1 ANÁLISIS COMPARATIVO DE LA ECONOMETRIA TRADICIONAL
Anuncio

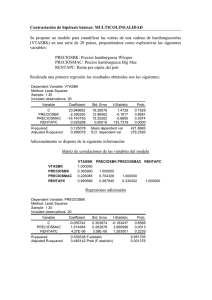
ANÁLISIS COMPARATIVO DE LA ECONOMETRIA TRADICIONAL CON LA DE SERIES DE TIEMPO Ejercicio 1: Análisis econométrico A. Enfoque tradicional Del ejercicio en el capitulo VIII del libro capturar la siguiente información: obs 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 I. Y 3 2 4 5 5 7 6 8 9 12 X1 1 2 2.5 3 4 5 7 8 9 15 “Introducción a la econometría” X2 8 15 10 9 7 6 8 4 3 1 X3 16 17 18 15 17 20 19 21 22 23 Marco teórico: Teoría del consumo Con Y: consumo, X1: Ingreso, X2: Inflación, X3: Inversión, con una serie de 10 años para cada una de las variables, haciendo Y=f(X1, X2) Verificar la teoría económica de que el consumo, Y varia en razón directa del ingreso X1, y en razón inversa de la inflación, X2. Lo anterior significa, entre otras cosas, comprobar que el coeficiente del regresor o variable exógena, X1, tiene signo positivo, en tanto que el coeficiente de la otra variable exógena, X2, tiene signo negativo. Así, vamos al programa EVIEWS, colocamos el cursor en Quick/ estimate equation/ escribimos Y X1 X2 ok y aparece el siguiente cuadro Dependent Variable: Y Method: Least Squares Sample: 1993 2002 Included observations: 10 Variable C X1 X2 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Coefficient 5.800837 0.442193 -0.309751 Std. Error 0.976443 0.076017 0.081265 t-Statistic 5.940785 5.817014 -3.811615 0.973305 0.965678 0.555441 2.159601 -6.526078 2.464587 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0006 0.0007 0.0066 6.100000 2.998148 1.905216 1.995991 127.6122 0.000003 1 Que le llamaremos “ecuación para predecir” II. Diagnóstico 1. La ecuación de regresión Y = 5.800837488 + 0.4421934197*X1 0.3097507478*X2 en lo que se refiere a los signos de los coeficientes de X1, X2 cumplen con lo especificado por la teoría del consumo. 2. Las pruebas de significación estadísticamente usando α=5% realizadas con 2 t, para β 1, β 2 y F para R tienen una probabilidad de casí cero, lo cual, corrobora que X1 y X2 e xplican satisfactoriamente a Y. 3. En ese sentido R2= 0.973305 como R 2 = 0.965678 muestra que X1, X2 son suficientes para explicar a Y; no se necesita otra variable para determinar el comportamiento presente y futuro de Y. 4. Sin embargo, independientemente de verificar si fueron o no violados algunos supuestos del modelo estimado con el método de mínimos cuadrados, digamos la homocedasticidad, la eficiencia, ausencia de autocorrelación o de multicolinealidad entre las variables exógenas, con este ejercicio haremos otras pruebas con el propósito de asegurarnos que la ecuación de regresión múltiple antes descrita sirva para pronósticar y visualizar escenarios futuros, es decir, para hacer planeación sobre el consumo. Dichas pruebas adicionales son: III. Pruebas de especificación del modelo. 1.- Omisión de variables explicativas, digamos X3. Para verificar si omitimos algún regresor explicativo en el modelo aplicamos la 2 X cuadrada en su “razón de verosimilitud” como el estadístico F, que permiten incorporar; uno o varios regresores explicativos y probar si su contribución al modelo es significativo estadísticamente. Así, planteamos con α=5% Ho: una o varias variable(s) explicativa(s) no es (son) significativa(s) estadísticamente. No debe(n) incorporarse al modelo: en este caso X3. Ha: Todo lo contrario de Ho, es decir, que si verificamos que es (son) significativa(s) estadísticamente, entonces debemos incorporarlo(s) al modelo porque también determina(n) el comportamiento de la variable endógena Y. Para contrastar la contribución de las variables explicativas nuevas se requiere que éstas, también llamadas “omitidas”, tengan el mismo tamaño de muestra que Y, X1, X2; además, que el modelo especifique la ordenada al origen; C, y, Y, X1, X2 . Así, de la ecuación partimos, de su cuadro, nos colocamos en view/coefficient tests/omitted variables- likelihood ratio/y en la caja de “omitted – redundant variable test, escribimos X3/ok y obtenemos el siguiente cuadro: 2 Omitted Variables: X3 F-statistic Log likelihood ratio 0.193073 0.316720 Probability Probability 0.675754 0.573585 Test Equation: Dependent Variable: Y Method: Least Squares Sample: 1993 2002 Included observations: 10 Variable Coefficient Std. Error t-Statistic Prob. C X1 X2 X3 4.609288 0.407127 -0.303439 0.071535 2.903669 0.113580 0.087583 0.162801 1.587402 3.584513 -3.464580 0.439401 0.1635 0.0116 0.0134 0.6758 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.974138 0.961206 0.590519 2.092274 -6.367718 2.324024 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 6.100000 2.998148 2.073544 2.194578 75.33212 0.000037 La diferencia entre ambas F’s es la siguiente, la F asociada a la prueba de omisión de variables y la F que asume un valor de 75.33212 es la evaluación de la R 2 / k −1 regresión Y f(X1 ,X2) y se construye F = (1 − R 2 ) / n − k Como la probabilidad de F y la razón de verosimilitud >5%, aceptamos Ho y decidimos no incluir en el modelo X3 como variable explicativa. Si hubiéramos aceptado Ha usaríamos la nueva ecuación de regresión Y=f(X1 , X2, X3). 2. Variables explicativas redundantes, digamos X2. En Eviews la prueba “Redundant variables- likelihood ratio contrasta la significación estadística de una o varias variables exógenas, con el fin de cerciorarse de que no sobran o de que son redundantes. Así con α=5% supóngase que Ho: X2 es redundante Ha: X2 no es redundante Como en el ejemplo anterior partimos del cuadro de la ecuación de regresión en que Y=f(X1 , X2), colocamos el cursor en view/coefficient tests/redundant 3 variables-likelihood ratio/ escribimos X2 en “omitted redundant variables test/ok y aparece el cuadro siguiente: Redundant Variables: X 2 F-statistic Log likelihood ratio 14.52841 11.23463 Probability Probability 0.006614 0.000803 Test Equation: Dependent Variable: Y Method: Least Squares Sample: 1993 2002 Included observations: 10 Variable Coefficient Std. Error t-Statistic Prob. C X1 2.263158 0.679087 0.497606 0.071805 4.548090 9.457435 0.0019 0.0000 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.917901 0.907638 0.911169 6.641826 -12.14339 2.526715 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 6.100000 2.998148 2.828679 2.889196 89.44309 0.000013 2 Vemos que las probabilidades de F y de X en la razón de verosimilitud son menores que 5%, por lo que aceptamos H a y al no ser redundante el X2, la conservamos en el modelo como regresor explicativo de Y. IV. Pruebas de estabilidad estructural I. Contraste de Chow Se usa cuando se piensa que dentro de la serie de años hay un año en que por razones extremas cambió la trayectoria de la variable endógena; en nuestro caso con 10 años suponga que en el año 6, ocurrió el desquiciamiento de la economía, es decir, que el año 6 es 1998. Por el desequilibrio económico hay razones de peso para pensar que cambió el valor de Y. Para verificarlo, con