IN CAE
11151
Regresi6n Lineal y Logistica
lntroducci6n usando S-Pius 6.2
La nota titulada REGRESION LINEAL Y LOGiSTICA , fue preparada por el Profesor
Carlos Quintanilla Armijo, para servir como base de discusi6n en clase, mas bien que como
ilustraci6n del manejo correcto o incorrecto de Ia gesti6n administrativa.
DISTRIBUCt6N RESTRINGIDA
Marzo del 2004
Contenidos
1
Regresi6n Lineal Simple
1
La Ecuaci6n de Regresi6n
1
El Problema de Estimaci6n: el Metodo de Mlnimos Cuadrados
2
5.
lntervalos de Confianza, Bondad de Ajuste y Predicci6n con
Regresi6n Simple 13
lntervalos de Confianza para los Coeficientes
13
Partici6n de Ia Varianza de Y: el Coeficiente de Determinacion, R2
Predicci6n
3
Variables Ficticias
16
21
(.Que es una variable ficticia?
21
Variables Ficticias como Regresores
22
Una Regresi6n con una variable dependiente continua y otra
ficticia
24
4
Regresi6n Logfstica
29
lntroducci6n
29
Usando Regresi6n Lineal
29
Derivando Ia regresi6n loglstica*
Pronosticando Probabilidades
30
32
Interpretacion de Coeficientes y Contraste de Hip6tesis
34
15
1v
Contents
Variables Ficticias como Regresores
36
Variables Continuas y Ficticias como Regresores
Clasificaci6n
39
38
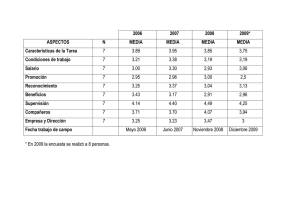
1 Regresi6n Lineal Simple
En este capftulo estudiaremos una de las tecnicas mas utilizadas en estadfstica para
analizar la relaci6n entre dos variables--e) metoda de regresi6n lineal. En el curso
de Metodos Cuantitativos I consideramos por primera vez Ia relaci6n entre dos variables. Hablabamos entonces de correlaci6n. La correlaci6n mide-decfamos-el grado de
relaci6n lineal que existe entre dos variables. Si Ia correlaci6n esta cerca a 1, las variables estan relacionadas linealmente (ya sea positiva o negativamente). Si Ia correlaci6n
esta cerca de 0, no hay mucha relaci6n lineal entre las variables. Eso era todo. Ahara
queremos hacer mas. Queremos hacer mas precisa, mas cuantitativa, Ia relaci6n entre
dos variables. Queremos ser capaces de contrastar formalmente Ia hip6tesis de si hay
relaci6n lineal o no entre dos variables 1• Queremos pronosticar Io que le ocurrini a una
de las variables si Ia otra cambia x unidades.
La Ecuaci6n de Regresi6n
EI modelo de regresi6n asume que Ia relaci6n entre dos variables, x y y esta resumida
por Ia ecuaci6n
Y = f3o + /31 * x + c
donde /3 0 y /3 1 son dos constantes y c es un termino aleatoric. La variable allado izquierdo de Ia ecuaci6n, y, se conoce como variable dependiente. Esta es Ia variable cuyo comportamiento nosotros queremos explicar con esta ecuaci6n. La variable a Ia derecha, x,
se conoce como variable independiente, variable explicativa o simplemente regresor.
Esta es Ia variable que explica el comportamiento dey.
Si ignoramos por un segundo el ultimo termino, c, esta es Ia ecuaci6n de una recta. Nada
mas, ni nada menos. A menudo, el material sabre regresi6n causa panico o ansiedad.
Para evitarlo les recuerdo que este material lo aprendieron probablemente al comienzo
de secundaria. La figura 1 nos muestra esta linea y hace evidente Ia interpretacion de los
1
Par ejemplo, si obtengo una correlacion de 0.1, i,Significa esto que hay o no hay relacion entre dos
variables? i.Puedo rechazar Ia hip6tesis de que Ia correlaci6n es igual a cera?
2
Chapter 1 Regresi6n Lineal Simple
f3o ______ .--·' ~
/
/
.
I .Graft co de una Linea Recta
coeficientes de esta ecuaci6n.
• /3 0 es el intercepto. Nos dice el valor que tamara Ia variable y cuando Ia variable x
es igual a 0.
• /3 1 es Ia pendiente. Nos dice cuanto cambia Ia variable y, cuando Ia variable x cambia
una unidad. Formalmente,
b.y
(31 = b.x.
Si Ia relaci6n lineal entre y y x fuera exacta o detennfnistica, todos los puntas {Yi , Xi }
caerfan exactamente sabre Ia lfnea recta de Ia figura I. Si conocieramos el valor que
toma x, automaticamente conocieramos el valor exacto que toma y. En Ia vida real, par
supuesto, es muy diffcil encontrar relaciones lineales que se ajusten perfectamente. La
relaci6n lineal es aproximada. He ahf Ia importancia del ultimo termino de Ia ecuaci6n.
El error o perturbaci6n representa Ia desviaci6n de una observaci6n real de esa linea
ideal. Hay varias razones que explican Ia existencia de este error. Las dos principales
son:
1. Errores de Medici6n. Aunque Ia relaci6n fuera perfecta, nosotros como investigadores
no podemos medir las variables perfectamente.
2. Omisi6n de Variables. Nuestro modelo de regresi6n, no debe ser vista como una
descripci6n completa de los que ocurre en Ia realidad, sino como una caricatura.
Como tal es una aproximaci6n que trata de capturar lo esencial.
Haremos un par de supuestos sabre el comportarniento de este error, c::
I. El valor esperado del error es igual a cero, E(c:) = 0.
3
Consurro
160 ;
150
140 t
..
'
130 t
..
..• •
120 t
110
Ingreso
80
90
100
110
120
2.Relaci6n Consumo e Ingreso.
2. La varianza del error es igual a a 2 , Var(c-)=E(c- 2 ) = a 2 .
EJEMPLO. Supongan que queremos estudiar Ia relaci6n entre los ingresos semanales
de un grupo de familias y su consumo en cierto producto o grupo de productos. La
figura 2 muestra los niveles de consume de 40 familias con ingresos entre 80 y 120
d6lares semanales. Dos casas de ben sal tar a Ia vista para ustedes. Primero, hay una clara
tendencia a que niveles de consume alto esten asociadas con niveles altos de ingreso. La
relaci6n es aproximadamente lineal. Segundo, Ia relaci6n lineal no es exacta. Es decir,
los puntos no caen exactamente sabre una lfnea recta. Hay variabilidad alrededor de una
linea imaginaria que se trace a traves de esos puntos (Ver figura 3).
Uno podrfa pensar que para cada nivel de x hay una media para y, llamemosla E(yjx),
alrededor de Ia cual se distribuyen los datos con cierta variabilidad. En el contexto de
nuestro ejemplo arriba, para cada nivel de ingreso, Ia variable consumo tiene una media
determinada. Los niveles de consumo de todas las familias con un mismo nivel de ingreso, sin embargo, no van a ser todas iguales (variabilidad alrededor de Ia media). El
modelo de regresi6n lineal asume que:
• Todas estas medias (una para cada nivel de x) se pueden representar con una funci6n
lineal, E(yjx) = /3 0 + /3 1 * x
• La variabilidad alrededor de estas medias (medida por la desviaci6n estandard de c)
es igual para todos los niveles de x.
• Las observaciones reales son generadas porIa regia y = E(yix) +c. Es decir para
generar una observaci6n dey, primero obtengo su media (que depende del nivel de
x asociado con esa y) y despues le agrego c.
4
Chapter 1 Regresi6n Lineal Simple
Consurro
160
150
0
..
0
140
130
120
110
Ingreso
80
90
100
110
120
3.Unea de Regresi6n para Ejemplo de Consume e Ingreso.
