Estadística Descriptiva
ÍNDICE
ESTADÍSTICA DESCRIPTIVA
1.
Población y Muestra
4
2.
Variables estadísticas
4
3.
Frecuencias
5
4.
Distribuciones
7
5.
Representación gráfica
11
5.1 De caracteres cuantitativos
11
5.1.1 De variables estadísticas discretas sin agrupar
5.1.1.1 Diagrama de barras
11
5.1.1.2 Polígono de frecuencias
12
5.1.1.3 Diagrama de frecuencias acumuladas
12
5.1.2 De variables estadísticas discretas con valores
14
agrupados en intervalos
5.1.2.1 Histograma
14
5.1.2.2 Polígono de frecuencias
14
5.1.2.3 Polígono de frecuencias acumuladas
16
5.2 De caracteres cualitativos
6.
7.
18
5.2.1 Diagramas de sectores
18
5.2.2 Pictogramas
18
5.2.3 Cartogramas
18
Medidas de posición o centralización
19
6.1 Media aritmética
19
6.2 Moda
22
6.3 Mediana
22
6.4 Cuantiles
26
Medidas de dispersión.
30
7.1 Rango o recorrido
30
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
8.
9.
7.2 Recorrido intercuartílico
30
7.3 Varianza
31
7.4 Varianza muestral o cuasivarianza
32
7.5 Desviación típica
32
7.6 Desviación típica muestral
32
7.7 Coeficiente de Variación de Pearson
33
7.8 Momentos
33
Características de forma:
35
8.1 Sesgo o Coeficiente de asimetría de Fisher
36
8.2 Curtosis o Coeficiente de apuntamiento
37
Diagrama de Caja
39
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
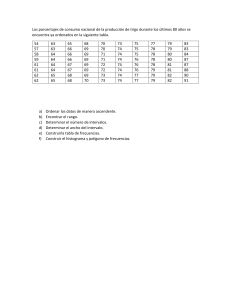
Es un hecho reconocido que la Estadística es necesaria en todos los campos donde se
avance en investigación.
Los principios estadísticos son independientes de la materia en la que se apliquen; los
principios son generales aunque las técnicas pueden ser distintas.
Se hace ciencia cuando el estudio se ocupa de la observación y clasificación de los
hechos. Estadística es la ciencia de los datos. Los datos o hechos numéricos son esenciales para
tomar decisiones en casi todas las áreas de nuestra vida.
Por ejemplo, llevar paraguas depende de la probabilidad de lluvia. Si observamos que
las medidas de una mujer son 90-60-90, esto significa que esa persona tiene unas proporciones
que se consideran perfectas.
En una empresa se manejan muchos datos sobre ventas, inventarios, personal, gastos,
clientes, equipos, etc. Todos estos datos han de ser interpretados de alguna forma, tarea que
requiere presentar los números de manera que su mensaje aparezca claramente.
Para poder usar los datos con fines concretos debemos resumirlos y describirlos; esta
tarea corresponde a la estadística descriptiva. El análisis de los datos combina resúmenes
numéricos con representaciones gráficas.
Imaginemos que asistimos a una partida de dados: primeramente observamos el
desarrollo de la partida y anotamos los resultados (estadística descriptiva), como sabemos que
con dos dados el resultado más probable es 7 (estadística matemática) y tomaremos la decisión
de jugar o no dependiendo de la comparación de los resultados (inferencia estadística).
En la estadística descriptiva se ven los DATOS, pero no se pueden probar de una manera
formal. La estadística descriptiva y la estadística matemática son complementarias.
El análisis de datos requiere una colaboración dinámica entre el especialista en el asunto
(el que posee los datos) y estadístico (el que los analiza).
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
El primer paso en un análisis de datos es su inspección, familiarizarse con los datos y
encontrar características extraordinarias. El siguiente paso es la comparación: comparar datos
y comparar modelos. Por último, la interpretación. Muy a menudo el ciclo entero comienza de
nuevo.
1. POBLACIÓN y MUESTRA
Población es un conjunto de elementos de los cuales nos interesa estudiar alguna
característica común. El estudio que se haga servirá para conocer y describir a esa población.
Muestra es una parte de la población. Los resultados que se obtienen de su estudio se
tratan de extrapolar para toda la población.
La característica que queremos estudiar de la población presentará diversas modalidades
que son los posibles valores que puede tomar.
Los caracteres pueden ser:
cualitativos: las diversas modalidades no son valores numéricos.
Ejemplo: "el color del pelo de un grupo de personas".
cuantitativos: las diversas modalidades son números reales.
Ejemplo: "el número de miembros de las familias que viven en Madrid".
Estos números son los diferentes valores que toma una variable estadística.
2. VARIABLES ESTADÍSTICAS
Variable estadística cuantitativa es una aplicación que asigna a cada elemento de la
población un número real, que es el valor de la característica cuantitativa que estamos
estudiando.
E = población→R
Una variable estadística es discreta si sus valores posibles pertenecen a un conjunto
numerable. El caso más frecuente de variables discretas es aquel en que los valores posibles
son números enteros. Así:
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
- El número de hijos en una familia.
- El número (o la proporción) de piezas defectuosas de un lote de 1000 piezas.
Una variable estadística es continua si sus valores posibles pertenecen a un
conjunto no numerable, en general valores de R o de un intervalo de R.
- El diámetro de una pieza.
- La temperatura de un cuerpo.
En general, todas las magnitudes, relacionadas con el espacio, con el tiempo, con la
masa o bien las combinaciones de estos elementos son variables estadísticas continuas.
Rango o recorrido de la variable es la diferencia entre el valor máximo y el valor mínimo de
la variable.
3. FRECUENCIAS
Sea una población de N elementos, de la cual estudiamos el carácter X que presenta las
modalidades x1 , x 2 ,......, x k . Para cada modalidad x i se define:
•
Frecuencia absoluta, n i , es el número de elementos que poseen la modalidad
x i . Se tiene que
•
k
∑n
i =1
i
= N.
Frecuencia relativa, fi , es el cociente entre la frecuencia absoluta n i y el número
n
total de elementos N, es decir, fi = i . Se tiene que
N
•
k
∑f
i =1
i
= 1.
Frecuencia absoluta acumulada, Ni, es el número de elementos que poseen la
modalidad x i . o alguna de las anteriores (para lo cual tienen que estar ordenadas
i
previamente), es decir, N i = ∑ n j . Se tiene que N k = N .
j =1
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Frecuencia relativa acumulada, Fi , es el cociente entre la frecuencia absoluta
•
acumulada y el número total de elementos N, es decir, Fi =
Ni
. Se tiene que Fk = 1.
N
El estudio de las distribuciones de frecuencia tiene como objeto construir tablas
verticales u horizontales que se utilizarán para una mejor presentación e interpretación de los
datos obtenidos en la muestra.
En la primera columna (fila) se escriben los valores de la variable y en la segunda el
número de veces que se repite el valor de la variable.
X
ni
x1
n1
x2
n2
.
.
.
