UNIVERSIDAD AUTONOMA METROPOLITANA
Anuncio

Casa abierta al ternpa
UNIVERSIDAD AUTONOMA METROPOLITANA
/
,-”
UNIDAD:
IZTAPALAPA
DIVISION:
CIENCIAS BASICAS E INGENIERIA
CARRERA:
LICENCIATURA EN INGENIERIA ELECTRONICA
MATERIA:
PROYECTO DE INGENIERIA ELECTRONICA I Y II
TITULO:
DISENO E IMPLEMENTACION DE PRIMITIVAS PARA UN
SISTEMA DE ARCHIVOS DISTRIBUIDO UTILIZANDO PVM
(PARALLEL VIRTUAL MACHINE)
/
FECHA:
’ ALUMNO:
~
ENERO DE 1999
--c
MAURlClO MUÑOZ GARCIA
MATRICULA: 89325717
ALUMNO:
CRISTOBAL ROMO DUARTE:
MATRICULA: 89328274
ASESOR:
ELIZABETH PEREZ CORTES
lndice
1 . ESTADO DEL ARTE
5
1. I . Transacciones
6
1.2. Protección
7
I .2.1. Dominios de protección
7
I .2.2. Listas de acceso y listas de capacidades
8
1.3. Sistema de Archivos NFS
9
1.3.I . El protocolo de montaje
10
I .3.2. El protocolo NFS
11
1.3.3. Arquitectura NFS
12
1.3.4. Traducción de nombres de rutas
13
1.4. Andrew File System
13
1.4.I . Espacio de nombres compartidos
14
1.4.2. Operaciones y consistencia de archivos.
14
1.5. AFS vs. NFS.
2. DESARROLLO DEL SAD
2.1. Arquitectura del SAD desarrollado.
15
16
17
2. I . I . Arquitectura.
17
Arbol de procesos.
18
2.1.3. Interface.
18
2.1.4. Nominación de Archivos.
19
2.1.5. Peticiones de operación sobre archivos.
20
2. I .6. Estructuras para la Administración de archivos.
21
2.1.7. Comunicación entre procesos.
23
2.2. Archivos de encabezado.
3. CONCLUSIONES
25
26
3.1. Trabajo Desarrollado.
26
3.2. Perspectivas.
26
4. BlBLlOGRAFÍA
28
5. APENDICE A (CÓDIGOS DE LOS PROGRAMAS)
29
*NOMBRE: Maestros
29
*NOMBRE: admonl .c
31
*NOMBRE: 1istas.h
52
*NOMBRE: distribuido.h
63
6. APENDICE B (MANUAL DE USUARIO)
Instalación de PVM.
73
73
6.1.1. Transferencia de PVM
73
6.1.2. Descompresión de PVM
73
6.1.3. Compilación de PVM
73
6.1.4. Ejecución del demonio
74
COMPILACION DEL SAD
74
6.1.5. Copiado de archivos
74
6.1.6. Edición del archivo adman#.c
74
6.1.7. Edición del archivo Makefile.aimk.
75
6.1.8. Compilación
76
ARRANQUE DEL SAD
76
6.1.9. Copiado del archivo mestro.c
76
6.1.1O. Edición del archivo maestr0.c
76
6.1.11. Compilación del archivo maestr0.c
77
6.1.12. Ejecución del maestro
77
EDlClON DE LAS APLICACIONES
77
COMPILACION DE LAS APLICACIONES
77
EJECUCION DE LA APLICACIÓN
77
FUNCIONES PRIMITIVAS DEL SAD
78
7. APENDICE C (PARALLEL VIRTUAL MACHINE)
82
Int roducción
El presente proyecto de investigación tiene como propósito la elaboración de un administrador de
archivos en un ambiente distribuido, esto es, implementar las operaciones básicas sobre un archivo que
son la apertura, creación, cerrado, escritura, lectura, desplazamiento y eliminación. Este proyecto
ayudará a la comprensión clara sobre sistemas distribuidos y a la administración de archivos.
Una tendencia reciente en los sistemas de computación es distribuir los cálculos entre varios
procesadores físicos. Básicamente hay dos esquemas para construir estos sistemas:
0
En un sistema fuertemente acoplado, los procesadores comparten memoria y reloj; en estos sistemas
multiprocesadores, la comunicación generalmente se lleva a cabo a través de la memoria compartida.
o
En un sistema débilmente acoplado los procesadores no comparten memoria ni reloj, estos se
comunican por medio de diversas líneas, como canales de alta velocidad o líneas telefónicas. A estos
sistemas generalmente se les conoce como sistemas distribuidos.
En un sistema distribuido, los procesadores varían en cuanto a tamaño y función e incluyen pequeños
microprocesadores, estaciones de trabajo, minicomputadoras y grandes sistemas de cómputo de
propósito general, ofreciendo al usuario acceso a los diversos recursos que mantiene el sistema. El
acceso a un recurso compartido permite acelerar los cálculos y mejorar la disponibilidad y confiabilidad
de los datos.
Definimos un sistema distribuido como un conjunto de procesadores débilmente acoplados que
permite el acceso a recursos compartidos.
Desde el punto de vista de un procesador específico en un sistema distribuido, los demás procesadores
y sus recursos respectivos son remotos, mientras que los propios recursos son locales.
Un sistema de archivos es el encargado de administrar tanto física como lógicamente los datos
almacenados en algún dispositivo secundario (generalmente un disco duro).
Un sistema de archivos distribuidos (SAD), es el software encargado de administrar tanto lógica como
físicamente los datos contenidos en uno o varios dispositivos secundarios los cuales no se encuentran
centralizados, es decir, pueden localizarse en diferentes computadoras interconectadas entre sí
mediante una red.
1
Un SAD es una implantación del clásico modelo de sistema de archivos de tiempo compartido, donde
varios usuarios comparten archivos y recursos de almacenamiento. El propósito de un SAD es apoyar el
mismo tipo de compartición cuando los archivos están dispersos físicamente en varias instalaciones de
un sistema distribuido.
Las funciones de un sistema de archivos son la organización, almacenamiento, nombrado, repartición y
protección de archivos.
Las partes que lo componen se dividen en módulos:
0
Servicio de archivos planos: el cual se compone de módulos de archivos y de acceso a archivos. Se
encarga de modificar el contenido de los archivos.
0
Servicio de directorios: se compone de módulos de directorios y de control de acceso. Se encarga de
traducir los nombres ASCII a Identificadores Únicos de archivos (UFID Unique File Identifiers).
0
Modulo de Clientes: está formado por módulos de bloques y de dispositivos. Se encarga de proveer
al usuario de una interfaz de programación. También se ocupa de las rutinas de bajo nivel para
accesar bloques de memoria y dispositivos.
Un SAD es un sistema de servicio de archivos cuyos usuarios, servidores y dispositivos de
almacenamiento están dispersos por las distintas instalaciones de un sistema distribuido. Por lo anterior,
la actividad de servicio corre a cargo de toda la red; en vez de un solo depósito de datos centralizado,
existen múltiples dispositivos independientes de almacenamiento.
Por lo general, el servidor, posee un recurso que el cliente (o usuario), desea usar. El propósito de un
sistema distribuido es ofrecer un entorno eficiente y adecuado para compartir los recursos.
El SAD puede implantarse como parte del sistema operativo distribuido, o bien como una capa de
software cuya tarea es administrar la comunicación entre los sistemas operativos y los sistemas de
archivos convencionales. Las características de un SAD. son la multiplicidad y autonomía de clientes y
servidores en el sistema.
Un sistema de archivos distribuido, también debe contar con las siguientes características que deben
resolverse:
0
Transparencia de acceso a datos locales y remotos: El usuario no distingue cuando los datos son
locales o remotos.
0
Transparencia de localización: El nombre de un archivo no revela ningún indicio sobre la ubicación
del almacenamiento físico del archivo. La independencia de la ubicación significa que no es
necesario modificar el nombre del archivo cuando cambia su ubicación en el almacenamiento físico.
2
Transparencia de concurrencia, para que varios usuarios puedan operar sobre los datos compartidos,
sin que se interfieran.
Transparencia de replicación, para que haya varias copias de los datos para mejorar el desempeño
sin que el usuario se entere.
Transparencia de fallos, para que el usuario pueda trabajar aún si fallan ciertos elementos del
sistema.
Transparencia de migración, para que los programas o datos de los usuarios puedan moverse sin
interferencia para el usuario.
Transparencia de escalamiento, para que el sistema pueda aumentar de tamaño sin cambiar de
estructura a los algoritmos de aplicación.
El presente documento consta de 5 capítulos y 3 apéndices que son:
Capítulo I Estado del Arte.
Se desarrollan los conceptos generales para la elaboración del proyecto, se estudian dos sistemas de
archivos distribuidos que son Andrew File System (AFS) y Networth File System (NFS) y se ve una tabla
comparativa entre estos dos sistemas.
Capítulo 3 Desarrollo del Sistema de Archivos Distribuido (SAD).
Se expone como se realizó el proyecto desarrollando la arquitectura, el árbol de procesos, la nominación
de archivos, las peticiones de operación sobre archivos, las estructuras para la administración de
archivos, la comunicación entre procesos y los archivos de encabezado.
Capítulo 4 Rendimiento.
Capítulo 5 Conclusiones.
Se exponen los puntos importantes del SAD desarrollado y los puntos que se pueden implementar como
mejoras.
Capítulo 6 Bibliografía.
Apéndice A Manual de Usuario.
Se desarrollan los procedimientos para la instalación de PVM,la compilación y arranque del SAD, la
edición, compilación y ejecución de las aplicaciones, se exponen las funciones primitivas del SAD dando
la sintaxis, descripción, valor de retorno y errores.
3
Apéndice B Parallel Virtual Machine.
Se explica de manera general lo que es PVM.
Apéndice C Código de Programas.
Se listan todos los códigos del proyecto.
4
1. Estado del arte
Este capítulo tiene como objetivo el estudio de algunos SAD, que nos permitirán comprender como se
han solucionado los problemas que se presentan al elaborar este tipo de sistemas.
Un sistema de archivos provee dos tipos de servicio:
Servicio de directorios: se encarga de la creación, manejo, adición y eliminación de archivos en un
directorio.
Servicio de archivos: está encargado de las operaciones sobre archivos individuales, lectura,
escritura, etc.
Los modelos de servicio de archivos que se pueden utilizar son:
Cargddescarga: el archivo es transferido del servidor al cliente, quien lo modifica y io devuelve al
servidor de archivos (Data shipping), ver figura I.
Acceso remoto: en este modelo todas las operaciones se efectúan donde se encuentra el archivo
físicamente (Query shipping), ver figura 2.
Figura 1
5
Peticiones sobre los archivos
Figura 2
Existen diversas semánticas que se pueden utilizar para el manejo de los archivos:
o
La semántica de UNlX hace que las escrituras efectuadas por un usuario a un archivo abierto, sean
visibles de inmediato para los otros usuarios que tengan el archivo abierto al mismo tiempo.
o
En la semántica de sesión las escrituras efectuadas por un usuario a un archivo abierto no son
visibles por los otros usuarios que tengan el archivo abierto al mismo tiempo. Los cambios son
efectuados al cerrar el archivo y son visibles para las sesiones que comiencen mas tarde.
A continuación explicaremos qué es una transacción, qué son los métodos de protección y veremos dos
ejemplos de sistemas de archivos distribuidos que son Network File Sistem (NFS) y Andrew File Sistem
(AFS), por ultimo damos una tabla comparativa entre estos dos sistemas.
1.I.
Transacciones
Una transacción es un conjunto lógico de operaciones caracterizadas por cuatro propiedades:
atomicidad, consistencia, aislamiento y durabilidad (ACID, Atomicity, Consistency, Isolation y
Durability).
o
Atomicidad: La propiedad de atomicidad significa que para un observador externo todas las
operaciones son completadas o ningunas de ellas sean ejecutadas.
o
Consistencia: La propiedad de consistencia significa que las operaciones son ejecutadas
correctamente.
0
Aislamiento: La propiedad de aislamiento significa que cualquier resultado parcial de las operaciones
que componen la acción atómica no es visible hasta que ésta se complete.
o
Durabilidad: La propiedad de durabilidad significa que los efectos de la transacción son durables.
6
Cuando un proceso da inicio a una transacción, el servidor de archivos lleva un registro de
transaciones en disco para llevar el control de su condición, esto permite la tolerancia a fallas del
servidor y del disco. Cuando el proceso lee un archivo por primera vez el servidor bloquea el archivo para
evitar que otros procesos lo accesen y hace una copia. Si el archivo no se puede bloquear, la transacción
falla y no se hacen cambios. La escritura se hace en la copia y no en el original. Cuando la escritura
termina, el servidor tendrá un conjunto de archivos recién creados que tienen que reemplazar a los
archivos originales que aún no se han modificado, entonces el servidor construye una lista de
intenciones, donde se listan todos los archivos que tienen que actualizarse. La lista de intenciones se
escribe en el registro de transacciones que se encuentra en disco, de modo que, aunque el servidor falle,
cuando se restablezca sabrá que hacer. Después inhibe todas las operaciones hasta que la transacción
se termine.
1.2. Protección
El papel de la protección en un sistema de computación consiste en proporcionar un mecanismo para
aplicar las políticas que gobiernan la utilización de los recursos. Estas políticas puedes establecerse de
varias maneras. Algunas están determinadas por el diseño del sistema, otras están formadas por los
administradores del sistema y algunas más son definidas por los usuarios para proteger sus propios
archivos y programas. Un sistema de protección debe tener la flexibilidad suficiente para aplicar las
diversas políticas que se le pueden indicar.
Un principio de importancia es la separación entre políticas y mecanismos. Los mecanismos determinan
cómo se hará algo, mientras que las políticas deciden qué se hará. Esta separación es importante
respecto a la flexibilidad, ya que es probable que las políticas cambien de un lugar a otro o con el
transcurrir del tiempo. En el peor de los casos, cada cambio en las políticas requerirá una modificación en
el mecanismo correspondiente. Por esto, será más deseable contar con mecanismos generales, pues un
cambio en una política requeriría alterar solo algún parámetro o tablas del sistema. Estos parámetros o
tablas se pueden expresar como dominios de protección, capacidad y accesos
I. 2. I . Dominios de protección
Un dominio es un conjunto de parejas de objetos y derechos. Cada pareja especifica un objeto y algún
subconjunto de las operaciones que se pueden efectuar con él. Un derecho en este contexto significa
autorización para ejecutar una de las operaciones sobre el objeto asociado.
7
Los procesos también pueden cambiarse de un dominio a otro durante su ejecución. Las reglas para el
cambio de dominio dependen en gran medida del sistema.
Una pregunta importante es, ‘cómo
controla el sistema las políticas entre objetos y dominios?. En
concepto, cuando menos, uno puede imaginar una matriz de accesos donde los renglones son los
dominios y las columnas son los objetos. Cada caja lista los derechos, si hay alguno, que el dominio
contiene para el objeto (figura 3). Dada esta matriz y el número de dominio corriente, el sistema siempre
puede indicar si se permite un intento por accesar un objeto específico de manera particular.
Objetos
1
Archivo 1
Archivo 2
Lectura
Lectura
Archivo 3
Archivo 4
Impresora 1
Dominio 1
Dominio 2
Dominio 3
Accesar
Escritura
2
3
Lectura
Escritura
Lectura
Escritura
Escntura
Ejecución
Figura 3
El cambio de dominio mismo, se puede incluir sin dificultad en el modelo de matriz comprendiendo que
un dominio es un objeto en sí.
