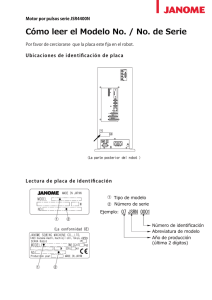
estudio de neuro-controladores evolutivos para navegación de
Anuncio

UNIVERSIDAD NACIONAL DEL CENTRO DE LA PR OVINCIA DE BUENOS AI RES FACULTAD DE CIENCIAS EXACTAS – DEPARTAMENTO DE COM PUTACIÓN Y SISTEMAS MAESTRÍA EN INGENIERÍA DE SISTEMAS ESTUDIO DE NEURO-CONTROLADORES EVOLUTIVOS PARA NAVEGACIÓN DE ROBOTS AUTÓNOMOS por José Alberto Fernández León Trabajo sometido a evaluación como requisito parcial para la obtención del grado de Magíster en Ingeniería de Sistemas Prof. Dr. Gerardo G. Acosta Director Prof. Dr. Miguel A. Mayosky Co-Director Tandil, 21 Noviembre 2005 ii ESTUDIO DE NEURO-CONTROLADORES EVOLUTIVOS PARA NAVEGACIÓN DE ROBOTS AUTÓNOMOS José Alberto Fernández León1-4-6 Gerardo G. Acosta2-4-6 Miguel A. Mayosky3-5 Escher, Sky & Water I, 1938 1 Instituto de Investigación INTIA – Departamento de Computación y Sistemas Facultad de Ciencias Exactas, Universidad Nacional del Centro de la Provincia de Buenos Aires (7000) Tandil - Buenos Aires – Argentina 2 Grupo INTELYMEC – Departamento de Ingeniería Electromecánica Facultad de Ingeniería, Universidad Nacional del Centro de la Provincia de Buenos Aires (B7400JWI) Olavarría - Buenos Aires – Argentina 3 Laboratorio LEICI - Departamento de Electrotecnia, Facultad de Ingeniería, Universidad Nacional de La Plata. (1900) La Plata - Buenos Aires – Argentina 4 CONICET 5 CICPBA 6 I+D – Consejo Nacional de Investigaciones Científicas y Técnicas, Argentina – Comisión de Investigaciones Científicas del Gob. de la Prov. de Buenos Aires, Argentina RIDIAAR – Red de Investigación y Desarrollo en Inteligencia Artificial Aplicada a Robótica Olavarría-Tandil, Argentina Universidad Nacional del Centro de la Provincia de Buenos Aires Tandil, Buenos Aires Argentina iii para Ana, Daniel, y Andrea para Nicolás y Paula, mis queridos Abuelos para mi Yo altruista v AGRADECIMIENTOS Desde lo profesional, quiero agradecer a todos aquellos que de algún modo colaboraron en el desarrollo de este trabajo y fueron una fuente de inagotable de paciencia, sustento y compañerismo, en mi búsqueda de la seriedad, sencillez, método y constancia. En primer lugar quiero agradecer ampliamente a Gerardo Acosta por el apoyo absoluto, por su optimismo, comentarios oportunos y buena predisposición desde el comienzo. Principalmente, por su gran paciencia ante mi marcada insistencia y perseverancia, y por compartir “un secreto olímpico” de mucha ayuda para mi trabajo. Al mismo tiempo quiero agradecer a Miguel Mayosky por sus comentarios concretos y siempre certeros, y particularmente por el “de cómo construir una cajita comestible” que me guío al inicio de mi formación. Además, a ambos por darme las pautas y el ejemplo de cómo hacer un trabajo científico. Realmente es grato trabajar con personas que ponen todo de sí, no solo la parte académica sino también la parte humana. Un agradecimiento muy especial a Juan M. Santos por su total predisposición ante mis requerimientos, y por su trato fuera de lo común hacia mis continuas inquietudes en todos los aspectos. También hago extensivo el agradecimiento a su Grupo de Inteligencia Computacional Aplicada a Robótica Cooperativa, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos Aires, Argentina, particularmente por la colaboración brindada durante la realización de pruebas experimentales con el robot real. Quiero expresar también mi agradecimiento a Ezequiel Di Paolo , que sin conocerme personalmente y a la distancia desde la Universidad de Sussex, Reino Unido, supo participar en etapas iniciales de mi investigación. En ello agradezco sus sugerencias, no sólo por nuestras charlas vinculadas a Robótica Evolutiva, sino que también por su ayuda incondicional y por su siempre buena voluntad. Del mismo modo, agradezco a Inman Harvey por su colaboración. A mis compañeros del Grupo de Investigación en Computación Aplicada (INCA) del Instituto INTIA, con quienes compartí un sin fin de cuestiones filosóficas y mundanas, no sólo a nivel personal sino también sobre temas vinculados a este trabajo. Desde el plano personal, quiero agradecer indudablemente a Ana, Daniel y Andrea quienes fueron los principales afectados de mis múltiples fluctuaciones de humor y de mis frecuentes abstracciones de la realidad. Sin ellos no podría haberlo hecho. A mis queridos abuelos, que gracias a sus esfuerzos, junto con los de Ana, Daniel y Andrea, hicieron de mí quien soy. Finalmente, quiero agradecer muy especialmente a la Comisión Nacional de Investigaciones Científicas y Técnicas (CONICET), por haberme apoyado con una Beca de Iniciación a la Investigación. Del mismo modo, a la Facultad de Ciencias Exactas de la Universidad Nacional del Centro de la Provincia de Buenos Aires que junto con CONICET, me dieron la posibilidad de formarme en Argentina, dado que, parafraseando a Bernardo Houssay, “es el país donde nací, me formé, tengo amigos, y aprendí”. vii “Pero, tan pronto como hube acabado el ciclo de estudios a cuyo término se acostumbraba a ser recibido en el rango de doctos [doctor, o nivel de postgrado], […] me encontraba embarazado por tantas dudas y errores que me parecía no haber obtenido otro provecho, al tratar de instruirme, que el de haber descubierto más y más mi ignorancia” René Descartes, Discurso del Método “[…] como la multiplicidad de leyes [en Ciencias] a menudo sirve de excusa para los vicios, de tal forma que un Estado está mucho mejor regido cuando no existen más que unas pocas, pero muy estrictamente observadas, […] estimé que tendría suficiente con los cuatro [preceptos] siguientes, con tal de que tomase la firme y constante resolución de no dejar de observarlos ni una sola vez. El primero consistía en no admitir jamás cosa alguna como verdadera sin haber conocido con evidencia que así era; es decir, evitar con sumo cuidado la precipitación y la prevención, y no admitir en mis juicios nada más que lo que se presentase tan clara y distintamente a mi espíritu, que no tuviese motivo alguno para ponerlo en duda. El segundo, en dividir cada una de las dificultades a examinar en tantas partes como fuera posible y necesario para su mejor solución. El tercero, en conducir con orden mis pensamientos, empezando por los objetos más simples y más fáciles de conocer, para ascender poco a poco, gradualmente, hasta el conocimiento de los más complejos, y suponiendo incluso un orden entre aquéllos que no se preceden naturalmente unos a otros. Y el último, en hacer en todo enumeraciones tan completas y revisiones tan amplias, que llegase a estar seguro de no haber omitido nada”. René Descartes, Discurso del Método. ix ESTUDIO DE NEURO-CONTROLADORES EVOLUTIVOS PARA NAVEGACIÓN DE ROBOTS AUTÓNOMOS Maestría en Ingeniería de Sistemas por José Alberto Fernández León [email protected] Director: Gerardo G. Acosta [email protected] Co-Director: Miguel Mayosky [email protected] Universidad Nacional del Centro de la Provincia de Buenos Aires Concejo Nacional de Investigaciones Científicas y Técnicas (CONICET) 21 Noviembre de 2005 RESUMEN Uno de los desafíos centrales de la Biología es entender cómo muchas especies constituyen colecciones de poblaciones de individuos diferenciados genéticamente (evolución). Dichas especies poseen el potencial de adaptarse a entornos locales en diferentes formas, principalmente manifestadas por su comportamiento dentro el entorno. Vinculado a esto, no sólo existe un interés profundo de entender cómo un agente natural (o artificial) puede alcanzar a adaptarse a un ambiente o situación cambiante, sino que también implica el desafío de construir mecanismos artificiales con iguales características adaptativas respecto de las naturales. Robótica Evolutiva es una nueva metodología para la creación automática de robots autónomos. Inspirado en el principio Darwiniano de la reproducción selectiva del más apto, es posible ver a los robots como organismos artificiales que pueden desarrollar sus propias habilidades sin la intervención humana. Por otra parte, basado principalmente en aspectos biológicos, son utilizadas redes neuronales, algoritmos genéticos, sistemas dinámicos, e ingeniería computacional para llevar a cabo el proceso de control robótico. Algunas de las características presentes en los robots desarrollados con dicha metodología, al igual que en los sistemas biológicos simples, involucran aspectos de robustez, simplicidad, flexibilidad y modularidad. Además, dentro de este contexto, los modelos vinculados con el comportamiento adaptativo autónomo pueden ser estudiados bajo el concepto de agentes robóticos, conjuntamente con la dinámica del ambiente con el cual interaccionan. En términos generales, el objetivo de este trabajo es estudiar controladores neuronales genéticamente determinados aplicados a robótica móvil autónoma, principalmente, con la finalidad de llevar a cabo tareas de navegación adaptativa dentro de entornos no conocidos. Una vez expuesto el enfoque de distintos autores dentro de la Biología y según el plano artificial, y particularmente luego del desarrollo incremental de experimentos dentro de Robótica Evolutiva, se planteará definir como objetivo secundario derivado del estudio realizado alguna postura en cuanto a la siguiente pregunta: ¿es posible definir mecanismos de diseño adaptativos y sistemático s que generen comportamientos emergentes? En síntesis, en este trabajo se desarrollará un estudio sistemático de controladores de robots móviles dentro de la Robótica Evolutiva, y particularmente la generación de controladores por niveles o estructuras modulares. El tema de combinar Robótica Evolutiva con estructuras modulares es muy amplio y todavía necesita ser estudiado suficientemente. Pero es posible lograrlo en casos donde los módulos son sub-redes x que realizan una simple tarea (p. ej. evasión de obstáculos), para luego dejarlos fijos y usar evolución para amalgamarlos en un controlador modular completo p( . ej. localizar un objeto y mover al robot hasta alcanzarlo). Lo antes descrito es uno de los temas de vanguardia a nivel mundial en donde puede ser aplicado el presente trabajo. Para ello se plantea también la descripción de una herramienta genérica, adaptable y extensible a partir de la cual desarrollar nuevos experimentos. Dicha herramienta ha sido utilizada para el desarrollo del presente trabajo. Palabras Clave: Sistemas Adaptativos y Evolutivos; Controladores Robóticos; Robótica Evolutiva; Redes Neuronales; Algoritmos Genéticos xi ESTUDIO DE NEURO-CONTROLADORES EVOLUTIVOS PARA NAVEGACIÓN DE ROBOTS AUTÓNOMOS Master in Systems Engineering by José Alberto Fernández León [email protected] Advisor: Gerardo G. Acosta [email protected] Co-Advisor: Miguel Mayosky [email protected] Universidad Nacional del Centro de la Provincia de Buenos Aires Concejo Nacional de Investigaciones Científicas y Técnicas (CONICET) 21 November 2005 ABSTRACT One of the central challenges of Biology is the understanding of how natural species constitute populations genetically differenced (evolution). These species possess the potential of adapting to local environments in different forms, mainly manifested by their behaviors into the environment. An increasing interest exists in understanding how a natural agent (or artificial) can adapt to an environment or changing situation, but rather it also implies a challenge of building artificial mechanisms with equal adaptive characteristics. Evolutionary robotics is a new methodology for the automatic creation of autonomous robots. Inspired by the Darwinian principle of selective reproduction of the most capable, it is possible to see robots as artificial organisms that can develop their own abilities without human intervention. On the other hand, based mainly on biological aspects, neural networks, genetic algorithms, dynamic systems, and computational engineering are used to carry out the robot control process. Some of the present characteristics in this methodology, as well as into the simple biological systems, involve characteristics of robustness, simplicity, flexibility and modularity. Also, in this context, models linked to the autonomous adaptive behavior can be studied under the concept of robotic agents, jointly with the dynamics of the environment. In general terms, the aim of this work is to study neural-controllers applied to autonomous mobile robotics, mainly with the purpose of carrying out tasks of adaptive navigation into a non-well-known environment. After exposing different works inside the biology and the artificial area, and mainly after the incremental development of experiments inside Evolutionary Robotics, it will be possible to give alternative answers to the following question: is it possible to define adaptive-systematic design mechanisms that generate emergent behaviors? Summarizing, in this work a systematic study of mobile robots’ controllers inside the Evolutionary Robotics paradigm will be exposed, with emphasis on the development of modularized co ntrollers. The topic of combining Evolutionary Robotics with modular structures is very wide and it still needs to be studied in depth. But it is possible to achieve it in cases where the modules are sub -nets carrying out a simple task (e.g. obstacle avoid ance), and then leaving modules fixed, using evolution to amalgamate them in a full modulate controller (e.g. to locate an object and move the robot until reaching it). This context is one of the topics of main interest where the present work can be applied. For that reason, the current work intends an experimental study of the controller’s development, as well as the description of a generic, adaptive and xii expandable tool for developing new experiments. This tool has been used for the development of the present work. Key Words: Evolutionary and Adaptive Systems; Robotic Controllers; Evolutionary Robotics; Neural Networks; Genetic Algorithms xiii TABLA DE CONTENIDOS Agradecimientos........................................................................................................................................................................v Resumen.................................................................................................................................................................................... ix Abstract..................................................................................................................................................................................... xi Tabla de Contenidos.............................................................................................................................................................xiii Lista de Figuras....................................................................................................................................................................xvii Lista de Tablas.....................................................................................................................................................................xxiii Glosario.................................................................................................................................................................................. xxv Prefacio....................................................................................................................................................................................... 1 CAPÍTULO 1 - INTRODUCCIÓN.................................................................................................................................... 1 1.1 1.2 MOTIVACIÓN.........................................................................................................................................................1 ORGANIZACIÓN DEL TRABAJO...........................................................................................................................7 CAPÍTULO 2 - CONTEXTO .............................................................................................................................................. 9 2.1 INTRODUCCIÓN.....................................................................................................................................................9 2.2 S ISTEMAS ARTIFICIALES : BIO -INSPIRACIÓN...................................................................................................9 2.2.1 Creando Robots Autónomos.......................................................................................................................10 2.2.1.1 2.2.1.2 2.2.1.3 2.2.1.4 2.2.1.5 2.3 2.3.1 2.3.2 2.3.3 2.4 2.5 2.5.1 2.6 2.6.1 2.6.2 Autonomía..............................................................................................................................................10 Posicionalidad y Corporeidad.................................................................................................................10 Adaptabilidad..........................................................................................................................................11 Agentes Reactivos...................................................................................................................................11 Adaptación en Sistemas Artificiales........................................................................................................12 ALGORITMOS GENÉTICOS................................................................................................................................13 Función de Fitness.......................................................................................................................................15 Fitness Landscape........................................................................................................................................16 Codificación Genética.................................................................................................................................16 REDES NEURONALES ARTIFICIALES ...............................................................................................................17 ROBÓTICA EVOLUTIVA .....................................................................................................................................17 La Robótica Basada en Comportamientos y la Robótica Evolutiva....................................................18 DISEÑO DE CONTROLADORES ..........................................................................................................................18 La Arquitectura por Subsumisión.............................................................................................................18 Evolución de Robots....................................................................................................................................19 2.6.2.1 2.6.2.2 Evolución de Robots: Mundo Real .........................................................................................................19 Evolución de Robots: Simulación ...........................................................................................................20 2.6.3 Enfoques en Evolución Artificial..............................................................................................................20 2.7 CIENCIA E INGENIERÍA ......................................................................................................................................22 2.7.1 Adaptación, Descomposición e Integración............................................................................................22 2.7.2 Descripciones de Comportamientos..........................................................................................................23 2.7.3 Auto-Organización.......................................................................................................................................24 2.7.4 Aprendizaje y Evolución.............................................................................................................................24 2.7.5 El Comportamiento, la Emergencia y el Entorno ..................................................................................25 2.8 EVOLUCIÓN ARTIFICIAL: IMPLICANCIAS ......................................................................................................25 2.8.1 Evolución Artificial e Ingeniería...............................................................................................................26 2.8.2 Evolución Artificial y Ciencia....................................................................................................................27 2.8.3 Discusión.......................................................................................................................................................27 2.9 CONCLUSIONES ...................................................................................................................................................29 xiv CAPÍTULO 3 - HERRAMIENTAS PARA EL DESARROLLO DE CONTROLADORES ............................31 3.1 3.2 3.2.1 3.2.2 3.2.3 3.2.4 3.2.5 3.2.6 3.3 3.4 3.4.1 3.4.2 3.4.3 3.4.4 3.4.5 3.5 3.5.1 3.6 INTRODUCCIÓN................................................................................................................................................... 31 ESTUDIOS BIBLIOGRÁFICOS PREVIOS............................................................................................................ 31 Estudio sobre Arquitecturas Homeostáticas............................................................................................33 Estudio sobre Tareas Específicas..............................................................................................................33 Estudio sobre Arquitecturas Evolutivas....................................................................................................34 Estudios sobre Robótica Evolutiva ............................................................................................................34 Estudios sobre Exploración en Navegación............................................................................................34 Estudios sobre Navegación por Sensores.................................................................................................35 EL ROBOT KHEPERA......................................................................................................................................... 35 SOFTWARE DE S IMULACIÓN ............................................................................................................................ 36 KIKS – Kiks Is a Khepera Simulator........................................................................................................36 Evorobot .........................................................................................................................................................37 Webots.............................................................................................................................................................37 WSU Java Simulator....................................................................................................................................38 YAKS – Yet Another Khepera Simulator..................................................................................................38 S ELECCIÓN DEL SOFTWARE DE S IMULACIÓN .............................................................................................. 39 Herramientas de Software y Técnicas.......................................................................................................41 CONCLUSIONES .................................................................................................................................................. 42 CAPÍTULO 4 - MÉTODO EXPERIMENTAL............................................................................................................45 4.1 INTRODUCCIÓN................................................................................................................................................... 45 4.2 MÉTODO EXPERIMENTAL ................................................................................................................................ 45 4.2.1 Entorno Simulado........................................................................................................................................46 4.2.2 Modelo Robótico: Modelo Simple..............................................................................................................47 4.2.3 Algoritmo Genético.......................................................................................................................................51 4.2.4 Neuro-Controladores...................................................................................................................................54 4.2.4.1 4.2.4.2 4.2.4.3 4.2.4.4 4.2.4.5 4.3 4.4 Controlador Feed-Forward Neural Network (FFNN)............................................................................. 55 Controlador Recurrent Feed-Forward Neural Network (RFFNN).......................................................... 58 Controlador Continuous-Time Recurrent Neural Network (CTRNN) .................................................... 59 Controlador Plastic Neural Network (PNN) ........................................................................................... 60 Controlador Homeostatic Plastic Neural Network (HPNN).................................................................... 63 TAREAS A RESOLVER ........................................................................................................................................ 64 CONCLUSIONES .................................................................................................................................................. 65 CAPÍTULO 5 - RESULTADOS EXPERIMENTALES CON CONTROLADORES MONOLÍTICOS .......67 5.1 INTRODUCCIÓN................................................................................................................................................... 67 5.2 EVOLUCIÓN......................................................................................................................................................... 67 5.3 ANÁLISIS FUNCIONAL ....................................................................................................................................... 69 5.3.1 Fototaxis.........................................................................................................................................................70 5.3.1.1 5.3.1.2 5.3.1.3 5.3.1.4 5.3.1.5 5.3.1.6 5.3.2 Evasión de Obstáculos.................................................................................................................................83 5.3.2.1 5.3.2.2 5.3.2.3 5.3.2.4 5.3.2.5 5.3.2.6 5.3.3 Experimentos con FFNN........................................................................................................................ 71 Experimentos con RFFNN..................................................................................................................... 73 Experimentos con CTRNN.................................................................................................................... 74 Experimentos con PNN.......................................................................................................................... 76 Experimentos con HPNN....................................................................................................................... 78 Fototaxis Condicional ............................................................................................................................ 80 Experimentos con FFNN........................................................................................................................ 84 Experimentos con RFFNN..................................................................................................................... 86 Experimentos con CTRNN.................................................................................................................... 87 Experimentos con PNN.......................................................................................................................... 89 Experimentos con HPNN....................................................................................................................... 90 Evasión de Obstáculos con Objetivo: Navegación.................................................................................. 92 Aprendizaje ....................................................................................................................................................95 5.3.3.1 5.3.3.2 5.3.3.3 5.3.3.4 5.3.3.5 5.3.3.6 Experimentos con FFNN........................................................................................................................ 96 Experimentos con RFFNN..................................................................................................................... 98 Experimentos con CTRNN.................................................................................................................... 99 Experimentos con PNN........................................................................................................................ 101 Experimentos con HPNN..................................................................................................................... 102 Aprendizaje con Variaciones Deliberadas ............................................................................................ 104 xv 5.4 CONCLUSIONES ................................................................................................................................................ 107 CAPÍTULO 6 - EVOLUCIÓN DE NEURO-CONTROLADORES MÚLTI-NIVEL ......................................109 6.1 INTRODUCCIÓN................................................................................................................................................ 109 6.2 EXPERIMENTOS CON EVOLUCIÓN POR NIVELES ....................................................................................... 110 6.2.1 Coordinación de Niveles Comportamentales........................................................................................110 6.2.2 Resultados Experimentales en Simulación Simple ..............................................................................112 6.2.2.1 6.2.2.2 6.2.2.3 6.2.2.4 6.2.2.5 6.2.2.6 6.2.3 Etapa 1: Incorporación del Nivel de Fototaxis.......................................................................................112 Etapa 2: Incorporación del Nivel de Evasión de Obstáculos..................................................................113 Etapa 3: Evaluaciones Parciales de los Controladores Jerárquicamente Organizados............................113 Etapa 4: Incorporación del Nivel de Aprendizaje..................................................................................115 Etapa 5: Evaluación Final de los Controladores Jerárquicamente Organizados.....................................116 Etapa 6: Análisis de las Implicancias y Discusión.................................................................................118 Resultados Experimentales en Simulación Compleja.........................................................................118 6.2.3.1 Estrategias de Navegación en Entornos No-Conocidos.........................................................................119 6.2.3.1.1 Seguimiento de Paredes...............................................................................................................121 6.2.3.1.2 Comportamiento de Búsqueda de Objetivo .............................................................................121 6.2.3.1.3 Evasión de Obstáculos Convexos ...............................................................................................122 6.2.3.1.4 Evasión de Obstáculos Cóncavos ...............................................................................................122 6.2.3.1.5 Coordinación de Comportamientos...........................................................................................122 6.2.3.1.6 Robustez a Variaciones Ambientales ........................................................................................123 6.2.3.1.7 Robustez a Variaciones Morfológicas .......................................................................................124 6.2.4 Resultados Experimentales en Entornos Reales...................................................................................125 6.3 IMPLICACIONES MÁS ALLÁ DE LA EVOLUCIÓN POR NIVELES TRADICIONAL ...................................... 132 6.3.1 Optimización de la Coordinación de Comportamientos......................................................................132 6.4 DISCUSIÓN......................................................................................................................................................... 133 6.5 CONCLUSIONES ................................................................................................................................................ 134 CAPÍTULO 7 - CONCLUS IONES ...............................................................................................................................135 7.1 7.2 7.2.1 7.2.2 7.2.3 7.2.4 7.2.5 7.2.6 7.2.7 7.2.8 7.2.9 7.3 7.4 7.5 INTRODUCCIÓN................................................................................................................................................ 135 CONCLUSIONES Y APORTES ........................................................................................................................... 135 Recomendaciones para la Optimización del Desempeño....................................................................135 Observaciones a Nivel Topológico..........................................................................................................136 Resultados en Simulación.........................................................................................................................138 Implicancias................................................................................................................................................138 Conclusiones sobre las Herramientas de Generación de Controladores.........................................139 Hipótesis sobre el Rol de la Adaptación en la Emergencia de Comportamientos..........................139 Discusión.....................................................................................................................................................140 Trabajos Futuros........................................................................................................................................141 Aportes Realizados.....................................................................................................................................143 PUBLICACIONES RELACIONADAS CON ESTE TRABAJO............................................................................. 143 ALGUNAS LECCIONES APRENDIDAS PARA EL DISEÑO DE NEURO -CONTROLADORES EVOLUTIVOS144 RESUMEN DE LOS EXPERIMENTOS DESARROLLADOS.............................................................................. 145 APÉNDICE - NOTAS PARA EL USUARIO ..............................................................................................................149 A.1. A.2. A.3. A.4. A.5. MÓDULOS DE SOFTWARE............................................................................................................................... 149 INTERFACES CON EL ROBOT.......................................................................................................................... 152 DEFINICIÓN DE UN EXPERIMENTO ............................................................................................................... 153 COMPILACIÓN.................................................................................................................................................. 153 S ETEO DE PARÁMETROS................................................................................................................................. 153 BIBLIOGRAFIA .................................................................................................................................................................155 xvii LISTA DE FIGURAS Figura 1 – Arquitectura principal de la herramienta responsable de crear los controladores neuronales para la navegación y su posterior prueba experimental...........................................................................................................6 Figura 2 – Módulo EmpiricalTest encargado de modelar la interacción de los componentes involucrados en la realización de pruebas experimentales ..........................................................................................................................7 Figura 3 – Esquema del proceso propuesto por los Algoritmos Genéticos.......................................................................14 Figura 4 – Espacio de Fitness..................................................................................................................................................15 Figura 5 – Fitness Landscape unidimensional......................................................................................................................16 Figura 6 – Diagrama genérico de una Arquitectura por Subsumisión...............................................................................19 Figura 7 – Tipos de descripciones ..........................................................................................................................................23 Figura 8 – Representación genérica del robot real [Khepera, 1999] ..................................................................................36 Figura 9 – Interfaz principal del simulador KIKS (Kiks Is a Khepera Simulator)...........................................................37 Figura 10 – Interfaz principal del simulador Webots...........................................................................................................38 Figura 11 – Interfaz principal del simulador WSU Java Simulator...................................................................................38 Figura 12 – Interfaz principal del simulador YAKS. (a) visión 2D; (b) Open GL acceleration ....................................39 Figura 13 – Distribución de los sensores infra-rojos del robot real Khepera ® [Khepera, 1999]....................................48 Figura 14 – Medición típica de la luz ambiental por la distancia a una fuente de luz de 1 Watt para el robot Khepera ® real..................................................................................................................................................................48 Figura 15 – Medición de la luz ambiental versus la distancia a una fuente de luz para el modelo simulado simple. .48 Figura 16 – Respuesta típica del sensor de proximidad para un obstáculo (7 mm. de ancho) a una distancia de 15 mm. La medición está dada versus el ángulo entre la orientación frontal del robot y la orientación del obstáculo..........................................................................................................................................................................49 Figura 17 – Respuesta del sensor de proximidad para un obstáculo ubicado a 15 unidades de longitud. La medición está dada por el ángulo entre la orientación frontal del sensor y la orientación del obstáculo para el simulador simple ...............................................................................................................................................................................49 Figura 18 – Perfil de velocidad utilizado para alcanzar la posición objetivo con una aceleración fija (acc) y velocidad máxima (max. speed) en el robot real Khepera ®......................................................................................49 Figura 19 – Perfil de velocidad utilizado para alcanzar la posición objetivo con una velocidad máxima (max. speed) en el robot simulado.......................................................................................................................................................49 Figura 20 – Diagrama esquemático de la conectividad de neuronal genérica (2 nodos motores, 6 nodos ocultos, 8 nodos de entrada, y 1 entrada adicional) y calculo del computo realizado por la salida de cada neurona........50 Figura 21 – Representación genética de las sinapsis de un nodo para los experimentos sobre la evolución de los genes ................................................................................................................................................................................50 Figura 22 – Diagrama UML de clases del modelo de red neuronal implementado.........................................................51 Figura 23 – Diagrama UML de clases del modelo genético implementado.....................................................................52 Figura 24 – Diagrama UML de clases del modelo de algoritmo genético implementado..............................................53 Figura 25 – Diagrama UML de clases del modelo de red neuronal genérico implementado.........................................54 Figura 26 – Representación de la salida proporcionada por la función sigmoide tangencial implementada...............56 Figura 27 – Diagrama esquemático de la conectividad entre las capas entrada-oculta y oculta-salida de la red tipo FFNN...............................................................................................................................................................................57 Figura 28 – Diagrama esquemático de la conectividad entre las capas entrada-oculta y oculta-salida de la red tipo RFFNN ............................................................................................................................................................................58 xviii Figura 29 – Variación de las reglas de Hebb en función del peso sináptico [Urzelai, 2000]......................................... 60 Figura 30 – Representación de la salida proporcionada por la función sigmoide utilizada por la HPNN. Las líneas en ±0.00001, las cuales sólo son relevantes para las redes homeostáticas, representan los umbrales homeostáticos................................................................................................................................................................. 63 Figura 31 – Diagrama UML de clases del modelo experimental genérico implementado............................................ 64 Figura 32 – Grafico comparativo de los diferentes niveles de fitness (mejor fitness promedio) para los distintos tests.................................................................................................................................................................................. 69 Figura 33 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red FFNN durante la tarea de fototaxis obtenida en el cuarto test del mejor controlador (300 generaciones).................... 72 Figura 34 – Ejemplos de trayectorias seguidas por el robot simulado para una red FFNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El segundo, (b) cuarto, y (c) octavo test. .......................................................................................................................................................................................... 72 Figura 35 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en fototaxis. ......................................................................................................................................................................... 73 Figura 36 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red RFFNN durante la tarea de fototaxis obtenida en el cuarto test del mejor controlador (300 generaciones).................... 73 Figura 37 – Ejemplos de trayectorias seguidas por el robot simulado para una red RFFNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) cuarto, y (c) séptimo test. .......................................................................................................................................................................................... 74 Figura 38 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo RFFNN en fototaxis. ......................................................................................................................................................................... 74 Figura 39 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red CTRNN durante la tarea de fototaxis obtenida en el noveno test del mejor controlador (300 generaciones).................. 75 Figura 40 – Ejemplos de trayectorias seguidas por el robot simulado para una red CTRNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) segundo, y (c) noveno test.................................................................................................................................................................................... 75 Figura 41 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo CTRNN en fototaxis. ......................................................................................................................................................................... 76 Figura 42 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red PNN durante la tarea de fototaxis obtenida en el noveno test del mejor controlador (300 generaciones).................. 77 Figura 43 – Ejemplos de trayectorias seguidas por el robot simulado para una red PNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El segundo, (b) quinto, y (c) noveno test............ 77 Figura 44 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo PNN en fototaxis. ......................................................................................................................................................................... 78 Figura 45 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de fototaxis obtenida en el noveno test del mejor controlador (300 generaciones).................. 79 Figura 46 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de fototaxis obtenidas para mejor controlador (300 generaciones); (a) El cuarto, (b) noveno, y (c) sexto test..... 79 Figura 47 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en fototaxis. ......................................................................................................................................................................... 79 Figura 48 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de fototaxis condicional obtenida en el séptimo test del mejor controlador (300 generaciones). .......................................................................................................................................................................................... 81 xix Figura 49 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de fototaxis condicional obtenidas para el mejor controlador (300 generaciones); (a) El tercer, (b) sexto, y (c) séptimo test.....................................................................................................................................................................81 Figura 50 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en fototaxis condicional......................................................................................................................................................81 Figura 51 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red FFNN durante la tarea de evasión de obstáculos obtenida en el décimo test del mejor controlador (300 generaciones)..................................................................................................................................................................85 Figura 52 – Ejemplos de trayectorias seguidas por el robot simulado para una red FFNN durante la tarea de evasión de obstáculos obtenidas para el mejor controlador (300 generaciones); (a) El cuarto, (b) sexto test, y (c) décimo test......................................................................................................................................................................85 Figura 53 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en evasión de obstáculos....................................................................................................................................................85 Figura 54 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red RFFNN durante la tarea de evasión de obstáculos obtenida en el noveno test del mejor controlador (300 generaciones)..................................................................................................................................................................86 Figura 55 – Ejemplos de trayectorias seguidas por el robot simulado para una red RFFNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El tercer, (b) noveno, y (c) décimo test. ..........................................................................................................................................................................................86 Figura 56 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo RFFNN en evasión de obstáculos....................................................................................................................................................87 Figura 57 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red CTRNN durante la tarea de evasión de obstáculos obtenida en el séptimo test del mejor controlador (300 generaciones)..................................................................................................................................................................88 Figura 58 – Ejemplos de trayectorias seguidas por el robot simulado para una red CTRNN durante la tarea de evasión de obstáculos para el mejor controlador (300 generaciones); (a) El primer, (b) séptimo, y (c) octavo test....................................................................................................................................................................................88 Figura 59 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo CTRNN en evasión de obstáculos....................................................................................................................................................88 Figura 60 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red PNN durante la tarea de evasión de obstáculos obtenida en el noveno test del mejor controlador (300 generaciones)..................................................................................................................................................................89 Figura 61 – Ejemplos de trayectorias seguidas por el robot simulado para una red PNN durante la tarea de evasión de obstáculos obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) cuarto, y (c) noveno test....................................................................................................................................................................................90 Figura 62 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo PNN en evasión de obstáculos...................................................................................................................................................................90 Figura 63 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de evasión de obstáculos obtenida en el sexto test del mejor controlador (300 generaciones). ..........................................................................................................................................................................................91 Figura 64 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de evasión de obstáculos obtenidas para el mejor controlador (300 generaciones); (a) El cuarto, (b) sexto, y (c) noveno test....................................................................................................................................................................................91 Figura 65 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en evasión de obstáculos....................................................................................................................................................91 xx Figura 66 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de fototaxis con evasión de obstáculos (navegación) obtenida en el sexto test del mejor controlador (50 generaciones)...................................................................................................................................... 93 Figura 67 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de fototaxis con evasión de obstáculos (navegación) obtenidas para el mejor controlador (50 generaciones); (a) El tercer, (b) sexto, y (c) décimo test.......................................................................................................................... 94 Figura 68 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en evasión de obstáculos con objetivo (navegación). .................................................................................................... 94 Figura 69 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red FFNN durante la tarea de aprendizaje obtenida en el segundo test del mejor controlador (300 generaciones)............ 97 Figura 70 – Ejemplos de trayectorias seguidas por el robot simulado para una red FFNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones); (a) El segundo, (b) tercer, y (c) séptimo test.................................................................................................................................................................................... 97 Figura 71 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en aprendizaje...................................................................................................................................................................... 97 Figura 72 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red RFFNN durante la tarea de aprendizaje obtenida en el séptimo test del mejor controlador (300 generaciones)............. 98 Figura 73 – Ejemplos de trayectorias seguidas por el robot simulado para una red RFFNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) séptimo, y (c) noveno test.................................................................................................................................................................................... 99 Figura 74 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo RFFNN en aprendizaje...................................................................................................................................................................... 99 Figura 75 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red CTRNN durante la tarea de aprendizaje obtenida en el cuarto test del mejor controlador (300 generaciones). ............100 Figura 76 – Ejemplos de trayectorias seguidas por el robot simulado para una red CTRNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones); (a) El tercer, (b) cuarto, y (c) sexto test. ........................................................................................................................................................................................100 Figura 77 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo CTRNN en aprendizaje....................................................................................................................................................................100 Figura 78 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red PNN durante la tarea de aprendizaje obtenida en el sexto test del mejor controlador (300 generaciones)...............101 Figura 79 – Ejemplos de trayectorias seguidas por el robot simulado para una red PNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones). (a) El quinto, (b) sexto, y (c) noveno test. ........................................................................................................................................................................................102 Figura 80 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo PNN en aprendizaje....................................................................................................................................................................102 Figura 81 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de aprendizaje obtenida en el cuarto test del mejor controlador (300 generaciones). ............103 Figura 82 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones; (a) El cuarto, (b) quinto, y (c) sexto test. ........................................................................................................................................................................................103 Figura 83 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje....................................................................................................................................................................103 xxi Figura 84 – (a) Representación de las actividades de los nodos y (b) del sensado del controlador para una red HPNN durante la tarea de aprendizaje con variaciones deliberadas obtenida en el sexto test del mejor controlador (1000 iteraciones)........................................................................................................................................................ 105 Figura 85 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de aprendizaje con variaciones deliberadas obtenidas para el mejor controlador (1000 iteraciones); (a) El sexto, (b) séptimo, y (c) noveno test.................................................................................................................................... 105 Figura 86 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones . Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje con variaciones deliberadas.................................................................................................................. 105 Figura 87 – Ejemplo de los movimientos obtenidos por un controlador HPNN durante pruebas con aprendizaje con variaciones deliberadas............................................................................................................................................... 107 Figura 88 – Diagrama esquemático de la conectividad de los neuro-controladores en una Arquitectura por Subsumisión................................................................................................................................................................. 110 Figura 89 – Esquema global de la estrategia de navegación adoptada: pruebas experimentales con el simulador complejo....................................................................................................................................................................... 111 Figura 90 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en fototaxis condicional con o bstáculos........................................................................................................................ 112 Figura 91 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en evasión de obstáculos................................................................................................................................................. 113 Figura 92 – Ejemplos de trayectorias generadas con un controlador por niveles......................................................... 114 Figura 93 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) sin obstáculos................................................................................................................................................ 115 Figura 94 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) sin obstáculos................................................................................................................................................ 115 Figura 95 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) con obstáculos.............................................................................................................................................. 115 Figura 96 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) con obstáculos.............................................................................................................................................. 115 Figura 97 – Performance obtenida al variar el objetivo en la evolución del controlador de aprendizaje (FFNN) asociado al nivel de fototaxis condicional. (a) Objetivo más favorecido en evolución; (b) 50% de selección de objetivo......................................................................................................................................................................... 117 Figura 98 – Área de prueba generada para el simulador YAKS. Escenario del tipo laberinto con fuente de luz central y obstáculos cilíndricos en las esquinas de las paredes............................................................................. 120 Figura 99 – Esquema global de estrategia de la navegación adoptada: pruebas experimentales con el robot real... 120 Figura 100 – Comportamiento de seguimiento de paredes: experimentación con simulador YAKS ........................ 121 Figura 101 – Comportamiento de evasión de obstáculos convexos: experimentación con simulador YAKS.......... 122 Figura 102 – Comportamiento de seguimiento de obstáculos cóncavos: experimentación con simulador YAKS .. 122 Figura 103 – Comportamiento de evasión de obstáculos cóncavos: experimentación con simulador YAKS .......... 