Econometría
Anuncio

Material Docente de Econometría Curso 2011-2012. Segunda parte Esquemas de teoría Cuarto curso de Administración y Dirección de Empresas Profesores: Jesús Cavero Álvarez Carmen Lorenzo Lago Mercedes Prieto Alaiz Material Docente de Econometría Segunda parte Curso 2011-2012 Tema 7.- Heteroscedasticidad ......................................................................... 1 Tema 8.- Análisis de regresión con series temporales. Autocorrelación ........ 15 Tema 9.- Regresores estocásticos ..................................................................... 35 Tema 10.- Modelos dinámicos ........................................................................... 43 Tema 11.- Introducción a los modelos de ecuaciones simultáneas .................... 49 Econometría Curso 2011-12 TEMA 7: HETEROSCEDASTICIDAD 7.1.- Planteamiento general Una de las hipótesis básicas del modelo de regresión lineal clásico, Yi = β0 + β1 ⋅ X1i + β 2 ⋅ X 2i + L + β k ⋅ X ki + ε i i = 1,2,K, N , o, en forma matricial, Y = Xβ + ε es que la matriz de varianzas-covarianzas de las ( ) perturbaciones es E εε ' = σ 2 I , siendo I la matriz identidad. Esto es, las varianzas de las perturbaciones son iguales (hipótesis de igualdad de varianzas u homoscedasticidad) y las covarianzas entre las mismas son nulas (hipótesis de incorrelación): Var (ε i ) = σ 2 ( ) i = 1,2,K, N Cov ε i ,ε j = 0 i , j = 1,2,K, N i≠ j Si no se verifica cualquiera de las dos hipótesis, las varianzas no son constantes (heteroscedasticidad) o las covarianzas no son todas nulas (autocorrelación de las perturbaciones), tendremos que, E (εε ' ) = σ 2 Ω donde Ω ≠ I Este modelo se conoce como Modelo de Regresión Lineal Generalizado (MRLG). Por tanto, el problema de heteroscedasticidad se produce cuando las varianzas de las perturbaciones son desiguales, esto es, Var (ε i ) = σ i2 ≠ cte ∀i = 1,2, ,... N y, por ello, σ 12 0 0 σ 22 E εε ' = .... .... 0 0 ( ) 0 0 .... .... .... σ N2 .... .... Si expresamos Var (ε i ) = σ i2 = σ 2 wi ∀i = 1,2, ,... N , entonces w1 0 0 w2 ' 2 E (εε ) = σ Ω , donde Ω = .... .... 0 0 0 .... 0 .... .... .... wN .... Para explicar mejor la diferencia entre heteroscedasticidad y homoscedasticidad, vamos a analizar un modelo de regresión de dos variables en el que la variable dependiente Y es el ahorro personal y la variable explicativa la renta personal disponible (X). La Figura 1a) muestra que a medida que aumenta la renta personal disponible, también aumenta, de media, el ahorro, pero la varianza del ahorro en torno a su valor medio permanece igual para todos los niveles de renta personal disponible, (recuérdese que la recta de regresión poblacional muestra el valor medio de la variable dependiente para determinados valores de la variable explicativa). Este es el caso de la homoscedasticidad o igual varianza. Por otra parte, como muestra la Figura 1b), aunque el nivel medio de los ahorros aumenta a medida que lo hace la renta personal disponible, la varianza del ahorro no permanece igual para todos los niveles de renta. Aquí aumenta con la renta personal disponible. Este es el caso de la heteroscedasticidad o varianza desigual. Dicho de otra manera la figura b) muestra que la 1 Econometría Curso 201-12 gente de rentas elevadas ahorra, de media, más que la gente de rentas bajas, pero también hay más variabilidad en sus ahorros. Figura 11 (a)Homoscedasticidad (igual varianza) (b) Heteroscedasticidad (varianza desigual) Simbólicamente podemos expresar la heteroscedasticidad como Var(Y / X i ) = Var(ε i ) = σ i2 = σ 2 wi ∀i = 1,2, ,...N Obsérvese el subíndice de σ i2 , que es un recordatorio de que la varianza de ε i ya no es constante sino que varía con cada observación. Causas: La heteroscedasticidad se presenta, normalmente, cuando trabajamos con datos de corte transversal. • La naturaleza del modelo. Ejs.: ahorro en función del ingreso (a mayor ingreso, más posibilidades de selección respecto a la forma de disponer de dicho ingreso, mayor probabilidad de que la varianza del ahorro aumente con el ingreso), estudios sobre los beneficios de empresas (mayor varianza de los beneficios al aumentar el tamaño de la empresa) … • Datos agrupados (sumas o medias de grupos). Si los datos de los que se dispone corresponden a medias de grupos o colectivos, el modelo a estimar sería: Yh = β o + β1 X 1h + .....β k X kh + ε h h = 1 L H y puede demostrarse fácilmente que la varianza de cada perturbación depende del tamaño del grupo o colectivo al que ( ) corresponde [ Var ε h = • 1 σ2 Nh ]. Errores de especificación del modelo: en general, algún error de omisión, cambio estructural no incorporado,… Gujarati (2006): Principios de Econometría. McGraw Hill. 2 Econometría Curso 2011-12 Consecuencias de aplicar MCO a un modelo con heteroscedasticidad Bajo los supuestos del MRLC los estimadores MCO son los mejores estimadores lineales, e insesgados, pues son los que tienen varianza mínima: son eficientes. En el caso de que exista heteroscedasticidad (o autocorrelación) en el modelo las principales consecuencias son las siguientes: 1) Los estimadores MCO siguen siendo lineales, insesgados, consistentes y con distribución normal pero ya no tienen varianza mínima. Esto es así incluso en grandes muestras. 2) Las formulas habituales para calcular las varianzas de los estimadores dejan de ser correctas y suelen dar varianzas sesgadas. - La expresión habitual de la matriz de Var-Cov de β̂ MCO es ∑ βˆβˆ = σ 2 ( X ' X )−1 sin embargo, si existe heteroscedasticidad se demuestra que ∑ βˆβˆ = E (βˆ − β )(βˆ − β )' = E[( X ' X ) - −1 −1 X ' εε ' X ( X ' X ) ] = σ 2 ( X ' X ) −1 X ' ΩX ( X ' X ) −1 S 2 , el estimador convencional de σ 2 , ya no es un estimador insesgado y recuérdese que S 2 interviene en el estimador de las varianzas de los estimadores. S 2 también deja de ser consistente. ( ) 3) Los EMCO del vector paramétrico no coinciden con los EMV ya que E εε ' ≠ σ 2 I 4) Como consecuencia, los contrastes de hipótesis y los intervalos de confianza basados en el la t y F ya no son válidos. Por tanto, existe la posibilidad de extraer conclusiones erróneas si se utilizan los procedimientos convencionales de contrastación de hipótesis. 7.2.- Procedimientos para detectar la heteroscedasticidad: La heteroscedasticidad, como la autocorrelación, es un problema de las perturbaciones, que son variables inobservables. Entonces, para detectarla vamos a utilizar los residuos de la estimación mínimo cuadrática ordinaria, cuyos valores se pueden considerar como estimaciones de las perturbaciones. Entre los métodos de detección de la heteroscedasticidad hay que distinguir los procedimientos gráficos y los procedimientos inferenciales. • Análisis gráfico de los residuos Es un método orientativo, útil cuando no tenemos información sobre la existencia de heteroscedasticidad, ni sobre la estructura de las varianzas de las perturbaciones, pero se piensa que dicha varianza es función de algún regresor. 1) Diagrama de dispersión con cada uno de los regresores, X ji , en el eje de abcisas y los residuos, los residuos al cuadrado o su valor absoluto, ei , ei2 o | ei | , en el eje de ordenadas. Si dependiendo de los valores de X j , los residuos son significativamente distintos de tamaño, este hecho indicaría que la dispersión de las perturbaciones depende del valor de X j y, por tanto, sus varianzas no serían constantes. Esta circunstancia se visualiza muy bien en un diagrama de dispersión entre el regresor y los residuos. La Figura 2 muestra una 3 Econometría Curso 201-12 forma habitual de heteroscedasticidad: como se observa, los residuos son mayores (positivos o negativos) para valores grandes del regresor. Residuos Figura 22 0 Variable explicativa X Por su parte, un diagrama de dispersión entre un regresor y los residuos al cuadrado no sólo puede servir para mostrar indicios de heteroscedasticidad; en este caso, la forma de la nube de puntos ( X ji , ei2 ) puede sugerir la forma funcional que presenta la heteroscedasticidad. Así, la nube de puntos de la Figura 3 indicaría que ei2 depende lineal o cuadráticamente de X ji . Dado que ei2 se puede considerar una estimación de Var (ε i ) , estimación con un único valor muestral3, el gráfico sugeriría cual es el regresor culpable de la heteroscedasticidad y la forma funcional de la misma. En este caso, Var(ε i ) = σ 2 X ji o Var (ε i ) = σ 2 X 2ji . 2 3 Gujarati (2006): Principios de Econometría. McGraw Hill. Dado que la perturbación ε i es inobservable, podemos considerar el residuo ei como una muestra de tamaño 1 de la variable ε i . Dado que E (ε i ) = 0 , entonces, ~ Va~ r (ε ) = E (ε 2 ) = e 2 i i i esto es, estimamos la media de las perturbaciones al cuadrado con la media de los cuadrados de la muestra de residuos, pero como sólo se dispone de un valor muestral, ei , esta media será ei2 . 4 Econometría Curso 2011-12 Residuos al cuadrado Figura 34 0 Variable explicativa X La Figura 4 representa posibles patrones para ei2 y, por tanto, para Var (ε i ) . Así, la Figura 4c) siguiere una forma lineal, mientras que 4d) y 4e) cuadrática. Por su parte 4a) refleja la no existencia de heteroscedasticidad y la forma en el caso de 4b) es más difícil de ajustar. Figura 45 Puede que la heteroscedasticidad no esté provocada por un único regresor, sino conjuntamente por varios. En este caso, sería conveniente obtener el diagrama de dispersión con la estimación de la variable a explicar, Yˆi (que no es más que una combinación lineal de los regresores) , en el eje de abcisas, y los residuos, los residuos al cuadrado o su valor absoluto en el eje de ordenadas. De esta manera, detectaríamos la heteroscedasticidad causada por los regresores conjuntamente. 4 5 Gujarati (2006): Principios de Econometría. McGraw Hill. Gujarati (2006): Principios de Econometría. McGraw Hill. 5 Econometría Curso 201-12 2) Otra representación gráfica para detectar la heteroscedasticidad es el diagrama de dispersión entre cada una de las variables explicativas, X ji , en el eje de abcisas y la variable a explicar, Yi , en el eje de ordenadas. En muchas ocasiones, el ajuste lineal entre Y y X j es más o menos bueno (residuos pequeños) para valores pequeños de X j , mientras que este ajuste empeora para valores grandes de X j (residuos grandes). La Figura 5 muestra este hecho que pone en evidencia la heteroscedasticidad del modelo. Variable a explicar Y Figura 56 Variable explicativa X • Pruebas estadísticas (contrastes de hipótesis) La hipótesis nula en todas las pruebas es la hipótesis de homoscedasticidad, es decir, varianzas constantes de las perturbaciones y la hipótesis alternativa presencia de heteroscedasticiad. Así, ( ) H o : Var(ε i ) = E ε i2 = σ 2 Por tanto, se trata de probar si el valor esperado de ε i2 se relaciona o no con una o más variables explicativas y dado que este valor no es observable utilizaremos en su lugar ei2 . De esta manera, si la Ho es falsa, ei2 será cualquier función de una o más variables explicativas. Con esta idea vamos a plantear varios contrastes que no sólo nos permitirán detectar la posible existencia (o no) de heteroscedasticidad sino que, en el caso de que la haya, algunos permitirán darnos una idea sobre la forma que adopta la misma. Contraste asintótico de White La idea del test7 se basa en ver si los residuos mínimo cuadráticos ordinarios al cuadrado son de algún modo función de los regresores; en este caso, deduciríamos que la varianza de las perturbaciones son función de los regresores y, por tanto, no son constantes (heteroscedasticidad). El test de White analiza la significación de una regresión auxiliar 6 7 Gujarati (2006): Principios de Econometría. McGraw Hill. Es un test asintótico basado en los multiplicadores de Lagrange. 