Acrobat PDF: Reconocimiento de texto OCR:
10/12/10
A veces nos encontramos con un documento en PDF, por ejemplo, que nos aparece como
una imagen y lo queremos convertir a un documento PDF “editable”.
En este caso, necesitamos como primer paso, hacer un “Reconocimiento de texto (OCR)”,
para así poder editar este documento.
El Reconocimiento de texto (OCR = Reconocimiento Óptico de Caracteres): Es una
aplicación dirigida a la digitalización de textos. El OCR identifica automáticamente símbolos
o caracteres que pertenecen a un determinado alfabeto, a partir de una imagen para
almacenarla en forma de datos con los que podremos interactuar mediante un programa de
edición de texto o similar.
Para reconocer un PDF sin OCR, seleccionaremos una parte del texto. Al intentar
seleccionar los diferentes caracteres no nos deja hacerlo individualmente, sino tal y como
aparece en la imagen de abajo (nos selecciona un fragmento de la imagen).
| Servicio TIC - Ext. 4042 |
Acrobat PDF: Reconocimiento de texto OCR:
10/12/10
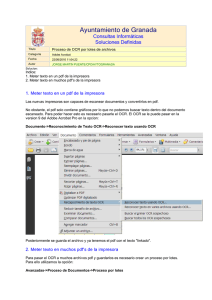
Para empezar, iremos a Documento – Reconocimiento de texto OCR - Reconocimiento
texto usando OCR.
El programa nos muestra una ventana dónde podemos escoger el número de páginas
donde queremos imputar el reconocimiento de texto.
En este manual escogemos atribuir el reconocimiento OCR a todas las páginas del
documento.
Podemos editar las características de la configuración si lo deseamos.
| Servicio TIC - Ext. 4042 |
Acrobat PDF: Reconocimiento de texto OCR:
10/12/10
Elegimos el lenguaje del texto, para que la aplicación identifique automáticamente los
símbolos y caracteres propios del idioma y los almacene en forma de datos.
Adobe Acrobat tardará un rato en hacer el proceso (dependiendo del número de páginas,
resolución del documento…).
Una vez terminado podemos comprobar que el texto del documento es seleccionable y por
tanto editable.
Finalmente, guardaremos el documento de nuevo en una ubicación conocida.
| Servicio TIC - Ext. 4042 |
 0
0