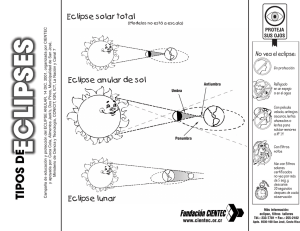
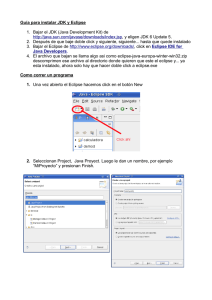
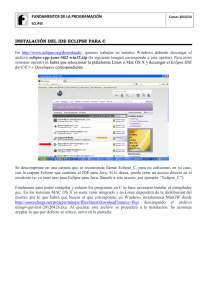
universidad de chile facultad de ciencias físicas y matemáticas
Anuncio

UNIVERSIDAD DE CHILE FACULTAD DE CIENCIAS FÍSICAS Y MATEMÁTICAS DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN SISTEMA GENERADOR DE APLICACIONES WEB MULTICAPA - CODEV TESIS PARA OPTAR AL GRADO DE MAGÍSTER EN TECNOLOGÍAS DE INFORMACIÓN DAVID ALBERTO MEZA GIRALDO PROFESOR GUÍA: SERGIO FABIÁN OCHOA DELORENZI MIEMBROS DE LA COMISIÓN: MARIA CECILIA BASTARRICA PIÑEYRO LUIS GUERRERO BLANCO YADRAN ETEROVIC SOLANO SANTIAGO DE CHILE JUNIO 2008 Resumen En el mundo de hoy, la tendencia a acortar el tiempo de desarrollo y la inversión en la construcción de sistemas de información provoca muchos problemas como que una gran cantidad de estos sistemas no lleguen a terminarse. Al iniciar un proyecto se requiere una buena cantidad de tiempo para establecer un ambiente de trabajo y el esqueleto de una aplicación Web que sea mantenible y estándar. En general estas son tareas repetitivas y pueden generar muchos errores y pérdida de tiempo. CodEv (Code Evolution) es un generador de código fuente para aplicaciones Web Java orientadas a base de datos con una arquitectura de sistemas multicapa. Este generador aportará a la solución de estos problemas al reducir el tiempo de desarrollo por medio de la automatización de las tareas repetitivas del proyecto. Además, facilitará y acelerará la definición de requerimientos y funcionalidad del sistema para un dominio específico de aplicaciones que son los sistemas de información Web en Java, reforzando una arquitectura multicapa que ha sido probada por su mantenibilidad, extensibilidad y escalabilidad en aplicaciones Web. El desarrollo de CodEv se realizó con prácticas ágiles y con una metodología iterativaincremental apoyada por prototipos evolutivos, lo que permitió que durante el tiempo de desarrollo de la tesis las definiciones de la herramienta fueran cambiando y evolucionando hasta establecerse la herramienta resultante, con un proceso sencillo, amigable y rápido. Además, permite la evolución de la aplicación generada por medio de la regeneración de código siguiendo un proceso no destructivo. Está fuertemente integrado con la plataforma Eclipse que es un ambiente de desarrollo robusto y poderoso. La validación de la herramienta se realizó con varios proyectos, pero principalmente por medio de un proyecto ficticio para la creación de un sistema académico, en donde se midieron los tiempos de desarrollo. Además, CodEv fue usado como base para la construcción de SIMPLe que es una herramienta para el soporte al proyecto de mejora de calidad de procesos con modelos CMMI e IDEAL. Agradecimiento El agradecimiento más grande y especial para mi esposa Jesi por su incondicional apoyo, pero especialmente por su gran amor y paciencia. Todas las metas que nos marcamos se van logrando porque estamos juntos. Segundo a nuestras familias y amigos por motivarnos a alcanzar este titulo. Un agradecimiento especial para Sergio Ochoa por su ayuda para la realización de este trabajo. ÍNDICE DE CONTENIDO 1. INTRODUCCIÓN...................................................................................................................................1 1.1. PROBLEMA A RESOLVER ..................................................................................................................4 1.2. SOLUCIÓN PROPUESTA ....................................................................................................................5 1.3. OBJETIVOS DEL SISTEMA .................................................................................................................6 1.3.1. Objetivo general........................................................................................................................6 1.3.2. Objetivos específicos................................................................................................................6 2. MARCO TEÓRICO................................................................................................................................7 2.1. HERRAMIENTAS PARA ASISTIR EN EL DESARROLLO DE SISTEMAS ........................................................7 2.2. PROTOTIPOS DE SISTEMAS...............................................................................................................9 2.3. ARQUITECTURA DE SISTEMAS W EB.................................................................................................11 2.4. ARQUITECTURA DE LA PLATAFORMA ECLIPSE ..................................................................................13 2.5. AMBIENTES DE DESARROLLO..........................................................................................................16 2.5.1. Visual Studio Express Edition C# ...........................................................................................16 2.5.2. Eclipse IDE RCP/Plug-in Development Enviroment (PDE)....................................................17 2.6. TRABAJOS RELACIONADOS .............................................................................................................19 3. ANÁLISIS DEL SISTEMA...................................................................................................................23 3.1. REQUISITOS DEL SISTEMA .............................................................................................................23 3.1.1. Descripción general ................................................................................................................23 3.1.2. Requisitos funcionales............................................................................................................24 3.1.3. Atributos de Calidad ...............................................................................................................25 3.2. PLAN DEL PROYECTO ....................................................................................................................26 3.2.1. Metodología ............................................................................................................................26 3.2.2. Planificación............................................................................................................................27 4. ARQUITECTURA Y DISEÑO DEL SISTEMA ....................................................................................30 4.1. DESCRIPCIÓN GENERAL .................................................................................................................30 4.2. ARQUITECTURA DEL GENERADOR CODEV .......................................................................................30 4.3. DISEÑO DETALLADO DE COMPONENTES IMPORTANTES DE CODEV....................................................33 4.3.1. Representación del modelo de datos .....................................................................................34 4.3.2. Manejador de Presentación....................................................................................................36 4.3.3. Manejador de BD....................................................................................................................38 4.3.4. Manejador de Generación ......................................................................................................40 4.4. ARQUITECTURA DE LAS SOLUCIONES GENERADAS...........................................................................41 4.4.1. Data Transfer Objects (DTO) .................................................................................................42 4.4.2. Capa de Presentación ............................................................................................................42 4.4.3. Capa de Negocio ....................................................................................................................43 4.4.4. Capa de Persistencia..............................................................................................................44 4.5. DISEÑO DETALLADO DE LAS SOLUCIONES GENERADAS .....................................................................46 5. CONSTRUCCIÓN DEL SISTEMA ......................................................................................................50 5.1. AMBIENTE DE DESARROLLO............................................................................................................50 5.2. PROTOTIPOS REALIZADOS..............................................................................................................51 5.2.1. Prototipo 1 ..............................................................................................................................51 5.2.2. Prototipo 2 ..............................................................................................................................51 5.2.3. Prototipo 3 ..............................................................................................................................52 5.3. METODOLOGÍA DE DESARROLLO APLICADA......................................................................................52 5.3.1. Iteración 1 ...............................................................................................................................53 5.3.2. Iteración 2 ...............................................................................................................................53 5.3.3. Iteración 3 ...............................................................................................................................54 5.3.4. Iteración 4 ...............................................................................................................................54 6. FUNCIONAMIENTO DE CODEV ........................................................................................................56 6.1. INSTALACIÓN Y CONFIGURACIÓN.....................................................................................................56 6.1.1. Pre-requisitos..........................................................................................................................56 6.1.2. Instalación de Codev ..............................................................................................................56 6.2. PROCESO DE GENERACIÓN ............................................................................................................59 6.2.1. Generación inicial ...................................................................................................................60 6.2.2. Regeneración – Evolución de la aplicación............................................................................67 6.2.3. Proceso de desarrollo recomendado......................................................................................67 6.3. BOSQUEJO DE LA SOLUCIÓN GENERADA..........................................................................................69 7. CASO PRÁCTICO - VALIDACIÓN DE LA HERRAMIENTA .............................................................75 8. CONCLUSIONES................................................................................................................................81 8.1. 8.2. 8.3. 9. CONCLUSIONES.............................................................................................................................81 RECOMENDACIONES ......................................................................................................................83 MEJORAS A FUTURO ......................................................................................................................83 BIBLIOGRAFÍA...................................................................................................................................85 APÉNDICE A – ESTIMACIÓN DE LA INVERSIÓN MUNDIAL EN TI Y CANTIDAD DE PROYECTOS DE TI ..................................................................................................................................................................87 ÍNDICE DE ILUSTRACIONES Y TABLAS Figura 1. Arquitectura típica para sistemas Web .........................................................................................11 Figura 2. Arquitectura de la plataforma Eclipse ...........................................................................................14 Figura 3. Elementos y proceso típico de MDA.............................................................................................21 Figura 4. Casos de uso para la generación .................................................................................................24 Figura 5. Representación en el tiempo del desarrollo Iterativo....................................................................26 Figura 6. Cronograma de actividades para la creación del sistema ............................................................28 Figura 7. Funcionamiento propuesto para el sistema..................................................................................31 Figura 8. Integración de CodEv y las aplicaciones generadas con Eclipse ................................................32 Figura 9. Arquitectura de CodEv ..................................................................................................................33 Figura 10. Modelo de clases que representan el modelo de datos a generar.............................................34 Figura 11. Modelo de clases de la implementación de los puntos de integración del Wizard de CodEv para generación de aplicaciones..........................................................................................................................37 Figura 12. Modelo de clases de la implementación de los puntos de integración del Editor de CodEv para regeneración de aplicaciones.......................................................................................................................38 Figura 13. Modelo de clases del componente manejador DB .....................................................................39 Figura 14. Modelo de clases del componente manejador de Generación ..................................................40 Figura 15. Componentes y conexiones de la capa de presentación basada en Struts...............................41 Figura 16. Componentes y conexiones de la capa de presentación basada en Struts2.............................43 Figura 17. Componentes y conexiones de la capa de negocio en un sistema multicapas .........................43 Figura 18. Componentes y conexiones de la capa de negocio en un sistema multicapas .........................44 Figura 19. Componentes y conexiones de la capa de persistencia basada en Hibernate ..........................45 Figura 20. Vista de alto nivel de la arquitectura de Hibernate .....................................................................46 Figura 21. Diagrama de clases para el soporte de servicio de filtros en consultas en la capa de negocio 47 Figura 22. Diagrama de clases para el soporte de ordenamiento en consultas en la capa de negocio .....48 Figura 23. Diagrama de clases de un DAO de ejemplo con sus métodos y relaciones ..............................49 Figura 24. Opción de menú para instalación de plug-ins en Eclipse ...........................................................57 Figura 25. Pantalla de instalación de un plug-in desde un sitio local ..........................................................58 Figura 26. Pantalla de selección de Features a instalar ..............................................................................59 Figura 27. Opción de menú para listar los tipos de archivos y proyectos....................................................61 Figura 28. Opción de menú para crear un nuevo proyecto CodEv..............................................................61 Figura 29. Pantalla de captura de opciones de configuración de CodEv ....................................................62 Figura 30. Pantalla de configuración de tablas y datos de log in de CodEv................................................63 Figura 31. Pantalla de configuración de campos por tabla..........................................................................64 Figura 32. Pantalla de avance de generación de CodEv.............................................................................65 Figura 33. Estructura de un proyecto Web Java creado con CodEv ...........................................................66 Figura 34. Editor para la regeneración de un proyecto CodEv....................................................................67 Figura 35. Modelo iterativo de desarrollo con generación de código ..........................................................68 Figura 36. Página de login del sistema generado........................................................................................69 Figura 37. Mensajes de error que presentará el sistema ............................................................................70 Figura 38. Menú generado para el sistema .................................................................................................70 Figura 39. Página con listado de datos ........................................................................................................71 Figura 40. Cabecera para filtrar el listado de elementos .............................................................................71 Figura 41. Página flotante para seleccionar elementos de una relación padre...........................................72 Figura 42. Página para seleccionar un elemento de tipo fecha...................................................................72 Figura 43. Paginación para los listados .......................................................................................................73 Figura 44. Página para agregar un nuevo elemento....................................................................................73 Figura 45. Página para modificar un elemento ............................................................................................74 Figura 46. Página para modificar un elemento ............................................................................................74 Figura 47. Modelo Físico inicial del esquema de BD para el caso práctico ................................................76 Figura 48. Modelo Físico final del esquema de BD para el caso práctico ...................................................77 Figura 49. Pantalla de login única para todos los usuarios del sistema ......................................................77 Figura 50. Pantalla de edición de datos personales y de usuario ...............................................................78 Figura 51. Pantalla de ingreso de notas por materia ...................................................................................78 Figura 53. Pantalla de visualización de notas para alumno.........................................................................79 1. Introducción El desarrollo de software es un proceso máximamente laborioso, altamente complejo y calificado, probablemente más que cualquier otra actividad profesional humana. El diseño y programación de software es tan complejo y propenso a errores que es subestimado por la mayoría. El grupo para el que se está tratando de desarrollar el software generalmente no tiene idea del tamaño o complejidad o cómo el software es diseñado, construido o inclusive cómo funciona. El desarrollo ocurre en una frágil matriz de aplicaciones, usuarios, exigencias del cliente, leyes, políticas internas, presupuestos, dependencias organizacionales y de proyecto que cambian constantemente. 