6 Econometría Curso 2011-12 que trata de explicar los residuos al cuadrado de la regresión inicial, ei 2 , a partir de los regresores, sus cuadrados y sus productos cruzados dos a dos. H0: Homoscedasticidad H1: Heteroscedasticidad El procedimiento es el siguiente: 1) Se estima el modelo por MCO calculando los residuos MCO: ei 2) Se estima una regresión auxiliar de los residuos MCO al cuadrado frente a cada uno de los regresores, cada uno de los regresores al cuadrado y los productos cruzados de los regresores dos a dos. 3) 2 2 → χ k2( aux ) . Siendo R aux Cuando N aumenta, se demuestra que N Raux el coeficiente de determinación de la regresión auxiliar realizada en 2) y la distribución χ 2k ( aux ) tiene como grados de libertad el nº de regresores de la regresión auxiliar excluido el término constante. Valores pequeños del estadístico indicarían que la regresión auxiliar no es 2 pequeño), que los residuos al cuadrado y, por tanto, las varianzas de las significativa ( Raux perturbaciones, no dependen de los regresores. De este modo, valores pequeños de N ⋅ R 2 llevarían a no rechazar (aceptar) la homoscedasticidad. En cambio, valores grandes llevarían a rechazar la homoscedasticidad. Contrastes basados en regresiones Estos contrastes siguen la misma idea del test de White y suponen que las varianzas de las perturbaciones son función de una o varias variables, generalmente, variables explicativas del modelo econométrico propuesto. El procedimiento concreto de la prueba Park consiste en plantear regresiones de los residuos al cuadrado en función de una o varias variables explicativas y analizar la significación conjunta de la regresión. Las variables explicativas incluidas pueden aparecer en sus niveles o como funciones de ellas, por ejemplo, al cuadrado, el inverso, etc. Si la regresión es significativa indica que existe heteroscedasticidad y nos da la pauta sobre la estructura de la varianza de las perturbaciones. En el caso de que existan varias regresiones con significación conjunta se elige aquella que proporcione mejores resultados. Este contraste también se puede realizar utilizando como variable a explicar los residuos en valor absoluto como aproximación de la raíz de la varianza de las perturbaciones (la desviación típica). Este es el caso planteado por Glejser introduciendo una sola variable explicativa y en él, como ya es sabido, la significación conjunta no es más que la significación individual. La ventaja de estos contrastes es que permiten detectar no sólo la existencia de heteroscedasticidad sino también la forma. Esto último es importante para poder solucionar el problema. Contraste de Goldfeld y Quandt Esta prueba supone que existe una relación creciente (o decreciente) entre la Var (εi) y el 1 valor de uno de los regresores: σ i2 = h( X ji ) , es decir, σ i2 = σ 2 X 2ji o bien σ i2 = σ 2 2 . De X ji 7 Econometría Curso 201-12 esta forma para los valores grandes de Xji la varianza será mayor si la hipótesis es cierta (si es decreciente la varianza será menor). La hipótesis a contrastar es: HO: Homocedasticidad σ i2 = σ 2 una constante H1: Heteroscedasticidad σ i2 = h( X ji ) El procedimiento del test es el siguiente: 1) Se ordenan las observaciones según los valores crecientes de Xj. 2) Se suprimen un nº central de observaciones (c), generalmente un cuarto o un tercio de todas las observaciones (esto no es imprescindible pero es más fácil detectar el problema), dividiendo la muestra en dos submuestras del mismo tamaño, la primera con los valores más pequeños de la variable y la segunda con los más grandes. 3) Se estima por MCO cada una de las submuestras con (N-c)/2 observaciones cada una, siendo c el número de observaciones eliminadas. 4) Calculamos sus respectivas SCR 5) Se construye un estadístico F de la forma: mayorSCR menorSCR → N −c − k −1 F N −2c − k −1 2 mayorS 2 o bien menorS 2 → N −c − k −1 F N −2c − k −1 2 Valores pequeños del estadístico indicarían que no hay grandes diferencias entre las varianzas estimadas en las dos submuestras y, por tanto, las varianzas de las perturbaciones serán constantes. De este modo, valores pequeños del estadístico llevarían a no rechazar la hipótesis de homoscedasticidad8. En cambio, valores grandes llevarían a rechazarla. Además, si mayorSCR corresponde a la segunda muestra, se rechazará frente a σ i2 = σ 2 X 2ji , mientras que si mayorSCR corresponde a la primera nos indica que la homoscedasticidad se 1 rechaza frente a σ i2 = σ 2 2 . X ji 7.3.- Estimación del modelo A) Mínimos cuadrados ponderados Para ver en qué consiste el método de Mínimos Cuadrados Ponderados (MCP) vamos a ver intuitivamente por qué no son eficientes los estimadores de MCO. Para ello vamos a partir de un modelo de dos variables representado en la Figura 6. La Figura 6a) muestra una población hipotética Y frente a diversos valores de la variable X. Como se comprueba, la varianza de la distribución de Y correspondiente a una determinada X no es constante, lo que indica la presencia de heteroscedasticidad en el modelo. Supongamos que elegimos aleatoriamente un valor Y para cada valor X. Las Y seleccionadas están marcadas con un punto y constituyen la muestra representada en la Figura 6b) a partir de la cual estimamos el modelo. 8 Nótese que si no se rechaza la hipótesis nula no significa que no exista heteroscedasticidad, dado que ésta podría estar asociada a otra variable y, tal vez haya que repetir el proceso con otras variables. 8 Econometría Curso 2011-12 Como ya vimos en los primeros temas, si estimamos la recta de regresión poblacional a partir de nuestra muestra seleccionada (Figura 6b) utilizando MCO, lo que hacemos es minimizar la suma de los errores al cuadrado. MCO min ∑ ei2 i Es decir, cada error recibe la misma ponderación independientemente de que provenga de una población con una varianza más elevada o una varianza pequeña (compara los puntos Y1 e Yn). Esto no parece muy razonable. Lo ideal es que diéramos más ponderación a las observaciones provenientes de poblaciones con menor varianza (más representativas de su valor medio) que a las de varianza mayor (menos representativas de su valor medio). Esto nos permitirá estimar con mayor precisión la recta de regresión poblacional y es precisamente lo que hace el Método de Mínimos Cuadrados Ponderados, en el que minimizamos e 2 MCP min ∑ i i σi por tanto, damos más peso a las observaciones con menor desviación típica y menos a las que tienen una desviación típica mayor. Figura 69 ¿Cómo se obtienen los estimadores de MCP? Estimador de Aitken o de MCG o de MCP (cuando se conoce σ i2 ) Se obtiene minimizando la suma de los cuadrados de los residuos ponderados: e min ∑ i i σi 2 −1 ~ El resultado es el siguiente: β MCG = ( X ' Σ −1 X ) −1 X ' Σ −1Y = (X ' Ω −1 X ) X ' Ω −1Y 9 Gujarati (2006): Principios de Econometría. McGraw Hill. 9 Econometría Curso 201-12 ~ Forma alternativa de derivar el estimador β MCG : La vía para obtener los estimadores de MCP consiste en transformar el modelo de cara a que las varianzas de las perturbaciones del modelo transformado sean constantes. Si eso se logra, el modelo transformado no presentará problemas de heteroscedasticidad y será un MRLC con lo que la estimación por MCO proporcionará los mejores estimadores, pudiéndose aplicar los procedimientos de inferencia habituales. De este modo, los estimadores MCP son los estimadores MCO del modelo transformado. Por ejemplo, si partimos de un modelo con dos variables explicativas, Yi = β0 + β1 ⋅ X1i + β 2 ⋅ X 2i + ε i , i = 1,2,K, N , con heteroscedasticidad ( Var (ε i ) = σ i2 , suponemos que σ i2 es conocida) los mejores estimadores (ELIO) son los estimadores MCP. Para obtenerlos transformaremos dicho modelo dividiéndolo por la raíz cuadrada de la varianza de las perturbaciones, es decir, por la desviación típica. El modelo transformado resultante será: Yi σ i2 = βo 1 + β1 σ i2 X 1i σ i2 + β2 X 2i σ i2 + εi σ i2 O lo que es lo mismo, Yi σ i2 1 = βo σ i2 X 1i + β1 σ i2 X 2i + β2 σ i2 + vi donde la perturbación, vi = εi σ i2 cumple la hipótesis de homoscedasticidad, Var (v i ) = Var ( εi σ i2 )= 1 ( σ i2 ) 2 var(ε i ) = σ i2 σ i2 = 1 = cte 2 Si sustituimos Var (ε i ) = σ wi , el modelo transformado vendría dado por: Yi wi = βo 1 wi + β1 X 1i wi + .......β k X ki wi + vi donde la perturbación, vi = εi wi cumple la hipótesis de homoscedasticidad, Var (v i ) = Var ( εi wi )= 1 ( wi ) 2 10 var(ε i ) = σ 2 wi wi = σ 2 = cte Econometría Curso 2011-12 Así, el modelo transformado no presenta el problema de la heteroscedasticidad (es un MRLC) y los mejores estimadores se obtienen aplicando el método MCO habitual. Los estimadores MCO de β o , β 1 , β 2 de este modelo transformado son los estimadores por Mínimos Cuadrados Ponderados (MCP), llamados también de Mínimos Cuadrados Generalizados; donde cada observación de Y, X1 y X2 se pondera (es decir, se divide) por la desviación típica ( σ i ) o por la raíz cuadrada de wi. Las observaciones de distribuciones con mayor varianza (o desviación típica) tienen menos peso que aquellas que provienen de distribuciones con varianza menor. Como el modelo transformado es un MRLC los estimadores MCO (y, por tanto, los MCP) serán ELIO y consistentes. Obsérvese que lo que se hace para conseguir perturbaciones con igual varianza es tipificar cada variable ( Zε i ), esto es, Vi = Zε i = ε i − E (ε i ) ε = i Var (ε i ) σ i2 Estimador de Aitken Factible o de MCGF o de MCPF (cuando no se conoce σ i2 pero se formulan hipótesis sobre su comportamiento) ( ~ ˆ −1 X βF = X ' Ω ) −1 ˆ −1Y X'Ω Donde se ha estimado la matriz de varianzas-covarianzas de las perturbaciones, es decir, se han estimado los elementos de la diagonal principal, las varianzas de las perturbaciones. El conocimiento de la auténtica varianza de las perturbaciones es muy infrecuente. Por ello es necesario plantearse ¿qué ocurre si no conocemos la auténtica varianza de las perturbaciones? La respuesta es recurrir a algún supuesto o hipótesis sobre σ i y transformar el modelo de regresión original para que el modelo transformado cumpla el supuesto de homoscedasticidad. 2 A la hora de hacer supuestos o hipótesis sobre la forma de la heteroscedasticidad, los gráficos y contrastes desarrollados anteriormente sirven de guía. Las hipótesis más frecuentes consisten en suponer que las varianzas de las perturbaciones son proporcionales a los valores absolutos de un determinado regresor, o bien a los cuadrados de los valores de dicho regresor o de Y estimado. Es decir, la verdadera varianza es: ( ) Var ε i = σ 2 wi Como no se conoce, wi, se estima a través de ŵi wˆ i = X ji o bien wˆ i = X 2ji o bien wˆ i = Yˆi 2 Partiendo de cualquiera de estos supuestos la forma de proceder es la misma que si la varianza fuera conocida. Así, si suponemos que Var (ε i ) = σ 2 wi y que wˆ i = X 2ji , el modelo transformado vendrá dado por: Yi X 2ji = βo 1 X 2ji + β1 11 X 1i X 2ji + .......β k X ki X 2ji + εi X 2ji Econometría Curso 201-12 O lo que es lo mismo Yi X X 1 = βo + β1 1i + .......