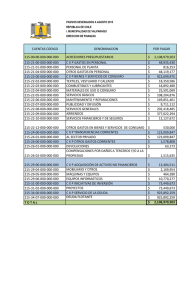
Instrucciones y Registros del procesador Intel(R) Core(TM) i5 450M
Anuncio
 Core(TM) i5 450M")
Tecnológico de Estudios Superiores de Jocotitlán Instrucciones y Registros del procesador Intel(R) Core(TM) i5 450M Autores: -Adelina Hernández Torres -Luis Angel Hermenegildo D. Arquitectura de Computadoras Contenido INTRODUCCIÓN ............................................................................................................................. 4 OBJETIVOS ..................................................................................................................................... 4 Intel® Core™ i5-450M Processor (3M cache, 2.40 GHz) ...................................................... 4 Nombre del procesador: i5-450M .............................................................................................. 4 Fecha de lanzamiento: Q2'10 .................................................................................................... 4 Marca: Intel® Core™ .................................................................................................................. 4 Máximo de memoria: 8 Gb ......................................................................................................... 4 Niveles de cache: 3 Mb .............................................................................................................. 4 Velocidad: 2.40 GHz ................................................................................................................... 4 Tipo de socket: PGA988............................................................................................................. 4 Datos (I/O) (FSB): 2500 MHz ..................................................................................................... 4 DMI: 2.5 GT/s .............................................................................................................................. 4 Tipo de memoria: DDR3-800/1066 ............................................................................................ 4 1. Instrucciones MMX ™ ............................................................................................................. 8 1.2 MMX Instrucciones de transferencia de datos ...................................................................... 8 1.3 Operaciones de conversión MMX ......................................................................................... 8 1.4 MMX Instrucciones aritméticas Almuerzos ........................................................................... 9 1.5 MMX Operaciones de comparación ...................................................................................... 9 1.6 Instrucciones lógicas MMX ................................................................................................ 10 1.7 MMX de desplazamiento y rotación ................................................................................... 10 2. Instrucciones SSE.................................................................................................................. 11 2.1 SSE SIMD de precisión simple operaciones en coma flotante .............................................. 11 2.2 ESE Instrucciones de transferencia de datos ....................................................................... 11 2.3 INSTRUCCIONES SET RESUMEN .......................................................................................... 11 2.4 ESE Instrucciones aritméticas pic ........................................................................................ 12 2.5 ESE Operaciones de comparación ....................................................................................... 13 2.6 ESE Instrucciones lógicas .................................................................................................... 13 2.3 INSTRUCCIONES SET RESUMEN .............................................................................................. 13 2.4 SSE aleatoria e Instrucciones Descomprimir........................................................................ 13 2.5 Operaciones de conversión SSE .......................................................................................... 14 2.6 SSE MXCSR instrucciones de administración de estado ....................................................... 14 2.7 SSE 64 bits enteros SIMD instrucciones............................................................................... 14 2.6 SSE Control de almacenamiento en caché , Prefetch , e Instrucción Instrucciones para Ordenar .................................................................................................................................................... 15 2.9 SSE SIMD de precisión simple operaciones en coma flotante .................................................. 16 2.9.1 ESE Instrucciones de transferencia de datos .................................................................... 16 2.10 INSTRUCCIONES SET RESUMEN ............................................................................................ 17 2.10.1 ESE Instrucciones aritméticas pic ....................................................................................... 17 2.10.2 ESE Operaciones de comparación ...................................................................................... 18 2.10.3 ESE Instrucciones lógicas ................................................................................................... 18 2.11 INSTRUCCIONES SET RESUMEN ............................................................................................ 18 2.11.1 Operaciones de conversión SSE ......................................................................................... 19 2.11.2 SSE MXCSR instrucciones de administración de estado ...................................................... 19 2.11.3 SSE 64 bits enteros SIMD instrucciones.............................................................................. 20 2.12 Instrucciones SSE2 ................................................................................................................ 21 2.12.1 SSE2 Bolsas y Scalar doble precisión operaciones en coma flotante ................................... 21 2.12.2 SSE2 Instrucciones de transferencia de datos .................................................................... 21 2.13 INSTRUCCIONES SET RESUMEN ............................................................................................ 22 2.13.1 SSE2 Instrucciones aritméticas Almuerzos ......................................................................... 22 2.13.2 SSE2 Instrucciones lógicas ................................................................................................. 23 2.13.4 SSE2 Instrucciones de comparación ................................................................................... 23 2.13.5 SSE2 aleatoria e Instrucciones Descomprimir..................................................................... 23 2.14 INSTRUCCIONES SET RESUMEN ............................................................................................ 23 2.14.1 SSE2 Operaciones de conversión ....................................................................................... 24 2.14.6 SSE2 Embalado precisión simple operaciones en coma flotante ......................................... 25 2.14.7 SSE2 de 128 bits SIMD enteros Instrucciones ..................................................................... 25 2.14.8 SSE2 Control de almacenamiento en caché y las instrucciones de pedido .......................... 26 2.15 SSE3 INSTRUCCIONES ........................................................................................................... 26 2.15.1 SSE3 x87 -FP Integer Instrucción de conversión ................................................................. 27 2.15.2 SSE3 Especializada datos Unaligned 128 bits de instrucciones de carga ............................. 27 2.15.3 SSE3 SIMD en coma flotante Almuerzos para ADD / Instrucciones SUB .............................. 27 2.15.4 SSE3 SIMD en coma flotante ADD horizontales / Instrucciones SUB ................................... 27 2.15.5 SSE3 SIMD en coma flotante LOAD / MOVE / Instrucciones DUPLICADO ............................ 28 2.15.6 Agente instrucciones SSE3 sincronización .......................................................................... 28 2.16 COMPLEMENTARIOS Extensiones Streaming SIMD 3 ( SSSE3 ) INSTRUCCIONES .................... 28 2.16.1 Horizontal suma / resta ..................................................................................................... 29 2.16.2 Valores absolutos pic ......................................................................................................... 30 2.16.3 multiplicar y sumar Almuerzos Bytes signo y sin signo ....................................................... 30 2.16.4 Embalado Multiply alta con la Ronda y Escala .................................................................... 30 2.16.5 Bytes aleatoria pic ............................................................................................................. 30 2.16.6 Packed Entrar .................................................................................................................... 