1 En el mundo de hoy, sigue creciendo la necesidad de soportar un modelo de empresa con distribución geográfica del trabajo con flexibilidad y seguridad, además de obtener ventajas competitivas por medio de la mejora de procesos y cambios constantes. Estas son algunas de las razones por las que las empresas siguen optando por utilizar o desarrollar sistemas de información que ayuden a automatizar sus procesos y a soportar la distribución geográfica. Esto ha hecho que siga creciendo al mismo ritmo la demanda por sistemas de información Web, y que además estos sistemas requieran ser flexibles y mantenibles al igual que lo son los procesos de las empresas. El valor estimado de inversión en proyectos de tecnología de información mundialmente para el año 2006 fue de más o menos 900,000 millones de USD para un aproximado de 1’000.000 proyectos [StG94], [StG03]. (Ver apéndice A). Todos estos valores se producen a pesar de que muchos de estos sistemas se terminen tarde o que ni siquiera lleguen a terminarse [InfQ06]. El proceso de desarrollo de sistemas es un proceso netamente manual, es decir que requiere ser realizado por personas que sean altamente calificados, como son los ingenieros de software (analistas, arquitectos, diseñadores, programadores, ingenieros de calidad, etc.). Y es el salario de los ingenieros o consultores donde está uno de los rubros más grandes de desarrollar un sistema de software de mediano o gran tamaño. Otro dato muy importante es que la mayor cantidad de sistemas computacionales que se producen están relacionados con sistemas de información, es decir son sistemas 1 Construido de la lógica de varios autores e ideas propias 1 computacionales organizados para facilitar el manejo (captura, almacenamiento, procesamiento y presentación) de información importante de la empresa, ya sea de sus procesos, productos, servicios, clientes y las relaciones entre ellos. Estos sistemas computacionales generalmente almacenan su información en bases de datos relacionales. En un proyecto de desarrollo de software se tienen al menos dos visiones de lo que debe ser y hacer el sistema resultante: la de los clientes o usuarios de la aplicación (visión de negocios) y la de los ingenieros de software (visión técnica). Estas visiones del sistema, aunque pueden coincidir, generalmente son muy diferentes, puesto que es difícil para los usuarios tratar de comunicar a los ingenieros de software, a través del lenguaje natural, el complejo funcionamiento de procesos, procedimientos, reglamentos e ideas que el sistema tendrá que automatizar. La visión de la parte de negocios de las empresas generalmente es que necesitan los sistemas implantados rápidamente y en la mayoría de ocasiones no entienden por qué el proceso de desarrollar sistemas es tan complejo y costoso. En muchos casos se quejan de la alta inversión y del ritmo demasiado lento de implantación tecnológica. Por otro lado se encuentra la visión de las personas de tecnología encargados del desarrollo e implantación de estos sistemas que están restringidos por varios aspectos tecnológicos y no tecnológicos como son: - la tecnología para el desarrollo de sistemas Web y las herramientas disponibles para hacerlo son altamente cambiantes. - restricciones en funcionalidad del sistema, ambiente de ejecución y en tiempo y dinero. - se debería seguir los estándares y mejores prácticas de la empresa y del mercado. - por último, una de las restricciones o características más importantes que deben resolver los ingenieros de software, es que los sistemas deben ser flexibles y mantenibles, ya que se espera que sean usados por un largo periodo de tiempo y por lo tanto, lo más probable es que sean modificados muchas veces durante su tiempo de vida. Como consecuencia de todas estas razones anteriormente mencionadas y la oposición entre los puntos de vista generalmente se crean problemas de comunicación entre el cliente o usuario y los ingenieros de software y esto crea problemas en la definición de los requerimientos del 2 sistema. Además, se ha creado un fenómeno en que los sistemas se tratan de realizar con inversiones y tiempos demasiado acotados para la realidad del proyecto que resultan en que lo que se sacrifica, en la mayoría de casos, es una buena definición de requerimientos, parte de la funcionalidad requerida del sistema final y/o la calidad del producto final [Gla02]. Durante mucho tiempo se ha buscado la manera de reducir el tiempo empleado en la producción de sistemas, y se han tratado de implementar distintas soluciones al problema. Una de las soluciones más exitosas y masificadas en el tiempo se dio en el apogeo de las aplicaciones cliente-servidor, en que los lenguajes y herramientas de desarrollo para crear cierto tipo de aplicaciones específicas, como sistemas orientados a datos, habían evolucionado y madurado hasta el punto de tener capacidad de generación de código y el uso de asistentes (wizards), en la década de los 90 [Mic01]. Esto facilitaba las tareas repetitivas, evitando los errores de programación o lógica en estas tareas que pueden costar gran cantidad de tiempo al programador. Un ejemplo de este tipo de herramientas son Visual Basic 6.0, Access u Oracle Forms. Los generadores de código y asistentes facilitan el trabajo y reducen el tiempo de desarrollo permitiendo a los desarrolladores concentrarse en las reglas de negocio y en realizar una mejor solución, puesto que no se requiere de un conocimiento tan profundo del lenguaje y sus estructuras para crear las aplicaciones, sino más bien de la herramienta y sus asistentes. Con este tipo de herramientas se facilitó la construcción de aplicaciones pequeñas y de prototipos de aplicaciones, simplificando el trabajo de la toma de requerimientos y evolucionándolos a sistemas completos. En este trabajo se pretende resolver los siguientes problemas para un dominio específico de aplicaciones que son los sistemas de información Web en Java: 1) facilitar y acelerar la definición de requerimientos y funcionalidad del sistema, 2) reducir el tiempo de desarrollo por medio de la automatización de las tareas repetitivas iniciales del proyecto, y 3) ayudar a crear una arquitectura de sistemas multicapa para que sea escalable, extensible y mantenible. Todo esto por medio de la creación rápida de prototipos evolutivos de aplicaciones Web multicapa. 3 Los generadores de aplicaciones orientados a manejo de datos, generan aplicaciones CRUD (Create, Read, Update and Delete), de manera simple y repetitiva. Lo que se quiere hacer es generar el mismo tipo de aplicaciones CRUD para aplicaciones Web con una arquitectura multicapa, ya que no existe una herramienta similar para Web que nos pueda ayudar a generar prototipos evolutivos. A continuación se presenta el problema a resolver, se detalla brevemente la solución propuesta, posteriormente se detallan los objetivos que se plantearon alcanzar con la construcción de la herramienta propuesta en esta tesis. 1.1. Problema a resolver Como se dijo anteriormente, la tendencia a cortar el tiempo e inversión en la construcción de sistemas provoca muchos problemas, generando que una gran cantidad de sistemas no lleguen a terminarse o no sean usados puesto que no satisfacen los requerimientos originales. Estos sistemas contienen errores causados por fallas en la toma de requerimientos, fallas en la comunicación o entendimiento de estos requerimientos por parte los ingenieros de software. Aun con todos los esfuerzos presentados para mejorar las técnicas y herramientas disponibles para los ingenieros, no se ha logrado que exista una comunicación ágil con el cliente y por tanto la definición clara de requerimientos. También por falta de tiempo se deja de lado, en muchos casos, lo que sería una buena arquitectura de sistemas con flexibilidad, capacidad de cambio y crecimiento; muchos de estos sistemas presentan importantes problemas por la reducción de calidad, específicamente problemas de mantenibilidad, extensibilidad y escalabilidad. Los métodos ágiles son un esfuerzo por ayudar a reducir el riesgo de construir el sistema equivocado ya que promueven una fuerte participación del cliente y la asimilación de los cambios al sistema por medio de la utilización de pequeñas iteraciones [Hem06]; pero cuando el cliente no puede o quiere participar tan cercanamente en el proyecto estos métodos no son aplicables. Esto se da especialmente cuando los ingenieros de software y el cliente no se encuentran en el mismo lugar, por ejemplo que se encuentren en diferentes ciudades o países y la comunicación no es eficiente. Todos estos problemas se presentan igualmente para el desarrollo de sistemas de información Web y en muchos casos en mayor medida puesto que es el ámbito tecnológico en 4 que más avances se realiza actualmente, se crean nuevos frameworks, mayores capacidades de las herramientas y lenguajes, nuevas capas de abstracción y funcionamiento. Todos estos avances y cambios tecnológicos dificultan aún más el poder establecer la infraestructura inicial para un proyecto Web y que el tiempo se utilice en aprender a usar estas tecnologías y no necesariamente en la toma de requerimientos o entendimiento del negocio del cliente. 1.2. Solución propuesta Este proyecto plantea la creación de un generador de aplicaciones Web Java orientadas a base de datos para operaciones CRUD con una arquitectura de sistemas multicapa que se lo ha denominado CodEv. Con esta herramienta se puede generar un esqueleto funcional de la aplicación en muy corto tiempo, evitando los errores comunes, y permitiendo tener ciclos de desarrollo más cortos o realizar prototipos rápidos ayudando de esta manera a tener una mejor interacción y trabajo con el cliente. El motivo para crear este generador es que como sabemos se requiere una buena cantidad de tiempo al iniciar un proyecto para establecer un ambiente de trabajo y el esqueleto de una aplicación Web que sea mantenible y estándar. En general estas son tareas repetitivas que generalmente requieren la revisión de proyectos pasados y la documentación de arquitectura de referencia para la empresa. Son estas actividades en donde se pueden generar muchos errores y pérdida de tiempo. Como se ha definido, el generador ayudará a crear esqueletos de aplicaciones Web Java muy rápidamente, acelerando también el proceso de creación de prototipos, ayudando de esta manera a definir los requerimientos más clara y rápidamente. Al interactuar con una aplicación funcional, el prototipo evolutivo se convierte en un puente de comunicación entre el usuario y el ingeniero de software. Con esto se ayuda a reducir el tiempo de desarrollo con necesidades claras de usuario y una aplicación con una arquitectura escalable y mantenible que puede ser evolucionada fácilmente, lo cual, visto de manera general, también ayudará a reducir costos. El generador está orientado a un dominio muy específico que son los sistemas de información para el Web con lenguaje Java; y por lo tanto, es en proyectos nuevos dentro de este dominio donde se podrán ver los beneficios planteados y podrá tener mayor utilidad y aporte, que es en donde podrá ahorrar mayor tiempo de set-up y programación. 5 En resumen, la ventaja de crear este proyecto es que permitirá reducir el tiempo de desarrollo creando un esqueleto funcional de la aplicación. De esta manera se eliminarán los posibles errores que se puedan cometer y reforzará una arquitectura multicapas que promueve la extensibilidad, escalabilidad y mantenibilidad [SEI00]. Esto permitirá crear prototipos evolutivos rápidamente y facilitará el manejo de requerimientos. 1.3. 1.3.1. Objetivos del sistema Objetivo general El objetivo general de este trabajo de tesis es diseñar e implementar una herramienta para la generación rápida de aplicaciones Web basadas en Java, las cuales son usadas principalmente como sistemas de información. Esta herramienta permitirá la creación de la funcionalidad necesaria para manejar operaciones CRUD (Create, Read, Update and Delete), con una arquitectura de sistemas multicapa, de forma de ayudar a crear prototipos evolutivos rápidamente y acelerar el tiempo de desarrollo. Se plantea que los prototipos generados sean esqueletos de aplicaciones totalmente funcionales, que se podrán poner en funcionamiento con mínimo esfuerzo, y estarán hechas para que puedan ser fácilmente adaptables y extensibles. Además dichas aplicaciones tendrán puntos de extensión para soportar múltiples bases de datos. 1.3.2. Objetivos específicos De lo anteriormente expuesto, se desprenden los siguientes objetivos específicos: • Garantizar que el código generado siga los lineamientos de una arquitectura multicapa. • Que la herramienta permita crear, con mínimo esfuerzo, la funcionalidad necesaria para manejar operaciones CRUD. • Que la herramienta pueda ejecutarse en múltiples sistemas operativos. • Permitir que la herramienta pueda generar las aplicaciones utilizando múltiples bases de datos. 6 2. Marco Teórico Dadas las condiciones anteriormente expuestas, a continuación se presentarán algunos de los conceptos que servirán de introducción y que se utilizarán extensamente en el desarrollo de esta tesis. 2.1. Herramientas para asistir en el desarrollo de sistemas La comunidad científica y tecnológica ha propuesto varias maneras de disminuir los riesgos y eliminar los problemas de crear sistemas a través de los años, tratando de que se puedan producir sistemas más rápidamente y que puedan ser mantenibles y escalables. Se ha atacado el problema desde varios frentes como son: Mejoras en lenguajes de programación. El concepto de orientación a objetos y lenguajes seguros son los aportes más grandes realizados para los lenguajes modernos. Son varios los lenguajes que han contribuido a la evolución de los lenguajes orientados a objetos desde la década de los 60 como son Simula I, Simula 67 y Beta, más tarde SmallTalk, Eiffel, Modula, Ada, Prolog. Posteriormente C++ y Pascal orientado a objetos [Bru02]. Estos lenguajes tenían un problema grave que era que permitían al programador cometer errores difíciles de encontrar causados en muchos casos por los punteros y el acceso a la memoria compartida. Estos podían causar daño a los archivos del sistema operativo. Con la aparición de Java a mediados de los 90, se eliminan muchos de estos problemas puesto que Java elimina el uso de punteros, agrega recolección de basura automática (eliminación de objetos que no están en uso de la memoria) y garantiza la seguridad restringiendo el acceso al sistema por medio de la eliminación del acceso directo a la memoria y la programación de bajo nivel. Java es un lenguaje, como C++, auto extensible, es decir que se pueden escribir clases y librerías para extender la funcionalidad del propio lenguaje. Con estas características, el trabajo del programador se hizo más fácil y se empezó a realizar una reutilización real de componentes. Posteriormente a inicios del 2000, se dio la adopción masiva de Java como tecnología empresarial, que fue una evolución basada en la orientación de Java hacia el Web y a arquitecturas empresariales robustas y escalables. 7 Ahora que Java ha madurado considerablemente y que existen otros lenguajes orientados a objetos como son C#, Ruby, Phyton, etc; se está buscando que los lenguajes y frameworks de desarrollo sean más ágiles y rápidos como son Ruby-on-Rails y un esfuerzo similar para Java llamado JRuby, que trata de atacar la facilidad y velocidad de desarrollo. Últimamente se ha hablado mucho sobre los lenguajes dinámicos o de scripting que permiten extender los programas en tiempo de ejecución por medio de la adición de nuevo código o por medio de la extensión de objetos y sus definiciones o modificando el sistema de tipos. Un ejemplo de este tipo de lenguajes es Ruby o Groovy. Evolución en las Metodologías de Desarrollo. Aunque no existe una metodología de desarrollo perfecta, se ha probado que los modelos evolutivos e iterativos son los más exitosos para sistemas de información Web, puesto que reducen el riesgo del proyecto al dividirlo en partes más pequeñas e ir aprendiendo del dominio de la aplicación y de las necesidades del cliente conforme avanza el desarrollo, permitiendo flexibilidad de las 2 partes [BS06]. También se crearon metodologías ágiles, con varios matices, que promueven la facilidad de cambios en los requerimientos y a la alta participación del cliente en el proceso de desarrollo, ya que se ha visto que es una de las características más importantes para el éxito de proyectos de software. Consenso en las abstracciones del sistema. Uno de los grandes problemas en el desarrollo de sistemas es el de comunicación con los clientes y entre personas técnicas encargadas del desarrollo de sistemas. Se trata de encontrar un lenguaje común y entendimiento de las abstracciones de un sistema. UML (Unified Modeling Lenguaje) es un esfuerzo por estandarizar el modelamiento para el análisis y diseño orientado a objetos. UML es un lenguaje estándar para especificar, visualizar, construir y documentar los artefactos de sistemas de software, así como para modelamiento de negocio [Fow03B]. Aunque UML sigue evolucionando y cambiando, logra en gran medida resolver el problema de comunicación entre personas técnicas encargadas del desarrollo de sistemas, pero no así la comunicación con el cliente ya que al no ser técnicos, en su gran mayoría, no comprenden al detalle este tipo de representaciones gráficas. Elementos de Arquitecturas de Sistemas. Para resolver los temas de atributos de calidad dentro de los sistemas de software y reducir el riesgo, se usan elementos que forman parte de los temas de “Arquitecturas de Sistemas”, “Frameworks” y “Patrones de Diseño” [GHJV98]. Estos elementos tratan de facilitar la construcción de sistemas presentando soluciones para problemas tipo, que pueden ser resueltos de la misma manera, garantizando así que se pueda resolver el problema en menor tiempo de desarrollo y aplicando una solución que anteriormente 8 fue implementada y funcionó. Aunque es un tema muy frecuente, el gran abanico de herramientas y la gran cantidad de documentación que existe al respecto ha llevado a la especialización de las personas en arquitecturas de dominio específico o en segmentos de la arquitectura como es la seguridad, haciendo que se requiera aún mayor cantidad de gente experta en las diferentes áreas para construir un sistema robusto. Esto ha llevado a que generalmente, se trate de estandarizar una arquitectura de referencia a nivel de cada empresa en base a la cual todos los sistemas deben ser desarrollados para facilitar su construcción, mantenimiento y extensibilidad sea quien sea que tenga que realizar los cambios al sistema. Como otros esfuerzos para facilitar el trabajo de la creación de sistemas están la creación de estándares de programación, mejores prácticas, etc. Todos estos esfuerzos se centran en mejorar las herramientas disponibles para comunicar, documentar y crear los sistemas pero aún con todo este abanico de herramientas se sigue teniendo grandes problemas en la creación de sistemas. 2.2. Prototipos de sistemas Una técnica muy usada para eliminar los riesgos en la fase de requerimientos es el realizar prototipos de sistemas, que es el proceso de crear un modelo incompleto pero funcional de lo que será el sistema de software final y que puede ser usado para permitir a los usuarios tener una idea inicial de lo que será el sistema completo y permitirles evaluarlo. El realizar prototipos tiene algunas ventajas y desventajas que pueden ser tangibles o abstractas. Algunas de las ventajas: - Reducción de tiempos y costos - realizar prototipos puede ayudar a mejorar la calidad de los requerimientos y especificaciones que se proveen a los desarrolladores, puesto que cualquier cambio cuesta exponencialmente más de implementar mientras más tarde se detectan en el ciclo de desarrollo; la determinación temprana de lo que el usuario realmente quiere, puede resultar en software menos costoso y hecho más rápidamente. El diseñador e implementador del software puede obtener retroalimentación de los usuarios temprano en el proyecto. - Incremento y mejora en la manera que se involucra el usuario – realizar prototipos requiere participación del usuario, los usuarios pueden ver e interactuar con el prototipo, permitiéndoles proveer una mejor y más completa retroalimentación y especificaciones. Ya 9 que los usuarios son los que conocen el dominio del problema mejor que cualquiera en el equipo de desarrollo, el incremento en la interacción puede resultar en un producto final que tiene mayor calidad tangible e intangible, ya que el producto final es más probable que satisfaga los deseos del usuario en los aspectos visual, emocional y de rendimiento. La comunicación alrededor del prototipo permite eliminar malos entendidos y errores de comunicación que ocurren con la interpretación y visión de lo que debe hacer del sistema. - Mejora en las estimaciones - permite al ingeniero de software tener una visión más clara del tamaño del proyecto y del nivel de conocimiento, compromiso y participación de los usuarios y así poder realizar una mejor estimación en tiempo y costo. No usar o mal usar prototipos, también puede tener algunas desventajas: - Análisis insuficiente – el enfocarse en un prototipo limitado puede distraer a los desarrolladores de realizar un análisis completo del proyecto. Esto puede llevar a ignorar mejores soluciones, realizar pobre ingeniería y arquitectura que hace un sistema difícil de mantener. Más aun si el prototipo no es una representación real del sistema puede que no escale bien cuando se realice el proyecto completo. - Confusión del usuario entre prototipo y sistema final – los usuarios pueden pensar que un prototipo construido para validar requerimientos e ideas, es el producto final casi listo y que solo necesita retoques. Este no siempre es el caso ya que puede que la arquitectura usada no sea escalable o siquiera válida o el sistema requiera aun mucho trabajo interno. - Exceso de costo y tiempo de desarrollo en el prototipo – una característica importante de la realización de prototipos es que deben ser realizados rápidamente, si el desarrollador pierde esta noción puede tratar de desarrollar un prototipo que es demasiado complejo y por lo tanto el costo se eleva proporcionalmente al tiempo invertido. Existen dos tipos de prototipos de software: desechables y evolutivos. Los desechables son prototipos que se crean rápidamente para probar teorías y después se descartan para iniciar el desarrollo de manera correcta desde el principio sin incluir el prototipo como parte del desarrollo final. Los prototipos evolutivos se realizan de una manera más robusta y estructurada y van evolucionando hasta convertirse en el producto final [AABN07]. 