Guión Práctica 2
Anuncio

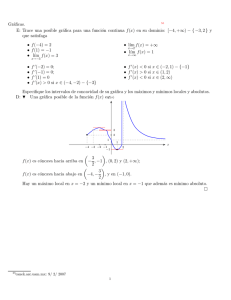
BASES DE ESTADÍSTICA 10 de CC. Ambientales, curso 2009-2010 Prácticas con el programa SPSS GUIÓN DE LA SEGUNDA PRÁCTICA CON SPSS 1. Cómo realizar un análisis de regresión simple Consideremos el siguiente ejemplo: En la siguiente tabla de datos la variable y representa la pureza (en porcentaje) del oxı́geno producido en un cierto proceso quı́mico de destilación y x es el porcentaje de hidrocarburos presentes en el condensador principal de la unidad de destilación. N0 de observación 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Nivel de hidrocarburo, x ( %) Pureza, y ( %) 0.99 90.01 1.02 89.05 1.15 91.43 1.29 93.74 1.46 96.73 1.36 94.45 0.87 87.59 1.23 91.77 1.55 99.42 1.40 93.65 1.19 93.54 1.15 92.52 0.98 90.56 1.01 89.54 1.11 89.85 1.20 90.39 1.26 93.25 1.32 93.41 1.43 94.98 0.95 87.33 (a) Calcular las medias y desviaciones tı́picas de ambas muestras. (b) Ajustar un modelo de regresión lineal simple para analizar la evolución de y en función de x. (c) Estimar el coeficiente de correlación. 1 1. Los datos pueden introducirse directamente en el programa o “bajarse” de la red en la siguiente dirección: http://www.uam.es/daniel.faraco/docencia/Estadistica/Reaccion.txt 2. Cuando ya se tienen los datos de la tabla cargados en el programa, en dos variables columna x e y, se seleccionan las opciones Analizar ,→ Estadı́sticos descriptivos ,→ Descriptivos . 3. En el recuadro que aparece en pantalla se “transporta” (haciendo clic en la flecha correspondiente) la variables x e y del recuadro de la izquierda al de la derecha, titulado Variables . A continuación haciendo clic en Opciones se eligen los valores que se quieren obtener (media, varianza,...). Por último, se hace clic en Continuar y Aceptar y aparecerán los resultados en pantalla. Estos resultados pueden guardarse (con extensión .spo) seleccionando Archivo ,→ Guardar . 4. Para las preguntas (b) y (c), se selecciona la ruta Analizar ,→ Regresión ,→ Lineal . 5. En el recuadro que aparece en pantalla se “transporta” (haciendo clic en la flecha correspondiente) la variable y al recuadro titulado Dependiente y la x a Independientes . A continuación se selecciona Aceptar . 6. Los valores â y b̂ de los coeficientes estimados del modelo de regresión lineal se pueden encontrar en la columna “B” de la tabla Coeficientes que aparece en el visor de resultados. En este caso se tiene â = 74,283 y b̂ = 14,947. El coeficiente de correlación estimado es el valor R que aparece en la tabla Resumen del modelo del visor de resultados. En este caso R = 0,937. 7. Para obtener un gráfico en el que aparezca la nube de puntos y la recta de regresión estimada, usar la opción Gráficos ,→ Dispersión ,→ Definir . Esto proporciona un gráfico con la nube de puntos. Para obtener la recta, hacer doble clic sobre este gráfico. Con esto se entra en el editor de gráficos. Elegir entonces Elementos ,→ Lı́nea de ajuste total ,→ Ajustar lı́nea ,→ Lineal . En las versiones del SPSS anteriores a la 13.0.1 la ruta a seguir es Diseño ,→ Opciones ,→ Ajuste de lı́nea . 2 Ejercicio 2: Realizar ahora un análisis similar con los datos del fichero Datosgeyser. Estos datos corresponden al problema 1 de la relación de ejercicios propuestos y se pueden encontrar en http://www.uam.es/daniel.faraco/docencia/Estadistica10/Datos-geyser.xls 2. Cómo obtener diagramas de cajas Utilizaremos nuevamente los datos de contaminación por mercurio en los peces de dos rı́os cercanos: http://www.uam.es/daniel.faraco/docencia/Estadistica10/Mercurio.txt Supongamos que se desea obtener dos diagramas de cajas para comparar la contaminación en los peces del rı́o Lumber y los del rı́o Wacamaw. Recordemos que todos los datos de contaminación están en la columna 5 del fichero Mercurio.txt y que en la primera columna de este fichero se indica con un 0 los datos que corresponden al rı́o Lumber y con un 1 los que corresponden al Wacamaw. Procederemos del siguiente modo: 1. Gráficos ,→ Diagramas de caja . . . . 