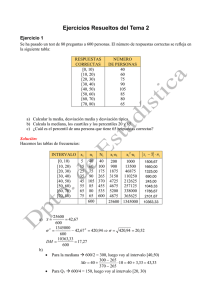
Estadística Estadística Descriptiva. ESTADÍSTICA DESCRIPTIVA 1. 2. 3. 4. 5. 6. 7. 8. 1 Introducción. Conceptos generales. Frecuencias y tablas. Gráficos estadísticos. 4.1 Diagrama de barras. 4.2 Histograma. 4.3 Poligonal de frecuencias. 4.4 Diagrama de sectores. Medidas de centralización. 5.1. Media. 5.2. Moda. 5.3. Mediana. Medidas de posición. Medidas de dispersión. 7.1. Rango o recorrido. 7.2. Varianza y desviación típica. 7.3. Coeficiente de variación. Interpretación de los parámetros estadísticos x y σ Ejemplos Problemas Introducción La Estadística es la parte de la Matemática que estudia los fenómenos que se prestan a cuantificación, que generan conjuntos de datos. La misión del estadístico es la de simplificar al máximo la información disponible, a fin de que pueda ser clara y útil. Además, si el fenómeno lo permite, tratará de inferir las leyes que expliquen el comportamiento de ese fenómeno. Por tanto, podemos distinguir dos aspectos de la Estadística: El de la Estadística descriptiva, que se ocupa de examinar todos los elementos de un conjunto, describir la información disponible con la ayuda de tablas y gráficos, y de resumirla al máximo mediante los parámetros estadísticos. El de la Estadística inferencial, que trata de generalizar, para todo un conjunto (población), los resultados obtenidos al estudiar una parte del mismo (muestra) Tampoco puede olvidarse que la Estadística debe su nombre al Estado. En el siglo pasado se entendió que la Estadística era la "Ciencia del Estado", esto es, que para gobernar de manera racional a los pueblos se hacía preciso disponer de conocimientos acerca de su población y riqueza, conocimiento que debía proporcionar la Estadística. Más tarde, la nueva ciencia desbordó este ámbito. Hoy, la aplicación de la Estadística es universal y sirve tanto para contrastar el efecto de los medicamentos, como para contribuir a la toma de importantes decisiones. 2 Conceptos generales La Estadística, como sabes, tiene por objeto el desarrollo de técnicas para el conocimiento numérico de un conjunto de datos empíricos (recogidos mediante experimentos o encuestas) Vamos a definir algunos conceptos básicos: EJEMPLOS Población: Es el conjunto de todos los elementos cuyo conocimiento nos interesa y que serán sujetos de nuestro estudio Muestra: Es un subconjunto, extraído de la población, cuyo estudio sirve para inferir características de toda la población. Al número de elementos de la muestra se le llama tamaño de la muestra. Un censo es una muestra que consiste en elegir a toda la población. Individuo: Es cada uno de los elementos de la población o muestra. Caracteres o variables: Caracteres son los aspectos que deseamos estudiar en los individuos de una población. Cada carácter puede tomar distintos valores o modalidades. Una variable estadística recorre todos los valores de un cierto carácter. Clasificación de las variables estadísticas: Cualitativas: No toman valores numéricos Cuantitativas discretas: Toman valores numéricos aislados Cuantitativas continuas: Pueden tomar todos los valores en un intervalo. IES “Fuerte de Cortadura” Los 18690 alumnos de una cierta universidad. 650 alumnos de esa universidad, elegidos al azar. Cada uno de los alumnos matriculados en esa universidad Edad, sexo, número de años que ha estado matriculado, estatura,...son caracteres. Cada uno de ellos lleva asociada una variable. La edad toma valores entre 17 años y 45 años, por ejemplo El sexo toma los valores o modalidades V y M El sexo, la carrera que estudian. Número de años matriculados, número de hermanos. Estatura, peso. Página 1 de 17 Estadística 3 Estadística Descriptiva. Frecuencias y tablas Imaginemos que hemos hecho N observaciones de valores de una variable estadística. La lista de N valores no permite apreciar fácilmente lo que sucede con esa variable en el colectivo estudiado, máxime si, como suele ocurrir, N es grande. Si la variable estudiada es cuantitativa, o es ordinal, pueden disponerse ordenadamente las N observaciones, según los valores obtenidos. No obstante, a menudo sucede que un mismo valor se presenta en varios de los N individuos estudiados. Por eso damos las siguientes definiciones: Se llama frecuencia absoluta del valor xi de una variable X al número de veces que se ha presentado dicho valor, en las N observaciones hechas. La representaremos por fi (Es obvio que debe cumplirse: f1 + f2 + f3 + ... + fn = N) Se llama frecuencia absoluta acumulada del valor xi al número de veces que se han presentado los valores inferiores o iguales a xi . La representaremos por Fi . Evidentemente, es la suma de las frecuencias absolutas de todos los valores de X inferiores o iguales a xi. La frecuencia absoluta de un valor nos dice, pues, si se presenta muchas o pocas veces. No obstante, "seis de cada diez veces" puede ser "mucho", mientras que "seis de cada mil veces" puede ser "poco". Por eso, para determinar si un valor es muy frecuente, o no, es mejor utilizar su frecuencia relativa: Se llama frecuencia relativa del valor xi de una variable X, al cociente entre la frecuencia absoluta de xi y el número total de datos (N) que intervienen en la distribución: fri = fi/N (ó hi ). Se llama frecuencia relativa acumulada del valor xi a la suma de las frecuencias relativas de todos los valores de X inferiores o iguales a xi . Se representa por Fri o Hi .Así pues Fri = fr1 + fr2 +...