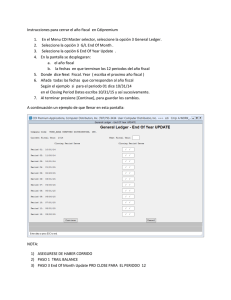
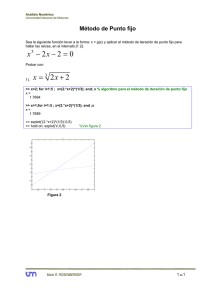
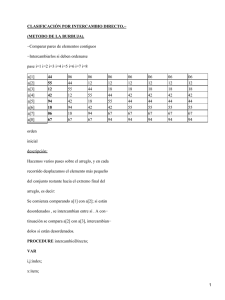
Matlab - David Perrin
Anuncio

MN50 - Computaciones de altas prestaciones
Matlab
Practicas 1 : Resolución de
sistemas de écuaciones lineales
David Perrin
ETSII / UTBM
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Sumario
—
•
Descomposición LU (I)
3
•
Descomposición LU prematurada
3
•
Descomposición LU (II)
4
•
Descomposición LU de Matlab
4
•
Métodos directos optimizados, generalidades
5
•
Método Cholesky optimizado
5
•
Apunte literario para Cholesky (método Gaxpy)
7
•
Método LU optimizada
8
•
Apunte literario para LU
9
•
Ordenes de costes de flops teoricos
10
•
Resolución de sistema
11
•
Método directos, costes relativo al tamaño
13
•
Matrices de Hilbert
16
•
Número de condición
17
•
Métodos iterativos, generalidades
18
•
Método de Gauss-Seidel (nivel escalar)
19
•
Método de Jacobi (nivel escalar)
20
•
Método de Gauss-Seidel (nivel matricial)
21
•
Método de Jacobi (nivel matricial)
21
•
Métodos iterativos, costes relativo al tamaño
22
•
Comparación costes métodos directos y iterativos
25
•
Deteción de la potencia del coste temporal
30
-2-
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Ejercicio 1
a) Implementa el algoritmo de descomposición LU visto en teoría.
•
Descomposición LU (I)
función lu_.m:
function [L,U]=lu_(a)
% descomposicion LU sin pivotacion
% a: matriz cuadrada
[n,m]=size(a);
if n~=m error('Matriz no cuadrada.'); end
for j=1:n-1
if a(j,j)==0 error('Pivote nulo.'); end
for i=(j+1):n
factor=a(i,j)/a(j,j);
a(i,j)=factor;
for k=j+1:n
a(i,k)=a(i,k)-factor*a(j,k);
end
end
end
L=tril(a,-1)+eye(n);
U=triu(a);
b) Dada la matriz de coeficientes siguiente, calcula la descomposición L-U. En
el caso en que el algoritmo termine prematuramente explica la causa
mediante una traza.
1
2
A=
1
2
•
2 1
4 −1
3 0
4 1
0
1
1
0
Descomposición LU prematurada
Explicación:
El pivot del algoritmo LU da un elemento de la diagonal nulo. Con pívot =2, el segundo
paso da A(2,2)=0. Por lo tanto, sin detección de pívot adecuado, la descomposición no
puede hacerse. Entonces eso necesita un paso de detección (ref. programa lu_.m, fila 9).
Aplicación en Matlab:
» A=[1 2 1 0;2 4 -1 1;1 3 0 1;2 4 1 0];
» lu_(A)
??? Error using ==> lu_
Pivote nulo.
Nota:
A(3,3)=A(4,4)=0, no molestan la descomposicón porque se cambian durante el tratamiento.
-3-
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
c) Aplica la descomposición LU a la matriz A permutando la segunda y tercera
filas. Comenta la razón por la que en este caso el algoritmo LU funciona
correctamente.
•
Descomposición LU (II)
Explicación:
Durante el tratamiento LU, el pívot no da nunca un elemento tal que A(i,i)=0.
Aplicación en Matlab:
» A_=[1 2 1 0;1 3 0 1;2 4 -1 1;2 4 1 0];
» lu_(A_)
ans =
1.0000
1.0000
2.0000
2.0000
0
1.0000
0
0
0
0
1.0000
0.3333
0
0
0
1.0000
d) Calcula la descomposición LU de la matriz A mediante el comando lu de
MATLAB.
•
Descomposición LU de Matlab
Explicación:
La decomposición LU de matlab funciona mediante una matriz de paso P para evitar
encontrar las situaciones anteriores. En este caso, P es tal que P ∗ A = L ∗ U .
Nota:
En Matlab, el resultado del mando [L,U,P]=lu(A) da:
1
0.5
L=
0
0
0
2
0
1
0
0 ,
U =
0
0
1
0
0 0.75 1
0
0
0
4 −1
1
0
0
1 0.5 0.5 ,
P=
0
0 2
−1
0 0 0.25
1
1
0
0
0
0
1
0
0
Coste en flops (matriz A con segunda y tercera filas permutadas):
Nota:
LU
teorico
practicacs
matlab
flops
2n 3
≈ 43
3
44
34
los algoritmos de Matlab son hiper-optimizados para el cálculo matricial
-4-
0
0
1
0
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Ejercicio 2
a) Implementa los algoritmos L-U y Cholesky, y después modifícalos de forma
que se minimice el número de operaciones a realizar para resolver un
sistema de ecuaciones lineales cuya matriz de coeficientes tenga una
estructura pentadiagonal simétrica.
•
Métodos directos optimizados, generalidades
Introducción
El principio del optimización es el mismo para los dos métodos de descomposición: dentro
de cada función, introduciremos un parámetro p - el ancho de la banda de la matriz
(aquí, p penta = 2 ) - y disminuiremos los límites de los bucles for. Teniendo cuidado con los
límites de la matriz.
Al nivel de Matlab, hay que saber que el coste en flops incluye las operaciones de las
bucles for. Así, a veces, no se nota la diferencia entre el algoritmo optimizado y el
original, o peor aún: se puede hacer el invertido, tal que toptimizado ≥ toriginal .
