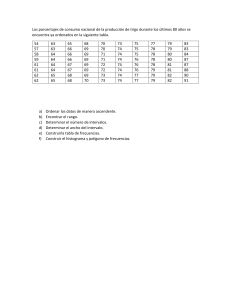
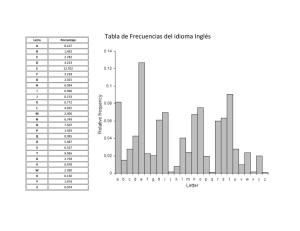
CognoSfera www.ugr.es/local/rruizb/cognosfera ESTADÍSTICA DESCRIPTIVA DE UNA VARIABLE M. Jorge Bolaños Carmona© Departamento de Estadística e I.O. Facultad de Biblioteconomía y Documentación Universidad de Granada 1.INTRODUCCION El concepto de Estadística es muy amplio, y sus aplicaciones directas o indirectas, muy numerosas; resulta difícil, por ello, dar una definición. Sin embargo, la idea más adecuada es considerar que incumbe a la Estadística la recogida, ordenación, resumen y análisis de datos de cualquier tipo sobre colectivos, lo que significa que no tiene sentido pensar en un dato aislado o individual como terreno de trabajo de la Estadística: es necesario, pues, considerar un grupo de elementos (personas, animales, cosas, experimentos, etc.) a los que se refieren los datos que se consideran. Este conjunto puede venir dado de dos formas que condicionan toda clasificación interna de la Estadística, y que son las siguientes: a) Población, o conjunto de todos los elementos cuyo estudio nos interesa. Si se dispone de datos de una o más variables sobre la población completa, o se puede acceder a ellos, la Estadística tendrá como misión que la recogida sea adecuada, se ordenen, se estructuren y se resuman dichos datos para su mejor comprensión, es decir, que se describan. Ello nos llevará a hablar de Estadística Descriptiva. Por ejemplo, el conjunto de los varones mayores de 65 años y residentes en una provincia sería una población. b) Muestra, o conjunto de elementos de los que efectivamente se dispone de datos, y que es una parte (a menudo pequeña) de la población. Cuando no se puede acceder a los datos de toda la población, que es lo más frecuente, y se debe trabajar con sólo los de la muestra, a la simple descripción de los datos se añade el interés por valorar hasta qué punto los resultados de la muestra son extrapolables o generalizables a la población; en consecuencia, será necesario utilizar no sólo las técnicas de la Estadística Descriptiva, siempre obligadas en todo caso para la comprensión de los resultados, sino también otras que permiten inferir afirmaciones sobre la población a partir de los datos de la muestra y que constituyen la Estadística Inferencial o Inferencia Estadística. Por ejemplo, el grupo de los varones mayores de 65 años y residentes en una provincia que son usuarios de bibliotecas públicas sería una muestra de la población citada en el párrafo anterior (otra cosa es que la muestra fuese o no representativa del conjunto de tal población). Los elementos fundamentales de la descripción de una variable son los que siguen en los apartados siguientes, que se pueden resumir de esta forma: - - En primer lugar, se hará hincapié en que lo que se estudia son en realidad las variables, lo que nos obligará a distinguir los tipos básicos de ellas, porque tienen un tratamiento distinto en todo lo que sigue. Las distribuciones de frecuencia son necesarias en el paso siguiente para expresar los resultados obtenidos mediante tablas estadísticas. 1 - Las gráficas estadísticas dan una información similar a la de las tablas, pero de forma más directa; de ellas trata otro apartado. Finalmente, el resumen de la información se realiza mediante las medidas de centralización, dispersión y posición. 2. TIPOS DE VARIABLES. Lo que se estudia en una muestra o población es una serie de variables en cada individuo o elemento. Lo usual es considerar primero las variables una a una, sin plantearse problemas de asociación entre ellas, por lo que podemos pensar sólo en una variable de cuyos datos imaginamos disponer en una muestra (el número de datos es el llamado Tamaño de Muestra, para el que habitualmente se utiliza la letra n). Los tipos de variables, y consecuentemente las clases de datos que se pueden encontrar, son básicamente las siguientes: A) Variables CUALITATIVAS, también llamadas CARACTERES, VARIABLES CATEGÓRICAS o ATRIBUTOS, que son aquellas que no necesitan números para expresarse; cada forma particular en que pueden presentarse se denomina modalidad. Por ejemplo, el sexo de una persona es una variable cualitativa y “varón” o “mujer” son sus únicas modalidades. En consecuencia, para una variable cualitativa, cada dato no es más que la información de que un determinado elemento de la muestra presenta una determinada modalidad. Entre la variables cualitativas cabe distinguir: a1) las variables cualitativas ORDINALES, que son las que teniendo más de dos modalidades tienen establecido un orden natural entre las mismas, de forma que sus modalidades se enuncian siguiendo una cierta ordenación ascendente o descendente y no de otra manera. Por ejemplo, la variable “gravedad del pronóstico de lesiones traumáticas” podría tener como orden natural entre sus modalidades “leve”, “moderado”, “grave”, etc., pero nunca diríamos “grave”, “leve”, “moderado”, etc. en este orden. a2) las variables cualitativas PURAS, que no tienen un orden natural preestablecido entre sus modalidades, y podemos utilizar cualquier ordenación para ellas, como por ejemplo el grupo sanguíneo o la nacionalidad de una persona (no hay que confundirse con ordenaciones arbitrarias, como el orden alfabético, pensando que convierten en ordinales a las variables, ya que no significan una verdadera ordenación natural de las modalidades). a3) las variables DICOTOMICAS, que tienen sólo dos modalidades posibles, y en las que ni siquiera tiene sentido plantearse si son o no ordinales; El hecho de tener sólo dos modalidades les confiere características especiales. Cabe citar como ejemplos el ya citado del sexo, el pertenecer o no a una asociación, o en general cualquier situación que sólo admita una respuesta “sí o no”. B) Variables CUANTITATIVAS o NUMERICAS, que son aquellas que necesitan números para ser expresadas, como la edad de alguien o el número de páginas de un libro. Cada forma particular en que se presentan es un valor numérico, y un dato es en estas variables un número que refleja el valor de la variable en un elemento de la muestra. También pueden distinguirse al menos dos subtipos: b1) las variables cuantitativas DISCRETAS, cuyos valores son aislados (habitualmente números enteros), de forma que pueden enumerarse y existen valores “consecutivos” entre los que no puede haber otro; Por ejemplo, un resumen puede tener 349 ó 350, pero no 349.17 palabras. b2) las variables cuantitativas CONTINUAS, que pueden tomar cualquier valor numérico, entero o decimal, de forma que teóricamente entre dos valores posibles siempre se pueden encontrar otros (entre 65.3 Kg. y 65.4 Kg. de peso siempre está 65.37 Kg., por ejemplo), aunque en la práctica el número de cifras decimales está limitado y la variable se maneja en cierto modo como discreta. La distinción entre los distintos tipos de variables es importante porque las técnicas a aplicar a cada uno pueden ser muy diferentes, y muchos parámetros y cálculos tienen sentido para las variables de un tipo y no para las de otro. Hay que tener en cuenta también que una misma variable de la realidad puede venir 2 expresada de diversas maneras, incluso como cualitativa o como cuantitativa, dependiendo de que usemos valores numéricos o sólo modalidades; piénsese, por ejemplo, en que la estatura puede darse en centímetros (variable cuantitativa continua) o diciendo de alguien que es “bajo”, “mediano” o “alto” (variable cualitativa ordinal). En estos casos, debe quedar claro que la variable es en esencia cuantitativa y que su tratamiento como cualitativa supone una pérdida de calidad en la información, sólo admisible si no podemos disponer de los datos numéricos. 3. DISTRIBUCIONES DE FRECUENCIA Y TABLAS ESTADISTICAS. Sea cual sea el tipo de variable, lo que se tiene como información de una variable en una muestra es un número finito n de datos, es decir, de valores o de anotaciones sobre qué modalidad (cualitativas) o qué valor (cuantitativas) tiene cada elemento de la muestra; a este conjunto de datos se le llama distribución y, salvo cuando el tamaño de muestra n sea muy pequeño, se debe resumir para que el lector pueda comprender bien los resultados. Un primer y obligado paso de ese resumen de datos es el simple recuento de las repeticiones de un mismo valor o modalidad; ello nos conduce al concepto fundamental de frecuencia, con dos enfoques: - Frecuencia absoluta es el número de veces que una modalidad o un valor de una variable aparece entre los datos de una muestra; si en una muestra de la variable “nivel de estudios” aparecen 148 personas con nivel de estudios “superiores”, diremos que 148 es la frecuencia absoluta de la modalidad “superiores”. Naturalmente, el número total de datos es n y, por tanto, la suma de las frecuencias absolutas de todas las modalidades o valores debe ser igual al tamaño muestral n. - Frecuencia relativa de una