31 2.16.7 Packed Alinear a la derecha ............................................................................................... 31 2.18 instrucciones SSE4 ................................................................................................................ 31 2.20 SSE4.1 INSTRUCCIONES ........................................................................................................ 32 2.20.1 Dword Instrucciones Multiplicar ........................................................................................ 32 2.20.2 coma flotante Dot Product Instructions ............................................................................. 32 2.20.3 Carga Streaming Instrucción Sugerencia ............................................................................ 32 2.20.4 Instrucciones de fusión pic ................................................................................................ 33 2.20.5 Bolsas enteros Instrucciones MIN / MAX ........................................................................... 33 2.20.6 Instrucciones Ronda de punto flotante con el modo de redondeo seleccionable ............... 33 2.20.7 Inserción y Extracciones de XMM Registros ....................................................................... 34 2.20.8 Bolsas Conversiones formato entero ................................................................................. 34 2.20.9 La mejora de las sumas de las diferencias absolutas ( SAD ) para bloques de 4 bytes ......... 35 2.20.10 Horizontal Buscar ............................................................................................................ 35 2.20.11 Prueba Packed................................................................................................................. 36 2.20.13 DWORD Embalaje Con Saturación Unsigned .................................................................... 36 2.21 SSE4.2 del conjunto de instrucciones .................................................................................... 36 2.21.1 cuerdas y texto Instrucciones de procesamiento ............................................................... 36 DISTRIBUCION DE REGISTROS ...................................................................................................... 38 Registros de propósito general ........................................................................................ 38 El registro EIP y el EFLAGS ............................................................................................................ 39 CONCLUSIONES............................................................................................................................ 40 INTRODUCCIÓN En el presente documento de dará a conocer más acerca del procesador Core i5 540-M. De cierta manera se verá lo que son sus registros y sus instrucciones que maneja dicho procesador. Un registro es la memoria donde se procesa toda información (CPU), de tal manera que en esta se encuentra lo que es un registro de segmento, de punteros y de uso general. Dentro del registro de segmento esta; el registro CS, registro DS, registro SS, registro ES y registro FS, GS. Una instrucción es una serie de pasos a seguir, esto para que la información o alguna operación aritmética o lógica sean procesadas correctamente. Dependiendo de qué tipo de procesador se esta manejando. OBJETIVOS Llevar a cabo una buena información Obtener buenos resultados Conocer más acerca del procesador que estamos utilizando Intel® Core™ i5-450M (3M cache, 2.40 GHz) Nombre del procesador: i5-450M Fecha de lanzamiento: Q2'10 Marca: Intel® Core™ Máximo de memoria: 8 Gb Niveles de cache: 3 Mb Velocidad: 2.40 GHz Tipo de socket: PGA988 Datos (I/O) (FSB): 2500 MHz DMI: 2.5 GT/s Tipo de memoria: DDR3-800/1066 Processor Essentials Estado EOIS Fecha de lanzamiento Q2'10 Número de procesador i5-450M Cantidad de núcleos 2 Cantidad de subprocesos 4 Veloc. reloj 2.4 GHz Frecuencia turbo máxima 2.66 GHz Caché inteligente Intel® 3 MB DMI 2.5 GT/s Conjunto de instrucciones 64-bit Extensiones instrucciones de conjunto Opciones integradas disponibles de SSE4.1, SSE4.2 No Litografía 32 nm Máximo de TDP 35 W Precio de cliente recomendado N/A Memory Specifications Tamaño de memoria máximo 8 GB (depende del tipo de memoria) Tipo de memoria DDR3-800/1066 Cantidad de canales de memoria 2 Máximo de ancho de banda de 17,1 GB/s memoria Extensiones de dirección física Compatible con memoria ECC ‡ Graphics Specifications 36-bit No Gráficos del procesador ‡ Intel® HD Graphics Frecuencia de base de gráficos Frecuencia gráficos dinámica máxima 500 MHz de 766 MHz Intel® Flexible Display Interface Yes Tecnología Intel® Clear Video HD Yes Licencia Macrovision* requerida No Nº de pantallas admitidas ‡ 2 Expansion Options Revisión de PCI Express 2.0 Configuraciones de PCI Express ‡ 1x16 Cantidad Express 16 máxima de líneas PCI Package Specifications Máximo de configuración de CPU 1 TJUNCTION 105°C Tamaño de paquete rPGA 37.5mmx 37.5mm, BGA 34mmx28mm Tamaño de chip de procesamiento 81 mm2 Cantidad de transistores de chip de 382 million procesador Litografía de IMC y gráficos 45 nm Tamaño de chip de IMC y gráficos 114 mm2 Cantidad de transistores de chip y 177 million gráficos Zócalos compatibles Baja concentración disponibles PGA988 de halógenos Ver MDDS Advanced Technologies Versión de la tecnología Intel® Turbo Yes Boost ‡ Tecnología Intel® vPro ‡ No Tecnología Hyper-Threading Intel® ‡ Yes Tecnología de virtualización Intel® (VT-x) ‡ Yes Tecnología de virtualización Intel® para E/S dirigida (VT-d) ‡ No Intel® VT-x con tablas de páginas extendidas (EPT) ‡ Yes Intel® 64 ‡ Yes Estados de inactividad Tecnología mejorada Intel Yes SpeedStep® Yes Tecnologías de monitoreo térmico Yes Acceso a memoria rápida Intel® Yes Intel® Flex Memory Access Yes Intel® Data Protection Technology Nuevas instrucciones de AES No Intel® Platform Protection Technology Tecnología Intel® Trusted Execution Bit de desactivación de ejecución ‡ ‡ No Yes 1. Instrucciones MMX ™ Cuatro extensiones se han introducido en la arquitectura IA - 32 para permitir que los procesadores IA - 32 para llevar a cabo singleinstruction ( SIMD ) las operaciones de datos múltiples. Estas extensiones incluyen la tecnología MMX, extensiones SSE , SSE2 extensiones y extensiones SSE3 . Para una discusión que pone instrucciones SIMD en su contexto histórico , ver Sección 2.2.7 , "Instrucciones SIMD . " Instrucciones MMX operan sobre lleno byte , palabra, palabra doble o quadword operandos enteros contenidos en la memoria , en registros MMX , y / o en registros de propósito general . Para más detalles sobre estas instrucciones , consulte el Capítulo 9 , "Programación con la tecnología Intel ® MMX ™ . " Instrucciones MMX sólo se pueden ejecutar en el procesador Intel 64 y IA- 32 que soportan la tecnología MMX . apoyar de estas instrucciones se pueden detectar con la instrucción CPUID . Ver la descripción de la instrucción CPUID en Capítulo 3 , " Instruction Set Reference, AM , " del Intel ® 64 e IA- 32 Arquitecturas de Software del desarrollador Manual , Volumen 2A . Instrucciones MMX se dividen en los siguientes subgrupos : transferencia de datos , la conversión , la aritmética envasados , comparación , lógica , desplazamiento y rotación , y las instrucciones de administración de estado . Las secciones que siguen presentan cada subgrupo . 1.2 MMX Instrucciones de transferencia de datos Las instrucciones de transferencia de datos se mueven doble palabra y palabra cuádruple operandos entre registros MMX y entre MMX Registros y memoria. MOVD Move doubleword MOVQ Move quadword 1.3 Operaciones de conversión MMX El paquete de instrucciones de conversión y desempaquetar bytes , palabras y palabras dobles PACKSSWB Paquete palabras en bytes con saturación firmado PACKSSDW Paquete palabras dobles en palabras con saturación firmado INSTRUCCIONES SET RESUMEN PACKUSWB Paquete palabras en bytes con signo de saturación . PUNPCKHBW Desembale bytes de orden superior PUNPCKHWD Desembale palabras de orden PUNPCKHDQ Desembale palabras dobles de alto orden PUNPCKLBW Desembale bytes de orden inferior PUNPCKLWD Desembale palabras de orden inferior PUNPCKLDQ Desembale palabras dobles de bajo orden 1.4 MMX Instrucciones aritméticas Almuerzos Las instrucciones aritméticas envasados realizan lleno aritmética de enteros en el byte lleno , la palabra y doble palabra enteros . PADDB Añadir byte enteros envasados PADDW Agregar enteros llenos de palabras PADDD Agregar enteros envasados doble palabra PADDSB Añadir envasada enteros de byte con saturación firmado PADDSW Añadir lleno enteros palabra firmados con saturación firmado PADDUSB Añadir envasados enteros byte sin signo con la saturación sin signo PADDUSW Agregar enteros sin signo de palabras llenas de saturación sin signo PSUBB Restar enteros lleno byte PSUBW Restar enteros lleno de palabras PSUBD Restar enteros lleno doble palabra PSUBSB Restar envasada enteros de byte con saturación firmado PSUBSW Restar enteros lleno de palabras firmados con saturación firmado PSUBUSB Restar enteros lleno de bytes sin signo con la saturación sin signo PSUBUSW Restar enteros lleno de palabras sin signo con signo saturación PMULHW Multiplicar enteros llenos de palabras firmados