texto de estadística computacional con r, excel, minitab y spss
Anuncio

UNIVERSIDAD NACIONAL DEL CALLAO
VICERECTORADO DE INVESTIGACIÓN
FACULTAD DE CIENCIAS ECONÓMICAS
TEXTO DE ESTADÍSTICA
COMPUTACIONAL CON R, EXCEL,
MINITAB Y SPSS
AUTOR:
JUAN FRANCISCO BAZÁN BACA
(Resolución Rectoral 1351-2008-R del 22-12-08)
01-12-08 al 30-11-10
CALLAO – PERÚ
2010
ÍNDICE
Pág.
INDICE
2
INTRODUCCIÓN
10
Capítulo 1. CONSTRUCCIÓN DE UNA BASE DE DATOS
11
1.1
Introducción
11
1.2
Definición de variables
13
1.3
Introducción de datos
27
1.4
Archivo de datos
30
1.5
Transformación de datos
39
1.6
Recodificación de datos
43
1.7
Manipulación de archivos
49
Capítulo 2. PRESENTACIÓN DE DATOS
50
2.1
Introducción
50
2.2
Cuadros estadísticos
50
2.3
Distribución de frecuencias
72
2.4
Gráficos estadísticos
87
2.5
Gráficos de variables cualitativas
89
2.6
Gráficos de frecuencias
98
2.7
Diagrama de tallos y hojas
112
Capitulo 3. MEDIDAS DE POSICIÓN
115
3.1
Introducción
115
3.2
Mediaaritmética
116
3.3
Mediana
120
3.4
Moda
124
3.5
Media geométrica
133
3.6
Media armónica
137
3.7
Los cuantiles: cuartiles, deciles y percentiles
140
Capítulo 4. MEDIDAS DE DISPERSIÓN Y FORMA
155
4.1
155
Introducción
2
4.2
Rango. Rango intercuartílico
156
4.3
Desviación media
158
4.4
La varianza
160
4.5
La desviación típica
166
4.6
El coeficiente de variación
167
4.7
El diagrama de cajas o boxplot
174
4.8
Medidas de forma de la distribución
182
Capítulo 5. CORRELACIÓN Y REGRESIÓN SIMPLE
190
5.1
Introducción
190
5.2
Diagrama de dispersión
191
5.3
Covarianza y coeficiente de correlación
196
5.4
Regresión lineal simple
200
5.5
Coeficiente de determinación
202
Capítulo 6. MODELOS DISCRETOS DE PROBABILIDAD
210
6.1
Introducción
210
6.2
Distribución binomial
211
6.3
Distribución Poisson
224
6.4
Distribución hipergeométrica
236
6.5
Distribución geométrica
246
Capítulo 7. MODELOS CONTINUOS DE PROBABILIDAD
258
7.1
Introducción
258
7.2
Distribución uniforme o rectangular
259
7.3
Distribución exponencial
269
7.4
Distribución normal
278
7.5
Distribución chi-cuadrado
288
7.6
Distribución T de student
295
REFERENCIAS BIBLIOGRÁFICAS
303
Anexo
304
3
ÍNDICE DE CUADROS Y FIGURAS
CUADROS
Pág.
1.1 Tabla de la masa corporal ideal
39
2.1 PBI por rama de la actividad económica, según año: 2000-07
55
2.2 Alumnos de estadística básica 09-A de la FCE-UNAC, por sexo, según hobby
58
2.3 Alumnos de estadística básica 09-A de la FCE-UNAC, por sexo, según
especialización y hobby
63
2.4 Alumnos de estadística básica 2009-A, de la FCE-UNAC, según hobby
73
2.5 Alumnos de estadística básica 2009-A, de la FCE-UNAC, según el número de
miembros en la familia
75
2.6 Pesos (Kg.) de los 60 alumnos de estadística básica 09-A UNAC
78
2.7 Distribución de frecuencias de los pesos de los alumnos de estadística básica
09-A FCE-UNAC
80
3.1 Resumen de los cuantiles calculados para los pesos (Kg.) de los alumnos de
estadística básica 09-A, FCE-UNAC, por la forma en que están los datos
150
3.2 Resumen de los percentiles calculados para los pesos (Kg.) de los alumnos de
estadística básica 09-A, de la FCE-UNAC, por programa usado
154
4.1 Resumen de las medidas de dispersión calculadas para los pesos (Kg.) de los
alumnos de estadística básica 09-A, de la FCE-UNAC, por programa usado
174
FIGURAS
1.1 Variables definidas en Excel
15
1.2 Variables definidas en Minitab
16
1.3 Editor de datos en SPSS
16
1.4 Definición del Tipo de variable
18
1.5 Cuadro de diálogo para definir Etiquetas de Valor
20
1.6 Cuadro de diálogo para Definir Valores Perdidos
21
1.7 Vista de Variables definidas en SPSS
23
1.8 Variables definidas en SPSS
24
1.9 Abriendo base de datos en R desde un block de notas
26
1.10
Base de datos en Excel
28
1.11
Base de Datos en MINITAB
28
1.12
Base de datos en SPSS
29
FIGURAS
Pág.
4
1.13
Base de datos en R
29
1.14
Ventana de archivamiento en Excel
30
1.15
Cuadro de diálogo para Guardar como, en Excel
31
1.16
Ventana de File (archivo), en Minitab
32
1.17
Cuadro de diálogo para Save Project As, en Minitab
33
1.18
Cuadro de diálogo para Guardar como, en SPSS
34
1.19
Cuadro de diálogo para Guardar área de trabajo, en R
35
1.20
Cálculo del imc en Excel
40
1.21
Cálculo de la talla_m en Minitab
41
1.22
Cálculo de la variable talla_m en SPSS
42
1.23
Tipos de recodificación en Minitab
43
1.24
Obtención de la Condición, recodificando el IMC en Minitab
44
1.25
Resultado de la Condición recodificando el IMC en Minitab
45
1.26
Obtención de la Condición, recodificando el IMC en SPSS
46
1.27
Recodificar Valores antiguos del IMC y nuevos de Condición en SPSS
47
1.28
Resultado de la Condición recodificando el IMC en SPSS
47
1.29
Resultado de la Condición recodificando el IMC en R
48
2.1 Estructura de un cuadro estadístico
51
2.2 Obtención de un cuadro bidimensional con SPSS
56
2.3 Mostrar en las casillas
57
2.4 Obtención de un cuadro bidimensional con Minitab
60
2.5 Escoger qué mostrar en las casillas con el Minitab
61
2.6 Cuadro tridimensional en SPSS
64
2.7 Creando tabla dinámica en Excel
65
2.8 Tabla dinámica para Sexo y Hobby en Excel
66
2.9 Tabla dinámica para Sexo y Hobby con porcentajes en Excel
67
2.10 Tabla dinámica para Sexo, Especialización y Hobby en Excel
67
2.11 Obtención de tablas de frecuencias en SPSS
73
2.12 Obtención de tabla de frecuencias en Excel
79
2.13 Argumentos de la función Frecuencia
80
2.14 Recodificación de la variable peso en Minitab
81
2.15 Variable peso recodificada en pesos (intervalos) con Minitab
82
2.16 Obtención de tabla de frecuencias en Minitab (variable pesos)
83
FIGURAS
Pág.
5
2.17 Recodificando la variable peso en SPSS
83
2.18 Recodificar Valores antiguos del peso y nuevos de pesos en SPSS
84
2.19 Resultado de la variable pesos, recodificando el peso en SPSS
85
2.20 Resultado de la variable pesos, recodificando el peso en R
86
2.21 Gráfico de sectores en Excel
90
2.22 Gráfico de sectores en SPSS
91
2.23 Gráfico de sectores en Minitab
91
2.24 Gráfico de sectores en R
92
2.25 Gráfico de barras de la variable hobby en Minitab
94
2.26 Datos de la variable hobby y clase en Excel
95
2.27 Herramientas del Análisis de datos en Excel
95
2.28 Obteniendo gráfico de Pareto en Excel
95
2.29 Gráfico de Pareto de la variable hobby en Excel
96
2.30 Gráfico de Pareto de la variable hobby en Minitab
97
2.31 Gráfico de barras de los miembros de la familia en Excel
98
2.32 Gráfico de barras de los miembros de la familia en SPSS
99
2.33 Gráfico de barras de los miembros de la familia en Minitab
100
2.34 Obteniendo el Histograma de peso en Excel
101
2.35 Histograma de frecuencia del peso en Excel
102
2.36 Obteniendo el histograma de peso en Minitab
103
2.37 Edición (en Binning) del histograma de peso en Minitab
104
2.38 Histograma de frecuencia del peso en Minitab
104
2.39 Histograma de frecuencia del peso en SPSS
105
2.40 Histograma de frecuencia del peso en R
106
2.41 Edición del histograma de densidad de peso en Minitab
108
2.42 Histograma de densidad de peso en Minitab
108
2.43 Datos para el Polígono de frecuencias y Ojiva del peso en Minitab
109
2.44 Scatterplot para el Polígono de frecuencias del peso en Minitab
110
2.45 Polígono de frecuencias del peso en Minitab
110
2.46 Scatterplot para la Ojiva del peso en Minitab
111
2.47 Ojiva del peso en Minitab
112
3.1 Cálculo de la media para datos agrupados en Excel
117
3.2 Cálculo de la media aritmética (PROMEDIO) en Excel
129
FIGURAS
Pág.
6
3.3 Resultados de la media aritmética, mediana y moda en Excel
129
3.4 Selección de la variable peso para calcular estadígrafos en Minitab
130
3.5 Selección de estadígrafos de posición a calcular en Minitab
130
3.6 Cálculo de estadígrafos de Tendencia central en SPSS
131
3.7 Cálculo de cuartiles en Excel
151
3.8 Resultado de cuartiles y percentiles en Excel
152
3.9 Cálculo de cuartiles y percentiles en SPSS
153
4.1 Medidas de dispersión obtenidas con Excel
169
4.2 Selección de estadígrafos de dispersión en Minitab
170
4.3 Cálculo de estadígrafos de dispersión en SPSS
171
4.4 Estructura del diagrama de cajas y bigotes (boxplot)
175
4.5 Ventana de diálogo para definir el boxplot de peso en Minitab
176
4.6 Diagrama de cajas y bigotes de la variable peso en Minitab
176
4.7 Efectuando Gráfico Múltiple de Boxplot para peso, por sexo
177
4.8 Boxplot del peso para hombres y mujeres en Minitab
178
4.9 Ventana de diálogo Explorar para definir el boxplot de peso en SPSS
179
4.10 Diagrama de cajas y bigotes de la variable peso en SPSS
179
4.11 Boxplot del peso para hombres y mujeres en SPSS
180
4.12 Diagrama de cajas y bigotes de la variable peso en R
181
4.13 Boxplot del peso para hombres y mujeres en R
182
4.14 Cálculo de la asimetría y curtosis en Excel
187
5.1 Definiendo el diagrama de dispersión en Excel
192
5.2 Diagrama de dispersión de la cantidad y precio en Excel
192
5.3 Definiendo el diagrama de dispersión en Minitab
193
5.4 Diagrama de dispersión de la cantidad y precio en Minitab
193
5.5 Creando el diagrama de dispersión en SPSS
194
5.6 Diagrama de dispersión de la cantidad y precio en SPSS
195
5.7 Diagrama de dispersión de la cantidad y precio en R
196
5.8 Aplicando Regresión en Excel
204
5.9 Resultado de la Regresión de cantidad y precio de muñecas en Excel
205
5.10 Aplicando Regresión en Minitab
205
5.11 Aplicando Regresión en SPSS
207
6.1 Cálculo de probabilidades para la distribución binomial en Excel
214
FIGURAS
Pág.
7
6.2 Solución del Ejemplo 6.2 en Excel
215
6.3 Probabilidad con la distribución binomial en Minitab
216
6.4 Probabilidad acumulada con la distribución binomial en Minitab
217
6.5 Probabilidad para varios valores con distribución binomial en Minitab
218
6.6 Cálculo de probabilidades con la distribución binomial en SPSS
220
6.7 Probabilidades acumuladas con la distribución binomial en SPSS
221
6.8 Cálculo de probabilidades para la distribución Poisson en Excel
227
6.9 Solución del Ejemplo 6.3 en Excel
228
6.10 Probabilidad con la distribución Poisson en Minitab
229
6.11 Probabilidad para varios valores con distribución Poisson en Minitab
230
6.12 Cálculo de probabilidades con la distribución Poisson en SPSS
231
6.13 Probabilidades acumuladas con la distribución Poisson en SPSS
232
6.14 Distribución de probabilidades Poisson del ejemplo 6.3 en SPSS
233
6.15 Cálculo de distribución hipergeométrica en Excel
238
6.16 Solución del Ejemplo 6.4 en Excel
239
6.17 Probabilidad con la distribución hipergeométrica en Minitab
240
6.18 Probabilidades con distribución hipergeométrica en Minitab
241
6.19 Cálculo de probabilidades con la distrib. hipergeométrica en SPSS
242
6.20 Probabilidades acumuladas con la distrib. hipergeométrica en SPSS
243
6.21 Distrib. de probabilidades hipergeométrica del ejemplo 6.4 en SPSS
243
6.22 Solución del Ejemplo 6.5 en Excel
248
6.23 Probabilidad con la distribución geométrica en Minitab
249
6.24 Probabilidades con distribución geométrica en Minitab
251
6.25 Cálculo de probabilidades con la distribución geométrica en SPSS
252
6.26 Probabilidades acumuladas con la distribución geométrica en SPSS
253
6.27 Distrib. de probabilidades geométrica del ejemplo 6.5 en SPSS
254
7.1 Probabilidad con la distribución uniforme en Minitab
261
7.2 Graficando probabilidades acumuladas para la uniforme en Minitab
263
7.3 Definiendo el área a sombrear para probabilidades acumuladas con la distribución uniforme en Minitab
263
7.4 Cálculo y gráfico de P(22 ≤ X ≤ 24) con la dist. uniforme en Minitab
264
7.5 Gráfico del inverso de probab. acum. Con la dist. uniforme en Minitab
265
7.6 Cálculo de las densidades f(x) con la distribución uniforme en SPSS
266
FIGURAS
Pág.
8
7.7 Probabilidades acumuladas con la distribución uniforme en SPSS
267
7.8 Densidades y probab. acumuladas con la distrib. uniforme en SPSS
267
7.9 Cálculo de probabilidades acumuladas con exponencial en Excel
271
7.10 Probabilidad acumulada con la distribución exponencial en Minitab
272
7.11 Graficando probabilidades acum. para la exponencial en Minitab
274
7.12 Cálculo de probab. acum. con la distribución exponencial en SPSS
276
7.13 Probabilidades acumuladas con la distrib. exponencial en SPSS
276
7.14 Cálculo de probabilidades acumuladas con la normal en Excel
281
7.15 Probabilidad acumulada con la distribución normal en Minitab
283
7.16 Graficando probabilidades acumuladas con la normal en Minitab
284
7.17 Cálculo de probab. acumuladas con la distribución normal en SPSS
286
7.18 Probabilidades acumuladas con la distribución normal en SPSS
287
7.19 Cálculo de probabilidades acumuladas con la chi-cuadrado en Excel
291
7.20 Gráfico de P(14.6 ≤ X ≤ 37.7) con la chi-cuadrado en Minitab
292
7.21 Cálculo de probab. acumuladas con la chi-cuadrado en SPSS
294
7.22 Cálculo de probabilidades acumuladas con la t en Excel
298
7.23 Gráfico de P(-1.316 ≤ X ≤ 2.060) con la t en Minitab
300
7.24 Cálculo de probab. acumuladas con la t en SPSS
301
9
INTRODUCCIÓN
La estadística ha desarrollado una serie de técnicas y procedimientos cuyas
aplicaciones procedimentales requieren de algunas herramientas de cálculo como
son las calculadoras programadas o los programas estadísticos desarrollados en
diferentes plataformas computacionales.
A fin de contribuir al proceso de enseñanza aprendizaje del instrumental
estadístico, hemos creído conveniente elaborar un “Texto de Estadística
computacional con R, Excel, Minitab y SPSS” que de manera sencilla y práctica
ayude a los estudiantes de la estadística a efectuar sus aplicaciones.
Las aplicaciones se desarrollan tanto en las versiones comerciales del Excel
2007, Minitab 15.0 English y SPSS 15.0 en español; como en la versión de uso
libre del programa R-2.11.1 cuya instalación se explica en la pág. 24.
El texto consta de siete capítulos. En el primero, se explica la Construcción
de una base de datos muy necesaria para procesar encuestas y otros cálculos. En el
capítulo 2, se describe la Presentación de datos a través de cuadros y gráficos.
En los capítulos tres, cuatro y cinco se presentan los indicadores de resumen
de los datos mediante las medidas de posición, dispersión y forma, así como el
análisis de correlación y regresión simple acompañadas del concepto, formas de
cálculo (con datos sin agrupar y agrupados), interpretación de resultados y
aplicaciones computacionales con cada uno de los programas.
En los capítulos seis y siete, se desarrollan los modelos discretos y continuos
de probabilidad, partiendo de una presentación sencilla de sus características,
acompañada de aplicaciones manuales y computacionales en cada programa.
Agradezco a nuestra querida UNAC por el continuo apoyo ofrecido para
alcanzar estos logros que permiten sistematizar conocimientos e incorporar temas
para la discusión en clases. El reconocimiento especial a los estudiantes de
economía de la FCE-UNAC, ya que gracias a su esfuerzo y comprensión en los
últimos años se han puesto en práctica los resultados de este modesto trabajo.
10
Capítulo 1. CONSTRUCCIÓN DE UNA BASE DE DATOS
“El hombre más feliz del mundo es aquel que sepa reconocer los méritos
de los demás y pueda alegrarse del bien ajeno como si fuera propio”
Johann Wolfgang von Goethe
CONTENIDO
1.1
1.2
1.3
1.4
1.5
1.6
1.7
Introducción.
Definición de variables.
Introducción de datos.
Archivo de datos.
Transformación de datos.
Recodificación de datos.
Manipulación de archivos.
1.1 INTRODUCCIÓN
Durante la fase de Elaboración de datos de una Encuesta, es necesario construir una
Base de Datos (BD) que facilite procesamiento electrónico de los mismos mediante la
obtención de cuadros, gráficos, indicadores estadísticos y relaciones entre variables en
las que esta interesado el investigador a partir de los propósitos de su investigación.
Una Base de Datos es un arreglo matricial cuyas columnas contienen los Campos (las
variables o preguntas del estudio) y las filas los Registros de datos (casos para el
SPSS correspondientes a cada unidad de investigación estudiada.
Para efectos de procesamiento en cualquiera de los programas que estamos trabajando
(R, Excel, Minitab y SPSS) es necesario que el programa reconozca las variables
consideradas y algunos detalles que se deben tomar en cuenta. Para abreviar esta parte
diseñaremos la base de datos inicialmente en Excel y de aquí veremos como se exporta
a R, Minitab y SPSS con sus particularidades especiales en el SPSS.
Para el presente trabajo, se usa el Cuestionario de “Características del Alumno” que se
muestra en la página siguiente, el mismo que fue aplicado a 60 alumnos del curso de
Estadística Básica, el semestre 2009-A, en la FCE-UNAC.
11
UNIVERSIDAD NACIONAL DEL CALLAO
FACULTAD DE CIENCIAS ECONÓMICAS
Asignatura: Estadística Básica
Profesor : Ingº Juan Francisco Bazán Baca
CARACTERÍSTICAS DEL ALUMNO
Nº…….........
Apellidos y Nombres: …………………………………………………………………….
1. Sexo: Masculino
1
Femenino
2. Edad: ….......
2
3. Peso (Kg.) …....... 4. Talla (cm.) ….......
5. Ingreso familiar mensual: S/.
……….
6. Nº de miembros en la familia: …… 7. Gastos de estudio medio mensual: S/. ……..
8. Créditos aprobados acumulados: ……
9. Promedio ponderado acumulado: ……..
10. ¿En que tipo de vivienda reside?
Casa independiente
1
Departamento en edificio
2
Quinta ………….
3
Otro ….............................
4
(Especifique)
11. Nº de dormitorios: ………..
12. Horas semanales de TV: ……..
13. Horas de estudio semanal fuera de clase: ………
14. Nº de libros leídos el 2008: …..
15. ¿Cuál es tu principal HOBBY?
Deportes
1
Música
2
Baile
TV/Cine
4
Otro …............................
3
5
(Especifique
16. Importancia de tus estudios:
Media
3
17. Importancia de tu físico:
Media
3
18. Colegio de procedencia:
Muy poca
1
Poca
2
Mucha
4
Muchísima
5
Muy poca
1
Poca
2
Mucha
4
Muchísima
5
Estatal
1
No Estatal
2
19. ¿En que desea especializarse? Teor. Económica
Callao, Abril de 2009
1 Gestión Empresarial
MUCHAS GRACIAS
12
2
1.2 DEFINICIÓN DE VARIABLES
Variable.- es una característica de interés observada en la población y que esta sujeta a
diferentes resultados o valores. Ejemplo: sexo, edad, peso, talla, ingreso, hobby, etc.
Tipos de Variables.- las variables pueden ser cualitativas o cuantitativas.
Variables cualitativas.- son aquellas que responden a una categoría, cualidad o
atributo observado en la unidad de investigación. Ejemplo: tipo de vivienda,
importancia de sus estudios, colegio de procedencia, especialización, etc.
La medición de las variables cualitativas puede ser Nominal (las cualidades
observadas no implican un orden particular. Ejemplo: Sexo, hobby, distrito de
residencia, etc.) y Ordinal (las cualidades observadas responden a un orden
determinado. Ejemplo: nivel educativo, calidad del servicio, etc.
Variables cuantitativas.- son aquellas cuyo resultado de la observación es un valor
numérico. Ejemplo: número de miembros en la familia, número de dormitorios, gastos
de estudio mensual, créditos aprobados, horas de estudio semanal, etc. Las variables
cuantitativas pueden ser discretas o continuas.
Variable cuantitativa discreta.- son aquellas que son el resultado del conteo y
asumen valores enteros. Ejemplo: edad (años cumplidos), número de libros leídos
el año anterior, número de perceptores de ingreso en el hogar, etc.
Variable cuantitativa continua.- son aquellas que son resultado de la medición y
pueden tomar cualquier valor dentro de un intervalo. Ejemplo: ingreso familiar,
gastos de estudio, promedio ponderado del alumno, etc.
La medición de variables cuantitativas puede ser Intervalo (cuando el cero y la escala
de medida son arbitrarios. Ejemplo: la temperatura, las notas o calificaciones en alguna
escala, etc.) y Razón (el valor cero indica la nulidad del estudio y el cociente de dos
valores tiene significado. Son la mayoría de variables cuantitativas. Ejemplo: peso,
talla, ingreso, etc.)
13
Para definir las Variables en una BD, se tiene que indicar en cada campo (columna) las
preguntas consideradas en el Cuestionario del estudio de manera abreviada.
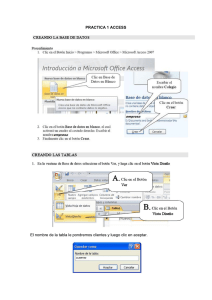
a) En EXCEL
En una primera línea de la hoja de cálculo de Excel se específica el nombre de la
variable utilizando el menor número posible de caracteres, de modo que recoja el
sentido de la pregunta. Se recomienda empezar con el número de cuestionario
(nº_cuest) para identificar la unidad de análisis a la que corresponden los datos y
corregir los mismos ante cualquier error.
A continuación se definen las siguientes variables, en el mismo orden en que se han
formulado las preguntas en el Cuestionario, para facilitar posteriormente el ingreso de
los datos. Así tenemos las variables:
sexo (pregunta 1)
edad (pregunta 2)
peso (pregunta 3)
talla (pregunta 4)
ing.fam (pregunta 5: Ingreso familiar mensual: S/.)
mie.fam (pregunta 6: Nº de miembros en la familia)
g.estud (pregunta 7: Gastos de estudio medio mensual S/.)
cr.aprob (pregunta 8: Créditos aprobados acumulados)
prom.acum (pregunta 9: Promedio ponderado acumulado)
t.viv (pregunta 10: ¿En que tipo de vivienda reside?)
nº.dormit (pregunta 11: Nº de dormitorios)
horas.tv (pregunta 12: Horas semanales de TV)
hrs.estu (pregunta 13: Horas de estudio semanal fuera de clase)
lib.leidos (pregunta 14: Nº de libros leídos el 2008)
hobby (pregunta 15: ¿Cuál es tu principal hobby?)
imp.estudio (pregunta 16: Importancia de tus estudios)
imp.físico (pregunta 17: Importancia de tu físico)
14
col.proc (pregunta 18: Colegio de procedencia) y
especial (pregunta 19: ¿En que desea especializarse?)
Las variables han sido definidas en la línea 6, tal como se muestra en la Figura 1.1
Figura 1.1 Variables definidas en Excel
b) En MINITAB
Al iniciar el programa Minitab 15, aparecen dos hojas: una de Session (Sesión: donde
se muestran los resultados de tareas resueltas con el programa) y otra Worksheet
(Hoja de Trabajo: similar a la de Excel y SPSS donde se definen las variables y se
ingresa los datos). Las columnas aparecen definidas por la letra C y un dígito (que
indica la columna. Debajo de C1 hemos definido el nº_cuest (número de cuestionario),
debajo de C2 sexo y así sucesivamente hasta C20 especial (ver figura 1.2)
15
Figura 1.2 Variables definidas en Minitab
c) En SPSS
Al abrir el programa SPSS 15, aparecen dos hojas: una de Resultados 1 [Dokument
1] – Visor SPSS (donde aparecen los resultados de las tareas efectuadas con SPSS) y
otra Sin título [Conjunto_de_datos0] – Editor de datos SPSS (donde se definen las
variables y se ingresan los datos del estudio) donde vamos a definir la base de datos.
Figura 1.3 Editor de datos en SPSS
16
En la parte inferior del Editor de datos SPSS (ver figura 1.3) se observan dos vistas:
una Vista de datos (donde se ingresan los datos para cada una de las variables en
estudio) y otra Vista de variables (donde se definen las variables en estudio).
Justamente la fig. 1.3 muestra la Vista de variables, en cada fila se van definiendo las
variables en el mismo orden como aparecen en el cuestionario (o como el investigador
quiera definirlas para cálculos estadísticos particulares).
Para cada Variable (o característica en estudio) debemos indicar: nombre, tipo,
anchura, decimales, etiqueta, valores, perdidos, columnas, alineación y medida;
tomando en cuenta algunas de las recomendaciones que a continuación señalamos.
Nombre
El nombre de la variable debe comenzar con una letra del alfabeto español y luego
utilizar las combinaciones de letras, dígitos o símbolos que se estimen necesarias
de modo que con a lo más 64 caracteres juntos (sin espacio en blanco) resuman el
significado de la variable o toda una pregunta del cuestionario.
Si el cuestionario contiene un número grande de preguntas se recomienda definir
cada una de las variables (preguntas) de la siguiente manera: pgta_01, pgta_02,
…. , pgta_150 y en el momento de definir la etiqueta de la variable indicar la
pregunta formulada.
En general, al especificar del nombre de las variables se debe tener en cuenta:
Debe comenzar por una letra y los demás caracteres pueden ser letras, dígitos,
puntos o los símbolos #, @, _ o $.
El nombre de variable no puede terminar en punto.
El nombre de la variable debe ser único; no se aceptan duplicados.
No utilizar caracteres especiales (por ejemplo: !, ?, ' y *).
Hay palabras reservadas que no se pueden utilizar como nombres de variable;
estas son: ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH.
Establecido el nombre de la variable, presionar Enter, inmediatamente el cursor se
ubica en Tipo (donde aparece automáticamente Numérico), con el que se
comienza indicar algunas especificaciones de la variable.
17
Tipo
Seleccionar el tipo de datos que se espera para la variable. En función del tipo
escogido se visualizan los valores de la variable y éstos estarán disponibles sólo
para aquellas operaciones que son esperables para los mismos.
Figura 1.4 Definición del Tipo de variable
Para definir, ubíquese en la casilla de Tipo, pulse el botón con los puntos
suspensivos después de la palabra Numérico y aparece el cuadro de diálogo
mostrado en la Figura 1.4, en el que se observa los tipos de variables siguientes:
Numérico.- define una variable cuyos valores son números, los mismos que
aparecen sin separadores cada tres posiciones.
Coma.- define una variable numérica cuyos valores se muestran con comas de
separación cada tres posiciones y con un punto como separador de la parte
decimal.
Punto.- define una variable numérica cuyos valores se muestran con puntos de
separación cada tres posiciones y con una coma como separador de la parte
decimal. El editor de datos acepta valores numéricos para este tipo de variables,
con o sin puntos, o en notación científica.
Notación científica.- define una variable numérica cuyos valores se muestran
con una E intercalada y un exponente con signo que representa una potencia de
base diez. El editor de datos acepta valores numéricos con o sin el exponente
para estas variables. El exponente puede ir precedido de E o D con un signo
18
opcional, o por el signo solamente. Por ejemplo, 123, 1,23E2, 1,23D2, 1,23E+2,
o incluso 1,23+2.
Fecha.- define una variable numérica cuyos valores se muestran en uno de los
diferentes formatos de fecha-calendario u hora-reloj. Seleccionar una plantilla de
la lista desplegable. Se puede introducir las fechas utilizando como
delimitadores: barras, guiones, puntos, comas o espacios en blanco. El rango de
siglo para los años de dos dígitos se toma de las opciones de configuración
(Menú Edición, Opciones, pestaña Datos)
Dólar.- define una variable numérica cuyos valores contienen un signo de dólar,
una coma para la separación de los decimales y múltiples puntos.
Moneda personalizada.- define una variable numérica cuyos valores se muestran
en uno de los formatos de moneda personalizados que se hayan definido
previamente en la pestaña Moneda del cuadro de diálogo Opciones del menú
Edición. Los caracteres definidos en la moneda personalizada no pueden
emplearse para la introducción de datos pero sí los mostrará el editor de datos.
Cadena.- define una variable cuyos valores no son numéricos; por lo tanto, no se
utilizan en los cálculos. También son conocidas como variables alfanuméricas.
Pueden contener diferentes caracteres hasta la longitud definida. Las letras
mayúsculas y las minúsculas son consideradas diferentes.
Anchura
Establecer el número máximo de caracteres que contienen los valores de la
variable. Automáticamente aparecen 8 caracteres.
Decimales
Determina el número de decimales para los valores de la variable. Si la variable es
tipo fecha o cadena, automáticamente aparecen 0 decimales y si es tipo numérica,
aparecen por defecto, 2 decimales.
Etiqueta
En este recuadro se indica el nombre completo de la variable o la pregunta
correspondiente formulada en el cuestionario hasta un máximo de 255 caracteres y
espacios en blanco. Se recomienda escribirla toda con mayúsculas, ya que esta
19
etiqueta es la que aparece en los cuadros de salida cuando se procesan algunos
resultados de interés y buscaremos de diferenciarlas de las etiquetas de valor.
Valores
En este recuadro por defecto, aparece Ninguno y sirve para asignar valores a los
resultados de variables de tipo cualitativo (Etiquetas de valor) o para definir los
rangos de variables cuantitativas transformadas con fines de procesamiento. Es
decir, que si una variable cualitativa responde a varias cualidades (categorías o
atributos) a cada una de ellas se le asigna un valor por lo general numérico,
pudiendo ser también alfabético.
Los valores los definimos así: estando ubicado en la casilla de Valores, pulsar el
botón con los puntos suspensivos después de la palabra Ninguno y aparece el
cuadro de diálogo mostrado en la Figura 1.5.
Para describir los valores de una variable de tipo cualitativo habrá que situar el
cursor en el recuadro Valor e introducir el número o letra correspondiente. A
continuación se pulsa el tabulador y el cursor se sitúa en el recuadro Etiqueta
donde se introduce la palabra o palabras que describen ese valor, luego pulsamos
Añadir; inmediatamente el cursos se ubica nuevamente en Valor y se repite el
proceso hasta que se define la etiqueta del último valor y se sale con Aceptar.
Figura 1.5 Cuadro de diálogo para definir Etiquetas de Valor
20
Se recomienda escribir las etiquetas de valor con mayúsculas y minúsculas (en el
ejemplo Hombre y Mujer) para que cuando se obtenga un cuadro con la variable
SEXO (con mayúsculas), se diferencie el nombre de la variable y sus categorías
componentes.
Perdidos
Son aquellos valores que no son considerados para realizar determinados cálculos
estadísticos. Existen dos tipos de valores perdidos:
Del sistema.- cualquier casilla en blanco de la matriz de datos.
Del usuario.- son aquellos que define el usuario por diferentes motivos, entre
los que podemos destacar aquellos que distorsionan los análisis estadísticos,
como por ejemplo cuando se han definido dos categorías de Sexo (1 = hombre
y 2 = mujer) pero por error de digitación se puede colocar cualquier otro valor.
Los valores perdidos los definimos así: estando ubicado en la casilla de
Perdidos, pulsar el botón con los puntos suspensivos después de la palabra
Ninguno y aparece el cuadro de diálogo mostrado en la Figura 1.6.
Figura 1.6 Cuadro de diálogo para Definir Valores Perdidos
Como se puede observar en la Figura 1.6, por defecto aparece No hay valores
perdidos; además existe la posibilidad que el usuario defina tres Valores
Perdidos Discretos o defina un Rango más un valor perdido discreto opcional
21
(un rango de valores perdidos definido por sus dos extremos junto con un solo
valor discreto individual). Se debe tener presente que sólo se pueden definir
rangos para variables de tipo numérico y que no se pueden definir valores
perdidos para variables de cadena larga (con más de 8 dígitos).
Columnas
Al igual que Anchura por defecto define un ancho de 8 para las Columnas de la
base de datos. De requerirse otro ancho, hay que definirlo ubicándose en la casilla
de Columnas y veremos que al extremo opuesto del 8 aparece un botón con un
triángulo hacia arriba para aumentar el ancho y otro triángulo hacia abajo para
disminuir dicho ancho de columna. También lo puede cambiar haciendo doble clic
en la correspondiente casilla de Columnas para la variable que esta definiendo y
digitar el ancho de columna deseado.
Alineación
Se tiene que escoger como van a estar alineados los valores en la base de datos,
por defecto aparece Derecha. Si quiere modificar la Alineación de valores para la
variable que esta definiendo, ubíquese en la correspondiente casilla de alineación
y haga clic en el botón que aparece al costado de Derecha e inmediatamente se
despliegan las tres posibles opciones de alineación Izquierda, Derecha y Centrado,
debiendo escoger la opción deseada haciendo clic sobre la palabra.
Medida
Indica el tipo de medición que le corresponde a la variable que estamos
definiendo, por defecto aparece Escala. Si quiere modificar la Medida para la
variable que esta definiendo, ubíquese en la correspondiente casilla de medida y
haga clic en el botón que aparece al costado de Escala e inmediatamente se
despliegan las tres posibles opciones de medida: Escala, Ordinal y Nominal,
debiendo escoger la opción deseada haciendo clic sobre la palabra.
Escala.- es utilizada para variables numéricas, como por ejemplo, las variables
edad, peso, talla, etc.
Nominal.- es utilizada para representar los valores de cualidades, atributos o
categorías sin un orden particular (por ejemplo, sexo; hobby, etc.). Las medidas
22
nominales pueden ser valores de cadena (alfanuméricos) o numéricos que
representen diferentes atributos (por ejemplo, 1 = Hombre, 2 = Mujer).
Ordinal.- es utilizada para establecer un determinado orden entre los valores de
la variable, por ejemplo, la variable Importancia de tus estudios con los valores
Muy poca, Poca, Media, Mucha y Muchísima. Las variables ordinales pueden
ser valores numéricos o de cadena (alfanuméricos) que representen diferentes
categorías (por ejemplo, 1 = Muy poca, 2 = Poca, 3 = Media, 4 = Mucha y 5 =
Muchísima).
Se recomienda utilizar valores numéricos para representar datos ordinales.
La Vista de variables para la base de datos Estadística Básica 09A, se presenta
en la Figura 1.7.
Figura 1.7. Vista de Variables definidas en SPSS
El encabezamiento para las variables definidas en la base de datos Estadística
Básica 09A, se observan en la Vista de datos y se presenta en la Figura 1.8.
Recordar que estas son las variables definidas a partir del cuestionario de
“Características del alumno” de Estadística Básica, del 09A, de la FCE-UNAC.
23
Figura 1.8. Variables definidas en SPSS
d) En R
El programa R es un paquete estadístico de libre uso, para cuya instalación se requiere
ingresar por internet a la página web:
http://www.r-project.org/
En el margen izquierdo escoger la opción CRAN, luego un país cuya web facilite la
instalación, por ejemplo Australia (http://cran.ms.unimelb.edu.au/ ).
En la página escogida, dentro de Download and Install R escoger Windows, luego
base, escoger la versión en la que se encuentra (que es única), por ejemplo Download
R 2.11.1 for Windows, a continuación en Abriendo R-2.11.1-win32.exe, escoger
Guardar archivo.
Una vez guardado el archivo, ejecutar la Instalación del programa la que al finalizar,
por defecto, deja en el escritorio para su ejecución el ícono:
Dando doble clic sobre el icono anterior, se inicia el programa R, el cursor por defecto
es el símbolo “ > ” indica que R esta listo para recibir y ejecutar un comando.
24
Según Paradis (2002) “R es un lenguaje orientado a objetos, …, lo cual significa que
los comandos escritos en el teclado son ejecutados directamente sin necesidad de
construir ejecutables. ….. La sintaxis de R es muy simple e intuitiva. Por ejemplo, una
regresión lineal se puede ejecutar con el comando lm(y~x). Para que una función sea
ejecutada en R debe estar siempre acompañada de paréntesis, inclusive en el caso que
no haya nada dentro de los mismos.”
Paradis, et.al., señala también que “Orientado a Objetos significa que las variables,
datos, funciones, resultados, etc., se guardan en la memoria activa del computador en
forma de objetos con un nombre específico. El usuario puede modificar o manipular
estos objetos con operadores (aritméticos, lógicos y comparativos) y funciones (que a
su vez son objetos)”.
Para tener una base de datos en una hoja de R, se tiene que hacer la lectura de la
misma por cualquiera de las siguientes maneras: desde un archivo con extensión *.txt,
desde un archivo de Excel con extensión csv, o mediante un copy/paste “clipboard”.
Caso 1.- Desde un archivo con extensión *.txt, como puede ser la base de datos
(Estadística básica 09-A.xls) trabajada en Excel y grabada con extensión *.txt o
copiar dicha base de datos de Excel, incluyendo los encabezados con el nombre de la
variable, a un block de notas y grabarla como Estadística básica 09-A.txt. Se procede
copiando en R la siguiente sintaxis:
> caso1=read.table(file.choose(),header=T)
Se esta pidiendo que cree el objeto caso1, como resultado de leer una tabla (read.table)
o base de datos. Al hacer enter, inmediatamente aparece la ventana de diálogo de la
Figura 1.9, solicitando la ruta correspondiente para escoger el archivo = file.choose()
con la base de datos (Estadística básica 09-A.txt) que se desea abrir. En la sintaxis,
header=T esta indicando que es verdadero (en inglés true = T) que la tabla a escoger
tiene encabezado (header) con el nombre de las variables (si no tiene encabezado,
header=F, de false = falso en inglés). Una vez escogida la base de datos, hacer clic en
Abrir y la base de datos queda almacenada en la hoja de R con la denominación del
objeto: caso1, el mismo que contiene 20 campos y 60 registros.
25
Figura 1.9 Abriendo base de datos en R desde un block de notas
Ha leído las variables de la base de datos de Estadística Básica 09A como un todo,
no reconoce a ninguna variable de manera independiente, para que ello ocurra
usamos el comando attach para unir las variables y reconozca a cada una de ellas
por el nombre que aparece en el encabezado. Escribir en R: > attach(caso1)
Si queremos editar los datos escribir: > fix(caso1)
También se puede leer la base de datos, en forma parecida a la anterior, sólo que
en vez de file.choose se debe colocar entre comillas la ruta que contiene el
archivo, así:
>
caso1=read.table("D:/Beatriz/UNAC/Investigación/Proyecto
8
computacional/Base de datos/ Estadística básica 09-A.txt ", header=T)
> attach(caso1)
26
Estadística
Caso 2.- Desde un archivo en Excel con extensión csv, en la que se ha definido los 20
campos (incluyendo los encabezados con el nombre de la variable) y los 60 registros,
se ha grabado como libro de Excel y como tipo CSV (delimitado por comas). La base
de datos se denomina Estadística Básica 09A-copia.csv. Se procede copiando en R la
siguiente sintaxis: > caso2=read.table(file.choose(),header=T,sep=",")
Al hacer enter, inmediatamente aparece una ventana de diálogo idéntica a la de la
Figura 1.9, solicitando la ruta correspondiente para escoger el archivo con separador
de comas (sep=”,”) aquí la base de datos (Estadística Básica 09A-copia.csv) que se
desea abrir. Una vez escogida la base de datos, hacer clic en Abrir y la base de datos
queda almacenada en R con la denominación del objeto: caso2, el mismo que contiene
20 campos y 60 registros idénticos a los del caso1. Es decir, que lo que cambia es la
forma de efectuar la lectura.
Para que el R junte y reconozca las variables escribir: > attach(caso2)
También se puede leer la base de datos, en forma parecida a la anterior, sólo que
en vez de file.choose se debe colocar entre comillas la ruta que contiene el
archivo, así:
>
caso2=read.csv("D:/Beatriz/UNAC/Investigación/Proyecto
8
Estadística
computacional/Base de datos/ Estadística Básica 09A-copia.csv ", header=T)
> attach(caso2)
Caso 3.- Mediante un copy/paste “clipboard” de un archivo en Excel, es la forma
más sencilla. En Excel sombrear el encabezado y los datos de la base de datos que
deseamos leer en R, escoger copiar (o Ctrl + C) y en R escribir:
> caso3=read.table("clipboard")
> attach(caso3)
1.3 INTRODUCCIÓN DE DATOS
Una vez que se ha aplicado la encuesta y se ha efectuado la crítica-codificación de
los cuestionarios, en la base de datos definida en el programa correspondiente, se
efectúa el ingreso de datos cuestionario por cuestionario, desde el número 1 (registro
1) hasta el último.
27
En el registro 1, se colocan los datos del alumno que aparecen en el cuestionario
número 1, en el mismo orden que se ha respondido, es decir: sexo = 1(hombre),
edad = 20 años, peso = 68 kg., talla = 169 cm., ingreso familiar = 3900, miembros
en la familia = 5, etc. Y del mismo modo todos los cuestionarios.
Figura 1.10 Base de datos en Excel
Figura 1.11 Base de Datos en MINITAB
28
Figura 1.12 Base de datos en SPSS
Para ver y corregir datos en R escribir: >fix(caso2). Al efectuar enter aparecen
los datos de la Figura 1.13. También con: > caso2 . Muestra los datos en la consola.
Figura 1.13 Base de datos en R
Las 20 variables trabajadas en los cuatro programas aparecen en las columnas y los
60 registros en filas. Es decir que la base de datos definida es una matriz de 60 x 20.
El Minitab, el SPSS y el R reconocen las variables por su nombre.
29
1.4 ARCHIVO DE DATOS
El archivamiento de datos se efectúa a través de los clásicos guardar, guardar como
y cerrar cuando se esta trabajando con una base de datos. Además de nuevo y abrir.
Figura 1.14 Ventana de archivamiento en Excel
a) Guardar y Guardar como.Guardar como: es el proceso inicial de almacenamiento en una unidad de disco
de una base de datos creada para volver a trabajar con ella en otro momento.
Guardar: es el archivamiento continuo que se hace sobre una base de datos ya
guardada y en la que se han efectuado cambios que se deben guardar antes de
cerrarla.
Para Guardar en EXCEL:
-
Hacer clic en el Botón de Office (el superior izquierdo, en la Figura 1.14) y
elegir Guardar como y aparece el cuadro de diálogo de la Figura 1.15.
-
Hacer clic sobre la flecha de la derecha en el recuadro Guardar en: y
seleccionar la unidad de disco y la carpeta donde se va a archivar la base de
datos (en este caso en el disco D y en la carpeta Base de datos).
-
En el recuadro Nombre de archivo, escribir el nombre que se desea poner a
la base de datos (en este caso Estadística Básica 09-A).
-
En el recuadro Guardar como tipo:, automáticamente aparece Libro de
Excel, si se desea cambiar el tipo, hacer clic sobre la flecha de la derecha y
seleccionar el tipo de guardado (en este caso CSV (delimitado por comas)
para usarlo al abrir la base de datos en R).
30
-
Por último, hacer clic sobre el botón Guardar.
Figura 1.15 Cuadro de diálogo para Guardar como, en Excel
Si se esta trabajando un archivo ya guardado y se hacen modificaciones, para
guardarlo con el mismo nombre, seleccionar la opción Guardar del Botón
Office (ver figura 1.14) que es la misma que aparece al lado derecho de este
Botón. También se puede utilizar la combinación de las teclas Ctrl + G.
Para Guardar en MINITAB:
-
Al hacer clic en el botón File (archivo) de la barra de menú se despliega la
ventana de la Figura 1.16, en la que se puede apreciar las opciones para un
Proyecto (Project) que es un conjunto de tareas que contiene hojas de trabajo
(worksheet), sesión (sesión), gráficos, etc. Y las opciones para una hoja de
trabajo (worksheet) que se pueden incorporar en un proyecto determinado.
Se observa entre otras las opciones New (nuevo), Open Project (abrir
proyecto), Save Project (guardar proyecto), Save Project As (guardar
proyecto como), Open Worksheet (abrir hoja de trabajo), Save Current
Woksheet (guardar hoja de trabajo corriente), Save Current Worksheet As
(guardar hoja de trabajo corriente como), etc.
31
Figura 1.16 Ventana de File (archivo), en Minitab
-
Hacer clic sobre la opción Save Project As (guardar proyecto como) y
aparece el cuadro de diálogo de la Figura 1.17.
-
Hacer clic sobre la flecha de la derecha en el recuadro Guardar en: y
seleccionar la unidad de disco y la carpeta donde se va a archivar la base de
datos (en este caso en el disco D y en la carpeta Base de datos).
-
En el recuadro Nombre:, escribir el nombre que se desea poner a la base de
datos (en este caso Estadística Básica 09-A).
-
En el recuadro Tipo: automáticamente aparece Minitab Project (*.MPJ) con
extensión MPJ, si se hubiese guardado como Worksheet (hoja de trabajo)
guarda con la extensión MTW.
-
Por último, hacer clic sobre el botón Guardar.
32
Figura 1.17 Cuadro de diálogo para Save Project As, en Minitab
Si se esta trabajando un archivo ya guardado y se hacen modificaciones, para
guardarlo con el mismo nombre, seleccionar la opción Save Project o Save
Current Worksheet (ver figura 1.16) que es idéntica al diskette que aparece en
la banda de opciones. También se puede guardar un proyecto utilizando la
combinación de las teclas Ctrl + S.
Para Guardar en SPSS:
-
Es similar al de los otros programas, cuyo guardado ya hemos visto. Estando
en el Editor de datos SPSS (Figura 1.13), hacer clic en el botón Archivo, se
despliega una ventana en la que se puede apreciar las opciones Nuevo, Abrir,
…., Cerrar, Guardar, Guardar como, etc.
-
Hacer clic sobre la opción Guardar como y aparece el cuadro de diálogo de
la Figura 1.18.
33
Figura 1.18 Cuadro de diálogo para Guardar como, en SPSS
-
Hacer clic sobre la flecha de la derecha en el recuadro Guardar en: y
seleccionar la unidad de disco y la carpeta donde se va a archivar la base de
datos (en este caso en el disco D y en la carpeta Base de datos).
-
En el recuadro Nombre:, escribir el nombre que se desea poner a la base de
datos (en este caso Estadística Básica 09-A).
-
En el recuadro Tipo: automáticamente aparece SPSS (*.sav) con extensión
sav para guardar datos en SPSS.
Nota.- cuando se archiva textos: como la hoja de Resultados 1 [Dokument
1] – Visor SPSS, donde aparecen los resultados de las tareas ejecutadas con
SPSS, se guarda con la extensión .spo; y si es sintaxis se guarda con la
extensión .sps.
-
Por último, hacer clic sobre el botón Guardar.
34
Para Guardar en R:
-
Hacer clic en el botón Archivo, se despliega una ventana en la que se puede
apreciar las opciones Interpretar código fuente R, Nuevo script, Abrir script,
etc.
-
Hacer clic sobre la opción Guardar área de trabajo (imagen) y aparece el
cuadro de diálogo de la Figura 1.19.
