Estadística Descriptiva e Inferencial II - Repositorio CB
Anuncio

COLEGIO DE BACHILLERES
SECRETARÍA ACADÉMICA
COORDINACIÓN DE ADMINISTRACIÓN
ESCOLAR Y DEL SISTEMA ABIERTO
COMPENDIO FASCICULAR
ESTADÍSTICA DESCRIPTIVA E
INFERENCIAL II
FASCÍCULO 1. VARIABLES ALEATORIAS
FASCÍCULO 1. CORRIENTE ELÉCTRICA E INDUCCIÓN
MAGNÉTICA
FASCÍCULO
2. TRANSMISIÓN
ONDULATORIA
DE LA
FASCÍCULO
2. FUNCIONES
DE DISTRIBUCIÓN
ENERGÍA
PROBABILIDAD
DE
FASCÍCULO 3. RADIACIÓN ELECTROMAGNÉTICA
FASCÍCULOE INTERACCIONES
3. FUNCIONES
DE DISTRIBUCIÓN
ATÓMICAS
Y NUCLEARES
NORMAL ESTÁNDAR
FASCÍCULO 4. INFERENCIA ESTADÍSTICA
DIRECTORIO
Roberto Castañón Romo
Director General
Luis Miguel Samperio Sánchez
Secretario Académico
Héctor Robledo Galván
Coordinador de Administración
Escolar y del Sistema Abierto
Derechos Reservados conforme a la ley
2004, COLEGIO BACHILLERES
Prolongación Rancho Vista Hermosa Núm. 105
Col. Ex Hacienda Coapa
Delegación Coyoacan, CP 04920, México, D.F.
ISBN 970 632 263-9
PRESENTACÍON GENERAL
El Colegio de Bachilleres, en respuesta a la inquietud de los estudiantes de contar con
materiales impresos que faciliten y promuevan el aprendizaje de los diversos campos del
saber, ofrece a través del Sistema de Enseñanza Abierta y a Distancia este compendio
fascicular; resultado de la participación activa, responsable y comprometida del personal
académico, que a partir del análisis conceptual, didáctico y editorial aportaron sus
valiosas sugerencias para su enriquecimiento y aunarse a la propuesta educativa de la
Institución.
Este compendio fascicular es producto de un primer esfuerzo académico del Colegio por
ofrecer a todos sus estudiantes un material de calidad que apoye su proceso de
enseñanza-aprendizaje, conformado por fascículos.
Por lo tanto, se invita a la comunidad educativa del Sistema de Enseñanza Abierta y a
Distancia a compartir este esfuerzo y utilizar el presente material para mejorar su
desempeño académico.
DIRECCIÓN GENERAL
P RE S E N T AC I Ó N D E L CO M P E N DI O F AS C I C UL AR
Estudiante del Colegio de Bachilleres, te presentamos este compendio fascicular que te
servirá de base en el estudio de la asignatura “Estadística Descriptiva e Inferencial II” y
funcionará como guía en tu proceso de Enseñanza-Aprendizaje.
Este compendio fascicular tiene la característica particular de presentarte la información
de manera accesible, propiciando nuevos conocimientos, habilidades y actitudes que te
permitirán el acceso a la actividad académica, laboral y social.
Cuenta con una presentación editorial integrada por fascículos, capítulos y temas que te
permitirá avanzar ágilmente en el estudio y te llevará de manera gradual a consolidar tu
aprendizaje en esta asignatura. Para que conozcas los modelos estadísticos básicos:
descriptivos, probabilísticas e inferenciales que te permitirán organizar la información
cualitativa y cuantitativa para representarla en forma ordenada, describirla e interpretarla
y hacer inferencias, de tal manera que puedas aplicar dichos modelos en la resolución
de problemas sociales, económicos y físicos naturales de las diversas áreas de
conocimiento.
COLEGIO DE BACHILLERES
ESTADÍSTICA DESCRIPTIVA E
INFERENCIAL II
FASCÍCULO 1. VARIABLES ALEATORIAS
Autor: Patricia Mata Olguín
1
2
ÍNDICE
INTRODUCCIÓN
5
PROPÓSITO
7
SIMBOLOGÍA
9
CAPÍTULO 1. VARIABLES ALEATORIAS
1.1 FENÓMENOS DETERMINÍSTICOS Y
ALEATORIOS
11
11
1.2 ELEMENTOS DE UNA FUNCIÓN DE
VARIABLE ALEATORIA
15
1.3 VARIABLES ALEATORIAS DISCRETAS Y
CONTINUAS
23
1.4 FUNCIÓN DE VARIABLE ALEATORIA
DISCRETA
26
1.5 DISTRIBUCIÓN DE PROBABILIDAD,
FUNCIÓN DE PROBABILIDAD Y FUNCIÓN
DE DENSIDAD
30
1.6 GRÁFICA DE UNA FUNCIÓN DE
PROBABILIDAD (HISTOGRAMA DE
PROBABILIDAD)
33
1.7 FUNCIÓN DE DISTRIBUCIÓN DE
PROBABILIDAD ACUMULADA
34
3
1.8 GRÁFICA DE UNA FUNCIÓN DE
DISTRIBUCIÓN DE PROBABILIDAD
ACUMULADA (HISTOGRAMA DE
PROBABILIDAD ACUMULADA OJIVA)
35
1.9 ESPERANZA MATEMÁTICA
38
RECAPITULACIÓN
52
ACTIVIDADES DE CONSOLIDACIÓN
53
AUTOEVALUACIÓN
54
ACTIVIDADES DE GENERALIZACIÓN
56
GLOSARIO
57
BIBLIOGRAFÍA CONSULTADA
59
4
INTRODUCCIÓN
La Estadística es una herramienta de la investigación de las Ciencias, tanto Formales
como Factuales.
Existen cuando menos cuatro buenas razones para estudiar estadística, al hacerlo serás
capaz de:
1. Aprender las reglas y métodos para tratar información estadística.
2. Evaluar y cuantificar la importancia de los resultados estadísticos que veamos
publicados.
3. Conocer los aspectos del pensamiento estadístico como un componente
esencial de una educación humanística.
4. Entender mejor el mundo real de nuestro entorno.
La razón número 1 y 2, son procedimientos estudiados en el curso de Estadística
Descriptiva, que comprende aquellos métodos usados para organizar y describir la
información recabada.
Y las razones 3 y 4, son aspectos que le competen a la Estadística Inferencial y
comprende aquellos métodos y técnicas usados para hacer generalizaciones,
predicciones o estimaciones sobre poblaciones a partir de una muestra.
Ambas te sirven para tomar decisiones. Y en particular, en este curso te introducirás en
el estudio de la Probabilidad, que es una herramienta básica para la Inferencia.
5
En tu vida diaria encontraras ejemplos como los siguientes:
a) El predominio de la diabetes en personas con sobrepeso es casi el triple que en
personas sin sobrepeso.
b) Cuatro de cada cinco dentistas declararon preferir la pasta dental “Dientes
Limpios”.
c) En 1960 se estimó que sólo el 1% de los estudiantes del último año de
bachillerato habían probado la mariguana, mientras que en 1980 se estimó que
el 60% lo había hecho.
d) Ninguna aspirina calma mejor el dolor que la de marca “Bayer”.
e) Más de 3,000 compañías aseguradoras pagan arriba de 8,800 millones de pesos
anuales en reclamaciones.
f)
La Llanta “Firestone” frena un 35% más rápido.
6
PROPÓSITO
Con el estudio de este fascículo:
¿QUÉ APRENDERÁS?
¿CÓMO LO LOGRARÁS?
¿PARA QUÉ TE VA A SERVIR?
Manejarás y clasificarás las variables
aleatorias
(discretas
y
continuas),
relacionándolas con el concepto de evento
estocástico.
A través del concepto de función y de esta
manera
conocerás
sus
elementos
esenciales:
dominio,
contradominio,
imagen,
gráfica,
etc.
Ejemplificando
además las funciones probabilísticas
básicas, tales como: las funciones de
distribución, acumulada y valor esperado.
Para así acceder al conocimiento de la
Estadística Inferencial como prueba de
hipótesis y estadísticos no paramétricos.
Además de que podrás verificar su
aplicación en problemas y/o fenómenos de
la vida cotidiana.
7
Observa el siguiente esquema donde se te presentan los temas que estudiarás:
8
SIMBOLOGÍA
SÍMBOLO
SIGNIFICADO
Espacio muestral
n!
“n” factorial
Xi
Variable aleatoria
Sumatoria
f(x)
Notación de función
P(Xi)
Probabilidad de la variable aleatoria
Media poblacional
fi
Frecuencia
N
Tamaño de la población
n
Tamaño de la muestra
E(X)
2
Esperanza matemática
Varianza
Desviación estándar
9
10
CAPÍTULO 1
VARIABLES ALEATORIAS
1.1 FENÓMENOS DETERMINÍSTICOS Y ALEATORIOS
En tus cursos de Física, Química y Biología estudiaste fenómenos naturales muy
diversos, algunos de los cuales tienen en común que SIEMPRE ocurren de la misma
manera, como son:
– El movimiento de los planetas
Figura. 1
– Encender una vela
Figura. 2
11
– Tomar el tiempo que un lápiz tarda en caer
Figura. 3
Todos estos fenómenos ocurren siempre de la misma forma, y se llaman:
DETERMINÍSTICOS.
Pero existen otros fenómenos que no pueden determinarse con seguridad, por que están
sujetos al “azar” como son:
– En Administración (control escolar):
De una generación de primer semestre, realizar una encuesta que indique cuantos
alumnos vienen de escuelas secundarias públicas o privadas.
Figura. 4
– En Medicina:
El número de nacimientos atendidos en una clínica en cierto día y registrar cuantos son
niños o niñas
Figura. 5
12
– En Matemáticas:
Lanzar un moneda y observar que pueda caer águila o sol.
Figura. 6
Este tipo de eventos también ocurren en otras áreas:
Mercadotecnia.
Criminología.
Agricultura.
Pesca.
Contabilidad.
Deportes.
Arquitectura.
Diseño gráfico.
Pedagogía.
Turismo.
En fin, muchos de los fenómenos que conoces y que no siempre ocurren de la misma
forma, y que están sujetos al azar, les llamamos FENÓMENOS ALEATORIOS.
ACTIVIDAD DE REGULACIÓN
Identifica en el siguiente listado, anotando una A en el paréntesis, si el fenómeno
ocurrido corresponde a un fenómeno aleatorio y una D, si se trata de un fenómeno
determinístico.
(
) La prima que cobra una compañía de seguros según la edad de las personas.
13
(
) Los salarios que reciben los empleados de una empresa.
(
) La Ley de las proporciones constantes en una reacción química.
(
) El fenómeno biológico de ósmosis.
(
) La resultante de un sistema de fuerzas.
(
) La cantidad administrada de penicilina a un paciente.
(
) La sincronización de los semáforos en la Ciudad de México.
(
) La cantidad de automóviles vendidos el año pasado.
(
) La temperatura a la que hierve el agua.
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Recuerda que los Fenómenos Determinísticos; son todos aquellos fenómenos que
ocurren siempre de la misma forma y siempre tienen los mismos resultados.
Los Fenómenos Aleatorios; son aquellos fenómenos que no siempre ocurren de la
misma forma, y que están sujetos al azar.
1.2 ELEMENTOS DE UNA FUNCIÓN DE VARIABLE ALEATORIA
Ahora ya distingues un fenómeno de variable aleatoria de un fenómeno de variable
determinístico, relacionando un fenómeno de variable aleatoria con una función de
variable aleatoria, observemos el siguiente ejemplo: Relaciona la figura con su nombre
Figura. 7
14
Las flechas indican la correspondencia entre elementos de los conjuntos A y B; las
primeras componentes de las parejas pertenecen al conjunto A, llamado conjunto de
partida o dominio, mientras las segundas componentes pertenecen al conjunto B,
denominado conjunto de llegada, codominio o contradominio.
En una relación, las primeras componentes de sus pares ordenados forman un conjunto
al cual se le llama dominio de la relación, y las segundas componentes forman otro
conjunto llamado rango o conjunto imagen.
Figura. 8
Para que relaciones el concepto de función con la función de variable aleatoria
estadística, vamos a ejemplificarlos en un experimento sencillo:
Experimento de variable aleatorio: Lanzar dos monedas al aire.
Para conocer el dominio, puedes utilizar un diagrama de árbol:
Figura. 9
Hemos llamado A = resultado de caer águila y
S = resultado de caer sol
Entonces el dominio es: { (A,A), (A,S), (S,A), (S,S) }
15
A este conjunto se le llama ESPACIO MUESTRAL y se designa por la letra . Además
es el dominio de la función de variable aleatoria y a cada uno de sus resultados, se le
llama EVENTOS.
ACTIVIDAD DE REGULACIÓN
Determina el Dominio ( ) de cada uno de los siguientes experimentos aleatorios:
1. Lanzar tres monedas al aire.
2. Lanzar una moneda y un dado.
3. Las respuestas de un examen, si las preguntas son las siguientes:
(
) 1810
1. Descubrimiento de América
(
) 1492
2. Conquista de México
(
) 1521
3. Declaración de Independencia
4. Los hijos varones y mujeres de una familia de tres hijos.
5. Los lugares ocupados en una fila de supermercados por 3 personas.
Una vez que hayas determinado el Dominio ( ) en cada experimento, compáralo con
los resultados que te presentamos a continuación.
SOLUCIÓN.
Ayudados por un diagrama de árbol, los resultados de las preguntas anteriores son:
1. Experimento aleatorio: Lanzar tres monedas al aire.
DIAGRAMA DE ARBOL
Figura. 10
16
Dominio o = { (A,A,A), (A,A,S), (A,S,A), (A,S,S), (S,S,A), (S,A,S), (S,S,A), (S,S,S) }
CONTEO DEL ESPACIO MUESTRAL
En el ejercicio anterior tuviste que hacer un diagrama de árbol para determinar el .
Algunas veces es demasiado laborioso y tedioso, por lo que es conveniente que
observes lo siguiente:
En el experimento de lanzar tres monedas al aire, se tiene:
2 resultados posibles = águila o sol.
Tres monedas = 3.
Por lo tanto el Conteo del se puede calcular 2 = 8.
3
17
2. Experimento aleatorio: Lanzar una moneda y un dado.
DIAGRAMA DE ARBOL
Figura. 11
Dominio o = { (A,1), (A,2), (A,3), (A,4), (A,5), (A,6), (S,1), (S,2), (S,3), (S,4), (S,5), (S,6) }
CONTEO DEL ESPACIO MUESTRAL
Experimento: lanzar una moneda al aire: Una moneda = 1. Con 2 resultados posibles
águila o sol. Un dado =1. Con 6 resultados posibles 1,2,3,4,5,6.
Por lo tanto el conteo del se calcula 2 X 6 = 12. Es decir, 12 resultados posibles.
3. Experimento aleatorio: Resultados de un examen, si las preguntas son las
siguientes:
(
) 1810
1. Descubrimiento de América
(
) 1492
2. Conquista de México
(
) 1521
3. Declaración de Independencia
DIAGRAMA DE ÁRBOL
Figura. 12
18
Dominio o
= { (1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,2,1), (3,1,2) }
CONTEO DEL ESPACIO MUESTRAL
En el experimento de las repuestas del examen, no se vale poner dos veces el mismo
número, así que:
1810 Puede tener tres respuestas
1492 Ya solo puede tener dos respuestas, y
1521 Sólo puede tener la respuesta sobrante.
Entonces el conteo de elementos del se calcula: 3 X 2 X 1 = 6 = .
3 X 2 X 1 se denota como 3! y se lee “tres factorial”.
Para generalizar se escribe n! (n Factorial) y es el producto de todos los eventos desde
uno hasta n. Por ejemplo: 6! (seis factorial) es 6 X 5 X 4 X 3 X 2 X 1 = 720.
Podemos entonces decir que en los casos en que las respuestas No se pueden repetir
(no hay repetición) el se determina con la fórmula factorial.
4. Experimento aleatorio: Hijos varones y mujeres en una familia de tres hijos.
Llamemos a los varones H y a la mujeres M.
DIAGRAMA DE ÁRBOL
Figura. 13
= { (H,H,H), (H,H,M), (H,M,H), (H,M,M), (M,H,H,), (M,H,M), (M,M,H), (M,M,M) }
CONTEO DEL ESPACIO MUESTRAL
Experimento. Hijos varones y mujeres en un familia de tres hijos: Tres hijos = 3. Con 2
3
resultados posibles en cada una. Por lo tanto el conteo del se calcula 2 = 8. Es decir,
8 resultados posible.
19
5. Experimento aleatorio: Los lugares ocupados en una fila de supermercado por
tres personas.
Llamemos P1 = Primera persona, P2 = Segunda persona y P3 = Tercera persona.
DIAGRAMA DE ARBOL
Figura. 14
Dominio o = { (P1,P2,P3), (P1,P3,P2), (P2,P1,P3), (P2,P3,P1), (P3,P1,P2), (P3, P2,P1)}
CONTEO DEL ESPACIO MUESTRAL
Experimento: Los lugares ocupados en una fila de supermercado por tres personas: Tres
personas = 3. Una persona no puede ocupar dos lugares al mismo tiempo. Por lo tanto el
conteo del se calcula como 3! = 3 X 2 X 1 = 6. Es decir, 6 resultados posibles.
En los ejercicios anteriores de lanzar las monedas, el conteo del está dado por:
= nx. Por lo que los resultados pueden repetirse
¡Recuerda! Solo cuando no hay repetición se usa el factorial.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
I.
En los ejercicios anteriores hemos aprendido a determinar el . Ayudándote con un
diagrama de árbol, resuelve ahora los dos siguientes ejercicios.
1. En Genética, se sabe que al cruzar dos especies de pollos (White Legorn) con
(Black Legorn), los vástagos son blancos y negros, es decir, que en la primera
generación no hay pintos. Supongamos que en una cruza nacen 5 pollos, de
recién nacidos todos son amarillos, pero a la séptima semana cambian el
plumaje, determina el del color de los pollos: llama B a los pollos blancos y N
a los negros.
20
2. En una encuesta realizada por el Colegio de Bachilleres en los Pedregales de
Coyoacan, Ciudad de México, se investigó el nivel educativo de los pobladores:
en el siguiente cuadro se dan los resultados:
NIVEL DE ESTUDIOS EN LOS PEDREGALES DE COYOACAN EN 1991
GRADO
NÚMERO
DE
PERSONAS
Analfabeto
Sabe leer y escribir
Terminó la Primaria
Terminó la Secundaria
Terminó el Bachillerato o similar
Profesión Técnica
Profesionista
Maestría o Doctorado
TOTAL
112
122
253
250
213
148
2
0
110
NIVEL
EDUCATIVO:
(Años de estudio)
Ninguno
De 1 a 3 años
De 4 a 6 años
De 7 a 9 años
De 9 a 12 años
De 13 a 15 años
De 16 a 18 años
De 19 o más
Supongamos que se seleccionan tres personas al azar ¿Cuál es el ?
Llama a los niveles educativos:
A= analfabetos,
L= sabe leer y escribir,
B= estudios de Bachillerato o similar,
T= estudios de Maestría o Doctorado
En tu cuaderno haz tu diagrama de árbol para determinar el y recuerda que usarás
sólo el grado superior de estudios.
21
II.
En los siguientes ejercicios determina el número de elementos del . Para tal
efecto, selecciona de acuerdo con tu criterio, la fórmula adecuada. No utilices
diagramas de árbol.
1.
2.
3.
4.
Lanzar cuatro monedas al aire.
Lanzar dos monedas y un dado al aire.
Número de hijos varones en una familia de 5 hijos.
Lugar que ocupan 4 personas en una fila de supermercado. Recuerda que dos
personas no pueden ocupan el mismo lugar.
5. Sacar tres fichas de una urna con reemplazo (es decir sacar una ficha y volver
a ponerla en la urna, repitiendo el procedimiento tres veces). La urna contiene
dos fichas negras y tres blancas (Este tipo de experimento se llama con
REEMPLAZO).
6. De 6 películas de video que no has visto y que te interesan, ¿De cuántas
maneras puedes seleccionar dos para verlas el fin de semana? Esto es el
número de elementos de tu .
7. De ocho temas que tienes que estudiar para el examen de filosofía, el maestro
selecciona tres ¿De cuántas maneras los puede seleccionar? El de dirá si
te conviene estudiar todos los temas o sólo algunos.
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Recuerda que el espacio muestral se designa por la letra . Además es el dominio de la
función de variable aleatoria y a cada uno de sus resultados, se le llama eventos.
Un evento es cada uno de los resultados del dominio de la función de variable aleatoria.
Función es una relación entre dos conjuntos, las primeras componentes de las parejas
pertenecen al conjunto A, llamado conjunto de partida o dominio. Las segundas
componentes pertenecen al conjunto B, denominado conjunto de llegada, codominio o
contradominio.
22
1.3 VARIABLES ALEATORIAS DISCRETAS Y CONTINUAS
Hasta ahora haz calculado funciones aleatorias DISCRETAS determinando el número de
elementos del , Los ejemplos más comunes de variable discretas son los que se
limitan a enteros (......., -3, -2, -1, 0, 1, 2, 3, .......).Las variables, pongamos por caso,
número de hijos por familia, número de águilas en una serie de intentos o repeticiones
del experimento , no pueden adoptar más que valores enteros.
Sin embargo, esto último en ocasiones resulta imposible porque existen espacios
muestrales no numerables, es decir, no se pueden contar porque se subdividen
infinitamente y la función aleatoria no se puede contar; estas variables aleatorias se
llaman CONTINUAS. Las variables continuas, generalmente son calculadas apoyándose
de formulas matemáticas o interpretadas por instrumentos de medición por lo que
pueden tomar cualquier valor dentro de un intervalo. La estatura de un grupo de
personas ilustra el carácter continuo de las variables, ya que entre dos valores
interpretados por una cinta métrica, digamos 1.68 m. y 1.69 m., es posible cualquier valor
como 1.687 m., y entre éste y 1.688m., sería posible registrar otra estatura, como 1.6873
m., y así hasta el infinito. El que las estaturas de las personas se reporten sólo con dos
decimales de aproximación, tiene que ver con una operación de redondeo por razones
prácticas; la variable sigue siendo continua ya que, teóricamente, es posible cualquier
valor entre dos límites dados.
Otros ejemplos de variables continuas, pueden ser:
El Tiempo,
Figura. 15
El clima
Figura. 16
23
El cálculo del perímetro de un círculo, etc.
Figura. 17
ACTIVIDAD DE REGULACIÓN
En los siguientes enunciados, indica con una C dentro del paréntesis, si se trata de una
función aleatoria continua y con una D, si se trata de una función aleatoria discreta:
(
) Medida de los niños al nacer.
(
) La contaminación en IMECAS del medio ambiente.
(
) La producción de toneladas de cocos en el Estado de Veracruz.
(
) La cantidad de galones de gasolina que consume un automóvil.
(
) Los juegos de fútbol ganados por el Guadalajara.
(
) El número de perros vacunados contra la rabia en la Ciudad de Monterrey.
(
) La cantidad en litros de agua que se consume en Puebla.
(
) El número de analfabetos en el país.
(
) El nivel educativo en años de estudio de la población de la colonia Coyoacan en
la Ciudad de México.
(
) Las ventas en dólares que se consumen de Coca-Cola.
(
) El potencial pesquero del Lago de Chapala.
(
) El cálculo matemático del perímetro de un rectángulo.
(
) El cálculo del área del pizarrón del salón de clases.
24
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Recuerda que una Función Aleatoria Continua; es aquella función, generalmente
calculada por medio de fórmulas matemáticas o interpretadas por instrumentos de
medición por lo que puede tomar cualquier valor dentro de un intervalo.
Una Función Aleatoria Discreta; es aquella función que sólo toma valores enteros.
25
1.4 FUNCIÓN DE VARIABLE ALEATORIA DISCRETA
Retomando el ejercicio 1 de la ACTIVIDAD DE REGULACIÓN de la página 20, en
Genética, se sabe que al cruzar dos especies de pollos (White Legorn) con (Black
Legorn), los vástagos son blancos y negros, es decir, que en la primera generación no
hay pintos.
Supongamos que en una cruza nacen 5 pollos, de recién nacidos todos son amarillos,
pero a la séptima semana cambian el plumaje, determina el Dominio o del color de
los pollos: llama B a los pollos blancos y N a los negros.
Para determinar el nos apoyaremos de su representación de un diagrama de árbol
= 25 = 32 Variable aleatoria x = pollo blanco (B).
Observa que B denota pollo blanco y N denota pollo negro, naturalmente estamos
interesados en el número de POLLOS BLANCOS. De esta forma a cada evento en el
se le asignará un valor numérico de 0, 1, 2, 3, 4 y 5. Estos valores son, por supuesto,
variables aleatorias discretas Xi determinadas por el resultado del experimento.
26
Figura. 18
En donde el conjunto de eventos se le llama Dominio o Espacio Muestral , la Regla de
correspondencia es el conteo del número de pollos de plumaje blanco de cada uno de
los eventos y el rango es el conjunto de imágenes que indica el número de pollos de
plumaje blanco.
27
La FUNCIÓN DE VARIABLE ALEATORIA DISCRETA, se escribe como el conjunto de
pares ordenados del Dominio o y rango, ejemplo:
F(Xi) = {[(B,B,B,B,B),5], [(B,B,B,B,N),4], [(B,B,B,N,B),4], [(B,B,B,N,N),3],
[(B,B,N,B,B),4], [(B,B,N,B,N),3], [(B,B,N,N,B),3], [(B,B,N,N,N),2],
[(B,N,B,B,B),4], [(B,N,B,B,N),3], [(B,N,B,N,B),3], [(B,N,B,N,N),2],
[(B,N,N,B,B),3], [(B,N,N,B,N),2], [(B,N,N,N,B),2], [(B,N,N,N,N),1],
[(N,B,B,B,B),4], [(N,B,B,B,N),3], [(N,B,B,N,B),3], [(N,B,B,N,N),2],
[(N,B,N,B,B),3], [(N,B,N,B,N),2], [(N,B,N,N,B),2], [(N,B,N,N,N),1],
[(N,N,B,B,B),3], [(N,N,B,B,N),2], [(N,N,B,N,B),2], [(N,N,B,N,N),1],
[(N,N,N,B,B),2], [(N,N,N,B,N),1], [(N,N,N,N,B),1], [(N,N,N,N,N),0] }
Entonces la FUNCIÓN ALEATORIA O FUNCIÓN DE VARIABLE ALEATORIA
DISCRETA, es el conjunto de parejas ordenadas, donde el primer elemento de la pareja
es el evento y el segundo elemento de la pareja es el número real de cada resultado de
su en un experimento.
ACTIVIDAD DE REGULACIÓN
En los siguientes ejercicios, determina la función de Variable Aleatoria Discreta:
1. En el ejercicio que hiciste del Nivel Educativo, determina la función aleatoria
como parejas ordenas, si consideramos a la variable aleatoria Xi como nivel
educativo.
2. En una convención hay tres intérpretes, uno es de Francés y dos de Inglés. Si
definimos la variable aleatoria Xi igual al número de intérpretes que hablan
inglés, determina.
a) El
con un diagrama de árbol.
b) El
por conteo.
c) La función de variable aleatoria discreta.
28
3. Seis estudiantes (S1, S2, S3, S4, S5, S6) solicitaron empleo para las vacaciones
en una empresa, pero solo contratarán a tres, en la prueba de aptitud obtuvieron
las siguientes puntuaciones:
SOLICITANTE DE EMPLEO
S2, S5 , S6
S3,
S1, S4
PUNTUACIONES
3
2
1
Toma como variable aleatoria Xi igual a la suma de puntuación de los tres
solicitantes.
Determina:
a) El
con un diagrama de árbol.
b) El
por conteo.
c) La función de variable aleatoria discreta.
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Recuerda que la Función de Variable Aleatoria Discreta, se describe como el conjunto de
pares ordenados del dominio o y rango.
La Función Aleatoria o Función de Variable Aleatoria Discreta, es el conjunto de parejas
ordenadas, donde el primer elemento de la pareja es el evento y el segundo elemento de
la pareja es el número real de cada resultado de su en un experimento.
29
1.5 DISTRIBUCIÓN DE PROBABILIDAD, FUNCIÓN DE PROBABILIDAD
Y FUNCIÓN DE DENSIDAD
Del ejemplo anterior en donde el número de pollos blancos expresa la Xi, de 5 pollos que
nacieron, ¿Encontremos la probabilidad de encontrar 0, 1, 2, 3, 4 y 5 pollos blancos?
Para una mejor comprensión ordenemos los datos en una distribución de probabilidades,
donde la probabilidad se obtiene del número de la frecuencia de la Xi entre el total de
eventos obtenidos del .
EVENTO
Xi
FRECUENCIA
fi
(N,N,N,N,N)
0
1
P( Xi 0)
1
32
1
5
P( Xi 1)
5
32
2
10
P( Xi 2)
10
32
3
10
P( Xi 3)
10
32
4
5
P( Xi 4)
5
32
5
1
P( Xi 5)
1
32
(B,N,N,N,N)
(N,B,N,N,N)
(N,N,B,N,N)
(N,N,N,B,N)
(N,N,N,N,B)
(B,B,N,N,N)
(B,N,B,N,N)
(B,N,N,B,N)
(B,N,N,N,B)
(N,B,B,N,N)
(N,B,N,B,N)
(N,B,N,N,B)
(N,N,B,B,N)
(N,N,B,N,B)
(N,N,N,B,B)
(B,B,B,N,N)
(B,B,N,B,N)
(B,B,N,N,B)
(B,N,B,B,N)
(B,N,B,N,B)
(B,N,N,B,B)
(N,B,B,B,N)
(N,B,B,N,B)
(N,B,N,B,B)
(N,N,B,B,B)
(B,B,B,B,N)
(B,B,B,N,B)
(B,B,N,B,B)
(B,N,B,B,B)
(N,B,B,B,B)
(B,B,B,B,B)
PROBABILIDAD
P(Xi= k)
Entonces las probabilidades son:
Xi = 0 Pollos blancos, la probabilidad es de
blancos en 32 resultados posibles.