I . 2.2. Listas de acceso y listas de capacidades
Cada columna de la matriz de accesos se puede implantar como una lista de accesos para un objeto.
Evidentemente pueden descartarse las entradas vacías. La lista para cada objeto consiste en pares
ordenados (dominio, derechos) que definen todos los dominios con un conjunto no vacío de derechos de
accesos para ese objeto (figura 4).
Archivo 1: (Dominio 1, Lectura)
Archivo 2: (Dominio 1, Lectura/Escritura)
Archivo 3: (Dominio 2, Lectura)
Archivo 4: (Dominio 3, Lectura/Escritura/Ejecución)
Impresora: (Dominio 2, Escritura), (Dominio 3, Escritura)
Dominio 2: (Dominio 1, Acceso)
Figura 4
8
En vez de asociar las columnas de la matriz de acceso a los objetos mediante listas de accesos,
podemos relacionar cada fila con su dominio. Una lista de capacidades para un dominio es una lista de
objetos y las operaciones que se permiten para ellos. Un objeto muchas veces está representado por su
dirección o nombre físico (figura 5).
3
Archivo
Lectura
Apuntador al archivo
4
Archivo
Lectura/Escritura/Ejecución
Apuntador al archivo
5
Impresora
Escritura
Apuntador a la Impresora
Figura 5.
1.3. Sistema de Archivos NFS
El sistema de archivos de red (Network File System) es tanto una implementación como una
especificación de un sistema de software para el acceso a archivos remotos a través de redes locales o
incluso de área ancha.
NFS considera un conjunto de estaciones de trabajo interconectadas como un conjunto de máquinas
independientes, cada una con su sistema de archivos. El objetivo es permitir que, en cierta medida, se
compartan los archivos en estos sistemas de manera transparente. La compartición se basa en una
relación cliente-servidor y una máquina puede ser tanto cliente como servidor.
Se permite la compartición entre cualquier par de máquinas, en vez de hacerlo Únicamente con máquinas
servidoras dedicadas. Para asegurar la independencia de las máquinas, la compartición de un sistema de
archivo remoto afectará exclusivamente a la máquina cliente.
Para que sea transparente el acceso de un directorio remoto de una máquina específica, el cliente
primero tiene que efectuar una operación de montaje. La semántica de la operación es que el directorio
remoto se monta sobre un directorio del sistema de archivos local, sustituyendo el subárbol que
desciende del directorio local; entonces el nombre del directorio local se convierte en el nombre de la raíz
del directorio montado. A partir de ese momento los usuarios de la máquina pueden tener acceso
completamente a los archivos del directorio remoto (figura 6 ) .
9
Máquina 2
Máquina 1
usr
Maquina 1
bin
...
Progl
Maquina 2
Máquina 1
Máquina
...
Eduardo
Máquina3
Joaquín
...
I
...
Máquina3
Máquina3
...
I
'
Arch1
..
Figura 6.
En potencia cualquier sistema de archivos o un directorio en cualquier máquina, puede montarse
remotamente sobre cualquier directorio local sujeto a la acreditación de derechos de acceso. En la
versión 4.0 de NFS las estaciones de trabajo sin disco pueden montar incluso sus propias raíces a partir
de los servidores.
Uno de los objetivos del diseño de NFS fue operar en un entorno heterogéneo compuesto por diferentes
máquinas, sistemas operativos y arquitectura de red. La especificación de NFS es independiente a estos
elementos, por lo tanto, estimula otras implementaciones. La independencia se obtiene usando primitivas
de Llamadas a Procedimientos Remotos (RPC, Remote Procedure Call), construidas sobre un
protocolo de representación de fecha externa (XDR, External Date Representation) utilizado entre dos
interfaces independientes de la implantación. De esta manera si un sistema se compone de máquinas y
sistemas de archivos heterogéneos con una interface adecuada para NFS, se pueden montar sistemas
de archivos de diferente tipo, tanto local como remotamente.
I . 3.I . El protocolo de montaje
El protocolo de montaje se usa para establecer la conexión lógica inicial entre un servidor y un cliente. En
la implantación de Sun, cada máquina tiene un proceso servidor, que lleva a cabo las funciones del
protocolo.
La operación de montaje incluye el nombre del directorio remoto que se desea montar y el nombre de la
máquina servidora que lo contiene. La solicitud de montaje se transforma en la RPC correspondiente y se
envía al servidor de montaje que se ejecuta en la máquina servidora específicada. Una máquina
acreditada puede montar remotamente cualquier directorio en un sistema de archivos exportado, por lo
que dicho directorio es una unidad componente. Cuando el servidor recibe una solicitud de montaje que
10
se ajusta a su lista de exportación, devuelve al cliente un indicativo de archivo que sirve como llave para
los accesos subsecuentes a los archivos del sistema montado. El indicativo de archivo contiene toda la
información que requiere el servidor para distinguir el archivo que almacena. Además del procedimiento
de montaje, el protocolo incluye otros procedimientos, como el desmontaje y devolver la lista de
exportaciones.
1.3.2. El protocolo NFS
El protocolo NFS proporciona un conjunto de llamadas a procedimientos remotos para las operaciones
con archivos. Estos procedimientos apoyan las siguientes operaciones:
0
Buscar un archivo en un directorio.
0
Leer un conjunto de registros del directorio.
0
Manipular directorios y directorios montados.
0
Acceder a los atributos del archivo.
0
Leer y escribir archivos.
Solo es posible invocar estos procedimientos después de haber establecido un identificador de archivo
para el directorio montado remotamente.
La omisión de las operaciones de apertura y cierre es intencional. Una de las características prominentes
de los servidores NFS es que operan sin estado y no conservan información acerca de sus clientes de
un acceso a otro. Otra consecuencia de esta filosofía es ocasionada por la sincronía de una RPC, esta
hace que los datos modificados deban almacenarse en el disco del servidor antes de ser enviados al
cliente. La disminución en el rendimiento puede ser considerable, ya que se pierde la mayoría de las
ventajas de la memoria caché.
El concepto de memoria caché es sencillo: si los datos necesarios para satisfacer la solicitud de acceso
no se encuentran en la memoria caché, se trae una copia del administrador a la aplicación y los accesos
se llevan a cabo con la copia en la memoria caché. La idea es conservar allí los bloques de disco de
acceso más reciente, para así manejar localmente los accesos repetidos a la misma información y no
aumentar el tráfico de la red.
Se garantiza que cada llamada a un procedimiento de escritura de NFS es atómica, y que no se mezcla
con otras llamadas de escritura al mismo archivo; sin embargo los protocolos NFS no ofrecen
mecanismos de control de concurrencia. Por lo que si dos usuarios se encuentran trabajando sobre el
mismo archivo, el Último que lo cierre es el que dejara los cambios escritos en el archivo, y los del otro se
perderán.
11
1.3.3. Arquitectura NFS
La arquitectura NFS consiste en tres capas principales:
0
La primera es la interface del sistema de archivos UNIX, basado en las llamadas de apertura,
lectura, escritura, cierre, y los descriptores de archivos.
0
La segunda capa se denomina sistema virtual de archivos (Virtual File System), y ofrece dos
funciones de importancia: separa las operaciones genéricas sobre el sistema de archivos de su
implantación al definir una interface VFS limpia. Varias implantaciones de interfaces VFS pueden
coexistir en la misma máquina, lo que permite el acceso transparente a distintos tipos de sistemas de
archivos montados localmente. El VFS está basado en una estructura de representación de archivos
llamados nodo-v, que contienen un identificador numérico para un archivo Único en toda la red
(Figura 7). El núcleo mantiene una estructura de nodo-v para cada nodo activo. De esta manera el
VFS distingue los archivos locales de los remotos y los locales se distinguen aún más de acuerdo con
su tipo de sistema de archivos. En esencia la estructura de nodo-v complementada por la tabla de
montaje, proporciona a cada archivo un apuntador a un sistema de archivos padre y al sistema de
archivos donde está montado.
0
La tercera capa es la que implementa el protocolo NFS y se le conoce como capa de servicio NFS.
número de máquina
b
paginas de disco
sistema de archivos
número de nodo-i
I
F
+
nodo-v
nodo-i
Figura 7
12
1.3.4. Traducción de nombres de rutas
Para traducir el nombre de una ruta, la dividimos en sus nombres componentes y ejecutamos una
llamada NFS de consulta para cada par compuesto por el nombre del componente y el nodo-v del
directorio. AI cruzar un punto de montaje, cada consulta del componente provoca una RPC distinta al
servidor. Sería mucho más eficiente entregar al servidor el nombre de una ruta y recibir un nodo-v destino
al encontrar un punto de montaje, sin embargo en cualquier punto de montaje puede existir otro más para
el cliente, que el servidor sin estado no conoce. Para que la consulta sea más rápida los nodos-v de los
nombres de directorios remotos se conservan del lado del cliente en una memoria caché de consulta de
nombres de directorios remotos.
El NFS permite montar un sistema de archivos sobre otro sistema ya montado; sin embargo un servidor
no puede actuar como intermediario entre un cliente y otro servidor sino que el cliente establece una
conexión directa con el segundo servidor montando directamente el directorio deseado. Cuando el cliente
tiene estos montajes, más de un servidor puede participar en el recorrido de la ruta.
1.4. Andrew File System
El sistema de archivos Andrew File System (AFS) representa un mecanismo de compartición de
información para los clientes. Uno de los atributos más formidables es su capacidad de crecimiento, pues
el objetivo del sistema es abarcar más de 5,000 estaciones de trabajo.
AFS establece una diferencia entre las máquinas clientes (estaciones de trabajo) y máquinas servidoras
dedicadas. Tanto los servidores como los clientes ejecutan el sistema operativo UNIX, y están
interconectados por una red compuesta a su vez por redes locales.
A los clientes se les presenta un espacio particionado de nombres de archivos: espacio de nombres
locales y espacio de nombres compartidos. Los servidores dedicados, que colectivamente se llaman
Vice, por el software que ejecutan, presentan a los clientes el espacio de nombres compartidos como una
jerarquía de archivos homogéneos, idéntica y transparente a la ubicación. El espacio de nombres locales
es el sistema de archivos raíz de una estación de trabajo, a partir del cual desciende el espacio de
nombres compartidos. Las estaciones de trabajo ejecutan el protocolo Virtue para comunicarse con Vice,
y se requiere que tengan discos locales para almacenar su espacio de nombres locales.
Desde un punto de vista más detallado, los clientes y servidores, están estructurados como
agrupamientos interconectados por una red local medular.
13
Para obtener el mejor rendimiento, las estaciones de trabajo deben utilizar la mayor parte del tiempo el
servidor de su propio agrupamiento, para que las referencias entre agrupamientos sean relativamente
poco frecuentes.
La arquitectura del sistema de archivos también se basa en la consideración de crecimiento. La lógica
básica es descargar el trabajo de los servidores a los clientes, partiendo de la experiencia que indica que
la velocidad de la CPU del servidor es el cuello de botella del sistema. Siguiendo este pensamiento, se
seleccionó la colocación de archivos enteros en memoria caché como mecanismo clave para las
operaciones con archivos remotos. AI abrir un archivo se coloca, por completo, en memoria caché en el
disco local, a donde se dirigen las lecturas y escrituras sin involucrar para nada a los servidores. En
ciertas circunstancias puede emplearse la copia en memoria caché para las aperturas subsecuentes.
Observamos que este diseño no permite el acceso remoto a archivos muy grandes por lo que se requiere
un diseño separado para el manejo de grandes bases de datos o programas en el entorno Andrew.
1.4.1. Espacio de nombres compartidos
El espacio de nombres compartidos está formado por unidades componentes llamadas volúmenes. Los
volúmenes son unidades componentes de tamaño excepcionalmente pequeños, por lo general asociados
a archivos de un solo cliente.
Un archivo o directorio Vice se reconoce por un identificador de bajo nivel llamado fid. Cada entrada del
i
ú
,el cual contiene: un
directorio establece una correspondencia entre un componente de la ruta y un f
número de volumen, un número de nodo-v y un identificador Único. El número de nodo-v se usa como
índice para un arreglo que contiene los i-nodos de los archivos en un volumen. El identificador permite
reutilizar los números de los nodos-v, con lo que ciertas estructuras de datos se mantienen compactas.
i
ú son transparentes a la ubicación, por lo que los movimientos de un servidor a otro no invalida el
Los f
contenido del directorio que se encuentra en memoria caché.
1.4.2. Operaciones y consistencia de archivos.
El principio fundamental de AFS es la colocación en memoria caché de archivos enteros de los
servidores. Por esto, una estación de trabajo cliente interactúa con los servidores Vice, solo durante la
apertura o cierre de los archivos, y en ocasiones ni siquiera esto es necesario. Ni la lectura ni la escritura
de archivos ocasionan interconexión remota. Esta característica clave tiene derivaciones de largo alcance
en lo referente al rendimiento y a la semántica de las operaciones sobre los archivos.
El sistema operativo de cada estación de trabajo intercepta las llamadas al sistema de archivos y las
dirige a un proceso cliente. Este proceso, llamado Venus, coloca en memoria caché los archivos de Vice
cuando éstos se abren, y al cerrarlos guarda las copias de los archivos modificados en los servidores de
14
~~
donde provinieron. Venus sólo puede establecer contacto con Vice cuando se abre o cierra un archivo,
pues la lectura o escritura de bytes en un archivo se lleva a cabo directamente sobre la copia en memoria
caché y no pasa por Venus. Como resultado, las escrituras en algunas instalaciones no son visibles de
inmediato a otras.
Para verificar la consistencia del archivo en memoria caché Andrew, utiliza el mecanismo de
reclamación. Cuando un cliente coloca un archivo o un directorio en memoria caché, el servidor
actualiza su información de estado, anotando este movimiento, y decimos que el cliente tiene una
reclamación para este archivo. Si un cliente cierra un archivo después de modificarlo, todos los demás
clientes de este archivo en memoria caché pierden sus reclamaciones; por consiguiente, cuando esos
clientes abran de nuevo el archivo, tendrán que recibir del servidor la nueva versión.
Básicamente, Andrew implanta la semántica de sesión. Las Únicas excepciones son las operaciones de
archivos distintas de la lectura o escritura primitivas, las cuales son visibles en toda la red
inmediatamente después de concluir la operación.
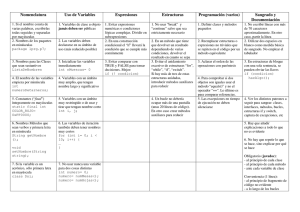
1.5. AFS vs. NFS.
Después de haber estudiado dos SAD de los mas conocidos. Podemos concluir con una tabla
comparativa de los puntos que revisamos.
I AFS
Acceso
archivos
a Espacio de nombres compartidos
para todas las estaciones de
trabajo
Rastreo
y Rastreo automático mediante
localización de procesos del sistema de archivos y
arch¡vos
bases de datos
El almacenamiento en memoria
Eficiencia
caché de los clientes reduce la
carga de la red; mecanismos de
reclamación
se
usan
para
mantener la consistencia en la
caché
Capacidad de Mantiene la eficiencia tanto en
pequeñas como en grandes
escalamiento
instalaciones.
Protección
Disponibilidad
sistema
NFS
Diferentes nombres de archivos para
diferentes estaciones de trabajo
Puntos de montaje para conjuntos de
archivos
configurados
Por
administradores y usuarios
Consistencia en la caché limitada.
Bueno para instalaciones pequeñas y
de tamaño mediano.
