Apuntes Estadistica Inferencial
Anuncio

UNIDADES TECNOLÓGICAS DE SANTANDER
APUNTES DOCENTES
ASIGNATURA: ESTADISTICA INFERENCIAL
PROFESOR: CARMENSOLANGE LUGO BUITRAGO
Ing. De Sistemas Especialista en Estadística
TP 68255125305STD
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
PRIMER CAPÍTULO: PROBABILIDADES
1. CONCEPTOS
ALEATORIOS
DE
SUCESOS
DETERMINÍSTICOSY
SUCESOS
Si dejamos caer una piedra o la lanzamos, y conocemos las condiciones iniciales de altura, velocidad, etc.,
sabremos con seguridad dónde caerá, cuánto tiempo tardará, etc. Esta es una EXPERIENCIA
DETERMINISTA.
Si al contrario lanzamos un dado sobre una mesa, ignoramos qué cara quedará arriba. El resultado depende
del azar. Esta una EXPERIENCIA ALEATORIA.
En general los experimentos o fenómenos aleatorios son los que no se puede predecir el resultado final,
hablamos pueden dar lugar a varios resultados, sin que pueda ser previsible enunciar con certeza cuál de
éstos va a ser observado en la realización del experimento.
2. LA INCERTIDUMBRE Y EL EXPERIMENTO ALEATORIO
En estadística se pueden presentar casos en los que es difícil predecir un resultado, por varios factores
externos como, falta de información, desacuerdo en conceptos, indecisión etcétera, es por ello que se habla
de INCERTIDUMBRE. Algunos autores distinguen la Matemática de la Estadística como la ciencia de la
certeza y de la incertidumbre, caracterizando a la estadística como una ciencia que busca establecer los
límites de la incertidumbre y no como una rama de la matemática.
Las situaciones prácticas que envuelven incertidumbre son los llamados experimentos aleatorios.
3. CONCEPTOS DE ESPACIO MUESTRAL, RESULTADO O PUNTO
MUESTRAL, EVENTO O SUCESO
En estadística se contempla como EXPERIMENTO la descripción de cualquier proceso que genere un
conjunto de datos un ejemplo puede ser las opiniones de los votantes respecto de un impuesto sobre las
ventas. En estos casos lo importante son las observaciones que se tiene por la repetición del experimento
varias veces. La mayor parte de los casos los resultados dependen del azar por tanto su predicción no tiene
certeza, si el experimento se realiza varias veces con las mismas condiciones se obtendrán diferentes
medidas, que mostraran un elemento de probabilidad en el procedimiento experimental.
Cada una de las posibles soluciones que se pueden presentar en un experimento se considera como
SUCESO, por tanto el suceso es el resultado particular proveniente de un experimento.
Un ejemplo claro de suceso se evidencia al sacar cara cuando se lanza una moneda.
Cuando se agrupa uno o más sucesos hablamos de EVENTO, un ejemplo lo tenemos al sacar número par al
lanzar un dado 2, 4, 6 tres resultados posibles satisfacen el evento.
En un estudio estadístico tratamos de interpretar los resultados fortuitos que ocurren en un estudio planeado,
por ejemplo al registrar el número de accidentes que ocurren mensualmente en la diagonal 15 con quebrada
seca de la ciudad de Bucaramanga, con la finalidad de justificar la instalación de un semáforo; o al clasificar
los artículos que salen de una unidad de ensamble como “defectuosos” o “no defectuosos”, o al revisar el
volumen de gas que se libera de una reacción química cuando se cambia la concentración de un ácido. Con
los datos anteriores ya sean numéricos o categóricos registramos una OBSERVACIÓN.Por tanto definimos
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
como ESPACIO MUESTRAL al conjunto de todos los posibles sucesos elementales de un experimento y su
identificación en Estadística se trabaja como S.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Ejemplos:
Experimento
Seleccionar un estudiante del salón y registrar
su nacionalidad
Lanzar una moneda balanceada
Lanzar un dado no cargado
Lanzar un par de dados no cargados
Medir el pH de una sustancia
Seleccionar 4 personas del grupo y realizarles
la prueba para detectar el virus AH1N1
Jugar el baloto
Revisar artículos de la producción
encontrar el segundo defectuoso
hasta
Espacio Muestral
S = {colombiano}
S = {cara,sello}
S = {1,2,3,4,5,6}
S = {(x,y): 1 <x <6; 1 <y <6}
S = {x: 0<x<14} ó {rojo, azul}
S = {eees, eeee, eese, eess, eses, esee, esse,
esss, sees, seee, sese, sess, sses, ssee, ssse,
ssss} s:sano e:enfermo 16 posibilidades
2x2x2x2
S ={ ¿? }8'145.060 posibilidades de
combinaciones de 6 números de los 45 posibles
45C6
S ={ ¿? }mínimo 2, sigue al infinito
n=2,3,4,5,6, ....., infinito porque no se sabe si
alguna vez en el futuro aparecerá algún otro
defectuoso, para que aparezcan dos
defectuosos, mínimo debe revisar dos artículos
4. CONCEPTO DE PROBABILIDAD
La probabilidad es una medida de la posibilidad de que algo suceda.Una probabilidad es una medida
numérica del grado de ocurrencia de un evento, esta medida está en relación con la proporción de veces
que se espera el evento ocurra cuando es repetido muchas veces.
5. ASIGNACIÓN DE PROBABILIDADES
RELATIVA, PROBABILIDAD SUBJETIVA
CLÁSICA,
FRECUENCIA
Las probabilidades deben calcularse para tener argumentos que nos permitan predecir el resultado a un
experimento y insistimos que esto se hace necesario sólo cuando los experimentos admiten más de un
resultado posible.
LA ESCALA DE PROBABILIDAD
+----------------------------+----------------------------+
0
0.5
1
Evento Imposible
Es igualmente probable
Evento seguro
que ocurra o que no ocurra
NUNCA SE CONSIDERAN PROBABILIDADES NEGATIVAS
Conviene analizar dos perspectivas para asignar probabilidades:
Los enfoques objetivo y subjetivo. La probabilidad objetiva se divide en probabilidad clásica y
probabilidad empírica
ENFOQUE OBJETIVO
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
PROBABILIDAD CLÁSICA:Parte del supuesto de que los resultados de un experimento son igualmente
posibles a esto se denomina equiprobables,
Si el espacio muestral es equiprobable no es necesario lanzar una moneda, un dado o tomar una carta.
No tenemos que efectuar experimentos para poder llegar a conclusiones simplemente justificamos por qué
los diferentes resultados en el espacio muestral son equiprobables. Lo interesante es que si lo hacemos, los
valores calculados siguiendo la ley de Laplace (Cada uno de los resultados aquí deben ser igualmente
posibles) son precisamente el valor límite de las frecuencias relativas.
Este planteamiento de la probabilidad tiene serios problemas cuando intentamos aplicarlo a los problemas
de toma de decisiones menos previsibles. El planteamiento clásico supone un mundo que no existe, supone
que no existen situaciones que son bastante improbables pero que podemos concebir como reales.
Probabilidad
Número de casos exitosos
Clásica = Número de casos posibles
Ejemplo: Para un físico una moneda podría caer de lado!
La lotería de Santander=
Casos posibles # ganador
serie
____ ____ ____ _____
10 10 10 10
____ ___
10 10
10^6 posibilidades de ganar = 1/10[6=0.000001
Como se ve todos los resultados de la lotería tienen la misma posibilidad de ocurrir, el problema se reduce a
un problema de conteo por esto es bueno estudiar algunas técnicas que nos facilitarán esto y que más
adelante se estudiaran.
PROBABILIDAD EMPÍRICA O FRECUENCIA RELATIVA:Se basa en el número de veces que ocurre el
evento como proporción del número de intentos conocidos. Este método utiliza la frecuencia relativa de las
presentaciones pasadas de un evento como una aproximación de la verdadera probabilidad. Determinamos
qué tan frecuente ha sucedido algo en el pasado y usamos esa cifra para predecir la probabilidad de que
suceda de nuevo en el futuro.
Cuando utilizamos el planteamiento de frecuencia relativa para establecer probabilidades, el número que
obtenemos como probabilidad adquirirá mayor precisión a medida que aumentan las observaciones.
Una dificultad presente con este planteamiento es que la gente lo utiliza a menudo sin evaluar el número
suficiente de resultados o por ejemplo cuando se trata con seres vivos, es imposible repetir el experimento
bajo las mismas condiciones un gran número de veces.
Probabilidad = Número de veces que el evento ocurre
Empírica Número total de observaciones
El enfoque empírico de la probabilidad se basa en la llamada LEY DE LOS GRANDES NÚMEROS,(en una
gran cantidad de intentos, la probabilidad empírica de un evento se aproximará a su probabilidad real) la
clave para determinar las probabilidades de forma empírica consiste en que una mayor cantidad de
observaciones proporcionarán un cálculo más preciso de la probabilidad.
Para explicar la ley de los grandes números, suponemos que lanzamos una moneda común. El resultado de
cada lanzamiento es cara o sello, si se lanza la moneda una sola vez, la probabilidad empírica de las caras
es cero o uno. Si lanzamos la moneda una gran cantidad de veces, la probabilidad del resultado de las
caras se aproximará a 0,5.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Actividad
Utilice el applet “Coinflip” disponible en http://www.betweenwaters.com/probab/probab.html y trabaje con el,
complete la siguiente tabla según la información solicitada en cada celda. Para abreviar denotaremos Fr :
Frecuencia relativa
No. De Lanzamientos
1
10
50
100
500
1.000
10.000
# de caras
0
3
26
52
236
494
5.27
Fr (Cara)
,00
,3
,52
,52
:,472
,494
,5027
Elabore un gráfico de líneas que muestre en el eje horizontal el No. De lanzamientos y en el eje
vertical la frecuencia relativa. Luego redacte conclusiones sobre sus observaciones más importantes.
En la Figura se presenta la evolución de la frecuencia relativa del número de caras obtenido en el
lanzamiento de una moneda en 100 ocasiones (simulado por un ordenador). En principio la evolución
de las frecuencias relativas es errática, pero a medida que el número de tiradas aumenta, tiende a lo
que entendemos por probabilidad de cara.
Con este ejercicio se demuestra que a partir de la definición clásica de la probabilidad, la posibilidad de
obtener cara en un solo lanzamiento de una moneda común es de 0,5, desde el enfoque empírico de la
frecuencia relativa de la probabilidad, la probabilidad del evento se aproxima al mismo valor determinado
de acuerdo con la definición clásica de la probabilidad.
Figura: Convergencia a 1/2 de la frecuencia relativa del número de caras obtenido en lanzamientos
sucesivos de una moneda (por simulación del experimento).
