capítulo 2. análisis matemático de la información
Anuncio

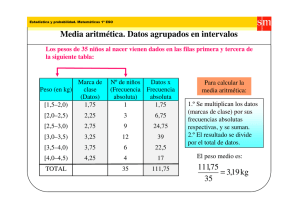
CAPÍTULO 2. ANÁLISIS MATEMÁTICO DE LA INFORMACIÓN Lección 6: Parámetros y Estadísticos Parámetro: Son medidas numéricas descriptivas, asociadas a la población, son valores fijos pero 2 desconocidos. Algunos de ellos: μ = La media. σ = Varianza. σ = Desviación típica o estándar. Los parámetros como valores fijos, no tienen distribución de probabilidad, siendo características propias de la población objeto de estudio. ∑ Promedio poblacional: Donde N = total de la población y μ = Promedio poblacional. ∑ Varianza poblacional: ( ) Estadísticos: Son medidas numéricas descriptivas, asociadas a la muestra, se consideras variables aleatorias. 2 Algunos de ellos: ̅ = La media o promedio. s = La varianza. s = Desviación típica. Los estadísticos como están asociados a la muestra aleatoria, tienen distribución de probabilidad, ya que según la muestra tomada, éste varia. Promedio muestral: ̅ ∑ Donde N = total de la población y μ = Promedio poblacional. Varianza muestral: ∑ ( ̅) Lección 7: Medidas de tendencia central: La media, la mediana y la moda INTRODUCCIÓN En las secciones anteriores se presentaron las técnicas para agrupar los datos (distribuciones o tablas de frecuencia) y se plantearon las técnicas gráficas para descubrir los patrones de distribución ocultos en un conjunto de datos; se mencionó que la estadística cumplía una función descriptiva mediante el uso de cuadros o tablas y gráficos para la clasificación, ordenación y presentación de datos estadísticos, limitando el análisis de la información a la interpretación porcentual de las distribuciones de frecuencia. El análisis estadístico propiamente dicho, parte de la búsqueda de parámetros sobre los cuales pueda recaer la representación de toda la información. En esta sección y en la próxima (medidas de tendencia central y de dispersión) se definirá algunas medidas numéricas que se emplean para describir conjuntos de datos. Una de las características más sobresalientes de la distribución de datos es su tendencia a acumularse hacia el centro de la misma; esta característica se denomina tendencia central. Las medidas de posición o de tendencia central nos permiten determinar la posición de un valor respecto a un conjunto de datos, el cual consideraremos como representativo o típico para el total de las observaciones. Página 41 de 177 Antes de entrar a definir las medidas de tendencia central, repasaremos algunas notaciones simbólicas que son de gran utilidad y son esenciales en la estadística. SUMATORIAS Y OTRAS NOTACIONES IMPORTANTES El uso de la notación simbólica es esencial en estadística. Por ejemplo, para distinguir entre los valores de n observaciones se emplea la notación simbólica x1, x2,…, xn. En el análisis estadístico de un conjunto de datos se requiere del uso de sumas de números, por lo cual, es conveniente introducir una notación simple para términos en secuencia. De esta manera, la suma de x1, x2,…, xn se designa por: n x i 1 i x 1 x 2 x 3 ... x n , Y se lee ―suma de las xi, con i variando desde 1 hasta n‖. La letra i recibe el nombre de índice de suma toma valores enteros sucesivos hasta e incluyendo a n, que es el límite superior o el valor más grande de i. Considere, por ejemplo, la sucesión de números: 1, 4, 7, 10, 13,…, y suponga que se desea referirse a la suma de los cuadrados de los primeros cuatro términos de la sucesión. En la notación de sumatoria esto se escribiría como 4 y i 1 2 i 12 4 2 7 2 10 2 1 16 49 100 166 De n a) x i 1 2 i x 12 x 22 x 32 ... x 2n , n b) (x i 1 i a) (x 1 - a) (x 2 - a) (x 3 - a) ... ( x n - a), i a) 2 (x 1 - a) 2 (x 2 - a) 2 (x 3 - a) 2 ... ( x n - a) 2 , n c) (x i 1 n d) x y i 1 i i x 1 y1 x 2 y 2 x 3 y 3 ... x n y n , n 1. Si c es cualquier constante, entonces c nc i 1 2. Si c es cualquier constante, entonces n 3. x i 1 i n n i 1 i 1 n n i 1 i 1 cx i c x i yi x i yi Como ejemplo, consideremos la sucesión de números 1, 2, 3, 4, y sean a=10 y c=5, entonces, Página 42 de 177 x 4 i 1 2 i 4 4 4 ax i 5 x i2 a x i 5 i 1 i 1 i 1 1 2 3 4 10 1 2 3 4 5 5 5 5 2 2 2 2 1 4 9 16 10 10 20 30 100 20 150 Otro símbolo útil e (pi). Esta letra se emplea para indicar el producto de los términos de una secuencia. Por ejemplo, dada la secuencia de observaciones x1, x2,…, xn se designa por: n x i x 1 . x 2 . x 3 .... x n i 1 Donde la letra i tiene el mismo propósito que en la suma. MEDIDAS DE TENDENCIA CENTRAL Las medidas de tendencia central, llamadas así porque tienden a localizarse en el centro de la información son de gran importancia en el manejo de las técnicas estadísticas, sin embargo, su interpretación no debe hacerse aisladamente de las medidas de dispersión, ya que la representatividad de ellas está asociada con el grado de concentración de la información. Las principales medidas de tendencia central son: Media aritmética Mediana Moda Sin embargo, existen otras medidas menos comunes; las medidas de tendencia central, también denominadas medidas de posición, pueden ser pueden ser de dos tipos: 1. CENTRALES: Medias: Aritmética, Geométrica, Armónica Medianas Moda 2. NO CENTRALES O DE POSICIÓN: Cuantiles: Cuartiles Deciles Centiles o percentiles La fórmula de cálculo de cada una de ellas depende de cómo se encuentren presentados los datos: agrupados o sin agrupar. Por datos agrupados entenderemos los presentados en una tabla de frecuencias (variable discreta o continua), mientras que por datos sin agrupar se entenderá los que se encuentran enlistados. Media Aritmética Es la medida de posición mas empleada, la más conocida y sencilla de calcular, de gran estabilidad en el muestreo y sus fórmulas admiten tratamientos algebraicos. También se le conoce como promedio aritmético o Página 43 de 177 simplemente como la media de un conjunto de observaciones. Cotidianamente e inconscientemente estamos utilizando la media aritmética. Cuando por ejemplo, decimos que un determinado fumador consume una cajetilla de cigarrillos diaria, no aseguramos que diariamente deba consumir exactamente los 20 cigarrillos que contiene un paquete, sino que es el resultado de la observación, es decir, dicho sujeto puede consumir 18 un día, 10 otro, 20, 21, 22; pero según nuestro criterio, el número de unidades estará alrededor de 20. Su desventaja principal es el de ser muy sensible a valores extremos, es decir, puede afectarse de manera desproporcionada por la presencia de valores grandes, o de valores muy pequeños. Se designará el símbolo (la letra griega miu) para designar una media poblacional, y x (que se leerá como ―x-barra‖) para designar una media muestral. Media para datos sin agrupar 1. Sean x1, x2,…, xN, los N datos correspondientes a una población. Entonces la media poblacional es, N xi x 1 x 2 x 3 ... x N 1 N i 1 μ xi N N N i 1 2. Sean x1, x2,…, xn, los n datos correspondientes a una muestra. Entonces la media muestral es, n xi x 1 x 2 x 3 ... x n 1 n i 1 x xi n n N i 1 Ejemplo Hallar la media aritmética de los siguientes números: 10, 8, 6, 5, 10, 7. SOLUCION: 6 x x i 1 6 i 1 6 10 8 6 5 10 7 xi 8 6 i 1 6 Ejemplo Cantidad de cigarrillos consumidos por un fumador en una semana. Lunes 18 Martes 21 Miércoles 22 Jueves 21 Viernes 20 Sábado 19 Domingo 19 Entonces la media aritmética es 7 x x 1 7 i 18 21 22 21 20 19 19 20 7 El fumador consume en promedio 20 cigarrillos diarios. Para algún campo de la ciencia, específicamente en la física, se dice que la media aritmética