2009-06-Ejemplos de estudios de series de tiempo
Anuncio

1 Ejemplos de estudios de series de tiempo Ejemplo 1 Pasajeros Aerolíneas Internacionales (PAI) Este estudio está realizado sobre un famoso conjunto de datos mensuales, el número de pasajeros de aerolíneas internacionales, que ha sido analizado por muchos autores incluyendo a Box y Jenkins. Problema Encontrar un modelo ARIMA adecuado que reproduzca la serie y predecir los doce meses siguientes al último mes para el que se dispone dato. Gráfica de los datos Una etapa importante en el análisis de una serie de tiempo es la representación gráfica de los datos en los sucesivos períodos de tiempo. Esta gráfica mostrará las características de la serie, si tiene tendencia, estacionalidad, discontinuidades, o existen datos situados fuera de los límites esperados. A continuación se observa la gráfica de los datos mensuales del número de Pasajeros de Aerolíneas Internacionales (PAI), para el período enero 1949 a diciembre 1960, 144 datos. 700 Pasajeros Aerolíneas Internacionales 600 500 400 300 200 100 0 49 50 51 52 53 54 55 56 57 58 59 60 SER01 La gráfica muestra que los datos tienen una tendencia creciente y un marcado patrón estacional. Además, a medida que el nivel medio de la serie aumenta, también se incrementa la magnitud de la variación estacional. En el lenguaje de los modelos ARIMA, esto indica que podría ser adecuado ajustar a los datos un modelo estacional multiplicativo. 2 Transformación de los datos En algunos casos, la gráfica de los datos sugiere considerar una transformación de los mismos, por ejemplo tomar los logaritmos o la raíz cuadrada Si hay tendencia en los datos y la varianza se incrementa con la media resulta aconsejable transformar los datos. En la serie que se estudia, Box y Jenkins decidieron tomar el logaritmo de la serie. Al observar que la desviación estándar de los datos es directamente proporcional a la media, la transformación logarítmica sería adecuada. 6.5 6.0 5.5 5.0 4.5 49 50 51 52 53 54 55 56 57 58 59 60 LPAI Cuando la serie tiene tendencia y la magnitud del efecto estacional se incrementa con la media, puede ser aconsejable transformar los datos para que el efecto estacional sea constante en el tiempo. De esta forma, en la serie transformada el efecto estacional se dice que es aditivo mientras que en los datos originales era multiplicativo. Esta transformación solamente estabilizará la varianza, si el término de error de la serie también crece cuando aumenta la media. Esta última circunstancia también tiene que ser considerada antes de la transformación de los datos. La gráfica que antecede, describe la serie transformada, elaborada con los logaritmos de la variable original, logaritmo del número de Pasajeros Aerolíneas Internacionales, LPAI. El argumento dado por Box y Jenkins para tomar el logaritmo de los datos originales, fue que “los logaritmos son tomados para analizar datos de ventas, porque es el porcentaje de variación el que sería comparable a diferentes volúmenes de ventas”. 3 Identificación del modelo Luego de transformados los datos y observada la gráfica transformados, examinamos el correlograma de los mismos. de los datos Correlograma de los datos transformados LPAI Sample: 1949:01 1960:12 Included observations: 144 Autocorrelation .