y alta almacenar el resultado PMULLW Multiplicar enteros llenos de palabras firmados y almacenar el resultado bajo PMADDWD multiplicar y sumar enteros llenos de palabras 1.5 MMX Operaciones de comparación Las instrucciones de comparación comparan bytes envasados , palabras o palabras dobles . PCMPEQB Comparar bytes envasados para la igualdad PCMPEQW Comparar palabras envasados para la igualdad PCMPEQD Comparar palabras dobles envasados para la igualdad PCMPGTB Comparar enteros envasados byte firmado por más de PCMPGTW Comparar enteros llenos de palabras firmadas por más de PCMPGTD Comparar enteros envasados doble palabra firmados por más de 1.6 Instrucciones lógicas MMX Las instrucciones lógicas realizar AND y NOT , OR, XOR y operaciones en operandos de palabra cuádruple . PAND bit a bit AND lógico PANDN bit a bit lógica AND NOT POR bit a bit OR lógico PXOR lógica OR exclusiva bit a bit Vol. . en 5 a 13 INSTRUCCIONES SET RESUMEN 1.7 MMX de desplazamiento y rotación El desplazamiento y rotación de desplazamiento y rotación bytes envasados , palabras o palabras dobles o quadwords en 64 bits operandos . PSLLW Shift palabras llenas dejaron lógica PSLLD Shift palabras dobles llenas dejaron lógica PSLLQ Shift lleno quadword dejó lógica PSRLW Shift lleno palabras correctas lógica Shift PSRLD embalado palabras dobles razón lógica PSRLQ Shift lleno quadword derecho lógica PSRAW Shift palabras lleno aritmético a la derecha PSRAD Shift lleno palabras dobles aritmético a la derecha 5.4.7 MMX instrucciones de administración de estado La instrucción EMMS borra el estado de los registros MMX MMX . Estado MMX vacío EMMS 2. Instrucciones SSE Instrucciones SSE representan una extensión del modelo de ejecución SIMD introducido con la tecnología MMX . para más detalles sobre estas instrucciones , consulte el Capítulo 10 , " Programación con extensiones Streaming SIMD ( SSE) . " Instrucciones SSE sólo se pueden ejecutar en el procesador Intel 64 y IA- 32 que soportan las extensiones SSE . Apoyo a estas instrucciones se pueden detectar con la instrucción CPUID . Ver la descripción de la instrucción CPUID en Capítulo 3 , " Instruction Set Reference, AM , " del Intel ® 64 e IA- 32 Arquitecturas de Software del desarrollador Manual , Volumen 2A . Instrucciones SSE se dividen en cuatro subgrupos ( tenga en cuenta que el primer subgrupo tiene subgrupos subordinados de su propia ) : • SIMD de precisión simple instrucciones de coma flotante que operan en el XMM registra • Instrucciones de manejo del estado MXSCR • Las instrucciones de 64 bits SIMD enteras que operan en los registros MMX Instrucciones de pedido • Control de almacenamiento en caché , prefetch , y la instrucción Las siguientes secciones proporcionan una visión general de estos grupos. 2.1 SSE SIMD de precisión simple operaciones en coma flotante Estas instrucciones operan sobre envasado y los valores de punto flotante de precisión sencilla escalares ubicados en registros XMM y / o de la memoria . Este subgrupo se subdivide en los siguientes subgrupos subordinados : transferencia de datos, empaquetados aritmética , comparación , lógicos , aleatoria y desempacar, y las instrucciones de conversión. 2.2 ESE Instrucciones de transferencia de datos Instrucciones de transferencia de datos ESE mueven para llevar y escalares de precisión simple operandos de coma flotante entre XMM registros y entre registros XMM y memoria. MOVAPS Mover cuatro alineados valores de punto flotante de precisión sencilla empaquetadas entre registros XMM o entre y XMM registro y la memoria MOVUPS Mover cuatro valores de precisión simple de punto flotante lleno alineados entre registros XMM o entre y XMM registro y la memoria 5-14 vol . 1 2.3 INSTRUCCIONES SET RESUMEN MOVHPS Mover dos valores de punto flotante de precisión simple llenos a una de la alta palabra cuádruple de un XMM registro y la memoria MOVHLPS Mover dos valores de punto flotante de precisión simple llenas de la alta quadword de XMM registrarse para el bajo palabra cuádruple de otro registro XMM MOVLPS Mover dos valores de punto flotante de precisión simple llenos a una baja de la palabra cuádruple de un XMM registro y la memoria MOVLHPS Mover dos valores de punto flotante de precisión simple para llevar en el bajo palabra cuádruple de XMM registrarse para el alto quadword de otro registro XMM MOVMSKPS Extracto máscara de señal de cuatro valores de punto flotante de precisión simple envasados MOVSS Move escalar de precisión simple valor de punto flotante entre registros XMM o entre un XMM registro y la memoria 2.4 ESE Instrucciones aritméticas pic SSE instrucciones aritméticas envasados realizan para llevar y operaciones aritméticas escalares de lleno y singleprecision escalar operandos de coma flotante . ADDPS Agregar valores de punto flotante de precisión sencilla empaquetadas ADDSS Agregar valores de punto flotante de precisión simple escalar SUBPS Restar los valores de punto flotante de precisión sencilla empaquetadas SUBSS Resta simple precisión valores de punto flotante escalares MULPS valores de punto flotante de precisión simple Multiply envasados MULSS Multiplicar los valores de punto flotante de precisión simple escalar DIVPS Divide los valores de punto flotante de precisión sencilla empaquetadas DIVSS Divide los valores de punto flotante de precisión simple escalar RCPPS Calcular recíprocos de los valores de punto flotante de precisión simple envasados RCPSS Calcular recíproco de los valores de precisión simple de punto flotante escalares SQRTPS calcular raíces cuadradas de los valores de punto flotante de precisión simple envasados SQRTSS Calcular la raíz cuadrada de precisión simple valores de punto flotante escalares RSQRTPS Calcular recíprocos de las raíces cuadradas de los valores de punto flotante de precisión simple envasados RSQRTSS Calcular recíproco de la raíz cuadrada de precisión simple valores de punto flotante escalares MAXPS máximo retorno lleno valores de punto flotante de precisión simple MAXSS Retorno de precisión simple máximos valores escalares de punto flotante MINPS Volver valores mínimos lleno de precisión simple de punto flotante MINSS Retorno de precisión simple valores mínimos escalares de punto flotante 2.5 ESE Operaciones de comparación SSE Instrucciones de comparación comparan embalado y escalares de precisión simple operandos de coma flotante. CMPPS Compara los valores de punto flotante de precisión sencilla empaquetadas CMPSS Compara los valores de punto flotante de precisión simple escalar COMISS Realizar comparación ordenada de simple precisión valores de punto flotante escalares y establecer indicadores de EFLAGS registro UCOMISS Realizar desordenada comparación de los valores de precisión simple de punto flotante escalares y establecer indicadores de EFLAGS registro 2.6 ESE Instrucciones lógicas Instrucciones lógicas realizan SSE bit a bit AND, AND NOT, OR, XOR y las operaciones de envasado de precisión simple operandos de coma flotante . ANDPS asigna el operador AND lógico de los valores de punto flotante de precisión simple envasados Vol. . 5 a 15 en 2.3 INSTRUCCIONES SET RESUMEN ANDNPS asigna el operador lógico AND NOT de valores de punto flotante de precisión sencilla empaquetadas Orps Realizar valores de punto flotante lógicas bit a bit OR de envasados de precisión simple XORPS Realiza bitwise XOR lógico de los valores de punto flotante de precisión simple envasados 2.4 SSE aleatoria e Instrucciones Descomprimir SSE barajar y descomprimir instrucciones aleatoria o valores de punto flotante de precisión simple intercalación en singleprecision embalado operandos de coma flotante . SHUFPS Shuffles valores repleto de precisión simple de punto flotante operandos Desempaqueta UNPCKHPS y entrelaza los dos valores de orden superior de dos de un solo punto flotante de precisión operandos Desempaqueta UNPCKLPS y entrelaza los dos valores de orden inferior de dos de un solo punto flotante de precisión operandos 2.5 Operaciones de conversión SSE Instrucciones de conversión ESE convertir enteros dobles palabras llenas e individual en lleno y single precision escalar valores de punto flotante y viceversa. CVTPI2PS Convertir enteros dobles palabras llenas de valores de punto flotante de precisión sencilla empaquetadas CVTSI2SS Convertir entero doble palabra a escalar de precisión simple valor de punto flotante CVTPS2PI convertir los valores de precisión simple de punto flotante a enteros envasados doble palabra envasados CVTTPS2PI convertir con truncamiento embalado valores de punto flotante de precisión simple a doble palabra llena enteros CVTSS2SI Convertir un escalar de precisión simple valor de punto flotante a un entero doble palabra CVTTSS2SI convertir con truncamiento un escalar de precisión simple valor de punto flotante a una doble palabra escalares entero 2.6 SSE MXCSR instrucciones de administración de estado MXCSR instrucciones de administración de estado permiten guardar y restaurar el estado del control MXCSR y estado registrarse. LDMXCSR carga MXCSR registro STMXCSR Guardar MXCSR estado registro 2.7 SSE 64 bits enteros SIMD instrucciones Estos SSE 64 bits instrucciones de enteros SIMD realizar operaciones adicionales en bytes envasados , palabras o palabras dobles contenida en los registros MMX. Representan mejoras en el conjunto de instrucciones MMX descrito en la sección 5.4 , "Instrucciones MMX ™. " PAVGB Compute promedio de envasados enteros byte sin signo PAVGW Calcular la media de los enteros sin signo lleno de palabras PEXTRW palabra Extract PINSRW Insertar palabra PMAXUB máximo de envasados enteros byte sin signo PMAXSW máximo de enteros con signo llenos PMINUB mínimo de envasados enteros byte sin signo PMINSW mínimo de enteros con signo llenos PMOVMSKB máscara de byte Move PMULHUW Multiplicar enteros sin signo para llevar y almacenar gran resultado 5-16 vol . 