Bueno en configuraciones de área
Excelente para configuraciones de local
área ancha
Listas de control de acceso en los No existen listas de control de acceso
directorios para los usuarios y los
grupos
I Replicación de los datos leídos No hay replicación
mas frecuentemente y un sistema
I
de trabaio
Frecuentemente invoca telnet a otras
estaciones de trabajo
15
2. Desarrollo del SAD
El presente proyecto de investigación tiene como propósito la elaboración de un administrador de
archivos en un ambiente distribuido, esto es, implementar las operaciones básicas sobre un
archivo que son la apertura, creación, cerrado, escritura, lectura, desplazamiento y eliminación.
Un Sistema de Archivos Distribuidos (SAD), es el software encargado de administrar tanto
lógicamente como físicamente los datos contenidos en uno o varios dispositivos secundarios, los
cuales no se encuentran centralizados es decir, pueden localizarse en diferentes computadoras
interconectadas entre sí mediante una red.
El SAD puede implantarse como parte del sistema operativo distribuido, o bien como una capa de
software cuya tarea es administrar la comunicación entre los sistemas operativos y los sistemas de
archivos convencionales.
Existen diversos conceptos que caracterizan a los SAD, como son: nominación, destrucción,
disponibilidad y coherencia, principalmente.
La nominación es la correspondencia entre objetos lógicos y físicos, esto es, que un usuario al
referirse a un archivo lo hace por su nombre mientras que el sistema manipula bloques de datos
físicos almacenados en las pistas de un disco. Esta correspondencia ofrece a los usuarios la
abstracción de un archivo que oculta los detalles de cómo y dónde se almacena en disco. En un
sistema de archivos distribuidos se agrega otra dimensión de abstracción, la ubicación del archivo
en la red.
La destrucción de un archivo debe ser controlada por el SAD para evitar inconsistencias. Se
requiere establecer en que casos se va a permitir que un archivo sea borrado (desfruíúo)del
sistema.
La disponibilidad indica en qué circunstancias un archivo puede ser utilizado por uno o varios
usuarios al mismo tiempo.
La coherencia de un archivo le garantiza a un usuario que la información que accesa en cada
momento contiene las Últimas actualizaciones del archivo.
Existen diversas formas de manejar las peticiones de los usuarios, un método utilizado puede ser
el de llamadas a procedimientos remotos (RPC), el sistema sólo transmite las llamadas al
sistema operativo de la máquina que puede atender la petición. Para el usuario el manejo de los
16
archivos es transparente, aunque cada acceso ocasiona tráfico en la red. La replicación de
archivos en máquinas diferentes es una redundancia útil para mejorar la disponibilidad y el
rendimiento, ya que al seleccionar una réplica cercana reduce el tiempo de servicio. Una variante
de la replicación es usar la memoria caché del equipo, en la cual se guarda la información mas
recientemente usada, reduciendo de esta forma el tráfico en la red.
A continuación presentamos un panorama de nuestro SAD, analizaremos como se implantó
arquitectura, el arranque del sistema, las operaciones sobre los archivos, la nominación de los
archivos, los archivos de encabezado, y archivos (.log). Después de abordar estos temas daremos
un ejemplo en donde estas piezas se ensamblan, investigando Io que sucede cuando una
aplicación de usuario ejecuta una llamada al SAD.
2.1. Arquitectura del SAD desarrollado.
2. I . 7. Arquitectura.
La Arquitectura consiste en cuatro capas. La primera capa es la interface del SAD, teniendo las
operaciones de apertura, lectura, escritura, cierre, creación, borrado de archivos y desplazamiento
dentro de un archivo. La segunda capa está formada por los programas administradores. La
tercera está formada por PVM; que permite la comunicación entre los diferentes administradores.
La cuarta capa la forman los sistemas de archivos de cada máquina que integran el SAD, como se
muestra en la Figura 3.1.
Cliente
Servidor
11 Interface
de llamadas
al sistema
4
Administrador de
arch¡vos
Administrador de
arch¡vos
4
I
PVM
I
V
r---
i
v
I
I
Sistema de archivos 1
Sistema de archivos
L-.-
I
I
_
_
_
,__._
- 3..
.___
~
.
i
Figura 3.1
17
2.1.2. Arbol de procesos.
ADMINSTRACION
1
EJECUTA
PETlClON
REMOTA
Administra peticiones sobre archivos y las responde.
ADMINISTRADOR:
PETlClON REMOTA:
Dirige las peticiones al administrador correcto.
EJECUTA LOCAL:
Ejecuta operaciones sobre archivos localizados en el mismo servidor
RESPONDE:
Contesta la petición al cliente correspondiente.
EJECUTA ABRIR:
Abrir archivo local.
EJECUTA CREAR:
Crear archivo local.
EJECUTA BORRAR:
Borrar archivo local.
EJECUTA CERRAR:
Cerrar archivo local.
EJECUTA LEER:
Leer una cadena de caracteres de tamaño n del archivo loca.
EJECUTA ESCRIBIR: Escribir una cadena de caracteres de tamaño n del archivo local.
EJECUTA DESPLAZAR:
Desplazarse n caracteres del archivo local.
2. I .3. interface.
La interface consiste en un conjunto de funciones escritas en C que el usuario puede incluir en el
código de alguna aplicación. Tabla 3.1
Tipo de
operación
¡Abrir
Parámetros de entrada
Nombre de archivo a abrir, señal de lecturalescritura, modo
Valor de respuesta
ldentificador de archivo
1 ¡Borrar
1 Nombre de archivo que se desea borrar
1 Condición
iCerrar
ldentificador del archivo que se cerrará
Condición
Crear
Nombre de archivo que se desea crear, modo
ldentificador de archivo
I iDeSDlaZar
I DescriDtor de archivo, distancia y posición
I Distancia
¡Escribir
Descriptor de archivo, buffer, número de bytes
Número de Bytes escritos
¡Leer
Descriptor de archivo, buffer, número de bytes
Número de Bytes leídos
I
I
Tabla 3.1
18
La operación ¡Abrir le indica al sistema que una aplicación quiere comenzar a trabajar sobre un
archivo, regresando un identificador con el cual hará referencia al archivo en las operaciones
siguientes. La aplicación especifica en la operación el nombre del archivo que va a manejar, el tipo
de acceso que puede ser lectura, escritura o lectura/escritura y el modo de acceso que son los
permisos que va a tener el archivo. En el SAD, un archivo puede ser abierto en modo de escritura
o lectura/escritura sólo por una aplicación, en cambio, si es abierto en modo de lectura puede ser
utilizado por varias aplicaciones a la vez.
La operación ¡Borrar, elimina un archivo del sistema. El usuario proporciona el nombre del archivo y
el sistema regresa el resultado de la operación. En el SAD sólo se podrá borrar un archivo si nadie
lo esta usando.
La operación Cerrar le indica al sistema que el usuario ha terminado de usar un archivo,
enviándole el identificador del archivo ha cerrar.
La operación Crear, crea un archivo nuevo en el sistema, el usuario proporciona el nombre del
nuevo archivo y el modo de acceso.
La operación ¡Desplazar mueve el puntero de un archivo abierto, una distancia indicada por el
usuario desde alguna posición en específico.
La operación ¡Escribir, sobrescribe una cadena de caracteres a partir de la posición actual del
puntero al archivo. El usuario indica la cadena y el número de caracteres a escribir. Sólo podrá
escribir en un archivo si lo abrió con el tipo de acceso de escritura o lectura/escritura.
La operación ¡Leer, toma una secuencia de caracteres y la envia al usuario, indicándole el tamaño
de la cadena leída. Una aplicación podrá leer un archivo si lo abrió con el tipo de acceso de lectura
o lectura/escritura.
2.1.4. Nominación de Archivos.
Para la nominación externa se utilizan nombres simbólicos puros y Únicos, que no indican la
ubicación. El sistema hace que el usuario no requiera saber en qué máquina se encuentra el
archivo ni en qué directorio, es decir la ubicación es transparente al usuario. En este proyecto no
se contempla la construcción de una estructura de directorios que clasifique los archivos, ya que
para esto se requiere un manejo de directorios: como montar directorios, desplazarse a través de
ellos, crear o borrar directorios, etc.
19
La nominación interna es única dentro de todo el sistema de archivos, se compone de un
identificador asignado por el sistema operativo al cual se le va a agregar el identificador del host en
el que se encuentra el archivo de la siguiente forma:
ldentificador asignado por el sistema operativo:
89546
Multiplicado por una constante (¡MAXTERM)
x 100
Resultado
Más identificador del host
ldentificador Único
8954600
+
05
8954605
Donde el identificador asignado por el sistema operativo es Único en cada maquina del SAD y no
necesariamente en todo el SAD, el identificador único es usado por el SAD y no se repite.
Para decodificarlo se divide el identificador por la constante, el resultado da el identificador
asignado por el sistema y el residuo de la división devuelve el identificador del host Most.
Los administradores son programas que interactuan entre sí y con
el SO local. Cada
administrador se encuentra en espera de las peticiones de las aplicaciones de otros
administradores. En cada máquina que forman parte del SAD existe una copia del programa
administrador, sólo varían en el valor de la constante ¡Host, la cual indica el número de máquina en
donde se ejecuta. El administrador es responsable de controlar los accesos a los archivos que
fueron creados por él, atender las peticiones a éstos archivos de parte de otros administradores o
de las aplicaciones.
2. I . 5. Peticiones de operación sobre archivos.
Existen dos tipos de peticiones de operación sobre archivos que son:
0
Petición Local: es cuando se quiere accesar a un archivo que esta controlado por el
administrador que recibió la petición. El administrador ejecuta la instrucción indicada para
resolverla y regresar el resultado, como se muestra en la Figura 3.2.
0
Petición Remota: ocurre cuando una petición es recibida por un administrador que no tiene el
control de los accesos a ese archivo. El administrador se encargara de enviar la petición al
administrador correspondiente, para que juntos resuelvan la petición, esto se muestra en la
Figura 3.3.
20
Máquina 2
Máauina 1
~
Máquina 3
Aplicación
I
I
1
Administrador 1
Administrador 2
Administrador 3
I
1
/~-
Figura 3.2
,+-
Máquina 3
Máquina 2
Máauina 1
Aplicación
Aplicación
~
Aplicación
I
4
Interface
Administrador 1
I
$
1
I
1
Administradw 2
I
I
1
Administrador 3
I
i
I
Figura 3.3
2.1.6. Estructuras para la Administración de archivos.
Los administradores usan y actualizan dos listas en su ejecución. La lista de Archivos del Sistema y
la Lista de Archivos en Uso.
La Lista de Archivos del Sistema es una lista ligada de estructuras SListaSistema.
En donde la variable zNomArch es el nombre del archivo; ¡Host es I número de administrador que
creó el archivo; iIdEscritura es el identificador del proceso que puede escribir en el archivo;
iContAbiertos indica cuantas veces ha sido abierto el archivo; bLectura es una bandera que indica
21
que el proceso que está escribiendo sobre el archivo tiene permiso de leerlo, pssSig es un
apuntador a la siguiente estructura de la lista.
Lista de Archivos en uso es una lista ligada de estructuras sListaUso.
En donde la variable ildArch es el identificador de archivo que ésta usándose, pssArchivo es un
apuntador a una estructura SListaSistema que tiene la información del archivo y psuSig es un
apuntador a la siguiente estructura de la lista.
La Lista del Sistema es Única en todo el SAD y cada máquina tiene una copia de esta lista que
contiene la información de todos los archivos existentes en el SAD, esto implica que cada vez que
se cree o borre un archivo se tenga que actualizar ésta lista en cada maquina del SAD. Una de las
ventajas de usar la lista del sistema es que no se tienen que escoger los archivos a compartir ni se
tienen que montar ningún directorio, lo que permite que cualquier máquina en cualquier momento
tenga conocimiento de los archivos existentes en el SAD.
La Lista de Uso se encuentra en cada máquina del SAD, y contiene la información de los archivos
que están controlados por él y que están en uso.
22
Estas listas se relacionan de la siguiente manera, Figura 3.4.
Lista de Uso
Lista del Sistema
Figura 3.4
Cada administrador lleva un registro de todas las operaciones efectuadas que se escriben en un
archivo llamado admon./og. Se almacena en el directorio donde se encuentra el ejecutable del
administrador. Las operaciones que se registran son las llamadas al sistema de archivos local y las
hechas a otro administrador. Este archivo se puede utilizar para seguir el funcionamiento del SAD.
2.7.7. Comunicación entre procesos.
Para este proyecto se hará uso de PVM (Paralell Virtual Machine) que es una herramienta que
permite a un conjunto de máquinas conectadas en red, verse como una sola computadora paralela,
llamada máquina virtual, la cual está formada por varias computadoras.
Existe un programa encargado del arranque del SAD llamado maestro que es ejecutado sólo en
una máquina, es el encargado de ejecutar a todos los administradores en las máquinas que
conforman el sistema además les proveé de un identificador de proceso a cada uno
y les
comunica a los otros su identificador para que se puedan comunicar posteriormente. Una vez que
realiza estas operaciones el programa termina.
23
Máquina 3
Máquina 2
Máquina 1
I
I
Maestro
G
1
Administrador 1
I
~
~
Administrador 2
I
Ii
I
\--Administrador 3
I
Figura 3.5
24
2.2. Archivos de encabezado.
En el sistema se utilizan dos archivos de encabezado /istas.h y distribuidos.h:
0
listash contiene las funciones para el manejo de la lista de archivos del sistema y la lista de
archivos en uso. Como ya vimos con estas se controlan los accesos a los archivos
0
distribuid0s.h es la interface de las aplicaciones de los usuarios hacia el SAD. Este contiene
las funciones primitivas que se pueden efectuar sobre los archivos. Las aplicaciones llaman a
éstas funciones para enviar una petición al administrador local junto con los parámetros que se
requieren y le devuelven al usuario el resultado de la petición.
Para usar las funciones del SAD, los archivos de encabezado deben ser incluidos en la aplicación
mediante una directiva #include.
25
3. Conclusiones
El propósito del proyecto fue la elaboración de un administrador de archivos en un ambiente
distribuido, esto es, implementar las operaciones básicas sobre un archivo que son la apertura,
creación, cerrado, escritura, lectura, desplazamiento y eliminación.
A continuación se listan algunos puntos que se implementaron y otros que se pueden implementar
como mejoras al SAD para futuros proyetos.
3.1. Trabajo Desarrollado.
En el sistema existe transparencia de localización. En donde se usan nombres de archivos
únicos en todo el sistema.
Un archivo puede ser usado en modo de lectura por varias aplicaciones al mismo tiempo y sólo
permite una en modo de escritura. Esto hace que no se tengan lecturas sucias.
Todas las funciones primitivas regresan como valor de retorno o error, lo que el administrador
de archivos de la máquina le regresó al SAD.
El SAD se puede escalar pero para esto se tienen que cambiar algunas constantes de algunos
programas e instalar PVM en el servidor donde se quiere instalar el SAD.
Se observó que se puede migrar a todas las plataformas donde se tenga un compilador de C y
se pueda instalar PVM.
El código del sistema esta comentado y es de fácil mantenimiento.
Las funciones del SAD solo amplían el alcance de las funciones de C para la manipulación de
archivos para un ambiente distribuido.
3.2. Perspectivas.
Se pueden incluir procedimientos para el manejo de transacciones.
o
Se pueden incluir procedimientos para el manejo de permisos de usuarios diferentes del SAD y
no los mismos que se tienen en la maquina donde están corriendo los administradores.
o
Se pueden incrementar los valores de retorno (errores) de las funciones primitivas.