|*******| .|*******| .|*******| .|****** | .|****** | .|****** | .|****** | .|****** | .|****** | .|****** | .|****** | .|****** | .|****** | .|***** | .|***** | .|**** | .|**** | .|**** | .|**** | .|**** | .|**** | .|**** | .|**** | .|**** | .|**** | .|*** | .|*** | .|*** | .|*** | .|** | .|** | .|** | .|** | .|** | .|** | .|** | Partial Correlación .|*******| *|. | .|. | .|. | .|* | .|. | .|. | .|* | .|** | .|. | .|* | .|. | ****|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | .|* | .|. | .|. | .|. | **|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob 0.954 0.899 0.851 0.808 0.779 0.756 0.738 0.727 0.734 0.744 0.758 0.762 0.717 0.663 0.618 0.576 0.544 0.519 0.501 0.490 0.498 0.506 0.517 0.520 0.484 0.437 0.400 0.364 0.337 0.315 0.297 0.289 0.295 0.305 0.315 0.319 0.954 -0.118 0.054 0.024 0.116 0.044 0.038 0.100 0.204 0.064 0.106 -0.042 -0.485 -0.034 0.042 -0.044 0.028 0.037 0.042 0.014 0.073 -0.033 0.061 0.031 -0.194 -0.035 0.036 -0.035 0.044 -0.045 -0.003 0.034 -0.020 0.028 0.029 -0.004 133.72 253.36 361.29 459.44 551.20 638.37 721.86 803.60 887.42 974.33 1065.2 1157.6 1240.0 1311.1 1373.4 1428.0 1476.9 1521.9 1564.1 1604.9 1647.3 1691.5 1737.9 1785.3 1826.6 1860.7 1889.5 1913.5 1934.3 1952.6 1969.0 1984.6 2001.1 2018.8 2038.0 2057.8 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 4 En primer lugar observemos que los 36 primeros coeficientes de autocorrelación son positivos, como consecuencia de la tendencia que tienen los datos. Es necesario diferenciar la serie. Veamos nuevamente el correlograma de la serie diferenciada una vez, Δ LPAIt. = LPAIt - LPAIt-1 En la terminología de los modelos ARIMA, d = 1. Correlograma de la primera diferencia de LPAI, o sea Δ LPAIt Sample: 1949:02 1960:12 Included observations: 143 Autocorrelation .|** | *|. | **|. | **|. | *|. | *|. | *|. | **|. | **|. | *|. | .|** | .|****** | .|** | *|. | **|. | **|. | *|. | *|. | *|. | **|. | *|. | *|. | .|** | .|***** | .|** | *|. | **|. | *|. | *|. | .|. | *|. | **|. | *|. | .|. | .|* | .|**** | Partial Correlation .|** **|. *|. **|. .|. **|. *|. ****|. **|. ****|. *|. .|**** *|. *|. .|* .|. .|. *|. .|. *|. .|. .|. .|. .|. .|. .|. .|. *|. *|. .|. .|. .|* *|. .|* *|. .|. | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob 0.303 -0.102 -0.241 -0.300 -0.094 -0.078 -0.092 -0.295 -0.192 -0.105 0.283 0.829 0.285 -0.106 -0.222 -0.231 -0.062 -0.066 -0.090 -0.297 -0.163 -0.083 0.256 0.701 0.257 -0.098 -0.196 -0.174 -0.069 -0.042 -0.078 -0.247 -0.157 -0.047 0.195 0.580 0.303 -0.213 -0.160 -0.222 0.010 -0.191 -0.154 -0.455 -0.234 -0.547 -0.130 0.571 -0.149 -0.172 0.067 0.062 0.008 -0.080 0.037 -0.095 -0.005 -0.008 -0.039 -0.042 -0.025 -0.035 0.016 -0.065 -0.126 0.007 0.026 0.067 -0.132 0.086 -0.116 -0.010 13.393 14.928 23.549 37.011 38.341 39.272 40.573 53.921 59.612 61.328 73.903 182.73 195.64 197.44 205.43 214.15 214.78 215.51 216.88 231.76 236.26 237.44 248.72 334.36 345.97 347.68 354.55 360.01 360.88 361.20 362.32 373.70 378.34 378.76 386.10 451.19 0.000 0.001 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 5 Con 144 observaciones en la serie ΔLPAI, una regla útil para decidir si un coeficiente de autocorrelación es significativamente diferente de cero