El Problema de Estimaci6n: el Metodo de Mlnimos Cuadrados
Familia
1
2
3
4
5
6
7
8
9
10
II
12
13
14
I5
16
I7
18
19
20
lngreso
119
85
97
95
120
92
105
110
98
98
81
81
91
105
IOO
107
82
84
100
108
Consumo
154
123
125
130
151
131
141
141
130
134
I15
117
123
144
I37
140
123
115
134
I47
Familia
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
Ingreso
116
115
93
105
89
104
108
88
109
112
96
89
93
1I4
81
84
88
96
82
II4
5
Consumo
144
144
126
141
124
144
144
129
137
144
132
125
126
I40
120
Il8
119
131
127
I 50
!.Datos sobre Consumo e Ingreso
El Problema de Estimaci6n: el Metodo de Minimos Cuadrados
La Hnea de regresi6n dada por la ecuaci6n y = /3 0 + /3 1 * x + E contiene panimetros-Q
val ores poblacionales--que nunca observaremos en Ia pnktica, pero que estamos interesados en estimar. Estos panimetros son /3 0 , (3 1 y a 2 . Detenganse a pensar un segundo!
Esto suena o deberla sonarles bastante familiar. Piensen en JL y en p de Metodos Cuantitativos I. Estos eran panimetros o valores poblacionales que nunca observabamos en Ia
realidad. Sin embargo, desarrollamos metodos para estimarlos efectivamente usando x
y fi a partir de una muestra tomada de la poblaci6n.
Ahora enfrentamos el rnismo problema. No tenemos acceso a toda la poblaci6n. Tenemos acceso a una muestra de pares {x, y} como Ia que detail a Ia tabla I y queremos,
basados en ella, obtener ~ 0 , ~ 1 y a2 . Los sombreros sabre los coeficientes significan
como siempre que estos son estimados. La pregunta del rnill6n de d6lares es: i,C6mo los
6
Chapter 1 Regresi6n Lineal Simple
estimamos? Queremos estimadores que satisfagan criterios como insesgadez y consistencia. (,Recuerdan estos conceptos? El mitodo de m(nimos cuadrados (MMC) satisface
ambos criterios y es muy intuitive. Dada una colecci6n de pares {x, y}, el MMC encuentra los coeficientes de la mejor lfnea que pasa a traves de esos puntas. La definicion
de mejor es aquella Hnea que minimiza Ia suma de las desviaciones del punto observado
a Ia Hnea elevadas al cuadrado (ver figura 4). Un poco de algebra simplifica Ia exposici6n inmensamente. Definamos para cada par {Xi, Yi}, es decir, para cad a fila de Ia tabla,
el residua
Ahora podemos elevar cada uno de estos terminos al cuadrado y sumarlos. Esto se convierte en una funci6n de {3 0 y {3 1 , llamemosla 8({30 , {3 1)
S(f3o. !3d =
L er = 2)Yi - f3o- {31 * Xi) 2
que podemos rninimizar usando calculo elemental. Esta no es una clase de calculo. Por
lo tanto, aquf simplemente reportare Ia soluci6n a este problema.
El coeficiente de Ia pendiente esta dado por
_.._ _ :E(xi - x)(Yi - Y)
{3
1E(xi-x) 2
El coeficiente del intercepto esta dado por
En la practica nunca tendremos que calcular estos coeficientes a mano, pero vale Ia
pena tratar de entenderlos. Par ejemplo, noten que si en Ia ecuaci6n para ~ 1 dividimos
numerador y denominador entre n, el coeficiente de Ia pendiente podrfa re-escribirse
como
~
_ cov(x, y)
var(x)
El coeficiente de Ia pendiente (como el de Ia correlaci6n) es igual a Ia covarianza dividido
1 -
entre algo mas. Si Ia covarianza entre las dos variables es cero, el coeficiente de Ia recta
es cero tambien. Verifiquen que en este caso particular, el coeficiente del intercepto se
reduce a fl.
Hagamos unos calculos en S-Plus para Ia tabla 1. La base de datos se llama dataconsumo.
> attach(dataconsumo)
El Problema de Estimaci6n: el Metodo de Mfnimos Cuadrados
7
> mean(ingreso)
[1] 98.35
> mean(consumo)
[1] 133
> cov(ingreso,consumo}
[1] 118.79
> var(ingreso)
[1) 139.31
> beta1 = cov(ingreso,consumo)/var(ingreso)
> beta1
[1) 0.85274
> betaO = mean(consurno) - betal*mean(ingreso)
> betaO
[1] 49.133
Esto produce la linea de regresi6n
consumo = 49,133 + 0,85274 * ingreso
Ahara estimemos esta lfnea un poco mas eficientemente, invocando el comando lm en
S-Plus
> consumo.lm = lm(consumo-ingreso,data=dataconsumo)
> surnmary(consurno.lm)
Residuals:
Min
-6.85
1Q Median
-2.72
-0.26
3Q
Max
2.64
7.94
Coefficients:
Estimate Std. Error t value Pr(>ltll
(Intercept)
49.1334
5.0145
9.8
ingreso
0.8527
0.0506
16.8
Signif. codes:
6e-12 ***
<2e-16 ***
0 '***' 0.001 '**' 0.01 '*' 0.05
0.1 '
Residual standard error: 3.73 on 38 degrees of freedom
Multiple R-Squared: 0.882,
Adjusted R-squared: 0.879
' 1
8
Chapter 1 Regresi6n Lineal Simple
F-statistic:
284 on 1 and 38 DF,
p-value:
0
Nuestro trabajo en este capitulo y en el proximo se reduce a interpretar los resultados
del programa. Lo primero que podemos extraer de estos resultados es la lfnea de regresi6n que habfamos estimado a mano. Noten que bajo Ia columna "Estimate" hay un
par de coeficientes, 49.1334 y 0.8527, que corresponden al intercepto y a Ia pendiente
respectivamente.
A continuaci6n tenemos Ia lfnea con los cuartiles y extremes de los residues.
Residuals:
Min
-6.85
1Q Median
-2.72
-0.26
3Q
Max
2.64
7.94
Si queremos ver todos los residues, usamos
> consumo.lm$res
1
3.3910015
6
3.4148736
11
2
3
4
5
1.3840257 -6.8488064 -0.1433344 -0.4617346
7
9
10
2.3293056 -1.9343745 -2.7015424
1.2984576
13
14
15
-3.2050303 -1.2 0503 03 -3.7323903
5.3293056
2.5929856
19
20
3.9422337 -5.7632383 -0.4070144
5.7710975
16
-0.3761665
21
12
8
17
22
18
23
-4.0507905 -3.1980545 -2.4378624
24
25
2.3293056 -1.0269183
26
27
6.1820416
2.7710975
4.8258177 -5.0816385 -0.6398465
31
32
35
28
29
33
34
1.0039296 -0.0269183 -2.4378624 -6.3453185
30
1.7949697
37
38
39
40
-2.7632383 -5.1741823
0.0039296
7.9422337
3.6546815
36
6 Que son los residues de una regresi6n? La ecuaci6n siguiente los define.
ei = Yi - (f3o + /31 *xi)
Son Ia diferencia entre el valor observado para la variable dependiente, Yi, y nuestro
pron6stico basado en Ia lfnea de regresi6n, (/3 0 + /3 1 *xi). Tomemos como ejemplo la
primera observaci6n de Ia tabla 1 con un nivel de ingreso de 119 y un nivel de consume
El Problema de Estimaci6n: el Metoda de Mfnimos Cuadrados
9
0
E
::J
l§
0
u
80
100
90
110
120
lngreso
4.Residuos de una Regresi6n Lineal. Las distancias verticales representan los residuos
de una regresi6n. El pron6stico esta dado por Ia recta. El error o residua es Ia diferencia
entre el verdadero valor de Y y su pronostico.
de 154 . .:,Cual es el pron6stico que obtenemos si usamos Ia ecuaci6n estimada?
consume
=
49,133 + 0,8527 * 119
150,6
residua
= 154- 150,6
3,4
Este es el primer residua 3.3910 redondeado. El metoda de rninimos cuadrados selecciona los coeficientes (3 0 y (3 1 de tal manera que Ia suma de estos residues al cuadrado
sea tan pequefia como se pueda.
