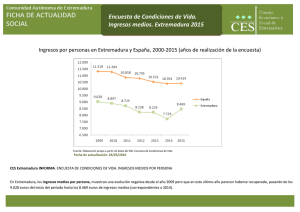
universidad de extremadura facultad de ciencias económicas y
Anuncio

UNIVERSIDAD DE EXTREMADURA FACULTAD DE CIENCIAS ECONÓMICAS Y EMPRESARIALES DEPARTAMENTO DE ECONOMÍA APLICADA Y ORGANIZACIÓN DE EMPRESAS MODELIZACIÓN ESTADÍSTICO ECONOMÉTRICA REGIONAL: EL CASO DE LA ECONOMÍA EXTREMEÑA Miguel Ángel Márquez Paniagua UNIVERSIDAD DE EXTREMADURA 1999 Edita: Universidad de Extremadura Servicio de Publicaciones c/ Pizarro, 8 Cáceres 10071 Correo e.: [email protected] http://www.pcid.es/public.htm "(...)Y es razón averiguada que aquello que más cuesta se estima y debe de estimar en más. Alcanzar alguno a ser eminente en letras le cuesta tiempo, vigilias, hambre, desnudez, vaguidos de cabeza, indigestiones de estómago y otras cosas a éstas adherentes..." Miguel de Cervantes Saavedra. "Don Quijote de la Mancha" A Remedios y a mis padres. NOTAS PRELIMINARES Y AGRADECIMIENTOS. Durante mi estancia en el Instituto L. R. Klein de la Universidad Autónoma de Madrid, asistía a los diversos seminarios que se imparten en este centro. Recuerdo que en uno de ellos, y dentro de las distintas intervenciones de los asistentes, el Profesor Antonio Pulido concretó lo que, en su opinión, eran los requisitos mínimos que se le debían pedir a un trabajo de investigación para que llegara a buen fin: "entroncamiento con la realidad social, entroncamiento con la labor conductora del director del mismo y la ilusión del tesinando”. Aquellos requisitos me parecieron tan razonables que cuando mi Director de Tesis, el Profesor Julián Ramajo, me propuso el tema, no dudé en ponerme manos a la obra, ya que los mínimos para iniciar una obra de este tipo estaban, en mi opinión, cubiertos de sobra. Así, en lo referente al "entroncamiento con la realidad social”, es fácil apreciar los vínculos y connotaciones sociales que este trabajo posee, ya sea como herramienta que nos acerca al conocimiento de la realidad económica de Extremadura, o como un instrumento de análisis que puede ser de gran utilidad. En lo que respecta al "entroncamiento con la labor conductora del director del mismo", una simple ojeada al "Curriculum Vitae" del Dr. D. Julián Ramajo, bastará para disipar las dudas que en este punto puedan aparecer . Por último, se señalaba "la ilusión del tesinando", que aplicado al contexto de una tesis doctoral sería lo mismo que pedir "la ilusión del doctorando". y ésta no ha faltado nunca en este trabajo, ya que es la que nos ha animado a seguir perseverando y pasar de los "¡ésto no hay quien lo modelice!" y "¡es que no hay una cifra en condiciones para esta región!", a la presentación de este. en nuestra opinión, digno trabajo. Quiero finalizar estas notas mostrando mi agradecimiento a las personas que han incidido de manera especial, de una u otra forma, para que esta obra haya llegado a su fin. En primer lugar, mi reconocimiento y gratitud a la gran labor directora del Profesor Julián Ramajo, que me marcó de manera clara los objetivos a conseguir, que me ha guiado dentro de la senda investigadora con paciencia, rigor, sabiduría y calidad personal, implicándose en todo momento en cada una de las fases de este trabajo. A los Profesores James Hamilton y Andrew Harvey, por las sugerencias recibidas en lo referente al proceso de estimación de las ecuaciones con parámetros variables; al Profesor Helmut Lütkepohl por facilitarnos el programa Multi con el que se estimaron dichas ecuaciones, y al Profesor James H. Stock por proporcionarnos las subrutinas GAUSS con las que se han llevado a cabo los contrastes de estabilidad. A todos y cada uno de los miembros del Instituto L.R. Klein de la Universidad Autónoma de Madrid, de los que siempre se aprende algo y que siempre me acogen con agrado. A Juan y Luis, porque les he hecho perder el tiempo con algún que otro dato y siempre se han brindado a ayudarme. Asímismo, a Luciano y Javier. A Pedro y Carmen, que siempre me han echado una mano cuando ha hecho falta. A mis padres, Alberto y María, a los que tanto les debo, porque en la vida no todos los momentos son igual de buenos y ellos siempre han estado, están y estarán ahí. A Remedios, que ha aguantado con estoicismo, comprensión, cariño y moral a raudales las distintas "fases cíclicas" en mi estado de ánimo, renunciando a lo largo de estos años de manera solidaria tanto a las vacaciones, puentes y fines de semana como a otras cosas que sé que eran muy importantes para ella. A ella, infinito. Y como no, a mis hermanos, a Talarrubias, a los Calaveras y a la Virgen Coronada ¡¡VIVA!! De los errores o deficiencias que se puedan detectar en este trabajo, yo soy el único responsable. Contenidos ÍNDICE INTRODUCCIÓN.......................................................................................................... 1 PARTE PRIMERA. ASPECTOS GENERALES: LA UANTIFICACIÓN EN ECONOMÍA. LAS BASES ESTADÍSTICAS Y LA ECONOMÍA EXTREMEÑA ............ 5 CAPÍTULO I. CONSIDERACIONES EN TORNO A LAS MODELIZACIONES ESTADÍSTICAS Y ECONOMÉTRICAS................................................................................. 7 PRESENTACIÓN.................................................................................................................... 7 I.1. REVISIÓN HISTÓRICA................................................................................................... 7 I.1.1. INTRODUCCIÓN..................................................................................................... 7 I.1.2. PREÁMBULOS DE LA CUANTIFICACIÓN ECONOMÉTRICA ............................. 8 I.1.3. CATALIZADORES DE LA METODOLOGÍA CUANTITATIVA ............................... 9 I.1.3.1. EL CICLO ECONÓMICO Y LA MEDICIÓN SIN TEORÍA. ......................... 9 I.1.3.2. LOS ESTUDIOS DE DEMANDA Y EL NACIMIENTO DE LA ECONOMETRÍA ........................................................................................................ 10 I.1.4. TEORÍA ECONÓMICA Y CICLO ECONÓMICO.................................................... 13 I.1.5. LA CRISIS DEL ENFOQUE ECONOMÉTRICO. ................................................... 17 I.1.6. SERES TEMPORALES: PROGRESOS Y ENGARCE CON LA CONOMETRÍA. ... 19 I.1.7. E VOLUCIÓN RECIENTE Y SITUACIÓN ACTUAL.............................................. 24 I.1.7.1. ECONOMETRÍA APLICADA. ...................................................................... 24 I.1.7.2. ESTRATEGIAS MODELIZADORAS ........................................................... 27 I.1.8. ECONOMÍA REGIONAL Y MODELIZACIÓN. ...................................................... 28 I.2. EL ESTUDIO DEL CICLO ECONÓMICO.................................................................... 33 I.2.1. CONCEPTOSBÁSICOS........................................................................................... 33 I.2.2. TEORÍAS DE LOS CICLOS..................................................................................... 36 I.2.3. CUANTIFICACIÓN CÍCLICA Y POLÍTICA ECONÓMICA. ................................ 47 CAPITULO II: LA INFORMACION ESTADISTICA ECONOMICA REGIONAL........ 49 II.1. INTRODUCCIÓN.......................................................................................................... 49 II.2. CONTABILIAD NACIONAL ANUAL, CONTABILIDAD NACIONAL TRIMESTRAL E INDICADORES ECONOMICOS. ........................................................... 49 II.3. LA CONTABILIAD REGIONAL DE ESPAÑA .......................................................... 54 II.4. LA PROBLEMATICA DE LOS DEFLACTORES REGIONALES............................. 60 II.4.1. RAMA DE LA AGRICULTURA (RAMA A01). ....................................................... 63 II.4.2. CONSTRUCCIÓN (RAMA B53) ............................................................................ 66 II.4.3. SERVICIOS DESTINADOS A LA VENTA.............................................................. 67 II.4.3.1. RAMA DE LA RECUPERACIÓN Y REPARACIÓN. SERVICIOS DE COMERCIO, HOSTELERÍA Y RESTAURANTE (RAMA L58). ............................ 67 II.4.3.2. SERVICIOS DE TRANSPORTES Y COMUNICACIONES (RAMA Z60) 68 II.4.3.3. RAMA DE OTROS SERVICIOS DESTINADOS A LA VENTA (RAMA L74).............................................................................................................................. 68 II.5.INDICADORES DISPONIBLES PARA EXTREMADURA ........................................ 70 II.5.1. ELABORACIÓN DE ÍNDICES DE PRODUCCIÓN INDUSTRIALES PARA EXTREMADURA .............................................................................................................. 72 Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña CAPITULO III. EVOLUCIÓN RECIENTE DE LA ECONOMÍA EXTREMEÑA. ......... 79 III.1. INTRODUCCIÓN ........................................................................................................ 79 III.2. ESTRUCTURA PRODUCTIVA Y CRECIMIENTO DE LA ECONOMÍA............... 80 III.2.1. ESTRUCTURAS PORCENTUALES SOBRE EL TOTAL NACIONAL. ................ 84 III.2.2. TASAS DE VARIACIÓN DEL VAB....................................................................... 88 III.2.2.1. INFLUENCIAS DEL CRECIMIENTO NACIONAL.................................. 88 III.2.2.2. CONTRASTE DE EXISTENCIA DE CICLO COMÚN ............................. 97 III.2.3. ESTRUCTURA PORCENTUAL INTERNA......................................................... 106 III.2.4. CONTRIBUCIÓN AL CRECIMIENTO............................................................... 116 III.2.5. COMPARACIÓN DE PRODUCTIVIDADES ..................................................... 118 III.2.6. ESTUDIO DE LA PRODUCCIÓN EN EXTREMADURA .................................. 126 III.3. RECAPITULACIÓN Y CONCLUSIONES............................................................... 136 PARTE SEGUNDA. MODELIZAICÓN ESTADÍSTICA............................................. 140 CAPÍTULO IV. MARCO METODOLÓGICO ................................................................... 143 IV.1. EL ANÁLISIS DE LA COYUNTURA ECONÓMICA............................................. 143 IV.1.1. CONCEPTO. ....................................................................................................... 143 IV.1.2. HERRAMIENTAS DE ANÁLISIS ........................................................................ 145 IV.2. CUESTIONES PRELIMINARES .............................................................................. 147 IV.2.1. IDEAS GENERALES........................................................................................... 