1 INSTRUCCIONES SET RESUMEN PSADBW Calcular suma de diferencias absolutas PSHUFW aleatoria lleno palabra entera en MMX registro 2.6 SSE Control de almacenamiento en caché , Prefetch , e Instrucción Instrucciones para Ordenar Las instrucciones de control de almacenamiento en caché proporcionan control sobre el almacenamiento en caché de datos que no son temporales al almacenar los datos de el MMX y XMM registra en la memoria. El PREFETCHh permite que los datos sean prefetched a un nivel de caché seleccionado . la Instrucción SFENCE controla la instrucción al comprar en las operaciones de almacén . MASKMOVQ tiendas no -temporal de bytes seleccionados de un MMX registra en la memoria MOVNTQ tiendas no -temporal de palabra cuádruple de un MMX registra en la memoria MOVNTPS tiendas no -temporal de los cuatro valores de punto flotante de precisión simple para llevar un registro de XMM en la memoria PREFETCHh cargar 32 o más bytes de memoria a un nivel seleccionado de la jerarquía de memoria caché del procesador SFENCE Serializa operaciones de la tienda instrucciones SSE Instrucciones SSE representan una extensión del modelo de ejecución SIMD introducido con la tecnología MMX . para más detalles sobre estas instrucciones , consulte el Capítulo 10 , " Programación con extensiones Streaming SIMD ( SSE) . " Instrucciones SSE sólo se pueden ejecutar en el procesador Intel 64 y IA- 32 que soportan las extensiones SSE . Apoyo a estas instrucciones se pueden detectar con la instrucción CPUID . Ver la descripción de la instrucción CPUID en Capítulo 3 , " Instruction Set Reference, AM , " del Intel ® 64 e IA- 32 Arquitecturas de Software del desarrollador Manual , Volumen 2A . Instrucciones SSE se dividen en cuatro subgrupos ( tenga en cuenta que el primer subgrupo tiene subgrupos subordinados de su propia ) : • SIMD de precisión simple instrucciones de coma flotante que operan en el XMM registra • Instrucciones de manejo del estado MXSCR • Las instrucciones de 64 bits SIMD enteras que operan en los registros MMX Instrucciones de pedido • Control de almacenamiento en caché , prefetch , y la instrucción Las siguientes secciones proporcionan una visión general de estos grupos. 2.9 SSE SIMD de precisión simple operaciones en coma flotante Estas instrucciones operan sobre envasado y los valores de punto flotante de precisión sencilla escalares ubicados en registros XMM y / o de la memoria . Este subgrupo se subdivide en los siguientes subgrupos subordinados : transferencia de datos, empaquetados aritmética , comparación , lógicos , aleatoria y desempacar, y las instrucciones de conversión. 2.9.1 ESE Instrucciones de transferencia de datos Instrucciones de transferencia de datos ESE mueven para llevar y escalares de precisión simple operandos de coma flotante entre XMM registros y entre registros XMM y memoria. MOVAPS Mover cuatro alineados valores de punto flotante de precisión sencilla empaquetadas entre registros XMM o entre y XMM registro y la memoria MOVUPS Mover cuatro valores de precisión simple de punto flotante lleno alineados entre registros XMM o entre y XMM registro y la memoria 5-14 vol . 1 2.10 INSTRUCCIONES SET RESUMEN MOVHPS Mover dos valores de punto flotante de precisión simple llenos a una de la alta palabra cuádruple de un XMM registro y la memoria MOVHLPS Mover dos valores de punto flotante de precisión simple llenas de la alta quadword de XMM registrarse para el bajo palabra cuádruple de otro registro XMM MOVLPS Mover dos valores de punto flotante de precisión simple llenos a una baja de la palabra cuádruple de un XMM registro y la memoria MOVLHPS Mover dos valores de punto flotante de precisión simple para llevar en el bajo palabra cuádruple de XMM registrarse para el alto quadword de otro registro XMM MOVMSKPS Extracto máscara de señal de cuatro valores de punto flotante de precisión simple envasados MOVSS Move escalar de precisión simple valor de punto flotante entre registros XMM o entre un XMM registro y la memoria 2.10.1 ESE Instrucciones aritméticas pic SSE instrucciones aritméticas envasados realizan para llevar y operaciones aritméticas escalares de lleno y singleprecision escalar operandos de coma flotante . ADDPS Agregar valores de punto flotante de precisión sencilla empaquetadas ADDSS Agregar valores de punto flotante de precisión simple escalar SUBPS Restar los valores de punto flotante de precisión sencilla empaquetadas SUBSS Resta simple precisión valores de punto flotante escalares MULPS valores de punto flotante de precisión simple Multiply envasados MULSS Multiplicar los valores de punto flotante de precisión simple escalar DIVPS Divide los valores de punto flotante de precisión sencilla empaquetadas DIVSS Divide los valores de punto flotante de precisión simple escalar RCPPS Calcular recíprocos de los valores de punto flotante de precisión simple envasados RCPSS Calcular recíproco de los valores de precisión simple de punto flotante escalares SQRTPS calcular raíces cuadradas de los valores de punto flotante de precisión simple envasados SQRTSS Calcular la raíz cuadrada de precisión simple valores de punto flotante escalares RSQRTPS Calcular recíprocos de las raíces cuadradas de los valores de punto flotante de precisión simple envasados RSQRTSS Calcular recíproco de la raíz cuadrada de precisión simple valores de punto flotante escalares MAXPS máximo retorno lleno valores de punto flotante de precisión simple MAXSS Retorno de precisión simple máximos valores escalares de punto flotante MINPS Volver valores mínimos lleno de precisión simple de punto flotante MINSS Retorno de precisión simple valores mínimos escalares de punto flotante 2.10.2 ESE Operaciones de comparación SSE Instrucciones de comparación comparan embalado y escalares de precisión simple operandos de coma flotante. CMPPS Compara los valores de punto flotante de precisión sencilla empaquetadas CMPSS Compara los valores de punto flotante de precisión simple escalar COMISS Realizar comparación ordenada de simple precisión valores de punto flotante escalares y establecer indicadores de EFLAGS registro UCOMISS Realizar desordenada comparación de los valores de precisión simple de punto flotante escalares y establecer indicadores de EFLAGS registro 2.10.3 ESE Instrucciones lógicas Instrucciones lógicas realizan SSE bit a bit AND, AND NOT, OR, XOR y las operaciones de envasado de precisión simple operandos de coma flotante . ANDPS asigna el operador AND lógico de los valores de punto flotante de precisión simple envasados Vol. . 5 a 15 en 2.11 INSTRUCCIONES SET RESUMEN ANDNPS asigna el operador lógico AND NOT de valores de punto flotante de precisión sencilla empaquetadas Orps Realizar valores de punto flotante lógicas bit a bit OR de envasados de precisión simple XORPS Realiza bitwise XOR lógico de los valores de punto flotante de precisión simple envasados 5.5.1.5 SSE aleatoria e Instrucciones Descomprimir SSE barajar y descomprimir instrucciones aleatoria o valores de punto flotante de precisión simple intercalación en singleprecision embalado operandos de coma flotante . SHUFPS Shuffles valores repleto de precisión simple de punto flotante operandos Desempaqueta UNPCKHPS y entrelaza los dos valores de orden superior de dos de un solo punto flotante de precisión operandos Desempaqueta UNPCKLPS y entrelaza los dos valores de orden inferior de dos de un solo punto flotante de precisión operandos 2.11.1 Operaciones de conversión SSE Instrucciones de conversión ESE convertir enteros dobles palabras llenas e individual en lleno y singleprecision escalar valores de punto flotante y viceversa. CVTPI2PS Convertir enteros dobles palabras llenas de valores de punto flotante de precisión sencilla empaquetadas CVTSI2SS Convertir entero doble palabra a escalar de precisión simple valor de punto flotante CVTPS2PI convertir los valores de precisión simple de punto flotante a enteros envasados doble palabra envasados CVTTPS2PI convertir con truncamiento embalado valores de punto flotante de precisión simple a doble palabra llena enteros CVTSS2SI Convertir un escalar de precisión simple valor de punto flotante a un entero doble palabra CVTTSS2SI convertir con truncamiento un escalar de precisión simple valor de punto flotante a una doble palabra escalares entero 2.11.2 SSE MXCSR instrucciones de administración de estado MXCSR instrucciones de administración de estado permiten guardar y restaurar el estado del control MXCSR y estado registrarse. LDMXCSR carga MXCSR registro STMXCSR Guardar MXCSR estado registro 2.11.3 SSE 64 bits enteros SIMD instrucciones Estos SSE 64 bits instrucciones de enteros SIMD realizar operaciones adicionales en bytes envasados , palabras o palabras dobles contenida en los registros MMX. Representan mejoras en el conjunto de instrucciones MMX descrito en la sección "Instrucciones MMX ™. " PAVGB Compute promedio de envasados enteros byte sin signo PAVGW Calcular la media de los enteros sin signo lleno de palabras PEXTRW palabra Extract PINSRW Insertar palabra PMAXUB máximo de envasados enteros byte sin signo PMAXSW máximo de enteros con signo llenos PMINUB mínimo de envasados enteros byte sin signo PMINSW mínimo de enteros con signo llenos PMOVMSKB máscara de byte Move PMULHUW Multiplicar enteros sin signo para llevar y almacenar gran resultado 5-16 vol . 