El siguiente numero que nos interesa esHi reportado en Ia linea inmediatamente debajo
de los coeficientes
Residual standard error: 3.73 on 38 degrees of freedom
Este numero que yo llamare error standard de La regresion mide Ia variabilidad de los
10
Chapter 1 Regresi6n Lineal Simple
Consurro
160
Variacion alrededor
de Ia media
150
t
140
• I
130
..
•
120
I
{
. . ..
:
I
~
Variaci6n alrededor
de Ia linea de regresi6n
110
Ingreso
80
90
100
110
120
5 .Comparando los Residuos de una Regresi6n Lineal con los Residuos alrededor de Ia
Media.
El Problema de Estimaci6n: el Metoda de Mfnimos Cuadrados
11
Desvlaciones
Alrededor de Ia Media
Alrededor de Ia Linea de Reg res ion
6.Comparaci6n de Residuos alrededor deJa Linea de Regresi6n y alrededor de la Media.
12
Chapter 1 Regresi6n Lineal Simple
residuos de Ia regresi6n. Esta definido como
1:---""-e-:?
eer = · ~~~
Vn-2~l
Es muy parecido a Ia desviaci6n esHindard de los residuos pero el divisor noes n- 1,
sino n- 2. Entre mas pequefio es este numero, mejor es el ajuste de ]a linea de regresi6n.
Si todos los puntas cayeran exactamente sabre una lfnea, todos los errores serfan cero y,
par lo tanto, el error estandard de Ia regresi6n serfa cera tambien.
Para entender mejor el progreso que hemos hecho al correr una regresi6n, es ilustrativo
comparar Ia desviaci6n esuindard de Ia variable dependiente con este error esH'indard de
Ia regresi6n.
>
sd(consurno)
[1] 10.7178260329133
Este valor es mucho mayor que el 3.73 que acabamos de calcular. Las figuras 5 y 62
explican el par que. Si no tuvieramos acceso a datos sabre el ingreso o si no estuvieramos
al tanto de Ia relaci6n que existe entre ingreso y consumo, el mejor pron6stico del que
serfamos capaces serfan Ia media del consumo. La desviaci6n estandard del consumo
mide Ia variaci6n alrededor de esta media. El primer diagrama de caja representa esta
variaci6n alrededor de Ia media del consumo.
Par otro lado, si sabemos que hay una relaci6n entre consumo e ingreso y tenemos datos
para ambos, ajustaremos nuestro pron6stico para el consumo de acuerdo al nivel de
ingreso. El error estandard de Ia regresi6n mide Ia variaci6n alrededor de este pron6stico, alrededor de esta media condicional. El segundo diagrama de caja representa esta
variaci6n. Noten que en este caso es considerablemente mas pequefia que el primer diagrama. Pueden reconocer el valor maximo 7.94 y valor rnfnimo -6.85 que fueron reportados arriba.
2 El primer gn1fico fue tornado dellibro "Practical Regresion and ANOVA"escrito par el Prof. Julian
Faraway de Ia Universidad de Michigan. Website: http://www.stat.lsa.umich.edu/-faraway/book!.
2 lntervalos de Confianza, Bondad de Ajuste y Predicci6n
con Regresi6n Simple
En el capftulo anterior introducimos los elementos basicos de regresi6n como Ia interpretacion de los coeficientes y el metodo 6ptimo de calcularlos. En esta clase, discutiremos intervalos de confianza para los coeficientes de Ia regresi6n, en particular, para Ia
pendiente. Esto nos perrnitini determinar si existe evidencia estadfstica a favor de una
relaci6n lineal entre las variables. Tambien desarrollaremos una medida que nos permita
evaluar que tan importante es una variable independiente para explicar el comportamiento de un variable dependiente. Esta medida es Ia R-Cuadrada de Ia regresi6n. El capitulo
cierra con Ia aplicad6n principal de una regresi6n-producir predicciones.
lntervalos de Confianza para los Coeficientes
Es facil demostrar que uno puede correr una regresi6n entre dos variables cualesquiera
y el coeficiente de Ia pendiente-que mide si existe una relaci6n lineal entre ambasraramente sera igual a cero. Por ejemplo, uno puede crear dos variables aleatorias, w y
z con el comando rnorm en S-Plus y correr una regresi6n entre los dos. Por definicion,
no hay relaci6n entre estas dos variables. Pero si corremos una regresi6n entre las dos,
el coeficiente de Ia pendiente no sera igual a cero. Hagamoslo. La primera lfnea solo nos
asegura que todos obtengamos Ia rnisma respuesta.
> set.seed(328)
> yl
rnorm(SO)
> xl
= rnorm(50)
> lm(yl-xl)
Call:
lm (formula
yl -xl)
14
Chapter 2 lntervalos de Confianza, Bondad de Ajuste y Predicci6n con Regresi6n Simple
Coefficients:
(Intercept)
xl
-0.00006747127 0.1989901
Degrees of freedom: 50 total; 48 residual
Residual standard error: 0.8654183
Necesitamos por lo tanto un metodo que nos permita distinguir los casos en que vale
Ia pena interpretar de los que hay que descartar. Para poder usar una regresi6n o las
predicciones de una regresi6n con mayor confianza, formaremos primero un intervale
de confianza para Ia pendiente de Ia regresi6n, /3 2 . Si el valor 0 esta contenido en este intervale, no podemos descartar Ia hip6tesis de que no hay relaci6n entre las dos variables.
t,Por que? El coeficiente obtenido pudo bien ser el resultado del azar mas que de una
relaci6n significativa entre las variables. En este caso, no podemos usar esta regresi6n
para hacer predicciones.
Un intervale de confianza para Ia pendiente esta dado por
~2 ± tn-2,af2 * &/3
2
donde ~ 2 es el coeficiente estimado, &73 2 es su error estandard y tn-2,a/ 2 es el multiplo
que regula las probabilidades que el intervale de confianza contenga el verdadero valor
de /3 2 .
Aqui reproduzco los resultados de la regresi6n del capitulo anterior:
> consumo.lm = lm(consumo-ingreso,data=dataconsumo)
> summary(consumo.lm)
Residuals:
Median
lQ
Min
-6.62588 -2.63991 -0.03378
3Q
Max
2.41740
8.30494
Coefficients:
Estimate Std. Error t value Pr(>ltll
Partici6n de Ia Varianza de Y: el Coeficiente de Determinacion, R2
(Intercept) 49.30123
4.90353
10.05 2.94e-12 ***
ingreso
0.04951
17.20
0.85139
Signif. codes:
< 2e-16
0 '***' 0.001 '**' 0.01 '*' 0.05
15
***
\
I
0.1 \ , 1
Residual standard error: 3.649 on 38 degrees of freedom
Multiple R-Squared: 0.8861,
Adjusted R-squared: 0.8831
F-statistic: 295.7 on 1 and 38 DF,
p-value: < 2.2e-16
Para formar un intervale de confianza del 95 % para Ia pendiente necesitamos
• El estimado puntual. En este caso es 0.8513.
• El error estandard de este estimado puntual. En este caso es 0.04951
•
EI multiple proveniente de Ia distribuci6n t con 38 grados de libertad (el numero de
observaciones era 60). Usando qt(l-0.05/2, 38) obtenemos 2.024394.
Por lo tanto el intervale de confianza esta dado par
{0,8513 ± 2,024394 * 0,04951}
{0,75, 0,95}
Dado que el 0 esta fuera de este intervale, puedo rechazar Ia hip6tesis de que no hay
relaci6n entre ingreso y consumo. Un doble negative es un positive. Hallamos evidencia
de que si hay relaci6n entre ingreso y consumo.
En S-Plus he escrito una funci6n que nos permitinl. calcular estos coeficientes automaticamente. El comando es confint y tiene por argumento el nombre que le hayamos dado
al objeto de Ia regresi6n; en este caso consumo.lm.
