Estimación no paramétrica, recursiva, de curvas
Anuncio

ESTADISTICA ESPAÑ(^LA
Vol. 35. Núm. 134, 1993, págs. 579 a 616
Estimación no paramétrica , recursiva , de
curvas
JUAN M. ViLAR
JOSE A. VILAR
Departamento de Maternáticas
Universidad de La Coruña
RESUMEN
Se definen estimadores tipo núcleo, recursivos, de las siguientes curvas: densidad, distribución, razón de fallo y regresión. Se realiza un estudio de !as
propiedades asintóticas de estos estimadores bajo la hipótesis de que las observaciones son dependientes, fuertemente mixing. Obteniéndose expresiones asintóticas de la Media del Error Cuadrático lntegrado de los estimadores definidos
así como su dístribución asintótica.
Finalmente, se presentan ejemplos de utilización de los estimadores definidos
con muestras simuladas.
Palabras Clave: Estimación no paramétrica de curvas, método núcleo, condiciones de dependencia.
Clasificación AMS: 62G99, 62G05.
I.
INTRODUCCION
Un problema estadistico de gran interés y ampliamente estudiado es la estimación
de una función g(x), x^ (Rd, asociada a una distribución, a partir, del conocimiento
de una muestra X^, X2, ..., X^. Habiéndose estudiado fundamentalmente las siguientes curvas: densidad, distribución, razón de fallo y regresión. Si la estimación se
realiza desde una perspectiva no paramétrica, esto es, no se asume una forma
funcional específica de la curva, sino que ésta se estima puntualmente a par#ir de
nr^rr^ ^
E ^,.^, l`^(;i
t7^( Í
la muestra, la mayoría de los estimadores no paramétricos de las curvas anteriores
(histograma, regresograma, tipo núcleo, desarrollos ortogonales) admiten una expresión de tipo &-fraccional (Marron-Hardle, 1986}, definida como sigue:
1
^ ^1 n 1 ^ x+ Xi^
9n^x) - ^ ^ ^ __ _
^ ^^n^ ^x^ Xj)
l' )
sienda b1 y S2 funciones de ponderación definidas en lRdx (Rd con valores en (R
y b(n) la sucesión de parámetros de suavizado que regulan el grado de suavización que se introduce en la estimación de 1a curva.
Estos estimadores han sido ampliamente estudiados, sobre todo en el supuesto de independencia de las observaciones, siendo referencias clásicas Prakasa
Rao { 1983), Silverman (1986) y Hardle (1990). Bajo la hipótesis de que las
observaciones verifican condiciones de dependencia, principalmente de tipo mixing, se han realizado distintos trabajos en Ios últimos años, destacando el de
Gyórfi y otros (1989) y la bíbliografía allí citada.
Sin embargo, comparativamente, son escasas las publicaciones de estudios
sobre estimadores no paramétricos funcionales de tipo recursivo como los que
se estudian en este trabajo.
Un estimadorcon el mismoformata que el definido en (1) pero con la propiedad
de ser recursivo tendrá la forma:
n
^
^n{x) =
^ ^bci> (X, Xi)
i=1 _ _.
_ _.__
n
^ ^b(jl ^Xa Xj^
1^ ^
(2)
que verifica la siguiente relación de recursividad:
^
gn + 1 (
siendo
^
)= 9n{X) Sn + bñ + ^^X^ Xn + 1^ Sn1+ 1
n
2
Sn = ^, ^b(i^ ^X, ^i)
i_ 1
La utilización de estimadores recursivos es razonable en muchas situaciones,
pues aunque son algo peores que los no recursivos en el sentido de que tienen
un mayor error cuadrático, como se verá en el apartado II, si se obtienen
observaciones adicionales, ios recursivos calculan con mayor rapidez las nuevas
estimaciones, utilizando menos tiempo de computación y no necesitando almacenar todas las observaciones. En particular su uso en métodos secuenciales o
estudio de procesos temporales parece aconsejable.
5a^
ES^^IMAC.;ION NC) PARAM^TRIC^'A, REC;IJ(2SiVF^, DE- C^:k_1F^VpS
De los estimadores no paramétricos el más utilizado y estudiado por ser
sencillo e intuitivo es el tipo núcleo (kernel), que en la versión recursiva y según
la función a estimar se define como sigue:
1.
Función de densidad: f(x)
Haciendo ^c;^ (x, X;) = bd^` K; (x - X;),
^c>> (x^ Xj> = bi^^^
con K; (u) = b;^ K(u/b;)
con i E IR
de la expresión (2) se deduce el siguiente estimador recursivo de la función de
densidad:
^__-_
fn(x=__.
)
n
n bdz K. x_ X.
^ i i( 1)
dT i = 1
^ bj
j= 1
(4)
siendo K(u) una función núcleo definida en IRd, normalmente una función de
densidad y i un parámetro que influye en el error cuadrático del estimador, en
este trabajo se supone que i E{0,1 ] para una más fácil interpretación y por ser
la elección más usual.
EI estimador definido en (4) es un caso particular de un estimador más general
introducido por Deheuvels (1974} y en un contexto de datos independientes ha
sido estudiado por Wolverton-Wagner ( 1969) para i= 0, por Wegman-Davies
(1979) para i = 0.5, Wertz ( 1985) y las referencias alli citadas. Bajo el supuesto
de dependencia ha sido estudiado por Masry ( 1986), Masry y Gyórfy (1987), Tran
(1989), y Tran (1990) entre otros.
2.
Función de distribución: F(x)
Haciendo bbc;^ (x, X;) = f
bd^ K; (u -- X;} du = bdT K; (x - X;); db ^(x, X^) = bd^
u<_x
siendo
K^ (u) = f
K(v) dv =
v<_u/b^
^>
1
>
>
b^ K(z/b^) dZ
z_<.u ^
^
De la expresión (2) se deduce el siguiente estimador recursivo de la función
de distribución:
Fn(x=_.^
__ ^bdtK* x-X. _
fn(u} du
)
f
i
i(
i)
n
u{x
^ bdT i--1
j =1
(5)
^.>1^^[^)I^>? ir .<, k `^,^^^1f^^^^ ^t T,
Utro estimador recursivo de la función de dístribución muy utilizado por su
sencillez, es (a distribución empírica, que tiene un error cuaairátíco de! mismo
orden y se define como sigue:
n
Gn(x ) = ^ ^ U;
n;^,
siendo
U; = I ^ x, < x ^
En un contexto de dependencia de estos estimadores han sid© estudiados por
Vilar Fern^ndez (1991).
3.
Función de razón de fallo; h^x)
Teniendo en cuenta que la función raZÓn de fallo se define como
h(x)=
f^X} __ ! f(X^
1 -- F(x) F(x)
parece razonable que su estimador tenga la forma siguiente:
"
hn^X)
^ _..___ fn(x)
_. _.. _._
n
1 -- Fn(x)
esto se consigue, haciendo en (2):
Sb(j)(x^ Xj) -. ^
^bc^,(X, X;) = b^^ K^ (x -- X^)
siendo
K(v) dv = j
K^ (u) = J
v > u/bj
bdt Kj (x - Xj)
bj^ K(z/b^) dz ^ 1- K^ (u)
z>u
se obtiene el siguiente estimador recursivo de h(x):
n
^bd^K;(x-X;)
n
__
^ bdT K^ ( x -- Xj )
1
Si utilizamos la distribución empirica, Gn(x} como estimador de la función de
distribución se obtiene el siguiente estirnador de h(x):
^
hn{ x
n
fn(x)
n
_ fn(x) _
._ ^„^n(x)
siendo
U^ = 1-- U^ = Icx, > Xa
Gn(x)
n
n
az
^ . ^_ b^ K^ ( x - X^ )
,r^n,^^t^ ^,:,rw
A
^^ ^ F'!"^flAME T f1^E .A
)^`^a^'^ A i)E c ^;
RE
.;
^f33
..,
Los estimadores hn(x) y h^(x) tienen el mismo término principal en el error
cuadrático, por tanto, ias estimaciones que proporcionan son asintóticamente
equivaientes y por ser más fácil de manejar computacionalmente el segundo será
el que se estudiará.
4.