•
Método Cholesky optimizado
Principio:
En el método de Cholesky, la ecuación regiendo la descomposición era : aik =
Pues, aquí, teniendo en cuenta el ancho de la banda (p), tendremos : aik =
Colocación en la función cholp.m:
function G=cholp(a)
% descomposicion de Cholesky
% a: matriz positive cuadrada simétrica
[n,m]=size(a);
if n~=m error('Matriz no cuadrada.'); end
if sum(sum(a<0,2))~=0 error('Matriz no positiva.'); end
if sum(sum(a~=a',2))~=0' error('Matriz no simetrica.'); end
G=zeros(size(a));
for k=1:n
aux=0;
for j=max(1,k-p):k-1
aux=aux+G(k,j)^2;
end
G(k,k)=(a(k,k)-aux)^.5;
for i=k+1:k+p
aux=0;
for j=max(1,k-p):k-1
aux=aux+G(i,j)*G(k,j);
end
G(i,k)=(a(i,k)-aux)/G(k,k);
end
end
-5-
k
∑g
j =1
ij
⋅ g kj
k
∑
j = max (1, k − p )
gij ⋅ g kj
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Coste del algoritmo :
Hablando de operaciones intrínsecas al programa, tenemos el esquema siguiente :
for k=1:n
for j=max(1,k-p) →k-1
{2 operaciones}
end
{2 operaciones}
for i=k+1→min(k+p,n)
for j=max(1,k-p) →k-1
{2 operaciones}
end
{2 operaciones}
end
end
Aquí, los límites de k son k = {1, p, p + 1, n − p, n − p + 1, n} . Calcular el coste es lo mismo
que sumar en esos intervalos. Pero en este caso, debemos añadir una condicón tal que
n − p ≥ p o lo mismo que n ≥ 2 p . Este condición nos garantiza que la suma siguiente
funcionará. En realidad, en el otro caso ( n < 2 p ) es una forma distinta de suma, así
nuestra condición se adapta al ejercico (matriz pentadiagonal con p=2 y n > 4 ). De tal
manera que obtenemos :
flopsCHOLp =
∑ {( k − 1 − ( k − p ) + 1) ⋅ 2 + 2 + ( k + p − ( k + 1) + 1) ⋅ ( k − 1 − ( k − p ) + 1) + 2} + …
p
k =1
…+
n− p
∑ {( k − 1 − 1 + 1) ⋅ 2 + 2 + ( k + p − ( k + 1) + 1) ⋅ ( k − 1 − 1 + 1) + 2} + …
k = p +1
n
∑ {( k − 1 − 1 + 1) ⋅ 2 + 2 + ( n − ( k + 1) + 1) ⋅ ( k − 1 − 1 + 1) + 2} + …
…+
k = n − p +1
ó a flopsCHOLp = 2 ⋅
p
∑ ( p + 1) +
2
k =1
n− p
Como
∑
( k + 2) ≈
k = p +1
∑
( p + 1) ⋅ ( k + 2 ) +
k = p +1
∫ ( k + 2 ) ⋅ dk =
n
∑ ( k ( n − 1) − k ) ≈ ∫
2
k = n − p +1
∑
2
f ( k ) ⋅ dk =
( n − 1) n
n − p +1
flopsCHOLp = 2 p ( p + 1) + ( p + 1)( n − 2 p − 5 )( n + 1) +
2
k ( n − 1) − k 2 + 2 ( n + 1)
k = n − p +1
n
( n − 2 p − 5)( n + 1)
p +1
n
Y
n− p
n− p
6
( 3 − 2n ) − ( 2n − 2 p + 5 )( n − p + 1)
2
1
2
( n − 1) n ( 3 − 2n ) − ( 2n − 2 p + 5)( n − p + 1) + 4 p ( n + 1)
3
-6-
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Utilizando el cálculo simbólico de matlab con que la expresión anterior, es decir el
mando :
>> Syms n p; pretty(simplify( flopsCHOLp ));
Da resultado en − n 4 . Eso no puede ser así, porque da un resultado negativo. ¿ Error ?
Para las comparaciones, nos serviremos del coste de Gaxpy seguramente cerca del nuestro.
•
Apunte literario para Cholesky (método Gaxpy)
En la literatura1, se encuentra una versión optimizada del algoritmo de Cholesky para
matriz con banda.
función gaxpy.m:
function G=gaxpy(a,p)
% descomposicion de Cholesky (version Gaxpy)
% a: matriz positive cuadrada simétrica
% p: ancha de la banda
[n,m]=size(a);
if n~=m error('Matriz no cuadrada.'); end
if sum(sum(a<0,2))~=0 error('Matriz no positiva.'); end
if sum(sum(a~=a',2))~=0' error('Matriz no simetrica.'); end
if p>n error('Ancha de banda inadecuada.'); end
G=zeros(size(a));
for k=1:n
aux=0;
for j=max(1,k-p):k-1
i=min(j+p,n);
a(k:i,k)=a(k:i,k)-a(k,j)*a(k:i,j);
end
i=min(k+p,n);
a(k:i,k)=a(k:i,k)/a(k,k)^.5;
end
G=tril(a);
Coste del algoritmo :
Este versión del algoritmo de Cholesky es también conocida como la de Gaxpy, « hiperoptimizada » para matrices positivas, simétricas y de ancha de banda p.
(
El coste temporal y en flops del algoritmo de Gaxpy es del orden de n p 2 + 3 p
)
1 Gene H.Golub y Charles F.Van Loan.- Matrix Computations 3th edition.- Johns Hopkins
University Press.- Baltimore, Maryland :1996. [BUPV]
-7-
UPV - Computación de Altas Prestaciones - Prácticas 1
•
David Perrin
Método LU optimizado
Principio:
Dada una j - elemento de columna -, después de recorrer j+p los elementos siguientes son
0, par eso limitaremos cada bucle dependiente de j antiguamente:
n
∑…
j+1
De tal forma que tengamos:
min ( j + p , n )
∑
…
j +1
Colocación en la función lup.m:
function [L,U]=lup(a,p)
% descomposicion LU sin pivotacion optimizada
% a: matriz cuadrada
% p: anchura de la tira
[n,m]=size(a);
if n~=m error('Matriz no cuadrada.'); end
flops(0);
for j=1:n
if a(j,j)==0 error('Pivote nulo.'); end
for i=j+1:min(j+p,n)
factor=a(i,j)/a(j,j);
a(i,j)=factor;
for k=j+1:min(j+p,n)
a(i,k)=a(i,k)-factor*a(j,k);
end
end
end
flops
L=tril(a,-1)+eye(n);
U=triu(a);
Coste del algoritmo:
Hablando de operaciones intrínsecas al programa, tenemos el esquema siguiente :
for j=1:n-1
for i=j+1→min(j+p,n)
{1 operacion}
for k=j+1→min(j+p,n)
{2 operaciones}
end
end
end
Aquí, los límites de j son j = {1, n − p, n − p + 1, n} . Como precedente eso da un total de
n− p
flopsLUp = ∑ ( j + p − ( j + 1) + 1) ⋅ 2 +
j =1
2
n
∑ ( n − ( j + 1) + 1)
j = n − p +1
-8-
2
⋅2
UPV - Computación de Altas Prestaciones - Prácticas 1
n− p
También igual a flopsLUp = 2
∑ p2 +
j =1
David Perrin
n
∑ (n − j)
2
j = n − p +1
Introduciendo J = n − j , tenemos flopsLUp = 2 ( n − p ) p 2 +
p +1
Y como
∑J
p +1
2
≈
J =1
∫
J 2 ⋅ dJ =
( p + 1)
3
∑J
J =1
2
−1
3
1
Entonces al final flopsLUp ≈ 2 p + p 2 ⋅ ( n + 1) −
O sea un coste del orden de 2np 2
•
p +1
2 p3
3
Apunte literario para LU
En la literatura2, se encuentra una versión optimizada de la descomposición LU.