modalidad o valor de una variable es su frecuencia absoluta dividida entre el tamaño muestral, es decir, la proporción de veces que aparece esa modalidad o valor entre todos los datos de la muestra; si la frecuencia absoluta 148 del ejemplo anterior corresponde a una muestra de 2000 personas, diremos que la frecuencia relativa de la modalidad AB es 148/2000 = 0.074. Es claro que la suma de las frecuencias relativas de todas las modalidades o valores debe ser 1, ya que las absolutas suman n y estamos dividiendo entre n. Es muy habitual expresar las frecuencias relativas como porcentajes (multiplicándolas por cien) y entonces la frecuencia relativa del ejemplo sería 7.4 % y la condición de la suma sería que deben sumar 100 %, lo que se entiende mejor (la frecuencia relativa es la parte del total de datos que corresponde a cada valor o modalidad). Las frecuencias absolutas y relativas son aplicables a cualquier tipo de variable, y de ahí su importancia; además, pese a su simplicidad, dan lugar a conceptos muy importantes, como el de proporción, y son la base sobre la que se construye cualquier resumen de los datos. Usando como ejemplo el grupo sanguíneo en una muestra de doscientas personas, la tabla siguiente sirve para resumir lo que, si no, sería una tediosa lista de doscientos grupos sanguíneos: Grupo sanguíneo de una muestra de 200 personas. Modalidades O A B AB Totales Frecuencia absoluta 85 53 48 14 200 Frecuencia relativa (%) 0.425 (42.5%) 0.265 (26.5%) 0.240 (24.0%) 0.070 ( 7.0%) 1.000 (100%) Una tabla como esta se denomina distribución de frecuencias, y puede incluir también las llamadas frecuencias acumulativas, que son la suma de las frecuencias del valor o modalidad que se considere y de todos los anteriores; puede haber frecuencias acumulativas absolutas o relativas, y en todo caso sólo tienen sentido con variables cuantitativas o cualitativas ordinales, ya que hay que poder fijar cuales son los valores o 3 modalidades “anteriores”. Así, por ejemplo, las frecuencias acumulativas no son definibles en el ejemplo del grupo sanguíneo, que es una variable cualitativa pura. Veamos un ejemplo donde sí lo son, de una variable cuantitativa discreta. En este segundo ejemplo, cuya tabla se encuentra a continuación, el número n de datos es 500 y la variable toma seis valores distintos (0,1,2,3,4 y 5) en la muestra. No se deben confundir los valores de la variable, que son el número de visitas (ninguna, una, dos, etc.) de cada persona a la biblioteca en ese mes, con las frecuencias absolutas, que son el número de personas cuyo número de visitas es uno determinado: que 210 sea la frecuencia absoluta del valor 0 quiere decir que de entre las 500 personas consideradas en el estudio 210 no han ido ninguna vez a la biblioteca en ese mes, es decir, que el valor de la variable es "cero" para ellas; esta frecuencia absoluta 210 supone el 42% de 500, por lo que 0.42 ó 42% es la frecuencia relativa del valor 0 de la variable. Visitas mensuales a una biblioteca de una muestra de 500 usuarios inscritos Valores Frec. absoluta Frec. relativa 0 1 2 3 4 5 Totales 210 178 68 24 14 6 500 42.0% 35.6% 13.6% 4.8% 2.8% 1.2% 100% Frec. absol. acumulativa 210 388 456 480 494 500 Frec. relat.acumulativa 42.0% 77.6% 91.2% 96.0% 98.8% 100.0% Por lo que se refiere a las frecuencias acumuladas o acumulativas (es lo mismo), y usando como ejemplo las que se recogen en la tabla, podemos observar que las frecuencias acumuladas del primer valor coinciden con las 210 y 42% ya comentadas para ese valor, lo que es lógico porque no hay ningún valor anterior con cuyas frecuencias sumarlas; a partir del segundo renglón sí tenemos acumulación (388=210+178 y 77.6% = 42.0% + 35.6%), para el tercer valor se suman tres sumandos y así sucesivamente. Nótese que las últimas frecuencias acumuladas tienen que coincidir con el número de datos válidos total (en este ejemplo 500) y con el 100%, ya que se han sumado todas las frecuencias absolutas y relativas, respectivamente. En el caso de las variables continuas, el número de valores distintos que puede tomar la variable es infinito, teóricamente, y en la práctica puede ser bastante grande: piénsese que si medimos, por ejemplo, la estatura en centímetros de una muestra de personas adultas podemos tener fácilmente sesenta o setenta valores distintos. Esto provoca que a menudo las tablas tuvieran que ser muy extensas, con muchísimos renglones, lo que las haría inútiles