+fri = Fi/N. El valor de la frecuencia relativa debe hallarse entre 0 y 1, por su misma definición. Además, la suma de las frecuencias relativas de todos los valores posibles debe ser 1, pues La frecuencia relativa puede expresarse con una fracción (la fracción fi/N que la define), con un número real entre 0 y 1 (obtenido al pasar a decimal la fracción fi/N), o con un porcentaje (obtenido al multiplicar por 100 el decimal anterior). Si se representa con un porcentaje, deberá hallarse entre 0% y 100%, y todas las frecuencias sumarán el 100%. Volvamos ahora al momento en qué sólo teníamos una "simple lista de valores". Podemos ver qué valores se han presentado, hacer su recuento y calcular sus frecuencias, con una simple tabla. Las tablas estadísticas o de frecuencias están formadas por una columna en la que colocamos los distintos valores de la variable estadística y, por otras en las que aparecen las correspondientes frecuencias y/o porcentajes. Veamos cómo, con un ejemplo. Supongamos que las notas obtenidas por los 40 alumnos de una clase, en una prueba de Matemáticas, han sido éstas: 2 5 8 6 7 3 6 1 9 7 4 6 6 0 2 3 4 4 7 0 4 10 5 8 4 7 3 4 2 8 4 9 5 4 3 5 6 2 6 3 En la tabla que sigue se procede a ordenar, recontar las notas y calcular las frecuencias de cada una: Nota Frecuencia absoluta xi 0 1 2 3 4 5 6 7 8 9 10 fi 2 1 4 5 8 4 6 4 3 2 1 40 IES “Fuerte de Cortadura” Frecuencia absoluta acumulada Fi 2 3 7 12 20 24 30 34 37 39 40 Frecuencia relativa hi 1/20 1/40 1/10 1/8 1/5 1/10 3/20 1/10 3/40 1/20 1/40 1 Frecuencia relativa acumulada Hi 2/40 3/40 7/40 12/40 20/40 24/40 30/40 34/40 37/40 39/40 1 Porcentajes hix100 5 2’5 10 12’5 20 10 15 10 7’5 5 2’5 100 Página 2 de 17 Estadística Estadística Descriptiva. En la tabla anterior se incluyen frecuencias de todo tipo, pero normalmente sólo consideraremos las frecuencias absolutas. Las frecuencias acumuladas, relativas y porcentajes no los incluiremos, si no se piden expresamente o no son necesarias para cálculos posteriores. En caso de que la variable sea continua, o bien discreta pero con un número de datos muy grande, en vez de contabilizar las frecuencias de cada valor por separado, suelen agruparse los valores en intervalos, denominados clases o intervalos de clase. Después se identifican todos los elementos que han sido agrupados en un mismo intervalo con el punto medio de éste, llamado marca de clase. Esta es la denominada técnica de agrupación de datos. Ahora bien, ¿cuál es el número idóneo de clases que debemos escoger a la hora de agrupar? ¿cómo realizamos este agrupamiento? No existe una contestación tajante a estas preguntas; existen incluso varios criterios para dar respuesta a estas cuestiones. Con carácter muy general podemos dar varios criterios y etapas para realizar el agrupamiento: Se localizan los valores extremos a y b y se halla su diferencia r = b - a. Se decide el número de intervalos que se quiere formar, teniendo en cuenta el número de datos que se poseen. En general entre 5 y 15 intervalos puede ser un número adecuado. Se toma un intervalo total algo mayor que el recorrido r y que sea múltiplo del número de intervalos, con objeto de que éstos tengan una longitud entera. Se forman los intervalos de modo que el extremo inferior del primero sea algo menor que a y el extremo superior del último sea algo superior a b. Es deseable que los extremos de los intervalos no coincidan con ninguno de los datos; de hacerlo, incluiremos en el intervalo un extremo y excluiremos el otro (Ej.: [2,5) ó (2,5]) Para evitarlo, puede convenir que dichos extremos tengan valores no enteros. Es conveniente que todos los intervalos tengan la misma longitud; ello facilita los cálculos. Si los datos son muy dispersos habrá que optar por longitudes distintas. Cuando se elabora una tabla con datos agrupados se pierde algo de información (pues en ella se ignora cada valor concreto, que se difumina en un intervalo). A cambio se gana en claridad y eficacia. Veamos cómo se realiza el agrupamiento, con un ejemplo. A los 100 empleados de una empresa de piezas de precisión, se les ha realizado una prueba de habilidad manual. En una escala de 0 a 100 se han obtenido las siguientes puntuaciones: 27 46 66 15 32 29 36 65 46 76 37 67 75 23 81 35 18 94 33 23 47 25 74 56 37 73 52 78 47 17 66 28 80 76 87 58 37 45 29 36 55 60 17 56 23 82 64 50 51 45 37 62 62 26 69 36 54 42 40 54 27 62 28 90 46 92 36 33 23 66 18 82 47 49 59 45 73 43 47 83 78 65 39 55 53 91 38 35 68 78 91 23 34 43 55 56 74 56 62 38 Observamos que los valores extremos son 15 y 94. La amplitud total entre los datos es de 80 puntos, ya que ambas puntuaciones están incluidas. Agruparemos los datos en 8 intervalos de amplitud 10: (14,24], (24,34],.., (84,94]. Realizando el recuento con atención, se obtiene la tabla de frecuencias. Clases (14,24] (24,34] (34,44] (44,54] (54,64] (64,74] (74,84] (84,94] IES “Fuerte de Cortadura” Marcas clase xi 19 29 39 49 59 69 79 89 de fi 10 12 17 18 13 13 13 11 100 Página 3 de 17 Estadística Estadística Descriptiva. 4 Gráficos estadísticos Las tablas estadísticas muestran la información de forma esquemática y están preparadas para cálculos posteriores. La misma información estadística puede mostrarse de forma global y más visual, utilizando los gráficos estadísticos. Los gráficos poseen un fuerte poder de comunicación de los resultados de un estudio estadístico. Como en las tablas, hay que indicar la fuente de los datos y las unidades en qué estos han sido medidos. Asimismo, conviene titularlos y numerarlos. Detallamos a continuación, los tipos de gráficos más frecuentes: 4.1. Diagrama de barras. Consiste en dibujar un rectángulo por cada una de las modalidades de la variable, de modo que las bases sean todas iguales y apoyadas en el eje de ordenadas, en el que se indican las modalidades, y la altura de cada rectángulo debe ser proporcional a la frecuencia de la modalidad representada. Este tipo de gráfico está indicado para variables cualitativas y cuantitativas no agrupadas en intervalos. Errores 0 1 2 3 4 5 6 7 8 9 Nº personas 1 5 12 10 15 17 11 7 0 2 frecuencia(nº de personas) El número de errores cometidos por 80 personas al realizar una tarea 20 17 15 15 12 11 10 10 7 5 5 2 1 0 0 0 1 2 3 4 5 6 7 8 9 Errores 4.2. Histograma. Número de pulsaciones por minuto en un grupo de 30 personas. Intervalo (puls/min) [50,56) [56,62) [62,68) [68,74) [74,80) [80,86) [86,92) fi (nº personas) 1 1 4 9 6 5 4 30 Frecuencia (nº de personas) El histograma se usa para variables agrupadas en intervalos, asignando a cada intervalo un rectángulo de superficie proporcional a su frecuencia. Para construir el histograma se representan sobre el eje de abscisas los límites de las clases. Sobre