147 IV.2,2. OBJETIVOS......................................................................................................... 151 IV.3. EXPERIENCIAS PREVIAS....................................................................................... 153 IV.4. METODOLOGÍA ESTADÍSTICA ............................................................................ 156 IV.4.1. ETAPA PRIMERA. DEFINICIÓN DEL PERÍODO TEMPORAL, RECOGIDA y ESTUDIO DE LOS INDICADORES DISPONIBLES PRESELECCIONADOS ............. 158 IV.4.2. ETAPA SEGUNDA. MODELIZACIÓN UNIV ARIANTE DE LOS INDICADORES PARCIALES SELECCIONADOS.................................................................................... 159 IV.4.3. ETAPA TERCERA. EXTRACCIÓN DE LA SEÑAL DE CADA INDICADOR PARCIAL SELECCIONADO .......................................................................................... 160 IV.4.4. ETAPA CUARTA. SELECCIÓN DE LAS SEÑALES EXTRAÍDAS DE LOS INDICADORES PARCIALES ......................................................................................... 161 IV.4.5. ETAPA QUINTA. A GREGACIÓN DE LAS "SEÑALES" DE LOS INDICADORES SELECCIONADOS PARA OBTENER EL INDICADOR SINTÉTICO. .......................... 162 IV.4.5.1. PONDERACIÓN ESEXÓGENAS............................................................. 164 IV.4.5.2. PONDERACIONES ENDÓGENAS.......................................................... 164 IV.4.6. PROCEDIMIENTOS BASADOS EN EL CONCEPTO DE DISTANCIA. ........... 165 IV.4.3.1. INTRODUCCIÓN. ..................................................................................... 165 IV.4.3.2. EL INDICADOR SINTÉTICO DE DISTANCIA DP2 .............................. 167 IV.4.3.3. CÁLCULO DEL INDICADOR SINTÉTICO DE DISTANCIA DP2 ........ 170 IV.4.7. ETAPA SEXTA. VALIDACIÓN DEL INDICADOR SINTÉTICO........................ 171 IV.5 RECAPITULACIÓN ................................................................................................... 173 Contenidos CAPÍTULO V. CONSTRUCCIÓN DE INDICADORES SINTÉTICOS PARA EXTREMADURA ................................................................................................................... 175 V.1. INTRODUCCIÓN........................................................................................................ 175 V.2. DATOS ESTADÍSTICOS............................................................................................ 176 V.3. APLICACIÓN DE LA METODOLOGÍA ESTADÍSTICA. ....................................... 176 V.3.1. ETAPA PRIMERA. DEFINICIÓN DEL PERÍODO TEMPORAL, RECOGIDA Y ESTUDIO DE LOS INDICADORES DISPONIBLES PRESELECCIONADOS. ............ 176 V.3.2. ETAPA SEGUNDA. MODELIZACIÓN UNIVARIANTE DE LOS INDICADORES PARCIALES PRESELECCIONADOS............................................................................. 177 V.3.3. ETAPA TERCERA. EXTRACCIÓN DE LA "SEÑAL" DE CICLO-TENDENCIA DE CADA INDICADOR PARCIAL....................................................................................... 177 V.3.4. ETAPA CUARTA. SELECCIÓN DE LAS SEÑALES EXTRAÍDAS DE LOS INDICADORES PARCIALES. ........................................................................................ 177 V:3.5. ETAPA QUINTA. A GREGACIÓN DE LAS "SEÑALES" SELECCIONADAS PARA OBTENER EL INDICADOR SINTÉTICO ...................................................................... 181 V.3.6. ETAPA SEXTA. VALIDACIÓN DEL INDICADOR SINTÉTICO......................... 183 V.4. INFLUENCIAS DEL CRECIMIENTO NACIONAL. ............................................... 187 V.5. ANÁLISIS CÍCLICO DE LAS RAMAS PRODUCTIVAS........................................ 189 PARTE TERCERA. MODELIZACIÓN ECONOMÉTRICA. ....................................... 197 CAPÍTULO VI. ALTERNATIVAS MODELIZADORAS Y CONCEPTOS .................... 199 VI.1. LOS MODELOS ECONÓMICOS REGIONALES ................................................... 199 VI.2. MODELOS REGIONALES y MODELOS ECONOMÉTRICOS ............................. 200 VI.2.1. ANÁLISIS "SHIFT-SHARE"................................................................................ 206 VI.2.2. MODELOS "INPUTS-OUTPUTS"...................................................................... 208 VI.2.3. MODELOS DE BASE ECONÓMICA ................................................................. 216 VI.2.3.1. PRESENTACIÓN y SUPUESTOS BÁSICOS. ......................................... 216 VI.2.3.2. ENFOQUE DE BASE ECONÓMICA y MODELOS ECONOMÉTRICOS.................................................................................................. 220 VI.2.3.3. LIMITACIONES ........................................................................................ 223 VI.2.4. MODELOS ECONOMÉTRICOS REGIONALES................................................ 227 VI.2.4.1. INTRODUCCIÓN ...................................................................................... 227 VI.2.4.2. ENFOQUES ............................................................................................... 228 VI.2.4.3. SUSTENTO TEÓRICO.............................................................................. 231 VI.2.4.4. ALGUNAS EXPERIENCIAS RECIENTES EN ESPAÑA....................... 232 Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña CAPITULO VII: UN MODELO ECONOMETRICO PARA EXTREMADURA............ 243 VII.1. INTRODUCCIÓN ..................................................................................................... 243 VII.2. EL MODELO ESTRUCTURAL BÁSICO ............................................................... 247 VII.2.1. DETERMINACIÓN DE LOS SECTORES BÁSICOS Y NO BÁSICOS. ............. 249 VII.2.2. RELACIONES INTERSECTORlALES. .............................................................. 252 VII.3. METODOLOGÍA ...................................................................................................... 259 VII.3.1. ESTRUCTURA ECONOMÉTRICA.................................................................... 259 VII.3.2. EL MODELO ESTADÍSTICO ............................................................................ 260 VII.4. RESULTADOS EMPÍRICOS ................................................................................... 267 VII.4.1. FUENTES ESTADISTICAS................................................................................ 267 VII.4.2. ESPECIFICACIÓN DEL MODELO................................................................. 268 VII.4.3. PROPIEDADES ESTOCÁSTICAS DE LOS DATOS ......................................... 273 VII.4.4. ESTIMACIÓN DEL MODELO ........................................................................... 277 VII.4.4.1. ESTIMACIÓN DE LAS RELACIONES A LARGO PLAZO. ................ 278 VII.4.4.2. ESTIMACIÓN DE LAS RELACIONES A CORTO PLAZO.................. 282 VII.4.4.2.1. P ARÁMETROS CAMBIANTES: MODELO DE VARIABLES FICTICIAS ........................................................................................................... 282 VII.4.4.2.2. PARÁMETROS CAMBIANTES: FILTRO DE KALMAN ............ 286 VII.4.5. ANÁLISIS PREDICTIVO EXPOST......................................................................... 292 PARIE CUARTA. RECAPITULACIÓN Y CONCLUSIONES. ................................... 294 CAPITULO VIII: RECAPITULACIÓN, CONCLUSIONES Y CONSIDERACIONES FINALES.................................................................................................................................. 296 VIII.1 INTRODUCCIÓN..................................................................................................... 296 VIII.2. OBJETIVOS............................................................................................................. 298 VIII.3. RECAPITULACIÓN ............................................................................................... 298 VIII.4. CONCLUSIONES.................................................................................................... 301 VIII.5. APORTACIONES ORIGINALES........................................................................... 305 VIII.6. CONSIDERACIONES FINALES ........................................................................... 307 Contenidos ANEXOS .................................................................................................................. 307 CONTENIDO DE LOS ANEXOS............................................................................................ 309 ANEXO 1: INDICADORES DISPONIBLES MENSUALES y TRIMESTRALES. .............. 313 ANEXO 2: CONTRASTES DE EXISTENCIA DE CICLOS COMUNES. ............................ 339 ANEXO 3: MODELIZACIÓN UNIVARIANTE Y EXTRACCIÓN DE SEÑALES DE VARIABLES ECONÓMICAS ................................................................................................. 345 ANEXO 4: PROCEDIMIENTOS PARA LA OBTENCIÓN DE INDICADORES COMPUESTOS......................................................................................................................... 375 ANEXO 5: INTEGRABILIDAD, COINTEGRACIÓN Y MODELOS DE CORRECCIÓN DE ERROR..................................................................................................... 395 ANEXO 6: CONTRASTES DE CAMBIO ESTRUCTURAL. ................................................ 407 ANEXO 7: ESTIMACIÓN DEL MODELO ECONOMÉTRICO............................................ 107 ANEXO 8: EL FILTRO DE KALMAN COMO HERRAMIENTA PARA ESTIMAR PARÁMETROS CAMBIANTES EN EL TIEMPO ................................................................. 447 REFERENCIAS BIBLIOGRÁFICAS ........................................................................ 