1.04 MB
Anuncio

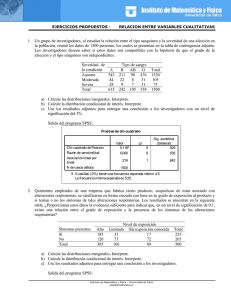
Cómo realizar un contraste de hipótesis con SPSS Asociación de dos variables categóricas y test exacto de Fischer para muestras pequeñas. Introducción En un primer ejercicio vamos a probar, con las encuestas que se realizaron en el estudio, la siguiente hipótesis: “Los niños y niñas en edad de secundaria que dejan la escuela reciben un trato diferente de sus padres (varones) respecto a animarlos a seguir estudiando”. Y un segundo ejemplo con la siguiente hipótesis: “Los niños y niñas que abandonaron la escuela tienen diferencias por urbano – rural en relación a que sus hermanos les animen para seguir estudiando”. Y finalmente probaremos que “Que los niños reciban ayuda con su tarea de parte de sus padres, no está relacionado con que tenga una buena comunicación con ellos” esto para los niños que abandonaron la educación básica. Primer ejercicio Selección de grupo de estudio Primero seleccionamos los niños y niñas que dejaron la secundaria. Esto se hace en el menú: Datos > Seleccionar casos… Seleccionamos “Si satisface la condición“, presionamos el botón “Si…” y escribimos la fórmula: P7N = "S" Presionamos el botón continuar, y en la siguiente ventana el botón “Aceptar”. Prueba de contraste de hipótesis con el programa SPSS Con la base de datos abierta en la ventana de datos del SPSS, con los registros seleccionados, activamos la secuencia: Analizar > Estadísticos descriptivos > Tablas de contingencia… Por consenso en los estudios sociales, colocamos en la ventana “Filas” la variable que consideremos como independiente (criterio o exposición) en este caso Sexo [P5], y en la ventana “Columnas” la variable dependiente (resultado, efecto, outcome) que corresponde a Papá le anima para seguir estudiando [P13a]. Es interesante señalar la celdilla de “Mostrar los gráficos de barras agrupadas”. En el botón “Exactas…” definimos el método de cálculo que deberá quedar seleccionado el método “Exacta” y sin límite de tiempo por prueba (que no marque el cuadrado). De la siguiente manera: Al terminar con esta ventana presionar el botón “Continuar.” En el botón “Estadísticos…” vamos a marcar Chi-cuadrado1 y Riesgo. En estricto sentido se escribe 𝜒 2 , y se pronuncia como “ji-cuadrado”, pero por compatibilidad con SPSS se utiliza este término Chi-cuadrado. 1 Al terminar con esta ventana presionar el botón “Continuar.” Presionamos el botón “Casillas”, aquí señalado la casilla correspondiente (filas) en la pestaña "Casillas..." para que nos muestre los recuentos en cada celda y sus porcentajes respecto a la fila. El resultado que se obtiene en la ventana de resultados del SPSS cuando presionamos el botón “Aceptar”: Esta primera tabla explica el total de casos analizados y si hubo casos perdidos (individuos que no tuvieran un valor recogido en alguna de las dos variables analizadas en el contraste). Resumen del procesami ento de los casos N Sexo * Papá le anima para seguir estudiando Casos Perdidos N Porcent aje Válidos Porcent aje 41 100.0% 0 Total Porcent aje N .0% 41 100.0% Luego aparece la tabla de contingencia, que en este caso concreto es una tabla 2x2. Tabla de contingencia Sexo * Papá l e anima para seguir estudiando Sexo Hombre Mujer Total Papá le anima para seguir estudiando Falso Verdadero 16 11 59.3% 40.7% 13 1 92.9% 7.1% 29 12 70.7% 29.3% Recuent o % de Sexo Recuent o % de Sexo Recuent o % de Sexo Total 27 100.0% 14 100.0% 41 100.0% E inmediatamente aparece la ventana con el contraste Chi-cuadrado. SPSS realiza la Chi-cuadrado y aporta también la corrección por continuidad (corrección de Yates2), la razón de verosimilitud y el test exacto de Fisher. Pruebas de chi -cuadrado Valor Chi-cuadrado de Pearson