función lupq.m :
function [L,U]=lupq(a,p,q)
% descomposicion LU sin pivotacion optimizada
% a: matriz cuadrada
% p: anchura de la tira sup
% q: anchura de la tira sup
[n,m]=size(a);
if n~=m error('Matriz no cuadrada.'); end
flops(0);
for j=1:n-1
if a(j,j)==0 error('Pivote nulo.'); end
for i=j+1:min(j+p,n)
a(i,j)=a(i,j)/a(j,j);
end
for k=j+1:min(j+q,n)
for i=j+1:min(j+p,n)
a(i,k)=a(i,k)-a(i,j)*a(j,k);
end
end
end
flops
L=tril(a,-1)+eye(n);
U=triu(a);
Coste del algoritmo :
Este versión del algoritmo de LU permite la descomposición de matrices teniendo un
p y n q.
ancho de banda superior p y un ancho de banda inferior q, tal que n
El coste temporal y en flops de este algoritmo es del orden de 2npq .
Nota:
Fíjase que si p=q, encontramos bien el coste del algoritmo LU anterior:
2np 2
2 Gene H.Golub y Charles F.Van Loan.- Matrix Computations 3th edition.- Johns Hopkins
University Press.- Baltimore, Maryland :1996. [BUPV]
-9-
UPV - Computación de Altas Prestaciones - Prácticas 1
•
David Perrin
Órdenes de costes de flops téoricos
Tabla recapitulativa :
flops
LU
Cholesky
original
2n 3
3
n3
3
optimizado
2np 2
∼ n ( p2 + 3 p )
apunte
2npq
n ( p2 + 3 p )
Gráfico de evoluciones:
flops
coste en flop (matriz pentadiagonal)
400
350
300
250
200
150
100
50
n
0
3
4
5
Lu
6
7
8
Lup
9
10
11
Chol
12
13
14
Cholp
15
Observaciones:
Para una matriz pentadiagonal, es decir p=2, la ventaja del método Cholesky optimizado
no se nota. Eso se encontrará cuando tengamos:
flopsLUp > flopsCholp o sea 2np 2 > n ( p 2 + 3 p ) , siendo aún p 2 − 3 p > 0 equivalente a p > 3
Entonces, para una matriz simétrica y positiva, de ancho de banda superior a 3,
tendremos una ventaja para utilizar el método Cholesky optimizado.
Nota:
para p=3 y para cualquier n, tenemos flopsLUp = flopsCholp (para A simétrica y positiva...)
- 10 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
b) Aplica los algoritmos a la resolución del sistema obtenido calculando la
matriz de coeficientes con la función A=Penta(50) y el término
independiente con la función b=crea_b(A)
Nota:
•
Para resolver los sistemas triangulares Ly=b, y Ux=y puedes utilizar el operador ‘\’ (ver help slash)
(Ejemplo: Ly=b se resolvería con el comando y=L\b)
Resolución de sistema
Operaciones que realizar:
Cholesky
LU
Ax = b
Ax = b
(G ∗ G ) x = b
( L ∗U ) x = b
y = G \ b
t
x = G \ y
y = L \ b∗
x = U \ y
t
*con una matriz P: y = L \ Pb
Programa de “arranque”
Para cada algoritmo, Matlab efectuará varios ensayos (aquí 10) para estimar la media
del coste en tiempo CPU con la función tic y toc. Por eso utilizaremos un programa de
“arranque”.
Sea el programa siguiente con n el tamaño de la matriz pentadiagonal y N el numeró de
ensayos que repetir.
Función launch.m:
function [F,T]=launch
% F: flops
% T: tiempo
h = waitbar(0, 'Espera...');
T=[];
N=10;
A=penta(50);
b=crea_b(A);
flops(0);
for i=1:N
tic;
G=chol_(A);
y=G\b;
x=G'\y;
if i==1
F=flops;
end
T(i)=toc;
waitbar(i/10)
end
close(h);
T=mean(T);
%[L,U]=lu_(A)
%y=L\b
%x=U\y
- 11 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Tabla de los costes de flops y temporal:
flops
LU
Cholesky
Matlab
16323 flops
48125 flops
0.0010 s
0.0030 s
91050 flops
50725 flops
0.2574 s
0.1011 s
8477 flops
11558 flops
0.0060 s
0.0500 s
8574 flops
5934 flops
0.0060 s
0.0060 s
prácticas
optimizado
apunte
Nota:
(
)
el error produce con Cholesky o Gaxpy es tal que G ∗ G t − A ∼ eps (con eps=1e-15).
- 12 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
c) Compara el coste temporal y en flops de los algoritmos modificados con el
coste de los originales, para tamaños de matriz de 16x16 a 128x128 en
incrementos de tamaño 16, creadas también utilizando la funcion Penta.
Nota:
•
En la presentación de resultados se deberán incluir los listados de los dos algoritmos, así como una
tabla en la que aparezca para cada algoritmo el número de flops y el coste temporal del mismo en
cada uno de los casos. Se valorarán especialmente las conclusiones que se extraigan de las
ejecuciones propuestas.
Método directos, costes relativo al tamaño
Introducción:
Construyo un programa efectuando una media del coste temporal. Como precedente,
cada algoritmo para cada tamaño sera calculado N veces.