es el CENTRO DE GRAVEDAD de los datos. Media para datos agrupados Cuando se cuenta con una variable discreta que se encuentra agrupada en una distribución de frecuencias de k valores, la media aritmética se calcula por la fórmula: Página 44 de 177 k x x .f i i 1 n i 1 xifi n Ejemplo Al organizar los datos en el ejemplo de la cantidad de cigarrillos consumidos por un fumador en una semana, se obtiene la siguiente distribución de frecuencias. Cantidad Frecuencia (Xi) (fi) 18 1 19 2 20 1 21 2 22 1 Total 7 7 x x f i i 1 7 18(1) 19(2) 20(1) 21(2) 22(1) 140 20 7 7 Para facilidad del cálculo de la media, se puede recurrir a construir primeramente en el cuadro, el valor del numerador así, Cantidad (Xi) Frecuencia (fi) Xi fi 18 1 18 19 2 38 20 1 20 21 2 42 22 1 22 Total 7 140 Si la información se encuentra relacionada en una distribución de frecuencias por intervalo (variable continua), se toman como valores de la variable las marcas de clase de los intervalos; recuérdese que por marca de clase se entiende el punto medio entre los límites de cada clase o intervalo. Ejemplo Mediante la siguiente distribución de frecuencias que nos muestra los espesores en pulgadas, de recipientes de acero, hallar la media aritmética. Página 45 de 177 Espesores en pulg 0.307 - 0.310 0.311 - 0.314 0.315 - 0.318 0.319 - 0.322 0.323 - 0.326 0.327 - 0.330 f 3 5 5 22 14 1 N= 50 SOLUCION: Espesores en pulg 0.307 - 0.310 0.311 - 0.314 0.315 - 0.318 0.319 - 0.322 0.323 - 0.326 0.327 - 0.330 f 3 5 5 22 14 1 mi 0,3085 0,3125 0,3165 0,3205 0,3245 0,3285 fmi 0,9255 1,5625 1,5825 7,051 4,543 0,3285 ̅ N= 50 15,99 ̅ De esta manera, el espesor promedio de los recipientes de acero es de 0,32 pulgadas. Media Aritmética Ponderada En lo que se ha venido presentando, se observa que la media aritmética se calcula otorgándole a los datos igual importancia a cada uno de ellos; sin embargo, existen casos donde los datos se encuentran ponderados por un determinado peso. La media aritmética ponderada tiene en cuenta la importancia relativa de cada uno de los datos, para lo cual, la definimos de la siguiente manera: n xw x w i 1 n w i 1 Donde i i , i x w es la media ponderada, xi es el valor de la variable para el i-ésimo elemento, y wi es la ponderación de la i-ésima variable para el i-ésimo elemento. Ejemplo Las calificaciones de un estudiante están conformadas por los siguientes factores: Un examen cuyo valor es el 60% en el cual obtuvo una nota de 3,0; talleres de resolución de ejercicios con ponderación del 25% con una calificación de 3,5 y por último, laboratorios de consulta y resolución de ejercicios con un valor del 15% y una nota de 4,5. ¿Cuál es la nota final del primer corte del estudiante? SOLUCIÓN El ejercicio brinda los siguientes datos. Ponderaciones: w1 = 0,6; w2 = 0,25 y w3 = 0,15. Datos de la Variable: x1 = 3,0; x2 = 3,5 y x3 = 4,5. De esta manera, se tiene que: 3 xw x w i 1 3 i w i 1 i 3,0(0,60) 3,5(0,25) 4,5(0,15) 1,80 0,875 0,675 3,35 3,35 0,60 0,25 0,15 1,00 1,00 i Así, la nota definitiva es 3,4. Página 46 de 177 Para datos agrupados, tenemos que la fórmula para calcular la media aritmética ponderada está dada por, n x f w xw i i i 1 n i w f i i i 1 Propiedades de la media aritmética 1. La suma de las diferencias de los datos con respecto a la media aritmética es igual a cero, es decir, n x i 1 i - x 0 Para comprobar esta propiedad recurriremos a las propiedades de la sumatoria descritas previamente. Tenemos que: n n n i 1 i 1 i 1 x i - x x i x Sin embargo, n x x i 1 n i , despejando tenemos que n nx x i i 1 Cabe mencionar que una vez calculada la media aritmética, esta es una constante, por tanto, por propiedades de la sumatoria: n x nx i 1 De esta manera, reemplazando las dos igualdades en la ecuación original tenemos que: n x i 1 i n n i 1 i 1 - x xi x nx - nx 0 Veamos un ejemplo de comprobación; para ello consideremos los datos dados para el problema del fumador cuya media es de 20 cigarrillos por día: X xi - x 18 18 – 20 = -2 21 21 – 20 = 1 22 22 – 20 = 2 21 21 – 20 = 1 20 20 – 20 = 0 19 19 – 20 = -1 19 19 – 20 = -1 Suma 0 Para una distribución de frecuencias, consideremos el mismo ejemplo con los datos agrupados: Página 47 de 177 X 18 21 22 20 19 Suma xi - x 18 – 20 = -2 21 – 20 = 1 22 – 20 = 2 20 – 20 = 0 19 – 20 = -1 fi 1 2 1 1 2 7 (xi - x )fi -2 2 2 0 -2 0 2. La suma de las diferencias cuadráticas de los datos, con respecto a la media aritmética es mínima. n 2 x i - x i 1 es mínima para x ; quiere decir que para cualquier otro parámetro p, diferente a la media n aritmética hacer mayor la expresión 2 n 2 x i - p > x i - x i 1 i 1 . 3. La media aritmética de una constante es igual a la constante. Es decir, dada x i=k, para i=1, 2, 3,…, n. x 1 n 1 n 1 x i k n.k k n i1 n i1 n Ejemplo Si un alumno presenta 5 parciales y en todos ellos alcanza una calificación de cuatro, su nota promedio será de cuatro: x 1 n 1 5 1 x i 4 5.4 4 n i1 5 i1 5 4. Si a cada uno de los resultados de una variable le sumamos o le restamos una constante C, la media aritmética de la nueva variable queda alterada en esa constante. Formalmente, la media de una variable mas (o menos) una constante es igual a la media aritmética de la variable mas (o menos) la constante. Sean x1, x2,…, xn datos de una variable X cuya media aritmética es x . Definimos una variable Y de tal manera que y1 = x1 c, y2 = x2 c,…, yn = xn c, es decir yi = xi c, i=1, 2,…, n. Entonces la media aritmética de la nueva variable es: y Es decir, n 1 n 1 n 1n 1 n 1 1 n y i x i c x i c x i c x n.c n i1 n i1 n i1 n i1 n i1 n i1 yxc Ejemplo Consideremos la siguiente distribución de frecuencias: Página 48 de 177 x 1 5 1 1 5 1 134 6,7 174 8,7 x ini y y ini n i 1 20 n i 1 20 y x 2 6,7 2 8,7 El ejemplo es válido para la diferencia: Ejemplo 2 Se tienen 100 baldosas y se midió sobre ellas su resistencia en Kg/m , obteniendo los siguientes datos: Con base en estos datos, tenemos que la resistencia media de las 100 baldosas es: x 1 5 1 44.800 448 Kg/m2 mi n i n i 1 100 Si hacemos Y = X – 450: y 1 5 1 200 2 Kg/m2 y ini n i 1 100 Página 49 de 177 y x 450 448 - 450 - 2 5. Si cada uno de los datos se multiplica por una constante K, entonces la media aritmética queda multiplicada por esa constante. Sean x1, x2,…, xn los datos de una variable X cuya media aritmética es x . De igual forma, sea y1 = k.x1, y2 = k.x2,…, yi = k.xi,…, yn = k.xn. La media aritmética de la nueva variable es y k.x : y 1 n 1 n k 5 1 5 y i k.x i x i k. x i k.x n i 1 n i 1 n i 1 n i 1 Ejemplo Considerando la siguiente distribución de frecuencias y tomando k=2 se tiene que: x 1 5 1 134 6,7 x ini n i 1 20 y 1 5 1 268 13,4 y ini n i 1 20 y 2.x 2(6,7) 13,4 Ejemplo Si multiplicamos cada una de las resistencias de las 100 baldosas por una constante k 1 , tenemos: 100 1 7 1 m y ni 100 448 4,48 n i 1 i 1 448 1 x y 4,48 100 100 y 6. Empleando las dos propiedades anteriores, podemos calcular la media de una combinación lineal de variables, esto es, una transformación de variables: Página 50 de 177 Sean x1, x2,…, xn los datos de una variable X cuya media aritmética es x ; de manera similar, sean C y K, dos constantes y Y una variable aleatoria tal que Y = C.X K. Entonces la media aritmética de la nueva variable es y c.x k . Ejemplo En una empresa constructora de vivienda los salarios semanales tienen una media de $169.000. Como una solución al conflicto laboral surgido se proponen dos soluciones al conflicto: 1. Aumento del 6% en el salario semanal, ó, 2. Aumento del 4% más una bonificación semanal de $5.800 a cada obrero. ¿Cuál de las dos alternativas mejora la situación de los obreros? Tenemos que, sea X la variable salario mensual, entonces: Y1 = 1,06.X y 1,06.x 1,06(169.000) 179.140 , es decir, si aplicamos la primera opción, obtendríamos un nuevo salario semanal de $179.140. Y2 = 1,04.X + 5800 y 1,04.x 5.800 1,04(169.000) 5.800 175.760 181.560 , es decir, si aplicamos la segunda opción, obtendríamos un nuevo salario semanal de $181.560. 