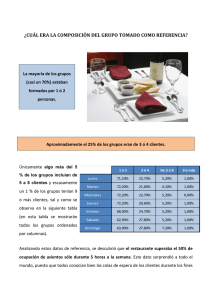
abrir - Universidad Nacional de Mar del Plata
Anuncio

Busha, Charles, Harter, Stephen P. Métodos de investigación en bibliotecología
: técnicas e interpretación -- México : UNAM, 1990. 407 p.
Capítulo 5
INVESTIGACION
DE
OPERACIONES
EN
BIBLIOTECOLOGIA:
ENFOQUES
CUANTITATITOS DEL ANALISIS DE LOS PROBLEMAS ADMINISTRATIVOS
INTRODUCCION
La Investigación de operaciones (IO) es la aplicación del método científico a las
operaciones administrativas en un esfuerzo por ayudar a la administración en la toma de
decisiones. Las técnicas de la investigación de operaciones se aplican a las actividades de
la organización o sistemas y están diseñadas para proporcionar a la administración una
base cuantitativa para la toma de decisiones. Así, lo mismo que la computadora y las
técnicas de análisis estadístico, la investigación de operaciones puede ser un valioso
instrumento administrativo. Las técnicas de la investigación de operaciones se han aplicado
a problemas de administración tan diversos como la formación de carteras de inversiones, la
distribución de recursos escasos, la congestión y el control del tráfico, la disposición de
fuerzas militares, el diseño de redes telefónicas, la determinación de políticas de inventarios,
y las estrategias en juegos.
La investigación de operaciones tuvo su comienzo en la investigación militar durante
la II Guerra Mundial, con la aplicación del análisis matemático a problemas tales como la
evaluación del armamento, la determinación de los datos causados por los bombardeos y el
desarrollo de una estrategia óptima para la búsqueda de submarinos. La ciencia se había
aplicado a los problemas de la guerra mucho antes de la década de los cuarentas, desde
los tiempos de Arquimedes y Leonardo Da Vinci hasta el presente, pero el enfoque filosófico
básico y el conjunto de técnicas analíticas que definen originalmente la investigación de
operaciones, puede atribuirse a los grupos de investigación ingleses y americaños que
llevaron el peso de la guerra. Después de ésta, organizaciones como la Rand Corporation
refinaron y continuaron aplicando las técnicas de la investigación de operaciones a los
problemas militares. Entretanto, otros investigadores entraron en la industria y en el mundo
de los negocios donde comenzaron a utilizar la investigación de operaciones en el análisis
de los diferentes tipos de problemas. Otros profesionales se incorporaron a las facultades
de las universidades y pusieron la semilla de programas académicos formales de
investigación de operaciones. Actualmente, muchas universidades y departamentos de
instituciones académicas ofrecen cursos o programas de investigación de operaciones.
Reflejando la creciente importancia de la investigación de operaciones en el análisis
de los fenómenos bibliotecarios, se han introducido en la currícula de varias escuelas de
bibliotecarios cursos sobre la materia, incluyendo los de la Universidad de Chicago, la
Universidad Estatal de Nueva York en Búfalo, y la Universidad de Illinois. En algunas
escuelas de bibliotecología, se alienta a los estudiantes a elegir cursos de IO de otras
unidades académicas de la universidad, especialmente de la administración de empresas.
Este capítulo presenta una introducción básica a la naturaleza especial de la IO, e indica
algunas de las aplicaciones de este enfoque a la investigación en bibliotecología.
La investigación de operaciones se ha definido un tanto jocosamente como "lo que
hacen los investigadores en operaciones". Aunque resulta evidente la tortuosidad de esta
definición, es difícil, no obstante, proporcionar una definición de la investigación de
operaciones que pueda satisfacer a todos los profesionales. En uno de los primeros libros
de texto que han tratado el tema, la investigación de operaciones se ha definido como "un
método científico de proporcionar a los departamentos ejecutivos una base cuantitativa para
las decisiones respecto a las operaciones bajo su control". La investigación de operaciones
es a la vez un enfoque filosófico y un conjunto de instrumentos analíticos que surgen de la
aplicación del método científico a los problemas de administración.
Filosóficamente, la IO está en armonía con el método científico:
El enfoque de IO tiene mucho en común con el método científico: requiere una
formulación precisa, a menudo abstracta, de las características esenciales de un
problema, una buena voluntad para emprender una investigación metodológica para
producir la información necesaria para la toma de decisiones y la capacidad analítica
para reconocer las consecuencias de esta información.
Así, un enfoque de investigación de operaciones implica tres pasos principales: (a)
planteamiento del problema; (b) diseño de metodología; y (c) recolección de datos y análisis.
La etapa de planteamiento del problema implica dos propiedades que son características del
enfoque de IO. Primera, las hipótesis son de naturaleza típicamente matemática, implicando
la formulación de un modelo matemático. Segunda, el planteamiento del problema implica
generalmente una definición operativa de las características de la solución "mejor" u óptima
para el problema administrativo que se que se estudia. La metodología empleada en un
estudio de IO es frecuentemente experimental o de un tipo que implique la observación
directa de los fenómenos de interés. En la etapa del análisis de la información se utilizan
frecuentemente conceptos matemáticos o estadísticos relativamente sofisticados.
Dos instrumentos relacionados con la administracion moderna son el análisis de
sistemas y la simulación de sistemas por computadora. Las Iíneas de demarcación entre la
investigación de operaciones, la simulación de sistemas y el análisis de sistemas no son en
modo alguno precisas y claras; estos términos son utilizados como sinónimos por algunos
autores. Realmente, los tres enfoques tienen en común su aplicación a los problemas
administrativos y su construcción y utilización de modelos de fenómenos del "mundo real" o
sistemas.
MODELOS
En el sentido en que la palabra se utiliza aquí, el término modelo se refiere a una
representación de un fenómeno real, el aeroplano o ferrocarril de juguete del niño es un
modelo rudimentario de los aeroplaños y ferrocarnles operativos. Otro tipo de modelo es un
mapa, que proporciona la configuración de ciudades, pueblos, ríos y carreteras de una
determinada localidad geográfica. Algunos mapas incluyen la representación de ciertas
caracteristicas geológicas y otros no. Pero incluso los mapas geológicos son solamente
modelos simples del verdadero terreno considerado; en algún nivel (por ej., al nivel de las
rocas y de los árboles) ciertos fenómenos físicos se ignoran y no están representados como
elementos del modelo.
Otro ejemplo de un modelo de mapa sencillo es la práctica de muchos bibliotecarios
al ofrecer a los lectores una guía en forma de un plano de la biblioteca que indica la
ubicación de las prinncipales secciones de la colección, asi como las mesas de información,
salas de descanso, escaleras y elevadores. Aunque escasamente exacto, este modelo
obviamente, sólo representa en forma parcial el verdadero edificio de la biblioteca.
Estos ejemplos ilustran el que generalmente no se alcanza que los modelos sean
representaciones fieles de la realidad, aunque por supuesto deben de algún modo "capturar
la esencia" de los sistemas que son modelados. Por ejemplo, los modelos sirven
frecuentemente para un fin instructivo; este fin es obviamente mal servido si las
características esenciales del sistema se ignoran o no tienen la representación adecuada.
Sin embargo, no aparece tan claro lo que se considera "esencial". Puede arguirse que la
identificación de esas características implica el asumir un determinado punto de vista. Por
ejemplo, desde la perspectiva del usuario, puede ser que el plano de una biblioteca deba
indicar todas las áreas de servicio en las que pueda esperarse que los usuarios hagan uso
del edificio y su contenido. Desde este punto de vista, las áreas de almacenamiento serían
probablemente identificadas ampliamente y la ubicación de las restantes salas y las mesas
de información sería proporcionada. Pero desde la perspectiva de un bibliotecario
profesional el piano debería enfatizar aspectos totalmente diferentes del edificio y los
servicios de la biblioteca. Diseñado para un bibliotecario, podría esperarse que la función
dictara las características que se muestran. Los detalles de los procesos técnicos, la
catalogación, la encuadernación, los registros de series y otras operaciones de entre
bastidores podrían ilustrarse, así como algunas (probablemente no todas) áreas de servicio
que se muestran en el plano dedicado al usuario. Asi, la misma biblioteca podría modelarse
en dos plaños completamente diferentes. (Puede arguirse legítimamente que el bibliotecario
debe ver su biblioteca como lo hace el usuario, que el servicio en vez de la función debe ser
el punto de vista fundamental en la creación del modelo, incluso para los bïbliotecarios. Este
argumento no ataca el modelo onentado a la funcibn per se; ataca las aceptaciones
subyacentes en la creación del modelo).
El ejemplo anterior ilustra varias características de un modelo. El que construye un
modelo generalmente tiene un propósito en mente y el propósito define un conjunto de
restricciones que deterrninan las propiedades finales del modelo. Un modelo es asi mucho
más que una fel reproducción o representación de la "realidad"; es la realidad vista de una
manera especial. Los modelos no pueden caracterizarse como correctos o incorrectos,
buenos o malos en si mismos; solamente pueden ser juzgados en términos del conjunto
de restricciones asumidas en su· construcción. Las restncciones mismas pueden ser
objetadas en otros terrenos.
ANALISIS DE SISTEMAS
El "acercamiento a sistemas" es a la vez una filosofía y un conjunto de técnicas
analíticas por medio de las cuales un analista intenta considerar todos los aspectos de un
sistema. En su más amplio sentido, el sistema se refiere a fenómenos tan diversos como la
estructura ósea de un animal, una empresa comercial, una computadora electrónica, un
fenómeno ecológico y las bibliotecas. No intentaremos definir el sistema sino en un sentido
muy amplio y general. En su excelente libro no técnico, The Systems Approach, C. West
Churchman define un sistema como "un conjunto de partes coordinadas para lograr un
conjunto de objetivos". Haciendo más precisa esta definición, Churchman enumera los
cinco aspectos pnncipales de un sistema como:
1. Los objetivos del sistema y las medidas ejecutivas que sustituyen a los objetivos.
2. El entorno del sistema: el conjunto de restricciones fijas que limitan el
funcionamiento del sistema y no están bajo el control directo de los administradores
del sistema.