30
1
, porque hay un evento con cero pollos
32
5
, porque hay cinco eventos con un pollo
32
Xi = 1 Pollos blancos, la probabilidad es de
blanco en 32 resultados posibles.
10
, porque hay diez eventos con dos pollos
32
Xi = 2 Pollos blancos, la probabilidad es de
blancos en 32 resultados posibles.
Xi = 3 Pollos blancos, la probabilidad es de
pollos blancos en 32 resultados posibles.
10
, porque hay diez eventos con tres
32
5
, porque hay cinco eventos con cuatro
32
pollos blancos en 32 resultados posibles.
Xi = 4 Pollos blancos, la probabilidad es de
Xi = 5 Pollos blancos, la probabilidad es de
blancos en 32 resultados posibles.
1
, porque hay un evento con cinco pollos
32
Observa la siguiente tabulación en donde la primera columna es la Xi y la segunda
columna P(Xi= k), a este arreglo se le conoce como DISTRIBUCIÓN DE
PROBABILIDAD, observa:
DISTRIBUCIÓN DE PROBABILIDAD
Xi
0
1
2
3
4
5
PROBABILIDAD
P(Xi= k)
1
P( Xi 0)
32
5
P( Xi 1)
32
10
P( Xi 2)
32
10
P( Xi 3)
32
5
P( Xi 4)
32
1
P( Xi 5)
32
Con frecuencia es conveniente representar todas las probabilidades de una Xi mediante
una fórmula.
31
Tal fórmula necesariamente sería una función de los valores numéricos x que
denotaremos con f(x). Por tanto, escribimos f(x) = P(Xi= k); es decir, f(0) = P(Xi= 0),
f(1) = P(Xi= 1), f(2) = P(Xi= 2), f(3) = P(Xi= 3), f(4) = P(Xi= 4), f(5) = P(Xi= 5). Llamada
como FUNCIÓN DE PROBABILIDAD.
La Función de probabilidad deberá satisfacer los siguientes axiomas:
1. La probabilidad es positiva f (x) 0
2. La suma de todas las probabilidades del experimento aleatorio es
igual a uno
n
f x 1
i1
3. P(Xi= k) = f(x)
El conjunto de pares ordenados [Xi, P(Xi= k)], se llama FUNCIÓN DE DENSIDAD.
1 5 10 10 5 1
D(x) = 0,
, 1, , 2, , 3, , 4, , 5, , está función se observa con
32
32 32 32 32 32
mayor claridad en una gráfica de una función de probabilidad.
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Se llama Función de Probabilidad; a la regla que origina probabilidades a los valores de
la variable aleatoria.
La Función de Probabilidad deberá satisfacer los siguientes axiomas:
1. La probabilidad es positiva f (x) 0
2. La suma de todas las probabilidades del experimento aleatorio es
igual a uno
n
f x 1
i1
3. P(Xi= k) = f(x)
Al conjunto de pares ordenados [Xi , P(Xi = K)], se llama Función de Densidad.
32
1.6 GRÁFICA DE UNA FUNCIÓN DE PROBABILIDAD (HISTOGRAMA
DE PROBABILIDAD)
Se puede construir gráficas para funciones de probabilidad. La gráfica de la función de
probabilidad puede construirse colocando los valores de Xi en el eje horizontal y las
probabilidades P(Xi= k) en el eje vertical; los rectángulos se construyen de modo que sus
bases, de igual ancho, se centren en cada valor de Xi y sus alturas sean iguales a la
probabilidades P(Xi= k). Las bases se construyen de forma tal que no dejen espacios
entre los rectángulos, la gráfica se llama HISTOGRAMA DE PROBABILIDAD, observa el
ejemplo:
Figura. 19
33
1.7 FUNCIÓN DE DISTRIBUCIÓN DE PROBABILIDAD ACUMULADA
Hay muchos problemas donde deseamos calcular la probabilidad de que el valor
observado de una Xi sea menor o igual que algún número real x. Al escribir
F(x) = P(X x) para cualquier número real x, definimos F(x) como la FUNCIÓN DE
DISTRIBUCIÓN DE PROBABILIDAD ACUMULADA.
Fx P X x
FRECUENCIA
PROBABILIDAD
EVENTO
Xi
(N,N,N,N,N)
0
1
P( X i 0)
1
32
1
5
P( X i 1)
5
32
2
10
P( X i 2)
10
32
3
10
P( X i 3
10
32
4
5
P( X i 4)
5
32
5
1
P( X i 5)
1
32
(B,N,N,N,N)
(N,B,N,N,N)
(N,N,B,N,N)
(N,N,N,B,N)
(N,N,N,N,B)
(B,B,N,N,N)
(B,N,B,N,N)
(B,N,N,B,N)
(B,N,N,N,B)
(N,B,B,N,N)
(N,B,N,B,N)
(N,B,N,N,B)
(N,N,B,B,N)
(N,N,B,N,B)
(N,N,N,B,B)
(B,B,B,N,N)
(B,B,N,B,N)
(B,B,N,N,B)
(B,N,B,B,N)
(B,N,B,N,B)
(B,N,N,B,B)
(N,B,B,B,N)
(N,B,B,N,B)
(N,B,N,B,B)
(N,N,B,B,B)
(B,B,B,B,N)
(B,B,B,N,B)
(B,B,N,B,B)
(B,N,B,B,B)
(N,B,B,B,B)
(B,B,B,B,B)
fi
f t
t x
PROBABILIDAD
ACUMULADA
P(Xi)
P ( X i 0)
P( X i 1)
P( X i 2)
P( X i 3)
P( X i 4)
P( X i 5)
1
32
1
32
1
5
6
32 32 32
1
5
10 16
32 32 32 32
1
5
10 10 26
32 32 32 32 32
1
5
10 10
5 31
32 32 32 32 32 32
5
10 10
5
1 32
1
32
32 32 32 32 32
Advierta que la suma de las longitudes de los segmentos verticales debe ser igual a 1.
Hasta aquí podemos mencionar que la Función de Distribución Acumulada, es la
acumulación de cada evento.
34
1.8 GRÁFICA DE UNA FUNCIÓN DE DISTRIBUCIÓN
PROBABILIDAD
ACUMULADA
(HISTOGRAMA
PROBABILIDAD ACUMULADA OJIVA)
DE
DE
La gráfica de la Función de Distribución de Probabilidad Acumulada se construye
colocando los valores de Xi en el eje horizontal y las probabilidades Acumuladas
P( X i k ) en el eje vertical; los rectángulos se construyen de modo que sus bases, de
igual ancho, se centren en cada valor de X i y sus alturas sean iguales a la
probabilidades Acumuladas P( X i k ) . La gráfica de la FUNCIÓN DE DISTRIBUCIÓN
DE PROBABILIDAD ACUMULADA aparece como una función escalonada creciente. Las
bases se construyen de forma tal que no dejen espacios entre los rectángulos, la gráfica
se llama HISTOGRAMA DE PROBABILIDAD ACUMULADA mejor conocida como
OJIVA, observa el ejemplo. Tal como se muestra en la siguiente figura:
Figura 20.
35
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
I. Completa con tus propias palabras. Si tienes duda vuelve a revisar el contenido o
consulta a tu asesor.
La probabilidad se define como: __________________________________________________
_______________________________________________________________________________
_______________________________________________________________________________
El dominio es: _________________________________________________________________
_______________________________________________________________________________
_______________________________________________________________________________
La regla de correspondencia es: _________________________________________________
_______________________________________________________________________________
_______________________________________________________________________________
El contradominio (Conjunto de imágenes) es: _____________________________________
_______________________________________________________________________________
_______________________________________________________________________________
II. De acuerdo con lo que has aprendido, resuelve lo siguiente:
1. En el siguiente cuadro, se proporcionan los resultados de una estadística realizada
por alumnos del Colegio de Bachilleres sobre el modelo de automóvil de los
profesores:
Modelo de automóvil de los profesores del plantel X del Colegio de Bachilleres
MODELO (X)
De 1975 y antes
De 1976 a 1978
De 1979 a 1981
De 1982 a 1984
De 1985 a 1987
De 1988 a 1990
De 1991 a 1993
TOTAL
FRECUENCIA
1
2
13
18
11
12
4
61
36
Si la variable aleatoria es X = Modelo de automóvil, determina:
a) La Distribución de probabilidad
b) La Gráfica de la Distribución de Probabilidad
c) La Función de Densidad
d) La Función de Distribución de Probabilidad Acumulada
e) La OJIVA.
2. Un lote contiene 20 T.V., de los cuales 3 están defectuoso. Si se muestrean 4 de
ellos y se define la variable aleatoria X = T.V. defectuoso. Entonces, determina:
a) El con un diagrama de árbol y recuerda que no puede haber más de tres
defectuosos.
b) La tabla de función de Distribución de probabilidad.
c) Las gráficas de densidad y distribución de probabilidad.
37
1.9 ESPERANZA MATEMÁTICA
Una de las preguntas que te hicimos al inicio del fascículo dice: ¿Cuál es la probabilidad
de que ganes en un juego de azar y cuánto esperas ganar o perder?
Recordaras que una fórmula para calcular el valor de la media poblacional es:
x i fi
N
E( X)
x iP( X x i )
P( x )
Donde fi es la frecuencia de una medida en particular, X i es la variable y N el tamaño de
la población. Esta fórmula puede rescribirse como:
x i
fi
N
P( X x i )
fi
representa la probabilidad de que ocurra x, P( x )
, la
N
P( x )
media poblacional puede escribirse como x iP( x) . Como consecuencia de estas
observaciones, si X es una variable aleatoria, definimos la media de X como sigue:
Como la frecuencia
Media de una variable aleatoria X
x iP( x)
donde representa la media de la variable aleatoria X. Por ejemplo:
Una planta industrial grande realiza una campaña para promover el uso compartido del
automóvil entre sus empleados; los datos se muestran en la siguiente tabla, obtenidos de
los empleados de la planta para conocer los efectos de la campaña.
Núm. De ocupantes
(x) por automóvil
fi
xi fi
1
425
1(425) = 425
2
235
2(235) = 470
3
205
3(205) = 615
4
52
4 (52) = 208
5
22
5 (22) = 110
6
6
6 (6) = 36
TOTALES
945
1864
P(x) = P(X = Xi)
P(x)
425
945
235
945
205
945
52
945
22
945
6
945
Suma de todas las
probabilidades :
38
P( x )
945
1
945
La media poblacional es
x i fi 1864
1.97
N
945
Ahora escojamos un coche al azar que transporte empleados al trabajo y contemos el
número de ocupantes; este número representa una variable aleatoria X, cuyos valores
425 235 205 205
22
6
,
,
,
,
,
,
son 1, 2, 3, 4, 5 y 6, con las probabilidades
945 945 945 945 945 945
respectivamente. La media de esta variable aleatoria es entonces:
x = [xiP(x)] = (1)P(1) + (2)P(2) + (3)P(3) + (4)P(4) + (5)P(5) + (6)P(6)
x = (1)
425
235
205
52
22
6
+ (2)
+ (3)
+ (4)
+ (5)
+ (6)
945
945
945
945
945
945
x = 1.97 En promedio hay dos ocupantes por automóvil.
Observa que este resultado concuerda con el valor calculado anteriormente.
La media de una variable aleatoria X se llama también el VALOR ESPERADO de X y se
denota por E(X); en consecuencia, tenemos los resultados siguientes para una variable
aleatoria discreta:
Media de una variable aleatoria discreta X
x
E( X)
xP( x)
ACTIVIDAD DE REGULACIÓN
Resuelve los siguientes ejercicios:
1.
Una fábrica produce artículos que se clasifican en tres categorías: A, B, C. Si las
ganancias y la producción están dadas en la siguiente tabla:
CATEGORIA
A
B
C
GANANCIA
POR UNIDAD
+ $ 35.00
+ $ 10.00
– $ 5.00
PRODUCCIÓN
(Núm. De piezas)
50,000
80,000
10,000
a) Determina el valor esperado de ganancia por unidad.
b) Determina el rango de la Esperanza Matemática.
39
2.
El América tiene una probabilidad de ganar de 1 . Para los próximos tres juegos,
15
determina:
a) La esperanza de ganar en todos.
b) La esperanza de que solo gane uno o dos.
c) La esperanza de que no gene ninguno.
En el siguiente ejemplo, si el experimento consiste en lanzar dos dados al aire y la
variable aleatoria es la suma de las caras de los dados, determinemos:
a) El diagrama de árbol, y rango.
b) La Función de Variable Aleatoria Discreta.
c) La Distribución de Probabilidad.
d) La Función de Densidad.
e) La Gráfica de una Función de Probabilidad.
f) La Función de Distribución de Probabilidad Acumulada.
g) La Gráfica de la Función de Distribución de Probabilidad Acumulada.
h) La Esperanza Matemática de ganar si la apuesta consiste en: Suma 7 pierdes $
10.00, suma par ganas $ 3.00 y si suma impar (excepto 7) pierdes $ 2.00.
40
a) Diagrama de árbol,
y rango
DIAGRAMA DE ÁRBOL
Figura. 21
41
RANGO
b) FUNCIÓN DE VARIABLE ALEATORIA
F(Xi) = { [ (1,1), 2], [ (1,2), 3], [ (1,3), 4], [ (1,4), 5], [ (1,5), 6], [ (1,6), 7]
[ (2,1), 3], [ (2,2), 4], [ (2,3), 5], [ (2,4), 6], [ (2,5), 7], [ (2,6), 8]
[ (3,1), 4], [ (3,2), 5], [ (3,3), 6], [ (3,4), 7], [ (3,5), 8], [ (3,6), 9]
[ (4,1), 5], [ (4,2), 6], [ (4,3), 7], [ (4,4), 8], [ (4,5), 9], [ (4,6), 10]
[ (5,1), 6], [ (5,2), 7], [ (5,3), 8], [ (5,4), 9], [ (5,5), 10], [ (5,6), 11]
[ (6,1), 7], [ (6,2), 8], [ (6,3), 9], [ (6,4), 10], [ (6,5),11], [ (6,6), 12] }
c) DISTRIBUCIÓN DE PROBABILIDAD
EVENTO
Xi
FRECUENCIA fi
(1,1)
2
1
3
2
4
3
P( Xi 4)
3
36
5
4
P( Xi 5)
4
36
6
5
P( Xi 6)
5
36
7
6
P( Xi 7)
6
36
8
5
P( Xi 8)
5
36
9
4
P( Xi 9)
4
36
10
3
P( Xi 10)
11
2
12
1
(1,2)
(2,1)
(1,3)
(2,2)
(3,1)
(1,4)
(2,3)
(3,2)
(4,1)
(1,5)
(2,4)
(3,3)
(4,2)
(5,1)
(1,6)
(2,5)
(3,4)
(4,3)
(5,2)
(6,1)
(2,6)
(3,5)
(4,4)
(5,3)
(6,2)
(3,6)
(4,5)
(5,4)
(6,3)
(4,6)
(5,5)
(6,4)
(5,6)
(6,5)
(6,6)
PROBABILIDAD P(Xi= k)
1
P( Xi 2)
36
2
P( Xi 3)
36
3
36
2
36
1
P( Xi 12)
36
P( Xi 11)
42
DISTRIBUCIÓN DE PROBABILIDAD
Xi
2
3
4
5
6
7
8
9
10
11
12
PROBABILIDAD
P(Xi= k)
1
36
2
P( Xi 3)
36
3
P( Xi 4)
36
4
P( Xi 5)
36
5
P( Xi 6)
36
6
P( Xi 7)
36
5
P( Xi 8)
36
4
P( X i 9)
36
3
P( Xi 10)
36
2
P( Xi 11)
36
1
P( Xi 12)
36
P( Xi 2)
d) FUNCIÓN DE DENSIDAD
1 2 3 4 5 6 5 4
3
2
1
D( x ) 2, , 3, , 4, , 5, , 6, , 7, , 8, , 9, , 10, , 11, , 12,
36
36
36
36
36
36
36
36
36
36
36
43
e) GRÁFICA DE UNA FUNCIÓN DE PROBABILIDAD
Figura. 22
44
f) FUNCIÓN DE DISTRIBUCIÓN DE PROBABILIDAD ACUMULADA
FRECUENCIA
PROBABILIDAD
EVENTO
Xi
(1,1)
2
1
3
2
4
3
P( X i 4)
3
36
5
4
P( X i 5)
4
36
6
5
P( X i 6)
5
36
7
6
P ( X i 7)
6
36
5
5
P( X i 8)
36
9
4
4
P( X i 9)
36
10
3
P( X i 10)
2
2
P( X i 11)
36
1
1
P( X i 12)
36
(1,2)
(2,1)
(1,3)
(2,2)
(3,1)
(1,4)
(2,3)
(3,2)
(4,1)
(1,5)
(2,4)
(3,3)
(4,2)
(5,1)
(1,6)
(2,5)
(3,4)
(4,3)
(5,2)
(6,1)
(2,6)
(3,5)
(4,4)
(5,3)
(6,2)
(3,6)
(4,5)
(5,4)
(6,3)
(4,6)
(5,5)
(6,4)
(5,6)
(6,5)
(6,6)
8
11
12
fi
PROBABILIDAD ACUMULADA
P(Xi)
1
36
2
P( X i 3)
36
P( X i 2)
3
36
P( Xi 2)
1
36
3
36
P( Xi 3)
1
36
2
36
P( Xi 4)
1
36
2
36
3
36
P( Xi 5)
1
36
2
36
3
36
4
36
P( Xi 6)
1
36
2
36
3
36
4
36
5
36
P( Xi 7)
1
36
2
36
3
36
4
36
5
36
6
36
P( Xi 8)
1
36
P( Xi 10)
P( Xi 11)
P( Xi 12)
45
10
36
15
36
21
36
2
36
3
36
4
36
5
36
6
36
5
36
2
36
3
36
4
36
5
36
6
36
5
36
3
36
4
36
5
36
6
36
5
36
4
36
5
36
6
36
5
36
6
36
5
36
26
36
P( Xi 9)
6
36
1
36
4
36
30
36
1
36
2
36
4
36
3
36
1
36
2
36
3
36
4
36
3
36
2
36
1
36
2
36
3
36
4
36
5
36
4
36
3
36
2
36
1
36
36
36
1
33
36
35
36
g) GRÁFICA DE UNA FUNCIÓN DE DISTRIBUCIÓN DE PROBABILIDAD
ACUMULADA
Figura. 23
46
h) ESPERANZA MATEMATICA
Xi
Xi
en pesos $
2
+ $ 3.00
3
– $ 2.00
4
+ $ 3.00
5
– $ 2.00
6
+ $ 3.00
7
– $ 10.00
8
+ $ 3.00
9
– $ 2.00
10
+ $ 3.00
11
– $ 2.00
12
+ $ 3.00
PROBABILIDAD
P(Xi)
P( X i 2)
1
36
P( X i 3)
2
36
P( X i 4)
3
36
P( X i 5)
4
36
P( X i 6)
5
36
P ( X i 7)
6
36
P( X i 8)
5
36
P( X i 9)
4
36
P( X i 10)
3
36
P( X i 11)
2
36
P( X i 12)
1
36
Xi P(Xi)
3
1 3
36 36
2 4
36
36
2
3
3 9
36 36
4 8
36
36
2
3
5 15
36 36
6 60
36
36
10
3
5 15
36 36
4 8
36
36
2
3
3 9
36 36
2
2 4
36
36
3
1 3
36 36
VALOR ESPERADO E ( X ) X i P X i
En promedio perderá $ 5.00 cada 6 juegos.
Por otra parte, el valor esperado de algunos eventos puede estar muy disperso. Cuando
se trata de tomar decisiones, es importante conocer la variación total de los eventos, ya
que sirve para ver la heterogeneidad de las variables aleatorias, cuando la variación es
muy alta y la homogeneidad cuando la variación es muy pequeña.
47
30 5
36
6
En el ejemplo que hicimos del experimento de lanzar dos dados y determinar como
variable aleatoria a la suma de las caras, el número de resultados del es 36 y :
a) La variable aleatoria xi es igual a la suma de los puntos de las caras, está dada
en la primera columna de la siguiente tabla.
b) La probabilidad P(x) de cada evento (suma de eventos) está dada en la segunda
columna de dicha tabla.
c) Encontramos que la Esperanza Matemática E(xi) menos el valor esperado E(x)
[E(xi) - E(x)], tal como se indica en la tercera columna del cuadro.
d) La variación total (varianza), está dada como la suma de los cuadrados de cada
una de las diferencias de los valores esperados, calculadas en la columna
anterior, tal y como se indica en la cuarta columna del cuadro.
Xi
P(xi)
E(xi) – E(x)
[E(xi) – E(x)]
2
1
36
1 30 31
36 36 36
961
1296
3
2
36
2 30 32
36 36 36
1024
1296
4
3
36
3 30 33
36 36 36
1089
1296
5
4
36
4 30 34
36 36 36
1156
1296
6
5
36
5 30 35
36 36 36
1225
1296
7
6
36
6 30 36
36 36 36
1296
1296
8
5
36
5 30 35
36 36 36
1225
1296
9
4
36
4 30 34
36 36 36
1156
1296
10
3
36
3 30 33
36 36 36
1089
1296
11
2
36
2 30 32
36 36 36
1024
1296
12
1
36
1 30 31
36 36 36
961
1296
TOTAL :
48
2
12206
9.4182
1296
El resultado de la tabla significa que:
La esperanza de ganar o perder en el juego es de $ 9.4182 ¿Consideras que es
mucho?, pero para asegurar ganar esta cantidad, necesitas jugar 1296 juegos con una
cantidad de $ 12,206.00 a esta variación se le llama VARIANZA.
La varianza se simboliza:
2
VARIANZA
Ex Ex
2
i
La desviación estándar, es una medida de la variación de los valores observados con
respecto a la media muestral.
DESVIACIÓN ESTANDAR
9.4182 3.0689
49
Ex Ex
2
i
ACTIVIDAD DE REGULACIÓN
Resuelve los siguientes ejercicios, utiliza tu cuaderno para dar tus respuestas:
1. En un juego hay tres máquinas, en la máquina M 1 tienes que pagar $ 1.00 por jugar,
pero si ganas la máquina te regresa $ 2.00 y tienes una probabilidad de 31 de ganar.
En la máquina M2 tienes que invertir $ 2.00, pero si ganas la máquina te devuelve $
5.00 y tienes una probabilidad de 81 . En la máquina M3 tienes que pagar $1.5 y si
ganas te da $ 3.00 con una probabilidad de
1
5
de ganar. Si juegas 2 juegos en la
máquina 1, tres juegos en la máquina 2, y 3 juegos en la máquina 3.
a) ¿Cuál es la esperanza que tienes de ganar en los 6 juegos?
b) ¿Cuál sería la variación total (VARIANZA) de tus pérdidas y ganancias?
2. En una investigación que hicieron los alumnos del Colegio de Bachilleres, sobre la
demanda de empleos que requieren un mínimo de estudios de Bachillerato en
diversos periódicos dominicales, encontraron lo siguiente:
EMPLEO
Chóferes
Secretarias
Odontólogos
Recepcionistas
Ingenieros
Otros
FRECUENCIA
6
2
1
3
1
3
SUELDO PROMEDIO PAGADO
$ 800.00
$ 750.00
$ 2,000.00
$ 600.00
$ 4,500.00
$ 850.00
Si decidieras solicitar alguno de estos empleos, determina:
a) El valor del sueldo esperado que puedes ganar.
b) La varianza de sueldos.
50
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Recuerda que la Media de una variable aleatoria X, es:
x iP( x)
La Media de una variable aleatoria X se llama también valor esperado de X y se denota
por E(X).
La Media de una variable aleatoria discreta X, es:
x
E( X)
51
xP( x)
RECAPITULACIÓN
Con la finalidad de que reafirmes tus conocimientos. A continuación te presentamos
algunos dibujos y gráficas que se relacionan con los temas que acabas de estudiar.
52
ACTIVIDADES DE CONSOLIDACIÓN
Con la finalidad de que apliques tus conocimientos que adquiriste en este fascículo,
resuelve el siguiente problema.
Una compañía contratará a 3 personas, para lo cual hace un examen de aptitudes. Se
presentan cuatro solicitantes y los resultados de la prueba de aptitud están dados en la
siguiente tabla:
SOLICITANTES
S1, S4
S2
S3
PUNTUACIÓN
3
2
1
SUELDO
$ 300.00
$ 100.00
$ 60.00
La variable aleatoria x es igual a la suma de puntuación de los tres solicitantes que van a
contratar:
DETERMINA:
a) El diagrama de árbol, o Espacio Muestral
, y rango.
b) La Función de Variable Aleatoria Discreta.
c) La Distribución de Probabilidad.
d) La Función de Densidad.
e) La Gráfica de la Función de Probabilidad.
f)
La Función de Distribución de Probabilidad Acumulada.
g) La Gráfica de la Función de Distribución de Probabilidad Acumulada.
h) La tabulación del salario que pagará la Compañía a las 3 personas que
contratará por cada suma de puntuaciones.
i)
El Valor Esperado de sueldo que pagará la Compañía.
53
AUTOEVALUACIÓN
Con la finalidad de que verifiques tu proceso de solución, a continuación te presentamos
los resultados que debiste obtener en tu Actividad de Consolidación:
a) Recuerda que un solicitante sólo puede tener una puntuación.
b) La Función de Variable Aleatoria Discreta.
F(Xi) = { [(3,2,1), 6], [(3,2,3), 8], [(3,1,2), 6], [(3,1,3), 7], [(3,3,2),8], [(3,3,1), 7]
[(2,3,1), 6], [(2,3,3), 8], [(2,1,3), 6], [(2,1,3), 6], [(2,3,3),8], [(2,3,1), 6]
[(1,3,2), 6], [(1,3,3), 7], [(1,2,3), 6], [(1,2,3), 6], [(1,3,3),7], [(1,3,2), 6]
[(3,3,2), 8], [(3,1,3), 7], [(3,2,3), 8], [(3,2,1), 6], [(3,1,3),7], [(3,1,2), 6] }
c) La Distribución de Probabilidad.
Xi
6
7
8
PROBABILIDAD
P(Xi=k)
12
P(Xi = 6) =
24
6
24
6
P(Xi = 8) =
24
P(Xi = 7) =
12 6 6
d) La Función de Densidad. D(x) = 6,
, 7,
, 8,
24 24 24
e) La Gráfica de la Función de Probabilidad.
Construye la gráfica de la Función de Probabilidad colocando los valores de Xi
en el eje horizontal y las probabilidades P(Xi=k) en el eje vertical; los rectángulos
se construyen de modo que sus bases, de igual ancho, se centren en cada valor
de Xi y sus alturas sean iguales a las probabilidades P(Xi=k).
54
f) La Función de Distribución de Probabilidad Acumulada.
Xi
6
PROBABILIDAD
P(Xi=k)
12
P(Xi = 6) =
24
7
P(Xi = 7) =
6
24
8
P(Xi = 8) =
6
24
PROBABILIDAD
ACUMULADA
12
P(Xi = 6) =
24
12 6
18
P(Xi = 7) =
=
24 24
24
12 6
6
24
P(Xi = 8) =
=
=1
24 24 24
24
g) La Gráfica de la Función de Distribución de Probabilidad Acumulada.
Construye la gráfica de la Función de Distribución de Probabilidad Acumulada
colocando los valores de Xi en el eje horizontal y las probabilidades acumuladas
P(Xi=k) en el eje vertical; los rectángulos se construyen de modo que sus
bases, de igual ancho, se centren en cada valor de Xi y sus alturas sean iguales
a las probabilidades acumuladas P(Xi=k).
h) La tabulación del salario que pagará la Compañía a las 3 personas que
contratará por cada suma de puntuaciones.
Xi
6
7
8
i)
SALARIO
$230.00
$165.00
$175.00
El valor esperado de sueldo que pagará la Compañía, es $570.00.
55
AC T I V I D AD E S D E G E N E R AL I Z AC I Ó N
Con la finalidad de que apliques y consolides tus conocimientos que adquiriste en este
fascículo, resuelve lo siguiente:
En un concurso de baile se asignarán tres premios para las personas que obtengan el
1°, 2° y 3° lugar; para lo cual se hace una convocatoria y un examen. Se presentan 8
participantes y los premios de la prueba son los siguientes:
PARTICIPANTES
S1, S2, S3
S4, S5, S6
S7, S8
PUNTUACIÓN
3°
2°
1°
PREMIOS
$ 500.00
$ 300.00
$ 150.00
La variable aleatoria x es igual a la suma de puntuación de las tres personas que
obtengan los tres primeros lugares.
DETERMINA:
a) El Espacio Muestral
, y rango.
b) La Función de Variable Aleatoria Discreta.
c) La Distribución de Probabilidad.
d) La Función de Densidad.
e) La Gráfica de la Función de Probabilidad.
f)
La Función de Distribución de Probabilidad Acumulada.
g) La Gráfica de la Función de Distribución de Probabilidad Acumulada.
h) El Valor Esperado de los premios que pagará el Organizador.
56
GLOSARIO
Desviación estándar: Es la raíz cuadrada positiva de la varianza.