Función de regresión: r(x) = E(Y/ X=x)
Si a partir de una muestra (X^, Y^), (X2, Y2) ... (X^, Y^) de la variable aleatoria
(X,Y), con valores en ff^2d x(R se desea estudiar la función regresión r(x) = E(Y/X =
i x), haciendo:
^
^b^^>(x, X^) = b^T K^ (x -- X^) Y^^
bb^j>(x, X;) = bd^ K^ (x - X^)
en la expresión (2) se obtiene la versión recursiva del estimador núcleo de la
función de regresión con diseño aleatorio, dada por:
n
^bd^K;(x-X;)Y;
^^(x^ ^ ^ - ^
n
(9)
^ bd^ K^ ( x - X^ )
^ ..^ ^
Para el caso z= 0, ha sido estudiado por Krzyzak-Pawlak ( 1984) y Greblicki-Pawlak (1987) en un contexto de independencia y Roussas y Tran (1992) para datos
dependientes.
Un caso de particular interés es la estimación de ia función de autorregresión,
de orden d, de una serie de tiempo real, muy utilizada como función de predicción.
Esto es, se desea estimar el valor de ZN +^ a partir de una muestra Z^, Z2, ...,
ZN, obtenida de una serie de tiempo real estacionaria {Zt: t E 71 } que se supone
próxima a un proceso markoviano de orden d y en la que, por tanto, Zt depende
---^
fundamentalmente de Z^d' _(Z t_ d, ..., Z t__ ^). Entonces se puede utilizar como
-^
--^
función de predicción r(ztd') = E(Zt ^ Zt^' - ztd') siendo un estimador de esta función el dado en la expresión (9) haciendo:
---^
Yt=Zt+d, Xt=Ztd^d
cont= 1,..., N-d
En este trabajo se estudia el comportamiento asintótico de los estimadores
recursivos definidos en (4), (5), (8) y( 9), que corno se ha comentado son
particularizaciones dei estimador general dado en (2), y se comparan los resultados con los conocidos por los estimadores no recursivos que se deducen de
la expresión ( 1). Aunque algunos de los resultados que se aportan son fácilmente
^:.)^^
E.`iT^,i1^`; f I(,t^ F.:^;>F'F^^i(!^ l"^
deducibles de resultados conocidos, se ha preferido incluirlos para tener una
visión global del comportamiento de los estimadores no paramétricos recursivos.
Es conocido que en la estimación no paramétrica de una curva, g(x), una buena
medida de ajuste de la estimación no paramétrica, ^^(x), viene dada par el MECI
(Media del Error Cuadrático Integrado), definido par:
MECI( ^^) = E j ^n(x) -- g(x)
(10)
W(x) f(x) dx
\
,I
siendo W(x) una función pes©, no negativa. En muchos casos se utiliza W(x) = 1
ó 1^a b^, fundamentalmente en ia estimación de la función de densidad o de
distribución, aunque algunos autores como Marron (1985) y(1987) han utilizado
pesos de ia forma W(x) = 1^a,bj f(x)^', i= 1, 2 para el estudio de seiectores banda
obtenidos por la técnica de cross-validación cruzada de Kullback-Leibler. Estas
funciones peso, como indica Marron, son bastante naturales ya que proporcionan
criterios de error útiles para la aplicación de la estimación de densidades a los
problemas de clasificación. En el estudio de estimadores con denominador aleatorio (función de regresión y razón de fallo} se utilizan funciones peso para reducir
el efecto de las estímaciones en los puntos próximos a las cotas del intervalo de
observación, donde las métodos de suavización son menos exactos. Además en
situaciones generales, como han demostrado Hardle-Marron (1986) y Víeu
(1991), el MECI es asintóticamente equivalente a las siguientes medidas cuadráticas más fáciles de calcular: el ECI (Error Cuadrática Integrado) y el ECP {Error
Cuadrático Panderado}, cuya expresión es la siguiente:
2
ECI(9n) = ,1 Jn^x) 9^x ) W(x ) f(x ) dx
n
n
n
ECP(9n) = ^_ ^ 9n^Xi) - 9tXi)
n;_^
2
W^^i)
(12)
En el apartado II se estudia el MECI de los estimadores definidos bajo condiciones débiles de dependencia, así como su distribución asintática. En el apartado ! I I se exponen las conclusiones del estudio realizado así como se plantea
alguno de los problernas, actualmente sin resolver, que conlleva la aplicación de
los estímadores definidos. Finalmente, en el apartado IV se presentan ejemplos
de utilización de los estimadores definidos, trabajando con muestras de datos
simulados, lo que permite comparar la curva teórica con la estimada y, a la vista
de los resultados, validar el buen comportamiento de la estimación recursiva bajo
distintas condiciones de dependencia si se utiliza un parámetra de suavización
adecuado. Las demastraciones de los resul#ados obtenidos se desarrollan en el
Apéndice final.
^
^ i lwll'^( Ii ^PJ ^`^^^'^ ^^ ^'t^f^AMf^ 1^lI( ^A i^í. t.. 1F^^,i^^^'^"^ 1 1^ i^ i^<^
II.
PROPIEDADES ASINTOTICAS
La hipótesis de que las observaciones muestrales son independientes no es
realista en muchas ocasiones, por ejemplo, al trabajar con procesos temporales,
donde son de gran interés los estimadores recursivos. Por ello, en este trabajo
se asume que ias observaciones puedan ser dependientes, aunque exigiendo
que la dependencia entre dos observaciones tienda a anularse al aumentar la
distancia temporal entre ellas. Para ello se utiliza la condición de dependencia
a-mixing (fuertemente mixing) introducida por Rosenblatt (1956) y que es más
débil que la mayoría de las utílizadas: uniforrnemente mixing, asintóticamente
incorrelada, etc. Su definición es como sigue:
«Sea Fá la cs-álgebra generada por Xt, a< t < b y sea
cx(n) = sup^^ ^ P(AB) - P(A) P(B)^ : A E F^.,; B E F,t;^n,; se dice que el proceso Xt es
fuertemente mixing (a-mixing) si la sucesíón de coeficientes mixing a(n) decrece a ce ro . »
Los resultados se han obtenido bajo el supuesto de que d= 1 para una mejor
comprensión de los mismos aunque su generalización para el caso d-dirnensional
es inmediata. A continuación se exponen las hipótesis que se utilizarán:
H.1. EI proceso Xt es estrictamente estacionario y fuertemente mixing, verificando los coeficientes rnixing ^ a(k) Y^'2 + Y' < ^ para algún y> 0.
H.2. La función de densidad, f, y la función peso, 1N, son acotadas, no
singulares mutuamente y fW es integrable.
H.3. La variable aleatoria bidirnensional (Xt, Xt + S) tiene densidad conjunta
f(x,y; s) para s? 1, satisfaciendo:
^ f(x,y;s)-f(x)f(y)^ <_M <^
H.4.
para todo x,y
La función en estudio g(x) es (s+1) diferenciable con derivadas acotadas.
H.5. La función núcleo K(u), es acotada, simétrica respecto al origen y verifica: jK{u)du=1, .^ K(u)^ du <^, y ^uK(u)^ -----^ 0 cuando ^u^ ---^ ^
H.6.
Adernás K(u) verifica:
jK(u)u^du = 0 para j= 1,...,s-1
jK(u)usdu = DS <^, y f K(u)u^+1 du <^
H.7.
La sucesión de parámetros de suavización verifica:
b^ --^^ o, n b^ ---^ ^, I i m ^
^ n
=^^<^,
paraj<_s+1
,,^fAt^)(^,T^(,.A E `^:,ij^t^Jf.^y1. ^+
Estas hipótesis son reiativamente débiles, la primera sobre los coeficíentes
mixing se verífíca si éstos son de tipo exponencial. La tercera se podría debiii#ar
a costa de obtener una cota superíor para la componente de la varianza del
estímador en lugar de su expresión asíntótica. La cuarta es típica de los estudias
de estimacián no paramétrica y se refere a la regularidad de la curva en estudio
y no a su forrna; j unto con ia sexta, cuanto más estricta sea, menor será el sesgo
de ia estimación. Par último, la séptima sobre la convergencia de la sucesión de
parámetros de suavización es clásica en ei estudio de estimadores recursivos y
la verifica ia elección usual de b^ = Cn-Y, en cuyo caso s^ = 1 I(1--^^ }.
Se utilizará la siguiente notac^ón:
DS =1 K(u) usdu
GK =^ K^(u}du
H(z}
^t5
et
.^.^(T}
_ ^2t 1
$t
(De H.S. se sigue que CK ^^ y de H.6. D^ ^^)
A.