Corrección por a continuidad Razón de v erosimilitudes Estadí stico exact o de Fisher N de casos v álidos Sig. asintótica (bilateral) gl b 5.027 1 .025 3.535 1 .060 5.868 1 .015 Sig. exacta (bilateral) Sig. exacta (unilateral) .033 .025 .033 .025 .033 .025 41 a. Calculado sólo para una tabla de 2x2. b. 1 casillas (25.0%) tienen una f recuencia esperada inf erior a 5. La f recuencia mínima esperada es 4.10. Nos fijamos en el Estadístico exacto de Ficher para la columna Sig. exacta (bilateral), que llamamos p. Este valor de p indicará la probabilidad de obtener una diferencia entre los grupos mayor o igual a la observada, bajo la hipótesis nula de independencia. Si esta probabilidad es pequeña (p<0.05) se deberá rechazar la hipótesis de partida y deberemos asumir que las dos variables no son 2 La corrección de Yates para la continuidad previene la sobrestimación de la significación estadística para los datos pequeños. Este método se utiliza principalmente cuando por lo menos una celda de la tabla tiene una frecuencia esperada menor a 5. Desafortunadamente, la corrección de Yates puede tender a subestimar. Esto puede dar lugar a un resultado excesivamente conservador que no pueda rechazar hipótesis nula cuando debe. independientes, sino que están asociadas. En caso contrario, se dirá que no existe evidencia estadística de asociación entre ambas variables. Entonces si p es menor a 0.05, decimos que hay diferencias. Tenemos 0.033 < 0.05, entonces hay un trato diferente por parte de los padres con respecto a niños y niñas que dejan la secundaria para alentarlos a seguir estudiando. Por último, el programa SPSS -si se lo hemos indicado marcando “Riesgo”- nos hace una evaluación de la fuerza que asocia (o no) a ambas variables, calculando OR y RR. Esti mación de riesgo Valor Razón de las v ent ajas para Sexo (Hombre / Mujer) Para la cohort e Papá le anima para seguir estudiando = Falso Para la cohort e Papá le anima para seguir estudiando = Verdadero N de casos v álidos Interv alo de conf ianza al 95% Inf erior Superior .112 .013 .984 .638 .452 .901 5.704 .817 39.797 41 También nos aporta el Intervalo de confianza del 95% para la OR, que se sitúa entre 0.13 y .984 (primer renglón de este cuadro). Con ello sabemos dos cosas: primero que el contraste de hipótesis debe ser significativo, esto es, que se rechazará la hipótesis nula de la "no-asociación entre las dos variables", ya que la OR no contiene el valor 1 (donde habría equidad en el trato); segundo que el intervalo de confianza es muy ancho y, por tanto, la estimación que hacemos de la verdadera OR (en la población) muy imprecisa, llegando a concluir que se incentiva más a hombres que mujeres por parte de los padres, pero con un rango de diferencia entre 1.02 y 78.6 veces más a hombres que a mujeres (con valor esperado en 9). Estos números son los inversos multiplicativos de los valores de la tabla. Por último podemos ver el gráfico de barras agrupadas para cada categoría de la variable dependiente (Papá le anima para seguir estudiando). A simple vista se aprecia la mayor proporción de hombres que les anima su papá para seguir estudiando. Código en sintaxis SPSS USE ALL. COMPUTE filter_$=(P7N = "S"). VARIABLE LABEL filter_$ 'P7N = "S" (FILTER)'. VALUE LABELS filter_$ 0 'No seleccionado' 1 'Seleccionado'. FORMAT filter_$ (f1.0). FILTER BY filter_$. EXECUTE . CROSSTABS /TABLES=P5 BY P13a /FORMAT= AVALUE TABLES /STATISTIC=CHISQ RISK /CELLS= COUNT ROW /COUNT ROUND CELL /BARCHART /METHOD=EXACT TIMER(0). Segundo ejemplo Ahora nos enfocamos a realizar la prueba para el siguiente enunciado: “Los niños y niñas que abandonaron la escuela tienen diferencias por urbano – rural en relación a que sus hermanos les animen