α=5% establecemos la hipótesis nula de estabilidad estructural. Ho: Hay un solo modelo para todos los datos (modelo restringido) Ha: Cada subgrupo en que se dividen los datos tiene un comportamiento diferente: no hay un solo modelo hay dos. Luego si no hay diferencias estadísticas significativas entre el modelo restringido y el otro aceptamos Ho: de estabilidad estructural del modelo; en caso contrario, aceptamos Ha y decimos que hubo un cambio estructural en el año 6 que fue 1998, en que todo el sistema económico se trastoco. Para probar Ho dividimos en dos muestras nuestros datos: la primera del año 1993 a 1998 y la segunda del año 1999 a 2002. Como siempre partimos del cuadro que muestra Y=f(X1 ,X2), de view/stability tests/chow break point test/ damos click y en la ventana que aparece escribimos 6 /ok genera el cuadro: 4 Chow Breakpoint Test: 1998 F-statistic Log likelihood ratio 0.962950 5.436099 Probability Probability 0.491917 0.142511 Al ver que la probabilidad de F y de la ra zón de verosimilitud es mayor que 5%, aceptamos H0. 2. Contraste de predicción de Chow Con α=5% planteamos: H0: Hay estabilidad estructural, en un modelo restringio a un solo comportamiento de todos los datos, cuyos residuos se comparan con los del período más largo de los dos en los que la serie ha sido dividida. Partimos de la ecuación de regresión Y=f(X1 , X2) e iniciamos el siguiente proceso: view/stability test/chow forecast tests/click y en “Chow test” escribimos el año en que pensamos a partir del cual pudo haber ocurrido un cambio estructural: 1998 / ok y aparece el cuadro: Chow Forecast Test: Forecast from 1998 to 2002 F-statistic Log likelihood ratio 0.630146 9.459914 Probability Probability 0.707345 0.092067 Variable Coefficient Std. Error t-Statistic Prob. C X1 X2 4.376115 0.688921 -0.234532 1.536202 0.305989 0.109844 2.848659 2.251456 -2.135147 0.1043 0.1532 0.1663 Test Equation: Dependent Variable: Y Method: Least Squares Sample: 1993 1997 Included observations: 5 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.876682 0.753364 0.647519 0.838561 -2.630928 2.091172 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 3.800000 1.303840 2.252371 2.018034 7.109128 0.123318 Aceptamos H0 ya que la probabilidad de los estadísticos es mayor que 5% y concluimos diciendo que hay estabilidad estructural, con esta muestra. 3. Estimación recursiva Es útil cuando se trabaja con datos temporales como estos y se desconoce el año en que se produjo el cambio estructural. Esta prueba consiste en la estimación secuencial del modelo especificado para distintos tamaños 5 muéstrales. Si k=número de parámetros, entonces la primera muestra, su tamaño es k+1, que usamos para estimar el modelo: de 1993 a 1995 porque son dos parámetros. En las siguientes muestras añadimos una a una todas las observaciones hasta agotar el total de la información (Carrascal; et al; 2000:193). De las sucesivas estimaciones del modelo con el resto de las muestras se generan “las series de los llamados coeficientes recursivos y residuos recursivos”. Si no hay cambio estructural: Ho. “Las estimaciones de los parámetros se mantendrán constantes al ir aumentando las muestras secuencialmente y los residuos no se desviarán ampliamente de cero” Así, de View/stability tests/Recursive Estimate (OLS only)/ok y en la caja de diálogo por default aceptamos C(1) C(2) / ok y aparece esta gráfica: 1 .5 1 .0 0 .5 0 .0 -0 .5 -1 .0 -1 .5 1 99 6 19 97 1 9 98 1 99 9 R ec ur sive R es idu als 2 00 0 2 00 1 20 02 ± 2 S .E . Claramente constatamos que hay estabilidad en el modelo en el período. Los residuos recursivos no se salen de las bandas construidas con dos errores estándar alrededor de Y ± 2S.E. 4. Errores de especificación en la forma funcional/ RESET Estos errores se analizan con el contraste RESET elaborado por RAMSEY en 1969, con el cual se verifica si se esta usando una forma funcional lineal incorrecta y cualquier error de omisión o la presencia de correlaciones entre las variables explicativas y la perturbación (Carrascal et. al, 2000:203) Con α=5% la probabilidad de rechazar una hipótesis cierta, establecemos; Ho: Hay linealidad en el modelo Ha: No hay linealidad en el modelo 6 Dar View/Stability tests/Ramsey Reset Test/ clic y aparece el cuadro de diálogo “RESET Specification” y escribimos el número de potencias de la variable endógena ajustada a incluir empezando por el cuadrado; así si indicamos se añadirá el cuadrado de dicha variable, si ponemos 2 se incluirá el cuadrado y el cubo, etc. Si dejamos la celda en blanco el programa entiende que se añadirá la variable al cuadrado. 2 El resultado son las variables de F y χ de ra zón de verosimilitud junto con la ecuación estimada. Luego de View/ Stability tests/Ramsey RESET y escribimos en la celda en blanco 1 /ok y aparece el cuadro. Ramsey RESET Test: F-statistic Log likelihood ratio 0.192822 0.316314 Test Equation: Dependent Variable: Y Method: Least Squares Sample: 1993 2002 Included observations: 10 Variable Coefficient C 5.911835 X1 0.541787 X2 -0.330648 FITTED^2 -0.011652 R-squared 0.974136 Adjusted R-squared 0.961205 S.E. of regression 0.590531 Sum squared resid 2.092359 Log likelihood -6.367921 Durbin-Watson stat 2.643707 Probability Probability 0.675950 0.573831 Std. Error t-Statistic 1.068461 5.533039 0.240775 2.250178 0.098638 -3.352133 0.026536 -0.439115 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0015 0.0654 0.0154 0.6760 6.100000 2.998148 2.073584 2.194618 75.32899 0.000037 Al tener F y χ 2 de ra zón de verosimilitud probabilidades mayores que 5% aceptamos Ho y concluimos que el modelo es lineal. V. Normalidad entre las perturbaciones Este supuesto es básico para determinar el uso de otro métodos de estimación distintos al de MCO y para hacer inferencias a partir del modelo. Para ello es fundamental plantear con α=5% y verificar: Ho: Hay normalidad en las perturbaciones: JB=0 Ha: No hay normalidad en las perturbaciones: JB ≠ 0 Como no son observables las perturbaciones se estudian con los residuos. Si verificamos Ho ello indica que la distribución empírica de los residuos debe ser similar a la de la distribución normal. Con la probabilidad de JB=0.847292 >5% aceptamos Ho, además de que la kurtosis se acerca a 3, a pesar de que la 7 asimetría no sea cero. De View/Residual tests/Histogram normality test/ click y aparecen el cuadro y la gráfica siguientes: 3.2 Series: Residuals Sample 1993 2002 Observations 10 2.8 2.4 Mean Median Maximum Minimum Std. Dev. Skewness Kurtosis 2.0 1.6 1.2 0.8 0.4 Jarque-Bera Probability 0.0 -1.0 -0.5 0.0 0.5 1.22E-15 -0.069172 0.846700 -0.765025 0.489853 0.315605 2.369937 0.331419 0.847292 1.0 VI. Predicción 1. Partimos de File/open/workfile/clic/ aparece todo el archivo, ahí selecciono solo mi archivo que llamo “ecuación para predecir” /abrir/clic y aparece ese archivo. 