Archivos 2
Anuncio

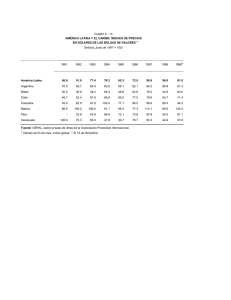
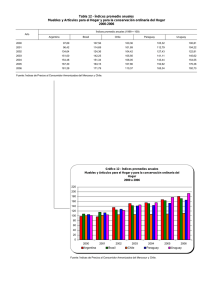
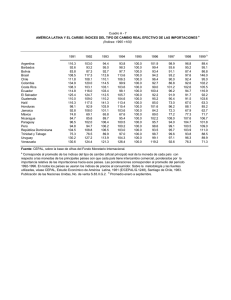
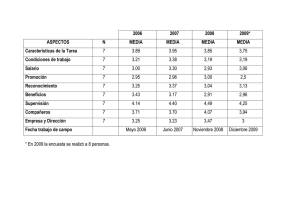
Archivos e índices Integrantes: Javier Carrasco Johnny Corbino Agenda Archivos de Registros del SGBD Organización e indexación de archivos Estructuración de índices Comparaciones de organización y costo Implementación de índices en SQL 1 Archivos de Registros Es la abstracción básica de datos en un DBMS Están organizados de acuerdo a un criterio Se definen operaciones sobre ellos Organización e Indexación ORGANIZACIÓN DE ARCHIVOS Archivos de registros no ordenados (HEAP) La mas simple Ineficiente Archivos de registros ordenados Costoso de mantener 2 Organización e Indexación Ejemplo: Considere un archivo con registros de empleados, cada uno con los campos edad, nombre y salario. 1) Obtener los registros de empleados ordenados por edad 2) Obtener registros de empleados cuyo salario sea mas de $5000 Organización e Indexación ÍNDICES Estructura de datos o de acceso a datos utilizada para optimizar la obtención de registros en respuesta a ciertas operaciones de búsqueda. Clave de búsqueda (no confundir con clave primaria) Múltiples índices para un solo archivo Record id (rid) Alternativas para entrada de Datos k* en un Índice 1.- Registro de datos con un valor k para la clave de búsqueda. 2.- Un par <k,rid> con un valor k para la clave de búsqueda. 3.- Un par <k,lista-rid> 3 Organización e Indexación Alternativa 1 Organización especial: Organización de archivo indexada Alternativa a archivos Heap o no ordenados Alternativa 2 Independiente de la organización del archivo Alternativa 3 Independiente de la organización del archivo Mejor uso de espacio que alternativa 2 pero la longitud de la entrada de datos es variable. Organización e Indexación Índices de agrupamiento (clustered) La entrada de datos del índice esta ordenada de igual manera que en el archivo Índices con alternativa 1 (Archivo agrupado) Índices Primarios y Secundarios Un índice es primario si contiene como entrada la clave primaria del registro del archivo, caso contrario es índice secundario. 4 Organización e Indexación Entradas de índice (Búsqueda directa) Índice Entrada de datos Archivo de Datos Índice no agrupado (unclustered) Organización e Indexación Entradas de índice (Búsqueda directa) Índice Entrada de datos Archivo de Datos Índice agrupado (clustered) 5 Estructuración de índices Indexación basada en Hash (Dispersión) Buckets Función Hash Búsqueda rápida de registros (con la clave de búsqueda) Rápida inserción y eliminación No soporta búsqueda de rangos Estructuración de índices h(edad)=00 edad h1 h(edad)=01 h(edad)=10 Smith,44,3000 Jones,40,6000 Tracy,44,5000 Ashby,25,3000 Basu,33,4000 Bristow,29,2000 Cass,50,5000 Daniels,22,6000 3000 3000 5000 5000 4000 2000 6000 6000 h(sal)=00 h2 sal h(sal)=11 Índice basado en hash (edad), e índice auxiliar con clave ‘sal’ 6 Estructuración de índices Indexación basada en árboles Estructura de datos de búsqueda jerárquica Eficiente en búsquedas de rango Ejemplo: buscar empleados con 24 < edad < 50 Estructuración de índices Comienzo de la búsqueda 12 78 19 56 33 44 A 3 9 86 94 B Nivel hoja L1 Daniels,22,6000 Ashby,25,3000 Bristow,29,2000 L2 Basu,33,4000 Jones,40,6000 L3 Smith,44,3000 Tracy,44,5000 Cass,50,5000 Índice basado en estructura de árbol 7 Estructuración de índices Indexación basada en Árboles B+ Caminos de igual longitud (balanceado en cuanto altura) Recorrer en orden secuencial y realizar búsquedas Mas rápido que la búsqueda binaria en un archivo ordenado Ejemplo: n=numero hijos de nodo (al menos 100 en la practica) h=altura (generalmente no mas