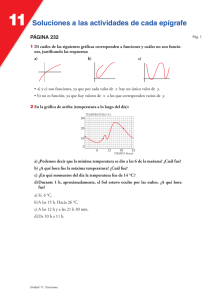
Diseño de un algoritmo de clasificación de nubes a partir de sus
Anuncio

Ciencias de la Tierra y el Espacio, julio-diciembre, 2014, Vol.15, No.2, pp.124-138, ISSN 1729-3790 Diseño de un algoritmo de clasificación de nubes a partir de sus características geométricas y de textura en imágenes de satélite Lianet Hernández-Pardo*(1) e Israel Borrajero-Montejo (2) (1) (2) Centro de Previsão de Tempo e Estudos Climáticos, Instituto Nacional de Pesquisas Espaciais, Brasil. E-mail: [email protected] Centro de Física de la Atmósfera, Instituto de Meteorología, Cuba. E-mail: [email protected] Recibido: noviembre 21, 2013 Aceptado: mayo 5, 2014 Resumen Se desarrolló un algoritmo de clasificación de nubes, a partir de las informaciones contenidas en imágenes de satélite visibles e infrarrojas, teniendo en cuenta criterios geométricos y de textura. Se valoraron dos métodos de detección de proyecciones de nubes: mediante análisis de radiancia espectral en los canales visible e infrarrojo y mediante análisis de textura en imágenes visibles. En las regiones delimitadas por análisis de radiancia espectral se evaluaron variables referentes a su forma y textura. Para crear las clases se utilizó el método de identificación de agrupamientos PAM (Partitioning Around Medoids), disponible en el software R. Los mejores agrupamientos se obtuvieron dividiendo en tres clases el espacio generado por las variables: área, perímetro y promedio del módulo del gradiente del nivel digital en la imagen visible. La clasificación lograda puede ser útil en la identificación de patrones referentes a condiciones meteorológicas análogas. Palabras clave: clasificación, geometría, nubes, satélite, textura Design of a cloud classification algorithm based on its geometric and texture features in satellite imagery Abstract A cloud classification algorithm was developed based on information contained in visible and IR satellite images, taking into account texture and geometrical criteria. Two methods of clouds detection were considered: through spectral radiance analysis in the visible and IR channels and through texture analysis in visible images. In regions delimited by the spectral radiance, variables related to form and texture were evaluated. To create the classes, the PAM (Partitioning Around Medoids) clustering method available from R software was applied. The best clusters were obtained dividing into three classes the space generated by the variables area, perimeter and average of the gradient of the visible image. The classification achieved can be useful in the identification of patterns related to analogous meteorological conditions. Key words: classification, clouds, geometry, satellite, texture 1. Introducción En meteorología, uno de los elementos que se pronostica es la nubosidad, aspecto que influye, además, sobre el balance de radiación (Bass et al., 2010; Goryachev y Mogilnitsky, 2008) y los valores de la temperatura del aire, del suelo y de la superficie marina (Schneider et al., 1978; Svensmark y Friis-Christensen, 1997; Zmudzka, 2008). Las nubes provocan dos efectos simultáneos y opuestos sobre el clima. Por un lado, reflejan la radiación solar e inducen un enfriamiento; por el otro, interfieren en la salida de la radiación terrestre y contribuyen al calentamiento (Ambach, 1974; Sanchez-Lorenzo et al., 2012; Wetherald y Manabe, 1980). El modo y la magnitud de dicha influencia están determinados por la densidad, la altura, el espesor, entre otros elementos de la cobertura nubosa. Lianet Hernández Pardo* Centro de Previsão de Tempo e Estudos Climáticos, Instituto Nacional de Pesquisas Espaciais. Rodovia Dutra, km 39, Cachoeira Paulista, São Paulo, Brasil. E-mail: [email protected] 124 Hernández-Pardo y Borrajero-Montejo La clasificación de la nubosidad se realiza comúnmente de forma visual desde estaciones en superficie, proceso en el que intervienen factores subjetivos como la experiencia, la agudeza visual y la perspectiva del observador. En Cuba existe una red de 68 estaciones meteorológicas con una densidad variable. Ciertos puntos de la bóveda celeste se pueden observar a la vez desde dos estaciones vecinas (en dependencia de su altura con respecto al nivel del terreno y de la distancia entre ellas), pero para que el área observable desde cada estación se solape con la de las estaciones contiguas, de modo que se pueda construir un campo continuo de observaciones de nubosidad, se requiere aumentar la densidad de la red. Esta dificultad se puede enfrentar acudiendo a la teledetección. El servicio meteorológico nacional de Cuba cuenta con una estación receptora de imágenes del satélite meteorológico GOES-E. La extracción de información de esas imágenes mediante la interpretación visual/manual es una tarea engorrosa y sus resultados dependen del operador. En el Instituto de Meteorología de Cuba se encuentran en fase de prueba algoritmos de detección de nubes para la estimación de la temperatura superficial del mar, el cálculo de la cobertura nubosa y de la precipitación (Suárez, 2010; Trujillo, 2011; Quevedo, 2012). Lavastida (2005) y Bárcenas (2011) implementaron técnicas de clasificación de nubes usando imágenes de satélite. Los métodos de clasificación de nubes desarrollados en Cuba hasta ahora, a partir de datos satelitales, se basan en técnicas espectrales. En ellos, mediante criterio de expertos, se