por incomprensibles. Para evitarlo, se hacen agrupaciones de varios valores ( por ejemplo, las estaturas 160, 161, 162, 163 y 164 se pueden agrupar en el intervalo 160-164); de esta forma, se pueden encontrar tablas construídas agrupando los valores en intervalos cuando hay muchos valores entre el mínimo y el máximo; el concepto importante es entonces el de marca de clase o valor medio del intervalo, que es, por ejemplo, 162 en el caso citado del intervalo 160-164. Además, es muy conveniente que los intervalos tengan todos la misma longitud. En las tablas así, con clases, las frecuencias se dan para cada intervalo, pero no para cada valor de la variable; podemos saber, por ejemplo, que en una muestra hay 32 personas que miden entre 160 y 164 cm., pero no cuántas de ellas miden en particular 163 cm.; hay, por tanto, una pérdida de información con respecto a lo que sería una tabla detallada. Por esta razón, y gracias a los avances de la Informática que permiten almacenar muchos valores y trabajar con ellos rápidamente, las tablas con intervalos ya no se usan, como hasta hace pocos años, para realizar cálculos sobre la variable, sino que su utilidad queda reducida a la mejor comprensión de las tablas y a la elaboración de gráficos. Todo ello significa que las ganancias en comprensión al hacer intervalos se corresponden necesariamente con pérdidas de información (se pierde el detalle) y por 4 ello para los cómputos numéricos se usan los datos originales de uno en uno, mientras que para tablas y gráficas es frecuente usar intervalos. 4. GRAFICAS ESTADISTICAS Las distribuciones de frecuencias se presentan en tablas como las anteriores, o bien en gráficas. La representación gráfica se utiliza para facilitar al lector la comprensión de los resultados, pero no añade ninguna información sobre la que contendría una tabla de frecuencias; el objetivo de las gráficas es que la información “impacte” directamente al lector y que se exprese el “perfil” de la distribución, pero no debe olvidarse el rigor en aras de la estética: las gráficas deben reflejar fielmente lo que tratan de representar, fundamentalmente las frecuencias de cada modalidad o valor. Por ello la regla fundamental para la construcción de una gráfica es que: Las áreas (o longitudes) han de ser proporcionales a las frecuencias, condición inexcusable para que una gráfica sea correcta. Además, con carácter general puede recomendarse que el pie de la gráfica explique convenientemente de qué se trata, que no se intente representar demasiada información en una sola gráfica, que los detalles sean lo suficientemente visibles, etc. Existen diversos tipos de gráficas, cada uno de ellos adecuado a un cierto tipo de variables, por lo que podemos clasificar las gráficas atendiendo a estos tipos. Así, para caracteres o variables CUALITATIVAS se pueden mencionar: - El diagrama de barras o rectángulos, consistente en asociar a cada modalidad de la variable un rectángulo cuya superficie refleje su frecuencia: las modalidades se suelen situar en horizontal y la escala de frecuencias absolutas o relativas en vertical. Si las bases de los rectángulos se dibujan todas iguales, par cumplir la regla fundamental antes citada basta tomar como alturas de los rectángulos directamente las frecuencias, sin mayor complicación (el rectángulo de una modalidad con frecuencia 7 tendrá altura 7 y así con todas). Los rectángulos suelen representarse separados en este tipo de gráficas, que también pueden aparecer con las barras horizontales y las modalidades situadas verticalmente. - El diagrama de sectores, que refleja como sectores de un círculo las frecuencias de cada modalidad. Como el radio es constante en un círculo, para cumplir la regla fundamental de proporcionalidad basta hacer al ángulo de cada sector proporcional a la frecuencia, lo que se consigue multiplicando los 360º del círculo por la frecuencia relativa de cada modalidad. Este tipo de gráficas es muy útil para comparar los resultados de una variable cualitativa en dos o más muestras. Hay otras gráficas menos frecuentes pero igualmente válidas para variables cualitativas; cabe citar los pictogramas, en los que se representa una misma figura para cada modalidad pero con tamaño proporcional a las frecuencias (pictograma por extensión) o una misma figura repetida tantas veces como sea necesario para reflejar la frecuencia de cada modalidad (pictograma por repetición), los cartogramas, en