.
xk
nk
La tabla (1) formada por la variable junto con sus respectivas
frecuencias
absolutas
se
denomina
distribución
de
frecuencias absolutas.
n1 + n 2 + ... + n=
k
k
∑ n=
i =1
i
N
fi
x1
f1
x2
f2
.
.
.
.
xk
fk
1
N
Tabla 2
La tabla (2), formada por los valores de la variable junto con
Tabla 1
X
sus respectivas frecuencias relativas, se denomina distribución de
frecuencias relativas.
X
Ni
x1
N1
x2
N2
.
.
.
.
xk
Nk = N
Tabla 3
n
f i = ∑ i = f1 + ... + f k = 1
∑
=i 1 =i 1 n
k
k
i
∑n
j=1
j
= N i , y se verifica N k = N
X
Fi
x1
F1
x2
F2
.
.
.
.
xk
Fk = 1
Tabla 4
La tabla (3) es la distribución de frecuencias absolutas
acumuladas.
Fi =
Ni
, y se verifica Fk = 1 .
N
La tabla (4) es la distribución de frecuencias relativas acumuladas.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
También es frecuente usar una tabla llamada sumario estadístico, en la que aparecen los
valores de la variable junto con los valores de los distintos tipos de frecuencia.
EJEMPLO 3:
El número de hectáreas radiadas por día, en un total de 90 días han sido:
0, 1, 1, 0, 1, 2, 2, 1, 0, 2, 3, 2, 0, 1, 1, 0, 1, 1, 4, 0, 1, 1, 0, 3, 0, 0, 1, 3, 1, 0, 1, 2, 2, 1, 3, 1, 1, 0,
0, 1, 1, 3, 0, 0, 1, 1, 0, 2, 2, 3, 0, 1, 2, 2, 1, 0, 1, 2, 2, 4, 1, 0, 4, 5, 0, 2, 2, 0, 0, 1, 1, 0, 1, 1, 0, 0,
1, 1, 0, 1, 1, 0, 1, 1, 1,1, 1, 1, 1, 1.
Obtener la distribución de frecuencias absolutas y la de frecuencias absolutas
acumuladas.
Solución:
Distribución de frecuencias:
Absolutas
Absolutas acumuladas
Nº de hectáreas
Nº de días
Nº de hectáreas
Nº de días
xi
ni
xi
Ni
0
26
0
26
1
40
1
66
2
14
2
80
3
6
3
86
4
3
4
89
5
1
5
90
Total
90
Total
90
4. DISTRIBUCIONES
Distribución de frecuencias: es el conjunto de modalidades con sus respectivas
frecuencias. Según sean éstas (absolutas, relativas,....) así lo será la distribución
correspondiente.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Las distribuciones de frecuencias se representan mediante tablas estadísticas.
Se clasifican en dos tipos:
- Sin agrupar: aparecen los datos individualizados con sus respectivas
frecuencias. Se utiliza cuando la variable toma pocos valores diferentes.
- Agrupados en intervalos se divide el campo de la variable en intervalos
llamados de clase, que tendrán como frecuencia el número de elementos que estén en el
intervalo. Se utiliza cuando la variable toma muchos valores distintos entre sí.
e0 < e1 < e 2 < ... < e k , siendo k el número de clases
La agrupación en intervalos tiene la ventaja de la simplicidad de los cálculos, y
el inconveniente de la pérdida de información.
Los intervalos serán todos de la misma amplitud procurando que los datos se distribuyan
más o menos homogéneamente a lo largo de todo el recorrido, de forma que no haya ninguna
clase con muchos elementos (más del 30%) ni varias clases con pocos o ningún elemento
(menos del 5%).
Es importante que no existan intervalos con frecuencia cero.
El nº de intervalos que se toma dependerá del número de datos y de la dispersión de los
mismos.
Algunos criterios a seguir es tomar k como el entero más próximo a:
a) 1+3.3log10(N) ;
b) 2 N
A los extremos del intervalo se les llama límites de clase (superior e inferior). Estos se
deben tomar de forma que se solapen los intervalos, es decir, que el extremo superior de uno
sea el inferior del siguiente.
Para evitar la ambigüedad que suponen los valores de la variable que coincidan con
algún extremo, se pueden seguir dos criterios:
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
- Incluir siempre el extremo superior, pero no el inferior de cada clase, salvo en la
primera que se incluyen los dos. Es decir, tomar intervalos de la forma (a,b].
- Tomar los extremos de los intervalos con un decimal más que los dados, de forma que
no pueda coincidir con ninguno de ellos.
Se llama marca de clase (xi) al punto medio del intervalo de clase ei-1- ei. En todos los
cálculos se opera como si la marca de clase tuviera la frecuencia absoluta de todo su intervalo.
La marca de clase se obtiene sumando los límites superior e inferior de clase y
dividiendo por 2, es decir, x i =
( e i −1 + e i )
.
2
Tamaño de clase o amplitud de clase "a" es la diferencia entre los límites de clase.
a=
ek − e0
La distribución de frecuencias quedaría así:
k
Intervalo
Marca de
Frecuencia
Frecuencia
Frecuencia
Frecuencia
clase x1
absoluta
relativa
relativa
absoluta
acumulada
acumulada
[e0 , e1 ]
x1
n1
f1
F1
N1
( e1 , e2 ]
x2
n2
f2
F2
N2
...........
...
...
...
...
...
( ei−1 , ei ]
xi
ni
fi
Fi
Ni
...........
...
...
...
...
...
( ek −1 , ek ]
xk
nk
fk
1
N
Designamos por (ni) al número de observaciones que quedan dentro del intervalo [ ei −1 , ei ) .
EJEMPLO 4:
Los precios de 95 ordenadores en diciembre de 2014, dados en euros, son los
siguientes:
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
3000 1200
3910
740 1750 3409
545 1380
815
580
565 3000
840 1700 2300
715
890 1580
800 3650
735
800
930
915 1100 1280 1163 1410 2050 3600 1260 1600
735
4260 1500 1000 1000 1600 1900 2150 2495 3200
850
2240 1975 1745 3030 2350 3700
990
540 2900 4500 3600 1035 1520 2495 1357
715
2775 2540 1470
395 3900
1995 2650 1335
885
360 2100 2400 1200 1335 3310
990
765 1020
600
755
500
995 2200
750
900 1500 1500
630 1555
640
950
630 1500 2300 3500 1825
Obtener una distribución de frecuencias agrupadas.
Solución:
El más caro es 4500 y el más barato 360, luego el recorrido es 4500-360 = 4140.
Elegimos intervalos de la misma amplitud de modo que, los datos se distribuyan de
forma relativamente homogénea a lo largo del recorrido.
Con el criterio, k igual al entero próximo a: 1 + 3.3 ⋅ log10 (95) ≈ 7.6 , elegimos 7
intervalos de amplitud 600 y semiabiertos (a,b].