asocia cada píxel perteneciente a una muestra multiespectral, a un tipo específico de nube, se agrupan en clases y se realiza un análisis probabilístico. Su mayor incertidumbre radica en los casos en que las probabilidades correspondientes a diferentes clases son semejantes, y en los que la probabilidad de pertenecer a cualquiera de las clases es pequeña. En ese punto es necesario aplicar otro criterio de clasificación. De ahí surge el problema científico de cómo implementar un método de análisis de la nubosidad, a partir de imágenes de satélite, que fortalezca la confiabilidad de los resultados alcanzados en Cuba en esa materia. Desde Tierra o desde la órbita de un satélite, se puede distinguir en las nubes diferencias y similitudes en cuanto a su geometría y textura. Lo anterior sugiere que es posible clasificar la nubosidad basándose en la representación de sus características geométricas y de textura en las imágenes satelitales, desarrollar un método para lograrlo, constituye el objetivo general de esta investigación. La elaboración de un eficiente método de clasificación de nubes puede ser de considerable utilidad en la confección y evaluación de los pronósticos diarios, gracias a que facilita en gran medida la interpretación operativa de las imágenes de satélite. Es una herramienta de potencial aplicación en el análisis del balance de radiación, en particular en la estimación de la radiación solar incidente. Podría, además, contribuir a la modelación del comportamiento de otras variables meteorológicas, como la temperatura del aire en superficie. 2. Materiales y métodos Se utilizaron imágenes de satélite en formato TIFF provenientes de mediciones realizadas con el satélite GOES 12 en los canales visible e infrarrojo (IR). Su resolución es de 1136 x 424 y 284 x 106, respectivamente. Un píxel en la imagen visible equivale a un área de 1 km 2, mientras en la IR, un píxel equivale a 16 km2. Esquema general de trabajo: Para delimitar regiones que se puedan asumir como proyecciones de nubes individuales (en lo adelante: regiones), fueron valorados dos métodos, el primero de ellos, la detección de nubes y su clasificación en tres tipos usando las funciones de probabilidad en dependencia de los niveles digitales en las imágenes visibles e IR correspondientes; y en segundo lugar la detección de zonas de textura semejante mediante el uso de las matrices de coocurrencia de niveles de gris. Una vez definido el modo de delimitar regiones, se analizó la posibilidad de diferenciar clases entre ellas. Para esto se utilizaron variables referentes a su forma y a su textura, y se experimentó con el método Partitioning Around Medoids, del software R para la detección de agrupamientos. A continuación se detallan los métodos utilizados. 2.1. Análisis de radiancia espectral Para analizar la radiancia espectral en diferentes bandas del espectro para un mismo punto, se trabajó con los valores de niveles digitales de píxeles análogos en imágenes visibles e infrarrojas. Como la resolución de la imagen visible es dieciséis veces mayor que la de la imagen IR, para generar una máscara cuya resolución fuera igual a la de la imagen del satélite visible se utilizó, al clasificar un píxel en una posición (i;j), el valor de nivel digital del píxel en la misma posición en la imagen visible y el del píxel en la posición [parte entera(i/4);parte entera(j/4)] en la imagen IR. 125 Algoritmo de clasificación de nubes 2.1.1 Funciones de probabilidad Empleando el criterio de expertos, Lavastida (2005) generó, para cada clase (mar, tierra, cumulus, cumulonimbus y cirrus), matrices de 256 x 256 que, en cada posición (i; j), guardan un valor proporcional a la probabilidad de que un punto con niveles digitales i y j en imágenes de satélite visible e IR, respectivamente, corresponda a la clase en cuestión. Dicho valor se considera la imagen de la función fc[i;j] denominada función de probabilidad (el subíndice c se refiere a la clase). Según el método de Lavastida (2005), la clasificación se deriva de una comparación, en cada punto, entre los valores de las fc[i;j], la clase asignada sería la de mayor probabilidad (Fig. 2a). En las zonas donde coexisten varios tipos de nubes en el mismo punto del plano de la imagen pero a diferente altura en la atmósfera, el criterio de expertos prioriza uno de ellos, en dependencia de su importancia según el fenómeno que produzca o simplemente por la fortaleza relativa de la evidencia visual de su existencia (v.g., si existen evidencias de la presencia de un cumulonimbus en el área ocupada por un píxel, se establece dicho tipo de nube como la clase presente en ese punto, aunque en sus topes haya cirrus, como ocurre en el caso representado en la figura 2a). 