Sensibilidad frente a datos anómalos de tres estimadores de efectos
Anuncio

ESTADISTICA ESPAÑOLA
Vol. 36, Núm. 135, 1994, págs. 59 a 74
Sensibilidad frente a datos anómalos de
tres estimadores de efectos de dispersión
con datos no necesariamente replicados
por
ALBERTO J. FERRER y RAFAEL ROMERO
Universidad Politécnica de Valencia
Departamento de Estadística e I.O.
RESUMEN
Se estudia el efecto de la presencia de observaciones contaminantes sobre el sesgo y la varianza de tres estimadores de efectos
de dispersión a partir de datos no replicados: 1) estimador de dos
pasos (TSP); 2) estimador por minimos cuadrados ponderados iterados (MCPI), y 3) estimador máximo-verosírnif (MV). La influencia de
la magnitud de la contaminación sobre el sesgo de los estimadores
depende del valor real del efecto de dispersión a estimar. La varianza de los estimadores aumenta con dicha magnitud de contaminación. EI estimador más sencillo, TSP, es el menos sensible a la presencia de datos anómalos en situaciones anáiogas a las simuladas,
para cualquier tamaño muestral. EI estimador MV es, por el contrario, el más sensible, incluso para tamañas grandes de muestra.
Palabras Clave: Heterocedasticidad, datos anómalos, contral de calidad «Off-Line», mejora de la calidad y de 1a productivídad.
Clasificación AMS: 62 F 11, 62 F35, 62 N 10, 65C05.
f^^1?\[^Itil1c^1 E^til'^tit^t.^^
f^11
1.
INTRODUCCION
Los recientes avances en el área de !a ingeniería de calidad han provocado
un gran interés en el análisis de efectos de dispersión, esto es, en el estudio de
los efectos que una o más variables explicativas tienen sobre la dispersión de
una variable respuesta. Para situaciones en que se dispone de replicaciones, se
han propuesto diversos modefos y técnicas de estimación coma puede verse en
Bartlett y Kendaff (1946); Box (1986}; Box y Ramírez (1986); León, Shoemaker y
Kacker (1987); Nair y Pregibon (1986}, Taguchi y Wu (1980), y Tort-Martorell
(1985}. Un estudio comparativo entre algunos de estos procedimientos puede
encontrarse en Nair y Pregibon (1988).
Box y Meyer (1986) propanen un método para estudiar e#ectos sobre la dispersión a partir de los resultados de fraccianes factariales no replicadas. Una
desventaja de este método es que sólo resulta apficable directamente a planes
o fraccíones factoriafes con factores a dos nivefes.
Sin embarga, en la práctica industrial es necesario a menudo estudiar la
existencia de efectos de dispersíón en condiciones mucho más generales. Este
es ef cas0, por ejempfo, cuando los datos disponibles no son ef resultado de
una experiencia diseñada, o cuando no se dispone de répficas para los diferentes valores de los factores o variables explicativas, y, particularmente, cuando
algunas de las variabfes explicativas son continuas y toman valores no replicados en la muestra. Este tipo de datos retrospectivos suele ser muy frecuente encontrarfos hoy día en las industrias como consecuencia del uso masivo de los
gráficos de control. En este tipo de situaciones la estimación efectiva de funciones de varianza a partir de modelos de regresión heterocedásticos puede ser
muy recomendable ( Davidian y Carroll,
1987). De entre todas las posibles fun,
ciones de varianza, diversos autores proponen utilizar el modelo logarítmico por
razones de cálculo y físicas, dado que dichos autores consideran que es más
frecuente encantrar efectos sobre varianzas muftiplicativos que ad'+tivos. Ver Aitkin (1987}, Sartlett y Kendall ( 1946), f3ox y Meyer (1986), Cook y Weisberg
(1983), McCullagh y Nelder ( 1989), y Pignatiello y Ramberg (1985}.
EI modefo de regresión lineaf can heterocedasticidad multiplicativa puede expresarse corno sigue (Aitkin, 1987):
.^^j = ^^xj + uj
2, ..., N
var (u^ ) = cs? = exp (a'z^ )
[1 J
[2l
donde z^ puede contener afgunas o todas las variables x^. Las u^ 's son perturbaciones aleatorias independientes y normalmente distribuidas con media nula,
pero cuya varianza no es constante, pudiendo depender de los valores de las z^
a través de la expresión [2J.
tif:NtifHll.Ill,A[,) F_kE:N`IE:.^ l)^lC):^ ;^N()^fAt.()^ [)F:7lZE:S F^"('Iti1.11)()Ft^:^, UF f F:f.(.'f^)^ (^F- 1^1.5F'F^.k.^l^)^
f^^
Los tres métodos analizados en este artículo permiten la estimación de los
parámetros [3 y a del modelo expuesto a parti r de datos no necesariamente replicados. Sus propiedades asintóticas han sido estudiadas por diversos autores
(Carroll y Rupert, 1988). Estos métodos se presentan a continuación:
a) Método TSP: Harvey (1976) propone como estimador de efectos sobre
la dispersión al obtenido mediante una regresión ordinaria sobre z^ utilizando
como variable dependiente el logaritmo neperiano ^del cuadrado de los residuos,
e^, estímados en la regresión ordinaria de y^ sobre x^. EI autor lo denomina método de estimación de dos pasos TSP .