Se puede implementar un sistema para la transparencia a fallos.
Los puntos anteriores no se llevaron a cabo porque se vio que el SAD se puede hacer tan grande y
tan complejo como se quiera pero repercute en tiempo de diseño y desarrollo. Se vieron las
limitaciones que se tienen para realizar estos proyectos por parte de los alumnos en la UAM, pues
no siempre se tienen los recursos (servidores y cuentas) necesarios. En el proyecto se tomaron
decisiones para la elaboración del sistema y se dieron algunas soluciones tal vez triviales a
26
algunos problemas, esto fue porque se vieron los pros y contras de las diferentes soluciones de
acuerdo ai alcance de este proyecto y se deja abierto para soluciones posteriores más elaboradas.
27
4. Bibliografía
Gerard0 J, Holzmann., Desing and validation of computer protocols, Prentice Hall
Douglas E. Comer., Internetworking with TCPllP Volumen I, Principies protocols and
architecture, Prentice Hall.
Andrew S. Tanenbawm., Organización de computadoras. Un enfoque estructurado, Prentice
Hall, Segunda edición.
Autores varios., The PC, Configuration Handbook. A complete guide to troubleshooting,
enhacing, and maintaining your PC, Bantam Computer Book.
AI Geist, Adam Beguelin, Jack Dongarra, Weicheng Jiang, Robert Manchek, Vaidy Sunderam.,
PVM: Parallel Virtual Machine. A User’s Guide and Tutorial for Networked Parallel
Computing, Scientific and Engineering Computation Janusz Kowalik.
Segunda edición.
Herber Schildt, Programación en Turbo C, Borland-Osborne/McGraw-Hill,
FCO.Javier Caballero, Curso de Programación C. Microsoft C, Macrobit.
Jack Tackett Jr., David Guter., Utilizando LINUX, Prentice Hall, segunda edición.
28
5.
Apéndice A (Códigos de los programas)
/*@@@C@@@*/
/*
*
*
NOMBRE:
maestro.c
*
OBJETIVO:
Mandar a ejecutar todos los
administradores
*
que forman parte del sistema de archivos distribuidos.
*
*
*
ENTRADAS:
*
AUTOR:
Ninguna.
Mauricio Muñoz Garcia.
89325717
*
Cristobal Romo Duarte.
89328274
*
*/
/*@@@C@@@*/
#include <stdio.h>
hll
#include 11pvm3.
#define MAXTERM 4
/*@@@F@@@*/
/*
*
*
NOMBRE:
maestro.c
*
OBJETIVO:
Mandar a ejecutar todos los
administradores
*
que forman parte del sistema de archivos distribuidos.
*
*
*
*
ENTRADAS:
SALIDAS:
administradores.
*
*
*
VALOR DE RETORNO:
*
REQUERIMIENTROS:
(pvm3).
Ninguna.
Ejecucion de los procesos
Entero con valor cero.
Que se este ejecutando el demonio de PVM
*
*
*/
NOTAS:
/*@@@F@@@*/
28
main ( )
{
int tid [MAXTERM] ,i ;
tid[Ol=pvm m y t i d o ;
fprintf (stdoui,"Comienza Maestro \n");
/*
if (pvm-spawn("admonO",NULL,O,"",l,&tid[Ol) !=l) pvm-exit();
*/
,1 I &t id 111 ! =1)
if (pvm-spawn ( Iladmonl NULL O,
pvm -exit ( 1 ;
if (pvm~spawn~~~admon2",NULL10,"",1,&tid~21~
!=l) pvm-exit() ;
I
I
/*
if (pvm-cpawn("admon3",NULL,O,"",l,&tid[31)!=l) pvm-exit();
*/
for ( i=i ;i<=2;i++)
{
pvm-initsend(PvmDataDefau1t);
p v m j k i n t (tid,4,l) ;
pvm-send(tid[il ,l) ;
1
fprintf (stdout,"Termina Maestro \n") ;
pvm-exit ( ) ;
exit ( O );
1
/*@@@IF@@@*/
29
/*@@@C@@@*/
/*
admonl .c
*
*
NOMBRE:
*
OBJETIVO:
Atender peticiones de los clientes
para despues dar su resultado.
*
ENTRADAS:
Un comando que es la primitiva a
ejecutar sobre un archivo.
*
*
*
*
*
AUTOR:
89325717
Mauricio Munoz Garcia.
*
Cristobal Romo Duarte .
89328274
*/
/*@@@C@@@*/
#includecstdio.h>
#includecsys/types.h>
#includecsys/stat.h>
#includecfcntl.h>
#include1Ilistas.
h1I
#in~lude~~pvm3.
h1I
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
iLOCAL
iREMOTO
iHOST
iMAXTERM
iMAXMENSAJE
iMAXNOMBRE
iABRIR
iCERRAR
iCREAR
iBORRAR
iLEER
iESCRIBIR
iDESPLAZAR
iINSERTARLISTA
iBORRARLISTA
iDEFAULT
1
O
1
4
225
225
1
2
3
4
5
6
7
8
9
10
/*
*
PROTOTIPOS
*/
void vServicioLoca1 (int char
int
void vServicioRemoto(int *,char *,int
int bTipoServicio (int * ;
* I
* I
;
);
30
int iAbrirLoca1(int * ,char * ) ;
void vAbrirRemoto0;
int iCerrarLocal( int * ,char * ) ;
void vCerrarRemoto( 1 ;
int iCrearLoca1 (int * ,char * 1 ;
void vCrearRemoto( ) ;
int iBorrarLocal(int *,char * ) ;
void vBorrarRemoto( ;
int iLeerLocal(int *,char * ) ;
void vLeerRemoto( ) ;
int iEscribirLocal(int *,char * ) ;
void vEscribirRemoto( ) ;
int iDesplazarLocal(int *,char * ) ;
void vDesplazarRemoto0;
/*
*
VARIABLES PUBLICAS
*/
char
char
int
int
int
int
int
int
int
int
int
int
int
int
int
FILE
1ong
extern
extern
zNomArch[ iMAXNOMBRE1 ;
zBuf [iMAXMENSAJEl ;
iTid [ iMAXTERM1 ;
iHost;
iBufid;
iBytes;
iType;
iTidFuente;
ioper;
iBand;
iInfo;
iModo;
iIdArch;
iTam;
iPos;
* fhArch;
1Desp;
struct sListaUso
*psuInicio;
struct sListaSistema *pssInicio;
/*@@@F@@@*/
/*
*
NOMBRE:
*
*
OBJETIVO:
Atender peticiones de los clientes
para despues dar su resultado.
*
ENTRADAS:
Un comando que es la primitiva a
ejecutar sobre un archivo.
*
*
*
main
31
*
*
El resultado de la operacion
SALIDA:
y una
*
bitacora que tiene como nombre Admonl.log donde se
escribe
*
*
*
*
*
un registro de cada operacion sobre un archivo.
VALOR DE RETORNO:
Ninguno,
REQUERIMIENTOS :
Este programa solo se debe
ejecutar por
*
un proceso maestro que aparte ejecute todos los
*
administradores.
*
*
*
NOTAS:
*/
/*@@@F@@@*/
main ( )
{
int
int
int
int
bLocal ;
iBufid,iBytes,iType;
ioperlista;
iIndice;
iBufid=pvm-recv ( - 1,- 1) ;
pm-upkint (iTid,iMAXTERM,1);
vInicializaListas ( 1 ;
while ( 1 )
{
fhArch = fopen ( 11/usr/pvm3/bin/LINüX/admonl.
log","ar1;
fprintf (fhArch,"INICIO OPERACION\nIl) ;
iBufid=pm-recv ( - 1,- 1 ) ;
pvm-buf info (iBufid,&iBytes,&iType,&iTidFuente);
bLocal=bTipoServicio(&iHost);
if (bLocal)
vServicioLocal(&iInfo,zBuf,iOper);
else
vServicioRemoto(&iInfo,zBuf,iOper) ;
fprintf(fhArch,Il\tiOper = %d\n\tResultado = %d\n\tBUFFER
= %s\n",ioper,iInfo,zBuf);
if(i0per ! = iINSERTARLISTA && ioper != iBORRARLISTA)
{
pvm-initsend(PvmDataDefau1t);
p m g k i n t ( &iInfo,1,l);
pvmskstr (zBuf) ;
pvm-send(iTidFuente,l);
1
if(i0per == iBORRAR
&&
iInfo == O
&&
bLocal == iLOCAL)
32
iOperLista = iBORRARLISTA;
for(i1ndice = O;iIndice<iMAXTERM;iIndice++)
{
if (iIndice ! = iHOST)
{
fprintf(fhArch,"Envia iOperLista,
%x\n",iTid [iIndicel)
1
;
1
1
pvm-initsend(PvmDataDefau1t);
pvmgkint ( &iOperLista,1,1 );
pvmjkstr (zNomArch);
pvm-send(iTid[iIndicel,l) ;
vimprimeUso ( ) ;
vimprimeSistema0;
;
fprintf (fhArch,"FIN OPERACION\n1I)
fclose ( fhArch) ;
1
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
vServicioLoca1
*
OBJETIVO:
Atender peticiones locales de los
clientes
*
o administradores para despues dar su resultado.
*
*
*
ENTRADAS:
iInfo:
Entero resultado de una
operation.
*
zBuf:
Cadena con el resultado de la
operation.
*
ioper :
Entero que indica la
operation que se
*
efectuara sobre un archivo.
*
*
SALIDA:
iInfo :
operation.
*
zBuf:
operation.
*
*
*
VALOR DE RETORNO:
*
REQUERIMIENTOS:
*
Entero resultado de una
Cadena con el resultado de la
Ninguno.
33
*
*
*
NOTAS:
*/
/*@@@F@@@*/
void vServicioLocal(int *iInfo,char *zBuf,int ioper)
{
switch (ioper)
{
case iABRIR:
iAbrirLoca1(&*iInfo,zBuf);
break ;
case iCERRAR:
.
iCerrarLocal(&*iInfo,zBuf);
break ;
case iCREAR:
iCrearLocal(&*iInfo,zBuf);
break ;
case iBORFtAR:
iBorrarLocal(&*iInfo,zBuf);
break ;
case iLEER:
iLeerLocal(&*iInfo,zBuf);
break;
case iESCRIBIR:
iEscribirLoca1(&*iInfo,zBuf);
break;
case iDESPLAZAR:
iDesplazarLocal(&*iInfo,zBuf);
break;
case iINSERTARLISTA:
pvm upkint ( &iHost ,1,1 ) ;
pssinsertalista (zNomArch,iHost);
break;
case iBORRARLISTA:
bBorraListaSistema(zNomArch);
break ;
default:
*iInfo = -1;
zBuf[O] = '\O';
break ;
/*@@@F@@@*/
/*
*
NOMBRE:
vServicioRemoto
34
*
*
*
*
*
OBJETIVO:
Atender peticiones remotas de los
administradores para despues dar su resultado.
ENTRADAS:
*iInfo:
Entero resultado de una
operation.
*
zBuf :
Cadena con el resultado de la
operation.
*
iOper :
Entero que indica la
operation que se
*
efectuara sobre un archivo.
*
*
*
*
SALIDA:
*iInfo:
operation.
*
zBuf :
operation.
Entero resultado de una
Cadena con 'el resultado de la
*
*
*
*
*
*
*
*/
VALOR DE RETORNO:
Ninguno.
REQUERIMIENTOS:
NOTAS:
/*@@@F@@@*/
void vServicioRemoto(int *iInfo,char *zBuf,int ioper)
{
switch (ioper)
{
case iABRIR :
vAbrirRemoto ( ) ;
break ;
case iCERRAR :
vCerrarRemoto ( 1 ;
break;
case iBORRAR :
vBorrarRemoto ( ;
break;
case iLEER :
vLeerRemoto ( 1 ;
break ;
case iESCRIBIR:
vEscribirRemoto ( 1 ;
break ;
case iDESPLAZAR:
vDesplazarRemot0( ;
break ;
35
default:
*iInfo = -1;
zBuf[O] = '\O';
break;
1
pm-recv(-i,-1);
pvm-upkint (&*iInfo,1,l);
pvm-upkstr (zBuf);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
*
OBJETIVO:
remoto.
*
*
*
ENTRADAS:
*iHost:
atendera
*
la peticion.
bTipoServicio.
Decidir si el servicio es local o
Entero que indica que maquina
*
*
SALIDA:
*
* iHost :
atendera
*
la peticion.
Entero que indica que maquina
*
*
VALOR DE RETORNO:
Entero que indica el tipo de
servicio, uno
*
Local, "cero" Remoto.
*
*
*
*
*
REQUERIMIENTOS:
NOTAS:
*/
/*@@@F@@@*/
int bTipoServicio(int *iHost)
{
struct cListaSistema *pssElemento;
int bServicio;
zNomArch[Ol = ' \ O r ;
iIdArch = -1;
pm-upkint ( &iOper ,1,1);
if(i0per == iCREAR I I iOper == iBORRAR I I iOper
ioper == iINSERTARLISTA I I ioper == iBORRARLISTA )
{
==
iABRIR
II
36
I
pvm-upkstr (zNomArch);
else
{
I
pvm-upkint (&iIdArch,1,l) ;
if(!(iOper
iBORRARLISTA))
{
==
iCREAR
II
iOper
==
iINSERTARLISTA
II
ioper ==
if (strcmp("",zNomArch) != O )
{
pssElemento = pssBuscaLista(zNomArch);
if (pssElemento ! = NULL )
if(pssE1emento->iHost == iHOST)
bServicio = iLOCAL;
else
bservicio = iREMOTO;
else
bServicio = iLOCAL;
1
else
{
iHost = iIdArch % iMAXTERM;
if(iHost>=iMAXTERM I I iHoste O )
{
loper = iDEFAULT;
iHost = iHOST;
1
1
I
if(iH0ST == iHost)
bServicio = iLOCAL;
else
bServicio = iREMOTO;
else
{
I
bServicio
=
iLOCAL;
return (bservicio);
I
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
OBJETIVO:
iAbrirLoca1.
Abrir un archivo local.
37
*
*
ENTRADAS:
*
*iInfo:
resultado de la operacion.
*
zBuf:
de la operacion.
*
*
*
Entero que contiene el
Cadena que contiene el resultado
SALIDA:
*iInfo:
resultado de la operacion.
*
zBuf :
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
VALOR DE RETORNO:
Resultado de la operacion -1 en
caso de
*
error y diferente de -1 en otro caso.
*
*
*
*
*
*/
REQUERIMIENTOS:
NOTAS :
/*@@@F@@@*/
int iAbrirLocal(int *iInfo,char *zBuf)
{
struct sListaSistema *pssElemento;
int iIdArchSisOp;
int iIdEscritura;
int blectura;
iIdEscritura =-1;
bLectura = O;
fprintf (fhArch, "\tAbriendo archivo\nI1);
pm-upkint ( &iBand,1,l) ;
pm-upkint ( &iModo,1,l) ;
fprintf(fhArch,"\tNombre = %s\n\tBandera = %d\n\tModo
%d\n",zNomArch,iBand,iModo);
pssElemento = pssBuscaLista(zNomArch);
if (pssElemento ! = NULL)
{
if (iBand ! = O-RDONLY)
=
if(pssE1emento->iIdEscritura == O )
{
iIüArchSisOp
*iInfo =
=
open (zNomArch,iBand,iModo);
iCalculaIüArch(iIdArchSisOp,iMAXTEFW,~HOST);
if(iBand == O-WRONLY)
{
iIdEscritura
=
*iInfo;
38
I
bLectura = O;
else
{
I
1
iIdEscritura = *iInfo;
bLectura = 1;
else
.
iIdArchSisOp = -1;
1
else
{
iIdArchSisOp = open (zNomArch,iBand,iModo) ;
*iInfo =
iCalculaIdArch(iIdArchSisOp,iMAXTERM,iHOST);
1
if (iIdArchSisOp ! = -1)
{
psuInsertaLista(*iInfo,pssElemento);
vModificaListaSistema(pssElemento,iIdEscritura,l,bLectura) ;
I
else
*iInfo = -1;
I
else
*iInfo = -1;
zBuf [ O ] = '\o';
return ( * iinfo) ;
I
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
iAbrirRemoto.