122 Figura 104 – Coordinación de comportamientos: experimentación con simulador YAKS......................................... 123 xxii Figura 105 – Comportamiento de seguimiento de obstáculos: experimentación con simulador YAKS ...................124 Figura 106 – Comportamiento de seguimiento de obstáculos con la incorporación de un nuevo obstáculo: experimentación con simulador YAKS ....................................................................................................................124 Figura 107 – Alteraciones ambientales. Comportamiento de seguimiento de obstáculos con disminución (mitad) de la capacidad de sensado: experimentación con simulador YAKS........................................................................124 Figura 108 – Alteraciones ambientales. Comportamiento de seguimiento de obstáculos con aumento de la capacidad de sensado al doble: experimentación con simulador YAKS .............................................................124 Figura 109 – Alteración morfológica. Comportamiento de seguimiento de obstáculos con inversión de sensado: experimentación con simulador YAKS ....................................................................................................................124 Figura 110 – Entorno experimental real y disposición de los componentes implicados..............................................126 Figura 111 – Respuesta del sensor lumínico respecto de la distancia a una fuente de luz. Medición obtenida para el robot Khepera® real utilizado (distancia en mm.). ..................................................................................................126 Figura 112 – Respuesta del sensor de proximidad (luz infra -roja reflejada) para un obstáculo en función de la distancia. Medición obtenida para el robot Khepera ® real utilizado (distancia en mm.). ..................................126 Figura 113 – Representación de la caracterización de los sensores de proximidad en función de la distancia.........128 Figura 114 – Variante propuesta como potencial solución de fin de pared....................................................................129 Figura 115 – Tres situaciones simuladas utilizando un controlador por niveles durante la navegación en un entorno tipo laberinto................................................................................................................................................................130 Figura 116 – Tres vistas obtenidas a partir de una configuración de entorno real vinculadas a cada situación simulada........................................................................................................................................................................130 Figura 117 – Situación en que la incidencia de la fuente de luz sobre el robot es mínima para generar un comportamiento de ir hacia el objetivo.....................................................................................................................131 Figura 118 – Esquema de ajuste automático propuesto....................................................................................................133 Figura 119 – Esquema general de la incidencia de la emergencia de comportamientos sobre las interacciones locales............................................................................................................................................................................140 Figura 120 – Principales clases implicadas con la clase NeuroController. ....................................................................150 Figura 121 – Diagrama de la asociación entre las principales clases desarrolladas......................................................151 Figura 122 – Principales clases implicadas con la interfaz de simulación.....................................................................152 xxiii LISTA DE TABLAS Tabla 1 – Relación entre diferentes tipos de evolución artificial........................................................................................22 Tabla 2 – Matriz de características de los simuladores analizados....................................................................................40 Tabla 3 – Matriz de características priorizadas.....................................................................................................................40 Tabla 4 – Matriz de características priorizadas según la ponderación de cada controlador............................................41 Tabla 5 – Herramientas de software y técnicas utilizadas...................................................................................................42 Tabla 6 – Características de los estudios analizados............................................................................................................42 Tabla 7 – Objetivos de diseño y otras características de los estudios y herramientas analizadas ..................................44 Tabla 8 – Resumen del método experimental utilizado para el desarrollo de las pruebas con controladores monolíticos......................................................................................................................................................................46 Tabla 9 – Representación del modelo de los actuadores .....................................................................................................47 Tabla 10 – Configuración utilizada en los experimentos con evolución simulada ..........................................................53 Tabla 11 – Resumen de las características del modelo de red FFNN implementado......................................................55 Tabla 12 – Codificación genética de los parámetros de evolución vinculados a las sinapsis de las redes FFNN, RFFNN y CTRNN (controlador genéticamente determinado)................................................................................56 Tabla 13 – Resumen de las características del modelo de red CTRNN implementado..................................................60 Tabla 14 – Resumen de las características del modelo de red PNN implementado........................................................62 Tabla 15 – Codificación genética de los parámetros de evolución vinculados a las s inapsis de las redes PNN y HPNN (controlador por sinapsis adaptativas)............................................................................................................62 Tabla 16 – Resultados promedios de la evolución de los neuro-controladores implementados para fototaxis (sección 5.3.1) sobre el total de generaciones (300 generaciones y 10 corridas); Función de fitness: Ecuación 9. .........68 Tabla 17 – Resultados promedios de la evolución de los neuro-controladores implementados para evasión de obstáculos (sección 5.3.2) sobre el total de generaciones (300 generaciones y 10 corridas); Función de fitness: Ecuación 10.....................................................................................................................................................................68 Tabla 18 – Resultados promedios de la evolución de los neuro-controladores implementados para aprendizaje (sección 5.3.3) sobre el total de generaciones (300 generaciones y 10 corridas); Función de fitness: Ecuación 12. .....................................................................................................................................................................................68 Tabla 19 – Mapeo sensor-entrada de la red utilizada para los experimentos con fototaxis, siendo SLj (i) la especificación de un sensor infra-rojo receptor (sensor lumínico) vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente............................................................................................................................................71 Tabla 20 – Mapeo sensor-entrada de la red utilizada para los experimentos con fototaxis condicional, siendo SLj (i) la especificación de un sensor infra-rojo vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente. Prom es un indicador del promedio de los valores sensados....................................................................................80 Tabla 21 – Resultados promedios de la evolución de los neuro-controladores implementados para fototaxis condicional sobre el total de las generaciones (300 generaciones y 10 corridas)..................................................82 Tabla 22 – Mapeo sensor-entrada de la red utilizada para los experimentos con evasión de obstáculos, siendo SO(i) la especificación de un sensor de proximidad vinculado al i-ésimo sensor del robot...........................................84 Tabla 23 – Mapeo sensor-entrada de la red utilizada para los experimentos con navegación, siendo SLj (i) y SO(h) la especificación de un sensor infra-rojo receptor (sensor lumínico) vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente, y al sensor de proximidad según el h-ésimo sensor del robot, respectivamente....93 Tabla 24 – Resultados promedios de la evolución de los neuro-controladores implementados para navegación sobre el total de las generaciones (50 generaciones y 10 corridas)....................................................................................94 xxiv Tabla 25 – Mapeo sensor-entrada de la red utilizada para los experimentos con aprendizaje, siendo SLj (i) la especificación de un sensor infra-rojo vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente. Prom es un indicador del promedio de los valores sensados.............................................................................................. 96 Tabla 26 – Resultados promedios de la evolución de los neuro-controladores HPNN implementados para aprendizaje con variaciones deliberadas sobre el total de las generaciones (300 generaciones, 1000 iteraciones y 10 corridas)................................................................................................................................................................106 Tabla 27 – Resumen del método experimental utilizado para el desarrollo de las pruebas con Evolución por Niveles ........................................................................................................................................................................................112 Tabla 28 – Resultados obtenidos en la evolución de neuro-controladores para Evolución Monolítica y por Niveles sobre el total de generaciones (300 generaciones y 10 corridas). .........................................................................113 Tabla 29 – Resumen del método experimental utilizado para el desarrollo de las pruebas en un entorno real.........125 Tabla 30 – Resumen del proceso de caracterización de las mediciones de los sensores..............................................127 Tabla 31 – Resumen de las mediciones realizadas vinculadas a la influencia del entorno sobre los sensores..........128 Tabla 32 – Resumen de los experimentos desarrollados, propósitos y motivaciones...................................................147 Tabla 33 – Ejemplos de parámetros de programa..............................................................................................................154 xxv GLOSARIO Adaptación: Tendencia de un organismo a “adecuarse” a su medio ambiente. Uno de los principales puntos de la teoría de la evolución por la selección natural de Charles Darwin la cual expresa que los organismos se adaptan a su medio ambiente. Aquellos organismos mejor adaptados tendrán mayor probabilidad de sobrevivir y pasar sus genes a la siguiente generación. Agente: Una definición consensuada del término agente en Inteligencia Artificial [Wooldridge, 1995] [Russell et al., 1995] corresponde a: “un agente es un sistema computacional que exhibe persistencia temporal, capaz de actuar de manera autónoma para satisfacer sus objetivos y metas cuando se encuentra situado en algún medio ambiente”. Tal definición permite (a) observar las facultades cognitivas de los agentes para encontrar cómo hacer lo correcto; (b) considerar diferentes tipos de agentes, incluyendo aquellos que no posean facultades cognitivas; (c) considerar diferentes especificaciones sobre los subsistemas que componen los agentes. Alelo: (m. Biol.) (a) Una de las formas variantes de un gen en un locus (una posición determinada en el cromosoma) o de un marcador particular en un cromosoma. Diferentes alelos de un gen producen variaciones en las características hereditarias; (b) Variaciones menores de un mismo gen. Aprendizaje Evolutivo: Mecanismo generacional por el cual los individuos logran adaptarse al entorno considerando aspectos evolutivos. Aprendizaje: Como ocurre con muchos otros términos, no existe una definición universal del concepto de aprendizaje. No obstante, en [Arkin, 1998] se propone una definición operacional según la cual “aprendizaje es el mecanismo por el cual se producen cambios dentro de un agente, los cuales, con el tiempo, permiten que se manifieste un desempeño más efectivo en el individuo dentro del entorno”. Caos: Conducta de un sistema complejo que aparece como impredecible y falsamente como aleatoria, cuando en realidad tiene un patrón subyacente. A primera vista tales sistemas no muestran aparente orden alguno, pero si se supieran acabadamente las reglas que lo rigen y las condiciones iniciales, sería predecible y descriptible. Ciencia: Término que en su sentido más amplio se emplea para referirse al conocimiento sistematizado en cualquier campo, pero que suele aplicarse sobre todo a la organización de la experiencia sensorial objetivamente verificable. La búsqueda de conocimiento en ese contexto se conoce como “ciencia pura”, para distinguirla de la “ciencia aplicada” -la búsqueda de usos prácticos del conocimiento científico- y de la tecnología, a través de la cual se llevan a cabo las aplicaciones. La ciencia suele definirse por la forma de investigar más que por el objeto de investigación, de manera que los procesos científicos son esencialmente iguales en todas las ciencias de la naturaleza; por ello la comunidad científica está de acuerdo en cuanto al lenguaje en que se expresan los problemas científicos, la forma de recoger y analizar datos, el uso de un estilo propio de lógica y la utilización de teorías y modelos. Comportamiento Adaptativo: Concepto vinculado con los medios por los cuales una entidad (natural o artificial) puede relacionarse con un entorno cambiante a través de una variedad de mecanismos de aprendizaje y adaptación, incluyendo aprend izaje por refuerzos, redes neuronales, lógica difusa, métodos evolutivos, y otros mecanismos artificiales. Comportamiento Emergente: Un comportamiento emergente o propiedad emergente ocurre cuando un número de entidades (por lo general, simples) denominadas agentes se desempeñan en un entorno, formando comportamientos más complejos, tales como los comportamientos colectivos. La emergencia en sí misma, reviste de impredecibilidad y de ser generada sin previa observación de su ocurrencia. En un sistema, tal comportamiento complejo no es una propiedad de una entidad simple, ni puede ser fácilmente predecida o deducida de los comportamientos simples en su conjunto. Una razón por la que un comportamiento emergente ocurre, se debe al número de interacciones entre componentes del sistema, el cual se incrementa combinacionalmente con el número de componentes. De esta manera, el comportamiento global de una entidad o sistema (p. ej. de un robot o del conjunto de ellos) surge como xxvi consecuencia de la interacción de comportamientos individuales activos, ya sea dentro de un entidad o en el sistema de entidades observado. Comportamiento: Se refiere a las acciones o reacciones de un objeto u organismo, normalmente respecto del ambiente. Desde el plano biológico, se relaciona la complejidad de la conducta de un organismo con la complejidad de su sistema nervioso. En la mayoría de los casos, los organismos con sistemas nerviosos complejos tienen una capacidad mayor para aprender nuevas acciones a fin de ajustar su conducta. Computación Evolutiva: Rama del conocimiento que estudia algoritmos de búsqueda y optimización inspirados en mecanismos genéticos y la selección natural. Los paradigmas principales que se utilizan hoy en día son: Estrategias Evolutivas, Programación Evolutiva, y Algoritmos Genéticos, siendo estos últimos los más utilizados. Cromosoma: (m. Biol.) Se denomina cromosoma a una de las cadenas de ADN (ácido desoxirribo nucleico) que se encuentra en el núcleo de las células. Los cromosomas son responsables de la transmisión de información genética. Desde el enfoque de la Robótica Basada en Comportamientos, un comportamiento corresponde al par acción/respuesta para una configuración del entorno determinada, la cual es modulada por la atención y determinada por la intención [Arkin, 1998]. Efecto Baldwin: Mecanismo por el cual se descubrió que la habilidad de aprender de un organismo puede ayudar también a la evolución de otros comportamientos. Escalabilidad: (en Inglés, Scaling up) Concepto que se refiere a complejidad e indirectamente al desempeño computacional. El desempeño de la escalabilidad refleja la linealidad de la expansión. El alcance de la escalabilidad, refleja cuán expandible es un sistema. Escalabilidad en Robótica Evolutiva trata de la creación de comportamientos complejos a partir de comportamientos simples, generalmente en forma incremental. Una manera de llevar a cabo esta tarea es a través del desarrollo de bloques comportamentales, los cuales son usados para crear niveles y estos son testeados en modelos robóticos simulados y reales. Evolución: Cambios de los organismos producidos por adaptación, variación, y reproducción/sobrevivencia diferencial, procesos a los que Charles Darwin y Alfred Wallace se refirieron como selección natural. Experimentación: La experimentación consiste en el estudio de un fenómeno, reproducido generalmente en un laboratorio, en las condiciones particulares de análisis que interesan, eliminando o introduciendo aquellas variables que puedan influir en los resultados esperados. Se entiende por variable a todo aquello que pueda causar cambios en los resultados de un experimento. Experimento Hipotético: Un experimento hipotético, o experimento pensado, es aquel que sigue un tren de pensamientos lógicos y consistentes, con la finalidad de permitir entender mejor un problema o alcanzar una solución final independiente del hecho meramente circunstancial o irrelevante de si es o no posible llevarlo a cabo. Experimento: Por lo general, concepto que se refiere a realizar operaciones destinadas a descubrir, comprobar o demostrar determinados fenómenos o principios científicos. Extensibilidad: Concepto referido al grado de crecimiento (amplitud) de una característica o elemento dentro de un sistema computacional. Extensibilidad en Robótica Evolutiva trata, principalmente, de la creación de módulos comportamentales los cuales permitan la variación de las características inherentes a la especificación del comportamiento del sistema. Fenotipo: (m. Biol.) Manifestación visible del genotipo en un determinado ambiente. En otras palabras, corresponde a los rasgos observables específicos de un individuo. Filogenia: (a) Parte de la biología que se ocupa de las relaciones de parentesco entre los distintos grupos de seres vivos; (b) Biol. Origen y desarrollo evolutivo de las especies, y en general, de las estirpes de seres vivos. xxvii Fototaxis: Acción o comportamiento condicionado a un foto-receptor. Gen: (m. Biol.) Un gen es una sección de ADN que codifica una cierta función bioquímica definida. Es fundamentalmente una unidad de herencia. Los genes están localizados en los cromosomas. Genética: Estudio científico de cómo se transmiten los caracteres físicos, bioquímicos y de comportamiento de padres a hijos. Este término fue acuñado en 1906 por el biólogo británico William Bateson. Los genetistas determinan los mecanismos hereditarios por los que los descendientes de organismos que se reproducen de forma sexual no se asemejan con exactitud a sus padres, y estudian las diferencias y similitudes entre padres e hijos que se reproducen de generación en generación según determinados patrones. La investigación de estos últimos ha dado lugar a algunos de los descubrimientos más importantes de la biología moderna. Genoma: Conjunto de genes que posee un organismo. Genoma es la totalidad de los genes que porta un individuo de una especie. Genotipo: Se denomina genotipo a la composición genética de un organismo (la información contenida en un genoma). Es decir, es lo que potencialmente puede llegar a ser un individuo. Comúnmente usado como sinónimo de genoma. Holonónico: en robótica, un robot holonómico es capaz rotar (variar de dirección de movimiento) mientras se mueve hacia adelante o hacia atrás, a derecha o a izquierda. En otras palabras, esta basado en movimientos con tres grados de libertad, siendo estos los máximos posibles para un robot móvil terrestre. Una característica distintoria es que el robot puede rotar mientras se mueve en línea recta. Homeostasis: (f. Biol.) Conjunto de fenómenos de autorregulación que conducen al mantenimiento de la constancia en la composición y propiedades del medio interno de un organismo. Autorregulación de la constancia de las propiedades de otros sistemas influidos por agentes exteriores. Método científico: Método de estudio sistemático de la naturaleza que incluye las técnicas de observación, reglas para el razonamiento y la predicción, ideas sobre la experimentación planificada y los modos de comunicar los resultados experimentales y teóricos. En el método científico la observación consiste en el estudio de un fenómeno que se produce en sus condiciones naturales. La observación debe ser cuidadosa, exhaustiva y exacta. A partir de la observación surge el planteamiento del problema que se va a estudiar, lo que lleva a emitir alguna hipótesis o suposición provisional de la que se intenta extraer una consecuencia. Existen ciertas pautas que han demostrado ser de utilidad en el establecimiento de las hipótesis y de los resultados que se basan en ellas; estas pautas son: probar inicialmente las hipótesis más simples, no considerar una hipótesis como totalmente cierta y realizar pruebas experimentales independientes antes de aceptar un único resultado experimental importante. Según algunos investigadores, el método científico es el modo de llegar a elaborar teorías, entendiendo éstas como configuración de leyes. Mediante la inducción se obtiene una ley a partir de las observaciones y medidas de los fenómenos naturales, y mediante la deducción se obtienen consecuencias lógicas de una teoría. Por esto, para que una teoría científica sea admisible debe relacionar de manera razonable muchos hechos en apariencia independientes en una estructura mental coherente. Así mismo, debe permitir hacer predicciones de nuevas relaciones y fenómenos que se puedan comprobar experimentalmente. Según [Burnet et al., 1964], “el método del hombre de ciencia no es en realidad más que una búsqueda organizada de respuestas.” Modelo: Concepto correspondiente a las leyes y las teorías que involucran a menudo una pretensión realista que conlleva la noción de modelo; éste es una abstracción mental que se utiliza para poder explicar algunos fenómenos y para reconstruir por aproximación los rasgos del objeto considerado en la investigación. Mutación: Cualquiera de los cambios que aparecen bruscamente en el fenotipo de un ser vivo y que se transmiten por herencia a los descendientes. La mayoría de estos cambios se producen por errores de copiado genético. Neuro-controlador: Por neuro-controladores dentro de la RE, nos referimos a controladores cuya superficie de control es un mapa de estrada/salida que tiene como soporte una red neuronal artificial. xxviii Éstas pueden procesar una gran cantidad de información, transmitiendo señales en paralelo mediante las conexiones entre neuronas. En evolución artificial de robots, la especificación de un neuro-controlador implica diferentes estructuras: (a) redes neuronales; (b) parámetros de control; (c) programas de computación en si mismos. Más aún, en el caso de las redes neuronales, la evolución de los controladores puede implicar aspectos adaptativos tales como aprendizaje durante la vida del controlador. Ontogenia: (m. Biol.) Desarrollo del individuo referido especialmente al período embrionario. Población: Conjunto de individuos sujetos a un proceso evolutivo, los cuales están afectados por la influencia de operadores genéticos (p. ej. mutaciones). Principio: Base, origen, o razón fundamental sobre la cual se procede discurriendo en cualquier materia. Cada una de las primeras proposiciones o verdades fundamentales por donde se empiezan a estudiar las ciencias o las artes. Programación Evolutiva: la Programación Evolutiva (PE) es virtualmente equivalente en muchos casos a los procedimientos utilizados por las Estrategias de Evolución (EE). Existen dos diferencias esenciales entre ellas: (1) Las EE utilizan una selección determinista. La PE enfatiza la naturaleza probabilística de la selección mediante un torneo estocástico para la supervivencia de cada generación; (2) Las EE utilizan estructuras abstractas de codificación consideradas como individuos. La PE utiliza estructuras abstractas de codificación como analogía a distintas especies. Las EE pueden utilizar la recombinación entre individuos. La PE no hace uso de ella, no existe comunicación entre las especies. Programación Genética: Caso particular de Algoritmos Genéticos. Está relacionado con la creación de programas de computadora de un modo automático. La disciplina data de 1985, aunque el gran difusor ha sido John Koza a principios de la década de los 90. La diferencia principal entre los Algoritmos Genéticos y la Programación Genética es la representación de las soluciones. Los cromosomas codifican, de algún modo, programas de ordenador. Naturalmente, los operadores genéticos han de adaptarse a la representación empleada. Robótica Basada en Comportamientos: (en Inglés, Behavior-Based Robotics) Es una rama de la robótica la cual no utiliza un modelo interno del entorno (p. ej. no existe una programación dentro del robot sobre cómo es el ambiente). Toda la información se obtiene de las entradas de los sensores del robot, la cual es utilizada para reaccionar ante cambios del ambiente. Robótica Evolutiva: Rama de la Robótica Basada en Comportamientos. Metodología que utiliza algoritmos evolutivos, principalmente, para desarrollar controladores de robots autónomos. Esto permite crear automáticamente controladores robóticos partiendo de una población aleatoria, seleccionándolos según una función de fitness predefinida. Típicamente, los controladores consisten en redes neuronales artificiales. Últimamente, la dificultad de “escalar” la complejidad de las tareas a resolver por los robots, ha cambiado la atención de dicha área levemente hacia el campo teórico en lugar de uno plenamente ingenieril. Sinapsis: Relación funcional de contacto entre las terminaciones de las células nerviosas. Sistema Dinámico: En ingeniería y matemáticas, un sistema dinámico es un proceso determinista en el cual el valor de una función cambia de acuerdo a una regla, definida en términos del valor actual de la función. En cuanto a la “dinamicidad de la cognición”, frente al funcionalismo computacionalista, la hipótesis de que la cognición es mejor modelada y comprendida en términos de sistemas dinámicos ha conseguido establecer un marco interpretativo general en el que integrar la corporalidad, la interacción, y la dinámica (pre-informacional) del sistema nervioso, cuerpo y entorno [van Gelder, 1998]. Teoría del Caos: Teoría matemática que se ocupa de los sistemas que presentan un comportamiento impredecible y aparentemente aleatorio aunque sus componentes estén regidos por leyes estrictamente deterministas. PREFACIO “Tan pronto me convencí de que las especies son susceptibles de sufrir transformaciones, no pude evitar pensar que el pensamiento del hombre debe obedecer a la misma ley” Charles Darwin El mecanismo de la evolución, la “selección natural” de Darwin, determina la manera en que las plantas y los animales han adquirido su aspecto físico y conducta. No obstante, hoy en día dicho término se sigue entendiendo de manera equivocada. Parte de la confusión surge de la sencilla frase: “teoría de la evolución”. Para los científicos, hablar de una “teoría” significa referirse a un postulado basado en la observación y la experimentación, el cual ofrece una explicación a alguna faceta del mundo observable de manera tan convincente que es aceptado como un hecho. “Teoría” no es cualquier idea surgida de la nada y mucho menos una creencia sin fundamentos. A lo largo del tiempo, algunos ingenieros y científicos de diferentes áreas de estudio, cuestionaron los principios básicos del diseño de sistemas robóticos. Con esto surgió una nueva generación de sistemas de control basados en bioinspiración, los cuales comparten varias de las características principales con los sistemas biológicos simples: robustez, simplicidad, tamaño reducido, flexibilidad y modularidad. Aunque el propósito primario del trabajo es presentar aspectos de la construcción de sistemas artificiales, aquí se ha introducido un tema secundario el cual sirve como matriz integradora: sistemas adaptativos y evolutivos. Se han añadido varias secciones breves que ofrecen una visión de lo que se conoce en la actualidad en distintas ramas de la ciencia sobre la “evolución natural”, y en especial a lo referido a la “adaptación de sistemas naturales y artificiales”. Esto se realiza a modo introductorio y como contexto temático para el estudio de una aplicación científico-ingenieril que presenta aspectos inherentes a la Biología, al Control y a la Inteligencia Artificial. El trabajo que aquí se expone provee un aporte dentro del área denominada Robótica Evolutiva. Parte del estudio desarrollado fue probado tanto en simulación como en un entorno real, y publicado en 2004 IEEE Conference on Cybernetics and Intelligent Systems, entre otras. Los capítulos que se presentan describen varias de las técnicas más utilizadas (algoritmos genéticos, redes neuronales, etc.), y se muestran diversos experimentos con una complejidad incremental, conjuntamente con referencias sobre la observación de los mismos tanto en la naturaleza como en sistemas artificiales. Tandil, Diciembre 2004. José A. Fernández León Capítulo 1 - INTRODUCCIÓN INTRODUCCIÓN “Si supiéramos lo que estamos haciendo no se llamaría investigación, ¿no le parece?” Albert Einstein 1.1 Motivación La Robótica Evolutiva (RE) es una nueva metodología para la creación de un sistema de control de alto nivel para robots móviles. Inspirado en el principio Darwiniano de la reproducción selectiva del más apto, es posible ver a los robots como organismos artificiales autónomos, los cuales desarrollan sus propias habilidades en estrecha relación con el entorno y sin la intervención humana. Asociado fuertemente con la biología y la etología, la RE utiliza actualmente herramientas tales como redes neuronales, algoritmos genéticos, sistemas dinámicos, e ingeniería biomórfica en implementaciones de sistemas de control en robots. En este contexto, los robots que pueden desarrollarse a través de ésta metodología, comparten con los sistemas biológicos simples características de robustez, simplicidad, tamaño reducido, flexibilidad y modularidad [Nolfi et al., 2000]. La tarea que es capaz de resolver un robot se vincula a un sistema de control que, al estar determinado genéticamente, es susceptible de ser optimizado a lo largo de un proceso de evolución artificial. En RE, una población inicial de cromosomas artificiales, cada uno codificando el sistema de control de un robot, es aleatoriamente creado y probad o en el entorno. Luego, cada robot es libre de actuar (moverse, manipular objetos, sensar el entorno, etc.) según su controlador, mientras es evaluado su desempeño en forma automática en la realización de tareas. Finalmente, los controladores que mejor desempeño obtengan, son sometidos a un proceso “reproductivo”, el cual consiste en el intercambio de “material genético” con una pequeña proporción de mutaciones aleatorias. Este proceso es repetido hasta que se satisfaga un criterio de desempeño o performance previamente determinado por el programador (p. ej. el número máximo de generaciones a alcanzar). Por lo tanto, y según lo anterior, es posible ver a un robot como una entidad capaz de percibir y actuar en forma autónoma y flexible [Nolfi et al., 2000][Russell et al., 1995]. En la literatura [Bradshaw, 1990], frecuentemente se utiliza el concepto de agente, para definir las características de percepción y capacidades de actuar en el entorno de una entidad computacional. En el presente trabajo, será utilizado el concepto de agente y agente robótico de manera análoga al concepto de robot móvil autónomo. La autonomía se refiere a la capacidad de realizar actividades sin intervención humana o de otros robots. Por otra parte, la flexibilidad especifica que un robot puede adecuarse a la variabilidad de su entorno cuando así se requiera (p. ej. cambios según la dinámica del medio ambiente), pudiendo esto estar guiado por objetivos [Jennings et al., 1998]. Además, y en relación con sistemas multi-robots, un robot puede ser capaz de interactuar con otros robots a fin de encontrar diferentes modos de realizar sus actividades o colaborar entre sí [Wooldridge, 1996]. Particularmente, el tipo de colaboración que surge de manera espontánea se denomina comportamiento emergente [Nolfi et al., 2000]. Los estudios realizados dentro de la RE son diversos: desde simples controladores [Fernández et al., 2004], arquitecturas de control [Brooks, 1986] e implementaciones en hardware [Tosini et al., 2004][Nolfi et al., 2000], hasta estudios de comportamientos complejos [Téllez et al., 2004][Togelius, 2003]. Particularmente, 2 Introducción muchos de los trabajos están enmarcados dentro de la perspectiva dada por la Robótica Basada en Comportamientos (RBC) [Arkin, 1998]. Cabe aclarar que por “comportamiento complejo” se entiende a todo aquel que se compone de subcomportamientos simples, los cuales son coordinados para obtener el comportamiento requerido. Por lo tanto, es posible decir que los controladores existentes son concebidos para realizar una extensa variedad de actividades, considerando distintas finalidades: reacción, interacción sensor-actuador, aprendizaje, etc. Uno de los mayores problemas que afronta la RE es el estudio de comportamientos complejos según la RBC. A pesar de que los comportam ientos simples pueden ser fácilmente obtenidos [Floreano et al., 2000][Floreano et al., 1998], comportamientos complejos con diferentes niveles de control requieren componentes adicionales (p. ej. reguladores adaptativos de la incidencia de la relación entre módulos comportamentales) así como mecanismos de coordinación entre subcomportamientos [Téllez et al., 2004]. A continuación, se resumen los principales factores que dificultan la construcción de controladores genéricos para RE: • Escalabilidad: Uno de los problemas más grandes en los sistemas artificiales evolutivos es el desarrollo de sistemas de control que resuelvan problemas complejos. Este problema se refiere a la escalabilidad de sistemas. Diversas estrategias para lograr escalabilidad han sido propuestas, de las cuales una de las más significativas es la Evolución por Niveles o Layered Evolution [Togelius, 2004]. Basada en la comparación entre Evolución Incremental [Urzelai et al., 1999] y Evolución Modularizada [Calabretta et al., 2000], la Evolución por Niveles obtiene un mejor desempeño en comparación con las otras dos, usando la Arquitectura por Subsumisión [Brooks, 1986] durante el proceso evolutivo. Según Tellez et al., éstas son propuestas inteligentes al problema de escalabilidad en sistemas evolutivos. • Modularidad (vs. Control monolítico): La idea es crear módulos generales para formar una base sólida que permita escalabilidad mientras se construyen capas comportamentales superiores, manteniendo una estructura coherente (evidenciado principalmente en neurociencia [Nolfi et al., 2000]) [Nolfi, 1997]. Tales bloques deben ser consistentes para alcanzar los objetivos para los cuales fueron desarrollados y no-específicos o suficientemente generales para aplicarse a distintas situaciones. La modularidad en los sistemas evolutivos es un factor que está siendo activamente estudiado. • Adaptabilidad: Esto no sólo incluye la idea de que los módulos son dinámicos, también sus estructuras y relaciones pueden variar durante la ejecución del sistema en forma dependiente de la experiencia. Hay varias técnicas que pueden aplicarse para investigar este tipo de dinámica. En el plano neuronal artificial [Haykin, 1999], ellas incluyen diferentes mecanismos de plasticidad neuronal como sinapsis plásticas o neuromodulación [Di Paolo, 2000]. Como es posible ver, la relevancia de la investigación propuesta está basada en temas específicos tal como los señalados previamente, no sólo desde la literatura presentada, sino también incluyendo ideas multidisciplinarias no descritas aquí, como por ejemplo ideas provenientes del campo de la neurociencia. Algunos avances en RE han sido realizados buscando generar en parte comportamientos complejos habitualmente usando modelos evolutivos modulares mediante redes neuronales artificiales. Algunos de estos involucran el uso de Evolución Incremental [Gómez et al., 1999], o evolución de más de una red neuronal artificial [Calabretta et al., 2000]. Pese a tales propuestas, la temática de la evolución de comportamientos complejos se mantenía casi intratable [Téllez et al., 2004]. Recientemente, nuevas direcciones de investigación fueron presentadas por Kaplan y Oudeyer [Kaplan et al., 2003] y por Togelius [Togelius, 2004]. Kaplan y Oudeyer proponen una medida del desempeño de los robots en el entorno (función de fitness) la cual permite la creación de comportamientos complejos, permitiendo ser modificados dinámicamente a lo largo del tiempo. Esta función es gobernada por lo que llaman “principios de motivación”, vinculados al continuo desarrollo del robot obteniendo nuevos comportamientos en forma automática. Los comportamientos que se pueden generar con el trabajo de Kaplan y Oudeyer, presentan un alto grado de complejidad y están casi por completo libres de restricciones Introducción 3 de diseño. Sin embargo, tales comportamientos están limitados en cuanto a su complejidad tanto como lo permita la estructura de la red neuronal que los modela. Por otro lado, tal como fue mencionado oportunamente, Togelius propone utilizar la idea de subsumisión (Subsumption Architecture) durante la evolución de comportamientos dentro de un controlador robótico. Por ejemplo, los niveles o capas representadas por los controladores neuronales son subsumidos1 uno dentro de otro [Brooks, 1986]. Cuando un nivel es desarrollado, el siguiente es creado y refinado sobre el primero con una función de fitness diferente. Al realizarse un análisis de los desarrollos existentes, y según el criterio de escalabilidad, estos pueden clasificarse en: • Aplicaciones no escalables: en términos generales, algunos desarrollos están concebidos para resolver una única problemática. En este caso, son generados los comportamientos requeridos de manera aislada, definiendo una funcionalidad concreta por el programador. Ejemplos de aplicaciones en dicha categoría son: [Floreano et al., 1997][Nolfi, 1996]. • Aplicaciones escalables: son definidos los comportamientos mediante un conjunto de módulos software escalables. Aquí, pueden usarse diferentes módulos comunes en distintas tareas a ser llevadas a cabo. Además, las aplicaciones que son desarrolladas según esta clasificación, posibilitan la incorporación de nuevos comportamientos, algoritmos u otras variantes por parte del programador. En esta categoría se encuentran las aplicaciones descritas en [Téllez et al., 2004][Kaplan et al., 2003][Togelius, 2003], aunque es una línea de investigación abierta dentro de la RE. En [Téllez et al., 2004] se adopta la propuesta de identificar cuándo un nuevo comportamiento debe ser creado según la especificación de Togelius antes señalada. No obstante, esto es llevado a cabo desde un enfoque poco claro en cuanto a la arquitectura planteada y usando hardware de propósito específico. En cambio, la propuesta de Togelius no ha sido desarrollada en su totalidad, dado que varios de sus aspectos (p. ej. tipos de controladores neuronales y dominio de aplicación) han sido parcialmente estudiados. Un análisis profundo de tal propuesta proveería no sólo de certeza de los supuestos planteados, sino que también marcaría un acercamiento concreto y real de escalabilidad en RE, con un potencial interés de ser combinado con otras técnicas (p. ej. redes neuronales, lazos de control, etc.). Como consecuencia de los escasos estudios realizados hasta el momento en RE sobre escalabilidad, en la mayoría de las oportunidades, los controladores robóticos son implementados por componentes software ad -hoc según el comportamiento deseado. Esto constituye uno de los mayores obstáculos para la adopción masiva de tecnologías vinculadas a RE. Por lo tanto, en el presente trabajo se propone profundizar en el análisis de las aplicaciones escalables y en cuanto a su extensibilidad, lo cual es uno de los temas centrales de esta tesis. Dada la amplia variedad de dominios a los cuales puede ser aplicada la RE [Nolfi et al., 2000], resultaría de gran impacto generar herramientas genéricas que no se limiten al dominio de aplicación del trabajo propuesto o a sólo unos pocos desarrollos. Por otro lado, una arquitectura que permita escalabilidad de manera genérica, podría definir una forma de reusabilidad común a las aplicaciones, permitiendo que el programador las adapte y extienda según las necesidades particulares de cada una de ellas. Por tales razones, las herramientas escalables parecen ser más adecuadas para desarrollar aplicaciones en RE, como así también en otros dominios, que las herramientas no extensibles. Las propuestas analizadas en la literatura disponible presentan además restricciones con respecto a la extensibilidad2, debido a que sólo es posible extender un subconjunto de capacidades soportadas por los agentes robóticos (p. ej. incorporar un mayor número de tipos de controladores que permitan un procesamiento temporal de las acciones a realizar). Además, no se especifican estudios de diferentes mecanismos o estructuras de representación de los comportamientos buscados. Si bien la información que De aquí en más, se tomará el concepto de subsumisión como un sinónimo de la acción o el efecto de considerar algo como parte de un conjunto más amplio, restringido a normas generales de precedencia [Brooks, 1986]. 2 Véase en el glosario el concepto de extensibilidad y su diferencia con escalabilidad. 1 4 Introducción posee un agente robótico del ambiente es representada por el mismo entorno (agentes reactivos) [Nolfi et al., 2000], no es posible contar con estudios comparativos de representaciones del comportamiento y su actualización frente a la dinámica del ambiente vinculados a estudios de escalabilidad en RE. A modo de resumen, los desarrollos de aplicaciones extensibles poseen limitaciones con respecto a: • Extensibilidad limitada y dependiente del programador: sólo es posible la extensión de sub comportamientos en base a capacidades pre-definidas. Como se presentó en estudios previos al trabajo de tesis aquí desarrollado (señalados en [Fernández et al., 2004]), los comportam ientos y las interacciones entre ellos son generadas en forma rígida, sin permitir que varíen durante la ejecución del sistema de control. En general, los niveles de comportamiento son extensibles, permitiendo que el programador defina funcionalidades durante el proceso de diseño, pero no mientras es evaluado el desempeño del robot. • No existen mecanismos de refinamiento de capacidades adquiridas: el modelo reactivo que el robot posee del entorno (logrado mediante un proceso incremental basado en mecanismos de acción-reacción), por lo general, no es refinado luego de que el comportamiento requerido (o conjunto de ellos) sea alcanzado. No obstante, nuevas situaciones podrían requerir un mayor grado de precisión. Por tal razón, la representación del modelo reactivo del robot debe contemplar mecanismos de actualización de comportamientos mediante percepciones del entorno. En general, en las aplicaciones analizadas el tema de refinar comportamientos ya alcanzados, es tratado de manera parcial o no es considerado. Sin embargo, algunas de las aplicaciones contemplan aspectos de aprendizaje para adaptar un comportamiento a las situaciones actuales del entorno (un ejemplo de esto es presentado en [Togelius, 2004]), según las percepciones y la finalidad buscada en el diseño del controlador. Por tal razón, es deseable crear herramientas o técnicas que construyan en forma automática controladores adaptables, y que permitan refinar el modelo del entorno para obtener un alto grado de precisión en la tarea a resolver. • Coordinación no selectiva de comportamientos: en la mayoría de las aplicaciones, no es contemplada la posibilidad de que un comportamiento sea desarrollado antes que otros según las necesidades del sistema. Por ejemplo, un controlador robótico podría dar prioridad al desarrollo del comportamiento de evadir obstáculos antes que al de ir hacia el objetivo, al momento que sea sensado un obstáculo en el ambiente durante la ejecución del sistema. • Falta de mecanismos simultáneos de modelado de comportamientos: el sensado de situaciones, por lo general, es llevado a cabo en paralelo por cada nivel comportamental, pero las acciones vinculadas a cada comportamiento presentan una secuencia (asociación) predefinida no incorporada de manera automática o emergente por el controlador. Generalmente, es predefinida por el programador. Es deseable que un controlador permitiese la concurrencia de comportamientos, dependiendo de la naturaleza de los objetivos y del dominio del problema. Como ejemplo de esto, es posible decir que mientras que un robot lleva a cabo una tarea, éste puede aprender de manera concurrente que la actividad llevada a cabo no es apropiada, y modificar dicha situación. El objetivo general del presente trabajo consiste en desarrollar un estudio incremental sobre escalabilidad en RE. Una de las finalidades derivadas es obtener una estructura de control capaz de gobernar a la navegación de un agente robótico, promoviendo reusabilidad y escalabilidad de comportamientos. En esto serán tratados aspectos no considerados por estudios existentes. Finalmente, y a modo de estandarización para la construcción de controladores con el enfoque propuesto, se desarrollará una herramienta para reducir los esfuerzos de obtención y definición tanto de los comportamientos, como de las pruebas con controladores. Con ello, se promueve la reusabilidad y su utilización en sistemas de control, y particularmente en sistemas de control robótico. Desde una perspectiva ingenieril, este trabajo de investigación es parte de un proyecto sobre robótica autónoma más extenso. Un grupo de investigadores de la red RIDIAAR (Red de Investigación y Desarrollo en Inteligencia Artificial Aplicada a Robótica) está desarrollando para dicho proyecto un vehículo submarino Introducción 5 autónomo (AUV – Autonomous Underwater Vehicle) con sensores para el reconocimiento del entorno [Acosta, 2005]. La meta del proyecto es tener un robot submarino completamente autónomo, y posteriormente un conjunto de ellos, capaz de navegar en ambientes naturales desconocidos con la capacidad de llevar a cabo tareas de reconocimiento. Un primer hito para lograr dicha meta es desarrollar un sistema de navegación reactivo en entornos no conocidos a priori. Una propuesta para tal desarrollo está orientada al estudio de un sistema de navegación basad o en controladores neuronales dentro del área de RE. Por neuro-controladores dentro de RE, nos referimos a controladores cuya superficie de control es un mapa de estrada/salida que tiene como soporte una red neuronal artificial. Éstas pueden procesar una gran cantidad de información, transmitiendo señales en paralelo mediante las conexiones entre neuronas. En este contexto, la especificación de un neuro-controlador implica la evolución de diferentes estructuras: (a) redes neuronales; (b) parámetros de control; (c) los programas de computación en si mismos. Más aún, en el caso de las redes neuronales, la evolución de los controladores puede implicar aspectos adaptativos, tales como aprendizaje durante la vida del controlador. En cuanto al problema de escalabilidad dentro de la RE considerando comportamientos complejos, o comportamientos compuestos por subcomportamientos, se propone alcanzar dicho estudio partiendo de la propuesta presentada por Togelius, incorporando un análisis comparativo entre diferentes neurocontroladores que componen un comportamiento complejo. Tales neuro-controladores serán desarrollados utilizando las siguientes redes neuronales artificiales: Continuous-Time Recurrent Neural Network (CTRNN) [Beer, 1995][Yamauchi et al., 1994][Beer et al., 1992][Beer, 1990], Plastic Neural Network (PNN) [Urzelai et al., 2001][Floreano et al., 1998][Floreano et al., 1996], Feed-Forward Neural Network (FFNN) [Fernández et al., 2004][Togelius, 2003], Recurrent Feed-Forward Neural Network (RFFNN), y Homeostatic Plastic Neural Network (HPNN) [Di Paolo, 2003][Di Paolo, 2002][Di Paolo, 2000]. El desempeño del agente robótico será evaluado en la realización de distintas tareas: navegación en un entorno estructurado y aprendizaje [Nolfi et al., 2000][Floreano et al., 1998b]. En suma, el desempeño de cada agente robótico desarrollado será evaluado en distintas representaciones del entorno de manera incremental, partiendo desde modelos simples hasta alcanzar una evaluación en un entorno real mediante un robot físico. El modelo del robot simulado, así como el del robot real, estará asociado al mini-robot Khepera [Khepera, 2004]. Las figuras de mérito a ser consideradas son: (a) optimización del tiempo de aprendizaje/adaptación de cada tarea mediante mecanismos adaptativos en RE en función de la división de problemas en sub-problemas; (b) búsqueda de estrategias optimales para la generación emergente de trayectorias a fin de maximizar la medida de desempeño en el entorno y minimizar las restricciones sobre la forma en que son obtenidas tales estrategias. Por otra parte, la herramienta propuesta consiste en el diseño de un conjunto de clases de software en un lenguaje orientado a objetos, las cuales pueden ser reusadas en diferentes dominios de aplicación bajo una misma temática. Concretamente, el enfoque seguido en el diseño de la herramienta obedece a la abstracción de las características comunes a diferentes comportamientos pertenecientes a un dominio en particular: navegación de robots [Codonie, 1997]. El proceso de creación de la herramienta fue incremental, refinándose en etapas sucesivas a medida que se desarrollaron nuevas instancias o tests. Con ello se buscó mejorar la flexibilidad y reusabilidad de la herramienta. Por lo tanto, la finalidad subyacente en el desarrollo de la herramienta propuesta, se vincula a reducir el tiempo de generación, esfuerzo, y costos de obtención de los controladores robóticos. Siguiendo con la descripción de algunas características relacionadas al estudio planteado, es válido señalar el concepto de modularidad emergente presentado por Nolfi en [Nolfi, 1997]. La idea es crear bloques genéricos (típicamente redes neuronales) que permitan obtener una base sustentable y escalable, construyendo nivel sobre nivel mientras se mantiene una estructura coherente. Desde la visión que Minsky propone [Minsky, 1988], la mente puede ser vista como una sociedad de agentes capaces de aprender, cooperar y emplear a otros agentes para alcanzar un objetivo final. De esta manera, en [Téllez et al., 2004] se propone que distintos agentes estén organizados en niveles, permitiendo además la interconexión entre ellos en un mismo nivel y entre niveles. Por el contrario, el presente trabajo adopta una tendencia tradicionalista de representar un controlador por niveles según una Arquitectura por Subsumisión. Esto se debe a que se quiere validar experimentalmente la idea presentada por Togelius mediante el desarrollo de diferentes 6 Introducción pruebas dentro del dominio de la navegación de robots autónomos. Con la herramienta y metodología generadas a partir de este trabajo, se espera facilitar el desarrollo de aplicaciones futuras con la concepción de que cada nivel esté basado en la colaboración entre uno o más agentes dentro de una estructura de control cooperativa en función de la emergencia de la modularidad de cada comportamiento. La primera fase en el desarrollo del estudio presentado, consistió en el análisis e implementación de neuro-controladores. Esto se realizó por medio de un conjunto de clases de software concretas según aspectos evolutivos (p. ej. definición de la estructura del genotipo vinculado a cada controlador neuronal). Luego, se realizaron varias implementaciones de los distintos tests a resolver. Así, por ejemplo, se agregó un componente software para permitir que los agentes robóticos sean evaluados apropiadamente en cada tarea de navegación en un entorno en el cual cada objeto está aleatoriamente ubicado, extendiéndose los componentes para soportar pruebas con robots reales. La materialización de los componentes responsables de la representación y ejecución del sistema de control robótico, se realizó mediante el lenguaje JAVA. Por otro lado, se desarrolló una aplicación de toma de datos relacionada con el entorno simulado. Cabe aclarar que la herramienta generada posibilita crear interfaces con diferentes entornos de simulación. En la Figura 1 se muestra un diagrama UML (Unified Modeling Language) [Rational, 1997] con las principales clases implementadas y sus relaciones, las cuales constituyen la estructura principal de la herramienta generada. Figura 1 – Arquitectura principal de la herramienta responsable de crear los controladores neuronales para la navegación y su posterior prueba experimental Para llevar a cabo pruebas con la herramienta presentada, es necesario definir y especializar algunas de las principales clases abstractas. El programador debe instanciar el comportamiento deseado vinculado con la prueba a realizar, definiendo los métodos abstractos presentes en la arquitectura de software de la herramienta. Básicamente, un método abstracto es la manera de especificar cuáles deben ser las definiciones a ser descritas para construir una aplicación o prueba. El flujo de control entre los diferentes componentes está definido de manera genérica. En otras palabras, los componentes son especificados de manera que posibilite invocar a uno o más métodos en forma genérica. Los métodos abstractos son aquellos en los cuales el programador vuelca la responsabilidad de codificar el comportamiento específico de cada prueba a resolver, tales como mecanismos de definición de neuro-controladores y su codificación o manipulación del modelo del entorno. Adicionalmente, y debido a las características presentes en la programación orientada a objetos, la arquitectura propuesta es adaptable y extensible en relación con la posibilidad de incorporar nueva funcionalidad o extender la existente. En la Figura 2 se muestra un diagrama de las principales clases involucradas en la creación de pruebas con los controladores. Los controladores son creados por el módulo EmpiricalTest. Introducción 7 Figura 2 – Módulo EmpiricalTest encargado de modelar la interacción de los componentes involucrados en la realización de pruebas experimentales Obsérvese que dicho módulo invoca a diferentes componentes: una red neuronal, un algoritmo y un genotipo. Éstos deben ser definidos por el programador para llevar a cabo una validación experimental o test. Como es posible ver, tales componentes especializados son particulares a cada prueba que se desarrolle. A modo de resumen, la herramienta propuesta permite construir controladores neuronales y realizar pruebas asociadas a tareas definidas por el programador. Además, especifica componentes de software adaptables y flexibles responsables de controlar el comportamiento de un robot. Los controladores que son desarrollados con la herramienta presentada, permiten la interacción con el entorno del robot, reaccionando en función a él, y de este modo asegurar la coherencia de las acciones a llevar a cabo. Aquí, los agentes robóticos pueden percibir y actuar según las características inherentes a su controlador neuronal genéticamente determinado. 1.2 Organización del Trabajo El presente capítulo ha presentado un descripción general del trabajo de Tesis propuesto así como también una introducción a los sistemas adaptativos y evolutivos artificiales vinculados a robótica autónoma. También se han presentado las motivaciones, objetivos y principales contribuciones del trabajo. Capítulo 2 - Contexto En el siguiente capítulo se definen los conceptos básicos empleados para abordar el problema: Robótica Evolutiva, adaptación en sistemas naturales y artificiales, agentes robóticos, algoritmos genéticos, y arquitecturas evolutivas de controladores. Además, se presentarán algunas justificaciones sobre la importancia del estudio propuesto considerando escalabilidad y modularidad desde dos perspectivas: el enfoque de la ingeniería y el enfoque científico. Asimismo, se describen algunas de las características de la Evolución por Niveles (Layered Evolution) utilizada en la evolución de los controladores. 8 Introducción Capítulo 3 - Herramientas para el Desarrollo de Controladores En el Capítulo 3, se muestran algunas de las aplicaciones y herramientas para el desarrollo de controladores empleados en robótica móvil, con la finalidad de establecer sus principales características, identificando sus capacidades y deficiencias. Capítulo 4 - Método Experimental Posteriormente, en el Capítulo 4 se presentará una descripción de los diferentes tipos de controladores neuronales estudiados. Con ello, se desarrollarán las características de cada uno encontradas en la literatura. Capítulo 5 - Resultados Experimentales con Controladores Monolíticos En el Capítulo 5, se mostrará el diseño y la implementación de diferentes experimentos con los tipos de controladores descritos en el Capítulo 4. Capítulo 6 - Evolución de Neuro-Controladores Multi-Nivel Luego, en el Capítulo 6 se expondrán diferentes pruebas con arquitecturas de control por niveles, correspondientes a implementaciones de comportamientos simples y complejos. Además, se compararán en dicho capítulo los resultados obtenidos (tanto a nivel simulado como en un ámbito real) con los alcanzados en otras implementaciones en el mismo área de estudio. Capítulo 7 - Conclusiones En el Capítulo 7 se expondrán las conclusiones y trabajos futuros. Apéndice - Notas para el Usuario Finalmente, en el Apéndice A, se describen las principales características de ejecución y materialización de tests sobre robots simulados y reales mediante la herramienta desarrollada. Capítulo 2 - CONTEXTO CONTEXTO “… lo voy a pre-estudiar” Nicolás Fellenz “Para entender algo, es necesario comenzar desde el principio” Aristóteles 2.1 Introducción En este capítulo se detallarán los conceptos y enfoques en los cuales se basa el presente trabajo. Particularmente, se definirá adaptación en sistemas naturales y artificiales, agentes robóticos, algoritmos genéticos, algunas arquitecturas evolutivas de controladores, y Robótica Evolutiva. Además, se presentarán justificaciones sobre la importancia del estudio propuesto considerando escalabilidad y modularidad desde dos perspectivas: el enfoque de la ingeniería, y el enfoque científico. Como es de esperar, y dado que la finalidad del trabajo no es llevar a cabo un estudio sobre la evolución de sistemas biológicos, sólo se contextualiza temáticamente cada punto a través de un paralelismo a conceptos e ideas inspiradas en la Biología. El capítulo está organizado de la siguiente manera. En la sección 2.2 se describen algunas particularidades de los sistemas artificiales bio-inspirados. En la sección 2.3 se presentan las características inherentes a los algoritmos genéticos, y en la sección 2.4 se hace lo propio en cuanto a las redes neuronales artificiales. Las secciones 2.5 y 2.6 tratan sobre Robótica Evolutiva y el diseño de controladores, respectivamente. Por otra parte, las secciones 2.7 y 2.8 describen desde el enfoque ingenieril y el científico las implicancias de la evolución artificial. Finalmente, en la sección 2.9 se presentan las conclusiones del capítulo. 2.2 Sistemas Artificiales: Bio-inspiración Una característica común presente en la mayoría de los sistemas biológicos, es la habilidad de adaptarse al entorno. Esto es frecuentemente considerado en un proceso evolutivo natural [Darwin, 1859], y contempla que los individuos han evolucionado para estar adaptados al medio en un período prolongado de tiempo. Alternativamente, desde el punto de vista de la adaptación en la vida de un individuo (diferente de aquélla producida durante el proceso evolutivo), ésta puede ser considerada a través de la expresión: “comportamiento apropiado” para una determinada situación. Ashby [Ashby, 1960] formalizó la visión de la “adaptación durante la vida del individuo” desde una perspectiva dinámica. Propuso que el comportamiento de un sistema adaptativo (biológico o artificial) está determinado por un conjunto de parámetros. Si el sistema posee estado interno (o un indicador de la situación interna actual), entonces dicho estado puede ser definido por un conjunto de variables que cambian para que el agente pueda comportarse de la manera apropiada, aprendiendo a adaptarse. La forma en que las variables varían está determinada por parámetros. Sin embargo, ciertas variables, las cuales Ashby definió como “variables esenciales”, son mantenidas homeostáticamente, lo cual significa que son conservadas entre límites predefinidos durante el comportamiento antes señalado. Si dichas variables se encuentran fuera de los 10 Contexto límites preestablecidos, los parámetros se modificarán hasta que las variables estén dentro de los límites normales. De esta manera, el agente se readapta a las nuevas circunstancias. Para este paradigma, la “estabilidad” es sinónimo de comportamiento adaptado, y el “cambio” con un comportamiento mal adaptado. Como es posible ver hasta el momento, existen diferentes mecanismos y métodos basados en lo que se conoce de la naturaleza (p. ej. adaptación sináptica de las neuronas y el proceso genético). Esto generalmente se presenta con el nombre de bio-inspiración. Más concretamente, el trabajo que aquí se presenta, está referido a sistemas adaptativos y evolutivos artificiales bio -inspirados. 2.2.1 Creando Robots Autónomos Un agente es una entidad que funciona continua y autónomamente en un ambiente [Shoham, 1997]. Esta misma definición puede ser interpretada también para el concepto de agentes robóticos. Además, un agente es capaz de actuar modificando su entorno, percibiendo y desempeñándose selectivamente (percepción y reactividad). La autonomía, posicionalidad y corporeidad se relacionan, dado que se espera que un agente robótico realice, primordialmente, sus actividades de una manera adaptativa. En ello, la autonomía cobra un interés particular debido a que no se contempla la necesidad de que un humano intervenga en las acciones a realizar [Bradshaw, 1997]. Por lo tanto, se busca desarrollar agentes con la capacidad de mejorar su desempeño y adaptar su comportamiento en función de la experiencia en el entorno. De este modo, se pretende desarrollar un sistema de control capaz de afrontar fuentes imprevisibles de cambio. Un amplio número de propuestas, con un mayor o menor grado de éxito, han sido desarrolladas en la literatura para diseñar robots físicos o simulados mostrando tales características. Las características consideradas esenciales para la creación de un agente robótico son las que a continuación se enumeran: autonomía (autonomy), posicionalidad (situatedness), corporeidad (embodiment), y adaptabilidad. 2.2.1.1 Autonomía La autonomía puede definirse como la cualidad de estar auto-gobernado, y debe ser diferenciado del concepto de auto-dirigido, el cual está vinculado a sistemas automáticos capaces de auto-regularse. En otras palabras, los sistemas automáticos desarrollan mecanismos regulatorios dando o construyendo en ellos un camino específico a seguir, corrigiendo o compensando los efectos de disturbios externos. Los sistemas autónomos, por el contrario, desarrollan para sí mismos leyes y estrategias de acuerdo a lo que regula sus comportamientos, lo cual establece la auto-regulación al igual que el auto-gobierno [Smithers, 1995]. El concepto de auto-organización es crucial en el caso de robots móviles autónomos. A diferencia de manipuladores robóticos, los robots autónomos por lo general operan en ambientes abiertos, impredecibles y dinámicos. En este contexto, no es posible programar a un robot para moverse a lo largo de un camino, pero a pesar de ello, es posible proveer al robot de la posibilidad de tomar decisiones dependiendo de las condiciones encontradas en el entorno. La autonomía fue definida como opuesta a control según Gomi [Gomi, 1998] (en el sentido que el control implica dirección y gobierno de una entidad por otra), por lo que autonomía abarca una condición en la cual una entidad auto-contenida dirige su propio comportamiento. Por lo tanto, la expresión “control autónomo” podría interpretarse como contradictoria. Según Urzelai [Urzelai, 2000], la manera correcta de referirse a los “controladores” de robots autónomos puede ser: “generadores de comportamientos” o “mapeos de estímulo-acción”. No obstante, en este trabajo se utilizarán los términos de “controlador” o “sistema de control” para referenciar a estructuras capaces de generar comportamientos autónomos. 2.2.1.2 Posicionalidad y Corporeidad Los conceptos de posicionalidad y corporeidad fueron introducidos por Brooks [Brooks, 1991] para remarcar la importancia del par acción-percepción. Posicionalidad afirma que un agente inteligente debe estar ubicado en Contexto 11 el mundo real y que su comportamiento debe estar formado por la interacción generada a través del sistema senso-motor con el entorno circundante. Por otra parte, corporeidad implica que un agente debe tener un cuerpo físico dentro del ambiente para interactuar con su entorno. Consecuentemente, un robot está continuamente sujeto a fuerzas físicas, a disipación de energía, u otras influencias del entorno. Esto implica sustanciales simplificaciones debido a que la física relacionada en el proceso puede extraer información que no es accesible para un observador externo [Pfeifer et al., 1999]. Tanto posicionalidad como corporeidad resaltan la importancia de la interacción con el entorno. Sin embargo, en muchos casos este aspecto no es considerado en la investigación dentro de robótica, dado que es bastante difícil diseñar de la nada un sistema capaz de aprovechar las interacciones senso-motoras con el entorno. La razón de esto es que cada acción realizada por un robot que interactúa con su entorno, determina al mismo tiempo el próximo patrón sensorio que el robot debe recibir, el cual define la próxima acción a realizar por el robot. Tal dinámica entre el robot y su entorno no es fácil de analizar para un diseñador humano. Los enfoques de aprendizaje y evolución, no obstante, pueden explotar tales tipos de interacciones complejas para generar comportamiento adaptativo [Urzelai, 2000]. 2.2.1.3 Adaptabilidad Un robot autónomo que se desempeña en el mundo real necesita ser adaptable para afrontar cambios imprevistos en el entorno. Un robot autónomo puede ser provisto de mecanismos de adaptación, tales como aprendizaje on-line o algoritmos auto-organizados capaces de modificar su comportamiento. En general, cualquier modificación vinculada a la “supervivencia” del robot en el entorno es considerada como adaptación. Por otra parte, la adaptabilidad debe ser diferenciada de la robustez, dado que un sistema puede ser robusto sin ser adaptativo. La robustez está relacionada con la habilidad de lograr un determinado objetivo bajo diferentes condiciones. Adaptabilidad concierne a modificaciones necesarias para afrontar los cambios. La robustez es una propiedad estática la cual describe de manera general cómo es el sistema. En cambio, adaptabilidad es una propiedad dinámica, la cual posibilita a un sistema adaptarse a nuevas condiciones del ambiente. En lo que respecta a este trabajo de tesis, se construirá un controlador dinámico capaz de generar comportamiento adaptativo. En cuanto a agentes reactivos se refiere, esto trata de la realización de cambios en sus capacidades reactivas. Por lo tanto, existen diversas razones por las cuales el aprendizaje (visto como un proceso de adaptación al entorno) puede ser útil [Nolfi et al., 2000]: (a) ciertos detalles no conocidos en el ambiente; (b) la información a considerar puede ser desconocida o ser muy grande para ser codificada explícitamente por humanos; (c) dinamicidad del ambiente. Además, el aprendizaje tiene diversas formas de ser considerado. Sin embargo, el aprendizaje constituye un campo de estudio muy reciente a nivel de agentes robóticos. El aprendizaje puede ser mejorado notoriamente si se provee algún tipo de información de retro-alimentación o feedback, indicando el nivel de desempeño alcanzado. Básicamente, se pueden distinguir dos tipos de mecanismos de feedback vinculados al presente trabajo: (a) aprendizaje supervisado, dónde el feedback representa la utilidad de la actividad deseada. El objetivo de este tipo de aprendizaje consiste en satisfacer un determinado criterio de la mejor manera posible; (b) aprendizaje por refuerzos: el feedback sólo especifica la utilidad de la actividad actual. El objetivo de este aprendizaje consiste en maximizar dicha utilidad. En todos los casos se asume que el feedback lo provee el entorno. 