3. Los recursos del sistema: el dinero, el personal y el equipo disponible para el
sistema.
4. Los componentes del sistema: las operaciones y funciones reatizadas en cada
uno de sus subsistemas.
5. La administración del sistema.
Se han escrito muchos documentos y monografías que explican aspectos del método
de sistemas en términos de bibliotecas, centros de comunicaciones y centros de información
(véase, por ejemplo, F. W. Lancaster) Uno de los primeros bibliotecarios que escribieron
sobre este tema fue Fremont Rider. Escribiendo hace más de 30 años sobre la práctica
bibliotecaria pasada, Rider señaló la necesidad de enfocar desde el punto de vista de los
sistemas modernos (y más generalmente, desde los principios del método científico), los
problemas de la bibliotecología.
Y la razón de nuestro fracaso en integrar lo que eran realmente facetas de un sólo
problema fue que estábamos cegados por el status quo. Insistíamos en continuar
aceptando como axiomas bibliotecarios, inalterables e incuestionables, ciertas
asunciones que ya no eran válidas; aforismos tales como, por ejemplo: Las
bibliotecas son colecciones de libros; los libros se almacenan en estanterias; los
materiales de la bibliotca tienen que ser catalogados; los catálogos tienen que
hacerse con fichas; los libros tienen que estar ordenados por su número de
clasificación, etc.
No fue sino hasta que dejamos atrás y abandonamos cada uno de estos -y otros
muchos supuestos axiomas básicos del método bibliotecario y cuestionamos
seriamente su validez como axiomas, cuando comenzamos a hacer algún progreso
real.
Fremont Rider indentificó asimismo la "explosión de información" como un simple
crecimiento exponencial, un modelo matemático que examinaremos detenidamente más
adelante en este capítulo.
Es frecuente el caso de que, con objeto de profundizar su conocimiento de un
sistema, un analista construya una representación abstracta del sistema, un modelo del
sistema. De especial interés aquí son los modelos de la investigación de operaciones, que
son de naruraleza analítica y matemática. Pero antes de preceder al examen de algunos de
los modelos de la investigación de operaciones y su aplicación a los problemas de la
administración de bibliotecas, examinaremos brevemente el concepto de un modelo de
simulación.
MODELOS DE SIMULACION DE SISTEMAS COMPUTARIZADOS
Es posible modelar sistemas muy complejos con un programa de computación.
Durante el "funcionamiento" de este programa de simulación, pueden variarse los
parámetros del sistema y pueden observarse los efectos de la variacibn sobre las medidas
del funcionamiento. Los programas de simulación utilizan a menudo los generc;íiores de
números aleatorios para simular fenómenos probabilísticos como lanzar al aire una moneda
o echar los dados. De esta manera pueden modelarse las características no deterministas
de un sistema. Como esta tecnica se basa en nociones de azar, a menudo se le denomina
el método Monte Carlo.
En una de las primeras aplicaciones de la simulación Monte Carlo a la
bibliotecología, la Biblioteca de la Universidad de Lancaster elaboró un programa de
simulación para ayudar a resolver el problema de determinar la politica óptima de préstamos
en su biblioteca. El modelo consideraba factores tales como la duración de los períodos de
préstamo, la posibilidad de renovaciones, reservaciones, recordatorios, la existencia de
varios ejemplares de determinados libros y el número y los modelos de las peticiones. Se
definieron tres medidas del funcionamiento como sustitutos operacionales del objetivo
general de la biblioteca al proporcionar a los usuarios un buen acceso a los materiales.
Estas fueron:
1. Disponibilidad inmediata: la probabilidad de que la petición de un determinado
libro pueda ser satisfecha inmediatamente.
2. Nivel de satisfacción: en un determinado período de tiempo, la probabilidad de
que una demanda fortuita pueda ser satisfecha inmediatamente.
3. Predisposición de la colección: la proporción del 10% de los libros más
populares que no están en los estantes.
Una biblioteca bien dotada y eficiente deberá tener altos índices de disponibilidad
inmediata, y nivel de satisfacción (idealmente, 1.00) y una baja predisposición de la
colección (idealmente, 0.00). Basándose en los valores obtenidos por computadora de estas
medidas para varios largos períodos de préstamo y clases de libros (''popular", "muy
popular" y "otros") la Universidad de Lancaster pudo seleccionar una óptima política de
préstamos.
CONCEPTO DE MODELO MATEMÁTICO
La investigación de operaciones hace un uso especial del modelo matemático. Un
modelo matemático es en parte una teoría que se expresa en términos matemáticos. Pero si
la teoría está relacionada con el mundo real, sus elementos abstractos deben también
identificarse con objetos físicos, prácticos. Por definición, la investigación de operaciones
se refiere al proceso de toma de decisiones de los administradores en el mundo real; asi
al igual que con otro tipo de investigación científica, debe haber a la vez aspectos teóricos
y prácticos para todos los modelos de investigación de operaciones.
Muchos de los modelos matemáticos creados psr los seres humaños han sido
aplicados a la solución de los problemas prácticos de la medición. La figura 5.1 ilustra un
problema que implica la medición de la distancia entre dos árboles, Ilamémoslos A y B.
Desgraciadamente, esta distancia no puede medirse directamente, porque una barrera (un
gran edificio) está directamente entre los dos árboles. Sin embargo, si se puede encontrar
una ubicación C tal que el ángulo ABC sea un ángulo recto y que los lados AC y BC puedan
medirse directamente, el problema práctico de medir la distancia AB puede resolverse
utilizando la teoría matemática de la geometría plana (o de Euclides). Si las lineas y puntos
abstractos de la geometría euclidiana se interpretan como ubicaciones A, B, y C, entonces
se produce un modelo matemático por el teorema de Pitágoras: "el cuadrado de la
hipotenusa de un triángulo rectángulo es igual a la suma de los cuadrados de los otros dos
lados" proporciona un modelo matemático del problema. Esta relación es una deducción (o
teorema) de la geometría euclidiana. Sin embargo, esta será una verdadera formulación de
nuestro hipotético problema práctico solamente si las asunciones subyacentes en el sistema
teórico de la geometria eucludiana son verdaderas en la situación fisica bosquejada.
La relación de Pitagoras puede expresarse mucho más sencillamente en el lenguaje
de las matemáticas que en el idioma ingles (o, realmente, en cualquier idioma natural). Si c,
a,y b son la hipotenusa y los catetos de un triángulo rectángulo, respectivamente, la
relación de Pitágoras puede expresarse simplemente por la ecuación algebraica c2 = a2 + b2
La identificación de este resultado teórico con nuestro problema práctico implica que
(AB)2 = (AC)2 + (BC)2
Puede ilustrarse una característica adicional de los modelos matemáticos
observando que el conocimiento del álgebra elemental nos permite solamente deducir otro
resultado más:
AB= (AC)2+(BC)2
Así, la distancia entre los dos árboles A Y B, puede hallarse indirectamente midiendo
las distancias AC y BC, elevando al cuadrado esos números y sumando los resultados y
finalmente, extrayendo la raíz cuadrada de la suma. Debe señalarse que una vez que se
expresa una relación en términos matemáticos, puede utilizarse todo un sistema de
matemáticas técnicas (en este caso, álgebra) para deducir nuevas relaciones. Es claro que
en este contexto las matemáticas son un poderoso instrumento. Es este aspecto del
modelo matemático el que lo diferencia de otros tipos de modelos conceptuales como los
que se derivan de la aplicación de argumentos filosóficos o análisis lógicos formales. Es
esta caracterítica del modelo matemático la que lo hace uno de los más poderosos
métodos analíticos para resolver problemas.
Tal vez deba anadirse una consideracibn final respecto al sentido en que empleamos
la expresión modelo matemático para referirnos tanto a la teoría matemática como a la
interpretación de esta teoría en el mundo real. Algunos escritores emplean la expresión
modelo matemático para referisrse solamente a la teoría y pueden ignorar la importante
cuestión de establecer una interpretación válida del modelo (o demostrar que la
interpretación que ellos sugieren es realmente válida). Es posible (y realmente ocurre
algunas veces) que una sencilla y elegante teoría matemática que es satisfactoria
matemáticamente, simplemente no describe el fenómeno real en cuestión. Tal teoría puede
ser un importante suplemento a la teoría abstracta ya establecida, pero no ha de contribuir
necesariamente a ella. Una teoría matemática elegante es claramente de limitado uso
práctico si las asunciones que la vinculan a la realidad no son realmente válidas.
EL CRECIMIENTO EXPONENCIAL COMO MODELO MATEMATICO ILUSTRATIVO
Interés Compuesto
Como se observó anteriormente, el hecho de que ciertos fenómenos bibliotecarios
puedan describirse por el modelo matemático de crecimiento exponencial ha sido conocido
desde hace más de 30 años. El crecimiento exponencial es tal vez más conocido por los
profaños en bibliotecología como la ley de "interés compuesto". Este modelo describe el
crecimiento de muchos organismos naturales y sociales.
Una caracteristica fundamental del crecimiento de interés compuesto es que el
incrcremento en tamaño en cualquier momento es proporcional al tamaño onginal. Asi si un
capital A produce un interés anual r (por ejemplo, r = 4%, 6 .04) acumulable anualmente, el
importe total del capital e interés A 1 al final del primer año será A 1 = A(1 + r). Así, si r= .04,
A1 = 1.004A. El número 1.04 se Ilama la constante de proporcionalidad.