7. La media de una muestra es igual a la media ponderada de las sub-muestras, tomándose como ponderación los tamaños de las sub-muestras, es decir, x n1 .x1 n2 .x 2 ... nk .x k , n Donde n = n1 + n2 + … + nk. Ejemplo 3 1 5 1 43 2,15 , x 1 1 x ini 1 16 1,33 , x ini n i 1 20 n1 i 1 12 De esta manera, n .x n 2 .x 2 12 1,33 8 3,375 43 x 1 1 2,15 n1 n 2 12 8 20 x x2 1 n2 2 x ini i 1 1 27 3,375 8 La Mediana Otra medida de tendencia central, utilizada principalmente en estadística no paramétrica es la mediana, la cual, a diferencia de la media, no busca el valor central del recorrido de la variable según la cantidad de observaciones, sino que busca determinar el valor que tiene aquella observación que divide la cantidad de Página 51 de 177 observaciones en dos mitades iguales. Por lo tanto es necesario atender a la ordenación de los datos, y debido a ello, este cálculo depende de la posición relativa de los valores obtenidos. Es necesario, antes que nada, ordenar los datos de menor a mayor (o viceversa). Hay que tener en cuenta que si x1, x2,…, xN-1, xN, se utiliza para denotar el conjunto de las observaciones, donde el subíndice indica el orden en el dato que fue obtenido o registrado, suele utilizarse x(1), x(2),…, x(N-1), x(N), para representar las mismas observaciones, pero ahora ordenadas de menor a mayor, por lo tanto ahora aparece primero el dato más pequeño y último el más grande. Mediana para datos sin agrupar Para determinar el valor de la mediana en datos enlistados, hay que tener en cuenta la cantidad de datos que se recolectaron; es decir, si se tiene un número de datos IMPAR o si por el contrario, el número de datos es PAR; a continuación se presentara la mecánica a emplear para su cálculo. a. Número impar de observaciones: La mediana es el valor del dato central así, la mediana puede expresarse como: Mediana Me x N 1 , en caso de que N (o n) sea impar. 2 Ejemplo En el ejercicio de los cigarrillos consumidos por un fumador, los datos suministrados fueron: Lunes (x1)=18, martes (x2)=21, miércoles (x3)=22, jueves (x4)=21, viernes (x5)=20, sábado (x6)=19 y domingo (x7)=19. En primer lugar, tenemos siete (7) datos, un número IMPAR. Ordenando ascendentemente los datos tenemos: x(1) = 18, x(2) = 19, x(3) = 19, x(4) = 20, x(5) = 21, x(6) = 21, x(7) = 22. Una vez ordenados los datos, determinamos el valor de la variable que se encuentra en la posición central de los datos, es decir: Me x N 1 x 7 1 x 8 x 4 20 2 2 2 De esta manera, consideramos que en el 50% de los días de la semana este fumador consume máximo 20 cigarrillos; mientras que en el restante 50% de los días fuma mas de 20 cigarrillos. Nótese que tras del cuarto dato ordenado se encuentran 3 valores observados, la misma cantidad de observaciones que superan el valor de la mediana, esto es: La mediana divide la cantidad de datos en dos ―partes‖ iguales. b. Número par de observaciones: La mediana esta determinado por el valor de la semisuma (promedio aritmético) de los valores de los dos datos centrales, esto es: x N x N Mediana Me 1 2 2 2 , en caso de que N (o n) sea par. Página 52 de 177 Ejemplo 3 Consideremos el consumo mensual de agua en m , por una fábrica de confecciones ―La Hilacha‖. Enero (x1) = 10, Mayo (x5) = 14, Septiembre (x9) = 18 Febrero (x2) = 12, Junio (x6) = 19, Octubre (x10) = 22 Marzo (x3) = 15, Julio (x7) = 17, Noviembre (x11) = 15 Abril (x4) = 18, Agosto (x8) = 18, Diciembre (x12) = 13 En primer lugar, tenemos doce (12) datos, un número PAR. Ordenando ascendentemente los datos tenemos: x(1) = 10, x(2) = 12, x(3) = 13, x(4) = 14, x(5) = 15, x(6) = 15, x(7) = 17, x(8) = 18, x(9) = 18, x(10) = 18, x(11) = 19, x(12) = 22. Una vez ordenados los datos, determinamos el valor de la variable que se encuentra en la posición central de los datos, es decir: x 12 x 12 Me 1 2 2 2 x 6 x 61 2 x 6 x 7 2 15 17 32 16 2 2 3 De esta manera, tenemos que el 50% de los meses la empresa tuvo un consumo de agua menor a 16 m , mientras en el restante 50% de los meses el consumo supero esta cifra. Como se puede observar, en este caso la mediana no es un dato perteneciente a la información recogida, sin embargo, es un parámetro que divide la información dejando el 50% por encima y el 50% por debajo de ella, esto es: Mediana para datos agrupados - Variable Discreta En el caso de variables discretas donde cada categoría es el valor de la variable, se puede tomar como un caso de intervalo de amplitud 1 y en este caso el cálculo de la mediana funciona exactamente como lo visto para datos sin agrupar; sin embargo, existe un par de reglas prácticas basadas en las frecuencias absolutas que pueden ser de utilidad: a. Cuando Nj-1 < b. Cuando Nj-1 = n n y Nj > , entonces Me = xj. 2 2 x j-1 x j n 2 , entonces Me = 2 . A continuación se presentará un par de ejemplos, casos típicos, donde se trabaja con datos agrupados para variables discretas. Página 53 de 177 Ejemplo Caso a: Consideremos la siguiente distribución de frecuencias para una variable cualquiera: Xi ni Ni 0 2 2 1 3 5 Nj-1 2 6 11 Nj 3 5 16 4 4 20 20 Para este caso, tenemos un número par de datos, de acuerdo a lo planteado para el caso de datos sin agrupar, la mediana tomaría el valor del promedio de los dos valores centrales, esto es, los valores que se encuentren en la posición 10 y 11; por tanto, la mediana para este caso es igual a 2. Comprobemos lo anterior con la fórmula presentada: Tenemos que n 20 n n 10 , además Nj-1 < es decir, 5<10 y Nj > o sea 11>10, por tanto, 2 2 2 2 Me = xj = 2. Ejemplo Caso b: Consideremos la anterior distribución de frecuencias con un leve cambio: Xi ni Ni 0 2 2 1 3 5 xj-12 5 10 Nj-1 xj3 6 16 Nj 4 4 20 20 Tenemos que n 20 n n 10 , además Nj-1= es decir, N3=10= , por tanto 2 2 2 2 Me x j-1 x j 2 23 5 2,5 2 2 Podemos comprobar el resultado anterior, transformando la distribución de frecuencias en una variable cuyos datos no estén agrupados, i 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 xi 0 0 1 1 1 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 Me 23 5 2,5 2 2 Mediana para datos agrupados - Variable Continua Página 54 de 177 Cuando trabajamos con variables agrupadas por intervalos es imposible determinar con precisión los valores que toman los datos, ya que esa información se ha perdido en privilegio del agrupamiento interval. Por lo tanto, en este caso, debemos buscar otro método para determinar el valor de la mediana. Consideremos como x Ij al límite inferior del j-ésimo intervalo, de manera análoga como x Sj al límite superior del j-ésimo intervalo. Para la variable continua también se tienen dos casos, como se verá a continuación: n , entonces Me = x Sj-1 . 2 n n b. Cuando Nj-1 < y Nj > , se puede calcular la mediana empleando las frecuencias absolutas mediante 2 2 a. Cuando Nj-1 = la siguiente fórmula n N j-1 M e LI 2 nj A , donde, LI: Límite Inferior del intervalo mediano, es decir, el intervalo donde se encuentra la mediana, el cual se determina observando en que intervalo n: Nj-1: nj: A: se encuentra la posición n . 