dicho eje se construyen unos rectángulos que tienen por base la amplitud del intervalo y por altura la frecuencia absoluta de cada intervalo, siempre que todos los intervalos tengan igual amplitud. En caso contrario, las alturas de los rectángulos han de ser calculadas teniendo en cuenta que sus áreas f recuencia deben ser proporcionales a las frecuencias de cada intervalo (altura = ) amplitud del int erv alo 9 5 1 50 56 Tiempo empleado por 80 personas en realizar una tarea Intervalo (min) [0,2) [2,3) [3,4) [4,5) [5,7) [7,10) fi (nº personas) 4 5 10 12 28 21 80 62 68 74 80 86 pulsaciones /minuto 92 14 12 10 8 6 4 Observa que la amplitud de los intervalos no es la misma. El intervalo 0-2 representa una frecuencia de 4; su altura es 4/2= 2. El intervalo 2-3 representa una frecuencia de 5; su altura es 5/1= 5. El intervalo 2 3-4 representa una frecuencia de 10; su altura es 10/1= 10. El intervalo 4-5 representa una frecuencia de 12; su altura es 12/1= 12. El intervalo 5-7 representa una frecuencia de 28; su altura es 28/2= 14. El intervalo 7-10 representa una frecuencia de 21; su altura es 21/3= 7. IES “Fuerte de Cortadura” 0 2 3 4 5 7 10 Tiempo (minutos) Página 4 de 17 Estadística 4.3. Estadística Descriptiva. Poligonal de frecuencias. frecuencia(nº de personas) Los histogramas y algunos diagramas de barras, también se pueden representar por una poligonal de frecuencias, que es la línea que une los puntos correspondientes a las frecuencias de cada valor (extremos superiores de las barras). Si esta poligonal es simple, las ordenadas se sitúan en la marca de clase de cada intervalo. Si se hace una poligonal de frecuencias acumuladas, el primer intervalo empieza en cero y alcanza, en su extremo superior, la ordenada de su frecuencia; el segundo intervalo continúa la misma línea, elevándola en él la frecuencia correspondiente, y así sucesivamente. La poligonal de frecuencias que representa el número de errores cometidos al realizar una tarea (ver ejemplo del diagrama de barras) se da en la figura adjunta. 20 17 15 15 12 11 10 10 7 5 5 2 1 0 0 0 1 2 3 4 5 6 7 8 9 Número de pulsaciones por minuto en un grupo de 30 personas. La poligonal de frecuencias que representa el número de pulsaciones por minuto en un grupo de 30 personas (ver ejemplo del histograma) se da en la figura adjunta. Frecuencia (nº de personas) Errores 9 5 1 50 56 62 68 74 80 86 pulsaciones /minuto 92 Vamos a construir la poligonal de frecuencias acumuladas correspondiente al ejemplo donde se medía el tiempo empleado por 80 personas al realizar una tarea. Primero construiremos la tabla de frecuencias con las acumuladas y después dibujaremos la poligonal. Intervalo (min) fi Fi 4.4. [0,2) 4 4 [2,3) 5 9 [3,4) 10 19 [4,5) 12 31 [5,7) 28 59 [7,10) 21 80 80 80 Diagrama de sectores. Es muy utilizado para variables cualitativas o cuantitativas en las que el número de estados en que clasifiquemos sea pequeño. Cada sector circular debe ser proporcional a la frecuencia de la clase. Es muy útil para representar situaciones similares y hacer comparaciones. En un instituto de Secundaria, se han obtenido los siguientes resultados al acabar el curso en la asignarura de Matemáticas: Notas Suspenso Suficiente Bien Notable Sobresaliente IES “Fuerte de Cortadura” Nº de alumnos 35 145 65 40 30 Suspenso Suficiente Bien Notable Sobresaliente Página 5 de 17 Estadística Estadística Descriptiva. 5 Medidas de centralización Para estudiar un conjunto de datos estadísticos, además de los gráficos y las tablas de frecuencias, conviene dar algunas medidas objetivas que describan de un modo conciso el comportamiento y las características generales de los datos estudiados. Estas medidas, que reciben el nombre de parámetros estadísticos, se suelen agrupar en las siguientes categorías: 5.1. Medidas de centralización: están relacionadas con el promedio de los datos. Es un valor lo más representativo posible del conjunto de datos. De ellas, la principal es la media, también se usan la mediana y la moda. Medidas de posición: indican, una vez ordenados, cuántos elementos quedan a la izquierda o derecha de uno dado. Las más usadas son los cuartiles y los percentiles. Medidas de dispersión: dan una idea de las desviaciones que sufren los datos respecto de los valores centrales, en especial con relación a la media. A mayor parámetro, más dispersión. Entre estas se encuentran: rangos, varianza, desviación media y desviación típica. Media aritmética. La media aritmética de una serie de valores se obtiene sumándolos, y dividiendo la suma por el número de datos. Se representa por x . Su cálculo se realiza, según las expresiones que siguen, atendiendo a la presentación de los datos: Para datos simples (sin agrupar por frecuencias): Si la variable toma los n valores x1, x2, …., xn , la media aritmética adopta la expresión: n x x1 x 2 ..... xn n x i i 1 n Para datos agrupados por frecuencias: Si la variable toma los valores x1 , x2 ,...,xn, siendo f1 , f2 ,...,fn las frecuencias absolutas correspondientes de la distribución, la media aritmética se calcula con la expresión: n x xi ·fi i 1 x1·f1 x 2·f2 .... xn·fn f1 f2 ..... fn N Cuando los datos están agrupados en intervalos, para hallar la media aritmética basta con tomar como valores de la variable xi las marcas de clase respectivas. La media también se puede calcular como: x n xi ·hi i 1 , siendo hi las frecuencias relativas. Consideraciones: La media aritmética es el parámetro de centralización más utilizado. Presenta la ventaja de tener en cuenta todos los datos de la distribución, además de resultar muy sencillo su cálculo. Tiene el inconveniente de que si la distribución pose valores extremos, éstos pueden producir una distorsión sobre el valor de la media, alterando el significado de ésta. No siempre es posible realizar el cálculo de la media aritmética: si los datos son cualitativos o cuando, estando los datos agrupados en clases, alguna de ellas está abierta. Si se suma una constante a todos los valores de una variable, su media aumenta en dicha constante. Si se multiplican todos los valores de la variable por una constante, la media queda multiplicada por dicha constante. 