> confint(consumo.lm)
Intervalos de Confianza del 95 % para
los Coeficientes de la Regresion son:
liminf
limsup
(Intercept) 38.982102 59.284725
ingreso
0.750237
0.955235
Partici6n de Ia Varianza deY: el Coeficiente de Determinacion, R2
Una de los estadfsticos mas reportados en analisis de regresi6n es el coeficiente de de-
terminacion, R 2 . El coeficiente de determinacion mide Ia proporci6n de la variaci6n en
16
Chapter 2 tntervalos de Confianza, Bondad de Ajuste y Predicci6n con Regresi6n Simple
las observaciones Yi 's que es explicada por los regresores Xi's. Este coeficiente esta
siempre contenido en el intervalo [0, 1]. De hecho, el coeficiente de determinacion en el
modelo de regresi6n simple es igual al coeficiente de correlaci6n entre X y Y al cuadrado. Como ustedes recordaran, el coeficiente de correlaci6n esta contenido en el interval a
[-1, 1]. ~Como podemos calcular R 2 ? Recordemos que
Var(Yi)
Var(}i) + Var(ei)
Var(Yi)
Var(Yi)
Var(}i) + Var(ei)
_
1
___:..~
----'-~
Var(Yi)
Var(Yi)
R 2 + Var(ei)
Var(Yi)
1 _ Var(ei)
Var(Yi)
Una R 2 alta nunca debe convertirse en Ia meta de nuestra investigaci6n. De hecho, como
aprenderemos en Ia secci6n sobre regresi6n multiple, un metoda seguro para obtener una
R 2 = 1 es incluir tantos regresores como observaciones. Por supuesto, las propiedades
de este metoda son cuestionables.
Predicci6n
Una vez que hemos estimado una ecuaci6n de regresi6n podemos usarla para producir
pron6sticos sobre los valores que tomani Ia variable dependiente cuando Ia variable independiente tome valores especfficos. Un pron6stico completo siempre debe incluir una
medida de su variabilidad. Con esta medida podemos construir intervalos de confianza
para nuestras predicciones.
Recordemos que las observaciones de Ia variable dependiente fueron generadas por la
ecuaci6n:
Yi = !31 + j32Xi + Ei
Nuestra predicci6n de los primeros dos tenninos sera:
131 + 132xi
mientras que nuestra predicci6n del ultimo termino (Ei) sera cero. Recuerden que este es
el componente de Yi que nunca podemos predecir. Por lo tanto usamos su valor medio
en Ia poblaci6n. Asf, la formula para nuestra predicci6n es:
Yi = 131 + ~2xi
Predicci6n
17
Por ejemplo, si queremos predecir el consumo de una familia con ingreso igual a 120,
este esta dado por:
"fi = 49,30123 + 0,8513(120) = 151,46
(,C6mo obtenemos errores estandard para esta predicci6n? Aquf hay dos casas a considerar.
• Predicci6n para Ia media de todas las familias con ingreso de 120
• Predicci6n para un individuo en particular que tiene ingreso de 120
Debe ser obvio que uno tendra mayor exito pronosticando un grupo que un individuo.
Por lo tanto los errores esuindard (y par lo tanto las varianzas) de Ia predicci6n son
menores para un grupo que para un individuo.
La varianza de Ia predicci6n cuando quiero pronosticar Ia media de individuos esta dada
par:
La varianza de la predicci6n cuando quiero pronosticar el comportamiento de un indi-
viduo en particular esta dada por:
- 2
V(:Yo) = 6"2(1 +.!. + (Xo- X) )
n
l:(Xi- X) 2
donde Xo es el valor de Ia variable independiente para Ia cual queremos producir un
pron6stico para Y. En el caso anterior, X 0 = 120. El termino a es reportado como parte
de Ia regresi6n como "Residual standard error".
(.Cuales son los factores que reducen Ia varianza de nuestra predicci6n?
• Una muestra grande
•
Suficiente variaci6n en las X's
•
El valor de X para el cual queremos una predicci6n no esta muy alejado de Ia media
de las observaciones. Ejemplo: si tenemos observaciones para el ingreso en un rango
del 80 al 120, predicciones para valores como 250 tendnin una varianza grande.
•
La varianza de Ia perturbaci6n es pequefia.
Un intervale de confianza para Ia predicci6n en cualquiera de los dos casas esta dado
por
Yo± tn-2,af2 * .jv(Yo)
18
Chapter 2 lntervalos de Confianza, Bondad de Ajuste y Predicci6n con Regresi6n Simple
En el caso de nuestro ejemplo, si conocemos Ia siguiente informacion:
a
3,649
x
98,35
2:)xi- X) 2
5433,1
Xo
120
n
40
podemos encontrar valores para el error estandard de una predicci6n.
La varianza de Ia predicci6n para un grupo es
(120- 98,35)2) = 1. 481.
40 +
5433,1
El error estandard de Ia prediccion es Ia rafz cuadrada de 1.481, igual a 1.216. Un intervalo de confianza del 95 o/o para el consumo promedio de familias con ingreso de $120
es
151,46 ± 2,024394(1,216) .
.La varianza de Ia prediccion para un individuo es
2
1
(120- 98,35)2
V(Yo) = (3,649) (1 + 40 +
) = 14.797
5433 1
'
El error estandard de Ia prediccion es Ia rafz cuadrada de 14.797, igual a 3.846687. Un
intervalo de confianza del 95 o/o para el consumo de una familia con ingreso de $120 es
V(Yc) = (3 649)2(2_
0
'
151,46 ± 2,024394(3,8466)
Nuevamente es un gran alivio tener un programa que pueda calcular ambos tipos de
intervalos con un solo click.
En S-Pius para obtener intervalos de confianza para predicciones primero tenemos que
dejarle saber al programa el valor de X para el cual queremos hacer el pron6stico
> nuevax = data.frame(ingreso=120)
Noten que el nombre de Ia variable X (en este caso ingreso) debe ser exactamente Ia
misma que se uso en la regresi6n.
Ahora para pronosticar para un individuo usamos el comando predict con la opci6n
pi.fit=T
> predict(consumo.lm,newdata=nuevax,pi.fit=T)
$fit:
1
Predicci6n
19
151.4617
$pi. fit:
lower
upper
1 143.4973 159.4261
Para pronosticar para un grupo usamos el comando predict con la opci6n ci.fit=T
> predict(regl,newdata=nuevax,ci.fit=T)
$fit:
1
151.4617
$ci.fit:
lower
upper
1 148.9415 153.9819
Cualquiera de los dos metodos produce tres numeros: el estimado puntual, el lfmite
inferior del intervale de confianza y ellfmite superior. Para cambiar el nivel de.confianza
de Ia predicci6n usen la opci6n confleve/=0.90.
> predict(reg1,newdata=nuevax 1 ci.fit=T,pi.fit=T,conf.level=0.9)
3 Variables Ficticias
(.Que es una variable ficticia?
Una variable ficticia, tambien llamada binaria, es una variable que asume dos valores
solamente (por lo general 0 y 1) de acuerdo a si una condici6n esta presente o no en una
observaci6n dada. Par ejemplo, podemos definir una variable ficticia llamada mujer de
Ia 'siguiente manera:
. = { O
1 si Ia persona entrevistada es una mujer
mUJer
si la persona entrevistada es un hombre
Los usos de las variables ficticias en el contexto.de analisis de regresi6n son multiples.
Entre ellos figuran:
• Comparacion de Dos o Mas Medias: Recuerden el ejemplo de Ia diferencia de las
ventas medias de dos tiendas que analizaron en Metodos I.
• Descripcion de Caracterfsticas Demograficas: Variables como el sexo, Ia raza, Ia
religion, el nivel de educaci6n, etc. pueden introducirse en el modelo de regresi6n
como variables ficticias.
• Otras caracteristicas cualitativas: Por ejemplo, afiliaci6n polftica, si el consumidor
compro o no un carro, si el consumidor miro o no un programa de television, etc.
• Estacionalidad: Los efectos de las estaciones en variables como Ia produccion o las
ventas pueden ser capturados usando variables ficticias estacionales.
En el capitulo anterior consideramos el caso de una variable dependiente continua (por
ejemplo el salario de una persona) y una variable independiente continua tambien (par
ejemplo, numero de afios trabajando para una compafifa o institucion). En esta seccion
consideraremos el caso de una variable dependiente continua, el salario, contra una variable dependiente binaria-por ejemplo, mujer. En el capitulo proximo consideraremos
los otros dos casas: binaria contra continua, binaria contra binaria.