β k ki + vi X ji X ji X ji X ji donde la perturbación, vi = εi X ji Puede o no cumplir la hipótesis de homoscedasticidad, Var (vi ) = Var ( εi X ji )= 1 ( X ji ) 2 var(ε i ) = σ 2 wi X 2ji = ?? ¿constante? Estimando el modelo transformado por MCO, se obtienen los estimadores MCPF (Mínimos cuadrados ponderados factibles). Pero las propiedades de dichos estimadores dependen de que se haya utilizado un buen estimador (en general, consistente) de la matriz de varianzas covarianzas de las perturbaciones (por tanto, de wi). En caso de que así fuera, en el modelo transformado no habría heteroscedasticidad. Por lo tanto, en este caso es necesario comprobar que el modelo transformado ya no tiene heteroscedasticidad. Para ello se pueden utilizar los gráficos y contrastes vistos anteriormente. De esta manera, si podemos aceptar que en el modelo transformado la perturbación es homoscedástica, afirmaremos que hemos estimado correctamente la matriz de varianzas covarianzas de las perturbaciones y, consecuentemente el estimador MCPF tiene las propiedades asintóticas del estimador MCP. En caso contrario, la estimación ponderada no mejora ninguna de las propiedades del EMCO del modelo original. De hecho, si no se estima adecuadamente ∑= σ 2 Ω, el EMCGF no tiene ninguna propiedad. B) Mínimos Cuadrados Ordinarios con la matriz de varianzas y covarianzas de White A veces resulta difícil encontrar una hipótesis adecuada para la estructura de la varianza de las perturbaciones ( σ i ). En estos casos la estimación ponderada no proporciona mejores estimadores que aplicar MCO al modelo original. Por ello, en estas situaciones es conveniente seguir estimando el modelo original por MCO pero calculando bien los estimadores de las varianzas de los estimadores para que la inferencia realizada a partir de los resultados del modelo así estimado sea válida. 2 White ha desarrollado un procedimiento para calcular correctamente la desviación típica de los estimadores MCO en presencia de heteroscedasticidad, que permite poder seguir utilizando los test de la t y de la F, aunque sólo son válidos asintóticamente, es decir, en muestras grandes. El estimador consistente de e12 1 donde Vˆ = X ' N ∑ ββ ˆˆ −1 −1 de White es: Σˆ WHITE = N ( X ' X ) Vˆ ( X ' X ) O X , siendo ei el error mínimo cuadrático ordinario. 2 e N 12 Econometría Curso 2011-12 C) Formas alternativas para corregir la heteroscedasticidad Existen otras vías para solventar los problemas de heteroscedasticidad que no pasan por cambiar el método de estimación sino que conllevan realizar transformaciones en los datos para que la variabilidad se reduzca. Concretamente, la transformación de los datos tomando logaritmos soluciona en muchos casos los problemas de heteroscedasticidad detectados. Otras posibilidades son deflacionar las series (si es que son monetarias) o trabajar en ratios. La siguiente tabla resume el comportamiento de los tres estimadores, MCO, MCG y MCGF, en un modelo RLNG (heteroscedasticidad y/o autocorrelación): Comparación entre estimadores en el MRLNG EMCO ≠ EMV EMCG = EMV EMCGF ( ) βˆ = ( X ' X ) X ' Y β = (X ' Ω −1 X ) X ' Ω −1Y Lineal ELIO y eficiente Propiedades finitas y Insesgado Consistente distribuciones exactas No óptimo y no eficiente Normal desconocidas Consistente Distrib. exactas válidas Si Ω̂ es consistente, en general: −1 ~ −1 Normal S *2 insesgado, consistente Distrib. Exactas no válidas ∑β S2 sesgado, inconsistente ~ MCG S β~ MCG Expresiones habituales para S β~β~ ( (X ' Ω = S *2 −1 insesgado −1 ˆ −1Y X 'Ω Consistente ) X) = σ 2 X ' Ω −1 X ~ ˆ −1 X β F = X 'Ω −1 −1 Asintóticamente Eficiente Asintóticamente Normal Distribuciones asintót. válidas MCG Si Ω̂ no es consistente: las varianzas incorrectas Expresión correcta: ( 2 ∑ βˆ = σ X ' X No se puede asegurar )−1 X ' Ω X ( X ' X )−1 ninguna propiedad 13 Econometría Curso 201-12 14 Econometría Curso 2011-12 TEMA 8. ANÁLISIS DE REGRESIÓN CON SERIES TEMPORALES. AUTOCORRELACIÓN 8.1.- Planteamiento general Cuando se proponen modelos econométricos, es muy importante tener en cuenta la naturaleza de los datos. En concreto, cuando se trabaja con series de tiempo existe un orden natural, aquel que impone el tiempo. Además, con los datos temporales es muy probable que las observaciones estén correlacionadas a lo largo del tiempo. Por ejemplo, la inversión realizada por una empresa durante un mes es seguro que esté determinada por los tipos de interés o de la propia inversión de la empresa en meses pasados. Por lo tanto, los efectos de los cambios en las variables no son todos instantáneos, sino que se dejan notar a lo largo de tiempo. En principio, se pueden considerar tres formas de plantear estas relaciones dinámicas10: a) Especificar un modelo cuya variable dependiente sea función de los valores actuales y pasados de las variables explicativas (Tema 10). b) Especificar un modelo en el que aparezca la variable dependiente retardada entre sus regresores (Temas 9 y 10). c) Especificar un modelo donde las relaciones dinámicas se introduzcan mediante la perturbación aleatoria. Por ejemplo, podemos suponer que ε t = f (ε t −1 ) O lo que es lo mismo ε t +1 = f (ε t ) . En este caso, se dice que las perturbaciones están autocorrelacionadas o que existe autocorrelación (esta es la cuestión que trataremos en este tema). Por lo tanto, la perturbación aleatoria afecta no sólo al valor actual de la variable dependiente, Yt, sino también a Yt+1,, Yt+2,…, Cuando existe autocorrelación, se rompe con la hipótesis de incorrelación entre las perturbaciones del modelo de regresión clásico E (ε t ε s ) = 0 . Por tanto, suponemos que: E (ε t ) = 0 E (ε t ε t − s ) ≠ 0 ∀s = 1, 2... E (ε )2 = σ 2 t . La matriz de varianzas y covarianzas de las perturbaciones será: σ 2 E (εε ' ) = σ 2 Ω = Cov(ε 1ε 2 ) K Cov(ε 1ε T ) σ 2 σ2 K Cov(ε 2 ε T ) = K M σ2 ≠ 0 K ≠ 0 σ 2 K ≠ 0 K M σ 2 Causas de la autocorrelación 1) La autocorrelación se produce principalmente cuando trabajamos con datos de series temporales. En este caso, la propia inercia de las series económicas hace que efectos de situaciones pasadas influyan en el momento actual. Por otra parte, si la variable 10 Como veremos posteriormente, las tres formas de introducir relaciones dinámicas están relacionadas y no son tan diferentes como se podría pensar en un principio. 15 Econometría Curso 201-12 endógena presenta una tendencia creciente y las variables explicativas no explican dicho comportamiento, será la perturbación quien recoja dicha tendencia y esto se manifiesta en la existencia de autocorrelación positiva. 2) Existencia de errores de especificación como: omisión de variables relevantes (que recojan ciclos, tendencias, variable endógena retardada) o mala especificación funcional. 3) Existencia de relaciones dinámicas entre las variables. 4) Manipulación de datos, como por ejemplo, la desestacionalización de una serie mediante la utilización de medias móviles. Dependiendo de la causa de la autocorrelación, el procedimiento para corregirla será uno u otro. Si se debe a un error de especificación lo que hay que hacer es solucionar dicho error y, por tanto, antes de actuar sobre la autocorrelación primero hay que evaluar el modelo. 8.2.- Estructuras de dependencia temporal. Un modelo con autocorrelación presenta una matriz de varianzas y covarianzas de T(T − 1) las perturbaciones que puede tener, en general, covarianzas desconocidas además 2 del parámetro de la varianza, σ 2 , y, por tanto, ya que sólo disponemos de T observaciones, supone un problema de estimación irresoluble. Aún suponiendo, como vamos a hacer, que las perturbaciones son procesos débilmente estacionarios, es decir, que sus momentos de primer y segundo orden no dependen del tiempo (en concreto, para las covarianzas entre las distintas observaciones nos encontramos que sólo dependen de la distancia entre dichas observaciones)11, el número de parámetros de dicha matriz sería igual a T y, en general, en el modelo tendríamos T+K+1 parámetros a estimar. Por ello, es necesario establecer posibles estructuras de enlace entre las perturbaciones que reduzcan dichos parámetros desconocidos. Así: Var (ε 1 ) Cov(ε 1ε 2 ) K Cov(ε 1ε T ) γ o Var (ε 2 ) K Cov(ε 2ε T ) 2 E (εε ') = σ Ω = = K M Var (ε T ) γ 1 K γ T −1 γ o K γ T −2 O M γ o Los esquemas más utilizados son: Proceso autorregresivo de orden p: AR(p): ε t = φ1ε t −1 + φ 2 ε t − 2 + ... + φ p ε t − p + u t donde ut es un ruido blanco (variable aleatoria que cumple las hipótesis clásicas). A los coeficientes φ se les impone ciertas restricciones para que se cumpla una condición de estacionariedad que veremos más adelante. Proceso AR(1) El esquema autorregresivo más habitual es el de orden 1 (AR(1)): ε t = ρ ε t −1 + u t donde ut es un ruido blanco(variable aleatoria que cumple las hipótesis clásicas) y ρ es el 11 Esto significa, por ejemplo, que Cov( ε 1ε 2 ) = Cov( ε 2 ε 3 ) = Cov( ε 7 ε 8 ) = ... = Cov( ε t ε t +1 ) . 16 Econometría Curso 2011-12 parámetro a estimar. Imponemos la restricción de que ρ < 1 denominada “condición de estabilidad del modelo” o “condición de estacionariedad”. Esta condición asegura que el modelo AR(1) tiene media constante y varianza finita. Veamos cómo sería en este caso la matriz de varianzas y covarianzas de las perturbaciones Partiendo del esquema AR(1) para la perturbación: ε t = ρ ε t −1 + u t Sustituimos en él la expresión para el periodo t-1: ε t −1 = ρ ε t −2 + u t −1 Tenemos, por tanto: ε t = ρ [ρε t − 2 + u t −1 ] + u t = ρ 2 ε t − 2 + ρ u t −1 + u t ∞ Y haciendo sucesivas sustituciones: ε t = ρ ∞ ε t −∞ + ∑ ρ τ u t −τ τ =0 ∞ Por la condición de estacionariedad ρ ∞ → 0 y, entonces: ε t = ∑ ρ τ u t −τ τ =0 Momentos: ∞ * E (ε t ) = ∑ ρ τ E (u t −τ ) = 0 τ =0 * γ 0 = Var (ε t ) = E (ε t ) 2 2 ∞ ∞ = E ∑ ρ τ u t −τ = ..... = ∑ ρ 2τ σ u2 = σ u2 (1 + ρ 2 + ρ 4 + ...) τ =0 τ =0 σ u2 γ o = Var (ε t ) = σ ε = = γ0 1− ρ 2 2 * γ 1 = Cov (ε t ε t +1 ) = E (ε t ε t +1 ) = E [ε t (ρε t + u t +1 )] = ... = ρσ ε2 = ργ 0 puesto que E (ε t u t +1 ) = 0 * γ 2 = Cov (ε t ε t + 2 ) = E (ε t ε t + 2 ) = ρ E (ε t ε t +1 ) = ρ 2σ ε2 = ρ 2 γ 0 En general: * γ s = Cov(ε t ε t + s ) = E (ε t ε t + s ) = ρ s σ ε2 = ρ s γ 0 ∀s = 1,2 ,... La matriz de varianzas-covarianzas será: 1 ρ ' 2 E εε = σ ε ρ 2 K T −1 ρ ρ 1 ( ) ρ K ρ T −2 ρ2 ρ 1 K ρ T −3 K ρ T −1 K ρ T −2 1 2 K ρ T −3 = σ u 1− ρ 2 K K K 1 1 ρ ρ2 K T −1 ρ ρ 1 ρ ρ2 ρ K 1 K ρ T −2 ρ T −3 K ρ T −1 K ρ T −2 2 K ρ T −3 = σ u Ω K K K 1 Relacionado con las matriz de varianzas y covarianzas se definen las funciones de autocorrelación simple (FAS) y parcial (FAP). 