Estadística Descriptiva
Anuncio

INSTITUTO TECNOLÓGICO MUNICIPAL
ANTONIO JOSE CAMACHO
ESTADÍSTICA DESCRIPTIVA
RUBEN DARIO CORRALES VELASCO
Estadístico - Esp. Admón. De Empresas
SANTIAGO DE CALI
2007
PROLOGO
Este texto es una ayuda para el estudiante, en su comprensión, facilidad y
aplicación de la ESTADÍSTICA DESCRIPTIVA.
Este texto espera brindar una guía para la exploración y el análisis de información,
sin recurrir a la rigurosidad de la probabilidad.
Gracias a las notas y conocimientos adquiridos en clases, a las que asistía, se ha
podido recopilar y presentar a ustedes este texto, además del aporte de algunos
textos y las notas de clase de Probabilidad y Estadística, dadas durante varios
semestres en diferentes tecnologías.
Se presenta inicialmente las aplicaciones de la Estadística, los conceptos básicos,
la guía metodológica de la investigación estadística y un repaso necesario de
algunos conceptos básicos de matemáticas.
Luego se introduce en la exploración de la información, a través de la tabulación,
graficación y reducción de los datos.
Gracias a la retroalimentación, esta segunda edición del texto espera nuevamente
su valiosa contribución, en el aporte de sugerencias y rectificaciones que puedan
brindar, para su mejoramiento.
A
Sandra Ximena y Luz Yoni
Un agradecimiento al Ingeniero Jairo Paneso, por su que hubo pues, y en especial
a los estudiantes que aportaron en clase a lo largo de cinco años y a los que
siguen aportando aún.
A las circunstancias, que me ha brindado el tiempo.
CONTENIDO
Pag.
I.
Introducción
II.
Áreas de Aplicación
III.
Terminología Básica en Estadística. Ejercicios
IV.
Etapas de la Investigación Estadística. Ejercicio
1.
Repaso de Sumatorias
1.1.
Algunas propiedades de las sumatorias.
1.2
Ejercicios
2.
Descripción de la información muestral
2.1.
Tabulación de datos caso atributos
2.1.1.Gráfico circular
2.1.2.Diagrama de Barras
3.
Distribución unidimensional de frecuencias
3.1.
Caso variable discreta
3.1.1.Función de distribución de frecuencias
3.1.2.Representación grafica
3.1.3.Función Empírica de Distribución Acumulada Relativa
3.1.4.Reducción de datos cuando la variable es Discreta
3.1.4.1.Medidas de tendencia central
3.1.4.1.1.La Media.
3.1.4.1.2.Propiedades de la Media.
3.1.4.1.3.La Mediana
3.1.4.1.4.La Moda.
3.1.4.1.5.La Media Geométrica
3.1.4.1.6.Cuartiles, Deciles y Percentiles
3.1.4.2.Medidas de dispersión
3.1.4.2.1.El Rango
3.1.4.2.2.La Varianza
3.1.4.2.3.Propiedades de la Varianza.
3.1.4.2.4.Desviación estándar y Regla empírica
3.1.4.2.5.Coeficiente de Variación
3.1.5.Medidas de deformación
3.1.5.1.Coeficiente de Asimetría
3.1.6.Medidas de apuntamiento
3.1.6.1.Coeficiente de Curtosis
3.2.
Caso variable continua
3.2.1Función de distribución de frecuencias
3.2.2.Tabulación de la Información.
3.2.3.Representación gráfica
3.2.4.Función empírica de densidad
3.2.5.Función empírica de distribución acumulada
3.2.5.1.Aplicaciones de esta función
3.2.6.Reducción de datos para variables continuas
3.2.6.1.Medidas de tendencia central
3.2.6.1.1.La Media
3.2.6.1.2.La Mediana
3.2.6.1.3.La Moda
3.2.6.2.Medidas de dispersión
3.2.6.2.1.La varianza muestral
3.2.6.2.2.Desviación estándar
3.2.6.2.3.Coeficiente de Variación
3.2.7.Coeficiente de Asimetría
3.2.8.Coeficiente de Curtosis
3.2.9.Percentiles
3.3.
Ejercicios
Bibliografía
I. INTRODUCCIÓN
La estadística es tanto una disciplina teórica como una herramienta práctica y
como toda ciencia cuantitativa, la estadística emplea las matemáticas como
lenguaje.
La teoría de la estadística está fuertemente ligada a la teoría de la probabilidad,
tanto que se puede decir que esta unión es indisoluble.
Vistas en detalle, las técnicas estadísticas son numerosas y variadas, pero en
suma constituyen un enfoque unificado, sistemático y lógico para el estudio de las
cuestiones humanas y del orden de la naturaleza.
En sus aplicaciones cotidianas, tales técnicas proporcionan a investigadores,
administradores y científicos, recopilaciones descriptivas resumidas de masas de
observaciones. Es decir, en la investigación una persona se encontrará a menudo
en la situación
de disponer de tantos datos, que le resulte difícil absorber la
información entera. Puede haber reunido por ejemplo 5.000 datos u observaciones
y preguntarse ¿Qué hago con todo esto?. Con tamaña información habría de
resultar excesivamente difícil, captar intuitivamente lo que los datos contienen.
En una forma u otra, la información ha de reducirse hasta que pueda verse y
analizar lo que ella contiene, resumiéndose con el empleo de medidas de cálculo,
tales como porcentajes, promedios, desviaciones estándar, coeficientes de
variación y correlación, etc.
Todos estos aspectos concernientes a la toma, organización, recopilación,
presentación y análisis de datos, se refieren a la Estadística Descriptiva, la otra
parte de la estadística, se interesa en dos tipos de problemas: La estimación de
los parámetros de la población y las pruebas de hipótesis, Estadística Inferencial
Técnicas Estadísticas.
Describen y Resumen una colección de datos con propósitos de análisis,
como es el caso de la Estadística Descriptiva.
Las técnicas que nos permiten tomar decisiones, en condiciones de
incertidumbre con base a unos cuantos datos representativos es la
Estadística analítica.
Los conceptos y las técnicas de la estadística se utilizan actualmente en muchos
campos, donde juegan un papel muy importante, constituyendo una parte integral
tanto de las actividades investigativas, de la recopilación de datos, como de sus
análisis,
originados
por
actividades
desarrolladas
por
instituciones
y
organizaciones.
Es posible que un trabajador no necesite conocer de la estadística sino, aquello
que lo faculte para saber cuando se requieren los servicios de un experto y para
poderse comunicar eficazmente con él, cuando trabajen juntos en la planeación,
dirección e interpretación de los resultados de una actividad que requiera la
metodología de esta ciencia.
El profesional que comprenda los conceptos estadísticos y su metodología sacará
mejor provecho de ellos. Este profesional estará preparado para evaluar los
resultados de una investigación y demás informaciones que se obtengan.
II. AREAS DE APLICACION
AGRICULTURA. Experimentos sobre reproducción de plantas y animales,
estudios de la bondad relativa de diversos fertilizantes, insecticidas, etc. Estudio
de métodos para aumentar el rendimiento de las cosechas, conocimiento de
aspectos económicos para la electrificación de granjas, estudio de métodos de
cultivo, distancia entre plantas, niveles de agua y nutrientes, el secado de granos,
definir si hay o no relación entre plantas y nivel de nutrientes, etc.
BIOLOGÍA. Se estudian las reacciones de las plantas y los animales ante
diferentes presiones ambientales y también para investigar la herencia.
NEGOCIOS. Se pueden predecir los volúmenes de ventas, medir las reacciones
de los consumidores ante los nuevos productos, tomar decisiones en cuanto a la
forma de invertir el presupuesto para publicidad y determinar el mejor método para
utilizar las habilidades y aptitudes de sus empleados. Con la planeación se mira al
futuro con los ojos del pasado, se hacen proyecciones de demandas con
información cuantitativa
y cualitativa, pues con base en ella se hará la
programación de la producción. Dicha demanda puede ser estimada con modelos
estadísticos de series de tiempo.
SALUD Y MEDICINA. Los resultados que se obtienen en las investigaciones sobre
fármacos se analizan por medio de los métodos estadísticos, para determinar la
efectividad de una vacuna, para determinar la etiología ó historia natural de una
enfermedad, determinando la interrelación entre el agente ó sea, quien la produce,
el ambiente ó sea, donde se produce y el huésped ó sea, en quien se produce, es
posible determinar cual etapa evitar.
La estadística proporciona la distribución de la enfermedad, en grupos con
diversas
características
socioeconómicas
(
Género,
edad,
condiciones
geográficas, raza, hábitos, etc), para así delimitar las condiciones ambientales y
del huésped, que conduzcan a la explicación de la historia natural de la
enfermedad.
Además hay leyes rigurosas para poder poner una droga en el mercado, debido a
los efectos colaterales, de ahí que haya que diseñar un experimento que
determine niveles de sensibilidad y la dosis adecuada que ataque la enfermedad y
no produzca molestias.
También se debe caracterizar la demanda del servicio de salud hospitalaria, es
importante conocer dicha distribución, ya que es muy variable a través del tiempo,
para así poder determinar los recursos humanos y físicos para su programación.
INDUSTRIA. La calidad es muy importante para las industrias, es factor de
competencia con la apertura de los mercados o globalización de los mercados, es
factor de riesgo de vida en alimentos y drogas.
Controlar el 100% es muy costoso y a veces imposible inspeccionar todo, se
puede diseñar un muestreo de confiabilidad, que arroje resultados confiables, en
las decisiones observando pocos elementos.
ECONOMETRIA. Con base en un modelo de regresión determinar las principales
características socioeconómicas que generen la inflación y como influye cada una
de ellas, al igual que determinar los indicadores económicos que definen el norte
en las empresas y en el gobierno.
ACTUARIAL. Se analizan los riesgos y frecuencias de muertes por grupos y
diferentes variables y así saber ¿cuánto cobrar por una póliza en un determinado
año según la edad?, como lo definen las empresas de seguros.
PSICOLOGÍA. Se mide y compara la conducta, las actitudes, la inteligencia y las
aptitudes del ser humano.
SOCIOLOGÍA. Se utiliza en estudios comparativos de diferentes grupos
socioeconómicos y culturales y en el estudio del comportamiento y las actitudes de
grupo.
INGENIERIA. En este campo y en el de todas las ciencias experimentales, el
empleo de valores estadísticos se hace necesario cuando se efectúan pruebas
rutinarias de laboratorio, al igual que en los trabajos de investigación de
producción y construcción.
Quizás se quiera saber si las pruebas son precisas ó si la variabilidad de los
resultados es mayor que lo esperado, o mayor que en cualquier otra prueba.
Tal vez de desee conocer si un cambio en los ingredientes afecta el resultado,
compara la eficacia de los procesos ó la eficiencia de la máquina.
El conocimiento de la variabilidad de las observaciones, causadas por un cierto
factor nos capacita para saber si en términos económicos, es conveniente
controlar más estrechamente ese factor.
III. TERMINOLOGÍA BASICA EN ESTADÍSTICA
Unidad Estadística: Es el elemento objeto de estudio en una investigación
estadística, por ejemplo, una persona, una familia, una vivienda, un producto
industrial, una fábrica, un árbol, etc.
Observación: Es el valor numérico ó el código asignado a cada característica, por
ejemplo, en la variable número de hijos una observación será 4 hijos, en la
variable ingreso una observación será $1´500.000.
Población: Es el conjunto de todos los posibles elementos que tienen una
propiedad común ó característica.
Muestra: Es cuando se toma solamente una parte bien seleccionada de la
población, la cual debe ser aleatoria y lo más representativa posible.
Muestreo estadístico: Es un método de investigación estadística, que consiste en
obtener resultados y conclusiones validos para la población con base en la
observación de una muestra; Se realiza un muestreo por los costos, imposibilidad
de hacer censo debido a que la población es infinita ó cuando la observación del
elemento implica su destrucción, también por tiempo y por mejor control y
supervisión del trabajo.
Tipos de muestreos: existen dos tipos de muestreos, el aleatorio y el no aleatorio,
entre los no aleatorios están el por conveniencia, el cual es muy sesgado, el de
selección intencional o de juicio, el cual lo hace un investigador de mucha
experiencia y conocimiento de la población en estudio, en algunos casos se logran
muestras muy representativas, el de bola de nieve, el de por cuota, etc.
Los muestreos aleatorios logran controlar el sesgo y el error de muestreo, la
selección de la muestra es al azar, brindando así la misma probabilidad a cada
elemento objeto de estudio de la población, de salir escogido en la muestra.
Por su procedimiento se difieren los muestreos aleatorios, como son: Muestreo
simple aleatorio y sistemático, si los elementos son homogéneos, pero si existe
alguna característica que los diferencie se recurrirá a el muestreo estratificado ó
por conglomerados. Se pueden combinar algunos muestreos en un mismo estudio
(procesos multietápicos).
Error de muestreo: Se produce solo en el muestreo, por la naturaleza aleatoria de
la muestra, lo cual hace que ésta no sea representativa de la población. Está dada
por la diferencia producida por el azar, entre la estimación hecha con base en la
muestra y el valor tomado de la población. Estos errores pueden cuantificarse y
pueden ser limitados en magnitud con muestras más grandes.