Distribución de probabilidad: Son las probabilidades que toman los eventos de la
variable aleatoria.
Espacio muestral: Es el dominio de la función de variable aleatoria y se designa con la
letra .
Esperanza matemática: Es la media o valor promedio de la variable aleatoria.
Estadística descriptiva: Comprende aquellos métodos usados para organizar y
describir la información recabada.
Estadística inferencial: Comprende aquellos métodos y técnicas usados para hacer
generalizaciones, predicciones o estimaciones sobre poblaciones a partir
de una muestra.
Evento:
Cada uno de los resultados del dominio de la función de variable
aleatoria.
Fenómeno determinístico: Son aquellos fenómenos que ocurren siempre de la misma
forma y siempre tienen el mismo resultado.
Fenómenos aleatorios: Son aquellos fenómenos que no siempre ocurren de la misma
forma, y que están sujetos al azar.
Función aleatoria continua: Es aquella función, generalmente calculada por medio de
fórmulas matemáticas o interpretadas por instrumentos de medición por
lo que puede tomar cualquier valor dentro de un intervalo.
Función aleatoria discreta: Es aquella función que sólo toma valores enteros.
57
Función de distribución de probabilidad acumulada: Es la acumulación de cada
evento.
Función de probabilidad: Regla que asigna probabilidades a los valores de la variable
aleatoria.
Función:
Es una relación entre dos conjuntos; las primeras componentes de las
parejas pertenecen al conjunto A, llamado conjunto de partida o dominio,
las flechas indican las correspondencias entre elementos de los
conjuntos A y B, mientras las segundas componentes pertenecen al
conjunto B, denominado conjunto de llegada, codominio o contradominio.
Varianza:
Es la variación de ganar o perder en un fenómeno determinístico.
58
BIBLIOGRAFÍA CONSULTADA
JOHNSON, Robert.; Estadística Elemental. Grupo Editorial Iberoamérica, México, 1993.
WALPOLE, Ronald E.; Probabilidad y Estadística para Ingenieros. Pearson Educación;
México, 1999.
WEIMER, Richard C.; Estadística. C.E.C.S.A.; México, 1999.
59
COLEGIO DE BACHILLERES
ESTADÍSTICA DESCRIPTIVA E
INFERENCIAL II
FASCÍCULO 2. FUNCIONES DE DISTRIBUCIÓN DE
PROBABILIDAD
Autores: Esther Barrera Padilla
Leobardo Sánchez Pimentel
1
2
ÍNDICE
INTRODUCCIÓN
5
PROPÓSITO
79
SIMBOLOGÍA
11
CAPÍTULO 1. FUNCIONES DE DISTRIBUCIÓN DE
PROBABILIDAD
1.1 DISTRIBUCIÓN BINOMIAL
13
14
1.1.1 MODELO MATEMÁTICO DE LA
DISTRIBUCIÓN BINOMIAL
19
1.1.2 MEDIA, VARIANZA Y DESVIACIÓN
ESTÁNDAR DE LA DISTRIBUCIÓN
BINOMIAL
29
1.1.3 TABLAS DE DISTRIBUCIÓN BINOMIAL
ACUMULADA
35
1.2 DISTRIBUCIÓN DE POISSON
41
1.2.1 MEDIA, VARIANZA Y DESVIACIÓN
ESTÁNDAR DE LA DISTRIBUCIÓN DE
POISSON
45
1.2.2 APROXIMACIÓN DE LA DISTRIBUCIÓN DE
POISSON A LA BINOMIAL
47
1.2.3 TABLAS DE DISTRIBUCIÓN DE POISSON
ACUMULADA
54
3
RECAPITULACIÓN
59
ACTIVIDADES DE CONSOLIDACIÓN
60
AUTOEVALUACIÓN
64
ACTIVIDADES DE GENERALIZACIÓN
65
ANEXO 1
66
ANEXO 2
73
BIBLIOGRAFÍA CONSULTADA
78
4
INTRODUCCIÓN
Creadores de las distribuciones, Binomial y de Poisson:
Jacob Bernoulli
Nació el 27 de diciembre de 1754 y fallece el 16 de agosto de 1705, en Basilea Suiza.
Se graduó con un grado de Teología en Basilea Suiza, en el año 1676. Recibió
enseñanza en matemática y astronomía, contra los deseos de su padre que era
banquero.
Enseño mecánica en la Universidad de Basilea a partir del año 1683 y posteriormente
fue nombrado profesor de matemáticas en el año 1687 puesto que ocupo hasta su
muerte, supliéndolo su hermano Johann Bernoulli, gran matemático y progenitor de una
familia de grandes matemáticos, los Bernoulli.
Jacob en 1685, debido a un consejo de Leibniz, trabajo en el campo de la teoría de las
probabilidades dedicándose a perfeccionar sus estudios realizados anteriormente y
debido a este trabajo el cálculo de las probabilidades adquirió estatus de ciencia.
Fue de los primeros en estudiar y aplicar las teorías de cálculo de Leibniz, que
resultaban muy confusas para los grandes matemáticos, siendo el Jacob el primero en
usar el término de integral.
En 1689 Bernoulli publica dos importantes trabajos, uno sobre series infinitas y otro que
demostraba la llamada ley de los grandes números.
En honor de Jacob Bernoulli, su nombre va asociado a varios conceptos matemáticos,
como los números de Bernoulli en la teoría de números, la lemniscata de Bernoulli en
cálculo y los experimentos de Bernoulli en probabilidad.
5
Simeón Denis Poisson
Nació el 21 de junio en Pitthiviers, Francia y muere el 25 de abril de 1840, en Sceaux
cerca de Paris Francia.
Denis Poisson fue un prolífico matemático que desempeño varios puestos dentro del
sistema educativo de Francia y que realizo gran cantidad de investigaciones de
investigaciones matemáticas, a continuación se mencionan algunos de los hechos
notables de su vida.
En 1796 Poisson ingresa a la Escuela Central, demostrando inmediatamente talento
para aprender matemáticas. En 1798 ingresa a la Escuela Politécnica siendo alumno de
Laplace y Lagrange quienes notaron su talento matemático y los cuales fueron sus
amigos durante el resto de sus vidas.
En 1809 él agregó otro puesto, al ingresar al departamento mecánica en la Facultad de
Ciencias, recientemente abierta.
En 1812 Poisson ingresa a la academia de física del Instituto a partir del trabajo
desarrollado sobre la distribución de la electricidad en la superficie de los cuerpos
conductores.
En una investigación sobre la probabilidad de los juicios en materia criminal y materia
civil, un importante trabajo de probabilidad publicado en 1837, la distribución de Poisson
aparece por primera vez. La distribución de Poisson describe la probabilidad que un
evento aleatorio ocurrirá en un intervalo de tiempo o espacio bajo las condiciones que la
probabilidad del evento a ocurrir sea muy pequeña, y el número de ensayos muy grande,
para que el evento posiblemente ocurra unas veces realmente. Aunque en su tiempo
este trabajo no se considero de gran importancia, actualmente se considera a este
trabajo como de gran importancia.
Poisson publicó entre 300 y 400 trabajos, todos ellos matemáticos. A pesar de este gran
rendimiento, él siempre trabajó un tema a la vez. Poisson nunca deseó ocuparse con dos
cosas al mismo tiempo.
En la investigación estadística a sí como en la vida cotidiana existen experimentos o
ensayos que tienen características comunes, por lo que se pueden analizar con un
mismo modelo matemático.
Por ejemplo en Matemáticas I aprendiste a obtener modelos matemáticos de funciones
2
lineales "f(x) = ax + b; en matemáticas II, de funciones cuadráticas "f(x) = ax + bx +
x
c", y exponenciales naturales "f(x) = e ". Estás funciones se trataron generalmente se
trataron como funciones continuas de variable continua.
Pero no todos los eventos que suceden en nuestro entorno se pueden trabajar con
funciones continuas, por ejemplo el número de hijos de en una familia, sabemos que
pueden ser ningún hijo o un o dos o tres hijos, etc. Pero no podemos hablar de 3 o 1 1
4
2
de hijo. Por eso es necesario en nuestra preparación matemática, el estudio de algunos
modelos matemáticos discretos.
6
Definida una variable de estudio discreta, por ejemplo; el número de hijos en una familia,
el número de goles en un partido de fútbol, el número de veces en que se muestra un
número al lanzar un dado o el número de veces que se muestra águila al lanzar una
moneda, etc.
Se considera importante determinar la probabilidad de que la variable de estudio tome
algún valor particular, por ejemplo; al visitar 6 familias cual es la probabilidad de que
tengan menos de dos hijos, o que al lanzar una moneda corriente 8 veces cuál es la
probabilidad que se muestren exactamente 3 águilas. Es esté tipo de problemas los que
se analizaran en éste fascículo, como, mediante un proceso matemático lo que nos
permitirá obtener un conocimiento más amplio sobre el estudio de los eventos aleatorios
sus probabilidades y sus posibles aplicaciones en la vida cotidiana.
Por ésta importancia en este fascículo se estudiara dos modelos de funciones discretas,
la Binomial y la de Poisson. La primera la desarrollo el matemático suizo Jocob
Bernoulli, y en honor a su autor, la distribución Binomial también se conoce como de
Bernoulli; la segunda correspondió al matemático francés Simion Denis Poisson que en
su honor se conoce como la distribución de Poisson.
En el caso de la distribución de Poisson, se determinaran las características de la
distribución de Poisson y sin deducir se indicara su formula, sus propiedades, media
varianza y desviación estándar, a sí como la aplicación de este modelo en la solución de
problemas. También se analizara la distribución de Poisson como el límite de la
distribución Binomial, deduciendo el modelo matemático de la distribución de Poisson a
partir de la expresión matemática de la distribución Binomial, en esta secuencia se
obtendrán las propiedades de la distribución de Poisson como aproximación de la
Binomial y sus aplicaciones a la solución de problemas.
7
8
PROPÓSITO
En este fascículo:
¿QUÉ APRENDERÁS?
Conocerás y analizarás dos importantes distribuciones de probabilidad discreta, la
Binomial y la de Poisson, sus modelos y aplicaciones.
¿CÓMO LO LOGRARÁS?
A través de las propiedades y el análisis de un experimento binomial que da como
resultado un modelo matemático y sus elementos como son la media, varianza y
desviación estándar.
¿PARA QUÉ TE VA SERVIR?
Para que apliques tus conocimientos en la solución de problemas reales y conozcas
el uso de las tablas binomiales.
9
10
SIMBOLOGÍA
SÍMBOLO
n x n–x
b(x,n,p) = p q
x
= np
2
SIGNIFICADO
Distribución binomial
Media de la distribución binomial
= npq
Varianza de la distribución binomial
= npq
Desviación estándar de la distribución binomial
x<b
x menor que b
x>b
x mayor que b
xb
x menor o igual que b
xb
x mayor o igual que b
f (x,n) =
x
e
x!
Distribución de Poisson
Media de la distribución de Poisson
2
=
Varianza de la distribución de Poisson
=
Desviación estándar de la distribución de Poisson
11
12
CAPÍTULO 1
FUNCIONES DE DISTRIBUCIÓN
DE PROBABILIDAD
Existen infinidad de sucesos en la vida cotidiana cuyos posibles resultados se puedan
limitar a solamente dos, por ejemplo; en buen estado o defectuoso, ganar o perder,
aprobado o reprobado, inocente o culpable, águila o sol, etc. Los cuales se pueden
analizar mediante un mismo modelo matemático de función de probabilidad f(x) con lo
que se facilita el análisis y la determinación de la probabilidad de este tipo de eventos.
Ejemplos:
Una agencia de trabajo recibe a 18 personas en respuesta a un anuncio de solicitud de
empleados publicado en el periódico. Uno de los requisitos para ser contratado es que la
persona sea casada. Si por experiencia de la agencia se sabe que tres de cuatro
personas que van a solicitar empleo son casadas. ¿Cuál será la probabilidad de que de
los 18 solicitantes al trabajo siete de ellos sean casados?
Si en trabajos hechos de investigación estadística se conoce que ocho de cada mil
alumnos de cierta escuela tienen sangre O ¿Cuál es la probabilidad de que en un día de
donación de sangre realizada por la Cruz Roja en dicha escuela, 200 estudiantes,
donantes de sangre, tres de ellos tengan sangre O?
¿Te interesa conocer y aplicar los modelos matemáticos que nos permitan analizar y
resolver este tipo de problemas de una manera sencilla? Si es a sí, continua con el
estudio de la variable discreta y la determinación de sus probabilidades mediante dos
modelos matemáticos de distribución de probabilidad, Binomial y Poisson.
13
1.1 DISTRIBUCIÓN BINOMIAL
Existen muchos experimentos que tienen características comunes por lo que se pueden
clasificar de alguna manera particular y analizar mediante un mismo modelo matemático.
En la investigación estadística a un conjunto particular de experimentos, que reúnen
ciertas condiciones se les conoce como Experimentos de Bernoulli.
Para que un experimento sea de Bernoulli tiene que cumplir las siguientes condiciones:
1. El experimento consista de n ensayos repetidos.
2. Cada ensayo proporciona dos posibles resultados que pueden clasificarse como éxito
o fracaso.
3. La probabilidad de éxito, designada por la letra p, permanece constante de un ensayo
a otro.
4. Los ensayos son independientes.
Analicemos los siguientes experimentos, para determinar si son o no experimentos de
Bernoulli.
–Sea el experimento de lanzar una moneda corriente (homogénea) cinco veces.
Análisis:
a) El experimento consiste en 5 ensayos, por lo tanto n = 5.
Cumple con la primera condición del experimento de Bernoulli.
b) Al lanzar la moneda hay dos posibles resultados, águila o sol. Se puede clasificar uno
de ellos como éxito, por ejemplo que muestre águila.
Se cumple con la segunda condición del experimento de Bernoulli.
c) La probabilidad de que al lanzar la primera vez la moneda muestre águila (éxito) es
uno de dos posibles resultados, es decir 21 .
Si lanza esa misma moneda por segunda vez, el estado físico de la moneda no varia,
sigue teniendo dos lados y sigue siendo homogénea, por lo que la probabilidad de
que muestre águila vuelve a ser de 21 .
Para los siguientes lanzamientos las condiciones se repiten y la probabilidad de éxito
de que la moneda muestre águila de un ensayo a otro se mantendrá constante e igual
a 21 .
Se cumple con la tercera condición del experimento de Bernoulli.
d) Los ensayos son independientes entre sí. Por que en cada ensayo se tienen los
mismos resultados, águila o sol, manteniendo cada resultado la misma probabilidad
de ocurrir de un ensayo a otro, la probabilidad de águila 21 y la probabilida de sol 21 .
Se cumple con la cuarta condición del experimento de Bernoulli.
14
Como el experimento cumple con las cuatro características de un experimento de
Bernoulli, se concluye que el lanzar una moneda siete veces o n, es un experimento de
Bernoulli.
–Sea el experimento de extraer al azar, en forma sucesiva y sin reposición, cuatro
canicas, de una bolsa que contiene 5 canicas azules y 7 canicas blancas.
a) El experimento consiste en 4 ensayos, por lo tanto n = 4
Por lo que cumple con la primera condición del experimento de Bernoulli.
b) Al sacar una canica hay dos posibles resultados, azul o blanca. Se puede considerar
un éxito obtener una canica color azul.
Se cumple con la segunda condición del experimento de Bernoulli.
c) La probabilidad de sacar en el primer intento una canica azul es de.
Figura. 1
Figura. 2
La probabilidad de sacar en el segundo intento una canica azul es de.
Figura.
3
15
La probabilidad de sacar en el tercer intento una canica azul es de:
Figura. 4
La probabilidad de éxito de obtener una canica azul varía de un ensayo a otro.
No se cumple con la tercera condición del experimento de Bernoulli.
En cada ensayo se tienen los mismos resultados, obtener una canica de color azul o de
color blanca. Pero la probabilidad de obtener una canica azul o una blanca varía de un
ensayo a otro, dependiendo de los resultados de los ensayos anteriores.
No se cumple con la cuarta condición del experimento de Bernoulli.
Por lo tanto no se trata de un experimento de Bernoulli.
Que pasara con el experimento, si en el ejemplo anterior el experimento se realiza de la
siguiente forma.
–Sea el experimento de extraer al azar, en forma sucesiva y con reposición, cuatro
canicas, de una bolsa que contiene 5 canicas azules y 7 canicas blancas.
¿Será un experimento de Bernolli?
Si tú respuesta fue sí, entonces ya entendiste lo que es un experimento de Bernoulli. Si
no, repasa las características de Bernoulli o pide asesoría con tu asesor de contenido.
16
ACTIVIDAD DE REGULACIÓN
En el paréntesis de la derecha escribe una B si el experimento es de Bernoulli y una X si
no lo es.
a) De una caja que contiene 18 calculadoras de las cuales 6 están
defectuosas, obtener en forma sucesiva y sin reemplazo 5 calculadoras.
( )
b) Resolver un examen con 18 preguntas de verdadero o falso.
( )
c) Realizar 20 llamadas telefónicas para investigar si ven cierto programa
televisivo.
( )
d) Sacar de una baraja tres cartas para repartirlas a tres jugadores.
( )
Determinación de los coeficientes binomiales:
n
n!
x
x
!
n
x!
Se descompone n! en x! o (n – x)! factores, en el menor de ellos, en forma decreciente
n(n – 1)(n – 2) . . .
Se dividen los factores del numerador n(n – 1) (n – 2). . ., con los factores del menor de
los factoriales x! o (n – x)! del denominador que tengan divisibilidad común. El resultado
será el producto de los factores del numerador.
Ejemplos:
6
6!
6!
6 5 4! 6 5
2!4!
1 2
2 2! 6 2 ! 2!4!
2
10
6 con 2, mitad
2 factores
35
1 1
6
4
15
20
20!
20!
20 19 18 17 16
2 19 6 17 4 15504
1 2 3 4 5
15 15! 20 15 ! 15!5!
1 1 1 1
17
20 con 2,
mitad
18 con 3,
tercera
16 con 4,
cuarta
10 con 5,
quinta
1
2
8 con 4, cuarta
2 con 2, mitad
6 con 3, tercera
2
8
8!
8765
7 2 5 70
4
4
!
4
!
1 2 3 4
1 1 1
Las siguientes condiciones ayudan a determinar los coeficientes binomiales.
n
1
0
n
n
1
n
n
n 1
n
1
n
5
5
1
5
5
4
5
1
5
Ejemplos:
5
1
0
ACTIVIDAD DE REGULACIÓN
Realiza los siguientes coeficientes binomiales:
12
3
2)
90
1
5)
1)
4)
7
7)
7
15
2
3)
4
7
13
0
6)
10
5
9)
18
4
15
14
8)
18
Algunas calculadoras científicas cuentan con la función de combinaciones, generalmente
indicada nCr. Sí tienes una de ellas práctica obteniendo los coeficientes binomiales
anteriores.
1.1.1 MODELO MATEMÁTICO DE LA DISTRIBUCIÓN BINOMIAL
El modelo matemático de la distribución binomial se deducirá a partir de un experimento
de Bernoulli, el lanzamiento de una moneda. Para lograr nuestro objetivo se
determinaran las distribuciones de probabilidad de los experimentos de lanzar la
moneda una, dos y tres veces, bajo las siguientes condiciones:
Se considera éxito que la moneda muestre águila, designando con la letra "p" como la
probabilidad de éxito de que la moneda muestre águila y "q" la probabilidad de
fracaso de que no muestre águila.
El número de ensayos se indica con la letra "n".
El número de éxitos, que muestre águila, se indica con la letra "x".
La probabilidad de que la variable aleatoria binomial sea igual a xi se indica como
f(xi).
Sea el experimento de lanzar una vez la moneda.
P(a) = p
P(s) = q
n=1
x: número de éxitos
Diagrama de árbol del experimento:
p
a–x=1
Conjunto imagen
X(S) = {0, 1}
Función de probabilidad:
q
s–x=0
f(1) = P(a) = p
f(0) = P(s) = q
19
Expresado cómo tabla:
xi
F(xi)
1
p
0
q
De la propiedad de la función de probabilidad f(xi) = 1, se tiene: p q 1
Gráficamente la función de distribución de probabilidad de una moneda que se lanza una
vez, es:
Figura. 5
Sea el experimento de lanzar dos veces la moneda.
P(a) = p
P(s) = q
n=2
x: número de éxitos
Diagrama de árbol del experimento
Conjunto imagen
X(S) = {0, 1, 2}
Función de probabilidad:
f(0) = P(s, s) = qq = q
2
f(1) = P(a, s) + P(s, a) = pq + qp = 2pq
f(2) = P(a, a) = pp = p
2
Expresado cómo tabla:
xi
F(xi)
2
2
p
1
2pq
0
2
q
2
2
De la propiedad de la función de probabilidad f(xi) = 1, se tiene: p + 2pq + q = 1
20
¿Con cuál de las siguientes expresiones la relacionas?
1
pq
3
(a + b)
pq
2
(a + b)
3/4
¿Por qué? ____________________________________________________________
n=2
n=2
n=2
De la tabla se observa que el exponente de p esta dado por el número de éxitos, por lo
x
que para x éxitos tendríamos p .
2
2
En la expresión p + 2pq + q , todos sus términos son de 2º grado absoluto, por lo que el
trino-mio se puede escribir de la forma:
2
2
2 0
1 1
0 2
p + 2pq + q = p q + 2p q + p q
En el primer término n = 2, x = 2 y el exponente de q es cero.
En el segundo termino n = 2, x = 1 y el exponente de q es uno.
En el tercer término n = 2, x = 0 y el exponente de q es dos.
¿Cual será la relación de n y x para determinar el exponente de q?
n
x
x
n
n x
n x
Gráficamente, la función de distribución de probabilidad de una moneda lanzada dos
veces, es:
Figura. 6
21
Sea el experimento de lanzar tres veces la moneda.
P(a) = p
P(s) = q
n=3
x: número de éxitos
Diagrama de árbol del experimento
Conjunto imagen
X(S) = {0, 1, 2, 3}
Función de probabilidad:
f(0) = P(s, s, s) = qqq = q
3
f(1) = P(a, s, s) + P(s, a, s) + P(s, s, a)
2
2
2
= pqq + qpq + qqp = pq + pq + pq
2
= 3pq
f(2) = P(a, a, s) + P(a, s, a) + P(s, a, a)
2
2
2
= ppq + pqp + qpp = p q + p q + p q
2
= 3p q
f(3) = P(a, a, a) = ppp = p
3
Expresado cómo tabla:
n=3
xi
f(xi)
3
3
P
2
3p2q
1
3pq2
0
3
q
De la propiedad de la función de probabilidad f(xi) = 1, se tiene:
3
3
3
p + 3p2q + 3pq2 + q = 1 que es equivalente a a + b) = 1
y en donde cada término es de tercer grado valor absoluto. La ecuación se puede
escribir:
3 0
1
1
0 3
p q + 3p2q + 3p q2 + p q = 1
El exponente de q es la diferencia del número de ensayos n con el número de éxitos x.
Por lo que cada término se puede expresar como:
x
p q
n–x
22
Gráficamente, la función de distribución de probabilidad de una moneda lanzada tres
veces, es:
Figura. 7
Dado el comportamiento de las distribuciones de probabilidad, se puede escribir:
p + q = (p + q)
2
1
2
p + 2pq + q = (p + q)
3
2
2
3
2
p + 3p q + 3pq + q = (p + q)
3
4
Para n = 4 y n = 5, se tendría respectivamente: (p + q) y (p + q)
5
n
Y para el enésimo ensayo n = n, se tiene (p + q) . El cual se puede determinar mediante
el teorema del binomio:
(p q) n
n
n
x p
x
q n x
x 0
El cual para un valor particular de de X = xi, se puede expresar como:
n
f (x i ) p x qn x
xi
Definición.
Distribución Binomial.
Si un ensayo binomial puede resultar en éxito con una probabilidad p y un
fracaso con una probabilidad q = 1 – p, entonces la distribución de probabilidad
de la variable aleatoria binomial X con x éxitos en n ensayos independientes, es:
n
b(x, n, p) p x qn x
x
.
x = 0,1,2,3...n
23
Utilizaremos la fórmula para determinar la función de distribución del lanzamiento de una
moneda tres veces, n = 3, con una probabilidad de éxito p y una probabilidad de fracaso
q, siendo x la variable aleatoria el número de veces que la moneda muestre águila.
n
b( x, n, p) p x q n x .
x
3
3!
3! 3
b(0,3, p) p 0 q 3 0
(1) q 3
q 1q 3 q 3 ,
0
0
!
(
3
0
)!
1
3
!
3
3!
3 2!
3
b(1,3, p) p 1q 3 1
p q2
pq 2 pq 2 3 pq 2 ,
1
1
!
(
3
1
)!
1
2
!
1
3
3!
3 2! 2
3
b(2,3, p) p 2 q 3 2
p 2q1
p q p 2 q 3p 2 q ,
2
2
!
(
3
2
)!
2
!
1
!
1
3
3!
3!
1
b(3,3, p) p 3 q 3 3
p3q 0
p 3 (1) p 3 p 3 .
3
3
!
(
3
3
)!
3
!
0
!
1
Con lo que obtendremos la misma función de distribución para el lanzamiento de una
moneda tres veces.
Antecedentes:
Para poder contestar las preguntas planteadas en los problemas de distribución binomial
y de Poisson, se estudiarán brevemente las desigualdades.
Desigualdades:
Las desigualdades se cumplen para un conjunto de números, a diferencia de las
igualdades que solamente se cumplen para algunos valores, dependiendo del grado de
la ecuación.
Simbología y significado de las desigualdades:
x < b “x menor que b”
x > b “x mayor que b”
x b “x menor o igual que b”
x b “x mayor o igual que b”
24
En los siguientes ejemplos, por comodidad y debido a que estamos en variables
discretas, se trabajarán únicamente cantidades enteras positivas (o números naturales).
Ejemplos:
Indicar todos los números enteros positivos que cumplan con las siguientes
desigualdades.
x<6
R. 0, 1, 2, 3, 4, 5,
x < 11
R.
x6
R. 0, 1, 2, 3, 4, 5, 6
x > 20
R.
x>8
R. 9, 10, 11, 12, ….+
x 11
R.
x8
R. 8, 9, 10, 11, ….+
x 30
R.
En nuestros problemas de distribución binomial y de la aproximación de Poisson a la
binomial se tendrá un número máximo indicado por el número de experimentos o
ensayos “n”.
Ejemplo:
Si n = 15, ¿Qué enteros positivos cumplen con las desigualdades x > 7 y x 7 ?
x>7
R. 8, 9, 10, 11, 12, 13, 14 y 15
x7
R. 7, 8, 9, 10, 11, 12, 13, 14 y 15
ACTIVIDAD DE REGULACIÓN
Si n = 9, indica que números enteros positivos cumplen con las siguientes
desigualdades:
x5
R.
x>4
R.
x<3
R.
x5
R.
25
En algunos casos se manejan intervalos abiertos y cerrados para los valores de x.
a<x<b
“x mayor que a y menor que b”
axb
“x mayor o igual que a y menor o igual que b”
Ejemplos:
¿Qué números naturales cumplen con las siguientes desigualdades?
6 < x < 14
R. 7, 8, 9, 10, 11, 12 y 13
6 x 14
R. 6, 7, 8, 9, 10, 11, 12, 13 y 14
ACTIVIDAD DE REGULACIÓN
1. Si n = 12, indica qué números enteros positivos cumplen con las siguientes
desigualdades:
x>3
R.
5x7
R.
x<5
R.
9 < x < 11
R.
2. Si n = 30, indica qué números enteros positivos cumplen con las siguientes
desigualdades:
15 < x < 22
R.
x6
R.
11 x 19
R.
x > 17
R.
x<8
R.
X 25
R.
26
La siguiente tabla da algunos enunciados de las condiciones más frecuentes que
plantean en problemas en que están involucradas las distribuciones Binomial y de
Poisson.
Tabla de condiciones
1) Exactamente a éxitos, solamente a éxitos.
x=a
f(x = a) = f(a)
2) a o b éxitos.
x = a,b
f(x = a,b) = f(a) + f(b)
3) Menos de a éxitos.
x<a
f(x < a)
4) A lo más a éxitos o cuando más a éxitos o menor o igual de a éxitos.
xa
f(x a) = f(a)
5) Más de b éxitos o mayor de b éxitos.
x>b
f(x > b) = 1 – f(x < b)
6) Al menos b éxitos o por lo menos b éxitos o mayor o igual de b éxitos.
xb
f(x b) = 1 – f(x < b)
7) Entre a y b éxitos o mayor de a éxitos y menor de b éxitos.
a<x<b
f(a < x < b)
8) De a a b éxitos o entre a y b inclusive o, mayor o igual de a éxitos y menor o igual de
b éxitos.
axb
f(a x b)
Ejemplo:
En un experimento con 10 ensayos, cómo se plantearía, obtener:
a)
b)
c)
d)
e)
f)
g)
h)
Solamente 1 éxito.
A lo más 3 éxitos.
Entre 2 y 5 éxitos.
Más de 2 éxitos.
De 4 a 6 éxitos.
4 o 5 éxitos.
Por lo menos 3 éxitos.
Menos de 3 éxitos.