b) Método MCPI: EI método de mínimos cuadrados ponderados iterados
--MCPI , propuesto por varios autores como Carroll y Rupert (1988) y Zúnica
y Romero (1988), resulta ser una modificación del método anterior para tener en
cuenta el carácter heterocedástico del modelo de efectos sobre medias. Es un
procedimiento iterativo que estima oc mediante una regresión ordinaria de In (e?)
sobre z^, donde e^ son los residuos estimados en la regresión par mínimos cuadrados ponderados de y sobre x^. Los mencionados autores utilizan el método
TSP para obtener los estimadores iniciales.
c) Método MV: Este método obtiene estimadores máximo verosímiles maximizando el logaritmo de la función de verosimilitud construida a partir de las
hipótesis del modelo considerado en [1 ] y[2]. Harvey (1976) propone utilizar
como estimadores iniciales los derivados de la aplicación del rnétoda TSP.
Los autores del presente artículo estudian en un trabajo previo, Ferrer y Romero (1993), las propiedades de estos estimadares para diferentes tamaños de
muestra, en el caso particular de una única variable explicativa distribuida uniformemente en su campo de variabilidad. Se observa que estas propiedades
para el caso de muestras pequeñas difieren sensiblemente de las que cabría
esperar a partír de su comportamiento asintótico. Así, los tres estimadores son
sesgados, tendiendo el MV y el MCPI a amplificar el efecto de dispersión real,
mientras que el estimador TSP tiende a reducirlo. Adicionalmente se obtiene
que las expresiones asintóticas subestirnan notablemente las varianzas reales
de los estimadores MCPI y MV. La conclusión más importante que se deriva de
ese estudio es que con un número elevado de observaciones el estimador MV
es preferible a los otros dos. Sin embargo, cuando el tamaño muestral es reducido, situación extremadamente frecuente en la práctica industrial, resulta más
aconsejable la utilización del estirnador más sencillo, TSP, al tener menor error
cuadrático medio.
Las conclusiones anteriores se obtuvieron a partir de datos simulados que
seguían exactamente el modelo [4] sin contaminación. En la práctica industrial
es, sin embargo, muy frecuente la presencia de observaciones contaminantes
debido a salidas de control de los procesos investigados. Para analizar la sensí-
F-ti i,^C)t`^ I 1( ,> F-.tif'A!^(Ji.r+^
f>?
bilidad de los métodos expuestos ante la presencia de observaciones anómalas,
se ha planteado la presente investigación, cuya metodología y resultados se exponen a continuación.
METODOLOGIA
La comparación del comportamíento de los tres estimadores en presencia de
datos contaminados se ha Ilevado a cabo mediante simulación Montecarlo y
partiendo del siguiente modelo con heterocedasticidad multiplicativa:
y^=40+6x^+ u^
j=1,2
[3]
Se asume que las perturbaciones, u^, son valores independientes e idénticamente distribuidos de una distribución norma! contaminada según:
t 1--p) N[0, cs? = exp (0.7 + cx, x^)] + pN (0, m2 cs? )
[4]
siendo p el porcentaje de contaminación y m!a magnitud de contaminación. Se
han considerado vaiores de x equiespaciados entre 0 y 10, y como valor del
efecto de dispersión a estimar a^ = 0.322, lo que implica que la desviacíón típica
de y cuand© x= 10 es cinco veces el valor cuando x= 0. En una fase posterior
de la investigación se realizaron simulaciones con a1 =-0.322 y a, = 0. La gravedad de la contaminación se ha simulado modificando la magnitud de contaminación de las perturbaciones (m = 2, 4, 6) y variando, dado un m, el porcentaje
de contaminación, p, desde un 10% a un 50%. Se han considerado tres tamaños de muestra, N= 11, 21 y 101.
Como se observa en [4], el modelo de contaminación propuesto únicamente
genera datos anómalos aislados en la variable respuesta. La razón de recurrir a
este sencillo modelo de contaminación resíde en que constituye una aproximación razonable a los tipos de contaminación que con mayor frecuencia pueden
aparecer en e! contexto industrial. En este sentido se ha desechado la posibilidad de simular observacíones atípicas en la variabie explicativa ( puntos de palanca}, ya que son bastante improbables en el contexto industrial, donde lo habitual es la realización de diseños de experimentos en los que las variables explicativas toman valores prefijados por el investigador o ingeniero (Harrison y
1990 , cap. 16). Por tanto, es de esperar que las posibles anoV1^adsworth
malías se presenten, aisladas, en la variable respuesta, donde sí son frecuentes
las safidas de control de los procesos.