Sesgo: Son errores no debido al azar, que hacen que el resultado del muestreo
difiera del verdadero, es de naturaleza sistemática ó sea en el mismo sentido,
generalmente no son cuantificables y a lo sumo se pueden prevenir con medidas
de tipo administrativo al realizar la encuesta.
Algunos sesgos se pueden producir por que no se da respuesta a todas las
unidades de observación, el encuestador hace mal su trabajo, no se enumeran
bien los elementos, se escoge mal el tipo de muestreo y estimación, por errores de
cálculo, omisiones, etc.
Tipos de características a estudiar:
Cualitativas: Si sus observaciones corresponden a atributos o cualidades de
los objetos en consideración, por ejemplo, el estado civil, la preferencia por
un determinado partido político, el género, variedad de un árbol, sondeos
de opinión en general, las distintas alternativas de una variable cualitativa
se llaman Atributos.
Cuantitativas: Son aquellas que vienen dadas por mediciones y
observaciones numéricas en los objetos de interés, por ejemplo, El peso, la
edad, el ingreso, costo de construcción, cantidad de madera aprovechable,
etc.
Atributo:
Son
todos
aquellos
fenómenos
que
pueden
ser
descritos
cualitativamente, es decir, mediante palabras, por ejemplo, la clasificación de
alumnos del tecnológico por ciudad de origen, la clasificación de un grupo árboles
por su variedad, etc.
Variable: Son todas aquellas características ó fenómeno susceptibles de ser
expresados cuantitativamente, es decir mediante números, por ejemplo, el
diámetro de un árbol, el peso de una persona, el ingreso familiar, etc.
Dentro de las variables cuantitativas, se definen dos grupos:
Variables Discretas: tienen su recorrido numerable con valores enteros, que
no son divisibles en la unidad, por ejemplo: El Número de hijos por familia,
Número de personas que llegan a un banco en una hora pico, la producción
anual de camisas en una fábrica.
Variables continuas: Cuando existe un valor cualquiera en un intervalo ó
que sea divisible en la unidad, por ejemplo, El peso, la estatura, el ingreso
por familia.
Parámetro de una población: Es una constante numérica que actúa como
indicador, simbolizadas con letras griegas, que define una característica de una
población, por ejemplo, Si la característica de interés es el ingreso por familias,
entonces un parámetro ó constante de interés, que ayuda a definir es el Ingreso
Medio de la población.
Estadígrafo: Es una función numérica dada, evaluada por los datos de una
muestra, actúa como estimador y es simbolizada por letras latinas.
Fuente de información primaria: Es cuando se proporcionan datos originales de
información, producidos por ella misma, por ejemplo, El DANE.
Fuente de información secundaria: Es cuando se trabaja o resume información
publicada por otros, por ejemplo, Boletines informativos sobre Colombia de la
ONU, basados en datos del DANE.
Recolección de información: Es cuando se recopila o produce información no
existente, puede ser por Observación, por entrevista a informantes sobre los datos
de las unidades de observación, por correo y la de registro, como por ejemplo los
nacimientos, defunciones, matrimonios, comercio exterior, etc.
La información de los datos resultantes de las observaciones, se presenta en
diferentes tipos de escalas.
Escala nominal: Cuando se utilizan cualidades para generar categorías y estas no
generan un orden explícito, sólo se usan como una etiqueta, además, cuando se
trabaja en una base de datos se utilizan números para dar nombre o caracterizar
una opción o cualidad y estos números no generan un orden. Ejemplo, Definir cuál
es el color que más le gusta, 1 azul, 2 verde, 3 rojo, 4 amarillo.
Se debe tener presente que las operaciones elementales aritméticas no tiene
resultado lógico, por ejemplo si sumamos 1 + 2 (azul más verde) nos daría 3 que
no equivale a que sea rojo, por lo tanto como la operación aritmética de la suma
no tiene un resultado lógico para este caso, la variable es cualitativa y no
cuantitativa (aunque tenga números)
Escala ordinal: En este caso las categorías generan un orden explícito sirven para
comparar, si se usa una base de datos los números (o códigos) sirven para
nombrar como etiquetas las categorías y comparar.
Ejemplo, Cómo considera el triunfo de la selección Colombia, 1 muy pequeño, 2
pequeño, 3 medio, 4 grande, 5 muy grande, en este caso las operaciones
elementales aritméticas no tienen sentido lógico (por lo cual se define como
cualitativa aunque tenga números), pero las respuestas expresan un orden de
importancia.
Ejemplo, a una persona se le solicita dar valores en orden de importancia de 1 a 4,
al empleo, vivienda, salud y servicios públicos.
A una persona se le solicita dar valores en orden de importancia de 1 a 4, al
empleo, vivienda, salud y servicios públicos.
Escala de intervalo: Las opciones son valores numéricos y estos números se
pueden utilizar para hacer comparaciones de valores, el cero es un valor arbitrario
en una escala y no absoluto
Ejemplo, la temperatura en grados centígrados, si se tiene 0 grados de
temperatura no significa que hay ausencia de temperatura, sino que es un valor
arbitrario en la escala de la temperatura.
También se define que una variable que depende en su resultado de otras estaría
medida en escala de intervalo (adición o resta)
Ejemplo la utilidad es una variable medida en escala de intervalo puesto que ella
depende de dos variables para ser obtenida (ingresos menos egresos), si una
empresa tiene utilidad cero no significa que no hizo nada.
Escala de razón: igual que la escala de intervalos, pero el cero es un punto
natural, absoluto, además se puede expresar con sentido lógico la razón entre dos
valores, por ejemplo, la variable peso corporal, si una persona pesa 100 kilos y
otra persona pesa 50 kilos, tiene sentido decir que una persona es el doble de
pesada que la otra persona. El cero actúa como ausencia de la variable que se
mide, Ejemplo, se consulta el número de hijos por familia y una de las familias
podría decir que tiene cero hijos y significa que no tienen hijos en la familia
TIPOS DE PREGUNTAS
Preguntas abiertas, Se utilizan para expresar una situación o lo que se percibe,
este tipo de pregunta cuando se utiliza una base de datos requiere ser
recodificada
Ejemplo, ¿qué opina usted de la situación del dólar actualmente?
Preguntas dicotómicas, Se utilizan cuando ante una consulta, se requiere que se
de una respuesta de dos opciones posibles
Ejemplo, ¿Cuál es su género?, ¿Usted estudia o trabaja?
Preguntas de opción múltiple con una sola respuesta, Se utiliza cuando la consulta
de interés presenta varias opciones de respuesta, pero, solo una deberá ser
escogida
Ejemplo, ¿Cuál es su estado civil? 1. Casado, 2 Soltero, 3 Unión libre, 4
Separado, 5 Viudo
Preguntas de opción múltiple con múltiple respuesta, Se utiliza cuando la consulta
de interés presenta varias opciones de respuesta, donde todas o algunas o alguna
respuesta puede o pueden ser escogidas
Ejemplo, ¿Con qué tipo de negocio tiene relación comercial su empresa? 1 De
servicios, 2 De producción, 3 De comercio, 4 Otro ¿Cuál?_________
EJERCICIOS
1. Se tiene un embarque de 1000 cajas con 50 bombillas en cada una. Existe el
interés de conocer el número de bombillas defectuosas en cada caja, ¿cuál es
la población de interés?
2. En un día determinado se elaboraron 200 artículos promocionales y se
etiquetaron
como
bueno
o
defectuoso,
según
cumpliera
con
las
especificaciones o no, Describa la población de interés.
3. Las tarjetas de circuito impreso se montan con una combinación de montajes
manual y automatizado. Las tarjetas pasan por el proceso de soldado por flujo
casi continua y cada hora se toman cinco de ellas y se analizan con la finalidad
de controlar el proceso, registrando el número de defectos en cada muestra,
¿cuál es la población de interés?
4. Determine la población objetivo ó de interés, del diámetro de los terminales de
un fusible empleado en motores de aviones, el cual es una importante
característica de calidad. Un ingeniero tomó una muestra aleatoria de 25 de
estos terminales de los 1000 producidos en el último año, encontrando que el
99% cumplían con las condiciones de calidad.
5. Clasifique cada una de las siguientes variables, según el tipo, ya sean
cualitativas o cuantitativas (discretas o continuas) y según la escala de
medición.
La profundidad en la ranura de una pieza
No de botellas de plástico producidas en un proceso de moldeado
No de defectos observados en la producción de gabinetes para
computadores
Tipos de chips para circuitos integrados
Temperatura interna de un horno durante su uso
Tiempo que tarda un técnico para reparar una bomba
Desperdicio de hojas en la fotocopiadora
Tipos de defectos en tarjetas de circuito impreso
Elongación de una barra de acero bajo una carga en particular
Fabricantes de transformadores de alta en la ciudad
Duración de un transistor
Técnicas de mezclado de cemento tipo A
Cantidad de corriente en microamperios en un cinescopio
Contenido de titanio en una aleación para aviones
Aceptación de los clientes del servicio de mantenimiento de un taller
mecánico
Test de conocimiento de un cargo
IV. ETAPAS DE LA INVESTIGACIÓN ESTADÍSTICA
1. Definición del problema, justificación, objetivos, revisión bibliográfica, hipótesis
a probar.
2. Definición de la población de interés.
3. Determinar las variables de interés, definiendo las características de la
población que proporcionan la información necesaria para lograr los objetivos.
4. Diseño del estudio, definir si se realiza censo ó muestreo, en caso de ser
muestreo se tiene que definir el tipo, la logística, el tamaño de la muestra, el
error tolerable y el nivel de confiabilidad.
5. Recolección de la información, debe tenerse mucho control, pues los errores
cometidos aquí no se pueden medir estadísticamente, como son la medición, la
trascripción.
6. Procesamiento descriptivo de los datos, se elaboran cuadros y se grafica la
información, además se hallan indicadores, esta es una fase exploratoria.
7. Inferencia Estadística, Es el proceso inductivo que permite inferir sobre la
población, con base en los resultados del muestreo, con ayuda de la
probabilidad que cuantifica los errores y el nivel de confianza y los asocia a los
resultados minimizando la incertidumbre.
8. Conclusiones y planteamientos de nuevas hipótesis, las conclusiones deben
ser claras, mirando sus limitaciones y alcances, observar si con la exploración
de los datos podrían resultar nuevas hipótesis.
EJERCICIO
Plantee un problema de aplicación y defina los pasos a seguir, aplicando las
etapas de investigación estadística.
1.
REPASO DE SUMATORIAS
Es importante recordar algunos conceptos de sumatorias, para manejar algunos
conceptos y aplicaciones básicos de estadística.
Como se necesita sumar cantidades de valores, se utiliza una sumatoria,
representada por la letra griega sigma Σ.
Si se desease sumar los siguientes valores de una muestra:
X1 = 1, X2 = 2, X3 = 1, X4 = 2 y X5 = 0.
Entonces, se recurre a una sumatoria, para sumar los valores desde X 1 hasta X5,
de ahí que se necesite un subíndice i que se itere ó vaya cambiando desde 1
hasta 5, o sea que la sumatoria iría desde i = 1 hasta i = 5, que es la posición
máxima, equivalente a n.
n
Xi
i=1
=
5
Xi = X1 + X2 + X3 + X4 + X5 = 1 + 2 + 1 + 2 + 0 = 6
i=1
Observe que la variable Xi varía su valor de acuerdo al valor que tome el subíndice
i (valor de posición).
3
Xi
i=1
=
X1 + X2 + X3 = 1 + 2 + 1 = 4
4
Xi
i=2
=
X2 + X3 + X4 = 2 + 1 + 2 = 5
4
Xi2
i=2
=
X22 + X32 + X42 = 22 + 12 + 22 = 9
Suponga que se le adiciona al ejercicio frecuencias de cada valor que toma X ó
veces que se repite el mismo valor, por ejemplo F1 = 2, significa que el valor de X1
= 1 se encuentra dos veces en la muestra.
F1 = 2, F2 = 1, F3 = 3, F4 = 1 y F5 = 2.
Por lo tanto Fi se mueve al igual que Xi desde 1 hasta 5 y ambas variables
cambian de valor ó se iteran de acuerdo al mismo subíndice i, el cual varía de 1
hasta 5.
Hallar las siguientes sumatorias por ejemplo:
5
XiFi = X1F1 + X2F2 + X3F3 + X4F4 + X5F5 = 1x2 + 2x1 + 1x3 + 2x1 + 0x2 = 9
i=1
Observe que las variables Xi y Fi varían sus valores de acuerdo al valor que tome
el subíndice i (valor de posición).