2. Expandimos en 3 años el rango del archivo: “ecuación para predecir” con procs/change workfile range: start 1; and 3/ ok 3. Le indicamos a Eviews que ahora deseamos ampliar el tamaño de la muestra con: procs/Sample o sample en el workfile(archivo) en esa caja de diálogo ponemos 1993 a 2005/ok. 4. Damos en la ventana de la ecuación estimate: procs/make regresión group, aparecen Y, X1, X2 en blanco 5. Editamos pulsando edit/ escribir sus valores proyectados ver siguiente cuadro obs 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 Y 3 2 4 5 5 7 6 8 9 12 X1 1 2 2.5 3 4 5 7 8 9 15 X2 8 15 10 9 7 6 8 4 3 1 8 2004 2005 Para llenar las celdas de X1 , X2 hay 2 procedimiento: 1. Escribimos sus valores como en el siguiente cuadro (llamado grupo 2) mismo que lo guardamos como grupo2 2. En la línea de comando escribir Data X1 X2 enter y aparece el cuadro del grupo 4 y llenamos los años con los datos correspondientes. Grupo 2 obs 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 Y 3 2 4 5 5 7 6 8 9 12 X1 1 2 2.5 3 4 5 7 8 9 15 13 14 15 X1 1 2 2.5 3 4 5 7 8 9 15 13 14 15 X2 8 15 10 9 7 6 8 4 3 1 1 2 2 X2 8 15 10 9 7 6 8 4 3 1 1 2 2 Grupo 4 obs 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 Regreso a EQ01: que fue la primera ecuación en el workfile: “ecuación para predecir” y ahí voy a Forecast /aparece una pantalla que además de mostrar YF nos pide sample range for forecast”, por default trae 1993- 2005 / ok y aparece el siguiente cuadro : 9 14 Forecast: YF Actual: Y Forecast sample: 1993 2005 Included observations: 10 12 10 Root Mean Squared Error Mean Absolute Error Mean Abs. Percent Error Theil Inequality Coefficient B ias Proportion V ariance Proportion Covariance Proportion 8 6 4 2 0.4 64715 0.3 69380 7.6 45546 0.0 34564 0.0 00000 0.0 06764 0.9 93236 0 1 994 19 96 1998 2000 2 002 20 04 YF Ahora en la pantalla de workfile: ecuación para predecir, seleccione (sombreo) Y y YF para conocer el valor pronosticado de YF/ open group/clic y aparece el siguiente cuadro que llamo grup03 obs 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 Y 3 2 4 5 5 7 6 8 9 12 YF 3.76502492522 2.03896311067 3.80881355932 4.33966101695 5.4013559322 6.1533000997 6.41818544367 8.09938185444 8.85132602193 12.1239880359 11.2396011964 11.3720438684 11.8142372881 Este cuadro también se obtendría así: En la línea de comando escribimos “Show Y YF” / enter y aparece igual al caso anterior. Puesto que ya conocemos YF con 13 datos, ahora podemos evaluar estadísticamente dicha predicción analizando en la figura anterior, la gráfica y las estadísticas del cuadro. En el caso de la grafica observamos primero una caída y luego un repunte; ello se debe a que X1, X2 en el período de predicción, primero caen sus valores y luego aumentan. Con respecto a las estadísticas, dado que casi todas (con la excepción de una: mean abs, percent error) tienen valores menores a uno, decimos que es buena estimación de la predicción. Por consiguiente resultó adecuada la ecuación de regresión Y=f(X1, X2) 10 B. ECONOMETRIA D E S ERIES DE TIEMPO La econometría de series de tiempo surgió porque el análisis tradicional aun cuando trabajaba con series de tiempo y suponía que eran estacionarias, es decir, que su media aritmética, µ, al igual que si varianza, σ 2 y su covarianza, γ 0 debían observar constancia en el tiempo, lo anterior no se verificaba como tampoco aspectos interesantes como los siguientes: a) El hecho de que en algunos casos la autocorrelación se gesta porque las series de tiempo en estudio no son estacionarias; b) La aparición de un alto grado de asociación (su coeficiente de determinación cercano a uno) sin sentido alguno y que no es real, al que se le llama regresión espuria, como una consecuencia de que las series de tiempo no son estacionarias; c) En el caso de la predicción, de que las series de tiempo observarán el fenómeno de caminata aleatoria, que de existir, como sucede en una serie de tiempo no estacionaria, reduce el calculo de la predicción a considerar digamos, en el caso de las acciones de una empresa, solamente su precio actual más un choque puramente aleatorio (o término de error), situación que en opinión de Gujaratí (2004:767), si fuera el caso, el pronóstico del precio de las acciones sería un ejercicio inútil. d) La conveniencia de realizar el análisis de la estacionalidad de las series de tiempo antes del análisis de su causalidad. e) Constatar la importancia de contar con una serie que tenga “ruido blanco”, es decir, que no exista autocorrelación, tal que el coeficiente de correlación sea cero. En opinión de las personas que se dedican al estudio de las predicciones, es fundamental corregir, eliminar o comprobar estas irregularidades, ya que limitan de manera significativa la precisión de los pronósticos, situación que en el caso de la planeación es muy importante hacerlo para poder crear escenarios confiables, en corto, mediano y largo plazo. Por otra parte, deb e aclararse que una serie no estacionaria se puede estudiar y usarse para pronosticar solo para el periodo de tiempo bajo consideración, en tanto que con una estacionaria se puede generalizar para todos los periodos, de ahí que se recomiende siempre ob tenerla. Al respecto, dicho en otras palabras, es necesario “descontaminar” la serie de la variable endógena de los elementos irregulares de las estacionalidades que inducen tendencias equivocadas. Esta descontaminación se logra con diversos métodos dentro de los que destacan el de las MA, AR, etc.,que veremos más adelante. Esta “limpia o descontaminación” debe hacerse porque hay datos que transportan componentes indeseables que generan “ruido” en la predicción. Luego hay que limpiar o descontaminar la serie depurándola, eliminándole los componentes irregulares estacionales y quitar la tendencia a que nos están conduciendo equivocadamente. Esta acción de descontaminación también se conoce como filtrado, su resultado es al hacerlo producen ahora una serie con ruido blanco: sin efectos negativos como por ejemplo la autocorrelación. 