de un spline cúbico depende de las
particularidades del problema que se desea resolver.
Tema 3
Producto interior. Ajuste
3.1
Producto interior.
Definición 3.1 Sea V un espacio vectorial. Llamaremos producto interior en V a cualquier
aplicación
< ., . >: V × V −→ IR
( u , v ) −→ < u , v >
que verifique las siguientes propiedades:
1. < u , v >=< v , u >,
∀u, v ∈ V .
2. < u + v, w >=< u, w > + < v, w >,
3. < ku , v >= k < u , v >,
4. < v , v >≥ 0,
∀u, v ∈ V,
∀u, v, w ∈ V .
∀k ∈ IR.
∀v ∈ V y < v , v >= 0 si y sólo si v = 0.
Algunos ejemplos de producto interior son:
1. El producto escalar habitual o euclídeo en IRn : si x = (x1 , x2 , . . . xn )t y y = (y1 , y2 , . . . yn )t
< x, y >=
n
X
xi yi .
(3.1)
i=1
2. En el espacio de matrices M2×2 :
<
a11 a12
a21 a22
b11 b12
,
>= a11 b11 + 2a12 b12 + 3a21 b21 + 4a22 b22 .
b21 b22
Ejercicio 3.1 Utilizando la definición, probar que cualquier producto interior verifica las siguientes propiedades:
1. < u , v + w >=< u , v > + < u , w >,
2. < u , kv >= k < u, v >,
3. < v , 0 >= 0,
∀v ∈ V.
∀u, v ∈ V,
∀u, v, w ∈ V
∀k ∈ IR
30 Producto interior. Ajuste
3.2
Ampliación de Matemáticas.
Normas.
Si consideramos el producto interior definido en IRn en (3.1) para el caso n = 2, 3, no es difícil
ver una relación entre < v, v > y la longitud (módulo) del vector v:
|v| =
√
< v, v >.
El producto interior va a permitir así extender la idea de módulo de un vector de IR2 o IR3
a un vector general como se recoge en la siguiente definición.
Definición 3.2 Sea V un e.v. con producto interior (en adelante p.i.). Denominaremos norma
asociada al producto interior a la siguiente aplicación
k.k : V
v
−→ IR
√
−→ kvk = < v, v >
Definiremos distancia entre dos vectores u y v de V por d(u, v) = ku − vk.
Nota 3.1 Con el producto interior euclídeo definido en (3.1), si V = IR, ||v|| = |v| es el valor
absoluto del número real v y si V = IR2 y V = IR3 , la norma coincide con la "longitud del
vector".
Ejemplo 3.1 En Π2 , espacio
R 1 de los polinomios de grado menor o igual que 2, con el producto
interior < p(x), q(x) >= −1 p(x)q(x)dx se tiene:
< x, x2 >= 0
k1k =
√
2,
kxk =
p
2/3,
d(1, x) =
p
8/3
Las normas asociadas a productos interiores son sólo un caso particular (y especialmente
importante) del concepto general de norma que a continuación definimos:
Definición 3.3 Sea V un e.v. Llamaremos norma a cualquier aplicación
k.k : V
v
−→ IR
−→ kvk
que verifique las siguientes propiedades:
1. kvk ≥ 0, ∀v ∈ V y kvk = 0 ⇐⇒ v = 0.
2. ku + vk ≤ kuk + kvk,
3. kkvk = |k| kvk,
∀u, v ∈ V .
∀v ∈ V, ∀k ∈ IR.
Ya hemos dicho que las normas asociadas al producto escalar en IR2 y IR3 representan la
longitud del vector. Las normas en general pueden entenderse como una forma de medir vectores.
Esta medida puede no ser identificable con una longitud (recuérdese que los vectores pueden ser
cualquier cosa (funciones, matrices,...). Aún cuando nos centremos en IRn , es posible definir
normas que para IR2 y IR3 no sean la longitud del vector. Veamos dos ejemplos.
Norma uno:
∀v = (v1 , v2 , . . . , vn )t ∈ IRn ,
kvk1 =
n
X
i=1
|vi |.
(3.2)
Ampliación de Matemáticas.
Norma infinito:
Producto interior. Ajuste 31
∀v = (v1 , v2 , . . . , vn )t ∈ IRn ,
kvk∞ = max{|vi | : i = 1, 2, . . . , n}.
(3.3)
La norma asociada al producto interior (3.1) (la que da la longitud del vector) se denomina
norma euclídea o norma 2.
No es difícil ver que las normas infinito, uno y dos, en general, no coinciden.
Ejemplo 3.2 Sea v = (1, −2, 3)t . Para este vector
kvk∞ = 3,
kvk1 = 6,
kvk2 =
√
14.
Los siguientes gráficos representan los vectores (x, y) ∈ IR2 unitarios (esto es, cuya norma
es 1) para las tres normas consideradas.
Fig. 3.1. kvk1 = 1
3.3
Fig. 3.2. kvk2 = 1
Fig. 3.3. kvk∞ = 1
Ángulo y Ortogonalidad.
Volvamos a las normas que derivan de productos interiores. Para estas normas es posible extender
los conceptos de ángulo y ortogonolidad conocidos en IR2 y IR3 . Este será nuestro siguiente
objetivo.
Teorema 3.1 (Desigualdad de Cauchy-Schwarz) Sea V un e.v. con p.i., entonces
∀u, v ∈ V se verifica
< u, v >2 ≤ < u, u >< v, v > .
(3.4)
Si u y v son no nulos, la desigualdad (3.4) puede escribirse así:
< u, v >2
≤1
kuk2 kvk2
o en cualquiera de las dos formas equivalentes siguientes:
< u, v >
≤1
kuk kvk
o
< u, v >
≤ 1.
kuk kvk
El cociente anterior puede ser visto como el coseno de un ángulo α ∈ [0, π] y podemos tomar
tal ángulo como el que forman u y v.
−1 ≤
32 Producto interior. Ajuste
Ampliación de Matemáticas.
Definición 3.4 Sea V un e.v. con p.i. y u, v ∈ V ambos no nulos. Llamaremos ángulo entre
los vectores u y v al número α ∈ [0, π] dado por:
< u, v >
.
(3.5)
α = arccos
kuk kvk
Definición 3.5 Sea V un e.v. con p.i. y u, v ∈ V . Diremos que u y v son ortogonales (se
denotará u ⊥ v) si < u, v >= 0.
Nota 3.2 Obsérvese que una consecuencia de las dos definiciones anteriores es que u y v no
nulos son ortogonales cuando el ángulo que forman es π/2.
Teorema 3.2 (Pitágoras generalizado) Sea V e.v. con p.i. y u, v ∈ V . Entonces
u ⊥ v ⇐⇒ ku + vk2 = kuk2 + kvk2 .
Demostración:
ku + vk2 =< u + v , u + v >=< u , u > +2 < u , v > + < v , v >= kuk2 + kvk2
puesto que al ser u y v ortogonales, < u , v >= 0.
Definición 3.6 Sea V e.v. con p.i., v ∈ V y W ⊂ V . Diremos que v es ortogonal a W
(v ⊥ W ) si v es ortogonal a todos los vectores de W .
Ejercicio 3.2 Sea W = lin(S). Demostrar que v ⊥ W ⇐⇒ v ⊥ S.
Definición 3.7 Sea V e.v. con p.i. y S ⊂ V . Se define el ortogonal de S de la siguiente
manera,
S ⊥ = { v ∈ V / v ⊥ S}.
Ejercicio 3.3 Demostrar las siguientes afirmaciones:
1. S ⊥ es un subespacio vectorial.
2. S ⊥ = (lin(S))⊥ .
3. Si A ⊂ B ⊂ V , entonces B ⊥ ⊂ A⊥ .
4. V ⊥ = {0},
{0}⊥ = V .
5. Sea W subespacio de V , entonces W ∩ W ⊥ = {0}.
Definición 3.8 Diremos que un subconjunto U de V es ortogonal si cualquier par de vectores
del conjunto U resulta ortogonal.
Diremos que un subconjunto de V es ortonormal si es ortogonal y todos sus vectores son
unitarios.
Al proceso de multiplicar un vector no nulo por un escalar, de forma que el vector resultante
sea de norma 1, se le llama normalizar el vector. Un conjunto ortogonal se convierte en
ortonormal si normalizamos todos los vectores.
Ampliación de Matemáticas.
Producto interior. Ajuste 33
Ejercicio 3.4 ¿Cuál es el escalar por el que hay que multiplicar un vector para normalizarlo?
Teorema 3.3 Sea V e.v. con p.i. y S = {v 1 , v 2 , . . . , v r } ⊂ V − {0} con S ortogonal. Entonces
S es linealmente independiente
Demostración: Consideremos una combinación lineal de los elementos de S igualada a cero
y veamos que todos los coeficientes deben ser nulos.
r
X
αi v i = 0
=⇒ <
i=1
r
X
αi v i , v j >= 0,
j = 1, 2, . . . , r.
i=1
Aplicando ahora las propiedades de linealidad del producto interior,
<
r
X
αi v i , v j >= 0
=⇒
r
X
< αi v i , v j >= 0
=⇒
i=1
i=1
r
X
αi < v i , v j >= 0.
i=1
y al ser S ortogonal, la expresión anterior se reduce a
αj < v j , v j >= 0.
Como v j es no nulo, necesariamente αj = 0,
j = 1, 2, . . . , r.
La ortogonalidad tiene sus ventajas a la hora de considerar bases y coordenadas como podemos ver en el siguiente resultado.
Teorema 3.4 Sea V e.v. con p.i. y B = {v 1 , v 2 , . . . , v n } una base ortonormal de V . Entonces
∀u, w ∈ V
1. u =
n
X
< u, v i > v i .
i=1
2. < u, w >=
n
X
< u, v i >< w, v i >.
i=1
v
u n
uX
u
3. kuk = t
< u, v i >2 .
i=1
Demostración:
1. Sean (α1 , α2 , . . . , αn ) las coordenadas de u en la base B
u=
n
X
αi v i
=⇒ < u, v j >=
i=1
lo que prueba el apartado.
n
X
i=1
αi < v i , v j >= αj < v j , v j >= αj
34 Producto interior. Ajuste
Ampliación de Matemáticas.
2. Sean (β1 , β2 , . . . , βn ) las coordenadas de w en la base B.
< u, w >=
n
X
αi βi < v i , v i >=
i=1
n
X
αi βi
i=1
y aplicamos el primer apartado.
3. Con la notación introducida,
kuk2 =< u, u >=
n
X
αi2 < v i , v i >=
i=1
n
X
αi2
i=1
y aplicamos el apartado primero.
El primer apartado del teorema anterior dice que las coordenadas de un vector en una base
ortonormal son los productos interiores del vector con los vectores de la base (muy fáciles de
calcular por tanto). El segundo y tercer apartado del teorema permiten ver que si en un espacio
vectorial con p.i. identificamos cada vector con sus coordenadas en una base ortonormal, el p.i.
se reduce al habitual de IRn (segundo apartado del teorema) y lo mismo puede decirse de la
norma asociada al p.i. (tercer apartado).
Una consecuencia inmediata del teorema anterior es el siguiente resultado.
Teorema 3.5 Sea V un e.v. con p.i. Entonces la matriz P de cambio de base entre dos bases
ortonormales de V cumple que P −1 = P t .
Ejercicio 3.5 ¿Por qué el resultado anterior es consecuencia inmediata del teorema (3.4)?
(Recuérdese qué es cada columna de una matriz de cambio de base)
Las matrices cuadradas que cumplen A−1 = At se denominan matrices ortogonales.
Ejemplo 3.3 En IR3 con el producto interior euclídeo B = {u1 , u2 , u3 } con
0
4/5
−3/5
0
u1 = 1 , u2 = 0 , u3 =
0
3/5
4/5
es una base ortonormal.
Si v = (1, 1, 1)t entonces
[v]B = (1, 7/5, 1/5)t
y
kvk =
p
√
12 + (7/5)2 + (1/5)2 = 3
Si u = u1 + 2u2 + 3u3 entonces
kuk =
p
12 + 2 2 + 3 2 .
¿Cual sería la matriz de cambio de la base canónica de IR3 a B?
De lo visto hasta ahora se deduce la ventaja de trabajar con bases ortonormales, pero ¿es
esto siempre posible? Vamos a ver que así es si estamos en un e.v. de dimensión finita, porque
siempre es posible modificar una base cualquiera para convertirla en ortonormal.
Ampliación de Matemáticas.
3.4
Producto interior. Ajuste 35
Proyección y componente ortogonal.
Consideremos el espacio vectorial IR3 con las operaciones y el p.i. habituales y sea W un plano
de IR3 . No es difícil admitir, a nivel intuitivo, la posibilidad de descomponer cualquier vector
v de IR3 en suma de un vector de W (v p ) y otro de W ⊥ (v o ) como se muestra en la figura,
de forma que v = v p + v o . Veamos que esto se puede generalizar a cualquier e.v. con p.i. y
cualquier subespacio W de dimensión finita. Empezaremos por el caso en que se conoce una base
ortonormal de W .
Teorema 3.6 Sea V e.v. con p.i., W subespacio
de V y B = {u1 , u2 , . . . , ur } base ortonormal de
W. Entonces ∀v ∈ V existen unos únicos v p ∈ W
y v o ∈ W ⊥ tales que
v
vo
vp
v = vp + vo.
W
Los vectores v p y v o reciben el nombre de proyección y componente ortogonal de v con
respecto a W , respectivamente.
Demostración: Sea
vp =
r
X
< v, ui > ui
i=1
y
vo = v − vp
(Obsérvese que si v ∈ W , por el teorema 3.4, v p = v)
Las definiciones dadas garantizan que v = v p + v o y que v p ∈ W . Veamos que v o ∈ W ⊥ y la
unicidad de la descomposición. Para ver lo primero basta probar que
< v o , uj >= 0,
j = 1, 2, . . . , r.
< v o , uj >= < v − v p , uj > = < v −
r
X
(3.6)
!
< v, ui > ui
, uj > =
i=1
= < v , uj > − <
r
X
< v, ui > ui , uj > = < v, uj > − < v, uj >< uj , uj > = 0
i=1
lo que prueba (3.6).
En cuanto a la unicidad, si
v = vp + vo
y
v = v 0p + v 0o
con v p , v 0 p ∈ W y v o , v 0 o ∈ W ⊥ , igualando los lados derechos de las expresiones anteriores
tenemos
v p − v 0p = v 0o − v o .
36 Producto interior. Ajuste
Ampliación de Matemáticas.
Dado que el lado derecho de la igualdad anterior pertenece a W ⊥ y el izquierdo a W , ambos
lados han de ser nulos (ver ejercicio 3.3 del apartado anterior), lo que garantiza la unicidad de
la descomposición.
Vemos ahora cómo ortonormalizar una base cualquiera de un e.v. con p.i. de dimensión
finita.
Teorema 3.7 (Método de ortonormalización de Gram-Schmidt) Sea V un e.v. de dimensión finita con p.i.. Entonces existe una base ortonormal.
Demostración: Sea B = {v 1 , v 2 , . . . , v n } una base cualquiera de V . Vamos a construir a
partir de ella una base ortonormal. Sean
u1 =
v1
kv 1 k
y
W1 = lin(u1 ).
Tomaremos como u2 la componente ortogonal de v 2 con respecto a W1 normalizada, es decir,
sean
u2 =
v 2 − < v 2 , u1 > u1
kv 2 − < v 2 , u1 > u1 k
W2 = lin(u1 , u2 ).
y
Tomemos u3 como la componente ortogonal de v 3 con respecto a W2 normalizada, es decir
v3 −
2
X
< v 3 , ui > ui
i=1
u3 =
kv 3 −
2
X
y
W3 = lin(u1 , u2 , u3 ).
< v 3 , ui > ui k
i=1
Repitiendo este proceder tendremos finalmente un conjunto de n vectores
v1
, si j = 1
kv
1k
j−1
X
v −
< v j , ui > ui
j
uj =
i=1
, si j = 2, 3, . . . , n.
j−1
X
kv j −
< v j , ui > ui k
(3.7)
i=1
Obsérvese que lin(u1 , u2 , . . . , ui ) = lin(v 1 , v 2 , . . . , v i ), i = 1, 2, . . . , n (¿por qué?) y por tanto
los vectores construidos forman una base de V . Por otra parte, al ser cada ui ortogonal a todos
los anteriores y unitario, la base obtenida es ortonormal.
Una consecuencia inmediata de los dos teoremas anteriores es el siguiente resultado.
Teorema 3.8 Sea V e.v. con p.i., W subespacio de dimensión finita de V. Entonces ∀v ∈ V
existen unos únicos v p ∈ W y v o ∈ W ⊥ tales que
v = vp + vo.
Ampliación de Matemáticas.