Al final del segundo año, el total acumulado de capital e interés será A 2 = (1+r 3)
[A(1 + r) = A(1 + r)2. Al cabo de tres años, se habrá acumulado un total de A 3 =A(1 + r) 3
En general, al cabo de n años, el total acumulado de An de capital e intereses viene dado
por la fórmula:
An= A(1 + r)n.(1)
en la que r es un parámetro característico de una determinada situación de crecimiento.
Es ilustrativo comparar el crecimiento a interés compuesto con el que resulta a
interés simple. En el crecimiento a interés simple, el interés se computa como un porcentaje
del capital inicial, en vez de un porcentaje del capital acumulado, capital mas intereses como
en el interés compuesto. La ilustración muestra el crecimiento de $100 al 6% anual de
interés simple y de la misma cantidad invertida al 6% anual de-interés compuesto. Es
evidente la ventaja del interés compuesto sobre el simple en cuanto a la ganancia
obtenida.
Acumulamiento Continuo
Un modelo de crecimiento matemático se deriva de acumular el interés
continuamente (en vez de hacerlo mensual o anualmente). Puede mostrarse que con el
acumulamiento continuo, la suma total An del capital inicial y los intereses acumulados
durante n periodos de crecimiento a una tasa r por período está dada por la fórmula:
An = Aern, (2)
en donde e es el trascendental número 2.71828..., la base de los logaritmos naturales. El
cuadro 5.2 proporciona valores de eX para varies valores de x y puede utilizarse para
resolver problemas relativos al interés compuesto continuo.
Ejemplo I
Las existencias de las bibliotecas de la Universidad Purdue están aumentando a un
ritmo "asombrosamente rápido" de alrededor del 6% anual. Si continúa este ritmo de
crecimiento, ¿por qué factor se habrá incrementado el acervo de las bibliotecas de la
Universidad Purdue en un período de 30 años?
Respuesta
Partiendodo de la ecuación An = Aern y haciendo r = .06 y n = 30. Resulta A30=Ae18
y en el cuadro 5.2 vemos e1.8 = 6.05. Así, si continúa el índice de crecimiento observado,
el acervo mencionado quedará multiplicado aproximadamente por un factor de 6 en un
período de 30 años: A30 = 6.050A.
Ejemplo 2
Cierta biblioteca escolar aumentó su acervo de 140,000 volúmenes en 1962 a
255,000 volúmenes en 1977. ¿Cuál es el índice de crecimiento de la colección,
incrementado continuamente Y cuando puede esperarse que la biblioteca alcance la marca
de un millón de volúmenes en existencia?
Respuesta
Se nos dice que n 15, A15 = 255,00O y A = 140,000. Substituyendo valores en la ecuación,
tenemos 255,000 = 140,000e15r. Dividiendo los dos miembros de la ecuación por 140,000
nos da e15r’ = 1.82. en cuandro 5.2 vemos que e6 es aproximadamente igual a 1.82. Por
tanto, 15r = .60 y r = .04
Con un índice de crecimiento del 4%, podemos ahora deducir cuando puede esperarse que
la bibIioteca alcance la marca de un millón de volúmenes en existencias.
Substituyendo valores en la ecuación (2), tendremos:
1,000,000 = 255,000e.04n
Dividiendo los dos miembros de la ecuación por 255,000, resulta e.04n = 3.92. En el cuadro
5.2 vemos que e1.4 es aproximadamente igual a 3.92. Por tanto, .04n = 1.4, yn = 35 años.
Con un índice de crecimiento del 4% anual, la biblioteca alcanzará un millón de volúmenes
en existencias aproximadamente el año 2012.
Ejemplo 3
¿Cuántos años tardará una biblioteca que crece con un índlce acumulativo anual del 8%
en duplicar su acervo?
Respuesta
Sustituyendo en la ecuación (2) nos da 2A = Ae.08n, de donde e.08n=2.
En el cuadro 5.2 vemos que e7 es aproximadamente igual a 2.0. Por tanto, .08n = .7 y
n = 0.7: 0.08 = 8.75 o cerca de 9 años.
Un estudio de Steven Leach sugiere que el modelo de crecimiento exponencial no
describe el crecimiento de las grandes bibliotecas académicas como lo haría un modelo
que reflejara una "desaceleración" del índice de crecimiento después de un cierto
momento.
OTRAS APLICACIONES DEL CRECIMIENTO EXPONENCIAL A LA
BIBLIOTECOLOCIA
El modelo de crecimiento exponencial simple sirve para describir otros muchos
fenómenos en bibliotecología, además del desarrollo de las colecciones bibliotecarias. Por
ejemplo, el número de revistas científicas y resúmenes científicos ha estado
incrementándose exponencialmente a una tasa anual del 5%. La frase tan frecuentemente
usada de "explosión de la información" puede así tener el significado preciso del crecimiento
exponencial de las revistas científicas.
A este respecto cabría preguntarse si la explosión actual de la información es
realmente mayor que hace algunas décadas, ya que el índice de crecimiento de la
información ha permanecido esencialmente constante y el mismo modelo matemático ha
descipto el crecimiento de la literatura científica durante muchas décadas. Sin embargo, sin
contradecir estos hechos, tanto el volumen total como la producción anual de literatura
científica continúan aumentando cada año y amenazan así nuestra capacidad de adquirir,
almacenar y acceder a este recurso nacional. Estos hechos implican una cierta urgencia de
desarrollar un conjunto de soluciones para "el problema de la información".
Concluimos nuestro estudio del crecimiento exponencial observando que, como
señala Derek Pnce en su libro Little Science, Big Science es Iógicamente imposible que
continúe indefinidamente un crecimiento incontrolado. Price sugiere que el modelo de
crecimiento logístico podría muy bien describir el crecimiento futuro de la ciencia y así, el
crecimiento de la publicación científica. Para un interesante estudio de esta posibilidad, se
dirige al lector a la obra de Price.
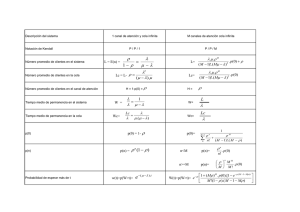
LA TEORÍA DE COLAS COMO UN SEGUNDO MODELO ILUSTRATIVO
Una sola cola para el servicio
Desde los primeros años de este siglo se ha desarrollado y refinado una teoría
matemática de ruta de espera o hacer colas. Aunque las primeras aplicaciones de esta
teoría fueron en el diseño de instalaciones de servicio en la industria telefónica, la teoría se
ha aplicado a muchísimas situaciones del mundo real que van desde el diseño del
transporte y los sistemas de producción en la industria hasta la determinación del número de
cajas requerido en un supermercado. Además de estas aplicaciones en el comercio y la
industria, hay muchas situaciones en una biblioteca que pueden ser descritas con propiedad
por medio de la teoría de cola.
El modelo básico de hacer colas es aplicable en una variedad de situaciones
caracterizadas por la congestión que resulta cuando las Ilegadas a una instalación de
servicio (demandas de servicio) son más frecuentes de lo que el servicio puede absorber.
En la figura 5.2 se da un diagrama de esta situación en su forma más sencilla,
representando la Ilegada de individuos a una instalación de un solo servicio, o canal. Los
individuos son atendidos por el orden en que van Ilegando. El ritmo del servicio realizado no
es suficiente para satisfacer la demanda; ocasionalmente se forma una línea o cola ante la
instalación.
Eventualmente, el servicio se Ileva a cabo para cada persona, la que abandona
luego el sistema. Como sólo hay un canal de servicio, ésta es la formulación más sencilla de
la situación. No obstante, es claro que el modelo conceptual básico representado en la
figura 5.2 puede generalizarse para incluir más de un canal de servicio.
Ahora, obviamente, ya hemos hecho algunas aproximaciones a la realidad. En el
mundo real las personas que Ilegan a pedir un servicio pueden encontrar intolerable la
longitud de la cola y rehusarse a formarse en ella. O bien, habiéndose formado en la cola,
Ilegar a impacientarse y eventualmente decidir abandonarla. A estas aberrantes situaciones
se les denomina amontonamiento y renuncia, respectivamente y no están tratadas en el
modelo de cola simple.
Las asunciones básicas subyacentes en la formulación matemática del modelo de
cola única son:
1. Las Ilegadas al sistema son aleatorias (descritas típicamente por la distribución
Poisson ) con un cierto ritmo promedio. Este ritmo se representa con la letra 1
griega λ (lambda).
2. La duración del servicio es variable (descrita típicamente por una distribución
exponencial) con el ritmo promedio representado por la letra griega µ (mu). Las
cantidades λ y µ son parámetros básicos del modelo de cola.
3. Ningún amontonamiento ni renuncia está considerado en el modelo.
Ahora, apliquemos este modelo a un problema bibliotecario. Las Ilegadas a una
mesa de control de préstamos en una biblioteca pueden ocurrir a un ritmo medio de dos
individuos por minuto (λ = 2), y dar el servicio en un promedio de 4 personas por minuto (µ =
4).
Los individuos son servidos en menos tiempo del que tardan en Ilegar y la mesa de
préstamos estará algunas veces ociosa. Por otra parte, como las Ilegadas son aleatorias,
durante algunos minutos pueden ser hasta de cuatro u ocho, en tanto que en otros minutos
puede no Ilegar nadie. Ocasionalmente, pues, se formaran colas. Algunas preguntas
básicas que surgirán naturalmente de esta formulación son: ¿Con qué frecuencia la
instalación del servicio estará desocupada?; ¿Cuál es el promedio de tiempo que se
requiere para recibir servicio?; y ¿Qué longitud tendrá la cola, en promedio?