Función tabla.m:
function T=tabla
h = waitbar(0,'Espera...');
T=[];
N=5;
Tlu=0; Tlu_=0; Tlup=0; Tlupq=0;
Tch=0; Tch_=0; Tchp=0; Tchgx=0;
for i=16:16:128
A=penta(i);
for j=1:N
flops(0);
tic;
lu(A);
if j==1 Flu=flops; end
Tlu=Tlu+toc/N;
flops(0);
tic;
lu_(A);
if j==1 Flu_=flops; end
Tlu_=Tlu_+toc/N;
flops(0);
lup(A,2);
if j==1 Flup=flops; end
Tlup=Tlup+toc/N;
flops(0);
tic;
lupq(A,2,2);
if j==1 Flupq=flops; end
Tlupq=Tlupq+toc/N;
flops(0);
tic;
chol(A);
if j==1 Fch=flops; end
Tch=Tch+toc/N;
flops(0);
tic;
chol_(A);
if j==1 Fch_=flops; end
Tch_=Tch_+toc/N;
- 13 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
flops(0);
tic;
cholp(A,2);
if j==1 Fchp=flops; end
Tchp=Tchp+toc/N;
flops(0);
tic;
gaxpy(A,2);
if j==1 Fchgx=flops; end
Tchgx=Tchgx+toc/N;
waitbar(i*j/(128*N));
end
T=[T;i Flu Tlu Flu_ Tlu_ Flup Tlup Flupq Tlupq Fch Tch Fch_ Tch_ Fchp
Tchp Fchgx Tchgx];
end
close(h);
save data.txt T -ASCII -double -tabs;
- 14 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Tablas de los resultados:
LU
n
16
32
48
64
80
96
112
128
Matlab
flops
seg
598
0,000
2478
0,000
5638
0,000
10078
0,002
15798
0,002
22798
0,002
31078
0,002
40638
0,006
Practicas
flops
seg
2992
0,016
22880
0,088
76048
0,332
178880
0,905
347760
2,007
599072
3,915
949200
7,359
1414528
14,451
n
16
32
48
64
80
96
112
128
Matlab
flops
seg
1496
0,002
11440
0,002
38024
0,002
89440
0,002
173880
0,002
299536
0,004
474600
0,006
707264
0,010
Practicas
flops
seg
1784
0,006
12528
0,032
40424
0,124
93664
0,331
180440
0,739
308944
1,422
487368
2,746
723904
5,226
Optimizado
flops
seg
489
0,016
1513
0,090
3049
0,338
5097
0,915
7657
2,025
10729
3,942
14313
7,395
18409
14,513
Aparte
flops
seg
518
0,004
1574
0,012
3142
0,014
5222
0,022
7814
0,028
10918
0,038
14534
0,050
18662
0,072
Cholesky
Optimizado
flops
seg
918
0,004
2902
0,010
5910
0,014
9942
0,024
14998
0,034
21078
0,044
28182
0,060
36310
0,088
Aparte
flops
224
464
704
944
1184
1424
1664
1904
seg
0,000
0,000
0,006
0,006
0,010
0,020
0,038
0,058
Graficós:
coste flops (matriz pentadiagonal, n=16,128)
flops
coste sec (matriz pentadiagonal, n=16,128)
s
140000
2,000
1,800
120000
1,600
100000
1,400
80000
1,200
1,000
60000
0,800
40000
0,600
0,400
20000
n
0
0,200
n
0,000
16
Lu_
32
48
Lup
64
Chol_
80
96
Cholp
112
128
Gaxpy
16
Lu_
32
48
Lup
64
80
Chol_
96
112
Cholp
128
Gaxpy
Observaciones:
Al nivel del coste en flops encontramos casi los aspectos de los tiempos téoricos vistos en
la parte anterior.
Fíjese, aún que el coste en flops del método LU optimizado es menos que el del método
original, su coste temporal en segundas es casi lo mismo... A lo mejor, son los pasos de
comparaciones en los bucles for en la función lup.m. Excepto eso, los costes temporales
siguen bastante bien los aspectos de los costes en flops corespondientes.
- 15 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Ejercicio 3
Las matrices de Hilbert son un tipo de matrices cuadradas mal condicionadas que se
suelen utilizar como benchmarks para algoritmos de resolución de sistemas. [ref
Kincaid]. En Matlab podemos obtener la matriz de Hilbert de dimensión n con el
comando hilb(n).
a) Utiliza el algoritmo de descomposición L-U que has implementado, para
resolver sistemas de ecuaciones que tengan como matriz de coeficientes
matrices de Hilbert (desde hilb(5) a hilb(13) ), y como vector de términos
independientes el generado por la función crea_b, aplicada sobre la matriz
de coeficientes correspondiente.
Nota:
•
Para resolver los sistemas triangulares Ly=b, y Ux=y puedes utilizar el operador ‘\’ (ver help slash)
(Ejemplo: Ly=b se resolvería con el comando y=L\b)
Matrices de Hilbert
Introducción:
El programa siguiente va a construir una matriz H de Hilbert y efectuar Hx = b con x
construido a partir de b y tal que normalmente x = {1,… ,1} , lo llamaremos I (aquí I es un
vector). La salida será una tabla dando el número de condiciones de la matriz H y
también una evaluación del error ε obtenido. Por eso, elegiremos el peor error elemento
del vector solución tal que ε = max I − x . Este función es norm(I-x,inf) con Matlab.
(
)
∞
Función test_hilb:
function T=test_hilb
% T: resultados: tamaño, cond y error
format short e;
T=[];
for i=5:13
H=hilb(i);
b=crea_b(H);
I=ones(i,1);
[L,U]=lu_(H);
y=L\b;
x=U\y;
T=[T; i cond(H) norm(I-x,inf)]
end
save data.txt T -ASCII -double -tabs;
- 16 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
b) Calcula el número de condición de cada una de las matrices de Hilbert,
utilizando el comando cond, y relaciona estos datos con la exactitud de las
soluciones de los sistemas que has resuelto, teniendo en cuenta la
información del punto 4.2.3 de la unidad temática 4. Para cuantificar la
exactitud de cada una de las soluciones puedes calcular el error absoluto de
la solución obtenida, utilizando la norma∞ , que en Matlab se puede obtener
con el comando norm(x,inf). (Ver help norm).
Nota:
•
En la memoria se deberá presentar un resumen tabulado de los datos obtenidos, así como los
comentarios que cada grupo considere pertinentes.
Número de condición
Introducción:
La función precedente da el fichero data.txt contenido los resultados de los números de
condición.