2.1.2 Modificación en la aplicación de las funciones de probabilidad Al evaluar las funciones de probabilidad en un punto (i;j) es posible encontrar diferentes situaciones (Fig.1): i. Todas las clases poseen una probabilidad relativamente baja (región señalada con el número 1 en la Figura 1). ii. Al menos una de las clases posee alta probabilidad. a) Solo una de las clases tiene alta probabilidad (zona identificada con el número 2 en la Figura 1). b) Las probabilidades de varias clases son similares y relativamente altas (zona identificada con el número 3 en la Figura 1). Fig. 1. Comportamiento de las funciones de probabilidad. Las etiquetas (números) señalan regiones con valores peculiares de fc[i;j]. Los óvalos encierran zonas donde se aplica la etiqueta 2. De estas situaciones, las que conducen a mayor incertidumbre en la clasificación son la i e la ii-b). Dado un píxel en la posición (i;j) dentro de una imagen, la probabilidad absoluta de que su contenido pertenezca a la clase l es el valor de la función de probabilidad correspondiente a dicha clase, evaluada en (i;j). La probabilidad relativa se define como la razón entre la probabilidad absoluta de pertenecer a la clase l y la suma de las probabilidades absolutas de pertenecer a cada clase y se expresa en porciento: donde p[l] representa la probabilidad relativa de pertenecer a la clase l , P[l] la probabilidad absoluta de pertenecer a la clase l y L es la cantidad total de clases. Al aplicar la restricción de que la suma de las probabilidades absolutas supere cierto valor se elimina la primera posibilidad relacionada. 126 Hernández-Pardo y Borrajero-Montejo Asumiendo el criterio de que, para asignar el contenido de un píxel a una clase, su probabilidad relativa debe superar cierto umbral, se precisó la proporción deseada entre la probabilidad absoluta de la clase elegida (le) y la suma de las probabilidades absolutas de las restantes, medida utilizada para neutralizar la influencia de la situación ii-b). Por lo general, en las imágenes de satélite, las fronteras de las nubes no están bien definidas, y el aspecto de los píxeles cercanos o pertenecientes a la frontera suele ser similar al de otros tipos de nubes, de ahí que la probabilidad absoluta de la clase elegida sea menor hacia los bordes de las nubes que hacia su interior. Por tanto, al exigir que la probabilidad supere cierto umbral, los píxeles de la frontera de las nubes se eliminan de la muestra, lo que causa una modificación en su perímetro, como se puede observar en la figura 2 (b). Para minimizar (o anular) este efecto indeseado se adoptó el siguiente criterio: 1. Asignar a cada píxel la clase de mayor probabilidad relativa 2. Analizar y restringir la distribución de p[le] dentro de las regiones delimitadas Así, para conformar la muestra, en lugar de adicionar píxel a píxel según su probabilidad, la decisión se centró en aglomerados de píxeles considerados proyecciones de nubes en el plano de la imagen. Es decir, si una región no cumple con los criterios establecidos para la distribución de probabilidad en sus píxeles, se excluye por completo, no solo aquellos píxeles con baja probabilidad, pues esto causaría una modificación en su forma y al incluir dicha región, se introduciría una fuente de error adicional. El promedio, como medida estadística de la distribución de p[le] dentro de una región, puede ser alto por la existencia de valores extremos, aunque estos se concentren en poca cantidad de píxeles. Resulta más significativo la presencia de valores relativamente altos de probabilidad distribuidos en la mayor cantidad de píxeles posible. De ahí que el criterio utilizado para restringir la distribución de p[le] fuera: porciento de píxeles con p[le] ≥ p o superior a un valor Co, siendo po y Co enteros positivos, menores que cien. Se excluyó de la muestra aquellas regiones cuya área fuera menor de 200 km2, pues resultan poco representativas de la realidad, producto de la resolución de medición del sensor. Fig. 2. Aplicación de las funciones de probabilidad a la detección de proyecciones de nubes individuales. Las regiones representadas con color rojo corresponden a regiones calificadas como cumulus, las azules a cumulonimbus y las blancas a cirrus. a) Clasificación obtenida a partir del criterio diseñado por Lavastida (2005) b) Clasificación obtenida al exigir mayores valores de probabilidad relativa en cada punto 2.1.3. Análisis de textura Teniendo en cuenta la relación espacial promedio entre los niveles de gris presentes en una imagen se puede extraer información sobre su textura. Las matrices de coocurrencia de niveles de gris (GLCM) consideran la relación entre dos píxeles, llamados píxel de referencia y píxel vecino. En cada posición (i;j) de la GLCM se guarda la cantidad de veces que en la imagen analizada se encuentra un píxel con nivel digital i, seguido de uno con nivel digital j en una dirección θ y a una distancia d, en ambos sentidos de exploración. Por tanto, la GLCM será simétrica y tendrá tantas filas y columnas como niveles digitales contenidos en la imagen (Haralick et al., 1973). Para que la información extraída no dependa del tamaño de la imagen a analizar, se debe normalizar la GLCM, dividiendo cada valor por la cantidad de pares de píxeles analizados. Esta técnica se puede aplicar a una imagen de forma íntegra, (i.e., calculando solo una GLCM para cada dirección y distancia de píxeles vecinos escogidos) o por secciones (ventanas), tomando cada sección como una imagen independiente y calculando sus respectivas GLCM. 127 Algoritmo de clasificación de nubes Para cada GLCM se pueden calcular magnitudes referentes a la textura de la imagen. Haralick et al. (1973) sugieren catorce variables que ayudan a interpretar la información contenida en una GLCM (Hall-Beyer, 2008). Las usadas en esta investigación fueron: Contraste donde P(i,j) es el valor de la GLCM en la posición (i,j) y N es la cantidad de niveles digitales presentes en la imagen. Al multiplicar P(i,j) por (i – j)2 se le adjudica un "peso" a cada valor de la GLCM que depende de su distancia