Producto interior. Ajuste 37
La proyección de un vector sobre un subespacio tiene un significado de gran importancia
y aplicación: representa la aproximación óptima del vector por vectores del subespacio. En la
figura puede verse, para el caso particular de IR3 , cómo la mejor aproximación a v por vectores
de W (la de diferencia más pequeña en norma) es la dada por la proyección.
Teorema 3.9 Sea V e.v. con p.i., W subespacio de dimensión finita de V, sea v ∈ V y v p ∈ W
la proyección de v sobre W . Entonces ∀w ∈ W
kv − v p k ≤ kv − wk.
Demostración:
v
vo
v−w
vp − w
vp
v − w = v − vp + vp − w
| {z } | {z }
W
v o ∈W ⊥
w
∈W
Aplicando entonces el teorema 3.2 tenemos
kv − wk2 = kv − v p k2 + kv p − wk2
=⇒
kv − wk2 ≥ kv − v p k2
=⇒
kv − wk ≥ kv − v p k.
Nota 3.3 De acuerdo con lo anterior definiremos distancia de un vector v a un subespacio
W como la norma de la componente ortogonal de v respecto de W , esto es,
d(v, W ) = kv − v p k.
3.5
Expresión de la proyección en una base arbitraria.
En la sección anterior hemos visto cómo obtener la proyección de un vector sobre un subespacio de dimensión finita encontrando una base ortonormal del espacio sobre el que se quería
proyectar. Veamos cómo encontrar la proyección de un vector utilizando una base cualquiera,
no necesariamente ortonormal.
Sea V un e.v. con p.i., W un subespacio de dimensión finita, B = {w1 , w2 , . . . , wr } una base
arbitraria de W y v ∈ V . Sabemos que existe una descomposición única de v de la forma
v = vp + vo
con v p ∈ W y v o ∈ W ⊥ . Otra forma de decir esto es que v p es el único elemento de W tal que
v − vp ⊥ W
o equivalentemente
< v − v p , wi >= 0,
i = 1, 2, . . . , r.
(3.8)
38 Producto interior. Ajuste
Ampliación de Matemáticas.
Puesto que v p ∈ W podrá expresarse en la base B de W en la forma
vp =
r
X
cj wj .
(3.9)
j=1
Sustituyendo esta última expresión en (3.8) tenemos
r
X
<v−
cj wj , wi >= 0,
i = 1, 2, . . . , r
(3.10)
j=1
que aplicando las propiedades del producto interior se convierte en
< v , wi > −
r
X
cj < wj , wi >= 0,
i = 1, 2, . . . , r.
(3.11)
j=1
Tenemos así un sistema de r ecuaciones con r incógnitas que matricialmente podemos escribir
de la siguiente manera:
< w1 , w1 > < w1 , w2 > . . .
< w , w > < w , w > ...
2
1
2
2
..
..
..
.
.
.
< wr , w1 > < wr , w2 > . . .
< w1 , wr >
c1
< v , w1 >
< w2 , wr >
c2 < v , w2 >
.. =
..
..
.
.
.
< wr , wr >
cr
(3.12)
< v , wr >
Las ecuaciones anteriores reciben el nombre de ecuaciones normales. Estas ecuaciones
tienen siempre solución única puesto que los valores ci que las satisfacen son las coordenadas de
la proyección de v sobre W que sabemos que existen y son únicas.
Ejemplo 3.4 Sea W = lin{1, cos(x)}. Vamos a encontrar la aproximación óptima a f (x) = |x|
por elementos de W con respecto al producto interior
Z π
< f, g >=
f (x)g(x)dx.
−π
Los vectores 1 y cos(x) forman una base de W puesto que claramente son generadores y la
independencia se sigue de considerar la combinación lineal α + β cos(x) = 0 en x = 0 y x = π/2,
por ejemplo.
Planteemos entonces las ecuaciones normales para obtener la proyección buscada.
< 1, 1 >
< 1 , cos(x) >
c1
< |x| , 1 >
=
.
< cos(x) , 1 > < cos(x) , cos(x) >
c2
< |x| , cos(x) >
Calculemos cada uno de los términos:
Z π
< 1 , 1 >=
1 dx = 2π,
−π
Z π
< 1 , cos(x) >=< cos(x) , 1 >=
−π
cos(x) dx = [sin(x)]π−π = 0,
Ampliación de Matemáticas.
Producto interior. Ajuste 39
1 + cos(2x)
sin(2x) π
1
< cos(x) , cos(x) >=
cos (x) dx =
x+
dx =
= π,
2
2
2
−π
−π
−π
Z π
Z π
< |x| , 1 >=
|x| dx = 2
x dx = π 2 ,
Z π
Z π
2
−π
0
Z π
Z π
|x| cos(x)dx = 2
< |x| , cos(x) >=
−π
x cos(x)dx = 2[x sin(x) + cos(x)]π0 = −4.
0
Resolviendo ya las ecuaciones normales,
2π 0
0 π
c1
c2
=
π2
−4
=⇒
π
c1 =
2
4
c2 = −
π
La aproximación óptima a |x| por elementos de W , en el sentido del producto interior dado,
es entonces
f ∗ (x) =
3.6
4
π
− cos(x).
2 π
Ecuaciones normales en IRn .
Consideremos ahora el caso de IRn con el producto interior habitual. Sea W un subespacio de
IRn , B = {w1 , w2 , . . . , wr } una base cualquiera de W y v ∈ IRn . Las ecuaciones (3.8) pueden
ahora escribirse en forma matricial de la siguiente manera
c1
c2
t
wi v − (w1 w2 . . . wr ) .
= 0,
.
.
cr
{z
}
|
i = 1, 2, . . . , r.
proyW v
Llamando A a la matriz que tiene por columnas los vectores de la base de W y c a la matriz
de coordenadas de la proyección, la ecuación anterior puede expresarse como
wti (v − Ac) = 0,
i = 1, 2, . . . , r
o equivalentemente
At (v − Ac) = 0
lo que nos lleva a la forma habitual de las ecuaciones normales (3.12) en IRn
At A c = At v
(3.13)
La matriz At A recibe el nombre de matriz normal.
¿Qué hubiera sucedido si en lugar de considerar una base de W hubiéramos trabajado con un
sistema generador, es decir, si las columnas de A no hubieran sido linealmente independientes? El
40 Producto interior. Ajuste
Ampliación de Matemáticas.
planteamiento de las ecuaciones normales garantiza que el sistema tiene solución puesto que hay
una combinación lineal (en este caso no única) del sistema generador de W que se corresponde con
la proyección. El sistema tendrá por tanto solución pero no única. Obsérvese que la proyección
sigue siendo única, lo que no lo es, es su expresión como combinación lineal de un sistema
generador que no es base.
3.7
Aplicaciones de la proyección. Ajuste Discreto.
Veremos ahora alguna de las aplicaciones de la proyección como aproximación óptima. En
concreto, resolveremos el problema de encontrar una curva que se adapte adecuadamente a una
nube de puntos.
3.7.1
Recta de ajuste.
Sea (x1 , y1 ), (x2 , y2 ) . . . (xm , ym ) un conjunto de puntos del plano. Nuestro objetivo es encontrar
una recta que se adapte (en un sentido que definiremos) lo mejor posible a este conjunto. Si
los puntos estuvieran sobre una recta y = c1 + c2 x, ésta sería la buscada y se verificaría yi =
c1 + c2 xi , i = 1, 2, . . . , m, es decir
x1
y1
x2
c1
y2
= .
.. c
..
2
.
1 xm
ym
1
1
..
.
(3.14)
Llamando A a la primera matriz e y al segundo miembro
A
c1
c2
=y
(3.15)
En general esto no será así y el sistema anterior será por tanto incompatible. Buscaremos
entonces para c1 y c2 valores que si bien no van a poder satisfacer (3.15), van a hacer que la
diferencia entre los dos miembros sea lo más pequeña posible. Puesto que queremos minimizar
una diferencia de vectores (los dos miembros de (3.15)) utilizaremos una norma para medir el
tamaño de ese vector diferencia: la norma euclídea.
Resumiendo lo dicho: buscamos c1 , c2 tales que
c1
A
−y
c2
sea mínima. Obsérvese que A
c1
c2
c1
c2
es una combinación lineal de las columnas de A de coefi-
cientes c1 y c2 , es decir,
A
− y = kc1 w1 + c2 w2 − yk
siendo w1 , w2 las columnas de A. La combinación lineal que hace mínima la norma anterior es,
como sabemos, la proyección de y sobre W = lin{w1 , w2 }, puesto que
Ampliación de Matemáticas.
Producto interior. Ajuste 41
||y p − y|| ≤ ||w − y||,
∀w ∈ W.
Como y p es una proyección sobre W (que puede verse como un subespacio de IRm ) con
respecto al producto interior habitual, la determinaremos resolviendo las ecuaciones normales
(3.13)
t
AA
c1
c2
= At y
donde A es la matriz cuyas columnas son w1 y w2 .
Repasemos las etapas que nos han llevado de la recta inicialmente buscada a la proyección
con la que hemos resuelto finalmente el problema:
1. Empezamos buscando una recta (sus coeficientes) que "pasara cerca" de una nube de
puntos.
2. Ese "pasar cerca" se concretó en buscar c1 , c2 que hicieran mínima
c1
A
−y .
c2
c1
3. La interpretación de A
como combinación lineal de las columnas de A presentó el
c2
problema de minimizar la norma como el de encontrar la combinación lineal de las columnas
de A más cercana a y (aproximación óptima).
4. La aproximación óptima a y por vectores de W = lin{w1 , w2 } es la proyección de y sobre
W.
Encontrados los coeficientes de la proyección, estos son los de la combinación lineal más
cercana, los que minimizan la norma, es decir, los de la recta buscada.
3.7.2
Caso general discreto.
Veamos ahora cómo encontrar una función de la forma f ∗ (x) = c1 g1 (x) + c2 g2 (x) + · · · + cn gn (x)
que se adapte lo mejor posible al conjunto de puntos (x1 , y1 ), (x2 , y2 ) . . . (xm , ym ) con m > n.
La recta estudiada en el apartado anterior es un caso particular de este planteamiento con
g1 (x) = 1 y g2 (x) = x.
La situación óptima sería poder determinar f ∗ (x) de forma que yi = c1 g1 (xi ) + c2 g2 (xi ) +
· · · + cn gn (xi ), i = 1, 2, . . . , m, es decir,
g1 (x1 )
g1 (x2 )
..
.
g2 (x1 )
g2 (x2 )
..
.
···
···
..
.
g1 (xm ) g2 (xm ) · · ·
gn (x1 )
c1
y1
gn (x2 )
c2 y2
.. = ..
..
. .
.
gn (xm )
cn
ym
(3.16)
42 Producto interior. Ajuste
Ampliación de Matemáticas.
Como sucedía en el caso de la recta de ajuste, el sistema anterior en general es incompatible
y nuestro objetivo es entonces determinar los parámetros c1 , c2 , . . . , cn de forma que
||c1 w1 + c2 w2 + · · · + cn wn − y||
sea mínima, siendo la norma considerada la euclídea y donde wi es el i-ésimo vector columna de
la matriz que aparece en (3.16).
Planteado en términos vectoriales, el problema se reduce a encontrar el elemento de W =
lin{w1 , w2 , . . . , wn } que más próximo se encuentra de y, es decir, la proyección de y sobre W .
Al tratarse de nuevo de una proyección en IRm las ecuaciones normales son
At Ac = At y
donde A es la matriz cuyas columnas son wi ,
i = 1, 2, . . . , n.
La expresión de la norma euclídea en términos de cuadrados hace que los ajustes que estamos
considerando se conozcan como ajustes en el sentido de mínimos cuadrados.
Una vez hallada la función f ∗ , podemos querer medir la bondad del ajuste que esa función proporciona. Una primera medida para ello es calcular la cantidad que nos proponíamos
minimizar:
n
X
ci wi − y .
i=1
Más razonable es la expresión
n
X
1
√
ci wi − y
m
i=1
pues de otra forma (3.17) podría ser grande por causa de un número de puntos elevado.
(3.17)
Tema 4
Resolución Numérica de Sistemas
Sea A una matriz cuadrada n×n tal que det(A) 6= 0. Podemos clasificar los métodos de resolución
de sistemas del tipo Ax = b en dos bloques:
1. Métodos directos: proporcionan la solución exacta del sistema, salvo errores de redondeo,
tras un número finito de operaciones. Son métodos directos, por ejemplo, la eliminación
gaussiana o la regla de Cramer.
2. Métodos Iterativos: proporcionan una sucesión de aproximaciones x(1) , . . . , x(n) a la
solución del sistema. Los ejemplos más conocidos de este tipo de métodos son los de Jacobi
y Gauss-Seidel que veremos más adelante.
No todos los métodos son utilizables en cualquier situación. Los métodos iterativos, por
ejemplo, pueden generar aproximaciones que no converjan a la solución. En cuanto a los métodos
directos, además de las limitaciones teóricas de ciertos algoritmos (la eliminación gaussiana sin
pivotaje, por ejemplo, sólo puede implementarse si no aparecen pivotes nulos) hay que tener en
cuenta las de carácter práctico como excesivo número de operaciones o una mala propagación del
error de redondeo. Estas consideraciones prácticas hacen que sea absolutamente inútil la regla
de Cramer pues, en cuanto el sistema pase de dimensión 3 o 4, el número de multiplicaciones que
requiere el cálculo de los n + 1 determinantes que se necesitan lo hace totalmente prohibitivo.
(Un ordenador que realizara 10,000,000,000 operaciones por segundo necesitaría del orden de
1018 años para resolver mediante la regla de Cramer un sistema 30 × 30).
La elección de un método u otro depende del sistema que se desee resolver. Si el sistema no es
muy grande (aquí el calificativo “grande" ha de entenderse en un sentido relativo a la máquina
que se va a utilizar para su resolución) son preferibles los métodos directos. Los métodos iterativos
se utilizan (cada vez menos debido a que cada vez es mayor el número de problemas que pueden
ser abordados por métodos directos) principalmente para resolver sistemas grandes con matriz
dispersa (muchos ceros) y estructurada (los elementos no nulos se agrupan por ejemplo en torno
a la diagonal principal). Este tipo de sistemas aparece por ejemplo en la resolución numérica de
ecuaciones en derivadas parciales.
Antes de entrar en las cuestiones propias de la resolución de sistemas veamos algunas generalidades sobre el error de redondeo.
44 Resolución Numérica de Sistemas
4.1
Ampliación de Matemáticas.
Errores de redondeo.
La resolución de sistemas de ecuaciones se efectúa la mayoría de las veces con la ayuda de
un ordenador. Es sabido que no todos los números reales tienen representación exacta en un
ordenador. Al introducir los datos de un sistema en un ordenador es habitual que estemos
trabajando ya con aproximaciones más o menos buenas de los datos exactos. Por otra parte
las operaciones que el ordenador realiza con esos datos tampoco se corresponden exactamente
siempre con las que nosotros haríamos a mano (con precisión infinita). Los errores procedentes de
la capacidad limitada de representación de números de los ordenadores, así como de la precisión
en las operaciones reciben el nombre de errores de redondeo.
Los errores de redondeo pueden conducir a soluciones muy imprecisas o totalmente distintas
de las correctas en la resolución de un sistema.
Sea x un valor y x∗ una aproximación del mismo. El error absoluto y el relativo (en caso de
que x sea no nulo) de esta aproximación viene dado por |x − x∗ | y |x − x∗ |/|x| respectivamente.
Las siguientes definiciones precisan la bondad de una aproximación en términos de error absoluto
y de error relativo respectivamente.
Definición 4.1 Diremos que x∗ es una aproximación a x con d cifras decimales correctas
si
1
|x − x∗ | ≤ 10−d .
2
Diremos que x∗ es una aproximación a x 6= 0 con d cifras significativas correctas si
|x − x∗ |
≤ 5 ∗ 10−d .
|x|
Obsérvese que la definición de "aproximación con d cifras decimales correctas" selecciona de
entre los decimales con d dígitos el (o los) que está más cerca del número que se quiere aproximar
y lo mismo sucede con la aproximación con d cifras significativas correctas.
Puede sorprender la presencia de un 5 en lugar del 1/2 esperable en la definición de número
de cifras significativas correctas, pero obsérvese que si en la definición apareciera 1/2, el número
0.1235 ∗ 103 no sería una aproximación con 4 cifras significativas correctas de 0.12347 ∗ 103 por
ejemplo.
4.1.1
Situaciones que merecen atención.
Los errores de redondeo son en general difíciles de controlar, pero en ocasiones su amplificación
puede paliarse con un algoritmo adecuado. Veamos algunas de estas situaciones.
1. Resta de números próximos. Esta situación puede conducir a una amplificación del error
relativo. Veamos un ejemplo. Sea x1 = 1.23456728 una aproximación de xe1 = 1.23456730
y x2 = 1.23456739 una aproximación de xe2 = 1.23456740. Los errores relativos de ambas
son, entonces, respectivamente:
x1 =
|x1 − xe1 |
≃ 1.62 ∗ 10−8
|xe1 |
y
x2 =
|x2 − xe2 |
≃ 0.81 ∗ 10−8 .
|xe2 |
Ampliación de Matemáticas.