Figura 1.19 Cuadro de diálogo para Guardar área de trabajo en R
-
Hacer clic sobre la flecha de la derecha en el recuadro Guardar en: y
seleccionar la unidad de disco y la carpeta donde se va a archivar la base de
datos (en este caso en el disco D y en la carpeta Base de datos).
-
En el recuadro Nombre:, escribir el nombre que se desea poner a la base de
datos (en este caso Estadística Básica-09A).
-
En el recuadro Tipo: automáticamente aparece R images (*.RData) con
extensión Rdata para guardar datos en R.
-
Por último, hacer clic sobre el botón Guardar.
35
El archivo guardado en R contiene la base de datos como un objeto (aquí se
llama caso2) y otros objetos que se definan, los que al Abrir con Cargar área
de trabajo, se pueden visualizar desde la ventana Misc / Listar objetos y se
puede seguir trabajando con todos ellos y crear nuevos objetos. Las
modificaciones efectuadas se vuelven a guardar del modo descrito. Si desea
saber el contenido de la base de datos guardada escriba: > str(caso2)
b) Cerrar.Una vez que se termina de trabajar con un archivo, se guarda y se procede a salir
de éste así:
-
En Excel:
Elija el Botón de Office y luego la opción Cerrar. Cierra el libro y puede
seguir trabajando con el programa Excel.
Otra manera es utilizar el botón Cerrar ventana
x
de la barra de menú (no
el de la barra de título del libro, ya que cierra el programa Excel).
También se cierra el libro con la combinación de teclas: Ctrl + F4.
-
En MINITAB:
Elija el botón File (Archivo) de la barra de menú y luego la opción Close
Worksheet (Cerrar hoja de trabajo). Cierra la hoja de trabajo y puede seguir
usando el programa Minitab.
Otra manera es utilizar el botón Cerrar
x
de la barra de menú (no el de la
barra de título, ya que cierra el programa).
También se cierra la hoja de trabajo con la combinación de teclas: Ctrl + F4,
sale un cuadro de diálogo preguntando si queremos guardarla y escogemos
Si o No.
-
En SPSS:
Elija el botón Archivo de la barra de menú y luego la opción Salir,
inmediatamente sale la pregunta ¿Desea guardar el contenido del Visor de
resultados en resultados 1 [Dokument 1]? Al escoger Sí, indique la carpeta
36
correspondiente y al terminar de guardar, sale automáticamente del
programa. Si escoge No, sale del programa.
Otra manera es utilizar el botón Cerrar
x
de la barra de título, sale la misma
pregunta del párrafo anterior y procede del modo allí indicado.
-
En R:
Se recomienda previamente Guardar área de trabajo, luego elija el botón
Archivo de la barra de menú y luego la opción Salir, inmediatamente sale la
pregunta
Guardar imagen de área de trabajo? Escoger No y sale del
programa.
Otra manera es utilizar el botón Cerrar
x
de la barra de título, sale la misma
pregunta del párrafo anterior. Escoger No y sale del programa.
c) Nuevo.- para crear un nuevo archivo de trabajo, se debe proceder así:
En Excel:
Si ha ingresado al programa, automáticamente tiene un nuevo libro de trabajo; si
no, elija el Botón de Office y luego la opción Nuevo. Otra manera es utilizar la
combinación de teclas: Ctrl + U.
En MINITAB:
Si ha ingresado al programa, automáticamente tiene un Worksheet 1 (hoja de
trabajo 1) o si no, elija el botón File y luego la opción Nuevo. Otra manera es
utilizar la combinación de teclas: Ctrl + N.
En SPSS:
Si ha ingresado al programa, automáticamente tiene una hoja Sin título
[Conjunto_de_datos0] – Editor de datos SPSS (donde se definen las variables
y se ingresan los datos del estudio) donde vamos a definir la base de datos.
Si esta trabajando en SPSS, elija el botón File, luego la opción Nuevo y escoja
Datos, apareciendo una hoja Sin título 1 [Conjunto_de_datos1] – Editor de datos
SPSS.
37
En R:
Proceder conforme se ha indicado en el acápite 1.2 Definición de variables en R.
d) Abrir.- si tenemos un archivo de datos ya guardado y se desea abrir para trabajar
con él, se procede así:
En Excel:
Elija el Botón de Office y luego la opción
Abrir o la combinación de teclas:
Ctrl + A. En el cuadro de diálogo, seleccione la carpeta donde esta guardado el
archivo, ubique el nombre y tipo, luego haga clic en el botón Abrir.
En MINITAB:
Elija el botón File y luego la opción
teclas: Ctrl + O) u
Open Project (o la combinación de
Open Worksheet. En el cuadro de diálogo, seleccione la
carpeta donde esta guardado el archivo, ubique el nombre y tipo, luego haga clic
en el botón Abrir.
En SPSS:
Elija el botón File, luego la opción Abrir y escoja Datos. En el cuadro de
diálogo, seleccione la carpeta donde esta guardado el archivo, ubique el nombre
y tipo, luego haga clic en el botón Abrir.
En R:
Proceder conforme se ha indicado en el acápite 1.2 Definición de variables en R.
Nota.- en R también se puede definir una variable por separado como un objeto,
presentado como un vector, de tal manera que cada vez que se especifique el
programa reconoce sus valores. Por ejemplo, la variable peso de la base de datos
caso2, se ingresa así:
>peso=c(68,69, 63, 55, 57, 48, 50, …. , 67, 77, 53)
El programa R reconoce en el objeto peso, los pesos de los 60 alumnos.
38
1.5 TRANSFORMACIÓN DE DATOS
Muchas veces interesa crear nuevas variables a partir de una base de datos
determinada, para ello es necesario efectuar algunos cálculos utilizando las variables
de esa base de datos.
Por ejemplo, con la base de datos Estadística básica 09-A (EB-09A), en cualquiera
de los programas, se puede crear la variable IMC = Índice de Masa Corporal
(Kg./m2), con las variables peso (en kilos) y talla (en metros).
Para la Organización Mundial de la Salud (1995): “El IMC es una manera sencilla y
universalmente acordada para determinar si una persona tiene peso adecuado”. La
fórmula de cálculo propuesta por el estadístico belga L.A.J. Quetelet es:
peso
imc
talla
2
La OMS clasifica a las personas en función de su correspondiente IMC de la
siguiente manera:
Cuadro 1.1 Tabla de la masa corporal ideal
CONDICIÓN
IMC (Kg./m2)
1
Delgado (bajo peso)
Menos de 18.5
2
Normal (peso saludable)
3
Sobrepeso
25 – 30
4
Obeso
30 - 40
5
Obesidad morbida
18.5 – 25
40 y más
En la base de datos EB-09A el peso esta en Kg. y la talla está en cm. La talla debe
transformarse en una nueva variable, por ejemplo: talla_m = talla en metros, para
poder calcular la variable imc con los datos transformados de la siguiente manera:
En Excel:
Los resultados aparecen en la Figura 1.20, en la que aparece la base de datos EB09A con los datos de peso (columna D); talla en cm. (columna E); talla_m en
metros (columna U) obtenidos dividiendo cada dato de la columna E entre 100; imc
39
(columna V) calculado en la barra de formulas
, estando en V2
=D2/(U^2)
y copiado en todas las celdas de la columna V; y condición (columna W) que en el
siguiente acápite se ve como se ha determinado.
Figura 1.20 Cálculo del imc en Excel
En MINITAB:
Para transformar la talla en centímetros a metros (talla_m) se tiene que escoger de la
barra de menú la opción Calc, luego Calculator (calculadora) y aparece la ventana
de diálogo de la Figura 1.21. Definida en la hoja de cálculo la variable talla_m, en
Store result in variable (almacenar resultado en variable) escribir talla_m y en
Expression (expresión) escribir talla / 100, para terminar clic en OK y
automáticamente aparece el cálculo en la columna talla_m en la base de datos
Current data window (ver la Figura 1.21).
Para calcular el IMC, escoger nuevamente de la barra de menú Calc, Calculator y
se abre una ventana de diálogo similar a la de la Figura 1.20. En Store result in
variable seleccionar o escribir imc y en Expression escribir la fórmula de cálculo
peso / talla**2, para terminar clic en OK y automáticamente en la base de datos
(Current data window) aparecen los datos del IMC calculados (ver la Figura 1.24).
40
Figura 1.21 Cálculo de la talla_m en Minitab
En SPSS:
Para transformar la talla en centímetros, a metros (talla_m) se tiene que escoger de
la barra de menú la opción Transformar, Calcular variable y aparece la ventana
de diálogo Calcular variable de la Figura 1.22. En Variable de destino: escribir
talla_m. Haciendo clic en Tipo y etiqueta definir etiqueta (el nombre de la variable)
TALLA (m.) y el Tipo: numérica. En Expresión numérica: escribir talla / 100. Para
terminar el cálculo hacer clic en Aceptar y aparece la variable talla_m con sus
valores en la Vista de datos, del Editor de datos SPSS, ver la Figura 1.28.
Para calcular la variable IMC, nuevamente se escoge de la barra de menú la opción
Transformar, Calcular variable y aparece la ventana de diálogo Calcular variable,
similar a la de la Figura 1.22. En Variable de destino: escribir imc. Haciendo clic
en Tipo y etiqueta definir etiqueta INDICE DE MASA CORPORAL (Kg./m2) y el
Tipo: numérica. En Expresión numérica: escribir peso / talla**2. Para terminar el
cálculo hacer clic en Aceptar y aparece la variable imc con sus valores, en la Vista
de datos del Editor de datos SPSS, ver la Figura 1.28.
41
Figura 1.22 Cálculo de la variable talla_m en SPSS
En R:
Para transformar la talla en centímetros, a metros (talla_m) se tiene que escribir:
> talla_m=talla/100
> talla_m
[1] 1.69 1.72 1.70 1.73 1.67 1.52 1.52 1.56 1.54 1.71 1.60 1.76 1.64 1.71 1.54
[16] 1.77 1.69 1.71 1.70 1.79 1.77 1.65 1.71 1.58 1.55 1.60 1.59 1.52 1.75 1.65
[31] 1.75 1.57 1.77 1.65 1.49 1.64 1.64 1.60 1.61 1.69 1.50 1.68 1.72 1.50 1.56
[46] 1.74 1.75 1.68 1.65 1.52 1.72 1.73 1.56 1.55 1.50 1.60 1.68 1.72 1.78 1.57
Para calcular el IMC escribir la fórmula así:
> imc=peso/talla_m^2
> imc
Los objetos talla_m e imc creados no se almacenan en la hoja de R, si queremos que
ello ocurra y guardarlos, debemos hacer transformaciones dentro de caso2, así:
> caso2=transform(caso2, talla_m=talla/100)
> caso2=transform(caso2, imc=peso/talla_m^2)
Para unir las nuevas variables en caso 2, escribir: > attach(caso2)
42
1.6 RECODIFICACIÓN DE DATOS
En el acápite anterior se han efectuado algunos cálculos con los datos, creando
nuevas variables y se esta interesado en recodificar los mismos. Por ejemplo, para
definir la Condición del peso del alumno con la variable IMC obtenida, usando la
propuesta del Cuadro 1, se procede de la siguiente manera:
En Excel:
Estando en W2, la condición (columna W) se calcula en la barra de fórmulas con la
expresión lógica siguiente:
=SI(V2<18.5,"Delgado",SI(V2<25,"Normal",SI(V2<30,"Sobrepeso",SI(V2<40,"Ob
eso","Obesidad morbida")))).
Luego se hace una copia para los demás datos de la columna W, los resultados se
observan en la Figura 1.20.
En MINITAB:
De la barra de menú escoger la opción Data, luego Code (código) y Numeric to
text (numérico a texto) porque se desea recodificar valores numéricos en texto, ver
la Figura 1.23, también se puede apreciar otros tipos de recodificación.
Figura 1.23 Tipos de recodificación en Minitab
Haciendo clic en Numeric to Text aparece la ventana de diálogo de la Figura 1.24
(Code – Numeric to Text) para recodificar los datos numéricos en texto.
43
Figura 1.24 Obtención de la Condición, recodificando el IMC en Minitab
En Code data from columns: (código de datos desde las columnas) seleccionar de
las variables a la izquierda imc o escribirla. En Store couded data in columns:
(almacenar datos codificados en la columna) seleccionar de las variables de la
izquierda condición o escribirla.
A continuación en Original values (valores originales) se va definiendo uno a uno
los intervalos definidos en el Cuadro 1.1, separándolos por dos puntos (:) y en New
los nuevos valores en texto.
Observar que el primer intervalo es para imc menor de 18.5, en Original values: se
coloca desde un valor muy bajo, que aquí se ha tomado el 0, por eso se escribe 0 :
18.49 (de ser necesario se agregan más nueves en los decimales, para estar más
cerca a 18.5) y en New: Delgado. El siguiente intervalo va de 18.5 hasta antes de 25,
en Original values: se escribe 18.5 : 24.99 y en New: Normal. Así sucesivamente,
para el último intervalo de 40 a más, en Original values: se escribe 40 : 100 (o un
valor más alto para que no queden datos sin recodificar) y en New: Obesidad
mórbida. Para finalizar la recodificación hacer clic en OK y en la base de datos
(Current data window) aparecen los datos de condición (ver Figura 1.25).
44
Figura 1.25 Resultado de la Condición recodificando el IMC en Minitab
En SPSS:
De la barra de menú escoger la opción Transformar, luego hacer clic sobre
Recodificar en distintas variables (si se escoge Recodificar en las mismas
variables, se pierden los valores originales ya que son reemplazados por los
recodificados). Aparece la ventana de diálogo Recodificar en distintas variables de
la Figura 1.26.
Escogiendo de la lista de variables que aparecen al lado izquierdo, en Var.
numérica → Var. de resultado: ingresar la variable imc, inmediatamente aparece
imc→ ? En Variable de resultado, en Nombre: escribir condición, en Etiqueta:
escribir CONDICIÓN (del peso) y luego hacer clic en el botón Cambiar (si no hace
esto, la recodificación no se realiza después, asegurarse de ello), inmediatamente en
Var. numérica → Var. de resultado: se modifica por imc→ condición.
45
Figura 1.26 Obtención de la Condición, recodificando el IMC en SPSS
Luego, hacer clic en Valores antiguos y nuevos y aparece la ventana de diálogo
Recodificar en distintas variables: Valores antiguos y nuevos de la Figura 1.27.
A continuación, en Valor antiguo se va definiendo uno a uno los intervalos
definidos en el Cuadro 1.1, y en Valor nuevo los nuevos valores del intervalo.
Observar que el primer intervalo es para imc menor de 18.5, en Valor antiguo, en
Rango, MENOR hasta valor se escribe 18.49 (de ser necesario se agregan más
nueves en los decimales, para estar más cerca a 18.5) y en Valor nuevo, en Valor
escribir 1, luego hacer clic en añadir. El siguiente intervalo va de 18.5 hasta antes de
25, en Valor antiguo, en Rango: se escribe 18.5 hasta 24.99 y en Valor nuevo
escribir 2, luego hacer clic en añadir. Así sucesivamente, para el último intervalo de
40 a más, en Valor antiguo, RANGO, valor hasta MAYOR se escribe 40 y en Valor
nuevo, en Valor escribir 5, luego clic en añadir.
Para finalizar la recodificación, al hacer clic en Continuar regresa a la ventana de la
Figura 1.26.
Luego hacer clic en Aceptar y aparece la variable condición con sus valores del 1 al
5 en la Vista de datos del Editor de datos SPSS.
46
Figura 1.27 Recodificar Valores antiguos del IMC y nuevos de Condición en SPSS
A continuación, en la Vista de variables, del Editor de datos SPSS, a la variable
condición se le definen las Etiquetas de valor, en un cuadro de diálogo similar al de
la Figura 1.5. Para ello asignar los valores y etiquetas siguientes: 1, Delgado; 2,
Normal; 3, Sobrepeso; 4, Obeso; y 5, Obesidad mórbida.
Una vez que termina de añadir los valores y etiquetas hacer clic en Aceptar, en la
Vista de datos, del Editor de datos SPSS aparecen las etiquetas de condición que se
muestran en la Figura 1.28.
Figura 1.28 Resultado de la Condición recodificando el IMC en SPSS
47
En R:
Antes de crear la Condición, debemos crear los intervalos del Cuadro 1.1, así:
> caso2=transform(caso2,condi=cut(imc,breaks=c(0,18.4999, 24.9999,29.9999,
39.9999,max(imc))))
> table(condi)
condi
(0,18.5] (18.5,25] (25,28.7] (28.7,30]
4
49
7
0
(30,40]
0
En el resultado anterior, hay 4 alumnos con imc menor de 18.5 (delgados), 49
alumnos con imc entre 18.5 y 25 (normales) y 7 alumnos con imc entre 25 y 30 (con
sobrepeso); no hay alumnos obesos, ni con obesidad mórbida, por lo que vamos a
colocar las etiquetas correspondientes a Condición, de la siguiente manera:
> caso2=transform(caso2, Condición=factor(condi, labels=c("Delgado", "Normal",
"Sobrepeso")))
Luego escribimos: > attach(caso2) y después: > table(Condición)
Condición
Delgado
4
Normal Sobrepeso
49
7
Con la sintaxis: > fix(caso2) obtenemos la hoja del R, donde aparecen las etiquetas
de Condición que se muestran en la Figura 1.29.
Figura 1.29 Resultado de la Condición recodificando el IMC en R
48
1.7 MANIPULACIÓN DE ARCHIVOS
Para los programas Excel, Minitab y SPSS el proceso de agregar o quitar variables
(en columnas) y registros o casos (en filas) es similar, simplemente hay que insertar
filas o columnas si es necesario o copiar las variables y/o casos. Así mismo, la
selección de variables para generar nuevos archivos se puede efectuar abriendo
nuevas hojas de datos para trabajar con ellas situaciones particulares.
Veamos la selección de variables en R y la obtención de casos.. Estando en caso2, la
forma más sencilla es escribir en R: >attach(caso2) y al hacer enter quedan
reconocidas todas las variable con el nombre del encabezado. Otra forma es, como
las variables aparecen dentro del objeto caso2 en columna: el n_cuest (columna 1),
sexo (columna 2), edad (col. 3), peso (col. 4), hasta col.proc (col. 19) y especial (col.
20). Cada una de las variables es trabajada como un objeto y se definen así:
> peso=caso2[,4]
Se pide crear el objeto peso y que lo obtenga de la columna 4, del objeto caso2 (la
base de datos trabajada). Dentro del corchete de caso2, la primera componente
indica fila (registro) y la segunda columna (variable). Al dejar vacía la primera
componente reconoce sólo los valores de la variable. Si se quiere visualizar el
contenido del objeto creado, escribimos peso y al hacer enter aparecen los pesos.
> peso
[1] 68.0 69.0 63.0 55.0 57.0 48.0 50.0 50.0 44.0 60.0 52.6 80.0 52.0 67.0 46.0
[16] 80.0 64.0 64.0 63.0 72.0 65.0 47.0 70.0 50.0 53.0 66.0 57.0 50.5 80.0 55.0
[31] 88.0 55.0 75.0 64.5 50.0 49.0 54.0 46.5 49.0 70.0 48.0 60.0 75.0 55.0 51.0
[46] 72.0 68.0 68.0 55.0 59.0 65.0 66.0 51.0 53.0 45.0 52.0 53.0 67.0 77.0 53.0
También se puede crear varios objetos a la vez separándolos con punto y coma, así:
> talla=caso2[,5] ; ing.fam=caso2[,6] ; mie.fam=caso2[,7]
Si desea visualizar los 20 datos del alumno 4 (registrados en la fila 4) escribir:
> reg.4=caso2[4,]
enter y luego > reg.4 al hacer enter obtenemos:
nº_cuest sexo edad peso talla ing.fam mie.fam g.estud cr.aprob prom.acum
4
4
1
20 55
173
1200
5
60
42
t.viviend nº.dormit horas.tv hrs.estu lib.leídos hobby imp.estudio
4
1
3
3
4
4
imp.físico col.proc especial
4
4
2
2
49
4
4
12.4
Capítulo 2. PRESENTACIÓN DE DATOS
“El propósito de la estadística es descubrir métodos para condensar la
información relativa a un gran número de hechos relacionados, en cortas y
compendiosas expresiones adecuadas para su discusión”
Francis Galton
CONTENIDO
2.1
2.2
2.3
2.4
2.5
2.6
2.7
Introducción.
Cuadros estadísticos.
Distribución de frecuencias.
Gráficos estadísticos.
Gráficos de variables cualitativas.
Gráficos de frecuencias.
Diagrama de tallos y hojas.
2.1 INTRODUCCIÓN
Uno de los propósitos fundamentales de la estadística es la “reducción de datos”,
la misma que se puede efectuar mediante la presentación de datos de tres maneras:
cuadros o tablas estadísticas, gráficos y texto.
Se recomienda la aplicación de todas ellas; siendo primordial la construcción del
cuadro estadístico con los datos, para poder realizar la presentación gráfica y/o
textual que permita describir, establecer relaciones y/o explicar las variables en
estudio, contribuyendo así a la aplicación del método científico.
En este capítulo se desarrollan los temas relacionados a cuadros estadísticos,
tablas de frecuencias y algunas formas de presentación gráfica tanto para variables
cualitativas como cuantitativas.
2.2 CUADROS ESTADÍSTICOS
En la estadística, como ciencia de la observación, se emplean las tablas o cuadros
estadísticos para resumir la información estadística (datos) obtenida mediante
encuestas, experimentos, registros administrativos, etc.
a) Definición.- un cuadro estadístico es un arreglo matricial que contiene las
variables con sus correspondientes categorías y los datos observados de
50
manera concisa, reflejando la relación o comparación fácil entre las variables
en un estudio determinado.
b) Estructura.- las partes de un cuadro estadístico son: número, título,
encabezamiento, columna matriz, cuerpo y pie (notas, llamadas y fuente). La
ubicación de cada uno de ellos se puede apreciar en la Figura 2.1.
NÚMERO
TÍTULO
COLUMNA
ENCABEZAMIENTO
MATRIZ
PIE
CUERPO
NOTAS
LLAMADAS
FUENTE
Figura 2.1 Estructura de un cuadro estadístico
Número.- si en un estudio o investigación se presenta más de un cuadro hay
que enumerarlos para diferenciarlos. Si el cuadro es único, no es necesario
enumerar. El número se ubica en la parte superior izquierda o central.
Se recomienda anteponer la palabra Cuadro o Tabla y a continuación
colocar el número (sin la abreviatura Nº previa) que puede ser arábigo o
alfanumérico, seguido de un punto, para luego indicar el título.
Ejemplo: Cuadro 5. ; Cuadro B10. ; etc.
Título.- el título indica de manera clara y precisa el contenido del cuadro.
Se coloca en la parte superior a continuación del número. Para su
construcción debe responder a las cuatro preguntas siguientes:
- ¿Qué? Estamos observando (unidad de análisis, objeto, característica
principal, valores, elementos, etc.)
- ¿Cómo? Están clasificados los datos (variables en el Encabezamiento
precedidas de la palabra POR y variables en la columna matriz
precedidas de la palabra SEGÚN)
51
- ¿Cuándo? Se realizó la observación de los datos (período al que se
refieren los datos)
- ¿Dónde? Se realizó la observación de los datos (lugar geográfico)
Ejemplo.¿Qué? Producto Bruto Interno.
¿Cómo? Por Años, Según Rama de la Actividad Económica.
¿Cuándo? Del 2000 al 2007.
¿Dónde? Perú.
Ya se puede indicar el número y el título del cuadro de la siguiente manera:
CUADRO 2.1 PRODUCTO BRUTO INTERNO, POR RAMA DE LA
ACTIVIDAD ECONÓMICA, SEGÚN AÑO: 2000-07.
Observación:
- Hay una reciprocidad entre el título y lo que aparece después de él, pues
el ¿cómo? del título permite ubicar las variables en el encabezamiento y
en la columna matriz; y viceversa, observando las variables en el
encabezamiento y en la columna matriz se puede poner el título.
- Cuando en el título del cuadro no se indica el lugar de observación,
significa que corresponde al país.
- La ubicación de variables en el encabezamiento y en la columna matriz
es indistinto, depende del criterio del investigador, pudiendo ser éstas de
cualquiera de los tipos definidos.
- Si los años observados son consecutivos, se recomienda colocar 2000-07
y si sólo son dos años, indicar 2000 y 2007.
Encabezamiento.- es la parte del cuadro que contiene las variables que
aparecen en el título después de la preposición “POR” y sus
correspondientes categorías o rangos, generando las columnas del mismo.
Recomendaciones:
- Colocar en la primera línea qué se va observar y el POR, preferentemente
cuando se esta diseñando cuadros preliminares para un estudio.
- Indicar en forma breve y precisa las variables (con mayúsculas) y sus
categorías o rangos (con mayúscula y minúsculas).
52
- Escribir preferentemente en forma horizontal o en forma vertical letra por
letra de arriba hacia abajo.
- Según sea el caso, ordenar las columnas tomando en cuenta un
ordenamiento: natural, geográfico, importancia o alfabético.
- Si hay que indicar unidad de medida, colocarla con mayúsculas y
minúsculas encima del encabezamiento después del título o en su primera
línea (si todos los valores del cuerpo del cuadro van a representar lo
mismo) y/o en cada columna (si las unidades de medida son distintas).
Ejemplo.Para el Cuadro 2.1, antes indicado, el encabezamiento es:
Agricultura
P.B.I., POR RAMA DE LA ACTIVIDAD ECONÓMICA (Millones de nuevos soles)
Pesca Minería Industria Electicidad Construcción Comercio Servicios
Total
Columna Matriz.- es la parte del cuadro que contiene las variables que
aparecen en el título después de la palabra “SEGÚN” y sus correspondientes
categorías o rangos, generando las filas del mismo.
Recomendaciones:
- Indicar en forma breve y precisa las variables a la altura del
encabezamiento (con mayúsculas) y debajo sus categorías o rangos al
lado del cuerpo del cuadro (con mayúscula y minúsculas).
- Escribir preferentemente en forma horizontal. Si hay más de una
variable, diferenciar las categorías con subrayado y/o negrita.
- Según sea el caso, ordenar las columnas tomando en cuenta un
ordenamiento: natural, geográfico, importancia o alfabético.
- Si hay que indicar unidad de medida, colocarla en la fila correspondiente.
- Cada cierto número de filas dejar espacio en blanco para no cansar al
lector.
Cuerpo.- es la parte del cuadro formada por casillas o celdas (resultado de
la intersección de filas y columnas) donde aparecen los resultados de los
conteos efectuados con los datos recogidos.
Recomendaciones:
- Ninguna casilla debe quedar vacía, debe contener un valor o indicación.
53
- Usar algunos signos convencionales:
Resultado nulo o no existe el fenómeno (-).
Cifra aún no disponible (…).
Cantidad inferior a la mitad de la unidad adoptada: 0, 0.0, 0.00, etc.
Dato provisional (P).
Cifra estimada (E).
Cifra revisada (R).
Pie.- es la parte inferior del cuadro, donde se colocan las notas, llamadas y
la fuente de los datos. Es recomendable, no abusar en el uso de notas y
llamadas; así mismo ordenarlas alfabética y numéricamente.
Notas.- Son aclaraciones breves referidas a algún aspecto general del título
del cuadro o definición de alguna variable. Se efectúa colocando en el
margen izquierdo, de la primera línea del pie, la palabra Nota: detallando lo
que se desea aclarar.
Llamadas.- son aclaraciones específicas referidas a una fila o columna.
Según el INEI (2006) “La llamada se indica con una barra oblicua “/”
siendo antecedida por una letra o un número. Se ubica a la derecha de lo que
se desea aclarar”. Si la aclaración esta referida a una categoría textual, usar
un número; y si la aclaración se refiere a un rango o número, usar una letra.
Según el INEI (2006) “Las llamadas deben ubicarse al pie del cuadro,
inmediatamente después de la nota, si hubiera. Se ubica primero las
“llamadas-números” de menor a mayor y luego las “llamadas-letras” en
orden alfabético”.
Fuente.- cuando los datos son obtenidos de una fuente secundaria se
recomienda indicar al “dueño” de la información (principio de cortesía y
respeto al autor) bajo la forma de una ficha bibliográfica (autor o entidad,
año, título de la publicación, edición, editorial, páginas y lugar). Es
recomendable aun cuando se haya efectuado algunas elaboraciones, ya que
el usuario puede recurrir a la fuente primigenia para cualquier consulta.
54
Igualmente, si la información se ha obtenido de alguna página web y para
que el lector pueda recurrir a esa fuente, indicar los elementos centrales de
una referencia web (autor o entidad, año, título de la publicación, país,
fecha de consulta y la página web donde está disponible).
Si no se indica fuente, se asume que los datos son del autor (persona o
entidad) que los publica. En el caso de pertenecer a una entidad grande, se
indica el área de Elaboración (gerencia o dirección) para poder acudir
directamente a ellos de requerirse.
En caso de haber efectuado algunas modificaciones o reagrupamientos a la
información presentada por algún productor de información, se recomienda
indicar la Fuente y Elaboración.
El diseño del cuadro 2.1 propuesto en el ejemplo queda así:
CUADRO 2.1 P.B.I., POR RAMAS DE LA ACTIVIDAD ECONÓMICA, SEGÚN AÑOS: 2000 - 08
AÑOS
Agricultura
P.B.I., POR RAMAS DE LA ACTIVIDAD ECONÓMICA (MILLONES DE NUEVOS SOLES)
Pesca Minería Industria Electicidad Construcción Comercio Servicios
Total
2000
2001
2002
2003
2004
2005
2006
2007
Fuente: Instituto Nacional de Estadística e Informática.
Aspectos complementarios.Si el cuadro se extiende es recomendable hacerlo verticalmente y se debe
poner en la parte inferior derecha de la primera página la indicación
(Continúa …. . En la página siguiente se debe indicar el título del cuadro y
luego escribir a la izquierda …. Continuación), repetir el encabezamiento y
en la columna matriz continuar con las categorías o intervalos que siguen
hasta que se concluya el cuadro, en cuyo caso en la parte superior izquierda
se coloca …. Conclusión).
55
c) Tipos de cuadro.- según el número de variables que se presentan, los cuadros
pueden ser unidimensionales (se presenta una sola variable), bidimensionales
(se presentan dos variables) y multidimensionales (se presentan más de dos
variables).
d) Formas de obtención.Habiendo definido una base de datos, la forma más sencilla de obtener cuadros
estadísticos es con el SPSS, ya que tiene la ventaja de reconocer las etiquetas
(texto) para variables categóricas (codificadas numéricamente). Con los otros
programas también se obtiene cuadros, sólo que hay que efectuar previamente
recodificaciones de valores numéricos a texto.
Veamos la obtención de un cuadro bidimensional con las variables hobby (en
las filas) y sexo (en las columnas) con SPSS y luego con Minitab.
En SPSS:
De la barra de menú escoger Analizar → Estadísticos descriptivos → Tabla
de contingencia, aparece la ventana de diálogo de la Figura 2.2.
Figura 2.2 Obtención de un cuadro bidimensional con SPSS
56
Entre las variables que aparecen al lado izquierdo, hacer clic sobre la variable
HOBBY e ingresarla debajo del recuadro Filas haciendo clic en el botón
,
luego hacer clic sobre la variable SEXO e ingresarla debajo del recuadro
Columnas haciendo clic en el botón
.
Si hacemos clic en el botón Casillas se abre la ventana de diálogo de la Figura
2.3, en la que se escoge que debe aparecer en las casillas.
Figura 2.3 Mostrar en las casillas
Por defecto, en Frecuencias aparece un check en el recuadro
Observadas y
la tabla va mostrar en las Casillas, los resultados del conteo (número de casos).
En Porcentajes, los recuadros al costado de Fila, Columna y Total aparecen
sin check.
Si hacemos clic al costado de
Fila, el programa saca porcentaje sobre el total
de casos en cada fila, de modo tal que en el cuadro los totales de fila van a
sumar 100%. Del mismo modo, si hacemos clic al costado de
Columna, el
programa saca porcentaje sobre el total de casos en cada columna, de modo tal
que en el cuadro los totales de columna van a sumar 100%. Finalmente si
hacemos clic al costado de
Total, el programa saca porcentaje sobre el total
de casos, de modo tal que en el cuadro la suma de los porcentajes de todas las
casillas es el 100%.
57
Queda a criterio del investigador escoger lo que desea: sólo frecuencias
observadas (número de casos), sólo alguno de los porcentajes, o cualquier
combinación de frecuencias observadas y/o porcentajes (incluyendo los cuatro
a la vez, sólo que para el análisis hay que tener mucho cuidado).
Escogido lo que va aparecer en las casillas, hacer clic en Continuar, regresa a
la Figura 2.2, para terminar el cuadro hacer clic en Aceptar.
Veamos algunos resultados:
Si para las casillas escogemos sólo frecuencias
Observadas, el cuadro de
salida es el siguiente:
Tabla de contingencia HOBBY * SEXO
Recuento
HOBBY
Deportes
Mus ica
Baile
TV / Cine
Otros
Total
SEXO
Hombre
Mujer
14
1
14
13
1
3
4
8
0
2
33
27
Total
15
27
4
12
2
60
Haciendo doble clic sobre el cuadro de salida anterior se pueden hacer
algunos arreglos de presentación y copiarlo en Excel o Word. Pudiendo
presentarse así:
CUADRO 2.2 ALUMNOS DE ESTADÍSTICA BÁSICA, DE LA FCEUNAC, POR SEXO, SEGÚN HOBBY: 09-A
SEXO
HOBBY
Hombre
Mujer
Total
Deportes
14
1
15
Música
14
13
27
Baile
1
3
4
TV / Cine
4
8
12
Otros
0
2
2
Total
33
27
60
Fuente: Base de datos del curso de Estadística Básica
58
Si para las casillas escogemos frecuencias
hacemos clic en
Observadas y en porcentajes
Fila, el cuadro de salida es el siguiente:
Tabla de contingencia HOBBY * SEXO
HOBBY
Deportes
Recuento
% de HOBBY
Recuento
% de HOBBY
Recuento
% de HOBBY
Recuento
% de HOBBY
Recuento
% de HOBBY
Recuento
% de HOBBY
Musica
Baile
TV / Cine
Otros
Total
SEXO
Hombre
Mujer
14
1
93.3%
6.7%
14
13
51.9%
48.1%
1
3
25.0%
75.0%
4
8
33.3%
66.7%
0
2
.0%
100.0%
33
27
55.0%
45.0%
Total
15
100.0%
27
100.0%
4
100.0%
12
100.0%
2
100.0%
60
100.0%
Cuadro que también se puede editar. En cada casilla se aprecia el mismo
número de casos anterior, ahora acompañado del porcentaje sobre el total de
cada fila. Así, en la segunda fila hay 27 alumnos (100%) cuyo hobby es la
música, de los cuales 14 (51.9%) son hombres y 13 (48.1%) son mujeres.
Si para las casillas sólo se escoge en porcentajes
Columna, el cuadro de
salida es el siguiente:
Tabla de contingencia HOBBY * SEXO
% de SEXO
HOBBY
Total
Deportes
Mus ica
Baile
TV / Cine
Otros
SEXO
Hombre
Mujer
42.4%
3.7%
42.4%
48.1%
3.0%
11.1%
12.1%
29.6%
7.4%
100.0%
100.0%
Total
25.0%
45.0%
6.7%
20.0%
3.3%
100.0%
Sobre los mismos 60 alumnos, se puede apreciar que del total de hombres
(33 alumnos = 100.0%) el 42.4% gustan de los Deportes, otro 42.4%
Música, el 3.0% Baile y el 12.1% TV/Cine. Análisis similar se hace para
mujeres y para el total de alumnos.
59
Si para las casillas sólo se escoge en porcentajes
Total, el cuadro de
salida es el siguiente:
Tabla de contingencia HOBBY * SEXO
% del total
HOBBY
Total
Deportes
Mus ica
Baile
TV / Cine
Otros
SEXO
Hombre
Mujer
23.3%
1.7%
23.3%
21.7%
1.7%
5.0%
6.7%
13.3%
3.3%
55.0%
45.0%
Total
25.0%
45.0%
6.7%
20.0%
3.3%
100.0%
Aquí los porcentajes en cada Casilla, se obtienen haciendo a los 60 alumnos
como el 100%.
En Minitab:
De la barra de menú escoger Stat → Tables → Descriptive Statistics aparece
la ventana de diálogo de la Figura 2.4.
Figura 2.4 Obtención de un cuadro bidimensional con Minitab
De las variables que aparecen al lado izquierdo, hacer clic sobre la variable
hobby que va ir en las filas (rows) e ingresarla en el recuadro en blanco al
60
costado de For rows: haciendo clic en el botón Select, luego hacer clic sobre
la variable sexo que va ir en las columnas (columns) e ingresarla al costado de
For columns: haciendo clic en el botón Select.
Si hacemos clic en el botón Categorical variables… se abre la ventana de
diálogo de la Figura 2.5, en la que se escoge que debe aparecer en las casillas,
de manera similar al SPSS.
Figura 2.5 Escoger qué mostrar en las casillas con el Minitab
Por defecto, en Display aparece un check en el recuadro
Count y la tabla va
mostrar en las Casillas, los resultados del conteo (número de casos).
Si hacemos clic al costado de
Row percents, el programa saca porcentajes
sobre el total de casos en cada fila, de modo tal que en el cuadro los totales de
fila van a sumar 100%. Del mismo modo, si hacemos clic al costado de
Column percents, el programa saca porcentajes sobre el total de casos en cada
columna, de modo tal que en el cuadro los totales de columna van a sumar
100%. Finalmente si hacemos clic al costado de
Total percents, el programa
saca porcentaje sobre el total de casos, de modo tal que en el cuadro la suma de
los porcentajes de todas las casillas es el 100%.
Al igual que en el SPSS se tiene que escoger lo que se desea mostrar en las
casillas, escogido lo que va aparecer en las casillas, hacer clic en el botón OK,
regresa a la Figura 2.4, para terminar el cuadro hacer clic en OK.
Veamos algunos resultados:
Si para las casillas escogemos sólo frecuencias
es el siguiente:
61
Count, el cuadro de salida
Tabulated statistics: hobby, sexo
Rows: hobby
1
2
3
4
5
All
Columns: sexo
1
2
All
14
14
1
4
0
33
1
13
3
8
2
27
15
27
4
12
2
60
La tabla obtenida no presenta las etiquetas de las categorías de hobby, ni las
de sexo, por lo que es necesario tenerlas definidas (Ver acápite 1.6
Recodificación de datos en Minitab, Data → Code → Numeric to Text)
antes de sacar el cuadro, algo que no necesita el SPSS ya que las reconoce
automáticamente al definir las variables y sus valores.
Realizada la recodificación de datos para las variables sexo y hobby,
efectuando el proceso anterior obtenemos la siguiente tabla:
Tabulated statistics: hoby, sex
Rows: hoby
Columns: sex
Hombre
Mujer
All
1
14
14
0
4
33
3
1
13
2
8
27
4
15
27
2
12
60
Baile
Deportes
Música
Otros
TV/Cine
All
En la tabla anterior ya aparecen las etiquetas de hobby y sexo recodificadas,
pero la presentación no es muy estética, requiere de un trabajo previo en
Excel, lo que no es necesario para las tablas en SPSS (es mejor trabajarlas
con este programa).
Si para las casillas escogemos
Count y hacemos clic en
el cuadro de salida es el siguiente:
62
Row percents,
Tabulated statistics: hoby, sex
Rows: hoby
Columns: sex
Hombre
Mujer
All
Baile
1
25.00
3
75.00
4
100.00
Deportes
14
93.33
1
6.67
15
100.00
Música
14
51.85
13
48.15
27
100.00
Otros
0
0.00
2
100.00
2
100.00
4
33.33
8
66.67
12
100.00
33
27
60
TV/Cine
All
Cuadro que también se puede editar. En cada casilla se aprecia el mismo
número de casos anterior, ahora acompañado del porcentaje sobre el total de
cada fila. Así, en la tercera fila hay 27 alumnos (100%) cuyo hobby es la
música, de los cuales 14 (51.85%) son hombres y 13 (48.15%) son mujeres.
Veamos ahora rápidamente la obtención de un cuadro tridimensional con las
variables especial(ización) y hobby (en las filas) y sexo (en las columnas) con
SPSS y luego con Minitab.
En SPSS:
De la barra de menú escoger Analizar → Estadísticos descriptivos → Tabla
de contingencia, aparece la ventana de diálogo de la Figura 2.2.
Se ingresa la variable hobby en Filas, sexo en Columnas y especial en Capa
1 de 1. Si desea escoge Casillas para indicar que va aparecer en las mismas,
veamos sólo valores observados. La tabla es la que muestra la Figura 2.5.
La tabla se puede editar haciendo doble clic sobre ella en SPSS o copiarla en
Word y efectuar las modificaciones necesarias. El número y título son:
CUADRO 2.3 ALUMNOS DE ESTADÍSTICA BÁSICA, DE LA FCEUNAC, POR SEXO, SEGÚN ESPECIALIZACIÓN Y HOBBY: 09-A
63
Tabla de contingencia HOBBY * SEXO * ESPECIALIZACIÓN
Recuento
ESPECIALIZACIÓN
Teoría Económica
HOBBY
Gestión Empres arial
Total
HOBBY
Deportes
Musica
TV / Cine
Deportes
Musica
Baile
TV / Cine
Otros
Total
SEXO
Hombre
Mujer
5
0
3
3
0
2
8
5
9
1
11
10
1
3
4
6
0
2
25
22
Total
5
6
2
13
10
21
4
10
2
47
Figura 2.6 Cuadro tridimensional en SPSS
En Minitab:
De la barra de menú escoger Stat → Tables → Descriptive Statistics aparece
la ventana de diálogo de la Figura 2.4.
Con las variables recodificadas previamente, se ingresa la variable hoby en
For rows, sexo en For columns y especialización en For layers. Si desea
escoge Categorical variables para indicar que va aparecer en las casillas,
veamos sólo Counts (conteos), OK, OK y los resultados son los siguientes:
Tabulated statistics: hoby, sex, especialización
Results for especialización = Gestión Empresarial
Rows: hoby
Columns: sex
Hombre
Mujer
All
1
9
11
0
4
25
3
1
10
2
6
22
4
10
21
2
10
47
Baile
Deportes
Música
Otros
TV/Cine
All
Cell Contents:
Count
Results for especialización = Teoría Económica
Rows: hoby
Columns: sex
64
Baile
Deportes
Música
Otros
TV/Cine
All
Hombre
Mujer
All
0
5
3
0
0
8
0
0
3
0
2
5
0
5
6
0
2
13
Para obtener tablas en Excel es necesario recurrir a Tabla dinámica que se
encuentran el menú Insertar. Veamos el procedimiento para una tabla
bidimensional con las variables hobby en filas y sexo en columnas.
En las columnas A, B y C se ha copiado las variables sexo, hobby y especial
con las etiquetas de sus categorías, entre las filas 1 y 61, las mismas que están
en la base de datos de los alumnos de Estadística Básica 09-A del Anexo. Al
hacer clic en Tabla dinámica aparece la ventana de diálogo Crear tabla
dinámica que aparece en la Figura 2.7.
Figura 2.7 Creando tabla dinámica en Excel
En Seleccione los datos que desea analizar, marcar Seleccione una tabla o
rango e indicar en Tabla o rango: los valores a analizar sombreando los
datos de la hoja de cálculo desde A1 hastaC61 y automáticamente aparece lo
indicado en la Figura 2.7. En elija dónde desea colocar el informe de la tabla
dinámica, elegir Hoja de cálculo existente e indicar Ubicación: aquí celda E2.
Luego hacer clic en Aceptar y aparece una estructura de tabla.
65
A continuación,
arrastrar la variable HOBBY, que aparece en el lado
derecho, sobre el mensaje Coloque campos de fila aquí; del mismo modo
arrastrar la variable SEXO sobre el mensaje Coloque campos de columna
aquí. Al volver a arrastrar la variable SEXO sobre el Cuerpo del cuadro en
el mensaje Coloque datos aquí, se obtiene la tabla dinámica requerida con el
resultado de los conteos visto en las tablas anteriores (ver Figura 2.8).
Figura 2.8 Tabla dinámica para Sexo y Hobby en Excel
Para obtener porcentajes sobre las filas, las columnas o el total como en SPSS
y Minitab, se debe arrastrar nuevamente la variable de conteo (SEXO) en
el Cuerpo del cuadro, sobre el área de lo que fue el mensaje Coloque datos
aquí. En las filas aparece Cuenta de SEXO y Cuenta de SEXO2. Al hacer
doble clic sobre Cuenta de SEXO2, aparece la ventana de diálogo
Configuración de campo de valor, hacer clic en el botón Mostrar valores
como aparece Normal, hacer clic en la flecha de selección
y se puede
escoger el porcentajes sobre las filas, las columnas o el total, al escoger el %
de la columna y Aceptar, aparece el cuadro de la Figura 2.9.
66
Figura 2.9 Tabla dinámica para Sexo y Hobby con porcentajes en Excel
Si se quiere obtener un cuadro tridimensional arrastrar la variable
ESPECIALIZACIÓN en las filas sobre HOBBY y aparece la tabla dinámica de
la Figura 2.10, donde haciendo doble clic sobre Cuenta de SEXO2 se ha
escogido mostrar valores como % de la fila.
Figura 2.10 Tabla dinámica para Sexo, Especialización y Hobby en Excel
67
Se reafirma nuevamente que el SPSS arroja una mejor presentación.
Para obtener tablas con el programa R, primero se definen las variables como
objetos. Tal como se plantea en el acápite 1.7 Manipulación de archivos, leída
la base de datos como caso2, al escribir >attach(caso2) y efectuar enter, se
identifican las variables con el nombre en el encabezado. También se pueden
crear las variables como objetos, separándolos con punto y coma, así:
> hobby=caso2[,16] ; sexo=caso2[,2] ; especialización=caso2[,20]
La tabla bidimensional con la variable hobby en las filas y sexo en las
columnas, se obtiene así:
> table(hobby,sexo)
sexo
hobby
1
2
1 14
1
2 14 13
3
1
3
4
4
8
5
0
2
Resultado idéntico al del Minitab, es necesario definir las etiquetas de hoby
y sexo.
La tabla tridimensional con la variable especial (especialización) y hobby en
las filas y sexo en las columnas, se obtiene así:
> table(hobby,sexo,especial)
, , especial = 1
sexo
hobby
1
2
1
5
0
2
3
3
3
0
0
4
0
2
5
0
0
68
, , especial = 2
sexo
hobby
1
2
1
9
1
2 11 10
3
1
3
4
4
6
5
0
2
Vamos a definir en R las etiquetas de las categorías correspondientes a las
variables sexo, hobby y especialización de la siguiente manera:
> caso2=transform(caso2, sexo=factor(sexo, labels=c("Hombres","Mujeres")))
> caso2=transform(caso2, hobby=factor(hobby, labels=c("Deporte","Música",
"Baile", "TV/Cine","Otro")))
> caso2=transform(caso2, especial=factor(especial, labels=c("Teoría Económica",
"Gestión Empresarial")))
Para que se reconozcan las nuevas variables con sus etiquetas escribir:
> attach(caso2)
Obtenemos las tablas anteriores de la siguiente manera:
> t1=table(hobby,sexo)
> t1
sexo
hobby
Hombres Mujeres
Deporte
14
1
Música
14
13
Baile
1
3
TV/Cine
4
8
Otro
0
2
> prop.table(t1)
sexo
hobby
Hombres
Mujeres
Deporte 0.23333333 0.01666667
Música
0.23333333 0.21666667
69
Baile
0.01666667 0.05000000
TV/Cine 0.06666667 0.13333333
Otro
0.00000000 0.03333333
Sea t2 la tabla tridimensional:
> t2=table(hobby,sexo,especial)
> t2
, , especial = Teoría Económica
sexo
hobby
Hombres Mujeres
Deporte
5
0
Música
3
3
Baile
0
0
TV/Cine
0
2
Otro
0
0
, , especial = Gestión Empresarial
sexo
hobby
Hombres Mujeres
Deporte
9
1
Música
11
10
Baile
1
3
TV/Cine
4
6
Otro
0
2
> prop.table(t2)
, , especial = Teoría Económica
sexo
hobby
Hombres
Mujeres
70
Deporte 0.08333333 0.00000000
Música
0.05000000 0.05000000
Baile
0.00000000 0.00000000
TV/Cine 0.00000000 0.03333333
Otro
0.00000000 0.00000000
, , especial = Gestión Empresarial
sexo
hobby
Hombres
Mujeres
Deporte 0.15000000 0.01666667
Música
0.18333333 0.16666667
Baile
0.01666667 0.05000000
TV/Cine 0.06666667 0.10000000
Otro
0.00000000 0.03333333
Para conservar los valores originales en la base de datos caso2 y poner etiquetas,
se debe cambiar el nombre de la variable.