de 4 en la practica) n elevado a la h = 100 millones de nodos hoja Todas las búsquedas requieren ‘h’ operaciones I/O (4 en este caso); mientras que busqueda binaria: log2 100,000,000 sobre 25 I/O Comparación organización-costo Modelo de costo: nos permite estimar el costo en términos de tiempo de ejecución de las distintas operaciones que se efectúan sobre los archivos de un tipo específico en la BD. B = # de paginas de datos R = # de registros por página D = tiempo promedio que implica leer o escribir una pagina en disco C = tiempo promedio para procesar un registro (comparar el campo) H = tiempo requerido por un registro para ser mapeado según Hash F = promedio de hijos por nodo no hoja (fan-out) según árboles Normalmente: D = 15ms, C = H =100ns. 8 Comparación organización-costo Archivos de montón (heap files): es el tipo simple y básico de organización, los registros se colocan en el archivo en el orden en que se insertan (al final). Esta organización suele utilizarse con caminos de acceso adicionales, como los índices secundarios. Costos: recorrido = B(D + RC), búsqueda exacta = ½ B(D + RC), búsqueda rango = B(D + RC). Comparación organización-costo Archivos ordenados (sorted files): los registros se encuentran ordenados en el archivo en base al valor de uno de sus campos llamado campo de ordenación, si el campo de ordenación también es un campo clave, a este se le denomina cave de ordenación. Costos: recorrido = B(D + RC), búsqueda = D(log2 B) + C(log2 R). 9 Comparación organización-costo Comparación de costos de E/S: un archivo de montón resulta eficiente de examinar e insertar pero este penaliza la búsqueda y la eliminación de registros. Por otro lado un archivo ordenado ofrece una inserción y eliminación lenta, sin embargo la búsqueda es más rápida comparada a la de montículos. Tipo de archivo Examinar Búsqueda exacta Búsqueda rango Insertar Eliminar Montón BD ½ BD BD 2D Búsqueda + D Ordenado BD D(log2 B) D(log2 B) Búsqueda + BD Búsqueda + BD Desempeño e implementación de índices: La elección de índices tiene un impacto tremendo en el desempeño del sistema y debe ser hecho en el contexto del trabajo de carga esperado, o en otras palabras la mezcla de consultas y operaciones de actualización. 10 Desempeño e implementación de índices: Impacto del trabajo de carga (workload): el primer punto a considerar son las operaciones comunes que se realizan en la BD, ya que diferentes tipos de organizaciones de archivos e índices soportan de manera eficiente dichas operaciones. Resulta más complejo implementar y mantener un árbol que una tabla o arreglo. Desempeño e implementación de índices: Claves de búsqueda compuestas: también llamadas claves concatenadas. Si se usa una cierta combinación de atributos muy frecuentemente, es mejor crear una estructura de acceso que proporcione un acceso eficiente mediante un valor clave que sea una combinación de esos atributos. (a0, a1, …, an) 11 Desempeño e implementación de índices: SELECT nombre FROM Empleado WHERE edad BETWEEN 20 AND 30 AND salario BETWEEN 1.000.000 AND 3.000.000 SELECT nombre FROM Empleado WHERE edad = 25 AND salario BETWEEN 800.000 AND 950.000 En este caso seria adecuado declarar una clave (edad, salario). Índices en SQL CREATE INDEX nombre_indice ON nombre_tabla WITH STRUCTURE = BTREE, KEY = (edad, salario) Esta sentencia crea un índice nombre_indice de tipo árbol B+ sobre la tabla nombre_tabla (archivo) y cuya clave es (edad, salario). 12 Referencias Ramakrishnan, R., Gehrke, J. [2003] “Database management systems” Elmasri, R., Navathe, S. [2005] “Fundamentos de sistemas de base de datos” Loomis, X. [1992] “Estructuras de datos y organización de archivos” Gracias por su atención … 13