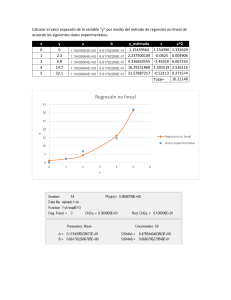
Regresión lineal múltiple
Riesgos de la regresión
Un primer riesgo del análisis de regresión es que, a partir de un modelo significativo, siempre se concluya de manera directa una relación causa-efecto entre X y Y. En ocasiones, esta conclusión puede ser
falsa, ya que al estar relacionadas dos variables no necesariamente implica que hay una relación causaefecto. Estrictamente hablando, lo único que indica que un análisis de regresión es significativo es que
existe la relación que respalda el modelo, y el usuario es quien debe investigar si tal relación es de tipo
causa-efecto. Esto puede ser más o menos difícil dependiendo del origen de los datos. Recordemos que
al inicio de este capítulo se dijo que los datos para hacer un análisis de regresión pueden originarse
de experimentos planeados, de observaciones de fenómenos no controlados o de registros históricos.
En cualquier interpretación de las razones de una relación significativa se debe recurrir al conocimiento del proceso. Además, se debe tomar en cuenta que algunas de las razones por las que las
variables X y Y aparecen relacionadas de manera significativa son:
• X influye sobre Y.
• Y influye sobre X.
• X y Y interactúan entre sí, una tercera variable Z influye sobre ambas y es la causante de tal relación.
• X y Y actúan en forma similar debido al azar.
• X y Y aparecen relacionadas debido a que la muestra no es representativa.
Otro riesgo es hacer extrapolaciones indiscriminadas con base en el modelo. Para no incurrir en
esto cuando se quieran predecir nuevas observaciones o estimar la respuesta media en algún punto x0,
se debe tener cuidado en cuanto a extrapolar más allá de la región que contienen las observaciones
originales. Es probable que un modelo que ajusta bien en la región de los datos originales ya no ajustará bien fuera de esa región. Esto se debe a que quizá muy fuera de la región de los datos originales
empiecen a actuar otros fenómenos no considerados en el modelo original. Este riesgo es más grande
en el análisis de regresión múltiple, ya que se trabaja con regiones multidimensionales.
Regresión lineal múltiple
En muchas situaciones prácticas existen varias variables independientes que se cree que influyen o
están relacionadas con una variable de respuesta Y, y por lo tanto, será necesario tomar en cuenta si
se quiere predecir o entender mejor el comportamiento de Y. Por ejemplo, para explicar o predecir el
consumo de electricidad en una casa habitación tal vez sea necesario considerar el tipo de residencia,
el número de personas que la habitan, la temperatura promedio de la zona, etcétera.
Sea Xl, X2, …, Xk variables independientes o regresoras, y sea Y una variable de respuesta, entonces
el modelo de regresión lineal múltiple con k variables independientes es el polinomio de primer orden:
Y = b 0 + b1 X1 + b 2 X 2 + + b k X k + e
(11.44)
donde los bj son los parámetros del modelo que se conocen como coeficientes de regresión y e es el error
aleatorio, con media cero, E(e) = 0 y V(e) = s2. Si en la ecuación (11.44) k = 1, estamos en el caso de
regresión lineal simple y el modelo es una línea recta; si k = 2, tal ecuación representa un plano. En
general, la ecuación (11.44) representa un hiperplano en el espacio de k dimensiones generado por las
variables {Xj}.
El término lineal del modelo de regresión se emplea debido a que la ecuación (11.44) es función
lineal de los parámetros desconocidos b0, b1, …, bk. La interpretación de éstos es muy similar a lo ya
explicado para el caso de regresión lineal simple: b0 es la ordenada al origen y bj mide el cambio esperado en Y por cambio unitario en Xj cuando el resto de las variables regresoras se mantienen fijas o
constantes.
