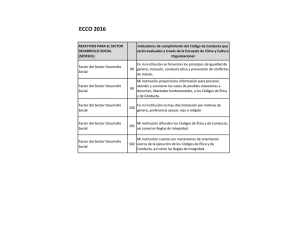
Apuntes #1
Codificación para la
detección y corrección
de errores
Marzo / 2020
Jorge Rojas Beltrán
Contenido
Introducción
Derivaciones de “Teoría de la Información”
Codificación Fuente y de Canal
Tx de Información por un Canal Discreto
Técnicas para Control de Errores
Códigos de Bloque
Introducción
El objetivo del Ingeniero en Comunicaciones es el de
diseñar sistemas de modo que la información se transmita
al medio con tan poco deterioro, al mismo tiempo, y que
satisfaga limitaciones de diseño (energía de Tx, ancho de
banda de la señal y los costos permisibles).
El objetivo de los sitemas de comunicación es el de
transmitir información desde una fuente hasta un canal y
que el receptor pueda extraer lo más fielmente dicha
información.
Es aquí donde la Teoría de la Información juega un rol
importante; la cual analiza el grado de incertidumbre de un
evento.
Introducción
Harry Nyquist
(1924)
R.V. L. Hartley
(1928)
Alec Reeves
(1937)
D. A. Huffman
(1952)
A. J. Viterbi (Qualcom)(1966)
Norbert Wiener
(1949)
Claude
Elwood
Shannon (1916-2001)
“1948-Una
teoría
matemática
de
la
comunicación”
(se
concentra más en la
información que en las
señales en sí).
¿Cómo se representarán los mensajes
para que la información sea conducida
de la mejor manera, con sus
limitaciones físicas inherentes.
Tx telegráfica
PCM
Códigos de redundancia
Com. coherentes
Teoría de la
detección (lado Rx)
Richard
Hamming
(1915-1998) Enfocó sus
estudios al control de
errores.
Introducción
Puntos medulares de la Teoría de la Información de Shannon:
• Nueva medida para la velocidad de Información
• Medida para la capacidad de Tx. de información de un canal
• Proceso de codificación para utilizar los canales a máx cap.
q
H
P( x ) I
i
i 1
Entropía:
Medida de la
información
promedio de
una
fuente
(s/memoria y
discreta)
H ( s) L
R( s ) C
1°
Teorema
de
Shannon: El mínimo
de bits requeridos para
codificar una fuente de
información es igual a
la entropía de la
misma. (Cod. Fuente)
2° Teorema de Shannon:
Establece que si la razón
de entropía es igual o
menor que la capacidad
del canal, entonces existe
una técnica de codificación
que reduce la cantidad de
errores sobre el canal.
i
Recordar relación de P----> 1 --- I --->0 Caso del WTC NY; remarcar no importa el significado del mensaje
Derivaciones de la Teoría de la
Información
Como sea ha podido ver, esta teoría tiene mucha aplicaciones
derivadas de su análisis:
Especificación
de fuentes de
información
Compresión
Encriptación
Capacidad
de canal
Digitalización
Teoría de la
Información
Almacenamiento
de datos
Corrección y
detección de
errores
Codificación Fuente y de Canal
• Códificación Fuente:
Su objetivo es extraer la
información esencial de
la fuente y codificarla a
forma digital de modo
que se pueda guardar o
transmitir
mediante
técnicas digitales
• Codificación de Canal:
Se agragan datos al tren
de bits de la fuente para
que el receptor pueda
detectar y corregir
errores provocados por
el ruido presente en el
canal.
Transmisión de Información sobre
Canales Discretos
a1
A
a2
b1
Canal
b2
de
B
Información
ar
Alfabeto de
entrada
bs
Alfabeto de
salida
Un canal de información discreto es
una función de mapeo cuyo dominio
es el alfabeto de símbolos de entrada
A = { a i } , i = 1, 2, ... r
y cuyo contradominio es el alfabeto
de símbolos de salida
B={bj},
P=(bj / a i )
j = 1, 2, ... s
y se caracteriza por un conjunto de
probabilidades condicionales
Conocida como la probabilidad de recibir
a la salida el símbolo bj cuando se envía
el símbolo de entrada ai
Transmisión de Información sobre
Canales Discretos
Todo
canal
discreto
queda
completamente caracterizado por su
matriz de transición (matriz de canal “P”)
El resto de las probabilidades que
intervienen en el canal se pueden deducir:
P(bj )
P(b1 / a1 ) P(b2 / a1 ) ... P(bs / a1 )
P(b / a ) P(b / a ) ... P(b / a )
2
2
s
2
P 1 2
:
:
:
P
(
b
/
a
)
P
(
b
/
a
)
...
