Clase teórica 8
Anuncio

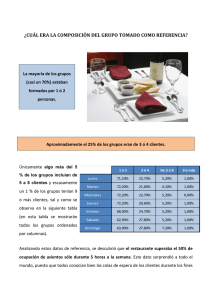
FLUCTUACIONES ESTADÍSTICAS
Los postulados fundamentales de la teoría estadística de “errores”
establecen que, dado un conjunto de medidas, todas efectuadas en
idénticas condiciones, suficientemente grande :
I.
El valor más probable de la serie de mediciones es el valor medio.
II.
Es igualmente probable cometer “errores” de igual valor y distinto
signo (Esto quiere decir que es igualmente probable obtener valores
mayores que el valor medio, errores por exceso, o menores que el valor
medio, por defecto).
III.
En una serie de mediciones es tanto más probable “cometer un
error” cuanto menor sea su valor absoluto respecto del valor medio. (Esto
significa que es más probable que los valores sean próximos al valor medio
que alejados de éste)
Distribución Gaussiana o normal
Curva de Gauss para distintos valores de h (inversamente proporcional
al “ancho” de la distribución)
h grande, valores
“concentrados”
h pequeña, valores
distribuídos
El área bajo la curva es:
si el área bajo la curva vale la unidad, K queda determinada, y la
curva quedará determinada por los parámetros m y h
VALOR MEDIO Y DESVIACION ESTANDAR DE UNA SERIE DE MEDIDAS
Si medimos N veces la magnitud de interés obtendremos los N datos
experimentales:
x1 , x2 , x3 , ........, xN
La media aritmética de las N medidas (valor medio o promedio) será:
< x > = (x1 + x2 + x3 + .....+ xN)/N
Valor más probable
El valor de la medida i-ésima podría escribirse como:
xi= < x >+ di
donde di= xi- <x>, es la desviación i-ésima respecto del valor medio <x>.
Es posible probar que
d1 + d2 + d3 + ....+ dN = 0,
es decir: la suma de las desviaciones es 0.
VALOR MEDIO Y DESVIACION ESTANDAR DE UNA SERIE DE MEDIDAS
Para medir la dispersión de los valores experimentales entorno al valor
medio se introduce otra magnitud: la desviación cuadrática media,
varianza S2:
S2 = (d12 + d22+ d32 + ....+ dN2)/N
(varianza, promedio de las desv.cuadráticas)
y
S= [(d12 + d22+ d32 + ....+ dN2) / N] ½ = [ (Σ (xi-<x>)2) / N ]½
S, desviación estándar, es la raíz cuadrada de la desviación cuadrática media.
S depende del valor que se elija como “mejor valor” de la medidas.
VALOR MEDIO Y DESVIACION ESTANDAR DE UNA SERIE DE MEDIDAS
A partir de
S= [ (Σ (xi-<x>)2) / N ]½
Operando algebraicamente y buscando el mínimo de la función
se puede demostrar que:
•
el promedio de los valores medidos (valor medio) minimiza la
desviación estándar (y la dispersión que queremos cuantificar) y es
igual al valor más probable.
•
el valor medio coincide con la moda y la mediana
Trabajamos con S y no con la varianza S2 ya que S posee las
mismas dimensiones que las observaciones.
En realidad la expresión correcta de la desviación estándar es:
S (= [ Σ (xi-<x>)2/(N-1)]½
para un solo evento N=1, S da infinito)
(para N tendiendo a infinito)
La desviación estándar S (o σ) se relaciona con h en la Gaussiana…
El número relativo de datos entre x
y x+dx, ΔN/N, es :
x2x1
representa la probabilidad de que una medida caiga en dicho intervalo.
Si (en el caso que N tienda a infinito) integro entre <X>- σ y <X>+ σ …
Si realizo una nueva medida habrá un 68% de probabilidad que ésta esté
comprendida en <x>± σ
un 95% en <x>±2 σ
y un 99.7 % en <x>±3 σ.
DISTRIBUCIÓN DE GAUSS Y MEDICIONES REALES (finitas)
“VARIAS (M) SERIES DE N MEDIDAS” DE UNA MISMA MAGNITUD.
