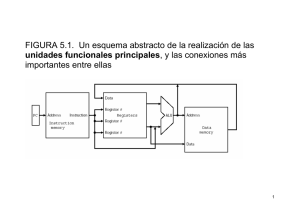
Descargar toda la información en un solo fichero pdf
Anuncio

FUNDAMENTOS DE COMPUTADORES CURSO 2005/2006 1. PROYECTO DOCENTE 2. TRANSPARENCIAS DEL CURSO 3. GUIONES DE PRÁCTICAS 4. COLECCIÓN DE PROBLEMAS DE EXÁMENES Carmelo Cuenca Hernández y Francisca Quintana Domínguez PROYECTO DOCENTE CURSO: 2005/06 13877 - FUNDAMENTOS DE COMPUTADORES ASIGNATURA: CENTRO: TITULACIÓN: DEPARTAMENTO: ÁREA: PLAN: CURSO: CRÉDITOS: 13877 - FUNDAMENTOS DE COMPUTADORES Escuela Universitaria Informática Ingeniero Técnico en Informática de Sistemas INFORMÁTICA Y SISTEMAS Arquitectura Y Tecnología de Computadores 11 - Año 2000 ESPECIALIDAD: Primer curso IMPARTIDA: Segundo cuatrimestre TIPO: Obligatoria 4,5 TEÓRICOS: 3 PRÁCTICOS: 1,5 Descriptores B.O.E. Organización básica de los computadores: elementos básicos; esquemas de funcionamiento, desripción de una máquina básica, programación. Temario 1 Arquitectura de un computador y jerarquía de niveles (3horas) 2 Arquitectura del nivel lenguaje máquina (10 horas) 2.1 Características generales del lenguaje máquina (3 horas) 2.2 Tipos de operandos e instrucciones (2 horas) 2.3 Modos de direccionamiento y formato de las instrucciones (2 horas) 2.4 Subrutinas (3 horas) 3 Diseño del procesador (15 horas) 3.1 Diseño y control cableado de un camino de datos monociclo (4 horas) 3.2 Diseño y control cableado de un camino de datos multiciclo ( 8 horas) 3.3 Diseño y control microprogramado de un camino de datos multiciclo (3 horas) 4 Rendimiento ( 2 horas) Conocimientos Previos a Valorar Los alumnos deberían haber cursado y aprobado la signatura de Sistemas Digitales, donde adquirirían los conocimientos acerca de los sistemas de numeración y representación de la información más usuales, el álgebra de Boole y su aplicación para simplificación de funciones booleanas, las técnicas de implementación de circuitos combinacionales simples, los fundamentos y componentes básicos de los sistemas secuenciales para desarrollar sistemas secuenciales síncronos. También son necesarios algunos conocimientos básicos de programación en algún lenguaje de alto nivel para saber diseñar programas sencillos, y representar esos algoritmos en pseudocódigo, diagramas de flujo o algún método equivalente. Objetivos Didácticos Fundamentos de Computadores es la asignatura que presenta los componentes de un computador y la organización de estos componentes para proporcionar, de una manera eficiente, las funciones necesarias para poder ejecutar programas. Página 1 Obtener una visión general de la jerarquía de niveles de un computador. Saber diferenciar entre los conceptos de estructura y arquitectura de un computador. Conocer y comprender las características más importante de la arquitectura y estructura de un computador. Conocer y comprender los elementos básicos de la arquitectura del repertorio de instrucciones. Dominar la programación en lenguaje ensamblador de algún procesador como, por ejemplo, el MIPS R2000. Conocer y comprender los elementos estructurales del procesador para la ejecución de las instrucciones. Conocer los principios básicos y métodos de diseño de unidades de control cableadas y microprogramadas. Evaluar las alternativas de diseño, así como el rendimiento de computadores. Metodología de la Asignatura La metodología docente a utilizar durante la impartición de la asignatura incluye los siguientes procedimientos: •Clases magistrales. •Clases prácticas en el laboratorio. •Resolución de problemas. •Tutorías. Evaluación La nota final de la asignatura será el resultado de la ponderación entre la nota de teoría y la nota de las prácticas de laboratorio. Para aprobar la asignatura es preciso haber superado ambas partes con una nota mayor o igual a 5 puntos. La nota de teoría tendrá un peso de un 70% sobre la nota final y la nota de prácticas de laboratorio un 30%. La nota de teoría y de prácticas de laboratorio se obtendrá a partir de los exámenes de convocatoria de la asignatura, uno para teoría y otro para práctica, en la fecha que el Centro fije para ello. Así para calcular la nota final se utilizará la siguiente fórmula: NF = 0.7 NT +0.3 NP (siempre que NT>=5 y NP>=5) donde NF es la nota final, NT es la nota de teoría y NP es la nota de prácticas de laboratorio. Descripción de las Prácticas Práctica nº 1 DescripciónEl simulador PCspim. ObjetivosFamiliarización con la herramienta para las prácticas de la asignatura. Material de laboratorio recomendadoOrdenador personal. Windows. Simulador Pcspim Nº horas estimadas en Laboratorio2Nº horas total estimadas para la realización de la práctica2 Práctica nº 2 DescripciónLos datos en memoria ObjetivosAdquirir soltura en cómo están ubicados los datos en memoria Material de laboratorio recomendadoOrdenador personal. Window NT 4.0. Simulador Pcspim Nº horas estimadas en Laboratorio2Nº horas total estimadas para la realización de la práctica2 Práctica nº 3 DescripciónCarga y almacenamiento de los datos Página 2 ObjetivosEstudio de la forma en que se cargan y almacenan los datos. Poner en práctica los conocimientos adquiridos en las clases teóricas sobre el repertorio de instrucciones MIPS. Material de laboratorio recomendadoOrdenador personal. Window NT 4.0. Simulador Pcspim Nº horas estimadas en Laboratorio2Nº horas total estimadas para la realización de la práctica2 Práctica nº 4 DescripciónLas operaciones aritméticas y lógicas. ObjetivosAdquirir soltura en el uso de las instrucciones aritméticas lógicas. Poner en práctica los conocimientos adquiridos en las clases teóricas sobre el repertorio de instrucciones MIPS. Material de laboratorio recomendadoOrdenador personal. Window NT 4.0. Simulador Pcspim2 Nº horas estimadas en Laboratorio2Nº horas total estimadas para la realización de la práctica2 Práctica nº 5 DescripciónInterfaz con el programa ObjetivosFamiliarización con la forma en que el PCSPIM permite realizar entrada y salida de datos. Material de laboratorio recomendadoOrdenador personal. Window NT 4.0. Simulador Pcspim Nº horas estimadas en Laboratorio2Nº horas total estimadas para la realización de la práctica2 Práctica nº 6 DescripciónEstructuras de control:condicionales y bucles ObjetivosAdquirir soltura en el uso de las instrucciones que permiten implementar estructuras condicionales y bucles Material de laboratorio recomendadoOrdenador personal. Window NT 4.0. Simulador Pcspim Nº horas estimadas en Laboratorio2Nº horas total estimadas para la realización de la práctica2 Práctica nº 7 DescripciónGestión de subrutinas ObjetivosEstudio de la forma en que se manejan las subrutinas en lenguaje ensamblador. Material de laboratorio recomendadoOrdenador personal. Window NT 4.0. Simulador Pcspim Nº horas estimadas en Laboratorio3Nº horas total estimadas para la realización de la práctica3 Bibliografía [1] Organización y diseño de computadores: la interfaz hardware/software Hennessy, John L. , McGraw-Hill, Madrid (1995) - (2ª ed.) 8448118294 [2] Computer organization and design: the hardware/software interface John L. Hennessy, David A. Patterson Morgan Kaufmann, San Francisco (California) (1998) - (2nd ed.) 1-55860-491-X [3] Introducción a la informática Alberto Prieto Espinosa, Antonio Lloris Ruiz, Juan Carlos Torres Cantero McGraw Hill, Madrid (2001) - (3ª ed.) 8448132173 Página 3 [4] Organización de computadoras: un enfoque estructurado Andrew S. Tanenbaum Prentice Hall, México [etc.] (2000) - (4ª ed.) 970-17-0399-5 [5] Organización y arquitectura de computadores: diseño para optimizar prestaciones William Stallings Prentice Hall, Madrid (2000) - (5ª ed.) 84-205-2993-1 [6] Problemas y tests de introducción a la informática: con más de 400 problemas y 700 preguntas de tests por Beatriz Prieto Campos, Alberto Prieto Espinosa Universidad de Granada, Departamento de Arquitectura y Tecnología de Computadores, Granada (2003) 8460791092 [7] Arquitectura de computadores: un enfoque cuantitativo John L. Hennessy, David A. Patterson , McGraw-Hill, Madrid (1993) 8476159129 Equipo Docente CARMELO CUENCA HERNANDEZ (COORDINADOR) Categoría: TITULAR DE ESCUELA UNIVERSITARIA Departamento: INFORMÁTICA Y SISTEMAS Teléfono: 928458713 Correo Electrónico: [email protected] WEB Personal: FRANCISCA QUINTANA DOMINGUEZ (RESPONSABLE DE PRACTICAS) Categoría: TITULAR DE ESCUELA UNIVERSITARIA Departamento: INFORMÁTICA Y SISTEMAS Teléfono: 928458736 Correo Electrónico: [email protected] WEB Personal: Página 4 Proyecto docente – Fundamentos de Computadores http://serdis.dis.ulpgc.es/~itis-fc Titulación de Ingeniería Técnica en Informática de Sistemas Escuela Universitaria de Informática Proyecto Docente - Profesorado – Carmelo Cuenca Hernández (coordinador) • [email protected] • Despacho 2-13 en el módulo 3 • Horario de T U T O R Í A S – Lunes de 11.00-13.00 y jueves 9.00-13.00 – Francisca Quintana Domínguez (responsable de prácticas) • [email protected] • Despacho 2-12 en el módulo 3 • Horario de T U T O R Í A S – Lunes de 9.30-12.30 y miércoles 9.30-12.30 Curso 2005/2006 Fundamentos de Computadores 2 Proyecto Docente – Horarios L M V 8:30-9:30 TA TB 9:30-10:30 TB 10:30-11:30 11:30-12:30 12:30-13:30 13:30-14:30 Curso 2005/2006 A-5 L3.3 A1-A2 L1.1 A3-A4 L1.1 B1-B2 L1.1 B3-B4 L1.1 Fundamentos de Computadores TA 3 Proyecto docente - Objetivos de la asignatura • Fundamentos de Computadores presenta los componentes de un computador y la organización de estos componentes para ejecutar programas – Obtener una visión general de la jerarquía de niveles de un computador – Conocer y comprender las características más importante de la arquitectura y estructura de un computador – Conocer y comprender los elementos básicos de la arquitectura del repertorio de instrucciones – Dominar la programación en lenguaje ensamblador de algún procesador como, por ejemplo, el MIPS R2000 – Conocer y comprender los elementos estructurales de un procesador para la ejecución de las instrucciones – Conocer los principios básicos y métodos de diseño de unidades de control cableadas y microprogramadas – Evaluar alternativas de diseño, así como el rendimiento de un computador Curso 2005/2006 Fundamentos de Computadores 4 Proyecto Docente - Temario 1. Arquitectura de un computador y jerarquía de niveles (3 horas) 2. Arquitectura del nivel lenguaje máquina (10 horas) 1. 2. 3. 4. Características generales del lenguaje máquina Tipos de operandos e instrucciones Modos de direccionamiento y formato de las instrucciones Subrutinas 3. Diseño del procesador (15 horas) 1. Diseño y control cableado de un camino de datos monociclo 2. Diseño y control cableado de un camino de datos multiciclo 3. Diseño y control microprogramado de un camino de datos multiciclo 4. Rendimiento (2 horas) Curso 2005/2006 Fundamentos de Computadores 5 Proyecto Docente - Prácticas 1. El simulador PCspim (2 horas) 2. Los datos en memoria (2 horas) 3. Carga y almacenamiento de los datos (2 horas) 4. Las operaciones aritméticas y lógicas (2 horas) 5. Interfaz con el programa (2 horas) 6. Estructuras de control condicionales y bucles (2 horas) 7. Gestión de subrutinas (3 horas) Curso 2005/2006 Fundamentos de Computadores 6 Proyecto Docente - Evaluación • Nota final = 0.7 Nota de teoría + 0.3 Nota de práctica (siempre que nota de teoría >=5 y Nota de práctica>=5) • La nota de teoría y de práctica se obtendrá en los exámenes de convocatoria de la asignatura, uno para teoría y otro para práctica Curso 2005/2006 Fundamentos de Computadores 7 Arquitectura de un computador y jerarquía de niveles “La arquitectura de un computador es la estructura de un computador que un programador en lenguaje máquina debe conocer para escribir un programa correcto (independiente del tiempo)” Amdahl 1964 Objetivos • • • • • • • Establecer características para nominar una máquina como computador Conocer los hitos de la arquitectura de los computadores Distinguir los diferentes niveles de estudio de los computadores Entender los mecanismos de traducción e interpretación de niveles Diferenciar entre la arquitectura y la estructura de un computador Describir los componentes básicos de un computador y las funcionalidades de cada uno de ellos por separados Explicar el funcionamiento global de un computador a partir de las relaciones de sus componentes básicos Curso 2005/2006 Fundamentos de Computadores 9 Contenidos • • Concepto de computador Historia de los computadores – La 1ª generación (los primeros computadores) – La 2ª generación (transistores) – La 3ª generación (SCI), la 4ª (LSI) y la 5ª (VLSI, UVLSI) • Organización estructurada de un computador – Lenguajes, niveles y máquinas virtuales – Computador multinivel • Funcionamiento de un computador – Componentes de un computador – Ciclo de instrucción – Interconexión con buses • El futuro de los computadores – Ley de Moore Curso 2005/2006 Fundamentos de Computadores 10 Concepto de computador • Diccionario de la Lengua Española – “Máquina electrónica dotada de una memoria de gran capacidad y de métodos de tratamiento de la información, capaz de resolver problemas aritméticos y lógicos gracias a la utilización automática de programas registrados en ella” • Microsoft Encarta – “Dispositivo electrónico capaz de recibir un conjunto de instrucciones y ejecutarlas realizando cálculos sobre los datos numéricos, o bien compilando y correlacionando otros tipos de información” • Enciclopedia Británica – “Device for processing, storing, and displaying information” • Wikipedia – “Sistema digital con tecnología microelectrónica capaz de procesar información a partir de un grupo de instrucciones denominado programa” Curso 2005/2006 Fundamentos de Computadores 11 Historia de los computadores "Quien olvida las lecciones de la historia queda condenado a repetirla." Will Durant, Lecciones de la Historia ENIAC – ¿Qué, quiénes, …? • • • • • • Electronic Numerical Integrator And Computer Eckert y Mauchly Universidad de Pennsylvania Tablas de trayectorias balísticas Año de inicio 1943 Año de finalización 1946 – Tarde para la Segunda Guerra Mundial (1939-1945) • En funcionamiento hasta 1955 Curso 2005/2006 Fundamentos de Computadores 13 ENIAC - detalles • • • • • • • • Decimal (no binario) 20 registros acumuladores de 10 dígitos Programado manualmente mediante 6000 interruptores 18000 tubos de vacío y 1500 relevadores 30 toneladas 15000 pies cuadrados 140 Kw de consumo de potencia 5000 sumas por segundo Curso 2005/2006 Fundamentos de Computadores 14 Von Neumann/Turing • • Concepto de programa almacenado Componentes de un computador – La memoria principal (MM) almacena programas y datos – La unidad aritmética lógica (ALU) opera con datos binarios – La unidad de control (UC) interpreta y provoca la ejecución de las instrucciones en memoria • Máquinas – EDSAC – la primera computadora de programa almacenado • Maurice Wilkes, Universidad de Cambridge, (¿?-1949) – La máquina IAS • John von Neumann y Herman Goldstine, Instituto para Estudios Avanzados de Princeton, (19461952) Curso 2005/2006 Fundamentos de Computadores 15 Estructura de una máquina von Neumann • Cinco partes básicas: – la memoria (M), almacena datos e instrucciones – la unidad aritmética lógica (ALU), capaz de hacer operaciones con datos binarios – la unidad de control (UC), interpreta y provoca la ejecución de las instrucciones en memoria – el equipo de entrada y salida (I/O) Curso 2005/2006 Fundamentos de Computadores 16 IAS - detalles • • • • Aritmética binaria 1000 palabras de 40 bits 2 registros de instrucciones de 20 bits Registros dentro de la CPU – R. temporal de memoria (MBR) – R. de direcciones de memoria (MAR) – R. de instrucciones (IR) – R. temporal de instrucciones (IBR) – R. contador de programa (PC) – R. acumulador (AC) – R. multiplicador cociente (MQ) Curso 2005/2006 Fundamentos de Computadores 17 Computadores comerciales • 1947 – Eckert-Mauchly Computer Comportation – UNIVAC I (Universal Automatic Computer) • Aplicaciones científicas y comerciales • Oficina del censo en 1950 • Operaciones algebraicas con matrices, problemas de matrices, primas para las compañías de seguro, problemas logísticos ... – Absorción por Sperry-Rand Comporation – UNIVAC II a finales de los 50 • Más rápido • Más memoria – Serie UNIVAC 1100 Curso 2005/2006 Fundamentos de Computadores 18 IBM • Fabricante de equipos de procesamiento con tarjetas perforadas • 1953 – El 701 para aplicaciones científicas • 1955 – El 702 para aplicaciones de gestión • Líder mundial con las series 700/7000 Curso 2005/2006 Fundamentos de Computadores 19 La segunda generación: los transistores (1955-1965) • Invención de Shockley y otros de los laboratorios Bell en 1947 • Sustitución de los tubos de vacío por transistores • Ventajas del transistor – – – – Más pequeño Más barato Menor disipación de calor Fabricado con silicio (arena) Curso 2005/2006 Fundamentos de Computadores 20 Computadores con transistores • NCR y RCA fueron los primeros en comercializar pequeñas máquinas con transistores • IBM 7000 • 1957 - Fundación de Digital Equipment Corporation (DEC) pionera de los minicomputadores – PDP 1 Curso 2005/2006 Fundamentos de Computadores 21 La 3ª, 4ª y 5ª generación: los circuitos integrados (1965-????) • • • Un computador consta de puertas, celdas de memoria e interconexiones Tales componentes podían ser fabricados a partir de un semiconductor como el silicio en un circuito integrado (Robert Noyce – 1958) Generaciones 3ª, 4ª y 5ª de computadores – 3ª generación • • • • Pequeña y mediana integración (SCI) 1965-1971 Hasta 100 componentes en un chip 1965 - IBM líder mundial inicia la “familia” 360 1965 - DEC lanza el minicomputador de bajo coste PDP-8 – 4ª generación • Gran integración (LSI ) 1972-1977 • Entre 3000 y 100000 componentes en un chip – 5ª generación • Alta Integración (VLSCI y UVLSI) 1978-???? • Más de 100000000 componentes en un chip Curso 2005/2006 Fundamentos de Computadores 22 Organización estructurada de un computador Los computadores están diseñados como una serie de niveles, cada uno construido sobre sus predecesores. Cada nivel representa una abstracción distinta, y contiene diferentes objetos y operaciones Lenguajes, niveles y máquinas virtuales • • La máquina virtual Mi ejecuta sólo programas escritos en el lenguaje de programación Li Ejecución de programas en Mi: – Traducción • Un programa “traductor” sustituye cada instrucción escrita en Li por una secuencia equivalente de instrucciones en Li-1. El programa resultante consiste exclusivamente en instrucciones de Li-1. Luego, Mi-1 ejecuta el programa en Li-1 – Interpretación • Un programa “intérprete” escrito en Li-1 examina las instrucciones una por una y ejecuta cada vez la sucesión de instrucciones en Li-1 que equivale a cada una Curso 2005/2006 Fundamentos de Computadores 24 Computador multinivel • N. aplicaciones – • N. lenguaje alto nivel – • • Puertas lógicas: AND, OR …, biestables, registros … N. dispositivos – Curso 2005/2006 Banco de registros, ALU, camino de datos N. lógica digital – • Salto, pila, … N. microarquitectura – • Archivo, partición, proceso, … N. arquitectura del repertorio de instrucciones (ISA) – • BASIC, C, C++, Java, Lisp, Prolog N. lenguaje ensamblador N. sistema operativo – • Microsoft Office, eMule… Transistores, diodos, estado sólido … Fundamentos de Computadores 25 Funcionamiento de un computador Componentes de un computador • Unidad central de proceso (CPU) – Unidad de control (UC) – Unidad aritméticalógica (ALU) • Memoria (M) • Entrada y salida (E/S) Curso 2005/2006 Fundamentos de Computadores 27 Ciclo de instrucción (1/2) • Ciclo de búsqueda de instrucción – El registro contador de programa (PC) contiene la dirección de la siguiente instrucción a ejecutar – El procesador busca la instrucción a partir de la localización de memoria señalada por el PC – El procesador incrementa el contador de programa (hay excepciones) – La instrucción es cargada en el registro de instrucciones (IR) Curso 2005/2006 Fundamentos de Computadores 28 Ciclo de instrucción (2/2) • Ciclo de ejecución (5 tipos) – Procesador-memoria: transferencia de datos desde la CPU a la memoria o al revés – Procesador-E/S: transferencia de datos a o desde el exterior – Procesamiento de datos: la CPU ha de realizar alguna operación aritmética o lógica con los datos – Control: una instrucción puede especificar que la secuencia de ejecución sea alterada – Combinaciones de las anteriores Curso 2005/2006 Fundamentos de Computadores 29 Ejemplo de ejecución de programa Curso 2005/2006 Fundamentos de Computadores 30 Diagrama de estados del ciclo de instrucción Curso 2005/2006 Fundamentos de Computadores 31 Esquema de interconexión mediante buses • • Conjunto de conductores eléctricos para la conexión de dos o más dispositivos Tipos de buses – De memoria, de datos y de control – Anchura de los buses: 8, 16, 32, 64 bits • ¿Cómo son los buses? – Pistas paralelas de los circuitos impresos – Cintas de plástico con hilos conductores – Conectores (ISA, PCI, …) – Cables sueltos Curso 2005/2006 Fundamentos de Computadores 32 Bus ISA (Industry Standard Architecture) Curso 2005/2006 Fundamentos de Computadores 33 Bus de alta prestaciones Curso 2005/2006 Fundamentos de Computadores 34 El futuro de los computadores La relación coste/rendimiento ha mejorado los últimos 45 años aproximadamente 240 000 000 (un 54% anual) Ley de Moore • La densidad de integración dobla cada 18 meses • ¿Válida hasta 2020?) Curso 2005/2006 Fundamentos de Computadores 36 Arquitectura del repertorio de instrucciones (ISA) “La arquitectura de un computador es la estructura del computador que un programador en lenguaje máquina debe conocer para escribir un programa correcto (independiente del tiempo)” Amdahl 1964 Objetivos • • • • • • • • • • • • Caracterizar una instrucción de acuerdo con el tipo de operación, de datos, de modos de direccionamiento y de formato de codificación Codificar una instrucción de lenguaje máquina a una instrucción de lenguaje ensamblador y viceversa Distinguir una pseudoinstrucción de una instrucción Explicar con comentarios la finalidad de un bloque básico de código ensamblador Determinar los valores intermedios y finales de los registros y los contenidos de la memoria tras la ejecución de un bloque básico de código ensamblador Escribir la secuencia de instrucciones de lenguaje ensamblador correspondiente a una pseudoinstrucción Traducir las sentencias básicas de asignación, operación, toma de decisiones, bucles y llamadas a procedimientos a lenguaje ensamblador Traducir un algoritmo escrito en un lenguaje de alto nivel a lenguaje ensamblador y viceversa Escribir procedimientos en lenguaje ensamblador consecuentes con los convenios de pasos de parámetros a procedimientos Corregir errores en un programa escrito en lenguaje ensamblador para que funcione correctamente Calcular el tiempo de ejecución y los ciclos por instrucción (CPI) de un bloque básico de código ensamblador Diseñar un repertorio de instrucciones con restricciones de diseño Curso 2005/2006 Fundamentos de Computadores 2 Índice • • • Estructura de una máquina Von Neumman Máquinas RISC MIPS R3000 – Nivel ISA – – Instrucciones aritmético-lógicas Instrucciones de acceso a memoria • • – – Instrucciones de salto condicional Lenguaje máquina • – – • • Instrucciones aritmético-lógicas, de acceso a memoria, de carga y almacenamiento, de salto condicional e incondicional Datos inmediatos Gestión de procedimientos • • • – Organización de la memoria Carga y almacenamiento Llamadas y retornos de procedimientos Convenio de uso de registros Gestión de la pila Otras instrucciones Máquinas CSIC IA – 32 – – – – Características del ISA Registros Instrucciones básicas Formato de las instrucciones Curso 2005/2006 Fundamentos de Computadores 3 Estructura de una máquina von Neumann • Cinco partes básicas – la memoria (M) – la unidad aritmética lógica (ALU – la unidad de control (UC) – el equipo de entrada y salida (I/O) • Ciclo de instrucción – Ciclo de búsqueda – Ciclo de ejecución Curso 2005/2006 Fundamentos de Computadores 4 RISC - Reduced Instruction Set Computer • RISC es una filosofía de diseño con las siguientes características: – Tamaño fijo de las instrucciones – Número reducido de codificaciones de las instrucciones, modos de direccionamientos y operaciones – Instrucciones de load/store para los accesos a memoria, registros • Usados por NEC, Nintendo, Silicon Graphics, Cisco, Sony... 1400 900 Other SPARC Hitachi SH PowerPC Motorola 68K MIPS IA-32 800 ARM 1300 1200 1100 1000 700 600 500 400 300 200 100 0 1998 Curso 2005/2006 1999 2000 2001 Fundamentos de Computadores 2002 5 MIPS R3000 – Nivel ISA • • • • Registros Instrucciones de 32 bits 3 formatos 4 direccionamientos 5 tipos de instrucciones – – – – – Aritmético-lógicas Acceso a memoria Ruptura de secuencia Gestión de memoria Especiales • 32 registros de 32 bits de propósito general (GPR) Curso 2005/2006 $0 - $31 PC HI LO 3 Instruction Formats:all 32 bits wide OP rs rt OP rs rt OP Fundamentos de Computadores rd sa immediate jump target funct R format I format J format 6 MIPS – Instrucciones aritméticológicas • Principio de diseño 1 – “La simplicidad favorece la uniformidad” • Todos los computadores deben ser capaces de realizar cálculos aritméticos y lógicos add a, b, c # a Å b + c sub a, a, d # a Å a + d = (b + c) - d or a, a, e # a Å a + e = (b + c + d) OR e Curso 2005/2006 Fundamentos de Computadores 7 Ejemplos básicos de compilación de sentencias • Dos sentencias de asignación de C en MIPS – Código fuente a = b + c; d = a – e; – Compilación add a, b, c sub d, a, e • Compilación de una sentencia compleja de C en MIPS – Código fuente f = (g + h) – (i + j); – Compilación add t0, g, h add t1, i, j sub f, t0, t1 Curso 2005/2006 Fundamentos de Computadores 8 MIPS - Registros Registers Control Input $0 - $31 Memory Datapath PC HI Processor Output I/O LO • Principio de diseño 2 – “Cuanto más pequeño más rápido” • • Los operandos de las instrucciones computacionales son registros Los compiladores asocian variables con registros – $s0, $s1,... para registros asociados a variables de C – $t0, $t1,... para registros temporales – Otros más Curso 2005/2006 Fundamentos de Computadores 9 Ejemplo de compilación de una asignación usando registros • Código fuente de C f = (g + h) – (i+j); f, g, h, i y j en $s0, $s1, $s2, $s3 y $s4 • Compilación en MIPS add $t0, $s1, $s2 add $t1, $s3, $s4 sub $s0, $t0, $t1 Curso 2005/2006 # el registro $t0 contiene # g+h # el registro $t1 contiene # i +j # f contiene $t0 - $t1, que # es (g+h) – (i+h) Fundamentos de Computadores 10 Accesos a memoria - Organización de la memoria • La memoria es un vector de bytes • La dirección es un índice dentro del vector de bytes • 2 posibles ordenaciones para las palabras: – Big Endian (IA-32) – Little Endian (MIPS) • Alineación de datos – address módulo size = 0 Curso 2005/2006 Little Endian MSB Memoria LSB …. 0x44332211 Big Endian MSB LSB 0x11223344 0x11 0x22 0x33 0x44 …. 55 Objeto Bien alineado Mal alineado Byte 0,1,2,3,4,5,6,.. (nunca) Media palabra 0,2,4,6,8, ... 1,3,5,7, ... Palabra (4 bytes) 0,4,8,... 1,2,3,5,6,7,9,10,11,... Doble palabra 0,8, .. 