es ver si su valor excede 2/√T. Aquí el valor crítico es 0.17 y encontramos coeficientes de autocorrelación significativos para los rezagos 1, 3, 4, 8, 9, 11, 12, 13, 15, 16, 20, 23, 24, 25, 27, 28, 32, 35 y 36. No hay signos de que la función de autocorrelación disminuya, por tanto se necesita otra diferenciación para obtener una serie estacionaria. Dado que los datos son mensuales y presentan una marcada estacionalidad se realiza la diferenciación de orden 12 de la primera diferencia de LPAI. Correlograma de la diferencia 12 de ΔLPAI, ΔΔ12 LPAIt Sample: 1949:02 1960:12 Included observations: 131 Autocorrelation Partial Correlation ***|. .|* **|. .|. .|. .|. .|. .|. .|* *|. .|. ***|. .|* *|. .|* *|. .|* .|. .|. *|. .|. *|. .|** .|. *|. .|. .|. .|. .|. .|. .|. .|* *|. .|* *|. .|. ***|. .|. **|. *|. .|. .|. *|. .|. .|** .|. .|. ***|. *|. *|. .|. *|. .|. .|* .|. *|. .|* *|. .|* *|. *|. .|. .|. *|. .|. .|. *|. .|. .|. .|. .|. *|. | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob -0.341 0.105 -0.202 0.021 0.056 0.031 -0.056 -0.001 0.176 -0.076 0.064 -0.387 0.152 -0.058 0.150 -0.139 0.070 0.016 -0.011 -0.117 0.039 -0.091 0.223 -0.018 -0.100 0.049 -0.030 0.047 -0.018 -0.051 -0.054 0.196 -0.122 0.078 -0.152 -0.010 -0.341 -0.013 -0.193 -0.125 0.033 0.035 -0.060 -0.020 0.226 0.043 0.047 -0.339 -0.109 -0.077 -0.022 -0.140 0.026 0.115 -0.013 -0.167 0.132 -0.072 0.143 -0.067 -0.103 -0.010 0.044 -0.090 0.047 -0.005 -0.096 -0.015 0.012 -0.019 0.023 -0.165 15.596 17.086 22.648 22.710 23.139 23.271 23.705 23.705 28.147 28.987 29.589 51.473 54.866 55.361 58.720 61.645 62.404 62.442 62.460 64.598 64.834 66.168 74.210 74.265 75.918 76.310 76.463 76.839 76.894 77.344 77.848 84.590 87.254 88.340 92.558 92.577 0.000 0.000 0.000 0.000 0.000 0.001 0.001 0.003 0.001 0.001 0.002 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 6 Examinando el correlograma y teniendo en cuenta que el valor crítico de los coeficientes de autocorrelación es también aproximadamente 0.17, encontramos valores significativos en los rezagos 1, 3, 9, 12 y 23, siendo el resto de los valores los suficientemente pequeños, para concluir que no hay signos de no estacionariedad. El valor significativo en el rezago 9 se puede considerar extraño y se ignora a menos que exista información externa indicando que debe considerarse. Ahora estamos en condiciones de identificar el modelo a ajustar a los datos. Previamente introducimos la notación habitual para el modelo general ARIMA con estacionalidad multiplicativa, el modelo llamado SARIMA. φp (L) ΦP (L) Wt = θq (L) ΘQ (Ls) εt donde L representa al operador del polinomio de rezagos, φp ,ΦP ,θq , ΘQ son polinomios de orden p,P, q,Q respectivamente, εt es un proceso puramente aleatorio y Wt es la variable Δd ΔD Yt. Examinamos en el último correlograma presentado los valores de la función de autocorrelación en los rezagos 12, 24, 36, comenzando con la parte estacional del modelo, para elegir los valores de P y Q, es decir el orden del polinomio de rezagos de la parte autorregresiva y el orden del polinomio de la parte de medias móviles El valor para el rezago 12 es grande, pero para los restantes resulta no significativo. Esta comprobación indicaría que no tiene términos autorregresivos, pero si