27
Indica dentro de los paréntesis los números faltantes.
a) x = 1
f(1)
b) x 3
f(x 3) = f(0) + f( ) + f( ) + f(3)
c) 2 < x < 5
f(2 < x < 5) = f(3) + f(4)
d) x > 2
x>2
f(x > 2) = f(3) + f( ) + f( ) + f( ) + f( ) + f( ) + f( ) + f(10) ó
f(x > 2) = 1 – f(x 2) = 1 – f(0) + f(1) + f(2)
e) 4 x 6
f(4 x 6) = f( ) + f(5) + f( )
f) x = 4,5
f(x = 4,5) = f(4) + f(5)
g) x 3
x3
f(x 3) = f(3) + f( ) + f(5) + f( ) + f(7) + f( ) + f( ) + f(10) ó
f(x 3) = 1 – f(x < 3) = 1 – f(0) + f(1) + f(2)
h) x < 3
f(x < 3) = f8 ) + f( ) + f(2)
Ejemplo
Supóngase que la probabilidad de que un estudiante no repruebe ninguna materia en el
bachillerato es de 1/3. Si se toma una muestra aleatoria de cinco estudiantes, encuentra
la probabilidad de que en ella no hayan reprobado ninguna materia:
a) 2 estudiantes.
b) Menos de 2 estudiantes.
Solución:
n=5
p = 1/3
q = 1 – p = 1 –(1/3) = (3/3) – (1/3) = 2/3
a) x = 2
n
b( x, n, p) p x q n x
x
5
5!
b(2,5,1 / 3) (1 / 3)2 (2 / 3)5 2
(1 / 3)2 (2 / 3)3 .
2! (5 2)
2
5! 1 4 5 4 3! 8
8 80
10
2! 3! 9 9 1 2 3! 243
243 243
28
El resultado indica que de 243 posibles muestras seleccionadas de cinco alumnos cada
una de ellas, probablemente 80 tengan dos alumnos que no reprobaron ninguna materia.
b) x < 2
0
1
1 5 1 2
b( x 2,5,1/ 3) b 0,5, b1,5,
3
3 0 3 3
5
5 0
1
5 1 2
1 3 3
5 1
4
5!
5!
5!
5! 1 16
2
1 2
32
(1)
(1)
0! (5 0)! 3
1! (5 1)! 3 3
1 5! 243 1 4! 3 81
32
32
80
112
32 5 4! 16
16
1
5
.
243
1
4
!
243
243
243
243
243
243
El resultado indica que de 243 posibles muestras seleccionadas, de cinco alumnos cada
una de ellas, probablemente 112 tengan menos de dos alumnos que no reprobaron
ninguna materia.
1.1.2 MEDIA, VARIANZA Y DESVIACIÓN ESTÁNDAR DE LA DISTRIBUCIÓN
BINOMIAL
Para determinar la media de la distribución binomial se utilizará la esperanza matemática
de la variable aleatoria discreta. Tomemos el ejemplo del lanzamiento de una moneda
considerando el número de águilas como éxitos.
El espacio muestral y su función de distribución, considerando el número de águilas
como éxitos, están dados por:
S = {a,s}
xi
0
1
ƒ(xi)
q
p
29
La media o valor esperado (esperanza matemática).
E( x )
n
x
i 1
i
f ( x i ) x1f ( x1 ) x 2 f ( x 2 ) ... x n f ( x n ) i ƒ( x i)
E( x ) 0(q ) 1( p) .
Después de lanzar la moneda dos veces, su función de distribución es:
xi
0
2
ƒ(xi)
q
1
2
2pq
p
2
La media será:
E( x )
n
x
i 1
i
f ( x i ) x1f ( x1 ) x 2 f ( x 2 ) ... x n f ( x n ) i ƒ( x i)
E( x ) 0(q 2 ) 1(2pq) 2p 2 2p(q p)1 ; como q + p = 1 , tenemos E (x) = 2p .
¿Piensas que el coeficiente de p varía según el número de veces
que se realiza un experimento?
Si así lo crees, al lanzar una moneda tres veces, la media debe ser E(x) = 3p.
La función de distribución del lanzamiento de una moneda tres veces es:
xi
0
1
3
ƒ(xi)
2
3pq
q
2
3
2
p
3p q
E( x ) 0(q 3 ) 1(3pq 2 ) 2(3p 2 q ) 3p 3 3pq 2 6p 2 q 3p 3 .
3p q 2 2pq p 2 3pq p 3p1 3p .
2
Conclusión
La media (µ) de la distribución binomial es igual a:
µ=np
30
3
Varianza
Para determinar la varianza de la distribución binomial aplicaremos la fórmula de la
varianza para una variable aleatoria discreta.
n
2 E ( x ) 2 2 x i2 f ( x i ) 2 ,
i 1
2 x12 f ( x1 ) x 22 f ( x 2 )... x n2 f ( x n ) 2 .
Para el experimento de un lanzamiento de una moneda se sustituye:
2 02 (q) 12 (p) (1p)2 p p2 p(1 p) pq
2 pq .
Y la desviación estándar:
pq
Del lanzamiento de una moneda dos veces:
2 0 2 (q 2 ) 12 (2pq) 2 2 ( p 2 ) (2p) 2 2pq 4p 2 4p 2 ,
2 2pq .
La desviación estándar:
2pq
La diferencia entre un lanzamiento de una moneda y dos lanzamientos de la misma, en
la varianza y la desviación estándar, es el coeficiente. ¿La igualdad 2 npq es cierta?
Si es así, para un experimento binomial que se repite tres veces la varianza debe ser
2 3 pq y la desviación estándar 3pq . Probemos:
Del lanzamiento de una moneda tres veces tendremos:
2 0 2 (q 3 ) 12 (3pq 2 ) 2 2 (3p 2 q ) 3 2 ( p 3 ) (3p) 2
3pq 2 12p 2 q 9 p 3 9p 2 3p(q 2 4pq 3p 2 3p) .
31
Sustituyendo las p que están dentro de los corchetes, por 1-q:
3pq
2 3p q 2 4(1 q )q 3(1 q ) 2 3(1 q )p 3p q 2 4q 4q 2 3(1 2q q 2 ) 3 3q
2
4q 4q 2 3 6q 3q 2 3 3q 3pq 3pq l.q.d
Este resultado también es cierto si lo hacemos n veces; por consiguiente, podemos
generalizar que la varianza para una distribución binomial es 2 npq , y la desviación
estándar npq .
Con lo analizado podemos definir la distribución binomial como un experimento binomial
o de Bernoulli, que tiene las siguientes propiedades:
1.
2.
3.
4.
5.
El experimento consiste de n pruebas (o ensayos) idénticos.
Cada prueba produce uno de dos resultados posibles: éxito o fracaso.
La probabilidad de éxito de una prueba es igual a p y es constante para todas.
La probabilidad de fracaso es q = 1 – p.
Las pruebas son independientes.
x representa el número de éxitos observados en n pruebas sin importar el orden
en que sucedan.
La distribución de probabilidad de la variable aleatoria binomial x, que representa el
número de éxitos en n ensayos independientes, con una probabilidad de éxito p en un
experimento de Bernoulli, es:
n
b(x, n, p) p x qn x , x = 0,1,2,...,n.
x
Las propiedades de esta distribución son:
Media
Distribución binomial
np
Varianza
2 npq
Desviación estándar
npq
32
En el siguiente ejemplo de distribución binomial se utiliza su modelo matemático.
Supongamos que la probabilidad de que un donante de sangre rechazado en el ISSSTE
es de 0.15. si un lunes se presentan 20 donantes, encontrar la probabilidad de que:
a)
b)
c)
d)
e)
Tres sean rechazados.
Seis o menos sean rechazados.
Ocho sean rechazados.
Menos de tres sean rechazados.
Al menos tres sean rechazados.
n
n
n!
Fórmula: b( x, n, p) p x q n x ;
x
x x! (n x )!
Datos:
n = 20
p = 0.15
q = 1 – p = 1 – 0.15 = 0.85
Desarrollo:
a)
x=3
20
20!
(0.15) 3 (0.85)17
b(3, 20, 0.15) (0.15) 3 (0.85) 20 3
3
3
!
(
20
3
)!
20!
(0.003375)(0.063113) 0.24282
3!17!
Completa el desarrollo llenando los espacios indicados:
b) x = < 6
b (x 6, 20, 0.15) = b(0, 20, 0.15) + b ( _________) + b(2, 20, 0.15) + b(_________)
+ b(_________) + b(_________) + b(6, 20, 0.15)
= 0.038759 + __________ + __________ + 0.24282
+ __________ + 0.102845 + __________ + = 0.9780053.
33
c) x = 8
20
b(8, 20, 0.15) (0.15) 8 (0.85) 20 8
8
!
(0.15) 8 (0.85)12
! ( )!
= _________ (2. 5628 x 107) ( ________ ) = _________ (3. 6453 x 108)
= ( ________) (3.6453 x 108) = 125 970 (3.6453 x 108)
= 4.591984 x 103
= 0.004592
d) x < 3
b ( x < 3, 20, 0.15) = b ( ,
,
)+b( ,
,
) + b(2, 20, 0.15) =
= __________+__________+_________ = 0.404895.
e) x 3
b (x 3, 20, 0.15) =
= b (3, 20, 0.15) + b (4, 20, 0.15) + b (4, 20, 0.15) + … + b (20, 20, 0.15).
Como se observa es muy laborioso calcular la probabilidad binomial para x
= 3,4,5,6,7,8,9,..., 20. Para evitarlo aplicaremos el teorema de probabilidad del
complemento de un evento, que dice:
Figura. 8
Si despejamos P(A), obtenemos:
P(A) = 1 – P(A’).
La probabilidad de que el evento A suceda, es igual a la probabilidad del espacio
muestral P(S) = 1 menos la probabilidad de que el evento A suceda (A’).
34
En nuestro ejemplo, los eventos que suceden son x 3, es decir,
x=
3, 4, 5, 6, 7, 8, 9,..., 19, 20, y los eventos que no suceden x < 3, esto es, x = 0,1,2. Por lo
tanto, nuestro problema quedaría planteado de la siguiente forma:
P(A) = 1 – (PA’)
b(x >3,20,0.15) = 1 b(x < 3,20,0.15) =
= 1 – [b(0,20,0.15) + b(1,20,0.15) + b(2,20,0.15)].
Que es más sencillo que el planteamiento original:
b(x > 3,20,0.15) = 1 – 0.404895 = 0.595105.
Este problema tiene gran cantidad de operaciones aritméticas. Se puede facilitar
mediante las tablas de distribución binomial acumulada. Veamos su uso.
1.1.3 TABLAS DE DISTRIBUCIÓN BINOMIAL ACUMULADA
Estas tablas proporcionan las probabilidades para los valores menores o iguales a un
número k de éxitos, expresada por:
b ( x k, n, p)
k
b( x, n, p) ,
x 0,1,2,....,k .
x 0
Para entender y manejar apropiadamente la tabla obtengamos por medio de la fórmula
las probabilidades binomiales para 0,1,2,3 y 4 éxitos y posteriormente la probabilidad
acumulada para 0,1,2,3 y 4 éxitos, en cuatro ensayos y con una probabilidad de éxito
igual a 0.05.
Fórmula
n
b( x, n, p) p x q n x
p
Datos
n=4
p = 0.05
p = 1 – p = 1 – 0.05 = 0.95
35
Desarrollo
si x = 0, b(0,4,0.05) = 0.814506
si x = 1, b(1,4,0.05) = 0.171475
si x = 2, b(2,4,0.05) = 0.013537
si x = 3, b(3,4,0.05) = 0.000475
si x = 4, b(4,4,0.05) = 0.000006
La probabilidad acumulada para:
x = 0; b(x 0,4,0.05) = b(0,4,0.05) = 0.814506 ;
x = 1; b(x 1,4,0.05) = b(0,4,0.05) + b(1,4,0.05) = 0.814506 + 0.171475
= 0.985981;
x = 2; b(x 2,4,0.05) = b(0,4,0.05) + b(1,4,0.05) + b(2,4,0.05)
= 0.814506 +0.171475 + 0.013537 = 0.999518;
x = 3; b(x 3,4,0.05) = b(0,4,0.05) + b(1,4,0.05) + b(2,4,0.05) + b(3,4,0.05)
= 0.999993 ;
x = 4; b(x 4,4,0.05) = b(0,4,0.05)+b(1,4,0.05)+b(2,4,0.05)+b(3,4,0.05)+b(4,4,0.05)
= 0.999999.
Estos resultados los comprobaremos posteriormente con las tablas. A continuación
tenemos una parte de la tabla de distribución binomial acumulada.
Columna
1
2
3
4
5
6....
n
2
x
0
1
0
1
2
0
1
2
3
0
1
2
3
4
0.05
0.9025
0.9975
0.8574
0.9927
0.9999
0.8145
0.9860
0.9995
1.0000
0.7738
0.9774
0.9988
1.0000
1.0000
0.10
0.8100
0.9900
0.7290
0.9720
0.9990
0.6561
0.9477
0.9963
0.9999
0.5905
0.9185
0.9914
0.9995
1.0000
0.15
0.20
3
4
5
36
En la columna uno tenemos el número de ensayos posibles n, en la segunda el número
de éxitos x, y en las siguientes, las probabilidades acumuladas para la probabilidad de
éxito p, indicada en la parte superior de la columna. El uso de la tabla de distribución
binomial acumulada es la siguiente:
Para determinar la probabilidad acumulada de que el número de éxitos sea menor o
igual que tres x 3 en 5 ensayos, con una probabilidad de éxito de p = 0.10. en la
primera columna descendemos hasta encontrar el número de ensayos que nos interesa,
en este caso 5, y en la segunda, buscamos el número de éxitos, 3 en 5 ensayos. En la
parte superior buscamos la probabilidad de éxito 0.10, y descendemos hasta el renglón
en que se encuentra el número de éxitos, 3 en 5 ensayos.
Probabilidad de éxito.
n
2
3
4
Cinco
Ensayos
5
Tres éxitos en
cinco ensayos
x
0
1
0
1
2
0
1
2
3
0
1
2
3
4
0.05
0.9025
0.9975
0.8574
0.9927
0.9999
0.8145
0.9860
0.9995
1.0000
0.7738
0.9774
0.9988
1.0000
1.0000
0.10
0.8100
0.9900
0.7290
0.9720
0.9990
0.6561
0.9477
0.9963
0.9999
0.5905
0.9185
0.9914
0.9995
1.0000
0.15
El número encontrado (0.9995) corresponde a la probabilidad binomial acumulada, para
3 éxitos en 5 ensayos, con una probabilidad de éxito de 0.10, que se expresa:
b(x 3,5,0.10) = 0.9995.
De acuerdo con las tablas las probabilidades acumuladas para x = 0,1,2,3, en 4 ensayos
y con una probabilidad de éxito de 0.05, son:
b(x 0,4,0.05) = 0.814
b(x 1,4,0.05) = 0.9860
b(x 2,4,0.05) = 0.9995
b(x 3,4,0.05) = 1
37
Si mediante la fórmula comparamos las probabilidades binomiales acumuladas con las
probabilidades acumuladas de la tabla, obtendremos lo siguiente:
Las probabilidades de la tabla están aproximadas hasta diezmilésimos, por lo que las
probabilidades acumuladas para el número de éxitos cercanos o iguales al número de
ensayos es equivalente a la unidad; por consiguiente, no se consideran los eventos en
que el número de éxitos es igual al número de ensayos.
Para determinar la probabilidad binomial cuando el número de éxitos x es igual a un
valor dado k, se restan las probabilidades adyacentes de la tabla por medio de la
siguiente expresión:
b(x = k,n,p) = b(x k,n,p) b(x k1,n,p).
Por ejemplo, para determinar la probabilidad de x = 2, en cuatro ensayos, con una
probabilidad de éxito de 0.05, se siguen los siguientes
Fórmula
b(x = k,n,p) = b(x k,n,p) b(x k1,n,p).
Datos
n=4
p = 0.05
k=2
b(x = 2,4,0.05) = b(x 2,4,0.05) – b(x 1,4,0.05)
De las tablas
= 0.9995 – 0.9860 = 0.0135
Al comparar el resultado obtenido mediante la fórmula, ¿qué concluyes?, ¿son
confiables las tablas?, ¿facilitan la solución del problema?
Resuelve el problema de los donantes de sangre mediante las tablas de probabilidad
binomial acumulada y compara resultados.
38
ACTIVIDAD DE REGULACIÓN
Contesta lo siguiente mediante la fórmula de la distribución binomial y sus parámetros,
posteriormente resuélvelas con el apoyo de las tablas. Utiliza tu cuaderno para dar tus
respuestas.
Imagina que el 5% de los focos producidos en una fábrica son defectuosos, y se
selecciona al azar una muestra de 13 focos:
a)
¿Cuál es la probabilidad de que ningún foco esté defectuoso?
b)
¿Cuál es la probabilidad de que cuatro focos estén defectuosos?
c)
¿Cuál es el valor esperado de focos defectuosos?
d)
¿Cuál sería su varianza?
e)
¿Cuál sería su desviación estándar?
Las fórmulas y resultados correspondientes son:
Para:
a, b
c
d
e
Fórmula
n
b( x, n, p) p x q n x
p
np
Resultado
a) 0.5133
b) 0.0028
npq
0.6165
npq
0.7858
2
39
0.651
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
El experimento de Bernoulli tiene cuatro características importantes:
a)
Repetición de ensayos.
b)
Cada ensayo es independiente de los demás ensayos.
c)
Hay dos únicos resultados p = éxito, q = fracaso.
d)
En cada ensayo no cambia la probabilidad.
Con base en estas características se obtuvo el modelo matemático de distribución
binomial:
n
b(x, n, p) p x qn x
p
Y también los parámetros pertenecientes a la distribución binomial:
Media
np
Varianza
2 npq
Desviación estándar
npq
40
1.2 DISTRIBUCIÓN DE POISSON
A inicios del siglo XIX, el matemático francés Simeon Denis Poisson (17811840)
dedujo la fórmula para hallar la probabilidad de que exactamente x éxitos ocurran en un
intervalo de tiempo dado o en una región especificada. Dividiendo el intervalo de tiempo
t, en n subintervalos y haciendo que n , se forma un proceso de Poisson, en donde
la probabilidad de que un subintervalo contenga uno ó ningún éxito es casi 1, en tanto
que la probabilidad de un subintervalo de tener más de un éxito es despreciable. La
probabilidad de un éxito durante uno de estos subintervalos no depende de lo que
suceda antes.
El valor especifico de n generalmente es desconocido, pero mientras se conozca la
cantidad de éxitos esperada en un intervalo de tiempo unitario o en una región
especificada, no es necesario conocer n para calcular la probabilidad de x éxitos.
Por ejemplo puede expresar el número esperado de llamadas telefónicas que se
reciban por minuto, el número esperado de artículos defectuosos por minuto, la
ocurrencia de imperfecciones en un rollo de tela continuamente producido, la medición
de radiación por medio de un contador Geiger, el número de ratones de campo por
hectárea, el número de bacterias por cultivo, etc.
Estableceremos sin demostrarlo, que la probabilidad de hallar exactamente x éxitos en
un intervalo de tiempo t previamente fijado, está dada por la fórmula:
f (x)
x
e
x!
La media y la varianza de la distribución de Poisson, tienen un valor igual a .
Media
Varianza
Desviación estándar
2
=
=
Antecedente:
El valor de e, se puede determinar mediante una calculadora científica. La función
exponencial natural en las calculadoras se encuentra arriba de la tecla del logaritmo
natural.
41
ACTIVIDAD DE REGULACIÓN
Determina con tu calculadora los siguientes exponenciales:
2
e =
e2 =
4
e =
e4 =
Observa que cuando el exponente de e es negativo, el resultado es menor a la unidad.
Ejemplos:
Los empleados de cierta oficina llegan al reloj checador en un promedio de 1.5 por
minuto. Calcúlese las probabilidades de que:
a) Dos lleguen en un minuto cualquiera.
b) A lo más 4 lleguen en un minuto cualquiera.
c) Al menos tres lleguen durante un intervalo de 2 minutos.
d) Menos de cinco lleguen durante un intervalo de 6 minutos.
Solución
a) = 1.5
f(2) =
x=2
1.5 2 1.5 2.25 1.5
1.5
e
e
= 1.125 e
= 1.125(0.22313) = 0.25102
2!
2
b) = 1.5
x4
f(x 4) = f(0) + f(1) + f(2) + f(3) + f(4) =
=
1.5 0 1.5 1.5 1 1.5
1.5 2 1.5
1.5 3 1.5 1.5 4 1.5
e
e
e
e
e
+
+
+
+
0!
2!
3!
4!
1!
42
Se observa que el factor común en los cinco términos es e 1.5 , por lo que f(x 4), se
puede escribir la siguiente forma:
f(x 4) = f(0) + f(1) + f(2) + f(3) + f(4)
1.5 0 1.5 1 1.5 2 1.5 3 1.5 4 1.5 elevando las potencias de los
=
numeradores y obteniendo los
e
1!
2!
3!
4!
0!
factoriales
de
los
denominadores
1 1.5 2.25 3.375 5.0625 1.5
=
e
1
2
6
24
1
obteniendo los cocientes
= [1 + 1.5 + 1.125 + 0.5625 + 0.21093] e 1.5
sumando los cinco términos
= 4.39843 e 1.5 = 4.39843(0.22313) = 0.98142
c) Como el valor de es por minuto, al pedir en un intervalo de 2 minutos, el valor de
se multiplica por 2, para encontrar el nuevo valor de a utilizar.
= 1.5(2) = 3
f x 3 1 – f(x < 3)
= 1– [f(0) + f(1) + f(2)]
3 0 3 1 3 2 1.5
1 3 9
e
= 1
= 1 e 1.5 = 1 1 3 4.5 e 1.5
1!
2!
1 1 2
0!
= 1 – 8.5 e 1.5 = 1 – 8.5(0.04978) = 1 – 0.42313 = 0.57687
d) = 1.5(6) = 9
x<5
f(x < 5) = f(0) + f(1) + f(2) + f(3) + f(4)
90 91 92 93 9 4 9
e =
=
0! 1! 2! 3! 4!
= 1 9 40.5 121.5 273.375e9
= 445.375e 9
= 0.05496
43
ACTIVIDAD DE REGULACIÓN
Resuelve los siguientes ejercicios considerando en tus cálculos cinco dígitos decimales
en cada uno de los pasos requeridos para llegar a la solución solicitada.
1. Si un alumno de 4º semestre del bachillerato al usar maquina de escribir, comete en
promedio 2 errores por pagina escrita. Cuál es la probabilidad de que:
a) En una pagina cometa de 3 a 5 errores de escritura.
b) En las dos siguientes paginas tenga uno o dos errores de escritura.
c) En que en tres paginas tenga exactamente 9 errores de escritura.
2. Si el número de lesiones menores que se puede esperar se presenten en un partido
de fútbol es de = 2.2. Calcule la probabilidad que durante un partido haya:
a) Ninguna lesión en un partido.
b) A los más dos lesiones durante un partido.
c) Tres o cuatro lesiones en los siguientes tres partidos.
3. Se estima que el número promedio de comercios por manzana en ciudad Azteca es
de 5. Halla la probabilidad de que se tengan tres comercios:
a) En una manzana.
b) En tres cuartos de manzana.
4. En cierto estado del país, en promedio es afectado por 1.8 temblores "fuertes" al año.
Encuentra la probabilidad de que este estado sea afectado, por:
a) Menos de tres temblores en un año.
b) De uno a cuatro temblores en año y medio.
c) Ningún temblor en medio año.
5. El promedio de automóviles que usan una autopista un fin de semana es de 4.5 por
minuto. Cuál es la probabilidad de que usen la autopista:
a) Exactamente seis autos en un minuto.
b) A lo mas dos automóviles en un tercio de minuto.
c) Por lo menos tres automóviles en el transcurso de los siguientes 30 segundos.
44
1.2.1 MEDIA, VARIANZA Y DESVIACIÓN ESTÁNDAR DE LA DISTRIBUCIÓN DE
POISSON
Media
Para determinar la media de la distribución de Poisson utilizaremos la esperanza
matemática de la variable aleatoria discreta:
E(x )
n
x f(x).
x 0
Considerando a n muy grande y a f (x ) como:
f (x)
µ x µ
e
x!
Por lo tanto, E (x ) se define como:
n
n
x 0
x 0
si x = 0,
E( x )
µ
x f ( x ) = x x! e
E( x )
x
n
µ
µ
µ x µ
µ 0 µ
e 0
e 0
x!
0!
x x! e
µ
x 0
=
n
x
x 1
µ x µ
e
x!
Factorizando tenemos:
n
E( x ) x
x 1
µ x µ
e =
x!
n
x 1 µ 1 µ x 1 µ
µ x 1 µ
e
µ
e .
x 1 x ( x 1)!
x 1 ( x 1)
n
Hagamos y = x –1, si x = 1, entonces y = 11 = 0, tenemos:
µ x 1 µ
e =
x 1 ( x 1)!
n
E( x ) µ
45
n
y 0
µ y µ
e .
y!
Como la suma de las probabilidades de todos los posibles resultados de un experimento
es igual a 1, se tiene:
n
y 0
n
µ y µ
e . f ( y ) 1,
y!
y 0
µ y µ
e µ(1) µ.
y!
n
E( x ) µ
y 0
E(x) = µ
Varianza
La varianza de una variable aleatoria discreta se define por:
2 =
n
x
2
f (x) µ2.
x 0
Para la distribución de Poisson, tenemos:
2 =
n
x
x 0
si x = 0, entonces: x 2
2
µ x µ
e µ2.
x!
µ µ
e 0 ; por lo tanto: 2 =
x!
n
x2
x 1
µ x µ
e µ2.
x!
Factorizando tenemos:
2 =
1
n
x 2 µ1µ x
xµ x 1 µ
µ
2
e
µ
e µ2.
µ
x 1 x ( x 1)!
x 1 ( x 1!
n
Considerando y = x –1, entonces x = y + 1, si x = 1, y = 0:
n
n
( y 1) µ y µ
yµ y µ
µy
e µ2 µ
e µ e µ µ 2 ,
y!
y 0
y 0 y !
y 0 y!
n
2 = µ
n
yµ y µ
yµ y -µ
e µ(1) µ 2 µ
e µ µ2.
y
!
y
!
y 0
y 1
n
2 = µ
46
Factorizando:
n
y 1 µ 1 µ y 1 µ
µ y 1 µ
e µ µ2 µ
e µ µ2.
x 1 y ( y 1)!
y 1 ( y 1)!
n
2 = µ
Hagamos ahora z = y 1, si y = 1, entonces z = 0:
n
2 = µ2
z 0
µ z µ
2
2
2
2
e µ µ 2 µ (1) + µ µ = µ + µ µ = µ
z!
2
Desviación Estándar.
La desviación estándar de la distribución de Poisson se obtiene extrayéndole la raíz
cuadrada a la varianza.
1.2.2 APROXIMACIÓN DE LA DISTRIBUCIÓN DE POISSON A LA BINOMIAL
Cuando n es relativamente grande y p pequeña, las probabilidades binomiales a menudo
se aproximan por medio de la fórmula de Poisson. La distribución de Poisson es una
forma límite de la binomial cuando n , p 0, y = np, permanece constante.
Antecedentes:
Cualquier número real, diferente de cero, dividido por una cantidad muy grande,
representada por infinito "", es equivalente a cero.
Demostración:
Dividamos, por ejemplo, el número 10, entre cantidades progresivamente más grandes, y
observemos los cocientes resultantes.
47
Realiza las divisiones faltantes.
10
10
1
10
0.1
100
10
1000
10
0.001
10000
10
100000
10
0.00001
1000000
10
10000000
Como "" es mucho mayor que cualquiera de los denominadores que dividieron al
10
0 , y por lo tanto, si n es cualquier número real
número 10, concluimos que
diferente de cero divido entre infinito, es:
n
0
El exponencial natural
n
1
La expresión 1 , cuando n es un número real muy grande, equivalente a infinito
n
"", tiende al número irracional 2.71828182846 conocido como exponencial natural "e".
Demostración:
Demos a n valores enteros progresivamente cada vez más grandes y observemos las
potencias resultantes.
48
Llena los cuadros vacíos con las operaciones faltantes.
n=1
n = 10
n = 100
1 11 1
1 101 10
1 1001 100
1 11
0 1
1 0.110
1 0.01100
0.9 10
0.99100
0
2.867971
2.731999
n = 10000
1
10000
1
10000
n = 100000
1
0.999910000
n = 1000
1 1000
1 1000
2.719642
n = 1000000
1
1 1000000
1000000
100000
1
100000
2.718295
2.718283
1
Por lo tanto, cuándo n , entonces: 1
n
n
0y
n
e.
n
1
1 e, cuando n , se utilizaran para la
n
demostración de la distribución de Poisson como una aproximación de la distribución
Binomial.
Estos dos resultados;
Distribución de Poisson como límite de la distribución Binomial
Consideremos la distribución Binomial:
n
n!
bx, n, p p x qn x
p x qn x , si x permanece constante y n es muy grande n
x! n x !
x
,
Desarrollando el coeficiente binomial, tendremos:
n
n!
bx, n, p p x qn x
p x qn x
x
x
!
n
x
!
nn 1n 2 ... n ( x 2)n ( x 1)n x ! x n x
p q
,
x! n x !
49
Dividiendo factores iguales (n – x)! Del numerador y del denominador y dado que q = 1
– p, sustituyendo q por 1 – p.
nn 1n 2 ... n x 2)n x 1 x
n x
p 1 p
x!