Para cada una de las combinaciones posibles del tamaño muestral, método
de estimación, porcentaje de contaminación y rnagnitud de contaminación se
han realizado 500 replicaciones, estimándose en cada caso oc^ , y efectuándose
un total de 67.500 simulaciones.
tif:NSIEiIL[L)A[) F^KE-:N^^^I^^E: A C)11^fOti ANC1Mr^l.U^ Uh: lKE•.5 E-5^t^1!^1;1UORE-.S t^f^^ f^^.Ff:(^^^I^^ti l>F^ I^i^l'f-k.tili^ati
6^
EI análisis de los resultados de las simulaciones se ha e#ectuado mediante
un ANOVA considerando como factores el rnétodo de estimación ME (TSP,
MCPI y MV), la magnitud de la contaminación MG (2, 4, 6), el porcentaje de contaminación PC (10%, 20%, 30%, 40%, 50%) y el tamaño muestral TM (11, 21,
101). Las variables dependientes han sido el sesgo y la varianza de a,, estimador del efecto de dispersión a1, que par tratarse de medias y varianzas muestrales de muestras de tamaño 500, pueden razonablemente considerarse normales. Se han incluido en el análisis todos los efectos, excepto la interacción cuádruple y la interacción triple en la que no interviene el factor método de
estimación. La interpretación del ANOVA no se ha realizado atendiendo estrictamente a la significación estadística de los efectos, sino en función de la variabilidad total explicada por cada efecto (% Factor) .
3.
EFECTO DE LA CONTAMINACION SOBRE EL SESGO
DE LOS ESTIMADORES
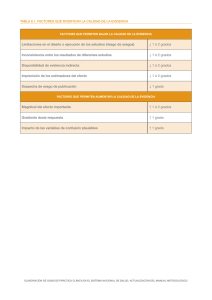
La tabla 1 presenta los resultados del ANOVA que estudia la posible influencia de los factores citados anteriormente sobre el sesgo del estimador de efectos de dispersión a^ . En ella se observa que éste viene afectado muy significativamente por el método de estimación y por su interacción con el tamaño muestral, explicando entre ambos el 84.3% de la suma de cuadrados total, SCT.
Estos resultados ya han sido obtenidos por Ferrer y Romero ( 1993) para m= 1,
es decir, en ausencia de contaminación. La magnitud de !a contaminación también aparece como factor muy significativo con un porcentaje explicado del
Tabla 1
ANALISIS DE VARIANZA DE LOS EFECTOS DEL METODO DE ESTIMACION (ME),
MAGNITUD DE CONTAMINACION (MC}, PORCENTAJE DE CONTAMINACION (PC}
Y TAMAÑO MUESTRAL (TM) SOBRE EL SESGO DEL ESTIMADOR
DE EFECTOS DE DISPERSION a1
ORIGEN
SC
ME
.11139
MC
PC
TM
MExMC
g. I.
CM
Fcalc
SC F'
% Factor
2
. 05570
772.30
.1 1125
61.6
.01082
.00157
.00048
. 00190
2
4
2
4
.00541
.00039
. 00024
.00047
75.05
5.45
3.36
6.57
. 01068
. 00128
.00034
. 00161
5.9
.7
.2
.9
M ExTM
. 04120
4
. 01030
142.82
. 04091
22.7
MCxPC
MCxTM
ERROR
TOTAL
. 00205
. 00365
. 00749
. 18056
8
4
104
134
. 00026
.00091
7.2E-5
--
3.55
12.66
--
. 00147
. 00336
. 00966
-
.8
1.9
5.3
-
% Factor = porcentaje de variabilidad asignable a cada efecto.
t^:ti l,^l )I.ti I I( A t• tiP:1ti( )l A
f^^
5.9%. Por el contrario, el porcenta^ e de contaminación no parece tener una influencia importante en el sesgo del estimador a^, ya que el aumento de dicho
porcentaje influye no en el sentido de modificar la pendiente del modelo [2J, sino
aumentando la variabilidad global estimada a través de ao, estimador de aa en
el rnodelo [4].
Las figuras 1 y 2 muestran los valores de los sesgos de los estimadores a^
obtenidos mediante los tres métodos en función de la magnitud de la contaminación m, con tamaño muestra! N= 11 y N= 101, promediando para los diversos
porcenta^ es de contamínacíón. Como ya se obtuvo en Ferrer y Romero (1993),
cuando no hay datos contaminados, esto es, m = 1, los estimadores MCPI y MV
tienen un sesgo positivo, mientras que el estirnador TSP lo tiene negativo. También vuelve a observarse cómo dicho sesgo disminuye conforme aumenta el tamaño muestral. EI hecho de que en el ANOVA no aparezca efecto simple del tamaño muestral sobre el valor medio del sesgo de a, se debe a que, como se deduce de su interacción con ei método y también se observa en las figuras 1 y 2,
se produce una compensacíón de los sesgos resultando un sesgo promedio
aproximadamente nulo. Dichas figuras tambíén muestran cómo en el caso de
existir un efecto de dispersión positivo, a^ = Q.322, el valor medio de los estima-
Figura 1
SESGO DEL ESTIMADOR a^ EN LOS METODOS TSP, MCPI Y MV EN FUNCION
DE LA MA+GNITUD DE CONTAMINACION, m. N= 11 observacíones. a1 = 0.322
Sesgo a 1
0.1
- -------------------;-------..,_.......- ------......----.. --.-.---.---..__...;.......-------.-----;---._.......__..._.._
o.os
0.06
.,^.:.'
Z
n
A
n
w
w^^.y ti
.-•-•--•-•-• ..
..................
....----'------•--
-
.......__._..._...
._.......----•----..
0.04
................... . ......_..._. -..^._---------_________^--._.......--------
0.02
.,^----------. .^ .........................................:....................:.....................