DISTRIBUCIÓN DE FRECUENCIAS
INTERVALO
MARCA
ABSOLUTA
DE CLASE
e i −1 − e i
xi
ABSOLUTA
RELATIVA
ACUMULADA
RELATIVA
ACUMULADA
ni
Ni
fi
Fi
300 - 900
600
27
27
0.2842
0.284
900 - 1500
1200
26
53
0.2737
0.558
1500 - 2100
1800
14
67
0.1474
0.705
2100 - 2700
2400
11
78
0.1158
0.821
2700 - 3300
3000
6
84
0.0632
0.884
3300 - 3900
3600
8
92
0.0842
0.968
3900 - 4500
4200
3
95
0.0316
1.000
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
5. REPRESENTACIÓN GRÁFICA
Una buena representación gráfica, junto con las tablas de frecuencias anteriormente citadas,
permiten captar rápidamente las características de la muestra así como resumir y analizar los
datos.
Según sean los datos, las gráficas se pueden clasificar en:
• De Caracteres Cuantitativos.
•
Variable estadística discreta sin agrupar. Diagrama de barras. Polígonos de
frecuencias. Diagrama de frecuencias acumuladas.
•
Variable estadística discreta con frecuencias agrupadas en intervalos.
• Histograma. Polígonos de frecuencias. Polígonos de frecuencias acumuladas.
• De Caracteres Cualitativos.
• Diagrama de barras. Diagrama de sectores. Pictogramas. Cartogramas
5.1 De caracteres cuantitativos
5.1.1 Para variables discretas (sin agrupar):
DIAGRAMA DE BARRAS
Esta representación es válida para las
frecuencias de una variable discreta, sin
agrupar. Se colocan sobre el eje de las
abscisas los distintos valores de la variable y
sobre cada uno de ellos se levanta una línea
o barra perpendicular, cuya altura es la
frecuencia (absoluta, relativa) de dicho
valor.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
En caso de utilizarse para comparar muestras distintas de una misma variable, se debe tener
precaución, ya que, en este caso, debemos usar frecuencias relativas para eliminar la
influencia visual que ejerce el tamaño de cada una de las muestras.
POLÍGONO DE FRECUENCIAS
Es una línea que se obtiene uniendo los extremos superiores de las barras en el diagrama
de barras.
16
1
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
14
12
10
8
6
4
2
0
frecuencia (absoluta o relativa)
DIAGRAMA DE FRECUENCIAS ACUMULADAS
Diagrama de frecuencias acumuladas o diagrama de barras acumulativo.
Representamos en el eje de abscisas los distintos valores de la variable estadística.
Levantamos sobre cada uno de ellos una perpendicular cuya longitud será la frecuencia
(absoluta o relativa) acumulada correspondiente a ese valor. De esta forma aparece un diagrama
de barras creciente. Trazando segmentos horizontales de cada extremo de barra a cortar la barra
situada a su derecha se obtiene el diagrama de frecuencias acumuladas.
40
35
Ni
30
25
20
15
10
5
0
xi
Se trata de poder observar la acumulación de frecuencias hasta un valor determinado de
la variable; por ello, es muy útil para calcular percentiles de una forma gráfica.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
EJEMPLO 5.1:
El número de hectáreas radiadas por día, en un total de 90 días han sido:
0, 1, 1, 0, 1, 2, 2, 1, 0, 2, 3, 2, 0, 1, 1, 0, 1, 1, 4, 0, 1, 1, 0, 3, 0, 0, 1, 3, 1, 0, 1, 2, 2, 1, 3, 1, 1, 0,
0, 1, 1, 3, 0, 0, 1, 1, 0, 2, 2, 3, 0, 1, 2, 2, 1, 0, 1, 2, 2, 4, 1, 0, 4, 5, 0, 2, 2, 0, 0, 1, 1, 0, 1, 1, 0, 0,
1, 1, 0, 1, 1, 0, 1, 1, 1,1, 1, 1, 1, 1.
Se pide:
a) Diagrama de barras.
b) Polígono de frecuencias.
c) Construir el diagrama de frecuencias acumuladas.
Solución:
a) Diagrama de barras de frecuencias absolutas
b) Polígono de frecuencias absolutas:
40
35
30
25
20
15
10
5
0
0
1
2
3
Polígono de frecuencias absolutas
c) Diagrama de frecuencias absolutas acumuladas
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
4
5
Estadística Descriptiva
5.1.2 Representación gráfica de variables estadísticas discretas con valores agrupados
en intervalos
HISTOGRAMA
Es la representación gráfica más frecuente para datos agrupados.
En un histograma se representan las frecuencias mediante áreas. De tal forma que un
histograma es un conjunto de rectángulos que tienen como base los intervalos de clase y cuya
superficie son las frecuencias (absolutas o relativas).
Por tanto, los rectángulos tienen que solaparse (variable agrupada en intervalos) y el
área de cada rectángulo será proporcional a la frecuencia (ni o fi) del intervalo. En cuyo caso
las alturas son proporcionales a las frecuencias, y será el cociente entre la frecuencia y la
amplitud del intervalo.
Si algún intervalo es de distinta amplitud, el cálculo de su altura (hi) se efectuará
f
n
hallando el cociente h i = i o h i = i , donde ai representa la amplitud del intervalo.
ai
ai
ni
ai
fi
ai
fi
ni
ei-1
ei
ei-1
ei
Ejemplo 2. La tabla representa la puntuación obtenida en un test de 10 preguntas
realizado a 45 alumnos.
Puntuación
Nº de alumnos
0
1
1 2 3 4
2 3 5 9
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
5
6
6 7
5 5
8
4
9
3
10
2
Estadística Descriptiva
Ahora bien, si agrupamos:
Calificación
Nº de
alumnos
Suspensos
Aprobados
Notables
Sobresalientes
20
11
9
5
POLÍGONO DE FRECUENCIAS
El polígono de frecuencias es una línea que se obtiene uniendo los puntos medios de las
bases superiores (los techos) de cada rectángulo en el histograma. De forma que empiece y
acabe sobre el eje de abscisas, en el punto medio del que sería el intervalo anterior al primero
y posterior al último respectivamente.
Siguiendo con el ejemplo 2:
INTERVALOS Marca
[-5,0)
-2,5
0
[0,5)
2,5
4
[5,7)
6
5,5
[7,9)
8
4,5
[9,10]
9,5
5
(10,11]
10,5
0
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
POLÍGONO DE FRECUENCIAS ACUMULADAS
En el eje de abscisas representamos los distintos intervalos de clase que han de estar
naturalmente solapados. Sobre el extremo superior de cada intervalo se levanta una línea
vertical de longitud equivalente a la frecuencia (absoluta o relativa) acumulada del mismo. Se
obtiene así un diagrama de barras creciente, que uniendo sus extremos da lugar al polígono de
frecuencias acumuladas.
Alcanzará su máxima altura en el último intervalo, que tendrá de frecuencia N o 1 según
se trate de frecuencias acumuladas absolutas o relativas.
Es muy útil para calcular percentiles de una forma gráfica. El gráfico se obtiene al unir
mediante una poligonal los puntos (ei, Ni) o (ei, Fi).
Al ser un gráfico de datos agrupados en intervalos, el polígono siempre empieza en (e0,
0) y acaba en (ek, N) o (ek, 1).