5.2. Moda. Se denomina moda de una variable estadística al valor de la variable que tiene mayor frecuencia absoluta. Se representa por Mo. La moda de una variable discreta es fácil de calcular, basta buscar el valor de la variable que presenta mayor frecuencia. Puede ocurrir que la moda no sea única, es decir, la distribución puede tener 2,3 o más modas, recibiendo el nombre de bimodal, trimodal, etc. IES “Fuerte de Cortadura” Página 6 de 17 Estadística Estadística Descriptiva. En el caso de que los datos se encuentren agrupados en intervalos de la misma amplitud, la clase con mayor frecuencia se denomina clase modal. Puede tomarse como moda la marca de clase de la clase modal Si los datos se agrupan en intervalos de distinta amplitud, la clase modal es aquella a la que le corresponde en f recuencia el histograma un rectángulo de mayor altura (altura = ) amplitud del int erv alo Consideraciones: Puede ocurrir que existan distribuciones que no tengan moda (cuando todos los datos son iguales) La moda es menos representativa que la media aritmética, pero a veces es más útil que ésta; por ej. cuando se trata de datos cualitativos. En la moda no intervienen todos los datos de la distribución. La moda no tiene por qué situarse en la zona central. La moda representa el valor dominante en la distribución 5.3 Mediana. La mediana de una variable estadística es el valor que divide el conjunto de datos en dos partes iguales, es decir, el número de datos menores que ella es igual al número de datos mayores. Se representa por Me o M. Para calcular la mediana distinguimos: Para datos simples (sin agrupar por frecuencias): En este caso se ordenan los datos de forma creciente y la media será el valor central: Si el número de datos es impar, el valor central es único:2,3,5,6,9,11,12 → Me=6 Si el número de datos es par se toma la media de los dos valores centrales:2,3,5,6,12,13 → Me = 5+6 2 = 5.5 Para datos agrupados por frecuencias: La mediana viene dada por el primer valor de la variable cuya frecuencia absoluta excede a la mitad del número de datos. En el caso de que la mitad del número de datos coincida con la frecuencia absoluta acumulada correspondiente a un valor, la mediana es la media entre ese valor y el siguiente. Para datos agrupados en intervalos: La clase que contiene a la mediana se llama clase mediana o intervalo mediano. Puede tomarse como mediana, en una primera aproximación, la marca de la clase del intervalo mediano. Si se desea mayor precisión en el cálculo de la mediana, ésta puede obtenerse dentro del intervalo mediano, mediante la expresión: N Fi 1 Me Li c· 2 fi siendo: Li = extremo inferior de la clase mediana c = amplitud de los intervalos N = número total de datos Fi-1 = frecuencia absoluta acumulada de la clase anterior a la clase mediana. fi = frecuencia absoluta de la clase mediana La mediana es especialmente útil en los siguientes casos: a) Cuando entre los datos existe alguno ostensiblemente extremo que afecta a la media. b) Cuando los datos están agrupados en clases y alguna de ellas es abierta. Como consecuencia de la definición de mediana, se tiene que el 50% de los datos son menores o iguales que ella y el 50% son mayores o iguales. La mediana es un parámetro de centralización que depende del orden de los datos y no de su valor. 6 Medidas de posición La mediana de los valores de una variable estadística divide a la distribución en dos partes iguales. Es decir, la mediana parte la distribución en dos mitades, cada una correspondiente al 50%. Generalizando la idea anterior, se puede pensar en obtener valores que dividen a los datos en diversas partes iguales. Estás dan lugar a los conceptos que siguen: Los valores de la variable que superan, exactamente, al 25%, 50% y 75% de los datos se llaman, respectivamente, cuartil primero (Q1 ), segundo (Q2) y tercero (Q3). IES “Fuerte de Cortadura” Página 7 de 17 Estadística Estadística Descriptiva. De la misma manera, podemos dividir la distribución en 100 partes, con lo cual podemos llegar a conocer cuál es el valor de la variable que deja un porcentaje de casos a su izquierda y derecha. El percentil de orden k o k-ésimo (Pk) de una distribución es un valor que, una vez ordenados los datos de forma creciente, el k% son iguales o inferiores a él. Para el cálculo de Q1 se parte de N/4, para el de Q3 de 3N/4 y para el de Pk de kN/100. Después se procede como en el caso de la mediana, tanto para variable discreta como para variable continua. Así para variables agrupadas en intervalos se tiene: 3N F kN N Fi 1 Fi1 i 1 Q1 Li c· 4 Q3 Li c· 4 Pk Li c· 100 fi fi fi Cuartiles y percentiles se denominan parámetros de estructura o de posición. Se tiene que Q1 = P25 ; Q2 = Me = P50 ; Q3 = P75 7 Medidas de dispersión Consideremos el siguiente ejemplo: se ha aplicado a dos grupos de ocho alumnos de 8º de EGB un test de 100 preguntas sobre capacidad numérica, obteniéndose los siguientes resultados: Grupo A 46 48 49 50 50 51 52 54 Grupo B 10 18 30 50 50 70 82 90 Si calculamos la media, la moda, y mediana de ambas distribuciones, observamos que todas son 50. En cambio, los dos grupos de alumnos son bien distintos. Así pues, la investigación acerca de la distribución queda incompleta si sólo se estudian las medidas de centralización, siendo imprescindible conocer si los datos numéricos están agrupados o no alrededor de los valores centrales, en especial con relación a la media aritmética. A esto se llama dispersión. Las medidas o parámetros de dispersión más usuales se describen a continuación. 