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
En el siglo XIX, los estadísticos británicos, interesados en la fundamentación teórica del cálculo del riesgo de
pérdidas en las pólizas de seguros de vida y comerciales, empezaron a recoger datos sobre nacimientos y
defunciones. En la actualidad, a este p
planteamiento se le llama FRECUENCIA RELATIVA de presentación
de un evento
o y define la probabilidad como la
la frecuencia relativa observada de un evento durante un gran
número de intentos, o la fracción de veces que un evento se presenta a la larga, cuando las
la condiciones son
estables. Cuando las probabilidades se interpretan en esta forma se dice que estamos usando un enfoque
frecuentista de probabilidad.
Este razonamiento permite emplear el enfoque empírico y de la frecuencia relativa para determinar una
probabilidad.
Ejercicio
El 1 de febrero de 2003, el transbordador espacial Columbia explotó. Éste fue el segundo desastre en 113
misiones espaciales de la NASA. Con base en esta información. ¿cuál es la probabilidad de que una futura
misión concluya con éxito?
Probabilidad de vuelo exitoso= Número de vuelos exitosos = 111= 0,98
Número total de vuelos
113
En otras palabras, por experiencia la probabilidad de que una futura misión del transbordador espacial
concluya con éxito es te 0,98.
ENFOQUE SUBJETIVO
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Estas probabilidades están basadas en las creencias de las personas que efectúan la estimación de
probabilidad. Es la probabilidad asignada a un evento por parte de un individuo, basada en la evidencia que
se tenga disponible. Esa evidencia puede presentarse en forma de frecuencia relativa de presentación de
eventos pasados o puede tratarse simplemente de una creencia meditada.
Ejemplos
Pronósticos del clima. (ver en el periódico local esta clase de pronósticos)
Calcular la posibilidad de que los patriotas de la Nueva Inglaterra jueguen en el Súper Tazón el año que
viene
Calcular la posibilidad de que usted contraiga matrimonio antes de los 30 años
Calcular la posibilidad de que el déficit presupuestario de Estados Unidos se reduzca a la mitad en los
siguientes 10 años.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Resumiendo, cómo Asignar Probabilidades?
Objetivo
Probabilidad clásica: Se basa en
resultados igualmente probables
(Equiprobables)
Probabilidad empírica: Se sustenta
en las frecuencias relativas
Para asignar una
probabilidad
Subjetivo
Parte de la inforamción disponible
opiniones, intuición, etc
Estadística Bayesiana
6. PROPIEDADES FUNDAMENTALES DE LAS PROBABILIDADES
Existen básicamente dos grandes propiedades de las probabilidades:
P(A) ≥0 : Toda probabilidad se define como mayor o igual que cero
La suma de las probabilidades es igual a uno
7. CLASES DE SUCESOS
En este estudio de probabilidades clásicas también se debe contemplar el concepto de MUTUAMENTE
EXCLUYENTE, el cual se define como el hecho de que un evento se presente significa que ninguno de los
demás eventos puede ocurrir al mismo tiempo.
Un ejemplo claro se detecta con la variable género la cual da origen a resultados mutuamente excluyentes:
hombre y mujer, una pieza fabricada es aceptable o no lo es, la pieza no puede ser aceptable e inaceptable
al mismo tiempo, en esta muestra el evento de seleccionar una pieza no aceptable y el evento de
seleccionar una pieza aceptable son mutuamente excluyentes.
SUCESOS COMPATIBLES
Dos sucesos, A y B, son compatibles cuando tienen algún suceso elemental común.
Si A es sacar puntuación par al tirar un dado y B es obtener múltiplo de 3, A y B son compatibles porque el 6
es un suceso elemental común.
SUCESOS INDEPENDIENTES
Dos sucesos, A y B, son independientes cuando la probabilidad de que suceda A no se ve afectada porque
haya sucedido o no B.
Al lazar dos dados los resultados son independientes.
SUCESOS DEPENDIENTES
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Dos sucesos, A y B, son dependientes cuando la probabilidad de que suceda A se ve afectada porque haya
sucedido o no B.
Extraer dos cartas de una baraja, sin reposición, son sucesos dependientes.
8. TÉCNICAS DE CONTEO
Si la cantidadde posibles resultados de un experimento es pequeña, resulta relativamente fácil contarlas, por
ejemplo los seis resultados del lanzamiento de un dado. Sin embargo, si hay un número muy grande de
resultados, tal como el número de caras y crucesen un experimento con 10 lanzamientos de una moneda,
sería tedioso contar todas las posibilidades. Todos podrían ser caras, una sello y nueve caras, dos caras y
ocho sellos, y así sucesivamente.
Existen diversas maneras de contar entre las que tenemos:
Regla de la Multiplicación
Combinaciones (no tienen orden, nCk),
Permutaciones
Para facilitar la cuenta, se analizan tres fórmulas para contar:
Fórmula de la multiplicación
Fórmula de la multiplicación = (m) (n)
Si hay m formas de hacer una cosa y n formas de hacer otra cosa, hay m x n formas de hacer ambas cosas
Ejemplo
Un distribuidor de automóviles quiere anunciar que por $60.000.000 usted puede comprar ocho modelos
diferentes entre convertibles y sedanes de diferentes categorías y elegir entre seis tipos de categorías de
rines que van desde rines de rayos hasta rines planos. Cuántas disposiciones de modelos y rines puede
ofrecer el distribuidor?
Con la fórmula de la multiplicación se diría entonces que (m)+(n)= (8)*(6)=48 posibles disposiciones
Fórmula de las permutaciones
La formula de la multiplicación se aplica para determinar el número de posibles disposiciones de dos o mas
grupos. La fórmula de las permutacionesse aplica para determinar el número de posibles disposiciones
cuando sólo hay un grupo de objetos.
Ejemplo
Tres piezas electrónicas se van a montar en una unidad conectable a un aparato de televisión. Las piezas
se pueden montar en cualquier orden. La pregunta es: ¿de cuántas formas pueden montarse tres partes?
Un orden para el primer ejemplo sería: primero el transistor, enseguida las LED y en tercer lugar el
sintetizador. A esta distribución se le conoce como permutación.
Las permutaciones están relacionadas con el orden
!
!
Cualquier distribución de r objetos seleccionados de un solo grupo de n posibles objetos,
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
donde n es el total de objetos y r el total de objetos seleccionados
Ejemplo
Respecto del grupo de tres piezas electrónicas que se van a montar en cualquier orden, ¿de cuántas formas
se puede montar?
Hay tres piezas electrónicas que van a montarse, así que n=3. Como las tres se van a insertar en la unidad
conectable, r=3. De acuerdo con la fórmula el resultado es:
nPr = n!
!=3! != 3! =3!¡= 6 ABC, BAC, CAB, ACB, BCA, CBA
(n - r)! (3-3)! 0!
1!
Con lo anterior determinamos cuántos espacios hay que llenar y las posibilidades para cada espacio. En el
problema de las tres piezas electrónicas, hay tres lugares en la unidad conectable para las tres piezas. Hay
tres posibilidades para el primer lugar, dos para el segundo (una se ha agotado) y una para el tercero.
Formula de las combinaciones
Si el orden de los objetos no es importante
Las combinaciones no tiene en cuenta el orden
!
! !
9. OPERACIONES CON PROBABILIDADES:
SUMA, COMPLEMENTO, MULTIPLICACIÓN
Una vez definida la probabilidad y descritos los diferentes enfoques se aplican algunas reglas como:
REGLA DE LA ADICION:
Existen dos reglas de la adición, la regla especial de la adición y la regla general de la adición.
REGLA ESPECIAL DE LA ADICIÓN
Para aplicarla, los eventos deber ser mutuamente excluyentes, recordemos que para que sean mutuamente
excluyentes significa que cuando un evento ocurre, ninguno de los demás eventos puede ocurrir al mismo
tiempo, un ejemplo consiste en que un producto proveniente de la línea de montaje no puede estar
defectuoso y en buen estado al mismo tiempo.
Si dos eventos A y Bson mutuamente excluyentes, la regla especial de la adición establece que la
probabilidad de que ocurra uno u otro es igual a la suma de sus probabilidades. Esta regla se expresa
mediante la siguiente fórmula:
Regla especial de la Adición = P (A o B) = P(A) + P (B)
En el caso de los tres eventos mutuamente excluyentes designados A, B y C, la regla se expresa de la
siguiente manera:
P(A o B o C) = P(A) + P(B) +P(C)
Ejemplo:
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Una máquina automática Shaw llena bolsas de plástico con una combinación de frijoles, brócoli y otras
verduras. La mayoría de las bolsas contienen el peso correcto, aunque, como consecuencia de la variación
del tamaño del frijol y de otras verduras, un paquete podría pesar menos o más. Una revisión de 4000
paquetes que se llenaron el mes pasado arrojó los siguientes datos:
Peso
Evento
Número de
paquetes
Menos peso
A
Peso satisfactorio B
Más peso
C
TOTAL
Probabilidad de que
ocurra el evento
100
3600
300
4000
0,025
0,9
0,075
¿Cuál es la probabilidad de que un paquete en particular pese menos o más?
El resultado “pesa menos” es el evento A, el resultado “pesa más” es el evento C. Al aplicar la regla especial
de la adición se tiene:
P(A o C)= P(A) + P(C) = 0,25 + 0,75 = 1,0
Los eventos son mutuamente excluyentes, lo cual significa que un paquete de verduras mixtas no puede
pesar menos, tener el peso satisfactorio y pesar más al mismo tiempo.
En diagrama de Venn:
Evento
A
Evento
B
Evento
C
REGLA DEL COMPLEMENTO:
La probabilidad de que una bolsa de verduras mixtas seleccionadas pese menos, P(A), más la probabilidad
de que no sea una bolsa con menos peso, P(˜A), que se lee no A, debe ser por lógica igual a 1. Esto se
escribe:
P(A) + P(˜A) = 1
Por tanto la fórmula para el complemento queda:
Regla del complemento = P(A) = 1 - P(˜A)
La regla del complemento se emplea para determinar la probabilidad de que un evento ocurra restando de 1
la probabilidad de un evento que no ha ocurrido. Esta regla es útil porque a veces es más fácil calcular la
probabilidad de que un evento suceda determinando la probabilidad de que no suceda y restando el
resultado de 1. Los eventos A y ˜A son mutuamente excluyentes
En diagrama de Venn:
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Evento
A
˜A
Ejemplo
Recordemos que la probabilidad de que una bolsa de verduras mixtas pese menos es de 0,025 y la
probabilidad de que una bolsa pese más es de 0,075. Aplique la regla del complemento para demostrar que
la probabilidad de una bolsa con un peso satisfactorio es de 0,90. Muestre la solución con un diagrama de
Venn.
La probabilidad de que la bolsa no tenga un peso satisfactorio es igual a la probabilidad de que la bosa
tenga un mayor peso más la probabilidad de que la bolsa pese menos. Es decir
P(A o C)= P(A) + P(C) = 0,25 + 0,75 = 0,100
La bolsa tiene un peso satisfactorio si no tiene menos peso ni más peso; así que
P(B) = 1 – [P(A) + P(C)] = 1 – [0,025 + 0,075] = 0,90.