para seguir estudiando”. Esto involucra las variables UR y P13c, realizamos los mismos pasos que el ejemplo anterior, pero no seleccionamos ningún grupo específico de población, que estén todos los niños y niñas seleccionados. La tabla de contingencia arroja el siguiente resultado: Tabla de contingencia Urbano / Rural * Hermanos les animan para seguir estudiando Urbano / Rural Rural Urbano Total Recuento % de Urbano / Rural Recuento % de Urbano / Rural Recuento % de Urbano / Rural Hermanos les animan para seguir estudiando Falso Verdadero 31 5 86.1% 13.9% 26 13 66.7% 33.3% 57 18 76.0% 24.0% Total 36 100.0% 39 100.0% 75 100.0% Pruebas de chi -cuadrado Valor Chi-cuadrado de Pearson Corrección por a continuidad Razón de v erosimilitudes Estadí stico exact o de Fisher N de casos v álidos Sig. asintótica (bilateral) gl b 3.880 1 .049 2.888 1 .089 4.002 1 .045 Sig. exacta (bilateral) Sig. exacta (unilateral) .061 .043 .061 .043 .061 .043 75 a. Calculado sólo para una tabla de 2x2. b. 0 casillas (.0%) tienen una f recuencia esperada inf erior a 5. La f recuencia mínima esperada es 8.64. Observamos que la nota b, de este cuadro, indica que 0 casillas tiene una frecuencia esperada inferior a 5 (0% < 20%), y la frecuencia mínima esperada es 8.64, lo cual significa que debemos utilizar el Chi-cuadrado de Pearson para realizar el test, entonces consideramos el valor de este renglón que corresponde a la columna Sig. asintótica (bilateral), es decir p = 0.049, como p < 0.05, rechazamos la hipótesis nula es decir tenemos evidencia para afirmar que los hermanos en las áreas rurales son diferentes de las áreas urbanas con respecto a animar para seguir estudiando. De paso tenemos la interpretación de que en las áreas urbanas los hermanos animan más para seguir estudiando que en las áreas rurales. Tercer ejemplo El tercer ejemplo está basado en probar el siguiente enunciado “Que los niños reciban ayuda con su tarea de parte de sus padres, no está relacionado con que tenga una buena comunicación con ellos”. En particular, combina respuestas de dos cuestionarios diferentes, uno a niños y otro a tutores. Como se trata de cruce de variables entre dos instrumentos, primero seleccionamos el conjunto de registros donde es válida esta operación, es decir donde obtuvimos información de los tutores. Esto es, utilizamos el filtro: TUnico = 1 | TUnico = 0, En el menú: Datos / Seleccionar casos… Después realizamos el cruce de variables con las variables T34 con la P11, que son las variables con las que se construye la afirmación. Igual que en el primer ejemplo, obtenemos los siguientes cuadros cuando ejecutamos las tablas de contingencia: Tabla de contingencia Comunicación y relación que tiene el tutor con su hijo * Le ayudaban con la tarea Recuento Nunca Comunicación y relación que tiene el tutor con su hijo Total Excelente Buena Regular Mala 2 16 15 2 35 Le ay udaban con la tarea A v eces Seguido 1 1 18 0 8 1 1 0 28 2 Siempre 1 1 2 0 4 Total 5 35 26 3 69 Pruebas de chi -cuadrado Valor Chi-cuadrado de Pearson Razón de v erosimilitudes Estadí st ico exact o de Fisher N de casos v álidos Sig. asintótica (bilateral) gl a Sig. exacta (bilateral) 11.702 9 .231 .245 9.591 9 .385 .404 11.439 .204 69 a. 12 casillas (75. 0%) tienen una f recuencia esperada inf erior a 5. La f recuencia mí nima esperada es .09. Entonces p = 0.204, mayor que 0.05, por lo que no tenemos evidencia para rechazar la hipótesis nula, es decir no podemos establecer una asociación entre ambas variables y concluimos su independencia, que es lo que queríamos demostrar. Anexo Notas En cualquiera de las siguientes situaciones se recomienda utilizar el test exacto de Fisher: 1. Si más del 20% de las frecuencias esperadas son menores que 5. Además, no es posible recombinar las categorías adecuadamente para tener menos categorías en la tabla de contingencia. 