458 Introducción INTRODUCCIÓN El objetivo esencial que se persigue en este trabajo es la modelización estadística y econométrica de la economía regional extremeña, con el fin último de proporcionar unos instrumentos que cubran algunas de las carencias existentes en Extremadura a la hora de realizar un análisis económico objetivo. La situación de partida es la imposibilidad de realizar estudios que aborden el seguimiento de la coyuntura económica extremeña (agregada y sectorial) mediante una estrategia diferente a la constituida por la descripción simple de múltiples indicadores económicos parciales1. El panorama inicial es el que se muestra en el Cuadro nº 1: Cuadro nº 1. Estrategias utilizadas para el seguimiento de la coyuntura económica de Extremadura. Estrategias Indicadores múltiples posibles Indicador sintético agregado. NO Indicadores sintéticos sectoriales. NO Contabilidad regional trimestral. NO Modelo econométrico trimestral. NO SI Estrategias existentes∗ Notas: ∗ Antes de los resultados obtenidos en esta tesis. Fuente: Elaboración propia a partir de un esquema planteado en Pulido (1997). En consecuencia, el primer objetivo es la elaboración de indicadores sintéticos de actividad económica (modelización estadística) para poder llevar a la práctica estrategias para el seguimiento de la coyuntura económica de Extremadura que hasta ahora son irrealizables. Por otra parte, la obtención de predicciones objetivas y lo más precisas posibles a corto y medio plazo del comportamiento de la economía extremeña, requiere la existencia de un modelo econométrico que consiga combinar y optimizar la utilización tanto de las metodologías más actuales como de las fuentes y datos estadísticos disponibles. El modelo econométrico existente en la actualidad para Extremadura es el de Ramajo (1990); que se puede caracterizar como “clásico”, puesto que no tiene en cuenta las orientaciones metodológicas más recientes. Por lo tanto, el segundo objetivo es la construcción de un modelo econométrico con fines fundamentalmente predictivos para la economía 1 Esto no implica que el seguimiento en base a los indicadores parciales sea una estrategia a desechar para el análisis coyuntural, sino que la información que estos proporcionan se verá complementada de manera muy importante. -Pág. 1- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña extremeña que incorpore las técnicas econométricas más rigurosas, novedosas y adecuadas a las características de la economía de que se trata. Somos conscientes de las numerosas áreas de estudio e investigación con los que entra en contacto este proyecto. Muchos de los ámbitos de estudio que se tratan darían por sí mismas para un trabajo de investigación con peso específico propio y de interés vigente en la actualidad2. No obstante, el hecho de pertenecer al equipo Hispalink de Extremadura nos hacía ver lo necesario de un trabajo de síntesis de las principales líneas de investigación de los diferentes equipos en España para su aplicación al caso particular extremeño. Esta razón, junto con el reducido número de componentes del equipo HispalinkExtremadura, nos han mostrado la necesidad de seguir adelante con este vasto campo de estudio. En función del objetivo propuesto, hemos considerado oportuno estructurar el trabajo en cuatro partes interrelacionadas entre sí. Así, en la parte primera se agrupa a una serie de Capítulos (I, II, y III) que son fundamentales a la hora de establecer premisas y condicionantes a las modelizaciones estadísticas y econométricas que se plantean y realizan en las partes segunda (Capítulos IV, y V) y tercera (Capítulos VI, y VII) respectivamente. Para finalizar, en la parte cuarta (Capítulo VIII) se exponen las recapitulaciones y conclusiones principales de este trabajo. Dentro del orden establecido para que la investigación logre las metas señaladas, se ha juzgado que la consecución razonable de los objetivos planteados pasa por la presentación y análisis de una serie de cuestiones que son imprescindibles para llegar a abordar de manera coherente el núcleo fundamental del trabajo (partes segunda y tercera). De esta forma, en la parte primera se tratan temas muy importantes para el desarrollo posterior de la investigación: reflexiones sobre la modelización estadística y econométrica, consideraciones en torno a las fuentes estadísticas disponibles y descripción de la economía extremeña como objeto del análisis. Así, en el Capítulo I se realiza, en primer lugar, una revisión histórica de la evolución de la cuantificación económica, situando en este contexto a los análisis de series temporales (como pieza fundamental de la modelización estadística) y a los modelos macroeconométricos con el fin último de justificar la vigencia y validez de las metodologías a aplicar a nivel regional. En segundo 2 Sirva como breve referencia la mención simple de algunas problemáticas con las que conecta este trabajo y que en la actualidad están siendo objeto de estudios de otros compañeros de distintas comunidades autónomas: marco teórico de los ciclos económicos, métodos de extracción de señal, elaboración de indicadores sintéticos, estudios relativos a los contrastes de raíces unitarias y/o cointegración a nivel nacional y regional, modelización econométrica regional, etc. -Pág. 2- Introducción lugar se abordan los estudios del ciclo económico como uno de los campos de mayor demanda en la utilización de las herramientas econométricas y de series temporales, tanto en el pasado como en el presente y en el futuro. En el Capítulo II se expone de manera concisa la producción estadística a nivel regional en la actualidad, ya que esta producción es uno de los ingredientes fundamentales para abordar los estudios que persiguen el análisis eficiente y objetivo de una economía regional. Se cita la fuente estadística oficial para las regiones españolas, destacando sus carencias y limitaciones, y justificando la elección del deflactor a aplicar. Además, se describen y comentan aspectos relativos a los indicadores económicos con los que se trabaja. Para finalizar esta parte primera, en el Capítulo III se hace un estudio que nos aproxima a las características esenciales de la economía extremeña como objeto de análisis de esta tesis. La descripción y conclusiones extraídas de este estudio es un requisito previo necesario para obtener una modelización eficiente. La parte segunda tiene como meta final la modelización estadística (también la denominamos “no estructural”) de la economía extremeña. Por esta razón, en el Capítulo IV definimos los análisis de coyuntura y la relación de este tipo de estudios con la modelización estadística y econométrica, justificando la utilización de la modelización no estructural en el corto plazo. A continuación se muestra el marco metodológico en el que se realiza la modelización estadística de la economía extremeña. Dicha modelización (Capítulo V) se plasma en la obtención de indicadores sintéticos de actividad económica que pueden posibilitar tanto la cuantificación de la economía extremeña como la determinación de su ciclo económico. En la parte tercera, el objetivo fundamental es la obtención de un modelo causal con fines fundamentalmente predictivos para la economía extremeña. Por este motivo, en el Capítulo VI se sitúa a los modelos econométricos dentro del conjunto de los modelos regionales de simulación. Además, se comentan los enfoques modelizadores que de una forma directa o indirecta se han utilizado en la tesis. Para concluir esta parte, en el Capítulo VII se lleva a cabo la modelización econométrica para Extremadura, haciendo especial hincapié -como cuestión metodológica relevante a examinar- en el tratamiento de los cambios estructurales que han afectado a Extremadura durante el período de análisis. Para finalizar, en la parte cuarta se presentan las recapitulaciones y conclusiones fundamentales que se extraen de esta tesis (Capítulo VIII). El trabajo incorpora una serie de Anexos que recogen cuestiones que hemos apartado de la exposición argumental principal con el fin de hacer más -Pág. 3- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña continua y sencilla su lectura. Tales Anexos posibilitan abundar en contenidos más técnicos y/o descriptivos que los que se presentan en el cuerpo esencial de la tesis. Cada uno de los Anexos tiene objetivos diferentes: - Aportar información relativa a la base estadística coyuntural utilizada (Anexo 1). - Desarrollar y profundizar en aspectos teóricos y/o técnicos en los que se sustentan las aplicaciones empíricas (Anexos 2, 3, 4, 5, 6 y 8). - Mostrar con mayor grado de detalle algunos resultados (Anexo 7). -Pág. 4- PARTE PRIMERA. ASPECTOS GENERALES: LA CUANTIFICACIÓN EN ECONOMÍA, LAS BASES ESTADÍSTICAS Y LA ECONOMÍA EXTREMEÑA. Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas CAPÍTULO I. CONSIDERACIONES EN TORNO A LAS MODELIZACIONES ESTADÍSTICAS Y ECONOMÉTRICAS. PRESENTACIÓN. En la primera parte de este capítulo nos ha parecido oportuno exponer una revisión histórica de algunos de los desarrollos substanciales que se han producido en los instrumentos que vamos a proponer para su explotación en esta tesis, es decir, los análisis de series temporales y los modelos econométricos. Así, pretendemos dar un esquema sobre la evolución de la cuantificación económica, logrando situar adecuadamente en este contexto a la modelos estadísticos (vinculados al análisis de series temporales) y a los modelos econométricos. Además, y dada la orientación regional de este trabajo, también se hace necesario perfilar los rasgos básicos de la economía regional como disciplina en la que las herramientas estadístico-econométricas han ejercido una influencia decisiva. Por consiguiente, nos acercamos a los métodos de análisis económico regional, argumentando las razones que legitiman la elección de los modelos estadísticos y econométricos como técnicas aptas para alcanzar los objetivos propuestos y que avalan la bondad de los resultados a obtener. Pero no todos los campos de estudio de la ciencia económica han tenido la misma trascendencia dentro de la historia económica cuantitativa. Por este motivo, en la parte segunda tratamos los estudios del ciclo económico como uno de los campos de mayor interés en las aplicaciones econométricas y de series temporales, tanto en el pasado como en el presente y en el futuro. I.1. REVISIÓN HISTÓRICA. I.1.1. INTRODUCCIÓN. Puesto que para alcanzar el objetivo de este trabajo se deben utilizar tanto el enfoque derivado del análisis de series temporales (no estructural o estadístico) como el enfoque econométrico, nos parece necesario abordar, aunque sea de forma sucinta e inevitablemente parcial, la evolución histórica de la cuantificación económica, de manera que logremos situar en el contexto adecuado tanto a los análisis de series temporales como a los modelos macroeconómicos. La revisión terciada de la historia de la economía cuantitativa que aquí presentamos no pretende aportar una perspectiva distinta o novedosa a -Pág. 7- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña la literatura ya existente sobre el tema3, sino que el fin perseguido es conglutinar en un reducido número de páginas algunos de los momentos más importantes de la evolución económica