2 Número de observaciones. Frecuencia absoluta acumulada anterior al intervalo mediano. Frecuencia absoluta del intervalo mediano. Amplitud del intervalo. Ó con base en las frecuencias relativas mediante la siguiente fórmula 0,5 Fj -1 Me LI fj A , Donde: LI: Límite Inferior del intervalo mediano, es decir, el intervalo donde se mediana, el cual se determina observando en que intervalo n: Fj-1: fj: A: Número de observaciones. Frecuencia relativa acumulada anterior al intervalo mediano. Frecuencia relativa del intervalo mediano. Amplitud del intervalo. Página 55 de 177 encuentra n se encuentra la posición . 2 la Ejemplo Caso a Consideremos la siguiente distribución de frecuencias: Tenemos que Xi-1 – Xi ni Ni 2–6 2 2 6 – 10 3 5 10 – 14 xSj 5 10 Nj-1 14 – 18 6 16 Nj 18 – 22 4 20 20 - n 20 n n 10 , además Nj-1= es decir, N3=10= , por tanto 2 2 2 2 Me = xSj = xS3 = 14. Ejemplo Caso b Consideremos la anterior distribución de frecuencias con un leve cambio: Xi-1 – Xi ni 2–6 2 2 6 – 10 3 5 Nj-1 Ni 6 nj 11 14 – 18 5 16 18 – 22 4 20 10 – 14 xSj 20 Tenemos que Nj Intervalo Mediano - n 20 n n 10 , además Nj-1 = N2 = 5 < =10; y Nj = N3 = 11 > =10, por tanto: 2 2 2 2 n N j-1 2 A M e LI nj 20 5 (14 10) 10 2 6 10 5 10 ( 4) 6 5 10 (4) 6 10 3,33 M e 13,33 Página 56 de 177 La Moda La moda, o valor modal, como su nombre lo indica, es el valor más común, es el valor de la variable que más se repite; es decir, aquel valor de la variable (que puede no ser un único valor) que observa con mayor frecuencia dentro de una distribución. Un conjunto de datos puede tener una sola moda, en este caso se suele llamar distribución unimodal, si tiene dos modas se denomina bimodal, o varias modas y llamarse multimodal. Sin embargo puede ocurrir que la distribución no posea moda. Cálculo para datos sin agrupar En los datos sin agrupar o en los datos agrupados para variables discretas donde cada clase es un valor diferente de la variable, basta una simple inspección ocular. Ejemplo Consideremos los siguientes datos: 5, 10, 8, 5, 10, 18, 5, 12, 5, 12. Para este conjunto de datos, el valor que mas se repite es 5, por tanto este valor representa la moda, esto es: Mo = 5. Cálculo para datos agrupados Se debe utilizar de preferencia cuando la amplitud de los intervalos es constante, para ello podemos observar y comprender su cálculo así: Variable Discreta Consideremos el ejemplo de los salarios de 50 operarias de cierta fábrica en particular, presentado en la siguiente tabla: Página 57 de 177 Miles de Pesos/Día Xi ni 50 1 51 3 52 5 53 9 54 12 55 10 56 5 57 3 58 2 50 El valor que presenta mayor frecuencia es 54 con una repetición de 12 personas con el mismo salario, de esta manera, afirmamos que el salario más común dentro de la fábrica es de $54.000 diarios. Consideremos el ejemplo del fumador, cuyos datos se encuentran resumidos a continuación: Cantidad (Xi) Frecuencia (fi) 18 1 19 2 20 1 21 2 22 1 Total 7 Observamos que los valores de mayor frecuencia corresponden a 19 y 21, por tanto, se trata de una distribución bi-modal con Mo1= 19 y Mo2 = 21. Variable Continua Existen diversas fórmulas para la estimación del valor modal cuando de una variable continua se refiere; sin embargo, tomaremos como valor modal la marca de clase del respectivo intervalo modal. Cabe mencionar que por intervalo modal entenderemos aquel intervalo que presenta la mayor frecuencia observada. Sin embargo, presentaremos las fórmulas que se pueden encontrar en los diversos textos para su debido conocimiento y aplicación Cálculo a partir de la frecuencia relativa Página 58 de 177 fm fm -1 A Mo LI 2fm fm - 1 fm 1 Donde, Mo: Moda LI: Límite inferior del intervalo modal fm: Frecuencia relativa del intervalo modal (clase modal) fm-1: Frecuencia relativa del intervalo pre-modal (clase pre-modal) fm+1: Frecuencia relativa del intervalo pos-modal (clase pos-modal) A: Amplitud del intervalo modal. La fórmula para estimar la moda a partir de la frecuencia absoluta es similar a la presentada anteriormente, tan solo se trabaja con las frecuencias absolutas: nm nm -1 A Mo LI 2nm nm - 1 nm 1 Ejemplo Consideremos el ejemplo de las 100 baldosas; cuyos datos se resumen a continuación: Kg/m Xi 2 mi ni 100 – 200 150 4 200 – 300 250 10 300 – 400 350 21 Clase premodal 400 – 500 450 33 Clase modal 500 – 600 550 18 Clase posmodal 600 – 700 650 9 700 – 800 750 5 100 Observamos que el cuarto intervalo presenta la mayor cantidad de datos, por tanto, este intervalo se denomina intervalo o clase modal. De esta manera, tenemos que el valor modal esta dado por: nm nm -1 33 21 A 400 100 444,44 Mo LI 2(33) 21 18 2nm nm - 1 nm 1 Página 59 de 177 A pesar de que el valor 444,44 no es un dato real de la información, asumimos ese parámetro como el de mayor ocurrencia. Relación: Media - Mediana - Moda Cuando trabajamos un problema de estadística, debemos decidir si vamos a utilizar la media, la mediana o la moda como medidas de tendencia central. Las distribuciones simétricas que sólo contienen una moda, siempre tienen el mismo valor para la media, la mediana y la moda. En tales casos, no es necesario escoger la medida de tendencia central, pues ya está hecha la selección. Obviamente, si todas las observaciones estuvieran concentradas en un solo valor de la variable, media, mediana y moda coincidirían en el mismo. Si las observaciones se fueran distribuyendo en forma simétrica, a la izquierda y a la derecha de ese valor central, media, mediana y modo seguirían coincidiendo. En una distribución positivamente sesgada (es decir, sesgada hacia la derecha), la moda todavía se encuentra en el punto más alto de la distribución, la mediana está hacia la derecha de la moda y la media se encuentra todavía más a la derecha de la moda y la mediana; es decir, en una distribución asimétrica a la derecha, la media, es mayor que la mediana y que la moda, tal como lo presenta el siguiente gráfico Supongamos ahora que las observaciones de la parte izquierda se alejan del valor central más que las observaciones de la parte derecha, generando una distribución asimétrica hacia la izquierda; en este caso como la media es la suma de los valores de las observaciones dividido por la cantidad total de observaciones, su valor se correrá a la izquierda también y por el mismo motivo, la media será menor que la mediana y ambas Página 60 de 177 menor que la moda; es decir, en una distribución negativamente sesgada, la moda sigue siendo el punto más alto de la distribución, la mediana está hacia la izquierda de ella y la media se encuentra todavía más a la izquierda de la moda y la mediana. Este corrimiento de la media se explica porque si tomamos un conjunto de datos cualquiera a los cuales calculamos media, mediana y moda y agregamos un dato extremo y volvemos a calcular la media, la mediana y la moda, veremos que la media puede variar notablemente, mientras que la mediana y la moda permanecen idénticas. Esta no variación de la mediana y la moda reciben el nombre de robustez. Las medidas basadas en el orden –como la mediana- gozan de ésta en tanto que las medidas basadas en la suma –como la media- se ven más afectadas por las observaciones extremas y son, por lo tanto, poco robustas. Cuando la población está sesgada negativa o positivamente, con frecuencia la mediana resulta ser la mejor medida de posición, debido a que siempre está entre la moda y la media. La mediana no se ve altamente influida por la frecuencia de aparición de un