7.1. Recorrido o rango. Se llama recorrido o rango de una distribución a la diferencia entre el mayor y el menor valor de la variable estadística. En el ejemplo anterior los recorridos son: de A, 54 - 46 = 8, y de B, 90 - 10 = 80. Por tanto, al tener el mismo número de datos, diremos que la distribución del grupo A está más concentrada que la del grupo B. Cuanto menor es el recorrido de una distribución, mayor es el grado de representatividad de los valores centrales. El recorrido tiene la ventaja de su sencillez de cálculo. Tiene gran aplicación en procesos de control de calidad, y de una manera general, en aquellos procesos que se pretenda verificar longitudes, pesos, volúmenes, estando prefijados de antemano los límites permitidos. El recorrido tiene el inconveniente de que sólo depende de los valores extremos. Para paliar de alguna manera este inconveniente se utiliza en ocasiones otros rangos: Rango intercuartílico: Q3 - Q1 Rango entre percentiles: P90 - P10 Estos rangos son algo más estables que el rango, ya que tienden a eliminar aquellos valores extremadamente alejados. 7.2. Varianza y desviación típica. 2 La varianza que denotamos por σ , es la media aritmética de las diferencias la cuadrado de cada dato respecto a la media de todos ellos. Su fórmula es: n (x x) ·f 2 (x x)2 ·f1 (x2 x)2 ·f2 ..... (xn x)2 ·fn σ 1 f1 f2 .... fn 2 i i i 1 N La varianza, al obtenerse a partir del cuadrado de las diferencias de los datos respecto de la media, hace que los valores más alejados tengan mayor peso en el resultado: en consecuencia, distingue mejor que la amplitud la variabilidad de los datos de las distribuciones. Otra fórmula equivalente, de mayor utilidad práctica, es: n x 2 ·f x 22 ·f2 .... xn2 ·fn 2 σ 1 1 x f1 f2 ... fn 2 IES “Fuerte de Cortadura” x ·f 2 i i i 1 N x 2 Página 8 de 17 Estadística Estadística Descriptiva. La varianza tiene el inconveniente de que su valor viene dado en unidades al cuadrado. Por ejemplo, para datos medidos en centímetros la varianza se expresa en centímetros cuadrados. Esto se resuelve considerando la desviación típica. La desviación típica, σ, es la raíz cuadrada de la varianza. En consecuencia: n n (xi x)2 ·fi x ·f 2 i i = i 1 x N N 2 La varianza y la desviación típica también se denotan por s y s. Tanto la varianza como la desviación típica dependen de todos los valores de la distribución. i 1 σ 2 Si a los valores de una variable se les suma la misma constante, la varianza y la desviación típica no varían. Si a los valores de una variable se les multiplica por la misma constante positiva, la varianza queda multiplicada por el cuadrado de la constante y la desviación típica queda multiplicada por dicha constante. 7.3. Coeficiente de variación. Los pesos de los toros de lidia de una ganadería se distribuyen con x t = 510 kg y σt = 25 kg. Los pesos de los perros de una exposición canina se distribuyen con x p = 19 kg y σp = 10 kg. La desviación típica de la manada de toros bravos es superior que la de los perros (σt= 25 > σp= 10). Sin embargo, esos 25 kg son poca cosa para el enorme peso de los toros ( es decir, los toros de esa manada son muy parecidos en peso), mientras que 10 kg en relación con el peso de un perro es mucho. Para poder comparar la dispersión de dos poblaciones muy distintas, no es buena la desviación típica. Por eso se define una nueva medida de dispersión, llamada coeficiente de variación: σ CV x Al dividir la desviación típica entre su media, x , se está relativizando la variación. Así como la media y la desviación típica se dan en las unidades en que vienen dados los datos, el coeficiente de variación es un número abstracto (no tiene unidades). Cuanto más pequeño sea este coeficiente de variación, los datos están más concentrados alrededor de la media, siendo ésta más representativa. En el ejemplo de los toros y los perros, sus respectivos coeficientes de variación son: 25 10 CVt 0.049 CVp 0.526 510 19 A veces el coeficiente de variación se da en tantos por ciento. En este caso sería: CVt = 0.049x100 = 4.9 % CVp = 0.526x100 = 52.6% Con este parámetro se ve claramente que el peso de los perros de la exposición canina es mucho más disperso que el de los toros de la manada. 8 Interpretación de los parámetros estadísticos x y σ La desviación típica y la media son las dos medidas más utilizadas para describir un conjunto de datos. La media: Es el valor del promedio, el que se obtendría al repartir igualitariamente un todo entre sus elementos. Gráficamente es el centro de gravedad de la distribución. Es decir, si las barras tuvieran peso, la media es el punto donde habría que sostener la tablilla en que se sitúan para mantenerse en equilibrio. Análogamente ocurre con las distribuciones dadas mediante histogramas. x La desviación típica: Nos dice cómo de alejados de la media, cómo de dispersos, se encuentran los datos. Es una medida de las diferencias habidas en ese reparto supuesto igualitario; a mayor desviación típica menor igualdad. Utilizando la media aritmética y la desviación típica conjuntamente podemos obtener resultados muy importantes sobre la distribución. Observemos la siguiente familia de distribuciones. Todas ellas tienen la misma media. Sus desviaciones típicas, sin embargo, son distintas: IES “Fuerte de Cortadura” Página 9 de 17 Estadística Estadística Descriptiva. 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 En la primera, todos los valores están acumulados en la media. Su desviación típica es cero (no hay dispersión. Al pasar a la segunda aumenta la dispersión, pues algunos individuos están separados de la media. Y, en general, para pasar de cada una a la siguiente, algunos individuos se alejan de la media y, por tanto, aumenta la dispersión. * Ejemplos 1) Un alumno obtuvo las siguientes calificaciones en Matemáticas: 3,8,5,8,3,9 y 6: N=7 3 8 5 8 3 9 6 42 Nota media: x =6 Moda: Mo= 3 M’o = 8 7 7 Mediana: 3, 3, 5, 6, 8, 8, 9 → Me = 6 Cuartiles: Percentiles: (1/4)·N = (1/4)7 = 1.75 → Q1 = 3 (30/100)·7 = 2.1 → P30 = 5 Q2 = Me = 6 (3/4)·N = (3/4)·7 = 5.25 → Q3 = 8 (67/100)·7 = 4.69 → P67 = 8 Recorrido: 9 – 3 = 6 Rango intercuartílico: Q3 – Q1 = 8 – 3 = 5 n (x x) 2 i Varianza: σ 2 i 1 n (3 6)2 (3 6)2 (5 6)2 (6 6)2 (8 6)2 (8 6)2 (9 6)2 = 5.14 7 n ó σ 2 x i 1 n 2 i x2 32 32 52 62 82 82 92 62 = 5.14 7 Desviación típica: σ = 5.14 = 2.26 Coeficiente de variación: CV = 2.26/6 = 0,376 37.6% 2) Las calificaciones en la asignatura de Historia del Arte de los 40 alumnos de una clase viene dada por: Calificaciones 1 2 3 4 5 6 7 8 9 Nº de alumnos 