Resolución Numérica de Sistemas 45
El error relativo de su diferencia es
x1 −x2 =
|x1 − x2 − (xe1 − xe2 )|
= 0.1
|xe1 − xe2 |
varios órdenes mayor que el de los términos que intervienen en la resta.
En ocasiones puede evitarse la cancelación de cifras significativas que venimos comentando
reescribiendo la expresión. Por ejemplo
√
1+x−
√
x= √
1
√
1+x+ x
pero mientras la expresión del primer miembro de la ecuación anterior puede conducir a
cancelación de cifras significativas para valores grandes de x, no sucede lo mismo con la
segunda.
2. Suma de números de magnitudes muy diferentes. En este caso el problema es la limitación
de cifras significativas en la representación de números en un ordenador. Por ejemplo si se
quiere sumar 0.1 ∗ 105 con 0.5 ∗ 10−1 y se está trabajando con cuatro cifras significativas,
la suma sería el primer número. Se debe, por tanto, evitar en la medida de lo posible la
suma de números excesivamente descompensados.
El ejemplo anterior se presta para comentar otra cuestión a tener en cuenta y es que
la asociatividad de las operaciones algebraicas (como la suma) no se mantiene a nivel
numérico. Para ver esto, supongamos que se quiere sumar un número grande, como 0.1∗105 ,
y 105 veces un número pequeño como 0.5 ∗ 10−1 . Si se suma al número grande el pequeño
(siempre con la limitación de las cuatro cifras significativas disponibles), una y otra vez,
la suma final será 0.1 ∗ 105 , mientras que si se suman los números pequeños entre sí (por
grupos de dos por ejemplo, que luego se agrupan a su vez de dos en dos etc.) las cifras
significativas no se perderán, al no darse nunca una suma entre números de muy distintos
tamaños.
3. División por números pequeños. Este fenómeno afecta frecuentemente a la resolución de
sistemas vía eliminación gaussiana y se produce por la presencia de pivotes pequeños. Las
divisiones por números pequeños tienen el inconveniente de la aparición de números grandes
(en el caso de la eliminación gaussiana, los multiplicadores) que pueden amplificar el error
de redondeo.
4.2
Aspectos computacionales de la eliminación gaussiana.
4.2.1
Necesidad computacional de pivotaje.
La necesidad de intercambio de filas ante un pivote nulo es evidente pero veamos que no es la
única situación en que el pivotaje es conveniente.
Consideremos el siguiente sistema:
0.0001 1
x
1
=
1
1
y
2
46 Resolución Numérica de Sistemas
Ampliación de Matemáticas.
d y = 0.9998.
d Si se resuelve empleando eliminación gaussiana
cuya solución exacta es x = 1.0001,
sin pivotaje en aritmética de tres dígitos, se obtiene como solución x=0.00, y=1.00. El valor de
y resulta razonable si se tiene en cuenta el número de dígitos utilizados, pero el de x tiene un
error relativo próximo a 1.
La explicación de este resultado poco satisfactorio está en el multiplicador m21 empleado:
m21 =
1.00
0.000100
que al ser extremadamente grande actúa como amplificador de los errores de redondeo. Si se
resuelve el mismo sistema intercambiando las filas ( es decir, con pivotaje) obtenemos como
solución x=1.00, y=1.00 que es lo razonable para el número de dígitos empleado.
De los comentarios anteriores sacamos la conclusión de que aunque, desde un punto de vista
teórico, el pivotaje sólo es imprescindible en presencia de un pivote nulo, la presencia de pivotes
pequeños es también desaconsejable desde el punto de vista numérico (porque generan multiplicadores grandes). Haremos siempre por tanto pivotaje (salvo casos de buen comportamiento
asegurado), es decir tomaremos en cada etapa como fila de pivotaje la que aporte un pivote más
grande para la variable en cuestión.
El pivotaje comentado recibe el nombre de pivotaje parcial para distinguirlo del pivotaje
total en el que la búsqueda del máximo pivote posible no sólo involucra intercambios de filas (de
ecuaciones) sino de columnas (de variables). Este último pivotaje no es muy utilizado porque
requiere muchas más comparaciones de elementos que el pivotaje parcial para la escasa ventaja
que suele aportar.
4.2.2
Número de operaciones de la eliminación gaussiana.
Vamos a dividir el cómputo del número de operaciones en tres bloques:
1. Factorización LU de la matriz.
2. Transformación del segundo miembro. (Sustitución progresiva)
3. Sustitución regresiva.
Factorización LU de la matriz.
Para conseguir los ceros en la 1a columna (eliminación de la primera variable) necesitaremos:
• (n − 1) divisiones para la obtención de los (n − 1) multiplicadores.
• (n−1)2 productos de multiplicar cada multiplicador por los elementos de la fila de pivotaje.
• (n − 1)2 restas ((n − 1) de cada fila a transformar).
Para la 2a columna
Ampliación de Matemáticas.
Resolución Numérica de Sistemas 47
• (n − 2) divisiones para la obtención de los (n − 2) multiplicadores.
• (n−2)2 productos de multiplicar cada multiplicador por los elementos de la fila de pivotaje.
• (n − 2)2 restas ((n − 2) de cada fila a transformar).
En general, entonces, para la columna i-ésima necesitamos
• (n − i) divisiones para la obtención de los multiplicadores.
• (n−i)2 productos de multiplicar cada multiplicador por los elementos de la fila de pivotaje.
• (n − i)2 restas ((n − i) de cada fila a transformar).
Como esto ha de hacerse desde la columna 1 hasta la n − 1 en total habremos realizado
n−1
X
((n − j) + (n − j)2 ) =
j=1
n3 n
−
3
3
multiplicaciones/divisiones y
n−1
X
j2 =
j=1
n3 n2 n
−
+
3
2
6
sumas/restas.
Transformación del segundo miembro. (Sustitución progresiva)
La transformación del segundo miembro se reduce a resolver el sistema triangular:
1
m21
m31
..
.
0
1
m32
..
.
0
0
1
..
.
···
···
···
..
.
mn1 mn2 mn3 · · ·
0
c1
b1
0
c2 b2
0
c3 = b3
.. .. ..
. . .
1
cn
bn
Para obtener c2 se necesita un producto y una suma, para c3 dos productos y dos sumas, . . . ,
para cn (n − 1) productos y (n − 1) sumas. En total:
n−1
X
i=1
i=
n(n − 1)
2
productos y el mismo número de sumas.
Nota 4.1 Obsérvese que las operaciones contabilizadas en el apartado anterior son exactamente
las mismas que se realizan cuando se modifica el segundo miembro a la vez que la matriz (cuando
lo colocamos como última columna).
48 Resolución Numérica de Sistemas
Ampliación de Matemáticas.
Sustitución regresiva.
Sólo falta por contabilizar la resolución del sistema de matriz triangular superior:
c1
x1
u11 u12 u13 · · · u1n
0 u22 u23 · · · u2n x2 c2
x3 c3
0
0
u
·
·
·
u
33
3n
=
..
..
..
.. .. ..
..
.
.
.
.
.
.
.
0
0
···
0
unn
xn
cn
En este cómputo utilizaremos el término “producto" para indicar producto o división.
Para obtener xn se necesita una división; para xn−1 dos productos y una suma; para xn−2
tres productos y dos sumas, . . . , para x1 n productos y (n-1) sumas. En total:
n
X
i=
n(n + 1)
2
i=
n(n − 1)
2
i=1
productos y
n−1
X
i=1
sumas.
Podemos resumir los resultados obtenidos en el siguiente cuadro:
Prod./div.
Sum./res.
Factorización LU
n3
n
−
3
3
n2 n
n3
−
+
3
2
6
T. seg. miembro
n(n − 1)
2
n(n − 1)
2
Sust. regres.
n(n + 1)
2
n(n − 1)
2
Cómputo total
n3
n
+ n2 −
3
3
n3 n2 5n
+
−
3
2
6
Veamos ahora el número de operaciones necesarias para calcular la inversa (por supuesto por
el método de resolver n sistemas lineales con matriz común). La factorización LU requiere el
número de operaciones comentado anteriormente. En cuanto a la modificación del lado derecho,
puede probarse que para cada ej , desde j = 1 hasta n − 2 inclusive, se necesitan
n−j−1
X
i=
i=1
(n − j)(n − j − 1)
2
productos y el mismo número de sumas, mientras que no se necesitan operaciones para modificar
en−1 ni en . Esto supone un total de
n(n − 1)(n − 2)
6
sumas y el mismo número de productos.
En cuanto a la sustitución regresiva, necesitaremos en total
n2 (n + 1)
2
Ampliación de Matemáticas.
Resolución Numérica de Sistemas 49
productos y
n(n − 1)2
2
sumas. El cálculo de la inversa supone pues
n3 n n(n − 1)(n − 2) n2 (n + 1)
− +
+
= n3
3
3
6
2
productos y
n3 n2 n n(n − 1)(n − 2) n(n − 1)2
−
+ +
+
= n3 − 2n2 + n
3
2
6
6
2
sumas.
De los datos sobre el número de operaciones que acabamos de dar podemos sacar algunas
conclusiones:
1. El número de operaciones en la resolución de un sistema por eliminación gaussiana es del
orden de n3 tanto en sumas como en productos. De este número de operaciones la mayor
parte corresponde a la factorización LU de la matriz de manera que si se van a resolver
varios sistemas con la misma matriz es conveniente conservar la factorización de ésta.
2. Para resolver un sistema nunca es rentable la obtención de la inversa puesto que solamente
este proceso ya requeriría un número de operaciones que sería O(n3 ), mientras que la
resolución completa del sistema sin utilizar la inversa sólo requiere O(n3 /3) operaciones.
3. Podría pensarse que si son muchos los sistemas a resolver con matriz común, podría resultar
rentable el cálculo de la inversa. Esto no es así: si resolvemos m sistemas con matriz
común utilizando la inversa necesitaremos los siguientes números de productos y sumas
respectivamente:
n3 + mn2
n3 − 2n2 + n + mn(n − 1)
donde el último sumando corresponde a la multiplicación de la inversa por el lado derecho. Si resolvemos los mismos sistemas sin utilizar la inversa necesitaremos los siguientes
números de productos y sumas.
n3 n
− + mn2
3
3
n3 n2 n
−
+ + mn(n − 1)
3
2
6
lo que confirma que para ningún número de sistemas es rentable el cálculo de la inversa.
4. El número de operaciones para calcular la inversa mediante la resolución de n sistemas
lineales de matriz común utilizando eliminación gaussiana y una sola factorización LU es
del orden de n3 , muy inferior por tanto al necesario para obtener la inversa utilizando su
expresión en términos de cofactores y el determinante (sólo el cálculo del determinante
mediante cofactores requiere más de n! multiplicaciones).
5. En consideración al número de operaciones necesarias, el cálculo del determinante de una
matriz debe hacerse a través de la matriz U de la factorización LU y no mediante desarrollo
directo por cofactores.
50 Resolución Numérica de Sistemas
4.2.3
Ampliación de Matemáticas.
Implementación práctica.
Finalicemos el apartado sobre eliminación gaussiana con algunos comentarios sobre su implementación práctica en un ordenador. Señalemos en primer lugar que aunque la base teórica
de la eliminación gaussiana es pasar por sistemas equivalentes al de partida hasta llegar a uno
triangular, no es necesario almacenar los resultados intermedios sino que sobre la misma matriz
(las mismas posiciones de memoria) se pueden ir efectuando las operaciones necesarias. Ni tan
siquiera es necesaria una matriz auxiliar para almacenar los multiplicadores (necesarios para
modificar nuevos segundos miembros) puesto que estos pueden ser almacenados en las posiciones
de los ceros a los que dan lugar.
En cuanto al intercambio de filas del pivotaje, hay que señalar que no es necesario un "intercambio real" de las filas sino simplemente recoger este cambio en un vector de posiciones
(que inicialmente será (1,2,3,...,n)) que será el que utilicemos para acceder a los elementos de la
matriz. Este vector debe estar disponible si se desea resolver un sistema para un nuevo segundo
miembro, puesto que nos indica en qué orden deben ser consideradas las componentes de este
segundo miembro.
4.3
Normas matriciales.
El espacio vectorial de las matrices cuadradas n × n puede ser visto como un caso particular
2
de IRk (de hecho como IRn ) y por tanto las normas más habituales (|| ||2 , || ||1 , || ||∞ ) son
también normas para las matrices. Estas normas no resultan de demasiado interés porque, así
como en un vector de IRn el conocer su norma-2 (longitud en el caso n=2 y n=3) o su norma
infinito (máximo módulo de sus componentes) suele resultar provechoso, en las matrices es más
interesante una norma que nos informe de su comportamiento como aplicación lineal, es decir,
que relacione la norma en IRn del vector x con la del vector Ax. (En lo sucesivo utilizaremos la
misma notación para un vector de IRn y para la matriz columna que lo representa). Se tiene la
siguiente definición.
Definición 4.2 Sea || || una norma vectorial en IRn . Llamaremos norma natural deducida
de la vectorial || || a la definida en el espacio de las matrices cuadradas n × n de la siguiente
manera:
||Ax||
||A|| = sup
(4.1)
x6=0 ||x||
Obsérvese que el tamaño de los cocientes
||Ax||
sólo depende de la dirección de x y no del
||x||
tamaño del vector, es decir
||Ax||
||A(tx)||
=
||x||
||tx||
(4.2)
y por tanto podemos reducir el conjunto en el que buscamos el supremo a vectores unitarios:
||Ax||
= sup ||Ax||.
x6=0 ||x||
||x||=1
sup
(4.3)
El supremo que aparece en las normas naturales es de hecho un máximo, es decir, la norma
natural deducida de una vectorial nos da la máxima dilatación sufrida por un vector de la esfera
unidad al someterlo a la transformación de matriz A.
Ampliación de Matemáticas.
Resolución Numérica de Sistemas 51
No es difícil comprobar que (4.1) es efectivamente una norma y que además de las propiedades
que verifican en su condición de norma, las normas naturales verifican las siguientes:
1. ||Ax|| ≤ ||A|| ||x||.
2. ||AB|| ≤ ||A|| ||B||.
3. ||I|| = 1 siendo I es la matriz identidad.
donde las normas vectoriales que aparecen en las anteriores expresiones son las correspondientes
a la norma natural en cuestión.
Ejercicio 4.1 Demostrar las tres propiedades anteriores.
La expresión de las normas naturales que nos proporciona la definición no resulta demasiado
manejable. Para las normas uno e infinito es posible probar lo siguiente:
Teorema 4.1 Sea A una matriz cuadrada n × n. Entonces las normas naturales deducidas de
las normas vectoriales 1 e infinito, respectivamente, vienen dadas por las siguientes expresiones:
||A||1 = max
1≤j≤n
||A||∞ = max
1≤i≤n
n
X
|aij |
(4.4)
|aij |
(4.5)
i=1
n
X
j=1
Para encontrar una expresión sencilla para la norma 2 necesitamos el concepto de radio
espectral.
Definición 4.3 Sea A una matriz cuadrada n × n. Llamaremos radio espectral de A y lo
denotaremos ρ(A) al máximo de los módulos de los autovalores de A.
Teorema 4.2 Si A es real se verifica
||A||2 =
p
ρ(At A)
(4.6)
Nota 4.2 Si A es una matriz simétrica, entonces se verifica ||A||2 = ρ(A).
El siguiente resultado señala una relación existente entre el radio espectral de una matriz y
cualquier norma natural suya.
Teorema 4.3 Para cualquier norma matricial natural se verifica
ρ(A) ≤ ||A||
(4.7)
Demostración: Sea x un autovector asociado al autovalor λ de A de módulo máximo. Entonces
||Ax||
|λ| ||x||
||A|| ≥
=
= |λ| = ρ(A).
||x||
||x||
52 Resolución Numérica de Sistemas
4.4
Ampliación de Matemáticas.
Análisis del problema del acondicionamiento.
Consideremos el siguiente sistema:
1 2
1 2.00001
x
y
=
3
3.00001
La solución de este sistema es x = y = 1. Si en lugar del sistema anterior, resolvemos el
siguiente
1 2
1 1.99999
x
y
=
3
3.00002
que sólo se diferencia en dos cantidades del orden de 10−5 del sistema original, la solución resulta
ser x = 7, y = −2. Podemos interpretar el segundo sistema como una perturbación del primero
y es sorprendente la repercusión que una pequeña variación en los coeficientes puede tener en la
solución final. Como no hemos cometido errores de redondeo en la resolución de ninguno de los
dos sistemas, hemos de concluir que el desplazamiento de soluciones está en la esencia misma
del sistema. La interpretación gráfica de esto es sencilla: las dos rectas cuyo punto de corte
queremos hallar son "casi paralelas", es decir, con pendientes muy próximas. Debido a esto una
pequeña modificación en sus coeficientes desplaza enormemente el punto de corte.