2.2.1.4 Agentes Reactivos Existen diferentes clasificaciones de agentes [Nolfi et al., 2000][Logan, 1998]. Una de ellas se refiere a agentes reactivos, los cuales no poseen ninguna información sobre el entorno, sino que actúan utilizando un comportamiento de tipo estímulo-respuesta reaccionando al estado actual del ambiente, se definirán representaciones que permitan un mapeo entre los estímulos del entorno (percepciones realizadas) y sus propias acciones en relación a las respuestas comportamentales requeridas. 12 Contexto En cuanto a percepción se refiere, un agente debe ser capaz de conocer lo que ocurre en el entorno. Por ejemplo, durante la exploración de un entorno no conocido, el robot debería ser capaz de percibir y distinguir objetos a su paso. De esta manera, el sistema de control podría actuar ante situaciones tales como colisiones, entre otras. Un punto importante de destacar es que la percepción puede estar afectada por el ambiente, dado que en la mayoría de los entornos reales, no se percibe información actualizada o correcta. Esto se debe a que existen perturbacio nes de los datos obtenidos. Por otra parte, un agente robótico con capacidad de reacción posee la habilidad de actuar en función de las percepciones recogidas [Nolfi et al., 2000]. Esto expresa que un agente es capaz de ejecutar acciones en función del ambiente cuando tales eventos afectan a los comportamientos, con la idea de satisfacer algún requerimiento. Básicamente, un comportamiento reactivo puede implicar un proceso de selección de acciones, el cual se realiza sin ningún tipo de proceso de razonamiento. Un ejemplo de esto es la Arquitectura por Subsumisión [Brooks, 1996] en la cual cada agente posee un conjunto de reglas condiciónacción organizadas por niveles de importancia. 2.2.1.5 Adaptación en Sistemas Artificiales Un tipo de adaptación utilizado en la actualidad en sistemas adaptativos artificiales, es la adaptación fenotípica. Desde un plano genético, las adaptaciones fenotípicas ocurren dentro de un agente, en un proceso basado en aspectos genéticos y en la evolución. Además, la adaptación puede diferenciarse según la escala temporal (generacional o durante la vida del controlador). En [Arkin, 1998] se clasifica a la adaptación en: • Adaptación Comportamental: los comportamientos de un agente en particular son ajustados en forma relativa a otro. • Adaptación Evolutiva: los cambios de los descendientes (elementos nuevos de una población), en cuanto a escalas temporales prolongadas, están basados en el éxito o fracaso de sus ancestros en el ambiente. • Adaptación Sensora: el sistema perceptual de un agente se vuelve más armonizado al ambiente. • Aprendizaje como adaptación: esencialmente, se refiere a cualquier cambio que resulte en un agente mejor adecuado según la perspectiva de entorno (p. ej. adaptación neuronal). La investigación en Inteligencia Artificial ha invertido un esfuerzo considerable en determinar cuáles son los métodos de aprendizaje o técnicas de programación por las cuales lograr que un sistema robótico pueda aprender. Particularmente, en robótica se presta gran interés a: • Aprendizaje en Redes Neuronales: es una técnica de programación vinculada a la utilización de redes neuronales artificiales mediante una forma de adecuación dependiente del tipo de red. El aprendizaje ocurre como resultado de alteraciones sinápticas [Arkin, 1998]. • Aprendizaje Evolutivo: corresponde a una técnica de programación asociada a la utilización de procesos bio-inspirados en adaptaciones genéticas. Los operadores genéticos tales como crossover y mutación, son usados en poblaciones de controladores, arrojando estrategias de control con algún grado de variación. En cuanto a las redes neuronales, el aprendizaje ocurre, por lo general, mediante el ajuste de los pesos sinápticos según un procedimiento de minimización del error, tal como la regla Hebbiana, la regla ∇ generalizada o back-propagation [Haykin, 1999]. Por el contrario, las estrategias evolutivas han sido usadas en adaptaciones on-line, así como también en aplicaciones más comunes de aprendizaje off-line dentro de sistemas de control. Contexto 2.3 13 Algoritmos Genéticos Los Algoritmos Genéticos3 fueron inicialmente introducidos por Holland en 1975 [Holland, 1975] como una técnica de búsqueda en paralelo basada en el principio Darwiniano de la reproducción selectiva de los mejores individuos. Un algoritmo genético opera sobre una población de cromosomas artificiales (genotipos), cada uno de los cuales codifican las propiedades de una población de individuos (fenotipos). Las propiedades de codificación se refieren a algunas de las variables de un individuo, tales como los parámetros para desarrollar la morfología de un individuo (p. ej. interconexionado neuronal), entre otros. Un cromosoma artificial puede ser visto como el A.D.N. de un individuo, compuesto de un número de genes cada uno conteniendo un símbolo o alelo de un conjunto de posibles símbolos. Además, diferentes tipos de métodos de codificaciones han sido usados. Los más comunes consisten en codificar cada gen del genotipo mediante un conjunto compuesto por dos alelos, 0 y 1. Este método es conocido como codificación binaria. Un algoritmo genético comienza con una población inicial de cromosomas aleatorios (en el caso de genotipos binarios, esto corresponde a strings aleatorios de 0s y 1s). Cada cromosoma es decodificado en el correspondiente fenotipo (por ejemplo, una red neuronal), uno por vez, y su desempeño es evaluado. El desempeño o performance de un individuo correspondiente a un genotipo específico se refiere a una función de fitness o medida del desempeño al momento de realizarse una acción en el entorno por parte del agente. Entonces, tres operadores genéticos pueden ser aplicados –reproducción selectiva, crossover, y mutación. Esto se realiza para crear nuevas generaciones de cromosomas. Dicho proceso evolutivo es repetido para varias generaciones hasta que un individuo cumpla una determinada condición (generalmente, que su medida de fitness sea mayor a un valor esperado). Es importante notar la diferencia entre genotipo y fenotipo en el contexto artificial, estando ésta relacionada a que mientras los operadores genéticos son aplicados en los genotipos, el fitness es medido sobre los fenotipos. Continuando con lo anterior, la reproducción selectiva consiste en hacer copias de los cromosomas en una población, con una probabilidad proporcional al fitness del individuo. Por ol tanto, los mejores individuos tendrán mayores posibilidades de reproducirse que los individuos clasificados con peor desempeño o performance. Algunos de los métodos más utilizados en reproducción selectiva son ([Urzelai, 2000][Goldberg, 1989]): • Método Roulette-weel: consiste en una rueda en la cual cada individuo es representado por un área en dicha rueda. El ancho de cada área es proporcional al fitness que el individuo representa. Por lo tanto, es seleccionado para reproducirse a aquel individuo en donde caiga un selector (una bola, haciendo una analogía con una ruleta). Los individuos con mayor fitness poseen mayor posibilidad de reproducción. Más precisamente, la probabilidad de reproducción pi de un individuo con un fitness de fi dentro de una población de N individuos es calculada según: pi = fi N ∑f i i La nueva generación de cromosomas es creada haciendo girar la rueda N veces y el número esperado de copias de individuos i sea Npi. Este método presenta dos limitaciones, (i) en poblaciones donde todos los individuos poseen similares valores de fitness, cada individuo tiende a realizar el mismo número de copias y el algoritmo genético realiza una búsqueda aleatoria, y (ii) en poblaciones donde un pequeño número de individuos poseen un valor de fitness mucho más alto que el resto, la mayoría de las copias corresponderán al mismo individuo, lo cual implica un riesgo de convergencia prematura. Una solución a tales limitaciones consiste en ordenar los valores de fitness antes de aplicar el operador de selección para acentuar las diferencias de fitness en el primero de los casos, y decrementarlos en el segundo de los casos. 3 Una buena introducción a los Algoritmos Genéticos puede ser encontrada en [Goldberg, 1989]. 14 Contexto • Método Rank-based: soluciona las limitaciones presentadas por el método anterior, seleccionando individuos de un ranking en el cual ellos están clasificados en forma descendente. La probabilidad de ser seleccionados es proporcional al ranking de individuos y no al valor de fitness. • Truncation Selection: consiste en otra forma de selección basada en ranking. Los N individuos son ordenados en forma descendente y los M mejores son elegidos para realizar K copias cada uno, con lo cual MK = N. Este es el método utilizado en las pruebas llevadas a cabo en el presente trabajo. • Tournament Selection: corresponde a una selección basada en competencia de dos individuos seleccionados de manera aleatoria. Si un número aleatorio entre 0 y 1 es menor que un valor predefinido T, el individuo con el fitness más alto es seleccionado, de otra manera el individuo “menos importante” será copiado a la siguiente generación. Las ventajas de este método es que no es necesario calcular el fitness para toda la población o realizar un ranking de individuos. Luego del proceso de selección, los operadores de crossover y mutación son aplicados con una probabilidad determinada de reproducción de individuos. Crossover4 consiste en tomar dos cromosomas, eligiendo un gen aleatorio en cada uno de ellos, para luego entrecruzar los genes circundantes a cada gen seleccionado. Este mecanismo de recombinación tiene por objetivo combinar en un único genotipo potencial la construcción de bloques que eventualmente puedan proporcionar ventajas a la selección. Por otra parte, la mutación introduce nuevo material genético mediante variaciones aleatorias sobre genes seleccionados al azar. En algunos de los casos, el mejor de los individuos de una generación es copiado a la siguiente generación sin modificaciones. Este mecanismo es conocido como elitismo e intenta preservar la mejor solución encontrada a lo largo del tiempo. genotipos actualización selección crossover mutación Población inicial 0.70 0.10 ….. ….. fenotipos decodificación 0.55 fitness Figura 3 – Esquema del proceso propuesto por los Algoritmos Genéticos 4 En el trabajo que aquí se presenta, no es considerado el operador crossover, por ejemplo, crossover de un punto (one-point crossover). Los lectores interesados en este tipo de operador, como en el caso de multi-point crossover, referirse a [Goldberg, 1989]. Contexto 15 2.3.1 Función de Fitness La función de fitness corresponde a un criterio de desempeño o performance determinada por el diseñador de un experimento. Las funciones de fitness deben cumplir algunas restricciones en cuanto a lo que expresan [Nolfi et al., 2000]. Tales restricciones o características de diseño son especificadas a continuación. implícita interna explícita externa funcional comportamental Figura 4 – Espacio de Fitness La función de fitness, generalmente incluye variables y restricciones, las cuales especifican el desempeño del comportamiento esperado. No obstante, tales variables y restricciones son difíciles de seleccionar debido a que el comportamiento generado por el robot no es del todo conocido previamente. Por tales razones, diseñar una función de fitness de manera efectiva es una tarea no trivial, y generalmente está asociado a un proceso de prueba y error. En la Figura 4 ([Nolfi et al., 2000]), la dimensión funcional-comportamental indica que la función de fitness considera modos de funcionamiento específicos del controlador o el comportamiento de un individuo. Por ejemplo, si se quiere obtener el comportamiento de caminar, una función de fitness calcularía la frecuencia de oscilación de las piernas mientras la función del desempeño del comportamiento (behavioral fitness function) considera la distancia cubierta por el robot. La dimensión explícita-implícita define la cantidad de variables y restricciones incluidas en la función. Por ejemplo, una función implícita seleccionaría los robots que se mantengan dentro del rango de energía correcto. En cambio, una función explícita incluiría variables y restricciones que evalúan varios componentes del comportamiento deseado, tales como si el robot se acerca a un área de fuente de energía, la velocidad, o la distancia con respecto a obstáculos, entre otros. La dimensión externa-interna indica si las variables y restricciones incluidas en la función de fitness son obtenidas utilizando la información disponible para evolucionar a un agente. Un ejemplo de función de fitness externa podría considerar la distancia entre el robot y su objetivo como una variable externa, debido a que no puede ser determinada utilizando información proveniente de los sensores del robot. Las funciones FEE (funcional, explicita, externa) expresadas en la Figura 4, describen cómo un controlador debe trabajar de manera funcional, y evalúa los sistemas en base a distintas variables y restricciones en forma explícita. Para ello se emplean dispositivos precisos de medición externos (p. ej. sensores robustos a variaciones ambientales), apropiados para optimizar el conjunto de parámetros complejos pero bien definidos del problema de control dentro de un entorno estructurado o controlado. Por otro lado, las funciones CII (comportamental, implícita, interna), establecen el resultado comportamental de un controlador evolutivo, basándose en unas pocas variables o restricciones (implícita) que son calculadas internamente (interna), convenientes para desarrollar robots adaptativos capaces de realizar operaciones autónomas en un entorno parcialmente desconocido y ambientes impredecibles sin la intervención humana. La línea diagonal entre los extremos de la FEE y la CII en el espacio de fitness, define un continuo entre el problema de optimización propuesto por la ingeniería tradicional y la síntesis presentada por los sistemas de vida artificial respectivamente. 16 Contexto 2.3.2 Fitness Landscape El fitness landscape es una metáfora generalmente usada para visualizar el espacio de búsqueda de un algoritmo evolutivo [Nolfi et al., 2000]. El fitness landscape asocia combinaciones de rasgos genéticos a valores de fitness. La dimensión landscape está dada por el número de combinaciones genéticas. Por ejemplo, para un organismo caracterizado por sólo dos genes correspondientes a la longitud y a la masa, el fitness landscape se verá como una superficie. La altura del landscape en un punto determinado está dada por el valor de fitness del individuo “potencial” resultante de una combinación específica de rasgos genéticos. En la práctica, el fitness landscape nunca es una superficie completa deb ido a que sólo una delgada fracción de todos los individuos potenciales es generada y testeada. Aun esto ocurre en los modelos computacionales más simples, aunque los rasgos genéticos bajo evolución son mucho más que sólo dos. En dicho caso, una visualización uni-dimensional del fitness landscape podría ser útil para proyectar un espacio multi-dimensional en una sola dimensión, graficando todos los valores de fitness, uno seguido de otro. fitness individuos combinación de rasgos Figura 5 – Fitness Landscape unidimensional La figura anterior muestra la representación en una dimensión de un fitness landscape con cuatro individuos. Esta simple representación no considera los cambios que se producen durante la vida de un individuo, ignorando las modificaciones ambientales, asumiendo que existe un mapeo uno-a-uno entre genes y rasgos. 2.3.3 Codificación Genética Para completar la especificación de un proceso genético artificial aplicado a controladores robóticos, es necesario decidir cómo codificar el sistema de control de un robot en el genotipo de una manera apropiada para la aplicación de los operadores genéticos. En la mayoría de los casos, las características fenotípicas sujetas a evolución están codificadas de manera uniforme. Así, la descripción de un individuo a nivel de genotipo asume la forma de “string” de elementos similares (como el caso de números binarios). La transformación de los genotipos a un robot completo es llamada mapeo genotipo-a-fenotipo. Por otra parte, una buena codificación genética debe exhibir diferentes propiedades. Un primer requisito es que pueda ser utilizada en el proceso de evolución, por ejemplo, la habilidad de producir mejoras mediante la aplicación de operadores genéticos. Esto sin duda es un criterio bastante importante de cumplir. Un segundo requisito es el potencial de expresividad de la representación. Esto se refiere a la posibilidad de codificar diferentes características fenotípicas tales como la arquitectura del controlador, la morfología del robot, las reglas de control de plasticidad de un individuo, y eventualmente las reglas que determinan el proceso genotipo-a-fenotipo. De hecho, sólo las características que son codificadas en el genotipo pueden ser desarrolladas a través de un proceso de auto-organización en vez de ser fijas o pre-diseñadas. Un tercer requerimiento es que sea compacta. La longitud del genotipo puede afectar la dimensionalidad del espacio de Contexto 17 búsqueda a ser contemplado por el algoritmo genético el cual, mediante las características de la superficie de fitness, puede afectar el resultado del proceso evolutivo. Finalmente, un cuarto criterio es la simplicidad. Estos factores tienen una importante consecuencia en el proceso evolutivo [Nolfi et al., 2000][Grau, 1994]. 2.4 Redes Neuronales Artificiales En RE, el sistema de control de un robot autónomo está generalmente implementado como una red neuronal artificial [Nolfi et al., 2000]. Existen distintas razones para esto, entre las cuales se encuentran: (i) las redes neuronales proveen un mapeo conveniente entre sensores y actuadores, y pueden representar tanto señales de entrada como salidas discretas o continuas dependiendo del tipo de red; (ii) las redes neuronales son robustas al ruido, dado que sus unidades están basadas en la suma ponderada de las señales. Por ello, las oscilaciones en valores individuales de dichas señales no afectan en forma drástica el comportamiento de la red. Esta propiedad es muy importante en el contexto de control de robots con sensores dentro de ambientes con ruido; (iii) las redes neuronales pueden ser entrenadas usando diferentes tipos de algoritmos de aprendizaje; (iv) las redes neuronales proveen varios niveles de granularidad. Es posible decidir aplicar técnicas evolutivas o de aprendizaje a un nivel bajo de especificación de una red neuronal, tal como los pesos sinápticos, o a niveles altos, tales como la coordinación de los módulos predefinidos compuestos de sub-redes pre-determinadas. Las redes neuronales artificiales5 son estructuras de cómputo paralelas inspiradas en alguna medida en los sistemas nerviosos biológicos. Las mismas están compuestas por un conjunto de unidades de procesamiento básico o nodos (relacionados con el concepto de neuronas biológicas), conectados por vínculos ponderados llamados sinapsis. Las redes neuronales pueden estar organizadas en diferentes tipos de arquitecturas. Una arquitectura de red convencional es la del tipo feed-forward, la cual consiste en uno o más unidades de entrada, las cuales reciben información externa, una característica común a todas las redes neuronales artificiales. Además, la red puede estar compuesta de cero o más unidades internas, y por uno o más unidades de salida, éstas últimas enviando información al exterior o ambiente. Las unidades internas generalmente se las denomina unidades ocultas debido a que no están en contacto con el ambiente externo. Otro tipo de red es la red neuronal recurrente la cual posee unidades de entrada, ocultas, y unidades de salida, pero sin que sea clara la dirección de la información (dirección de las flechas que representan las conexiones sinápticas). Esto se debe a que existen varias conexiones mucho -a-muchas entre neuronas, incluyendo autoconexiones. Las arquitecturas recurrentes presentan mayor complejidad en cuanto a la dinámica dependiente del tiempo en comparación a las redes del tipo feed -forward. Cabe destacar que estos temas serán desarrollados con mayor detenimiento en el Capítulo 5. 2.5 Robótica Evolutiva RE es una técnica avocada al desarrollo de robots y de sistemas de control senso-motor a través de un proceso de diseño automático, el cual involucra evolución artificial [Nolfi et al., 2000]. Básicamente, la idea que subyace detrás de la RE es la siguiente: una población inicial de diferentes “genotipos” (o genomas), cada uno codificando el sistema de control (y posiblemente la morfología) de un robot, es creada de manera aleatoria. Luego, cada genotipo es mapeado dentro del correspondiente fenotipo y testeado en el ambiente para determinar su habilidad para desarrollar una tarea específica. Posteriormente, el robot que haya alcanzado el mejor desempeño (medido a través de una función de fitness), está habilitado para reproducirse 5 Una buena introducción a la temática de redes neuronales artificiales puede encontrarse en [Beale et al., 1990], y [Haykin, 1999] para una descripción más avanzada del tema. 18 Contexto (o en otros términos, el controlador de dicho robot será considerado en futuras pruebas). Esto es llevado a cabo generando copias de sus genotipos e incorporándole a cada una de ellas cambios según operadores genéticos predeterminados, tales como mutación y crossover. El proceso es repetido a lo largo de un cierto número de “generaciones” hasta que el criterio deseado de finalización sea alcanzado (función de fitness). Con respecto a la función de fitness, es el diseñador del experimento quien la determina. Dicha función es utilizada para medir el grado de capacidad de un robot para una tarea. Por otra parte, es el diseñador quien usualmente especifica cuál va a ser la información genética a ser volcada dentro del correspondiente fenotipo. Sin embargo, los mapeos entre el genotipo y el fenotipo son usualmente tareas independientes. Como consecuencia, los comportamientos obtenidos en la evolución y la forma en que estos son producidos, son el resultado de un proceso auto-organizado [Nolfi et al., 2000]. 2.5.1 La Robótica Basada en Comportamientos y la Robótica Evolutiva En términos generales, se podría decir que el enfoque propuesto por la RE comparte muchas de sus características con otros enfoques dentro del mismo contexto temático. Uno de ellos es el propuesto por la Robótica Basada en Comportamientos (RBC)[Arkin, 1998], el cual está fundado en la idea de proveer a los robots de un conjunto de procesos senso-motores (comportamientos) organizados jerárquicamente. Además, incorpora la idea de que el entorno determina cuál de los comportamientos debe tener el control en un determinado instante de tiempo. En este enfoque, al igual que en la RE, el entorno posee un papel relevante. En particular, las condiciones presentes en el entorno determinan cual será el comportamiento activo durante tales condiciones. Tanto en RE como en RBC, los robots están usualmente diseñados de forma incremental dentro de un proceso de prueba y error, en el cual el diseñador incorpora un nuevo nivel en lo alto de la jerarquía comportamental solo después de haber testeado y comprobado en el ambiente el comportamiento resultante de los niveles inferiores. Sin embargo, la RE, basándose en un proceso de evaluación automático, usualmente realiza un uso mucho más amplio del proceso de prueba y error antes referido. Mientras que con el enfoque basado en comportamientos, el comportamiento con el cual un robot resuelve una tarea está al menos parcialmente determinado por la persona que realiza el experimento (siendo quien decide la articulación entre los subcomponentes comportamentales), en RE esto es el resultado de un proceso auto-organizado. De hecho, la organización total del sistema dentro del proceso evolutivo, incluyendo su eventual organización en subcomponentes, es el resultado de un proceso de adaptación en algunas de las implementaciones descritas en la literatura. 2.6 Diseño de Controladores Para diseñar un controlador robótico, pueden adoptarse distintos enfoques basados en comportamientos. Entre los más representativos vinculados al presente trabajo, se destacan (a) el propuesto por Brooks (Arquitectura por Subsumisión), y (b) el conducido por evolución artificial. 2.6.1 La Arquitectura por Subsumisión La RE no es el único enfoque moderno vigente en robótica. En los 80s, Brooks propone la Arquitectura por Subsumisión (Subsumption Architecture [Brooks, 1986]). Con esto activó el área de investigación denominada RBC, la cual domina la actividad de investigación académica en robótica moderna. Los principios básicos de la Arquitectura por Subsumisión pueden resumirse de la siguiente forma: la arquitectura está organizada en niveles, donde cada nivel es responsable de producir uno o pocos comportamientos. Los niveles poseen un orden estrictamente o parcialmente vertical en el cual los niveles superiores presentan precedencia sobre los niveles inferiores. Generalmente, los comportamientos controlados por los niveles superiores son más complejos y “cognitivos” que aquellos representados por los niveles inferiores. Además, todos los niveles, excepto el de más abajo, presuponen la existencia de niveles Contexto 19 Comportamiento 2 Comportamiento 1 Acción Percepción Comportamiento 3 Coordinación inferiores, pero no la existencia de niveles superiores. En pocas palabras, el robot es construido con la modalidad buttom-up, en el cual cada etapa de la construcción es capaz de operar en forma independiente. Figura 6 – Diagrama genérico de una Arquitectura por Subsumisión El enfoque de Brooks ha probado ser más exitoso que el enfoque tradicionalista de dividir el problema en percepción, planning y acción [Nolfi et al., 2000]. Más aún, se ha demostrado que tanto los niveles responsables de comportamientos simples como los mecanismos de coordinación, pueden ser obtenidos a través de un proceso auto-organizado más que por medio de un diseño explícito (véase [Urzelai et al., 1998][Maes, 1992]). La RBC ha sido usada en muchas aplicaciones y ha estado inspirada tanto en aspectos de investigación biológicos como comportamentales [Prescott et al., 1999]. Al mismo tiempo, la construcción de robots mediante el diseño pre-establecido (o diseño en el cual los componentes siguen una lógica de interconexión fija) se ven limitados por la creatividad humana y por los prejuicios de diseño. Esto es un umbral drástico para los experimentos científicos. 2.6.2 Evolución de Robots La manera más eficiente de obtener resultados mediante RE, es realizando el proceso propuesto en el entorno real. Por ejemplo, durante el proceso evolutivo cada individuo de la población puede ser corporizado en un robot real, para luego evaluar su desempeño en el entorno real. Por esta razón, el proceso evolutivo puede requerir un tiempo considerable. Otra posibilidad es obtener controladores mediante evolución simulada, para luego evaluar tal controlador en el mundo real. Esta forma de proceder puede reducir significativamente el tiempo requerido en realizar un experimento. Para ser eficaz, sin embargo, esta forma de obtención requiere que todos los aspectos relevantes del robot, el entorno y la interacción robot-entorno, estén modelados con exactitud en un proceso de simulación previo. De otro modo, los robots podrían no comportarse de la manera deseada al momento de que sea transferido al ambiente real. No obstante, la evolución de robots en simulación sin una validación en robots reales no tiene sentido, dado que no existe forma de asegurar que la simulación realmente captura todas las complejidades y oportunidades del mundo real [Nolfi et al., 2000][Floreano et al., 1998]. 2.6.2.1 Evolución de Robots: Mundo Real Para evolucionar robots en ambientes reales, es necesario considerar distintos problemas. Primeramente, la robustez mecánica. Durante el proceso de evolución, y especialmente con los individuos de las generaciones tempranas, pueden encontrarse comportamientos con alta probabilidad de dañar el hardware del robot. Esto puede deberse a colisiones a altas velocidades contra objetos o a corrientes fuertes sostenidas en los motores al momento de empujar contra la pared. Una forma de resolver este problema es usar pequeños robots. De hecho, las leyes fundamentales de la física (p. ej. fuerzas implicadas en el choque del robot dentro del 20 Contexto entorno de prueba), otorgan mayor robustez mecánica a robots miniatura tales como el Khepera ® [Khepera, 2004]. Otro problema a considerar está asociado al suministro de energía. Los experimentos que utilizan evolución presentan un tiempo mayor que el tiempo medio de duración de la mayoría de las baterías. Por esta razón, es necesario proveer al robot de la habilidad de recargar sus baterías o desviar dicho problema a otra solución. Una posibilidad es usar un cable fino con conexiones rotativas como medio de alimentación de energía. Esta técnica permite ahorrar el tiempo requerido para recargas periódicas, y además permite la posibilidad de comunicación con una computadora, junto con el almacenamiento de datos, los cuales pueden ser utilizados luego en el análisis de los experimentos. Otra característica importante es el análisis del comportamiento obtenido y del curso de la evolución. El sistema de control de un robot generado mediante evolución, puede ser bastante complejo y estar íntimamente vinculado con el entorno. Por esta razón, extraer el controlador del robot y estudiarlo en forma aislada, por lo general, ayuda a comprender el comportamiento del robot. Diferentes métodos inspirados en neuroetología pueden proporcionar puntos de vista útiles, poniendo en correlación las conductas y las dinámicas de los controladores [Nolfi et al., 2000][Floreano et al., 1994]. 2.6.2.2 Evolución de Robots: Simulación Para hacer más precisas las interacciones entre el robot y su entorno, es necesario afrontar varios problemas. El primero de ellos se refiere a que diferentes sensores y actuadores, a pesar de que parezcan idénticos, pueden presentar un comportamiento diferente debido a pequeñas diferencias en su electrónica o en sus mecanismos. Por ejemplo, si miramos los sensores infra-rojos de un simple robot Khepera, es posible notar que distintos sensores (pero de iguales prestaciones) responden de manera significativamente diferente cuando son expuestos a los mismos estímulos externos. Esto implica que diferentes robots pueden desempeñarse de distintas maneras bajo idénticas condiciones, según las diferencias en las características de sus sensores. En otras palabras, los comportamientos a ser desarrollados poseen un mapeo -sensor actuador dependiente de lo que se perciba del entorno. Por lo tanto, los comportamientos son sensibles ante diferencias de percepción del ambiente respecto de sensores y actuadores presuntamente idénticos. Una manera de considerar las diferencias de cada sensor, es mediante la obtención en forma empírica de valores de mediciones del entorno con diferentes clases de objetos a través de los sensores reales del robot. Las matrices resultantes de mediciones, por ejemplo al variar los rangos de ángulo y la distancia con respecto de diferentes tipos de obstáculos, podrían ser utilizadas por el simulador para setear los niveles de activación de los sensores infra-rojos del robot, dependiendo de la posición actual en el entorno simulado. Otro problema que debe ser tenido en cuenta al realizar pruebas con un simulador, es que los sensores físicos de los robots reales entregan valores y comandos inciertos a los actuadores, presentándose efectos igualmente aleatorios sobre los actuadores. En definitiva, los sensores no retornan valores precisos, en cambio, presentan aproximaciones difusas de lo que ellos han medido. De manera similar, los actuadores exhiben efectos que pueden variar en el tiempo dependiendo de distintas causas no predecibles. Tal problema puede ser abordado mediante la introducción de ruido en todos los niveles de simulación. Cabe destacar que dicha simulación debe contarse con un modelo o al menos con indicadores de las variaciones potenciales de tales dispositivos. Finalmente, debido a que la evolución artificial puede explotar características no previstas de la interacción robot-entorno, el cuerpo del robot y las particularidades del ambiente deben ser reproducidas en forma precisa en la simulación [Minglino et al., 1995]. 2.6.3 Enfoques en Evolución Artificial La descripción que a continuación se presenta es bastante general aunque existe un número significativo de detalles, muchos vinculados a distintos tipos de implementaciones, que aún siguen sujetos a investigación. En términos generales, la temática presentada en esta sección gira alrededor del siguiente postulado: gran parte del secreto detrás de realizar un trabajo en evolución artificial se vincula a definir la tarea a llevar a cabo Contexto 21 y determinar una evaluación apropiada o función de fitness. Por ejemplo, si la tarea que debe realizar un robot es moverse alrededor de un círculo, el desempeño de genomas (o potenciales controladores) imperfectos debe estar ranqueado como una función continua, donde a movimientos circulares le corresponden mayor puntuación y a los movimientos rectilíneos de corresponden puntuaciones menores. Por otro lado, con un esquema de ponderación que asigna máxima calificación a movimientos curvilíneos perfectos y mínima en cualquier otro caso, el comportamiento deseado es muy improbable de generar mediante evolución. A continuación se presentan distintos enfoques orientados a concebir evoluciones artificiales relativas a la definición de la función de fitness y a la estructura del controlador. • Monolithic Evolution: La mayoría de las aplicaciones desarrolladas en RE, buscaban obtener un controlador mediante evolución artificial por medio de una única red neuronal simple. Esto en relación con una sola tarea y una función de fitness específica para todos los procesos. Este enfoque de generación de controladores se denomina Evolución Monolítica (Monolithic Evolution [Togelius, 2004]). • Incremental Evolution: Aunque parece trivial, por lo general, no es tan simple diseñar una función de fitness continua para una tarea compleja. Para la mayoría de las tareas, el desempeño no es fácilmente graduado en forma continua. Una solución que ha sido utilizada en tales casos es denominada Evolución Incremental o Incremental Evolution [Togelius, 2004][Blynel et al., 2003][Urzelai et al., 1999][Gómez et al., 1996]. En Evolución Incremental, la tarea cambia a lo largo de la evolución del controlador. Cuando la evolución ha producido un controlador aceptable, el cual resuelve fielmente la tarea para la cual fue creado, la tarea es aumentada en cuanto a su complejidad y la evolución puede generar soluciones a la nueva tarea partiendo de aquella ya evolucionada. La ventaja con ello puede ser explicada en términos de fitness landscape (sección 2.3.2). Algunos problemas, tales como recolectar objetos en el entorno, poseen un fitness landscape muy variado. Si el fitness es una medida aproximada de la habilidad del robot en cuanto a la tarea encomendada, un robot que al menos realice algún esfuerzo de resolverla p( . ej. de acercarse a los objetos a recolectar) será categorizado por encima de otro que se mueva aleatoriamente. Con Evolución Incremental, la tarea de recolectar objetos puede estar inicialmente premiada sólo por acercarse a los objetos que deben ser tomados, y luego que dicho comportamiento sea alcanzado, modificar la función de fitness para que, por ejemplo, pondere la tarea de tomar los objetos correctos. • Modularised Evolution: Otra técnica que ha sido definida es utilizar más de un sub-controlador en la evolución, pero manteniendo una única función de fitness. Típicamente esto se ha propuesto utilizando varias redes neuronales en forma de componentes independientes. Nolfi [Nolfi, 1997] expresa que dividiendo la red total en sub-redes separadas o “módulos”, mejora la evolución de un controlador robótico. En [Calabretta et al., 2000] se concluye que al duplicar una red neuronal evolutiva y dejando que éstas se diferencien en cuanto a sus funciones (donde los mecanismos para dividir el control entre las dos redes también es afectado por la evolución), puede mejorar la evolución total en un mayor grado. Particularmente, diferentes redes neuronales son mantenidas en cada instante de los experimentos (o generándose una red y luego duplicándola), dependiendo esto de cada autor en particular. No obstante, en ninguno de los experimentos analizados existe una diferenciación funcional concreta por el diseñador (para un mayor entendimiento véase [Venema et al., 2001] utilizando redes feed-forward). • Layered Evolution: La Evolución por Niveles o Layered Evolution, propone combinar las características principales de la Arquitectura por Subsumisión (la cual según Togelius siempre fue diseñada en forma fija y manual), con características presentes en RE. Como una alternativa al particionamiento de estructuras monolíticas de controladores, la Evolución por Niveles organiza al controlador de la siguiente manera: Arquitectura por Subsumisión con coordinación basada en prioridad [Arkin, 1998]. Cada nivel consiste de una red neuronal conectada a un subconjunto de sensores y actuadores del robot. Los niveles están conectados por una estructura donde los niveles superiores pueden influir en los inferiores. Ahora, si varios niveles son evolucionados en forma simultanea con una misma función de fitness, estamos en presencia de Evolución Modularizada. 22 Contexto Según Brooks, la “metáfora evolutiva” empleada en su trabajo indica que cada nuevo nivel era una innovación evolutiva reciente. Esta metáfora puede ser adaptada en RE mediante la evolución de niveles en forma secuencial, usando distintas funciones de fitness. Esto es, una vez que el primer nivel (nivel inferior) ha sido desarrollado en forma plena (alcanzando un valor de fitness satisfactorio), se procede a incorporar un segundo nivel por sobre el primero y evolucionar el segundo usando una nueva función de fitness hasta que se satisfaga una condición de finalización pre-fijada. Este enfoque de generación de un controlador es el mismo que el propuesto por Togelius. Un punto importante de señalar es que las ventajas de la Evolución Incremental también son válidas para la Evolución por Niveles. A continuación se presentan las principales características de cada uno de los enfoques evolutivos señalados en esta sección en cuanto a la división del controlador y a las funciones de fitness utilizadas. Tipo de Evolución Función de Fitness Niveles Evolución Monolítica Única Único Evolución Incremental Múltiple Único Evolución Modularizada Única Múltiple Evolución por Niveles Múltiple Múltiple Tabla 1 – Relación entre diferentes tipos de evolución artificial Al realizarse una comparación entre los distintos enfoques, con el objetivo de construir un controlador para un robot móvil que realice fototaxis en un entorno cerrado (sólo en simulación), y con capacidad de aprendizaje durante la vida del controlador, se encontró que la Evolución por Niveles fue más adecuada [Togelius, 2003]. Esto en cuanto al desempeño del controlador en la tarea señalada. Con ello, se investigó de alguna forma y de manera sistemática, aunque incompleta, la temática de escalabilidad en RE. En conclusión, las características asociadas a la afirmación de que la Evolución por Niveles produce resultados más satisfactorios en comparación con otros enfoques evolutivos, puede mencionarse: (a) la incorporación de los beneficios de la definición de niveles relacionados con la evolución incremental, y su repercusión en el alisamiento del fitness landscape. (b) la reducción del tamaño de las redes y su influencia en la velocidad de actualización y la dimensionalidad del espacio de búsqueda; (c) preservación funcional de mecanismos comportamentales ya desarrollados sin que se produzca “desaprendizaje”; (d) robustez a determinadas lesiones del controlador [Nolfi, 2002]; (e) multiplicidad de neuro-controladores en un único controlador; (f) utilización de principios de diseño relacionados con reusabilidad. Finalmente, las objeciones contra la Evolución por Niveles están apuntadas a una perspectiva científica bio-inspirada (sección 2.8.3). 2.7 Ciencia e Ingeniería En ésta sección se expondrán diferentes puntos vinculados a distintos enfoques y conceptos, asociados a desarrollos tanto en ingeniería como en investigaciones científicas sobre los temas del presente trabajo. 2.7.1 Adaptación, Descomposición e Integración La principal estrategia utilizada para diseñar robots móviles ha sido Divide y Conquista: (a) dividir el problema en una lista de pequeños problemas fáciles de resolver; (b) construir un conjunto de módulos o niveles capaces de resolver cada sub-problema; (c) integrar los módulos para resolver el problema general. Desafortunadamente, no es claro cómo un comportamiento que quiere ser obtenido puede ser dividido en sub-comportamientos. Hasta este punto, según la RE, es necesario rever un conjunto de experimentos usando evolución artificial y discutir diferentes características generales. Contexto 23 La primera de las características a señalar, es el hecho de que la evolución artificial es potencialmente más poderosa que el enfoque basado en descomposición e integración [Nolfi, 1998]. Enfoques clásicos en robótica generalmente han asumido un enfoque inicial de división basado en: Percepción, Planning, y Acción. Sin embargo, esta forma de dividir el problema ha producido limitados resultados y varios investigadores, siguiendo la propuesta de Brooks [Brooks, 1986], consideraron a tal división inapropiada. Por esta razón, Brooks propuso un enfoque radicalmente diferente, en el cual la división es lograda a nivel de comportamientos. El comportamiento deseado es dividido en un conjunto de pequeños subcomportamientos, los cuales son activados o suprimidos mediante un mecanismo de coordinación [Arkin, 1998]. Este enfoque ha probado ser más exitoso que el anterior. Sin embargo, aún no se especifica la decisión de cómo particionar un comportamiento en sub-comportamientos simples [Nolfi et al., 2000]. 2.7.2 Descripciones de Comportamientos La razón principal de por qué es difícil dividir un comportamiento en pequeñas piezas simples, se debe a que el comportamiento no sólo es el resultado del sistema de control del robot, sino que también es el resultado de la interacción del robot con su entorno. Para entender mejor esto, es importante distinguir dos formas de describir a un comportamiento. Una descripción del tipo distante o distal description corresponde a aquella referida al punto de vista del observador, en el cual términos de alto nivel, tales como “acercarse” o “discriminar”, son usados para describir los resultados de una secuencia de iteraciones senso-motoras. Por otro lado, una descripción del tipo próxima o proximal description está vinculada al punto de vista del sistema senso-motor del agente, el cual describe cómo un agente reacciona en distintas situaciones sensoriales. espacio motor discriminar acercarse evadir ambiente explorar espacio sensor descripción distante descripción próxima Figura 7 – Tipos de descripciones Es necesario notar que el comportamiento obtenido de una descripción del tipo distante, por ejemplo el comportamiento de exploración, es el resultado no sólo del comportamiento de una descripción del tipo próxima (ej. mapeo senso-motor) sino también del entorno. Concretamente, un comportamiento más preciso vinculado a la descripción del tipo distante, es el resultado de la interacción dinámica entre el agente y su entorno. De hecho, los patrones sensoriales que el ambiente provee al agente determinan en forma parcial las reacciones motoras de éste. Dichas reacciones, a su vez, modifican el entorno o la posición relativa del agente en el ambiente, determinando parcialmente el tipo de patrones sensoriales que el agente recibirá. En general, la división de comportamientos es obtenida en forma intuitiva por el investigador en base a la descripción del comportamiento global de su propio punto de vista (p. ej. desde el punto de vista de una descripción distante). Sin embargo, debido a que el comportamiento deseado es generado de manera emergente a partir de la interacción dinámica entre el sistema de control y el ambiente, es difícil de predecir 24 Contexto qué tipo de comportamiento producirá un determinado sistema de control. La inversa es también cierta: es difícil predecir que sistema de control producirá el comportamiento deseado. O sea, no existe un mapeo directo entre sub -comportamientos del sistema de control del agente y sub-componentes del correspondiente comportamiento (desde el punto de vista de una descripción del tipo distante). Esto significa que no tiene mucho sentido proyectar la descomposición al nivel de descripción distante del sistema de control. La RE, basándose en la evaluación del sistema como un todo y en su comportamiento global, deja en manos del diseñador el problema de decidir cómo particionar un comportamiento en comportamientos simples [Nolfi, 1997]. 2.7.3 Auto-Organización Cuando se observa el comportamiento de un robot que obtuvo su controlador mediante auto-organización, es posible interpretar una secuencia determinada de ciclos senso-motores como un comportamiento distante (distal behavior). Con ello, es posible decir que el robot está inicialmente explorando para luego evadir un obstáculo, etc. En cada paso, el robot tiende a reaccionar para maximizar su oportunidad de producir el comportamiento general buscado. Por ejemplo, cuando el entorno es explorado, el robot intenta maximizar su oportunidad de encontrar patrones sensoriales que sí conoce cómo discriminar. Finalmente, es necesario destacar que la solución proporcionada por la evolución artificial, es cualitativamente diferente de aquellas que pueden ser obtenidas mediante descomposición e integración, o aquellas más generales a través de un diseño parcial o total. En cambio, las estrategias emergentes están basadas en la interacción dinámica robot-entorno y en la interacción entre cómo el robot reacciona en cada posible circunstancia. Esta forma de estrategia es imposible de diseñar de manera pre-fijada dado que surge como resultado de un número grande de interacciones no lineales [Nolfi, 1997][Nolfi, 1996]. 2.7.4 Aprendizaje y Evolución Finalmente, existe una relación entre aprendizaje y evolución, la cual se describe brevemente a continuación: • Son aplicadas diferentes escalas temporales, diferentes mecanismos, con efectos similares [Nolfi et al., 2000] [Sasaki et al., 1997]: como se mencionó oportunamente, el aprendizaje posee la misma función vinculada con la evolución: la adaptación al entorno. El aprendizaje complementa a la evolución en que éste último permite a un organismo adaptarse a los cambios del entorno, los cuales ocurren con mayor rapidez para ser seguidos por la evolución. • Ventajas del aprendizaje en la evolución [Nolfi et al., 2000]: (a) la adaptación a los cambios ocurre más rápidamente en comparación a lo que ocurre a escala generacional; (b) es posible extraer información utilizable en la definición del curso de la evolución; (c) reduce la complejidad genética e incrementa la diversidad de la población. • Costos del aprendizaje en la evolución [Mayley, 1997]: (a) demora la habilidad de lograr la conducta del comportamiento buscado; (b) incrementa la falta de fiabilidad (debido a que son aprendidas cosas erróneas); (c) presencia de daños físicos, pérdidas de energía y seguimiento marcado. • Efecto Baldwin [Baldwin, 1896][Waddington, 1942]: el aprendizaje acelera la evolución debido a que individuos sub-optimales pueden reproducirse, adquiriendo durante su vida las características necesarias para sobrevivir. Sin embargo, el aprendizaje requiere tiempo. Baldwin sugiere que la evolución tiende a seleccionar individuos que poseen al nacer aquellas características útiles que se aprenderían si no se tienen. Este último aspecto del efecto Baldwin, llamado indirectamente “asimilación genética de los rasgos aprendidos”, ha sido avalado mediante evidencia científica y definido por Waddington como “un efecto de canalización”. Baldwin [Baldwin, 1896] describe un mecanismo que sugiere que el aprendizaje individual altera el curso de la evolución. El efecto Baldwin está basado en las siguientes observaciones: (a) si una especie está evolucionando en un ambiente cambiante, habría una presión evolutiva a favor de los individuos con la capacidad de aprender durante su tiempo de vida; (b) aquellos individuos que son capaces de aprender varios Contexto 25 rasgos, dependen menos de su código genético. Como resultado, estos individuos pueden soportar un abanico genético más diverso, basándose en el aprendizaje individual para resolver los rasgos perdidos o no optimizados de su código genético. Este abanico genético diverso, puede a su vez soportar una adaptación por evolución más rápida. Un número especial de Evolutionary Computation [Turney et al., 1997], contiene varios artículos sobre el Efecto Baldwin en los algoritm os genéticos. Por otro lado, y como un interrogante a resolver, si se considera una arquitectura por niveles que contempla aspectos de aprendizaje en lo alto de dicha estructura, y haciendo una analogía de cómo se supone que trabaja el cerebro, ¿sería posible desarrollar mecanismos de aprendizaje asociativos entre niveles? Este interrogante apunta a crear un nivel de control autónomo interno, sometido a un proceso evolutivo capaz de controlar a otros niveles sin ningún tipo de señales externas, como por ejemplo señales por refuerzo. Esto se propone como un trabajo futuro al aquí desarrollado. 2.7.5 El Comportamiento, la Emergencia y el Entorno El comportamiento es un proceso dinámico resultante de interacciones no lineales entre un agente (natural o artificial), su cuerpo, y el ambiente externo (incluyendo su entorno social) [Nolfi et al., 2000]. Por lo tanto, los sistemas comportamentales son difíciles de diseñar desde la perspectiva de un observador externo, y pueden ser efectivamente desarrollados mediante métodos auto-organizados (p. ej. métodos evolutivos artificiales) los cuales permitan descubrir y mantener propiedades comportamentales emergentes de las interacciones entre un agente y el entorno. Secuencias de tales formas de interacción guían a los procesos dinámicos (comportamientos), dónde la contribución de los diferentes aspectos (p. ej. el agente y su entorno) no pueden separarse. Esto implica que aun el conocimiento completo de los elementos que gobiernan las interacciones provee un pequeño impacto en la emergencia de comportamientos a partir de tales interacciones [Maturana et al., 1980]. En este contexto, Nolfi [Nolfi, 2005] utiliza el término “emergencia” para indicar una propiedad resultante de una secuencia de interacciones que pueden ser difícilmente predecidas o inferidas por un observador externo a partir de un conocimiento completo de la interacción de los elementos y de las reglas que gobiernan las interacciones. Más aun, en [Nolfi et al., 2000] se expone que “emergencia” hace referencia a una “solución adaptativa” (un mecanismo o un comportamiento) que no es diseñada o esperada. En definitiva, la relación entre las reglas de interacción y el comportamiento resultante es altamente compleja dado que, cuando las interacciones no son lineales (pequeñas variaciones a nivel reglas de control de dichas interacciones), puede transformarse en formas diferentes de comportamiento debido a un proceso acumulativo y a efectos de amplificación internos al agente. En otras palabras, es posible decir que “el carácter adaptativo de la emergencia de un comportamiento está determinado por la relación agente-entorno, y la adecuación del agente (adaptación) a tal relación, así como a lo percibido a partir de un criterio de adecuación o finalidad del agente” (p. ej. función de fitness). Ejemplos de comportamientos emergentes a partir de soluciones adaptativas en función de la interacción agente-entorno y de interacciones a escala micro-temporal incorporadas dentro del controlador del robot, serán presentadas en el Capítulo 5. Por lo tanto, es posible decir que efectivamente la emergencia de comportamientos depende de la interacción del agente con el entorno, y que en dicho proceso las características adaptativas, ya sea del algoritmo genético utilizado o los mecanismos adaptativos internos del controlador (p. ej. reglas plásticas), permiten la emergencia de comportamientos tal que estén adaptados al entorno [Nolfi, 2005]. 2.8 Evolución Artificial: Implicancias La evolución artificial prescribe una serie de implicancias que van tanto desde la forma en que se desarrolla el proceso de creación de controladores, hasta otros aspectos que se presentarán a continuación. 26 Contexto 2.8.1 Evolución Artificial e Ingeniería Los investigadores en RE, así como también en otras disciplinas, han notado que existen ventajas al dividir un problema en diferentes partes. Ésta es la razón detrás de la evolución incremental, y por ende de la Evolución por Niveles. Ahora, la pregunta a responder es: ¿por qué motivo es conveniente separar un controlador en niveles en vez de evolucionar uno general? Algunas de las razones por las cuales es ventajoso dividir a un controlador son: • Tamaño de las redes con que se trabaja: con esto se logra principalmente disminuir el tiempo de actualización de las redes y de búsqueda genética. Las redes neuronales comúnmente son medidas a través del número de neuronas empleadas, pero el principio fundamental del costo algorítmico es que la complejidad computacional es medida por el número de veces en que la operación más frecuente ocurre [Cormen et al., 2001]. Cuando se modifica una red neuronal, la operación más frecuente, por lo general, es la propagación de una activación a lo largo de las sinapsis correspondientes, existiendo más sinapsis que neuronas en la mayoría de las topologías de redes neuronales. Con lo anterior, no sólo existe el beneficio de la velocidad de modificación al reducir el tamaño de una red neuronal, sino que también existe una influencia significativa en el proceso evolutivo. En efecto, habitualmente, cada genotipo es proporcional al número de neuronas junto con el de sinapsis. Por lo tanto, decrementar la dimensión del espacio de búsqueda es bastante importante en muchos de los algoritmos de aprendizaje clásicos, principalmente para las redes neuronales [Bishop, 1995]. • Diferenciación modular: en estructuras neuronales monolíticas (p. ej. en Evolución Monolítica) es imposible separar las neuronas responsables de un comportamiento en particular de otras [Ziemke, 2000]. Desde esta perspectiva, la Evolución por Niveles presenta dos ventajas sobre la Evolución Incremental. La primera de ellas corresponde a que no se emplean evaluaciones del desempeño (fitness) de la red que ya fue evolucionada. Por otra parte, una ventaja no tan intuitiva y no tan bien corroborada, es indicada por Nolfi [Nolfi, 2003]. En dicho trabajo, se enuncia que si se lesiona en forma estratégica una red neuronal en una estructura monolítica, se podría mejorar su evolución. Presumiblemente, esto se debe a que en una red que ha sido evolucionada durante algún tiempo, no ocurre que los pesos sinápticos asuman valores “significativos” sólo donde las sinapsis estén contribuyendo al mecanismo o a la habilidad buscada, y en forma nula en otro caso, como intuitivamente se asumió. En cambio, se encontró que algunas pocas sinapsis presentaban pesos cercanos a cero. Así, cuando un mecanismo ha sido evolucionado en una red, si algún peso cambia en alguna posición, esto es considerado como una perturbación a dicho mecanismo, pero otro mecanismo podría no evolucionar en la red sin que se modifique algunos pesos sinápticos. De este modo, separar la red en niveles independientes puede ser visto como una estrategia completa de lesión, sólo permitiendo la comunicación entre los niveles en algunos lugares, y de este modo haciendo posible la evolución de nuevas funciones sin perturbar las existentes. • Múltiples tipos de redes en un controlador: diferentes tipos de redes neuronales son utilizadas en RE. En redes monolíticas, como es de esperar, sólo es utilizado un único tipo de red. No obstante, algunos investigadores incorporan características a una red pertenecientes a otras redes [Di Paolo, 2000]. Una arquitectura por capas, posibilita seleccionar el tipo de controlador apropiado para cada nivel. En mayor detalle, en capítulos venideros se describirá como estructurar múltiples redes en un controlador. • Principios de diseño: muchos trabajos han sido desarrollados con la finalidad de investigar principios en ingeniería que permitan, entre otras cosas, escalabilidad. Por lo tanto, y como propone Togelius, es de interés incorporar dichos principios a la investigación dentro de RE. Concretamente, la modularidad ha sido una práctica fundamental en la ingeniería de software y una ventaja que acarrea la modularidad es la reusabilidad. Hoy en día, muchos investigadores del área invierten mucho tiempo en replicar lo que otros han logrado. Es por ello que se espera que en el futuro existan Contexto 27 repositorios modulares de controladores ya evolucionados y que esto se transforme en una práctica útil sobre la cual poder construir nuevos controladores en base a los existentes. 2.8.2 Evolución Artificial y Ciencia En la sección anterior se trato el tema de los aspectos considerados en ingeniería vinculados a arquitecturas de control por niveles. Si bien esto es posible, cabe señalar que la RE es a menudo desarrollada como ciencia más que como ingeniería. Es por ello que es interesante ver cómo la Evolución por Niveles puede ser utilizada como una herramienta científica. Los desarrollos principales dentro de RE (generalmente, Evolución Monolítica) pueden ser vistos como un caso especial de la Evolución por Niveles. Según [Togelius, 2003], todas las investigaciones científicas en RE pueden ser llevadas a cabo con dicho tipo de evolución. De hecho, muchas investigaciones usando las mismas metodologías actualmente vigentes para desarrollos monolíticos, pueden probablemente ser llevadas a cabo con una perspectiva por niveles de evolución, lo cual permitiría investigar comportamientos más complejos. Algunas de las razones por las cuales es conveniente la utilización de la Evolución por Niveles en el ámbito científico, se presentan a continuación: • Niveles Neurofisiológicos: primeramente, es conveniente señalar que existe evidencia de que el sistema nervioso central de los vertebrados está organizado de manera similar a una organización por subsumisión [Prescott et al., 1999]. De este modo, y con una pobre analogía con la realidad, Brooks basó su propuesta de estructurar los controladores de acuerdo a la evolución natural. Las evidencias señalan que el sistema nervioso muestra muchas de las características de una arquitectura por niveles con un orden más o menos claro de niveles desde abajo hacia arriba. Por ejemplo, ha sido demostrado que si se lesionan los niveles superiores en muchos animales vertebrados, se mantienen prácticamente intactos los comportamientos de los niveles inferiores. No obstante, aun no queda en claro el orden en el cual las diferentes partes del cerebro fueron evolucionadas, o si la organización del cerebro es un buen diseño y si la mayoría de los niveles están, o podrían haber sido, evolucionados en forma simultánea. Aquí, la evolución artificial podría ayudar de alguna forma, por ejemplo, buscando si una determinada función es fácilmente evolucionada y/o su desempeño es apropiado. • Niveles comportamentales: desde el enfoque propuesto por la etología, se establece que el comportamiento de los animales está organizado de manera jerárquica. De este modo, se supone que los comportamientos individuales están organizados en sistemas y subsistemas con influencias positivas y negativas entre ellos. Por lo tanto, es de interés general, tanto en el plano práctico como en el teórico, comenzar con el estudio de una arquitectura modelada a partir de la descripción de sistemas comportamentales de determinados organismos y tratar de evolucionar los subsistemas que lo constituyen. 2.8.3 Discusión Como es de esperar, existen algunas objeciones al enfoque propuesto por la Evolución por Niveles. Transcribiendo en algún grado los puntos actuales de discusión e incorporando otros, a continuación son presentadas las objeciones encontradas: • Diseño no restringido: en términos generales, la evolución presupone trabajar sin restricciones o preconceptos del diseño humano. Es por esto que al diseñar explícitamente la arquitectura del controlador mediante la Evolución por Niveles, se interfiere con el precepto de la RE, el cual es: diseño sin restricciones. No obstante, si nunca es controlada la evolución de ciertos comportamientos complejos, no sería posible descubrir alguna solución evolutiva ingeniosa para la producción de dicho comportamiento. 