de medias móviles en la parte estacional. Por este motivo se hace Q = 1 y P = 0. Los valores p y q de la parte no estacional son establecidos luego de examinar los primeros valores de la función de autocorrelación. Son valores significativos los correspondientes a 1 y 3 rezagos. Comenzamos probando con un término de medias móviles haciendo p = 0 y q = 1. Estimación Luego de identificado el modelo a ajustar, que en este caso es un modelo ARIMA estacional con p = 0, q = 1, P = 0 y Q = 1, es decir ( 0, 1, 1) ( 0, 1, 1 )12 se procede a estimar los parámetros del modelo. En la tabla siguiente se presenta la estimación del modelo realizada utilizando el EVIEWS. 7 El resultado es: ΔΔ12 LPAIt = ( 1 - 0.3765 L) ( 1 - 0.6242 L12 ) εt Sample: 1950:02 1960:12 Included observations: 131 Convergence achieved after 6 iterations Backcast: 1949:01 1950:01 Variable Coefficient Std. Error t-Statistic Prob. C MA(1) MA(12) -0.000215 -0.376502 -0.624213 0.000909 0.080696 0.070534 -0.236397 -4.665673 -8.849842 0.8135 0.0000 0.0000 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.364299 0.354366 0.036840 0.173717 248.0909 1.960799 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.000291 0.045848 -3.741845 -3.676001 36.67621 0.000000 (** Esta especificación del modelo difiere de la elegida en Práctico 9 Ejercicio 4 (2009). En este último no se incluyó término constante en el modelo). Luego de la estimación del modelo se procede a examinar si el modelo ajustado proporciona una adecuada descripción de los datos. Para esto, como es usual se estudian los residuos del modelo. Tenemos un buen modelo cuando los residuos son aleatorios y próximos a cero. En la gráfica siguiente en la parte superior se presentan el valor ajustado y las observaciones superpuestos y en la parte inferior los residuos del ajuste. La gráfica de los residuos parece indicar que estamos frente a un proceso puramente aleatorio. Examinamos el correlograma de los residuos para confirmar esta afirmación. 0.2 0.1 0.0 -0.1 0.10 -0.2 0.05 0.00 -0.05 -0.10 -0.15 51 52 53 54 Residual 55 56 57 Actual 58 59 Fitted 60 8 Correlograma de los residuos del modelo ajustado Sample: 1950:02 1960:12 Included observations: 131 Q-statistic probabilities adjusted for 2 ARMA term(s) Autocorrelation Partial Correlation .|. .|. *|. *|. .|. .|* *|. .|. .|* *|. .|. .|. .|. .|. .|. *|. .|. .|. *|. *|. .|. .|. .|** .|. .|. .|. .|. .|. .|. *|. .|. .|* *|. .|. .|. .|. .|. .|. *|. *|. .|. .|. *|. .|. .|* *|. .|. .|. .|* .|. .|. *|. .|. .|. *|. *|. .|. .|. .|* .|. .|. .|* .|. *|. .|. .|. .|. .|. *|. .|. *|. *|. | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob 0.014 0.010 -0.125 -0.141 0.059 0.069 -0.073 -0.042 0.104 -0.080 0.045 -0.008 0.042 0.031 0.050 -0.150 0.028 0.008 -0.105 -0.109 -0.029 -0.030 0.229 0.037 -0.017 0.060 -0.043 -0.053 -0.054 -0.073 -0.051 0.116 -0.126 -0.001 -0.050 -0.016 0.014 0.009 -0.125 -0.139 0.065 0.059 -0.115 -0.051 0.153 -0.095 -0.012 0.031 0.083 -0.019 0.041 -0.111 0.047 0.004 -0.129 -0.167 0.036 -0.043 0.152 -0.017 0.049 0.072 0.006 -0.097 -0.036 -0.047 -0.041 0.018 -0.094 -0.008 -0.059 -0.068 0.0249 0.0374 2.1526 4.8620 5.3360 6.0042 6.7536 6.9986 8.5568 9.4835 9.7818 9.7914 10.057 10.199 10.568 13.992 14.110 14.119 15.835 17.689 17.822 