4
XiFi = X2F2 + X3F3 + X4F4 = 2x1 + 1x3 + 2x1 = 7
i=2
3
Xi2Fi = X12F1 + X22F2 + X32F3 = 12x2 + 22x1 + 12x3 = 11
i=1
4
Xi2Fi2 = X12F12 + X22F22 + X32F32 + X42F42= 12x22 + 22x12 + 12x32 22x12= 21
i=1
4
(XiFi) 2 = (X2F2)2 + (X3F3)2 + (X4F4)2 = (2x1)2 + (1x3)2 + (2x1)2 = 17
i=2
4
(Xi2Fi) 2 = (X22F2)2 + (X32F3)2 + (X42F4)2 = (22x1)2 + (12x3)2 + (22x1)2 = 41
i=2
1.1. Algunas propiedades de las sumatorias.
La sumatoria de una constante desde 1 hasta n, es n veces la constante.
n
C = C + C + .…. + C = n C
i=1
La sumatoria de una variable afectada por una constante, es igual a la
constante por la sumatoria de la variable.
n
CXi = CX1 + CX2 + .…. + CXn = C (X1 + X2 + …… + Xn) =
i=1
n
C Xi
i=1
La sumatoria de una variable afectada de una combinación lineal con una
constante, es igual a la sumatoria de la variable más ó menos n veces la
constante.
n
(C + Xi) = (C + X1) + (C + X2) +.….+ (C + Xn) = X1 + X2 +……+ Xn + C +....+ C
i=1
n
= Xi + n C
i=1
n
(Xi - C) = (X1 - C) + (X2 - C) +.….+ (Xn - C) = X1 + X2 +……+ Xn - C – C -....- C
i=1
n
= Xi - n C
i=1
La sumatoria de una constante cuando la sumatoria comienza en una
posición diferente a 1, se define como:
n
C = (n – m + 1) C
i=m
1.2. Resuelva los siguientes ejercicios:
1.
Sean : X1=5, X2=4, X3=6, X4=0, X5=1 y F1=2, F2=3, F3=1, F4=2, F5=4
Halle:
5
a. Xi = 16
i=1
4
b. Xi = 10
i=2
5
c. (Xi)2 = 78
i=1
5
d. (Fi) (Xi) = 32
i=1
5
e. (Fi Xi)2 = 296
i=1
5
f. Fi(Xi)2 = 138
i=1
5
g. (Fi)2 Xi = 78
i=1
5
h. 9 (Xi) = 144
i=1
5
i. (9 + Xi) = 61
i=1
5
j. (Xi - 2) = 6
i=1
5
k. (Xi + 2) = 26
i=1
l.
5
9 = 45
i=1
4
m. 9 (Xi) = 90
i=2
5
n. 9 (Xi + 6) = 414
i=1
5
o. 9 (Xi - 2) 2= 306
i=1
5
p. (Xi - 2)/n = 1.2
i=1
5
5
2
q. (Xi + 5) / (Xi - 2) 2= 14.52
i=1
i=2
5
4
r. (Xi + 5) 3/ (Xi + 2) 2= 15.6928
i=2
i=1
2.
Escriba los términos de las siguientes sumatorias:
6
a. (Xi - i) =
i=2
4
b. (Xi +hi ) 2=
i=1
5
c. (Xi * hi + i ) 2=
i=1
3.
Exprese en forma de sumatoria los siguientes términos
( X1 + 2 )
2
+ ( X2 + 2 )
3
+ ( X3 + 2 )
4
2.
DESCRIPCIÓN DE LA INFORMACIÓN MUESTRAL
Se analizan situaciones de tipo muestral no poblacional.
Representación de la información por medio de tablas.
Representación de la información por medio de gráficos.
Representación de la información por reducción de datos.
2.1.
TABULACION DE DATOS CASO ATRIBUTOS
Se desea analizar el flujo turístico por nacionalidad, durante un mes en un hotel de
la ciudad de Cali, se toma una muestra de veinte personas, con la siguiente
información: C, M, P, A, M, B, P, C, V, A, M, P, B, B, V, V, M, V, A, M.
Donde A es Argentina, B Brasil, C Cuba, M México, P Perú y V Venezuela.
Distribución de Frecuencias del Flujo turístico por nacionalidad.
NACIONALIDAD
ARGENTINA
BRASIL
CUBA
MÉXICO
PERU
VENEZUELA
FREC ABS ni
3
3
2
5
3
4
FREC RELAT hi
0.15
0.15
0.10
0.25
0.15
0.20
Grados 0º
54
54
36
90
54
72
Grados: se utiliza para el diagrama circular, a través de una regla de tres simple,
como es
360º
20
¿?
Ni
ó utilizando un programa que tenga la opción de gráficos de pastel, torta ó circular.
2.1.1. Gráfico circular
FLUJO TURISTICO EN EL HOTEL X
15%
20%
Argentina
Brasil
15%
Cuba
Mexico
15%
Perú
10%
Venezuela
25%
Observe que el mayor flujo de turistas de otros países en dicho hotel, está a cargo
de mexicanos con un 25% y el menor por los cubanos con un 10%.
2.1.2. Diagrama de Barras
Comparación del flujo turístico por nacionalidad en el Hotel X en el
mes de octubre
5
4
3
2
1
0
Argentina
Brasil
Cuba
Oct-97
Mexico
Perú
Venezuela
Oct-98
Observe que se puede comparar un mismo periodo de una misma característica.
3.
DISTRIBUCION UNIDIMENSIONAL DE FRECUENCIAS
3.1.
CASO VARIABLE DISCRETA
3.1.1. FUNCION DE DISTRIBUCIÓN DE FRECUENCIAS
Sea la variable X : No de hijos por familia en un barrio de la ciudad, se toma una
muestra de tamaño 10, o sea (n = 10), obteniéndose los siguientes resultados:
{0,2,1,2,1,2,2,3,3,3}.
Esta información hay que tabularla, graficarla y hallar estimadores a través de una
reducción de datos.
TABLA DE LA DISTRIBUCIÓN DE FRECUENCIAS PARA EL No DE HIJOS POR
FAMILIA EN UN BARRIO DE LA CIUDAD.
Variable Xi
Frecuencia
Absoluta ni
Frecuencia
Relativa hi
X1= 0
X2=1
X3=2
X4=3
1
2
4
3
10 = n
0.1
0.2
0.4
0.3
=1
Frecuencia
Acumulada
Absoluta Ni
1
3
7
10
Frecuencia
Acumulada
Relativa Hi
0.1
0.3
0.7
1.0
La Frecuencia Absoluta (ni), se determina por el número de veces que se repite un
valor específico de la variable, para el caso n 2= 2, es que en la muestra se
encontraron dos familias que tienen de un hijo.
La Frecuencia Relativa (hi), se determina por el número de veces que se repite un
valor específico ( frecuencia absoluta), sobre el total de la muestra, h i = ni / n, para
el caso h3 = 0.4 = 4 / 10 = 40%, o sea, que el 40% de las familias de la muestra en
el barrio de la ciudad, tienen 2 hijos.
La Frecuencia Absoluta Acumulada (Ni), se determina por la acumulación de las
Frecuencias Absolutas hasta un valor específico de la variable, para el caso N 2=3,
= n1 + n2 = 1 + 2 = 3, o sea, que en la muestra se encontraron tres familias que
tienen a lo sumo un hijo, ó que se encontraron tres familias que tiene entre cero
hijos y un hijo.
La Frecuencia Relativa Acumulada (Hi), se determina por la acumulación de las
Frecuencias Relativas hasta un valor específico de la variable, ó se determina por
el número de veces que se repite un valor específico acumulado ( frecuencia
absoluta acumulada), sobre el total de la muestra, Hi = h1 + h2 + ...+ hi = Ni / n para
el caso H3 = 0.7 = h1 + h2 + h3 = 0.1 + 0.2 + 0.4 = N3 / n = 7 / 10 = 0.7, o sea, que
en la muestra se encontró que el setenta porciento de las familias tienen a lo sumo
dos hijos, ó que se encontró que el setenta porciento de las familias tiene entre
cero hijos y dos hijos.
Deducciones:
k
ni = n, donde k = No de valores distintos que toma la variable X.
i =1
k
hi = 1
i =1
j
Nj = ni
i =1
ijk
k
Nk = ni = n
i =1
j
Hj = hi
i =1
ijk
k
Hk = hi = 1
i =1
hi = ni / n
Hi = Ni / n
Los ni y los Ni son números naturales incluyendo el cero, los hi y los Hi están entre
cero y uno.
3.1.2. REPRESENTACIÓN GRAFICA
Diagrama de Barras, donde el eje Y corresponde a 3 / 4 del eje X y se realiza con
las frecuencias absolutas y relativas en el eje Y, contra los valores que toma la
variable X, que se tabulan sobre el eje X.
Diagrama de Frecuencias Acumuladas donde el eje Y corresponde a 3 / 4 del eje
X y se realiza con las frecuencias absolutas y relativas Acumuladas en el eje Y
contra los valores que toma la variable X, los cuales se tabulan sobre el eje X.
Diagrama circular, de torta ó de Pastel, representa las frecuencias relativas y se
construye de la siguiente manera:
360º = n
ó
360º = 1.0
¿? º = ni
¿? º = hi
Gráfico de Barras de la muestra tomada en un barrio de la ciudad sobre el número
de hijos por familia, donde en el eje Y están los valores de n i Frecuencia absoluta.
No de hijos por familia en una
muestra de un barrio de la ciudad
No de familias
5
4
3
2
1
0
0
1
2
No de hijos por familia
3
Diagrama de Frecuencias Acumuladas, donde en el eje Y están los valores de Ni.
Hi
1.0
0.7
o
o
0.3
0.1
o
0
0
1
2
3
X (No hijos / familia)
3.1.3. Función Empírica de Distribución Acumulada Relativa
H*(X) =
0
si
X X1
Hi
si
Xi X X(i + 1)
1
si
X Xk
Para el ejercicio estaría definida como :
H*(X) =
0
si
X 0
0.1
si
0 X 1
0.3
si
1 X 2
0.7
si
2 X 3
1
si
X 3
Obsérvese un ejemplo de aplicación, supóngase que se está interesado en saber,
que porcentaje de familias tiene a lo sumo 2 hijos.
O sea, que se desea saber H*(2), donde X = 2, se observa en la función empírica
de Distribución acumulada ¿dónde está contenido X = 2? y se define que está
contenido en el intervalo 2 X 3, donde se tiene que H*(2) = 0.7, por lo tanto, el
número de familias que tienen a lo sumo 2 hijos es el 70% de la muestra.
Si se desease saber que porcentaje de familias tienen entre uno y dos hijos, se
tendría que hallar: H*(2) – H*(1) = 0.7 – 0.3 = 0.4, o sea, que el 40% de las
familias en la muestra tienen entre dos y un hijo.
3.1.4. ¿Ahora cómo reducir datos cuando la variable es Discreta?
A través de la localización o centramiento, de la dispersión, deformación ó
Asimetría y del Apuntamiento ó achatamiento ó curtosis.
Las características que sirven para definir una distribución son:
Medidas de Localización ó de Tendencia Central, ó de ubicación, tales
como
La Media ó Media Aritmética, Media Geométrica
La Mediana
La Moda
Deciles, Percentiles y Cuartiles.
Medidas de Dispersión, tales como
El Rango
La Varianza Muestral
La Desviación Estándar
Coeficiente de Variación
Medidas de Formación tal como
El coeficiente de Asimetría
Medidas de Apuntamiento
El Coeficiente de Curtosis
3.1.4.1.
3.1.4.1.1.
MEDIDAS DE TENDENCIA CENTRAL
La Media. Es el valor promedio de un grupo de datos y es
equivalente a sumar todos los datos y dividirlos por el número de ellos.
Se representa como parámetro de una población con la letra griega miu ( ) y
como estadígrafo ó estimador en una muestra por la letra X con una barra ( X ).
n
Xi
i=1
X = ------------n
Si se tienen frecuencias será :
k
Xi ni
i=1
X = ------------n
k
= Xi hi
i=1
3.1.4.1.2.
Propiedades de la Media.
1. La suma de las desviaciones de los datos con respecto a la media debe ser
cero.
(Xi – X) = 0
2. Si todos los valores de los datos X1, X2, X3,........., Xn, son iguales a una
constante k, entonces la Media será igual a esa constante k.
Si
Xi = k
X=k
Por ejemplo, si todos los niños del grado cero en la escuela Honorio
Villegas tienen cinco años, entonces el promedio de edad del salón de
grado cero de la escuela Honorio Villegas será cinco años.
3. Si todos los datos de una muestra se multiplican por una misma constante
el promedio resulta multiplicado por la misma constante.
Si
Y = a Xi
Y = a X
Por ejemplo, si el salario promedio de los trabajadores de una empresa es
cuatrocientos mil pesos en el año 2000, al hacer un aumento del 10% en el
año 2001 a cada uno de los trabajadores, el nuevo salario promedio en
dicha empresa para los trabajadores será igual al salario promedio del año
anterior por el incremento del 10%, en este caso la constante sería el 10%.
4. La Media de una combinación lineal es igual a la Media de cada una de las
combinaciones.
Si W = X + Y
W =
X + Y
Por ejemplo, si en su familia usted y su compañera (o), generan el ingreso
familiar, entonces el ingreso promedio de su familia, será igual al ingreso
promedio suyo más el ingreso promedio de su compañera (o).
5. La Media de una muestra de tamaño n, es igual a la Media ponderada de
las Medias de las r-submuestras mutuamente excluyentes de la muestra
original, tomando como ponderaciones los tamaños de las r-submuestras.
X=
n1 X1 + n2 X2 + n3 X3 + ............. + nk Xk
------------------------------------------------------------n
Por ejemplo, si en un salón del tecnológico de treinta estudiantes, la nota
promedia de matemáticas del salón es 3.5 y la nota promedia de las
mujeres de ese salón es 3.9 y la nota promedia de los hombres de ese
mismo salón es 2.4. ¿Cuántos hombres y cuántas mujeres hay en dicho
salón?.