cuantitativa, logrando acomodar dentro de la crónica económica progresos determinados acaecidos en el ámbito del análisis de series temporales (como pieza básica de la modelización estadística) y los progresos más relevantes que se han producido en los modelos macroeconométricos (que a la vez mantienen una relación estrecha con el análisis de series temporales). I.1.2. PREÁMBULOS DE LA CUANTIFICACIÓN ECONOMÉTRICA Situándonos dentro del acontecer histórico, se puede decir que el interés por el análisis numérico de la sociedad surge en los siglos XVI y XVII, se reduce en el XVIII, y se manifiesta otra vez con fuerza en el siglo XIX. Pesaran (1990, Pág. 3) escribe que la primera tentativa de realizar economía cuantitativa se atribuye a Gregory King, el cual ya intentaba analizar en 1699 la influencia del volumen de las cosechas de cereales sobre el precio de los mismos. La Aritmética Política fue pionera en la utilización de los métodos numéricos dentro del campo de las ciencias sociales, y por lo tanto, es de obligada referencia cuando se buscan los antecedentes de la econometría. En esta línea de trabajo se sitúan un conjunto de escritos del siglo XVII y XVIII de autores como Gregory King, Willian Petty, John Graunt y Charles Davenant. La Aritmética Política tenía como meta el estudio objetivo de la sociedad para llegar a la obtención de generalizaciones fundamentadas en un proceso inductivo. Sin embargo, y siguiendo a Darnell (1994, Pág. x) "El estudio objetivo de la sociedad a través del análisis numérico tiene mucho en común con los principios y objetivos de la Econometría, pero no captura la unión entre la teoría económica expresada en lenguaje matemático, la inferencia estadística y los contrastes de hipótesis, los cuales son vistos hoy en día como componentes de la econometría". De esta forma, a lo largo del siglo XIX aparecen los datos estadísticos en los libros de economía, pero la explotación que de tales datos se hacía era, generalmente, muy simple, siendo habitual culminar dicha explotación con la presentación de tablas de datos y cálculos de porcentajes. A finales de este siglo, J. N. Keynes es un exponente de la metodología “más moderna”; sin embargo, y como nos advierten en los textos que tratan esta época, hay que matizar el hecho de que "estadísticas" (“statistics”) para Keynes y para sus escritores coetáneos es sinónimo de datos, y no de método estadístico. Este autor escribe: 3 Un ejemplo de revisión de la historia de los métodos estadísticos se puede encontrar en Kendall(1968). Por otra parte, Hendry y Morgan(1995) nos aportan una visión del recorrido histórico de la econometría, destacando en cada etapa las ideas que ellos consideran más relevantes. -Pág. 8- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas "Las funciones de las estadísticas en la investigación económica son, primero, sugerir leyes empíricas, con las cuales poder o no poder ser capaces de la subsiguiente explicación deductiva; y, en segundo lugar, completar el razonamiento deductivo, contrastando sus resultados, y sometiéndoles al examen de la experiencia". (1891, Pág. 326; en Hendry y Morgan (Eds) (1995, Pág. 87)). Según Hendry, D.F, y Morgan, M.S.(Eds., 1995, Pág. 7) “Keynes otorga a las estadísticas un papel inductivo en economía, lo cual implica funciones diversas. El método estadístico puede ser usado para descripción de datos, para sugerir ‘leyes empíricas’(…), para contrastar y modificar las premisas de las leyes deductivas, para contrastar y verificar las conclusiones de tales leyes y para medir las causas de alteraciones. No obstante, el método no es un susbstituto para la experimentación empírica (sólo refuta hipótesis, no las prueba) sin embargo Keynes lo contempla como un instrumento científico esencial de investigación económica.” En definitiva, podemos destacar que en estas etapas iniciales de la cuantificación económica aún no estaba consumada la composición de teorías y datos que daría lugar posteriormente a un progreso del método estadístico en economía: "el desarrollo del método estadístico tuvo que esperar la integración de la teoría de la probabilidad y la teoría de los errores con los modelos económicos teóricos y además con los datos económicos", (Darnell (1994), Pág. xi). I.1.3. CATALIZADORES DE LA METODOLOGÍA CUANTITATIVA. Dentro de la evolución de la cuantificación económica, es necesario destacar el papel fundamental que ejercieron tanto el análisis del ciclo económico como el estudio de la demanda. Los trabajos aplicados en estos campos fueron una fuente importante de ideas nuevas, y contribuyeron a acelerar la progresión de la metodología cuantitativa. En consecuencia, son unos ámbitos de investigación de forzada referencia dentro de la revisión que estamos realizando, ya que su desarrollo se incrusta en la misma esencia histórica de la cuantificación económica. I.1.3.1. EL CICLO ECONÓMICO Y LA MEDICIÓN SIN TEORÍA. En primer lugar, y en lo referente al análisis del ciclo económico, se suele situar su inicio en la segunda mitad del siglo XIX4; por lo tanto, también se puede fechar ahí el inicio del desarrollo de los análisis de coyuntura, aunque estos estudios no se sistematizan hasta principios del siglo XX, llegando a 4 En 1860 se edita en París la obra de Clement Juglar: “Des Crises Commerciales et de leur retour périodique en France, et Angleterre et aux Etats Units”. -Pág. 9- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña adquirir su mayor Schumpeter(1939)6. apogeo con los trabajos de Mitchel(1913)5 y En los estudios del ciclo económico se consideraba como objetivo fundamental la determinación del ciclo (morfología y fases), pero no se daba importancia a los mecanismos causales subyacentes en los movimientos cíclicos. Esta línea de trabajo la desarrollaron investigadores como Kitchin, Kuznets y Kondratieff, e institutos como el National Bureau of Economic Research (NBER) dirigido por Mitchell. En el National Bureau of Economic Research destinaron sus esfuerzos tanto a la medición del ciclo como a la obtención de indicadores adelantados, coincidentes y retrasados para el análisis del ciclo económico. Mitchell(1913), en su obra "Business Cycles and their Causes", partía del estudio de los datos para un período de tiempo y concluía afirmando que los ciclos eran irregulares, con diversas pautas de desfases e intensidades distintas. El continuador de esta línea de investigación fue Persons, que en su obra de 1919 trató de obtener un 'barómetro de los negocios' o índice de las condiciones económicas generales. Según Persons, las fluctuaciones de las series económicas aparecen debido a la afluencia de fuerzas seculares, cíclicas, estacionales e irregulares. Dentro de este marco conceptual, el punto de partida para Persons era realizar un análisis de los datos, con el objetivo de obtener el ciclo. Según Morgan(1990) el trabajo de Persons es menos conocido que el de Mitchell, pero es más importante dentro de la econometría, ya que de él emana el tratamiento de los datos y los métodos de ajuste que en la actualidad son práctica habitual en la econometría. Dentro de las investigaciones orientadas al estudio del ciclo, Raymond (1993) también destaca los trabajos de Yule y Slutsky. Yule (1926) señala el problema de la correlación espuria que se da en series temporales crecientes en el tiempo y trabaja con modelos autorregresivos aplicados al estudio del ciclo económico (antecedente de la metodología Box-Jenkins). Slutsky (1927) ve el ciclo como una acumulación de factores (causas) aleatorios. Por lo tanto, en todos los casos comentados se aborda el estudio del ciclo económico desde una perspectiva estadística, sin búsqueda alguna de la causalidad implícita en el ciclo. I.1.3.2. LOS ESTUDIOS DE DEMANDA Y EL NACIMIENTO DE LA ECONOMETRÍA. Por otra parte, y en lo que respecta al campo del análisis de la demanda, ya en el siglo XX la teoría estadística desarrollada por Galton, Pearson, Weldon 5 Mitchel, W.C.(1913): “Business Cycles”. Berkeley. Schumpeter J. A.(1939): “Business Cycles”. Nueva York”. 6 -Pág. 10- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas y Edgeworth posibilitó la realización de los primeros estudios de funciones de demanda en los que se aplicaba el modelo de regresión. Los trabajos de Edgeworth de 1883 y 1887 sobre la ley del error tuvieron influencia notable dentro del campo de la economía, y tenían como objetivo "hacer adaptar el método estadístico de la teoría de los errores a la cuantificación de la incertidumbre en las ciencias sociales, particularmente a la economía" (Stigler, 1978, Pág. 295). Con anterioridad hemos dicho que el trabajo cuantitativo más primitivo puede ser encontrado dentro de los escritos de la Aritmética Política; sin embargo, la econometría debió esperar a finales del siglo XIX el impulso que supuso el desarrollo de la teoría estadística para obtener, ya en el siglo XX, el primer trabajo econométrico "moderno" (que hace uso de la regresión y de la inferencia estadística). Dentro de los primeros intentos serios de estimación de funciones de demanda se puede situar el trabajo de Schulz (1938). También hubo que esperar hasta el 29 de Diciembre de 1930 para que se formara la Sociedad Econométrica ("Econometric Society"); este hecho generó un optimismo en aquellos tiempos que se puede explicar por lo novedoso que resultaba el método econométrico. La primera tirada de "Econometrica" fue publicada en 1933, firmando la primera declaración editorial Frisch (1933). En ella, según Darnell (1994, Pág. xi), Frisch abundó en que "la Econometría, como antes lo hizo la Aritmética Política, se basaba en la observación y en el acercamiento numérico para el estudio de la sociedad, pero se apartaba de la Aritmética Política haciendo hincapié sobre las interrelaciones entre la teoría y la evidencia: los objetivos de la econometría incluyen promover <<estudios que aspiran a una unificación del cuantitativismo teórico y del cuantitativismo empírico para abordar los problemas económicos, y que son entendidos por pensamientos constructivos y rigurosos similares a los que han dominado en las ciencias naturales>> (Frisch (1933), Pág. 1)". Frisch (1933, Pág. 2) dice que la econometría "no es como la estadística económica. No es idéntica a la teoría general económica...No vendría a ser sinónimo de la matemática aplicada a la economía...Cada uno de estos tres puntos de vista (estadística, teoría