> caso2=transform(caso2, colegio.proc=factor(col.proc, labels=c("Estatal", "No
Estatal")))
> attach(caso2)
NOTA.- Un caso particular de los cuadros estadísticos son las denominadas
Tablas de Frecuencias (que veremos en el acápite siguiente) que son cuadros
unidimensionales, es decir, con una sola variable acompañada por lo general de
los resultados del conteo y porcentajes.
71
2.3 DISTRIBUCIÓN DE FRECUENCIAS
La información obtenida puede provenir de un censo o de una muestra. Los
resultados observados los podemos representar de la siguiente manera:
Las variables, con las últimas letras mayúsculas del alfabeto: X, Y, Z, etc. o
con algunas siglas que las abrevia el investigador o propias de algunas
disciplinas como en la economía: PBI (Producto Bruto Interno), M
(importaciones), etc.; en salud: IMC (Índice de Masa Corporal), etc.
Los subíndices, con las letras minúsculas: i, j, k, l, m, t, etc. representan
números enteros y sirven para diferenciar las unidades de análisis (U.A.) a
quienes corresponde el valor que toma la variable.
Con Xi representamos el valor de la variable X observado en laU.A. i-ésima.
Por ejemplo, si en la base de datos de los alumnos de Estadística Básica 09-A,
ver en el Anexo, X = Peso de los alumnos, entonces:
Xi = Peso del alumno i-ésimo de Estadística Básica 09-A; i = 1, 2, 3, …., 60.
X40 = 70 Kg., es el peso del alumno 40 o valor observado 40 de la variable.
Veamos las diferentes formas de presentación de datos.
DATOS SIN AGRUPAR:
Población: X1, X2, X3, …. , XN (N = tamaño de la población)
Muestra: X1, X2, X3, …. , Xn (n = tamaño de la muestra)
En la base de datos de los 60 alumnos de Estadística Básica 09-A, se tiene
información de 19 variables estudiadas, tanto cualitativas como cuantitativas.
DATOS AGRUPADOS:
a) Tabla de Frecuencia para Datos Cualitativos.- en este tipo de tablas se
indican los atributos o categorías de la variable, acompañadas del número (ni),
la proporción (hi), y/o el porcentaje (100 hi), de unidades de análisis (U.A.).
Su estructura es:
Nº de Clase Categoría de
(i)
la variable
1
Atributo 1
2
Atributo 2
….
….
k
Atributo k
Total
Nº de U.A.
(ni)
n1
n2
….
nk
n
U.A. = unidades de análisis.
72
Proporción
de U.A (hi)
h1
h2
….
hk
1
% de U.A.
(100 hi)
p1
p2
….
pk
100%
Tal como se presenta en el acápite anterior, veamos la obtención de una tabla
de frecuencias por ejemplo, para la variable hobby en SPSS: Analizar →
Estadísticos descriptivos → Frecuencias. Inmediatamente se abre la ventana
de diálogo de la Figura 2.11.
Figura 2.11 Obtención de tablas de frecuencias en SPSS
De las variables al lado izquierdo escogemos hobby, haciendo doble clic o clic
en el botón
la ingresamos en Variables, luego Aceptar y se obtiene los
resultados del Cuadro 2.4 editado en spss haciendo doble clic.
CUADRO 2.4 ALUMNOS DE ESTADÍSTICA BÁSICA 2009-A, DE LA
FCE-UNAC, SEGÚN HOBBY
HOBBY
Deportes
Musica
Baile
TV / Cine
Otros
Total
ALUMNOS
15
27
4
12
2
60
% DE
ALUMNOS
25.0
45.0
6.7
20.0
3.3
100.0
Un cuadro similar se puede obtener con el Minitab si se tiene previamente
etiquetadas las categorías de la variable hobby, de la siguiente manera: Stat →
Tables → Tally Individual Variables … Escoger la variable hobby y Select
73
para que ingrese en Variables. En display, por defecto aparece
Counts,
marcar también Percents, luego OK y aparecen los resultados del Cuadro 2.4.
Tally for Discrete Variables: hoby
hoby
Baile
Deportes
Música
Otros
TV/Cine
N=
Count
4
15
27
2
12
60
Percent
6.67
25.00
45.00
3.33
20.00
También en R, estando etiquetadas las categorías de la variable hobby,
attachada la base de datos y usando table obtenemos lo mismo, así:
> caso2=transform(caso2, hoby=factor(hobby, labels=c("Deporte", "Música",
"Baile", "TV/Cine","Otro")))
> attach(caso2)
> table(hoby)
hoby
Deporte
Música
15
27
Baile TV/Cine
4
Otro
12
2
b) Tabla de Frecuencias para Datos Cuantitativos Discretos.- la variable
discreta toma valores en un rango pequeño (por ejemplo: número de hijos,
número de dormitorios en la vivienda, etc.). Para su resumen en la presentación
se indican esos pocos valores de la variable
(Xi) acompañados de las
siguientes frecuencias en las columnas:
Frecuencias absolutas o repeticiones = ni = Nº de unidades de análisis
(U.A.) que toman el valor Xi (resultado del conteo).
Frecuencia relativa = (hi) = Proporción de U.A. que toman el valor Xi .
pi = 100 hi = Porcentaje de U.A. que toman el valor Xi .
Frecuencia absoluta acumulada o repeticiones acumuladas = Ni = Número
acumulado de U.A. que toman el valor Xi o menos.
Frecuencia relativa acumulada = Hi = la proporción acumulada de U.A. que
toman el valor Xi o menos.
Pi = 100 Hi = porcentaje acumulado U.A. que toman el valor Xi o menos.
74
La estructura general de este tipo de tablas es la que se muestra a continuación,
cuando se efectúan presentaciones reales de datos sólo se muestran algunos
elementos de esta estructura.
Clase
(i)
Valores
(X i)
Nº de
U.A.
(n i)
Proporc.
U.A.
(h i)
% U.A.
pi = 100 h i
Nº
Acum
U.A.
(N i)
Prop.
Acum.
U.A.
(H i)
% Acum.
U.A.
P i =100H i
1
2
….
k
X1
X2
….
Xk
n1
n2
….
nk
h1
h2
….
hk
p1
p2
….
pk
N1
N2
….
Nk =
n
H1
H2
….
Hk = 1
P1
P2
….
Total
n
1
100%
Donde: Ni = Ni - 1 + ni ,
hi = ni / n = Hi - Hi - 1 ,
Pk =
100%
Hi = Ni / n = Hi - 1 + hi
Tal como se presenta en el acápite anterior, veamos la obtención de una tabla
de frecuencias por ejemplo, para la variable número de miembros en la familia
mie.fam en SPSS: Analizar → Estadísticos descriptivos → Frecuencias.
Inmediatamente se abre la ventana de diálogo de la Figura 2.11.
De las variables al lado izquierdo escogemos mie.fam, haciendo doble clic o
clic en el botón
la ingresamos en Variables, luego Aceptar y se obtiene
los resultados del Cuadro 2.5 editado en spss haciendo doble clic.
CUADRO 2.5 ALUMNOS DE ESTADISTICA BASICA 2009-A, DE LA
FCE-UNAC, SEGÚN EL NÚMERO DE MIEMBROS EN LA FAMILIA
MIEMBROS EN
LA FAMILIA
2
3
4
5
6
7
8
9
Total
Alumnos
2
5
11
27
8
5
1
1
60
75
% de
Alumnos
3.3
8.3
18.3
45.0
13.3
8.3
1.7
1.7
100.0
Porcentaje
acumulado
3.3
11.7
30.0
75.0
88.3
96.7
98.3
100.0
Tabla que trabajada en Excel, queda con las frecuencias indicadas a
continuación:
Alumnos
(ni)
Proporción
alumnos
(hi)
Porcentaje
alumnos
(p i = 100 h i)
Nº acum.
alumnos
(Ni)
Prop. acum.
alumnos
(Hi)
2
3
4
2
5
11
0.033
0.083
0.183
3.3%
8.3%
18.3%
2
7
18
0.033
0.117
0.300
5
6
7
8
9
Total
27
8
5
1
1
60
0.450
0.133
0.083
0.017
0.017
1.000
45.0%
13.3%
8.3%
1.7%
1.7%
100.0
45
53
58
59
60
0.750
0.883
0.967
0.983
1.000
Miembros en la
Familia (X i)
En esta tabla se puede interpretar que:
n4 = 27, hay 27 alumnos con 5 miembros en su familia cada uno.
h3 = 0.183, 18.3% de los alumnos tienen 4 miembros en su familia cada uno.
N5 = 53, hay 53 alumnos con 6 o menos miembros en su familia cada uno.
H4 = 0.75, 75% de los alumnos tienen 5 o menos miembros en su familia cada
uno.
Un cuadro similar se puede obtener con el Minitab de la siguiente manera:
Staat → Tables → Tally Individual Variables … Escoger la variable
mie.fam y Select para que ingrese en Variables. En display, por defecto
aparece
Counts, marcar también Percents, Cumulative counts y
Cumulative percents, luego OK y aparecen los resultados del Cuadro 2.5, tal
como se aprecia a continuación:
Tally for Discrete Variables: mie.fam
mie.fam
2
3
4
5
6
7
8
9
N=
Count
2
5
11
27
8
5
1
1
60
CumCnt
2
7
18
45
53
58
59
60
Percent
3.33
8.33
18.33
45.00
13.33
8.33
1.67
1.67
CumPct
3.33
11.67
30.00
75.00
88.33
96.67
98.33
100.00
También en R, estando attachada la base de datos y usando table obtenemos lo
mismo, así:
76
> attach(caso2)
> table(mie.fam)
mie.fam
2
3
4
5
6
7
8
9
2
5 11 27
8
5
1
1
c) Tabla de Frecuencias con intervalos para Datos Cuantitativos.- en este
caso tanto la variable discreta como la continua toma valores en un rango
relativamente grande y para su resumen hay que construir intervalos de clase,
para lo cual se debe seguir los siguientes pasos:
Determinar el Rango (R) de la variable: como la diferencia entre el valor
máximo y mínimo de la variable.
R = Xmáx – Xmín = {X / Xmín ≤ X ≤ Xmáx}
Determinar el número de intervalos (k) con algún criterio del investigador
o usando fórmulas como la de Sturges: k = 1 + 3.32 log10 N = 1 + log 2 N
Tomar el valor de k redondeado (donde N es el número de observaciones
en la población y si es n número de observaciones en la muestra).
Hallar el ancho o amplitud (C) del intervalo: C = R/k,
Tomar el valor de C redondeado con un determinado número de decimales,
en función de las unidades de la variable.
Construir los k intervalos de clase, desde un límite inferior (LI) hasta un
límite superior (LS): LIi
-
LSi
Intervalo 1
:
[Xmín
-
Xmín + C)
Intervalo 2
:
[Xmín + C
-
Xmín + 2C)
Intervalo 3
:
[Xmín + 2C
-
Xmín + 3C)
Intervalo k – 1
:
[Xmín + (k – 2)C
-
Xmín + (k – 1)C)
Intervalo k
:
[Xmín + (k – 1)C
-
Xmín + kC]
…………..
Obtener las marcas de clase (Xi) como los valores representativos de la
clase, mediante la semisuma de los límites superior e inferior de la clase
correspondiente:
Xi
LI i
LSi
2
77
, i = 1, 2, …., k
En la presentación de la distribución de frecuencias de la variable X, se indican
los intervalos de clase [LIi - LSi), las marcas de clase (Xi) acompañadas de las
siguientes frecuencias en las columnas:
Frecuencias absolutas o repeticiones = ni = Nº de unidades de análisis
(U.A.) en el intervalo i (resultado del conteo).
Frecuencia relativa = (hi) = Proporción de U.A. en el intervalo i.
pi = 100 hi = Porcentaje de U.A. en el intervalo i.
Frecuencia absoluta acumulada o repeticiones acumuladas = Ni = Número
acumulado de U.A. hasta el límite superior i (LSi).
Frecuencia relativa acumulada = Hi = la proporción acumulada de U.A.
hasta el límite superior i (LSi).
Pi = 100 Hi = porcentaje acumulado U.A. hasta el límite superior i (LSi).
Su estructura es:
Clase Intervalo
(i)
LIi - LSi
1
2
….
k
LI1 -LS1
LI2 –LS2
….
LIk –LSk
Marca
clase
(X i)
Nº de
U.A.
(n i)
Proporc.
U.A.
(h i)
% U.A.
pi =
100 h i
#
Acum
U.A.
(N i)
Prop.
Acum.U.A.
(H i)
% Acu.
Pi =
X1
X2
….
Xk
n1
n2
….
nk
h1
h2
….
hk
p1
p2
….
pk
N1
N2
….
Nk = n
H1
H2
….
Hk = 1
P1
P2
….
n
1
100%
Total
100 H i
Pk =
100%
Donde: N1 = n1, Ni = Ni - 1 + ni , hi = ni / n , H1 = h1 , Hi = Ni / n = Hi - 1 + hi
Vamos a obtener una tabla de frecuencias, con k = 5 intervalos, para los pesos
de los alumnos de Estadística Básica 2009-A, cuyos datos aparecen en el
Anexo y de manera ordenada se muestran en el Cuadro 2.6 siguiente:
CUADRO 2.6. PESOS (Kg.) DE LOS 60 ALUMNOS DE ESTADISTICA BÁSICA 09-A UNAC
44
50
53
57
65
70
45
50
53
59
66
72
46
50
53
60
66
72
46.5
50.5
54
60
67
75
47
51
55
63
67
75
48
51
55
63
68
77
48
52
55
64
68
80
49
52
55
64
68
80
El rango de los pesos es R = Xmáx – Xmín = 88 – 44 = 44 Kg.
= {X / 44 ≤ X ≤ 88}
78
49
52.6
55
64.5
69
80
50
53
57
65
70
88
Por interés particular, se desean construir k = 5 intervalos.
Los intervalos son de igual amplitud, donde C = R/k = 44 / 5 = 8.8 Kg.
Los intervalos son cerrados por la izquierda y abiertos por la derecha: [44 –
52.8), [52.8 – 61.6), [61.6 – 70.4), [70.4 - 79.2) y [79.2 – 88.0]. El Excel toma
los intervalos abiertos por la izquierda y cerrados por la derecha: (LI - LS].
La tabla completa se ha obtenido en Excel, de la siguiente manera:
En la figura 2.12 se puede apreciar que en la hoja de cálculo de Excel, en la
columna A, se ha copiado los pesos de los 60 alumnos, ocupando las celdas
desde A3 hasta A62. Así mismo, en las columnas D y E se han definido los
límites inferior y superior de clase, ocupando desde la fila 12 a la 16.
Figura 2.12 Obtención de Tabla de Frecuencias en Excel
Para obtener las frecuencias absolutas (ni) en Excel, es necesario sombrear las
celdas donde se deposita el resultado automático de los conteos, que en este
caso es en la columna G, de la celda G12 a la G16, tal como se muestra en la
Figura 2.12. A continuación, con la opción de funciones
del Excel, escoger
dentro de Seleccionar una categoría →Estadísticas → Frecuencia y aparece
la ventana de diálogo de la Figura 2.13 solicitando los Argumentos de la
función Frecuencia: Datos (de la variable peso, que están ubicados de la celda
A3 hasta la A62) sombrear los datos o escribir A3:A62 y en Grupos (indicar
79
los límites superiores de los intervalos, que están en las celdas de E12 hasta
E16).
Figura 2.13 Argumentos de la función Frecuencia
Para terminar no usar Aceptar, sino la combinación de las teclas
MAYUSCULA + Ctrl + Enter, automáticamente aparece el resultado de los
conteos en las celdas de la columna de los ni con los valores 19, 15, 17, 5 y 4.
El resto de columnas se han obtenido usando las fórmulas indicadas en la
estructura general. Los resultados de este proceso se muestran en el cuadro
siguiente:
CUADRO 2.7 DISTRIBUCIÓN DE FRECUENCIAS DE LOS PESOS DE
LOS ALUMNOS DE ESTADÍSTICA BÁSICA 09-A FCE-UNAC
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
% de
Acum. Prop.Ac. % Acum.
Alum-nos
alumnos alumnos alumnos alumnos alumnos
clase
Xi
ni
hi
100hi
Ni
Hi
100 Hi
48.4
19
0.317
31.7%
19
0.317
31.7%
57.2
15
0.250
25.0%
34
0.567
56.7%
66.0
17
0.283
28.3%
51
0.850
85.0%
74.8
5
0.083
8.3%
56
0.933
93.3%
83.6
4
0.067
6.7%
60
1.000 100.0%
60
1.000 100.0%
En esta tabla se puede interpretar que:
n3 = 17, hay 17 alumnos que pesan entre 61.6 y 70.4 Kg. cada uno.
h2 = 0.250, el 25.0% de los alumnos pesan entre 52.8 y 61.6 Kg. cada uno.
80
N4 = 56, hay 56 alumnos que pesan menos de 79.2 Kg. cada uno.
H3 = 0.85, 85% de los alumnos pesan menos de 70.4Kg. cada uno.
Para obtener Tablas de frecuencias con el Minitab, el SPSS y el R, se tiene que
proceder con la recodificación de datos planteada en el acápite 1.6. Veamos:
En Minitab.De la barra de menú escoger la opción Data, luego Code (código) y Numeric
to text (numérico a texto) porque se desea recodificar valores numéricos en
texto (la denominación de los intervalos). Aparece la ventana de diálogo de la
Figura 2.14.
Figura 2.14 Recodificación de la variable peso en Minitab
En Code data from columns: (código de datos desde las columnas)
seleccionar de las variables a la izquierda peso o escribirla. En Store couded
data in columns: (almacenar datos codificados en la columna) seleccionar de
las variables de la izquierda pesos o escribirla.
A continuación en Original values (valores originales) se va definiendo uno a
uno los intervalos definidos en el Cuadro 2.7, separándolos por dos puntos (:) y
81
en New los nuevos valores en texto para representar los intervalos, tal como se
muestra en la Figura 2.14.
Para finalizar la recodificación hacer clic en OK y en la base de datos (Current
data window) aparecen los datos de pesos (ver Figura 2.15).
Figura 2.15 Variable peso recodificada en pesos (intervalos) con Minitab
Para obtener la tabla de frecuencias proceder de la siguiente manera: Stat →
Tables → Tally Individual Variables … Aparece la ventana de diálogo de la
Figura 2.16. Escoger la variable pesos y Select para que ingrese en Variables.
En display, por defecto aparece
Counts, marcar también Percents,
Cumulative Counts y Cumulative percents,
luego OK y aparecen los
resultados siguientes (similares a los del Cuadro 2.7):
Tally for Discrete Variables: pesos
pesos
44.0 - 52.8
52.8 - 61.6
61.6 - 70.4
Count
19
15
17
CumCnt
19
34
51
82
Percent
31.67
25.00
28.33
CumPct
31.67
56.67
85.00
70.4 - 79.2
79.2 - 88.0
N=
5
4
60
56
60
8.33
6.67
93.33
100.00
Figura 2.16 Obtención de Tabla de Frecuencias en Minitab (variable pesos)
En SPSS.De la barra de menú escoger la opción Transformar, luego hacer clic sobre
Recodificar en distintas variables. Aparece la ventana de diálogo Recodificar
en distintas variables de la Figura 2.17.
Figura 2.17 Recodificando la variable peso en SPSS
83
Escogiendo de la lista de variables que aparecen al lado izquierdo, en Var.
numérica → Var. de resultado: ingresar la variable peso, inmediatamente
aparece peso → ? En Variable de resultado, en Nombre: escribir pesos, en
Etiqueta: escribir PESO (Kg.) y luego hacer clic en el botón Cambiar (si no
hace esto, la recodificación no se realiza después), inmediatamente en Var.
numérica → Var. de resultado: se modifica por peso→ pesos.
Luego, hacer clic en Valores antiguos y nuevos y aparece la ventana de diálogo
Recodificar en distintas variables: Valores antiguos y nuevos de la Figura 2.18.
Figura 2.18 Recodificar Valores antiguos del peso y nuevos de pesos en SPSS
A continuación, en Valor antiguo se va definiendo uno a uno los intervalos
definidos en el Cuadro 2.7, y en Valor nuevo los nuevos valores del intervalo.
Observar que el primer intervalo es para peso entre 44.0 hasta antes de 52.8,
en Valor antiguo, en Rango: se escribe 44.0 hasta 52.79 (de ser necesario se
agregan más nueves en los decimales, para estar más cerca a 52.8) y en Valor
nuevo, en Valor escribir 1, luego hacer clic en añadir. El siguiente intervalo va
de 52.8 hasta antes de 61.6, en Valor antiguo, en Rango: se escribe 52.8 hasta
61.59 y en Valor nuevo escribir 2, luego hacer clic en añadir. Así
sucesivamente, el último intervalo va de 79.8 hasta 88.0, en Valor antiguo, en
84
Rango: se escribe 79.8 hasta 88.0 y en Valor nuevo, en Valor escribir 5, luego
clic en añadir.
Para finalizar la recodificación, al hacer clic en Continuar regresa a la ventana
de la Figura 2.17.
Luego hacer clic en Aceptar y aparece la variable pesos con sus valores del 1 al
5 en la Vista de datos del Editor de datos SPSS.
A continuación, en la Vista de variables, del Editor de datos SPSS, a la variable
pesos se le definen las Etiquetas de valor, en un cuadro de diálogo similar al
de la Figura 1.5. Para ello asignar los valores y etiquetas siguientes: 1, 44.0 –
52.8; 2, 52.8 – 61.6; 3, 61.6 – 70.4; 4, 70.4 – 79.2; y 5, 79.2 – 88.0.
Una vez que termina de añadir los valores y etiquetas hacer clic en Aceptar, en
la Vista de datos, del Editor de datos SPSS aparecen las etiquetas de condición
que se muestran en la Figura 2.14.
Figura 2.19 Resultado de la variable pesos, recodificando el peso en SPSS
Para obtener la tabla de frecuencias ejecutar: Analizar → Estadísticos
descriptivos → Frecuencias. Inmediatamente se abre la ventana de diálogo de
la Figura 2.11.
De las variables al lado izquierdo escogemos pesos, haciendo doble clic o clic
en el botón
la ingresamos en Variables, luego Aceptar y se obtiene los
mismos resultados del Cuadro 2.7 que se muestran a continuación:
85
PESO (Kg.)
PESO (Kg.)
44.0 - 52.8
52.8 - 61.6
61.6 - 70.4
70.4 - 79.2
79.2 - 88.0
Total
Frecuencia
19
15
17
5
4
60
Porcentaje
31.7
25.0
28.3
8.3
6.7
100.0
Porcentaje
acumulado
31.7
56.7
85.0
93.3
100.0
En R.Para crear los intervalos del Cuadro 2.7, estando en la base de datos caso 2, se
procede así:
> caso2=transform(caso2,pesos=cut(peso,breaks=c(43.99, 52.79, 61.59, 70.39,
79.19, 88.0)))
> attach(caso2)
Para visualizar la base de datos caso2 con los intervalos escribir:
> fix(caso2)
En el R Editor de datos aparece la variable pesos con los intervalos definidos,
tal como se muestra en la Figura 2.20.
Figura 2.20 Resultado de la variable pesos, recodificando el peso en R
86
Para obtener la tabla de frecuencias ejecutar:
> table(pesos)
pesos
(44,52.8] (52.8,61.6] (61.6,70.4]
19
15
(70.4,79.2]
17
(79.2,88]
5
4
Los resultados obtenidos son idénticos a los del Cuadro 2.7.
2.4 GRÁFICOS ESTADÍSTICOS
Es una forma de presentación de datos, cuya elaboración requiere necesariamente de
una tabla o cuadro estadístico y mediante el cual se busca que el lector de un golpe de
vista pueda destacar aspectos importantes de la(s) variable(s) en estudio, ya que como
dice el adagio popular “una imagen vale más que mil palabras”.
En esta parte vamos a desarrollar algunas formas de presentación gráfica básica, de tal
manera que permita descripciones importantes de las variables en estudio. En capítulos
posteriores se verá algunas otras formas gráficas propias de los tópicos tratados.
a) Definición.- para Correa y González (2002) “Un gráfico estadístico es una
representación visual de datos estadísticos.” o las distribuciones estadísticas
mediante figuras geométricas, reflejando la relación o comparación fácil entre
las variables en un estudio determinado.
b) Estructura.- las partes de un gráfico estadístico son: número, título, cuerpo,
leyenda y fuente.
Número.- si en un estudio se presenta más de un gráfico hay que
enumerarlos para diferenciarlos. Si el gráfico es único, no es necesario
enumerar. El número se ubica en la parte superior izquierda o central.
Se recomienda anteponer la palabra Gráfico y a continuación colocar el
número (sin la abreviatura Nº previa) que puede ser arábigo o alfanumérico,
seguido de un punto, para luego indicar el título.
Ejemplo: Gráfico 4. ; Gráfico A13. ; etc.
Título.- el título indica de manera clara y precisa el contenido del gráfico.
Se coloca en la parte superior a continuación del número. Su elaboración es
87
similar a la del cuadro a partir del que se construye, por ello ambos títulos
(del cuadro y del gráfico) son idénticos.
Ejemplo: Alumnos de Estadística básica 09-A, según su Hobby.
Cuerpo.- es la parte central del gráfico, representada por lo general en
forma rectangular (en una relación de 1.5 para el largo y como 1 para el
ancho) en la que con algunas representaciones geométricas, acompañadas de
datos y símbolos se busca establecer contrastes de las variables y sus
categorías a través de escalas apropiadas a las magnitudes en estudio.
Se recomienda colocar el título de los ejes, con el nombre de la variable o
sus categorías, indicando la unidad de medida si hubiera. Así mismo, se
debe buscar efectuar diferenciaciones entre los componentes del gráfico
bien mediante colores, tramas, sombreados, etc.
Leyenda.- son aclaraciones respecto a las partes componentes de un gráfico
expresadas a través de lo que representan ciertos colores, tramas, etc. y van
colocados por lo general al costado de gráfico con su indicación de lo que
representan.
Fuente.- al igual que los cuadros, es necesario indicar los elementos
esenciales que permitan identificar a los “dueños” de los gráficos e
información para cualquier consulta mediante una breve Ficha Bibliográfica
o Referencia Web, tal como se indica en la fuente de cuadros estadísticos.
En el caso de ser propio el gráfico, se recomienda indicar la Elaboración.
c) Tipos de gráficos.- al igual que los cuadros estadísticos, los gráficos pueden
ser unidimensionales, bidimensionales o pluridimensionales, según el número
de variables que se presenten.
d) Formas de obtención.- se va a presentar la obtención de estos gráficos
utilizando los programas Excel, Minitab, SPSS y R, los mismos que veremos
para variables cualitativas y cuantitativas, tal como se pase a detallar.
88
2.5 GRÁFICOS DE VARIABLES CUALITATIVAS
Entre los principales gráficos de variables cualitativas tenemos los gráficos de sectores,
el gráfico de barras y el gráfico de Pareto.
a) Gráfico de sectores.- llamado también pie o pastel, es muy apropiado para
representar las categorías de una variable cualitativa en una circunferencia con
particiones proporcionales al número de casos en cada categoría que se busca
representar.
Para efectuar las particiones en la circunferencia se establece la proporcionalidad
tomando en cuenta que los 360º de la circunferencia equivale al total de
observaciones realizadas o el 100% y se efectúa las equivalencias a cada categoría
en grados sexagesimales según el número de observaciones o porcentaje que le
corresponde mediante una regla de tres simple.
Tomemos como referencia la distribución de la variable hobby de los alumnos de
estadística básica 09-A, obtenida en el Cuadro 2.4 siguiente:
Nº DE
% DE
GRADOS
ALUMNOS
ALUMNOS
SEXAGESIMALES
Deportes
15
25.0
90
Música
27
45.0
162
Baile
4
6.7
24
TV/Cine
12
20.0
72
Otros
2
3.3
12
Total
60
100.0
360
HOBBY
Si a los 60 alumnos les corresponde una circunferencia de 360º, la
proporcionalidad que se guarda aquí es de 6º por cada alumno y de este modo a los
15 alumnos que les gusta el deporte les corresponde 15 x 6 = 90º, a los 27 que les
89
gusta la música 27 x 6 = 162º, a los 4 alumnos que les gusta el baile 4 x 6 = 24º, a
los 12 que les gusta TV/Cine 12 x 6 = 72º y a los 2 que les gusta Otros 2 x 6 = 12º.
Con estos datos es que los programas efectúan de modo automático la
representación del pie correspondiente. Veamos.
En Excel:
Seguir la secuencia siguiente: Insertar → Gráficos → Circular → Gráfico 2D,
escoger en Diseños de gráfico (diseño 1) → Seleccionar datos → Rango de datos
del gráfico: indicar las celdas donde se encuentran los datos → en Etiquetas del
eje horizontal (categoría) escoger Editar, en Rango de rótulos de eje: indicar las
celdas donde están los hobbies, Aceptar y para finalizar Aceptar y aparece título
del Gráfico, ponerle el número y el título, tal como se muestra a continuación:
Figura 2.21 Gráfico de sectores en Excel
En SPSS:
Siguiendo el procedimiento para obtener el cuadro 2.4 (Analizar → Estadísticos
descriptivos → Frecuencias) aparece la ventana de la Figura 2.11. Con la
variable hobby ya ingresada, escoger dentro de la opción
Tipo de
gráfico: Gráficos de sectores, en Valores del gráfico: marcar Porcentajes, luego
Continuar, para finalizar Aceptar y en la Ventana de resultados aparece el
gráfico de sectores, con doble clic se ha editado (Ver Figura 2.22).
90
Gráfico 2.1 % DE ALUMNOS DE ESTADÍSTICA BÁSICA 09-A, SEGÚN HOBBY
Deportes
Musica
Baile
TV / Cine
Otros
3,3
%
20,0%
25,0%
6,7%
45,0%
Figura 2.22 Gráfico de Sectores en SPSS
En Minitab:
En el menú escoger Graph → Pie Chart… Aparece la ventana de diálogo Pie
Chart, en Categorial variables: ingresar hoby de la lista de variables a la izquierda,
en Labels… poner número y título del gráfico, OK, y aparece el gráfico de
sectores que se muestra en la Figura 2.23.
Gráfico 2.1 % DE ALUMNOS DE ESTADÍSTICA BÁSICA 09-A, SEGÚN HOBBY
6.7%
20.0%
25.0%
3.3%
45.0%
Figura 2.23 Gráfico de Sectores en Minitab
91
Category
Baile
Deportes
Música
Otros
TV/Cine
En R:
Estando attachada la base de datos obtenemos lo mismo, así:
> attach(caso2)
> pie(table(hoby))
Aparece el gráfico siguiente:
Figura 2.24 Gráfico de Sectores en R
Como se puede apreciar, con sus propios matices, cada uno de los gráficos de
sectores es parecido, por lo que para los otros tipos de gráficos se explicará como
obtenerlos y presentaremos alguno de ellos.
b) Gráfico de barras.- es una representación rectangular en el plano cartesiano,
indicando en el eje de las abscisas (X) la variable con sus categorías y en el eje de
las ordenadas (Y) el número y/o el porcentaje de unidades de análisis que se
presenta.
Veamos la presentación de la variable hobby en gráfico de barras, tomando como
referencia los resultados del Cuadro 2.4.
92
En Excel:
Seguir la secuencia siguiente: Insertar → Gráficos → Columna → Columna en
2D, Columna agrupada, escoger (Estilo 2) → Seleccionar datos → en Rango de
datos del gráfico: indicar las celdas donde se encuentran los datos → en Etiquetas
del eje horizontal (categoría) escoger Editar, en Rango de rótulos de eje: indicar las
celdas donde están los hobbies, Aceptar y para finalizar Aceptar y aparece el
gráfico sin título; no olvidar ponerle el número y el título.
En Minitab:
En el menú escoger Graph → Bar Chart… → escoger Simple. Aparece la
ventana de diálogo Bar Chart – Counts of unique values, Simple. En Categorial
variables: ingresar hoby de la lista de variables a la izquierda, en Labels… poner
número y título del gráfico, OK, y aparece el gráfico de sectores que se muestra en
la Figura 2.25. Este gráfico ha sido editado poniendo la variable con mayúsculas,
colores, etc.
En SPSS:
Siguiendo el procedimiento para obtener el cuadro 2.4 (Analizar → Estadísticos
descriptivos → Frecuencias) aparece la ventana de la Figura 2.7. Con la variable
hobby ya ingresada, escoger dentro de la opción
Tipo de gráfico:
Gráficos de barras, en Valores del gráfico: marcar Porcentajes, luego
Continuar, para finalizar Aceptar y en la Ventana de resultados aparece el gráfico
de sectores, que se puede editar con doble clic.
En R:
Estando attachada la base de datos, se usa la función barplot así:
> attach(caso2)
> barplot(table(hoby), col=c(3,4,5,6,7), main="GRÁFICO 2.2 ALUMNOS E.B.09-A, SEGÚN HOBBY", xlab="HOBBY", ylab="Alumnos")
A continuación se muestra el gráfico de barra obtenido en Minitab, donde la
presentación parece ser “más representativa”.
93
Gráfico 2.2 ALUMNOS DE ESTADÍSTICA BÁSICA 09-A, SEGÚN HOBBY
30
27
25
Alumnos
20
15
15
12
10
5
4
2
0
Baile
Deportes
Música
HOBBY
Otros
TV/Cine
Figura 2.25 Gráfico de Barras de la variable Hobby en Minitab
c) Gráfico de Pareto.- es un gráfico muy utilizado cuando se quiere mostrar las
categorías más representativas de una variable cualitativa en forma de frecuencia
descendente, a fin de tomar algunas decisiones, como sucede en los controles de
calidad en los que por ejemplo se busca controlar los defectos más importantes (en
un 90 o 95%). Su elaboración se puede obtener con herramientas para el análisis
en Excel y de control de calidad que poseen el Minitab y el SPSS.
En Excel:
Procede sólo si los valores de la variable son numéricos, por lo que utilizaremos
las etiquetas numéricas para hobby (1, 2, 3, 4 y 5). Consideremos que los datos
para los 60 alumnos están en la columna A, entre A2 y A61; y las clases de hobby
(1, 2, 3, 4 y 5) en la columna D, entre D3 y D7, ver Figura 2.26.
Para obtener el gráfico de Pareto, se necesita herramientas para el Análisis
(versiones anteriores de Excel en el menú tenían la opción Herramientas), proceder
así: en la barra de menú Datos → Análisis de datos (ubicado en el extremo
superior derecho) y aparece la ventana de diálogo Análisis de datos de la Figura
2.27.
94
Figura 2.26 Datos de la variable hobby y clase en Excel
Figura 2.27 Herramientas del Análisis de datos en Excel
En la Figura 2.27, de Funciones para análisis escoger Histograma, luego Aceptar
y aparece la ventana de diálogo Histograma de la Figura 2.28.
Figura 2.28 Obteniendo gráfico de Pareto en Excel
95
En la parte de Entrada, de la Figura 2.28, en Rango de entrada: sombrear el área
de los datos de hobby de la Figura 2.26 (desde A3 hasta A62); en Rango de
clases: sombrear el área de CLASE de la Figura 2.26 (desde D3 hasta D7) y se
marca Rótulos si se utilizaran para los dos rangos anteriores.
En Opciones de salida, de la Figura 2.28, indicar donde queremos que salga el
resultado, si es en la misma hoja, marcar Rango de salida: y en el recuadro indicar
la celda a partir de donde queremos que salgan los resultados (H2 aquí); si es En
una hoja nueva: marcar y en el recuadro ponerle nombre; y por último si queremos
En un libro nuevo, marcarlo. Luego marcar Pareto (Histograma ordenado),
marcar Porcentaje acumulado y Crear gráfico. Para finalizar hacer clic en
Aceptar y aparecen los resultados de la Figura 2.29.
Figura 2.29 Gráfico de Pareto de la variable hobby en Excel
96
En Minitab:
En el menú escoger Stat → Quality Tools → Pareto Charts…. Aparece la
ventana de diálogo Pareto Chart . En Chart defects data in: ingresar hoby de la
lista de variables a la izquierda y para finalizar OK y muestra el gráfico.
En SPSS:
En el menú escoger Analizar → Control de calidad → Gráficos de Pareto →
escoger Simple, luego Definir. Aparece la ventana de diálogo Gráfico de Pareto
simple: Recuentos o sumas para grupos de casos.
En eje de categorías: ingresar la variable hobby que aparece en la lista de variables
a la izquierda, en Títulos… indicar el número y título del gráfico, luego
Continuar y finalmente Aceptar, aparece el gráfico de Pareto.
En la Figura 2.30, se muestra el gráfico de Pareto obtenido en Minitab y editado
en sus ejes y colores para las barras de las categorías de hobby.
Gráfico 2.3 Gráfico de Pareto de los alumnos de Estadística Básica 09-A, según Hobby
60
100
50
Alumnos
40
60
30
40
20
20
10
0
Hobby
Count
Percent
Cum %
Música
27
45.0
45.0
Deportes
15
25.0
70.0
TV/Cine
12
20.0
90.0
Baile
4
6.7
96.7
Other
2
3.3
100.0
Figura 2.30 Gráfico de Pareto de la variable Hobby en Minitab
97
0
Porcentaje
80
2.6 GRÁFICOS DE FRECUENCIAS
Entre los principales gráficos de variables cuantitativas tenemos los gráficos de barras,
histograma de frecuencias, polígono de frecuencia y la ojiva.
a) Gráfico de barras para Datos Cuantitativos Discretos.- se usa si la variable
discreta toma valores en un rango pequeño como el número de hijos. Es una
representación rectangular en el plano cartesiano, indicando en el eje de las
abscisas (X) la variable con sus pocos valores y en el eje de las ordenadas (Y) el
número y/o el porcentaje de unidades de análisis que se presenta. La gráfica de
barras se obtiene de manera similar al de la variable cualitativa. Veamos
como queda la presentación de la variable número de miembros en la familia en
gráfico de barras, tomando como referencia los resultados del Cuadro 2.5.
MIEMBROS EN
LA FAMILIA
2
3
4
5
6
7
8
9
Total
Alumnos
2
5
11
27
8
5
1
1
60
% de
Alumnos
3.3
8.3
18.3
45.0
13.3
8.3
1.7
1.7
100.0
Porcentaje
acumulado
3.3
11.7
30.0
75.0
88.3
96.7
98.3
100.0
Figura 2.31 Gráfico de barras de los Miembros de la familia en Excel
98
Gráfico 2.4 % DE ALUMNOS DE ESTADÍSTICA BÁSICA 09-A, SEGÚN
MIEMBROS EN LA FAMILIA
30
Alumnos
20
45,0%
10
18,3%
13,3%
8,3%
8,3%
3,3%
0
2
3
4
5
6
7
1,7%
1,7%
8
9
MIEMBROS EN LA FAMILIA
Figura 2.32 Gráfico de barras de los Miembros de la familia en SPSS
En términos estrictos, la variable número de miembros toma valores enteros y por
lo tanto su gráfico no debería ser una barra sino más bien una línea (“gráfico de
líneas”), el mismo que se puede obtener con el Minitab de la siguiente manera:
En el menú escoger Graph → Bar Chart… → escoger Simple. Aparece la
ventana de diálogo Bar Chart – Counts of unique values, Simple. En Categorial
variables: seleccionar mie.fam de la lista de variables a la izquierda.
A continuación escoja Chart Options… y marcar Show Y as Percent, OK. En
Labels… poner número y título del gráfico; luego seleccionar Data Labels y
marcar la opción Use y-value labels, OK. En Data View… deshabilitar Bars y
marcar Project lines, OK. Para finalizar hacer clic en OK y aparece el gráfico de
de la Figura 2.33 ya editado en el tipo de letra, tamaño de letra, disminución del
número de decimales, color de las líneas, etc.
99
Gráfico 2.4 % de Alumnos de Estadística Básica 09-A, según el Número de miembros en su familia
50
45.0
Percent
40
30
20
18.3
13.3
10
8.3
8.3
3.3
0
2
3
4
5
6
7
1.7
1.7
8
9
Miembros en la familia
Percent within all data.
Figura 2.33 Gráfico de barras de los Miembros de la familia en Minitab
b) Histograma de Frecuencias para Datos Cuantitativos en intervalos.- se usa si
la variable cuantitativa discreta o continua se presenta en intervalos. El Histograma
de Frecuencias es un conjunto de rectángulos (barras) en el plano cartesiano,
indicando en el eje de las abscisas (X) la variable con sus intervalos y en el eje de
las ordenadas (Y) las frecuencias absolutas, relativas o la densidad. La base de los
rectángulos es la amplitud del intervalo (pueden ser de igual o diferente amplitud)
y la altura la frecuencia (absoluta o relativa) o la densidad que alcanza en cada
intervalo.
Para intervalos de igual amplitud, veamos la presentación de la variable peso de
los alumnos de Estadística Básica mediante histograma de frecuencias, tomando
como referencia los resultados del Cuadro 2.7 siguientes:
Clase
1
2
3
4
5
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Xi
48.4
57.2
66.0
74.8
83.6
100
ni
19
15
17
5
4
60
hi
0.317
0.250
0.283
0.083
0.067
1.000
En Excel:
El proceso es similar a la construcción del gráfico de Pareto antes visto, es decir,
que se requiere de herramientas para el análisis de datos.
Escoger en la barra de menú Datos → Análisis de datos (ubicado en el extremo
superior derecho) y aparece la ventana de diálogo Análisis de datos. De Funciones
para análisis escoger Histograma, luego Aceptar y aparece la ventana de diálogo
Histograma de la Figura 2.34.
Figura 2.34 Obteniendo el Histograma de peso en Excel
En la parte de Entrada, de la Figura 2.34, en Rango de entrada: sombrear el área
de los datos de peso de la Figura 2.12 (desde A3 hasta A62); en Rango de clases:
sombrear el área de LSi de la Figura 2.12 (desde E12 hasta E16) y se marca
Rótulos si se utilizaran para los dos rangos anteriores.
En Opciones de salida, de la Figura 2.34, indicar donde queremos que salga el
resultado, si es en la misma hoja, marcar Rango de salida: y en el recuadro indicar
la celda a partir de donde queremos que salgan los resultados (N2 aquí); si es En
una hoja nueva: marcar y en el recuadro ponerle nombre; y por último si queremos
En un libro nuevo, marcarlo. Luego marcar Crear gráfico. Para finalizar hacer
clic en Aceptar y aparecen los resultados del histograma.
101
En Excel se obtiene los resultados para los límites superiores de clase indicados y
los rectángulos del histograma separados, por lo que se tiene que editar haciendo
clic sobre los rectángulos y con botón derecho seleccionar Formato de serie de
datos y en la ventana de diálogo del mismo nombre escoger Opciones de series y
en Ancho del intervalo poner 0%. Al hacer clic en el botón Cerrar, los
rectángulos del histograma aparecen juntos. Se pone número y título del gráfico,
así como colores, etc. y se tiene los resultados del la Figura 2.35.
Figura 2.35 Histograma de frecuencia del peso en Excel
En Minitab:
Estando en la base de datos Estadística Básica 09-A.MPJ, seguir la secuencia
Graph → Histogram… → Simple → OK y aparece la ventana de diálogo
Histogram – Simple de la Figura2.36. En Graph variables: ingrese la variable peso
seleccionándola de las variables del lado izquierdo.
102
Figura 2.36 Obteniendo el Histograma de peso en Minitab
Haciendo clic en el botón Scale… luego en Y-Scale Type aparece marcado
automáticamente Frecuency, también se puede escoger Percent o Density
(densidad para intervalos de diferente amplitud) dejemos Frecuency, OK.
Hacer clic en el botón Labels… en Title: poner el número y título del gráfico, en
Data Labels escoger Use y-value labels, OK. Para finalizar OK y aparece un
histograma que debe ser editado para obtener los intervalos de clase deseados. Para
ello hacer doble clic sobre el histograma y aparece la ventana de diálogo Edit
Bars de la Figura 2.37donde ya se ha escogido Binning.
En la ventana de Binning, en Interval Type aparece automáticamente marcado
Midpoint, escoger Cutpoint.
Luego en Interval Definition escoger Midpoint/Cutpoint positions: en el
recuadro en blanco escribir el valor mínimo (44), dos puntos, el valor máximo
(88), diagonal, y el valor de la amplitud de clase C (8.8). Es decir, 44:88/8.8.
También se puede escribir los 6 puntos de corte (cutpoint) de los 5 intervalos
separados por un espacio en blanco: 44 52.8 61.6 70.4 79.2 88 y para finalizar
OK, e inmediatamente aparece el histograma de frecuencia de la Figura 2.38.
103
Figura 2.37 Edición (en Binning) del Histograma de peso en Minitab
GRÁFICO 2.6 HISTOGRAMA DEL PESO DE LOS ALUMNOS DE ESTADÍSTICA BÁSICA 09-A
20
19
17
15
Frequency
15
10
5
5
0
4
44.0
52.8
61.6
70.4
79.2
Peso (Kg.)
Figura 2.38 Histograma de frecuencias del peso en Minitab
104
88.0
En SPSS:
Seguir el procedimiento para obtener el cuadro 2.4 (Analizar → Estadísticos
descriptivos → Frecuencias) aparece la ventana de la Figura 2.11. Con la
variable peso ya ingresada, escoger dentro de la opción
Tipo de
gráfico: Histogramas, luego Continuar, para finalizar Aceptar y en la Ventana
de resultados aparece el histograma, que se puede editar haciendo doble clic sobre
el histograma dos veces y aparece la ventana de Propiedades. En intervalos,
dentro de Eje X marcar Personalizado, escoger Número de intervalos (e
indicarlos) o Ancho de intervalo (e indicarlo 8.8), Aplicar y luego Cerrar. Poner
número y título del gráfico, colores, etc. Y se tiene el histograma de la Figura 2.39.
Gráfico 2.6 HISTOGRAMA DEL PESO DE LOS ALUMNOS DE ESTADÍSTICA
BÁSICA 09-A
20
Alumnos
15
10
19
17
15
5
5
4
Media =59,87
Desviación típica =10,53
N =60
0
40
50
60
70
80
90
100
PESO (Kg)
Figura 2.39 Histograma de frecuencias del peso en SPSS
En R:
Estando attachada la base de datos, para que reconozca la variable peso, se escribe
la sintaxis sencilla siguiente:
105
hist(variable,
breaks=seq(mínimo,
máximo,
by=amplitud,
col=”color”,
labels=TRUE, main=”título del gráfico”, xlab=”título eje X”, ylab=”título eje Y”)
Donde: variable (datos para obtener el histograma), mínimo = valor mínimo de los
datos, máximo = valor máximo, amplitud = ancho de los intervalos, color =
colores (blanco = 0, 8, “White”; negro= 1, 9, “black”; rojo = 2, 10, “red”; verde =
3, 11, “green”; azul = 4, 12, “blue”; magenta = 5, 13; violeta =6, 14, “violet”;
amarillo = 7, 15, “yellow”; anaranjado = orange; purpura = purple; rosado =pink;
fucsia=”magenta”; gris=”gray”; etc.)
Para la variable peso en la base de datos caso2, el histograma se obtiene así:
> attach(caso2)
> hist(peso, breaks=seq(44,88,by=8.8), col="13", labels=TRUE, main="Gráfico
2.6 Histograma del Peso de los Alumnos", xlab="Peso(Kg.)", ylab="Alumnos")
Figura 2.40 Histograma de frecuencias del peso en R
106
Histograma de densidad.- se presenta, por lo general, para tablas con intervalos
de clase de diferente amplitud, situación que ocurre para algunas variables
económicas. En las columnas de frecuencias se agrega una de densidad (di) que se
obtiene dividiendo las frecuencias relativas entre la amplitud de clase. Es decir,
di = hi / Ci .
Las barras del histograma de densidad tienen por base la amplitud del intervalo y
por altura la densidad alcanzada. El área debajo del histograma de densidad es
k
igual a1. Area
k
di Ci
i 1
i 1
hi
Ci
Ci
k
hi
1.00
i 1
Si para la variable peso trabajada, se juntan los dos últimos intervalos y se hace los
conteos correspondientes, el Cuadro 2.7 se transforma en:
Clase
1
2
3
4
LIi
44.0
52.8
61.6
70.4
LSi
52.8
61.6
70.4
88.0
Xi
48.4
57.2
66.0
79.2
ni
hi
di
19
0.317 0.0360
15
0.250 0.0284
17
0.283 0.0322
9
0150 0.0085
60
1.000
El último intervalo, tiene el doble de amplitud que los otros tres y por lo tanto
mayor número de repeticiones (5 +4 = 9). Para contrarrestar el efecto del mayor
ancho del intervalo es que se representa la densidad en vez de la frecuencia.
El Minitab es el programa apropiado para obtener el histograma de densidad.