1,2,3,4,5,6,7,9,10,11,12,13,14,15,.... Fundamentos de Computadores 11 Accesos a memoria – Organización de la memoria del MIPS • • • • El tamaño de las palabras es de 32 bits Big Endian 232 posiciones de memoria de bytes, 0, 1, 232-1 Accesos alineados – 231 posiciones de memoria de medias palabras, 0, 2… 232-2 – 230 posiciones de memoria de palabras, 0, 4, 232-4 – 228 posiciones de memoria de dobles palabras, 0, 8… 232-8 Curso 2005/2006 Fundamentos de Computadores 12 MIPS – Cargas y almacenamientos • Instrucciones para accesos a memoria de palabras – lw $t0, 4($s3) # $t0 Å M[$s3+4] – sw $t0, 4($s3) # M[$s3+4] Å $t0 • La suma del registro base ($s3) y el desplazamiento (4) forma la dirección de memoria del dato – El desplazamiento tiene signo (complemento a dos) – Los accesos están limitados a una región centrada en el registro base de ±213 palabras Curso 2005/2006 Fundamentos de Computadores 13 Ejemplo de compilación con un dato en memoria • Código fuente de C g = h + A[8]; La base del vector asignada a $s3, las variables g y h asignadas a $s1 y $s2 • Compilación en MIPS lw $t0, 32($s3) # $t0 contiene A[8] add $s1, $s2, $t0# $s1 contiene g = h + A[8] Curso 2005/2006 Fundamentos de Computadores 14 Ejemplo de compilación de una asignación con un índice variable • Código fuente de C g = h + A[i]; la base del vector en $s3, g y h e i en $s1, $s2 y $s4 • Compilación en MIPS add $t1, $s4, $s4 add $t1, $t1, $t1 add $t1, $t1, $s3 lw $t0, 0($t1) add $s1, $s2, $t0 Curso 2005/2006 # $t1 contiene 2 * i # $t1 contiene 4 * i # $t1 contiene $s3 + 4 * i # $t0 contiene A[i] # $s1 contiene g = h + A[i] Fundamentos de Computadores 15 MIPS – Instrucciones de salto condicional • Instrucciones de salto condicional (sólo dos) – bne $s0, $s1, L1 – beq $s0, $s1, L1 # branch to L1 if no equal # branch to L1 if equal • Pseudoinstrucciones de salto condicional – slt (set si menor que), beq, bne y $zero permiten las condiciones restantes blt $s1, $s2, etiqueta slt $at, $s1, $s2 bne $at, $zero, etiqueta # salta si menor que – El ensamblador expande las pseudoinstrucciones • $at, registro utilizado por el programa ensamblador Curso 2005/2006 Fundamentos de Computadores 16 Ejemplo de compilación de una sentencia de salto condicional • Código fuente de C If (i==j) h = i + j; h, i y j en $s0, $s1 y $s2 • Compilación en MIPS bne $s1, $s2, etiqueta add $s0, $s1, $s2 etiqueta: … Curso 2005/2006 Fundamentos de Computadores 17 Lenguaje máquina – Instrucciones aritmético-lógicas • • El tamaño de las instrucciones es de 32 bits Las instrucciones aritmético-lógicas son codificadas con el formato tipo-R – add $rd, $rs, $rt • Significado de los campos – – – – op rs, rt, rd shamt funct 6-bits código de operación 5-bits registro source, target, destination 5-bits número de bits a desplazar (cuando aplicable) 6-bits código de función (extensión del código de operación) op 6 bits rs 5 bits rt 5 bits rd 5 bits 000000 01010 11111 00011 Curso 2005/2006 shamt funct Formato de instrucciones aritméticas 5 bits 6 bits Todas las instrucciones MIPS de 32 bits 00000 100000 0x015f1820 Fundamentos de Computadores add $3,$10,$31 18 Lenguaje máquina – Instrucciones de acceso a memoria • Principio de diseño 3 – “Un buen diseño necesita buenas soluciones de compromiso” • Las instrucciones de load y store especifican dos registros y un desplazamiento – Formato tipo I (16 bits para el dato inmediato) – lw $rt, inmediato($rs), sw $rt, inmediato($rs – lh, lhu, lb, lbu sh, sb (load half, half unsigned, byte, byte unsigned; store half, byte) op 6 bits rs 5 bits rt 5 bits 100011 00011 00101 Curso 2005/2006 Dirección/inmediato 16 bits 0000000000100000 Formato de instruciones de carga Todas las instrucciones MIPS de 32 bits 0x8c650020 lw $5,32($3) Fundamentos de Computadores 19 Traducción de lenguaje ensamblador a lenguaje máquina • Código fuente de C A[300] = h + A[300]; La base del vector asignada a $t1 y h a $s2 • Compilación en MIPS lw $t0, 1200($t1) add $t0, $s2, $t0 sw $t0, 1200($t1) • Lenguaje máquina 1000 1101 0010 1000 0000 0100 1011 0000 0000 0010 0100 1000 0100 0000 0010 0000 1010 1101 0010 1000 0000 0100 1011 0000 Curso 2005/2006 Fundamentos de Computadores 20 Lenguaje máquina – Instrucciones de salto condicional • Formato tipo I (16 bits para el dato inmediato) – El inmediato codifica el nº de palabras desde la siguiente instrucción a la instrucción de salto (PC+4) hasta la instrucción destino – Los saltos están limitados a una región centrada en el PC + 4 de ±215 palabras from the low order 16 bits of the branch instruction 16 offset sign-extend 00 32 32 Add PC 32 Curso 2005/2006 32 4 32 Add branch dst address 32 32 Fundamentos de Computadores ? 21 MIPS – Instrucciones de ruptura de secuencia incondicional • j etiqueta • Formato tipo J – 6 bits código de operación + 26 bits para el dato inmediato – El inmediato de 26 bits codifica la dirección absoluta de la palabra con la instrucción destino de salto dentro de un segmento de 256MB op 26-bit address from the low order 26 bits of the jump instruction 26 00 32 4 PC Curso 2005/2006 32 Fundamentos de Computadores 22 Ejemplo de compilación de una sentencia de salto if-then-else • Código fuente de C If (i==j) f = g + h; else f = g – h; i, j, f, g y h en $s0… $s4 • Compilación en MIPS L1: L2: Curso 2005/2006 bne $s0, $s1, L1 add $s2, $s3, $s4 # f = g + h j L2 # salto incondicional sub $s2, $s3, $s4 # f = g - h … Fundamentos de Computadores 23 MIPS – Datos inmediatos (1/2) • Instrucciones aritmético-lógicas con un operando constante slti $t0, $s2, 15 #$t0 = 1 si $s2<15 • La constante almacenada en la propia instrucción – Formato tipo I – El dato inmediato está limitado a 16 bits (-215 a +215-1) op Curso 2005/2006 rs rt 16 bit immediate Fundamentos de Computadores I format 24 MIPS – Datos Inmediatos (2/2) • Gestión de datos inmediatos de más de 16 bits – Almacenaje en memoria .data muchosbits: .word 4294967295 # 0x7FFFFFFF .text … lw $t0, muchosbits($zero) – Descomposición en partes lui ori Curso 2005/2006 $at, 0x7FFFF # load upper inmediate $t0, $at, 0xFFFF Fundamentos de Computadores 25 MIPS – Gestión de procedimientos • Llamada a procedimiento – jal address • Escribe PC+4 en el registro $ra (return adress, $31) para posibilitar el retorno del procedimiento • Instrucción tipo J – jalr $rs • Instrucción tipo R • Retorno de procedimiento – jr $ra • Instrucción tipo R Curso 2005/2006 Fundamentos de Computadores 26 MIPS – Convenio de uso de registros Name Register number 0 $zero 2-3 $v0-$v1 4-7 $a0-$a3 8-15 $t0-$t7 16-23 $s0-$s7 24-25 $t8-$t9 28 $gp 29 $sp 30 $fp 31 $ra Curso 2005/2006 Usage the constant value 0 values for results and expression evaluation arguments temporaries saved more temporaries global pointer stack pointer frame pointer return address Fundamentos de Computadores 27 MIPS – Pila (stack) Memoria • Operaciones Dirección Baja – Guardar (Push) sp-4 addi $sp, $sp, -4 sw $rs, 0(Sp) Valor guardado sp Alta – Recuperar (Pop) lw $rs, 0(Sp) addi $sp, $sp, 4 Memoria Dirección Baja sp Valor leído sp+4 Alta Curso 2005/2006 Fundamentos de Computadores 28 MIPS - Instrucciones aritméticas Instrucción sumar sumar sin signo sumar inmediato sumar inmediato sin signo restar restar sin signo dividir dividir sin signo multiplicar multiplicar sin signo dividir dividir sin signo multiplicar multiplicar multiplicar sin signo Curso 2005/2006 Ejemplo add $1,$2,$3 addu $1,$2,$3 addi $1,$2,10 addiu $1,$2,10 sub $1,$2,$3 subu $1,$2,$3 Significado $1= $2+$3 $1=$2+$3 $1=$2+10 $1=$2+10 $1=$2-$3 $1=$2-$3 Lo=$1÷$2 div $1,$2 Hi=$1mod$2 Lo=$1÷$2 divu $1,$2 Hi=$1mod$2 mult $1,$2 Hi,Lo=$1*$2 multu $1,$2 Hi,Lo=$1*$2 Pseudoinstrucciones $1=$2÷$3 div $1,$2,$3 (cociente) $1=$2÷$3 divu $1,$2,$3 (cociente) mul $1,$2,$3 $1=$2*$3 mulo $1,$2,$3 $1=$2*$3 mulou $1,$2,$3 $1=$2*$3 Comentarios Posible excepción por desbordamiento Posible excepción por desbordamiento Posible excepción por desbordamiento Posible excepción por desbordamiento Posible excepción por desbordamiento Posible excepción por desbordamiento Posible excepción por desbordamiento Fundamentos de Computadores 29 MIPS – Intrucciones lógicas Instrucción and or xor nor andi ori xori shift left logical shift left logical variable shift right logical shift right logical variable shift right arithmetic shift right arithmetic variable Curso 2005/2006 Ejemplo and $1,$2,$3 andi $1,$2,10 xor $1,$2,$3 nor $1,$2,$3 andi $1,$2,10 ori $1,$2,10 xori $1,$2,10 sll $1,$2,10 sllv $1,$2,$3 srl $1,$2, 10 srlv $1,$2,$3 sra $1,$2,10 srav $1,$2,$3 Significado $1= $2&$3 $1=$2&10 $1=$2⊕$3 $1=~($2|$3) $1=$2&10 $1= $2|10 $1=$2|10 $1= $2<<10 $1= $2<<$3 $1=$2>>10 $1=$2>>$3 $1=$2>>10 $1=$2>>$3 Fundamentos de Computadores Comentarios 30 MIPS - Instrucciones de transferencia de datos (1/2) Instrucción carga byte carga byte sin ext. signo carga media palabra carga media palabra sin extensión de signo carga palabra carga inmediata de la parte más significativa “load upper inmediate” Carga registro del coprocesador z almacena byte almacena media palabra almacena palabra almacena registro en memoria registro del coprocesador z Ejemplo lb $1,10($2) lbu $1,10($2) lh $1,10($2) Significado $1=M[10+$2] $1=M[10+$2] $1=M[10+$2] Extiende el bit de signo No extiende el bit de signo Extiende el bit de signo lhu $1,10($2) $1=M[10+$2] No extiende el bit de signo lw $1,10($2) $1=M[10+$2] lui $1,50 $1=50*216 lwc1 $f0,10($2) $f0= M[10+$2] sb $1,10($2) sh $1,10($2) sw $1,10($2) M[10+$2]=$1 M[10+$2]=$1 M[10+$2]=$1 swc1 $f0,10($2) M[10+$2]=$f0 Carga inmediata li $1,1000 Carga dirección la $3,label Curso 2005/2006 Comentarios Carga un dato de 16 bits en la parte más significativa del registro. Pseudoinstrucciones Carga de un dato de 32 bits $1=1000 $3=dirección de Transfiere la dirección de memoria no el contenido. label Fundamentos de Computadores 31 MIPS – Instrucciones de movimiento de datos (2/2) Instrucción mover desde Hi mover desde Lo mover a Hi mover a Lo mover desde coprocesador z mover al coprocesador z transfiere o mueve transfiere doble desde coproc. 1 Curso 2005/2006 Ejemplo Significado Comentarios mfhi $1 $1= Hi mflo $1 $1= Lo mthi $1 Hi=$1 mtlo $1 Lo=$1 $f0-$f30: Registros del coprocesador 1 mfcz $1,$f0 $1=$f0 mtcz $1,$f0 $f0=$1 Pseudoinstrucciones move $1,$2 $1=$2 $4=$F0 mfc1.d $4,$f0 $5=$F1 Fundamentos de Computadores 32 Instrucciones de comparación Instrucción Inicializar menor que Ejemplo slt $1,$2,$3 Significado if ($2<$3) then $1=1 else $1=0 endif Comentarios inicializar menor que sin signo sltu $1,$2,$3 Inicializar menor que inmediato slti $1,$2,5 Inicializar menor que inmediato sin signo sltiu $1,$3,$5 Inicializa igual inicializa mayor o igual inicializa mayor que inicializa menor o igual inicializa no igual Curso 2005/2006 Pseudoinstrucciones si ($2==$3) then $1=1 seq $1,$2,$3 else $1=0 endif sge $1,$2,$3 sgt $1,$2,$3 sle $1,$2,$3 sne $1,$2,$3 Fundamentos de Computadores 33 MIPS – Instrucciones de salto y bifurcación Instrucción Ejemplo Significado si($1==$2 )ir a PC+4 +100 salta sobre igual beq $1,$2,100 si($1!=$2) ir a PC+4 +100 salta sobre no igual bne $1,$2,100 si($1>=0) ir a PC+4 +100 salta sobre mayor o igual que cero bgez $1,100 salta sobre mayor o igual que cero y bgezal $1,1000 si($1>=0) $31=PC+4; ir a 1000 enlaza ..... ir a 2000 bifurcar j 2000 ir a $1 bifurcar registro jr $1 $31=PC+4; ir a 10000 Bifurcar y enlazar jal 10000 $31=PC+4; ir a $1 bifurcar y enlazar registro jalr $1 Pseudoinstrucciones si($1>=$2) ir a PC+4 +100 salta sobre mayor o igual bge $1,$2,100 si($1>$2) ir a PC+4 +100 salta sobre mayor que bgt $1,$2,100 si($1<=$2) ir a PC+4 +100 salta sobre menor o igual ble $1,$2,100 si($1<$2) ir a PC+4 +100 salta sobre menor que blt $1,$2,100 ..... Curso 2005/2006 Fundamentos de Computadores Comentarios 34 MIPS - Modos de direccionamientos 1. Immediate addressing op rs rt Immediate 2. Register addressing op rs rt rd ... funct Registers Register 3. Base addressing op rs rt Memory Address + Register Byte Halfword Word 4. PC-relative addressing op rs rt Memory Address PC + Word 5. Pseudodirect addressing op Address PC Curso 2005/2006 Fundamentos de Computadores Memory Word 35 CISC - Complex Instruction Set Computer • CISC es una filosofía de diseño con las siguientes características: – Instrucciones con mayor contenido semántico para conseguir una reducción del número de instrucciones ejecutadas – Mayor tiempo de ciclo (Tc) o mayor número de ciclo por instrucción (CPI) que una arquitectura RISC Curso 2005/2006 Fundamentos de Computadores 36 IA - 32 • • • 1978 µP 8086/88 (16 bits, 40 pines) 1980 coprocesador Intel 8087 1982 µP 80286 – – • 1986 µP 80386 – • Bus interno 128 – 256 bits 1995-1999 Familia P6 – – • Coprocesador integrado Caché L1 de 8KB 1993 Pentium – • Direcciones de 32 bits 1989 µP 80486 – – • Direcciones de 24 bits Niveles de privilegio Superscalares MMX (57 instrucciones “MMX”) 1999 – 2005 Familia Pentium IV (478 pines) – – Hyper Threading 70 instrucciones Streaming SIMD Extensions Curso 2005/2006 Fundamentos de Computadores 37 IA - 32 • Características del ISA – Longitud de instrucciones 1..17 bytes – Máquina de 2 operandos • SUB AX, AX – Máquina registro-memoria • ADD AX, [BX] – Modos de direccionamientos complejos Curso 2005/2006 Fundamentos de Computadores 38 IA–32 Registros • 8 registros de 32 bits de “casi propósito general” – GPR0-GPR7: EAX, ECX, EDX, EBX, ESP, EBP, ESI, EDI • 6 registros de segmento de 16 bits – CS, SS, DS, ES, FS, GS • Un registro puntero de instrucción de 32 bits Use Name 31 EAX GPR 0 ECX GPR 1 EDX GPR 2 EBX GPR 3 ESP GPR 4 EBP GPR 5 ESI GPR 6 EDI GPR 7 – EIP • Un registro de estado de 32 bits – EFLAGS EIP EFLAGS Curso 2005/2006 0 Fundamentos de Computadores CS Code segment pointer SS Stack segment pointer (top of stack) DS Data segment pointer 0 ES Data segment pointer 1 FS Data segment pointer 2 GS Data segment pointer 3 Instruction pointer (PC) Condition codes 39 IA-32 Restricciones de uso de los registros de propósito general Curso 2005/2006 Fundamentos de Computadores 40 IA-32 Instrucciones básicas • Movimiento de datos – MOV, PUSH, POP • Aritmético-lógicas – El destino registro o memoria – Aritmética entera y decimal – CMP activa los bits del registro CFLAGS • Control de flujo – Saltos condicionales, incondicionales, llamadas y retornos de procedimientos • Manipulación de cadena – Movimiento y comparación de cadenas Curso 2005/2006 Fundamentos de Computadores 41 IA-32 Formato de las instrucciones a. JE EIP + displacement 4 4 8 Condi- Displacement tion JE b. CALL 8 32 CALL Offset c. MOV 6 MOV EBX, [EDI + 45] 1 1 8 d w r/m Postbyte 8 Displacement d. PUSH ESI 5 3 PUSH Reg e. ADD EAX, #6765 4 3 1 32 ADD Reg w f. TEST EDX, #42 7 1 TEST Curso 2005/2006 w Immediate 8 32 Postbyte Immediate Fundamentos de Computadores 42 Resumen • • El nivel ISA es el interfaz hardware/software de un computador Principios de diseño – “La simplicidad favorece la uniformidad” • Tamaño de instrucciones fijo • No muchos formatos de instrucciones • Fácil codificación de las instrucciones – “Cuanto más pequeño más rápido” • Número de instrucciones y modo de direccionamientos bajo • Número registros no excesivo – “Un buen diseño necesita buenas soluciones de compromiso” • Equilibrio número de registros, número de instrucciones, tipos y tamaño de las instrucciones – “Hacer el caso común rápido” • Máquina registro-registro • Datos inmediatos en la propia instrucción • La complejidad de las instrucciones es sólo un parámetro de diseño – Menor recuento de instrucciones, pero mayor CPI y mayor Tc Curso 2005/2006 Fundamentos de Computadores 43 Otros puntos… • Gestión de procedimientos – Enlazador (link) – Cargador (loader) – Gestión de la pila (stack) • Bloque de activación • Puntero de marco (frame pointer) • Subrutinas recursivas • • • • Manipulación de cadenas (strings) Punteros Interrupciones y excepciones Llamadas al sistema Curso 2005/2006 Fundamentos de Computadores 44 Diseño del procesador “Mientras el ENIAC está equipado con 18000 válvulas de vacio y pesa 30 toneladas, los ordenadores del futuro pueden tener 1000 válvulas y quizás pesen sólo 1 tonelada y media.” Popular Mechanics, Marzo de 1949 Objetivos • • • • • • • • • • • • • • • • • Calcular el número total de ciclos de reloj de la ejecución de un trozo de código ensamblador para diferentes implementaciones de un procesador básico Trazar ciclo a ciclo de reloj (sobre una ruta de datos) un trozo de código ensamblador para diferentes implementaciones de un procesador básico Plantear una ruta de datos para un repertorio de instrucciones simple en un procesador básico Modificar una ruta de datos para la inclusión de nuevas instrucciones en un procesador básico Modificar una ruta de datos para satisfacer determinadas características de diseño Especificar una unidad de control con una máquina de estados finitos para una ruta de datos y un repertorio de instrucciones simples Modificar una unidad de control específica de un procesador básico para la inclusión de nuevas instrucciones Modificar una unidad de control específica de un procesador básico para satisfacer determinadas características Calcular las ecuaciones de implementación de una unidad de control descrita mediante una máquina de estados finitos Rellenar el contenido de una memoria ROM para una especificación de una unidad de control mediante una máquina de estados finitos Implementar con PLA una especificación de una unidad de control mediante una máquina de estados finitos Especificar la unidad de control de un procesador básico con un microprograma Diseñar un formato de microinstrucciones para un procesador básico Modificar un microprograma para la inclusión de nuevas instrucciones en un procesador básico Modificar un microprograma para satisfacer determinadas características de diseño Modificar el formato de microinstrucciones para un procesador básico Escribir una rutina de tratamiento de excepción para interrupciones o excepciones básicas Curso 2005/2006 Fundamentos de Computadores 2 Contenidos (1/4) • Metodología de sincronización • Diseño de un procesador MIPS R3000 reducido – Rutas de datos individuales • Búsqueda de instrucción • Decodificación de la instrucción • Ejecución (aritmético-lógicas, cargas y almacenamientos, saltos condicionales y bifurcaciones) Curso 2005/2006 Fundamentos de Computadores 3 Contenidos (2/4) • Diseño monociclo – Diseño de la ruta de datos • • • • Integración de las rutas de datos individuales Señales de control Integración de la ruta de datos y de la unidad de control Ejemplos de flujo de datos + control – Diseño de la unidad de control de la ALU (También válida para el diseño multiciclo) • • • • Estructura de la ALU Especificación del control ALU Tabla de verdad del control ALU Implementación del control ALU – Diseño de la unidad de control • Funcionalidad de las señales de control • Implementación de la UC – Ventajas y desventajas Curso 2005/2006 Fundamentos de Computadores 4 Contenidos (3/4) • Diseño multiciclo – Diseño de la ruta de datos • Esbozo de la ruta de datos • Integración de la ruta de datos y de la unidad de control • Etapa de la ejecución de las instrucciones – Ejemplo de la ejecución de la instrucción lw – Diseño de la unidad de control • Control cableado – – – – – – Especificación de la UC con una FSM (diagrama) Especificación de la UC con una FSM (tabla) Implementación de la FSM Ecuaciones de implementación de la FSM Implementación de FSM con ROM Implementación de FSM con PLA • Control microprogramado – – – – Curso 2005/2006 Formato de la microinstrucción Señales asociadas a los campos y valores Microprograma de la UC Secuenciador del microprograma Fundamentos de Computadores 5 Contenidos (4/4) • Excepciones e interrupciones – Tratamiento de excepciones en MIPS – Implementación de excepciones en MIPS – Ruta de datos con soporte de excepciones – Especificación de la UC con soporte de excepciones – Instrucciones para excepciones en MIPS Curso 2005/2006 Fundamentos de Computadores 6 Metodología de sincronización • • La metodología de sincronización define cuándo pueden leerse y escribirse las diferentes señales Características de la metodología de sincronización por nivel – Un elemento de estado puede ser actualizado sólo en el flanco de reloj – Un elemento de estado puede ser leído y modificado en un mismo ciclo – Señales de habilitación de escritura explícitas State element 1 Combinational logic State element 2 clock one clock cycle Curso 2005/2006 Fundamentos de Computadores 7 Diseño de un procesador MIPS R3000 reducido • Soporte del subconjunto de instrucciones – Acceso a memoria: lw (load word) y sw (store word) – Aritmético-lógicas: add, sub, and, or, slt – Salto y bifurcación: beq (branch if equal) y j (jump) • Ciclo de instrucción – Lectura de la instrucción M[PC] – Decodificación de la instrucción y lectura de los registros – Ejecución de la instrucción Curso 2005/2006 Fundamentos de Computadores 8 Ruta de datos individuales – Búsqueda de la instrucción • Lectura de la memoria de instrucciones • Actualización del PC a la siguiente instrucción Add 4 Instruction Memory PC Curso 2005/2006 Read Address Instruction Fundamentos de Computadores 9 Ruta de datos individuales – Decodificación de la instrucción • Envío de los campos de código de operación y función a la unidad de control • Lectura del banco de registro de los registros $rs y $rt Control Unit Instruction Curso 2005/2006 Read Addr 1 Register Read Read Addr 2 Data 1 File Write Addr Read Data 2 Write Data Fundamentos de Computadores 10 Ruta de datos individuales – Aritmético-lógicas (ejecución) • op y funct especifican la operación aritmético-lógica • Escritura del registro $rd del banco de registros con la salida de la ALU 31 R-type: op 25 rs 15 rt rd RegWrite Instruction Read Addr 1 Read Register Read Addr 2 Data 1 File Write Addr Read Write Data Curso 2005/2006 20 Fundamentos de Computadores 10 5 0 shamt funct ALU control ALU overflow zero Data 2 11 Ruta de datos individuales– Cargas y almacenamientos (ejecución) • Cálculo de la dirección de memoria – address Å $rs + extensión-signo(IR[15:0]) • Carga de un registro (load) – $rt Å M[$rs + extensión-signo(IR[15:0])] • Almacenamiento de un registro (store) – M[$rs + extensión-signo(IR[15:0])] Å $rt RegWrite Instruction Sign Extend MemWrite overflow zero Read Addr 1 Read Register Read Addr 2 Data 1 File Write Addr Read Data 2 Write Data 16 Curso 2005/2006 ALU control Address ALU Data Memory Read Data Write Data MemRead 32 Fundamentos de Computadores 12 Ruta de datos individuales – Saltos condicionales (ejecución) • Resta de $rs y $rt y comprobación de la señal zero de la ALU • Cálculo de la dirección efectiva de salto – address Å PC + 4 + extensión-signo(IR[15:0]<<2) Add Add 4 Shift left 2 Branch target address ALU control PC Instruction Read Addr 1 Read Register Read Addr 2 Data 1 File Write Addr zero (to branch control logic) ALU Write Data 16 Curso 2005/2006 Sign Extend 32 Fundamentos de Computadores 13 Ruta de datos individuales – Bifurcaciones (ejecución) • Reemplazo del PC por la dirección efectiva de salto – PC Å PC[31:28] || (IR[25:0]<<2) Add 4 4 Instruction Memory PC Curso 2005/2006 Read Address Shift left 2 Jump address 28 Instruction 26 Fundamentos de Computadores 14 Diseño monociclo • Integración de las rutas de datos individuales – Recursos hardware + multiplexores + señales de control + restricciones de diseño • Restricción de diseño – Todas las instrucciones tardan un único ciclo de reloj – La instrucción más lenta determina el tiempo de ciclo – Ningún componente de la ruta de datos puede ser reutilizado • Memorias separadas de instrucciones y datos • Sumadores… Curso 2005/2006 Fundamentos de Computadores 15 Diseño de la RD - Integración de las individuales (no beq, no j) Add RegWrite ALUSrc ALU control 4 Instruction Memory PC Read Address Instruction Curso 2005/2006 MemtoReg ovf zero Read Addr 1 Address Read Register Read Addr 2 Data 1 File Write Addr Read Data 2 Write Data Sign 16 Extend MemWrite ALU Data Memory Read Data Write Data MemRead 32 Fundamentos de Computadores 16 Diseño de la RD – Señales de control • Selección de la operación a realizar – Operación ALU: ALUControl – Escritura y lectura del banco de registros: RegWrite – Escritura y lectura de las memorias: MemRead, MemWrite • Selección de entradas de los multiplexores (flujo de datos) – ALUSrc, MemToReg 31 R-type: op 31 I-Type: op 31 J-type: Curso 2005/2006 op 25 rs 25 rs 20 15 rt rd 20 10 5 shamt funct 15 rt 0 0 address offset 25 0 target address Fundamentos de Computadores 17 Diseño de la RD – Integración de la RD y de la UC 0 Add Add Shift left 2 4 ALUOp 1 PCSrc Branch MemRead MemtoReg MemWrite Instr[31-26] Control Unit ALUSrc RegWrite RegDst Instruction Memory PC Read Address Instr[31-0] ovf Instr[25-21] Read Addr 1 Address Read Register Instr[20-16] Read Addr 2 Data 1 File 0 Write Addr Read 1 Data 2 Instr[15 Write Data -11] Instr[15-0] Sign Extend 16 zero 0 ALU Data Memory Read Data 1 Write Data 0 1 32 ALU control Instr[5-0] Curso 2005/2006 Fundamentos de Computadores 18 Diseño de la RD – Flujo de datos y control para tipo R 0 Add Add Shift left 2 4 ALUOp 1 PCSrc Branch MemRead MemtoReg MemWrite Instr[31-26] Control Unit ALUSrc RegWrite RegDst Instruction Memory PC Read Address Instr[31-0] ovf Instr[25-21] Read Addr 1 Address Read Register Instr[20-16] Read Addr 2 Data 1 File 0 Write Addr Read 1 Data 2 Instr[15 Write Data -11] Instr[15-0] Sign Extend 16 zero 0 ALU Data Memory Read Data 1 Write Data 0 1 32 ALU control Instr[5-0] Curso 2005/2006 Fundamentos de Computadores 19 Diseño de la RD – Flujo de datos y control para lw 0 Add Add Shift left 2 4 ALUOp 1 PCSrc Branch MemRead MemtoReg MemWrite Instr[31-26] Control Unit ALUSrc RegWrite RegDst Instruction Memory PC Read Address Instr[31-0] ovf Instr[25-21] Read Addr 1 Address Read Register Instr[20-16] Read Addr 2 Data 1 File 0 Write Addr Read 1 Data 2 Instr[15 Write Data -11] Instr[15-0] Sign Extend 16 zero 0 ALU Data Memory Read Data 1 Write Data 0 1 32 ALU control Instr[5-0] Curso 2005/2006 Fundamentos de Computadores 20 Diseño de la RD – Flujo de datos y control para beq 0 Add Add Shift left 2 4 ALUOp 1 PCSrc Branch MemRead MemtoReg MemWrite Instr[31-26] Control Unit ALUSrc RegWrite RegDst Instruction Memory PC Read Address Instr[31-0] ovf Instr[25-21] Read Addr 1 Address Read Register Instr[20-16] Read Addr 2 Data 1 File 0 Write Addr Read 1 Data 2 Instr[15 Write Data -11] Instr[15-0] Sign Extend 16 zero 0 ALU Data Memory Read Data 1 Write Data 0 1 32 ALU control Instr[5-0] Curso 2005/2006 Fundamentos de Computadores 21 Integración de la RD – Flujo de datos y control para j Instr[25-0] Shift left 2 26 1 28 32 0 PC+4[31-28] 0 Add Add Shift left 2 4 Jump ALUOp 1 PCSrc Branch MemRead MemtoReg MemWrite Instr[31-26] Control Unit ALUSrc RegWrite RegDst Instruction Memory PC Read Address Instr[31-0] ovf Instr[25-21] Read Addr 1 Address Read Register Instr[20-16] Read Addr 2 Data 1 File 0 Write Addr Read 1 Instr[15 -11] Instr[15-0] Write Data zero 0 ALU Data 2 Data Memory Read Data 1 Write Data 0 1 Sign Extend 16 32 ALU control Instr[5-0] Curso 2005/2006 Fundamentos de Computadores 22 Diseño de la UC de la ALU – Estructura de la ALU Binvert A L U o p e r a ti o n Operation CarryIn a 0 a 1 Z ero ALU R e s u lt O v e r f lo w Result b b 0 2 1 3 Less C a rry O u t a. CarryOut Curso 2005/2006 Entradas de control (ALUctr) FUNCIÓN 000 001 010 110 111 AND OR ADD SUB SLT Fundamentos de Computadores 23 Diseño de la UC de la ALU – Especificación del control ALU • Operación ALU – lw, sw ($rs + extensión-signo(IR[15:0])) – beq ($rs-$rt) – add, sub, or, and y slt (operación específica) Cod. Op. Curso 2005/2006 ALUop Instrucción FUNCT Op. deseada Entradas de control de la ALU (ALUctr) LW 00 Carga XXXXXX suma 010 SW 00 Almacena XXXXXX suma 010 Branch Equal 01 salto XXXXXX resta 110 R-Type 10 suma 100000 suma 010 R-Type 10 resta 100010 resta 110 R-Type 10 AND 100100 and 000 R-Type 10 OR 100101 or 001 R-Type 10 set on less than 101010 set on less than 111 Fundamentos de Computadores 24 Diseño de la UC de la ALU – Tabla de verdad del control ALU ALUop ALUop1 ALUop0 0 0 x 1 1 x 1 x 1 x 1 x 1 x 31 Instrucción Tipo R: F5 x x x x x x x F4 x x x x x x x 26 op 6 bits funct F3 F2 x x x x 0 0 0 0 0 1 0 1 1 0 F1 x x 0 1 0 0 1 21 16 rs 5 bits 6 Main Control 6 ALUop Curso 2005/2006 rt 5 bits 6 0 rd shamt funct 5 bits 5 bits 6 bits ALU Control (Local) ALUctr 3 ALU N 11 funct<3:0> Instruction Op. func op F0 x x 0 0 0 1 0 ALUctr bit2 bit1 bit0 0 1 0 1 1 0 0 1 0 1 1 0 0 0 0 0 0 1 1 1 1 Fundamentos de Computadores 0000 add 0010 subtract 0100 and 0101 or 1010 set-on-less-than 25 Diseño de la UC de la ALU Implementación del control ALU ALUop ALUop1 ALUop0 0 0 x 1 1 x 1 x 1 x 1 x 1 x F5 x x x x x x x F4 x x x x x x x funct F3 F2 x x x x 0 0 0 0 0 1 0 1 1 0 F1 x x 0 1 0 0 1 F0 x x 0 0 0 1 0 Operación (ALUctr) bit2 bit1 bit0 0 1 0 1 1 0 0 1 0 1 1 0 0 0 0 0 0 1 1 1 1 ALUOp ALU control block ALUOp0 ALUOp1 F3 F2 Operation2 Operation1 Operation F (5– 0) F1 Operation0 F0 Curso 2005/2006 Fundamentos de Computadores 26 Diseño de la UC de la ALU – Unidad de control Tipo R: Bits: op 31-26 rs 25-21 rt 20-16 Tipo I: Bits: op 31-26 rs 25-21 rt 20-16 Tipo J: Bits: op 31-26 rd 15-11 shamt 10-6 funct 5-0 Inmediato16 15-0 Dirección 26-0 PCSrc Add ALU Add result 4 Shift left 2 RegWrite Instruction [25–21] PC Read address Instruction [31–0] Instruction memory Instruction [20–16] 0 M u Instruction [15–11] x 1 RegDst Instruction [15–0] Read register 1 Read data 1 Read register 2 Read Write data 2 register Write data Registers 16 Sign extend 0 M u x 1 MemWrite ALUSrc 0 M u x 1 Zero ALU ALU result 32 ALU control MemtoReg Address Read data Write Data data memory 1 M u x 0 MemRead Instruction [5–0] ALUOp Curso 2005/2006 Fundamentos de Computadores 27 Diseño de la UC – Funcionalidad de las señales de control Señal RegDst RegWrite AluSrc PCSrc MemWrite MemRead MemToReg Acción cuando es desactivada (0) Acción cuando se activa (1) El registro destino para las escrituras viene del El registro destino