10 En general las metodologías evolutivas, iterativas y ágiles son una combinación de prototipos evolutivos con otras técnicas; ya que tratan de aclarar los requerimientos del sistema creando partes funcionales del sistema que el usuario puede utilizar, revisar y criticar. 2.3. Arquitectura de sistemas Web La arquitectura de sistemas de un programa o sistema computacional es la estructura o estructuras del sistema que está compuesta de elementos de software, las propiedades externamente visibles de esos elementos y las relaciones entre ellos, es decir la distribución de funciones a nivel de frontera dentro del sistema, y la definición precisa de esa frontera. La frontera en arquitectura de sistemas se define como la línea que separa las funciones o subcomponentes que forman parte de un componente y cuales no. La disciplina de la arquitectura de software está centrada en la idea de reducir la complejidad a través de la abstracción y la separación de las responsabilidades [Bus96]. Client Presentation Layer Business Layer Persistence Layer Any convencional DB Figura 1. Arquitectura típica para sistemas Web Uno de los tipos de arquitectura de sistemas son las arquitecturas multicapa o de n-capas (ver Figura 1). Cada capa es una partición lógica (no necesariamente física) de los componentes de la aplicación y que al ser lógica involucra la disciplina por parte del programador de mantener el encapsulamiento de las capas y las invocaciones en el orden adecuado en base a la definición de la jerarquía de capas de la arquitectura. 11 La partición multicapa es el modelo natural para aplicaciones Web, ya que es una arquitectura que ha sido probada por ser escalable, extensible y mantenible. Aunque el uso de esta arquitectura puede producir tiempos de respuesta más lentos que otras arquitecturas, las aplicaciones Web tienen un tiempo de respuesta inherentemente más lento que otro tipo de aplicaciones, pues dependen en gran medida de la latencia de la red. Además, una aplicación Web multicapa bien diseñada y programada generalmente podrá mejorar sus tiempos de respuesta en base a hardware. Se recomienda separar la aplicación en un mínimo de 3 capas: presentación, negocio y persistencia [Fow03A], ya que son el mínimo de componentes básicos de separación de responsabilidades de un sistema de información en el Web. La capa de presentación se encarga de toda la lógica de despliegue y envío de información a los clientes. La capa de negocio se encarga de aislar y centralizar la lógica de validaciones y restricciones de la aplicación. La capa de persistencia se encarga del acceso y manejo de datos sean locales o remotos. Dentro de estas capas podrán implementar otros patrones o tener varias capas que la componen y es por esto que esta arquitectura es llamada multicapa o de n-capas. Se dice que esta arquitectura es inherentemente más mantenible y escalable ya que cada una de las capas es independiente y de esta manera se aísla los detalles de implementación específicos de cada una de ellas. Cualquier cambio que se requiera realizar estará focalizado y aislado a esa capa o a la inmediatamente superior, haciendo más fácil y simple el cambio posterior de lógica o, inclusive, de capas completas. Se puede escalar las aplicaciones con arquitectura multicapa por medio de hardware al poder colocar las diferentes capas en servidores separados y colocar varios servidores para cada capa. Esto se logra al agregar Wrappers a cada capa para que funcionen por medio de Corba (Common Object Request Broker Architecture) [Omg07] u otra tecnología similar de acceso remoto. Por ejemplo en el caso de Java serian los Session Beans [Sun07] que implementan internamente Corba transparentemente para la aplicación. La anterior explicación está simplificada ya que existen otros requerimientos de implementación para lograr esta distribución de capas en diferentes servidores. 12 2.4. Arquitectura de la plataforma Eclipse Eclipse es una plataforma extensible de desarrollo de software de código abierto y gratuita (http://www.eclipse.org/). Está orientada a construir ambientes de desarrollo integrados (IDEs – Integrated Development Enviroment). Es desarrollada y mantenida por el “Eclipse Foundation” bajo licencia “Eclipse Public License” que garantiza su extensibilidad y gratuidad y su ultima versión para producción es la 3.3.1.1 del 23 de Octubre del 2007 con nombre código Europa. Eclipse es la plataforma de desarrollo y ejecución de aplicaciones Java más popular en la actualidad, con más de 50’000.0000 de descargas al año. Eclipse está soportado por muchas organizaciones como son Borland Software Corp., Merant Internation Ltd., Oracle, Rational Software Corp., Red Hat Inc., SuSe Inc., y TogetherSoft Corp., además de muchos constructores de herramientas que contribuyen a la plataforma Eclipse al empaquetar sus herramientas como plug-ins de Eclipse. La plataforma entrega una arquitectura extensible, con puntos de extensión claramente definidos y documentados llamados plug-ins de Eclipse, que está soportado por la arquitectura del ambiente de desarrollo de plugins (PDE – Plugin Development Enviroment) [ML05]. El mecanismo básico de extensibilidad en Eclipse es que los nuevos plug-ins pueden añadir nuevos elementos de procesamiento al ambiente y/o a los plug-ins existentes. Cada plug-in tiene que estar de acuerdo con el contrato o API definido para los plug-ins de Eclipse para que pueda funcionar y trabajar con el ambiente. Todo su ambiente, excepto una pequeña porción de código para ejecución inicial, está escrito y configurado como un plug-in de Eclipse. Es decir, la plataforma está compuesta por un núcleo y un grupo de plug-ins que extienden el núcleo para el inicio y ejecución estándar de los procesos de otros plug-ins y de esta manera se puede extender y personalizar el ambiente de ejecución. El núcleo de servicios está para controlar el ambiente, las herramientas y componentes acoplables que están trabajando juntos para soportar las tareas de programación o trabajo en general. La arquitectura de la plataforma Eclipse incluye muchos de los patrones de diseño de GUI (Interfaz Gráfica de Usuario), por ejemplo, provee el versionamiento de plug-in y un sistema de ayudas integrado. También puede ser usado como una arquitectura de IDE de propósito general. Como el IDE está basado en una arquitectura genérica de plug-ins, se hace fácil 13 soportar otros lenguajes como C/C++, PHP, Ruby. A través de su infraestructura definida, plugins de varios proveedores pueden comunicarse entre ellos de manera fácil y sencilla. Se puede extender la parte visual de IDE por medio de Vistas, Editores, Perspectivas, Asistentes (Wizards) y Ayudas. Cada plugin está empaquetado de manera estándar y es configurado por medio de un archivo XML (eXtensible Markup Language) que es el que contiene la definición de qué clases son los puntos de integración con el IDE para cada una de las funcionalidades visuales y no visuales. Figura 2. Arquitectura de la plataforma Eclipse Como se puede apreciar en la Figura 2, la base para la arquitectura de Eclipse es el RCP – Rich Client Platform (Plataforma de cliente enriquecido) que es el mínimo grupo de plug-ins requeridos para construir aplicaciones de cliente enriquecido y está constituida por los siguientes componentes: - Plataforma principal – inicio de Eclipse, ejecución de plug-ins. - Equinox - un framework de componentes basado en el estándar OSGi que es una plataforma para empaquetamiento estándar de componentes. - El SWT (Standard Widget Toolkit) – Un widget toolkit visual portable y que puede ser ejecutado fuera de la plataforma. 14 - JFace – capa de GUI intermedia para manejo de archivos, editores de texto y manejo de texto. - El Workbench de Eclipse – vistas, editores, perspectivas y asistentes (ayudas) La librería SWT (The Standard Widget Toolkit) entrega funcionalidad nativa de componentes de presentación para la plataforma Eclipse de manera independiente del sistema operativo. La librería SWT puede ser usada para proveer un look and feel nativo al usuario final, así no sabrán si la aplicación es una aplicación nativa o Java. Eclipse dispone de varias características y funcionalidades, pero las básicas y más importantes para este proyecto son: - Editor de texto - Resaltado de sintaxis - Compilación en tiempo real - Integración con Ant - Asistentes (wizards): para creación de proyectos, clases, tests, etc. - Refactorización - Pruebas unitarias con JUnit - Control de versiones con CVS - Integración con servidores de aplicaciones Java como: Tomcat Asimismo, a través de "plugins" libremente disponibles es posible añadir: - Control de versiones con Subversion, vía Subclipse. - Integración con Hibernate, vía Hibernate Tools. Eclipse viene empaquetado en varias versiones para los diferentes IDEs de programación, como son: - Eclipse IDE para desarrolladores Java - Eclipse IDE para desarrolladores Java Enterprise Edition (Web) - Eclipse IDE para desarrolladores C/C++ - Eclipse para desarrolladores de RCP/Plug-ins (PDE) - Otros empaquetamientos de terceros. 15 2.5. Ambientes de desarrollo En el desarrollo de la presente tesis se utilizarán dos ambientes de desarrollo: Visual Studio Express Edition C# para lenguaje C# [Lho06] y la plataforma Eclipse IDE RCP/Plug-in Development Enviroment para el lenguaje Java. Los dos lenguajes tienen grandes similitudes en sus construcciones, sintaxis y uso de librerías. Y, dado que se utilizará un paradigma de componentes, se ha decidido que será bastante reutilizable el esfuerzo de diseño y codificación; además, de rápida y transparente la migración del trabajo realizado en C# hacia Java, excepto por los componentes visuales. Lo anteriormente expuesto ha sido comprobado por los varios frameworks que han cruzado desde el mundo Java a C# como Hibernate a NHibernate, Velocity y NVelocity, JUnit a NUnit, etc. También, existen herramientas que automatizan la migración de código de un lenguaje al otro, como por ejemplo el proyecto de código abierto NET2Java (https://net2java.dev.java.net/) de aplicaciones .Net (C#, Visual Basic.Net) a Java y el Microsoft Java Language Conversion Assistant (JLCA - http://msdn.microsoft.com/vstudio/java/migrate/jlca/default.aspx) que migra desde Java a C# o J#. A continuación se presenta en detalle los dos ambientes de ejecución que se utilizarán durante el desarrollo de la presente tesis. 2.5.1. Visual Visual Studio Express Edition C# Studio Express Edition C# (VS Express C#) (http://www.microsoft.com/express/vcsharp/) es un IDE de desarrollo gratuito para lenguaje C# que tiene todo el soporte de diseñador visual del Windows Presentation Foundation (WPF) para crear aplicaciones de Windows Forms. Esta versión está restringida sólo para este tipo de aplicaciones, pero tiene las ventajas de contar con las herramientas completas para crear, desarrollar, probar, depurar y empaquetar este tipo de aplicaciones de una manera sencilla y rápida. Dado que la versión de VS EE C# es restringida en su funcionalidad no cuenta con integración con otras herramientas. Es por esto que para la planificación, control y avance de las tareas se utilizará Mantis (Issue tracker - http://www.mantisbt.org/). También, se utilizará 16 Subversión para el manejo de versiones junto con TortoiseSVN (http://tortoisesvn.net/) que es un cliente de SVN para Windows. 2.5.2. Eclipse IDE RCP/Plug-in Development Enviroment (PDE) Existe una versión del IDE Eclipse para desarrolladores de RCP/Plug-in llamada Plug-in Development Enviroment (PDE) especialmente empaquetada con una serie de plug-ins que proveen herramientas para crear, desarrollar, probar, depurar y poner en producción plug-ins de Eclipse. Dentro del PDE se tiene disponibles wizards, plantillas y otros elementos para proyectos de plug-ins de Eclipse. Básicamente todos estos elementos ayudan al programador, que está creando un plug-in de Eclipse, a que pueda definir los diferentes parámetros de configuración y los puntos de extensión de manera visual sencilla. Los proyectos pueden ser de tipo: Plug-in (fragment), Feature, Update site y RCP product, que se los describe a continuación. La idea general de la separación y composición de proyectos para construir plug-ins de la plataforma Eclipse es dar más flexibilidad de distribución y de reutilización de componentes y proyectos. - Plug-In (Fragment) – este tipo de proyecto es el que contendrá la funcionalidad en sí del plug-in que se desea crear. También puede ser sólo un proyecto que contenga un fragmento de la funcionalidad de un plug-in (Fragment). Contiene una definición de los puntos de extensión a la interfaz de usuario de Eclipse como pueden ser wizards, editores, vistas, ayudas, etc. Este tipo de proyecto contiene un archivo XML llamado plugin.xml que tiene la definición del proyecto y está asociado con un editor visual para facilitar el ingreso de los valores de configuración para este archivo. Entre los parámetros de configuración, además de los puntos de extensión a la interfaz de usuario en la instalación, se puede ingresar valores de los que depende el plug-in que se está construyendo para su correcta ejecución, como son: dependencias de otros plug-ins de eclipse, parámetros para el ambiente de ejecución del Java Virtual Machine(JVM) como el Classpath, los puntos de extensión que expondrá este plug-in y si se debe incluir el código fuente como parte del empaquetamiento. - Feature – este tipo de proyecto agrupará a varios plug-in o fragmentos y se encarga de empaquetarlos y colocar un conjunto información para la instalación como son: descripción de empaquetamiento, derechos de autor, licenciamiento e información extra en el Web. Un feature es el grupo de funcionalidades que en conjunto presentan las herramientas completas para que el usuario pueda realizar un trabajo. Se pueden seleccionar todas o solo algunas características de los plug-ins para ser empaquetadas 17 como funciones configurables dentro de Eclipse. También se puede definir parámetros de instalación para sistemas operativos específicos. Este tipo de proyecto contiene un archivo XML llamado feature.xml que tiene la definición del proyecto y esta asociado un editor visual para facilitar el ingreso de los valores de configuración para este archivo. - Update Site – este tipo de proyecto agrupa Features para su fácil empaquetamiento para distribución masiva. Un Update site es un lugar ya sea local (en disco o recursos compartidos) o remoto (red local o Web) desde donde se podrá instalar el plug-in en Eclipse. Los Update Site son la manera estándar y fácil de instalar plug-ins dentro de Eclipse, ya que se lo hace por medio de un wizard y Eclipse se encarga del proceso de descarga, instalación y notificación de progreso al usuario. Este tipo de proyecto contiene un archivo XML llamado site.xml que tiene la definición del proyecto y está asociado un editor visual para facilitar el ingreso de los valores de configuración para este archivo. - RPC product - este tipo de proyecto es una aplicación de Rich Client Aplication que permite crear aplicaciones con la misma interfaz visual de Eclipse para usuarios finales. Para los propósitos de esta tesis, no se requerirá el uso de este tipo de proyecto. Para el apoyo en la planificación, diseño y desarrollo de esta tesis se utilizarán algunos plugins de Eclipse que no vienen integrados directamente con la distribución y de los que se presentará una descripción detallada a continuación: - eUML2 para Java – Diagramas UML – (http://www.soyatec.com/update) - es un modelador de diagramas UML completamente integrado con el ambiente Eclipse y que permite la sincronización de código / modelo en tiempo real, además la creación de modelos de clases desde código automáticamente y la exportación de modelos a imágenes. Existen 2 versiones una gratuita y una comercial. Esta herramienta será utilizada principalmente en el diseño y modelamiento UML de CodEv. - Mylyn – Manejo de tareas – (http://www.eclipse.org/mylyn/) - es un grupo de extensiones a la interfaz de usuario de Eclipse enfocadas al manejo de tareas y que ayuda a monitorear y manejar el contexto de las tareas por medio de información relevante. Tiene capacidad de edición fuera de línea para repositorios de tareas como Jira, Bugzilla, Mantis o Trac. En este caso se utilizará Mantis (Issue tracker http://www.mantisbt.org/) para el trabajo en equipo. Mylyn facilita: el trabajo en multitarea al permitir manejar el contexto de la tarea ocultando información irrelevante, la planificación al poder registrar las fechas de ejecución, inicio y fin de las tareas, además de poder sincronizarlas con un repositorio de tareas, además de compartir el conocimiento ya que permite compartir la tarea y su contexto de edición y archivos. 18 - Subversive – Integración con Subversion (SVN) - (http://www.polarion.org/index.php?page=overview&project=subversive) es un plug-in que ayuda a la integración de Eclipse con repositorios de versiones Subversion (SVN http://subversion.tigris.org/). SVN es un sistema para el control de versiones que es de código abierto y que apunta a ser un reemplazo del muy conocido Concurrent Versioning System (CVS) al mejorarlo en varios aspectos. 2.6. Trabajos relacionados Se encontraron muchos sitios con información sobre productos para generación de código, pero un sitio que destaca fue Code Generation Network (http://www.codegeneration.net/). En este sitio se puede encontrar un listado bastante completo sobre las herramientas existentes para generación de código, comerciales y de código abierto, creados en y para generación de varios lenguajes de programación. Entre las herramientas listadas en el sitio, se encontró herramientas con una variedad de características que los hacen mejores para ciertas tareas específicas o en cierto dominio concreto de generación. Dado el gran número de herramientas listadas en este sitio, se decidió filtrar a los sistemas a ser analizados por un criterio simple, se analizaron los generadores para Java, específicamente, y de esta clasificación se eliminaron los generadores que no eran de código abierto por limitar la capacidad de extensión que se le puede dar a los productos que se quiere generar. La clasificación de los generadores de código abierto que se encontraron y se evaluaron se divide en: - Generadores orientados a una función específica como la generación de persistencia y que no generan una aplicación funcional completa. - Generadores que tienen su lógica de generación mezclada o integrada con el código que no usan plantillas y por lo tanto son difíciles de extender. Muchos de estos generadores, crean capas de persistencia o negocio ad-hoc y sin muchos estándares. - Herramientas con funciones similares a la propuesta de este trabajo, pero que no cumplen con todos los requisitos para poder generar prototipos rápidos y evolutivos. - Generadores basados en MDA (detallados más adelante). - Muchas otras herramientas que ya no han sido mantenidas en el tiempo, se han transformado en comerciales o ya no existen los sitios de referencia, por lo tanto no fueron valoradas. 