Análisis de correlación y de regresión simple
''jjJK'f
| Análisis de correlación y de regresión simple
Análisis de correlación
Técnica estadística usada para
medir la cercanía de la relación
lineal entre dos o más variables
en una escala de intervalo.
Análisis de regresión
Técnica estadística usada para
derivar una ecuación que relaciona una variable de criterio
con una o más variables de predicción; cuando se usa sólo una
variable de predicción, es el
análisis de regresión simple, y si
se utilizan dos o más, es el análisis de regresión múltiple.
El National Fluid Milk Processors Promotion Board tiene a su
cargo los anuncios de bigotes de
leche de celebridades. Una de
sus promociones actuales es un
"Milk Mustache Celebrity Calendar Event" anual, en que se envían
calendarios a diversos hogares. El
consejo mencionado está interesado en averiguar la correlación
de su presentación de calendarios de celebridades con las ventas de leche en galones. Según
información de Nielsen Homescan Data, las ventas de leche en
galones aumentaron 3.6%, en relación con las de un año atrás, en
los hogares que recibieron el
calendario de 1997, además de
incrementos de 9.7% de las mismas ventas en hogares con niños
de 6-12 años de edad.
Los análisis de correlación y de regresión son de uso frecuente entre los investigadores de mercados
para estudiar la relación entre dos o más variables. Aunque es común el uso indistinto de estos términos, existe una diferencia en su propósito. El análisis de correlación mide la cercanía de la relación
entre dos o más variables (véase el ejemplo del anuncio de leche), considerando la variación conjunta de las dos mediciones, ninguna de las cuales está sujeta a restricción por el experimentador. Por su
parte, el análisis de regresión se usa para derivar una ecuación que relaciona la variable de criterio
con una o más variables de predicción. En ello se considera la distribución de frecuencias de la variable de criterio cuando se mantienen fijas en diversos valores una o más de las variables de predicción.2
Es totalmente válido medir la cercanía de la relación entre variables sin derivar una ecuación estimada. De igual manera, puede entenderse el análisis de regresión sin investigar la cercanía de la
relación de las variables. Empero, es común derivar la ecuación y estudiar tal cercanía, por lo que
el conjunto de estas técnicas, no una u otra, suele denominarse análisis de regresión o correlación.
En cuanto a éste, debe comentarse también la distinción entre correlación y causalidad. El uso de
los términos variable dependiente (de criterio) y variable independiente (de predicción) para referirse a las mediciones en el análisis de correlación se deriva de la relación matemática funcional entre
las variables y no tiene nada que ver con la dependencia de una variable con respecto de otra en sentido causal. Por ejemplo, las técnicas podrían mostrar cierta correlación del ingreso alto con la tendencia a tomar vacaciones invernales en islas caribeñas, si bien sería un error suponer que el ingreso alto
es causa de que una persona viaje al sur cuando se desploman las temperaturas ambientales.
No existe nada en el análisis de correlación ni en ningún otro procedimiento matemático que
pueda usarse para establecer la causalidad. Lo único para lo que sirven estos procedimientos es pa-
Kroger no es ajeno a los beneficios del Milk Mustache Celebrity Calendar Event. Para quienes gustan de los
números, Nielsen Homescan Data reportó un aumento de 3.6% en las ventas de leche en galón, contra las
de un año atrás, en los hogares que recibieron el calendario 1999. Además, otro de 9.7% en las ventas de un
año antes en los hogares con niños de 6 a 12 años. Los desplegados publicitarios acerca del producto, como
éste, son una manera certera de impulsar la compra de galones de leche y mover el lechímetro. ¿Desea el
Celebrity Calendar 2000? Escríbame.
¿Quiere leche?