0
-- 0.02
- o.oa
- O.o6
- o.os
- o.^
0
1
METODO TSP
2
s
4
3
5
Magnitud de contaminación (m)
-^- METODO MCP!
Alfa 1 pasitiva - 11 obs.
--L-^ -
METODO MV
tiF-.ti^1K11.11);^I) t^Rf^:N^I^F. :^ I).^^^(^(^S .-^ti^)ti1r^l Oti [)F: ^^1^Itf=^`i F^S^^^Iti1.^I)t)kl S I^t^ }^F t t^^It)^, 1)f. ial^;E^I k^,l^ ^!^
Figura 2
SESGO DEL ESTIMADOR a^ EN LOS METODOS TSP, MCPI Y MV EN FUNCION
DE LA MAGNITUD DE CONTAMINACION, m. N= 1 Q1 observaciones. a^ = 0.322
Sesgo a1
0.1
----------------- ---------------------------------------- ...---._......._.. _._...__........._ ......_......----- .--.-..-.---....----
o.oa
0.06
0.04
0.02
a
^
I
.................:....................;----------._....---- -----------^--...- ----._......------ --------------.._. ....__...__._._.._..
.
.
^
^
....................;......_........--^^
- 0.02
- 0.04
- 0.06
- 0.08
- 0.1
0
1
METODO TSP
2
4
5
3
Magnitud de contaminación (m}
-^4^-
METODO MCPI
6
--r^ -
7
MEEODO MV
Alfa 1 positivo - 101 obs.
dores a1 tiende a disminuir cuando aumenta la magnitud de la contarninación m.
Esto provoca un aumento del sesgo negativo del estimador TSP y una disminución del sesgo positivo de los estimadores MV y MCPI, que en este último Ilega
a convertirse en negativo.
La causa de esta modificación del sesgo radica en ta diferente forma en que
un dato anómalo puede afectar a la varianza residual del modelo de regresión
de efectos sobre medias según el valor de la variable explicativa X que le corresponda.
EI método MCPI pondera los residuos de dicho rnodelo de forma inversamente proporcional a la desviación típica de las observaciones. Esto quiere decir que
da más peso a aquellas observaciones con menor varianza, en este caso a observaciones correspondientes a valores pequeños de la variable X, puesto que
a1 > 0. En ausencia de datos anómalos esto provoca un aumento de la pendiente
del modelo logarítmico de varianzas, y por tanto un sesgo positivo en la estirnación de a1 (Ferrer y Romero, 1993). Sin embargo, en presencia de datos anórnalos se producen algunas modificaciones. Así, si un dato anómalo cae en la zona
de alta varianza tiende a tomar valores mucho más alejados del resto de las observaciones que si cae en la zona de baja varianza, y aunque también tiende a
t^ ti l Al )Iti I It ^^ #-:^ti?';^ti( )1.:^
aumentar la varianza de las observaciones en esa zona, el efecto conjunto puede resultar en que a pesar de estar en 1a zona de alta varianza, siga teniendo un
peso importante en !a suma de cuadrados de los residuos del modelo de efectos
sobre medias, SCR. Esto provocará que en el proceso de minimización de dicha
suma, el modelo tienda a rninimizar tambi^én los residuos de la zona de alta varianza, subestirnando la variabilidad residual en esa zona, y reduciendo la pendiente del modelo logarítmico de varianzas incrementada por el prop'ro método
de estimación, lo que provocará una disminución del sesgo positivo. La subestimación de la variabilidad residual en la zona de alta varianza puede Ilegar a ser
tan grande si la magnitud de contamínación es elevada, que puede incluso superar a la disminución de la varianza resídual de la zona de baja varianza, propia
de este método de estímacíón, provocando un sesgo negativo.
En el método TSP en la estimación del modelo de efectos de posición se minimiza la surna de los cuadrados de !os residuos no ponderados. Esto implica
que los residuos de la zona de alta varianza tienen una influencia muy importante en la minirr^ización de dicha suma, que lleva a una subestímacíón de la varianza residual en esa zona aun a costa de aumentar la varianza residual en la
zona de baja varianza. Esto provoca una disminución en la pendiente del modelo logarítmico de varianzas, es decir, un sesgo negativo en la estimación de a1.
En este caso, el efecto promedio de los datos anómalos, tal y como se ha explicado en el párrafo anterior, no hace más que reforzar esa subestimación de la
variabilidad residual en la zona de alta varianza, y por tanto hacer más negatívo
el sesgo del estimador de efectos de dispersión a1.
Con el fin de comprobar esta hipótesis, se han realízado dos nuevas simulaciones, una considerando un efecto de dispersión nulo y la segunda tomando un
efecto de dispersión negativo a1 =-0.322. En ambos casos se ha considerado
sólo un tamaño de muestra pequeño, N= 11, dado que ésta es la sítuación en
la que resalta más marcadamente ei efecto a estudiar. Los resultados se presentan en las figuras 3 y 4, y son coherentes con los que cabría esperar de la
hipótesis avanzada.