P
(
b
/
a
)
2
r
s
r
1 r
Para un canal BSC
P(b / a )P(a )
j
i
i
i 1
P(ai / b j )
1
P(b j / ai ) P(ai )
P(b j / ai ) P(ai )
2
i 1
P(ai)
Prob. de que la fuente seleccione el
símbolo ai para Tx. (a priori, entrada)
P(bj)
Prob. de que el símbolo bj es recibido
a la salida. (salida)
Prob. condicional que b es recibido
j
P(bj/ai) dado que a fue transmitido.
(hacia
i
delante, transición)
Su
matriz
de
canal
será:
p
1 p
PBSC
p
1
p
P(ai/bj)
Prob. condicional que ai fue transmitido
dado que bj es recibido. (hacia atrás, a
posteriori)
Cálculo de las Probabilidades de
un Canal de Información - Ejemplo
Considerando un canal binario
con las los alfabetos A={0,1},
B={0,1},
probabilidades de
entrada P(a=0)=3/4 y P(a=1)=1/4,
con la siguiente matriz de canal:
2 / 3 1/ 3
P
1/ 10 9 / 10
Calculando las probabilidades de
salida utilizando ec. 1
𝑃(𝑏𝑗 ) =
𝑃(𝑎𝑖 )𝑃(𝑏𝑗 /𝑎𝑖 )
𝑖=1
1
P(b=0)= [ P(b=0/a=0) • P(a=0) ] +
+ [ P(b=0/a=1) • P(a=1) ]
3/4}
2/3
0
1/3
0
= (2/3)(3/4) + (1/10)(1/4)= 21/40
1/10
P(b=0)= 21/40
1/4}
1
9/10
¿Qué tan ruidoso será
dicho canal?
1
continuando con la otra probabilidad
P(b=1)= 19/40
Cálculo de las Probabilidades de
un Canal de Información - Ejemplo
Después se calculan las probabilidades
condicionales hacia atrás utilizando ec. 2
P(ai / b j )
P(b j / ai ) P(ai )
P(b / a )P(a )
j
i
2
Por último se calculan las
otras
dos
probabilidades
condicionales hacia atrás de
la misma manera, se tiene:
i
i 1
P(a 0 / b 0)
P(a 0 / b 0)
P(b 0 / a 0) P(a 0)
P(b 0 / a 0) P(a 0) P(b 0 / a 1) P(a 1)
(2 / 3)(3 / 4)
P(a=0/b=0)= 20/21
(2 / 3)(3 / 4) (1/ 10)(1/ 4)
y calculando su probabilidad condicional
hacia atrás de complemento P(a=1/b=0):
P(a 1/ b 0)
P(a 1/ b 0)
P(a=1/b=1)= 9/19
P(a=0/b=1)= 10/19
P(b 0 / a 1) P(a 1)
P(b 0 / a 0) P(a 0) P(b 0 / a 1) P(a 1)
(1/ 10)(1/ 4)
P(a=1/b=0)= 1/21
(2 / 3)(3 / 4) (1/ 10)(1/ 4)
Entropías de un Canal de
Información
P(ai) es la probabilidad a priori de los símbolos de entrada, es decir
antes de recibir un símbolo de salida determinado.
P(ai/bj) es la probabilidad a posteriori, de los símbolos de entrada
después de la recepción bj.