Como hay dos incógnitas, se tendría que solucionar por un sistemas de
ecuaciones y para que halla una solución optima se necesitarían dos
ecuaciones.
Ecuación 1 :
n=H+M
Ecuación 2 : Utilizaríamos la propiedad 5
XM M +
XH H
XT = ---------------------------------n
Se despeja una de las dos incógnitas de la ecuación 1 y se reemplaza en la
ecuación 2. ( Usted la puede resolver por el método que desee).
Aquí se resolverá por sustitución.
M = n - H
XM ( n - H)
+
XH H
XT = ---------------------------------n
XT * n =
XM ( n - H)
+
XH H
Se destruyen los paréntesis
XT * n =
XM * n - XM * H
+
XH * H
Se reemplazan los valores y se despeja la incógnita H.
3.5 * 30 = (3.9 * 30) - (3.9 * H) + (2.4 * H)
105 = 117 - 3.9H + 2.4H
105 - 117 = - 1.5 H
-12 = -1.5H
H = -12 / -1.5
H=8
O sea, que el número de hombres en el salón es ocho y el número de
mujeres será :
30 – 8 = 22.
Ahora se puede averiguar, a través de la aplicación del concepto ¿cuál es el valor
promedio ó la Media del número de hijos por familia en un barrio de la ciudad?.
Se recurre a la tabla de frecuencias del número de hijos por familia en un barrio de
la ciudad, recuérdese que se tienen frecuencias, por lo tanto la solución se puede
hallar utilizando cualquiera de las siguientes formulas:
k
Xi ni
i=1
X = ------------n
=
k
Xi hi
i=1
Por la primera ecuación se tendría:
4
Xi ni
i=1
----------n
=
(0*1) + (1*2) + (2*4) + (3*3)
19
------------------------------------ = ----- = 1.9
10
10
Por la segunda ecuación se tendría:
4
Xi hi
i=1
=
(0*0.1) + (1*0.2) + (2*0.4) + (3*0.3) = 1.9
O sea, que el promedio de hijos por familia en un barrio de la ciudad es 2.
Obsérvese, que el promedio dio 1.9, pero como es una variable discreta su
interpretación se asume como un valor entero.
3.1.4.1.3.
La Mediana. Representa el valor de la mitad de los datos, o sea el
50%. Su notación es Me. La cantidad de datos que están por encima de dicho
valor es el 50% de los datos que es la misma de la que está por debajo, el otro
50% de los datos.
Se puede hallar con la Frecuencia Relativa Acumulada buscando en ella el 50% ó
con la Frecuencia Absoluta Acumulada de la siguiente forma:
Si el número de datos es impar será :
Me = X ((n + 1)/2), donde el término ((n + 1)/2) define la posición en que se encuentra
la mediana y X el valor de esa posición.
Si el número de datos es par será :
Me = (X ((n/2) + 1) + X (n/2))/2
Para este caso como n = 10, es par, por lo tanto la Mediana en esta situación será
= (X ((n/2) + 1) + X (n/2))/2
Primero se busca las posiciones que interesan:
(n/2) = 10/2 = 5
(n/2) + 1 = 5+1 = 6
Ahora en la columna de Frecuencias absolutas acumuladas se busca que valores
contienen dichas posiciones.
Frec. Abs. acum..
1
3
7
10
Obsérvese que las posiciones 5 y 6 están contenidas en el 7, ya que en él están
contenidas las posiciones 4, 5, 6 y 7.
Ahora bien los valores de X, para estas dos posiciones es 2, por lo tanto la
Mediana será igual a:
2 + 2
Me = ----------- = 2
2
Si se resuelve con la Frecuencia Relativa Acumulada se observa que el 50% está
contenido en H3 = 0.7, ya que en él están contenidos los valores 0.4, 0.5, 0.6 y 0.7,
este valor H3 corresponde al valor de X = 2, o sea que la Mediana es 2.
Interpretando este resultado se tiene que en ese barrio de la ciudad el 50% de las
familias tienen dos hijos ó más y el otro 50% tienen entre dos hijos ó menos.
Nótese que al tomar los valores de la tabla de frecuencias ya se tienen ordenados
los datos de menor a mayor.
Es importante anotar que cambios irrelevantes en una muestra pueden producir
grandes cambios
en
un
indicador, lo
cual ocasionaría
interpretaciones
equivocadas, este caso ocurre en particular con la Media, cuando la distribución
es asimétrica, o sea que cuando hay unos pocos valores muy grandes ó muy
pequeños, la Media se afecta por ellos y la Mediana en este caso es un indicador
que no se afecta por los valores extremos.
Véase el siguiente ejemplo, los salarios semanales por empleado de una empresa
tienen la siguiente distribución:
Salario semanal
Porcentaje de personas
(Xi) $
(hi) %
10.000
20
12.000
10
13.000
25
15.000
40
120.000
5
-------------100%
Para tener una idea de la magnitud de los salarios a través de un indicador
adecuado, obsérvese lo que ocurre con la Media y la mediana.
k
X = Xi hi = (10.000*0.2) + (12.000*0.1) + (13.000*0.25) + (15.000*.4)
i =1
+(120.000*0.05) = $ 18.450
Este valor es superior al 95% de los datos, por lo cual no es un adecuado
indicador, para representar esta muestra.
Me = 50% de la Frecuencia relativa Acumulada, como se tienen frecuencias
relativas simplemente se acumulan y así saber donde se encuentra el 50%,
0.2 + 0.1 + 0.25 = 0.55, luego entonces aquí estaría contenido el 50%, de ahí se
tiene que:
Me = $ 13.000 que si es un indicador más representativo de esta muestra.
3.1.4.1.4.
La Moda. En los datos de una muestra es aquel que tiene la mayor
frecuencia, con lo cual se denominaría moda absoluta, en caso de que exista más
de un valor con la mayor frecuencia se denominará Multimodal, si es una será
unimodal y si son dos será bimodal y así sucesivamente. Su notación es Mo.
La Moda en el número de hijos por familia será X = 2, ya que la frecuencia
absoluta más alta es 4, o sea, que el número de hijos por familia más frecuente en
ese barrio de la ciudad es 2.
3.1.4.1.5.
La Media Geométrica. Define un valor promedio de una muestra de
datos, que tengan la característica de tener un comportamiento de progresión
geométrica (Tasas de crecimiento), su notación es Mg.
Se halla en forma general de la siguiente forma:
Es la raíz n-ésima de la multiplicación de los n valores
n
Mg
= X1 * X2 * ......* Xn ,
donde los Xi son los valores a promediar
Si se tienen frecuencias sería:
n
Mg
= X1
n1
* X2 n2 * ......* Xn nk
, donde n1 + ……. + nk = n
Si son valores continuos se utiliza Mi ( Marca de clase) por los Xi.
Por ejemplo si se desease saber el crecimiento de US $ 1.000 en depósito en una
cuenta de ahorro al cabo de cinco años.
AÑO
TASA DE
INTERES
ANUAL %
7
8
10
12
18
1
2
3
4
5
El factor de crecimiento
FACTOR DE
CRECIMIENTO
ANUAL
1.07
1.08
1.1
1.12
1.18
AHORROS AL
FINAL DEL AÑO
$
1.070,0000
1.155,6000
1.271,1600
1.423,6992
1.679,9650
Tasa de interés
= 1 + -------------------------100
Calcular el factor de crecimiento más adecuado.
Como es un promedio se hará con la Media y la Media Geométrica, para observar
su diferencia
k
Xi ni
i=1
X = -------------n
=
1.07 + 1.08 + …. + 1.18
-------------------------------5
= 1.11
5
Mg
= 1.07 * 1.08*….. *1.18 =1.109327
Como se está hallando un valor futuro al quinto año de 1.000 dólares, se recurre a
la fórmula financiera de valor futuro.
F = P ( Factor de crecimiento promedio ) 5
Se hallará el valor futuro con los dos promedios y así determinar cual es el más
apropiado.
F = 1.000( 1.11 )
5
F = 1.000( 1.109327 )
= 1.685,068
5
= 1.679,956
Con lo cual se puede observar que el promedio más adecuado cuando se trabaja
con tasas es la Media Geométrica.
Cuando se requiera encontrar la tasa anual de cambio de un periodo a otro,
teniéndose la información de los periodos tanto inicial como final se recurre a la
siguiente fórmula
MG = n
Valor .al. final .del . periodo
1
Valor .al. principio .del . periodo
3.1.4.1.6.
Cuartiles, Deciles y Percentiles. Los cuartiles se definen, para
repartir proporcionalmente una distribución de frecuencias en cuatro partes.
Se denomina Q1 al primer cuartil y equivale al 25% de los datos, Q2 al segundo
cuartil y equivale al 50% de los datos y es el valor también equivalente a la
Mediana el tercer cuartil es el equivalente al 75% de los datos y se denomina Q3 y
el último cuartil Q4 es el equivalente al 100%, ahora bien los deciles resultan de
repartir la distribución de frecuencias pero esta vez es diez partes y se denominan
por la letra D.
El Percentil P(n), es el área bajo la curva de un valor específico porcentual, se
utiliza con frecuencias absolutas ó relativas pero acumuladas y se halla como una
función empírica de distribución acumulada.
Se puede resolver cada caso con una fórmula específica, o sea, una para
cuartiles, otra para deciles y otra para percentiles, pero el cuartil 1 es igual al
percentil 25 y los otros cuartiles tendrán también su equivalente, lo mismo es con
los deciles, por ejemplo el decil 2 es el percentil 20 y así también los otros deciles.
Por lo tanto se sugiere aprender hallar los percentiles y se realiza luego su
equivalente.
PERCENTILES.
Para el caso discreto es equivalente al porcentaje acumulado, por ejemplo en el
ejercicio del número de hijos pro familia en un barrio de la Ciudad, el primer cuartil
es el percentil 25, que es equivalente al 25%, por lo cual el valor que contiene el
25% es X2 = 1, por lo tanto el primer cuartil es que tengan 1 hijo por familia ó
menos en ese barrio de la ciudad, si fuese el quinto decil, sería equivalente al
percentil 50, o sea al 50%, si se observa la tabla X3 = 2 contiene el 50%, de ahí
que el 50% de las familias de ese barrio de la ciudad tiene 2 hijos ó menos.
3.1.4.2.
3.1.4.2.1.
MEDIDAS DE DISPERSIÓN
El Rango. Mide la amplitud en una muestra ó la dispersión de los
valores extremos únicamente.
Rango = Valor Máximo - Valor Mínimo
Para el caso de la muestra del número de hijos por familia en un barrio de la
ciudad, el Rango será = 3 – 0 = 3, por lo cual diferencia entre la familia que más
hijos tiene y la que menos hijos tiene es de 3.
3.1.4.2.2.
La Varianza. Mide la variabilidad de una muestra, pero en la practica
se utiliza para hallar la desviación estándar, que es la medida de dispersión más
importante. Cuando es un parámetro, o sea de la población, se denomina como
y si es un estadígrafo ó estimador se denomina como S
forma general:
1
2
S =
----n
n
(Xi – X)2
i=1
Si se cuenta con frecuencias la forma sería:
2
S =
k
ni (Xi – X)2
i=1
----------------------------n
ó
2
S =
k
hi (Xi – X)2
i=1
2
2
y tiene la siguiente
Para cálculos se trabaja con :
2
S =
k
Xi2 ni
i=1
--------------------n–1
n X2
–
-------------n-1
si n 30
y con :
k
Xi2 ni
i =1
--------------n
2
S =
-
X2
si n 30
3.1.4.2.3.
Propiedades de la Varianza.
Siendo X una característica numérica,
1. Si todos los datos de una muestra son iguales ó constantes su varianza
será cero.
S2 ( K ) = 0
2. La varianza siempre es mayor o igual que cero ó sea, no negativa.
3. Si una muestra tiene por varianza S
2
y cada dato de la muestra se
multiplica por una constante K, la nueva varianza será igual a la constante
al cuadrado por la varianza anterior.
2
2
2
2
S ( X ), para Xi, si Y = K * Xi , entonces S ( Y ) = K * S ( X )
4. Si todos los datos de una muestra se le suma la misma constante, o sea
que si cambian los datos de origen, la varianza sigue siendo la misma.
Si Xi tiene por varianza a S2 , entonces la varianza de (Xi + K ) será S2 ,
S
2
(X+k) =S
2
(X)+S
2
( k ), como la varianza de una constante es
2
cero, entonces queda igual a S ( X ).
3.1.4.2.4.
Desviación estándar. Mide cuanto se desvían los datos con
respecto a la media, y se denomina si es un parámetro, sino S si es un
estimador ó estadígrafo, se halla simplemente sacando la raíz cuadrada a la
varianza.
Para el caso del número de hijos por familia en un barrio de la ciudad, se desea
saber cual es su variabilidad y que tanto se desvían los datos de la Media.