Vamos a efectuar el mismo procedimiento de la construcción del histograma de
frecuencias. Es decir, Graph → Histogram… → Simple → OK y aparece la
ventana de diálogo Histogram – Simple de la Figura2.36. En Graph variables:
ingresar la variable peso seleccionándola de las variables del lado izquierdo.
Haciendo clic en el botón Scale… luego en Y-Scale Type aparece marcado
automáticamente Frecuency, desactivarla y marcar Density, OK.
Hacer clic en el botón Labels… en Title: poner el número y título del gráfico, en
Data Labels escoger Use y-value labels, OK. Para finalizar OK y aparece un
histograma de densidad que debe ser editado para obtener los intervalos de clase
deseados. Para ello hacer doble clic sobre el histograma y aparece la ventana de
diálogo Edit Bars de la Figura 2.41 donde ya se ha escogido Binning.
107
Figura 2.41 Edición del Histograma de densidad de peso en Minitab
En la ventana de Binning, en Interval Type aparece marcado Midpoint, escoger
Cutpoint. Luego en Interval Definition escoger Midpoint/Cutpoint positions: en
el recuadro en blanco escribir los 5 puntos de corte (cutpoint) de los 4 intervalos
separados por un espacio en blanco: 44 52.8 61.6 70.4 88 y para finalizar OK, e
inmediatamente aparece el histograma de densidad de la Figura 2.42.
GRÁFICO 2.7 HISTOGRAMA DE DENSIDAD DEL PESO DE LOS ALUMNOS E.B. 09-A
0.04
0.0360
0.0322
Density
0.03
0.0284
0.02
0.01
0.00
0.0085
44.0
52.8
61.6
70.4
PESO (Kg.)
88.0
Figura 2.42 Histograma de densidad de peso en Minitab
108
c) Polígono de frecuencias.- es un gráfico de líneas que une los puntos medios
superiores de las barras del histograma, es decir, une los pares ordenados marcas
de clase y frecuencias absolutas o relativas, (Xi, ni) o (Xi, hi) con el fin de tener una
visión global de la distribución de frecuencias cuando son suavizadas.
Para efectuar la representación del polígono de frecuencias y la ojiva de la variable
peso, las trabajaremos en el Minitab, siendo necesario para ello definir en el
workshet (hoja de trabajo) los datos del Cuadro 2.7, en columnas nuevas: límite
superior (Lím.Sup.), Marca de clase, frecuencia relativa (Frec. relat.) y frecuencia
relativa acumulada (Frec. relat. acum.) en las que, para poder cerrar las gráficas, se
han agregado la primera y última clase con los valores que le corresponderían, tal
como se muestra en la Figura 2.43.
Figura 2.43 Datos para el Polígono de frecuencias y Ojiva del peso en Minitab
El procedimiento para construir el Polígono de frecuencias es el siguiente: Graph
→ Scatterplot → With Connect Line → OK, y aparece la ventana de diálogo de
la Figura 2.44.
De la lista de variables del lado izquierdo seleccionar Frec. relat. e ingresarla en Y
variables y Marca de clase en X variables, como se muestra en la Figura 2.44.
Hacer clic en Data View… y en Data display marcar Connect line, OK. Luego
escoger Labels en Tittle: poner el número y título del gráfico, y en Data Labels
marcar Use y-value labels, OK.
Para finalizar hacer clic en OK y aparece el polígono de frecuencias de la Figura
2.45.
109
Figura 2.44 Scatterplot para el Polígono de frecuencias del peso en Minitab
Gráfico 2.8 POLÍGONO DE FRECUENCIA DEL PESO DE LOS ALUMNOS E.B. 09-A
0.35
0.322
0.30
0.288
0.254
Frec. relat.
0.25
0.20
0.15
0.10
0.085
0.051
0.05
0.00
0.000
40
0.000
50
60
70
Marca de clase
80
Figura 2.45 Polígono de frecuencias del peso en Minitab
110
90
100
d) Ojiva.- sirve para representar las frecuencias (absolutas o relativas) acumuladas
“menor o igual que” para una variable determinada. Su representación se hace con
un gráfico de líneas, no decreciente, que une los pares ordenados formados por los
límites superiores de los intervalos de clase y las frecuencias (absolutas o relativas)
acumuladas, (LSi, Ni) o (LSi, Hi).
Para efectuar la representación de la ojiva de la variable peso, la trabajaremos en el
Minitab con los datos de la Figura 2.43.
El procedimiento para construir la Ojiva es el siguiente: Graph → Scatterplot →
With Connect Line → OK, y aparece la ventana de diálogo de la Figura 2.46.
Figura 2.46 Scatterplot para la Ojiva del peso en Minitab
De la lista de variables del lado izquierdo seleccionar Frec. relat. acum. e
ingresarla en Y variables y Lim. Sup. en X variables, tal como se muestra en la
Figura 2.46.
Hacer clic en Data View… y en Data display marcar Connect line, OK. Luego
escoger Labels en Tittle: poner el número y título del gráfico, y en Data Labels
marcar Use y-value labels, OK.
Para finalizar hacer clic en OK y aparece la Ojiva de la Figura 2.47.
111
Gráfico 2.9 OJIVA DEL PESO DE LOS ALUMNOS DE ESTADÍSTICA BÁSICA 09-A
1.000
1.0
1.000
0.949
0.864
Frec. relat. Acum.
0.8
0.576
0.6
0.4
0.322
0.2
0.000
0.0
40
50
60
70
80
Lím. Sup. PESO (Kg.)
90
Figura 2.47 Ojiva del peso en Minitab
2.7 DIAGRAMA DE TALLOS Y HOJAS
Es un gráfico sencillo de realizar y fue propuesto por Tukey (1977) para ver la
distribución de frecuencias preliminar de una variable cuantitativa con pocas
observaciones. Para su elaboración se toma en cuenta el número de dígitos que poseen
los valores de la variable. El tallo viene dado por los dígitos de mayor orden,
acompañado por las hojas que es la parte complementaria del número representado.
Veamos su obtención para la variable peso.
En Minitab.Seguir la secuencia: Graph → Stem-and-Leaf… (Tallos y Hojas) y aparece la ventana
de diálogo Stem-and-Leaf. En Graph variables: ingresar la variable peso de las
variables del lado izquierdo. En Increment: escribir 5 (para que salgan los tallos con
incrementos de 5 en 5 a partir del valor mínimo). Al hacer clic en OK, aparecen los
siguientes resultados.
112
100
Stem-and-Leaf Display: peso
Stem-and-leaf of peso
Leaf Unit = 1.0
1
9
24
(8)
28
21
11
7
4
1
4
4
5
5
6
6
7
7
8
8
N
= 60
4
56678899
000001122233334
55555779
0033444
5566778889
0022
557
000
8
En la primera columna aparecen las frecuencias absolutas acumuladas, crecientes
desde la primera línea hasta antes del número entre paréntesis (8) que indica que son 8
observaciones y que en esa línea se ubica el valor central (mediana). Después aparecen
valores decrecientes, ya que la acumulación empieza desde la última línea.
En la columna central se presentan los tallos, representando los pesos en decenas (de
kg.) y en la última columna las hojas con un dígito por cada observación (sus unidades
se dan al comienzo del gráfico como Leaf Unit) aquí = 1.0 Kg. En la primera línea
aparece el peso mínimo (44) y en la última línea el peso máximo (88) Kg.
En SPSS.Estando en la base de datos de Estadística Básica 09-A, escoger del menú Analizar →
Estadísticos descriptivos → Explorar y aparece la ventana de diálogo Explorar. En
Dependientes: ingresar la variable peso de las variables del lado izquierdo. Hacer clic en
el botón Gráficos y aparece la ventana de diálogo Explorar: Gráficos, en Descriptivos
aparece activado automáticamente Tallo y hojas. Hacer clic en Continuar, regresa a
Explorar y para finalizar clic en Aceptar. En la ventana de Resultados aparece:
PESO (Kg) Stem-and-Leaf Plot
Frequency
1.00
8.00
15.00
Stem &
4 .
4 .
5 .
Leaf
4
56678899
000001122233334
113
8.00
7.00
10.00
4.00
3.00
3.00
1.00
Stem width:
Each leaf:
5
6
6
7
7
8
8
.
.
.
.
.
.
.
55555779
0033444
5566778889
0022
557
000
8
10
1 case(s)
El ancho del tallo (Stem width) 10 indica que está en decenas de Kg.
En R.Estando attachada la base de datos de los alumnos de Estadística Básica 09-A
representada por caso2, se usa la función stem(variable). Se procede así:
> attach(caso2)
> stem(peso)
Aparece el diagrama de tallos y hojas siguiente:
The decimal point is 1 digit(s) to the right of the |
4|4
4 | 56778899
5 | 000011122333334
5 | 55555779
6 | 003344
6 | 55566778889
7 | 0022
7 | 557
8 | 000
8|8
Sólo muestra los tallos en la primera columna (en decenas de Kg.) y las hojas (en
Kg.).
114
Capítulo 3. MEDIDAS DE POSICIÓN
“La estadística es una ciencia que demuestra que si mi vecino tiene dos
coches y yo ninguno, los dos tenemos uno”
George Bernard Shaw
CONTENIDO
3.1
3.2
3.3
3.4
3.5
3.6
3.7
Introducción.
Media aritmética.
Mediana.
Moda.
Media Geométrica.
Media armónica.
Los cuantiles: cuartiles, deciles y percentiles.
3.1 INTRODUCCIÓN
En este capítulo se da inicio a otras modalidades de descripción de los datos a
través de los denominados estadígrafos que son medidas de resumen del
conjunto de datos obtenidos a partir de una muestra o un censo (enumeración
completa de las unidades de análisis de la población).
Si el estadígrafo es obtenido en la muestra se denomina estimador (estadístico) y
es usado en inferencia estadística como estimación (aproximación) al parámetro
desconocido en la población.
Los estadígrafos puedes ser de: posición, dispersión, forma y concentración. Para
una mejor comprensión de estos estadígrafos presentaremos su definición, cálculo
para datos sin agrupar y para datos agrupados (tabla de frecuencias), así como su
interpretación.
En este capítulo veremos las medidas de posición, llamadas también estadígrafos
de tendencia central, porque al obtenerlos reflejan un valor entre el mínimo y
máximo. Entre estos tenemos: la media aritmética, la mediana, la moda, la media
geométrica, la media armónica y los cuantiles.
Las aplicaciones con los programas se ven al final del capítulo.
115
3.2 MEDIA ARITMÉTICA
Llamada también media o promedio simple, es el centro de gravedad o centroide
de la distribución de frecuencias. Es decir, es el punto en donde están en equilibrio
todas las fuerzas.
En física, centroide es el centro de masa de un objeto con densidad uniforme. Para
un objeto unidimensional uniforme de longitud L, el centroide es el punto medio
del segmento de línea. Entonces, para cada barra (rectángulo) del histograma es su
marca de clase y para todo el histograma de frecuencias es la media aritmética
ponderada por las frecuencias absolutas o relativas o las ponderaciones
consideradas.
Fórmulas de cálculo para datos sin agrupar.N
Xi
i 1
a) Media o promedio poblacional:
N
n
Xi
b) Media o promedio muestral:
X
i 1
n
Fórmulas de cálculo para datos agrupados.k
X i ni
k
i 1
a) Media o promedio poblacional:
N
k
X i hi
i 1
k
X i ni
b) Media o promedio muestral:
X
i 1
k
X i ni
k
i 1
ni
n
X i hi
i 1
i 1
Donde:
k = número de intervalos de clase.
Xi = Marca de clase
ni = frecuencias absolutas o repeticiones.
hi = frecuencia relativa.
N = tamaño de la población.
n = tamaño de la muestra.
Ejemplo 3.1
Si trabajamos con los datos sin agrupar del Cuadro 2.6, peso en Kg. de los 60
alumnos de Estadística Básica 09-A, tenemos que la media aritmética es:
116
N
60
Xi
i 1
Xi
i 1
N
60
44 45 46 .... 80 88
60
3592.1
59.868 Kg.
60
Interpretación.- el peso promedio de los alumnos de Estadística Básica 09-A es
59.868 Kg. También podemos apreciar que el numerador representa el total
poblacional, es decir que la suma de los pesos de los 60 alumnos en la
población es de 3592.1 Kg.
Si trabajamos con los datos agrupados del Cuadro 2.7, peso en Kg. de los 60
alumnos de Estadística Básica 09-A, tenemos que la media aritmética es:
k
5
X i ni
i 1
N
=
X i ni
i 1
X 1n1
X 2 n2
60
X 3n3
60
X 4 n4
48.4(19) 57.2(15) 66.0(17) 74.8(5) 83.6(4)
60
X 5 n5
3608.0
60
60.133 Kg.
Interpretación.- el peso promedio de los alumnos de Estadística Básica 09-A es
60.133 Kg. También podemos apreciar que el numerador sigue representando
el total poblacional, es decir que la suma de los pesos de los 60 alumnos en la
población es de 3608.0 Kg., resultado diferente al anterior (normalmente
difieren ya que se está agrupando datos).
Resultado similar se obtiene usando la fórmula con frecuencias relativas (hi),
así:
5
X i hi
i 1
(48.4)
19
15
17
5
4
(57.2)
(66.0)
(74.8)
(83.6)
60
60
60
60
60
60.133
Figura 3.1 Cálculo de la media para datos agrupados en Excel
117
En la Figura 3.1 se muestra en Excel como se ha efectuado el cálculo de la
media aritmética para datos agrupados.
Primero hay que ingresar las marcas de clase (Xi), las frecuencias absolutas (ni)
y las frecuencias relativas (hi) en las columnas C, D, y E respectivamente. La
forma más sencilla de efectuar el cálculo es la que aparece en la casilla F10
utilizando la función matemática suma de
productos que se indica así:
e inmediatamente aparece el peso
promedio igual a 60.133 Kg. En la celda F9 se muestra el cálculo de la suma de
5
productos de
X i ni = 3608.0 Kg. y en la G9 la suma de productos de
i 1
5
X i hi = 60.133 Kg., que es la media solicitada.
i 1
Media Ponderada.n
X iWi
X
i 1
n
Wi
i 1
Donde Xi = valor de la i-ésima observación y Wi = ponderación o peso de la iésima observación.
El cálculo del ejemplo 3.1 es una forma de media ponderada, donde los Xi son las
marcas de clase y las ponderaciones vienen dadas por las frecuencias absolutas
(ni) o las frecuencias relativas (hi). Dicho cálculo también lo podemos resolver
usando el programa R así:
Primero se definen los vectores de Xi, ni y/o hi de la siguiente manera:
> Xi=c(48.4, 57.2, 66.0, 74.8, 83.6)
> ni=c(19, 15, 17, 5, 4)
> hi=ni/60
Luego usar la función weighted.mean, así:
> weighted.mean(X,ni)
[1] 60.13333
> weighted.mean(X,hi)
[1] 60.13333
Con resultados similares a los del acápite anterior.
118
Para el caso de un índice de precios Xi es un relativo de precios (Pti / P0i) y para un
índice de cantidad Xi es un relativo de cantidad (Qti / Q0i).
Para el índice de precios de Laspeyres Wi = P0i Q0i , luego este índice es el
siguiente promedio ponderado:
n
Pti
( P0i Q0i )
P0i
i 1
IPL t
n
n
Pti Q0i
i 1
n
P0i Q0i
0
P0i Q0i
i 1
i 1
Para el índice de precios de Paasche Wi = P0i Qti , luego este índice es el
siguiente promedio ponderado:
n
Pti
( P0i Qti )
P0i
i 1
IPPt
n
n
Pti Qti
i 1
n
P0i Qti
0
P0i Qti
i 1
i 1
Propiedades de la media aritmética.a) “La suma de las desviaciones de los valores observados con respecto a su
n
media aritmética es cero”.
n
(Xi
X)
i 1
Xi
nX
nX
nX
0
i 1
b) “La suma de las desviaciones al cuadrado, de los valores observados con
respecto a su media aritmética, es mínima”.
n
X ) 2 es mínima.
(Xi
i 1
c)
El cálculo de la media aritmética se ve afectado por los valores extremos
(outliers) muy grandes o muy pequeños.
Ejemplo 3.2.- si los ingresos de 5 trabajadores son: 450, 500, 500, 550 y
2000. Entonces el ingreso promedio es de 800 muy distante del ingreso de la
mayoría de los trabajadores. Se recomienda usar la mediana.
d)
Si a y b son números reales e Yi
aX i b, entonces : Y
Demostración:
n
n
Yi
Y
i 1
n
n
(aX i b)
i 1
n
n
a
Xi
b
i 1
i 1
n
n
119
aX
b
aX
b.
Ejemplo 3.3.- si el ingreso promedio de los trabajadores es X = S/. 1 000.
Hallar los ingresos promedio si se producen los siguientes incrementos:
S/. 100 para cada trabajador, entonces el nuevo ingreso de cada
trabajador es: Yi = Xi + 100 .
Luego el nuevo ingreso promedio de los trabajadores es:
Y = X + 100 = S/. 1 100.
10% para cada trabajador, entonces el nuevo ingreso de cada trabajador
es Yi = 1.10 Xi .
Luego el nuevo ingreso promedio de los trabajadores es:
Y = 1.10 X = 1.10 (1 000) = S/. 1 100.
5% más S/. 50 a cada trabajador, entonces el nuevo ingreso de cada
trabajador es Yi = 1.05 Xi + 50 .
Luego el nuevo ingreso promedio de los trabajadores es:
Y = 1.05 X + 50 = 1.05 (1 000) + 50 = S/. 1 100.
3.3 MEDIANA (Me)
Es el valor central que divide en dos partes iguales la distribución de frecuencias
(conjunto de observaciones).
50% observaciones
Me
120
50% observaciones
Cálculo para datos sin agrupar.a) Ordenar los datos en forma ascendente: X(1) , X(2) , …. , X(n)
b) Calcular la mediana:
Si el número de observaciones n es par: Me
1
X
2
Si el número de observaciones n es impar: Me
X
n
2
X
n
1
2
n 1
2
Ejemplo 3.4
Si se calcula la mediana con los datos sin agrupar del Cuadro 2.6, peso en Kg. de
los 60 alumnos de Estadística Básica 09-A, se tiene que:
a) Los 60 datos ordenados en forma ascendente son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
b) Dado que n = 60 es par, se necesitan las observaciones ordenadas 30 y 31
para calcular la mediana, así:
Me
1
X
2
30
X
31
1
57 57
2
57 Kg.
Interpretación.- el 50 % de los alumnos de Estadística Básica 09A tienen un
peso menor o igual a 57 Kg y el otro 50% por encima de 57 Kg.
Cálculo para datos agrupados.a) Ubicar la clase j que contiene el valor Me
Como en las tablas de frecuencias los valores de la variable están ordenados
en forma ascendente, se determina n/2 y ayudándonos de las frecuencias
acumuladas se ve que clase j contiene (o donde esta) la Me.
b) Calcular la Me usando cualquiera de las siguientes expresiones:
121
Me
n
Nj
2
nj
LI j
1
Cj
LI j
1
Hj
2
hj
1
Cj
Donde:
j = clase que contiene o donde esta la Me.
LIj = límite inferior de la clase que contiene la Me.
nj = repeticiones en la clase que contiene la Me.
Nj-1 = repeticiones acumuladas hasta la clase anterior a la que contiene Me.
Cj = amplitud de la clase Me = LSj – LIj .
hj = frecuencia relativa en la clase que contiene la Me.
Hj-1 = frec. relativa acumulada hasta la clase anterior a la que contiene Me.
Ejemplo 3.5
Calcular la mediana con los datos agrupados del Cuadro 2.7, peso de los 60
alumnos de Estadística Básica 09-A FCE-UNAC, siguientes:
Clase
PESOS (Kg.)
i
1
2
3
4
5
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos
alumnos
alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución.a) Ubicar la clase j que contiene el valor Me.
n
2
60
2
30 . ¿En que intervalo de clase se contó la observación o peso del
alumno 30?
Observando los Ni del Cuadro 2.7, se aprecia que en la clase 1, N1 = 19, se
han contado los pesos de los 19 primeros alumnos (recordemos que los pesos
están ordenados de manera ascendente en el cuadro).
Entonces, en el intervalo de clase 2 se cuentan los pesos de los alumnos 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 y 34.
Luego, la clase en la que se cuenta la talla del alumno
clase j = 2. La mediana es un peso entre 52.8 y 61.6 Kg.
122
n
2
60
2
30 es la
b) Calcular la Me usando la expresión:
Me
LI j
n
Nj
2
nj
1
Cj
Donde:
j = 2,
n = 60,
LIj = LI2 = 52.8
nj = n2 = 15,
C3 = LS3 – LI3 = 61.6 – 52.8 = 8.8
Nj-1 = N1 = 19,
Reemplazando valores en la fórmula se tiene:
Me
LI 2
n
N1
2
C2
n2
60
19
2
8.8 59.253 Kg.
15
52.8
Interpretación.- el 50 % de los alumnos de Estadística Básica 09A tienen un
peso menor o igual a 59.253 Kg y el otro 50% por encima de 59.253 Kg.
Propiedades de la mediana.a) La suma de las desviaciones, en valor absoluto, de los valores observados
con respecto a la mediana es mínima; es decir, que es menor que la suma de
las desviaciones, en valor absoluto, con respecto a cualquier otro valor a de
la distribución.
n
n
Xi
Me
i 1
k
a
,
para datos sin agrupar.
k
Xi
i 1
Xi
i 1
Me ni
Xi
a ni ,
para datos agrupados.
i 1
b) Robustez: la mediana no se ve afectada por los valores extremos, sólo por
los valores centrales. Es decir, que la mediana es un valor más representativo
de la tendencia central de un conjunto de datos, que la media aritmética,
cuando estos son asimétricos (los valores extremos reflejan desigualdades).
Ejemplo 3.6.- para los ingresos de 5 trabajadores (450, 500, 500, 550 y
2000) del ejemplo 3.2, el promedio es de 800 muy distante del ingreso de la
mayoría de los trabajadores. Se recomienda usar la mediana, que en este caso
es 500, mucho más representativa que la media aritmética 800.
123
c) Si a y b son números reales e Yi
a X i b, entonces : Me(Y ) a Me( X ) b .
Propiedad similar a la de la media aritmética.
3.4 MODA
Es el valor observado más común, el que más se repite o el más frecuente. Para una
distribución de frecuencias o probabilidades, la moda es el valor que hace máxima
dicha distribución.
X
Cálculo para datos sin agrupar.Observar en el conjunto de datos el valor o los valores que más se repiten.
Ejemplo 3.7
Si se calcula la moda con los datos sin agrupar del Cuadro 2.6, peso en Kg. de los
60 alumnos de Estadística Básica 09-A, se tiene que los pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
124
Se aprecia que el peso 55 es el que más se repite, luego: Mo = 55 Kg.
Interpretación.- el mayor número (no la mayoría) de alumnos tiene un peso de 55
Kg.
Cálculo para datos agrupados.a) Ubicar la clase j que contiene el valor Mo.
Si los intervalos de clase son de igual amplitud, la clase j que contiene (o
donde esta) la Mo es aquella que tiene la mayor repetición ni o la mayor
frecuencia relativa hi. Puede haber más de una clase modal.
Si los intervalos de clase son de diferente amplitud, la clase j que contiene (o
donde esta) la Mo es aquella que tiene la mayor densidad di = hi / Ci . Puede
haber más de una clase modal.
b) Calcular la moda usando la expresión:
Mo
1
LI j
1
Cj
2
Donde:
j = clase(s) que contiene(n) o donde esta(n) la(s) Mo.
LIj = límite inferior de la clase que contiene la Mo.
Cj = amplitud de la clase Mo = LSj – LIj .
1
nj
nj
1
hj
hj
1
dj
dj
1
2
nj
nj
1
hj
hj
1
dj
dj
1
Ejemplo 3.8
Calcular la moda con los datos agrupados del Cuadro 2.7, peso de los 60 alumnos de
Estadística Básica 09-A FCE-UNAC, siguientes:
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos
alumnos
alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución.a) Ubicar la clase j que contiene el valor Mo.
125
Considerando que los intervalos son de igual amplitud, ¿en que intervalo de clase
se puede haber dado el mayor número de repeticiones ni o h i?
Observando los ni del Cuadro 2.7, se aprecia que el mayor es n1 = 19. Entonces,
en el intervalo de clase j = 1 se encuentra la moda. La moda es un peso entre 44 y
52.8 Kg.
b) Calcular la moda usando la expresión: Mo
1
LI j
1
Cj
2
Donde:
j = 1,
LIj = LI1 = 44.
C1 = LS1 – LI1 = 52.8 – 44 = 8.8.
1
nj
nj
1
n1 n0
19 0 19
2
nj
nj
1
n1 n2
19 15 4
Reemplazando valores en la fórmula se tiene:
Mo
1
LI1
1
C1
2
44
19
8.8 51.270 Kg.
19 4
Interpretación.- el mayor número (no la mayoría) de alumnos tiene un peso de
51.27 Kg.
Propiedades de la moda.a) Es el único estadígrafo que se puede determinar para variables cualitativas.
b) La moda no se ve afectada por los valores extremos, al igual que la mediana.
c) Si a y b son números reales e Yi
a X i b, entonces : Mo(Y ) a Mo( X ) b .
Propiedad similar a la de la media aritmética y la mediana.
d) Para una distribución determinada puede haber más de una moda o en su defecto
de no existir moda, puede haber antimoda (valor menos frecuente).
Relación entre la moda, la media y la mediana. Si la distribución de frecuencias es simétrica se cumple que las tres medidas son
aproximadamente iguales. Entonces: X
126
Me
Mo
Distribución simétrica
30
Nº de U. de A.
25
20
15
10
5
0
140
145
150
155
160
165
170
175
180
Valores de la variable
Si X
Me
Mo entonces la distribución de frecuencias tiene asimetría negativa
o asimetría hacia la izquierda.
Distribución asimétrica negativa
30
Nº de U.A.
25
20
15
10
5
0
140
Si Mo
Me
145
150 155 160 165 170
Valores de la variable
175
180
X entonces la distribución de frecuencias tiene asimetría positiva
o asimetría hacia la derecha.
Distribución asimética positiva
30
Nº de U.A.
25
20
15
10
5
0
140
145
150
155
160
165 170
Valores de la variable
175
180
Si la distribución de frecuencias es moderadamente asimétrica y unimodal,
según Karl Pearson se cumple la siguiente relación: X
127
Mo
3X
Me
Para los pesos de los alumnos de Estadística Básica 09-A de la FCE-UNAC se
pueden resumir los estadígrafos calculados así:
Datos:
Me
Mo
Sin agrupar
X
59.868
57.000
55.000
Agrupados
60.133
59.253
51.270
Se puede apreciar que en ambos casos Mo
Me
X entonces la distribución de los
pesos tiene asimetría positiva.
Cálculo de la media aritmética, la mediana y la moda con los programas
Veamos como se puede obtener rápidamente los estadígrafos anteriores para la
variable peso, desde la base de datos construida y utilizando los programas.
En Excel:
Estando copiados los datos de la variable peso de los 60 alumnos en la columna D,
desde D3 hasta D62, cuando en el programa se pide el rango de valores (como
Número 1), se sombrean estos o se escribe D3:D62.
Para efectuar cualquier cálculo nos ubicamos en una celda posterior. Para calcular la
media aritmética nos ubicaremos en la celda D63.
A continuación, con la opción de funciones
del Excel, escoger dentro de
Seleccionar una categoría →Estadísticas → Promedio y aparece la ventana de
diálogo de la Figura 3.2 solicitando los Argumentos de la función PROMEDIO. En
Número 1 (indicar la ubicación de los datos de la variable peso, que están desde la
celda D3 hasta la D62) sombrear los datos o escribir D3:D62. Luego hacer clic en
y aparece el resultado de la media aritmética 59.8683333 Kg. De manera
similar se hace escogiendo las funciones Mediana y Moda.
Conociendo la sintaxis de la función, se hace mucho más sencillo así:
Ubicarse en la celda D63 y al lado de
escribir =PROMEDIO(D3:D62). Al hacer
Enter, aparece el resultado 59.8683333 Kg. (ver la Figura 3.3). De manera similar
para calcular la mediana, Ubicarse en la celda D64 y al lado de
escribir
=MEDIANA(D3:D62). Al hacer Enter, aparece el resultado 57 Kg. (ver la Figura
3.3); y para calcular la moda, Ubicarse en la celda D65 y al lado de
escribir
=MODA(D3:D62). Al hacer Enter, aparece el resultado 55 Kg. (ver la Figura 3.3).
128
Figura 3.2 Cálculo de la media aritmética (PROMEDIO) en Excel
Figura 3.3Resultados de la media aritmética, mediana y moda en Excel
En Minitab:
Estando en la base de datos Estadística Básica 09A, escoger del menú Stat →Basic
Statistics → Display Descriptive Statistics… aparece la ventana de diálogo de la
Figura 3.4. En variables: seleccionar la variable peso de las variables que están a la
izquierda. Hacer clic en el botón
y aparece la ventana de diálogo de la
Figura 3.5. Escoger los estadígrafos a calcular: Mean (media), Median (mediana),
Mode (moda) y hemos agregado Sum (suma), Minimum (mínimo) y Maximum
(máximo). Hacer clic en OK y regresa a la Figura 3.4.
129
Figura 3.4 Selección de la variable peso para calcular estadígrafos en Minitab
Figura 3.5 Selección de estadígrafos de posición a calcular en Minitab
Para terminar hacer clic en OK y en la ventana de Session aparecen los resultados
solicitados (se ha subrayado la media, la mediana y la moda) siguientes:
Descriptive Statistics: peso
N for
Variable
peso
Mean
59.87
Sum
Minimum
3592.10
44.00
130
Median
57.00
Maximum
Mode
88.00
55
Mode
5
En SPSS:
Estando en la base de datos Estadística Básica 09A, seguir la secuencia para obtener
la tabla de frecuencias: Analizar → Estadísticos descriptivos → Frecuencias.
Inmediatamente se abre la ventana de diálogo Frecuencias.
En Variables: ingresar la variable peso, luego hacer clic en el botón
y se
muestra la ventana de diálogo Frecuencias: Estadísticos de la Figura 3.6.
Figura 3.6 Cálculo de estadígrafos de Tendencia central en SPSS
En Tendencia central marcar los estadígrafos: media, mediana, moda y suma, luego
hacer clic en Continuar, regresando a la ventana de diálogo Frecuencias y efectuar
clic en Aceptar para terminar. Inmediatamente en el Visor de Resultados aparece:
Estadísticos
PESO (Kg)
N
Válidos
Perdidos
Media
Mediana
Moda
Suma
60
0
59.87
57.00
55
3592
Estadígrafos de tendencia central calculados con el SPSS
131
En R:
Estando en la base de datos Estadística Básica 09A y habiendo attachado la misma,
para que reconozca las variables y sus valores, se escribe en la consola la sintaxis
para el estadígrafo requerido: mean(variable) para la media, median(variable) para la
mediana, min(variable) para el valor mínimo y max(variable) para el valor máximo.
Aplicando a la variable peso se obtiene:
> mean(peso)
[1] 59.86833
> median(peso)
[1] 57
> min(peso)
[1] 44
> max(peso)
[1] 88
El R no permite el cálculo de la moda, aparece lo siguiente.
> mode(peso)
[1] "numeric"
132
3.5 MEDIA GEOMÉTRICA
Es la raíz n-ésima del producto de los valores observados.
Se utiliza para calcular promedios de datos con cierta tendencia geométrica, tasas
medias de crecimiento, etc.
Cálculo para datos sin agrupar.-
G
n
X1 X 2
Xn
X1 X 2
Xn
1
n
Considerando que el producto de los valores observados puede ser muy elevado, se
sigue el siguiente procedimiento para hallar G:
a) Determinar el logaritmo decimal de G:
log G
1
log X 1 log X 2
n
log X n
1
n
n
log X i
i 1
b) Hallar G, tomando el antilogaritmo de log G:
G 10log G
Ejemplo 3.9
Si se calcula la media geométrica con los datos sin agrupar del Cuadro 2.6, peso en
Kg. de los 60 alumnos de Estadística Básica 09-A, cuyos pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
a) Determinamos el logaritmo decimal de G:
log G
1
60
60
log X i
i 1
1
log 44 log 45
60
1
log X 1 log X 2
60
log X 60
log 88
1
1.6434526765 1.6532125138
60
133
1.9444826722
106.2486352942
1.7708105882
60
b) Hallamos G tomando el antilogaritmo de log G:
G 10log G
101.7708105882
58.994 Kg.
Interpretación.- el peso medio de los alumnos es de 58.994 Kg.
Cálculo para datos agrupados.-
G
n
n1
1
X X
n2
2
X
nk
k
n1
1
X X
n2
2
X
nk
k
1
n
Considerando que el producto de las potencias de las marcas de clase elevadas a las
repeticiones observados puede ser muy grande, se sigue el siguiente procedimiento
para hallar G:
a) Determinar el logaritmo decimal de G:
1
n1 log X 1 n2 log X 2
n
log G
nk log X k
1
n
k
k
ni log X i
i 1
hi log X i
i 1
b) Hallar G, tomando el antilogaritmo de log G:
G 10log G
Ejemplo 3.10
Calcular la media geométrica con los datos agrupados del Cuadro 2.7, peso de los
60 alumnos de Estadística Básica 09-A FCE-UNAC, siguientes:
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos alumnos alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución.a) Determinamos el logaritmo decimal de G:
log G
1
60
5
ni log X i
i 1
1
n1 log X 1 n2 log X 2 n3 log X 3 n4 log X 4 n5 log X 5
60
1
19 log 48.4 15 log 57.2 17 log 66.0 5 log 74.8 4 log 83.6
60
134
32.01206187 26.36094043 30.93224690 9.36950799 7.68882511
60
106.36358231
1.772726.37
60
b) Hallamos G tomando el antilogaritmo de log G:
G 10log G
101.77272637
59.255 Kg.
Interpretación.- el peso medio de los alumnos es de 59.255 Kg.
Aplicación de la media geométrica.Una de las aplicaciones importantes de la media geométrica es la referida a la
determinación de tasas medias de crecimiento de la población (r), para lo cual se
cuenta con información de los censos de población en dos períodos de tiempo no
consecutivos (la ONU recomienda la realización de censos de población cada 10
años debiendo realizarse los mismos el 30 de junio de los años terminados en cero).
Asimismo, se hacen proyecciones de población (similar al crecimiento del capital)
con la expresión:
Pn
1 r
n
P0
Es a partir de esta expresión que se obtiene la fórmula para hallar la tasa media de
crecimiento intercensal (r) de la población siguiente:
r
n
Pn
P0
1
Po = Población en el año 0.
Pn = Población en el año n.
n = Períodos (años, meses, etc.) transcurridos desde el período 0 hasta el período n.
Ejemplo 3.11
Según el INEI (2009) la población total del Perú el año 1993 fue de 22‟639,443
habitantes y el 2007 de 28‟220,764 habitantes. Se pide determinar:
a) La tasa media de crecimiento intercensal anual.r
n
Pn
P0
1
14
P07
P93
1
14
28' 220, 764
1 = 1.015864843 -1 = 0.015864843
22 '639, 443
135
Si se hubiera solicitado la tasa media de crecimiento intercensal mensual, se
tendría que haber obtenido la raíz 168 (meses transcurridos del ‟93 al ‟07).
Interpretación.- entre el año 1993 y el 2007 la población del Perú creció a un
1.59% anual. Es decir, que por cada 100 habitantes nacieron 1.59 niñ@s
(también se puede interpretar en tanto por mil o diez mil, etc.).
b) La población del Perú el año 2010.Para proyectar la población se usa la expresión: Pn
1 r
n
P0
Donde:
Po = P2007 = Población en el año 0 = 2007 (Tomar el año más cercano).
Pn = P2010 = Población en el año n = 2010.
r = Tasa media de crecimiento intercensal anual = 0.015864843.
n = Años transcurridos desde el año 2007 hasta el año 2010 = 3 años.
Asumiendo que la tasa media de crecimiento intercensal anual es la misma para
los años siguientes y reemplazando valores en la fórmula de proyección de
población se tiene:
Pn
P2010
1 r
n
P0
P2010
3
1 0.015864843 P2007
3
1 0.015864843 28220764 1.048353602(28220764) =
= 29‟585,340 habitantes.
El año 2010 el Perú tiene 29.6 millones de habitantes.
c)
¿En que año el Perú tendrá 40 millones de habitantes?
Despejando n de la fórmula Pn
1 r
n
P0 se tiene que:
log
n
Pn
P0
log 1 r
n = año buscado.
Pn = 40 millones (Población que tendrá el Perú el año n).
P0 = P2007 = 28‟220,764 habitantes (Tomar como año 0, el más cercano).
r = Tasa media de crecimiento intercensal anual = 0.015864843.
Reemplazando valores en la expresión anterior se tiene:
136
40000000
28220764
log 1 0.015864843
log
n
22.2 años
Entonces: 2007 + 22.2 años = 2029. El año 2029 el Perú tendrá 40 millones de
habitantes (si la tasa de crecimiento de la población es del 1.59%).
Nota.- También se utiliza la media geométrica para determinar la inflación media
mensual y a su vez hacer proyecciones de la inflación anual a partir del promedio
mensual.
3.6 MEDIA ARMÓNICA
Se define como la inversa de la media aritmética de los inversos de los valores
observados.
Es utilizada para hallar determinadas tasas promedio o rendimientos promedio para
una misma actividad.
Cálculo para datos sin agrupar.H
n
n
i 1
1
Xi
Ejemplo 3.12
Si se calcula la media armónica con los datos sin agrupar del Cuadro 2.6, peso en
Kg. de los 60 alumnos de Estadística Básica 09-A, cuyos pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
Reemplazando valores en la fórmula se tiene:
137
H
60
1
1 Xi
60
60
i
1
44
1
X1
1
X2
60
1
46
1
45
1
X3
1
X 59
1
80
1
X 60
60
1.0316135533
1
88
58.161 Kg.
Interpretación.- el peso promedio de los alumnos es de 58.161 Kg.
Cálculo para datos agrupados.H
k
i
n
ni
1 Xi
1
k
i 1
hi
Xi
Fórmula para trabajar bien con las repeticiones o frecuencias absolutas ni o para
trabajar con las frecuencias relativas hi. Por tratarse de datos agrupados Xi
representa la marca de clase para los intervalos o el valor indicado para los casos
discretos con poca variabilidad de los valores observados.
Ejemplo 3.13
Calcular la media armónica con los datos agrupados del Cuadro 2.7, peso de los 60
alumnos de Estadística Básica 09-A FCE-UNAC, siguientes:
Clase
PESOS (Kg.)
i
1
2
3
4
5
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos alumnos alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución.Desarrollando la fórmula se tiene:
H
k
i
n
ni
1 Xi
60
ni
1 Xi
5
i
n1
X1
n2
X2
60
n3
X3
n4
X4
138
n5
X5
=
=
19
48.4
15
57.2
60
17
66.0
60
58.419 Kg.
1.0270673130
5
4
74.8 83.6
Interpretación.- el peso promedio de los alumnos es de 58.419 Kg.
RELACIÓN ENTRE LAS MEDIAS ARITMÉTICA, GEOMÉTRICA Y
ARMÓNICA
Si se calcula estas tres medias para los mismos datos se tiene que:
H
G
X
Para los pesos de los alumnos se han obtenido los siguientes resultados:
Datos:
H
G
Sin agrupar
58.161
58.994
X
59.868
Agrupados
58.419
59.255
60.133
Vemos que se cumple la relación.
139
3.7 CUANTILES
Son particiones de la distribución de frecuencias en un determinado número de
partes iguales.
Entre los cuantiles más conocidos se tiene: mediana (dos partes iguales), cuartiles
(cuatro partes iguales), quintiles (cinco partes iguales), deciles (diez partes iguales),
veintiles (veinte partes iguales) y percentiles (cien partes iguales).
Desarrollaremos los de mayor uso viendo su forma de cálculo e interpretación. Se
calculan de modo similar a la mediana.
a) CUARTILES (Qk )
Son particiones de la distribución de frecuencias en cuatro partes iguales de
modo que cada una de ellas acumula un cuarto de las observaciones (25% de los
datos).
X
25% datos
Q1 25% datos
Q2
25% datos
Q3
25% datos
Para dividir la distribución de frecuencias en cuatro partes iguales necesitamos 3
puntos, por ello los cuartiles son tres y se denotan de la siguiente manera:
Cuartil 1 = Q1 acumula la cuarta parte de las observaciones (25%).
Cuartil 2 = Q2 acumula las dos cuartas partes de las observaciones (50%).
Cuartil 3 = Q3 acumula las tres cuartas partes de las observaciones (75%).
140
El cuartil dos es igual a la mediana (acumula el 50% de los valores observados).
Es decir, Q2 = Me ya estudiada.
Cálculo para datos sin agrupar.a) Ordenar las observaciones en forma ascendente: X(1) , X(2) , …. , X(n)
b) Obtención de los cuartiles 1 y 3:
Cuartil 1 (Q1)
Ubicar su posición calculando
n 1
, si es entero Q1
4
X
n 1
4
.
Si no es entero, el resultado es de la forma E.F, donde E es la parte entera
y F la fracción decimal, entonces hacer una interpolación lineal entre las
observaciones ordenadas E y (E + 1) entre las cuales esta la fracción F.
Dicha interpolación lineal es similar para cualquier cuantil que vamos a
estudiar, se efectúa así: Cuantil X
Aquí el cuartil 1 es: Q1 X
E
F X
F X
E
E 1
X
X
E 1
E
E
Cuartil 3 (Q3)
Ubicar su posición calculando
3( n 1)
, si es entero Q3
4
X
3( n 1)
4
.
Si no es entero, el resultado es de la forma E.F, donde E es la parte entera
y F la fracción decimal, entonces hacer una interpolación lineal antes
indicada entre las observaciones ordenadas E y (E + 1) entre las cuales esta
la fracción F.
Entonces el cuartil 3 es: Q3 X
E
F X
E 1
X
E
Ejemplo 3.14
Calcular los cuartiles 1 y 3 con los datos sin agrupar del Cuadro 2.6, peso en Kg.
de los 60 alumnos de Estadística Básica 09-A, cuyos pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
141
Solución:
Cálculo del cuartil 1 (Q1)
Ubicar su posición con
n 1
4
60 1
15.25 . Como no es un valor entero, (E =
4
15 y F = 0.25), el cuartil 1 esta entre los pesos ordenados 15 y 16 (51 y 51 Kg.).
Aplicando la interpolación lineal recomendada, el cuartil 1 es:
Q1 X 15
0.25 X 16
X 15
= 51 + 0.25 [51 - 51] = 51 Kg.
Interpretación.- El 25 % de los alumnos de Estadística Básica 09-A tiene un peso
menor o igual a 51 Kg. y el 75% restante por encima de 51 Kg.
Cálculo del cuartil 3 (Q3)
Ubicar su posición con
3(n 1)
4
3(60 1)
4
45.75 . Como no es un valor
entero, (E = 45 y F = 0.75), el cuartil 3 esta entre los pesos ordenados 45 y 46
(67 y 68 kg.). Aplicando la interpolación lineal recomendada, el cuartil 3 es:
Q3
X
45
0.75 X
46
X
= 67 + 0.75 [68 - 67] = 67.75 Kg.
45
Interpretación.- El 75 % de los alumnos de Estadística Básica 09-A tiene un peso
menor o igual a 67.75 Kg. y el 25% restante por encima de 67.75 Kg.
Cálculo de los cuartiles con datos agrupados.-
a) Ubicar la clase j que contiene el cuartil k
Como en las tablas de frecuencias los valores de la variable están ordenados
en forma ascendente, se determina
kn
, k = 1, 2 ó 3. Ayudándonos de las
4
frecuencias acumuladas se ve que clase j contiene (o donde esta) el cuartil k
(Qk).
b) Calcular el cuartil k (Qk) usando cualquiera de las siguientes expresiones:
Qk
LI j
kn
4
Nj
nj
1
Cj
Donde:
142
LI j
k
Hj
4
hj
1
C j , k = 1, 2, 3.
j = clase que contiene o donde esta el cuartil k (Qk).
LIj = límite inferior de la clase que contiene el cuartil k (Qk).
nj = repeticiones en la clase que contiene el cuartil k (Qk).
Nj-1 = repeticiones acumuladas hasta la clase anterior a la que contiene Qk.
Cj = amplitud de la clase Qk = LSj – LIj .
hj = frecuencia relativa en la clase que contiene el cuartil k (Qk).
Hj-1 = frec. relativa acumulada hasta la clase anterior a la que contiene Qk.
Ejemplo 3.15
Calcule e interprete los cuartiles con los datos agrupados del Cuadro 2.7, peso de
los 60 alumnos de Estadística Básica 09-A FCE-UNAC, siguientes:
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos
alumnos
alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución. Cálculo del cuartil 1 (Q1)
k = 1.
a) Ubicar la clase j que contiene el valor del cuartil k = 1 (Q1):
kn
4
n
4
60
15 . ¿En que intervalo de clase se contó la observación o
4
peso del alumno 15?
Observando los Ni del Cuadro 2.7, vemos que en la clase 1, N1 = 19, se han
contado los pesos de los 19 primeros alumnos (recordemos que los pesos
están ordenadas de manera ascendente en el cuadro).
Luego, la clase en la que se contó la talla del alumno
kn
4
clase j = 1. El cuartil 1 es un peso entre 44.0 y 52.8 Kg.
b) Calcular el cuartil 1 (Q1) usando la expresión:
143
n
4
60
15 es la
4
Q1
LI j
n
Nj
4
nj
1
Cj
LI j
1
Hj
4
hj
1
Cj
Donde:
j = 1,
n = 60,
LIj = LI1 = 44.0,
nj = n1 = 19
C1 = LS1 – LI1 = 52.8 – 44.0 = 8.8.
Nj-1 = N0 = 0,
Reemplazando valores en la fórmula se tiene:
Q1
LI1
n
N0
4
C1
n1
44.0
60
0
4
8.8 46.947 Kg.
19
Interpretación.- El 25 % de los alumnos de Estadística Básica 09-A tiene un
peso menor o igual a 46.947 Kg. y el 75% restante por encima de46.947 Kg.
Cálculo del cuartil 2 (Q2) es la mediana ya fue determinado.
Cálculo del cuartil 3 (Q3)
k = 3.
a) Ubicar la clase j que contiene el valor del cuartil k = 3 (Q3):
kn
4
3n
4
3(60)
4
45 . ¿En que intervalo de clase se contó la observación o
peso del alumno 45?
Observando los Ni del Cuadro 2.7, vemos que hasta la clase 2, N2 = 34, se
han contado los pesos de los 34 primeros alumnos.
Entonces, en el intervalo de clase 3 se cuenta el peso del alumno 45.
Luego, la clase en la que se contó el peso del alumno
kn
4
3n
4
es la clase j = 3. El cuartil 3 es un peso entre 61.6 y 70.4 Kg.
b) Calcular el cuartil 3 (Q3) usando la expresión:
Q3
LI j
3n
Nj
4
nj
Donde:
144
1
Cj
LI j
3
Hj
4
hj
1
Cj
3(60)
4
45
j = 3,
n = 60,
LIj = LI3 = 616,
nj = n3 = 17.
C3 = LS3 – LI3 = 70.8 – 61.6 = 8.8.
Nj-1 = N2 = 34,
Reemplazando valores en la fórmula se tiene:
Q3
LI 3
3n
4
3(60)
34
4
8.8 66.259 Kg.
17
N2
n3
C3
61.6
Interpretación.- El 75 % de los alumnos de Estadística Básica 09-A tiene un
peso menor o igual a 66.259 Kg. y el 25% restante por encima de 66.259 Kg.
b) DECILES (Dk )
Son particiones de la distribución de frecuencias en diez partes iguales de modo
que cada una de ellas acumula un décimo de las observaciones (10% de los
datos).
10%
D1
10%
D2 ..…
10%
D9
10%
Para dividir la distribución de frecuencias en diez partes iguales se necesita 9
puntos, por ello los deciles son nueve y se denotan de la siguiente manera:
Decil 1 = D1 acumula la décima parte de las observaciones (10%).
Decil 2 = D2 acumula las dos décimas partes de las observaciones (20%).
Decil 3 = D3 acumula las tres décimas partes de las observaciones (30%).
Decil 4 = D4 acumula las cuatro décimas partes de las observaciones (40%).
Decil 5 = D5 acumula las cinco décimas partes de las observaciones (50%).
Decil 6 = D6 acumula las seis décimas partes de las observaciones (60%).
Decil 7 = D7 acumula las siete décimas partes de las observaciones (70%).
Decil 8 = D8 acumula las ocho décimas partes de las observaciones (80%).
Decil 9 = D9 acumula las nueve décimas partes de las observaciones (90%).