La figura 3 muestra que cuando no existe efecto de dispersión, es decir a, = o,
coma no existen diferencias de varianzas entre zonas, la infiuencia de los datos
anómalos es la misma en todas las zonas. Esto implica que !a pendiente del
modelo sobre varianzas no cambie en promedio y por lo tanto el valor medio del
estimador a1 no se ve afectado por la magnitud de la contaminación m de los
datos anómalos.
EI fenómeno contrario al ocurrido cuando a^ es positivo se presenta cuando
el efecto de dispersión es negativo. En efecto, en la figura 4 se observa cómo
cuando aumenta la magnitud de la contaminación de los datos anómalos, se
produce también un aumento del valor medio del estimador ai . Es#e resultado
es coherente con la hipótesis enunciada anteriormente, ya que en este caso la
zona de alta varianza, que es ia más afectada por la presencia de los datos
tif=NSlEi1^_IDAI.:)f^RE;N^(,E r^ I)A"I^(1^ r^ti(}!lqA(.()S U^-: 1'RF;.^ f^^`i.l!^1A1)t:>FZF-.^ E)f^ E-F=f:('1^)^ [)F^ l^itif'F k^lt>!ti
fi!
Figura 3
SESGO DEL ESTIMADOR a^ EN LOS METODOS TSP, MCPI Y MV EN FUNCION
DE LA MAGNITUD DE CONTAMINACION, m. N= 11 observaciones. a1 = 0
Sesgo a 1
0.1
..................
....---^----.._.
0.08
..............._..-
-^------....._..._
..._......._..---- ---.-^---^----..._..;........_......--^---
0.06
'^
0.04 ^ ................ , .........._._..... , ------........---._ , ......._........._ , _...----.......... . ......_...........
0.02
^
_.._..._._........ ^
.................^..............._....I....................
A...._...............\....................^....................J.....................
- 0.02
........--••---•-^ ....................^.......---------....
...._...........,_.,._.........----•-•-^3••-•---.....-----.._;..._..........-----..
- 0.04
................
..-----...........
..-^-----...........;............-------
-._....----^----..
- 0.06 '^-------------------^
..__..........----
^--..........._....
.._._...----^----- --.._...........---. --^---^-^------^----
0
..................
.........--^-------;-^-------............
- 0.08
- 0.1
1
0
--^-
2
4
3
5
Magnitud de contaminación (m)
METODO TSP
-^}-
METODO MCPI
6
7
- ^- METODO MV
Alfa 1 nulo - 11 obs.
Figura 4
SESGCJ DEL ESTIMADOR a1 EN LOS METC}DOS TSP, MCPI Y MV EN FUNCION
DE LA MAGNITUD DE CONTAMINACION, m. N= 11 observaciones. oc^ _--0.322
Sesgo a1
0.1
................ . .................. . .................. . .._...---------.-.-:----......
0.08
0.06
0.04
0.02
0
- 0.02
................^;------------------^----....
- 0.04
.................:................... . ................... ^ ---..._......----._, ....-^---....------. ........_......--- , -----........_..._._
^ _____ -_- _ _ _ _
^_ _.^. .^_ . . .^. . - - - - - - - - --d.----........._....
-------------- -^.--r----- -"- -"- --^`-^^-`. --^- - . . .±.
- 0.06
--^ .................:....................;---------........_...
- 0.08
- 0.1
0
-E^-
1
METODO TSP
2
3
4
5
Magnitud de contaminación (m}
-8- METODO MCPI
Alfa 1 negativo - 11 obs.
6
7
- 0- METODO MV
1`i?'i
k^+l -11^Iti I Ii ^ F`,f':^^.^ )k.;^
anórnalos, corresponde a vaiores pequeños de X. Por lo tanto, (a subestimación
de la varianza residual en esta zona hace disminuir la pendiente negativa del
m©de(o Iogarítmico de varianzas, lo que implica hacer menos negativo el efecto
de dispersión estimado a^ .
En todas las figuras expuestas se observa claramente que el sesgo del estimador MV es el que menos se ve afectado por el aumento de la magnítud de la
contaminación de 1os datos anórnalos.
4.
EFECTO DE LA CONTAMINACIfJN SC)BRE L.A VARIANZA
DE LQS ESTIMADORES
La tabla 2 muestra los resultadas del ANOVA que estudia la posible influencia de los factores investigados sobre la varianza de! estimador a^ de efect©s de
dispersión. Se observa que existe una clara influencia del tamaño muestral, del
mptodo de estirnación y de ia interacción entre ambos, con un porcentaje de variabilidad explicado del 84.3, resultados ya obtenidos por Ferrer y Romero
(1993) en ausencia de contaminación. También aparecen como efectos importantes la magnitud de contaminación y sus interacciones con el tamaño muestral
y con el método de estimación, explicando un 12.1 % de la SCT. Por el contrario,
el efecto dei porcentaje de contaminación, aunque significativo estadísticamente, tiene una importancia muy inferior al del resto de los efectos señalados, con
Tabla 2
ANALISIS DE VARIANZA DE LOS EFECTOS DEL METODO DE ESTIMACION (ME),
MAONITUD DE CONTAMINACION (MC), PORCENTAJE DE CONTAMlNACION (PC)
Y TAMAÑO MUESTRAL (TM} SOBRE LA VARIANZA DEL ESTIMADOR DE
EFECTOS DE DISPERSION a1
ORIGEN
SC
ME
MC
PC
TM
MExMC
MExPC
MExTM
MCxPC
MCxTM
PCxTM
MExMCxPC
MExMCxTM
ERROR
SCT
.01995
2
.02069
2
.00148
.20815
.00532
.00139
.02270
.00121
.01069
.00098
.00144
.00278
.00268
. 29945
4
2
4
8
4
$
4
8
16
8
64
134
g. I.