Aplicando el concepto de entropía a este conjunto de probabilidades
de los símbolos de entrada, se tiene que:
H ( A)
A
P(a) log
1
P(a)
3
Entropía a priori: significa el
número
medio
de
bits
necesarios para representar
un símbolo de una fuente con
probabilidad a priori P(ai),
i=1,2, ... r
H ( A / bj )
A
P(a / b j ) log
1
P( a / b j )
4
Entropía a posteriori: significa el
número medio de bits necesarios
para representar un símbolo de una
fuente
con
probabilidad
a
posteriori
P(ai/bj), i=1,2, ... r
(recibiendo bj)
Entropías de un Canal de
Información - Ejemplo de Cálculo
Aprovechando
el
ejemplo
anterior, calcular las entropías
de dicho canal de información:
3/4}
H ( A)
2/3
0
1/3
Aplicando la ec. 3 para calcular la
entropía a priori
0
A
1
1
P(a)
3
1/10
H ( A) P(a 1) log 2
1/4}
P(a) log
9/10
1
Las probs. condicionales
obtenidas
anteriormente
son:
P(a=0/b=0)= 20/21
P(a=1/b=0)= 1/21
P(a=1/b=1)= 9/19
P(a=0/b=1)= 10/19
1
1
P(a 0) log 2
P(a 1)
P(a 0)
H ( A) (1/ 4)3.32 log10
1
1
(3 / 4)3.32 log10
1/ 4
3/ 4
H(A) = 0.811 bits/símb.
este resultado será útil para aplicarlo
en el siguiente concepto
Entropías de un Canal de
Información - Ejemplo de Cálculo
Ahora se calcularán las entropías
a posteriori según sea el
símbolo bj de salida que se
reciba, usando ec. 4
H ( A / bj )
A
1
P(a / b j ) log
4
P( a / b j )
H ( A / b 0) P(a 0 / b 0) log 2
1
P(a 0 / b 0)
P(a 1 / b 1) log 2
1
P(a 0 / b 1)
1
P(a 1 / b 1)
1
H ( A / b 0) (10 / 19)3.32 log 10 (
)
10 / 19
1
(9 / 19)3.32 log 10 (
)
9 / 19
H(A/b=1) = 0.9974 bits/símb.
1
P(a 1/ b 0) log 2
P(a 1 / b 0)
H ( A / b 0) (20 / 21)3.32 log10 (
H ( A / b 1) P(a 0 / b 1) log 2
¿Qué significan los resultados?
1
)
20 / 21
1
(1/ 21)3.32 log 10 (
)
1 / 21
H(A/b=0) = 0.276 bits/símb.
Por
lo
tanto
hay
menos
incertidumbre sobre la entrada
enviada sí se recibe un “0” que sí
se recibiese un “1” a la salida del
canal de información.
Información mutua
Si el canal de información es libre de ruido, entonces la recepción de algún
símbolo bj determina unívocamente el mensaje transmitido. Sin embargo, debido
al ruido, existe cierta cantidad de incertidumbre en lo que se refiere al símbolo
transmitido cuando se recibe bj.
Por lo que la entropía a posteriori del canal H(A/bj) se le denomina “la pérdida
promedio de información” cuando se recibe bj
Y para obtener esta incertidumbre promedio para todos los símbolos recibidos:
H ( A / B)
P(b )H ( A / b )
j
j
5
j
“equivocación de A con
respecto a B”
Además la entropía a priori del canal H(A) se aplica como el promedio de la
cantidad de información recibida sí no hay ruido (ec. 3). Por lo tanto:
I(A;B) = H(A) - H(A/B)
6
“Información Mutua”
Esta última expresión establece la cantidad de información promedio que será
recibida al final del canal.
Información mutua - Ejemplo
Aplicando los datos y cálculos del mismo canal ruidoso, se determinará
su información mutua, utilizando las ecs. 5 y 6 se tiene:
H ( A / B)
P(b )H ( A / b )
j
j
H(A) = 0.811 bits/símb.
5
j
H(A/b=1) = 0.9974 bits/símb.
H(A/b=0) = 0.276 bits/símb.
I(A;B) = H(A) - H(A/B)
6
H(A/B) = P(b=0)H(A/b=0) + P(b=1)H(A/b=1)
= (21/40)(0.276) + (19/40)(0.9974)
= 0.6188 bits/símb.
I(A;B) = 0.811 - 0.6188 = 0.1924 bits/símb.