Dado que = np, se puede sustituir p por
n
nn 1n 2 ... n x 2)n x 1
1
x!
n
n
x
a
Aplicando la propiedad de los exponentes,
b
m
am
bm
, en
x
n x
x
nn 1n 2 ... n x 2)n x 1 x
1
x
x!
n
n
n x
x
Como el orden de los factores no afecta al producto ab = ba. La potencia n , pasa
dividiendo al numerador del coeficiente binomial que está en función de n y x! Dividiendo
x
x
a , para obtener el coeficiente
de la distribución de Poisson.
x!
nn 1n 2 ... n x 2)n x 1 x
x!
nx
1
n
n x
x
Descomponiendo n , en igual número de factores del numerador y descomponiendo en
n x
dos factores a 1
n
m n
m-n
, mediante la ley de los exponentes a a = a
nn 1n 2 ... n x 2)n x 1 x
1 1
n n n ... n n
x!
n
n
n
x
Dividiendo cada factor del numerador con un factor del denominador, en el coeficiente
binomial.
n
n n 1 n 2
n x 2 n x 1 x
=
1 1
...
n n n
n
n
x
!
n
n
50
x
Realizando las divisiones:
n
1
2
x 2
x 1 x
11 1 ... 1
1 1
1
n
n
n
n x!
n
n
x
n
n
n
1
0 y considerando a la potencia 1 semejante a 1
n
n
e, ya que ambas tienen como exponente a n que tiende a , la potencia deberá ser
diferente de 1. Por lo tanto.
Si n , entonces
11 01 0 ... 1 01 0
n
x
x
1 1 0
x!
n
n
n
1
Trataremos de expresar a 1 con la misma estructura que 1 , para lograrlo,
n
n
1
se puede indicar como el reciproco de su reciproco, por lo que
, realizando la
n
n n
sustitución
n
x
1
x
111 ... 11
1 1
n
x!
m
Dado que la unidad elevada un exponente real, es la unidad, 1 = 1, por lo tanto
(1)x = 1
n
1
x
1
1
n
x!
n
1
n
Se necesita que 1 tenga de exponente a , para que sea idéntico en estructura
n
1
a 1
n
n
.
51
Sabemos que cuando se tiene una potencia de potencia, los exponentes se multiplican
n
n
1
1
y para que matemáticamente no se
a m a mn . Por lo que 1 se elevara a
n
modifique se volverá a elevar a la –
1
n
x
1
1
n
x!
n
x
1
=
1
n
x!
n
1
1
Demostramos que 1 e, cuando n , entonces 1
n
n
tiene:
x
x
e e
x!
x!
n
e. Por lo que se
En forma matemática, el desarrollo anterior se puede resumir de la siguiente forma:
El límite de la distribución Binomial cuando n tiende al infinito, p tiende a cero y np
permanece constante, es la distribución de Poisson, expresado mediante notación de
limite.
n
x
lím p x q n x
e
x!
x
n
p0
En la mayoría de los casos la distribución de Poisson se puede usar como una buena
aproxi-mación a la distribución de Binomial, cuando n 20 y p 0.05, si n 100, la
aproximación es excelente a condición de que np 10.
52
Para utilizar la distribución de Poisson como aproximación de la Binomial se considera
que el valor medio o promedio es = np, donde "n" es el número de ensayos, "p" la
probabilidad de éxito "p" y "x" el número de éxitos.
x
f x,
e
x!
Ejemplo de distribución de Poisson mediante su modelo matemático
Supón que la probabilidad de que cierta tienda de aparatos electrónicos venda un radio
defectuoso es de 3%. Si vende 100 radios en un mes, ¿cuál es la probabilidad de que
haya vendido:
a)
b)
c)
d)
Dos radios defectuosos?
Menos de dos radios defectuosos?
Entre 8 y 10, inclusive 8 y 10 radios defectuosos?
Al menos dos radios defectuosos?
Datos
Fórmula
n = 100
p = 3% = 0.03
µ = np = 100 (0.03) = 3
p( x, )
x
x!
e
Desarrollo
a) x = 2
p(2,3)
3 2 3 9
e (0.049787) = 4.5 (0.049787) = 0.224041
2
2!
b) x < 2
p( x 2,3) p(0,3) p(1,3)
3 0 3 3 1 3 1 3 3 3
e
e e e e 3 3e 3 4e 3
0!
1!
1
1
= 4(0.049787) = 0.199148.
53
ACTIVIDAD DE REGULACIÓN
Completa lo siguiente:
c) 8 x 10
p(8x10,3) = p(8,3) + p( ___,3) + p(10,3) = ___________ +
3 9 3
e + ____________
9!
6561 3
10499 3
e + _________ + _________ =
e = 0.233236(
40320
44800
) = 0.011612
d) x 2
p( x 2,3) p(2,3) p(3,3) p(4,3) p(5,3) ... p(100,3),
o mediante el Teorema: p (A) = 1 – p(A’)
p( x 2,3) 1 p( x 2,3) 1 __________ 0.800852
1.2.3 TABLAS DE DISTRIBUCIÓN DE POISSON ACUMULADA
Igual que la distribución binomial, existen tablas de probabilidad acumulada para la
distribución de Poisson, y ambas tienen uso semejante. La tabla proporciona los valores
menores o iguales a k éxitos, obtenidos mediante la expresión:
p( x k, µ )
k
x 0
54
µ x µ
e .
x!
A continuación tenemos parte de la tabla de Poisson que se encuentra al final de este
fascículo.
µ
x
0
1
2
0.02
0.04
0.06
0.08
0.10
0.980
0.961
0.942
0.923
0.905
1.000
0.999
0.998
0.997
0.995
1.000
1.000
1.000
1.000
0.15
0.20
0.25
0.30
0.861
0.819
0.779
0.741
0.990
0.982
0.974
0.963
0.999
0.999
0.998
0.996
3
1.000
1.000
1.000
1.000
En este caso la tabla se aproxima hasta milésimos. En su parte superior se encuentran
el número de éxitos y, en la primera columna los valores esperados de µ.
Ejemplo: Para determinar la probabilidad acumulada de que el número de éxitos sea
menor o igual a dos, con un valor esperado de µ = 0.25, localizamos en el primer renglón
el número 2, y en la primera columna el valor 0.25.
µ
x
0
1
2
0.02
0.04
0.06
0.08
0.10
0.980
0.961
0.942
0.923
0.905
1.000
0.999
0.998
0.997
0.995
1.000
1.000
1.000
1.000
0.15
0.20
0.25
0.30
0.861
0.819
0.779
0.741
0.990
0.982
0.974
0.963
0.999
0.999
0.998
0.996
3
1.000
1.000
1.000
1.000
En la intersección de columna y renglón, encontraremos el valor correspondiente a la
probabilidad acumulada de:
p(x 2, 0.25) = 0.998.
55
Ejemplo. Las probabilidades acumuladas para µ = 0.15 y x = 0, 1, 2, y 3, de la tablas son:
p(x 0, 0.15) = 0.861
p(x 1, 0.15) = 0.990
p(x 2, 0.15) = 0.999
p(x 3, 0.15) = 1.000
Si queremos determinar la probabilidad de Poisson para x = k, utilizaremos una
expresión semejante al caso de la binomial:
p (x = k, µ) = p(x k,µ) – p(x k – 1, µ).
Ejemplo: Queremos determinar la probabilidad de Poisson cuando = 0.15 y x = 1.
Fórmula
p (x = k, µ) = p(x k, µ) – p(x k – 1, µ).
Datos
µ = 0.15
k=1
p (x = 1, 0.15) = p(x 1, 0.15) – p(x = 0, 0.15).
De las tablas obtenemos:
p (x = 1, 0.15) = 0.990 – 0.861 = 0.129.
Resuelve el problema de los radios defectuosos con base en las tablas de Poisson.
¿Obtuviste los mismos resultados?
56
ACTIVIDAD DE REGULACIÓN
1. En una fábrica de artículos navideños se presentan defectos que en ocasiones
provocan que las piezas no se envíen al mercado. Se sabe que en promedio, una de
cada 1 000 piezas tiene uno o más defectos. ¿Cuál es la probabilidad de que en una
muestra aleatoria de 8 000 piezas se encuentren menos de siete piezas con
defectos? También encuentra la esperanza o media aritmética, la varianza y
desviación estándar.
Datos
Fórmula
n = 8 000
p (x, µ) =
p=
1
0.001
1000
µ x µ
e
x!
µ = np = (8 000) ( 0.001) = 8
x < 7, por lo tanto, x 6
2. Completa los espacios en blanco:
p(x < 7, 8) = p(0,8) + p(1,8) + p(2,8) + p(3,8) + p(4,8) p(5,8)+ p(6,8).
p(x < 7,8) =
8 4 8
8 6 8
8 0 8
e + _______ +
e + ________ + ________ + ________ +
e .
4!
0!
6!
p(x < 7,8) =
1 8
512 8
e + _________ + __________ +
e +__________ + __________.
1
3
p(x< 7,8) = _____________;
p (x < 7,8) =
42037 8
e = 934.15556 (3.35462 x 104) = 0.31337.
45
¿Laborioso? En las tables de distribución de Poisson (anexo 2) localiza µ = 8 en la
primera columna y x < 6, que nos da la probabilidad buscada. Compara los resultados.
p(x < 7, 8) = p(x 6, 8) = _________________.
57
Las tablas de distribución acumulada de Poisson simplifican la solución de los problemas
que requieras resolver, te invitamos a que las uses, tanto las de distribución binomial
como las de distribución de Poisson. Continuando con el problema, la media µ = np es
2
un valor que necesitaste en la solución anterior, la varianza = µ tiene como resultado
el mismo valor de la media, y la desviación estándar es igual a = µ =
8=
2.82.
EXPLICACIÓN INTEGRADORA
Podemos concluir que el modelo matemático de la distribución de Poisson se expresa
por:
p (x; µ) =
µ x µ
e
x!
La distribución de Poisson es una buena aproximación a la distribución binomial cuando
np 5, el número de ensayos n sea muy grande, y que la probabilidad de p esté próxima
a cero. Los parámetros de la distribución de Poisson son:
Media
µ = np
Varianza
= np = µ
Desviación estándar
=
2
np =
58
µ.
RECAPITULACIÓN
Con la finalidad de que recuerdes los temas importantes que acabas de estudiar. A
continuación te presentamos el siguiente esquema:
Distribución binomial
Modelo:
Propiedades:
Media
Varianza
Desv. Est.
n
b( x, n, p) p x q n x
p
Distribución de Poisson
f(x) =
µ = np
2
= npq
=
µ x µ
e
x!
µ
2
=µ
=
npq
59
µ
Aprox. de Poisson a la
Binomial
f(x) =
µ x µ
e
x!
µ = np
2
= µ =np
=
µ =
np
ACTIVIDAD ES DE CONSOLIDACIÓN
Con la finalidad de que apliques los conocimientos adquiridos en este fascículo.
Contesta lo que se te indica en cada caso y en los resultados de tus operaciones
considera cinco dígitos decimales en cada uno de los pasos requeridos para llegar a la
solución solicitada.
I. De los siguientes eventos, indica cuáles son binomiales.
1. Se lanzan dos dados cinco veces; un jugador gana si los dados muestran el mismo
número.
2. Se sacan cuatro bolas sucesivamente sin reemplazo de una urna que tiene cinco
bolas rojas y seis blancas.
3. Se sacan cuatro bolas con reemplazo de una urna que tiene cinco bolas rojas y seis
blancas.
4. Se transmite por radio un comercial sobre el sida, y se realiza una encuesta entre
jóvenes de 12 a 18 años, para saber si lo han escuchado.
5. Un comerciante recibe cinco máquinas de escribir sin defecto, de una compañía que
tenía almacenadas seis máquinas defectuosas y cinco no defectuosas.
6. El supervisor de producción de una industria lechera toma una muestra de 100
envases y revisa cuántos de éstos tienen un litro de leche.
7. Un señor compra un billete de Lotería, si su esposa se viste con alguna prenda roja.
8. De una caja que contiene 20 huevos, siete están descompuestos; se sacan
sucesivamente ocho sin reemplazo.
60
II. Realiza los siguientes problemas de distribución binomial.
1. Determina:
a) b(2,3,0.5) =
b) b(x<2,3,0.5)
c) b(x2,3,0.5)
d) b(5,5,0.75)
2. La probabilidad de que un agente de tránsito infraccione a un automovilista por
conducir ebrio es de 0.05. Encontrar la probabilidad de que, de 10 conductores que
infraccionó; hayan estado ebrios:
a) Exactamente dos
b) Menos de tres
c) Al menos tres
d) Dos de tres
e) Calcular µ y
3. La probabilidad de que un cobrador de microbús discuta con un pasajero en un viaje
es de 0.35. Encontrar la probabilidad de que en seis viajes, discuta:
a) Exactamente una vez
b) Ninguna vez
c) Exactamente seis veces
d) Al menos dos veces
e) El número de veces que se espera que discuta en los seis viajes
f) Varianza y desviación estándar
4. Supóngase que el 15% de amas de casa escuchan determinada estación de radio
cuando cocinan. Si se entrevistan a 15 de ellas, encontrar la probabilidad de que 15
escuchen esa estación:
a) Ninguna de ellas
b) Exactamente cinco
c) Entre cuatro y siete
d) Menos de dos
e) Cuántas de ellas se espera que escuchen la estación
f) Determinar la varianza y la desviación estándar
5. Suponiendo que la probabilidad de que un alumno estudie en la biblioteca de la
escuela es de uno de cinco, encontrar la probabilidad que de un grupo de 19
alumnos, estudien en la biblioteca:
a) Ninguno
b) Exactamente cinco
c) Al menos tres
61
6. La probabilidad de que un pantalón tenga un defecto es de 0.45. Si un abonero
compra un lote de 12 pantalones, encontrar la probabilidad que estén defectuosos:
a) Ocho pantalones
b) Menos de cuatro pantalones
c) Al menos cuatro pantalones
d) Número esperado de pantalones defectuosos
III. Realiza los siguientes problemas de distribución de Poisson.
1. Si un alumno de 4° semestre del bachillerato al usar máquina de escribir, comete en
promedio 2 errores por página escrita. Cuál es la probabilidad de que:
a) En una página cometa de 3 a 5 errores de escritura.
b) En las dos siguientes páginas tenga uno o dos errores de escritura.
c) En tres páginas tenga exactamente 9 errores de escritura.
2. Si el número de lesiones menores que se puede esperar se presenten en un partido
de fútbol es de 2.2 . Calcule la probabilidad que durante un partido haya:
a) Ninguna lesión en un partido.
b) A lo más dos lesiones durante un partido.
c) Tres o cuatro lesiones en los siguientes tres partidos.
3. Se estima que el número promedio de comercios por manzana en Ciudad Azteca es
de 5. Halla la probabilidad de que se tengan tres comercios:
a) En una manzana.
b) En tres cuartos de manzana.
4. En cierto estado del país, en promedio es afectado por 1.8 temblores “fuertes” al año.
Encuentra la probabilidad de que este estado sea afectado, por:
a) Menos de tres temblores en un año.
b) De uno a cuatro temblores en año y medio.
c) Ningún temblor en medio año.
5. El promedio de automóviles que usan una autopista un fin de semana es de 4.5 por
minuto. Cuál es la probabilidad de que usen la autopista:
a) Exactamente seis autos en un minuto.
b) A lo más dos automóviles en un tercio de minuto.
c) Por lo menos tres automóviles en el transcurso de los siguientes 30 segundos.
62
IV. Realiza los siguientes problemas de la aproximación de la distribución de Poisson a la
binomial.
1. El 3% de la producción de una fábrica de lámparas es defectuosa. Si en un día se
producen 140 lámparas, encontrar la probabilidad de que sean defectuosas:
a) Exactamente ocho lámparas
b) Menos de tres lámparas
c) Entre cinco y siete, incluso cinco y siete lámparas
d) Al menos dos lámparas defectuosas
2. Suponiendo que uno de 500 autos que circulan en la autopista México–Toluca sufren
una falla mecánica, determinar la probabilidad de que en un día cualquiera, de mil
autos en circulación, tengan fallas mecánicas:
a) Exactamente 10 autos
b) Menos de dos autos
c) Entre tres y siete autos
d) Dos o menos autos
3. Supongamos que la probabilidad de pronunciar mal una palabra por cierto locutor es
de 4%. Si en una participación suya pronuncia 100 palabras, encontrar la probabilidad
que mencionen mal:
a) Ninguna palabra
b) Exactamente tres palabras
c) Menos tres palabras
d) Tres o cuatro palabras
4. 1700 votantes deben decidir sobre la construcción de un centro comercial. Si la
probabilidad de que una persona vote en favor de la construcción es de 0.001,
determinar la probabilidad de que voten en favor de la construcción del centro
comercial:
a) Menos de dos votantes
b) Ningún votante
c) Al menos tres votantes
5. Supóngase que el 2% de los empleados de cierta compañía tienen casa propia. Si
esta compañía tiene 250 empleados, determinar la probabilidad de que tengan casa
propia:
a) Exactamente 10 empleados
b) Al menos dos empleados
c) Entre cinco y nueve empleados
6. Supongamos que el 1.7% de los motores eléctricos de cierta marca fallarán antes de
tres años. Obténgase la probabilidad de que de 500 motores eléctricos vendidos
fallen:
a) Seis o más antes de los tres años
b) Exactamente nueve antes de los tres años
c) menos de diez antes de los tres años
63
AUTOEVALUACIÓN
A continuación te presentamos las posibles respuestas a las que debiste haber llegado
en las Actividades de Consolidación. Si tienes alguna duda, consulta a tu asesor de
contenido:
I. Eventos binomiales.
1. Sí.
2. No (no son eventos independientes).
3. Sí.
4. Sí.
5. No (las probabilidades no son constantes.
6. Sí.
7. Sí.
8. No.
II. Distribución binomial.
1. a) 0.375;
2. a) 0. 0746;
3. a) 0.2437;
4. a) 0.0874;
5. a) 0.0144;
6. a) 0.0811;
b) 0.500;
b) 0.98885;
b) 0.0754;
b) 0.0449;
b) 0.1636;
b) 0.1345;
c ) 0.500;
c ) 0.0115;
c ) 0.0041;
c ) 0.9347;
c ) 0.2369.
c ) 0.8655.
d) 0.2637.
d) 0.0851; e) µ = 0.5, = 0.6892.
2
d) 0.6809; e) 2; f) = 1.36, = 1.16.
2
d) 0.3186; e) 2; f) = 1.912, = 1.382.
III. Distribución de Poisson.
1. a) 0.30675;
2. a) 0.11080;
3. a) 0.14020;
4. a) 0.73058;
5. a) 0.1281;
b) 0.21972;
b) 0.62269;
b) 0.20663.
b) 0.79563;
b) 0.80884;
c) 0.003426.
c) 0.17268.
c) 0.40656.
c) 0.39072.
IV. Aproximación de la distribución de Poisson a la binomial.
1. a) 0.0036;
2. a) 0.018 ;
3. a) 0.018 ;
4. a) 0.493;
5. a) 0.07;
6. a) 0.0850;
b) 0.0210;
b) 0.034;
b) 0.195;
b) 0.183;
b) 0.0960;
b) 0.0130;
c) 0.526;
c) 0.027;
c) 0.238;
c) 0.243.
c) 0.548.
c) 0.653.
d) 0.922.
d) 0.125.
d) 0.931.
64
ACTIVIDADES DE GENERALIZACIÓN
Con la finalidad de que consolides tu aprendizaje. Realiza lo siguiente:
1. Suponiendo que la probabilidad de que un alumno participe en el taller de Música del
Colegio de Bachilleres es de uno de cinco. Encuentra la probabilidad que de un grupo
de 25 alumnos, estudien en la clase de música:
a) Exactamente 8 alumnos.
b) Más de 10 alumnos.
c) Menos de 5 alumnos.
2. El promedio de automóviles que usan la autopista México–Cuernavaca un fin de
semana es de 6.5 por minuto. ¿Cuál es la probabilidad de que usen la autopista:
a) Exactamente 9 autos por minuto.
b) A lo más 4 automóviles en un cuarto de minuto.
c) Por lo menos 6 automóviles en el transcurso de los siguientes 45 segundos.
3. La probabilidad de que un sombrero tenga un defecto es de 0.65. Si un grupo tropical
compra un lote de 15 sombreros, encuentra la probabilidad de que estén defectuosos:
a) 6 Sombreros.
b) Menos de 8 sombreros.
c) Al menos 10 sombreros.
d) El número esperado de sombreros defectuosos.
65
ANEXO 1
A continuación te presentamos el Anexo 1 que contiene: Tablas de la función de
distribución binomial acumulada.
66
67
68
69
70
71
72
A N E X O 2
A continuación te presentamos el Anexo 2 que contiene: Tablas de la distribución de
Poisson acumulada.
73
74
75
76
77
BIBLIOGRAFÍA CONSULTADA
JOHN E. Freud y Richard. Estadística. 4ª ed., Prentice-Hall Hispanoamericana, México.
JOHSON, Robert. Estadística elemental. Grupo Editorial Iberoamérica, México.
LINCOLN L., Chao. Introducción a la Estadística. CECSA, México.
MEYER. Probabilidad y aplicaciones estadísticas. Fondo Educativo Interamericano.
MORENO, Alberto y Javier, Jauffred. Elementos de probabilidad y estadística.
Representaciones y servicios de Ingeniería.
MURRAY R., Spiegel. Probabilidad y Estadística. (Serie Schaum). McGraw-Hill, México.
R. E., WALPOLE, R. H. Myers. Probabilidad y Estadística para ingenieros. 3ª ed.,
Interamericana.
TARO, Yamane. Estadística. 3ª ed. Harla, México, 1979.
WILLOUGHBY, Stephens. Probabilidad y Estadística. Publicaciones Cultural, México,
1983.
78
COLEGIO DE BACHILLERES
ESTADÍSTICA DESCRIPTIVA
E INFERENCIAL II
FASCÍCULO 3. FUNCIONES DE DISTRIBUCIÓN
NORMAL ESTÁNDAR
Autores: Emigdio Arroyo Cervantes
Juan Matus Parra
1
2
ÍNDICE
INTRODUCCIÓN
5
PROPÓSITO
7
SIMBOLOGÍA
9
CAPÍTULO 1. FUNCIONES PROBABILÍSTICAS
CONTINUAS
1.1 DISTRIBUCIÓN NORMAL ESTÁNDAR
11
14
1.1.1 NORMALIZACIÓN
16
1.1.2 VALORES NORMALIZADOS “Z” Y ÁREA BAJO
LA CURVA
23
1.1.3 APROXIMACIÓN NORMAL A LA DISTRIBUCIÓN
BINOMIAL
37
1.2 DISTRIBUCIONES MUESTRALES Y EL
TEOREMA CENTRAL DEL LÍMITE
43
1.2.1 DISTRIBUCIONES MUESTRALES
43
1.2.2 EL TEOREMA CENTRAL DEL LÍMITE
54
1.2.3 DISTRIBUCIÓN T–STUDENT
58
RECAPITULACIÓN
76
ACTIVIDADES DE CONSOLIDACIÓN
77
AUTOEVALUACIÓN
79
3
ACTIVIDADES DE GENERALIZACIÓN
85
GLOSARIO
86
ANEXOS
87
BIBLIOGRAFÍA CONSULTADA
4
100
INTRODUCCIÓN
La distribución normal es la más utilizada para variables aleatorias continuas. Los
conceptos básicos de esta distribución fueron planteados por primera vez por Abraham
de Moire (Matemático francés: 1667–1754) y por el marqués Pedro Simón de Laplace
(Astrónomo francés: 1749–1855). Posteriormente fue Kart Friedrich Gauss (Matemático
alemán; 1777–1855) quien presentó las leyes fundamentales de la distribución normal de
probabilidad, es por eso que esta distribución se conoce como distribución Gaussiana y
su curva se conoce como campana de Gauss.
Existen otras distribuciones de probabilidad, las de variables aleatorias continuas cuya
determinación de la probabilidad difiere de las anteriores toda vez que las observaciones
del experimento generan un espacio muestral infinito y cada intervalo de este tiene un
número infinito no numerable de posibles resultados los cuales incluyen valores reales.
De lo anterior podemos concluir que para determinar la probabilidad de una variable
aleatoria continua, se desarrolla un método distinto a los anteriores.
En este fascículo estudiarás la distribución normal como modelo de fenómenos
aleatorios en los que se efectúan mediciones continuas y te capacitarás en el cálculo de
la probabilidad de fenómenos aleatorios de regularidad estadística, aplicando para ello,
la distribución normal estándar.
En el fascículo anterior estudiaste las distribuciones de probabilidad binomial y de
Poisson. Estas son distribuciones de variable aleatoria discretas, en que cada valor de
las variables se le asigna una probabilidad.
La distribución de probabilidad normal te servirá para resolver problemas que involucran
variables aleatorias continuas tales como: la altura y los pesos de seres humanos y
animales, errores de medición en experimentos de laboratorio, el tiempo de vida de
lámparas incandescentes en la industria eléctrica, etc. Así mismo, estudiarás la
aplicación de a distribución de medias muestrales mediante el uso del Teorema del
Límite Central para muestras grandes y la distribución de Student en muestras
pequeñas.
5
6
PROPÓSITO
En los fascículos anteriores de esta asignatura aprendiste a clasificar y manejar variables
aleatorias (discretas y continuas) y las funciones probabilísticas discretas (binomial y
Poisson). Ahora en este fascículo:
¿QUÉ APRENDERÁS?
Comprenderás las características esenciales de las funciones probabilísticas
continuas, tales como: Distribución Normal y t–student, además de las distribuciones
maestrales y Teorema del Límite Central.
¿CÓMO LO LOGRARÁS?
A partir de la gráfica de la curva de Gauss, asociando la probabilidad de una
variable aleatoria normalmente distribuida al área bajo la curva, apoyándote en el
uso de tablas de distribución normal, t–student y calculadoras científicas.
A partir de la ejecución de muestreo simple y del cálculo de la media x de una
distribución normal y utilizando tablas de distribución.
¿PARA QUÉ TE VA A SERVIR?
Para acceder a los conceptos básicos y modelos necesarios para el análisis de la
inferencia (deducción) estadística.
7
8
SIMBOLOGÍA
SÍMBOLO
Z
t
E
SIGNIFICADO
Xi
Normalización
x
s
Distribución t de Student
n
Z
2
n
y f ( x)
1
2
Muestra para estimar la media cuando n 30
e
x2
2
n
f ( x ) p x (1 p)n x
x
Curva normal estándar
Distribución binomial
9
10
CAPÍTULO 1
FUNCIONES PROBABILÍSTICAS CONTINUAS
Sabemos que las aguas negras de la Ciudad de México se utilizan para el riego de los
campos de cultivo circunvecinos al Valle de México.
Esta agua negras contienen entre otras sustancias, el cloro en cantidades perjudiciales
al sembradío de cereales porque en lugar de beneficiarlo con el riego, lo quema y lo
seca.
Por lo anterior, es necesario darle al agua un tratamiento con el fin de disminuir o
eliminar el contenido de cloro. Para ello el Departamento del D.F. tiene establecido un
laboratorio en los colectores de aguas para determinar el contenido de cloro y dar el
tratamiento correspondiente antes de abrir las compuertas.
Para el análisis se toma una muestra de 5 lt. De aguas negras diariamente. Los
resultados correspondientes al mes de noviembre de 1993 fueron las que se muestran
en la siguiente tabla. Las cantidades de cloro se registran en partes por millón (ppm).
16.2 15.4 16.0 16.6 15.9 15.8 16.0 16.8 16.9 16.8
15.7 16.4 15.2 15.8 15.9 16.1 15.6 15.9 15.6 16.0
16.4 15.8 15.7 16.2 15.6 15.9 16.3 16.3 16.0 16.3
11
Usemos estos datos para realizar un recordatorio de los conceptos estudiados en tu
curso de Estadística I. Esto nos servirá para abordar los nuevos conceptos que
estudiarás en este fascículo y para ello realiza el siguiente ejercicio:
1. Ordena los datos en sentido creciente.
2. Determina el rango de variación de los datos.
3. Elabora una tabla de frecuencia de datos agrupados de 5 clases.
4. Determina la moda, la mediana y la media de la muestra.
5. Determina la desviación estándar.
6. Traza el histograma.
7. Traza el polígono de frecuencia.
8. Analiza e polígono de frecuencias y determina:
a) De qué tipo es (platicúrtica, mesocúrtica, etc.)
b) Determina el sesgo.
c) Determina el orden de la media, la moda y la mediana.
9. Analiza la desviación estándar y determina como es la dispersión de las puntuaciones.
En el fascículo anterior aplicamos las distribuciones de probabilidad de variables
aleatorias discretas para la solución de problemas de ventas, producción, de seguros,
etc.
¿Qué sucede con la solución de problemas de probabilidad
donde intervienen variables aleatorias continuas?
¿Se podrán aplicar las distribuciones binomial y de Poisson para resolver
problemas donde la variable sea continua?
¿Sabías que una de las soluciones del problema de las aguas negras de la
Ciudad de México es utilizarla para riego de cultivos en otros Estados,
pero como esta agua contienen altas cantidades de cloro es necesario
analizarlas y darles un tratamiento para reutilizarlas?
En el siglo XVIII a los jugadores profesionales les interesaba conocer a priori, las
probabilidades de éxito en los distintos juegos de azar, para ello acudieron a los
matemáticos de la época en busca de ayuda. Como una respuesta a una necesidad
planteada a los matemáticos, en 1973 Abraham D’Moavre (1667-1754) es quien obtiene
por primera vez la ecuación matemática de la curva normal.
La distribución normal nos permite el cálculo de probabilidades de variables aleatorias
continuas y discretas de cualquier problema de: Ingeniería, Medicina, Ciencias Sociales,
Agricultura, Psicología, Física, Química, etc.
