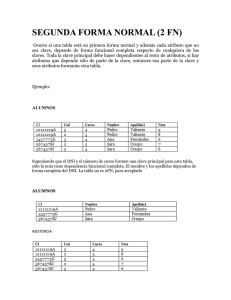
Todas las empresas requieren almacenar información. Desde siempre lo han hecho. La información puede ser de todo tipo. Cada elemento informativo (nombre, dirección, sueldo, etc.) es lo que se conoce como dato (en inglés data). Las soluciones utilizadas por las empresas para almacenar los datos son diversas. Antes de la aparición de la informática se almacenaban en ficheros con cajones y carpetas y fichas. Tras la aparición de la informática estos datos se almacenan en archivos digitales dentro de las unidades de almacenamiento del ordenador (a veces en archivos binarios, o en hojas de cálculo,...). Además las empresas requieren utilizar aplicaciones informáticas para realizar tareas propias de la empresa a fin de mecanizar a las mismas. Estas aplicaciones requieren manejar los datos de la empresa. En los inicios de la era informática, cada programa almacenaba y utilizaba sus propios datos de forma un tanto caótica. La ventaja de este sistema (la única ventaja), es que los procesos eran independientes por lo que la modificación de uno no afectaba al resto. Pero tiene grandes inconvenientes: Coste de almacenamiento elevado Datos redundantes (se repiten continuamente) Probabilidad alta de inconsistencia en los datos Difícil modificación en los datos y facilidad de problemas de inconsistencia al realizar esas modificaciones (ya que es difícil que esa modificación afecte a todos los datos) Lógicamente la solución a este problema es hacer que todas las aplicaciones utilicen los mismos datos. Esto provoca que los datos deban estar mucho más protegidos y controlados. Además los datos forman una estructura física y funcional que es lo que se conoce como base de datos. De esta forma una base de datos es una serie de datos relacionados que forman una estructura lógica, es decir una estructura reconocible desde un programa informático. Esa estructura no sólo contiene los datos en sí, sino la forma en la que se relacionan. Las bases de datos empiezan a aparecer en los años 60 y triunfan en los años setenta y ochenta. Modelo de datos ¿Qué es un Modelo de Datos (MD)? Una de las características fundamentales de los sistemas de bases de datos es que proporcionan cierto nivel de abstracción de datos, al ocultar las características sobre el almacenamiento físico que la mayoría de usuarios no necesita conocer. Los modelos de datos son el instrumento principal para ofrecer dicha abstracción a través de su jerarquía de niveles. Un modelo de datos es un conjunto de conceptos que sirven para describir la estructura de una base de datos, es decir, los datos, las relaciones entre los datos y las restricciones que deben cumplirse sobre los datos. Los modelos de datos contienen también un conjunto de operaciones básicas para la realización de consultas (lecturas) y actualizaciones de datos. Además, los modelos de datos más modernos 1 incluyen mecanismos para especificar acciones compensatorias o adicionales que se deben llevar a cabo ante las acciones habituales que se realizan sobre la base de datos. Un modelo de datos proporciona un conjunto de conceptos, reglas y convenciones que nos permiten especificar y manipular los datos que queremos almacenar en la BD. Todo modelo de datos se compone de una parte estática y una parte dinámica Los modelos de datos se pueden clasificar dependiendo de los tipos de conceptos que ofrecen para describir la estructura de la base de datos, formando una jerarquía de niveles. Los modelos de datos de alto nivel, o modelos conceptuales, disponen de conceptos muy cercanos al modo en que la mayoría de los usuarios percibe los datos, mientras que los modelos de datos de bajo nivel, o modelos físicos, proporcionan conceptos que describen los detalles de cómo se almacenan los datos en el ordenador. Los conceptos de los modelos físicos están dirigidos al personal informático, no a los usuarios finales. Entre estos dos extremos se encuentran los modelos lógicos, cuyos conceptos pueden ser entendidos por los usuarios finales, aunque no están demasiado alejados de la forma en que los datos se organizan físicamente. Los modelos lógicos ocultan algunos detalles de cómo se almacenan los datos, pero pueden implementarse de manera directa en un SGBD. Los modelos conceptuales utilizan conceptos como entidades, atributos y relaciones. Una entidad representa un objeto o concepto del mundo real como, por ejemplo, un cliente de una empresa o una de sus facturas. Un atributo representa