a la diagonal. Mientras mayores sean los valores alejados de la diagonal, mayor contraste tendrá la imagen. Segundo Momento Angular Cada valor de la GLCM se toma como peso para sí mismo. Si la GLCM está muy ordenada, se obtienen altos valores de esta variable. Entropía Para P(i,j) = 0 se asume que entropía es igual a cero. El máximo de la suma (i.e. Entropía) se alcanza cuando P(i,j) es el mismo en cada punto. Conceptualmente esto tiene sentido, porque si todas las combinaciones de niveles digitales tienen la misma probabilidad de ocurrir en una imagen, quiere decir que sus valores fueron distribuidos aleatoriamente, lo que conduce al máximo de desorden o entropía. Correlación donde µi representa la media, por filas, de los valores de la GLCM; µj, la media, por columnas, de los valores de la GLCM y (σi)2 y (σj)2, las respectivas varianzas. 128 Hernández-Pardo y Borrajero-Montejo Si el área de la imagen es completamente uniforme, la varianza de la GLCM es 0, y se indefine la expresión, en este caso, se establece el valor 1, porque la imagen está, en efecto, perfectamente correlacionada. Esta variable mide la dependencia lineal entre los niveles de gris de píxeles vecinos (el píxel de referencia y el vecino designado). Usando imágenes visibles, se elaboraron GLCM para “ventanas" de 8 x 8 píxeles, que se superponen a lo largo y ancho de toda la imagen. Se calcularon las magnitudes de textura según las expresiones (2), (3), (4) y (5) y se asignó su valor por cada ventana al píxel en la posición (4;4) dentro de ella (Fig. 3). Como consecuencia se obtuvo una matriz de 1129 x 417 para cada variable calculada. Considerando como objeto cada posición en dicha matriz, se sometió a un método de agrupamiento (ver sección 2.5) el conjunto de valores de las variables calculadas. El resultado de asignar a cada píxel el código correspondiente a un grupo determinado, es una imagen clasificada según su textura. Fig. 3. Modo de empleo de las ventanas en el análisis de la textura de una imagen 2.2. Exploración de regiones Para explorar una región en una imagen I, cualquiera que fuera su forma, se implementó un algoritmo recursivo que funciona según las operaciones representadas en el diagrama de flujo de la Figura 4. Fig. 4. Diagrama de flujo del algoritmo para la exploración de regiones 2.3. Magnitudes empleadas Una vez definidas las regiones, se calcularon magnitudes referentes a su forma y a su textura. Como variables relacionadas con la forma se utilizaron: el área, el perímetro y la razón de aspecto (elongación); mientras que, relativas a la textura, se emplearon el promedio del módulo del gradiente de nivel digital en la imagen visible y las variables que extraen información de las GLCM, elaboradas teniendo en cuenta la distribución de niveles digitales de la imagen visible en cada región, según las expresiones (2), (3), (4) y (5). Además se emplearon el promedio del nivel digital en la imagen visible y en la imagen IR, que no pertenecen directamente a ninguna de las categorías mencionadas, pero brindan importante información sobre la naturaleza del fenómeno objeto de estudio. El cálculo de las variables relacionadas con la forma se aplicó a regiones provenientes de imágenes de satélite tomadas con intervalos de tiempo de 3,5 horas, período en que se considera que la forma de las nubes varía considerablemente. Dicha medida evita introducir errores por sobrevaloración del “peso” de los casos analizados. Por otra parte, la textura de la imagen visible depende del ángulo de incidencia de la radiación solar. Para evitar 129 Algoritmo de clasificación de nubes introducir variaciones en los resultados, producto de diferencias en las condiciones iniciales, se trabajó con una imagen diaria correspondiente a la misma hora durante cada día del mismo mes. 2.3.1. Área y perímetro Se utilizó el algoritmo descrito en la Sección 2.3 para recorrer todos los puntos pertenecientes a cada región (nube) detectada. El aporte de cada píxel al área y al perímetro depende de su localización dentro de la región correspondiente. Se define como frontera todo punto (i, j) en la imagen I que cumpla alguna de las siguientes condiciones: Si se cumple solo una de las condiciones anteriores, el aporte al área (A) es de 1 km2 y al perímetro (P) de 1km. Si se cumplen dos condiciones, se considera como aporte al perímetro la diagonal del cuadrado de arista unitaria, 2 1/2 km y al área, ½ km 2. Si se cumplen tres condiciones, el aporte al perímetro es 21/2 km y al área ¼ km2. Se excluye la posibilidad de que se cumplan las cuatro condiciones a la vez, pues correspondería a una región de solo un píxel de área. Si no se comprueba ninguna de las relaciones antes descritas, se considera que el punto en cuestión pertenece a la región interior de la nube, por lo que no aporta al perímetro, mientras que suma al área 1km2. 2.3.2. Dimensión fractal Para el cálculo de la dimensión fractal se utilizó el método área-perímetro. Se consideró como dimensión fractal (D) el valor resultante del ajuste de la expresión (8) para un conjunto amplio de mediciones de área (A) y perímetro (P). Haciendo Y=log P; X=log A y C=log C. Se utilizó el software Gnuplot para el ajuste de los datos y el análisis del error en los parámetros ajustados. 