19 A continuación se presenta una descripción más detallada del funcionamiento de algunos de los tipos de generadores que se encontraron valiosos en esta clasificación, y que algunos de ellos han sido usados por el autor o se probaron para revisar su funcionamiento. XDoclet (http://xdoclet.sourceforge.net/xdoclet/index.html) – Es un motor de generación de código que permite realizar programación orientada a atributos para Java. Funciona por medio de plantillas y de la adición de meta-datos al código fuente por medio de etiquetas de JavaDoc. Las etiquetas de JavaDoc se deben colocar por atributo por archivo por componente, permitiendo flexibilidad y control muy granular sobre lo que se quiere generar. Fue creado especialmente para generación de código de EJB (Enterprise Java Beans) facilitando la creación de los múltiples archivos que requiere cada EJB, que pueden llegar a ser hasta 7, facilitando el mantenimiento de un solo un archivo por EJB. Aunque originalmente ese fue su propósito, XDoclet permite generar cualquier tipo de archivos basados en las plantillas que se utilice. Las limitaciones de XDoclet en relación a lo propuesto en esta tesis, es que se requiere de un tiempo de programación considerable para tener un prototipo funcional, puesto que se debe establecer el proyecto inicial con las plantillas y crear cada clase y sus etiquetas para los elementos que se quiera generar. Además, se requiere un conocimiento bastante profundo del API de XDoclet, Java, JavaDoc y de Ant que es la única manera de realizar el proceso de generación y construcción por el momento. El generador propuesto en esta tesis podría ser usado en conjunto con XDoclet para generar la definición y configuración inicial del proyecto y de ahí tomar XDoclet para generar otro tipo de archivos. Generadores basados en MDA® (Model Driven Architecture®) (http://www.omg.org/mda/) – MDA® es una manera de desarrollar aplicaciones basados en modelos independientes de la plataforma (PIM), más uno o más modelos específicos de la plataforma (PSM) para su transformación (ver Figura 3). Especialmente, se basa en el uso de UML estándar y la transformación de modelos de meta-datos en XML para intercambio independientes de la plataforma (XMI). Es decir, separa el modelamiento de la lógica del negocio y de la aplicación de la plataforma tecnológica. 20 Figura 3. Elementos y proceso típico de MDA Un ejemplo de un generador MDA es la herramienta Sculptor de la plataforma Fornax (http://fornax-platform.org/), que permite que en base a un Lenguaje de Dominio Específico (DSL) se construya modelos válidos para la generación y generar el código basado en cartuchos (plantillas) de lo que se quiere generar. Una de las características muy útiles de esta herramienta es que permite código generado sea modificado y sea regenerado. La diferencia más grande entre el generador propuesto en esta tesis y los generadores basados en MDA, es que parten de diferentes premisas para la generación de código. Es decir MDA basa su generación en modelos exportados a XML (generalmente XMI) obtenidos a partir de un modelo UML y de un DSL, y el generador propuesto en esta tesis, basa su generación en un modelo de datos almacenado en una base de datos relacional. Otra de las ventajas del generador propuesto en esta tesis es su facilidad de uso, ya que permitirá realizar la generación en poco tiempo y con bajo conocimiento de la herramienta. AppFuse (http://appfuse.org/) – fue creado originalmente para eliminar el tiempo de inicio o establecimiento de un nuevo proyecto cuando se construyen nuevas aplicaciones web. Esta aplicación genera un esqueleto de proyecto funcional pero sin relación a un modelo de datos, similar a los que se crean en un IDE de desarrollo cuando se hace a través de un asistente para crear un nuevo proyecto. También permiten la generación de otros archivos del proyecto, tipo CRUD, pero su generación es bastante especializada y se requiere un conocimiento y 21 configuración de la herramienta bastante profundos. Otro proyecto muy similar a AppFuse y que está creciendo es J2EE Spider (http://www.j2eespider.org/features/en/). Las principales diferencias del generador propuesto con este tipo de generadores es que generan solo archivos generales para la definición estándar (el esqueleto) del proyecto, en cambio el generador propuesto toma el modelo de datos y genera mantenedores CRUD Web para cada uno de las tablas en el modelo. Como se detalló anteriormente existe una gran cantidad de generadores para múltiples propósitos y con gran variedad de capacidades, y se ha encontrado que la gran diferencia con el generador que se desarrolló como parte de esta tesis está en su facilidad de uso al poder generar una aplicación funcional basada en el modelo de datos en pocos minutos, amigabilidad ya que su operación es sencilla e intuitiva e integrada totalmente con un ambiente de desarrollo robusto, además tiene la capacidad de evolucionar la aplicación generada por medio de la regeneración de código. Todas estas características anteriormente descritas justificaron, a criterio del autor, la creación del generador CodEv. 22 3. Análisis del Sistema En este capítulo se identifican los requisitos que satisfacen los objetivos planteados, el cómo se llegó a estos requisitos y posteriormente se presenta la metodología que se utilizó para la realización de CodEv, la planificación inicial y su evolución en el tiempo. 3.1. Requisitos del Sistema Los requisitos que serán presentados a continuación para el desarrollo de CodEv fueron cambiando y evolucionando en el tiempo con el conocimiento adquirido por el autor con la investigación de técnicas y tecnologías usadas para la generación de código, la creación de prototipos evolutivos de puntos críticos del generador y con cada incremento de funcionalidad en cada iteración. 3.1.1. Descripción general Como ya se ha definido, CodEv es una herramienta orientada a acelerar y facilitar la creación de aplicaciones Web Java orientadas a base de datos con una arquitectura de sistemas multicapa, por medio de la generación de código fuente para operaciones CRUD para cada una de las tablas seleccionadas del esquema de datos. Su funcionamiento se basará en un modelo de datos del cual se desea crear la aplicación Web, y el generador tomará las definiciones de las tablas, campos y sus relaciones y generará la persistencia, la capa de negocio y la presentación para cada una de sus tablas seleccionadas para que se pueda hacer el mantenimiento CRUD de cada tabla con sus respectivas relaciones. Cuando el generador se ejecute contra el modelo de datos seleccionado, lo que se obtendrá será una aplicación Web multicapa con código Java estándar lista para hacer deploy (ejecutar). La herramienta debe permitir al usuario varios parámetros de configuración para la generación con un proceso sencillo y amigable, que además esté fuertemente integrado con un ambiente de desarrollo robusto y poderoso y que permita la evolución de la aplicación generada por medio de la regeneración de código siguiendo un proceso no destructivo. Estos son los requisitos de manera general que deberá cumplir la aplicación y aunque parecen ser simples y claros, la mayoría del trabajo es altamente técnico y se encuentra en las decisiones arquitectónicas y en los atributos de calidad. 23 3.1.2. Requisitos funcionales Los parámetros de configuración para la generación son capturados en forma organizada (asistente - Wizard) y son los siguientes: - Datos generales del proyecto de generación: nombre del proyecto, paquete java para marcar el namespace en el que se organizará el código fuente de la aplicación. - Datos de la conexión a la BD: nombre o IP del servidor, puerto de conexión, usuario, password y esquema de datos. - Selección de tablas a ser generadas en base al esquema de datos seleccionado. - Selección de tabla de manejo de usuarios y de campos de usuario y password dentro de esta tabla y que serán usados para tener una autenticación básica de usuarios a la aplicación generada. - Selección de campos a generar, esta será una selección por tabla. Además, se podrá especificar el campo de búsqueda que será usado por las tablas hijo relacionadas a la tabla que se está configurando. - Pre-visualización de la plantilla de presentación de aplicación generada. - Al ejecutar la generación se presentarán una serie de mensajes de avance del proceso de generación. Figura 4. Casos de uso para la generación Después de observaciones realizadas y de la creación de los primeros prototipos se encontró que para que las aplicaciones generadas sean realmente útiles, deberían tener ciertas funcionalidades ya generadas, como son: 24 - Autenticación de usuarios por medio de usuario y password que deberán ser validados contra una tabla en el esquema de base de datos. - Menú de navegación para acceso a la administración CRUD de cada tabla. Para la administración CRUD de cada tabla: - Presentación descriptiva de relaciones padre - cuando exista una clave foránea perteneciente a una tabla padre, se deberá presentar el campo de búsqueda o descripción de la tabla padre a cambio del identificador. Esto permitirá que sea mucho más descriptiva y clara la información que se presenta como parte de cada registro. - Filtrado de resultados - en los listados existirá filtrado de resultados por todos los campos, excepto por la clave primaria. En el caso de la búsqueda de relaciones padre, se deberá tener la capacidad de búsqueda y selección fácil del resultado. - Paginación de resultados - los resultados de los listados podrán ser paginados, con una administración de la paginación que permita definir el número de resultados por página y la página a la que se desea ir. 3.1.3. Atributos de Calidad Entre los atributos de calidad más importantes que se ha definido que deberá tener el generador y su ambiente de ejecución, son los siguientes: - Usabilidad, que permita la instalación del generador y del ambiente de manera sencilla y que además el proceso de generación sea rápido y sencillo (tiempo de generación menor a 5 minutos) para alguien con experiencia media en el ambiente de desarrollo. - Portable, es decir que pueda ser ejecutado en múltiples sistemas operativos. - Mantenibilidad, que se puedan realizar modificaciones y aumentos de funcionalidad al generador con mínimo esfuerzo. - Extensibilidad, que se pueda agregar al proceso de generación de manera sencilla nuevas bases de datos desde donde se obtiene el modelo de datos. Como atributos no funcionales, se tomó en cuenta los puntos críticos o áreas de riesgo para el desarrollo como son: - Integración del generador con un ambiente de desarrollo robusto, que permita al usuario del generador poder editar los archivos generados con ayudas visuales y probar la aplicación generada con pasos simples y en poco tiempo. - Creación de una abstracción del modelo de datos y sus relaciones. Esta abstracción debe ser simple, pero a la vez lo suficientemente completa y robusta para que se pueda 25 generar una serie de elementos de código en base a este modelo de datos y sus relaciones. - Generación de código en base a plantillas de archivos a ser generados, para hacer que el resultado de la generación pueda ser mantenible y editable de manera más sencilla. - Regeneración de código de la aplicación, permitirá que siguiendo un proceso no destructivo, se pueda actualizar la aplicación generada con los cambios hechos al esquema de base de datos. - Proceso de generación y regeneración configurable en base a parámetros. 3.2. 3.2.1. Plan del Proyecto Metodología Para la realización del proyecto se utilizó una metodología iterativa-incremental en la cual se realizaron 4 iteraciones y en cada una de ellas se agregó al sistema parte de la funcionalidad requerida y se realizaron mejoras. El desarrollo Iterativo dice que se deben hacer repeticiones que pasan por todas las actividades del desarrollo como son: análisis, arquitectura, diseño, implementación, pruebas e instalación, etc. Se dice que un proceso es iterativo incremental cuando en cada iteración se añade algo nuevo de valor que nos acerca cada vez más al objetivo final del desarrollo [BS06]. Figura 5. Representación en el tiempo del desarrollo Iterativo En la Figura 5 se puede ver una representación en el tiempo de lo que es desarrollo iterativo incremental y el esfuerzo empleado en cada una de las actividades del desarrollo conforme avanza el proyecto. 26 Para el desarrollo de CodEv además del uso de incrementos se usó prototipos evolutivos, lo que permitió que la definición de los requisitos y necesidades de la herramienta fueran madurando y evolucionando, durante el tiempo de desarrollo, hasta convertirse en el producto funcional y deseado. También, se tomó en cuenta los puntos críticos o áreas de riesgo para el desarrollo, para valorar los elementos que requerían ser parte de un prototipo o serían implementados en las primeras iteraciones; de esta manera se logró reducir el riesgo de la construcción de la herramienta en las etapas más tempranas del desarrollo. Todos estos elementos serán descritos en mayor detalle en los capítulos de requerimientos, diseño y construcción. 3.2.2. Planificación Las actividades y plazos definidos originalmente para alcanzar los objetivos planteados para la creación del proyecto fueron las siguientes: 1. Investigar sistemas similares existentes en el mercado (3 semanas) 2. Especificar los requisitos de la solución (3 semanas) 3. Diseño de la solución que permita alcanzar el objetivo (1 mes) 4. Iteración 1: Pantallas del sistema, conexión a BD (3 semanas) 5. Pruebas Iteración 1 (1 semana) 6. Iteración 2: Capacidad de generación de: Capa de Persistencia, Negocio y Presentación – MVC (2 meses) 7. Pruebas Iteración 2 (2 semanas) 8. Iteración 3: Capacidad de generación de: scripts de ANT y archivos de proyecto de eclipse (1 mes) 9. Pruebas Iteración 3 (2 semanas) 10. Pruebas finales y generación del caso de estudio (3 semanas) 27 El cronograma de actividades asociado a este plan de trabajo es el siguiente: Tarea 1 Mes 1 Mes 2 Mes 3 Mes 4 Mes 5 Mes 6 Mes 7 Mes 8 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 2 3 4 5 6 7 8 9 10 Figura 6. Cronograma de actividades para la creación del sistema Aunque el proyecto se terminó en el tiempo estimado, la planificación se alteró en gran medida en base a las necesidades y avance del proyecto. Muchas de las actividades fueron variando conforme el proyecto avanzó y se encontraron prioridades más altas de ciertos componentes y dependencias entre componentes y tareas, además del cambio de algunos requerimientos y nuevos requerimientos, que sirvieron para alcanzar los objetivos planteados para el proyecto. El proyecto final usó 4 iteraciones y cambió las actividades que se realizaron en cada iteración. Este fue el plan de ejecución del producto final: 1. Investigar sistemas similares existentes en el mercado (3 semanas) 2. Especificar los requisitos de la solución (3 semanas) 3. Diseño de la solución que permita alcanzar el objetivo (1 mes) 4. Iteración 1: Prototipos 1 y 2 de validación de conceptos de generación y capacidad de generación de la aplicación completa en base a plantillas (1 mes) 5. Iteración 2: Pruebas de generación de varios proyectos de prueba y evolución de la generación en base al uso en un proyecto real aplicado, mejoras sustanciales al proceso de generación (1 mes) 28 6. Iteración 3: Capacidades de regeneración (1 mes y 2 semanas) 7. Iteración 4: Integración de la herramienta con ambiente de desarrollo (1 mes y 2 semanas) Pruebas finales y generación del caso de estudio (1 semana) 29 4. Arquitectura y Diseño del Sistema En el capítulo de arquitectura y diseño se presenta una descripción general que servirá de introducción a las decisiones que se tomaron como parte de la arquitectura y el diseño. Posteriormente se describirán 3 de los niveles importantes de la arquitectura que son: el ambiente de ejecución del generador, la arquitectura del generador en sí y, por último, la arquitectura que tendrán las soluciones a ser generadas. También, se presentará el diseño detallado de los componentes más importantes que componen el generador y las soluciones generadas. 4.1. Descripción general Para el desarrollo de CodEv, además del uso de incrementos, se usó prototipos evolutivos lo que permitió que la definición de los requisitos, el diseño y la arquitectura de la herramienta fueran madurando y evolucionando, durante el tiempo de desarrollo, hasta convertirse en el producto funcional deseado. También, se tomaron en cuenta los puntos críticos o áreas de riesgo para el desarrollo, para valorar los elementos que requerían ser parte de un prototipo o serían implementados en las primeras iteraciones; de esta manera se logró reducir el riesgo de la construcción de la herramienta en las etapas más tempranas del desarrollo. Una de las decisiones más importantes para poder satisfacer los atributos de calidad y los requisitos no funcionales planteados para CodEv, es la del ambiente de ejecución que debe ser una plataforma completa que permita ser extensible, flexible y que se pueda ejecutar en múltiples plataformas (sistemas operativos). Se seleccionó la plataforma Eclipse (como se describió en la sección 2.4) por cumplir con todas estas características. 4.2. Arquitectura del generador CodEv El contexto en el cual funciona el sistema generador se basa en tomar los meta-datos del esquema de BD que se quiere generar directamente desde el repositorio de datos. El generador toma las definiciones de las tablas, campos, tipos de datos, sus relaciones, claves primarias y foráneas, etc [Par07]. Con esto construye una representación en memoria de estas definiciones y genera los elementos necesarios en base a las plantillas para que se pueda hacer el mantenimiento CRUD de cada tabla con sus respectivas relaciones. Se crearán elementos generales de la aplicación y elementos específicos por tabla. 30 A continuación se presenta, en la Figura 7, un esquema de frontera del funcionamiento de CodEv en donde se puede apreciar el funcionamiento básico del generador. Toma los metadatos del esquema de datos que se desea generar desde el motor de base de datos y en base a plantillas crea archivos físicos, que en conjunto componen el sistema generado. Meta-Data de la BD seleccionada DB Sistema Generador de Aplicaciones Web Multicapa. Plantillas Archivos Generados Figura 7. Funcionamiento propuesto para el sistema CodEv fue creado con una arquitectura y diseñado como plug-in de Eclipse para poder obtener todas las ventajas de la plataforma Eclipse como son fácil instalación, configuración y ejecución. Las aplicaciones que son generadas también están integradas dentro de Eclipse como proyectos Web Java, lo cual hace que las aplicaciones generadas también puedan tener todas las ventajas de la plataforma y sea transparente el proceso de generación y edición para el usuario. Los factores que más influyeron en la decisión para el uso de la plataforma Eclipse como ambiente de ejecución, en el que se integra CodEv, fueron la robustez y extensibilidad de la plataforma, que se pueda ejecutar en múltiples plataformas (Portabilidad), la necesidad de facilidad de uso para la instalación, generación y edición (Usabilidad) y la necesidad de que sea fácilmente extensible. En la Figura 8 se ve en un esquema de alto nivel como se integran CodEv y las aplicaciones generadas dentro del contexto de la plataforma Eclipse. El desarrollador instala, ejecuta y 31 configura Codev dentro de Eclipse para acceder a la información de metadatos del esquema del que se desea generar la aplicación Web Java. La aplicación generada también funciona dentro de la plataforma Eclipse y es modificada y ejecutada por el desarrollador para manejar los datos del esquema de datos seleccionado en la generación. Configura Modifica / Ejecuta Sistema Generador de Aplicaciones Web Multicapa - CodEv Genera Metadatos DB Maneja Datos Aplicación Web Java generada Figura 8. Integración de CodEv y las aplicaciones generadas con Eclipse CodEv está compuesto por 3 grandes componentes que son: - Manejador de Presentación: es el componente que se encarga de la integración con la plataforma Eclipse; es decir contiene la implementación de los elementos visuales específicos de la plataforma para que el desarrollador pueda interactuar y realizar la generación de manera sencilla. Se encarga de la captura de información, de las notificaciones al desarrollador y de las actualizaciones necesarias a la plataforma Eclipse. El tener un solo componente como punto de integración con la plataforma Eclipse hace más fácil la extensión y cambio de CodEv. - Manejador de BD: es el componente que se encarga de proveer el manejo de la conexión al motor de base de datos y la creación del modelo de abstracción o representación de metadatos (tablas, campos, tipos de datos, relaciones, claves primarias y foráneas, etc) que será usado por CodEv para que el desarrollador configure cuáles de estos elementos desea generar y para la generación en sí. Por medio de este componente se logra desacoplar el generador del lugar que se obtiene la representación de los metadatos, pudiendo tener varias fuentes de datos e implementaciones de acceso a datos. - Manejador de Generación: es el componente que se encarga de la generación de los archivos físicos en base a plantillas. En este componente se encuentra la 32 implementación de la creación de todos los archivos necesarios para tener una aplicación Web Java multicapa en base a la representación de metadatos y parámetros de configuración. Este componente tiene lógica para controlar la generación y regeneración de la aplicación, creación o sobre-escritura de archivos y directorios seleccionados. Figura 9. Arquitectura de CodEv En la Figura 9 se pueden apreciar los 3 grandes componentes de CodEv y su relación con la plataforma Eclipse al ser un plugin y también la relación de la aplicación generada y sus capas como componentes de presentación, de negocio y de persistencia. 