JUD WELLS, DAIRY CATEGORY MANAGER-KROGER COLUMBUS
© 1999 NATIONAL FLUID MILK PROCESSOR PROMOTION BOARD
Análisis de correlación y de regresión simple
677
automáticos disminuyó durante el periodo estudiado. Al mismo tiempo, las transacciones en puntos de venta con tarjetas de débito (es decir, pagar con tarjetas de débito en las cajas registradoras)
aumentaron en un sorprendente 35%. Los editores atribuyeron esta correlación inversa al desagrado
de los consumidores con los cargos por servicios en los cajeros automáticos. Señalaron que muchos
establecimientos minoristas no sólo permiten que sus clientes paguen las compras con tarjetas de
débito, sino que también les permiten hacer retiros de efectivo. Además, los minoristas, a diferencia de una porción creciente de cadenas de cajeros automáticos, no cobran ese servicio.4
El tema de los análisis de regresión y correlación se analiza a la luz de un ejemplo. Así, considere que un fabricante nacional de bolígrafos está interesado en investigar la eficacia de sus actividades
de mercadotecnia. La compañía usa mayoristas para distribuir los bolígrafos y complementa sus esfuerzos con representantes de ventas y anuncios televisivos. La empresa planea usar las ventas
anuales por territorio como medición de eficacia. Esos datos y la información del número de representantes de ventas que atienden un territorio están disponibles ya en los registros de la compañía.
Son más difíciles de determinar las otras características, con las cuales el fabricante busca relacionar
las ventas: anuncios televisivos y eficiencia de los mayoristas. A efecto de obtener información
sobre los anuncios televisivos en un territorio, los investigadores deben analizar las cédulas de publicidad y la cobertura de área de estudio por canal, a fin de determinar a cuáles áreas llegan los canales televisivos. Evaluar la eficiencia de los mayoristas requiere calificarlos en diversos criterios
y sumar las calificaciones en una medición global, en que 4 es sobresaliente, 3 es bueno, 2 es promedio y 1 es deficiente. El tiempo y gastos necesarios para generar datos de estas características de
publicidad y distribución ha hecho que la compañía decida analizar sólo una muestra de los territorios de ventas. Los datos de una muestra aleatoria simple de 40 territorios se presentan en el
anexo 21.1.
El efecto de cada una de las variables de la mezcla de mercadotecnia en las ventas puede estudiarse de diversas maneras. Una más bien evidente sería granear las ventas como función de cada una de
las variables. En la figura 21.1 se muestran las gráficas, llamadas diagramas de dispersión. La parte
A hace suponer que las ventas se incrementan cuando aumenta el número de anuncios televisivos
mensuales, y la parte B, que aumentan con el número de representantes de ventas que atiende el territorio. Por último, la parte C indica que existe poca relación entre las ventas de un territorio y la eficiencia del mayorista que los atiende.
Un vistazo más cercano a las partes A y B también refleja que sería posible resumir la relación entre las ventas y cada una de las variables de predicción si simplemente se traza una recta por los puntos de datos. Una forma de generar la relación de las ventas con los anuncios televisivos por número
de representantes sería "imaginarla", es decir, trazar visualmente una recta que pase por los puntos de
las gráficas. Esa recta correspondería a la línea de la relación "promedio" e indicaría el valor promedio de la variable de criterio, las ventas, con los valores dados de cualquiera de las variables de predicción, anuncios televisivos o número de representantes. Luego, podría añadirse a las gráficas, por
ejemplo, el número de anuncios televisivos en el territorio y leer el valor promedio de ventas esperadas en el territorio mismo. La dificultad del enfoque gráfico es que dos analistas podrían generar rectas distintas para describir la relación. Ello hace surgir la pregunta de cuál sería la recta más correcta
o cuál de ellas encajaría mejor en los datos.
Un enfoque alterno es generar matemáticamente una recta que una los datos. La ecuación general de una recta es y = a + f3X, donde a es la intersección 7, y /3 el coeficiente de la pendiente.
En este caso de Y ventas y X\ anuncios televisivos, la ecuación podría escribirse como Y= a¡ + P\X\,
mientras que la relación entre las Y ventas y los X2 representantes de ventas se representaría como
7= a2 + $2X2, donde el subíndice corresponde a la variable de predicción que se considera. Tal como está escrito, cada uno de estos es un modelo determinista. Cuando se sustituye el valor de la variable de predicción en la ecuación con los valores especificados de a y (3, se determina un valor
único de Y, sin considerar un margen de error.