Es posible contestar estas y otras preguntas aplicando la teoría de la cola a una
situación determinada. Si los valores de los parámetros λ y µ son conocidos (han sido
estimados por la información sobre la utilización de la biblioteca), es posible inferir valores
para las siguientes magnitudes:
L = promedio del número de individuos del sistema
Lq = promedio de la longitud de la cola
T = promedio del tiempo de espera en el sistema (incluyendo el tiempo del
servicio
ο = promedio de tiempo que la instalación de servicio está ocupada. (p es la
letra griega ro)
Pn = la probabilidad de que haya n individuos en el sistema
Estos valores pueden ser utilizados por la administración del sistema como ayuda
para determinar una óptima configuración de las instalaciones de servicio. Proporcionan al
administrador información para ser utilizada en el proceso de toma de decisiones.
Debemos tener en cuenta que el modelo y sus implicaciones no dice y no puede
decir al admnistrador lo que tiene que hacer; únicamente proporciona bases cuantitativas
para poder tomar decisiones más inteligentes. Superficialmente, una solución obvia al
problema de la formación de la cola es simplemente establecer un número suficiente de
instalaciones de servicio de manera que la cola se forme sólo en raras ocasiones. (Así, la
provisión de varios cientos de cajas en el supermercado típico podría eliminar
efectivamente la formación de colas salve en las circunstancias más extraordinarias). Sin
embargo la provisión de estas facilidades es costosa. Es claro que existe una interrelación
entre los costos ocasionados por la provisión de facilidades para un servicio mejor y el costo
ocasionado por la insatisfacción del usuario. El administrador puede solamente sopesar toda
la evidencia disponible y tomar una determinación final basada en esa evidencia.
APLICACIONES DE LA TEORÍA DE COLAS A LA BIBLIOTECOLOGIA
Philip Morse ha descrito los elementos básicos de la teoría de colas y algunas de sus
aplicaciones a la bibliotecología. Pueden encontrarse ejemplos obvios de colas en las
bibliotecas; en las mesas de referencia, reserva y circulación. También, como señala
Morse, la biblioteca misma puede considerarse como un sistema de cola. Los usuarios
entran en la biblioteca a un ritmo promedio λ permanecen en ella durante un cierto tiempo
(es decir, son servidos), y salen a un ritmo µ. Sin embargo aquí existe esencialmente un
número ilimitado de canales y no se forman nunca colas (a menos que haya un guardia
situado en la salida).
Otros ejemplos de sistemas de colas en la biblioteca pueden referirse a la cola de
libros esperando ser catalogados, la cola de documentos esperando ser ordenados, o la
cola de publicaciones esperando ser registradas. Existen también en la biblioteca modelos
de colas más complejos. Para un estudio de algunos de estos modelos y otras aplicaciones
de la teoría de cola a la bibliotecología en general, se remite al lector al excelente examen
que ha hecho Morse de estos temas.
UNA SOLA COLA PARA EL SERVICIO: MODELO MATEMATICO Y
FORMULA PREDICTIVA
En esta sección hacemos explícita la formulación matemática de un sistema de una
sola cola para el servicio como ejemplo de un modelo de investigación de operaciones y
proporcionamos, sin prueba, una fórmula predictiva para cantidades de interés tales camo
ο, el porcentaje de tiempo que es utilizado el canal de servicio. Podemos comenzar por
explicar más detalladamente la noción de un proceso Poisson, el modelo usual de "Ilegadas
aleatorias". Esencialmente, un proceso Poisson se da bajo las siguientes condiciones:
1. Los sucesos en nuestro caso, las Ilegadas, pueden ocurrir lo mismo en un
intervalo de tiempo que en cualquier otro (la característica matemática del
azar).
2. La ocurrencia de un suceso no tiene efecto en la ocurrencia de cualquier otro
suceso (la característica matemática de la independencia).
3. La probabilidad de que dos sucesos ocurran simultáneamente en un intervalo
de tiempo arbitrariamente pequeño, es cero.
La formulación matemática del proceso Poisson se deriva de estas tres asunciones y
queda expresada (sin prueba) por la fórmula:
Donde P(k) es la probabilidad de que k ocurrencias tengan lugar en una unidad de
tiempo y es el ritmo promedio de Ilegada por unidad de tiempo. La base de los logaritmos
naturales es e, y k! se lee como k factorial.
Los valores de eX para varias valores de x se dan en el cuadro 5.2. Consultando el
cuadro 5.2, tenemos, por ejemplo, que para λ = 2, e-λ = 0.135. Así, para un proceso
Poisson con un promedio λ = 2, tendremos:
Así si el promedio de Ilegadas por minutos es 2.0, en 100 intervalos de tiempo de 1
minutos, podemos esperar que en aproximadamente 13 intervalos no haya Ilegadas, en 27
intervalos habrá exactamente una Ilegada, así sucesivamente.
La distribución exponencial describe comúnmente la distribución de la duración de
los tiempos de servicio en situaciones de cola. La distribución exponencial tiene la
importante propiedad de que es "sin memoria", la probabilidad de que la duración de un
servicio exceda un tiempo determinado no depende de la duración del servicio. Es claro que
esta asunción puede no describir ciertas situaciones de servicio, por ejemplo, las duraciones
de las Ilamadas telefónicas de larga distancia. Sin embargo, describe una amplia variedad
de situaciones reales.
Para una distribución exponencial con un promedio µ, la probabilidad de que un
servicio exceda t unidades de tiempo es dada por la fórmula P(t) = e –t/µ. Supóngase, por
ejemplo, que el promedio de duración de un servicio en una mesa de circulación de una
biblioteca se sabe que es µ = 5 minutos, y que la distribución de la duración de los servicios
es exponencial. Entonces, la probabilidad de que la duración de un determinado servicio
exceda de 5 minutos está dada por la fórmula P(5) = 2-5/5= e-1 . Consultando el cuadro 5.2
encontramos que e -1.0 = .368. Así, en alrededor del 37 por ciento de los casos, se
necesitarán más de 5 minutos para sevir a un usuario en esta situación de cola. Del mismo
modo, podemos calcular que:
P(O)= 1
P(1)= .819
P(2)= .670
P(10)= .135
Basándose en la asunción de Poisson sobre las Ilegadas y la distribución
exponencial de la duración de los servicios, pueden inferirse algunas propiedades del
modelo básico de cola.
Se remite al estudiante a cualquier libro bueno sobre la investigación de operaciones
(por ejemplo, el de Hillier y Lieberman) para pruebas de los siguientes resultados:
Las fórmulas anteriores asumen condiciones "estables", es decir que haya
transcurrido suficiente tiempo desde el estado inicial del sistema para que los resultados
sean esencialmente independientes (o no afectados por) ese estado, cualquiera que haya
sido.
La cola ante una mesa de circulación, por ejemplo, es inicialmente de longitud cero al
comienzo de cada día de trabajo. Este es el estado inicial (diario) del sistema de circulación.
Observamos también que aunque puede haber los picos naturales en la demanda de
servicio en un sistema determinado, esto no significa que la distribución Poisson en
particular o la teoría de cola en general, no puedan utilizarse en la descripción de ese
sistema. Sin embargo, puede ser necesario dividir un día en distintos intervalos, cada uno
caracterizado por su propia distribución Poisson.
Ejemplo 4
Suponiendo que las Ilegadas a una mesa de reserva de lectura estén descriptas por
una distribución Poisson en la que λ = 6.0 (o sea, un promedio de 6.0 personas por minutos
Ilega fortuita e independientemente a la mesa de reservas). Suponiendo después que las
personas son atendidas a un ritmo de ocho por minutos, y que la distribución de la duración
de los servicios es exponencial. Entonces el canal estará ocupado, en promedio, alrededor
del 75% del tiempo (p = λ/µ = .75). entonces L, el número promedio de individuos del
sistema, es 3.0, la longitud promedio de cola Lq es 2.25, y T, el tiempo de espera del sistema
es aproximadamente 30 segundos. Finalmente, la probabilidad de que haya exactamente
tres individuos en el sistema es (1-.75)(.753), o alrededor de .11.
Hemos obtenido lo que puede ser, para algunos lectores, resultados cuantitativos un
tanto inesperados, resultados que no pueden deducirse sin recurrir a las matemáticas. La
aplicación de la teoría matemática de la formación de cola nos ha permitido calcular
estimaciones precisas para algunas magnitudes interesantes. Ni la intuición, ni el análisis
Iógico formal permite este grado de precisión. Así, las deducciones matemáticas de la teoría
de cola pueden considerarse como medios para profundizar nuestra intuición natural y la
comprensión Iógica del problema de cola.
COMPROBACION DE LA IDONEIDAD DEL MODELO
La sección anterior presentó algunos de los resultados teóncos básicos de uno· de
los más sencillos sistemas de cola. Antes que esta teoría y sus implicaciones pueda
indicarnos algo referente a un determinado sistema del mundo real, como la mesa de
circulación de una biblioteca, en todo caso, las asunciones básicas subyacentes, en el
modelo deben ser válidas en ese sistema empírico (como en cualquier otro modelo de
investigación de operaciones).
En particular, el modelo de cola previamente descrito asume que la distribución de
las Ilegadas al sistema puede ser descripta por una distribución Poisson y que la duración
de los servicios puede ser descrita por una distribución exponencial. Estas asunciones
pueden analizarse recogiendo y analizando los datos del mundo real.
Un método tosco, pero sencillo, puede emplearse para comprobar la hipótesis de
Poisson sobre las Ilegadas es el cálculo del promedio y las variaciones de un conjunto de
datos de las ilegadas. (Véase el capítulo 9 para estudio del promedio y las variaciones.). En
una distribución Poisson teórica, estos dos parámetros son iguales. Así, la información
empírica generada por el proceso Poisson revelará un promedio y unas variaciones que son
aproximadamente iguales. En forma similar, se puede hacer una rápida revisión de la
información empírica para comprobar la hipótesis de que los datos están descritos por una
distribución exponencial haciendo uso del hecho teónco de que el promedio y la desviación
normal de una distribución exponencial son iguales. Un método más sofisticado y seguro de
comprobar la "bondad de idoneidad" de la información empírica para un modelo teórico es la
utilización de la prueba x cuadrada, que se estudia con detalle en el capítulo 12.