4.3. Diseño detallado de componentes importantes de CodEv Al igual que con los requerimientos, el diseño detallado de CodEv fue evolucionando con la construcción de los diferentes prototipos evolutivos que ayudaron a validar algunos de los puntos de riesgo que se encontraron para la construcción del generador. A continuación se presenta el diseño detallado de CodEv, presentando el modelo de objetos que se usa para la 33 representación del modelo de datos en memoria, además de los modelos de clases de los 3 grandes componentes de CodEv. 4.3.1. Representación del modelo de datos Uno de los puntos de riesgo importantes era el poder crear una abstracción o representación del modelo de metadatos (tablas, campos, tipos de datos, relaciones, etc) [Par07] que sea lo suficientemente completo para tener una funcionalidad rica en relaciones y características, pero que sea lo suficientemente simple y liviana para que pueda ejecutarse rápidamente la generación, sin el uso de muchos recursos computacionales. Para solucionar esto se crearon clases que representan el modelo de datos en memoria que se pueden apreciar en la Figura 10. En estas clases se cargan las tablas, sus campos y sus relaciones. Estas clases están relacionadas para que se pueda navegar desde una tabla (TableInfo) hacia sus campos (FieldInfo) y hacia sus relaciones padre e hijo (FKInfo). Figura 10. Modelo de clases que representan el modelo de datos a generar El Manejador de base de datos (DB) está encargado del proceso de carga de esta representación en objetos de los metadatos del esquema. Esta representación es pasada al Manejador de presentación para desplegarla al usuario y permitir seleccionar las tablas y 34 campos que desea generar. Finalmente, esta representación modificada es pasada al Manejador de Generación para que genere la aplicación Web Java con los mantenedores CRUD para cada una de las tablas y campos seleccionados. Cada tabla a ser generada es cargada en un objeto de tipo TableInfo y tiene algunos atributos, entre los que se destacan: el nombre de la tabla, de la clase, listado de sus campos, el campo que es la clave primaria, listado de las claves foráneas y el campo de búsqueda de la tabla. También, tendrá un atributo con el nombre de la clase transformado a notación de camello (Camel notation), que es la notación normalmente usada en Java donde el nombre de la clase se escribe seguido, sin espacios, ni guiones, en minúsculas excepto las primeras letras de cada palabra que van en mayúsculas. El campo de búsqueda es el campo que será desplegado en vez de la clave foránea de la tabla padre en los listados de tablas hijo. Es decir en una relación de 1-N donde se está mostrando un registro del lado N (hijo) en vez de mostrar la clave foránea del lado 1 (padre), se mostrará el campo de búsqueda obtenido desde el registro de la tabla padre. Cada campo a ser generado es cargado en un objeto de tipo FieldInfo que contendrá principalmente el nombre del campo y el tipo de dato del campo. También tendrá un atributo que es el nombre del campo transformado a notación de camello. El nombre del campo se escribe bajo las mismas reglas explicadas para los nombre de clases excepto la primera letra de todo el nombre que también deberá estar en minúsculas. Cada relación padre en una relación 1-N será cargada en un objeto de tipo FKInfo, el que tendrá una referencia al objeto que contiene la definición de la tabla padre (TableInfo), una referencia al campo que representa la clave primaria de la tabla padre (FieldInfo) y una referencia al campo que representa la clave foránea de la tabla hijo (FieldInfo). Aquí no se cargan relaciones padre de las cuales la tabla padre o el campo de clave foránea no estén seleccionados para generación. El objeto CodevProject es donde se carga los valores de los datos de configuración ingresados por el usuario para la generación y que son capturados por medio de la interfaz gráfica. Posteriormente en este objeto también se cargarán los valores de configuración almacenados en el archivo .codev para la regeneración. 35 4.3.2. Manejador de Presentación Como ya se ha dicho, el punto crítico de la integración con un ambiente robusto fue solucionado por medio de la integración con la plataforma Eclipse, y tanto CodEv como las aplicaciones generadas, se ejecutan dentro del mismo ambiente de la plataforma Eclipse. Por la parte de CodEv, se tiene un asistente para la creación de un nuevo proyecto y un editor para el archivo de proyecto CodEv para la regeneración del proyecto, los cuales están integrados con el Workbench IDE UI por medio de los puntos de extensión. Los puntos de extensión en la plataforma Eclipse están definidos por clases que son extendidas y donde se implementa la funcionalidad visual y otras que se desea dar a la extensión. La mayor cantidad de funcionalidad del componente de presentación está construida en base a la clase GeneradorView que es usada por los puntos de extensión específicos para Eclipse. GeneradorView extiende el elemento visual org.eclipse.swt.Composite, que es un elemento de posicionamiento (layout) para contener otros elementos visuales y de esta manera es fácil de componer con los otros elementos visuales de los puntos de extensión. Además, GeneradorView implementa la interfaz INotifiable que es usada por el Manejador de BD y de Generación para realizar paso de mensajes a la presentación y para notificar del avance de tareas. De esta manera se logra desacoplar de la implementación específica de Eclipse hacia los componentes no visuales. GeneradorView es el que se encarga de obtener la representación del modelo de metadatos desde el manejador de BD y presentar al usuario las opciones de configuración que se indicaron en los requisitos funcionales, capturar estas opciones y pasarlas al manejador de generación junto con la representación del modelo de datos para la generación. 36 Figura 11. Modelo de clases de la implementación de los puntos de integración del Wizard de CodEv para generación de aplicaciones En la Figura 11 se puede observar el modelo de clases que representa las implementaciones específicas de CodEv para los puntos de integración del Wizard para generación de aplicaciones. La clase CodevWizard, que es una implementación de un Wizard de Eclipse, tiene una o más páginas que en el caso de CodEv está implementado por medio de CodevNewWizardPage y está compuesta en su parte visual por GeneradorView. En la Figura 12 se puede observar el modelo de clases que representa las implementaciones específicas de CodEv para los puntos de integración del Editor para regeneración de aplicaciones. La clase CodevPageEditorContributor, que es una implementación de un MultiPageEditor de Eclipse, tiene una o más páginas que en el caso de CodEv está implementado por medio de CodevPageEditor y está compuesta en su parte visual por GeneradorView. 37 Figura 12. Modelo de clases de la implementación de los puntos de integración del Editor de CodEv para regeneración de aplicaciones 4.3.3. Manejador de BD El Manejador de BD es el componente que se encarga de proveer todo el manejo de conexión y recuperación de información desde el motor de base de datos. Sus dos métodos públicos disponibles son la recuperación de los esquemas disponibles en el motor de base de datos por medio del método getSchemaNames y el obtener la representación del modelo de metadatos (tablas, campos, tipos de datos, relaciones, claves primarias y foráneas, etc) por medio del método getDBStructure. Internamente se encarga de la conexión al motor de base de datos, de ejecutar selects para una sola columna o múltiples columnas en diferentes esquemas como el esquema de metadatos. Por medio de este componente se logra aislar en un solo lugar la lógica de manejo de datos y el como se obtiene la representación de los metadatos, pudiendo tener varias fuentes de datos e implementaciones de acceso a datos. 38 Figura 13. Modelo de clases del componente manejador DB En la Figura 13 se puede observar el modelo de clases del manejador DB que se basa en una interfaz IDBConnector que establece el contrato para nuevas implementaciones. La clase abstracta DBConnector implementa la interfaz IDBConnector y sólo tiene un método de conveniencia que ayuda a buscar el objeto del campo (FieldInfo) de un objeto tabla (TableInfo). Una implementación concreta de IDBConnector, y que extiende DBConnector, es MysqlConnector que se encarga de todos los manejos de conexión y datos explicados para un motor de base de datos Mysql. Como se ha podido observar la función más importante del manejador de DB es el cargar la representación de metadatos como objetos y el método encargado de esta función es getDBStructure al que se le pasa los datos para conexión al motor de base de datos como son: nombre y puerto del servidor, usuario y password para la conexión, esquema de la base de datos del que se quiere obtener la representación. Este método retorna una colección de objetos TableInfo representados por List<TableInfo>. Esta colección contiene un listado de todas las tablas del esquema con sus campos y relaciones. El proceso de carga de la representación de metadatos, puede llegar a ser un proceso largo, dependiendo de la cantidad de tablas, campos y relaciones que existan en el esquema de datos, por lo que el Manejador de DB notifica de su avance a quien lo ha invocado por medio de la referencia a un objeto de tipo INotifiable que es pasado a él en la invocación del método getDBStructure. 39 4.3.4. Manejador de Generación En este componente se encuentra la implementación de la creación de todos los archivos necesarios para tener aplicaciones Web Java multicapa en base a la representación de metadatos y parámetros de configuración; la generación de los archivos físicos se la realiza en base a plantillas. Este componente tiene lógica para controlar la generación y regeneración de la aplicación, creación o sobre-escritura de archivos y directorios seleccionados. El riesgo de la generación en base a plantillas fue reducido con el uso de un framework de plantillas llamado Velocity, que es un framework de código abierto creado por el Apache Software Foundation (http://velocity.apache.org/). Velocity es un motor de plantillas hecho en Java que permite el uso de un lenguaje de plantillas, simple pero poderoso, para referenciar objetos Java en las plantillas. Velocity puede ser usado para generar en base a plantillas cualquier tipo de archivos de texto o planos. Figura 14. Modelo de clases del componente manejador de Generación En la Figura 14 se puede observar el modelo de clases del manejador de generación que aísla la implementación del proceso de generación por medio de la clase Generator en el método generate al que se le pasa los datos de configuración ingresados por el usuario (CodevProject) y la colección de tablas (List<TableInfo>). La clase Generator recorre el grupo de archivos plantilla a ser generados, carga los parámetros para Velocity e invoca los métodos necesarios para realizar la generación o reemplazo de variables en los archivos. El proceso de generación de los archivos físicos de la aplicación Web Java es generalmente un proceso largo, dependiendo de la cantidad de tablas, campos y relaciones que existan en 40 representación de metadatos, por lo que el manejador de Generación notifica de su avance a quien lo ha invocado por medio de la referencia a un objeto de tipo INotifiable que es pasado a él en la invocación del método generate. Una vez finalizada la generación de la aplicación Web Java el manejador de generación almacena la representación de metadatos y la configuración de la generación en un archivo con formato XML con extensión .codev. El propósito de este archivo es poder recuperar los datos de configuración ingresados por el usuario y que se usaron para la generación inicial y presentárselos al usuario para poder regenerar la aplicación y evolucionarla. 4.4. Arquitectura de las Soluciones generadas Client * Código genérico multi-browser Presentation Layer * MVC con Struts2 + JSP’s + Javascript (AJAX) Business Layer * Manejadores > reglas de negocio Persistence Layer * Persistores + Hibernate Any convencional DB * Mysql, Oracle y PostgreSQL Figura 15. Componentes y conexiones de la capa de presentación basada en Struts Lo que será presentado a continuación es una visión de las tecnologías utilizadas en cada una de las capas que se genera para las aplicaciones Web Java. Especificaremos cada una de las capas con una explicación detallada de la arquitectura de referencia final de las tecnologías involucradas en cada una de ellas. Para mantener la independencia de las diferentes capas se utilizan varios patrones de diseño muy conocidos que serán explicados a continuación y que son: Data Transfer Object (DTO), MVC (Model-View-Controller), Facade (Manager) y Data Access Object (DAO) [GHJV98]. 41 4.4.1. Data Transfer Objects (DTO) En el caso de la aplicación generada, los DTOs representan al dominio de la aplicación o a las tablas que existen en el modelo de datos. Existirá un DTO con atributos por cada una de las tablas y campos seleccionados para ser generados como parte de la aplicación Web Java. Data Transfer Object (DTO) es un patrón de diseño usado para transferir datos (información) a través de subsistemas o capas de una aplicación para de esta manera mantener el bajo acoplamiento entre los subsistemas y/o las capas. Los DTOs son livianos puesto que no contienen ningún comportamiento (funcionalidad) excepto el encapsulamiento (set y get) de sus propios datos. Son Plain Old Java Objects (POJOs), que como se dijo no tienen dependencias en otras clases o datos, excepto en otros DTOs u objetos básicos de java. Generalmente los DTOs representan a los objetos del dominio de la aplicación ya que estos son los datos que la aplicación requiere que se muevan entre capas para su presentación, operación sobre ellos y recuperación o almacenamiento. También pueden ser objetos que no son parte del dominio pero que requieren transportar información entre capas y que por lo tanto han sido compuestos por conveniencia para ese propósito. Los DTOs representan al mismo patrón de diseño que los Value Objects (VA) o Transfer Objects (TO) que tienen la responsabilidad del transporte información. 4.4.2. Capa de Presentación Esta capa será implementada por medio de JSP’s y Struts2 que es un framework que incentiva el uso del clásico patrón de diseño Model-View-Controler (MVC) que es una buena manera de manejar la capa de presentación para aplicaciones Web Java [Rou07]. La arquitectura de la capa de presentación de la aplicación basada en MVC se puede ver en la Figura 16. Struts2 implementa su propio componente controlador y se integra con otras tecnologías para proveer el modelo y la vista, de esta manera facilita la separación entre elementos de presentación (vista): páginas JSP (o cualquier otro elemento de presentación que se desee), elementos de lógica de flujo y navegación (controlador): filtro de control y archivo XML de configuración y la lógica de acceso al negocio y datos (modelo). Struts es un proyecto del grupo Apache y es open source. (http://struts.apache.org/) 42 Client 1 - Request Struts Filter 4 – Forward to view and display data 5 - Response 2 - Load Struts XML Configuration File 3 – Execute model and load data JSP Java Bean Business layer Figura 16. Componentes y conexiones de la capa de presentación basada en Struts2 4.4.3. Capa de Negocio La capa de negocio es implementada por medio de Managers que siguen las reglas del patrón de diseño Facade que provee una interfaz unificada a un grupo de funcionalidades de un subsistema. El Facade define una interfaz de acceso de alto nivel que hace que el subsistema sea más fácil de usar. En nuestro caso los Managers generados son Facades que formarán la capa de negocio y darán acceso a la capa de presentación a los servicios o funcionalidad requerida. Estos Managers son los que acceden a los DAO para la administración por tabla. Se pueden crear muchos otros Managers que agrupen lógica de negocio y que hagan uso de de otros managers y DAOs. Figura 17. Componentes y conexiones de la capa de negocio en un sistema multicapas En la Figura 17 se puede apreciar los beneficios de usar el patrón de diseño facade para desacoplar subsistemas o componentes centralizando las invocaciones en un solo componente y haciendo más sencillo el mantenimiento y evolución de la aplicación. 43 Es a este nivel en donde se deben realizar los cambios necesarios para implementar las reglas de negocio para cálculos, operaciones, validaciones u otros. En esta capa también se podrá realizar la conexión con otras aplicaciones que se requieran. Web Front End WS Exposed Fat Clients Business Layer Persistence Legacy Systems WS consumed Figura 18. Componentes y conexiones de la capa de negocio en un sistema multicapas Por ejemplo, si se requiere la conexión con una aplicación legada, se puede crear un Manejador para esa lógica y se lo colocaría en esta capa. Otro ejemplo sería, si se quiere presentar algunos servicios de la aplicación como servicios Web se debe cambiar la capa de presentación por (o aumentar) una capa de Servicios Web sin tener que cambiar la capa de negocio o persistencia. Esta capa se ha implementado por medio de clases regulares de Java ver Figura 18. 4.4.4. Capa de Persistencia Esta capa es implementada por medio de clases que siguen las reglas del patrón de diseño DAO (Data Access Objects). Los objetos que implementan el patrón DAO hacen transparente, para los objetos que los usan, el cómo son almacenados los datos y cómo se realizan los accesos a estos datos. Maneja u obtiene la conexión a la fuente de datos para obtener y almacenar datos. Aquí se implementan las operaciones CRUD (Create, Read, Update and Delete). En nuestro caso los DAO´s ocultarán el uso de Hibernate para el acceso a la información almacenada en la base de datos. Hibernate es un framework para persistencia relacional para Java y .Net que es un poderoso servicio de consulta y persistencia objeto-relacional de alta capacidad, y es el que se encarga de realizar las operaciones requeridas para mapear los objetos de la aplicación para reflejar el modelo de base de datos [BK06] - ver Figura 19. 44 Business Layer Hibernate Persistor Table 2 Persistor Table N DB Table 1 Persistent Object Table 2 XML Mappings Persistor Table 1 Persistent Object Table 1 Persistent Object Table N Table 2 : : : Table N Figura 19. Componentes y conexiones de la capa de persistencia basada en Hibernate Hibernate realiza el “mapeo objeto-relacional” (ORM) que se refiere a la técnica de mapear una representación de datos desde un modelo de objetos a un modelo relacional de datos con un esquema basado en SQL. Hibernate es un proyecto open source de JBoss, que es una división de RedHat. (http://www.hibernate.org) En la Figura 20 se puede ver una vista de alto nivel de la arquitectura de Hibernate. El diagrama muestra como Hibernate usa la DB y los datos de configuración para proveer servicios de persistencia (y objetos persistentes) a la aplicación. Además del código de la aplicación se generarán archivos de ayuda para el proyecto. Se generarán todos los archivos necesarios para que el proyecto pueda ser editado como una aplicación Java Web dentro de Eclipse y también scripts de Ant para que se pueda compilar y empaquetar el proyecto automáticamente, así como poder hacer deploy directamente en Tomcat o en cualquier contenedor de Servlets. 