11 Los “filtros” de mayor uso son, como arriba se indicó: los autorregresivos o diferenciados, (AR: auto regression) y los aditivos o de medias móviles, (MA:moving averages) Dentro de los primeros ( Gabriel Tapia Gómez, et al, 2002) el filtro univariante más sencillo, AR,es aquel en que el operador diferencia, digamos que obtiene la primera diferencia ordinaria y se denota así: AR(1).Con este procedimiento se eliminan las frecuencias bajas pero se acentúan las más altas. Comenta que en series suaves permite obtener estimaciones de los componentes estacional e irregular y aproximar la tasa de crecimiento de la serie original cuando se filtra el logaritmo y, por consiguiente se deduce que se utiliza como indicador del ciclo cuando las series tienen comportamientos suaves. En este contexto es interesante decir que existen otros filtros autoregresivos como el AR de orden mayor, que consiste en obtener la diferencia de orden estacional, con lo que se eliminan las frecuencias bajas y los ciclos armónicos de la frecuencia fraccional correspondiente. El segundo filtro, MA, se útil para extraer componentes en análisis del ciclo, ya que “dejan pasar intacta la información contenida en determinada banda de frecuencias mientras que eliminan o acentúan las restantes”. Con este método se desestacionaliza extra yendo el componente ciclo tendencia. Derivado de lo anterior podemos decir que con los filtros AM y AR, sucesivamente, se tendrán como resultados correspondientes, la atenuación de altas frecuencias y la atenuación de bajas frecuencias, resultando un pico en la función de transferencia de la serie filtrada y una atenuación de determinadas frecuencias intermedias. En opinión del investigador Gabriel Tapia, et al, los filtros más usados son los de Hodrick & Prescott (1980), Prescott (1986) y los de Henderson. Así, de la lectura anterior se deduce que es conveniente completar el análisis de regresión tradicional hasta ahora efectuado, con el de series de tiempo, haciendo hincapié en las pruebas de estacionalidad de las series de tiempo, en aquellas que tienen raíz unitaria, como también en las que presentan correlación espuria etc, para transformarlas en estacionarias. Agréguese a lo anterior que una vez “limpia” la serie, es conveniente hacer las pruebas de cointegración con objeto de que la serie de tiempo expresada en la ecuación de regresión sirva para pronosticar con un alto grado de confianza estableciendo el equilib rio entre el corto y largo plazo. 1.- Pruebas de estacionalidad Se toma como referencia la ecuación de regresión ya familiar, llamada “ECUACIÓN PARA PREDECIR” donde: Yt=f(X1,X2). 1.1 Prueba gráfica En eviews: Quick/graph/escribimos en “Series list: Y/ok luego/en graph type escogemos: Line graph/ok y aparece 12 14 12 10 8 6 4 2 0 19 94 1996 1998 2000 2002 2 004 Y Al analizar la evolución de Yt en 10 años vemos que el consumo (Yt) aumentó porque su gráfica muestra una tendencia ascendente, situación que hace suponer que su µ no ha permanecido constante, sino que ha cambiado, lo cual sugiere que la serie de Yt es no estacionaria: Ahora probemos con una técnica más rigurosa. 1.2 Función de autocorrelación (FAC) y Correlograma Ahora si trabajamos Yt en función de X1 e X2, vamos al archivo general que guarda la “Equation:EQ01” para 10 años (si no se localiza, obtengase con Quick/Estímate Equation/ Y C X1 X2 /ok y aparece; ahí vamos a View/Residual test/Correlogram Q-statistics/lags to include: aceptamos 11 /ok 13 y aparece el siguiente cuadro. Para saber si la serie es estacionaria planteamos. H0: No hay autocorrelación, la serie es estacionaria; ρ k=0 Ha : Si hay autocorrelación, la serie es no estacionaria, ρ k ≠ 0 Donde ρ k= coeficiente de autocorrelación con k rezagos Con α=5% nivel de significación= probabilidad de rechazar H0 aún cuando es verdadera, es decir, para aceptar H0 es necesario que la probabilidad sea mayor a 5%. La columna AC=función de autocorrelación muestral usada para estimar la función de autocorrelación poblacional, muestra los coeficientes de autocorrelación (ρi) para ocho rezagos. Para saber si son estadísticamente significativos , construimos el intervalo de confianza del 95% para cualquier ρk con ρˆ k ± Z α σ pk , como k=8 rezagos y n=10, varianza= 1/10= 0.100 luego el error estándar= 0.10 = 0.31 y como α=5%; ξ =95% en una 1 distribución normal de ρ k que tiene µ=0 y σ 2 = . Fuente Gujarati (2004:786). n Sustituimos ρˆ k ± 1.96( 0. 31) ρˆ k ± 0.61 Tal que Pr ob (ρˆ k − 0.61 ≤ ρ k ≤ ρˆ k + 0. 61) = 95% = ξ Así tenemos que para cualquier ρ k existe un límite inferior (LI) y un límite superior LS). Si estos límites incluyen el cero no se rechaza la hipótesis de que el verdadero ρ κ sea cero; sino incluye el cero, se rechaza la hipótesis de que el verdadero ρ κ sea cero. Si lo anterior lo aplicamos a ρˆ k = −0.371; primer rezago Tendremos LI=-0.371-0.61=-0.98 LS=-0.371+0.61=0.24 También si en el cuadro vemos que: ρˆ k = 0. 159; segundo rezago 14 Tendremos LI=0.159-0.61=-0.45 LS=0.159+0.61=0.77 Igualmente si: ρˆ k = 0. 022; séptimo rezago Tendremos LI=0.022-0.61=-0.59 LS=0.022+0.61=0.63 Vemos que estos y el resto incluyen al cero, luego se tiene la confianza del 95% de que el verdadero ρ k=0, que no es significativamente diferente de cero; que indica que se acepta la H0 de que la serie es estacionaria, lo que contradice a la prueba gráfica quizá porque la curva tiene altibajas. 1.3. Estadística Q Si en lugar de probar la significación estadística de cualquier ρ i, se prueban todos en conjunto, se usa Q. Aquí. H 0 = ρˆ 1 = ρˆ 2 = ... = ρˆ k = 0 donde k=1,2,3,...8 H a = ρˆ 1 ≠ ρˆ 2 ≠ ... ≠ ρˆ k ≠ 0 Q se usa para probar una serie de tiempo si es de ruido blanco (totalmente aleatoria y sin autocorrelación) en muestras grandes como χ2 con m grados de libertad. Si Q>Qα, valor 2 crítico, de la tablas χ se rechaza H0 de que todas las ρ k son iguales a cero; también decimos que si Q> χ α2 se rechaza H0; obviamente algunas son diferentes de cero. Con estas referencias, si con α=5% y 8 gl tenemos χ α2 =2.73 vemos en este caso que algunos Q’s son mayores y otras menores a 2.731 por lo que queda indefinida la decisión por lo pequeño de la muestra. 1.3.1 Estadístico Ljung-Box (LB) Es una variante de Q y se recomienda para muestras pequeñas. Así, decimos que si el valor del estadístico Q<LB aceptamos H0. En el cuadro anterior el valor de Q oscila entre 1.84 y 4.71; vemos que la probabilidad (última columna) de obtener estos valores bajo la H0 de que las ρ k sean cero es muy alta; en cada una de ellas es mayor al 5%=α. En consecuencia aceptamos la H0 y decimos que la serie de tiempo de Yt es estacionaria, que es de un proceso de ruido blanco: puramente aleatorio. 1.4. Correlograma Esto representado gráficamente en la primera y numéricamente en la tercer columna del cuadro con el nombre de AC: autocorrelación, su línea vertical continua representa el cero y las punteadas sus límites de confianza; luego las “barras” a su izquierda expresan valores negativos y las de la derecha positivos de las ρ k . Ejemplo el rezago 1 tiene una autocorrelación negativa –0.371 y por eso está al izquierda del cero; el rezago 7 tiene una autocorreelación =0.022 y por eso está a la derecha del cero. Como ninguna autocorrelación 15 rebasa los límites de confianza, aceptamos H0 de que Yt es una serie estacionaria con ruido blanco, los ρ k no son significativamente diferentes de cero, sus valores son pequeños. 2.