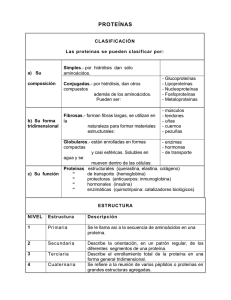
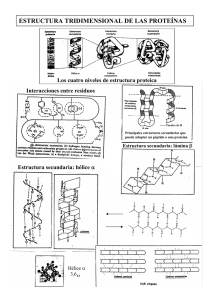
Predicción de la estructura terciara de las proteínas
Anuncio

Predicción de la estructura terciara de las proteínas Cuando la estructura terciaria de una proteína no se ha determinado experimentalmente, se puede intentar construir un modelo tridimensional a partir de su secuencia de aminoácidos. Los métodos predictivos se basan en los experimentos llevados a cabo en 1961 por Christian B. Anfinsen con la ribonucleasa A. Este investigador observó que tras desnaturalizar la proteína por completo utilizando urea y -mercaptoetanol era posible encontrar condiciones en las que la proteína recuperaba su estructura tridimensional y su actividad catalítica. Este experimento permite demostrar que la información necesaria para adoptar la estructura secundaria y terciaria de la proteína nativa está contenida en la propia secuencia de aminoácidos. El objetivo de la predicción de la estructura terciaria de las proteínas consiste en estimar la posición espacial de todos y cada uno de los átomos de la molécula proteica a partir de la secuencia de aminoácidos utilizando métodos computacionales. Este es uno de los retos más difíciles a los que se enfrentan los bioinformáticos y algunos lo han definido como “el santo grial de la Bioinformática”. Hay dos estrategias básicas a la hora de construir un modelo 3D para una proteína: a partir de un molde: es la estrategia más precisa, y la utilizan los métodos de (1) modelado por homología (homology modeling) y (2) reconocimiento del plegamiento (fold recognition). sin utilizar un molde: es una estrategia mucho menos precisa que la anterior y se utiliza (1) en los métodos basados en fragmentos y (2) en los métodos que parten de cero (ab initio). 1.- Modelado por homología (homology modeling, comparative modeling) Este método se basa en el hecho de que las proteínas relacionadas evolutivamente presentan conformaciones similares y, por tanto, la estructura 3D de una proteína obtenida experimentalmente puede servir como punto de partida para crear un modelo 3D de otros miembros de su misma familia. Es uno de los métodos de predicción más utilizados ya que genera modelos de gran calidad y con un coste computacional razonable. Durante la construcción del modelo, se va modificando la estructura del molde para que se ajuste lo mejor posible a la secuencia problema. La calidad del modelo depende, sobre todo, (1) de la capacidad para detectar una proteína homóloga a la secuencia problema con una estructura 3D conocida y (2) de la precisión del alineamiento entre la secuencia problema y la secuencia del molde a la hora de colocar los aminoácidos relacionados evolutivamente en la misma posición. El primer paso consiste en buscar proteínas con una secuencia parecida a la secuencia problema y con estructura conocida. Lo más sencillo es realizar una búsqueda con BLASTP en la BD PDB. Si el porcentaje de aminoácidos idénticos entre las secuencias es > 25%, se puede esperar que sean homólogas y que tengan una estructura similar. Sin embargo, no debemos olvidar que la ausencia de similitud entre dos secuencias no indica necesariamente que sus estructuras sean diferentes. Puede ocurrir que secuencias muy distintas adopten una estructura similar por mecanismos de convergencia evolutiva. Después, hay que seleccionar la proteína que se utilizará como molde. El mejor molde será aquél que tenga la secuencia más parecida a la de la proteína problema. Si hay dos moldes con igual similitud, se utilizarán otros criterios como la resolución de la estructura o la estructura que abarque mayor longitud de la secuencia. En la tabla siguiente, la figura de la derecha indica qué proteínas pueden utilizarse como molde en función del porcentaje de identidad y de la longitud del alineamiento. También puede ocurrir que el grado de similitud no sea constante a lo largo de la secuencia. En este caso, si hay más de un molde posible, se pueden utilizar distintos moldes para distintas regiones de la proteína (usando en cada región el