1 INSTRUCCIONES SET RESUMEN PSADBW Calcular suma de diferencias absolutas PSHUFW aleatoria lleno palabra entera en MMX registro 5.5.4 SSE Control de almacenamiento en caché , Prefetch , e Instrucción Instrucciones para Ordenar Las instrucciones de control de almacenamiento en caché proporcionan control sobre el almacenamiento en caché de datos que no son temporales al almacenar los datos de el MMX y XMM registra en la memoria. El PREFETCHh permite que los datos sean prefetched a un nivel de caché seleccionado . la Instrucción SFENCE controla la instrucción al comprar en las operaciones de almacén . MASKMOVQ tiendas no -temporal de bytes seleccionados de un MMX registra en la memoria MOVNTQ tiendas no -temporal de palabra cuádruple de un MMX registra en la memoria MOVNTPS tiendas no -temporal de los cuatro valores de punto flotante de precisión simple para llevar un registro de XMM en la memoria PREFETCHh cargar 32 o más bytes de memoria a un nivel seleccionado de la jerarquía de memoria caché del procesador SFENCE Serializa operaciones de la tienda 2.12 Instrucciones SSE2 SSE2 extensiones representan una extensión del modelo de ejecución SIMD introducido con la tecnología MMX y la Extensiones SSE. Instrucciones SSE2 operan sobre lleno de doble precisión operandos de punto flotante y el envasado byte , palabra, doble palabra y palabra cuádruple operandos situados en los registros XMM . Para más detalles sobre estas instrucciones, consulte el Capítulo 11 , " Programación con extensiones Streaming SIMD 2 ( SSE2 ) . " Instrucciones SSE2 sólo se pueden ejecutar en el procesador Intel 64 y IA- 32 que soportan las extensiones SSE2. El apoyo a estas instrucciones se puede detectar con la instrucción CPUID . Véase la descripción de la CPUID instrucción en el Capítulo 3, " Instruction Set Reference, mañana, " el Intel ® 64 e IA32 Arquitecturas Software Manual del desarrollador, volumen 2A. Estas instrucciones se dividen en cuatro subgrupos ( tenga en cuenta que el primer subgrupo se divide en subordinadas subgrupos ): • Almuerzos y escalar doble precisión las instrucciones de punto flotante • Las instrucciones de conversión de punto flotante de precisión simple Almuerzos • Las instrucciones de enteros SIMD de 128 bits • almacenamiento en caché de control e instrucción de las indicaciones de pedido Las siguientes secciones proporcionan una visión general de cada subgrupo. 2.12.1 SSE2 Bolsas y Scalar doble precisión operaciones en coma flotante SSE2 envasados y escalar doble precisión las instrucciones de punto flotante se dividen en las siguientes subordinadas subgrupos: el movimiento de datos , cálculo , comparación, conversión, lógica , y las operaciones en orden aleatorio de doble precisión operandos de coma flotante . Estos se introducen en las secciones que siguen. 2.12.2 SSE2 Instrucciones de transferencia de datos Instrucciones SSE2 movimiento de datos se mueven de datos de doble precisión de punto flotante entre registros XMM y entre XMM registros y la memoria. MOVAPD Move dos alinea a lleno valores de punto flotante de doble precisión entre registros XMM o entre y XMM registro y la memoria Move MOVUPD dos valores de doble precisión de punto flotante lleno alineados entre registros XMM o entre y XMM registro y la memoria MOVHPD Move alta precisión doble valor de punto flotante llena a una de la gran palabra cuádruple de un XMM registro y la memoria Vol. . en 5 a 17 2.13 INSTRUCCIONES SET RESUMEN MOVLPD Move precisión simple valor de punto flotante de baja llena a una baja de la palabra cuádruple de XMM registro y la memoria MOVMSKPD máscara de signos Extracto de dos valores de punto flotante de precisión doble empaquetadas MOVSD Move escalar de precisión doble valor de punto flotante entre registros XMM o entre un XMM registro y la memoria 2.13.1 SSE2 Instrucciones aritméticas Almuerzos Las instrucciones aritméticas realizan la suma , resta, multiplicación, división , raíz cuadrada, y el máximo / mínimo operaciones de envasado y escalar doble precisión operandos de coma flotante . ADDPD Agregar valores de punto flotante de precisión doble empaquetadas ADDSD Agregar valores de punto flotante de precisión doble escalares Doble precisión valores de punto flotante SUBPD Restar escalares Doble precisión valores de punto flotante SUBSD Restar escalares Valores de punto flotante de doble precisión MULPD Multiply envasados MULSD Multiplicar doble precisión valores de punto flotante escalares DIVPD Divide los valores de punto flotante de precisión doble empaquetadas Doble precisión valores de punto flotante DIVSD escalares Divide SQRTPD Compute envasados raíces cuadradas de los valores de punto flotante de precisión doble empaquetadas Doble precisión valores de punto flotante SQRTSD Compute escalar raíz cuadrada de escalar Volver máxima MAXPD lleno valores de punto flotante de doble precisión Doble precisión valores de punto flotante MAXSD máxima escalares Volver Valores de punto flotante de doble precisión embalada retorno mínimo MINPD Doble precisión valores de punto flotante MINSD Volver escalares mínimo 2.13.2 SSE2 Instrucciones lógicas Instrucciones SSE2 lógicas preformas AND y NOT , OR, XOR y operaciones en embalados punto flotante de doble precisión valores . ANDPD asigna el operador AND lógico de los valores de punto flotante de precisión doble empaquetadas ANDNPD Realizar valores de punto flotante bit a bit lógica y no de concentrado de doble precisión ORPD asigna el operador lógico OR de valores de punto flotante de precisión doble empaquetadas XORPD Realiza bitwise XOR lógico de los valores de punto flotante de precisión doble empaquetadas 2.13.4 SSE2 Instrucciones de comparación Comparar instrucciones SSE2 comparar lleno y doble precisión valores de punto flotante escalares y devolver el resultados de la comparación ya sea para el operando de destino o a los EFLAGS registran . CMPPD Comparar los valores de punto flotante de precisión doble empaquetadas CMPSD Comparar escalar los valores de punto flotante de doble precisión COMISD Realizar comparación ordenada de doble precisión valores de punto flotante escalares y establecer indicadores de EFLAGS registro UCOMISD Perform desordenada comparación de los valores de doble precisión de punto flotante escalares y establecer indicadores de Registran EFLAGS . 2.13.5 SSE2 aleatoria e Instrucciones Descomprimir Doble precisión valores de punto flotante SSE2 barajar y descomprimir instrucciones aleatoria o intercalado en doubleprecision embalado operandos de coma flotante . 5-18 vol . 1 2.14 INSTRUCCIONES SET RESUMEN SHUFPD valores Shuffles en empaquetado de doble precisión de punto flotante operandos Desempaqueta UNPCKHPD e intercala los altos valores de dos llenas de doble precisión de punto flotante operandos Desempaqueta UNPCKLPD e intercala los valores bajos de dos operandos de doble precisión de punto flotante para llevar 2.14.1 SSE2 Operaciones de conversión Instrucciones SSE2 conversión convertir enteros dobles palabras llenas e individual en lleno y doubleprecision escalar valores de punto flotante y viceversa. También convertir entre lleno y escalar de precisión simple y valores de punto flotante de doble precisión . CVTPD2PI convertir los valores de doble precisión de punto flotante a enteros dobles palabras envasados para llevar. CVTTPD2PI convertir con truncamiento lleno valores de punto flotante de doble precisión de doble palabra llena enteros CVTPI2PD Convertir enteros dobles palabras llenas de valores de punto flotante de precisión doble empaquetadas CVTPD2DQ convertir los valores de doble precisión de punto flotante a enteros envasados doble palabra envasados CVTTPD2DQ convertir con truncamiento lleno valores de punto flotante de doble precisión de doble palabra llena enteros CVTDQ2PD Convertir enteros dobles palabras llenas de valores de punto flotante de precisión doble empaquetadas CVTPS2PD convertir los valores de precisión simple de punto flotante lleno de lleno de doble precisión de punto flotante valores CVTPD2PS convertir los valores de doble precisión de punto flotante lleno de lleno de punto flotante de precisión simple valores CVTSS2SD convertir valores de punto flotante de precisión simple escalar a escalar de doble precisión de punto flotante valores CVTSD2SS Convertir doble precisión de punto flotante valores escalares para escalar de precisión simple de punto flotante valores CVTSD2SI Convertir doble precisión valores de punto flotante escalar a una doble palabra entera CVTTSD2SI convertir con doble precisión valores de punto flotante escalares truncamiento a doubleword escalar enteros CVTSI2SD Convertir entero doble palabra a escalar con precisión doble