45 Figura 20. Vista de alto nivel de la arquitectura de Hibernate Ant es una herramienta de build automático hecha en Java y que sus scripts se escriben en XML, muy similar a “make”, “jam” u otros. Su función es el automatizar la ejecución de tareas como son las de: creación de directorios, reemplazo de variables, compilación, empaquetamiento, distribución, etc. Ant es parte del grupo Apache y es open source. (http://ant.apache.org/) 4.5. Diseño detallado de las soluciones generadas Las soluciones generadas tienen una serie de servicios y consultas genéricas que están disponibles para ser usadas por el programador en la capa de negocio. Para esto se ha creado un API de consulta de objetos donde se puede recuperar listados de objetos en base a un filtro específico, y si se desea, con ordenamiento y paginación. Todos estos servicios creados facilitan el trabajo del programador. El API de consultas de objetos fue creado para permitir los filtros por múltiples campos que maneja la aplicación y también para permitir realizar consultas con condiciones y ordenamiento, manteniendo la independencia de la capa de negocio y de la implementación de estos filtros, condiciones y ordenamientos de la capa de persistencia. Ya en la parte de implementación, aunque Hibernate tiene su propio lenguaje de consultas, el API creado para el generador nos independiza de esta implementación específica y abre las puertas a nuevas implementaciones. Además le permite al programador concentrarse en los cambios de la capa de negocio y no en 46 tener que realizar cambios en la capa de persistencia, sólo si se requirieran servicios o consultas demasiado específicas o avanzadas. Figura 21. Diagrama de clases para el soporte de servicio de filtros en consultas en la capa de negocio La Figura 21 muestra el diagrama de clases que es usado para la implementación de filtros y condiciones en consultas en la capa de negocio. Cada instancia de la clase Filtro contendrá un filtro, con su condición, para la consulta a realizar. Esta clase tiene como atributos el campo que se desea filtrar, los valores inicial y/o final (si aplican), también el tipo de filtro (TipoFiltro) que nos indica qué tipo de condición se aplicará para este filtro. Filtro es suficiente para contener la mayoría de condiciones básicas de consulta, pero para filtros más avanzados se ha implementado una serie de clases que extienden de Filtro y que tienen otros atributos necesarios para implementar sus consultas. 47 Figura 22. Diagrama de clases para el soporte de ordenamiento en consultas en la capa de negocio La Figura 22 muestra el diagrama de clases para el soporte de ordenamiento de consultas en la capa de negocio. Cada instancia de la clase Orden contendrá una opción de ordenamiento, una dirección del ordenamiento (TipoOrden). Como se comentó, las consultas (filtros, condiciones y ordenamientos) son codificadas por el desarrollador en la capa de negocio para acceder a listados de datos específicos que se desea obtener y por lo tanto serán pasadas a la capa de persistencia para ser ejecutadas y que retorne el listado de datos. La capa de persistencia ya tiene creados los servicios para obtener listados de datos filtrados y ordenados que pueden estar paginados o no. Por ejemplo, en la Figura 23 se muestra un DAO implementado, AlumnoDAO, que cuenta con métodos básicos que implementan las operaciones CRUD para el manejo datos de la tabla ALUMNO. Y además cuenta con varios métodos para obtener listados de datos desde la tabla ALUMNO por medio de consultas que cumplen con todas la combinaciones que van desde un solo Filtro sin ordenamiento ni paginación, hasta múltiples filtros con múltiples ordenamientos y paginación. Esto hace que se facilite la obtención de listados de datos desde la capa de persistencia. 48 Figura 23. Diagrama de clases de un DAO de ejemplo con sus métodos y relaciones 49 5. Construcción del Sistema Esta sección describe las herramientas que se utilizaron para construir CodEv, los prototipos evolutivos realizados y por último especifica la metodología de desarrollo aplicada detallando las iteraciones realizadas. 5.1. Ambiente de desarrollo A continuación se detalla los elementos de los dos ambientes de desarrollo utilizados para crear CodEv; esto porque en los tres prototipos evolutivos creados para llegar a la aplicación final se utilizó dos diferentes lenguajes, ambientes de desarrollo y configuraciones. El primer ambiente es VS Express Edition C# para crear la primera versión de CodEv programado en lenguaje C# (como se describió en la sección 2.5.1) y el segundo es el Eclipse RCP/IDE Plug-in Development Enviroment (PDE) para crear la versión final del sistema programado en lenguaje Java, que en general es el ambiente más completo e importante (como se describió en la sección 2.5.2). El enfoque principal de los prototipos fue el reducir los riesgos de la generación de la aplicación, sin poner mayor énfasis en los atributos de calidad. Dadas las facilidades que brinda Visual Studio para la creación de aplicaciones de escritorio en Windows (Windows Forms), con un ambiente visual, rápido, de fácil instalación y configuración para el desarrollo de este tipo de aplicaciones, se decidió usar esta plataforma para la creación de los primeros prototipos evolutivos de CodEv. El énfasis principal en esta primera etapa no era el tener un ambiente robusto e integrado, sino el poder crear los prototipos evolutivos de manera rápida y así poder demostrar las teorías de diseño de la aplicación y reducir los riesgos. El énfasis en la segunda etapa del proyecto, ya con la mayoría de los riesgos reducidos, se enfocó en alcanzar todos los objetivos del proyecto y los atributos de calidad planteados. Es por esto que CodEv, en su versión final y como herramienta, está diseñado y empaquetado como plug-in de Eclipse para tener todas las ventajas de la plataforma. En su construcción también se usó el IDE Eclipse en su versión para desarrolladores de RCP/Plug-in para poder hacer uso de las mismas ventajas que entrega la plataforma. 50 Para crear el plug-in de CodEv se tuvo que crear un proyecto de Plug-in que contiene la funcionalidad en sí y que está contenido dentro de un proyecto de Feature que define los derechos de autor, licencia y otras características de CodEv en el momento de la instalación dentro de Eclipse. Este a su vez está contenido dentro de un proyecto de Update Site que es el que tiene los jars y directorios como los requiere Eclipse para que CodEv pueda ser instalado de manera estándar, como un plug-in regular, dentro de Eclipse desde un sitio remoto o local. 5.2. Prototipos realizados A continuación se presenta una descripción detallada de los 3 grandes prototipos realizados los que permitieron que la definición de los requisitos y necesidades de la herramienta fueran madurando y evolucionando. 5.2.1. Prototipo 1 El primer prototipo fue creado en C# como aplicación Windows Forms y su objetivo principal fue el tomar las definiciones del modelo de metadatos desde un motor de BD Mysql y construir la representación del modelo de metadatos en memoria. En este prototipo sólo se tiene la captura de algunos parámetros de conexión a la Base de datos como parte de la interfaz gráfica y un proceso de generación bastante básico con el contenido de los archivos a ser generados quemados (mezclados) en código. Con el primer prototipo se eliminó el riesgo de la generación en base a un modelo de metadatos, se creó una abstracción o representación del modelo de metadatos (tablas, campos, tipos de datos, relaciones, etc). Esta representación fue bastante básica inicialmente y fue mejorando con el uso de la herramienta en los siguientes prototipos e iteraciones. Este prototipo genera aplicaciones Windows Forms multicapa con NHibernate como capa de persistencia. Las aplicaciones generadas pueden ser importadas en el mismo VS Express para poder ser editadas y ejecutadas. 5.2.2. Prototipo 2 El segundo prototipo atacó el riesgo de la generación en base a plantillas con el prototipo hecho en C#. El lenguaje de plantillas utilizado fue NVelocity que es una versión portada a .Net de Velocity. Tiene un asistente (wizard) de configuración y generación de una aplicación Windows Forms que se debe importar manualmente en VS Express para poder ser editado y ejecutado. Este prototipo se construyó para validar la generación en base a plantillas y en base 51 a esto separar la aplicación (generador) de los archivos que se generan, por medio de los parámetros de reemplazo. Para crear este prototipo se tomó la versión del generador creado en el prototipo 1 y se lo extendió para que tenga el uso de plantillas para la generación. Cuando estuvo lista la funcionalidad de generación en base a plantillas, se probó que el modelo de metadatos y la generación en base a plantillas funcionaran con un ejemplo de validación por medio de la creación de plantillas para generar aplicaciones Java Web. Al realizar estas pruebas se realizó mejoras al modelo de metadadatos y los valores de reemplazo disponibles a las plantillas para la generación. 5.2.3. Prototipo 3 El último prototipo realizado atacó el punto crítico de la integración con un ambiente robusto que se redujo por medio de la integración con plataforma Eclipse. En este prototipo se creó un proyecto de Plug-in de eclipse en Java con el cual se demostraba el uso de algunos elementos visuales que son específicamente un asistente para la creación de un archivo de texto dentro del IDE por medio de un asistente (wizard) y también el crear un editor para este archivo de texto los cuales están integrados con el Workbench IDE UI por medio de los puntos de extensión. Se tuvo que realizar este prototipo para validar que era posible crear, en un tiempo restringido, un plug-in de Eclipse con las características deseadas. Se estaban evaluando 2 plataformas en ese momento que eran Eclipse y NetBeans, pero dada las facilidades y extensibilidad de Eclipse, se decidió continuar con esta plataforma. Antes de iniciar el desarrollo de este prototipo se realizó el trabajo de migración de la aplicación de generación existente de C# a Java, y por lo tanto este prototipo también incluyó una llamada a la ejecución de esa aplicación que genera aplicaciones Java Web que se deben importar manualmente en la plataforma Eclipse para ser editadas y ejecutadas. 5.3. Metodología de desarrollo aplicada Para el desarrollo del sistema se utilizó una metodología iterativa incremental en donde se realizaron 4 iteraciones y en cada una de ellas se agregó al sistema parte de la funcionalidad requerida y se realizaron mejoras, a continuación se detalla el trabajo realizado en ellas. 52 5.3.1. Iteración 1 La iteración uno de la construcción de CodEv comprendió la creación de los prototipos 1 y 2, además de su evolución hasta que se obtuvo una aplicación Windows Forms funcional para generación de aplicaciones Java Web que pudieran ser importadas como proyectos de Eclipse, editados y evolucionados. El objetivo de esta primera iteración fue el reducir la mayor cantidad de riesgos posibles para la generación de aplicaciones, pero además que se pudiera tener una primera versión de CodEv que pudiera ser probada y usada. Es por esto que se atacó los 2 puntos críticos que son complementarios, que son: el de creación de la representación del modelo de metadatos y el de generación de la aplicación en base a plantillas. Esta primera versión era visualmente muy rústica para el usuario y además requería de varios procesos manuales de importación y actualización de archivos y proyectos para poder usar las aplicaciones generadas. Esto porque al estar hecho en C# y generar código que seria importado en Eclipse requería de varios cambios de contexto y de mucho cuidado. Pero aun así se vio el potencial que tendría el generador final y se vio una buena reducción del tiempo de desarrollo. También, el contar con plantillas hace que sea más fácil de mantener, ya que los cambios para el producto final generado se los realizaba en las plantillas, sin tener que tocar el código de la aplicación. 5.3.2. Iteración 2 La primera versión totalmente funcional de CodEv se usó como una de las herramientas para la creación del sistema SIMPLe - Sistema de Implementación de Mejora de Procesos, con lo cual se pudo obtener retroalimentación sobre las limitaciones y necesidades del sistema de generación deseado. Uno de los hallazgos más importantes de la validación realizada (para el autor de esta tesis), fue que existe la necesidad de regeneración de las aplicaciones generadas, para que puedan ser evolucionadas o de otra manera la utilidad de CodEv sería muy limitada y marginal. El objetivo de la segunda iteración fue el poder corregir algunas de las limitaciones y necesidades encontradas por el uso de CodEv en el proyecto real. Estas limitaciones se enfocaron principalmente en mejorar las plantillas para la generación de aplicaciones Web Java y también en la representación del modelo de metadatos en el que se basan, ya que se 53 requería de funciones CRUD más ricas hacia los usuarios, como son las de búsqueda (filtrado) por varios campos, ordenamiento, paginación y búsqueda de relaciones de clases padre. En esta iteración se hizo un trabajo conjunto y cercano con el proyecto SIMPLe para que este proyecto fuera utilizando los avances que se realizaban en CodEv para seguir construyendo la herramienta. La capacidad de poder contar con una validación casi al instante aceleró la evolución de las plantillas para aplicaciones Java Web y de la representación de modelos de metadatos, hasta llegar a un punto donde el autor las consideró bastante maduras para poder crear otras aplicaciones. 5.3.3. Iteración 3 La Iteración tres implicó la migración de la aplicación desde C# a Java, ya que aunque la aplicación de generación era bastante robusta, no cumplía con todos los objetivos planteados en la tesis, ni con todos los atributos de calidad planteados. El primer paso en el proceso de migración fue, en una etapa inicial, a una aplicación de escritorio Java no integrada con Eclipse. En este paso se realizó una migración de uno a uno de los componentes de la aplicación, como son el componente de BD y la representación de modelo de metadatos, el componente de generación y también el cambio de plantillas de NVelocity a Velocity. Este último cambio se lo realizó ya que se requirió el reemplazo de algunos valores en las plantillas, más por una cuestión de notación y correctitud. El proceso más largo de la migración fue el paso de los componentes visuales, ya que es lo que difiere mucho entre las implementaciones del lenguaje C# y Java, los componentes visuales fueron realizados en JFace y SWT para que la integración con Eclipse pueda ser más fácil. Una vez terminada la migración de CodEv a Java, se realizó el prototipo 3 para la integración con la plataforma Eclipse para poder reducir este riesgo. Una vez finalizado el prototipo, se procedió a la integración completa de CodEv con el IDE Eclipse, esto implicó la refactorización de algunos de los componentes para poder ajustarse de mejor manera a los puntos de extensión de Eclipse. 5.3.4. Iteración 4 La última iteración se centró en la capacidad de regeneración de los proyectos generados, dado que este es uno de los puntos más valiosos de CodEv. Se refactorizó la aplicación para 54 que se pueda reutilizar muchos de los elementos visuales que se usan en el Wizard de generación para el Editor de regeneración, también se creó la funcionalidad para almacenar los valores ingresados por el usuario en la generación en el archivo .codev que sirven para la regeneración. En esta iteración se trató de cerrar todos los pequeños cambios pendientes para finalizar el proyecto, como por ejemplo parámetros de configuración faltantes. Otra funcionalidad importante que se realizó como parte de esta iteración fue la creación del proyecto de Feature y del proyecto de Update site para poder empaquetar y distribuir CodEv de manera estándar para su instalación como plug-in en Eclipse. En todas las iteraciones y prototipos se realizaron pruebas generando aplicaciones de ejemplo; pero al final de esta iteración se creó un ejemplo de validación final de CodEv que es presentado como parte de esta tesis en el capítulo 8. 55 6. Funcionamiento de Codev En el siguiente capítulo se presenta los requisitos para la instalación y configuración de CodEv, cómo usar la herramienta para generación y regeneración junto con un proceso de desarrollo recomendado. Por último se presentará una guía de los elementos que componen las soluciones generadas y cómo usarlas. 6.1. 6.1.1. Instalación y configuración Pre-requisitos Los pre-requisitos para la instalación de CodEv y ejecución de los sistemas generados por medio de CodEv son los siguientes: - Java 2 Platform, Standard Edition – J2SE 5.0 – distribución básica 51.76 MB (http://java.sun.com/javase/downloads/index_jdk5.jsp) (también conocido como JDK 1.5) - Eclipse IDE para Java EE Developers versión Europa 3.3 o superior – 126 MB (http://www.eclipse.org/downloads/) - Apache Tomcat 5.5 o superior distribución Core – 6.6MB (http://tomcat.apache.org/) - Mysql Comunity Server o Enterprise Database 5.0 o superior – 42.4.MB (http://dev.mysql.com/downloads/mysql/5.0.html) 6.1.2. Instalación de Codev A continuación se presentará los pasos a seguir para la instalación del plug-in de CodEv dentro de la plataforma Eclipse. El proceso de instalación es el proceso estándar de Eclipse para la instalación de plug-ins. Se debe tener J2SE y Eclipse IDE instalados previamente, con las versiones descritas en la sección de pre-requisitos, para proceder con la instalación de CodEv. Se debe ejecutar el IDE Eclipse y acceder al menú “Help” ubicado en la parte superior de la herramienta, seleccionar “Software Updates” y de ahí “Find and Install…”, como se muestra en la Figura 24. 56 Figura 24. Opción de menú para instalación de plug-ins en Eclipse En la siguiente pantalla se selecciona “Search for new features to install” y se presiona el botón “Next”. Aparece una pantalla en la que se debe seleccionar “New Remote Site…” si se desea instalar CodEv desde un sitio remoto (red local o Web) o “New Local Site…” si se instalará desde un sitio local (en disco o recursos compartidos), de aquí se ingresa el URL o se selecciona el directorio donde de encuentra CodEv y se ingresa el nombre con el que se desea registrar el instalador del plug-in de CodEv dentro de Eclipse, como en la Figura 25. Aparece seleccionado CodEv para su instalación y se presiona el botón “Finish”. 57 Figura 25. Pantalla de instalación de un plug-in desde un sitio local Si la instalación se la está realizando desde un sitio remoto, Eclipse se encargará de descargar los archivos, ir notificando al usuario del avance de esta descarga y colocarlos en un lugar temporal para su instalación. Este proceso tomará alrededor de 10 a 30 minutos dependiendo de la velocidad de la conexión a Internet que se esté usando y el tráfico en la red. El plug-in CodEv tiene alrededor de 18.87MB. La siguiente pantalla presenta los Features de CodEv y su versión a ser instalados, se debe seleccionar todos y presionar el botón “Next”, como en la Figura 26. 58 Figura 26. Pantalla de selección de Features a instalar En la siguiente pantalla se presenta la licencia definida para CodEv, aquí se debe seleccionar “I accept the terms in the license agreement” y presionar el botón “Next” para continuar con la instalación. Se presentará una pantalla de confirmación final de la instalación donde se muestra el nombre, versión, tamaño del plug-in a instalarse y el directorio desde donde se está instalando, se debe presionar el botón “Finish” para proceder con la instalación. Se presentará una pantalla donde se muestra la confirmación de instalación de cada Feature. Aquí se puede instalar uno por uno por medio del botón “Install” o instalar todos de una vez por medio del botón “Install All”. Eclipse notificará al desarrollador del avance de la instalación que podrá tomar unos minutos. Una vez finalizada la instalación, Eclipse recomendará al usuario reiniciar la plataforma Eclipse para que se reflejen los cambios de esta instalación. Se debe presionar el botón “Yes” o cerrar y abrir la plataforma manualmente. Y con esto ya se tiene una copia de CodEv dentro de Eclipse totalmente funcional. 6.2. Proceso de generación El proceso de generación de aplicaciones Web Java se lo puede realizar una vez que se tiene instalado CodEv dentro de Eclipse y también se han instalado Mysql y Tomcat, con las versiones descritas en la sección de pre-requisitos. Los procesos de generación o regeneración son guiados y bastante simples por lo que, dependiendo de las opciones de configuración deseadas, pueden durar tan poco como 5 minutos para generar la aplicación Web Java completa. Después de esto se puede editar o ejecutar la aplicación generada directamente desde Eclipse. Como se comentó anteriormente, uno de los puntos importantes que se obtuvo de la retroalimentación con el uso de CodEv es que se requiere que tenga capacidad para 59 regeneración de código para que sea realmente útil en un contexto de desarrollo evolutivo o iterativo de aplicaciones. Esto se lo logró implementar por medio de la investigación de los modelos de generación usados en otras herramientas. Existen dos modelos conocidos para la regeneración de código, el primero se basa en la comparación de archivos, es decir que se compara archivo por archivo para ver si hay diferencias, permitiendo al desarrollador combinar los cambios. El segundo se basa en la herencia o extensión de clases base, en el cual las clases base no son modificadas por el desarrollador y pueden ser regeneradas en cualquier momento, el desarrollador puede modificar las clases extendidas sin riesgo de perder sus cambios por el proceso de regeneración. La herramienta ha sido construida para permitir la evolución de la aplicación generada por medio de regeneración de código siguiendo un proceso no destructivo en base a herencia. Para esto se tienen que respetar una serie de lineamientos y prácticas de modificación de la aplicación generada, pero que permitirán el realizar la evolución y la regeneración de la aplicación en cualquier momento. La restricción se basa en que la primera vez que se genera la aplicación, se generarán los archivos completos de la aplicación Web Java para las tablas y campos seleccionados, además de los archivos de proyecto Web Java de Eclipse y queda listo el proyecto en el IDE Eclipse, pero en las siguientes regeneraciones sólo se generarán un grupo de archivos base. Si el programador desea tener la capacidad de regenerar sin perder los cambios, deberá respetar estos archivos base sin realizar modificaciones, pero tendrá la libertad total de extender la funcionalidad del sistema por medio de los archivos de extensión, u otros que él cree, que heredan de la funcionalidad base y que no serán reescritos al regenerar la aplicación. 