El diagrama de Venn que representa este caso es el siguiente:
A
0,025
no A o C
0,90
C
0,075
REGLA GENERAL DE LA ADICIÓN
Los resultados de un experimento pueden no ser mutuamente excluyentes. Como ilustración, supongamos
que una empresa de turismo seleccionó 200 turistas que visitaron Colombia durante el año anterior. La
encuesta reveló que 120 turistas fueron al Eje cafetero y 100 a Cartagena. ¿Cuál es la probabilidad de que
una persona seleccionada haya visitado el Eje cafetero o Cartagena?. Si se emplea la regla especial de la
adición, la probabilidad de seleccionar un turista que haya ido al Eje cafetero es de 0,60 mas la probabilidad
de que un turista haya ido a Cartagena es de 0,50 al sumarlas daría 1,10, pero sabemos que esta
probabilidad no puede ser mayor a 1, la explicación radica en que muchos de los turistas visitaron ambas
atracciones turísticas y se les está contando dos veces. Una revisión de las respuestas de la encuesta
reveló que 60 de los 200 encuestados visitó ambos sitios.
Por consiguiente para hallar esta probabilidad debemos:
P(Eje cafetero o Cartagena) = P(Eje cafetero) + P(Cartagena) – P(tanto Eje cafetero como Cartagena)
= 0,60
+ 0,50
- 0,30
=
0,80
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Cuando dos eventos ocurren al mismo tiempo, la probabilidad se denomina probabilidad conjunta. La
probabilidad de que un turista visite ambas atracciones turísticas (0,30), es un ejemplo de probabilidad
conjunta.
El siguiente es el diagrama de Venn para ilustrar el ejemplo anterior:
P(Eje cafetero)=0,60
P(Cartagena)=0,50
P(Eje cafetero y
Cartagena)=0,30
La probabilidad conjunta mide la posibilidad de que dos o más eventos sucedan simultáneamente. Esta
regla para dos eventos designados A y B se escribe:
Regla General de la adición = P(A o B) = P(A) + P(B) -P(A y B)
En la expresión (A o B) la letra o sugiere que puede ocurrir A o puede ocurrir B, como incluye la posibilidad
que A y B ocurran, por tanto el uso de la o se denomina inclusivo. También es posible escribir P(A o B o
ambos) para hacer hincapié en el hecho de que la unión de dos eventos incluye la intersección de A y B.
Si se comparan las reglas general de la adición y la especial de la adición, la diferencia consiste en
determinar si los eventos son mutuamente excluyentes. Si los eventos son mutuamente excluyentes,
entonces la probabilidad conjunta (A y B) es 0 y podríamos aplicar la regla especial de la adición. De lo
contrario, debemos tomar en cuenta la probabilidad conjunta y aplicar la regla general de la adición.
Ejemplo
¿Cuál es la probabilidad de que una carta, escogida al azar, de una baraja convencional sea rey o corazón?
REGLA ESPECIAL DE LA MULTIPLICACIÒN
En este caso se estudia la probabilidad de combinar dos eventos es decir que la ocurrencia sea simultánea.
Por ejemplo, una empresa de marketing desea calcular la probabilidad de que una persona de 21 años de
edad o mayor compre un back berry. Los diagramas de Venn ilustran este evento como la intersección. En
la regla especial se requiere que dos eventos sean independientes y lo son si el hecho de que uno ocurra
no altera la posibilidad de que el otro suceda.
Regla especial de la multiplicación = P(A y B) = P(A) P(B)
INDEPENDENCIA, si un evento ocurre, no tiene ningún efecto sobre la probabilidad de que otro
acontezca
Ejemplo
Una encuesta llevada a cabo por AVIANCA reveló que el año pasado el 60% de sus miembros hicieron
reservaciones en líneas aéreas. Dos de ellos fueron seleccionados al azar. ¿Cuál es la probabilidad de que
ambos hicieran reservaciones el año pasado?
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
La probabilidad de que el primero haya hecho reserva el año pasado es de 0,60 P(R1)=0,60, y la
probabilidad de que el segundo miembro elegidos haya hecho un reserva es también de 0,60 P(R22)=0,60.
Como el número de miembros de AVIANCA es muy grande, suponemos que R1y R2 son independientes.
P(R1y R2)= P(R1)P(R2)= (0,60)(0,60) = 0,36
Todos los posibles resultados serían tomando como R hizo reservación y NR no la hizo.
Resultados
R1y R2
R1y NR
NR y R2
NR y NR
TOTAL
Probabilidad conjunta
(0,60)(0,60)
(0,60)(0,40)
(0,40)(0,60)
(0,60)(0,60)
0,36
0,24
0,24
0,36
1,00
REGLA GENERAL DE LA MULTIPLICACIÒN
Si dos eventos no son independientes se dice que son dependientes.
Ejemplo
Supongamos que hay 10 latas de refresco en un refrigerador, siete de las cuales son normales y 3 dietéticos.
Se selecciona una lata del refrigerador. La probabilidad de seleccionar una lata de refresco dietético es de
3/10, y la probabilidad de seleccionar una lata de refresco normal es de 7/10. Entonces se elige una
segunda lata del refrigerador sin devolver la primera. La probabilidad de que la segunda lata sea un refresco
dietético depende de que la primera sí lo haya sido o no. La probabilidad de que la segunda lata sea de
refresco dietético es:
2/9 si la primera bebida es dietética (ya solo quedan dos latas en el refrigerador)
3/9 si la primera lata elegida es normal (aún quedan los tres refresco en el refrigerador)
La denominación adecuada de la fracción 2/9 o 3/9 es probabilidad condicional, ya que su valor se
encuentra condicionado (o depende) por el hecho de que un refresco normal o dietético haya sido el
primero en ser seleccionado del refrigerador.
PROBABILIDAD CONDICIONAL: Probabilidad de que un evento en particular ocurra, dado que otro evento
haya acontecido.
La regla general de la multiplicación sirve para determinar la probabilidad conjunta de dos eventos cuando
éstos no son independientes. Por ejemplo, cuando el evento B ocurre después del evento A y A influye en la
probabilidad de que el evento B suceda, entonces A y B no son independientes.
La regla general de la multiplicación establece que en caso de dos eventos A y B, la probabilidad conjunta de
que ambos eventos ocurran se determina multiplicando la probabilidad de que ocurra el evento a por la
probabilidad condicional de que ocurra el evento B, dado que A ha ocurrido. Los símbolos de la probabilidad
conjunta se calculan de la siguiente manera:
Regla general de la multiplicación = P(A y B) = P(A) P(B|A)
Ejemplo
Un golfista tiene 12 camisas en su clóset. Suponga que 9 son blancas y las demás azules. Como se viste
de noche, simplemente toma una camisa y se la coloca. Juega golf dos veces seguidas y no las lava, pero
utiliza una camiseta diferente para cada juego. ¿Cuál es la probabilidad de que las dos camisas elegidas
sean blancas y limpias? El evento que tiene que ver con el hecho de que la primera camisa seleccionada
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
sea blanca es S1, la probabilidad es de P(S1) es de 9/12, el evento de que la segunda camisa seleccionada
también sea blanca S2 es de 8/11, entonces
P(S1 yS2) = P(S1)P(S2|S1) = (9/12)(8/11)= 0,55
Por lo anterior la probabilidad de seleccionar dos camisas de color blanco es de 0,55, se debe aclarar que
este experimento se llevo a cabo sin reemplazo, es decir que la primera camisa no se lavó y se colocó en el
clóset antes de hacer la selección de la segunda.
10.
TEOREMA DE BAYES
En términos más generales y menos matemáticos, el teorema de Bayes es de enorme relevancia puesto que
vincula la probabilidad de A dado B con la probabilidad de B dado A. Es decir que sabiendo la probabilidad
de tener un dolor de cabeza dado que se tiene gripe, se podría saber -si se tiene algún dato más-, la
probabilidad de tener gripe si se tiene un dolor de cabeza, muestra este sencillo ejemplo la alta relevancia
del teorema en cuestión para la ciencia en todas sus ramas, puesto que tiene vinculación íntima con la
comprensión de la probabilidad de aspectos causales dados los efectos observados.
Sea {A1,A3,...,Ai,...,An} un conjunto de sucesos mutuamente excluyentes y exhaustivos, y tales que la
probabilidad de cada uno de ellos es distinta de cero. Sea B un suceso cualquiera del que se conocen las
probabilidades condicionales P(B | Ai). Entonces, la probabilidad P(Ai | B) viene dada por la expresión:
Teorema de Bayes= P(A1|B)=P(A1)P(B|A1).
P(A1)P(B|A1) + P(A2)P(B|A2)
donde:
P(A1) son las probabilidades a priori.
P(B|A1) es la probabilidad de B en la hipótesis A1.
P(A1|B) son las probabilidades a posteriori.
Ejemplo
Suponga que el 5% de la población del Playón, tiene una enfermedad propia de su situación de inundación.
Sea A1el evento “padece la enfermedad” yA2 “no padece la enfermedad”. Por tanto, si selecciona al azar a
una persona del Playón, la probabilidad de que el individuo elegido padezca la enfermedad es de 0,05 o
P(A1)=0,05 denominada la Probabilidad a priori, dado que se asigna antes de obtener los datos empíricos
y está basada en el nivel de información actualy por endela probabilidad a prioride que una persona no
padezca la enfermedad es de 0,95 o P(A2)=0,95, la cual se calcula de 1 - 0,05.
En el anterior ejemplo existe una técnica de diagnóstico para detectar la enfermedad, pero no es muy
precisa. Sea Bel evento “la prueba revela la presencia de la enfermedad” suponga que la evidencia histórica
muestra que si una persona padece realmente la enfermedad, la probabilidad de que la prueba indique la
presencia de ésta es de 0,90. De acuerdo con las definiciones de probabilidad condicional, el enunciado se
expresa:
P(B|A1) = ________
Si la probabilidad de que la prueba indique la presencia de la enfermedad en una persona que no la padece
es de 0,15, el enunciado se expresa:
P(B|A2) = _________
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Elija una persona al azar del Playón y aplique la prueba. Los resultados de la prueba indican que la
enfermedad está presente. ¿Cuál es la probabilidad de que la persona en realidad padezca la enfermedad?.
Lo que desea saber, en forma simbólica, es P(A1|B), que se interpreta como la probabilidad de padecer la
enfermedad dado que la prueba resulto positiva y esta Probabilidad es a posteriori, dado que es revisada
a partir de información adicional.
Con el teorema de Bayes determinamos la probabilidad a posteriori:
Teorema de Bayes= P(A1|B)=P(A1)P(B|A1).
P(A1)P(B|A1) + P(A2)P(B|A2)
Con el anterior resultado cómo se puede leer la respuesta?