Se halla primero la Varianza y luego su Desviación estándar.
k
Xi2 ni – n X2
i=1
----------------------------n-1
2
S =
Donde
Y
X2 = (1.9) 2 = 3.61
k
Xi2 ni = (02 * 1) + (12 * 2) + (22 * 4) + (32 * 3) = 45
i =1
45 – 10 (3.61)
2
8.9
de ahí se tiene que S = ------------------ = --------- = 0.99
9
9
que es la variabilidad general de la muestra y su desviación estándar será:
S = 0.994
Por lo tanto los datos se desvían 0.994 con respecto al promedio, según
Tchebycheff se puede generar un intervalo con centro en la Media y los extremos
se forman aumentando y quitando la desviación estándar k-veces, para definir que
2
% de los datos está contenido en dicho intervalo, a través de (1 – (1/k )) = %.
Con base en la regla empírica (cuando la distribución de los datos tenga forma de
campana) la mayoría de los datos (68%) estarán alrededor de la media a una
desviación de diferencia:
1.9 (+/-) 0.994
= 2.894 ; 0.906
Luego entonces la mayoría de familias tiene entre 3 y 1 hijo en ese barrio de la
ciudad.
Así mismo la gran mayoría el (95.5%) de los datos estarán a dos desviaciones de
diferencia de la media y la gran totalidad ó nuevamente la gran mayoría (99.7%)
de los datos estarán alrededor de la media a una diferencia de tres desviaciones.
Observemos una aplicación de la regularidad empírica, una muestra tiene media
40, varianza 16 y distribución simétrica acampanada. Esto significa que:
Responda falso o verdadero justificando la respuesta.
¿Aproximadamente el 99.7 de los datos están entre 38 y 42?
La desviación es 4, como el 99.7% son tres desviaciones, entonces sumamos y
restamos tres desviaciones a la media, 40 + 12 =52 y 40-12 = 28, por lo cual se
comprueba que es falso.
¿Entre 38 y 48 hay más del 75% de los datos?
Si a la media le sumamos dos desviaciones queda 48, y dos desviaciones
pertenece al intervalo del 95.5%, como solo se sumo sería la mitad de 95.5% que
sería 47.75%, ahora observemos el otro valor, si le restamos una desviación a la
media 40 – 4 = 36, estaría en la mitad del intervalo del 68% que es 34% pero
como no se le resta sino la mitad de la desviación sería solo 17%, ahora sumemos
los dos resultados, 47.75 + 17 = 64.75%, por lo tanto en ese intervalo no hay más
del 75% de los datos.
¿El valor aproximado para el percentil 84 es 44?
Un percentil es el valor porcentual acumulado desde 0% hasta el 84%, el valor 44
resulta de sumar una desviación a la media, por lo cual se estaría en el intervalo
alrededor de la media con una desviación de diferencia, que equivale al 68%, pero
como se está sólo sumando, sería la mitad 34%, ahora como la distribución es
acampanada y simétrica, entonces la media estará en la mitad de la distribución, o
sea, en el 50% de la distribución, luego entonces 50 + 34 será 84%.
¿El valor aproximado hasta el que se acumula el 97.75% de los datos es 55.?
De forma similar al punto anterior, para hallar el percentil el intervalo con dos
desviaciones sería el 95.5%, más el 2.25% inicial daría el 97.75%, luego entonces
el valor a busca es la media más dos desviaciones, 40 + 8 = 48 y no 55.
Realiza este ejercicio de aplicación. Para el rector de una universidad, los puntos
obtenidos por los aspirantes en las pruebas de admisión constituyen una variable
aleatoria con polígono de frecuencias relativas que sugiere una distribución
simétrica y en forma de campana. A su juicio la proporción de estudiantes que
obtienen más de 400 puntos es 0.0225 y además la proporción de estudiantes que
obtienen más de 370 puntos es 0.17. ¿Cuáles son la media y la desviación
estándar en esta prueba?.
3.1.4.2.5.
Coeficiente de Variación. Mide la variabilidad relativa de una
muestra porcentualmente. Se denomina por CV y se halla de la siguiente forma:
S
CV (%) = _____ x 100%
X
Para el caso del número de hijos por familia la variabilidad relativa es:
0.994
CV = --------- * 100% = 52.3 %
1.9
Que se considera heterogénea, lo cual es debido al tamaño tan pequeño de la
muestra, para poder tomar decisiones hacia el futuro hay dos opciones cuando los
datos son heterogéneos, uno aumentar la muestra y la otra es, si es lo
suficientemente grande, entonces es escoger otra muestra.
Al tener que compararse dos muestras, para escoger una de las dos, se escogería
la de menor coeficiente de variación.
Es importante tener en cuenta el coeficiente de variación, por que para hacer
trabajos posteriores y de estimación con base en el promedio de una muestra
anterior, la confiabilidad y el poderla utilizar depende en gran parte de la
homogeneidad de los datos.
Muchos autores consideran homogeneidad por debajo del 15%, aunque
dependiendo de la variable se puede considerar ó asumir hasta un 20%.
3.1.5. MEDIDAS DE FORMACIÓN
3.1.5.1.
Coeficiente de Asimetría. Define una de las propiedades físicas de
las distribuciones, para definir la Simetría de cualquier distribución sea continua ó
discreta se consideran dos criterios:
1. El que involucra La Media, La Moda y La Mediana, y que establece que si
los tres indicadores son iguales, entonces la distribución se considera como
Simétrica.
Si la Moda es menor que la Media, entonces la distribución es Asimétrica
positiva y si la Moda es mayor que la Media, entonces la distribución es
Asimétrica negativa.
Este criterio se aplica a distribuciones unimodales.
La Mediana siempre se considera entre La Media y La Moda.
2. Este segundo criterio se apoya en el coeficiente de Asimetría, que se
denomina g1 y está definido por :
k
g1 =
3
((Xi – X) / S)
* hi
i=1
Para datos sin agrupar, con S desviación estándar de la muestra, X la Media de
la muestra, hi la frecuencia relativa de cada Xi observación diferente que toma la
variable.
Si es con datos agrupados, solamente es cambiar los Xi por sus Marcas de Clase
Mi.
Si g1 = 0, la distribución es Simétrica, si g1 es mayor que cero (0) la distribución
será Asimétrica positiva y si g1 es menor que cero (0) la distribución será
Asimétrica negativa.
También se puede utilizar la siguiente fórmula:
3 (Media – mediana)
CA : ___________________
(Desviación estándar)
Este coeficiente estará entre –3 y +3, si es 0 es simétrica y si da (+) será
asimétrica positiva ó con sesgo positivo, por lo tanto si es (-) será asimétrica
negativa ó con sesgo negativo.
Simétrica
Asimétrica Positiva
Asimétrica negativa
3.1.6. MEDIDAS DE APUNTAMIENTO
3.1.6.1.
Coeficiente de Curtosis. Define
si la distribución es achatada,
puntuda ó normal en su forma de campana.
Se define por:
k
g2 =
4
((Xi – X) / S)
* hi
i=1
El criterio se basa en Ec, donde Ec = g2 – 3
Si Ec = 0 La distribución tiene apuntamiento normal ó Mesocúrtica, si Ec es menor
que cero (0), entonces es de apuntamiento bajo
ó inferior a lo normal, es
achatada ó Platicúrtica, si el Ec es mayor que cero (0), la distribución será puntuda
ó con apuntamiento excesivo mayor que el normal ó leptocúrtica.
En este criterio se sigue teniendo en cuenta que la distribución patrón de
normalidad, la deben tener la misma Media y la desviación estándar.
Mesocúrtica
Platicúrtica
Leptocúrtica
EJERCICIOS
2. Responda Falso o verdadero Justificando la respuesta.
a. La media de una muestra divide siempre a los datos en dos partes, la mitad
con valores mayores y la otra valores menores que aquella.
b. Una media de tendencia central es un valor cuantitativo que describe la
variabilidad de los datos con respecto a un valor central.
c. Algunas veces la suma de los cuadrados de las desviaciones con respecto
a la media, es negativa.
d. En cualquier distribución, la suma de las desviaciones con respecto a la
media es igual a cero.
e. La desviación estándar del conjunto de valores, 2, 2, 2, 2 y 2 es 2.
f. En un examen, la calificación de Carlos ocupa el percentil 50 y la de
Guillermo el percentil 25; por lo tanto la calificación de Carlos es dos veces
la de Guillermo.
g. En una distribución normal (en forma de campana), la amplitud es
aproximadamente igual a seis desviaciones estándares.
3. Responda y justifique la respuesta
La empresa XY vende fuentes de energía y de las últimas 100 fuentes
vendidas, 4 eran de 20 kv; 39 de 30 kv; 20 de 50 kv; 29 de 70 kv y 8 de 100 kv.
¿Qué medida de tendencia central permite resumir los datos más
objetivamente?
Resuelva los siguiente ejercicios
3. Entre los clientes de una empresa de mantenimiento, se tomó una muestra de
50 clientes, para observar el número de virus que han atacado su equipo en un
mes, con el propósito de estimar algunos indicadores sobre demanda potencial
de servicio. Esta arrojó los siguientes resultados por cliente:
1
2
3
1
2
4
3
1
3
2
1
2
1
3
1
3
0
1
0
2
3
0
1
2
2
1
4
3
2
1
4
2
3
1
2
0
1
3
2
2
4
2
3
3
2
0
2
4
2
0
a.
¿Cuál es la variable de interés?
b.
¿Qué tipo de variable es y su escala de medición?
c.
¿Cuál es la población de interés?
d.
¿Cuál es la muestra?
e.
Haga una tabla de frecuencias e interprete algunos de los resultados
4. En la empresa de mantenimiento de computadores Guilena Ltda.. Se consultó
a 50 clientes, sobre la calidad del servicio de atención, con los siguientes
resultados (Donde: 1 es muy insatisfecho, 2 Insatisfecho, 3 Satisfecho y 4 Muy
Satisfecho).
2
1
2
1
4
4
3
3
3
4
4
4
3
3
3
3
2
2
3
2
2
2
2
3
3
1
3
2
4
3
2
2
2
3
2
3
3
1
1
4
2
2
3
3
2
3
2
1
4
2
a. ¿Cuál es la variable de interés?
b. ¿Qué tipo de variable es y su escala de medición?
c. ¿Cuál es la población de interés? ¿Cuál es la muestra?
d. Haga una tabla de frecuencias e interprete algunos de los resultados
e. Realice los gráficos pertinentes a los ejercicios 3 y 4
5.
En una población del Cauca se tomó una muestra de 50 familias para
observar el número de personas menores de 12 años, con el propósito de
estimar algunos indicadores sobre demanda potencial de educación escolar.
Esta arrojó los siguientes resultados:
4
0
1
2
3
0
2
5
3
1
3
2
1
2
1
3
0
3
0
1
0
2
3
0
1
4
2
1
5
4
2
1
4
2
3
1
2
0
1
3
2
2
5
0
3
3
2
0
1
5
Resolver:
a. Hallar La Media, La Moda, La Mediana, La Desviación Estándar y el
Coeficiente de Variación.
b. Grafique El Diagrama de Frecuencias Absolutas y Relativas, El Diagrama de
Frecuencias Acumuladas.
c. Que porcentaje de las familias tienen 3 personas ó menos que son menores de
12 años.
d. Si la población consta de 1200 familias, estime usted el número de personas
menores de 12 años. (Estimación del Total = n X).
6.
Redondee los siguientes valores:
a. 1.0549 a un decimal
b. 2.30449 a tres decimales
c. 0.096 a dos lugares decimales
d. 20.5% al porcentaje mas cercano
e. Exprese en porcentajes el valor resultante de : 15 / 60
f. Exprese con dos decimales el valor resultante de : 10 / 3
7. Se quiere estudiar las características de las familias de un barrio para
considerar la necesidad de un control de natalidad. La Población del barrio está
conformada por 20 familias y en las cuales hay el siguiente número de hijos de
familia.
Familia No
No de Hijos
1
6
2
5
3
7
4
3
5
7
6
6
7
4
8
5
9
5
10
9
11
3
12
6
13
9
14
3
15
8
16
7
17
6
18
5
19
6
20
4
¿Cuál es el tamaño de la Población para este caso? ¿Cuál es la Variable de
interés? ¿Es continua ó Discreta?
Ordene los Datos. Tabúlelos, Calcule las Frecuencias Absolutas, Relativas,
Absolutas Acumuladas y Relativas Acumuladas, Haga un cuadro donde muestre
todos los cálculos anteriores, Grafique los diagramas de Barras, de Distribución
Acumulada y defina la Función empírica para este caso.
3.2.
CASO VARIABLE CONTINUA
Los conceptos son los mismos en forma general, que para el caso de variable
discreta, lo diferente son las fórmulas utilizadas.
3.2.1. FUNCION DE DISTRIBUCIÓN DE FRECUENCIAS
Sea X la variable Nivel de glucosa en la sangre de los niños, que asisten a control
en un Centro de Salud de la ciudad.
Se toma una muestra de a 30 niños en ayunas, en la cual se obtiene la siguiente
información:
64 36
49
53
67
57
61
58
72
58
40
56
68 63
42
50
56
30
79
54
65
63
34
54
74 52
50
42
51
45
57
51
32
49
58
55
60 42
53
50
38
69
47
59
49
50
76
66
Lo primero que se hace es tabular la información obtenida en una tabla de
frecuencias, que contenga Intervalos reales, frecuencias absolutas, relativas
simples y acumuladas y la Marca de clase.