Tabla recapitulativa:
n
5
6
7
8
9
10
11
12
13
cond
476607,25
14951058,64
475367356,28
15257575253,67
493153214118,79
16025336322027,10
521838915546882,00
17680654104131500,00
3682277791113050000,00
norma
2,591E-12
4,254E-10
1,522E-08
9,222E-07
1,875E-05
3,012E-04
2,598E-03
8,180E-01
9,681
Observaciones:
La función cond() da un número de condiciones de la matriz tal que cond(H)=norm(H)*
norm(inv(H)). Eso significa que la matriz de Hilbert tiene una capacidad de invertirse
mal (ó incapacidad...), el resultado es directamente ligado al tamaño n de H. Al final con
n=13 el vector solución contenido un elemento 10,3455 es decir con relación a la solución
inicial (ó sea 1) ¡ un error de 968 % !
los valores de cond() siguen una evolución exponencial respecto al tamaño de H.
cond
evolucion cond(H)
1,00E+20
1,00E+18
1,00E+16
1,00E+14
1,00E+12
1,00E+10
1,00E+08
1,00E+06
1,00E+04
1,00E+02
n
1,00E+00
5
6
7
8
- 17 -
9
10
11
12
13
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Ejercicio 4
Una técnica iterativa para resolver un sistema lineal Ax = b donde A es una matriz de
0
orden n × n , empieza con una aproximación inicial x ( ) a la solución x, y genera una
sucesión de vectores
{ x( ) }
k
k = 0…∞
de la cual se espera que converja a x. La mayoría de
estas técnicas iterativas involucran un proceso que convierte el sistema Ax = b en un
sistema equivalente de la forma x = M ⋅ x + v para alguna matriz M de orden n × n y un
0
vector v. Una vez seleccionado el vector inicial x ( ) la sucesión de vectores de solución
aproximadas se genera calculando:
x
(k )
= M ⋅x
( k −1)
M = I − C −1 ⋅ A
+ v , siendo
−1
v = C ⋅ b
donde A es la matriz de coeficientes y b el término independiente. Según la elección de la
matriz C se obtiene un método iterativo particular.
a) Implementa el algoritmo de Gauss-Seidel en forma escalar que se describe a
continuación.
•
Métodos iterativos, generalidades
Entradas/salidas métodos iterativos:
Para cada método iterativo, tendrémos siempre como parámetros de entradas:
- La matriz de coeficientes A ∈
n× n
, A( i ,i ) ≠ 0 i = {1,… , n}
- El vector de términos independientes b ∈
- La solución inicial x0 ∈
n
n
- La tolerancia tol
- El número máximo de iteraciones iter.
Y como parámetros de salidas:
- La solución x
- El valor del error err
- El valor de iter
Criterio de parada:
Como criterio de parada de los algoritmos, utilicé el error absoluto, sea ε = x (
k +1)
− x(
k)
∞
.
Pero, para facilitar lo que seguirá, vamos a crear una función para todos los algoritmos
iterativos. Así, en la parte siguiente, elegiremos el criterio de parada cambiando esta
función construída con el mando switch.
- 18 -
UPV - Computación de Altas Prestaciones - Prácticas 1
Función criterr.m:
function err=criterr(x,x0,metodo)
% criterio de error
switch metodo
case 'absoluto', err=norm(x-x0,inf);
case 'relativo', err=norm(x-x0,inf)/norm(x,inf);
otherwise err=norm(x-x0);
end
•
Método de Gauss-Seidel (nivel escalar)
función Gseidel_s:
function [x,err,k]=Gseidel_s(A,b,x0,tol,iter)
% Método iterativo, Gauss-Seidel escalar
% A: Matriz de coeficientes
% b: Vector de terminos
% x0: solucion inicial
% tol: tolerancia
% iter: numero de iteraciones
[n,m]=size(A);
if n~=m error('Matriz no cuadrada.'); end
k=0;
condi=0;
while (condi==0 & k<iter)
for i=1:n
if A(i,i)==0 error('A(i,i)=0'); end
aux=0;
for j=1:i-1
aux=aux+A(i,j)*x(j);
end
for j=i+1:n
aux=aux+A(i,j)*x0(j);
end
x(i)=(b(i)-aux)/A(i,i);
end
err=criterr(x,x0,'absoluto');
if err<tol condi=1;
else
k=k+1;
x0=x;
end
end
- 19 -
David Perrin
UPV - Computación de Altas Prestaciones - Prácticas 1
•
Método de Jacobi (nivel escalar)
Función Jacobi_s.m:
function [x,err,k]=Jacobi_s(A,b,x0,tol,iter)
% Método iterativo, Jacobi escalar
% A: Matriz de coeficientes
% b: Vector de terminos
% x0: solucion inicial
% tol: tolerancia
% iter: numero de iteraciones
[n,m]=size(A);
if n~=m error('Matriz no cuadrada.'); end
k=0;
condi=0;
while (condi==0 & k<iter)
for i=1:n
if A(i,i)==0 error('A(i,i)=0'); end
aux=0;
for j=1:i-1
aux=aux+A(i,j)*x0(j);
end
for j=i+1:n
aux=aux+A(i,j)*x0(j);
end
x(i)=(b(i)-aux)/A(i,i);
end
err=criterr(x,x0,'absoluto');
if err<tol condi=1;
else
k=k+1;
x0=x;
end
end
- 20 -
David Perrin
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
b) Implementa el algoritmo de Gauss-Seidel en forma matricial, dado a
continuación.
•
Método de Gauss-Seidel (nivel matricial)
función Gseidel_M:
function [x,err,k]=Gseidel_M(A,b,x0,tol,iter)
% Método iterativo, Gauss-Seidel matricial
% A: Matriz de coeficientes
% b: Vector de terminos
% x0: solucion inicial
% tol: tolerancia
% iter: numero de iteraciones
[n,m]=size(A);
if n~=m error('Matriz no cuadrada.'); end
k=0;
condi=0;
while (condi==0 & k<iter)
aux=-(triu(A,1))*x0+b;
x=tril(A)\aux;
err=criterr(x,x0,'absoluto');
if err<tol condi=1;
else
k=k+1;
x0=x;
end
end
•
Método de Jacobi (nivel matricial)
function [x,err,k]=Jacobi_M(A,b,x0,tol,iter)
% Método iterativo, Jacobi matricial
% A: Matriz de coeficientes
% b: Vector de terminos
% x0: solucion inicial
% tol: tolerancia
% iter: numero de iteraciones
[n,m]=size(A);
if n~=m error('Matriz no cuadrada.'); end
k=0;
condi=0;
while (condi==0 & k<iter)
D=diag(diag(A));
aux=-(A-D)*x0+b;
x=D\aux;
err=criterr(x,x0,'absoluto');
if err<tol condi=1;
else
k=k+1;
x0=x;
end
end
- 21 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
c) Compara el coste temporal y el número de flops de los algoritmos, para
tamaños de la matriz de coeficientes variando desde 16x16 hasta 128x128, en
incrementos de tamaño 16. Para ello crea los sistemas utilizando las
funciones diagdomi y crea_b.