2. El total de muestras del estudio, para la población de interés, es menor a 20. Sí ninguna de las dos situaciones anteriores se cumple, entonces utilizamos el valor de Chi-cuadrado de Pearson. Situaciones en las cuales es válido el test exacto de Fisher: 1. Ambas variables de interés son dicotómicas o de categorías finitas, recomendado para tablas de 6x6 o menores debido al tiempo de cálculo que puede ser excesivo para una computadora moderna. En tablas grandes que no cubran los requisitos de la prueba Chi-cuadrado de Pearson se utilizan métodos recursivos que aproximan la solución. 2. La asignación de cada categoría son mutuamente excluyentes. 3. Los datos contenidos en la tabla son frecuencias, no porcentajes. La hipótesis nula y la alternativa son: H0: No hay asociación entre las categorías de un factor y las categorías del otro factor en la población. H1: Los dos factores están asociados en la población. El siguiente diagrama de flujo provee las reglas de decisión utilizadas para elegir correctamente el valor de p. ¿Es el cuadro una tabla de 2x2? Sí No La frecuencia mínima esperada es menor a 5. Menos del 20% de las casillas tienen una frecuencia esperada inferior a 5. Sí No Chi-cuadrado no es válido, realizar el Estadístico Exacto de Fisher. Tomar Chi-cuadrado de Pearson. (Ver primer ejemplo) (Ver segundo ejemplo) Importante: Los criterios utilizan las frecuencias esperadas, no las observadas. Esta información se encuentra al pie de las tablas. No La frecuencia mínima esperada es mayor que 1. Sí Recombinar las categorías, agrupar o simplificar columnas o renglones, repetir desde el inicio de este diagrama de flujo. Tomar Chi-cuadrado sin corrección. Si vuele a caer aquí y la tabla es 6x6 o menor, considerar el Estadístico Exacto de Fisher. (Ver tercer ejemplo) Referencias http://www.exactoid.com/fisher/index.php?a=16&b=11&c=13&d=1 http://www.fisterra.com/mbe/investiga/fisher/fisher.asp#fisher http://www.physics.csbsju.edu/cgi-bin/uncgi/stats/fisher.sh http://www.physics.csbsju.edu/stats/exact_NROW_NCOLUMN_form.html http://en.wikipedia.org/wiki/Fisher's_exact_test Bibliografía A Handbook of Numerical and Statistical Techniques: With Examples Mainly from the Life Sciences, J. H. Pollard, CUP Archive, 1979. A handbook of statistical analyses using SPSS, Sabine Landau, Brian Everitt, CRC Press, 2004. Categorical data analysis, Alan Agresti, John Wiley and Sons, 2002. Complex datasets and inverse problems: tomography, networks, and beyond, Volumen 54 de Lecture notes-monograph series, Regina Y. Liu, William E. Strawderman, Cun-Hui Zhang, IMS, 2007. Estadística para la investigación biomédica, Edward N. Armitage, G. Berry, Elsevier España, 1997. Exact analysis of discrete data, Karim F. Hirji, CRC Press, 2006 Handbook of parametric and nonparametric statistical procedures, David Sheskin, CRC Press, 2004. Statistics using SPSS: an integrative approach, Sharon L. Weinberg, Sarah Knapp Abramowitz, Cambridge University Press, 2008. PDQ statistics, Geoffrey R. Norman, David L. Streiner, PMPH-USA, 2003. Practical statistics for medical research Texts in Statistical Science Series Statistics texts, Douglas G. Altman, CRC Press, 1991. Sample size calculations in clinical research, Shein-Chung Chow, Jun Shao, Hansheng Wang, CRC Press, 2007. SPSS for introductory statistics: use and interpretation, George Arthur Morgan, Lawrence Erlbaum Associates, 2004. Statistical applications for health information management, Carol E. Osborn, Jones & Bartlett Publishers, 2005. Statistics for the social sciences, R. Mark Sirkin, SAGE, 2006.