los que se representa cada modalidad sobre puntos o regiones de un mapa, o los diagramas de superficie, en los que se divide una figura geométrica, generalmente un rectángulo, en trozos proporcionales a las frecuencias. Por su parte, para variables CUANTITATIVAS los tipos de gráficas más importantes son los siguientes: - Para variables discretas, el diagrama de segmentos. Las variables discretas toman valores aislados, como puntos sueltos, en la “recta de los números”; ésta suele representarse horizontalmente con los 5 valores negativos a la izquierda del cero y los positivos a la derecha; por esos puntos sueltos, la gráfica adecuada para las variables discretas es el diagrama de segmentos, en el que sobre cada valor de la variable se coloca verticalmente un segmento que tiene una longitud proporcional a su frecuencia; así se consigue que la abscisa (horizontal) refleje los valores y que la ordenada (vertical) exprese las frecuencias de la variable. Es lo mismo usar para ello frecuencias absolutas o relativas, ya que las dos clases de frecuencias son a su vez proporcionales por la propia definición de frecuencia relativa; por ello podemos hacer el diagrama con frecuencias absolutas o relativas, a voluntad. Junto con el diagrama de segmentos, puede dibujarse una línea quebrada que una los extremos superiores de los segmentos, que se llama polígono de frecuencias; a veces este polígono (que matemáticamente no es tal, sino una “poligonal”) se representa sólo, como si se hubieran borrado los segmentos verticales. El polígono de frecuencias también puede usarse junto con: - El histograma o histograma de rectángulos, que es la gráfica adecuada para representar variables cuantitativas continuas. Estas variables cubren teóricamente con sus valores a la recta de los números reales, o al menos de un cierto intervalo, de manera que “infinitamente” junto a un valor se encontraría otro y no se producen “saltos” entre ellos. En la práctica, esto se traduce en que casi siempre se maneja un gran número de valores distintos y ello hace poco adecuado para estas variables un diagrama de segmentos; por ello, y para respetar la continuidad de la variable, lo que se hace es agrupar los valores en intervalos y gráficamente se representan rectángulos yuxtapuestos cuyas bases descansan sobre la horizontal y cuyas alturas son tales que el área de cada rectángulo sea proporcional a la frecuencia de cada intervalo. A veces estos histogramas son llamados erróneamente diagramas de barras. 5. PARAMETROS DE UNA DISTRIBUCION Se trata de resumir más la información de una tabla o de una gráfica, y de encontrar algunos valores lo más simples posible que nos permitan dar información sobre la muestra o comparar dos muestras entre sí. Para hacer ese resumen o información de los datos hay tres enfoques fundamentales: - En primer lugar, dar un valor lo más representativo posible de todos los valores de la muestra, que no sea, por tanto, ni de los más bajos ni de los más altos. Así se crean las medidas ó parámetros de centralización, tendencia central o posición central. - En segundo lugar, y como complemento a lo anterior, dar una valoración de hasta qué punto los datos se parecen entre sí o bien están muy diferenciados (dispersos); además, cuanto más se parezcan entre sí los valores que nos salen, más se parecerán al representante o parámetro de centralización que elijamos, y mejor sería éste. Por todo esto conviene medir las diferencias internas de los datos mediante las medidas ó parámetros de dispersión. - Finalmente, en tercer lugar, se puede también tratar de medir qué valor supera a una cierta porción o proporción de valores, o lo que es lo mismo, tratar de informar sobre la distribución de la variable diciendo a cuántos de sus valores supera uno dado. Para ello se usan los cuantiles como medidas ó parámetros de posición. Definiremos a continuación los más importantes entre todos los parámetros de estos tres tipos y para ilustrar su cálculo usaremos el ejemplo siguiente, donde los datos son el número de hermanos (excluido él mismo) de una muestra de 13 niños; presentamos los datos ordenados de menor a mayor para mejor comprensión, pero en principio los datos nos vendrían en cualquier orden. Supongamos que son los siguientes: 0 0 0 0 1 1 1 2 Vamos a definir ahora las medidas más importantes: 6 2 3 4 5 7 Primer grupo: PARAMETROS DE CENTRALIZACION. Entre los parámetros de centralización, también