Sin que esto pretenda ser una definición rigurosa, llamaremos sistema mal acondicionado
a aquel cuya solución varía mucho ante pequeñas variaciones de los datos. Nótese que los sistemas
mal acondicionados pueden verse como sistemas “próximos” a la singularidad. (Las rectas del
ejemplo no son paralelas pero casi).
Veamos de qué manera podemos medir el buen o mal acondicionamiento de un sistema.
Empecemos por analizar el comportamiento de la solución de un sistema con segundo miembro
perturbado (b + δb) y matriz A regular sin perturbaciones. Sea x la solución de Ax = b y sea
x + δx la solución de este sistema:
A(x + δx) = b + δb
(4.8)
Restando los dos sistemas tenemos
δx = A−1 δb
(4.9)
y, por tanto, para cualquier norma natural
||δx|| ≤ ||A−1 || ||δb||
(4.10)
lo que nos da una relación entre la perturbación del lado derecho y la de la solución. Si queremos
una medida que relacione perturbaciones relativas basta tener en cuenta que
||b|| ≤ ||A|| ||x||
(4.11)
para obtener la desigualdad de Turing para normas naturales y matriz regular
||δx||
||δb||
≤ (||A|| ||A−1 ||)
||x||
||b||
(4.12)
Ampliación de Matemáticas.
Resolución Numérica de Sistemas 53
Definición 4.4 Llamaremos número de condición de una matriz regular A a
µ(A) = ||A|| ||A−1 ||.
El número de condición de una matriz nos da pues una medida de cómo puede responder un
sistema ante la perturbación de su lado derecho. Como
1 = ||I|| = ||AA−1 || ≤ ||A|| ||A−1 || = µ(A)
el valor óptimo que podemos esperar para el número de condición de una matriz regular es 1.
Cuanto más próximo a uno esté este número mejor acondicionada está la matriz.
Si A es regular y simétrica y consideramos la norma matricial deducida de la euclídea
µ2 (A) =
max{ |λ| / λ autovalor de A}
.
min{ |λ| / λ autovalor de A}
(4.13)
¿Por qué?
La expresión (4.13) muestra que para una matriz simétrica, el número de condición nos da la
razón entre las deformaciones extremas producidas por A como transformación lineal (la norma
sólo nos daba la máxima deformación).
Otra cuestión que conviene señalar es la siguiente: si nos basamos en la idea intuitiva de que
los sistemas mal acondicionados son los "próximos a la singularidad", podríamos pensar en tomar
el determinante como medida del mal acondicionamiento (que determinantes pequeños sean
indicativos de mal acondicionamiento). Sin embargo, según lo dicho en el párrafo anterior, una
matriz como 10−3 I tiene número de condición 1 mientras que su determinante es extremadamente
pequeño (10−3n ).
Supongamos ahora que tenemos perturbaciones en el lado derecho y en la matriz. Entonces:
(A + δA)(x + δx) = b + δb.
(4.14)
Si ||A−1 || ||δA|| < 1 (lo que sucederá por ejemplo si δA es suficientemente pequeño) se verifica
la siguiente acotación:
||δx||
µ(A)
||δb|| ||δA||
≤
+
(4.15)
||δA|| ||b||
||x||
||A||
1 − µ(A)
||A||
en la que vemos cómo el error relativo de la solución queda acotado por los errores relativos de
las perturbaciones de la matriz y del lado derecho, y cómo el número de condición repercute en
esta acotación.
4.5
Métodos iterativos para la resolución de sistemas lineales.
¿Cómo generar una sucesión de aproximaciones que converja a una solución del sistema Ax = b?
Empecemos por expresar A como resta de dos matrices
A=N −P
de forma que N sea inversible. Entonces una solución del sistema cumplirá
Nx = Px + b
(4.16)
54 Resolución Numérica de Sistemas
Ampliación de Matemáticas.
y por tanto
x = N −1 P x + N −1 b.
(4.17)
Fijado un x0 inicial, podemos entonces definir una sucesión de aproximaciones a la solución
buscada de la siguiente manera:
x(n) = N −1 P x(n−1) + N −1 b.
(4.18)
Aunque la última expresión es la que determina teóricamente un aproximante a partir del
anterior, desde un punto de vista práctico, es más conveniente obtener una aproximación x(n) a
partir de la expresión anterior, resolviendo un sistema de matriz N
N x(n) = P x(n−1) + b.
(La razón de esto está en la inconveniencia ya comentada de obtener la inversa). Será, por tanto,
imprescindible desde el punto de vista práctico que la resolución de un sistema de matriz N sea
mucho más sencilla que la de un sistema de matriz A. Esto hace que elijamos normalmente la
matriz N diagonal o triangular.
Los métodos iterativos se ven afectados de un error, además del de redondeo, conocido como
error de truncación, consecuencia de tomar un término de una sucesión como aproximación
del límite de la misma. Si calculamos por ejemplo 10 aproximaciones para aproximar la solución
de un sistema Ax = b, aunque los cálculos se hayan efectuado en modo exacto y ningún error de
redondeo se haya producido, la aproximación x(10) no será la solución exacta buscada sino una
aproximación de la misma. La aproximación x(10) se ve afectada de un error de truncación.
Nota 4.3 Obsérvese la diferencia con un método directo como la eliminación gaussiana. En
este último, si los errores de redondeo no aparecieran, al final del proceso tendríamos la solución
exacta.
Dado el carácter iterativo del método es necesario establecer un criterio de parada. Lo
deseable sería parar cuando ||x(m) − x|| o ||x(m) − x||/||x|| (es decir, el error absoluto o relativo)
sea pequeño, pero ante el desconocimiento de la solución exacta podemos detenernos cuando la
distancia entre un aproximante y el siguiente (error relativo estimado) sea pequeña:
||x(m) − x(m−1) ||
< .
||x(m) ||
Veamos ahora el problema general de la convergencia de los métodos iterativos. Para un
método iterativo como el de la ecuación (4.17), llamaremos matriz de iteración del método
a la matriz M = N −1 P . Obsérvese que el método puede escribirse entonces como
x(n) = M x(n−1) + c,
(4.19)
con c = N −1 b, y que si llamamos e(n) a la diferencia entre el aproximante n-ésimo y la solución
(e(n) = x(n) -x) se verifica
e(n) = M e(n−1) = · · · = M n e(0) .
(4.20)
La convergencia de la sucesión de aproximantes, es decir, la convergencia a cero de los e(n)
depende, pues, del comportamiento de las potencias de la matriz de iteración M . Y para analizar
este comportamiento son útiles los siguientes resultados.
Ampliación de Matemáticas.
Resolución Numérica de Sistemas 55
Definición 4.5 Diremos que una matriz cuadrada A es convergente si
lim Ak = 0,
k→∞
es decir, si ∀i, j ∈ {1, 2, . . . , n}
lim (Ak )ij = 0.
k→∞
Nota 4.4 Observar que si A fuera una matriz real de dimensión 1 (es decir, un número real) el
comportamiento de las potencias de A al tender el exponente a infinito estaría claro: si |a11 | <
1, las potencias van a 0; si a11 > 1 a infinito; si a11 = 1 a 1 y si a11 ≤ −1 las potencias
no se aproximan a nada (la sucesión (an11 )n∈IN no tiene límite). La definición anterior es la
generalización a matrices cuadradas de dimensión arbitraria.
Nótese la diferencia entre el significado del término convergente en Cálculo, en general, y la
dada para matrices. Mientras que en Cálculo, convergente viene a significar "con límite", matriz
convergente significa más bien "con límite 0".
Teorema 4.4 Son equivalentes:
1. A es convergente.
2. limk→∞ ||Ak || = 0 para alguna norma natural.
3. ρ(A) <1.
4. ∀x ∈ IRn , limk→∞ Ak x = 0.
La cuarta de las equivalencias del teorema 4.4 garantiza que un método iterativo es convergente si y solo si su matriz de iteración es convergente. La tercera de las equivalencias dice que
una forma de determinar la convergencia de una matriz es hallando sus autovalores. De hecho,
mas que conocer los autovalores, lo que se necesita es acotar su tamaño. En este sentido el
teorema 4.3 asegura que cualquier norma natural es una cota.
Así pues si M es la matriz de iteración de un método de manera que ||M || < 1 para cierta
norma natural, el método converge. En este caso se verifica además la siguiente cota para el
error de truncación en la etapa k-ésima
||x(k) − x|| ≤
||M ||k
||x(1) − x(0) ||
(1 − ||M ||)
(4.21)
El siguiente resultado proporciona otra forma de acotar el tamaño de los autovalores de una
matriz y por tanto puede resultar útil para estudiar su convergencia.
Teorema 4.5 (Círculos de Gerschgorin) Sea A una matriz n × n (real o compleja). Para
i=1,2,. . . , n sea Di el círculo trazado en el plano complejo con centro en el elemento aii de la
matriz y radio
n
X
ri =
|aij |.
j=1
j 6= i
Entonces los autovalores de la matriz A se encuentran en la unión de los n círculos. Además
cada componente conexa de esa unión contiene tantos autovalores como círculos haya en ella,
tanto círculos como autovalores contados con multiplicidad.
56 Resolución Numérica de Sistemas
4.5.1
Ampliación de Matemáticas.
Métodos de Jacobi y Gauss-Seidel
Si A tiene diagonal sin elementos nulos una elección posible para N es la diagonal de A. El
método iterativo que obtenemos para esta N recibe el nombre de Jacobi y su expresión
N x(n) = P x(n−1) + b
resulta ser
a11 0 · · ·
0 a22 · · ·
..
..
..
.
.
.
0
0 ···
(n)
x1
0
−a12 · · ·
(n)
0
···
x2 −a21
= .
.
..
.
.
.
.. .
.
.
(n)
ann
−an1 −an2 · · ·
xn
0
0
..
.
(4.22)
(n−1)
x1
b1
−a1n
(n−1)
−a2n
b2
x2
+ .
..
.
.
..
.
.
(n−1)
bn
0
xn
Obsérvese que el método anterior equivale a despejar la incógnita i-ésima de la ecuación
i-ésima del sistema.
Una posible mejora de este método consiste en lo siguiente: puesto que cuando se quiere
(n)
(n) (n)
(n)
obtener xi , ya están disponibles x1 , x2 , . . . , xi−1 , pueden utilizarse estos en lugar de
(n−1)
(n−1)
(n−1)
x1
, x2
, . . . , xi−1 . El método que procede de esta manera recibe el nombre de GaussSeidel y su expresión matricial es la siguiente:
(n)
(n−1)
x1
x1
a11 0 · · ·
0
0 −a12 · · · −a1n
b1
(n)
(n−1)
a12 a22 · · ·
0
0
· · · −a2n
b2
x2 0
x
2.
+ .
=
..
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . .
.
.
.
.
(n)
(n−1)
an1 an2 · · · ann
0
0
···
0
bn
xn
xn
Para algunos tipos de matrices la convergencia de los métodos de Jacobi y Gauss-Seidel está asegurada. Un ejemplo son las matrices de diagonal estrictamente dominante de frecuente aparición
en la resolución de ecuaciones en derivadas parciales.
Definición 4.6 Diremos que una matriz A ∈ Mn×n es de diagonal estrictamente dominante si para i=1,2,. . . ,n
|aii | >
n
X
|aij |.
(4.23)
j=1
j 6= i
Teorema 4.6 Si A es una matriz de diagonal estrictamente dominante, el sistema Ax = b puede
ser resuelto por los métodos de Jacobi o Gauss-Seidel con garantía de convergencia.
Tema 5
Cálculo diferencial en varias variables
En el estudio de diversos fenómenos y en la resolución de numerosos problemas técnicos aparecen
cantidades que quedan determinadas por más de una variable independiente. Por ejemplo, el
área del rectángulo (a) es función de sus dos lados (b y h): a=f (b, h)=bh. Si además del área
nos interesa el perímetro y la diagonal, debemos considerar la aplicación que a cada par (b,h) le
asocia la terna (área, perímetro, diagonal), es decir
p
( b, h ) −→ ( bh, 2b + 2h,
b2 + h2 )
Esto es un ejemplo del tipo de funciones que se tratarán en este tema.
5.1
Funciones.
Definición 5.1 Sea A ⊂ IRn y B ⊂ IRm (n, m ∈ IN). Llamaremos función de varias variables a cualquier aplicación f : A −→ B.
El conjunto A recibe el nombre de dominio y f (A) = { y ∈ B / ∃x ∈ A con f (x) = y } se
denomina imagen o rango.
Un ejemplo de función de varias variables (que en este tema en adelante se denominará
√
simplemente función) puede ser f (x, y, z) = (xz − y, xz). Desde un punto de vista estricto,
para que la función esté definida necesitaríamos conocer A y B, pero al igual que sucedía con
las funciones de una variable, mientras no se especifique lo contrario, supondremos que A es el
mayor conjunto para el que la expresión tenga sentido, y B todo el espacio. En nuestro caso
entonces A = {(x, y, z) ∈ IR3 /zx ≥ 0} y B = IR2 .
En ocasiones el dominio, aunque no se de explícitamente, viene determinado por el proceso
que la función modeliza. En el ejemplo del rectángulo del comienzo de la sección, las expresiones
matemáticas utilizadas para el área, perímetro y diagonal tienen sentido en todo el espacio, pero
¿cuál es el dominio?
Cuando m = 1 las funciones se denominan funciones escalares o campos escalares, en
otro caso se denominan funciones vectoriales o campos vectoriales. En el ejemplo anterior
f es un campo vectorial y
√
f1 (x, y, z) = xz − y
f2 (x, y, z) = xz
son campos escalares. En este ejemplo se pone de manifiesto que un campo vectorial con llegada
en IRm tiene asociados m campos escalares componente. En adelante los campos vectoriales se
denotarán en letra negrita.
58 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
Algunas de las clasificaciones de funciones de una variable no tienen sentido en este nuevo
contexto (es el caso de función periódica, par o impar) porque están estrechamente relacionadas
con el orden existente en IR que no tiene paralelo en IRn . Otras clasificaciones como la de función
inyectiva, suprayectiva, biyectiva o acotada, siguen teniendo validez. De las tres primeras nada
hay que mencionar puesto que se trata de conceptos definidos para cualquier tipo de aplicación.
En cuanto a la definición de función acotada, al igual que en el caso real, es aquella cuyo conjunto
imagen es acotado, es decir:
Definición 5.2 Sea f : A −→ IRm . Diremos que es una función acotada si
∃K ≥ 0
5.1.1
/
∀x ∈ A,
||f(x)|| ≤ K
Representación gráfica.
Definición 5.3 Sea A ⊂ IRn y f : A −→ IRm . Llamaremos gráfica de f al conjunto
gr(f ) = { (x, y) ∈ IRn × IRm / x ∈ A, y = f (x) }
Definición 5.4 Sea A ⊂ IRn y f : A −→ IR. Para cada c ∈ IR llamaremos conjunto de nivel
Lc al siguiente subconjunto del dominio
Lc = { x ∈ A / f (x) = c }
Nota 5.1 Obsérvese que los conjuntos de nivel correspondientes a valores de c fuera del rango
de la función , son vacíos.
La representación gráfica de funciones, al estilo de las de
una variable, necesita de n + m dimensiones (n para el dominio y m para la imagen). Como nuestra capacidad de
visualización termina en IR3 , este tipo de representaciones
queda limitada a funciones de IR2 en IR (como la de la
gráfica ) o de IR en IR2 . Estas gráficas, como representaciones en el plano de conjuntos de IR3 que son, no siempre
proporcionan una idea clara de las funciones.
f (x)
x
Algunas alternativas para la representación gráfica son
1. Para funciones de IR en IR2 o de IR en IR3 , representar sólo la imagen, y sobre ella, señalar
el valor del dominio al que esa imagen corresponde.
2. Para funciones escalares con dominio en IR2 o IR3 , representar sobre el dominio los conjuntos
de nivel, es decir, conjuntos de puntos con imagen común.
La mayor parte de lo que se diga a continuación en estas notas se ejemplificará sobre funciones
de IR2 en IR, y esto tanto porque se dispone de una cierta representación similar a la conocida
para funciones de una variable, como porque su representación a través de conjuntos de nivel
(que en este caso se llamarán curvas de nivel) proporciona una visualización bastante aceptable
de la función.
Las curvas de nivel suelen representarse para valores de c en progresión aritmética para que
una distancia entre curvas de nivel signifique la misma variación de la función, con independencia
de entre qué curvas concretas se de.
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 59
En la figura siguiente puede verse un mapa de curvas de nivel correspondiente a la función
que aparece a la izquierda. Obsérvese la proximidad de las curvas de nivel en las zonas de mayor
variación de la función y cómo quedan reflejados los extremos relativos en el mapa de curvas.