17 Econometría Curso 201-12 La FAS de las perturbaciones se calcula a partir de los coeficientes de correlación entre perturbaciones de diferentes periodos ( ρ s ). Así, para cada valor del retardo γ Cov (ε t , ε t + s ) s=0,1,2,3... y cada momento t, la función sería ρ s = = s Var (ε t ) Var (ε t + s ) γ 0 La FAP de las perturbaciones se obtiene calculando la correlación entre las perturbaciones de diferentes periodos, pero eliminando el efecto de las perturbaciones intermedias. Así, para cada valor del retardo s=1,2,3... y cada momento t, la función es igual al coeficiente de correlación parcial entre ε t y ε t + s que denotaremos por ρ s . • ρs = • R*s Rs Rs es el determinante de la matriz de correlaciones de s filas y s columnas y R s* es el determinante de la matriz anterior en la que la última columna se sustituye por un vector de valores (ρ1 ρ 2 K ρ s ) . Las FAS y FAP de los esquemas débilmente estacionarios siguen comportamientos conocidos y ellas, junto con su representación gráfica (correlogramas), sirven de base para identificar los diferentes esquemas. ρ s = Corr (ε t ε t + s ) = ρ sσ ε2 = ρs 2 σε FAS ρ 0 = 1 s = 0 s s = 1,2,... ρ ρs = Correlogramas (FAS) ρ>0 ρ<0 ρs ρs s s FAP ρ1 = ρ1 • ρ 2 − ρ 12 ρ 2 − ρ 2 = =0 ρ2 = 1 − ρ 12 1− ρ2 • Así, ρ 1 = ρ 0 ρs = • s =1 s≥2 18 Econometría Curso 2011-12 Correlograma (FAP) ρ>0 ρs ρ<0 ρs • • s s En definitiva, en un proceso AR(1), la FAS va decreciendo con todos los coeficientes distintos de cero, mientras que la FAP sólo tendría el primer coeficiente distinto de cero. Se dice que el proceso AR(1) tiene memoria infinita. Proceso AR(p) Generalizando para un AR(p), se demuestra que la matriz de varianzas y covarianza depende de “p” parámetros, además de la varianza de las perturbaciones. La FAS sigue un comportamiento decreciente, la FAP sólo presenta p coeficientes distintos de cero, los p primeros. Por ejemplo, en un AR(2) serán sólo dos coeficientes, los 2 primeros. Proceso de medias móviles de orden q: MA(q) ε t = u t − θ 1 u t −1 − ..... − θ q u t − q donde ut es un ruido blanco. A los coeficientes θ también se les impone ciertas restricciones. Normalmente, trabajaremos con órdenes pequeños. Proceso MA(1) El más frecuente es el de medias móviles de orden 1(MA(1)): ε t = u t − θ1u t −1 donde ut es un ruido blanco y θ1 < 1 es una condición de invertibilidad. Calculemos cómo serían sus varianzas y covarianzas * E (ε t ) = 0 * γ o = Var (ε t ) = σ u2 (1 + θ 2 ) * γ 1 = Cov (ε t , ε t +1 ) = −θσ u2 * γ 2 = Cov(ε t , ε t + 2 ) = 0 * γ s = Cov(ε t , ε t + s ) = 0 ∀s ≥ 2 Por lo tanto la matriz de varianzas y covarianzas será: (1 + θ 2 ) −θ ' 2 E (εε ) = σ u 0 K 0 −θ (1 + θ 2 ) 0 −θ −θ (1 + θ ) K K 0 0 2 K 0 = σ u2 Ω K K K (1 + θ 2 ) K K 0 0 19 Econometría Curso 201-12 FAS: γs ρs = = γo s=0 1 γ1 θ =− γo 1+θ 2 γs =0 γo s =1 ∀s ≥ 2 Correlograma (FAS) θ <0 θ >0 ρs ρs s s FAP ρs = • θ 1+θ 2 2 ρ 2 − ρ1 − θ 2 1 − θ 2 = 1 − ρ 12 1−θ 6 −θ s 1−θ 2 1 − θ 2 ( s +1) ρ1 = − ( ( ) ) ( ( ) s =1 ) s=2 ∀s Correlograma (FAP) θ <0 ρs θ >0 ρs • • s s En un proceso MA(1) la FAS tendrá sólo un coeficiente de autocorrelación distinto de cero mientras que será la FAP la que irá decreciendo hacia cero. Se dice que un proceso MA(1) sólo tiene memoria de un periodo. Proceso MA(q) Generalizando para un MA(q), la matriz de varianzas y covarianzas depende, además de la varianza de las perturbaciones, de “q” parámetros. La FAS se anula para retardos mayores que “q”, tiene, por tanto, una memoria limitada de q periodos. La FAP no se anula, sus coeficientes decrecen hacia 0. 20 Econometría Curso 2011-12 Proceso autorregresivo de medias móviles de orden p, q: ARMA(p,q) Estos procesos son una generalización de los procesos AR y MA. ε t = φ1 ε t −1 + φ 2 ε t − 2 + ...... + φ p ε t − p + u t − θ 1u t −1 − ..... − θ q u t − q donde ut es un ruido blanco. Normalmente utilizaremos órdenes pequeños. ARMA(1,1) ε t = φ1ε t −1 + u t − θ1u t −1 Estos procesos, igual que los anteriores, se caracterizan por la FAS y la FAP, pero en la práctica son más difíciles de identificar. En los ARMA(p,q), la FAS se comporta como la de un AR(p) para valores de s>q. Respecto a la FAP ésta se comporta como la de un MA(q) para s >p. De todos estos esquemas el más utilizado en el contexto de los modelos de regresión es el AR(1), pues representa de forma aceptable las correlaciones encontradas entre perturbaciones. Otras estructuras son complejas de manejar y no han ofrecido ventajas relativas superiores. Además, Es más adecuado mejorar la especificación del modelo original para que la perturbación no presente complicados esquemas de correlación. 8.3.- Procedimientos para detectar la autocorrelación • Métodos gráficos 1. Representaciones gráficas de los residuos et frente al tiempo 2. Representaciones gráficas de los residuos et frente a et −1 Figura 112 12 Gujarati (2006): Principios de Econometría. McGraw Hill. 21 Econometría Curso 201-12 Figura 1113 3. Identificación de los residuos (combinación de métodos gráficos y contrastes) En la práctica la perturbación no es observable y no se pueden calcular los verdaderos coeficientes de correlación simple y parcial, sino que hay que obtener estimadores de dichas funciones utilizando las series de los residuos de mínimos cuadrados ordinarios. Así, la función de autocorrelación simple muestral (FASE) se calcula como: T −s ρ̂ s = ∑ et et + s t =1 T ∑e t =1 2 t Y la función de autocorrelación parcial muestral (FAPE) como: ρˆ s = • R*s Rs Donde las matrices se calculan a partir de los coeficientes de correlación estimados que a su vez utilizan las series de los residuos mínimo cuadráticos. 13 Gujarati (2006): Principios de Econometría. McGraw Hill. 22 Econometría Curso 2011-12 El comportamiento de los coeficientes estimados no es exactamente el de los teóricos. Dado que son variables aleatorias con distribución conocida, se decide si el coeficiente es cero o no mediante la aplicación de contrastes o a partir del cálculo de su intervalo de confianza. En un MA(q): H0: ρ S = 0 ∀s > q HA: ρ S ≠ 0 ρˆ s → N (0, Var ( ρˆ s )) donde Vaˆr ( ρˆ s ) = s 1 (1 + 2∑ ρˆ 2j ) T j =1 En un AR(p): H0: ρ S• = 0 ∀s > p HA: ρ S • ≠ 0 ρˆ s• → N ( 0 ,Var( ρˆ s . )) donde Vâr( ρˆ s• ) ≅ • 1 T Contrastes estadísticos Todos ellos utilizan para su elaboración los residuos obtenidos en la estimación mínimo cuadrática ordinaria y plantean en la hipótesis nula la ausencia de autocorrelación. La hipótesis alternativa difiere de unos contrastes a otros planteando distintos procesos de correlación entre las perturbaciones según los casos. 1.- Contraste de Durbin-Watson La hipótesis nula del contraste plantea la ausencia de autocorrelación, mientras que la alternativa considera la existencia de autocorrelación mediante un AR(1): (ε t = ρε t −1 + u t ) . Es un contraste de una sola cola según se establezca que ρ < 0 o ρ > 0, es decir: H0 : ρ = 0 H1 : ρ < 0 o ρ >0 El estadístico del contraste se define como: T d= ∑ (e t =2 t − et −1 ) T ∑e t =1 2 2 t donde e son los residuos MCO. Se suele considerar la siguiente aproximación: d = 2(1 − ρˆ ) siendo ρ̂ el coeficiente de correlación muestral entre et y et −1 y, por lo tanto, como ρ̂ está comprendido entre -1 y 1, el estadístico de Durbin-Watson estará comprendido entre 0 y 4: ρˆ = −1 ⇒ d=4 ⇒ Existe Autocorrelación negativa ρˆ = 0 ⇒ d=2 ⇒ No existe autocorrelación 23 Econometría Curso 201-12 ρˆ = 1 ⇒ d=0 ⇒ Existe Autocorrelación positiva La distribución de probabilidad exacta del estadístico es difícil de encontrar, ya que, como demostraron Durbin y Watson, depende en forma complicada, de los valores de las X en una muestra dada. Sin embargo, Durbin y Watson tabularon un límite inferior (dL) y un límite superior (dU) para diferentes tamaños muestrales y diferente número de regresores, de forma que al comparar el valor muestral del estadístico con esas cotas se puede tomar una decisión sobre la posible presencia de autocorrelación. Durbin y Watson sólo buscaron dichas cotas para el caso de autocorrelación positiva, por lo que el contraste es de una cola. No obstante debido a la simetría del estadístico también es posible contrastar el caso de autocorrelación negativa. Autoc. Posit. Zona duda 0 dL Incorrelación dU Zona duda 2 4-dU Autoc.Negat. 4-dL 4 Inconvenientes: 1. No es válido cuando el modelo no tiene término constante. 2. No se puede utilizar si el modelo incluye regresores estocásticos y por lo tanto no se puede utilizar en los llamados modelos autorregresivos (modelos en los que la variable endógena retardada está entre los regresores). Para ese caso Durbin propuso: h = ρˆ T 1 − TVar ( βˆ i ) a → N (0,1) donde Var ( βˆi ) es la varianza del parámetro que acompaña al primer retardo de la variable endógena (en la práctica se utiliza S β2ˆ ) y ρ̂ es el estimador de ρ obtenido a i partir de la regresión de et sobre et −1 . 3. Existen dos zonas de indeterminación en las cuales el contraste no nos dice nada y hemos de recurrir a otro. 4. Para un T pequeño y un k grande, las condiciones del contraste no son muy fiables. 5. La hipótesis alternativa que se propone es la de un AR(1). Wallis hizo una extensión del test de Durbin-Watson para el caso de series trimestrales con problemas de estacionalidad y propuso un estadístico de Durbin-Watson modificado: T d4 = ∑ (e t =5 t − et − 4 ) T ∑e t =1 24 2 t 2 Econometría Curso 2011-12 2.- Contraste de Breusch y Godfrey Hipótesis: H 0 : Ausencia de autocorrelación ( ρ1 = ρ 2 = ... = ρ m = 0) H 1 : AR(m) o MA(m) Es un contraste asintótico de multiplicadores de Lagrange. Procedimiento: 1) Estimar el modelo por MCO y calcular los residuos: e = Y − Xβˆ 2) Hacer la regresión auxiliar de dichos residuos sobre m retardos suyos y todas las variables explicativas del modelo (tanto exógenas como endógenas retardadas). El número de retardos es el del orden del esquema AR o MA que estamos suponiendo en la hipótesis alternativa. 3) a 2 Bajo la H0 el estadístico es: T Raux → χ m2 Donde m es el orden del esquema propuesto en la hipótesis alternativa. Este contraste se puede utilizar cuando la variable endógena aparece retardada como un regresor. Nota: En teoría para realizar la regresión auxiliar se pierden m observaciones, pero el programa Eviews toma los valores de los errores retardados m periodos iguales a cero. 8.4.- Estimación del modelo Vamos a considerar dos formas de estimar un modelo con autocorrelación, en el caso más relevante, cuando la matriz de varianzas y covarianzas de las perturbaciones es desconocida: mínimos cuadrados no lineales y MCO utilizando la corrección de NeweyWest. A) Mínimos cuadrados no lineales. Consideremos el modelo original Yt = β 0 + β 1 X 1t + ... + β k X kt + ε t En un principio, supondremos que las perturbaciones siguen un esquema AR(1): ε t = ρ ε t −1 + u t . Dado que u t = ε t − ρ ε t −1 es una variable aleatoria que cumple las hipótesis clásicas, por ser un ruido blanco, podemos intentar buscar una trasformación del modelo original que conserve los parámetros de interés y que esté en función de ut. Si multiplicamos al modelo expresado en la observación t-1 por ρ obtenemos: ρYt −1 = ρβ 0 + ρβ 1 X 1t −1 + ... + ρβ k X kt −1 + ρε t −1 Si restamos, miembro a miembro, el modelo expresado en la observación t y el modelo expresado en la observación t-1 multiplicado por ρ , obtenemos 25 Econometría Curso 201-12 Yt − ρYt −1 = (1 − ρ )β 0 + β1 ( X 1t − ρX 1t −1 ) + ... + β k ( X kt − ρX kt −1 ) + ε t − ρε t −1 Este modelo se conoce como el modelo en diferencias generalizado. Es un modelo que cumple las hipótesis clásicas si realmente el esquema de las perturbaciones del modelo original es un AR(1). Además está en función de los parámetros de interés ( β y ρ ). A) Si ρ fuera conocido podríamos aplicar MCO sobre el modelo en diferencias generalizado, obteniendo unos estimadores que son ELIO y consistentes. Al estimador del vector paramétrico, se le denomina estimador de mínimos cuadrados generalizados. B) Sin embargo, generalmente, ρ es desconocido y debe tratarse como un parámetro adicional a estimar. En este caso se puede proceder de dos formas diferentes. 1.- Una forma es mediante algún método secuencial, con el que se estima primero ρ y después β . El proceso se puede repetir hasta conseguir un determinado nivel de precisión en las estimaciones. Ejemplos de este método secuencial son Cochrane-Orcutt y el bietápico de Durbin. 2.