solo valor como es el caso de la moda, ni se distorsiona con la presencia de valores extremos como la media. Relación Empírica entre Media, Mediana y Moda Para curvas de frecuencia unimodales que sean poco asimétricas tenemos la siguiente relación empírica Media – Moda = 3(media- mediana). CUANTILES: Cuartiles, Deciles y Percentiles Son medidas de localización similares a las anteriores, las cuales las denominamos medidas de tendencia central, sin embargo, también pueden ser llamadas medidas de localización ya que, igual determinan posiciones ―centrales‖ de la información. Se les denomina CUANTILES (Q). Su función es informar del valor de la variable que ocupará la posición (en tanto por cien) que nos interese respecto de todo el conjunto de variables. Podemos decir que los Cuantiles son unas medidas de posición que dividen a la distribución en un cierto número de partes de manera que en cada una de ellas hay el mismo de valores de la variable. Las más importantes son: CUARTILES, dividen a la distribución en cuatro partes iguales (tres divisiones): C 1, C2, C3, correspondientes al 25%, 50%, 75%. DECILES, dividen a la distribución en 10 partes iguales (9 divisiones): D 1,..., D9, correspondientes a 10%,...,90%. Página 61 de 177 PERCENTILES, cuando dividen a la distribución en 100 partes (99 divisiones): P 1,..., P99, correspondientes a 1%,...,99%. Existe un valor en cual coinciden los cuartiles, los deciles y percentiles esto es cuando son iguales a la Mediana y así veremos 2 5 50 4 10 100 Para su cálculo distinguiremos entre distribuciones agrupadas y enlistadas: En las distribuciones sin agrupar, primero hallaremos el lugar que ocupa: Entonces tendremos que: Ni-1 < (%).n < Ni Q = xi En el supuesto que (%).n = Ni Q x i x i 1 2 Primero encontraremos el intervalo donde estará el cuantil: Lugar Ni-1 < (%) n< Ni Intervalo [Li-1, Li) , en este caso: Q L i 1 Ejemplo: DISTRIBUCIONES AGRUPADAS: En la siguiente distribución xi fi 5 10 15 20 25 % N N i 1 ni ai Fi 3 7 5 3 2 n = 20 3 10 15 18 20 Calcular la mediana (Me); el primer y tercer cuartil (C1, C3); el 4º decil (D4) y el 90 percentil (P90). Mediana (Me) Lugar que ocupa la mediana lugar 20/2 = 10. Como es igual a un valor de la frecuencia absoluta acumulada, realizaremos el cálculo: Me x i x i 1 10 15 12,5 2 2 Primer cuartil (C1) Lugar que ocupa en la distribución (¼). 20 = 20/4 = 5 Como Ni-1 < (25%).n < Ni, es decir 3 < 5 < 10 esto implicara que C1 = xi = 10 Tercer cuartil (C3) Lugar que ocupa en la distribución (3/4).20 = 60/4 = 15, que coincide con un valor de la frecuencia absoluta acumulada, por tanto realizaremos el cálculo: C3 x i x i 1 15 20 17,5 2 2 Cuarto decil (D4) Lugar que ocupa en la distribución (4/10).20 = 80/10 = 8. Como Ni-1 < (%).n < Ni ya que 3 < 8 < 10 por tanto D4 =10. Página 62 de 177 Nonagésimo percentil (P90) Lugar que ocupa en la distribución (90/100).20 = 1800/100 = 18, que coincide con un valor de la frecuencia absoluta acumulada, por tanto realizaremos el cálculo: P90 x i x i 1 20 25 22,5 2 2 Ejemplo: DISTRIBUCIONES AGRUPADAS: Hallar el primer cuartil, el cuarto decil y el 90 percentil de la siguiente distribución: [Li-1 , Li) fi Fi [ 0 , 100) [100 , 200) [[200 , 300) [300 , 800) 90 140 150 120 n = 500 90 230 380 500 Primer cuartil (C4) Lugar ocupa el intervalo del primer cuartil: (1/4). 500 = 500/4 = 125. Por tanto C4 estará situado en el intervalo [100 – 200). Aplicando la expresión directamente, tendremos: C 4 100 125 90 100 125 140 Cuarto decil (D4) Lugar que ocupa: (4/10).500 = 200. Por tanto D4 estará situado en el intervalo [100 – 200). Aplicando la expresión tendremos: D 4 100 200 90 100 178,57 140 Nonagésimo percentil (P 90) Lugar que ocupa: (90/100).500 = 450. Por tanto P90 estará situado en el intervalo [300 – 800). Aplicando la expresión tendremos: P90 300 450 380 70 500 300 500 591,67 120 120 Lección 8: Medidas de dispersión: Rango, Varianza, Desviación típica, coeficiente de variación, puntaje estandarizado. Como se mencionó anteriormente, las medidas de tendencia central tienen como objetivo sintetizar los datos en un valor representativo; como complemento, las medidas de dispersión nos dicen hasta que punto estas medidas de tendencia central son representativas como síntesis de la información; de esta manera, las medidas de dispersión cuantifican la separación, la dispersión, la variabilidad de los valores de la distribución respecto al valor central como la media aritmética. Cuanto menor es la dispersión, tanto mayor será la precisión Página 63 de 177 del sistema de medición. Si los estadígrafos de posición se relacionan con el concepto de exactitud, los de dispersión se relacionan con la precisión de las técnicas. La dispersión es importante porque: Proporciona información adicional que permite juzgar la confiabilidad de la medida de tendencia central. Si los datos se encuentran ampliamente dispersos, la posición central es menos representativa de los datos. Ya que existen problemas característicos para datos ampliamente dispersos, debemos ser capaces de identificarlos antes de abordar esos problemas. Quizá se desee comparar las dispersiones de diferentes muestras. Si no se desea tener una amplia dispersión de valores con respecto al centro de distribución o esto presenta riesgos inaceptables, necesitamos tener habilidad de reconocerlo y evitar escoger distribuciones que tengan las dispersiones más grandes. Ya que la dispersión ocurre frecuentemente y su grado de variabilidad es importante, ¿cómo medimos la variabilidad de una distribución empírica? Vamos a considerar sólo algunas medidas de dispersión: el rango, el rango inter-cuartílico, la varianza, la desviación estándar y el coeficiente de variación. EL RANGO O RECORRIDO ( R ): Es la medida de variabilidad más fácil de calcular. Para datos finitos o sin agrupar, el rango se define como la diferencia entre el máximo valor (X n ó XMax) y el mínimo (X1 ó XMin) en un conjunto de datos, de manera más formal: R = XMáx – XMín = Xn - X1 Ejemplo: Se tienen las edades de cinco estudiantes universitarios de 1er año, a saber: 18,23, 27,34 y 25., para calcular el rango o recorrido de la variable, se tiene que: R = Xn – X1 = 34 – 18 = 16 años Rango para datos agrupados Con datos agrupados no se saben los valores máximos y mínimos. Si no hay intervalos de clases abiertos podemos aproximar el rango mediante el uso de los límites de clases. Se aproxima el rango tomando el límite superior de la última clase menos el límite inferior de la primera clase, de manera más formal: R= (lim. Sup. de la clase n – lim. Inf. de la clase 1) Página 64 de 177 Ejemplo: Dada la siguiente distribución de frecuencia determinar el rango o recorrido: Clases P.M. mi ni fi Ni Fi 7,420 – 21,835 14,628 10 0,33 10 0,33 21,835 – 36,250 29,043 4 0,13 14 0,46 36,250 – 50,665 43,458 5 0,17 19 0,63 50,665 – 65,080 57,873 3 0,10 22 0,73 65,080 – 79,495 72,288 3 0,10 25 0,83 79,495 – 93,910 86,703 5 0,17 30 1,00 30 1,00 Total El rango de la distribución de frecuencias se calcula así: R = (lim. Sup. de la clase n – lim. Inf. De la clase 1) = (93.910 – 7.420) = 86.49 Propiedades del Rango o Recorrido: El recorrido es la medida de dispersión más sencilla de calcular e interpretar puesto que simplemente es la distancia entre los valores extremos (máximo y mínimo) en una distribución. Puesto que el recorrido se basa en los valores extremos, éste tiende a ser errático. No es extraño que en una distribución de datos económicos o