Clase 4 - Universidad del CEMA
Anuncio

Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
IV - DISTRIBUCIONES MUESTRALES
4.1 Muestreo
Muestreo, distribuciones, procedimientos, etc. conciernen todos con el siguiente tipo de
situacion.
En primera instancia estamos interésados en ganar información acerca de particulares
medidas asociadas con un set bien definido de unidades. Nos referimos a este grupo de
unidades como la población (objetivo). Por ejemplo, la población puede muy bien ser los
clientes de una compañía, y la variable de interés puede ser el monto de dinero qie se gasta
con la compañía, sus niveles de satisfacción con el servicio, etc. Idealmente nos gustaría
contar con la totalidad de información sobre estas variables entrevistando a toda la
población (referendum), pero esto es muy costos, y los relevamientos llevan mucho tiempo.
En consecuencia, lo que hacemos es tomar un subconjunto del grupo y obtener los datos de
interés, procediendo a hacer inferencias desde esos datos hacia el total de la población.
Este subconjunto es denominado la MUESTRA, y existen métodos bien definidos a los
efectos de extraer la mayor cantidad de informacion util de la misma.
La población puede ser finita (los empleados de una compañía en particular) o infinita (tirar
una moneda indefinidamente), siendo que una población muy grande puede ser tomada
como infinita en tamaño a los efectos prácticos.
En este capítulo las distribuciones muestrales de algunos estadísticos importantes, cuando
una muestra es extraida de una población infinita (a los efectos practicos). Por Muestra
Aleatoria Simple entendemos que la muestra es elegida de manera tal que cada miembro de
la población tiene la misma probabilidad de integrar la muestra, independientemente de
otros miembros de la población. Para ello se pueden usar tablas o generadores de numeros
aleatorios. No obstante, el muestreo simple no es necesariamente el método mas eficiente
1
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
cuando la población objeto posee heterogeneidades bien conocidas. Tampoco es el mas
eficiente desde el punto de vista económico. Por ello al elaborar un muestreo, otras técnicas
deben ser objeto de análisis.
4.2 Planificación y Dirección de un Muestreo o Encuesta
Conducir una encuesta o muestreo implica mas que seleccionar un diseño, implica
planificación. Esta plainificación requiere de pasos, siendo los sugeridos por Scheaffer,
Mendenhall y Ott (1986) los siguientes:
1- Seleccione los objetivos: Que inferencias necesitamos obtener, y que es lo que no
sabemos?
2- Identifique la población objetivo: Sobre quienes queremos obtener conclusiones?
3- Seleccione un marco de muestreo: en esta etapa pueden ocurrir lo siguientes problemas;
bases de datos a ser utilizadas no se encuentran completas, error de selección o sesgo de
diseño de la muestra, error de falta de respuesta, lo que hace que la muestra no sea
representativa.
4- Seleccione un diseño de muestreo: como se seleccionarán los encuestados y cual será el
tamaño de la muestra.
5- Seleccione un método de muestreo: decidiendo como se recogerán los datos, sea en
forma personal, telefónica, por correo, étc.
6- Desarrolle un cuestionario: escriba el cuestionario, decidiendo el tipo y cantidad de
preguntas. El error de respuesta sucede a menudo en encuestas de opinión; depende de
cómo se formule una pregunta o que tipo de palabras se utilicen se recibirán distintos
porcentajes de opinión.
7- Realice un prueba previa del cuestionario: lleve a cabo la encuesta en una pequeña
muestra, y vea como evoluciona la misma.
2
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
8- Lleve a cabo el muestreo: monitoree los encuestadores para verificar habilidades de
entrevista consistentes.
9- Analice los datos: aún antes de llevar a cabo la encuesta, determine el método de
análisis de los datos.
4.3 Comparación de distintos diseños de Muestreo
Diseño
Como seleccionar la
Fortalezas/Debilidades
muestra
Muestra Simple
Asigne números a los
El elemento básico de
elementos de la población.
construcción.
Utilice tabla de números
Simple, pero usualmente
aleatorios para seleccionar la
costoso.
muestra.
No se puede utilizar a menos
que se asigne un número a
cada elemento de la
población
Muestra estratificada
Divida la población en
Con estratos apropiados
grupos que sean homogéneos puede producir estimadores
Muestra Sistemática
internamente y heterogéneos
muy acertados.
entre sí.
Más barato que el muestreo
Utilice números aleatorios
simple, requiere de una
para seleccionar muestras en
correcta estratificación de la
cada estrato
población.