EJEMPLO 5.2:
Los precios de 95 ordenadores en diciembre de 2014, dados en euros, son los
siguientes:
3000 1200
3910
740 1750 3409
545 1380
815
580
565 3000
840 1700 2300
715
890 1580
800 3650
735
800
930
915 1100 1280 1163 1410 2050 3600 1260 1600
735
4260 1500 1000 1000 1600 1900 2150 2495 3200
850
2240 1975 1745 3030 2350 3700
990
540 2900 4500 3600 1035 1520 2495 1357
2775 2540 1470
395 3900
995 2200
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
750
715
900 1500 1500
Estadística Descriptiva
1995 2650 1335
600
755
500
885
360 2100 2400 1200 1335 3310
990
765 1020
630 1555
640
950
630 1500 2300 3500 1825
a) Dibujar el histograma
b) Polígono de frecuencias.
c) Polígono de frecuencias acumuladas.
Solución:
a) Previamente realizamos un agrupamiento por clases o intervalos de amplitud 600:
xi
ni
Ni
Histograma
300 - 900
600
27
27
900 - 1500
1200
26
53
1500 - 2100
1800
14
67
2100 - 2700
2400
11
78
2700 - 3300
3000
6
84
3300 - 3900
3600
8
92
3900 - 4500
4200
3
95
Sumas =
30
25
frecuencias absolutas
e i −1 − e i
20
15
10
5
0
0
1
b)
Pol¡gono de frecuencias
30
25
Frecuencia absoluta
20
15
10
5
0
1
2
3
4
5
(X 1000)
Precio
c)
Pol¡gono de frecuencias acumuladas
100
Frecuencias acumuladas
80
60
40
20
0
0
1
3
Precio
95
0
2
2
3
Precio
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
4
5
(X 1000)
4
5
(X 1000)
Estadística Descriptiva
5.2 Representaciones gráficas de variables estadísticas cualitativas.
Existe una gran multitud de gráficos para representar los datos de una muestra o
población de una variable estadística cualitativa. Nosotros solo mostramos algunos de ellos.
DIAGRAMAS DE BARRAS
Se representan en el eje de abscisas los distintos caracteres cualitativos y se levantan
sobre ellos rectángulos de bases iguales que no tienen que estar solapados y cuyas alturas serán
las correspondientes a la frecuencia absoluta de cada carácter.
4328
3870
2060
Económicas
Derecho
Filosofia
1830
Químicas
2136
Matemáticas
5000
4000
3000
2000
1000
0
DIAGRAMA DE SECTORES
En un círculo se asigna un sector circular a cada uno de los caracteres cualitativos,
siendo la amplitud del sector proporcional a la frecuencia relativas o absolutas del carácter.
Económicas
Químicas
15%
30%
Derecho
13%
Matemát.
15%
Filosofía
27%
PICTOGRAMAS
Cada modalidad se representa por un dibujo de tamaño proporcional a la frecuencia de
la misma. También es frecuente tomar un dibujo estándar y repetirlo un número de veces
proporcional a la frecuencia.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
CARTOGRAMA
Es la representación sobre mapas del carácter estudiado. Usualmente las distintas
modalidades que adopta este carácter se representan con colores de distinta intensidad o
distintas tramas; como ejemplo podemos observar el cartograma elaborado por el Instituto de
Estadística de la Comunidad de Madrid. Consejería de Economía y Consumo sobre “la renta
per cápita del año 2004 en la Comunidad de Madrid”.
Los parámetros estadísticos son ciertos valores representativos de un conjunto de datos, en el
sentido de condensar en ellos la información contenida en dicho conjunto. Estos parámetros
estadísticos nos proporcionarán información acerca de la situación, dispersión y forma de los
datos. En este curso estudiamos las siguientes medidas o parámetros:
6. MEDIDAS DE POSICIÓN Y CENTRALIZACIÓN
Tienen por objeto dar una idea del valor o valores de la variable, alrededor de los cuales
se agrupa una cantidad de datos.
6.1. Media aritmética.
La media, media aritmética o promedio de una variable estadística es la suma
ponderada de los valores posibles por sus respectivas frecuencias.
X=
k
1 k
n1x1 + n 2 x 2 + ... + n k x k
= ∑ n i x i = ∑ fi x i
N i =1
N
i =1
x i = valores que toma la variable o marca de clase.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
fi = frecuencias relativas.
n i = frecuencias absolutas.
N = número total de la población o muestra.
PROPIEDADES:
1) La media de las diferencias a la media es nula, es decir, la suma de las desviaciones
de los valores de la variable estadística respecto de su media es cero.
k
∑ (x
=i 1
i − X) ⋅ f i =
k
k
∑ x ⋅ f − ∑X⋅f
i
i
=i 1 =i 1
k
i
= X − X∑ fi = X − X = 0
=i 1
2) La suma de los cuadrados de las desviaciones de los valores de la variable respecto
de cualquier número α es mínima para α = X
=
f (α )
k
∑ (x
i =1
α)
f '(=
k
∑ 2 ⋅ (x
i =1
k
Y en efecto, es mínimo: f ''(α) =
∑2⋅f
i =1
i
k
∑ x ⋅ f −∑ α ⋅ f
i − α ) ⋅ ( −1) ⋅ f i = 0 ⇒
k
− α) 2 fi
i
i =1
i
i
i =1
k
i
= 0 ⇒ ∑ x i ⋅ fi = α ⇒ α= X
i =1
= 2>0
3) Si se suma una constante “a” a los N valores de la variable, la media queda aumentada
en dicho valor “a”. Geométricamente representa una traslación de origen.
k
k
a + X =∑ ( a + x i )fi =a + ∑ x i fi =a + X
=i 1 =i 1
4) Si se multiplican todos los valores de la variable estadística X por una constante “b”,
la media queda multiplicada por la constante “b”. Representa un cambio de escala.
=
bX
k
k
bx i f i b=
∑=
∑ x ifi bX
=i 1 =i 1
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Podemos concluir que para una nueva variable Y=a+bX se cumple que Y= a + bX .
5) La media aritmética está comprendida entre el valor máximo y el valor mínimo del
conjunto de datos.
Solo es aplicable para variables estadísticas cuantitativas.
No depende del orden en el que estén colocados los datos.
Es más representativa cuanto mayor sea la concentración de los valores alrededor suyo y más
simétrica sea la distribución.
Es muy sensible a la presencia de datos extremos.
Nota:
Cuando no todos los datos tienen la misma importancia con respecto del resto, se le
asigna los llamados pesos o ponderaciones, se le llama media aritmética ponderada.
k
x1w1 + x 2 w 2 + ... + x k w k
X =
=
w1 + w 2 + ... + w k
∑x w
i =1
k
i
∑w
i =1
i
i
x i = valores que toma la variable o datos.
wi = pesos.
6.2 Moda, M0, es el valor de la variable que se presenta con más frecuencia dentro de
la distribución.
En las distribuciones sin agrupar se observa directamente el valor de mayor frecuencia.
En las agrupadas, definimos la clase o intervalo modal como la que tiene mayor
frecuencia.