Si para cada serie defino <x>i= [(Σ xi)/N
Puedo definir=promedio de los promedios =(Σ<x>i) / M
= [Σ xi (suma de todos los valores obtenidos)]/NM (número total de
mediciones)=
Aquí=<X> = promedio total= mejor valor
Considerando a los promedios de cada serie como datos individuales de
una serie de M mediciones podremos determinar la desviación estándar, que
notaremos σ, para esa serie (o sea la desviación estándar de los promedios)
De acuerdo con la definición de desviación estándar (S):
σ = [ Σ(<x>i-<X>)2 / M ]½ desviación estándar de los promedios o
desviación estándar de la media.
La teoría estadística demuestra que puede expresarse en términos de las
desviaciones de cada una de las series de N medidas mediante la ecuación
σ = { Σ di2/ N (N-1)}½ = S / N½
Es un resultado
práctico muy
poderoso !!
donde S es la desviación estándar de una de las M series de medidas.
Si hacemos varios muestreos, o sea si tomamos M conjuntos de N
observaciones caracterizados por sus respectivas <x>i y Si
1) la distribución de los valores medios de los conjuntos <x>i es
Gaussiana y está centrada en <X> (centro de la distribución total).
2) la distribución de los promedios σ es más estrecha que la original S,
σ < S (σ = S / √N ).
(σ da el orden de magnitud con el cual podemos esperar que los
promedios fluctuen alrededor del valor más representativo de la
medida)
Una nueva muestra (M+1) tiene un 68% de probabilidad de estar
comprendida en el intervalo <X>± σ y un 95% de estar en el intervalo
<X>± 2σ.
Como no medimos infinitamente, podemos expresar la medida
como:
x=<X>i ± σ incluye al mejor valor (con un 68% de probabilidad)
DETERMINACIÓN DE LA DESVIACION ESTANDAR DEL PROMEDIO
σ=
[(Σ (xi-<xi>)2)]/N(N-1)]1/2= S / √N
CONSECUENCIA Æ En cualquier proceso de medida cuanto mayor sea el
número de observaciones N más exacta será nuestra afirmación:
-Sobre el valor más probable (o mejor valor) estimado por <X>i puesto que σ
(que disminuye con N ) me habla de esta estimación pues
xmedido = <X>i ± σ
- Sobre la desviación estándar Si (que me habla de la dispersión o precisión de
la medida, y NO disminuye con N )
- Limite al número de medidas
Resumen tratamiento de incertidumbres en una medición rea
Si:
xm ± Δt
N=1
donde xm: valor medido
ΔT = [( Δ s)2 + ( Δ a)2 + ( Δ d)2 + ( Δ i)2 ]1/2
N < 10
ΔT = [( Δ s)2 + ( Δ a)2 + ( Δ d)2 + ( Δ i)2 + ( Δ f)2]1/2
donde Δf estima la incertidumbre máxima debida a las fluctuaciones, a partir
del valor mayor medido – el valor menor medido.
N > 10
ΔT = [( Δ s)2 + ( Δ a)2 + ( Δ d)2 + ( Δ i)2 + ( Δσ)2]1/2
con σ , la desviación estándar del promedio
σ=
[(Σ (xi-<xi>)2)]/N(N-1)]1/2= S / √N
σ depende de N, y es menor cuanto más grande sea N,
¿hasta qué punto tiene sentido seguir realizando medidas para lograr σ≈0?
ΔT = [( Δ s)2 + ( Δ a)2 + ( Δ d)2 + ( Δ i)2 + ( Δσ)2]1/2
no es razonable esforzarse en disminuir σ mucho más que ( Δ a)
Número óptimo
σ ≈ ( Δ a)
Así para determinar el número óptimo de medidas, como S es independiente
de N, realizamos entre 5 a 10 medidas preliminares y calculamos S
Usando que σ ≈ ( Δ a)
S (= [ Σ (xi-<x>)2/(N-1)]½
podemos hacer un tratamiento estadístico de los datos:
Resultado:
X = (Σ xi) / N
Δf=σ
(si queremos el resultado con un 68 % de probabilidad)
Δ f = 2σ
(95 % probabilidad)
Δ f = 3σ
(99 % probabilidad)
σ ={ Σ (xi-<x>) 2 / N (N-1)} ½ = [ 1/N] ½ S