comerciales incluya a unos pocos valores en extremo pequeños o grandes. Cuando tal cosa sucede, entonces el recorrido solamente mide la dispersión con respecto a esos valores anormales, ignorando a los demás valores de la variable. La principal desventaja del recorrido es que sólo esta influenciado por los valores extremos, puesto que no cuenta con los demás valores de la variable. Por tal razón, siempre existe el peligro de que el recorrido ofrezca una descripción distorsionada de la dispersión. En el control de la calidad se hace un uso extenso del recorrido cuando la distribución a utilizarse no la distorsionan y cuando el ahorro del tiempo al hacer los cálculos es un factor de importancia. RANGO INTERCUARTÍLICO: Teniendo en cuenta la principal desventaja del rango (toma en cuenta solo los valores extremos), surge el rango intercuartílico, denotado por RI, su cálculo se limita a la diferencia entre el tercer y el primer cuartil, es decir Página 65 de 177 Esto nos dice en cuántas unidades de los valores que toma la variable se concentra el cincuenta por ciento central de los casos. VARIANZA 2 Se representa por S . Se define como el promedio de las desviaciones de los datos entre si. La suma de los cuadrados de los desvíos de la totalidad de las observaciones, respecto de la media aritmética de la distribución, es menor que la suma de los cuadrados de los desvíos respecto de cualquier otro valor que no sea la media aritmética. Si observamos, veremos que la varianza no es más que el desvío estándar al cuadrado. Precisamente la 2 manera de simbolizarla es S . ∑( ̅) Propiedades de la varianza: Es siempre un valor no negativo, que puede ser igual o distinta de 0. Será 0 solamente cuando X i= X La varianza es la medida de dispersión cuadrática optima por ser la menor de todas. Si a todos los valores de la variable se le suma una constante la varianza no se modifica. Veámoslo: Si a Xi le sumamos una constante Xi’ = Xi + K. tendremos (sabiendo que ) Si todos los valores de la variable se multiplican por una constante la varianza queda multiplicada por el cuadrado de dicha constante. Veámoslo: Si a xi’ = xi · k tendremos (sabiendo que ) Si en una distribución obtenemos una serie de subconjuntos disjuntos, la varianza de la distribución inicial se relaciona con la varianza de cada uno de los subconjuntos mediante la expresión Siendo Ni el nº de elementos del subconjunto (i) Página 66 de 177 S i2 la varianza del subconjunto (i) LA DESVIACIÓN ESTÁNDAR También recibe el nombre de desviación tipo o desvío típico. Es posible identificar conjuntos de datos que a pesar de ser muy distintos en términos de valores absolutos, poseen la misma media. Una medida diferencial para identificar esos conjuntos de datos es la concentración o dispersión alrededor de la media. Desviación estándar para datos sin agrupar Una manera que aparece como muy natural para construir una medida de dispersión sería promediar las desviaciones de la media, pero como vimos Una manera de evitar que los distintos signos se compensen es elevarlas al cuadrado, de manera que todas las desviaciones sean positivas. La raíz cuadrada del promedio de estas cantidades recibe el nombre de desviación estándar, o desviación típica y es representada por la siguiente fórmula: √ ∑ ( ̅) La desviación estándar sólo puede utilizarse en el caso de que las observaciones se hayan medido con escalas de intervalos o razones. A mayor valor de la desviación estándar, mayor dispersión de los datos con respecto a su media. Es un valor que representa los promedios de todas las diferencias individuales de las observaciones respecto a un punto de referencia común, que es la media aritmética. Se entiende entonces que cuando este valor es más pequeño, las diferencias de los valores respecto a la media, es decir, los desvíos, son menores y, por lo tanto, el grupo de observaciones es más ―homogéneo‖ que si el valor de la desviación estándar fuera más grande. O sea que a menor dispersión mayor homogeneidad y a mayor dispersión, menor homogeneidad. Desviación estándar para datos agrupados 1. Cálculo usando las frecuencias absolutas 2. Cálculo usando las frecuencias relativas Página 67 de 177 Propiedades de la Desviación Estándar La desviación estándar es siempre un valor no negativo. Es la medida de dispersión óptima por ser la más pequeña. La desviación estándar toma en cuenta las desviaciones de todos los valores de la variable. Si a todos los valores de la variable se le suma una misma constante la desviación estándar no varía. Si a todos los valores de la variable se multiplican por una misma constante, la desviación estándar queda multiplicada por el valor absoluto de dicha constante. EL COEFICIENTE DE VARIACIÓN: Para comparar la dispersión de variables que aparecen en unidades diferentes (metros, kilos, etc.) o que corresponden a poblaciones extremadamente desiguales, es necesario disponer de una medida de variabilidad que no dependa de las unidades o del tamaño de los datos. Este coeficiente únicamente sirve para comparar las dispersiones de variables correspondientes a escalas de razón. Una manera de construir una medida de variabilidad que cumpla los requisitos anteriores es el llamado coeficiente de variación: (Las barras del denominador representan el valor absoluto, es decir, indican que debe prescindirse de la unidad de medida de la media). A menor coeficiente de variación consideraremos que la distribución de la variable medida es más homogénea. PUNTAJE ESTANDARIZADO: Cuando se tiene una distribución simétrica, su polígono de frecuencias revelará una forma de campana muy común en estadística. Esta curva es llamada curva normal, de error, de probabilidad o campana de Gauss. En ella la media aritmética se localiza en la mitad de la distribución. En el eje horizontal se ubican los valores que toma la variable y en el vertical la frecuencia absoluta o relativa. El área bajo la curva tendrá un valor del 100% Figura: Curva normal o campana de Gauss Página 68 de 177 El puntaje típico o estandarizado o variable normalizada, es una medida de dispersión muy utilizada como variable estadística en este tipo de distribución, denominada distribución normal. El puntaje estandarizado mide la desviación de una observación con respecto a la media aritmética, en unidades de desviación estándar, determinándose así la posición relativa de una observación dentro del conjunto de datos. Por lo general se simboliza por Z. Z X x s Por ser adimensional, el puntaje Z es útil para comparar datos individuales de distribuciones que tienen distintas unidades de medida, así como diferentes medias y desviaciones estándar. Propiedades: z 0 2 2. z 1 1. EJEMPLO Al terminar el segundo semestre de laño 2010, un grupo de 150 estudiantes de primer semestre de Ingeniería 10.110.1 de un CEAD, obtuvieron los siguientes resultados en el puntaje final de los cursos Lógica Matemática y Estadística Descriptiva: Lógica Matemática: puntuación media de 3.9 y varianza 3.2. Estadística Descriptiva: puntuación media de 3.7 y desviación estándar 1.7. a. ¿En cuál curso hubo mayor dispersión absoluta? ¿En cuál hubo mayor dispersión relativa? b. Si un estudiante obtuvo como nota final en Lógica Matemática 3.8 y en Estadística Descriptiva 3.5. ¿En cuál curso fue su puntuación relativa superior? Solución: a. Para determinar la dispersión absoluta: Lógica Matemática: s 3.2 Estadística Descriptiva: s 1,7 2 s 3.2 1.79 Se tiene entonces que en Lógica