2.3.3. Razón de aspecto Se definió la razón de aspecto de una figura como la mayor relación entre uno de sus ejes y el eje perpendicular a él. La medición de la longitud de los ejes se realizó calculando la cantidad de píxeles que, en una dirección dada, se encontraron desde el centro hasta la frontera en ambos sentidos. Las direcciones de los ejes fueron definidas por intervalos de 5º desde 0 o hasta 360º. Las coordenadas del centro geométrico de cada figura fueron calculadas como el promedio de las abscisas y las ordenadas de todos los puntos dentro de la misma. Módulo del gradiente de nivel digital en la imagen visible Se calculó el módulo del gradiente de nivel digital en la imagen visible (GND) dentro de las regiones delimitadas, según la expresión: 130 Hernández-Pardo y Borrajero-Montejo donde N es el nivel digital del píxel analizado en la matriz donde se almacenan los valores de niveles digitales de la imagen. Método de agrupamiento Para la detección de agrupamientos en los datos se utilizó el software R, mediante el método PAM (Partition Around Medoids) (Kaufman y Rousseeuw, 1990). El método consiste en seleccionar k objetos (llamados objetos representativos) en el conjunto de datos. Los grupos se construyen asignando cada objeto restante al objeto representativo más cercano. Estos deben elegirse de forma tal que se localicen en el centro del grupo que definen, o sea, que la distancia promedio entre ellos y los restantes objetos de su grupo sea mínima. Como medida de distancia se utilizó la Distancia Euclidiana: El método PAM proporciona como salida gráfica una “silueta” del agrupamiento. En ella se representa el valor de una función S(i) característica de cada objeto i del conjunto, y que depende del agrupamiento logrado. S(i) se define de la siguiente manera (Kaufman y Rousseeuw, 1990): Tómese cualquier objeto i del conjunto. Sea A el grupo a que se ha asignado i y a(i) la distancia promedio entre i y todos los objetos de A. Sea C cualquier grupo diferente de A, se define d(i,C) como la distancia promedio de i a todos los objetos de C. Se selecciona b(i) como el mínimo de d(i,C). El grupo B para el cual se detectó b(i) se llamará “vecino” de i (su segunda mejor opción para agruparse). Entonces, S(i) se puede calcular mediante la expresión: Como la construcción de b(i) depende de la disponibilidad de grupos diferentes de A, las “siluetas” no se definen para el caso trivial de agrupamiento (cantidad de clases = 1). S(i) indica cuán confiable es el agrupamiento, mientras más se acerque a 1, con mayor certeza pertenece el objeto en cuestión al grupo asignado. El promedio de S(i) para i= 0,1,2,…,n, S(k) (siendo k la cantidad de grupos en que se dividió el conjunto), se puede utilizar para seleccionar el mejor valor de k (Kaufman y Rousseeuw, 1990). 3. Resultados 3.1. Detección de regiones 3.1.1. Análisis de radiancia espectral El análisis del comportamiento de los valores de niveles digitales en las imágenes visible e IR (Fig. 5 a, b) para un mismo punto (píxel) mediante las funciones de probabilidad permitió delimitar regiones que pueden asumirse como proyecciones de nubes individuales (Fig. 5 c), aunque la baja resolución de la imagen limita la definición individual de los cumulus. 131 Algoritmo de clasificación de nubes (a) (b) (c) Fig. 5. Ejemplo de utilización de una imagen visible y una IR para detectar regiones asociadas a diferentes tipos de nubes a) Imagen visible b) Imagen IR c) Clasificación producto del análisis de radiancia espectral en los canales visible e IR Por la naturaleza de las funciones de probabilidad (i.e., criterio de expertos), que prioriza un tipo de nube cuando hay multicapas, los cirrus que se forman por la circulación vertical de los cumulonimbus, y que se extienden sobre (y radialmente desde) sus topes, aparecen solo como arcos alrededor de cumulonimbus. Al estudiar la geometría de las nubes esto debe constituir una fuente de error. 3.1.2. Análisis de textura Utilizando el método de las GLCM, unido al cálculo de las magnitudes de textura derivadas de ellas y al análisis de agrupamientos en el espacio generado por dichas magnitudes evaluadas en cada punto de la imagen, se logró definir regiones de textura relativamente homogénea en una imagen visible (Fig. 6). Fig. 6. Clasificación producto del análisis de la textura de una imagen visible (ver Fig. 5a) Si se usan cuatro clases, una de ellas (regiones de color verde en la Figura 6) se corresponde con las zonas que contienen cumulus, muy rugosas en la imagen visible; otra (representada en color blanco) coincide con las fronteras de las regiones con cumulus y otra (color rojo), representa regiones de textura más lisa, en ocasiones ocupadas por cirrus. Una clase (color azul) abarca la mayoría de los píxeles de la imagen y refleja la menor variación de textura en la imagen visible, correspondiente a mar, tierra y superficies muy lisas en las nubes, como los cirrus de los topes de los cumulonimbus. La cantidad de tipos de regiones depende de la cantidad de clases definidas en el agrupamiento. A medida que se aumenta el número de clases, disminuye el tamaño de detalle a diferenciar. En una imagen de satélite visible, dentro de un mismo tipo de nube, la textura presenta gran variabilidad, causa de que el método de delimitación de regiones basado en el comportamiento de esta variable detectara zonas de 132 Hernández-Pardo y Borrajero-Montejo naturaleza independiente dentro del área de una nube. Dicho resultado contradice los propósitos prácticos que pretendía alcanzarse al aplicar el método. No obstante, sugiere que podría utilizarse para caracterizar el comportamiento de la rugosidad de los diferentes tipos de nubes. 