molde que más se parezca a la secuencia diana). La segunda etapa consiste en hacer el mejor alineamiento posible entre las secuencias de la proteína molde y de la proteína problema para establecer la correspondencia entre los aminoácidos de una y otra. Cualquier error en esta etapa, por pequeño que sea, puede provocar efectos devastadores sobre el modelo final. Hay que tener en cuenta que el mejor alineamiento entre dos secuencias (que trata de maximizar el número de aminoácidos idénticos o parecidos) puede no coincidir con el mejor alineamiento estructural (en el que los aminoácidos conservados ocupan la misma posición relativa dentro de la estructura de la proteína). Para hacer un buen alineamiento, lo mejor es utilizar las secuencias de otros miembros de la familia y hacer un alineamiento múltiple de secuencias (AMS). Un AMS nos indica el grado de conservación de cada posición de la secuencia y las regiones más adecuadas para introducir indels. Utilizaremos la estructura de la proteína molde para verificar que no se introduzcan indels en los elementos de estructura secundaria o en las regiones compactas del interior de la proteína y que no haya cargas sin neutralizar en el núcleo interno de la proteína. Además del AMS, cualquier resultado experimental obtenido con la proteína molde, con la proteína problema o con otros miembros de la familia puede ser útil para mejorar el alineamiento correcto. En la tercera etapa, se empieza a construir un modelo 3D a partir del alineamiento entre la secuencia de la proteína problema y la estructura de la proteína molde. Lo primero que se construye es la trayectoria de la cadena principal (backbone). Los residuos que aparecen en el alineamiento adoptan las coordenadas de los átomos de la cadena principal de la proteína molde (N, C, C, O, C). En el caso de residuos conservados también se pueden adoptar, en una primera aproximación, las coordenadas de los átomos de la cadena lateral. Si hay indels, la cadena principal presenta interrupciones. El cuarto paso consiste en modelar la estructura de los bucles. Generalmente, son las regiones que presentan más dificultad porque es aquí donde se introducirán los indels del alineamiento entre la secuencia problema y el molde. Es importante predecir bien estas regiones porque suelen tener un papel funcional. Como la predicción no puede hacerse por homología, se suele utilizar alguno de estos tres métodos: métodos basados en la secuencia: van bien si los bucles son cortos (3 ó 4 aminoácidos) y conectan estructuras . Tienen en cuenta las interacciones locales que los pueden estabilizar (puentes de hidrógeno o interacciones hidrofóbicas), ignorando las interacciones de largo alcance. métodos basados en la búsqueda en bases de datos estructurales: buscan ejemplos de bucles que conecten elementos de estructura secundaria similares a los de nuestro modelo y que tengan una longitud parecida. métodos basados en cálculos energéticos: computan la energía de las interacciones interatómicas de todas las conformaciones posibles y determinan la más estable (la que representa un mínimo de energía libre). Ninguno de estos métodos garantiza un buen resultado y es en esta etapa en donde se suelen producir los errores más graves en la predicción. Sin embargo, en muchos casos puede ser suficiente para nuestros intereses construir un modelo parcial en el que falten algunos bucles que estén alejados de las regiones funcionales de la proteína. El quinto paso consiste en modelar las cadenas laterales. Cuando el porcentaje de aminoácidos idénticos entre la proteína problema y el molde es elevado, se pueden copiar directamente los ángulos diedros de las cadenas laterales de los aminoácidos del molde. Así se obtiene un buen modelo inicial que luego habrá que optimizar. En los demás casos, se recurre a las denominadas bibliotecas de rotámeros, que incluyen, para cada aminoácido, una lista de las combinaciones de ángulos diedros que se observan con más frecuencia (ya que las cadenas laterales de cada aminoácido presentan ciertas preferencias conformacionales