28 Contexto • Evolución Artificial y Natural: la evolución de un comportamiento en forma tradicional según las técnicas de la RE, puede ser considerada como una prueba de que comportamientos similares podrían evolucionar del mismo modo en la naturaleza. La dinámica de la evolución de estos comportamientos puede ser usada como argumento de que la evolución natural de dichos comportamientos presenta una dinámica similar. No obstante, es objetable que la Evolución por Niveles podría no usarse de la misma manera que en el estudio de la evolución natural. En principio, puede que sea improbable evolucionar y combinar distintos niveles en un único mecanismo y que éste emerja espontáneamente. Si bien dicha afirmación tiene algún sentido, se puede argumentar que la evolución por niveles puede generar modelos de la evolución natural de acuerdo a los siguientes principios: (a) mantiene al controlador con una estructura totalmente neuronal dado que no es necesaria lógica pre-especificada (tal como pasa en sistemas basados en reglas); (b) existe una secuencia posible de evolución de los niveles. Ahora bien, según Togelius, se expresa que es posible que un organismo inicialmente se beneficie de la evolución de un determinado comportamiento (p. ej. fototaxis) y luego, cuando se encuentre en entornos más complejos, se generen nuevas situaciones que se manifestarán en nuevos comportamientos a los cuales adaptarse. Con esto, se concluye que si la suma de un nuevo nivel es justificable, la totalidad de la arquitectura también lo es. Pese a esto, el autor del presente trabajo considera que es difícil de concebir que en la naturaleza, como es lógico, se den idealizaciones del entorno. En definitiva, cualquier organismo debe afrontar en toda su vida la confluencia de múltiples acciones que generan diversos comportamientos en forma simultánea, muchos de los cuales pueden o no ser conocidos. Por lo tanto, se concluye que los sistemas naturales son capaces de procesar y evolucionar comportamientos en forma paralela (al igual que ocurren con Evolución Modularizada) junto con la consideración de nuevos comportamientos al estilo de la Evolución por Niveles. • Paralelismo con lo real: según la tradición conexionista, es común modelar funciones cognitivas con redes neuronales de una manera bastante abstracta, sin que se analice si los datos son presentados y extraídos de la red de una manera biológicamente posible. Por ejemplo, en una red que intenta modelar la adquisición del lenguaje, puede estar representada dicha información mediante alguna formalización compleja sin que se sepa a ciencia cierta si esto es posible. En la mayoría de los casos, esto se debe a que se ignora o no se considera qué es lo que ocurre en los sistemas naturales. Ahora, en el caso de que no se conozca qué es lo que sucede en la realidad, es posible abstraerse en algún grado y plantear una solución a un problema, y que en la realidad biológica la tarea sea realizada de forma diferente, en cuyo caso la critica inicial perdura. Analicemos el caso de una red de aprendizaje asociativo, la cual toma por sí misma sus entradas y salidas. Esto, en alguna forma, parece una abstracción y una idealización. No obstante, resuelve en cierta forma el problema del aprendizaje asociativo. Según la solución a este problema presentada por Cliff y Brooks, corresponde a posicionalidad y corporeidad (sección 2.2.1.2) Mediante la conexión de entradas y salidas al mundo físico o a un simulador, es posible, en algún grado, adquirir el significado de los eventos del entorno (aunque parezca poco plausible). Ésta es la idea subyacente en la evolución de redes neuronales, incluyendo a aquellas generadas mediante estructuras por niveles. Con ello, es posible concebir a los agentes o robots como un todo que necesitan estar en contacto con su entorno, lo cual posibilita aprender cuáles son las asociaciones a modelar en su red de aprendizaje asociativo. • Generalidad: como es de esperar, no todos los comportamientos son modelables con un enfoque por niveles. Es por ello que la identificación de los tipos de comportamientos que presentan esta característica es una cuestión interesante de desarrollar y, probablemente, la manera indicada de realizar dicha búsqueda es mediante la Evolución por Niveles. Con ello, es posible que proporcione a su vez una pista sobre dónde buscar la esencia neuronal de dichos comportamientos en la naturaleza. Contexto 2.9 29 Conclusiones En este capítulo se mostraron las principales características que hacen al enfoque de la RE conveniente para el estudio adaptativo del comportamiento en agentes naturales y artificiales. De hecho, se concluye que al usar evolución artificial el rol del diseñador queda limitado a la especificación de la función de fitness para medir la habilidad de un robot para realizar la tarea estipulada. Por lo tanto, desde el enfoque de la ingeniería, la principal ventaja de contar con un proceso autoorganizado es el hecho de que el diseñador no necesita dividir el comportamiento en sub-comportamientos (o módulos) dentro del sistema de control en forma taxativa. Mediante la selección de individuos, y según la habilidad para realizar el comportamiento deseado, los comportamientos complejos pueden emerger de la interacción de simples procesos en el sistema de control y de la interacción entre el robot y su entorno. Desde el punto de vista del estudio de los sistemas naturales y del enfoque científico, la posibilidad de evolucionar robots (los cuales son libres de seleccionar la manera de resolver una tarea), puede ayudar a entender cómo organismos naturales producen comportamientos adaptativos. Finalmente, el esfuerzo por obtener comportamientos complejos escalables puede ayudar a desarrollar hipótesis sobre algunas características de la evolución natural, las cuales a su posibilitará la generación de nuevos desarrollos en RE. Capítulo 3 - HERRAMIENTAS PARA EL DESARROLLO DE CONTROLADORES HERRAMIENTAS PARA EL DESARROLLO DE CONTROLADORES "Un descubrimiento científico nunca es el trabajo de una sola persona." Louis Pasteur 3.1 Introducción La construcción de agentes robóticos es un proceso complejo, debido a que se trata de desarrollar múltiples componentes que presenten características de autonomía, adaptación y robustez. Para permitir la construcción de tales sistemas, se han generado herramientas que facilitan la especificación de componentes de software junto con la coordinación apropiada entre ellos. La mayoría de dichas herramientas, se vinculan a simuladores de modelos robóticos o a interfaces de comandos de control hacia el hardware. Las herramientas existentes permiten construir controladores con las características presentadas en el capítulo anterior: autonomía, evolución simulada, aprendizaje y adaptación, entre otras. Algunas de estas herramientas proveen ambientes visuales de desarrollo e interfaces con el robot real. En este capítulo se describen algunas de las herramientas existentes para desarrollar controladores, con la finalidad de establecer sus principales capacidades e inconvenientes. Este capítulo está organizado de la siguiente manera. La sección 3.2 muestra algunas de las características de los estudios previos. En la sección 3.3 se presenta una breve descripción del hardware del robot Khepera. En la sección 3.4 se exponen las principales características de los simuladores analizados. En la sección 3.5 se detalla el proceso de selección del software con el cual desarrollar experimentos realistas. Finalmente, la sección 3.6 presenta las conclusiones del capítulo. 3.2 Estudios Bibliográficos Previos Al momento de realizar un estudio como el propuesto, es necesario analizar cómo otros trabajos relacionados presentes en la literatura han resuelto el problema de la generación de controladores, y principalmente, cuáles fueron las herramientas y recursos para ello. La temática descrita aquí, se asocia tanto a elementos de software que permiten desarrollar controladores, así como también a estudios abarcativos de construcción de controladores. Se analizaron características generales de cada uno de los trabajos encontrados en la bibliografía disponible, referentes a cómo son generadas las capacidades de cada controlador para resolver el problema de esta aplicación. Esto desde el punto de vista de flexibilidad y robustez. A continuación se describen las características analizadas: • Amplitud de estudio: los estudios desarrollados para la generación de controladores, se han basado principalmente en: (1) análisis específicos sobre aplicaciones particulares o en (2) cuestiones vinculadas a explicar los pasos del desarrollo de controladores. Esto en un contexto abarcativo de propuestas (p. ej. análisis de múltiples configuraciones de controladores). Ejemplos del primer grupo son: [Fernández et al., 32 Herramientas para el Desarrollo de Controladores 2004][Nelson et al., 2004]; en el segundo [Togelius, 2004][Greer, 2002][Maaref et al., 2002][Nolfi et al., 2000][Nolfi, 1999]. En términos generales, los estudios llevados a cabo comparten una característica: estudian un conjunto reducido de alternativas o variaciones de casos de estudio. En consecuencia, a menudo no queda del todo claro cual fue el proceso de selección de las decisiones que ponderaron la utilización de las alternativas seleccionadas. • Experimentos realistas: algunos de los estudios disponibles en la literatura, tratan del desarrollo de controladores que sólo son probados en modelos simulados, sin que se demuestren los resultados del mismo en la realidad. Básicamente, los controladores sometidos a la realidad sufren algún tipo de ajuste, con lo cual la generalización de los resultados obtenidos no son formalmente demostrados en un control real. • Extensibilidad: consiste en la capacidad de rehusar los resultados/estudios en la concreción de las capacidades del controlador. Típicamente, se refiere al potencial de crear un repositorio de controladores. En otras palabras, esto se vincula a identificar si se tiene o no como objetivo la extensibilidad del controlador. • Reusabilidad: corresponde al tipo de desarrollo que se pretende obtener. Particularmente, si se trata de la generación de un conjunto de componentes de software y módulos que facilitan la especificación de nuevos experimentos y resultados. Por ejemplo, una herramienta basada en componentes arquitectónicos reusables, posibilita el uso de tales componentes en futuros estudios. Este tipo de herramientas definen la relación entre componentes y su utilización. De esta manera, se reduce el esfuerzo de diseño e implementación de nuevas funcionalidades. Por lo tanto, ya sean estudios o herramientas, es importante diferenciar si éstos permiten o no reusabilidad. • Herramientas visuales: corresponde a la generación de componentes gráficos (herramientas) que faciliten captar datos y los muestren en forma entendible al programador. De esta manera, el conjunto de herramientas visuales posibilitan la interacción con el usuario para configurar y construir aplicaciones. Por lo tanto, resultan interesantes las herramientas que permiten la adquisición on-line de los datos sensados por el robot en el entorno real. En términos generales, las diferentes herramientas disponibles para la generación de controladores, definen distintos componentes de software responsables de codificar el control a llevar a cabo. Tales componentes pueden ser adaptados o extendidos según las necesidades del programador. Por ejemplo, una herramienta puede permitir que se seleccione el tipo de red neuronal que utilizará el controlador para decidir sus acciones, o posibilitar que el programador desarrolle otros tipos para ser usados en el futuro. Por lo tanto, es posible analizar la flexibilidad de la implementación con respecto de las características del controlador y clasificarlas en las siguientes categorías: • Posibilidad de extensión de componentes: se refiere a que el programador tenga o no que utilizar determinadas características tal como están definidas en la herramienta, sin que exista la posibilidad de utilizar otras, p. ej. tipo de algoritmo genético. • Posibilidad de adaptar componentes: el programador puede adaptar una característica proporcionada por la herramienta, y en especial propiedades predefinidas. Por ejemplo, parámetros propios del controlador neuronal, tal como número de neuronas en la capa oculta. Además, es posible tener una combinación de ambas categorías, por lo que se puede presentar una categoría que permita adaptar y extender componentes de la herramienta. En las siguientes secciones, se describen algunas de las herramientas existentes según las características presentadas en esta sección. Herramientas para el Desarrollo de Controladores 33 3.2.1 Estudio sobre Arquitecturas Homeostáticas El estudio desarrollado por Greer [Greer, 2002] está referido al desarrollo de arquitecturas viables para generar controladores robóticos homeostáticos. Dicho trabajo está basado en trabajos previos tales como [Beer, 1996][Floreano et al., 1998][Di Paolo, 2000], entre otros. El trabajo reporta el desarrollo y análisis de cuatro redes dinámicas evolutivas para control de un robot simulado. Los controladores fueron sometidos a un proceso evolutivo en relación a una tarea de intercepción de objetos, concretam ente pelotas, basada en la definición del problema presentado en [Beer, 1996]. Particularmente, el objetivo fue evaluar la habilidad cognitiva del controlador. En [Greer, 2002] se desarrollaron experimentos con diferentes redes neuronales. Redes del tipo CTRNN y plásticas fueron utilizadas desde una perspectiva dinámica. Además, un tipo de controlador homeostático fue evaluado considerando reglas plásticas. En suma, una extensión de dicho controlador se utilizó de acuerdo a la propuesta de “gas modulation” descrita en [Husbands et al., 1998] a fin de regular el aprendizaje de dicha red. Se encontró que las redes homeostáticas son rápidas de evolucionar y robustas. Además, se observó que fueron capaces de adaptarse a radicales alteraciones senso-motoras. Por otra parte, las redes con modulación del tipo gaseoso mostraron alguna capacidad de re-adaptación a perturbaciones. Finalmente, los resultados se vincularon a consideraciones en el uso del Efecto Baldwin en cuanto a la evolución de controladores, así como también al rol del entorno sobre la adaptación, junto con los diferentes tipos de reglas plásticas dentro de la RE. Según se reporta, los controladores analizados (principalmente los homeostáticos) representan el primer paso al uso de redes homeostáticas para un enfoque corporal del robot, ubicado en el entorno, y dinámico dentro de la RE. Cabe destacar que la mayor limitación del trabajo antes descrito consiste en que no posee ningún resultado experimental vinculado a control robótico real. Como consecuencia de esto, los agentes robóticos construidos siguen patrones de comportamiento sujetos a validaciones futuras. Otra limitación, hasta donde pudo observarse del informe del trabajo, consiste en que no es posible modificar o extender la herramienta propuesta en dicho trabajo. Particularmente, la definición experimental sólo fue enmarcada en un único escenario. Sin embargo, el trabajo estuvo orientado a la realización de pruebas con múltiples configuraciones de controladores en una tarea simple (Minimal Cognitive Behavior [Slocum et al., 2000]), lo cual dio, en cierto modo, claridad a los resultados obtenidos. 3.2.2 Estudio sobre Tareas Específicas El trabajo presentado en [Dale, 1994], está orientado a estudiar e investigar la utilización de algoritmos genéticos en la evolución de neuro-controladores, en cuanto a tareas específicas a ser realizadas por robots. En ello se emplearon técnicas formalizadas por [Holland, 1975] buscando diferentes métodos de codificación para representar redes neuronales en un genoma, con el objetivo de encontrar los mejores controladores al momento de llevar a cabo la tarea de vigilancia de zona o “comportamiento de perro guardián”. Una desventaja del trabajo presentado en esta sección consiste en que el controlador es relativamente simple de obtener, por lo que resulta un análisis poco desarrollado en cuanto a generación de controladores se refiere. Además, no se estudia un conjunto de controladores a fin de identificar cual es el tipo de controlador que mejor se adapta a la situación a resolver. En suma, no se propone ningún tipo de metodología o herramienta que permita la generación de nuevos experimentos a partir de los mostrados. Sin embargo, se exhibe un análisis básico y de interés ante alteraciones en los sensores (ruido). 34 Herramientas para el Desarrollo de Controladores 3.2.3 Estudio sobre Arquitecturas Evolutivas En [Togelius, 2003], y posteriormente en [Togelius, 2004], se presentó el enfoque evolutivo llamado Evolución por Niveles para control robótico mediante evolución artificial. El mismo, introduce características de la Arquitectura por Subsumisión [Brooks, 1986] dentro del área denominada Robótica Evolutiva [Nolfi et al., 2000]. Además, se presenta el problema desde dos perspectivas: la ingenieril y la científica. El estudio analizado es usado para la construcción de un controlador por niveles sobre un robot simulado, el cual aprende a distinguir cuál fuente de luz es la apropiada para aproximarse en un entorno con obstáculos. Dentro de dicho estudio, se presenta una comparación empírica con respecto a otras formas de evolución: Evolución Monolítica (Monolithic Evolution), Evolución Incremental (Incremental Evolution) [Gómez et al., 1996][Urzelai et al., 1999][Blynel et al., 2003], y Evolución Modularizada (Modularised Evolution) [Nolfi, 1997][Calabretta et al., 2000]. Los resultad os reportados argumentan que la Evolución por Niveles provee un enfoque superior a las otras alternativas de evolución. Si bien los resultados son de gran interés, principalmente desde la perspectiva de escalabilidad de comportamientos, no se presenta un estudio significativo que contemple multiplicidad de controladores analizados y variedad de situaciones a resolver. Principalmente, el mayor inconveniente surge en que durante el proceso evolutivo se utiliza un entorno simulado simple, junto con su respectivo modelo de robot, sin que en etapas posteriores se realice ningún tipo de comprobación en un entorno real. En suma, no se especifica claramente cuál fue el desempeño del robot simulado a la hora de presentar estrategias en su desempeño, p. ej. evasión de obstáculos. 3.2.4 Estudios sobre Robótica Evolutiva El trabajo de Nolfi y Floreano [Nolfi et al., 2000] representa uno de los trabajos más completos dentro del área de RE sobre el desarrollo de controladores robóticos (principalmente neuronales). El mismo corresponde a un libro el cual describe los conceptos básicos y metodologías evolutivas, así como algunos de los resultados publicados en la literatura. Una característica importante de remarcar de dicho trabajo, es que presenta un conjunto de experimentos empíricos de manera incremental, tanto a nivel simulado como a nivel robot real. Principalmente, los resultados apuntan a pruebas sobre robots Khepera , pero también sobre otras configuraciones robóticas. Además, está disponible una versión gráfica de un simulador de manera gratuita [Evorobot, 2000], la cual permite al lector replicar y variar acotadamente algunos de los experimentos presentados en dicho trabajo. No obstante, tal simulador no corresponde a un entorno de desarrollo de controladores robóticos. De todas maneras, el estudio en sí representa una de las mejores fuentes de consulta dentro de la RE. 3.2.5 Estudios sobre Exploración en Navegación El trabajo [Nelson et al., 2004] muestra resultados generados dentro de RE en entornos simulados junto con entornos reales en un contexto neuronal. Particularmente, se muestra la forma de producir controladores que resuelven la tarea de búsqueda en un laberinto, junto con el comportamiento de exploración utilizando sensores binarios de tacto como entradas. Si bien existe un considerable número de investigaciones experimentales y demostraciones dentro de la RE aplicada a control, es de creciente interés la investigación sobre la generación de comportamientos básicos, tal como la evasión de obstáculos y búsqueda de objetivo. Es por dicho motivo que se propone en tal trabajo estudiar cómo generar neuro-controladores como paradigma de evolución. Para ello se afronta el desarrollo de redes neuronales complejas, para luego implementarlas en robots reales de manera rápida y eficiente. En consecuencia, el estudio se focaliza en pruebas con una colonia de ocho robots con avanzadas habilidades de computación y comunicación. Herramientas para el Desarrollo de Controladores 35 Tanto el desarrollo simulado como el real, está abocado a la definición y entrenamiento de una arquitectura específica de red neuronal, la cual incluye múltiples niveles ocultos, variaciones temporales internas, y conexiones recurrentes. En cuanto al robot físico, fue orientado a maximizar el poder computacional y de comunicación, mientras que se trató de minimizar el tamaño, peso y consumo de energía. El proceso de simulación fue desarrollado en Matlab. El estudio planteado presupone diferentes requerimientos, tanto a nivel hardware como software (debido este último al poder computacional). En general, si bien se plantea un estudio completo y de interés para el desarrollo de un tipo específico de controlador, no se plantea una herramienta que permita al diseñador extender y adaptar componentes en función de sus necesidades. 3.2.6 Estudios sobre Navegación por Sensores En [Maaref et al., 2002] es presentado un estudio vinculado a navegación de un robot móvil tanto en un entorno conocido como en uno desconocido. El método de navegación en un entorno desconocido está basado en la combinación de elementos comportamentales. Muchos de esos comportamientos son desarrollados mediante un sistema de inferencia difuso. La navegación propuesta combina dos tipos de comportamientos de evasión de obstáculos, uno para obstáculos convexos y otro para cóncavos. Considerando un entorno no conocido, el sistema de inferencia difuso utilizado para generar comportamientos elementales (tal como seguimiento de paredes), es simple y natural. Sin embargo, está basado en el conocimiento del diseñador, por lo cual se lo considera sub-optimal. Dado esto, se argumenta que su utilización es provechosa. Por otra parte, se presenta una técnica basada en el algoritmo de back-propagation (véase [Haykin, 1999]). Dicha técnica permite optimización on-line de los parámetros del sistema difuso mediante la minimización de la función de costo. Además, considerando entornos parcialmente conocidos, se desarrolla una estrategia de navegación a través de la memorización del entorno recorrido. Ambas situaciones, navegación en entornos conocidos como parcialmente conocidos, han sido implementadas considerando un modelo de robot Khepera equipado con sensores de precisión limitada. Dado el desempeño del robot en cuanto a navegación, se argumenta que las reglas difusas son robustas a las imperfecciones de los sensores. Como uno de los inconvenientes encontrados en el estudio analizado, es que el mismo presupone un alto nivel de conocimiento por parte del diseñador para la definición experimental y del controlador. No obstante, provee un interesante marco experimental vinculado a navegación de un robot móvil. 3.3 El Robot Khepera El Khepera es un robot con fines educativos y de investigación el cual es desarrollado y manufacturado por la compañía suiza K-Team. Las imágenes que se mostrarán en esta sección son obtenidas del sitio oficial de K-Team (www.k-team.com). 36 Herramientas para el Desarrollo de Controladores (1) LEDs; (2) Conector serial (S); (3) Botón reset; (4) Jumpers para selección del modo de ejecución; (5) Sensores de proximidad infra-rojo; (6) Conector de recarga de batería; (7) Switch de encendido de batería; (8) Segundo botón de reset Figura 8 – Representación genérica del robot real [Khepera, 1999] Las dimensiones del robot corresponden a 60 mm. de diámetro, 30 mm. de alto y su peso es de 80 gr. El mismo está equipado con una memoria UV EPROM junto con un pequeño sistema operativo. Además, cuenta con un procesador Motorota 68311 de 16 Mhz. de 256 Kb. de RAM. Dicho robot se vincula con el entorno mediante 8 sensores infra-rojos con un rango de medición de 50 mm., y se comunica con una computadora mediante un puerto serial standard de 38400 baudios o mediante una torreta de radio (RS-232 por puerto serie). Posee dos motores (uno por cada rueda) los cuales le otorgan una velocidad mínima de 0.02 metros por segundo, teniendo una cota superior de 0.6 metros por segundo, y un brazo opcional (gripper arms). El entorno por defecto para aplicaciones autónomas es el KTProject y el GNU C Cross Compiller. El robot Khepera puede tener a su vez un equipamiento adicional con un rango extenso de accesorios, los cuales van desde pinzas para agarrar objetos hasta componentes de video. 3.4 Software de Simulación Existe un amplio rango de software de simulación para el hardware del robot Khepera. A grandes rasgos, se distinguen dos categorías de simuladores: una esta basada en software encapsulado y la otra esta referida a aplicaciones de código abierto. La primera de las categorías es utilizada para simular y reemplazar la necesidad de acceder a hardware real, en vez de ser usada en desarrollos a medida (stand-alone). En tanto, en el segundo grupo se presenta el mayor número de aplicaciones existentes y provee características especiales para llevar a cabo análisis matemáticos y simulaciones a partir del criterio de “código abierto”. A continuación se presenta una breve descripción de algunos simuladores disponibles. 3.4.1 KIKS – Kiks Is a Khepera Simulator El simulador denominado KIKS (Kiks Is a Khepera Simulator) corresponde a un software director vinculado a MatLab, el cual simula la versión Khepera I y II de dicho robot. KIKS fue originalmente realizado como una tesis de la Universidad de Umea [Storm, 2003]. Herramientas para el Desarrollo de Controladores 37 Figura 9 – Interfaz principal del simulador KIKS (Kiks Is a Khepera Simulator) Como se puede ver en la Figura 9, KIKS provee una interfaz gráfica al usuario apropiada para la correcta supervisión durante la generación del controlador. 3.4.2 Evorobot Evorobot [Evorobot, 2000] es un simulador complejo de Khepera, el cual incluye una interfaz gráfica de usuario bajo Windows 95/98/NT. Evorobot permite ejecutar una serie de experimentos con evolución artificial tanto a nivel simulador como a nivel robot real. El paquete Evorobot consiste en un archivo zipeado conteniendo un ejecutable, el manual en formato postcript, los archivos fuente (archivos *.c, *.h, *.rc), y un conjunto de archivos de ejemplo (*.cf, *.env, *.sam) que permiten replicar experimentos descritos en determinadas secciones del trabajo de Nolfi et al. [Nolfi et al., 2000]. Si bien la herramienta que permite replicar diferentes experimentos es de utilidad para generar experimentos, no corresponde a un entorno de desarrollo de controladores robóticos en su totalidad. 3.4.3 Webots El simulador denominado Webots es creado y mantenido por la empresa Cyberbotics, una compañía que produce simuladores robóticos [Webots, 2002]. Las aplicaciones con Webots posibilitan construir controladores en el lenguaje de programación C/C++. Dicho controlador puede ser transferido posteriormente al hardware real del robot. El simulador muestra un espacio tri-dimensional, pero la visualización puede ser cambiada a un modo de ejecución rápido. Controlando la rapidez de la simulación mediante la interacción con la computadora. Esta característica es útil especialmente cuando se realiza un proceso de testing. Como una de las desventajas registradas de este simulador, se puede mencionar que no es de libre distribución, ni de código libre. 38 Herramientas para el Desarrollo de Controladores Figura 10 – Interfaz principal del simulador Webots Probablemente es el producto más completo pero también de carácter comercial (la versión “Pro” cuesta unos 1500 €). Es un entorno que posibilita la construcción de prototipos, el modelado, la programación y la simulación de robots móviles en los lenguajes C, C++ y Java. Soporta la transferencia de los controladores desarrollados a varios modelos de robots reales como: Aibo , Lego Mindstorms, Khepera, Koala y Hemisson. 3.4.4 WSU Java Simulator El simulador WSU Java Simulator está desarrollado en lenguaje JAVA vinculado al modelo de robot Khepera [Gallagher, 1999]. El simulador modela un simple robot que opera en un área de 4x4 pies con la opción de muros reconfigurables, objetos y pelotas móviles, junto con fuentes de luz fijas. A su vez, las tenazas (gripper arms) son modeladas para otorgar movimientos de manipulación de objetos en el entorno. Figura 11 – Interfaz principal del simulador WSU Java Simulator Este simulador, desarrollado por la universidad de Wright State (WSU), permite que los controladores creados en la plataforma puedan ejecutarse en un robot Khepera sólo en la versión 7.0. Su documentación es muy escasa (escasísima). Es sencillo de utilizar. Básicamente el controlador es un thread que se ejecuta constantemente. A su vez es posible controlar el robot a través de los actuadores. 3.4.5 YAKS – Yet Another Khepera Simulator YAKS (Yet Another Khepera Simulator) [Karlson, 2002] es un simulador de Khepera de código libre, el cual soporta Win32, Linux, controladores C++, etc. YAKS utiliza valores sensados pre-registrados de un Herramientas para el Desarrollo de Controladores 39 robot real. Esto es realizado para proveer velocidades de simulación del orden de las 3600 unidades de velocidad (tiempo). Dicho simulador soporta sensores infra-rojos, sensores de luz, un componente de visión K213, pinzas, y más. El mismo, posee una interfaz GTK, Open GL acceleration y permite la coordinación de múltiples robots. (a) (b) Figura 12 – Interfaz principal del simulador YAKS. (a) visión 2D; (b) Open GL acceleration Al simulador es posible realizarle una modificación en cuanto a su forma de control. Se ha modificado para permitir que sea controlado a través de otro programa independiente, utilizando los mismos comandos que el robot real6. 3.5 Selección del Software de Simulación El desarrollo de experimentos con un tipo de robot móvil, herramientas y técnicas implicadas, debe ser evaluado para encontrar los componentes que más se adapten a los requerimientos necesarios. En especial, esto debe ser decidido a partir del simulador de software a utilizar, las arquitecturas de control más apropiadas, y las características de diseño a ser consideradas. La presente sección describe la selección del simulador a ser utilizado en la etapa final de desarrollo de un controlador neuronal, partiendo de un proceso de clasificación de las características de cada simulador. Por lo tanto, una evaluación y selección de los simuladores robóticos es presentada a continuación. Para dar comienzo al proceso de clasificación, es posible decir que es preferible seleccionar un software de simulación que ofrezca la posibilidad de trabajar con el robot Khepera sin tener acceso directo a su versión hardware. Esto se debe a que se requiere que la abstracción del modelo permita un manejo de alto nivel en los comand os de control. Un simulador que pueda modelar el hardware del robot, con la particularidad de correr en diferentes sistemas operativos, y de código abierto, es preferible a aquellos que no lo provean. Los diferentes simuladores mencionados anteriormente, son comparados en esta sección. La siguiente tabla resume las principales diferencias en cuanto a las aplicaciones de simulación [Skånhaug, 2003]. Algunas de estas diferencias están basadas en experiencias desarrolladas, lectura de los manuales respectivos y búsquedas de experiencias en Internet. En los casos que así se lo marque, no se conocen las prestaciones del simulador. 6 El mísmo puede obtenerse en http://www.dc.uba.ar/people/materias/robotica/yaks (Grupo de Inteligencia Computacional Aplicada a Robótica Cooperativa (GICARC) – FCEN - (UBA) Universidad de Buenos Aires, Argentina). Modo rápido de simulación Código libre Linux compatible Windows compatible Código del controlador Soporte de posición Visión WSU 6.4 no java no no si si no - java no 2D WSU 7.0 no java no si si si no - java no 2D KIKS no MatLab si si si si si - ? si 2D Webots si C/C++ si no si si no - C/C++ si 3D Evorobot no C/C++ si si no si no - Especial ? 2D Yaks no C/C++ si si si si no - C/C++ ? 3D Yaks Modificado no C/C++ si si si si no - Java C/C++ ? 3D Simulador Requiere otro software Limitado al hardware del Khepera Lenguaje de programación Herramientas para el Desarrollo de Controladores Comercial 40 Tabla 2 – Matriz de características de los simuladores analizados Para seleccionar la conveniencia de las diferentes características, en el proceso de evaluación se dio prioridad a aquellas según el siguiente criterio. Se ponderó con 0 cuando no sean de interés para el estudio planteado en este trabajo; con 1 si presenta algo de importancia; con 2 si es realmente importante; y con 3 sí es crucial. Característica Prioridad Código del controlador Código libre Comercial Compatibilidad Linux Compatibilidad Windows Lenguaje de programación Java No requiere otro software Soporte de posicionado Visual Limitado al hardware Khepera Modo de ejecución rápido 3 3 3 2 2 2 2 2 2 0 0 Tabla 3 – Matriz de características priorizadas La tabla que a continuación se presenta, muestra los resultados luego del proceso de ponderación de las diferentes características analizadas. El simulador que se seleccionará será aquel con mayor puntaje. Visión Resultados 2 0 2 0 0 1 2 12 WSU 7.0 3 2 0 3 2 2 2 0 0 1 2 17 KIKS 3 0 0 2 2 2 0 0 2 0 2 13 Webots 3 0 0 0 2 2 2 0 2 2 2 15 Evorobot 3 0 0 2 0 2 2 0 0 0 2 11 Yaks 3 0 0 3 2 2 2 0 0 1 2 14 Yaks Modificado 3 0 0 3 2 2 2 0 0 3 2 17 Código del controlador 0 Soporte de posición 0 Windows compatible Requiere otro software Limitado al hardware del Khepera 2 Modo rápido de simulación 3 Simulador Leguaje de programación WSU 6.4 Comercial Linux compatible 41 Código libre Herramientas para el Desarrollo de Controladores Tabla 4 – Matriz de características priorizadas según la ponderación de cada controlador Si bien la comparación de los controladores arroja una ponderación equivalente entre WSU 7.0 y Yaks modificado, se selecciona a éste último como mejor alternativa. Esto se debe a que permite una comunicación simple de realizar con el robot real. Además, presenta la particularidad de programar el controlador en diferentes lenguajes y comunicar las acciones de control por el puerto de comunicación serie. Al modificar el simulador YAKS la idea fue que éste acepte, a través de un socket TCP/IP, el mismo protocolo que los robots Khepera reales para el control remoto vía serie o radio. El simulador Yaks modificado, provee una interfaz gráfica para el control básico del robot simulado, p. ej. inicio y fin de la ejecución y posicionamiento del robot en el entorno. Si bien la creación de escenarios es poco amistosa para el usuario (dado que se realiza mediante la edición de un archivo de configuración), su utilización es simple de realizar. 3.5.1 Herramientas de Software y Técnicas La documentación, diseño, desarrollo y testing de los diferentes experimentos a generar, requiere de la utilización de diversas herramientas de software. Para ello, se ha evaluado la utilización de algunas de ellas en función de la experiencia y el contexto a ser desarrollado. A continuación se presenta cuál fue la selección de herramientas para cada característica implicada. 42 Herramientas para el Desarrollo de Controladores Características Software/Técnica Documentación Microsoft Word XP Codificación Borland JBuilder 7.0 Enterprise Edition Compilación JDK 1.3.1 Testing YAKS modificado Modelamiento UML Lenguaje de Programación Java Tabla 5 – Herramientas de software y técnicas utilizadas 3.6 Conclusiones [Maaref et al., 2002] [Nelson et al., 2004] Características [Nolfi et al., 2000] [Togelius, 2003] [Dale, 1994] [Greer, 2002] En las secciones anteriores se describieron y analizaron algunos de los estudios encontrados en la literatura para construir controladores robóticos, según los criterios definidos en la sección 3.2. La tabla que a continuación se muestra resume las características encontradas de los estudios previamente mencionados, según la flexibilidad de la herramienta y los resultados implementados. Amplitud de estudio ••• • ••• ••• •• ••• Experimentos realistas --- --- --- ••• ••• ••• Extensibilidad •• --- ••• ••• --- --- Reusabilidad --- --- ••• --- --- --- Herramientas visuales --- --- • •• --- --- Herramienta de generación --- --- +++ ++ --- --- Alcance de los estudios: (•) Mínima consideración. ( ••) Consideración media. (•••) Alta consideración. Alcance de la herramienta: (+) Posibilidad de extensión de componentes. (++) Posibilidad de adaptar componentes. (+++) Posibilidad de adaptar y extender componentes. Tabla 6 – Características de los estudios analizados Como es posible observar en la tabla anterior, existe un grupo de estudios vinculados a aplicaciones concretas para el desarrollo de controladores, mientras que otro se asocia a estudios abarcativos incluyendo Herramientas para el Desarrollo de Controladores 43 un planteo de herramientas que permita adaptar y extender tales desarrollos. En cuanto al primer grupo, el programador es responsable de diseñar y materializar todos los componentes de un controlador y del experimento a resolver, sin utilizar en algunos casos una herramienta de soporte genérico. En cambio, en el segundo grupo existe una herramienta que permite que el diseñador especifique componentes a partir de los existentes. Es deseable que una herramienta de desarrollo de controladores se enmarque dentro del segundo grupo, prescribiendo la estructura general de los elementos a ser considerados en la definición del controlador y de los experimentos a desarrollar. A la vez, debe ofrecer flexibilidad y adaptabilidad a los diferentes dominios de aplicación. En general, la extensibilidad tanto a nivel de definición de la especificación del controlador como a nivel experimento, sólo es tratado en forma parcial o acotadamente en la mayoría de los trabajos analizados. Con respecto a las capacidades de las herramientas desarrolladas para la generación de controladores, existen temas que no son tratados. Algunos de ellos son: • No poseen mecanismos genéricos para representar asociaciones de componentes para el desarrollo de pruebas experimentales: la representación del entorno (simulado o real), y tipo de controlador, como así también otros componentes de un experimento, deberían ser especificados de manera general, aportando a la herramienta reusabilidad de componentes. De este modo, un conjunto de componentes podría estar disponible para varios experimentos. • No se considera la reusabilidad de controladores: la definición de controladores optimales para resolver una tarea en particular, puede ser de gran interés para la resolución de sub -tareas en otros experimentos. Los puntos antes señalados, no siempre son contemplados en el desarrollo de aplicaciones o estudios dentro de RE, y en especial en el desarrollo de neuro-controladores mediante evolución simulada. Ambos puntos son de gran interés para los requerimientos de herramientas genéricas que posibiliten realizar estudios abarcativos y aplicados de controladores. La tabla que a continuación se presenta muestra las principales características de las herramientas analizadas. Simulador Tipo de estudio Objetivo Tipo de controlador Tipo de herramienta Lenguaje de desarrollo [Greer, 2002] Estudio comparativo, controladores homeostáticos, minimal cognitive behavior Estudios sobre homeostasis Neuronal monolítico No corresponde C/C++ [Dale, 1994] Estudio aplicado, controlador simple Controlador de propósito específico Neuronal monolítico No corresponde C [Togelius, 2003] Estudio comparativo, definición de componentes extensibles Comparación evolutiva, escalabilidad de comportamientos Neuronal monolítico, modular y por niveles Basado en reglas de coordinación de comportamientos Java 44 Herramientas para el Desarrollo de Controladores Estudio abarcativo, Robótica Evolutiva Abarcamiento temático dentro de RE No específico Herramienta de demostración configurable No específico Estudio aplicado, neuro [Nelson et al., 2004] controlador extenso Navegación por sensores Neuronal monolítico No corresponde MatLab Estudio [Maaref et al., 2002] aplicado, Lógica Difusa Navegación según sistema difuso Difuso No corresponde C++ [Nolfi et al., 2000] Tabla 7 – Objetivos de diseño y otras características de los estudios y herramientas analizadas En este capítulo se presentaron algunos estudios y herramientas para el desarrollo de controladores de robots móviles. En el capítulo siguiente se describen los experimentos preliminares desarrollados en este trabajo. Capítulo 4 - MÉTODO EXPERIMENTAL MÉTODO EXPERIMENTAL "El verdadero premio del científico está en hacer buenos experimentos, no en los premios que se le otorgan" Luis F. Leloir 4.1 Introducción En el capítulo anterior se describieron y analizaron trabajos existentes vinculados al desarrollo de controladores robóticos basados en redes neuronales. Dichos trabajos posibilitaron desarrollar aplicaciones de software que implementan los conceptos descriptos en el Capítulo 2. Como se demuestra en la bibliografía propuesta, el análisis de módulos que implementen comportamientos simples de manera eficiente, permite construir controladores a partir de la unión de dichos módulos, escalando comportamientos. De esta manera, se logra especializar controladores simples en un comportamiento específico dentro de un dominio de aplicación concreto. En el presente capítulo se describe el desarrollo de cinco controladores aplicados a un sistema adaptativo-evolutivo de control, especializados en navegación autónoma de un robot móvil. Los detalles de la tarea a resolver, así como de la morfología de los controladores y del robot, son descritos en este capítulo. Seguidamente, se describirá el Algoritmo Genético utilizado para evolucionar a los controladores. Las diferentes secciones muestran las características más relevantes de los cinco tipos de redes neuronales implementados: Feed-Forward Neural Network (FFNN), Recurrent Feed-Forward Neural Network (RFFNN), Continuous-Time Recurrent Neural Network (CTRNN), Plastic Neural Network (PNN) y Homeostatic Plastic Neural Network (HPNN). Cabe destacar que se referenciarán a los distintos neuro-controladores con el nombre del tipo de red neuronal que los implementa. A continuación se describe la organización del capítulo. En la sección 4.2 se presenta brevemente el método experimental propuesto para la generación de controladores simples. Principalmente, en dicha sección se describe el algoritmo genético utilizado y la implementación de los neuro-controladores responsables de la especialización de los comportamientos. La sección 4.3 enuncia brevemente las tareas a resolver por los controladores con el fin de evaluar el desempeño de cada uno de ellos. Finalmente, se presentan las conclusiones del capítulo en la sección 4.4. 4.2 Método Experimental Las redes neuronales descritas en esta sección implican diferentes métodos de control al momento de definir un neuro-controlador. No obstante, las tareas para las cuales ellos fueron generados son las mismas de prueba en prueba. De manera similar, el robot simulado fue idéntico para cada experimento durante un conjunto de operaciones, aunque algunas modificaciones fueron hechas en aquellas experiencias que se indiquen sobre el controlador y en el entorno. Con el objetivo de probar cual es el tipo de neuro-controlador más apropiado para cada tarea, y con la finalidad de obtener un controlador confiable (mediante la emergencia de comportamientos) con las características de robustez y adaptabilidad, se procede a comparar diferentes tipos de controladores. 46 Método Experimental Característica del Método Descripción Motivaciones Obtención de controladores optimales asociados a comportam ientos simples mediante un controlador monolítico en un proceso evolutivo. Búsqueda del mejor neuro-controlador para cada tarea simple según los criterios de robustez y adaptabilidad. Hipótesis a probar La evolución artificial permite obtener controladores adaptativos optimales para cada comportamiento simple. Metodología • Experimentación con neuro-controladores del tipo FFNN, RFFNN, CTRNN, PNN, HPNN. • Comportamientos a realizar: evasión de obstáculos, fototaxis, y aprendizaje durante la vida del controlador. Verificación Experimental: Simulador (simple). Experimentos Combinación de los diferentes neuro-controladores y distintos comportamientos simples. Configuración experimental Véase tablas del Capítulo 4. Resultados obtenidos Véase tablas del Capítulo 5. Tabla 8 – Resumen del método experimental utilizado para el desarrollo de las pruebas con controladores monolíticos Por otra parte, los comportamientos que serán expuestos en este capítulo son de interés general, debido a que están presentes en muchos de los problemas vinculados a navegación autónoma y aprendizaje. Si bien dichos comportamientos ya fueron tratados en la literatura, se busca con el estudio planteado la obtención empírica de resultados, tratando de que éstos sean independientes, en algún grado, de cualquier otro supuesto observado en la literatura. En suma, el estudio planteado representa un desafío relevante de ser llevado a cabo, dado que los comportamientos que involucran aprendizaje son usualmente difíciles de evolucionar (véase [Tuci et al., 2003][Yamauchi et al., 1994]). A modo de resumen, en la Tabla 8 se presentan los distintos puntos considerados en el método experimental propuesto. 4.2.1 Entorno Simulado El entorno simulado corresponde a un área predefinida donde el robot puede moverse libremente en el plano horizontal. Los movimientos fueron controlados por dos actuadores ideales mediante la salida de una red neuronal (véase Figura 20). La velocidad del agente robótico fue determinada sumando la salida total de los actuadores a una constante predefinida (δ), siendo ésta nula cuando el robot está en la posición objetivo. La dirección del robot fue generada mediante la diferencia de la salida de los nodos que controlan a los actuadores (nodos motores). Un valor negativo de la diferencia antes señalada indica un movimiento hacia la derecha, mientras que uno positivo hacia la izquierda. Por lo tanto, la velocidad del agente se mantuvo en el rango [(-2+δ); (2+δ)] u/t 7 mientras que la dirección de desviación del robot se estableció en el rango [-2; 2] radianes. 7 Las unidades u/t (p. ej. metros sobre segundos) son usadas hipotéticamente para todas las descripciones de los controladores, con el fin de lograr una consistencia en relación al simulador. Sin embargo, debe aclararse que las escalas de objetos del simulador no tiene relación con el mundo real, por lo que las unidades usadas son arbitrarias. Método Experimental 47 A su vez en el ambiente, puede incorporarse un número de objetos aleatoriamente ubicados, además de distintos puntos u objetivos que el robot debe alcanzar. Estos corresponden a objetos simulados representando fuentes de luz de distintos colores. Como características relevantes a señalar, puede decirse que las fuentes de luz no tienen tamaño ni extensión. Por otro lado, los obstáculos son representados mediante áreas rectangulares de tamaño fijo. Las especificaciones del entorno se asocian al trabajo descrito en la sección 3.2.3, a fin de comparar resultados con dicho trabajo. La ubicación aleatoria de los diferentes componentes y del robot tiene por finalidad no permitir que el controlador neuronal evolucione con una influencia no deseada de la configuración del entorno. Por ejemplo que la ubicación de las fuentes de luz esté a la misma distancia unas de otras en todas las pruebas, ocasiona un acostumbramiento del controlador en cada evaluación. De esta forma, es posible decir que se busca que el controlador final presente robustez en cuanto al comportamiento requerido. Una forma de lograr esto es aleatorizando la ubicación de los componentes a lo largo del proceso evolutivo. 4.2.2 Modelo Robótico: Modelo Simple El agente robótico simulado, o simplemente robot, en el presente trabajo está representado mediante un área circular. La misma posee una proporción menor con respecto del área de los obstáculos, siendo ésta de 50%. Las principales características físicas del robot real Khepera® se incluyeron en el modelo, teniendo en cuenta la forma, la cantidad de actuadores (ruedas) y sensores. Dicho modelo sirve inicialmente como base de comparación con los trabajos estudiados de otros autores, aunque posteriormente se utilizará un modelo más complejo de robot. Concretamente, el robot fue modelado mediante dos ruedas tractoras paralelamente ubicadas a ambos lados del cuerpo del robot. Las mismas, permiten simular un movimiento hacia adelante o atrás de manera independiente entre sí. Por lo tanto, esto otorga al robot la posibilidad de movimientos rectilíneos, como así también movimientos curvilíneos con variaciones angulares en el rango [0°; 360°]. Parámetro ν = χ + (νm1+νm2)/2 µ = ƒ(V0, … ,V8) ∆x = ν.sen(µ).∆t ∆y = ν.cos(µ).∆t Referencia • ƒ , diferencia de las salidas (mi) generadas por el neuro-controlador dependiente de las entradas de la red neuronal • µ, diferencia entre la salidas del neuro-controlador expresando el ángulo de desviación • ∆t, diferencial de tiempo igual a 1 • ν, velocidad lineal • χ, velocidad de referencia Tabla 9 – Representación del modelo de los actuadores A su vez, y como otra de las características respetadas para la comparación de resultados, se propuso que cada vez que el robot se acerque al borde del área (ambiente simulado), se corrige la dirección del robot para que evada tal situación. Esto ocurre cuando el robot no posee sensores de evasión de obstáculos (p. ej. tarea de fototaxis simple que posteriormente se detallará). Dicha corrección está determinada por el ángulo de incidencia original (ángulo entre el robot y la pared), pero con la componente invertida del eje perpendicular a la pared. Esto simula que el robot evade los muros del entorno, posibilitando que el mismo no se quede inmovilizado en el borde del área simulada. 48 Método Experimental Otro de los componentes modelados fueron los sensores8 del robot. La salida de cada medición realizada en el Khepera real, corresponde a un valor analógico convertido a un valor digital mediante un conversor A/D de 10 bits en el rango [0; 1023]. Dicho rango de medición fue mantenido o normalizado en el rango [0, 1] cuando así se lo indique en las pruebas experimentales desarrolladas en el presente trabajo. Más concretamente, se especificaron dos tipos de funcionalidad para dichos sensores: como sensores lumínicos, los cuales captan la intensidad de la luz emitida por las fuentes de luz simulada, y como sensores de obstáculos. Por otra parte, para el sensado de obstáculos se presenta una salida proporcional a la distancia relativa a un objeto en la dirección donde se enfoca el sensor, estando la salida condicionada a que la distancia entre el sensor y el obstáculo no sea superior a una distancia prefijada. En la figura que a continuación se muestra (Figura 13), se representa la distribución de los sensores infra-rojos utilizados. Figura 13 – Distribución de los sensores infra-rojos del robot real Khepera® [Khepera, 1999] Figura 14 – Medición típica de la luz ambiental por la distancia a una fuente de luz de 1 Watt para el robot Khepera® real 8 Figura 15 – Medición de la luz ambiental versus la distancia a una fuente de luz para el modelo simulado simple. Si bien el Khepera ® cuenta con un tipo de sensor infrarrojo, el conjunto de sensores puede utilizarse para captar obstáculos (emitiendo infrarrojo y captando la magnitud de dicha emisión reflejada en el entorno), o para cuantificar la cantidad de luz infrarroja proveniente del entorno (captación de todo estímulo infrarrojo del entorno pero sin que exista algún tipo de emisión del sensor). Método Experimental Figura 16 – Respuesta típica del sensor de proximidad para un obstáculo (7 mm. de ancho) a una distancia de 15 mm. La medición está dada versus el ángulo entre la orientación frontal del robot y la orientación del obstáculo 49 Figura 17 – Respuesta del sensor de proximidad para un obstáculo ubicado a 15 unidades de longitud. La medición está dada por el ángulo entre la orientación frontal del sensor y la orientación del obstáculo para el simulador simple El sensado infra-rojo de luz, está modelado para que capten un determinado color según la fuente de luz objetivo. Se modela el valor de salida del sensor de manera que esté negativamente correlacionado el ángulo de incidencia de un sensor y el ángulo relativo a la fuente de luz. En pocas palabras, el valor sensado es inversamente proporcional a la distancia. En la Figura 15 se muestra la representación de la medición del sensor simulado. En tal figura, se grafica el rango de valores posibles encerrados entre dos rectas: la superior expresa los valores medidos cuando el valor de incidencia (ángulo) de la luz hacia el sensor es mínimo; la recta inferior señala los valores máximos en función de la distancia, siendo 1 el valor de representación de oscuridad y 0 el valor máximo de luz. El rango dentro del cual cada sensor capta la señal de entrada, es de 30º. Además, en las figuras restantes que se presentan a continuación, se grafican algunas características del sensado del robot simulado respecto del real. Figura 18 – Perfil de velocidad utilizado para alcanzar la posición objetivo con una aceleración fija (acc) y velocidad máxima (max. speed) en el robot real Khepera® Figura 19 – Perfil de velocidad utilizado para alcanzar la posición objetivo con una velocidad máxima (max. speed) en el robot simulado El neuro-controlador propuesto en este trabajo engloba distintos tipos de topologías neuronales) posee entre sensores y actuadores un conjunto de nodos interconectados o neuronas artificiales. Éstas serán especializadas de acuerdo con las características que se mostrarán para cada red neuronal implementada. Los nodos internos de la red procesan inicialmente la información proporcionada por los sensores (V1…V8 de la 50 Método Experimental Figura 20), y luego los de la capa oculta (ni), devolviendo una señal de control hacia los actuadores m1 y m2 (o nodos motores). n1 V0 n2 V1 V2 V3 n3 m1 V4 V5 m2 n4 V6 V7 n5 V8 n6 Figura 20 – Diagrama esquemático de la conectividad de neuronal genérica (2 nodos motores, 6 nodos ocultos, 8 nodos de entrada, y 1 entrada adicional) y calculo del computo realizado por la salida de cada neurona En la figura anterior, cada señal de entrada x i es multiplicada por el correspondiente peso de conexión wij y los resultados son sumados entre si. Luego, la entrada de la red es pasada por una función de activación σ cuya salida puede implicar la consideración de umbrales (Figura 20). La morfología del controlador de la Figura 19 fue razonablemente estricta, pero los métodos para establecer los pesos sinápticos (o pesos entre nodos), y el cálculo de la conectividad de los nodos, difirió considerablemente entre los controladores analizados. nodos motores nodos de entrada nodos intermedios … 0 1 2 … … 9 10 … n offset Figura 21 – Representación genética de las sinapsis de un nodo para los experimentos sobre la evolución de los genes Método Experimental 51 El software desarrollado para modelar estructuras neuronales en el presente trabajo, soporta varios tipos de redes neuronales, especialmente las totalmente interconectadas. Como ejemplo de esto, es posible decir que para una red como la señalada en la Figura 20 con 8 neuronas de entrada, 1 entrada adicional, 6 intermedias y 2 de salida, su representación genotípica genérica consta de un total de 172 genes9. Cabe destacar que los pesos que interconectan dos neuronas son los mismos en el presente trabajo. En otras palabras, el peso wij es el mismo que el wji para todas las interconexiones. Figura 22 – Diagrama UML de clases del modelo de red neuronal implementado. Las implementaciones de redes neuronales asociadas a los distintos tipos de redes, son representadas por diferentes clases de software. Tales clases son instancias de una clase abstracta denominada network mostrada en la Figura 22. 4.2.3 Algoritmo Genético En todos los experimentos que serán descritos en este capítulo, se usará un Algoritmo Genético semejante al propuesto por Harvey [Harvey, 1992]10 para generar la evolución de las soluciones (controladores neuronales). Mediante la utilización de este método, cada individuo corresponde a un controlador vinculado a la representación específica de una red neuronal. Con esto, los individuos fueron seleccionados más frecuentemente a medida que presentaban un mejor desempeño o mayor valor de la función de fitness. En la implementación desarrollada, la población consistió de 30 individuos. En cada generación, cada individuo o genotipo, fue evaluado en cuanto a su desempeño en una tarea determinada dentro del entorno. Según el desempeño observado, a cada genotipo se le asigna una puntuación o medida de fitness que sirve para obtener una escala de comparación. Luego, aquellos genotipos que estaban ranqueados en la parte inferior de dicha escala (mitad inferior), son descartados como individuos en la próxima generación, siendo reemplazados por copias de los individuos de la parte superior. Luego, todos los individuos, excepto los cinco primeros sufrieron mutaciones. 9 El cálculo es el siguente: 9 neuronas de entrada * 6 neuronas intermedias + 6 neuronas intermedias * (9+6+2) neuronas + 2 neuronas de salida * (6 +2) neuronas. 10 SAGA – Species Adaptation Genetic Algorithm. Una forma de evolución artificial caracterizada por una población que se mueve en un espacio genético mediante mutaciones graduales, en vez de efectos por crossover, logrando una convergencia paulatina (incremental) y una evolución neutral (véase [Nolfi et al., 2000, Cap. 2]) 52 Método Experimental Figura 23 – Diagrama UML de clases del modelo genético implementado. La clase genotype mostrada en la Figura 23 es responsable de modelar la funcionalidad de un genotipo genérico. Típicamente, las instancias de dicha clase implementan la lógica interna de un genoma asociado a un tipo de red neuronal, y en especial al tipo de codificación genética a representar. Cabe mencionar que una instancia genotípica debe implementar métodos tales como clonar y mutar un gen dentro del genoma. En cuanto al modelo del algoritmo genético utilizado, vale destacar que la descendencia de un par de individuos puede tener una representación cercana a sus predecesores. En tal sistema es mantenida la diversidad genética en una población debido a que, aún si el valor de fitness es grande, la descendencia no puede reemplazar soluciones espacialmente distantes. Por lo tanto, diferentes soluciones o alternativas de resolución de una misma tarea son generadas en cada prueba sólo seleccionando las que mejor resuelven un problema determinado. En todos los casos, la evolución de los controladores utilizó los datos mostrados en la tabla que a continuación se presenta. Parámetro Cantidad de neuronas de entrada11 Cantidad de neuronas ocultas12 Cantidad de neuronas de salida Modelo de selección Modelo simulado13 Nivel de ruido en los sensores Número de corridas (runs) Número de iteraciones por corrida Número de generaciones Número de objetos en el entorno Población inicial Rango de pesos sinápticos Rango inicial de pesos sinápticos 14 Porcentaje de selección Tasa de mutación Valor 8 (+1 entrada adicional) 6 2 Elitismo (5 primeros) Simple --10 200 300 0 (Fototaxis|aprendizaje.) 10 (Evasión de obst) Aleatoria [-1; 1] [0; 0.01] ó [-1; 1] 50% 5% 11 La entrada adicional sólo es utilizada cuando así se lo indique. 12 El número de nodos en la capa oculta fue obtenido mediante un proceso de prueba y error previo a la realización del presente trabajo. En esto fueron considerados resultados experimentales anteriores (véase [Fernández et al., 2004]). 13 Simulador basado en descripciones del trabajo [Togelius, 2004], con la incorporación de mejoras en cuanto a su desempeño. 14 El rango [0; 0.01] sólo válido para las redes plásticas. Método Experimental 53 Rango de sensores de luz Rango de sensores de proximidad Tamaño de la población Tipo de función de activación Tipo de mutación Tipo de selección [0; 1] [0; 1] 30 Sigmoide (tangencial) Uniforme Ranking Tabla 10 – Configuración utilizada en los experimentos con evolución simulada Inicialmente, la población fue generada de manera aleatoria y la medida de fitness de cad a controlador fue evaluada aun cuando el fitness de la población comienza a converger a un valor estable, los controladores con un valor ligeramente alto de fitness fueron considerados en próximas generaciones. Por otra parte, al momento de mapear el genotipo al fenotipo, se usó uno de dos métodos posibles de codificación. En el primer caso, cada gen actúa como un selector entre diferentes valores posibles (p. ej. una de cuatro reglas de plasticidad sinápticas). En dicho caso, el operador de la división modular (el resto entero de una división) fue usado para extraer el valor requerido. El segundo método de codificación se utilizó cuando el fenotipo requirió que un valor real sea extraído del genotipo, por lo que el valor del gen fue mapeado dentro del rango del parámetro al cual representa. En la Figura 24, se muestra el diagrama de clases desarrollado encargado de modelar la funcionalidad de un Algoritmo Genético. Dicho modelo sólo define el comportamiento básico, mientras que las instancias asociadas a dicha clase implementan la funcionalidad deseada. Es decir, el modelo no define las operaciones inherentes al algoritmo genético tales como la función de fitness y mutación. Las operaciones serán desarrolladas en las instancias asociadas con la clase GeneticAlgorithm. Figura 24 – Diagrama UML de clases del modelo de algoritmo genético implementado. Un proceso de selección por ranking fue usado a fin de obtener individuos a ser reproducidos [Goldberg, 1989]. Mutación, pero no crossover, se utilizó como operador genético ante cada nueva descendencia. La tasa de mutación utilizada al cabo de todos los experimentos fue, en promedio 15, 14.5 mutaciones por cromosoma. La mutación consistió en modificar aleatoriamente los genes de los individuos usando una tasa de variación del 5%, o sea que sólo dicho porcentaje influencia la modificación de un gen 15 Considerando todas las representaciones implementadas. 54 Método Experimental dentro de un rango de valores permitidos. De esta manera, se obtiene que en el caso de tener una red neuronal con veinte sinapsis, en promedio, existe una sinapsis modificada en cada generación. Usando el criterio de mutación propuesto, se logra que los individuos con buen desempeño en la generación anterior pasen a la generación siguiente incorporando variaciones con alta probabilidad de que presenten un desempeño aceptable en la próxima evaluación. A menos que se especifique lo contrario, la evolución en las pruebas llevadas a cabo corresponde a un total de 300 generaciones, y en cada una de ellas se evalúan 30 genomas. Además, el número de veces que cada uno de los genomas es evaluado en una determinada generación, corresponde a 10 corridas, usando la medida del mejor fitness como ranking entre los individuos. En cada corrida la red fue modificada y el robot realizó la tarea especificada un número de 200 veces para cada prueba. 4.2.4 Neuro-Controladores Realizar el seteo de los pesos de un neuro-controlador en forma no automática, no es una tarea simple de llevar a cabo en la mayoría de las redes. Afortunadamente, distintas técnicas han sido desarrolladas para permitir que las propias redes ajusten sus pesos de manera automática. Esto se realiza para producir los mapeos de entrada-salida buscados. Particularmente, el trabajo propuesto se refiere al aprendizaje no supervisado [Haykin, 1999], en el cual no es necesario ningún tipo de señal de supervisión. Cabe aclarar que no se desarrolla una exposición de cómo es el proceso de cálculo de cada una de las redes. No obstante, se deja constancia para el lector interesado referencias bibliográficas para tal fin. Como se mencionó previamente, la mayoría de los experimentos en RE utilizan neuro-controladores. Una de las principales razones es que permiten distintos niveles de adaptación: filogenético (phylogenetic) llevado a cabo en la evolución; generacional (developmental) durante la maduración del controlador; ontogenético (ontogenetic) realizado a escala de vida del controlador. Por otra parte, son estructuras robustas al ruido y viables para soportar comportamientos adaptativos [Nolfi et al., 2000, Cap. 2]. En la Figura 25 se muestra un diagrama UML con las principales clases involucradas en la creación de los diferentes tipos de neuro-controladores implementados, mediante la definición de distintas redes neuronales. En dicho modelo, sólo se define las características mínimas que un neuro-controlador debe presentar. Es decir, existe un conjunto de instancias del modelo que implementan la funcionalidad propia de un tipo de red neuronal. Figura 25 – Diagrama UML de clases del modelo de red neuronal genérico implementado. Método Experimental 55 Por otra parte, en este capítulo podrán verse dos tipos de codificación genética de neurocontroladores: codificación de sinapsis y codificación de nodos [Floreano et al., 1999b]16. En la primera de ellas, son codificados en forma individual tanto los valores de los pesos sinápticos, como así también las reglas de adaptación, si las hubiere. Por el contrario, en la codificación de los nodos sólo se representan las propiedades inherentes a cada uno de ellos. Seguidamente, se mostrarán las características principales de cada controlador. 4.2.4.1 Controlador Feed-Forward Neural Network (FFNN) La primera arquitectura utilizada para controlar los robots fue una red Feed-Forward (FFNN) o una red del tipo multi-layer perceptron (MLP) [Haykin, 1999]. Este controlador neuronal se refiere a una arquitectura no recurrente y corresponde a una red simple, la cual produce una señal de salida en respuesta directa al rango de lectura de los sensores. En términos de evolución, sólo los pesos de la red fueron evolucionados de manera similar a la desarrollada en [Floreano et al., 1999]. El MLP posee una función del tipo sigmoide en cada unidad o neurona (Figura 26) [Haykin, 1999]. En esta arquitectura, los pesos de las conexiones sinápticas quedan fijos luego de que sea creada la red neuronal (fenotipo). Esto se refiere a que los pesos sinápticos no son modificados durante la vida del controlador. Particularmente, tal tipo de red se enmarca en una instancia simple de controlador no adaptativo a nivel fenotipo. No obstante, el proceso evolutivo, mediante la selección del más apto, encuentra soluciones apropiadas a la tarea a desarrollar [Fernández et al., 2004]. Función de Activación Dinámica • Tipo umbral (sigmoide σ(x)=tgh(x)) con salidas en [-1,1] • Sincrónica, actualización total de los estados de cada neurona. • No existe adaptación de los pesos sinápticos. Arquitectura • Red multicapa (3 capas): entrada, oculta y salida (no recurrente en cada nivel). • wii=0 y wij=wji para todas las capas • conexión entre niveles: entrada-oculta, y oculta-salida. Aprendizaje • Sin aprendizaje asociado a la actualización sináptica. Tabla 11 – Resumen de las características del modelo de red FFNN implementado Cabe mencionar que la salida de cada nodo está inspirada en la propuesta de McCulloch y Pitts [McCulloch et al., 1943], y posteriormente descrito en [Haykin, 1994] desde una perspectiva orientada a ingeniería. Una vez que el proceso evolutivo determina los pesos de cada conexión sináptica, la morfología de la red no cambia durante la vida del agente, estando cada uno de estos valores representado por un valor real. La salida de un nodo está dada por la función tgh(x) la cual es la función sigmoide tangencial (o tangente hiperbólica) estándar según: −x e j −e j x −x e j +e j x σ ( x j ) = tgh( x j ) = (Ecuación 1) La estructura de datos del cromosoma mostrado en la Tabla 12, representa un controlador como el especificado en [Floreano et al., 1999b] para controladores genéticamente determinados, como en el caso de las redes 16 Codificación de sinapsis es también conocida como “codificación directa” [Yao, 1993]. 