valor de punto flotante 2.14.6 SSE2 Embalado precisión simple operaciones en coma flotante SSE2 lleno de precisión simple instrucciones de punto flotante realizar operaciones de conversión de precisión simple operandos de punto flotante y entero. Estas instrucciones representan mejoras en precisión simple SSE instrucciones de coma flotante . CVTDQ2PS Convertir enteros dobles palabras llenas de valores de punto flotante de precisión sencilla empaquetadas CVTPS2DQ convertir los valores de precisión simple de punto flotante a enteros envasados doble palabra envasados CVTTPS2DQ convertir con truncamiento embalado valores de punto flotante de precisión simple a doble palabra llena enteros 2.14.7 SSE2 de 128 bits SIMD enteros Instrucciones SSE2 SIMD instrucciones enteras realizar operaciones adicionales en las palabras llenas, palabras dobles y quadwords que figura en el XMM y MMX registros. Movdqa Move alineado doble palabra cuádruple. MOVDQU Mueva doble quadword no alineados MOVQ2DQ Move quadword entero de MMX de XMM registra MOVDQ2Q Move quadword entero de XMM a los registros MMX Vol. . en 5 a 19 INSTRUCCIONES SET RESUMEN PMULUDQ Multiplicar enteros envasados doble palabra sin signo PADDQ Agregar enteros quadword envasados PSUBQ Restar enteros lleno quadword PSHUFLW aleatoria lleno palabras de baja PSHUFHW aleatoria lleno altas palabras Mezclar PSHUFD lleno palabras dobles PSLLDQ Shift doble quadword dejó lógica PSRLDQ Shift doble quadword derecho lógica PUNPCKHQDQ Desembale alta quadwords PUNPCKLQDQ Desembale bajo quadwords 2.14.8 SSE2 Control de almacenamiento en caché y las instrucciones de pedido SSE2 instrucciones de control de almacenamiento en caché proporcionan funciones adicionales para el almacenamiento en caché de datos que no son temporales al almacenar los datos de XMM registra en la memoria. LFENCE y MFENCE proporcionan un control adicional de instrucción de ordenar el operaciones de la tienda. Vacía CLFLUSH e invalida un operando de memoria y su línea de caché asociados de todos los niveles de la jerarquía de caché del procesador LFENCE Serializa las operaciones de carga MFENCE Serializa las operaciones de carga y almacén PAUSA Mejora el rendimiento de "bucles spin- espera" MASKMOVDQU tiendas no -temporal de bytes seleccionados de un registro XMM en la memoria MOVNTPD tiendas no -temporal de dos valores de punto flotante de precisión doble empaquetadas de una XMM registrar en la memoria MOVNTDQ tiendas no -temporal de la doble palabra cuádruple de un registro XMM en la memoria MOVNTI tiendas no -temporal de una doble palabra de un registro de uso general en la memoria 2.15 SSE3 INSTRUCCIONES El SSE3 extensiones ofrece 13 instrucciones que aceleran el rendimiento de la tecnología de las extensiones Streaming SIMD. Streaming SIMD Extensions 2 tecnología y x87 - PF capacidades matemáticas. Estas instrucciones pueden ser agrupadas en las siguientes categorías: • Una instrucción x87FPU utilizado en la conversión de número entero • Un número entero de instrucciones SIMD que aborda cargas de datos no alineados • Dos de punto flotante para llevar instrucciones ADD / SUB SIMD • Cuatro SIMD instrucciones ADD / SUB horizontales de punto flotante • Tres SIMD CARGA punto flotante / mover / DUPLICADO instrucciones • Dos instrucciones de sincronización de subprocesos Instrucciones SSE3 sólo se pueden ejecutar en el procesador Intel 64 y IA- 32 que soportan las extensiones SSE3 . apoyar de estas instrucciones se pueden detectar con la instrucción CPUID . Ver la descripción de la instrucción CPUID en Capítulo 3 , " Instruction Set Reference, AM , " del Intel ® 64 e IA- 32 Arquitecturas de Software del desarrollador Manual , Volumen 2A . Las secciones siguientes describen cada subgrupo . 2.15.1 SSE3 x87 -FP Integer Instrucción de conversión FISTTP comporta como la instrucción FISTP pero utiliza truncamiento, con independencia de la modalidad de redondeo especificado en el código de control de punto flotante ( FCW ) 5-20 vol . 1 INSTRUCCIONES SET RESUMEN 2.15.2 SSE3 Especializada datos Unaligned 128 bits de instrucciones de carga LDDQU especial de carga alineados 128 bits diseñado para evitar la línea de caché se divide 2.15.3 SSE3 SIMD en coma flotante Almuerzos para ADD / Instrucciones SUB ADDSUBPS Realiza además de precisión simple en el segundo y cuarto pares de elementos de datos de 32 bits dentro de los operandos ; precisión simple resta en el primer y tercer pares ADDSUBPD Realiza además de doble precisión en el segundo par de quadwords y doble precisión resta en el primer par 2.15.4 SSE3 SIMD en coma flotante ADD horizontales / Instrucciones SUB HADDPS Realiza una adición simple precisión en los elementos de datos contiguos . El primer elemento de datos de el resultado se obtiene mediante la adición de los primero y segundo elementos de la primera operando ; la segunda elemento mediante la adición de los elementos tercero y cuarto de la primera operando ; el tercero mediante la adición de la elementos primero y segundo del segundo operando , y el cuarto por la adición de la tercera y cuarta elementos del segundo operando . HSUBPS Realiza una precisión simple sustracción de elementos de datos contiguos . El primer elemento de datos de el resultado se obtiene restando el segundo elemento del primer operando de la primera elemento del primer operando , el segundo elemento restando el cuarto elemento de la primera operando desde el tercer elemento del primer operando ; la tercera restando la segunda elemento del segundo operando desde el primer elemento del segundo operando , y el cuarto restando el cuarto elemento del segundo operando desde el tercer elemento de la segunda operando . HADDPD Realiza una suma de doble precisión en los elementos de datos contiguos . El primer elemento de datos de el resultado se obtiene mediante la adición de los primero y segundo elementos de la primera operando ; la segunda elemento mediante la adición de los primero y segundo elementos del segundo operando . HSUBPD Realiza una doble precisión sustracción de elementos de datos contiguos . El primer elemento de datos del resultado se obtiene restando el segundo elemento del primer operando de la primera elemento del primer operando , el segundo elemento restando el segundo elemento de la segundo operando desde el primer elemento del segundo operando . 2.15.5 SSE3 SIMD en coma flotante LOAD / MOVE / Instrucciones DUPLICADO Cargas MOVSHDUP / se mueve 128 bits; duplicación de los segundo y cuarto elementos de datos de 32 bits Cargas MOVSLDUP / se mueve 128 bits; duplicación de los primero y tercer elementos de datos de 32 bits Cargas MOVDDUP / mueve 64 bits (bits [ 63:0 ] Si la fuente es un registro ) y devuelve los mismos 64 bits de ambas las mitades inferior y superior del registro de resultado de 128 bits ; duplica los 64 bits de la fuente 2.15.6 Agente instrucciones SSE3 sincronización MONITOR Establece un rango de direcciones se utiliza para controlar write-back tiendas MWAIT Permite que un procesador lógico para entrar en un estado óptimo a la espera de una tienda de write-back al rango de direcciones definido por la instrucción MONITOR 2.16 COMPLEMENTARIOS Extensiones Streaming SIMD 3 ( SSSE3 ) INSTRUCCIONES SSSE3 proporciona 32 instrucciones ( representado por 14 teclas de acceso ) para acelerar los cálculos de enteros para llevar. Estos incluyen: • Doce instrucciones que realizan además horizontal u operaciones de resta . Vol. . en 5 a 21 INSTRUCCIONES SET RESUMEN • Seis instrucciones que evalúan los valores absolutos . • Dos instrucciones que realizan operaciones de multiplicar y sumar y acelerar la evaluación de los productos de punto . • Dos instrucciones que aceleran las operaciones de multiplicar empaquetado enteros y producen valores enteros con el escalamiento . • Dos instrucciones que realizan un byte a byte , en lugar de mezclar de acuerdo con el segundo operando de control de reproducción aleatoria . • Seis instrucciones que niegan enteros envasados en el operando destino si las señales de la correspondiente elemento en el operando fuente es menor que cero . • Dos instrucciones que se alinean los datos de la composición de dos operandos . Instrucciones SSSE3 sólo se pueden ejecutar en el procesador Intel 64 y IA- 32 que apoyan SSSE3 extensiones. Apoyar de estas instrucciones se pueden detectar con la instrucción CPUID . Ver la descripción de la instrucción CPUID en Capítulo 3 , " Instruction Set Reference, AM , " del Intel ® 64 e IA- 32 Arquitecturas de Software del desarrollador Manual , Volumen 2A . Las secciones siguientes describen cada subgrupo . 