alguna propiedad de interés de una entidad como, por ejemplo, el nombre o el domicilio del cliente. Una relación describe una interacción entre dos o más entidades, por ejemplo, la relación que hay entre un cliente y las facturas que se le han realizado. Cada SGBD soporta un modelo lógico, siendo los más comunes el relacional, el de red y el jerárquico. Estos modelos representan los datos valiéndose de estructuras de registros, por lo que también se denominan modelos orientados a registros. Hay una familia más moderna de modelos lógicos, son los modelos orientados a objetos, que están más próximos a los modelos conceptuales. En el modelo relacional los datos se describen como un conjunto de tablas con referencias lógicas entre ellas, mientras que en los modelos jerárquicos y de red, los datos se describen como conjuntos de registros con referencias físicas entre ellos (punteros). Tipos de modelos de datos Modelo conceptual El primer paso en el diseño de una base de datos es la producción del es quema conceptual. En este capítulo se presenta una metodología para producir estos esquemas, denominada entidad-relación. Modelo entidad-relación El diseño conceptual parte de las especificaciones de requisitos de los usuarios y su resultado es el esquema conceptual de la base de datos. Una opción para recoger los requisitos consiste en examinar los diagramas de flujo de datos, que se pueden haber producido previamente, para identificar cada una de las áreas funcionales. La otra opción consiste en entrevistar a los usuarios, examinar los procedimientos, los informes y los formularios, y también observar el funcionamiento de la empresa. 2 Un esquema conceptual es una descripción de alto nivel de la estructura de la base de datos, independientemente del SGBD que se vaya a utilizar para manipularla. Para especificar los esquemas conceptuales se utilizan modelos conceptuales. Los modelos conceptuales se utilizan para representar la realidad a un alto nivel de abstracción. Mediante los modelos conceptuales se puede construir una descripción de la realidad fácil de entender. En el diseño de bases de datos se usan, en primer lugar, los modelos conceptuales para lograr una descripción de alto nivel de la realidad, y luego se transforma el esquema conceptual en un esquema lógico (diseño lógico). Los modelos conceptuales deben ser buenas herramientas para representar la realidad, por lo que deben poseer las siguientes cualidades: Expresividad: Deben tener suficientes conceptos para expresar perfecta- mente la realidad. Simplicidad: Deben ser simples para que los esquemas sean fáciles de entender. Minimalidad: Cada concepto debe tener un significado distinto. Formalidad: Todos los conceptos deben tener una interpretación única, precisa y bien definida. El modelo entidad-relación es el modelo conceptual más utilizado para el diseño conceptual de bases de datos. Fue introducido por Peter Chen en 1976. El modelo entidad-relación está formado por un conjunto de conceptos que permiten describir la realidad mediante representaciones gráficas y lingüísticas. Estos conceptos se muestran en la figura siguiente: Las tareas a realizar en el diseño conceptual son los siguientes: 1.- Identificar las entidades. 2.- Identificar las relaciones. 3.- Identificar los atributos y asociarlos a entidades y relaciones. 4.- Determinar los dominios de os atributos 5.- Determinar los identificadores 6.- Determinar las jerarquías de generalización (si las hay). 7.- Dibujar el diagrama entidad-relación. 8.- Revisar el esquema conceptual local con el usuario. Entidades 3 En primer lugar, hay que definir los principales conceptos que interesan al usuario. Estos conceptos serán las entidades. Se puede definir como entidad a cualquier objeto, real o abstracto que existe en un contexto determinado o puede llegar a existir y del cual deseamos guardar información, por ejemplo: “Profesor”, “Curso”, “Alumno”. Las entidades las podemos clasificar en: a) Regulares: Son aquellas que existen por sí mismas y que la existencia de un ejemplar en la entidad no depende de la existencia de otros ejemplares en otra entidad. Por ejemplo “Empleado”, “Profesor”. La representación gráfica dentro del diagrama es la siguiente: Profesor a) Débiles: Son aquellas entidades en las que se hace necesaria la existencia de ejemplares de otras entidades distintas para que puedan existir ejemplares en esta entidad. La representación gráfica dentro del diagrama es la siguiente: Empleado