Antes de entrar en accion, quiero recordarles una propiedad del metoda de mfnimos
cuadrados que necesitamos tener presente en el analisis de este capitulo. Si yo corro
una regresion contra una constante-es decir, sin regresores, sin x's, el coeficiente de Ia
22
Chapter 3 Variables Ficticias
constante se interpreta como Ia media de Ia variable dependiente.
salario = (3 1
Verifiquemos en S-Pius. Primero calcularemos Ia media, Ia desviaci6n estandard y el
error estandard de Ia media por el metoda tradicional
> attach(salario1)
> mean(salario)
[1) 15037
> sd(salario)
[1] 2336.1
> sd(salario)/sqrt(length(salario))
[1) 233.61
Ahara corramos Ia regresi6n. Noten Ia sintaxis en S-Pius. Estamos corriendo una regresi6n de salario contra un numero 1.
> constante.lm <- lm(salario-1,data=salario1)
> summary{constante.lm)
Coefficients:
Estimate Std. Error t value Pr(>jtj)
234
64.4
<2e-16 ***
(Intercept)
15037
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05
0.1 '
Residual standard error: 2340 on 99 degrees of freedom
La media del salario es el coeficiente del intercepto, 15037. Noten tambien que el error
estandard del coeficiente del intercepto, 234, noes otra cosa que el error estandard de Ia
media (igual a Ia desviaci6n estandard de la variable, 2336.1 dividido entre la raiz del
niimero de observaciones).
Variables Ficticias como Regresores
Supongan que tenemos datos sabre los salarios en una empresa clasificados de acuerdo
, 1
Variables Ficticias como Regresores
23
a sexo: hombres y mujeres. Nuestra meta es explicar las diferencias en salarios entre
hombres y mujeres. Para eso queremos correr una regresi6n de salario contra mujer
salario = /3 1 + (3 2 * mujer
donde el salario esta medido en d6lares y "mujer" es la variable ficticia definida arriba.
(.Cwil es Ia interpretacion de los coeficientes en esta regresi6n? Recuerden que usamos
Ia tecnica de regresi6n primordialmente como un metoda de pron6stico. Pronostiquemos
el salario de una persona para todos los valores que tome Ia variable independiente en
este caso y Ia interpretacion de los coeficientes sera obvia.
(.Cual es el pron6stico para el salario de un hombre?
salario
(.Cual es el pron6stico para el salario de una mujer?
salario
Cuando corremos una regresi6n contra una variable independiente ficticia (y ninguna
otra variable mas) el coeficiente del intercepto, /3 1 , se interpreta como el promedio de Ia
variable dependiente para el grupo excluido (el grupo que obtiene cero para la variable
ficticia): en este caso los hombres. (.Que es /3 2 ? Resten el pron6stico para los hombres
del pron6stico para las mujeres
salario mujeres - salario hombres
= (/3 1 + /3 2 ) - (/3 1 )
(32
La interpretacion de /3 2 entonces es Ia diferencia en contra del grupo excluido en el
salario promedio de los dos grupos.
EnS-Plus yo obtengo
> salariol.lm <- lm(salario-mujer,data=salariol)
> summary(salariol.lm)
Coefficients:
Estimate Std. Error t value Pr(>lti)
24
Chapter 3 Variables Ficticias
(Intercept)
15131.9
331.8
45.609
rnujer
-189.5
469.2
-0.404
Signif. codes:
<2e-16 ***
0.687
0.1 '
0 '***' 0.001 '**' 0.01 '*' 0.05
, 1
Residual standard error: 2346 on 98 degrees of freedom
Multiple R-Squared: 0.001662,
Adjusted R-squared: -0.008525
F-statistic: 0.1631 on 1 and 98 DF,
p-value: 0.6872
Esta regresi6n nos dice que el salario de los hombres es 15,131.9 y el de las mujeres es
(15131.9-189.5=14942.4). No solo eso, la regresi6n nos dice que las diferencias entre
salarios de hombres y mujeres en la muestra no pueden ser extrapolados a Ia poblacion.
Por que?
Una Regresi6n con una variable dependiente continua y otra ficticia
Este el caso mas simple de una regresi6n multiple (hay mas de una x). Resulta, sin
embargo, que tambien es un caso especial de una regresi6n simple, como venin mas
adelante.
Corramos primero que nada una regresi6n de salario contra antigiiedad.
> salario2.lrn
= lm(salario-antiguo,data=salario1)
> surnrnary(salario2.lrn)
Call: lrn(forrnula = salario -antiguo, data
= salariol)
Residuals:
Min
1Q Median
3Q
Max
-4717 -1680 -258.5 1521 5124
Coefficients:
Value Std. Error
(Intercept) 14047.3021
antiguo
66.5074
t value
Pr (>It I)
636.6508
22.0644
0.0000
39.8485
1.6690
0.0983
Residual standard error: 2315 on 98 degrees of freedom
Multiple R-Squared: 0.02764
F-statistic: 2.786 on 1 and 98 degrees of freedom,
the p-value
Una Regresi6n con una variable dependiente continua y otra ficticia
25
is 0.09831
Convenzance de que, de acuerdo a esta regresi6n, no hay evidencia estadistica (al 95 %
de confianza) de que Ia antigi.iedad afecte el salario de una persona. Corrimos atnis una
regresi6n de salario contra mujer y vimos que no habia relaci6n tampoco. i,Significa
esto que si corremos una regresi6n de salario contra ambos, antigi.iedad y sexo, no habra
relacion tampoco? Veremos que no.
EnS-Plus
> salario3.lm = lm(salario-antiguo+mujer,data=salario1)
> summary{salario3.lm)
Coefficients:
Estimate Std. Error t value Pr (>It I )
(Intercept)
9244.5
917.7
10.07 < 2e-16 ***
anti guo
621.8
92.5
6.73 1.2e-09 ***
mujer
-6924.1
1074.5
-6.44 4.5e-09 ***
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05'
'0.1'
Residual standard error: 1950 on 97 degrees of freedom
Multiple R-Squared: 0.319,
Adjusted R-squared: 0.305
F-statistic: 22.7 on 2 and 97 DF,
p-value: Be-009
i, Que pas6 aqui? Ambas variables son significativas aun al 1 % de nivel de significaci on.
Antes de aclararles el misterio, interpretemos los resultados de Ia regresion. La ecuaci6n
estimada es
salario = 9244,5 + 621,8 antiguo - 6924,1 mujer.
Recordemos que Ia variable "mujer" solo puede tamar dos valores: 0 y I. Esto quiere
decir que Ia presencia de esta variable lo que hace es permitirnos correr dos regresiones 3
3
Dos regresiones con distintos interceptos pero forzando Ia pendiente a ser Ia misma para ambos grupos.
La regresi6n mas general serf a salario=b l+b2*antiguo+b3*mujer+b4*(antiguo*mujer).
En S-Pius se corre usando Ia notaci6n lm(salario-antiguo*mujer.data=salario I).
'1
26
Chapter 3 Variables Ficticias
al mismo tiempo. (.Cual es Ia linea de regresi6n para los hombres?
9244,5 + 621,8 antiguo - 6924,1 * 0
salario
9244,5 + 621,8 anti guo
(.Cual es Ia lfnea de regresi6n para las mujeres?
9244,5 + 621,8 antiguo - 6924,1 * 1
salario
-
9244,5 + 621,8 antiguo - 6924,1
2320,4 + 621,8 anti guo
La figura 7 grafica ambas lfneas.
Antiguedad
25000
20000
15000
10000
5000
Salario
5
10
15
20
25
30
7 .Salario como Funci6n de Sexo y Antiguedad. Linea Raja son los hombres. Linea Azul
las mujeres.
Ahara tratemos de descubrir que paso con las regresiones individuales. El gnifico de
los datos es la figura 8 que muestra claramente dos grupos de puntas. Los puntas a
Ia izquierda (H's rojas) son los salarios de los hombres en esta compafifa. Los de Ja
derecha (M's azules) los de las mujeres. Primero noten que las medias de los dos grupos
estan localizadas aproximadamente al mismo nivel. Si obtenemos medias para ambos
grupos tenemos que los hombres ganan en promedio $15,131.9 y las mujeres $14942.4.