Con lo anterior, resuma en la siguiente tabla los cálculos del problema del Playón:
Evento, Ai
Probabilidad a
priori, P(Ai)
Probabilidad
condicional, P(B|Ai)
Probabilidad
conjunta, P(Aiy
B)
Probabilidad a posteriori,
P(Aiy B)
Padece la
enfermedad
No padece la
enfermedad Ai
TÉCNICA DE ÁRBOL DE PROBABILIDAD O DIAGRAMA DE ÁRBOL
Se utiliza para organizar cálculos que implican varias etapas, cada rama o segmento del árbol implica una
etapa del problema, estas se ponderan por medio de probabilidades
En el siguiente ejemplo un banco informa que el 35% de sus créditos son para vivienda, el 50% para
industrias y el 15% para consumo diverso. Su departamento de cartera registra que el 20% de los créditos
para vivienda entran en mora, el 15% de los créditos para industrias es moroso y el 70% de los créditos para
consumo también son morosos.
El auditor del banco elige un crédito al azar y resulta moroso. Cuál es la probabilidad de que haya sido un
crédito otorgado para vivienda?
0,20
Vivienda
Moroso
0,07
No Moroso
0,28
0,80
0,35
0,15
0,50
Industria
0,075
No Moroso
0,425
0,85
0,15
0,70
Consumo
Moroso
Moroso
0,30
No Moroso
DEPARTAMENTO DE CIENCIASBÁSICAS
0,105
0,045
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
P(Moroso otorgado para vivienda)=0,07
0,07 + 0,075 + 0,105
.= 0,28 = 28%
En una clase que consta de 6 niñas y 10 niños, si se escoge un comité de 3 al azar, hallar la probabilidad de
que los seleccionados sean 3 niños
11.
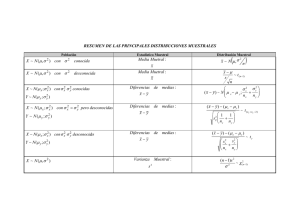
DISTRIBUCIONES DE PROBABILIDAD
Una distribución de probabilidad muestra los posibles resultados de un experimento y la probabilidad de que
cada uno se presente.
Las características fundamentales de una distribución de probabilidad son:
1. La probabilidad de un resultado en particular se encuentra entre 0 y 1, inclusive.
2. Los resultados son eventos mutuamente excluyentes.
3. La lista es exhaustiva. Así, la suma de las probabilidades de los diversos eventos es igual a 1
Algunos conceptos antes de continuar:
Variable aletoria: Cantidad que resulta de un experimento que, por azar, puede adoptar diferentes valores.
Variable aleatoria Discreta:Variable aleatoria que adopta sólo valores claramente separados.
Variable aleatoria Continua: Si la variable aleatoria es continua, es una distribución de probabilidad
continua y esta se da cuando es el resultado de algún tipo de medición.
Por lo general una distribución discreta es el resultado de contar algo como:
•
•
•
El número de caras que se presentan en tres lanzamientos de una moneda
El número de estudiantes que obtienen “A” en clase
El número de empleados de producción que se ausentaron hoy en el segundo turno
Las distribuciones continuas son el resultado de algún tipo de medición como:
•
•
•
La duración de cada canción en el último álbum de Sándalo
El peso de cada estudiante de esta clase
La temperatura ambiente en el momento en que se leen estos apuntes
Media, varianza y desviación estándar de una distribución de probabilidad
Recordemos que la media indica la localización central de los datos y la varianza describe la dispersión de
los mismos, de forma similar una distribución de probabilidad queda resumida por su media y su
varianza.
La media de una distribución de frecuencias se indica como µ (miu)
Donde P(x) es la probabilidad de un valor particular x, se multiplica cada valor por la probabilidad de que
ocurra luego se suman los productos.
2
La desviación estándar se identifica como σ (sigma) y la varianza como σ (sigma cuadrado)
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
12. DISTRIBUCION
DISCRETAS
DE
PROBABILIDADES
PARA
VARIABLES
DISTRIBUCIÓN BINOMIAL
Principales características para definir una distribución de probabilidad binomial
El resultado de cada prueba de un experimento se clasifica en una de dos categorías mutuamente
excluyentes: éxito o fracaso
La variable aleatoria de interés permite contar el número de éxitos en una cantidad fija de pruebas
La probabilidad de éxito y fracaso es la misma para cada prueba
Las pruebas son independientes, lo cual significa que el resultado de una prueba no influye en el resultado
de otra prueba.
Primer experimento
Éxito
Fracaso
Segundo experimento
Éxito
Fracaso
Tercer experimento
Éxito
Fracaso
n experimento
Éxito
E
F
E
1er
exp
Fracaso
F
2do
exp
F
F
E
E
F
E
F
E
F
E
: Combinación (n combina x)
es el número de pruebas o experimentos
Variable aleatoria definida como el número de éxitos
esla probabilidad de un éxito en cada prueba
Ejemplo
TAM tiene cinco vuelos diarios de Fortaleza al Aeropuerto Internacional de Sao Pablo en Brasil, suponga que
la probabilidad de que cualquier vuelo llegue tarde sea de 0,20. ¿Cuál es la probabilidad de que ninguno de
los vuelos llegue tarde hoy?. Cuál es la probabilidad de que exactamente uno de los vuelos llegue tarde
hoy?
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
La probabilidad de que un vuelo llegue tarde es de p=0,20, hay cinco vuelos n=5 y la variable aleatoria x=0
pues se refiere al número de éxitos que sería el hecho de que un avión llegue tarde y como no hay demoras
en las llegadas entonces tenemos cero éxitos.
ó
! "
ó
#
'
& ( %, *%
%
%
%
$
#
%, *%
'$%
= (1)(1)(0,3277)
Probabilidad binomial
= 0,3277
La probabilidad de que exactamente uno de los cinco vuelos llegue tarde hoy es de 0,4096 y sería
ó
! "
ó
#
'
& ( %, *%
#
#
#
$
#
%, *%
'$#
= (5)(0,20)(0,4096)
Probabilidad binomial
La media de una distribución binomial
= 0,4096
+
La varianza de una distribución binomial
,-
En el ejemplo de los vuelos retrazados:
+ 1
+
+
5 0,20
1
,
-
,-
+ 1 +
5 0,20 1 0,20
, - 1 0,80
, - 0,80
La media de 1,0 y la varianza de 0,80 y la distribución de probabilidad se observan en la siguiente tabla
Número de
vuelos
retrazados
0
1
2
3
P(x)
0,3277
0,4096
0,2048
0,0512
DEPARTAMENTO DE CIENCIASBÁSICAS
xP(x)
0
0,4096
0,4096
0,1536
2
2
(x-μ)
x-μ
-1
0
1
2
1
0
1
4
(x-μ) P(x)
0,3277
0
0,2048
0,2048
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
4
5
0,0064
0,0003
0,0256
0,0015
μ=1,0000
3
4
9
16
0,0576
0,0048
σ2=0,7997
DISTRIBUCIÓN POISSON
Esta distribución describe el número de veces que se presenta un evento durante un intervalo especificado.
El intervalo puede ser de tiempo, distancia, área o volumen.
La distribución se basa en dos supuestos, el primero consiste en que la probabilidad es proporcional a la
longitud del intervalo. El segundo supuesto consiste en que los intervalos son independientes.
Cuanto más grande sea el intervalo, mayor será la probabilidad y el número de veces que se presenta un
evento en un intervalo no influye en los demás intervalos.
Principales características para definir una distribución de probabilidad Poisson
1. La variable aleatoria es el número de veces que ocurre un evento durante un intervalo definido.
2. La probabilidad de que ocurra el evento es proporcional al tamaño del intervalo
3. Los intervalos no se superponen y son independientes
Es la media de la cantidad de veces (éxitos) que se presenta un evento en un intervalo particular
Es la constante que vale 2,71828
Es el número de veces que se presenta un evento
Es la probabilidad para un valor específico de x
Binomial
Éxito
1
Fracaso
0
DEPARTAMENTO DE CIENCIASBÁSICAS
Éxito
1
Fracaso
0
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Ejemplo
La Compañía Albergar Ltda. asegura propiedades frente a la playa a lo largo de Virginia, Carolina del Norte y
del sur y las costas de Georgia; el cálculo aproximado es que, cualquier año, la probabilidad de que un
huracán de categoría III (vientos sostenidos de más de 110 millas por hora) o más intenso azote una región
de la costa (la isla de St. Simons, Georgia, por ejemplo) es de 0,05. Si un dueño de casa obtiene un crédito
hipotecario de 30 años por una propiedad recién comprada en StSimons, ¿cuáles son las posibilidades de
que el propietario experimente por lo menos un huracán durante el periodo del crédito?
Primero se determina la media o número esperado de tormentas:
+
n= número de años
p= probabilidad de que toque tierra un huracán
= número esperado de tormentas en un período de 30 años
30 0,05
1,5
Para determinar la probabilidad de que por lo menos una tormenta azote la isla de St. Simons, Georgia,
primero se calcula la probabilidad de que ninguna tormenta azote la costa y luego se resta dicho valor de 1.
41
6
0!
0
1 0,2231
0
0,7769
1
0
41
1
41
1
1
5 $7,8
Se concluye entonces que las posibilidades de que un huracán de ese tipo azote la propiedad durante el
periodo de 30 años, mientras el crédito exista son de 0,7769. Debe insistirse en que se espera que haya 1,5
tormentas que azotan la costa cada periodo de 30 años.
En este anterior ejemplo se utilizó la distribución de Poisson como aproximación de la binomial y se
cumplieron con las características de:
1. Solo hay dos posibles resultados: un huracán azote la zona o no lo haga
2. Hay una cantidad fija de pruebas, en este caso son 30 años
3. Existe una probabilidad constante de éxito; es decir, la probabilidad de que un huracán azote la zona es
de 0,05 cada año
4. Los años son independientes, o sea si una tormenta importante azota en el quinto año, esto no influye
en ningún otro año.
Ahora para calcular la probabilidad de que por lo menos una tormenta azote el área en un período de 30
años se aplica la distribución binomial:
41
1
41
41
DEPARTAMENTO DE CIENCIASBÁSICAS
0
1
! "
<%
1
& ( %, %'% %, ='
1
%
#
#
<%
# %, *#>?
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
La probabilidad de que por lo menos un huracán azote el área durante un periodo de 30 años con la
distribución binomial es de 0,7854.
La respuesta obtenida con la distribución binomial es la más “correcta técnicamente”. La que se obtuvo con
la distribución de Poisson puede tomarse como una aproximación de la binomial,, cuando n, el número de
pruebas es grande y pla probabilidad de éxito pequeña.
En resumen, la distribución de Poisson es en realidad una familia discreta de distribuciones. Todo lo que se
necesita para construir una distribución de Poisson es la media del número de defectos, errores, etc. Que se
designa como µ.