Función de Densidad
Se obtiene en primer lugar el MECI del estimador ^^ (x) definido en (4).
ieorema 1.1
Bajo las hípótesís H 1-^H7 se verifica que
^
MECI(f„} = b^s J 8f (x) W(x) f(x) dx + ^-- ^ Vf W(x) f(x) dx + o b^s +^
nb^
nb^
siendo Bf^x) =-^- H(T) DS^S'(x} la componente del sesgo
s!
y
V^ (x^ =^^T) cKf{x)
Ia camponente de la varianza
(13)
comentari©
Para la elección usual b^ = Cn^-7, el valor de y que minimiza el ME^I es 1/( ^1+2s},
siendo el orden del MECI iguai a n-2S^4^ + 2S^, resultado igual al obtenido para el
estimador núcleo no recursivo {Rosenb^att-Parzen}.
blamando BNf(X} a la componente del sesgo del estirnador no recursiva se
verifica que Bf(X) = S^N^(X}H(i), siendo H{i) =--- -^----^ --- función estrictamente
1 -- Yr - Ys
creciente en [Q,1 ^ y acotada inferiormente por 1. Análogamente, liamando
VÑf(x) a la componente de la varianza del estimador no recursívo se obtiene que
^^ %
E^TIMAC;Ii)tv ^J() NAF^AMETRic";A F2E C;i.1R511^A t)f t l ^F^^^A.^;
2
Vf (x )= VÑf( x} G( i) siendo G( T) _^ 1^` ^^ función estricta mente decreciente en
1 -- 2^r + ^y
[0,1) y acotada superiormente por 1.
De lo anterior se concluye que ei estimador recursivo tiene mayor sesgo que
el no recursivo (se multiplica por un número entre 2.77 y 4 para ^y = 1/5, según
el vator de i) pero menor varianza (se multiplica por un número entre 0,833 y
0,8); teniéndose que globalrnente el estimador no recursivo presenta un MECI
menor que el recursívo aunque de igua! orden. Además, eligiendo un i E[0,1 ],
cuánto mayor sea T mayor será su sesgo y rnenor su varianza, siendo el decrecimiento de ia varianza inferior al crecimiento del sesgo y, consecuentemente, el
estimador recursivo con menor MECi se obtiene para i= 0.
Es conocido que la dependencia de las observaciones no afecta a fa componente del sesgo del error cuadrático pero sí hace que aumente la varianza aunque
bajo la hipótesis impuesta (H.1) los términos adicionales debidos a la dependencia son de orden inferior a 1/nb^. Por ello ia ecuación (13) es la misma que en
el supuesto de observaciones independientes.
La normalidad asintótica del estimador ^n(x) se ha obtenido utilizando un Teorema Central del Límite de Bradley (1981 }{Teorema 3, pp. 4), para disposiciones
triangulares de variables aleatorias fuertemente mixing, no necesariamente estacionarias. Previamente introducimos la siguiente definición:
Denótese por
P(n) = p Fi, Fk+ n= Sup^Corr(f, 9): f E L2(Fi), 9 E ^2(F^ + ^)
Y
p*= iim p( ^)
n --^ «^
Entonces, para b> o y o < p< 1 se define
p2^^t2 -+ d} + 2p2^c2 + b^
9(S^ P) ^
Teorema 1.2
_
_
__
2^/2 ^^ ^ _ p^c2 + ^^i2
Si se verifican las hipótesis del Teorema 1.1 y además:
H.8.
nbn + 2S ---^ 0 cuando n--^ ^
H.9.
Existe un ó, o< S<_ 1, tai que g(ó,p*) < 1
Entonces ( nb^)
1/2
(i'^(x) - f( x ))
^ N (0, V^ (x)
(14}
E.,i^.^^; .,'t4
fi. f; f'.:^,P^+ 1i
Este resultado es de interós ya que permite calcular intervalos asintóticos de
f(x) utilizando solamente la información que proporciona la muestra de partida.
La hipótesis H.9 afecta a la dependencia de los datos muestrales, trivialmente
se verifica para p* = 0, que es la condici©n de que e! proceso sea asintóticamente
incorrelado, condición intermedia entre uniformemente y fuertemente mixing.
B.
Funci^n de Distribucitnn
,^ La expresián de! MECI del estimador recursivo de !a función de distribución
F^(x) definido en (5) es la dada en el siguiente teorema:
Teorema 2.1
Bajo las hipátesis H 1-H7 se v+erifica que:
MECi ( F^ ^) = b^S J BF (x) W (x) f (x) d x + J VF W (x) f(x) d x + O b^ s ,
n
bl
siendo BF(x) _ ^ H{T^ DS f'S ^-''(x) la componente del sesgo
s!
Y Uf (x) _^ ^^(^) T^(X) - bn ^2(T) Tv f(x) + Tp + C7b^
n
la componente de la varianza, dande se ha Ilamado:
TF(x} = F(x) -- F(x)^
G^(t) = ^^^ ;
^2(T
eT
Tv =^^ uK(u}K*(u)du con K*(u} = f
^^^
K(v)dv
y
,
H 2T+2 .
2
gt
'
Tp un término
©casionado por !a dependencia de los datos y acotado por
Tp ^ 1^G^(T)
^ ^^
^
^ cx(k}Y^^^ + ^^
k ^- 1
Comentario
Para la elección usual b^ = Cn^Y, ef valor de y que minimiza el MECI es 1/(2s-^ ),
resultando e! orden del MECI igual a n--' en e! término principa! (debido a la
varianza de! estimador) y n-2Si(2S ^ ^^ ei orden de los términos secundarios,
resultado igual al obtenido para el estimador núcleo no recursivo. Llamando
f. `i ( lMA{.I( ÍN NC.i Pé"^FZAME:_ i f^1C^^
f1f: c;l 1fZS4VA f lE ^.t JF^`'A`^
BNF(x) a la componente del sesgo del estimador no recursivo se establece una
relación con BF(x) igual que la comentada en el caso de la estimación de la
densidad. Pero en el término principal de la varianza del recursivo se obtiene
2
TF(x) - TNF(x}G^(x), donde G^(i) _^-^-- -^ ^^ función estrictamente creciente en
1 - 2yr
[0,1 ] y acotada inferiormente por 1{para T= 0). Por tanto el estimador recursivo
tiene mayor sesgo y varianza que el no recursivo, siendo ambos mayores cuanto
mayor sea el valor de i, por lo que en este caso se debe de trabajar con i= o,
en cuyo caso, el término principal del MECI es el mismo en ambos estimadores,
siendo los términos de segundo orden mayores en el recursivo.
Un estimador no paramétrico recursivo muy utilizado es la distribución empírica. Este estimador es centrado pero su varianza aumenta respecto a la de los
estimadores núcleo (tanto en su versión recursiva como en la no recursiva),
totalizando un MECI mayor que la de estos últimos.
^
Sobre la distribución asintótica del estimador Fn(x) se ha obtenido el siguiente
resultado:
Teorema 2.2
H.10
Si se verifican las hipótesis del Teorerna 2.1, H.9 y
nb^s --^ 0 si n--3 ^
^
Entonces
d
n ^^2 (F„( x) - F(x )) -^ N (0 , VF( x ))
( 1 6)
Comentario
La hipótesis H.9 en los Teoremas 1.2 y 2.2 se podria debilitar exigiendo
condiciones menos restrictivas respecto a la dependencia de los datos pero
imponiendo condiciones más fuerkes a la sucesión de parámetros de suavización,
en cuyo caso para la demostración de estos Teoremas se utiliza el «método
Bernstein» [ver Peligrad, M. (1985)] que consiste en descornponer la suma de
1as variables aleatorias que definen ei estimador en sumas de grandes bloques
separadas por bloques más pequeños, probándose que la aportación de éstos
es asintóticamente nula, mientras que los grandes bloques tienden a ser independientes lo que permite aplicar el Teorema Central del Limite de LindenbergFeller para variables aleatorias independientes. Este procedimiento ha sido ampliamente utilizado entre otros por Masry (1986).
^ k, r.^,^ r,^, ^^^^ r^ f r,F^Ar^^^^^ n
C.
Función Razón de Fallo
En este apartado se estudian las propiedades del estirnador de la función razón
de fallo: hn(x}, definido en (8}. Se ha elegido este estimador en lugar de ^in(x) por
ser rnás fácil de calcular aunque se obtienen con ambos estimadores unos
resultados muy parecidos, ya que, como se verá a continuación, en !a estimación
de ia función razón de fallo influye mucho rnás la estimación de la densidad que
1a de la distribución.
....