- La prueba de raíz Unitaria con un rezago. Dependent Variable: Y Method: Least Squares Sample(adjusted): 1994 2002 Included observations: 9 after adjusting endpoints Variable Coefficient Std. Error C 1.593287 1.945672 X1(-1) 1.020252 0.188746 X2(-1) 0.018857 0.151202 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.914784 0.886379 0.998670 5.984054 -10.93388 1.728872 t-Statistic 0.818888 5.405423 0.124712 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.4442 0.0017 0.9048 6.444444 2.962731 3.096417 3.162159 32.20468 0.000619 Se usa la estadística o prueba tau (τ) de Dickey-Fuller (DF) para verificar si hay o no estacionalidad en la serie con: H0:δ=0, luego ρ=1 y existe raíz unitaria por lo que Yt es una serie de tiempo no estacionaria; Ha :δ ≠0, luego ρ ≠1 y no existe raíz unitaria por lo que Yt es una serie de tiempo estacionaria; Donde δ= coeficiente estimado de la pendiente de X1t-1 y de X2t-1 usadas para estimar Yt, con un rezago para ver si es o no estacionaria. Si se rechaza H0 se puede usar t y no τ. En este caso se gestó un resultado mixto: con X1t-1 se rechaza H0 y con X2t-1 se acepta. Sin embargo con la prueba del correlograma Yt es estacionaria, también lo es con AC y con la estadística de Ljung-Box para muestras pequeñas. Está prueba ha sido muy criticada por expertos como M addala y Kim, quienes sugieren que no se aplique. (Gujarati, 2004:793). MODELOS CON VARIABLES RETARDADAS Comentan los estudiosos del tema que el efecto de una variable exógena sobre una endógena no termina en el periodo de análisis, por el contrario su efecto es prolongado en el tiempo, como lo podemos observar digamos en el caso del ingreso (X1) sobre el consumo(Y), éste continúa por varios periodos de tiempo más. Como la evidencia muestra que lo anterior es cierto, también lo es que se requiere se ha establecido una metodología apropiada dado que al meter el factor tiempo ahora se pasa de un análisis estático a uno dinámico de las series de tiempo. La incorporación de efectos diferidos en el tiempo en un modelo uniecuacional se realiza mediante la incorporación de variables “retardadas o rezagadas”, que es la razón por la que se conoce como modelos con variables retardadas, que pueden ser de dos clases: I.- Los modelos autoregresivos y 16 II.- Los modelos de retardos distribuidos I.-MODELOS AUTORREGRESIVOS ( Carrascal, et al, 294) Estos modelos suponen la violación de la hipótesis establecida en el modelo de regresión lineal clásico: la hipótesis de que los regresores no son aleatorios, ya que la variable endógena retardada depende de la perturbación aleatoria y, por consiguiente, tiene un carácter estocástico. Así, los resultados del modelo están condicionados al tipo de dependencia que exista entre los regresores estocásticos y las perturbaciones. Puede haber 3 tipos de dependencia: 1.- Independencia total, con la que se mantienen todas las propiedades de los estimadores obtenidos con M CO. 2.- Dependencia parcial: aquí el regresor estocástico sólo depende de la perturbación en periodos de tiempo pasados, no existiendo dependencia en tiempos presente y futuros: en este caso el estimador es consistente pero ya es sesgado. 3.- Dependencia total. El regresor estocástico depende de la perturbación en todos los periodos: pasados, presente y futuros. En este caso el estimador además de ser sesgado es inconsistente, obligando a buscar un método alterno de estimación que al menos garantice que sea consistente. Aquí usaremos el método de variables instrumentales, que parte de la definición de una matriz Z de instrumentos que sustituye a la matriz X de regresores del modelo .Las variables que componen Z tienen que cumplir dos requisitos. 1.- estar fuertemente correlacionadas con la variable que instrumentan o sustituyen. 2.- No estar correlacionadas con la perturbación. La forma más común de instrumentar las variables del modelo autoregresivo consiste en sustituir los regresores exógenos por ellos mismos, porque cumplen a la perfección con los dos supuestos exigidos, y la variable endógena retardada por otra variable exógena con la que observe mayor correlación, retardada en el mismo número de periodos. La determinación del tipo de dependencia en este tipo de modelos entre el regresor estocástico ( la variable endógena retardada) y la perturbación, en la práctica se realiza estudiando la existencia de autocorrelación entre las residuos del modelo. Así, la incorrelación de las perturbaciones implica una situación de dependencia parcial, en tanto que la presencia de correlación conlleva a la dependencia total. Para detectarla usaremos h de Durbin modificada, el contraste h; correlogramas, Q y la prueba Breusch- Godfrey. Sean los datos ya conocidos: obs 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 Y 3.000000 2.000000 4.000000 5.000000 5.000000 7.000000 6.000000 8.000000 9.000000 12.00000 X1 1.000000 2.000000 2.500000 3.000000 4.000000 5.000000 7.000000 8.000000 9.000000 15.00000 X2 8.000000 15.00000 10.00000 9.000000 7.000000 6.000000 8.000000 4.000000 3.000000 1.000000 X3 16.00000 17.00000 18.00000 15.00000 17.00000 20.00000 19.00000 21.00000 22.00000 23.00000 17 Para copiarlos y traerlos hacia acá: Abro el programa “Econometric Views”con Inicio/ file/new/workfile/1993-2002/ok, enseguida escribo en barra de control:data y x1 x2 x3 y voy al archivo en que están estos datos ( unas hojas atrás),baño sus datos ( sólo ellos, es decir, empiezo con el 3 de y y termino con el 23 de x3)/editar /copiar regreso aEviews, ahí le doy enter y aparecen las celdas en blanco de las 4 variables, oprimo el botón derecho del cursor, lo coloco en la primera celda / edit/ paste y se llena el cuadro que aparece arriba. Le doy un nombre al archivo:” modelo autocorrelac”, lo salvo con file/ save as GSB/Econometría/series de tiempo/abrir ejercicio 1/guardar. Obtenemos su ecuación de regresión. Ahora el archivo contiene los datos en Group 1/ lo abro/ voy a “quick”/estimate equation/ en barra de control escribimos y c x1 x2 x3/ok y aparece el siguiente cuadro. Dependent Variable: Y Method: Least Squares Date: 06/27/06 Time: 05:56 Sample: 1993 2002 Included observations: 10 Variable C X1 X2 X3 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Coefficient 4.609288 0.407127 -0.303439 0.071535 Std. Error 2.903669 0.113580 0.087583 0.162801 t-Statistic 1.587402 3.584513 -3.464580 0.439401 0.974138 0.961206 0.590519 2.092274 -6.367718 2.324024 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.1635 0.0116 0.0134 0.6758 6.100000 2.998148 2.073544 2.194578 75.33212 0.000037 Queremos ver el efecto del tiempo: Planteamos Ho: ρ=0, que significa ausencia de correlaciones y la Ha: ρ<0 ó ρ >0, que expresa la existencia de autocorrelación AR(1) positiva o negativa, con un nivel de significación (alfa) del 5%. Cabe señalar que la especificación de AR(1) significa de orden 1: que sólo hay una autocorrelación entre el último y el penúltimo término de la serie; será de segundo orden cuando haya autocorrelación entre el último y el antepenúltimo término, y así sucesivamente para el resto de las perturbaciones del periodo analizado. La autocorrelación se ve gráficamente por medio del diagrama de dispersión ( una curva) y del correlograma (como una sola barra que se sale del intervalo de confianza establecido para los residuos en estudio, cuando el rezago es de orden uno,AR(1). Al respecto, es lógico suponer que las observaciones cercanas en el tiempo están muy correlacionadas y que las observaciones lejanas entre si apenas tendrán alguna relación, comportamiento que es congruente con las características del modelo AR(1). Al meter la variable tiempo estamos dinamizando el modelo, pasando de un enfoque estático de las variables a uno en movimiento para cualquier lapso de tiempo que deseemos. 