56 Método Experimental FFNN y RFFNN (un signo y una magnitud de peso para cada sinapsis). Cabe aclarar que para controladores de sinapsis adaptables (p. ej. PNN) se especificará lo propio en secciones venideras. Figura 26 – Representación de la salida proporcionada por la función sigmoide tangencial implementada. Codificación del genotipo FFNN, RFFNN y CTRNN Codificación para una sinapsis signo peso sináptico Tabla 12 – Codificación genética de los parámetros de evolución vinculados a las sinapsis de las redes FFNN, RFFNN y CTRNN (controlador genéticamente determinado) Cada nodo motor en una representación del tipo FFNN (con 8 neuronas de entrada, 6 ocultas, y 2 neuronas de salida o motoras) requiere 6 genes para su descripción, mientras que los nodos internos necesitan 10, y para los nodos de entrada son requeridos 6 genes (Figura 27). En cuanto a la codificación total de la red (genotipo), se necesitan 120 genes17 o codificaciones sinápticas totales, con pesos sinápticos iguales a cero cuando así lo requiera la topología de la red (al igual que ocurre con las diferentes topologías neuronales que se presentarán). 17 El cálculo es el siguente: 8 neuronas de entrada * 6 neuronas intermedias + 6 neuronas intermedias * (8+2) neuronas + 2 neuronas de salida * 6 neuronas intermedias. Método Experimental 57 n1 V1 n2 V2 V3 n3 V4 m1 V5 V6 n4 V7 V8 m2 n5 n6 Figura 27 – Diagrama esquemático de la conectividad entre las capas entrada-oculta y oculta-salida de la red tipo FFNN Por lo tanto, el resultado de la codificación del genotipo genérico vinculado a las FFNN es la siguiente para cada nodo18: (wm1, wm2, wv1, …, wv8, wn1, …, wn6) donde m indica motor, n corresponde a un nodo de la capa oculta, y v indica una entrada; w indica el peso sináptico. Cabe aclarar que existirán pesos sinápticos iguales a cero cuando no existan conexiones establecidas entre los nodos de la red. En experimentos con redes del tipo FFNN que no se vinculan con evolución, es común encontrar una entrada adicional con una constante positiva conectada a la red, la cual permite tener un valor de salida positivo aun cuando ninguna de las entradas “reales” sea positiva. Esto no es realizado en el presente trabajo. No obstante, se adiciona un valor predefinido a la velocidad final del robot para proporcionar movimiento en todo momento de la experimentación. Por lo tanto, es posible decir que cada neurona de salida posee una unidad adicional de “bias” (o umbral) debido a que en una arquitectura como la presentada, esto provee algún tipo de respuesta, aún cuando no existan entradas sensoras. No obstante, dicho valor no es incorporado dentro del valor a ser procesado por σ(x), sino que es una constante externa. Como una de las características a destacar de este tipo de red es que una MLP con una capa oculta y neuronas de salida lineales, constituye un aproximador universal de funciones [Haykin, 1999]. 18 Los valores de los pesos sinápticos corresponden a valores reales con signo, y están asociados a la codificación genérica de una red totalmente recurrente. Esto se realiza para obtener con la misma estructura capacidad de representación múltiple. 58 Método Experimental 4.2.4.2 Controlador Recurrent Feed-Forward Neural Network (RFFNN) La red que aquí se describe corresponde a una red del tipo multi-layer perceptron con unidades sigmoides continuas. La capa oculta consiste en un número de neuronas con conexiones recurrentes [Elman, 1990]. A diferencia de la red del tipo FFNN, la RFFNN presenta la posibilidad, al igual que la mayoría de las redes recurrentes, de desarrollar un procesamiento temporal. Las conexiones recurrentes posibilitan que la red “recuerde” una acción previa19. De acuerdo con [Nelson et al., 2004], los controladores que hacen uso de información temporal poseen el potencial de desarrollar un control co mpletamente reactivo considerando simples sensores en los robots. Según se expresa en [Urzelai, 2000], las arquitecturas recurrentes muestran una dinámica dependiente del tiempo más compleja que aquellas asociadas a las redes del tipo FFNN. Por lo tanto, las características señaladas para las FFNN (Tabla 12), son utilizadas para la definición de los controladores RFFNN con la excepción de la codificación de la topología de la red. Cada nodo de entrada requiere 6 genes para su descripción, 8 genes los nodos de salida, mientras que los nodos internos necesitan 16 para describir los pesos adicionales requeridos. n1 V1 n2 V2 V3 n3 V4 m1 V5 V6 n4 V7 V8 m2 n5 n6 Figura 28 – Diagrama esquemático de la conectividad entre las capas entrada-oculta y oculta-salida de la red tipo RFFNN A diferencia de la red FFNN, la característica distintiva de las RFFNN (Figura 28) es la recurrencia en la capa oculta, por lo que para todo peso w ocurre que wii ≠ 0 en dicha capa como así también en la capa de salida. En suma, las demás características señaladas para las FFNN, se mantienen inalteradas. Por lo tanto, se necesitan 160 genes20 para la representación sináptica total a nivel genotipo. 19 Esto en realidad depende del grado de recursión presente en la red. 20 El cálculo es el siguente: 8 neuronas de entrada * 6 neuronas intermedias + 6 neuronas intermedias * (8+6+2) neuronas + 2 neuronas de salida * (6+2) neuronas. Método Experimental 4.2.4.3 59 Controlador Continuous-Time Recurrent Neural Network (CTRNN) Una de las arquitecturas utilizadas para controlar a los agentes fue una red neuronal recurrente de tiempo continuo, o de aquí en más Continuous-Time Recurrent Neural Network (CTRNN). Con este tipo de arquitectura, los pesos que gobiernan las conexiones entre los nodos son genéticamente determinados y permanecen fijos en el fenotipo. Una vez configurada, la morfología de la red no cambia a través del tiempo de vida del agente. Cada nodo posee además un umbral o bias, una ganancia, y una constante de tiempo. Cada uno de estos valores está representado por un valor real. Dicha morfología, en un contexto diferente, es similar a la descrita por Beer [Beer, 1996]. Debido a que las unidades individuales o nodos pueden tener diferentes constantes temporales, la dinámica de tal tipo de red puede volverse compleja. Es por este motivo que en la literatura es estudiada en forma extensa. Cada nodo en la red utiliza la siguiente ecuación para modificar su estado: τ⋅ dy = τ ⋅ ∆y = − y j + dt N ∑w j =1 ji ⋅ σ (g j ( y j + θ j )) + I i i = 1,..., N (Ecuación 2) donde por analogía con las neuronas reales, y es el estado de cada nodo; τ es la constante de tiempo que define la tasa de decaimiento de la actividad del nodo; yi es la activación del nodo en cuestión; wji es el peso que define el grado de conexión desde el nodo i al nodo j; gj es la ganancia de la señal de entrada (gj ∈[-1; 1]) y θj es el bias en dicho nodo (θj ∈[-1; 1]); Ii es la señal de entrada de los sensores. No obstante, debe aclararse que para los nodos motores, el término I es ignorado dado que dichos nodos no reciben entradas provenientes del entorno. La salida de cada nodo está dada por la Ecuación 1. Con una complejidad temporal mayor, es posible decir que las conexiones recurrentes y las entradas son continuamente integradas sobre una constante de tiempoτ. La función sigmoide actúa como límite de cada nodo, lo cual asegura que el valor de salida de cada nodo sea como máximo 1 y como mínimo -1, sin importar los valores de activación superiores o inferiores a tales límites. La ecuación que a continuación se presenta, muestra la tasa de variación de cada nodo por unidad de tiempo. El intervalo mínimo de simulación fue especificado en 0.1 segundos. De este modo, la ecuación de modificación de cada nodo fue calculada usando la integración de Euler: y t +1 = y t + 0. 1⋅ ∆y (Ecuación 3) Básicamente, la ecuación es un integrador con pérdida, la cual suma las entradas en una variable interna que decae exponencialmente cuando no recibe entrada. No obstante la posible combinación de distintas constantes de tiempo, permite que la red CTRNN tenga una dinámica mucho más compleja que las redes conexionistas tradicionales. La interpretación biológica es que la variable y es el potencial de membrana que puede cambiar su polarización y consecuentemente la probabilidad de que la neurona emita salida. Pero estas redes no modelan las salidas en sí, sino directamente la tasa de disparo o firing rate que se obtiene aplicando la función sigmoide al potencial de membrana desplazado por el bias. Para este tipo de red (Tabla 13), cada nodo intermedio requiere 19 genes para su descripción genérica, mientras que los nodos de entrada necesitan 9 genes y los de salida 11 genes para describir los pesos adicionales requeridos (incluyendo τj, gj, θj), resultando en una codificación genérica como la siguiente: (τ, g, θ, wm1, wm2, wv1, …, wv8, wn1, …, w n6) donde m indica motor, n un nodo, y v indica una entrada. Por lo tanto, se obtiene un genotipo para de 208 genes21 para representar la red. 21 El cálculo es el siguente: 8 neuronas de entrada * (6 neuronas intermedias + 3 parámetros) + 6 neuronas intermedias * ((8+6+2) neuronas +3 parámetros) + 2 neuronas de salida * ((6+2) neuronas + 3 parámetros). 60 Método Experimental Figura 29 – Variación de las reglas de Hebb en función del peso sináptico [Urzelai, 2000] Neurona • Tipo umbral (sigmoide σ(x)=tgh(x)) con salidas en [-1,1] Dinámica • Sincrónica, actualización total de los estados de cada neurona. • No existe adaptación de los pesos sinápticos. • Dinámica temporal (Ecuación 2). Arquitectura • Red multicapa (3 capas): entrada, oculta y salida (recurrente en el nivel oculto y de salida). • wii=0 sólo para la capa de entrada y wij=wji para todas las capas. • Conexión entre niveles: entrada-oculta, y oculta-salida. Aprendizaje • Sin aprendizaje asociado a la actualización sináptica. Tabla 13 – Resumen de las características del modelo de red CTRNN implementado La topología de la red es similar a la señalada en la Figura 20. La codificación genérica corresponde a la mostrada para los controladores genéticamente determinados (Tabla 12) con la incorporación de los parámetros antes mencionados, propios de la CTRNN. 4.2.4.4 Controlador Plastic Neural Network (PNN) Las redes neuronales plásticas o PNN, en contraste con las redes del tipo FFNN, RFFNN, y CTRNN, no poseen pesos genéticamente determinados gobernando las conexiones entre los nodos en el proceso evolutivo. Por el contrario, cada conexión posee una regla y una tasa de variación plástica, y los pesos son modificados durante el tiempo de vida del agente. Este tipo de red, tal como se planteó en el presente trabajo, utilizó, al igual que las redes anteriores, una función sigmoide del tipo tangencial (tgh(x)). Método Experimental 61 Debido a que se pretende obtener comportamientos reactivos mediante la variación (ajuste) de pesos sinápticos, se implementaron redes neuronales plásticas donde cada sinapsis es capaz de variar según las actividades de las neuronas que conecta: pre-sináptica y post-sináptica. Una neurona post-sináptica se refiere a que la misma está ubicada en el extremo final de la sinapsis que conecta a dos neuronas, mientras que la neurona que se encuentra al inicio de dicha sinapsis, o neurona que genera el impulso en la sinapsis, se denomina neurona pre-sináptica. La red PNN descrita aquí es similar a la presentada por Floreano y Mondada [Floreano et al., 1998]. Las reglas plásticas, así como también la tasa de plasticidad, fueron definidas genéticamente en forma simultánea. A diferencia con la CTRNN, los nodos de la PNN, no poseen umbrales o bias, constantes temporales, ni ganancias. Los pesos fueron modificados en cada paso de tiempo según la siguiente regla: wijt = wijt −1 + η ⋅ ∆wijt (Ecuación 4) donde η es la tasa de cambio plástico para cada conexión. La tasa de cambio plástico puede estar dentro del rango [0; 1], lo cual está genéticamente determinado. El valor ∆wt fue calculado mediante una de las cuatro reglas plásticas que se presentan a continuación, y la especificación de cuál regla utilizar para cada conexión también fue determinada genéticamente: • Regla Plana Hebbiana (Plain Hebb): esta regla pondera la eficacia entre un nodo y otro si el nodo presináptico presenta su salida al mismo momento que lo hace el nodo post-sináptico. Esta regla no permite que la conexión sea subsecuentemente debilitada si los dos nodos no presentan sus salidas en forma simultánea: ( ) ∆wt = 1 − wt −1 xy (Ecuación 5) donde ∆w se refiere a la variación del peso sináptico; w es el valor actual del peso; x es el valor de activación pre-sináptico; y es el valor de activación post-sináptico. • Regla Post-sináptica (Postsynaptic): Esta regla está compuesta por dos términos. El primero debilita la conexión entre dos nodos si el nodo post-sináptico está presentando su salida pero el presináptico no. El segundo término, es el mismo que para la regla Plana Hebbiana. ( ) ∆wt = wt −1 y( x − 1) + 1 − wt −1 xy • Regla Pre-Sináptica (Presynaptic): es similar a la regla post-sináptica pero el primer término causa que la conexión entre dos nodos sea debilitada si el nodo pre-sináptico presenta su salida pero el postsináptico no: ( ) ∆wt = wt −1x ( y − 1) + 1 − wt−1 xy • (Ecuación 6) (Ecuación 7) Covarianza (Covariance): esta regla sólo incrementa la eficacia de la conexión si la diferencia entre las salidas pre-sinápticas y post-sinápticas es menor que la mitad del máximo valor de salida en ambos nodos: ( ) 1 − wt −1 F ( x, y ) si ⋅ F ( x, y ) > 0 ∆wt = t −1 otro w F ( x, y) (Ecuación 8) F ( x, y ) = tanh(4 ⋅ (1 − x − y ) − 2 ) tanh( x) = e x − e− x e x + e− x donde F(x, y) es la medida de la diferencia entre la actividad pre-sináptica y la post-sináptica; F(x, y)>0 ocurre cuando la diferencia es mayor o igual a 0.5 (mitad de la activación del máximo valor) y F(x, y)<0 si la diferencia es inferior a 0.5. 62 Método Experimental Neurona • Tipo umbral (sigmoide σ(x)=tgh(x)) con salidas en [-1,1] Dinámica • Sincrónica, actualización total de los estados de cada neurona. • Adaptación de los pesos sinápticos mediante reglas de Hebb. Arquitectura • Red multicapa (3 capas): entrada, oculta y salida (recurrente en el nivel oculto y de salida). • wii=0 sólo para la capa de entrada y wij=wji para todas las capas. • Conexión entre niveles: entrada-oculta, y oculta-salida. Aprendizaje • Aprendizaje asociado a la actualización sináptica. Tabla 14 – Resumen de las características del modelo de red PNN implementado La estructura de datos del cromosoma mostrado en la tabla siguiente, representa un controlador como el especificado en [Floreano et al., 1999b] o controlador de sinapsis adaptables. Por otra parte, la topología de la red corresponde a la señalada para las CTRNN. Codificación del genotipo PNN y HPNN Codificación para una sinapsis signo regla de Hebb tasa de aprendizaje (η) Tabla 15 – Codificación genética de los parámetros de evolución vinculados a las sinapsis de las redes PNN y HPNN (controlador por sinapsis adaptativas) Al comienzo de cada período durante la vida del controlador, cada uno de los pesos en la red fue determinado aleatoriamente en el rango [0; 0.01]. Por lo tanto, las reglas plásticas causaron cambios espontáneos a los pesos según la especificación de una de las cuatro reglas plásticas antes señaladas. El genotipo para un nodo en este tipo de red es señalado a continuación (codificación genérica): (r m1, em1, sm1, r m2, em2, sm2, rv1, ev1, sv1, ..., r v8, ev8, sv8, r n1, en1, sn1, ..., r n6, en6, sn6) donde r indica una regla plástica; e es la magnitud de la tasa plástica de cambio o tasa de aprendizaje (η); s es el signo de conexión, el cual pudo no cambiar a lo largo de la vida del agente. Al igual que para la CTRNN, el subíndice m indica motor, n especifica nodo de la capa oculta, y v señala una entrada. Esto resulta en un genotipo de longitud de 48 genes para los nodos internos, 24 genes para los nodos motores y 18 genes para los nodos de las entradas, dando un total de 480 genes22 por genotipo para representar a la totalidad de la red. Debido a que los pesos sinápticos fueron inicializados en un pequeño valor distinto de cero en el fenotipo, el comportamiento de un agente no fue conocido hasta que ellos fuesen especificados. Esto se debe a que sólo se conocía durante el proceso evolutivo las reglas sinápticas. Por tal razón, cada agente fue evaluado en diferentes oportunidades, y al comienzo de cada tiempo de vida, los pesos fueron reinicializados a pequeños valores aleatorios. 22 El cálculo es el siguente: 8 neuronas de entrada * (6 neuronas intermedias * 3 parámetros) + 6 neuronas intermedias * ((8+6+2) neuronas * 3 parámetros) + 2 neuronas de salida * ((6+2) neuronas * 3 parámetros). Método Experimental 4.2.4.5 63 Controlador Homeostatic Plastic Neural Network (HPNN) El controlador que se describirá aquí, fue inspirado por la red homeostática propuesta por Ashby [Ashby, 1960], y por trabajos más recientes enmarcados dentro de la evolución de agentes homeostáticos, los cuales realizaban fototaxis de acuerdo a lo especificado por Di Paolo [Di Paolo, 2000]. Los pesos de esta red homeostática fueron controlados por el mismo conjunto de reglas Hebbianas utilizadas para las redes plásticas (véase sección anterior). De igual manera las tasas de plasticidad fueron determinadas genéticamente. No obstante, en contraste con las redes PNN, los pesos no cambiaron de forma continua a lo largo del tiempo de vida del agente. Figura 30 – Representación de la salida proporcionada por la función sigmoide utilizada por la HPNN. Las líneas en ±0.00001, las cuales sólo son relevantes para las redes homeostáticas, representan los umbrales homeostáticos. Del mismo modo que para las redes plásticas, los pesos de la red HPNN fueron inicializados a pequeños valores aleatorios en el rango [0; 0.01]. Además, los pesos pudieron ser modificados por varias razones. Primero, sus magnitudes sufrían continuos cambios durante los primeros 20 instantes de tiempo de la vida del agente. Esta etapa representó un período de desarrollo ontogenético, como puede verse en el desarrollo de sistemas biológicos, durante el cual los agentes establecen un conjunto de pesos sinápticos. Segundo, los pesos pudieron cambiar si la red se vuelve inestable debido a cambios en el agente o en el entorno. Para ello, la red utilizó una función sigmoide anti-simétrica (Figura 30) con un umbral en ±0.00001. Si la activación cae por debajo de –0.00001 o está por sobre 0.00001, entonces la plasticidad es inducida en las sinapsis de dicho nodo. Al igual que para el controlador plástico, cada agente fue evaluado en varias oportunidades (lifetime), estando cada una compuesta por 10 corridas. Cabe aclarar que el conjunto de acciones realizadas por los agentes fue el mismo que aquel usado para evaluar las redes plásticas. Debido a costos computacionales, los agentes no pudieron ser evaluados durante la evolución de sus habilidades de adaptación a los cambios en el entorno o de su propia morfología. Pese a ello, el objetivo de utilizar una red homeostática fue el hecho de verificar que la red sea capaz de modificar apropiadamente su configuración sólo cuando las activaciones de sus nodos salieran de los límites estipulados. No obstante, dada a la presión evolutiva, esto sólo debe pasar cuando un agente está mal adaptado a su entorno. Finalmente, el genotipo de este controlador fue idéntico al del controlador plástico al igual que su topología. Además, las características señaladas en la Tabla 14 y Tabla 15 para las redes PNN valen para las HPNN, estando el aprendizaje de estas últimas vinculado a aspectos homeostáticos. 64 4.3 Método Experimental Tareas a Resolver Al momento de evaluar el desempeño de un controlador, es de vital importancia definir cuál va a ser la medida de evaluación. En ello, la tarea a desempeñar por el robot determina cuál va a ser el criterio de selección de los individuos en cada generación. Como se mencionó previamente, el comportamiento final buscado consistirá en que el robot aprenda a moverse hacia un objetivo (fuente de luz) mientras evade obstáculos, lo cual puede dividirse en diferentes tareas: • Fototaxis: el robot debe ser capaz de alcanzar una fuente de luz objetivo acercándose a ella. Una variante analizada es cuando el robot puede moverse hacia una de varias fuentes de luz y decidir a cuál acercarse. Esta alternativa se denomina fototaxis condicional. Cabe aclarar que la elección de cuál fuente de luz debe ser alcanzada, es decidido mediante una entrada externa. En este subcomportamiento, se utilizó como referencia el trabajo descrito en la sección 3.2.3 y [Nolfi et al., 2000, Cap. 6]. • Evasión de Obstáculos: esta sub-tarea se refiere a que el robot debe tener la capacidad de evadir obstáculos, principalmente, cuando se dirige hacia un punto en particular. La medida de fitness está asociada parcialmente con el trabajo de Nolfi [Nolfi et al., 2000, Cap. 4]. • Aprendizaje: como referencia para el desarrollo del sub-comportamiento de aprendizaje, se optó por tomar como trabajos base, principalmente, los siguientes: trabajo descrito en la sección 3.2.3 y [Nolfi et al., 2000, Cap. 7]. Aventurando lo que se verá en detalle en el siguiente capítulo, es posible decir que la evaluación de cada genoma comprende un número determinado de pruebas. En cada una de ellas, la red es re-configurada a su estado original, el cual es establecido por el genoma en cuestión. En la mitad de las pruebas, el objetivo a ser alcanzado por el robot varía por otro, sin que esto esté previamente estipulado. En este caso, el robot no sabe cuál fuente de luz debe alcanzar al comienzo de cada prueba. De este modo, se busca que con el correr del tiempo el robot aprenda a distinguir su objetivo mediante prueba y error. Figura 31 – Diagrama UML de clases del modelo experimental genérico implementado. Las diferentes instancias de experimentos desarrollados, son mostradas en la Figura 31, junto con su relación con la clase abstracta EmpiricalTest. Las instancias de dicha clase están compuestas por métodos que representan las características propias del experimento. Cabe señalar que tales instancias codifican el criterio de evaluación de los controladores durante el proceso evolutivo. Concretamente, implementan tanto el ciclo de evaluación como la función de fitness. Método Experimental 4.4 65 Conclusiones En este capítulo se describió el método experimental empleado. Dicho método ha sido desarrollado a partir de trabajos disponibles en la literatura y mediante la herramienta de software generada, la cual prescribe robots simulados capaces de concebir comportamientos como los señalados. La materialización básica de tal herramienta ha sido extendida para soportar múltiples representaciones de controladores neuronales y tareas a resolver. En cuanto a la decisión de qué tipo de red neuronal es la apropiada para desarrollar las diferentes tareas (fototaxis, evasión de obstáculos y aprendizaje), en el capítulo siguiente se presentan los resultados experimentales obtenidos a tal fin. Capítulo 5 - RESULTADOS EXPERIMEN TALES CON CONTROLADORES MONOLÍTICOS RESULTADOS EXPERIMENTALES CON CONTROLADORES MONOLÍTICOS "Una forma de estudiar fenómenos [naturales] es observar sus posibles desviaciones, e investigar qué sucede cuando las condiciones se alteran de alguna forma. Esta es la base de la experimentación: la variación controlada de un aspecto de un fenómeno a fin de ver cómo los demás aspectos se ven afectados" Gabriel Gellon 5.1 Introducción En este capítulo se muestran los resultados de los experimentos desarrollados con cada una de las redes neuronales señaladas en el Capítulo 4. Cada experimento es generado con un controlador monolítico o controlador compuesto por una única red neuronal. Los diferentes tipos de redes fueron evolucionados reiteradas veces a fin de obtener métricas de sus capacidades respecto de la tarea a resolver. Cabe aclarar que un método asociado a aprendizaje vinculado a evolución, es presentado en este capítulo, el cual fue originalmente explorado en sistemas naturales por Baldwin [Baldwin, 1896], y ha demostrado ser un método apropiado para suavizar fitness landscapes en algoritmos genéticos [Hinton et al, 1987]. En la sección 5.2, se presentarán los resultados del proceso evolutivo, al mismo tiempo que se expondrán algunas de las razones que justifican las diferencias del desempeño de cada red. Seguidamente, en la sección 5.3 la mejor red de cada tipo es evaluada en cuanto a su desempeño en la realización de diferentes tareas. Esto constituirá el análisis funcional de cada neuro-controlador. Primeramente, las redes son analizadas en términos de su estrategia para realizar la tarea para la cual fueron evolucionadas. Luego, es evaluada la forma en cómo ellas son capaces de alcanzar tales estrategias dentro de los límites de sus morfologías. Finalmente, en la sección 5.4, son presentadas las conclusiones del capítulo. 5.2 Evolución Los controladores descriptos en este capítulo fueron evolucionados usando el mismo Algoritmo Genético, pero el tiempo que demoró cada controlador en evolucionar fue notablemente diferente. Las tablas presentadas en esta sección proveen una selección estadística de algunas de las características más importantes de la evolución de cada controlador. Para comprobar la consistencia de cada uno de ellos, las pruebas fueron llevadas a cabo de acuerdo a los datos presentados en la Tabla 10 mostrada en el Capítulo 4. Sin embargo, a pesar de la diferencia en la topología de las redes y de las tareas a realizar, los controladores evolucionaron sin relación temporal aparente entre sí. Con esto se trata de expresar que en algunas oportunidades un determinado controlador evolucionó más rápidamente que otros, mientras que para otras actividades esto no ocurrió. Pese a ello, es posible decir que generalmente, y como es de esperar, aquellos neuro-controladores con representaciones genotípicas más extensas demoraron más en evolucionar (como es el caso de los controladores plásticos) respecto de otros tipos de controladores. Además, el mejor agente para cada tipo de neuro-controlador fue evaluado un número fijo de veces al momento de realizar una determinada acción. En cada oportunidad, la posición desde la cual el agente comienza a moverse fue especificada en forma aleatoria. No obstante, ésta se enmarca dentro de los límites impuestos por el entorno del robot. 68 Resultados Experimentales Las tablas siguientes muestran que en muchas de las oportunidades el agente ha alcanzado casi la puntuación máxima que indica la función de fitness (en el rango [0; 1] para fototaxis y evasión de obstáculos, y [0; α] para aprendizaje, con α un número menor a 5). Cabe mencionar que la función asociada al indicador de “porcentaje de éxito” en las tablas que a continuación se muestran, expresa el número de veces en que fue alcanzado el objetivo correcto sobre el total de corridas, considerando las tres tareas (comportamientos) a resolver: fototaxis, evasión de obstáculos, y aprendizaje. En cuanto al número de generaciones empleado en cada prueba, corresponde a 300 generaciones y a 10 corridas por cada una de ellas. Tipo de controlador Mejor Fitness Prom. Fitness Promedio Peor Fitness Prom. Tiempo Porcentaje de Éxito Estabilidad23 FFNN RFFNN CTRNN PNN HPNN 0.7106 0.4939 0.1785 35’ 04’’ 9/10 40 0.7264 0.4863 0.1261 31’ 05’’ 9/10 40 0.5125 0.1497 0.0173 37’ 43’’ 8/10 70 0.6319 0.4045 0.1073 53’ 05’’ 9/10 85 0.6623 0.4302 0.1040 57’ 51’’ 10/10 80 Tabla 16 – Resultados promedios de la evolución de los neuro-controladores implementados para fototaxis (sección 5.3.1) sobre el total de generaciones (300 generaciones y 10 corridas); Función de fitness: Ecuación 9. Tipo de controlador Mejor Fitness Prom. Fitness Promedio Peor Fitness Prom. Tiempo Porcentaje de Éxito Estabilidad FFNN RFFNN CTRNN PNN HPNN 0.9116 0.8121 0.4945 22’ 57’’ 10/10 20 0.8994 0.7911 0.4230 31’ 06’’ 9/10 40 0.6767 0.3338 0.0579 38’ 60’’ 6/10 60 0.8387 0.6762 0.3762 50’ 34’’ 5/10 50 0.8390 0.6851 0.3902 49’ 06’’ 9/10 50 Tabla 17 – Resultados promedios de la evolución de los neuro-controladores implementados para evasión de obstáculos (sección 5.3.2) sobre el total de generaciones (300 generaciones y 10 corridas); Función de fitness: Ecuación 10. Tipo de controlador Mejor Fitness Prom. Fitness Promedio Peor Fitness Prom. Tiempo Porcentaje de Éxito Estabilidad FFNN RFFNN CTRNN PNN HPNN 2.8124 1.8358 0.4396 31’ 31’’ 10/10 95 4.8314 2.5823 0.2258 39’ 00’’ 10/10 120 1.9914 0.5048 0.090 39’ 32’’ 8/10 180 2.3004 1.3217 0.1884 52’ 44’’ 10/10 130 3.1135 1.5592 0.1813 54’ 21’’ 10/10 80 Tabla 18 – Resultados promedios de la evolución de los neuro-controladores implementados para aprendizaje (sección 5.3.3) sobre el total de generaciones (300 generaciones y 10 corridas); Función de fitness: Ecuación 12. Las tablas anteriores caracterizan algunos de los aspectos del fitness landscape para cada controlador mostrado en el capítulo anterior en función a los datos de la Tabla 10. Como se puede observar, la red del tipo CTRNN fue una de las más lentas en evolucionar, con un margen considerable de generaciones hasta obtener una puntuación estable en su mejor fitness promedio. Sin embargo, las redes FFNN, RFFNN y la HPNN típicamente encontraron soluciones en pocas generaciones en la mayoría de las pruebas. Las redes 23 Número de generaciones en alcanzar estabilidad por primera vez en el mejor fitness promedio. En otras palabras, número de generaciones en el que es computado una medida de fitness igual al promedio general. Resultados Experimentales 69 FFNN y RFFNN presentaron un comportamiento aceptable en aquellas pruebas puramente reactivas (fototaxis y evasión de obstáculos). En cuanto a la HPNN, su desempeño fue aceptable pero remarcado durante los experimentos relativos a aprendizaje o a variaciones durante la vida del controlador. Por lo que es posible decir que su desempeño fue positivo cuando se necesitó de un comportamiento no solamente reactivo, sino que también dependiente de la experiencia. Fototaxis Evación de Obst. Aprendizaje 6 Fitness 5 4 3 2 1 0 FFNN RFFNN CTRNN PNN HPNN Tipo de neuro-controlador Figura 32 – Grafico comparativo de los diferentes niveles de fitness (mejor fitness promedio) para los distintos tests. La red CTRNN muestra una gran variación en su desempeño de corrida en corrida, y en ninguna oportunidad alcanzó un fitness máximo superior al obtenido para los otros controladores. Esto indica que el fitness landscape para esta red fue menos estable que para los demás controladores. En otras palabras, la tendencia de la función de fitness presenta variaciones significativas con el correr de las generaciones. En HPNN, es posible que el mecanismo de homeostasis, el cual es parte de su morfología, pueda haber causado variaciones de los pesos hasta que el agente realizara la tarea en forma apropiada. Tan pronto como el agente llevara a cabo la acción de manera correcta, los cambios sinápticos se detendrían y se mantendrían en esta situación para no generar “malas adaptaciones”. Esto pudo haber ocurrido en el caso que la morfología no fuese optimizada en relación a la tarea. No obstante, puede que se realizara la acción de mejor manera que en aquellos controladores que no incorporen homeostasis. Por otro lado, cabe señalar que a pesar de que las redes del tipo PNN posean adecuación de pesos sinápticos, generalmente, no ocurrió lo mismo que lo expresado para las redes homeostáticas. En el caso que las redes plásticas encontraran un conjunto de pesos sinápticos que permitieran al agente realizar la tarea en forma correcta, los pesos tendieron a estar estáticos, mientras que las reglas plásticas simultáneamente continuaron causando variaciones sinápticas. Es importante señalar que los pesos en las PNN no eran parámetros de evolución, por el contrario eran variables durante la ejecución. Finalmente, en el caso de las CTRNN los pesos sí constituían parámetros, pero como al igual que otros parámetros evolutivos, éstos pudieron no ser modificados en forma apropiada durante la vida del controlador. Estas reglas escapan a la posibilidad de que el efecto Baldwin pueda sumar alguna característica deseable a la evolución del controlador. 5.3 Análisis Funcional A continuación se expondrá un análisis inicial sobre la evolución de los controladores neuronales antes señalados. Si bien el objetivo final es la obtención de controladores apropiados para cada tarea, se señala que existen diferentes estudios futuros a ser implementados los cuales no son tratados en éste trabajo (p. ej. análisis de la topología neuronal óptima). 70 Resultados Experimentales Un punto a remarcar es que no es posible realizar un análisis pleno de cada red según el alcance propuesto para este trabajo. Por ejemplo, con respecto a los controladores del tipo FFNN, CTRNN y PNN no se propone un estudio extenso en el presente trabajo dado que han sido analizados con algún grado de detalle en análisis previos disponibles en la bibliografía (p. ej. [Fernández et al., 2004] [Beer, 2001][Floreano et al., 1998]). Por el contrario, el controlador homeostático recibe un mayor grado de detalle, dado que sólo existen algunos pocos trabajos recientes sobre el mismo ([Di Paolo, 2002]). Con respecto al análisis realizado vinculado a la evolución de los controladores, si bien es difícil realizar una gráfica del fitness landscape, debido a que posee varias dimensiones a graficar dado el número de genes en el genotipo, es factible desarrollar algunas inferencias acerca de las variaciones en la evolución de las distintas redes. Esto es lo que se mostrará en cada prueba. 5.3.1 Fototaxis La tarea asociada a fototaxis se encuadra con un comportamiento simple o comportamiento que no se compone de sub-tareas elementales. Básicamente, es posible definirla como un “problema de búsqueda de objetivo”. La configuración del experimento que se llevó a cabo en el presente trabajo, está inspirada en el desarrollo realizado por Nolfi y Parisi [Nolfi et al., 1997], y principalmente en el experimento propuesto por Floreano y Mondada [Floreano et al., 1996a]. Si bien el entorno no fue el mismo, la idea subyacente en el experimento se mantiene inalterada. Concretamente, se buscó evolucionar controladores capaces de adaptarse a cambios en el entorno a través de las generaciones. En el caso del presente trabajo, se buscó además capacidades de adaptación mediante la evolución de individuos al momento de ser evaluados en ámbitos que difieren significativamente de aquellos utilizados durante la evolución. La configuración del entorno, como así también la del robot, fue descrita en el Capítulo 4. Como características adicionales, en la configuración de los experimentos cada robot fue posicionado aleatoriamente sin que se incorporaran objetos dentro del ambiente. Pese a ello, se ubicó al azar una fuente de luz distinguible como un punto rojo, simbolizando la posición a la que el robot debe llegar. Cada individuo de la población fue evaluado independientemente al cabo de 300 generaciones de 200 iteraciones por corrida cada una. La función de fitness, como fue expresado anteriormente, selecciona individuos capaces de buscar el objetivo en el menor tiempo posible. Dicha función corresponde a una variación de la función propuesta en [Floreano et al., 1996a] dentro del problema de búsqueda de una fuente de recarga de energía. Es importante notar que cada individuo fue evaluado de acuerdo con la función de fitness simplificada, utilizada en el problema de navegación con obstáculos que luego se describirá. Esto se relaciona a que cuando se emplea un procedimiento evolutivo sobre un problema complejo, la función de fitness no necesariamente necesita también ser compleja. Con ello se trata de expresar que en forma emergente surge un cambió de las características del controlador sujetas a evolución en estrecha relación con el entorno. En el experimento de Floreano y Mondada, solo se utilizó una configuración de red del tipo RFFNN con 5 neuronas en la capa oculta. Cabe aclarar que en dicho trabajo no se hicieron intentos por optimizar el número de neuronas requeridas, ni lo propio sobre la conectividad neuronal del controlador. La función de fitness propuesta está compuesta por dos variables directamente cuantificables en el robot real en cada instante de tiempo: Φ1 = k ⋅ (1 − i) (Ecuación 9) donde k es el valor promedio de la activación de los sensores frontales del robot (sensor V3 y V4 de la Figura 13) (0 ≤ k ≤ γ, con γ un valor predefinido), multiplicado por un valor γ constante igual a 4; i es el valor absoluto de la diferencia entre la actividad de los dos nodos motores, representando el ángulo de desviación expresado en radianes. Po r lo tanto, en este caso, se considera que una desviación es válida cuando no supere un radian (aprox. 56º). El primer componente de la Ecuación 9, es maximizado por la proximidad a la fuente de luz, mientras que el segundo componente es maximizado por los movimientos directos al objetivo. Resultados Experimentales 71 Nuevamente, es importante notar que la función de fitness no se refiere a cuál es la dirección a la que el robot debe moverse, sino que es calculada acumulando en cada paso el valor Φ 1, excepto cuando el robot está en proximidad del área marcada por la fuente de luz. Posteriormente, el valor de fitness de cada individuo (el cual depende tanto de la performance del robot como de la duración de su vida) fue dividido por el mismo número de pasos o generaciones (300). A modo de comparación, es posible decir que en el trabajo de la sección 3.2.3, no se utilizó una medida de fitness que pudiera ser obtenida directamente de un robot Khepera real según la configuración planteada en dicho trabajo. Básicamente, se planteaba una medida del desempeño de cada agente en función de la distancia entre el robot y la posición objetivo. Como es de esperar, y en el caso que los controladores sean evaluados en robots reales, habría que modificar los criterios de evaluación debido a que sería necesario especificar la distancia al objetivo en todo momento por un observador del experimento. Por lo tanto, esto sería un inconveniente deseable de evitar, por cuanto en el presente trabajo se buscó no caer en dicho inconveniente. El mapeo entre sensores y entradas de la red, fue el siguiente: Entrada Sensor V0 V1 V2 V3 V4 V5 V6 V7 V8 0 SL0 (1) SL0 (2) SL0 (3) SL0 (4) SL0 (5) SL0 (6) SL0 (7) SL0 (8) Tabla 19 – Mapeo sensor-entrada de la red utilizada para los experimentos con fototaxis, siendo SLj(i) la especificación de un sensor infra-rojo receptor (sensor lumínico) vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente. 5.3.1.1 Experimentos con FFNN Como observación de la estrategia obtenida luego de realizar los experimentos con el controlador FFNN, puede decirse que éste corresponde a un controlador simple de evolucionar. Tal conclusión surge como consecuencia de analizar los datos de la Tabla 16 junto con su desempeño al momento de ir hacia el objetivo. La Figura 34 muestra algunos ejemplos de las estrategias más significativas del desplazamiento con dicho controlador. Cuando la posición inicial del robot lo permite, los sensores captan la fuente de luz, lo cual genera una acción sobre los actuadores posibilitando que el robot se aproxime al objetivo. La forma general en que el robot se movió fue constante y consistente, lo cual puede verse en lo continuo de las activaciones de sus neuronas (Figura 33.a) generando una trayectoria gradual hacia el objetivo. Una característica interesante de mencionar es que la estrategia de aproximación converge hacia la posición final sin que el recorrido sea un movimiento plenamente rectilíneo. Esto se debe a que el controlador fue determinado y seleccionado por el proceso evolutivo sin que en la función de fitness se especifique la forma en que el robot debe aproxim arse. En el caso que dicha función se refiera a minimizar la distancia de recorrido entre la posición inicial y la posición objetivo, se obtendrá un movimiento puramente rectilíneo. No obstante, se ponderó en el presente trabajo la utilización de parámetros netamente cuantificables en una configuración de robot real, sin algún tipo de sensado respecto del camino óptimo. 72 Resultados Experimentales Por otro lado, debido a que el controlador no depende de constantes determinadas por el proceso evolutivo vinculadas a afectar a la función de activación de las neuronas (Figura 33.a) en base a las entradas de la red (Figura 33.b), las gráficas de cada nodo fueron suaves y fluidas. Pese a ello, sin un análisis profundo, es difícil especificar e identificar la función exacta que cada nodo desempeña en la red. Esto vale para las redes FFNN, como así también para los controladores que se describen en próximas secciones. De todos modos, y analizando las gráficas de las actividades de cada nodo en una FFNN, es posible decir que los nodos se comportan de forma similar entre sí, pero difieren en el signo. Básicamente, esto es causado por la definición de los pesos sinápticos seleccionados por el proceso evolutivo. (a) (b) Figura 33 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red FFNN durante la tarea de fototaxis obtenida en el cuarto test del mejor controlador (300 generaciones). (a) (b) (c) Figura 34 – Ejemplos de trayectorias seguidas por el robot simulado para una red FFNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El segundo, (b) cuarto, y (c) octavo test. Resultados Experimentales 73 Figura 35 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en fototaxis. Como se puede observar en la figura anterior, existe un número de generaciones iniciales en las cuales el nivel de fitness comienza a incrementarse drásticamente. Esto sugiere que el agente alcanza a adaptarse (generacionalmente hablando) a la acción de fototaxis en forma temprana (aproximadamente 40 generaciones), presentándose un patrón de fitness estable a partir de dicho punto. 5.3.1.2 Experimentos con RFFNN La estrategia de fototaxis planteada por el controlador RFFNN en cuanto a la forma de aproximarse al objetivo, no difiere significativamente de la mostrada para FFNN. Pese a ello, es posible ver que existen algunas variaciones poco estables en las actividades de los nodos del controlador. Principalmente, esto se debe a las conexiones recurrentes en la topología de la red asociada a su dinámica interna. (a) (b) Figura 36 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red RFFNN durante la tarea de fototaxis obtenida en el cuarto test del mejor controlador (300 generaciones). 74 Resultados Experimentales (a) (b) (c) Figura 37 – Ejemplos de trayectorias seguidas por el robot simulado para una red RFFNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) cuarto, y (c) séptimo test. Figura 38 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo RFFNN en fototaxis. Al igual que en la sección anterior, la gráfica de la función de fitness (Figura 38) presenta un comportamiento estable de manera temprana, pero con algunas oscilaciones con tendencia a decrementar el desempeño global cerca de la generación 200. Una interpretación de este comportamiento puede estar asociada a que pequeñas actividades neuronales ocasionaron que el robot procesara acciones no apropiadas a la situación actual, vinculadas a una acción previa. Por lo tanto, una explicación de la caída de la tendencia de la función de fitness, puede vincularse a malas variaciones genéticas en cuanto a conexiones de la capa oculta de la red RFFNN se refiere. 5.3.1.3 Experimentos con CTRNN Una de las características más notables de las redes CTRNN al momento de realizar fototaxis, es que no fue simple de obtener un comportamiento apropiado. La Figura 40 muestra cómo variaron las distintas estrategias de aproximación al objetivo. Mientras los caminos tomados por el agente fueron consistentes, la forma de tales movimientos parece variar a medida que el agente se desplaza. En la Figura 40.a y Figura 40.b puede observarse que el agente es atraído por la fuente de luz en forma lenta, generando un movimiento curvilíneo amplio, moviéndose de manera gradual hacia dicha posición. Por el contrario, en la trayectoria mostrada en la Figura 40.c el agente realmente varía de dirección al acercarse al objetivo. Este comportamiento puede justificarse dado que el número de parámetros sometidos al proceso evolutivo es mayor que en el caso de la FFNN y RFFNN. Por lo tanto, es más difícil de obtener una combinación óptima de dichos parámetros a fin de generar un comportamiento aceptable. Esto puede ser observado en el mejor fitness promedio mostrado en la Tabla 16, siendo para la CTRNN menor en todos los casos. Dicho inconveniente puede ser resuelto potencialmente a través de un proceso evolutivo con un mayor número de generaciones. Debido a que el agente utiliza constantes temporales determinadas genéticamente, las activaciones de los nodos (véase Figura 39.a) se caracterizan por ser relativamente armoniosas, debido a que el proceso Resultados Experimentales 75 evolutivo tiende a descartar combinaciones de tales constantes no apropiadas a la función de fitness señalada (Ecuación 9). No obstante, sin realizar un análisis profundo, es difícil identificar la funcionalidad específica de cada nodo. Además, es notoriamente difícil analizar redes del tipo CTRNN a pesar del hecho que posean pocos nodos, siendo que el alto grado de conectividad de los nodos significa que el efecto de una conexión repercutirá en toda la red. Con respecto al desempeño (porcentaje de éxito) con este tipo de controlador en fototaxis, fue levemente menos adecuado que el propuesto por otros controladores. Esto puede observarse en la Tabla 16 de la sección 5.2. (b) (a) Figura 39 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red CTRNN durante la tarea de fototaxis obtenida en el noveno test del mejor controlador (300 generaciones). (a) (b) (c) Figura 40 – Ejemplos de trayectorias seguidas por el robot simulado para una red CTRNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) segundo, y (c) noveno test. 76 Resultados Experimentales Figura 41 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo CTRNN en fototaxis. Posiblemente, dado lo complejo de la dinámica de los controladores CTRNN, y a la determinación de los parámetros genéticos que afectan a la activación de los nodos, inicialmente la medida de fitness es considerablemente más baja en generaciones tempranas, estabilizándose luego de la generación 70. Un punto a destacar es que en la Figura 41 aparecen valores negativos del peor fitness. Esto expresa que existieron alternativas de controladores que no se adecuaron a la función de fitness antes especificada. En comparación con las FFNN, las CTRNN presentan movimientos que indican la presencia de actividad neuronal sin que se presenten actividades exitatorias en las entradas. Un indicador de esto puede verse en la Figura 40.b cuando el robot luego de sensar la fuente de luz, modifica su trayectoria en forma circular. En el caso de que esto no ocurriese, estaríamos probablemente en presencia de un movimiento como el señalado para las RFFNN. 5.3.1.4 Experimentos con PNN Al igual que para las CTRNN, la estrategia de resolución propuesta por el mejor controlador plástico o PNN, varía radicalmente de acuerdo al tiempo que demora en evolucionar respecto de otros controladores (Tabla 16). Sin embargo, en general se encontró que dicho controlador es ligeramente más consistente que las CTRNN. La Figura 43 muestra ejemplos representativos de la estrategia de aproximación del agente utilizando un controlador plástico. Al inicio, el agente se mueve rápidamente sin que se produzcan movimientos circulares (tal como fue visto para CTRNN), similares al generado con FFNN o RFFNN. Luego se mueve satisfactoriamente durante el resto de la trayectoria hacia el objetivo. Lo segundo que puede observarse es que el desplazamiento es armonioso y estable. Una característica a destacar de este tipo de red es que la variación de pesos entre dos neuronas ocurre a lo largo de la vida del agente. Por ello, puede decirse que tal variación se produce en forma de adaptación paulatina a diferencia de las activaciones generadas en una CTRNN, lo cual repercute en la activación de las neuronas que conectan dicha sinapsis. No obstante, varios de los pesos sinápticos son mantenidos en un valor cercano a cero durante la vida del agente (véase Figura 42.a). De forma similar, en [Greer, 2002] se concluye que “las reglas de aprendizaje plásticas” para las PNN poseen poca incidencia en la adaptación del controlador. Esta observación está basada en la variación de las actividades de los nodos, lo cual se debe a que existen modificaciones sinápticas no beneficiosas, pudiéndose producir alteraciones sinápticas no deseables para el desempeño final del agente. Nótese que existen oscilaciones incrementales en las actividades de algunos nodos, pudiendo estas generar comportamientos erráticos. En pruebas iniciales con PNN, se pudo observar que tales oscilaciones se generan cuando no pueden ser equilibradas con otras, por lo que aparecen comportamientos no previstos, tales como giros rápidos sobre el eje vertical del robot. Resultados Experimentales 77 En el rango entre 100 y 300 generaciones mostrado en la Figura 44, el fitness comienza a oscilar significativamente. Posiblemente, dicha variación se debe a una alteración de la incidencia sináptica sobre un conjunto de neuronas, la cual se equiparó con otras variaciones neuronales plásticas. Pese a esto, extrañamente no resulta en un marcado cambio del comportamiento del agente. Del mismo modo que la variación en las activaciones de los nodos, las conexiones sinápticas fueron constantemente modificadas por las reglas plásticas. Al mismo tiempo, la variación de las entradas de los sensores y de la actividad de las neuronas produjo que este tipo de red fuera más difícil de analizar que las CTRNN. Al momento de exponer los resultados del desempeño final de las PNN, se encontró que presentaban un comportamiento no previsto a largo plazo. Luego de realizar un número no específico de acciones, el comportamiento del agente comenzó a ser errático sin que se observase signos de recuperación por parte del agente. Nuevamente se señala que tal comportamiento ocurre debido al surgimiento de adaptaciones plásticas que no son controladas, o en otras palabras, son realizadas en todo momento. (b) (a) Figura 42 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red PNN durante la tarea de fototaxis obtenida en el noveno test del mejor controlador (300 generaciones). (a) (b) (c) Figura 43 – Ejemplos de trayectorias seguidas por el robot simulado para una red PNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El segundo, (b) quinto, y (c) noveno test. 78 Resultados Experimentales Figura 44 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo PNN en fototaxis. Como puede verse en la Figura 44, el desempeño del agente mejora rápidamente en generaciones tempranas, pese a que los pesos sinápticos no fueron generados antes de la evolución del comportamiento del agente. Esto señala que existe una adecuación inicial satisfactoria por parte de las reglas de Hebb (sección 4.2.4.4). 5.3.1.5 Experimentos con HPNN Mientras los pesos de la CTRNN permanecieron estáticos, y los de la PNN fueron variando proporcionalmente a las actividades de las neuronas, los de la red homeostática o HPNN ocuparon un punto intermedio. Durante una etapa inicial, el mejor agente sufría alteraciones de pesos durante los primeros 20 movimientos. Luego de esto, los pesos sinápticos sólo sufrían modificaciones si la actividad neuronal superaba o estaba por debajo de un umbral predefinido (±0.00001 respectivamente24). La actividad de los nodos se asemeja a la actividad de las redes plásticas con respecto a cambios rápidos en su salida, junto con períodos intermitentes de oscilaciones (véase Figura 45.a). El comportamiento de una red del tipo HPNN con un proceso evolutivo apropiado, se vuelve más interesante que las dos redes anteriores. Con esto se trata de expresar que existe una habilidad de adaptarse a los cambios sólo cuando corresponde hacerlo. La Figura 47 muestra con mayor claridad el proceso de adaptación durante la vida del agente. Luego del período inicial de desarrollo, no se produjeron cambios durante las primeras 20 acciones, pero la Figura 45.a muestra además la variación de las actividades durante un período de mal adaptación (véase actividad del nodo 6). En pocas palabras, sólo las sinapsis que sufren notables cambios presentan notables oscilaciones. Mientras que muchas de las conexiones no variaron, se encontró que algunas no realizaron una adecuación apropiada sobre el espacio de pesos durante el período de mal-adaptación. En contraste con esto, en Di Paolo [Di Paolo, 2000] se encontró que la variación de los pesos en su agente homeostático, ocurría sólo un instante previo a la adaptación. Ashby [Ashby, 1960] propuso que la adaptación a nuevas circunstancias puede ser alcanzada realizando modificaciones aleatorias a los parámetros de seteo. Pero aún en un sistema simple (tal como la red diseñada en el presente trabajo), y en mayor medida en sistemas biológicos, dicho método de modificación aleatoria puede tomar bastante tiempo. Además, la modificación de pesos en el presente trabajo fue restringida en función de la morfología del sistema, utilizando conexiones específicas y habiéndose determinado el modo de variación a alguna de las Reglas de Hebb. La red fue evaluada en cuanto a su habilidad para re-adaptarse a dichas circunstancias 10 veces, y en todas de ellas se obtuvo un resultado exitoso. 24 Dicho valor de umbral fue obtenido mediante un proceso de prueba y error. Resultados Experimentales 79 (b) (a) Figura 45 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de fototaxis obtenida en el noveno test del mejor controlador (300 generaciones). (a) (b) (c) Figura 46 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de fototaxis obtenidas para mejor controlador (300 generaciones); (a) El cuarto, (b) noveno, y (c) sexto test. Figura 47 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en fototaxis. Como observación de la estrategia planeada por el HPNN, es posible decir que el agente presenta un comportamiento aceptable para el problema en cuestión (aproximación al objetivo, Figura 46), a pesar de que fue el controlador que más demoró en evolucionar. En cuanto a la evolución del fitness, el nivel del 80 Resultados Experimentales mejor fitness es superior al presentado por PNN. No obstante, no corresponde al mejor fitness promedio en comparación con la totalidad de controladores estudiados. Particularmente, en cuanto a los controladores plásticos (PNN y HPNN), se encontró que su evolución fue más costosa en términos temporales. Esto se debe a que la combinación de reglas por sinapsis es alta. Con ello, si bien la característica principal de tal tipo de controlador es su capacidad de adaptación al entorno, el comportamiento final está restringido por las mismas reglas plásticas encontradas luego del proceso evolutivo. Esto trae aparejado que sea complejo el estudio de la validez de la selección de reglas para cada sinapsis, junto con el estudio de la relación entre niveles del controlador en forma automática. Posiblemente, un estudio que implique un mayor número de generaciones, podría ayudar a descubrir la influencia generacional en la determinación de un conjunto de reglas optimales para la resolución de la tarea en cuestión. No obstante, se considera que la evolución del controlador antes descrito es válida en función de los resultados alcanzados. 5.3.1.6 Fototaxis Condicional El significado de fototaxis condicional es que el robot debe ser capaz de alcanzar uno de dos posibles objetivos lumínicos y permanecer en él o aproximarse a una distancia mínima. Con ello, la determinación de cuál objetivo es el apropiado es decidido por una entrada externa. Inspirado en el trabajo en el trabajo de Togelius (sección 3.2.3), es posible decir que el problema a resolver con fototaxis condicional es de interés dado que requiere comportamientos diferentes. Si bien se utilizó fototaxis condicional junto con evasión de obstáculos simple de manera reactiva, no es claro el funcionamiento de cada comportamiento, lo cual dificulta la apreciación de los “efectos condicionales” sobre el comportamiento del robot. Por lo tanto, en la presente sección se propone el análisis de fototaxis condicional únicamente. Además, dicho problema es poco predecible si lo comparamos con fototaxis simple. Pese a ello, es posible llevarlo a cabo en forma reactiva. Nuevamente, al igual que para fototaxis simple, la propuesta de Togelius referida a la medida del fitness en fototaxis condicional es dependiente de la cuantificación de la distancia a la fuente de luz correcta, lo cual es poco apropiado para ser medido desde un robot real. Es por ello que en esta tesis se consideró como medida del desempeño del robot a la misma que se utilizó para fototaxis simple (Ecuación 9). Se utilizó un controlador del tipo HPNN para realizar la tarea de fototaxis condicional dado que se buscó probar si un controlador plástico puede adaptarse a una actividad como la señalada, mediante adaptaciones a escala de vida del controlador. Además, y en base a la literatura disponible, no se pudo observar que esto se realizara con dicho tipo de controlador, pero sí con controladores del tipo FFNN. El mapeo entre sensores y entradas de la red, fue el siguiente: Entrada Sensor V0 V1 V2 V3 V4 V5 V6 V7 V8 0 prom(SL0(3), SL0(4)) prom(SL1(3), SL1(4)) prom(SL0(2), SL0(3)) prom(SL1(2), SL1(3)) prom(SL0(1), SL0(2)) prom(SL1(1), SL1(2)) variable condicional 0 Tabla 20 – Mapeo sensor-entrada de la red utilizada para los experimentos con fototaxis condicional, siendo SLj(i) la especificación de un sensor infra-rojo vinculado al i-ésimo sensor del robot relativo a la jésima fuente. Prom es un indicador del promedio de los valores sensados. Resultados Experimentales 81 (b) (a) Figura 48 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de fototaxis condicional obtenida en el séptimo test del mejor controlador (300 generaciones). (a) (b) (c) Figura 49 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de fototaxis condicional obtenidas para el mejor controlador (300 generaciones); (a) El tercer, (b) sexto, y (c) séptimo test. Figura 50 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en fototaxis condicional. 82 Resultados Experimentales Luego de realizar el experimento con fototaxis condicional, se obtuvieron los siguientes resultados: HPNN Mejor Fitness Prom. Fitness Promedio Peor Fitness Prom. Tiempo Porcentaje de Éxito Estabilidad 0.2285 0.1439 0.0244 57’ 10’’ 9/10 65 Tabla 21 – Resultados promedios de la evolución de los neuro-controladores implementados para fototaxis condicional sobre el total de las generaciones (300 generaciones y 10 corridas). Cabe aclarar que como variable condicional (o variable que determina cuál va a ser el valor de la entrada vinculado al objetivo correcto), se probaron varias alternativas. Las principales fueron: (a) especificar que en el 50% de los casos se asocie como objetivo una determinada fuente de luz; (b) asociar a la variable condicional una función aleatoria que establezca que el 75% de las veces el robot deba ir a una fuente de luz, y el 25% restante a la otra fuente. Cabe aclarar que dichos porcentajes fueron establecidos durante el proceso evolutivo. Para el primer caso, (a) se obtuvo que cuando se evalúa el desempeño del controlador final y se setea que el objetivo correcto sea una fuente de luz específica, el robot no adapta su comportamiento durante su vida al objetivo prefijado. Con ello se trata de expresar que el controlador aún queda fuertemente ligado a lo que la evolución determinó: ajuste de los parámetros evolutivos para alcanzar cada objetivo el 50% de las veces. Por el contrario, con el caso (b) se encontró que el agente confluía al objetivo correcto cuando éste era favorecido con el 75% de las veces durante la evolución. Cabe mencionar que cada vez que el robot alcanza una fuente de luz, éstas se vuelven a reubicar aleatoriamente, y el proceso de búsqueda de objetivo vuelve a repetirse, como puede observarse en la Figura 49. Por lo tanto, en pocas palabras puede decirse que los intentos de adaptación mediante Reglas de Hebb con la configuración de red HPNN señalada, no fueron suficientes para que el robot adapte la morfología de su controlador a una situación en particular de búsqueda de objetivo, opuesta a la predefinida en el proceso evolutivo. Con ello se requiere expresar que según los experimentos realizados, el proceso adaptativo en la vida del controlador influye en menor grado que lo que genera el proceso evolutivo artificial. Esto parece lógico de concluir si se considera que se realizó un número mucho mayor de generaciones contra un único proceso de evaluación durante la vida del controlador. Pese a ello, y dado que las adaptaciones durante la vida del controlador deben influir de manera rápida en el comportamiento del controlador, se encontró que su influencia es relativamente débil sobre la adaptación generacional. Además, debe mencionarse que lo antes dicho ocurrió con la configuración experimental planteada, lo cual puede no ocurrir cuando se varían parámetros tales como el intervalo mínimo de simulación (Ecuación 3) en futuras evaluaciones. La Figura 48.a, vinculada a la activación de los nodos, muestra que cada nodo genera un comportamiento oscilante. Pese a ello, fue posible observar que el robot se comportó adecuadamente (véase Figura 49), con lo cual puede decirse que se generaron compensaciones internas a tales variaciones en las activaciones neuronales. Un ejemplo de ello puede verse en el grado de simetría de las oscilaciones entre los nodos motores. Por otro lado, en la Figura 50 relacionada con la evolución del fitness, existen valores negativos cercanos a cero. Esto se debe a que el robot, durante el proceso evolutivo, alcanzó objetivos inapropiados, lo cual generó una medida de fitness negativa. Finalmente, en la Figura 49 es posible observar que la trayectoria del robot fue poco rectilínea, lo cual fue apropiado para el problema analizado. Esto se debe a que aleatoriamente se ubicaron nuevos objetivos cada vez que se alcanzó uno previamente. Por lo tanto, puede concluirse que una HPNN para fototaxis condicional generó un comportamiento aceptable. Resultados Experimentales 5.3.2 83 Evasión de Obstáculos En esta sección se hablará de evasión de obstáculos sin objetivo. Navegación con obstáculos es una tarea clásica y aparece en la mayoría de los experimentos de los investigadores que trabajan en robótica móvil. En la mayoría de los casos, es necesario especificar cuestiones tales como el análisis de los sensores, características de los motores, disposiciones sobre la movilidad del robot, parámetros del controlador, y la velocidad del robot al momento de proponer un modelo simple del agente para una tarea como evasión de obstáculos [Nolfi et al., 2000]. Más aún, con la consideración de un enfoque evolutivo para la generación de controladores de manera automática, se pretende buscar una solución para la navegación y la evasión de obstáculos sin asumir ningún conocimiento previo sobre los sensores, motores, o del entorno que influya en las decisiones del controlador. El objetivo de la presente sección, al igual que en varios de los trabajos encontrados en la literatura, fue generar mediante evolución un sistema de control capaz de maximizar el movimiento hacia delante mientras se realiza la evasión de obstáculos. La definición de la función de fitness Φ 2 está basada en tres variables directamente cuantificables sobre el robot, según lo especificado en [Nolfi et al., 2000, Cap. 4]: ( ) Φ 2 = z ⋅ 1 − ∆z ⋅ (1 − j) (Ecuación 10) donde z es el valor de la diferencia entre la activación de los nodos motores m1 y m2 (véase Figura 20), representando el ángulo de desviación del robot en radianes (-2 ≤ z ≤ 2); ∆z es el valor absoluto de la diferencia algebraica de las activaciones de los nodos motores m1 y m2, maximizando su valor cuando ambos actuadores proporcionan igual dirección y magnitud. Con la raíz cuadrada ∆z se da mayor importancia a pequeñas diferencias de las velocidades de los nodos motores; (1-j) es la diferencia entre el máximo valor de activación (1) y el máximo valor sensado (sensores infra-rojos de proximidad). Esta función es evaluada y sumada para cada ciclo de ejecución y luego es dividida por el total de iteraciones durante la evaluación del robot. Cabe aclarar, que en la función no se dice nada acerca de cual es la dirección a la que el robot debe moverse. A lo largo de esta sección, se expondrá que evasión de obstáculos, cuando es generada mediante evolución, en pocas generaciones pued e alcanzar un valor de fitness elevado. Si bien los controladores utilizados fueron los mismos que para fototaxis, no es posible decir que la diferencia entre los niveles de fitness se deba a una variación morfológica de un mismo tipo de controlador en fototaxis y en evasión de obstáculos. En cambio, y como conclusión que se desprende a partir de los experimentos realizados, es posible sugerir que la diferencia en el desempeño entre los comportamientos de fototaxis y evasión de obstáculos obedece a dos factores. Primero, y el más significativo, es la definición de la función de fitness, la cual puede ser más apropiada para el problema de evasión de obstáculos que aquella propuesta para el problema de fototaxis. Segundo, probablemente, la diferencia entre el desempeño de ambos comportamientos esté relacionado a la generación de mutaciones más apropiadas para uno que para otro comportamiento. Aunque el indicador de fitness crece durante generaciones tempranas en todas las pruebas (luego de lo cual se mantiene estable), cerca de la mitad del proceso evolutivo el mejor individuo comienza a exhibir una navegación armoniosa en el entorno sin chocarse contra los muros. En casi todos los controladores, es importante decir que el fitness máximo pudo ser obtenido sólo cuando el robot se mueve en línea recta en un espacio abierto. Al final de esta sección, se presenta el efecto combinado del comportamiento de fototaxis y evasión de obstáculos mostrando la evolución obtenida del fitness (sección 5.3.2.6). Cabe aclarar que la búsqueda de la funcionalidad deseada para el agente generada por la evolución artificial es más compleja, debido a que involucra parámetros del sistema de control que genera la velocidad apropiada, como así también los vinculados al control de evasión y aproximación al objetivo. 