El decil cinco es igual a la mediana (acumula el 50% de los valores observados).
Es decir, D5 = Me.
El cálculo de los deciles y otros cuantiles se pueden efectuar mediante el cálculo
del percentil correspondiente, que pasamos a desarrollar.
145
c) PERCENTILES (Pk )
Son particiones de la distribución de frecuencias en cien partes iguales de modo
que cada una de ellas acumula un centésimo de las observaciones (1% de los
datos).
Para dividir la distribución de frecuencias en cien partes iguales necesitamos 99
puntos, por ello los percentiles son noventa y nueve y se denotan de la siguiente
manera:
Percentil 1 = P1 acumula una centésima parte de las observaciones (1%).
Percentil 2 = P2 acumula dos centésimas partes de las observaciones (2%).
Percentil 3 = P3 acumula tres centésimas partes de las observaciones (3%).
………….
Percentil k = Pk acumula las k centésimas partes de las observaciones (k%).
………….
Percentil 99 = P99 acumula las 99 centésimas partes de las observaciones (99%).
Nota.Todas los cuantiles calculados anteriormente son también percentiles (según el
% de observaciones que acumule cada uno de ellos).
Así tenemos que: la mediana (acumula el 50% de los valores observados) es
igual al percentil 50. Es decir, Me = P50.
También:
Q1 = P25,
Q2 = P50 = Me,
Q3 = P75.
D10 = P10,
D5 = P50 = Me,
D9 = P90.
Cálculo para datos sin agrupar.a) Ordenar las observaciones en forma ascendente: X(1) , X(2) , …. , X(n)
b) Obtención del k-ésimo percentil (Pk), k = 1, 2, 3, …., 99
Ubicar su posición calculando
k ( n 1)
, si es entero Pk
100
X
k ( n 1)
100
.
Si no es entero, el resultado es de la forma E.F, donde E es la parte entera y F
la fracción decimal, entonces hacer la interpolación lineal antes indicada entre
las observaciones ordenadas E y (E + 1) entre las cuales esta la fracción F.
Entonces el percentil k es:
Pk
X
E
F X
E 1
146
X
E
,
k = 1, 2, 3, …., 99
Ejemplo 3.16
Calcular los percentiles 10 y 80 con los datos sin agrupar del Cuadro 2.6, peso
en Kg. de los 60 alumnos de Estadística Básica 09-A, cuyos pesos ordenados
son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
Solución:
Cálculo del percentil 10 (P10)
10 (n 1)
100
Ubicar su posición con
10 (60 1)
100
6.1 . Como no es un valor
entero, (E = 6 y F = 0.10), el percentil 10 está entre los pesos ordenados 6 y 7
(48 y 48 Kg.). Aplicando la interpolación lineal recomendada, el percentil 10 es:
P10
X
6
0.10 X
X
7
= 48 + 0.10 [48 - 48] = 48 Kg.
6
Interpretación.- El 10 % de los alumnos de Estadística Básica 09-A tiene un peso
menor o igual a 48 Kg. y el 90% restante por encima de 48 Kg.
Cálculo del percentil 80 (P80)
Ubicar su posición con
80 (n 1)
100
80 (60 1)
100
48.80 . Como no es un valor
entero, (E = 48 y F = 0.80), el percentil 80 esta entre los pesos ordenados 48 y 49
(68 y 69 kg.). Aplicando interpolación lineal, el percentil 80 es:
P80
X
48
0.80 X
49
X
48
= 68 + 0.80 [69 - 68] = 68.80 Kg.
Interpretación.- El 80 % de los alumnos de Estadística Básica 09-A tiene un peso
menor o igual a 68.80 Kg. y el 20% restante por encima de 68.80 Kg.
Cálculo de los percentiles para datos agrupados.-
a) Ubicar la clase j que contiene el decil k
147
Como en las tablas de frecuencias los valores de la variable están ordenados
en forma ascendente, se determina
kn
, k = 1, 2, 3, …., 98 ó 99.
100
Ayudándonos de las frecuencias acumuladas se ve que clase j contiene (o
donde esta) el percentil k (Pk).
b) Calcular el percentil k (Pk) usando cualquiera de las siguientes expresiones:
Pk
LI j
kn
Nj
100
nj
1
Cj
LI j
k
Hj
100
hj
1
C j , k = 1, 2, 3, …., 98, 99.
Donde:
j = clase que contiene o donde esta el percentil k (Pk).
LIj = límite inferior de la clase que contiene el percentil k (Pk).
nj = repeticiones en la clase que contiene el percentil k (Pk).
Nj-1 = repeticiones acumuladas hasta la clase anterior a la que contiene Pk.
Cj = amplitud de la clase Pk = LSj – LIj .
hj = frecuencia relativa en la clase que contiene el percentil k (Pk).
Hj-1 = frec. relativa acumulada hasta la clase anterior a la que contiene Pk.
Ejemplo 3.17.Calcule e interprete los percentiles 10 y 80 con los datos agrupados del Cuadro
2.7, peso de los 60 alumnos de Estadística Básica 09-A FCE-UNAC, siguientes:
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos alumnos alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución. Cálculo del percentil 10 (P10)
k = 10.
a) Ubicar la clase j que contiene el valor del percentil k = 10 (P10):
148
kn
100
10n
100
10 (60)
100
6 . ¿En que intervalo de clase se contó la observación
o peso del alumno 6?
Observando los Ni del Cuadro 2.7, vemos que en la clase 1, N1 = 19, se han
contado los pesos de los 19 primeros alumnos. Luego, la clase en la que se
contó el peso del alumno
kn
100
10n
100
10 (60)
100
6 , es la clase j = 1. El
percentil 10 es una talla entre 44.0 y 52.8 Kg.
b) Calcular el percentil 10 (P10) usando la expresión:
P10
LI j
10n
100
Nj
10
Hj
100
hj
1
nj
Cj
LI j
1
Cj
Donde:
j = 1,
n = 60,
LIj = LI1 = 44.0,
nj = n1 = 19.
C1 = LS1 – LI1 = 52.8 – 44.0 = 8.8.
Nj-1 = N0 = 0,
Reemplazando valores en la fórmula se tiene:
P10
LI1
10n
N0
100
C2
n1
44.0
10(60)
0
100
8.8 46.779 Kg.
19
Interpretación.- El 10 % de los alumnos de Estadística Básica 09-A tiene un peso
menor o igual a 46.779 Kg. y el 90% restante por encima de 46.779 Kg.
Cálculo del percentil 80 (P80)
k = 80.
a) Ubicar la clase j que contiene el valor del percentil k = 80 (P80):
kn
100
80n
100
80 (60)
100
48 .
¿En que intervalo de clase se contó la
observación o peso del alumno 48?
Observando los Ni del Cuadro 2.7, vemos que hasta la clase 2, N2 = 34, se
han contado los pesos de los 34 primeros alumnos. Entonces, en el intevalo
de la clase 3 se cuenta los pesos de los alumnos desde el 35 hasta el 51.
Luego, la clase en la que se contó el peso del alumno 48, es la clase j = 3. El
percentil 80 es una talla entre 61.6 y 70.4 Kg.
b) Calcular el percentil 10 (P10) usando la expresión:
149
P80
Donde: j = 3,
Nj-1 = N2 = 34,
80n
100
LI j
Nj
1
Cj
nj
n = 60,
LI j
80
Hj
100
hj
LIj = LI1 = 61.6,
1
Cj
nj = n3 = 17.
C3 = LS3 – LI3 = 70.4 – 61.6 = 8.8.
Reemplazando valores en la fórmula se tiene:
P80
LI3
80n
N2
100
C3
n3
80(60)
34
100
8.8 68.447 Kg.
17
61.6
Interpretación.- El 80 % de los alumnos de Estadística Básica 09-A tiene un peso
menor o igual a 68.447 Kg. y el 20% restante por encima de 68.447 Kg.
CUADRO 3.1 RESUMEN DE LOS CUANTILES CALCULADOS PARA LOS
PESOS (KG.) DE LOS ALUMNOS DE ESTADÍSTICA BÁSICA 09A , DE LA
FCE-UNAC, POR LA FORMA EN QUE ESTÁN LOS DATOS
CUANTIL
DATOS SIN AGRUPAR
DATOS AGRUPADOS
Cuartil 1
51.00
46.947
Cuartil 2 (mediana)
57.00
59.253
Cuartil 3
67.75
66.259
Percentil 10
48.00
46.779
Percentil 80
68.80
68.447
Cálculo de cuartiles y percentiles con los programas
Veamos como se pueden obtener los cuartiles y percentiles para la variable peso,
desde la base de datos construida (datos sin agrupar) utilizando los programas.
En Excel:
Con los datos de la variable peso de los 60 alumnos en la columna D, desde D3 hasta
D62, cuando en el programa se pide Matriz se sombrean estos o se escribe D3:D62.
Para calcular los CUARTILES, por ejemplo el CUARTIL 1, primero ubicarse en la
celda D66.
150
Luego, con la opción de funciones
del Excel, escoger dentro de Seleccionar una
categoría →Estadísticas → Cuartil, aparece la ventana de diálogo de la Figura 3.7.
Figura 3.7 Cálculo de cuartiles en Excel
Indicar los Argumentos de la función CUARTIL, en Matriz (dar la ubicación de los
pesos, desde la celda D3 hasta la D62) sombrear los datos o escribir D3:D62.
En Cuartil escribir un número (0 = valor mínimo, 1, 2, o 3 para el cuartil deseado y
4 = valor máximo) aquí 1.
Luego hacer clic en
y aparece el resultado del Cuartil 1= 51 Kg.
Similarmente se obtiene los cuartiles 2 y 3 en las celdas 67 y 68.
Conociendo la sintaxis de la función, =CUARTIL(matriz, cuartil) se hace así:
Ubicarse en la celda D66 y al lado de
escribir =CUARTIL(D3:D62,1).
Al hacer Enter, aparece el resultado 51 Kg. (ver la Figura 3.8).
Para obtener los PERCENTILES también se puede seleccionar la función
PERCENTIL o utilizar la sintaxis =PERCENTIL(matriz, k).
En matriz indicar la ubicación de los datos y k es un número entre 0 y 1 para indicar
el percentil como una proporción.
Para obtener el percentil 10, con matriz (D3:D62) y k = 0.10, se obtiene así: ubicarse
en la celda D69 y escribir =PERCENTIL(D3:D6, 0.10) al hacer Enter, aparece el
resultado 48 Kg. (ver la Figura 3.8). En dicha figura, se muestra también la sintaxis
de cálculo y el resultado del percentil 80, en la celda D70.
151
Figura 3.8 Resultado de cuartiles y percentiles en Excel
En Minitab:
Estando en la base de datos Estadística Básica 09A, escoger del menú Stat →Basic
Statistics → Display Descriptive Statistics… aparece la ventana de diálogo Display
Descriptive Statistics (ver Figura 3.4).
En variables: seleccionar la variable peso de las variables que están a la izquierda.
Hacer clic en el botón
y aparece la ventana de diálogo Descriptive
Satatistcs – Statistics (Figura 3.5).
Escoger los CUARTILES a calcular: First quartile (primer cuartil), Median (segundo
cuartil o mediana), Third quartile (tercer cuartil) y hemos agregado Minimum
(mínimo) y Maximum (máximo).
Hacer clic en OK y regresa a la ventana Display Descriptive Statistics.
Para terminar hacer clic en OK y en la ventana de Session aparecen los resultados
solicitados siguientes:
Descriptive Statistics: peso
Variable
peso
Minimum
44.00
Q1
51.00
Median
57.00
Q3
67.75
Maximum
88.00
En SPSS:
Estando en la base de datos Estadística Básica 09A, seguir la secuencia para obtener
la tabla de frecuencias: Analizar → Estadísticos descriptivos → Frecuencias.
Inmediatamente se abre la ventana de diálogo Frecuencias.
152
En Variables: ingresar la variable peso, luego hacer clic en el botón
y se
muestra la ventana de diálogo Frecuencias: Estadísticos de la Figura 3.9.
Figura 3.9 Cálculo de cuartiles y percentiles en SPSS
En Valores percentiles, seleccionar Cuartiles y Percentiles, debiendo escribir el
número de percentil deseado (10 y 80) por separado y luego hacer clic en Añadir.
Luego hacer clic en Continuar, regresando a la ventana de diálogo Frecuencias y
efectuar clic en Aceptar para terminar. Inmediatamente en el Visor de Resultados
aparece:
Estadísticos
PESO (Kg)
N
Percentiles
Válidos
Perdidos
10
25
50
75
80
60
0
48.00
51.00
57.00
67.75
68.80
Resultado de cuartiles y percentiles en SPSS
En los resultados del SPSS se aprecia que los cuartiles aparecen como los percentiles
25 (primer cuartil), 50 (segundo cuartil o mediana) y 75 (cuartil 3).
153
En R:
Estando en la base de datos Estadística Básica 09A y habiendo attachado la misma,
para que reconozca las variables y sus valores, se escribe en la consola la sintaxis
para PERCENTILES: quantile(variable, p)
Donde variable es un conjunto de datos cuantitativos (peso aquí) y p es una
proporción para identificar a uno o varios percentiles determinados. Es decir, que
quantile es el valor por abajo del cual se encuentra el p% de las observaciones.
El percentil 10 (p =0.10) para la variable peso se obtiene así:
> quantile(peso,0.10)
10%
48
Si se requiere los percentiles 10 (0.10), 25 (0.25 = cuartil 1), 50 (0.50 = cuartil 2 o
mediana), 75(0.75 = cuartil 3) y 80 (0.80), entonces se define p como un vector con
las proporciones indicadas y luego la función cuantile, así:
> p=c(0.10, 0.25, 0.50, 0.75, 0.80)
> quantile(peso,p)
10%
25%
50%
75%
80%
48.00 51.00 57.00 67.25 68.20
CUADRO 3.2 RESUMEN DE LOS PERCENTILES CALCULADOS PARA
LOS PESOS (KG.) DE LOS ALUMNOS DE ESTADÍSTICA BÁSICA 09A,
DE LA FCE-UNAC, POR PROGRAMA USADO
PERCENTIL
MANUAL
EXCEL
MINITAB
SPSS
R
10
48.00
48.00
-
48.00
48.00
25 o cuartil 1
51.00
51.00
51.00
51.00
51.00
50 o cuartil 2
57.00
57.00
57.00
57.00
57.00
75 o cuartil 3
67.75
67.25
67.75
67.75
67.25
80
68.80
68.20
-
68.80
68.20
154
Capítulo 4. MEDIDAS DE DISPERSIÓN Y DE FORMA
“Vivimos en la era de la televisión. Una sola toma de una enfermera
bonita ayudando a un viejo a salir de una sala dice más que todas las
estadísticas sanitarias”
Margaret Thatcher
CONTENIDO
4.1
4.2
4.3
4.4
4.5
4.6
4.7
4.8
Introducción.
Rango. Rango intercuartílico.
Desviación media.
La varianza
La desviación típica.
El coeficiente de variación.
El diagrama de caja (Box- Plot).
Medidas de forma de la distribución.
4.1 INTRODUCCIÓN
En el capítulo anterior vimos la caracterización de los datos de una variable mediante
un solo punto, es decir, el resumen de los datos a través de un solo valor, el mismo que
no es suficiente para formarse una idea de la distribución de la variable.
En el presente capítulo se continúa haciendo resúmenes de la información cuantitativa
obtenida, describiendo el mayor o menor alejamiento de los valores observados en
formas absolutas y relativas.
Entre las formas absolutas de medición tenemos el rango, el rango intercuartílico, la
desviación media, la varianza y la desviación estándar; en tanto que como medición
relativa usaremos el coeficiente de variación.
También se presenta una forma gráfica de apreciar la dispersión de los datos, a través
del diagrama de caja y bigotes (box-plot) como herramienta importante para el análisis
exploratorio de datos.
155
4.2 RANGO Y RANGO INTERCUARTÍLICO
RANGO
El Rango (R), Recorrido o Amplitud de la variable es la diferencia entre el valor
máximo y mínimo.
Es el indicador usado para construir tablas de frecuencias.
Cálculo para datos sin agrupar:
R = Xmáx – Xmín = {X / Xmín ≤ X ≤ Xmáx}
Cálculo para datos agrupados:
R = LSk – LI1 = {X / LSk ≤ X ≤ LI1 }
Ejemplo 4.1
Si trabajamos con los datos sin agrupar del Cuadro 2.6, peso en Kg. de los 60
alumnos de Estadística Básica 09-A, tenemos que el rango es:
R = Xmáx – Xmín = {X / Xmáx ≤ X ≤ Xmín }
R= 88 – 44 = 44 Kg.
o
R = {X / 44 ≤ X ≤ 88}
Interpretación.- la diferencia entre el peso máximo y mínimo de los alumnos de
Estadística Básica 09-A es de 44 Kg. También podemos decir que los pesos de
los 60 alumnos fluctúan entre 44 y 88 Kg.
Si trabajamos con los datos agrupados del Cuadro 2.7, peso en Kg. de los 60
alumnos de Estadística Básica 09-A, tenemos que el rango es:
R = LS5 – LI1 = {X / LSk ≤ X ≤ LI1 }
= 88 – 44 = 44 Kg.
o
R = {X / 44 ≤ X ≤ 88}
Interpretación.- la diferencia entre el peso máximo y mínimo de los alumnos de
Estadística Básica 09-A es de 44 Kg. También podemos decir que los pesos de
los 60 alumnos fluctúan entre 44 y 88 Kg.
Tal como se puede apreciar el Rango es una medida muy gruesa de la dispersión
de los datos ya que nos da una idea de la diferencia o fluctuación de los valores
extremos.
156
RANGO INTERCUARTÍLICO
El rango intercuartílico (RIQ o RIC) es la diferencia entre el cuartil 3 y el cuartil 1
y nos indica entre que valores se encuentra el 50% central de las observaciones.
25% datos
Q1
25% datos
Q2
25% datos
Q3
25% datos
Tanto para datos sin agrupar, como para datos agrupados la fórmula de cálculo es:
RIQ = Q3 – Q1 = P75 – P25
Ejemplo 4.2
En el ejemplo 3.14 de cuartiles, con los datos sin agrupar del Cuadro 2.6, peso
en Kg. de los 60 alumnos de Estadística Básica 09-A, se ha determinado que el
cuartil 1 es Q1 = 51 Kg. y el cuartil 3 es Q3 = 67.75 Kg. Reemplazando valores
RIQ = 67.75 – 51.00 = 16.75 Kg.
en la fórmula del RIQ se tiene:
Interpretación.- el 50% central de los pesos se encuentra entre 51 y 67.75 Kg.
En el ejemplo 3.15, con los datos agrupados del Cuadro 2.7, peso en Kg. de los
60 alumnos de Estadística Básica 09-A, se ha determinado que el cuartil 1 es
Q1 = 46.95 Kg. y el cuartil 3 es Q3 = 66.26 Kg. Reemplazando valores en la
fórmula del RIQ se tiene:
RIQ = 66.26 – 46.95 = 19.31 Kg.
Interpretación.- el 50% central de los pesos se encuentra entre 46.95 y 66.26
Kg.
157
4.3 DESVIACIÓN MEDIA
Mide la desviación absoluta promedio de los valores observados bien con respecto a
la media aritmética o con respecto a la mediana.
Utiliza la idea de distancia como la diferencia en valor absoluto de cada valor
observado con respecto a su media aritmética o su mediana.
Cálculo para datos sin agrupar.-
n
n
Xi
X
X i Me
i 1
DM X
ó
n
DM X
i 1
n
Primero se calcula la media aritmética o mediana, luego la desviación media.
Ejemplo 4.3
Calcular la desviación media respecto a la media aritmética con los datos sin
agrupar del Cuadro 2.6, peso en Kg. de los 60 alumnos de Estadística Básica 09-A,
cuyos pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
Solución.En el ejemplo 3.1 se ha determinado que el peso promedio de los 60 alumnos de
Estadística Básica 09-A es X = 59.87 Kg. y en el ejemplo 3.4 la mediana Me = 57
Kg. Para calcular la desviación media respecto a la media aritmética, se tiene que:
n
60
Xi
DM X
X
i 1
X i 59.87
i 1
n
44 59.87
60
45 59.87
15.87 14.87 13.87
60
46 59.87
60
20.13 28.13
158
80 59.87
540.38
60
88 59.87
9.006 Kg.
Interpretación.- el promedio de las desviaciones absolutas de los pesos de los
alumnos respecto a su media aritmética es de 9.006 Kg.
Nota.- el cálculo y la interpretación de la desviación media respecto a la mediana se
efectúa de modo similar al de la media aritmética, sólo que se trabaja con Me = 57
Kg.
Cálculo para datos agrupados.k
k
Xi
DM X
X ni
Xi
k
i 1
Xi
n
X hi ó DM Me
i 1
Me ni
k
i 1
n
Xi
Me hi
i 1
Primero se calcula la media aritmética o mediana, luego la desviación media.
Ejemplo 4.4
Calcular la desviación media respecto a la mediana, con los datos agrupados del
Cuadro 2.7, peso de los 60 alumnos de Estadística Básica 09-A FCE-UNAC,
siguientes:
Clase
PESOS (Kg.)
i
1
2
3
4
5
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos
alumnos
alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución.En el ejemplo 3.1 se ha encontrado la media aritmética X = 60.13 kg. y en el
ejemplo 3.5 la mediana Me = 59.25 Kg.,
Usando la fórmula de datos agrupados para la desviación media se tiene que:
k
5
X i Me ni
DM Me
i 1
X i 59.25 ni
i 1
n
60
159
X 1 59.25 n1
X 2 59.25 n2
X 3 59.25 n3
X 4 59.25 n4
X 5 59.25 n5
60
1 48.4 59.25 19 57.2 59.25 15
60 74.8 59.25 5 83.6 59.25 4
66.0 59.25 17
= [206.15 + 30.75 + 114.75 + 77.75 + 97.4] / 60 = 526.8 / 60 = 8.78 Kg.
Interpretación.- el promedio de las desviaciones absolutas de los pesos de los
alumnos respecto a su media aritmética es de 8.78 Kg.
Nota.- el cálculo y la interpretación de la desviación media respecto a la media
aritmética se efectúa de modo similar al de la mediana, sólo que se trabaja con X =
60.13 kg.
4.4 VARIANZA
Mide el promedio de las desviaciones al cuadrado de los valores observados con
respecto a la media aritmética.
Se denota por:
o
2
X
V (X )
2
S X2
V (X )
S2
para la población.
para la muestra.
Cálculo para datos sin agrupar.-
N
N
)2
(Xi
2
X
a) Varianza poblacional:
i 1
N
2
N
n
X )2
(Xi
S X2
N
i 1
n
b) Varianza muestral:
X i2
i 1
X i2 n X 2
i 1
n 1
n 1
Cálculo para datos agrupados.k
k
(Xi
a) Varianza poblacional:
2
X
i 1
X i2 ni
i 1
N
160
) 2 ni
N
N
2
k
k
(Xi
S X2
b) Varianza muestral:
X )2 ni
i 1
X i2 ni n X 2
i 1
n 1
n 1
Primero se calcula la media aritmética para datos agrupados y luego la varianza.
Ejemplo 4.5
Calcular la varianza con los datos sin agrupar del Cuadro 2.6, peso en Kg. de los 60
alumnos de Estadística Básica 09-A, cuyos pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
Solución.En el ejemplo 3.1 se ha determinado que la media aritmética µ = 59.87 Kg.
Primera forma de cálculo:
N
60
)2
(Xi
2
( X i 59.87) 2
i 1
i 1
N
60
(44 59.87)2 (45 59.87)2 (46 59.87)2
60
251.8569 221.1169 192.3769
60
6542.47
60
(80 59.87)2 (88 59.87)2
405.2169 791.2969
109.0412 (Kg.)2.
Otra forma de cálculo es:
N
60
X i2
2
i 1
N
2
X i2 60
2
…………. (1)
i 1
N
60
161
60
X i2
442
452
462
802 882
i 1
= 1 936 + 2 025 + 2 116 + ….+ 6 400 + 7 744 = 221 595.5
Reemplazando este resultado en (1) se tiene:
60
X i2 60
2
2
221,595.5 60(59.87) 2
60
i 1
60
6,542.47
109.0412 Kg.2
60
Nota.- la mayor precisión en este cálculo se obtiene con µ = 59.8683333.
Interpretación.- el promedio de las desviaciones al cuadrado de los pesos de los
alumnos respecto a su media aritmética es de 109.0412 (Kg.)2.
Ejemplo 4.6
Calcular la varianza de los pesos de los 60 alumnos de Estadística Básica 09-A
FCE-UNAC, con los datos agrupados del Cuadro 2.7, siguientes:
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos
alumnos
alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
Solución.En el ejemplo 3.1 se ha encontrado que la media aritmética es µ = 60.133 kg.
Primera forma de cálculo:
k
5
) 2 ni
(Xi
2
i 1
( X i 60.133) 2 ni
i 1
N
60
2
2
2
1 ( X 1 60.133) n1 ( X 2 60.133) n2 ( X 3 60.133) n3
60 ( X 4 60.133)2 n4 ( X 5 60.133)2 n5
162
2
2
2
1 (48.4 60.133) 19 (57.2 60.133) 15 (66.0 60.133) 17
60 (74.8 60.133)2 5 (83.6 60.133)2 4
= (2615.7511 + 129.0667 + 585.1022 + 1075.5555 + 2202.7378) / 60
= (6608.2133) / 60 = 110.1369 (Kg.)2.
Otra forma de cálculo:
k
5
X i2 ni
2
N
2
i 1
X i2 ni 60
2
…………. (2)
i 1
N
60
5
X i2 ni
(48.4)219 (57.2)215 (66.0)217 (74.8)2 5 (83.6)2 4
i 1
= 223 569.28
Reemplazando este resultado en (2) se tiene:
5
X i2 ni 60
2
2
223569.28 60(60.1333333) 2
60
i 1
60
6608.2133
60
= 110.1369 (Kg.)2.
Interpretación.- el promedio de las desviaciones al cuadrado de los pesos de los
alumnos respecto a su media aritmética es de 110.1369 (Kg.)2.
Propiedades de la varianza.a) La varianza de un conjunto de datos es mayor o igual que cero, S X2 ≥ 0.
b) Si a y b son números reales e Yi
2
SaX
b
aX i b, entonces:
V (aX
b)
a 2V ( X )
Demostración:
n
(Yi Y )2
SY2
V (Y )
i 1
n 1
……….
163
(3)
a 2 S X2
Sabemos que si a y b son números reales e Yi
aX i b, entonces : Y
aX
b
Reemplazando este resultado en (3) se tiene:
n
n
b)]2
[aX i b (aX
SY2
V (Y )
i 1
a2 ( X i
i 1
n 1
2
SaX
Entonces:
Si b = 0, entonces:
2
SaX
S X2
n 1
b
V (aX
V (aX )
2
Si a = 0, entonces: S b
Si a =1, entonces:
X )2
b)
a 2V ( X )
a 2V ( X )
a 2V ( X ) a 2 S X2
a 2 S X2
a 2 S X2
V ( b) 0
b
V (X
b) V ( X )
S X2
Ejemplo 4.7.- si la varianza del ingreso de los trabajadores es S X2 = 250,000
(S/.)2. Hallar la varianza de los ingresos si se producen los siguientes
incrementos:
S/. 100 para cada trabajador, entonces el nuevo ingreso de cada
trabajador es: Yi = Xi + 100. Donde: a = 1 y b = 100.
Luego la varianza del nuevo ingreso de los trabajadores es:
SY2 = V(X + 100) = S X2 = 250,000 (S/.)2.
10% para cada trabajador, entonces el nuevo ingreso de cada trabajador
es Yi = 1.10 Xi. Donde: a = 1.10 y b = 0.
Luego la varianza del nuevo ingreso de los trabajadores es:
SY2 = V(1.10 X) = (1.10)2 S X2 = (1.10)2 250,000 = 302,500 (S/.)2.
5% más S/. 50 a cada trabajador, entonces el nuevo ingreso de cada
trabajador es Yi = 1.05 Xi + 50. Donde: a = 1.05 y b = 50.
Luego la varianza del nuevo ingreso de los trabajadores es:
SY2 = V(1.05 X + 50) = (1.05)2 S X2 = (1.05)2 250,000 = 275,625 (S/.)2.
c) Si se tiene k subgrupos (submuestras o estratos) de tamaños n1, n2, …., nk, tales
k
que
ni
n ; con medias aritméticas de los subgrupos: x1 , x2 ,
i 1
164
, xk y varianzas
de los subgrupos: S12 , S22 ,
, Sk2 , entonces la varianza de la muestra de tamaño n
esta dada por:
K
K
(ni 1) Si2
S2
i 1
( xi
x ) 2 ni
i 1
n 1
,
n 1
k
ni xi
i 1
donde x
es la media aritmética ponderada de los subgrupos.
n
Observación.- en el muestreo estratificado la variabilidad (varianza) total S2 se
descompone en la suma de la variabilidad dentro de los estratos (intravarianza
S w2 ) más la variabilidad entre los estratos (intervarianza Sb2 ). Es decir:
S2
Sw2
Sb2
K
(ni 1) Si2
La intravarianza esta definida por:
S w2
i 1
n 1
K
( xi
La intervarianza esta definida por:
Sb2
x )2 ni
i 1
n 1
Nota.- al construir estratos (clases, grupos o rangos) se busca que la
intravarianza ( S w2 ) sea pequeña y la intervarianza ( Sb2 ) sea grande.
Ejemplo 4.8.- en una muestra de 400 hombres y 600 mujeres, el estudio de
los ingresos de ambos grupos dio los siguientes resultados:
SEXO
Número
Ingreso Medio
Varianza
ni
xi (S/.)
Si2 (S/.)2
1.Hombres
400
1,500
360,000
2.Mujeres
600
1,000
250,000
Hallar la media aritmética y la varianza de los ingresos de ambos grupos
juntos; así como la intravarianza e intervarianza.
La media aritmética de los ingresos de ambos grupos es:
165
2
ni xi
i 1
x
n
n1 x1 n2 x2
n
400(1,500) 600(1, 000)
1, 000
1' 200, 000
=
1, 000
= S/. 1,200
La intravarianza de los ingresos es:
2
(ni 1) Si2
S w2
(n1 1) S12 (n2 1) S22
n 1
i 1
n 1
=
399(360, 000) 599(250, 000)
999
218'390, 000
999
= 218,608.60 (S/.)2.
La intervarianza de los ingresos es:
2
( xi
Sb2
x )2 ni
i 1
n 1
=
( x1 x )2 n1 ( x2
n 1
x ) 2 n2
(1,500 1, 200) 2 (400) (1, 000 1, 200) 2 (600)
999
60'000, 000
999
= 60,060.06 (S/.)2.
La varianza de los ingresos de ambos grupos es:
S2
Sw2
Sb2 = 218,608.60 + 60,060.06 = 278,668.66 (S/.)2.
4.5 DESVIACIÓN ESTÁNDAR O DESVIACIÓN TÍPICA
Mide el promedio de las desviaciones de los valores observados con respecto a la
media aritmética.
Se denota por:
X
o
SX
S
Tanto para datos sin agrupar como para datos agrupados se define como la raíz
cuadrada de la varianza (bien poblacional o muestral).
2
o
S
S2
Nota.- en la teoría del muestreo la desviación estándar recibe la denominación de
error estándar.
166
Ejemplo 4.9.- en el ejemplo 4.5, se ha determinado la varianza (para datos sin
agrupar) de los pesos de los alumnos, siendo la misma σ2 = 109.0412 (Kg..)2.
Luego la desviación estándar será:
109.0412 = 10.442 Kg.
Interpretación.- el promedio de las desviaciones de los pesos de los alumnos
respecto a su media aritmética es de 10.442 Kg.
Ejemplo 4.10.- en el ejemplo 4.6, se ha determinado la varianza (para datos
agrupados) de los pesos de los alumnos, siendo la misma σ2 = 110.1369 (Kg..)2.
Luego la desviación estándar será:
110.1369 = 10.495 Kg.
Interpretación.- el promedio de las desviaciones de los pesos de los alumnos
respecto a su media aritmética es de 10.495 Kg.
4.6 COEFICIENTE DE VARIACIÓN
Mide el promedio de las variaciones porcentuales de los valores observados respecto
a la media aritmética.
Tanto para datos sin agrupar como para datos agrupados se define como:
CV ( X )
X
100
100
para la población.
X
cv( X )
SX
100
X
S
100
X
para la muestra.
Nota.- en la teoría del muestreo el coeficiente de variación recibe la denominación
de error relativo.
Ejemplo 4.11
En el ejemplo de los pesos de los 60 alumnos de Estadística Básica 09A-FCEUNAC, (para datos sin agrupar) se ha determinado que µ = 59.87 y σ = 10.442 Kg.
Luego el coeficiente de variación de los pesos de los alumnos es:
CV ( X )
100
10.442
.100 =17.44 %
59.87
Interpretación.- el promedio de las variaciones porcentuales de los pesos de los
alumnos de Estadística Básica 09A-FCE-UNAC, respecto a su media aritmética es
del 17.44 %.
167
Ejemplo 4.12
En el ejemplo de los pesos de los 60 alumnos de Estadística Básica 09A-FCEUNAC, (para datos agrupados) se ha determinado que µ = 60.133 y σ = 10.495 Kg.
Luego el coeficiente de variación de las tallas de los alumnos es:
CV ( X )
100
10.495
.100 = 17.45 %
60.133
Interpretación.- el promedio de las variaciones porcentuales de los pesos de los
alumnos de Estadística Básica 09A-FCE-UNAC, respecto a su media aritmética es
del 17.45 %.
Cálculo de los estadígrafos de dispersión con los programas
Veamos como se pueden obtener los estadígrafos de dispersión para la variable peso,
desde la base de datos construida (datos sin agrupar) utilizando los programas.
En Excel:
Con los datos de la variable peso de los 60 alumnos de estadística Básica 09-A en la
columna D, desde D3 hasta D62, cuando en el programa se pide Matriz se sombrean
estos o se escribe D3:D62.
Una primera forma de obtener los estadígrafos es con la opción de funciones
del
Excel, escoger dentro de Seleccionar una categoría →Estadísticas → escoger
estadígrafo y aparece ventana de diálogo en la que se indica los argumentos
requeridos y se obtiene el resultado.
Otra forma de obtenerlos es con la sintaxis para cada estadígrafo, que es la que
utilizaremos.
Para calcular el rango necesitamos el valor máximo y el valor mínimo. La sintaxis
correspondiente es: MAX(Matriz) y MIN(Matriz) respectivamente.
Para hallar el máximo de la variable peso, en la celda D71 escribir =MAX(D3:D62)
al hacer enter aparece 88 y para hallar el mínimo, en la celda D72 escribir
=MIN(D3:D62) al hacer enter aparece 44. Para hallar el rango, en la celda D73
escribir =D72-D7, al efectuar enter aparece 44(Ver figura 4.1).
Para hallar el rango intercuartílico (RIQ), se debe utilizar los resultados de los
cuatiles 1 y 3 calculados anteriormente en las celdas D66 y D68 respectivamente (ver
168
figura 3.8). En la celda D74 escribir =D68-D66, al efectuar enter aparece 16.25 (Ver
figura 4.1).
Para calcular la desviación media (Excel obtiene con respecto a la media aritmética)
usar la sintaxis: =DESVPROM(Matriz). Para la variable peso, en la celda D75
escribir =DESVPROM(D3:D62) al hacer enter aparece el resultado 9.006.
Para hallar la varianza de la muestra usar la sintaxis =VAR(Matriz) y para la
varianza de la población usar =VARP(Matriz). Para determinar la varianza de la
variable peso, en la casilla D76 escribir =VARP(D3:D62) al hacer enter aparece el
resultado 109.0412 (ver Figura 4.1).
Para calcular la desviación estándar muestral usar la sintaxis =DESVEST(Matriz)
y para la desviación estándar poblacional usar =DESVESTP(Matriz). Para la
variable peso, en la casilla D77 escribir =DESVESTP(D3:D62) al hacer enter
aparece el resultado 10.442 (ver Figura 4.1).
Para calcular el coeficiente de variación se divide la desviación estándar de la celda
D77 entre la media aritmética de la celda D63 así: en la casilla D78 escribir
=D77/D63 al hacer enter y luego clic en %, aparece 17.44%.
Figura 4.1 Medidas de Dispersión obtenidas con Excel
169
En Minitab:
Estando en la base de datos Estadística Básica 09A, escoger del menú Stat →Basic
Statistics → Display Descriptive Statistics… aparece la ventana de diálogo Display
Descriptive Statistics (vista en la Figura 3.4).
En variables: seleccionar la variable peso de las variables que están a la izquierda.
Hacer clic en el botón
y aparece la ventana de diálogo Descriptive
Satatistcs – Statistics (ver la Figura 4.2).
Figura 4.2 Selección de estadígrafos de dispersión en Minitab
Escoger los estadígrafos de dispersión a calcular: Range (rango) Interquartile range
(rango intercuartílico), variance (varianza), Standard deviation (desviación estándar)
y Coefficient of variation (coeficiente de variación).
Adicionalmente se ha solicitado mean (media) y N total (total de observaciones) ya
que el Minitab hace cálculos muestrales para la varianza y se necesita reajustar este y
otros cálculos.
Hacer clic en OK y regresa a la ventana Display Descriptive Statistics.
Para terminar hacer clic en OK y en la ventana de Session aparecen los resultados
solicitados siguientes:
Descriptive Statistics: peso
Variable
peso
Total
Count
60
Mean
59.87
StDev
10.53
Variance
110.89
170
CoefVar
17.59
Range
44.00
IQR
16.75
Se puede apreciar que los resultados obtenidos corresponden a cálculos muestrales,
por lo que hay que hacer reconversiones a valores poblacionales, así la varianza será:
N
)2
(Xi
2
i 1
N
( N 1) S 2
N
(50 1) 110.89
109.0412 Kg2.
60
Con este valor, ya se puede calcular la desviación estándar
109.0412 = 10.442
Kg. y el coeficiente de variación 17.44% (por ello solicitamos también la media
aritmética).
En SPSS:
Estando en la base de datos Estadística Básica 09A, seguir la secuencia para obtener
la tabla de frecuencias: Analizar → Estadísticos descriptivos → Frecuencias.
Inmediatamente se abre la ventana de diálogo Frecuencias.
En Variables: ingresar la variable peso, luego hacer clic en el botón
y se
muestra la ventana de diálogo Frecuencias: Estadísticos de la Figura 4.3.
Figura 4.3 Cálculo de estadígrafos de dispersión en SPSS
En Dispersión, seleccionar Desviación típica, Varianza, Amplitud (o Rango),
Mínimo y Máximo. Adicionalmente se ha solicitado media ya que, al igual que el
Minitab, el SPSS hace cálculos muestrales para la varianza y se necesita reajustar
este y otros cálculos. También se solicita cuartiles para calcular el RIQ.
171
Luego hacer clic en Continuar, regresando a la ventana de diálogo Frecuencias y
para terminar, efectuar clic en Aceptar. Inmediatamente en el Visor de Resultados
aparece:
Estadísticos
PESO (Kg)
N
Media
Des v. típ.
Varianza
Rango
Mínimo
Máximo
Percentiles
Válidos
Perdidos
25
50
75
60
0
59.87
10.530
110.889
44
44
88
51.00
57.00
67.75
Resultado de estadígrafos de dispersión en SPSS
Al igual que en el Minitab se tiene que reajustar la varianza muestral así:
N
(Xi
2
i 1
N
)2
( N 1) S 2
N
(50 1) 110.889
109.0412 Kg2.
60
Con este valor, ya se puede calcular la desviación estándar
109.0412 = 10.442
Kg. y el coeficiente de variación 17.44% (por ello solicitamos también la media
aritmética). Igualmente el RIQ = P75 – P25 = 67.75 – 51.00 = 16.75 Kg.
En R:
Estando en la base de datos Estadística Básica 09A y habiendo attachado la misma,
para que reconozca las variables y sus valores, donde variable es un conjunto de
datos cuantitativos (peso aquí).
Para calcular el Rango, escribir en la consola:
> range(variable) al hacer enter se obtiene el valor mínimo y el máximo.
> diff( range(variable)) al hacer enter se obtiene el rango (diferencia entre el valor
máximo y el mínimo).
Para la variable peso, se tiene:
> range(peso)
[1] 44 88
172
> diff(range(peso))
[1] 44
Para calcular el Rango intercuartílico (RIQ) usar la sintaxis IQR(variable), para la
variable peso se calcula así:
> IQR(peso)
[1] 16.25
Para obtener la Desviación media respecto a la media aritmética, escribir en la
consola:
> dm=sum(abs(peso-mean(peso)))/60
> dm
[1] 9.006222
Si se quiere calcular la desviación media respecto a la mediana, escribir en la
consola:
> dm=sum(abs(peso-median(peso)))/60
> dm
[1] 8.881667
Tanto la varianza como la desviación estándar calculadas en R son muestrales,
debiéndose efectuar los mismos ajustes realizados en Minitab y en SPSS.
La sintaxis para la varianza es var(variable) y para la desviación estándar
sd(variable). Los cálculos para la variable peso son:
> var(peso)
[1] 110.8893
> sd(peso)
[1] 10.5304
Al igual que en Minitab y SPSS se tiene que reajustar la varianza muestral así:
> N=length(peso)
>N
[1] 60
> var=(N-1)*var(peso)/N
> var
[1] 109.0412
173
> sd=var^0.5
> sd
[1] 10.44228
> cv=sd/mean(peso)*100
> cv
[1] 17.44207
En el Cuadro 4.1 se muestra el resumen de los estadígrafos de dispersión calculados.
CUADRO 4.1RESUMEN DE LAS MEDIDAS DE DISPERSIÓN CALCULADAS
PARA LOS PESOS (KG.) DE LOS ALUMNOS DE ESTADÍSTICA BÁSICA 09A,
DE LA FCE-UNAC, POR PROGRAMA USADO
ESTADÍGRAFO MANUAL
EXCEL
MINITAB
SPSS
R
Rango
44.00
44.00
44.00
44
44
RIQ
16.75
16.25
16.75
16.75
16.25
Desviación media
9.006
9.006
-
-
9.006
109.0412
109.0412
110.89 (a)
110.89 (a)
110.89 (a)
10.442
10.442
10.530 (a)
10.53 (a)
10.53 (a)
17.44%
17.44%
17.59 (a)
17.59 (a)
17.59 (a)
Varianza
Desviación
estándar
Coeficiente
de
variación
(a) Son resultados muestrales, que deben reajustarse.
4.7 DIAGRAMA DE CAJAS O BOXPLOT
El diagrama de cajas y bigotes o boxplot es un gráfico sencillo de realizar y fue
propuesto por Tukey (1977) para hacer el análisis exploratorio de datos de una variable
cuantitativa usando principalmente los cuartiles .
Para su elaboración, en un rectángulo (caja) se representan los cuartiles: en el extremo
inferior el cuartil 1, al extremo superior el cuartil 3 y entre ambos una línea divisoria para
174
representar el cuartil 2. Es decir, que la caja representa el RIQ, pues concentra el 50%
central de los valores observados.
De los extremos centrales de la caja se extienden los “bigotes” en la parte inferior hasta
el máx[Q1 - 1.5RIQ, mín (X1, X2, …., Xn)] y en la parte superior hasta el min[Q3 +
1.5RIQ, máx (X1, X2, …., Xn)]. Así mismo, por debajo de la parte inferior y por encima
de la parte superior de los bigotes se colocan los valores extremos (outliers) con
asteriscos, tal como se indica en la figura 4.4.
Figura 4.4 Estructura del diagrama de cajas y bigotes (boxplot)
Por lo general el boxplot se presenta rotado en 90º. Veamos la obtención del
diagrama de cajas para la variable peso usando los programas Minitab, SPSS y R.
En Minitab:
Estando en la base de datos Estadística Básica 09A, escoger del menú Graph
→Boxplot → Simple → OK aparece la ventana de diálogo Boxplot – One Y,
Simple (ver la Figura 4.5).
De la lista de variables del lado izquierdo seleccionar la variable peso e ingresarla en
Graph variables:.
Hacer clic en el botón
y en Title: poner el número y título del
gráfico. En este caso es:
GRÁFICO 4.1 BOXPLOT DEL PESO DE LOS ALUMNOS DE ESTADÍSTICA
BÁSICA 09-A, DE LA FCE-UNAC.
175
Para continuar hacer clic en OK y regresa a la ventana de Boxplot – One Y, Simple,
hacer clic en OK e inmediatamente aparece el boxplot (ver la figura 4.6).
Figura 4.5 Ventana de diálogo para definir el boxplot de peso en Minitab
Figura 4.6 Diagrama de cajas y bigotes de la variable peso en Minitab
176
Ubicándose dentro de la caja con el puntero del mouse, aparecen automáticamente
los cuartiles (ver la parte inferior de la figura 4.6). La lectura de los datos que allí
aparecen, permite describir que son 60 alumnos (N = 60), cuyos pesos fluctúan
entre 44 y 88 Kg. (Whiskers to = bigotes hasta: 44, 88) y que no hay pesos
extremos (outliers). Así mismo, los cuartiles indican que el 25% de los alumnos con
menos peso se encuentran por debajo de los 51 kg. (Q1) y el 25% de los alumnos
con más peso se encuentra por encima de los 67.75 Kg. (Q3). También que el 50%
de los alumnos pesa 57 Kg. o menos (median = mediana = 57 Kg.) y que el 50%
central de los pesos de los alumnos está entre 51 (Q1) y 67.75 Kg. (Q3).
También se puede obtener boxplot para hacer comparaciones entre una variable
cuantitativa, con alguna variable categórica; como puede ser en este caso ver el
comportamiento del peso de los alumnos por sexo (hombres y mujeres).
Para ello, estando en la ventana de diálogo de la figura 4.5 y con las etiquetas de
sexo como texto, hacer clic en el botón
y aparece la ventana de
diálogo Boxplot – Multiple Graphs, hacer clic en By variables (ver la figura 4.7).
Figura 4.7 Efectuando Gráfico Múltiple de Boxplot para peso, por sexo
177
Seleccionar la variable sexo (con las etiquetas en texto) en By variables with
groups in separate panels: si se desea en un solo gráfico, pero en paneles
separados, el boxplot para hombres y mujeres (el que se ha escogido aquí); y si se
desea dos gráficos separados de boxplot uno para hombres y otro para mujeres
selecciona la variable sexo en By variables with groups on separate graphs:.
Para continuar hacer clic en OK y regresa a la ventana de la figura 4.5 de Boxplot –
One Y, Simple, hacer clic en OK e inmediatamente aparece el Gráfico 4.2 boxplot
para cada sexo (ver la figura 4.8).
GRÁ FICO 4.2 BOXPLOT DEL PESO DE LOS A LUMNOS DE ESTA DÍSTICA BÁ SICA 09-A FCE-UNA C,
POR SEXO
Hombre
90
Mujer
Peso (Kg.)
80
70
60
50
40
Panel variable: sexo
Figura 4.8 Boxplot del peso para hombres y mujeres en Minitab
Se puede hacer las comparaciones pertinentes y enriquecer el análisis de la variable
cuantitativa comparada para algunas variables categóricas consideradas en el
estudio.
Aquí se puede apreciar que las mujeres pesan mucho menos que los hombres; no
obstante dentro de ellas hay dos alumnas cuyos pesos sobresalen del resto
(outliers). Haciendo clic con el puntero del mouse en los asteriscos, nos indica que
se trata de las alumnas 19 con 63 Kg. de peso y la alumna 26 con 66 Kg.
178
En SPSS:
Estando en la base de datos Estadística Básica 09A, seguir la secuencia: Analizar →
Estadísticos descriptivos → Explorar y aparece la ventana de la Figura 4.9.
Figura 4.9 Ventana de diálogo Explorar para definir el boxplot de peso en SPSS
En Dependientes: ingresar la variable peso. En Mostrar esta seleccionado Ambos,
ya que saca Estadísticos (descriptivos) y Gráficos (tiene seleccionado el boxplot) por
lo que sólo queda hacer clic en Aceptar y aparece el Boxplot de la figura 4.10.
90
80
70
60
50
40
PESO (Kg)
Figura 4.10 Diagrama de cajas y bigotes de la variable peso en SPSS
179
Si se desea un gráfico de boxplot para hombres y mujeres en un solo gráfico;
entonces, en la ventana de diálogo Explorar de la figura 4.9, en Factores: se ingresa
la variable sexo y para finalizar hacer clic en Aceptar e inmediatamente aparece el
resultado de la Figura 4.11.
90
PESO (Kg)
80
70
26
19
60
50
40
Hombre
Mujer
SEXO
Figura 4.11 Boxplot del peso para hombres y mujeres en SPSS
En R:
Estando en la base de datos Estadística Básica 09A y habiendo attachado la misma,
para que reconozca las variables y sus valores, donde variable es un conjunto de
datos cuantitativos (peso aquí).