Por otra parte, si el estimador en estudio es el cociente de términos aleatorios
como ocurre en el caso de la función razón de fallo o de la función de regresión,
el MECI na es una buena medida del ajuste de la estimación, como han indicado
Marron-Hardle (1986) ya que admitiendo funciones núcleo que tomen valores
negativos, puede no existir. Por ello razonando camo en el citado trabajo de
Marron-Hardle, y teniendo en cuenta que:
i)
Gn(x)
---^ F{x) casi seguro {Ver Gy^irfi y otros, 1989).
ii) Se supone que inf ;F{x): x F Soporte {W); > 0, para evitar problemas en el
denaminador.
Se obtiene que:
n
_ -.
^ln(X) - il(x
Sb i-: 1
,^
n ^
bi Ki ^X - Xi) __ ^ ujil^x)
n j 1
n
1
_
1
n
*
^ H (x, X;) 1 + 0(1)
b i ,. 1
--
^ u^^
nj=^
17)
bi Ki(x - Xi) ' Sb vih(x)
H*{x, Xi) = _ _ _ _ _
n_
F(x)
^
Y parece razonable utilizar en lugar del MECI (hn} la siguiente expresión
siendo
n
Sb ^ ^, b;
y
^
MECI*(hn) = E
J
1
^b
n
^;, H*{x, X;)
2
W{x)f(x)dx
(18
n
Además, Ilamando h^{x) = 1
^ H*(x, Xi), de la expresión de H* (x,X;) se
Sb i=-1
n
--
deduce que h^(x) =^^-^x) `^G^(x) h(x) es un estimador tipo núcleo de la función
F(x)
^
CERO. Por tanto, el cálculo del MECI* {hn) = MECI{h^) se puede hacer de forma
análoga a la realizada en Ios dos apartados anteriores. Y asi se ha obtenido:
F^^ f iM^t.l^ ^^^ r•JC ) F^ARAME T RIC;.A ^^E t..^ )F^`^,ivA í)f ( 11F1^, A,^,
Teorema 3.1
^
MECI* (h^
Bajo las hipótesis H 1-H7 se verifica que:
Bf (x) W^x) f(x^ dx + 1 J V^(x) W{.x) f^x) dx + o b^s + 1
nb^
F(x)2
nb^ (19}
F(x)2
Comentario
^
De las expresiones (13) y(19) se deduce que el MECI ( ^) y el MECI* (h^) son
iguales, excepto que en las integrales de este Último aparece el factor F(x)^2. Por
tanto, hay una estrecha relación entre la estimación de la densidad y de la función
razón de fallo, como ya han indicado otros autores (Singpurwalla-Wong, 1983);
siendo, en consecuencia, válidos los comentarios realizados en el apartado de
la densidad para la razón de fallo.
A partir de la normalidad asintótica del estirnador ^n(x) y de la consistencia
puntual fuerte de G^(x) se obtiene la normatidad asintótica del estimador hn(x),
como se expone a continuación:
.^r
Teorema 3 .2
S i se verifican la s h ipótesi s del Teorema 1 . 2
Entonces (rlb^)^^2 (h ^( x ) - h (x )) --^ N ( 0 , V^( x ))
siendo V^(x) = G(T) CK f( x ) F-2( x) = Vf (x) F-2(x)
D.
Función de Regresión
En este apartado se estudia el estimador no paramétrico de la función de
regresión definido en (9), rn(x), y que es la versión recursiva del clásico estirnador
de Nadaraya-Watson. Se supondrá, para evitar que el denominador se anule,
que existe un c>o, tal que f(x)>0 para todo x perteneciente al soporte de la función
peso W(x), siendo f(x) la densidad marginal de la variable aleatoria X.
Por los argumentos expuestos en el apartado anterior el MECI no es una buena
medida de ajuste de este estimador y teniendo en cuenta que
n
n
r^(x) - r(x) _
n
^ bi Ki (x - xi)Yi
i=^
1_
^ b^ K^ ( x _ X^ ) r( x)
Sb^^1
n
^ b^ K^ (x ~ X^)
Sb i-1
n
^ R* (x, X^) 1 + 0(1)
{21)
E^.,;1 A[)1 `^ ' I f., C^ f_ `i ^'' A ^,I t a 1 A
^' >^-^ ^
siendo
R`
bTK, (x-X,)Y,-btK, ( x-X;) r(x)
f(x^
,x,,^
Se utilizará en lugar de! MECI (r^) la siguiente expresión:
n
2
MECI*(r^) = E J ^^, R*(x, X;)
Sb^^^
v1/(x) f(x)dx
(22)
Llamando q(x) = r(x)f(x), un estimador de esta función viene dado por:
n
qn(x) = ^ ^ b^ Ki (x -- X^)Yi
Sb^-^
n
,Í
Donde, por tanto, r^(x) = S
b
^,_
- g„( x) r( x
es un estimador, tipo
f( x)
núcleo, de la función CERO.
A partir de !as expresiones del sesgo y varianza de Ivs estimadores ^`^(x) y qn(x)
se calcula el MECI* (rn):
Teorema 4.1
^1.11.
Se verifican las hipótesis H 1-H7, y además:
E(Y2) ^^, lo que garantiza la existencia de ia varianza condiciona!
2 = E ( Y - r(X})2 /
v(x)
x= x que suponemos continua.
Entonces:
MECI*(r^) = bn^ J B?(x) W(x) f(x) dx +--^ ^ V2(x) W(x) f(x) dx + o^bñs
n b„
t'1bn )
(23)
^
siendo Br(x) _-^ H(T)DS ^^^5^ _^ s>>(X) la componente del sesgo
si
f(x)
Y
V?(x) = G(^)CK v2{X)
f(x)
la de la varianza
Comentario
Para la elecci©n usual b^ = Gn^Y, e! valor de y que minimiza e! M ECI es 1/(1 +2s),
siendo el orden de! MECI igual a n-25^^^+25^, resultado ígual al obtenído para los
estimadores no paramétricos recursivos de la densidad y de la razón de fallo.
Además la influencia de! parámetro T en el MECI y la relación entre e! estimador
recursivo y el no recursivo (de (Vadaraya-Watson) es igual que en el estudio de
la función de densidad.
t.,1iM^r.it^^^r^^ r^J+'7 F^^ARAME^^ TFZi^^.^ F^F ^^^^;^ ^^^.^^;i^a.
f^E^ ^^^^ ^ iF^^^^^.^
`_^93
Sabre la distribución asintótica del estimador r^(x) se ha obtenido el siguiente
resultado:
Teorema 4.2 Si se verifican las hipótesis de los Teoremas 1.2 y 4.1.
112
Entonces
III.
nb^
n
d
r^(x) - r(x) ------^ N 0, V?(x)
(24)
CONCLUSIONES
Se ha definido una amplia clase de estimadores no paramétricos, recursivos,
de curvas y se han estudiado propiedades asintóticas del estimador tipo núcleo,
de las cuatro curvas de mayor interés desde un punto de vista estadístico. En la
definición de estos estimadores se introduce un parámetro T que, excepto para
la función de distribución, actúa de balanza entre el sesgo y la varianza del
estimador, ya que el sesgo aumenta con T, pero disminuye su varianza, efecto
similar al que produce la elección del parámetro de suavización aunque en menor
orden.
Comparando el MECI de los estimadores definidos con el de sus análogos no
recursivos [ver Vieu (1990)] se concluye que estos estimadores son competitivos
ya que asintóticamente tienen un error cuadrático del mismo orden aunque algo
mayor. Este es el precio que hay que pagar por la ventaja de la recursividad,
propiedad muy deseable si los datos son obtenidos secuencialmente, ya que se
ahorra tiempo de computación y memoria.
Además las propiedades asintóticas demostradas se han obtenido bajo hipótesis generales de dependencia, por lo que son válidas aun en el supuesto de
trabajar con datos de series de tiempo. En general, la dependencia de las
observaciones hace que aumente la varianza del estimador pero en orden inferior
al de la componente principal de ésta, si la dependencia no es muy fuerte, esto
es, la suma de las autocorrelaciones es finita (ver Hall-Hart, 1990), aunque sí
puede influir muy significativamente al trabajar con muestras finitas como ha
indicado Wand { 1992).
Finalmente comentar que un problema de interés, en el que estamos trabajando, es la obtención del parámetro de suavización a par#ir de los datos muestrales.