25
0.2
20
0
−0.2
15
−0.4
−0.6
10
−0.8
30
30
20
5
25
20
15
10
10
0
5.2
5
5
0
10
15
20
25
Límites
Para disponer de apoyo gráfico empecemos por la definición de límite para campos escalares. Al
igual que sucedía en una variable, para la definición de límite necesitamos previamente las de
entorno y punto de acumulación en IRn :
Definición 5.5 Sea b ∈ IRn . Llamaremos entorno de b de radio δ al siguiente conjunto:
E(b, δ) = {
x ∈ IRn
/
||x − b|| < δ
}
Llamaremos entorno reducido de b de radio δ al conjunto E ∗ (b, δ) = E(b, δ) − {b}
De la definición se sigue que los entornos de puntos de IR2 son círculos (circunferencia límite
excluida) con centro en el punto en cuestión, y los de puntos de IR3 , esferas macizas excluida la
superficie frontera.
Definición 5.6 Sea A ⊂ IRn . Diremos que b ∈ IRn es un punto de acumulación de A (y lo
denotaremos b ∈ A0 ) si ∀δ > 0, A ∩ E ∗ (b, δ) 6= ∅
Definición 5.7 Sea A ⊂ IRn , f : A −→ IR y b ∈ A0 .
Diremos que limx→b f (x) = s si
∀ > 0,
∃δ > 0 / ∀x ∈ A con 0 < ||x − b|| < δ se tiene
s
f (E(b, δ ))
|f (x) − s| < E(b, δ )
La unicidad del límite, caso de existir, se deduce de modo inmediato de la definición.
El comportamiento del límite de la suma, producto y cociente de denominador no nulo es el
mismo que para funciones de una variable, de manera que no lo detallaremos.
60 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
Para campos vectoriales la definición es la misma si se hace la salvedad de que al ser ahora
el espacio de llegada IRm , para medir distancias entre imágenes se utilizarán normas en lugar de
valores absolutos.
Definición 5.8 Sea A ⊂ IRn , f : A −→ IRm y b ∈ A0 . Diremos que limx→b f (x) = s si
∀ > 0,
∃δ > 0 / ∀x ∈ A con 0 < ||x − b|| < δ se tiene ||f (x) − s|| < El siguiente teorema nos da la relación entre el límite de un campo vectorial y el de sus
campos escalares componente:
Teorema 5.1 (Teorema de equivalencia) Sea A ⊂ IRn ,
(f1 (x), f2 (x), . . . , fm (x))t y b ∈ A0 . Entonces
lim f (x) = s = (s1 , s2 , ..., sm )t
⇐⇒
x→b
f : A −→ IRm
lim fi (x) = si ,
x→b
con
f (x) =
i = 1, 2, ..., m
Para funciones escalares ampliaremos la definición de límite de la siguiente manera:
Definición 5.9 Sea A ⊂ IRn , f : A −→ IR y b ∈ A0 . Diremos que limx→b f (x) = ∞ (resp. −∞)
si
∀H > 0
∃δH > 0 / ∀x ∈ A con 0 < ||x − b|| < δH se tiene
(resp. < 0),
f (x) > H
(resp. < H)
Hasta ahora hemos tratado sólo de las definiciones de límite, pero ¿qué pasa con su cálculo? El
cálculo de límites de funciones escalares de varias variables, en los casos en los que las propiedades
inmediatas sobre límite (límite de suma, producto etc.) no resuelven el problema, se centra en el
estudio de límites restringidos, esto es, límites de restricciones de la función a dominios menores
que siguen teniendo a b como punto de acumulación.
Teorema 5.2 Sea A ⊂ IRn , f : A −→ IR y b ∈ A0 . Sea S ⊂ A tal que b ∈ S 0 , y sea fS la
restricción de f a S. Entonces si limx→b f (x) = s, también se cumple limx→b fS (x) = s.
El resultado anterior tiene la inmediata consecuencia de que si para un límite encontramos
dos restringidos diferentes, el límite no puede existir.
Ejemplo 5.1 lim(x,y)→(0,0)
xy
x2 + y 2
no existe, puesto que los límites restringidos a los conjuntos
S1 = {(x, y) ∈ IR2 /x = y},
toman valores distintos:
lim
(x, y) → (0, 0)
x=y
lim
(x, y) → (0, 0)
x = y2
xy
x2 + y 2
S2 = {(x, y) ∈ IR2 /x = y 2 }
x2
xy
1
=
lim
=
2
2
2
x→0
x +y
2x
2
= lim
y3
y→0 y 4 + y 2
= lim
y
y→0 y 2 + 1
=0
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 61
Ejercicio 5.1 ¿Tiene sentido en el caso del límite anterior, plantearse la restricción al conjunto
S = {(x, y) ∈ IR2 /ex = y}?
Hemos visto que restringidos con distinto valor aseguran que no existe el límite. Veamos un
resultado en el que, bajo ciertas hipótesis, la coincidencia de restringidos asegura que ese es el
límite.
Teorema 5.3 Sea A ⊂ IRn , f : A −→ IR y b ∈ A0 . Sean S1 , S2 , . . . , Sk subconjuntos de A tales
k
[
que A =
Sj y b ∈ Sj0 , j = 1, 2, . . . , k. Supongamos que limx→b fSj (x) = s, ∀j ∈ {1, 2, . . . , k}.
j=1
Entonces se cumple que limx→b f (x) = s.
Ejemplo 5.2 Vamos a calcular el límite en (0,0) de la siguiente función.
x+y
xy
f (x, y) =
x−y
si
si
si
S1 = { (x, y)t ∈ IR2 / x > y }
S2 = { (x, y)t ∈ IR2 / x = y }
S3 = { (x, y)t ∈ IR2 / x < y }
x>y
x=y
x<y
Como A = S1 ∪ S2 ∪ S3 , el punto (0, 0) es de acumulación de los tres conjuntos y
x+y =0
(x, y) → (0, 0)
(x, y) → (0, 0)
x>y
x>y
lim
f (x, y) =
lim
xy = 0
(x, y) → (0, 0)
(x, y) → (0, 0)
x=y
x=y
x−y =0
f (x, y) =
lim
lim
(x, y) → (0, 0)
(x, y) → (0, 0)
lim
x<y
f (x, y) =
lim
⇒
lim
f (x, y) = 0
(x,y)→(0,0)
x<y
Ejercicio 5.2 ¿Existe el límite de la función anterior en (1, 2)? ¿Y en (3, 3)?
El ejemplo anterior nos lleva al cálculo de límites restringidos porque la función venía definida
por varias expresiones. Es algo parecido a lo que hacíamos en una variable con el cálculo de límites
laterales. En otras ocasiones recurrimos a los límites restringidos como una forma de trabajar
con límites más sencillos que el propuesto. Estos límites pueden darnos información sobre el
límite que nos interesa.
La elección de restringidos, para el caso de dos variables, es usual hacerla de manera que
el nuevo límite resulte ser de una variable. Por ejemplo puede referirse una variable a la otra
(S = {(x, y)/y = y(x)} o S = {(x, y)/x = x(y)}). Pueden también referirse ambas variables
a una tercera (S = {(x, y)/x = x(t), y = y(t)}). Dentro de estos últimos conjuntos merecen
62 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
mención especial las semirrectas expresadas en coordenadas polares, es decir, los conjuntos de la
forma
Sα = {(x, y)t /x = a + r cos α, y = b + r sin α},
α ∈ [0, 2π)
Estos conjuntos tienen como punto de acumulación a (a, b) y barren todas las direcciones del
dominio. El límite restringido a estos conjuntos se puede obtener conjuntamente para todos
ellos arrastrando α como parámetro. Si para algún valor de α se obtiene un límite con valor
distinto, el límite no existe.
(a + r cos α, b + r sin α)
r
α
(a, b)
Ejemplo 5.3 Calculemos el límite del ejemplo 5.1 utilizando coordenadas polares:
xy
r2 cos(α) sin(α)
=
lim
= cos(α) sin(α)
r2
(x,y)→(0,0) x2 + y 2
r→0+
lim
Como el límite restringido depende de la semirrecta considerada (depende de α), el límite pedido
no existe.
¿Qué sucede si para todo α el valor del límite es el mismo? ¿Puede concluirse que ese es
el valor del límite puesto que en todas direcciones las imágenes se aproximan a este valor? La
respuesta es negativa como puede verse en el siguiente ejemplo:
y 2
(x + y 2 ) si x 6= 0 y f (0, y) = 0.
x
Calculemos los límites de la función anterior en (0,0), restringidos a semirrectas. Para
α = π/2 y α = 3π/2, la restricción de la función a las correspondientes semirrectas es 0, y este
será por tanto el valor límite. Para cualquier otro α de [0, 2π):
Ejemplo 5.4 Sea f (x, y) =
r sin α 2
r = lim r2 tan α = 0
r→0+
r→0+ r cos α
lim
Sin embargo, lim(x,y)→(0,0) f (x, y) no es 0 puesto que
lim
(x, y) → (0, 0)
x = y3
y 6
(y + y 2 ) = lim (y 4 + 1) = 1
y→0 y 3
y→0
f (x, y) = lim
¿Cual es la explicación de que siendo el límite por todas las semirrectas común, no sea este el
límite global? Analicemos un poco más qué significa que el límite exista y sea común por todas
las semirrectas. Fijado un > 0 tenemos una "porción" en cada semirrecta tal que las imágenes
de esos puntos están en el entorno de radio del valor límite. Por ejemplo, para = 0.1 la figura
5.1 muestra en trazo más grueso los puntos de la semirrecta correspondiente a α = π/4, que
tienen su imagen en E(0, 0.1). En la figura 5.2 no se han representado las semirrectas completas
sino sólo la porción de las mismas formada por puntos con imagen en E(0, 0.1). La longitud de
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 63
estos segmentos es el δ máximo que encontramos para cada α y en esta figura puede apreciarse
cómo los segmentos se acortan a medida que el ángulo α aumenta. La figura 5.3 muestra los
segmentos correspondientes a diferentes semirrectas y una curva que recoge hasta dónde llegarían
los demás segmentos no representados. Tenemos así que en el conjunto formado por la región
limitada por la curva y el eje OY están todos los puntos del dominio con imagen en E(0, 0.1).
Como este conjunto no contiene ningún entorno de (0,0), la condición de límite no se cumple.
Fig. 5.1. δ para α = π4
Fig. 5.2. δ para α = π8 , π4 , 3π
8
Fig. 5.3. δ para diferentes α
Para poder garantizar que el límite por semirrectas es el límite global ha de poderse encontrar
un δ común a todas las semirrectas. (Esto hubiera permitido en nuestro ejemplo conseguir un
entorno de (0,0) formado por puntos con imagen en E(0, 0.1)). Llamaremos a esto convergencia
uniformemente independiente del ángulo.
Definición 5.10 Sea g(r, α) = f (a + r cos α, b + r sin α) la función que se obtiene al pasar a
coordenadas polares al calcular el lim(x,y)→(a,b) f (x, y). Diremos que g(r, α) converge a s de
forma uniformemente independiente del ángulo si
∀ > 0
∃δ > 0
/
∀r ∈ E ∗ (0, δ ),
|g(r, α) − s| < ,
∀α
Nota 5.2 Un caso particular y frecuente de convergencia uniformemente independiente del ángulo, se da cuando g(r, α) = h1 (r)h2 (r, α), con limr→0+ h1 (r) = 0 y h2 (r, α) acotada.
Ejemplo 5.5
(x − 1)3 + y 3
(x,y)→(1,0) x2 + y 2 − 2x + 1
lim
=
r3 cos3 α + r3 sin3 α
=
r2
r→0+
lim
↑
x = 1 + r cos α
y = r sin α
= lim |{z}
r (cos3 α + sin3 α)
|
{z
}
r→0+
↓
0
Acotada
=
↑
U nif ormemente
Independiente
de α
0
64 Cálculo diferencial en varias variables
5.3
Ampliación de Matemáticas.
Continuidad.
La definición de continuidad es análoga a la de funciones de una variable.
Definición 5.11 Sea A ⊂ IRn , f : A −→ IRm . Diremos que f es continua en b ∈ IRn si o
bien es un punto aislado del dominio, o bien es un punto de acumulación y se cumplen las tres
condiciones siguientes:
1. b ∈ A
2. ∃ limx→b f (x)
3. limx→b f (x) = f (b)
Diremos que f es continua en A si lo es en todos los puntos del conjunto.
La definición anterior incluye como caso particular la de campos escalares. A efectos prácticos,
y como consecuencia del teorema de equivalencia de límites, ésta será la única continuidad que
se estudie.
Al igual que sucedía para funciones de una variable, las propiedades de los límites permiten
concluir de modo inmediato que la suma, producto y cociente de denominador no nulo de funciones escalares continuas, es otra función continua.
Para campos vectoriales las operaciones se reducen a la suma y composición. La suma de
campos vectoriales continuos, también lo es, y en cuanto a la composición tenemos el siguiente
resultado:
Teorema 5.4 Sean f y g funciones vectoriales tales que f es continua en b y g continua en f (b).
Entonces (g ◦ f ) es continua en b.
Las funciones de una variable continuas en intervalos cerrados, verificaban una serie de resultados cuyo equivalente para funciones de varias variables veremos a continuación.
Empecemos por definir un tipo de conjunto que llamaremos compacto y que será el "equivalente" en varias variables de los intervalos cerrados de IR.
Definición 5.12 Sea A ⊂ IRn . Diremos que A es un conjunto cerrado si contiene a todos sus
puntos de acumulación. Si un conjunto es cerrado y acotado diremos que es compacto.
Teorema 5.5 Sea A ⊂ IRn , f : A −→ IR continua en A. Si A es compacto, entonces existen p
y q en A tales que
∀x ∈ A,
f (p) ≤ f (x) ≤ f (q)
Nota 5.3 Obsérvese que una consecuencia del resultado anterior es que las funciones continuas
sobre compactos están acotadas.
Ampliación de Matemáticas.
5.4
Cálculo diferencial en varias variables 65
Diferenciabilidad.
Empezaremos por considerar sólo campos escalares. Sea A ⊂ IRn , f : A −→ IR, y b ∈ A tal que es
posible encontrar un entorno de b totalmente contenido en A (en adelante esto lo representaremos
de la siguiente forma: b ∈ int(A)).
Recordemos que la derivada para funciones de una variable se definía como
f (b + h) − f (b)
h→0
h
lim
en caso de que ese límite existiera y fuera finito. El significado de este número era el de razón de
cambio instantánea de la variable dependiente frente a la independiente. Si en varias variables
queremos hacer algo similar, podemos empezar por el caso fácil de comparar la imagen en el
punto que nos interesa (llamémosle (a, b) ) con la de puntos de la forma (a + h, b) y (a, b + h).
Calcularemos entonces los límites
lim
h→0
f (a + h, b) − f (a, b)
h
lim
h→0
f (a, b + h) − f (a, b)
h
(5.1)
Puesto que para el primero de los límites anteriores sólo consideramos puntos de la forma
(x, b), el valor obtenido, caso de existir, coincide con el de la derivada en a de la función g(x) =
f (x, b) cuya gráfica puede verse en la figura 5.4.
b
b
a
a
Fig. 5.4. g(x) = f (x, b)
Fig. 5.5. g(y) = f (a, y)
Llamaremos al primero de los límites de (5.1), si existe y es finito, derivada parcial de f
con respecto a x en (a, b) y lo denotaremos por cualquiera de estos símbolos:
fx (a, b)
D1 f (a, b)
df
(a, b)
dx
∂f
(a, b)
∂x
Lo mismo puede decirse del segundo límite de (5.1), pero esta vez la función cuya derivada
estamos calculando es g(y) = f (a, y) (figura 5.5); el nombre que recibe el límite, caso de existir
y ser finito es el de derivada parcial con respecto a y, y los símbolos para representarlo son:
fy (a, b)
D2 f (a, b)
df
(a, b)
dy
∂f
(a, b)
∂y
Ejemplo 5.6 Sea f (x, y) = yx2 − x + 5y. Calculemos las dos derivadas parciales de la función
anterior en (1, 3). Si aplicamos la definición tendremos que calcular los dos límites de la expresión
66 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
(5.1) para (a, b) = (1, 3). Ahora bien, según se ha dicho anteriormente, la parcial con respecto a
x corresponde a derivar la función g(x) = f (x, 3) = 3x2 − x + 15. Si en una variable hay que
derivar la función g(x) ¿calcularíamos de modo efectivo algún límite? Por supuesto que no. Se
utilizarían las reglas de derivación para obtener la función derivada y se evaluaría en el punto
en que nos interesara. Lo mismo haremos aquí:
fx (x, y) = 2xy − 1
⇒
fx (1, 3) = 6 − 1 = 5
fy (x, y) = x2 + 5
⇒
fy (1, 3) = 1 + 5 = 6
Análogamente
En el ejemplo anterior se ha visto que al calcular una derivada parcial en un punto, puede
ser más sencillo obtener previamente la expresión genérica de esa derivada parcial en un punto
cualquiera, es decir, obtener la función que a cada valor del dominio para el que la derivada
parcial exista, le asocia el valor de esa derivada parcial. Llamaremos a esta función función
derivada parcial.
