Modelos no lineales
Anuncio

Modelos no lineales
Modelos ARCH y GARCH
Modelos no lineales
Mogens Bladt
March 3, 2009
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
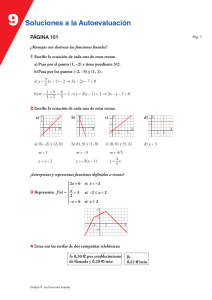
Cuando un modelo lineal (ARIMA) se ha analizado a fondo y no
produce un resultado satisfactorio se puede intentar espcificar un
modelo no lineal.
Algunos de los fallas en el ajuste de modelos lineales podrı́a indicar
hacia un cierto tipo de modelo no–lineal.
Por ejemplo se podria espcificar un modelo auto–regresivo no lineal
de la siguiente forma
Xt = µ(Xt−1 , Xt−2 , ..., Xt−p ) + t ,
donde t es un ruido blanco con medio zero y varianza σ 2 .
También se podria extender este modelo para permitir que la varianza
depende de los Xt ’s anteriores, i.e.
Xt = µ(Xt−1 , Xt−2 , ..., Xt−p ) + σ(Xt−1 , ..., Xt−p )Wt
donde {Wt } es un ruido blanco con medio zero y varianza 1.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
Supongamos que Wt son i.i.d. ∼ N(0, 1) y p = 1, i.e.
Xt = µ(Xt−1 ) + σ(Xt−1 )Wt .
Entonces Xt |Xt−1 = x ∼ N(µ(x), σ 2 (x)).
Entonces la distribución de Xt es una mezcla (continua) de
distribuciones normales.
Este tipo de distribuciones tienen colas más pesadas y más kurtosis
(veamos más adelante).
Supongamos que las funciones µ y σ dependen de un parámetro
no–conocido θ.
Si el ruido blanco tiene una distribución normal, entonces la función
de vero–similitud L esta dado por un producto de densidades
normales:
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
L(x1 , ..., xn ; θ) ∝ f (x1 , ..., xn ; θ)
= f (xn |xn−1 , ..., x0 ; θ)f (xn−1 , ..., x0 )
= f (xn |xn−1 ; θ) · · · f (x1 |x0 ; θ)
Entonces
θ̂n = argmaxθ
n
X
log f (xi |xi−1 ; θ).
i=1
Por la normalidad
n X
1
(xi − µ(xi−1 , θ))2
1
2
θ̂n = argmaxθ
− log(2π) − log σ (xi−1 , θ) −
2
2
2σ 2 (xi−1 )
i=1
La dificultad númerico de maximizar esta expressión depende de la
forma explicta de µ y σ, pero en principios no es más dificil que para
el caso lineal.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
El estimador para θ es consistente (θ̂n → θ cuando n → ∞) y
asintoticamente normal
Si el ruido no es normal es en general mucho más dificil de estimar θ.
Si se utilisa la normal aún sabiendo que no es la distribución correcta,
el estimador θ̂n se conoce como estimador de pseudo–maximo
vero–similitud o de quasi–maximo vero–similitud.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
La motivación hemos visto en series de IBM, GM, Dell etc. donde
básicamente los log–rendimientos se comportaban como ruido blando
en el sentido que estaban no–correlacionadas, pero el cuadrado del
ruido si tenian corrlaciones.
Este implica que los datos no pueden seguir una distribución normal
porque en este caso la no–correlación implicarı́a independencia.
Si la distribución es normal se puede checar con un plot Q-Q.
Evidencia demuestra que en general las colas son más pesadas en
datos obervados que para la normal.
En la modelación de ARCH y GARCH se modela tanto el desarrollo
del los datos tanto como la volatilidad, i.e. la desvición estandar del
ruido blanco que ahora se supone que depende del tiempo t.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
La justificación empirica de este tipo de modelo es por (1) evidencia
que hay cambios en la volatilidad con el tiempo (periodos con alta y
baja volatilidad) y (2) colas más pesadas de los obervaciones.
Definición
(Auto–Regresivo Condicionalmente Heterocedástico)
Una series de tiempo {Xt } es de tipo ARCH(p) si
Xt = σt Wt ,
σt2
= α0 +
p
X
2
αj Xt−j
j=1
donde {Wt } son i.i.d. con media zero y varianza 1 y α0 > 0, αj ≥ 0.
Frecuentemente se supone que Wt ∼ N(0, 1) para simplificar la
estimación.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
En el caso del ARCH(1) tenemos, iterando
Xt2 = σt2 Wt2
2
= α0 Wt2 + α1 Xt−1
Wt2
2
2
2
= α0 Wt2 + α1 α0 Wt−1
Wt2 + α12 Xt−2
Wt−1
Wt2
= ...