económica y matemática) son necesarios, pero en sí mismos no son suficientes para un entendimiento de la relación cuantitativa en la vida económica moderna. Es la unificación de las tres la que es poderosa. Y es esta unificación lo que es la econometría". Fue el propio Ragnar Frish quien en 1936 acuñó el término econometría7. En definitiva, la econometría aspiraba a integrar los dos enfoques fundamentales existentes en el 7 No obstante, según Pesaran (1990, Pág. 1) parece ser que el término “econometría” ya había sido utilizado por Pawell Ciompa en 1910. -Pág. 11- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña siglo XIX para la economía: el enfoque deductivo (proporcionado por los modelos matemáticos) y el enfoque inductivo (aportado por la estadística ). En ese momento, Frisch, al igual que otros económetras y economistas, pensaba que con las nuevas técnicas cuantitativas se posibilitaría que la economía se acercara a las ciencias exactas, ya que para un fenómeno económico en concreto, la econometría daría un único modelo, proporcionándose una base sólida para la elaboración de leyes económicas. Una de las limitaciones a las que se enfrentan los economistas es que no pueden utilizar datos experimentales (al igual que se hace en las ciencias experimentales), es decir, que no pueden reproducir en el mundo real las condiciones de la teoría; no obstante, el método estadístico utilizado como aparato de medida posibilitaba la extracción de las regularidades existentes en las masas de datos y parecía ser un buen sustituto de la experimentación. Sin embargo, en esa época la teoría estadística estaba en una fase de desarrollo que no posibilitó una valoración adecuada de las consecuencias que se podrían derivar de la utilización de datos no experimentales en el análisis estadístico, de manera que las expectativas optimistas que se generaron en los inicios de la Sociedad Econométrica ("Econometric Society") se transformarían con el tiempo en una desilusión y un desengaño que alentarían el que de manera periódica se pusiera en tela de juicio a la econometría en los aspectos relativos a su papel, sus logros y sus límites. Dentro de las primeras aplicaciones en economía del análisis de regresión se pueden observar algunos estudios de demanda. Stigler (1957) sostiene que fue el estadístico italiano Benini, en 1907, el primero que utilizó el modelo de regresión múltiple aplicado a la estimación de una función de demanda de café en la que el precio del café y del azúcar eran las variables explicativas. La retórica que dominaba en esta época apuntaba a la utilización de los métodos matemáticos y estadísticos con el objetivo de acercar a la economía a las ciencias exactas. Lo más destacable de estas primeras aplicaciones (Darnell (1994), Pág. xiv) es la falta de una especificación apropiada de un modelo estocástico y el enfoque incorrecto que se daba a la naturaleza del origen del error (ya sea como resultado de errores en la ecuación y/o de errores de medida): se reconocía que la omisión de variables (error en la ecuación) tiene su origen en la teoría económica, que se basaba en el fracaso en el mundo real de la cláusula "ceteris paribus" y que era causa de la divergencia existente entre la teoría y los datos; por otra parte, se pensaba que los errores de medida tenían su origen en la teoría estadística. Es decir, que generalmente se ignoraba el papel de los factores (variables) omitidos. El análisis de la demanda utilizó los métodos estadísticos sin usar un modelo probabilístico (la investigación no perseguía la inferencia, sino medir la elasticidad de la demanda); además, la asunción en el análisis de la demanda de la utilización de modelos de ecuaciones únicas planteó el problema de la -Pág. 12- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas identificación, el cual se refiere a las dudas que presenta la determinación simultánea del precio y de la cantidad en cuanto a si la relación estimada es una función de demanda, una función de oferta o una combinación de ambas. Este tema fue abordado por diversos autores, pero probablemente el más famoso y expresivo al respecto sea el trabajo de Working (1927): "¿Qué muestran las 'curvas de demanda' estadísticas?" ("What do Statistical 'Demand Curves' show?"). De esta forma, el cúmulo de escritores decepcionados empezó a hacerse notar. Un ejemplo evidente es Robins (1932), quien satirizó los análisis de demanda. Este autor niega las regularidades existentes en las masas de datos como 'leyes estadísticas': "…nos encontramos en un campo de investigación en el que no hay razón para suponer que estas uniformidades se van a encontrar. Las ‘causas’ que provocan que las valoraciones últimas prevalezcan en algún momento son inherentes a ese momento, son de naturaleza heterogénea: no hay base para suponer que los efectos resultantes exhibirían una uniformidad significante en el tiempo y en el espacio.” (Robins (1932, Pág. 99). Además, Robins argumenta que no está justificado que las leyes estadísticas en el campo de la economía puedan tener la misma categoría que las leyes estadísticas de las ciencias naturales: “Pero no hay razón para suponer que el estudio de una muestra aleatoria de muestras aleatorias probablemente conduzca a generalizaciones de alguna significación" (Pág. 99). A pesar de todo ésto, se continuó utilizando el método de análisis estadístico en los estudios de demanda por la sencilla razón de que los resultados que se obtenían proporcionaban elasticidades estimadas que parecían razonables. En otros campos de aplicación, tampoco se utilizaba de una forma explícita la probabilidad; así Yule (1926) en el trabajo anteriormente mencionado sobre la correlación espuria, demostraba los peligros de aplicar teorías estadísticas a los datos, debido a que éstos no satisfacían las asunciones de independencia. Persons (1924, Pág.11), abundó en lo mismo como presidente de la American Statistical Association, "Admitiendo como él (el estadístico) debe, que los puntos consecutivos de una serie temporal estadística están de hecho relacionados, admite que la teoría matemática de la probabilidad es inaplicable". I.1.4. TEORÍA ECONÓMICA Y CICLO ECONÓMICO. Aunque Raymond (1993) muestra a Frisch (1933b) como un precedente del enfoque econométrico del ciclo al tratar de incorporar a su estudio del ciclo mecanismos causales, es a finales de la década de los treinta cuando se inicia el enfoque estructural del análisis del ciclo económico con el trabajo de Tinbergen -Pág. 13- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña (1937), aplicado a la economía holandesa, y empieza a perder crédito el estudio del ciclo con una fundamentación básicamente empírica. El deseo de Tinbergen es utilizar los modelos econométricos como instrumento de intervención económica. En su trabajo, Tinbergen podía simular el efecto de distintas políticas económicas, siendo ésto lo novedoso y la diferencia fundamental entre las posturas estadísticas y estructurales. De esta forma se inicia una nueva etapa del análisis del ciclo económico, dándose los primeros pasos para pasar de la medición sin teoría subyacente imperante en la época, a la estimación y contrastación de las relaciones postuladas por la teoría económica. Posteriormente, Tinbergen traslada su experiencia holandesa a los Estados Unidos. El trabajo de Tinbergen (1939) sobre los ciclos económicos (aplicado a la economía de Estados Unidos) utilizaba la econometría para contrastar teorías (rechazar o no rechazar teorías). De esta forma, Tinbergen logra enlazar con el ulterior (y en la actualidad prevalente) enfoque propugnado por Popper, el cual propuso un método de constrastación deductiva que desemboca en el hecho de que el contraste estadístico permite rechazar o no rechazar teorías; es decir, no se busca la verificabilidad ("no exigiré que un sistema científico pueda ser seleccionado, de una vez para siempre, en un sentido negativo", (Popper (1982, Pág. 40)) sino la falsabilidad ("ha de ser posible refutar por la experiencia un sistema científico empírico" (Popper (1982, Pág. 40). El trabajo de Tinbergen dió lugar a cierta controversia por parte de los economistas, siendo el más célebre y polémico debate el establecido en los años 1939-40 entre J. M. Keynes y Tinbergen. Aunque hoy en día parece existir consenso en torno al hecho de que Keynes (1939) no leyó el trabajo de Tinbergen con suficiente atención y rigor, la crítica de Keynes de aquellos años achacaba a Tinbergen la falta de examen de la estabilidad estructural del modelo y de su capacidad predictiva. Sin embargo, la mayor discrepancia y principal foco de atracción para la crítica de Keynes, procedía del hecho de que este autor sólo veía para la econometría el papel de medida, mientras que Tinbergen la veía como una forma de inferir si una teoría era o no errónea. Según Pesaran (1990, Pág. 8) “Tinbergen abordó el problema de contrastar teorías desde una posición metodológica bastante débil. Keynes vió esta debilidad y la atacó con una perspicacia característica”. El trabajo de Tinbergen fue, en general, muy criticado, pero también tuvo apoyos importantes. Este es el caso de Haavelmo (1943), quien respondió a la crítica de Keynes; además, desarrolló la econometría como una forma de contrastar teorías alternativas. Haavelmo consideraba que cuando una teoría se contrasta y no se rechaza, la confianza que se tiene en esa teoría para su utilización futura debe aumentar. Como explica Pesaran (1990, Pág. 8): “La contribución de Haavelmo marca el inicio de una nueva era en la econometría, y prepara el camino para el rápido desarrollo de la econometría a ambos lados expuso en su trabajo de 1944 el método del Atlántico”. Haavelmo probabilístico, siendo éste un momento crítico en la historia de la econometría. -Pág. 14- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas Haavelmo buscó introducir un modelo de probabilidad en los contrastes de hipótesis. El trabajo de Trygve Haavelmo publicado en 1944 como un suplemento de la revista Econometrica (“El Enfoque Probabilístico en Econometría” (“The Probability Approach in Econometrics”)) contribuyó de manera decisiva al establecimiento de las bases conceptuales en las que se fundamentan los métodos econométricos. Haavelmo vino a arrojar luz sobre la justificación de la aplicación de la estadística teórica a la economía. Según Haavelmo, dicha justificación