Para graficar el Boxplot, escribir en la consola: boxplot (variable).
El diagrama de cajas y bigotes para la variable peso se obtiene así:
> boxplot(peso, col="yellow", main="BOXPLOT PESO", ylab="Peso (Kg.)")
La representación del boxplot se muestra en la Figura 4.12.
180
Figura 4.12 Diagrama de cajas y bigotes de la variable peso en R
Para obtener el boxplot de hombres y mujeres en un solo gráfico escribir:
> plot(sex, peso,xlab="Sexo",ylab="Peso (Kg.)", main="BOXPLOT PESO DE LOS
ALUMNOS")
La representación se muestra en la Figura 4.13
En los tres programas se obtienen las representaciones del diagrama de cajas,
debiendo escogerse aquella que este disponible o tenga una mejor presentación,
quedando en potestad del investigador escoger la misma.
181
Figura 4.13 Boxplot del peso para hombres y mujeres en R
4.8 MEDIDAS DE FORMA DE LA DISTRIBUCIÓN
Cuando se quiere caracterizar mejor la distribución de frecuencias, muchas veces se
recurre a la distribución normal de probabilidades, que es una distribución simétrica
respecto a su media aritmética, concentrando por debajo de este valor a la mitad de las
observaciones y la otra mitad por encima de dicho valor.
Para saber si la concentración de observaciones por debajo de la media es menor o
mayor a la mitad de las mismas se usan las medidas de asimetría. Por otro lado, la poca
o fuerte concentración de observaciones entorno a la media se va estudiar con las
medidas de curtosis o apuntamiento.
182
MEDIDAS DE ASIMETRÍA
Según Pérez (2002) “Las medidas de asimetría tienen como finalidad el elaborar un
indicador que permita establecer el grado de simetría (o asimetría) que presenta una
distribución sin necesidad de llevar a cabo su representación gráfica. Supongamos hemos
representado gráficamente una distribución de frecuencias. Si trazamos una
perpendicular al eje de las abscisas por x y tomamos esta perpendicular como eje de
simetría, diremos que una distribución es simétrica si existe el mismo número de valores
a ambos lados de dicho eje, equidistantes de x dos a dos, y tales que cada par de valores
equidistantes de x tengan la misma frecuencia. En caso contrario, las distribuciones
serán asimétricas”
a) Coeficiente de asimetría de Pearson.Para distribuciones unimodales y ligeramente asimétricas, Karl Pearson encontró
que la relación empírica entre la media aritmética, la mediana y la moda es:
X
Mo
Me , la misma que es utilizada en su coeficiente:
3X
Ap
X
Mo
3 X
S
Me
S
Donde S es la desviación estándar.
Si Ap = 0, la distribución es simétrica.
Si Ap > 0, la distribución es asimétrica positiva o asimétrica a la derecha.
Si Ap < 0, la distribución es asimétrica negativa o asimétrica a la izquierda.
b) Coeficiente de asimetría de Fisher.El coeficiente de asimetría propuesto por R.A. Fisher es:
Af
Af
1
n
n
Xi
X
3
i 1
, para datos sin agrupar.
3
1
n
k
3
Xi
X ni
i 1
3
, para datos agrupados.
Donde σ es la desviación estándar poblacional.
Si Af = 0, la distribución es simétrica.
Si Af > 0, la distribución es asimétrica positiva o asimétrica a la derecha.
Si Af < 0, la distribución es asimétrica negativa o asimétrica a la izquierda.
183
Ejemplo 4.13
Con los datos sin agrupar del Cuadro 2.6, peso en Kg. de los 60 alumnos de
Estadística Básica 09-A, cuyos pesos ordenados son:
44
45
46
46.5
47
48
48
49
49
50
50
50
50
50.5
51
51
52
52
52.6
53
53
53
53
54
55
55
55
55
55
57
57
59
60
60
63
63
64
64
64.5
65
65
66
66
67
67
68
68
68
69
70
70
72
72
75
75
77
80
80
80
88
Hallar los coeficientes de asimetría de Pearson y el de Fisher.
Solución.En ejemplos anteriores se obtuvo µ = 59.868, Me = 57 y σ = 10.442 Kg.
Luego el coeficiente de asimetría de Pearson es:
Ap
3 X
Me
3 59.868 57
10.442
S
= 0.82 > 0, los pesos tienen distribución
asimétrica positiva.
El coeficiente de asimetría de Fisher es:
Af
1
n
n
Xi
X
3
i 1
3
1
(38558.56)
60
(10.442)3
= 0.56 > 0, entonces los pesos tienen
distribución asimétrica positiva.
Ejemplo 4.14
Hallar los coeficientes de asimetría de Pearson y el de Fisher, de los pesos de los 60
alumnos de Estadística Básica 09-A FCE-UNAC, con los datos agrupados del
Cuadro 2.7, siguientes:
Clase
i
1
2
3
4
5
PESOS (Kg.)
LIi
44.0
52.8
61.6
70.4
79.2
LSi
52.8
61.6
70.4
79.2
88.0
Marca
Prop.
Acum. Prop.Ac.
Alum-nos
alumnos alumnos alumnos
clase
Xi
ni
hi
Ni
Hi
48.4
19
0.317
19
0.317
57.2
15
0.250
34
0.567
66.0
17
0.283
51
0.850
74.8
5
0.083
56
0.933
83.6
4
0.067
60
1.000
60
1.000
184
Solución.En ejemplos anteriores se obtuvo µ = 60.133, Me = 59.253 y σ = 10.495 Kg.
Luego el coeficiente de asimetría de Pearson es:
3 X
Ap
Me
3 60.133 59.253
10.495
S
= 0.25 > 0, los pesos tienen distribución
asimétrica positiva.
El coeficiente de asimetría de Fisher es:
Af
1
n
n
Xi
3
X
ni
i 1
3
1
(39828.25)
60
(10.495)3
= 0.57 > 0, entonces los pesos tienen
distribución asimétrica positiva.
MEDIDAS DE CURTOSIS O APUNTAMIENTO
Según Chue J.y Otros (2007) “La curtosis cuantifica la cantidad de observaciones
que se agrupan alrededor de las medidas de tendencia central de la distribución de los
datos”.
La fórmula de cálculo de la curtosis es:
K
K
1
n
n
Xi
X
4
i 1
3 , para datos sin agrupar.
4
1
n
k
4
Xi
X ni
i 1
4
3 , para datos agrupados.
Donde σ es la desviación estándar poblacional.
Si K = 0, la distribución es mesocúrtica (apuntamiento normal).
Si K > 0, la distribución es leptocúrtica (puntiaguda).
Si K < 0, la distribución es platicúrtica (achatada).
Ejemplo 4.15
Con los datos sin agrupar del Cuadro 2.6 (ver ejemplo 4.13), peso en Kg. de los 60
alumnos de Estadística Básica 09-A, hallar el coeficiente de curtosis.
Solución.En ejemplos anteriores se obtuvo µ = 59.868 y σ = 10.442 Kg.
185
Luego el coeficiente de curotosis es:
K
1
60
60
X i 59.868
4
i 1
4
1762855.81
60
3
(10.442) 4
3 = -0.53 < 0, entonces la distribución
es platicúrtica o achatada.
Ejemplo 4.16
Hallar el coeficiente de curtosis de los pesos de los 60 alumnos de Estadística
Básica 09-A FCE-UNAC, con los datos agrupados del Cuadro 2.7, dados en el
ejemplo 4.14.
Solución.En ejemplos anteriores se obtuvo µ = 60.133 y σ = 10.495 Kg.
Luego el coeficiente de curtosis es:
K
1
60
5
Xi
4
60.133 ni
i 1
4
1825739.21
60
3
(10.495)3
3 = -0.41 < 0, por lo tanto, la
distribución es platicúrtica o achatada.
Cálculo de las medidas de forma con los programas
Veamos como se pueden obtener los estadígrafos de forma para la variable peso,
desde la base de datos construida (datos sin agrupar) utilizando los programas.
En Excel:
Con los datos de la variable peso de los 60 alumnos de estadística Básica 09-A en la
columna D, desde D3 hasta D62, cuando en el programa se pide Matriz se sombrean
estos o se escribe D3:D62.
Una manera de obtener los estadígrafos de forma es con la opción de funciones
del Excel, escoger dentro de Seleccionar una categoría →Estadísticas → escoger
estadígrafo y aparece ventana de diálogo en la que se indica los argumentos
requeridos y se obtiene el resultado. Otra manera de obtenerlos es con la sintaxis para
el estadígrafo, que es la que utilizaremos. Para la asimetría usar la sintaxis
=COEFICIENTE.ASIMETRIA(Matriz)
=CURTOSIS(Matriz).
186
y para calcular la curtosis usar
Para el peso, en la casilla D79 escribir =COEFICIENTE.ASIMETRIA(D3:D62) al
hacer enter aparece el resultado 0.58 (ver Figura 4.14). Entonces los pesos tienen
distribución asimétrica positiva.
Así mismo, en la casilla D80 escribir =CURTOSIS(D3:62) al hacer enter aparece el
resultado -0.47 (ver Figura 4.14). Entonces los pesos tienen distribución platicúrtica
o achatada.
Figura 4.14 Cálculo de la asimetría y curtosis en Excel
En Minitab:
Estando en la base de datos Estadística Básica 09A, escoger del menú Stat →Basic
Statistics → Display Descriptive Statistics… aparece la ventana de diálogo Display
Descriptive Statistics (vista en la Figura 3.4).
En variables: seleccionar la variable peso de las variables que están a la izquierda.
Hacer clic en el botón
y aparece la ventana de diálogo Descriptive
Satatistcs – Statistics (ver la Figura 4.2). Escoger Skewness (asimetría) y Kurtosis.
Al hacer clic en OK, regresa a la ventana Display Descriptive Statistics, hacer
nuevamente clic en OK y aparecen los resultados siguientes:
Descriptive Statistics: peso
Variable
peso
Total
Count
60
Skewness
0.58
Kurtosis
-0.47
Resultados idénticos a los obtenidos en Excel.
187
En SPSS:
Estando en la base de datos Estadística Básica 09A, seguir la secuencia para obtener
la tabla de frecuencias: Analizar → Estadísticos descriptivos → Frecuencias.
Inmediatamente se abre la ventana de diálogo Frecuencias.
En Variables: ingresar la variable peso, luego hacer clic en el botón
y se
muestra la ventana de diálogo Frecuencias: Estadísticos (ver la Figura 4.3).
En Distribución, seleccionar Asimetría y Curtosis. Luego hacer clic en Continuar,
regresando a la ventana de diálogo Frecuencias y para terminar, efectuar clic en
Aceptar. Inmediatamente en el Visor de Resultados aparece:
Estadísticos
PESO (Kg)
N
Válidos
Perdidos
Asimetría
Error típ. de asimetría
Curtosis
Error típ. de curtosis
60
0
.579
.309
-.469
.608
Resultado de estadígrafos de forma en SPSS
Al igual que en el Excel y el Minitab se tiene el mismo resultado.
En R:
Estando en la base de datos Estadística Básica 09A y habiendo attachado la misma,
para que reconozca las variables y sus valores, donde variable es un conjunto de
datos cuantitativos (peso aquí).
J. Arriaza y Otros (2008) recomiendan en el Apéndice B “Medidas de forma, con el
paquete fBasics del R”.
Por ello, primero instalar el paquete fBasics. En el menú del R escoger Paquetes,
luego Instalar paquetes, escoger un país (Australia, por ejemplo) aparece una lista
de Packages (paquetes) buscar fBasics y hacer doble clic para que se instale en la
pc. Luego, desde el menú escoger en Paquetes, cargar paquete y aparece una lista,
dar doble clic en fBasics, para calcular los estadígrafos de forma. Si el fBasics esta
instalado, sólo hay que cargarlo.
188
Para calcular la Asimetría, escribir en la consola:
> skewness(variable) al hacer enter se obtiene el resultado.
Para calcular la Curtosis, escribir en la consola:
> kurtosis(variable) al hacer enter se obtiene el resultado.
Las medidas de forma de la variable peso se obtienen así:
> skewness(peso)
[1] 0.550345
attr(,"method")
[1] "moment"
> kurtosis(peso)
[1] -0.6106151
attr(,"method")
[1] "excess"
Cuyos resultados son parecidos a los obtenidos con los otros programas, es decir, que
la distribución de la variable peso es asimétrica positiva y platicúrtica.
189
Capítulo 5. CORRELACIÓN Y REGRESIÓN SIMPLE
“Las cifras no mienten, pero los mentirosos también usan cifras”
Anónimo
CONTENIDO
5.1
5.2
5.3
5.4
5.5
Introducción.
Diagrama de dispersión.
Covarianza y coeficiente de correlación.
Regresión lineal simple.
Coeficiente de determinación.
5.1 INTRODUCCIÓN
Uno de los propósitos de la estadística es efectuar predicciones al futuro, para lo cual
es necesario explicar el comportamiento de una variable dependiente o explicada
(denotada por Y) mediante una o más variables independientes o explicativas
(denotadas por X‟s) basados en fundamentos teóricos del fenómeno que se estudia.
Así, vemos que en economía se busca explicar la demanda de los bienes y servicios en
función de los precios de los mismos.
Igualmente, basados en la información observada sobre la producción de un bien o
servicio a través del tiempo, tratamos de predecir las cantidades a producir en el futuro.
En el presente capítulo se busca establecer algunas formas sencillas de establecer la
relación entre las variables construyendo los diagramas de dispersión delos datos, así
como la medición de la relación entre las variables usando la covarianza y el
coeficiente de correlación.
También se presenta la determinación de algunos modelos de regresión lineal simple
entre dos variables y los de series de tiempo que permitan hacer pronósticos en
situaciones de incertidumbre.
190
5.2 DIAGRAMA DE DISPERSIÓN
Es la representación en el plano cartesiano de los valores que toma la variable
dependiente Y conjuntamente con los valores que toma la variable independiente X,
acompañados por alguna función (recta, hoja de parábola, etc.) a la que se ajustan
dichos datos.
Es decir, que se representan las parejas ordenadas (Xi, Yi) los mismos que aparecen
como puntos en el plano cartesiano y dan una idea del tipo de relación funcional
matemática para las variables.
Es un gráfico recomendado para establecer el tipo de asociación entre las variables (si
es directa o inversa), así como el tipo de relación funcional entre las mismas.
Ejemplo 5.1
Una compañía productora de muñecas quiere establecer la relación entre las variables
X = precio de las muñecas ($) e Y = cantidad de muñecas vendidas. Los datos son:
X
6.5
8.0
10.0
12.5
14.0
16.0
17.5
20.0
Y
276
250
238
212
190
183
156
125
Efectuar el diagrama de dispersión.
Solución.Vamos a utilizar los programas Excel, Minitab, SPSS y R para realizar el diagrama de
dispersión.
En Excel:
En una hoja de Excel ingresar los valores de X e Y en las columna A y B
respectivamente. Sombrear la variable y los datos.
En Insertar, Gráficos, escoger XY (Dispersión) y el recuadro Dispersión sólo con
marcadores, tal como se muestra en la Figura 5.1.
Al hacer clic en Aceptar, aparecen los puntos del diagrama de dispersión. Hacer clic
con el botón derecho sobre los puntos del plano y seleccionar agregar línea de
tendencia y aparece una ventana de diálogo. Escoger el tipo (automáticamente aparece
191
lineal, que es la que interesa en este caso). Al hacer clic en Cerrar se muestra el
diagrama de dispersión y la línea de tendencia de la Figura 5.2
Figura 5.1 Definiendo el diagrama de dispersión en Excel
Figura 5.2 Diagrama de dispersión de la cantidad y precio en Excel
En Minitab:
192
Con los datos de la variable precio (X) y cantidad (Y) en el Worksheet, del menú
escoger Graph, Scatterplot, aparece la ventana de diálogo Scatterplots; escoger With
Regression y hacer clic en OK. Se muestra la ventana de diálogo de la Figura 5.3.
Figura 5.3 Definiendo el diagrama de dispersión en Minitab
En Y variables seleccionar Cantidad y en X variables Precio. Al efectuar clic en OK se
muestra el diagrama de dispersión con la línea de regresión de la Figura 5.4.
Scatterplot of Y = Cantidad vs X = Precio
280
260
Y = Cantidad
240
220
200
180
160
140
120
5.0
7.5
10.0
12.5
X = Precio
15.0
17.5
20.0
Figura 5.4 Diagrama de dispersión de la cantidad y precio en Minitab
En SPSS:
193
Con los datos de la variable precio (X) y cantidad (Y) en el Editor de datos SPSS, del
menú escoger Gráficos, Interactivos, Diagrama de dispersión, aparece la ventana de
diálogo Crear diagrama de dispersión de la Figura 5.5.
Figura 5.5 Creando el diagrama de dispersión en SPSS
De la lista de variables arrastrar primero la variable dependiente (Cntidad) en el primer
recuadro y luego la variable independiente (precio) en el siguiente, tal como se muestra
en la Figura 5.5.
Para finalizar hacer clic en Aceptar y aparece el diagrama de dispresión de la Figura
5.6.
194
280
CANT IDAD
240
200
160
120
8.0 0
12. 00
16. 00
20. 00
PRECIO
Figura 5.6 Diagrama de dispersión de la cantidad y precio en SPSS
En R:
Definir los valores de las variables Precio y Cantidad, por los vectores X e Y
respectivamente siguientes:
> X=c(6.5, 8.0, 10.0, 12.5, 14.0, 16.0, 17.5, 20.0)
> Y=c(276, 250, 238, 212, 190, 183, 156, 125)
A continuación utilizar la función plot para definir el diagrama de dispersión, así:
> plot(X, Y, xlab="PRECIO", ylab="CANTIDAD", main="Diagrama de dispersión
de Precios y Cantidad")
Donde:
X es la variable independiente e Y la variable dependiente.
xlab es la etiqueta del eje X e ylab la etiqueta del eje Y.
main es para ponerle título al gráfico. El resultado aparece en la Figura 5.7.
195
Figura 5.7 Diagrama de dispersión de la cantidad y precio en R
5.3 COVARIANZA Y COEFICIENTE DE CORRELACIÓN
Los indicadores del grado de asociación lineal entre dos variables son la covarianza y
el coeficiente de correlación.
COVARIANZA.La covarianza entre las variables X e Y, denotada por Cov (X, Y), mide el promedio
de las discrepancias conjuntas del producto de las desviaciones de las variables X e
Y con respecto a sus respectivas medias. Se calcula como:
Cov( X , Y )
1
n
n
Xi
i 1
196
X Yi Y
1
SPXY
n
Donde SPXY representa la Suma de Productos de las desviaciones de X e Y con
respecto a sus medias, calculada así:
n
n
SPXY
Xi
X Yi Y
i 1
X iYi n X Y
i 1
La covarianza tiene el inconveniente de las unidades de medida de las variables, por
ello lo fundamental de la covarianza es el signo, ya que proporciona una idea de la
discrepancia conjunta de las variables en estudio. Así, si el signo es positivo indica una
variación directa entre los valores de la variable, es decir, que si X aumenta, entonces
Y también aumenta o si uno disminuye el otro también disminuye; mientras que si el
signo es negativo, indica una variación inversa, es decir, que si X aumenta, entonces Y
disminuye y viceversa, si X disminuye entonces Y aumenta.
Como solución al inconveniente planteado en el párrafo anterior, surge el coeficiente
de correlación lineal de Pearson que a continuación se explica.
COEFICIENTE DE CORRELACIÓN.El coeficiente de correlación lineal entre las variables X e Y, denotada por ρ (X, Y),
mide el grado de asociación lineal entre las variables en estudio. Se calcula así:
Cov( X , Y )
( X ,Y )
X
r ( X ,Y )
Cov( X , Y )
n 1
S X SY
n
r
, para la población; y
Y
SPXY
, para la muestra.
SCX SCY
Donde:
n
SCX
Xi
i 1
X
2
n
n
X i2 n X 2 y SCY
i 1
Yi Y
i 1
2
n
Yi 2 nY 2
i 1
El coeficiente de correlación toma valores entre -1 y 1.
Cuanto más cercano a -1 o a 1 se encuentra es más fuerte la asociación lineal entre las
variables X e Y, y cercano a 0 indica que la asociación entre la variable es muy baja o
que no existe relación entre X e Y.
197
Ejemplo 5.2
Para los datos del ejemplo 5.1, calcular e interpretar la covarianza y el coeficiente de
correlación lineal simple entre X e Y.
Solución.Las variables X = precio de las muñecas ($) e Y = cantidad vendida. Los datos son:
X
6.5
8.0
10.0
12.5
14.0
16.0
17.5
20.0
Y
276
250
238
212
190
183
156
125
Cálculos necesarios:
8
n = 8,
8
X i 104.5 ,
X 13.0625 ,
Yi 1630 ,
i 1
Y
i 1
8
X i2
(6.5) 2 (8.0) 2 .... (17.5) 2 (20.0) 2 1,520.75
i 1
n
X i2 n X 2 1520.75 8(13.0625)2
SCX
155.7188
i 1
8
Yi 2
(276) 2 (250) 2 .... (156) 2 (125) 2
349,814
i 1
n
Yi 2 nY 2 349,814 8(203.75)2 17, 701.5
SCY
i 1
8
X iYi
(6.5)(276) (8.0)(250) .... (20.0)(125) 19, 642
i 1
n
SPXY
X iYi n X Y 19, 642 8(13.0625)(203.75)
i 1
Luego:
a) Cov( X , Y )
SPXY
n
1649.875
8
206.2344
198
1, 649.875
203.75
b) r
SPXY
SCX SCY
1, 649.875
0.994
155.7188 17, 701.5
Interpretación.- La covarianza negativa y el coeficiente de correlación cercano a -1, nos
indican que existe una alta relación inversa entre los precios de las muñecas y las
cantidades vendidas.
A continuación ilustramos los cálculos de la covarianza realizados en Excel y su
gráfico de dispersión correspondiente.
X = Precio
6.5
8.0
10.0
12.5
14.0
16.0
17.5
20.0
13.1
Media
Y = Cantidad
276
250
238
212
190
183
156
125
203.8
Media
( Xi
X)
-6.6
-5.1
-3.1
-0.6
0.9
2.9
4.4
6.9
En el eje de las X‟s se ha representado ( X i
199
(Yi
Y)
72.3
46.3
34.3
8.3
-13.8
-20.8
-47.8
-78.8
SPXY =
COV(X, Y) =
( Xi
X ) (Yi
Y)
-474.14
-234.14
-104.89
-4.64
-12.89
-60.95
-211.89
-546.33
-1649.88
-206.2344
X ) y en el eje de las Y‟s (Yi Y ) .
5.4 REGRESIÓN LINEAL SIMPLE
Es el proceso que consiste en poner en relación a una variable dependiente (Y) en
función de otra independiente (X), llamada también variable explicativa o predictora,
mediante la ecuación de una recta, basados en una relación de causalidad para el
fenómeno en estudio.
Así, en el ejemplo 5.1 vemos que las cantidad demandada de muñecas (Y), es una
función del precio de las mismas (X). Es decir, que Y = f(X).
La relación funcional a la que se postula es la ecuación de una recta, por lo tanto, se
postula que: Yi = a + bXi.
Donde a y b son los coeficientes de regresión, siendo b la pendiente de la recta y es
negativa porque recoge el efecto de la relación inversa entre el precio de las muñecas y
la cantidad demandada.
En el diagrama de dispersión obtenido antes, se puede apreciar que no todos los puntos
caen sobre la recta postulada, por lo que es necesario agregarle al modelo una
componente de error, así el modelo queda como:
Yi = a + bXi + ei
Ahora el problema se reduce a encontrar los valores de a y de b que permitan hacer
pronósticos de Y asumiendo determinados valores de X,. Para poder determinar los
valores de a y de b, se postula que los errores promedien cero, es decir buscando que
todos los puntos caigan sobre la recta y que la varianza de estos errores sea mínima,
surgiendo así el método de los mínimos cuadrados ordinarios.
Método de los Mínimos Cuadrados Ordinarios
Es un método de aproximación a los valores verdaderos de a y de b, buscando
minimizar la varianza de los errores, la misma que se traduce en:
n
n
ei2
Minimizar
i 1
200
Yi
i 1
a bX i
2
Siendo la suma de los errores al cuadrado función de los parámetros a y b, se tiene que
tomar derivadas parciales con respecto a dichos parámetros e igualar a cero, así:
n
ei2
n
i 1
2
a
Yi
a bX i ( 1) 0
Yi
a bX i ( X i ) 0
i 1
n
ei2
n
i 1
2
b
i 1
Resultado de igualar a cero y aplicar el operador sumatoria, surgen las denominadas
Ecuaciones normales siguientes:
n
na b
n
Xi
n
a
……………. (1)
Yi
i 1
i 1
n
i 1
n
X iYi ……... (2)
X i2
Xi b
i 1
i 1
Cuyas soluciones algebraicas son:
n
bˆ
n
X iYi
nXY
i 1
n
Xi
X Yi Y
i 1
n
X
2
i
i 1
nX
2
Xi
X
2
SPXY
;
SCX
y
i 1
â Y bˆ X
Fórmulas de cálculo para los valores de a y de b en regresión simple. Cabe resaltar que
el símbolo ˆ sobre a y sobre b indica que son valores estimados obtenidos con la
información muestral y son una buena aproximación hacia a y b en la estadística
inferencial.
Interpretación de â y b̂
Al ser b̂ la pendiente de la recta, entonces en bˆ
Y
, si X
X
1
bˆ
Y ; quiere
decir que si X se incrementa en una unidad, entonces Y se incrementa en b̂ unidades.´
201
Por otro lado â representa el intercepto con el eje Y, cuando X se aproxima cero y en
algunos casos no tiene mayor sentido.
5.5 COEFICIENTE DE DETERMINACIÓN (R2)
El coeficiente de determinación mide el porcentaje de explicación de la variabilidad de
la variable dependiente Y, que es debido a la regresión (explicada por la variable
independiente X) y el resto que se queda sin explicar se atribuye al error.
En la práctica se aproxima (estima) con el coeficiente de correlación al cuadrado
multiplicado por 100, o sea: 100r2 %.
Ejemplo 5.3
Para los datos del ejemplo 5.1, se pide: a) calcular e interpretar los coeficientes de
regresión y el coeficiente de determinación entre X e Y; y b) determinar la cantidad
demandada de muñecas cuando el precio sea de $ 15.
Solución.a) Para las variables X = precio de las muñecas ($) e Y = cantidad vendida, en la
solución del ejemplo 5.2 tenemos los cálculos que necesitamos, así:
n
SPXY
X iYi n X Y 19, 642 8(13.0625)(203.75)
i 1
n
X i2 n X 2 1520.75 8(13.0625)2
SCX
155.7188
i 1
n
Yi 2 nY 2 349,814 8(203.75)2 17, 701.5
SCY
i 1
Luego:
bˆ
SPXY
SCX
aˆ Y bˆ X
1649.875
155.7188
- 10.5952
203.75 ( 1.085)(13.0625)
r2 = (0.994)2 = 0.988 ≡ 98.8%
202
342.15
1, 649.875
La ecuación de regresión simple queda establecido como:
Yi
aˆ bˆ X i
342.15 10.595 X i
Interpretación.-
b̂ = - 10.595 significa que por cada dólar de incremento en el precio de la muñecas,
la cantidad demandada disminuye en casi 11 muñecas y viceversa, por cada dólar
que disminuye el precio de las muñecas, la demanda se incrementa en cerca de 11
muñecas.
â = 342.15, indica que la demanda tope bordeará las 342 muñecas, con el precio de
las mismas alrededor de cero dólares.
r2 = 0.988 ≡ 98.8%, indica que 98.8% de la variabilidad de la demanda de muñecas
es explicado por el precio de estas. Es decir, que el precio de las muñecas ajusta
muy bien la cantidad demandada de éstas.
b) Para determinar la cantidad de muñecas demandadas a un precio X = $15,
reemplazamos en la ecuación de regresión de la parte a), así:
Yi
342.15 10.595 X i
342.15 10.595(15) 183.2 = 183 muñecas.
Entonces, se espera vender 183 muñecas al precio de $15.
Veamos como obtener los indicadores del modelo de regresión usando los programas
Excel, Minitaab, SPSS y R.
En Excel:
En una hoja de Excel ingresar los valores de X e Y en las columna A y B
respectivamente. Sombrear la variable y los datos.
En Datos, escoger Análisis de datos y en Funciones para análisis, seleccionar
Regresión, y aparece la ventana de diálogo Regresión de la Figura 5.8.
203
Figura 5.8 Aplicando Regresión en Excel
En Entrada, indicar el Rango Y de entrada: $B$1:$B$9, Rango X de entrada:
$A41:$A$9 y marcar el recuadro Rótulos (para indicar los nombres de las variabes).
En Opciones de salida, escoger donde queremos que aparezcan los resultados de la
regresión, seleccionamos Rango de salida: indicándole donde queremos que salga,
aquí a partir de la celda A12. También se puede escoger obtener los resultados En una
hoja nueva: (precisar la hoja en el recuadro) o En un libro nuevo (el programa lo crea).
Para terminar hacer clic en Aceptar y se obtiene los resultados de la Figura 5.9.
A partir de la celda A12, aparece el Resumen de los cálculos de regresión, que para el
caso están sombreados y son:
Coeficiente de correlación = r = 0.993746364, Coeficiente de determinación R2 =
0.987531836, Coeficiente de intercepción = â = 342.1501104; y Coeficiente para X =
Precio = b̂ = -10.595223376.
Además, el Resumen muestra una serie de resultados de la estadística inferencial
aplicados a la regresión como es el Análisis de Varianza, intervalos de confianza y
pruebas estadísticas para los coeficientes de regresión.
204
Figura 5.9 Resultado de la Regresión de cantidad y precio de muñecas en Excel
En Minitab:
Con los datos de la variable precio (X) y cantidad (Y) en el Worksheet, del menú
escoger Stat, luego Regression y nuevamente la opción Regression; y aparece la
ventana de diálogo Regression de la Figura 5.10.
Figura 5.10 Aplicando Regresión en Minitab
205
De la lista de variables del lado izquierdo, seleccionar la variable Y = cantidad e
ingresarla en Response: (variable de respuesta o dependiente) y en Predictors:
seleccionar X = Precio.
Para terminar hacer clic en OK. Inmediatamente en la ventana de Session del Minitab
aparecen los resultados siguientes:
Regression Analysis: Y = Cantidad versus X = Precio
The regression equation is
Y = Cantidad = 342 - 10.6 X = Precio
Predictor
Constant
X = Precio
Coef
342.150
-10.5952
S = 6.06500
SE Coef
6.701
0.4860
R-Sq = 98.8%
T
51.06
-21.80
P
0.000
0.000
R-Sq(adj) = 98.5%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
6
7
SS
17481
221
17702
MS
17481
37
F
475.23
P
0.000
Se puede apreciar los mismos resultados obtenidos antes, es decir, la ecuación de
regresión, los coeficientes de regresión y el R-cuadrado obtenidos con el Minitab.
En SPSS:
Con los datos de las variables precio (X) y cantidad (Y) definidos e ingresados en el
editor de datos del SPSS, del menú seleccionar Analizar → Regresión → Lineal e
inmediatamente aparece la ventana de diálogo de la Figura5.11.
De la lista de variables del lado izquierdo, seleccionar la variable CANTIDAD e
ingresarla en el recuadro Dependiente:, del mismo modo seleccionar la variable
PRECIO e ingresarla en el recuadro Independientes:.
Una vez ingresadas las variables, hacer clic en Aceptar y aparecen los resultados
mostrados después de la Figura 5.11.
206
Figura 5.11 Aplicando Regresión en SPSS
La vista de resultados del SPSS muestra en el Resumen del modelo los coeficientes de
correlación y determinación, mientras que en los Coeficientes se presenta la constante
â = 342.150 y b̂ = -10.595.
Resumen del modelo
Modelo
1
R
R cuadrado
a
.994
.988
R cuadrado
corregida
.985
Error típ. de la
estimación
6.06500
a. Variables predictoras : (Cons tante), PRECIO ($)
Coeficientesa
Modelo
1
(Constante)
PRECIO ($)
Coeficientes no
estandarizados
B
Error típ.
342.150
6.701
-10.595
.486
a. Variable dependiente: CANTIDAD
207
Coeficientes
estandarizad
os
Beta
-.994
t
51.059
-21.800
Sig.
.000
.000
Al igual que el Minitab, también presenta el análisis de varianza para la regresión
siguiente:
ANOVAb
Modelo
1
Regres ión
Res idual
Total
Suma de
cuadrados
17480.795
220.705
17701.500
gl
1
6
7
Media
cuadrática
17480.795
36.784
F
475.226
Sig.
.000a
a. Variables predictoras : (Cons tante), PRECIO ($)
b. Variable dependiente: CANTIDAD
En R:
Definidos los valores de las variables Precio y Cantidad, por los vectores X e Y
respectivamente siguientes:
> X=c(6.5, 8.0, 10.0, 12.5, 14.0, 16.0, 17.5, 20.0)
> Y=c(276, 250, 238, 212, 190, 183, 156, 125)
A continuación utilizar la función lm para definir
> modelo=lm(Y~X)
> modelo
Call:
lm(formula = Y ~ X)
Coefficients:
(Intercept)
342.15
X
-10.60
> resumen=summary(modelo)
> resumen
208
Call:
lm(formula = Y ~ X)
Residuals:
Min
1Q
Median
-7.3883 -4.1741
0.5342
3Q
Max
2.3974 10.3735
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
342.150
6.701
51.06 3.79e-09 ***
X
-10.595
0.486
-21.80 6.09e-07 ***
--Signif. codes: 0 „***‟ 0.001 „**‟ 0.01 „*‟ 0.05 „.‟ 0.1 „ ‟ 1
Residual standard error: 6.065 on 6 degrees of freedom
Multiple R-squared: 0.9875,
Adjusted R-squared: 0.9855
F-statistic: 475.2 on 1 and 6 DF, p-value: 6.086e-07
209
Capítulo 6. MODELOS DISCRETOS DE PROBABILIDAD
“La estadística es como una mujer con bikini, muestra casi todo, pero lo
fundamental lo oculta …. Olvidaba decir que lo fundamental es …. lo
que yo quiera creer”
Robert Frost
CONTENIDO
6.1
6.2
6.3
6.4
6.5
Introducción.
Distribución binomial.
Distribución de Poisson.
Distribución hipergeométrica.
Distribución geométrica.
6.1 INTRODUCCIÓN
En el presente capítulo se presentan los modelos de probabilidad discretos cuyo cálculo
ha sido adaptado a los programas que estamos presentando y que permiten dinamizar
el aprendizaje del cálculo de probabilidades por la simplificación de los procesos.
Se presentan los principales modelos de probabilidad para variables aleatorias
discretas, en las que estamos interesados en el número de éxitos en un determinado
número de ensayos o pruebas.
La determinación del éxito o fracaso en este tipo de pruebas esta sujeto al interés
particular de quién realiza una determinada prueba.
Entre los modelos a estudiar tenemos las distribuciones: binomial, Poisson,
hipergeométrica y la Geométrica.
En cada caso se presenta las características principales de cada distribución, es decir, la
función de probabilidad, la esperanza, la varianza, la función de distribución
acumulativa de probabilidades y las respectivas formas de cálculo de probabilidades.
210
6.2 DISTRIBUCIÓN BINOMIAL
Distribución Bernoulli.Según Bazán y Corbera (1997) la distribución de Bernoulli “es el modelo más sencillo
de probabilidad y proporciona la base para derivar otras distribuciones de probabilidad
discreta”.
Las pruebas de Bernoulli tienen dos posibles resultados uno de los cuales es fijado
convencionalmente como éxito (E) y el otro como fracaso (F). Por tanto: Ω= {F, E}.
La variable aleatoria X = número de éxitos en una prueba de Bernoulli toma los
valores: Rx = {0, 1}.
La probabilidad de éxito se denota por P (E) = p = P (X = 1) y la probabilidad de
fracaso es el complemento, P (F) = q = 1 – p = P (X = 0); las mismas que se calculan
con la función de probabilidad siguiente:
p ( x ) P( X
x) p x q1 x ; x 0, 1.
La distribución de probabilidades Bernoulli es:
x
0
1
p (x) = P (X = x)
p
q=1-p
La media y la varianza de la distribución Bernoulli son: E (X) = p y Var (X) = pq
respectivamente.
Ejemplo 6.1
Son ensayos Bernoulli los siguientes:
El resultado observado en el lado superior al lanzar una moneda (cara o sello).
El estado en que se encuentra un artículo fabricado (bueno o defectuoso).
El ingreso de una familia es menor o igual a S/. 2500 o es mayor de 2500.
211
Características del ensayo binomial
Una prueba binomial se caracteriza por estar constituida por n pruebas de Bernoulli
repetidas o independientes, cada una con la misma probabilidad p de éxito y la variable
aleatoria X = número de éxitos. Rx = {0, 1, 2 , …. , n}.
Ley de probabilidad
La distribución de probabilidad binomial esta dada por la siguiente función:
p ( x) P( X
Donde: C xn
x) Cxn p x q n
x
; x 0, 1, 2,3,...., n
n!
n x ! x!
Los parámetros de la distribución binomial son n y p. Si una variable X tiene
distribución binomial, se le denota así X ~B (n,p) y la ley de probabilidades es la antes
indicada.
Media y varianza de la distribución binomial
La media y la varianza de la distribución binomial son:
y σ2 = Var (X) = npq.
µ = E (X) = np
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades de la binomial esta dada por:
F ( x) P( X
x)
P( X
xi x
Cxni p xi q n
xi )
xi
xi x
Todas estas probabilidades son calculadas por los programas estudiados, tal como
veremos a continuación.
Ejemplo 6.2
Se lanza una moneda correcta 5 veces. Sea X = el número de caras obtenidas. Calcule
la probabilidad de obtener: a) 3 caras; b) a lo más 2 caras; c) la distribución de
probabilidades; y d) la función de distribución acumulativa de probabilidades.
212
Solución
Cada lanzamiento de la moneda es una prueba de Bernoulli, ya que estamos
interesados en observar si sale cara (éxito) o no sale (fracaso), con p = q = 0.5.
Así mismo, se trata de n = 5 pruebas independientes, puesto que el resultado de un
lanzamiento no influye en los sucesivos.
Por lo tanto, la variable aleatoria X = número de caras obtenidas ~B (n=5, p = 0.5) y su
función de probabilidad es:
p ( x) P( X
x) Cx5 (0.5) x (0.5)5
1
3) C35 ( )5
2
a) p(3) P( X
x
10
32
Cx5 (0.5)5 ; x 0, 1, 2,3, 4,5.
0.3125
b) P (X ≤ 2) = p(0) + p(1) + p(2) =
1
1
1
= C05 ( )5 C15 ( )5 C25 ( )5
2
2
2
1
5 10
32 32 32
16
32
0.50
c) La distribución de probabilidades binomial, calculadas con la función de
probabilidad, se presentan en el cuadro siguiente:
x
0
1
2
3
4
5
1/32 =
5/32 =
10/32 =
10/32 =
5/32 =
1/32 =
0.03125
0.15625
0.31250
0.31250
0.15625
0.03125
1/32 =
6/32 =
16/32 =
26/32 =
31/32 =
32/32 =
0.03125
0.18750
0.50000
0.81250
0.96875
1.00000
p(x)
F(x)
d) La distribución acumulativa de probabilidades se ha determinado con la función
F ( x) P( X
x)
P( X
xi x
Cx5i (0.5) xi y se presentan en la tabla
xi )
xi x
anterior de la pregunta c).
213
Veamos el procedimiento de cálculo de estas probabilidades con los programas, las
mismas que están sintetizadas en la tabla de la pregunta c) y d).
En Excel:
Para hallar la distribución de probabilidades binomial, en la hoja de cálculo definimos
en la columna A los valores de la variable x = 0, 1, 2, 3, 4 y 5. En la columna B,
definimos las probabilidades p(x) para cada uno de los valores.
Para ello, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas
(de seleccionar una categoría) y buscamos la función DISTR.BINOM y aparece la
ventana de diálogo de la Figura 6.1.
Figura 6.1 Cálculo de probabilidades para la distribución binomial en Excel
En Argumentos de función se define: el número de éxitos, Núm_éxito A2 (0) para
poder efectuar una copia para los demás valores de x. Ensayos 5 (número de ensayos
independientes = 5 lanzamientos de la moneda). La probabilida p de éxito Prob_éxito
214
0.5 y en Acumulado escribir FALSO, porque no se desea calcular probabilidad
acumulada. Al hacer enter, aparece la probabilidad p(0) = 0.03125.
Para obtener las probabilidades para los otros valores de x, se efectúa una copia de lo
anterior para las celdas sucesivas en B3, B4, B5, B6 y B7, cuyos resultados se
muestran en la Figura 6.2.
Para obtener las probabilidades acumuladas, estando en la casilla C2, seleccionamos la
ventana de diálogo de la Figura 6.1, con los mismos Argumentos de función, salvo el
de Acumulado en el que se escribe VERDADERO. Al hacer enter, aparece la
probabilidad F(0) = 0.03125.
Para obtener las probabilidades acumuladas para los otros valores de x, se efectúa una
copia de lo anterior para las celdas sucesivas en C3, C4, C5, C6 y C7, cuyos resultados
se muestran en la Figura 6.2.
Figura 6.2 Solución del Ejemplo 6.2 en Excel
En Minitab:
En este programa se puede hacer cálculos de probabilidades individuales o para el
conjunto de valores que toma la variable, tal como se ha efectuado en Excel.
Del menú escoger Calc → Probability Distributions → Binomial y aparece la
ventana de diálogo de la Figura 6.3.
Esta función permite tres tipos de cálculos: Probabililty (calcular una probabilidad para
un valor de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor determinado) e Inverse cumulative probability (calcular el valor de la
215
variable para una probabilidad acumulada dada). Cálculos que son realizados
indicando previamente los parámetros de la distribución binomial, es decir, n =
Number of trials (número de pruebas) y p = Event probability (probabilidad de éxito).
Figura 6.3 Probabilidad con la distribución binomial en Minitab
Veamos el cálculo de probabilidades individuales.
En el ejemplo 6.2, la variable aleatoria X = número de caras obtenidas ~B (n=5, p =
0.5) parámetros indicados en la Figura 6.3. En la parte a) se solicita p (3) = P (X = 3)
por ello se ha activado Probability
e
donde se escribe 3.
Al hacer clic en OK, en la hoja de Session aparece el resultado siguiente:
Probability Density Function
Binomial with n = 5 and p = 0.5
x
3
P( X = x )
0.3125
En la parte b) del ejemplo 6.2 se solicita la probabilidad acumulada F (2) = P (X ≤ 2)
por lo que se hace necesario seleccionar
escribir 2, tal como se muestra en la Figura 6.4.
216
y en
Figura 6.4 Probabilidad acumulada con la distribución binomial en Minitab
Al hacer clic en OK, en la hoja de Session aparece el resultado siguiente:
Cumulative Distribution Function
Binomial with n = 5 and p = 0.5
x P( X <= x )
2
0.5
Resultados similares a los del ejemplo 6.2.
Veamos el cálculo de probabilidades para un conjunto de valores
Primero definir los valores en una columna de la Worksheet (hoja de trabajo del
Minitab); para el ejemplo 6.2, en la columna C1 con la denominación x se han definido
los valores 0, 1, 2, 3, 4 y 5.
Para calcular las probabilidades para cada uno de los valores de la variable, se procede
de manera similar a lo realizado en la Figura 6.3, sólo que no se selecciona Input
constant:, sino
en donde se selecciona la columna C1 o x, tal como se
muestra en la Figura 6.5.
217
Como son seis probabilidades las que se van a calcular se tiene que indicar donde se
quiere colocar dichos resultados.
Figura 6.5 Probabilidad para varios valores con distribución binomial en Minitab
Si se desea seguir usando estos resultados para hacer otros cálculos, los mismos deben
aparecer en la Worksheet del Minitab, por ello en Optional storage: (deposito
opcional de resultados) escribir C2. Para terminar hacer clic en OK y los resultados se
muestran en la columna C2 de la Worksheet.
Si no se van hacer otros cálculos con los resultados, hacer clic en OK y dichos
resultados se muestran en la hoja de Session así:
Probability Density Function
Binomial with n = 5 and p = 0.5
x
0
1
2
3
4
5
P( X = x )
0.03125
0.15625
0.31250
0.31250
0.15625
0.03125
218
Para calcular las probabilidades acumuladas para los seis valores del ejemplo 6.2 y con
los resultados en la hoja de Session, en la Figura 6.5 seleccionar
y al hacer clic en OK aparecen los resultados siguientes:
Cumulative Distribution Function
Binomial with n = 5 and p = 0.5
x P( X <= x )
0
0.03125
1
0.18750
2
0.50000
3
0.81250
4
0.96875
5
1.00000
Los dos últimos resultados son idénticos a los que aparecen en la Figura 6.2, los que a
continuación se presentan tal como se han obtenido en la Worksheet del Minitab.
El gráfico de la distribución binomial obtenido con el Minitab es el siguiente:
Gráfico 6.1 Distribución binomial (n = 5, p = 0.5)
0.35
0.30
p(x)
0.25
0.20
0.15
0.10
0.05
0.00
0
1
2
3
x
219
4
5
En SPSS:
Para calcular las probabilidades simples (P) y las acumuladas (F) del ejemplo 6.2, en la
vista de variables se define x y en la vista de datos se ingresan los mismos (0, 1, 2, 3, 4
y 5). Veamos el cálculo de probabilidades simples (P).
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 6.6. En Variable de destino: escribir P.
Del Grupo de funciones: del lado derecho, escoger FDP y FDP no centrada; y de
Funciones y variables especiales: seleccionar Pdf.Binom y con un clic en
ingresarla en el recuadro Expresión numérica: donde aparece PDF.BINOM(?,?,?).
Figura 6.6 Cálculo de probabilidades con la distribución binomial en SPSS
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
PDF.BINOM(cant,n,prob) que se precisan en el recuadro central de la Figura 6.6. Así
cant representa los valores de la variable x, n el número de ensayos = 5 y prob =
220
probabilidad de éxito = 0.5. Para finalizar hacer clic en Aceptar y en la vista de datos
aparece los resultados siguientes:
Para el cálculo de las probabilidades acumuladas (F) del ejemplo 6.2, proceder de
manera similar al cálculo de probabilidades simples, con las variantes indicadas, tal
como se muestra en la Figura 6.7.
Figura 6.7 Probabilidades acumuladas con la distribución binomial en SPSS
En la Variable de destino: se escribe F. Del Grupo de funciones: escoger FDA y FDA
no centrada; y de Funciones y variables especiales: seleccionar Cdf.Binom e
ingresarla en el recuadro Expresión numérica y definir los argumentos cant, n y prob
221
así: CDF.BINOM(x,5,0.5). Para finalizar hacer clic en Aceptar y en la vista de datos
aparece los resultados siguientes:
Nota.- para el cálculo de probabilidades simples en SPSS se usa la función FDP y
FDP no centrada y para calcular las probabilidades acumuladas la función FDA y
FDA no centrada.
En R:
Para calcular probabilidades simples con la distribución binomial usar la función
dbinom(x,n,p). Donde x puede ser un valor o un conjunto de valores definidos
previamente, n el número de ensayos y p la probabilidad de éxito.
En el ejemplo 6.2, X = número de caras obtenidas ~B (n=5, p = 0.5). En la parte a) se
solicita p (3) = P (X = 3), esto se calcula así:
> dbinom(3,5,0.5)
[1] 0.3125
Si se desea determinar la distribución de probabilidades de la variable aleatoria X,
primero se define el vector de valores y luego se calculan las probabilidades así:
> x=c(0,1,2,3,4,5)
> dbinom(x,5,0.5)
[1] 0.03125 0.15625 0.31250 0.31250 0.15625 0.03125
El resultado anterior muestra las probabilidades para cada valor de X, pero la
presentación del resultado no permite una adecuada lectura. Por ello se recomienda
definir las probabilidades anteriores a través del objeto P definido así:
222
> P=dbinom(x,5,0.5)
Para mejorar la presentación de la distribución de probabilidades (x, P) usar la función
cbind que permite presentar los resultados de los objetos definidos en columna, uno a
continuación de otro, así:
> cbind(x,P)
x
P
[1,] 0 0.03125
[2,] 1 0.15625
[3,] 2 0.31250
[4,] 3 0.31250
[5,] 4 0.15625
[6,] 5 0.03125
Para calcular probabilidades acumuladas con la distribución binomial usar la función
pbinom(x,n,p). Donde x puede ser un valor o un conjunto de valores definidos
previamente, n el número de ensayos y p la probabilidad de éxito.