Es frecuente que en la práctica se requieran modelos de mayor orden para explicar el comportamiento de Y en función de las variables regresoras. Por ejemplo, supongamos que se tienen dos varia-
317
318
CAPÍTULO 11
Análisis de regresión
bles independientes y que se sospecha que la relación entre Y y algunas de las variables independientes
es cuadrática, por ello quizá se requiera un polinomio de segundo orden como modelo de regresión:
Y = b 0 + b1 X1 + b 2 X 2 + b12 X1 X 2 + b11 X12 + b 22 X 22 + e
(11.45)
Éste también es un modelo de regresión lineal múltiple, ya que la ecuación (11.45) es una función
lineal de los parámetros desconocidos b0, b1, ..., b22. Pero, además, si definimos X 3 = X1 X 2 , b 3 = b12 ,
X 4 = X12 , b 4 = b11 , X 5 = X 22 y b5 = b 22 , entonces la ecuación (11.45) puede escribirse así:
Y = b 0 + b1 X1 + b 2 X 2 + b 3 X 3 + b 4 X 4 + b5 X 5 + e
la cual tiene la misma forma que el modelo general de regresión lineal múltiple de la expresión (11.44).
Con lo visto antes, estamos en posibilidades de abordar el problema de estimación de los parámetros
del modelo de regresión múltiple, que será aplicable a una amplia gama de modelos que pueden reducirse a la forma general de la expresión (11.44).
Para estimar los parámetros de la regresión lineal múltiple se necesita contar con n datos (n > k),
que tienen la estructura descrita en la tabla 11.8. En ésta se aprecia que para cada combinación de valores de las variables regresoras, (x1i, …, xki), se observa un valor de la variable dependiente, yi .
Tabla 11.8
Estructura de los datos para
la regresión lineal múltiple
Y
X1
X2
…
Xk
y1
y2
x11
x12
.:
y1n
x21
x22
.:
x2n
…
…
xk1
xk2
.:
xkn
yn
…
En términos de los datos, el modelo de regresión lineal múltiple puede escribirse de la siguiente
manera:
yi = b 0 + b1 x1i + b 2 x 2i + + b k x ki + ε i
(11.46)
k
= b 0 + ∑ b j x ji + ε i ,
i = 1, 2, …, n
j =1
Al despejar los errores, elevarlos al cuadrado y sumarlos, obtenemos la siguiente función:
n
n
S=∑ e =∑
2
i
i =1
i =1
k
⎛
⎞
⎜ yi − b 0 − ∑ b j x ji ⎟
⎜
⎟
j =1
⎝
⎠
2
(11.47)
esta función depende de los parámetros bj. Los estimadores de mínimos cuadrados para bj se obtienen
al minimizar los errores, es decir, minimizando S. Esto se logra si derivamos a S con respecto a cada
parámetro b j , ∂∂βSj , ( j = 0, 1, 2, …, k ), las k + 1 ecuaciones resultantes se igualan a cero. La solución de
las k + 1 ecuaciones simultáneas son los estimadores de mínimos cuadrados, bˆj .
Ilustrar el procedimiento de estimación por mínimos cuadrados es más sencillo si se utiliza notación matricial. En términos de los datos, ecuación (11.46), el modelo puede escribirse en notación
matricial como:
y = Xb + e
Regresión lineal múltiple
donde:
⎡ y1 ⎤
⎢ ⎥
y2
y =⎢ ⎥
⎢⎥
⎢ ⎥
⎣ yn ⎦
⎡1 x11
⎢
1 x12
X =⎢
⎢ ⎢
⎣1 x1n
x 21
x 22
x 2n
… x k1 ⎤
⎥
… xk2 ⎥
… ⎥
⎥
… x kn ⎦
⎡ b0 ⎤
⎢ ⎥
b1
b =⎢ ⎥
⎢⎥
⎢ ⎥
⎣ bk ⎦
y
⎡ e1 ⎤
⎢ ⎥
e2
e=⎢ ⎥
⎢⎥
⎢ ⎥
⎣ en ⎦
Queremos encontrar el vector de los estimadores de mínimos cuadrados, bˆ, que minimice:
n
S = ∑ e2i = e′e = ( y − X b )′( y − X b )
i =1
= y ′y − b′X ′y − y ′X b + b′X ′ X b
= y ′y − 2 b′X ′y + b′X ′ X b
La última igualdad se debe a que b¢X¢y es una matriz (1 × 1), o un escalar, y por lo tanto, su transpuesta (b¢X¢y)¢ = y¢Xb es el mismo escalar. De aquí que los estimadores de mínimos cuadrados deban
satisfacer la siguiente expresión
∂S
∂b βˆ
= −2X ′y + 2X ′X bˆ = 0
esto implica que:
X¢X bˆ = X¢y
(11.48)
Para resolver esta ecuación en términos de bˆ, se multiplica por ambos lados de la ecuación (11.48)
por la matriz inversa de X¢X, y se obtiene que el estimador de mínimos cuadrados de b es:
bˆ = (X¢X)–1X¢y
(11.49)
por lo tanto, el modelo ajustado está dado por:
ŷ = X bˆ
(11.50)
Además, se puede demostrar que bˆ es un estimador insesgado, E(bˆ ) = b, y la matriz de covarianza
ˆ
de b es:
Cov (bˆ) = s2(X¢X)–1
Para hacer inferencias sobre b o, en general sobre el modelo, es necesario encontrar una forma de
estimar s 2. A partir de la ecuación (11.50) es claro que el vector de residuos está dado por e = y – ŷ =
y – X bˆ. De aquí que la suma de cuadrados del error esté dada por:
n
SC E = ∑ e 2i = e′e
i =1
= ( y − X bˆ )′( y − X bˆ ) = y ′y − 2 bˆ ′X ′y + bˆ ′X ′X bˆ
(11.51)
De acuerdo con la ecuación (11.48): X¢X b = X¢y, entonces esta última ecuación toma la siguiente
forma:
SC E = y ′y − b̂′X ′y
(11.52)
319
320
CAPÍTULO 11
Análisis de regresión
La suma de cuadrados del error dada por esta última expresión tiene n – k – 1 grados de libertad,
donde k + 1 es igual al número de parámetros estimados en el modelo. Entonces, el cuadrado medio del
error es:
CME =
SC E
n − k −1
Se puede demostrar que el valor esperado de CME es s 2, por lo que es natural que el estimador de
s esté dado por:
2
ŝ 2 = CME
(11.53)
La raíz cuadrada del CME se conoce como error estándar de estimación del modelo.
11.3
En Ramírez et al. (2001) se presenta un experimento secuencial para optimizar la producción de un colorante natural. En la
etapa final se delimitó una zona de experimentación en la que
se sospecha que se encuentran las condiciones óptimas para la
Tabla 11.9
producción de este colorante en función de la concentración de
carbono (X1) y temperatura (X2). En la tabla 11.9 se muestran
los niveles de X1 y X2 con los que se experimentó, así como la
producción observada en cada una de las condiciones.
Datos para el ejemplo 11.3
X1: Carbono
X2: Temperatura
Y: Producción
17
17
25
25
21
21
15.34
26.66
21
21
21
21
5 707
5 940
3 015
2 673
5 804
6 700
5 310
725
7 521
7 642
7 500
7 545
9
13
9
13
8.17
13.8
11
11
11
11
11
11
A continuación ajustaremos un modelo de segundo orden:
yi = b0 + b1 x1i + b 2 x 2i + b12 x1i x 2i + b11 x12i + b 22 x 22i + ei
De aquí que si expresamos esto en forma matricial, y = X b + e, toma la siguiente forma (sólo se
muestra parcialmente):
1 x1
x2
x1 x 2
x12
x 22
⎡ b 0 ⎤ ⎡ e1 ⎤
⎡5 707⎤ ⎡1 9 17 153 81 289⎤ ⎢ ⎥ ⎢ ⎥
⎢
⎥ ⎢
⎥ ⎢ b1 ⎥ ⎢ e2 ⎥
⎢5 940⎥ ⎢1 13 17 221 169 289⎥ ⎢ b ⎥ ⎢ e ⎥
⎢3 015⎥ = ⎢1 9 25 225 81 625⎥ ⎢ 2 ⎥ + ⎢ 3 ⎥
e4
⎢
⎥ ⎢
⎥ b12
⎥⎢ ⎥ ⎢ ⎥
⎢ ⎥ ⎢ ⎢ b11 ⎥ ⎢ ⎥
⎢⎣7 543⎥⎦ ⎢⎣1 11 21 231 121 141⎥⎦ ⎢ ⎥ ⎢ ⎥
⎣ b 22 ⎦ ⎣ e12 ⎦
Pruebas de hipótesis en regresión lineal múltiple
A partir de aquí se obtiene bˆ = (X¢X)–1X¢y, que al hacer los cálculos obtenemos el siguiente modelo
ajustado:
Y = −75 732.8 + 4 438.69 X1 + 5 957.79 X 2 − 17.9688 X1 X 2 − 181.316 X12 − 146.404 X 22
En la tabla 11.10 se presentan las observaciones, los valores predichos y los residuos de este modelo. En la figura 11.7 se muestran gráficas de estos residuos para diagnosticar la calidad de ajuste del
modelo. La interpretación de estas gráficas es similar a lo explicado para la regresión lineal simple. En
la figura 11.7a) se muestra la gráfica de probabilidad normal para los residuos, en ésta se aprecia que
la normalidad se cumple de manera satisfactoria.