3.2.2. Tabulación de la Información.
Se generan los Intervalos de Clase, hay varias maneras de realizarlos, una de
ellas es de acuerdo a los siguientes pasos:
Hallar el Rango de los datos, el cual se encuentra de la siguiente manera:
Rango = Valor máximo - valor mínimo
Rango = 79 - 30 = 49
Definir el número de intervalos (K) en la distribución, que como mínimo se
sugiere que sean cinco y no más de veinte.
Si usted tiene experiencia en el manejo de la información a analizar, puede definir
con cuantos intervalos se puede trabajar ó si hay estudios anteriores, trabajar con
el mismo número de intervalos utilizados en dichos estudios, de lo contrario
existen unas ayudas para estimar y tener una idea de con cuantos intervalos se
puede trabajar una información, como son:
K = n , donde n es el número de datos
Utilizar la fórmula de Sttugers, la cual es
K = 1 + ( 3.3 * log (n) )
donde n es el número de datos y log es logaritmo en base 10.
En ambos casos se aproxima al siguiente entero el resultado.
K = 48
= 6.9 , se aproxima a 7
K = 1 + ( 3.3 * log (48) ) = 1 + (3.3 * 1.68) = 1 + 5.548 = 6.548 , se aproxima a 7
Definir el tamaño de los intervalos (C), si no se tiene idea, con que tamaño
de intervalos trabajar, ya que el investigador los puede construir a su
manera, se halla de la siguiente forma:
Rango
C = -------------K
Si los datos contienen valores muy pequeños, el tamaño de los intervalos se deja
tal como da, si por el contrario son valores grandes se puede aproximar a valores
enteros, fáciles de manejar.
En lo posible se debe tratar de construir intervalos del mismo tamaño, ya que esto
simplifica algunos cálculos y facilita la interpretación de la información.
49
C = ------------ = 7
7
Ahora si se pueden generar los intervalos de clase, de esta forma:
Se construye el primer intervalo como ( Límite inferior - Límite superior), donde
el límite inferior será el valor mínimo de la muestra y a partir de ahí se construyen
los demás intervalos así:
(Valor mínimo -
Valor mínimo + 7), el límite superior de este intervalo será el
límite inferior del siguiente intervalo y su límite superior será, este nuevo valor de
límite inferior más 7 unidades y así sucesivamente.
Es importante tener en cuenta que debe existir continuidad entre los intervalos, o
sea que el valor que es límite superior en un intervalo dado, será límite inferior en
el siguiente.
Construcción de los intervalos, para el caso de la muestra de niños en el centro de
salud.
No del intervalo
Intervalo
Límite inferior
Límite superior
1
30
37
2
37
44
3
44
51
4
51
58
5
58
65
6
65
72
7
72
79
Nótese que todos los valores deben quedar contenidos en los intervalos, esto se
garantiza con el 30 y el 79 que son los valores máximo y mínimo, estén contenidos
en la tabla de frecuencias, ahora bien, si entre los datos estuviera el valor 44,
existiría la duda que origina la siguiente ambigüedad, que el valor 44 pertenece al
intervalo No 2 y al No 3.
Entonces, ¿en cuál de los dos colocarlo?, pero un valor debe pertenecer a un
intervalo y solo uno. Hay varias opciones de solucionar dicha ambigüedad, una es
definiendo intervalos cerrados ó abiertos en los límites, por ejemplo si el intervalo
2, su límite superior es abierto y el intervalo 3 su límite inferior es cerrado, esto
significa que el 44 no estará contenido en el segundo intervalo, pero si lo estará en
el tercer intervalo, otra forma es generando Intervalos Reales de clase, que en
últimas son los que se colocarían en la tabla de frecuencias en vez de los
intervalos iniciales y se construyen de la siguiente forma:
Si son valores enteros los datos de la muestra, se le resta 0.5 a cada límite y en el
caso de que el último intervalo al restarle 0.5 no contendría el valor 79, entonces
en vez de quitarle 0.5 al límite superior, se le aumenta ó se deja tal como está, si
los datos de la muestra tienen un decimal, se le quita 0.05 a cada límite y si los
datos constan de dos decimales, se les quitará 0.005 a cada límite y así
sucesivamente.
Hay que construir los límites reales, para que cada valor pertenezca a un solo
intervalo y solo uno.
No del intervalo
Intervalo Reales
Límite inferior
Límite superior
1
29.5
36.5
2
36.5
43.5
3
43.5
50.5
4
50.5
57.5
5
57.5
64.5
6
64.5
71.5
7
71.5
79.5
volviendo al caso del valor 44, ahora si se puede decir sin ninguna duda a que
intervalo pertenece dicho valor, al intervalo No 3, note que por uniformidad y para
que contuviera el máximo valor 79, se le aumentó 0.5 al límite superior del último
intervalo 79.
En la tabla de Frecuencias aparecerán las siguientes columnas: Intervalos reales,
frecuencias absolutas y frecuencias relativas, al igual que las frecuencias tanto
absoluta como relativa pero acumuladas, que se hallan igual que en las variables
discretas y además una columna nueva, la Marca de clase (Mi), que es el valor
que representa al intervalo en todo sentido y se halla con la semisuma de los
límites de cada intervalo.
Por ejemplo para el primer intervalo No 1, su Marca de Clase será igual a sumar
sus límites y dividirlos por dos, así:
M1 = (29.5 + 36.5) / 2 = 33.
Cabe anotar que al agrupar los datos en intervalos de clase, se produce pérdida
de información, puesto que no se cuenta con los datos en forma individual sino de
un valor global, la Marca de clase, pero se gana rapidez en las operaciones.
Al construirse los intervalos todos deben contener datos, sino hay que
reconstruirlos, ya que un intervalo sin datos, distorsiona la idea de la distribución
de la información, en esta fase exploratoria a través de la muestra.
TABLA DE LA DISTRIBUCIÓN DE FRECUENCIAS DEL NIVEL DE GLUCOSA EN
LA SANGRE DE LOS NIÑOS DE UN CENTRO DE SALUD DE LA CIUDAD.
INTERVALOS FRECUENCIAS FRECUENCIAS
ABSOLUTAS
RELATIVAS
REALES
29.5-36.5
36.5-43.5
43.5-50.5
50.5-57.5
57.5-64.5
64.5-71.5
71.5-79.5
ni
4
5
9
12
9
5
4
hi
0.0833
0.1042
0.1875
0.2500
0.1875
0.1042
0.0833
FRECUEN.
ABSOL.
ACUMUL. Ni
FRECUEN.
RELATIV.
ACUMUL. Hi
MARCA
DE
CLASE Mi
4
9
18
30
39
44
48
0.0833
0.1875
0.3750
0.6250
0.8125
0.9167
1.0000
33
40
47
54
61
68
75.5
Las frecuencias se obtienen de la misma manera que se obtuvieron con el caso de
variables discretas, por lo tanto se interpretará un valor de cada columna.
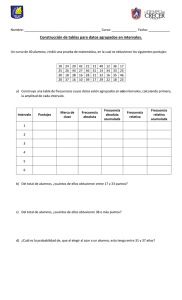
Intervalo No 3 : 43.5 - 50.5 : Indica que el nivel de glucosa en la sangre de los
niños está entre 43.5 y 50.5.
La frecuencia absoluta n2 = 5, define que 5 niños en la muestra tienen un nivel de
glucosa en la sangre entre 36.5 y 43.5.
La frecuencia relativa h4 = 0.25, indica que en el 25% de la muestra los niños
tienen un nivel de glucosa en la sangre entre 50.5 y 57.5.
La frecuencia absoluta acumulada N3 = 18, indica que 18 niños de la muestra
presentan un nivel de glucosa en la sangre de a lo sumo de 50.5 ó que 18 niños
de la muestra, presentan un nivel de glucosa en la sangre entre 29.5 y 50.5.
La frecuencia relativa acumulada H3 = 0.375, define que el 37.5% de la muestra de
los niños tienen un nivel de glucosa en la sangre entre 29.5 y 50.5 ó de a lo sumo
50.5.
3.2.3 REPRESENTACIÓN GRAFICA
Una de las representaciones gráficas se define como el Histograma de
Frecuencias, tanto para frecuencias absolutas como para frecuencias relativas y
se conforma por rectángulos, que tienen como lados el tamaño del intervalo y su
frecuencia.
Histograma
Frecuencia absoluta ni
14
12
10
8
6
4
2
0
33
40
47
54
61
68
75,5
Marcas de Clase
Normalmente se colocan en el eje X los valores de los límites de los intervalos, (en
este caso se omiten por espacio solamente y se colocaron las marcas de clase).
Al unir las marcas de clase a través de una línea, se forma otro gráfico como es el
Polígono de Frecuencias, el cual empieza en el límite inferior del primer intervalo y
termina en el límite superior del último intervalo.
Note que en el polígono de frecuencias se unen las Marcas de clase con la
frecuencia absoluta del intervalo.
Frecuencias Absolutas ni
Polígono de Frecuencias
14
12
10
8
6
4
2
0
29,5
33
40
47
54
61
68
75,5
79,5
Marcas de Clase
Para graficar las frecuencias acumuladas se utiliza el gráfico denominado La
Ojiva, el cual comienza con el límite inferior del primer intervalo y va acumulando
de intervalo en intervalo, al igual que con las variables discretas a partir del último
límite superior, el cual es igual al 100%, la gráfica se vuelve asíntota al eje X, o
sea paralela.
Ojiva
120,00%
Frecuencia
100,00%
80,00%
60,00%
40,00%
20,00%
,00%
29,5
36,5
43,5
50,5
57,5
64,5
71,5
79,5
Intervalos de Clase
Existen otros tipos de gráficos como el de línea, que utilizado si en el eje X está el
tiempo.
EJERCICIO
Analice e interprete cada uno de los siguiente gráficos (Fuente Planeación
Municipal Cali).
Muncipio Santiago de Cali
Consumo anual de agua
1987 - 2005
180,000
160,000
Miles de m3
140,000
120,000
100,000
80,000
60,000
40,000
20,000
0
1987
1989
1991
1993
1995
1997
1999
2001
2003
2005
Año
Residencial
Comercial-industrial
Oficial-otros
Municipio Santiago de Cali
3,500,000
Consumo anual de energía
1987 - 2005
3,000,000
Mwh
2,500,000
2,000,000
1,500,000
1,000,000
500,000
0
1987
1989
1991
1993
1995
1997
1999
2001
2003
Año
Total
Comercial-industrial
Residencial
Oficial-otros
2005
Municipio Santiago de Cali
Instituciones Educación Superior
Distribución de alumnos matriculados según modalidad
2002
Maestría
1%
Especialización
4%
Técnica
Profesional
4%
Doctorado
0%
Tecnología
11%
Universitaria
80%
Municipio de Santiago de Cali
Emergencias atendidas
1998 - 2004
8,000
7,000
Número
6,000
5,000
4,000
3,000
2,000
1,000
0
1998
1999
2000
2001
2002
2003
Año
Incendios
Otros
2004
Municipio Santiago de Cali
Población total
1999 - 2005
2,423,381
2,450,000
2,369,696
2,400,000
2,316,655
2,350,000
2,264,256
Habitantes
2,300,000
2,250,000
2,212,430
2,200,000
2,161,130
2,150,000 2,110,571
2,100,000
2,050,000
2,000,000
1,950,000
1999
2000
2001
2002
2003
2004
2005
Año
Municipio de Santiago de Cali
Coeficiente de empleo, tasas de desempleo,
participación global y bruta
1999 - 2005
90.0
80.0
70.0
Tasa
60.0
50.0
40.0
30.0
20.0
10.0
0.0
1999
2000
2001
Coef iciente de empleo
2002
Año
Tasa global de participación
%PET/PT
2003
2004
Tasa de desempleo
Tasa bruta de participación
2005
En ocasiones los tamaños de los intervalos son diferentes, por lo tanto se requiere
de una función que defina donde se agrupa más información en los intervalos, o
sea donde hay mayor densidad.
Dicha función es la (3.2.4.) Función empírica de densidad, que tiene la siguiente
forma general:
h*(X) =
0
si
X
hi
------Ci
si
Li
L1
ó
X Lm
X
L(i + 1)
La función empírica de densidad para la distribución de frecuencias del nivel de
glucosa en la sangre de los niños de la muestra en un centro de salud de la ciudad
será: (Ver página siguiente)
Observe que el intervalo 50.5 y 57.5, es el intervalo de mayor densidad ó el de
mayor frecuencia.
Como los tamaños de los intervalos en esta distribución son iguales, exceptuando
el último se puede definir la mayor frecuencia a través de las frecuencias
absolutas ó relativas simples.
0
si
X
29.5
0.0833
------------ = 0.0119 si
7
29.5
X
36.5
0.1042
------------ = 0.0149 si
7
36.5
X
43.5
0.1875
------------ = 0.0268 si
7
43.5
X
50.5
0.2500
------------ = 0.0357 si
7
50.5
X
57.5
0.1875
------------ = 0.0268 si
7
57.5
X
64.5
0.1042
------------ = 0.0149 si
7
64.5
X
71.5
0.0833
------------ = 0.0104 si
8
71.5
X
79.5
h*(X) =
0
si
X 79.5
Cuando se quiera definir un valor porcentual de la distribución en un punto
cualquiera, se recurre a la (3.2.5.)Función empírica de distribución acumulada,
la cual utiliza la función empírica de densidad dentro de la composición de su
fórmula, esta función empírica de distribución acumulada, podría ser usada en
forma inversa para encontrar un percentil.