llamados de tendencia central o de posición central, tres son las definiciones destacables: La MODA: es el valor de la variable que tiene mayor frecuencia en la muestra, es decir, el que se repite más (moda se asocia con lo más frecuente). En nuestro ejemplo es el valor 0, que tiene una frecuencia absoluta de cuatro, que es la más grande. La moda puede definirse para cualquier tipo de variables. También se puede hablar de moda local o secundaria, que sería cualquier valor más frecuente que sus adyacentes, es decir, con más frecuencia que la que tengan el anterior y el posterior, lo que requiere al menos orden en los datos; no hay ninguna moda secundaria en nuestro ejemplo. La MEDIANA: es el valor que está en el centro de la distribución, es decir, el valor que supera a la mitad de los de la muestra y se ve superado por la otra mitad (salvo empates en ambos casos); se calcula buscando el valor de la muestra que ocupa el lugar (n+1)/2, con los datos ordenados. En nuestro ejemplo es el valor 1, que corresponde al séptimo lugar (que deja seis por debajo y seis por encima). La mediana no puede definirse para variables cualitativas puras, sino sólo para ordinales y cuantitativas, ya que necesita un orden en los datos. La MEDIA ó MEDIA ARITMETICA: es el centro de gravedad de la distribución, o fiel de la balanza entre todos los datos. Se calcula sumando los datos y dividiendo entre el tamaño de la muestra, esto es, entre el número de datos. En nuestro ejemplo, la suma de los datos es 26 y el número de ellos 13, de forma que la media vale 26/13 = 2.00 ; por su propia naturaleza, la media sólo es definible para variables cuantitativas, ya que si no hay números no se puede sumar. Es la más importante de las medidas de centralización y en general de todos los parámetros estadísticos y al ser centro de gravedad tiene la propiedad de que si hallamos las diferencias de cada dato con ella (llamadas desviaciones), la suma de estas diferencias o desviaciones es SIEMPRE CERO para cualquier distribución de cualquier variable, lo que resulta clave para la definición de las medidas de dispersión. En nuestro ejemplo, con media de 2, las desviaciones (que se obtienen restando cada dato menos la media) son: -2 -2 -2 -2 -1 -1 -1 0 0 +1 +2 +3 +5 que como puede calcularse suman cero (las negativas, que proceden de datos inferiores a la media, suman –11, y las positivas, que proceden de datos superiores a la media, suman +11, de modo que todas suman 0). Existen otras medidas de centralización de uso menos frecuente, como la media ponderada (que es una media aritmética con distintos pesos de importancia para los distintos datos), la media geométrica (raíz enésima del producto de los datos) o la media armónica (la inversa de la media aritmética de los inversos de los datos). Segundo grupo: PARAMETROS DE DISPERSION. Por su parte, las medidas de dispersión se basan en la idea de medir las diferencias entre unos datos y otros midiendo las diferencias de cada dato con la media, esto es, usando las desviaciones; sin embargo, como éstas siempre suman cero, es preciso considerar su valor absoluto o su cuadrado para que ello no ocurra (serían ya todas positivas). Las más importantes medidas de dispersión son las siguientes: La DESVIACION ABSOLUTA MEDIA: es la media aritmética de los valores absolutos de las desviaciones, por lo que se calcula tomando como positivas todas las desviaciones, sumándolas y dividiendo entre n; en nuestro ejemplo la suma de los valores absolutos (no confundir con frecuencias absolutas, que no tiene nada que ver) sale 22 y por tanto la desviación absoluta media vale 22/13 = 1.69 ; el tener que usar valores absolutos complica los desarrollos matemáticos con este parámetro y por eso se usa poco, pese a su valor intuitivo. Es mucho más importante: 7 La VARIANZA: es la media aritmética de los cuadrados de las desviaciones, por lo que se calcula elevando al cuadrado cada desviación, sumando esos cuadrados y dividiendo entre n; en nuestro ejemplo resulta 58 la suma de cuadrados de las desviaciones, con lo que la varianza es 58/13 = 4.46 ; el cuadrado es matemáticamente mucho más manejable que el valor absoluto, lo que hace de la varianza la reina de los parámetros de dispersión desde un punto de vista teórico. Sin embargo, el hecho de que carezca de interpretación intuitiva y que sus unidades sean cuadradas (¿hermanos cuadrados?) hace que es la práctica se use mucho más su raíz