17.963 26.454 26.682 26.732 27.329 27.645 28.121 28.626 29.553 30.000 32.366 35.200 35.200 35.645 35.691 0.142 0.088 0.149 0.199 0.240 0.321 0.286 0.303 0.368 0.459 0.525 0.598 0.647 0.450 0.517 0.590 0.536 0.476 0.534 0.590 0.190 0.224 0.268 0.289 0.324 0.353 0.379 0.385 0.414 0.351 0.276 0.319 0.345 0.389 Al mirar el valor de los coeficientes de autocorrelacion para 1, 2 y 12 vemos que no son significativamente distintos de cero. Si lo fueran habría que modificar el modelo para tener en cuenta esos valores significativos. 9 PREDICCIÓN Dado el último dato observado PAI60:12 del proceso SARIMA (0, 1, 1) (0, 1, 1)12 se desea estimar la variable para el período 1961/1 a 1961/12.Veamos en detalle como hacerlo. La variable modelada fue ΔΔ12 LPAIt, la predicción para el período t+1, es decir 61/1, de esta variable es 0.010814. La variable ΔΔ12 LPAIt se nombra Wt y se escribe la relación entre esa variable y las originales PAI: Wt = ΔΔ12 LPAIt = ( 1 – L ) ( 1 - L12 ) LPAIt = LPAIt - LPAIt-1 - LPAIt-12 + LPAIt-13 == ( 1 - 0.3765 L) ( 1 - 0.6242 L12 ) εt Por tanto, el proceso LPAI se obtiene sumando, o lo que es lo mismo integrando el proceso W. Tengamos en cuenta que partimos de una serie no estacionaria PAI, que fue diferenciada para alcanzar un proceso estacionario, sin tendencia y sin estacionalidad. Por tanto el modelo integrado es aquel obtenido por suma o integración de un proceso estacionario, luego de remover la tendencia y estacionalidad de la serie. El valor de LPAI61/1 es 6,1084 siendo el antilogaritmo 450. De esta forma se obtiene la predicción de la serie original el número de pasajeros aerolíneas internacionales, PAI para enero de 1961 y operando en forma similar se completa la predicción hasta diciembre de1961. 0.15 0.10 0.05 0.00 -0.05 -0.10 -0.15 50 51 52 53 54 55 56 57 58 59 60 61 D1D12LPAI D1D12LPAIF 10 El gráfico anterior contiene la predicción de la variable, Wt, para el período 1949/1 a 1961/12 (línea punteada) y las observaciones disponibles del período 1949/1 a 1960/12. Conclusiones La serie estudiada, tiene tendencia y estacionalidad muy marcadas, y el modelo estacionario resultante después de removidas ambas, es decir luego de la diferenciación conveniente de los datos, es un modelo de medias móviles, tanto en la componente estacional como en la no estacional. Luego de realizar éste ejercicio, cabe preguntarse si no hubiera sido más razonable utilizar el método de alisamiento exponencial, examinado en la primera parte del curso, para modelar la tendencia y estacionalidad de esta serie, y realizar una predicción de corto plazo. Utilizando el EVIEWS 3, aplicando la técnica de alisamiento exponencial, a la misma serie (PAI) le ajustamos un modelo de tendencia lineal con estacionalidad multiplicativa, para realizar una predicción mensual de enero de 1961 a diciembre de 1961, de la misma forma que lo hicimos con la aproximación ARIMA. Aplicamos el método de Holt – Winters multiplicativo, método apropiado para la predicción cuando la serie tiene una tendencia lineal y una variación estacional multiplicativa. A continuación se presenta la gráfica con los valores observados y la predicción de la serie LPAI. 7.0 6.5 6.0 5.5 5.0 4.5 50 51 52 53 54 55 56 57 58 59 60 61 LPAISM LPAI El valor de LPAI61/1 es 6,109579 siendo el antilogaritmo 450. Por tanto el resultado de la predicción es idéntico al obtenido con el modelo SARIMA. 