NOTA: Algunas distribuciones pueden presentar varias modas. Cada moda corresponde a un
máximo absoluto del diagrama de barras o histograma.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
La moda tiene la ventaja de ser fácil su cálculo, pero tiene el inconveniente de que dos muestras
con datos muy parecidos pueden tener modas muy distintas.
Es importante observar que al agrupar en intervalos perdemos información acerca del auténtico
valor modal.
6.3 Mediana, M, es el valor de la variable que ocupa el lugar central de los valores de
la variable una vez que éstos han sido ordenados en sentido creciente. Por tanto, la mediana M
es un valor de la variable tal que el 50% de los datos son inferiores y el otro 50% de los datos
son superiores.
La mediana es un valor M tal que F(M)=1/2, se define así como raíz de una ecuación.
Cálculo de la mediana.
En primer lugar, ordenamos los datos de menor a mayor.
a) Si los datos no están agrupados en intervalos, en general, no tiene solución, puesto que la
función F(x) varía por saltos:
1) Si ningún valor posible x i corresponde a F( x i )=1/2 se conviene en considerar como
mediana el valor x i tal que:
F( x i −1 ) <
1
< F( x i )
2
o lo que es igual:
f1 + f2 +...... + fi −1 <
1
< f1 + f2 +..... + fi −1 + fi
2
y con frecuencias absolutas:
n1 + n 2 +..... + n i −1 <
N
< n1 + n 2 +..... + n i −1 + n i
2
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
F(x)
1
1/2
1/2
x
M
EJEMPLO:
Sea la variable estadística X={5, 1, 5, 2, 4, 2, 3, 6, 5}, entonces X={1, 2, 2, 3, 4, 5 , 5,
5, 6,},resultando el término central M=4.
2) Si uno de los valores xi corresponde a F( x i ) =
1
(lo que ocurre solamente si el total
2
N de la población es par) la mediana está indeterminada entre los valores xi y xi+1. El intervalo
(xi, xi+1) se denomina mediano, o bien llamamos mediana al punto medio de dicho intervalo.
F(x)
1
1/2
x
i
xM
i+1
x
EJEMPLO:
Sea la variable estadística X={4, 1, 5, 2, 2, 3, 4, 5,}, entonces X={1, 2, 2, 3, 4, 4, 5, 5},
resultando el intervalo mediano [3, 4], o bien M=3.5.
En la tabla estadística, la mediana se determina a partir de la columna que da las
frecuencias relativas (o las frecuencias absolutas) acumuladas.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Otra forma de calcular la mediana es:
x1 ≤ x 2 ≤ ... ≤ x N
si N es impar
x N +1
2
M=
1
x N + x N si N es par
+1
2 2
2
b) Si los datos están agrupados en intervalos:
1)
INTERVALO
xi
ni
Ni
e0 --- e1
x1
n1
N1
e1 --- e2
x2
n2
N2
............
...
...
....
ei-1 --- ei
xi
ni
Ni
............
...
...
...
ek-1 --- ek
xk
nk
N
N
coincide con uno de los recogidos en la columna de frecuencias acumuladas, por
2
ejemplo Ni, en este caso la mediana es ei.
2)
N
está entre Ni-1 y Ni. La mediana se encontrará en el intervalo ( ei-1 , ei ) .
2
La mediana será =
M e i-1 + h y por interpolación lineal se obtiene h.
Se tiene:
Ni
ni
N/2
ni
Ni-1
N
- N i-1 ↔ h
2
=
M e i-1 + h
h
ei-1
↔ ei - ei-1 =
a
Mediana
ei
Gráfico 6.3
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
⇒
Estadística Descriptiva
N
− N i −1 a
2
= ei −1 +
La interpolación lineal anterior puede resumirse en la fórmula: M
ni
EJEMPLO:
Consideremos los salarios de los empleados en una fábrica, el director gana 48000
€/mes, el subdirector 20000 €/mes, seis jefes 5000 €/mes cada uno, los cinco capataces 4000
y los diez operarios 2000 cada uno ¿Cuál es el salario medio? ¿Cuál el salario mediano? y
¿Cuál el salario modal?
Solución:
=
X
xi
2000
4000
5000
20000
48000
totales
ni
10
5
6
1
1
23
Ni
10
15
21
22
23
k
n i x i 138000
=
=
∑
23
i =1 N
6000 media aritmética.
N 23
=
= 11.5 ⇒ N1 = 10 < 11.5 < 15 = N 2 luego la mediana es x2=4000 y la moda corresponde
2
2
a n1=10 que es 2000.
¿Cuál de los tres valores anteriores describe mejor los sueldos percibidos por los empleados
de ésta fábrica?
La generalización del concepto de la mediana da lugar a nuevas medidas de posición que
llamaremos cuantiles.
6.4. Cuantiles
Cuantil de orden α es un valor de la variable estadística que deja a su izquierda
una parte α de la población y a la derecha una parte 1- α de la población.
El Cuantil de orden α (0 ≤ α ≤ 1) es x α | F( x α )=α.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Los más utilizados son los cuartiles Q1, Q2 y Q3 que dejan a su izquierda 1/4, 1/2 y
3/4 de la población respectivamente.
Obsérvese que Q2 = M (Mediana).
Los deciles D1, D2, ..... , D9 dejan a su izquierda 1/10, 2/10, ..., 9/10 de la población
respectivamente.
Los percentiles P1, P2, ........, P99 dejan a su izquierda 1/100, 2/100, ..... 99/100 de la
población respectivamente.
El cálculo de los mismos es similar al cálculo de la mediana.
Cálculo de cuantil de orden α
x1 ≤ x 2 ≤ ... ≤ x N
x[ αN]+1
xα = 1
( x αN + x αN +1 )
2
si αN no es un número natural
si αN es un número natural
Donde [ ], los corchetes significan la parte entera del producto, es decir, el menor entero mayor
o igual que α N.
Observen que en todos los casos depende de que αN sea entero o no lo sea.
En el caso de que los datos estén agrupados en intervalos, el cálculo se realiza de forma
semejante a como se realiza para la mediana, pero todo referido al intervalo que contenga el
valor de la frecuencia αN , según sea el cuantil a calcular.
Si αN está en el intervalo [ei-1, ei);
Ni
αN
ni
Ni-1
n i
→ ei − ei −1 = a
⇒ P=
ei −1 + h por
α
αN − N i −1
→h
tanto, la interpolación lineal anterior se
ei-1
h
Pα
Gráfico 6.4
ei
puede resumir en la fórmula:
=
P
ei −1 +
α
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
( αN − Ni−1 ) a .
ni
Estadística Descriptiva
EJEMPLO 6.4:
Los precios de 95 ordenadores en diciembre de 2014, dados en euros, son los
siguientes:
3000 1200
3910
740 1750 3409
545 1380
815
580
565 3000
840 1700 2300
715
890 1580
800 3650
735
800
930
915 1100 1280 1163 1410 2050 3600 1260 1600
735
4260 1500 1000 1000 1600 1900 2150 2495 3200
850
2240 1975 1745 3030 2350 3700
990
540 2900 4500 3600 1035 1520 2495 1357
715
2775 2540 1470
395 3900
1995 2650 1335
885
360 2100 2400 1200 1335 3310
990
765 1020
600
755
500
995 2200
750
900 1500 1500
630 1555
640
950
630 1500 2300 3500 1825
Se pide:
a) Cuartiles.
b) Segundo decil.
c) Percentil ochenta y seis.
d) ¿Para un precio de 3000€ que posición ocupa en la distribución?