El salario de los hombres es un poco mayor, pero nada que podamos extrapolar a Ia
poblaci6n.
Par otro !ado, si no hacemos distinci6n de sexo el salario graficado contra antigtiedad
no muestra tendencia alguna. Si con·ieramos regresiones separadas para hombres y mujeres el efecto de Ia antigtiedad saltarfa a Ia vista. Lo que ocultaba el grafico es que los
Una Regresi6n con una variable dependiente continua y otra ficticia
0
0
0
0
H
M
N
H
H
H
fi..i
M
H
H
0
0
0
~
H
HH
g_
co
~MM
M
M
M
M
M
MM
M
HH
H
,H H H H
·~
<a
"ia
f·~
H
CIJ
H
0
g-
0
0
0
~
~
H H
-
1\f.A
H
~ ~
M
M
M
M
MM
H
r\-J
M
rJ
H
tjiH
M
~
1::1
~H
MM
H
M
H
M
MM
M
M
H
5
M
M
"<I'
M
M
H
H
0
0
M
M
H
HH
27
10
15
20
25
Antiguedad
8.Salarios de Hombres (H's) y de Mujeres (M's).
hombres en esta rnuestra tienen aproximadarnente el mismo salario promedio, pero una
antigi.iedad prornedio mucho mas baja (9.46 contra 20.26) que Ia de las rnujeres como
grupo.
La figura 9 muestra 3 lfneas de regresi6n: una para cada grupo por separado y una para
los dos grupos revueltos. La hip6tesis nula que el coeficiente de Ia pendiente de Ia ultima
lfnea es cero no se puede rechazar.
28
Chapter 3 Variables Ficticias
80
H
0
C\1
H
M
H
k
fi-J
M
0
M
8
~
H
0
.g
8<D
~
H
.S!
as
H
"''I
HH
, H
H
HH
'
M
M
' /
~
M
H
H
(f)
M
8
~
M
,H
~
IM1
ff
~H
rJ
H
i;~-jH
80
M
MM
H
'1-l
M
MM
C\1
H
~
M
H
M
M
H
5
10
15
Antiguedad
9.£1 Misterio de los Salaries.
20
25
4 Regresi6n Logfstica
lntroducci6n
En est capitulo aprenderemos a lidiar con un caso especial en regresi6n: variables dependientes ficticias o binarias. Inicialmente consideraremos los problemas que crea este
tipo de variables para la regresi6n lineal comun y corriente. Despues generalizaremos el
modelo lineal e introduciremos la regresi6n logistica. Aunque las matematicas detnis de
este nuevo modelo sean mas complicadas, Ia interpretacion de los resultados--que sera
nuestra tarea principal-se complica muy poco.
Usando Regresi6n Lineal
Consideren el siguiente ejemplo. Tenemos datos sabre las preferencias de 1,000 consumidores y algunas variables demograficas sabre elias. En particular, supongan que
estamos estudiando quienes son los subscriptores a un peri6dico local como funci6n,
inicialmente, de Ia edad del subscriptor. Mas adelante consideraremos edad y sexo.
La variable dependiente y esui codificada de Ia siguiente manera:
y= {
1 si la persona se subscribe
0 sino
Aparte de que ser binaria, no hay nada especial sabre esta y y podrfamos intentar correr
una regresi6n como Ia siguiente:
y = f3o + (31 xi + e
donde x 1 es Ia edad de Ia persona.
Antes de discutir Ia interpretacion de los coeficientes pensemos par un segundo sabre
el significado de un pron6stico formulado a partir de esta ecuaci6n. Recuerden que el
pron6stico de una regresi6n es nuestro estimado del valor esperado de Ia variable depen-
30
Chapter 4 Regresi6n Logfstica
diente como funci6n de los regresores. Pero, t,cual es el valor esperado de una variable
que solo toma dos valores 0 y 1?
E(yjx)
1 * prob(y = ljx) + 0 * prob(y = Ojx)
= prob(y = llx)
El pron6stico no es otra cos a que nuestro estimado de Ia probabilidad de ex ito (y = 1)
como funci6n de las x's; en nuestro ejemplo, Ia probabilidad de que una persona se
subscriba al peri6dico como funci6n de Ia edad. Pongamosle numeros.
Supongan que corro Ia regresi6n y obtengo los siguientes resultados (errores estandards
omitidos. Ambos coeficientes son significativos al 1 %)
fj = -1,7007 + 0,06454 X
La probabilidad de que una persona se subscriba al peri6dico es una funci6n .lineal de
Ia edad de esta persona. A mayor sea Ia edad, mayor sera Ia probabilidad de que esta
persona se subscriba. Dado que las edades oscilan entre 20 y 55, podemos concluir
que este es un peri6dico que llama Ia atenci6n a personas mayores principalmente. El
coeficiente de la pendiente puede interpretarse de Ia siguiente manera: par cada afio de
edad, Ia probabilidad de que una persona se subscriba al peri6dico aumenta 6.45 %.
Supongamos que quiero hacer mi pron6stico sabre Ia probabilidad de que una persona se
subscriba al peri6dico para tres edades distintas: 25, 35 y 45. "Facil", diran ustedes. S6lo
usamos Ia ecuaci6n arriba y substituimos x par los valores 25, 35 y 45 respectivamente.
Los pron6sticos puntuales para las tres edades son: -0.087, 0.558, 1.203. El problema es
que s6lo el pron6stico del centro tiene sentido. Las probabilidades son numeros mayores
que 0, pero menores que 1. t,Que quiere decir una probabilidad de -8.7% ode 120.3 %?4
Derivando Ia regresi6n logfstica*
El problema inmediato que enfrentamos es c6mo forzamos nuestros pron6sticos a caer
siempre en el interval a {0,1}. Una posible soluci6n implementada par Ia regresi6n logfstica es hacer a Ia probabilidad de exito una funci6n no lineal de los regresores. En particular, renombrando prob(y = 11 x) como p simplemente:
exp(,8 0 + ,8 1 x1)
p=
1 + exp(,8 0 + ,B 1 xi)
Esta expresi6n podra Iucir intimidante al principia, pero veran que resulta en un modelo
lineal muy facil de interpretar. Noten primero que nada que cuando definimos p de esta
4
Este es el problema mas obvio, pero no el unico. Para algunos de ustedes que ya han estudiado estadistica
o econometria antes de venir a INCAE, otro problema de esta regresi6n es que los errores no tienen una
varianza constante. Tenemos el problema de heterocedasticidad.
Derivando Ia regresi6n logfstica*
31
manera, esta esta forzosamente comprendida entre 0 y 1. El numerador es siempre un
numero positive y el denominador (tambien siempre un numero positivo) es un poco
mayor que el numerador. El objetivo de las derivaciones a continuaci6n es dejar en el
!ado derecho de Ia ecuaci6n una expresi6n lineal de las xs.
exp(,80 +,8 1x1) ~( 1 - exp(,80 +,8 1x1) )
1 + exp(,B0 + ,8 1 x1) ·
1 + exp(,8 0 + ,8 1 xi)
exp(,B0 + ,8 1 x 1 )
•
1
1 + exp(,8 0 + ,8 1xl) --=- 1 + exp(,B 0 + ,8 1x1)
exp(,8
1 + exp(,8
,8 1:_______:
x1)_
0 + ,8 1 xl)
_
___;..__;_...::.__-=----'-..,.* ___
;. ___:0:__+ ____:
1+exp(,80 +,8 1 x 1 )
1
p
1-p
p
1-p
p
1-p
p
exp(,B0 + .81x1)
1-p
log(-p-)
1-p
=
log(exp(,8 0 + $ 1 xi))
log(-p-)
1-p
La probabilidad de ex ito podni no ser una funci6n lineal de las x 's, pero una funci6n
bastante simple de la probabilidad, log(~), si lo es. La ultima lfnea de Ia derivaci6n
es Ia unica que me importa. Cuando corramos en S-Plus, o en cualquier otro programa
estadfstico una regresi6n log:lstica esta sera Ia ecuaci6n que estimemos.