84 Resultados Experimentales El mapeo entre sensores y entradas de la red, fue el siguiente: Entrada Sensor V0 V1 V2 V3 V4 V5 V6 V7 V8 0 SO (1) SO (2) SO (3) SO (4) SO (5) SO (6) SO (7) SO (8) Tabla 22 – Mapeo sensor-entrada de la red utilizada para los experimentos con evasión de obstáculos, siendo SO(i) la especificación de un sensor de proximidad vinculado al i-ésimo sensor del robot. 5.3.2.1 Experimentos con FFNN Al realizar un análisis de los resultados experimentales obtenidos, es posible decir que corresponde a un controlador simple de evolucionar, tanto a escala temporal como así también a lo relativo con el desempeño final alcanzado en cuanto a la evasión de obstáculos se refiere. La Figura 52 muestra algunos ejemplos de trayectorias seguidas en evasión de obstáculos. Según la estrategia de movimientos planteada por el controlador FFNN, se pudo apreciar que fue constante y consistente, lo cual puede verse en lo relativo a la armoniosa actividad de las neuronas. Si bien existen oscilaciones iniciales, éstas no se vinculan a la inestabilidad del controlador, pero sí al sensado del entorno (véase Figura 51.b). Una característica interesante de mencionar es que existen secuencias de movimientos rectilíneas sólo alteradas por la presencia de obstáculos. En relación a esto, la función de fitness se refiere a maximizar la distancia recorrida por el robot. Por otro lado, según se muestra en la Figura 51.a, los nodos presentan un comportamiento similar entre sí pero difieren en el signo. Nuevamente, se señala que ésto depende de la magnitud y el signo de los pesos encontrados genéticamente. Resultados Experimentales 85 (b) (a) Figura 51 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red FFNN durante la tarea de evasión de obstáculos obtenida en el décimo test del mejor controlador (300 generaciones). (a) (b) (c) Figura 52 – Ejemplos de trayectorias seguidas por el robot simulado para una red FFNN durante la tarea de evasión de obstáculos obtenidas para el mejor controlador (300 generaciones); (a) El cuarto, (b) sexto test, y (c) décimo test. Figura 53 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en evasión de obstáculos. 86 Resultados Experimentales En la Figura 53, existe un número de generaciones iniciales (antes de la generación 20) dentro del cual el agente alcanza a adaptarse (generacionalmente) a la acción de evasión de obstáculos de manera temprana, lo cual produce un patrón estable de fitness máximo. Como es posible apreciar, existen grandes variaciones del peor fitness. Probablemente, esto esté relacionado con mutaciones acontecidas durante cada generación, las cuales no fueron apropiadas en relación con la medida del desempeño del agente según la tarea a resolver. 5.3.2.2 Experimentos con RFFNN En cuanto a la estrategia presentada por el controlador RFFNN, y de igual forma que ocurrió en fototaxis, ésta no varió significativamente de aquella obtenida con FFNN, aunque su medida de fitness fue levemente menor (véase Tabla 17). Un punto a destacar es que a diferencia de la FFNN, debido a la recurrencia de su morfología, existen períodos de oscilación neuronal sin que existan mediciones sensoriales que las causen. En pocas palabras, en las RFFNN dada la incidencia de entradas exitatorias del ambiente, éstas se prolongan en la actividad de las neuronas luego que desaparezcan tales entradas, lo cual no puede observarse en las FFNN (véase Figura 54) en el rango temporal 70-80. (b) (a) Figura 54 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red RFFNN durante la tarea de evasión de obstáculos obtenida en el noveno test del mejor controlador (300 generaciones). (a) (b) (c) Figura 55 – Ejemplos de trayect orias seguidas por el robot simulado para una red RFFNN durante la tarea de fototaxis obtenidas para el mejor controlador (300 generaciones); (a) El tercer, (b) noveno, y (c) décimo test. Resultados Experimentales 87 Figura 56 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo RFFNN en evasión de obstáculos. En relación a la gráfica del fitness anterior, se aprecia que es similar a la presentada por FFNN, con lo cual se concluyen idénticos resultados señalados en la sección 5.3.2.1. No obstante, existe una leve tendencia a producirse algunas variaciones que generan pequeños saltos (aproximadamente en la generación 20). Esto puede estar causado por procesos mutacionales no adecuados con la evolución. Pese a ello, existe una tendencia positiva a la estabilidad generacional. 5.3.2.3 Experimentos con CTRNN Una de las características peculiares de las CTRNN al momento de realizar la tarea de evasión de obstáculos, es que no es simple de generar un comportamiento apropiado. Frecuentemente, si bien en todos los experimentos realizados con otros tipos de controladores es posible obtener comportamientos tal que un robot no salga de situaciones de encierro (véase Figura 58.c), con una configuración CTRNN éstas situaciones fueron más factibles de encontrar. Es posible decir que el controlador CTRNN desarrollado utiliza constantes temporales no apropiadas, lo cual produce que en determinadas oportunidades tales parámetros no sean los óptimos para el problema a afrontar. Esto particularmente ocurrió con este tipo de controlador, dado que posee un número significativamente alto de parámetros libres a ser determinados genéticamente. En principio, ésto puede ser solucionado mediante un proceso evolutivo con un número mayor de generaciones. 88 Resultados Experimentales (a) (b) Figura 57 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red CTRNN durante la tarea de evasión de obstáculos obtenida en el séptimo test del mejor controlador (300 generaciones). (a) (b) (c) Figura 58 – Ejemplos de trayectorias seguidas por el robot simulado para una red CTRNN durante la tarea de evasión de obstáculos para el mejor controlador (300 generaciones); (a) El primer, (b) séptimo, y (c) octavo test. Figura 59 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo CTRNN en evasión de obstáculos. Resultados Experimentales 89 Como es mostrado en la Tabla 17, el desempeño del controlador no fue el mejor, tanto a escala temporal como así también en cuanto a su desempeño. Según se muestra en la evolución del fitness, éste es bajo en relación a los controladores previamente analizados, generándose además medidas del desempeño del robot negativas. Esto se debe a la compleja dinámica interna del controlador y a los parámetros sujetos a evolución. 5.3.2.4 Experimentos con PNN El comportamiento de un controlador tipo PNN para evasión de obstáculos resultó ser poco apropiado. La Figura 61 muestra algunas de las trayectorias generadas durante la evaluación del controlador. A pesar de que el valor de fitness fue considerablemente alto, el desempeño fue malo, tal como se puede ver en las figuras. Al igual que en fototaxis, los valores de las actividades de los nodos casi todo el tiempo fueron cercanos a cero (Figura 60.a) en función a los valores sensados (Figura 60.b). Con esto se concluye que las reglas de aprendizaje poseen poca incidencia en la adaptación del controlador. Tal como se puede ver en la Figura 61.b, se puede percibir que un comportamiento errático fue frecuente en este tipo de control, probablemente debido a la configuración de valores de los parámetros genéticos y a la influencia de las variaciones plásticas, las cuales en la mayoría de los casos generan alteraciones no deseables (p. ej. véase en Figura 60.a el rango temporal 50-70 del nodo 1). (a) (b) Figura 60 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red PNN durante la tarea de evasión de obstáculos obtenida en el noveno test del mejor controlador (300 generaciones). 90 Resultados Experimentales (a) (b) (c) Figura 61 – Ejemplos de trayectorias seguidas por el robot simulado para una red PNN durante la tarea de evasión de obstáculos obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) cuarto, y (c) noveno test. Figura 62 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo PNN en evasión de obstáculos. La Figura 62 señala que el desempeño del agente se eleva rápidamente al inicio y permanece estable pero con una leve tendencia a crecer. Una posible mejora sobre esta red en evasión de obstáculos, puede estar orientada a buscar un mayor grado de adecuación de los pesos sinápticos mediante reglas plásticas por medio de la modificación de los parámetros implicados, p. ej. la tasa de cambio plástico (sección 4.2.4.4). Con ello se buscaría que el controlador se adecue, en mayor medida, al entorno, lo cual se vería reflejado en la actividad neuronal obtenida (véase Figura 60.a). 5.3.2.5 Experimentos con HPNN Una red del tipo HPNN generó un comportamiento similar al de las PNN, en cuanto a la actividad de las neuronas, pero con trayectorias acordes al problema de evasión de obstáculos. Un punto a diferenciar es que las oscilaciones en las actividades en los nodos fueron relativamente más tenues que aquellas presentadas por la PNN, y en especial con mayor amplitud. Resultados Experimentales 91 (b) (a) Figura 63 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de evasión de obstáculos obtenida en el sexto test del mejor controlador (300 generaciones). (a) (b) (c) Figura 64 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de evasión de obstáculos obtenidas para el mejor controlador (300 generaciones); (a) El cuarto, (b) sexto, y (c) noveno test. Figura 65 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en evasión de obstáculos. 92 Resultados Experimentales Como observación de la estrategia planteada por este tipo de controlador, es posible decir que genera un comportamiento apropiado. Pese a ello, demoró un tiempo considerablemente mayor que la propuesta planteada por FFNN y con un menor valor de fitness promedio. Por lo tanto, y debido a la naturaleza del problema de evasión de obstáculos, el cual es un problema puramente reactivo, no se aprecia gran utilidad de contar con reglas plásticas de adaptación tal como con la configuración planteada. No obstante, puede ser de utilidad analizar distintas configuraciones plásticas-homeostáticas para concluir en mayor detalle tal incidencia. 5.3.2.6 Evasión de Obstáculos con Objetivo: Navegación Como es de esperar, el problema de navegación presupone tener una meta a ser alcanzada por el robot. Tal problema es desarrollado extensamente en la bibliografía con controladores del tipo FFNN, RFFNN, y CTRNN. De acuerdo a la literatura disponible, pocos son los trabajos que presentan resultados con controladores plásticos y más aún con HPNN asociados a navegación. En esta sección, si bien se encontró que un desempeño conveniente de evasión de obstáculos es generado con FFNN, se analiza qué ocurre con un controlador HPNN al momento de resolver el problema de navegación. Inspirado en diferentes trabajos descritos en la sección 3.2.3 y en [Nolfi et al., 2000, Cap. 4], se propone analizar en esta sección la aproximación de un robot a una determinada fuente de luz en un entorno cerrado pequeño25 evadiendo obstáculos. Esto significa que existe una parte del comportamiento final del robot la cual está asociada a la detección del objeto y otra vinculada a evadir obstáculos. Dicho problema es poco predecible si lo comparamos con evasión de obstáculos (puramente reactivo), dada la combinación de sub-comportamientos dentro del mismo controlador. No obstante, es posible llevarlo a cabo de manera reactiva con un resultado satisfactorio. La medida de fitness utilizada corresponde a la señalada para fototaxis (Ecuación 9). La manera en que los comportamientos son coordinados autónomamente dadas las actividades de los sensores de obstáculos o de luz es la siguiente. Al momento de ser detectado un obstáculo en la cercanía del robot (esto dependiendo del valor de salida de la red de evasión de obstáculos), la sub-red de evasión toma el control sobre los actuadores. En otro caso, la sub-red de fototaxis es la encargada de controlar al robot hacia el objetivo. Un punto importante de mencionar es que tanto la coordinación de los comportamientos, como así también la especificación de ambos comportamientos a través de sus sub-redes neuronales, estuvieron dentro de un único controlador. 25 Se redujo el tamaño del entorno para poder apreciar en mayor medida lo que ocurre en relación a la tarea a realizar, sin que se produzcan demoras debido a la distancia a recorrer por el robot. Resultados Experimentales 93 El mapeo entre sensores y entradas de la red, fue el siguiente: Entrada Sensor V0 V1 V2 V3 V4 V5 V6 V7 V8 0 SL0 (2) SO (2) 0 prom(SO (3), SO (4)) SL0 (5) SO (5) SL0 (3) SL0 (4) Tabla 23 – Mapeo sensor-entrada de la red utilizada para los experimentos con navegación, siendo SLj(i) y SO(h) la especificación de un sensor infra-rojo receptor (sensor lumínico) vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente, y al sensor de proximidad según el h-ésimo sensor del robot, respectivamente. (a) (b) Figura 66 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de fototaxis con evasión de obstáculos (navegación) obtenida en el sexto test del mejor controlador (50 generaciones). 94 Resultados Experimentales (a) (b) (c) Figura 67 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de fototaxis con evasión de obstáculos (navegación) obtenidas para el mejor controlador (50 generaciones); (a) El tercer, (b) sexto, y (c) décimo test. Figura 68 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en evasión de obstáculos con objetivo (navegación). Luego de realizar el experimento propuesto se obtuvieron los siguientes resultados: HPNN Mejor Fitness Prom. Fitness Promedio Peor Fitness Prom. Tiempo Porcentaje de Éxito Estabilidad 0.6104 0.3983 0.1299 5’ 51’’ 9/10 28 Tabla 24 – Resultados promedios de la evolución de los neuro-controladores implementados para navegación sobre el total de las generaciones (50 generaciones y 10 corridas). Un punto importante de destacar es que la experimentación se realizó sobre 50 generaciones. Esto se debe a que no fue necesario un número mayor de generaciones para obtener un desempeño aceptable. A lo largo del proceso evolutivo el objetivo se mantuvo fijo, especificándose como una fuente de luz en particular. Luego, durante la vida del controlador, el objetivo perseguido por el robot fue el mismo que para el proceso antes mencionado. Como se puede ver en la Figura 68, el desempeño del controlador alcanza aprox. en la generación 28 el valor máximo promedio por primera vez, mientras que para dicha generación en la Figura 65 (HPNN en evasión de obstáculos) se obtiene un valor mucho mayor, pero con un valor similar cuando se evaluó en fototaxis simple (Figura 47). Esto señala que fototaxis influye en mayor medida en el problema de Resultados Experimentales 95 navegación que lo propio por evasión de obstáculos, ratificándose que el problema de ir hacia el objetivo es un problema más difícil de evolucionar que uno puramente reactivo como es evasión de obstáculos. Nótese que existe una escalada incremental en el fitness (Figura 68) similar a la presentada por fototaxis simple (Figura 47). En cuanto a la actividad de los nodos (Figura 66.a), éstos se comportaron de manera semejante a lo mostrado por la Figura 63.a relacionada a HPNN con evasión de obstáculos, pero con mayor permanencia en valores próximos a cero debido a los sensores de luz, lo cual es propio del problema de fototaxis. Con respecto a cada uno de los comportamientos individuales, se concluye que ellos se comportaron tal como se señaló en las secciones 5.3.2.5 y 5.3.1.5. En relación al desempeño de ambos comportamientos en navegación, es posible decir que el comportamiento conjunto se realizó de manera apropiada, tal como se muestra en la Figura 67. 5.3.3 Aprendizaje Como se describió en la sección 2.7.4, evolución y aprendizaje son dos formas de adaptación biológica que difieren en espacio y tiempo. Evolución es un proceso de reproducción selectiva y sustitución basada en la existencia de algunas variaciones. Por el contrario, aprendizaje es un conjunto de modificaciones generadas dentro de cada individuo durante su propia vida. Varios son los intentos de definir experimentalmente el problema de aprendizaje con robots. A modo general, la configuración utilizada a lo largo de esta sección está basada en los trabajos presentados en la sección 3.2.3 y en [Nolfi et al., 2000]. En términos generales, la experimentación con cada controlador obedece a la evaluación de cada individuo en cuanto a alcanzar un objetivo. Este problema, si bien es predecible considerando el comportamiento final del robot, reviste de interés en observar qué ocurre cuando se lo combina con la técnica de Aprendizaje por Refuerzos [Arkin, 1998]. El aprendizaje propuesto en esta sección tiene por objetivo que el robot sea capaz de alcanzar una de dos posibles posiciones en varias oportunidades (especificadas por distintas fuentes de luz). Con ello, la determinación de cuál es el objetivo apropiado es decidido explícitamente durante el proceso evolutivo. Cada vez que el robot alcance alguna fuente de luz correcta, éstas se re-ubican en forma aleatoria para que la búsqueda continúe. Durante este ciclo, cada vez que el robot alcanza la posición final, es premiado con un valor positivo de entrada el cual es ingresado a la red por una entrada adicional. Por el contrario, cuando es alcanzada una fuente de luz que no es la apropiada, en tal entrada adicional se ingresa un valor negativo, mientras que en el caso que no ocurra algo de lo anterior, la entrada permanece nula. A continuación se presenta el criterio de ponderación seleccionado para llevar a cabo el aprendizaje por refuerzos (ϕ): δ ϕ = − δ si el objetivo alcanzado es correcto si el objetivo alcanzado es incorrecto 0 (Ecuación 11) otro donde δ es un valor predefinido, siendo 1 para el experimento propuesto. Al momento de evaluar el comportamiento del mejor controlador, el proceso de especificación del objetivo es el mismo que el acontecido durante la evolución. Así, se buscó el análisis de aprendizaje a fin de generar mediante evolución un sistema capaz de maximizar el número de veces que el robot alcanza el objetivo correcto en un entorno libre de obstáculos. Cabe aclarar que la definición del fitness está basada en la propuesta de Togelius (sección 3.2.3), pero se incorporaron modificaciones a la misma: 96 Resultados Experimentales n=200 n=200 ∑ ϕi si ∑ ϕi ≥ 1 i =0 Φ 3 = i =0 max (V f ) otro caso (Ecuación 12) donde Vf se refiere al valor sensado por el f-ésimo sensor (1 ≤ f ≤ 8). Esta función es evaluada y sumada para cada ciclo de ejecución. Cabe destacar que los componentes de la Ecuación 12 no expresan cuál es la dirección a la que el robot debe moverse y los mismos pueden ser cuantificables en un robot real. El mapeo entre sensores y entradas de la red, fue el siguiente: Entrada Sensor V0 V1 V2 V3 V4 V5 V6 V7 V8 refuerzo ϕ prom(SL0(3), SL0(4)) prom(SL1(3), SL1(4)) prom(SL0(2), SL0(3)) prom(SL1(2), SL1(3)) prom(SL0(4), SL0(5)) prom(SL1(4), SL1(5)) alcanzó objetivo 0 à 1 alcanzó objetivo 1 à 1 Tabla 25 – Mapeo sensor-entrada de la red utilizada para los experimentos con aprendizaje, siendo SLj(i) la especificación de un sensor infra-rojo vinculado al i-ésimo sensor del robot relativo a la j-ésima fuente. Prom es un indicador del promedio de los valores sensados. Con respecto al comportamiento en aprendizaje, son necesarias señales adicionales para llevar a cabo dicho comportamiento (Tabla 25). Las señales en cuestión corresponden a una por cada tipo de objetivo que indiquen cuando el robot se encuentra en una determinada fuente de luz, junto con una señal de estímulo (refuerzo) que es positiva únicamente cuando el robot alcanza la fuente deseada, negativa si alcanza una fuente no deseada y un valor neutro en otro caso. Adem ás, cabe mencionar que la designación de cuál es la fuente de luz a ser buscada cambia de prueba en prueba aleatoriamente. 5.3.3.1 Experimentos con FFNN El desempeño de los experimentos con este tipo de controlador arrojó ser positivo (Tabla 18). En mayor medida a lo esperado, la manera en que el robot presentó sus movimientos para alcanzar el objetivo fue correcta, siendo esta constante y consistente al igual que rápida, tal como lo muestra la línea levemente continua en la Figura 70. Una característica importante de señalar es que la aproximación del robot al objetivo no es plenamente rectilínea. Esto es a causa de que la selección evolutiva especifica la manera en que el robot debe desplazarse, sin que ninguna determinación previa por parte del programador condicione la obtención de los resultados según a cómo aproximarse al objetivo. En cuanto a esto, la medida del desempeño está relacionada a maximizar el número de veces en que el robot alcanza el máximo de puntuación, dándose sólo cuando mayor sea la cantidad de veces que se aproxime a la fuente de luz correcta. Resultados Experimentales 97 (b) (a) Figura 69 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red FFNN durante la tarea de aprendizaje obtenida en el segundo test del mejor controlador (300 generaciones). (a) (b) (c) Figura 70 – Ejemplos de trayectorias seguidas por el robot simulado para una red FFNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones); (a) El segundo, (b) tercer, y (c) séptimo test. Figura 71 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en aprendizaje. 98 Resultados Experimentales Los nodos presentan un comportamiento similar entre sí con oscilaciones propias del sensado del entorno. En cuanto a la Figura 71 relativa al fitness, ésta posee una tendencia creciente a medida que transcurren las generaciones, lo cual señala que existe una mejora generacional. Nótese, además, que prácticamente al inicio del proceso la puntuación de la función de fitness es alta. De esta manera, considerando los resultados de la Tabla 18, existe una buena adecuación de la red para resolver la tarea señalada. En particular, esto puede relacionarse a que el controlador FFNN posee una configuración fácil de evolucionar, y por ende de encontrar combinaciones apropiadas de valores de variables sujetas al proceso evolutivo. 5.3.3.2 Experimentos con RFFNN A diferencia con el controlador FFNN, la estrategia planteada por RFFNN fue menos eficiente con respecto a la trayectoria recorrida, no así al número promedio de veces que alcanzó el objetivo correcto (véase Tabla 18). Como puede observarse en la Figura 73, el controlador generó rotaciones del robot (manifestadas como pequeños círculos en el gráfico), principalmente cuando era necesario cambiar de dirección. Muchas veces esto fue una estrategia apropiada dado que requería poco tiempo de variación de dirección hacia la nueva posición objetivo. No obstante, en algunas oportunidades esto era generado sin causas aparentes. Probablemente, se debe a las conexiones recursivas en su topología, junto con la combinación de pesos sinápticos no apropiados, causa por la cual se generó tal comportamiento. (a) (b) Figura 72 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red RFFNN durante la tarea de aprendizaje obtenida en el séptimo test del mejor controlador (300 generaciones). Resultados Experimentales 99 (a) (b) (c) Figura 73 – Ejemplos de trayectorias seguidas por el robot simulado para una red RFFNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones); (a) El primer, (b) séptimo, y (c) noveno test. Figura 74 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo RFFNN en aprendizaje. Un punto significativo de señalar es la escalada de la función de fitness (Figura 74). A diferencia de la Figura 71 vinculada con FFNN, la cual muestra estabilidad en la tendencia del fitness, en RFFNN se ve que un número mayor de generaciones presenta un alto valor continuamente creciente. Una posible interpretación de esto, contemplando además que en la Tabla 18 la RFFNN fue la que mayor nivel de fitness presentó, puede estar referida a las combinaciones de pesos sinápticos (particularmente en la capa oculta de la red) que causaron los movimientos circulares mostrados en la Figura 73. En pocas palabras, la aparición de dichos movimientos fue beneficiosa, en alguna manera, al momento de sensar la posición del objetivo. En el caso de que tales movimientos no se hubiesen realizado, posiblemente no se habría alcanzado el objetivo dada la falta de sensado de la fuente. Por lo tanto, lo antes planteado puede reflejar que paulatinamente tal combinación de pesos perdure generacionalmente, alcanzando el controlador resp ectivo mayores niveles de fitness con el correr de las generaciones. Una posible solución al movimiento del robot puede estar orientada a la realización de pruebas con un número mayor de generaciones, o incorporando algún indicador que minimice el recorrido del robot dentro de la función de fitness. 5.3.3.3 Experimentos con CTRNN Si bien el desempeño del controlador CTRNN con una configuración de aprendizaje como la planteada, se asemeja en algún grado al presentado por RFFNN (respecto de giros bruscos), éste es muy diferente. Principalmente, se encontró la realización de un número mayor de acciones no justificadas, las cuales generaban pequeñas rotaciones (rulos) en la trayectoria hacia el objetivo (Figura 76). Además, estas trayectorias se llevaron a cabo de forma más pausada (baja movilidad del robot) en relación a otros controladores previamente vistos. 100 Resultados Experimentales (a) (b) Figura 75 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red CTRNN durante la tarea de aprendizaje obtenida en el cuarto test del mejor controlador (300 generaciones). (a) (b) (c) Figura 76 – Ejemplos de trayectorias seguidas por el robot simulado para una red CTRNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones); (a) El tercer, (b) cuarto, y (c) sexto test. Figura 77 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo CTRNN en aprendizaje. Resultados Experimentales 101 Un hecho curioso fue la tendencia del fitness (Figura 77). Como se puede ver en generaciones previas a 100, su tendencia fue negativa, mientras que luego ascendió muy lentamente. Posteriormente, se elevó de manera abrupta, muy probablemente a causa de mutaciones a favor de la medida del fitness propuesta. Particularmente, tal como se señaló para las RFFNN, el comportamiento de la función de fitness pudo deberse a combinaciones sinápticas no apropiadas durante el proceso evolutivo. Una diferencia en cuanto a las RFFNN puede verse en la Figura 75.a, asociada a variaciones menores de las actividades sinápticas respecto de su magnitud, mientras que para las RFFNN éstas fueron mayores. Nuevamente, se indica que posiblemente la combinación de influencias sinápticas no benefició el desempeño presentado por la CTRNN. Además, vale señalar que en su mayoría tales activaciones fueron abruptas y poco armoniosas, lo cual puede verse en las actividades de los nodos motores, explicando la falta de coordinación entre los actuadores a fin de generar movimientos hacia el objetivo. 5.3.3.4 Experimentos con PNN El comportamiento de la red PNN durante el proceso de aprendizaje generó altas velocidades del robot, lo cual permitió que sea alcanzado un número mayor de objetivos. La Figura 79 muestra con claridad cuáles fueron algunas de las trayectorias del controlador plástico, siendo éstas en su mayoría movimientos prácticamente rectilíneos. (a) (b) Figura 78 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red PNN durante la tarea de aprendizaje obtenida en el sexto test del mejor controlador (300 generaciones). 102 Resultados Experimentales (a) (b) (c) Figura 79 – Ejemplos de trayectorias seguidas por el robot simulado para una red PNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones). (a) El quinto, (b) sexto, y (c) noveno test. Figura 80 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo PNN en aprendizaje. En lo referido a la gráfica de la función de fitness (Figura 80), ésta presentó una escalada similar a la generada por RFFNN pero no tan marcada en lo que se refiere a la pendiente de crecimiento. Esto produjo que el valor de fitness promedio no fuera tan alto como para RFFNN. No obstante, el comportamiento final fue aceptable, posiblemente dado a algún tipo de adecuación neuronal combinada con reglas sinápticas apropiadas al final del proceso evolutivo. 5.3.3.5 Experimentos con HPNN Al observarse la estrategia de movimientos planteada por la red HPNN, es posible decir que si bien es altamente aceptable el comportamiento generado, presenta una serie de alteraciones que lo hacen muy particular. Básicamente, éstas se refieren a cambios de su trayectoria, tal como ocurre con RFFNN, manifestándose como movimientos circulares cerrados pero con un radio de giro mayor que para las RFFNN. Con ello, es posible decir que genera una combinación deseable de velocidades y cambios de dirección de forma rápida (véase Figura 82). Resultados Experimentales 103 (a) (b) Figura 81 – (a) Representación de las actividades de los nodos y (b) sensado del controlador para una red HPNN durante la tarea de aprendizaje obtenida en el cuarto test del mejor controlador (300 generaciones). (a) (b) (c) Figura 82 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de aprendizaje obtenidas para el mejor controlador (300 generaciones; (a) El cuarto, (b) quinto, y (c) sexto test. Figura 83 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje. 104 Resultados Experimentales En lo que respecta al fitness, éste es creciente y en las generaciones finales tiende a estabilizarse. Por lo tanto, es posible decir que el comportamiento final está mejor adaptado para la problemática estudiada que para otros controladores. Cabe señalar que en la Figura 82 sólo se señalan las posiciones finales de las fuentes de luz, mientras que aquellas fuentes previamente alcanzadas por el robot no son representadas. De este modo, sólo se grafica cuál fue la trayectoria del robot, siendo la misma apropiada en relación a la tarea a resolver. 5.3.3.6 Aprendizaje con Variaciones Deliberadas El mecanismo de aprendizaje empleado en [Hinton et al., 1987], está basado en una búsqueda aleatoria. Sin embargo, el aprendizaje biológico parece ser más direccional que aleatorio en cuanto a la variación sináptica (p. ej. aprendizaje Hebbiano) [Urzelai, 2000]. Una propuesta de combinar tal mecanismo direccional con evolución, presupone copiar en algún grado los cambios del entorno, los cuales ocurren más rápido que a nivel generacional. Uno de estos enfoques es el aprendizaje por refuerzo evolutivo. En [Ackley et al., 1990] se presenta un enfoque original combinando aprendizaje y evolución, capaz de extraer información del entorno para ser utilizada como supervisión del controlador. Según Ackley et al., la combinación de evolución y aprendizaje mejora el desempeño o comportamiento final del robot. Esto indica que durante las generaciones iniciales el controlador no es capaz de generar un comportamiento apropiado, pero una vez que éste aprenda tal habilidad utilizando una señal de refuerzo, mejora su desempeño con el tiempo. No obstante, en las generaciones finales la habilidad buscada está presente. Esto representa un claro ejemplo del Efecto Baldwin, dado que la habilidad adquirida mediante el aprendizaje durante la vida del controlador es gradualmente fijada en el genotipo. La red a ser utilizada en el experimento que se mostrará en esta sección, corresponde a una HPNN dado que sus características están vinculadas con el criterio adaptativo durante la vida del controlador antes señalado. Debido a su topología, se incorporaron dos nodos adicionales, los cuales proveen de entradas que indican si fue alcanzada una determinada fuente u objetivo. La activación de tales nodos adicionales (uno por cada objetivo posible para el experimento propuesto) puede tomar valores ±1. Adicionalmente, se incorpora un nodo que representa la señal de refuerzo (sección 5.3.3). Durante la evolución, dichos nodos pueden ser la causa de una mayor inestabilidad. No obstante, la evolución pudo siempre seleccionar reglas para minimizar el grado de conexión de dicho nodo adicional en relación a otros nodos. Esto ocurre cuando la señal de refuerzo lo establezca mediante una señal negativa. Las conexiones desde tales nodos adicionales hacia otros nodos en la red, se especificó como se señala en la Tabla 25. La función de fitness de esta prueba corresponde a la señalada en la Ecuación 12. Como se expresa en [Urzelai, 2000], el aprendizaje por refuerzo evolutivo decide autónomamente “cuándo” y “qué” debe ser aprendido. Inspirado en el trabajo de Togelius (sección 3.2.3), en esta sección se presentan los resultados de incorporar aprendizaje evolutivo en el problema de discernir cuál es el objetivo apropiado. Cabe aclarar que en la bibliografía disponible no se observó que se realizara esto utilizando HPNN. Por lo tanto, dicho problema reviste de un alto grado de imprevisibilidad si lo comparamos con los experimentos anteriormente descritos. Pese a ello, es posible llevarlo a cabo de forma reactiva. En cuanto al mapeo sensor-entrada de la red, éste fue el mismo que el utilizado para aprendizaje (sección 5.3.3). Resultados Experimentales 105 (a) (b) Figura 84 – (a) Representación de las actividades de los nodos y (b) del sensado del controlador para una red HPNN durante la tarea de aprendizaje con variaciones deliberadas obtenida en el sexto test del mejor controlador (1000 iteraciones). (a) (b) (c) Figura 85 – Ejemplos de trayectorias seguidas por el robot simulado para una red HPNN durante la tarea de aprendizaje con variaciones deliberadas obtenidas para el mejor controlador (1000 iteraciones); (a) El sexto, (b) séptimo, y (c) noveno test. Figura 86 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje con variaciones deliberadas. 106 Resultados Experimentales Luego de realizar el experimento con fototaxis condicional, se obtuvieron los siguientes resultados: HPNN Mejor Fitness Prom. Fitness Promedio Peor Fitness Prom. Tiempo Porcentaje de Éxito Estabilidad 5.3715 2.6261 0.3776 4hs. 28’ 36’’ 10/10 250 Tabla 26 – Resultados promedios de la evolución de los neuro-controladores HPNN implementados para aprendizaje con variaciones deliberadas sobre el total de las generaciones (300 generaciones, 1000 iteraciones y 10 corridas). Como variable condicional (o variable que determina cuál va a ser el valor de entrada que indica el objetivo correcto), se utilizó una configuración similar a la descrita en fototaxis condicional (sección 5.3.1.6). Por otro lado, un número mayor de iteraciones fue utilizado con el propósito de observar cómo influye el aprendizaje por refuerzos a un nivel generacional, de manera más amplia al visto en otros experimentos. En forma breve, se señalará a continuación algunos de los resultados encontrados al variar de tipo de controlador, así como también en el porcentaje de veces que se especifica cuál va a ser el objetivo a ser alcanzado por el robot. • HPNN: 100% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: predominó un comportamiento hacia el objetivo 0, influido por lo generado durante la evolución. • HPNN: 75% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: predominó un comportamiento hacia el objetivo 0, influido por lo generado durante la evolución. • HPNN: 50% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: predominó un comportamiento hacia el objetivo 0, influido por lo generado durante la evolución. Luego de que varias veces sea alcanzado algún objetivo, comienza un comportamiento errático seguido de giros abruptos en el lugar. Probablemente, esto esté generado por variaciones sinápticas que afectaron la dinámica interna del controlador. • CTRNN: 50% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: comportamiento aceptable, pero no suficiente en comparación con RFFNN. Probablemente, los parámetros evolutivos carecieron del suficiente ajustarse al problema. • PNN: 50% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: generó un comportamiento poco aceptable en comparación con el propio para HPNN, particularmente al final de cada prueba realizada. Al principio el robot se aproximó mayoritariamente a la fuente correcta. Luego se presentaron comportamientos erráticos y oscilaciones. • RFFNN: 50% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: altamente aceptable con un 98% de éxito. Esto se debió a que la evolución generó algún tipo de especialización del controlador en cuanto a los parámetros evolutivos de la red. Resultados Experimentales • 107 FFNN: 50% de selección de la variable condicional al objetivo 0 durante evolución, y 100% de selección del objetivo 1 durante la vida del controlador. Resultado: comportamiento aceptable, pero el porcentaje de éxito en alcanzar el objetivo correcto fue el 50%. A lo largo del proceso evolutivo, utilizando una configuración de controlador homeostático como la señalada en una proporción 75% durante la evolución y 100% al objetivo primario durante las pruebas, se obtuvieron los resultados mostrados en la Tabla 26. El desempeño del controlador fue altamente satisfactorio, tal como se puede ver en la Figura 86. Nótese el incremento del desempeño de los controladores durante el proceso evolutivo a partir de la generación 200. En cuanto a la actividad de los nodos, estos se comportaron de manera semejante a la mostrada para HPNN en aprendizaje (sección 5.3.3.5). Por otro lado, el desempeño final del robot produjo una combinación altamente interesante: movimientos rápidos junto con movimientos paulatinos. Cuando el robot podía sensar el objetivo, se generaban en los actuadores las acciones correctas de aproximación, junto con una elevada velocidad. Por el contrario, cuando no era posible sensar el objetivo, el movimiento era más lento pero preciso. Un hecho que remarca la efectividad del controlador fue la forma en que era realizada la evasión del objetivo secundario (o fuente de luz que no debía de ser alcanzada). Un ejemplo de ésto se muestra en la Figura 87, dónde el robot evade una fuente de luz y se dirige a la apropiada. Figura 87 – Ejemplo de los movimientos obtenidos por un controlador HPNN durante pruebas con aprendizaje con variaciones deliberadas Como conclusión, es posible afirmar que la incidencia de aprendizaje por refuerzos en la evolución, combinado con un proceso adaptativo en la vida del controlador, es altamente efectivo en cuanto al comportamiento final buscado, no así en cuanto al cambio pleno de objetivo durante la vida del controlador en relación al propuesto durante el proceso evolutivo. Esta afirmación está basada en los resultados experimentales obtenidos. 5.4 Conclusiones En este capítulo se mostró el proceso de desarrollo de controladores neuronales con evolución monolítica. Principalmente, se presentaron los resultados de cinco tipos de neuro-controladores diferenciados por las topologías de redes neuronales que implementan. Estos desarrollos comprenden la creación de nuevas y más fuertes, o débiles, conexiones entre los componentes (nodos) de la red neuronal del controlador. Esto puede ocurrir dependiendo del tipo de controlador creado, mediante adaptaciones a escala generacional o durante el tiempo de vida en el entorno. A medida que el desarrollo generacional progresa, las relaciones entre los componentes internos de los controladores se adecuan al comportamiento deseado, incrementando además la complejidad de sus patrones comportamentales en la mayoría de los casos. Tal especialización surge como consecuencia de reacciones a acciones en el entorno, tanto en el proceso generacional como durante el tiempo de vida del 108 Resultados Experimentales fenotipo. No obstante, y bajo un enfoque acotado, es posible decir que la especialización se observa principalmente debido al proceso generacional. En cuanto a la decisión de qué tipo de red neuronal es la apropiada para desarrollar las diferentes tareas (fototaxis, evasión de obstáculos y aprendizaje), y en relación a los resultados presentados en este capítulo, es posible decir lo siguiente. Los controladores que implementan redes del tipo FFNN presentaron un comportamiento altamente satisfactorio en la mayoría de los experimentos, principalmente aquellos de carácter reactivo. De igual manera, la configuración de controlador HPNN generó soluciones a las tareas planteadas válidas en la mayoría de las oportunidades. En lo relativo al resto de las configuraciones de redes, no se destaca ninguna característica que las distinga de ser seleccionadas para implementar el controlador final. Considerando la codificación de controladores genéticamente determinados (Tabla 12) al momento de resolver el problema de navegación simple, dicho tipo de neuro-controlador produce en pocas generaciones controladores levemente mejor adaptados que aquellos controladores de sinapsis adaptativas (Tabla 15), a pesar de la similitud del desempeño observado en las diferentes pruebas experimentales. Sin embargo, es válido señalar la necesidad de realizar un análisis más profundo respecto de la codificación de sinapsis adaptativas en comparación con las representaciones genéticamente determinadas. Esto se propone como trabajo futuro. En el capítulo siguiente se presentan los resultados experim entales obtenidos con la utilización de los controladores FFNN y HPNN generados en este capítulo, a fin de desarrollar un estudio sobre un entorno realista de simulación, para luego construir un neuro-controlador complejo de un robot real. Capítulo 6 - EVOLUCIÓN D E NEURO CONTROLADORES MÚLTI-NIVEL EVOLUCIÓN DE NEURO -CONTROLADORES MULTI-NIVEL "Si buscas resultados distintos, no hagas siempre lo mismo" Albert Einstein 6.1 Introducción En el capítulo anterior se describió y analizó la materialización de diferentes comportamientos mediante evolución simulada, con el objetivo de desarrollar neuro-controladores robóticos específicos. Tal estudio provee las bases y componentes de control que implementan las capacidades del controlador final descrito en este capítulo. En la mayoría de los entornos no conocidos, la navegación es llevada a cabo de manera plenamente reactiva (véase el trabajo descrito en la sección 3.2.6). Métodos clásicos como campos potenciales [Khatib, 1986] pueden ser usados, a pesar de que acarrean algunos inconvenientes, tales como problemas de mínimos locales y situaciones de bloqueo. Por otra parte, diferentes metodologías para la generación de controladores vinculados a navegación han sido abordadas en la literatura. Algunas de ellas están referidas al ajuste automático de coeficientes atractivos y repulsivos mediante reglas difusas [Maaref et al., 1996]. Tales metodologías presentan problemas de oscilaciones en entornos estrechos, lo cual representa una limitación en su utilización específica en robótica de entornos restringidos (indoor robotics y AUV en cañones submarinos). Mejoras en dichas metodologías fueron propuestas en la sección 3.2.6 por Maaref et al. sobre un sistema de inferencia difuso inspirado en el comportamiento humano. Principalmente, dicho trabajo aborda el problema de resolver situaciones conflictivas en la navegación de robots autónomos, como en el caso de obstáculos cóncavos y convexos. Por otro lado, desde un enfoque comportamental, el problema de navegación presupone la coordinación de módulos o comportamientos en forma individual o grupal, ante diferentes estrategias de navegación frente a diversos entornos u obstáculos. Como es de esperar, la idea que subyace en dicho problema es “anticipar situaciones” de bloqueo en vez de “descubrirlas y luego actuar” [Maaref et al., 2002]. Si bien tal problema no fue abordado en el presente trabajo, se prevén futuros desarrollos para dicho fin. Por otra parte, tal como se mencionó en capítulos anteriores, una forma de afrontar la creación y coordinación de comportamientos fue propuesta en la sección 3.2.3. Dicha propuesta se denomina Evolución por Niveles y combina características de la Arquitectura por Subsumisión (sección 2.6.1) conjuntamente con un proceso evolutivo artificial. La Evolución por Niveles es utilizada en el presente capítulo para construir un controlador jerárquico que resuelve la tarea de navegación en un entorno cerrado. Debido a lo reciente de dicha propuesta de obtención de controladores evolutivos, no se ha encontrado en la bibliografía disponible un estudio tal como se desarrolla aquí. El desempeño del controlador final es evaluado en función a los resultados mostrados en el Capítulo 5 sobre un simulador simple. Posteriormente, se presentan los resultados obtenidos al utilizar el controlador al momento de ser incorporado dentro de un simulador complejo, el cual tiene la propiedad de modelar el sistema de control de un robot real Khepera. Además, se realizan pruebas en un entorno real no conocido a 110 Evolución de Controladores Multi-Nivel priori. Cabe destacar que a lo largo de este capítulo se exponen diferentes situaciones a resolver en navegación autónoma, tal como fue abordada en el trabajo señalado en la sección 3.2.6. A continuación, se describe la organización del capítulo. En la sección 6.2, se postula el contexto en el que se sitúa la metodología utilizada para el desarrollo de un controlador por niveles. Particularmente, en la sección 6.2.2 se presenta cuál fue la estrategia de coordinación de comportamientos empleada. La sección 6.2.2 detalla las etapas del desarrollo del controlador por niveles. Luego, la sección 6.2.3 se exponen los resultados experimentales en simulación compleja, al momento de evaluar al controlador desarrollado. A continuación, en la misma sección se describen diferentes situaciones en navegación de entornos no conocidos utilizando un robot real. Las secciones 6.3 y 6.4 presentan diferentes implicaciones sobre los resultados obtenidos. Finalmente, la sección 6.5 expone las conclusiones del capítulo. 6.2 Experimentos con Evolución por Niveles Uno de los mayores desafíos que afronta la RE es generar mecanismos automáticos para obtener controladores adaptativos. Esto se refiere a escalabilidad. Como se mencionó anteriormente, escalabilidad hace referencia dentro del contexto planteado a obtener controladores robóticos que puedan resolver problemas complejos en entornos variables. Algunas de las propuestas planteadas en la bibliografía para resolver dichos problemas, presentan soluciones con algún grado de inconveniente en el desempeño final del controlador (véase sección 2.6.3). Seguidamente, las diferentes etapas desarrolladas con la Evolución por Niveles implementada son expuestas. 6.2.1 Coordinación de Niveles Comportamentales En cuanto a la conexión entre comportamientos, puede decirse que la configuración seleccionada es la mostrada en la Figura 88, existiendo tres niveles neuronales (sección 4.3). En el caso que el segundo nivel de evasión de obstáculos presente una salida de referencia Sr superior a un determinado valor b, la entrada vinculada a los actuadores corresponderá a dicho nivel (S obst). En otro caso, las salidas del nivel de fototaxis serán las que generen acciones en los actuadores (S phot). V0,...,Vi V0,...,Vi V0,...,Vi Sensado Señal cond. Controlador de Evasión de Obstáculos Controlador de Fototaxis Condicional Salida de Referencia Sob st. Sr (Sr > b) Señ al de salida Controlador de Aprendizaje Condicional ((S r > b)? Sobst.:SP hot.) Figura 88 – Diagrama esquemático de la conectividad de los neuro-controladores en una Arquitectura por Subsumisión. Evolución de Neuro-Controladores Multi-Nivel Datos sensados 111 objetivo único Navegación Aprendizaje Condicional Fototaxis Condicional Obstáculo Comportamiento de evasión de obstáculos ante posible bloqueo Acciones sobre actuadores Figura 89 – Esquema global de la estrategia de navegación adoptada: pruebas experimentales con el simulador complejo. El proceso evolutivo consiste en una configuración similar a la mostrada en la sección 4.2.3, pero con modificaciones relacionadas con el tiempo de evolución de la población de controladores y con el tipo de topología neuronal. Como característica a destacar, es necesario remarcar que las funciones de fitness utilizadas no se refieren a mediciones de la distancia hacia una fuente de luz objetivo, tanto para el comportamiento de fototaxis y para el nivel de evasión de obstáculos (véase sección 5.3.1 y sección 5.3.2). En cuanto al nivel de aprendizaje (sección 5.3.3), la función de fitness correspondió a la diferencia entre las veces que se alcanzó el objetivo correcto menos las que se alcanzó otro (véase la Ecuación 11). De acuerdo a lo expuesto en la sección 2.6.3, puede decirse que con el enfoque de Evolución por Niveles la evolución de los controladores mejora. Por lo tanto, y a raíz de estos resultados, en la sección que a continuación se presenta, se prosigue con el estudio de la generación de controladores utilizando un enfoque evolutivo por niveles. Principalmente, esto se debe a que no se encuentra ninguna otra metodología mejor, capaz de combinar comportamientos dentro de una misma estructura para una tarea completa mediante evaluación simulada (véase [Téllez et al., 2004]). En la Tabla 27, se resume la metodología seguida. Método Motivaciones Descripción • Estudio inicial presentado en [Togelius, 2004]. • Comparación de la Evolución Monolítica con respecto a la Evolución por Niveles con múltiples neuro-controladores, considerando estudios con controladores simples. Hipótesis a probar • La Evolución por Niveles es un mecanismo apropiado para la generación de controladores complejos. Metodología • Verificación experimental sobre escalabilidad y robustez de neuro-controladores. • Comportamientos complejos que incluyen evasión de obstáculos, fototaxis y aprendizaje durante la vida del controlador. Verificación Experimental: Simulador simple; simulador complejo (YAKS); robot real Khepera. 112 Evolución de Controladores Multi-Nivel Experimentos Combinación de los diferentes neuro-controladores obtenidos con la Evolución Monolítica y distintos comportamientos simples, sobre una tarea compleja (comportamiento de navegación en un entorno no conocido). Datos experimentales Véase descripción en la sección 6.2.3. Resultados Obtenidos Véase figuras de la sección 6.2.3. Tabla 27 – Resumen del método experimental utilizado para el desarrollo de las pruebas con Evolución por Niveles 6.2.2 Resultados Experimentales en Simulación Simple A lo largo de la sección 6.2, se presentará la manera en que se realizó la evolución de un controlador para resolver la tarea compleja de navegación en un entorno no conocido a priori, el cual puede estar basado en la combinación de los comportamientos vistos en la sección 5.3. Este proceso correspondió a la incorporación de controladores en niveles separados en forma incremental con una organización como la señalada en la Figura 88. 6.2.2.1 Etapa 1: Incorporación del Nivel de Fototaxis Inicialmente, se evolucionó el nivel de fototaxis condicional, utilizando para ello una red del tipo FFNN. Esto se debe a que, según lo mostrado en la sección 5.2, presentó el mejor desempeño en relación a otros controladores. Básicamente, consistió en una red con la configuración señalada en la sección 5.3.1.6. [mejor: 0. 3306, promedio: 0. 2180, peor: 0. 0626, tiempo: 5’ 13’’] Figura 90 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en fototaxis condicional con obstáculos En la Figura 90 se muestra la evolución del controlador en fototaxis condicional, obteniéndose que el mejor nivel de fitness rondó 0.3306, el promedio 0.2180, mientras que el peor 0.0626. Además, el tiempo que demoró fue 5’ 13’’26. Como es posible observar en la figura, un buen desempeño pudo ser obtenido en pocas generaciones asociadas al nivel de fitness alcanzado. Cabe destacar que dicho comportamiento fue alcanzado con la presencia de obstáculos en el entorno, y de manera que no se registraron inconvenientes en su utilización. 26 El tiempo que demoró el controlador en ser obtenido, es considerablemente menor a los tiempos señalados en la sección 5. Esto se debe a que no se realizó la toma de datos de las señales del entorno, ni de los nodos del controlador en forma gráfica. Evolución de Neuro-Controladores Multi-Nivel 6.2.2.2 113 Etapa 2: Incorporación del Nivel de Evasión de Obstáculos Seguidamente, se procedió a generar el nivel de evasión de obstáculos, con una configuración tal como la señalada en la sección 5.3.2.1. Nuevamente se indica que la configuración de red neuronal para implementar el neuro-controlador fue FFNN. Esto se debe a que presentó el mejor desempeño final para dicha tarea (sección 5.3.1). La Figura 91 muestra la evolución del controlador, obteniéndose en un tiempo de 7’ 01’’ con 0.7736, 0.5882 y 0.2625 niveles de fitness del mejor, promedio y peor controlador respectivamente. [mejor: 0.7736, promedio: 0.5882, peor: 0.2625, tiempo: 7’ 01’’] Figura 91 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en evasión de obstáculos. 6.2.2.3 Etapa 3: Evaluaciones Parciales de los Controladores Jerárquicamente Organizados Posteriormente, se realizaron diferentes evaluaciones con ambos controladores jerárquicamente organizados. Se procedió a evolucionar el nivel de evasión de obstáculos por sobre el nivel de fototaxis. En otras palabras, se dejó fija la configuración del nivel de fototaxis y se realizó la evolución del nivel de evasión de obstáculos. Ambos, uno independientemente del otro, se comportaron tal como se especifica en la Figura 90 y Figura 91. No obstante, las pruebas experimentales arrojaron que la combinación de ambos niveles mejora el desempeño global del sistema en cuanto a la aproximación a un objetivo evadiendo obstáculos (Tabla 28). Tal conclusión surge de la comparación de resultados de la sección 5.3.2.6 y los que aquí se exponen. -- Fototaxis cond. con obstáculos -- -- Navegación con obstáculos -- Evolución Monolítico Por Niveles Monolítico Por Niveles Mejor Fitness Prom. 0.228 0.330 0.610 0.773 Fitness Promedio 0.143 0.218 0.398 0.588 Peor Fitness Prom. 0.024 0.062 0.129 0.262 Porcentaje de Éxito 9/10 9/10 9/10 10/10 Estabilidad 65 40 28 150 Tabla 28 – Resultados obtenidos en la evolución de neuro-controladores para Evolución Monolítica y por Niveles sobre el total de generaciones (300 generaciones y 10 corridas). 114 Evolución de Controladores Multi-Nivel Como se puede ver en la Figura 91, la obtención del comportamiento de evasión de obstáculos es simple de generar. Una observación a destacar es que el robot usualmente se encuentra en una situación de evasión de obstáculos cuando se dirige hacia su objetivo y su movimiento no es totalmente armonioso. Esto se debe a que el comportamiento de evasión, puramente reactivo, depende de lo que registran los sensores, y el comportamiento final (o el comportamiento que surge de la combinación ellos) depende del ángulo de incidencia del obstáculo y del objetivo. Dicho movimiento, a veces, es curvilíneo debido a que el robot intenta retomar su camino hacia su destino, encontrándose en una posición similar a la inicial, excepto que presenta un ángulo menor respecto de la posición final, lo cual mejora su postura para sensar la fuente de luz objetivo. En determinadas situaciones, puede repetirse lo antes planteado un número no definido de veces, con lo cual no existe una minimización del recorrido del robot en cuanto ir hacia el objetivo (véase Figura 92). Una posible mejora a tal fin puede orientarse a cuestiones de navegación sobre un entorno conocido [Maaref, et al., 2002]. Según esto, en función a los experimentos realizados con evasión de obstáculos, no se espera obtener un mejor desempeño en futuras pruebas sobre dicha tarea. Figura 92 – Ejemplos de trayectorias generadas con un controlador por niveles. Particularmente, en el caso de evasión de obstáculos, la red neuronal inicial, entrenada mediante evolución, es optimal. Por ejemplo, durante la evolución un conjunto de pesos sinápticos pueden acercarse al valor óptimo esperado (respecto de aquel controlador buscado que resuelva la tarea tal como se espera), posibilitando que el robot varíe de rumbo. De esta manera, es posible decir que los pesos sinápticos de una red que resuelva una tarea específica tal como se espera son óptimos, al menos en algún grado. Principalmente, y en el caso de que los pesos sinápticos no sean los óptimos, se esperaría que el robot, por ejemplo, pondere girar hacia un lado más que hacia el otro. Esto puede observarse en la última de las imágenes de la Figura 92. Por otro lado, el hecho de que ocurran tales movimientos se debe a varios factores: la combinación de red neuronal puramente reactiva (tal como la FFNN) para evasión de obstáculos, y la arquitectura de comportamiento complejo propuesta, no presupone una mejora en el desempeño del robot. Experimentos con otras configuraciones de neuro-controladores p( . ej. HPNN) en el nivel de evasión de obstáculos, causaron similares inconvenientes. Dicha afirmación está basada en los test preliminares mostrados en la sección 5.3.2. Cabe destacar, que resultados similares fueron obtenidos en el trabajo descrito en la sección 3.2.3, por lo cual se sugiere, como es de esperar, que la clave para mejorar el comportamiento final debe enfocarse en el neuro-controlador del nivel de evasión de obstáculos. Otras potenciales soluciones estarían orientadas a incorporar, por ejemplo, sub-comportamientos de evasión de obstáculos, tales como seguimiento de patrones espaciales (zócalos en paredes, o fallas geológicas en el lecho marino) a fin de generar una activación de los comportamientos durante los movimientos de evasión. De este modo, se podría crear ante determinadas circunstancias un movimiento más armonioso y preciso del robot hacia su objetivo. Además, diferentes conexiones (o reglas) entre niveles pueden ser combinadas, particularmente generando combinaciones que inhiban ciclos de movimientos como el señalado en la Figura 92, y activen comportamientos combinados para salir de situaciones no deseadas, que será motivo de futuros estudios. Evolución de Neuro-Controladores Multi-Nivel 6.2.2.4 115 Etapa 4: Incorporación del Nivel de Aprendizaje Continuando con el desarrollo del controlador final, se incorporó un nivel por sobre el de evasión de obstáculos, vinculado a aprendizaje y en relación a la función de fitness mostrada en la Ecuación 12. La configuración de dicho neuro-controlador correspondió a la señalada en la sección 5.3.3.6, a excepción de que las entradas relacionadas a los sensores (V1 ...V6 de la Tabla 25), no fueron incorporadas. Esto fue dado que el nivel de fototaxis cuenta con las entradas necesarias para la consideración de la percepción de las fuentes de luz. Se probaron dos configuraciones al respecto, FFNN y HPNN. [mejor: 2.1196, promedio: 1.2141, peor: 0.4026, tiempo: 17’ 44’’] [mejor 2.1473, promedio: 1.2130, peor: 0.3880, tiempo: 36’ 46’’] Figura 93 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) sin obstáculos. Figura 94 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) sin obstáculos. [mejor: 0.9540, promedio: 0.3105, peor: 0.1803, tiempo: 19’ 28’’] [mejor: 0.9230, promedio: 0.3000, peor: -0.1860, tiempo: 37 33’’] Figura 95 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo FFNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) con obstáculos. Figura 96 – Performance del fitness del mejor, promedio, y peor controlador durante las diferentes generaciones. Medición realizada según la función de fitness sobre una población de controladores del tipo HPNN en aprendizaje condicional, por sobre los niveles de fototaxis condicional (FFNN) y evasión de obstáculos (FFNN) con obstáculos. Como se puede ver en las figuras anteriores, el desempeño del controlador fue muy similar en las configuraciones señaladas (aprendizaje con un controlador del tipo FFNN y HPNN). Una posible interpretación está vinculada a que sólo difieren en el nivel de aprendizaje al momento de ser probado el controlador en un entorno simulado con y sin obstáculos. Además, nótese en algún grado que los tiempos fueron menores a aquellos señalados en la sección 5.3.3 (principalmente en la Tabla 18). Esto, desde un punto de vista arquitectónico, se debe a que la evolución sólo se vinculó a una pequeña red de aprendizaje, 116 Evolución de Controladores Multi-Nivel junto con la actualización de aquellos controladores relativos a la evasión de obstáculos y a fototaxis. Además, un hecho importante de señalar es que las gráficas muestran una estabilización de la función de fitness desde generaciones tempranas. Muy probablemente, esto esté asociado a una adecuación generacional en la evolución de los controladores respecto de la función de fitness o a una convergencia de los genotipos a un mínimo local sostenida en el tiempo. Posiblemente, el último de los motivos pueda ser analizado y mejorado mediante la variación de los operadores genéticos (p. ej. tasa de mutación). Particularmente, se observó que la configuración mostrada en la Figura 95 fue superior en cuanto a la armonía de los movimientos en comparación con otras alternativas (p. ej. Figura 96), mientras que la representada para la Figura 96 generó movimientos cíclicos no deseados del robot en forma frecuente. A diferencia con el controlador de la sección 5.3.3.6 (aprendizaje con variaciones deliberadas), el fitness promedio en todos los casos fue mucho menor. Esto se debe a que el entorno es diferente, particularmente por la presencia de obstáculos, disminuyendo la posibilidad de alcanzar el objetivo. 6.2.2.5 Etapa 5: Evaluación Final de los Controladores Jerárquicamente Organizados En aquellos experimentos con entornos sin obstáculos, y en los que sí los había, se encontró una fuerte incidencia del módulo de evasión de obstáculos, lo cual se ve reflejado en la medida del fitness en los cuatro gráficos anteriores. Esto se debe a que las gráficas son similares a las mostradas en la sección 5.3.2, principalmente en la evolución de la tendencia del mejor fitness. No obstante, se puede observar que en las alternativas señaladas en pocas generaciones el controlador se estabiliza, con lo cual es posible concluir que la habilidad de aprender a identificar, en alguna medida, el objetivo apropiado es simple de generar. Tal como se pudo encontrar en la sección 5.3.3.6, el nivel de aprendizaje utilizado se obtiene sin mucha complicación. Pese a esto, un análisis más profundo revela un hecho no esperado. A continuación se presentan diferentes experimentos vinculados a aprendizaje, desarrollados con el objetivo de analizar dicha característica no esperada. Se encontró que las implementaciones generadas con el controlador FFNN y HPNN en el nivel de aprendizaje, presentan un comportamiento similar en el controlador final. Si bien la adaptación durante la vida del controlador es más propicia de ser llevada a cabo por un controlador plástico, se encontró que una configuración del tipo FFNN como la utilizada puede ser desarrollada satisfactoriamente en dicho nivel. Por lo tanto, cabe preguntarse ¿cómo una configuración de red neuronal no plástica, y sin la capacidad de adaptarse a las situaciones del entorno durante la vida del controlador, generó los mismos resultados que una red plástica? La respuesta, tentativamente, está asociada con la evolución del controlador en el nivel de aprendizaje. En este nivel, la evolución artificial generó soluciones no anticipadas antes del desarrollo de los experimentos. Con el controlador tipo HPNN, se obtuvo que la salida generada por la red proporcionaba un valor positivo cada vez que se alcanzaba el objetivo correcto (véase sección 5.3.3.6). En cualquier otro caso, a excepción de cuando se alcanzaba una fuente de luz no deseada, presentó un valor cero como salida de la red. Con ello, puede decirse que la asociación plástica encontrada entre las entradas y la salida de la red presentaba una relación directamente proporcional a los valores de “refuerzo” (cero, positivo o negativo). Lamentablemente, luego de analizar la distribución de las reglas sinápticas (reglas de Hebb), no se encontró alguna relación aparente por la selección artificial durante el proceso evolutivo. A modo general, y luego de analizar cuál fue la propuesta encontrada durante la evolución del controlador homeostático en aprendizaje, se obtuvo lo siguiente. En el controlador existió una serie de conexiones con reglas dispares. Particularmente, la conexión sináptica entre la señal de refuerzo con respecto a las neuronas ocultas, no fue una en especial. Por ejemplo, las reglas de conexión sináptica de los indicadores de que se alcanzó un objetivo (V7 y V8) y la señal por refuerzo (V0) hacia las neuronas de la capa oculta (Tabla 25), fueron (véase Figura 21 para un mayor entendimiento): V0: (-,-,-,-,-,-,-,-,-,-,-,2,0,3,2,3,1) V 7: (-,-,-,-,-,-,-,-,-,-,-,1,0,2,0,0,1) V8: (-,-,-,-,-,-,-,-,-,-,-,3,0,3,0,3,0) Evolución de Neuro-Controladores Multi-Nivel 117 siendo los números en las representaciones alelos expresando reglas sinápticas27. Por lo tanto, la correlación positiva entre las entradas y la salida de la red, si bien es notoria cuando se pone en funcionamiento el controlador, no es observada directamente en base a las reglas que gobiernan las conexiones sinápticas implicadas. En lo que respecta a las conexiones hacia los actuadores, estas fueron: m1: (0,0,-,-,-,-,-,-,-,-,-,2,3,2,1,3,2) m 2: (0,2,-,-,-,-,-,-,-,-,-,3,2,1,0,0,0) Como se puede concluir al considerar el comportamiento de las reglas mediante el funcionamiento del controlador, si la entrada de refuerzo era negativa, la conexión correspondiente se reforzaba en algún grado. Esta suposición surge principalmente de analizar los resultados obtenidos en el aprendizaje del controlador. No obstante, la actividad de la red rápidamente reforzaba las conexiones de la capa de salida, lo cual provocaba una salida estable positiva o negativa, seleccionando correctamente la conveniencia o no de la fuente de luz. Luego, al momento de intentar cambiar de objetivo durante la vida del controlador, la red siempre devolvía un valor cero de salida. Esto se generó cuando no se estaba en presencia de alguna percepción de luz, lo cual significa ir hacia el objetivo predefinido por el nivel de fototaxis condicional. La causa de tal comportamiento radicó en que el controlador no posee la capacidad de recordar cuál es el objetivo apropiado. Por tal motivo, se indica que la utilización de estados dentro del controlador de aprendizaje sería una probable solución, por ejemplo, a la característica de aprendizaje del controlador plástico. Compárese ésto con los resultados señalados en la sección 5.3.3.6 vinculados a fototaxis condicional con variación de objetivo. Otro aspecto digno de mencionar trata sobre la poca capacidad de adaptación durante la vida del controlador plástico. Particularmente, se encontró que el nivel de fototaxis dominaba en gran medida el desempeño general del controlador final. Al momento de definir que el objetivo era el mismo que mayoritariamente seleccionaba el controlad or en el nivel de fototaxis condicional, el desempeño fue como el mostrado en la sección 5.3.3.6, manteniéndose en un rango aceptable de éxito en comparación con el mejor nivel de fitness. En el caso que el objetivo difiriera del más favorecido por el nivel de fototaxis (véase sección 5.3.1.6), el desempeño final se volcó a la selección del objetivo predefinido por el nivel de fototaxis, con lo cual no pudo observarse algún tipo de adaptación significativa al nuevo objetivo. Algo similar ocurre cuando en la evolución del nivel de aprendizaje se establece un 50% de selección de cada fuente de luz, sin que nuevamente se logre una adaptación apropiada del controlador (ésto tanto para FFNN o HPNN). En las figuras que a continuación se presentan, se muestra el desempeño alcanzado según lo antes referido. (a) [mejor: 2.5200, medio: 1.4337, peor: 0.5120, tiempo: 4’ 15’’] (b) [mejor: 1.0940, medio: 0.0196, peor: -1.0020, tiempo: 3’ 16’’] Figura 97 – Performance obtenida al variar el objetivo en la evolución del controlador de aprendizaje (FFNN) asociado al nivel de fototaxis condicional. (a) Objetivo más favorecido en evolución; (b) 50% de selección de objetivo. 