Solución:
e i −1 − e i
xi
ni
Ni
300 - 900
600
27
27
900 - 1500
1200
26
53
1500 - 2100
1800
14
67
2100 - 2700
2400
11
78
2700 - 3300
3000
6
84
3300 - 3900
3600
8
92
3900 - 4500
4200
3
95
Sumas =
95
Mediana: La mediana es el valor de la variable cuya frecuencia acumulada es N/2.
N 95
= = 47.5 ∈ ( 900,1500 )
2
2
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Observando la tabla de frecuencias acumuladas, vemos que la mediana está en el
intervalo 900 - 1500
El valor exacto lo calculamos por interpolación, suponiendo que los elementos de un
intervalo se distribuyen uniformemente a lo largo del mismo.
La frecuencia acumulada al final del intervalo anterior (300, 900) es 27. Por tanto, faltan
20.5 de los 26 elementos que constituyen el intervalo (900, 1500) de amplitud 600.
Gráficamente
53
47.5
27
900
47.5 − 27= 20.5 ↔ h
53 − 27
= 26 ←→ 600
M
1500
(47.5 − 27) ⋅ 600
= 473.077
26
=
h
M= 900 + h= 900 + 473.077= 1373.077
Por tanto, el precio mediano es 1373.077 €.
Los cuartiles los obtenemos de forma similar a la mediana.
Al primer cuartil le corresponde frecuencia acumulada
N 95
= = 23.75
4
4
3N 3 ⋅ 95
Al tercer cuartil le corresponde frecuencia acumulada = = 71.25
4
4
Gráficamente
27
78
23.75
71.25
0
67
300
900
Q
M
1
900
1500
2100
23.75 −=
0 23.75 ↔ h
27 − 0 = 27 ↔ 600
=
h
Gráficamente
23.75
=
600 527.777
27
Q
3
2700
71.25 − 67= 4.25 ↔ h
78 − 67 =11 ↔ 600
=
h
⇒ Q1= 300 + h= 300 + 527.777= 827.777
4.25
=
600 231.818
11
Q=
2100 + =
h 2100 + 231.818
= 2331.818
3
El segundo cuartil es la mediana = 1373.077€.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
b) Al segundo decil le corresponde
frecuencia
acumulada
2N 95
= = 19
10
5
27
19
27
0
19 −=
0 19 ←
→h
300
27 −
=
0 27 ←
→ 600
D 2= 300 + h= 300 +
19 ⋅ 600
= 722.22
27
c) Al percentil ochenta y seis le corresponde
frecuencia
acumulada
900
D2
84
81.7
6
78
86N 86 ⋅ 95
= = 81.7
100
100
2700
(81.7 − 78) ⋅ 600
P86
h 2700 +
= 2700 + =
= 3070
6
d) Se plantea el problema reciproco del anterior
(3000 − 2700) ⋅ 6
N i = 78 + k = 78 +
= 81 Sobre el
600
total representa aproximadamente el percentil 85.
h
h
3300
P86
84
Ni
k
78
2700
3000
6
3300
http://asignaturas.topografia.upm.es/matematicas/videos/Percentil.wmv
http://asignaturas.topografia.upm.es/matematicas/videos/Percentil.mp4
7. MEDIDAS DE DISPERSIÓN
Las medidas de dispersión nos dan una idea de la mayor o menor concentración de los
valores de la variable alrededor de algún valor.
EJEMPLO:
Si consideramos 8 alumnos con calificación de 10 y 8 alumnos con un cero; la media
aritmética será 5. Si los 16 alumnos tienen un 5, la media también será cinco, sin embargo, las
dos situaciones son claramente distintas y la media es más representativa en el segundo caso,
al estar los valores concentrados en un único valor. La diferencia entre uno y otro caso se pone
de manifiesto con las medidas de dispersión.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
7.1. Rango o recorrido
Es la diferencia entre el mayor y el menor valor de la variable estadística.
EJEMPLO:
Si las observaciones son: 8, 3, 5, 7, 1, 1, 8, el recorrido es 8-1=7.
Es una medida muy sencilla de calcular, pero, poco robusta, pues solo tiene en cuenta
los valores extremos. Para evitar la influencia en el rango de los datos con valores extremos,
suele ser frecuente utilizar el rango o recorrido intercuartílico.
7.2. Rango o recorrido intercuartílico
El rango o recorrido intercuartílico o desviación cuartílica es la diferencia entre los
cuartiles Q1 y Q3 y se representa por IQR.
IQR
= Q3 − Q1
Su cálculo es muy sencillo, y es una medida muy robusta en el sentido de no estar
influenciada por la presencia de valores extremos.
Del ejemplo 6.4, sabemos que Q3 = 2331.818 y Q1 = 827.777 , por tanto, IQR=1514.041.
Es fácil observar que el recorrido intercuartílico contiene el 50% de las observaciones centrales.
7.3. Varianza
Es la media de los cuadrados de las desviaciones a la media.
k
2
2
1 k
x
X
n
x i − X fi
−
=
∑
∑
i
i
N i 1 =i 1
=
=
σ2
(
)
(
)
x i = valores que toma la variable o marca de clase.
fi = frecuencias relativas.
n i = frecuencias absolutas.
N = número total de elementos de la población o muestra.
Propiedades de la varianza
1) La varianza es siempre positiva o nula.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
2) Si se multiplican todos los valores de la variable por una constante “a”, la varianza queda
multiplicada por la constante “a2”.
Si y = ax entonces:
k
(
)
k
2
(
)
2
σ 2y =
a 2 ∑ x i − X fi =
a 2 σ2x
∑ yi − Y f i =
=i 1 =i 1
3) Si sumamos una constante “b” a los valores de la variable, la varianza no cambia.
Si y= b + x entonces:
k
(
)
2
k
(
)
k
2
(
)
2
σ2y =∑ yi − Y f i =∑ (b + x i ) − (b + X) f i =∑ x i − X f i =σ2x
=i 1 =i 1
=i 1
Podemos concluir que para una nueva variable Y=aX+b se cumple que σ2y = a 2 σ2x .
4) La varianza es la media de los cuadrados de la variable, menos el cuadrado de la media
de la variable.
=
σ 2x
f ) ∑x f −X
) f ∑ ( x f − 2x Xf + X=
∑ ( x − X=
k
k
2
i
i
=i 1 =i 1
k
=
σ2x
∑x n
i =1
2
i
N
i
k
2
2
i i
i
2
−=
X
i
k
i
∑x f
i =1
2
i i
−X
i =1
2
i i
2
2
5) Cuanto mayor sea la varianza, menos representativa es la media.