18 También reiteremos que ρ es el coeficiente de correlación serial de primer orden y que al no ser observables las correlaciones entre las perturbaciones, se utilizan las variables de los residuos mínimos cuadráticos. Ojo: ver autocorrelación en carrascal, pp 266. Por otra parte, se usa h de Durbin en lugar de la d de Durbin Watson, porque tienen las siguientes ventajas: a).-cuando el tamaño de la muestra es menor que 12 y b).- en la ecuación de regresión se omite la ordenada al origen y c).- se pone la variable endógena en función de si misma, como variable exógena, pero rezagada. Para obtener la h que necesitamos en la prueba de Durbin-Watson modificada, en esta ecuación vamos a proces/ make residual series/ aparece”ordinary y en “name for residual series” escribimos EM CO/OK y aparece la siguiente serie de residuos, que son 10 porque ese es el número de datos Last updated: 06/27/06 06:02 Modified: 1993 2002 // eq04.makere sid -0.733465 -0.088056 0.119651 0.827254 -0.329821 0.745008 -0.390834 -0.154786 0.063112 -0.058064 De esta ecuación genero la serie de rezagos/retardos en un periodo de la siguiente forma: estimate equation/ escribo emco emco(-) y aparece ahora ya para 9 datos por el rezago que hicimos de un año. Dependent Variable: EMCO Method: Least Squares Date: 06/27/06 Time: 06:08 Sample(adjusted): 1994 2002 Included observations: 9 after adjusting endpoints Variable Coefficient Std. Error t-Statistic Prob. 19 EMCO(-1) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood 0.019677 -0.016503 -0.016503 0.587856 2.764598 -7.458965 0.341350 0.057646 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat 0.9554 0.071518 0.583065 1.879770 1.901684 2.072389 A continuación calculo “ρ” porque la necesitamos para el cálculo de h, usando la literal r en su lugar . para ello almacenamos la ecuación alterior en un escalar. Escribimos en línea de comandos :scalar r = @coefs(1)/enter y aparece hasta abajo el valor de r=0.0196772976114, que sustituimos en la fórmula para calcular h cuyo valor resulta ser 0.0645623444212. El valor de h también lo podemos obtener en Eviews así: escribimos en la barra de control scalar h = r*@sqrt(@regobs/(1-@regobs*(@stderrs(2))^2)), damos enter y hasta abajo aparece el valor de h antes mencionado. Notas a).- el símbolo anterior se obtiene con “Alt 94”; b).- Cuando abajo no aparece el valor de r o de h, escribimos en la barra de control,”show r” o también “show scalar r” y su valor aparecerá en seguida. Ahora establezco Ho: ρ=0 y la Ha: ρ<0 ó ρ >0 con α=5% en una prueba de dos extremos tenemos que Ζ (distribución normal) de alfa es igual a más menos 1.64> que el estadístico h=0.0645623444212.Así aceptamos la Ho, es decir no hay autocorrelación. Conviene reiterar como ya lo hicimos cuando vimos el problema de la autocorrelación, que ésta provoca que el estimador del parámetro deje de ser eficiente aun cuando sigue siendo insesgado y asintóticamente consistente cuando aumenta el tamaño de la muestra. El resultado obtenido con h, de que no hay autocorrelación también se verifica con el contraste de Breusch-Godfrey en la primer ecuación, ahí vamos a view/ residual test/ serial correlation LM test, lags( rezagos deseados )en este caso son 2/ok que por default aceptamos, y aparece para dos y un rezago/retardo: Breusch-Godfrey Serial Correlation LM Test: F-statistic Obs*R-squared 0.001106 0.000000 Probability Probability Test Equation: Dependent Variable: RESID Method: Least Squares Date: 06/22/06 Time: 23:44 Presample missing value lagged residuals set to zero. Variable Coefficient Std. Error t-Statistic X1 0.001352 0.144885 0.009329 X2 0.000982 0.107654 0.009122 X3 -0.000789 0.082635 -0.009545 RESID(-1) 0.019873 0.449109 0.044249 RESID(-2) 0.007926 0.487570 0.016256 R-squared Adjusted R-squared S.E. of regression Sum squared resid -0.000782 -0.801408 0.770670 2.969661 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion 0.998895 1.000000 Prob. 0.9929 0.9931 0.9928 0.9664 0.9877 0.019064 0.574199 2.623740 2.775032 20 Log likelihood -8.118699 Durbin-Watson stat 1.922721 Los resultados ( sus probabilidades mayores a 5%) para dos y un retardo aceptan la hipótesis nula, decisión que se corrobora porque el valor de F es mayor que 5% aquí también aceptamos la hipótesis nula Ho. Ahora bien,como señala Carrascal et al ( 2002, pp299), si observamos los resultados para dos y un retardo, podemos comprobar la no significación individual de RESID (-1) y RESID (-2) es decir, hay incorrelación.Sin embargo, ello revela la dependencia entre la variable endógena retardada y la perturbación, situación que determina la existencia de un esquema AR(1) y hace que los estimadores mínimos cuadrados ordinarios “ni siquiera sean consistentes, lo que determina la necesidad de obtener estimadores por el método de variables instrumentales, que aprovechamos para exponer en que consiste este método. Método de variables instrumentales. Se requiere encontrar unos instrumentos que sustituyan a los regresores del modelo. Se acostumbra utilizar como instrumento de la variable endógena retardada uno de los regresores también retardado; en nuestro ejemplo usaremos X1(-1) en lugar de Y(-1). Así, nos situamos en la ecuación original y pulsamos el botón Estimate de su barra de herramientas. La ecuación específica seguirá siendo la misma, pero en la celda “method” seleccionamos como método de estimación la opción TSLS- Two stages least squares ( tsls and ARMA). En instrument list indicaremos la lista de instrumentos: x1 x1(-1),x2 x2(-1), x3 x3(-1), porque el número de instrumentos debe ser al menos el número de variables independientes incluidas en el modelo . La peculiaridad de este método( Carrascal et al, 300) consiste en que en la primera etapa calcula las regresiones por M CO de cada uno de los regresores de la ecuación inicial frente a todos los instrumentos seleccionados; en la segunda etapa efectúa la regresión por M CO de la variable endógena original utilizando como variables explicativas los valores estimados de cada una de las regresiones de la primera etapa. Se demuestra que estas dos etapas son equivalentes a la obtención de los estimadores por variables instrumentales cuando se utilizan como instrumentos los valores estimados de cada regresor del modelo frente a todos los instrumentos considerados, en otras palabras, los valores estimados de las regresiones de la primera etapa. Dependent Variable: Y Method: Tw o-Stage Least Squares Date: 06/23/06 Time: 00:21 Sample(adjusted): 1994 2002 Included