P(b=0)= 21/40
P(b=1)= 19/40
Lo que responde a
la pregunta inicial
del ejemplo.
Introducción a la Detección de Errores
El “BER” es habitualmente el parámetro más importante a tener en cuenta, desde el
punto de vista de los diseñadores de sistemas de comunicación. La velocidad de
encapsulamiento de salida de la información es también decisiva, ya que el
diseñador desea transmitir información a cierta tasa de símbolos R, necesidad que
viene determinada por cada aplicación. Otros criterios de diseño incluyen:
* Complejidad
* Disipación de calor
* Costo
* Tolerancia a fallos
* Peso del equipo
Esto deja poca flexibilidad al proceso de diseño ya que según nuestro razonamiento
simplista parece indicar que: una vez se ha seleccionado el formato de modulación,
la velocidad de encapsulamiento de salida y el BER, éstos determinan el nivel de
potencia del transmisor, que a su vez determina el peso de la batería, la disipación
térmica y otros factores. En algunos casos, este análisis puede indicar que la
construcción del sistema deseado es físicamente imposible. Por ejemplo, en el
diseño de un satélite de comunicaciones, la ecuación potencia/velocidad/BER
puede llegar a dictar un nivel de potencia P mayor del que puede ser proporcionado
por los amplificadores de las ondas portadoras o los amplificadores de estado sólido
disponibles para las construcciones de satélites. En otro ejemplo, podemos
encontrar que las necesidades de potencia para el diseño de un teléfono móvil
indican el uso de baterías del tamaño más bien para la espalda de un elefante que
para el bolsillo de una camisa.
Introducción a los Códigos de Control de Errores
Hubo un tiempo en el que estos obstáculos resultaban insuperables. Sin
embargo a finales de los 40 los trabajos de Shannon y Hamming en los
Laboratorios Bell sentaron las bases para los códigos de control de error, un
campo que hoy nos proporciona un conjunto de técnicas potentes para
alcanzar los BER deseados con potencias de transmisión bajas.
Estos caballeros atacaron el problema del control de error en canales con
ruidos usando técnicas completamente diferentes. Shannon utilizó un enfoque
estadístico/existencial mientras que Hamming podría decirse que utilizó un
planteamiento combinatorio/constructivo. Consecuentemente, sus resultados
fueron también radicalmente distintos: Shannon encontró los límites para el
control de errores ideal, mientras que Hamming mostró la manera de construir
y analizar los primeros sistemas de control de error prácticos.
Recordemos que existen tres tipos distintos de codificaciones en las
comunicaciones digitales: Códigos Fuentes (eliminan redundancia), Códigos de
Confiabilidad y Secretos, por último, Códigos para el Control de Errores los
cuales hacen uso de la Matemática Discreta.
Introducción a la Detección de Errores
El decodificador puede reaccionar ante la detección de un error de tres
maneras diferentes:
• Pedir una retransmisión de la palabra
• Tomar la palabra como incorrecta e ignorarla
• Tratar de corregir los errores de la palabra recibida.
La petición de retransmisión es utilizada en un conjunto de estrategias de
control de errores denominado petición automática de respuesta (ARQ =
Automatic Repeat Request). Para ello es necesario que exista un enlace
bidireccional entre el transmisor y el receptor y que la información inicial
todavía esté disponible.
La segunda opción se denomina comúnmente como “mutting". Es típica de
aplicaciones en las que los retrasos no permiten la retransmisión de la palabra
transmitida y parece mejor dejar la palabra recibida como un valor "apagado"
que intentar corregir los errores. (p.e. comunicación por voz y audio digital).
La opción final se denomina corrección del error (FEC=Forward Error
Correction). En los sistemas FEC la estructura aritmética o algebraica del
código se utiliza para determinar cuáles de las palabras código válidas han
sido enviadas, dada la palabra errónea recibida.
Técnicas para Control de
Errores
La clave para realizar una comunicación libre de errores es
mediante la utilización de una redundancia adecuada (ej. díg.
paridad).
Las distintas técnicas de control de errores (Det-correc.) son
para que el flujo de datos sea consistente, a pesar de los
diversos errores que generar el ruido dentro de un canal.