3.2. Selección de la muestra La muestra se extrajo tomando como criterio que las regiones clasificadas con mayor seguridad fueran aquellas en que más del 70% de sus píxeles cumplieran con p[le] ≥ 90%, en el caso de los cumulonimbus; más del 90% de sus píxeles cumplieran con p[le] ≥ 90%, para los cumulus; y más del 70% de sus píxeles cumplieran con p[le] ≥ 70%, para los cirrus. La elección de los umbrales de distribución de p[le] se realizó mediante un mecanismo de prueba y error. Al definir una cantidad mínima de píxeles Co cuyo valor de p[le] fuera mayor que po, donde Co y po son valores arbitrarios, y establecer dicha combinación como criterio de selección común a todas las clases, la calidad de la muestra resultante fue diferente para cada una de ellas, de ahí la necesidad de estimar estos valores críticos según el tipo de nube. En el caso de los cumulus, se decidió utilizar valores de distribución de probabilidad muy altos para ser estrictos en su selección, pues, en el caso contrario, se introducen regiones no representativas de la clase, producto de la agrupación de regiones en el límite de resolución de la imagen. Al aplicar simultáneamente la restricción en la distribución de probabilidad y la exigencia del límite inferior en el valor del área (200 km2), se elimina la mayoría de los cumulus de la muestra. Luego, las zonas calificadas de cumulus por el método de las funciones de probabilidad están fuertemente influenciadas por la resolución de la imagen y llevan implícita gran incertidumbre. 3.3. Cálculo de magnitudes Se encontraron diferencias entre las magnitudes calculadas para cirrus (Ci) y cumulonimbus (Cb) (como se trabaja con la muestra extraída teniendo en cuenta la distribución de probabilidad no se incluye los cumulus). La variable que más lo refleja es el promedio del nivel digital en la imagen visible (Fig. 7). Para determinar qué variables provocan mayor diferenciación entre los valores correspondientes a cada clase, se debe analizar, además del promedio, una medida de la dispersión de los datos como la desviación absoluta media. Una alta variación en el promedio de una variable de una clase a otra puede resultar insignificante si los intervalos [promedio-desviación;promedio+desviación] presentan un alto grado de solapamiento. Fig. 7. Promedio y desviación absoluta media normalizados1 de las variables calculadas para Ci y Cb Los intervalos correspondientes a las variables que miden promedio de nivel digital en la imágenes visible e IR no muestran solapamiento alguno. El resto de las variables muestra algún grado de solapamiento, que llega al extremo para el perímetro, la elongación (razón de aspecto), el promedio de GND y la correlación. Si, para diferentes clases, una magnitud toma valores comprendidos dentro del mismo intervalo, esta no se puede emplear para determinar a qué clase pertenece un caso; pero, si se construye un espacio multidimensional de variables-criterio, este solapamiento puede neutralizarse, por la conformación de grupos en el espacio n-dimensional que no tienen, necesariamente, que coincidir entre sí. 133 Algoritmo de clasificación de nubes En una representación gráfica del espacio bidimensional formado por los valores de las variables área y perímetro, calculadas según el tipo de nube, se evidencia el solapamiento de los puntos pertenecientes a diferentes clases, característica que se acentúa hacia los bajos valores de área y perímetro (Fig. 8). Fig. 8. Solapamiento de los puntos pertenecientes a distintas clases en el espacio área-perímetro Para normalizar el promedio y la desviación absoluta media se dividieron sus valores por la suma de los promedios de la magnitud correspondiente para cada clase. El ajuste de la relación área-perímetro (A -P) a la muestra seleccionada (regiones confiablemente clasificadas) resultó en diferentes dimensiones fractales para los cumulonimbus (1,27±0,04) y para los cirrus (1,37±0,02). Los valores obtenidos se aproximan razonablemente a los encontrados en la literatura (Benner y Curry, 1998; Lovejoy, 1982). Dichos valores de dimensión fractal generan diferentes expresiones de perímetro en función del área según la clase. Mientras que los intervalos definidos por las bandas de predicción correspondientes, según un 95% de probabilidad, se solapan en gran medida. De lo anterior se deduce que esta magnitud de la fractalidad de la nube no se puede utilizar para clasificar las regiones detectadas. En el espacio tridimensional formado por las variables área, perímetro y promedio de GND (Fig. 9) el mezclamiento de los grupos pertenecientes a diferentes clases de nubes es casi nulo. Si se realizan cortes paralelos al plano A − P la dimensión fractal estará bien definida para cada tipo, pero su valor dependerá del nivel del eje z (promedio de GND) definido. Esta tercera dimensión se expresa como una medida de la rugosidad de la superficie superior de la nube, es posible, entonces, que la fractalidad de la misma sea un buen indicador del tipo de nube de que se trate. Para su utilización como criterio de clasificación sería idóneo la implementación de un método de estimación de la dimensión fractal que tenga en cuenta la rugosidad de la superficie superior, en conjunción con la contorsión del perímetro de la proyección de la