Tarea 2
Estadística
Integrantes: Mayela W. Marquínez M. 4 – 761 – 124
Walys M. Marquínez M. 4 – 761 – 123
Test estadísticos
Son el instrumento o procedimientos matemáticos para testar la hipótesis
estadística que, al contrario de la estadística paramétrica, no hacen ninguna
asunción sobre las distribuciones de frecuencia de las variables que son
determinadas. El nivel de medición puede ser nominal u ordinal. La muestra no tiene
que ser aleatoria.
1. Hipótesis alternativas
Es una afirmación sobre la población que es contradictoria con 𝑯𝑶 y lo que
concluimos cuando rechazamos 𝑯𝑶 . Esto es normalmente lo que el investigador
está tratando de probar.
Dado que las hipótesis nula y alternativa son contradictorias, debe examinar las
pruebas para decidir si tiene suficiente evidencia para rechazar la hipótesis nula o
no. Las pruebas se presentan en forma de datos de muestra.
Una vez que haya determinado qué hipótesis apoya la muestra, tome una decisión.
Hay dos opciones para tomar una decisión. Son "rechazar 𝑯𝑶 " si la información
de la muestra favorece la hipótesis alternativa o "no rechazar 𝑯𝑶 " o "negarse a
rechazar 𝑯𝑶 " si la información de la muestra es insuficiente para rechazar la
hipótesis nula.
1.1 Riesgo y potencia
Hasta aquí hemos realizado tests con una sola hipótesis de modelación 𝑯𝑶 . El
único error que podía ser cuantificado consistía en rechazar 𝑯𝑶 erróneamente. La
probabilidad de este rechazo es el umbral
del test. No rechazar 𝑯𝑶 significa
solamente que no ha sucedido nada que nos permita ponerla en duda. Esto no
significa que 𝑯𝑶 es ''verdadera'' (las leyes de probabilidad no existen en la
naturaleza). De ahora en adelante vamos a situarnos en una situación donde dos
modelos están compitiendo el uno contra el otro. Los datos disponibles deberán
permitirnos tomar una decisión sobre 𝑯𝑶 , con referencia a otra hipótesis 𝑯𝟏 .
Decimos
entonces
que
hacemos
un
Tomemos el ejemplo de un indicador fisiológico
test
de 𝑯𝑶 contra 𝑯𝟏 .
(tasa de una cierta substancia
en la sangre) la cual con un valor elevado es un síntoma de una cierta enfermedad.
Como es habitual, se considerará que la tasa observada en un individuo es la
realización de una cierta variable aleatoria. Supongamos que estudios anteriores
han mostrado que en un sujeto sano, el valor de
mientras que en un sujeto enfermo ella sigue la
sigue la ley
ley . Si la
enfermedad no es grave, y si el tratamiento comporta riesgos para el paciente, el
médico decidirá favorecer la hipótesis que su paciente goza de buena salud: esa
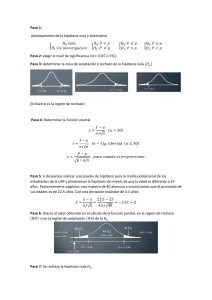
será su hipótesis nula 𝑯𝑶 . Ella será comprobada por un test unilateral a la derecha
(rechazo de los valores de
decisión es:
Rechazo de
muy grandes). Con el umbral 𝛼 = 0,05, la regla de
Se decidirá, por tanto, que el paciente está enfermo si su tasa es mayor que
𝒍𝟎 = 𝟏. 𝟒𝟗𝟑. El umbral
enfermo
a
un
mide el riesgo de rechazar 𝑯𝑶 erróneamente (declarar
individuo
sano).