EJEMPLOS SELECTOS DE INVESTIGACION DE OPERACIONES
La obra de Morse en el Institute Tecnológico de Massachusetts
¿Cómo se han aplicado las técnicas de la investigación de operaciones (IO) a los
problemas bibliotecarios? Tal vez debiéramos citar y describir brevemente algunas de las
pnncipales realizaciones y hechos memorables respecto a la investigación en
bibliotecología.
Una de las primeras y más completas aplicaciones de los principios de la
investigación de operaciones la la bibliotecología puede hallarse en la obra de Philip Morse
Library Effectiveness. Morse, miembro del personal académico en el Institute Tecnológico
de Massachusetts, estudió las operaciones bibliotecarias como un proyecto de clase en un
curso de investigación de operaciones para graduados; su libro desarrollaba ese estudio.
Library Efectiveness presenta un examen inicial de consideraciones sobre la teoría
de probabilidades. El libro proporciona después un estudio detallado de las aplicaciones de
la teoría de la cola y la teoría de las cadenas de Markov a problemas tales como los
métodos para satisfacer la demanda de circulación, para predecir la solicitud futura, para
decidir cuándo retirar un libro o pedir varios ejemplares, así como otros problemas. El texto
no está escrito en un nivel elemental. Se requieren algunos conocimientos de matemáticas
para entenderlo cabalmente.
La obra de Leimkuhler en la Universidad Purdue
Ferdinand Leimkuhler, otro de los primeros investigadores que han aplicado la
investigación de operaciones a los problemas bibliotecarios, es profesor de ingeniería
industrial en la Universidad Purdue. Como en el caso de Philip Morse, la obra de Leimkuhler
se hizo en clases de ingeniería utilizando la biblioteca como laboratorio.
Leimkuhler ha publicado numerosos artículos de investigación que describen
modelos matemáticos de circulación, almacenamiento, ordenación en los estantes y
organización de archives en la biblioteca, así como trabajos de interés general.
La obra de Buckland en la Universidad de Lancaster
La obra de Buckland se ha considerado la primera en el contexto de un modelo de
simulación del proceso de circulación. Este modelo fue solamente una parte de un análisis
total de las operaciones bibliotecarias, Ilevado a cabo por la Biblioteca de la Universidad de
Lancaster. La Universidad de Lancaster y su biblioteca se fundaron en los primeros años de
1960 a 1970 y los bibliotecarios iniciaron allí un proyecto de investigación para explorar y
analizar en detalle los procesos implícitos en la provisión de servicios bibliotecarios. El
informe final del proyecto se publicó en 1970 como System análisis of a University Library. El
espiritu del análisis de sistemas y la investigación de operaciones estaba bien expresado en
la introducción al informe donde se estudia la elaboración de un modelo de investigación de
operaciones.
El propósito de este modelo de simulación es formar una adecuada abstracción de la
realidad, preservando la estructura esencial de los problemas de tal modo que el
análisis pueda penetrar tanto en la situación original concreta como en otras
similares. La forma en que estos modelos y simulaciones estén vinculados
dependerá de la información especial que se requiera.
El intenso análisis de operaciones realizado por la Universidad de Lancaster fue uno
de los primeros estudios de investigación de operaciones en gran escala Ilevados a cabo
por el personal de una biblioteca. System Análisis of a University Library trata aspectos del
proceso técnico, estrategias de compra y descarte, y políticas de préstamo y duplicación,
entre otras materias. Incluye también una extensa bibliografía de materiales publicados
antes de 1970 que tratan aspectos de la aplicación de sistemas de análisis, modelos de
simulación e investigación de operaciones en bibliotecología.
Otras publicaciones selectas
El número de Library Quarterly de enero de 1972 contiene la memoria de la
Trigésima Quinta Conferencia Anual de la Escuela de Bibliotecología de la Universidad de
Chicago. Esta publicación es notable porque combina en un volumen varias aplicaciones
diferentes de IO a la bibliotecoiogía descritas por algunos expertos, incluyendo entre otros,
a Morse, Leimkuhler y Buckland. Este número contiene asimismo una bibliografía selectiva
de IO bibliotecarias preparada por Vladimir Slamecka.
Muchas de las aplicaciones de IO a la bibliotecología están tratadas en un capítulo
de un volumen publicado por el Profesor Morris Hamburg et al, de la Escuela Wharton,
Universidad de Pennsylvania. Esta obra es excelente por su presentación del desarrollo
histórico de los modelos de IO en muchos problemas de bibliotecología. Las descripciones
proporcionadas por Hamburg son (necesariamente) muy concretas, y los estudiantes que
tienen pocos conocimientos o experiencia respecto a los modelos de IO encontrarán partes
del texto que son difíciles de entender.
CONCLUSIONES
Al igual que la teoría estadística y la computación electrónica, la investigación de
operaciones es un instrumento de investigación que está siendo aplicado cada vez más a
los problemas bibliotecarios. Pero la IO es más que esto; es también una filosofía, un
estado mental. La IO es considerada, a veces erróneamente, como una simple colección de
técnicas analíticas. Pero los componentes matemáticos de la IO resultan esencialmente de
la aplicación de una estructura intelectual, que puede caracterizarse como un método
científico, al análisis de los problemas administrativos. En un contexto más amplio, el
enfoque filosófico básico del método "científico es mucho mas imporante que cualquiera
de los modelos de la investigación de operaciones. Es cierto que, a diferencia de algunas
de las otras aplicaciones del método científico a la realización de la investigación, la IO
requiere una cierta sofisticación matemática, tanto en la formulación de un problema como
en el análisis subsecuente. Esta característica de Ia IO no debe arrojar sombra sobre el
hecho de que para que los modelos de la IO sean significativos para nosotros debe
establecerse la validez de los modelos. A este respecto, deben aplicarse rigurosamente los
principios de la investigación científica para asegurar que las asunciones subyacentes en
los de investigación de operaciones de los fenómenos bibliotecarios sean realmente
representaciones válidas de la realidad.
APENDICE: PROBLEMAS PARA RESOLVER
1. Defina una cuarta medida de rendimiento operativo para proporcionar un acceso
adecuado a los materiales bibliotecarios (es decir, una medida no utilizada en el estudio de
simulación de la Universidad de Lancaster). Analice las ventajas e inconvenientes de la
medida propuesta.
2. En qué se convertirán $100 al cabo de 20 años a un interés compuesto continuo de
6%? Compare su respuesta con las cantidades del cuadro 5.1 y comente la comparación
Respuesta
La respuesta es $332.00. El interés compuesto evidentemente aumenta, pero no
substancialmente, el interés compuesto a ganado anualmente.
3. Según el Bowker Annual (vigésima edición), el número total de volúmenes que tenían
las bibliotecas escolares y universitarias de EE.UU. en el otoño de 1964 era de
244000,000 y esta cifra aumentó a 445,000,000 en el otoño de 1974. ¿Cuál fue el índice
de crecimiento, acumulado continuamente, durante los 10 años?
Respuesta
Aproximadamente, 6.5%~
4. Cierta biblioteca pública aumentó su colección de 65,000 volúmenes en 1957 a
aproximadamente 220,000 en 1970. (a) ¿Cuál fue el índice de crecimiento de la colección
acumulado continuamente? (b) Asumiendo que el mismo índice de crecimiento continúe en
el futuro, ¿cuál será el tamaño de la colección en 1996?
Respuesta
a) Aproximadamente 9.2%. (b) aproximadamente, (11.02) (220,000) = 2,424,000
volúmenes
5. Por el ejemplo 3 puede verse que la relación entre el número de años que requiere un
organismo para doblar n y el índice anual de crecimiento compuesto continuo r está dado
aproximadamente por la fórmula rn = .70. (a) Explique esta aserción. (b) Utilice la fórmula
para calcular el índice de crecimiento necesario para que una biblioteca duplique el tamaño
de su colección cada 10 años; cada 13 años. (c) Utilice la fórmula para hallar n (el tiempo
necesario para duplicar la colección) para un organismo que crezca con un índice de
crecimiento del 4%, 5% y 6%.
Respuesta
(b) 7.0%; 5.4%; (c) 17.5 años; 14.0 años; 8.8 años.
6. Dibuje el diagrama de un modelo de una situación general de cola en la que haya más
de una instalación de servicio.
7. Proporcione un ejemplo, que no se haya analizado en el texto, de una actividad
bibliotecaria en la que tiendan a formarse colas. Considere las asunciones básicas
subyacentes en el modelo de cola con respecto a esta actividad y formule una hipótesis en
relación con la aplicabilidad de las asunciones sobre la actividad seleccionada. Explique
cómo comprobaría usted su hipótesis.
8. Considere un proceso Poisson con un promedio λ = 2 que describa la frecuencia de las
Ilegadas a un sistema de cola. Es claro que debe haber, en cualquier intervalo dado de un
minutos, ya sea cero Ilegadas, una Ilegada, dos Ilegadas y así sucesivamente. Puede
haber, de hecho, 10 ó 50 Ilegadas, pero ambos casos son improbables (es decir, eventos
relativamente raros). Así la suma de todas las probabilidades implicadas debe sumar hasta
1.0: Po + P1 + P2 + P3 ... + Pn = 1, ó εPn = 1. Utilice este hecho para calcular la
probabilidad de que seis o más usuarios Ileguen en el lapso de un minutos.
REFERENCIAS
1. Philip M. Morse and Kimball, G.E., Methods of Operations Research. Cambridge, Mass.:
M.I.T Press, 1951.