observations: 9 after adjusting endpoints Instrument list: X1 X1(-1) X2 X2(-1) X3 X3(-1) Variable C X1 X2 X3 Y(-1) R-squared Adjusted R-squared S.E. of regression Coefficient 6.219008 0.321778 -0.372650 0.034205 0.035999 0.982163 0.964327 0.559581 Std. Error 3.232678 0.165332 0.097526 0.158260 0.252038 t-Statistic 1.923795 1.946254 -3.821023 0.216131 0.142832 Mean dependent var S.D. dependent var Sum squared resid Prob. 0.1267 0.1235 0.0188 0.8395 0.8933 6.444444 2.962731 1.252525 21 F-statistic Prob(F-statistic) 55.11518 0.000941 Durbin-Watson stat 3.250657 Sabiendo que Ho: ρ=0 y la Ha: ρ<0 ó ρ >0 ahora usamos la d Durban Watson para contrastar: como d= 3.25 > 2 de manera rápida decimos que hay autocorrelación; sin embargo no debemos de apresurarnos, mejor verifiquemos o corroborémoslo con un análisis pormenorizado de la estimación trabajando ahora con el Correlograma de los residuos Para ello en la ecuación anterior coloco el cursos en view/ Residual test/ Correlogram Qstatistics, mismo que aparecen enseguida como Date: 06/23/06 Time: 08:03 Sample: 1994 2002 Included observations: 9 Autocorrelation *****| . | . |** . | . *| . | . | . | . *| . | . |* . | . | . | Partial Correlation *****| . | . **| . | . | . | . *| . | . **| . | . **| . | . *| . | 1 2 3 4 5 6 7 AC -0.645 0.304 -0.133 0.028 -0.144 0.081 0.002 PAC -0.645 -0.190 -0.040 -0.059 -0.294 -0.291 -0.100 Q-Stat 5.1414 6.4499 6.7416 6.7574 7.2697 7.4856 7.4858 Prob 0.023 0.040 0.081 0.149 0.201 0.278 0.380 Aun cuando el gráfico está defectuoso, en Eviews se ve que ninguna barra se sale de los límites de confianza tanto en la autocorrelación como en la correlación parcial de los residuos, lo cual se corrobora con los valores de las ρ que salvo la excepción del primer rezago en que toman los valores de -0.645, para el resto de ellos son bajos, es decir no hay autocorrelaciones significativas. A una conclusión análoga llegamos con Q, cuyas probabilidades para la mayoría de los rezagos son mayores a 5%, corroborando la hipótesis nula de que no hay autocorrelación. Ahora trabajando con el contraste de BREUSCH-GODFREY que, como recordamos sirve para verificar si es que existe o no correlación serial, partimos de la ecuación inicial y hacemos: view/ Residual tests / Serial Correlation LM Test en la barra de herramientas y aparecen los siguientes resultados para dos y un retardo ( conviene decir que el programa por default nos ofrece 2 retardos, los cuales aceptamos) son: Breusch-Godfrey Serial Correlation LM Test: F-statistic 0.001106 Probability Obs*R-squared 0.000000 Probability 0.998895 1.000000 Test Equation: Dependent Variable: RESID Method: Least Squares Date: 06/23/06 Time: 09:03 Presample missing value lagged residuals set to zero. Variable X1 X2 X3 RESID(-1) Coefficient 0.001352 0.000982 -0.000789 0.019873 Std. Error 0.144885 0.107654 0.082635 0.449109 t-Statistic 0.009329 0.009122 -0.009545 0.044249 Prob. 0.9929 0.9931 0.9928 0.9664 22 RESID(-2) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood 0.007926 -0.000782 -0.801408 0.770670 2.969661 -8.118699 0.487570 0.016256 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat 0.9877 0.019064 0.574199 2.623740 2.775032 1.922721 De nuevo aceptamos Ho: ρ=0 y rechazamos la Ha: ρ<0 ó ρ >0 con α=5% en una prueba de dos extremos porque el valor de F es > a 5%, así como también los valores de las probabilidades de RESID (-1) Y RESID(-2), corroborando que los errores muestran un esquema sin autocorrelaciones. Esta decisión de aceptar Ho también se sustenta en el valor de d=1.922721 que es casi igual a 2, indicando que no hay autocorrelación. Ahora bien por la importancia que tiene para hacer análisis de corto y largo plazo ilustremos con estos datos el uso del método de variables instrumentales acompañado de AR(1). Como lo hicimos en el ejercicio anterior pero ahora en la barra de herramientas o de control agregamos AR(1), es decir: quick/estimate equation/ en barra de control escribimos y c x1 x2 x3 y(-1) AR(1), en el method escribimos TSLS , en “instruments list” escribimos x1 x1(-1) x2 x2(-1) x3 x3(-1)/ok y aparecen los siguientes resultados: Dependent Variable: Y Method: Tw o-Stage Least Squares Date: 06/23/06 Time: 11:19 Sample(adjusted): 1995 2002 Included observations: 8 after adjusting endpoints Convergence achieved after 7 iterations Instrument list: X1 X1(-1) X2 X2(-1) X3 X3(-1) Variable C X1 X2 X3 Y(-1) AR(1) Coefficient 7.606910 0.424144 -0.403514 -0.003625 -0.164103 -0.775286 R-squared Adjusted R-squared S.E. of regression F-statistic Prob(F-statistic) 0.990126 0.965440 0.486811 40.09538 0.024512 Inverted AR Roots -.78 Std. Error 2.500207 0.168943 0.200635 0.180319 0.344662 0.831568 t-Statistic 3.042512 2.510579 -2.011184 -0.020105 -0.476127 -0.932317 Mean dependent var S.D. dependent var Sum squared resid Durbin-Watson stat Prob. 0.0932 0.1287 0.1820 0.9858 0.6809 0.4496 7.000000 2.618615 0.473970 2.800310 Interpretación: Con este modelo podemos decir por ejemplo, si sólo interpretamos el efecto de x1 en Y, lo siguiente: el efecto a corto plazo del ingreso (x1) sobre el consumo(Y) es igual a 0.424144, que indica que si el ingreso aumenta en una unidad en el periodo, el consumo crece en 0.424144 unidades en ese mismo lapso. De igual manera esa unidad adicional de ingreso produce efectos sobre el consumo de los periodos siguientes de tal manera que a largo plazo ( Carrascal et al, 305) el efecto del ingreso sobre el consumo es de 0.36 unidades ( 0.424144/1-(-0.164103)=0.36). Este método de interpretación de los 23 coeficientes de las variables explicativas sobre la variable explicada también se puede generalizar para X2 e X3 sobre Y. Corolario: Es importante señalar que si persistiera la autocorrelación la expresaríamos como R(1) de orden 1 ó R(2) de orden 2, trataríamos de eliminarla con retardos o rezagos de las variables explicativas, todos los que fueran necesarios hasta lograr su erradicación. Al respecto, recuerde que R(1) significa autocorrelación de orden 1, interpretación: sólo hay una barra fuera del rango; y R(2) la autocorrelación de orden 2, interpretación: sólo hay dos barras fuera del rango o intervalo de confianza establecido. También es bueno comentar que, como se vio, la d Durban-Watson produjo resultados dudosos, nada confiables, sobre si había o no autocorrelación, de ahí que mejor sea recomendable aplicar su h y complementar dicho contraste con el del autocorrelograma y la Q, así como la prueba Breusch-Godfrey. Finalmente podemos decir que la ausencia de correlación serial en este modelo hace que los estimadores conserven sus propiedades de consistencia, eficiencia, inses gamiento y de suficiencia. Ahora ya podemos usar la ecuación para estudios de estructura y predicción. II.-MODELOS CON RETARDOS DIS TRIBUIDOS II.1.