En la investigación de fenómenos sociales pocas veces, si acaso, el error es cero. Así, podría sustituirse el modelo determinista por un modelo probabilistic, que debería incluir algunos supuestos
acerca del error. Por ejemplo, para trabajar con la relación de las ventas y el número de anuncios televisivos, considere el modelo:
Yi = aí+ftlXil + €i
678
Capítulo 21: Análisis de datos: investigación de relaciones
A N E X O 21 .1
Territorio
005
019
033
039
061
082
091
101
115
118
133
149
162
164
178
187
189
205
222
237
242
251
260
266
279
298
306
332
347
358
362
370
391
408
412
430
442
467
471
488
Ventas
(en miles),
Y
Publicidad
(anuncios televisivos por mes)
*
Número de
representantes de ventas
índice de
eficiencia de mayoristas
*2
*3
260.3
5
7
6
9
12
8
11
16
13
7
10
4
9
17
19
9
11
8
13
14
7
16
9
5
18
18
5
7
12
13
8
6
16
19
17
10
12
8
10
12
3
5
3
4
6
3
7
8
4
3
6
4
4
8
7
3
6
3
5
5
4
6
5
3
6
5
3
6
7
6
4
3
8
8
7
4
5
3
5
5
4
2
3
4
1
4
3
2
3
4
1
1
3
4
2
2
4
3
4
2
4
3
3
3
4
3
2
2
1
4
3
2
2
2
8
3
3
3
4
2
286.1
279.4
410.8
438.2
315.3
565.1
570.0
426.1
315.0
403.6
220.5
343.6
644.6
520.4
329.5
426.0
343.2
450.4
421.8
245.6
503.3
375.7
265.5
620.6
450.5
270.1
368.0
556.1
570.0
318.5
260.2
667.0
618.3
525.3
332.2
393.2
283.5
376.2
481.8
donde Y¡ es el valor de ventas en el territorio /-ésimo, Xü es la intensidad de la publicidad en ese mismo territorio y e, es el error relacionado con la observación z-ésima. Ésta es la forma del modelo que
se usa en el análisis de regresión. El término de error es parte del modelo. Representa el hecho de no
incluir todos los factores en el modelo, que hay un elemento impredecible en el comportamiento humano y que ocurren errores de medición.5 El modelo probabilístico considera el hecho de que el va-
Análisis de correlación y de regresión simple
619
F I G U R A2 1 . 1
FIGURA 21.2
lor Y no está determinado de manera unívoca por un valor dado de X¡. En vez de ello, lo único determinado por este último valor es el "valor promedio" de Y. Cabe esperar que sus valores fluctúen en
torno a ese promedio.
La solución matemática para encontrar la línea de ajuste óptimo del modelo probabilístico requiere de ciertos supuestos acerca de la distribución del término de error. La recta de ajuste óptima podría
definirse de maneras diversas. Es habitual considerar que es la línea que minimiza la suma de desviaciones al cuadrado alrededor de la línea (la solución de cuadrados mínimos). Considere la figura 21.2
y suponga que la línea trazada en la figura es una ecuación estimada. Use el acento circunflejo (A) para indicar un valor estimado y el error en la observación /-ésima es la diferencia entre el valor real de
6W
Capítulo 21: Análisis de datos: investigación de relaciones
Y, Y¡, con el valor estimado de Y, Y¡, es decir, e¡ =Y¡- Y¡. La solución de cuadrados mínimos se basa
en el principio de que la suma de estos errores al cuadrado debe ser tan pequeña como resulte posible,
es decir, que se debe minimizar 2"e?. Las estimaciones de muestras a\ y fi\ de los parámetros poblacionales verdaderos a\ y fi\ se determinan para satisfacer esta condición.
Son tres los supuestos simplificadores del término de error en la solución de cuadrados mínimos:
1. La media o valor promedio del término de error es cero.
2. La varianza del término de error es constante e independiente de los valores de la variable
de predicción.