Nota:
En la memoria se deberán incluir los listados de los algoritmos, así como una tabla con los
resultados obtenidos, que deberá incluir los valores calculados de número de iteraciones, tiempo,
número de flops y error relativo, para cada uno de los algoritmos en cada uno de los casos. El error
relativo se deberá calcular de la siguiente manera:
x( k +1) − x ( k )
x
•
(k )
∞
∞
Métodos iterativos, costes relativo al tamaño
Introducción:
El programa que se construirá será casi lo mismo que el precedente. Además como antes,
para cada algoritmo y cada tamaño sera calculado N ensayos.
En este parte, cogeremos los parámetros de entrada siguientes:
- tol=1e-4
- iter=50
- x(0)={2,...,2}.
- 22 -
UPV - Computación de Altas Prestaciones - Prácticas 1
Función tabla_.m:
function T=tabla_
format short e;
h=waitbar(0,'Espera...');
T=[];
N=3;
FGs=0; TGs=0; FGM=0; TGM=0; FJs=0; TJs=0; FJM=0; TJM=0;
EGs=0; kGs=0; EGM=0; kGM=0; EJs=0; kJs=0; EJM=0; kJM=0;
tol=1e-4;
iter=50;
for i=16:16:128
A=diagdomi(i);
b=crea_b(A);
x0=ones(i,1)+1;
for j=1:N
flops(0);
tic;
[x,EGs,kGs]=Gseidel_s(A,b,x0',tol,iter);
if j==1 FGs=flops; end
TGs=TGs+toc/N;
flops(0);
tic;
[x,EGM,kGM]=Gseidel_M(A,b,x0,tol,iter);
if j==1 FGM=flops; end
TGM=TGM+toc/N;
flops(0);
tic;
[x,EJs,kJs]=Jacobi_s(A,b,x0',tol,iter);
if j==1 FJs=flops; end
TJs=TJs+toc/N;
flops(0);
tic;
[x,EJM,kJM]=Jacobi_M(A,b,x0,tol,iter);
if j==1 FJM=flops; end
TJM=TJM+toc/N;
waitbar(i*j/(128*N));
end
T=[T;i FGs TGs EGs kGs FGM TGM EGM kGM
FJs TJs EJs kJs FJM TJM EJM kJM];
end
close(h);
save data.txt T -ASCII -double -tabs;
- 23 -
David Perrin
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Tablas de los resultados:
Gauss-Seidel
escalar
matricial
n
flops
sec
error
iter
flops
sec
error
iter
16
3933
15021
33277
58701
91293
131053
177981
232077
0,0200
0,0767
0,1800
0,3600
0,6237
1,0543
1,6053
2,3463
4,88E-05
5,13E-05
5,24E-05
5,30E-05
5,33E-05
5,36E-05
5,38E-05
5,39E-05
6
6
6
6
6
6
6
6
5837
22413
49741
87821
136653
196237
266573
347661
0,0000
0,0000
0,0067
0,0133
0,0367
0,0533
0,0800
0,1367
4,88E-05
5,13E-05
5,24E-05
5,30E-05
5,33E-05
5,36E-05
5,38E-05
5,39E-05
6
6
6
6
6
6
6
6
32
48
64
80
96
112
128
Jacobi
escalar
matricial
n
flops
sec
error
iter
flops
sec
error
iter
16
12925
55795
128357
226421
365175
524215
711927
928311
0,0503
0,2373
0,6443
1,3753
2,4870
4,6670
6,8033
9,7207
9,80E-05
8,08E-05
8,01E-05
9,78E-05
7,51E-05
8,15E-05
8,65E-05
9,04E-05
22
25
26
26
27
27
27
27
25069
109875
254069
449333
725815
1042999
1417527
1849399
0,0033
0,0067
0,0303
0,0707
0,1407
0,2473
0,3907
0,6247
9,80E-05
8,08E-05
8,01E-05
9,78E-05
7,51E-05
8,15E-05
8,65E-05
9,04E-05
22
25
26
26
27
27
27
27
32
48
64
80
96
112
128
Graficós:
flops
s
coste flops (err=1e-4, n=16,128)
2,E+06
11
2,E+06
10
2,E+06
9
1,E+06
8
coste temporal (err=1e-4, n=16,128)
7
1,E+06
6
1,E+06
5
8,E+05
4
6,E+05
3
4,E+05
2
2,E+05
n
0,E+00
1
n
0
16
32
48
Gauss escalar
Jacobi escalar
64
80
96
112
128
Gauss matricial
Jacobi matricial
16
32
48
Gauss escalar
Jacobi escalar
64
80
96
112
128
Gauss matricial
Jacobi matricial
Observaciones:
La teoría se verifica muy bien. Se nota que los métodos iterativos a nivel matricial son
muy eficientes con relación a los a nivel escalar. Además, aún que el coste en flops sea
importante (se nota bien con Jacobi matricial por ejemplo), su coste temporal es mucho
mejor que los métodos escalares. Al final, encontramos bien las relaciones entre estos
métodos. Es decir lo que hemos visto en la parte teórica, hablando de la potencia de estos
métodos, y con la condición de convergencia, tenemos:
Gauss-Seidel Matricial > Jacobi Matricial > Gauss-Seidel escalar > Jacobi escalar
- 24 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Ejercicio 5
a) Averigua para qué tamaño de un sistema comienza a ser más adecuado el
uso de un método iterativo en comparación con un método directo. Para ello
resuelve los sistemas de ecuaciones generados en el ejercicio 4 utilizando el
algoritmo de resolución de sistemas que implementaste en el Ejercicio 3, y
calcula el coste temporal y en flops.