Ejemplo: Identifica la entidad fuerte y la débil. Identificando entidades Una forma de identificar las entidades es examinar las especificaciones de requisitos de usuario. En estas especificaciones se buscan los nombres o los sintagmas nominales que se mencionan (por ejemplo: código del cliente, nombre del cliente, número de la factura, fecha de la factura, IVA de la factura). También se buscan conceptos importantes como personas, lugares o conceptos abstractos, excluyendo aquellos nombres que sólo son propiedades de otros objetos. Por ejemplo, se pueden agrupar el código del cliente y el nombre del cliente en una entidad denominada cliente, y agrupar el número de la factura, la fecha de la factura y el IVA de la factura en otra entidad denominada factura. 4 Ejemplo: Entidades. CIUDADES y ASIGNATURAS se han representado como entidades porque de ellas se requiere almacenar información: nombre de la ciudad, provincia en la que se encuentra, número de habitantes, nombre de la asignatura, créditos teóricos y prácticos, titulación a la que pertenece, etc. Relaciones Una vez definidas las entidades, se debe definir las relaciones existentes entre ellas. Del mismo modo que para identificar las entidades se buscaban nombres en las especificaciones de requisitos, para identificar las relaciones se suelen buscar las expresiones verbales. Por ejemplo: ciudad donde ha nacido el estudiante y ciudades en que ha residido; cada director tiene a su cargo a un conjunto de empleados. Si las especificaciones de requisitos reflejan estas relaciones es porque son importantes para la empresa y, por lo tanto, se deben reflejar en el esquema conceptual. La mayoría de las relaciones son binarias (entre dos entidades), pero también puede haber relaciones en las que participen más de dos entidades, así como relaciones recursivas. Es muy importante repasar las especificaciones para comprobar que todas las relaciones, explícitas o implícitas, se han encontrado. Si se tienen pocas entidades, se puede comprobar por parejas si hay alguna relación entre ellas. De todos modos, las relaciones que no se identifican ahora se suelen encontrar cuando se valida el esquema con las transacciones que debe soportar. Una vez identificadas todas las relaciones, hay que determinar la cardinalidad mínima y máxima con la que participa cada entidad en cada una de ellas. De este modo, el esquema representa de una manera más explícita la semántica de las relaciones. La cardinalidad es un tipo de restricción que se utiliza para comprobar y mantener la calidad de los datos. La cardinalidad mínima indica si la participación de la entidad en la relaciones opcional (se indica con 0) o si es obligatoria (se indica con 1). Que sea obligatoria implica que todas las ocurrencias de la entidad deberán relacionarse con, al menos, una ocurrencia de la entidad que se encuentra al otro lado de la relación. La cardinalidad máxima indica si cada ocurrencia de la entidad sólo puede relacionarse con una ocurrencia de la entidad del otro lado de la relación (se indica con 1), o si puede relacionarse con varias a la vez (se indica con n). Conforme se van identificando las relaciones, se les van asignando nombresque tengan significado para el usuario. En el diccionario de datos se anotan los nombres de las relaciones, su descripción y las restricciones que existen sobre ellas. Ejemplo: Tipos de relaciones. Las entidades se relacionan entre ellas o consigo mismas, lo cual se representa en el esquema conceptual mediante líneas y un rombo en donde se da nombre a la relación. En la línea se expresa la cardinalidad con la que cada entidad participa en la relación mediante dos componentes entre paréntesis. 5 Los esquemas de la figura corresponden a los siguientes requisitos: (a) De cada estudiante se sabe la ciudad en donde ha nacido (será una y sólo una) y también las ciudades en donde ha residido (al menos aquella en la que reside en la actualidad). (b) Cada empleado es dirigido por otro empleado (obligatoriamente por uno y sólo por uno), y un empleado puede ser director de varios empleados (o no serlo de ninguno). Atributos Las entidades se componen de atributos que son cada una de las propiedades o características que tienen las entidades. Cada ejemplar de una misma entidad posee los mismos atributos, tanto en nombre como en número, diferenciándose cada uno de los ejemplares por los valores que toman dichos atributos. Si consideramos la entidad profesor y definimos los