7.4. Varianza muestral o cuasivarianza.
Si los datos que estamos analizando son todos los elementos de la población la varianza
nos es útil para analizar la dispersión de dichos datos respecto de la media. Por el contrario, si
los datos son una muestra de la población, la varianza nos sirve para analizar la dispersión de
dicha muestra, pero, ¿nos sirve para analizar la dispersión de la población? Si tomamos ahora
otra muestra de la misma población, obtendremos una varianza de esta segunda muestra, etc.
Para cada muestra tendremos el valor de su varianza correspondiente. Sería deseable que la
media de todo este conjunto de varianza muéstrales fuese la varianza de la población. Pero esto
no es así (como se demuestra en Inferencia Estadística). Sin embargo, sí hay una medida de
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
dispersión, la varianza muestral que cumple esta condición, es decir tal que la media de las
cuasivarianzas muéstrales es la varianza de la población. Es por esto por lo que a veces se
calcula la cuasivarianza (varianza muestral) en lugar de la varianza.
La varianza muestral viene dada por:
k
(x i − X) 2 n i
N 2
N k (x i − X) 2 n i
N
2
2
=
σ
S
σ , es decir: =
S =
∑ N = ∑
N −1
−1
N=
N −1 i 1=
N −1
i 1
2
Nótese que para N suficientemente grande la diferencia entre σ2 y S2 es muy pequeña.
7.5 Desviación típica
La desviación típica o desviación cuadrática media es la raíz cuadrada positiva de la
varianza.
σ = + (σ 2 ) = +
k
∑ ( x i − X) 2 fi
o bien, σ = +
k
∑x f
i =1
i =1
2
i i
−X
2
Tiene la ventaja sobre la varianza de que está medida en las mismas unidades que la
variable.
7.6 Desviación típica muestral.
La desviación típica muestral es la raíz cuadrada positiva de la varianza muestral.
=
S
(x i − X) 2 n i
=
∑
N −1
i =1
k
N
σ
N −1
7.7 Coeficiente de variación de Pearson
Es el cociente de la desviación típica y la media. CV =
σ
X
Es frecuente expresarlo en tanto por ciento.
Es independiente de la unidad que se utilice, pues no tiene unidades y por tanto nos
permite comparar la dispersión de dos distribuciones que tengan unidades diferentes, o que
tengan medias muy distintas.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Tiene el inconveniente de no estar definido para distribuciones con media cero. Además,
cuando la media se aproxima a cero el coeficiente de variación tiende a infinito.
EJEMPLO 7:
Con los datos del ejemplo 5.2, calcular:
a) Varianza y desviación típica.
b) Varianza y desviación típica muestral.
c) Coeficiente de variación de Pearson.
Solución:
xi
ni
xi ni
Ni
x 2i
x 2i n i
0
26
0
26
0
0
1
40
40
66
1
40
2
14
28
80
4
56
3
6
18
86
9
54
4
3
12
89
16
48
5
1
5
90
25
25
90
103
Sumas
a)
Media: x =
223
1 5
1
x i n i = 103 = 114
.
∑
90
N i=0
2
1 5
1
103
2
= 11680
Varianza: σ = ∑ x i2 n i − X =
223 −
.
90
N i=0
90
2
Desviación típica; σ = ( σ 2 ) = 1.1680 = 1. 0807
b)
Varianza muestral; S2 =
N
90
σ 2 = 1.1680 = 1.1811
N −1
89
Desviación típica muestral; S =
c)
Coeficiente de variación; CV
=
N
90
σ=
1. 0807 = 1. 0867
N −1
89
σ 1.0807
=
= 0.9443
X 1.1444
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
7.8. Momentos
Se llama momento de orden r respecto al valor "c", a la cantidad:
k
k
i =1
i =1
ni
, donde r es un entero positivo.
N
∑ ( x i − c) r fi = ∑ ( x i − c) r
Según los valores de "c", se definen varias clases de momentos:
Momentos no centrales o respecto al origen,
c = 0⇒ m =
r
k
r ni
rf =
x
x
∑ ii ∑ iN
i =1
i =1
k
Los primeros momentos no centrales son iguales a:
m0 = 1 ; m1 = X
Momentos centrales o respecto a la media
k
k
i =1
i =1
c = X ⇒ µ r = ∑ ( x i − X) r fi = ∑ ( x i − X) r
ni
N
Los primeros momentos centrales son iguales a:
µ 0 = 1; µ1 = 0 ; µ 2 = σ 2 = m2 − m12
Relación entre los momentos centrales y no centrales.
Desarrollando por la fórmula del binomio de Newton las relaciones de definición:
k
k
i =1
i =1
µ r = ∑ ( x i − X) r fi = ∑ ( x i − m1 ) r fi =
r
r
r
r r
m1 ∑ f i
= ∑ x ir f i − ∑ x ir −1f i m1 + ∑ x ir − 2 f i m12 + .......... + (−1) r =
i
0 i
1 i
2 i
r
r
r
r
r r
= m r − m r −1m1 + m r − 2 m12 + .......... + (−1) r m=
1
0
1
2
r
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
r
r
∑ (−1) j m
j= 0
j
r− j
m1j
Estadística Descriptiva
µ=
r
r
r
∑ (−1) j m
j= 0
j
r− j
m1j
2
2
2
En particular: µ 2= m 2 − m1m1 + m12= m 2 − m12 ,resultado ya conocido.
0
1
2
µ 3 = m3 − 3m2 m1 + 2 m13
µ 4 = m4 − 4 m3 m1 + 6 m12 m2 − 3m14
8. CARACTERÍSTICAS DE FORMA
Además de la tendencia central y de la dispersión, se puede tratar de caracterizar la
forma de una distribución mediante índices que determinen la asimetría y el apuntamiento de
la distribución.
Asimetría. Una distribución de frecuencias es simétrica si su correspondiente gráfico es
simétrico respecto a un eje vertical.
• Si la distribución es simétrica, la mediana y la media coinciden.
Me = X
• Si la distribución es simétrica y unimodal, la mediana, media y moda coinciden.
M=
X= M o
e
Una distribución con asimetría por la derecha o positiva,
quiere decir que la gráfica de frecuencias desciende más
lentamente por la derecha que por la izquierda. En este caso
se verifica que:
Mo ≤ Me ≤ X .
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Una distribución asimétrica por la izquierda o negativa, quiere decir que la gráfica de
frecuencias desciende más lentamente por la izquierda que por la derecha. En este caso se
verifica que:
X ≤ Me ≤ Mo .
8.1 Coeficiente de Asimetría de Fisher o sesgo.
El coeficiente de asimetría de Fisher, se define como el cociente
k
g=
1
µ3
=
σ3
∑(x
i =1
i
)
3
− X fi
σ3
Si la muestra es simétrica respecto de la media, entonces
k
∑ (x
i =1
i
− X) 3 = 0 ; mientras que esta
suma será mayor en valor absoluto cuanto más asimétricos son los datos.