para las escrituras viene del campo campo rt (bits 20-16) rd (bits 15-11) Ninguno Escribe el dato en "WriteData" en el registro dado por "WriteRegister". El segundo operando de la ALU viene del banco de El segundo operando de la ALU son los 16 bits menos registro (salida 2) significativos de la instrucción extendidos en signo Selecciona PC+4 como nuevo valor del PC Selecciona la dirección de salto computada como nuevo valor del PC Ninguna Escribe en la dirección de memoria "Address" el dato "WriteData" Ninguna Lee un dato de la dirección de memoria "Address" y lo deja en la salida "ReadData" El valor a realimentar al campo "WriteData" viene El valor a realimentar al campo "WriteData" viene de la de la salida de la ALU memoria PCSrc Add 4 RegWrite Instruction[25–21] PC Read address Instruction [31–0] Instruction memory Instruction[20–16] 0 M Instruction[15–11] u x 1 RegDst Instruction[15–0] Read register1 Read data1 Read register2 Read Write data2 register Write Registers data 16 Sign 32 extend Shift left2 ALU Add result 0 M u x 1 MemWrite ALUSrc 0 M u x 1 Zero ALU ALU result ALU control MemtoReg ead Address R data ata Write mD data emory 1 M u x 0 MemRead Instruction[5–0] ALUOp Curso 2005/2006 Fundamentos de Computadores 28 Diseño de la UC – Implementación de la UC Implementación con PLA Inputs Op5 Op5-0 -> (bits 31-26) RegDst ALUSrc MemToReg RegWrite MemRead MemWrite Branch ALUOp1 ALUOp0 00 0000 0D R-Format 1 0 0 1 0 0 0 1 0 10 0011 35D lw 0 1 1 1 1 0 0 0 0 10 1011 43D sw x 1 x 0 0 1 0 0 0 00 0100 4D beq x 0 x 0 0 0 1 0 1 Op4 Op3 Op2 Op1 Op0 Outputs R-format Iw sw beq RegDst ALU ALUSrc MemtoReg RegWrite MemRead MemWrite Branch ALUOp1 ALUOpO Curso 2005/2006 Fundamentos de Computadores 29 Diseño monociclo – Ventajas y desventajas • • • Todas las instrucciones tardan un ciclo Aprovechamiento ineficiente del área del chip (componentes repetidos) Ciclo de reloj grande para acomodar la instrucción más lenta – Las instrucciones de punto flotante requerirían un tiempo de ciclo extra largo Cycle 1 Cycle 2 Clk lw Curso 2005/2006 sw Fundamentos de Computadores Waste 30 Diseño multiciclo • División del ciclo de instrucción en etapas (cada etapa un ciclo de reloj) – CPI (ciclos por instrucción) variables (instrucciones lentas y rápidas) – Las etapas presentan cargas de trabajo equilibradas • Reutilización de las unidades funcionales – Memoria unificada, pero un único acceso por ciclo – Una única ALU, pero una única operación ALU por ciclo Curso 2005/2006 Fundamentos de Computadores 31 Diseño de la RD – Esbozo de la ruta de datos Inclusión de registros a la salida de las unidades funcionales para preservar los datos (generalmente entre ciclos adyacentes) – – – – Write Data Curso 2005/2006 ALU Fundamentos de Computadores ALUout A Read Addr 1 Register Read Read Addr 2Data 1 File Write Addr Read Write Data Data 2 B Memory Address Read Data (Instr. or Data) IR IR actualiza el contenido cada instrucción, el resto de los registros cada ciclo de reloj PC • IR, registro de instrucciones MDR, registro de dato leído de memoria A, B registros de datos leídos desde el banco de registro ALUOut, registro de salida de la ALU MDR • 32 Diseño de la RD – Integración de la RD y de la UC (1/2) • Los multiplexores a las entradas de las unidades funcionales y la ejecución multiciclo permiten el compartimiento de los recursos hardware IorD PC 0 M u x 1 MemRead MemWrite RegDst Memory MemData Instruction register Instruction [15– 0] Memory data register 0 M u x 1 Read register 1 Read Read data 1 register 2 Registers Write Read register data 2 Instruction [20– 16] Instruction [15– 0] ALUSrcA RegWrite Instruction [25– 21] Address Write data IRWrite 0 M Instruction u x [15– 11] 1 A B 0 M u x 1 16 Sign extend 32 Shift left 2 ALUOut 0 4 Write data Zero ALU ALU result 1 M u 2 x 3 ALU control Instruction [5– 0] MemtoReg Curso 2005/2006 Fundamentos de Computadores ALUSrcB ALUOp 33 Diseño de la RD – Integración de la RD y de la UC (2/2) PCWriteCond PCSource PCWrite IorD IorD Outputs ALUSrcB MemRead MemWrite Control ALUSrcA RegWrite MemtoReg IRWrite ALUOp Op [5– 0] RegDst 0 M 26 Instructi [25– 0] Instruction PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 0 M Instruction u x [15– 11] 1 Instruction [15– 0] Instruction register Instruction [15– 0] Memory data register B 0 M u x 1 16 Sign extend extend 32 x 2 Zero ALU ALU result ALUOut 0 4 Write data Jump address [31-0] PC [31-28] 0 M u x 1 A 28 1 u Shift left 2 1 M u 2 x 3 ALU control Instruction [5– 0] Curso 2005/2006 Fundamentos de Computadores 34 Diseño de la RD - Etapas de la ejecución de las instrucciones (1/3) 1. Búsqueda de la instrucción y actualización del PC (IF) IR Å M[PC]; PC Å PC + 4 2. Decodificación instrucción, lectura de registros y cálculo de dirección efectiva de salto (DEC/REG) A Å RegFile[$rs]; B Å RegFIle[$rt]; ALUOut Å PC + extensión-signo(IR[15:0])<<2 Curso 2005/2006 Fundamentos de Computadores 35 Diseño de la RD - Etapas de la ejecución de las instrucciones (2/3) 3. Ejecución (EX) – Tipo R (add, sub, and, or, slt) ALUOut Å A op B – Referencia a memoria (lw, sw) ALUOut Å A + extensión-signo(IR[15:0]) – Salto (beq) if (A=B) PC Å ALUOut – Bifurcación (j) PC Å PC[31:28] || IR[25:0]<<2 Curso 2005/2006 Fundamentos de Computadores 36 Diseño de la RD - Etapas de la ejecución de las instrucciones (3/3) 4. Acceso a memoria o fin ejecución tipo R (MEM) – Acceso a memoria para lectura MDR Å M[ALUOut] – Acceso a memoria para escritura M[ALUOut] Å B – Fin ejecución tipo R $rd Å ALUOut 5. Fin de lectura en memoria (WB) MDRÅ M[ALUOut] Curso 2005/2006 Fundamentos de Computadores 37 Etapas de la ejecución de las instrucciones - lw Etapa IF PCWriteCond PCSource PCWrite ALUOp IorD Outputs ALUSrcB MemRead ALUSrcA MemWrite Control RegWrite MemtoReg IRWrite Op [5– 0] RegDst 0 26 Instruction [25–0] PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Write data 0 M Instruction u x [15– 11] 1 Instruction [15– 0] Instruction register Instruction [15– 0] Memory data register 0 M u x 1 16 Sign extend 32 B 4 Shift left 2 Jump address [31-0] M 1 u x 2 PC [31-28] 0 M u x 1 A 28 Zero ALU ALU result ALUOut 0 1M u 2 x 3 ALU control Instruction [5– 0] Curso 2005/2006 Fundamentos de Computadores 38 Etapas de la ejecución de las instrucciones - lw Etapa DEC/REG PCWriteCond PCSource PCWrite ALUOp IorD Outputs ALUSrcB MemRead ALUSrcA MemWrite Control RegWrite MemtoReg IRWrite Op [5– 0] RegDst 0 26 Instruction [25–0] PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Write data 0 M Instruction u x [15– 11] 1 Instruction [15– 0] Instruction register Instruction [15– 0] Memory data register 0 M u x 1 16 Sign extend 32 B 4 Shift left 2 Jump address [31-0] M 1 u x 2 PC [31-28] 0 M u x 1 A 28 Zero ALU ALU result ALUOut 0 1M u 2 x 3 ALU control Instruction [5– 0] Curso 2005/2006 Fundamentos de Computadores 39 Etapas de la ejecución de las instrucciones - lw Etapa EX PCWriteCond PCSource PCWrite ALUOp IorD Outputs ALUSrcB MemRead ALUSrcA MemWrite Control RegWrite MemtoReg IRWrite Op [5– 0] RegDst 0 M 26 Instruction [25–0] PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Write data Instruction [15–0] Instruction register Instruction [15– 0] Memory data register 0 M Instruction u x [15– 11] 1 B 4 0 M u x 1 16 Sign extend 32 1 u x 2 PC [31-28] 0 M u x 1 A 28 Jump address [31-0] Zero ALU ALU result ALUOut 0 1M u 2 x 3 Shift left 2 ALU control Instruction [5– 0] Curso 2005/2006 Fundamentos de Computadores 40 Etapas de la ejecución de las instrucciones - lw Etapa MEM PCWriteCond PCSource PCWrite ALUOp IorD Outputs ALUSrcB MemRead ALUSrcA MemWrite Control RegWrite MemtoReg IRWrite Op [5– 0] RegDst 0 26 Instruction [25–0] PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Write data Instruction [15–0] Instruction register Instruction [15– 0] Memory data register 0 M Instruction u x [15– 11] 1 0 M u x 1 16 Sign extend 32 B 4 Jump address [31-0] M 1 u x 2 PC [31-28] 0 M u x 1 A 28 Zero ALU ALU result ALUOut 0 1M u 2 x 3 Shift left 2 ALU control Instruction [5– 0] Curso 2005/2006 Fundamentos de Computadores 41 Etapas de la ejecución de las instrucciones - lw Etapa WB PCWriteCond PCSource PCWrite ALUOp IorD Outputs ALUSrcB MemRead ALUSrcA MemWrite Control RegWrite MemtoReg IRWrite Op [5– 0] RegDst 0 26 Instruction [25–0] PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Write data Instruction [15–0] Instruction register Instruction [15– 0] Memory data register 0 M Instruction u x [15– 11] 1 0 M u x 1 16 Sign extend 32 B 4 M 1 u x 2 PC [31-28] 0 M u x 1 A 28 Jump address [31-0] Zero ALU ALU result ALUOut 0 1M u 2 x 3 Shift left 2 ALU control Instruction [5– 0] Curso 2005/2006 Fundamentos de Computadores 42 Diseño multiciclo - Diseño de la unidad control • Máquina de estados finitos (FSM) – Especificación del control mediante un diagrama de estados finitos (representación gráfica o tabular) – Máquina de estados finitos • Conjunto de estados • Función estado siguiente – Si ×Ij Æ Sk • Función salida – Máquinas de Moore: Si Æ Ok – Máquinas de Mealy: Si ×Ij Æ Ok • Microprogramación – Especificación del control mediante un programa – Necesaria para simplificar la especificación de una UC compleja Curso 2005/2006 Fundamentos de Computadores 43 Control cableado - Especificación de la UC con una FSM (diagrama) Instruction In struction decode/ register fetch Instruction fetch (Op 2 or W ') = 'L (O p = 'S W') 6 Branch completion ') e) EQ typ R- 'B = (Op Execution ALUSrcA = 1 USrcB = 10 ALUSrcB AL ALUOp = 00 8 ALUSrcA =1 ALUSrcB = 00 ALUOp = 10 Jump completion 9 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 PCWrite PCSource = 10 (O p = 'S W ') (Op = 'LW') ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 (Op = 'J') Memory address computation 1 = Start MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 (O p 0 Memory access 3 Memory access 5 MemRead IorD = 1 R-type completion 7 MemWrite IorD = 1 RegDst = 1 RegWrite MemtoReg = 0 Write-back step 4 RegDst = 0 RegWrite MemtoReg = 1 Curso 2005/2006 Fundamentos de Computadores 44 Control cableado - Especificación de la UC con una FSM (tabla) Entradas Salidas op2 op1 op0 s3 s2 s1 s0 ns3 ns2 ns1 ns0 pCWrite PCWriteCond IorD MemRead MemWrite IRWRite MemToReg PCSource1 PCSource0 ALUOp1 ALUop0 ALUSrcB1 ALUSrcB0 ALUSrcA Regwrite RegDst Señales de Control para el Camino de Datos op3 0 Estado Actual op5 op4 Código Operación Estado Siguiente x x x x x x 0 0 0 0 0 0 0 1 1 0 0 1 0 1 0 0 0 0 0 0 1 0 0 0 1 lw 1 0 0 0 1 1 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 sw 1 0 1 0 1 1 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 R 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 beq 0 0 0 1 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 j 0 0 0 0 1 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 2 2 3 4 5 6 7 8 9 lw sw 1 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 x x x x x x x 0 x x x x x x x 1 x x x x x x x 0 x x x x x x x 1 x x x x x x x 1 x x x x x x x 0 0 0 0 0 0 1 1 0 0 1 1 1 1 0 0 1 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 0 1 0 0 1 0 0 0 0 0 0 0 1 0 0 Curso 2005/2006 Fundamentos de Computadores 45 Control cableado – Implementación de la FSM PCWrite PCWriteCond IorD MemRead MemWrite IRWrite Control logic MemtoReg PCSource ALUOp Outputs ALUSrcB ALUSrcA RegWrite RegDst NS3 NS2 NS1 NS0 Curso 2005/2006 S0 S1 S2 S3 Op0 Op1 Op2 Op3 Op4 Op5 Inputs Instruction register r opcode field Estado Siguiente State register Estado Actual Fundamentos de Computadores 46 Control cableado – Ecuaciones de implementación de la FSM Señal Control Ecuación lógica (S3'S2'S1'S0) (OP5'OP4'OP3'OP2OP1'OP0') + (S3'S2'S1'S0) (OP5'OP4'OP3'OP2'OP1OP0') = -> NS3 NS2 Estado 1 (op[5:0] = 'beq') + Estado 1 (op[5:0] = 'jmp') -> Estado 1 (op[5:0] = 'R-format') + Estado 2 (op[5:0] = 'sw') + Estado 3 + Estado 6 NS1 -> Estado 1 (op[5:0] = 'lw') + NS0 PCWrite PCWriteCond IorD MemRead MemWrite IRWrite MemToReg PCSource1 PCSource0 ALUOp1 ALUOp0 ALUSrcB1 ALUSrcB0 ALUSrcA RegWrite RegDst -> Estado 0 + Estado 9 -> Estado 8 -> Estado 3 + Estado 5 -> Estado 0 + Estado 3 -> Estado 5 -> Estado 0 -> Estado 4 -> Estado 9 -> Estado 8 -> Estado 6 -> Estado 8 -> Estado 1 + Estado 2 -> Estado 0 + Estado 1 -> Estado 2 + Estado 6 + Estado 8 -> Estado 4 + Estado 7 -> Estado 7 Curso 2005/2006 Estado 1 (op[5:0] = 'sw') + Estado 1 (op[5:0] = 'R-format') + Estado 2 (op[5:0] = 'lw') + Estado 2 (op[5:0] = 'sw') + Estado 6 -> Estado 0 + Estado 1 (op[5:0] = 'jmp') + Estado 2 (op[5:0] = 'lw') + Estado 2 (op[5:0] = 'sw') + Estado 6 Fundamentos de Computadores 47 Control cableado - Implementación de FSM con ROM Diseño unificado (Tamaño 210 × 20 = 20Kb) IRWrite Diseño no unificado (Tamaño 4.25Kb) MemtoReg PCSource ROM de señales de control (Tamaño 24 × 16 = 256b) 4 bits de los estados = 2 posiciones de memoria 16 salidas de control = 4 bits de anchura • Curso 2005/2006 NS3 NS2 NS1 NS0 Inputs Instruction register r opcode field Fundamentos de Computadores S0 6 bits código de operación + 4 bits de los estados = 210 posiciones de memoria 4 salidas de nuevo estado = 4 bits de anchura RegDst S1 • RegWrite S2 ROM de nuevo estado (Tamaño 210 × 4 = 4Kb) ALUSrcB ALUSrcA 4 S3 • ALUOp Outputs Op3 • – Control logic Op2 – PCWriteCond IorD MemRead MemWrite Op5 • PCWrite Tamaño: 20 Kbits vs 4.25 Kbits Op0 – 6 bits código de operación + 4 bits de los estados = 210 posiciones de memoria 16 salidas de control + 4 salidas de nuevo estado = 20 bits de anchura Op1 – Op4 • State register 48 Control cableado - Implementación de FSM con PLA • Tamaño de la PLA Op5 Op4 – #inputs × #minterms + #outputs × #minterms = (10 × 17)+(20 × 17) = 510 celdas Op3 Op2 Op1 Op0 S3 S2 S1 S0 PCWrite PCWriteCond IorD MemRead MemWrite IRWrite MemtoReg PCSource1 PCSource0 ALUOp1 ALUOp0 ALUSrcB1 ALUSrcB0 ALUSrcA RegWrite RegDst NS3 NS2 NS1 NS0 Curso 2005/2006 Fundamentos de Computadores 49 Diseño de la unidad de control – Control microprogramado Control unit Microcode memory Outputs Input PCWrite PCWriteCond IorD MemRead MemWrite IRWrite BWrite MemtoReg PCSource ALUOp ALUSrcB ALUSrcA RegWrite RegDst AddrCtl Datapath 1 Microprogram counter Adder Address select logic Op[5– 0] • El estado siguiente es frecuentemente el estado actual + 1 • Las señales de control están almacenadas en una memoria Instruction register opcode field Secuenciador externo Curso 2005/2006 Fundamentos de Computadores 50 Control microprogramado – Formato de la microinstrucción • 7 campos: 6 campos de control + 1 campo de secuenciación Control ALU SRC1 SRC2 Control Registro Memoria Control PCWrite Secuenciamiento Nom bre del cam po Control ALU Función del cam po Especifica la operación que va a realizar la ALU add subt durante el ciclo. SRC1 Especifica la fuente para el primer operando de la ALU Especifica la fuente para el segundo operando de la ALU SRC2 Control Registro Especifica el número de registro y dato que se escribe en el mismo Mem oria Especifica lectura o escritura y la fuente de la dirección Control PCW rite Especifica la escritura del PC Secuenciam iento Especifica la siguiente microinstrucción que se va a ejecutar Curso 2005/2006 fuente del Fundamentos de Computadores Valores del cam po Func code PC A B 4 Extend ExtShft Read W rite ALU (rd <- ALUout) W rite MDR (rt <- MDR) Read PC (IR <- M[PC]) Read ALU (MDR <- M[ALUout] W rite ALU (M[ALUout] <- B) ALU ALUOut-Cond Jump Address Seq Fetch Dispatch i 51 Control microprogramado– Señales asociadas a los campos y valores C o n tro l A L U ALUop1 ALUO p0 0 0 O p e r a c ió n SRC1 Sum a 0 PC 1 A 0 1 R e s ta 1 0 Func. code R e g is t e r C o n t r o l R e g W r ite R egD st M em ToReg 1 1 0 1 0 1 O p e ra c ió n A L U S rB 1 A L U S rcB 0 0 0 B 0 1 4 1 0 E xte n d 1 1 E xtS h ft M e m o ria O p e r. O p e r. IR W rite M em R ead M e m W rite Io rD W r ite A L U 1 1 0 0 Read PC W r ite M D R 0 1 0 1 Read ALU 0 0 1 1 W rite A L U Sec Control PCWrite Oper. PCSrc1 PcSrc0 PCwrite PCWrtCond 0 0 1 0 ALU 0 1 0 1 ALUOut-Cond 1 0 1 0 Jump address Curso 2005/2006 SRC2 O p e r a c ió n A d d rS rc A O p e ra c ió n A d d rC tl1 A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 Fundamentos de Computadores 52 Control microprogramado – Microprograma de la UC Estado 0 1 2 3 4 5 6 Etiqueta Fetch Mem1 LW 2 Control SRC1 ALU Add PC Add PC Add A Control Registros 4 Extshft Read Extend Mem oria Read PC Read ALU W rite MDR SW 2 Rform at1 Func Cod W rite ALU A B BEQ1 9 JUMP1 Curso 2005/2006 Subt A B Fundamentos de Computadores AddrCtl0 Control Secuenc. PCW rite ALU Seq. Dispatch 1 Dispatch 2 Seq Fetch Fetch Seq W rite ALU 7 8 Sec. AddrCtl1 PCWriteCond PCWrite PCSource0 PCSource1 Control PCWrite MemWrite IorD MemRead Memoria IRWrite MemToReg RegDst ALUSrcB0 ALUSrcB1 SRC2 RegWrite Control Registro SRC2 AluSrcA Aluop0 18 señales de control -> Aluop1 Control ALU SRC1 ALUOutcond Jump Address Fetch Fetch Fetch 53 Control microprogramado – Secuenciador del microprograma • La lógica de selección de direcciones genera la dirección de la siguiente microinstrucción a ejecutar Sec O p e ra c ió n A d d rC tl1 A d d rC tl0 1 1 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 PLA or ROM 1 Seq. State Adder 3 Mux 2 1 AddrCtl 0 0 Dispatch ROM 1 Dispatch ROM 2 Dispatch ROM2 Op [5:0] Nombre Valor 100011 lw LW2 (3) 101011 sw SW2 (5) Curso 2005/2006 Op Address select logic Instruction register opcode field Op [5:0] 000000 000010 000100 100011 101011 Fundamentos de Computadores Dispatch ROM1 Nombre Valor R-Format R-Format1 (6) jmp JUMP1 (9) beq BEQ1 (8) lw MEM1 (2) sw MEM1 (2) 54 Excepciones e interrupciones • Definiciones – Eventos inesperados que cambian el flujo normal de ejecución de las instrucciones – Excepción • Evento que tiene su origen en el interior del procesador (desbordamiento aritmético, instrucción ilegal, etc.) – Interrupción • Evento que tiene su origen en el exterior del procesador (dispositivos de entrada/salida, fallo de página, etc.) Curso 2005/2006 Fundamentos de Computadores 55 Tratamiento de excepciones en MIPS • Acciones básicas – Guardar la dirección de la instrucción causante en el registro Contador de Programa de Excepciones (EPC) – Registrar la causa de la excepción (Registro CAUSE) – Transferir el control al sistema operativo en alguna dirección especificada (0xC0000000) donde se tratará la excepción (ejecución de una rutina de servicio) Programa Interrupción Rutina de servicio de la interrupción Curso 2005/2006 Fundamentos de Computadores 56 Implementación de excepciones en MIPS • Excepciones a implementar – Desbordamiento aritmético – Instrucción ilegal o no definida • Registros adicionales requeridos – EPC: registro de 32 bits para guardar la dirección de la instrucción causante de la excepción – CAUSE: Registro de 32 bits para registrar la causa de la excepción. Utilizaremos sólo el bit menos significativo • bit 0 = 0 -> Instrucción ilegal • bit 0 = 1 -> Desbordamiento aritmético • Señales de control adicionales – – – – Intcause (0: instr. ilegal; 1: desbordamiento) CauseWrite (1: escritura en el registro CAUSE; 0: no escribe) EPCWrite (1: escritura en el registro EPC; 0: no escribe) Constante: C000 0000 0000 0000 (dirección a donde se transfiere el control cada vez que se interrumpe) Curso 2005/2006 Fundamentos de Computadores 57 Ruta de datos con soporte de excepciones CauseWrite IntCause EPCWrite PCSource ALUOp PCWriteCond PCWrite IorD Outputs MemRead MemWrite ALUSrcB ALUSrcA Control MemtoReg IRWrite RegWrite Op [5– 0] RegDst 0 26 Instruction [25– 0] PC 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Instruction register Instruction [15– 0] Memory data register Jump address [31-0] 0 M Instruction u x [15– 11] 1 B 4 Write data 0 M u x 1 Zero ALU ALU result Sign extend 32 Shift left 2 3 0 1M u 2x 3 ALU ALUOut EPC 0 M u x 1 0 1 16 u x PC [31-28] 0 M u x 1 A 1M 2 CO 00 00 00 Instruction [25– 21] Instruction [15– 0] 0] 28 Cause ALU control 11 Instruction [5– 0] 10 IntCause = 0 CauseWrite ALUSrcA = 0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PC++Source = 11 Curso 2005/2006 Fundamentos de Computadores IntCause = 1 CauseWrite ALUSrcA = 0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 PCSource = 11 To state 0 to begin next instruction 58 Especificación de la UC con soporte de excepciones Instruction de decode/ code/ Register fetch 1 Instruction fetch 0 MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 (Op = 'J') 'B EQ ') = 9 PCWrite PCSource = 10 p= (O ') W 'S (Op = 'LW') Jump completion r) ALUSrcA = 1 ALUSrcB = 00 ALUOp = 10 e oth ALUSrcA = 1 ALUSrcB = 00 ALUOp = 00 ) ype R-t = (Op Branch completion 8 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 p= (O W') = 'S (Op r o Execution W') = 'L 6 (Op Memory address computation 2 ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 (O p Start Memory access 3 Memory access 5 MemRead IorD = 1 R-type completion 7 MemWrite IorD = 1 11 RegDst = 1 RegWrite MemtoReg = 0 Overflow IntCause = 1 CauseWrite A ALUSrcA =0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 10 IntCause = 0 CauseWrite ALUSrcA = 0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 Write-back step 4 Overflow RegWrite MemtoReg = 1 RegDst = 0 Curso 2005/2006 Fundamentos de Computadores 59 Instrucciones para excepciones en MIPS • mfc0 $rt, $rd (move from coprocesador 0) – Transfiere la información desde el registro de propósito general $rd al registro de propósito especial $rt (0 para CAUSE, 1 para EPC) – Tipo R • 010000 0000 ttttt ddddd 00000000000 • mtc0 $rd, $rt (move to coprocesador 0) – Transfiere la información desde el registro de propósito especial $rt (0 para CAUSE, 1 para EPC) al registro de propósito general $rd – Tipo R • 010000 0100 ttttt ddddd 00000000000 • rfe (return from exception) – Transfiere el contenido del EPC al registro contador de programa – Tipo J • 010000 10000000000000000000100000 Curso 2005/2006 Fundamentos de Computadores 60 Rendimiento, coste y prestaciones “El tiempo descubre la verdad”, Séneca Contenidos (1/3) • Métricas de rendimiento, coste y prestaciones • Definiciones – Tiempo de respuesta, tiempo de CPU, productividad y rendimiento • Medidas del rendimiento – MIPS, MFLOPS – Tiempo de ejecución – Ecuación clásica del tiempo de CPU • Fórmula básica • CPImedio • Dependencias Curso 2005/2006 Fundamentos de Computadores 2 Contenidos (2/3) • • Programas para la evaluación del rendimiento - Benchmarks SPEC Benchmarks – SPEC’89 – SPEC’92 y SPEC’95 • SpecInt, SpecFp, SPECbase • SPEC’95 – Programas • SPEC’95 – Pentium – SPEC CPU2000 • CINT2000, CFP2000 • Programas • SPEC CINT2000 y CFP2000 - Pentium – SPECweb99 • Sistemas Dell PowerEdge – Benchmarks para embedded computing systems • • Fiabilidad de los programas de prueba Más métricas del rendimiento – MIPS y MFLOPS Curso 2005/2006 Fundamentos de Computadores 3 Contenidos (3/3) • Métodos de comparación y resumen de rendimientos • Ley de Amdahl (o ley de rendimientos decrecientes) • Rendimiento, potencia y eficiencia de energía – Limitaciones de los sistemas empotrados y portátiles – Técnicas de ahorro de potencia – Familia Pentium • Conclusiones Curso 2005/2006 Fundamentos de Computadores 4 Objetivos • • • • • • • • • • Definir coste, rendimiento, productividad y prestaciones Dar las principales métricas para el coste, el rendimiento, productividad y prestaciones y su importancia para los usuarios y diseñadores Distinguir entre tiempo de ejecución del tiempo de CPU Aplicar la ecuación básica del rendimiento Señalar la influencia de los parámetros de diseño de un computador sobre los parámetros de la ecuación básica del tiempo de CPU Categorizar los diferentes programa para la evaluación del rendimiento Conocer las características de las medidas de rendimiento SPECS, MIPS y MFLOPS Métodos de resumen de rendimientos Aplicar la ley de Amdahl para el cálculo del rendimiento Enumerar las principales limitaciones de los sistemas empotrados y portátiles eficiencia de energía Curso 2005/2006 Fundamentos de Computadores 5 Métricas de rendimiento, coste y prestaciones • Métricas del rendimiento – Tiempo de respuesta, productividad… • Métricas del coste – Generalmente €, $..., • Métricas de las prestaciones – Relación entre rendimiento y productividad • Importan a los clientes y vendedores de computadores – ¿Qué máquina proporciona el mayor rendimiento? – ¿Qué máquina tiene el menor coste? – ¿Qué máquina tiene la mejor relación rendimiento/coste? • Importan a lo diseñadores de computadores – ¿Qué diseño proporciona mayor rendimiento? – ¿Qué diseño tiene menor coste? – ¿Qué diseño tiene la mejor relación rendimiento/coste? Curso 2005/2006 Fundamentos de Computadores 6 Definiciones -Tiempo de respuesta, tiempo de CPU y productividad • Tiempo de respuesta o latencia o tiempo de ejecución – Tiempo entre el comienzo y finalización de una tarea • Tiempo de CPU – No incluye tiempo de: accesos a memoria secundaria y discos, entrada y salida, otros procesos… • Productividad (throughput) – Cantidad total de trabajo realizado por unidad de tiempo Curso 2005/2006 Fundamentos de Computadores 7 Tiempo de respuesta y productividad - Ejemplos • Un tren de lavado de coches comienza un coche nuevo cada 30s y en el tren de lavado coexisten 6 coches en distintas fases de lavado – Tiempo de respuesta (usuario) de 180s (30*6) – Productividad de 1 coche/30 segundos • El cambio de procesador de un computador ¿disminuye el tiempo de respuesta, aumenta la productividad o ambos? • La adición de procesadores a un computador que asigna un procesador a cada tarea ¿disminuye el tiempo de respuesta, aumenta la productividad o ambos? Curso 2005/2006 Fundamentos de Computadores 8 Definición de rendimiento • El rendimiento de un computador es el inverso del tiempo de ejecución Rendimiento X = 1 Tiempo de ejecución X – Un computador X es n veces más rápido que un computador Y cuando Rendimiento X =n Rendimiento Y – Un computador X (Y) es n% veces más rápido (lento) que un computador Y (X) cuando Rendimiento X − Rendimiento Y *100 = n Rendimiento Y Curso 2005/2006 Rendimiento X − Rendimiento Y *100 = n Rendimiento X Fundamentos de Computadores 9 Definición de rendimiento - Ejemplo • La máquina A ejecuta un programa en 10s y la máquina B ejecuta el mismo programa en 15 s, – ¿cuánto más rápida1 es 1A respecto de B? − n% = 100 TCPU A TCPU B RA − RB % = 100 1 RB TCPU B 1 1 − 10 15 = 50% % = 100 1 15 – ¿cuánto más lenta es B respecto de A? 1 n% = 100 Curso 2005/2006 − 1 TCPU A TCPU B RA − RB % = 100 1 RA TCPU A 1 1 − % = 100 10 15 = 33.3% 1 10 Fundamentos de Computadores 10 Medidas del rendimiento • • MIPS (Million Instructions Per Second ) MFLOPS (Millions of Floating Point Operations Per Second ) – TOP 1 de 2005: IBM BlueGene/L 280600 GFLOPS y 131072 P – TOP 8 de 2005: IBM Mare Nostrum 27910 GLOPS con 4800 P • Frecuencia del reloj (MHz, GHz) inversa del periodo de reloj – A 4GH = 250ps • one clock period Tiempo de ejecución – MIPS, MFLOPS… no son medidas fiables – El tiempo es la única medida fiable del rendimiento de un computador – Medida del tiempo • El sistema operativo UNIX proporciona la orden time “nombre de programa” para medir el tiempo • Ejemplo de salida de time: 90.7u 12.9s 2:39s 65% Curso 2005/2006 Fundamentos de Computadores 11 Ecuación clásica del TCPU Fórmula básica • El tiempo de CPU es el tiempo que la CPU tarda en la ejecución de un programa TCPU = # ciclos de reloj por programa × Tiempo de ciclo • Ciclos por instrucción (medio) CPI medio = # ciclos de reloj por programa # instrucciones • Tiempo de CPU = # de instrucciones por programa × Ciclos por instrucción (medio) × Tiempo de ciclo Curso 2005/2006 Fundamentos TCPU = Nde×Computadores CPI × TC 12 Ecuación clásica del TCPU - CPImedio • El cálculo del CPImedio considera los tipos, los CPI individuales y los promedios de uso de las instrucciones n CPI medio = ∑ CPI i × IC i i =1 – ICi es el porcentaje del # de instrucciones de tipo-i ejecutadas – CPIi es el # de ciclos de reloj por instrucción del tipo-i – n es el # de instrucciones • CPImedio varía con los programas y los datos de entrada Curso 2005/2006 Fundamentos de Computadores 13 Ecuación clásica del TCPU Dependencias TCPU = N × CPI × TC Tc #instrucciones CPImedio Algoritmo X X Lenguaje de programación X X Compilador X X ISA X X X X X Estructura del computador Tecnología Curso 2005/2006 X Fundamentos de Computadores 14 Ecuación clásica del TCPU – Autoevaluación I • Considere dos máquinas A y B con idénticas arquitecturas del repertorio de instrucciones: – A tiene Tc = 1ns y CPI = 2 para un programa concreto – B tiene Tc = 2ns y CPI de 1.2 para ese programa • ¿Cuánto más rápida (en %) sería una máquina que la otra? • ¿Cuánto