Tabla 11.10 Valores observados predichos y residuos para el
ejemplo 11.3
yj
ŷi
ei = yi – ŷi
5 707
5 940
3 015
2 673
5 804
6 700
5 310
725
7 521
7 642
7 500
7 545
5 751.1
6 328.2
2 927.9
2 929.9
5 896.7
6 306.2
5 066.7
667.3
7 552.0
7 552.0
7 552.0
7 552.0
–44.1
–388.2
87.1
–256.9
–92.7
393.8
243.3
57.7
–31.0
90.0
–52.0
–7.0
La figura 11.7b) corresponde a la gráfica de residuos contra predichos, donde se observa una
ligera tendencia en forma de embudo que podría indicar un mayor error de ajuste para valores grandes de la variable de respuesta; pero, al observar con detenimiento la distribución de los puntos se
aprecia que la apariencia referida básicamente se debe a dos puntos (los residuos 2 y 6). Por ello, de
acuerdo con los resultados de esta gráfica podemos considerar que el supuesto de varianza constante
se cumple aceptablemente.
En la figura 11.7c) se muestran los residuales contra los niveles de temperatura y no se nota ningún patrón fuerte. En la figura 11.7d) se aprecia la gráfica de residuales contra los valores de carbono,
y en ésta se observa una ligera tendencia de embudo, pero no demasiado fuerte; por ello, de acuerdo
con este criterio podemos considerar que el modelo es aceptable.
Pruebas de hipótesis en regresión
lineal múltiple
Las hipótesis sobre los parámetros del modelo son equivalentes a las realizadas para regresión lineal
simple, pero ahora son más necesarias porque en regresión múltiple tenemos más parámetros en el
modelo y es necesario evaluar su verdadera contribución a la explicación de la respuesta. También
requerimos de la suposición de que los errores se distribuyen en forma normal, independientes, con
media cero y varianza s 2 (ei ~ NID(0, s 2)). Una consecuencia de esta suposición es que las observak
ciones yi son: NID(b0 + S j = 1 bj Xji, s 2).
321
322
CAPÍTULO 11
Análisis de regresión
a)
b)
400
99.9
200
95
80
Residuos
Porcentaje acumulado
99
50
20
0
–200
5
1
0.1
–400
–390
–190
10
210
410
0
2
4
Residuos
c)
8
(X 1 000)
d)
400
400
200
200
Residuos
Residuos
6
Predichos
0
0
–200
–200
–400
–400
15
17
19
21
23
25
27
8.1
Temperatura
9.1
10.1
11.1
12.1
13.1
14.1
Carbono
Figura 11.7 Gráficas de residuos para el ejemplo 11.3, a) probabilidad normal, b) residuales contra predichos, c) residuales contra los
niveles de temperatura, d) residuales contra los niveles de carbono.
Análisis de varianza
La hipótesis global más importante sobre un modelo de regresión múltiple consiste en ver si la regresión es significativa. Esto se logra probando la siguiente hipótesis:
H0: b1 = b2 = … bk = 0
HA: bj π 0
para al menos un j = 1, 2, …, k
Aceptar H0 significa que ningún término o variable en el modelo tiene una contribución significativa al explicar la variable de respuesta, Y. Mientras que rechazar H0 implica que por lo menos un
término en el modelo contribuye de manera significativa a explicar Y. En forma similar a lo hecho en
regresión lineal simple, aquí también se descompone la suma total de cuadrados en la suma de cuadrados de regresión y en la suma de cuadrados del error:
S yy = SC R + SC E
(11.54)
Pruebas de hipótesis en regresión lineal múltiple
2
Si H0 : bj = 0 es verdadera, entonces SCR /s 2 tiene una distribución c k, donde el número de grados de libertad, k, es igual al número de términos en el modelo de regresión. Además,
SC E /s 2 ∼ c2n − k −1 , y SC E y SC R son independientes. Luego, es natural que el estadístico de prueba para
la significancia del modelo de regresión lineal múltiple esté dado por:
F0 =
SC R /k
CMR
=
SC E /( n − k − 1) CME
(11.55)
que bajo H0 tiene una distribución F(k, n – k – 1). Así, se rechaza H0 si F0 > F(a, k, n – k – 1) o también si valor-p
= P(F > F0) < a.