Aleatorios (random)
Canales sin/mem, com-satelitales,
deep-space .
Ráfagas (burst)
Canales con/mem,
com, diafonía, fading.
Compuesto
Random-burst, caract. atmosféricas
extremas, pérdida del enlace por
bastante tiempo (meteor-burst)
radio/cable
Técnicas para Control de
Errores
ARQ (Automatic Repeat
Request). Retransmisión de
bloque detectados en el Rx
con error, modo duplex
ACK (LAN’s), distancias
cortas.
FEC
(Forward
Error
Correcion): Corrección de
errores
anticipadaadelantada, donde los datos
transmitidos se codifican de
modo que el Rx puede
detectar y corregir los errores.
Modo simplex - com. Con
largas demoras en la Transm.
Parada-Espera ”Stop and wait”
“Go back - N”
“Selective Reject”
Ventanas deslizante
Códigos de Bloque
Códigos Cíclicos
CRC
RS, BCH
Códigos de Convolución
Turbo Codes
Códigos de Bloque
La codificación de bloque es una transformación de “k”
símbolos de entrada en “n” símbolos de salida, donde n > k.
Ello por medio de la segmentación en bloques de los datos
binarios del mensaje. Se considera un dispositivo sin memoria.
d1
d2
dk
c1
Codificador
de canal
(n, k)
c2
cn
d = (d1, d2, ... dk)
c = (c1, c2, ... cn)
Para cada bloque de
dato habrá un bloque
distinto de código (2k)
La matriz generadora de estos
códigos es la que se encarga de
realizar
la
combinación
lineal
(adiciones módulo 2) de estos dígitos
de dato y código.
c = d G
1+1=0
0+0=0
1+0=1
0+1=1
Tabla de
suma
módulo 2
Códigos de Bloque
g11 g12 ... g1n
g
g
...
g
22
2n
... d k 21
:
:
:
g
g
...
g
k2
kn
k1
c = d G
c1
c2 ... cn d1 d 2
Sumas de mod 2
La G de un código (n,k) de bloque
sistemático está integrado por:
G =
I
P
Un un código (n,k) de bloque será
sistemático si en su palabra de código
está integrada la propia palabra de
dato, esto es:
c1 = d1, c2 = d2, ... ck = dk
ck+1 a cn
Matriz
Identidad
k x k
m=n-k
Matriz de
Paridad
k x m
Dígitos de redundancia
y
es una comb. lineal
Dato
Parte de
redundancia
k
n-k
+
Códigos de Bloque - Ejemplo
Un código de bloque (7,4) está dado por su matriz generadora G, si se
tiene a la entrada (1 1 0 1); ¿Cuál es la palabra de código (salida)?
k=4;n=7
c = d G
[d1 d2 d3 d4] = [ 1 1 0 1]
[c1 c2 c3 c4 c5 c6 c7] = [ ?..? ]
1101
Codificador
Bloque
(7,4)
1101000
1
0
G
0
0
0 0 0 1 1 0
1 0 0 0 1 1
0 1 0 1 1 1
0 0 1 1 0 1
c1 = d1
c2 = d2
c3 = d3
Ahora, para el caso general de
cualquier palabra de dato, las
palabras de este código (7,4) se
calcularán por las siguientes
relaciones, según su G.
c4 = d4
c5 = d1 + d3 + d4
c6 = d1 + d2 + d3
c7 = d2 + d3 + d4
Ecuaciones
de
verificación
de paridad
Códigos de Bloque - Ejemplo
Circuito
c1
El diagrama del codificador
anterior, se puede elaborar
con base en las ecuaciones
anteriores.
c1 = d1
c3
d
c2 = d2
c3 = d3
c2
d4 d 3 d2 d1
c
c4
c4 = d4
c5 = d1 + d3 + d4
c6 = d1 + d2 + d3
c5
c6
c7 = d2 + d3 + d4
sumas mod 2
c7
Síndrome - Detección Error
c
CANAL
r
ruido
Porque el canal es ruidoso r
puede ser diferente de c, por lo
que:
e = r + c
donde: e = 1 si r c
i
i
i
ei = 0 si ri = ci
e es el vector error ó patrón de
error, y los 1’s son los errores
transmitidos y causados por el
ruido del canal.
r=101, c=100
También se puede definir que
con base en operación mod 2:
r = c + e
En el lado Rx no se sabe de
c ni de e al recibir r, por
lo que el decoder debe
primero
determinar
los
errores contenidos en la
transmisión.