más lenta (en %) sería una máquina que la otra? Curso 2005/2006 Fundamentos de Computadores 15 Ecuación clásica del TCPU – Autoevaluación II • Para una declaración particular de un lenguaje de alto nivel, el diseñador del compilador considera dos secuencias de código diferentes – ¿Cuál ejecutará mayor # de instrucciones? – ¿Cuál es más rápida? – ¿Cuál es el CPI de cada secuencia? Curso 2005/2006 Instrucción CPI A 1 B 2 C 3 Tipo A Tipo B Tipo C Sec1 2 1 2 Sec2 4 1 1 Fundamentos de Computadores 16 Ecuación clásica del TCPU – Autoevaluación III • ¿Cuánto más rápida sería la máquina si una cambio… – del sistema de memoria reduce el CPIload 2 ciclos? – del sistema de predicción de saltos reduce el CPIbranch 1ciclo? – del ISA reduce el # de instrucciones ALU a la mitad Op ICi ICi× CPIi CPIi ALU 50% 1 0.5 Load 20% 5 1.0 Store 10% 3 0.3 Branch 20% 2 0.4 2.2 Curso 2005/2006 Fundamentos de Computadores 17 Ecuación clásica del TCPU – Autoevaluación IV • Una aplicación escrita en Java tarda 25s en un procesador. Con la nueva versión del compilador Java el número de instrucciones a ejecutar es reducido en un 40% pero el CPI aumenta en un 1.1%. ¿Cuánto tiempo tardará la aplicación en terminar? Curso 2005/2006 Fundamentos de Computadores 18 Programas para la evaluación del rendimiento - Benchmarks • Programas de una carga de trabajo estándar para predecir el rendimiento con una carga de trabajo real – Programas reales típicos • Compiladores (gcc), tratamiento de texto (TeX), herramientas CAD (SPICE)… – Núcleos de programas reales (Kernels) • Colección de pequeñas partes intensivas temporalmente de programas reales • Ejemplo: Livermore Loops, Linpack… – Programas triviales (toy bechmarks) • 10-100 líneas de programa. • Ejemplo: quickshort, puzzle,.. – Programas sintéticos • Programas artificiales para evaluar una determinada característica • Ejemplo: Whetstone (punto flotante), Dhrystone (aplicaciones no numéricas) • ¿Fiabilidad de resultados? – Mejoras específicas (caso matrix300 de los SPEC89) – Mejoras erróneas (caso Intel) Curso 2005/2006 Fundamentos de Computadores 19 SPEC Benchmarks • Standard Perfomance Evaluation Cooperative (desde 1988) – AMD * Apple * ATI * Borland * Dell * HP * IBM * Intel * Microsoft * NVIDIA * Oracle * SGI * Sun * Symantec … • Benchmarks para CPU, HPC, aplicaciones gráficas, servidores/clientes java, servidores/clientes de correo, sistemas de ficheros, web… • htpp://www.spec.org Curso 2005/2006 Fundamentos de Computadores 20 SPEC’89 • Conjunto pequeño de programas – 4 de aritmética entera y 6 de punto flotante – No hay distinción entre SPECs de aritmética entera y punto flotante • Media geométrica – Es independiente de la máquina de referencia – No predice tiempos SPEC programa = SPEC global = Curso 2005/2006 Tiempo de ejecución de un VAX 11/780 Tiempo de ejecución de la máquina a medir (∏ SPEC programai ) 1 n Fundamentos de Computadores 21 SPEC’92 y SPEC’95 • SPEC’92 – SpecInt92 (6 programas aritmética entera) – SpecFp92 (14 programas de aritmética en FP) – SPECbase • Medida obtenida sin hacer uso de los flags del compilador que optimiza el código generado según el programa específico. Los flags específicos llegan a aumentar el rendimiento entre un 15% y un 30% • VAX 11/780 -> 1 Spec(int/fp)92 • SPEC’95 – SpecInt95 (8 programas aritmética entera) – SpecFp95 (10 programas de aritmética en FP) – Los SPECs de cada programa se normalizan respecto a una Sun SPARCStation 10/40 (la VAX 11/780 ya no es operativa) • SparcStation 10/40 -> 1 Spec(int/fp)95 • SparcStation 10/40 -> 41.26 SpecInt92 - 34.35 Specfp92 Curso 2005/2006 Fundamentos de Computadores 22 SPEC’95 - Programas Benchmark go m88ksim gcc compress li ijpeg perl vortex tomcatv swim su2cor hydro2d mgrid applu trub3d apsi fpppp wave5 Curso 2005/2006 Description Artificial intelligence; plays the game of Go Motorola 88k chip simulator; runs test program The Gnu C compiler generating SPARC code Compresses and decompresses file in memory Lisp interpreter Graphic compression and decompression Manipulates strings and prime numbers in the special-purpose programming language Perl A database program A mesh generation program Shallow water model with 513 x 513 grid quantum physics; Monte Carlo simulation Astrophysics; Hydrodynamic Naiver Stokes equations Multigrid solver in 3-D potential field Parabolic/elliptic partial differential equations Simulates isotropic, homogeneous turbulence in a cube Solves problems regarding temperature, wind velocity, and distribution of pollutant Quantum chemistry Plasma physics; electromagnetic particle simulation Fundamentos de Computadores 23 SPEC’95 – Pentium Procesador Pentium 100 -> 200 MHz (x2) Pentium Pro 150 -> 200 MHz (x1.33) SpecInt95 (mejora) 1.7 1.4 1.24 1.18 10 10 9 9 8 8 7 SPECfp 7 SPECint SpecFp95 (mejora) 6 5 6 5 4 4 3 3 2 2 1 1 0 0 50 100 150 Clock rate (M Hz) 200 250 50 P entium P entium Pro Curso 2005/2006 Fundamentos de Computadores 100 150 Clock rate (M Hz) 200 250 Pentium Pentium Pro 24 SPEC CPU2000 • SPEC programa = Tiempo ejecución Sun Ultra5_10 (300MHz 256MB) Tiempo de ejecución SPEC global = (∏ SPEC programai ) 1 n • CINT2000 (Integer Component of SPEC CPU2000) – 12 aplicaciones enteras (11 C, 1 C++) – Cint_rate, Cint_non_rate • CFP2000 (Floating Point Component of SPEC CPU2000) – 14 aplicaciones FP (6 F77, 4 F90, 4 C) – Cfp_rate, Cfp_non_rate Curso 2005/2006 Fundamentos de Computadores 25 SPEC CPU2000 - Programas • • CINT2000 – – – – – – – – – – – – 164.gzip → Compresión de datos 175.vpr → Circuitos FPGA 176.gcc → Compilador de C 181.mcf → Resuelve flujos de red de mínimo coste 186.crafty → Programa de ajedrez 197.parser → Procesamiento de lenguaje natural 252.eon → Ray tracing 253.perlbmk → Perl 254.gap → Teoría computacional de grupos 255.vortex → Base de datos orientada a objetos 256.bzip2 → Utilidad de compresión de datos 300.twolf → Simulador Curso 2005/2006 CFP2000 – – – – – – – – – – – – – – 168.wupwise → Cromodinámica cuántica 171.swim → Modelo de agua 172.mgrid → Resuelve campo potencial en 3D mutimalla 173.applu → Ecuaciones diferenciales parciales parabólicas/elípticas 177.mesa → librería gráfica 3D 178.galgel → Dinámica de fluidos 179.art → Simulación de redes neuronales 183.equake → Simulación de elementos finitos 187.facerec →Reconocedor de caras 188.ammp →Química computacional 189.lucas → Teoría de números: Nº primos 191.fma3d → simulación de choques mediante elementos finitos 200.sixtrack → modelo de acelerador de partículas 301.apsi → Meteorología: temperatura, viento y distribución de la polución Fundamentos de Computadores 26 SPEC CINT2000 y CFP2000 para Pentium III y Pentium IV Curso 2005/2006 Fundamentos de Computadores 27 SPECweb99 • La primera versión de benchmarks para servidores web data de 1996. Actualizados en 1999 y 2005 • Características – Orientados a medir throughput ( número máximo de conexiones que puede soportar un sistema servidor web). El sistema debe proporcionar respuesta en un tiempo dado y con un número máximo de errores – Son benchmarks de entornos multiprocesadores – El programa para realizar las peticiones forma parte del benchmark – El rendimiento depende en gran medida de las características del sistema, incluyendo el sistema de discos y la red Curso 2005/2006 Fundamentos de Computadores 28 SPECweb99 - Sistemas Dell PowerEdge • La frecuencia de reloj no es la característica más importante en servidores web – El 8400 tiene el doble de procesadores lentos que el 6600 y ofrece mejor rendimiento • La configuración adecuada de los sistemas permite obtener mejor rendimiento (adición de discos e incremento de la conectividad hasta que el procesador sea el cuello de botella) Sistema Procesador Nº discos Nº CPUs Nº redes f (GHz) Resultado 1550/1000 Pentium III 2 2 2 1.00 2765 1650 Pentium III 3 2 1 1.40 1810 2500 Pentium III 8 2 4 1.13 3435 2550 Pentium III 1 2 1 1.26 1454 2650 Pentium 4 Xeon 5 2 4 3.06 5698 4600 Pentium 4 Xeon 10 2 4 2.20 4615 6400/700 Pentium III 5 4 4 0.70 4200 6600 Pentium 4 Xeon MP 8 4 8 Curso 2005/2006 Fundamentos de Computadores 8450/700 Pentium III Xeon 7 8 8 2.00 6700 29 8001 0.70 Benchmarks para embedded computing systems • • • • Un sistema empotrado es un sistema informático de uso específico construido dentro de un dispositivo mayor Las aplicaciones dispares de los sistemas empotrados (tiempo real restringido, tiempo real flexible, coste/rendimiento…) dificultan el diseño de benchmarks Los benchmarks están en un estado primitivo. Los fabricantes tienen preferencias de benchmarks diferentes (kernels como Dhrystone) EDN Embedded Microprocessor Benchmark Consortium (EEMBC) – 34 benchmarks divididos en 5 clases: automoción/industrial, consumo, networking, automatización de oficinas, telecomunicaciones – Mejor conjunto de benchmarks estandarizados en el entorno embedded – Permite a los fabricantes dar resultados tanto para versiones modificadas del código fuente como para versiones codificadas a mano de las aplicaciones (los kernels pequeños posibilitan la tarea. Curso 2005/2006 Fundamentos de Computadores 30 Fiabilidad de los programas de prueba • El fabricante mejorar el rendimiento con optimizaciones específicas de los benchmarks (los programas reales no mejoran en factores similares) • Generalmente, los benchmarks reducidos y los sintéticos – No cargan la memoria principal del sistema de forma realista – No calculan nada útil para un usuario (existen excepciones) – No reflejan el comportamiento de ningún programa • Los benchmarks reales son difíciles de realizar, situación que se agudiza en los casos de: – Máquinas no construidas, simuladores más lentos – Benchmarks no portables – Compiladores no disponibles Curso 2005/2006 Fundamentos de Computadores 31 Más métricas del rendimiento – MIPS (1/3) • MIPS (millones de instrucciones por segundo) MIPS Nativos = Recuento de Instrucciones Tiempo de Ejecución x 106 MIPS Nativos = Frecuencia del reloj CPI x 106 • MIPS de pico – MIPS obtenidos con un programa de CPI mínimo (el programa podría ser inútil) – Dan una idea del rendimiento teórico máximo de la máquina. – Algunos fabricantes la utilizan a veces en la publicidad de los productos Curso 2005/2006 Fundamentos de Computadores 32 Más métricas de rendimiento – MIPS (2/3) • MIPS relativos – MIPS obtenidos respecto a una máquina de referencia MIPS Re lativos = Tiempo Tiempo Re ferencia x MIPS Re ferencia En _ la _ maquina TiempoRe ferencia = Tiempo de ejecución de un programa en la máquina de referencia TiempoEn _ la _ máquina = Tiempo de ejecución del mismo programa en la máquina a medir MIPS Re ferencia = MIPS para el computador de referencia – Proporcionales al tiempo de ejecución SÓLO para un programa dado con una entrada dada – A medida que pasan los años la máquina de referencia deja de estar operativa – ¿Debería el computador de referencia ser actualizado con una nueva versión de sistema operativo y compilador? Curso 2005/2006 Fundamentos de Computadores 33 Más métricas de rendimiento – MIPS (3/3) • Inconvenientes de la métrica MIPS: – Los MIPS dependen del # de instrucciones ejecutadas y por tanto del repertorio de instrucciones – Los MIPS no posibilitan comparar distintas arquitecturas – Los MIPS varían entre programas en el mismo computador (no es una medida absoluta por máquina) – Los MIPS no tienen en cuenta los tres factores de la ecuación de tiempo de CPU (sólo dos de ellos) – Es posible una variación de los MIPS inversamente proporcional al rendimiento Curso 2005/2006 Fundamentos de Computadores 34 Más métricas de rendimiento – MFLOPS • MFLOPS (Millones de operaciones en coma flotante por segundo) MFLOPS • = Nº operaciones en punto flotante Tiempo de ejecución x 106 Inconvenientes – Depende del programa y SÓLO es aplicable a las operaciones en coma flotante – Instrucciones en coma flotante no comparables entre diferentes máquinas Máquina A: +, -, * y / Máquina B: No tiene “/” (dará mas MFLOPS) – Depende de la mezcla de operaciones coma flotante rápidas y lentas • Los MFLOPS para 100 sumas serán mayores que para 100 divisiones • MFLOPS normalizados – +, -, * y comparaciones: peso 1 OP – / y raíz cuadrada: peso 4 OP – Exponencial y trigonométricas: 8 OP Curso 2005/2006 Fundamentos de Computadores 35 Métodos de comparación y resumen de los resultados Media aritmética ponderada Media aritmética 1 n TMedio = ∑ Ti n i =1 n TMedio = ∑ Pesoi * Ti Media armónica n 1 donde Vi = n 1 Ti ∑ i =1 Vi i =1 Pesoi = Frecuencia del programa iésimo. Suma de los pesos igual a 1. (Si el rendimiento se expresa como una frecuencia (ej. MFLOPS,)) Media armónica ponderada Media geométrica para tiempos normalizados 1 n Pesoi ∑ Vi i =1 TMedio = n ∏T Normalizado i i =1 Ti Normalizado = Tiempo de ejecución, normalizado para la máquina de referencia, para el programa iésimo de un total de n. Ti = Tiempo de ejecución del programa iésimo Curso 2005/2006 n n = Nº de programas de la carga de trabajo Fundamentos de Computadores 36 Ley de Amdahl (o ley de rendimientos decrecientes) • El posible aumento de rendimiento para una mejora dada está limitado por la cantidad que se utiliza la característica mejorada Rendimiento después de la mejora Tiempo de ejecución antes de la mejora = Rendimiento antes de la mejora Tiempo de ejecución después de la mejora Tiempo de ejecución después de la mejora = Tiempo de ejecución afectado por la mejora = + Tiempo de ejecución no afectado por la mejora Cantidad de la mejora Ganancia velocidad = • Si suponemos que la mejora acelera una fracción F de la tarea en un factor de S, entonces la ganancia de velocidad (speedup) vendrá dada por: G= 1 F + (1 − F ) S F 1-F 1 • Corolario: Procurar hacer rápido el caso común Curso 2005/2006 Fundamentos de Computadores 37 Ley de Amdahl – Ejemplos (1/3) • Calcula la ganancia de rendimiento obtenida con la modificación de la unidad de control de un procesador si el tiempo de ejecución de la tarea disminuye de 2,8s a 1,9s • La ejecución de un programa tarda en una máquina 100s, de los cuales 80 corresponden a instrucciones de multiplicar – ¿Cuánto hay que mejorar la velocidad de la multiplicación para que mi programa sea cuatro veces más rápido? – ¿Y para que sea cinco veces más rápido? Curso 2005/2006 Fundamentos de Computadores 38 Ley de Amdahl – Ejemplos (2/3) • Una propuesta de mejora de un computador implica que el precio del computador sea el doble. Si el procesador está activo durante el 60% del tiempo de ejecución total de la tarea y la mejora supone aumentar la velocidad del procesador al triple, averigua el interés de introducir la mejora usando para ello la relación precio/ganancia de rendimiento • La adquisición de un nuevo modelo de computador supone un incremento en la ganancia de rendimiento del 50% respecto al antiguo. Teniendo en cuenta que el antiguo tardaba en ejecutar una tarea 22 segundos, ¿cuánto tiempo empleará el nuevo en ejecutar la misma tarea? Curso 2005/2006 Fundamentos de Computadores 39 Ley de Amdahl – Ejemplos (3/3) • Suponga paralela un 90% o lo que es lo mismo, una tarea que puede ejecutarse por varios procesadores simultáneamente, calcula la mejora cuando P = 10, 100 y 100 Speedup P = Speedup10 = • 1 0.9 0.1 + 10 = 5.3 Speedup100 = 1 1 0.9 0.1 + 100 Speedup1000 = 1 0.9 0.1 + 1000 = 9.91 Calcula la mejora (para P = 100), si mejoramos en una cantidad 2 la parte no paralela 1 Speedup100, 2 = • 0.9 P = 9.17 0.1 + 0.1 0.9 + 2 100 = 16.95 Calcula la mejora si a continuación aumentamos la fracción paralelizable en 0.05? Speedup100 = Curso 2005/2006 1 0.95 0.05 + 100 = 16.80 Fundamentos de Computadores 40 Rendimiento, potencia y eficiencia de energía • Los sistemas empotrados y portátiles están limitados por el consumo de potencia (además de por el coste y rendimiento) – Utilizan enfriamiento pasivo (ventiladores versus tubos de calor) y alimentación con baterías (la duración de las baterías no ha aumentado) • Técnicas de ahorro de potencia – Desconexión de las partes no utilizadas – Reducción estática o dinámica de la frecuencia de reloj y el voltaje Curso 2005/2006 Fundamentos de Computadores 41 Rendimiento, potencia y eficiencia de energía – Familia Pentium (1/2) • Intel Mobile Pentium y Serie Pentium M – Procesadores diseñados para aplicaciones móviles alimentadas por baterías – Tienen una frecuencia máxima (máximo rendimiento) y una frecuencia reducida (mayor vida de la batería) – Rendimiento/potencia optimizados mediante cambios dinámicos de frecuencia • • El Pentium M tiene mejor rendimiento a fmáxima y a fadaptativa El Pentium M a fmínima es más lento que el Pentium 4-M y más rápido que el Pentium III-M Curso 2005/2006 Fundamentos de Computadores 42 Rendimiento, potencia y eficiencia de energía – Familia Pentium (2/2) • La eficiencia energética mide la relación entre rendimiento y consumo medio de potencia de entornos con limitaciones de potencia • Los Pentium M (diseño específico) tienen mayor eficiencia energética que las versiones mobile de Pentium III y Pentium IV (rediseño) Curso 2005/2006 Fundamentos de Computadores 43 Conclusiones • El arte del diseño consiste en encontrar el equilibrio entre coste y rendimiento • El TIEMPO es la medida del rendimiento de un computador TCPU = N × CPI × Tciclo • Imprescindible usar buenos benchmarks para medir el rendimiento de forma fiable...No excesiva credibilidad... • Las medidas “populares” del rendimiento no reflejan siempre la realidad, a veces son utilizadas malintencionadamente para inducir a error • Ley de Amdahl establece que la ganancia de rapidez está limitada por la parte del programa que no mejora Curso 2005/2006 Fundamentos de Computadores 44 Prácticas de Fundamentos de Computadores Ingeniería Informática Facultad de Informática Universidad de Las Palmas de Gran Canaria PRESENTACIÓN Las prácticas de laboratorio de esta asignatura se centran en el conocimiento y uso de la arquitectura del R2000 a través de su conjunto de instrucciones. Para ello se han elaborado unas prácticas en las que el alumno utilizará el lenguaje ensamblador de este procesador y conocerá su funcionamiento mediante el simulador SPIM. Estas prácticas se han diseñado para que el alumno pueda seguirlas de forma casi autónoma, requiriendo únicamente puntuales aclaraciones por parte del profesor. Con ello se pretende que el alumno pueda repasar fuera del horario de prácticas aquellas partes que no hayan quedado lo suficientemente claras. Las prácticas se han dividido en las siguientes partes: • Parte 1: El simulador SPIM Introducción. Descripción del simulador PCSpim Sintaxis del Lenguaje ensamblador del MIPS R2000. Problema propuesto. • Parte 2: Los datos en memoria Introducción. Declaración de palabras en memoria. Declaración de bytes en memoria. Declaración de cadenas de caracteres. Reserva de espacio en memoria. Alineación de datos en memoria. Problemas propuestos. • Parte 3: Carga y almacenamiento de los datos Introducción. Carga de datos inmediatos (constantes). Carga de palabras (transferencia de palabras desde memoria a registros). Carga de bytes (transferencia de bytes desde memoria a registros). Almacenamiento de palabras (transferencia de palabras desde registros a memoria). Almacenamiento de bytes (transferencia de bytes desde registros a memoria). Problemas propuestos. • Parte 4: Las operaciones aritméticas y lógicas Introducción. Operaciones aritméticas con datos inmediatos (constantes). Operaciones aritméticas con datos en memoria . Operaciones lógicas. Operaciones de desplazamiento. Problemas propuestos. • Parte 5: Interfaz con el programa Introducción. Impresión de una cadena de caracteres. Impresión de enteros. Lectura de enteros. Lectura de una cadena de caracteres. Problemas propuestos. • Parte 6: Estructuras de control: condicionales y bucles Introducción. Estructura de control condicional Si-entonces con condición simple. Estructura de control condicional Si-entonces con condición compuesta. Estructura de control condicional Si-entonces-sino con condición simple. Estructura de control condicional Si-entonces-sino con condición compuesta. Estructura de control repetitiva para. Estructura de control repetitiva mientras. Problemas propuestos. • Parte 7: Gestión de subrutinas Introducción. Gestión de la pila. Llamada y retorno de una subrutina. Llamadas anidadas de subrutinas. Paso de parámetros. Bloque de activación de una subrutina. Problemas propuestos. Cada una de estas partes no se corresponde con una sesión de prácticas. Así, salvo la primera sesión que será más guiada, en el resto de sesiones el alumno o equipo de alumnos seguirá un ritmo de aprendizaje propio, teniendo en cuenta que deberá haber cubierto todas las partes de estas prácticas en 7 sesiones de 2 horas. Desde este enlace puedes descargar el simulador que se va a utilizar (SPIM) para Windows: o Ejecutable SPIM para Windows (comprimido .zip) El simulador SPIM--> Parte I. El simulador SPIM • • • • Introducción. Descripción del simulador PCSpim. Sintaxis del Lenguaje ensamblador del MIPS R2000. Problema propuesto. Introducción El SPIM (MIPS al revés) es un simulador que ejecuta programas en lenguaje ensamblador para los computadores basados en los procesadores MIPS R2000/R3000. La arquitectura de este tipo de procesadores es RISC, por lo tanto simple y regular, y en consecuencia fácil de aprender y entender. La pregunta obvia en estos casos es por qué se va a utilizar un simulador y no una máquina real. Las razones son diversas: entre ellas cabe destacar la facilidad de poder trabajar con una versión simplificada y estable del procesador real. Los procesadores actuales ejecutan varias instrucciones al mismo tiempo y en muchos casos de forma desordenada, esto hace que sean más difíciles de comprender y programar. El simulador a utilizar en prácticas es una versión gráfica del SPIM, denominadaPCSPIM. La instalación del PCSpim es sencilla: Windows Ejecutar el programa “spimwin.exe”. Se realizará la instalación y sólo habrá que ejecutar el icono “PCSpim for Windows” para arrancar el programa. Descripción del Simulador PCSpim Al ejecutar PCSpim aparece la siguiente ventana La ventana principal de PCSpim se divide en cuatro partes: 1. La parte superior de la ventana es la barra de menús. Permite acceder a las operaciones con ficheros (menú File), especificar las opciones del simulador (menú Simulator), seleccionar la forma de visualización de las ventanas incluidas en la ventana principal (menú Window), y obtener información de ayuda (menú Help). 2. Debajo de la barra de menús se encuentra la barra de herramientas que incluye en forma de botones algunas de las acciones más comunes en PCSpim. 3. La parte central de la ventana de la aplicación sirve para visualizar cuatro ventanas: Registros (Registers), Segmento de Texto (Text Segment), Segmento de Datos (Data Segment) y Mensajes (Messages). A continuación se presentan las características de estas cuatro ventanas: • Registros (Registers) Aparecen el nombre y el contenido de los registros enteros, R0 a R31, con sus correspondientes alias entre paréntesis, los registros de coma flotante, FP0 a FP31, los registros de control de la CPU (BadVAddr, Cause, Status, EPC) y los registros especiales para la multiplicación y división entera, HI y LO. • Segmento de Texto (Text Segment) Se pueden ver cada una de las direcciones, el código máquina, las instrucciones ensambladas y el código fuente del programa de usuario (a partir de la dirección 0x00400000) y del núcleo del simulador (a partir de la dirección 0x80000000). Antes de que se cargue ningún programa aparecen una serie de instrucciones, introducidas por el simulador para lanzar adecuadamente la ejecución de nuestro código. • Segmento de Datos (Data Segment) Aparecen las direcciones y datos almacenados en las zonas de memoria de datos del usuario (a partir de la dirección 0x10000000 en adelante), el núcleo del simulador (a partir de la dirección 0x90000000) y la pila (el puntero de pila, registro sp, se encuentra cargado con la dirección 0x7fffeffc, y ésta crece hacia direcciones decrecientes). • Mensajes (Messages) En este panel se observan los diversos mensajes que comunica el simulador, que nos tendrán informados del resultado y evolución de las acciones que éste lleva a cabo. Existe una quinta ventana, llamada Consola, independiente, a la que se accede con la opción Window->Console, y que sirve para realizar la entrada/salida del programa simulado. En esta ventana se teclean los datos de entrada, cuando sean necesarios, y se lee la información que pueda imprimir nuestro programa. Carga y ejecución de programas Los ficheros de entrada a PCSpim son de tipo texto ASCII, que incluyen las instrucciones ensamblador del programa que se desea simular. Para cargar un programa se selecciona File->Open (o el botón Open de la barra de herramientas, con el icono de la carpeta abriéndose) con lo que aparecerá un cuadro de diálogo donde se puede seleccionar el fichero que se quiere abrir. Para ejecutar el programa, Simulator->Go (o el botón Go de la barra de herramientas, con el icono de un programa con una flecha que indica ejecución), hará que PCSpim comience a simularlo. Previamente pedirá que se le indique la dirección de comienzo del programa (en hexadecimal). En nuestro caso este valor será normalmente 0x00400000 (donde comienza nuestro segmento de texto). Si se desea detener la ejecución del programa, Simulator->Break (Ctrl-C). Para continuar con la ejecución, Simulator->Continue. Si el programa incluye operaciones de lectura o escritura desde el terminal, PCSpim despliega una ventana independiente llamada Console, a través de la cual se realiza la entrada-salida (se simula un terminal de la máquina MIPS). Depuración de programas Si un programa no hace lo que se esperaba, hay algunas características del simulador que ayudarán a depurar el programa. Con Simulator->Single Step (o bien la tecla F10) es posible ejecutar las instrucciones del programa una a una (paso a paso). Esto permite verificar el contenido de los registros, la pila, los datos, etc., tras la ejecución de cada instrucción. Empleando Simulator->Multiple Step se consigue ejecutar el programa un número determinado de instrucciones. PCSpim también permite ejecutar todas las instrucciones de un programa hasta llegar a un determinado punto, denominado breakpoint (punto de ruptura), a partir del cual se puede recuperar el control del programa y, por ejemplo, continuar paso a paso. Para ello, se selecciona Simulator->Breakpoints (o el botón Breakpoints de la barra de herramientas, con el icono de una mano indicando detención). Una vez seleccionada esa opción, PCSpim muestra una ventana en la que pide la(s) dirección(es) en la(s) que se quiere que el programa se detenga, para recuperar el control sobre el mismo. Se debe mirar cuál es la dirección en que interesa parar el programa, en la ventana del segmento de texto, e introducirla (en hexadecimal) en la ventana, pulsando a continuación la tecla ‘Add’, para añadir dicho breakpoint. Se pueden introducir tantos puntos de ruptura como se desee. Una vez encontrado el error y corregido, se vuelve a cargar el programa con Simulator>Reload<nombre_fichero>. Con Simulator->Clear Registers se pone el contenido de los registros a cero (excepto $sp), mientras que Simulator->Set Value permite cambiar el valor actual de un registro o de una posición de memoria por un valor arbitrario. Otras opciones útiles disponibles en el menú principal son las contenidas en el menú de ventana (Window). Con ellas se pueden mostrar y ocultar las barras de herramientas y de estado, así como las distintas ventanas del simulador, organizar visualmente las mismas y limpiar la consola de entrada/salida. PCSpim también proporciona ayuda en línea (Opción Help->Help Topics), que muestra un documento con ayuda sobre el programa, y el icono de la barra de herramientas con una flecha y una interrogación, que sirve para pedir ayuda sobre una opción concreta de los menús. Opciones del simulador Al elegir la opción Simulator->Settings se muestran las diversas opciones que ofrece el simulador. PCSpim utiliza estas opciones para determinar cómo cargar y ejecutar los programas. Una vez escogida esta opción aparece la siguiente ventana El significado de las opciones es el siguiente: 1. Save window positions. PCSpim guarda la posición de las ventanas al salir, y la recupera al ejecutar de nuevo PCSpim. 2. General registers/Floating point registers in hexadecimal. Fija el formato de los registros en hexadecimal. En caso de no estar seleccionada esta opción, se muestra el contenido en decimal (con signo; es decir, interpretado en complemento a 2). 