13. DISTRIBUCION
CONTINUAS
DE
PROBABILIDADES
PARA
VARIABLES
DISTRIBUCIÓN NORMAL ESTANDAR
Las distribuciones normales ocupan un lugar importantísimo en la estadística aplicada y teórica por múltiples
razones, una de estas es que coincide muy estrechamente con las distribuciones de frecuencia observadas
de muchas mediciones de fenómenos físicos y naturales. Su mayor importancia radica en que aquellas
distribuciones de medias muestrales y proporciones de muestras grandes tienden a distribuirse como lo hace
la función de distribución normal lo cual hace resaltar su amplia aplicación en la teoría de muestreo.
Las características principales de la distribución de probabilidad normal son:
1. Tiene forma de campañay posee una sola cima en el centro de la distribución. La media aritmética, la
mediana y la moda son iguales, y se localizan en el centro de la distribución. El área total bajo la curva
es de 1,00. La mitad del área bajo la curva normal se localiza a la derecha de este punto central, y la
otra mitad, a la izquierda.
2. Es simétricarespecto a la media. Si hace un corte vertical, por el valor central, a la curva normal, las
dos mitades son imágenes especulares.
3. Desciende suavemente en ambas direcciones del valor central. Es decir, la distribución es asintótica.
La curva se aproxima más y más al eje X, sin tocarlo en realidad. En otras palabras, las colas de la
curva se extienden indefinidamente en ambas direcciones.
4. La localización de una distribución normal se determina a través de la media, µ. La dispersión o
propagación de la distribución se determina por medio de la desviación estándar σ.
La fórmula de la distribución de probabilidad normal tiene una fórmula muy compleja, sin embargo a parte de
su complejidad ya se conocen varios de estos valores:
µ y σ se refieren a la media y desviación estándar, la letra griega π es una constante matemática natural,
cuyo valor es aproximadamente 22/7 o 3,1416. La letra etambién es una constante matemática, es la base
del sistema de logaritmos naturales y es igual a 2,718; y x es el valor de una variable aleatoria continua. Así
una distribución normal se base en su media y su desviación estándar.
La curva normal es simétrica, dos
mitades idénticas
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Cola
En teoría la curva
tiende a -∞
Cola
La media, mediana y moda son iguales
En teoría la curva
tiende a +∞
Con la distribución normal no se requiere hacer cálculos con la fórmula anterior, se requiere una tabla para
buscar las diversas probabilidades.
Una distribución de probabilidad normal estándar resulta de restar la media de cada observación y dividir
esta diferencia entre la desviación estándar. Los resultados reciben el nombre de valores z o valores
tipificados.
Valor z:: Distancia con signo entre
ent un valor seleccionado, designado x,, y la media, µ, dividida entre la
desviación estándar σ.
Es el valor de cualquier observación y medición
medició
Es la media de la distribución
Es la desviación estándar de la distribución
Ejemplo:
Se desea calcular la probabilidad de que las cajas de Sugar pesen entre 283 y 285,4 gramos, el peso de la
caja de Sugar tiene una distribución normal con una media
med de 283 gramos y una desviación estándar de 1,6
gramos. Se quiere conocer la probabilidad o á
área
rea bajo la curva entre la media, 283 gramos y 285,4 gramos.
Para determinar la probabilidad es necesario convertir tanto 283 gramos como 285,4 gramos a valores z.
Z = 283-283 / 1,6 = 0
Z = 285,4-283/1,6 =1,50
Después con ayuda de la tabla de distribuci
distribución
ón de Áreas bajo la curva normal establecemos los valores para
z=1,5 y la probabilidad bajo la columna 0,00 que corresponde a 0,4332, (favor observar la imagen adjunta)
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Esto significa que el área bajo la curva entre 0,00 y 1,50 es de 0,4332. Tal es la probabilidad de que una caja
seleccionada al azar de Sugar pese entre 283 y 285,4 gramos. Esto se ilustra en la siguiente gráfica
.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
SEGUNDO CAPÍTULO: MUESTREO
1. TEORIA DEL MUESTREO
En ocasiones en que no es posible o conveniente realizar un censo (analizar a todos los elementos de una
población), se selecciona una muestra, entendiendo por tal una parte representativa de la población. El
muestreo es por lo tanto una herramienta de la investigación científica, cuya función básica es determinar
que parte de una población debe examinarse, con la finalidad de hacer inferencias sobre dicha población. La
muestra debe lograr una representación adecuada de la población, en la que se reproduzca de la mejor
manera los rasgos esenciales de dicha población que son importantes para la investigación. Para que una
muestra sea representativa, y por lo tanto útil, debe de reflejar las similitudes y diferencias encontradas en la
población, es decir ejemplificar las características de ésta. Los errores más comunes que se pueden cometer
son:
a. Hacer conclusiones muy generales a partir de la observación de sólo una parte de la Población,
se denomina error de muestreo.
b. Hacer conclusiones hacia una Población mucho más grandes de la que originalmente se tomo la
muestra. Error de Inferencia. En la estadística se usa la palabra población para referirse no sólo
a personas si no a todos los elementos que han sido escogidos para su estudio y el término
muestra se usa para describir una porción escogida de la población.
TIPOS DE MUESTREO
Existen diferentes criterios de clasificación de los diferentes tipos de muestreo, aunque en general pueden
dividirse en dos grandes grupos:
Métodos de muestreo probabilísticos y Métodos de muestreo no probabilísticos.
MUESTREO PROBABILÍSTICO
Los métodos de muestreo probabilísticos son aquellos que se basan en el principio de equiprobabilidad. Es
decir, aquellos en los que todos los individuos tienen la misma probabilidad de ser elegidos para formar parte
de una muestra y, consiguientemente, todas las posibles muestras de tamaño n tienen la misma probabilidad
de ser seleccionadas. Sólo estos métodos de muestreo probabilísticos nos aseguran la representatividad de
la muestra extraída y son, por tanto, los más recomendables.
Dentro de los métodos de muestreo probabilísticos encontramos los siguientes tipos:
MUESTREO ALEATORIO SIMPLE: El procedimiento empleado es el siguiente:
a) Se asigna un número a cada individuo de la población y
b) A través de algún medio mecánico (bolas dentro de una bolsa, tablas de números aleatorios,
números aleatorios generados con una calculadora u ordenador, etc.) se eligen tantos sujetos como
sea necesario para completar el tamaño de muestra requerido.
Este procedimiento, atractivo por su simpleza, tiene poca o nula utilidad práctica cuando la población que
estamos manejando es muy grande.
MUESTREO ALEATORIO SISTEMÁTICO: Este procedimiento exige, como el anterior, numerar todos los
elementos de la población, pero en lugar de extraer n números aleatorios sólo se extrae uno. Se parte de
ese número aleatorio i, que es un número elegido al azar, y los elementos que integran la muestra son los
que ocupa los lugares i, i+k, i+2k, i+3k,...,i+(n-1)k, es decir se toman los individuos de k en k, siendo k el
resultado de dividir el tamaño de la población entre el tamaño de la muestra: k= N/n. El número i que
empleamos como punto de partida será un número al azar entre 1 y k. El riesgo este tipo de muestreo está
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
en los casos en que se dan periodicidades en la población ya que al elegir a los miembros de la muestra con
una periodicidad constante (k) podemos introducir una homogeneidad que no se da en la población.
Imaginemos que estamos seleccionando una muestra sobre listas de 10 individuos en los que los 5 primeros
son varones y los 5 últimos mujeres, si empleamos un muestreo aleatorio sistemático con k=10 siempre
seleccionaríamos o sólo hombres o sólo mujeres, no podría haber una representación de los dos sexos. 3.MUESTREO ALEATORIO ESTRATIFICADO: Trata de obviar las dificultades que presentan los anteriores ya
que simplifican los procesos y suelen reducir el error muestral para un tamaño dado de la muestra. Consiste
en considerar categorías típicas diferentes entre sí (estratos) que poseen gran homogeneidad respecto a
alguna característica (se puede estratificar, por ejemplo, según la profesión, el municipio de residencia, el
sexo, el estado civil, etc.).
Lo que se pretende con este tipo de muestreo es asegurarse de que todos los estratos de interés estarán
representados adecuadamente en la muestra. Cada estrato funciona independientemente, pudiendo
aplicarse dentro de ellos el muestreo aleatorio simple o el estratificado para elegir los elementos concretos
que formarán parte de la muestra. En ocasiones las dificultades que plantean son demasiado grandes, pues
exige un conocimiento detallado de la población. (Tamaño geográfico, sexos, edades,...). La distribución de
la muestra en función de los diferentes estratos se denomina afijación, y puede ser de diferentes tipos:
Afijación Simple: A cada estrato le corresponde igual número de elementos muéstrales.
Afijación Proporcional: La distribución se hace de acuerdo con el peso (tamaño) de la población en cada
estrato.
Afijación Óptima: Se tiene en cuenta la previsible dispersión de los resultados, de modo que se considera
la proporción y la desviación típica. Tiene poca aplicación ya que no se suele conocer la desviación.
MUESTREO ALEATORIO POR CONGLOMERADOS: Los métodos presentados hasta ahora están
pensados para seleccionar directamente los elementos de la población, es decir, que las unidades
muéstrales son los elementos de la población. En el muestreo por conglomerados la unidad muestral es un
grupo de elementos de la población que forman una unidad, a la que llamamos conglomerado. Las unidades
hospitalarias,los departamentos universitarios, una caja de determinado producto, etc., son conglomerados
naturales.
En otras ocasiones se pueden utilizar conglomerados no naturales como, por ejemplo, las urnas electorales.
Cuando los conglomerados son áreas geográficas suele hablarse de "muestreo por áreas". El muestreo por
conglomerados consiste en seleccionar aleatoriamente un cierto número de conglomerados (el necesario
para alcanzar el tamaño muestral establecido) y en investigar después todos los elementos pertenecientes a
los conglomerados elegidos.
MUESTREO NO PROBABILÍSTICO
A veces, para estudios exploratorios, el muestreo probabilístico resulta excesivamente costoso y se acude a
métodos no probabilísticos, aun siendo conscientes de que no sirven para realizar generalizaciones
(estimaciones inferenciales sobre la población), pues no se tiene certeza de que la muestra extraída sea
representativa, ya que no todos los sujetos de la población tienen la misma probabilidad de se elegidos. En
general se seleccionan a los sujetos siguiendo determinados criterios procurando, en la medida de lo
posible, que la muestra sea representativa. En algunas circunstancias los métodos estadísticos y
epidemiológicos permiten resolver los problemas de representatividad aun en situaciones de muestreo no
probabilístico, por ejemplo los estudios de caso-control, donde los casos no son seleccionados
aleatoriamente de la población. Entre los métodos de muestreo no probabilísticos más utilizados en
investigación encontramos:
MUESTREO POR CUOTAS
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
También denominado en ocasiones "accidental". Se asienta generalmente sobre la base de un buen
conocimiento de los estratos de la población y/o de los individuos más "representativos" o "adecuados" para
los fines de la investigación. Mantiene, por tanto, semejanzas con el muestreo aleatorio estratificado, pero no
tiene el carácter de aleatoriedad de aquél. En este tipo de muestreo se fijan unas "cuotas" que consisten en
un número de individuos que reúnen unas determinadas condiciones.