12
Otros grandes matemáticos contribuyeron dándole impulso, entre ellos podemos citar a
Friedrich Gauss (1777-1855) quien perfeccionó y la utilizó ampliamente en su teoría de
errores de las mediciones físicas. Laplace la usó en el cálculo de lo errores de las
observaciones astronómicas. El matemático Ruso P.L. Chebyshev estableció varios
teoremas relacionados con la curva de la distribución normal.
Los experimentos realizados por muchos científicos, permiten determinar que la mayor
parte de las variables aleatorias se pueden estudiar considerando que tiene una función
de densidad normal.
13
1.1 DISTRIBUCIÓN NORMAL ESTÁNDAR
Retomemos el problema de las aguas negras. Los resultados que debiste obtener son:
R = 1.7
Mo = 16.01
Me = 16.05
X = 16.08
S = 0.42
El histograma y el polígono de frecuencias son los siguientes:
Figura. 1
Del polígono de frecuencias podemos ver que la curva es asimétrica; está sesgada a la
izquierda por lo tanto su asimetría es negativa. Por su puntiagudez es del tipo
leptocúrtica.
Recordarás que los polígonos de frecuencias pueden ser:
1. Simétricos (Figura 2 gráfico A).
2. Asimétricos (Figura 2 gráfico B).
a) En la asimetría positiva el sesgo es a la derecha (Figura 2 gráfica B).
b) En la asimetría negativa el sesgo es a la izquierda (Figura 2 gráfica C).
14
Figura. 2
1. Los polígonos simétricos se clasifican en:
a) Platicúrtico (Figura 3 gráfico A).
b) Mesocúrtico (Figura 2 gráfico B).
c) Leptocúrtico (Figura 2 gráfico C).
Figura. 3
De los gráficos anteriores podemos concluir que la forma de cada una, está íntimamente
relacionada con las medidas de tendencia central y de dispersión.
En las simétricas, las medidas de tendencia central coinciden en el mismo punto, es
decir µ = Mo = Md.
15
Las medidas de dispersión son diferentes, de la figura 3 obtenemos que:
A B C
En las asimétricas las medidas de tendencia central son diferentes y lo mismo ocurre con
las de dispersión.
a) Sesgo positivo < Md < Mo
b) Sesgo negativo > Md > Mo
A B C
En cualquier problema de variable aleatoria continua, su polígono de frecuencia es
alguna de las gráficas anteriores y éstas dependen de sus parámetros de tendencia
central y de dispersión.
La gráfica que tiene forma de campana, su media µ = 0 y = 1, se llama curva normal
estándar o campana de Gauss pro haber sido el primer científico que usó esta
representación.
Las curvas simétricas tienen la forma de campana y las asimétricas no tienen esa forma
pero pueden transformarse a simétricas.
El procedimiento para transformar las curvas asimétricas en simétricas, es mediante una
normalización de los datos del problema y que estudiaremos a continuación.
1.1.1 NORMALIZACIÓN
El proceso de transformación de un polígono de frecuencias a una curva normal, se
llama normalización y para ello se hace un cambio de escala mediante la normalización
o tipificación de las puntuaciones, es decir, los valores ( x ) se transforman en valores Z
mediante la ecuación de transformación.
Z
Xi µ
... (1)
Donde:
Z = Puntuación normalizada o tipificada
Xi = Cada una de las puntuaciones de la población
µ = Media de las puntuaciones de la población
= Desviación estándar de la población
16
Veamos el siguiente ejemplo:
Se desea conocer el peso promedio de los alumnos del turno vespertino del plantel 2 del
Colegio de Bachilleres. Para ello se toma una muestra representativa de 150 alumnos y
se pesan. Los pesos ya organizados en 13 clases, se muestran en la siguiente tabla de
frecuencias:
Clases en Kg.
30–34
35–39
40–44
45–49
50–54
55–59
60–64
65–69
70–74
75–79
80–84
85–89
90–94
Frecuencia (fi)
1
5
8
8
10
18
12
36
28
12
8
3
1
Tabla 1.
ACTIVIDAD DE REGULACIÓN
Con los datos del ejemplo anterior, calcula (peso promedio de los alumnos del plantel 2
del Colegio de Bachilleres):
a) La media x .
b) La desviación estándar .
c) Traza el polígono de frecuencias.
17
POLÍGONO DE FRECUENCIAS
Figura 4.
De esta gráfica podemos concluir que es asimétrica con sesgo negativo y del tipo
leptocúrtica.
Ahora vamos a normalizar estos datos y trazar la curva normal estándar sobre este
polígono de frecuencias para poder constatar el cambio de escala.
18
Para explicar el procedimiento vamos a construir la siguiente tabla:
Normalización de una Distribución Asimétrica
1
CLASE
2
fi
3
Lr
SUP
9094
8589
8084
7579
7074
6569
6064
5559
5054
4549
4044
3539
3034
1
3
8
12
28
36
12
18
10
8
8
5
1
94.5
89.5
84.5
79.5
74.5
69.5
64.5
59.5
54.5
49.5
44.5
39.5
34.5
4
5
x=xi–x Z = x/
30.6
25.6
20.6
15.6
10.6
5.6
0.6
4.4
9.4
14.4
19.4
24.4
29.4
2.51
2.10
1.69
1.28
0.87
0.46
0.05
0.36
0.77
1.18
1.59
2.00
2.41
6
PARTE
MAYOR
7
PARTE
MENOR
8
fe
9
fe
redondeada
0.9940
0.9821
0.9545
0.8997
0.8078
0.6772
0.5199
0.6406
0.7994
0.8810
0.9441
0.9720
0.9920
0.0060
0.0179
0.0455
0.1003
0.1922
0.3228
0.4801
0.3594
0.2206
0.1190
0.0559
0.0228
0.0080
1.785
4.140
8.220
13.875
19.590
23.595
24.075
20.820
15.240
9.465
4.965
2.220
1.200
1.8
4.1
8.2
13.9
19.6
23.6
24.1
20.8
15.2
9.5
5.0
2.2
1.2
Tabla 2.
Nota. Se restan los valores consecutivos de la columna 6 para obtener el valor de la columna 7.
Por ejemplo: 0.9940 – 0.9821 = 0.0119
0.9821 – 0.9545 = 0.0276
0.9545 – 0.8997 = 0.0548
Las columnas 1 y 2 de la tabla 2 corresponden a la clase y la frecuencia establecidas en
la primera tabla 1.
La columna 3 corresponde al límite real superior de cada clase el cual se determina
aumentando medio punto a cada valor del límite superior.
La columna 4 es igual a la desviación de cada puntuación con respecto a la media y se
obtiene mediante la ecuación:
x = xi – x
... (1)
Se toma como xi, al límite real superior de cada clase.
19
La columna 5 es el valor de Z correspondiente a cada puntuación y se obtiene mediante
la ecuación de normalización o tipificación, esto es:
Z
x
xi x
... (2)
La columna 6 se determina de los valores de la tabla del apéndice ( A ) “Áreas y
x
ordenadas de la curva de distribución normal en función de
” que enseguida
explicaremos.
En la primera columna de la tabla del anexo A de la página 90, se localizan los valores
de z, en la tercera columna se lee el valor del área bajo la curva normal de la parte
mayor.
En la cuarta columna se lee el área bajo la curva normal de la parte menor y se registra
en la columna siete de nuestra tabla.
EJEMPLO:
Para z = 2.51 el área de la parte mayor que se lee en la tercera columna es 0.9940.
Para z = 2.41 en la cuarta columna se lee el área de la parte menor correspondiente a
0.0080.
Regresando a la tabla 2, la columna ocho corresponde a la frecuencia esperada (fe) y se
calcula multiplicando el total de casos N =150 por el área de la parte menor (columna 7)
de cada puntuación.
Ejemplo:
(0.0119) (150) = 1.785
La columna nueve es la frecuencia esperada (fe) redondeada a una cifra decimal.
Con estos valores de la tabla trazamos el polígono de frecuencias y la curva normalizada
para ver el cambio que sufre el polígono de frecuencias de cualquier problema que se
normalizan los datos:
20
Figura. 5
En la figura 5, se observa:
A= Polígono de frecuencia de los pesos de 150 alumnos del plantel 2 del turno
vespertino del Colegio de Bachilleres.
B = Curva normal del mismo problema.
En la escala Z se determinan los valores de la desviación típica ( ), a uno y otro lado de
la media ( x ).
Del ejemplo anterior habrás notado que normalizar los datos de un problema es
equivalente a cambiar la escala “x” por la “z” y calcular las nuevas frecuencias que son
las ordenadas de cada punto. Para ello usamos los valores de la tabla. Estos valores
corresponden a las áreas bajo la curva normal y se han calculado mediante la ecuación
que define a la función normal y ésta es:
y = f (x) =
1
2
e
x µ 2
...(3)
2
21
Donde:
= 3.1416....
= media proporcional
e = 2.718281...
= desviación estándar de la población
x = cada uno de los datos u observaciones.
Con la ecuación ( 3 ) podemos trazar la curva normal que tiene la forma de campana.
Primero obtenemos y de los datos del problema y sustituimos en la fórmula ( 3 ).
Para obtener un par ordenado, usamos un valor arbitrario de x, obtenemos un valor de y.
Esta sucesión de puntos nos da la curva normal.
La Curva Normal Estándar
La curva normal estándar o campana de Gauss es la misma curva normalizada
solamente que mediante una traslación se lleva la curva hasta el origen . En este caso
usamos µ = 0 y = 1.
La siguiente gráfica muestra la curva normalizada con µ = 30 y = 10
Figura. 6
Donde:
A = Curva normalizada
B = Curva normalizada y estandarizada
Al trasladar la gráfica anterior al origen, hemos transformado los parámetros µ y en :
= 0
y
22
=1
Con estos valores reducidos, la curva normal estándar se obtiene mediante la gráfica de
la función:
y = f (x) =
1
2
e
x
2
...(4)
2
Y la ecuación de tipificación es la ya conocida:
x= + Z
Z=
x
...(1)
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide a continuación:
Con los datos del problema de las aguas negras (pág. 11), elabora la tabla con los datos
normalizados y traza la curva normal sobre el polígono de frecuencias que ya obtuviste
antes. Utiliza tu cuaderno para dar las respuestas.
1.1.2 VALORES NORMALIZADOS “Z” Y ÁREA BAJO LA CURVA NORMAL
Ya quedó establecido que para normalizar el polígono de frecuencias y transformarlo en
una campana de Gauss, se tipifican las observaciones ( xi ) del problema cambiándolos
a una escala (Z) mediante la ecuación ( 1 ).
Esta curva normal es necesaria estandarizarla para poder calcular la probabilidad
mediante una misma tabla ya elaborada para toda curva normal estandarizada, que se
obtiene trasladando la media al origen como ya se indicó.
23
La curva normal estandarizada tiene las siguientes características:
a) La altura alcanza su valor máximo como µ = 0 y su valor es 0.4, es decir; el punto
máximo es Pm(0,0.4)
b) La curva normal estándar es simétrica con respecto a la media por lo tanto los
parámetros de tendencia central son iguales, es decir:
µ = Mo = Md = 0
...(5)
c) La desviación estándar es = 1
d) El área bajo la curva es
A=1
Figura. 7
El área sombreada vale 1 y como la curva es simétrica cada región a los lados del eje y
vale 0.5.
e) El eje Z es una asíntota horizontal de la curva ya que lim( z) 0 .
Z
f)
El área más importante donde se distribuye la probabilidad de un suceso, se
encuentra comprendida entre + 3σ y esto lo puedes constatar en la siguiente gráfica
de la Fig. 8.
g) De acuerdo con el teorema de Chebishev relacionado con la desviación estándar y el
área bajo la curva, podemos establecer los siguientes porcentajes de la misma:
24
Figura. 8
De esta gráfica podemos ver que el área antes y después de + 3 corresponde al 1%, es
decir el 0.5% para cada lado de la gráfica.
Por la simetría que tiene la curva normal estándar, existen tablas correspondientes al
área bajo al curva que únicamente contemplan la parte positiva de la gráfica y estos
mismos valores se usan para el lado negativo.
Ejemplo: Con los siguientes valores de “Z” determinaremos el valor de área bajo la curva
utilizando la tabla de áreas bajo la curva del anexo A de la página 85 y trazaremos un
esquema del área correspondiente:
Z = + 0.5, + 0.7, + 1.5
En la primera columna de la tabla localizamos el valor de Z = 0.5 y en la segunda
columna leemos el valor del área.
Z = 0.5 ; A = 0. 1915
Figura. 9
25
Figura. 10
Figura. 11
Figura. 12
Figura. 13
26
Figura. 14
De las gráficas anteriores podemos ver, que el valor del área es el mismo para valores
positivos y negativos de Z solamente que para el valor negativo, el área se representa a
la izquierda de la media.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
Normaliza los valores de X = 4, 6, 9, 12, 18, 20, usando = 10 y = 5. Traza una
gráfica para cada valores de x, compárala con la gráfica de los valores normalizados y
traza una para cada “Z” sombreando en ambas gráficas la región correspondiente.
El área bajo la curva normal estándar representa la probabilidad de un evento; toda el
área bajo la curva vale uno y representa la probabilidad del evento seguro.
Figura. 15
27
Si queremos la probabilidad de un evento cuyo valor está limitado por dos puntuaciones,
por ejemplo:
P ( x, X x2 )
Probabilidad de “x” comprendida entre x1 y x2.
Para determinar esta probabilidad, tipificamos los valores “x”.
Sabemos que la curva normalizada de la escala “x” es equivalente a la curva normall
estándar en la escala “Z”.
P ( x1 x x2) = P ( Z1 Z Z2 )
Determinamos
Z1
=
Z2
=
X1
X2
P (Z) = P (Z1) + P (Z2)
Las gráficas correspondientes en ambas escalas son:
Figura. 16
Si las “x” están en el lado positivo entonces, debemos recordar que los valores que se
leen en la tabla normalizada son a partir de la media hasta el valor de Z.
Las gráficas de las variables x y z son las que se muestran a continuación:
P (Z) = P (Z2) – P (Z1)
Si los valores de “x” están en la parte negativa de “z” es decir a la izquierda de la media,
entonces los gráficos son:
Figura. 17
28
Si solamente tenemos una “X” a la derecha de la media entonces el área bajo la curva
es:
Figura. 18
Recuerda que la primera mitad del área bajo la curva vale 0.5, es por eso que a la
probabilidad de Z, le sumamos 0.5.
Figura. 19
Si nos interesa la probabilidad de x<µ, entonces la gráfica es:
Figura. 20
Si queremos la probabilidad de las partes sombreadas de las siguientes gráficas:
Figura. 21
29
Recuerda que la probabilidad de “Z” , es la parte sin sombrear de la media a la izquierda
hasta “Z”, y la probabilidad de Z2, es la parte sin sombrear de la media a la derecha
hasta Z2.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
Con los siguientes valores determina la probabilidad y traza la gráfica correspondiente
para cada inciso.
1. a) Z = 0 y Z = 0.94
b) Z = 0 y Z = -2.15
c) A la derecha de Z = 0.62
d) A la derecha de Z = - 0.93
e) A la izquierda de Z = 0.84
f) A la izquierda de Z = -0.35
2. a) Z = - 0.59 y Z = 0.59
b) Z = -0.71 y Z = 1.99
c) Z = 0.32 y Z = 0.92
d) Z = -0.81 y Z = -0.42
e) Z = -1.65 y Z = -0.25
Si se conoce la probabilidad de un evento y queremos determinar el valor de Z, entonces
nos situamos en la segunda columna de la tabla (Área desde la media), localizamos los
valores de la probabilidad y en el mismo renglón y en la misma columna 1 determinamos
el valores de Z.
Ejemplo: Si P (Z) = 0.4429 entonces ¿el valore de Z es?
De la tabla obtenemos que Z = 1.58
Figura. 22
30
Determina Z si P (Z) = 0.7580. Este valor es mayor que 0.5 correspondiente a la mitad
de la gráfica por lo tanto hacemos la siguiente transformación:
P (Z) = 0.5 + P (Z)
P (Z1 ) = P ( Z ) – 0.5 = 0.7589 – 0.5 = 0.2589
Figura. 23
En la tabla nos situamos en este valor y en la columna 1 está el valor de Z = 0.70
Si la probabilidad de z a la izquierda de la media es P (Z) = 0.1331, entonces ¿Z es?
En la segunda columna de la tabla localizamos el valor de la probabilidad y en la misma
línea en la primera columna determinamos el valor de Z = –0.34. El valor del signo
negativo es por estar a la izquierda de la media.
Figura. 24
31
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
1. Determina el valor de Z y traza la gráfica de cada inciso, si la probabilidad de Z es:
a) Entre 0 y Z, P ( Z ) = 0.4864
b) A la izquierda de Z, P ( Z ) = 0.9983
c) A la derecha de Z, P ( Z ) = 0.7324
d) A la derecha de Z, P ( Z ) = 0.2981
e) A la izquierda de Z, P ( Z ) = 0.1314
f) Entre –Z y Z, P ( Z ) = 0.7286
2. Una variable aleatoria tiene una distribución normal con media = 60 y desviación
estándar = 5.2 ¿Cuáles son las probabilidades de que la variable aleatoria tome un
valor como el que se indica? Traza la gráfica de cada inciso:
a) Menor que 62.5
b) Mayor que 70.5
c) Entre 60.0 y 66.2
d) Entre 48 y 72
Si tienes alguna duda consulta a tu asesor de contenido.
Ejemplo:
Con los siguientes valores, calcula la probabilidad de la distribución binomial y traza el
polígono de frecuencia de cada una.
1) n = 10, p = 0.2, q = 0.8, x = 0, 1, 2, . . . 10
2) n = 10, p = 0.8, q = 0.2, x = 0, 1, 2, . . . 10
3) n = 10, p = 0.5, q = 0.5, x = 0, 1, 2, . . . 10
32
Para el problema 1 sustituimos valores en ( 6 ) y obtenemos:
10
0
10
F( 0 ) = ( 0.2 ) ( 0.8 ) = ( 1 ) ( 1 ) ( 0.1073 ) = 0.1073
0
10
1
9
F( 1 ) = ( 0.2 ) ( 0.8 ) = ( 10 ) ( 0.2 ) ( 0.1342 ) = 0.2684
1
10
2
8
F( 2 ) = ( 0.2 ) ( 0.8 ) = ( 45 ) ( 0.04 ) ( 0.1677 ) = 0.3019
2
10
3
7
F( 3 ) = ( 0.2 ) ( 0.8 ) = ( 120 ) ( 0.0008 ) ( 0.2097 ) = 0.2013
3
10
4
6
F( 4 ) = ( 0.2 ) ( 0.8 ) = ( 210 ) ( 0.0016 ) ( 0.2621 ) = 0.0881
4
10
5
5
F( 5 ) = ( 0.2 ) ( 0.8 ) = ( 252 ) ( 0.00032 ) ( 0.3276 ) = 0.0264
5
Calcula los siguientes valores:
F( 6 ) =
F( 7 ) =
F( 8 ) =
F( 9 ) =
F( 10 ) =
Cálculo del segundo problema:
10
0
10
F( 0 ) = ( 0.8 ) ( 0.2 ) = ( 1 ) ( 1 ) ( 0.000000102 ) = 0.0000001
0
10
1
9
F( 1 ) = ( 0.8 ) ( 0.2 ) = ( 10 ) ( 0.8 ) ( 0.000000512 ) = 0.0000009
1
10
2
8
F( 2 ) = ( 0.8 ) ( 0.2 ) = ( 45 ) ( 0.64 ) ( 0.000002 ) = 0.0000737
2
33
10
3
7
F( 3 ) = ( 0.8 ) ( 0.2 ) = ( 120 ) ( 0.512 ) ( 0.000012 ) = 0.0008
3
10
4
6
F( 4 ) = ( 0.8 ) ( 0.2 ) = ( 210 ) ( 0.4096 ) ( 0.000064 ) = 0.0055
4
10
5
5
F( 5 ) = ( 0.8 ) ( 0.2 ) = ( 252 ) ( 0.3276 ) ( 0.00032 ) = 0.02642
5
Calcula los siguientes valores:
F( 6 ) =
F( 7 ) =
F( 8 ) =
F( 9 ) =
F( 10 ) =
Cálculo para el tercer problema:
10
0
10
f( 0 ) = ( 0.5 ) ( 0.5 ) = ( 1 ) ( 1 ) ( 0.00097 ) = 0.0009
0
10
1
9
f( 1 ) = ( 0.5 ) ( 0.5 ) = ( 10 ) ( 0.5 ) ( 0.00195 ) = 0.009
1
10
2
8
f( 2 ) = ( 0.5 ) ( 0.5 ) = ( 45 ) ( 0.25 ) ( 0.0039 ) = 0.039
2
10
3
7
f( 3 ) = ( 0.5 ) ( 0.5 ) = ( 120 ) ( 0.125 ) ( 0.00781 ) = 0.1172
3
10
4
6
f( 4 ) = ( 0.5 ) ( 0.5 ) = ( 210 ) ( 0.0625 ) ( 0.0156 ) = 0.2051
4
10
5
5
f( 5 ) = ( 0.5 ) ( 0.5 ) = ( 252 ) ( 0.03125 ) ( 0.03125 ) = 0.2461
5
34
Calcula los siguientes valores:
f( 6 ) =
f( 7 ) =
f( 8 ) =
f( 9 ) =
f( 10 ) =
Representación la gráfica de las probabilidades de cada uno de los problemas:
Para poder trazar la gráfica como si fuese una variable continua, cerramos los espacios
entre cada barra del histograma, para ello tomemos medio punto después de cada valor
para obtener el límite real superior de clase.
Gráfica del problema 1.
Figura. 25
La gráfica 1 es asimétrica y sesgada a la derecha.
35
Gráfica del problema 2.
Figura. 26
La gráfica 2 es asimétrica y sesgada a la izquierda.
Gráfica del problema 3.
Figura. 27
La gráfica 3 es simétrica muy parecida a la campana de Gauss.
36
1.1.3 APROXIMACIÓN NORMAL A LA DISTRIBUCIÓN BINOMIAL
En el fascículo anterior estudiaste el cálculo de probabilidades de variables discretas
cuya distribución es binomial.
Veamos la representación gráfica de una variable de distribución binomial cuando n
(número de elementos de la población) aumenta.
Figura. 28
En las gráficas anteriores podemos ver si “n“ aumenta, los espacios entre las barras se
van cerrando y la gráfica se aproxima a la campana de Gauss que es la gráfica de una
variable aleatoria continua.
Veamos el cálculo de los siguientes problemas correspondientes a una distribución
binomial definida por la ecuación:
n
f ( x ) p x (1 p)n x
x
Donde:
n = Número de observaciones
x = Número de éxitos esperados
p = Probabilidad de éxito
q = 1 – p = Probabilidad de fracaso
Con estos ejemplos podrás notar que el cálculo en la distribución binomial, es muy
laborioso, aunque existen tablas para algunos valores; pero no son suficientes cuando
“n“ crece.
37
Por ejemplo si en un problema de distribución binomial se han realizado 100
observaciones y se desea saber la probabilidad de obtener al menos 45 éxitos.
Para determinar esta probabilidad tenemos que calcular
f (45) + f (46) + . . . + f (100) = P(x)
Otra forma de calcular esta Probabilidad es restándole a la unidad las probabilidades de
la siguiente forma:
P (x ) = 1 – [ f (0) + f (1) + f (2) + . . . + f (44) ]
Una forma de ahorrar este trabajo laborioso es haciendo el cálculo de probabilidades por
medio de la distribución normal.
Ya vimos en las gráficas anteriores cómo el polígono de frecuencias de un problema de
distribución binomial se aproxima a la campana de Gauss, por lo tanto podemos usar la
distribución normal para calcular una probabilidad binomial con una aproximación
aceptable.
Se recomienda usar la distribución cuando “n” es grande y P se aproxima al valor de 0.5.
se considera que n es grande si n>30
Para usar la distribución normal se calculan los parámetros aplicando las siguientes
ecuaciones:
np
np(1 p)
Veamos el siguiente ejemplo:
Determinar la probabilidad de obtener 6 águilas en 15 lanzamientos de una moneda
equilibrada y comparar el resultado mediante la distribución normal.
Solución:
6
15 1
1
f (x) = f (6) = 1
2
6 2
156
15 1
6 2
f (x) = 0.1527
38
15
5005 0.0000305 0.1527
Solución usando la distribución normal.
Para aplicar esta distribución corregimos los espacios para considerar a la variable como
si fuese continua o sea para 6 águilas tomamos medio punto antes y medio punto
después, es decir:
1
np = 15 = 7.2
2
1 1
1
np(1 p) (15)( )( )
15 1.9365
2 2
2
x = 5.5
Z1 =
5.5 7.5
2
1.033
1.9365 1.9365
x = 6.5
Z2 =
6.5 7.5
1
0.5164
1.9365 1.9365
P(z) = P(Z2) – P(Z1) =
= P(–1.033) – P(–0.5164)
=0.3485 – 0.1950 = 0.1535
P(Z) –f(x) = 0.1535 – 0.1527
=0.0008
Z
Figura. 29
De estos cálculos concluimos que la diferencia de la probabilidad normal y binomial es
de 8 diezmilésimos. Este ejemplo nos ilustra que podemos usar la distribución normal
para calcular la probabilidad de una distribución binomial, con una aproximación tal que
no afecta la toma de decisiones.
Veamos otro ejemplo:
Una editorial de libros técnicos obsequia un porcentaje de libros para dar a conocer una
nueva edición. Con el libro de obsequio se envía un cuestionario que deben contestar los
lectores y devolver a la editorial. En el cuestionario se incluyen preguntas con respecto
de las personas para mejorar su contenido y preparar nuevos tirajes; pero la experiencia
de ésta es que la probabilidad de que devuelvan el cuestionario es de P ( x ) = 0.18.
Se envían por correo 100 ejemplares a profesionistas que pudiesen interesarles el
contenido, del libro “Aplicación industrial de la probabilidad”. A la editorial le interesa
saber la probabilidad que al menos reciban 15 cuestionarios de regreso.
39
Solución:
El problema es de recibir o no el cuestionario, por lo tanto es una distribución binomial
con n = 100 y P = 0.18 por lo que para hallar el resultado debemos calcular:
P ( x ) = f ( 15 ) + f ( 16 ) + . . . + f ( 100 )
. . . ( 11 )
O bien
P ( x ) = 1-[f ( 0 ) + f ( 1 ) + . . . + f ( 14 )]
. . . ( 12 )
El Segundo cálculo es menos laborioso, sin embargo no deja de serlo. Sabemos que una
buena aproximación es mediante la distribución normal cuyo cálculo es más sencillo.
Veamos el desarrollo:
np = 100 (0.18 ) = 18
np(1 p) 100(.18)(. 82 ) 3.84
Para transformar la variable binomial a continua tomamos el límite real inferior de clase
14.5 18
X = 14.5 o sea medio punto antes. Con este valor calculamos Z1 =
0.9114
3.84
P(Z) = P (Z1) + 0.5
.. .
( 13 )
De las tablas obtenemos:
P (Z1) = P (-0.9114) = 0.3186
Sustituyendo este valor en ( 13 )
Obtenemos: f(x) = P(Z) = 0.3186+0.5
Z
f(x) = 0.8186
Figura. 30
De acuerdo con este resultado la editorial recibirá el 82% de los cuestionarios enviados.
40
ACTIVIDAD DE REGULACIÓN
Realiza los siguientes problemas aplicando la distribución binomial y compara el
resultado usando la distribución normal.
1. Aplica la distribución binomial y determina la probabilidad de recibir al menos 15
cuestionarios. Compara los resultados e indica el error de aproximación, si es positivo
o negativo.
2. La policía tiene conocimiento que la probabilidad del robo de automóviles en la ciudad
de México es de P( x ) = 0.4 y tiene reportados 10 automóviles robados en el mes de
diciembre. Calcular la probabilidad de recuperar:
a) A lo más 3 de los 10 robados
b) Al menos 6 de los 10 robados
3. En el plantel 11 del Colegio de Bachilleres se tiene el conocimiento de que la
probabilidad de mujeres en el primer ingreso es de 0.45. Si seleccionamos una
muestra al azar de 10 alumnos de primer ingreso, ¿Cuál es la probabilidad de que :
a) Seis de los 10 sean mujeres
b) A lo mas 6 de los 10 sean mujeres
c) Al menos 5 de los 10 sean mujeres
41
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Recuerda que la Distribución Normal Estándar; es aquella distribución probabilística de
la variable normal estándar Z.
Los Polígonos de Frecuencias, son:
a) Simétricos.
b) Asimétricos.
Estos se clasifican en:
1) Platicúrtico.
2) Mesocúrtico.
3) Leptocúrtico.
Normalización; es el proceso de transformación de un polígono de frecuencias a una
curva normal, se representa mediante la ecuación:
Z
Xi
Donde:
Z = Puntuación normalizada o tipificada.
Xi = Cada una de las puntuaciones de la población.
= Media de las puntuaciones de la población.
= Desviación estándar de la población.
Recuerda que la curva normal es simétrica, es decir, en forma de campana.
42
1.2 DISTRIBUCIONES MUESTRALES Y EL TEOREMA CENTRAL DEL
LÍMITE
En el fascículo 1 del curso de Estadística Descriptiva e Inferencial I se definieron los
conceptos:
1) Población:
a) finita
b) infinita
2) Muestra aleatoria
3) Estadística
4) Parámetros
También se estableció por qué es conveniente estudiar una muestra aleatoria en lugar
de la población.
Se recomienda que repases estos conceptos que usaremos en esta unidad.
1.2.1 DISTRIBUCIONES MUESTRALES
Cuando vamos al mercado nos dan una prueba de barbacoa y del sabor de esta muestra
se infiere el sabor de toda y si nos gusta entonces la compramos. Lo mismo ocurre si
queremos comprar queso, pedimos una prueba y de esta deducimos si todo el queso
está bueno o no.