2
2
2
= α0 Wt2 + α0 α1 Wt2 Wt−1
+ ... + α0 α1n Wt2 Wt−1
· · · Wt−n
+
2
2
2
α1n+1 Wt2 wt−1
· · · Wt−n
Xt−n−1
Si {Xt } es estacionaria, entonces IE(Xt2 ) es constante y por lo tanto
n
X
2
j
2
2
2
IE Xt − α0
α1 Wt · · · Wt−j = α1n+1 IE Wt2 · · · IE Wt−n
j=0
2
·IE Xt−n−1
2
= α1n+1 IE Xt−n−1
→0
cuando n → ∞.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
Entonces
Xt2
= α0
∞
X
2
α1j Wt2 · · · Wt−j
.
j=0
La media de Xt esta dado por
IE(Xt ) = IE(σt Wt ) = IE(σt )IE(Wt ) = 0
y el segundo momento por
IE(Xt2 ) = α0
∞
X
α1j =
j=0
α0
.
1 − α1
Las covarianzas de {Xt } estan dadas por
IE(Xt Xt+h ) = IEIE (Xt Xt+h |Wt+h−1 , Wt+h−2 , ...)
= IE (Xt IE (Xt+h |Wt+h−1 , Wt+h−2 , ...)) = 0
por dado Wt+h−1 , ..., σt+h es constante y Xt+h = σt+h Wt+h entonces
tiene medio condicional zero.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
Entonces la función ACF es igual a zero.
Calculus similares se puede hacer para ARCH(p).
Para el ARCH(1) tenemos
2
σt2 = α0 + α1 Xt−1
y introduciendo νt = Xt2 − σt2 se puede escribir como
2
Xt2 = α0 + α1 Xt−1
+ νt .
Como
2
νt = Xt2 − σt2 = σt2 (Wt2 − 1) = (α0 + α1 Xt−1
)(Wt2 − 1)
tenemos que
2
IE(νt |Xt−1 , Xt−2 , ...) = (α0 + α1 Xt−1
)IE(Wt2 − 1) = 0.
Entonces IE(νt νt+h ) = 0 para h > 0, pero obviamente las varianzas IE(νt2 )
no son constantes, i.e. es heterocesdástico.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
Entonces {Xt } es un proceso ARCH(1) si y solo si {Xt2 } es un
proceso AR(1) en un sentido un poco más amplio que lo tradicional.
Entonces un ARCH(1) se puede identificar con el uso del PACF.
Definición
(Auto–Regresivo Condicionalmente Heterocedástico Generalizado)
Una series de tiempo se llama GARCH(p, q) si
Xt = σt Wt , σt2 = α0 +
p
X
i=1
2
αi Xt−i
+
q
X
2
βj σt−j
.
j=1
donde {Wt } es una sucessión de variables i.i.d. con media zero y varianza
1.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
Usando el mismo método como para ARCH(1),
definiendo
νt = Xt2 − σt2 ó
P
P
p
q
2 +
2
σt2 = Xt2 − ν, se obtiene desde σt2 = α0 i=1 αi Xt−i
j=1 βj σt−j que
Xt2
= α0 +
= α0 +
p
X
i=1
p
X
2
αi Xt−i
+
2
αi Xt−i
+
i=1
q
X
j=1
q
X
2
βj σt−j
+ νt
2
βj Xt−j
−
j=1
max (p,q)
= α0 +
X
2
(αi + βi )Xt−j
−
i=1
q
X
βj νt−j + νt
j=1
q
X
βj νt−j + νt
j=1
definiendo αj = 0 para j > p y βj = 0 para j > q.
Con la misma técnica que antes se demuestra que
IE(νt |Xt−1 , Xt−2 , ...) = 0 y por lo tanto que Cov(Xt , Xt+h ) = 0 para
h 6= 0. Otra vez tenemos la heterocedadisticidad presente como tienen
varianzas distintos.
Mogens Bladt
Modelos no lineales
Modelos no lineales
Modelos ARCH y GARCH
En un amplio sentido, {Xt } sigue un modelo GARCH(p., q) si y solo
si {Xt2 } sigue un proceso ARMA(p, q) con un ruido no homogeneo.
Investigamos condiciones de estacionariedad. Tomando especranzas
en la representación ARMA y usando que IE(νt ) = 0 para todo t,
max (p,q)
IE(Xt2 )
X
= α0 +
2
(αj + βj )IE(Xt−j
)
j=1
y suponiendo estacionariedad para {Xt }, implicando que su varianza
IE(Xt2 ) es constante, se obtiene que
α0
IE(Xt2 ) =
Pmax (p,q)
1 − i=1
(αi + βi )
implicando que debemos imponer la condición
max (p,q)
X
(α1 + βi ) < 1.
i=1
Mogens Bladt
Modelos no lineales