Por ejemplo: 20 individuos de 25 a 40 años, de sexo femenino y residentes en Girón. Una vez determinada
la cuota se eligen los primeros que se encuentren que cumplan esas características. Este método se utiliza
mucho en las encuestas de opinión.
MUESTREO INTENCIONAL O DE CONVENIENCIA
Este tipo de muestreo se caracteriza por un esfuerzo deliberado de obtener muestras "representativas"
mediante la inclusión en la muestra de grupos supuestamente típicos. Es muy frecuente su utilización en
sondeos preelectorales de zonas que en anteriores votaciones han marcado tendencias de voto. También
puede ser que el investigador seleccione directa e intencionadamente los individuos de la población. El caso
más frecuente de este procedimiento el utilizar como muestra los individuos a los que se tiene fácil acceso
(los profesores de universidad emplean con mucha frecuencia a sus propios alumnos).
BOLA DE NIEVE
Se localiza a algunos individuos, los cuales conducen a otros, y estos a otros, y así hasta conseguir una
muestra suficiente. Este tipo se emplea muy frecuentemente cuando se hacen estudios con poblaciones
"marginales", delincuentes, sectas, determinados tipos de enfermos, etc.
MUESTREO DISCRECIONAL
A criterio del investigador los elementos son elegidos sobre lo que él cree que pueden aportar al estudio.
Ventajas e inconvenientes de los distintos tipos de muestreo probabilístico
ERROR DE MUESTREO
Cada método de muestreo que se utilice para cualquier posible muestra de determinado tamaño de una
población, tiene una posibilidad o probabilidad conocidas, sus medias y sus desviaciones estándar tienden a
ser diferentes entre la población y la muestra.
Por tanto, puede esperarse una diferencia entre un estadístico de la muestray el parámetro de la
poblacióncorrespondiente. Esta diferencia se le llama error de muestreo.
Ejemplo
Dayana y Brayan administran el Viajero, una pensión donde dan alojamiento y desayuno, localizada en
Florianopolis-Brasil. Se rentan ocho habitaciones en esta pensión. A continuación aparece el número de
estas ocho habitaciones rentadas diariamente durante junio 2010, con un trabajo estadístico preliminar se
estableció que la muestra se realizaría con 10 días de junio.
Habitaciones
en renta
Junio
1
2
3
4
0
2
3
2
DEPARTAMENTO DE CIENCIASBÁSICAS
Habitaciones
en renta
Junio
11
12
13
14
3
4
4
4
Habitaciones
en renta
Junio
21
22
23
24
3
2
3
6
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
5
6
7
8
9
10
3
4
2
3
4
7
15
16
17
18
19
20
7
0
5
3
6
2
25
26
27
28
29
30
0
4
1
1
3
3
Se seleccionan tres muestras aleatorias de cinco días, se les calcula la media muestral y se compara con la
media poblacional. Cuál es el error de muestreo en cada caso.
Ejercicio para realizar como taller
2. DISTRIBUCIÓN MUESTRAL DE LA MEDIA
La posibilidad de que se presente un error de muestreo cuando se emplean los resultados del muestreo para
aproximar un parámetro es casi inevitable. Las medias muestrales varían de una muestra a otra, si se
organiza las medias de todas las muestras posibles en una distribución de probabilidad, el resultado recibe
el nombre de distribución muestral de la media.
Ejemplo
Se tienen los ingresos por hora del personal administrativo de una oficina de cobranzas jurídicas
(considerada como toda la población) y se presentan en la siguiente tabla.
Ingresos
por hora en
Empleado
Cargo
miles de
pesos
1 Omar García
Auxiliar de Cartera
12.500
2 Stella Vega
Secretaria
5.000
3 Orlando Ávila Gerente Comercial
75.000
4 Edgar Galván
Auxiliar de Cobro
12.500
5 Javier Ayala
Auxiliar de Recaudo
12.500
6 Socorro Neira Gerente Cartera
75.000
7 Rafael Afanador Gerente Administrativo
75.000
Lo primero que se calcula es la media poblacional que para este caso es.
∑ AB
C
267.500
7
38214
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Seguido calculamos la distribución muestral de la media para muestras de tamaño 2, se selecciona sin
reemplazo de la población, todas las muestras posibles de tamaño 2 y se calculan las medias de cada
muestra. Hay 21 posibles muestras, que se calculan con la fórmula de las combinaciones, tomando los 7
empleados y se agrupan por parejas
C!
! C
C
7 2
!
7!
2! 7 2 !
70 2
21
El N es el número de elementos de la población que para este caso es de 7 y n es el número de elementos
de la muestra que corresponde a 2.
Con las 21 medias muestrales de todas las muestras posibles de tamaño 2 que pueden tomarse de la
población se construye una distribución de probabilidad, que es la distribución muestral de la media, la cual
se resuma en la siguiente tabla:
Medias muestrales
Muestra
Empleados
Ingresos por Hora
1 Omar García Stella Vega
12.500
5.000
2 Omar García Orlando Ávila
12.500
75.000
3 Omar García Edgar Galván
12.500
12.500
4 Omar García Javier Ayala
12.500
12.500
5 Omar García Socorro Neira
12.500
75.000
6 Omar García Rafael Afanador 12.500
75.000
7 Stella Vega Orlando Ávila
5.000
75.000
8 Stella Vega Edgar Galván
5.000
12.500
9 Stella Vega Javier Ayala
5.000
12.500
10 Stella Vega Socorro Neira
5.000
75.000
11 Stella Vega Rafael Afanador 5.000
75.000
12 Orlando Ávila Edgar Galván
75.000
12.500
13 Orlando Ávila Javier Ayala
75.000
12.500
14 Orlando Ávila Socorro Neira
75.000
75.000
15 Orlando Ávila Rafael Afanador 75.000
75.000
16 Edgar Galván Javier Ayala
12.500
12.500
17 Edgar Galván Socorro Neira
12.500
75.000
18 Edgar Galván Rafael Afanador 12.500
75.000
19 Javier Ayala Socorro Neira
12.500
75.000
20 Javier Ayala Rafael Afanador 12.500
75.000
21 Socorro Neira Rafael Afanador 75.000
75.000
Suma
17.500
87.500
25.000
25.000
87.500
87.500
80.000
17.500
17.500
80.000
80.000
87.500
87.500
150.000
150.000
25.000
87.500
87.500
87.500
87.500
150.000
Media
8.750
43.750
12.500
12.500
43.750
43.750
40.000
8.750
8.750
40.000
40.000
43.750
43.750
75.000
75.000
12.500
43.750
43.750
43.750
43.750
75.000
Distribución muestral de la media para n=2
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
DISTRIBUCIÓN MUESTRAL DE LA MEDIA
Media
Número de
Probabilidad
muestral
medias
8750
3
0,14
12500
3
0,14
40000
3
0,14
43750
9
0,43
75000
3
0,14
21
1,00
La media de la distribución muestral de la media se obtiene de sumar las medias muestrales y dividir la
suma entre el número de muestras. La media de todas las medias muestrales se representa mediante FG , la
µ es un valor poblacional el subíndice G , indica la distribución muestral de la media.
FG
HIJK L6 MNLKO PKO J6LBKO JI6OM KP6O
QNMKP L6 PKO JI6OM KO
8750 R 12500 R S R 75000
21
38214
La media de la distribución muestral de la media 38214 es igual a la media de la población 38214, µ= FG
La dispersión de la distribución muestral de las medias es igual que la dispersión de los valores de la
población. La media de las muestras varía de 8.750 – 75.000 igual que los valores de la población que
están entre 5.000 y 75.000 ingresos por hora.
La forma de la distribución muestral de la media y la forma de la distribución de frecuencias de los valores de
población son diferentes. La distribución muestral de las medias tiende a adoptar más forma de campana y
a aproximarse a la distribución de probabilidad normal.
Distribución de frecuencias de los valores de población
0,45
0,40
0,35
Probabilidade
0,30
0,25
0,20
0,15
0,10
0,05
0,00
5.000
DEPARTAMENTO DE CIENCIASBÁSICAS
12.500
Ingresos por hora
75.000
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Distribución muestral de las medias n=2
0,45
0,40
0,35
Probabilidade
0,30
0,25
0,20
0,15
0,10
0,05
0,00
8750
12500
40000
Ingresos por hora
43750
75000
3. TEOREMA DEL LIMITE CENTRAL
La relación entre la forma de la distribución de la población y la forma de la distribución muestral de la media
se conoce como el “Teorema del Límite Central”. Este teorema asegura que la distribución muestral de la
media se acerca a la normal a media que crece el tamaño de la muestra. Este teorema es quizá uno de los
más importantes en la Estadística Inferencial.
En términos generales el teorema se resuma en los siguientes términos:
Sin tener en cuenta la forma funcional de la población de donde se extrae la muestra, la distribución de las
medias muestrales, calculadas con muestras de tamaño n extraídas de una población con media µ y
2
varianza σ , se aproxima a una distribución normal cuando nse incrementa. Si nes grande, la distribución de
las medias muestrales puede aproximarse mucho a una distribución normal.
Distribución de frecuencias de los valores de población
0,45
0,40
0,35
Probabilidade
0,30
0,25
0,20
0,15
0,10
0,05
0,00
5.000
12.500
Ingresos por hora
75.000
Gráfica de la distribución de la población, cuando N=7, µ=38.214
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Distribución muestral de las medias n=2
0,45
0,40
0,35
Probabilidade
0,30
0,25
0,20
0,15
0,10
0,05
0,00
8750
12500
40000
Ingresos por hora
43750
75000
Gráfica de la distribución muestral de la media, Muestras = 21 y n=2
Distribución muestral de las medias n=3
0,30
0,25
Probabilidade
0,20
0,15
0,10
0,05
0,00
10.000
12.500
30.833
33.333
Ingresos por hora
51.667
54.167
75.000
Gráfica de la distribución muestral de la media, Muestras = 35 y n=3
Se concluye de este ejemplo que el teorema del límite central indica que sin importar la forma de la
distribución de la población, la distribución muestral de la media se aproximará a una distribución de
probabilidad normal. Cuando mayor sea el número de observaciones en cada muestra, más evidente será la
convergencia.
Se habla en estadística que una muestra grande es a partir de 30 elementos, por tanto n > 30 es
suficientemente grande para justificar el uso del teorema.
El teorema del limite central no dice nada sobre la dispersión de la distribución muestral de medias, ni de la
comparación entre la media de la distribución muestral de medias y la media de la población. Sin embargo
en algunos casos existe menor dispersión en la distribución muestral de medias que en la distribución de la
población, lo que indica la diferencia en el rango de la población y en el rango de las medias muestrales.