3. Los valores del término de error son independientes entre sí.
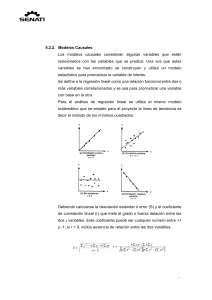
Dados estos supuestos, es posible despejar fórmulas para obtener estimaciones seguras de los parámetros poblacionales «j, la intersección, y jo l5 la pendiente, pero es más usual calcularlos mediante computadora.6
Si se usan los datos del anexo 21.1 respecto de ventas (7) y anuncios televisivos mensuales (X{),
las estimaciones de «j y /3j serían 135.4 y 25.3, respectivamente.7 La ecuación se representa gráficamente en la figura 21.3. La pendiente de la recta está dada por p t . El valor de ésta, 25.3, hace suponer
que las ventas aumentan en 25 300 dólares por cada unidad de aumento en los anuncios televisivos.
Como se mencionó, se trata del estimado de una condición poblacional verdadera basada en una
muestra específica de 40 observaciones. Sin duda alguna, otra muestra distinta generaría un estimado
diferente. Por añadidura, todavía no se ha planteado si se trata de un resultado estadísticamente significativo o que podría haber ocurrido al azar. No obstante, es un elemento de información de suma importancia, que ayuda a determinar si el gasto en publicidad vale su rendimiento esperado. El estimado
del parámetro de intersección es a{ = 135.4, lo cual indica dónde cruza la recta al eje Y, puesto que se
trata del valor estimado de 7 cuando la variable de predicción es igual a cero.
FIGURA 21.3
Análisis de correlación y de regresión simple
681
Error estándar de la estimación
El examen de la figura 21.3 muestra que, a pesar de que la línea parece encajar razonablemente bien
en los puntos, todavía existe desviación de éstos en torno a ella. La magnitud de su desviación mide el ajuste. Es posible calcular una medición numérica de la variación de los puntos alrededor de
la línea, de manera similar al cálculo de la desviación estándar de una distribución de frecuencias.
Al igual que la media de la muestra es una estimación de la media verdadera de la población original, la recta dada por Y¡ = a{ + faX^ + e¡ es una estimación de la recta de regresión verdadera,
Yj = «! + jSjJQj + €j. Considere la varianza del error aleatorio e en torno a la recta de regresión verdadera o2^ es decir, oy/^2. Cuando se desconoce la varianza poblacional o2, una estimación sin sesgo
está dada por la raíz cuadrada de la desviación estándar de la muestra, s, a saber:
En forma similar, suponga que SY/X es una estimación sin sesgo de la varianza poblacional alrededor de la recta de regresión, (rY/x2. Ahora bien, puede demostrarse que la estimación de la muestra
de la varianza alrededor de la recta de regresión se relaciona con la suma de los errores al cuadrado; de
manera específica, es igual a:
Error estándar de la
estimación
Término usado en el análisis de
regresión para referirse al valor
absoluto de la variación en la variable de criterio, que se deja sin
explicación, o que no cuenta, en
la ecuación de regresión ajustada.
FIGURA 2 1 4
donde n es nuevamente el tamaño de la muestra, y sY/x2, el estimador sin sesgo de crY/x2, con Y¡ y Y¡
como valores observado y estimado de 7 para la observación /-ésima. La raíz cuadrada de esa cantidad, SY/X, se llama frecuentemente error estándar de la estimación, si bien es más descriptivo el término desviación estándar de la regresión.
La interpretación del error estándar de la estimación guarda paralelismo con el de la desviación
estándar. Considere un valor X{1. El error estándar de la estimación significa que Y¡ (ventas) tiende a
distribuirse en torno al valor Y¡ correspondiente -el punto en la recta- con desviación estándar igual
al error estándar de la estimación, con cualquier valor dado Xi{ de anuncios televisivos. Además, la
variación en torno a la línea es la misma en toda la longitud de la recta. La media aritmética, que es
el punto en la recta, cambia al hacerlo X^\ pero la distribución de los valores Y¡ alrededor de la línea
no se modifica con el número de anuncios televisivos. En la figura 21.4 se muestra la situación en el
supuesto de que el término de error tiene distribución rectangular, por dar un ejemplo.8 Note que
682
Capítulo 21: Análisis de datos: investigación de relaciones
el supuesto de SY/X constante sin importar el valor de Xix produce bandas paralelas en torno a la recta
de regresión.