Para el caso de FEC, el Rx
procede a computar el
llamado síndrome por medio
del vector r. Patrones de errores
indetectables
Síndrome - Detección Error
Para calcular el síndrome:
s = r
HT =
Y los vectores que intervienen:
s1, s2, ... sm
Entonces si s = 0 si y sólo si r
es la palabra código ( c ), por lo
tanto, si s 0 se sabe que hay
error, y donde H es la matriz
verificadora de paridad:
H = [ PT I ]
Ejemplo de cálculo, caso anterior:
1
0
I
0
0
0 0 0
1 0 0
0 1 0
0 0 1
1
0
P
1
1
1 0
1 1
1 1
0 1
7
r = ( r1, r2, r3, ... r7 )
s = ( s1, s2, s3 )
Las ecuaciones
del
síndrome
después
de
aplicar la fórmula
7, quedan:
1
0
1
H T 1
1
0
0
1 0
1 1
1 1
0 1
0 0
1 0
0 1
s1 = r1 + r3 + r4 + r5
s2 = r1 + r2 + r3 + r6
s3 = r2 + r3 + r4 + r7
Si c=[1101000] code word ok, r = c para no error
Síndrome - Detección Error
En caso de haber falla, la
determinación del e no es tan
simple. El decodificador tiene que
determinar el verdadero vector de
error.
Considerando otra vez el código
(7,4) anterior, suponga que se
transmite la siguiente palabra de
código y se recibe con error:
Rx no sabe qué
error hay y ¿dónde?
Ahora el Rx sabe que hay error,
pero no dónde, esto implica que
se
tiene
un
sistema
de
ecuaciones de error que debe
cumplir con el síndrome. ***
s = e HT
e1 + e3 + e4 + e5 = 1
e1 + e2 + e3 + e6 = 1
e2 + e3 + e4 + e7 = 1
c=1011100
r=1001100
Cálculo síndrome:
s1 = r1 + r3 + r4 + r5 = 1
s2 = r1 + r2 + r3 + r6 = 1
s3 = r2 + r3 + r4 + r7 = 1
s=111
s0
hay error
s = r HT
r = c + e
El síndrome sólo depende
del patrón de error.
Hay
16
patrones
de error
para sol.
(0 0 1 0 0 0 0)
(1 0 1 0 1 1 0)
(0 0 1 1 1 0 1)
(1 0 1 1 0 1 1)
(1 1 0 0 0 1 0)
(1 1 0 1 1 1 1)
Síndrome - Detección Error
Para tomar la mejor decisión, se
adopta el vector de error que tenga el
# de 1’s menor. Esto considerando a
un BSC y que lo más probable es
que se presente un sólo error en toda
la palabra (verosimilitud-máx.) Hamming
e=(0010000)
Podemos concluir que el código
(7,4) puede detectar cualquier
error individual dentro de un
bloque de 7 dígitos y corregirlo.
r
Circuito del síndrome
r1 r2 r3 r4 r5 r6 r7
Entonces el decoder procesa r y el
error para dar con la palabra de
código transmitida
c* = r + e
=1001100 +0010000=
= 1 0 1 1 1 0 0 ---> code word
s1
s2
s3
Decodificador - CB
Para la decodificación sistemática
de este tipo de código, se prepara
una tabla de todos los errores
corregibles
y
sus
correspondientes síndromes.
r
Buffer de registros r
r1
Circuito calculador del
síndrome
Por ejemplo, para el código (7,4)
anterior se tendrán 3 bits para s y
7 bits para e en un total de ocho
tuplas:
s
e
000
110
011
111
101
100
010
001
0000000
1000000
0100000
0010000
0001000
0000100
0000010
0000001
r7
s1
s2
s3
Circuito lógico para patrón
de error detectado
e1
r1
r7
c1
Problemática orden mayor
e7
Salida corregida
c7