*
OBJETIVO:
Abrir un archivo remoto.
*
*
ENTRADAS:
Ninguna.
*
*
SALIDA:
*
VALOR DE RETORNO:
*
REQUERIMIENTOS :
*
*
Ninguna.
Ninguno.
39
*
*
*
*/
NOTAS:
/*@@@F@@@*/
void vAbrirRemoto0
{
;
fprintf (fhArch, ll\tEnviandoabriendo archivo\nfl)
pvm-upkint ( &iBand,1,l) ;
pvm-upkint ( &iModo,1,l);
fprintf (fhArch,ii\n")
;
pvm-initsend(PvmDataDefau1t);
pvmgkint ( &iOper,1,l) ;
pvmgkstr (zNomArch);
pvmskint ( &iBand,1,l) ;
p m g k i n t ( &iModo,1,l) ;
pm-send(iTid[iHostl ,l) ;
}
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
*
OBJETIVO:
*
*
*
iCerrarLoca1.
Cerrar un archivo local.
ENTRADAS:
*iInfo:
resultado de la operacion.
*
zBuf:
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
*
SALIDA:
*iInfo :
resultado de la operacion.
*
zBuf:
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
Resultado de la operacion -1 en
*
VALOR DE RETORNO:
caso de
*
error y diferente de -1 en otro caso.
*
*
*
*
*
REQUERIMIENTOS :
NOTAS:
*/
/*@@@F@@@*/
40
int iCerrarLocal(int *iInfo,char *zBuf)
{
struct sListaUso *psuElemento;
fprintf (fhArch, l'\tCerrando archivo\n");
fprintf(fhArch,Il\tId Archivo = %d\n",iIdArch);
psuElemento = psuBuscaLista(i1dArch);
if (psuElemento != NULL)
{
*iInfo = close(iIdArch/iMAXTERM);
if (*iinfo ! = -1)
{
if(psuE1emento->pssArchivo->iIdEscritura
==
iIdArch)
vModificaListaSistema(psuE1emento-
>pssArchivo O, - 1 O ;
else
I
I
vModificaListaSistema(psuE1emento>pssArchivo,-1,-1,O);
bBorraListaUso (iIdArch);
1
1
else
*iInfo = -1;
zBuf[O] = '\O';
return(*iInfo);
1
/*@@@F@@@*/
/*@@@OF@@@*/
/*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
NOMBRE :
vCerrarRemoto.
OBJETIVO:
Cerrar un archivo remoto.
ENTRADAS :
Ninguna.
SALIDA:
VALOR DE RETORNO:
Ninguna.
Ninguno.
REQUERIMIENTOS:
NOTAS :
*/
/*@@@F@@@*/
void vCerrarRemoto( )
41
fprintf ( fhArch, \ tEnviando Cerrando archivo\n"
pm-initsend(PvmDataDefau1t) ;
pvmxkint ( &iOper,1 ,1) ;
pvmjkint (&iIdArch,1,l) ;
pm-send ( iTid [ iHostI ,1 ) ;
;
1
/*@@@IF@@@*/
/*@@@Fa@@*/
/*
*
*
*
*
NOMBRE:
*
*
ENTRADAS:
OBJETIVO:
*iInfo:
resultado de la operacion.
*
zBuf :
de la operacion.
*
*
*
iCrearLocal.
Crear un archivo local.
Entero que contiene el
Cadena que contiene el resultado
SALIDA:
*iInfo:
resultado de la operacion.
*
zBuf :
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
VALOR DE RETORNO:
Resultado de la operacion -1 en
caso de
*
error y diferente de -1 en otro caso.
*
*
*
*
*
REQUERIMIENTOS:
NOTAS:
*/
/*@@@F@@@*/
int iCrearLocal(int *iInfo,char *zBuf)
{
struct sListaSistema *pssElemento;
int iIdArchSisOp;
int ioperlista;
int iIndice;
fprintf (fhArch, Il\tCreando archivo\n");
pvm-upkint ( &iModo,1,l) ;
fprintf (fhArch,Il\tNombre = %s\n\tModo =
%d\nlI,zNomArch,iModo) ;
pssElemento = pssBuscaLista(zNomArch);
if (pssElemento == NULL)
42
{
iIdArchSisOp = creat(zNomArch,iModo);
if (iIdArchSisOp ! = -1)
{
*iinfo = iCalculaIdArch(iIdArchSisOp,
iMAXTERM,iHOST) ;
pssElemento = pssInsertaLista(zNomArch,iHOST);
vModificaListaSistema(pssElemento,*iInfo,1,0);
psuInsertaLista(*iInfo,pssElemento);
iOperLista = iINSERTARLISTA;
for(i1ndice = O;iIndice<iMAXTERM;iIndice++)
{
if (iIndice != iHOST)
{
fprintf (fhArch,"Envia iOperLista,
%x\nr1,
iTid [iIndicel )
;
pm-initsend(PvmDataDefault) ;
pvmgkint (&iOperLista,1,l) ;
pvm2kstr (zNomArch);
iHost = iHOST;
pvm2kint (&iHost,1,1) ;
pm-send(iTid[iIndicel ,1) ;
1
1
1
else
*iInfo =-1;
1
else
*iInfo =-1;
zBuf [O] = ' \ O 1 ;
return(*iInfo);
1
/*@@@IF@@@*/
/*@@@F@@@*/
/*
*
*
*
*
*
NOMBRE:
OBJETIVO:
iBorrarLoca1.
Borrar un archivo local.
ENTRADAS:
*
*iInfo :
resultado de la operacion.
*
zBuf:
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
SALIDA:
43
*
*iInfo:
resultado de la operacion.
*
zBuf:
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
VALOR DE RETORNO:
Resultado de la operacion -1 en
caso de
*
error y diferente de -1 en otro caso.
*
*
*
*
*
REQUERIMIENTOS:
NOTAS:
*/
/*@@@F@@@*/
int iBorrarLocal(int *iInfo,char *zBuf)
{
struct sListaSistema *pssElemento;
int iIdArchSisOp;
int ioperlista;
int iIndice;
fprintf (fhArch, "\tBorrando archivo\n");
pssElemento = pssBuscaLista(zNomArch);
if (pssElemento != NULL)
{
if(pssE1emento->iContAbiertos == O )
{
*iInfo = unlink(zN0mArch);
bBorraLis taSistema ( zNomArch);
I
else
I
*iInfo =-1;
else
*iInfo =-1;
~Buf
[O] = '\O';
return( * iInfo);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
*
*
*
NOMBRE:
vBorrarRemoto.
OBJETIVO:
Borrar un archivo Remoto.
ENTRADAS:
Ninguna.
44
*
*
SALIDA:
*
*
VALOR DE RETORNO:
*
REQUERIMIENTOS:
*
*
NOTAS:
*
Ninguna.
Ninguno.
*/
/*@@@F@@@*/
void vBorrarRemoto0
{
fprintf (fhArch, "\tEnviando Borrando archivo\n");
pvm-initsend(PvmDataDefau1t) ;
pvmjkint ( &iOper ,1,l) ;
pvmjkstr (zNomArch);
pvm-send ( iTid [ iHost1 ,1) ;
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
*
*
OBJETIVO:
*
ENTRADAS:
*
*iInfo:
resultado de la operacion.
*
zBuf :
de la operacion.
iLeerLoca1.
Leer un archivo local.
Entero que contiene el
Cadena que contiene el resultado
*
*
SALIDA:
*
*iInfo :
resultado de la operacion.
*
zBuf :
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
VALOR DE RETORNO:
Resultado de la operacion -1 en
caso de
*
error y diferente de -1 en otro caso.
*
*
*
*
*
REQUERIMIENTOS:
NOTAS:
*/
45
/*@@@IF@@@*/
int iLeerLocal(int *iInfo,char *zBuf)
{
struct sListaUso *psuElemento;
fprintf (fhArch, "\tLeer archivo\n");
pvm-upkstr (zBuf ;
zBuf[O] = '\O';
pvm-upkint ( &iTam,1 , l ) ;
psuElemento = psuBuscaLista(i1dArch);
if (psuElemento ! = NULL)
{
if( psuElemento->pssArchivo->iIdEscritura == iIdArch)
{
if(psuE1emento->pssArchivo->bLectura ! = 1)
*iInfo = -1;
else
{
*iInfo = read(iIdArch/iMAXTERMM,zBuf,iTam);
fprintf(fhArch,l'\t\t\tzBuf = %s\n\t\t\tiTam =
%dflzBuf ,iTam);
zBuf [iTaml = ' \ O ' ;
1
1
else
{
*iInfo = read(iIdArch/iMAXTER,zBuf,iTam);
fprintf(fhArch,"\t\t\tzBuf = %s\n\t\t\tiTam =
%d", zBuf ,iTam);
zBuf [iTaml
1
=
I
\O ' ;
1
else
*iInfo = -1;
return(*iinfo);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
*
*
*
*
*
*
NOMBRE:
vLeerRemoto.
OBJETIVO:
Leer un archivo remoto.
ENTRADAS:
Ninguna.
SALIDA:
VALOR DE RETORNO:
Ninguna.
Ninguno.
*
*
*
*
*
REQUERIMIENTOS:
NOTAS:
*/
/*@@@F@@@*/
void vLeerRemoto0
{
fprintf (fhArch, "\tEnviando Leer archivo\n");
pm-upkstr (zBuf);
pm-upkint ( &iTam ,1,1 ) ;
pm-initsend(PvmDataDefau1t) ;
p m j k i n t ( &iOper ,1,1) ;
pvmjkint (&iIdArch,1,l) ;
p m j k s t r (zBuf ;
p m j k i n t ( &iTam,1,1) ;
pm-send (iTid[iHostl,1 ) ;
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
*
*
ENTRADAS:
*
OBJETIVO:
*iInfo :
resultado de la operacion.
*
zBuf:
de la operacion.
iEscribirLoca1.
Escribir un archivo local.
Entero que contiene el
Cadena que contiene el resultado
*
*
SALIDA:
*
*iInfo :
resultado de la operacion.
*
zBuf :
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
VALOR DE RETORNO:
Resultado de la operacion -1 en
caso de
*
error y diferente de -1 en otro caso.
*
*
*
REQUERIMIENTOS:
*
NOTAS:
*
*/
47
/*@@@F@@@*/
int iEscribirLocal(int *iInfo,char *zBuf)
{
struct sListaUso *psuElemento;
fprintf (fhArch,"\tEscribiendo en archivo\n");
pvm-upkstr (zBuf ;
pvm-upkint ( &iTam,1,l) ;
fprintf (fhArch,"\tident = %d\n\tBuffer = %s\n\tTam =
%d\n",iIdArch,zBuf , iTam) ;
psuElemento = psuBuscaLista(i1dArch);
fprintf(fhArch,Ig\tpsuElemento= %p\nlI,psuElemento);
if (psuElemento ! = NULL)
{
fprintf(fhArch,"\t psuElemento->pssArchivo->iIdEscritura
=
%d\nI1,psuElemento->pssArchivo->iIdEscritura);
if( psuElemento->pssArchivo->iIdEscritura == iIdArch)
{
*iInfo = write(iIdArch/iMAXTERM,zBuf,iTam);
fprintf (fhArch,"\tiInfo= %d\nIl,*iInfo);
1
else
*iInfo = -1;
1
else
*iInfo = -1;
return(*iinfo);
1
/*@@@F@@@*/
/*@@@IF@@@*/
/*
*
*
NOMBRE:
*
*
OBJETIVO:
Escribir un archivo remoto.
*
ENTRADAS:
Ninguna.
*
SALIDA:
*
*
*
*
*
*
*
*
*/
VALOR DE RETORNO:
vEscribirRemoto.
Ninguna.
Ninguno.
REQUERIMIENTOS:
NOTAS:
/*@@@F@@@*/
void vEscribirRernoto0
48
{
fprintf(fhArch,"\tEnviando Escribiendo en archivo\nIl);
pvm-upkstr (zBuf);
pvm-upkint ( &iTam,1 , 1 ) ;
pvm-initsend(PvmDataDefau1t);
pvmjkint ( &iOper,1,1 ) ;
pvmjkint (&iIdArch,1,1 ) ;
pvmjkstr (zBuf1 ;
pvmgkint (&iTam,1,l) ;
pvm-send ( iTid [ iHostI ,1) ;
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
NOMBRE:
*
*
*
*
OBJETIVO:
*
iDesplazarLoca1.
Desplazarse en un archivo local.
ENTRADAS:
*iInfo:
resultado de la operacion.
*
zBuf :
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
*
SALIDA:
*iInfo:
resultado de la operacion.
*
zBuf:
de la operacion.
Entero que contiene el
Cadena que contiene el resultado
*
*
VALOR DE RETORNO:
Resultado de la operacion -1 en
caso de
*
error y diferente de -1 en otro caso.
*
*
*
*
*
REQUERIMIENTOS:
NOTAS :
*/
/*@@@F@@@*/
int iDesplazarLocal(int *iInfo,char *zBuf)
{
struct sListaUso *psuElemento;
fprintf (fhArch,"\tDesplazando en archivo\nIl) ;
pvm-upklong (&lDesp,1,l) ;
pvm-upkint (&iPos,1,1 ) ;
psuElemento = psuBuscaLista(i1dArch);
49
if (psuElemento ! = NULL)
lDesp = lseek (iIdArch/iMAXTERM,
lDesp,iPos) ;
if ((psuElemento == NULL) I 1 (1Desp == -1))
*iInfo = -1;
else
*iInfo = O;
1Desp);
sprintf (zBuf, ii%ldll,
return (*iinfo);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
*
*
*
*
NOMBRE:
*
*
*
VALOR DE RETORNO:
*
*
*
*
*/
vDesplazarRemoto.
OBJETIVO:
Desplazarse en un archivo remoto.
ENTRADAS:
Ninguna.
SALIDA:
Ninguna.
Ninguno.
REQUERIMIENTOS:
NOTAS:
/*@@@F@@@*/
void vDesplazarRemoto0
{
fprintf(fhArch,"\tEnviando Desplazando en archivo\n");
pm-upklong(&lDecp,i,l);
pvm-upkint (&iPos,1,1);
p m -initsend(PvmDataDefau1t);
p m j k i n t ( &iOper ,1,1) ;
p m x k i n t (&iIdArch,1,l);
pmsklong (&lDecp,1,l);
p m j k i n t ( &iPos ,1,1) ;
pm-send ( iTid [ iHostI ,1);
50
#ifndef -LISTAS-H
#define -LISTASH
/*
*
*
listas.h
NOMBRE:
*
Funciones para el manejo de
OBJETIVO:
listas
*
1igadas
*
*
Mauricio Muñoz Garcia.