Suponemos que se obtendrán buenos resultados, considerando que éste es de
la forma b^ = CnTY, siendo y el valor que minimiza el MECI y calculando C por
validación cruzada de mínimos cuadrados, elirninando en la técnica «leave-oneout» más de un dato en condiciones de fuerte dependencia (Ver Hart-Vieu, 1990)
o utilizarfdo otros métodos basados en el Bootstrap o la técnica «plug-in», ya que
en la actuaildad, se están obteniendo buenos resultados con estas técnicas de
cálculo del parámetr0 de suavización en !a estimación no paramétrica de cur^as
tanto en el supuesto de datos independientes [Ver Marron (1989) y Cao-Cuevas-
E. `>TA[)i`,1li.;A E `^^'AP^(.)l A
`^^^
González (1993)] como en un contexto de dependencia [Cao-C^uintela-ViIlar (1993}].
IV.
SIMULAGIONES
Para observar el comportamiento de !os estimadores definidos con muestras
finitas se exponen a continuacián diversos ejemplos de su utilización en la
estimación de las distintas curvas estudiadas y bajo diferentes condiciones de
dependencia. Los datos muestrales se han obtenido por simulación y los resultados obtenidos pueden verse en las figuras 1-16. Todos los ejemplos estudiados
va#idan el buen comportamienta de los estimadores recursivos definidos y su
competitividad frente a los no recursivos, cuando el parámetro de suavización es
elegido adecuadamente.
En las cuatro primeras figuras se estudia la función de densidad, en las figuras
5-8 la función de distribución, representando la función teórica, la empírica y las
estimaciones recursiva y no recursiva. En las figuras 9-12 se estudia ia función
razón de fallo, representando la función teórica y ef estimador recursivo. Finalmente en las figuras 13-16 se estudian modelos de regresión, en los dos primerOs
casos, y de autorregresión en los dos últimos.
Los modelos estudiados son los siguientes:
En las figuras 1-5-9 los datos son generados por un modelo AR(1) con p= 0, 5,
siguiendo una distribución N(0,1). En las figuras 2-6-10 los datos provienen de
rriixturar dos mOdelOS AR(1) (al 50 por 100), el primero con distribución N(-1,6)
y el segundo N(+1,a), con p= 0,5 en ambos casos. En las figuras 2 y 10 se ha
utilizado a= 0,5 y en la figura 6, a= 0,3. En las figuras 3-7-11 los datos se han
generado con un modelo AR{1) y distribución exponencial con ^, = 1 y p= 0,5.
Finalmente, en las figuras 4-8-12 los datos son 4-dependientes, con distribución
Gamma (2,1).
A continuacián se exponen las características de los ejemplos de simulación
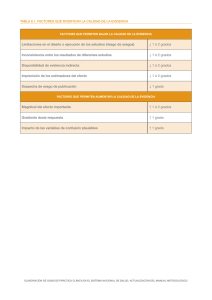
estudiados, indicando el Error Cuadrático Medio ob#enido en cada cas0, habiéndOSe elegido el parámetro de suavización de la forma: bn = Cn-Y, con ^y = 1/5,
except0 para la distribución que es 1/3, 1a constante C se ha calcuiado de forma
empírica. En los estimadores recursivos se ha utilizado T= 0 y como función
núcieo la de Epanechnikov. ^
Figura
Tam. Mues.
1.
Normal
100
2.
Bimodal
200
3.
Exponen.
100
Estim.
NO Rec.
Recurs.
NCl Rec.
Recurs,
NO Rec.
C
2,48
2, 04
2,1s
1,76
0,45
E.C.M.
0, 000
0,001
0,002
0, 003
0,004
784
112
947
017
677
59^
f`-^^TIMAC;1ON N(^^) PAf2AME TF^f(.;A f^E^C.:I.JRSI'^A E)E^ (:Uk`^^A;^,
4.
5.
6.
Figura
Tam. Mues.
Gamma
100
Normal
Bimodal
E C.M.
Recurs.
NO Rec.
0,45
1,40
0,004
0,000
534
577
Recu rs .
1, 40
0, 000
579
NO Rec.
3, 55
0, 002
394
100
Recurs,
Empír.
NO Rec.
2, 90
1,50
0, 002
0,002
0,003
098
882
693
Recurs.
Empír.
NO Rec.
Recu rs.
Empír.
NO Rec.
Recurs.
1,00
-5,20
3, 50
4,55
3,90
0,003
0,003
0,001
0, 001
0,001
0,001
0,001
692
795
253
122
965
707
456
Empír.
-
0,001
904
Recurs.
Recurs.
Recurs.
Recurs.
1,50
0,40
2,00
2,80
0,064
0,024
0,021
0,008
631
556
484
640
Exponen.
100
8.
Gamma
100
Normal
Bimodal
Exponen
Gamma
C
100
7.
9.
10.
11.
12.
Estim.
200
500
500
200
En las cuatro últirnas figuras se estudian modelos de regresión y autorregresión
con datos dependientes, siendo sus características las siguientes:
Figura 13. Regresión. Modelo Y=-4X /(1 + X2) +^, siendo X un ARMA(2,2),
con cs = 1, y^ E N(0,0'S), para n= 100 y C= 1 se obtiene: ECM = 0,018 799.
Figura 14. Regresión. Modelo Y= sen (4X + 2} +£, siendo X un AR(1), con
p= 0,8, 6= 1 y E E N(0,0'2), para n= 200 y C= 0,4, ECM = 0,015 767.
Figura 15. Autorregresión. Modelo X(t) = 0,8X (t-1) +^(t), siendo ^ E N(0,0'S),
para n = 100 y C= 0,9 se obtiene: ECM = 0,002 559.
Figura 16. Autorregresión. Modelo X(t) = sen (3X(t - 1}) + F(t), siendo
^ E N(0,0'S), para n= 100 y C= 0,9 se obtiene: ECM = 0,018 733.
c.^ C:^ ^j
T^ti f t ^^:, r 1 r^
^-,F>^^r^^ .>^ ^°^
J. U
t^f^^^ t-1I^ L
f ± I C-^.
f31 t-It^Dl1t_
E.`.^11MA^_,IC^Jf^.l N(^.) F^AFZAM^E:^^iFll(^.:A F1Ei_,IJF^t^^i^^./r'^^, {.ik
FIG. 3
OENS i p^.tl
^
1_ J ^
^
1
.7 _
1^^^r'^.^
1
^ ~^^:
^T--- T --T
^^ y. ^^ r
.
--':'`"i
^1^1 ^
,^ , (,)
.U
^
^^:^s^n^i^
.q
I..__.4
^ xr ^c,r^ir. ric: ^^
^,^ .
ú . l^
,, , , - F,(
. ;(_
`^ ^3f-3
^
'
i
^
. .^ ?E l,
F1G. ^
F_( T E. N. R}
1. 0
l
/
%.
^ ^
/
r ^ ^^
/,^
^ ,^^^f
^•: .
r.'^,
I --
T
__ ^
--T-^
1- -_ ^
2. 2
(
1
T
. 7
pi sr_ N oRMn^
T
2. 2
^
E STiMA( ;1C)N NC> F'ARAME TRIC^A
RF(^:11R:^1 ^^^
^'f
t::1 1RVA^^
5^g
^ I G. 7
(-^-_^^.^.N.R^
.s
.z ^
i
2. 0
T----^
i
1--1-T-1
^.0
6.^
D.^ST._ CxF'Q^VENC I hL
FIG. 8
3. 0
9. 0
6. P^
GnMMA
...^...
^t^t^^
E `.;T,A()I ;TIt:A ESPAN(^1 f^
^. 3
2. 9 ,_.;
1. 5 ._,,
I
- 2. P1
2. P^
7
^______+'tr^E^r^i,^^
^
r- ^ ^. ^ c^
r----f^^-^^E^E^_^
S . 6 ^1
^
3. © _...
! . ^ ......i
0
'
^_ ,I`
^
i-r-t--r^-r-r
-. ^
-z. 0
^\
T^TT -T^T
+
BIMOD/+l_
I
E. `-^^fIMR(^:ICIN NC) F^A^ME: TF^IC::A HF^_Cl.)f^^,i^dF^
}^/^ ZI^RU
OE t.l.1k^JA^
1
2_ 0
1. 3
^^_.--.,...^,.^`^^^..^.1,`r`^l
r-T^-- r^ - T -^ -^-- i -T-- r--T---T-T-I
].. 7
3. 3
5. 0
F_XPONENCIAI•.
r
F ^G. ^z
.e
2. FJ
4. 0
6. 0
!_c^nnrin ^
F STAf)^^;ii(;A E SF'ANOi_A
Figura 13. Regresión. Modelo Y =-4X/t1 + X2) +^., siendo X un
ARMA^2, 2), con a= 1, y ^ E^V (0,0'S^, para n= 100 y C= 1 se obtiene:
ECM = 4,018 T99.