Seleccione cada elemento kth Produce estimadores
de una lista a partir de un
acertados cuando los
comienzo aleatorio.
elementos en la población
3
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
exhiben un cierto orden.
Utilizar cuando muestreo
simple o estratificado es
impracticable: e.g. no se
conoce el tamaño
poblacional.
Simplifica el proceso de
selección.
No utilizar con poblaciones
de características repetidas
en forma periódica.
Muestreo por agrupamientos Agrupamientos (clusters)
Con agrupamientos
(clustering)
elegidos en forma aleatoria y
apropiados, puede producir
luego encuesta de cada
estimadores muy acertados.
elemento del cluster.
Util cuando un marco de
muestreo no está disponible o
los costos de traslado son
altos.
Los agrupamientos deben ser
representativos de la
población.
4.4 Principios Generales al escribir preguntas
Un estudio exitoso requiere que se encueste a la persona correcta, que la misma posea la
información de interés, y que esté dispuesta a proporcionarla. Las preguntas pueden ser: de
final abierto (Que fábrica construye los mejores autos?), de final cerrado (Que fábrica
construye los mejores autos?A- Una, B-Dos, étc.), y entre las de final cerrado: alternativas
4
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
sin orden, de final cerrado parciales (se incluye Otro), alternativas en orden (Mucho, Poco,
Nada), alternativas binarias (Sí, Nó). Entre los principios generales al escribir preguntas se
puedne citar:
Entendiendo la Pregunta
Dirija la elección de palabras a la inteligencia o nivel del encuestado.
Evite preguntas vagas
Evite preguntas con doble interpretación
Haga las respuesta excluyentes entre sí.
Teniendo la Información
Escriba preguntas que la gente pueda contestar
Escriba preguntas que la gente pueda contestar sin mucho esfuerzo
Disposición a dar información
Evite preguntas que invaden la privacidad de las personas
Diseñe las preguntas de manera tal que incentivos sociales no jueguen un rol al
elegir una respuesta.
Nunca haga preguntas embarazosas
Evite preguntas que dirijan al encuestado a elegir una respuesta en lugar de otra.
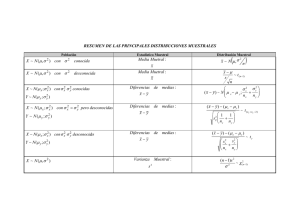
4.5 Distribuciones Muestrales
En la práctica, un set de datos es considerado como una muestra, y sus estadísticos como
representativos estimadores de los parámetros poblacionales. Una notación diferente es
utilizada para distinguir entre elementos de una muestra y población.
5
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
Asi tendremos
Muestra
Población
Histograma
Distribución de probabilidad
Media m
Media µ
Desviacion Estándar s
Desviacion Estándar σ
Varianza, s2
Varianza, σ2
Proporcion muestral r/n,
Proporcion p
Existe generalmente confusion entre características muestrales y poblacionales. Es
importante tener a esta altura una visión clara de la diferencia para entender los siguientes
tópicos. Como veremos, los estadísticos muestrales (bajo ciertas condiciones) se acercan a
sus contrapartes poblacionales a medida que el tamaño de la muestra se agranda;
haciendose iguales cuando la muestra es igual a la población. Sin embargo, cuando el
tamaño de la muestra es chico, segundas y terceras muestras tendran asociadas distintos (o
no) estadísticos muestrales, en tanto que las caracteristicas poblaciónales se mantienen
constantes.
Estadísticos muestrales varían de muestra a muestra debido a la naturaleza aleatoria de la
muestra, de alli que los estadísticos muestrales tengan asociados distribuciones de
probabilidades.
Asi, obtenemos lo que es denominado DISTRIBUCIÓN MUESTRAL. Tenemos la
distribución muestral del maximo, del rango, de la media muestral, etc.
El principal proposito de este capitulo es estudiar estas distribuciónes.
6
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
4.6 Distribución Muestral de la media muestral
Consideremos una gran población (infinita) que posee una distribución normal con media µ
y deviacion estándar σ. Tomemos ahora una muestra aleatoria de n valores y computemos
su media m1; tomemos ahora otra muestra de igual tamaño y computemos su media m2, y
asi sucesivamente, hasta obtener un gran numero de medias mi. Estos valores por lo general
variarán de muestra en muestra, con lo que podemos construir un histograma que los
describa, como ya lo hicimos, para tener una imagen de los mismos. Esto pone énfasis en el
hecho que la media muestral tiene asociada una distribución de frecuencia, y estaremos
capacitados para determinar la forma exacta de esta distribución desde la teoria sin tener
que correr una simulación como la descripta.