La forma general de esta función está dada por:
0
H*(X) =
H( i-1)+
si
hi
-------( X – Li )
Ci
1
Donde:
X
L1
si Li X L(i + 1)
si
X Lm
hi / Ci, es hi* (función de densidad) del valor X.
H (i – 1), es la Frecuencia acumulada relativa del intervalo
Anterior, de donde se encuentra el valor X.
Li, es el límite inferior del intervalo donde se encuentra el
valor X.
L1, Límite inferior del primer intervalo de la distribución
Lm, Límite superior del último intervalo de la distribución
X, valor al que se le quiere hallar el porcentaje de
equivalencia en la función.
Vale la pena recordar el concepto de a lo sumo, o sea a lo máximo ó como
máximo, al igual que el concepto de a lo mínimo ó como mínimo ó a lo menos, ya
que son términos utilizados por esta función.
Por ejemplo tener a lo sumo 2 hijos, significa que desea tener 0 ó 1 ó 2 hijos, si se
dice que desea ganar a lo menos tres materias de las cinco que ve, está diciendo
que desea ganar 3 ó 4 ó 5 materias.
Se define la función empírica de distribución acumulada, para el nivel de glucosa
en la sangre de los niños, en un centro de salud de la ciudad, así:
0
X 29.5
si
0 + 0.0119 ( X – 29.5)
si
29.5 X 36.5
0.0833 + 0.0149 ( X – 36.5)
si
36.5 X 43.5
0.1875 + 0.0268 ( X – 43.5)
si
43.5
0.375 + 0.0357 ( X – 50.5)
si
50.5 X 57.5
0.625 + 0.0268 ( X – 57.5)
si
57.5 X 64.5
0.8125 + 0.0149 ( X – 64.5)
si
64.5 X 71.5
0.9167 + 0.0104 ( X – 71.5)
si
71.5 X 79.5
si
X 79.5
X
50.5
H*(X) =
1
3.2.5.1.
Aplicaciones de esta función, recuérdese que esta función es
acumulada, o sea que va desde 0 hasta el valor que se desee.
¿Qué porcentaje de niños tienen un nivel de glucosa de a lo sumo 55?
Lo primero es definir en que intervalo está contenido el valor 55 y aplicar la función
en ese intervalo, ya que piden es desde 0 hasta 55.
H (55) = 0.375 + 0.0357 ( X – 50.5) = 0.375 + 0.0357 (55 – 50.5)
= 0.375 + 0.0357 ( 4.5 )
= 0.375 + 0.16065
= 0.53565
O sea, el 53.57% de los niños en la muestra tienen un nivel de glucosa en la
sangre de a lo sumo 55.
¿Qué porcentaje de niños tienen un nivel de glucosa de a lo menos 55?.
Aquí lo que se pide es los niños que tienen un nivel de glucosa entre 55 y 100, por
lo tanto se resuelve de la siguiente manera:
100% - H (55), o sea que al 100% se le quita el acumulado desde 0 hasta 55 y
quedaría desde 55 hasta 100.
100 – 53.57 = 46.43%
Luego entonces, el 46.43% de los niños en la muestra tienen un nivel de glucosa
de a lo menos 55.
¿Qué porcentaje de niños tienen un nivel de glucosa de a lo menos 85?.
Como está por encima del valor máximo 79.5, se tiene lo siguiente:
100% - 100% = 0%, ya que el H (85) vale 100%, o sea que ningún niño presenta
un nivel de glucosa de a lo menos 85.
¿Qué porcentaje de niños tienen un nivel de glucosa de a lo sumo 25?
Como este valor está por debajo de 29.5 vale 0%, igual que el caso anterior.
¿Qué porcentaje de niños tienen un nivel de glucosa de a lo sumo 63 y de a lo
menos 42?
Es lo mismo que si preguntaran sobre en que porcentaje de los niños, su nivel de
glucosa está entre 63 y 42, observe que sigue siendo un intervalo esta pregunta,
luego entonces se resuelve como un intervalo, el valor mayor menos el valor
menor.
H (63) - H (42)
Se hallan por separado y luego se restan sus resultados.
H (63) = 0.625 + 0.0268 (63 – 57.5)
= 0.625 + 0.0268 (5.5)
= 0.625 + 0.1474
= 0.7724
H (42) = 0.0833 + 0.0149 (42 – 36.5)
= 0.0833 + 0.0149 (5.5)
= 0.0833 + 0.08195
= 0.16525
de ahí = 0.7724 - 0.16525
= 0.60715
Luego entonces el porcentaje de los niños en la muestra que tienen un nivel de
glucosa de no menos 42 y no más de 63, es del 60.72%.
3.2.6. REDUCCIÓN DE DATOS PARA VARIABLES CONTINUAS
En los indicadores tanto de Tendencia Central como los de Dispersión, en sus
conceptos y propiedades son los mismos que para el caso de la variable discreta.
3.2.6.1.
3.2.6.1.1.
MEDIDAS DE TENDENCIA CENTRAL
La Media, es el valor promedio de la muestra y la forma de hallarla
es la siguiente:
k
Mi ni
i=1
X = ------------n
donde:
=
k
Mi hi
i=1
Mi es la marca de clase del intervalo i
K es el número de intervalos en la distribución
Las frecuencias absolutas y relativas simples ni y hi respectivamente
Por ejemplo, La Media para la distribución de frecuencias del nivel de glucosa en
la sangre de los niños en un centro de salud de la ciudad se tiene:
Por la primera ecuación se tendría:
7
Mi ni
(33*4) + (40*5) + (47*9) + (54*12) + (61*9) + (68* 5) + (75.5*4)
i =1
-----------
= ------------------------------------------------------------------------------------
n
48
2.594
= ---------------- = 54.04
48
Por la segunda ecuación se tendría:
7
Mi hi = (33*0.0833) + (40*0.1042) + (47*0.1875) + (54*0.25) +
i =1
(61*0.1875) + (68* 0.1042) + (75.5*0.0833)
= 54.04
Luego entonces el nivel promedio de glucosa en la sangre de los niños es de
54.04, ubicado en el 4º intervalo.
3.2.6.1.2.
La Mediana, representa el valor que parte en dos partes iguales la
distribución y que para datos continuos se halla de dos formas así:
Me
= Li
Donde :
+
(Número de datos)/2 - N (i-1)
----------------------------------------ni
*
Ci
Li, es el límite inferior del intervalo donde se encuentre la Mediana
N(i-1), Es la frecuencia absoluta acumulada del intervalo anterior
al que se encuentra la Mediana.
ni, Es la frecuencia absoluta del intervalo donde se encuentre la
Mediana.
Ci, Es el tamaño del intervalo en donde se encuentre la Mediana.
Número de datos, es el tamaño de la muestra.
ó
Me
= Li
Donde :
+
0.5
H(i-1)
--------------------------hi
*
Ci
Li, es el límite inferior del intervalo donde se encuentre la Mediana
H(i-1), Es la frecuencia relativa acumulada del intervalo anterior al
que se encuentra la Mediana.
hi, Es la frecuencia relativa del intervalo donde se encuentre la
Mediana.
Ci, Es el tamaño del intervalo en donde se encuentre la Mediana.
Para la distribución de frecuencias del nivel de glucosa en la sangre de los niños
en un centro de salud de la ciudad se tiene:
Como primera medida se busca en la columna de frecuencias relativas
acumuladas donde se encuentra la Mediana, ubicando el 50%.
El 50% está ubicado en el 4º intervalo, entre 50.5 y 57.5
Por la primera fórmula sería:
Me
= 50.5 +
(48)/2
- 18
---------------------12
*
= 50.5 +
24 - 18
--------------- *
12
7
6
= 50.5 + --------- *
12
= 50.5 +
7
7
3.5
= 54
Para La segunda forma sería:
Me
= 50.5 +
0.5
0.375
--------------------------0.25
0.125
= 50.5 + --------------0.25
*
= 50.5 + 0.5
7
*
*
7
7
= 50.5 + 3.5
= 54
Por lo tanto el 50% de los datos de la muestra del nivel de glucosa en la sangre de
los niños, están por encima de 54 y el otro 50% está por debajo.
3.2.6.1.3.
La Moda, el valor más alto en la muestra ó el que más se repite, y su
forma de hallarlo es, si los intervalos son del mismo tamaño, ubicar el intervalo
que más se repite a través de las frecuencias absolutas ó relativas simples, siendo
ese el intervalo de mayor frecuencia, definido como el Intervalo modal, si los
intervalos son de diferente tamaño se halla el intervalo de mayor densidad a través
de la función empírica de densidad.
Luego que esté definido el intervalo de mayor frecuencia, se determina que valor
corresponde a la Moda, con la siguiente fórmula, en algunos casos específicos:
hi/Ci
Mo = Li
+
h(i-1)/C(i-1)
-------------------------------------------------------------2hi/Ci
Donde :
-
-
h(i-1)/C(i-1)
-
* Ci
h(I+1)/C(I+1)
Li, es el límite inferior del intervalo donde se encuentre la Moda
h(i-1), Es la frecuencia relativa del intervalo anterior al que se
encuentra la Moda.
hi, Es la frecuencia relativa del intervalo donde se encuentre la
Moda.
Ci, Es el tamaño del intervalo en donde se encuentre la Moda.
h(i+1), Es la frecuencia relativa del intervalo posterior al que se
encuentra la Moda.
C(i+1), Es el tamaño del intervalo posterior, en donde se encuentra
La Moda.
C(i-1), Es el tamaño del intervalo anterior, en donde se encuentra
La Moda.
El intervalo Modal , para la distribución de frecuencias del nivel de glucosa en la
sangre de los niños en un centro de salud de la ciudad es:
El intervalo con mayor frecuencia es el No 4, entre los valores 50.5 y 57.5
Siendo este el intervalo más frecuente del nivel de glucosa encontrado en los
niños muestreados.
Ahora bien si se deseara encontrar el valor puntual más frecuente, este sería:
= 50.5 +
0.25/7
0.1875/7
------------------------------------------------------ * 7
2(0.25/7) - 0.1875/7 - 0.1875/7
Mo
= 50.5 +
0.0625
-------------- * 7
0.125
Mo
= 50.5 + (0.5 *
Mo
= 54
Mo
7)
El nivel de glucosa de 54 sería el valor más frecuente en la distribución.
3.2.6.2.
3.2.6.2.1.
MEDIDAS DE DISPERSIÓN
La varianza muestral, define la variabilidad en una muestra y para
variables continuas con frecuencias se halla de la siguiente forma:
k
ni (Mi – X)2
i=1
2
S =
----------------------------n
ó
k
2
S =
hi (Mi – X)2
i=1
Para cálculos se trabaja con :
k
Mi2 ni
n X2
i=1
2
S =
–
-------------------n–1
---------n–1
si n 30
y con :
k
Mi2 ni
i =1
2
S =
---------------
-
X2
n
si n 30
Para la distribución de frecuencias del nivel de glucosa en la sangre de los niños
en un centro de salud de la ciudad, se utilizaría la fórmula para datos mayores de
30 y se tiene que:
7
Mi2 ni
(332*4) + (402*5) + (472*9) + (542*12) + (612*9) + (682* 5) + (75.52*4)
i =1
----------- = ---------------------------------------------------------------------------------------------n
48
de ahí se obtiene :
146.639
S
2
=
-----------------
-
54.042
48
S
2
=
134.66
Que sería la variabilidad general de la información
3.2.6.2.2.
Desviación estándar, mide la variación de los datos con respecto al
valor promedio y simplemente es hallar la raíz cuadrada de la varianza.
S
= 11.6
Una forma practica de interpretar este resultado sería utilizando el argumento de la
regla empírica : la media (+/-) una desviación estándar, se espera que contengan
el 68% de los datos, si la distribución es simétrica, lo cual es cierto, puesto que la
media, la mediana y la moda están en 54, entonces se diría que la mayoría de los
niños en ese centro de salud de la ciudad, tienen un nivel de glucosa entre 54.04
(+/-) 11.6, lo que daría que la mayoría de estos niños tienen un nivel de glucosa en
la sangre entre 65.64 y 42.44.
También se puede interpretar como, que los datos se desvían en 11.6 con
respecto al valor promedio, pero ¿es mucha la dispersión o es poca?
Para dar respuesta a esta pregunta se halla el (3.2.6.2.3.)Coeficiente de
Variación porcentual (CV),
S
CV(%)
= -----------
*
100%
X
11.6
CV (%)
=
-----------
*
100%
54.04
CV(%)
= 0.214
CV(%)
= 21.4%
*
100%
Valor que se puede considerar como poco homogéneo.
Observe que La Media, La Mediana y La Moda tienen valores muy similares, por lo
cual esta información se puede considerar una distribución simétrica.