En la parte b) del ejemplo 6.2 se solicita F (2) = P (X ≤ 2), esto se calcula así:
> pbinom(2,5,0.5)
[1] 0.5
Para obtener la distribución de probabilidades y las probabilidades acumuladas
efectuamos el siguiente proceso.
> F=pbinom(x,5,0.5)
> cbind(x,P,F)
x
P
F
[1,] 0 0.03125 0.03125
[2,] 1 0.15625 0.18750
223
[3,] 2 0.31250 0.50000
[4,] 3 0.31250 0.81250
[5,] 4 0.15625 0.96875
[6,] 5 0.03125 1.00000
Resultados idénticos a los obtenidos con los demás programas.
Observación.- para las siguientes distribuciones de probabilidades los cálculos
efectuados con los programas estudiados son similares a los de la distribución
binomial.
6.3 DISTRIBUCIÓN DE POISSON
La distribución Poisson se deduce como un límite de la distribución binomial y como
un proceso de Poisson.
Como un límite de la distribución binomial, se toma con media igual a λ = np
asumiendo p pequeño (p → 0) y n grande (n → ∞). La distribución de probabilidades
de la variable aleatoria discreta de Poisson X = número de éxitos viene dada por:
x
p( x) P( X
e
; x 0, 1, 2,3,....
x!
x)
El parámetro de la distribución Poisson es λ. Si una variable X tiene distribución
Poisson, se le denota así X ~ P (λ) y la ley de probabilidades es la antes indicada.
Media y varianza de la distribución Poisson
La media y la varianza de la distribución Poisson es la misma e igual a λ.
µ = E (X) = σ2 = Var (X) = λ.
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades de la Poisson esta dada por:
xi
F ( x) P( X
x)
P( X
xi x
xi )
xi x
e
xi !
224
La deducción como un proceso de Poisson, surge cuando hay eventos discretos que
se generan en un intervalo continuo t (unidad de medida: longitud, área, volumen,
tiempo, etc.) y forman un proceso de Poisson con parámetro λ, si tiene las siguientes
propiedades.
El promedio de éxitos que ocurren en una unidad de medida t es conocido e igual a
λt.
La ocurrencia de los eventos son independientes.
La probabilidad de éxito en una unidad de medida pequeña de longitud h es
proporcional a su longitud: λh.
La probabilidad de ocurrencia de 2 o más éxitos en esta unidad pequeña h es
aproximadamente cero.
Si en un proceso de Poisson de parámetro λ se observa t unidades de medida, se define
X = número de ocurrencias de eventos en las t unidades de medida. Entonces, el
recorrido de la variable es RX = {0, 1, 2, 3, …. }.
La variable aleatoria X tiene distribución Poisson definida por:
p ( x) P( X
x)
( t)x e
x!
t
; x 0, 1, 2,3,....
Donde λt es el promedio de ocurrencias de los eventos en las t unidades de medida.
En ambas fórmulas del cálculo de probabilidades con la distribución de Poisson lo
primero que se tiene que determinar es la media, bien λ o λt.
Ejemplo 6.3
El promedio de llamadas recibidas por una central telefónica en un minuto es igual a 2.
Calcule la probabilidad de que en 2 minutos se reciban: a) 3 llamadas; b) a lo más 2
llamadas; c) la distribución de probabilidades; y d) la función de distribución
acumulativa de probabilidades.
225
Solución
Como λ = 2 y t = 2, λt = 4 llamadas promedio en 2 minutos.
Sea X = el número de llamadas recibidas en 2 minutos ~ P (4) y la ley de
probabilidades es:
p( x) P( X
x)
4x e 4
; x 0, 1, 2,3,.... Luego:
x!
a) p(3) = P(X = 3) =
43 e 4
= 0.195367
3!
b) P (X ≤ 2) = p(0) + p(1) + p(2) =
40 e 4
0!
41 e 4
1!
42 e 4
= 0.23810
2!
c) La distribución de probabilidades Poisson, calculadas con la función de
probabilidad, se presentan en el cuadro siguiente:
x
p(x) = P(X = x)
F(x) = P(X ≤ x)
0
0.018316
0.018316
1
0.073262
0.091578
2
0.146525
0.238103
3
0.195367
0.433470
4
0.195367
0.628837
5
0.156293
0.785130
6
0.104196
0.889326
7
0.059540
0.948866
8
0.029770
0.978637
9
0.013231
0.991868
10
0.005292
0.997160
11
0.001925
0.999085
12
0.000641
0.999726
226
d) La distribución acumulativa de probabilidades se ha determinado con la función
F ( x) P( X
x)
P( X
xi x
xi )
xi
4 xi e 4
y se presentan en la tabla anterior
xi !
x
de la pregunta c).
Veamos el procedimiento de cálculo de estas probabilidades con los programas, las
mismas que están sintetizadas en la tabla de la pregunta c) y d).
En Excel:
Para hallar la distribución de probabilidades Poisson, en la hoja de cálculo definimos
en la columna A los valores de la variable x = 0, 1, 2, 3, 4, …., 15, ….. En la columna
B, definimos las probabilidades p(x) para cada uno de los valores.
Para ello, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas
(de seleccionar una categoría) y buscamos la función POISSON y aparece la ventana
de diálogo de la Figura 6.8.
Figura 6.8 Cálculo de probabilidades para la distribución Poisson en Excel
227
En Argumentos de función se define: el número de éxitos, x A2 (0) para poder
efectuar una copia para los demás valores de x. Media 4 y en Acumulado escribir
FALSO, porque no se desea calcular probabilidad acumulada. Al hacer enter, aparece
la probabilidad p(0) = 0.01832.
Para obtener las probabilidades para los otros valores de x, se efectúa una copia de lo
anterior para las celdas sucesivas en B3, B4, hasta B17, cuyos resultados se muestran
en la Figura 6.9.
Para obtener las probabilidades acumuladas, estando en la casilla C2, seleccionamos la
ventana de diálogo de la Figura 6.8, con los mismos Argumentos de función, salvo el
de Acumulado en el que se escribe VERDADERO. Al hacer enter, aparece la
probabilidad F(0) = 0.01832.
Para obtener las probabilidades acumuladas para los otros valores de x, se efectúa una
copia de lo anterior para las celdas sucesivas en C3, C4, hasta C17, cuyos resultados
se muestran en la Figura 6.9.
Figura 6.9 Solución del Ejemplo 6.3 en Excel
228
En Minitab:
En este programa, al igual que en la distribución binomial, se puede hacer cálculos de
probabilidades individuales o para el conjunto de valores que toma la variable.
Del menú escoger Calc → Probability Distributions → Poisson y aparece la ventana
de diálogo de la Figura 6.10. En el ejemplo 6.3, la variable aleatoria X = número de
llamadas recibidas ~P (λ=4) parámetro indicado en la Figura 6.10.
Esta función permite tres tipos de cálculos: Probabililty (calcular una probabilidad para
un valor de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor determinado) e Inverse cumulative probability (calcular el valor de la
variable para una probabilidad acumulada dada). Cálculos que se realizan indicando
previamente el parámetro de la distribución Poisson, es decir, λ = 4 = Mean (media).
Figura 6.10 Probabilidad con la distribución Poisson en Minitab
Veamos el cálculo de probabilidades individuales.
Para calcular la probabilidad de X = 3, activar
, seleccionar
y en el recuadro escribir 3. Al hacer clic en OK, en la hoja de Session
aparece este resultado:
229
Probability Density Function
Poisson with mean = 4
x
3
P( X = x )
0.195367
Para calcular las probabilidades individuales para todos los valores de x= 0, 1, 2, 3, 4,
…., 15 especificados en la columna C1 de la Worksheet se activa Probability
. Seleccionar
y escoger x en el recuadro; y en Optional
storage; se escoge p(x) para que los resultados los deposite en la misma Worksheet. Al
hacer clic en OK, en la Worksheet aparecen los resultados de la Figura 6.11.
Figura 6.11 Probabilidad para varios valores con distribución Poisson en Minitab
Para calcular las probabilidades acumuladas para los valores del ejemplo 6.3 y
con los resultados en la Worksheet, en la Figura 6.10 seleccionar
y en Optional storage: seleccionar F(x). Al hacer clic en OK
en la Worksheet aparecen los resultados de la Figura 6.11.
El gráfico de la distribución Poisson obtenido con el Minitab es el siguiente:
230
Gráfico 6.2 Distribución de Poisson con λ = 4
0.20
p(x)
0.15
0.10
0.05
0.00
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
x
En SPSS:
Para calcular las probabilidades simples (P) del ejemplo 6.3, en la vista de variables se
define x y en la vista de datos se ingresan los mismos (0, 1, 2, 3, 4, …., 15, …).
Figura 6.12 Cálculo de probabilidades con la distribución Poisson en SPSS
231
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 6.12. En Variable de destino: escribir P.
Del Grupo de funciones: del lado derecho, escoger FDP y FDP no centrada; y de
Funciones y variables especiales: seleccionar Pdf.Poison y con un clic en
ingresarla en el recuadro Expresión numérica: donde aparece PDF.POISSON(?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
PDF.POISSON(cant,media) que se precisan en el recuadro central de la Figura 6.12.
Así cant representa los valores de la variable x, y media = λ = 4. Para finalizar hacer
clic en Aceptar y en la vista de datos aparece los resultados de la Figura 6.14.
Para el cálculo de las probabilidades acumuladas (F) del ejemplo 6.3, proceder de
manera similar al cálculo de probabilidades simples, con las variantes indicadas, tal
como se muestra en la Figura 6.13.
Figura 6.13 Probabilidades acumuladas con la distribución Poisson en SPSS
232
En la Variable de destino: se escribe F. Del Grupo de funciones: escoger FDA y FDA
no centrada; y de Funciones y variables especiales: seleccionar Cdf.Poisson e
ingresarla en el recuadro Expresión numérica y definir los argumentos cant y media
así: CDF.POISSON(x,4). Para finalizar hacer clic en Aceptar y en la vista de datos
aparece los resultados de la Figura 6.14.
Figura 6.14 Distribución de probabilidades Poisson del ejemplo 6.3 en SPSS
En R:
Para calcular probabilidades simples con la distribución Poisson usar la función
dpois(x,λ). Donde x puede ser un valor o un conjunto de valores definidos previamente
y λ la media.
En el ejemplo 6.3, X = número de llamadas recibidas ~ P (λ = 4). En la parte a) se
solicita p (3) = P (X = 3), esto se calcula así:
> dpois(3,4)
[1] 0.1953668
233
Si se desea determinar la distribución de probabilidades de la variable aleatoria X,
primero se define el vector de valores y luego se calculan las probabilidades así:
> x=c(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)
> P=dpois(x,4)
Para presentar la distribución de probabilidades (x, P) usar la función cbind que
permite presentar los resultados de los objetos definidos en columna, uno a
continuación de otro, así:
> cbind(x,P)
x
P
[1,]
0 1.831564e-02
[2,]
1 7.326256e-02
[3,]
2 1.465251e-01
[4,]
3 1.953668e-01
[5,]
4 1.953668e-01
[6,]
5 1.562935e-01
[7,]
6 1.041956e-01
[8,]
7 5.954036e-02
[9,]
8 2.977018e-02
[10,]
9 1.323119e-02
[11,] 10 5.292477e-03
[12,] 11 1.924537e-03
[13,] 12 6.415123e-04
[14,] 13 1.973884e-04
[15,] 14 5.639669e-05
[16,] 15 1.503912e-05
Para calcular probabilidades acumuladas con Poisson usar la función ppois(x,λ).
Donde x puede ser un valor o un conjunto de valores definidos y λ la media.
234
En la parte b) del ejemplo 6.3 se solicita F (2) = P (X ≤ 2), esto se calcula así:
> ppois(2,4)
[1] 0.2381033
Para obtener la distribución de probabilidades y las probabilidades acumuladas
efectuamos el siguiente proceso.
> F=ppois(x,4)
> cbind(x,P,F)
x
P
F
[1,]
0 1.831564e-02 0.01831564
[2,]
1 7.326256e-02 0.09157819
[3,]
2 1.465251e-01 0.23810331
[4,]
3 1.953668e-01 0.43347012
[5,]
4 1.953668e-01 0.62883694
[6,]
5 1.562935e-01 0.78513039
[7,]
6 1.041956e-01 0.88932602
[8,]
7 5.954036e-02 0.94886638
[9,]
8 2.977018e-02 0.97863657
[10,]
9 1.323119e-02 0.99186776
[11,] 10 5.292477e-03 0.99716023
[12,] 11 1.924537e-03 0.99908477
[13,] 12 6.415123e-04 0.99972628
[14,] 13 1.973884e-04 0.99992367
[15,] 14 5.639669e-05 0.99998007
[16,] 15 1.503912e-05 0.99999511
235
6.4 DISTRIBUCIÓN HIPERGEOMÉTRICA
Esta distribución esta asociada a experimentos del siguiente tipo: de un conjunto de N
objetos, de los cuales M poseen cierta característica de interés y el resto N – M no la
poseen, se extrae n objetos al azar y sin reemplazo; y se observa el número x de
objetos en la muestra que poseen la característica de interés.
Dicho experimento tiene asociada una variable aleatoria X que da el número x de
éxitos (objetos en la muestra que poseen la característica de interés) en n ensayos de
Bernoulli cuya distribución de probabilidades esta dada por:
p( x) P( X
x)
CxM CnN xM
; máx {o, n + M - N} ≤ x ≤ mín {n, M}
CnN
Los parámetros de la distribución hipergeométrica son N, M y n. Si una variable X
tiene distribución hipergeométrica, se le denota así X ~ Hiper (N, M, n) y la ley de
probabilidades es la antes indicada.
Media y varianza de la distribución hipergeométrica
La media y la varianza de la distribución hipergeométrica son:
µ = E (X) = np y σ2 = Var (X) = npq(N –n) / (N – 1)
Donde: p = M/N y q = (N – M) / N = 1 - p
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades de la hipergeométrica esta
dada por:
F ( x) P( X
x)
P( X
xi x
CxMi CnN xiM
xi )
xi x
CnN
Ejemplo 6.4
De la baraja de 52 cartas se reparten 5 naipes sin reposición. Sea X el número de
naipes de color negros repartidos. Calcule la probabilidad de que entre los 5 naipes
236
repartidos hayan: a) 3 naipes negros; b) a lo más 2 naipes negros; c) la distribución de
probabilidades; y d) la función de distribución acumulativa de probabilidades.
Solución
En la baraja N = 52 cartas, M = 26 cartas negras, n = 5 cartas repartidas sin reposición.
Sea X = el número de naipes negros repartidos ~ Hiper (52, 26, 5) y la ley de
probabilidades es:
p ( x) P( X
Cx26 C526x
x)
; x 0,1, 2,3, 4,5 Luego:
C552
a) p(3) P( X
3)
C326 C226
= 0.32513
C552
b) P (X ≤ 2) = p(0) + p(1) + p(2) =
C026 C526
C552
C226 C326
=
C552
C126 C426
C552
= 0.02531 + 0.14956 + 0.32513 = 0.50000
c) La distribución de probabilidades, calculadas con la función de probabilidad
hipergeométrica, se presentan en el cuadro siguiente:
x
0
1
2
3
4
5
p(x)
0.02531
0.14956
0.32513
0.32513
0.14956
0.02531
F(x)
0.02531
0.17487
0.50000
0.82513
0.97469
1.00000
d) La distribución acumulativa de probabilidades se ha determinado con la función
F ( x) P( X
x)
P( X
xi x
Cx26i C526xi
xi )
xi x
C552
y se presentan en la tabla anterior
de la pregunta c).
Veamos el procedimiento de cálculo de estas probabilidades con los programas, las
mismas que están sintetizadas en la tabla de la pregunta c) y d).
237
En Excel:
Para hallar la distribución de probabilidades hipergeométrica, en la hoja de cálculo
definimos en la columna A los valores de la variable x = 0, 1, 2, 3, 4 y 5. En la
columna B, definimos las probabilidades p(x) para cada uno de los valores.
Para ello, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas
(de seleccionar una categoría) y buscamos la función DISTR.HIPERGEOM y
aparece la ventana de diálogo de la Figura 6.15.
Figura 6.15 Cálculo de distribución hipergeométrica en Excel
En Argumentos de función se define: el número de éxitos en la muestra,
Muestra_éxito A2 (0) para poder efectuar una copia para los demás valores de x.
Num_de_muestra 5 (es el tamaño de la muestra n). Población_éxito 26 (es el
número de éxitos en la población = M) y en Num_de_población 52 (el tamaño de la
población N). Al hacer enter, aparece la probabilidad p(0) = 0.02531.
Para obtener las probabilidades para los otros valores de x, se efectúa una copia de lo
anterior para las celdas sucesivas en B3, B4, B5, B6 y B7, cuyos resultados se
muestran en la Figura 6.16.
238
Las probabilidades acumuladas F(x) se han determinado haciendo los cálculos en la
columna C usando los de la columna B, estos se muestran en la Figura 6.16.
Figura 6.16 Solución del Ejemplo 6.4 en Excel
En Minitab:
En este programa, al igual que en la distribución binomial y Poisson, se puede hacer
cálculos de probabilidades individuales o para el conjunto de valores que toma la
variable.
Del menú escoger Calc → Probability Distributions → Hipergeometric y aparece
la ventana de diálogo de la Figura 6.17. En el ejemplo 6.4, la variable aleatoria X =
número de naipes negros repartidos ~ Hiper (52, 26, 5) parámetros indicados en la
Figura 6.17.
Esta función permite tres tipos de cálculos: Probabililty (calcular una probabilidad para
un valor de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor determinado) e Inverse cumulative probability (calcular el valor de la
variable para una probabilidad acumulada dada).
Cálculos que se realizan indicando previamente los parámetros de la distribución
hipergeométrica, es decir:
Population size (N): = el tamaño de la población = 52;
Event count in population (M) = número de éxitos en la población = 26; y
Sample size (n): = tamaño de la muestra = 5.
239
Figura 6.17 Probabilidad con la distribución hipergeométrica en Minitab
Veamos el cálculo de probabilidades individuales.
Para calcular la probabilidad de X = 3, se activa
, seleccionar
y en el recuadro escribir 3. Al hacer clic en OK, en la hoja de Session
aparece este resultado:
Probability Density Function
Hypergeometric with N = 52, M = 26, and n = 5
x
3
P( X = x )
0.325130
Para calcular las probabilidades individuales para todos los valores de x= 0, 1, 2, 3, 4,
…., 15 especificados en la columna C1 de la Worksheet se activa Probability
. Seleccionar
y escoger x en el recuadro; y en Optional
storage; se escoge p(x) para que los resultados los deposite en la misma Worksheet. Al
hacer clic en OK, en la Worksheet aparecen los resultados de la Figura 6.18.
Para calcular las probabilidades acumuladas para los valores del ejemplo 6.4 y
con los resultados en la Worksheet, en la Figura 6.17 seleccionar
240
y en Optional storage: seleccionar F(x). Al hacer clic en OK
en la Worksheet aparecen los resultados de la Figura 6.18.
Figura 6.18 Probabilidades con distribución hipergeométrica en Minitab
El gráfico de la distribución hipergeométrica obtenido con el Minitab es el siguiente:
Gráfico 6.3 Distribución hipergeométrica con N = 52, M = 26, n = 5
0.35
0.30
p(x)
0.25
0.20
0.15
0.10
0.05
0.00
0
1
2
3
4
5
x
En SPSS:
Para calcular las probabilidades simples (P) del ejemplo 6.4, en la vista de variables se
define x y en la vista de datos se ingresan los mismos (0, 1, 2, 3, 4, 5).
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 6.19. En Variable de destino: escribir P.
241
Figura 6.19 Cálculo de probabilidades con la distrib. hipergeométrica en SPSS
Del Grupo de funciones: del lado derecho, escoger FDP y FDP no centrada; y de
Funciones y variables especiales: seleccionar Pdf.Hiper y con un clic en
ingresarla en el recuadro Expresión numérica: donde aparece PDF.HIPER(?,?,?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
PDF.HIPER(cant,total,muestra,aciertos) que se precisan en el recuadro central de la
Figura 6.19. Así cant representa los valores de la variable x, total = N = 52, muestra =
n = 5 y aciertos = M = 26. Para finalizar hacer clic en Aceptar y en la vista de datos
aparece los resultados de la Figura 6.21.
Para el cálculo de las probabilidades acumuladas (F) del ejemplo 6.4, proceder de
manera similar al cálculo de probabilidades simples, con las variantes indicadas, tal
como se muestra en la Figura 6.20.
En la Variable de destino: se escribe F. Del Grupo de funciones: escoger FDA y FDA
no centrada; y de Funciones y variables especiales: seleccionar Cdf.Hiper e
242
ingresarla en el recuadro Expresión numérica y definir los argumentos cant, total,
muestra y aciertos, así: CDF.HIPER(x,52,5,26).
Figura 6.20 Probabilidades acumuladas con la distrib. hipergeométrica en SPSS
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 6.21.
Figura 6.21 Distrib. de probabilidades hipergeométrica del ejemplo 6.4 en SPSS
243
En R:
Para calcular probabilidades simples con la distribución hipergeométrica usar la
función dhyper(x,M,N-M,n). Donde x puede ser un valor o un conjunto de valores
definidos previamente, M = objetos con la característica de interés, N-M = objetos sin
la característica de interés y n el tamaño de la muestra.
En el ejemplo 6.4, X = número de naipes negros repartidos ~ Hiper (N = 52, M =26, n
= 5). En la parte a) se solicita p (3) = P (X = 3), esto se calcula así:
> dhyper(3,26,26,5)
[1] 0.3251301
Si se desea determinar la distribución de probabilidades de la variable aleatoria X,
primero se define el vector de valores y luego se calculan las probabilidades así:
> x=c(0,1,2,3,4,5)
> P=dhyper(x,26,26,5)
Para presentar la distribución de probabilidades (x, P) usar la función cbind que
permite presentar los resultados de los objetos definidos en columna, uno a
continuación de otro, así:
> cbind(x,P)
x
P
[1,] 0 0.02531012
[2,] 1 0.14955982
[3,] 2 0.32513005
[4,] 3 0.32513005
[5,] 4 0.14955982
[6,] 5 0.02531012
244
Para calcular probabilidades acumuladas con la hipergeométrica usar la función
phyper(x,M,N-M,n). Donde x puede ser un valor o un conjunto de valores definidos
previamente, M = objetos con la característica de interés, N-M = objetos sin la
característica de interés y n el tamaño de la muestra.
En la parte b) del ejemplo 6.4 se solicita F (2) = P (X ≤ 2), esto se calcula así:
> phyper(2,26,26,5)
[1] 0.5
Para obtener la distribución de probabilidades y las probabilidades acumuladas
efectuamos el siguiente proceso.
> F=phyper(x,26,26,5)
> cbind(x,P,F)
x
P
F
[1,] 0 0.02531012 0.02531012
[2,] 1 0.14955982 0.17486995
[3,] 2 0.32513005 0.50000000
[4,] 3 0.32513005 0.82513005
[5,] 4 0.14955982 0.97468988
[6,] 5 0.02531012 1.00000000
Resultados idénticos para cada uno de los programas empleados. Cabe resaltar que
cualquiera de los cálculos de probabilidades con otras distribuciones son similares,
vemos ahora la distribución geométrica de probabilidades.
245
6.5 DISTRIBUCIÓN GEOMÉTRICA
Es una distribución que se relaciona con el proceso de Bernoulli excepto que el
número de ensayos no es fijo.
La variable aleatoria geométrica se define como X = número de ensayos
independientes requeridos hasta obtener el primer éxito, con probabilidad de éxito p y
probabilidad de fracaso q.
La ley de probabilidades geométrica está dada por:
p ( x ) P( X
x) p q x 1 ; x 1, 2,3, 4,5,....
El parámetro de la distribución geométrica es p. Si una variable X tiene distribución
geométrica, se le denota así X ~ Geom (p) y la ley de probabilidades es la antes
indicada.
Media y varianza de la distribución geométrica
La media y la varianza de la distribución geométrica son:
µ = E (X) = 1/p y σ2 = Var (X) = q/p2
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades de la geométrica esta dada
por:
F ( x) P( X
x)
P( X
xi x
q xi
xi ) p
1
xi x
Ejemplo 6.5
Se lanza una moneda cargada con probabilidad de cara igual a 1/4. Sea X el número de
lanzamientos de la moneda hasta obtener cara. Calcule la probabilidad de que se
hayan realizado: a) 3 lanzamientos; b) a lo más 2 lanzamientos; c) la distribución de
probabilidades; y d) la función de distribución acumulativa de probabilidades.
246
Solución
El éxito es obtener cara, entonces p = P(C) = ¼= 0.25 y q = ¾ = 0.75.
Sea X = el número de lanzamientos de la moneda hasta obtener cara ~ Geom (0.25) y
la ley de probabilidades es:
p( x) P( X
1
4
x)
a) p(3) P( X
3)
3
4
1
4
x 1
; x 1, 2,3, 4,.... Luego:
3
4
3 1
1
b) P (X ≤ 2) = p(1) + p(2) =
4
= 0.14063
3
4
1 1
1
4
3
4
2 1
=
= 0.25000 + 0.18750 = 0.4375
c) La distribución de probabilidades, calculadas con la función de probabilidad
geométrica, se presenta en el cuadro siguiente:
x
p(x) = P(X = x)
F(x) = P(X ≤ x)
1
0.25000
0.25000
2
0.18750
0.43750
3
0.14063
0.57813
4
0.10547
0.68359
5
0.07910
0.76270
6
0.05933
0.82202
7
0.04449
0.86652
8
0.03337
0.89989
9
0.02503
0.92492
10
0.01877
0.94369
11
0.01408
0.95776
247
d) La distribución acumulativa de probabilidades se ha determinado con la función
F ( x) P( X
x)
P( X
xi x
1
xi )
4 xi
x
3
4
xi 1
y se presentan en la tabla
anterior de la pregunta c).
Veamos el procedimiento de cálculo de estas probabilidades con los programas, las
mismas que están sintetizadas en la tabla de la pregunta c) y d).
En Excel:
La distribución de probabilidades geométrica no esta definida en el Excel, pero se
pueden obtener en la hoja de cálculo trabajando con la fórmula. Para ello definir en la
columna A, los valores de la variable x, luego en la columna B definir las
probabilidades p(x) como fórmula de cálculo. Del mismo modo en la columna C,
definir los acumulados, bajo la forma tradicional de acumulación y se obtiene el
resultado mostrado en la Figura 6.22.
Figura 6.22 Solución del Ejemplo 6.5 en Excel
248
En Minitab:
En este programa, al igual que para las distribuciones anteriores, se puede hacer
cálculos de probabilidades individuales o para el conjunto de valores que toma la
variable.
Del menú escoger Calc → Probability Distributions → Geometric y aparece la
ventana de diálogo de la Figura 6.23. En el ejemplo 6.5, la variable aleatoria X = el
número de lanzamientos de la moneda hasta obtener cara ~ Geom (0.25) parámetro
indicado en la Figura 6.23.
Figura 6.23 Probabilidad con la distribución geométrica en Minitab
Esta función permite tres tipos de cálculos: Probabililty (calcular una probabilidad para
un valor de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor determinado) e Inverse cumulative probability (calcular el valor de la
variable para una probabilidad acumulada dada).
Cálculos que se realizan indicando previamente el parámetro de la distribución
geométrica, es decir: p = 0.25 escrito en Event probability.
249
Veamos el cálculo de probabilidades individuales.
Para calcular la probabilidad de X = 3, se activa
, seleccionar
y en el recuadro escribir 3. Al hacer clic en OK, en la hoja de Session
aparece este resultado:
Probability Density Function
Geometric with p = 0,25
x
3
P( X = x )
0,140625
* NOTE * X = total number of trials.
Para calcular las probabilidades individuales para todos los valores de x= 0, 1, 2, 3, 4,
…., 15 especificados en la columna C1 de la Worksheet se activa Probability
. Seleccionar
y escoger x en el recuadro; y en Optional
storage; se escoge p(x) para que los resultados los deposite en la misma Worksheet. Al
hacer clic en OK, en la Worksheet aparecen los resultados de la Figura 6.24.
Para calcular las probabilidades acumuladas para los valores del ejemplo 6.5 y
con los resultados en la Worksheet, en la Figura 6.23 seleccionar
y en Optional storage: seleccionar F(x). Al hacer clic en OK
en la Worksheet aparecen los resultados de la Figura 6.24.
Las probabilidades acumuladas presentadas en la Figura 6.24, se encuentran
alrededor de 0.987, para X = 15, por lo que existen más valores de X cuyas
probabilidades acumuladas no se han evaluado. Así tenemos que para X = 40: el
Minitab arroja una probabilidad más cerca de uno y es la siguiente:
Cumulative Distribution Function
Geometric with p = 0.25
x
40
P( X <= x )
0.999990
* NOTE * X = total number of trials.
250
Figura 6.24 Probabilidades con distribución geométrica en Minitab
El gráfico de la distribución geométrica obtenido con el Minitab es el siguiente:
Gráfico 6.4 Distribución geométrica con p = 0.25
0.25
p(x)
0.20
0.15
0.10
0.05
0.00
1
2
3
4
5
6
7
8
9
10 11 12 13 14 15 16 17 18
x
251
En SPSS:
Para calcular las probabilidades simples (P) del ejemplo 6.5, en la vista de variables se
define x y en la vista de datos se ingresan los mismos (0, 1, 2, 3, …, 14, 15, ….).
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 6.25. En Variable de destino: escribir P.
Figura 6.25 Cálculo de probabilidades con la distribución geométrica en SPSS
Del Grupo de funciones: del lado derecho, escoger FDP y FDP no centrada; y de
Funciones y variables especiales: seleccionar Pdf.Geom y con un clic en
ingresarla en el recuadro Expresión numérica: donde aparece PDF.GEOM(?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
PDF.GEOM(cant,prob) que se precisan en el recuadro central de la Figura 6.25. Así
cant representa los valores de la variable x, prob = probabilidad de éxito = p = 0.25.
252
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 6.27.
Para el cálculo de las probabilidades acumuladas (F) del ejemplo 6.5, proceder de
manera similar al cálculo de probabilidades simples, con las variantes indicadas, tal
como se muestra en la Figura 6.26.
En la Variable de destino: se escribe F. Del Grupo de funciones: escoger FDA y FDA
no centrada; y de Funciones y variables especiales: seleccionar Cdf.Geom e
ingresarla en el recuadro Expresión numérica.
Luego definir los argumentos cant, y prob, así: CDF.GEOM(x,0.25).
Figura 6.26 Probabilidades acumuladas con la distribución geométrica en SPSS
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 6.27.
253
Figura 6.27 Distrib. de probabilidades geométrica del ejemplo 6.5 en SPSS
En R:
El cálculo de probabilidades para la distribución geométrica en R se realiza con una
variante en los valores de la variable que van desde cero hacia adelante. Para ello se
define una variable Y = X - 1 = número de pruebas (lanzamientos de la moneda)
menos uno hasta obtener el éxito (cara). Es decir que: P(X = x) = P(Y = x – 1).
Por lo tanto, la función de probabilidad y la distribución acumulativa de probabilidades
para el R son:
p( y) P(Y
y) p q y ; y
0,1, 2,3, 4,5,....
F ( y) P(Y
y)
yi ) p
P(Y
yi y
q yi
yi y
Para calcular probabilidades simples con la distribución geométrica usar la función
dgeom(y,p). Donde y puede ser un valor o un conjunto de valores definidos
previamente y p = probabilidad de éxito.
En el ejemplo 6.5, se definió X = el número de lanzamientos de la moneda hasta
obtener cara ~ Geom (0.25). En la parte a) se solicita p (3) = P (X = 3) = P(Y = 2), esto
se calcula en R así:
254
> dgeom(2,0.25)
[1] 0.140625
Si se desea determinar la distribución de probabilidades de la variable aleatoria Y,
primero se define el vector de valores y luego se calculan las probabilidades así:
> y=c(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)
> P=dgeom(y,0.25)
Para presentar la distribución de probabilidades (y, P) usar la función cbind que
permite presentar los resultados de los objetos definidos en columna, uno a
continuación de otro, así:
> cbind(y,P)
y
P
[1,]
0 0.250000000
[2,]
1 0.187500000
[3,]
2 0.140625000
[4,]
3 0.105468750
[5,]
4 0.079101563
[6,]
5 0.059326172
[7,]
6 0.044494629
[8,]
7 0.033370972
[9,]
8 0.025028229
[10,]
9 0.018771172
[11,] 10 0.014078379
[12,] 11 0.010558784
255
[13,] 12 0.007919088
[14,] 13 0.005939316
[15,] 14 0.004454487
[16,] 15 0.003340865
Para calcular probabilidades acumuladas con la geométrica usar la función
pgeom(y,p). Donde x puede ser un valor o un conjunto de valores definidos
previamente, p = probabilidad de éxito.
En la parte b) del ejemplo 6.5 se solicita F (2) = P (X ≤ 2) = P(Y ≤ 1), esto se calcula
en R así:
> pgeom(1,0.25)
[1] 0.4375
Para obtener la distribución de probabilidades y las probabilidades acumuladas
efectuamos el siguiente proceso.
> F=pgeom(y,0.25)
> cbind(y,P,F)
y
P
F
[1,]
0 0.250000000 0.2500000
[2,]
1 0.187500000 0.4375000
[3,]
2 0.140625000 0.5781250
[4,]
3 0.105468750 0.6835938
[5,]
4 0.079101563 0.7626953
[6,]
5 0.059326172 0.8220215
[7,]
6 0.044494629 0.8665161
256
[8,]
7 0.033370972 0.8998871
[9,]
8 0.025028229 0.9249153
[10,]
9 0.018771172 0.9436865
[11,] 10 0.014078379 0.9577649
[12,] 11 0.010558784 0.9683236
[13,] 12 0.007919088 0.9762427
[14,] 13 0.005939316 0.9821821
[15,] 14 0.004454487 0.9866365
[16,] 15 0.003340865 0.9899774
Las probabilidades acumuladas presentadas hasta aquí, se encuentran alrededor de
0.98998, para Y = 15, por lo que existen más valores de Y cuyas probabilidades
acumuladas no se han evaluado. Así tenemos que para Y = 40: el R arroja una
probabilidad más cerca de uno y es la siguiente:
> pgeom(40,0.25)
[1] 0.9999925
También para Y = 50:
> pgeom(50,0.25)
[1] 0.9999996
Nota: el cálculo de probabilidades para las distintas distribuciones discretas vistas
y otras, tienen la misma forma de cálculo en cada uno de los programas
estudiados, siendo cuestión de explorar cada uno de ellos.
257
Capítulo 7. MODELOS CONTINUOS DE PROBABILIDAD
“Democracia: es una superstición muy difundida, un abuso de la
estadística”.
Jorge Luis Borges
CONTENIDO
7.1
7.2
7.3
7.4
7.5
7.6
7.7
Introducción.
Distribución uniforme o rectangular.
Distribución exponencial.
Distribución normal.
Distribución chi-cuadrado.
Distribución T de student.
Distribución F.
7.1 INTRODUCCIÓN
En el presente capítulo se presentan los modelos de probabilidad continuos cuyo
cálculo basado en integrales, ha sido adaptado a los programas que estamos estudiando
y que facilitan el cálculo de probabilidades por la simplificación de los procesos.
Se presentan los principales modelos de probabilidad para variables aleatorias
continuas, cuyo cálculo de probabilidades esta basado en la distribución acumulativa
x
de probabilidades F(x) = P(X ≤ x)
f (t ) dt ; las mismas que permiten calcular
probabilidades como:
P(a ≤ X ≤ b) = F(b) – F(a)
P(X > c) = 1- P(X ≤ c) = 1 – F(c)
o
Entre los modelos a estudiar tenemos las distribuciones: uniforme, exponencial,
normal, chi-cuadrado, T de student y F.
En cada caso se presenta las características principales de cada distribución, es decir, la
función de probabilidad, la esperanza, la varianza, la función de distribución
acumulativa de probabilidades y las respectivas formas de cálculo de probabilidades.
258
7.2 DISTRIBUCIÓN UNIFORME O RECTANGULAR
Definición.- se dice que una variable aleatoria continua X se distribuye uniformemente
en el intervalo [a, b], si su función de densidad de probabilidades está dada por:
1
f ( x)
,a x b
b a
0
, otros casos
Los parámetros de la distribución uniforme son a y b. Si una variable X tiene
distribución uniforme, se le denota así X ~ Uniforme (a, b) y la ley de probabilidades
es la antes indicada.
Media y varianza de la distribución uniforme
La media y la varianza de la distribución uniforme son:
µ = E (X) = (a + b)/2 y σ2 = Var (X) = (b – a)2/12
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades de la uniforme esta dada por:
0
F ( x) P( X
x)
,x
a
x a
,a x b
b a
1
, x b
Ejemplo 7.1
El tiempo en minutos que cierta persona invierte en ir de su casa a la estación del tren
es un fenómeno aleatorio que obedece a una ley de distribución uniforme en el
intervalo de 20 a 25 minutos.
a) ¿Cuál es la probabilidad de que alcance el tren que sale de la estación a las 7:28
a.m. en punto, si sale de su casa exactamente a las 7:05 a.m.?
b) Hallar P(22 ≤ X ≤ 24).
259
Solución
La variable aleatoria X = tiempo que se demora la persona en ir de su casa a la estación
del tren saliendo a las 7:05 a.m. ~ Uniforme (20, 25) y la función de densidad de
probabilidades esta dada por:
f ( x)
1
, 20 x 25
5
0 , otros casos
Así mismo, su función de distribución acumulativa de probabilidades es:
0
F ( x) P( X
x)
,x
20
x 20
, 20 x 25
5
1
, x 25
a) Si sale de su casa a las 7:05, para que alcance el tren que sale a las 7:28, debe
demorarse a lo más 23 minutos, es decir X ≤ 23, luego la probabilidad solicitada
usando la función de distribución acumulativa de probabilidades es:
P( X
23)
F (23)
23 20
5
3
= 0.6.
5
Significa que el 60% de las veces que sale de su casa a las 7:05 alcanzará el tren.
b) P(22 ≤ X ≤ 24) = F(24) – F(22) =
24 20
5
22 20
5
2
= 0.4.
5
Veamos el procedimiento de cálculo de estas probabilidades con los programas
estudiados, reiterando que en la mayoría de los casos dichos cálculos se realizan
utilizando las probabilidades acumuladas.
En Excel:
La distribución uniforme no ha sido definida en Excel, pero con la función de
distribución acumulativa de probabilidades planteada, se pueden efectuar algunos
cálculos de probabilidades acumulativos definiendo la fórmula correspondiente.
260
En Minitab:
Del menú escoger Calc → Probability Distributions → Uniform y aparece la
ventana de diálogo de la Figura 7.1.
Figura 7.1 Probabilidad con la distribución uniforme en Minitab
La función permite tres tipos de cálculos: Probabililty density (para hallar f(x) para un
valor x de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor x determinado) e Inverse cumulative probability (calcular el valor de la
variable para una probabilidad acumulada dada). Las más usadas son las dos últimos.
En el Ejemplo 7.1, la variable aleatoria X = tiempo que se demora la persona en ir de
su casa a la estación del tren ~ Uniforme (20, 25) parámetros indicados en la Figura
7.1. Para resolver la parte a) y b) se necesita el cálculo de probabilidades acumuladas
F(23), F(24) y F(22) que se explican a continuación.
Para el cálculo de probabilidades acumuladas seleccionar
e
indicar los parámetros de la distribución uniforme, es decir: a = 20 escrito en Lower
endpoint (valor más pequeño de X) y b = 25 escrito en Upper endpoint (valor más
grande de X).
261
Para efectuar el cálculo F(23) de la parte a) del Ejemplo 7.1 necesitamos seleccionar
y en el recuadro escribir 23. Al hacer clic en OK, en la hoja de Session
aparece este resultado:
Cumulative Distribution Function
Continuous uniform on 20 to 25
x
23
P( X <= x )
0.6
Se procede del mismo modo para hallar F(24) y F(22) de la parte b).
Si de antemano sabemos que se requiere calcular probabilidades acumuladas para
varios valores de X, en una columna de la worksheet definimos dichos valores como x
y en otra columna F(x) para obtener los resultados. Para ello, en la figura 7.1 en vez de
escoger Input constant: se selecciona
y escoge x en el recuadro; y en
Optional storage; se escoge F(x) para que los resultados los deposite en la misma
Worksheet. Al hacer clic en OK, en la Worksheet aparecen los resultados siguientes:
De la tabla, se obtiene rápidamente P(22 ≤ X ≤ 24) = F(24) – F(22) = 0.8 – 0.4 = 0.4.
Una representación gráfica de la solución anterior en Minitab (cuyo procedimiento es
similar para otras distribuciones continuas), se obtiene seleccionando del menú Graph
→ Probability Distribution Plots, de la ventana mostrada seleccionar View
Probability, luego hacer clic en OK y aparece la ventana de diálogo de la Figura 7.2.
En Distribution: hacer clic en
, escoger la distribución uniforme e indicar sus
parámetros. Luego hacer clic en
(Área a sombrear) y aparece la ventana de
diálogo de la Figura 7.3. En Define Shaded Area By escoger
, luego
e
indicar los valores X1 = 22 y X2 = 24 [ya que queremos hallar P(22 ≤ X ≤ 24) y el
gráfico con dicha área sombreada].
Para finalizar hacer clic en OK y aparece el gráfico de la Figura 7.4.
262
Figura 7.2 Graficando probabilidades acumuladas para la uniforme en Minitab
Figura 7.3 Definiendo el área a sombrear para probabilidades acumuladas con la
distribución uniforme en Minitab
263
Distribution Plot
Uniform, Lower=20, Upper=25
0.4
0.20
Density
0.15
0.10
0.05
0.00
20
22
24
X
25
Figura 7.4 Cálculo y gráfico de P(22 ≤ X ≤ 24) con la dist. uniforme en Minitab
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x, para una probabilidad acumulada dada) seleccionar
en la
Figura 7.1 e indicar los parámetros de la distribución uniforme.
Para determinar el valor de x, para una probabilidad acumulada F(x) =0.05 en el
Ejemplo 7.1 necesitamos seleccionar
y en el recuadro escribir 0.05. Al
hacer clic en OK, en la hoja de Session aparece este resultado:
Inverse Cumulative Distribution Function
Continuous uniform on 20 to 25
P( X <= x )
0.65
x
20.25
Cuyo gráfico (válido para la distribución uniforme y otras variables continuas) se
obtiene de manera similar al anterior, sólo que en la Figura 7.3 en Define Shaded Area
By se escoge
, luego seleccionar
(cola del lado izquierdo en
inferencia estadística) y en el recuadro de Probability: escribir 0.05.
Para finalizar hacer clic en OK e inmediatamente aparece el gráfico de la Figura 7.5.
264
Distribution Plot
Uniform, Lower=20, Upper=25
0.20
0.05
Density
0.15
0.10
0.05
0.00
20 20.3
X
25
Figura 7.5 Gráfico del inverso de probab. acum. Con la dist. uniforme en Minitab
Nota.- todos los procedimientos vistos aquí con el Minitab son válidos para las otras
distribuciones continuas de probabilidad y que serán abreviados cuando se vea para
esas otras distribuciones.
En SPSS:
Para calcular las densidades f(x) (f) del ejemplo 7.1, sólo para hacer el gráfico de la
función, en la vista de variables se define x y en la vista de datos se ingresan los
mismos (22, 23, 24, ….).
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 7.6. En Variable de destino: escribir f.
Del Grupo de funciones: del lado derecho, escoger FDP y FDP no centrada; y de
Funciones y variables especiales: seleccionar Pdf.Uniform y con un clic en
ingresarla al recuadro Expresión numérica: donde aparece PDF.UNIFORM(??,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
PDF.UNIFORM(cant,mín,máx) que se precisan en el recuadro central de la Figura 7.6.
265
Así cant representa los valores de la variable x, mín = valor mínimo = 20 y máx =
valor máximo = 25.
Figura 7.6 Cálculo de las densidades f(x) con la distribución uniforme en SPSS
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 7.8, cuyos resultados no son de mucha trascendencia para variables continuas,
ya que sirven para realizar la gráfica de la distribución [distinto al caso discreto, donde
se obtenía probabilidades p(x) con esta función], por lo que para las siguientes
distribuciones los obviaremos, pero se obtienen de manera similar en el SPSS.
Sin embargo, las probabilidades acumuladas son de interés por lo que serán tratadas en
cada una de las distribuciones continuas que se presentan y cuyo procedimiento es
similar al que se ve a continuación.
Para el cálculo de las probabilidades acumuladas (F) del ejemplo 7.1, proceder de
manera similar al cálculo de densidades, con las variantes indicadas, tal como se
muestra en la Figura 7.7.
266
En la Variable de destino: se escribe Fx. Del Grupo de funciones: escoger FDA y
FDA no centrada; y de Funciones y variables especiales: seleccionar Cdf.Uniform e
ingresarla en el recuadro Expresión numérica.
Luego definir los argumentos cant representa los valores de la variable x, mín = valor
mínimo = 20 y máx = valor máximo = 25, así: CDF.UNIFORM(x,20,25).
Figura 7.7 Probabilidades acumuladas con la distribución uniforme en SPSS
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 7.8.
Figura 7.8 Densidades y probab. acumuladas con la distrib. uniforme en SPSS
Resultados que son idénticos a los obtenidos con el Minitab.
267
En R:
Para calcular las densidades con la distribución uniforme se usa la función
dunif(x,mín,máx). Donde x puede ser un valor o un conjunto de valores definidos
previamente, mín = a = valor más pequeño de X y máx = b = valor más grande de X.
En el ejemplo 7.1, X = tiempo que se demora la persona en ir de su casa a la estación
del tren ~ Uniforme (20, 25). Para determinar las densidades correspondientes a los
valores 22, 23 y 24se define un vector x con dichos valores y luego las densidades f se
calculan así:
> x=c(22,23,24)
> f=dunif(x,20,25)
> cbind(x,f)
x
f
[1,] 22
0.2
[2,] 23
0.2
[3,] 24
0.2
Para calcular probabilidades acumuladas con la uniforme usar la función
punif(x,mín,máx). Donde x puede ser un valor o un conjunto de valores definidos
previamente, mín = a = valor más pequeño de X y máx = b = valor más grande de X.
Para determinar las probabilidades acumuladas F para los valores x ya definidos y
presentar las densidades f también, se procede así:
> F=punif(x,20,25)
> cbind(x,f,F)
x
f
F
[1,] 22
0.2
0.4
[2,] 23
0.2
0.6
[3,] 24
0.2
0.8
268
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x, para una probabilidad acumulada dada) usar la función qunif(p,mín,máx). Donde p
puede ser una probabilidad acumulada o un conjunto de probabilidades acumuladas
definidas previamente, mín = a = valor más pequeño de X y máx = b = valor más
grande de X.
Para hallar el valor del cuantil x correspondiente a una probabilidad acumulada de
0.05, se procede así:
> qunif(0.05,20,25)
[1] 20.25
Resultados idénticos a los del Minitab y del SPSS. Cabe resaltar que cualquiera de los
cálculos de probabilidades con otras distribuciones es similar.
7.3 DISTRIBUCIÓN EXPONENCIAL
Definición.- se dice que una variable aleatoria continua X tiene distribución
exponencial con parámetro λ positivo, si su función de densidad de probabilidades está
dada por:
f ( x)
e
x
0
,x 0
, otros casos
El parámetro de la distribución exponencial es λ. Si una variable X tiene distribución
exponencial, se le denota así X ~ Exp (λ) y la ley de probabilidades es la antes
indicada.
Media y varianza de la distribución exponencial
La media y la varianza de la distribución exponencial son:
µ = E (X) = 1/ λ
σ2 = Var (X) = 1/ λ2
269
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades esta dada por:
F ( x) P( X
x)
0
, x 0
1 e
x
, x 0
Ejemplo 7.2
El tiempo de vida de un tipo de focos es una variable aleatoria X, que tiene distribución
exponencial con una vida media de 1000 horas. a) ¿Qué proporción de focos no sirve
antes de las 1000 horas? y b) ¿Qué proporción de focos dura entre 800 y 1200 horas?
Solución
La variable aleatoria X = tiempo de vida de los focos tiene distribución exponencial
con media µ = 1/ λ = 1000 horas. Por lo tanto, λ = 0.001. Luego X ~ Exp (0.001) y la
función de densidad de probabilidades esta dada por:
f ( x)
0.001 e
0
0.001 x
,x 0
, otros casos
Así mismo, la función de distribución acumulativa de probabilidades esta dada por:
F ( x) P( X
x)
0
, x 0
1 e
0.001 x
, x 0
Entonces las probabilidades solicitadas son:
a) P(X < 1000) = F(1000) = 1 – e-0.001(1000) = 1 – e-1 = 0.6321
Significa que el 63.21% de los focos no sirve antes de las 1000 horas.
b) P(800 ≤ X ≤ 1200) = F(1200) - F(800) = [1 – e-0.001(1200)] – [1 – e-0.001(800)] =
= [1 - e-1.2] – [1 - e- 0.8 = 0.698806 – 0.550671 = 0.148135.