Matemática hubo una mayor dispersión absoluta que en Estadística Descriptiva. Página 69 de 177 Para la dispersión Relativa: 1.79 100 45.9% 3.9 1.7 Estadística Descriptiva: CV 100 46% 3.7 Lógica Matemática: CV En Estadística Descriptiva hubo una mayor dispersión relativa 46% > 45.9% b. Para el cálculo de la puntuación relativa, se hace uso del puntaje estandarizado. Es decir, se requiere estandarizar las calificaciones convirtiéndolas en puntuaciones Z. x x 3.8 3.9 0.06 s 1.79 x x 3.5 3.7 Estadística descriptiva: Z 0.12 s 1.7 Lógica Matemática: Z Estos valores de puntuación Z negativos indican que ambas calificaciones se encuentran por debajo de la media. Este es un principio del puntaje estandarizado: Siempre que un valor sea menor que la media, su puntuación Z correspondiente será negativa. Estos resultados afirman entonces que el estudiante con calificaciones de 3.8 en Lógica Matemática y 3.5 en Estadística Descriptiva, está por debajo del promedio del grupo en ambos cursos. Dado que -0.06 se encuentra más cera a 0 (la media de la variable estandarizada), se dice que la puntuación relativa del estudiante fue superior en Lógica Matemática. Lección 9: Medidas de forma: Asimetría y Curtosis. Después de conocer cómo varía un grupo de datos respecto a su media e identificar otras medidas de variación, a continuación se estudiará algunos aspectos sobre la forma de las curvas que presentan los datos. Asimetría: La primera característica que se estudia es el coeficiente de asimetría, el cual mide el grado de simetría en la distribución de los datos, ya que conocer la distribución de los datos, permite tomar ciertos caminos para el análisis de los mismos. Si un conjunto de datos tiene distribución simétrica es porque se cumple: x Me Mo En las distribuciones asimétricas la media se corre en el sentido del alargamiento o sesgo por efecto de las frecuencias y de los valores extremos de la variable; la mediana también se corre pero menos que la media ya que en ella sólo influyen las frecuencias; en tanto que la moda no es influenciada ni por las frecuencias ni por los valores extremos. Una distribución es asimétrica positiva cuando presenta un alargamiento o sesgo a la derecha: Mo Me x Una distribución será asimétrica negativa cuando presenta un alargamiento o sesgo a la izquierda: x Me Mo Las asimetrías positivas son las más frecuentes que las sesgadas hacia la izquierda, porque con frecuencia es más fácil obtener valores excepcionalmente grandes que valores excepcionalmente pequeños. Ejemplo de ello es la distribución de valores en los consumos de servicios públicos, las calificaciones en pruebas, los sueldos, etc. Se reconocen, entre otras, las siguientes medidas para calcular el grado de la asimetría: Página 70 de 177 Coeficiente de Pearson. Asimetría en función de la media y la moda. Varía entre ±3 y es 0 en la distribución normal. As As 3 ( x Me) s Media cuartil de asimetría o media de Bowley. Varía entre ±1 y es 0 en la distribución normal. As Si Si Si x Mo s Q1 Q3 2Q2 Q3 Q1 As 0 la distribución es simétrica. As 0 la distribución es asimétrica positiva. As 0 la distribución es asimétrica negativa. Apuntamiento O Curtosis: Las curvas de distribución, comparadas con la curva de distribución normal, pueden presentar diferentes grados de apuntamiento o altura de la cima de la curva. Esta agudeza en la cima se observa en la moda. Si la curva es más plana que la normal se dice que la curva es platicúrtica; si es más aguda que la normal, recibe el nombre de apuntada o leptocúrtica. Si la distribución es normal, la curva se conoce también como mesocúrtica. La curtosis es la medida de la altura de la curva y está dada por: Si Si Ap 3 Ap 3 Ap 3 Z Ap 4 i ns fi 4 la distribución es normal o mesocúrtica. la distribución es apuntada o leptocúrtica. Si la distribución es achatada o platicúrtica. Otra medida de curtosis que se emplea está basada en el rango semiintercuartílico y los percentiles 10 y 9: Ap QD 2 Q3 Q1 P90 P10 2( P90 P10 ) En el siguiente ejemplo se puede comprender de una manera práctica, la forma de calcular éste tipo de medidas. Página 71 de 177 EJEMPLO El coordinador académico del programa de Administración de Empresas, desea conocer el rendimiento 10.110.1 académico de los estudiantes de primer semestre en el 2010, en los cursos de Lógica Matemática, Competencias Comunicativas, Cultura Política, Estadística Descriptiva y Herramientas Informáticas. Para esto selecciona una muestra de 55 estudiantes de los distintos programas que se ofrecen en el CEAD. La siguiente tabla, arroja los resultados de la investigación realizada por el funcionario. Tabla: Distribución de frecuencias de las calificaciones de primer semestre Calificación 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 Total Lógica Competencias Cultura Estadística Herramientas Matemática Comunicativas Política Descriptiva Informáticas 1 3 2 1 1 4 3 2 1 2 7 5 3 2 3 9 6 4 4 7 9 7 6 11 9 8 7 8 14 11 6 7 9 12 9 4 6 9 6 7 3 5 7 3 3 2 3 4 1 2 2 3 1 0 1 55 55 55 55 55 En la tabla siguiente se reporta un resumen de las medidas estadísticas por cada uno de los cursos. Medida x Me Mo s2 s Q1 Q2 Q3 Lógica Matemática 2.25 2.0 1.5 y 2.0 Competencias Comunicativas 2.5 2.5 2.0, 2.5 y 3.0 Cultura Política 2.75 3.0 3.0 y 3.5 Estadística Descriptiva 2.53 2.5 2.5 Herramientas Informáticas 2.5 2.5 2.5 1.45 1.20 1.84 1.36 1.45 1.20 0.76 0.87 1.12 1.06 1.5 1.5 2.0 2.0 2.0 2.0 2.5 3.0 2.5 2.5 3.0 3.5 3.5 3.0 3.4 a-) Asimetría: Para Lógica Matemática: Se observa que Mo Me x , lo que indica que la distribución tiene asimétrica positiva. Para confirmarlo se hace uso del coeficiente de Pearson y la media de Bowley: En este caso se trabajará con la media de Bowley, pues la distribución tiene dos modas y no permite un resultado seguro con el coeficiente de Pearson. Página 72 de 177 As Q1 Q3 2Q2 1.5 3 2(2) 0.33 0 Q3 Q1 3 1.5 El polígono de frecuencias de las calificaciones de Lógica Matemática confirma los resultados. Figura: Curva asimétrica positiva Polígono de frecuencias de calificaciones de Lógica Matemática 10 9 Frecuencia 8 7 6 5 4 3 2 1 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 Calificación La curva lleva a concluir que la mayoría de los estudiantes están por debajo de la media en el curso de Lógica Matemática y son pocos los estudiantes que la superan. Para Competencias Comunicativas: Se observa que Mo Me x , lo que indica que la distribución es simétrica. Para confirmarlo se hace uso del coeficiente de Bowley, pues la distribución tiene tres modas y no permite un resultado seguro con el coeficiente de Pearson. As Q1 Q3 2Q2 1.5 3.5 2(2.5) 0 Q3 Q1 3.5 1.5 El polígono de frecuencias de las calificaciones de Competencias Comunicativas confirma los resultados. Figura: Curva simétrica platicúrtica Polígono de frecuencias de calificaciones de Competencias Comunicativas con el coeficiente de Pearson. 