2. Abraham Bookstein, "Implications for Library Educations", Library Quaterly, 42(January
1972): 140-151
3. C. West Churchman, The Systems Approarh. New York: Dell, 1968.
4. F.W. Lancaster, ed., Systems Design and Analysis for Libraries. Library Trends 21(April
1973).
5. Fremont Rider, The Scholar and the Future of the Research Library. New York: Hadham
Press,. 1944.
6. Michael K. Buckland, Hindle, A., Mackenzie, A. G., and Whitfield, Ronald M., Systems
Analysis of a University Library, Final Report on a Research Project. University of Lancaster
Occasional Papers, No. 4. University of Lancaster Library, 1970.
7. Ferdinand F. Leimkuhler, "Systems Analysis in University Libraries." College and
Research Libraries, 27(January 1966): 15.
8. Steven Leach, "The Growth Rates of Major Academic Libraries: Rider and Purdue
Reviewed.", College and Research Libraries, 37(November 1976):531-542.
9. Derek J. de Solla Price, Little Science, Big Science. New York: Columbia University Press,
1965, p. 7.
10. Philip M. Morse, Library Effectiveness: A Systems Approach. Cambridge, Mass.: M.I.T.
Press, 1968.
11. Frederick S. Hillier and Lieberman, Gerald J., Introduction to Operations Research. San
Francisco: Holden-Day, 1967.
12. Ferdinand F. Leimkuhler, "A literature Search and File Organization Model.", American
Documentation, 19(April 1968): 131-135.
13. Ferdinand F. Leimkuhler. "Operations Research and Information Science- A Common
Cause.", JASIS, 24(January-February 1973):2-8.
14. Morris Hamburg, Clelland, Richar C., Bommer, Michael R.W.,Ramist, Leonard E , and
Whitfield, Ronald M., Library Planning and Decision-Making Systems. Cambridge: M.I.T.
Press, 1974.
Busha, Charles, Harter, Stephen P. Métodos de investigación en bibliotecología :
técnicas e interpretación -- México : UNAM, 1990. 407 p.
CAPITULO 10
LA DISTRIBUCIÓN NORMAL
INTRODUCCIÓN
La familia de curvas que se conoce como las dristribuciones normales constituye
probablemente la más teórica distribución de frecuencias que se presenta en este texto.
Las distribuciónes normales son importantes, porque describen muchas
distribuciónes empíricas de frecuencias en una variedad amplia de situaciones desde las
estaturas de los hombres hasta los pesos de las ratas blancas, las variaciones en
productos manufacturados yel cociente de inteligencia.
Quizá más importante, las distribuciónes normales son básicas EN la teoría de
muestreo y como tal, son aplicables a todas las poblaciones empíricas de las cuales
provienen muestras aleatorias de tamaño suficiente. Encuestas de la opinión pública y de
la comunidad y otras situaciones de muestreo surgen frecuentemente en bibliotecología y
por esta razón, la comprensión de la curva normal es importante.
La forma general de una curva normal se muestra en la figura 10.1. Las curvas
normales son curvas continuas, simétricas y en forma de una campana. En la medida en
que se desplaza la media de una distribución normal en cualquiera de las dos direcciones,
la curva se acerca más y más estrechamente al eje X, pero nunca lo toca. Se caracteriza
una distribución normal completamente por dos parámetros, su media y su desviación
estándar. La Figura 10.2 demuestra dos distribuciónes normales con la misma media pero
con desviaciones estándar diferentes, mientras que la Figura 10.3 demuestra dos
distribuciónes normales con diferentes medias pero las desviaciones estándar son
iguales.
AREAS BAJO LA CURVA NORMAL
El porcentaje de una población normalmente distribuida que se encuentra entre
cualquiera de dos valores es igual a la proporción relativa del área bajo la curva y entre
estos puntos. La Figura 10.4 resume los porcentajes de una población normalmente
distribuida que se encuentra entre la media y una desviación estándar de la media, entre
una desviación estándar y dos desviaciones estándar de la media, entre dos y tres
desviaciones estándar de la media y más allá de tres desviaciones estándar de la media
Nótese que el área total bajo la curva es igual al 100%.
Estoss porcentajes son descriptivos de cada distribución normal, no importa el valor de su
media ni el de su desviación estándar.
Así por ejemplo, alrededor del 34% de una población normalmente distribuida queda entre
la media de la población y una desviación estándar arriba de la media, mientras que
alrededor de 14% de la población queda entre una desviación estándar abajo de la media
y dos desviaciones estándar bajo la media. Se pueden usar estos porcentajes para
calcular ciertos porcentajes en una distribución normal.
Ejemplo 1.
Calcule el percentil asociado a una desviación estándar arriba de la media en una
distribución normal.
Respuesta
Cincuenta por ciento de la población queda abajo de la media y otro 34.13% queda entre
la media y una desviación estándar arriba de la media. Por lo tanto, se asocia una
desviación estándar arriba de la media con el 84.13th percentil.
Ejemplo 2
Un estudiante logra una calificación en una prueba de catalogación que es dos
desviaciones estándar bajo la media de la población de todos aquellos que tomaron la
prueba. ¿Si las calificaciones son distribuidas normalmente, qué percentil es asociado con
la calificación del estudiante?
Respuesta
El porcentaje de la población con una calificación menos de tres desviaciones estándar
abajo de la media es 0.13% y el porcentaje de la población entre dos y tres desviaciones
estándar abajo de la media es 2.14%. Así, el percentil que se asocia a la calificación bajo
consideración es 0.13% + 2.14% = 2.27%.
Ejemplo 3
¿Qué proporción de una población normalmente distribuida se encuentra dentro de + 1 y
-2 desviaciones estándar de la media?
Respuesta
Al sumar las áreas bajo consideración, obtenemos 13.59% + 34.13% + 34.13% = 81.85 %
Ejemplo 4
Exprese el decimocuarto percentil de una distribución normal en términos de las
desviaciones estándar de la media de la distribución.
Respuesta
Se puede contestar este problema sólo en términos aproximados de la Figura 10.4. Al
sumar sucesivamente las áreas bajo la curva normal, se puede ver que 15.86% de la
población está abajo de -1ο. Así, el decimocuarto percentil está justamente a la izquierda
de este punto, o sea alrededor de –1.1ο. Se presentará un método más exacto para
resolver este problema, posteriormente en esta sección.
Ejemplo 5.
La distribución de calificaciones del cociente de inteligencia (CI) en una población está
distribuida normalmente con una media de 100 y una desviación estándar de 15.
Convierta las calificaciones del CI de 70 y 145 a percentiles.
Respuesta
Una calificación de 70 está exactamente a dos desviaciones estándar abajo de la media.
Así, como en el Ejemplo 2, esta calificación está al 2.27th percentil. Una calificación de
145 está a tres desviaciones estándar arriba de la media. Sólo el 0.13% de la población
está arriba de este punto. Así, un CI de 145 está al 99.87th percentil.
Se puede usar la Figura 10.4 para resolver los problemas que tengan un número exacto
de desviaciones estándar de la media pero esta puede proporcionar sólo resultados
aproximados para otros problemas. Afortunadamente, se ha tabulado extensivamente Ia
distribución normal. El Apéndice C reporta las áreas entre la media y una calificación dada
bajo la curva normal que tiene una media iguai a O y una desviación igual a 1. (Ver la
Figura 10.5)
Para esta distribución, que a veces se conoce como la distribución normal
estándar, las
calificaciones individuales son exactamente iguales a las desviaciones estándar de la
media; por lo tanto, se pueden obtener las áreas correspondientes a las calificaciones
directamente. Para las distribuciones normales con una media µ y una desviación
estándar a que no sea O y 1 respectivamente, tiene que convertirse una cali£icación X en
una calificación Z antes de consultar la tabla. Se hace de la siguiente manera: z = (Xµ)−ο.
Nótese que z es solamente el número de desviaciones estándar ο de la calificación
X de la media µ en la distribución bajo consideración. La tabla proporciona valores de z
hasta z 3.69. No se proporcionan valores de z mayores en este punto porque las áreas
asociadas a tales valores están iguales a 0.5000, al diezmilésimo más cercano.
Ejemplo 6.
¿Qué percentil se asocia con una calificación que está a 1.4 desviaciones estándar arriba
de la media en una distribución normal?
Respuesta
La media de la distribución normal estándar que está en la tabla del Apéndice C es cero.
Luego, el área entre la media y 1.40 desviaciones estándar arriba de la media es .4192 ).
Esta cifra corresponde al 50 + .4192 = 92.92th percentil.
Ejemplo 7.
¿Qué percentil se asocia con CI de 120?
Respuesta
Del Apéndice C,el área bajo consideración es .50 + .4082, que corresponde al 90.82th
percentil.
Ejemplo 8
Mensa, una organización para individuos que poseen un CI excepcional, anuncia que
aceptará la afiliación de personas que se encuentren dentro del último 2% de la población
en inteligencia, cuando sea determinada por las pruebas estándarizadas. ¿A qué
calificación del CI corresponde el nonagésimo octave percentil?
Resuesta
Debido a que el Apéndice C proporciona solamente las áreas desde la media hasta los
valores positivos de z, buscamos .4800 en la porción del área de la tabla Un área de
.4800 corresponde a alrededor de 2.05 desviaciones estándar arriba de la media. Debido
a que
Ejemplo 9
Suponga que las estaturas de la población de mujeres se distribuyen normalmente con
una media de 64.3 pulgadas (162.32 cm) y una desviación estándar de 2.4 pulgadas (6.1
cm) ¿Qué proporción de las mujeres de esta población tiene una estatura menor de 5 pies
~54.4 cm)?
Respuesta
Primero, convertimos 5 pies = 60 pulgadas a un valor z
Del Apéndice C, se encuentra el 46.33% de la población entre 1.79 desviaciones estándar
abajo de la media y la media. Asi, 50.00% -46.33% = 3.67% de la población se encuentra
abajo de una estatura de 5 pies.