pasa por la caracterización del proceso generador de datos (que hipotéticamente ha generado las observaciones económicas disponibles como una realización concreta) a través de una función de densidad de probabilidades conjuntas, posibilitándose la realización de la inferencia estadística clásica dentro del campo de la economía. Morgan (1990), en su línea argumental, sostiene que, desde un punto de vista práctico, la principal aportación del trabajo de Haavelmo es que el método probabilístico provee un marco conceptual que posibilita la contrastación de teorías. En resumen, este trabajo no sólo formó la base de un nuevo consenso para el programa de investigación en econometría, sino que aportó la base necesaria para el entendimiento del modelo de probabilidad que subyace en la econometría. Como afirma Darnell (1994), Haavelmo reconoció la paradoja en la que se incurría en los trabajos en los que se utilizaban métodos estadísticos a la vez que se evitaban unas bases probabilísticas: "ha sido considerado legítimo usar algunas de las utilidades desarrolladas en la teoría estadística sin aceptar la verdadera base sobre la que se construye la teoría estadística". (1944, Prefacio, Pág. iii). Según Haavelmo, el método estadístico exige necesariamente unas bases probabilísticas. Además, demostró que el modelo de probabilidad no se rechazaba por el hecho de reconocer la falta de independencia entre los datos económicos de series temporales, argumentando la generalidad del uso de la probabilidad y la adopción del modelo de probabilidad para facilitar el contraste de hipótesis. Haavelmo identificaba correctamente los límites de la econometría como un instrumento para el "descubrimiento" de "verdades económicas" y advertía a los que veían la econometría como un aparato con el cual revelar "leyes económicas": "no olvidemos que ellas (las teorías económicas) son nuestras propias invenciones artificiales en una búsqueda de un entendimiento de la vida real; no son verdades ocultas para descubrir" (Pág. 3). Se puede concluir que Haavelmo consiguió aportar un enfoque en lo referente al papel de la econometría (como un modo de contrastación de teorías) y al concepto de estructura muestral que después obtendría un amplio asenso. -Pág. 15- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña Alfred Cowles (un magnate americano) había fundado en 1932 un centro de investigación llamado "Cowles Commision", que adoptó la perspectiva aportada por Haavelmo y la dotó posteriormente de un armazón técnico: "desarrolló el núcleo teórico de la econometría moderna en un admirable corto plazo de tiempo" (Epstein (1987, Pág.62)). Así, por ejemplo, la "Cowles Commision" dió una solución satisfactoria al problema de la identificación a mediados de los años 40. Mientras tanto, el debate acerca de la relación existente entre la medición y la teoría seguía abierto. Como prueba de ello, Darnell(1994) recoge la polémica servida en 1947 y 1949 por Koopmans y Vining. El punto de partida de la discusión es la revisión de Koopmans (1947) del trabajo de Burns y Mitchell, "Measuring Business Cycles" (1946), en el que criticaba el tratamiento inductivo que se daba a los datos y la no adopción por estos autores del enfoque de Haavelmo. Por su parte, Rutledge Vining8 veía el trabajo en cuestión como un enfoque inductivo bastante adecuado para la búsqueda de hipótesis. En definitiva, Koopmans (1947, Pág.162) acabó defendiendo el papel de la teoría económica, "la utilización de los conceptos e hipótesis de la teoría económica como parte del proceso de observación y medida promete ser la vía más corta...para el entendimiento (de un fenómeno económico)" y rechazando el enfoque inductivo. La Comisión Cowles fue la impulsora del empleo y auge de modelos estructurales en las décadas de los 50 y de los 60. Sus principales trabajos son las monografías editadas por Koopmans (1950), Klein (1950) y Hood y Koopmans (1953), en las cuales se consigue asentar el paradigma de la econometría, estableciendo las bases del enfoque econométrico. Mientras que la econometría aplicada ganaba terreno poco a poco gracias en buena medida a los avances de la informática, la econometría teórica de esta época no fue excesivamente innovadora, dedicándose más bien a trabajar en torno al desarrollo de los métodos ya existentes. No obstante, también se introducen producen avances y extensiones como los métodos de estimación por mínimos cuadrados en dos y tres etapas, el método de Zellner de estimación de sistemas de ecuaciones aparentemente no relacionadas, el método de máxima verosimilitud con información completa, el método de máxima verosimilitud con información limitada, el método de variables instrumentales, etc... El elemento típico de los años 50 y 60 fue la estimación de macromodelos, destacando las experiencias llevadas a cabo en la economía USA con el modelo de Klein-Goldberger (1955) y el modelo Brookings (como hito de los macromodelos de los años 60). Según Bodkin, Klein y Marwah (1991, pág 58) "La estructura del modelo de Klein-Goldberger puede ser vista como la primera representación empírica de un sistema con una marcada base 8 Vining, R.(1949). -Pág. 16- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas keynesiana."; este modelo llegó a constituir el paradigma de los modelos que estudiaban el ciclo económico. Por otra parte, el modelo Brookings fue el mayor modelo de los años 60, y según Raymond (1993, Pág.113) "Posiblemente este modelo represente el punto álgido de la confianza en los macromodelos". En esta época se produjo un enorme desarrollo de los modelos macroeconómicos en todo el mundo, comenzando los gobiernos a elaborar sus propios modelos como instrumentos de predicción y de apoyo al proceso de toma de decisiones de política económica. Fue en estos años en los que de forma más patente y clara se vió el papel de la econometría para contrastar y discriminar teorías. I.1.5. LA CRISIS DEL ENFOQUE ECONOMÉTRICO. La década de los 70 es la del "desengaño", ya que los resultados obtenidos no estuvieron a la altura de las expectativas generadas; así, los sistemas de ecuaciones macroeconómicas no alertaron vía predicciones de la crisis que se avecinaba y no fueron capaces de dar recomendaciones de política económica que posibilitaran una salida de la "crisis del petróleo" de 1974. Sirva como muestra del fracaso predictivo de estos modelos la publicación de Lucas y Sargent (1978), los cuales destacan que estos modelos predecían a finales de los años 60 que elevadas tasas de desempleo irían asociadas a bajas tasas de inflación, es decir, lo contrario a lo que verdaderamente ocurrió. Además, se producen críticas teóricas a los modelos econométricos estructurales, resaltando las críticas de Bassman (1972) y, sobre todo, la de Lucas (1976). Bassman argumenta que las hipótesis económicas que subyacen en los modelos macroeconómicos no están suficientemente especificadas9, resultando difícil en la práctica su contrastación. La crítica de Lucas proviene de la escuela de expectativas racionales, y es la más notable en lo que se refiere a su trascendencia metodológica. En esencia, mantiene que los modelos econométricos carecen de una base teórica fuerte, cuestionando la validez de las predicciones que se realizan con los modelos econométricos como apoyo a las decisiones de política económica. Lucas (1976), dentro del contexto de la evaluación de modelos de política económica, sostiene que como un modelo (su estructura) es el resultado de unas reglas de actuación (decisiones) óptimas de los agentes económicos, que están basadas parcialmente en expectativas racionales acerca de la evolución futura de unas variables relevantes, "cualquier cambio de política alterará sistemáticamente la estructura de los modelos econométricos" (Pág. 41). En definitiva, Lucas argumenta que, al cambiar el patrón de política seguido, se producen cambios en los parámetros. Estos cambios son debidos, por una parte, a que en la especificación de gran 9 En particular, en el modelo Brookings. -Pág. 17- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña cantidad de modelos se produce una combinación de la estructura dinámica con el proceso de formación de expectativas, y por otra parte, a que los parámetros son una función de unas actuaciones óptimas de los agentes económicos que dependen del tipo de política seguido. Lucas (1976, Pág. 279) en sus conclusiones afirma que "Para cuestiones relativas a la predicción a corto plazo, o a la capacidad de los modelos econométricos para captar la evolución de las variables económicas, se ha visto que este argumento tiene una importancia secundaria. Por contra, para la evaluación de políticas, su importancia es fundamental. Implica que la comparación de efectos de políticas alternativas no es válida, independientemente del comportamiento muestral de los modelos o de su capacidad predictiva...". Se trata pues de una crítica a las simulaciones realizadas con modelos econométricos. La respuesta a la problemática planteada por Lucas (Raymond (1993, Pág. 14)) viene dada por “tratar de especificar modelos en los que, por un lado, se separe el proceso de formación de expectativas de la estructura dinámica del modelo. Además, para que los parámetros sean invariables ante las intervenciones de política económica, la estructura del modelo debe derivarse de un proceso de maximización de una función objetivo (véase Wallis, 1980)”. Por otra parte, existe consenso en afirmar que la esencia de la crítica a las simulaciones se verifica en muchos modelos, pero que desde el punto de vista empírico, la solución viene dada por la realización de simulaciones que no supongan un cambio estructural en el modelo. En definitiva, en los años 70 nos encontramos, por un lado, con críticas referentes a la capacidad de predicción, a la interpretación de la realidad y a la teoría subyacente en los modelos econométricos estructurales que genera un descontento en su utilización; pero, por otro lado, se aprecia un afianzamiento del desarrollo y uso entre los economistas del llamado "análisis de series temporales". Este análisis se basa en la búsqueda de regularidades estadísticas en los datos, es decir, prescinde de la base teórica que requieren los modelos econométricos estructurales y, en esencia, trata de explicar una variable en función de su propio pasado o del de otras variables, dando lugar a modelos