3. Bare machine. Simula el ensamblador sin pseudoinstrucciones o modos de direccionamiento suministrados por el simulador. 4. Allow pseudo instructions. Determina si se admiten las pseudoinstrucciones. 5. Load trap file. Indica si se debe cargar el manejador de interrupciones (fichero ‘trap.handler’). En tal caso, cuando se produce una excepción, PCSpim salta a la dirección 0x80000080, que contiene el código necesario para tratar la excepción. 6. Mapped I/O. Si se selecciona esta opción, se activa la entrada-salida mapeada en Memoria. Los programas que utilizan llamadas al sistema (syscall), para leer o escribir en el terminal, deben desactivar esta opción. Aquellos otros programas que vayan a hacer entrada-salida mediante mapeo en memoria deben tenerla activada. 7. Quiet. Si se activa, PCSpim no imprime mensaje alguno cuando se producen las excepciones. De otra manera, se muestra un mensaje cuando ocurre una excepción. Sintaxis del Lenguaje ensamblador del MIPS R2000 La sintaxis del lenguaje ensamblador es algo que se descubrirá poco a poco, pero es interesante introducir algunos conceptos básicos: Comentarios Estos son muy importantes en los lenguajes de bajo nivel ya que ayudan a seguir el desarrollo del programa y, por tanto, se usan con profusión. Comienzan con un carácter de almohadilla “#” y desde este carácter hasta el final de la línea es ignorado por el ensamblador. Identificadores Son secuencias de caracteres alfanuméricos, guiones bajos (_) y puntos (.), que no comienzan con un número. Los códigos de operación son palabras reservadas que no pueden ser utilizadas como identificadores. Etiquetas Son identificadores que se sitúan al principio de una línea y seguidos de dos puntos. Sirven para hacer referencia a la posición o dirección de memoria del elemento definido en ésta. A lo largo del programa se puede hacer referencia a ellas en los modos de direccionamiento de las instrucciones. Pseudoinstrucciones No son instrucciones que tengan su traducción directa al lenguaje máquina que entiende el procesador, pero el ensamblador las interpreta y las convierte en una o más instrucciones máquina reales. Permiten una programación más clara y comprensible. A lo largo del desarrollo de las prácticas se irán introduciendo diferentes pseudoinstrucciones que permite utilizar este ensamblador. Directivas Tampoco son instrucciones que tengan su traducción directa al lenguaje máquina que entiende el procesador, pero el ensamblador las interpreta y le informan a éste de cómo tiene que traducir el programa. Son identificadores reservados, que el ensamblador reconoce y que van precedidos por un punto. A lo largo del desarrollo de las prácticas se irán introduciendo las distintas directivas que permite utilizar este ensamblador. Por otro lado, los números se escriben, por defecto, en base 10. Si van precedidos de 0x, se interpretan en hexadecimal. Las cadenas de caracteres se encierran entre comillas dobles (“). Los caracteres especiales en las cadenas siguen la convención del lenguaje de programación C: • • • Salto de línea: \n Tabulador: \t Comilla: \” A la hora de generar un fichero con un programa en ensamblador (extensión .s), hay que tener en cuenta que algunas versiones del SPIM tienen un “bug”, que se evita haciendo que los códigos en ensamblador almacenados en estos ficheros terminen siempre con una línea en blanco (vacía). Problema propuesto Dado el siguiente ejemplo de programa ensamblador: .data dato: .byte 3 # inicializo una posición de .text .globl main: main lw $t0, dato($0) # debe ser global memoria a 3 Indica las etiquetas, directivas y comentarios que aparecen en el mismo. <--Presentación Los datos en memoria--> Parte II. Los datos en memoria • • • • • • • Introducción. Declaración de palabras en memoria. Declaración de bytes en memoria. Declaración de cadenas de caracteres. Reserva de espacio en memoria. Alineación de datos en memoria. Problemas propuestos. Introducción Se comienza viendo cómo se definen los datos en memoria. Para ello hay que recordar que, aunque la unidad base de direccionamiento es el byte, las memorias de estos computadores tienen un ancho de 4 bytes o 32 bits, que se llamará palabra o word, el mismo ancho que el del bus de datos. Así pues, cualquier acceso a una palabra de memoria supondrá leer cuatro bytes (el byte con la dirección especificada y los tres almacenados en las siguientes posiciones). Las direcciones de palabra deben estar alineadas en posiciones múltiplos de cuatro. Otra posible unidad de acceso a memoria es transferir media palabra (half-word). El ensamblador permite reservar posiciones de memoria para los datos de un programa de usuario, así como inicializar los contenidos de esas direcciones utilizando directivas. En este apartado se describen y crean programas en ensamblador para utilizar estas directivas. Declaración de palabras en memoria Utilización de las directivas .data y .word valor Primer ejercicio En el directorio de trabajo crea un fichero con la extensión ‘.s’, por ejemplo "ejer1.s", y con el siguiente contenido: .data palabra1: palabra2: .word 15 .word 0x15 # comienza zona de datos # decimal # hexadecimal Este programa en ensamblador incluye diversos elementos que se describen a continuación: la directiva .data dir indica que los elementos que se definen a continuación se almacenarán en la zona de datos y, al no aparecer ninguna dirección como argumento de dicha directiva, la dirección de almacenamiento será la que hay por defecto (0x10010000). Las dos sentencias que aparecen a continuación reservan dos números enteros, de tamaño word, en dos direcciones de memoria, una a continuación de la otra, con los contenidos especificados. Ejecuta el programa ‘xspim’ desde el directorio de trabajo y cárgalo con la opción File>Open... Cuestiones • • • Encuentra los datos almacenados por el programa anterior en memoria. Localiza dichos datos en el panel de datos e indica su valor en hexadecimal. ¿En qué direcciones se han almacenado dichos datos? ¿Por qué? ¿Qué valores toman las etiquetas palabra1 y palabra2? Segundo ejercicio Crea otro fichero (ejer2.s) o modifica el anterior con el siguiente código: .data 0x10010000 palabras: .word 15,0x15 # comienza zona de datos # decimal/hexadecimal Borra los valores de la memoria con la opción Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • • Comprueba si hay diferencias respecto al programa anterior. Crea un fichero con un código que defina un vector de cinco palabras (word), que esté asociado a la etiqueta “vector”, que comience en la dirección 0x10000000 y con los valores 0x10, 30, 0x34, 0x20 y 60. Comprueba que se almacena de forma correcta en memoria. ¿Qué ocurre si se quiere que el vector comience en la dirección 0x10000002? ¿En qué dirección comienza realmente? ¿Por qué? Declaración de bytes en memoria La directiva .byte valor inicializa una posición de memoria, de tamaño byte, a valor. Tercer ejercicio Crea un fichero con el siguiente código: .data octeto: .byte 0x10 # comienza zona de datos # hexadecimal Borra los valores de la memoria Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • ¿Qué dirección de memoria se ha inicializado con el contenido especificado? ¿Qué valor se almacena en la palabra que contiene el byte? Cuarto ejercicio Crea otro fichero o modifica el anterior con el siguiente código: .data # comienza zona de datos palabra1: palabra2: .byte .word 0x10,0x20,0x30,0x40 0x10203040 # hexadecimal # hexadecimal Borra los valores de la memoria con la opción Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • • ¿Cuáles son los valores almacenados en memoria? ¿Qué tipo de alineamiento y organización de los datos (Big-endian o Littleendian) utiliza el simulador? ¿Por qué? ¿Qué valores toman las etiquetas palabra1 y palabra2? Declaración de cadenas de caracteres La directiva .ascii “tira” permite cargar en posiciones de memoria consecutivas, de tamaño byte, el código ascii de cada uno de los caracteres que componen “tira”. Quinto ejercicio Crea un fichero con el siguiente código: .data cadena: .ascii "abcde" octeto: .byte 0xff # defino string Borra los valores de la memoria con la opción Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • • Localiza la cadena anterior en memoria. ¿Qué ocurre si en vez de .ascii se emplea la directiva .asciiz? Describe lo que hace esta última directiva. Crea otro fichero cargando la tira de caracteres “cadena” en memoria utilizando la directiva .byte. Reserva de espacio en memoria La directiva .space n sirve para reservar espacio para una variable en memoria, inicializándola a 0. Sexto ejercicio Crea un fichero con el siguiente código: .data # comienza zona de datos espacio: .space 8 # reservo espacio .byte 0xff Borra los valores de la memoria con la opción Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • ¿Qué rango de posiciones se han reservado en memoria para la variable espacio? ¿Cuántos bytes se han reservado en total? ¿Y cuántas palabras? Alineación de datos en memoria La directiva .align n alinea el siguiente dato a una dirección múltiplo de 2n. Séptimo ejercicio Crea un fichero con el siguiente código: .data byte1: espacio: byte2: palabra: # comienza zona de datos .byte .space .byte .word 0x10 4 0x20 10 Borra los valores de la memoria con la opción Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • • ¿Qué rango de posiciones se han reservado en memoria para la variable espacio? ¿Estos cuatro bytes podrían constituir los bytes de una palabra? ¿Por qué? ¿A partir de que dirección se ha inicializado byte1? ¿y byte2? ¿A partir de que dirección se ha inicializado palabra? ¿Por qué? Octavo ejercicio Crea un fichero con el siguiente código: .data byte1: .align espacio: byte2: palabra: # comienza zona de datos .byte 2 .space .byte .word 0x10 4 0x20 10 Borra los valores de la memoria con la opción Simulator->Reinitialize y carga el nuevo fichero. Cuestiones • • ¿Qué rango de posiciones se ha reservado en memoria para la variable espacio? ¿Estos cuatro bytes podrían constituir los bytes de una palabra? ¿Por qué? ¿Qué ha hecho la directiva .align? Problemas propuestos 1. Diseña un programa ensamblador que reserva espacio para dos vectores A y B de 20 palabras cada uno a partir de la dirección 0x10000000. 2. Diseña un programa ensamblador que realice la siguiente reserva de espacio en memoria a partir de la dirección 0x10001000: o una palabra o un byte o una palabra alineada en una dirección múltiplo de 4. 3. Diseña un programa ensamblador que realice la siguiente reserva de espacio e inicialización en memoria a partir de la dirección por defecto: 3 (palabra), 0x10 (byte), reserve 4 bytes a partir de una dirección múltiplo de 4, y 20 (byte). 4. Diseña un programa ensamblador que defina, en el espacio de datos, la siguiente cadena de caracteres: “Esto es un problema” utilizando o o o .ascii .byte .word 5. Sabiendo que un entero se almacena en un word, diseña un programa ensamblador que defina en la memoria de datos la matriz A de enteros definida como a partir de la dirección 0x10010000 suponiendo que: o La matriz A se almacena por filas. o La matriz A se almacena por columnas. <--El simulador SPIM Carga y almacenamiento de los datos--> Parte III. Carga y almacenamiento de los datos • • • • • • • Introducción. Carga de datos inmediatos (constantes). Carga de palabras (transferencia de palabras desde memoria a registros). Carga de bytes (transferencia de bytes desde memoria a registros). Almacenamiento de palabras (transferencia de palabras desde registros a memoria). Almacenamiento de bytes (transferencia de bytes desde registros a memoria). Problemas propuestos. Introducción En esta tercera parte se estudia cómo cargar los datos en los registros del R2000 (empleando los registros generales del procesador) y almacenar después su valor en memoria. Dado que la arquitectura del R2000 es RISC, utiliza un subconjunto concreto de instrucciones que permiten las acciones de carga y almacenamiento de los datos entre los registros del procesador y la memoria. Generalmente, las instrucciones de carga de un dato de memoria a registro comienzan con la letra “l” (de load en inglés) y las de almacenamiento de registro en memoria con “s” (de store en inglés), seguidos por la letra inicial correspondiente al tamaño de dato que se va a mover (en inglés), b para byte, h para media palabra y w para palabra. Carga de datos inmediatos (constantes) Primer ejercicio Crea un fichero con el siguiente código: .text main: # zona de instrucciones lui $s0, 0x8690 La directiva .text sirve para indicar el comienzo de la zona de memoria dedicada a las instrucciones. Por defecto esta zona comienza en la dirección 0x00400000 y en ella, se pueden ver las instrucciones que ha introducido el simulador para ejecutar, de forma adecuada, nuestro programa. La primera instrucción de nuestro programa debe estar referenciada con la etiqueta main:. Esta etiqueta le indica al simulador dónde está el principio del programa que debe ejecutar. Por defecto hace referencia a la dirección 0x00400020. A partir de esta dirección, el simulador cargará el código de nuestro programa en el segmento de memoria de instrucciones. La instrucción lui es la única instrucción de carga inmediata real, y almacena la media palabra que indica el dato inmediato de 16 bits en la parte alta del registro especificado, en este caso s0. La parte baja del registro se pone a 0. Borra los valores de la memoria con la opción del menú principal Simulator>Reinitialize y carga el nuevo fichero. Cuestiones Localiza la instrucción en memoria de instrucciones e indica: La dirección donde se encuentra. El tamaño que ocupa. La instrucción máquina, analizando cada campo de ésta e indicando que tipo de formato tiene. Ejecuta el programa con la opción del menú principal Simulator->Go . Comprueba el efecto de la ejecución del programa en el registro. Segundo ejercicio El ensamblador del MIPS ofrece la posibilidad de cargar una constante de 32 bits en un registro utilizando una pseudoinstrucción. Ésta es la pseudoinstrucción li. Crea un fichero con el siguiente código: .text main: # zona de instrucciones li $s0, 0x12345678 Borra los valores de la memoria con la opción del menú principal Simulator>Reinitialize , carga el nuevo fichero y ejecútalo con la opción del menú principal Simulator->Go Cuestiones Comprueba el efecto de la ejecución del programa en el registro. Comprueba qué conjunto de instrucciones reales implementan esta pseudoinstrucción. Carga de palabras (transferencia de palabras desde memoria a registros) Tercer ejercicio Crea un fichero con el siguiente código: .data palabra: .word 0x10203040 .text main: lw $s0, palabra($0) # zona de instrucciones La instrucción "lw" carga la palabra contenida en una posición de memoria, cuya dirección se especifica en la instrucción, en un registro. Dicha posición de memoria se obtiene sumando el contenido del registro (en este caso $0, que siempre vale cero) y el identificador "palabra". Borra los valores de la memoria con la opción del menú principal Simulator>Reinitialize, carga el nuevo fichero y ejecútalo con la opción del menú principal Simulator->Go Cuestiones Localiza la instrucción en memoria de instrucciones e indica cómo ha transformado dicha instrucción el simulador. Explica cómo se obtiene a partir de esas dos instrucciones la dirección de “palabra”. ¿Por qué crees que el simulador traduce de esta forma la instrucción original? Analiza cada uno de los campos que componen estas instrucciones e indica el tipo de formato que tienen. Comprueba el efecto de la ejecución del programa. ¿Qué pseudoinstrucción permite cargar la dirección de un dato en un registro? Modifica el programa original para que utilice esta pseudoinstrucción, de forma que el programa haga la misma tarea. Comprueba qué conjunto de instrucciones sustituyen a la pseudoinstrucción utilizada una vez el programa se carga en la memoria del simulador. Modifica el código para que en lugar de transferir la palabra contenida en la dirección de memoria referenciada por la etiqueta palabra, se intente transferir la palabra que está contenida en la dirección referenciada por palabra+1. Explica qué ocurre y por qué. Modifica el programa anterior para que guarde en el registro $s0 los dos bytes de mayor peso de "palabra". Nota: Utiliza la instrucción lh que permite cargar medias palabras (16 bits) desde memoria a un registro (en los 16 bits de menor peso del mismo). Carga de bytes (transferencia de bytes desde memoria a registros) Cuarto ejercicio Crea un fichero con el siguiente código: #------------------------------------------------# # zona de datos # .data #------------------------------------------------# octeto: .byte 0xf3 siguiente: .byte 0x20 #------------------------------------------------# # zona de instrucciones # .text #------------------------------------------------# main: lb $s0, octeto($0) • La instrucción "lb" carga el byte de una dirección de memoria en un registro. Al igual que antes la dirección del dato se obtiene sumando el contenido del registro $0 (en este caso siempre vale cero) y el identificador "octeto". Borra los valores de la memoria con la opción del menú principal Simulator>Reinitialize, carga el nuevo fichero y ejecútalo con la opción del menú principal Simulator->Go Cuestiones Localiza la instrucción en memoria de instrucciones e indica cómo ha transformado dicha instrucción el simulador. Comprueba el efecto de la ejecución del programa. Cambia en el programa la instrucción "lb" por "lbu". ¿Qué sucede al ejecutar el programa? ¿Qué significa esto? Si "octeto" se define como: octeto: .byte 0x30 ¿existe diferencia entre el uso de la instrucción lb y lbu ¿ ¿Por qué¿ ¿Cuál es el valor del registro s0 si “octeto” se define como: octeto: .word 0x10203040 ?. ¿Por qué? ¿Cuál es el valor del registro s0 si se cambia en "main" la instrucción existente por la siguiente main: lb $s0, octeto+1($0)? ¿Por qué? ¿Por qué en este caso no se produce un error de ejecución (excepción de error de direccionamiento)? Almacenamiento de palabras (transferencia de palabras desde registros a memoria) Quinto ejercicio Crea un fichero con el siguiente código: #------------------------------------------------# # zona de datos # .data #------------------------------------------------# palabra1: .word 0x10203040 palabra2: .space 4 palabra3: .word 0xffffffff #------------------------------------------------# # zona de instrucciones # .text #------------------------------------------------# main: lw $s0, palabra1($0) sw $s0, palabra2($0) sw $s0, palabra3($0) La instrucción "sw" almacena la palabra contenida en un registro en una dirección de memoria. Esta dirección se obtiene sumando el contenido de un registro más un desplazamiento especificado en la instrucción (identificador). Borra los valores de la memoria con la opción del menú principal Simulator>Reinitialize, carga el nuevo fichero y ejecútalo con la opción del menú principal Simulator->Go Cuestiones Localiza la primera instrucción de este tipo en la memoria de instrucciones e indica cómo ha transformado dicha instrucción el simulador. Comprueba el efecto de la ejecución del programa. Almacenamiento de bytes (transferencia de bytes desde registros a memoria) Sexto ejercicio Crea un fichero con el siguiente código: #------------------------------------------------# # zona de datos # .data #------------------------------------------------# palabra1: .word 0x10203040 octeto: .space 2 #------------------------------------------------# # zona de instrucciones # .text #------------------------------------------------# main: lw $s0, palabra1($0) sb $s0, octeto($0) La instrucción “sb” almacena el byte de menor peso de un registro en una dirección de memoria. La dirección se obtiene sumando el desplazamiento indicado por el identificador y el contenido de un registro. Borra los valores de la memoria con la opción del menú principal Simulator>Reinitialize, carga el nuevo fichero y ejecútalo con la opción del menú principal Simulator->Go Cuestiones Localiza la instrucción en memoria de instrucciones e indica cómo ha transformado dicha instrucción el simulador. Comprueba el efecto de la ejecución del programa. Modifica el programa para que el byte se almacene en la dirección "octeto+1". Comprueba y describe el resultado de este cambio. • Modifica el programa anterior para transferir a la dirección de octeto el byte en la posición palabra+3. Problemas propuestos Diseña un programa ensamblador que defina el vector de palabras V=(10,20,25,500,3) en la memoria de datos a partir de la dirección 0x10000000 y cargue todos sus componentes en los registros s0-s4. Diseña un programa ensamblador que copie el vector definido en el problema anterior a partir de la dirección 0x10010000. Diseña un programa ensamblador que, dada la palabra 0x10203040, almacenada en una posición de memoria, la reorganice en otra posición de memoria, invirtiendo el orden de sus bytes. Diseña un programa ensamblador que, dada la palabra 0x10203040 definida en memoria la reorganice en la misma posición, intercambiando el orden se sus medias palabras. Nota: utiliza las instrucciones lh y sh. Diseña un programa en ensamblador que inicialice cuatro bytes a partir de la posición 0x10010002 a los siguientes valores 0x10, 0x20, 0x30, 0x40, y reserve espacio para una palabra a partir de la dirección 0x10010010. El programa transferirá los cuatro bytes contenidos a partir de la posición 0x10010002 a la dirección 0x10010010. <--Los datos en memoria Las operaciones aritméticas y lógicas>--> Parte 4. Las operaciones aritméticas y lógicas • • • • • • Introducción. Operaciones aritméticas con datos inmediatos (constantes) . Operaciones aritméticas con datos en memoria. . Operaciones lógicas. . Operaciones de desplazamiento. . Problemas propuestos. Introducción En este apartado se presentan las instrucciones que permiten realizar operaciones aritméticas, lógicas y de desplazamiento. Entre las primeras se encuentran las instrucciones de suma y resta (add, addu, addi, addiu, sub, subu) y las instrucciones de multiplicación y división (mult, multu, div, divu ). Las instrucciones acabadas en u consideran los operandos como números en binario puro, mientras que las instrucciones no acabadas en u consideran los operandos de las instrucciones como números en complemento a dos. En ambos casos, se producirá una excepción aritmética si el resultado de la operación no es representable en 32 bits. Recuerda que el rango de representación de los números enteros con signo de 32 bits en complemento a 2 va desde –2.147.483.648 a 2.147.483.647 (0x80000000 a 0x7fffffff). Dentro del grupo de instrucciones que permiten realizar operaciones lógicas están: suma lógica (or y ori), producto lógico (and y andi) y la or exclusiva (xor y xori). Finalmente, se presentan las instrucciones de desplazamiento aritmético y lógico (sra, sll, srl). Operaciones aritméticas con datos inmediatos (constantes) Primer ejercicio numero: main: • .data .word 2147483647 .text lw $t0,numero($0) addiu $t1,$t0,1 La instrucción addiu es una instrucción de suma con un dato inmediato y sin detección de desbordamiento. Borra los valores de la memoria, carga el fichero y ejecútalo paso a paso. Cuestiones • • • • Localiza el resultado de la suma efectuada. Comprueba el resultado. Cambia la instrucción "addiu" por la instrucción "addi". Borra los valores de la memoria, carga el fichero y ejecútalo paso a paso. ¿Qué ha ocurrido al efectuar el cambio? ¿Por qué? Operaciones aritméticas con datos en memoria Segundo ejercicio numero1: numero2: numero3: main: .data .word 0x80000000 .word 1 .word 1 .text lw $t0,numero1($0) lw $t1,numero2($0) subu $t0,$t0,$t1 lw $t1,numero3($0) subu $t0,$t0,$t1 sw $t0,numero3($0) Borra los valores de la memoria, carga el fichero y ejecútalo paso a paso. Cuestiones • • ¿Qué hace el programa anterior? ¿Qué resultado se almacena en numero3? ¿Es correcto? ¿Se producirá algún cambio si las instrucciones "subu" son sustituidas por instrucciones "sub"? ¿Por qué? Multiplicación y división con datos en memoria Tercer ejercicio Crea un fichero con el siguiente código: numero1: numero2: main: .data .word .word .space .text lw lw mult 0x7fffffff 16 8 $t0,numero1($0) $t1,numero2($0) $t0,$t1 mflo mfhi sw sw • $t0 $t1 $t0,numero2+4($0) $t1,numero2+8($0) La instrucción mult multiplica dos registros de propósito general (en el ejemplo anterior los registros t0 y t1) y deja el resultado de 64 bits en dos registros especiales de 32 bits llamados HI y LO. Las instrucciones mfhi y mflo sirven para mover los contenidos de estos registros especiales a los registros de propósito general (en este caso otra vez los registros t0 y t1). El código realiza la multiplicación de dos números, almacenando el resultado de la multiplicación a continuación de los dos multiplicandos. Borra los valores de la memoria, carga el fichero y ejecútalo. Cuestiones • • • • • • • • ¿Qué resultado se obtiene después de realizar la operación? ¿Por qué se almacena en dos palabras de memoria? Modifica los datos anteriores para que numero1 y numero2 sean 0xffffffff y 1 respectivamente. ¿Cuál es el valor del registro HI? ¿Por qué? La instrucción de tipo R mul multiplica dos registros y guarda el resultado en un tercero. Escribe un programa en ensamblador que utilice la instrucción mul para multiplicar numero1 y número2 y deje el resultado en el registro $t2. ¿Deja el resultado también en algún otro registro? ¿Qué ocurre al cambiar la instrucción mul en el programa anterior por la pseudoinstrucción mulo? ¿Qué ocurre al cambiar la pseudoinstrucción mulo en el programa anterior por la pseudoinstrucción mulou? Modifica los datos anteriores para que numero1 y numero2 sean 10 y 3 respectivamente. Escribe el código que divida numero1 entre numero2 (dividendo y divisor respectivamente) y coloque el cociente y el resto a continuación de dichos números. La pseudointrucción div divide dos registros y guarda el resultado en un tercero (de manera similar a cualquier instrucción tipo-R). Escribe un programa en ensamblador que utilice la pseudoinstrucción div para dividir numero1 y número2 y deje el resultado en el registro $t2. ¿Comprueba excepciones? ¿Cuál? ¿Qué ocurre al cambiar la pseudoinstrucción div en el programa anterior por la pseudoinstrucción divu? ¿Qué es diferente en el código generado para las pseudoinstrucciones div y divu? Operaciones lógicas Cuarto ejercicio Crea un fichero con el siguiente código: .data numero: main: • .word 0x3ff41 .space 4 .text $t0,numero($0) andi $t1,$t0,0xfffe sw $t1,numero+4($0) lw El código anterior pone a 0 los 16 bits más significativos y el bit 0 de número, almacenando el resultado en la siguiente palabra. Esto se consigue utilizando la instrucción andi, que realiza el producto lógico bit a bit entre el dato contenido en un registro y un dato inmediato. El resultado que se obtiene es: aquellos bits que en el dato inmediato están a 1 no se modifican con respecto al contenido original del registro, es decir, los 16 bits de menor peso excepto el bit 0. Por otro lado, todos aquellos bits que en el dato inmediato están a 0, en el resultado también están a 0, es decir, los 16 bits de mayor peso y el bit 0. Los 16 bits da mayor peso se ponen a 0 puesto que, aunque el dato inmediato que se almacena en la instrucción es de 16 bits, a la hora de realizar la operación el procesador trabaja con un dato de 32 bits, poniendo los 16 de mayor peso a 0, fijando, por tanto, los bits del resultado también a 0. Borra los valores de la memoria, carga el fichero y ejecútalo. Cuestiones • • Modifica el código para obtener, en la siguiente palabra, que los 16 bits más significativos de número permanezcan tal cual, y que los 16 bits menos significativos queden a 0, excepto el bit 0 que también debe quedar como estaba. La solución debe ser válida independientemente del valor almacenado en número. Modifica el código para obtener, en la siguiente palabra, que los 16 bits más significativos de número permanezcan tal cual, y que los 16 bits menos significativos queden a 1, excepto el bit 0 que también debe quedar como estaba. La solución debe ser válida independientemente del valor almacenado en numero. Operaciones de desplazamiento Quinto ejercicio Crea un fichero con el siguiente código: numero: main: .data .word 0xffffff41 .text lw $t0,numero($0) sra $t1,$t0,4 • El código desplaza el número cuatro bits a la derecha, rellenando con el bit del signo. Borra los valores de la memoria, carga el fichero y ejecútalo. Cuestiones • • • ¿Para qué se ha rellenado el número con el bit del signo? ¿Qué ocurre si se sustituye la instrucción "sra" por "srl"? Modifica el código para desplazar el número tres bits a la izquierda. Problemas propuestos 1. Diseña un programa ensamblador que defina el vector de enteros de dos elementos V=(10,20) en la memoria de datos a partir de la dirección 0x10000000 y almacene su suma a partir de la dirección donde acaba el vector. 