Ejemplo 10.
Encuentre la proporción de una población normalmente distribuida que queda entre +2 y
-2 desviaciones estándar de la media.
Respuesta
Al sumar las áreas pertinentes, la proporción bajo consideración (de la Figura 10.4) es:
13.59% + 34.13% + 34.13% + 13.59% = 95.44% a, al porcentaje más cercano, 95%.
Así, aproximadamente el 95% de la población queda entre +2 desviaciones estándar de la
media. Este es un resultado útil y se hará referencia a él posteriormente cuando
trabajaremos con las distribuciones normales. El Apéndice C demuestra que el 95% de la
población está contenida más exactamente dentro de +1.96 desviaciones estándar de la
media.
Con frecuencia los datos recogidos por investigadores en bibliotecología no se
distribuyen normalmente. Como hemos visto antes, las distribuciones de frecuencia para
variables tales como "el número de volúmenes que hay en bibliotecas académicas" y "el
número de páginas en libros" no son distribuciones normales de hecho, son asimétricas
fuertemente .
En cambio, otros datos bibliotecológicos tales como calificaciones de pruebas, de
actitudes, etc., están distribuidos normalmente. En comparación con otras disciplinas, la
investigación en bibliotecología está en su infancia; así, puede que nuestra afirmación de
que muchos tipos de datos bibliotecológicos tienden a no distribuirse normalmente, se
convierta en una generalización no muy útil en el futuro. Pero al menos en la actualidad,
descnbe como verdadero lo que sabemos en cuanto a las estadísticas de bibliotecas.
DISTRIBUCIÓN DE LAS MEDIAS DE LA MUESTRA
La distribución normal es extremadamente importante en la teoría de muestreo
porque describe una amplia variedad de situaciones donde se escogen muestras
aleatorias de poblaciones sin hacer caso de la identidad de la distribución de frecuencias
que describa la población original. Así, aunque una población podría ser asimétrica, la
distribución de las medias de muestras aleatorias provenientes de la población se
inclinaría a ser normal en la medida en que aumente el tamaño de las muestras.
Se representa esta situación en la Figura 10.6, en la cual se demuestra una
porción de una distribución asimétrica negativa. Imagínese que se escojan diez muestras
aleatorias del tamaño n de una población y se calculen y registren sus medi-xi. La Figura
10.6 ilustra la ubicación de la media µ de la población así como las medias xi de 10
muestras hipotéticas aleatorias del tamaño n escogidas de la población. Nótese que
aunque la población es asimétrica, las medias de las muestras se distribuyen más o
menos simétricamente alrededor de la media µ de la población. Además, la mayoría de
las medias de las muestras están relativamente cerca de la media de la población.
Finalmente, la media x de las medias de las muestras,
xi = Σxi
10
está muy cerca de la población.
Las relaciones observadas son características de una variedad amplia de
situaciones de muestreo. Ahora presentaremos una exposición más precisa de estas
ideas.
EL TEOREMA DEL LIMITE CENTRAL
El teorema del límite central afirma que, para cualquier distribución, no
necesariamente normal, con una media µ y una variananza o2, la distribución de las
medias de muestras aleatorias seleccionadas de la población es aproximadamente
normal. Por lo tanto, si la población es asimétrica, las muestras seleccionadas de la
población son asimétricas también. Sin embargo, la distribución de las medias de estas
muestras no serán asimétricas sin que serán aproximadamente normales. La distribución
de las medias de las muestras se vuelve más y más cerca de normal en la medida en que
se aumente el tamaño n de las muestras.
Si la distribución de las medias de las muestras es normal, entonces ¿qué es su
media y su desviación estándar? El Teorema del Límite Central afirma que la media de la
distribución de las medias de las muestras desviación estándar de la distribución es µ, es
decir, la media de la población y la n. Nótese que en la medida en que n se incrementa,
la desviación estándar de la distribución de las medias de las muestras disminuye. La
Figura 10.6 ilustra esto: las 10 medidas de las muestras se dispersan en un grado mucho
menor alrededor de µ que lo hace la población de donde provienen las muestras.
El lector puede tener dudas todavía sobre el significado del concepto "la
distribución de las medias de las muestras". ¿De dónde surge la variación de una
población de medias? La respuesta es que debido a que se asocian las medias bajo
consideración a muestras seleccionadas al azar de una població, puede esperarse que el
acto de muestreo en sí resulte con bastante fluctuación de los xi desde la media u
verdadero de la población. Esto se puede demostrar fácilmente en la práctica, al
seleccionar algunas muestras al azar del tamaño n de una clase de estudiantes, o de
alguna otra población tal como el personal de una biblioteca, y calcular la media de las
edades o pesos asociados a cada muestra.
La desviación estándar o/n de la distribución de las medias de las muestras se conoce a
veces como el error estándar de la media SEµ.
Ejemplo 11
Una población de libros tiene una media de µ = 260 páginas y una desviación estándar de
o = 180 páginas. Encuentre la media y la desviación estándar de la distribución de las
medias de las muestras aleatorias del tamaño 16 seleccionadas de la población. También
calcule para las muestras del tamaño 49 y 100.
Respuesta
La media de cada una de las tres distribuciones es 260. Los errores estándar son,
respectivamente,
Ahora presentaremos una discusión de cómo se puede utilizar el Teorema del Límite
Central para inferir las características de una población a partir de las características de
una muestra aleatoria seleccionada de la población.
¿Cuándo es n "suficientemente grande" para la distribución del muestreo de una
población sea distribuida aproximadamente normal? Desafortunadamente, esto depende
de la población; cuando más asimétrica esté la población original, más grande tiene que
ser n.
INTERVALOS DE CONFIANZA EN µ CUANDO SE CONOCE ο
Con mucha frecuencia queremos estimar la media de una población a partir de las
características de una muestra. En este caso, debido a que no se ha examinado toda la
población, sólo se puede conocer la media de la población de manera aproximada. Un
intervalo de confianza sobre µ es un rango de números dentro del cual se puede esperar
encontrar la media µ verdadera de la población con una probabilidad declarada. Un
intervalo de confianza de 95% sobre µ es un rango de números dentro del cual puede
esperarse encontrar la media verdadera en 95 de 100 cases. Es decir, si se Ileva a cabo
el experimento "seleccione una muestra aleatoria del tamaño n" 100 veces, y se construye
un intervalo diferente de confianza de 95% con base en cada media de las muestras,
entonces la media µ verdadera se encontrará dentro de aproximadamente 95 de los 100
intervalos de confianza.
Ahora presentaremos el cálculo de un intervalo de confianza de 95% sobre µ.
Ya hemos hecho la observación en el Ejemplo 10 de que 95% de los miembros de
una distribución normal se encontrará dentro de + 1.96 y -1.96 desviaciones estándar de
la media de la población. Así, en una distribución de muestreo, el 95% de las medias de
las muestras se encuentra dentro de + 1.96 SEµ de la media verdadera de la población;
95 de 100 muestras tendrán la media dentro de + 1.96 SEµ de Ia media de la población
(ver la Figura 10.7)
Este razonamiento puede invertirse. Si 95 de las 100 muestras tienen la media
dentro de 1.96 SEµ de la media µ de la población, entonces µ estará dentro de 1.96
desviaciones estándar de una media de una muestra dada 95_a 100 veces. Es decir, la
media verdadera de la población se encontrara dentro del rango x + 1.96 SEµ en 95 de
100 muestras.
Ejemplo 12
Suponga que se haya escogido una muestra aleatoria del tamaño 100 de una población
de school media specialist en el Medio Oeste. El promedio de salario de los individuos en
la muestra se calcula ser $12,300. De un estudio anterior, se calculó el valor de o ser
alrededor de $1,800. ¿Qué se puede concluir acerca de la media salarial de la población
de school media specialist de la cual provino la muestra?
Respuesta
Nuestra media de muestra fue $12,300. Así, un intervalo de confianza sobre la media µ
verdadera, pero desconocida, es $12,300 +1.96 (180), o ($11,947.20, $12,652.80). es
decir, podemos tener 95% de confianza en que la media salarial verdadera de la
población school media specialist se da por la desigualdad de $11,947.20 <µ <
$12,652.80. Nuestra mejor estimación en un solo número de la media u de la población es
$12,300. Nótese que la base de una muestra relativamente pequeña, se puede hacer una
estimación más o menos cercana a la media µ verdadera. Este ejemplo ilustra el poder de
muestreo. Imagínese la dificultad y el costo implicados al calcular la media de la población
de school media specialist, digamos todo el Medio Oeste, pues se tendría que encuestar
hasta al último individuo. Una muestra aleatoria de sólo 100 miembros de la población
proporciona una estimación que probablemente sea adecuada para la mayoría de los
propósitos. Así, mediante el acopio de una muestra relativamente pequeña, podemos
inferir las características de una población de donde se escogió la muestra con un grade
bastante alto de exactitud.
Ejemplo 13
Construya un intervalo de confianza de 99% para los datos del ejemplo 12.
Respuesta
Queremos que el 99% de la población esté entre z SEµ de la media; es decir, que la 1/2
de 1% de la población esté a cada lado del intervalo. Por lo tanto, determinamos el valor
de z, que corresponde área de .495 en la posición de área del Apéndice C. Aquel valor
entonces se da un intervalo de confianza de 99% sobre µ por z,
DETERMINACION DEL TAMAÑO MINIMO DE LA MUESTRA
Los ejemplos anteriores tratan del cálculo de intervalos de confianza para un
tamaño dado de la muestra. Un problema estrechamente relacionado tiene que ver con la
determinación del tamaño mínimo de la muestra para un nivel especificado de precisión,
es decir, para un intervalo de confianza de una anchura dada En vez de utilizar la media
de la muestra, la desviación estándar, un nivel deseado de confianza, por ejemplo el 95%,
y el tamaño de la muestra y calcular un intervalo de confianza a base de estos datos, esta
sección presenta el cálculo de un tamaño mínimo de la muestra desde un nivel deseado
de confianza, la anchura máxima deseada del intervalo de confianza y la desviación
estándar de la población.