Ahora derivamos la distribución muestral de la media muestral de n valores muestreados en
forma aleatoria, x1, x1, ......xn de N {µ, σ2}.
Consideremos la variable T = x1 + x2 + ..........xn,
Como la variable T es una función lineal de variables aleatorias normalmente distribuidas,
T es normal. Solo queda por derivar su media y su varianza:
E (T) = E(x1) + E(x2) + ......E(xn) = nµ
µ
V (T) = V(x1) + V(x2) + ......V(xn) = nσ
σ 2,
Entonces, T se distribuye normalmente con media nµ y varianza nσ2,
Dividiendo T por n, obtenemos la distribución muestral de T/n
7
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
E (T/n) = {E(x1) + E(x2) + ......E(xn)}/n = µ
V (T/n) = {V(x1) + V(x2) + ......V(xn)}/n2 = σ2/n
Resumimos este resultado importante de la siguiente manera: si m es la media muestral de
n valores de una distribución N {µ, σ2}, entonces m:
(a) Se distribuye normalmente
(b) Tiene media µ.
(c) Tiene varianza σ2/n
Nótese que la distribución de la media muestral es la misma que para las observaciones
particulares , excepto por el hecho de estar la varianza dividida por n; esto nos dice que
medias muestrales son menos variables que los valores individuales, y su variabilidad
decrece a medida que la muestra se agranda, tornandose 0 cuando N tiende a ∞, de forma
tal que m se hace µ con certeza en el limite.
La deviacion estándar de m es σ√n, pero para distingirla de su contraparte poblaciónal se lo
suele denominar ERROR ESTÁNDAR.
Asi, una media muestral simple m es en si misma una muestra de la población normal, con
media µ y desviacion estándar √σ/n.
Es fácil mostrar que si una muestra similar es tomada de una población con una
distribución no conocida, pero con media µ y varianza σ2,b y c todavia se mantienen. Lo
qie si es mas sorpresivo es que si n es razonablemente grande, entonces a es
aproximadamente cierto. Este poderoso resultado es conocido como teorema del Limite
Central, y puede ser verificado tanto teóricamente como empíricamente. Una consecuencia
8
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
es que si estamos tratando con una media muestral, y el tamaño de la muestra supera 30,
podemos asumir que ha sido obtenida de una distribución normal.
Notese que los resul;tados (b) y (c) implican que
(a)
medias muestrales basadas en muestras grandes tienen mayores chances de
estar cerca del verdadero valor poblacional que aquellas obtenidas de
muestras pequeñas.
(b)
Si incrementamos el tamaño de la muestra indefinidamente, la distribución
normal resultante se transforma en una linea sobre la media poblaciónal.
De aquí nuestro uso de la media muestral como un estimado de la media poblaciónal.
Corrección de la Varianza de la media muestral para poblaciones finitas
Si la muestra se toma, sin reposición de una población finita de tamaño N, entonces es
inmediatamente aparente que el error estándar de m es 0 cuando n = N y no √σ/n.
En este caso es necesario utilizar una fórmula mas general para el error estandar de la
media muestral, de manera que,
Varianza de la media muestral = {σ2/n} * (1 – 1/N), donde el factor (1 – 1/N) es conocido
como Factor de Corrección de Poblaciones Finitas, y se hace insignificante cuando el
tamaño de la muestra es pequeño comparado con el tamaño de la población.
9
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
4.7 Distribución Muestral de la Población
La Aproximacion de la Distribución Normal a la Binomial
Esta distribución se aplica cando tenemos n pruebas de Bernoulli con parámetro de éxito p,
donde n es bastante grande pero p no es un valor muy extremo. Nótese que cuando p si es
extremo, podemos usar la aproximacion de Poisson a la Binomial, conforme fuera ya
explicado. Caso contrario, la distribución normal es la que corresponde utilizar.
Asumamos que tenemos n pruebas de Bernoulli con parametros de éxito p; la distribución
exacta del numero de exitos es la Binomial pero si n es grande podemos utilizar el siguiente
argumento:
Definamos Xi = 1 si la i – gesima prueba es exitosa, y = 0 si es fracaso,
Entonces el número total de éxitos es igual a
R = X1 + X2 +............Xi, de manera tal que la proporcion de exitos es igual a R/n = X
De alli que la proporción es la media muestral de un gran número de variables aleatorias
independientemente e idénticamente distribuidas, se sigue entonces del Teorema del Límite
Central que la proporción muestral se distribuye en forma normal. De la distribución
Binomial se sigue que que R posee una media igual a np, y varianza igual a npq, de donde
se sigue que la aproximacion normal a la binomial posee los mismos parametros.