Observe que la media de las muestras se encuentra cerca de la media de la población. Se puede demostrar
, y si
que la media de la distribución muestral es la media de la distribución poblacional, es decir que FG
la desviación estándar de la población es σ, la desviación estándar de las medias muestrales es σ/√ , en la
que n es el número de observaciones de cada muestra. Entonces, σ/√ es el error estándar de la media.
U N 6OMá LK L6PKJ6LBK
DEPARTAMENTO DE CIENCIASBÁSICAS
,FG
,
√
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Con todo lo anterior se concluye entonces:
1. La media de la distribución muestral de las medias será exactamente igual a la media poblacional si
selecciona todas las muestras posibles del mismo tamaño de una población dada.
FG
Auque no seleccione todas las muestras, es de esperar que la media de la distribución muestral de medias
se aproxime a la media poblacional.
2. Habrá menos dispersión en la distribución muestral de las medias que en la población. Si la desviación
estándar de la población es σ, la desviación estándar de la distribución muestral de medias es σ/√ .
Note que, cuando se incrementa el tamaño de la muestra, disminuye el error estándar de la media.
El uso de la distribución muestral de las medias reviste importancia pues en la mayoría de las decisiones
tomadas en los negocios tienen como fundamento los resultados de un muestreo.
Recordemos que para convertir cualquier distribución normal debemos conocer un valor z y se debe utilizar
la tabla del área bajo la curva para determinar la probabilidad de seleccionar una observación que caerá
dentro de un intervalo específico. La fórmula para determinar el valor z es:
V
,
x= variable aleatoria
µ= media de la población
σ= desviación estándar de la población
Sin embargo, la mayor parte de las decisiones de negocios se refieren a una muestra, no a una sola
observación. Así, lo importante es la distribución de AW, la media muestral, en lugar de x, el valor de una
observación. Este es el primer cambio de la fórmula que se trabajó para hallar la z en la distribución normal,
el segundo cambio consiste en emplear el error estándar de la media de n observaciones en lugar de la
desviación estándar de la población. Es decir, se usa σ/√ en el denominador en lugar de σ. Por lo tanto
para determinar la probabilidad de una media muestral con rango especificado, primero se aplica la fórmula
para determinar el valor z correspondiente y luego con ayuda de la tabla para calcular el área bajo la curva
se localiza la probabilidad.
áPXIPNL6PYKPN VL6 G XIK LNO6XN NX6PKL6OYBKXBó 6OMá LK L6PK+NZPKXBó V
AW
,/√
Ejemplo
El departamento de control de calidad de cierta bebida refrescante conserva registros sobre la cantidad de
bebida en su botella gigante. La cantidad real de bebida en cada botella es de primordial importancia, pero
varía en una mínima cantidad de botella en botella. La entidad no desea llenar botellas con menos líquido
del bebido, pues tendría problemas en lo que se refiere a la confiabilidad de la etiqueta. Por otra parte, no
puede colocar líquido de más en las botellas porque regalaría bebida, lo cual reduciría sus utilidades. Los
registros indican que la cantidad de bebida tiene una distribución normal. La cantidad media por botella es
de 31,2 onzas y la desviación estándar de la población es de 0,4 onzas. Hoy, a las 8 de la
mañana, el técnico de calidad seleccionó al azar 16 botellas de la línea de llenado. La cantidad media de
bebida en las botellas es de 31,38 onzas. Es un resultado poco probable?, Es probable que el proceso
permita colocar demasiada bebida en las botellas? En otras palabras, es poco común el error de muestreo
de 0,18 onzas?
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Primero debemos determinar la probabilidad de seleccionar una muestra de 16 botellas de una población
normal con media 31,2 onzas y una desviación estándar de la población de 0,4 y encontrar la media
muestral de 31,38, aplicamos la fórmula para determinar z:
V
V
31,38
AW
,/√
31,20
0,4/√16
1,80
El numerador de esta ecuación es el error muestral o sea 0,80 y el denominador es el error estándar de la
distribución muestral de la media o sea 0,1.
Este valor z de 1,80 se ubica en la tabla de área bajo la curva y se determina que corresponde a 0,4641, la
probabilidad de un valor z mayor que 1,80 es de 0,0359, que se calcula restando 0,5000 – 0,4641
Por tanto se concluye:
No es probable (menos del 4% de probabilidad) que seleccione una muestra de 16 observaciones de una
población normal con una media de 31,2 onzas y una desviación estándar poblacional de 0,4 onzas y
determine que la media de la muestra es igual o mayor que 31,38 onzas. La conclusión es que en el
proceso se vierte demasiada bebida en las botellas. El técnico de control de calidad debe entrevistarse con
el supervisor de producción para sugerir la reducción de la cantidad de bebida en cada botella.
La gráfica para entender mejor este ejercicio quedaría de la siguiente manera:
Distribución muestral de la cantidad media de bebida en una botella gigante
4. DISTRIBUCIÓN DE LA PROPORCIÓN
Una proporción es la fracción, razón o porcentaje que indica la parte de la muestra de la población que
posee un rasgo de interés particular.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
En muchos casos se emplea la proporción de una muestra +G para hacer inferencias estadísticas sobre la
proporción poblacional e incluso sobre el tamaño N de la población. Como en el caso de las medias, se
puede decir en general que muestras distintas darán proporciones distintas: La distribución muestral de +G es
la distribución de las probabilidades de todos los valores de +G , calculados en muestras del mismo tamaño n,
extraídas aleatoriamente de la misma población.
El análisis de la distribución muestral de +G, sigue los mismos pasos que se emplearon para la media.
En realidad, la distribución de proporciones de muestras es una variante de la distribución binomial, en la
que se opta por trabajar con la proporción de éxitos en n=ensayos x/n, en lugar del número de x de éxitos en
n ensayos. Este resultado plantea el hecho de que la distribución de proporciones es una distribución
discreta, y aunque el teorema del límite central permita aproximarla con la distribución normal, se deberá
tener presente el uso del factor de corrección por continuidad.
Por otro lado, al igual que en el caso de la distribución de medias de muestras, la distribución de
proporciones estará distribuida aproximadamente en forma normal (teorema del límite central) si el tamaño
de la muestra es grande. Sin embargo, en este caso la regla práctica para considerar una muestra como
grande es que se cumplan simultáneamente.
np 4 5 y n(1-p)4 5
Ejemplo
Una encuesta reciente indicó que 92 de cada 100 entrevistados estaban de acuerdo con el horario de verano
para ahorrar energía. La proporción de la muestra es del 92/100 o sea 92%. Si Proporciónrepresenta la
proporción de la muestra, X el número de éxitos y n el número de elementos de la muestra, se determina
una proporción muestral de la siguiente manera:
N+
A
La proporción de la población se define por medio de p. Por consiguiente p se refiere al porcentaje de éxitos
en la población (concepto de una distribución binomial).
Para cumplir con un intervalo de confianza para una proporción es necesario cumplir con los siguientes
supuestos:
1. Las condiciones binomiales, quedan satisfechas:
a. Los datos de la muestra son resultado de conteos
b. Sólo hay dos posibles resultados (éxito y fracaso)
c. La probabilidad de éxito permanece igual de una prueba a la siguiente
d. Las pruebas son independientes
2. Los valores npy n(1-p)deben ser mayores o iguales que 5. Esta condición permite recurrir al
teorema del límite central y emplear la distribución normal estándar, es decir, z, para contemplar un
intervalo de confianza.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
TERCER CAPÍTULO: ESTIMACIÓN E HIPÓTESIS
1. ESTIMACION
Una pregunta fundamental respecto a ciertas especies, es el tamaño de población. Se puede tomar el caso
de las ballenas. Estos mamíferos gigantescos no se quedan quietos para contarlos. Viajan por grandes
extensiones y pasan la mayor parte del tiempo bajo el agua aunque suben a la superficie a respirar en
intervalos regulares. El método más sencillo para estimar la población consiste en marcar un cierto número
de ballenas; se les dispara un cilindro metálico de un pie de longitud, de modo que queda colocado en la
grasa bajo la piel. En la época de caza, las ballenas marcadas dan información sobre su movimiento y la
proporción de ballenas marcadas. La utilidad de la información anterior puede verse más fácilmente
simulando el experimento con una bolsa de canicas. Como en el caso de las ballenas, el número de canicas
en la bolsa es desconocido. Se seleccionan aleatoriamente unas cuantas canicas de la bolsa, por ejemplo
10, se marcan y se regresan a la bolsa. Después se agita la bolsa y se extraen nuevamente, en forma
aleatoria, cierto número de canicas. Se cuenta el número de canicas marcadas y las no marcadas,
obteniéndose la proporción muestral.
En inferencia estadística se llama estimación al conjunto de técnicas que permiten dar un valor aproximado
de un parámetro de una población a partir de los datos proporcionados por una muestra.
Ejemplo
Una estimación de la media de una determinada característica de una población de tamaño N podría ser la
media de esa misma característica para una muestra de tamaño n=1
2. ESTIMADORES
Estimador de intervalo:
Intervalo donde probablemente se localiza un parámetro de población, basado en información de la muestra.
Ejemplo
De acuerdo con los datos de la muestra, la media de la población está en el intervalo entre 0.9 y 2.0 libras.
Estimador puntual:
Valor único calculado a partir de una muestra para calcular un parámetro poblacional.
Ejemplo
Si la media de la muestra es del 1020 psi, éste constituye el mejor estimador de la fuerza de tensión media
de la población.
3. PROPIEDADES DE LOS ESTIMADORES
En el corte anterior se inició el estudio de la estadística inferencial. En ese capítulo se presentaron razones
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
por las cuales se debe hacer muestreo, ahora se estudiarán aspectos importantes del muestreo como el
estudio del estimador puntual que consiste en un solo valor deducido de una muestra para estimar una
población, pero es solo un valor, si se quiere un enfoque más profundo se presenta un intervalo de valores
del que se espera que se estime el parámetro poblacional, a eso se le llama INTERVALO DE CONFIANZA.
4. INTERVALOS DE CONFIANZA PARA LA MEDIA.
El análisis de estimadores puntuales y los intervalos de confianza comienza con el estudio del cálculo de la
media poblacional:
•
•
Se conoce la desviación estándar de la población (σ)
Se desconoce la desviación estándar de la población (σ). En este caso se sustituye la desviación
estándar de la muestra (s) por la desviación estándar de la población (σ)
Ahora bien, un estimador puntual sólo dice parte de la historia. Aunque se espera que el estimador puntual
se aproxime al parámetro poblacional, sería conveniente medir cuán próximo se encuentra en realidad. Un
intervalo de confianza sirve para este propósito.