Se evalúa el (3.2.7.)Coeficiente de Asimetría (g1), para confirmar esta
apreciación.
g1 =
k
3
((Mi – X) / S)
i=1
* hi
g1 =
7
3
((Mi –54.04 ) / S)
i=1
g1 =
0.0258
* hi
con lo cual se corrobora la simetría con el valor tan cercano a cero, lo que
determina una muy leve asimetría positiva que se puede desapercibir.
Se halla el (3.2.8.) Coeficiente de Curtosis (g2), para visualizar su apuntamiento.
g2 =
k
4
((Mi – X) / S)
i=1
g2 =
7
4
((Mi – 54.04) / 11.6)
i=1
g2 =
2.369
Ec = g2
* hi
* hi
- 3
Ec = 2.369
- 3
Ec = - 0.631
Por lo cual es considerada esta distribución como una distribución tendiendo a ser
Platicúrtica, o sea que presenta un apuntamiento levemente por debajo de lo
normal.
3.2.9. Percentiles
Ya se sabe que los deciles y los cuartiles se pueden expresar a través de los
percentiles, pero se debe definir ¿cómo resolver un percentil?, se sabe además,
que la función empírica de distribución acumulada se utiliza, si se conoce el valor
de la variable y se requiere encontrar el porcentaje, pero cuando se conoce el
porcentaje y se requiere saber a que valor de la variable corresponde, se debe
utilizar Percentiles.
PASOS PARA ENCONTRAR UN PERCENTIL
1. Encuentre el valor que corresponde al percentil n P(n)
Pn * (n + 1)
P(n) =
________________
100
2. Ubique en que fila (i) está contenido el valor P(n) en la columna de la frecuencia
acumulada absoluta (Ni)
3. Halle el valor de razón K
K = P(n) – N(I
- 1)
4. Defina una regla de tres de la siguiente manera, para encontrar X que
correspondería al K
K * Ci
X = __________
ni
De ahí se tiene que el valor de X para el percentil P(n) es : Li + X
Si el percentil que se requiere está en la tabla como frecuencia acumulada relativa
el valor de X será el límite superior del intervalo donde esté el percentil a
encontrar.
¿Qué nivel de glucosa tienen como máximo el 62.5% de los niños de ese centro
de salud de la ciudad de Cali?
57.5 es el nivel de glucosa que como máximo tienen el 62.5% de los niños de ese
centro de salud de la ciudad de Cali.
Observe que no hubo necesidad de realizar el proceso puesto que el percentil a
buscar estaba en la tabla.
¿Qué nivel de glucosa tienen como máximo el 75% de los niños de ese centro de
salud de la ciudad de Cali? (que corresponde al tercer cuartil)
75 * (48 + 1)
P(75) =
______________ = 36.75
100
Está contenido en la quinta fila, i = 5 en N5 = (39)
K = 36.75 - 30 = 6.75
6.75 * 7
X=
__________ = 5.25
9
Luego entonces el valor del Percentil de 75 será: 57.5 + 5.25 = 62.75
P(75) = 62.75, el 75% de los niños de ese centro de salud de la ciudad de Cali
tienen como máximo un nivel de glucosa en la sangre de 62.75.
También se puede hallar, usando la generalización de la ecuación para la mediana
como:
0.75 – 0.625
57.5 + ______________ * 7 = 62.2
0.1875
Con esta forma se obtiene un valor muy aproximado al anterior, ambos métodos
me proporcionan una excelente aproximación al valor
¿Qué nivel de glucosa tienen como mínimo el 10% de los niños de ese centro de
salud de la ciudad de Cali, que tienen el nivel de glucosa más alto?
Aquí en realidad de verdad el percentil que se está queriendo hallar es el de 90,
puesto que los niveles más altos están a la derecha (al final) de la distribución.
90 * (48 + 1)
P(90) =
______________ = 44.1
100
Está contenido en la séptima fila, i = 7 en N7 = (48)
K = 44.1 - 44 = 0.1
0.1 * 7
X=
__________ = 0.175
4
luego entonces el valor del Percentil de 75 será: 71.5 + 0.175 = 71.675
P(90) = 71.675, el 10% de los niños de ese centro de salud de la ciudad de Cali
tienen como mínimo un nivel de glucosa en la sangre de 71.675.
También se puede hallar como:
0.90 - 0.8125
64.5 + ____________ * 7
= 70.4
0.1042
Recuerde que ambos métodos dan una buena aproximación del percentil.
¿Qué nivel de glucosa tienen entre el 75% y el 90% de los niños de ese centro de
salud de la ciudad de Cali?
P(90) – P(75)
Entre el 75% y el 90% de los niños de ese centro de salud, tienen entre 71.675 y
62.5 de nivel de glucosa.
3.3.
Resuelva los siguientes ejercicios:
1. Una entidad encargada del control de contaminación de cierto río, lleva
registros sobre el oxígeno disuelto X, expresada en mg/lt, éstos se
presentan a continuación.
3.6
3.1
2.6
2.7
3.9
2.4
2.7
2.5
2.3
4.0
2.5
1.7
3.1
2.6
1.3
4.3
1.5
2.8
1.8
4.2
2.4
2.2
3.4
3.7
0.8
2.3
1.9
4.5
1.2
2.2
2.2
2.1
1.8
2.9
3.8
3.5
1.6
3.2
4.4
1.4
0.7
2.8
3.2
3.5
3.0
3.3
0.5
2.3
0.3
2.6
Resolver:
a. Hallar La Media, La Moda, La Mediana, La Desviación Estándar y el
Coeficiente de Variación.
b. Grafique El Histograma, El Polígono de Frecuencias y La Ojiva.
c. ¿Qué porcentaje de registros son inferiores a 3.1 mg/lt.?
d. ¿Qué porcentaje de registros son mayores que 1.5 mg/lt, pero, son menores
que 3.5 mg/lt.?
e. ¿Cuánto oxígeno disuelto en mg/lt tienen como máximo el 70% de los
registros?
f. ¿Cuánto oxígeno disuelto en mg/lt tienen como mínimo el 15% de los registros
más altos?
2. En una granja cafetera se estudia cierta Variedad de Café.
Se requiere saber las características de la variable altura de dicha variedad, con
este propósito se tomaron los siguientes datos.
No del árbol
1
No del árbol
2
Altura en cms
52.0
Altura en cms
45.7
3
47.0
4
31.8
5
34.0
6
43.2
7
46.0
8
49.0
9
49.5
10
53.0
11
41.0
12
44.2
13
39.0
14
37.0
15
40.0
16
47.8
17
43.0
18
39.0
19
43.4
20
47.4
21
46.0
22
51.3
23
48.7
24
46.9
25
52.6
26
58.8
27
53.5
28
55.4
29
52.6
30
54.9
¿Cuál es su Población y cuál su tamaño? ¿Cuál es la muestra y cuál su tamaño?
¿Cuál es la variable de interés? Ordene los datos, tabúlelos utilizando intervalos
de clase, calcule las Frecuencias Absolutas, Frecuencias Relativas, Absolutas
Acumuladas y Relativas Acumuladas. ¿Qué puede decir acerca del procesamiento
ó la información? ¿Los resultados son exactos? ¿Hay pérdida de información?.
¿Si la hay cuál es la compensación?
Grafique el Histograma, El Polígono de Frecuencias y El Ojiva, además defina la
Función empírica para este caso.
3. Una compañía especializada en la fabricación de ejes para máquina está
planeando la compra de una máquina de corte controlada por computadora. El
ingeniero de la compañía prueba dos máquinas de diferentes fabricantes. Los
diámetros (en centímetros) de las barras cortadas por las máquinas fueron los
siguientes:
Fabricante 1:
2.001 2.000 2.004 1.998 1.997
Fabricante 2:
2.002 2.008 1.995 1.990 2.005
¿Qué máquina le recomienda comprar al ingeniero? Justifique la respuesta
4. El gráfico muestra el consumo de energía mensual (kv) de 80 salas de micros
en una ciudad.
%
Consumo de Energia - mes
100
90
80
70
60
50
40
30
20
10
0
250
500
750
1000
1250
1500
1750
2000
Kv/h
a. Determine e interprete los valores n2 y S.
b. Hallar e interpretar el percentil 80 y el cuartil 2.
c. Qué porcentaje de salas presentaron consumos de energía menores a
1000 kv?
d. Si Yi = 40 Xi - 2500 es el costo de energía para una sala i, siendo X el
consumo, calcular el promedio y la desviación estándar del costo de
energía de todas las salas en la muestra.
5. Dada la rapidez necesaria en el mantenimiento de máquinas eléctricas, el jefe
de mantenimiento de una empresa que brinda este tipo de servicio, decide
evaluar el servicio prestado por tres funcionarios a su cargo. Los últimos 90
mantenimientos se distribuyen aleatoriamente y por igual entre los tres
funcionarios distintos y se registró el número de horas que requirió cada
mantenimiento. A juzgar por los diagramas de caja, ¿cuál servicio presenta el
mejor promedio?, ¿cuál servicio presenta la desviación estándar mas
pequeña? Justifique las respuestas.
I
*
II
*
III
20
horas
25
30
35
40
45
50
55
60
65
70
El Diagrama de Cajas, se construye con el primer y tercer cuartil, además de la
mediana ó la media y también interviene el Rango intercuartil (RIC), que es la
diferencia entre el tercer cuartil y el primer cuartil, donde los valores que estén
alejados 1.5 * RIC del primer ó tercer cuartil, se denomina un valor inusual y si
está alejado a 3 * RIC, será un valor extremadamente inusual, del resto los valores
alejados se denominan moderados, observemos una caja.
Mediana
Q1
Q3
Bigotes
Primer Cuartil
Tercer cuartil
En algunos casos se coloca la media con un símbolo que puede ser un más ó un
por.
6. Una máquina produce piezas de acero. Se tomaron 80 piezas consecutivas y
se midió el grosor. Con esta información se construyó el siguiente gráfico:
Determine:
a. La media, la mediana, la moda, el rango, la desviación estándar, la varianza y
el CV(%)
b. Los cuartiles, Qué tan homogéneos son los datos?
Porcentaje de piezas
30
Porcentaje
25
20
15
10
5
0
0
10
20
30
40
50
Grosor
7. Se midió los tiempos de CPU en segundos aproximados al segundo decimal,
de los trabajos realizados en un equipo y se obtuvo el siguiente diagrama de
tallo y hojas:
Tallo
H
o
j
a
s
0
02 15 19 47 71 75 82 92 96
1
16 17 23 38 40 59 61 94
2
01 16 41 59
3
07 53 76
4
75
Calcule el promedio, la mediana, la desviación estándar y a partir de ellos,
presente un análisis descriptivo de los datos.
El Diagrama de Tallos y Hojas, es una alternativa para el histograma ó el diagrama
de barras, donde los tallos son las decenas ó centenas, mientras que las hojas
son las unidades ó como en el caso del ejercicio planteado, las hojas son las
unidades y las decenas, mientras que los tallos son las centenas, observe que en
el cuarto tallo 3 los valores representados son : 307, 353 y 376.
8. Para incrementar la rapidez del etiquetado de botellas por una máquina de
modelo antiguo en una compañía de jugos, se decide observar la variabilidad
del proceso mediante la elaboración de un histograma de frecuencias. Para
iniciar este proyecto, se tomaron datos, para conocer la cantidad de cajas de
botellas etiquetadas por día. Se hicieron 50 observaciones, cuyos resultados
son:
7532
7932
8115
8119
7593
8457
6549
7457
6429
8240
6275
6897
8745
7470
6953
5944
7396
7253
8019
7495
8963
8254
6485
6581
8230
6501
7453
5985
6825
7645
7883
7032
8736
7318
9121
6854
7693
6584
7569
8337
8457
6867
6578
8457
6337
8643
6991
8011
7352
7237
a. Construya la tabla de frecuencias, haga una breve interpretación de ella.
b. ¿Qué porcentajes de días se etiquetaron entre 7800 y 8200 cajas?
c. Si se define que el estándar de cajas etiquetadas es de a lo menos de
7850, ¿en qué porcentaje de días no se cumplió con el estándar?.
d. El rublo del costo de mano de obra se dispara, si la cantidad de cajas
etiquetadas en un día no supera las 7000. ¿en qué porcentaje de días
se disparó este rublo?.
e. Se da bonificación por día, si la cantidad de cajas etiquetadas es a lo
menos 8350, ¿en que porcentaje de días se dio bonificación?.
f. El 75% de los días que cantidad de botellas se etiquetaron como
máximo?
g. ¿Qué cantidad de botellas se etiquetaron como mínimo en el 5% de los
días que más etiquetaron botellas?.
h. Halle e interprete los indicadores de tendencia central.
BIBLIOGRAFÍA
CORRALES V. RUBEN DARIO, Notas de clase de ESTADÍSTICA, 1996-2007
LINCOYAN PORTUS GOVINDEN, Curso Práctico de ESTADÍSTICA, Editorial Mc
Graw Hill, 1985.
BEHAR R. y YEPES M., ESTADÍSTICA un Enfoque Descriptivo,
Ingeniería Univalle, 1986
Publicaciones
MENDENHALL REINMUTH Y TERRY SINCICH, Estadística para Ingeniería y
Ciencias, Editorial Iberoamericana, 1997.
MOOD, GRAYBILL AND BOES, Introducción a la Estadística, Editorial Aguilar,
1985.