Para completar el procedimiento anterior necesitamos una forma explícita para calcular SCR. En la
ecuación (11.52) vimos que una fórmula para calcular la suma de cuadrado del error es:
SC E = y ′y − b̂′X ′y
(11.56)
Además, como la suma total de cuadrados, Syy, está dada por:
n
S yy = ∑ y2i −
( Σni =1 yi )2
i =1
n
= y′y −
( Σin=1 yi )2
n
La SCE puede expresarse como:
⎡
( Σni = 1 yi )2 ⎤ ⎡ ˆ
( Σin= 1 yi )2 ⎤
SC E = ⎢y ′y −
⎥ − ⎢ b′X ′y −
⎥
n
n
⎢⎣
⎥⎦ ⎢⎣
⎥⎦
= S yy − SC R
Así, hemos obtenido una forma explícita para la suma de cuadrados de la regresión:
SC R = bˆ ′X ′y −
( Σni =1 yi )2
(11.57)
n
El procedimiento de análisis de varianza para el modelo de regresión lineal múltiple se sintetiza
en la tabla 11.11.
Tabla 11.11
Fuente de
variación
ANOVA para la significancia del modelo de regresión lineal múltiple
Suma de
cuadrados
Grados de
libertad
Cuadrado
medio
F0
Valor-p
k
CMR
CMR/CME
Pr (F > F0)
n–k–1
CME
( Σni =1 yi )2
Regresión
SC R = βˆ ′X′y −
Error o residuo
SC E = y′y − β̂ ′X′y
Total
S yy = y′y −
n
( Σni =1 yi )2
n
n–1
Coeficiente de determinación
El que un modelo sea significativo no necesariamente implica que sea bueno en términos de que explique un buen porcentaje de variación de los datos. Por ello es importante tener mediciones adicionales
de la calidad del ajuste del modelo, como las gráficas de residuales y el coeficiente de determinación.
Con la información del análisis de varianza de la tabla 11.11 es muy sencillo calcular el coeficiente de
2
determinación, R2, y el coeficiente de determinación ajustado, Raj :
323
324
CAPÍTULO 11
Análisis de regresión
R2 =
R aj2 =
SC R
SC
= 1− E
S yy
S yy
S yy /(( n − 1) − CME CMtotal − CME
=
S yy / ( n − 1)
CMtotal
= 1−
CME
CMtotal
Ambos coeficientes se interpretan de forma similar al caso de regresión lineal simple, es decir,
2
como el porcentaje de variabilidad de los datos que explica el modelo. Se cumple que 0 < Raj £ R2 < 1;
en general, para hablar de un modelo que tiene un ajuste satisfactorio es necesario que ambos coeficientes tengan valores superiores a 0.7. Cuando en el modelo hay términos que no contribuyen de manera
2
significativa a éste, el Raj tiende a ser menor que el R2. Por lo tanto, es deseable depurar el modelo y para
ello las pruebas de hipótesis para los coeficientes del modelo son de mucha utilidad.
Coeficiente de
correlación múltiple
Es la raíz cuadrada del coeficiente de determinación R2 y mide la intensidad de la
relación entre la variable dependiente y
las variables o términos en el modelo.
Coeficiente de correlación múltiple
Es la raíz cuadrada del coeficiente de determinación R2:
R = R2
y es una medida de la intensidad de la relación entre la variable dependiente, Y, y el
conjunto de variables o términos en el modelo (X1, X2, …, Xk).
Error estándar de estimación y media
del error absoluto
Al igual que en regresión lineal simple, el error estándar de estimación y la media del error absoluto
proporcionan dos medidas del error de ajuste de un modelo, éstas tienen una interpretación similar a
la que se dio para el caso de regresión lineal simple (véanse ecuaciones 11.36 y 11.37). En cuanto al
cálculo en el caso múltiple, la mea = ( Σni =1 e i ) /n y el error estándar de estimación, sˆ = SC E / ( n − k − 1) .