•
Comparacion costes métodos directos y iterativos
Introducción:
El programa siguiente es lo mismo que los precedentes. Genera una tabla T en el fichero
data.txt, contenido los resultados.
función comp.m:
function comp;
% comparación costes flops
% métodos diretos o iterativos
% ti: tamaño inicial
% tf: tamaño final
format short e;
h = waitbar(0,'Espera...');
ti=1;
tf=50;
N=3;
tol=1e-6;
iter=500;
T=[];
Flu_=0; Tlu_=0; Fch_=0; Tch_=0;
FGs=0; TGs=0; FGM=0; TGM=0;
FJs=0; TJs=0; FJM=0; TJM=0;
for i=ti:tf
for j=1:N
A=diagdomi(i);
b=crea_b(A);
x0=zeros(i,1);
flops(0);
tic;
[L,U]=lu_(A);
y=L\b;
x=U\y;
if j==1 Flu_=flops; end
Tlu_=Tlu_+toc/N;
flops(0);
tic;
G=chol_(A);
y=G\b;
x=G'\y;
if j==1 Fch_=flops; end
Tch_=Tch_+toc/N;
- 25 -
UPV - Computación de Altas Prestaciones - Prácticas 1
flops(0);
tic;
G=Gseidel_s(A,b,x0',tol,iter);
if j==1 FGs=flops; end
TGs=TGs+toc/N;
flops(0);
tic;
G=Jacobi_s(A,b,x0',tol,iter);
if j==1 FJs=flops; end
TJs=TJs+toc/N;
flops(0);
tic;
G=Gseidel_M(A,b,x0,tol,iter);
if j==1 FGM=flops; end
TGM=TGM+toc/N;
flops(0);
tic;
G=Jacobi_M(A,b,x0,tol,iter);
if j==1 FJM=flops; end
TJM=TJM+toc/N;
waitbar(i*j/((tf-ti)*N),h)
end
T=[T;i Flu_ Tlu_ Fch_ Tch_ FGs TGs FJs TJs FGM TGM FJM TJM];
end
close(h);
save data.txt T -ASCII -DOUBLE -tabs;
- 26 -
David Perrin
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Tabla recapitulativa:
Directos
Lu
n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
flops
4
26
58
108
180
278
406
568
768
1010
1298
1636
2028
2478
2990
3568
4216
4938
5738
6620
7588
8646
9798
11048
12400
13858
15426
17108
18908
20830
22878
25056
27368
29818
32410
35148
38036
41078
44278
47640
51168
54866
58738
62788
67020
71438
76046
80848
85848
91050
seg
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,003
0,010
0,013
0,017
0,023
0,033
0,040
0,050
0,063
0,087
0,107
0,130
0,164
0,194
0,230
0,274
0,320
0,380
0,441
0,507
0,584
0,668
0,761
0,864
1,138
1,442
1,770
2,144
2,555
3,019
3,493
3,980
4,548
5,176
5,817
6,498
7,269
8,083
8,958
9,866
10,811
11,818
12,899
Chol
flops
seg
6
0,000
29
0,000
59
0,000
102
0,000
160
0,000
235
0,000
329
0,007
444
0,010
582
0,010
745
0,017
935
0,020
1154
0,027
1404
0,030
1687
0,040
2005
0,043
2360
0,053
2754
0,060
3189
0,067
3667
0,083
4190
0,090
4760
0,110
5379
0,127
6049
0,147
6772
0,164
7550
0,184
8385
0,204
9279
0,234
10234 0,261
11252 0,294
12335 0,334
13485 0,384
14704 0,491
15994 0,621
17357 0,761
18795 0,915
20310 1,095
21904 1,272
23579 1,476
25337 1,702
27180 1,912
29110 2,136
31129 2,383
33239 2,660
35442 2,947
37740 3,257
40135 3,561
42629 3,905
45224 4,272
47922 4,667
50725 5,064
Iterativos escalar
Gauss Seidel
Jacobi
flops
seg
flops
seg
13
0,000
13
0,000
127
0,000
207
0,003
231
0,003
492
0,010
367
0,003
965
0,020
602
0,010
1540
0,027
827
0,017
2299
0,037
1088 0,020
3266
0,057
1385 0,020
4311
0,084
1718 0,027
5538
0,110
2087 0,033
6959
0,140
2492 0,040
8586
0,174
2933 0,050 10105
0,207
3410 0,067 12127
0,250
3923 0,084 14387
0,301
4472 0,104 16400
0,364
5057 0,124 19107
0,431
5678 0,147 21453
0,501
6335 0,177 23935
0,571
7028 0,200 27334
0,664
7757 0,227 30169
0,764
8522 0,254 33144
0,877
9323 0,284 36259
1,001
10160 0,318 40643
1,134
11033 0,361 44135
1,281
11942 0,401 47771
1,445
12887 0,448 51551
1,612
13868 0,494 55475
1,785
14885 0,541 61197
1,985
15938 0,584 65526
2,199
17027 0,641 70003
2,429
18152 0,695 74628
2,676
19313 0,875 79401
3,330
20510 1,058 84322
4,071
21743 1,248 89391
4,796
23012 1,435 97165
5,630
24317 1,656 102675
6,508
25658 1,859 108337
7,453
27035 2,086 114151
8,411
28448 2,341 120117
9,392
29897 2,595 126235 10,433
31382 2,858 132505 11,618
32903 3,132 138927 12,777
34460 3,402 145501 13,985
36053 3,693 152227 15,277
37682 4,020 159105 16,553
39347 4,344 166135 17,894
41048 4,704 177878 19,350
42785 5,058 185405 20,888
44558 5,412 193088 22,450
46367 5,802 200927 24,043
- 27 -
Iterativos Matricial
Gauss Seidel
Jacobi
flops
seg
flops
seg
11
0,000
13
0,000
175
0,007
337
0,000
327
0,007
849
0,000
527
0,007
1721
0,003
872
0,007
2805
0,007
1205
0,007
4249
0,013
1592
0,007
6101
0,013
2033
0,007
8119
0,013
2528
0,007
10497
0,020
3077
0,007
13259
0,023
3680
0,007
16429
0,033
4337
0,010
19405
0,037
5048
0,010
23359
0,037
5813
0,010
27785
0,047
6632
0,010
31745
0,050
7505
0,010
37059
0,057
8432
0,010
41683
0,070
9413
0,010
46579
0,084
10448 0,010
53269
0,084
11537 0,010
58869
0,090
12680 0,013
64749
0,097
13877 0,023
70909
0,104
15128 0,023
79559
0,104
16433 0,023
86471
0,107
17792 0,023
93671
0,117
19205 0,027 101159 0,124
20672 0,027 108935 0,134
22193 0,027 120249 0,141
23768 0,027 128833 0,147
25397 0,030 137713 0,154
27080 0,037 146889 0,161
28817 0,040 156361 0,191
30608 0,043 166129 0,217
32453 0,053 176193 0,254
34352 0,053 191595 0,287
36305 0,053 202539 0,314
38312 0,057 213787 0,361
40373 0,060 225339 0,394
42488 0,063 237195 0,427
44657 0,070 249355 0,474
46880 0,073 261819 0,517
49157 0,077 274587 0,551
51488 0,080 287659 0,597
53873 0,087 301035 0,657
56312 0,100 314715 0,711
58805 0,117 328699 0,757
61352 0,117 352013 0,824
63953 0,124 366989 0,871