27 0 (Regla Plana Hebbiana); 1 (Regla Post -Sináptica); 2 (Regla Pre-Sináptica); 3 (Covarianza). 118 6.2.2.6 Evolución de Controladores Multi-Nivel Etapa 6: Análisis de las Implicancias y Discusión Un punto a señalar se vincula a la diferencia acontecida al utilizar el genotipo respecto de la red generada del mejor controlador para HPNN. Al variar la forma de considerar al controlador de acuerdo a su genoma o red neuronal, no se obtuvo un mismo comportamiento de aproximación al objetivo, principalmente esto se observó cuando se realizaron pruebas con el nivel de fototaxis condicional (sección 5.3.1.6). La utilización del genotipo o de la red neuronal acarreó una diferencia en la selección del objetivo por parte del controlador. Particularmente, para las HPNN se justifica dicho comportamiento dado su proceso evolutivo y su adaptación sináptica a una de las fuentes de luz durante la vida del controlador. Por lo tanto, como es de esperar, se generó un inconveniente a la hora de seleccionar cuál sería la alternativa a incorporar dentro del controlador por niveles. En este trabajo, se decidió que la red encontrada en la evolución de un controlador HPNN fuera seleccionada para implementar el controlador final. Por otro lado, considérese nuevamente la conectividad interna del controlador homeostático del nivel de aprendizaje, en relación con el controlador del tipo FFNN (nivel de fototaxis condicional), y éste último con el control sobre los actuadores. Además, recuérdese que el tipo de nodo utilizado en los diferentes controladores es incapaz de producir una salida sin que se produzca una entrada. Entonces, en función al comportamiento general del controlador final descrito en este capítulo, es posible diagramar algunas inferencias sobre la forma en que trabajó una parte del controlador. En la red de aprendizaje es relativamente simple de ver qué es lo que sucede cuando se detecta la presencia de una fuente de luz en el borde del campo de sensado del robot. Si sólo un sensor (p. ej. el sensor 1 de la Figura 8) fuera activado, mientras que simultáneamente el robot busca aproximarse hacia su objetivo, entonces los nodos del controlador FFNN del nivel de fototaxis reciben un estímulo (entrada positiva) de dicho sensor. Con ello, se produce un giro del robot hacia su objetivo. Al momento de que los sensores en su totalidad detecten la presencia del objetivo, entonces la red de aprendizaje tendrá como entrada un valor positivo alto, junto con una señal de refuerzo positiva. Esto genera que se refuerce internamente el controlador mediante la modificación de los pesos sinápticos, haciendo que el robot se dirija hacia dicha fuente de luz con un mayor grado de probabilidad cada vez que sea sensada. Si bien ésta es la idea que subyace en el problema de ir al objetivo, cabe preguntarse lo siguiente: ¿cuál es el motivo por el cual el controlador no se adapta apropiadamente cuando se quiere modificar el objetivo, y de este modo acostumbrarlo a uno diferente del propuesto en su evolución? La respuesta, posiblemente, se relaciona con la falta de salida de la red en la capa de aprendizaje cuando no se presentan entradas de los sensores respecto del entorno. Cuando se intentó cambiar el objetivo, la red siempre volvía hacia el objetivo predefinido por el nivel de fototaxis, posiblemente debido al tipo de neurona considerada (sección 4.2.4). Nuevamente, se indica que la utilización de estados dentro del controlador de aprendizaje, sería una probable solución a la característica de aprendizaje del simulador plástico. Finalmente, como conclusión de los resultados presentados en esta sección, puede decirse que la incidencia del aprendizaje estuvo principalmente influenciada por la adaptación generacional del controlador, considerándose el denominado Efecto Baldwin (sección 2.7.4) en vez de aquella generada durante la vida del controlador. 6.2.3 Resultados Experimentales en Simulación Compleja En la sección anterior, se presentaron diferentes evaluaciones en la evolución de un controlador por niveles. En ello, se utilizó un modelo simplificado del entorno. La razón principal fue que la utilización de modelos complejos asociados a la red puede acarrear considerables demoras en cuanto a la obtención de un controlador (véase [Nolfi et al., 2000]). Concretamente, en pruebas no especificadas en el presente trabajo, se concluyó que la incorporación de simuladores más complejos y costosos en términos computacionales, acarrearían retardos en cuanto a la generación de un control mediante evolución simulada. Es por ello que la presente sección tiene por finalidad no sólo ver cuál es el comportamiento del controlador desarrollado, sino que también validar la hipótesis de que la consideración de un modelo simple del entorno durante el proceso evolutivo es viable de utilizar, para luego proceder a la evaluación del mismo en un entorno realista. Evolución de Neuro-Controladores Multi-Nivel 119 Luego de que fueran generados los niveles de evasión de obstáculos, fototaxis condicional y aprendizaje antes descritos, se procedió de la siguiente manera. Dado que los resultados de aprendizaje fueron como los señalados en la sección anterior, y debido a que el robot real disponible no poseía la capacidad de discernir entre dos fuentes de luz determinadas, se utilizó la coordinación de evasión de obstáculos junto con fototaxis simple28 como controlador final. Además, se propuso que la coordinación de comportamientos esté asociada a un conjunto de reglas tal que funcionen como un mecanismo preestipulado de coordinación. Esto surge a partir de los resultados mostrados en la sección 6.2.2. Particularmente, el conjunto de reglas servirá como complemento a la Evolución por Niveles, dado que combinará los resultados del proceso evolutivo con un conjunto de reglas de asociación. Tales reglas buscarán generar un comportamiento de seguimiento de obstáculos (wall-seeking) a partir del nivel de evasión de obstáculos. Finalmente, la funcionalidad buscada en los diferentes experimentos con un modelo complejo del entorno, están asociados al problema de navegación en entornos no conocidos. En ello, diferentes situaciones son analizadas, tal como son planteadas en [Maaref et al., 2002], considerando un modelo del entorno como el propuesto por el simulador YAKS (sección 3.4.5). Las motivaciones para trabajar con dicho simulador son presentadas a continuación: (a) la metodología utilizada en el presente trabajo está basada en un modelo preciso de robot Khepera®, por lo que transferir el proceso de control a un simulador como el señalado no es un problema difícil de resolver a partir de YAKS; (b) Provee una interfaz de comunicación conveniente para comunicar el control a un robot real; (c) permite la separación de los módulos de control de lo que es el simulador; (d) finalmente, es apropiado el manejo de modificaciones del entorno. 6.2.3.1 Estrategias de Navegación en Entornos No-Conocidos Algunos de los inconvenientes presentados en navegación se vinculan al paso del robot por lugares estrechos o pasadizos, lo cual es una restricción para la utilidad de robots en entornos cerrados. Una posible estrategia para resolver tal problema es la navegación hasta alcanzar el espacio libre entre objetos (véase trabajo descrito en la sección 3.2.6). Esto permite evadir mínimos locales a fin de alcanzar el punto medio disponible cuando el robot pasa a través de entornos cerrados [Benreguieg et al., 1998]. Particularmente, se propone analizar el desempeño de la navegación de un robot en escenarios en los cuales se presentan obstáculos del tipo cóncavo y convexo. Debido a que las estrategias reactivas utilizadas en entornos desconocidos están basadas exclusivamente en información sensorial, la localización absoluta no es requerida. Sólo es necesaria la interacción relativa entre el robot y el entorno en el cual se encuentra. En este contexto, se busca garantizar, en alguna medida, una solución para la navegación encomendada evadiendo problemas de bloqueo. A continuación se presentan los resultados experimentales en diferentes escenarios planteados por Maaref et al. considerando el simulador YAKS (Figura 98). 28 Esto es equivalenete a fototaxis condicional con objetivo fijo, o a fototaxis condicional con el objetivo más favorecido durante el proceso evolutivo. 120 Evolución de Controladores Multi-Nivel Figura 98 – Área de prueba generada para el simulador YAKS. Escenario del tipo laberinto con fuente de luz central y obstáculos cilíndricos en las esquinas de las paredes. La finalidad de los experimentos que se presentarán, consistió en ver la capacidad del controlador en resolver estrategias de navegación de bajo costo en entornos cerrados. En este contexto, se pretendió validar la construcción del controlador según su eficiencia en navegación, dándole mayor prioridad a cuestiones de seguridad más que a optimización. La Figura 99 presenta un esquema general de la estrategia de control adoptada. Tal estrategia está basada en el hecho de que generalmente es posible abstraerse de la construcción de un mapa dentro del cual muros y otros objetos están fijos. Datos sensados Navegación Fototaxis bloqueo Obstáculo S1 Comportamiento de evasión de obstáculos ante posible bloqueo sin bloqueo S2 Comportamiento de seguimiento de pared gracias a la creación de reglas de coordinación Acciones sobre actuadores Figura 99 – Esquema global de estrategia de la navegación adoptada: pruebas experimentales con el robot real. A continuación se muestran los resultados obtenidos en diferentes situaciones con los controladores descritos en la sección 6.2.2. Particularmente, y como fue enunciado en la sección 6.2.2, se utilizará una configuración de controlador FFNN para los niveles de fototaxis y evasión de obstáculos, dada la conveniencia de ello. Evolución de Neuro-Controladores Multi-Nivel 6.2.3.1.1 121 Seguimiento de Paredes El esquema básico de seguimiento de paredes o wall-seeking29 es mostrado en la Figura 100. El objetivo a cumplir es que el robot pueda ajustarse a la forma de los muros. Este comportamiento puede ser adecuado también a la forma de los obstáculos si están presentes en el entorno. En la figura antes mencionada, aparecen algunos indicadores (cuadrados pequeños) los cuales manifiestan alguna dificultad presentada por los movimientos del robot simulado. Aquellos casos en los que aparecen dos de dichos indicadores, se quiere expresar que el controlador, por momentos, presentó una situación de bloqueo, la cual fue superada luego de maniobras realizadas por el robot para desbloquearse. Figura 100 – Comportamiento de seguimiento de paredes: experimentación con simulador YAKS En la Figura 100, es importante notar que el recorrido del robot se ajustó tanto a un lado del muro como al otro en aquellas situaciones en las que se estaba en un pasadizo. Esto puede observarse en que las gráficas de la trayectoria del robot son menos obscuras en los bordes del camino seguido. En conclusión, en la situación antes descrita el comportamiento del controlador fue aceptable. Esto expresa que cuanto más recto sea el camino por el cual el robot debió pasar, más fácil fue la decisión del controlador en cuanto al ángulo de desvió a especificar sobre los actuadores, y por ende más rápidamente el robot se movió. De esta manera, el robot logró seguir correctamente los muros a una distancia determinada en cualquiera de las formas presentadas con una trayectoria continua y armoniosa. 6.2.3.1.2 Comportamiento de Búsqueda de Objetivo En navegación reactiva la seguridad del robot es esencial. Por esta razón, es posible distinguir dos casos a tratar: • Si un obstáculo es detectado en la proximidad del robot, a uno de los lados o al frente, entonces la evasión de obstáculos posee mayor prioridad que la atracción al objetivo. • La acción de los actuadores surge como una combinación lineal entre la evasión de obstáculos y la atracción hacia el objetivo. Un ejemplo de la implementación de esta fusión sobre un modelo complejo de robot Khepera, es mostrada en la siguiente sección. 29 Wall-following generalization track. 122 Evolución de Controladores Multi-Nivel 6.2.3.1.3 Evasión de Obstáculos Convexos La tarea que a continuación se describirá, consiste en sobrepasar un área libre en un entorno tipo habitación. Para clarificar el tema, este comportamiento de navegación combina dos tipos de sub -comportamientos: un comportamiento que permite alcanzar la parte media del espacio libre disponible para pasar entre obstáculos, y otro que posibilita ir hacia el objetivo. Además, cuando el robot se está moviendo hacia su meta, y los sensores detectan un obstáculo, en este momento es necesaria una estrategia de evasión, mientras se intenta alcanzar algún punto libre para poder pasar. A tal fin, se pretende verificar si con una configuración de controlador como la señalada en la sección anterior, es posible resolver un comportamiento de navegación en un entorno tipo laberinto. Figura 101 – Comportamiento de evasión de obstáculos convexos: experimentación con simulador YAKS La Figura 101 presenta un ejemplo de navegación en un entorno simulado complejo. El controlador muestra suficiencia para realizar la tarea, pero para alcanzar su meta el robot debe ser provisto de un comportamiento de búsqueda de objetivo. Por lo tanto, se activa el comportamiento de fototaxis luego de que la evasión fuera alcanzada. Como se puede observar, el comportamiento en la situación planteada fue satisfactorio. 6.2.3.1.4 Evasión de Obstáculos Cóncavos En un entorno compuesto por obstáculos cóncavos, y teniendo como objetivo evadir situaciones de bloqueo, es de importancia combinar diferentes comportamientos. En ello, un método para superar dicho tipo de obstáculos es activar el comportamiento de seguimiento del obstáculo (contorno) para lograr rodearlo. Figura 102 – Comportamient o de seguimiento de obstáculos cóncavos: experimentación con simulador YAKS Figura 103 – Comportamiento de evasión de obstáculos cóncavos: experimentación con simulador YAKS En las figuras anteriores, el objetivo planteado es seguir las paredes a una distancia determinada, considerando los sensores definidos para el nivel de evasión de obstáculos. Como se puede notar en las figuras anteriores, el robot resuelve ambas situaciones, particularmente aquella en que el robot va hacia el centro de la fuente de luz luego de superar un obstáculo. 6.2.3.1.5 Coordinación de Comportamientos En esta sección, la estrategia completa de navegación reactiva en un entorno complejo es aplicada (como la mostrada en la Figura 99 y la descrita en la sección 6.2.3.1). Un ejemplo de los resultados obtenidos es Evolución de Neuro-Controladores Multi-Nivel 123 presentado en la Figura 104, donde el robot evade y circunda exitosamente la totalidad de los obstáculos de varias formas, antes de alcanzar su objetivo. Figura 104 – Coordinación de comportamientos: experimentación con simulador YAKS En efecto, la estrategia de seguimiento de paredes es activada en “Z1”, “Z2”, “Z3” y “Z4”. Esto es logrado a través de la coordinación de comportamientos propuesta. Además, en dichas zonas está presente la activación del comportamiento de evasión de obstáculos cuando así se requiera, p. ej. en “Z2” y “Z3”. En las zonas “Z3” como en “Z4”, se activa el comportamiento de ir hacia el objetivo (fototaxis), lo cual es reflejado por la trayectoria descrita por el robot. 6.2.3.1.6 Robustez a Variaciones Ambientales En esta sección se analiza la habilidad del controlador a adaptarse a perturbaciones ambientales [Greer, 2002]. Dos experimentos específicos fueron realizados para clarificar la viabilidad del controlador. En el primer experimento, los dos tipos de sensores (sensores de proximidad y lumínicos) fueron reducidos en un factor del 50%. El segundo experimento trata de la variación de los sensores en un incremento del sensado del 100% en cuanto a su medición. En el primer experimento, el controlador presentó un desempeño considerablemente aceptable (Figura 107) en comparación con el desempeño obtenido sin la perturbación (Figura 105). Por otra parte, el comportamiento del controlador fue afectado en mayor medida en el segundo experimento, y en la Figura 108 puede observarse al robot actuar erráticamente al momento de pasar por el corredor. En el segundo experimento se pudo observar que las variaciones del desempeño del controlador fueron mayores, dado que existía una mayor capacidad de aventurar obstáculos. Esto producía que se realizaran acciones inapropiadas a la situación a superar. Como se explicó en secciones previas, los sensores poseían un conjunto de conexiones hacia los nodos motores, las cuales pasaban por nodos intermedios. Si la señal era exitatoria o inhibitoria dentro del controlador fue una característica invariante de la morfología del controlador. Para enviar una señal desde un sensor con magnitud aumentada, el mecanismo neuronal necesitó estabilizar completamente la nueva conexión entre el sensor y el nodo implicado, lo cual no fue posible debido a que los pesos sinápticos del neuro-controlador no podían variar en el tiempo. Como consecuencia, el comportamiento del robot no fue apropiado en cuanto a la trayectoria generada considerando una trayectoria óptima hipotética. No obstante, en ambos experimentos el robot, llegó a su objetivo. 124 Evolución de Controladores Multi-Nivel Figura 105 – Comportamiento de seguimiento de obstáculos: experimentación con simulador YAKS Figura 107 – Alteraciones ambientales. Comportamiento de seguimiento de obstáculos con disminución (mitad) de la capacidad de sensado: experimentación con simulador YAKS Figura 106 – Comportamiento de seguimiento de obstáculos con la incorporación de un nuevo obstáculo: experimentación con simulador YAKS Figura 108 – Alteraciones ambientales. Comportamiento de seguimiento de obstáculos con aumento de la capacidad de sensado al doble: experimentación con simulador YAKS El hecho de estas perturbaciones ambientales, es un caso especial, el cual puede ser visto como una alteración del propio ambiente (alteraciones en la luminosidad del entorno). Como resultado, puede decirse que no se observa alguna inclinación a que el controlador pueda adaptarse a esta nueva circunstancia, a pesar de que se obtuvo una considerable cantidad de acciones satisfactorias. Principalmente, ésto se debe al tipo de neuro-controlador utilizado (FFNN), el cual no posee capacidad de adaptación durante la vida del controlador. 6.2.3.1.7 Robustez a Variaciones Morfológicas Continuando con el análisis de viabilidad del controlador en cuanto a perturbaciones, en la presente sección se muestran los resultados de la replicación de un tipo de perturbación realizado por Di Paolo [Di Paolo, 2000], en el cual se procedió a la inversión de las entradas de los sensores del robot. Un experimento similar fue desarrollado en [Greer, 2002] para controladores plásticos. Figura 109 – Alteración morfológica. Comportamiento de seguimiento de obstáculos con inversión de sensado: experimentación con simulador YAKS Evolución de Neuro-Controladores Multi-Nivel 125 El controlador al ser evaluado en cuanto a su habilidad para adaptarse a alteraciones en su morfología, fue sometido a una inversión de sus entradas, tanto en el nivel de fototaxis como en el nivel de evasión de obstáculos. El hecho de esta perturbación es un caso especial, el cual puede ser visto como una alteración de la morfología del robot o daños en los sensores. Como resultado, puede decirse que los neuro-controladores no son robustos frente a variaciones morfológicas, tal como se puede observar en la Figura 109 desde diferentes posiciones iniciales a partir de las cuales el robot comienza a moverse. Brevemente, esta situación ocurre dado que la configuración de las redes neuronales implicadas, no poseen la capacidad de adaptación durante la vida del controlador. 6.2.4 Resultados Experimentales en Entornos Reales En esta sección se presentará una breve descripción de los resultados encontrados al desarrollar experimentos sobre un robot móvil real Khepera30, así como también en simulaciones complejas previas. El controlador presentado en la sección 6.2.3 fue mantenido con el fin de ser usado en un robot real. El entorno está representado por un laberinto físico similar al utilizado para validar su desempeño durante la etapa de simulación. En la Tabla 29 se resumen los principales puntos del método a seguir. Método Descripción Motivaciones y Objetivos • Obtener un controlador útil para el control de un robot real. Análisis y ajuste de las diferencias generadas ante un entorno simulado complejo y la realidad. Hipótesis a probar • Verificar el desempeño del controlador final por niveles en un entorno simulado complejo y uno real aplicado a un robot Khepera . Replicar parcialmente experimentos propuestos en [Nelson et al., 2004]. Metodología • Utilización de la herramienta generada mediante una interfaz de control con un robot Khepera real en un entorno controlado. Verificación • Experimental: entorno real. Experimentos • Control sobre una tarea compleja en un ámbito tipo laberinto. Entorno asociado al utilizado durante pruebas simuladas. Datos experimentales • Los datos a recopilar durante el inicio de las pruebas se refieren a la caracterización de los diferentes sensores, a prestaciones del robot en cuanto a capacidad de giro y detección, y a cuantificar la influencia del entorno sobre el experimento. Resultados Obtenidos • Determinación de coeficientes de ajuste aceptables (caracterización). • Parametrización del controlador según variables ambientales. • Comportamiento del robot acorde a lo esperado según experimentos simulados. Tabla 29 – Resumen del método experimental utilizado para el desarrollo de las pruebas en un entorno real 30 Tanto las pruebas como los resultados obtenidos fueron generados en el Grupo de Inteligencia Computacional Aplicada a Robótica Cooperativa – Facultad de Ciencias Exactas y Naturales, UBA (Universidad de Buenos Aires), Argentina. 126 Evolución de Controladores Multi-Nivel El entorno real consistió de un área de 105x105 cm. delimitada por paredes de plástico blanco (telgopor) y el piso de goma compacta verde (véase Figura 110). Además, existían una serie de muros internos de acuerdo a lo mostrado en la figura antes referida. Una fuente de luz equipada con una bombilla de 75 Watts se orientaba perpendicularmente al piso del área en un extremo, aproximadamente a 3 cm. de altura. Cabe destacar que el salón donde se realizaron las pruebas, presentaba otras fuentes de luz no controladas, tales como luces cenitales tipo fluorescentes y luz natural proveniente de las ventanas del recinto. En cuanto al robot utilizado, las características del mismo pueden encontrarse en la sección 3.2. Figura 110 – Entorno experimental real y disposición de los componentes implicados. En la Figura 111 y Figura 112 se presentan las principales mediciones obtenidas con el robot Khepera® real utilizado. Dichas mediciones fueron realizadas a fin de ajustar los parámetros del controlador desarrollado en simulación. Figura 111 – Respuesta del sensor lumínico respecto de la distancia a una fuente de luz. Medición obtenida para el robot Khepera® real utilizado (distancia en mm.). Figura 112 – Respuesta del sensor de proximidad (luz infraroja reflejada) para un obstáculo en función de la distancia. Medición obtenida para el robot Khepera® real utilizado (distancia en mm.). La Figura 111 señala la influencia de la fuente de luz sobre los sensores. Esto no pretende ser una validación experimental de la especificación de dichos sensores propuesta en [Khepera, 1999], sino que corresponde a una caracterización de la influencia de la fuente de luz utilizada para ajuste de parámetros del controlador. Vale aclarar que los sensores permitían la emisión y recepción de luz infra-roja31. Se encontró 31 Para mayor información sobre los sensores, véase la especificación provista por el fabricante (nombre del componente: SFH900-2; fabricante: SIEMENS). Evolución de Neuro-Controladores Multi-Nivel 127 que existían variaciones en el sensado del entorno en cuanto a otras mediciones realizadas en diferentes instantes de tiempo bajo una aparente misma situación ambiental. Como se puede observar en la Figura 111, la medición lumínica decrece cuando la distancia a la fuente aumenta. El valor estándar en la oscuridad ronda las 450 unidades de medición (en un rango [0; 500]). La medición señalada, vinculada en algún grado a la Figura 14, sólo con un criterio conceptual, se analizó según la capacidad de sensado del robot respecto de una fuente de luz de 75 Watts. Esto se llevó a cabo sin que existiera una incidencia directa de la fuente respecto del sensor. Cabe aclarar que las mediciones buscan magnificar en alguna medida la influencia perpendicular de la luz respecto del sensor. Por otra parte, se pudo constatar que la medición de la proximidad de los obstáculos mediante la reflexión de la luz emitida, depende de dos factores: la reflectividad del obstáculo (color, tipo de superficie, etc.) y de la luz ambiente. La Figura 112 muestra la medición obtenida en cuanto a la respuesta del sensor respecto de la constitución del material de los muros (mediciones similares a las obtenidas para plástico blanco reportadas en [Khepera, 1999]). Otro punto importante a señalar es la susceptibilidad del sensado infra-rojo a fuentes externas controladas y no controladas de iluminación. En el caso de que la influencia sea significativa (p. ej. fuentes de luz próximas no frías cenitales), la variabilidad del sensado es mayor. En consecuencia, como luz ambiente se utilizó fuentes frías (luces fluorescentes) alejadas del entorno de experimentación. Básicamente, ésto se refiere a que los sensores infra-rojos (sea para medir incidencia de fuentes de luz o proximidad), son perturbados por el grado de emisión infra-roja (o calor) ambiental. Con ello se registró que la variabilidad del valor de sensado lumínico se encontraba acotado dentro del rango [72; 176] en ±140 unidades. Con respecto al sensado por proximidad, las variaciones ambientales estaban comprendidas entre ±5 unidades (en un rango entre [0;5] sin obstáculos próximos). Caracterización de los Sensores 1. Medición de luz ambiente a través de los sensores de proximidad y lumínicos (separadas cada t unidades de tiempo) 2. Determinación del promedio de las mediciones de luz ambiente para ambos tipos de sensores 3. Incorporación al entorno de un emisor infra-rojo (para sensores de luz) o incorporación de un obstáculo (para sensores de proximidad) 4. Mediciones de luz total para sensores de luz (luz ambiente y luz infraroja entrante) o mediciones infra-rojas de proximidad (luz ambiente y luz infra-roja reflejada) (separadas cada t unidades de tiempo) 5. Determinación del promedio de las mediciones de infra-rojo total de los sensores de luz y de infra-rojo total de los sensores de proximidad 6. Determinación del ajuste de las mediciones (ϖp y ϖl) Referencia 10 mediciones para cada tipo de sensor constantes de entorno ψp y ψl 1 fuente infra-roja/1 obstáculo 10 mediciones para cada tipo de sensor constante de entorno λp y λl ϖp = λp - ψp y ϖl = λl - ψl Tabla 30 – Resumen del proceso de caracterización de las mediciones de los sensores. Por otro lado, como uno de los pasos iniciales para la realización de los experimentos, se procedió a la caracterización de cada uno de los sensores del robot. Dicho proceso se realizó considerando la incidencia de la luz ambiente (no controlada) por sobre el entorno de experimentación (laberinto), procediéndose de la siguiente manera. Se tomó un muestreo de 10 tomas de datos por cada sensor lumínico. Para cada uno de ellos se obtuvo el menor y el mayor dato sensado, los cuales corresponden al rango de variación de los sensores respecto a la incidencia del entorno. Tales valores fueron relativamente similares entre el conjunto total de los sensores, por cuanto la caracterización de cada uno de ellos dentro del modelo de controlador, no fue necesaria de ser especificada por separado. En cambio, se propuso que la caracterización fuera parametrizada con un valor máximo y mínimo de variación común al grupo de sensores. Dichos valores 128 Evolución de Controladores Multi-Nivel fueron utilizados para ajustar todas las mediciones infra-rojas realizadas a fin de eliminar en promedio, por ejemplo, el ruido captado por los sensores del entorno. Referencia Valor Aproximado (promedio) 32 Sensor infra-rojo (lumínico): Rango propuesto por el fabricante Variación ambiental sin fuente cercana Ajuste en cono de sombra próximo a la fuente de luz Rango de sensores al momento de cubrirlos totalmente Rango en cercanía de fuente de luz Sensor de Proximidad: Rango propuesto fabricante Variación ambiental sin obstáculo cercano Rango de proximidad cercano (aprox. 3 mm.) [0; 1023] (<60 máx. luminosidad a 1 cm. de distancia); > 450 máx. oscuridad. [72; 176] (valor de normalización seleccionado ±140 unidades) 0,75 sobre el valor normalizado [752; 820] [65; 73] [1023; 0] [0; 5] (valor de normalización seleccionado ±5) [1023; 1011] Tabla 31 – Resumen de las mediciones realizadas vinculadas a la influencia del entorno sobre los sensores. Cabe destacar que la caracterización de los sensores lumínicos de manera conjunta, se realizó debido a que no fue requerida extrema precisión del sensado del entorno por el controlador. En otras palabras, y como se señaló anteriormente, el controlador, en algún grado, presentó características de robustez a pequeñas variaciones del ruido del entorno. Junto con la conclusión de que cada sensor se comportó relativamente de igual manera, la caracterización de los mismos fue común a todos ellos. Como es de esperar, y dado que dos sensores aparentemente idénticos no sensan de la misma forma, en el caso de que se necesite alta precisión por el controlador, será necesario realizar una caracterización individual por sensor. Figura 113 – Representación de la caracterización de los sensores de proximidad en función de la distancia Para realizar la caracterización de los sensores de proximidad, se procedió a analizar el sensado de cada uno de los ellos respecto a un obstáculo tipo pared en función de la distancia (Figura 112). Como resultado, se encontró que la medición de proximidad era similar respecto del conjunto de sensores, por cuanto la caracterización se realizó nuevamente en común a todos ellos, obteniéndose un rango de variación entre [0; 5] unidades. Cabe destacar que la incidencia de fuentes de luz no frías alteró significativamente la 32 Expresado en unidades de medición vinculadas a la descripción del conversor A/D de 10 bits señalado en la sección 4.2.2. Evolución de Neuro-Controladores Multi-Nivel 129 variabilidad del sensado al momento de anteponerle al robot un obstáculo en su proximidad (p. ej. 1,5 cm.). Por lo tanto, se procedió a anular cualquier generador infra-rojo no frío cercano al entorno de experimentación, a excepción de la fuente de luz indicada en el experimento. Tal fuente de luz se mantuvo a una distancia fija mínima del suelo a fin de disminuir el efecto infra-rojo no deseado en el ambiente. Con respecto a la medición proporcionada por los sensores de proximidad, en la Figura 16 se mostró la relación entre el sensado y el ángulo relativo a un objeto reportado por los fabricantes del robot Khepera. Dicha caracterización también fue observada en pruebas experimentales previas asociadas al desarrollo del presente trabajo. Concretamente, se pudo observar que cuando se supera los 70º entre la posición del sensor y el obstáculo, se pierde toda capacidad de percepción de dicho obstáculo. Particularmente, se ha encontrado que esto ocurrió al momento de que el robot se encontraba en un extremo libre de un muro, dado a que dicho extremo sólo tenía 1,3 cm. de ancho. De esta manera, se producía que los sensores de los costados del robot perdieran contacto con la pared al momento de realizar la acción de seguimiento de muro a fin de rodearlo. Como solución se plantearon dos experimentos secundarios. El primero se vincula al ajuste de los parámetros de ángulo de giro y velocidad en el sistema de reglas del comportamiento de seguimiento de pared. Esto acarreó una serie de pruebas hasta obtener parámetros aceptables. Se encontró, por ejemplo, que era necesario reducir el ángulo de giro aproximadamente en 0,27º (en el simulador33 44,5º; en el entorno real 44,23º) para que el robot realizara un movimiento de giro acorde hacia la derecha. No obstante, si esto se realiza en el simulador, el robot queda atascado al intentar girar en el extremo de una pared, dado a que el ángulo de giro no es el apropiado. En cambio con el ángulo original de giro en el entorno real, el robot en algún momento tiende a perder contacto con la pared en un extremo, dado que la superficie de la pared se ve reducida a un valor imperceptible por los sensores durante el movimiento de giro. De igual manera fue determinado el ángulo de giro hacia la izquierda. Otra solución se refiere a mantener los parámetros de giro propuestos en simulación, pero incorporando dentro del entorno una mayor superficie de percepción de fin de pared. La misma puede observarse en las siguientes figuras. Figura 114 – Variante propuesta como potencial solución de fin de pared Si bien el comportamiento fue el esperado (seguimiento de pared) con una circunferencia de 80 mm. de diámetro, se propuso el ajuste de parámetros antes referido como solución final. La Figura 115 muestra los resultados de tres situaciones experimentales simuladas en cuanto al desempeño del controlador. Esto fue realizado en un entorno complejo sobre un robot Khepera® con la configuración señalada en la sección 6.2.3. 33 Considerándose 45º como la trayectoria sin variación de dirección respecto de la dirección actual del robot en el entorno. Esto se debe a que los actuadores del robot fueron controlados mediante las funciones de seno y coseno del ángulo de desviación presentado por el controlador neuronal. 130 Evolución de Controladores Multi-Nivel Figura 115 – Tres situaciones simuladas utilizando un controlador por niveles durante la navegación en un entorno tipo laberinto El robot en los paneles de la Figura 115, muestra diferentes comportamientos que permiten tanto la evasión de obstáculos, fototaxis, y la evasión de objetos cóncavos y convexos, como así también el seguimiento de paredes. Como es posible observar, el agente simulado es capaz de desempeñarse apropiadamente en el entorno. Luego de encontrar un muro y alejarse de él, el robot presenta secuencias de movimientos que buscan estabilizar el control de los actuadores. Esto indica que la respuesta del neurocontrolador se ve afectada de manera directa en la información provista por los sensores. En cada panel de la Figura 116, las líneas indican el camino tomado por el robot. La posición inicial utilizada para el robot real corresponde a aquella mostrada para el agente simulado (Figura 115). Es claro que el robot real se desvía levemente del camino seguido en la simulación, luego de encontrarse con varios muros. Esto corresponde al comportamiento esperado, dado que existen diferencias entre el ángulo de aproximación y rangos de sensado dependientes de la luz ambiente, por ejemplo, en el caso de los sensores lumínicos. Además, en la Figura 116 el robot es mostrado en su posición final luego de cada corrida en el laberinto. Figura 116 – Tres vistas obtenidas a partir de una configuración de entorno real vinculadas a cada situación simulada. Por otra parte, se ha encontrado que el controlador en el entorno real es poco dinámico, pero presentó una amplia variedad de respuesta. Pese a ello, tales respuestas no fueron idénticas al momento de encontrar un muro o una fuente de luz. Por ejemplo, como se muestra en la figura siguiente, el robot simulado, si bien pasa por una zona mínima de luz, no es capaz de variar su dirección en forma plena para acercarse al centro de ella. Esto se debe al ángulo de incidencia del robot respecto al centro de la fuente. Evolución de Neuro-Controladores Multi-Nivel 131 Figura 117 – Situación en que la incidencia de la fuente de luz sobre el robot es mínima para generar un comportamiento de ir hacia el objetivo Desde un plano cualitativo, el comportamiento del robot fue similar tanto en simulación como en la realidad. Debe notarse que para una secuencia exacta de tiempo-sensado, el robot real y el simulado presentan las mismas secuencias de comandos. Por otra parte, pequeñas diferencias en las entradas del controlador (sensado) ocasionaron leves variaciones sobre los actuadores, acarreando pequeñas alteraciones en el comportamiento final del robot. Es importante notar que un controlador reactivo como el propuesto, y sin un procesamiento temporal, puede computar un conjunto acotado de entradas, con lo cual aquellas acciones de control que no surjan como consecuencia directa de las combinaciones de valores sensados del entorno no podrán ser generadas. Particularmente, se destaca que la combinación entre comportamientos generados mediante evolución simulada y reglas ó sistema de producción con encadenamiento hacia delante en el controlador final, es viable de llevar a cabo. No obstante, dichas reglas surgen, por lo general, de un proceso de prueba y error, lo cual presupone un considerable tiempo de desarrollo de la coordinación deseada entre módulos comportamentales. Mecanismos o propuestas que exploten la automatización de la coordinación entre dichos módulos, ya sea mediante evolución o a través de optimizaciones on-line de parámetros de asociación (p. ej. incidencia inhibitoria o exitatoria de un comportamiento sobre otro, o la búsqueda de parámetros auto-ajustables tales como la velocidad y ángulo de desviación del robot), pueden ser de utilidad para el programador. En la siguiente sección, se propone una posible extensión sobre dicho tema. Como conclusión de las pruebas realizadas, y luego de generar un controlador robótico real, se pudo demostrar que la aplicación y el uso de una plataforma integrada de desarrollo dentro de la RE, es posible a partir del estudio propuesto, lo cual sustenta futuros estudios. Cabe destacar que no se realizó un estudio exhaustivo del hardware disponible a fin de caracterizar cada uno de los componentes involucrados. Esto representaría un mayor grado de precisión experimental (p. ej. validar mediante fotómetro la luz ambiente en todo el entorno experimental). Otra posible mejora asociada al experimento real, puede estar vinculada a la incorporación de entradas adicionales (sensores) a los controladores a fin de que midan la luz ambiente, y de este modo ser decrementada dentro del controlador (p. ej. en las neuronas de la capa oculta). Finalmente, en cuanto a los resultados obtenidos con la metodología utilizada, una variante posible puede vincular un entorno completamente oscuro, excepto de la fuente de luz de referencia (véase [Nolfi et al., 2000, sección 6.3]). Con ello se obtendría un entorno de experimentación controlado en cuanto a la influencia del entorno. Si bien esto puede clarificar la interpretación de los resultados finales, el experimento de esta sección buscó analizar el desempeño del controlador en un entorno no completamente controlado. No obstante, no fue necesario realizar un estudio de mayor precisión debido al alcance del trabajo y a los resultados cualitativos obtenidos en la prueba final. 132 6.3 Evolución de Controladores Multi-Nivel Implicaciones más allá de la Evolución por Niveles Tradicional Si bien parece que la Evolución por Niveles es una manera confiable de obtener controladores y comportamientos emergentes en cada nivel, no es posible afirmar esto cabalmente en base a los resultados de las secciones anteriores. Es por este motivo que en el capítulo siguiente (sección 7.2.6) se analizará, en algún grado y en forma hipotética, si la evolución planteada corresponde a un mecanismo sistemático en RE para obtener “comportamientos emergentes robustos y adaptativos”. Dicho análisis no se ha observado que se llevara a cabo en la literatura dentro de RE ni en RBC y es parte del análisis propuesto en [Fernández, 2005]. Por otra parte, vale señalar que la mayoría de los experimentos desarrollados con arquitecturas de control rígidas del tipo presentado en este capítulo, presupone un conocimiento cabal de la problemática a resolver. Esto trae aparejado reglas de comportamientos pre-impuestas por el diseñador, con lo cual vale preguntarse si existen comportamientos emergentes realmente. Además, encontrar un mecanismo que permita relacionar de manera emergente sub-comportamientos en forma automática, obtendría el beneficio potencial de ser simple de definir por el diseñador del controlador. Es por este motivo es que se proponen futuros trabajos a partir del aquí presentado. A continuación se expone un planteo teórico sobre una posible mejora del sistema de coordinación entre comportamientos, a partir del controlador desarrollado y de los resultados antes presentados. 6.3.1 Optimización de la Coordinación de Comportamientos Las estrategias de navegación puramente reactivas, tales como fototaxis, seguimiento de paredes, y evasión de obstáculos, están completamente basadas en la información sensada del entorno. Si bien la evolución simulada de cada comportamiento arroja estrategias optimales, al momento de coordinar dichos módulos a través de un sistema basado en el conocimiento del programador, pueden encontrarse diferentes inconvenientes (véase sección 2.6.1). Una de las alternativas planteadas en el presente trabajo como desarrollo futuro, fue la coordinación de comportamientos auto-ajustables. Particularmente, y luego de un proceso de prueba y error al generar la coordinación utilizada, se observó que la misma acarrea un esfuerzo considerable. Como se mencionó anteriormente, es posible plantear que dicha coordinación surja de un proceso emergente, el cual someta a evolución simulada parámetros que relacionan a los comportamientos o niveles dentro de un controlador modular. Otra alternativa puede ser que tales parámetros sean adaptables durante la vida del controlador en forma on-line. En ello no sólo intervendrían características plásticas-homeostáticas, sino que también adaptaciones (optimizaciones) del tipo “lazo de control”. Si bien de alguna manera tales alternativas fueron estudiadas en trabajos no mostrados en esta tesis, los cuales exceden el alcance del presente trabajo, a continuación se propone una potencial mejora a la coordinación de comportamientos a ser implementada en corto plazo. Desde un plano adaptacionista fenotípico, en [Maaref et al., 2002] se propone un sistema de inferencia difuso auto-ajustable, el cual controla la velocidad angular y lineal de un robot. Seguidamente se propone una alternativa de acuerdo al trabajo de tesis aquí presentado vinculado al trabajo antes mencionado. El objetivo de tener un sistema auto-ajustable es generar parámetros (velocidad angular y lineal) que provean una base sobre la cual sea posible obtener un sistema de control auto-ajustable. En ello, principalmente, pueden intervenir reglas que gobiernan dicho ajuste, tal como ocurre con las reglas Hebbianas (sección 4.2.4.4). Con la utilización de mecanismos auto -ajustables de coordinación comportamental, se pueden obtener las siguientes mejoras: (a) evitar el ajuste manual de los parámetros; (b) no descartar soluciones optimales no consideradas por el programador; (c) ajuste de los parámetros de manera automática al momento de trasladar el problema de control a un entorno real, lo cual busca que el controlador se adapte a nuevas situaciones (p. ej. ruido en el entorno). Evolución de Neuro-Controladores Multi-Nivel 133 Figura 118 – Esquema de ajuste automático propuesto En la figura anterior, se representa un esquema general de ajuste, el cual es una versión simplificada de un control tipo “distal” aplicado a neuro-controladores [Jordan et al., 1991]. En dicha figura, FC representa la función costo utilizada como evaluación del grado de adaptación a realizarse. Por otra parte, SCC representa el “sistema de coordinación de comportamientos”. Principalmente, ésto corresponde a una serie de variables que intervienen en la coordinación, las cuales pueden ser ajustadas en relación al comportamiento general del controlador. De esta manera, es posible trabajar con un modelo no totalmente preciso del sistema a controlar, que en nuestro caso es la coordinación de los niveles comportamentales del controlador robótico. Por ende, no es necesario que desde un comienzo se obtenga un control especializado (véase [Renders, 1994] en un contexto neuronal, y [Saerens, 1991] en uno de control difuso). Con ello, paulatinamente, se buscaría que el propio controlador tendiera a optimizar su desempeño. 6.4 Discusión Las secciones previas presentaron los resultados de diferentes pruebas realizadas con controladores por niveles. En ello, se utilizaron los resultados previamente señalados en el Capítulo 5. Como un resultado no esperado, las redes FFNN combinadas con un proceso evolutivo apropiado, obtuvieron resultados equivalentes a las HPNN al momento de ser evolucionadas mediante la Evolución por Niveles. En experimentos con alteraciones morfológicas y ambientales, el controlador final mostró ser capaz, de alguna manera, en cumplir con sus objetivos según las nuevas circunstancias, pero desde la visión de eficiencia, esto no ocurrió. Vale señalar que la decisión de seleccionar neuro-controladores para cada nivel según el mejor desempeño en pruebas individuales (Capítulo 5), se realizó de esa forma debido a que no se disponía de una manera significativa de evaluar un controlador por niveles en un entorno no conocido. Dado que no existe información previa del entorno, no se puede determinar cuál es el camino óptimo a fin de conformar una figura de mérito a optimizar. Por lo tanto, y como una posible alternativa para afrontar dicho inconveniente, se concluye que la selección de cada nivel, basado en los mejores desempeños de diferentes configuraciones de neuro-controladores, constituye una alternativa viable de realizar según los resultados experimentales obtenidos. Al momento de comparar los resultados obtenidos al generar los controladores con un enfoque por niveles respecto de uno monolítico, es posible decir que las soluciones generadas mejoran substancialmente con el enfoque por niveles, basándose en comparaciones de fitness landscape y resultados cualitativos sobre una misma tarea a resolver. Por otra parte, reducciones temporales fueron obtenidas dependiendo del tamaño de las redes neuronales en cada nivel comportamental, incidiendo los niveles previamente congelados sobre el comportamiento que se esta evolucionando. Por lo tanto, la emergencia de comportamientos que pudo obtenerse con un enfoque por niveles generó al menos soluciones cualitativamente equivalente a aquellas obtenidas mediante un enfoque puramente monolítico. 134 6.5 Evolución de Controladores Multi-Nivel Conclusiones En este capítulo se desarrolló un controlador robótico el cual combina aspectos de la RE y determinadas características de RBC. En cuanto a su desempeño, fueron presentados diferentes experimentos simulados, como así también reales junto con predicciones e interpretaciones de los resultados obtenidos. Además, se realizaron análisis comportamentales y estructurales de los controladores respecto a las estrategias de navegación. Los mismos se enmarcaron dentro de los resultados esperados, a excepción de la tarea de aprendizaje con el controlador final. Una de las principales conclusiones es que la Evolución por Niveles es apropiada para la generación de controladores complejos. No obstante, hereda aquellas características rígidas de la Arquitectura por Subsumisión, las cuales están en función a la visión del diseñador más que a un proceso emergente de coordinación de comportamientos. Capítulo 7 - CONCLUSIONES CONCLUSIONES "Si he hecho descubrimientos […] ha sido más por tener paciencia que por cualquier otro talento" Sir Isaac Newton "No he fracasado, he encontrado diez mil maneras en las que la cosa no funciona" Benjamín Franklin 7.1 Introducción Se resumen en este capítulo las conclusiones, aportes realizados, trabajos futuros y las publicaciones generadas. Para finalizar, se seleccionan las principales recomendaciones para la generación de neurocontroladores mediante evolución simulada. 7.2 Conclusiones y Aportes Se han presentado experimentos sobre varias configuraciones de redes neuronales (FFNN, RFFNN, CTRNN, PNN, HPNN). Estas configuraciones comparten una estructura básica de toma de datos sensados del ambiente, y luego de un proceso interno, aportan una acción de control a cada actuador. La mayor parte de los experimentos muestran que las topologías de redes propuestas son independientes de suposiciones iniciales de cómo generar soluciones, es decir, las soluciones que son obtenidas por la evolución simulada emergen de dicho proceso. Esta tesis y las conclusiones que se detallan más adelante, se basan en resultados experimentales de más de 45 configuraciones de controladores. Las técnicas de obtención de controladores presentadas en esta tesis tratan de reducir el esfuerzo del diseñador, y en especial buscan no limitar, al menos parcialmente, la solución final al conocimiento específico de él. A esto le siguen ciertos temas tales como: balance entre esfuerzo y conocimiento para generar un control óptimo, aprovechamiento del poder computacional y el conocimiento de sistemas naturales para modelar sistemas artificiales. Por otra parte, y como es de esperar, un mejor control es obtenido cuando se logra un mayor grado de adaptación del controlador a la tarea a realizar. Cuanto más profundo sea el estudio de un controlador, mucho más se puede determinar las prestaciones del mismo, optimizaciones a nivel arquitectura, y los algoritmos o sistemas que pueden beneficiar su desempeño. Además, cuanto más amplio sea el análisis sobre los potenciales controladores en una tarea determinada, mayor será el grado de obtención de variantes de controladores o variantes que ayuden a encontrar un mejor desempeño del controlador final. 7.2.1 Recomendaciones para la Optimización del Desempeño Los experimentos descritos en el presente trabajo permiten generar un método heurístico para encontrar el controlador que mejor se adapte a una tarea de guiado autónomo de robots. Dos formas son las que 136 Conclusiones producen tal adaptación: una a nivel generacional (proceso evolutivo artificial) y la otra a nivel vida del controlador (proceso adaptativo fenotípico). La primera recomendación al momento de buscar mejoras en los desarrollos presentados, aunque trivial, es realizar un proceso evolutivo más extenso contemplando un número mayor de generaciones durante el proceso simulado. Otra alternativa, aunque más difícil de realizar, es considerar aprendizaje vinculado al fenotipo, es decir durante la evaluación del robot en el entorno en relación a una tarea específica. Esto último permitiría que el Efecto Baldwin guíe la emergencia del controlador mejor adaptado. Una vez determinada la tarea a realizar, existen diferentes alternativas en cuanto a la selección del tipo de neuro-controlador a evolucionar. Si la tarea implica adaptación del tipo aprendizaje, las mejores alternativas, según las experiencias realizadas, corresponden a redes auto-adaptables (tipo plásticas) o a redes fáciles de evolucionar (tipo feed-forward). Caso contrario, redes del tipo feed-forward también pueden ser utilizadas cuando la tarea no implique aprendizaje (p. ej. en tareas puramente reactivas). La codificación óptima de las arquitecturas de las redes depende de la topología que se quiera modelar. No obstante, existen dos variantes posibles: representaciones genéricas, y representaciones específicas. En esta tesis, se decidió utilizar una representación genérica de los controladores en cuanto al nivel fenotípico se refiere, particularmente al momento de modelar las interconexiones neuronales y sus pesos sinápticos. Si la topología es pequeña, no superando, por ejemplo, la interconexión total de 16 neuronas, la codificación propuesta en la sección 4.2.2 es aceptable en términos de costo computacional. No obstante, con representaciones mucho mayores, es necesario realizar un proceso de búsqueda de estructuras más adecuadas de representación. Esto se debe a que cuanto mayor sea la representación sometida a evolución, mayor será el tiempo computacional empleado. Para ejemplos de cómo influye en la evolución un número mayor de variables a actualizar, véase los tiempos señalados en la sección 5.2. 7.2.2 Observaciones a Nivel Topológico En el Capítulo 5, se han presentado experimentos con el objeto de determinar las características propias de un número significativo de redes neuronales. Con esto se buscó generar una idea práctica para mostrar al lector la realidad que subyace en cada topología de controlador. Adicionalmente, en el Capítulo 6 se han analizado los resultados de un controlador complejo en diversas situaciones o escenarios. Las conclusiones más sobresalientes entre otras son: • Proceso evolutivo: para una especificación de controlador robótico final como el desarrollado, cada módulo o nivel comportamental con mejor desempeño individual, normalmente, será el que controle un determinado comportamiento. Por lo tanto, el conjunto de controladores mejor adaptados a diferentes tareas deberá coordinarse con la finalidad de resolver una tarea compleja o problema que requiera multiplicidad de comportamientos. Esta coordinación puede ser llevada a cabo por el diseñador en cuanto a un proceso de prueba y error, aunque pueden ser aplicados criterios similares a los de evolución de controladores sobre dicha coordinación. En otras palabras, es posible someter a un proceso evolutivo artificial las relaciones entre comportamientos siguiendo algunas reglas pre-fijadas (p. ej. restricciones asociadas a un sistema experto). Esto último se propone como trabajo futuro. Si el diseñador debe elegir entre diferentes topologías en cada nivel de comportamiento, ni el desempeño individual, ni la evolución del controlador por sí solos son válidos para predecir el desempeño final del controlador. Esto depende de cómo se coordinen los comportamientos y cuando se lleve a cabo dicha coordinación, conjuntamente con un proceso de prueba y error. Cabe aclarar que la relación entre evolución y coordinación no es clara de definir. Algunas de las técnicas señaladas apuntan a realizar un proceso evolutivo paralelo de comportamientos, mientras que otras utilizan uno secuencial. Con respecto a este trabajo de tesis, se seleccionó una Evolución por Niveles (principalmente, proceso evolutivo secuencial) debido a los resultados previos expresados en [Togelius, 2004], en relación a otras formas de coordinación. Concretamente, la Evolución por Niveles secuencial obtiene mejores resultados respecto de la tarea a resolver en menor tiempo que otras técnicas de generación de controladores que impliquen escalabilidad de comportamientos, y en especial considerando la Evolución Monolítica. Conclusiones • 137 Adaptabilidad: a lo largo de las diferentes secciones, se expusieron distintos ejemplos que bajo ciertas condiciones muestran el grado de adaptación que tienen los controladores. Además, se presentó el impacto generado a partir de la variación de algunos de los parámetros del controlador (p. ej. rango de variación sensorial), como así también variaciones a nivel definición del problema. En ello, se hizo hincapié en las particularidades de las redes plásticas, dado el interés creciente de su estudio, y en redes del tipo feed-forward debido al desempeño apropiado presentado en distintos experimentos. Un punto a remarcar es que en pruebas sobre aprendizaje con controladores multi-nivel, las redes homeostáticas-plásticas y feed -forward obtuvieron resultados similares, pese a que ésto no era presupuesto. Las causas de la adaptación vista como un proceso de aprendizaje por ambas redes, obedece a un proceso adaptacionista generacional en ambos casos, y como así también a un proceso plástico en cuanto a las redes homeostáticas. Vale aclarar que este último proceso no dio los resultados esperados según se planteó en el análisis teórico de dicha red. Las causas de tal diferencia, posiblemente, sea consecuencia de la influencia generacional sobre el controlador al momento de construir el fenotipo correspondiente (neuro-controlador), produciendo que los parámetros sujetos a evolución estén adecuados a las situaciones expuestas en la evolución. Por ende, cualquier alteración significativa a tales situaciones, conlleva a una inercia al cambio. Cabe aclarar que los mecanismos plásticos pueden ser de utilidad si se consideran a la hora de elegir un proceso de auto-ajuste fenotípico, pero suscita un estudio mucho más profundo para elegirlos como alternativas de control. Los neuro-controladores, gracias a sus características de robustez, posibilitan que el proceso adaptacionista sea realizado de manera simple, pero el consumo de cálculos computacionales es alto, por cuanto las mejoras relacionadas con la codificación de los mismos es un problem a a resolver. • Emergencia: una observación importante es que la emergencia de comportamientos, principalmente a nivel controlador monolítico y en el conjunto de comportamientos, se ve beneficiada si se consideran aspectos adaptativos. Esto no sólo dentro de la topología del controlador, sino también al someter a una representación genotípica del mismo (p. ej. pesos sinápticos) a un proceso evolutivo como el propuesto. • Robustez: la existencia de unidades de cálculo autónomas (neuronas artificiales) y las relaciones entre éstas sujetas a cambios de performance (sinapsis), tiene un fuerte impacto en la adaptación, y por ende en la robustez. Las actividades internas del controlador son útiles a la hora de analizar que es lo qué sucede internamente, y para entender en alguna medida, cómo la adaptación se logra. En el caso de alteraciones ambientales, y considerando que las unidades o neuronas corresponden a funciones dependientes de las entradas, acarrean variaciones en las acciones sobre los actuadores, y en consecuencia sobre el comportamiento final del controlador. Para los experimentos realizados (sección 6.2.3.1.6 y 6.2.3.1.7 ), se encontró que los neuro-controladores fueron capaces de realizar las acciones que se esperaban. No obstante, algunas alteraciones se observaron al momento de analizar las trayectorias del robot. Con respecto a las alteraciones morfológicas, los resultados marcaron que los controladores no fueron capaces de adaptarse. • Niveles fijos: una consecuencia de la realización de los experimentos presentados, conlleva a poner en tela de juicio la influencia de tener niveles fijos durante la Evolución por Niveles luego de que estos sean obtenidos por evolución, o por el contrario que puedan incorporar adaptaciones luego de su obtención. Tales adaptaciones estarían vinculadas no sólo a la interacción de los componentes internos del controlador en un nivel específico, sino que también en función de la interacción entre controladores en una organización por niveles. La experiencia de la interacción entre comportamientos, y la definición explícita de la influencia entre comportamientos (coordinación) por parte del programador, indica que es necesario contar con mecanismos automáticos que faciliten no sólo la coordinación, sino también la adaptación de los niveles en cuanto a la tarea a ser afrontada en conjunto. La técnica descrita en la sección 4.2.3 (algoritmo genético), con una adecuación significativa en cuanto a relaciones adaptativas 138 Conclusiones entre módulos, puede ser aplicada a la coordinación de comportamientos según se estima de las pruebas preliminares realizadas a partir del presente trabajo. • Selección de topologías: una de las técnicas más convenientes de seleccionar un controlador para una determinada tarea, es basarse en resultados comparativos entre diferentes alternativas de control. La alternativa planteada por redes del tipo feed -forward son simples de implementar y entender, y además reportan, por lo general, buenos resultados, en especial en tareas puramente reactivas. Alternativas como redes plásticas y plásticas-homeostáticas ofrecen buenos resultados en cuanto a la adecuación del controlador. Esto puede ser visto en la sección 5.3.3.6. Tales alternativas ganan relevancia cuando se somete a evolución todo el controlador, ya que la combinación evolución-adaptación es potente. No obstante, cuando se realiza la evolución de una parte del controlador dejando a otras fijas, puede que el resultado final no sea del todo óptimo. Con ello se quiere expresar que la selección de las topologías no depende únicamente de la performance individual, sino que también de la grupal. 7.2.3 Resultados en Simulación Durante el Capítulo 6 se examinaron algunos experimentos que implicaron dos tipos de controladores (simple y complejo). Además, se llevaron a cabo pruebas con un robot real Khepera. Por un lado, fueron examinadas las características de evolucionar un controlador utilizando un modelo simplista de robot. Esto con el objetivo de agilizar el proceso evolutivo y evaluar la robustez de los neuro-controladores al momento de enfrentarlos con modelos de robots reales. Luego se presentó un experimento cuyos resultados no fueron del todo esperados desde el punto de vista funcional (evolución de una red de aprendizaje HPNN vs. una FFNN). Por último se analizó, entre otras cosas, el control realizado sobre un entorno real estructurado. A continuación se señalan algunos de los puntos vinculados a esto: • La representación de las diferentes estructuras utilizadas por los distintos algoritmos, así como la influencia entre ellas, son muy relevantes a la hora de generar experimentos. Por ejemplo, la definición de la evaluación del desempeño (función de fitness) sobre la representación del controlador, si bien no es aparente, trae efectos en el comportamiento final. Concretamente, cuanto más rápido y mayor sea la cantidad de ciclos (generaciones) de evaluación, potencialmente mejores resultados serán seleccionados. Por lo tanto, la representación es crítica en este problema, como así también el costo computacional asociado a ella. • La modularidad de los neuro-controladores es una característica altamente deseable para la generación de especializaciones en el comportamiento, al igual que la secuencialización de los mismos, principalmente si se considera una coordinación pre-definida por el diseñador. • La aplicación de evolución por niveles vinculados a comportamientos, ofrece importantes disminuciones del tiempo de cómputo cuando se quiere obtener un controlador para resolver una tarea compleja, y por ende del necesario para el desarrollo del controlador final. La reducción depende del tamaño de las redes que fueron congeladas en cada nivel y de la incidencia de ellas sobre el nivel que está siendo evolucionado. 