10 9 8 Frecuencia 7 6 5 4 3 2 1 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 Calificación Para determinar el grado de apuntamiento o curtosis, se debe determinar el puntaje típico o estandarizado de cada clase y luego aplicar la fórmula que lo calcula. En la siguiente tabla se indican estos valores. Página 73 de 177 Tabla: Cálculo de Z para la distribución de frecuencias de las calificaciones de Competencias Comunicativas 4 Calificación f Z Zi f i 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 3 3 5 6 7 7 7 6 5 3 3 -1,838235294 -1,470588235 -1,102941176 -0,735294118 -0,367647059 0 0,367647059 0,735294118 1,102941176 1,470588235 1,838235294 34,2551328 14,0309024 7,39910869 1,7538628 0,12788583 0 0,12788583 1,7538628 7,39910869 14,0309024 34,2551328 Total 55 0 115,133785 Z Ap 4 fi i ns 4 Ap 115.13 0.62 3 55 1.36 4 Por lo tanto, la curva es simétrica platicúrtica o achatada. Estos resultados indican que la mayoría de los estudiantes en Competencias Comunicativas están en el rango de la media del curso, además sus notas son muy homogéneas alrededor de la media. Para Cultura Política: Se observa que Mo Me x , lo que indica que la distribución es asimétrica negativa. Para confirmarlo se hace uso de la media de Bowley, pues la distribución tiene dos modas y no permite un resultado seguro con el coeficiente de Pearson. As Q1 Q3 2Q2 2.0 3.5 2(3.0) 0.33 0 Q3 Q1 3.5 2.0 El polígono de frecuencias de las calificaciones de Cultura Política confirma los resultados. Figura: Curva asimétrica negativa Polígono de frecuencias de calificaciones de Cultura Política 10 9 8 Frecuencia 7 6 5 4 3 2 1 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 Calificación Esto quiere decir que las calificaciones de la mayoría de los estudiantes del curso Cultura Política están por encima de la media. Página 74 de 177 Para Estadística Descriptiva: Se observa que Mo Me x , lo que indica que la distribución es simétrica. Para confirmarlo se hace uso del coeficiente de Pearson y la media de Bowley: As x Mo 2.53 2.5 0.03 0 s 0.87 As y Q1 Q3 2Q2 2.0 3.0 2(2.5) 0 Q3 Q1 3.0 2.0 Para determinar el grado de apuntamiento o curtosis, se debe determinar el puntaje típico o estandarizado de cada clase y luego aplicar la fórmula que lo calcula. En la tabla siguiente tabla se indican estos valores. Tabla: Cálculo de Z para la distribución de frecuencia de las calificaciones de Estadística Descriptiva 4 Calificación f Z Zi f i 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 1 1 2 4 11 14 12 6 3 1 0 -2,908045977 -2,333333333 -1,75862069 -1,183908046 -0,609195402 -0,034482759 0,540229885 1,114942529 1,689655172 2,264367816 -1,352941176 71,516306 29,6419753 19,1301647 7,85835926 1,51502275 1,9794E-05 1,02210536 9,27173856 24,4519547 26,289837 0 Total 55 -4,571331981 190,697484 Z Ap 4 i ns 4 fi Ap 190.70 6.05 3 55 0.87 4 Por lo tanto, la curva es simétrica leptocúrtica o apuntada. Lo anterior indica que las calificaciones de Estadística Descriptiva de la muestra de 55 estudiantes están muy cerca de la media y que existe además, un pico en 2.5, señalando una alta frecuencia en esta calificación. Frecuencia Figura: Curva simétrica leptocúrtica Polígono de frecuencias de calificaciones de Estadística Descriptiva 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 0,0 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 Calificación Para Herramientas Informáticas: Se observa que Mo Me simétrica. Para confirmarlo se hace uso del coeficiente de Pearson: Página 75 de 177 x , lo que indica que la distribución es As x Mo 2.5 2.5 0 s 1.06 El polígono de frecuencias de las calificaciones de Herramientas Informáticas confirma los resultados. La curva es simétrica mesocúrtica o normal. MEDIDAS DE TENDENCIA CENTRAL Y DE DISPERSION EN EXCEL El proceso a seguir, cuando los datos estén SIN AGRUPAR, es decir, tal como se recolectaron, si trabajamos con la variable número de hermanos, para la aplicación de las diferentes medidas, serán las siguientes: Consideremos los datos del CUADRO No. 1, que contiene información de 10 variables correspondiente a 50 estudiantes seleccionados como muestra, de una población de 1.080 estudiantes, que a continuación se reedita: Cuadro No. 1. No. Promedio No. No. Facultad Sexo libros calificación orden hermanos leídos matemáticas 2 2 2 2 2 4,1 9 3 2 0 6 3,4 12 3 1 6 3 3,6 35 2 2 0 7 3,6 41 3 1 3 5 4,1 63 3 2 4 2 3,1 74 2 2 2 4 3,6 113 1 1 1 3 3,4 147 3 1 1 8 5,0 175 1 2 3 2 2,6 199 2 2 0 2 3,9 214 1 1 1 7 3,5 234 1 1 1 2 3,6 268 3 1 3 12 3,9 327 3 1 1 8 5,0 331 1 2 0 6 3,4 364 1 2 3 2 3,3 400 3 2 0 6 3,6 405 1 2 2 11 4,6 470 1 2 3 2 3,0 507 3 1 1 8 5,0 512 1 2 0 3 2,8 545 2 1 6 10 3,9 557 2 1 6 2 3,1 587 3 1 1 4 3,3 589 3 2 2 3 2,6 590 1 1 0 2 2,7 616 3 2 0 3 3,8 621 3 1 0 3 3,0 653 1 1 1 3 3,4 Actualmente Calificaciones Edad Estatura Peso trabaja ICFES (años) (Cm) (Kg) 1 2 2 1 2 2 2 2 1 1 2 2 2 1 1 2 2 2 2 1 1 1 2 1 2 1 1 2 2 2 Página 76 de 177 360 320 330 280 320 320 325 280 310 270 290 310 320 310 310 380 280 280 400 300 310 310 310 270 300 270 280 265 290 280 20 20 18 22 16 24 20 23 17 15 26 22 20 21 17 20 16 17 24 20 17 20 17 21 32 17 19 19 17 23 158 170 174 155 170 172 169 178 174 165 171 172 168 166 174 165 166 148 165 164 174 171 171 168 160 165 168 156 171 178 48 70 78 60 72 69 66 82 83 60 66 80 70 64 83 58 58 46 60 70 83 59 64 60 65 59 71 54 82 82 665 669 721 747 748 761 771 825 873 876 923 933 936 943 976 982 1001 1017 1025 1037 2 3 2 2 1 3 3 2 1 3 1 1 2 3 3 3 3 2 2 3 1 2 1 2 2 1 1 2 2 2 1 2 2 2 2 1 1 1 1 2 1 1 3 2 3 3 1 8 3 6 1 3 3 2 0 0 3 5 1 0 2 1 4 2 2 5 1 2 5 2 3 10 10 6 3 6 5 2 2 2 3,2 4,0 2,6 4,0 3,3 4,1 2,8 3,7 4,2 4,0 4,2 2,8 2,8 3,8 3,8 3,0 3,1 3,8 3,2 3,3 2 1 1 1 2 2 1 1 2 2 1 2 2 2 2 2 2 2 2 2 Ubiquémonos en la barra de MENU, con el MOUSE aparecer la siguiente figura: 360 315 410 330 310 320 290 320 350 380 390 260 260 280 265 410 280 290 360 325 21 16 18 18 17 16 24 22 22 20 22 20 28 20 19 18 17 15 21 19 158 165 140 158 159 170 171 167 169 165 174 165 158 168 156 174 169 162 158 164 haciendo CLIC en HERRAMIENTAS Página 77 de 177 72 61 46 60 58 72 79 54 64 58 80 58 55 64 54 86 76 70 72 60 debiendo Figura No. 1. Microsoft Excel Al hacer CLIC en el submenú ANÁLISIS DE DATOS , debe aparecer la siguiente figura (Fig. 2): Figura No. 2. Funciones para análisis Con la figura No. 2, correspondiente a ANÁLISIS DE DATOS, procederemos a seleccionar una de las funciones, en nuestro caso la opción identificada como ESTADÍSTICA DESCRIPTIVA, luego al hacer CLIC en ésta y ACEPTAR debe aparecer la figura siguiente (Fig. 3): Página 78 de 177 Figura No. 3. Estadística Descriptiva Teniendo en cuenta la Figura No. 3 ESTADÍSTICA DESCRIPTIVA, se comienza el procesamiento de los datos. Recordemos que el RANGO DE ENTRADA es el correspondiente a la variable número de hermanos registrados en el Cuadro No. 1. En la misma figura anterior, aparecen unas opciones de salida, con alternativa de ser una HOJA NUEVA o en un LIBRO NUEVO. Además, aparecen: RESUMEN DE ESTADÍSTICAS; NIVEL DE CONFIANZA PARA LA MEDIA: 95% o cualquier otro valor establecido; K-ESIMO MAYOR y, finalmente, K-ESIMO MENOR, activando o haciendo CLIC en cada uno de ellos, En caso de considerar la obtención de un mayor número de resultados para el análisis. Al hacer CLIC en ACEPTAR, se obtiene la información, tal como puede observarse en la figura No. 4. Medidas Resultados Media Error típico Mediana Moda Desviación estándar Varianza de la muestra Curtosis Coeficiente de asimetría Rango Mínimo Máximo Suma Cuenta Mayor (1) Menor(1) Nivel de confianza (95.0%) 2,04 0,27547362 1,5 1 1,94789263 3,79428571 0,92539916 1,11511128 8 0 8 102 50 8 0 0,55358463 Figura No. 4. Resultados Para lograr los anteriores resultados en todas y cada una de las opciones (Resumen de estadísticas; nivel de confianza para la media, K-ésimo mayor y K-ésimo menor), deben señalarse. Los resultados de la figura No. 4, nos muestra un cuadro resumen con los valores de la Media, Error Típico; Mediana; Asimetría; Mínimo; Máximo; Suma; Conteo para la variable NUMERO DE HERMANOS. Página 79 de 177