- Finitos En este tipo de modelos son las variables exógenas y no la endógena retardada Las que ejercen efectos subsecuentes o prolongados sobre la variable endógena o dependiente. Aquí hay que tener en cuenta que se debe determinar el número de periodos,M, en los “que se mantiene el efecto”, razón por la que se denominan modelos de retardos distribuidos finitos. Aun cuando no se viola ninguno de los supuestos clásicos del M CO, no obstante tienen las siguientes limitantes, en un modelo de una variable endógena: a).- M ulticolinealidad imperfecta, dado que se incluyen como variable regresoras tanto la exógena como retardos, situación que provoca una fuerte relación lineal entre ellas que deriva en problema de multiolinealidad fuerte. b).-Pérdida de grados de libertad. Se produce por dos razones: la primera, al aumentar el número de retardos se pierden observaciones; la segunda, al aumentar el número de retardos aumenta el número de parámetros ( ahora serán K+ 1+M ), por lo que si K: número de parámetros, T: total de observaciones, M : número de periodos, los grados de libertad del modelo serán T-2M -K-1, la reducción será en 2M . Lo anterior impacta la precisión de los estimadores obtenidos los parámetros del modelo. Para resolver estos dos problemas se incorpora información sobre la forma que adopta la influencia de la variable exógena en el devenir del tiempo, que, en otras palabras significa el establecer restricciones sobre los parámetros. Longitud del retardo: Con estas referencias teóricas ahora empezaremos por ilustrar cómo se determina la longitud del retardo. Dados los valores de Y e X1 de los ejemplos anteriores, es decir si queremos explicar el consumo (Y) a partir de la variable ingreso(X1) retardada en un número diferente de periodos, en Eviews, pasos: 1.-Vamos al archivo file/open/ workfile/modelo autoregresión/las seleccionamos pulsando en Y e X1 CTRL y el botón izquierdo del cursor y luego las abrimos como un grupo 24 haciendo doble clic en cualquier parte del área sombreada y eligiendo tal opción en el el cuadro resultante. Y 3.000000 2.000000 4.000000 5.000000 5.000000 7.000000 6.000000 8.000000 9.000000 12.00000 X1 1.000000 2.000000 2.500000 3.000000 4.000000 5.000000 7.000000 8.000000 9.000000 15.00000 2.- Nombramos el grupo pulsando el cursor en “name” y por default aparece Group01, mismo que aceptamos. 3.- Enseguida calculamos los valores de los coeficientes: En Group01 pulsamos el botón Procs/ make equation de la ventana del objeto grupo. En su cuadro de diálogo especificamos los retardos requeridos para x1. por ejemplo si cero retardos;, escribimos Y C X1/ok y salen los siguientes resultados: Dependent Variable: X1 Method: Least Squares Date: 06/29/06 Time: 02:58 Sample: 1993 2002 Included observations: 10 Variable Y C R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Coefficient 1.351669 -2.595179 Std. Error 0.142921 0.961936 t-Statistic 9.457435 -2.697872 0.917901 0.907638 1.285497 13.22002 -15.58512 2.500257 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0000 0.0272 5.650000 4.229854 3.517025 3.577542 89.44309 0.000013 4.- Si ahora queremos un solo rezago, reespecificamos el modelo, vamos en su cuadro de diálogo a “estimate “ y especificamos los retardos ahora requeridos para x1, digamos 1, luego escribimos y c x1 x1(-1)/ok y sale: Dependent Variable: Y Method: Least Squares Date: 06/29/06 Time: 03:08 Sample(adjusted): 1994 2002 Included observations: 9 after adjusting endpoints Variable C X1 X1(-1) Coefficient 1.893576 0.318743 0.560664 Std. Error 0.583155 0.231511 0.339015 t-Statistic 3.247123 1.376795 1.653802 Prob. 0.0175 0.2177 0.1493 25 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.935075 0.913433 0.871703 4.559192 -9.710091 1.974996 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 6.444444 2.962731 2.824465 2.890206 43.20702 0.000274 5.- Ahora para dos rezagos, en esa misma equation, vamos en su cuadro de diálogo a “estimate “ y especificamos así : y c x1 x1(-1) x1(-2)/ok y sale: Dependent Variable: Y Method: Least Squares Date: 06/29/06 Time: 03:12 Sample(adjusted): 1995 2002 Included observations: 8 after adjusting endpoints Variable Coefficient Std. Error t-Statistic C 2.691799 0.777559 3.461857 X1 0.383904 0.247584 1.550601 X1(-1) 0.114224 0.702856 0.162514 X1(-2) 0.286175 0.843348 0.339333 R-squared 0.945684 Mean dependent var Adjusted R-squared 0.904948 S.D. dependent var S.E. of regression 0.807333 Akaike info criterion Sum squared resid 2.607147 Schwarz criterion Log likelihood -6.866768 F-statistic Durbin-Watson stat 3.225951 Prob(F-statistic) Prob. 0.0258 0.1959 0.8788 0.7514 7.000000 2.618615 2.716692 2.756413 23.21457 0.005430 6.- Como son pocos datos finalmente probemos con tres rezagos: vamos en su cuadro de diálogo a “estimate “ y especificamos así : y c x1 x1(-1) x1(-2) x1(-3)/ok y obtenemos: Dependent Variable: Y Method: Least Squares Date: 06/29/06 Time: 03:15 Sample(adjusted): 1996 2002 Included observations: 7 after adjusting endpoints Variable C X1 X1(-1) X1(-2) X1(-3) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Coefficient 3.336029 0.042132 -0.000381 -0.229475 1.377233 0.944113 0.832340 1.026577 2.107720 -5.731508 3.182406 Std. Error t-Statistic 1.366625 2.441071 0.638635 0.065971 0.945374 -0.000403 1.326342 -0.173014 2.103171 0.654837 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.1347 0.9534 0.9997 0.8786 0.5798 7.428571 2.507133 3.066145 3.027509 8.446703 0.108650 7.- Comparemos y hagamos análisis con los siguientes datos: M : No. retardos T: total de Coef.determina. Criterio de Criterio observaciones ajustado información de Schwarz Akaike 0 10 0.92 3.52 3.58 1 9 0.93 2.82 2.89 2 8 0.945 2.72 2.75 de 26 3 7 0.944 3.07 3.03 De acuerdo con estos resultados decidimos seleccionar el modelo que comprende una longitud de dos retardos de la variable X1 porque: a). representa el mayor coeficiente de determinación ajustado; b).- el menor valor del criterio de información de Akaike y c).- el menor valor del criterio de Schwarz, que aparece enseguida. Dependent Variable: Y Method: Least Squares Date: 06/29/06 Time: 03:12 Sample(adjusted): 1995 2002 Included observations: 8 after adjusting endpoints Variable C X1 X1(-1) X1(-2) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Coefficient 2.691799 0.383904 0.114224 0.286175 Std. Error 0.777559 0.247584 0.702856 0.843348 t-Statistic 3.461857 1.550601 0.162514 0.339333 0.945684 0.904948 0.807333 2.607147 -6.866768 3.225951 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0258 0.1959 0.8788 0.7514 7.000000 2.618615 2.716692 2.756413 23.21457 0.005430 BIBLIOGRAFÍA Carrascal Ursicino, González Yolanda y Rodríguez Beatriz. Editorial Alfa Omega Ra-M a, España. 2001. Gujarati, Damodar N. Econometría,cuarta edición. M cGraw Hill, julio 2004. Sánchez Barajas, Genaro. Introducción a la Econometría. Facultad de Economía, UNAM ,2005. Tapia Tovar Gabriel –Carmona Rocha José Gerardo. M odelización regional: técnica aplicada al desarrollo regional, en Desarrollo Regional, Local y Empresas.ININEE,UM SNH, PP. 66 Y 67, 2004. 27