7.2.4 Implicancias Los resultados del Capítulo 5 y del Capítulo 6 brindan ciertas conclusiones particularmente orientadas a la emergencia de comportamientos y al proceso adaptacionista artificial. A continuación se detallan algunas de ellas: • Mecanismo de adaptación: como se ha expuesto a lo largo de este trabajo, el proceso de adaptación (generacional o fenotípico) tiende a generar individuos “mejor adecuados o adaptados” a una tarea. Sin la existencia de dichos mecanismos (considerando sucesivas actualizaciones o variaciones de variables estructurales), la existencia de la emergencia de la adaptación comportamental no sería posible tal como se observó. Por cuanto, se postula que la emergencia de comportamientos depende del grado de adaptación interno y externo, junto con interacciones adaptativas entre los componentes de un sistema. Conclusiones 139 Desde un punto de vista evolutivo artificial, se prueba que la evolución es significativamente un mecanismo generador de adaptación. Desde el plano fenotípico, se concluye que el aprendizaje es una forma de adaptación que guía a la evolución (Efecto Baldwin). Ambos, permiten que la emergencia de individuos bien adaptados a un problema se produzca. • Evolución por Niveles: si bien la utilización de un proceso evolutivo por niveles es una alternativa viable para la construcción de controladores robóticos, es necesario extender los resultados de su desarrollo en cuanto a aspectos de coordinación entre niveles se refiere. • Neuro-Controladores Evolutivos: el estudio que se llevó a cabo presupone una serie de experimentos, los cuales aportan al estado actual del conocimiento una serie de resultados que dan base a futuros trabajos. Algunos de los temas, tales como coordinación y emergencia comportamental, necesitan ser desarrollados en profundidad. No obstante, es posible continuar el estudio planteado a partir de optimizaciones de los temas y desarrollos propuestos o llevados a cabo en este trabajo de tesis. 7.2.5 Conclusiones sobre las Herramientas de Generación de Controladores Paralelamente a los experimentos con controladores robóticos, se ha realizado un estudio básico sobre la disponibilidad de herramientas que permiten la generación de controladores de manera evolutiva (según escalabilidad y extensibilidad). Ante todo, hay que destacar que el proceso de obtención de un controlador mediante evolución simulada es un proceso lento, que requiere de bastante tiempo, y un posterior análisis de los resultados. Esto lo convierte, en muchos casos, en un método difícil de realizar, en especial dada su alta carga de tiempo guiada por prueba y error. Los resultados observados para los controladores desarrollados son bastante aceptables. En ello fue crítica la utilización de modelos simulados. En el caso de que ello no hubiese ocurrido, y al plantearse desde el inicio un estudio totalmente realista mediante la evolución de controladores evaluados con un robot real, los resultados no hubiesen sido como los presentados. Particularmente, la generación automática hubiese acarreado días de simulación y como así también la búsqueda de patrones de entrada. No obstante, resulta de interés la combinación entre procesos simulados y su eventual aplicación al control real, donde el tiempo de simulación y la generación de un control real de validación estén acotados. 7.2.6 Hipótesis sobre el Rol de la Adaptación en la Emergencia de Comportamientos A partir de los resultados obtenidos, es posible decir que los comportamientos podrían implicar procesos dinámicos emergentes jerárquicamente organizados que afectan unos a otros en forma bottom-up y topdown. La naturaleza adaptativa de los comportamientos deriva de la relación indirecta entre las propiedades de la interacción de los elementos intervinientes dentro del controlador y de los resultados emergentes de tales interacciones, y de su adecuación al entorno (véase [Fernández, 2005]). Por otra parte, un sistema comportamental puede ser difícilmente diseñado en forma planificada, mientras que puede ser efectivamente sintetizado a partir de procesos auto -organizados en donde las propiedades emergentes de las interacciones pueden ser descubiertas y mantenidas mediante procesos adaptativos basados en exploración y selección, tal como sucede con los algoritmos genéticos. Esto ha sido demostrado en el presente trabajo con ejemplos de comportamientos individuales sintetizados mediante una técnica evolutiva artificial. A tal fin, se entrenaron redes neuronales artificiales que realizaron un mapeo sensor/actuador en el robot. Por lo tanto, es posible decir que los algoritmos genéticos asociados con un proceso de adecuación al entorno, pueden ser considerados como mecanismos de diseño adaptativos y sistemáticos que generen comportamientos emergentes. En relación con esto, pruebas experimentales preliminares fueron realizadas coordinando módulos comportamentales en forma evolutiva, los cuales no fueron presentados en este trabajo de tesis. Si bien no pudo ser observado ningún patrón de coordinación entre los módulos, es posible decir que existe un conjunto de relaciones entre los ellos que permite emerger un comportamiento tal como el que fue generado en la sección 6.2.3.1. Por lo tanto, la coordinación lograda 140 Conclusiones por reglas de coordinación como así también aquella que emerge del proceso evolutivo, son coordinaciones válidas de realizar desde un plano cualitativo en función de los resultados generados. Comportamiento Global Emergente Interacciones Locales Figura 119 – Esquema general de la incidencia de la emergencia de comportamientos sobre las interacciones locales. Finalmente, se propone un estudio más profundo sobre la emergencia de comportamientos y de la adaptación en sistemas compuestos por múltiples componentes comportamentales en un único individuo, como así también en sistemas compuestos por múltiples individuos. 7.2.7 Discusión En este trabajo se han presentado resultados los cuales constituyen un aporte al diseño de neurocontroladores evolutivos dentro de la RE y la RBC. Se han desarrollado una serie de análisis comportamentales y estructurales sobre controladores luego del proceso evolutivo, conjuntamente con estrategias para la resolución de tareas. Además, se presentaron pruebas con varios tipos de redes neuronales, sobre dos clases de simuladores y dentro del mundo real. Finalmente, el controlador obtenido mediante Evolución por Niveles, fue capaz de superar una serie de problemas tanto a nivel simulado como a nivel real. Sobre la base de los resultados obtenidos y de la variedad de los experimentos, es posible concluir que el desarrollo de mecanismos evolutivos permite la consideración de componentes adaptativos de manera emergente. La Evolución por Niveles es apropiada para resolver dicha tarea. No obstante, acarrea las complicaciones de coordinación procedentes de la propuesta de Brooks (sección 2.6.1). Dentro de los aportes logrados en relación a estudios previos encontrados en la bibliografía, es posible decir que se generó un aporte experimental al estudio de “escalabilidad en RE”, implementándose estructuras de control capaces de gobernar la navegación de un agente robótico, promoviendo reusabilidad y escalabilidad de comportamientos. Para ello, se implementó una herramienta con la cual reducir los esfuerzos de obtención y definición tanto de los comportamientos como de las pruebas con controladores reales y simulados. En suma, se presentaron comparaciones desde la perspectiva científica e ingenieril, no sólo en el plano robótico sino también desde el plano bio -inspirado. En relación a esto, se llevó a cabo un planteo hipotético, el cual busca concluir cuáles son las causas de la emergencia de comportamientos (sección 7.2.6). Los resultados presentados, tanto experimentales como hipotéticos, revisten de potencial para contribuir a la obtención de mejores soluciones parciales en el diseño e implementación de controladores robóticos desde una perspectiva ingenieril, y a una mejor comprensión de la adaptación desde un enfoque científico, al menos no en forma directa. Finalmente, se espera que los experimentos propuestos puedan brindar un poco de claridad sobre las cuestiones vinculadas a emergencia y adaptabilidad, como así también a la construcción de neurocontroladores evolutivos aplicados al control de navegación de robots móviles autónomos. Conclusiones 7.2.8 141 Trabajos Futuros Como se ha mencionado anteriormente, el objetivo general de este trabajo de tesis es presentar un estudio completo de neuro-controladores para control de robots autónomos. De esta manera, se buscó dar soluciones en el diseño de los mismos. Dado que ésta es una meta ambiciosa, se ha reducido la cantidad de experimentos y evaluaciones técnicas llevadas a cabo. La ampliación de tales experimentos y estudios implica posiblemente varios temas de tesis. Las líneas de trabajo que se desprenden del presente trabajo incluirían, entre otros, los siguientes temas a desarrollar: Estudio de la adaptación y emergencia entre comportamientos. Si bien los comportamientos biológicos complejos, en su mayoría, presuponen una serie de sub -comportamientos, es posible argumentar la necesidad de coordinación de un mayor número de niveles de coordinación comportamental, y por ende la definición de estructuras de control más complejas. Cada uno de estos niveles puede ser tanto una red neuronal de mayor complejidad que las presentadas, o simplemente ser aproximadores universales del tipo feed -forward. En ello, tanto la definición del tamaño de las redes, como así también su tipo, pueden estar sometidos a un proceso evolutivo artificial. En especial, y como principal objetivo, dicho trabajo podría encaminar un estudio profundo de mecanismos adaptativos-evolutivos entre comportamientos a nivel generacional y fenotípico. Generación de mecanismos de aprendizaje en la Robótica Evolutiva. Estudiar cómo mecanismos de aprendizaje, vistos a través de procesos de adaptación, pueden ser incorporados en una arquitectura por niveles para soportar el ajuste de los sub-comportamientos, reviste de un alto interés teórico-práctico. Tales mecanismos podrían estar orientados a soportar procesos de re-aprendizaje (p. ej. cambios de objetivo a nivel fenotipo). En ello se podría estudiar el efecto que fue dilucidado en el presente trabajo de tesis, el cual se orienta a la comparación de neuro-controladores del tipo feedforward, plásticos, y homeostáticos-plásticos en aprendizaje. De este modo, se podría encontrar y proponer un estudio mayor al presentado en la sección 6.2.2. Aplicación de neuro-controladores a un sistema robótico real complejo. Como una de las posibles continuaciones del presente trabajo, es posible construir una arquitectura comportamental similar a la propuesta e implementarla en un sistema robótico real. En ello, pueden ser considerados otros tipos de componentes del robot, tales como diferentes sensores (p. ej. de visión y sonar) y lazos de control cerrado sobre componentes de navegación. Además, sería interesante que la aplicación fuera realizada en un nuevo contexto, tal como puede ser la navegación de vehículos submarinos o aéreos. Con ello, el sistema de control no estaría fuera del robot sino que dentro o parcialmente dentro de él. Finalmente, un estudio experimental simulado y principalmente real que implique la interacción de una cantidad mayor de comportamientos, así como reglas de coordinación, establecería un estudio concluyente de los objetivos y resultados planteados en el presente trabajo. Estudios sobre escalabilidad y replicación de experimentos. Una de las alternativas puede estar abocada a replicar experimentos encontrados en la literatura desde un plano evolutivo, utilizando una arquitectura por niveles tradicional. De esta manera, se podría proponer realizar aportes sobre los límites y beneficios de la utilización de dicha forma de evolución, tanto desde plano propuesto por la RBC como así también en RE. De este modo, se lograría no sólo desarrollar controladores para un número significativo de problemas, sino también constituir una base de controladores útiles para el problema de escalabilidad. Principalmente, sería de interés ver la posibilidad de resolver problemas comportamentales no resueltos con un enfoque tradicional, y buscar la forma de resolverlos a través de la evolución por niveles en base a los resultados encontrados en el presente trabajo. Estudio de la emergencia de módulos comportamentales. Estudios sobre posibles mecanismos naturales y su posterior sintetización artificial como módulos de software, pueden ser de utilidad para comprender cómo se generan comportamientos complejos sin la intervención de un diseñador, y por ende sin la restricción que ello conlleva a nivel definición de problema. De esta manera, las 142 Conclusiones interacciones individuo(s)-entorno, junto con un proceso adaptativo-evolutivo puede originar un nuevo paradigma de programación, el cual a partir de un conjunto de reglas y de un proceso evolutivo clásico origine una serie de comportamientos para resolver un problema complejo. Para ello, el estudio profundo de las arquitecturas presentadas en la sección 2.6.3 es de gran importancia. Desarrollo de un framework para la generación de neuro-controladores. Una de las principales alternativas para proseguir con el estudio presentado, es desarrollar un modelo formal de desarrollo en base a la herramienta generada en este trabajo de tesis. No sólo se debería especificar un modelo tipo framework, considerando patrones de diseño vinculados a la Ingeniería de Software, sino que además debe de poder vincularse a interfaces de control entre la aplicación y los simuladores robóticos disponibles. En suma, se deberían proveer herramientas para el diseño vía interfaz visual de los neurocontroladores, como así también diferentes tipos de interfaz de control de robots reales. En ello un análisis de la posibilidad de incluir simuladores realistas o robots reales dentro del proceso evolutivo es un punto crucial a ser desarrollado. Como principal objetivo, se buscaría formalizar un conjunto de componentes de software extensibles tanto a nivel experimentos, como así también a nivel algoritmos y topologías neuronales, junto con herramientas visuales para la toma de datos estadísticos durante la experimentación. Estudio de un controlador basado en la adaptación homeostática. Desde un plano científico, sería interesante construir un agente robótico que esté controlado por un conjunto de módulos neuronales (posiblemente en una organización por niveles) sujetos a adaptación homeostática. En ello, dispositivos variables internos son esenciales para la definición del robot, teniendo como finalidad la de “sobrevivir” en el entorno donde el robot sea capaz de mantenerse en un rango de variables internas aceptable. Si se utiliza evolución artificial para seleccionar la estabilidad interna, se podría implementar un mecanismo por medio del cual reconfiguraciones plásticas ocurran cuando las variables entren en zonas peligrosas. Además, dicho estudio podría implicar un análisis de sistemas biológicos animales a fin de reflejar sus características naturales, como por ejemplo la influencia del aprendizaje entre individuos y el aprendizaje a nivel fenotípico sobre la evolución y en relación a la genética de la descendencia del individuo. Temas como la emergencia de comportamientos, adaptación y parasitismo animal, y la Teoría del Caos serían posibles dominios a explorar. Estudio sobre la acumulación de adaptaciones. Desde un plano biológico, sabemos cómo todo individuo comienza su existencia. La ciencia nos dice que existe una continuidad de la vida, y que los seres vivos provienen de otros seres vivos. Pero cada generación es distinta a la anterior, y los cambios se acumulan a nivel generacional o fenotípico. De manera compleja, no dilucidada en su totalidad, cada uno de los individuos que viven hoy en la tierra deriva de uno mejor adaptado. Por lo tanto, un posible trabajo futuro sería desarrollar experimentos con la herramienta presentada en este trabajo de tesis los cuales busquen desarrollar controladores en un proceso adaptativo-evolutivo acumulativo. De esta forma, los posibles resultados podrían brindar un poco de luz a cómo esto puede explicar lo que ocurre en las generaciones de individuos a escala natural. Estudios sobre control adaptativo-evolutivo aplicado a múltiples componentes. Considerando un enfoque relacional entre componentes, una posible extensión del trabajo puede estar orientada a generar mecanismos de coordinación basados en relaciones simbióticas inspiradas en sistemas naturales, como en el caso del sistema inmunológico. Este estudio puede estar aplicado a la coordinación de múltiples robots y a la especificación de un control interno de cada robot. Para ello, puede desarrollarse un control jerárquico de comportamientos en cada robot sin que aspectos de comunicación explícita de directivas sea propuesto a nivel centralizado. Un primer paso para modelar conflictos entre niveles dentro de cada robot, o entre robots, podría orientarse a la definición de componentes de ponderación para resolver conflictos. Conclusiones 7.2.9 143 Aportes Realizados A continuación se especifica un resumen de los aportes generados: • Desarrollo de un “estudio incremental sobre escalabilidad comportamental en RE”, obteniendo un controlador capaz de gobernar la navegación de un agente robótico móvil, promoviendo reusabilidad y escalabilidad de comportamientos. • Implementación de una herramienta para reducir los esfuerzos de obtención y definición tanto de los comportamientos como de los experimentos con controladores, promoviendo reusabilidad y su utilización en sistemas de control robótico móvil. • Desde una perspectiva ingenieril, concreción de estudios preliminares para el Proyecto de I+D AUVI (Autonomous Underwater Vehicle for Inspections) [Acosta, 2005]. El primer hito propuesto en cuanto al sistema de navegación, fue logrado en este trabajo: desarrollo de un sistema de navegación reactivo en entornos no conocidos a priori basados en controladores neuronales dentro del área de RE. • En cuanto al problema de escalabilidad dentro de la RE considerando comportamientos complejos, o comportamientos compuestos por subcomportamientos, se logró alcanzar dicho estudio partiendo de la propuesta de Evolución por Niveles con “un número mayor de neuro-controladores”, “pruebas con un simulador complejo”, “experimentos con robótica real”, y “con un número mayor de tareas” en relación a trabajos disponibles en la literatura. 7.3 Publicaciones Relacionadas con este Trabajo Se han generado artículos vinculados a partes de este trabajo en diferentes revistas, congresos y workshops de divulgación sobre Ciencias de la Computación y Robótica. Las publicaciones más relevantes son las siguientes: • Fernández León, J. A.; Acosta, G. G.; Mayosky, M. A. “An Experimental Study of Scaling Up in Mobile Robot Motion Control using Evolutionary Neuro-controllers”. Enviado al IEEE Transactions on Robotics (IEEE T-RO). En referato. 2005. • Fernández León, J. A.; Tosini, M.; Acosta, G. G.; Acosta, N. “An Experimental Study on Evolutionary Reactive Behaviors for Mobile Robots Navigation”. Journal of Computer Science & Technology (JCS&T), Vol. 5, Nro. 4, pp. 183-188 (Paper Invitado). 2005. • Fernández León, J. A.; Tosini, M.; Acosta, G. G. “Evolutionary Reactive Behavior for Mobile Robots Navigation”. IEEE Conference on Cybernetics and Intelligent Systems (IEEE CIS). Proceedings of the 2004 IEEE CIS, Singapore, pp. 532-537. 2004. • Tosini, M.; Fernández León, J. A.; Acosta, G. G. “Controladores Evolutivos en Robots Móviles y su Sintetización en una Aplicación de Lógica Programable”. Simposio Latino Americano en Aplicaciones de Lógica Programable y Procesadores Digitales de Señales en Procesamiento de Videos, Visión por Computador y Robótica. Anales SLALP 2004 (CD-Rom), Brasil. 2004. Además, se han presentado otros resultados y exposiciones parciales en: • Fernández León, J. A.; Tosini, M.; Acosta, G. G.; Acosta, H. N. “Estudio experimental sobre Comportamientos reactivos-evolutivos en navegación de robots móviles”. Presentado al XI Congreso Argentino de Ciencias de la Computación (CACIC 2005). Entre Ríos, Argentina. 17-21/10/05. • Fernández León, J. A.; Tosini, M.; Acosta, N. “Estudio de la Adaptación de Controladores en Robótica Evolutiva”. VII Workshop de Investigadores en Ciencias de la Computación (WICC´05). Anales del WICC 2005 (CD-Rom). Río Cuarto, Córdoba, Argentina. 13-14/05/05. 144 Conclusiones • Fernández León, J. A. “Hipótesis sobre el rol de la Adaptación en la Emergencia de Comportamientos”. INCA/INTIA, Research Report INCA-RR-001-05. Departamento de Computación y Sistemas, UNCPBA. 2005. • Fernández León, J. A.; Acosta, G. G. “Controladores Neuronales en Robótica Evolutiva”. Workshop de Investigadores en Ciencias de la Computación (WICC´04). Facultad de Economía y Administración, Universidad del Comahue. Anales WICC´04 (CD-Rom), pp. 521-525. Neuquén, Argentina. 2021/05/04. • Fernández León, J. A.; Vulcano, A. S.; Tosini, M. “Estudio de una Arquitectura Modular para Control Robótico Autónomo”. Workshop de Investigadores en Ciencias de la Computación (WICC´04). Facultad de Economía y Administración, Universidad del Comahue. Anales WICC´04 (CD-Rom), pp. 488-491. Neuquén, Argentina. 20-21/05/04. • Fernández León, J. A. “Robótica Evolutiva: la Próxima Generación de Robots Autónomos”. I Workshop en Inteligencia Artificial aplicada a Robótica Móvil. Facultad de Ciencias Exactas, UNCPBA. Anales del CAFR 2004 (CD-Rom). Tandil, Buenos Aires, Argentina. 9-11/06/04. 7.4 Algunas Lecciones Aprendidas para el Diseño de Neuro-Controladores Evolutivos A modo de resumen final de los resultados de esta tesis, se presentan una serie de reglas empíricas que se deberían de considerar en el diseño de un controlador robótico basado en evolución artificial. Aquí se seleccionan aquellas reglas de aplicación inmediata por parte del diseñador. • No sobredimensionalizar el tamaño de los neuro-controladores en cada nivel de comportamiento. Utilizar un mayor número de neuronas en cada nivel implica un crecimiento lineal (o a veces exponencial) de costo computacional. Por lo tanto, esto puede implicar desechar arquitecturas que resuelvan apropiadamente una tarea. • Reducir la cantidad de generaciones a un valor que presente estabilidad generacional. Los ciclos evolutivos son la principal fuente de consumo de cálculo computacional. La manera más directa de reducirlos es a través de un estudio generacional, el cual busque estabilidad en la función de fitness a valores aceptables. Una vez que dicha estabilidad sea encontrada, es posible cortar el proceso y obtener el controlador que mejor desempeño presente. Un punto importante es que dicho criterio puede ser un buen factor para detener la evolución, en lugar de una cantidad de generaciones de antemano. • Considerar mecanismos que aceleren la evolución. Mecanismos como el aprendizaje pueden ser de gran utilidad a la hora de desarrollar controladores mejor adaptados y de manera más rápida. Además, la consideración de una arquitectura por niveles de comportamientos es beneficiosa, debido a que sólo se somete a un proceso evolutivo a una parte del controlador, desactivando partes del mismo que ya fueron generadas. • Explorar y explotar las características de adaptación. El diseño de algoritmos que adapten o ajusten sus comportamientos a la tarea a resolver, son las fuentes más directas de ahorro de poder computacional. La modularidad de los algoritmos es una de las características más deseables para la obtención de un controlador evolutivo. Definitivamente, los resultados a nivel comportamental no son suficientes para evaluar la calidad del algoritmo respecto de control. Existen otras características a tener en cuenta, como la capacidad de producir o no acciones no planeadas, y principalmente aspectos de robustez morfológica y del entorno. • Registrar siempre que sea posible. Es importante registrar siempre que sea posible tanto las entradas como las salidas del controlador. Más aún, en las señales de salida de cada controlador es conveniente registrar sus acciones a fin de ser utilizadas para potenciales análisis del comportamiento grupal de los componentes comportamentales. • En la selección del algoritmo genético, cuidar el proceso de selección. Para determinados problemas, es conveniente utilizar algoritmos genéticos basados en la selección de los mejores Conclusiones 145 adaptados. En cambio para otros, es mejor seleccionar los que peor se adapten y mantener un rango de diversidad generacional mayor. Eventualmente, debe ser estudiado en forma profunda la utilización de mecanismos tales como cruzamiento y mutación de individuos. • Diseño cuidadoso de los experimentos a realizar. Como es de esperar, se debe prestar especial interés al desarrollo de las pruebas a resolver. Particularmente, aquí debe considerarse la función de evaluación del desempeño de los controladores (función de fitness). Dicha definición conllevará posiblemente al éxito o fracaso del experimento. 7.5 Resumen de los Experimentos Desarrollados Finalmente, se presenta una tabla resumiendo las características de los experimentos desarrollados. Sección Motivación Objetivo 5.3.1 Replicar parte del experimento propuesto por Nolfi y Parisi [Nolfi et al., 1997], y principalmente el experimento presentado por Floreano y Mondada [Floreano et al., 1996a] considerando la búsqueda de objetivo (fototaxis). Obtención de controladores optimales para comportamientos simples mediante un controlador monolítico. Búsqueda del mejor neuro-controlador para cada tarea simple según el criterio de robustez y adaptabilidad dentro de un proceso evolutivo. Comparación parcial con controladores monolíticos en relación con [Togelius, 2003] y otros trabajos. Controladores: FFNN, RFFNN, CTRNN, PNN, y HPNN. 5.3.1.6 Replicar el experimento propuesto en Analizar y verificar en forma experimental [Togelius, 2003] sobre búsqueda de objetivo con la finalidad de comparar los resultados condicional (fototaxis condicional). obtenidos con otros experimentos desarrollados en [Togelius, 2003]. Verificar en forma experimental el mejor controlador obtenido durante el proceso evolutivo (sección 5.3.1) ante alteraciones del objetivo. Controlador: HPNN. 5.3.2 Replicar parte del experimento de Nolfi et al. Objetivos similares a los señalados para la [Nolfi et. al, 2000, Cap. 4] considerando la sección 5.3.1, pero enfocado en observar evasión de obstáculos. cuáles son los resultados del desarrollo de controladores considerando un entorno cerrado con obstáculos. 5.3.2.6 Replicar en parte el experimento propuesto en [Togelius, 2003] y [Nolfi et al., 2000, Cap. 4] considerando la evasión de obstáculos con objetivo (navegación). Objetivos similares a los señalados para la sección 5.3.1.6, pero enfocado en observar cuáles son los resultados del desarrollo de controladores considerando un entorno cerrado con obstáculos según la búsqueda de objetivo. Controlador: HPNN. 146 Conclusiones 5.3.3 Replicar en parte el experimento propuesto Objetivos similares a los señalados para la en [Togelius, 2003] y [Nolfi et al., 2000] sección 5.3.1, pero enfocado en observar considerando aprendizaje de objetivo. cuáles son los resultados del desarrollo de controladores considerando un aprendizaje por refuerzos. 5.3.3.6 Replicar en forma parcial el experimento Objetivos similares a los señalados en la propuesto en [Togelius, 2003] en aprendizaje sección 5.3.1.6, pero enfocado en observar con variaciones deliberadas del objetivo. cuáles son los efectos del aprendizaje por refuerzos evolutivo. Controlador: HPNN. 6.2.2 Experimentos con Evolución por Niveles. Coordinación de comportamientos en una organización por Subsumisión [Brooks, 1986]. Desarrollo sobre un simulador complejo. Comparación de la evolución monolítica con respecto a la Evolución por Niveles con múltiples redes, considerando estudios con los mejores controladores simples desarrollados en las secciones anteriores. Comparaciones con los resultados obtenidos en [Togelius, 2003]. 6.2.3.1.1 Experimentos con el controlador generado en la sección 6.2.2 sobre seguimiento de paredes en un ambiente tipo laberinto. Replicación parcial del experimento propuesto en [Maaref et al., 2002]. Desarrollo sobre un simulador complejo. El objetivo a cumplir es que el robot pueda ajustarse a la forma de las paredes, y a la forma de los obstáculos que están presentes en el entorno. 6.2.3.1.2 Repetir los experimentos previos sobre un simulador simple y realizarlo en un modelo complejo del ambiente. Comportamiento de Búsqueda de Objetivo. Se tiene por objetivo que el robot se acerque a una fuente de luz mientras evade obstáculos. Comparación con resultados en entorno simple. 6.2.3.1.3 Verificar si con una configuración por niveles Similar a la sección 6.2.3.1.2 pero con es posible generar un comportamiento de evasión de obstáculos convexos. navegación en un entorno tipo laberinto [Maaref et al., 2002][Nolfi et al., 2000]. Desarrollo sobre un simulador complejo. 6.2.3.1.4 Verificar si con una configuración por niveles Similar a la sección 6.2.3.1.2 pero con es posible generar un comportamiento de evasión de obstáculos cóncavos. navegación en un entorno tipo laberinto teniendo como objetivo evitar situaciones de bloqueo. Combinar diferentes comportamientos [Maaref et al., 2002]. Desarrollo sobre un simulador complejo. 6.2.3.1.5 Coordinar diferentes comportamientos Coordinación de Comportamientos en un [Maaref et al., 2002]. Desarrollo sobre un entorno con diferentes tipos de simulador complejo. obstáculos. 6.2.3.1.6 Verificar robustez a variaciones ambientales Establecer la habilidad del controlador a [Greer, 2002]. Desarrollo sobre un simulador adaptarse a perturbaciones ambientales. complejo. Conclusiones 147 6.2.3.1.7 Verificar robustez a variaciones morfológicas Establecer la habilidad del controlador a [Greer, 2002][Di Paolo, 2000]. Desarrollo adaptarse a perturbaciones morfológicas. sobre un simulador complejo. 6.2.4 Verificar el desempeño del controlador final por niveles en un entorno real aplicado a un robot Khepera. Replicar parcialmente experimentos propuestos en [Nelson et al., 2004]. Obtener un controlador viable para el control de un robot real. Análisis y ajuste de las diferencias generadas entre un entorno simulado complejo y la realidad. Tabla 32 – Resumen de los experimentos desarrollados, propósitos y motivaciones. Apéndice - NOTAS PARA EL USUARIO NOTAS PARA EL USUARIO Para realizar los experimentos presentados en este trabajo de tesis, se desarrolló un conjunto de clases de software, las cuales constituyen una herramienta para la generación de resultados experimentales con controladores robóticos. En este apéndice, se detallan brevemente algunas de las características de la herramienta, la cual fue mencionada a lo largo del presente trabajo. No se especificará aquella información referida a cómo utilizar la herramienta en forma completa. Sin embargo, se detalla cómo compilar la totalidad de los componentes, junto con un esquema general de la relación entre ellos. A.1. Módulos de Software Los diferentes módulos de software fueron desarrollados en el lenguaje de programación Java, por lo cual tienen la utilidad de ser usados bajo Windows y Linux, según la especificación del lenguaje. Los diferentes componentes, tales como la descripción de la funcionalidad de las redes neuronales, los correspondientes a los tests experimentales, así como también la funcionalidad de la representación del genotipo de cada controlador, son modelados como una clase abstracta. Las diferentes implementaciones de tales clases, se modelan como extensiones para luego crear instancias de las mismas. Todos los parámetros fueron especificados en el programa, y aquellos que presentaron un carácter general a varios tipos de representaciones, p. ej. el caso de la cantidad de neuronas de cada capa para las redes neuronales, fueron definidos en una clase especial denominada ResBundle.java. La interacción principal entre la herramienta y el simulador está dada a través de un conjunto de interfaces. Cada una de ellas especifica la forma de comunicación con un simulador en particular. Cabe aclarar que la definición de las mismas es extensible a otros simuladores por parte del programador. Del mismo modo, la única interacción desarrollada con el usuario fue a través de un conjunto de clases que muestran de manera gráfica los datos de un experimento, p. ej. las actividades de las neuronas y las señales de entrada y salida. Básicamente, dado que se utilizó un lenguaje orientado a objetos, se buscó modularizar cada uno de los componentes. Como es de esperar, cada uno de ellos se agrupó en paquetes de clases con funcionalidad en común (p. ej. diferentes tipos de redes neuronales). En cuanto a uno de los componentes de visualización desarrollados, la clase PlotTester.java es la encargada de graficar las señales de las neuronas o los datos sensados del entorno. 150 Apéndice Figura 120 – Principales clases implicadas con la clase NeuroController. La clase principal en la cual se especifica el test a realizar, conjuntamente con los tipos de controladores implicados, corresponde a NeuroController.java. La clase denominada EmpiricalTest.java especifica las características mínimas (métodos y definiciones de estructuras) que debe poseer la definición de un test experimental. Cada una de las clases señaladas contiene la funcionalidad concreta del componente al que modela. Por ejemplo, la definición de una red neuronal genérica (Network.java) contiene la representación de las diferentes conexiones sinápticas junto con sus pesos. Esto representa una funcionalidad común a todas las definiciones fenotípicas de las redes a generar. De manera similar, la definición del genotipo (Genotype.java) modela las distintas representaciones neuronales durante el proceso evolutivo. De esta forma, la extensión de dichas clases hereda la definición de estructuras específicas a cada clase genérica (clase abstracta), y permite que sean incorporadas definiciones adicionales. Por ejemplo, para la creación de un genotipo homeostático-plástico (GenotypeHPNN.java) se definirá una estructura vinculada a las reglas plásticas, mientras que para una representación del tipo CTRNN (GenotypeCTRNN.java) se definirán, por ejemplo, constantes temporales (véase sección 4.2.4). En la Figura 121 se muestra un diagrama de clases de la herramienta. Las principales clases son: NeuroController.java, GeneticAlgorithm.java, Network.java, Genotype.java, Neuron.java, EmpiricalTest.java y ResBundle.java 151 Apéndice Figura 121 – Diagrama de la asociación entre las principales clases desarrolladas. 152 Apéndice A.2. Interfaces con el Robot Al momento de definir un test experimental, es necesario especificar tanto la interfaz de simulación como la comunicación con el robot real. Esto se lleva a cabo de diferentes maneras. En el caso de realizar un experimento simulado, se define una interfaz de comunicación con el simulador, considerando la funcionalidad mínima necesaria representada en SimulatorInterface.java. De esta manera, cualquier experimento puede comunicarse de manera genérica con cualquier simulador disponible. Posteriormente, dependiendo de una configuración interna de dicha clase, se dirigirán los diferentes comandos de control según el simulador deseado. En ello intervendrá otro tipo de interfaz, la cual mapeará la funcionalidad provista por cada simulador para ser entendida por el test implementado. Como ejemplo de tal tipo de interfaz, la clase YAKSModel.java modela el mapeo antes referido para el simulador YAKS [Karlson, 2002]. Por otro lado, en el caso de realizar un experimento en un entorno real, se debe establecer la comunicación con el robot real, y dado que fue seleccionado el simulador YAKS modificado (véase sección 3.4.5) se procede a habilitar el seteo run_real 1, baud_rate 38400, serial_line /dev/ttyS0 del archivo de configuración de dicho simulador (p. ej. simple.opt en el directorio raíz). Así, la misma funcionalidad presentada al momento de trabajar en forma simulada, está disponible cuando se realizan pruebas en el entorno real. En la Figura 122 se muestra un diagrama de clases de la relación entre la interfaz genérica con los simuladores, asociado a una definición del test experimental. Figura 122 – Principales clases implicadas con la interfaz de simulación. Para poder interceptar los mensajes (especialmente el sensado del entorno) de un simulador o del robot real, existen una serie de comandos a ser definidos. Los principales son: communication, readProximitySensors, readLightSensors, turnRobot , advance. Estos comandos permiten captar los valores sensados, como así también enviar señales sobre los actuadores en forma de ángulo de desviación y avance. Particularmente, el método communication es el responsable dentro de la clase SimulatorInterface.java, y en su eventual instancia (p. ej. YAKSModel.java) de comunicarse vía socket a un puerto de comunicación que será leído por el simulador respectivo. En el caso que se quiera realizar la comunicación entre la aplicación de control y un simulador, se deberá modificar solamente la interfaz entre ambos componentes. Así, se reflejarán los métodos necesarios por la aplicación vinculados al simulador. 153 Apéndice Por lo tanto, resulta de gran importancia disponer de interfaces que reflejen fielmente la funcionalidad de cada simulador, junto con su respectiva documentación. Esto resulta útil con simuladores que posean depuradores internos y herramientas de visualización. En general, lo antes expresado permite extender la funcionalidad del conjunto de experimentos en función del simulador o entorno a utilizar. A.3. Definición de un Experimento Cuando se quiere llevar a cabo un test experimental, es necesario especificar los componentes intervinientes. Según el contexto planteado en este trabajo, se deberá definir que tipo de red neuronal definirá la funcionalidad de los controladores, junto con su representación genotípica. Además, será necesario precisar cuál será el criterio de evaluación del desempeño de cada controlador (función de fitness). Dicha función estará definida dentro de la clase que codifica al test. Esta clase contiene, entre otras cosas, información acerca de los métodos que captan la señal del entorno (simulado o real) junto con la sentencia de invocación a la actualización de los valores internos de la red o sentencia de generación de una señal de control. Tal señal será enviada vía interfaz con el simulador a los actuadores del robot. Por lo tanto, la clase que extenderá de EmpiricalTest.java será responsable de asociar todos los componentes que deben ser activados al ejecutarse un experimento. Para determinar cuál va a ser el experimento a ser ejecutado, y con qué algoritmo, la clase principal NeuroController.java, activará una instancia de un experimento, junto con el algoritmo encargado de seleccionar controladores en base a la definición de la función de fitness. A.4. Compilación El desarrollo de los diferentes componentes fue evolucionando a través del tiempo. Al inicio se desarrolló bajo JDK 1.3.1 y 1.4.1, pasando por herramientas gráficas que utilizan dicho compilador, hasta entornos de trabajo más avanzados. Finalmente, se decidió realizar el proyecto final bajo Borland JBuilder 7.0 Enterprise Edition. La totalidad de archivos (clases Java) que representan la funcionalidad de la aplicación, pueden ser compilados de manera conjunta utilizando comandos Java sobre la clase principal NeuroController.java. Además, y de manera más simple, es posible desarrollar un proyecto mediante JBuilder 7.0 o superior desde Windows. A.5. Seteo de parámetros Los diferentes parámetros de la aplicación están agrupados dentro de la clase ResBundle.java. Tales parámetros pueden ser modificados antes de la compilación a fin de obtener la morfología y aspectos del controlador y del entorno a ser considerados en el programa. Además, se codifican algunos parámetros intervinientes en el algoritmo genético. Algunas de las definiciones son: Parámetro Descripción INFRA_POTENC_SENSOR Factor de importancia de los sensores ELITISM Modelo de selección genético. MAXIMUM_SYNAPTIC_WEIGHT Máximo valor de peso sináptico. MINIMUN_SYNAPTIC_WEIGHT Mínimo valor de peso sináptico. 154 Apéndice INIT_SYNAPTIC_WEIGHT Proporción de inicialización de los pesos. RUNS Número de corridas. MAX_GENERATIONS Cantidad de generaciones. ITERATIONS Número de movimientos por corrida MUTATION_RATE Tasa de mutación. POPULATION_SIZE Tamaño de la población. NUMBER_OBSTACLES Número de objetos en el entorno. NUMBER_SOURCES Cantidad de obstáculos. I_NEURONS Número de neuronas de entrada. H_NEURONS Cantidad de neuronas ocultas. O_NEURONS Cantidad de neuronas de salida. INFRA_NOISE Nivel de ruido en los sensores infra-rojo. LIGHT_NOISE Nivel de ruido en los sensores de luz. Tabla 33 – Ejemplos de parámetros de programa BIBLIOGRAFIA [Abbott et al., 2004] Abbott, L. F.; Regehr W. G. Synaptic Computation. Nature, Vol. 431, pp. 796-803. 2004. [Ackley et al., 1990] Ackley, D. H.; Littman, M. L. Generalization and scaling in reinforcement learning. In Touretsky, D. S. (Ed.). Advances in Neural Information Processing Systems 2, pp. 550-557. Morgan Kaufmann, San Mateo, CA. 1990. [Acosta, 2005] Acosta, G. G. (2005). Proyecto 03027 – AUVI (Autonomous Underwater Vehicle for Inspections), 6th European Framework Programme for Research and Development, financiado por la Unión Europea, contrato MIF1-CT-2004-003027, septiembre 2004/septiembre 2007. [Ansel, 1999] Ansel, L. W. A quantitative model of the Simpson–Baldwin effect. J. Theor. Biol. 196, 197–209. 1999. [Aristoteles, 1955] Aristoteles. Aristotle: Parts of Animals. Cambridge, Mass., Hardvard University Press, pp. 103. 1955. [Arkin, 1998] Arkin, R. C. Behavior-Based Robotics. The MIT Press, Cambridge, Massachusetts, 1998. [Ashby, 1960] Ashby, W. R. Design for Brain: The Origin of Adaptive Behaviour. London: Chapman and Hall, 2nd edition, 1960. [Baker et al., 1996] Baker, G. L.; Gollub, J. B. Chaotic Dynamics: An Introduction, 2nd ed. Cambridge, England: Cambridge University Press, 1996. [Baldwin, 1896] Baldwin, J. M. A new factor in evolution. American Naturalist, 30:441-451, 1896. [Beale et al., 1990] Beale R.; Jackson, T. Neural Computing, an Introduction. Adam Hilger, Bristol, 1990. [Beer et al., 1992] Beer, R. D.; Gallagher, J. C. Evolving dynamical neural networks for adaptive behaviour. Adaptive Behavior, 1(1):91-122, 1992. [Beer, 1990] Beer, R. D. Intelligence as Adaptive Behavior: An Experiment in Computer Neuroscience. San Diego: Academic Press, 1990. [Beer, 1995] Beer, R. On the dynamics of small continuous-time recurrent neural networks. Adaptive Behaviour 3(4):471-511, 1995. [Beer, 1996] Beer, R. D. Towards the evolution of dynamical neural networks for minimally cognitive behaviour. In Maes, P.; Mataric, M. J.; Meyer, J-A.; Pollack, J. B.; Wilson, S. W., editors, From Animals to Animats 4: Prooceedings of the 4th Int. Conf. on Simulation of Adaptive Behaviour, pp. 421-429. MIT Press, 1996. [Beer, 2001] Beer, R. D. The dynamics of active categorical perception in an evolved model agent. Submitted to Behavioral and Brain Sciences, 2001. [Beer, 2003] Beer, R. D. The dynamics of active categorical perception in an evolved model agent. Adaptive Behavior, 11(4):209-243, 2003. [Belovsky, 1984] Belovsky, M. G. American Midland Naturalist, 111, pp. 209-222. 1984. [Benreguieg et al., 1998] Benreguieg, M.; Maaref, H.; Barret, C. Navigation of an autonomous mobile robot by coordination of behaviors. In Proceedings of the Third IFAC Symposium on Intelligent Agent Autonomous Vehicles, pp. 589-594, Madrid, March 25-27. 1998. [Bishop, 1995] Bishop, C. Neural Networks for Pattern Recognition. Clarendon Press, 1995. [Blynel et al., 2003] Blynel, J.; Floreano, D. Exploring the T-Maze: Evolving Learning-like Robot Behaviors CTRNNs. In Proceedings of EvoROB2003: 2nd European Workshop on Evolutionary Robotics, 2003. [Bradshaw, 1997]. Bradshaw, J. M. Software Agents. AAAI Press, Menlo Park, USA, 1990. [Braitenberg, 1987] Braitenberg, V. Vehicles – Experiments in Synthetic Psychology. The MIT Press, CA. 1987. 156 Bibliografía [Brooks, 1986] Brooks, R. A. A robust Layered control System for a Mobile Robot. IEEE Journal of Robotics and Automation, 2: 14-23, 1986. [Brooks, 1991] Brooks, R. A. Intelligence without representation. Artificial Intelligence, 47:139-159, 1991. [Brooks, 1991a] Brooks, R. A. Intelligence without reason. A.I. Memo Nro. 1293, MIT AI Laboratory. April 1991. [Brooks, 1999] Brooks, R. A. Cambrian Intelligence. Cambridge, MA: MIT Press. 1999. [Burnet et al., 1964] Burnet, A. L.; Eisner, T. Adaptación Animal. Serie Moderna de Biología. Continental (Ed.). 1964. [Calabretta et al., 2000] Calabretta, R.; Nolfi, S.; Parisi, D.; Wagner, G. Duplication of Modules Facilitates Functional Specialization. Artificial Life, 6(1), 69-84, 2000. [Cecconi et al., 1996] Cecconi, F.; Menczer, F.; Belew, R. W. Maturation and the evolution of imitative learning in artificial orgenisms. Adaptive Behavior, 4: 29-50. 1996. [Codonie et al., 1997] Codonie, W.; Hondt, K. D.; Steyaert, P.; Vercammen, A. From custom applications to domain-specific frameworks. Communications of the ACM, 40(10):71-77, 1997. [Cormen et al., 2001] Cormen, T. H.; Leiserson, C. E.; Rivest, R. L.; Stein, C. Introduction to Algorithms. Second Edition, Cambridge, MA: MIT Press, 2001. [Dale, 1994] Dale, K. Evolving Neural Network Controllers for Task Defined Robots. MSc in Knowledge-Based Systems. University of Sussex. 1994. [Darwin, 1859] Darwin, Ch. On the Origin of Species by Means of Natural Selection. Londres: Murria, 1859. El origen de las especies. Traducción de Juan Godo. Barcelona: Ediciones Zeus, 1970. [Dawkins, 1986] Dawkins, R. The Blind Wachmaker. Nueva York, W. W. Norton. 1986. Traducción al Español: El Relojero Ciego, Barcelona, RBA, 1993. [Descartes, 1637] Descartes, R. Discours de la méthode pour bien conduite sa raison et checher la verité dans les sciences, 1637. Discurso del método – Meditaciones Metafísicas. Biblioteca de los grandes pensadores. Traducción de Rodríguez Huéscar, A., 2004. [Di Paolo, 2000] Di Paolo, E. Homeostatic adaptation to inversion of the visual field sensorimotor disruptions. Proceedings of SAB 2000, MIT Press, 2000. [Di Paolo, 2002] Di Paolo, E. A. Evolving robust robots using homeostatics oscillators. Cognitive Science research paper 536, School of Cognitive and Computing Sciences: University of Sussex, 2002. [Di Paolo, 2002a] Di Paolo, E. A. Fast homeostatic oscillators induce radical robustness in robot performance. Proc. of SAB´2002, MIT Press. 2002. [Di Paolo, 2003] Di Paolo, E. A. Organismically-inspired robotics: Homeostatic adaptation and natural teleology beyond the closed sensorimotor loop. K. Murase & T. Asakura (Eds), Dynamical Systems Approach to Embodiment and Sociality, Advanced Knowledge International, Adelaide, Australia, pp 19 - 42. 2003. [Dopazo et al., 2003] Dopazo, H.; Gordon, M. B.; Perazzo, R. S.; Risau-Gusman, S. A Model for the Emergence of Adaptive Subsystems. Bulletin of Mathematical Biology, 65, Elsevier, pp. 27–56. 2003. [Elman, 1990] Elman, J. L. Finding structure in time. Cognitive Science, 14:179-211, 1990. [Encarta, 2003] Biblioteca de Consulta Microsoft® Encarta®, 2003. [Evorobot, 2000] Nolfi, S. Evorobot evorobot/ simulator.html. 2000. 1.1 – User Manual. URL: http://gral.ip.rm.cnr.it/ [Fernández et al., 2004] Fernández León, J. A.; Tosini, M. A.,; Acosta, G. G. Evolutionary Reactive Behavior for Mobile Robots Navigation. 2004 IEEE Conference on Cybernetics and Intelligent Systems (CIS), Singapore, December 1-3, 2004. Bibliografía 157 [Fernández et al., 2005a] Fernández León, J. A.; Acosta, G. G.; Mayosky, M. A. An Experimental Study of Scaling Up in Mobile Robot Motion Control using Evolutionary Neuro-controllers. Enviado al IEEE Transactions on Robotics (IEEE T-RO). En referato. 2005. [Fernández et al., 2005b] Fernández León, J. A.; Tosini, M.; Acosta, G. G.; Acosta, N. An experimental study on Evolutionary Reactive Behavior for Mobile Robots Navigation. Enviado al Journal of Computer Science & Technology (JCS&T), Vol. 5, Nro. 4, pp. 183-188 (Paper Invitado). 2005. [Fernández, 2005] Fernández León, J. A. Hipótesis sobre el rol de la Adaptación en la Emergencia de Comportamientos. INCA/INTIA, Research Report INCA-RR-001-05. Dep artamento de Computación y Sistemas, UNCPBA. 2005. [Floreano et al., 1994] Floreano, D.; Mondada, F. Automatic creation of an autonomous agent: genetic evolution of a neural-network driven robot. In D. Cliff, P. Husbands, J. Meyer and S.W. Wilson (Eds.). From Animals to Animats 3: Proceedings of Third Conference on Simulation of Adaptive Behavior. Cambridge, MA: MIT Press/Bradford Books. 1994. [Floreano et al., 1996] Floreano, D.; Mondada, F. Evolution of Plastic Neurocontrollers for Situated Agents. In P. Maes, M. Mataric, J. A. Meyer, J. Pollack & S. Wilson (Eds.). From Animals to Animats 4, Proceedings of the International Conference on Simulation of Adaptive Behavior, Cambridge, MA: MIT Press, 1996. [Floreano et al., 1996a] Floreano, D.; Mondada, F. Evolution of Homing navigation in a real mobile robot. IEEE Transaction on Systems, Man, and Cybernetics-Part B: Cybernetics, 26(3):396-407. 1996. [Floreano et al., 1997] Floreano, D.; Mondada, F. Evolutionary neurocontrollers for autonomous mobile robots. Neural Networks, 11:1461-1478, 1997. [Floreano et al., 1998] Floreano , D.; Mondada, F. Evolutionary Neurocontrollers for Autonomous Mobile Robots. Neural Networks, 11, pp. 1461-1478, 1998. [Floreano et al., 1998b] Floreano, D.; Urzelai, J. I. Evolution and learning in autonomous robots. In D. Mange and M. Tomassini, editors, Bio-Inspired Computing Systems, PPUR, Lausanne, 1998. [Floreano et al., 1999] Floreano, D.; Urzelai, J. (1999) Evolution of Adaptive-Synapse Controllers. In D. Floreano et al. (Eds.), Advances in Artificial Life. Proceedings of the 5th European Conference on Artificial Life, Berlin: Springer Verlag. (ECAL'1999). 1999. [Floreano et al., 1999b] Floreano, D.; Urzelai, J. Evolution of Neural Controllers with Adaptive Synapses and Compact Genetic Encoding. In D. Floreano, J-D. Nicoud, and F. Mondada, editors, Advances in Artificial Life. Springer Verlag, Berlin. 1999. [Floreano et al., 2000] Floreano, D.; Urzelai, J. Evolutionary Robotics with on-line self-organization and Behavioral Fitness. Neural Networks, 13, pp. 431-443, 2000. [Forde et al., 2004] Forde, S. E. ; Thompson, J. ; Bohannan, B. J. M. Adaptation varies through space and time in a coevolving host-parasitoid interaction. Nature, Vol. 431. 2004. [Gallagher, 1999] Gallagher, J. WSU Java Simulator. URL:http://gozer.cs.wright.edu/ classes/ceg499/resources/WSU_Sim_v50.zip. 1999. [Gell-Mann, 1994] Gell-Mann, M. Complex Adaptive Systems. In Morowitz H, Singer JL - The Mind, the Brain and Complex Adaptive Systems - Addison-Wesley. 1994 [Gellon, 2004] Gellon, G. El huevo y la Gallina - Manual de instrucciones para construir un animal. Colección Ciencia que Ladra..., Siglo XXI Ed., 2004. [Goldberg, 1989] Goldberg, D. E. Genetic algorithms in search, optimization and machine learning. Addison –Wesley, Redwood, Ontario, Canada, 1989. [Gómez et al., 1996] Gómez, F.; Miikkulainen, R. Incremental Evolution of Complex General Behavior. Technical report AI96-248, Austin, TX: University of Texas, 1996. 158 Bibliografía [Gómez et al., 1999] Gómez, F.; Miikkulainen, R. Solving non-markovian Control Tasks with Neuroevolution. Proceedings of the 16 th Internacional Joint Conference on Artificial Intelligence, Denver, Co, Morgan Kaufmann, 1999. [Gomi, 1998] Gomi, T. Non-Cartesian Robotics – The First 10 years. In Gomi, T. (Ed.), Evolutionary Robotics, From Intelligent Robots to Artificial Life, Katana, Canada. AAI Books, 1998. [Grau, 1994] Grau, F. Automatic definition of modular neural neworks. Adaptive Behavior, 3:151-183, 1994. [Greer, 2002] Greer, D. An Exploration of Viable Architectures for Homeostatic Robot Controllers. MSc Thesis, University of Sussex. 2002. [Harvey et al., 1996] Harvey, I.; Stone, J. V. Unicycling helps your French: spntaneous recovery of associaciations by learning unrelated tasks. Neural Computation, 8:697-704. 1996. [Harvey, 1992] Harvey, I. The SAGA cross. The mechanics of recombination for species with variable length genotypes. In R. Manner and B. Manderick (Eds.), Parallel Problem Solving from Nature 2. Amsterdam: NorthHolland, 1992. [Harvey, 1996] Harvey, I. Relearning and evolution in neural networks. Adaptive Behavior, 4(1): 1-84. 1996. [Harvey, 1997] Harvey, I. Is there another new factors in evolution? Evolutionary Computation, 4(3): 313-329. 1997. [Haykin, 1999] Haykin, S. Neural Networks, A comprehensive Foundation. Second Edition. Prentice Hall, 1999. [Hinton et al., 1987] Hinton, G.; Nowlan, S. How learning can guide evolution. Complex Systems, 1:495-502, 1987. [Holland, 1975] Holland, J. H. Adaptation in natural and artificial systems – An introductory analysis with applications to biology, control, and artificial intelligence. The University of Michigan Press, Ann Arbor, 1975. [Husbands et al., 1998] Husbands, P.; Smith, T. ; Jakobi, N.; O’Shea, M. Better living through chemistry : Evolving gasnets for robot control. Connection Science, 10:185-210. 1998. [Jennings et al., 1998]. Jennings, N. R.; Sycara, K.; Wooldridge, M. A roadmap of agent research and development. Journal of Autonomous Agents and Multi-Agents Systems, 1(1):7-38, 1998. [Jordan et al., 2001] Jordan, M. I.; Rumelhart, D. Intenal world models and supervised learning. In Proceedings of the Eighth International Workshop on Machine Learning, pp. 70-74. Ithaca, NY.1991. [Kaplan et al., 2003] Kaplan, F.; Oudeyer, P-Y. Motivational Principles for Visual Know-How Development. Proceedings of the 3rd Epigenetic Robotic Workshop, pp. 72-80, 2003. [Karlson, 2002] Karlson, J. YAKS - Yet Another Khepera Simulator . URL: http://r2d2.ida.his.se/ [Keijzer, 2001] Keijzer, F. Representation and Behavior. Cambridge, MA: MIT Press, 2001 [Khatib, 1986] Khatib, O. Real time obstacla avoidance for manipulators and mobile robot. International Journal of Robotics Research 5 (1), pp. 90-99. 1986. [Khepera, 1999] Khepera User Manual, Version 5.02. K-Team, Lausanne, 1999. [Khepera, 2004] Khepera, mini robot . K-Team. http://www.k-team.com/robots/khepera /index.html, 2004. [Logan, 1998] Logan, B. Classifying agent systems. In AAAI-98 Workshop on Software Tools for Developing Agents, Madison, Wisconsin, USA. 1998. [Maaref et al., 1996] Maaref, H.; Benreguieg, M.; Barret, C. Navigation of a mobile robot in fuzzy turned artificial potential field. In Proceedings of the IEEE/IMACS International Conference, CESA’96, Robotics and Cybernetics. pp. 189-191, Lille, July 10-13. 1996. [Maaref et al., 2002] Maaref, H.; Barref, C. Sensor-based navigation of a mobile robot in an indoor environment. In Robotics and Autonomous Systems, 38, pp. 1-18. Elsevier. 2002. [Maes, 1992] Maes, P. Learning behavior networks from experience. In F. J. Varela, P. Bourgine (Eds.), Towards a Practice of Autonomous Systems: Proceedings of the First European Conference on Artificial Life. Cambridge, MA: MIT Press/Bradford Books, 1992. Bibliografía 159 [Mataric, 1997] Mataric, M. J. Reinforcement Learning in the Multi-Robot Domain. Autonomous Robots, 4(1), pp. 73-83, 1997. [Maturana et al., 1980] Marturana, H. R.; Varela, F. J. Autopoiesis and cognition: the realization of the living. Dordrecht: Reidel, 1980. [Mayley, 1997] Mayley, G. Landscapes, learning costs, and genetic assimilation. Evolutionary Computation, 4(3):213234, 1997. [McCulloch et al., 1943] McCulloch, W.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics, 5, 115-133, 1943. [McFarland et al., 1993] McFarland, D.; Bosser, U. Intelligent Behavior in Animals and Robots. MIT Press, Cambridge, MA. 1993. [Michell, 1996] Michell, M. An Introduction to Genetic Algorithms. MIT Press, 1996. [Minglino et al., 1995] Minglino, O.; Luna, H.; Nolfi, S. Evolving mobile robots in simulated and real environments. Artificial life, 2:417-434. 1995 [Minsky, 1988] Minsky, M. The Society of Mind. Touchtone Books. 1988. [Moravec, 1988] Moravec, H. Mind Children: the nature of robot and human Intelligence. Harvard University Press, Cambridge, MA, 1988. [Nature, 2004] Tanguy, Ch. Plasticity & Neural Computation. Nature, Vol. 431, Nro. 7010, pp. 759-803. 2004. [Nelson et al., 2004] Nelson, A. L.; Grant, E.; Galeotti, J. M.; Rhody, S. Maze exploration behaviors using an integrated evolutionary robotic environment. Elsevier. Robotic and Autonomous Systems 46, pp. 159-173, 2004. [Nesse et al., 1994] Nesse, R. M.; Williams, G. C. Why We Get Sick. Vintage Books, Random House Inc. NY. 1994. Traducción al Español: ¿Por qué enfermamos? Por Francisco Ramos. Grijalbo. 2000. [Nolfi et al., 1997] Nolfi S.; Parisi, D. Learning to adapt to changing environments in evolving neural networks. Adaptive Behavior, 5, 75-98. 1997. [Nolfi et al., 2000] Nolfi, S.; Floreano, D. Evolutionary Robotics: The Biology, Intelligence, and Technology of SelfOrganizing Machines. MA: MIT Press/Bradford Books, 2000. [Nolfi, 1996] Nolfi, S. Adaptation is a more powerful tool than decomposition and integration. In T.fogarty and G. Venturini (Eds.) Proceedings of the Workshop on Evolutionary Computing and Machine Learning, 13th International Conference on Machine Learning, Bari, 1996. [Nolfi, 1997] Nolfi, S. Using Emergent Modularity to Develop Control Systems for Móbile Robots. Connection Science, 10, 3-4, 167-183, 1997. [Nolfi, 1998] Nolfi, S. Adaptation as a more powerful than decomposition and integration: Experimental evidences from evolutionary robotics. In P. K. Simpson (Ed.), Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE’98), New York: IEEE Press, 141-146, 1998. [Nolfi, 1999] Nolfi, S. How learning and evolution interact: the case of a learning task which differs from the evoutionary task. Adaptive Behaviour, 7(2):231-236. 1999. [Nolfi, 2002] Nolfi, S. Evolving robots able to self-localize in the environment: the importance of viewing cognition as the result of processes ocurring at different time scales. Connection Science (14) 3:231-244. 2002. [Nolfi, 2005] Nolfi, S. Behaviour as a Complex Adaptive System: On the role of Self-Organization in the Development of Individual and Collective Behaviour. Unpublished, 2005. [Parisi et al., 1992] Parisi, D.; Nolfi, S.; Cecconi, F. Learning, Behavior and Evolution. In F. Varela and P. Bourgine (Eds.). Toward a Practice of Autonomous Systems, pp. 207-216. Cambridge, MA: MIT Press. 1992. [Parker, 1998] Parker, L. E. ALLIANCE: an architecture for fault tolerance multi-robot cooperation. IEEE Transactions on Robotics and Automation. 1998. 160 Bibliografía [Pfeifer et al., 1999] Pfeifer, R.; Scheier, C. Understanding Intelligence. MIT Press, Cambridge, MA, 1999. [Potgieter, 2004] Potgieter, A. E. G. The engineering of emergence in complex adaptive systems. Doctoral Thesis. Univ. of Pretoria, 2004. http://upetd.up.ac.za/thesis/available/etd-09222004-091805/ [Prescott et al., 1999] Prescott, T. J.; Redgrave, O.; Gurney, K. Layered control architectures in robots and vertebrates. Adaptive Behavior, 7, 99-127, 1999. [Quammen, 2004] Quammen, D. ¿Estaba equivocado Darwin?. National Geographic – En Español, pp. 2-35, Noviembre 2004. [Rational, 1997] Rational Software. UML Notation Guide. Racional Software, 1997. [Renders, 1991] Renders, J. M. Biological methaphor applied to process control. PhD Dissertation. Université Libre de Bruxelles. 1994 (en Francés) [Russell et al., 1995] Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach. Prentice-Hall, Inc., 1995. [Saerens, 1994] Saerens, M. Connection approach of process control. PhD Dissertation, Université Libre de Bruxelles. 1991. (en Francés) [Sasaki et al., 1997] Sasaky, T.; Tokoro, M. Adaptation toward changing environments: Why darwinian in nature?. In P. Husbands and I. Harvey (Eds.), Proceedings of the Fourth European Conference on Artificial Life, Cambridge, MA: MIT Press, 1997. [Shoham, 1997] Shoham, A. An overview of agent-oriented programming. In Software Agents. AAAI Press, Menlo Park, USA. 1997. [Skånhaug, 2003] Skånhaug, S. R. Architectural aspects of software for mobile robot systems. Master Thesis. Norges Teknisk-Naturvitenskapelige Universitet. 2003. [Slocum et al., 2000] Slocum, A.; Downey, D.; Beer, R. Further Experiments in the Evolution of Minimally Cognitive Behavior: From Perceiving Affordances to Selective Attention. Sixth International Conference on Simulation of Adaptive Behavior, Sept. 11-15, France. 2000. [Smith, 1998] Smith, P. Explaining Chaos. Cambridge, England: Cambridge University Press, 1998. [Smithers, 1995] Smithers, T. Are autnomomous agents information processing systems? In Steels, L., & Brooks, R. (Eds.), The Artificial Life Route to Artificial Intelligence. Lawrence Erlbaum, New Haven, 1995. [Steels, 1990] Steels, L. Exploring analogical representations. In Designing Autonomous Agents, Ed. P. Maes, MIT Press, Cambridge, MA, pp. 71-88. 1990. [Storm, 2003] Storm, T. KiKS. http://www.tstorm.se/projects/kiks/. 2003 [Sutton et al., 1998] Sutton, R .S.; Barto, A. G. Introduction to Reinforcement Learning. Cambridge, MA: MIT Press. 1998. [Téllez et al., 2004] Téllez, R. A.; Angulo, C. Towards a general architecture for scaling up in evolutionary robotics. Technical Report. University of Catalonia, Spain, 2004. [Togelius, 2003] Togelius, J. Evolution of the Layers in a Subsumption Architecture Robot Controller . Master of Science in Evolutionary and Adaptive Systems. University of Sussex, UK, 2003. [Togelius, 2004] Togelius, J. Evolution of a Subsumption Architecture Neurocontroller . Journal of Intelligent & Fuzzy Systems 15:1, pp. 15-21, 2004. [Tosini et al., 2004] Tosini, M. A.; Fernández León, J. A.; Acosta, G. G. Controladores Evolutivos en Robots Móviles y su Sintetización en una Aplicación de Lógica Programable. Simposio Latino Americano en Aplicaciones de Lógica Programable y Procesadores Digitales de Señales en Procesamiento de videos, Visión por Computador y Robótica, USP São Carlos, SP, Brasil, 8-10 de Noviembre de 2004. [Tuci et al., 2003] Tuci, E., Quinn, M.; Harvey, I. An evolutionry ecological approach to the study of learning using a robot based model. Adaptive Behavior, Vol. 10, Num. ¾, pp. 201-221, 2003. Bibliografía 161 [Turney et al., 1997] Turney, P. D.; Whitley, D.; Anderson, R. The Baldwin Efect. Evolutionary Computation, 4(3), 1997. [Urzelai et al., 1998] Urzelai, J.; Floreano, D.; Dorigo, M.; Colombetti, M. Incremental robot shaping. Connection Science, 10(3-4):341-360, 1998. [Urzelai et al., 1999] Urzelai, J.; Floreano, D. Incremental Evolution with Minimal Resources. Proceedings of IKW99. 1999. [Urzelai et al., 2001] Urzelai, J.; Floreano, D. Evolution of adaptive synapses: Robots with fast adaptive behavior in new environments. Evolutionary Computation, 9:495-524, 2001 [Urzelai, 2000] Urzelai Intza, J. Evolutionary Adaptive Robots: Artificial Evolution of Adaptation Mechanisms for Autonomous Agents. Docteur These, Lausanne, EPFL, 2000. [van Gelder, 1998] van Gelder, T. The dynamical hypothesis in cognitive science. Behavioural and Brain Sciences, 21:615-665. 1998. [Varela et al., 1991] Varela, F. J.; Thompson, E.; Rosh, E. The Embodied Mind: Cognitive Science and Human Experience. Cambridge, MA: MIT Press, 1991. [Venema et al, 2001] Venema, R. S.; Spaanenburg, L. Learning feed forward multi-nets. Proceedings of ICANNGA’01, Prague. 2001 [Waddington, 1942] Waddington, C. H. Canalization of development and the inheritance of acquired characters. Nature, 150:563-565, 1942. [Wallace, 1858] Wallace, A. R. On the Tendency of varieties to depart indefinitely from the original type. J. Proc. Linn. Soc. (Zool.) 3:53-62, 1858. [Webots, 2002] K-Team Webots. http://www.k-team.com/software/ webots.html [Wooldridge, 1995] Wooldridge, M.; Jennings, N.R. Intelligent agents: Theory and practice. The Knowledge Engineering Review, 10(2):115–152. 1995. [Wooldridge, 1996] Wooldridge, M.; Jennings, N. R. Software Agents. IEEE Review, pages 17-20, 1996. [Yamauchi et al., 1994] Yamauchi, B. M.; Beer, R. D. Sequential behavior and learning in evolved dynamical neural netwoks. Adaptive Behaviour, 2(3):219-246, 1994. [Yao, 1993] Yao, X. A review of evolutionary artificial neural networks. International Journal of Intelligent Systems, 4: 203-222. 1993. [Ziemke, 2000] Ziemke, T. On “Parts” and “Wholes” of Adaptive Behavior: Functional Modularity and Diachronic Sructure in Recurrent Neural Robot Controllers. In From animals to animats 6 - Proceedings of the Sixth International Conference on the Simulation of Adaptive Behavior (SAB 2000). Cambridge, MA: MIT Press. 2000. To facilitate academic research it has referenced papers that are not restricted by copyrights whenever these are of an equal or better quality than restricted alternatives