predictivos con muy pocas variables. Dentro del campo de las series temporales existe un trabajo primordial y de obligada referencia, el de Box y Jenkins (1970), el cual revisa, actualiza y sistematiza los trabajos fundamentales dentro de los ya existentes en esta línea de trabajo. En torno a los años 70 es cuando se inicia una etapa de desarrollos teóricos importantes en las técnicas de las series temporales, incrementándose de manera muy señalada la utilización en los trabajos econométricos de dichas técnicas. -Pág. 18- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas I.1.6. SERIES TEMPORALES: PROGRESOS Y ENGARCE CON LA ECONOMETRÍA. En este apartado aportamos una visión panorámica de algunos desarrollos referentes a los temas principales en los trabajos de series temporales, exponiendo su relación con la econometría. Orientamos esta breve exposición a los temas que nos parecen más relevantes con respecto al ámbito de trabajo de esta tesis10, ya sea porque las utilizamos o porque enlazan de manera directa con las problemáticas que tratamos. Existen dos tipos de modelos en el campo del análisis de las series temporales que juegan en la actualidad un papel muy importante: los modelos autorregresivos integrados de medias móviles (ARIMA) y los modelos estructurales de series temporales. Los primeros son la unificación y culminación de una serie de trabajos publicados por Box y Jenkins en la década de los 60. Estos autores ponen de manifiesto que la teoría clásica de los procesos estocásticos lineales estacionarios se puede aplicar a la predicción de series no estacionarias previa diferenciación de la serie. La llamada metodología Box y Jenkins (1970, 1976) se suele esquematizar en cuatro etapas11: identificación del modelo que puede haber generado la serie temporal que se está estudiando; estimación de los parámetros del modelo; chequeo, tanto de los residuos del modelo como de la calidad de las estimaciones y del cumplimiento por parte de los parámetros del modelo de una serie de condiciones de estacionariedad e invertibilidad. En lo que respecta a los modelos estructurales de series temporales, Harvey (1995) expone como ejemplo más simple el mostrado en el trabajo de Muth (1960), que está constituido por un paseo aleatorio y un ruido blanco; el primero representando el nivel fundamental, y el segundo un componente irregular. Según Harvey (1995), esta estructura básica se verá enriquecida con un término de pendiente en los trabajos de Theil y Wage (1964) y Nerlove y Wage (1964); pero el avance de los trabajos en esta dirección no continuó hasta que el trabajo de Schweppe (1965) mostrara cómo utilizar el filtro de Kalman “para derivar expresiones nuevas para la función de verosimilitud de señales gausianas contaminadas por ruidos gausianos aditivos” (Pág. 62). Sin embargo, como este trabajo se desarrolló en el campo de la ingeniería, tuvo que pasar cierto tiempo hasta que se valorara adecuadamente en el ámbito económico y se recuperara esta línea de investigación dentro de la formulación en el espacio de 10 De esta forma, la línea conductora de este apartado puede resultarle al lector poco fundamentada, pero los objetivos que perseguimos en este trabajo aconsejan no extendernos más de lo estrictamente necesario. 11 Existe numerosa bibliografía acerca de la metodología ARIMA; dentro de la literatura española se pueden consultar, entre otros, Pulido (1989), Aznar y Trívez (1993b), Espasa y Cancelo (Eds.) (1993) y Otero(1993). -Pág. 19- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña los estados, (algunos ejemplos son Belsley (1973) y Sarris (1973)). Harvey (1995) muestra como primeras contribuciones las publicaciones de Pagan (1975), Engle (1978), y Kitagawa y Gersch (1984), las cuales desembocan en “una clase de modelos y una estrategia de modelización que proporciona una alternativa a la modelización ARIMA” (Harvey (1995, Pág. xiii)). Dentro de este enfoque, Harvey (1993, Pág. 120) sostiene que “un modelo estructural de series temporales es aquél que se establece en términos de componentes que tienen una interpretación directa”. Como libro exponente de este tipo de modelos está el de Harvey (1989), dentro del cual “tales modelos se pueden ver como modelos de regresión en los que las variables explicativas son función del tiempo y los parámetros son variables en el tiempo” (Harvey (1995, Pág. xiii)). En el contexto de los modelos econométricos, Granger y Newbold (1974 y 1977) obtuvieron mediante ejercicios de simulación la confirmación de lo que llamaron correlación espúrea, y Phillips (1986) los corroboró de forma analítica. Aznar y Trívez (1993a, Pág. 129) sintetizan de esta forma las conclusiones de estos trabajos: “según sea la estructura no estacionaria de las variables que se incluyen en el modelo, las propiedades de los estimadores y de los contrastes habitualmente utilizados variarán respecto a las que tradicionalmente se venían utilizando en Econometría. Esto es de vital importancia porque se puede llegar a resultados totalmente erróneos si se sigue prestando atención a estos contrastes sin tener en cuenta la particular estructura no estacionaria de las variables incluidas en el modelo.” De esta forma, se trata de decidir si una serie es o no es estacionaria, y los contrastes que se utilizan para verificar la estacionariedad de una serie reciben el nombre de contrastes de raíces unitarias. No obstante, también se puede utilizar como instrumento para detectar la presencia de raíces unitarias los métodos derivados del trabajo de Box y Jenkins (1970), los cuales deciden acerca de la existencia de raíces unitarias a través de las funciones de correlación simple y parcial de la serie que se analiza. Volviendo a los contrastes de raíces unitarias, Fuller (1976) y Dickey y Fuller (1979 y 1981) son las publicaciones que establecerán los fundamentos analíticos de los contrastes de raíces unitarias que más se han utilizado posteriormente; por ejemplo, evidencian que los contrastes de raíces unitarias se deben basar en tablas estadísticas de valores críticos especiales. Por otra parte, Nelson y Plosser (1982) distinguen entre dos tipos de series no estacionarias, series con tendencia determinista (“trend stationary”) y series con tendencia estocástica (“difference stationary”); estos autores, mediante la utilización de contrastes de raíces unitarias, se decantan a favor de la formulación con tendencia estocástica. La distinción que realizan Nelson y Plosser será una reseña de gran valor en los estudios posteriores realizados en el ámbito de la caracterización de las series no estacionarias. La formulación con -Pág. 20- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas tendencia estocástica implica la eliminación de la tendencia de la serie previa a la realización de cualquier análisis. En ocasiones, puede ser de interés descomponer una serie en sus componentes clásicos, a saber: tendencia, ciclo, estacionalidad y componente irregular. A lo largo de la historia, una de las razones fundamentales para realizar ésto ha sido la eliminación del componente estacional. Ya hemos señalado anteriormente que los modelos estructurales de series temporales se formulan en términos de componentes explícitos, de manera que ésto posibilita la descomposición inmediata de las series económicas en, por ejemplo, sus componentes tendenciales, cíclicos, estacionales e irregulares. Sin embargo, la descomposición de un modelo ARIMA12 en tales componentes no es tan inmediata, debiéndose verificar una serie de requisitos recogidos en Hillmer y Tiao (1982). De cualquier modo, se conoce como ajuste estacional basado en modelo a aquél que se realiza mediante “la consideración explícita de los procesos generadores de los componentes” (Espasa y Cancelo (1993, Pág. 288)), ya se basen en el modelo ARIMA o en el modelo estructural de la serie temporal. Esta característica es la nota que distingue a estos métodos de descomposición de los métodos llamados empiricistas, siendo los más conocidos y utilizados inicialmente el X-1113 y el X-11 ARIMA14. En otra línea de investigación, Engle y Granger (1987) llevan a cabo un análisis del concepto de cointegración. De manera intuitiva, se puede afirmar que si las variables de un modelo son no estacionarias, pero existe en dicho modelo una relación a largo plazo (relación de equilibrio), existe cointegración. Stock (1987) se centró en estudiar las consecuencias estadísticas que se derivaban de la existencia de cointegración en la estimación de una única ecuación estática, concluyendo que los estimadores mínimocuadráticos de relaciones de largo plazo entre dos variables cointegradas son superconsistentes (tienden a los verdaderos valores de los parámetros con una velocidad mayor que la habitual). Esta conclusión se matizará en estados posteriores de la investigación para el caso de muestras finitas, en el que el sesgo del estimador mínimo cuadrático puede ser importante. A partir del trabajo de Davidson et al. (1978) aparecen los modelos de corrección de error, que son modelos con una representación dinámica y que utilizan un mecanismo automático para corregir las desviaciones actuales 12 La bibliografía básica de este método de descomposición es Box, Hillmer y Tiao (1978), Burman (1980), Hillmer y Tiao (1982), Bell y Hillmer (1984), Maravall (1987) y Maravall y Pierce (1987). 13 Este método se publica en Shiskin et al. (1967) como la culminación de una serie de trabajos iniciados en 1954. 