AUTOR:
89325717
*
Cristóbal Romo
Duarte. 89328274
*
*
*/
#include<stdio.h>
#define
struct sListaSistema
{
char zNomArch[ iMAXNOMBRE1 ;
int iHost;
int iIdEscritura;
int iContAbiertos;
int blectura;
struct slistasistema *pssSig;
iMAXNOMBRE 225
1;
struct sListaUso
{
int iIdArch;
struct sListaSistema *pssArchivo;
struct sListaUso *psuSig;
1;
struct SListaSistema *pssNuevoElemento();
struct sListaUso *psuNuevoElementoo;
void vInicializaListas( ) ;
struct sListaSistema *pssInsertaLista(char *,int);
struct sListaUso *psuinsertaLista(int,struct sListaSistema * ) ;
void vModificaListaSistema(struct sListaSistema *,int ,int ,int 1 ;
struct sListaSistema *pssBuscaLista(char * ) ;
struct sListaUso *psuBuscaLista(int * ) ;
int bBorraListaSistema(char * ) ;
int bBorraListaUso(int ;
int iCalculaIdArch(int int , int) ;
void vImprimeUso( ) ;
I
51
void vImprimeSistema0;
I
extern FILE
ctruct sLictaUco
struct cLictaSistema
* fhArch ;
*psuInicio;
*pscInicio;
/*@@@F@@@*/
/*
*
*
NOMBRE:
*
OBJETIVO:
sistema.
*
*
*
ENTRADAS:
*
SALIDA:
*
VALOR DE RETORNO:
*
REQUERIMIENTOS :
*
*
*
*
*
pccNuevoElemento.
Crea un nuevo elemento para la de
Apuntador a un nuevo elemento.
NOTAS:
*/
/*@@@F@@@*/
struct sListaSistema *pssNuevoElemento()
{
return( (struct sListaSistema *)malloc(sizeof(struct
cLictaSistema ) I ) ;
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
*
OBJETIVO:
psuNuevoElemento.
Crea un nuevo elemento para la de
uso.
*
*
*
*
ENTRADAS:
SALIDA:
*
*
*
VALOR DE RETORNO:
*
REQUERIMIENTOS :
Apuntador a un nuevo elemento
52
*
*
*
*/
NOTAS:
/*@@@F@@@*/
struct sListaUso *psuNuevoElemento()
{
return( (struct sListaUso *)malloc(sizeof(struct sListaUso)1 ) ;
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
*
OBJETIVO:
psuInicio
vinicializalistas.
Pone a nulo la lista pssInicio y
*
*
*
*
ENTRADAS:
SALIDA:
apuntada a nulo
La lista de uso y de sistema
*
*
*
*
*
*
*
*/
VALOR DE RETORNO:
REQUERIMIENTOS :
NOTAS:
/*@@@IF@@@*/
void vInicializaListas0
{
pssInicio=NüLL;
psuInicio=NULL;
1
/*@@@IF@@@*/
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
OBJETIVO:
Sistema
pssInsertaLista.
Inserta un elemento en la lista de
*
*
ENTRADAS:
53
*
zNomArch:
Cadena con el nombre del archivo a
abrir.
*
*
SALIDA:
insertado.
Lista Sistema con el elemento
*
*
*
*
VALOR DE RETORNO:
*
NOTAS:
*
*
*/
Ninguno.
REQUERIMIENTOS:
/*@@@F@@@*/
struct sListaSistema *pssInsertaLista(char *zNomArch,int iHost)
{
struct sListaSistema *pssElemento;
pssElemento = pssNuevoElemento0;
strcpy ( pssE1emento- > zNomArch , zNomArch) ;
pssElemento->iHost=iHost;
pssElemento->iIdEscritura=O;
pssElemento->iContAbiertos=O;
pssElemento->pssSig=pssInicio;
pssInicio=pssElemento;
return ( pssElemento) ;
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
NOMBRE:
*
OBJETIVO:
*
vInsertaListaUso.
Inserta un elemento en la lista de
uso
*
*
ENTRADAS:
*
iIdARch;
Entero con el identificador a un
archivo.
*
pssElemento:
Apuntador al elemento del sistema
que le
*
corresponde al archivo que se va a usar.
*
*
SALIDA:
insertado.
*
*
VALOR DE RETORNO:
*
REQUERIMIENTOS :
*
Lista Uso con el elemento
Ninguno.
54
*
*
*
NOTAS:
*/
/*@@@F@@@*/
struct sListaUso *psuInsertaLista(int iIdArch, struct
sListaSistema *pssElemento)
{
struct sListaUso *psuElemento;
psuElemento = pcuNuevoElemento0;
psuElemento->iIdArch=iIdArch;
psuElemento->pssArchivo=pssElemento;
psuElemento->psuSig=psuInicio;
psuInicio=psuElemento;
return ( psuE1emento1 ;
}
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
OBJETIVO:
elemento en la
*
lista de sistema.
vModificaListaSistema.
Modifica los valores de un
*
*
*
ENTRADAS:
pcsElemento:
Apuntador al elemento del sistema
que le
*
corresponde al archivo que se va a usar.
*
iIdEscritura:
Entero que contiene el
identificador de archivo
*
iContAbiertos:
Entero que incrementa a la cuenta
de accesos a un
*
archivo.
*
bLectura :
Entero que contiene la bandera de
lectura de el
*
proceso que esta escribiendo.
*
*
SALIDA:
sistema modificado.
*
*
*
*
*
*
*
VALOR DE RETORNO:
Elemento de la lista de
Ninguno.
REQUERIMIENTOS:
NOTAS:
55
*/
/*@@@F@@@*/
void vModificaListaSistema( struct SListaSistema *pssElemento,int
iIdEscritura,int iContAbiertos,int blectura)
{
pssElemento->iContAbiertos = pssElemento>iContAbiertos+iContAbiertos;
if(i1dEscritura != -1)
{
pssElemento->iIdEscritura =iIdEscritura;
pssElemento->bLectura=bLectura;
1
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
NOMBRE:
pssBuscaLista.
*
OBJETIVO:
Sistema
Busca un elemento en la lista de
ENTRADAS:
*
zNomArch:
buscar.
Cadena con el nombre del archivo a
*
*
*
*
*
SALIDA:
*
VALOR DE RETORNO:
o nulo si
*
no se encontro.
Ninguna.
Apuntador al elemento encontrado
*
*
*
*
*
*/
REQUERIMIENTOS :
NOTAS:
/*@@@F@@@*/
struct sListaSistema *pssBuscaLista(char *zNomArch)
{
struct sListaSistema *pssIndice;
int
bEncontrado;
bEncontrado = O ;
pssIndice = pssInicio;
while (!(bEncontrado I I pssIndice == NULL))
{
if (strcmp(pssIndice-zzNomArch,zNomArch) ==
{
bEncontrado = 1;
O)
1
else
{
pssIndice = pssIndice->pssSig;
1
1
return (pssIndice);
}
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
NOMBRE:
*
OBJETIVO:
*
psuBuscaLista.
Busca un elemento en la lista de
uso
*
*
*
ENTRADAS:
iIdArch:
archivo
*
a buscar.
Entero con el identificador del
*
*
*
*
SALIDA:
VALOR DE RETORNO:
o nulo si
*
no se encontro.
Ninguna.
Apuntador al elemento encontrado
*
*
*
REQUERIMIENTOS:
*
*
NOTAS:
*/
/*@@@F@@@*/
struct sListaUso *psuBuscaLista(int *iIdArch)
{
struct sListaUso
*psuIndice;
int
bEncontrado;
bEncontrado = O ;
psuIndice = psuInicio;
while (!(bEncontrado I I psuIndice == NULL))
if (psuIndice->iIdArch== iIdArch)
bEncontrado = 1;
else
psuIndice = psuIndice->psuSig;
1
return (psuIndice);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
bBorraListaSistema.
NOMBRE:
Borra un elemento en la lista del
OBJETIVO:
Sistema
*
*
ENTRADAS:
zNomArch:
buscar.
*
*
*
*
*
Cadena con el nombre del archivo a
Ninguna.
SALIDA:
VALOR DE RETORNO:
Entero resultado de la operacion O
borrado
*
con exito, -1 en otro caso.
*
*
*
REQUERIMIENTOS :
*
NOTAS:
*
*/
/*@@@F@@@*/
int bBorraListaSistema(char *zNomArch)
{
int bResult;
struct SListaSistema *pssElemento, *pssIndice;
bResult = O;
pssElemento = pssBuscaLista(zNomArch);
if (pssElemento ! = NULL)
{
if (pssInicio == pssElemento)
{
pssinicio = pscinicio->pssSig;
pssElemento = NTJLL;
free (pssElemento);
1
else
{
pssIndice = pssInicio;
while ( ! (pssIndice->pssSig== pssElemento))
58
{
pssIndice = pssIndice->pssSig;
1
pssIndice->pssSig = pssElemento->pssSig;
pssElemento->pssSig= NULL;
free (pssElemento);
1
bResult
= 1;
1
return (bResult);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
OBJETIVO:
bBorraListaUso.
Borra un elemento en la lista de
uso.
*
*
*
ENTRADAS:
iIdArch:
Entero con el identificador del
archivo
*
a borrar de la lista.
*
*
*
*
SALIDA:
Ninguna.
VALOR DE RETORNO:
Entero resultado de la operacion O
borrado
*
con exito, -1 en otro caso.
*
*
*
*
*
*/
REQUERIMIENTOS:
NOTAS:
/*@@OF@@@*/
int bBorraListaUso(int iIdArch)
{
int bResult;
struct sListaUso *psuElemento, *psuIndice;
bResult = O;
psuElemento = psuBuscaLista(i1dArch);
if (pcuElemento ! = NULL)
{
if (psuInicio == psuElemento)
{
psuinicio = psuinicio->psuSig;
59
psuElemento = NULL;
free (psuElemento);
1
else
{
psuIndice = psuInicio;
while ( ! (psuIndice->psuSig== psuElemento))
{
psuIndice = psuIndice->psuSig;
1
psuIndice->psuSig = psuElemento->psuSig;
psuElemento->psuSig= NULL;
free (psuElemento);
1
bResult
=
1;
1
return (bResult);
1
/*@@@IF@@@*/
/*@@@F@@@*/
/*
*
NOMBRE:
iCalculaIdArch.
*
*
OBJETIVO:
Calcula un identificador unico
para el
*
sistema de archivos a partir del identificador que nos
da el
*
sistema operativo.
*
*
*
ENTRADAS:
iIdArchSisOp:
Entero con el identificador del
sistema
*
operativo del archivo.
.*
I
*
SALIDA:
*
*
VALOR DE RETORNO:
*
REQUERIMIENTOS:
*
*
*/
NOTAS:
*
*
Identificador unico del sistema.
/*@@@F@@@*/
int iCalculaIdArch(int iIdArchSisOp,int iMAXTERM,int iHOST)
{
return(iIdArchSis0p * iMAXTERM + iHOST);
I
/*@@@F@@@*/
void vImprimeUso (
{
struct sListaUso *psuIndice;
psuIndice = psuInicio;
fprintf (fhArch,"\tLISTA USO\n") ;
while ( ! (psuIndice == NULL) 1
{
fprintf (fhArch,"<%p><%d><%p><%p>\n"
,psuIndice
,psuIndice->iIdArch ,psuIndice->pssArchivo ,psuIndice->psuSig);
psuIndice = psuIndice->psuSig;
1
I
void vImprimeSistema ( )
{
struct sListaSistema *pssIndice;
pssIndice = pssInicio;
fprintf (fhArch,"\tLISTA SISTEMA\nI1);
while ( ! (pssIndice == NULL)
fprintf(fhArch,11<%pz<%s><%d><%d><%d><%d><%p>\n11,pssIndice,pss
Indice->zNomArch ,pssIndice->iHost ,pssIndice->iIdEscritura
,pssIndice-~iContAbiertos,pssIndice-~bLectura,pssIndice-~pssS~g~
;
pssIndice = pssIndice->pssSig;
1
1
#endif
61
#ifndef
#define
DISTRIBUIDO-H
DISTRIBUIDO-H
/*
* NOMBRE:
distribuid0.h
*
*
OBJETIVO:
Funciones para el manejo de
archivos
*
distribuidos (Interface entre la aplicacion y el
administrador
*
local) .
*
* AUTOR:
Mauricio Muñoz Garcia.
89325717
*
Cristóbal Romo Duarte.
89328274
*
*
*/
#includecstdio.h>
#include<sys/types.h>
#includecsys/stat.h>
#include<fcntl.h>
#include1Ipvm3.
h1I
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
#define
zSERVIDOR
iMAXTASK 1 0 0
iMAXTERM 4
iMAXMENSAJE
iMAXNOMBRE 225
iABRIR
iCERRAR
2
iCREAR
iBORRAR
4
iLEER
iESCRIBIR 6
iDESPLAZAR
11admon21'
225
1
3
5
7
int iAbrir(int *,char *,int ,int ) ;
int iEscribir(int ,char *,int 1 ;
FILE
char
int
*fhArch;
zNomArch[ iMAXNOMBRE1 ,zBuf iMAXMENSAJE1 ;
iTid[iMAXTERM],iBufid,iBytes,iType,iTidFuente;
62
int
long
ioper,iBand,iInfo,iModo,iIdArch,iTam,iPos;
1Desp;
struct pvmtaskinfo
int
*sInfTarea;
iNumTarea,iTidAdmon,iIndTarea;
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
iAbrir.
OBJETIVO:
Manda la peticion de abrir un
archivo de
*
una aplicacion al administrador local.
*
*
ENTRADAS:
iIdArch:
Entero con el identificador del
archivo
*
a abrir.
*
zNomArch:
Cadena con el nombre del archivo a
abrir.
*
iBand :
Entero que indica el tipo de
apertura ;
*
O-RONLY solo lectura, O-WONLY solo escritura y O-RDWR
lectura/
*
escritura.
*
iModo:
Entero que indica los
permisos que va a
*
tener el archivo.
*
*
*
*
SALIDA:
iInfo :
operation.
*
zBuf :
operation.
*
*
*
*
*
*
*
*/
VALOR DE RETORNO:
Entero resultado de la
Cadena con el resultado de la
Entero resultado de la operacion.
REQUERIMIENTOS:
NOTAS:
/*@@@F@@@*/
int iAbrir(int *iIdArch,char *zNomArch,int iBand,int iModo)
{
iIndTarea = O ;
iOper=iABRIR;
63
if ( (pvm-tasks( O, &iNumTarea, &sInfTarea ) ) < O ) pvm -exit ( ) ;
while(! (iIndTarea==iNumTarea(
~strcmp(sInfTarea[iIndTareal.ti~
a-out,ZSERVIDOR)= = O )
{
iTidAdmon=sInfTarea[iIndTarea].ti-tid;
iIndTarea++;
1
pvm-initsend(PvmDataDefau1t);
pvmjkint (&iOper,1,l) ;
p m j k s t r (zNomArch);
pvm-pkint ( &iBand,1 ,1 ) ;
pvmjkint ( &iModo ,1 ,1 ) ;
printf ("iModo = %d\n",iModo) ;
pvm-send (sInfTarea[iIndTarea].ti-tid, 1 ) ;
pvm-recv(-l,- 1 );
pm-upkint (&iInfo,1,l) ;
pvm-upkstr (zBuf);
*iIdArch = iInfo;
return(i1nfo);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
NOMBRE:
*
iCerrar.