2. En la ventana Diagrama de cajas seleccionar las opciones Simples y Resúmenes para grupos de casos ,→ Definir . 3. A continuación pasamos la variable que corresponde a la quinta columna del fichero al recuadro Variable y la variable de la primera columna al recuadro Eje de categorı́as 4. Por último, ,→ Aceptar . También con este procedimiento podemos obtener, de modo que aparezcan en la misma pantalla, gráficos de caja para diferentes variables 1. Gráficos ,→ Diagramas de caja . . . . 2. En la ventana Diagrama de cajas seleccionar las opciones Agrupado y Resúmenes para distintas variables ,→ Definir . 3. A continuación pasamos las variables que queremos estudiar del recuadro izquierdo al derecho. 4. Por último, ,→ Aceptar . 3 Ejercicio 3: El fichero Paises.txt consta de ocho columnas en las que se indica, respectivamente, los siguientes datos socioeconómicos para 91 paı́ses del mundo: Tasa de natalidad por cada 1000 habitantes, tasa de mortalidad por cada 1000 habitantes, tasa de mortalidad por cada 1000 habitantes menores de 1 año, esperanza de vida de los hombres al nacer, esperanza de vida de las mujeres al nacer, PNB per capita (dólares USA), grupo al que pertenece el paı́s (1 = Europa Oriental 2 = Sudamérica y Méjico 3 = Europa Occidental, Norteamérica, Japón, Australia, Nueva Zelanda 4 = Oriente Próximo 5 = Asia 6 = Africa), nombre del paı́s. Comparar, mediante diagramas de cajas, los datos de PNB en el grupo 6 y en el resto del mundo. Comparar también, mediante dos diagramas de cajas, los datos de esperanza de vida para los hombres y para las mujeres. En algunos casos, los ficheros de datos que se encuentran en la red tienen los decimales indicados con puntos y nuestro programa está configurado para introducir los decimales con comas (o viceversa). En estos casos, se puede bajar el fichero a nuestro ordenador, editarlo con el programa adecuado y utilizar la opción de reemplazar”, que nos proporcione el correspondiente editor, para cambiar los puntos por comas. Por ejemplo, si se trata de un fichero de texto esto puede hacerse con la opción Edición → Reemplazar. Como ejercicio, cargar en el SPSS los datos del fichero Paises2.txt, que son los mismos del fichero Paises.txt con los decimales expresados con puntos. 3. Cómo obtener un histograma Por ejemplo, consideremos la penúltima columna (PNB per cápita en dólares USA) del fichero de datos Paises.txt. 1. Se cargan los datos según se indicó en la Práctica 1. 2. En el editor de datos se selecciona (haciendo clic sobre el nombre) la columna correspondiente a los datos de los que se quiere obtener el histograma. 3. Se sigue la ruta Gráficos ,→ Histograma . 4. En el cuadro de diálogo que aparece se selecciona (en la lista de variables de la izquierda) el nombre de la variable elegida. 5. Se hace clic en Aceptar . 4 Con este procedimiento el programa elige automáticamente el número de clases (o intervalos) del histograma. Para cambiar este número y elegir la agrupación por clases de otro modo se puede utilizar la siguiente opción: 1. Después de obtener el histograma por el procedimiento anterior, hacer doble clic sobre el gráfico resultante. Con esto se entra en el .editor de gráficos allı́, haciendo nuevamente doble clic sobre el histograma, se entra en un cuadro de diálogo titulado Propiedades. En la pestaña Opciones del histograma se puede modificar la estructura del histograma (origen de la primera clase, número de intervalos, ancho del intervalo,...) 2 2. En las versiones del SPSS anteriores a la 13.0.1 la ruta a seguir en el editor de gráficos es Diseño ,→ Ejes ,→ Intervalo ,→ Aceptar ,→ Personalizado ,→ Definir . Dos observaciones finales: La opción Gráficos ,→ Galerı́a proporciona información muy útil y cómoda acerca de los diferentes gráficos disponibles y de cómo obtenerlos. Los gráficos que aparecen en el visor de resultados se puede modificar en algunos aspectos (por ejemplo, cambiar la rotulación de los ejes, el color, etc.) accediendo al Editor de gráficos. Para ello basta hacer doble clic sobre el gráfico. 5