Pero
otro
riesgo
consiste
en
no
rechazar 𝑯𝑶 mientras que 𝑯𝟏 es verdadera (no diagnosticar la enfermedad
cuando el paciente está verdaderamente enfermo). Se denota 𝛽 la probabilidad
correspondiente:
𝛽 = ℙℋ1 [𝑁𝑜 𝑟𝑒𝑐ℎ𝑎𝑧𝑎𝑟 ℋ0 ]
En este caso la ley de
bajo la hipótesis 𝑯𝟏 es la ley
normal y por tanto:
Rechazar 𝑯𝑶 erróneamente es el error de primera especie y el umbral
es
el riesgo de primera especie. No rechazar 𝑯𝑶 erróneamente es el error de
segunda especie y la probabilidad 𝜷 de este error es el riesgo de segunda especie.
La probabilidad 1 − 𝛽 de rechazar 𝑯𝑶 bajo 𝑯𝟏 se llama la potencia del test.
Como hemos mostrado en los ejemplos, puede ser que el riesgo de segunda
especie 𝜷 sea bastante importante, mientras que el umbral del test
se fija al
definir el test. El error de primera especie es el que se elige controlar, aún cuando
esto signifique no tener en cuenta el error de segunda especie. Esto induce una
disimetría en el tratamiento de las dos hipótesis. La regla de rechazo del test está
definida únicamente a partir de
y 𝑯𝑶 . Ante dos alternativas, se tomará
como 𝑯𝑶 la hipótesis que sería más grave rechazar erróneamente.
Retomemos el ejemplo del diagnóstico, pero supongamos ahora que la enfermedad
es potencialmente muy grave pero fácilmente curable. El peligro sería no detectar
la enfermedad. El médico tomará como hipótesis nula la hipótesis que el paciente
está enfermo.
ℋ0′ : 𝑇 𝑠𝑖𝑔𝑢𝑒 𝑙𝑎 𝑙𝑒𝑦 𝒩 (2,0.16)
El test será ahora unilateral a la izquierda (rechazo de los valores muy pequeños).
Al umbral 𝛼 = 0,05, la regla de decisión es:
′
Rechazo de ℋ0
⇔ 𝑇 < 𝑙1 = 𝒬𝒩(2,0.16) (0.05) = 1.342
Se constata que 𝒍𝟏 es menor que 𝒍𝑶 . Este test es, por tanto, diferente del anterior.
Según el valor de
, las decisiones pueden coincidir o no.
Si 𝑇
< 𝑙1 : se acepta 𝑯𝑶 y se rechaza ℋ0′ , las decisiones son coherentes.
Si 𝑙1
< 𝑇 < 𝑙0 : se aceptan 𝑯𝑶 y ℋ0′ , resultado no interpretable.
Si 𝑇
< 𝑙0 : rechazo de 𝑯𝑶 y se acepta ℋ0′ , las decisiones son coherentes.
1.2 Tests paramétricos
Nos situamos en el caso más frecuente, donde las variables son modeladas por una
muestra de una cierta ley desconocida. Hasta ahora, hemos considerado hipótesis
que tienen que ver con una sola ley
, lo que permitía determinar la ley de
un estadígrafo de test en función de la muestra, y por tanto calcular las
probabilidades de error (umbral o riesgo). Cuando una hipótesis tiene que ver con
una sola ley se dice que es simple. En el caso contrario, decimos que es compuesta.
Frecuentemente, el modelo presupone que la ley desconocida pertenece a una
cierta familia de leyes prefijada, que dependen de uno o más parámetros (leyes
binomiales, leyes normales...). Denotaremos por
desconocida. Un test sobre los valores de
al parámetro y por 𝑷𝜽 a la ley
se llama paramétrico. Una hipótesis
simple será del tipo 𝜽 = 𝜽𝟎 , donde 𝜽𝟎 es un valor prefijado. Las hipótesis
compuestas
serán
del
tipo 𝜽 < 𝜽𝟎 , 𝜽 > 𝜽𝟎 o 𝜽 ≠ 𝜽𝟎 .