Pruebas sobre coeficientes individuales del modelo
Un aspecto clave en un análisis de regresión múltiple es valorar qué tanto contribuye cada término a
la explicación de la variable de respuesta, para de esa forma eliminar los que tienen una contribución
poco importante o quizá pensar en agregar otras variables no consideradas. Las hipótesis para probar la
significancia de cualquier coeficiente individual, bj, se especifica de la siguiente manera:
H 0: b j = 0
H A: b j ≠ 0
j = 0, 1, 2, …, k
(11.58)
De acuerdo con la sección anterior, el estimador de mínimos cuadrados bˆ es un vector aleatorio,
cuya distribución es normal con media b y matriz de covarianza s 2(X¢X)–1. De aquí que la distribución
de los coeficientes de regresión bˆj sea:
bˆ j ∼ N ( b j , s 2C j+1, j+1 )
donde Cj + 1, j + 1 es el elemento de la diagonal de la matriz (X¢X)–l correspondiente al parámetro b̂j. De
aquí, y dado que s 2 se estimó con el CME (ecuación 11.53), entonces el estadístico de prueba para
examinar la hipótesis de la expresión (11.58) está dado por:
Pruebas de hipótesis en regresión lineal múltiple
t0 =
bˆ j
325
(11.59)
CMEC j+1, j+1
donde se rechaza H0 si t0 > t(α / 2, n − k −1) , o en forma equivalente si valor-p = P(T > t0 ) < a . En la tabla
11.12 se muestra un resumen del análisis sobre el modelo de regresión basado en la prueba antes descrita.
Tabla 11.12
Análisis de regresión para el modelo Y = b0 + b1 X1 + … + bk Xk
Parámetro
Estimación
Intercepción
bˆ0
b1
bˆ1
.:
.:
bk
bˆk
Error estándar
Estadístico
Valor-p
CMEC11
β̂0
CMEC11
Pr(T > |t0|)
CMEC 22
β̂ 1
CMEC 22
Pr(T > |t0|)
.:
.:
.:
CMEC k +1, k +1
βˆ k
CMEC k +1, k +1
Pr(T > |t0|)
11.4
Aplicamos las pruebas y cálculos descritos en esta sección a los
datos del ejemplo 11.3; en la tabla 11.13 se muestran los resultados obtenidos para el análisis del modelo de regresión.
Recordemos que se ajustó un modelo de segundo orden:
Y = –75 732.8 + 4 438.69X1 + 5 957.79X2 – 17.9688X1X2 –
2
2
181.316 X 1 – 146.404 X 2. A partir de esta tabla vemos que el
único término que no es significativo, de acuerdo con la prueba
t, es la interacción X1X2 y los términos que tienen una mayor
Tabla 11.13
2
contribución a la respuesta son X2 y X 2. En el análisis de varianza se aprecia que el modelo de regresión es significativo, y
2
de acuerdo con los coeficientes de determinación, R2 y R aj, el
modelo explica bien la variabilidad presente en los datos. También se aprecia el error estándar de estimación, ŝ, y la media del
error absoluto, que dada la escala de medición de la variable de
respuesta, éstos tienen una magnitud relativamente pequeña.
Análisis para el modelo de regresión lineal múltiple ajustado a los datos del ejemplo 11.3
Parámetro
Constante
X1: Carbono
X2: Temperatura
X1X2
2
X1
2
X2
Estimación
Error estándar
–75 732.8
4 438.69
5 957.79
–17.9688
–181.316
–146.404
6 313.95
708.101
347.095
17.3848
27.488
6.87186
Estadístico
Valor-p
–11.9945
6.2684
17.1647
–1.03359
–6.5962
–21.3049
0.0000
0.0008
0.0000
0.3412
0.0006
0.0000
Análisis de varianza
Fuente de
variación
Suma de cuadrados
7
Grados de
libertad
Modelo
residual
5.51626 ¥ (10)
464 228.0
5
6
Total (corr.)
5.56268 ¥ (10)7
11
R = 0.992
2
Raj = 0.985
2
Cuadrado
medio
7
1.10325 ¥ (10)
77 371.3
Error estándar de estimación = 278.157
Media del error absoluto = 145.324
F0
Valor-p
142.59
0.0000