en función del elemento de estructura secundaria en donde esté presente). En cada posición se introduce el rotámero adecuado para que todas las cadenas laterales puedan acomodarse en la estructura del modelo. La precisión en esta etapa depende directamente de la calidad del modelado de la cadena principal. Cualquier mejora realizada en éste último se traducirá directamente en un mejor modelado de las cadenas laterales. La sexta etapa consiste en la optimización del modelo. La introducción de los rotámeros obliga a remodelar la cadena principal lo que, a su vez, vuelve a afectar al empaquetamiento de las cadenas laterales. Se genera así un proceso iterativo en el que alternan el modelado de los rotámeros y un proceso de minimización de la energía. El proceso se repite hasta alcanzar la convergencia (el modelo no mejora). Para obtener un buen modelo hay que utilizar una función energética muy precisa. La optimización también se puede hacer mediante simulaciones por dinámica molecular. La última etapa consiste en la validación del modelo Llegados a este punto es importante comprobar: que la longitud y los ángulos de enlace son correctos que se mantienen los ángulos de torsión correspondientes a cada elemento de estructura secundaria que los aminoácidos hidrofílicos e hidrófobos están correctamente distribuidos que no haya errores estereoquímicos, impedimentos estéricos, interacciones desfavorables o regiones en las que el empaquetamiento no sea óptimo Si se detectan errores, se pueden corregir repitiendo la etapa del proceso correspondiente. Si los errores son graves, lo mejor es empezar de nuevo utilizando otro molde. Ejemplos de programas que permiten hacer modelado por homología son SWISSMODEL, MODELLER y BISKIT. 2.- Reconocimiento del plegamiento (fold recognition) Cuando las bases de datos de estructuras tridimensionales no contienen ninguna estructura homóloga a la proteína problema es posible replantear el problema de la predicción intentando encontrar alguna proteína que presente un plegamiento parecido, independientemente de la similitud entre sus secuencias. En este caso, las secuencias del molde y de la proteína problema no muestran un elevado grado de similitud porque no están emparentadas evolutivamente o porque han divergido tanto a partir del ancestro común que los métodos de comparación son incapaces de detectar la homología. La lógica de este planteamiento se basa en que, a lo largo de la evolución, la estructura se conserva mejor que la secuencia. De hecho, más de la mitad de las estructuras proteicas recién determinadas presenta un plegamiento ya conocido. Se dice que dos proteínas tienen el mismo tipo de plegamiento cuando presentan los mismos tipos principales de estructura secundaria dispuestos en el mismo orden y conectados mediante la misma topología. En las últimas versiones de las BD SCOP y CATH hay aproximadamente 1.400 plegamientos distintos y alrededor de 100 de ellos están presentes en la mitad de las superfamilias proteicas descritas hasta la fecha. Y no sólo eso, 10 de ellos se denominan “superplegamientos” (superfolds) porque son compartidos por aproximadamente el 30% de las proteínas conocidas. Los científicos están convencidos de que el número de plegamientos distintos que hay en la naturaleza es finito, y se ha estimado que podrían haber entre 8.000 y 10.000. Se trata, por tanto, de buscar en las BD algún plegamiento que pueda ser compatible con la proteína problema y que pueda servir de molde para la construcción de un modelo 3D siguiendo, básicamente, los mismos pasos que en el modelado por homología. Hay dos tipos de métodos de predicción que utilizan esta estrategia: los métodos basados en el perfil físico-químico y los métodos de enhebrado (threading). Métodos basados en el perfil físico-químico Estos métodos se basan en que las propiedades físico-químicas de los aminoácidos de la secuencia problema tienen que adecuarse al entorno que ocupan en la estructura del modelo. Cada aminoácido tiene unas propiedades físico-químicas distintas que determinan la