cuadrada, la DESVIACION STANDARD o DESVIACION TIPICA, con mucho la más usada de las medidas de dispersión, y que en nuestro ejemplo valdría 2.11, con lo que el informe más habitual para nuestros datos daría una media de 2.00 y la desviación típica de 2.11 como parámetros más informativos. Por motivos difíciles de explicar aquí, relacionados con cuestiones de inferencia estadística, es más recomendable usar el denominador n-1 en lugar del n al calcular la varianza y la desviación típica de una muestra, quedándose el n para el caso en que se conoce toda la población; en nuestro ejemplo, pues, sería mejor calcular como varianza 58/12 = 4.83 y como desviación standard su raíz cuadrada 2.20 (estos últimos serían la varianza muestral o quasivarianza y la desviación típica muestral y serían los utilizados en la práctica, aunque la definición teórica sea con denominador n por ser la varianza una "media"). A efectos comparativos entre distintas muestras e incluso entre distintas variables, se define: El COEFICIENTE DE VARIACION, que es el cociente, a menudo expresado en tanto por ciento, entre la desviación típica y la media de una distribución. Es una especie de desviación típica “relativa”, y en nuestro ejemplo valdría 2.2011/2.00 = 1.100055 ó bien 11005.05% (nótese que no es un verdadero porcentaje, porque puede valer más del 100%); este resultado indicaría mucha dispersión en los datos del ejemplo en relación con la media. Además de las citadas, la más simple de las medidas de dispersión es el RANGO, RECORRIDO ó AMPLITUD, que es la diferencia entre el valor máximo y el mínimo de la muestra, y que indica qué extensión de la recta de los números ocupan los datos de nuestra muestra. Tercer grupo: CUANTILES O PARAMETROS DE POSICION Los cuantiles completan el cuadro de los parámetros de una distribución. En cierto modo pueden ser considerados como medidas de centralización (de hecho la mediana es uno de ellos) y también como medidas de dispersión (algunas pueden construirse a partir de ellos) pero en realidad son medidas de posición. Se define el cuantil p como aquel valor de la variable (que puede estar o no en la muestra) que supera al p% de los datos de la muestra; resultan útiles sólo cuando la muestra es numerosa y permiten saber en que “posición” se encuentra un valor dado con respecto al conjunto de una muestra o población. Se definen entre los más importantes: Los CUARTILES, que definen las cuartas partes de la muestra mediante tres “cortes”: el primer cuartil deja por debajo al 25% de la distribución, el segundo coincide con la mediana y el tercero deja por debajo al 75% de la distribución. No tienen mucho sentido en muestras pequeñas, pero en nuestro ejemplo valdrían respectivamente 0, 1 y 3.5 (que están situados en las posiciones “tercera y media”, séptima y “décima y media” de los datos ordenados). Los DECILES, que dan nueve cortes para definir de diez en diez por ciento los valores de la distribución; así, el primer decil deja por debajo una décima parte de la distribución, el segundo dos décimas partes, etc., hasta nueve deciles. Los PERCENTILES, que son como los deciles pero de uno en uno por ciento, y por tanto son noventa y nueve; por ejemplo, el percentil 37 deja por debajo al 37% de la distribución, y está claro que no tienen sentido en muestras tan pequeñas como la de nuestro ejemplo, ya que trece elementos no se pueden “partir” en cien partes. Todos los cuantiles son definibles sobre variables cuantitativas o sobre cualitativas ordinales, porque requieren siempre que los datos estén ordenados. 8 Los cuantiles más próximos al percentil 50, como la propia mediana o los cercanos a ella, pueden considerarse como parámetros de centralización y sin embargo los más lejanos al centro ayudan a medir la dispersión; por ejemplo, si restamos el tercer cuartil menos el primero obtenemos el RANGO INTERCUARTÍLICO, que es una medida de dispersión. Con el rango intercuartílico estamos midiendo la extensión que nos cubre la mitad central de nuestros datos; recuérdese que el RANGO era la extensión cubierta por toda la muestra ordenada (se define como máximo menos mínimo), mientras que el RANGO INTERCUARTILICO es la extensión cubierta por la mitad central de los datos ordenados, excluyendo la cuarta parte inicial (los que son inferiores al primer cuartil) y la cuarta parte final (los que son superiores al tercer cuartil). CognoSfera www.ugr.es/local/rruizb/cognosfera 9