Aunque hasta ahora sólo nos hemos referido a funciones de dos variables, las definiciones
de derivada parcial en un punto y función derivada parcial pueden darse para campos escalares
cualesquiera:
Definición 5.13 Sea A ⊂ IRn , f : A −→ IR, b ∈ int(A). Para cada i ∈ {1, 2, ..., n} se define la
derivada parcial i-ésima de f en b de la siguiente manera, siempre que el límite exista y sea
finito:
f (b + hei ) − f (b)
h→0
h
Di f (b) = lim
donde ei es el i-ésimo vector de la base canónica de IRn .
Llamaremos función derivada parcial i-ésima a la que asocia a cada punto de A para el
que exista la derivada parcial i-ésima, el valor de esta derivada parcial.
Nota 5.4 Obsérvese que b + hei = ( b1 , b2 , . . . , bi−1 , bi + h, bi+1 , . . . , bn )
Frecuentemente manejaremos todas la derivadas parciales en un punto en forma de vector
fila. Llamaremos a este vector gradiente de f en b y lo denotaremos ∇f (b) o f 0 (b). Es decir, si
f es un campo escalar y existen todas las parciales de f en b, el gradiente de f en b es
f 0 (b) = (D1 f (b), D2 f (b), . . . , Dn f (b))
Ejemplo 5.7
f (x, y, z) = xy 2 e3z
⇒
f 0 (x, y, z) = ( y 2 e3z , 2xye3z , xy 2 3e3z )
⇒
f 0 (2, 3, 0) = ( 9 , 12 , 18 )
Para campos vectoriales manejaremos las parciales de los campos escalares componente en
una matriz que llamaremos matriz jacobiana y denotaremos Jf (b) o f 0 (b). La matriz jacobiana
de un campo vectorial tiene por filas los gradientes de los campos escalares componente.
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 67
Ejemplo 5.8
x + y3
f (x, y) = xy
exy
1
3y 2
x
f 0 (x, y) = y
xy
ye
xexy
⇒
La información que proporcionan las derivadas parciales sobre el comportamiento de una
función en un punto, es muy incompleta. Desde luego es mucho más débil que la proporcionada
por la derivada en funciones de una variable. En una variable, la existencia de derivada no sólo
aseguraba la continuidad de la función, sino que ésta tenía la suficiente regularidad como para
ser "bien" aproximada por su recta tangente:
rb (x)
z
}|
{
f (x) − (f (b) + f 0 (b)(x − b))
=0
(5.2)
lim
x→b
x−b
Que existan las derivadas parciales es obvio que ni siquiera implica continuidad puesto que se
desconoce qué sucede en otras direcciones no paralelas a los ejes coordenados. Definamos pues
una nueva derivada correspondiente a la función de una variable que se obtiene si restringimos el
dominio de la función de partida, a una recta cualquiera de las que pasan por el punto de interés.
Definición 5.14 Sea A ⊂ IRn , f : A −→ IR, b ∈ int(A) y u un vector unitario cualquiera. Se
define la derivada direccional según u de f en b de la siguiente manera, siempre que el límite
exista y sea finito:
Du f (b) = lim
h→0
f (b + hu) − f (b)
h
Para funciones de dos variables la derivada direccional es
la derivada de una función restringida como la representada en la figura 6.
¿Son las derivadas direccionales equivalentes en significado
o en consecuencias si se quiere, a la derivada de las funciones de una variable? La respuesta es negativa: una
función puede tener todas las derivadas direccionales en
un punto y no ser continua en ese punto como es el caso
de la siguiente:
b
a
fig.6
Ejemplo 5.9 Calculemos todas las derivadas direccionales en (0,0) de la función f (x, y) =
xy 2
si x 6= 0 y f (0, y) = 0:
x2 + y 4
Si u1 6= 0
f (hu1 , hu2 ) − f (0, 0)
= lim
h→0
h→0
h
D(u1 ,u2 ) f (0, 0) = lim
Si u1 = 0
h3 u1 u22
−0
2
h (u21 + h2 u42 )
h
f (hu1 , hu2 ) − f (0, 0)
0−0
= lim
=0
h→0
h→0
h
h
D(u1 ,u2 ) f (0, 0) = lim
=
u22
u1
68 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
Existen por tanto todas las derivadas direccionales. La función sin embargo no es continua
puesto que
lim
y4
1
= 6= f (0, 0) = 0
y→0 2y 4
2
f (x, y) = lim
(x, y) → (0, 0)
x = y2
Volviendo a nuestro intento de obtener en varias variables algo similar a la derivada en una,
puesto que lo que queremos es que el concepto tenga como consecuencia la regularidad de la función, definamos función diferenciable como la que tenga esa regularidad que tenían las funciones
derivables de una variable, es decir, aquellas que tengan la capacidad de ser aproximadas por
una función lineal en el entorno del punto de estudio:
Definición 5.15 Sea A ⊂ IRn , f : A −→ IR, b ∈ int(A) . Diremos que f es diferenciable en
b si existe una aplicación lineal de IRn en IR que llamaremos diferencial de f en b y denotaremos
df (b), tal que
lim
h→0
f (b + h) − f (b) − df (b)(h)
=0
||h||
Teorema 5.6 Sea A ⊂ IRn , f : A −→ IR diferenciable en b. Entonces:
1. f es continua en b
2. Existen todas las derivadas direccionales en b y para cualquier vector unitario u de IRn , se
cumple
Du f (b) = df (b)(u)
(5.3)
Demostración. Veamos primero la continuidad.
f (b + h) − f (b)
=
||h||
f (b + h) − f (b) − df (b)(h) df (b)(h)
lim ||h||
+
= lim df (b)(h) = 0
h→0
h→0
||h||
||h||
lim (f (b + h) − f (b)) = lim ||h||
h→0
h→0
Nota 5.5 El límite anterior es 0 porque la condición de diferenciabilidad asegura la anulación
de la primera fracción y en cuanto a la segunda, las aplicaciones lineales son funciones continuas
(sólo están formadas por sumas y productos) que en 0 se anulan.
Veamos ahora la existencia de derivadas direccionales:
f (b + tu) − f (b)
Du f (b) = lim
= lim
t→0
t→0
t
f (b + tu) − f (b) − df (b)(tu) df (b)(tu)
+
t
t
=
tdf (b)(u)
= df (b)(u)
t→0
t
lim
Donde el primer sumando del penúltimo miembro tiende a cero por ser una restricción (salvo
signo) del límite de la condición de diferenciabilidad.
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 69
Veamos dos consecuencias de (5.3):
• La matriz estándar de la diferencial de f en b es el gradiente f 0 (b). La matriz
estándar de una aplicación lineal tiene por columnas las imágenes de los vectores de la base
canónica, es decir:
df (b)(h) = Sh = (df (b)(e1 ), df (b)(e2 ), . . . , df (b)(en ))h = f 0 (b)h
| {z } | {z }
| {z }
D1 f (b)
D2 f (b)
Dn f (b)
• Cálculo de las derivadas direccionales en puntos de diferenciabilidad y valor
máximo de la derivada direccional. Si f es diferenciable en b, podemos obtener las
derivadas direccionales en b sin recurrir al límite puesto que
Du f (b) = df (b)(u) = f 0 (b)u
De la expresión anterior podemos también obtener el valor máximo de la derivada direccional en el punto puesto que un producto escalar en IRn puede expresarse como el producto
de las normas de los vectores por el coseno del ángulo que forman
Du f (b) = f 0 (b)u = ||f 0 (b)|| ||u|| cos α = ||f 0 (b)|| cos α
|{z}
1
El valor máximo de la expresión anterior es por tanto ||f 0 (b)|| y se alcanza cuando α = 0,
es decir en la dirección y sentido que indica el gradiente.
Para funciones de dos variables el gradiente en b es un vector
perpendicular a la curva de nivel en b, es decir, perpendicular
a la tangente a la curva de nivel en b.
El gradiente señala la dirección y sentido de máximo crecimiento de la función en el punto. El máximo decrecimiento se da
en la dirección del gradiente y el sentido opuesto.
∇f (b)
b
La dirección de la tangente a la curva de nivel, es la de mínima
variación. Recuérdese que en la curva de nivel de b están los
puntos con la misma imagen que b.
Ahora que conocemos la expresión de la función diferencial que aparece en la definición (5.15),
podemos resumir los pasos que se deben seguir para el estudio de la diferenciabilidad según la
definición:
1. Debemos obtener las parciales en el punto a. Si alguna no existe, la función no es diferenciable en a.
2. Comprobamos si
f (a + h) − f (a) − f 0 (a)h
=0
h→0
||h||
lim
70 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
Podemos expresar el límite anterior en la variable x = a + h:
Ha (x)
}|
{
z
f (x) − (f (a) + f 0 (a)(x − a))
lim
=0
x→a
||x − a||
Nótese que la expresión roja que aparece en el límite anterior coincide formalmente con la
de la recta tangente para funciones de una variable, aunque f 0 (a)(x − a) es ahora un producto
escalar. Esta expresión roja recibe el nombre de hiperplano tangente de f (x) en a. Nótese
también que al igual que sucedía con la recta tangente para funciones derivables en un punto
(ver (5.2)), la diferencia f (x) − Ha (x) es un infinitésimo de mayor orden en a que x − a. Esto
significa que el hiperplano es una buena aproximación de la función en un entorno del punto.
En el caso de campos escalares de dos variables, el hiperplano tangente tiene una gráfica que
es el plano tangente a la gráfica de f (x) en el punto a.
Veamos un ejemplo de estudio de la diferenciabilidad de una función en un punto según la
definición.
Ejemplo 5.10 Sea f (x, y) = x + 2y 2 y veamos si es diferenciable en (2, 1). Las parciales en este
punto son:
fx (x, y) = 1 ⇒ fx (2, 1) = 1
fy (x, y) = 4y
⇒
fy (2, 1) = 4
Veamos ahora si el siguiente límite es 0:
f (2 + h, 1 + k) − f (2, 1) − f 0 (2, 1)
√
lim
(h,k)→(0,0)
h2 + k 2
h
k
=
(2 + h + 2(1 + k)2 ) − (2 + 2) − (h + 4k)
√
=
(h,k)→(0,0)
h2 + k 2
lim
lim
(h,k)→(0,0)
√
2k 2
2r2 sin2 α
2
= lim
= lim |{z}
2r sin
α} = 0
|
{z
+
+
2
2
r
r→0
r→0
h +k
↓
0
acotada
Como los límites restringidos a semirrectas son cero de forma uniformemente independiente
del ángulo, éste es el valor del límite de partida, y por tanto la función es diferenciable en el
punto.
El ejemplo anterior pone de manifiesto que pese a la sencillez de la función propuesta, la
comprobación de la diferenciabilidad resulta bastante engorrosa. Veamos una condición suficiente
de diferenciabilidad que simplifica las cosas.
Teorema 5.7 Sea A ⊂ IRn , f : A −→ IR, b ∈ int(A), tales que existen todas las derivadas
parciales en un entorno de b y son continuas en b. Entonces f es diferenciable en b
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 71
Utilizando este resultado, la diferenciabilidad de f (x, y) = x + 2y 2 en cualquier punto es
inmediata sin más que tener en cuenta que sus derivadas parciales son fx (x, y) = 1 y fy (x, y) =
2y, continuas en todo IR2 .
Hasta ahora sólo hemos hablado de la diferenciabilidad de campos escalares, veamos qué
sucede con los vectoriales. La definición de diferenciabilidad para éstos es:
Definición 5.16 Sea A ⊂ IRn , f : A −→ IRm , b ∈ int(A) . Diremos que f es diferenciable en b
si existe una aplicación lineal de IRn en IRm que llamaremos diferencial de f en b y denotaremos
df(b), tal que
lim
h→0
f(b + h) − f(b) − df(b)(h)
=0
||h||
Dada la relación entre el límite de un campo vectorial y el de sus campos escalares componente, es bastante esperable el siguiente resultado:
Teorema 5.8 Sea A ⊂ IRn , f : A −→ IRm , con f= (f1 , f2 , ..., fm )t y b ∈ int(A). Entonces f es
diferenciable en b si y sólo si lo son f1 , f2 , ..., fm .
Además, en caso de diferenciabilidad se verifica que la diferencial de f tiene por matriz estándar la matriz jacobiana f 0 (b), es decir,
df(b)(h) = f 0 (b)h =
f10 (b)
D1 f1 (b)
0
f2 (b)
D1 f2 (b)
.. h =
..
.
.
0 (b)
fm
D2 f1 (b)
D2 f2 (b)
..
.
···
···
..
.
D1 fm (b) D2 fm (b) · · ·
Dn f1 (b)
Dn f2 (b)
h
..
.
Dn fm (b)
p
Ejemplo 5.11 Estudiar la diferenciabilidad de la función f (x, y) = (xy, 2x + 2y, x2 + y 2 ) en
IR2 .
Para estudiar la diferenciabilidad, puesto que se trata de un campo vectorial, trabajaremos
con la de sus campos escalares componente. Como necesitamos las derivadas parciales de todos
ellos escribamos la matriz jacobiana del campo vectorial de partida.
y
x
2
2
f0 (x, y) =
y
x
√
√
x2 +y 2
x2 +y 2
Obsérvese que la primera fila corresponde a las parciales del primer campo escalar componente, la segunda al segundo y la tercera al tercero.
A la vista de las parciales es inmediato que los dos primeros campos escalares son diferenciables en todo IR2 puesto que sus parciales son continuas. Para el tercero sólo tenemos asegurada
la condición suficiente para IR2 − {(0, 0)}, puesto que en este punto las parciales no pueden calcularse mediante reglas de derivación como hemos hecho con los demás. Si se aplica la definición
obtenemos que las parciales de f3 no existen en (0,0) (ejercicio), con lo que se trata de un punto
de no diferenciabilidad de f.
72 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
Teorema 5.9 (Regla de la Cadena) Si f es diferenciable en b y g lo es en f(b), entonces (g◦f)
es diferenciable en b y
d(g ◦ f)(b) = dg(f(b)) ◦ df(b)
Nota 5.6 La relación entre las diferenciales dada en el teorema conduce de modo inmediato a
la siguiente igualdad para las matrices jacobianas:
(g ◦ f)0 (b) = g0 (f(b))f 0 (b)
Ejemplo 5.12 Sea f (x, y) = (xy, x2 + y, 2, x sin y) y g(u, v, s, t) = (us + t, vs2 , uv t ). Estudiar la
diferenciabilidad de g◦f en (1, 0) y en caso de diferenciabilidad, hallar su matriz jacobiana.
Hallemos las matrices jacobianas de ambas funciones:
y
x
2x
1
f 0 (x, y) =
0
0
sin y x cos y
s
0
u
1
s2
2vs
0
g0 (u, v, s, t) = 0
t
t−1
t
v utv
0 uv ln v
Dado que las parciales de f son continuas en (1, 0), tenemos que f es diferenciable en (1, 0).
También lo es g en f(1, 0) = (0, 1, 2, 0), puesto que las parciales de g son continuas en este punto.
Entonces la regla de la cadena nos asegura que (g ◦ f) es diferenciable en (1, 0) y su diferencial
viene dada por la siguiente matriz jacobiana:
0
2 0 0 1
2
(g ◦ f)0 (1, 0) = g0 (f (1, 0))f 0 (1, 0) = 0 4 4 0
0
1 0 0 0
0
5.5
1
0 3
1
8 4
=
0
0 1
1
Extremos.
La definición de extremo relativo para campos escalares es análoga a la dada para funciones de
una variable.
Definición 5.17 Sea f un campo escalar y b un punto del dominio de f. Diremos que f presenta
un máximo (resp. mínimo) relativo en b si existe δ > 0 tal que
∀x ∈ E(b, δ) ∩ Dom(f ),
f (x) ≤ f (b)
(resp.
f (x) ≥ f (b))
Teorema 5.10 Si en un extremo relativo existe alguna derivada parcial, ésta es nula.
Ejercicio 5.3 Demostrar el resultado anterior.
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 73
El caso más habitual es que existan todas las derivadas parciales en el punto. Si todas las
parciales se anulan en un punto, éste recibe el nombre de punto estacionario y es un candidato
a extremo relativo. Cuando un punto estacionario no es extremo relativo se dice que es punto
de silla.