Significa que el 14.81% de los focos dura entre 800 y 1200 horas.
Veamos el cálculo de estas probabilidades acumuladas con los programas en estudio.
270
En Excel:
Para hallar la distribución de probabilidades acumuladas exponenciales, en la hoja de
cálculo definimos en la columna A los valores de la variable x = 800, 1000 y 1200. En
la columna B, definimos las probabilidades acumuladas F(x) para cada uno de los
valores.
Para ello, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas
(de seleccionar una categoría) y buscamos la función DISTR.EXP y aparece la
ventana de diálogo de la Figura 7.9.
Figura 7.9 Cálculo de probabilidades acumuladas con exponencial en Excel
En Argumentos de función se define: el valor de X = A2 (800) para poder efectuar
una copia para los demás valores de x, Lambda = λ = 0.001 (es el valor del parámetro)
y en Acum escribir VERDADERO [para obtener las probabilidades acumuladas, si se
escribe FALSO se obtiene la densidad de probabilidades f(x)]. Al hacer enter, aparece
la probabilidad acumulada F(800) = 0.550671.
271
Para obtener las probabilidades acumuladas para los otros valores de x, se efectúa una
copia de lo anterior para las celdas sucesivas en B3 y B4, cuyos resultados son:
En Minitab:
Del menú escoger Calc → Probability Distributions → Exponential y aparece la
ventana de diálogo de la Figura 7.10.
Figura 7.10 Probabilidad acumulada con la distribución exponencial en Minitab
La función permite tres tipos de cálculos: Probabililty density (para hallar f(x) para un
valor x de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor x determinado) e Inverse cumulative probability (calcular el valor de la
variable para una probabilidad acumulada dada). Las más usadas son las dos últimos.
En el Ejemplo 7.2, la variable aleatoria X = tiempo de vida de los focos ~ Exp (0.001)
parámetro indicado en la Figura 7.10. Para resolver la parte a) y b) se necesita el
272
cálculo de probabilidades acumuladas F(800), F(1000) y F(1200) que se explican a
continuación.
Para el cálculo de probabilidades acumuladas seleccionar
e
indicar el parámetro requerido por la distribución exponencial en Scale, es decir: media
µ = 1/ λ = 1000.
Para efectuar el cálculo F(800) de la parte a) del Ejemplo 7.2 necesitamos seleccionar
y en el recuadro escribir 1000. Al hacer clic en OK, en la hoja de
Session aparece este resultado:
Cumulative Distribution Function
Exponential with mean = 1000
x
1000
P( X <= x )
0.632121
Se procede del mismo modo para hallar F(800) y F(1200) de la parte b).
También se puede calcular probabilidades acumuladas para varios valores de X, en una
columna de la worksheet definimos dichos valores como x y en otra columna F(x) para
obtener los resultados. Para ello, en la figura 7.10 en vez de escoger Input constant: se
selecciona
y escoge x en el recuadro; y en Optional storage; se escoge
F(x) para que los resultados los deposite en la misma Worksheet. Al hacer clic en OK,
en la Worksheet aparecen los resultados siguientes:
De la tabla, se obtiene rápidamente P(800 ≤ X ≤ 1200) = F(1200) – F(800) = 0.698806
– 0.550671 = 0.148135.
La representación gráfica de la solución anterior en Minitab, se obtiene seleccionando
del menú Graph → Probability Distribution Plots, de la ventana mostrada
seleccionar View Probability, luego hacer clic en OK y aparece la ventana de diálogo
de la Figura 7.11.
273
Figura 7.11 Graficando probabilidades acum. para la exponencial en Minitab
En Distribution: hacer clic en
, escoger la distribución Exponential e indicar la
media = 1000 en Scale. Luego hacer clic en
escoger
, luego
. En Define Shaded Area By
e indicar los valores X1 = 800 y X2 = 1200 [ya que
queremos hallar P(800 ≤ X ≤ 1200) y el gráfico con dicha área sombreada].
Para finalizar hacer clic en OK y aparece el gráfico siguiente:
Distribución exponencial
Scale= µ = 1/ λ = 1000, Thresh=0
0.0010
Density
0.0008
0.0006
0.0004
0.148
0.0002
0.0000
0
800 1200
X
274
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x, para una probabilidad acumulada dada) seleccionar
en la
Figura 7.10 e indicar el parámetro de la distribución exponencial.
Para determinar el valor de x, para una probabilidad acumulada F(x) =0.05 en el
Ejemplo 7.2 necesitamos seleccionar
y en el recuadro escribir 0.05. Al
hacer clic en OK, en la hoja de Session aparece este resultado:
Inverse Cumulative Distribution Function
Exponential with mean = 1000
P( X <= x )
0.05
x
51.2933
El 5% de los focos tiene un duración menor o igual a 51.29 horas.
El valor de x, para una probabilidad acumulada F(x) =0.95 es:
Inverse Cumulative Distribution Function
Exponential with mean = 1000
P( X <= x )
x
0.95 2995.73
El 95% de los focos tiene una duración menor o igual a 2995.73 horas.
En SPSS:
Para calcular las probabilidades acumuladas F(x) (F) del ejemplo 7.2, en la vista de
variables se define x y en la vista de datos se ingresan los mismos (800, 1000, 1200).
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 7.12. En Variable de destino: escribir F.
Del Grupo de funciones: del lado derecho, escoger FDA y FDA no centrada; y de
Funciones y variables especiales: seleccionar Cdf.Exp y con un clic en
ingresarla al recuadro Expresión numérica: donde aparece CDF.EXP(?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
CDF.EXP(cant,escala) que se precisan en el recuadro central de la Figura 7.12. Así
cant representa los valores de la variable x y escala = λ = 0.001.
275
Figura 7.12 Cálculo de probab. acum. con la distribución exponencial en SPSS
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 7.13.
Figura 7.13 Probabilidades acumuladas con la distrib. exponencial en SPSS
En R:
Para calcular probabilidades acumuladas con la exponencial usar la función pexp(x,λ).
Donde x puede ser un valor o un conjunto de valores definidos previamente y λ =
parámetro de la exponencial.
276
En el ejemplo 7.2, X = tiempo de vida de los focos ~ Exp (0.001). Para determinar las
probabilidades acumuladas correspondientes a los valores 800, 1000 y 1200 se define
un vector x con esos valores y luego las probabilidades acumuladas F se calculan así:
> x=c(800,1000,1200)
> F=pexp(x,0.001)
> cbind(x,F)
x
[1,]
F
800
0.5506710
[2,] 1000
0.6321206
[3,] 1200
0.6988058
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x o q, para una probabilidad acumulada dada) usar la función qexp(p,λ). Donde p es
una o un conjunto de probabilidades acumuladas definidas previamente y
λ =
parámetro de la exponencial.
Para hallar el valor del cuantil q correspondiente a las probabilidades acumulada de
0.05 y 0.95 se procede así:
> p=c(0.05,0.95)
> q=qexp(p,0.001)
> cbind(p,q)
p
q
[1,] 0.05 51.29329
[2,] 0.95 2995.73227
277
7.4 DISTRIBUCIÓN NORMAL
Definición.- se dice que una variable aleatoria continua X tiene distribución normal
con parámetros µ y σ2, si su función de densidad de probabilidades está dada por:
f ( x)
2
)2
(x
1
2
e
2
2
,
x
La distribución normal es simétrica respecto a µ.
Media y varianza de la distribución normal
La media y la varianza de la distribución normal son:
E (X) = µ
y
Var (X) = σ2
Si una variable aleatoria X tiene distribución normal con media µ y varianza σ2, se le
denota así X ~ N (µ y σ2) y la ley de probabilidades es la antes indicada. La gráfica de
la distribución normal tiene la siguiente forma:
Distribution Normal
Mean = µ, StDev = σ
0.8
0.7
0.6
Density
0.5
0.4
0.3
0.2
0.1
0.0
µ
X
La función de distribución acumulativa de probabilidades
La función de distribución acumulativa de probabilidades esta dada por:
278
F ( x)
P( X
x)
2
)2
(t
1
x
e
2
2
2
dt
Calcular estas probabilidades acumuladas es complicado ya que los cálculos varían
para cada media y cada varianza. Problema que es resuelto mediante el proceso de
estandarización (transformación) de la variable X ~ N (µ, σ2) en otra variable
Z
X
~ N (0, 1) llamada distribución normal estándar.
La distribución normal estándar
Si una variable aleatoria X ~ N (µ, σ2) y se define la variable Z
variable aleatoria Z tiene distribución normal estándar
X
entonces la
= N (0, 1) y su función de
densidad de probabilidades esta dada por:
f ( z)
1
e
2
z2
2
,
z
La función de distribución acumulada de la distribución normal estándar se denota y
define así:
2
Φ(z) = P( Z
z)
z
t
1
2
e dt . Se cumple que Φ(-z) = 1 - Φ(z), para z > 0.
2
Estas probabilidades han sido calculadas y aparecen en la denominada tabla de la
distribución normal estándar y facilitada por el uso de los programas estadísticos como
los que estamos estudiando.
Estandarización.- es el proceso por el cual una variable aleatoria X ~ N (µ, σ2) se
transforma en otra variable aleatoria Z
X
~ N (0, 1); permitiendo el cálculo de
probabilidades cuando X se encuentra entre dos números reales a y b del siguiente
modo:
P(a ≤ X ≤ b) = P[(a - µ) /σ ≤ (X - µ) /σ ≤ (b - µ) /σ] =
= P[(a - µ) /σ ≤ Z ≤ (b - µ) /σ] = Φ((b - µ) /σ) - Φ((b - µ) /σ)
279
Ejemplo 7.3
Los diámetros de los tubos fabricados por cierta máquina tienen distribución normal
con media de 9.8 mm. y desviación estándar de 0.53 mm. a) ¿Qué proporción de tubos
serán rechazados, si no se aceptan diámetros inferiores a 9 mm?; b) ¿Qué proporción
de tubos tiene un diámetro entre 8.5 y 11.0 mm?; y c) ¿por debajo de que diámetro se
encuentra el 95% de los tubos?
Solución
La variable aleatoria X = diámetro de los tubos en mm. ~ N (9.8, 0.53).
Estandarizando se tiene que Z
X 9.8
~ N (0, 1)
0.53
a) Se rechazan los tubos si X < 9 mm., entonces:
P( X
9)
P
X 9.8
0.53
9 9.8
0.53
P( Z
1.51) = Φ(-1.51) = 0.06552
Significa que alrededor del 6.55% de los tubos fabricados será rechazado.
b) P(8.5 ≤ X ≤ 11.0) = P
8.5 9.8
0.53
X 9.8
0.53
9 9.8
0.53
P( 2.45 Z
3.40)
= Φ(3.40) - Φ(-2.45) = 0.99966 - 0.00714 = 0.99252.
Significa que alrededor del 99.25% de los tubos fabricados tienen diámetro entre
8.5 y 11.0 mm.
c) Necesitamos halla el cuantil q0.95 = x, tal que:
0.95 = P(X ≤ x) = P Z
x 9.8
x 9.8
→
0.53
0.53
Z 0.95
1.645 → x = 10.67 mm.
Significa que el 95% de los tubos fabricados tienen un diámetro de alrededor de los
10.67 mm.
Veamos la solución del ejemplo 7.3 utilizando los programas y basados
fundamentalmente en las probabilidades acumuladas de la normal.
280
En Excel:
Para hallar la distribución de probabilidades acumuladas normales, en la hoja de
cálculo definimos en la columna A los valores de la variable x = 8.5, 9.0 y 11.0. En la
columna B, definimos las probabilidades acumuladas F(x).
Para hallar las probabilidades acumuladas, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas (de seleccionar una categoría) y buscamos la
función DISTR.NORM y aparece la ventana de diálogo de la Figura 7.14.
Figura 7.14 Cálculo de probabilidades acumuladas con la normal en Excel
En Argumentos de función se define: el valor de X = A2 (8.5) para poder efectuar
una copia para los demás valores de x, Media = µ = 9.8, Desv_estándar = σ = 0.53 y
en Acum escribir VERDADERO [para obtener las probabilidades acumuladas, si se
escribe FALSO se obtiene la densidad de probabilidades f(x)]. Al hacer clic en
Aceptar, aparece la probabilidad acumulada F(8.5) = 0.007087.
281
Para obtener las probabilidades acumuladas para los otros valores de x, se efectúa una
copia de lo anterior para las celdas sucesivas en B3 y B4, cuyos resultados son:
Nota.- para hallar los resultados iniciales del ejemplo 7.3, se hizo una aproximación de
los valores Z, para poder usar la “vieja” tabla de la distribución normal estándar,
resultados que difieren de los acumulados F(x) encontrados con el programa, ya que
éste internamente hace la estandarización y da una mejor aproximación. Sin embargo,
el Excel también permite obtener los Φ(z) con la función DIST.NORM.ESTAND(z).
Tal como se muestra en los resultados anteriores difieren los F(x) y Φ(z).
Para hallar el inverso de probabilidades acumuladas (calcular el valor del cuantil x ,
para una probabilidad acumulada = p) usar la función DIST.NORM.INV(p, µ, σ) que
para la parte c) del ejemplo 7.3 escribir =DIST.NORM.INV(0.95,9.8,0.53) en el
recuadro al lado de
, al hacer enter se obtiene x = 10.67177 mm. similar al
anteriormente hallado.
En Minitab:
Del menú escoger Calc → Probability Distributions → Normal y aparece la ventana
de diálogo de la Figura 7.15.
La función permite tres tipos de cálculos: Probabililty density (para hallar f(x) para un
valor x de la variable), Cumulative probability (calcular la probabilidad acumulada
hasta un valor x determinado) e Inverse cumulative probability (calcular el valor de la
variable para una probabilidad acumulada dada). Las más usadas son las dos últimos.
En el Ejemplo 7.3, la variable aleatoria X = diámetro de los tubos en mm. ~ N (9.8,
0.53) parámetro indicado en la Figura 7.15.
Para resolver la parte a) y b) se necesita el cálculo de probabilidades acumuladas
F(8.5), F(9.0) y F(11.0) que se explican a continuación.
282
Figura 7.15 Probabilidad acumulada con la distribución normal en Minitab
Para el cálculo de probabilidades acumuladas seleccionar
e
indicar los parámetros requeridos por la distribución normal en Mean = media = µ =
9.8 y en Standard deviation = desviación estándar = σ = 0.53.
Para efectuar el cálculo F(8.5) de la parte b) del Ejemplo 7.3 necesitamos seleccionar
y en el recuadro escribir 8.5. Al hacer clic en OK, en la hoja de
Session aparece este resultado:
Cumulative Distribution Function
Normal with mean = 9.8 and standard deviation = 0.53
x
8.5
P( X <= x )
0.0070869
Se procede del mismo modo para hallar F(9.0) y F(11.0).
También se puede calcular probabilidades acumuladas para varios valores de X, en una
columna de la worksheet definimos dichos valores como x y en otra columna F(x) para
obtener los resultados. Para ello, en la figura 7.15 en vez de escoger Input constant: se
selecciona
y escoge x en el recuadro; y en Optional storage: se escoge
283
F(x) para que los resultados los deposite en la misma Worksheet. Al hacer clic en OK,
en la Worksheet aparecen los resultados siguientes:
De la tabla, se obtiene rápidamente P(8.5 ≤ X ≤ 11.0) = F(11.0) – F(8.5) = 0.988218 –
0.007087 = 0.981131. Ligeramente diferente al 0.99252 encontrado en b).
La representación gráfica de la solución anterior en Minitab, se obtiene seleccionando
del menú Graph → Probability Distribution Plots, de la ventana mostrada
seleccionar View Probability, luego hacer clic en OK y aparece la ventana de diálogo
de la Figura 7.16.
Figura 7.16 Graficando probabilidades acumuladas con la normal en Minitab
En Distribution: hacer clic en
= 0.53. Luego hacer clic en
luego
, escoger la distribución Normal e indicar µ = 9.8 y σ
. En Define Shaded Area By escoger
,
e indicar los valores X1 = 8.5 y X2 = 11.0 [ya que queremos hallar P(8.5 ≤
X ≤ 11.0) y el gráfico con dicha área sombreada].
284
Para finalizar hacer clic en OK y aparece el gráfico siguiente:
Distribution Normal
Mean=9.8, StDev=0.53
0.8
P(8.5 ≤ X ≤ 11.0) = 0.981
0.7
0.6
Density
0.5
0.4
0.3
0.2
0.1
0.0
8.5
9.8
X
11
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x, para una probabilidad acumulada dada) seleccionar
en la
Figura 7.15 e indicar los parámetros de la distribución normal.
Para determinar el valor de x, para una probabilidad acumulada F(x) =0.95 en la parte
c) del Ejemplo 7.3 necesitamos seleccionar
y en el recuadro escribir
0.95. Al hacer clic en OK, en la hoja de Session aparece este resultado:
Inverse Cumulative Distribution Function
Normal with mean = 9.8 and standard deviation = 0.53
P( X <= x )
0.95
x
10.6718
El 95% de los tubos tiene un diámetro menor o igual a 10.6718 mm.
En SPSS:
Para calcular las probabilidades acumuladas F(x) (F) del ejemplo 7.3, en la vista de
variables se define x y en la vista de datos se ingresan los mismos (8.5, 9.0, 11.0).
285
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 7.17. En Variable de destino: escribir F.
Del Grupo de funciones: del lado derecho, escoger FDA y FDA no centrada; y de
Funciones y variables especiales: seleccionar Cdf.Normal y con un clic en
ingresarla al recuadro Expresión numérica: donde aparece CDF.NORMAL(?,?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
CDF.NORMAL(cant,media,desv_típ) que se precisan en el recuadro central de la
Figura 7.17. Así cant representa los valores de la variable x, media = µ = 9.8 y desv_típ
= σ = 0.53.
Figura 7.17 Cálculo de probab. acumuladas con la distribución normal en SPSS
Para finalizar hacer clic en Aceptar y en la vista de datos aparece los resultados de la
Figura 7.18.
Los resultados obtenidos son idénticos a los del Excel y Minitab.
286
Figura 7.18 Probabilidades acumuladas con la distribución normal en SPSS
En R:
Para calcular probabilidades acumuladas con la exponencial usar la función
pnorm(x,µ,σ). Donde x puede ser un valor o un conjunto de valores definidos
previamente, µ = media, y σ = desviación estándar.
En el ejemplo 7.3, X = diámetro de los tubos en mm. ~ N (9.8, 0.532). Para determinar
las probabilidades acumuladas correspondientes a los valores 8.5, 9.0 y 11.0 se define
un vector x con esos valores y luego las probabilidades acumuladas F se calculan así:
> x=c(8.5,9.0,11.0)
> F=pnorm(x,9.8,0.53)
> cbind(x,F)
x
F
[1,]
8.5
0.007086862
[2,]
9.0
0.065593960
[3,] 11.0
0.988217584
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x o q, para una probabilidad acumulada dada) usar la función qnorm(x,µ,σ). Donde p
es una o un conjunto de probabilidades acumuladas definidas previamente.
Para hallar el valor del cuantil q correspondiente a las probabilidades acumulada de
0.95 se procede así:
> qnorm(0.95,9.8,0.53)
[1] 10.67177
El 95% de los tubos tiene un diámetro menor o igual a 10.6718 mm.
287
7.5 DISTRIBUCIÓN CHI-CUADRADO
Definición.- Sean Z1, Z2, ..., Zr, variables aleatorias independientes, cada una con
distribución normal estándar, Zi ~ N(0 , 1) . Entonces, la variable aleatoria
x²
Z12
Z22 ... Z r2
tiene una distribución chi-cuadrado con r grados de libertad, si su función de
densidad de probabilidades está dada por:
r
1
f X 2 ( x) =
2
r
2
r
2
1
x2 e
x/2
= 0
,
0<x<
,
en otros casos
Donde:
Γ representa el gamma de un número,
entero positivo
( n)
(n) = (n – 1)! . Además,
0
X n 1e x dx , n > 0. Si n es
1
2
.
r = grados de libertad (GL) representa el número de variable aleatorias
independientes que se suman o el número de variables que pueden variar
libremente. En regresión y econometría es el rango de una matriz (máximo
número de columnas linealmente independientes)
asociadas a formas
cuadráticas delas sumas de cuadrados.
Si la variable aleatoria X tiene distribución chi-cuadrado con r grados de libertad,
la denotaremos como X ~ X r2 .
Media y varianza de la distribución chi-cuadrado
La media y la varianza de la distribución chi-cuadrado son:
= E(x²) = r
y
² = Var(x²) = 2r
La función de distribución acumulativa de probabilidades
El cálculo de probabilidades para la variable aleatoria chi-cuadrado, se efectúa
utilizando las Tablas de Chi – Cuadrado, las mismas que han sido elaboradas
288
utilizando la función de distribución acumulativa de probabilidades que en la
mayoría de los casos son del tipo de acumulación menor o igual que.
Así tenemos que, la probabilidad que la variable aleatoria X con distribución
xr2 1 r
30 sea menor o igual a un valor constante x 2 , representada por:
PX
X2
0≤
,
≤1
Está dada por:
PX x
2
x2
0
f X 2 x dx
1
x2
0
2
r
2
r
2
x
r
1
2
x
2
e dx
y su gráfica es:
Distribution chi-cuadrado
Chi-Square, df=25
0.06
0.05
Density
0.04
0.03
0.02
0.01
0.00
α
Xα
X
Ejemplo 7.4
Si la variable aleatoria X ~ X 252 . Hallar: a) ¿Qué proporción de valores de X son
mayores que 40.6?; b) ¿Qué proporción de valores de X se encuentran entre 14.6 y
37.7?; y c) ¿por debajo de que valor se encuentra el 10% de los valores de X?
Solución
La variable aleatoria X ~ X 252 . Entonces, usando la tabla de chi-cuadrado se tiene que:
289
a) P[X > 40.6] = 1 - P[ X 252 ≤ 40.6] = 1 – 0.975 = 0.025.
Significa que el 2.5% de los valores de X ~ X 252 son mayores que 40.6.
b) P(14.6 ≤ X ≤ 37.7) = P[ X 252 ≤ 37.7] - P[ X 252 ≤ 14.6] = 0.95 – 0.05 = 0.90
Significa que el 90% de los valores de X ~ X 252 se encuentran entre 14.6 y 37.7.
c) Necesitamos halla el cuantil q0.10 = x, tal que:
2
0.10 = P( X 252 ≤ x) → x = X 25,0.10
= 16.5
Significa que el 10% de los valores de X ~ X 252 son menores que 16.5.
Veamos la solución del ejemplo 7.4 utilizando los programas y basados
fundamentalmente en las probabilidades acumuladas de la chi-cuadrado.
En Excel:
Para hallar la distribución de probabilidades acumuladas chi-cuadrado, en la hoja de
cálculo definimos en la columna A los valores de la variable x = 14.6, 37.7 y 40.6. En
la columna B, definimos las probabilidades acumuladas, que en Excel vienen dadas
por F(x) = P(X > x).
Para hallar las probabilidades acumuladas, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas (de seleccionar una categoría) y buscamos la
función DISTR.CHI y aparece la ventana de Argumentos de función donde se
define: el valor de X = A2 (14.6) para poder efectuar una copia para los otros valores
de x, y en el recuadro de Grados_de libertad escribir 25. Una forma directa de
cálculo es escribir =DISTR.CHI(A2,25) en el recuadro al lado de
. Al hacer clic en
Aceptar, aparece la probabilidad acumulada F(14.6) = 0.950239.
Para obtener las probabilidades acumuladas para los otros valores de x, se efectúa una
copia de lo anterior para las celdas sucesivas en B3 y B4, los resultados se presentan en
la Figura 7.19. Se puede apreciar que se ha calculado una columna de 1 – F(x) cuyos
resultados son parecidos a los usados en la solución manual del Ejemplo 7.4.
290
Figura 7.19 Cálculo de probabilidades acumuladas con la chi-cuadrado en Excel
Para hallar el inverso de probabilidades acumuladas (calcular el valor del cuantil x ,
para una probabilidad acumulada = p) usar la función PRUEBA.CHI.INV(1-p, GL)
que para la parte c) del ejemplo 7.4 es PRUEBA.CHI.INV(0.90, 25) al hacer enter se
obtiene x = 16.4734 similar al 16.5 hallado con la tabla de chi-cuadrado.
En Minitab:
Del menú escoger Calc → Probability Distributions → Chi-Square y aparece la
ventana de diálogo Chi-Square Distribution. El procedimiento de cálculo es similar
al ejecutado con las distribuciones de probabilidades antes vistas. Es decir, el cálculo
para una constante (Input constant, con el resultado en la ventana Session) o para
varios valores definidos previamente en una columna de la Worksheet (Input column,
con los resultados en la worksheeet) que usaremos de aquí en adelante.
Para el cálculo de probabilidades acumuladas seleccionar
e
indicar el parámetro requerido Degrees of freedom (grados de libertad) escribir 25 en
el recuadro.
Para calcular las probabilidades acumuladas para los valores de X del ejemplo 7.4, en
una columna de la worksheet definimos como x los valores 14.6, 37.7 y 40.6; y en otra
columna F(x) para obtener los resultados. Para ello, seleccionar
y
escoge x en el recuadro; y en Optional storage: se escoge F(x) para que los resultados
los deposite en la misma Worksheet. Al hacer clic en OK, en la Worksheet aparecen
los resultados siguientes:
291
Resultados idénticos a los obtenidos con el Excel en la columna 1 – F(x).
De la tabla, se obtiene rápidamente P(14.6 ≤ X ≤ 37.7) = F(37.7) – F(14.6) = 0.950526
– 0.049761 = 0.900765. Ligeramente diferente al 0.90 encontrado en b).
La representación gráfica de la solución anterior en Minitab, se obtiene seleccionando
del menú Graph → Probability Distribution Plots, de la ventana mostrada
seleccionar View Probability, luego hacer clic en OK y aparece la ventana de diálogo
Probability Distribution Plot – Probability.
En Distribution: hacer clic en
, escoger la distribución Chi-Square e indicar el
parámetro requerido Degrees of freedom (grados de libertad) escribir 25 en el
recuadro.
Luego hacer clic en
. En Define Shaded Area By escoger
, luego
e indicar los valores X1 = 14.6 y X2 = 37.7 [ya que queremos hallar P(14.6 ≤ X
≤ 37.7) y el gráfico con dicha área sombreada].
Para finalizar hacer clic en OK y aparece el gráfico de la Figura 7.20.
Distribution Plot
Chi-Square, df=25
0.06
0.901
0.05
Density
0.04
0.03
0.02
0.01
0.00
14.6
X
37.7
Figura 7.20 Gráfico de P(14.6 ≤ X ≤ 37.7) con la chi-cuadrado en Minitab
292
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x, para una probabilidad acumulada dada) seleccionar
en la
ventana de diálogo Chi-Square Distribution e indicar los grados de libertad 25.
Para determinar el valor de x, para una probabilidad acumulada F(x) =0.10 en la parte
c) del Ejemplo 7.4 necesitamos seleccionar
y en el recuadro escribir
0.10. Al hacer clic en OK, en la hoja de Session aparece este resultado:
Inverse Cumulative Distribution Function
Chi-Square with 25 DF
P( X <= x )
0.1
x
16.4734
El 10% de los valores de X ~ X 252 son menores que 16.5.
En SPSS:
Para calcular las probabilidades acumuladas F(x) (F) del ejemplo 7.4, en la vista de
variables se define x y en la vista de datos se ingresan los mismos (14.6, 37.7, 40.6).
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 7.21. En Variable de destino: escribir F.
Del Grupo de funciones: del lado derecho, escoger FDA y FDA no centrada; y de
Funciones y variables especiales: seleccionar Cdf.Chisq y con un clic en
ingresarla al recuadro Expresión numérica: donde aparece CDF.CHISQ(?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
CDF.CHISQ(cant,gl) que se precisan en el recuadro central de la Figura 7.21. Así cant
representa los valores de la variable x y gl = grados de libertad = 25. Para finalizar
hacer clic en Aceptar y en la vista de datos aparece los resultados siguientes:
293
Figura 7.21 Cálculo de probab. acumuladas con la chi-cuadrado en SPSS
En R:
Para calcular probabilidades acumuladas con la chi-cuadrado usar la función
pchisq(x,gl). Donde x puede ser un valor o un conjunto de valores definidos
previamente, gl = grados de libertad.
En el ejemplo 7.4, X ~ X 252 . Para determinar las probabilidades acumuladas
correspondientes a los valores 14.6, 37.7 y 40.6 se define un vector x con esos valores
y luego las probabilidades acumuladas F se calculan así:
> x=c(14.6,37.7,40.6)
> F=pchisq(x,25)
> cbind(x,F)
x
F
[1,] 14.6
0.04976093
294
[2,] 37.7
0.95052629
[3,] 40.6
0.97471962
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x o q, para una probabilidad acumulada dada) usar la función qchisq(x,gl). Donde p es
una o un conjunto de probabilidades acumuladas definidas previamente.
Para hallar el valor del cuantil q correspondiente a las probabilidades acumulada de
0.10 se procede así:
> qchisq(0.10,25)
[1] 16.47341
El 10% de los valores de X ~ X 252 son menores que 16.5.
7.6 DISTRIBUCIÓN T DE STUDENT
Definición.- Sea Z una variable aleatoria normal estándar N(0, 1). Sea X2 ~ X r2 una
variable aleatoria que tiene una distribución chi-cuadrado con r grados de libertad, y si
Z y X2 son independientes, entonces la variable aleatoria (v.a.)
T
Z
X2
r
Z r
~ tr
Y
tiene una distribución t , con r grados de libertad, y su función de densidad de
probabilidades está dada por:
f t
r 1
2
r
r
2
t²
1
r
r 1
2
,
- <t<
Notación: decir que la variable aleatoria T tiene distribución t con r grados de
libertad, la denotaremos como T ~ t r .
295
Media y Varianza:
La media y la varianza de la v. a. T con r grados de libertad son:
E(T) =
Var(T) =
T
=0
,
r
2
T
r
r>1
,
2
r>2
Función de Distribución Acumulativa de Probabilidades.El cálculo de probabilidades para variable aleatoria t, se efectúa utilizando las
Tablas de t, las mismas que han sido elaboradas utilizando la función de
distribución acumulativa de probabilidades que en la mayoría de los casos son del
tipo de acumulación menor o igual que.
Así tenemos que, la probabilidad que la variable aleatoria T con distribución tr (1
r < 30) sea menor o igual a un valor constante t , representada por:
,
PT t
0<
<1
Está dada por:
PT
t
t
t
f t dt
r 1
2
r
r
2
cuya representación gráfica es la siguiente:
Distribution t
gl = df=25
0.4
Density
0.3
0.2
0.1
α
0.0
Tα
296
0
X
t²
1
r
r 1
2
dt
La distribución t es una distribución simétrica como la normal y se cumple que:
F(-a) = P[ T ≤ -a] = 1 - P[ T ≤ a] = 1 - F(a)
Ejemplo 7.5
Si la variable aleatoria X ~ T25. Hallar: a) ¿Qué proporción de valores de X son
mayores que 2.485?; b) ¿Qué proporción de valores de X se encuentran entre -1.316 y
2.060?; y c) ¿por debajo de que valor se encuentra el 5% de los valores de X?
Solución
La variable aleatoria X ~ T25. Entonces, usando la tabla de t se tiene que:
a) P[X > 2.485] = 1 - P[T25 ≤ 2.485] = 1 – 0.99 = 0.01.
Significa que el 1.0% de los valores de X ~ T25 son mayores que 2.485.
b) P(-1.316 ≤ X ≤ 2.060) = P[T25 ≤ 2.060] - P[T25 ≤ -1.316] =
= P[T25 ≤ 2.060] – {1 - P[T25 ≤ 1.316]} = 0.975 – {1 - 0.90} = 0.875
Significa que el 87.5% de los valores de X ~ T25 se encuentran entre -1.316 y 2.06.
c) Necesitamos halla el cuantil q0.05 = x, tal que:
0.05 = P(T25 ≤ x) → x = T25, 0.05 = -1.708
Significa que el 5% de los valores de X ~ T25 son menores que -1.708.
Veamos la solución del ejemplo 7.5 utilizando los programas y basados
fundamentalmente en las probabilidades acumuladas de la distribución t.
En Excel:
Para hallar la distribución de probabilidades acumuladas T, en la hoja de cálculo
definimos en la columna A los valores de la variable x = 1.316, 2.060 y 2.485. En la
columna B, definimos las probabilidades acumuladas, que en Excel vienen dadas por
F(x) = P(X > x). Excel considera x > 0 y en el cálculo usar la simetría.
297
Para hallar las probabilidades acumuladas, estando en la casilla B2, en funciones
del Excel, escogemos Estadísticas (de seleccionar una categoría) y buscamos la
función DISTR.T y aparece la ventana de Argumentos de función donde se define:
el valor de X = A2 (1.316) para poder efectuar una copia para los otros valores de x,
en el recuadro de Grados_de libertad escribir 25 y en colas escribir 1. Una forma
directa de cálculo es escribir =DISTR.T(A2,25,1) en el recuadro al lado de
. Al
hacer clic en Aceptar, aparece la probabilidad acumulada F(1.316) = 0.100057.
Para obtener las probabilidades acumuladas para los otros valores de x, se efectúa una
copia de lo anterior para las celdas sucesivas en B3 y B4, los resultados se presentan en
la Figura 7.22. Se puede apreciar que se ha calculado una columna de 1 – F(x) cuyos
resultados son parecidos a los usados en la solución manual del Ejemplo 7.4.
Figura 7.22 Cálculo de probabilidades acumuladas con la t en Excel
Para hallar el inverso de probabilidades acumuladas (calcular el valor del cuantil x ,
para una probabilidad acumulada = p) usar la función DISTR.T.INV(2p, GL) que es
para 2 colas (por eso 2p). Para la parte c) del ejemplo 7.5 es DISTR.T.INV(0.10, 25) al
hacer enter se obtiene x = 1.708141(en valor absoluto) similar al -1.708 hallado con la
tabla de T.
En Minitab:
Del menú escoger Calc → Probability Distributions → t y aparece la ventana de
diálogo t Distribution. El procedimiento de cálculo es similar al ejecutado con las
distribuciones de probabilidades anteriores. Es decir, el cálculo para una constante
(Input constant, con el resultado en la ventana Session) o para varios valores definidos
previamente en una columna de la Worksheet (Input column, con los resultados en la
worksheeet) que se esta usando.
298
Para el cálculo de probabilidades acumuladas seleccionar
e
indicar el parámetro requerido Degrees of freedom (grados de libertad) escribir 25 en
el recuadro.
Para calcular las probabilidades acumuladas para los valores de X del ejemplo 7.5, en
una columna de la worksheet definimos como x los valores -1.316, 2.060 y 2.485; y en
otra columna F(x) para obtener los resultados. Para ello, seleccionar
y
escoge x en el recuadro; y en Optional storage: se escoge F(x) para que los resultados
los deposite en la misma Worksheet. Al hacer clic en OK, en la Worksheet aparecen
los resultados siguientes:
Resultados idénticos a los obtenidos con el Excel en la columna 1 – F(x).
De la tabla, se obtiene rápidamente P(-1.316 ≤ X ≤ 2.060) = F(2.060) – F(-1.316) =
0.975024 – 0.100057 = 0.874967. Aproximadamente el 0.875 encontrado en b).
La representación gráfica de la solución anterior en Minitab, se obtiene seleccionando
del menú Graph → Probability Distribution Plots, de la ventana mostrada
seleccionar View Probability, luego hacer clic en OK y aparece la ventana de diálogo
Probability Distribution Plot – Probability.
En Distribution: hacer clic en
, escoger la distribución t e indicar el parámetro
requerido Degrees of freedom (grados de libertad) escribir 25 en el recuadro.
Luego hacer clic en
. En Define Shaded Area By escoger
, luego
e indicar los valores X1 = -1.316 y X2 = 2.060 [ya que queremos hallar P(-1.316
≤ X ≤ 2.060) y el gráfico con dicha área sombreada].
Para finalizar hacer clic en OK y aparece el gráfico de la Figura 7.23.
299
Distribution T
gl = df=25
0.4
0.875
Density
0.3
0.2
0.1
0.0
-1.316
0
X
2.06
Figura 7.23 Gráfico de P(-1.316 ≤ X ≤ 2.060) con la t en Minitab
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x, para una probabilidad acumulada dada) seleccionar
en la
ventana de diálogo Chi-Square Distribution e indicar los grados de libertad 25.
Para determinar el valor de x, para una probabilidad acumulada F(x) =0.05 en la parte
c) del Ejemplo 7.4 necesitamos seleccionar
y en el recuadro escribir
0.05. Al hacer clic en OK, en la hoja de Session aparece este resultado:
Inverse Cumulative Distribution Function
Student's t distribution with 25 DF
P( X <= x )
0.05
x
-1.70814
El 5% de los valores de X ~ T25 son menores que -1.70814.
En SPSS:
Para calcular las probabilidades acumuladas F(x) (F) del ejemplo 7.5, en la vista de
variables se define x y en la vista de datos se ingresan los mismos (-1.316, 2.060 y
2.485).
300
Del menú escoger Transformar → Calcular variable y aparece la ventana de
diálogo de la Figura 7.24. En Variable de destino: escribir F.
Del Grupo de funciones: del lado derecho, escoger FDA y FDA no centrada; y de
Funciones y variables especiales: seleccionar Cdf.T y con un clic en
ingresarla
al recuadro Expresión numérica: donde aparece CDF.T(?,?).
A continuación, hay que definir cada uno de los argumentos ? indicados en la función
CDF.T(cant,gl) que se precisan en el recuadro central de la Figura 7.24. Así cant
representa los valores de la variable x y gl = grados de libertad = 25. Para finalizar
hacer clic en Aceptar y en la vista de datos aparece los resultados siguientes:
Figura 7.24 Cálculo de probab. acumuladas con la t en SPSS
301
En R:
Para calcular probabilidades acumuladas con la T usar la función pt(x,gl). Donde x
puede ser un valor o un conjunto de valores definidos previamente, gl = grados de
libertad.
En el ejemplo 7.5, X ~ T25. Para determinar las probabilidades acumuladas
correspondientes a los valores (-1.316, 2.060 y 2.485) se define un vector x con esos
valores y luego las probabilidades acumuladas F se calculan así:
> x=c(-1.316,2.060,2.485)
> F=pt(x,25)
> cbind(x,F)
x
F
[1,] -1.316
0.1000570
[2,]
2.060
0.9750238
[3,]
2.485
0.9899976
Para el cálculo del inverso de probabilidades acumuladas (calcular el valor del cuantil
x o q, para una probabilidad acumulada dada) usar la función qt(x,gl). Donde p es una
o un conjunto de probabilidades acumuladas definidas previamente.
Para hallar el valor del cuantil q correspondiente a las probabilidades acumulada de
0.05 se procede así:
> qt(0.05,25)
[1] -1.708141
El 5% de los valores de X ~ T25 son menores que -1.708141.
302
REFERENCIAS BIBLIOGRÁFICAS
1. Arriaza A.J. y Otros (2008). “Estadística Básica con R y R-Commander”. UCA,
Universidad de Cádiz. Documento HTML.
http://knuth.uca.es/repos/ebrcmdr/pdf/actual/ebrcmdr.apendices.pdf
2. Bazán, Juan y Corbera, José (1997). “Problemas de probabilidad”. Trabajo de
investigación para la Facultad de Ciencias Económicas de la Universidad
Nacional del Callao, Callao, Perú, 156 p.
3. Correa, Juan y González, Nelfy (2002). “Gráficos estadísticos con R”, Manual
pdf. Posgrado en Estadística de la Universidad Nacional de Medellín, Colombia,
299 p.
4. Chué, Jorge y Otros (2007). “Estadística descriptiva y probabilidades”. Lima,
Perú. Fondo Editorial Universidad de Lima, 294 p.
5. Instituto Nacional de Estadística e Informática (2006). “Norma Técnica para la
elaboración de cuadros estadísticos”. Resolución Jefatural Nº 312-2006 INEI,
publicada en la página web:
http://www.inei.gob.pe/documentospublicos/nt_cestadisticos.pdf
6. Instituto Nacional de Estadística e Informática (2009).
“Indicadores
Demográficos-Población”. Censos Nacionales de Población y Vivienda,
publicada en la página web: http://www.inei.gob.pe/ . Perú en cifras.
7. Paradis, Emmanuel (2002). “R para principiantes”, Manual pdf del Institut des
Sciences de l‟Évolution Universit Montpellier II, F-34095 Montpellier cdex 05,
Francia, 61 p. Traducido por Jorge A. Ahumada, University of Hawai, 2003.
8. Pérez, César (2002). “Estadística aplicada a través de Excel”. Madrid, España.
Editorial Pearson-Prentice Hall, 596 p.
9. Tukey, John Wilder. 1977. “Exploratory Data Analysis”. Adisson-Wesley
Publishing Company: Reading, Massachusetts.
10. Visauta, Bienvenido. “Análisis estadístico con SPSS para Windows”. Madrid,
España. Editorial Mc Graw-Hill, 1997.
303
304
ANEXO
305
BASE DE DATOS: ESTADÍSTICA BÁSICA 09-A
nº_cuest
sexo
edad
peso
talla
ing.
fam
mie.
fam
g.estud
cr.aprob
prom.
acum
t.vi viend
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
1
1
1
1
1
2
2
2
2
1
2
1
2
1
2
1
1
1
2
1
1
2
1
2
2
2
2
2
1
1
1
2
1
1
2
2
1
2
2
1
2
1
1
2
1
1
21
16
20
20
21
19
19
17
19
19
22
20
19
18
17
20
18
18
18
23
19
20
20
22
21
23
19
19
20
19
18
20
20
21
18
21
19
19
19
21
19
20
20
19
21
21
68
69
63
55
57
48
50
50
44
60
52.6
80
52
67
46
80
64
64
63
72
65
47
70
50
53
66
57
50.5
80
55
88
55
75
64.5
50
49
54
46.5
49
70
48
60
75
55
51
72
169
172
170
173
167
152
152
156
154
171
160
176
164
171
154
177
169
171
170
179
177
165
171
158
155
160
159
152
175
165
175
157
177
165
149
164
164
160
161
169
150
168
172
150
156
174
3900
800
1000
1200
800
1000
700
1000
600
3000
800
1800
1200
1000
1600
750
3000
2800
2000
4500
3500
2200
4000
1000
800
800
950
1000
1500
1800
1000
4000
800
800
800
900
3000
2000
1300
2500
600
750
2100
2500
600
800
5
5
5
5
5
5
5
4
6
7
4
6
4
4
7
4
6
3
5
5
6
5
5
6
5
2
5
4
5
7
3
5
3
5
2
6
5
5
5
5
4
6
6
5
5
5
150
50
250
60
90
250
150
400
20
80
180
150
150
250
300
170
200
240
160
300
200
150
200
120
250
120
180
150
150
200
80
230
250
70
250
300
250
160
80
100
100
120
140
150
200
120
36
42
38
42
34
42
38
42
50
39
50
38
38
50
30
47
35
35
35
44
42
39
35
43
43
40
34
25
31
35
34
37
34
38
34
50
34
38
37
34
40
27
30
38
50
43
11.30
13.33
13.49
12.40
12.29
13.19
12.40
12.60
13.96
12.00
15.92
13.00
12.00
15.92
13.00
14.00
12.00
11.99
12.00
12.00
13.00
12.00
11.00
11.00
11.00
11.00
12.00
11.00
14.60
12.20
12.00
12.30
13.00
13.50
13.00
12.00
11.95
12.35
12.30
11.35
12.63
10.00
11.70
11.00
13.00
11.50
2
1
3
1
1
1
1
1
1
1
1
1
1
1
1
1
1
2
1
1
2
2
1
1
1
1
1
1
4
3
2
1
1
1
1
1
1
1
2
3
1
1
1
1
4
1
(Continúa ….
306
…. Continuación)
nº_cuest
sexo
edad
peso
talla
ing.
fam
mie.
fam
g.estud
cr.aprob
prom.
acum
t.vi viend
47
48
49
50
51
52
53
54
55
56
57
58
59
60
1
1
1
2
1
1
2
2
2
2
1
1
1
2
22
21
21
22
22
20
22
23
19
20
19
18
19
22
68
68
55
59
65
66
51
53
45
52
53
67
77
53
175
168
165
152
172
173
156
155
150
160
168
172
178
157
1500
2000
1500
1300
1000
1000
900
1250
650
900
1000
1300
1200
600
3
4
5
8
9
4
7
4
7
4
5
5
5
3
150
180
100
240
300
250
100
250
125
150
250
180
150
150
34
52
34
48
32
29
16
40
34
44
36
39
30
35
11.00
11.79
12.00
11.00
12.09
11.70
12.00
12.00
14.00
14.00
15.00
13.00
12.00
11.00
2
1
1
1
3
1
1
1
1
2
1
2
1
1
nº_cuest
nº.dor
mit
horas.
tv
hrs.
estud
lib.
leidos
hobby
imp.
estudio
imp.
fisico
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
3
7
2
3
4
2
4
3
4
5
3
7
4
4
3
3
4
3
6
4
2
3
4
7
6
3
4
3
3
10
3
8
4
30
3
4
6
8
10
8
15
10
6
26
7
8
12
10
6
12
5
14
6
14
8
7
14
5
3
6
21
16
8
25
35
4
6
30
12
12
30
30
15
16
26
15
10
14
14
18
10
10
20
25
24
8
6
15
8
5
15
9
9
1
15
5
4
3
2
3
4
5
4
10
3
3
3
4
3
2
5
8
3
2
3
2
4
7
4
4
3
3
3
3
2
2
1
4
2
2
2
5
4
1
4
2
4
1
3
3
2
2
5
4
2
2
1
2
2
4
2
2
1
4
1
4
4
5
4
4
5
4
5
5
4
5
5
5
4
5
5
5
4
4
5
4
4
4
3
4
4
5
5
5
5
4
4
3
3
4
4
2
3
3
3
2
3
3
5
3
3
4
5
3
2
4
4
4
4
4
5
3
3
3
3
3
4
col. proc espe cial
2
2
1
2
1
1
1
1
1
2
1
1
2
1
2
1
2
2
2
1
1
2
1
1
1
1
1
1
1
2
1
2
1
2
2
2
2
2
2
1
2
1
2
2
1
2
2
2
1
2
2
2
2
1
2
2
2
2
2
1
2
2
(Continúa ….
307
…. Conclusión)
nº_cuest
nº.dor
mit
horas.
tv
hrs.
estud
lib.
leidos
hobby
imp.
estudio
imp.
fisico
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
4
3
3
1
4
4
4
3
3
3
2
7
3
3
5
2
3
3
10
4
5
8
3
4
2
3
3
3
2
3
8
12
12
12
14
10
30
12
16
6
10
14
7
21
10
21
10
8
5
10
10
9
4
8
14
14
14
15
9
14
16
12
30
14
5
28
28
14
10
7
14
12
35
10
14
18
10
10
14
18
10
10
8
5
14
30
16
3
4
3
6
8
5
3
5
4
10
0
3
2
1
3
2
3
2
3
7
5
4
2
3
8
2
5
5
3
2
2
2
4
2
2
3
4
2
1
1
4
4
2
2
1
1
2
2
1
1
2
3
2
4
1
1
1
2
5
5
4
4
5
4
5
5
5
5
3
4
5
5
4
2
5
5
4
5
5
4
4
4
5
3
4
4
3
1
4
3
2
3
3
3
4
2
3
3
3
4
3
3
4
4
4
3
5
5
5
4
5
4
3
3
3
4
col. proc espe cial
1
1
2
1
1
2
1
1
1
1
1
2
1
1
1
1
2
1
1
1
2
1
1
1
1
1
1
1
1
1
2
2
2
1
2
2
2
2
2
2
2
2
1
2
1
1
2
2
2
2
1
2
2
2
2
2
2
2
Codificación:
SEXO
TIPO DE VIVIENDA
HOBBY
IMPORTANCIA DE ….
1 = Hombre
1 = Casa Independiente
1 = Deporte
2 = Mujer
2 = Dpto. en Edificio
2 = Música
3 = Quinta
3 = Baile
4 = Otro
4 = TV/Cine
1 = Muy Poca
2 = Poca
3 = Media
4 = Mucha
5 = Muchísima
5 = Otro
COLEGIO DE PROCEDENCIA
ESPECIALIZACIÓN
1 = Estatal
2 = No Estatal
1 = Teoría Económica
2 = Gestión Empresarial
308