603
ESTIMACION NC) PARAMETRiCA, REC^IJRSIVA. C)E ^:.1..1RVA^
_
__
_.. _
_
_ _ . ._. ._._
_ _ ._ _
_
Figura 14. Regresión. Modelo Y= sen{4X + 2) +^, siendo X un AR{1),
conp=0,8,a=1,yEE N(0,0'2),paran=200yC=0'4,ECM=0,015767.
^
^^
,
,
__
^,''
-
_
,^^,
^;
,
.
'^!,
^
^
^
^;
'r
,, .
,,^..
... -,
.,:.. ,,^
^ ^^
^
_
,
^
,
^, ^
'
,
^
.^
^^
^
!
^
f^
,^
,,
^^ ,
:^
.^,^
,.
,
',^.
\
,.
^.
I
1
E^; i nr>>^>T ^^ ,^ F;^Fár,,r,^^ ^i ^
IJVt^
Figura 15. Autorregresió^n. Modeio X(t) = 0,8X(t - 1) +^.(t), sienda F E N
{O,o'5), para n= 100 y C= 4,9 se obtiene: ^CM = 0,002 559.
A
F IG. 15
. %',., .
,.-,^
^
,^ ,, ^ %
^,--.,,
^
.2
^
.2
.^
/
r
^^^r+^
nuTC^r^CGh^E j IoN
k',,f^IMF,(;IC^I`^J f^^J^_) PARAME ^FlIC:^ F^E^C.Uf=ZSI^^A [jE (_t.i^^^ ✓ ^`,^^^
605
Figura 16. Autorregresión. Modelo X(t) = sen[3X(t-1)] +^(t), siendo ^ E N
(0,0'S), para n= 100 y C= 0'9 se obtiene: ECM = 0,018 ?33.
FIG. 16
3
-. 3
-1. 0
1. 0
^UTOREGR E SION
E^ STA(^JI^yTiC^1A F SPAN("^}! Fa
^QFj
APENDICE. Demostraciones
Demostrac^án Teoremas 1.1 y ^.1
Las demostraciones de estos teoremas se basan en descomponer el MECI en
una componente debida al sesgo y otra a la varianza. Esto es,
^
MECI(fn) = E
!
+ I Ef^( x) - f(x ) ^^ W( x) f(x ) dx
I f( x ) - Ef^( x )^
^
= J l^ Sesgo(f n(X))
^
^
+ Var I f^( x) ^ W(x ) f(x) dX y calcular el sesgo y la varianza
^
J
n
de f^( X ).
A
-1
n
n
^ b; J K; (x - u) f(u) du.
^„ b^
EI primero est^ dado por: Sesgo fn{x) = f(x} -
j=1
i=1
Haciendo un desarrollo de Tayior de orden s de la funcián f(u) en el punto x,
el cambio de variable X-^-u = v y de las hipótesis H5 y H6 se sigue:
b;
-1
n
Sesg(fn(x)) = f(x) -^, bTJ
j=1
n
^ bi f(x) +^S^^X^
i=1
+ M j K(v) (vb;)S + 1 dv
S^
r
J
K(v) (vb;)S dv +
)1
siendo M una constante.
Ahora de H.6. y H.7. se sigue la expresión de Bf(x) dada en (13).
Por otro lado la cornponente de la varianza viene dada por:
^
n
Var fn(x) _
^ b^
j= 1
n
+
^ b^
j=1
_2
_2
n
^ b?^ Var K; (x -- X;) +
i= 1
n
^ b; bt Cov K;(x- X;), Kt(x - Xt)
i^t
f S(VMAC;VON N(:) PARAME TRiCA. RE^;IJRSIVA
607
UE ^:iJiiVA^^
A continuación se desarroila el primer sumando (s ^) y se prueba que el
segundo (S2) es de orden inferior.
n
n
^
^ b?t-1 b; E(K; (x - X;))2
. ^ .b?^ E(K; (x - X;))
S^ _ _' = _^_ ____ __ . .___. ___ ___._ . ^ __ ^__ __ __ ___._.__ _ ! =_.
,
n
^ bj
1=1
De ios Lemas de Bochner [ver lemas 1 y 2 de Masry (1986)] se tiene:
E K; (x - X;) ---^ f(x } y E K? { x-- X; } b; ---^ f( x) f K( u)2d u, cua ndo i--^ ^
De ello, la aplicacián del Lema de Toepliz y la hipátesis H.7. de la expresión
anterior se deduce:
S^ _(nb^) ^ G(2) CK f(x ) - ñ^ f( x )2 (62t/A?)= ( nb„) ^ G(T) CK f(x) ( 1 + 0( 1 ) )
En cuanto a S2 se procede como sigue:
Por H 1 existe {cn^ c[1, +^} tal que
^
^_ _^[oc( k)]' - µ ------3 0
b ñ µ k-^ Cn
cn --^^,
cnbn ---^ 6
pa ra aig ú n 0< µ< 1
(25)
En efecto:
__.-____
[a(k)]^
bn '- µ k '^C^
-N^
---_1 _ _ _
^^
^ k^ ^a(k)l' - µ
-^ C^k= 1
b'^3>0
Si ^y es el de la hipótesis H 1, eiigiendo µ ta1 que 0< µ<^^^`, y tomando:
2
(2+Y)(^ --^)_1
Y
R
v
en°bn
11 -- µ )/^3
se verifica trivialmente que b^ - µ c^ --^ 1, y, en virtud de H 1 y la monotonía de
^
la sucesián mixing oc(k;: ^ k^ [a(k)]^ ^ u<^, probando así (25}.
k =- 1
Ahora se descompone S^ en la forma:
n
S2-
j
2 ^^, n-k
^b^
1
^ ^b^ b^+kCov K;(x-Xi)^K^tk(X-xitk) +
k- 1i 1
^^^:^ t^.i)It^, P I( ,A f`>F^'ANt a^ ^.
F^?L1^^
n
!2
^
n--k
n- 1
1
k
b; b^*kCov(K,(x-Xi),Ki^k(x--Xi+k))-S3+S4
^
^.,
ib^
+
^
c^, + 1
1
EI lema de Toeplitz, H3 y H5, permiten acotar S3:
n
-2 Cn n-k
^ ^ bi b^ + k ,)J (K^ (x - u), Ki + k (x - ^/)I I f(u, ^/, k) -
^ b;^
IS3! ^
j=.1
k--1i=1
--^ f(u) f(v) ^ du dv = O(cn/n) = o(1/nbn)
Para acotar S4 se utilizará la desigualdad de Davydov para momentos de
variables rnixing (Hall-Heyde, 1980). Para ello, dado y> 0 se obtiene:
2+Y
2+Y
(x-ul
_ b^1-Y J b;1
E( K; ( x - X;)
l
b f
f( u)d u
= b; ^^ Y H;
2+Y
2+Y
du <^, cuando
f(u)du ---^ f(x) J ^K(u)^
K x- u
b;
i--^ ^, por ser K(u) acatado y utilizan o el Lema de Bochner [Lema 1, Masry
(1986)^.
dande Hi= J b; 1
De la desigualdad de Davydav se sigue que:
1/(2 + Y>
Cov Ki tx - X;), Kt (X - Xc) <g b^1_YH^bt1_. Ht
Y/(2 + y)
cx ^i-t^
por tanto,
l2 n.-_1
n
^ b^
^
^
S ^ C 16
j=1
^( k)Y^^ 2+ Y^
k=c^+1
1 1
n--k j t- 1 ^Y
^ bl
2+ Y H 2+ Y
r
i
^
1
!
r-
1 +Y
^
bi+k
Hi+k
1}Y ^+Y^
De la desigualdad de Cauchy-Schwartzy el carácter decreciente de bn:
2
n-1
^ ^^k)Y/t2 + y1
n
S4<16 ^b^
j -- 1
Lk
c^^ + 1
1
n
1'Y
^ b^ 2t y H2+y
1
De la convergencia de H; y el Lema de Toeplitz se sigue:
Y
S4 <(Cte.) ^
nbn
µ ^ 2 ).