No todos los extremos relativos se alcanzan en puntos estacionarios. Pensemos por ejemplo
en la función f (x, y, z) = |x| + |y| + |z|. Esta función presenta un mínimo relativo (de hecho
es absoluto) en (0,0,0) y este punto no es estacionario al no existir las parciales en él. En el
ejemplo que acabamos de ver (0,0,0) es un punto interior del dominio. Lo mismo sucede con los
puntos estacionarios, pero un extremo relativo puede alcanzarse en un punto del dominio que no
sea interior. Los puntos de un conjunto que no son interiores se denominan puntos frontera.
Un ejemplo de extremos relativos que se alcanzan en puntos frontera lo tenemos con la función
f (x, y) = x + y con dominio [0,1]×[0,1]. Esta función tiene un máximo (absoluto y por tanto
relativo) en (1,1) y un mínimo en (0,0) que no son puntos interiores del dominio.
Empecemos el estudio de extremos por el caso de puntos interiores del dominio. Tienen
que darse entre los puntos estacionarios o aquellos en los que no existe alguna parcial. Para
estos últimos no veremos ningún resultado especial y decidir si es extremo o no dependerá de
la comparación directa de la imagen en el punto con la de los puntos de un entorno (aplicar
la definición de extremo relativo). En cuanto a los puntos estacionarios, podemos caracterizar
su condición de extremo en función del carácter de una forma cuadrática como a continuación
veremos.
Definición 5.18 Sea A ⊂ IRn , f : A −→ IR tal que existen todas las derivadas parciales de
Di f (x), i = 1, 2, ..., n en b ∈ int(A) (llamaremos a estos valores, parciales de segundo orden
de f en b y los representaremos Di,j f (b) = Dj (Di f (b))).
Se define la matriz hessiana de f en b de la siguiente manera:
D11 f (b) D12 f (b) · · · D1n f (b)
D21 f (b) D22 f (b) · · · D2n f (b)
Hf (b) =
..
..
..
..
.
.
.
.
Dn1 f (b) Dn2 f (b) · · · Dnn f (b)
La matriz hessiana se denota también f 00 (b).
Ejemplo 5.13 La matriz hessiana de f (x, y) = xey en (x, y) es:
fxx (x, y) fxy (x, y)
0 ey
00
f (x, y) =
=
fyx (x, y) fyy (x, y)
ey xey
Cuando un campo escalar tiene todas sus funciones derivadas parciales continuas en un
conjunto A, decimos que f es de clase 1 en A. Si tiene continuas las parciales de segundo orden
decimos que es de clase 2 y así sucesivamente. Representaremos esto con la notación f ∈ C k (A)
(f es de clase k en A).
Teorema 5.11 Sea A ⊂ IRn , f : A −→ IR, b ∈ A tales que existen todas las derivadas parciales
Di f (x), i = 1, 2, ..., n en un entorno de b. Existe también Dij f (x) en un entorno de b y es
continua en b. Entonces existe Dji f (b) y Dji f (b) = Dij f (b).
La matriz hessiana en varias variables juega un papel análogo al de la derivada segunda en
una variable a la hora de clasificar extremos relativos. Para detallar esto necesitaremos algunas
definiciones y resultados asociados a formas cuadráticas.
74 Cálculo diferencial en varias variables
5.5.1
Ampliación de Matemáticas.
Formas Cuadráticas.
Definición 5.19 Llamaremos forma cuadrática sobre IRn a cualquier aplicación de la forma
Q : IRn −→ IR
x −→ xt Ax
donde A ∈ Mn×n (IR)
Obsérvese que una forma cuadrática puede venir dada en la forma Q(x) =
n
X
aij xi xj para
i,j=1
x = (x1 , x2 , . . . , xn )t .
Una forma cuadrática puede venir descrita por diferentes matrices. Todas ellas tendrán en
común los elementos diagonales y las sumas aij + aji , ∀i, j ∈ {1, 2, . . . , n}, i 6= j.
Ejemplo 5.14 Si Q(x, y, z) = 3x2 + yz − 2xy + z 2 + 7zy es una forma cuadrática en IR3 ,. Una
expresión matricial para esta forma cuadrática puede ser
3 0 0
x
Q(x, y, z) = ( x y z ) −2 0 1 y .
0 7 1
z
Otra puede ser
x
3 −1 0
0 4 y .
Q(x, y, z) = ( x y z ) −1
z
0
4 1
Dada una forma cuadrática Q(x) hay una única matriz simétrica A tal que Q(x) = xt Ax.
Llamaremos a esta matriz, matriz asociada a la forma cuadrática.
Definición 5.20 Si Q(x) es una forma cuadrática sobre IRn diremos:
1. Q es definida positiva si Q(x) > 0 para todo x ∈ IRn − {0}.
2. Q es definida negativa si Q(x) < 0 para todo x ∈ IRn − {0}.
3. Q es indefinida si existen x, y ∈ IRn tales que Q(x) > 0 y Q(y) < 0.
Las formas cuadráticas que no están en ninguno de los casos anteriores se denominan semidefinidas.
Dado que existe una biyección entre las formas cuadráticas sobre IRn y las matrices simétricas
reales n × n, las definiciones anteriores se extienden de modo imediato a matrices simétricas.
Definición 5.21 Diremos que una matriz real simétrica A es definida positiva si la forma
cuadrática Q(x) = xt Ax lo es. Diremos que A es definida negativa si Q(x) lo es y diremos
que A es indefinida si Q(x) lo es
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 75
Los siguientes teoremas ayudan a decidir si una matriz simétrica (y por tanto una forma
cuadrática) es definida positiva, definida negativa o indefinida.
Teorema 5.12 (Caracterización por autovalores.) Sea A ∈ Mn×n (IR) simétrica.
1. A definida positiva ⇐⇒ λi > 0, ∀λi autovalor de A.
2. A definida negativa ⇐⇒ λi < 0, ∀λi autovalor de A.
3. A indefinida ⇐⇒ existen λ1 , λ2 autovalores de A con λ1 < 0 < λ2 .
Teorema 5.13 (Caracterización por submatrices principales.) Sea A ∈ Mn×n (IR) simétrica
y Ak la submatriz principal de orden k de A
a11
a21
Ak = .
..
a12
a22
..
.
...
...
..
.
a1k
a2k
.. .
.
ak1
ak2
...
akk
es decir, la matriz formada por los elementos de las k primeras filas y las k primeras columnas
de A.
1. A definida positiva ⇐⇒ det(Ak ) > 0,
∀k = 1, 2, . . . , n.
2. A definida negativa ⇐⇒ signo(det(Ak )) = signo((−1)k ),
∀k = 1, 2, . . . , n.
3. Si det(A) 6= 0, A es indefinida ⇐⇒ no se da ninguna de las dos situaciones anteriores
Los resultados anteriores nos van a permitir clasificar formas cuadráticas como definidas
positivas, definidas negativas o indefinidas. Esto tiene utilidad en la localización de extremos
relativos de funciones de varias variables como puede verse en el siguiente resultado.
Teorema 5.14 Sea A ⊂ IRn , f : A −→ IR de clase 2 en un punto estacionario b de f . Sea
Q(h) = ht f 00 (b)h la forma cuadrática definida por la matriz hessiana de f en b. Entonces
1. Si Q es definida positiva, f presenta un mínimo relativo en b
2. Si Q es definida negativa, f presenta un máximo relativo en b
3. Si Q es indefinida, f presenta un punto de silla en b
Nota 5.7 Obsérvese que el resultado anterior no ofrece conclusión para los casos en los que la
forma cuadrática sea semidefinida.
Aunque no veremos la demostración del resultado anterior, vamos a comentar, utilizando la
fórmula de Taylor para funciones de varias variables, la relación existente entre el carácter de la
forma cuadrática determinada por la matriz hessiana y la condición de extremo del punto.
76 Cálculo diferencial en varias variables
5.5.2
Ampliación de Matemáticas.
Polinomio de Taylor.
Se recordará que en una variable el polinomio de Taylor de una función desarrollado en un punto
se obtuvo imponiendo la coincidencia de función y polinomio así como cuantas derivadas fuera
posible en el punto de desarrollo. Podemos buscar un polinomio similar para funciones de varias
variables, imponiendo la coincidencia de las derivadas parciales, las parciales de segundo orden,
etc.
Nos centramos en el caso de dos variables y más concretamente en un polinomio genérico de
grado 2:
P2 (x, y) = a00 + a10 x + a01 y + a20 x2 + a11 xy + a02 y 2
Fijado un punto (a,b) del dominio de un campo escalar f , ¿cuántas derivadas parciales
podemos hacer que tengan en común función y polinomio? Para determinar esto, reescribiremos
el polinomio utilizando esta vez en lugar de la base 1, x, y, x2 , xy, ..., la obtenida sustituyendo x
por (x − a) e y por (y − b). El polinomio que buscamos es entonces de la forma,
P2 (x, y) = c00 + c10 (x − a) + c01 (y − b) + c20 (x − a)2 + c11 (x − a)(y − b) + c02 (y − b)2
Suponiendo que f tiene en (a, b) tantas parciales como necesitemos, obtenemos:
f (a, b) = P2 (a, b) = c00
⇒
c00 = f (a, b)
fx (a, b) = D1 P2 (a, b) = c10
⇒
c10 = fx (a, b)
fy (a, b) = D2 P2 (a, b) = c01
⇒
c01 = fy (a, b)
fxx (a, b) = D11 P2 (a, b) = 2c20
⇒
c20 =
fxy (a, b) = D12 P2 (a, b) = c11
⇒
c11 = fxy (a, b)
fyy (a, b) = D22 P2 (a, b) = 2c02
⇒
c02 =
fxx (a, b)
2
fyy (a, b)
2
El polinomio queda por tanto
P2 (x, y) = f (a, b) + fx (a, b)(x − a) + fy (a, b)(y − b)+
fyy (a, b)
fxx (a, b)
(x − a)2 + fxy (a, b)(x − a)(y − b) +
(y − b)2
2
2
Si la función cumple fxy (a, b) = fyx (a, b) (esto sucede si es de clase 2 en el punto por ejemplo),
el polinomio puede escribirse en la forma
1
P2 (x, y) = f (a, b) + f 0 (a, b)(x − a, y − b)t + (x − a, y − b)f 00 (a, b)(x − a, y − b)t
2
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 77
Para un campo escalar de n variables, el polinomio de Taylor de grado 2 quedaría:
1
P2 (x) = f (a) + f 0 (a)(x − a) + (x − a)t f 00 (a)(x − a)
2
Se define el polinomio de Taylor de orden k desarrollado en a correspondiente a un campo
escalar f como el único polinomio de grado menor o igual que k tal que coincide con f en
evaluación y todas las parciales de orden menor o igual que k en el punto a. Su expresión es :
Pk (x) = f (a) +
k
X
1
i=1
i!
X
Dj1 j2 ...ji f (a)(xj1 − aj1 )(xj2 − aj2 ) . . . (xji − aji )
j1 ,j2 ,...,ji ∈{1,2,...,n}
Obsérvese que el polinomio de Taylor de grado 1 de una función es el hiperplano tangente de
la misma en el punto de desarrollo.
Ejemplo 5.15 Sea f (x, y, z, t) = xz 3 + 5y + 7et y vamos a obtener su desarrollo de Taylor de
orden 3 en a = (2, 3, 1, 0)t .
4
1
1 X
P (x) = f (a) + f 0 (a)(x − a) + (x − a)t f 00 (a)(x − a) +
Dijk f (a)(xi − ai )(xj − aj )(xk − ak )
2
3!
i,j,k=1
f (2, 3, 1, 0) = 24
f 0 (x, y, z, t) = ( z 3 , 5 , 3xz 2 , 7et ) ⇒
0 0 3z 2 0
0 0 0
0
f 00 (x, y, z, t) =
2
3z 0 6xz 0
0 0 0 7et
f 0 (2, 3, 1, 0) = (1, 5, 6, 7)
0
0
⇒ f 00 (2, 3, 1, 0) =
3
0
0 3 0
0 0 0
0 12 0
0 0 7
A la vista de f 00 (x, y, z, t), las únicas terceras parciales no nulas son:
fxzz = fzxz = fzzx = 6z,
fzzz = 6x,
fttt = 7et
que evaluadas en el punto de desarrollo dan como resultado
fxzz (2, 3, 1, 0) = fzxz (2, 3, 1, 0) = fzzx (2, 3, 1, 0) = 6
fzzz (2, 3, 1, 0) = 12
fttt (2, 3, 1, 0) = 7
El polinomio pedido es entonces
x−2
0 0 3 0
x−2
y−3 1
0 0 0 0 y − 3
P (x, y, z, t) = 24+(1, 5, 6, 7)
z − 1 + 2! (x − 2, y − 3, z − 1, t) 3 0 12 0 z − 1 +
t
0 0 0 7
t
|
{z
}
|
{z
}
(x−2)+5(y−3)+6(z−1)+7t
6(x−2)(z−1)+12(z−1)2 +7t2
78 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
1
(6(x − 2)(z − 1)2 + 6(z − 1)(x − 1)(z − 1) + 6(z − 1)2 (x − 2) +12(z − 1)3 + 7t3 ) =
{z
}
3! |
18(x−2)(z−1)2
7
7
24 + (x − 2) + 5(y − 3) + 6(z − 1) + 7t + 3(x − 2) + 6(z − 1)2 + t2 + 3(x − 2)(z − 1)2 + 2(z − 1)3 + t3
2
6
Teorema 5.15 Sea A ⊂ IRn , f : A −→ IR de clase k+1 en A. Supongamos que el segmento
[x, a] = { v ∈ IRn / v = a + t(x − a), t ∈ [0, 1] } está contenido en A. Entonces existe λ ∈ (0, 1)
tal que
f (x) − Pk (x) =
1
(k + 1)!
X
Dj1 j2 ...jk+1 f (a + λ(x − a)) (xj1 − aj1 )(xj2 − aj2 ) . . . (xjk+1 − ajk+1 )
j1 ,j2 ,...,jk+1 ∈{1,2,...,n}
Para el caso particular de k = 0 el teorema anterior proporciona la expresión
f (x) − f (a) = f 0 (c)(x − a)
donde c es algún punto del segmento [x, a]. Este teorema es la generalización a varias variables
del teorema de Lagrange.
Volvamos a nuestra explicación pendiente sobre la relación entre la forma cuadrática dada
por la matriz hessiana y el carácter de extremo relativo de un punto estacionario. Para un punto
estacionario la expresión del polinomio de Taylor de orden 2 junto con su error es
1
1 X
f (x) − f (a) = Q(x − a) +
Dijk f (cx )(xi − ai )(xj − aj )(xk − ak )
2
3!
i,j,k
La función presentará un extremo relativo en a si el signo del primer miembro es constante
para x suficientemente próximo a a. Para estos x, el signo viene determinado por Q(x−a) puesto
que el sumando del error contiene "cantidades pequeñas" (xi −ai ), elevadas a una potencia mayor.
Nota 5.8 Lo anterior es una explicación válida para funciones de clase 3 pero el estudio de
extremos relativos a través de la forma cuadrática es posible, tal y como se enuncia en el teorema
10 para funciones de clase 2.
5.5.3
Extremos relativos condicionados.
Estudiaremos ahora extremos relativos sobre conjuntos S = {x ∈ IRn /g(x) = 0}, es decir,
extremos relativos de fS . Llamaremos a éstos extremos relativos de f condicionados a
g(x) = 0.
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 79
Por ejemplo, queremos extremos relativos de la función f (x, y) = x2 + 3y 2 − 2xy sobre el conjunto S =
{(x, y)/x2 + y 2 = 1}. Puesto que la función es continua
y el conjunto S compacto, los extremos que buscamos es
claro que existen. El mapa de curvas de nivel representadas en negro conjuntamente con el conjunto S (en rojo)
nos muestra gráficamente dónde están los puntos buscados. En la gráfica aparecen también los gradientes nomalizados de la función f en dos de los extremos. Obsérvese
que los puntos señalados no son extremos si consideramos
la función definida sobre IR2 , pero resultan extremos si nos
restringimos a S.
En la gráfica puede observarse también que en los extremos, la correspondiente curva de nivel
de la función y la curva que describe S son tangentes (los gradientes de f y g serán por tanto
linealmente dependientes en el punto, es decir, f 0 (a, b) + λg 0 (a, b) = 0). Otra forma de decir esto
es "(a,b) es punto estacionario de la función F (x, y) = f (x, y) + λg(x, y)". Esta propiedad será la
clave de la localización de extremos sobre conjuntos descritos por condiciones del tipo g(x) = 0.
Estas condiciones en adelante se denominarán condiciones de ligadura o simplemente ligadura.