*
OBJETIVO:
Manda la peticion de cerrar un
archivo de
*
una aplicacion al administrador local.
*
*
*
ENTRADAS:
iIdArch:
archivo
*
a abrir.
*
*
*
SALIDA:
iInfo :
Entero con el identificador del
Entero resultado de la
operation.
*
zBuf :
Cadena con el resultado de la
operation.
*
*
*
*
*
*
*
VALOR DE RETORNO:
Entero resultado de la operacion.
REQUERIMIENTOS:
NOTAS:
*/
64
/*@@@F@@@*/
int iCerrar(int iIdArch)
{
iIndTarea = O;
iOper=iCERRAR;
if ( (pvm-tasks( O, &iNumTarea, &sInfTarea
< O ) pm-exit ( 1 ;
while(! (iIndTarea==iNumTareal
/strcmp(sInfTarea[iIndTarea].tia-out,zSERVIDOR)= = O ) )
{
iTidAdmon=sInfTarea[iIndTarea].ti-tid;
iIndTarea++;
1
pvm-initsend(PvmDataDefault);
p m j k i n t (&iOper,1 1) ;
pvmjkint (&iIdArch,1/11;
pm-send(sInfTarea[iIndTarea] .ti-tid,1) ;
pvm-recv(-1,-1);
pvm-upkint ( &iInfo 1 1) ;
pvm-upkstr (zBuf);
return(iinfo1;
I
I
I
1
/*@@@F@@@*/
/*Q@@F@@@*/
/*
*
*
NOMBRE:
iCrear.
Manda la peticion de crear un
*
OBJETIVO:
archivo de
*
una aplicacion al administrador local.
*
*
*
ENTRADAS:
iIdArch :
archivo
*
a crear.
*
zNomArch:
crear.
*
iModo:
permisos que va a
*
tener el archivo.
Entero con el identificador del
Cadena con el nombre del archivo a
Entero que indica los
*
*
SALIDA:
iInfo :
operation.
*
zBuf :
operation.
*
Entero resultado de la
Cadena con el resultado de la
*
*
VALOR DE RETORNO:
Entero resultado de la operacion
*
*
*
REQUERIMIENTOS:
*
*
NOTAS:
*/
/*@@@F@@@*/
int iCrear(int *iIdArch,char *zNomArch,int iModo)
{
iIndTarea = O ;
iOper=iCREAR;
if ( (pvm-tasks( O , &iNumTarea, &sInfTarea ) ) < O ) pvm-exit ( 1 ;
while(! (iIndTarea==iNumTareal(strcmp(sInfTarea[iIndTareal.tia-out,ZSERVIDOR)= = O ) )
{
iTidAdmon=sInfTarea[iIndTareal.ti-tid;
iIndTarea++;
1
pvm-initsend(PvmDataDefau1t);
pvmgkint ( &iOper ,1,1) ;
pvmgkstr (zNomArch);
p m g k i n t ( &iModo ,1,1);
pvm-send(s1nfTarea [iIndTareal .ti-tid,1) ;
pm-recv(-í,-1);
pvm-upkint ( &i Info,1,l);
pm-upks tr ( zBuf) ;
*iIdArch = iInfo;
return (iInfo);
1
/*@@@F@@@*/
/*@@@IF@@@*/
/*
*
*
NOMBRE:
iBorrar.
*
OBJETIVO:
Manda la peticion de borrar un
archivo de
*
una aplicacion al administrador local.
*
*
ENTRADAS:
zNomArch:
borrar.
*
Cadena con el nombre del archivo a
*
*
*
SALIDA:
iInfo :
operation.
*
zBuf:
operation.
Entero resultado de la
Cadena con el resultado de la
66
*
*
VALOR DE RETORNO:
*
REQUERIMIENTOS:
Entero resultado de la operacion.
*
*
*
*
*/
NOTAS:
/*@@@F@@@*/
int iBorrar(char *zNomArch)
{
iIndTarea = O;
iOper=iBORRAR;
if ( (pvm-tasks ( O , &iNumTarea, &sInfTarea ) ) < O ) pvm-exit ( ) ;
while(! (iIndTarea==iNumTareal~strcmp(sInfTarea[iIndTareal.tia-out,ZSERVIDOR)= = O ) )
{
iTidAdmon=sInfTarea[iIndTarea].ti-tid;
iIndTarea++;
1
pvm-initsend(PvmDataDefau1t) ;
pvmgkint (&iOper,1,l);
pvmgkstr (zNomArch);
pvm-send(s1nfTarea [iIndTarea].ti-tid,1);
pvm-recv(-i,-1);
pvm-upkint (&iInfo ,1,l);
pvm-upkstr (zBuf ;
return (iinfo);
1
/*@@@F@@@*/
/*@@@F@@@*/
/*
*
*
*
NOMBRE:
iLeer.
OBJETIVO:
Manda la peticion de leer un
archivo de
*
una aplicacion al administrador local.
*
*
*
ENTRADAS:
iIdArch:
Entero con el identificador del
que se va a leer.
zBuf:
Cadena con el resultado de la
iTam :
Entero que contiene el numero
archivo
*
*
operation.
*
caracteres
*
que se van a leer.
67
,
*
*
*
SALIDA:
iInfo :
operation.
*
zBuf:
operation.
Entero resultado de la
Cadena con el resultado de la
*
*
*
*
*
*
*
*/
VALOR DE RETORNO:
Entero resultado de la operacion.
REQUERIMIENTOS :
NOTAS:
/*@@@F@@@*/
int iLeer(int iIdArch,char *zBuf,int iTam)
{
iIndTarea = O;
iOper=iLEER;
< O ) pvm-exit ( 1 ;
if ( (pvm-tasks ( O, &iNumTarea, &sInfTarea
while(! (iIndTarea==iNumTareal(strcmp(sInfTarea[iIndTareal.tia-out,zSERVIDOR)= = O ) )
{
iTidAdmon=sInfTarea[iIndTarea].ti-tid;
iIndTarea++;
1
pvm-initsend(PvmDataDefault);
p m g k i n t (&iOper,1,l);
pvmgkint (&iIdArch,1,l) ;
pvmgkstr (zBuf) ;
pvmgkint (&iTam,1,l);
pvm-send(s1nfTarea [iIndTareal .ti-tid,1 ) ;
pm-recv ( - 1,- 1 ) ;
pvm-upkint (&iInfo ,1,1 ) ;
pvm-upkstr (zBuf ;
return ( iinfo1 ;
I
/*@@@F@@@*/
/*@@@IF@@@*/
/*
*
*
*
NOMBRE:
iEscribir.
OBJETIVO:
Manda la peticion de escribir un
archivo de
*
una aplicacion al administrador local.
*
*
ENTRADAS:
68
*
iIdArch:
Entero con el identificador del
archivo
*
*
*
que se va a escribir.
zBuf :
Cadena que se va a escribir.
iTam :
Entero que contiene el numero
caracteres
*
*
que se van a escribir.
*
*
SALIDA:
iInfo:
operation.
*
zBuf:
operation.
*
*
*
*
*
*
*
VALOR DE RETORNO:
Entero resultado de la
Cadena con el resultado de la
Entero resultado de la operacion.
REQUERIMIENTOS :
NOTAS:
*/
/*@@@F@@@*/
int iEscribir(int iIdArch,char *zBuf,int iTam)
{
iIndTarea = O;
iOper=iESCRIBIR;
if ( (pm-tasks( O, &iNumTarea, &sInfTarea ) c 0 ) pm-exit ( ;
while(! (iIndTarea==iNumTarealI strcmp (sInfTarea[iIndTareal .tia-~~~,ZSERVIDOR)==O))
{
iTidAdmon=sInfTarea[iIndTareal.ti-tid;
iIndTarea++;
1
pm-initsend ( PvmDataDefault ;
p m j k i n t ( &iOper,1,1 ) ;
pvmskint (&iIdArch,1 , l ) ;
p m j k s t r (zBuf) ;
p m x k i n t (&iTam,1,l) ;
pm-send(sInfTarea[iIndTarea] .ti-tid,1);
pm-recv( -1,-1) ;
pm-upkint ( &iInfo,1,l);
pvm-upkstr (zBuf ;
return (iinfo) ;
-
1
/*@@@F@@@*/
69
*
*
iDesplazar.
NOMBRE:
Manda la peticion de desplazar una
*
OBJETIVO:
distancia
*
dentro de un archivo de
una aplicacion al
administrador local.
*
*
ENTRADAS:
iIdArch:
Entero con el identificador del
archivo
*
en el que se va a desplazar.
*
1Desp:
Distancia gue se va a
desplazar dentro
*
del archivo.
Position desde la que se va a
*
iPos:
desplazar
*
dentro del archivo; SEEK-SET inicio del archivo,
SEEK-CUR
*
posicion actual, SEEK-END fin del archivo.
*
*
*
*
SALIDA:
iInfo :
operation.
*
zBuf:
operation.
Entero resultado de la
Cadena con el resultado de la
*
*
VALOR DE RETORNO:
*
*
REQUERIMIENTOS:
*
*
*/
NOTAS:
*
Entero resultado de la operacion.
/*@@@F@@@*/
int iDesplazar(int iIdArch,long *lDesp,int iPos)
{
iIndTarea = O;
iOper=iDESPLAZAR;
if ( (pvm-tasks ( O, &iNumTarea, &sInfTarea ) ) < O ) pm-exit 0 ;
while(! (iIndTarea==iNumTareal~strcmp(sInfTarea[iIndTareal.tia-out,ZSERVIDOR)= = O ) )
{
iTidAdmon=sInfTarea[iIndTarea].ti-tid;
iIndTarea++;
1
pm-initsend(PvmDataDefau1t)
;
pvmgkint ( &iOper,1,l) ;
pvmgkint (&iIdArch,1,l) ;
pmgklong ( & * 1Desp,1,1) ;
70
p v m g k i n t ( &iPos,1,l);
pm-send(s1nfTarea [iIndTareal .ti-tid, 1) i
pm-recv(-l, - 1 );
pvm -upkint (&iInfo,1,l) ;
pvm-upkstr (zBuf);
*lDesp = ato1 (zBuf,NULL,O ) ;
return(i1nfo) ;
#endif
71
Apéndice B (Manual de usuario)
6.
En este apéndice explicaremos la instalación de Parallel Virtual Machine (PVM), la instalación de
Sistema de Archivos Distribuido (SAD), la manera de iniciar el sistema y su uso.
Para la instalación y uso del sistema se debe contar con una cuenta en una maquina multiusuario y
un compilador de C.
Instalación de PVM.
La instalación consta de cuatro pasos que indican como sé optiene
PVM, la manera de
descomprimir PVM, la manera de compilar PVM, y como ejecuta PVM.
Paso 1
6.1.I. Transferencia de PVM
O
PVM se puede obtener en Internet en la dirección ¡Error! Marcador no definido..
O
Se debe transferir la versión necesaria según la plataforma que se use al directorio HOME/.
O
Para este proyecto se utilizo la ultima versión disponible que se encuentra en el archivo
pvm3.1.1.1. tar .gz.
o
En esta misma dirección se puede obtener el manual de usuario de PVM, donde se explica
entre otras cosas las diferentes versiones de PVM que existen.
Paso 2
6.1.2. Descompresión de PVM
O
Ejecute el comando gzip pvm3.1. I . I .tar.gz.
O
El resultado es el archivo pvm3 .l. 1.1. tar
0
Ejecute el comando tar -xvt pvm3.1.I
.I
.tar
O
Los resultados son los archivos de instalación de PVM en el subdirectorio / H o ~ ~ / p v m 3 .
Paso 3
6.1.3. Compilaciónde PVM
O
Para la compilación es necesario configurar el ambiente del usuario utilizado.
72
~~
o
Concatenar el archivo, cshrc que se encuentra en el directorio HOME/ con el archivo
cshrc.stub que se encuentra en el directorio HOME/pvm3/pvm/ib, Dejando el resultado en el
archivo HOME / c shrc.
O
Reinicia la sesión. Para que se carguen las variable necesarias para la compilación.
o
Ejecute el comando make en el directorio HOME/pvm3.
O
El resultado es la creación de los programas y archivos que forman PVM.
Debido a que PVM fue diseñado para diferentes plataformas. Se requiere repetir los pasos
anteriores para cada máquina que forma parte del sistema.
Paso 4
6.1.4. Ejecución del demonio
0
Ejecute el comando pvm en el directorio HOME/PVM3/lib.
0
Esté comando ejecuta la consola con la cual se monitorean los procesos que esta ejecutando
PVM. Se pueden cancelar procesos, agregar y eliminar máquinas de la máquina virtual que
forma PVM, entre otras cosas. AI salir de la consola con la función quit, el demonio (pvmd)
queda en espera de las aplicaciones que llamen a las funciones de PVM.
COMPILACION DEL SAD
O
La compilación del SAD consta de cuatro pasos que son: Copiado de archivos, Edición de
archivo admon#.c,Edición de archivo Makefile. aimk, compilación.
Paso 1
6.1.5. Copiado de archivos
0
Se tienen que copiar los archivos admon#.c,distribuidos.h, listas.h,Makef ile .aimk
al directorio H O M E / ~ ~ ~ / A D Masignando
ON
un número al nombre del archivo admon# para
localizar la máquina en donde se hace la copia.
o
El archivo makefile viene con la versión de pvm que se instaló anteriormente.
Paso 2
73
6. I . 6. Edición del archivo admon#.c
o
El archivo admon#.c es el código del programa admon#, este archivo se tiene que editar
cambiando el valor de la constante iHost la cual indica en que máquina se esta ejecutando el
programa. La línea que se tiene que cambiar es:
#define iHost
#
En donde # es el número que se le asigno a la máquina en el paso anterior .
Paso 3
6.1.7. Edición del archivo Makefile.aimk.
o
Cada administrador (ahon#.c) se tiene que compilar usando el comando aimk que es parte
de PVM, este comando utiliza la información del archivo Makef ile.aimk.
o
El archivo makef ile .aimk viene con PVM y trae la información para la compilación de los
ejemplos de PVM. Se tiene que agregar el programa admon#.c que se quiere compilar.
A continuación mostramos un ejemplo:
#
# Makefile.aimk for PVM example programs.
#
# Set PVM-ROOT to the path where PVM includes and libraries are installed.
# Set PVMARCH to your architecture type (SUN4,HP9K, RS6K, SGI, etc.)
# Set ARCHLIB to any special libs needed on PVM-ARCH (-lrpc, -Isocket, etc.)
# otherwise leave ARCHLIB blank
#
# PVMARCH and ARCHLIB are set for you if you use "$PVM-ROOT/lib/aimk"
# instead of "make".
#
# aimk also creates a $PVMARCH directory below this one and will cd to it
# before invoking make - this allows building in parallel on different arches.
#
SDIR
#BDIR
BDIR
XDIR
=
=
=
=
$( HOM E)/pvm3/bin
$(SDIR)/. ./bin
$(BDIR)/$(PVMARCH)
OPTIONS
CFLAGS=
-
LIBS
=
GLIBS
=
-1p~m3$(ARCHLIB)
-1gpvm3
-0 -w
$(OPTIONS) -I. ./../include $(ARCHCFLAGS)
LFLAGS =
$( LOPT) -L. ./. ./lib/$(PVMARCH)
CPROGS=
maestro admonl admon2 admon3 admon4 appl app2
all: c-all
c-all:
$(CPROGS)
74
clean:
rm -f *.o $(CPROGS)
$(XDIR):
mkdir $(BDIR)
mkdir $(XDIR)
maestro: $(SDIR)/maestro.c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/maestro.c $(LFLAGS) $(LIBS)
mv $@ $(XDIR)
admonl: $(SDIR)/admonl .c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/admonl .c $(LFLAGS) $(LIBS)
mv $@ $(XDIR)
admon2: $(SDIR)/admon2.c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/admon2.c $(LFLAGS) $(LIBS)
inv $@ $(XDIR)
admon3: $(SDIR)/admon3.c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/admon3.c $(LFLAGS) $(LIBS)
mv $@ $(XDIR)
admon4: $(SDIR)/admon4.c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/admon4.c $(LFLAGS) $(LIBS)
mv $@ $(XDIR)
appl : $(SDlR)/appl .c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/appl .c $(LFLAGS) $(LIBS)
mv $@ $(XDIR)
app2: $( SDI R)/app2.c $(XDIR)
$(CC) $(CFLAGS) -o $@ $(SDIR)/app2.c $(LFLAGS) $(LIBS)
mv $@ $(XDIR)
Paso 4
6.1.8. Compilación
0
Se ejecuta aimk admon# .c en el directorio ~ o M E / p v m 3 / m ~ O Ndando
,
como resultado el
programa ejecutable admon#.