11 Ejemplo 2 Para este segundo ejemplo de aplicación de las técnicas de modelización ARIMA se eligió una serie de datos mensuales, que presentan tendencia y estacionalidad. Se trata de la entrada mensual de leche a plantas de Conaprole, en millones de litros, desde enero de 1990 a julio de 1998. Problema Elaborar un modelo ARIMA estacional que sea útil para la predicción mensual del período agosto 1998 / diciembre 1998. Gráfica de los datos El examen gráfico de la serie mensual de “Entrada de leche a plantas de Conaprole” (de aquí en más LECHE), es el primer paso para atender las características que presenta la serie, considerar si tiene tendencia, es decir si es no estacionaria en media, que ocurre con la varianza y tener en cuenta la estacionalidad de la misma. 90000 80000 70000 60000 50000 40000 30000 90 91 92 93 94 95 96 97 98 LECHE Se observa que la serie LECHE tiene tendencia y estacionalidad, contiene un componente periódico que se repite cada doce observaciones, s = 12. En este caso, se espera que la leche entrada en plantas de Conaprole en el mes de setiembre de 1998, dependa de la entrada de setiembre de 1997 y posiblemente de la entrada de 1996. A diferencia con el Ejemplo 1, serie PAI, en éste caso, no se observa que la varianza se incremente con la media. Cuando se examinó la serie PAI, para remover ese efecto se realizó la transformación logarítmica de los datos. No se considera necesario en este caso. 12 Identificación del modelo En primer lugar observemos el correlograma de los datos Leche Autocorrelation . |****** | . |**** | . |*. | .*| . | **| . | ***| . | **| . | .*| . | . |*. | . |*** | . |***** | . |****** | . |***** | . |*** | . |*. | .*| . | **| . | ***| . | **| . | .*| . | . |*. | . |*** | . |**** | . |***** | . |**** | . |** | .|. | **| . | ***| . | ***| . | **| . | .*| . | .|. | . |** | . |*** | . |*** | Partial Correlation . |****** | ****| . | **| . | .|. | .|. | **| . | . |** | . |*. | . |*** | . |** | . |*. | .|. | **| . | . |*. | .*| . | . |*. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | .|. | **| . | .|. | . |*. | .|. | .*| . | . |*. | .|. | .*| . | .|. | .|. | .|. | . |*. | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob 0.835 0.525 0.164 -0.129 -0.291 -0.357 -0.295 -0.145 0.120 0.435 0.681 0.779 0.638 0.381 0.068 -0.175 -0.302 -0.344 -0.274 -0.133 0.096 0.355 0.548 0.615 0.472 0.225 -0.045 -0.240 -0.335 -0.342 -0.257 -0.131 0.055 0.258 0.396 0.433 0.835 -0.572 -0.235 0.065 0.065 -0.204 0.221 0.135 0.443 0.301 0.077 0.015 -0.305 0.159 -0.129 0.131 0.027 -0.037 -0.012 -0.029 -0.027 0.052 -0.020 0.034 -0.215 -0.021 0.115 -0.026 -0.079 0.084 -0.015 -0.152 -0.051 0.014 -0.040 0.070 73.997 103.51 106.41 108.23 117.61 131.83 141.66 144.06 145.71 167.73 222.31 294.46 343.34 360.95 361.51 365.32 376.78 391.82 401.49 403.81 405.02 421.89 462.45 514.17 545.06 552.15 552.44 560.77 577.13 594.50 604.39 607.01 607.48 617.87 642.87 673.15 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 Los coeficientes de los 36 primeros coeficientes de autocorrelación son todos significativos. En éste resultado está influyendo la tendencia de la serie y su marcada estacionalidad. Por tanto, diferenciamos la serie para eliminar a ambas, una diferencia de orden 1 y otra de orden 12: ( 1 - L )( 1 - L12 ) 13 Correlograma de la serie ΔΔ12 Leche Included observations: 90 Autocorrelation Partial Correlation .