Cuanto menor sea el error estándar de la estimación, mayor será la coincidencia de la recta con
los datos. En el caso de la recta relacionada con las ventas y los anuncios televisivos se trata de
SY/X = 59.6.
Inferencias acerca del coeficiente de pendiente
A
Se calculó anteriormente que el valor del coeficiente de pendiente j3j era 25.3. En dicho momento, no
se planteó la pregunta de si el resultado era estadísticamente significativo o aleatorio. Responder a
dicha pregunta requiere un supuesto adicional, a saber, que los errores se distribuyen de manera normal,
no rectangular, como se había pensado. Empero, antes de continuar debe resaltarse que los estimadores de cuadrados mínimos de los parámetros de la población original son los mejores estimadores lineales sin sesgo de los parámetros poblacionales verdaderos, sin importar la forma de la distribución
del término de error. Basta que se satisfagan los supuestos previos. Éste es un resultado notable del
teorema de Gauss-Markov. Se requieren supuestos de errores con distribución normal sólo si se pretende elaborar inferencias estadísticas acerca de los coeficientes de regresión.
Puede demostrarse que si e¿ son variables aleatorias de distribución normal, entonces ¡3l también
tiene distribución normal. En otras palabras, si se seleccionan muestras repetidas de la población de
territorios de ventas y se calcula un valor de j3j para cada muestra, la distribución de estas estimaciones sería normal y centrada en el parámetro poblacional verdadero fir Por añadidura, es posible
demostrar que la varianza de la distribución de los valores jSj o crfa2, es igual a:
Puesto que es desconocida la población crY/x2, tampoco se conoce erg 2 y se precisa estimarla. Esta estimación, que se denota como sfi2, se genera al sustituir aY/xcon el error estándar de la estimación SY/X:
Hasta este punto, la situación es la siguiente: dado el supuesto de errores de distribución normal,
/3t también tiene distribución normal, con media j3j y varianza afe 2 desconocida. Puesto que se carece de la varianza de la distribución de la muestra, es necesario usar un procedimiento similar al
utilizado cuando se derivó una inferencia de la media con desconocimiento de la varianza poblacional. Ese conjunto de condiciones requiere una prueba t para examinar la significancia estadística. La
prueba de significancia de j3j tiene un requisito similar. La hipótesis nula consiste en la ausencia de
relación lineal entre las variables y la hipótesis alternativa, si existe tal relación, es decir:
El estadístico de prueba es t = (J3, - j8,)/^, es decir, la pendiente estimada a partir de la muestra
menos la pendiente hipotética, resultado que se divide entre el error estándar de la estimación que tiene distribución t con n — 2 grados de libertad. En el ejemplo:
Análisis de correlación y de regresión simple
; 683
Con un nivel de significancia de 0.05, el valor de / en tablas con v = n — 2 = 38 grados de libertad
es 2.02. Puesto que el valor calculado de / excede su valor crítico, se rechaza la hipótesis nula; p\
difiere de cero en grado suficiente para justificar el supuesto de la relación lineal entre las ventas y
anuncios televisivos. Ahora bien, ello no significa que esa relación en verdad sea necesariamente lineal, sino sólo que la evidencia indica que Y (ventas) cambia al hacerlo X\ (anuncios televisivos) y
que si se usan X\ y la ecuación lineal podría tenerse una predicción de Y mejor que en caso de simplemente omitir X\.
¿Qué pasa si no se rechaza la hipótesis nula? Como se señaló, j3j es la pendiente de la recta supuesta sobre la región de observación e indica el cambio lineal en Y con el cambio de una unidad en
X\. Que no se rechace la hipótesis nula, de que /^ = O, no significa que sea inexistente la relación de
Yy X{. Son dos las posibilidades. En primer término, simplemente podría ser que se cometa un error
de tipo II al no rechazar una hipótesis nula falsa. En segundo lugar, sería factible que 7 y Xl tengan
una relación curvilínea perfecta y que se haya escogido el modelo incorrecto para describir la situación verdadera.