2 2 4 5 8 9 3 4 3 xi fi 1 2 3 4 5 6 7 8 9 2 2 4 5 8 9 3 4 3 40 Fi xifi xi2fi 2 4 8 13 21 30 33 37 40 2 4 12 20 40 54 21 32 27 212 2 8 36 80 200 324 147 256 243 1296 1x2 2x2 3x4 4x5 5x8 6x9 7x3 8x4 9x3 212 5'3 2 2 45893 43 40 Moda: Mo = 6 Mediana: (1/2)·40 = 20 → Me = 5 Cuartiles: Q1 deja la cuarta parte de la distribución a la izquierda; como N/4=40/4=10 , se verifica que Q1 = 4. Q2 = Me = 5 Q3 deja tres cuartas partes de la distribución a la izquierda; como 3N/4 = 340/4 = 30, se tiene que Q3 =(6+7)/2 = 6.5 Media : x IES “Fuerte de Cortadura” Página 10 de 17 Estadística Estadística Descriptiva. Percentiles: P10 deja el 10% de la distribución a la izquierda; como 10N/100 = 4,se obtiene P10 =2.5 P30 deja el 30% de la distribución a la izquierda; como 30N/100 = 12,se obtiene P30 =4 P40 deja el 40% de la distribución a la izquierda; como 40N/100 = 16,se obtiene P40 =5 P70 deja el 70% de la distribución a la izquierda; como 70N/100 = 28, se obtiene P70= 6 Recorrido: 9 – 1 = 8 Recorrido intercuartílico: Q3 – Q1 = 6.5 – 4 = 2.5 n Varianza: σ 2 n x ·f (x i x) 2 fi i 1 N 2 i = i i 1 N x2 = 1296 2 5.3 = 4.31 40 Desviación típica: σ = 4.31 2.08 Coeficiente de variación: CV = 2.08/ 5.3 = 0,392 3) 39.2% La estación meteorológica de Pueblaseca registró 88 días de lluvia el pasado año, según se muestra en la tabla siguiente: Litros/m2 (0,5) [5,10) [10,15) [15,20) [20,25) [25,30) [30,35] Nº de días 3 7 19 23 18 12 Clases xi fi Fi xifi xi2fi (0,5) 2.5 3 3 7.5 18.75 [5,10) 7.5 7 10 52.5 393.75 [10,15) 12.5 19 29 237.5 2968.75 [15,20) 17.5 23 52 402.5 7043.75 [20,25) 22.5 18 70 405 9112.5 [25,30) 27.5 12 82 330 9075 [30,35] 32.5 6 88 195 6337.5 1630 34950 88 6 n x ·f i Media: x i 1 N i 1630 = 18’52 l/m2 88 Moda: El mayor valor de la frecuencia, 23, da como clase modal el intervalo [15,20). En una primera aproximación, la moda es la marca de clase del intervalo anterior, es decir, Mo=17.5. Mediana: En la citada distribución, el nº total de datos es 88. El intervalo mediano es [15,20), ya que contiene el dato número 44. Utilizando la expresión que permite calcular la mediana aplicada al intervalo anterior, se tiene: N F 88 29 i 1 Me Li c· 2 15 5· 2 18.26l/m2 fi 23 Cuartiles: Q1 deja la cuarta parte de la distribución a la izquierda: como N/4 = 22, resulta que la clase que contiene el primer cuartil es [10,15). Aplicando una expresión análoga a la de la mediana, se tiene: N F i 1 22 10 Q1 Li c· 4 10 5· 13.2 fi 19 Q3 deja tres cuartas partes de la distribución a la izquierda: 3N/4 = 66, resulta que la clase que contiene el tercer cuartil es [20,25). Se tiene que: 3N F i 1 66 52 Q3 L i c· 4 20 5· 23.9 fi 18 Percentiles: P40 deja el 40% de la distribución a la izquierda; como 40N/100= 35.2, resulta que la clase que contiene el percentil de orden 40 es [15,20). Aplicando la expresión correspondiente: 40N F 100 i 1 15 5·35.2 29 16.3 P40 Li c· fi 23 IES “Fuerte de Cortadura” Página 11 de 17 Estadística Estadística Descriptiva. P90 deja el 90% de la distribución a la izquierda; como 90N/100=79.2, resulta que la clase que contiene el percentil de orden 90 es [25,30). Por tanto: 90N F 100 i 1 25 5·79.2 70 28.8 P90 L i c· fi 12 Rango o recorrido: 35 – 0 = 35 Rango intercuartílico: Q3 – Q1 = 23.9 – 13.2 = 10.7 n Varianza: σ 2 n x ·f (x i x) 2 fi i 1 i 1 = N Desviación típica: : σ = 2 i N i x2 = 34950 2 18.52 = 54.06 88 54.06 7.35 Coeficiente de variación: 7.35/ 18.52 = 0,396 39.6% * Problemas 1) Clasifica las variables que siguen en cualitativas y cuantitativas, indica el tipo, y pon ejemplos de los valores que puede tomar cada una: a) Temperatura registrada cada hora del día b) El número de miembros de cada una de las familias de un cierto país c) En un centro, conjunto musical preferido por los alumnos. d) Número de espectadores que han asistido a un pabellón durante los partidos de baloncesto de toda la liga. e) Las velocidades con las que circulan los automóviles por un determinado lugar f) En un centro, número de alumnos de cada clase. g) El sexo de los habitantes de una ciudad h) Duración de las llamadas telefónicas hechas en una cabina. i) En un grupo de 2º de Bachillerato, lugar preferido para realizar un viaje fin de curso. j) La talla de ropa que utilizan los habitantes de las Islas Canarias k) Opinión de los españoles sobre una decisión política Dígase cuál es la población estudiada en cada uno de los casos citados en el problema anterior. 2) En una población de 25 familias se ha observado la variable número de coches y se han obtenido los siguientes datos: 0,1,2,3,1,0,1,1,1,4,3,2,2,1,1,2,2,1,1,1,2,1,3,2,1. Elabora la tabla de frecuencias de la distribución de X. 3) Las medidas de concentración de ozono en la atmósfera de una ciudad fueron las siguientes: 3,5 1,4 6,6 6,0 4,2 4,4 5,3 5,6 6,8 2,5 5,4 4,4 5,4 4,7 3,5 4,0 2,4 3,0 5,6 4,7 6,5 3,0 4,1 3,4 6,8 1,7 5,3 4,7 7,4 6,0 6,7 11,7 5,5 1,1 5,1 5,6 5,5 1,4 3,9 6,6 6,2 7,5 6,2 6,0 5,8 2,8 6,1 4,1 9,4 3,4 5,8 3,1 5,8 7,6 1,4 3,7 2,0 3,7 6,8 3,1 a) Agrupa estos datos en intervalos de clase de longitud 1 y en clases de longitud 2 b) Realiza una tabla con las frecuencias absolutas, relativas y acumuladas, porcentajes y porcentajes acumulados para cada uno de los casos. 4) En una clase de 28 alumnos las notas de Matemáticas han sido las siguientes: MD NT NT SB NT NT SF SF MD MD BI NT SF IS SB MD NT NT MD SF BI SB IS MD SF SF BI BI donde: MD: Muy deficiente ( de 0 a 3 puntos) IS: Insuficiente (de 3 a 5 puntos) SF: Suficiente ( de 5 a 6 puntos) BI: Bien ( de 6 a 7 puntos) NT: Notable ( de 7 a 9 puntos) SB: Sobresaliente (de 9 a 10 puntos) Determina los intervalos de clase de cada nota y agrupa los datos según los intervalos determinados. Presenta estos datos en una tabla con las frecuencias absolutas, relativas y acumuladas, porcentajes y porcentajes acumulados. 