CM
Fca^c
SCF'
% Factor
.00997
.01034
.00037
237.38
246.19
8.81
2477.86
31.67
4. 05
135.24
3.57
63.57
2.86
2.14
8.33
.01987
.02061
.00131
.20807
.00515
.00105
.02253
.00087
.01052
.00064
.00077
.00244
.00562
6.6
6.9
.4
69.5
1.7
.4
7.5
.3
3.5
.2
.3
.8
1 .9
.10407
.00133
.00017
.00568
.00015
.00267
.00012
.00009
.00035
4.2E-5
% Factor - porcentaje de variabilidad asignable a cada efecto.
SF-.Nti1^31LIllAL) F^ftHN"^f^ ^ 1),A"I^^U^ _^NOti1Al.OS l:)^^. "^I^F^kti E.S^I^11^1.A[)ORE-.ti U1^ t^.F-f-('^I(^ti ^7t^- I)I^Pt^:ktil(^!^
^t)
un 0.4% de variabilidad explicada. EI resto de los efectos no manifiestan una influencia importante sobre la varianza del estimador a^ .
Las figuras 5 y 6 presentan para tamaños rnuestrales N= 11 y N= 101 la relación de la varianza de los tres estimadores a^ con la magnitud de contaminación m. Como cabía esperar, la varianza de los estimadores disminuye al aumentar el tamaño muestral. También se observa cómo a medida que aumenta la
magnitud de ta contaminación, la varianza de los tres estimadores se va incrementando. Este hecho se explica ya que al aumentar m, se incrementa la varianza de los datos contaminados, y puesto que estos tienden a aumentar o disminuir la pendiente del rnodelo logarítrnico de varianzas según la posición donde caigan, dicha pendiente se ve afectada tanto más cuanto mayor sea la
magnitud m de la contarninación, lo que provoca un aumento en la varianza de
dichos estimadores.
Sin embargo, este aumento es diferente según e! método de estimación utilizado, como recoge la existencia de una interacción MExMC irnportante. En la figura 7 se representa en función del tamaño muestral el cociente entre las varianzas de dichos estimadores cuando la magnitud del dato contaminado es m= 6
respecto a cuando m= 1. En ella se observa cómo este aumento es particularmente acusado en el estimador MV, que se muestra rnuy sensible, incluso para
Figura 5
VARIANZA DEL ESTIMADOR a1 EN LOS METODOS TSP, MCPI Y MV
EN FUNCION DE LA MAGNITUD DE CONTAMINACION, m. N= 11 observaciones
Varianza a 1
0.2
0.18
o.1s
0.14
0.12
0.1
0.08
o.os
0.04
0.02
1
METODO TSP
2
4
3
5
Magnitud de cvntaminación (m)
--8--
METODO MCPI
11 obs.
6
- ^- METODO MV
F^.ti^í,^lllti"I^I(^;^ E-tiE';1ti^)L^^
Figur^ 6
VARIANZA DEL ESTIMADOR a, EN LOS METODOS TSP, MCPI Y MV
EN FUNCION DE LA MAGNITUD DE CONTAMINACION, m. N= 101 observaciones
Varian2a a1
0.016
0.014
0.012
o.o^
o.oos
0.006
0.004
0.002
1
0
E^-
2
-^--
METODO TSP
7
6
4
3
5
Magnítud de contaminacíón (m)
METODO MCPI
METODO MV
101 ©bs.
Figura 7
RATIO ENTRE LA VARIANZA DEL ESTIMADOR a, CUANDO LA MAGNITUD
DE CONTAMINACI©N ES ALTA, m= 6, FRENTE A CUANDO NO EXISTE
CONTAMINACION, m= 1, EN FUNCION DEL TAMAÑO MUESTRAL, N
Var a1 (m=6) / Var a1 {m=1)
$
...............^---
7
6
---------.._..._.._.-
---^-^--.__....------ -------------------... ----------------- -.^4----------------------_._._......._....-•---
•--------------•--- •;`----.........__...._,.
.._
y + r_.-•--•--^-
-._.._....---•--^------:._..--•------•------•---
5
_...--•-----... _ ,,. .. t --• .................... { ..-------••------....._. + ._..........__..-•---__. F ........-•-•-•--------•-
4
'r-- .................r' . ---........._._._.....;._.._..._.....-•----.._.^............_._._.......f----_..__...----••------^--•---...---.......---.,
.
.
3
^...----._.,.'^, .....
..................•--•<---....--------•---....
---...._...-•--•----...;._._...--•----._...----
-.........._...----•---
I
©
.
,
.
.
.
----------------------^-------------------------------^-------------------------------------------------,--------------------2
._.,...._._._.......- ----......---._._.-.--- -.^---------....------ ----.......----------- ---------^-----....._..