6.2.1. Generación inicial Para ejecutar los procesos de generación y regeneración de CodEv se debe tener el motor de BD Mysql corriendo al igual que el IDE Eclipse en el cual se instaló el plug-in de CodEv. También se debe haber creado previamente el esquema de datos del cual se quiere generar la aplicación. Para generar un nuevo proyecto Web Java con CodEV se debe ir al menú en la parte superior a la opción “File” >> “New” >> “Other”, como en la Figura 27. 60 Figura 27. Opción de menú para listar los tipos de archivos y proyectos Se presentará una pantalla con el listado de todos los tipos de archivos y proyectos que se pueden crear en Eclipse, se debe seleccionar el tipo “Codev” >> “Codev Project” y presionar el botón “Next”, como se muestra en la Figura 28. Figura 28. Opción de menú para crear un nuevo proyecto CodEv Se presenta la primera pantalla del wizard para crear el proyecto CodEv que es la pantalla de captura de opciones de configuración, ver Figura 29, en donde se debe ingresar los siguientes valores: - Nombre del Proyecto (Project Name) – es el nombre con el que se creará el proyecto dentro de Eclipse y en todas las referencias de la generación de código. - Nombre del Paquete (Package Name) – es el paquete java para marcar el namespace en el que se organizará el código fuente de la aplicación, este paquete es el que se coloca en cada una de las clases java generadas. Para representar este paquete físicamente en disco se crean directorios que contendrán este código fuente. Por ejemplo com.altura.notas, crea la estructura de directorios com/altura/notas/ y dentro de ella estarán las carpetas de código fuente. - Nombre del Servidor (Server) – IP del servidor o nombre del recurso de red donde se encuentra corriendo el servidor de BD Mysql que contiene el esquema de datos del que se desea generar la aplicación Web Java. 61 - Puerto del Servidor (Port) – puerto del servidor donde se encuentra corriendo el servidor de BD Mysql. - Usuario (User) – usuario de conexión al servidor de BD Mysql. - Password – password de conexión al servidor de BD Mysql. Una vez ingresada la información anteriormente descrita se debe presionar el botón “Load Schemas” para cargar la lista de esquemas disponibles en el servidor de BD Mysql y se debe proceder a seleccionar el esquema de datos del que se desea generar la aplicación Web Java. Luego de seleccionado el esquema se activará el botón “Next” el cual debe ser presionado para continuar. Figura 29. Pantalla de captura de opciones de configuración de CodEv 62 En la siguiente página del wizard es donde se permite seleccionar que tablas se van a generar. Inicialmente CodEv tiene marcadas para generación todas las tablas del esquema, pero se pueden seleccionar sólo las tablas que se desea generar. En esta pantalla también se permite seleccionar la tabla que servirá para autenticación de usuarios de la aplicación, además de los campos de usuario y password en los que se realizará la autenticación en sí, ver Figura 30. Figura 30. Pantalla de configuración de tablas y datos de log in de CodEv Los campos a ser generados en cada una de las tablas podrán ser configurados presionando el botón “Edit…” que está al lado derecho del nombre de cada tabla y aparece una ventana como en la Figura 31 que muestra todos los campos para esa tabla, su tipo de dato y si el campo es clave primaria (PK), clave foránea (FK) o ninguno. Inicialmente CodEv tiene marcados para generación todos los campos, pero se pueden seleccionar sólo los campos que se desea generar. En esta pantalla también se permite seleccionar el campo de búsqueda (Search) para esta tabla. 63 El campo de búsqueda es el campo que será desplegado en vez de la clave foránea de la tabla padre en los listados de tablas hijo. Es decir en una relación de 1-N donde se está mostrando un registro del lado N (hijo) en vez de mostrar la clave foránea del lado 1 (padre), se mostrará el campo de búsqueda obtenido desde el registro de la tabla padre. Figura 31. Pantalla de configuración de campos por tabla En este punto se debe aclarar que CodEv no genera código para la administración de relaciones para tablas o campos foráneos que no se hayan seleccionado para su generación. Es decir, en una relación de 1-N donde se está mostrando un registro del lado N (hijo) y no se ha seleccionado para generación la clave foránea dentro de esta tabla no se mostrará el campo y por lo tanto la relación con la tabla 1 (padre). En el caso que no se haya seleccionado la tabla del lado 1 (padre) para generación, sólo se mostrará el valor del campo de clave foránea desde la tabla N (hijo), sin obtener el valor del campo de búsqueda desde la tabla 1 (padre). Una vez que se ha configurado las tablas y campos que se desea generar se presiona el botón “Next” y se presenta la pantalla de generación. Hasta este momento se puede regresar a las pantallas anteriores y modificar cualquiera de las opciones de configuración. Una vez que el desarrollador está listo para generar la aplicación deberá presionar el botón “Generar” y el sistema irá notificando del avance de la generación por medio de mensajes y de una barra de avance (status bar), ver Figura 32. El proceso de generación puede demorar algunos minutos dependiendo de la cantidad de tablas, campos y relaciones que exista en el esquema de datos seleccionado. Una vez finalizado el proceso de generación se presentará un mensaje de confirmación y al presionar el botón “Finish” se cerrará el wizard de generación y se habrá completado el proceso. 64 Figura 32. Pantalla de avance de generación de CodEv El proceso de generación crea un proyecto Web Java dentro de Eclipse con el nombre de proyecto ingresado y el cual tiene todos los componentes necesarios y está listo para ser probado. El proyecto generado tiene la estructura presentada en la Figura 33, en cual se resaltan la carpeta “src” que contendrá todas las clases Java del proyecto, sean estas clases base “static” o extendidas y editables por el usuario “modificable”. También, se debe notar que las clases son creadas dentro del directorio que representa al paquete Java, ingresado en las opciones de configuración. 65 Figura 33. Estructura de un proyecto Web Java creado con CodEv Otra de las carpetas que resalta es la carpeta “WebContent” que contiene todos los recursos web de la aplicación, como son archivos de Java Server Pages (jsp), css, javascript, además de las imágenes y otros directorios requeridos para que el proyecto sea una aplicación Web Java. Por último vale resaltar el archivo .codev, que es donde se almacena la definición de los parámetros de configuración ingresados por el usuario para la generación y que nos da la capacidad de regeneración de la aplicación. 66 6.2.2. Regeneración – Evolución de la aplicación La regeneración de la aplicación Web Java por medio de CodEv tiene las mismas restricciones que la generación inicial y tiene pantallas muy similares. El proceso se inicia haciendo doble click sobre el archivo .codev, lo que abre un editor para la regeneración del proyecto, como en la Figura 34. Este editor tiene los datos de configuración ya cargados, es decir los valores de la primera generación. Aquí también se presentarán las nuevas tablas y campos para que el usuario los pueda seleccionar para la regeneración de la aplicación. Figura 34. Editor para la regeneración de un proyecto CodEv De aquí en adelante el proceso de generación es el mismo que ya ha sido descrito, sólo que, como ya se ha dicho, sólo se sobrescribirán los archivos de extensión o crearán los archivos completos para las nuevas tablas. 6.2.3. Proceso de desarrollo recomendado CodEv podrá ser usado en conjunto con cualquier metodología de desarrollo, con sus concebidas limitaciones y ajustes, pero en el caso que se obtendrá su mejor aprovechamiento para la creación de prototipos o de programas funcionales finales, será con una metodología 67 evolutiva o iterativa-incremental, dado que de esta manera se podrá ir aumentando y refinando los requerimientos del cliente. Figura 35. Modelo iterativo de desarrollo con generación de código Como se muestra en la Figura 35, primeramente se debe realizar un análisis y diseño del dominio y de la solución, para posteriormente crear un modelo de datos en base al dominio de aplicación y crear el esquema de base de datos. El generador se ejecutará contra este esquema de datos para obtener la aplicación funcional, se alterará esta aplicación generada para obtener la funcionalidad de acuerdo a las necesidades del cliente. Una vez finalizados estos cambios se revisa la aplicación con el cliente y se reinicia el ciclo de análisis y diseño de las modificaciones o aumentos a la aplicación. Se altera el modelo de datos y se ejecuta el generador el cual no dañará la programación ya realizada en el sistema, sino que se generará la aplicación y sus cambios, en base al nuevo modelo de datos. En este punto puede ser necesario refactorizar partes de la aplicación para que funcionen con el nuevo modelo de datos generado y realizar los nuevos cambios. Esto formará un ciclo de iteraciones y evolución de la aplicación que ayudará al desarrollador a cumplir sus objetivos de aclarar y satisfacer las necesidades del cliente de una manera rápida, al poder presentar elementos funcionales que dan al cliente una visión mucho más clara de lo que desea y lo que obtendrá. 68 El proceso descrito se asimila al modelo espiral creado por Barry W. Bohem, que basa sus características en sucesivas iteraciones (ciclos) que contienen una serie de pasos, los cuales permiten la evolución del producto deseado [Boh88]. Por el lado del equipo de desarrollo, el uso de CodEv también debe ir acompañado de un proceso de capacitación al personal en las tecnologías que son generadas y en el mejor uso del generador como herramienta y como proceso. Esto ayudará a asegurar el éxito del proceso y el mejor aprovechamiento de la herramienta. 6.3. Bosquejo de la solución generada Las descripciones y pantallas que se presentan a continuación son un listado de las páginas (elementos de presentación) que son generados y que serán los puntos de interacción del usuario con el sistema. Todos estos elementos son páginas Web estándar (XHtml, CSS y Javascript) que serán procesados en el servidor dinámicamente por medio de páginas JSP. Se generan elementos de presentación que serán generales para la aplicación y otros que serán para la visualización y administración de datos por tabla. El sistema generará una pantalla de login en base a una tabla que es seleccionada por el usuario, Figura 36. Esta será la página principal que será el punto de ingreso al sistema desde donde se podrá acceder a las funcionalidades del sistema. Figura 36. Página de login del sistema generado El sistema contará con control y validación de datos para todas las pantallas del sistema por medio de validaciones de Struts2 en el servidor. En la Figura 37, encerrados en un círculo rojo, se encuentran el tipo de mensajes que se presentan en pantalla para los errores de validación que ocurran en el sistema: 69 Figura 37. Mensajes de error que presentará el sistema Además, se generará un menú que contendrá el listado de tablas que fueron seleccionadas para generación, como en la Figura 38, las cuales tendrán mantenimiento CRUD. El menú también tendrá la opción para logout del sistema: Figura 38. Menú generado para el sistema A continuación se presentan los elementos que son generados por cada una de las tablas con sus respectivas relaciones en el modelo de datos. Para cada tabla se genera una página de listado de elementos de datos de la tabla. Esta pantalla tendrá acceso a funciones para: crear, modificar y eliminar datos de la tabla listada, además tendrá capacidad de búsqueda (filtrado) y de paginación. Al hacer click en un elemento de menú para la tabla que se desea revisar, se presentará la página de listado de elementos para esa tabla (Figura 39). A continuación se describen los elementos que componen esta página en mayor detalle: 70 Figura 39. Página con listado de datos La página de listado cuenta con la capacidad de búsqueda o filtrado de datos por cada uno de los campos de la tabla, excepto por la clave primaria, como en la Figura 40. Se podrá colocar todas las opciones por las que se desee filtrar el listado de elementos y este filtro se mantendrá para las siguientes interacciones y se presentará el listado de resultados paginado. Figura 40. Cabecera para filtrar el listado de elementos Se generarán varios tipos de elementos de filtrado dependiendo del tipo de dato en la base de datos que se esté filtrando. A continuación se presenta una descripción detallada de estos elementos de filtrado: Para los elementos de búsqueda que representan una relación padre, lado 1 en una relación 1-N desde la tabla que se está listando hacia otra, existe la capacidad de búsqueda de estos elementos padre. Al hacer click en “Buscar”, aparecerá una pantalla flotante con el listado de elementos padre (Figura 41) que pueden ser filtrados por nombre y paginados, para posteriormente, al hacer click en el enlace de la clave primaria, seleccionar el elemento deseado. Una vez seleccionado el elemento se cierra la ventana flotante y se actualiza la caja de selección de listado con el nombre del elemento padre seleccionado. 71 Figura 41. Página flotante para seleccionar elementos de una relación padre Para los elementos de filtro de tipo texto o numérico se crea un cajón de texto en donde se debe llenar el texto que se desea filtrar. Para todos los campos que sean de tipo fecha se crea un cajón de texto en el que, al seleccionarlo, aparece un calendario (figura 42) en una ventana flotante para la selección de la fecha. Figura 42. Página para seleccionar un elemento de tipo fecha La opción de paginación del listado (Figura 43) permite ir hacia la página inicial, anterior, posterior, final o ir a una página determinada; además se permite cambiar el número de elementos que se están mostrando por página y muestra el número total de filas que existen en el listado. 72 Figura 43. Paginación para los listados Al hacer click en el enlace para la creación de un nuevo elemento, se presentará la página para agregar un nuevo elemento de datos a la tabla, con capacidad de búsqueda de las relaciones padre, de funcionamiento igual al que se detalló en el literal 1.1. Esta página contiene validaciones para cada uno de sus datos, basadas en validaciones en el servidor de Struts2, ver Figura 44. Figura 44. Página para agregar un nuevo elemento Al hacer click en el enlace para la modificación del elemento seleccionado, se presenta la página de modificación del elemento con los datos del registro de la tabla cargados al igual que los datos de las relaciones con tablas padre, ya seleccionados, como en la Figura 45. Esta página funciona igual que la página de creación con validaciones y capacidad de búsqueda de las relaciones padre. 73 Figura 45. Página para modificar un elemento Al hacer click en el enlace (x) para eliminar el elemento seleccionado, se presentará el siguiente mensaje de confirmación antes de ser eliminado, ver Figura 46. El generador realizará eliminación física de los datos y no solamente lógica. Figura 46. Página para modificar un elemento 74 7. Caso Práctico - Validación de la herramienta A continuación se presenta uno de los casos prácticos en el que se ha usado el generador para crear una aplicación bastante completa y el que se usó para registrar los tiempos de codificación. No se tomaron en cuenta para la comparación el tiempo de las actividades de: análisis, diseño de aplicación, de interfaces o pruebas funcionales, sólo las tareas de codificación. Estos ítems mencionados no se ven afectados por la generación de código y deberían ser muy similares en el caso de desarrollo sin el generador y usando el generador, tomando en cuenta que se utilizan metodologías de desarrollo y equipos de personas con habilidades y conocimiento similares. La lógica de negocio a ser implementada es bastante simple y nos permitirá hacer una evaluación y comparación básica del generador y de sus capacidades. A continuación se presentará información relevante para dar un contexto lo más completo posible del alcance del sistema creado para validar la herramienta. Se presenta información sobre el proceso, los requerimientos, modelos de datos usados y pantallas de sistema. El proceso de desarrollo que se siguió para el desarrollo de este ejemplo de validación, se basó en 2 iteraciones que fueron el tomar un modelo de datos inicial, generar la aplicación con CodEv y modificar el código generado de la aplicación en base a los requerimientos. Posteriormente modificar el modelo de datos, regenerar la aplicación con CodEv y refactorizar la aplicación para soportar los cambios en el modelo de datos y requerimientos. Los requerimientos del sistema se detallan a continuación. Este será un sistema Web para la gestión académica y estas serán sus funcionalidades: - Login para tres tipos de usuarios: Administrador, Profesores y Alumnos; que tendrán diferentes menús y funcionalidades. - El profesor podrá editar sus datos personales y de usuario, además podrá ingresar notas para los alumnos que se encuentren registrados en las materias que él dicta. - El alumno podrá editar sus datos personales y de usuario, además podrá tomar materias que estén disponibles y ver sus notas para las materias en las que se encuentra inscrito. - El administrador podrá gestionar todas las tablas, es decir podrá crear nuevos profesores, alumnos, materias y usuarios para el sistema. 75 A continuación se presenta el modelo de datos inicial y el modelo de datos modificado. En la Figura 47 se presenta el modelo de datos inicial para soportar este sistema, donde tendremos que un profesor podrá dictar una o más materias las cuales tendrán notas para los alumnos registrados en esas materias. Además, se tendrá usuarios en el sistema con sus respectivos roles. Figura 47. Modelo Físico inicial del esquema de BD para el caso práctico En la Figura 48 se presenta el modelo de datos modificado con algunos cambios de normalización. Se manejan los conceptos básicos del modelo inicial, el cambio grande es que en un curso se dicta una materia en fechas específicas por un profesor en un aula determinada. De esta manera se normaliza el que se dicten varios cursos de una misma materia y que se dicten varios cursos en la misma aula, sin tener redundancia de datos. 76 Figura 48. Modelo Físico final del esquema de BD para el caso práctico A continuación se presentan las interfaces gráficas más importantes que componen el sistema: - pantalla de login única para todos los usuarios: Figura 49. Pantalla de login única para todos los usuarios del sistema 77 - pantalla de edición de datos personales y de usuario para los usuarios profesor y alumno: Figura 50. Pantalla de edición de datos personales y de usuario - Ingreso de notas por materia por parte del profesor que dicta la materia: Figura 51. Pantalla de ingreso de notas por materia 78 - Pantalla de toma de materias o registro de materias por parte del alumno: Figura 52. Pantalla de toma de materias para alumno - Pantalla de visualización de notas por materia para las materias del alumno: Figura 53. Pantalla de visualización de notas para alumno Como se mencionó en capítulos anteriores, el generador redujo las tareas repetitivas del proyecto y creó funcionalidades CRUD para cada tabla. Esto prestó una base de funcionalidad para poder modificar el sistema y presentar los datos ajustados a los requerimientos de la 79 interfaz y poder evolucionarlos, posteriormente refactorizarlos, para que se ajusten al nuevo modelo de datos, lo cual nos permitió hacer un desarrollo ágil y evolutivo de la aplicación. El tiempo de desarrollo de este prototipo, con la evolución de datos y refactorización al sistema final, fue de 15 horas. El tiempo estimado de desarrollo de la manera tradicional, sin usar el generador, se estimó en 40 horas (5 días laborables de 8 horas), es decir el tiempo de desarrollo se redujo en un 62.5% en relación al tiempo de desarrollo tradicional. 