nube como sugiere Batista (2012). Fig. 9. Distribución de puntos en el espacio área-perímetro-promedio de GND 134 Hernández-Pardo y Borrajero-Montejo Detección de agrupamientos y clasificación Partiendo de una imagen visible y una IR simultáneas, después de detectar regiones y calcular las variables de estudio en cada una, se procedió a la detección de agrupamientos en los espacios generados por diferentes combinaciones de ellas (como en el ejemplo de la Figura 9, alterando la cantidad de dimensiones y la naturaleza de las mismas). Para cada par de imágenes, visible e IR, se obtuvo una imagen con las regiones detectadas, representadas según la clase en que el agrupamiento las haya situado (Fig. 10). Es importante tener en cuenta que al efectuar el proceso de agrupamiento, se identifican conjuntos existentes de forma natural en los datos. En el método PAM se especifica la cantidad de conjuntos, clases, que se quiere buscar, pero el significado físico del resultado no es trivial. De ahí que relacionar las clases obtenidas con otras, previamente concebidas, como los tipos de nubes según observaciones desde superficie, necesite ser objeto de un análisis profundo, que se recomienda para estudios posteriores. Por tanto, en esta investigación se menciona la palabra “clases”, en general, sin nombrar cada una de ellas, para evitar resultados especulativos. Variando las magnitudes empleadas y la cantidad de clases a encontrar, resultó que, para algunas regiones, el grupo asignado varió, mientras para otras se mantuvo constante, lo que se puede interpretar como signo de estabilidad en su clasificación. Esta fue más estable cuando se emplearon tres clases. La silueta es el perfil que se forma al representar el valor de S(i) para cada i (objeto). Si S(i)>0, mientras mayor es el valor de S(i) (donde N es la cantidad de objetos incluidos en el agrupamiento), más seguridad existe de que cada objeto corresponde al grupo asignado. Si S(i)<0, significa que el objeto se encuentra más cercano a otro grupo que al que fue asignado, por lo que se puede decir que fue clasificado erróneamente. (a) (b) (c) Fig. 10. Ejemplo de utilización de una imagen visible y una IR para clasificar la nubosidad según su geometría y su textura a) Imagen visible b) Imagen IR c) Clasificación obtenida agrupando las regiones en tres clases a partir de las variables área, perímetro y promedio de GND Comparando los valores de S(i) de cada agrupamiento (Fig. 11), se determinó que los mayores valores de S(i) promedio se obtuvieron en los agrupamientos que usaron como variables el área, el perímetro y el promedio de GND (promedio de S(i) = 0.92). Por tanto, dicho conjunto de variables es el más adecuado, desde el punto de vista de la geometría de la distribución de los puntos, para clasificar las regiones detectadas. 135 Algoritmo de clasificación de nubes (a) (b) Fig. 11. Salidas gráficas del método PAM del software R: Siluetas de agrupamientos en tres clases, a) usando las variables área, perímetro y promedio de GND, b) usando todas las variables La clasificación lograda tiene en cuenta, no solo la naturaleza radiativa de las nubes, sino su forma y textura. Varios ejemplares del mismo tipo de nube (i.e., cirrus, cumulus o cumulonimbus) pueden ser geométricamente diferentes, en dependencia de la situación atmosférica imperante durante su génesis. En ese caso, el criterio desarrollado los incluirá en diferentes clases. Esta característica le adjudica utilidad en la identificación de patrones o condiciones meteorológicas análogas. La principal desventaja del método desarrollado radica en la necesidad de utilizar, previamente, un algoritmo de delimitación de regiones, pero otorga la ventaja de poder manipular la cantidad de grupos a incluir, aumentando o disminuyendo el nivel de la escala de interés. Cabe destacar que la importancia de esta investigación radica en el diseño y descripción de un método de clasificación de nubes distinto, enfocado en su geometría y su textura, no en el reconocimiento de tipos de nubes convencionales en la imagen. Aunque esa posibilidad no se excluye: es posible alcanzar una correlación mayor entre la clasificación convencional de nubes (cumulus, cirrus, etc) y la clasificación resultado del método descrito anteriormente, encontrando la óptima combinación: variables-cantidad de clases, en función de ese objetivo. Aquí se especifica cual es la mejor combinación atendiendo al indicador S(i), pero esta no es, necesariamente, la que mejor se ajusta a los tipos de nubes según la clasificación desde superficie. Conclusiones Se logró desarrollar un algoritmo de clasificación de nubes a partir de imágenes de satélite, utilizando criterios geométricos y de textura. El análisis de los valores de niveles digitales en imágenes visibles e infrarrojas permitió delimitar proyecciones de nubes en el caso de los cirrus y los cumulonimbus. No fue posible obtener resultados acerca de la geometría y la textura de los cumulus, pues su escala característica se sitúa en los límites de resolución de las imágenes de satélite utilizadas. El análisis de la textura en imágenes visibles no permitió delimitar proyecciones de nubes, aunque posibilitó reconocer cierta coincidencia entre regiones de textura semejante y algunos tipos convencionales de nubes y evidenció las variaciones de rugosidad en el interior de las nubes. Se reconoció la utilidad potencial, para la