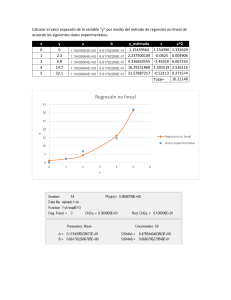
ANÁLISIS DE REGRESIÓN El análisis de regresión permite encontrar una función que describe la forma de la relación entre variables. Si se estudian dos variables, una independiente, X, y otra dependiente, Y, entonces tendremos una “regresión simple”. Si se tuvieran k variables independientes, X1,…, Xk, y una variable dependiente, Y, el análisis se llamaría “regresión múltiple”. En este caso la relación entre las dos variables es una recta, de la forma: Yi β0 β1Xi ε i Donde: Yi es la variable dependiente Xi es la variable independiente β0 es el intercepto de la recta β1 es la pendiente de la recta i es el término de error aleatorio, el cual tiene distribución normal de media 0 y varianza 2 El primer paso, para ver si existe o no una relación lineal entre las variables, es construir un diagrama de dispersión de los datos. En el gráfico podemos observar que existe relación lineal directa entre las variables. Para estimar los parámetros β0 y β1, se aplica el método de los mínimos cuadrados, con base a una muestra de tamaño n, mediante el cual se minimiza la función: n n D ε Yi Ŷi Donde i 1 2 i i 1 Ŷi β̂ 0 β̂1 Xi 2 Al minimizar D los estimadores obtenidos son: n β̂1 x y i 1 n i x i 1 i 2 i β̂ 0 y β̂1x n x y n x 2 Los estimadores encontrados se reemplazan en la ecuación obteniéndose la ecuación estimada de la forma: Ŷi β̂ 0 β̂1Xi Con esta recta estimada se pueden hacer estimaciones del valor de Y para valores fijos de X Se definen los residuales como: Yi Ŷi Generalmente la varianza del error es desconocida, y podemos estimarla a partir del “Error Estándar de Estimación”, Se, donde: 2 y β̂ 0 y β̂1 xy Se σ̂ n2 Valores pequeños de Se indican que los puntos observados están cercanos a la recta de Regresión. EJEMPLO Los siguientes datos corresponden a: Y : Monto de ventas X : Gasto en publicidad Se ingresan los datos al Minitab cada variable en una columna. La secuencia a seguir es: Stat < Regression < Regression < Fit Regression Model… Completar los datos pedidos: En Storage…, seleccionar “Residuals” En Options…, rectificar, de ser necesario, la confianza de los intervalos. En resultados tablas expandidasojo Los resultados son: Este valor sirve para medir la fuerza de la relación lineal entre X e Y. Se calcula mediante la expresión: n r x y i 1 i i nxy n n 2 2 2 2 x n x y n y i i i 1 i 1 Cuando r es positivo la relación lineal entre X e Y es directa. Cuando r es negativo la relación lineal entre X e Y es inversa. Cuando r = 0 no existe relación lineal entre las variables. Cuando más se acerca el valor absoluto de r a uno, la relación es más fuerte y cuando más se acerca a cero la relación es más débil. Se desea probar las hipótesis: H0: β1= 0 , la relación no es significativa H1: β1≠ 0 , la relación si es significativa El estadístico de prueba está dado por: β̂1 tc ˆ1 El criterio de decisión es: Rechazar H0 si t c t (n 2 , 1α/2) El rechazo de H0 lleva a la conclusión que existe una buena relación lineal entre las variables. Esta misma prueba se puede llevar a cabo con el estadístico F de la tabla ANOVA, en este caso se rechaza H0 si Fc F1, n 2 , 1α Mide el porcentaje de explicación de la variable dependiente debida a la variable independiente o a la regresión. Se calcula como el cuadrado de r. Coef.Determ = r2*100 Con MINITAB el coeficiente de determinación está dado por R-sq. 1. Particularmente nos van ha interesar tres intervalos de confianza: Intervalo de confianza para la pendiente de la recta al (1-α)100%: β̂1 t n 2;1α/2 σ̂1 donde : σ̂1 Se n 2 2 x n x i i 1 2. Intervalo de confianza del Valor Medio de Y, para un valor fijo x0, al (1-α)100%: 2 x0 x 1 ŷ t n 2;1α/2Se 2 2 n x nx 3. Intervalo de confianza del predictor de Y, para un valor fijo x0, al (1-α)100%: 2 x0 x 1 ŷ t n 2;1α/2Se 1 2 2 n x nx Cuando necesite los intervalos de confianza para la media de Y o para la predicción de Y, seguir la secuencia: Stat < Regression < Regresssion < Predit…, y colocar los nuevos valores de X. Para X = 155 tenemos: El intervalo CI es el intervalo de confianza para la media de Y, en cambio PI es el intervalo para el predictor de Y, ambos para un valor de X de 155 y una confianza del 95%.