2. Diseña un programa ensamblador que divida los enteros 18,-1215 almacenados a partir de la dirección 0x10000000 entre el número 5 y que a partir de la dirección 0x10010000 almacene el cociente de dichas divisiones. Es posible usar más de una directiva .data para ubicar las sección de datos. 3. Pon a cero los bits 3,7,9 del entero 0xABCD12BD almacenado en memoria a partir de la dirección 0x10000000, sin modificar el resto. 4. Cambia el valor de los bits 3,7,9 del entero 0xFF0F1235 almacenado en memoria a partir de la dirección 0x10000000, sin modificar el resto. 5. Multiplica el número 0x1237, almacenado en memoria a partir de la dirección 0x10000000, por 32 (25) sin utilizar las instrucciones de multiplicación ni las pseudoinstrucciones de multiplicación. Interfaz <--Carga y almacenamiento con el de datos en programa> memoria -- Parte 5. Interfaz con el programa • • • • • • Introducción. Impresión de una cadena de caracteres. Impresión de enteros. Lectura de enteros. Lectura de cadena de caracteres. Problemas propuestos. Introducción El SPIM ofrece un pequeño conjunto de servicios tipo Sistema Operativo a través de la instrucción de llamada al sistema (syscall). Estos servicios permiten introducir datos y visualizar resultados, de forma cómoda, en los programas que se desarrollan. Para pedir un servicio, el programa debe cargar el número identificador del tipo de llamada al sistema en el registro $v0 y el/los argumento/s en los registros $a0-$a3 (o f12 para valores en coma flotante). Las llamadas al sistema que retornan valores ponen sus resultados en el registro $v0 ($f0 en coma flotante). La interfaz con nuestro programa se hará a través de una ventana o consola que puede visualizarse u ocultarse mediante el botón "terminal". A continuación se muestra una tabla resumen del número de identificación de cada una de las funciones disponibles y de los parámetros que son necesarios en cada una de ellas: Servicio Número de identificación (en $v0) Argumentos Imprimir_entero 1 $a0=entero Imprimir_cadena 4 $a0=dir_cadena Leer_entero 5 Leer_string 8 Entero (en $v0) $a0=dir_cadena, $a1=longitud Impresión de una cadena de caracteres Primer ejercicio dir: .data .asciiz "Hola. Ha funcionado." .text Resultado main: • li $v0,4 la $a0,dir syscall #codigo de imprimir cadena #direccion de la cadena #llamada al sistema La pseudoinstrucción "li" carga de forma inmediata el dato que acompaña la instrucción en el registro. La pseudoinstrucción "la" carga de forma inmediata la dirección que acompaña la instrucción en el registro especificado. Borra los valores de la memoria, carga el fichero y ejecútalo. Cuestiones • • • Comprueba que se imprime la cadena de caracteres "Hola. Ha funcionado." Vuélvelo a ejecutar. Acuérdate que antes de volver a ejecutar el programa se debe borrar el contenido de los registros. ¿Dónde se imprime el mensaje? Introduce al final de la cadena los caracteres "\n". Ejecútalo dos veces y comprueba cuál es la diferencia con respecto al código original. Modifica la línea de la instrucción "la ..." para que sólo se imprima "Ha funcionado.". Impresión de enteros. Segundo ejercicio Crea un fichero con el siguiente código: dir: entero: .data .asciiz "Se va a imprimir el entero: " .word 7 .text li $v0,4 la $a0,dir syscall main: li $v0,1 li $a0,5 syscall #codigo de imprimir cadena #direccion de la cadena #llamada al sistema #codigo de imprimir entero #entero a imprimir #llamada al sistema Borra los valores de la memoria, carga el fichero y ejecútalo. Cuestiones • • Comprueba la impresión del entero "5". Modifica el programa para que se imprima el entero almacenado en la dirección "entero". Comprueba su ejecución. Lectura de enteros. Tercer ejercicio Crea un fichero con el siguiente código: dir: entero: .data .asciiz "Introduce el entero: " .align 2 .space 4 .text li $v0,4 #codigo de imprimir cadena la $a0,dir #direccion de la cadena syscall #llamada al sistema main: li $v0,5 #codigo de leer entero syscall #llamada al sistema Borra los valores de la memoria, carga el fichero y ejecútalo. Introduce, a través de la consola, el entero que te parezca. Cuestiones • • • Comprueba el almacenamiento del entero introducido en el registro v0. Modifica el programa para que el entero leído se almacene en la dirección de memoria "entero". Elimina la línea align 2 del programa anterior y ejecútalo. ¿Qué ocurre? ¿Por qué? Lectura de cadena de caracteres. Cuarto ejercicio Crea un fichero con el siguiente código: dir: buffer: main: .data .asciiz "Introduce la cadena de caracteres: " .space 10 .text li $v0,4 #codigo de imprimir cadena la $a0,dir #direccion de la cadena syscall #llamada al sistema li $v0,8 #codigo de leer el string la $a0,buffer #direccion de lectura de cadena li $a1,10 #espacio maximo de la cadena syscall #llamada al sistema Borra los valores de la memoria, carga el fichero y ejecútalo. Introduce, a través de la consola, la cadena de caracteres que te parezca. Cuestiones • • Comprueba el almacenamiento de la cadena de caracteres en "buffer". ¿Qué ocurre si la cadena de caracteres que se escribe es más larga que el tamaño reservado en "buffer"? Problemas propuestos 1. Diseña un programa ensamblador que pida por la consola dos enteros "A" y "B" dando como resultado su suma "A+B". 2. Diseña un programa que pida los datos de un usuario por la consola y los introduzca en memoria, reservando espacio para ello. La estructura de la información es la siguiente: Nombre cadena de 10 bytes Apellidos cadena de 15 bytes DNI entero A continuación se deberá imprimir los datos introducidos para comprobar el correcto funcionamiento del programa. <-Estructuras Operaciones de aritméticas control> -y lógicas Parte 6. Estructuras de control: condicionales y bucles • • • • • • • • Introducción. Estructuras de control condicional Si-entonces con condición simple . Estructuras de control condicional Si-entonces con condición compuesta . Estructuras de control condicional Si-entonces-sino con condición simple . Estructuras de control condicional Si-entonces-sino con condición compuesta . Estructuras de control repetitiva para . Estructuras de control repetitiva mientras . Problemas propuestos. Introducción El lenguaje ensamblador no dispone de estructuras de control de flujo de programa definidas a priori, que permitan decidir entre dos (o varios) caminos de ejecución de instrucciones distintos (como por ejemplo la sentencia if de otros lenguajes de programación). En esta práctica se describe cómo implementar algunas de estas estructuras de control. En primer lugar se realiza un breve recordatorio de las instrucciones que dispone el MIPS R2000 a partir de las cuales se llevan a cabo las implementaciones de estructuras de este tipo. Estas se agrupan en tres grupos: instrucciones de ruptura de secuencia condicional e incondicional, e instrucciones de comparación. Instrucciones de salto condicional El ensamblador del MIPS incluye dos instrucciones básicas de ruptura de secuencia condicional beq (branch if equal, saltar si igual) y bne (branch if no equal, saltar si distinto). La sintaxis de estas instrucciones es la siguiente: beq rs, rt, etiqueta bne rs, rt, etiqueta. Ambas comparan el contenido de los registros rs y rt y saltan a la dirección de la instrucción referenciada por etiqueta si el contenido del registro rs es igual al del rt (beq) o distinto (bne). Además dispone de instrucciones de salto condicional para realizar comparaciones con cero. Estas instrucciones son: bgez (branch if greater or equal to zero, saltar si mayor o igual a cero), bgtz (branch if greater than zero, saltar si mayor que cero), blez (branch if less or equal to zero, saltar si menor o igual que cero), bltz (branch if less than zero, saltar si menor que cero), y tienen la siguiente sintaxis: bgez rs, etiqueta bgtz rs, etiqueta blez rs, etiqueta bltz rs, etiqueta Todas ellas comparan el contenido del registro rs con 0 y saltan a la ón de la instrucción referenciada por etiqueta si rs >=0 (bgez), rs > 0 (bgtz), rs<=0 (blez) ó rs<0 (bltz). Instrucciones de salto incondicional La instrucción j permite romper la secuencia de ejecución del programa de forma incondicional y desviarla hacia la instrucción referenciada mediante la etiqueta. Esta instrucción presenta el siguiente formato: j etiqueta Instrucciones de comparación El ensamblador del MIPS dispone de una instrucción que compara dos registros, y pone un 1 en un tercer registro si el contenido del primero es menor que el segundo y pone un 0 si no se cumple esta condición. Esta instrucción es slt (set if less than, poner a 1 si menor que) y tiene la siguiente sintaxis: slt rd, rs, rt A partir de este conjunto de instrucciones se puede implementar cualquier estructura de control de flujo del programa. Pseudoinstrucciones de salto condicional Para facilitar la programación, el lenguaje ensamblador del MIPS aporta un conjunto de pseudoinstrucciones de salto condicional que permiten comparar dos variables almacenadas en registros (a nivel de mayor, mayor o igual, menor, menor o igual) y según el resultado de esa comparación saltan o no, a la instrucción referenciada a través de la etiqueta. Estas pseudoinstrucciones son: bge (branch if greater or equal, saltar si mayor o igual ), bgt (branch if greater, saltar si mayor que), ble (branch if less or equal, saltar si menor o igual), blt (branch if less, saltar si menor que). El formato es el mismo para todas ellas: bxx rs,rt, etiqueta El salto a la instrucción referenciada por etiqueta se efectúa si el resultado de la comparación entre las variables contenidas en rs y rt es: mayor o igual (ge), mayor (gt), menor o igual (le), o menor (lt). La implementación de estas pseudoinstrucciones se realiza a partir de la instrucción slt y de las instrucciones de salto condicional básicas: beq y bne, principalmente. Una vez introducidos el conjunto de instrucciones y pseudoinstrucciones que permiten implementar cualquier estructura de control de flujo de programa, se va a describir cómo se implementan las estructuras más típicas de un lenguaje de alto nivel. Estas son: Si-entonces, Si-entonces-sino, Mientras y Para si se habla en lenguaje algorítmico, o las estructuras if-then, if-then-else, while, y for del lenguaje Pascal. De ellas, las dos primeras son estructuras de control de flujo condicionales, y el resto son estructuras de control de flujo repetitivas. Estas estructuras dependen, implícita o explícitamente, de la verificación de una o varias condiciones para determinar el camino que seguirá la ejecución del código en curso. La evaluación de esta condición (o condiciones) vendrá asociada a una o varias instrucciones de salto condicional e incondicional o pseudoinstrucciones. Estructura de control condicional Si-entonces con condición simple Primer ejercicio Crea un fichero con el siguiente fragmento de código que implementa una estructura de control condicional Si-entonces: dato1: dato2: res: main: Si: entonces: finsi: .data .word .word .space 40 30 4 .text lw $t0, dato1($0) lw $t1, dato2($0) and $t2, $t2,$0 #cargar dato1 en t0 #cargar dato2 en t1 #pone a 0 t2 add $t3, $t0,$t1 #t3 = t0+t1 beq $t1, div $t0, mflo $t2 add $t2, sw $t2, #si t1 = 0 finsi #t0/t1 #almacenar LO en t2 #t2= t3 + t2 #almacenar en memoria t2 $0, finsi $t1 $t3, $t2 res($0) Disponible en ejercicio1.s Borra los valores de la memoria, carga el fichero en el simulador y ejecútalo. Cuestiones • Identifica la instrucción que determina la condición y controla el flujo de programa. ¿Qué condición se evalúa? • • • • • Identifica el conjunto de instrucciones que implementan la estructura condicional si-entonces. ¿Qué valor se almacena en la variable "res" después de ejecutar el programa? Si dato2=0, ¿Qué valor se almacena en la variable res después de ejecutar el programa?¿Qué hace entonces el programa? Dibuja el diagrama de flujo asociado a la estructura de control implementada en el fragmento de código anterior. Modifica el código anterior para que la instrucción resaltada en negrita (sumar el contenido de t0 y t1) se realice después de la estructura de control Si-entonces en lugar de antes, sin modificar el resultado de la ejecución del programa. Estructura de control condicional Si-entonces con condición compuesta Segundo ejercicio Crea un fichero con el siguiente fragmento de código que implementa una estructura de control condicional Si-entonces: dato1: dato2: res: .data .word .word .space 40 30 4 .text main: Si: entonces: finsi: lw $t0, lw $t1, and $t2, add $t3, beq $t1, beq $t0, div $t0, mflo $t2 add $t2, sw $t2, dato1($0) dato2($0) $t2,$0 $t0, $t1 $0, finsi $0, finsi $t1 $t3, $t2 res($0) #cargar dato1 en t0 #cargar dato2 en t1 #pone a 0 t2 #t3=t0 + t1 #si t1=0 saltar a finsi #si t0 =0 saltar a finsi #t0/t1 #almacenar LO en t2 #t2=t2+t3 #almacenar en memoria t2 Disponible en ejercicio2.s Borra los valores de la memoria, carga el fichero en el simulador y ejecútalo. Cuestiones • • ¿Qué condición compuesta se evalúa? Modifica el código anterior para que la condición evaluada sea ((t1 > 0) y (t0 <> t1)). Comprueba el correcto funcionamiento ante los siguientes valores: o dato1=40, dato2=30 o o dato1=0, dato2=40 dato1=40, dato2=-40 Estructura de control condicional Si-entonces-sino con condición simple Tercer ejercicio Crea un fichero con el siguiente fragmento de código que implementa una estructura de control Si-entonces-sino. dato1: dato2: res: main: Si: entonces: sino: finsi: .data .word .word .space 30 40 4 .text lw lw $t0,dato1($0) $t1,dato2($0) bge sw j sw $t0,$t1,sino $t0, res($0) finsi $t1, res($0) #almacenar t0 en res #almacenar t1 en res Disponible en ejercicio3.s Borra los valores de la memoria, carga el fichero en el simulador y ejecútalo. Cuestiones • Identifica qué condición se evalúa. <li< ¿Qué valor se almacena en "res" después de ejecutar el programa? Si dato1=50 y dato2=0, ¿qué valor se almacena en res después de ejecutar el programa? ¿Qué hace entonces el programa? • • Dibuja el diagrama de flujo asociado a la estructura de control implementada en el fragmento de código anterior. Identifica en el lenguaje máquina generado por el simulador el conjunto de instrucciones que implementan la pseudoinstrucción bge. Estructura de control condicional Si-entonces-sino con condición compuesta Cuarto ejercicio Crea un fichero con el siguiente fragmento de código que implementa una estructura de control Si-entonces-sino. .data .word .word .word .space 30 40 -1 4 .text lw lw lw $t1,dato1($0) $t2,dato2($0) $t3,dato3($0) blt $t3, $t1, entonces #si t3 < t1 saltar a $t3, $t2, sino $t4, $0, 1 finsi $t4, $0,$0 #si t3 <= t2 #t4 = 1 sino: ble addi j add finsi: sw $t4, res($0) #almacenar en memoria t4 dato1: dato2: dato3: res: main: si: entonces entonces: #cargar dato1 en t1 #cargar dato2 en t2 #cargar dato3 en t3 saltar a sino #t4 = 0 Disponible en ejercicio4.s Borra los valores de la memoria, carga el fichero en el simulador y ejecútalo. Cuestiones • • • • Identifica qué condición compuesta se evalúa. ¿Qué valor se almacena en "res" después de ejecutar el programa? Si dato1=40 y dato2=30, ¿qué valor se almacena en res después de ejecutar el programa? ¿Qué hace entonces el programa? Dibuja el diagrama de flujo asociado a la estructura de control implementada en el fragmento de código anterior. Modifica el código anterior para que la condición evaluada sea ((dato3>=dato1) y (dato3<=dato2)). Estructura de control repetitiva para Quinto ejercicio Crea un fichero con el siguiente fragmento de código que implementa una estructura de control repetitiva Para: .data .word .space 6,7,8,9,10,-1 4 .text la and li $t2, vector $t3, $0, $t3 $t1, 6 #t2 = vector #pone a 0 t3 #carga 6 en t1 beq lw $t1, $0, finpara $t4, 0($t2) # si t1 = 0 saltar a finpara # carga un elemento del vector add elementos del vector addi addi j $t3, $t4, $t3 #acumula la suma de los $t2, $t2, 4 $t1, $t1, -1 para #suma 4 a t2 #resta 1 a t1 #saltar a para finpara: $t3, res($0) #almacena t3 en res vector: res: main: para: en t4 sw Disponible en ejercicio5a.s Borra los valores de la memoria, carga el fichero en el simulador y ejecútalo. Cuestiones • • • • • • • ¿Qué hace la instrucción "la $t2, vector"? Identifica en el fragmento de código anterior qué conjunto de instrucciones constituyen el bucle repetitivo y cuántas veces se va a repetir. Dentro del bucle se incrementa el contenido del registro t2 en cuatro unidades cada iteración, ¿por qué? Dentro del bucle se decrementa el contenido del registro t1 en una unidad en cada iteración, ¿por qué? ¿Qué valor se almacena en "res" después de ejecutar el código anterior? ¿Qué hace entonces el programa? Dibuja el diagrama de flujo asociado a la estructura de control implementada en el fragmento de código anterior. Indica si el siguiente fragmento de código es equivalente al anterior. ¿Cuál de las dos implementaciones es más óptima? ¿por qué? vector: res: .data .word .space 6,7,8,9,10,-1 4 main: .text la $t2, vector #t2 = vector para: and li li $t3, $0, $t3 $t0, 1 $t1, 6 #pone a 0 t3 #carga 1 en t1 bgt lw $t0, $t1, finpara # si t1 = 0 saltar a finpara $t4, 0($t2) # carga un elemento del vector en t4 add elementos del vector addi addi j $t3, $t4, $t3 finpara: $t3, res($0) sw $t2, $t2, 4 $t0, $t0, 1 para #acumula la suma de los #suma 4 a t2 #resta 1 a t1 #saltar a para #almacena t3 en res Disponible en ejercicio5b.s Estructura de control repetitiva mientras Sexto ejercicio Crea un fichero con el siguiente fragmento de código que implementa una estructura de control repetitiva Mientras: cadena: n: main: cadena en t0 mientras: .data .asciiz .align .space "hola" 2 4 .text la $t0, cadena #cargar la direccion de andi $t2, $t2, 0 #poner a 0 t2 lb beq $t1, 0($t0) #almacena un byte en t1 $t1, $0, finmientras #si t1 = 0 saltar a finmientras finmientras: addi $t2, $t2, 1 addi $t0, $t0,1 j mientras sw $t2, n($0) #sumar 1 a #sumar 1 a #saltar #almacenar t2 t0 a mientras t2 en n Disponible en ejercicio6a.s Borra los valores de la memoria, carga el fichero en el simulador y ejecútalo. Cuestiones Parte 7. Gestión de Subrutinas • • • • • • • Introducción. Gestión de la pila. Llamada y retorno de una subrutina. Llamadas anidadas de subrutinas. Paso de parámetros. Bloque de activación de una subrutina. Problemas propuestos. Introducción El diseño de un programa que resuelve un determinado problema puede simplificarse si se plantea adecuadamente la utilización de subrutinas. Éstas permiten dividir un problema largo y complejo en subproblemas más sencillos o módulos, más fáciles de escribir, depurar y probar que si se aborda directamente el programa completo. De esta forma se puede comprobar el funcionamiento individual de cada rutina y, a continuación, integrar todas en el programa que constituye el problema global de partida. Otra ventaja que aporta la utilización de subrutinas es que en ocasiones una tarea aparece varias veces en el mismo programa; si se utilizan subrutinas, en lugar de repetir el código que implementa esa tarea en los diferentes puntos, bastará con incluirlo en una subrutina que será invocada en el programa tantas veces como sea requerida. Yendo más lejos, subproblemas de uso frecuente pueden ser implementados como rutinas de utilidad (librerías), que podrán ser invocadas desde diversos módulos. Con el fin de dotar de generalidad a una subrutina, ésta ha de ser capaz de resolver un problema ante diferentes datos que se le proporcionan como parámetros de entrada cuando se le llama. Por tanto, para una correcta y eficaz utilización de las subrutinas es necesario tener en cuenta, por un lado, la forma en que se realizan las llamadas y, por otro, el paso de parámetros. Como paso previo a la realización de la práctica se van a realizar algunos ejercicios sencillos que nos ayuden al manejo de la pila, estructura muy utilizada para una buena gestión de las subrutinas. Gestión de la pila Una pila es una estructura de datos caracterizada por que el último dato que se almacena es el primero que se obtiene después. Para gestionar la pila se necesita un puntero a la última posición ocupada de la misma, con el fin de conocer dónde se tiene que dejar el siguiente dato a almacenar, o para saber dónde están situados los últimos datos almacenados en ella. Para evitar problemas, el puntero de pila siempre debe estar apuntando a una palabra de memoria. Por precedentes históricos, el segmento de pila siempre "crece" de direcciones superiores a direcciones inferiores. Las dos operaciones más típicas con esta estructura son: Transferir datos hacia la pila (push o apilar). Antes de añadir un dato a la pila se tienen que restar 4 unidades al puntero de pila. Transferir datos desde la pila (pop o desapilar). Para eliminar datos de la pila, después de extraído el dato se tienen que sumar 4 unidades al puntero de pila. El ensamblador del MIPS tiene reservado un registro, $sp, como puntero de pila (stack pointer). Para realizar una buena gestión de la pila será necesario que este puntero sea actualizado correctamente cada vez que se realiza una operación sobre la misma. El siguiente fragmento de código muestra cómo se puede realizar el apilado de los registros $t0-$t1 en la pila: Primer ejercicio .text li li addi sw addi sw main: $t0,10 $t1, 13 $sp, $sp, -4 $t0, 0($sp) $sp, $sp, -4 $t1, 0($sp) #inicializar reg. t0,t1 #actualizar el sp #apilar t0 #actualizar el sp #apilar t1 Disponible en ejercicio1.s Edita el programa, reinicializa el simulador y carga el programa. Cuestiones Ejecuta el programa paso a paso y comprueba en qué posiciones de memoria, pertenecientes al segmento de pila se almacena el contenido de los registros t0t1. Modifica el programa anterior para que en lugar de actualizar el puntero de pila cada vez que se pretende apilar un registro en la misma, se realice una sola vez al principio y después se apilen los registros en el mismo orden. Añade el siguiente código al programa original después de la última instrucción: Modifica el contenido de los registros t0-t1, realizando algunas operaciones sobre ellos. o Recupera el contenido inicial de estos registros desapilándolos de la pila, y actualiza el puntero de pila correctamente (limpiar la pila). o Ejecuta el programa resultante y comprueba si finalmente t0-t1 contienen los datos iniciales que se habían cargado. Comprueba también que el contenido del registro sp es el mismo antes y después de la ejecución del programa. Implementa el siguiente programa: o o o Almacena en memoria una tira de caracteres de máximo 10 elementos. Lee la cadena de caracteres desde el teclado. Invierte esta cadena, almacenando la cadena resultante en las mismas posiciones de memoria que la original. (Sugerencia para realizar el ejercicio: Apila los elementos de la tira en la pila y, a continuación, se desapilan y se almacenan en el mismo orden que se extraen). Llamada y retorno de una subrutina El juego de instrucciones del MIPS R2000 dispone de una instrucción específica para realizar la llamada a una subrutina, jal etiqueta. La ejecución de esta instrucción conlleva dos acciones: • • Almacenar la dirección de memoria de la siguiente palabra a la que contiene la instrucción jal en el registro ra. Llevar el control de flujo de programa a la dirección etiqueta. Por otra parte, el MIPS R2000 dispone de una instrucción que facilita el retorno de una subrutina. Esta instrucción es jr $ra, instrucción de salto incondicional que salta a la dirección almacenada en el registro ra, que justamente es el registro dónde la instrucción jal ha almacenado la dirección de retorno cuando se ha hecho el salto a la subrutina. Para ejecutar cualquier programa de usuario el simulador xspim hace una llamada a la rutina main mediante la instrucción jal main. Esta instrucción forma parte del código que añade éste para lanzar a ejecución un programa de usuario. Si la etiqueta main no está declarada en el programa se genera un error. Esta etiqueta deberá siempre referenciar la primera instrucción ejecutable de un programa de usuario. Para que cualquier programa de usuario termine de ejecutarse correctamente, la última instrucción ejecutada en éste debe ser jr $ra (salto a la dirección almacenada en el registro ra), que devuelve el control a la siguiente instrucción desde donde se lanzó la ejecución del programa de usuario. A partir de este punto se hace una llamada a una función del sistema que termina la ejecución correctamente. Segundo ejercicio El siguiente código es un programa que realiza la suma de dos datos contenidos en los registros a0 y a1. main: .text li li add jr $a0,10 $a1,20 $v1,$a0,$a1 $ra Disponible en ejercicio2.s Reinicializa el simulador, carga el programa y ejecútalo paso a paso, contestando a las siguientes cuestiones: Cuestiones ¿Cuál es el contenido del PC y del registro ra antes y después de ejecutar la instrucción jal main? ¿Cuál es el contenido de los registros PC y ra antes y después de ejecutar la instrucción jr $ra? Reinicializa el simulador, carga el programa de nuevo y ejecútalo todo completo. Comprueba que la ejecución termina correctamente sin que salga el mensaje de error que salía en ejecuciones anteriores cuando no se incluía la instrucción jr $ra. Llamadas anidadas de subrutinas Cuando una subrutina llama a otra utilizando la instrucción jal se modifica automáticamente el contenido del registro $ra con la dirección de retorno (dirección de memoria de la siguiente palabra a la que contiene la instrucción que ha efectuado el salto). Esto hace que se pierda cualquier contenido anterior que pudiera tener este registro, que podría ser a su vez otra dirección de retorno suponiendo que se llevan efectuadas varias llamadas anidadas. Así pues, en cada llamada a una subrutina se modifica el contenido del registro ra, y sólo se mantiene en este registro la dirección de retorno asociada a la última llamada, ¿Qué ocurre entonces con todas las direcciones de retorno que se deberían guardarse en llamadas anidadas? Una solución a este problema es que antes de ejecutar una llamada desde una subrutina a otra se salve el contenido del registro ra en la pila. Como la pila crece dinámicamente, las direcciones de retorno de las distintas llamadas anidadas quedarán almacenadas a medida que éstas se van produciendo. La última dirección de retorno apilada estará en el tope de la pila, y ésta es justamente la primera que se necesita recuperar. Así pues, una pila es la estructura adecuada para almacenar las direcciones de retorno en llamadas anidadas a subrutinas. Tercer ejercicio El siguiente código implementa una llamada anidada a dos subrutinas, rutina main y subr. A la primera se le llamará desde el fragmento de código que tiene el simulador para lanzar la ejecución de un programa de usuario y a la subrutina subr se la llamará desde main. La primera necesita apilar la dirección de retorno (contenido de ra) para que sea posible la vuelta a la instrucción siguiente desde donde se hizo la llamada a la rutina main. La segunda como no hace ninguna llamada a otra subrutina no necesita apilar el contenido de ra: suma: main: subr: .data .space 4 .text addi sw li li jal sw lw addi jr $sp, $sp, -4 $ra,0($sp) $a0,10 $a1,2 subr $v0,suma($0) $ra, 0($sp) $sp,$sp,4 $ra add jr $v0, $a0,$a1 $ra #apilar dir. ret. #desapilar dir. ret. Disponible en ejercicio3.s Reinicializa el simulador, carga el programa y ejecútalo paso a paso respondiendo a las siguientes cuestiones: Cuestiones Comprueba qué contiene el registro ra y el PC antes y después de ejecutar la instrucción jal main. Comprueba qué hay almacenado en el tope de la pila después de ejecutar las dos primeras instrucciones del programa. Comprueba el contenido de los registros ra y PC antes y después de ejecutar la instrucción jal subr. Comprueba el contenido de los registros ra y PC antes y después de ejecutar la instrucción jr $ra que está en la subrutina subr. Comprueba el contenido de los registros ra y PC antes y después de ejecutar la instrucción jr $ra que está en la subrutina main. ¿Qué hubiera ocurrido si antes de ejecutar la instrucción jr $ra de esta subrutina main no se hubiese desapilado el contenido del registro ra? Añade el código necesario para realizar las siguientes modificaciones sobre el código original: o La subrutina subr debería calcular la siguiente operación $v0=$a0 DIV $a1. Esta división sólo se realizará si ambos operandos son mayores que 0. La comprobación se realizará en una segunda subrutina llamada comp que almacenará en v0 un 1, si los datos contenidos en los registros a0 y a1 son mayores que 0, y un 0 en caso contrario. La llamada a esta segunda subrutina se realizará desde la subrutina subr, y &eeacute;sta almacenará en v0 el cociente de la división, si &eacue;sta se realiza y un -1 en caso contrario. Paso de parámetros A la hora de implementar una subrutina hay que decidir: Parámetros a pasar a la rutina. Tipo de parámetros: por valor: se pasa el valor del parámetro, por referencia: se pasa la dirección de memoria donde esté almacenado el parámetro. Lugar donde se van a pasar los parámetros: registros, pila El ensamblador del MIPS establece el siguiente convenio para realizar el paso de parámetros: Los 4 primeros parámetros de entrada se pasarán a través de los registros $a0-$a3. A partir del quinto parámetro se pasar&iacutea a través de la pila. Los dos primeros parámetros de salida se devuelven a través de los registros $v0-$v1, el resto a través de la pila. Cuarto ejercicio El siguiente programa implementa la llamada a una subrutina y el código de la misma, que devuelve una variable booleana que vale 1 si una determinada variable está dentro de un rango y 0, en caso contrario. La subrutina tendrá los siguientes parámetros: Parámetros de entrada: Las dos variables que determinan el rango, pasados por valor, a través de a0 y a1. La variable que se tiene que estudiar si está dentro del rango, pasada por valor, a través de a2. Parámetros de salida: Variable booleana que indica si la variable estudiada está o no dentro del rango, por valor, devuelto a través de v0. .data rango1: rango2: dato: res: .word .word .word .space 10 50 12 1 .text main: addi sw lw lw lw jal sb lw addi jr $sp,$sp,-4 $ra,0($sp) #apilar ra $a0,rango1($0) #a0=rango1 $a1,rango2($0) #a1=rango2 $a2,dato($0) #a2=dato subr #saltar a subr $v0,res($0) #res=v0 $ra,0($sp) $sp,$sp,4 #desapilar ra $ra #terminar ejecucion programa subr: a sino entonces: addi j sino: finsi: blt add jr $a2,$a0,sino #Si a2a1 saltar $v0, $0,1 #v0=1 finsi #saltar a finsi $v0,$0,$0 #v0=0 $ra #retornar Disponible en ejercicio4.s Reiniciliza el simulador, carga el programa, ejecútalo y comprueba el resultado almacenado en la posición de memoria res. Cuestiones Identifica las instrucciones que se necesitan en: El programa que hace la llamada para: 1. La carga de parámetros en los registros. 