Teorema 5.16 Sea A ⊂ IRn . Sean f : A −→ IR, y g : A −→ IRm , con m < n, funciones
de clase 1. Sean S = {x ∈ A/ g(x) = 0} y b ∈ S tal que rango(g’(b)) = m. Entonces si f
restringida a S alcanza un extremo relativo en b, existen m números reales λ1 , λ2 , . . . , λm tales
que b es punto estacionario de la función
m
X
F (x) = f (x) +
λi gi (x)
i=1
La función F que aparece en el resultado anterior recibe el nombre de función auxiliar de
Lagrange, los números λ1 , . . . , λm , multiplicadores de Lagrange y los puntos de S que como
el del teorema cumplen rango(g’(b)) = m, es decir, que la matriz jacobiana de g es de rango
máximo, se denominan puntos regulares de S.
El teorema anterior nos proporciona una forma de buscar candidatos a extremos relativos
condicionados (encontrar puntos estacionarios de funciones de Lagrange). Una vez encontrados,
¿cómo saber si son o no extremos? Puesto que sobre el conjunto S, F y f coinciden, si el
candidato hallado es extremo relativo de F , también es extremo relativo condicionado de f .
Estudiaremos esto mediante el carácter de la forma cuadrática definida por la matriz hessiana
de F . Nótese que en los casos en que esta forma cuadrática dada por F 00 (b) sea semidefinida o
indefinida no podremos concluir nada. Si es semidefinida no sabemos si el punto es extremo de
F y si es indefinida sabemos que no lo es, pero en ambos casos el punto podría ser un extremo
relativo condicionado de f . El siguiente teorema resulta de ayuda en esta situación.
Teorema 5.17 Bajo las hipótesis del P
teorema 5.16, sea b un punto estacionario de la función
t 00
auxiliar de Lagrange F (x) = f (x) + m
i=1 λi gi (x). Sea Q(x) = x F (b)x y sea E = {x ∈
n
IR /g’(b)x = 0}. Entonces si Q restringida a E es
1. definida positiva, f presenta un mínimo relativo condicionado en b.
2. definida negativa, f presenta un máximo relativo condicionado en b.
3. indefinida, f no presenta extremo relativo condicionado en b.
80 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
Ejemplo 5.16 Hallar los extremos relativos condicionados de la función f (x, y, z) = x + y + z
1 1 1
con la condición de ligadura + + = 1.
x y z
1 1 1
+ + −1
x y z
Todos los puntos del conjunto S = {(x, y, z)/g(x, y, z) = 0} son regulares puesto que
Sea g(x, y, z) =
1
1
1
g 0 (x, y, z) = [− 2 , − 2 , − 2 ]
x
y
z
Los extremos relativos se hallarán entonces, en caso de existir, entre los puntos estacionarios
de la función auxiliar de Lagrange que estén en S. Puesto que
1 1 1
F (x, y, z) = x + y + z + λ
+ + −1
x y z
hay que resolver el sistema,
λ
=0
x2
λ
Fy (x, y, z) = 1 − 2 = 0
y
λ
Fx (x, y, z) = 1 − 2 = 0
z
1
1 1
+ + =1
x y z
Fx (x, y, z) = 1 −
(5.4)
De las tres primeras ecuaciones se obtiene x2 = y 2 = z 2 = λ. De entrada tenemos como
posibilidades
√ todas las combinaciones que se obtienen permitiendo que las variables tomen valor
√
λ o − λ, pero la ligadura restringe estas posibilidades a "todas las variables positivas"
o
√
"dos de las variables positivas y una negativa". Siguiendo la primera (x = y = z = λ), de
la condición de √
ligadura obtenemos el punto (3, 3, 3) (λ = 9). De las otras tres posibilidades
(x = y = −z = λ ,etc.) se obtienen los puntos (1, 1, −1), (1, −1, 1, ), y (−1, 1, 1) ( λ = 1 para
todos ellos).
Tenemos pues cuatro candidatos. Para decidir si son extremos hallamos la matriz hessiana
de F :
2λ
x3
F 00 (x, y, z) = 0
0
0
0
2λ
y3
0
2λ
0
z3
y la evaluamos en cada uno de los puntos de interés:
2
3
F 00 (3, 3, 3) = 0
0
2
F 00 (1, −1, 1) = 0
0
0
2
3
0
0
0
2
3
0 0
−2 0
0 2
2 0
0
0
F 00 (1, 1, −1) = 0 2
0 0 −2
−2 0 0
F 00 (−1, 1, 1) = 0 2 0
0 0 2
La forma cuadrática que define F 00 (3, 3, 3) es definida positiva con lo que F presenta un
mínimo relativo en (3, 3, 3) y por tanto f , un mínimo relativo condicionado en ese punto. Como
Ampliación de Matemáticas.
Cálculo diferencial en varias variables 81
las otras tres formas cuadráticas son indefinidas podemos afirmar que los restantes puntos son
puntos de silla de F pero no se puede asegurar nada acerca de si son o no extremos relativos
condicionados de f .
Estudiemos pues la forma cuadrática restringida. Haremos el estudio para el punto (1,-1,1)
(para los otros dos el estudio sería análogo).
x
Queremos averiguar el carácter de la forma cuadrática Q(x, y, z) = (x, y, z)t F 00 (1, −1, 1) y
z
x
sobre los (x, y, z) tales que g 0 (1, −1, 1) y = 0, es decir, tales que
z
x
(−1, −1, −1) y = −(x + y + z) = 0
z
Estos puntos son los de la forma (−y − z, y, z) (solución del sistema de una ecuación con tres
incógnitas que tenemos). Para ellos
Q(−y − z, y, z) = 2(−y − z)2 − 2y 2 + 2z 2 = 4z 2 + 4yz
Si reescribimos la expresión anterior en forma matricial tenemos
y
0 −2
2
4z − 4yz = (y, z)
z
−2
4
lo que pone de manifiesto el carácter indefinido de la restricción. El punto (1, −1, 1) no es pues
un extremo relativo condicionado de f . El estudio de los dos puntos restantes conduce a la misma
conclusión.
Los multiplicadores de Lagrange no son la única forma de encontrar candidatos a extremos
sobre conjuntos de tipo S = {x ∈ IRn / g(x) = 0} . En ocasiones las condiciones de ligadura
permiten referir unas variables a otras y estudiar la función obtenida como un problema de
extremos sin restricciones.
Ejemplo 5.17 Busquemos los extremos de f (x, y, z) = xy + z condicionados a x + y + z = 1
Lo haremos primero utilizando multiplicadores de Lagrange:
g(x, y, z) = x + y + z − 1
⇒
g 0 (x, y, z) = (1, 1, 1)
Todos los puntos de S son por tanto regulares.
Buscamos ahora los puntos estacionarios de F (x, y, z, t) = xy + z + λ(x + y + z − 1)
Fx (x, y, z) = y + λ = 0
Fy (x, y, z) = x + λ = 0
⇒ x = y = −λ = 1
Fz (x, y, z) = 1 + λ = 0 ⇒ λ = −1
x+y+z−1=0
Llevando lo obtenido a la condición de ligadura obtenemos que z = −1
82 Cálculo diferencial en varias variables
Ampliación de Matemáticas.
0 1 0
F 00 (x, y, z) = 1 0 0 = F 00 (1, 1, −1)
0 0 0
Obtenemos los autovalores de F 00 (1, 1, −1):
−λ 1
0
1 −λ 0
0
0 −λ
= −λ(λ2 − 1) = 0
⇒
λ=0
λ=1
λ = −1
Los autovalores 1 y −1 nos dicen que (1, 1, −1) es punto de silla de F , pero no sabemos si es
o no extremo relativo condicionado. Estudiamos la forma cuadrática restringida:
x
x
−y − z
y
g 0 (1, 1, −1) y = 0 ⇒ y =
z
z
z
2
Q(−y − z, y, z) = 2(−y − z)y = −2y − 2yz = (y, z)
−2 −1
−1
0
y
z
indefinida. Concluímos entonces que no es extremo relativo condicionado.
La otra forma de proceder es:
x+y+z =1
⇒
z =1−x−y
La función que nos interesa es entonces h(x, y) = f (x, y, 1 − x − y) = xy + 1 − x − y.
Buscamos ahora posibles extremos relativos de esta función de dos variables.
hx (x, y) = y − 1 = 0 ⇒ y = 1
hy (x, y) = x − 1 = 0 ⇒ x = 1
0 1
= h00 (1, 1)
h00 (x, y) =
1 0
Los autovalores de h00 (1, 1) son λ = 1 y λ = −1, es decir, se trata de una matriz indefinida
y por tanto (1, 1) es un punto de silla de h(x, y).
Concluímos que no hay extremos de f (x, y, z) = xy + z condicionados a x + y + z = 1 puesto
que el único candidato ha resultado ser punto de silla.
Para finalizar comentamos brevemente el caso particular de búsqueda de extremos absolutos
sobre conjuntos compactos. La primera cuestión a tener en cuenta es que si la función es continua
y el dominio es compacto, los extremos se alcanzan. Bastará por tanto hallar los "candidatos"
a extremos y decidir entre ellos por evaluación (no es necesario averiguar si son o no extremos
relativos). En cuanto a la localización de estos candidatos, recordemos que entre los puntos
interiores del dominio han de encontrarse los estacionarios y aquellos para los que no existe
alguna derivada. Para puntos pertenecientes a una frontera del tipo g(x) = 0, el teorema de los
multiplicadores de Lagrange, nos puede ayudar a encontrar los candidatos a extremo, aunque
hemos visto en el ejemplo anterior que no son la única alternativa.
Tema 6
Programación Lineal
6.1
Un primer ejemplo.
Un fabricante de dulces tiene en su almacén 130 Kg de cerezas cubiertas de chocolate y 170 Kg
de almendras cubiertas de chocolate. El fabricante decide vender sus existencias haciendo dos
mezclas diferentes. Una contendrá la mitad de cerezas y la mitad de almendras, vendiéndose a
2 C el Kg. La otra mezcla, con una tercera parte de cerezas y dos terceras partes de almendras,
se vende a 1.25 C el Kg. ¿Cuántos Kilos de cada mezcla deberá preparar el fabricante para
maximizar sus ingresos por ventas?
Llamemos x al número de Kg de la primera mezcla e y al número de Kg de la segunda mezcla.
Si llamamos z a los ingresos por ventas, suponiendo que se vendan todas, tendremos
z = 2x + 1.25y.
Como cada Kg de la primera mezcla contiene 1/2 Kg de cerezas, y cada Kg de la segunda contiene
1/3 de Kg de cerezas, el número total de Kg de cerezas para las dos mezclas será:
1
1
x + y.
2
3
Análogamente el total de Kg de almendras será:
1
2
x + y.
2
3
Y como el fabricante sólo dispone de 130 Kg de cerezas y 170 Kg de almendras, se deberá verificar
que:
1
1
x + y ≤ 130 y
2
3
1
2
x + y ≤ 170.
2
3
Además, como x e y no pueden ser negativos, se deberá verificar que
x ≥ 0 y y ≥ 0.
84
Programación Lineal
Ampliación de Matemáticas.
Por tanto, el problema anterior se formula matemáticamente como:
Maximizar
z = 2 x + 1.25y
sujeto a
1
1
x + y ≤ 130
2
3
1
2
x + y ≤ 170
2
3
x≥0
y ≥ 0.
Los pares (x, y) que satisfacen todas las restricciones del
planteamiento anterior son los de la zona sombreada de la gráfica. Nuestro problema es, entonces, encontrar el máximo en
la zona sombreada de la función
z = 2x + 1.25y.
Para ver qué valores toma la función en los puntos del conjunto
que nos interesa, representemos curvas de nivel de la función
(en nuestro caso rectas de nivel), correspondientes a diversos
valores de c
Lc : 2x + 1.25y = c.
Puesto que cada recta 2x+1.25y = c agrupa a todos los puntos
de IR2 cuya imagen por la función es c, en la gráfica de la
izquierda puede verse lo que sucede con las imágenes de la
función. Se aprecia que a medida que nos desplazamos a la
derecha en el conjunto la función crece. La última recta de
nivel que toca al conjunto (la que corresponde a un valor c
mayor) lo hace en el punto (260,0). En este punto, por tanto,
se alcanzará el máximo que estábamos buscando.
Ampliación de Matemáticas.
6.2
Programación Lineal 85
Definiciones y Terminología.
El ejemplo anterior es un caso particular de problema de programación lineal. Llamaremos
así al siguiente tipo de problemas:
Minimizar (o Maximizar) z = c1 x1 + c2 x2 + · · · + cn xn
Sujeto a a11 x1 + a12 x2 + · · · + a1n xn ≥ (= o ≤) b1
a21 x1 + a22 x2 + · · · + a2n xn ≥ (= o ≤) b2
..
.
(6.1)
am1 x1 + am2 x2 + · · · + amn xn ≥ (= o ≤) bm
x1 , x2 , . . . , xn ≥ 0.
En la siguiente tabla se recogen algunos nombres asociados a los problemas de programación
lineal (en adelante P.L.):
z = c1 x1 + c2 x2 + · · · + cn xn Función de coste o función objetivo
x1 , x2 , . . . , xn
Variables de decisión
c1 , c2 , . . . , cn
Coeficientes de coste
Pn
Restricción general
aij
Coeficientes Tecnológicos
xi ≥ 0
Restricción de no negatividad
j=1 aij xj ≥ (= o ≤)bi
Llamaremos solución factible o punto factible de un problema de P.L. a cualquier nupla (x1 , x2 , . . . , xn ) que satisfaga todas las restricciones. Llamaremos región factible de un
problema de P.L. al conjunto de todos sus puntos factibles. Denotaremos la región factible
habitualmente por la letra Π.
Nuestro objetivo ante un problema de P.L. será encontrar entre todos los puntos factibles
aquel que minimice o maximice la función objetivo. Llamaremos a éste, solución óptima o
punto óptimo.
Aunque en la mayoría de los problemas prácticos de P.L. las variables representan cantidades
y en consecuencia serán no negativas, en algunas ocasiones se podrían necesitar variables que
tomen valores negativos. Si xk no está restringida en signo, podemos sustituir en el planteamiento
−
+ −
del problema xk por x+
k − xk y añadir las restricciones xk , xk ≥ 0.
86
6.3
Programación Lineal
Ampliación de Matemáticas.
Solución gráfica de problemas en IR2 .
El ejemplo que se presentó al comienzo del tema puso de manifiesto cómo utilizar la representación
de la región factible y las curvas de nivel de la función objetivo para resolver un problema de
P.L. en dos variables. Veremos a continuación diversos ejemplos de problemas de P.L. junto con
su representación gráfica. El vector que aparece en cada gráfica indica la dirección perpendicular
a las rectas de nivel y el sentido de crecimiento de la función objetivo.
Ejemplo 1
Max. z = 0.1x + 0.07y
s. a. x + y ≤ 10
x≤6
y≥2
x≥y
x, y ≥ 0.
Región factible acotada.
Óptimo único en (6, 4).
Ejemplo 2
Max. z = x + y
s. a. x + y ≤ 10
x≤6
y≥2
x≥y
x, y ≥ 0.
Región factible acotada.
Óptimo múltiple en los puntos de la forma:
λ(5, 5) + (1 − λ)(6, 4),
λ ∈ [0, 1].
Ampliación de Matemáticas.
Programación Lineal 87
Ejemplo 3
Max. z = 0.1x + 0.07y
x
s. a. − + y ≤ 2.5
2
y≥2
x≥y
x, y ≥ 0.
Región factible no acotada.
No hay óptimo. La función objetivo alcanza, en la
región factible, valores tan grandes como se desee.
Ejemplo 4
Max. z = −0.1x − 0.07y
x
s. a. − + y ≤ 2.5
2
y≥2
x≥y
x, y ≥ 0.
Región factible no acotada.
Óptimo único en (2, 2).
Ejemplo 5
Min. z = x − y
x
s. a. − + y ≤ 2.5
2
y≥2
x≥y
x, y ≥ 0.
Región factible no acotada.
Óptimo múltiple en:
λ (5, 5) + (1 − λ) (2, 2) ,
λ ∈ [0, 1].
88
Programación Lineal
Ampliación de Matemáticas.
Ejemplo 6
Max. z = y −
x
2
x
+ y ≤ 2.5
2
y≥2
x≥y
x, y ≥ 0.
s. a. −
Región factible no acotada.
Óptimo múltiple en:
(5, 5) + λ (2, 1) ,
λ ∈ [0, ∞).
Ejemplo 7
x
2
s. a. x + y ≥ 10
x≤6
y≤2
x≥y
x, y ≥ 0.
Max. z = y −
Región factible vacía.
Algunas características que se pueden observar en los ejemplos anteriores son en realidad
conclusiones de validez general.
• La región factible de un problema de P.L. puede ser vacía. De no serlo, puede ser acotada
o no acotada.
• Si la región factible es acotada y no vacía el óptimo se alcanza siempre.
• Si la región es no acotada el óptimo puede alcanzarse o no.
• Cuando el óptimo se alcanza, sea la región factible acotada o no, esto sucede siempre en una
"esquina" o "vértice" quizás no de forma única (puede alcanzarse en un "lado frontera").