- La otra forma de estimar el modelo es mediante algún método que proporcione simultáneamente un estimador para β y para ρ . Para obtener los estimadores hay que tener en cuenta que el modelo en diferencias generalizado se puede expresar como Yt = ρYt −1 + (1 − ρ )β 0 + β 1 X 1t − β1 ρX 1t −1 + ... + β k X kt − β k ρX kt −1 + ε t − ρε t −1 Obtenemos una ecuación donde la perturbación cumple las hipótesis clásicas (ε t − ρε t −1 = u t ) , pero que no es lineal en los k+2 parámetros de los que depende. Este modelo se puede estimar minimizando la suma de cuadros de los errores mediante de algún algoritmo de optimización no lineal. Precisamente, este es el procedimiento que utiliza el programa Eviews. Si la perturbación siguiera un esquema AR de mayor orden o un MA la forma de proceder sería muy similar. Propiedades de los estimadores cuando ρ es desconocido: Los estimadores que se obtienen se denominan estimadores factibles. Las propiedades del estimador factible dependen de si la estructura que se ha supuesto para las perturbaciones es correcta o no. Por ello es importante comprobar si las perturbaciones de dicho modelo están o no autocorrelacionadas utilizando el test de Breusch-Godfrey. Si no presentan autocorrelación entonces el estimador factible tiene buenas propiedades asintóticas (consistente, asintóticamente eficiente y la distribución asintótica es una normal), aunque se desconocen las propiedades finitas. Si la estructura que hemos supuesto para las perturbaciones es incorrecta (la perturbación del modelo resultante no cumple las hipótesis clásicas), el estimador factible ni siquiera tiene estas propiedades. B) MCO utilizando la corrección de Newey-West Como ya hemos comentado cuando las perturbaciones están autocorrelacionadas, se viola una de las hipótesis clásicas. Las consecuencias de aplicar MCO a un modelo en el que hay autocorrelación son las mismas que aplicar MCO a un modelo con heteroscedasticidad. 26 Econometría Curso 2011-12 a) El estimador de MCO sigue siendo un estimador lineal, insesgado y consistente, pero ya no es óptimo. Es posible encontrar un estimador alternativo con menor varianza. b) Σ βˆβˆ ≠ σ 2 ( X ' X ) . Por tanto, las expresiones habituales de las varianzas de los −1 estimadores por MCO no son correctas y consecuentemente los contrastes realizados a partir de ellas no son adecuados . No obstante, podemos estimar el modelo por MCO, pero corrigiendo las desviaciones típicas de los estimadores por el procedimiento de Newey-West. Dicho procedimiento obtiene desviaciones típicas de los estimadores consistentes ante la presencia de autocorrelación y/o heteroscedasticidad (a diferencia del procedimiento de White que sólo está diseñado para casos de heteroscedasticidad). Dado que se consigue consistencia, es evidente, que el procedimiento (implementado entre los resultados de la mayoría de paquetes estadísticos) será válido si la muestra es grande. De esta manera, la estimación MCO proporcionaría estimadores que son, como ya sabemos, insesgados y consistentes (aunque no eficientes) y que, con la corrección de Newey-West presentarían estimaciones consistentes de sus varianzas que podríamos utilizar para realizar inferencia, siempre de forma asintótica. C) Otras formas alternativas de estimación Otra forma alternativa de estimación sería añadir dinámica al modelo, es decir, introducir en el modelo como regresor la variable endógena retardada. Consistiría en plantear una especificación alternativa para el modelo, tal que el modelo estático no sería más que un modelo restringido del dinámico bajo una alternativa que podría ser cierta o falsa. 8.5.- Predicción Supongamos que hemos obtenido el estimador factible de los parámetros del ~ modelo, β y ρ̂ . A la hora de predecir podemos hacerlo a partir del modelo de diferencias generalizadas deshaciendo posteriormente la transformación o directamente a partir del modelo original estimado por Mínimos cuadrados generalizados. Vamos a plantearlo de esta última forma incluyendo el esquema de autocorrelación en la perturbación: Yt = β 0 + β 1 X 1t + ... + β k X kt + ε t Por tanto: ε t = Yt − β 0 + β 1 X 1t + ... + β k X kt Además suponemos que: ε t = ρ ε t −1 + u t De esta forma sustituyendo en el modelo: Yt = β 0 + β1 X 1t + ... + β k X kt + ρε t −1 + u t ~ ~ ~ eT La predicción en T+1 sería: YˆT +1 = β 0 + β1 X 1T +1 + ... + β k X kT +1 + ρ~ ~ Donde ~ ~ ~ e~T = YT = β 0 + β1 X 1T + ... + β k X kT La predicción para el período T+2: ~ ~ ~ YˆT + 2 = β 0 + β1 X 1T + 2 + ... + β k X kT + 2 + ρ~ e~T +1 27 Econometría Curso 201-12 Dado que: ε T +1 = ρ ε T + uT +1 y que e~T +1 = ρ~ e~T ~ ~ ~ YˆT + 2 = β 0 + β1 X 1T + 2 + ... + β k X kT + 2 + ρ~ 2 ~ eT ~ ~ ~ eT Generalizando para el período T+s: YˆT + s = β 0 + β1 X 1T + s + ... + β k X kT + s + ρ~ s ~ Analizar las propiedades de este predictor no es tarea sencilla, ya que depende de la ~ distribución conjunta de β y ρ̂ . Una aproximación de la desviación típica del error de predicción se puede obtener, considerando que ρ es conocido. 28 Econometría Curso 2011-12 Apéndice.- Representaciones de FAS y FAP de diferentes esquemas AR 29 Econometría Curso 201-12 MA 30 Econometría Curso 2011-12 ARMA(1,1) 31 Econometría Curso 201-12 Ejemplos de correlogramas de algunos esquemas RUIDO BLANCO 32 Econometría Curso 2011-12 33 Econometría Curso 201-12 AR(1) 34 Econometría Curso 2011-12 TEMA 9. REGRESORES ESTOCÁSTICOS 9.1.- Posible carácter estocástico de las variables explicativas La presencia de regresores estocásticos en un modelo incumple la hipótesis clásica de que la matriz de variables explicativas X es no estocástica, hipótesis que implicaba que los valores de las variables explicativas se mantendrían fijos si pudiésemos repetir el experimento. El problema fundamental cuando en un modelo hay regresores estocásticos es que no se garantizan ciertas propiedades del EMCO que sí se cumplían en temas anteriores. Si X no es estocástica y se cumplen las hipótesis sobre ε, el EMCO es el mejor estimador posible entre los estimadores lineales e insesgados (el de mínima varianza). Cuando X es aleatoria, el supuesto crucial es la relación entre dichas variables y la perturbación aleatoria. A nivel estadístico, podríamos medir la relación entre X y ε a partir del coeficiente de correlación lineal. Sin embargo, dado que dicho coeficiente sólo mide dependencia lineal, lo que vamos a estudiar, puesto que ambas son variables aleatorias, es el valor esperado de ε dado cualquier valor de X: E(ε|X). En los temas anteriores suponíamos que las variables explicativas no eran aleatorias y que, además, E (ε ) = 0 , es decir, que en promedio los factores no observables se anulaban para todos los individuos de la población. Todo ello implicaba que E(ε|X)=0, pues como X es fija E(ε|X)=E(ε) y como E(ε)=0, finalmente, E(ε|X)=0. Cuando hay regresores estocásticos, podemos seguir manteniendo el supuesto E (ε ) = 0 , pero lo que ya no está claro es que se cumpla que E(ε|X)=0, el supuesto de media condicional nula. Al ser X aleatoria se define la matriz de momentos poblacionales de los regresores en el momento t como ΣXX y suponemos que está definida en el campo real. Si ΣXX es finita y además no singular ⇒ Existe Σ −XX1 Llamando X t' al vector fila que recoge las observaciones de todos los regresores en el momento t: X t' =(1 X1t X2t ... Xkt) la matriz ΣXX sería la siguiente: Σ XX 1 X 1t ' (1 X 1t = E Xt Xt = E M X kt ( ) 1 E ( X 1t ) L E ( X kt ) 2 E ( X 1t ) E X 1t L E ( X 1t X kt ) L X kt ) = M M M M 2 E X kt E ( X kt ) E ( X 1t X kt ) L ( ) ( ) A esta matriz se le llama también matriz de momentos contemporáneos por estar referida a un mismo periodo t. En esta situación se cumplen las siguientes propiedades: ε 'ε =σ2 • plim • X'X X'X plim = Σ XX finita y no singular ( plim T T T 35 −1 = Σ −XX1 ). Econometría Curso 201-12 9.2.- Variables contemporáneamente exógenas y estrictamente exógenas A) Los regresores Xjt ∀ j=1,...,k son contemporáneamente exógenos cuando se cumple: ( ) E (ε t | X 1t , X 2t ,..., X kt ) = E ε t | X t' = 0 ∀t Esto implica que εt y las variables explicativas están contemporáneamente incorrelacionadas, es decir, Cov(εt,Xjt)=0 para todo j. Por tanto, también E (ε t X jt ) = 0. Nota: Cuando hablamos de contemporaneidad nos referimos a las variables tal como aparecen en el modelo, es decir, el vector X t' puede tener como uno de sus elementos Yt-1. B) Los regresores Xjt ∀ j=1,...,k son estrictamente exógenos cuando se cumple: E (ε t | X ) = 0 ∀t = 1,..., T Esto significa que εt no se correlaciona con ninguna variable explicativa en ningún periodo: Cov (ε t , X jt ' ) = 0 ∀j , ∀t t ' = 1,2,...T . Por tanto, también E (ε t X jt ' ) = 0. Esta condición es mucho más fuerte que la anterior ya que suponemos que para cada t, el valor esperado de εt, dadas las variables explicativas en todos los periodos, es cero. C) Los regresores no son exógenos ni estricta ni contemporáneamente cuando: E (ε t | X ) ≠ 0 Los supuestos A) y B) son muy importantes para definir las propiedades de los estimadores de MCO en regresores estocásticos, especialmente cuando trabajamos con series temporales: 1) Si se da el supuesto A) es decir, existe exogeneidad contemporánea entre los regresores y las perturbaciones ⇒ el EMCO es consistente, pero no es insesgado. 2) Si se cumple el supuesto B) es decir, existe exogeneidad estricta entre los regresores y las perturbaciones ⇒ el EMCO es insesgado, eficiente y consistente. 3) Si no se cumple ni siquiera el supuesto A), el estimador de MCO es sesgado e inconsistente. 9.3.- Propiedades de los estimadores de MCO en modelos con regresores estocásticos β̂ = (X’X)-1X’Y = β + (X’X)-1X’ε 1) β̂ no es lineal en Y por ser X aleatoria y por tanto β̂ es una función estocástica de X y ε o de X y de Y. 2) Insesgadez E( β̂ ) = E(β + (X’X)-1X’ε) = β+ EX[E((X’X)-1X’ε|X)]= β+ EX[(X’X)-1X’E(ε|X)] Por propiedad de la esperanza E [h( x, y )] = E x [E (h( x, y ) | x)] Supuestos: a) Exogeneidad estricta: E(ε|X)=0 ⇒ EX[(X’X)-1X’E(ε|X)]=0 ⇒ E( β̂ ) =β ⇒ insesgado 36 Econometría Curso 2011-12 b) Exogeneidad contemporánea: E(εt|Xt)=0, pero E(εt|Xs)≠0 ⇒ EX[(X’X)-1X’E(ε|X)] ≠ 0⇒ E( β̂ )≠β ⇒ sesgado ≠0 3) β̂ no es óptimo en el sentido indicado hasta ahora pues no es lineal, pero: a) Si las variables explicativas son estrictamente exógenas, β̂ es eficiente (de mínima varianza entre los insesgados), siendo su matriz de varianzas y covarianzas: Σ ˆ ˆ =E[( β̂ -β)( β̂ -β)’]=E[(X’X)-1X’εε’X(X’X)-1]=EX[E((X’X)-1X’εε’X(X’X)-1|X)]= ββ =EX[ (X’X)-1X’ E(εε’ |X)X(X’X)-1)] =σ2 EX[ (X’X)-1X’X(X’X)-1)] =σ2 EX[ (X’X)-1] =σ2I b) Si las variables explicativas son contemporáneamente exógenas no tiene sentido hablar de eficiencia pues el estimador es sesgado. Pero es asintóticamente eficiente. 4) Consistencia −1 X 'ε X 'ε X'X p lim βˆ = β + p lim( X ' X ) −1 X ' ε = β + p lim = β + Σ −XX1 * p lim p lim T T T El estimador será consistente si el p lim 1 X 'ε 1 X 11 = p lim p lim T T M X k1 1 X 12 M X k2 X 'ε =0 T ∑ ε t E (ε t ) 0 L 1 ε 1 L X 1T ε 2 1 ∑ ε t X 1t E (ε t X 1t ) 0 = p lim = = M M L M M M T ε X E (ε X ) 0 L X kT ε T t kt ∑ t kt Esto se cumplirá si E (ε t ) =0 y, por lo menos, las variables explicativas son contemporáneamente exógenas, pues en este caso cov(ε t X jt ) = 0 = E (ε t X jt ) . En definitiva, no hace falta la exogeneidad estricta para que el estimador sea consistente, aunque si se da, por supuesto, también lo será. Propiedades del estimador S 2 1) Insesgadez El S2 es insesgado sólo si se da la exogeneidad estricta. 2) Consistencia El S2 es consistente si se da la exogeneidad estricta o la contemporánea. Distribución de los EMCO Estrictamente la distribución exacta de β̂ no se conoce ya que depende no sólo de la distribución de ε que podemos seguir considerando Normal, sino también de la de X que es desconocida. Además, β̂ no es lineal en Y y por tanto, β̂ no sigue una distribución normal. Los estadísticos que contrastan las restricciones lineales, tanto individuales como conjuntas, no siguen una distribución exacta conocida, en concreto no siguen una t ni una F respectivamente. 