2. La llamada a la subrutina. 3. El almacenamiento del resultado. La subrutina para: 1. La lectura y procesamiento de parámetros. 2. La carga del resultado en v0 3. El retorno al programa que ha hecho la llamada. Modifica el código anterior para que los parámetros que se pasan a la subrutina subr, tanto los de entrada como el de salida, se pasen por referencia. Los pasos a realizar tanto por el programa que hace la llamada como por la subrutina son los siguientes: En el programa que hace la llamada: 1. Cargar la dirección de los parámetros en los registros correspondientes (entrada y salida). 2. Llamada a la subrutina. En la subrutina: 1. Lectura de los parámetros de entrada a partir de las direcciones pasada como parámetro. 2. Procesamiento de los parámetros de entrada y generación del resultado. 3. Almacenamiento del resultado en la dirección de memoria pasada a través del parámetro de salida 4. Retorno al programa que hizó la llamada. Ejecuta el programa obtenido y comprueba que el resultado obtenido es el mismo que el del programa original. Modifica el código anterior para que los parámetros de entrada a la subrutina se pasen por valor mediante la pila y el de salida se pase también a través de la pila pero por referencia. A continuación se muestra un esquema de cómo debe ser la situación de la pila en el momento que empieza a ejecutarse la subrutina: rango1 + rango 2 dato sp --> res Bloque de activación de la subrutina El bloque de activación de la subrutina es el segmento de pila que contiene toda la información referente a una llamada a una subrutina (parámetros pasados a través de la pila, registros que modifica la subrutina y variables locales). Un bloque típico abarca la memoria entre el puntero de bloque (normalmente llamado regisro $fp en el ensamblador del MIPS, se trata del registro 30), que apunta a la primera palabra almacenada en el bloque, y el puntero de pila ($sp), que apunta a la última palabra del bloque. El puntero de pila puede variar su contenido durante la ejecución de la subrutina y, por lo tanto, las referencias a una variable local o a un parámetro pasado a través de la pila podrían tener diferentes desplazamientos relativos al puntero de pila dependiendo de dónde estuviera éste en cada momento. De forma alternativa, el puntero de bloque apunta a una dirección fija dentro del bloque. Así pues, la subrutina en ejecución usa el puntero de bloque de activación para acceder mediante desplazamientos relativos a éste a cualquier elemento almacenado en el bloque de activación independientemente de dónde se encuentre el puntero de pila. Los bloques de activación se pueden construir de diferentes formas. No obstante, lo que realmente importa es que el programa que hace la llamada y la subrutina deben estar de acuerdo en la secuencia de pasos a seguir. Los pasos que se enumeran a continuación describen la convención de llamada y retorno de una subrutina que se adopta. Esta convención interviene en tres puntos durante una llamada y retorno a una subrutina: Inmediatamente antes de llamar a la subrutina e inmediatamente después del retorno de la misma, en el programa que hace la llamada, en el momento justo en el que la subrutina empieza su ejecución e inmediatamente antes de realizar el retorno en la subrutina: En el programa que hace la llamada: Inmediatamente antes de hacer la llamada a la subrutina: Se deben cargar los parámetros de entrada (y los de salida si se pasan por referencia) en los lugares establecidos, los cuatro primeros en registros y el resto en la pila. Inmediatamente despus del retorno de la subrutina: Se debe limpiar la pila de los parámetros almacenados en ella, actualizando el puntero de pila. o En la subrutina: En el momento que empieza la ejecución: Reservar espacio en la pila para apilar todos los registros que la subrutina vaya a modificar y para las variables locales que se almacenarán en la pila. Puesto que el registro $fp es uno de los registros modificados por la subrutina, va a ser utilizado como puntero al bloque de activación, deberá apilarse. Para que la posterior limpieza del bloque de activación sea más sencilla, conviene apilarlo como primera palabra detrás de los parámetros que ha apilado el programa que ha hecho la llamada (si los hubiese). Actualizar el contenido del registro fp, para que apunte a la posición de la pila donde acabamos de almacenar el contenido del fp. Apilar el contenido del resto de registros que se van a modificar, que pueden ser: $t0-$t9, $s0-$s7, $a0-$a3, $ra. Inmediatamente antes del retorno: Recuperar el contenido de los registros apilados y actualizar el puntero de pila para limpiar la pila. o El Bloque de activación de una subrutina tendría, por lo tanto, la siguiente estructura: Parámetros Parámetros apilados por el programa que hace la + llamada 5,6.... fp -Registro fp Registros apilados por la subrutina > Registro ra Registros a0-a3 Registros s0-s7 Registros t0-t9 sp -- variables locales > Quinto ejercicio El siguiente programa implementa una subrutina que calcula los elementos nulos de un vector. Los parámetros que se le pasan son: Parámetros de entrada: La dimensión del vector (pasado por valor). La dirección del primer elemento del vector (pasado por referencia). Estos parámetros se pasarán a través de la pila ya que el objetivo que se pretende remarcar con este programa es la gestión del bloque de activación de una subrutina. Según el convenio establecido, estos parámetros se pasarían a través de los registros a0 y a1. o Parámetros de salida: Contador de elementos nulos del vector. Este parámetro se devolverá a traves del registro v0. o En la subrutina se termina de crear el bloque de activación de la subrutina, que estará formado por los parámetros que se han pasado a través de la pila (parámetros de entrada) y por los registros que vaya a modificar la subrutina, que apilará al principio de la ejecución de la subrutina. No se reserva espacio para variables locales puesto que se utilizan registros para almacenarlas. Por otro lado, para que se pueda apreciar mejor la evolución del bloque de activación de la subrutina en distintos puntos del programa, en el programa main lo primero que se hace es inicializar los registros s0, s1, s2 y fp a unos valores. Al finalizar la ejecución del programa el contenido de estos registros debería ser el mismo. .data n1: vec1: nul1: .word .word .space 4 1,0,0,2 .text #en primer lugar main: li li li se inicializan los registros s0, s1, s2 y fp li $s0,1 $s1,2 $s2,3 $fp,4 4 addi sw $sp,$sp,-4 $ra,0($sp) addi lw sw la sw $sp, $sp,-8 $t0, n1($0) $t0,4($sp) $t0, vec1 $t0, 0($sp) jal subr ret: addi $sp,$sp,8 sw $v0,nul1($0) lw addi jr $ra,0($sp) $sp,$sp,4 $ra sw addi sw sw sw addi $sp,$sp,-16 $fp, 12($sp) $fp,$sp,12 $s0,-4($fp) $s1,-8($fp) $s2,-12($fp) lw lw $s0,4($fp) $s1,8($fp) subr: and $v0, $v0,$0 #bucle cuenta elem. nulos. bucle: beq $s1,$0,finb # si s1 = 0 saltar a finb lw $s2, 0($S0) # cargar s2=Mem(s0) bne $s2, $0, finsi #si s3<>0 saltar a finsi addi $v0,$v0,1 #v0=s2 finsi: addi $s0, $s0,4 # s0 = s0+4 addi $s1, $s1,-1 # s1=s1-1 j bucle #saltar a bucle finb: lw lw addi lw addi jr lw $s0,-4($fp) $s1,-8($fp) $s2,-12($fp) $sp,$fp,0 $fp,0($sp) $sp,$sp,4 $ra Disponible en ejercicio5.s Cuestiones Identifica la instrucción o conjunto de intrucciones que realizan las siguientes acciones en programa que hace la llamada a la subrutina subr y en la subrutina: En el programa que hace la llamada: 1. Carga de parámetros en la pila. 2. Llamada a la subrutina. 3. Limpieza de la pila de los parámetros pasados a través de ella. 4. Almacenamiento del resultado. En la subrutina: 1. Acutalización del bloque de activación de la subrutina. 2. Lectura de los parámetros de la pila y procesamiento de los mismos. 3. Carga del resultado en v0. 4. Desapilar bloque de activación los registros apilados y eliminar las variables locales. Actualizar el puntero de pila. 5. Retorno al programa que ha hecho la llamada. Ejecuta paso a paso el programa anterior y dibuja la situación del bloque de activación y de los registros s0, s1, s2, fp, sp, ra y PC en cada una de las siguientes situaciones: Programa que hace la llamada a la subrutina subr, hasta el momento que hace la llamada: 1. Antes y después de ejecutar la instrucción addi $sp, $sp, 8 (situación uno). 2. Antes y despueacute;s de ejecutar la instrucción jal subr. (situación justo antes de llamar a la subrutina) Subrutina: 1. Después de ejecutar la instrucción addi $sp, $sp, -16. 2. Después de ejecutar la instrucción sw $fp, 12($sp). 3. Después de ejecutar la instrucción addi $fp, $sp, 12. 4. Despue´s de ejecutar la instrucción sw $s2, -12($fp). 5. Después de ejecutar la instrucción lw $s0, 4($fp). 6. Después de ejecutar la instrucción lw $s1, 4($fp). 7. Después de ejecutar el bucle (denominado bucle). 8. Antes y después de ejecutar addi $sp, $fp, 0. 9. Después de ejecutar lw $fp, 0($sp). 10. Después de ejecutar addi $sp, $sp, 4. Comprobar qué la situación de la pila y de los registros sp y fp es la misma que justo antes de llamar a la subrutina). 11. Después de ejecutar jr $ra Programa que hace la llamada después de retornar de la subrutina: 1. Antes y después de ejecutar addi sp, sp, 8. Comprobar qué el contenido de los registros y de la pila se corresponde con la situación uno. Modifica el código para que los parámetros se pasen a través de los registros $a0-$a1 y el de salida a través de v0. Supongamos que el programa que hace la llamada pretende que después de ejecutar la subrutina estos registros contengan el mismo contenido que el que se ha cargado inicialmente en el programa. Problemas propuestos Implementa una subrutina en ensamblador que calcule cuántos elementos de un vector de enteros de dimensión n son iguales a un elemento dado: Parámetros de entrada a la subrutina: 1. dirección del primer elemento del vector, 2. total de elementos del vector (dimensión), 3. elemento a comparar. Parámetro de salida de la subrutina: 1. contador calculado. Realiza las siguientes implementaciones: Implementa la subrutina de forma que todos los parámetros que se le pasan sean por valor excepto aquéllos que obligatoriamente se deban pasar por referencia, y a través de registros. Implementa la subrutina de forma que todos los parámetros se pasen por referencia y a través de registros. Implementa la subrutina donde los parámetros que se pasan sean del mismo tipo que en el primer caso pero utilizando la pila como lugar para realizar el paso de parámetros. Implementa una subrutina en ensamblador, tal que dado un vector de enteros de dimensión n obtenga el elemento (i) de dicho vector. La subrutina tendrá como parámetros de entrada: la dirección del vector, la dimensión del mismo y el del elemento a devolver. La subrutina devolverá el elemento i-ésimo. Realiza la llamada y el retorno a la subrutina según el convenio establecido. Implementa una subrutina en ensamblador, tal que dada una matriz de enteros de dimensión n x m, almacenada por filas, obtenga el elemento (i,j) de dicha matriz. La subrutina tendrá como parámetros de entrada: la dirección de la matriz, las dimensiones de la misma y los índices elemento a devolver. La subrutina devolverá el elemento (i,j). Realiza la llamada y el retorno a la subrutina según el convenio establecido. <--Estructuras de control El simulador SPIM > --> Examen de Teoría Fundamentos de Computadores de Ingeniería Informática Facultad de Informática. Universidad de Las Palmas de GC 15 de diciembre de 2005 1. (2 puntos) Ha aparecido en el mercado una nueva versión de un procesador en la que la única mejora con respecto a la versión anterior es una unidad de coma otante mejorada que permite reducir el tiempo de las instrucciones de coma otante a tres cuartas partes del tiempo que consumían antes. Suponga que en los programas que constituyen la carga de trabajo habitual del procesador las instrucciones de coma otante consumen un promedio del 13 % del tiempo del procesador antiguo: a ) (0.75 puntos) ¾Cuál es la máxima ganancia de velocidad que puede esperarse en los programas si se sustituye el procesador de la versión antigua por el nuevo? b ) (1.25 puntos) ¾Cuál debería ser el porcentaje de tiempo de cálculo con datos en coma otante (en la versión antigua del procesador) en sus programas para esperar una ganancia máxima de 4? 2. (3 puntos) El tratamiento de las excepciones del procesador MIPS básico consiste en la escritura de la dirección de la instrucción causante de la excepción en el registro EP C , la escritura en el registro Cause de la causa de la excepción (0 para instrucción desconocida y 1 para desbordamiento aritmético) y la ruptura del secuenciamiento de las instrucciones a la dirección 0x0C000000. Las guras 1 y 2 son la ruta de datos y la especicación del control para el procesador MIPS básico. Realiza las modicaciones de la ruta de datos y especica el control mediante una tabla de verdad para incluir el tratamiento de las excepciones tal y como ha sido denido anteriormente. 3. (2.0 puntos) Las guras 3 y 4 representan la ruta de datos y la especicación del control para la implementación multiciclo del procesador MIPS básico 1 con la inclusión del hardware y control necesarios para tratar las excepciones por instrucción desconocida y desbordamiento aritmético. Además, las guras 5 y 6 especican el control microprogramado de la implementación multiciclo del procesador MIPS básico. Realiza las modicaciones necesarias del microprograma y del secuenciador del microprograma de la gura 7 para que incluya el tratamiento de excepción por desbordamiento aritmético. Es necesario especicar el contenido de las ROM de "dispatch"que hayan sido modicadas. El tratamiento de la excepción por instrucción desconocida no es necesario incluirlo. 4. (0.5 puntos) Cambia el valor de los bits 3, 7, 9, 21, 29 (sin modicar el resto de los bits) de la posición de memoria etiquetada palabra y de contenido 0xFF0F1235 almacenada en memoria a partir de la dirección 0x10000004. 5. (2.5 puntos) Diseña un programa en ensamblador que dado un vector de enteros V obtenga cuántos elementos de este vector están dentro del rango determinado por dos variables rango1 y rango2 (ambos inclusives). El programa deberá inicializar los elementos del vector en memoria, una variable que almacenará el número de elementos que tiene ese vector y dos variables donde se almacenarán los rangos. También deberá reservar espacio para la variable resultante. 2 Figura 1: Ruta de datos monociclo 3 PC Instruction memory Read address 4 Instruction [31–0] Add Instruction [15 0] Instruction [15 11] Instruction [20 16] Instruction [25 21] Instruction [31 26] 0 M u x 1 16 Instruction [5 0] Write data Sign extend Read data 1 Read Re register 2 Registers Read Write data 2 register Read register 1 RegDst Branch Branch MemRead MemtoReg Control ALUOp MemWrite ALUSrc RegWrite 32 ALU control 0 M u x 1 Shift left 2 Zero ALU ALU result ALU Add result Write data Address 1 Read data Data memory PCSrc M u x 0 1 M u x 0 Figura 2: Control monociclo 4 RegDst ALUSrc MemToReg RegWrite MemRead MemWrite Branch ALUOp1 ALUOp0 Op5-0 -> (bits 31-26) 00 0000 0D R-Format 1 0 0 1 0 0 0 1 0 10 0011 35D lw 0 1 1 1 1 0 0 0 0 10 1011 43D sw x 1 x 0 0 1 0 0 0 00 0100 4D beq x 0 x 0 0 0 1 0 1 R-format Op0 Op3 Op2 Op1 Op4 Op5 Iw sw beq Implementación con PLA Inputs ALUOpO ALUOp1 Branch MemWrite MemRead RegWrite MemtoReg ALU ALUSrc RegDst Outputs 5 Figura 3: Camino de datos con excepciones PC 0 M u x 1 Write data MemData Memory Address Instruction [15– 0] 0] Instruction [20– 16] Instruction [25– 21] Instruction [31-26] Memory data register Instruction [15– 0] Instruction register Op [5– 0] Control Outputs 0 M u x 1 0 M Instruction u x [15– 11] 1 Instruction [25– 0] IRWrite MemtoReg MemWrite MemRead PCWrite IorD PCWriteCond Sign extend 32 Instruction [5– 0] 16 Write data Read Read register 2 data 1 Registers Write Read register data 2 Read register 1 RegDst RegWrite ALUSrcA ALUSrcB CauseWrite IntCause EPCWrite PCSource ALUOp Shift left 2 B A 4 0 1M u 2x 3 0 M u x 1 28 Zero ALU ALU result PC [31-28] Shift left 2 ALU control 26 1 0 ALU ALUOut CO 00 00 00 Jump address [31-0] u x 0 M u x 1 Cause EPC 3 2 1M 0 6 5 RegWrite MemtoReg = 1 RegDst = 0 Overflow R-type completion RegDst = 1 RegWrite MemtoReg = 0 Overflow 7 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 10 ') 'SW Execution 6 = (Op Memory access MemWrite IorD = 1 Write-back step MemRead IorD = 1 = (Op ') o r 'LW 11 ) ype R-t = (Op Branch completion 8 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 9 PCWrite PCSource = 10 10 Jump completion ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 Instruction decode/ decode/ Register fetch 1 IntCause = 1 CauseWrite A ALUSrcA =0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 (O p MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 Instruction fetch 'B EQ ') = 0 (Op = 'J') Start ') W 'S 4 3 p (O = Memory access ALUSrcA = 1 ALUSrcB = 00 ALUOp = 00 Memory address computation 2 (Op = 'LW') ) er oth = p (O Figura 4: Especicación del control con excepciones IntCause = 0 CauseWrite ALUSrcA = 0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 C o n tr o l A L U SRC1 O p e r a c ió n ALUO p0 0 0 Sum a 0 PC 0 1 R e s ta 1 A 1 0 F unc. code R e g is t e r C o n t r o l R e g W r ite R egD st M em ToR eg 1 1 0 1 0 1 SRC2 O p e r a c ió n A d d rS rc A ALUop1 O p e ra c ió n A L U S rB 1 A L U S rc B 0 0 0 B 0 1 4 1 0 E x te n d 1 1 E x tS h ft M e m o ria O p e r. O p e r. IR W rite M em Read M e m W rite Io rD W r ite A L U 1 1 0 0 R ead PC W r ite M D R 0 1 0 1 R ead ALU 0 0 1 1 W rite A L U Sec Control PCWrite PCSrc1 PcSrc0 PCwrite PCWrtCond 0 0 1 0 Oper. A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 ALU 0 1 0 1 ALUOut-Cond 1 0 1 0 Jump address O p e ra c ió n A d d rC tl1 Figura 5: Campos y codicación de los valores de las microinstrucciones Estado 0 1 2 3 4 5 6 Etiqueta Fetch Mem1 LW2 Control SRC1 ALU Add PC Add PC Add A Control Registros 4 Extshft Read Extend Memoria Read PC Read ALU Write MDR Write ALU SW2 Rformat1 Func Cod A B Subt A B BEQ1 9 JUMP1 ALUOutcond Jump Address Figura 6: Microprograma 7 AddrCtl0 Control Secuenc. PCWrite ALU Seq. Dispatch 1 Dispatch 2 Seq Fetch Fetch Seq Write ALU 7 8 Sec. AddrCtl1 PCWriteCond PCWrite PCSource0 PCSource1 Control PCWrite MemWrite IorD MemRead Memoria IRWrite MemToReg RegWrite ALUSrcB0 ALUSrcB1 SRC2 RegDst Control Registro SRC2 AluSrcA Aluop0 Aluop1 Control ALU SRC1 Fetch Fetch Fetch Sec O p e ra c ió n A d d rC tl1 A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 PLA or ROM 1 State Adder 3 Mux 2 1 A ddrCtl 0 0 Dispatch ROM 1 Dispatch ROM 2 Dispatch ROM2 Op [5:0] Nombre Valor 100011 lw LW2 (3) 101011 sw SW2 (5) Op Address select logic Op [5:0] 000000 000010 000100 100011 101011 Instruction register opcode field Dispatch ROM1 Nombre Valor R-Format R-Format1 (6) jmp JUMP1 (9) beq BEQ1 (8) lw MEM1 (2) sw MEM1 (2) Figura 7: Secuenciador del microprograma 8 Examen de Teoría Fundamentos de Computadores de Ingeniería Informática Facultad de Informática. Universidad de Las Palmas de GC 7 de septiembre de 2005 1. (3.0 puntos) La gura 1 representa una ruta de datos alternativa para la implementación multiciclo del procesador MIPS básico estudiado. En esta implementación, los registros temporales A y B han sido eliminados con la intención de realizar en un único ciclo un acceso de lectura al banco de registro y una operación ALU. La gura 2 es la especicación del control multiciclo para el procesador MIPS básico estudiado y es incluida aquí por si fuera de ayuda. Escribe la especicación completa de la nueva unidad de control para esta nueva ruta de datos que incluya el control para las instruciones load, store, aritméticas y jump. El control para la instrucción beq no es necesario hacerlo. 2. (1.5 puntos) Considera que una ventaja de la nueva implementación del procesador es la reducción de los ciclos por instrucción en una unidad para todas las instrucciones, mientras que una desventaja es el aumento del tiempo de ciclo. A partir de la mezcla de instrucciones de la tabla 1, ¾Cuál es el máximo incremento de frecuencia permitido para la nueva implementación respecto a la implementación original (en tanto por ciento) para que la propuesta no haga más lento la ejecución del programa gcc? Tipo Tipo-R Load Store Saltos y bifurcaciones Frecuencia ( %) 41 24 14 21 Cuadro 1: Frecuencia simplicada de usos de las instrucciones para el programa gcc 3. (2.5 puntos) Las guras 3 y 4 especican el control microprogramado de la implementación multiciclo del procesador MIPS básico estudiado. Realiza las modicaciones necesarias del microprograma para que sea válido para la ruta de datos de la gura 1. 1 Figura 1: Camino de 2datos con excepciones 3 5 RegWrite MemtoReg = 1 RegDst = 0 Overflow R-type completion RegDst = 1 RegWrite MemtoReg = 0 Overflow 7 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 10 ') 'SW Execution 6 = (Op Memory access MemWrite IorD = 1 Write-back step MemRead IorD = 1 = (Op ') o r 'LW 11 ) ype R-t = (Op Branch completion 8 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 9 PCWrite PCSource = 10 10 Jump completion ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 Instruction decode/ decode/ Register fetch 1 IntCause = 1 CauseWrite A ALUSrcA =0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 (O p MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 Instruction fetch 'B EQ ') = 0 (Op = 'J') Start ') W 'S 4 3 p (O = Memory access ALUSrcA = 1 ALUSrcB = 00 ALUOp = 00 Memory address computation 2 (Op = 'LW') ) er oth = p (O Figura 2: Especicación del control con excepciones IntCause = 0 CauseWrite ALUSrcA = 0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 C o n tr o l A L U SRC1 O p e r a c ió n ALUO p0 0 0 Sum a 0 PC 0 1 R e s ta 1 A 1 0 F unc. code R e g is t e r C o n t r o l R e g W r ite R egD st M em ToR eg 1 1 0 1 0 1 SRC2 O p e r a c ió n A d d rS rc A ALUop1 O p e ra c ió n A L U S rB 1 A L U S rc B 0 0 0 B 0 1 4 1 0 E x te n d 1 1 E x tS h ft M e m o ria O p e r. O p e r. IR W rite M em Read M e m W rite Io rD W r ite A L U 1 1 0 0 R ead PC W r ite M D R 0 1 0 1 R ead ALU 0 0 1 1 W rite A L U Sec Control PCWrite PCSrc1 PcSrc0 PCwrite PCWrtCond 0 0 1 0 Oper. A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 ALU 0 1 0 1 ALUOut-Cond 1 0 1 0 Jump address O p e ra c ió n A d d rC tl1 Figura 3: Campos y codicación de los valores de las microinstrucciones Estado 0 1 2 3 4 5 6 Etiqueta Fetch Mem1 LW2 Control SRC1 ALU Add PC Add PC Add A Control Registros 4 Extshft Read Extend Memoria Read PC Read ALU Write MDR Write ALU SW2 Rformat1 Func Cod A B Subt A B BEQ1 9 JUMP1 ALUOutcond Jump Address Figura 4: Microprograma 4 AddrCtl0 Control Secuenc. PCWrite ALU Seq. Dispatch 1 Dispatch 2 Seq Fetch Fetch Seq Write ALU 7 8 Sec. AddrCtl1 PCWriteCond PCWrite PCSource0 PCSource1 Control PCWrite MemWrite IorD MemRead Memoria IRWrite MemToReg RegWrite ALUSrcB0 ALUSrcB1 SRC2 RegDst Control Registro SRC2 AluSrcA Aluop0 Aluop1 Control ALU SRC1 Fetch Fetch Fetch Examen de Teoría Fundamentos de Computadores de Ingeniería Informática Facultad de Informática. Universidad de Las Palmas de GC 13 de julio de 2005 1. (3 puntos) La instrucción Move Conditional on Zero MOVZ rd, rs, rt es una instrucción tipo R del repertorio de instrucciones del procesador MIPS que mueve condicionalmente el registro rs al registro rd cuando el registro rt es igual 0. El formato de la instrucción es el siguiente: b31 . . . b26 b25 . . . b21 b20 . . . b16 b15 . . . b11 b10 . . . b6 b5 . . . b 0 0...0 rs rt rd 0...0 0 0 1 0 1 0 a ) (1.5 puntos) Añada los caminos de datos y las señales de control necesarias al camino de datos multiciclo de la gura 1 para la ejecución de esta instrucción. b ) (1.5 puntos) Indique las modicaciones necesarias de la máquina de estados nitos de la gura 2 para la inclusión de la instrucción M OV Z . 2. (1.5 puntos) Una ventaja de incluir la instrucción MOVZ en el repertorio de instrucciones consiste en la posibilidad de sustituir cada pieza de código con la siguiente estructura: bne rs, nocopiar add rd, rt, r0 nocopiar: . . . por el código: movz rd, rs, rt Ten en cuenta que cuando hacemos esta sustitución disminuye el número de instrucciones del programa y también el número de ciclos de ejecución (de 3 ciclos del beq más 4 ciclos del add pasamos a 4 ciclos del movz ). Considerando que esta mejora es aplicable sólo al 2 por ciento del total de las instrucciones de salto y bifurcación, calcula la máxima mejora de rendimiento introducida al incluir esta instrucción en el repertorio de instrucciones para el programa gcc que tiene la distribución de instrucciones del cuadro 1. 1 Tipo Tipo-R Load Store Saltos y bifurcaciones Frecuencia ( %) 41 24 14 21 Cuadro 1: Frecuencia simplicada de usos de las instrucciones para el programa gcc 3. (2.5 puntos) Las guras 1 y 2 representan la ruta de datos y la especicación del control para la implementación multiciclo del procesador MIPS básico con la inclusión del hardware y control necesarios para tratar las excepciones por instrucción desconocida. Además, las guras 3 y 4 especican el control microprogramado de la implementación multiciclo del procesador MIPS básico. Realiza las modicaciones necesarias del microprograma y del secuenciador del microprograma de la gura 5 para que incluya el tratamiento de excepción por instrucción desconocida. Es necesario especicar el contenido de las ROM de "dispatch"que hayan sido modicadas. El tratamiento de la excepción por desbordamiento aritmético no es necesario incluirlo. 