Desviación estándar de la población conocida σ
Ejemplo
Se estima que el ingreso anual medio de 500 los trabajadores de la construcción en el área de Nueva York a
Nueva Jersey es de $65.000. Un intervalo para este valor aproximado puede oscilar entre $61.000 y
$69.000. Para describir cuánto es posible confiar en que el parámetro poblacional se encuentre en el
intervalo se debe generar un enunciado probabilístico. Por ejemplo: se cuenta con 90% de seguridad de
que el ingreso anual medio de los trabajadores de la construcción en el área de Nueva York a Nueva Jersey
se encuentra entre 61000 y 69000. La información relacionada con la forma de la distribución muestral de
medias, es decir, de la distribución muestral de AW , permite localizar un intervalo que tenga una probabilidad
específica de contener la media poblacional, µ. En el caso de muestras razonablemente grandes, los
resultados del teorema del límite central permiten afirmar lo siguiente:
1) 95% de las medias muestrales seleccionadas de una población se encontrará a ± 1.96
desviaciones estándar de la media poblacional, µ.
2) 99% de las medias muestrales se encontrará a ± 2.58 desviaciones estándar de la media
poblacional.
3)
Para los anteriores casos se utilizan las siguientes fórmulas:
W
Para el intervalo de confianza de 95%:A
\ 1,96
√^
W
Para el intervalo de confianza de 99%:A
\ 2,58
√^
]
]
En resumen la formula quedaría así para cualquier intervalo de confianza.
W
Intervalo de confianza para la media poblacional con una σ conocida A
\V
]
√^
Los valores de ± 1,96 y ± 2,58 son valores zcorrespondientes a 95% medio y 99% de las observaciones
respectivamente, por tanto estos intervalos de confianza para la media poblacional se utilizan cuando la
desviación estándar σ es conocida.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Ejemplo
Una firma de enlatados distribuye duraznos en trozo en latas de 4 onzas, para asegurar que cada lata
contenga por lo menos la cantidad que se requiere, la empresa establece que el proceso de llenado debe
verter 4,01 onzas de duraznos y almíbar en cada lata. Así 4,01 es la media poblacional. Por supuesto no
toda lata contendrá exactamente 4,01 onzas de duraznos y almíbar. Suponga que la desviación estándar
del proceso es del 0,02 onzas y el proceso se rige por una distribución normal, ahora se selecciona una
muestra aleatoria de 16 latas y se determina la media de la muestra. Esta es de 4,015 onzas de duraznos y
almíbar. El intervalo de confianza de 95% para la media poblacional de esta muestra en particular es de:
4,015 ± 1,96 (0,02 / √16 ) = 4,015 ± 0,0098
El nivel de confianza de 95% se encuentra entre 4,0052 y 4,0248. Estos puntos extremos reciben el nombre
de límites de confianza. El grado de confianza o nivel de confianza es de 95%, y el intervalo de confianza
abarca de 4,0052 a 4,0248. Con frecuencia, ± 0,0098 se conoce como margen de error.
Por supuesto en este caso, la media poblacional de 4,01 onzas se encuentra en este intervalo. Pero no
siempre será así. En teoría, si selecciona 100 muestras de 16 latas de la población , se calcula la media
muestral y se crea un intervalo de confianza basado en cada media muestral, se esperaría una media
poblacional de aproximadamente 95 de los 100 intervalos.
Desviación estándar de la población desconocida σ
Por fortuna se utiliza la desviación estándar de la muestra para estimar la desviación estándar de la
población. Es decir, se utiliza spara estimar σ. No obstante al hacerlo no es posible utilizar la fórmula antes
vista. Como no se conoce σ, no puedo utilizar la distribución z, por tanto se utiliza la distribución tla cual es
una distribución de probabilidad continua, con muchas características similares a las de la distribución z y su
fórmula es:
Distribución t =
_W $`
a
√b
Acá ses un estimador de σ. La distribución “t” es mas plana y se extiende mas que la distribución normal
estándar, esto se debe a que la desviación estándar de la distribución t es mayor que la distribución normal
estándar.
W
Intervalo de confianza para la media poblacional con una σ desconocida A
\M
c
√^
Ejemplo
Un fabricante de llantas desea investigar la durabilidad de sus productos. Una muestra de 10 llantas para
recorrer 50.000 millas reveló una media muestral de 0,32 pulgadas de cuerda restante con una desviación
estándar de 0,09 pulgadas. Construya un intervalo de confianza de 95% para la media poblacional. Sería
razonable que el fabricante concluyera que después de 50.000 millas la cantidad media poblacional de
cuerda restante es de 0,30 pulgadas?
Primero se supone que la distribución de la población es normal. No se conoce la desviación estándar de la
población, pero sí se conoce la desviación estándar de la muestral, que es de 0,09 pulgadas.
W
Intervalo de confianza para la media poblacional con una σ desconocida A
Intervalo de confianza para la media poblacional con una σ desconocida 0,32\2,262
DEPARTAMENTO DE CIENCIASBÁSICAS
\M
5,5d
√75
c
√^
0,32 \ 0,064
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
Para hallar el valor de tse debe ubicar en la tabla el nivel de confianza y los grados de libertad gl el cual se
escribe como n-1, en este caso 10-1=9, en ese ejercicio el valor de tes de 2,262.
La interpretación de la respuesta quedaría:
El fabricante puede estar seguro (95% seguro) de que la profundidad media de las cuerdas oscila entre
0,256 y 0,384 pulgadas. Como el valor de 0,30 se encuentra en este intervalo, es posible que la media de la
población sea de 0,30 pulgadas.
5. INTERVALOS DE CONFIANZA PARA LA PROPORCIÓN
El desarrollo de un estimador puntual para la proporción de la población y un intervalo de confianza para una
proporción de población es similar a hacerlo para una media.
La interpretación de un intervalo de confianza resulta de mucha utilidad en la toma de decisiones y
desempeña un papel importante en eventos como las elecciones.
Ejemplo
Danny Guerrero se postula para representar ante el Congreso a Piedecuesta. Suponga que se entrevista a
los electores que acaban de votar y 275 indican que votaron por Guerrero. Considere que 500 electores es
una muestra aleatoria de quienes votan en Piedecuesta. Esto significa que 55% de los electores de la
muestra votó por Guerrero.
_
p=
^
-e8
855
0,55
Ahora, para estar seguros de la elección, Guerrero debe ganar más de 50% de los votos de la población de
electores. En estos momentos se conoce un estimador puntual, que es de 0,55, de la población de electores
que votarán por él. Ahora bien, no se conoce el porcentaje de la población que votará por el candidato. Así,
la pregunta es: ¿Es posible tomar una muestra de 500 electores de una población en la que 50% o menos
de los electores apoye a Guerrero para encontrar que 55% de la muestra lo apoya? En otras palabras, ¿el
error de muestreo, que es p-P = 0,55 - 0,5 = 0,05, se debe al azar, o la población de electores que apoya a
Guerrero es superior a 0,50?. Si se establece un intervalo de confianza para la proporción de la muestra y
halla que 0,50 no se encuentra en el intervalo, concluirá que la proporción de electores que apoya a
Guerrero es mayor que 0,50. ¿Qué significa esto? Bien, significa que puede resultar electo. ¿Qué pasa si
0,50 pertenece al intervalo? Entonces concluirá que es posible que 50% o menos de los electores apoyen
su candidatura y no es posible concluir que será electo a partir de la información de la muestra. En este
caso, si se utiliza el nivel de significancia de 95% la formula sería:
Intervalo de confianza de la proporción de una población
Intervalo de confianza de la proporción de una población
= + \ Vf
= 0,55\1,96f
g 7$g
5,88 7$5,88
855
^
0,55 \ 0,044
Así los puntos extremos del intervalo de confianza son 0,55 – 0,044 = 0,506 y 0,55 + 0,44 = 0,594. El valor
de 0,50 no pertenece al intervalo. Por tanto, se concluye que probablemente más del 50% de los electores
apoya a Guerrero, lo cual es suficiente para que salga electo.
Este es el procedimiento que utilizan las cadenas de televisión, revistas de noticias y sondeos en la noche
de las elecciones.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011
UNIDADES TECNOLÓGICAS DE SANTANDER
ELEMENTOS DE UNA PRUEBAS DE HIPÓTESIS
En este nuevo capítulo en lugar de crear un conjunto de valores en el que se espera que se presente el
parámetro poblacional, se expone un procedimiento para probarla validez de un enunciado relativo a un
parámetro poblacional, algunos ejemplos de enunciados por probar son los siguientes:
•
•
•
La cantidad media de kilómetros recorridos en una camioneta Chevrolet Captiva rentada durante
tres años es de 32000 kilómetros
El tiempo medio que una familia estadounidense vive en una vivienda en particular es de 11,8 años.
En 2005, el salario inicial medio en ventas para un graduado de universidad es de $37.130
Este capítulo trata de pruebas de hipótesis estadísticas, primero se definen los términos de hipótesis y
pruebas de hipótesis, luego se aplican pruebas de hipótesis para medias y proporciones.
HIPÓTESIS
En el sistema legal estadounidense, una persona es inocente hasta que se prueba su culpabilidad. Un
jurado platea como hipótesis que una persona a la que se le imputa un crimen es inocente, y someten esta
hipótesis a verificación, para lo cual revisan la evidencia y escuchan el testimonio antes de llegar a un
veredicto. En forma similar, un paciente visita al médico y acusa varios síntomas. Con base en ellos, el
médico indicará ciertos exámenes, determina el tratamiento.
En el análisis estadístico se establece una afirmación, una hipótesis, se recogen datos que posteriormente
se utilizan para probar la aserción. Entonces una hipótesis estadística es la afirmación relativa a un
parámetro de población sujeta a verificación.
PRUEBA DE HIPÓTESIS
Los términos prueba de hipótesisy probar una hipótesis se utilizan indistintamente. La prueba comienza con
una afirmación o suposición, sobre un parámetro de la población, como la media poblacional. Esta
afirmación recibe el nombre de hipótesis
Ejemplo
Una hipótesis puede ser que la comisión mensual media de las comisiones de los vendedores de tiendas al
menudeo de aparatos electrónicos, como Royal Circuitos es de $20.000. No es posible entrar en contacto
con todos los vendedores para asegurarnos de que la media en realidad es esa. El costo de localizarlos y
entrevistarse con ellos sería exorbitante. Para probar la validez de la afirmación (µ=20.000), se debe
seleccionar una muestra de la población de vendedores de dichos aparatos, calcular el estadístico muestraly
, con base en ciertas reglas de decisión, aceptar o rechazar la hipótesis. Una media muestral de $10.000
para dichos vendedores provocaría con certeza rechazo de la hipótesis. Sin embargo, suponga que la
media de la muestra es de $19.995. Está lo bastante cerca de $20.000 para aceptar la suposición de que la
media de la población es de $20.000? La diferencia de $5 entre las dos medias se puede atribuir al error de
muestreo, o dicha diferencia resulta estadísticamente significativa?
Entonces la prueba de hipótesis es el procedimiento basado en evidencia de la muestra y la teoría de la
probabilidad para determinar si la hipótesis es una afirmación.
DEPARTAMENTO DE CIENCIASBÁSICAS
Versión 2 – Agosto de 2011