probabilidad de encontrarlo o no en un determinado ambiente: en una región hidrofílica o hidrofóbica, en un tipo de estructura secundaria o en otro y más o menos expuesto al disolvente. El número de posibilidades distintas es 18, ya que se distinguen 3 tipos de estructuras secundarias (, , otros), 3 grados de exposición al disolvente (baja, intermedia, alta) y 2 tipos de polaridad (hidrofilico, hidrofóbico), tal y como se indica en la siguiente tabla: Accesibilidad al disolvente: baja (< 40 Ǻ2) Accesibilidad al disolvente: elevada (> 100 Ǻ2) Accesibilidad al disolvente: intermedia Hidrofóbico (a) Hidrofílico (d) Hidrofóbico (g) Hidrofílico (j) Hidrofóbico (m) Hidrofílico (p) Hidrofóbico (b) Hidrofílico (e) Hidrofóbico (h) Hidrofílico (k) Hidrofóbico (n) Hidrofílico (q) otros Hidrofóbico (c) Hidrofílico (f) Hidrofóbico (i) Hidrofílico (l) Hidrofóbico (o) Hidrofílico (r) A partir de un análisis estadístico de las estructuras proteicas conocidas se puede calcular la probabilidad de encontrar cada residuo en un tipo de ambiente o en otro. También se puede calcular esta probabilidad para una secuencia proteica concreta a partir de métodos de predicción de estructura secundaria y de accesibilidad al disolvente. Con esta información se puede reescribir la secuencia de la proteína problema ignorando el aminoácido concreto que ocupa cada posición y sustituyéndolo por un símbolo (de la a a la r) que indica cuál de las 18 características posibles está más favorecida en esa posición. De este modo se genera un perfil físico-químico. Por otro lado, se pueden obtener los perfiles físico-químicos de todas las proteínas con estructura conocida. De este modo se codifica la estructura 3D de una proteína en forma de un perfil 1D que puede compararse directamente con el de la proteína problema. Para comparar el perfil de la proteína problema con los perfiles de una BD se utilizan métodos muy parecidos a los empleados para alinear secuencias mediante el algoritmo de programación dinámica, utilizando un sistema de puntuación adecuado y penalizaciones en caso de introducir indels. La estructura que tenga un perfil más parecido al de la proteína problema servirá como molde para la construcción del modelo 3D. Métodos de enhebrado (threading) En muchos casos, proteínas con secuencias muy distintas adoptan plegamientos parecidos. Por tanto, se puede esperar que la estructura de una secuencia problema se parezca a la de alguna proteína ya caracterizada. La estrategia que utilizan los métodos de enhebrado consiste en enhebrar la secuencia problema en una estructura ya conocida para después evaluar si se ajustan bien o no. Para ello, se generan modelos estructurales de la proteína problema utilizando todos los plegamientos conocidos como posibles moldes y después se intenta determinar cuál es el mejor. El mejor modelo estructural será aquél que minimice la energía libre de la secuencia problema. La etapa crucial del proceso consiste en evaluar la calidad de los modelos. Se utiliza una función que calcula la energía de la molécula utilizando (1) los potenciales de interacción entre parejas de aminoácidos obtenidos a partir de un análisis estadístico de las interacciones observadas en estructuras proteicas conocidas y (2) el potencial de solvatación de cada residuo. Estos métodos son muy costosos desde el punto de vista computacional. 3.- Métodos basados en fragmentos Cuando no se encuentra ni una secuencia homóloga ni un plegamiento suficientemente bueno, no queda más remedio que predecir la estructura de novo. Es muy probable que la secuencia problema presente un plegamiento nuevo pero que, aun así, comparta numerosos motivos estructurales con otros plegamientos ya conocidos. Los métodos basados en fragmentos utilizan fragmentos cortos de proteínas con estructura conocida para construir un modelo 3D de la secuencia problema. Parten de la suposición de que una secuencia corta de aminoácidos sólo puede adoptar un pequeño número de conformaciones con baja energía que son el resultado, principalmente, de interacciones locales. También