5) Completa los datos que faltan en la siguiente tabla estadística, donde f, F y h representan, respectivamente, la frecuencia absoluta, acumulada y relativa. x 1 2 f 4 4 F h IES “Fuerte de Cortadura” 3 16 0,08 0,16 4 5 7 5 28 6 7 8 7 38 45 0,14 Página 12 de 17 Estadística 6) Estadística Descriptiva. Completa los datos que faltan en las tablas estadísticas siguientes: Calificación fi hi Nº de hijos fi hi xi fi Insuficiente 1 3 2 4 0.375 0 Suficiente 20 1 Notable 16 2 Sobresaliente TOTAl 80 0.2 15 3 hi 16 0.15 3 5 4 7 4 4 5 5 28 7 38 45 5 TOTAL 7) Fi 0.02 6 7 8 TOTAL Las producciones de trigo (en toneladas) de unas granjas son las que figuran en la tabla adjunta: Granja A B C D E F Producción 16 12 20 17 3 12 Representa gráficamente estos datos en un diagrama de barras. 8) Las dianas logradas en un campeonato por 25 tiradores fueron: 8, 10, 12, 12, 10, 10, 11, 11, 10, 13, 9, 11, 10, 9, 9, 11, 12, 9, 10, 9, 10, 9, 10, 8, 10 Resume los datos anteriores en una tabla de frecuencias absolutas y relativas, y dibuja el correspondiente diagrama de barras. 9) Se ha realizado un test de habilidad numérica a los alumnos de una clase. Los resultados obtenidos son: Puntuaciones [10,15) [15,20) [20,25) [25,30) [30,35) [35,40) [40,45) [45,50] Nº de alumnos 4 6 6 10 8 10 3 3 Representa los datos mediante un histograma. 10) Se ha aplicado un test a los empleados de una fábrica, obteniéndose la siguiente tabla: Puntuaciones (38,44] (44,50] (50,56] (56,62] (62,68] (68,74] Nº de trabajadores 7 8 15 25 18 9 Construye el histograma y el polígono de frecuencias absolutas acumuladas. (74,80] 6 11) Un pediatra realizó un estudio sobre la edad a la que comenzaron a andar 50 niños de su consulta: Meses 9 10 11 12 13 14 15 Niños 1 4 9 16 11 8 1 Realiza el diagrama de barras, el polígono de frecuencias y el polígono de frecuencias acumuladas. 12) De una muestra de 75 pilas se han obtenido los siguientes datos sobre la duración en horas: Duración en horas (25,30] (30,35] (35,40] (40,45] (45,50] (50,55] Nº de pilas 3 5 21 28 12 6 a) Representa los histogramas correspondientes, el de frecuencias y el acumulado. b) A partir de los histogramas del apartado anterior, construye los dos polígonos de frecuencia. Nº de alumnos 13) El siguiente histograma representa el número de dianas obtenidas por un grupo de 40 alumnos de un instituto en unas competiciones de tiro 11 10 9 8 7 6 5 4 3 2 1 0 8 11 14 17 20 nº de dianas a) Obtén la tabla de frecuencias asociada a esta representación b) Representa el polígono de frecuencias acumuladas IES “Fuerte de Cortadura” 2 5 Página 13 de 17 Estadística Estadística Descriptiva. 14) Halla la tabla de frecuencias asociada a este histograma: 15) Los sueldos mensuales en una empresa son los siguientes: 1 director, 3000 € ; 3 jefes, 2500 €; 6 encargados, 1500 € , y 9 operarios, 800 € Calcula el sueldo medio 16) La dirección de tráfico ha recogido la siguiente información relativa al número de multas diarias, en un período de 50 días, que sus agentes han impuesto a los conductores que circulan por una autopista. Nº de multas (0,5] (5,10] (10,15] (15,20] Días 6 14 20 10 Halla el número medio de multas diarias. 17) En primero de Bachillerato de un centro escolar hay tres grupos, A, B y C, con 30,35 y 25 alumnos, respectivamente. La nota media en Matemáticas fue, también respectivamente, de 5.3, 6.5 y 5.6. Halla la nota media de Matemáticas de todos los alumnos de primero. 18) A un conjunto de cinco números cuya media aritmética es 7.31 se le añaden 4.47 y 10.15. ¿Cuál es la media del nuevo conjunto de números? 19) Para el siguiente conjunto de datos: 10,13,4,7,8,11,10,16,18,12,3,6,9,9,4,13,20,7,5,10,17,10,16,14,8,18 Obtén su media, moda y mediana. 20) Los gastos mensuales en lectura (periódicos, revistas y libros) de 7 personas fueron, en euros, 27, 29 , 9, 28, 27.5, 30 y 28.5. a) Calcular la media y la mediana de los datos anteriores. ¿Cuál de ellas es más representativa para estos datos? b) Si el precio del tabaco sube en un 10 % y se mantiene el consumo, deducir los nuevos valores de la media y la mediana a partir de los resultados obtenidos en el apartado anterior. 21) Supongamos que los precios de los distintos artículos producidos por una empresa vienen dados por: Precios 5-15 15-25 25-35 35-45 Frecuencias 15 k 2k 3 a) Deduce el valor de k sabiendo que el precio medio es 25. b) Calcula la moda y la mediana. 22) Los siguientes datos corresponden a la altura en centímetros de los alumnos de una determinada clase: 150, 169, 171, 172, 172, 175, 176, 177, 178, 179, 181, 182, 183, 184, 184 Calcula la moda, mediana y los cuartiles de la variable. Indica el significado de los parámetros encontrados. 23) Se ha pasado un test de 79 preguntas a 600 personas. El número de respuestas correctas se refleja en la siguiente tabla: Respuestas [0,10) [10,20) [20,30) [30,40) [40,50) [50,60) [60,70) [70,80) Nº de personas 40 60 75 90 105 85 80 65 a) Representa los datos mediante un histograma. b) Calcula la media y la moda de respuestas correctas. c) Calcula la mediana y el primer cuartil. ¿Qué miden estos parámetros? 24) La calificación obtenida por un grupo de 200 alumnos en la asignatura de matemáticas es: Calificación 1 2 3 4 5 6 7 8 Nº de alumnos 10 10 20 25 40 45 15 20 a) Calcula el rango intercuartílico. b) Calcular los percentiles de orden 20 y 70. IES “Fuerte de Cortadura” 9 15 Página 14 de 17 Estadística Estadística Descriptiva. 25) Dada la siguiente distribución estadística, calcula el primer y tercer cuartil, Q 1 y Q3, y los percentiles de orden 40 y 80, P40 y P80. Clases [30,35) [35,40) [40,45) [45,50) [50,55) [55,60) fi 7 8 15 20 17 9 26) Habiéndose medido el coeficiente intelectual (C.I.) de los alumnos de un colegio se han obtenido los siguientes resultados: C.I. 61-69 69-77 77-85 85-93 93-101 101-109 109-117 117-125 Nº de alumnos 2 10 12 20 25 18 9 4 ¿Qué puntuación corresponde al percentil 80? ¿Qué puntuación corresponde a un alumno que es superado por el 30% de los alumnos? ¿ Qué tanto por cien de los alumnos representan aquellos que tienen un CI en el intervalo 93-123? 