|. ****| . .|. .|. .|. . |*. .|. .*| . .|. . |** . |*. ****| . .*| . . |*** .|. .*| . . |*. .*| . .*| . .|. .|. . |*. .|. .|. . |*. .*| . .*| . . |** .*| . .|. . |*. .|. .|. .*| . .*| . .|. .|. ****| . .*| . **| . .|. .|. .|. .*| . .*| . . |*. . |*. ***| . .|. .|. .|. .|. . |** .*| . .*| . **| . .*| . .|. . |*. .*| . . |*. .|. .*| . .|. .|. .|. .*| . .|. .|. .|. .|. .*| . | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob -0.016 -0.460 -0.039 0.017 0.057 0.075 -0.048 -0.082 -0.055 0.198 0.140 -0.485 -0.093 0.368 0.053 -0.083 0.105 -0.147 -0.141 0.034 0.054 0.068 -0.021 0.047 0.073 -0.162 -0.112 0.198 -0.072 -0.013 0.115 0.016 0.006 -0.104 -0.092 0.049 -0.016 -0.460 -0.071 -0.253 -0.010 -0.043 -0.034 -0.073 -0.120 0.171 0.091 -0.440 -0.031 -0.014 -0.022 -0.051 0.230 -0.127 -0.069 -0.216 -0.155 0.048 0.077 -0.135 0.082 -0.014 -0.170 0.040 -0.034 -0.025 -0.093 0.056 0.042 -0.010 0.019 -0.099 0.0230 19.896 20.038 20.065 20.383 20.937 21.170 21.854 22.167 26.212 28.265 53.237 54.172 68.962 69.273 70.040 71.297 73.770 76.092 76.228 76.575 77.141 77.195 77.470 78.149 81.563 83.204 88.427 89.135 89.157 91.020 91.056 91.061 92.651 93.924 94.299 0.879 0.000 0.000 0.000 0.001 0.002 0.004 0.005 0.008 0.003 0.003 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 El valor crítico para los coeficientes de autocorrelación es 0.21 y encontramos valores significativos para estos coeficiente en los rezagos 2, 12, y 14, siendo el resto de los mismos lo suficientemente pequeños para concluir que no hay signos de no estacionariedad. Si ΔΔ12 Leche es una serie estacionaria, estamos en condiciones de identificar el modelo ARMA que se ajusta mejor a los datos. 14 A partir del correlograma de la serie ΔΔ12 Leche se identifica el siguiente modelo: SARIMA (0,1,2)(0,1,12)12. Estimación Utilizando el software EVIEWS 3.0 se estiman los parámetros del modelo. El resultado es: ΔΔ12 Lechet = (1 + 0.039L - 0.506L2 ) ( 1 - 0.658L12 ) εt La tabla que sigue contiene el resultado detallado de la estimación. Sample(adjusted): 1991:02 1998:07 Included observations: 90 after adjusting endpoints Convergence achieved after 11 iterations Backcast: 1989:12 1991:01 Variable Coefficient Std. Error t-Statistic Prob. MA(1) MA(2) SMA(12) 0.038573 -0.506095 -0.658028 0.091660 0.076612 0.067051 0.420824 -6.605953 -9.813843 0.6749 0.0000 0.0000 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.537982 0.527361 2667.851 6.19E+08 -836.1915 1.908953 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 29.78644 3880.582 18.64870 18.73203 50.65220 0.000000 Respecto de los coeficientes estimados del modelo, cabe señalar que el coeficiente del MA(1) no es significativo, en cambio tanto el del MA(2) como el del SMA(12), correspondiente a la componente estacional, son altamente significativos. En la parte inferior de la tabla se presentan un conjunto de estadísticos, entre los cuales Akaike Information Criterion (AIC), es de utilidad para considerar la bondad