1 I-------------------0
0
20
^--
METODO TSP
40
60
Tamaño muestral
-^--
METODO MCPI
100
80
-•LS -
120
METODO MV
.tit=N^IFill.ll)AI) t^RE:N-i^f: A[)n"I^()^; ANc)ti1Al.C)S l)l^ "^Rf:S }^::5`I149.•^[)()RE^^ I)F-. h.F-E-('Ic)ti ()F. I^l^l'l-:ktil(^ti
71
tamaños grandes de muestra, a la presencia de datos anómalos muy contaminados, es decir, con una varianza muy superiar a la que cabría esperar según el
modelo multiplicativo. Así, la varianza de este estimador cuando existen datos
anómalos con una magnitud de contaminación alta (m = 6) Ilega a ser de más
del doble cuando el tamaño muestral es pequeño, y hasta sie#e veces superior
con tamaños muestrales grandes a la correspondiente cuando no existe contaminación ( m = 1). Por el contrario, las varianzas del estimador MCPI y especialmente la del estimador TSP se ven mucho menos afectadas por el aumento de
la magnitud de la contaminación.
La mayor sensibilidad de la varianza del estimador MV a la presencia de datos altamente contaminados, incluso con tamaños muestrales grandes, se produce principalmente cuando el porcentaje de datos contaminados es pequeño,
situación que es la más probable en la práctica. Esto puede observarse en la tabla 3 donde se presentan los cocientes entre las varianzas de los estimadores
cuando m = 6 respecto a cuando m= 1 con IV = 101 observaciones y para dos
porcentajes de contaminación (10°l° y 50%).
Tabla 3
RATIO ENTRE LA VARIANZA DEL ESTIMADOR a^
EN LOS METODOS TSP, MCPI Y MV CUANDO
LA MAGNiTUD DEL DATO CONTAMINADO ES
ALTA, m= 6, FRENTE A CUANDO NO EXISTE
CONTAMINACION, m=1, CON DOS PORCENTAJES
DE CONTAMINACION (p = 10% y 50%).
N = 101 observaciones
p
TSP
MCPI
MV
10%
1.5
1.3
8.7
50%
1.7
1.8
2.3
La varianza del estimador MV si la magnitud del dato contaminado es alta y
el porcentaje de contaminación es pequeño (p = 10%) Ilega a ser casi nueve veces superior a la carrespandiente en ei caso de no existir contaminación. Por el
contrario, los estirnadores MCPI y TSP prácticamente no modifican su varianza,
sobre todo si se compara con el aumento que se produce en el estimador MV.
Sin embargo, cuando el porcentaje de contaminación es alto {p = 50%) las varianzas de los estimadores no se modifican sustancíalmente con el aumento de
la magnitud de contaminación, aunque el estimador MV sigue comportándose
como el más sensible de los tres.
Dado que las magnitudes de los cuadrados de los sesgos de los estimadores son pequeñas en relación a sus varianzas, la comparación de la eficiencia
de los estimadores a través de sus errores cuadráticos medios puede hacerse
utilizando sus varianzas.
f:ti ^ ^^ulti ^ !c ^^ F.^t^,^ti^ ^t. ^>
5.
CONCLUSIONES
Las conclusiones respecto a la sensibilidad frente a datos anómalos de los
estimadores en el caso de muestras grandes obtenidas er. este trabajo son coherentes con los resultados asintóticos obtenidos por Davidian y Carroll (1987).
Así, aunque asintóticarnente la utilización del estimador MCPI o TSP supone un
59% de pérdida de eficiencia respecta al ernplea del estimador MV, una pequeña fracción de datos contaminados es suficiente para acabar drásticamente con
la superiaridad del estimador máximo-verosímil.
De las consideraciones anteriores se deduce que 1a utilización del estimador
máximo-verosímil en un contexto industrial puede ser cuestionable debido a la
alta probabilidad de que en la práctica aparezcan datas anómalos en las observaciones, y a la extremada sensibiiídad que presenta el estimador MV a estas
anomaiias y que es independiente del tamaño muestral con el que se trabaje.
Por el contrario, el estimador TSP, más sencillo, constituye un método que
puede funcionar razonablemente bien en los casos en los que exista una ligera
contaminación en 1os valores de la variable respuesta.
De todos modos, como se observa en las figuras presentadas, ningun0 de
los tres estimadores analizados en este artículo puede considerarse estadísticamente robusto. De hecho, como ha puntualizada uno de los evaluadores, sus
puntos de ruptura son 0 en los tres casos. Por ello, en contextos en los que quepa esperar magnitudes de contaminación elevadas será necesario recurrir a técnicas de diagnóstico de datos anómalos, o bien a la utilización de estimadores
robustvs (Rousseeuw y Leroy, 1986).
AGRADECIMIENTOS
Los autores expresan su agradecimiento a ios evaluadores por todas las sugerencias y observaciones realizadas, que han contribuido a una mejor presentación del trabajo.
BIBLIOGRAFIA
AITKIN, M. (^ 987}: «Modeiing Variance Heterogeneity in Normal Regression
Using GL111/I», Applied Statistics, 36, 332-339.