27) Para reclasificar a sus empleados, una empresa decide hacer unas pruebas que arrojan los siguientes resultados: Puntuación 0-30 30-50 50-70 70-90 90-100 Nº de empleados 94 140 160 98 8 La nueva estructura de la empresa exige que el 64% de los empleados pertenezcan a la categoría básica, el 20% a la categoría media, el 10% a la superior y el resto sean cargos directivos. ¿Cuáles deben ser las distintas puntuaciones mínimas exigidas para que un empleado pase a formar parte de las diferentes categorías, suponiendo que éstas van aumentando según la puntuación de la prueba? 28) Calcula todos los parámetros de dispersión para las siguientes distribuciones estadísticas: a) Calificaciones de 20 estudiantes: 6, 3, 2, 5, 7, 5, 9, 7, 6, 1, 4, 6, 6, 4, 2, 10, 8, 7, 5, 9. b) Goles por partido en la liga de fútbol 86-87: Goles 0 1 2 3 4 5 6 7 Nº de partidos 32 71 80 62 36 15 6 2 c) Prueba, con puntuación de 0 a 10, a 20 personas: Intervalo [0,2) [2,4) [4,6) [6,8) Nº de personas 2 4 8 5 8 2 [8,10) 1 29) Las puntuaciones obtenidas en un test de razonamiento abstracto por 20 alumnos son las siguientes:16, 22, 21, 20, 23, 22, 17, 15, 13, 22, 17, 18, 20, 17, 22, 16, 23, 21, 22, 18. Hallar la moda, la media, los percentiles de orden 30 y 70, el recorrido y la varianza 30) Un inversor ha adquirido 1000 acciones de una determinada sociedad en cinco sesiones diferentes de Bolsa. Los cambios de adquisición se registran en la tabla adjunta. Halla el cambio medio, la mediana, la moda y la desviación típica. Cambio 900 870 840 800 700 Nº de acciones 150 300 100 250 200 31) Se ha controlado el peso en 50 recién nacidos, obteniéndose los resultados de la tabla. Hallar los cuartiles, la desviación típica y el recorrido intercuartílico. Peso (en kg) 2.5-3 3-3.5 3.5-4 4-4.5 Nº de niños 6 23 12 9 32) Para comprobar la resistencia de unas varillas de nylon, se someten 250 a un test de resistencia, que consiste en comprobar si se rompen o no cuando se aplica una fuerza sobre 5 puntos diferentes. El número de roturas por varilla ensayada es: Nº de varillas 141 62 31 14 1 1 Nº de roturas 0 1 2 3 4 5 a) Calcula el número medio de roturas por varilla y el porcentaje de varillas que sufren más de dos roturas. b) Halla la moda, media y varianza de la serie. 33) En la siguiente distribución de frecuencias: X (60,76] (76,92] (92,108] (108,124] (124,140] (140,156] Frecuencia 12 13 18 19 11 7 ¿Cuántos valores hay en el intervalo x , x ? ¿Qué porcentaje del total representan? IES “Fuerte de Cortadura” Página 15 de 17 Estadística Estadística Descriptiva. 34) La altura (en cm) y el número de zapato que usan seis alumnas de primero de Bachillerato son: Altura 164 158 162 166 168 172 Zapato 37 37 36 38 39 41 a) Halla la media y la desviación típica de los datos. b) ¿Qué conjunto es más disperso, el de alturas o el de número de zapato? 35) Las edades, en años, de los asistentes a cierto curso fueron: 37, 35, 38, 36, 37, 40, 38, 25, 38. a) ¿Cuál es la edad media de los asistentes? b) La varianza del conjunto de datos anterior es 16.9. Las mismas personas asistirán a otro curso dentro de dos años. Obtén razonadamente la media, la varianza y la desviación típica del nuevo conjunto de datos a partir de los correspondientes al conjunto de datos inicial. 36) Considérense los siguientes valores: 2,3,3,5,7. Obtener otro conjunto de 5 datos que incluya los valores 2,3,6, y que tenga la misma media, la misma mediana y mayor varianza. 37) Inventa seis notas (enteras) cuya media sea 5 y cuya desviación típica sea a) la menor posible,b) la mayor posible . Justifícalo. 38) Inventa seis notas diferentes (enteras) cuya media sea 5 y cuya desviación típica sea a) la menor posible, b) la mayor posible. 39) Un test aplicado a 40 alumnos de 2º de ESO ha dado los siguientes resultados: Puntuaciones (14,20] (20,26] (26,32] (32,38] (38,44] (44,50] (50,56] Nº de alumnos 2 8 13 8 5 3 1 Se pide: a) Calcula la moda, la media , la mediana, el recorrido, el rango entre percentiles , la varianza y el coeficiente de variación de las puntuaciones. b) Calcula a partir de qué puntuación se encontrará el 30% de la clase con mayor puntuación c) ¿ d) Si debido a un error en la corrección de los test las puntuaciones deberían ser un 20% inferiores a las de la tabla ¿cuál es la verdadera media? 40) El número de hijos de 32 matrimonios se distribuye según la tabla adjunta Nº de hijos 1 2 3 4 5 6 7 8 9 a) b) Nº de matrimonios 1 2 4 3 7 5 6 3 1 Representa gráficamente el diagrama de barras y la poligonal de frecuencias acumuladas Calcula la moda, los cuartiles, la media y la varianza IES “Fuerte de Cortadura” Página 16 de 17 Estadística Estadística Descriptiva. 41) Se considera una distribución de datos agrupados en intervalos cuyo polígono de frecuencias acumuladas es el de la figura Calcular razonadamente: a) Tabla de distribución de frecuencias absolutas b) Media y desviación típica c) Mediana 42) Al preguntar a un grupo de personas cuánto tiempo dedicaron a ver televisión durante un fin de semana se obtuvieron estos resultados: Tiempo (en horas) [0,0.5) [0.5,1.5) [1.5, 2.5) [2.5,4) [4,8) Nº de acciones 10 10 18 12 12 Dibuja el histograma correspondiente y halla la media y la desviación típica. 43) La tabla siguiente da las ganancias brutas, en millones de pesetas, durante seis años consecutivos, de dos tiendas de iguales características situadas en barrios distintos: Año 1 2 3 4 5 6 Tienda A 5,9 2,5 7,4 8,1 4,8 3,7 Tienda B 4,5 3,8 5,7 3,5 5,5 4,6 a) ¿Qué tienda da mayores beneficios? b) ¿Qué tienda es más estable? 44) Dos fabricantes de baterías de automóviles ofrecen sus productos a una fábrica de automóviles, al mismo precio. Ésta, para elegir la más duradera, hace una prueba con 50 baterías de cada marca, obteniendo los siguientes resultados : Vida de la batería(en meses) 20 22 24 26 28 30 Marca A (frec. absoluta) 5 8 12 15 7 3 Marca B (frec. absoluta) 1 7 18 19 5 0 Realice los cálculos que considere necesarios para justificar la elección efectuada por la fábrica. 45) Se ha medido el colesterol en cuatro grupos de personas sometidas a diferentes dietas. Las medias y las desviaciones típicas son las que figuran en esta tabla: DIETA A B C D 211.3 186.6 202.2 188.6 x 37.4 52.6 39.1 43.1 Las gráficas son, no respectivamente: Asocia a cada dieta la gráfica que le corresponde. IES “Fuerte de Cortadura” Página 17 de 17