La distribución muestral de la proporcion es igual entonces a
10
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
R/n ~ N { p, pq/n}, siendo conocida como la aproximacion normal a la Binomial.
Es particularmente relevante para realizar inferencias sobre proporciones poblaciónales
como veremos mas adelante. Notese que tambien significamos que
R ~ N { np, npq}
Ejemplo
Un vendedor inicia contactos telefónicos con potenciales clientes que luego puede o
no redituar en una visita personal. Su experiencia le indica que en un 40% de los casos, los
contactos telefónicos conducen a una visita personal. En caso que el núemro de personas a
contactar fuese 100, cual es la probabilidad que entre 45 y 55 personas arreglen una vista
personal?. Si X es el numero de visitas, que sigue una distribución binomial con n=100 y
p=.4, entonces la aproximación será:
45 − (100).4
50 − (100).6
P(45 ≤ X ≤ 55) ≈ P
≤Z≤
(100)(.4)(.6)
(100)(.4)(.6)
= P(1.02 ≤ Z ≤ 2.04)
= Fz(2.04)-Fz(1.02) = .1332
La Aproximación de la Distribución Normal a la Poisson
Cuando el número de ocurrencias λ es grande, y el intervalo de tiempo de interés es
subdividido en partes mas pequeñas de igual tamaño. Entonces el total de ocurrencias en un
período dado es igual a la suma de las ocurrencias en cada uno de los subintervalos.
11
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
Entonces se puede ver que cuando λ es grande, el número total de ocurrencias puede ser
visto como una suma moderada de variables aleatorias, donde cada una represneta
ocurrencias en el subintervalo. Invocando el Teorema del Límite Central, se podría decir
que
Z=
X − E( X ) X − λ
=
Var ( X )
λ
es aproximadamente normal estándar.
Ejemplo
Un centro de servicios al consumidor recibe en promedio 25 llamadas por dia,
pudiéndose asumir que la distribución de las llamadas es Poisson. Estimando la
probabilidad que el numero de llamadas en un dia esté entre 20 y 30, tenemos que λ=25
20 − 25
30 − 25
P(20 ≤ X ≤ 30) ≈ P
≤Z≤
25)
25
= P(-1 ≤ Z ≤ 1)
= Fz(1)-Fz(-1) = .6826
4.8 Distribución Muestral de la Varianza Muestral
A diferencia de la media muestral, esta distribución es sensitiva a la distribución subyacente
de las variables de donde la muestra fue obtenida. Como hemos visto en la sección anterior,
12
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
es en nuestro provecho si podemos construir un estadístico relacionado cuya distribución
sea independiente de los parámetros (el caso de la distribución normal estándar), lo que será
extremadamente útil.
Puede ser mostrado que la varianza muestral s2 para una muestra aleatoria de una
distribución normal con media µ y varianza σ2, tiene una distribución conocida con media
σ2 y varianza 2σ4/(n-1). Sin embargo, podemos remover la dependencia del error estándar
del parámetro desconocido a través de simplemente tomar una funcion de s2,
(n − 1)
s 2 S yy
o
σ2 σ2
La forma matematica de esta distribución es conocida y tabulada, y es llamada la
distribución CHI – CUADRADA (χ2). La media de esta distribución es (n-1) y su varianza
2(n-1), de manera tal que claramente se ve que para diferentes tamaños de muestras se
obtienen diferentes distribuciones.
No obstante la dependencia en s2 ha sido removida, todavia tenemos distintas distribuciones
χ2 (no como en el caso de la norma, que una vez estandarizada es única). Esto es asi porque
la distribución chi- cuadrada depende en el número de observaciones que han sido
utilizados para computar la varianza muestral. Mas formalmente, depende en los GRADOS
DE LIBERTAD asociados con el cálculo de la varianza muestral; para una varianza
muestral calculada de una muestra de tamaño n, los grados de libertad son siempre (n-1).
Explicaremos mas adelante el término de grados de libertad cuando los encontremos en un
contexto mas general.
13
Universidad del CEMA
Métodos Cuantitativos
Prof. José P Dapena
De esta manera, utilizamos tablas estadisticas o softwares especiales para calcular las
probabilidades que la varianza muestral se encuentre en un determinado rango. También se
utiliza para testear valores probables de la varianza poblacional.
14


![( ) ( )2 ( )[ ] ( )ξ ( ) PQ](http://s2.studylib.es/store/data/006099496_1-61f82d8b006ba0985f60bbb263d08047-300x300.png)