atributos, Nombre, Teléfono y salario, podríamos obtener los siguientes ejemplares: Luis García Juan Antonio Álvarez Marta López 91.555.55.55 80,500 91.666.66.66 92,474 91.777.77.77 85,396 El siguiente paso consiste en identificar los atributos y asociarlos con las entidades y las relaciones en función de su significado. Al igual que ha procedido con las entidades, para identificar los atributos se buscan nombres en las especificaciones de requisitos. Son atributos los nombres que identifican propiedades, cualidades, identificadores o características de entidades o de relaciones. Lo más sencillo es preguntarse, para cada entidad y cada relación, qué información se quiere saber de ellas. La respuesta a esta pregunta se debe encontrar en las especificaciones de requisitos. Pero, en ocasiones, será necesario preguntar a los usuarios para que aclaren los requisitos. Desgraciadamente, los usuarios pueden dar respuestas a esta pregunta que también contengan otros conceptos, por lo que hay que considerar sus respuestas con mucho cuidado. Al identificar los atributos, hay que tener en cuenta si son simples o compuestos. Por ejemplo, el atributo dirección puede ser simple, teniendo la dirección completa como un solo valor: ‘San Rafael 45, Almazora’; o puede ser un atributo compuesto, formado por la calle (‘San Rafael’), el número (‘45’) y la población (‘Almazora’). El escoger entre atributo simple o compuesto depende de los requisitos del usuario. Si el usuario no necesita acceder a cada uno de los componentes de la dirección por separado, se puede representar como un atributo simple. Pero si el usuario quiere acceder a los componentes de forma individual, entonces se debe representar como un atributo compuesto. 6 En el esquema conceptual se debe reflejar la cardinalidad mínima y máxima de cada atributo, ya sea simple o compuesto. La cardinalidad mínima indica si el atributo es opcional (se expresa con 0) o si es obligatorio (se expresa con 1). La cardinalidad máxima indica si el atributo tiene, como mucho, un solo valor (se indica con 1) o si puede tener varios valores, es decir, si es multi evaluado (se indica con n). Puesto que el valor más usual en la cardinalidad de los atributos es «(1,1)» (tienen un valor y sólo uno), ésta se omite para estos casos, siendo el valor por defecto. En esta fase también se debe identificar los atributos derivados o calculados, que son aquellos cuyo valor se puede calcular a partir de los valores de otros atributos. Por ejemplo, el número de estudiantes matriculados, la edad de los estudiantes o el número de ciudades en que residen los estudiantes. Algunos diseñadores no representan los atributos derivados en los esquemas conceptuales. Si se hace, se debe indicar claramente que el atributo es derivado y a partir de qué atributos se obtiene su valor. El momento en que hay que considerar los atributos derivados es en el diseño físico. Cuando se están identificando los atributos, se puede descubrir alguna entidad que no se ha identificado previamente, por lo que hay que volver al principio introduciendo esta entidad y viendo si se relaciona con otras entidades. Es muy útil elaborar una lista con los atributos que aparecen en los requisitos e ir eliminándolos de la lista conforme se vayan asociando a una entidad o relación. De este modo, uno se puede asegurar de que cada atributo se asocia a una sola entidad o relación, y que cuando la lista se ha acabado, se han asociado todos los atributos. Hay que tener mucha precaución cuando parece que un mismo atributo se debe asociar a varias entidades. Esto puede ser por una de las siguientes causas: Se han identificado varias entidades, como director, supervisor y administrativo, cuando, de hecho, pueden representarse como una sola entidad denominada empleados. En este caso, se puede escoger entre introducir una jerarquía de generalización (se presentan más adelante), o dejar las entidades que representan cada uno de los puestos que ocupan los empleados. Se ha identificado una relación entre entidades. En este caso, se debe asociar el atributo a una sola de las entidades y hay que asegurarse de que la relación ya se había identificado previamente. Si no es así, se debe actualizar el esquema y el diccionario, para recoger la nueva relación. Conforme se van identificando los atributos, se les asignan nombres que tengan significado para el usuario. De cada atributo se debe anotar la siguiente información en el diccionario: Nombre y descripción del atributo. Alias o sinónimos por los que se conoce al atributo. Tipo de dato y longitud. Valores por defecto del atributo (si se especifican). Si el atributo es compuesto, especificar qué atributos simples lo forman y describirlos como se indica en esta lista. Si el atributo es derivado, indicar cómo se calcula su valor. 