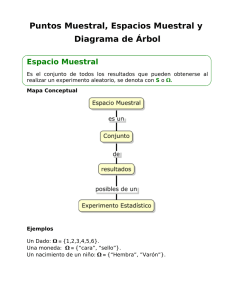
debe estar más hacia la derecha, más cercano a 78, de
Anuncio

118
debe estar más hacia la derecha, más cercano a 78, de forma tal que el área sombreada bajo
la curva que grafica el comportamiento de la media muestral bajo la hipótesis nula H! , área de
la derecha, sea igual a 0,05. De esta manera la magnitud del error tipo II, valor de " ,
corresponde al área sombreada bajo la curva de la media muestral bajo la hipótesis alternativa
H" . Visualmente se aprecia que la magnitud de " es bastante mayor que la magnitud de !. Es
fácil apreciar, que en esta misma situación, al disminuir " aumenta ! y viceversa, por el hecho
de tener que mover la posición de K hacia la izquierda o hacia la derecha respectivamente (fig.
3.2).
La única forma de disminuir " manteniendo fijo el valor de !, consiste en aumentar el
tamaño muestral, es decir aumentando n. De esa forma se consigue que ambas curvas sean
más leptocúrticas, o sea estén más concentradas alrededor de su media y por lo tanto el área
de traslape entre ellas sea menor, como se aprecia en la figura 3.3, en la cual la distribución
de las medias muestrales corresponde a muestras tamaño 25, mayor que en el caso anterior.
Nótese que la posición de K se mueve hacia la izquierda, debido a que las áreas disminuyen y
q
K, como se dijo, es el límite de un área del 5% bajo la curva X! . Un ejemplo numérico
ayudará a aclarar estos conceptos.
Ejemplo 3.3.
Supongamos
que X œ NÐ.ß "%%Ñ, es el comportamiento del rendimiento de la nueva
variedad híbrida, del ejemplo 6.3.1 c), donde el valor de . depende de cual hipótesis, H! o H" ,
es la verdadera. Se asumió que la desviación típica del rendimiento es 12 qq/ha, ya que para
los cálculos se necesitará de tal información. Si, como se hace frecuentemente, se fija
q
q
arbitrariamente en 16 el tamaño de la muestra, se tendrá que X0 œ NÐ(#ß *Ñ y X1 œ NÐ()ß *Ñ,
#
pues 58 = "%%
"' es 9. De esta manera el valor de K se determina asignando ! = 0,05
q
Ê ProbÐrech. H! / H! verdadera) = 0,05 Ê T ÐX OÎ . œ (#Ñ œ !ß !&
O(#
O(#
Ê T Ð^ O(#
$ Ñ œ !ß !& Ê " 9( $ ) œ !ß !& Ê 9( $ ) œ !Þ*&
Ê O(#
œ 9" Ð!ß *&Ñ Ê O(#
œ "ß '%& Ê O œ ('ß *Þ Con este valor se puede calcular la
$
$
probabilidad de cometer el error tipo II: " œ Prob(aceptar H! / H! falsa)
q
Ê " œ T ÐX Ÿ O Î. œ ()Ñ Ê " œ T Ð^ Ÿ ('ß*()
Ñ Ê " œ 9Ð !ß $(Ñ œ !ß $&', que corresponde
$
al área sombreada de la izquierda de la figura 3.2.