2.16.1 Horizontal suma / resta PHADDW añade dos adyacentes , enteros de 16 bits horizontalmente desde el origen y destino de operandos y los paquetes de los resultados firmados de 16 bits del operando destino. PHADDSW añade dos adyacentes , enteros de 16 bits horizontalmente desde el origen y destino de operandos y los paquetes de los suscritos , saturados resultados de 16 bits para el operando destino. PHADDD Suma dos adyacentes, firmado enteros de 32 bits horizontalmente desde el origen y el destino de los operandos y los paquetes de los resultados firmados de 32 bits para el operando destino. PHSUBW Realiza restas horizontales en cada par adyacente de enteros con signo de 16 bits al restar la palabra más significativa de la palabra menos significativa de cada par en el origen y el destino operandos . Los resultados firmados de 16 bits se empaquetan y se escriben en el operando destino. PHSUBSW Realiza restas horizontales en cada par adyacente de enteros con signo de 16 bits al restar la palabra más significativa de la palabra menos significativa de cada par en el origen y el destino operandos . Los suscritos, saturados resultados de 16 bits se empaquetan y se escriben en el destino operando . PHSUBD Realiza restas horizontales en cada par adyacente de enteros con signo de 32 bits al restar la doble palabra más significativa de la doble palabra de menor valor de cada par en el operandos de origen y de destino . Los resultados firmados de 32 bits se empaquetan y se escriben en el operando de destino . 2.16.2 Valores absolutos pic PABSB Calcula el valor absoluto de cada elemento de datos byte con signo . PABSW Calcula el valor absoluto de cada elemento de datos de 16 bits con signo . PABSD Calcula el valor absoluto de cada elemento de datos de 32 bits con signo . 2.16.3 multiplicar y sumar Almuerzos Bytes signo y sin signo PMADDUBSW multiplica cada valor de byte sin signo con el valor de byte con signo correspondiente para producir una intermedio de 16 bits con signo . Cada par adyacente de valores con signo de 16 bits se añaden horizontalmente. Los suscritos, saturados resultados de 16 bits se empaquetan al operando destino. 2.16.4 Embalado Multiply alta con la Ronda y Escala PMULHRSW Multiplica verticalmente cada entero de 16 bits con signo del operando destino con la correspondiente entero con signo de 16 bits del operando de origen , produciendo intermedios , firmado de 32 bits números enteros . Cada número entero de 32 bits intermedia se trunca a los 18 bits más significativos. El redondeo se realiza siempre mediante la adición de 1 en el bit menos significativo del intermedio 18 bits 5-22 vol . 1 INSTRUCCIONES SET RESUMEN como resultado . El resultado final se obtiene mediante la selección de los 16 bits inmediatamente a la derecha de los más poco significativo de cada resultado intermedio de 18 bits y envasados al operando destino. 2.16.5 Bytes aleatoria pic PSHUFB permuta cada byte en el lugar , de acuerdo con una máscara de control aleatorio. El menor valor de tres o cuatro bits de cada byte de control aleatorio de la máscara de control forman el índice de reproducción aleatoria. La reproducción aleatoria la máscara no se ve afectada . Si se establece el bit más significativo (bit 7 ) de un byte de control de reproducción aleatoria , la constante cero se escribe en el byte de resultado . 2.16.6 Packed Entrar PSIGNB / W / D Niega cada elemento entero con signo del operando destino si la señal de la correspondiente elemento de datos en el operando fuente es menor que cero . 2.16.7 Packed Alinear a la derecha PALIGNR operando fuente se añade después del operando destino formando un valor intermedio de el doble de la anchura de un operando . El resultado se extrae a partir del valor intermedio en el operando destino seleccionando el valor del bit 128 bits o 64 que están alineados a la derecha en el byte desplazamiento especificado por el valor inmediato . 2.18 instrucciones SSE4 Intel ® Streaming SIMD Extensiones 4 ( SSE4 ) presenta 54 nuevas instrucciones . 47 de las instrucciones SSE4 son conoce como SSE4.1 en este documento , 7 nuevas instrucciones SSE4 se conocen como SSE4.2 . SSE4.1 está dirigido a mejorar el rendimiento de los medios de comunicación , formación de imágenes , y las cargas de trabajo 3D . SSE4.1 añade instrucciones que mejoran compilador vectorización y aumentar significativamente el apoyo a lleno cómputo dword . La tecnología también proporciona un indicio de que puede mejorar el rendimiento de memoria en la lectura de la memoria no almacenable en caché WC tipo. Los 47 SSE4.1 instrucciones incluyen: • Dos instrucciones realizan dword lleno multiplica. • Dos instrucciones que realizan productos de punto de punto flotante con entrada / salida selecciona. • Una instrucción realiza una carga con un toque de streaming. • Seis instrucciones simplifican la mezcla para llevar. • Ocho instrucciones de ampliar el apoyo a lleno entero MIN / MAX . • Cuatro instrucciones de soporte circular de punto flotante con el modo de redondeo seleccionable y precisión excepción de anulación. • Siete instrucciones de mejorar la inserción de datos y extracción de XMM registra • Doce instrucciones de mejorar las conversiones de formato enteros envasados ( señal cero y extensiones) . • Una instrucción mejora la generación de SAD ( diferencia absoluta suma ) para los pequeños tamaños de bloque . • Una instrucción de las operaciones de búsqueda ayudas horizontales. • Una instrucción de mejora comparaciones enmascarados. • Una instrucción suma comparaciones de igualdad QWORD llevar. • Una instrucción suma dword embalar con saturación sin signo. Los siete SSE4.2 instrucciones incluyen: • Cadena y procesamiento de texto que puede tomar ventaja de la programación de múltiples datos de una sola instrucción técnicas. • ( ATA ) las instrucciones de aplicación específicas del acelerador . Vol. . en 5 hasta 23 INSTRUCCIONES SET RESUMEN • Un número entero de instrucciones SIMD que mejora la capacidad de la capacidad enteros SIMD de 128 bits en SSE4.1 . 2.20 SSE4.1 INSTRUCCIONES SSE4.1 instrucciones pueden usar un registro XMM como origen o destino. Programación SSE4.1 es similar a programación de instrucciones SIMD en coma flotante en SSE/SSE2/SSE3/SSSE3 . 128-bit Integer SIMD y SSE4.1 hace no proporcionar instrucciones SIMD enteros de 64 bits que funcionan en registros MMX. Las secciones siguientes describen cada subgrupo. 2.20.1 Dword Instrucciones Multiplicar PMULLD Devuelve cuatro menores de 32 bits de los resultados de 64 bits del entero con signo de 32 bits multiplica . PMULDQ Devuelve dos 64-bit firmado resultado de entero con signo de 32 bits multiplica . 2.20.2 coma flotante Dot Product Instructions DPPD Realice precisión doble producto escalar para un máximo de 2 elementos y difusión. DPPS Realizar productos de punto de precisión simple para un máximo de 4 elementos y difusión 2.20.3 Carga Streaming Instrucción Sugerencia MOVNTDQA Proporciona un toque intemporal que puede causar artículos 16 bytes adyacentes dentro de una de 64 bytes alineados región ( una línea de transmisión ) que se fue a buscar y se mantiene en un pequeño conjunto de búferes temporales ( " Buffers de transmisión de carga ") . Posteriores cargas de transmisión a otros elementos de 16 bytes alineados en la misma línea de transmisión puede ser suministrado desde el buffer de carga de transmisión y puede mejorar rendimiento . 2.20.4 Instrucciones de fusión pic BLENDPD condicional copia de doble precisión los elementos de datos de punto flotante especificados en la fuente operando a los elementos de datos correspondientes en el destino , utilizando un byte inmediata controlar . BLENDPS condicional copia elementos de datos de punto flotante de precisión simple especificado en la fuente operando a los elementos de datos correspondientes en el destino , utilizando un byte inmediata controlar . BLENDVPD condicional copia de doble precisión los elementos de datos de punto flotante especificados en la fuente operando a los elementos de datos correspondientes en el destino , utilizando una máscara implícita . BLENDVPS condicional copia elementos de datos de punto flotante de precisión simple especificado en la fuente operando a los elementos de datos correspondientes en el destino , utilizando una máscara implícita . PBLENDVB condicional copia elementos de bytes especificados en el operando origen al correspondiente elementos en el destino , utilizando una máscara implícita . PBLENDW condicional copia elementos denominativos especificados en el operando origen al correspondiente elementos en el destino , utilizando un byte de control inmediato . 2.20.5 Bolsas enteros Instrucciones MIN / MAX PMINUW Comparar enteros palabra sin signo para llevar. PMINUD Comparar envasados dword enteros sin signo. PMINSB Comparar enteros llenos de bytes con signo. PMINSD Comparar enteros envasados dword firmados. PMAXUW Comparar enteros palabra sin signo para llevar. 5-24 vol . 1 INSTRUCCIONES SET RESUMEN PMAXUD Comparar envasados dword enteros sin signo. PMAXSB Comparar enteros llenos de bytes con signo. PMAXSD Comparar enteros envasados dword firmados. 2.20.6 Instrucciones Ronda de punto flotante con el modo de redondeo seleccionable ROUNDPS Round valores de precisión embalaje individual de punto flotante en valores enteros y regresan redondeadas valores de punto flotante . Ronda ROUNDPD lleno valores de doble precisión de punto flotante en valores enteros y devolver redondeado valores de punto flotante . ROUNDSS Round the precisión el valor de punto flotante única baja embalado en un valor entero y devuelven un redondeada valor de punto flotante . ROUNDSD Alrededor de la precisión de valor de punto flotante de doble bajo embalado en un valor entero y devuelven un redondeada valor de punto flotante . 