clasificación de nubes, de la dimensión fractal de la superficie de la nube. 136 Hernández-Pardo y Borrajero-Montejo Se utilizaron diferentes variables para agrupar las regiones detectadas en distintas cantidades de clases, las magnitudes geométricas y de textura más adecuadas para discriminar entre diferentes tipos de nubes fueron el área, el perímetro y el módulo del gradiente de niveles digitales en imágenes visibles. Los mejores agrupamientos se lograron particionando en tres categorías el espacio generado por los valores de las diferentes variables en cada una de las nubes detectadas. Recomendaciones El resultado de esta investigación puede ser mejorado a partir de las siguientes recomendaciones: Analizar qué condiciones de agrupamiento (cantidad de clases, variables utilizadas) resultan en clases con mayor semejanza con las clasificaciones clásicas de nubes. Estudiar y diseñar criterios de clasificación de nubes basados en la dimensión fractal de la superficie de las nubes. Validar la clasificación de nubes por imágenes de satélite utilizando criterios geométricos y de textura. Analizar la correlación entre la dimensión fractal del perímetro de las nubes y las áreas de lluvia detectadas por RADAR. Referencias Ambach, W. 1974. The influence of cloudiness on the net radiation balance of a snow surface with high albedo. Journal of Glaciology, 13(67). Bárcenas, M. 2011. Método de clasificación de nubes mediante imágenes de satélite. Tesina de diplomado. Instituto de Meteorología. Bass, L. P., Nikolaeva, O. V., Kuznetsov, V. S. y Kokhanovsky, A. A. 2010. Radiation balance in a cloudy atmosphere with account for the 3d effects. Atmospheric Research, (98). Batista, A. 2012 Rugosidad y fractalidad en el estudio de sistemas atmosféricos y geofísicos. Tesis de licenciatura. Universidad de La Habana. Benner, T. C. y Curry, J. A. 1998. Characteristics of small tropical cumulusclouds and theirimpactonthe environment. Journal of Geophysical Research: Atmospheres (1984–2012), 103(D22), 28753–28767. Goryachev, B. V. y Mogilnitsky, S. B. 2008. Formation of radiation balance in a cloudy atmosphere. In Proc. SPIE 6936, Fourteenth International Symposium on Atmospheric and Ocean Optics/Atmospheric Physics. Hall-Beyer, M. 2008. GLCM texture tutorial [En línea]. Disponible en: www.fp.ucalgary.ca/mhallbey. [Consultado el 20 de abril de 2013]. Haralick, R. M., Shanmugam, K. y Dinstein, I. 1973. Textural features for image classification. Systems, Man and Cybernetics, IEEE Transactions on, (6), 610–621. Kaufman, L. y Rousseeuw, P. J. 1990. Finding groups in data, an introduction to cluster analysis. Hoboken, New Jersey: John Wiley&Sons, Inc. Lavastida, L. 2005. Estimación de flujos de radiación solar a partir de imágenes de satélite GOES. Tesis de maestría. Instituto de Meteorología. Lovejoy, S. 1982. Area-perimeter relation for rain and cloud areas. Science, 216(4542), 185–187. Quevedo, J. L. (2012) Estimación de las áreas de lluvia sobre Cuba a partir de las imágenes VIS e IR obtenidas del satélite GOES – E. Tesis de licenciatura. Instituto Superior de Tecnologías y Ciencias Aplicadas. Sanchez-Lorenzo, A., Calbó, J., y Wild, M. 2012. Increasing cloud cover in the 20th century: review and new findings in spain. Climate of the Past, 8, 1199–1212. Schneider, S. H., Washington, W. M. y Chervin, R. M. 1978. Cloudiness as a climate feedback mechanism: effects on cloud amount of prescribed global and regional surface temperature changes in the ncargcm. Journal of Atmospheric Sciences, 35(12). Suárez, H. L. 2010. Estimación de la temperatura superficial del mar a partir de las imágenes del satélite GOES-E. Tesis de licenciatura. Instituto Superior de Tecnologías y Ciencias Aplicadas. Svensmark, H. y Friis-Christensen, E. 1997. Variation of cosmic ray and global cloud coverage, a missing link in solar-climate relationships. Journal of Atmospheric and Solar-Terrestrial Physics, 59(11), 1225–1232. Trujillo, G. 2011. Estimación de la cobertura nubosa sobre Cuba a partir de las imágenes del satélite GOES–E. Tesis de licenciatura. Instituto Superior de Tecnologías y Ciencias Aplicadas. Wetherald, R. T. y Manabe, S. 1980. Cloud cover and climate sensitivity. Journal of the Atmospheric Sciences, 37(7), 1485–1510. Zmudzka, E. 2008. The influence of cloudiness on air temperature and precipitation on the territory of Poland (19512000). Miscellanea Geographic, 13, 89–103. 137 Algoritmo de clasificación de nubes Acerca de los autores: Lianet Hernández-Pardo Graduada de Licenciatura en Meteorología, con Diploma de Oro, en Julio de 2013, en el Instituto Superior de Tecnologías y Ciencias Aplicadas, con la investigación titulada: Diseño de un algoritmo de clasificación de nubes a partir de sus características geométricas y de textura en imágenes de satélite. Actualmente es bolsista de Coordenação de Aperfeiçoamento de Pessoal de Nível Superior y alumna de Mestrado em Meteorologia del Instituto Nacional de Pesquisas Espaciais, Brasil. Israel Borrajero-Montejo Graduado de Licenciatura en Física, de la Universidad de La Habana, en 1983. Ha realizado especialización en estadística multivariada, métodos numéricos y configuración avanzada del modelo WRF. Desde enero de 2014 realiza doctorado en el Instituto de Meteorología, con el tema: Cálculo de Radiación Solar a partir de imágenes de satélite. Actualmente es Investigador Agregado en el Instituto de Meteorología. 138