BARTLETT, M. S., y KENDALL ,
D. G. (1946): <iThe Statistical Analysis of VarianceHeterogeneity and the Logarithmic Transformation», Journal of the Royal Statistical Society, B, 8, 128-138.
tiF^:N^IEit!_It)AI) F^}2FN^ft^ A!):tT():^ AN(.)MAI.t)^ UE-. "IR^•.:^ t.5"IIti1^^[)()KF-^ I)t E^.F^t.( I()ti l)f 1)I^,1't F^^It ^ !^
Box, G. E. P. (1986): «Studies in Quality Irnprovement: Signal to Noise Ratios,
Performance Criteria, and Statistical Analysis: Part I», University ofi Wisconsin-Madison, Center for Quality and Productivity Improvement, Report 11.
Box, G. E. P., y MEYER, R. D. (1986): «Dispersion Effects From Fractional Designs», Technometrics, 28, 19-27.
Box, G. E. P., y RAMÍREZ, J. (1986): «Studies in Quality Improvement: Signal to
Noise Ratios, Performance Criteria and Statistical Analysis: Part II», University
of Wisconsin-Madison, Center for Quality and Productivíty Improvement, Report 12.
CARROLL ,
R. J., y RUPPERT, D. (1988): Transformations and Weíghtings in Regression, Nueva York, Ed. Chapman and Hall.
CooK, R. D.,
y WEISBERG ,
S. (1983): «Diagnostics for Heterocedasticity in Re-
gression», Biometrika, 74, 1-10.
DAVIDIAN ,
M.,
y CARROLL ,
R. J. {1987): «Variance Function Estimation», Journal
of the American Statistica/ Association, 82, 1079-1091.
R. (1993): «Small samples estimation of dispersion effects from unreplicated data», Communications in Statistics: Simulation and
FERRER ,
A.,
y ROMERO ,
Computation, 22, 4, 975-995.
HAMPEL, F. R.; RONCHETTI, E. M.; ROUSSEEUW, P. J., y STAHEL, W. A .
(1986): «RO-
bust Statistics: The Approach Based on Influence Functions, Nueva York,
John Wiley & Sons.
I. (1990): Handbook of Statistical Methods for Engineers and Scientists, Nueva York, Ed. McGraw-Hill, Inc.
HARRISON, M., y WADSWORTH ,
HARVEY, A. C. (1976): «Estimated Regression Models With Multiplicative Heteroscedasticity», Econometrica, 44, 3, 461-465.
LEóN, R.; SHOEMAKER, A. C., y KACKER, R. (1987): «Performance Measures Independent of Adjustment: An Explanation and Extensíon of Taguchi's Signai-toNoise-Ratios (with response)» , Technometrics, 29, 253-265, 283-285.
P., y NELDER , J. A. (1989): Generalized Linears Models, 2.^ ed., Londres, Chapman and Hall.
MCCULLAG ,
y PREGIBON ,
D. (1986): «A Data Analysis Strategy for Quality Engineering Experiments», AT^T Technical Journal, 65, 73-84.
NAIR ,
V. N.,
NAIR, V. N., y PREGIBON, D. (1988): «Analyzing Disperssion Effects From Replicated Factorial Experiments», Technometrics, 30, 247-257.
PIGNATIELLO, J. J., y RAMBERG, J. S. (1985): « Discussion
of Off-Line Quality Con-
trol, Parameter Design and the Taguchi Method, by R. N. Kacker», Journal of
Quality Techno/ogy, 17, 198-206.
F^:!i'T,^^f)[^ 1 1('A E-:tiF'A!^t)t_,1
RoussEEUw, P. J., y LEROY, A. M. (1987): Robust Regression and Outlier Detectíon, Nueva York, Ed. John Wiley & Sons.
TACUCHi, G., y Wu, Y. (1980): Introduction to Dff-Line Quality Control, Nagoya,
Ed. Central Japan Quality Control Association.
ToRT-MARTORELL, J. (1985): «Diseños factoriales fraccionaies. Aplicación al control de calidad mediante el diseño de productos y procesos», Tesis doctoral,
Universidad Politécnica de óarcelona.
ZÚNICA, L., y RonnERO, R. (1988): «Un modelo para el estudio de efectos sobre la
dispersión en ausencia de replicaciones», Estadistica Españo/a, 116, 55-74.
OUTLIERS INFLUENCE oN THREE ESTIMATORS
OF DISPERSSION EFFECTS FROM UNREPLICATED DATA
SUMMARY
We study the influence of outliers on the bias and variance of
three estimators of dispersion effects from unreplicated data: 1) Twostep estimator (TSP); 2) Iterated weighted least squares estimator
(IWLS), and 3) Maximum likelihood estimator (ML). The influence of
the severity of the contamination on the bias of estimators depends
on the actual dispersion effect. As the severity of the contamination
increases, the variance of estimators increases. The simpfest estimator, TSP, turns out as the least sensitive to outlíers in situations
similar to the ones simulated, with whatever sample size. on the
contrary, the ML estimator is the most sensitive even with large sample sizes.
Key words: Heteroscedasticity, outliers, <COff-Line» quality control,
Quality and productivíty improvement.
AMS Classification: 62F ^ 1, 62F35, 62N 10, 65C05.

![( ) ( )2 ( )[ ] ( )ξ ( ) PQ](http://s2.studylib.es/store/data/006099496_1-61f82d8b006ba0985f60bbb263d08047-300x300.png)