2 3 Figura 1: Camino de datos con excepciones PC 0 M u x 1 Write data MemData Memory Address Instruction [15– 0] 0] Instruction [20– 16] Instruction [25– 21] Instruction [31-26] Memory data register Instruction [15– 0] Instruction register Op [5– 0] Control Outputs 0 M u x 1 0 M Instruction u x [15– 11] 1 Instruction [25– 0] IRWrite MemtoReg MemWrite MemRead PCWrite IorD PCWriteCond Sign extend 32 Instruction [5– 0] 16 Write data Read Read register 2 data 1 Registers Write Read register data 2 Read register 1 RegDst RegWrite ALUSrcA ALUSrcB CauseWrite IntCause EPCWrite PCSource ALUOp Shift left 2 B A 4 0 1M u 2x 3 0 M u x 1 28 Zero ALU ALU result PC [31-28] Shift left 2 ALU control 26 1 0 ALU ALUOut CO 00 00 00 Jump address [31-0] u x 0 M u x 1 Cause EPC 3 2 1M 0 4 5 RegWrite MemtoReg = 1 RegDst = 0 Overflow R-type completion RegDst = 1 RegWrite MemtoReg = 0 Overflow 7 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 10 ') 'SW Execution 6 = (Op Memory access MemWrite IorD = 1 Write-back step MemRead IorD = 1 = (Op ') o r 'LW 11 ) ype R-t = (Op Branch completion 8 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 9 PCWrite PCSource = 10 10 Jump completion ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 Instruction decode/ decode/ Register fetch 1 IntCause = 1 CauseWrite A ALUSrcA =0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 (O p MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 Instruction fetch 'B EQ ') = 0 (Op = 'J') Start ') W 'S 4 3 p (O = Memory access ALUSrcA = 1 ALUSrcB = 00 ALUOp = 00 Memory address computation 2 (Op = 'LW') ) er oth = p (O Figura 2: Especicación del control con excepciones IntCause = 0 CauseWrite ALUSrcA = 0 ALUSrcB = 01 ALUOp = 01 EPCWrite PCWrite PCSource = 11 C o n tr o l A L U SRC1 O p e r a c ió n ALUO p0 0 0 Sum a 0 PC 0 1 R e s ta 1 A 1 0 F unc. code R e g is t e r C o n t r o l R e g W r ite R egD st M em ToR eg 1 1 0 1 0 1 SRC2 O p e r a c ió n A d d rS rc A ALUop1 O p e ra c ió n A L U S rB 1 A L U S rc B 0 0 0 B 0 1 4 1 0 E x te n d 1 1 E x tS h ft M e m o ria O p e r. O p e r. IR W rite M em Read M e m W rite Io rD W r ite A L U 1 1 0 0 R ead PC W r ite M D R 0 1 0 1 R ead ALU 0 0 1 1 W rite A L U Sec Control PCWrite PCSrc1 PcSrc0 PCwrite PCWrtCond 0 0 1 0 Oper. A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 ALU 0 1 0 1 ALUOut-Cond 1 0 1 0 Jump address O p e ra c ió n A d d rC tl1 Figura 3: Campos y codicación de los valores de las microinstrucciones Estado 0 1 2 3 4 5 6 Etiqueta Fetch Mem1 LW2 Control SRC1 ALU Add PC Add PC Add A Control Registros 4 Extshft Read Extend Memoria Read PC Read ALU Write MDR Write ALU SW2 Rformat1 Func Cod A B Subt A B BEQ1 9 JUMP1 ALUOutcond Jump Address Figura 4: Microprograma 5 AddrCtl0 Control Secuenc. PCWrite ALU Seq. Dispatch 1 Dispatch 2 Seq Fetch Fetch Seq Write ALU 7 8 Sec. AddrCtl1 PCWriteCond PCWrite PCSource0 PCSource1 Control PCWrite MemWrite IorD MemRead Memoria IRWrite MemToReg RegWrite ALUSrcB0 ALUSrcB1 SRC2 RegDst Control Registro SRC2 AluSrcA Aluop0 Aluop1 Control ALU SRC1 Fetch Fetch Fetch Sec O p e ra c ió n A d d rC tl1 A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D is p a tc h 1 1 0 D is p a tc h 2 PLA or ROM 1 State Adder 3 Mux 2 1 A ddrCtl 0 0 Dispatch ROM 1 Dispatch ROM 2 Dispatch ROM2 Op [5:0] Nombre Valor 100011 lw LW2 (3) 101011 sw SW2 (5) Op Address select logic Op [5:0] 000000 000010 000100 100011 101011 Instruction register opcode field Dispatch ROM1 Nombre Valor R-Format R-Format1 (6) jmp JUMP1 (9) beq BEQ1 (8) lw MEM1 (2) sw MEM1 (2) Figura 5: Secuenciador del microprograma 6 Examen de Fundamentos de Computadores de II Facultad de Informática. Universidad de Las Palmas de GC 7 de septiembre de 2004 1. (0.75 puntos) El formato de instrucción de un procesador tiene 6 bits para el código de operación y 10 para la dirección del operando. Suponiendo que una instrucción de bifurcación con direccionamiento relativo al contador de programa, almacenada en la posición 530 (en decimal), origina un salto a la posición 620 (en decimal), y si además el código de operación de la instrucción de salto es 110011, justifica una posible codificación binaria de dicha instrucción. 2. (1.25 puntos) En un procesador con instrucciones de 0 direcciones (procesador con pila), ¿qué expresión matemática calcula la secuencia de instrucciones? P USH M[C] P USH M[D] ADD P USH M[C] P USH M[D] ADD MULT P OP M[A] 3. Suponga que hubiera una instrucción MIPS llamada bcp, que copiara un bloque de palabras de una dirección a otra. Suponga que esta instrucción requiera que la dirección del principio del bloque fuente sea el registro t1, la dirección destino esté en el registro t2, y el número de palabras a copiar esté en t3 (que es ≥ 0). Además suponga que los valores de estos registros, ası́ como el registro t4 puedan destruirse al ejecutar esta instrucción (para que los registros puedan usarse como temporales). (2 puntos)Escriba un programa en lenguaje en ensamblador MIPS sustitutivo de la instrucción bcp para realizar la copia del bloque. ¿Cuántas instrucciones se ejecutarán para copiar un bloque de 100 palabras? Utilizando el CPI de las instrucciones en la realización multiciclo, ¿cuántos ciclos se necesitan para copiar n palabras? 1 (2 puntos) Diseñe una estrategia para incluir la instrucción bcp al camino de datos de la figura 1 y a la especificación del control de la figura 2. Probablemente se necesitará hacer algunos cambios en el camino de datos para realizar la instrucción eficientemente. Dé una descripción de los cambios propuestos y de cómo funciona el secuenciamiento de la instrucción. (2 puntos) Modifique el formato original de las microinstrucciones MIPS (figura 3) y el microprograma inical (figura 4) para que incluya la instrucción bcp. Describa detalladamente cómo se extiende el microcódigo para soportar estructuras de control más complejas (como un bucle) con microcódigo. ¿Ha cambiado el soporte para la instrucción bcp el tamaño del código? Además de la instrucción bcp, ¿alguna otra instrucción se verá afectada por el cambio en el formato de instrucciones? (2 puntos) Estime la mejora del rendimiento que se puede conseguir al realizar la instrucción en circuiterı́a (respecto de la solución por programa del apartado anterior) y explique de dónde procede el incremento del rendimiento. 2 PCWriteCond PCSource PCWrite IorD IorD Outputs ALUSrcB MemRead MemWrite Control ALUSrcA RegWrite MemtoReg IRWrite ALUO p Op [5– 0] RegDst 0 PC 3 Figura 1: Camino de datos M 26 Instructi [25– 0] Instruction 0 M u x 1 Shift left 2 Instruction [31-26] Address Memory MemData Write data Instruction [25– 21] Read register 1 Instruction [20– 16] Read Read register 2 data 1 Registers Write Read register data 2 Instruction [15– 0] Instruction register Instruction [15– 0] Memory data register 0 M Instruction u x [15– 11] 1 B 0 M u x 1 16 Sign extend e xtend 0 4 Write data 32 Instruction [5– 0] Shift left 2 Zero ALU ALU result 1 M u 2 x 3 ALU control 1 u x 2 PC [31-28] 0 M u x 1 A 28 Jump address [31-0] ALUOut struction decode/ Instruction In register fetch Instruction fetch ( Op 2 W = 'L ( Op ') or ) pe R-t y = ( Op Branch completion W') = 'S Execution 6 ALUSrcA = 1 USrcB = 10 ALUSrcB AL ALUOp = 00 8 ALUSrcA =1 ALUSrcB = 00 ALUOp= 10 p = 'S ') W Memory access Memory access 3 5 MemRead IorD = 1 R-type completion 7 MemWrite IorD = 1 RegDst = 1 RegWrite MemtoReg = 0 Write-back step 4 RegDst =0 RegWrite MemtoReg = 1 Figura 2: Especificación del control 4 Jump completion 9 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 (O (Op = 'L W') ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 (Op = 'J') Memory address computation 1 =' BE Q' ) Start MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 (O p 0 PCWrite PCSource = 10 C o n tr o l A L U SRC1 O p e r a c ió n SRC2 O p e r a c ió n A d d rS rc A ALU op1 ALUO p0 0 0 Sum a 0 PC 0 1 R e s ta 1 A 1 0 Func. code A L U S rcB 0 0 0 B 0 1 4 1 0 E xte n d 1 1 E xtS h ft Sec Control PCWrite PCSrc1 PcSrc0 PCwrite PCWrtCond 0 0 1 0 Oper. 1 0 1 ALUOut-Cond 1 0 1 0 Jump address O p e ra c ió n A d d rC tl1 A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D isp a tc h 1 1 0 D isp a tc h 2 ALU 0 O p e ra c ió n A L U S rB 1 Figura 3: Campos y codificación de los valores de las microinstrucciones Estado 0 1 2 3 4 5 6 Etiqueta Fetch Mem1 LW2 Control SRC1 ALU Add PC Add PC Add A Control Registros 4 Extshft Read Extend Memoria Read PC Read ALU Write MDR Write ALU SW2 Rformat1 Func Cod A B Subt A B BEQ1 9 JUMP1 ALUOutcond Jump Address Figura 4: Microprograma 5 AddrCtl0 Control Secuenc. PCWrite ALU Seq. Dispatch 1 Dispatch 2 Seq Fetch Fetch Seq Write ALU 7 8 Sec. AddrCtl1 PCWriteCond PCWrite PCSource0 PCSource1 Control PCWrite MemWrite IorD MemRead Memoria IRWrite MemToReg RegWrite ALUSrcB0 ALUSrcB1 SRC2 RegDst Control Registro SRC2 AluSrcA Aluop0 Aluop1 Control ALU SRC1 Fetch Fetch Fetch Examen de Teorı́a Fundamentos de Computadores de Ingenierı́a Informática Facultad de Informática. Universidad de Las Palmas de GC 14 de julio de 2004 1. (0.5 puntos) Diseña el formato de las instrucciones de un máquina de registromemoria que tiene las siguientes caracterı́sticas: El repertorio de instrucciones contiene en total 32 instrucciones, de las cuales 16 son instrucciones del tipo: • op Ry , (Rx ); esto es Ry ← Ry op M [Rx ] Otras 8 instrucciones son del tipo: • op Ry , Rx ; esto es Ry ← Ry op Rx Y las otras 8 restantes están todavı́a por especificar. Sólo admite para acceder a la memoria el modo de direccionamiento indirecto por registro. Tiene un banco de 8 registros. En el formato de la instrucción se especifican 3 campos: el primero, para el código de operación; el segundo, para especificar el registro que es el segundo operando fuente o que contiene la dirección de memoria del segundo operando fuente; y el tercero, para especificar el primer registro fuente que es además siempre registro destino en las instrucciones especificadas. 2. (2.0 puntos) Para el repertorio de instrucciones del problema anterior: (1.5 puntos) Diseña una ruta de datos monociclo que soporte la ejecución de las instrucciones especificadas. Explica claramente el nombre y la funcionalidad de cada una de las señales de control en el camino y el funcionamiento de cada uno de los bloques funcionales que utilices. (0.5 puntos) Especifica la unidad de control para esa ruta de datos mediante una tabla de verdad o método equivalente. 3. (3 puntos) Las figuras 1 y 2 muestran la estructura y la especificación del control de la implementación básica multiciclo del procesador MIPS R3000. 1 En esta implementación tanto la instrucción de bifurcación jump como la de salto condicional beq tardan 3 ciclos en ser ejecutadas por el procesador. Nuestro objetivo como diseñadores de este procesador es considerar la implementación de estas dos instrucciones en dos ciclos. a) (1.5 puntos) Añada los caminos de datos y las señales de control necesarias al camino de datos multiciclo de la figura 1 para que ambas instrucciones sean ejecutadas por el procesador en 2 ciclos. b) (1.5 puntos) Indique las modificaciones necesarias a la máquina de estados finitos de la figura 2 para que ambas intrucciones sean ejecutadas por el procesador en 2 ciclos. Especifica claramente la máquina de estados finitos modificada. 4. (3 puntos) En nuestra compañı́a además de la versión cableada del procesador básico MIPS R3000, tenemos también una versión que implementa el control mediante la técnica de microprogramación. Las figuras 3 y 4 resumen la especificación del control mediante la técnica de microprogramación. a) (2 puntos) Realiza las modificaciones necesarias sobre las figuras 3 y 4 para que ahora el control microprogramado funcione para el camino de datos modificado para que las instrucciones de bifurcación y salto funcionen en 2 ciclos. En el caso que algún cambio sea necesario, especifica los nuevos valores de las tablas de Dispatch. b) (1 punto) Codifica en binario o en hexadecimal las microinstrucciones que hayas modificado o añadido. 5. (1.5 puntos) Cabe esperar que las modificaciones del procesador MIPS R3000 para que realice los saltos y las bifurcaciones en tan sólo 2 ciclos disminuya la frecuencia de reloj del procesador. Por este motivo, antes de seguir adelante con nuestro procesador modificado, estamos interesados en saber: a) (1 punto) ¿Cuál es la frecuencia mı́nima (en relación con la frecuencia actual factual a partir de la cual deja de ser interesante el cambio que proponemos? b) (0.5 puntos) ¿Cuál es la frecuencia mı́nima necesaria para una frecuencia original de 100MHz? 2 Tipo Tipo-R Load Store Saltos y bifurcaciones Frecuencia ( %) 41 24 14 21 Cuadro 1: Frecuencia simplificada de usos de las instrucciones para el programa gcc Para realizar el cálculo de esta frecuencia mı́nima, al menos de manera aproximada, disponemos de los datos de la mezcla de instrucciones del programa gcc en la tabla 1. 3 PC 4 Figura 1: Camino de datos 0 M u x 1 Write data MemData Memory Address Instruction [15– 0] Instruction [20– 16] Instruction [25– 21] Instruction [31-26] Memory data register Instruction [15– 0] Instruction register Op [5– 0] Control Outputs 0 M u x 1 0 M Instruction u x [15– 11] 1 Instructi [25– 0] Instruction IRWrite MemtoReg MemWrite MemRead IorD IorD PCWrite PCWriteCond Sign extend e xtend 32 Instruction [5– 0] 16 Write data Read Read register 2 data 1 Registers Write Read register data 2 Read register 1 RegDst RegWrite ALUSrcA ALUSrcB ALUO p PCSource Shift left 2 B A 4 1 M u 2 x 3 0 0 M u x 1 28 Zero ALU ALU result PC [31-28] Shift left 2 ALU control 26 ALUOut Jump address [31-0] M 2 x 1 u 0 Instruction In struction decode/ register fetch Instruction fetch ( Op 2 W = 'L (O ') or p= ) pe R-t y = ( Op Branch completion ') 'SW Execution 6 ALUSrcA = 1 ALUSrcB = 10 ALUSrcB ALUOp = 00 8 ALUSrcA =1 ALUSrcB = 00 ALUOp= 10 p = 'S ') W Memory access 3 Memory access 5 MemRead IorD = 1 R-type completion 7 MemWrite IorD = 1 RegDst = 1 RegWrite MemtoReg = 0 Write-back step 4 RegDst =0 RegWrite MemtoReg = 1 Figura 2: Especificación del control 5 Jump completion 9 ALUSrcA = 1 ALUSrcB = 00 ALUOp = 01 PCWriteCond PCSource = 01 (O (Op = 'L W') ALUSrcA = 0 ALUSrcB = 11 ALUOp = 00 (Op = 'J') Memory address computation 1 =' BE Q' ) Start MemRead ALUSrcA = 0 IorD = 0 IRWrite ALUSrcB = 01 ALUOp = 00 PCWrite PCSource = 00 (O p 0 PCWrite PCSource = 10 C o n tr o l A L U SRC1 O p e r a c ió n ALUO p0 0 0 Sum a 0 PC 0 1 R e s ta 1 A 1 0 Func. code PcSrc0 PCwrite Oper. PCWrtCond 0 0 1 0 ALU 0 1 0 1 ALUOut-Cond 1 0 1 0 Jump address O p e ra c ió n A L U S rB 1 A L U S rcB 0 0 0 B 0 1 4 1 0 E xte n d 1 1 E xtS h ft Sec Control PCWrite PCSrc1 SRC2 O p e r a c ió n A d d rS rc A ALU op1 O p e ra c ió n A d d rC tl1 A d d rC tl0 1 1 Seq. 0 0 F e tc h 0 1 D isp a tc h 1 1 0 D isp a tc h 2 Figura 3: Campos y codificación de los valores de las microinstrucciones Estado 0 1 2 3 4 5 6 Etiqueta Fetch Mem1 LW2 Control SRC1 ALU Add PC Add PC Add A Control Registros 4 Extshft Read Extend Memoria Read PC Read ALU Write MDR Write ALU SW2 Rformat1 Func Cod A B Subt A B BEQ1 9 JUMP1 ALUOutcond Jump Address Figura 4: Microprograma 6 AddrCtl0 Control Secuenc. PCWrite ALU Seq. Dispatch 1 Dispatch 2 Seq Fetch Fetch Seq Write ALU 7 8 Sec. AddrCtl1 PCWriteCond PCWrite PCSource0 PCSource1 Control PCWrite MemWrite IorD MemRead Memoria IRWrite MemToReg RegWrite ALUSrcB0 ALUSrcB1 SRC2 RegDst Control Registro SRC2 AluSrcA Aluop0 Aluop1 Control ALU SRC1 Fetch Fetch Fetch Examen de Prácticas Fundamentos de Computadores de Ingenierı́a Informática Facultad de Informática. Universidad de Las Palmas de GC 14 de julio de 2004 Las figuras 1, 2 y 3, muestran parte del estado en un instante determinado de una máquina MIPS R2000. La figura 1 muestra el valor de los registros, la figura 2 indica el contenido de la memoria y la figura 3 corresponde al segmento de texto. 1. (5 puntos) Escribe el código en ensamblador de la secuencia de instrucciones ejecutadas desde el estado actual hasta que el registro contador de programa P C toma el valor 0x0040009C. Utiliza si lo consideras conveniente la tabla de códigos de operación 1 2. (2.5 puntos) ¿Cuál es el contenido de los registros después de que el registro P C tome el valor 0x0040009C? 3. (2.5 puntos) ¿Cuál es el contenido de la memoria después de que el registro P C tome el valor 0x0040009C? nemónico lw rt, rs, inmediato ori rt, rs, inmediato addiu rt, rs, inmediato slti rt, rs, inmediato bne rs, rt, inmdiato cód-op. 0x23 0x0D 0x09 0x0A 0x05 nemónico sw rt, rs, inmediato addu rd, rs, rt mult rt, rs slt rd, rs, rt bgez rs, inmediato jr rs cód-op. campo función 0x2B 0 0x21 0 0x18 0 0x2A 0x01 0 8 Cuadro 1: Tabla de códigos de operación Figura 1: Contenido de los registros Figura 2: Contenido del segmento de datos Figura 3: Lenguaje máquina de un procedimiento Examen Fundamentos de Computadores de la Ingenierı́a Informática Facultad de Informática. Universidad de Las Palmas de Gran Canaria 12 de diciembre de 2003 1. (2.5 puntos) Para un computador de longitud de palabra de 36 bits, diseña (razonablemente) los formatos de las instrucciones para que permitan construir un repertorio de instrucciones con: 7 instrucciones con dos direcciones de 15 bits y una de 3 bits. 500 instrucciones con una dirección de 15 bits y una de 3 bits 50 instrucciones con 0 direcciones. 2. (2.5 puntos) Se está interesado en 2 realizaciones de una máquina, una con una circuiterı́a especial de punto flotante y otra sin ella. Considérese un programa P , con la siguiente mezcla de operaciones: multiplicación en punto flotante suma en punto flotante división en punto flotante instrucciones de enteros 10 % 15 % 5% 70 % La máquina MPF (máquina con punto flotante) tiene circuiterı́a de punto flotante y puede por lo tanto realizar operaciones de punto flotante directamente. Se requiere el siguiente número de ciclos de reloj para cada tipo de instrucción: multiplicación en punto flotante 6 suma en punto flotante 4 división en punto flotante 20 instrucciones de enteros 2 La máquina MSPF (máquina sin punto flotante) no tiene circuiterı́a de punto flotante y por lo tanto debe emular las operaciones de punto flotante usando instrucciones de enteros. Las instrucciones de enteros necesitan todas dos ciclos de reloj. El número de INSTRUCCIONES de enteros necesarias para realizar cada operación de punto flotante es el siguiente: 1 multiplicación en punto flotante 30 suma en punto flotante 20 división en punto flotante 50 Ambas máquinas tienen una frecuencia de reloj de 100MHz. a) Calcula la tasa de MIPS (millones de instrucciones por segundo) para ambas máquinas. b) Si la máquina MPF necesita 300 millones de instrucciones para un programa, ¿cuántas instrucciones de enteros requerirá la máquina MSPF para el mismo programa? c) ¿Cuál es el tiempo de ejecución para dicho programa de 300 millones de instrucciones en la máquina MPF y MSPF? 3. (2.5 puntos) Escribe un programa en ensamblador MIPS que inicialice un vector de palabras con la constante 0. Asume que la dirección de comienzo del vector está en el registro a0 y el tamaño del vector de palabras está en el registro a1. 4. (2.5 puntos) Se quiere añadir la instrucción jm (jump memory, salto a memoria) al camino de datos multiciclo. Su formato de instrucción es igual al de lw excepto que el campo rt no se utiliza porque el dato cargado de memoria se coloca en el P C en vez de hacerlo en registro destino. a) Añada los caminos de datos y las señales de control necesarias al camino de datos multiciclo. b) Indica las modificaciones necesarias a la máquina de estados finitos. Especifica claramente cuántos ciclos necesita la nueva instrucción para ejecutarse en su camino de datos y la máquina de estados finitos modificada. 2 3 Figura 1: Camino de datos multiciclo. Figura 2: Especificación del control para la ruta de datos multiciclo. 4 Convocatoria extraordinaria de septiembre (septiembre 2003). Examen de FCI. Duración 2 horas. 1. (1 punto) Utilizando reiteradamente las leyes de Morgan, obtener una expresión en forma de suma de productos para las siguientes funciones: a) F = (x + y)(xȳ + z) b) G = (x̄ȳ + xz) (x̄ + ȳz) 2. (1 punto) Obtener una expresión como suma de minterms y otra como producto de maxterms para la siguiente función: f (x, y, z) = xȳ + x̄z + yz̄ 3. (1 punto) Dada la siguiente función como suma de minterms, pasarla a producto de maxterms. Minimizar la expresión resultante de la función empleando maxterms. P f (x, y, z, w) = m(0, 2, 3, 4, 5, 6, 11) 4. (2 puntos) Obtener el resultado de las siguientes operaciones binarias: a) 110101 + 1001001 b) 1110010110 − 101011001 c) 0,01001 × 101,1001 d ) 1011,001/0,1101 5. (2.5 puntos) Minimizar la tabla de estado utilizando uno de los dos métodos estudiados. 0 1 2 3 A B,1 A,1 E,0 D,0 B F,1 C,0 E,1 A,1 C I,1 B,0 F,1 I,1 D F,1 B,0 I,1 A,1 E H,0 A,1 I,1 F,0 F B,0 A,1 I,1 F,0 G B,1 A,1 F,0 I,0 H E,1 C,0 F,1 A,1 I B,0 A,1 G,1 I,0 1 6. (2.5 puntos) Diseña con biestables tipo D un sistema secuencial sı́ncrono con dos entradas, E y C, y dos salidas, Z y S. Si durante tres pulsos de reloj se mantiene C=1, entonces Z = E y S = 1; si durante tres pulsos de reloj se mantiene C = 0, entonces Z = Ē y S = 1; en cualquier otro caso ha de ser Z = 0 y S = 0. 2 Examen Fundamentos de Computadores de la Ingenierı́a Informática Facultad de Informática. Universidad de Las Palmas de Gran Canaria Septiembre de 2003 1. (2.5 puntos) Comparar las máquinas de 0, 1 y 2 direcciones, escribiendo programas para calcular la expresión: X = (A + B · C)/(D − E · F − G · H) Para cada una de los tres tipos de máquinas el repertorio de instrucciones disponibles es el siguiente: 0 direcciones PUSH M POP M SUM SUB MUL DIV 1 direcciones LOAD M STORE M SUM M SUB M MUL M DIV M 2 direcciones MOVE X, Y SUM X, Y RES X, Y MUL X, Y DIV X, Y donde M es una dirección de memoria de 16 bits y X e Y son direcciones de 16 bits o números de registros de 4 bits. La máquina de 0 direcciones usa una pila, la de 1 dirección usa un acumulador y la de dos direcciones tiene 16 registros e instrucciones en las que cada operando puede estar en un registro o en memoria. Suponiendo códigos de operación de 8 bits y longitudes de instrucción que son múltiplos de 4 bits. ¿Cuántos bits necesita cada computadora para representar el programa que calcula el valor de X? 2. (2.0 puntos) Asuma la personalidad del diseñador jefe de un nuevo procesador. El diseño del procesador y el compilador están completados, y ahora se debe decidir si se fabrica el diseño actual tal y como está o se utiliza tiempo adicional para mejorarlo. Se discute el problema con el grupo de ingenierı́a de circuitos y se llega a las siguientes opciones: Dejar el diseño tal y como está. A esta máquina base se le da el nombre de Mbase. Tiene una frecuencia de reloj de 500MHz y se han tomado las siguientes medidas usando un simulador: Tipo de instrucción CPI Frecuencia A 2 40 % B 3 25 % C 3 25 % D 5 10 % Optimizar la circuiterı́a. El grupo de ingenierı́a de circuitos indica que puede mejorar el diseño del procesador para dar una frecuencia de 600MHz. A esta máquina se le da el nombre Mopt. Se han tomado las siguientes medidas usando un simulador para Mopt: 1 Tipo de instrucción A B C D CPI 2 3 3 4 Frecuencia 40 % 25 % 25 % 10 % a) ¿Cuál es el CPI para cada máquina? (0.5 puntos) b) ¿Cuáles son las tasas de MIPS originales para Mbase y Mopt? (0.5 puntos) c) ¿Cuánto más rápida es Mopt que Mbase? (1.0 puntos) 3. (1.5 puntos) El procedimiento strcpy copia la cadena y en la cadena x usando la convención de C de terminación con byte nulo: void strcpy(char x[], char y[]) { int i; i = 0; while ((x[i]=y[i])!=0) /* copia y comprueba el byte */ i = i+1; } 4. (1.5 puntos) Se quiere añadir la instrucción jm (jump memory o salto a memoria) al camino de datos multiciclo. El formato de la nueva instrucción es igual al de la instrucción lw excepto que el campo rt no se utiliza porque el dato cardado de memoria se coloca en el PC en lugar de escribirlo en el registro destino. Añada los caminos de datos y las señales de control necesarias al camino de datos multiciclo de la figura 1, e indique las modificaciones necesarias a la máquina de estados finitos de la figura 2. Intente encontrar una solución que minimice el número de ciclos de reloj requeridos para la nueva instrucción. especifique claramente cuántos ciclos necesita la nueva instrucción para ejecutarse en el camino de datos con la máquina de estados finitos modificados. 5. (2.5 puntos) Añada los caminos de datos y las señales de control necesarias al camino de datos multiciclo de la figura 1 y las modificaciones del diagrama de estados de la figura 2 para gestionar las excepciones debidas a instrucciones no definidas o desbordamientos aritméticos. Explica también cómo el procesador trata una excepción. 2 3 Figura 1: Camino de datos multiciclo. Figura 2: Especificación del control para la ruta de datos multiciclo. 4 Examen Fundamentos de Computadores de la Ingenierı́a Informática Facultad de Informática. Universidad de Las Palmas de Gran Canaria 14 de julio de 2003 P1 1.75 P2 2.5 P3 1 P4 1.75 P5 3 1. 1.75 puntos. Un computador tiene palabras de 24 bits. Los operandos se pueden direccionar de las formas siguientes: Registro (R): se requieren 4 bits. Memoria (M): se requieren 4 bits para el registro base y 9 para el desplazamiento Inmediato (I): 9 bits. a) Diseñar los formatos de instrucciones necesarios para tener un repertorio con 2 instrucciones de M-I, 63 instrucciones de M-R, 15 instrucciones de R-I y 64 instrucciones de R-R. b) ¿Variarán los formatos diseñados en el apartado anterior si en las especificaciones del mismo repertorio de instrucciones nos piden 14 instrucciones de R-I en vez de 15? 2. 2.5 puntos. Considere el siguiente fragmento de código C: for(i=0; i<=1000; i=i+1){a[i] = b[i] + c} Suponga que a y b son vectores de palabras y la dirección base de a está en el registro $a0 y la de b en $a1 . El registro $t0 se asocia con la variable i y $s0 con la variable c . Escriba el código MIPS. ¿Cuántas instrucciones se ejecutan a lo largo de este código? ¿Cuántas referencias de datos a memoria se producirán durante la ejecución? 3. 1.0 punto. El código siguiente trata de implementar un salto condicional a la dirección noes-cero, cuyo valor es 0xABCD1234. Sin embargo, dicho salto no funciona de la forma que está implementado. Explique por qué e indique de qué manera habrı́a que codificarlo para que funcione. 0x00000004 0x00000008 no-es-cero: add $8, $15, $16 bne $8, $0, no-es-cero ... sub $9, $12, $13 1 Tipo Tipo-R Load Store Saltos y bifurcaciones Frecuencia ( %) 41 24 14 21 Cuadro 1: Frecuencia simplificada de usos de las instrucciones para el programa gcc 4. 1.75 puntos. Sus amigos de la C 3 (Creative Computer Corporation) han determinado que el camino crı́tico que establece la longitud del ciclo de reloj del camino de datos multiciclo es el acceso a memoria para la carga o almacenamiento de datos (no para la búsqueda de instrucciones) Esto ha dado lugar a su más reciente realización de la MIPS 30000 para ejecutar con una frecuencia de 500MHz en vez del objetivo de alcanzar los 750MHz. De todas formas, Beatriz e Ibrahin, de C 3 , tienen una solución. Si todos los ciclos que acceden a memoria para datos se dividen en dos ciclos, entonces la máquina puede funcionar con la frecuencia de reloj final. Utilizando la combinación de instrucciones del gcc mostrada en la tabla 1, determine cuánto más rápida será la máquina con accesos a memoria de dos ciclos respecto a la máquina de 500MHz con acceso a memoria en un sólo ciclo. Suponga que todos los saltos necesitan el mismo número de ciclos y que las instrucciones del repertorio y las aritméticas inmediatas se realizan como de tipo R. 5. 3.0 puntos. Se quiere añadir la la instrucción aritmética de 4 operandos add3, la cual suma tres números en vez de dos: add3 $t5, $t6, $t7, $t8 # $t5 = $t6 + $t7 + $t8 Añada los caminos de datos y las señales de control necesarias al camino de datos multiciclo de la figura 1, e indique las modificaciones necesarias a la máquina de estados finitos de la figura 2. Especifique claramente cuántos ciclos necesita la nueva instrucción para ejecutarse en su camino de datos y la máquina de estados finitos modificada. Suponga que la arquitectura del repertorio de instrucciones está modificada con un nuevo formato de instrucción similar al formato R, excepto que los bits 0-4 se utilizan para especificar el registro adicional (se seguirá utilizando los rs, rt y rd) y, por supuesto, se utiliza un nuevo código de operación. Su solución no deberı́a depender de añadir nuevos puertos de lectura al banco de registro, ni deberı́a utilizar una nueva ALU. 2 3 Figura 1: Camino de datos para el problema 5. Figura 2: Especificación del control para el problema 5 . 4