37 Econometría Curso 201-12 Sin embargo, Wooldridge establece que, si los regresores son estrictamente exógenos, la distribución de β̂ condicionada a X es normal y, por tanto, los estadísticos t y F son válidos si hablamos de distribuciones condicionadas. En cambio, si los regresores son contemporáneamente exógenos las distribuciones finitas no son válidas y tendremos que recurrir a las asintóticas. Recordemos que ( ) −1 X ' X a T βˆ − β N 0, σ 2 p lim → T Esto implica que su distribución asintótica nos va a permitir justificar el uso de las distribuciones habituales, aunque sólo tendrán validez de forma aproximada. En este sentido, también podríamos utilizar los contrastes asintóticos de Wald, LM o RV. Resumen: A) Si los regresores son estrictamente exógenos los resultados son muy similares a los del MRLC pero condicionado todo por X. • β̂ es insesgado, eficiente y consistente y coincide con el estimador de MV. • S2 es insesgado y consistente. • Hablando de distribuciones condicionadas a X los test de hipótesis son válidos para muestras finitas y no es necesario recurrir a la teoría asintótica. B) Si los regresores son sólo contemporáneamente exógenos • β̂ es sesgado, y, por tanto, no eficiente (ni óptimo), pero sí es consistente y asintóticamente eficiente. • S2 es sesgado pero consistente. • Como S2 es sesgado entonces S βˆβˆ = S 2 ( X ' X ) −1 es sesgado, pero su utilización está justificada en base a la distribución asintótica. • Los contrastes son válidos asintóticamente. • Hay que recurrir al comportamiento asintótico de los estimadores y contrastes. C) Cuando ni siquiera se cumple la exogeneidad contemporánea, la estimación de MCO no es válida porque no se cumple ninguna propiedad. En este caso, hay que recurrir a otro método de estimación que se denomina de Variables Instrumentales. • β̂ es sesgado e inconsistente. • S2 es sesgado e inconsistente. • No disponemos de una distribución asintótica, a partir del EMCO, para aproximar la distribución exacta de los estadísticos cuando T tiende a infinito. 38 Econometría Curso 2011-12 9.4.- Modelos con variables estocásticas correlacionadas con la perturbación. Método de variables instrumentales Este método consiste en encontrar una matriz de variables, Z, tales que cumplan los requisitos siguientes: • Las variables Z están incorrelacionadas con las perturbaciones, es decir, Z 'ε p lim =0 T • Las variables Z están fuertemente correlacionadas con las variables X, es decir, Z' X p lim = Σ ZX finita y no singular T • Las variables Z tienen buenas propiedades en el límite, es decir, p lim Z'Z = Σ ZZ . T A estas variables Z1,...,Zk se las llama instrumentos o variables instrumentales. Nota: Si algún regresor no está correlacionado con las perturbaciones puede utilizarse él mismo como variable instrumental. El estimador de variables instrumentales se define como: βˆVI = (Z ' X )−1 Z ' Y = β + (Z ' X )−1 Z ' ε Propiedades • No es lineal en Y pues también depende de X y de Z (que son aleatorias). • No es insesgado: X no es ni contemporáneamente exógena por lo que E (ε / X ) ≠ 0 y E ( βˆ ) ≠ β . • Por lo anterior, no es eficiente ni óptimo. • Z 'ε Z' X Es consistente: p lim βˆVI = p lim β + p lim = β + Σ −ZX1 0 = β p lim T T • Distribución asintótica: −1 ( ) a T βˆVI − β → N (0,VVI ) −1 donde VVI = σ 2 Σ ZX Σ ZZ (Σ −ZX1 )' es la matriz de varianzas-covarianzas asintótica de dicha distribución. Z' X Un estimador de dicha matriz es: VˆVI = σˆ VI2 T donde σˆ VI2 = −1 Z'Z X 'Z T T −1 eVI' eVI es un estimador consistente de σ2 y eVI = Y − Xβ̂ VI T − k −1 Una aproximación del estimador de VVI es: S βˆ = σˆ VI2 (Z ' X ) Z ' Z ( X ' Z ) −1 −1 VI Nota: No se puede decir que el estimador de VI es eficiente pues la elección de instrumentos diferentes genera distintos estimadores por VI. Lo que sí se puede afirmar, sin embargo, es que cuanto mayor sea la correlación entre X y Z más eficiente asintóticamente será el estimador por variables instrumentales. 39 Econometría Curso 201-12 9.5.- Errores en las variables Sea el modelo Y = Xβ + ε donde, por error, no disponemos de observaciones de Y ni de X sino de unos datos aproximados Y* y X* donde: Y*=Y+V X*=X+U Siendo U y V matrices aleatorias de errores de medida que cumplen las hipótesis clásicas y además están incorrelacionadas entre sí y cada una de ellas con X y ε. El modelo estimado es un modelo en el que los regresores y las perturbaciones están correlacionados incluso contemporáneamente: ( ) V − Uβ ⇒ Y * = X * β + W Y = Xβ + ε ⇒ Y * − V = X * − U β + ε ⇒ Y * = X * β + ε1+4 243 W Simplificando a un modelo de dos variables: Yt = β 0 + β 1 X t + ε t ⇒ Yt * − vt = β 0 + β 1 ( X t* − u t ) + ε t ⇒ Yt* = β 0 + β 1 X t* + ε t + vt − β 1u t ⇒ Yt * = β 0 + β 1 X t* + wt ⇒ wt = ε t + vt − β 1u t 14 4244 3 wt E (wt ) = E (ε t + vt − β 1u t ) = 0 [( ] ) Cov ( X t* , wt ) = E ( X t* , wt ) = E X t + u t (ε t + v t − β 1u t ) = ( ) ( ) E ( X t ε t ) + E ( X t vt ) − β 1 E ( X t u t ) + E (u t ε t ) + E (u t v t ) − β 1 E u t2 = − β 1 E u t2 = − β 1σ u2 ≠ 0 Por lo tanto, los estimadores de MCO son sesgados e inconsistentes y habría que utilizar el método de variables instrumentales para obtener estimadores consistentes. Por otra parte, si el error en los datos sólo afectase a la variable Y, no surgiría el problema anterior. 9.6.- Test de exogeneidad de Hausman La consistencia de los EMCO en los modelos con regresores estocásticos depende de la X 'ε hipótesis p lim =0. T Hausman propuso un estadístico para contrastar esta hipótesis: H 0 : p lim X 'ε =0 T H 1 : p lim X 'ε ≠0 T La lógica del contraste es comparar el comportamiento de dos estimadores β̂ MCO y β̂ VI , cuyas distribuciones asintóticas son: ( ) a T βˆ MCO − β → N (0,VMCO ) donde VMCO = σ 2 Σ −XX1 y y ( ) a T βˆVI − β → N (0,VVI ) −1 VVI = σ 2 Σ ZX Σ ZZ (Σ −ZX1 )' . 40 Econometría Curso 2011-12 X 'ε = 0 , tanto β̂ MCO como β̂ VI son consistentes, T X 'ε sin embargo, bajo la alternativa H 1 : p lim ≠ 0 , sólo lo es β̂ VI . Si la hipótesis nula es T cierta entonces p lim βˆ MCO − βˆVI = 0 y el valor de βˆ MCO − βˆVI debería ser pequeño; al contrario, si la hipótesis nula no es cierta. Bajo la hipótesis nula H 0 : p lim ( ) ( ) El estadístico de Hausman se define, bajo la H0 , como: ( H Hausman = T βˆ MCO − βˆVI ) [Vˆ ' VI − VˆMCO ] (βˆ −1 MCO ) a − βˆVI → χ H2 donde H es el número de regresores que se quiere ver si son o no exógenos, VˆVI y VˆMCO son −1 −1 Z ' X Z 'Z X 'Z estimadores consistentes de VVI y de VMCO, es decir, VˆVI = σˆ T T T −1 2 X'X 2 ˆ y VMCO = σˆ y σˆ 2 el estimador consistente de σ utilizando el estimador de T 2 VI para obtener los residuos. Si el valor del estadístico de Hausman supera el valor crítico se rechaza la H0 de que no hay correlación entre los regresores y la perturbación; en caso contrario, se acepta la no existencia de correlación entre los regresores y la perturbación. Este contraste se puede realizar también a partir de una serie de regresiones auxiliares: 1) Realizar la regresión de las variables que posiblemente sean endógenas sobre los instrumentos y las exógenas del modelo y quedarnos o bien con los residuos o con el valor estimado. 2) Introducir en la regresión original los valores estimados (o los residuos) y contrastar si son o no significativos, de modo que si no lo son aceptaríamos la H0 y si lo son la rechazaríamos. 41 Econometría Curso 201-12 42 Econometría Curso 2011-12 TEMA 10. MODELOS DINÁMICOS 10.1.- Planteamiento general Los modelos estudiados hasta ahora eran modelos estáticos en los que todas las variables estaban referidas al mismo periodo de tiempo. Estos modelos se plantean cuando se considera que un cambio en X en el momento t ejerce un efecto inmediato en Y. Sin embargo, la Teoría Económica sugiere que, en muchos casos, las relaciones entre las variables son dinámicas, de forma que el efecto de una variable X j sobre Y no tiene por qué ser instantáneo y se puede distribuir en distintos periodos de tiempo. Vamos a distinguir dos tipos de modelos dinámicos: a) Modelos autorregresivos. b) Modelos de retardos distribuidos. Nota: En este tema vamos a utilizar frecuentemente el llamado operador de retardo (que se denota por L o B) y que retarda la variable a la que acompaña del siguiente modo: Ls X t = X t − s De esta forma: LX t = X t −1 ; L2 X t = X t − 2 ; Ls X t = X t − s ; (1 − L) X t = X t − X t −1 . 10.2.- Modelos autorregresivos Son aquellos en los que se plantea como regresor la variable endógena retardada en algún periodo de tiempo. Un ejemplo sería: Yt = β 0 + β 1 X t + β 2Yt −1 + ε t Este tipo de modelos son estocásticos ya que la variable Yt-1 es aleatoria. Además, no podemos considerar que los regresores sean estrictamente exógenos ya que podemos comprobar que Yt-1 estará relacionada con ε t −1 , ε t −2 ,.... . Por tanto, no se va a cumplir que E(εt | X)=0 ∀ t=1,...,T Sin embargo, si εt cumple las hipótesis clásicas, podemos aceptar la exogeneidad X 'ε contemporánea, de tal forma que E (ε t | X t' ) = 0 y se cumple que p lim = 0 . Los T EMCO son sesgados y no eficientes, pero son consistentes y las distribuciones asintóticas son válidas, es decir, los resultados habituales de inferencia estadística son válidos asintóticamente. Si εt está autocorrelacionada, ni siquiera se cumpliría el supuesto de regresores X 'ε contemporáneamente exógenos, p lim ≠ 0 y, por tanto, el EMCO no tiene ninguna T propiedad y la inferencia no es válida ni asintóticamente. El estimador consistente será el de Variables Instrumentales donde podríamos tomar como instrumento de Yt-1 a Xt-1. En la práctica, cuando nos encontremos con un modelo autorregresivo lo que hay que analizar, en principio, es si la perturbación está autocorrelacionada o no (con el contraste de la h de Durbin el de Breusch-Godfrey) y si existe relación contemporánea entre los regresores y la variable endógena (con el contraste de Hausman). En algunos modelos econométricos, la introducción de ciertas hipótesis teóricas también da lugar a la aparición de la variable endógena retardada entre los regresores. Dos ejemplos son los siguientes: 43 Econometría Curso 201-12 Modelo de expectativas adaptativas o adaptables Estos modelos plantean que el comportamiento de los agentes económicos depende de las expectativas que se formen sobre la evolución futura de determinadas variables económicas. A su vez, el tratamiento de esas expectativas se realiza suponiendo una hipótesis sobre su formación. Concretamente, la hipótesis de expectativas adaptativas supone que las expectativas se actualizan cada periodo en función de la diferencia entre la última observación de la variable y la expectativa para ese periodo: Et X t +1 − Et −1 X t = λ ( X t − Et −1 X t ) 0 < λ <1 con Ejemplo: Demanda de saldos monetarios reales (Yt) en función del valor esperado en t de la tasa de inflación (X) futura, es decir, de EtXt+1. Yt = β 0 + β1 Et X t +1 + ε t Si, suponemos que: Et X t +1 − Et −1 X t = λ ( X t − Et −1 X t ) 0 < λ <1 O, también, que la expectativa de inflación futura que hoy se forma el individuo es una combinación lineal del valor actual de la tasa de inflación y de la expectativa de inflación que se formó en el periodo anterior: Et X t +1 = λX t + (1 − λ )Et −1 X t Operando, obtenemos: Et X t +1 − (1 − λ )Et −1 X t = λX t ⇒ (1 − L + λL )Et X t +1 = λX t ⇒ E t X t +1 = λX t (1 − L + λL ) Sustituyendo en el modelo: Yt = β 0 + β1 = λ (1 − L + λL) λ (1 − L + λL ) Xt Xt + εt Y, finalmente: Yt = λβ 0 + β 1λX t + (1 − λ )Yt −1 + v t donde v t = ε t − (1 − λ )ε t −1 El modelo resultante es un modelo autorregresivo y por lo tanto, a la hora de elegir el método más adecuado para estimar sus parámetros, habrá que analizar si vt presenta autocorrelación o no y realizar el test de Hausman. Modelo de ajuste parcial Estos modelos plantean que hay situaciones en que la relación entre variables no se ajusta de forma inmediata en un periodo t, sino que tarda un tiempo (un periodo de ajuste). Ejemplo: Supongamos que queremos estudiar el nivel “deseado” de capital en una economía Yt* en función del nivel de producto (Xt): ( ) Yt* = β 0 + β1 X t + ε t Y que se especifica el siguiente mecanismo por el que el nivel de stock de capital observado se ajusta al nivel deseado (modelo de ajuste parcial: el stock observado varía de un periodo a otro en una proporción de su distancia respecto al stock deseado): Yt − Yt −1 = δ (Yt* − Yt −1 ) con 0 < δ <1 Operando en el modelo de ajuste parcial tenemos: Yt = δYt* + (1 − δ )Yt −1 ⇒ δYt* = Yt − (1 − δ )Yt −1 ⇒ Yt* = 44 1 δ Yt − (1 − δ ) δ Yt −1 Econometría Curso 2011-12 ( ) 1 Sustituyendo Yt* en el modelo: Yt* = Yt − δ (1 − δ ) δ Yt −1 = β 0 + β1 X t + ε t Y, despejando: Yt = δβ 0 + δβ 1 X t + (1 − δ )Yt −1 + δε t El modelo resultante, al igual que en expectativas adaptativas, es un modelo autorregresivo, y por lo tanto, habrá que analizar si sus perturbaciones están o no autocorrelacionadas y realizar el test de Hausman para elegir el método de estimación adecuado. 