del ajuste en el caso de que en la etapa de identificación se especifiquen varios modelos alternativos. El criterio de AKAIKE consiste en seleccionar aquel modelo para el que se obtiene el estadístico AIC más bajo. En el caso a estudiado el modelo seleccionado, fue el que tuvo el mínimo AIC, entre las especificaciones probadas. Luego del examen de los estadísticos anteriores preparamos el correlograma de los residuos del modelo ajustado. Si el modelo especificado es correcto, los residuos, es decir la diferencia entre los valores observados y los estimados, tienen que tener un comportamiento similar a un ruido blanco. Los coeficientes de autocorrelación y autocorrelación parcial estimados que se presentan en ese correlograma , no deben ser significativamente distintos de cero. 15 Sample: 1991:02 1998:07 Included observations: 90 Q-statistic probabilities adjusted for 3 ARMA term(s) Autocorrelation Partial Correlation .|. .|. .|. .*| . .|. .|. .*| . .*| . .|. .|. . |*. .*| . .|. . |** . |*. .|. .|. **| . .*| . .|. .|. .|. .|. . |*. .|. . |*. .*| . . |*. .*| . .|. .|. .*| . .|. .*| . .*| . .|. .|. .|. .|. .*| . .|. .|. .*| . **| . .|. .|. . |*. .*| . .|. . |** . |*. .*| . .|. .*| . .*| . .*| . .|. .|. .|. .|. .*| . .|. .*| . . |*. .*| . .|. . |*. .|. . |*. .*| . .*| . .|. | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 AC PAC Q-Stat Prob 0.028 -0.026 -0.044 -0.133 -0.037 -0.011 -0.146 -0.167 -0.017 0.012 0.183 -0.064 0.016 0.253 0.076 -0.032 0.008 -0.230 -0.129 -0.044 -0.041 0.015 0.034 0.077 0.063 0.066 -0.132 0.190 -0.089 -0.014 0.050 -0.114 0.046 -0.076 -0.129 -0.025 0.028 -0.026 -0.043 -0.132 -0.034 -0.019 -0.162 -0.193 -0.043 -0.028 0.124 -0.143 -0.004 0.259 0.074 -0.085 0.033 -0.118 -0.073 -0.107 -0.020 0.042 0.046 0.032 -0.059 0.037 -0.173 0.119 -0.089 0.017 0.070 0.006 0.151 -0.110 -0.171 -0.037 0.0729 0.1341 0.3198 2.0232 2.1584 2.1705 4.2902 7.1222 7.1529 7.1673 10.678 11.110 11.138 18.129 18.761 18.876 18.884 24.955 26.900 27.132 27.333 27.361 27.501 28.249 28.751 29.317 31.594 36.396 37.467 37.495 37.852 39.712 40.024 40.887 43.394 43.486 0.155 0.340 0.538 0.368 0.212 0.307 0.412 0.221 0.268 0.347 0.079 0.094 0.127 0.169 0.051 0.043 0.056 0.073 0.097 0.122 0.133 0.152 0.170 0.137 0.066 0.068 0.086 0.101 0.089 0.104 0.110 0.086 0.105 16 10000 5000 0 10000 -5000 5000 -10000 0 -5000 -10000 92 93 94 95 Residual 96 97 Actual 98 Fitted La gráfica de los residuos también estaría indicando que estamos frente a una serie de ruido blanco. Predicción La predicción realizada con el modelo SARIMA (0,1,2)(0,1,1)12 para 1998/8 de leche entrada a plantas de Conaprole es de 65004 millones de litros. Se recuerda que el último dato observado para el estudio, fue 1998/7. La predicción realizada por el método de Alisamiento Exponencial (Holt Winters multiplicativo), para igual mes es de 65793 millones de litros. El gráfico siguiente presenta con línea punteada la variable Leche estudiada y con línea llena el resultado del alisamiento exponencial, incluido la predicción hasta 1998/12. 100000 80000 60000 40000 20000 90 91 92 93 94 LECHESM 95 96 97 LECHE 98


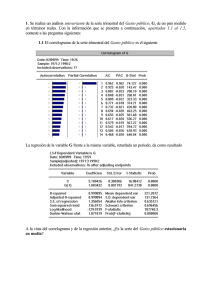


![[ ] ε](http://s2.studylib.es/store/data/004599547_1-2f20235d60ac9bc80564c7074e516da7-300x300.png)