Para hacer un test sobre el valor del parámetro, lo más lógico consiste en emplear
como estadígrafo de test a un estimador convergente de este parámetro. Un
estimador convergente es un estadígrafo (función de la muestra), que toma valores
que estarán más cercanos a
Si
mientras más grande sea el tamaño de la muestra.
es un estimador convergente de
𝓗 𝟎 : 𝜽 = 𝜽𝟎 ,
, entonces bajo la hipótesis
𝜽𝟎 .
Se
< 𝜽𝟏 , el test será unilateral a la derecha (rechazo de los valores de
muy
debe
rechazará 𝓗𝟎 cuando
tomar
valores
cercanos
a
toma valores muy alejados de 𝜽𝟎 .
Veamos el caso de dos hipótesis simples:
𝓗𝟎 : 𝜽 = 𝜽𝟎 contra 𝓗𝟏 : 𝜽 = 𝜽𝟏
Si 𝜽𝟎
grandes). Pero la definición del test no tiene en cuenta a 𝜽𝟏 : será la misma para
cualquier valor 𝜽𝟏 > 𝜽𝟎 , y también para:
𝓗𝟎 : 𝜽 = 𝜽𝟎 contra 𝓗𝟏 : 𝜽 > 𝜽𝟎
igual en el caso:
𝓗𝟎 : 𝜽 ≤ 𝜽𝟎 contra 𝓗𝟏 : 𝜽 > 𝜽𝟎
En este último caso, como la hipótesis 𝓗𝟎 es compuesta, el umbral será definido
como la probabilidad maximal de rechazar 𝓗𝟎 erróneamente.
Se empleará un test bilateral para probar:
𝓗𝟎 : 𝜽 = 𝜽𝟎 contra 𝓗𝟏 : 𝜽 ≠ 𝜽𝟎
Una manera frecuentemente empleada para definir un test paramétrico a partir de
una estimación de
es de utilizar un intervalo de confianza.
Definición 4.1 Sea (𝑋1 , . . . , 𝑋𝑛 ) una muestra de la ley 𝑷𝜽 . Se llama intervalo de
confianza de nivel 1 − 𝛼 a un intervalo aleatorio [𝑇1 , 𝑇2 ] , donde
𝑇1 ≤ 𝑇2
son dos estadígrafos, funciones de la muestra, tales que:
Por tanto, un intervalo de confianza contiene al valor del parámetro con una fuerte
probabilidad. Si la hipótesis 𝓗𝟎 : 𝜽
= 𝜽𝟎 es verdadera, el intervalo de confianza
debe contener a 𝜽𝟎 .
Proposición 4.2 Sea [𝑇1 , 𝑇2 ] un intervalo de confianza de nivel 𝟏 − 𝜶 para
Se define un test de umbral
para la hipótesis 𝓗𝟎 : 𝜽
= 𝜽𝟎 por
.
la regla de
decisión:
Rechazo de 𝓗𝟎 ⇔ 𝜽𝟎
∉ [𝑇1 , 𝑇2 ]
Consideremos el caso de una muestra de la ley exponencial 𝜺(𝝀) . Queremos un
test bilateral de la hipótesis 𝓗𝟎 : 𝝀
la media empírica 𝑻
=
𝟏
= 𝟏 . El estimador natural de 𝝀 es el inverso de
. Para una muestra de la ley 𝜺(𝝀), la media
𝑿
empírica 𝑿 sigue la ley gamma 𝓖(𝓷, 𝓷𝝀), por tanto la variable aleatoria
𝝀
𝑻
sigue
la ley gamma 𝓖(𝓷, 𝓷). Se deduce que el siguiente intervalo es un intervalo de
confianza de nivel 𝟏 − 𝜶 para
𝝀:
La regla de decisión para el test de umbral
que se deduce de este intervalo de
confianza será:
Rechazo de
En este caso, el test basado en el intervalo de confianza es equivalente al test
basado en el intervalo de dispersión simétrico de la ley de
siempre es así).
bajo 𝓗𝟎 (pero no
 0
0