66608 0,137 382277 0,941
69317 0,144 397877 0,985
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Grafico comparativo del coste en flops:
flops
comparacion coste flops (e=1e-6)
14000,00
12000,00
10000,00
Directos Lu
Directos Cholesky
Iterativos escalar Gauss Seidel
Iterativos escalar Jacobi
Iterativos Matricial Gauss Seidel
Iterativos Matricial Jacobi
8000,00
6000,00
4000,00
2000,00
n
0,00
n
1
2
3
4
5
6
7
8
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
Grafico comparativo del coste temporal:
seg
comparacion coste temporal (e=1e-6)
0,40
0,35
0,30
0,25
Directos Lu
Directos Chol
Iterativos escalar Gauss Seidel
Iterativos escalar Jacobi
Iterativos Matricial Gauss Seidel
Iterativos Matricial Jacobi
0,20
0,15
0,10
0,05
n
0,00
n 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
- 28 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
Gráfico comparativo del nivel de potencia:
En este gráfico, representamos un nivel de potencia tal que:
y ( x) =
tseg
flops
(es decir el tiempo necesitado para una operación)
Eso permite la comparación con el coste temporal y el coste en flops conjuntos. El
principio de este análisis no permite una contestación con el tema de un método
específico. Pero a partir de n=10, los costes (sobre todo temporal) se estabilizan.
Así, los métodos baratos en tiempo a pesar de sus números de flops (el menos
significativo para Matlab) se notan. Los métodos matriciales, Jacobi o Gauss-Seidel, son
muy eficientes porque su nivel de potencia se va hacia cero, es decir un conjunto de tipo:
tseg ∼ 0
flops → ∞
Los otros métodos se parcen muy parejos, a partir de n=30, se nota un cambio de aspecto.
seg/flops
comparacion coste temporal (e=1e-6)
1,40E-04
1,20E-04
Directos Lu
Directos Cholesky
Iterativos escalar Gauss Seidel
Iterativos escalar Jacobi
Iterativos matricial Gauss Seidel
Iterativos matricial Jacobi
1,00E-04
8,00E-05
6,00E-05
4,00E-05
2,00E-05
n
0,00E+00
n
1
2
3
4
5
6
7
8
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
- 29 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
b) Compara estos costes con los que has obtenido utilizando los métodos de
Gauss-Seidel a nivel escalar y matricial (Ejercicio 4) e indica a partir de qué
dimensión de las matrices comienzan a ser más eficientes cada uno de estos
métodos.
Nota:
•
Se deberá incluir una tabla con los resultados para cada uno de los algoritmos variando el tamaño
de la matriz (tiempo y número de flops), junto con una explicación de los resultados obtenidos y las
representaciones gráficas que se necesiten.
Deteción de la potencia del coste temporal
Introducción:
Para comparar los costes temporales de los métodos directos y iterativos al nivel de las
dimensiones de las matrices entradas, construímos un programa comparando el coste en
segundos entre un método de LU y un de Jacobi Matricial. Lo haremos después con
Cholesky a plaza de LU. El principio es aumentar la dimensión de las matrices y
comparar el coste temporal (estadistico, con N ensayos).
Por supuesto la salida sera i tal que tdirecto > titerativo , este programa supone que sepamos
que al inicio tdirecto < titerativo .
Por fin, el resultado que saldrá de este programa no es un valor fijado, porque el coste de
un método iterativo es función del nivel de precisión y de la solución inicial. Por eso,
como precedemente, eligiremos una solución inicial nula y un nivel de precisión de 1E-6.
Nota:
El coste temporal es más significativo que el coste en flops para la elección de un método de
resolución de sistemas de ecuaciones lineales. Además Matlab esta optimizado para operaciones
matriciales (MATrix LABoratory...)..
función comp_.m:
function i=comp_;
% comparación costes toc/N
% métodos diretos o iterativos
format short e;
h=waitbar(0,'Espera...');
tol=1e-6; iter=500;
i=1; imax=50; N=20;
Td=0; Ti=0;
while (Td<=Ti & i<imax)
for j=1:N
A=diagdomi(i);
b=crea_b(A);
x0=zeros(i,1);
tic;
[L,U]=lu_(A);
y=L\b;
x=U\y;
Td=Td+toc/N;
% G=chol_(A);
% y=G\b;
% x=G'\y;
- 30 -
UPV - Computación de Altas Prestaciones - Prácticas 1
David Perrin
tic;
G=Jacobi_M(A,b,x0,tol,iter);
Ti=Ti+toc/N;
end
i=i+1;
waitbar(i*j/(imax*N))
end
close(h);
Resultados:
El mando >>comp_ da los resultados siguientes
Jacobi Matricial
Nota:
O sea,
t LU > t Jacobi ( M )
para n=16 y
LU
Cholesky
n=16
n=22
tCholesky > t Jacobi ( M )
para n=22. Estos resultados se notan muy
bien con el gráfico de los costes temporales precedentes. Es decir con el gráfico siguiente:
seg
comparacion coste temporal (e=1e-6)
0,14
0,12
0,10
tjacobi>tCholesky
0,08
0,06
tjacobi>tLU
0,04
0,02
n
0,00
n
1
2
3
4
Directos Lu
5
6
7
8
9
10 11 12 13 14 15 16 17 18 19 20 21 22
Directos Cholesky
Iterativos Matricial Jacobi
Observaciones:
Es muy dificil de concluir sobre el tema del mejor método para la resolución de sistems
de ecuaciones lineales. En verdad, esta comparación depende del ordenador utilizado
pero sobre todo del nivel de tolerancia pedido y de la solución inicial.
Nota:
Todos los ensayos han sido efectuados en un portatil Duron 1200 MHz y 128 Mo de ram.
- 31 -