80 8. Conclusiones A continuación se presentan las conclusiones a las que se llegaron con el desarrollo de la presente tesis, las recomendaciones y mejoras a futuro. 8.1. Conclusiones Los objetivos principales planteados como parte de esta tesis de diseñar e implementar una herramienta para la generación rápida de aplicaciones Web Java con una arquitectura multicapa para la administración CRUD de un modelo de datos, se cumplieron. CodEv permite la generación de aplicaciones Web Java ricas en funcionalidad en un tiempo muy corto. Además, apoya al desarrollador para crear prototipos evolutivos o aplicaciones completas que pueden evolucionar de manera sencilla, y que funcionan dentro de un ambiente de desarrollo integrado y que se pueden poner en funcionamiento con mínimo esfuerzo. Se cumplieron todos los requisitos funcionales y no funcionales, como son la generación en base a plantillas, la integración con una plataforma robusta, abstracción del modelo de metadatos y capacidad de regeneración de las aplicaciones. También, se logró alcanzar en gran medida los atributos de calidad como son: - el de usabilidad, donde la instalación del ambiente y del generador son sencillas y rápidas. Y el proceso de generación es muy fácil, guiado y puede tomar menos de 5 minutos, dependiendo de la configuración de la generación deseada por el usuario. - que se pueda ejecutar en múltiples sistema operativos (portable), ya que la plataforma Eclipse está desarrollada en Java y se ejecuta en todos los sistemas operativos para los que exista un J2SE 5.0. - se cumplió la extensibilidad y mantenibilidad por medio de la componentización de la aplicación, ya que el sistema está diseñado para que cada componente aísle su propia lógica y función (separación de responsabilidades) por medio de interfaces claras de comunicación entre componentes. También por medio de la generación en base a plantillas, ya que esto hace más fácil de cambiar y extender la aplicaciones que son generadas. El objetivo que no se pudo cumplir, por restricción de tiempo, es que la herramienta pueda conectarse a múltiples motores de BD. Sólo se llego a implementar la conexión al motor de BD 81 Mysql, pero la herramienta ha sido arquitecturada y diseñada para que pueda ser extendida y pueda soportar múltiples motores de BD. Se concluyó que las herramientas de generación de código son mejores y/o peores en ciertos ámbitos de generación específicos, por ejemplo: más fáciles de usar, mayores capacidades de generación, fácilmente configurables; pero será muy difícil el poder crear una herramienta que pueda cumplir con todas estas características y por lo tanto esperar que sea útil en todos los contextos de generación. La mayoría de generadores son usados por un grupo reducido de personas que incluye a sus creadores, empresa en la que trabajan y grupo con conocimientos similares, dado que los generadores generalmente son creados para un dominio y un proceso específico de desarrollo, que no es fácilmente trasladable a otras empresas o contextos sin cambios o amplia capacitación. Es relativamente sencillo el crear o usar una herramienta de generación de código, dado que se tenga una base de conocimiento sólida; el gran problema, como con todo cambio organizacional es el poder lograr el equilibrio entre las herramientas, las personas y los procesos. En el caso del generador creado como parte de esta tesis, se empezó con el plan de crear un generador genérico, y se terminó realizando un generador muy ajustado al proceso de trabajo de la empresa en la que trabaja el autor, realizando procesos de capacitación y entrenamiento, modificando los procesos de análisis y diseño para incluir prototipos evolutivos y en general una metodología más ágil de interacción con el cliente. También, se incorporaron algunas herramientas nuevas como plug-ins de eclipse y otras herramientas de soporte al trabajo de la empresa. No se ha logrado probar la herramienta en un contexto externo a la empresa, por lo que, por el momento, todos los resultados presentados de uso son de proyectos realizados en un ambiente controlado y de soporte por parte del autor de la herramienta, lo cual hace que estos resultados puedan variar grandemente en otros contextos. Por ultimo, una de las observaciones realizadas es que será mucho más fácil incorporar un ambiente de generación de código dentro de una empresa con procesos maduros, dado que los proyectos se llevarán de manera similar y la capacitación será más sencilla y de esta manera 82 las experiencias en un proyecto con la generación de código pueden ser usadas en los siguientes. Además, el uso del generador en proyectos reales crea retroalimentación necesaria y, como para todo software, un generador de código y sus plantillas de generación requerirán mantenimiento y mejoras que involucran un tiempo no despreciable o se corre el riesgo de que la herramienta de generación llegue a desactualizarse rápidamente sin mantenimiento. 8.2. Recomendaciones Por lo dicho anteriormente, es muy importante seleccionar o crear herramientas de generación de código que vayan en la línea de conocimiento del personal y del funcionamiento de la empresa en sí. No se puede esperar, en la mayoría de los casos, que la empresa de un vuelco de 180º para ajustarse al uso de una herramienta. También, para que sea en cierta medida exitoso el crear o usar una herramienta de generación de código, debe venir acompañado de ajustes en la metodología de trabajo, en la capacitación al personal y en las otras herramientas complementarias usadas por la empresa, para poder aprovechar de mejor manera los beneficios del generador de código; de lo contrario se corre el riesgo de que la generación de código se convierta en una traba más que en una ayuda. Por el lado del uso de la herramienta, se recomienda realizar pruebas con el uso de la herramienta por parte de personas externas a la empresa, para poder validar si la herramienta sería usable en un contexto diferente y menos controlado que el actual. Al ser usado el generador en un contexto externo, se debería empezar por capacitar a las personas que participarán en el proyecto en el cual se desea usar la herramienta, para que conozcan adecuadamente sobre el uso de la herramienta y realizar el ajuste necesario al proceso de desarrollo usado, para obtener mayores beneficios de la herramienta. 8.3. Mejoras a futuro Existen muchas mejoras que se pueden realizar a la herramienta, pero entre las más importantes, en la opinión del autor, están: - Incorporar nuevos motores de base de datos de las que se pueda realizar generación, por ejemplo: Oracle y SQLServer, que son de los más populares en el mercado. Por el momento sólo se tiene soporte para Mysql. 83 - Crear nuevas plantillas de presentación, con colores y menús, para que se pueda seleccionar variedad de estilos. Por el momento sólo existe una plantilla de presentación. - Incorporar capacidades de internacionalización para Struts2. Esto permitiría que el generador sea usado para generar aplicaciones para múltiples idiomas y extendería la base de usuarios de la herramienta. La aplicación generada está en español. - Incorporar capacidades de generación de Spring, que es un framework de Inversión de Control (IoC) y otros servicios que es muy popular en aplicaciones Java empresariales. Esto para que las aplicaciones generadas sean más fácilmente configurables y mantenibles, haciéndolas más cercanas a nivel empresarial. - Incorporar capacidad de comparación de cambios para los archivos base que son regenerados y que pueden ser alterados por el usuario del generador. - Permitir mejor control de generación por medio de la selección de campos de relación y de tablas que rompen relaciones de muchos a muchos (M-N). 84 9. Bibliografía [AABN07] Arnowitz Jonathan, Arent Michael, Berger Nevin, NetLibrary Inc, Effective Prototyping for Software Makers. Elsevier, 2007 [BK06] Bauer Christian, King Gavin, Java Persistence with Hibernate. USA, Manning, 2006 [BS06] Bittner Kurt, Spence Ian, Managing Iterative Software Development Projects. Addison-Wesley, 2006 USA, [Boh88] Bohem Barry. Paper. A Spiral Model of Software Development and Enhancement, 1988 [en línea] <http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?tp=&arnumber=59&isnumber=6> [consulta: 05 junio 2008] [Bru02] Bruce Kim B., Foundations of Object-oriented Languages: Types and Semantics. En su: Varieties of Object-Oriented Programming Languages. Londres, Inglaterra, MIT Press, 2002, pp.124-132. [Bus96] Buschmann, F., Meunier, R., Rohnert, H., Sommerlad, P., Stal, S. Pattern-oriented software architecture: a system of patterns. New York, USA, John Wiley & Sons, 1996. [Fow03A] Fowler Martin, Patterns of Enterprise Application Architecture. Boston, USA, AddisonWesley, 2003. [Fow03B] Fowler Martin, UML Distilled: A Brief Guide to the Standard Object Modeling Language Third edition. Boston, USA, Addison-Wesley, 2003 [GHJV98] Gamma Erich, Helm Richard, Johnson Ralph, Vlissides John, Elements of Reusable Object-Oriented Software. USA, Addison-Wesley, 1998 [Gla02] Glass Robert L., Facts and Fallacies of Software Engineering. USA, Addison-Wesley, 2002 [Har06] Hartmann, D. Interview: Jim Johnson of the Standish Group. InfoQueue, 2006 [en línea]. <http://www.infoq.com/articles/Interview-Johnson-Standish-CHAOS> [consulta: 20 Mayo 2007] [Hem06] Hemrajani Anil , Agile Java Development with Spring, Hibernate and Eclipse. USA, Sams, 2006 [InfQ06] InfoQueue. Article. Interview: Jim Johnson of the Standish Group, 2006 [en línea] <http://www.infoq.com/articles/Interview-Johnson-Standish-CHAOS> [consulta: 13 junio 2007] [Lho06] Lhotka Rockford, Expert C# 2005 Business Objects Second Edition. USA, Apress, 2006 [Mad08] Madrid Jesica. SIMPLe - Sistema de Implementación de Mejora de Procesos con modelos CMMI e IDEAL. Tesis de Magíster en Tecnologías de Información. Santiago, Chile. Universidad de Chile, Facultad de Ciencias Físicas y Matemáticas, 2008. [Mic01] Microsoft. Microsoft Hails 10 Years 85 of Publisher, 2001 [en línea] <http://www.microsoft.com/presspass/press/2001/oct01/1015TenYearsPublisherPR.mspx> [consulta: 09 junio 2008] [ML05] Mcaffer Jeff, Lemieux Jean-michel, Eclipse Rich Client Platform: Designing, Coding, And Packaging Java Applications. USA, Addison-Wesley, 2005 [Omg07] OMG (Object Management Group), CORBA® BASICS, 2007 <http://www.omg.org/gettingstarted/corbafaq.htm> [consulta: 08 junio 2008] [en línea] [Par07] Parsian Mahmoud, JDBC Metadata, MySQL, and Oracle Recipes: A Problem-Solution Approach. NYC, USA, Apress, 2006 [Rou07] Roughley Ian. Starting Struts 2, 2007 <http://www.infoq.com/minibooks/startingstruts2> [consulta: 5 agosto 2007] [Sch01] Schmidt, H. Trusted Components- Towards Automated Assembly with Predictable Properties. Proceedings of ICSE 2001. ACM & IEEE Press. 2001. [SEI00] SEI, Three Tier Software Architectures, 2000 [en <http://www.sei.cmu.edu/str/descriptions/threetier.html> [consulta: 15 junio 2007] línea] [StG94] Standish Group. The CHAOS Report, 1994 [en línea]. <http://www.standishgroup.com/sample_research/chaos_1994_1.php> [consulta: 5 Mayo 2007] [StG03] Standish Group. Press Release. Latest Standish Group CHAOS Report Shows Project Success Rates Have improved by 50%, 2003 [en línea]. <http://www.standishgroup.com/press/article.php?id=2> [consulta: 16 mayo 2007] [Sun07] Sun Microsystems, The Java EE Tutorial. 2007 [en línea] <http://java.sun.com/javaee/5/docs/tutorial/doc/bnbly.html> [consulta: 08 junio 2008] [Wik06] Wikipedia. Lista de países ordenados por PIB (Producto Interno Bruto), 2006 [en línea]. <http://en.wikipedia.org/wiki/List_of_countries_by_GDP_%28nominal%29> [consulta: 20 Abril 2007] 86 Apéndice A – Estimación de la inversión mundial en TI y cantidad de proyectos de TI La estimación de la inversión mundial en TI y la cantidad de proyectos de TI para el año 2006, se realizó utilizando resultados del “CHAOS report” para los años 1994 y 2004. El “CHAOS report” es realizado por el Standish Group y busca las razones para la falla de proyectos de Tecnologías de Información en los EEUU (Estados Unidos) basados en encuestas realizadas. A continuación se presenta como se realizó la extrapolación a valores mundiales, todos estos valores son solo un supuesto para analizar estos datos y no deben ser tomados como datos reales. Con el total de inversión mundial en TI presentado por el “CHAOS report” se calculó el valor a la fecha actual proyectando el crecimiento anual y multiplicado por el número de años. Luego se tomó el PIB (Producto Interno Bruto) nominal por país y se lo comparó al PIB de EEUU, y se extrapoló estos resultados a los de inversión en SW basado en el tamaño de las economías de cada país. El PIB de un país se define como el valor de mercado de todos los productos y servicios producidos dentro de un país en periodo de tiempo determinado. También es considerado como la suma de valor agregado en cada paso de la producción de todos los productos terminados o servicios producidos dentro de un país en un periodo de tiempo determinado. El acercamiento más común para medir y entender el PIB es el método de gastos: PIB = consumos + inversiones + (gasto gubernamental) + (exportaciones – importaciones) El PIB de una región es una de las maneras de determinar el tamaño de su economía y es una visión económica usada por los países de primer mundo. Aunque el PIB puede no ser el mejor reflejo de una economía, son valores usados por el FMI (Fondo Monetario Internacional) y BM (Banco Mundial) y de los cuales existen valores disponibles y nos permite hacer una comparación a gran escala del tamaño de las economías y por lo tanto una estimación aproximada de la inversión económica en TI por país. En el rubro de inversión en TI, el “CHAOS report” presenta los resultados para los años 1994 y 2004, y se obtiene un crecimiento promedio anual de: ((255000* – 250000*) / (2004 - 1994)) = 500* Inversión en TI en US (millones de USD) * en millones de USD 1994 2004 2006 250000* 255000* 256000* En el rubro número de proyectos de TI, el “CHAOS report” presenta los resultados para los años 1994 y 2004, y se obtiene un crecimiento promedio anual de: ((280000 – 175000) / (2004 1994)) = 10500 No. de Proyectos de TI 1994 2004 2006 175000 280000 301000 87 Las proyecciones por país son las siguientes: Rank ing — 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 País World United States Japan Germany China United Kingdom France Italy Spain Canada Brazil South Korea India Mexico Russia Australia Netherlands Switzerland Belgium Turkey Sweden Saudi Arabia Austria Poland Indonesia Norway Denmark South Africa Greece Ireland Iran Finland Argentina Hong Kong, PRC Thailand Portugal Venezuela Malaysia Israel Czech Republic Colombia Singapore Chile Pakistan Hungary New Zealand PIB (millones de USD) según BM 44,384,871 12,455,068 4,505,912 2,781,900 2,228,862 2,192,553 2110185 1,723,044 1,123,691 1,115,192 794,098 787,624 785,468 768,438 763,720 700,672 594,755 365,937 364,735 363,300 354,115 309,778 304,527 299,151 287,217 283,920 254,401 240,152 213,698 196,388 196,343 193,176 183,309 177,722 176,602 173,085 138,857 130,143 123,434 122,345 122,309 116,764 115,248 110,732 109,154 109,041 88 % relación US 356.36% 100.00% 36.18% 22.34% 17.90% 17.60% 16.94% 13.83% 9.02% 8.95% 6.38% 6.32% 6.31% 6.17% 6.13% 5.63% 4.78% 2.94% 2.93% 2.92% 2.84% 2.49% 2.45% 2.40% 2.31% 2.28% 2.04% 1.93% 1.72% 1.58% 1.58% 1.55% 1.47% 1.43% 1.42% 1.39% 1.11% 1.04% 0.99% 0.98% 0.98% 0.94% 0.93% 0.89% 0.88% 0.88% Inversión en TI (millones de USD) 912,281 256,000 92,614 57,179 45,812 45,065 43,372 35,415 23,096 22,922 16,322 16,189 16,144 15,794 15,697 14,402 12,225 7,521 7,497 7,467 7,278 6,367 6,259 6,149 5,903 5,836 5,229 4,936 4,392 4,037 4,036 3,971 3,768 3,653 3,630 3,558 2,854 2,675 2,537 2,515 2,514 2,400 2,369 2,276 2,244 2,241 No de Proyectos de TI 1,072,643 301,000 108,894 67,230 53,865 52,987 50,997 41,641 27,156 26,951 19,191 19,034 18,982 18,571 18,457 16,933 14,373 8,844 8,815 8,780 8,558 7,486 7,359 7,230 6,941 6,861 6,148 5,804 5,164 4,746 4,745 4,668 4,430 4,295 4,268 4,183 3,356 3,145 2,983 2,957 2,956 2,822 2,785 2,676 2,638 2,635 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 United Arab Emirates Algeria Nigeria Romania Philippines Egypt Ukraine Peru Kuwait Bangladesh Kazakhstan Vietnam Morocco Slovakia Libya Croatia Ecuador Slovenia Luxembourg Guatemala Belarus Tunisia Qatar Dominican Republic Angola Sudan Serbia and Montenegro Bulgaria Syrian Arab Republic Lithuania Oman Sri Lanka Lebanon Costa Rica Kenya Cameroon El Salvador Uruguay Côte d'Ivoire Latvia Panama Cyprus Iceland Trinidad and Tobago Yemen Uzbekistan Estonia Bahrain Jordan Iraq Azerbaijan Tanzania Ethiopia 104,204 102,257 98,951 98,559 98,306 89,336 81,664 78,431 74,658 59,958 56,088 52,408 51,745 46,412 38,756 37,412 36,244 34,030 33,779 31,683 29,566 28,683 28,451 28,303 28,038 27,699 27059 26,648 26,320 25,495 24,284 23,479 22,210 19,432 17,977 16,985 16,974 16,792 16,055 15,771 15,467 15,418 15,036 14,762 14,452 13,667 13,107 12,995 12,861 12,602 12,561 12111 11,174 89 0.84% 0.82% 0.79% 0.79% 0.79% 0.72% 0.66% 0.63% 0.60% 0.48% 0.45% 0.42% 0.42% 0.37% 0.31% 0.30% 0.29% 0.27% 0.27% 0.25% 0.24% 0.23% 0.23% 0.23% 0.23% 0.22% 0.22% 0.21% 0.21% 0.20% 0.19% 0.19% 0.18% 0.16% 0.14% 0.14% 0.14% 0.13% 0.13% 0.13% 0.12% 0.12% 0.12% 0.12% 0.12% 0.11% 0.11% 0.10% 0.10% 0.10% 0.10% 0.10% 0.09% 2,142 2,102 2,034 2,026 2,021 1,836 1,679 1,612 1,535 1,232 1,153 1,077 1,064 954 797 769 745 699 694 651 608 590 585 582 576 569 556 548 541 524 499 483 457 399 369 349 349 345 330 324 318 317 309 303 297 281 269 267 264 259 258 249 230 2,518 2,471 2,391 2,382 2,376 2,159 1,974 1,895 1,804 1,449 1,355 1,267 1,251 1,122 937 904 876 822 816 766 715 693 688 684 678 669 654 644 636 616 587 567 537 470 434 410 410 406 388 381 374 373 363 357 349 330 317 314 311 305 304 293 270 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 Ghana Jamaica Bosnia and Herzegovina Botswana Bolivia Uganda Albania Senegal Paraguay Gabon Honduras Nepal Zambia Afghanistan Democratic Republic of Congo Turkmenistan Mozambique Mauritius Georgia Namibia Republic of Macedonia Malta Bahamas, The Chad Cambodia Burkina Faso Mali Republic of Congo Madagascar Nicaragua Armenia Papua New Guinea Benin Haiti West Bank and Gaza Niger Zimbabwe Equatorial Guinea Barbados Moldova Laos Fiji Swaziland Guinea Kyrgyz Republic Tajikistan Isle of Man Togo Rwanda Malawi Mauritania Mongolia 10,695 9,696 9,369 9,350 9,334 8,712 8,379 8,318 8,152 8,055 7,976 7,346 7,257 7,168 0.09% 0.08% 0.08% 0.08% 0.07% 0.07% 0.07% 0.07% 0.07% 0.06% 0.06% 0.06% 0.06% 0.06% 220 199 193 192 192 179 172 171 168 166 164 151 149 147 258 234 226 226 226 211 202 201 197 195 193 178 175 173 6,974 6,774 6,630 6,447 6,395 6,126 5,762 5,570 5,502 5,469 5,391 5,171 5,098 5,091 5,040 4,911 4,903 4,731 4,287 4,245 3,454 3,405 3,364 3,231 2,976 2906 2,855 2,810 2,731 2,689 2,441 2,326 2,265 2,203 2,131 2,072 1,888 1,880 0.06% 0.05% 0.05% 0.05% 0.05% 0.05% 0.05% 0.04% 0.04% 0.04% 0.04% 0.04% 0.04% 0.04% 0.04% 0.04% 0.04% 0.04% 0.03% 0.03% 0.03% 0.03% 0.03% 0.03% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 0.02% 143 139 136 133 131 126 118 114 113 112 111 106 105 105 104 101 101 97 88 87 71 70 69 66 61 60 59 58 56 55 50 48 47 45 44 43 39 39 169 164 160 156 155 148 139 135 133 132 130 125 123 123 122 119 118 114 104 103 83 82 81 78 72 70 69 68 66 65 59 56 55 53 51 50 46 45 90 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 Lesotho Central African Republic Suriname Sierra Leone Belize Cape Verde Eritrea Antigua and Barbuda Bhutan St. Lucia Maldives Burundi Guyana Djibouti Seychelles Liberia Gambia, The Grenada St. Kitts and Nevis St. Vincent and the Grenadines Samoa Comoros Timor-Leste Vanuatu Guinea-Bissau Solomon Islands Dominica Tonga Micronesia, Fed. Sts. Palau Marshall Islands Kiribati São Tomé and Príncipe 1,453 1,369 1,342 1,193 1,105 1,024 986 905 840 825 817 800 783 702 694 548 461 454 453 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.01% 0.00% 0.00% 0.00% 0.00% 30 28 28 25 23 21 20 19 17 17 17 16 16 14 14 11 9 9 9 35 33 32 29 27 25 24 22 20 20 20 19 19 17 17 13 11 11 11 428 399 382 349 341 301 286 279 244 232 145 144 76 57 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% 0.00% Totales : 9 8 8 7 7 6 6 6 5 5 3 3 2 1 900,516 10 10 9 8 8 7 7 7 6 6 4 3 2 1 1,058,810 91