Se tiene que realizar los cuatro pasos en cada máquina del SAD.
ARRANQUE DEL SAD
0
El arranque del SAD se realiza ejecutando el programa maestro. Este programa tiene que
ejecutarse sólo en una máquina, y es el encargado de ejecutar los programas administradores
en todas las máquinas del SAD. Este proceso consta de cuatro pasos que son: copiado del
75
archivo maestrox, edición del archivo maestro, compilación del archivo maestro, y ejecución
del archivo maestro.
Paso 1
6.1.9. Copiado del archivo mestro.c
0
Se debe elegir una máquina que forma parte del sistema virtual de PVM, en donde se realizará
la copia del archivo maestro. c al directorio HOME/pm3/ADMON.
Paso 2
6.1.10.
Edición del archivo maestro.c
0
Este archivo tiene la información de las máquinas que van a formar parte del SAD.
o
Insertando el nombre de la máquina o la dirección IP y el nombre del programa ha ejecutar, que
en este caso es admon#. Actualiza el valor de la constante y iMAXHOST con el número de
máquinas que van a formar parte del SAD.
Paso 3
6.1.1I .
o
Compilación del archivo maestro.c
Para la compilación del programa maestro.c se tiene que editar el archivo Makef ile.aimk
como en el paso tres de la Compilación del SAD.
0
Se ejecuta aimk maestr0.c en el directorio HOME/pm3/ADMON, dando como resultado el
programa ejecutable maestro.
Paso 4
6.1.12.
0
Ejecución del maestro
Se ejecuta maestro en el directorio H O M E / ~ ~ ~ / A D M dando
O N , como resultado la ejecución
de los administradores llamados en el programa.
EDlClON DE LAS APLICACIONES
o
Las aplicaciones son programas escritos en c, los cuales llaman a las funciones del SAD, que
son iAbrir,icerrar,ileer,iEscribir,iDesplazar,iCrear,iBorrar.
o
A las aplicaciones se les deben incluir las bibliotecas distribuid0s.h y listas.h,en las
cuales estan las funciones y variables con las que trabaja el SAD,y una copia del código fuente
de las aplicaciones deben de estar en el directorio HOME/pvm3/ADMON.
76
COMPILACION DE LAS APLICACIONES
0
Para la compilación se tiene que editar el archivo Makef ile.aimk como en el paso tres de la
Compilación en el SAD, en donde se tiene que agregar la aplicación a compilar.
0
Se ejecuta ai&
<aplicación.c> en el directorio HOME/pm3/ADMON, dando como
resultado el programa ejecutable <aplicación>.
EJECUCION DE LA APLICACI~N
o
Para que las aplicaciones funcionen se debe verificar que los diferentes administradores se
estén ejecutando en todas las máquinas del sistema.
FUNCIONES PRIMITIVAS DEL SAD
Las funciones primitivas del SAD son abrir un archivo iAbrir,cerrar un archivo icerrar,leer un
archivo iLeer,escribir en un archivo iEscribir,desplazarce en un archivo iDesplazar,crear
un archivo icrear y borrar un archivo iBorrar.A continuación se explica la sintaxis y el modo de
usar estas funciones.
Nombre
Crear - Crea un nuevo en el SAD.
Sintaxis
int ¡Crear( int *ildArch, char *zNomArch, int ¡Modo)
Descripción
Crea un archivo nuevo en el SAD y lo deja abierto para solo escritura.
ildArch es un entero asociado al archivo que se creo en caso de no haber errores.
zNomArch es el nombre del archivo que se quiere crear.
iModo indica los permisos que va a tenerse sobre el archivo, los valores que se pueden usar son:
S-IWRITE Permiso de escritura.
S-IREAD Permiso de lectura.
S-IWRITE
I S-IREAD
Permiso de lectura y escritura.
Valores de retorno
n Operación exitosa. En donde n es un numero entero positivo asociado al archivo recién creado.
-1 Error.
77
Errores
[EACCES] Permiso denegado.
[ENAMETOOLONG] Nombre de archivo muy grande.
[ENFILE] La tabla de archivos del sistema esta llena.
Nombre
¡Desplazar. Moverse en un archivo cuando lo esta leyendo o escribiendo
Sintaxis
int ¡Desplazar (int, ildArch, long, iDesp., intiPos.)
Descripción
Esta función, mueve el puntero de UE asociado con el Archivo abierto con el número ildArch, a una
nueva posición desplazada ldesp desde la posición ¡Pos.
Donde la posición ¡Pos puede tomar los valores siguiente:
EEK-SET: Principio del archivo
SEEK-CUT: Posición actual del puntero de UE
SEEK-END: Final del Archivo
Valor devuelto
n Operación exitosa. Donde n es el desplazamiento en bytes de la nueva posición relativa al principio
del archivo.
-1 Error.
Errores
[EBDF] archivo no abierto
[EINVAL] valor de ¡Pos no es soportado
Nombre
¡Abrir -Abre un archivo existente en el SAD.
Sintaxis
int ¡Abrir (ind ildArch, char zNomArch, int Band)
78
Descripción
Esta función, abre el archivo zNomArch, Band indica la forma en que se va abrir el archivo y puede
tomar los siguientes valores:
O-APPEND Abre un archivo para añadir información al final del archivo
O-RDNLY Abre un archivo solo para lectura
O-RDW Abre un archivo para lectura y escritura
O-WRONLY Abre un archivo solo para escritura
En el sistema se puede abrir un archivo para escritura, solo una vez y para lectura varias veces.
En la variable i/dArchse regresa el número asociado al archivo abierto.
Valor de retorno
n Operación exitoca. En donde n es un numero entero positivo asociado al archivo recién creado.
-1 Error.
Errores
[EACCES] Permiso denegado
ENOENT No existe el archivo
EMWRITE Archivo ya esta abierto en modo de lectura
Nombre
¡Borrar - Borrar un archivo del sistema
Sintaxis
int ¡Borrar (Char* zNomArch)
Descripción
Esta función, borra el archivo zNomArch del SAD, solo si el archivo no esta siendo usado por otra
aplicación.
Valor de retorno
O Operación exitosa.
-1 Error.
Errores
[EACCES] Permiso denegado
79
[ENAMETOLONG] Nombre de archivo muy grande
[ENOENT] Nombre de archivo no existe
Nombre
Cerrar- Cierra un archivo
int ¡Cerrar (Int ildArch)
Descripción
Cierra un archivo asociado al número ildArch,este número se obtiene por las funciones Crear 6 ¡Abrir
Valor de retorno
O Operación exitosa.
-1 Error.
Errores
[EBADT] ildArch no eta asociado a un archivo abierto.
Nombre
¡Leer - Lee una cadena de caracteres de un archivo
Sintaxis
int iLeer(int ildArch, char *zBuf, int ¡Tam)
Descripción
La función de ¡Leer, lee de ildArch una cadena de tamaño iTam bytes y la coloca en zBuf.
Valor de retorno
n Operación exitosa. Donde n es el número de bytes leídos
-1 Error.
Errores
[EBDF] archivo no abierto
80
Nombre
¡Escribir - Escribe una cadena de caracteres a un archivo
Sintaxis
int iEscribir(int ildArch, char *zBuf, int ¡Tam)
Descripción
La función de ¡Escribir, Escribe en ildArch la cadena zBuf que es de tamaño Tarn.
Valor de retorno
n Operación exitosa. Donde n es el número de bytes escritos
-1 Error.
Errores
[EBDF] archivo
81
7.
Apéndice C (Parallel Virtual Machine)
PVM está compuesto de dos partes: La primera parte es un proceso demonio llamado pvmd3 y
algunas veces abreviado pvmd, el cual debe estar ejecutándose en todos los hosts que formen la
máquina virtual. Pvmd3 esta diseñado para que cualquier usuario con un login valido pueda instalar
el demonio en su máquina. Cuando un usuario desea correr una aplicación PVM, primero debe
iniciar PVM en las máquinas que estén implicadas en el desarrollo del proceso distribuido. La
aplicación PVM puede ser iniciada desde cualquier máquina que corra algún sistema operativo
UNlX compatible con PVM. Múltiples usuarios pueden configurar maquinas virtuales traslapadas, y
cada usuario puede ejecutar diversas aplicaciones PVM simultáneamente.
La segunda parte del sistema en,una librería de rutinas PVM que sirven de interface con el usuario.
Estas contienen un completo y funcional repertorio de primitivas que son requeridas para la
cooperación de las tareas de una aplicación. Esta librería contiene rutinas que puede llamar al
usuario para el paso de mensajes, ejecutar procesos, coordinar tareas, y modificar la máquina
virtual.
PVM también incluye una consola con la cual se podrá verificar el estado de los procesos,
configurar la máquina virtual, pudiendo agregar o eliminar computadoras o clientes de ella, ejecutar
varias aplicaciones a la vez y poder eliminarlas manualmente.
A todos los procesos que se involucran con PVM se les asignará un identificador de tarea llamado
tid, (task identifier) el cual será asignado de manera única por PVM, existiendo varias rutinas que
regresen valores de fid para que los programas de aplicación puedan identificar otras tareas en el
sistema, Los mensajes son enviados y recibidos por medio de los fids. Dado que los tids son Únicos
a través de toda la máquina virtual, éstos son designados por el pvmd local y no se pueden
escoger. PVM permite que un proceso se convierta en una tarea PVM y que regrese a ser un
proceso normal de nuevo. PVM puede comunicar tareas que se encuentran en una misma máquina
y tareas que se encuentran en diferentes máquinas conectadas por medio de una red.
Hay aplicaciones que es natural pensarlas como un grupo de tareas, y hay casos donde a un
usuario le gustaría identificar estas tareas por número. PVM incluye el concepto de grupos. Cuando
una tarea entra a formar parte de un grupo se le asigna un número Único dentro del grupo. Estos
números comienzan en cero y se van incrementando. A fin de mantener la filosofía PVM, las
funciones de grupo fueron diseñadas para ser muy generales y transparentes al usuario. Por
82
ejemplo, cualquier tarea PVM puede entrar y salir de un grupo en cualquier momento sin tener que
informarlo a las otras tareas en los grupos afectados. También una tarea puede pertenecer a varios
grupos y pueden enviar mensajes a todo un grupo del cual no sea miembro.
PVM actualmente soporta los lenguajes C, C++, y Fortran, de modo que sólo se requiere que las
máquinas que van a formar parte de la máquina virtual cuenten con alguno de éstos. Para los
lenguajes C y C++. La interface con el usuario es una librería que cuenta con un conjunto de
funciones con la estructura de la mayoría de los sistemas de C, incluyendo los sistemas operativos
basados en UNIX.
Los principios en los que se basa PVM son los siguientes:
Conjunto de máquinas que forman la máquina virtual definidas por el usuario: Las tareas de una
aplicación son ejecutadas en el conjunto de máquinas que son seleccionadas por el usuario para
correr los programas PVM. Tanto máquinas con un sólo CPU como las que tienen
multiprocesadores (incluyendo las que tienen memoria compartida y las computadoras con
memoria distribuida) pueden ser partes de la máquina virtual. La máquina virtual puede ser alterada
agregando y eliminando máquinas durante la operación (una importante consideración para la
tolerancia a fallas).
Transparente acceso a hardware: Las aplicaciones pueden ver el hardware como una colección de
atributos de elementos de procesamiento virtual o pueden escoger explotar las capacidades de
máquinas específicas en la máquina virtual colocando ciertas tareas en las computadoras más
apropiadas.
Computación basada en procesos: La unidad de paralelismo en PVM es la tarea. Un independiente
conjunto de secuencias de control que alternan entre la comunicación y la computación. Ningún
mapeo proceso-procesador es implicado o forzado por PVM, en particular, múltiples tareas pueden
ser ejecutadas en un solo procesador.
Modelo de paso de mensajes explícito: Conjuntos de tareas, cada una ejecutando una parte del
trabajo de una aplicación, usando descomposición por función, datos o híbrida, cooperan para
enviar y recibir explícitamente mensajes de una a otra. El tamaño de los mensajes está limitado
solo por la cantidad de memoria disponible.
83
Heterogeneidad: PVM soporta heterogeneidad en términos de máquinas, redes y aplicaciones.
Para permitir el paso de mensajes, PVM contempla que estos contengan más de un tipo de datos
para ser intercambiados entre máquinas que tienen diferente representación de los datos.
Soporte multiproceso: PVM usa las facilidades nativas del paso de mensajes en los
multiprocesadores para tomar ventaja del hardware.
El modelo computacional de PVM es muy sencillo, y se acomoda a una amplia variedad de
estructuras de programas de aplicación. La interface de programación es deliberadamente
poderosa, esto permite estructurar programas simples para ser implementados de manera intuitiva.
El usuario escribe sus aplicaciones como una colección de tareas cooperantes. Las tareas acceden
los recursos a través de las librerías. Estas rutinas permiten inicializar y finalizar tareas a través de
la red, así como la comunicación y la sincronización entre tareas. Las primitivas de paso de
mensajes están orientadas hacia la heterogeneidad de las operaciones, involucrando
construcciones para el intercambio de los buffers y la transmisión. La construcción de la
comunicación incluye estructuras para el envío y la recepción de datos así como primitivas de alto
nivel como el broadcast, la sincronización y la globalización.
Las tareas PVM poseen control arbitrario y dependencia de las estructuras. En otras palabras, en
cualquier punto de la ejecución de una aplicación. Cualquier tarea existente puede iniciar o terminar
otras tareas o agregar o borrar computadoras de la máquina virtual. Cualquier proceso puede
comunicarse y/o sincronizarse con cualquier otro. Cualquier tipo de control específico y
dependencia de las estructuras puede ser implementada bajo el sistema PVM mediante el
apropiado uso de PVM, los estatutos del lenguaje y control del flujo.
PVM puede ser usado en diversos niveles. En el nivel más alto, es el modo transparente, las tareas
son automáticamente ejecutadas en la computadora más apropiada. En el modo dependiente de la
arquitectura, el usuario especifica cual es el tipo de computadora que se requiere para correr una
tarea en particular. En el modo de bajo nivel, el usuario puede especificar una computadora en
particular para ejecutar una tarea, PVM toma el cuidado necesario para la conversión de datos de
computadora a computadora, así como los problemas de comunicación a bajo nivel. PVM puede
manejar computadoras que se encuentran en distintos tipos de redes.
84