Por ejemplo, suponga que, antes de seleccionar una muestra durante un proyecto
de investigación, los investigadores decidan que su estimación de la media sea exacta
dentro de +10 unidades, a un nivel de confianza de 95%. Es decir, los investigadores
quieren que un intervalo de confianza de 95% sea al menos tan exacto como µ + 10.
Debido a que la precisión de una estimación se mejora en la medida en que se
incrementa el tamaño de la muestra, nuestro investigador podrá lograr la exactitud
deseada para un tamaño dado de la muestra. El problema es, ¿cual es el tamaño de la
muestra que resultaría en el nivel deseado de exactitud al nivel de 95% de confianza?
Nuestro razonamiento es similar a aquel de la sección anterior. Queremos:
LA DISTRIBUCIÓN t
Los resultados de las secciones anteriores se basan en el supuesto de que se
conoce la desviación estándar de la población, al menos aproximadamente, mientras que
no se conoce la media y tiene que estimarse. Por ejemplo, puede conocerse la desviación
estándar de una investigación anterior y suponer que su valor no haya cambiado para los
propósitos del estudio actual. Usualmente, no se conocen ni la media ni la desviación
estándar de la población y se tienen que estimar ambas en el proceso de muestreo. En
estos casos, se emplea la "distribución t", y no la distribución normal, para construir un
intervalo de confianza en µ.
Como se presentó en el Capítulo 9, se da la desviación estándar de una población
estimada a base de una muestra por
media de la muestra y la desviación estándar para construir un intervalo de confianza
sobre la media como antes, pero se usan las tablas de la distribución t, más bien que las
de la distribución normal. Se proporciona una tabla de la distribución t en el Apendice D.
En las secciones anteriores, cuando se conocieron las desviaciones estándar de las
poblaciones, se daba un intervalo sobre la media por la expresión µ = x + z(o/√n). En
particular, para los intervalos de confianza de 99% y 95%, z era 2.58 y 1.96,
respectivamente. Se sigue un procedimiento análogo cuando no se conoce la desviación
estándar σ. En este caso, un intervalo de confianza sobre µ se da por µ = x + t
(s/√n),donde la desviación estándar s se calcula de los datos de la muestra, n es eI
tamaño de la muestra y t es un número obtenido de una tabla que proporciona los valores
de la distribución t para varias probabilidades (ver el Apéndice D). Así, el procedimiento
es idéntico a aquel de la sección anterior, salve que se utiliza t en vez de z.
Para utilizar el Apéndice D, se obtienen los valores de t al buscar el número de grados de
libertad (n-1) donde n es el tamaño de la muestra, y el nivel deseado de confianza. Por
ejemplo, con una muestra del tamaño 16, los valores de t se asocian con los intervalos de
confianza de 95% y 99% son 2.131 y 2.947, respectivamente. En estos ejemplos, la
probabilidad deseada de error, es .05 y .01, respectivamente. (Ver el Capítulo 12).
Ejemplo 15.
Calcule un intervalo de confianza de 95% sobre la media µ de una población a base de la
siguiente muestra aleatoria del tamaño 8: 8, 18, 16, 10, 12, 13, 13, 14.
Respuesta
Del Apéndice D, t = 2.365 - 7 grados de libertad. Se obtiene una estimación del error
estándar de la media por s/√n = 1.118. Luego se da un intervalo de confianza de 95%
sobre µ por 13.0 + 2.365 (1.118) ó 10.356 ≤ µ ≤ 15.644.
En la medida en que se aumenta el tamaño de la muestra, la distribución t se acerca a la
distribución normal. Una inspección del Apéndice D para p = .05 revela que aun con una
muestra del tamaño 12, con 11 grados de libertad, t=2.201, que es solamente alrededor
de 12% más grande que el valor de z para ia misma probabilidad en una distribución
normal (z = 1.96 para un intervalo de confianza de 95%). Así, para muestras grandes, la
distribución se aproxima a la distribución normal y aún para muestras moderadamente
pequeñas, la diferencia entre los valores de f y los valores de z para la misma
probabilidad no es substanciosa.
ESTIMACION DEL VALOR DE UNA PROPORCION
Hemos presentado en algún caso el concepto del error estándar de la media.
Estimaciones de otros parámetros donde también una población tienen errores estándar.
Ver Arkin y Colton para un listado de muchos de estos parámetros.
Una fórmula del error estándar de bastante utilidad trata la estimación del valor de
una proporción en una población que tiene, o no, una característica en particular. ¿Qué
proporciones de una población pertenecen a un cierto partido político? ¿Fumadores?
¿Adictos de la televisión? ¿Jugadores de golf? ¿Varones? Si p es la proporción bajo
consideración, entonces se da el error estándar de la estimación de p por
donde n es el tamaño de la muestra, al utilizar esta fórmula para SEp, se calculan los
intervalos de confianza sobre p de manera parecida a las secciones anteriores.
Ejemplo 16
Una muestra aleatoria de 100 miembros de una comunidad revela que el 92% "nunca
utiliza la biblioteca pública". Construya un intervalo de confianza de 95% sobre el
parámetro de la población p.
Ejemplo 17.
Dentro de la consideración de una biblioteca especializada respecto a implementar el
subsistema de control de seriedades del Ohio College Library Center, se seleccionó una
muestra aleatoria de 140 capítulos serieados del acervo de ]a biblioteca. Se inspeccionó
el último número de cada título para averiguar la presencia de CODEN o ISSN. Se
encontraron uno y otro o ambos en sólo 26 títulos. Construya un intervalo de confianza de
95% sobre esta estimación.
APENDICE:
Problemas para solución
1. Calcule los percentiles que corresponden a los siguientes valores z en una distribución
normal: (a)z = 1.60; (b)z = -.36; (c)z = O; (d)z = 1.42; (e)z = 2.28.
Respuesta
(a) 5.48%; (b) 35.94%; (c) 50.00%; (d) 92.22%; (e) 98.87%.
2. Calcule los valores z que corresponden a los siguientes percentiies en una distribución
normal: (a) 10th; (b) 40th; (c) 75th; (d) 90th; (e) 99th.
Respuestas
(a) z = -1.28; (b) z =-.25; (c) r = .67; (d) z = 1.28; (e) 2 = 2.33.
3. Juan y María tienen cocientes de inteligencia (CI) de 90 y 105, respectivamente. Si se
distribuyen los CI normalmente en la población con una media de 100 y una desviación
estándar de í5, convierta la calificación de CI de Juan y Mana a percentiles de la
población.
Respuesfa
El CI de Juan está al 25.14th percentil y el de María está al 62.93th percentil.
4. Considere una población con una media ~ 4· una desviación están a. ¿Cómo se afecta
el error estándar de la media si: (a) el valor de a aumenta; (b) el tamaño de la muestra n
aumenta; (c) el valor de µ aumenta?
5. Considere un intervalo dado de confianza construido sobre la media estimada de una
población. Presente dos maneras de estrechar este intervalo (hacerlo mas compacto y
pequeño).
Respuestas
Disminuir el nivel de confianza requerido; incrementar el tamaño de la muestra.
6. Proporcione un ejemplo complete ilustrado del Problema 5.
7. Una biblioteca quiere seleccionar una muestra aleatoria del conjunto de credenciales de
la biblioteca con el propósito de recabar datos en cuanto al uso de la biblioteca. En una
muestra de 200 usuarios, el número media de libros circulados en un año dado fue 8.6,
con una desviación estándar de 6.6. Calcule un intervalo de confiabilidad de 95% sobre
esta estimación de la media.
Respuesta
7.7 ≤ µ ≤ 9.5. Nótese que aunque se requiere de la distribución t para construir el
intervalo de confianza, el tamaño grande de la muestra hace que esta distribución sea
equivalente a la distribución normal, o sea, t = z = 1.96.
8. Una clase de catalogación seleccionó una muestra aleatoria de 20 tarjetas del catálogo
topográfico de una biblioteca universitaria y tomó la decisión de que el número de
clasificación asignado a S de estos 20 libros correspondientes a estas tarjetas fue "en el
mejor de los cases, dudoso; en el peor, incorrecto". Construya un intervalo de confianza
de 95% sobre esta estimación.
Respuesta
SEp = .097 y.06 ≤ ο ≤I .44. Debe seleccionar una muestra más grande para hacer la
estimación más precisa.
9. Se encontró que el número medio de anos de educación después de la preparatoria en
una muestra de 15 usuarios de bibliotecas públicas fue de 2.2, con una desviación
estándar de 2.4, también calculada de la muestra. Construya un intervalo de confianza de
95% sobre esta estimación.
Respuesta
.87 ≤ µ ≤ 3.53.
10.Resuelva el Problema 9, al suponer que se conoció que la desviación estándar
asociada con la población fue de 2.4 antes del muestreo.
Respuesta
.99 ≤ µ ≤ 3.41.
11.Suponga que se conozca que σ es de 3.8 para una población dada y que se desee
construir un intervalo de confianza de 95% sobre la media de la población dentro de + 1.0
de la media de la muestra. ¿Cuál es el tamaño mínimo de la muestra que se requiere para
lograr la exactitud deseada?
REPERENCIAS
1. George W. Snedecor and Cochran, William G., Statistical Methods, 6th ed. Ames:
Iowa State University Press, 1968. pp 51-56.
2. Herbert Arkin and Colton, Raymond R., Statistical Methods, 5th ed. New York:
Barnes & Noble, 1970. pp. 149-150.