Prcil::abilidad
1
0.8
0.6
0.4
0.2
Edad
30
35
40
45
50
1O.Probabilidad de Subscripci6n como funci6n de Ia ectad.
32
Chapter 4 Regresi6n Logfstica
Pronosticando Probabilidades
Corramos entonces la regresi6n logfstica
p
log() = {3 0 + {3 1 x1.
1-p
Usando S-Plus yo obtengo,
> attach(periodico)
> periodico.glm
= glm(subscribe -
edad,
family
binomial )
> summary(periodico.glm)
Call: glm(formula = subscribe -edad, family=
binomi~l)
Deviance Residuals:
Min
Median
1Q
3Q
Max
-2.812961 -0.226625 0.04140823 0.2888369 2.790715
Coefficients:
Value Std. Error
t value
(Intercept) -26.5240119 1.82816556 -14.50854
edad
0.7810531 0.05356157
14.58234
La ecuaci6n estimada es:
log(-p-) = -26,5240 + 0,7810 * x 1 .
1-p
Despues de comprobar que los coeficientes son estadfsticamente significativos (ver proxima secci6n) podemos usar esta ecuaci6n para pronosticar Ia probabilidad de subscripci6n para personas de distintas edades. Usemos los valores que pusieron en problemas a
Ia regresi6n lineal simple x={25,35,45}. Para una edad de 35,
-26,5240 + 0,7810 * 35
log(-p-)
1-p
log(-p-)
1-p
0,81
exp(1og(-p-))
1-p
p
1-p
-
exp(0,8111)
-
2. 2504
p
-
0,69.
Para los otros dos valores, las probabilidades son 0.0091% y 99.9% respectivamente.
Pronosticando Probabilidades
33
En S-Plus podemos usar para pronosticar tanto log(~) como p los siguientes comandos respectivamente:
> xO = data.frame(edad=35)
> predict(periodico.glm,newdata
= xO)
0.81284
> predict(periodico.glm,newdata
= xO,type="response")
1
0.6927155
lntervalo de Confianza para Ia Predicci6n
Una vez que tengo mi pron6stico de la probabilidad de que una persona se subscriba
a! peri6dico, ,:,como tomo en cuenta la incertidumbre asociada con la estimaci6n de los
coeficientes? Naturalmente, Ia respuesta tiene que ver con un intervalo de confianza.
> xO = data.frame(edad=35)
> predict(periodico.glm,newdata = xO,type="response",ci.fit=Tl
$fit:
1
0.6927155
$ci.fit:
lower
upper
1 0.6384455 0.7421296
Y tenemos lo que querfamos. Un intervalo de confianza del 95% para Ia probabilidad
(cuyos limites respetan que las probabilidades estan entre 0 y 1) es {0.6385, 0.7420}.
Noten que tambien podriamos obtener un intervalo de confianza para Ia probabilidad
de un individuo en particular reemplazando ci..fit por pi.fit. Estos intervalos obviamente
senin mas anchos.
34
Chapter 4 Regresi6n Logistica
Interpretacion de Coeficientes y Contraste de Hip6tesis
La interpretacion de coeficientes de Ia regresi6n loglstica difiere de lo que aprendimos
en capftulos anteriores sobre Ia regresi6n lineal simple. Recuerden que si yo estimo una
ecuaci6n lineal, digamos
Y = f3o + f3Ixi
el coeficiente fji mide la sensitividad de la variable dependiente, y, a cambios en Ia
variable independiente xi. Mas precisamente, decimos que (3 1 es el cambio en y cuando
XI cambia una unidad.
Cuando corremos una regresi6n logfstica estamos estimando la ecuaci6n
p
log( 1 -'- p} = /3 0 + /31 x 1
Aquf podrlamos decir que (3 1 es el cambio en log(~) cuando x 1 cambia una unidad.
Estarlamos en lo cierto, pero log( i:p) no es una variable "natural". Lo que queremos
hacer es medir el efecto de un cambio de una unidad en x 1 sobre p. Queremos decir
cosas como: un aumento en 1 afio en Ia edad de una persona, aumenta (o reduce) la
probabilidad de que esta persona se subscriba al peri6dico en 0.03. Resulta que podemos
hacer ese calculo sin mayor problema, pero Ia expresion ya noes tan simple como lo era
en regresi6n simple.
Recuerden que
exp(/30 + /3 1 x1)
1 + exp((30 + (3 1 xi)
Bien podrfamos tomar Ia derivada de p con respecto a x 1 .
dp
exp(/30 + /3 1x1)
dx1 = (1 + exp(/30 + /3 1x 1 )) 2 * /3 1
p=
Noten que ahora, el efecto sobre Ia variable p de un cambio unitario en xi depende del
valor de XI. Esto es de esperarse dado que la variable pes una funci6n no-lineal de Ia
variable x 1 . El efecto de x 1 sobre la probabilidad p es mayor (Ia curva mas empinada)
cuando estamos cerca de p = 0,5. y es menor (la curva casi horizontal) cuando p esta
cerca de 0 o 1. Los refiero a Ia figura 10.
Volvamos al ejemplo numerico. Estimamos Ia siguiente ecuaci6n
log( _1!_) = -26,5239 + 0, 7810 * x 1
1-p
Ahora nos podemos preguntar: t,Cwil es el efecto del aumento de un afio en Ia edad de
una persona sobre su probabilidad de subscripci6n? La respuesta es:
dp
exp( -26,5239 + 0,7810 * x 1 )
* 0 ,7810
2
dx 1
(1 + exp( -26,5239 + 0, 7810 * x 1 ))
Interpretacion de Coeficientes y Contraste de Hip6tesis
35
que depende claramente del valor que tome xi. De hecho, podemos graficar el cambia
en p como funci6n de Ia variable x 1 . Vean la figura 11. Como ven, el efecto no es
constante, alcanza un pico cuando la edad esta entre 30 y 40 y aproxima 0 para edades
menores que 25 o mayores que 45.
dp/d Edad
0.2
0.15
0.1
0.05
20
30
50
40
ll.Midiendo el Efecto de Edad sabre la Probabilidad de Subscripcion.
Tradicionalmente se acostumbra reportar estas derivadas evaluadas cuando las variables
independientes toman sus valores promedios. Es decir,
dp
exp( -26,5239 + 0,7810 * xl)
* 0 ,7810
dx1
(1 + exp( -26,5239 + 0,7810 * xi)) 2
.
Dado que xi = 35,22,
dp
=
exp( -26,5239 + 0,7810 * 35,22)
* 0, 7810
2
(1 + exp( -26,5239 + 0,7810 * 35,22))
0,1547.
Cuando Ia edad es igual a 35.22, Ia edad promedio, un afio adicional de ectad resulta en
un incremento del 15% en Ia probabilidad de subscripci6n.
Contraste de Hip6tesis
La siguiente tabla resume los resultados de Ia estimaci6n de Ia ecuaci6n en S-Plus:
Coefficients:
Value Std. Error
t
value
36
Chapter 4 Regresi6n Loglstica
(Intercept) -26.5240119 1.82816556 -14.50854
edad
0.7810531 0.05356157 14.58234
El contraste de hip6tesis en este modelo se conduce de forma semejante al de regresi6n simple. A !ado de Ia columna de coeficientes estimados tenemos Ia columna de
errores estandard. Pruebas de hip6tesis sobre coeficientes individuales se llevan a cabo
formando los estadfsticos z
fi- f3o
z = ~:-'--..::.
(j-
(3
doride (3 0 es el valor especificado por Ia hip6tesis nula,
fi es el valor del coeficiente
estimado y (j{J es el error estandard del coeficiente. El valor del estadfstico z se compara
con un valor crftico Za o Za; 2 dependiendo de Ia forma de Ia hip6tesis altemativa.
Val ores muy grandes para el estadfstico z son evidencia en contra de la hip6tesis nula.