Coeficiente de correlación
Coeficiente de correlación
Término usado en el análisis de
regresión para designar la fuerza
de la relación lineal entre las variables de criterio y predictivas.
FIGURA 21.5
Hasta este punto, se ha analizado la relación funcional de Y con X. Suponga que también interesa la
intensidad de la relación lineal entre esas dos variables, lo cual lleva al concepto de coeficiente de
correlación. Se partió de dos supuestos adicionales al analizar el modelo de correlación. El primero,
que X¡ es una variable aleatoria. Una observación de muestra permite obtener valores de X¡ y Y¡. El
segundo, que las observaciones provienen de una distribución normal de dos variables, es decir, una
en que la variable Atiene distribución normal, al igual que la variable Y.
Ahora bien, considere la representación gráfica de una muestra de n observaciones, de una distribución normal de dos variables. Sea p la íuerza de la relación lineal entre dos variables en la población
original, y r la estimación de la muestra de p. Suponga también que la muestra de n observaciones ge-
684
Capítulo 21: Análisis de datos: investigación de relaciones
ñera la dispersión de puntos que se presenta en la figura 21.5 y divida la figura en cuatro cuadrantes,
que se forman al trazar líneas perpendiculares a los ejes x y y.
Considere las desviaciones de estos bisectores. Tome cualquier punto P con coordenadas (Xh 7¿)
y defina las desviaciones:
donde las minúsculas indican desviaciones en torno a una media. Está claro, con la observación de la
figura 21.5, que el producto x^ es:
• Positivo en cualquier punto del cuadrante I
• Negativo en cualquier punto del cuadrante II
• Positivo en cualquier punto del cuadrante III
• Negativo en cualquier punto del cuadrante IV
Por ende, parecería que es factible usar la cantidad S"= \x¡yi como medición de la relación lineal
entre ^ y 7, y:
• Si la relación es positiva, de modo que gran parte de los puntos se sitúa en los cuadrantes I y III,
S"= \x¡y¡ tiende a ser positiva.
• Si la relación es negativa, con muchos de los puntos en los cuadrantes II y IV, S"= [X^
tiende a ser negativa.
• Si no existe relación entre Xy Y, los puntos se dispersan en los cuatro cuadrantes y S"= \x-y¡ tiende a ser muy pequeña.
No obstante lo anterior, la cantidad 2" = py,- tiene dos defectos como medida de la relación lineal entre
Xy Y. El primero, que se puede incrementar arbitrariamente con la inclusión de más observaciones, es
decir, al incrementar el tamaño de la muestra. El segundo, que también puede recibir influencia arbitraria del cambio en la unidad de medición de X, Yo ambas, por ejemplo, al cambiar de metros a centímetros. Estos defectos pueden eliminarse al hacer que la medición de la fuerza de la relación lineal
sea una cantidad sin dimensiones y dividir entre n. El resultado es el coeficiente de correlación pearsoniano o de producto-momento, a saber:
donde sx es la desviación estándar de la variable X, y SY, la desviación estándar de la variable Y.
El coeficiente de correlación calculado a partir de los datos de la muestra es un estimado del parámetro de la población original p, y una parte del trabajo del investigador es usar r para poner a prueba hipótesis acerca de p. Ello resulta innecesario en el ejemplo, ya que la prueba de la hipótesis nula
HQ. p = O es equivalente a la prueba de la hipótesis nula H0: f3i = 0. En virtud de que ya se realizó
esta última prueba, la evidencia de la muestra lleva al rechazo de la hipótesis de que no existe relación lineal entre las ventas y los anuncios televisivos, es decir, al rechazo de //0: p = 0.
El coeficiente de correlación de producto-momento puede variar de - 1 a +1. La correlación positiva perfecta, en que un aumento dado de X determina con exactitud otro de 7, tiene coeficiente +1.
La correlación negativa perfecta, en que un incremento de ^determina exactamente una disminución
de 7, produce un coeficiente — 1. En la figura 21.6 se ilustran estas situaciones y otros diagramas de
dispersión y sus coeficientes de correlación respectivos. El examen de estos diagramas brinda cierta
apreciación de la magnitud del coeficiente de correlación relacionado con un grado de dispersión es-
Análisis de correlación y de regresión simple
^a^^ttliimr
FIGURA 21.6
Fuente: Ronald. E. Frank, Alfred A. Kuehn y William F. Massy, Quantitative Techniques in Marketing Analysis, Homewood, IL, Richard D. Irwin,
1962, p. 71. Reproducido con autorización.