2.20.7 Inserción y Extracciones de XMM Registros EXTRACTPS Extrae un valor de punto flotante de precisión simple de un desplazamiento en un registro XMM especificado y almacena el resultado en la memoria o un registro de propósito general INSERTPS Inserta un valor de punto flotante de precisión simple de cualquiera de una posición de memoria de 32 bits o seleccionados de un desplazamiento especificado en un registro XMM a un desplazamiento en el destino XMM registro especificado. Además, INSERTPS permite la puesta a cero de los elementos de datos seleccionados en el destino, utilizando una máscara. PINSRB Introduzca un valor de bytes de un registro o memoria en un registro XMM PINSRD Introduzca un valor DWORD del registro de 32 bits o de memoria en un registro XMM PINSRQ Introduzca un valor QWORD del registro de 64 bits o de memoria en un registro XMM PEXTRB Extracto de un byte de un registro XMM e insertar el valor en un registro de propósito general o memoria PEXTRW Extracto de una palabra a partir de un registro XMM e insertar el valor en un registro de propósito general o memoria PEXTRD Extraiga una dword de un registro XMM e insertar el valor en un registro de propósito general o memoria PEXTRQ Extracto de un QWORD de un registro XMM e insertar el valor en un registro de propósito general o memoria 2.20.8 Bolsas Conversiones formato entero PMOVSXBW Registrarse ampliar el número entero de 8 bits inferior de cada elemento denominativo lleno en lleno palabra firmada números enteros. PMOVZXBW Zero ampliar el número entero de 8 bits inferior de cada elemento denominativo lleno en lleno palabra firmada números enteros. PMOVSXBD Entrar ampliar el entero de 8 bits más baja de cada elemento dword lleno en lleno firmado dword números enteros . PMOVZXBD Zero ampliar el entero de 8 bits más baja de cada elemento dword lleno en lleno firmado dword números enteros . PMOVSXWD Entrar ampliar el entero de 16 bits más baja de cada elemento dword lleno en lleno firmado dword números enteros . PMOVZXWD Zero ampliar el entero de 16 bits más baja de cada elemento dword lleno en lleno dword firmado enteros .. PMOVSXBQ Entrar ampliar el entero de 8 bits más baja de cada elemento QWORD lleno en lleno firmado QWORD números enteros . Vol. . 5-25 en INSTRUCCIONES SET RESUMEN PMOVZXBQ Zero ampliar el entero de 8 bits más baja de cada elemento QWORD lleno en lleno firmado QWORD números enteros . PMOVSXWQ Entrar ampliar el entero de 16 bits más baja de cada elemento QWORD lleno en lleno firmado QWORD números enteros . PMOVZXWQ Zero ampliar el entero de 16 bits más baja de cada elemento QWORD lleno en lleno firmado QWORD números enteros . PMOVSXDQ Entrar ampliar el entero de 32 bits más baja de cada elemento QWORD lleno en lleno firmado QWORD números enteros . PMOVZXDQ Zero ampliar el entero de 32 bits más baja de cada elemento QWORD lleno en lleno firmado QWORD números enteros . 2.20.9 La mejora de las sumas de las diferencias absolutas ( SAD ) para bloques de 4 bytes MPSADBW Realiza ocho de ancho Sum 4 bytes de las operaciones de las diferencias absolutas para producir ocho palabras números enteros. 2.20.10 Horizontal Buscar PHMINPOSUW Busca el valor y la ubicación de la palabra sin signo de un mínimo de 8 embalan horizontalmente palabras sin signo . El valor resultante y la ubicación ( desplazamiento dentro de la fuente ) se empaquetan en el bajo dword del destino XMM registro . 2.20.11 Prueba Packed PTEST Realiza una operación lógica AND entre el destino con esta máscara y establece el indicador ZF si el resultado es cero . La bandera CF ( cero TEST) se establece si la máscara invertida AND'd con el destino es todos cero 10/05/12 Almuerzos comparaciones de igualdad QWORD PCMPEQQ 128 bits empaquetado prueba de igualdad QWORD 2.20.13 DWORD Embalaje Con Saturación Unsigned PACKUSDW PACKUSDW paquetes dword a la palabra con la saturación sin signo 2.21 SSE4.2 del conjunto de instrucciones Cinco de los siete SSE4.2 instrucciones puede utilizar un registro XMM como origen o destino. Estos incluyen cuatro texto / string instrucciones de procesamiento y uno lleno quadword comparar instrucciones SIMD . Programación estos cinco SSE4.2 instrucciones es similar a la programación de 128 bits de enteros SIMD en SSE2/SSSE3 . SSE4.2 no proporciona ningún 64 bits enteros instrucciones SIMD . Los otros dos SSE4.2 instrucciones utiliza registros de propósito general para realizar las funciones de procesamiento acelerado en áreas de aplicación específicas . Las secciones siguientes describen cada subgrupo . 2.21.1 cuerdas y texto Instrucciones de procesamiento PCMPESTRI Embalado comparar cadenas explícita de longitud , devuelva índice en ECX / RCX PCMPESTRM Embalado comparar cadenas explícita de longitud , devuelva máscara XMM0 PCMPISTRI Embalado comparar cadenas implícita de longitud , índice de rentabilidad en ECX / RCX 5-26 vol . 1 INSTRUCCIONES SET RESUMEN PCMPISTRM Embalado comparar cadenas implícita de longitud , devuelva máscara XMM0 5.11.2 Packed Comparación SIMD entero Instrucción PCMPGTQ Realiza lógico comparar de mayor que en empaquetado entero quadwords . 5.11.3 Instrucciones Acelerador de aplicación selectivas CRC32 Proporciona aceleración de hardware para el cálculo de los controles de redundancia cíclica para una rápida y eficiente implementación de protocolos de integridad de datos . POPCNT Esta instrucción calcula del número de bits puestos a 1 en el segundo operando (origen) y devuelve el recuento en el primer operando ( un registro de destino ) 5.12 AESNI Y PCLMULQDQ Seis instrucciones AESNI operan en XMM registra para proporcionar primitivas aceleradas para el cifrado de bloque / descifrado utilizando Advanced Encryption Standard (FIPS -197 ) . Instrucción PCLMULQDQ llevar a cabo , menos la multiplicación de dos números binarios de hasta 64 bits de ancho. AESDEC Realizar una ronda de descifrado AES mediante un estado de 128 bits y una clave de ronda AESDECLAST Realizar la última ronda AES descifrado usando un estado de 128 bits y una clave de ronda AESENC Realice un ciclo de cifrado AES con un estado de 128 bits y una clave de ronda AESENCLAST Realizar la última ronda de cifrado AES con un estado de 128 bits y una clave de ronda AESIMC Realizar una mezcla de transformación inversa columna primitiva AESKEYGENASSIST Ayuda a la creación de claves de ronda con un programa de expansión de clave PCLMULQDQ carryless realizar la multiplicación de dos números de 64 bits DISTRIBUCION DE REGISTROS Registros de propósito general Los registros de propósito general son los siguientes: Estos registros tienen un uso especial en algunas instrucciones: EAX Registro acumulador. Fuente y destino en algunas operaciones. EBX Puntero a los datos en el segmento DS. ECX Contador en las operaciones de cadena y bucles. EDX Puntero a los puertos de E/S. ESI Puntero fuente en las operaciones de cadena y puntero a datos en el segmento DS. EDI Puntero destino en las operaciones de cadena y puntero a datos en el segmento ES. ESP Puntero de pila. EBP Puntero a los datos alojados en la pila. AX - acumulador, se utiliza para cálculos. Habitualmente se utiliza como registro de retorno del resultado. DX - extensión de AX. Lo mismo uso como AX. CX - count register -- contadores, especialmente de bucles con número predeterminado de ejecuciones. BX - registro base. Se utiliza como índice, pero también para cálculos. SI - source index - se utiliza para direccionar datos que principalmente se leen, pero no se escriben. DI - destination index - se utiliza para direccionar datos que principalmente se escriben, pero no se leen. BP - base pointer - se utiliza para pasar parámetros en la pila. SP - stack pointer - se utiliza sólo implícitamente para indexar la pila con PUSH POP,CALL RET, INT IRET y para valor inicial de BP. CS - segmento de código. Uso exclusivamente según su propósito según el hardware de 8086. SS - segmento de pila. Uso exclusivamente según su propósito según el hardware de 8086. DS - segmento de datos. Datos utilizados con alta frecuencia. ES - extra segment. El resto de los datos. Si el programa es pequeña, es normal que DS=ES. El registro EIP y el EFLAGS El registro EIP apunta a la siguiente instrucción a ejecutar del segmento de código. Su valor se ve modificado con la ejecución de cada instrucción o como resultado de ejecutar una instrucción de control de flujo (JMP, Jxx, CALL, RET, RET n, IRET). Al registro EIP se le conoce como el puntero a instrucción o contador de programa. El registro EFLAGS contiene el estado del procesador en un momento dado, incluyendo los bits de condición (S, Z, P, C, ...). CONCLUSIONES (Adelina Hernández Torres) Al buscar más información del procesador como lo es grupo de instrucciones que esta maneja y sus registros es de gran importancia, ya que, de cierta manera la computadora es utilizada en muchas ocasiones, ya sea para hacer un proyecto, ver videos, comprender algo más sobre esta, etc. Generalmente hay que informarnos más de nuestra máquina, saber con qué se está trabajando y que funciones al ser utilizada por un usuario. (Luis Angel Hermenegildo Dominguez) Una instrucción es una serie de pasos a seguir, esto para que la información o alguna operación aritmética o lógica sean procesadas correctamente. Dependiendo de qué tipo de procesador se está manejando. REFERENCIAS BIBLIOGRÁFICAS http://sop.upv.es/dso/es/t2-arquitectura/gen-t2-arquitectura.html http://www.pmzone.org/chapter01.html