10.3.- Modelos con retardos distribuidos o escalonados. Estructura finita e infinita de retardos Son aquellos en los que una o más variables exógenas influyen en la variable endógena con algún retardo. Son modelos del tipo: Yt = β 0 + β1 X 1t + β 2 X 1t −1 + β 3 X 1t −2 + ... + ε t Dentro de estos modelos vamos a plantear dos posibilidades: n 1) Modelos con estructura finita de retardos: Yt = α + ∑ β i X t −i + ε t i =0 ∞ 2) Modelos con estructura infinita de retardos: Yt = α + ∑ β i X t −i + ε t i =0 A cada parámetro βi se le llama coeficiente de retardo y a la secuencia βi (∀ i=1, 2,...) se le llama estructura del retardo. La interpretación de estos coeficientes es muy interesante y está asociada al conocido concepto de multiplicadores cuya descripción puede realizarse en torno a dos preguntas: 1) ¿Qué efecto tendrá sobre Y un cambio concreto en un momento determinado de la variable X? 2) ¿Qué efecto tendrá sobre Y una desviación permanente de X respecto a su valor inicial? 1) Ante una variación concreta de una unidad en X en el momento t, β 0 es el cambio inmediato en Y en el momento t, β 1 es el cambio en Y un periodo después de la modificación temporal y β 2 es el cambio en Y dos periodos después de la modificación temporal y así sucesivamente. Al coeficiente β 0 se le denomina multiplicador de impacto o a corto plazo y a la secuencia ( β 0 , β 1 , β 2 ,…) se le denomina función de respuesta al impulso. Si por ejemplo suponemos un modelo con retardos distribuidos finitos de segundo orden (n=2), el efecto de X sobre Y sólo se mantiene durante dos periodos después de la modificación. Si el modelo es de infinitos retardos el efecto de X sobre Y se mantendría de forma indefinida. 2) Un cambio permanente en X a partir del momento t produce un cambio en Y, si suponemos un modelo con retardos distribuidos finitos con n=2, igual a β 0 en t, igual a β 0 + β 1 en t+1 e igual a β 0 + β1 + β 2 en t+2 y siguientes (puesto que es un modelo con retardos distribuidos finitos de segundo orden). Si el modelo fuera de infinitos retardos 45 Econometría Curso 201-12 el cambio en t sería igual a β 0 , en t+1 igual a β 0 + β 1 , en t+2 igual a β 0 + β 1 + β 2 , en t+3 igual a β 0 + β1 + β 2 + β 3 , y así sucesivamente. A la suma de todos los coeficientes de retardo (en el caso de finitos retardos con n=2: ∞ β 0 + β1 + β 2 y en el de infinitos retardos ∑ β i ) se le denomina multiplicador de largo i =0 plazo y a la secuencia ( β 0 , β 0 + β1 , β 0 + β1 + β 2 ) si se trata de un polinomio con 2 retardos se le denomina función de respuesta al escalón. La respuesta al escalón en un modelo con infinitos retardos sería ( β 0 , β 0 + β1 , β 0 + β1 + β 2 , β 0 + β1 + β 2 + β 3 ,…..). Si tipificamos los coeficientes dividiéndolos por su suma (multiplicador a largo plazo): calculamos la proporción del efecto total que se deja notar en el periodo i después del cambio en Xt. En modelos de retardos distribuidos finitos β i* = βi n ∑ βi i =0 En modelos con infinitos retardos β i* = βi ∞ ∑ βi i =0 1) Modelos con estructura finita de retardos o con retardos distribuidos finitos Son aquellos en los que suponemos que los efectos de una o varias variables explicativas sobre la variable endógena no se producen de forma instantánea sino que perduran durante un cierto periodo de tiempo que suponemos finito. Por ejemplo: n Yt = α + ∑ β i X t −i + ε t i =0 Problemas en la estimación de estos modelos 1) La elección de n: Un valor pequeño puede ocasionar error de especificación por omisión o en la forma funcional, y un valor de n grande nos puede dejar sin grados de libertad. 2) Posible existencia de multicolinealidad y, por tanto, posibilidad de estimaciones imprecisas de los parámetros. 3) Si el modelo no está especificado dinámicamente de forma correcta podría haber autocorrelación. Todo ello nos lleva a utilizar, cuando hay problemas, ciertas hipótesis sobre la estructura del retardo. Estructura polinomial de Almon Sea el modelo con estructura finita de retardos n Yt = α + ∑ β i X t −i + ε t t=n+1,...,T i =0 Supongamos la siguiente estructura polinomial β i = a 0 + a1i + a 2 i 2 + ... + a m i m donde i=0,1,2,...n con n>m 46 Econometría Curso 2011-12 Dando valores a i tendremos un sistema de ecuaciones que relaciona los n+1 coeficientes de retardos β con los m+1 coeficientes de la estructura polinomial. Para simplificar vamos a suponer un polinomio de grado 2: β 0 = a0 β1 = a0 + a1 + a 2 β 2 = a 0 + a1 2 + a 2 2 2 …………………….. β n = a 0 + a1 n + a 2 n 2 En definitiva, consiste en imponer restricciones sobre los n+1 coeficientes del retardo y el problema radica en estimar el modelo con retardos finitos sujeto a la restricción de que los coeficientes de retardo siguen una distribución polinomial. Por tanto, introduciendo las restricciones en el modelo: n ( ) n n n Yt = α + ∑ a 0 + a1i + a 2 i 2 X t −i + ε t = α + a 0 ∑ X t −i + a1 ∑ iX t −i + a 2 ∑ i 2 X t −i + ε t i =0 i =0 i =0 i=0 1 23 1 424 3 1 424 3 Z 0t Z 1t Z2t Yt = α + a 0 Z 0 t + a1 Z 1t + a 2 Z 2 t + ε t Estimaríamos este modelo restringido por MCO obteniendo α̂ , â 0 , â1 y â 2 y a continuación desharíamos el cambio para obtener α̂ , β̂ , βˆ , βˆ ,…, β̂ 0 1 2 n αˆ = αˆ βˆ 0 = aˆ 0 βˆ1 = aˆ 0 + aˆ1 + aˆ 2 βˆ2 = aˆ 0 + aˆ1 2 + aˆ 2 2 2 .................................................... βˆ n = aˆ 0 + aˆ1n + aˆ 2 n 2 Nota: en la estimación con Eviews éste centra el polinomio de modo que: n 2 si n es par 2 m β i = a 0 + a1 (i − c ) + a 2 (i − c ) + ... + a m (i − c ) siendo c = n-1 si n es impar 2 2) Modelos con estructura infinita de retardos. Una alternativa al planteamiento de truncar la distribución de retardos a un número finito consiste en especificar una distribución con infinitos retardos. Esta especificación es aceptable especialmente cuando se trabaja con observaciones frecuentes o cuando esta estructura se deriva de distintas consideraciones teóricas. El modelo sería: 47 Econometría Curso 201-12 ∞ Yt = α + ∑ β i X t −i + ε t i=0 Obviamente, aún suponiendo que cumple las hipótesis clásicas, la estimación sin restricciones de este modelo no es posible ya que necesitaríamos estimar infinitos parámetros con una muestra siempre finita. La forma de proceder en estos casos es establecer alguna hipótesis sobre los coeficientes de retardo de modo que podamos reducir su número. Koyck propuso que los coeficientes de retardo, aunque infinitos, decrecían en progresión geométrica de la forma: β i = βλ i con 0 < λ < 1 para i=0,1,... Introduciendo las restricciones, el modelo quedaría Yt = α + ∑ βλ i X t −i + ε t ⇔ Yt = α + β (X t + λX t −1 + λ 2 X t − 2 + ...) + ε t ∞ i =0 Si escribimos el modelo para Yt −1 , lo multiplicamos por λ y hacemos Yt − λYt −1 obtenemos finalmente: Yt − λYt −1 = α (1 − λ ) + β X t + (ε t − λε t −1 ) y despejando Yt : Yt = α (1 − λ ) + β X t + λYt −1 + ε t − λε t −1 ⇔ Yt = α * + β X t + λYt −1 + v t 1 424 3 1424 3 α* vt El modelo resultante es un modelo autorregresivo por lo que habrá que analizar si sus perturbaciones están o no autocorrelacionadas y realizar el test de Hausman para elegir el método de estimación adecuado. Una vez obtenidos los estimadores más adecuados para α*, β y λ y teniendo en cuenta que β i = βλ i y que α * = α (1 − λ ) , podemos calcular los estimadores de los parámetros del αˆ * i ˆ ˆ ˆ modelo original: β i = β λ y αˆ = . 1 − λˆ 48 Econometría Curso 2011-12 TEMA 11. INTRODUCCIÓN A LOS MODELOS DE ECUACIONES SIMULTÁNEAS 12.1.- Planteamiento del problema Los modelos analizados en los temas anteriores eran modelos uniecuacionales, es decir, modelos que recogían la relación causa-efecto que existía entre una variable endógena (Y) y un conjunto de variables exógenas (X). Este planteamiento no es, sin embargo, el más adecuado para modelizar la interdependencia que existe entre las variables económicas ya que la cadena causal entre ellas no siempre es unidireccional, es decir, una variable puede ser a la vez causa y efecto. Por ello, para modelizar este tipo de relaciones es necesario recurrir a estructuras más complejas, como los llamados modelos de ecuaciones simultáneas o modelos multiecuacionales. Se trata de modelos formados por más de una ecuación y en los que variables que son explicadas en alguna de las ecuaciones, pueden aparecer como explicativas en otra u otras. El caso más sencillo es un modelo de dos ecuaciones. Por ejemplo: Y1t = γ 21Y2t + β 11 X 1t + β 21 X 2t + u1t Y2t = γ 12Y1t + β 32 X 3t + u 2t t=1,2,…T En él se explica el comportamiento de dos variables endógenas (Y1 e Y2) a partir de tres variables predeterminadas (X1, X2 y X3). En la primera ecuación la variable endógena Y1 se modeliza como función de las variables predeterminadas X1 y X2 y de la endógena Y2 que en esta ecuación aparece como explicativa. De la misma forma, la variable endógena Y1 se incluye, en la segunda ecuación, como una variable explicativa. Ambas ecuaciones no se pueden considerar por separado, porque las relaciones se producen simultáneamente. Además Y1t aparece en la segunda ecuación como explicativa, pero por la primera ecuación es función de Y2t que a su vez depende de u2t, de modo que Y1t es función de u2t, por lo tanto Y1t no es contemporáneamente exógena, y lo mismo ocurre con Y2t. También es absurdo plantearnos en este tipo de modelos la hipótesis de que las perturbaciones u1t y u2t están incorrelacionadas, ya que, por ejemplo, u1t = f (Y1t , Y2t ) pero Y2t = f (u 2t ) . Especificación de un modelo lineal de ecuaciones simultáneas Un modelo lineal multiecuacional para el periodo t puede especificarse mediante un sistema de g ecuaciones en las que aparecen g variables endógenas (Y1 , Y2 ,..., Yg ) y k variables predeterminadas ( X 1 , X 2 ,..., X k ) . γ 11Y1t + γ 21Y2t + ... + γ g1Ygt + β11 X 1t + β 21 X 2t + ... + β k1 X kt + u1t = 0 γ 12Y1t + γ 22Y2t + ... + γ g 2Ygt + β12 X 1t + β 22 X 2t + ... + β k 2 X kt + u 2t = 0 M γ 1g Y1t + γ 2 g Y2t + ... + γ gg Ygt + β1g X 1t + β 2 g X 2t + ... + β kg X kt + u gt = 0 Matricialmente el sistema, para el periodo o la observación t, se puede expresar: Yt ' Γ + X t' β + u t' = 0 donde X t' = ( X 1t , X 2t ,..., X kt ) 49 Econometría Curso 201-12 Yt ' = (Y1t , Y2t ,..., Ygt ) u t' = (u1t , u 2t ,..., u gt ) γ 11 γ 12 L γ 1g β11 γ 21 γ 22 L γ 2 g β 21 Γ= = β M M M L M γ β γ L γ g 1 g 2 gg k1 Para todas las observaciones, t=1,…,T sería: YΓ + Xβ + u = 0 X 1' X 11 ' X X 12 donde: X = 2 = M M X' X T 1T X 22 M X 2T M βk 2 M L β kg L Y1' Y11 ' Y Y12 Y = 2= M M Y ' Y T 1T X k1 L X k2 L M L X kT L X 21 β12 L β1g β 22 L β 2 g Y21 Y22 M Y2T L Yg 1 L Yg 2 L M L YgT u1' u11 u21 L u g1 ' u2 u12 u22 L u g 2 u= = M M L M M u' u u L u 2T gT T 1T La especificación anterior se conoce como forma estructural del modelo, pero el sistema de ecuaciones simultáneas se puede especificar también en forma reducida expresando cada variable endógena en función de las variables predeterminadas. Y1t = π 11 X 1t + π 21 X 2t + ... + π k1 X kt + v1t Y2t = π 12 X 1t + π 22 X 2t + ... + π k 2 X kt + v 2t M Ygt = π 1g X 1t + π 2 g X 2t + ... + π kg X kt + v gt O bien en forma matricial que puede deducirse a partir de la forma estructural: Yt ' Γ + X t' β + u t' = 0 ⇒ Yt ' Γ = − X t' β − u t' ⇒ Yt ' = − X t' β Γ −1 − u t' Γ −1 ⇒ Yt ' = X t' Π + vt' donde Π = − β Γ −1 y vt' = −u t' Γ −1 π 11 π 12 π 21 π 22 Π= M M π k1 π k 2 L π 1g L π 2g L M L π kg vt' = (v1t , v 2t ,..., v gt ) Para todas las observaciones, t=1,…,T sería: Y = X Π + v donde v = −u Γ −1 , siendo v1' v11 ' v v12 v= 2= M M v' v T 1T v 21 v 22 M v 2T L v g1 L vg 2 L M L v gT 50 Econometría Curso 2011-12 Hipótesis del modelo de ecuaciones simultáneas Para la forma estructural del modelo: 1) E (u t' ) = 0 E (u1t [ ∀t L u gt ) = (0 L 0 ) ] 2) E u t u t' = Σ u12t u u ' E u t u t = E 2t 1t M u gt u1t [ ] ∀ t siendo Σ una matriz simétrica y definida positiva u1t u 2t u 22t M u gt u 2t L u1t u gt L u 2t u gt = L M L u gt2 σ 12 σ 12 M σ 1g σ 12 σ 22 M σ 2g L σ 1g L σ 2g =Σ L M L σ g2 Esta hipótesis recoge: En la diagonal principal: que en la primera ecuación hay homoscedasticidad pues E (u1t ) = σ 12 para todo t, lo mismo en la segunda y en todas las demás. En el resto de elementos: E (u1t u 2t ) = σ 12 para todo t, lo que significa que las perturbaciones de la ecuación 1 y 2 están correlacionadas para el mismo instante de tiempo y la correlación es la misma para cualquier instante de tiempo E (u1t u 2 t ) = E (u11u 21 ) = E (u12 u 22 ) = ... = E (u1T u 2T ) = σ 12 y lo mismo ocurre con el resto de ecuaciones. Es decir, existe correlación contemporánea entre las perturbaciones de dos ecuaciones y no cambia al cambiar el instante de tiempo considerado. [ ] 3) E u t u s' = 0 ∀ t≠ s u1t u1s u1t u 2 s L u1t u gs 0 0 L 0 u u u 2t u 2 s L u 2t u gs 0 0 L 0 2t 1s =0 L u gs ) = E = M M L M M M L M u gt u1s u gt u 2 s L u gt u gs 0 0 L 0 Significa que las perturbaciones correspondientes a distintos periodos de tiempo están incorrelacionadas, sean perturbaciones de una misma ecuación (E (u1t u1s ) = 0 ) o de distintas ecuaciones (E (u1t u 2 s ) = 0 ) . u1t E u t u s' = E M (u1s u gt [ ] 4) u t → N (0, Σ ) ∀t 5) Las variables predeterminadas (Xt) no son aleatorias, o si lo son, serán estrictamente exógenas o contemporáneamente exógenas. 6) La matriz Γ no es singular, es decir, Γ ≠ 0 . Además las perturbaciones en la forma reducida ( vt ) tienen las mismas características que las vistas para las perturbaciones en la forma estructural. 12.2.- Identificación de un sistema de ecuaciones simultáneas La estimación de la forma reducida del modelo siempre es posible, ya que se especifica de modo que, en cada ecuación, aparece sólo una variable endógena en función de las predeterminadas. Sin embargo, la estimación relevante, desde el punto de vista de la Economía, es la correspondiente a la forma estructural, que contienen las relaciones derivadas de los modelos de la Teoría Económica. 51 Econometría Curso 201-12 Las relaciones entre los parámetros de ambas formas están recogidas en el sistema de ecuaciones Π = − β Γ −1 donde hay (gxk) parámetros de la forma reducida y (gxg)+(gxk) parámetros de la forma estructural. La identificación de un modelo de ecuaciones simultáneas consiste en saber, si a partir de un conjunto de observaciones muestrales, que permite la estimación de la forma reducida es posible estimar los parámetros de la forma estructural. El análisis se hace para cada ecuación (de la forma estructural) y si es posible se dice que la ecuación está identificada, y si no lo es, que no está identificada. Además, cuando la ecuación está identificada se puede distinguir según que la solución sea única o no, entre identificación exacta y sobreidentificación, respectivamente. Para saber cómo es la identificación de la ecuación, sin necesidad de intentar resolver el sistema, se utilizan las denominadas condiciones de orden (que es una condición necesaria pero no suficiente) y condiciones de rango (que es una condición necesaria y suficiente). Estas condiciones, si en el sistema existen restricciones de normalización y de exclusión, es decir, si en cada ecuación existe una variable endógena con coeficiente igual a 1 o –1 y algunos parámetros que acompañan a las variables predeterminadas son cero en algunas ecuaciones, se pueden expresar como se muestra a continuación. Condición de orden Para aplicar esta condición a una ecuación, se compara el número de variables, tanto endógenas como predeterminadas, excluidas en la ecuación, g 2 y k 2 , con el número de ecuaciones del sistema menos una (g-1), de modo que: - Si g 2 + k 2 < g − 1 la ecuación no está identificada (no hace falta aplicar después la condición de rango, pues no se va a cumplir). - Si g 2 + k 2 = g − 1 la ecuación puede estar exactamente identificada. Lo estará si se cumple la de rango. - Si g 2 + k 2 > g − 1 la ecuación puede estar sobreidentificada. Lo estará si se cumple la de rango. Por lo tanto, la condición de orden es: g 2 + k 2 ≥ g − 1 Condición de rango La aplicación de esta condición requiere obtener la matriz de coeficientes de la forma estructural, A, que es igual a: A = (Γ' | β ') . Sea A* la submatriz de A formada por los coeficientes que en las demás ecuaciones del sistema acompañan a las variables excluidas de la ecuación que se quiere identificar, de modo que: - Si rg ( A* ) ≠ g − 1 entonces la ecuación no está identificada - Si rg ( A* ) = g − 1 entonces la ecuación está identificada, pero puede estar exactamente identificada o sobreidentificada, para saberlo recurrimos a la condición de orden. Por tanto, la condición de rango es: rg ( A* ) = g − 1 Si todas las ecuaciones del sistema están identificadas se dice que el sistema está identificado. Si sólo lo están algunas, sólo esas se pueden estimar. 52 Econometría Curso 2011-12 12.3.- Estimación de un sistema de ecuaciones simultáneas Los métodos de estimación en modelos de ecuaciones simultáneas se clasifican en: a) Métodos con información limitada b) Métodos con información completa Los primeros se caracterizan porque estiman cada una de las ecuaciones del sistema por separado y proporcionan estimaciones menos eficientes al utilizar menos información, ya que no utilizan ninguna información sobre la matriz de varianzascovarianzas contemporánea de las perturbaciones de la forma estructural, es decir, de Σ. Por su parte, los métodos con información completa consideran toda la información del modelo para su estimación conjunta, aunque si hay errores de especificación en una ecuación, se trasladan a todo el sistema, y en ese caso, este tipo de métodos serían menos eficientes que los de información limitada, ya que en ellos el error de especificación de una ecuación sólo la afecta a ella. Entre los que utilizan información limitada, los más utilizados son, Mínimos Cuadrados Indirectos (MCI), Variables Instrumentales (VI), Mínimos Cuadrados en dos etapas (MC2E) y Máxima Verosimilitud con información limitada. Entre los que utilizan información completa, los más utilizados son Mínimos Cuadrados en tres etapas (MC3E) y Máxima Verosimilitud con información completa. De todos estos métodos, los de Máxima verosimilitud son los más complejos y no los vamos a abordar en esta introducción así como el Método de Mínimos Cuadrados en tres Etapas. El método de Mínimos Cuadrados Ordinarios en la forma estructural, por su parte, generalmente no se utiliza puesto que requiere el cumplimiento de las hipótesis clásicas y en los sistemas de ecuaciones es frecuente la dependencia entre la perturbación y la matriz de regresores. Además, la utilización de un método u otro está condicionada por el resultado de la identificación de las ecuaciones. - Si la ecuación no está identificada no se pueden estimar los parámetros de la forma estructural. - Si la ecuación está identificada se pueden estimar por Mínimos Cuadrados Indirectos (MCI), por Variables Instrumentales (VI) o por Mínimos Cuadrados en dos etapas (MC2E). Si está exactamente identificada se obtiene una única solución y los métodos coinciden. Si está sobreidentificada, se obtienen varias soluciones. 1) Mínimos Cuadrados Indirectos La aplicación de este método parte, en primer lugar, de la obtención de los estimadores de la forma reducida Π̂ por MCO para después aplicar la relación ˆ = − βˆ Γˆ −1 para despejar los elementos de β̂ y Γ̂ . Π = − βΓ −1 , es decir, Π ( ) Si la ecuación no está identificada, para algún parámetro de la forma estructural no obtendremos solución. Si la ecuación está sobreidentificada, para algún parámetro de la forma estructural obtendremos más de una solución. Si la ecuación está exactamente identificada, para cada parámetro de la forma estructural obtendremos una solución. 53 Econometría Curso 201-12 Como los resultados (cuando los haya) son funciones de estimadores consistentes y asintóticamente eficientes, estos también lo serán. 2) Variables Instrumentales - Si la ecuación está exactamente identificada, Variables Instrumentales proporciona un resultado para cada estimador, pues disponemos del número exacto de instrumentos necesarios. - Si la ecuación está sobreidentificada, tenemos excesivos instrumentos y, por lo tanto, obtenemos varios estimadores de Variables Instrumentales. - Si la ecuación no está identificada, no hay instrumentos suficientes y no podemos estimar por VI. 3) Mínimos Cuadrados en dos Etapas Es el estimador de Variables Instrumentales que utiliza todos los instrumentos disponibles, o un instrumento que es combinación lineal de ellos. Es el mejor de todos los estimadores de Variables Instrumentales. Aunque la ecuación esté sobreidentificada, este método proporciona una solución única. Comparación entre estos estimadores - Si la ecuación está exactamente identificada EMCI=EVI=EMC2E Propiedades: consistentes y asintóticamente eficientes. - Si la ecuación está sobreidentificada Si por ejemplo para un parámetro obtenemos por MCI dos soluciones, una coincide con una de VI (usando un instrumento) y la otra con la otra utilizando el otro instrumento. El EMC2E combina las dos soluciones y propone un resultado que es el mejor, puesto que todos los estimadores son consistentes, pero el más eficiente es el de MC2E que es el de VI que usa como instrumento una combinación lineal de los instrumentos. 54
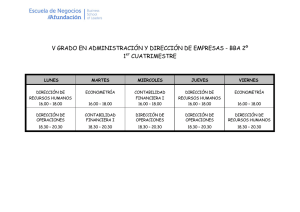




![[ ] ε](http://s2.studylib.es/store/data/004599547_1-2f20235d60ac9bc80564c7074e516da7-300x300.png)