asumen que el abanico de conformaciones que puede adoptar un segmento local de la cadena polipeptídica estará razonablemente bien representado en el PDB. Así, combinando fragmentos cortos con estructura conocida generan un gran número de posibles modelos 3D para la proteína problema. El modelo final será aquél que presente menor energía libre. El programa ROSETTA utiliza esta estrategia para predecir la estructura de una secuencia problema. En primer lugar, a partir de proteínas con estructura conocida, utiliza la técnica de la ventana deslizante para generar una librería de fragmentos de 9 aminoácidos. En este paso se evitan las proteínas homólogas a la secuencia problema (las que tengan más del 25% de los aminoácidos idénticos). Después, se divide la secuencia problema en fragmentos de 9 aminoácidos de longitud y, para cada uno de ellos, se seleccionan 25 fragmentos de la librería que tengan una secuencia igual o lo más parecida posible. El modelo 3D se construye combinando todas las estructuras posibles de estos fragmentos y seleccionando la conformación que tenga menor energía libre. Librería de fragmentos de 9 aminoácidos Ensamblaje de los fragmentos La función que calcula la energía libre tiene en cuenta que debe tratarse de una estructura compacta en la que los aminoácidos hidrofóbicos deben estar en el interior y las hebras tienen que estar emparejadas. En la etapa de minimización de energía se utiliza el algoritmo de Monte Carlo para seleccionar la estructura 3D que mejor se ajusta a la secuencia problema. 4.- Métodos ab initio Estos métodos también tratan de construir el modelo sin utilizar un molde. Basándose únicamente en principios físico-químicos, tratan de reconstruir el proceso natural de plegamiento proteico hasta alcanzar la conformación nativa, que será aquélla que presente un estado de mínima energía libre. Para ello, estos métodos necesitan (1) encontrar una función que permita calcular la energía libre de la forma más precisa posible y (2) desarrollar potentes algoritmos de búsqueda para seleccionar la mejor conformación de entre todas las posibles. Para calcular la energía libre de una cadena polipeptídica se puede utilizar (1) una función que calcula la energía potencial de la molécula utilizando parámetros obtenidos a partir de cálculos basados en la mecánica cuántica, o (2) una función basada en el conocimiento, que calcula la energía potencial de la molécula a partir de un análisis estadístico de las interacciones observadas en estructuras proteicas ya conocidas y almacenadas en la base de datos PDB. En ambos casos, la energía potencial obtenida deben representar la totalidad de las fuerzas que determinan la conformación de una macromolécula: energía de solvatación, energías de enlace, ángulos de torsión, interacciones covalentes, interacciones electrostáticas, puentes de hidrógeno, interacciones de van der Waals, etc. Para determinar cuál es la conformación con menor energía libre se utilizan algoritmos de búsqueda conformacional como (1) la dinámica molecular, (2) el algoritmo de Monte Carlo o (3) algoritmos genéticos. Estos métodos presentan dos problemas importantes: Por un lado, la energía libre asociada a cada conformación se calcula teniendo en cuenta todas las interacciones que tienen lugar dentro de la proteína y entre los átomos de la proteína y el disolvente. Esta energía suele ser de unas pocas kilocalorías por mol. Por tanto, los cálculos energéticos deben ser muy precisos para poder apreciar pequeñas diferencias energéticas entre una conformación y otra. Por otro lado, el número de conformaciones posibles que puede adoptar una proteína es inmenso, con lo que se necesitan ordenadores muy potentes para seleccionar la que corresponde al estado nativo. Estas dificultades hacen que el progreso en este campo sea lento. Hoy en día, estos métodos no son aconsejables para proteínas con más de 150 aminoácidos. Para que esta situación mejore tendrá que aumentar la precisión del cálculo de la energía potencial y la eficacia de los algoritmos de búsqueda conformacional.