2+y
n-1
bn 2+ Y
^ cx(k)^`2 ' Y' = ot 1/nb^,), según (25) (basta hacer
k
c„ ^ 1
i in.^^^ ^f^^^r^^
I^ ^)
f'7^f`C/',iVI^ ^ Í'`^^.,^
^E. ^
,^ ^fS.^`^^'v^I^^
h0^3
^ ^^ F
D^ la expresión abtenida para S^ y!a cota para S^ se deduce la expresión de
Var[f^(x)j dada en (13), fo que concluye la dernostración del Teorema.
La demostración del Teorema 1.2. es análoga y para el caso más general de
estimadares tipo delta puede verse en Vilar Fernández (1991).
Demostración Teoremas 3.1
De (18) se sigue que:
ti
MECI* (hn) = E
!
t
2
1
Sh;
H^ (x, X;)
VN(x) f(x) dx
f
n
=E
2
_
^fn(x> -- G^(x) h(x
F (x)
J
W( x ) f( x ) dx I= E J[(f^( x ) - E (f^( x )))+
2
"
-E(fn(x))
Gn(x) h(x)
W(x)
f(x)
.
._ dx
F(x)2
= T^ + T2 + T3
donde T^, T2 y T3 son ios términos obtenidos al descomponer el binomio.
"
A partir de las expresiones del MECI de los estimadores f^ ^Teorema 1.1.) y
G^ [ver Vilar Fernández { 1991 }] se obtiene:
T^ = J[ Var (f„( x )^] W(X) f(X) dx = ^ J Vf( x ) w^X) f(X) dx
nb^
F^x^z
F^x^2
2
W( x ) f( x ) dx =
Tz = J E[^E( f „( x )) - G„(x) H ( x ))]
F ( x )2
n
lll 2
(E(fn(X)) - f( x ))+ ( f^x^ (F( x ) - G^(X)i II W(x) f( x ) dX =
,.,,
^. ^
' ^^
^ F (X> ^
F(x)
!
"
^
Sesg f^(x) +
+^f^X^ l Sesg lFn x
F ( x >^
)
2
E^F(x) - G„(x)
+ 2 SeSg ^f„(x) )2 +
w^_X) f(x) dx = bñs ,^ Bf (x) w^_X) f(x^ dx 1+ 0(1)
,
F(x)2
F(x)2
E•. ^^ADI^ T I(..;A E;^G'AN(^)l. A
6 Í f^
Finalmente, de la desigualdad de H^ilder se sigue que:
T3=2
l
^ E L^fn^x) -
E ( ^n(X))) (E^fn( X )) - Gn(X) h^X
^] w^X^
f^X^ dx ^
F(x)2
1/2
<_ 2
<
,(
1
1/2
E E{fn(x}) - =
Gn(x) h(x)
E fn(x) - E(fn))
Var { f x 1f2
Var G x
1^2 ^(_x_)W(x)f(_x) dx <_
( n( ))
))
nt
F(x)2
,^
-_ _
dx _
W(x)
f (x)
<
F(x)z
oVar f x h(x)W(x)f(x) dx
( n( ))
F(x)2
sustítuyendo estas expresiones se deduce la concfusión del teorema 3.1.
Demostración Teorema 4.1
La demostración dei Teorema 4.1 se hace de forma análoga, llamando q(x) _
= f(x) r(x}, su estimador nv paramétrico recursivo será:
n
n
^Ín(x) _
^ bj
j=1
-1
n
^ bi Ki (x -- Xi) Yi
i=-1
n
cuyo sesgo y varianza se calculan de igual forma que los del estimador fn(x},
obteniendo:
Ses9a qn{x) =^ H(^) ^s q^S^{x) bñ^
s!
Var^q „( x)) = G(t) CK f(x) ^v2(x) + r( x )^
nb n
^
COV c!n(x); fn(X) ^ G^T) CK q(x) __^
nbn
^
De estas expresiones, las del sesgo y varianza del estimador fn(x) dadas en
^
^
.,
*
q {x) -- f (x) r(x)
el teorema 1.1, y de la expres^on rn(x) = ^
- se sigue que:
fx
O
Sesgo r^(x) _ ^ H(T) C^
S^
i r(x) ^S'(x) - g_ts'(X>
^
f(x)
bsn
Var n(
r^) x= T C v2(x) 1
G^ ) K f( x) nb n
De donde se deduce la expresión del MECI^ (rn) dada en (23)
E 5 T IMA(;ION NC^ F'ARAME TRIC.^;A
_
_ .
RECURS^VA C^E (: l_JRVA^>
_
_
61 1
Demostración Teorema 1.2
Teniendo en cuenta que:
1!2
^
1/2
f^(x) - f(x) = nb^
nb^
1/2
nb^
n
n
f^{x) -- Ef„(x)
+
n
Ef^(x) - f(x) = An{x) + D^(x)
Por la hipótesis H.8. la parte determinística [Dn(x)] debida al sesgo tiende a cero.
Respecto a la componente aleatoria A^(x), considerernos la disposición triangular
de variables aleatorias ^;' = b; K; (x - X;) - EK; (x -- X;)
1 i2
de ésta construimos Z;' _^;'/ var(^ x)
1
si
i= 1, 2,.. .n, y a partir
i> 1/2
, con a=^
que es fuertemenn si T <_ 1/2
te mixing y no estacionaria. Demostramos que Z;' verifica las h^pótesis del Tesorema 3 de Bradley ( 1981).
Trivia lmente E^Z," )= 0 y Va r^Z ;" )
Por otra parte:
n
n
n
Va
^ Z;' = Va
i=1
1/2
^ ^;' / Var ^ ^^
i=1
^
n
1/2
n
= Va
^ b; fn(x) / Va
í=-1
i-1
^ ^^,
i^=1
Se ha demostrado anteriormente que utilizando el lema de Bochner se sigue
que Var K; (x - X;) = O(b; 1), por tanto, Va ^;' = o(b?^ -1). De esto y la expresión
de !a Var [^)^
fn x, se obtiene sus#ituYendo q ue Var ^ Z^
^ = nb^^
2T _ 1
1
i
1
^ Y P or la forma
bcx
n
de cx se sigue que Var ^ Z;' ---^ ^ cuando n--3 ^.
i = 1
Por razonamientos análogos se obtiene que:
E ^ Z;'
E1^inI 2+^i t_^ =O
t^__
O b2T - ^
bt,2 + h) - { 1+ t^) b(1 - 2i)(2 + t^)
^
^
cx
así pues, eligiendo á suficientemente pequeño, se obtiene que para todo i, n, se
verifica que E^Z;'r2 + b < ^.
f^ 1^
E. `^^f ^^Oli^^^^ f I(;,A E^^^^.^AN(. ^t ^
En vírtud de las afirmaciones anteriores y la hípótesis H.9. se cumplen las
n
condiciones del Teorema 3 de Bradley, por tanto si S„ =^, Z;', se verifica que:
^
1/2
S„I VaC(S^)
-
Í^
n
^ ^n
^ ^- ^
/
^ ^
n
(
n
^ ^n
Val^
l,:_ 1
^^
n
n
1/2
= fn(x) - E(fn(x)) / Var(fn(x)
c^onverge en distribución a una N(o, 1). De esto y la expresión asintótica de Var
[fn(x)] abtenida en (13) se sigue que:
An^x=
Efn(x)
n(x-)
) n b n^^2 f
d---^ N 0 + V2f( x
)
io que concluye la demostración del teorema.
Demostración Teorema 2.2
La demostración es análoga a la del Teorema 1.2. Teniendo en cuenta que:
n'^2 Fn{x) - F(x) = n'/2 Fn(x) - EFn(x) + n1^2 EF
+ D(x
n {x) - F(x) = A(x)
F
F ^
De la hipótesis H.10 se sigue que DF(x) tiende a cero. La normalidad asintótica
n
de la componente aleatoria
AF{x) ^ n'/2 Fn(x) - EFn(x) _^^;'
con
^-=1
n
^;' = n1/2
^ b^
-1
b; K^ (x -- X;) - EK; (x - X;) , se obtiene aplicando el Teorema
j^1
3 de Bradley a la disposición triangular de variables aleatorias:
i =1,2,...,n
n - 1, 2, . . . . .