Noten que, a pesar que el programa reporte valores-t, el cociente ya no sigue una distribuci6n t, sino una distribuci6n normal. De hecho, Ia distribuci6n normal es apropiada
solo para muestras grandes.
Tomemos, como ejemplo, Ia hip6tesis nula de que el coeficiente de Ia pendiente en la
regresi6n arriba es igual a cera contra Ia hip6tesis alternativa de que es diferente de cera.
Ho
(3 1 = 0
HA
/31 f 0
La hip6tesis alternativa es bilateral. Esto significa que nuestro valor crftico para un nivel
de significaci6n del 5 % es igual Zo,o2 5 = 1 ,96. El valor del estadfstico es
0,7811-0
z=
0,0535
= 14 ' 6 '
Dado que el estadfstico es mucho mayor que el valor crftico, rechazamos Ia hip6tesis nula facilmente. La edad es un deterrninante importante de Ia probabilidad de subscripci6n
a un peri6dico.
Variables Ficticias como Regresores
Ahara consideraremos el caso de regresores binarios. Par ejemplo, supongan que estamos interesados en las diferencias en subscripci6n entre dos grupos demograficos:
hombres y mujeres. Para estudiar estas diferencias podemos correr una regresi6n logfs-
Variables Ficticias como Regresores
37
tic a:
log( 1 ~ p) = /3 0 + /3 1 * mujer
donde "mujer"esta definida como en el capitulo anterior. Es igual a 1 si la persona entrevistada es una mujer y 0 si es un hombre. S-Plus produce los siguientes resultados:
> periodico2.glm = glm{subscribe-mujer,
family= binomial
> summary(periodico2.glm)
Coefficients:
{Intercept)
Value Std. Error
t value
0.4641576 0.09186219
5.052760
mujer -0.3359824 0.12834159 -2.617876
Basados en esta regresi6n queremos contestar dos preguntas:
• (.Existen diferencias significativas entre hombres y mujeres en cuanto a preferencias
de subscripci6n?
• ;, Cuales son nuestros pron6sticos para Ia probabilidad de subscripci6n para cada uno
de los dos grupos?
La primera pregunta se responde chequeando si el coeficiente de mujer es igual a cera.
Podemos fonnar un intervale de confianza para este coeficiente sumando y restando al
coeficiente el producto de 1.96 y el error estandard del coeficiente 0.1283. Este intervale
es: {-0.58,-0.08}. Dado que el 0 esta fuera de este intervale podemos concluir que hay
diferencias significativas entre los dos grupos. EI signa negative del coeficiente de mujer
indica que esta es una publicaci6n que atrae principalmente a hombres. 5
La segunda pregunta se responde formando intervalos de confianza para los dos casos:
mujer= I, mujer=O. Yo obtengo en S-Plus para las mujeres {0.48, 0.57} · y para los hombres {0.57, 0.68}
5
Podemos contrastar estas hip6tesis en S-Plus usando el comando que usabamos para hacer intervalos de
confianza para Ia proporci6n. Usamos prop.test(c(x I ,x2),c(nl.n2)) donde xI y x2 son el niimero de exitos en
cada uno de los dos grupos y nl y n2 son los tamafios de muestra. La ventaja de Ia regresi6n logistica es que
nos permite agregarle otras variables al ancilisis.
38
Chapter 4 Regresi6n Logfstica
Variables Continuas y Ficticias como Regresores
El ultimo caso que tenemos que considerar es una combinaci6n de una variable continua
(como edad) y una variable ficticia (como mujer). Tengan presente los resultados del
capftulo anterior. La interpretacion es amiloga a lo que desarrollamos en esa secci6n.
La regresi6n que queremos correr ahora es:
log( -1 p ) = /3 0 + /3 1 * edad + /3 2 * mujer
-p
EnS-Pius:
> periodico3.glm = glm(subscribe-edad+mujer,family=binomial}
> summary(periodico3.glm}
Coefficients:
Value Std. Error
t value
(Intercept) -26.4653257 1.84243044 -14.364355
edad
mujer
0.7872132 0.05425373
14.509843
-0.5577946 0.23117009
-2.412919
Ambos coeficientes-el de edad y el de mujer-son significativos al 5 % de nivel de
significaci6n. Formen intevalos de confianza para ambos coeficientes para verificarlo.
Ambos intervalos excluyen al cero. La ecuaci6n estirnada para los hombres es:
log(-p-)
1-p
=
-26,46 + 0,7872 * edad -0,5578 * (0)
=
-26,46 + 0,7872 * edad
=
-26,46 + 0,7872 * edad -0,5578 * (1)
=
-27,01 + 0,7872 * edad
Para las mujeres:
log( -1 p
-p
)
La Figura 12 muestra las curvas con edad en el eje horizontal y dos posibilidades en
el eje vertical: log(p/(1 - p)) y p. La lfnea raja representa a los hombres; Ia azul a
las mujeres. Noten que cuando graficamos edad contra log(.) obtenemos el gnifico del
capitulo anterior. Cuando graficamos edad contra p todavfa obtenemos una linea para
cada grupo pero no es un desplazamiento paralelo.
Clasificaci6n
39
l..cg [P/ (1-Pl J
Edad
o.a
0.6
0.4
o. 2
28
30
32
34
36
JS
40
12.Probabilidad de Subscripcion como Funcion de Sexo y Edad.
Clasificaci6n
Finalmente, consideren Ia siguiente aplicaci6n de esta nueva tecnica. Dado que tenemos
informacion sobre un grupo de consumidores, por ejemplo, Ia tabla abajo, queremos
clasificar a estos consumidores como subscriptores o no subscriptores. 6 (,C6mo decidirfan ustedes? Piensen antes de seguir leyendo.
6
Ustedes pueden imaginar ejemplos mas interesantes. lmaginen un banco que tiene que clasificar un
cliente que acaba de solicitar un prestamo como "Buena Paga." "Mala Paga"para asi poder aceptar o rechazar
Ia solici tud.
40
Chapter 4 Regresi6n Logfstica
Consumidor
Edad
Mujer
1
32
1
2
38
0
3
42
Un criterio aceptable seri'a voy a clasificar a un individuo como subscriptor si Ia probabilidad de que sea subscriptor es alta. Cuando hay s61o dos posibilidades: exito o fracaso,
una probabilidad alta es una probabilidad mayor que 0.5. Nuestro criterio entonces es: si
Ia probabilidad de subscripci6n es mayor que 0.5 clasifico a Ia persona como subscriptor.
De otra forma lo clasifico como no-subscriptor.
Cuando aplicamos los resultados de Ia regresi6n anterior a esta tabla obtenemos Ia siguiente tabla:
Consumidor
Edad
Mujer
Probabilidad
Clasificaci6n
1
32
1
0.137
"No subscriptor"
2
38
0
0.969
"Subscriptor"
3
42
0.997
"Subscriptor"
Anexo
Descripci6n de Datos Utilizados
SUMMARY:
The 'dataconsumo' data frame has 40 rows and 2 columns.
DATA DESCRIPTION:
Contiene datos sobre ingreso y consumo de 40 unidades familiares.
This data frame contains the following columns:
ARGUMENTS:
consumo
Nivel de Consumo.
ingreso
Nivel de Ingreso.
SUMMARY:
The 'salario 1' data frame has 100 rows and 3 columns.
DATA DESCRIPTION:
Contiene datos sabre salarios, sexo y antiguedad de I 00 empleados hipoteticos.
This data frame contains the following columns:
ARGUMENTS:
salario
Salario anual medido en dolares americanos.
sexo
Igual a "hombre" o "mujer''.
antiguo
Anos de Antiguedad .
. mujer
lgual a 1 si Ia persona es una mujer, 0 si es un hombre.
SUMMARY:
The 'periodico' data frame has 1000 rows and 3 columns.
DATA DESCRIPTION:
Contiene datos sobre subscripciones a un periodico por edad y sexo de 1000
consumidores.
ARGUMENTS:
edad
Edad de la Persona Entrevistada.
subscribe
lgual a 1 si la persona se subscribe a un periodico especifico e igual a 0 si no se
subscribe.
mujer
Igual a 1 si la persona es una mujer, 0 si es un hombre.