Es un coeficiente adimensional y mide la
•
asimetría respecto de la media.
Si g1=0 la distribución es simétrica o no
•
sesgada.
• Si g1<0 la distribución es asimétrica o sesgada a la izquierda y X ≤ M e ≤ M o .
• Si g1>0 la distribución es asimétrica o sesgada a la derecha y M o ≤ M e ≤ X .
8.2
Coeficiente de apuntamiento o curtosis
El coeficiente de apuntamiento de Fisher se define e interpreta como sigue:
k
g2 =
µ4
− 3=
σ4
∑(x
i =1
i
)
4
− X fi
σ4
−3.
Se mide en relación a la distribución Normal, de la misma media y desviación típica.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
De forma que es nulo para la distribución normal. Si el coeficiente es positivo la
distribución está más apuntada que la distribución Normal (de la misma media y desviación
típica), y se dice leptocúrtica. Si es menos apuntada el coeficiente es negativo y se dice
platicúrtica. Mesocúrtica es cuando el coeficiente es nulo.
Si la distribución estudiada tiene por media X y desviación típica muestral S, entonces:
(
)
• Si g2>0, la distribución es más apuntada que la normal N X,S .
(
)
• Si g2<0, la distribución es menos apuntada que la normal N X,S .
• El apuntamiento como medida de forma es relativa. Su definición se hace por
comparación con la distribución normal de la misma media y varianza.
• Es mayor cuanto mayor sea la concentración de los valores alrededor de la media.
EJEMPLO: 8
Con los datos del ejemplo 5.2, calcular:
a) Coeficiente de asimetría.
b) Coeficiente de curtosis.
Solución:
a) Las operaciones para el cálculo de
e i−1
μ3 y μ4 las disponemos en la siguiente tabla:
ni xi
n i x 3i
n i x i4
27
16200
5832.106
34992.108
900 1500 1200
26
31200
44928.106
539136.108
1500 2100 1800
14
25200
81648.106
1469664.108
2100 2700 2400
11
26400
152064.106
3649536.108
2700 3300 3000
6
18000
162000.106
4860000.108
3300 3900 3600
8
28800
373248.106 13436928.108
300
ei
xi
900
600
ni
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
3900 4500 4200
∑=
3
95
222264.106
12600
9335088.108
158400 1041984.106 33325344.108
Según vimos en el ejemplo 5.2:
7
m=
X= 1667.368, m=
1
2
∑n x
i =1
7
m3
=
i
N
7
3
i i
i 1 =i 1
4
∑n x
y m
= 10968252630=
N
2
i
= 3857684.21, y ahora,
∑n x
i
4
i
= 3507930947.104
N
Utilizando las fórmulas del 7.8, tenemos:
µ3= m3 − 3m 2 m1 + 2m13= 942669.108
y como σ = 1038.06 el coeficiente de asimetría es: g=
1
µ3
= 0.842755>0
σ3
Asimétrica por la derecha
b) µ 4= m 4 − 4m3 m1 + 6m 2 m12 − 3m14 =3,08857.108
µ
g 2 = 44 − 3= - 0.34 <0
σ
resulta
Menos apuntada que la distribución Normal con la misma media y la misma desviación típica
muestral.
9. DIAGRAMA DE CAJA
Uno de los objetivos principales de la Estadística es el de obtener informaciones útiles
a partir de los datos disponibles. Por ello, es muy importante que los datos que utilicemos sean
fiables (no contengan errores) y, por tanto, en todo tratamiento estadístico es conveniente
efectuar un proceso de depuración y estudio de los datos.
Los valores atípicos o erróneos, por ser inusualmente grandes o pequeños, en general
son atribuibles a una de las siguientes causas:
• El valor se observa y se registra o introduce en el ordenador incorrectamente.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
• El valor proviene de una población distinta.
• El valor es correcto, pero representa un suceso poco común.
El problema que se nos presenta es decidir si un determinado dato, con un valor poco
común, puede ser utilizado, o por el contrario lo hemos de rechazar. La respuesta no es fácil,
ya que, si rechazamos datos de forma inadecuada, podemos perder información valiosa y, por
el contrario, si los aceptamos, puede variar los resultados de forma que nuestras conclusiones
sean erróneas. En la actualidad existe gran multitud de procedimientos que nos facilitan el tomar
una decisión sobre la depuración de datos.
Los histogramas y los polígonos de frecuencia proporcionan impresiones visuales
acerca de un conjunto de datos. Las cantidades numéricas, tales como la media o varianza,
proporcionan información acerca de alguna característica particular de los datos.
Los diagramas de caja son unas representaciones gráficas que describen
simultáneamente varias características importantes de un conjunto de datos, como son la
mediana, la dispersión y la asimetría, pero también permiten identificar observaciones que caen
inusualmente lejos del grueso de los datos, los puntos atípicos, (Outliers). Es un gráfico
representativo de las distribuciones de un conjunto de datos en cuya construcción se usan cinco
medidas descriptivas de los mismos, a saber: mediana, primer cuartil, tercer cuartil, valor
máximo y valor mínimo.
Una vez calculados los valores anteriores, procedemos de la siguiente forma. Dibujamos
una caja cuyos lados verticales corresponden a los valores de Q1 y Q3, trazamos una línea
vertical en el valor de la mediana, y dos pequeñas líneas verticales (barreras) para los valores
de LI y LS. A continuación, trazamos un segmento a cada lado de la caja hasta las barreras y
por último colocamos el valor de la media y de los posibles puntos atípicos.
LI=máx(xmín, Q1-1.5(Q3 – Q1))
LS=mín (xmáx, Q3+1.5(Q3 - Q1)).
Donde xmín y xmáx son los valores mínimo y máximo del conjunto de datos.
Opcionalmente se puede representar la media con una cruz.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
Todo dato que esté fuera del intervalo [LI, LS] será considerado como posible dato atípico,
anómalo o Outlier y corresponde a un dato que debería ser estudiado.
EJEMPLO 9:
En el conjunto de datos, 23.39, 23.45, 23.47, 23.47, 23.50, 23.50, 23.58, el valor de la
mediana es M=23.47, la media 23.48, el primer cuartil Q1=23.45, el tercer cuartil Q3=23.50
y los valores de los datos mínimo y máximo son respectivamente 23.39 y 23.58.
Los valores de las barreras son:
Q1-1.5(Q3-Q1)=23.375,
por tanto,
LI=xmin=23.39.
Q3+1.5(Q3-Q1)=23.575,
por tanto,
LS=23.575.
En consecuencia, el dato 23.58 es un valor atípico y se representa como el gráfico.
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.
Estadística Descriptiva
En este gráfico hemos de observar que LS es menor que algunas observaciones; estas
observaciones corresponden a puntos atípicos. La media es mayor que la mediana y, por
tanto, es asimétrica hacia la derecha.
http://asignaturas.topografia.upm.es/matematicas/videos/variable_estadistica.wmv
http://asignaturas.topografia.upm.es/matematicas/videos/variable_estadistica.mp4
Unidad Docente de Matemáticas de la E.T.S.I.T.G.C.