Y;' = b^ K; ( x- X; )-- E K^ { x-- X;)
Razonamientos análogos a los realizados en la demostración del Teorema 1.2
nos permiten concluir que AF(x)
d--^ N 0, VF(x)
Demostración Teorema 3.2
1 /2 ,^
Teniendo en cuenta que nbn
^^
Gn(x)
n
nbn ^t2 fn(x) - ^(x
hn(x) - h(x
^ _ (X)
bñ/2
n1/2
^„-rn(x) ` F{x)
Gn(X) F(X)
Roussas ( 198^9} ha dern©strado que n'/2 Gn(x) - F(x) d^ N 0, c^^
siendo
6c - F(x) (1 -- F(x)) + Dn, con D^ un término debido a la dependencia de la muestra
E ST IMAC'.IC)N NO PARAME-TRICA. RE Cl.1RSIVA. C)E_ C;:t 1R^J/^,S
^13
que por la hipótesis H.1 es acotado, por tanto bñ/^ n'/2 Gn(x) - F(x)
de donde se sigue !a convergencia a cero del segund© sumando.
---3 0,
Por otra parte, Gy^irfi y otros ( 1989} han demostrado la consistencia fuerte del
estimador Gn(x), esto es, sup ^G^(x) -- F(x)^ ----^ o casi seguro {Teorema 5.2.1,
X
pp. 97). De esto y del Teorema 1.2 utilizando el teorema de Slutsky de convergencia de funciones racionales de variables aleatorias se sigue la normalidad
asintótica del primer sumando, esto es:
2
n
^i2/fn
_ ^ .__ ((n b^ 1
(x) - f(X) ) ^ -^ N ^'_v^.^X^ l
G^(x) ll
l^
F Z (x) 1
de donde se sigue la conclusión del teorema.
Demostración Teorema 4.2
1/2
De la hipótesis H.8 se sigue que la parte determinística nbn
Ern(x) - r(x} _
= D^(x) tiende a cero, por otra parte, del teorema 1.2 se sigue que:
1/2 ^^n(x) - E ^ n(x) ^
C^ b"J
sie n do
^ N (o, Ma),
^^n^ X ) - E^^(X ) I
/
Ma =^ 6f9
6f9
6f9 = G^T ^ C K 9 (X^ ;
^ ^
6^ = G ( T ^ C K f(X ) (VZ (X ) + f( X )^
6f = G(i) CK f(x);
De la aplicación del método «b» de Bishop y otros (1975) a ta función H(a, b) _
= alb se sigue la conclusión del teorema.
BIBLIQGRAFIA
BISHOP-FIENBERF-HOLLAND {1975). «Discrete Multivariate Analysis: Theory and
Practice». MIT. Press Cambridge.
BRADLEY, R. { 1981). «Central Limit Theorems under Weak Dependence» Journal
of Multivariate Analysys,11, 1-16.
CAO, R., CuEVAS, A. GONZÁLEZ, W. (1993). «A comparative study of several smoothing methods in density estimation». (En prensa, Comput. Statist. and Data
Analysis).
^}^ `^
k`^TAE:)!:>; ^(,r^ E.:.;F>t,t^^{^t A
CAO, R., QUINTELA, A. VILAR, J. M. (1993}. «Bandwidth seiection in nonparametric
density estimation under dependence: a simultation study». Computational
Statistics, v. 8, pp. 313-332.
DEHEUVELS, P. {^1974). «Conditions nécessaires et suffisantes de convergence
ponctuelle presque súre... >? C. R. Acad. Sci. Paris Ser. A, 278, 1217-20.
GREBLICKY, W. y PAU^A, K. M. (1987). «Necessary and sufficient consistency
conditions for a recursive kernel regression estimate» Journal of Multivariate
Analysis 23, 67-7fi .
GYOR^^-HARDLE- SARDA-V^EU { 1989). «Nonparametric curve estimation fron time
series», Lecture Notes in Statistics, 60.
HALL-HEYDE (1980). «Martingale limit theory and its applications». New York.
Acadernic Press.
HARDLE, W. (1988), «Applied nonparametric regression», Springer Verlag.
HALL, P. y HART, J. (1990). «Convergence rates in density estimation for data from
infinite order moving average processes». Probability Th. Rel. Fields, v. 87, pp.
253-274.
HART, D. y V^EU, P. {1990). «Data Driven Bandwidth choice for Density Estima#ion
based on dependent data». The Anals af Stat, v. 18, , n. 2, 873-890.
KRZYZAK - PAWLAK. ( 1984). «Almost everywhere convergence of recursive function
estimate and classification». IEEE Trans. Inforrn. Theory, 30, 91-93.
MARRaN, J. S. ( 1985), «An asymptotícally efficíent solution to the bandwith problem
of kernel density estimation». The Annals of Statistics, voi. 13, n.° 3, pp.
1011-1023.
MARRbN, J. S. (1987). «A comparison of cross-validation techniques in density
estimation» . The Annals of Statistics, vol. 15, n.° 1, pp. 152-162.
MARRÓN, J. S. (1989). «Automatic smoothing parameter selection: a survey».
Empirical Econom. 13, 187-208.
MARRÓN, I., HARDLE, W. (1986). «Random aproximations to some measures of
accuracy in nonparametric curve estimation». Journal of Multivaríate Analysis,
20, 91-113.
MasRY, E. (1986). «Recursive Probability Density Estimation for Weakly Dependent Stationary Processes», IEEE, vol IT-32, n.2, 254-267.
MASRY-GYORFI. {1987). «Strong consistency and rates for recursive probability
density estimators of stationary processes». Journal of Multivariate Analysis,
vol. 22, n. 1, pp. 79-93.
E: ^.>TIMAC^IC)N NC) PARAME jRft:;A, REC;IJf^^,IVA C^E (;^ )R^r^t,
615
PELIGRAD, M. (1985). «Recent advances in the central limit theorem and its weak
invariance principie for mixing sequences of random variables (A survey)». In
Dependence in probability and Statistics., Eberlein, Taqqu ed. Birkhayser.
PRAKASA- RAO, B. ^. S. (1983). «Nonparametric Functional Estirnation». Academic
Press.
ROSENBLATT, M. (1956). c<A central limit theorem and strong rnixing condition»,
Proc. Nat. Acad. Sci., 43, 43-47.
RoussAS, G. (1990). «Asymptotic normality properties of an estimate of the survival function under dependence conditions». Statistics & Probability Letters, 8,
335-243.
RoussAS- TRAN. (1992}. «Asymptotic normality of the recursive kernel regression
estimate under dependence conditions». The Annals for Statistics, voi. 30, n.
1, pp. 98-120.
SILVERMAN, B. W. (1986). «Density Estimation for Statistics and Data Analysis».
Champman and Hall.
SINGPURWALLA, N. y WoNG, M. (1983). «Kernel estimators of the failure rate function
and density estimation an Anaiogy, JASA, v. 78, n. 382, 478-481.
TRAN ( 1989). «Recursive density estimation under dependence». IEEE Transactions on information Theory, v. 35, n. 5, 1103-^! 108.
TRAN (1990). «Recursive density estimation under a weak dependence condition».
Ann. Inst. Statist. Math., vol. 43, pp. 305-329.
V^EU, P. ( 1990). «Quadratic error for nonparametric estimates under dependence» . Jaurnal of Multivariate Analysis, 2, 324-347.
VILAR FERNÁNDEZ, J. M. (1989). «Estimación recursiva, tipo núcleo, de ia función
de autorregresión para datos dependientes». Estadística Española, v. 31, n.
121, pp. 207-226.
VILAR FERNÁNDEZ, J. M. (1991). <cEstimación no paramétrica de la función de
distribución». Q^iestiio, v.14, n. 1, 3-20.
WAND, M. P. (1992). «Finite sample performance of densi#y estimators under
moving average dependence», Statistics & Probability Letters, v. 13, 109-115.
WEGMAN-DAVIES. ( 1979). «Remarks on some recursive estimators of a probability
density». Ann. Statis, v. 7, 316-327.
WERTZ, W. (1985). «Sequential and Recursive Estimators of the Probability Density» . Statistics, 16, n . 2, 277-295.
f> 1 E^
í ,^<, ^ i^ ^^ f <;F'F,r^WC;^ ^
i/vOLVERT4N, ^. - UvAGNER, T. ^19^9^. t<RE'CUrS1ve eStlmateS Of probábl^lty denSlt».
IEEE Trans. Systems Sci. Cybernet 5, 246-247.
SUMMARY
Recursive kernel estimators are defined for the following curves: density, distribution, hazard function and regression. Asymptotic properties for these estimators under strongly mixing dependence on the observations are studied. Some
asymptotic expresions are obtained for the Mean Integrated Square Error as well
as for its iimit distribution.
Finally, some examples show the behaviour of the previous estimators with
simulated data.
Key words: Nonparametric curve estimation, kernel method, dependence conditions.
AMS Classification: 62G99, 62GO5