Si el industrial quiere determinar el número de horas de vida que tiene un foco, toma una
muestra de todo el lote y los mantiene encendidos hasta que se funden.
De estos casos podemos deducir que no es posible analizar todo el queso o la barbacoa
porque no quedaría para vender. El industrial no puede fundir todos los focos porque no
tendría qué vender.
En toda investigación estadística el objetivo general de esta, es hacer generalizaciones
de inferencias válidas obtenidas de la muestra. En otras palabras, se trata de conocer las
características de la población a partir de los datos de una o mas muestras obtenidas de
la población.
Las muestras pueden ser:
a) Las muestras no probabilísticas no nos permiten hacer generalizaciones.
b) Las muestras probabilísticas son la base de la inferencia estadística y a este tipo
corresponde el muestreo aleatorio.
43
Definición:
Se llama muestreo aleatorio de una población finita de n elementos, si cada muestra
tiene la misma probabilidad de ser seleccionada y cada elemento de la población
tiene la misma probabilidad de ser incluido en la muestra.
Los tipos de muestras aleatorias son:
1.
2.
3.
4.
Muestreo sistemático.
Muestreo estratificado.
Muestreo por conglomerados.
Muestreo aleatorio simple.
En lo que sigue nos ocuparemos de cada uno de ellos.
Muestreo Sistemático
En este muestreo los elementos de la población se seleccionan con un intervalo
uniforma que se mide en el tiempo, en el espacio o en el orden.
Ejemplo:
Se desea entrevistar a cada décimo estudiante del S.E.A. del Plantel 2 del Colegio de
Bachilleres, para ello se toma una lista de todos los estudiantes. Supongamos que
escogimos el 5º., entonces el siguiente será de los 10 primeros seleccionados al azar y a
partir de este vamos tomando los números décimos de toda la lista.
Este muestreo tiene ventajas y desventajas.
a) Ventajas:
1. Cada elemento de la población tiene la misma probabilidad de ser seleccionado.
2. El muestreo requiere de poco tiempo.
3. El costo es reducido.
b) Desventajas:
1. No todas las muestras tienen la misma probabilidad de ser seleccionadas.
2. Debido a lo anterior se puede cometer el grave error de tomar una muestra que
no sea representativa, por ejemplo:
Se muestrea un determinado número de familias para saber si el miércoles está
incluido un platillo de carne de res en su alimentación. La respuesta es negativa
porque solamente el domingo la consume ya que es el día en que van al pueblo
a comprarla. Esta forma de tomar la muestra no es representativa.
44
Muestreo Estratificado
Para este muestreo, dividimos la población en grupos homogéneos llamados
estratificados. Determinamos la proporción correspondiente de cada estrato en
base a la población y esta misma proporción se toma cada estrato para formar la
muestra.
Este método es útil cuando la población ya esta dividida en grupos.
Por ejemplo:
Los estudiantes del S.E.A. del plantel 2 del Colegio de Bachilleres están
divididos por edades con intervalos de 5 años y los porcentajes son los
siguientes:
Intervalos de clase
(edad)
18 – 23
24 – 29
30 – 35
36 – 41
42 – 47
48 – 53
54 – más
Porcentaje
30%
25%
20%
10%
7%
5%
3%
Se desea saber cuantas horas estudian diariamente; para ello de cada grupo se
toma un porcentaje igual al del grupo, es decir del primer grupo tomamos el 30%
del grupo. De la misma forma se toma el porcentaje de los siguientes grupos
para formar la muestra representativa para su estudio.
Muestreo con Conglomerados
Para este tipo de muestreo, dividimos a la población en grupos conglomerados y
de estos seleccionamos una muestra aleatoria, para su estudio.
Por ejemplo:
En una investigación de mercados se desea saber el número de coches por
familia de la ciudad de México. Para ello dividimos las colonias en manzanas y
de este número seleccionamos aleatoriamente un número de manzanas para
entrevistar a cada familia.
45
Muestreo Aleatorio Simple
El muestreo aleatorio simple tiene las características de la población y es una
muestra representativa de ésta. Es el muestreo más recomendable para el
estudio estadístico, solamente que tiene sus inconvenientes.
Para poder hacer el
siguientes preguntas:
muestreo aleatorio simple debemos
contestarnos las
1. Dada una población finita de N elementos, ¿Cuántas muestras de “n”
elementos podemos formar?
2. Conociendo las “n” muestras ¿Cómo podemos tomar una de ellas que sea
representativa de la población?
Para dar respuesta a la primera pregunta, nos trasladamos al fascículo donde estudiaste
el análisis y aplicamos la ecuación:
N
N!
C
n n! (N n)!
. . .(14)
EJEMPLO:
Determina ¿Cuántas muestras de tamaño n se pueden formar de una población finita N
para los siguientes datos?
a) n = 2 y N = 20
b) n = 3 y N = 100
Solución:
a)
20
20!
201918!
C
190
2! (18)!
2 2! (20 2)!
Este resultado nos dice que con una población de 20 elementos podemos tomar 190
muestras de dos elementos cada una.
b)
100
100!
100999897! !
50 33 98 = 161, 700
C
123! (97)!
3 3! (100 3)!
Este resultado nos indica que de una población de 100 elementos podemos formar 161,
700 muestras de 3 elementos.
Para contestar la segunda pregunta observamos lo siguiente:
Para que estas muestras sean representativas en el primer caso cada muestra debe
tener
1
de probabilidad de ser seleccionada.
190
46
En el 2° caso cada muestra debe tener
1
de probabilidad de ser seleccionada.
161700
¿Cómo debemos tomar cada muestra para que sea representativa?
Hay varias formas de tomar la muestra. Estas formas son las siguientes:
a) en el primer caso cuando el número de muestras no es muy grande se pueden
numerar recortes de papel, doblarlos y meterlos en un recipiente donde se puedan
mezclar ampliamente. Una vez mezclados, se saca la muestra.
Por ejemplo:
En una empresa se premiará con un viaje a Europa a solo 2 de los 5 empleados de
mayor eficiencia. ¿Cómo seleccionamos a los dos que deben ir?
Solución:
A cada empleado lo representamos con la primera letra de su nombre.
1.
2.
3.
4.
5.
Abraham
Dionisio
Efraín
Fausto
Iván
(A)
(D)
(E)
( F)
(I )
Determinamos el número de muestras
5
N
5!
543! 20
C C
10
2
2 2! (5 2)! 2! (3)!
n
P(n)=
1
10
Cada muestra la escribimos en un recorte de papel y éstas son:
1
A–D
2
A–E
3
A–F
4
A–I
5
D–E
6
D–F
7
D–I
8
E–F
9
E–I
10
F–I
Doblamos bien el corte de papel de cada muestral, la introducimos en una vasija; la
agitamos ampliamente y extraemos a la pareja afortunada.
Quizá hayas visto este procedimiento en el sorteo de los equipos para el campeonato
mundial de fútbol. En el sorteo se usaron esferas huecas bisectadas y en su interior se
colocó el nombre de cada equipo, se revolvían ampliamente, se sacaba una esfera de la
cual se tomaba el nombre del equipo y se colocaba en el grupo correspondiente.
47
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
1) Si para el campeonato mundial de fútbol hay 24 equipos de los cuales se deben
formar 6 grupos de 4. ¿Cómo organizarías los equipos para que cada muestra sea
aleatoria? ¿Cómo tomarías cada muestra y qué equipos la compondrían? Determina
los dos posibles finalistas.
2) Calcula el número de muestras de tamaño 3 para una población de:
a) 7 elementos
b) 15 elementos
c) 50 elementos
3) Calcula el número de muestras de tamaño 5 para una población de:
a) 10 elementos
b) 25 elementos
c) 75 elementos
Si tienes alguna duda consulta a tu asesor de contenido.
b) Si el número de muestras es muy grande como en el último ejercicio 15, que son
17,259, 390; la forma explicada con recortes de papel no es la adecuada. Para estos
casos se usa otro procedimiento que consiste en usar una tabla de números
aleatorios como la que se incluye en el apéndice “B”.
Esta tabla de números aleatorios se puede constituir fácilmente con un programa de
computación.
Uso de la tabla de números aleatorios.
Para explicar su uso, veamos el siguiente ejemplo:
El Banco Nacional de México tiene una promoción para tarjetas habientes que consiste
en condonarles la cuenta a 10 personas de cada sucursal, en la primera quincena del
mes de enero de 1994. La lista de cuenta habientes es de 550 y para determinar la
muestra aleatoria numeramos cada cliente con tres cifras en orden ascendente esto es:
001, 002, 003, ..., 550 y nos situamos al azar en una columna de números aleatorios y
nos desplazamos en ella en la dirección que queramos analizando las tres primeras
cifras de cada número hasta completar los 10 números de la muestra.
48
Para nuestro ejemplo nos situamos en la última página de números aleatorios del
apéndice “B”, en la columna 27 renglón 31 y nos desplazamos hacia abajo, los números
obtenidos de 3 cifras son:
187, 155, 388, 320, 281, 088, 520, 275, 480 y 273
Como la tabla es de números aleatorios, podemos asegurar que esta muestra es
aleatoria.
Como habrás notado mediante el uso de números aleatorios, es muy fácil tomar una
muestra aleatoria.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
Mediante el uso de las tablas del anexo “B”, realiza e siguiente ejercicio.
En una empresa de 120 empleados se desea obtener una muestra aleatoria de 10
empleados para darles un curso de actualización. ¿Qué empleados formarían la
muestra? Utiliza tu cuaderno para dar la respuesta.
Distribución de Media Muestrales
Ya sabemos cómo determinar e número de muestras de una población y cómo
seleccionar una muestra aleatoria, ahora estudiaremos cómo se organiza una
distribución de medias muestrales.
La distribución de medias muestrales son las probabilidades de todas las medias
posibles de las muestras de una población finita.
Toda distribución de probabilidad puede describirse mediante su media y su desviación
estándar.
Al tomar las muestras aleatorias se cometen ciertos errores que se reflejan en que la
media y la distribución de cada muestra no son iguales, y por lo tanto la media y la
desviación estándar de la población tampoco coinciden con los de la muestra. Por esta
razón, la desviación estándar de la distribución de un estadístico muestral recibe el
nombre de error estándar estadístico.
El error estándar no solamente indica el tamaño del error accidental, sino también la
exactitud que alcanzaremos si usamos un estadístico muestral para estimar un
parámetro de la población.
49
Veamos el siguiente ejemplo:
De una población cuyos elementos son ( 1, 3, 5, 7, 9 ), formar el número de muestras
aleatorias de 2 elementos, construir la distribución de medias muestrales, determinar la
media de la distribución de medias ( µ ); determinar la desviación estándar de la
distribución de medias y comparar estos resultados con los parámetros de la población.
Solución:
n=2
N=5
Media de la población:
1 3 5 7 9 25
5
5
5
5
2 Varianza de la población:
2
1
[(1–5)+(3–5)+(5–5)+(7–5)+(9–5)]
5
2 8
= 8 = 2.83
= 2.83
5
5!
Número de muestras: C
= 10
2
2
!
(
5
2)
Conjunto de muestras
{(1, 3), (1, 5), (1, 7), (1, 9), (3, 5), (3, 7), (3, 9), (5, 7), (5, 9), (7, 9)}
Conjunto de medias maestrales: {2, 3, 4, 5, 4, 5, 6, 6, 7, 8}
Probabilidad de las medias maestrales:
x
Probabilidad
2
1
10
3
1
10
4
2
10
5
2
10
6
2
10
7
1
10
8
1
10
50
Media de la distribución de medias maestrales:
x = 2 (
1
1
2
2
2
1
1
) + 3( ) + 4 ( ) + 5 ( ) + 6 ( ) + 7 ( ) + 8 ( )
10
10
10
10
10
10
10
x = 5
Varianza de la distribución de medias muestrales:
2 = (2–5) (
2 = 3
1
1
1
1
1
1
1
) + (3–5) ( ) + (4–5) ( ) + (5–5) ( ) + (6–5) ( ) + (7–5) ( ) + (8–5) ( )
10
10
10
10
10
10
10
σ =
3 = 1.73
De estos resultados concluimos que:
1. La media de la distribución de medias x es igual a la media poblacional ( ).
2. La desviación estándar de la distribución de medias x es menor que la desviación
estándar poblacional ( ).
De este ejemplo podemos ver el error estándar de la media en que
habíamos mencionado.
x
< σ, el cual ya
Ilustramos el proceso de la distribución de media muestrales mediante las siguientes
gráficas.
Dada una población de N elementos, ésta tiene una media µ y una desviación estándar
σ cuya relación entre ellos se muestra en la gráfica siguiente:
Figura. 31
51
Figura. 32
De esta población se pueden formar un gran número de muestras pero solamente
mostramos 4 de ellas para ilustrar el procedimiento.
Figura. 33
Con estas gráficas podemos darnos mejor idea de la secuencia de operaciones que
realizamos para obtener la distribución de medias muestrales representada por la gráfica
C. Esta gráfica es simétrica y tiene la forma de la curva normal o campana de Gauss.
De esta misma gráfica podemos constatar que la media poblacional es igual a la media
de la distribución de medias, lo cual no ocurre con la desviación estándar en la que hay
un error.
La desviación estándar de la distribución muestral de medias para poblaciones finitas de
tamaño N, se puede calcular por la ecuación
x
Nn
N1
n
. . . (15)
Esta ecuación se llama error estándar de las medias.
52
Nn
le llamamos factor de corrección por población finita, toda vez que para
N1
. . . (16)
poblaciones infinitas se aplica la ecuación x
n
A la raíz
Si la muestra es al menos el 5% de la población entonces el factor de corrección no
afecta porque tiende a la unidad.
Veamos el ejemplo que usamos para la distribución de medias en que:
N=5
n=2
= 8
x = 3
Con estos valores sustituimos en la fórmula y obtenemos:
x =
x =
8
2
∙
52
=
5 1
8
2
3(8)
3
=
4
2( 4)
3
De este resultado concluimos que por ser la muestra al menos el 5% de la
población, el factor de corrección no afecta a la distribución estándar de medias.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
1. De una población finita N = { 3, 4, 5, 6, 7, 8 y 9}, se toman muestras aleatorias de 2
elementos.
a) Calcula la media µ y la desviación estándar de la población, σ.
b) Calcula el número de muestras aleatorias que se pueden formar, establece el
conjunto de muestras u determina la probabilidad de cada una.
c) Construye la distribución de medias muestrales de la población.
d) Calcula la media, la varianza de la distribución de medias; valor de la desviación
estándar de las medias, aplicando la ecuación del error estándar.
e) Realiza las gráficas de la secuencia de operaciones.
2. Determina el factor de corrección para una población N = 10, 000 con muestras de
n = 100 e indica si afecta o no a la desviación estándar de la distribución de medias
muestrales x .
53
1.2.2 EL TEOREMA CENTRAL DEL LÍMITE
En los ejemplos anteriores quedó establecido que las muestras aleatorias tomadas de
una población tienen diferentes medias y comparadas con la media muestral, hay
un determinado error.
Con respecto a este error, el teorema de Chebyshev dice:
1
que la media de
k2
una muestra aleatoria de tamaño (n) difiere de la media de la población en un valor
igual a x k.
Podemos afirmar con una probabilidad de cuando menos 1 –
Este teorema de Chebyschev afirma que para estimar la media poblacional, cuando
utilizamos la media de una muestra aleatoria podemos afirmar con una probabilidad de
1
cuando menos 1– 2 que nuestro error será menor que: x (k).
k
EJEMPLO:
Dada una población de N elementos ¿Cuál es el error para K = 2, si tomamos una
muestra n = 64 con una desviación estándar = 20?
Solución:
20
Calculamos x =
= 2.5
64
Se afirma con una probabilidad de 1–
1
= 1
1
= 0.75 que la media de la muestra
k
22
difiere de la media de la población, y que el error que se comete es menor que:
x k = 2.5 ( 2 ) = ( 5 )
2
Con este teorema podemos conocer el error que cometemos sin tener que hacer el
desarrollo de la distribución de medias muestrales.
Existe otro teorema aún más preciso que el de Chebyshev, éste teorema se llama:
Teorema del límite central y dice:
Si el tamaño de la muestra ( n ) es grande, entonces se aplica la distribución
muestral teórica de las medias.
54
Este teorema es fundamental en la estadística, ya que justifica el uso de los métodos de
la curva normal en la solución de una amplia gama de problemas. Se aplica a
poblaciones infinitas y a poblaciones donde n es una parte de la población. Es difícil
especificar con exactitud cuan grande debe ser (n) para poder aplicar el teorema central
del límite. Sin embargo para n=20 ya se puede obtener un polígono de frecuencias
simétricas y en forma de campana; para n=30, ya podemos considerar a (n)
suficientemente grande.
Si la población que muestreamos tiene un polígono de frecuencias simétrico y en forma
de campanas, entonces podemos aplicar el teorema del límite central sin importar el
tamaño de (n).
EJEMPLO:
Apliquemos el teorema del límite central en el mismo problema donde aplicamos el
teorema de Chebyshev, o sea
N=64
=20
Chebyshev dice: ¿cuál es la probabilidad de que el error que se comete al tomar la
media de la muestra como parámetro de la población sea menor que 5? Y con su
teorema se obtiene cuando menos de 0.75. Este resultado nos indica que puede ser más
pero no se precisa.
Veamos el cálculo con el teorema central del límite.
El área bajo la curva es para:
Z1
5
2
20 / 64
y
Z2
5
2
20 / 64
Con los valores de Z nos vamos a las tablas del apéndice A, que se encuentran al final
del fascículo, obtenemos
P(Z) = P(Z1) = 0.472
P(Z) = P(Z1) + P(Z2) = 2(0.4772) = 0.9544
Con este ejemplo podemos ver como el teorema central del límite es más preciso que el
de Chebyshev, toda vez que Chebyshev da un rango de aproximación y el del límite
central nos fija el valor de la probabilidad.
La gráfica de la curva normal de este problema se muestra en la siguiente figura cuya
área está sombreada.
55
Figura 34.
El tamaño (n) cobra importancia cuando el polígono de frecuencias no es simétrico, en
estos casos en la medida en que (n) aumenta, el error estándar disminuye.
Veamos el siguiente ejemplo:
Si tomamos a x como estimación de , ¿cómo es el error estándar de la media si n = 50
se incrementa a n = 200.
Solución:
200 50 50 1 1
200
200 4 2
50
Con este ejemplo podemos ver que al aumentar el valor de (n), el error de la media
disminuye; en nuestro ejemplo disminuyó la mitad.
Si la naturaleza del problema que se está resolviendo tiene distribución normal, entonces
el teorema del límite central cobra mayor importancia en el cálculo del error estándar de
la media. Veamos el siguiente ejemplo:
Dada una población normal de =100 y =25, formamos muestras de 5 elementos y
determinamos la media de cada muestra X. Sin duda la media de cada muestra es
mayor que la media poblacional y la desviación estándar de la distribución muestral es
menor que la de la población, porque la dispersión de la muestra es menor que la de la
población. Gráficamente lo podemos ver de la siguiente forma:
56
Figura 35.
La gráfica A es la distribución muestral de la población =100 y =25.
La gráfica B es la distribución de las medias maestrales con n=5 y x 25.
Ahora formemos muestras con n=20 y la gráfica de esta nueva distribución de medias
maestrales es la C.
=0
Figura 36.
De la gráfica C concluimos que al aumentar el valor de (n) estamos intensificando el
efecto de promediar la muestra y por ello la dispersión disminuye aún más, es decir en
la gráfica C x 25.
57
De lo anterior concluimos que:
si (n) crece, el error estándar que se comete al tomar a la media muestral como
estimador de la población () es cada vez más pequeño.
Ya dijimos que para n30 podemos considerar que (n) es grande y aunque el teorema
central del límite se puede aplicar a una muestra cuya n30, el error estándar es mayor.
En estos casos se recomienda aplicar otra distribución que nos permite cálculos más
precisos en muestras pequeñas y que veremos a continuación.
ACTIVIDAD DE REGULACÓN
Realiza lo que se te pide. Utiliza tu cuaderno para dar las respuestas:
1. La media de una muestra aleatoria de tamaño n = 400 se utiliza para estimar la
media de una población infinita que tiene desviación estándar = 5. ¿Qué podemos
decir acerca de la probabilidad de que el error será menor que 0.4 mediante el uso
de:
a) El teorema de Chebyshev
b) El teorema central del límite
2. En los equipos de detección de la contaminación por humo, se usan pequeñas
baterías cuya duración tiene una desviación = 77 horas. Se utiliza la media de una
muestra de tamaño n = 49 para estimar la media poblacional. Mediante la aplicación
del límite central, ¿qué podemos decir acerca de la probabilidad de que la estimación
tenga un error?
a) ¿Menor de 10 horas?
b) ¿Menor de 20 horas?
58
1.2.3 DISTRIBUCIÓN T–STUDENT
En la inferencia estadística se hacen generalizaciones con base en muestras, mediante
estimaciones y pruebas de hipótesis.
La estimación consiste en asignar un valor numérico a un parámetro de una población
sobre la base de datos de muestras; y la prueba de hipótesis está basada en la
aceptación o rechazo de suposiciones concernientes a los parámetros de una población.
En el subtema 1.2.2 se hicieron estimaciones de medias poblacionales a través de
medias muestrales cuando el tamaño de la muestra es grande (Teorema del límite
central).
Sin embargo, cuando la muestra involucrada es pequeña es muy probable que la
desviación típica muestral S sea bastante distinta de la desviación típica de la población
; en consecuencia en estos casos no se puede utilizar el teorema central del límite para
estimar la media de una población a través de la media de una muestra. En estos casos
se utiliza otra distribución llamada t de Student.
La teoría de las muestras pequeñas sacadas de una población normal de desviación
típica Í desconocida, fue descubierta por el inglés William Gosset en 1908 con el
seudónimo de Student.
La distribución t de Student se representa mediante la expresión:
t
Donde:
X-
s/ n
, ……..(12)
X = media de la muestra
= media de la población
s = desviación típica de la muestra
n = tamaño de la muestra
La distribución t de Student se basa en la consideración de que la población a partir de la
cual se obtiene la muestra tiene una distribución normal, o al menos aproximadamente
normal.
Con la distribución Student es posible estimar parámetros de una población a partir de
los estadísticos calculados para una muestra cuando ésta es pequeña.
Dicha estimación puede ser puntual o por intervalos.
La estimación es puntual cuando se estiman parámetros empleando valores de una
muestra única; y por intervalos cuando se establece un rango de valores dentro de los
cuales se espera que el parámetro caiga.
59
Como ejemplo para ilustrar un problema en la estimación de medias, considérese un
estudio en el cual un médico desea determinar el incremento promedio real del pulso
cardiaco de una persona que realiza cierta tarea ardua. Los siguientes datos representan
los incrementos de pulso cardiaco en pulsaciones por minuto que el médico obtuvo en
relación con 32 personas:
27, 25, 19, 28, 35, 23, 24, 22,
14, 30, 32, 34, 23, 26, 29, 27,
27, 24, 31, 22, 23, 38, 25, 16,
32, 29, 26, 25, 28, 26, 21, 28.
Calculando la media de la muestra se obtiene que X =26.2 pulsaciones por minuto y en
ausencia de otra información este número sirve como estimador de la media de la
población .
Una estimación de este tipo es una estimación puntual ya que consta de un solo número.
Pero esta manera de estimar un parámetro no es la más confiable ya que no nos dice en
cuanta información se basa la estimación y tampoco nos dice nada acerca del posible
tamaño del error. Una estimación por intervalos es mucho más útil que una estimación
puntual, debido a que posee más información; no solo da el valor estimado, sino también
la precisión y el nivel de confianza.
Propiedades de la distribución T - Student
Comparando la variable normal estandarizada Z
t
X-
/ n
y la variable “t de student”,
X-
se observa que son similares y que el único cambio está en el denominador
s/ n
donde se sustituye S en lugar de .
Como la distribución normal estándar Z, la distribución t también es continua, en forma
de campana y perfectamente simétrica. La única diferencia entre las dos distribuciones,
es que la distribución t tiene mayor variabilidad; la curva t está más extendida en la parte
de las clases y es más achatada en la zona del centro.
60
En la siguiente figura se comparan los dos tipos de curvas.
CURVA Z
Figura 37.
La siguiente figura muestra el comportamiento de la distribución t comparada con la
distribución Z.
g.l = grados de libertad.
Figura 38.
De la figura se puede observar que conforme aumenta el tamaño de la muestra, la curva
t se aproxima a la curva normal; cuando el tamaño de la muestra n tiende a infinito, la
curva t es idéntica a la curva normal. También de la figura se puede afirmar que no hay
una sola distribución para la distribución t de Student, sino una familia de distribuciones;
esto es debido al efecto del tamaño de la muestra. Si n es pequeña, la t de Student
correspondiente es muy ancha, pero si n<30, la distribución t y la normal Z son casi
61
indistinguibles. De todo lo anterior se pueden establecer propiedades de la distribución
de t de Student.
Características de la distribución t de Student
1. Es simétrica con respecto a la media
2. Tiene media =0 y 1
3. La desviación típica 1, cuando el tamaño de la muestra tiende a infinito.
4. La distribución Z tiene solamente una distribución con media =0 y desviación
típica =1; mientras que la distribución t tiene una familia de distribuciones.
5. La distribución t no se tabula según el tamaño de la muestra, sino en términos del
número de grados de libertad.
6. La distribución t es continua, en forma de campana.
7. La distribución t se basa en la consideración de que la población a partir de la
cual se obtiene la muestra tiene una distribución normal o aproximadamente
normal.
8. La variabilidad de la distribución t, depende de dos variables aleatorias (S y X ).
9. La distribución t se Student se utiliza para estimar parámetros poblacionales a
través de los valores de las muestras, para muestras pequeñas (n30) y cuando
la desviación típica S es conocida.
10. El número de grados de libertad es el único parámetro de la distribución t. Esto
es, la forma de la curva t está totalmente definida cuando se conoce el número
de grados de libertad (g.l=n-1).
El término “grados de libertad” abreviado (g.l.), se refiere al número de datos que pueden
variar libremente, después de haber impuesto ciertas restricciones a nuestros datos.
El número de grados de libertad es el tamaño de la muestra menos uno; es decir
g.l.=n-1.
Cuando se quiere calcular la media de una población a través de la media muestral,
debido a la variabilidad de la media muestral X; ésta no será exactamente igual a la
media poblacional , por lo tanto siempre habrá un margen de error llamado error
muestral; es decir:
= X error muestral
El máximo error que se comete cuando se utiliza X como estimación de , cuando n30
está dado por:
EZ
2
62
n
Donde:
Z
denota el valor de Z para el cual el área situada debajo de la curva normal
2
estándar a su derecha es igual a /2.
La selección del valor de es arbitraria, depende de qué tanto error se esté dispuesto a
tolerar.
El error que se está dispuesto a tolerar se llama nivel de confianza.
EJEMPLO:
Z0.05, significa que estamos dispuestos a tolerar un 5% de error.
Hallando este nivel de confianza en una gráfica, se tiene:
Z
Figura 39.
En las tablas del área bajo la curva normal se obtiene Z 2=1.96; y como la curva es
simétrica, Z1=-1.96.
Lo anterior significa que el 95% de las diferencias maestrales cae entre -1.96 y 1.96
desviaciones estándares.
En base al ejemplo anterior, obtener Z0.01 y representarlo en una gráfica.
EJEMPLO:
Un experto en mecánica utiliza la media de una muestra aleatoria de tamaño n=30 para
estimar el tiempo promedio que le toma a un mecánico realizar cierta tarea. Si con base
en la experiencia, el experto puede suponer f=2.5 minutos para estos datos, ¿qué se
puede decir con un nivel de confianza del 1% acerca del tamaño máximo de su error?
63
SOLUCIÓN:
n = 30
= 2.5
= 1% = 0.01
=»
/2 = 0.005
Utilizando las tablas del área bajo la curva normal se tiene:
Z0.005 = 2.57
Sustituyendo estos datos en la fórmula E = Z/2
E = (2.57)
x
se tiene:
(2.5) 6.425
1.17
30 5.477
El resultado obtenido significa que el experto en mecánica puede afirmar con una
certeza del 99% que su error será cuando mucho de 1.17 minutos.
ACTIVIDAD DE REGULACÓN
Realiza lo que se te pide:
Con referencia al problema de los pulsos cardiacos de las 32 personas, ¿qué se puede
decir con un nivel de confianza del 5% acerca del error máximo si se utiliza X = 26.5
como estimación del incremento promedio real del pulso de una persona que realiza la
tarea dada? Utiliza tu cuaderno para dar tu respuesta:
Formato de una muestra para estimar la media cuando n30
Z
, también se puede utilizar para determinar el tamaño de la
2
n
muestra que se necesita para lograr un grado de exactitud deseada. Despejando n de la
expresión anterior se tiene:
La fórmula E =
2
Z /2
n=
……….(16)
E
La fórmula anterior se utiliza para determinar el tamaño de la muestra.
64
EJEMPLO:
El profesor de Estadística de la Universidad desea emplear la media de una muestra
tomada para estimar la cantidad promedio de tiempo que los estudiantes requieren para
pasar de una clase a la siguiente. Además desea que esta estimación tenga un error de
cuando mucho 0.30 minutos con probabilidad 0.95. Si se sabe de estudios similares
anteriores que es razonable tomar = 1.50 minutos, ¿de qué tamaño tendrá que tomar
una muestra?