7 Ejemplo: Atributos simples. De los estudiantes del diagrama de la figura arriba se quiere conocer el nombre, el DNI y la carrera que están estudiando. Conocer la ciudad de nacimiento es, en este caso, opcional (cardinalidad (0, 1)) y, si se conoce, se conocerá también la fecha de nacimiento. Es por ello que este último atributo está en la relación y no en la entidad estudiante: va ligado a conocer o no la ciudad de nacimiento. Además, de los estudiantes también interesan las ciudades en donde han residido y la fecha en que han comenzado a hacerlo en cada una de ellas. De las ciudades, interesa su nombre y su número de habitantes, y si es posible, su altitud. El que las ciudades participen en ambas relaciones con cardinalidad (0, n) significa que hay ciudades en donde puede que no haya nacido ningún estudiante o que hayan nacido varios, y que hay ciudades en donde puede que no haya residido ningún estudiante o que hayan residido varios. Ejemplo: Atributos compuestos. El diagrama de atributos compuestos: corresponde a unos requisitos muy similares a los del ejemplo anterior: datos de empleados, lugar de nacimiento y lugares de residencia. En este caso, las ciudades no se han considerado como entidad porque de ellas no hay que conocer otras propiedades aparte de su nombre. En este ejemplo aparecen atributos compuestos y atributos multievaluados (con cardinalidad máxima n). La interpretación del esquema es la siguiente: de los empleados interesa su nombre y su DNI, además del título o títulos que tienen, si es el caso (puede haber empleados sin titulación). Si se conoce el lugar de nacimiento, interesa el nombre de la ciudad y la fecha. Además, interesa conocer los lugares en que ha residido y, para cada uno de ellos, el nombre de la ciudad y la fecha de inicio de la residencia. Dominios En este paso se deben determinar los dominios de los atributos. El dominio de un atributo es el conjunto de valores que puede tomar el atributo. Por ejemplo, el dominio de los DNI son las tiras de nueve caracteres en donde los ocho primeros son dígitos numéricos y el último es un carácter de control que se obtiene al aplicar un determinado algoritmo; el dominio de los códigos postales en 8 España son cadenas de cinco dígitos, correspondiendo los dos primeros a un número de provincia válido. Un esquema conceptual está completo si incluye los dominios de todos sus atributos, es decir, los valores permitidos para cada atributo, su tamaño y su formato. También se puede incluir información adicional sobre los dominios como, por ejemplo, las operaciones que se pueden realizar sobre cada atributo, qué atributos pueden compararse entre sí o qué atributos pueden combinarse con otros. Aunque sería muy interesante que el sistema final respetara todas estas indicaciones sobre los dominios, esto es todavía una línea abierta de investigación. Toda la información sobre los dominios se debe anotar también en el diccionario de datos. Cuando se determinan los identificadores es fácil darse cuenta de si una entidad es fuerte o débil. Si una entidad tiene al menos un identificador, es fuerte (otras denominaciones son padre, propietaria o dominante). Si una entidad no tiene atributos que le sirvan de identificador, es débil (otras denominaciones son hijo, dependiente o subordinada). Ejemplo: Identificadores de entidades fuertes. El diagrama de la figura muestra cómo se identifican estudiantes y ciudades. No conviene olvidar que estamos trabajando ante unos supuestos requisitos. En este caso, se sabe que los estudiantes se identifican de modo único por su DNI, y las ciudades por su nombre. Ejemplo: Identificadores de entidades débiles. En el diagrama de la figura se muestra una entidad débil: la de los empleados. Cada empleado se identifica por su número de empleado dentro de su departamento. Nótese que los departamentos tienen dos posibles formas de identificarse: bien mediante su número o bien mediante su nombre. Por lo tanto hay también dos maneras de identificar a los empleados: por la combinación de su número de empleado y el número de su departamento, o bien, por la combinación de su número de empleado y el nombre de su departamento. 9