Coeficiente de
determinación
Término usado en el análisis de
regresión para denotar la proporción relativa de la variación
total en la variable de criterio
que puede explicarse mediante
la ecuación de regresión ajustada.
pecífico. El cuadrado del coeficiente de correlación es el coeficiente de determinación. Ciertas manipulaciones algebraicas permiten demostrar que es igual a:
es decir, r2 = 1 menos el error estándar del estimado al cuadrado, dividido entre la varianza de la
muestra de la variable de criterio. A falta de variable de predicción, el mejor estimado de la variable de
criterio sería la media de la muestra. Si hubiera poca variabilidad en las muestras de un territorio a
otro, la media de la muestra sería un buen estimado de las ventas esperadas en cualquier territorio. Empero, la variabilidad considerable haría que fuese una estimación deficiente. Así, la varianza de las
muestras, sY2, es una medición del grado de "deficiencia" de ese procedimiento de estimación. La introducción de la covariable X podría mejorar los estimados de las ventas por territorio. Ello depende
686
;
Capítulo 21: Análisis de datos: investigación de relaciones
de cuan bien se adecué la ecuación a los datos. Puesto que sY/x2 mide la dispersión de los puntos
en torno a la recta de regresión, puede considerarse que es una medición de cuan "deficiente" es
un procedimiento de estimación que toma en cuenta la covariable. Ahora bien, si sY/x2 es de poca
cuantía en relación con sY2, sería factible afirmar que añadir la covariable mediante la ecuación de
regresión mejora sustantivamente las predicciones de la variable de criterio, las ventas. A la inversa, cuando sY/x2 es aproximadamente igual a sY2, se consideraría que agregar la covariable X no
sirve para mejorar las predicciones de Y. Por tanto, la proporción sY/x2/sY2 se conceptuaría como
la proporción de la variación que no se explica con la recta de regresión dividida entre la variación total, es decir:
r2 = 1 -
variación inexplicada
variación total
El miembro derecho de esta ecuación puede combinarse en una sola fracción, de modo que se tenga:
<,
r¿ =
variación total - variación inexplicada
: —
:
variación total
Al restar la variación inexplicada de la variación total, queda la "variación explicada", o sea, la
variación de Y que se explica con la inclusión deX. De tal suerte, puede considerarse que el coeficiente de determinación es igual a:
r2 =
variación explicada
variación total
donde se entiende que la variación total se mide con la varianza de Y. En el ejemplo de las ventas y
anuncios televisivos, r2 = 0.77. Ello significa que 77% de la variación en las ventas de un territorio a
otro se explica con la variación de la publicidad televisiva entre territorios. Por consiguiente, la estimación de las ventas en un territorio es mejor si se toman en cuenta los anuncios televisivos que al
hacer caso omiso de esa actividad publicitaria.
I Análisis de regresión múltiplí
La idea básica subyacente al análisis de regresión múltiple es la misma que en la regresión simple:
determinar la relación entre las variables independientes y dependiente, o variables de predicción y
de criterio. El análisis de regresión múltiple permite añadir diversas variables, de modo que la ecuación refleje los valores de un cierto número de variables de predicción, no una sola. El objetivo de esto es mejorar las predicciones de la variable de criterio.
Un observador irónico de muchos proyectos de investigación hizo diversos comentarios astutos
acerca del comportamiento de las variables y la forma en que suelen correlacionarse (Ventana de investigación 21.2). Convendría que el lector los tenga en mente mientras lee este apartado del análisis
de regresión múltiple.
Nomenclatura modificada
Un marco de notación modificado y más formal es valioso para comentar el análisis de regresión
múltiple. Considere el modelo de regresión general con tres variables de predicción. La ecuación
modificada:
la cual es una estado simplificado de la más elaborada y precisa ecuación.