SOLUCIÓN:
La probabilidad 0.95 de que al hacer la estimación se tenga un error de cuando mucho
0.30 significa que se está tomando un nivel de confianza del 5%, por lo tanto = 5% =»
/2 = 2.5% = 0.025.
De tablas se tiene Z0.025 = 1.96; además = 1.50, E = 0.30
Sustituyendo los datos de la fórmula:
Z /2
n
E
2
se tiene
2
(1.96) (1.50)
n
= 96.04
0.30
Se requiere una muestra aleatoria de tamaño n = 96 para la estimación.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
1. En un estudio de los hábitos de ver televisión, se busca estimar el número de horas
en promedio que los alumnos de bachillerato ven televisión por semana. Si es
razonable suponer = 3 horas, ¿de qué tamaño deberá ser la muestra de manera
que se pueda afirmar con la probabilidad de 0.99 que la media de la muestra fallará
cuando mucho en 35 minutos? Utiliza tu cuaderno para dar tu respuesta.
Intervalos de confianza
Anteriormente ya se dijo que para estimar parámetros, lo más adecuado es formar un
intervalo de confianza, el cual generalmente incluirá al parámetro por estimar.
65
Como ya vimos al estimar en base a la media de la muestra X , la estimación no será
perfecta; es decir, siempre habrá un margen de error, tal que:
= X error muestral;
Pero ya vimos que el máximo error muestral que se puede cometer es E =
lo tanto podemos escribir:
X
Z
2
Donde:
X
Z
2
n
n
Z
2
n
, por
……….(17)
= media muestral
= Es el valor de Z para el cual el área bajo la curva normal a la derecha de Z
es /2
= Nivel de confianza
= Desviación típica de la media
Puesto que los niveles de confianza más utilizados son 0.05 y 0.01, entonces podemos
establecer los siguientes intervalos de confianza:
= X 1.96
= X 2.58
n
n
; intervalo de confianza de 95%
; intervalo de confianza de 99%
Recuerda que para = 0.01 =» /2 = 0.025 y que Z0.025 = 1.96.
EJEMPLO:
Obtener el intervalo de confianza del 95% del conjunto de datos:
X
1
5
2
3
4
1
2
2
4
3
27
2
X
1
25
4
9
16
1
4
4
16
9
89
(1, 5, 2, 3, 4, 1, 2, 2, 4, 3)
1er. Paso: Se determina la media
X = 27
N = 10
X
66
X
N
X
27
2.7
10
2do. Paso: Se obtiene la desviación estándar de la muestra
S=
X
-X
N
S=
1.61 0 1.27
S=
89
- (2.7) 8.9 - 7.29
10
S 1.27
3er. Paso: se obtiene el error estándar de la media.
S
X
N-1
nótese que el denominador en la fórmula se escribió N–1 en vez
de N; la razón es que N-1 corrige el sesgo del error estándar.
1.27
1.27
o.42
X
3
10 - 1
0.42
X
4o. paso: Se multiplica el error estándar de la media por 1.96 que es el valor de Z al nivel
de confianza de 0.05.
= X 1.96
X
= 2.7 1.96 (0.42)
= 2.7 0.82
1.88 3.52
Lo anterior significa que se puede asegurar con un 95% de confianza que la verdadera
muestra poblacional está entre 1.88 y 3.52.
EJEMPLO:
Un fabricante de productos especiales de acero necesita la dureza media de un lote
grande de piezas de acero que acaba de recibir. Es muy importante la determinación de
la dureza ya que si ésta sale de cierto rango, es necesario aplicar un tratamiento costoso
para llevarla al grado de dureza deseado. Imagina que tú trabajas en el departamento
de pruebas de cierta compañía y le han enviado el resultado de una prueba de dureza
efectuada en una muestra aleatoria de 40 piezas, siendo la medida de la muestra X = 70
y la desviación estándar S = 2. ¿Qué harías?
SOLUCIÓN:
Se tiene que estimar la dureza media en base a una muestra con n = 40, X = 70
y S = 2 y un nivel de confianza del 99%, ya que la situación es bastante delicada.
67
= X 2.58
n
2
= 70 (2.58)
40
= 70 (2.58) (0.82)
o sea:
69.18 70.82
El gerente, al recibir el informe, observa que este resultado cae muy cerca del extremo
del rango aceptable (de 68.3 ________), pide que se aumente la precisión del intervalo de
confianza del 0.82 a 0.50, preservando el nivel de confianza en 99%.
¿Qué harías tú?
SOLUCIÓN:
Hay que determinar el tamaño de la muestra necesaria para alcanzar la precisión de
E = 0.50.
Z /2
n
E
2
podemos tomar = 5
2
2
(2.58) (2) 5.16
n
(10.32)2 106.50
0.50 0.50
Entonces nos bastaría una muestra de 107 piezas. Como ya teníamos 40 piezas, se
manda completar la muestra probando la dureza de 67 piezas adicionales. Se calculan
las nuevas X y S en base a la muestra total y se obtiene el nuevo intervalo de confianza
a 99% con precisión de 0.50.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide. Utiliza tu cuaderno para dar tu respuesta:
La actividad de ciertas vacunas puede mediarse únicamente a través de pruebas en
organismos vivos (conejos por ejemplo). Este procedimiento es costos y tardado, pero
esencial para asegurar el funcionamiento correcto de estas vacunas.
a)
Si la muestra de 30 pruebas dio un índice medio de actividad de X = 880 unidades
con S = 110, forma un intervalo de confianza de 95% para la actividad media de la
vacuna.
68
b)
Calcula el tamaño de muestra total necesaria para tener un error de estimación
E 25 unidades con 99% de confianza.
c)
Para 0.01 obtener:
d)
Del conjunto de datos del problema anterior, encuentra el intervalo de confianza del
99%.
= _____ y Z1 = _____ .
2
2
Confiabilidad de Promedios en Muestras Pequeñas
Anteriormente ya se comparó la distribución Z con la distribución t de Student.
Si en la distribución Z =
X-
/ n
t=
, se reemplaza t por Z y por S se tiene la distribución:
X-
/ n
distribución de Student.
Esta distribución se utiliza para estimar parámetros para muestras pequeñas.
Los intervalos de confianza se forman de la misma manera que en la distribución Z.
La forma de la curva de la distribución t de Student está basada en el número de grados
de libertad (g. l. = n-1), en lugar del tamaño n de la muestra. A medida que aumenta el
número de grados de libertad, la curva de la distribución t es menos variable.
Una muestra la vamos a considerar pequeña cuando sea n30.
La tabla de valores t es diferente de la de valores Z. en la tabla de valores de la
distribución t de Student cada fila corresponde a una distribución t distinta. La última
columna da el número de grados de libertad.
EJEMPLO:
Para 10 g. l., el 10% del área de la curva está a la derecha del valor t = 1.383, y como la
curva es simétrica, el 10% del área de la curva está a la izquierda del valor t = -1.383.
Figura 40. Distribución t para 10 g. l. y /2 = 0.10.
69
De la figura se tiene que el 80% de los casos están comprendidos entre -1.383 y 1. 383.
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide:
Para 10 g. l. y un nivel de confianza de 5%, determinar el intervalo de confianza y dibujar
su gráfica.
, de la misma forma como se definió Z ,
2
2
de manera que el área situada debajo de la curva que está a la derecha de t
es igual
2
a -t . Sin embargo t
depende del número de grados de libertad.
2
2
Para la distribución t de Student se define t
Utilizando el hecho de que la distribución t es simétrica con respecto a t = 0 (media de la
distribución t), entonces la probabilidad de que la variable aleatoria que tiene una
distribución t tome un valor entre -t/2 y t/2; es decir, -t/2 t t/2 es 1-.
t
Figura. 41
Distribución t
Igual que en la distribución Z, el intervalo de confianza en muestras pequeñas se puede
escribir:
70
X t /2
S
n
Fórmula para determinar intervalos de confianza para muestras pequeñas.
EJEMPLO:
La curva de la distribución t con 10 g. l. se muestra en la siguiente figura. Hallar el valor
de t para que:
Figura 42.
a)
b)
c)
d)
El área rayada de la derecha sea 0.05
El área total rayada sea 0.10
El área no rayada sea 0.99
El área rayada de la izquierda sea 0.01
SOLUCIÓN
a) /2 = 0.05
En las tablas de la distribución t se busca el nivel de confianza 0.05 con 10 g. l.
(n = 10 + 1 = 11), es decir, el tamaño de la muestra n = 11.
t0.05 = 1.812
ACTIVIDAD DE REGULACIÓN
De acuerdo al ejemplo anterior, realiza lo que se te pide:
Resuelve los incisos b, c y d del problema anterior. Utiliza tu cuaderno para dar tu
respuesta.
71
EJEMPLO:
Los contenidos de ácido sulfúrico en siete recipientes similares son: 9.8, 10.2, 10.4, 9.8,
10.0, 10.2 y 9.6 litros. Encuentra un intervalo de confianza al 95% para la media de todos
los recipientes, suponiendo una distribución aproximadamente normal.
SOLUCIÓN:
La media y la desviación estándar de la muestra para los datos proporcionados son:
X = 10.0 y S = 0.283 (Checar estos resultados)
Empleando la tabla de la distribución t, se encuentra que t 0.025 = 2.447, para 6 g. l.
Recuerda que = 0.05 y /2 = 0.025
el intervalo de confianza al 95% para es:
0.283
= 10.0 (2.447)
7
= 10.0
0.6925
2.64575
= 10.0 0.26174
9.738 10.26174
redondeando
9.74 10.26
ACTIVIDAD DE REGULACIÓN
Realiza lo que se te pide. Utiliza tu cuaderno para dar tu respuesta:
1. Una muestra aleatoria de 25 automóviles del mismo modelo se conducen de la
misma forma y usando la misma calidad de gasolina. Los automóviles recorren un
promedio de 9 Km. por litro de gasolina, con una desviación tipo de 1.2 Km. Estimar
el recorrido medio por litro y dar su intervalo de confianza a un nivel de confianza del
95%.
72
2. En un estudio de la contaminación del aire, una estación de experimentos obtuvo una
medida de 2.36 miligramos de materia orgánica suspendida soluble de benceno por
metro cúbico con una desviación estándar de 0.48 de una muestra tomada al azar de
tamaño n = 10.
a) Construye un intervalo de confianza del 99% de la media de la población
muestreada.
b) ¿Qué se puede afirmar con el 95% de confianza acerca del error máximo, si
X = 2.36 miligramos se utiliza como estimación de la media de la población
muestreada?
Pruebas de hipótesis
Al hacer inferencias de características de poblaciones a través de muestras se utilizan
los métodos de Estimación y Pruebas de Hipótesis.
Cuando se analizan características de poblaciones por el método de pruebas de
hipótesis, es necesario tener en cuenta los siguientes conceptos:
NIVEL DE CONFIANZA. Es el nivel de error que se esté dispuesto a tolerar.
ESTADÍSTICO DE PRUEBA. Es una variable aleatoria cuyo valor se utiliza para llegar a
la decisión de rechazar o no la hipótesis nula.
REGIÓN CRÍTICA. Es el conjunto de valores para el estadístico de prueba que llevará a
rechazar la hipótesis nula.
REGIÓN DE ACEPTACIÓN. Es el conjunto de valores para el estadísticos de prueba
que provocará la aceptación de la hipótesis nula.
VALOR CRÍTICO. Es el valor que separa a la región de rechazo y la región de
aceptación.
HIPÓTESIS ESTADÍSTICA. Es una afirmación o conjetura acerca del parámetro o
parámetros de una población.
73
La siguiente gráfica muestra el valor crítico, la región de rechazo y la región de
aceptación.
REGIÓN DE
RECHAZO
VALOR
CRÍTICO
REGIÓN DE
ACEPTACIÓN
VALOR
CRÍTICO
REGIÓN DE
RECHAZO
Figura 43.
Se ha aprendido a estimar la media de una población , dando un intervalo de confianza
o acompañando la estimación de punto X con una evaluación del error posible. Ahora
aprenderás cómo demostrar una hipótesis referente a la media de una población ; es
decir, se presentarán métodos para decidir si se acepta o se rechaza una afirmación
acerca de un valor específico de .
Estos conceptos serán abordados en la siguiente unidad, prepárate para acceder a ellos.
74
EXPLICACIÓN INTEGRADORA
Hasta aquí podemos mencionar lo siguiente:
Existen diferentes tipos de muestras en Estadística:
a) Las muestras no probabilísticas no nos permiten hacer generalizaciones.
b) Las muestras probabilísticas con la base de la inferencia estadística y a este tipo
corresponde el muestreo aleatorio.
Se llama muestreo aleatorio de una población finita de n elementos, si cada muestra
tiene la misma probabilidad de ser seleccionada y cada elemento de la población tiene la
misma probabilidad de ser incluido en la muestra.
El teorema de Chebyshev nos dice:
Podemos afirmar con una probabilidad de cuando menos 1
1
que la media de una
k2
muestra aleatoria de tamaño (n) difiere de la media de la población en un valor igual a
Xk .
La distribución T–Student se representa mediante la expresión:
t
x
s
75
n
RECAPITULACIÓN
Con la finalidad de mostrarte los temas importantes de este fascículo, a continuación te
presentamos el siguiente esquema.
76
ACTIVIDADES DE CONSOLIDACIÓN
Para reafirmar los conceptos aprendidos de este fascículo, resuelve el siguiente
ejercicio. Si tienes alguna duda, consulta a tu asesor.
PROBLEMA:
I.
La Cía. General Motor Company tiene la intención de promover a sus trabajadores
a un tabulador salarial mejor que el actual y para ello aplica un examen de
conocimientos culturales, habiendo obtenido las siguientes puntuaciones:
27, 28, 28, 28, 29, 30, 30, 30, 30, 31, 31, 31, 32, 32, 32,
33, 33, 33, 33, 34, 34, 34, 34, 35, 35, 35, 35, 35, 35, 35,
36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 38, 38,
38, 38, 38, 39, 39, 39, 39, 40, 40, 40, 40, 40, 40, 40, 40,
41, 41, 41, 41, 41, 41, 41, 41, 42, 42, 42, 42, 42, 42, 43,
43, 43, 43, 44, 44, 44, 44, 44, 44, 44, 45, 45, 45, 45, 45,
46, 46, 46, 47, 47, 47, 47, 47, 47, 47, 48, 48, 48, 48, 49,
49, 49, 49, 50, 50, 51, 51, 51, 52, 52, 53, 53, 53, 54, 54,
55, 56, 56, 57, 57, 58, 59, 61, 62, 62.
Determina:
1)
2)
3)
4)
5)
6)
7)
8)
La media
La moda
La mediana
La varianza
La desviación estándar
Traza el polígono de frecuencias
Normaliza los datos y traza la curva de mejor ajuste sobre la gráfica anterior
para contrastar el cambio
Determina el tanto por ciento de casos que se espera hallar entre la media y
las puntuaciones 28, 38 y 60
77
9)
Calcula el tanto por ciento y el número de casos esperados entre los
siguientes pares de puntuaciones:
a)
b)
c)
10)
35 y 45
50 y 55
56 y 60
¿Cuántos casos se espera hallar por encima de una puntuación igual a 50?
¿Cuántos por debajo de 35?
PROBLEMA:
II.
Los datos dados a continuación corresponden a incrementos de pulso cardiaco en
pulsaciones por minuto que un médico determina en relación con diez personas
que realizan una tarea ardua:
27, 14, 27, 32, 25, 30, 24, 29, 19, 32
a)
estimar el incremento promedio real del pulso cardiaco de una persona que
realiza una tarea ardua, mediante el estimador puntual X.
b)
Estimar el alejamiento de las pulsaciones por minuto con respecto al
promedio, utilizando un estimador puntual.
c)
Determinar el número de grados de libertad para la muestra dada.
d)
Determinar el error máximo que se comete al estimar el incremento
promedio del pulso cardiaco de una persona mediante el estimador puntual
X, con un nivel de confianza del 95%.
e)
Obtener el tamaño que deberá tener la muestra, de tal manera que al
emplear la media X, de una muestra para estimar el incremento promedio
del pulso cardiaco de una persona, se tenga un error máximo de 25
pulsaciones por minuto con un nivel de confianza de 95%.
f)
Construir un intervalo con un nivel del 99% en relación con el incremento
promedio real del pulso de personas que realizan la tarea dada.
78
AUTOEVALUACIÓN
Los resultados que debiste obtener son los siguientes, si alguno no coincide, entonces
revisa tus cálculos, localiza el error y corrígelo. Si tienes alguna duda, consulta a tu
asesor.
I. SOLUCIÓN DEL PROBLEMA.
1)
2)
3)
4)
5)
X = 47.1
Mo = 48.7
Md = 50.6
2 = 64.2
= 8.04
6)
TABLA DE FRECUENCIAS
CLASE
Xm
Fi
Fa
60-62
57-59
54-56
51-53
48-50
45-47
42-44
39-41
36-38
33-35
30-32
27-29
61
58
55
52
49
46
43
40
37
34
31
28
5
10
15
18
20
17
14
10
8
6
4
3
5
15
30
48
68
85
99
109
117
123
127
130
X
XmFi
Xm- X
305
580
825
936
980
782
602
400
296
204
124
84
6118
13.9
10.9
7.9
4.9
1.9
-1.1
-4.1
-7.1
-10.1
-13.1
-16.1
-19.1
Xmfi 6118
47.1
n
130
2
fi (Xm - X) 8332.2 833.2
= 64.6
n -1
130 - 1
129
64.590698 8.04
79
(Xm- X )2
193.21
118.81
62.1
24.01
3.61
1.21
16.81
50.41
102.01
171.61
259.21
364.81
Fi(Xm- X )2
966.5
1188.1
936.2
432.2
72.2
20.6
235.3
504.1
816.1
1029.7
1036.8
1094.4
8332.2
6
2
Mo = 47.5 + 3
47.5 48.7
5
2 3
130
- 48
2
48 51 50.6
Md = 48 + 3
20
20
POLÍGONO DE FRECUENCIAS
7)
TABLA DE NORMALIZACIÓN PARA EL AJUSTE DE CURVAS
CLASE
60-62
57-59
64-56
51-53
48-50
45-47
42-44
39-41
36-38
33-35
30-32
27-29
X = 47.1
fi
Ls.
5
10
15
18
20
17
14
10
8
6
4
3
,
X=Xi X
62.5
59.5
56.5
53.5
50.5
47.5
44.5
41.5
38.5
35.5
32.5
29.5
= 8.04
15.4
12.4
9.4
6.4
3.4
0.4
-2.6
-5.6
-8.6
-11.6
-14.6
-17.6
y
X I
DEBAJO
ENCIMA
fe
1.92
1.54
1.12
0.80
0.42
0.05
-0.32
-0.70
-1.07
-1.44
-1.82
-2.19
0.9726
0.9382
0.8686
0.7881
0.6628
0.5199
0.3745
0.2420
0.1423
0.0749
0.0344
0.0143
0.0344
0.0696
0.0805
0.1253
0.1429
0.1454
0.1325
0.0997
0.0674
0.0405
0.0201
0.0143
4.47
9.05
10.47
16.29
18.58
18.90
17.23
12.96
8.76
5.27
2.61
1.86
Z=
N = 130
80
Fe. red.
4.5
9.1
10.5
16.3
18.6
18.9
17.2
13.0
8.8
5.3
2.6
1.9
A) POLÍGONO DE FRECUENCIAS (A)
B) Curva NORMALIZADA
(B)
8)
a) 49%
b) 37%
9)
a) 33%, 43 casos
b) 19.6%, 26 casos
10)
a) 47 casos
b) 9 casos
c)45%
II. SOLUCIÓN DEL PROBLEMA.
a)
Para estimar la media de una población, hay varios estimadores puntuales, los
más conocidos son: media, mediana y moda.
De estos estimadores el más adecuado es la media, ya que es la más confiable
por considerar todos los datos de la muestra, cosa que no ocurre con la mediana y
la moda.
X
27 14 24 32 25 30 24 29 19 32 259
= 25.9
10
10
X = 25.69
Esto significa que el incremento promedio real del pulso cardiaco es 25.9
pulsaciones por minuto.
81
Este error que se comete al estimar a través de X se determina mediante la
fórmula:
E = t /2
n
Donde:
E=
error
t /2 = área bajo la curva a la derecha de /2
=
desviación estándar de la población
n=
N° de datos
NOTA: Recuerda que en ausencia de se puede utilizar s.
= 0.05
/2 = 0.025
De las tablas de la distribución t de Student y tomando g. l. = 9, se tiene:
t(0.025) = 2.262
5.44 12. 305
= 3.89
E = 2.262
10 3.162
E = 3.89
Esto significa que podemos asegurar con un grado de confianza del 95% que el
error que se comete al estimar a través de X es menor de 3.89 pulsaciones por
minuto.
La confiabilidad de X como estimador de la media de la población depende del
tamaño de la muestra y el tamaño de la desviación estándar de la población.
b)
Para estimar el alejamiento promedio de las pulsaciones por minuto con respecto
al incremento promedio real existen varios estimadores. Los más usuales son: la
desviación media, varianza y desviación estándar.
De ellos utilizaremos el estimador s (desviación estándar de la muestra).
Dado que generalmente no se conoce el parámetro, que es la desviación estándar
de la muestra; es estadístico s (desviación estándar de lamuestra), puede servir
como estimador de .
82
X
14
19
24
25
27
29
30
32
f
1
1
1
1
2
1
1
2
2
2
X
196
361
576
625
729
841
900
1024
5252
s=
fix
196
361
576
625
1458
841
900
2048
7005
Para determinar s se utiliza la fórmula
S=
donde
fx 2
2
-X
N
N = N° de datos
f = frecuencia de cada dato
X = media de la muestra
7005
( 25.9) 2 700.5 - 670.81 29.69 = 5.44
10
s = 5.44
Esto significa que en promedio el incremento promedio del pulso cardiaco se aleja
5.44 pulsaciones por minuto de la media.
c)
g. l. = n – 1
d)
Sabemos que al estimar la media poblacional a través de la media muestral X
existe un error, es decir:
g. l. = 10 – 1 = 9
g. l. = 9
= X error muestral
e)
Para determinar el tamaño que deberá tener la muestra con un nivel de confianza
del 95% para tener un error máximo de 2.5 pulsaciones por minuto se utiliza la
fórmula:
E = t /2
n
Despejando n se tiene: n =
t /2
E
Sustituyendo valores y realizando operaciones, se tiene:
n=
(2.262) (5.44)2
2
(4.922112) = 24.22
2.5
83
Redondeando se tiene: n = 24
Esto Significa que el tamaño de la muestra debe ser 24 para cometer un error
menor de 2.5 pulsaciones por minuto al estimar a través de X .
f)
La estimación de parámetros puede ser puntual o por intervalos.
La estimación de la media poblacional por intervalos tiene la ventaja sobre la
estimación puntual de que en la estimación por intervalos es posible conocer el
tamaño del error, así como la precisión y el nivel de confianza, cosa que no se
puede tener con la estimación puntual.
Como ya vimos al estimar en base a la media muestral X, la estimación no es
perfecta, es decir, siempre hay un margen de error.
= X E
pero E = t /2
= X = t /2
n
intervalos de confianza para estimar
n
donde : = nivel de confianza
Para un nivel de confianza del 99% se tiene que:
= 0.0
/2 = 0.005
t (0.005) = 4.032
con 9 grados de libertad
5.44
= 25.9 4.032
10
= 25.9
21.934
3.162
= 25.9 6.936
18.96 32.83
Esto significa que se puede asegurar con un 99% de confianza que la verdadera
muestra poblacional está entre 18.96 y 32.83 pulsaciones por minuto.
84
ACTIVIDADES DE GENERALIZACIÓN
Con la finalidad de que consolides tu aprendizaje. Realiza lo siguiente:
I. Una máquina está diseñada para llenar botellas de crema para el cuerpo con una
media de 750 ml y una desviación estándar de 10 ml. Si se considera que la cantidad
que se utiliza para llenar las botellas se distribuye normalmente y se escoge una
botella al azar, entonces:
a) ¿Cuál es la probabilidad de que tenga menos de 770.8 ml.?
b) ¿Cuál es la probabilidad de que contenga más de 751.6 ml.?
c) ¿Cuál es la probabilidad de que contenga entre 740 ml. y 761 ml.?
85
GLOSARIO
CURVA NORMAL: Curva simétrica con forma de campana.
DESVIACIÓN NORMAL: Es el valor de Z al número de desviaciones típicas.
DISTRIBUCIÓN NORMAL ESTÁNDAR: Se trata de la distribución probabilística de la
variable normal estándar Z.
PUNTUACIÓN Z: Es la diferencia entre el valor observado (x) y su media expresada en
términos de su desviación típica.
VARIABLE ALEATORIA DISCRETA: Es aquella que toma un número finito de posibles
valores, principalmente enteros no negativos.
VARIABLE ALEATORIA CONTINUA: Es aquella que toma un número infinito de
posibles valores y dichos valores pueden diferir unos de otros por
cantidades infinitesimales.
86
ANEXOS
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
X
A
(3)
B
ÁREA DE LA
PARTE MAYOR
87
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
A
X
(3)
B
ÁREA DE LA
PARTE MAYOR
88
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
A
X
(3)
B
ÁREA DE LA
PARTE MAYOR
89
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
X
A
(3)
B
ÁREA DE LA
PARTE MAYOR
90
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
A
X
(3)
B
ÁREA DE LA
PARTE MAYOR
91
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
X
A
(3)
B
ÁREA DE LA
PARTE MAYOR
2.69
92
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
X
A
(3)
B
ÁREA DE LA
PARTE MAYOR
93
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO A
ÁREAS Y ORDENADAS DE LA CURVA
DE DISTRIBUCIÓN NORMAL EN FUNCIÓN DE X/
(1)
Z
PUNTUACIÓN
TIPIFICADA
X
(2)
A
ÁREA DESDE
LA MEDIA
X
A
(3)
B
ÁREA DE LA
PARTE MAYOR
94
(4)
C
ÁREA DE LA
PARTE MENOR
(5)
Y
ORDENADA
EN
X
ANEXO B
Tabla. Valores críticos de t
t2
n
t.100
t.050
t.025
95
t.010
t.005
d.f
ANEXO C
NÚMEROS ALEATORIOS
APÉNDICE C
96
ANEXO C
NÚMEROS ALEATORIOS
97
ANEXO C
NÚMEROS ALEATORIOS
98
ANEXO C
NÚMEROS ALEATORIOS
99
BIBLIOGRAFÍA CONSULTADA
DOWNIE, N. M. y HEAT, R. W. Métodos Estadísticos Aplicados. Ed. Harla.
FREUD, John E. , WILLIAM, Frank J., PERLES. Benjamín M. Estadística para la
Administración. Ed. Prentice Hall Hispanoamericana S. A.
GRAY, William A. y OTIS M, Ulm. Probabilidad y Estadística Elemental. Editorial
C.E.C.S.A.
HOEL, Paul G. Estadística Elemental. Ed. C. E. C. S. A. México, 1976.
KREYSZING, Edwin. Introducción a la Estadística Matemática. Ed. Limusa. México,
1981.
LEVÍN, Richard I. Estadística para Administradores. Ed. Pretince Hall.
LINCONL L., Chao. Introducción a la Estadística. Ed. CECSA. México, 1985.
LINCOYAN Portus, Goviden. Curso Práctico de Estadística. Ed. McGraw-Hill, México,
1985
LIZÁRRAGA G., Ignacio Manuel. Estadística. Ed.; McGraw-Hill. México, 1986.
MENDENHALL, William. Trad. SEGAMI, Carlos. Introducción a la Probabilidad y la
Estadística. Grupo Editorial Iberoamérica. México, 1989.
PARSEN, Emanuel. Teoría Moderna de Probabilidad y sus Aplicaciones. Ed. Limusa.
México, 1973.
SEYMOR, Lipschutz, Ph. D. Teoría y Problemas de Probabilidad. Editorial McGraw-Hill.
100
DIRECTORIO
Dr. Roberto Castañón Romo
Director General
Mtro. Luis Miguel Samperio Sánchez
Secretario Académico
Lic. Filiberto Aguayo Chuc
Coordinador Sectorial Norte
Lic. Rafael Torres Jiménez
Coordinador Sectorial Centro
Biol. Elideé Echeverría Valencia
Coordinadora Sectorial Sur
Dr. Héctor Robledo Galván
Coordinador de Administración Escolar
y del Sistema Abierto
Lic.José Noel Pablo Tenorio
Director de Asuntos Jurídicos
Mtro. Jorge González Isassi
Director de Servicios Académicos
C.P. Juan Antonio Rosas Mejía
Director de Programación
Lic. Miguel Ángel Báez López
Director de Planeación Académica
M.A. Roberto Paz Neri
Director Administrativo
Lic. Manuel Tello Acosta
Director de Recursos Financieros
Lic. Pablo Salcedo Castro
Unidad de Producción Editorial
AGRADECEMOS LA PARTICIPACIÓN DE:
Mario Arturo Badillo Arenas
Esther Barrera Padilla
Leonel Bello Cuevas
Javier Darío Cruz Ortiz
Guadalupe Florián Martínez
José Luis Pérez Coss
Leobardo Sánchez Pimentel






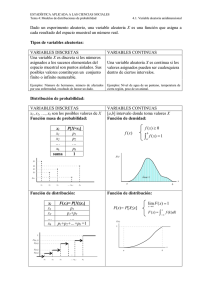
![[ ] [ ] np [ ] npq [ ] [ ] λ [ ] λ [ ] µ [ ] 2](http://s2.studylib.es/store/data/007002888_1-705516d827e27927517f29d628d99e04-300x300.png)