14 Desarrollado por Dagum, y cuyas referencias básicas son Dagum (1980) y Dagum (1988). -Pág. 21- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña respecto a la situación de equilibrio a largo plazo. De esta forma, partiendo de un modelo con una estructura de retardos, se llega a la relación a largo plazo o de equilibrio mediante la utilización del llamado término de corrección de error. La bibliografía existente en la actualidad en lo referente al análisis de cointegración es muy amplia, y entrar a comentar todos los desarrollos ocurridos en este campo se escapa de los objetivos de este capítulo. Por ésto, vamos a concluir esta breve reseña referente al análisis de cointegración con las conclusiones que Aznar y Trívez (1993a) recogen en su libro: - “A la hora de especificar un modelo econométrico debemos prestar atención al orden de integrabilidad de las variables incluidas en el modelo para no utilizar instrumentos de inferencia que sean inapropiados para la situación que se analiza.” (Pág. 143). -“Cuando dos o más variables están cointegradas, se ha interpretado la relación de cointegración como una relación de equilibrio sobre la cual la teoría económica puede proporcionar información a priori que se puede utilizar a la hora de estimar y contrastar el modelo. En este caso, el modelo de corrección de error deja de ser una (simple) reparametrización y pasa a ser (…) algo diferente que puede permitir un tratamiento y análisis, asimismo, diferentes.” (Pág. 144) Por lo tanto, se debe “utilizar aquella reparametrización que mejor sirva como vehículo para dar cauce a la información procedente de la teoría económica”. En el marco de los modelos econométricos se suele distinguir entre variables endógenas y exógenas15. De manera intuitiva, se puede decir que una variable es exógena si el análisis que se realiza se lleva a cabo sin especificar una ecuación explicativa para dicha variable. Una referencia obligada dentro del campo de la exogeneidad es el de Engle et al. (1983), que examina y dota de significación de una manera muy completa al concepto de exogeneidad, analizando sus implicaciones en la estimación. Otro libro que trata el tema de la exogeneidad y su relación con el análisis de cointegración es Ericsson (1992). Antes hemos comentado que el filtro de Kalman supuso un avance muy importante para los modelos estructurales de series temporales; pues bien, ésto se puede generalizar afirmando que la representación en el espacio de estados es fundamental para los modelos de series temporales, ya que significó un aumento del número de modelos operativos. Los trabajos claves son los de Kalman (1960 y 1963) que implican la representación de un sistema dinámico en la forma llamada de espacio de estados. La idea de estado de un sistema se refiere a un conjunto de variables que describen las propiedades inherentes del sistema en un momento de tiempo determinado. Intuitivamente, el filtro de Kalman pretende 15 Ya se trató el tema de la exogeneidad en la monografía número 10 de la Cowles Comission: Koopmans (Ed.)(1950). -Pág. 22- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas utilizar la información acerca de cómo las medidas de un aspecto en particular de un sistema están correlacionadas con el estado actual del sistema, de manera que permite actualizar la estimación de un estado del sistema. Las ventajas más importantes que aporta el filtro de Kalman son las siguientes: “proporciona una vía para calcular predicciones exactas en muestras finitas y la función de verosimilitud exacta para un proceso ARMA, para factorizar funciones generadoras de matrices de autocovarianza o de densidad espectral, y para estimar vectores autorregresivos con coeficientes que cambian en el tiempo” (Hamilton (1994, Pág. 372). Además, la representación en el espacio de estados permite un tratamiento fácil de las irregularidades que en ocasiones se dan en los datos (como las observaciones perdidas). Hoy en día está bastante generalizada la aplicación de esta técnica dentro del campo de la economía. En la actualidad, y según Maravall(1996, Pág. 6.), “las dos direcciones importantes de investigación son: (1) Ampliaciones multivariantes, donde las investigaciones relativamente frecuentes sobre cointegración y factores comunes pueden conducir a una importante ruptura (a través de una reducción en la dimensionalidad y una mejora en la especificación del modelo) (2) Ampliaciones no lineales, tales como el uso de modelos bilineales, modelos que se basan en la llamada heteroscedasticidad autorregresiva condicional (ARCH), modelos ARCH generalizados (GARCH), parámetros estocásticos, y así sucesivamente. Esperaría que la dirección (1) juegue con el tiempo un importante papel en la predicción aplicada en el corto tiempo en la próxima década. En cuanto al futuro impacto de la dirección (2), dudo de que en los próximos años los modelos estocásticos no lineales llegarán a ser un instrumento estándar para el profesional medio.” Como se ha podido apreciar en esta breve y sesgada panorámica, los avances en los últimos 30 años han sido numerosos y diversos (y aún existen amplias líneas de investigación abiertas en la actualidad), produciéndose una relación muy enriquecedora entre los modelos econométricos y el estudio de las series temporales, siendo habitual que los segundos utilicen a los primeros como instrumentos de análisis previos a sus aplicaciones. -Pág. 23- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña I.1.7. EVOLUCIÓN RECIENTE Y SITUACIÓN ACTUAL. I.1.7.1. ECONOMETRÍA APLICADA. Los fracasos que se observaron en los resultados obtenidos por los económetras en la década de los setenta, condujeron a posicionamientos diversos de los economistas respecto a la Econometría aplicada; así, Charemza y Deadman (1992) los clasifica en tres grupos: a) Los que comenzaron a catalogar a la Econometría como alquimia16. b) Los que vieron en los problemas de especificación y métodos de estimación imperfecta las causas del fracaso y reclamaron una revisión en profundidad de tales cuestiones para poder continuar con el paradigma clásico (caracterizado por la formulación de hipótesis a partir de alguna teoría económica más o menos establecida para posteriormente contrastar las mismas con los datos). c) Aquellos que pidieron una revisión general de los postulados de la Comisión Cowles17, proponiendo metodologías alternativas a la tradicional. Entre las líneas de investigación que aparecen como consecuencia de la crítica de Lucas, podemos señalar tanto a la escuela de expectativas racionales (con Lucas y Sargent (1981) como principales precursores) como a la línea de investigación que culminó con las teorías del ciclo económico real (el trabajo pionero fue el de Kydland y Prescott (1982)). También hubo otras propuestas, como la de los investigadores de la “London School of Economics” (con Hendry (1979) como precursor) o la metodología de Leamer (ver Leamer y Leonard (1983)). Nosotros sólo vamos a hacer referencia18 al enfoque de la escuela de expectativas racionales y al de la ”London School of Economics”. 16 Ver al respecto el Capítulo 1 del libro de D. Hendry (1993) que lleva el mismo título que el libro, “Econometrics, Alchemy or Science?” y que es una reproducción de su artículo de Economica de 1980. 17 Según Christ (1994), las hipótesis implícitas en la mayor parte del trabajo teórico de la Comisión Cowles son: a) el comportamiento económico viene dado a través de un conjunto de ecuaciones simultáneas; b) las ecuaciones del modelo son lineales en los parámetros y en las perturbaciones; c) las variables del modelo se miden sin error; d) las variables cambian a intervalos de tiempo discreto (anual, trimestral, mensualmente, etc.); e) se conoce qué variables son exógenas, y cuáles son predeterminadas en cada instante t; f) la forma reducida del modelo existe (el determinante de la matriz de coeficientes de las variables endógenas es no nulo); g) las variables predeterminadas son linealmente independientes; h) las ecuaciones estructurales están ‘identificadas’ mediante restricciones a priori sobre sus parámetros (estructurales o de la distribución de las perturbaciones), y estas restricciones son correctas; i) las perturbaciones tienen una distribución normal con media cero, varianzas y covarianzas finitas, y la matriz de covarianzas es no singular; j) no existe correlación temporal en las perturbaciones; y, k) el sistema de ecuaciones es dinámicamente estable. 18 Lo justificamos tanto por el gran uso que en la actualidad se hace de la metodología que integra a ambos enfoques como porque en el Capítulo VII utilizamos ecuaciones en forma de modelo de corrección de error. -Pág. 24- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas En 1980, y apostando por un cambio de paradigma, Sims (1980) propone un enfoque nuevo, calificado como ateórico inicialmente (Cooley y Leroy (1985)), que sostiene que un vector de variables se explica por su propio comportamiento pasado, es decir, no distingue entre variables endógenas y exógenas. De esta forma, reacciona ante la hipótesis de causalidad, y propone como principios básicos la inexistencia de conocimientos teóricos suficientes para clasificar las variables en endógenas y exógenas así como la imposibilidad a priori de establecer restricciones cero. Esta alternativa nueva consiste en utilizar un sistema de ecuaciones en el que no se distinga entre variables endógenas y exógenas, de forma que un vector de variables (estacionarias) se explica a partir de su propio comportamiento pasado (de ahí que se denominen modelos vectoriales autorregresivos (modelos VAR)). Estos modelos aparecieron como una alternativa atractiva a los modelos econométricos “clásicos”, y es el tipo de modelo multivariante más extendido entre los económetras. En principio, se obtuvieron resultados bastante satisfactorios a efectos de predicción , pero no así a efectos de análisis estructural y de simulación (por lo tanto, los modelos VAR no saciaban las necesidades que se planteaban dentro del ámbito de la política económica). Sirva como ejemplo de crítica contraria a este tipo de modelos el siguiente párrafo de Maravall (1990, Pág. 166): “En general presentan una inestabilidad considerable en sus parámetros, predicen mal, con frecuencia son poco parsimoniosos y la interpretación del efecto de una variable sobre otra depende del orden en que éstas se coloquen en el modelo”. Ésto último significa que los resultados que se obtienen con los modelos VAR son sensibles a la ordenación dada a las variables, lo cual nos lleva al campo de la inferencia causal, de manera que se entren primero las variables causa y después las variables efecto. El enfoque de la ”London School of Economics” hace una distinción entre el modelo teórico y el empírico, de manera que la teoría generalmente influye sobre este último a través de la solución a largo plazo, mientras que la especificación de la dinámica a corto plazo viene determinada por la estructura de los datos. Al enfoque de Hendry se le ha criticado su débil sustento teórico, ya que limita el papel de la teoría a proporcionar alguna(s) restricción(es) de equilibrio en el largo plazo, en el contexto de modelos (uniecuacionales) dinámicos con mecanismos de corrección de error (MCE). Como compendio de las opiniones que a principio de los noventa suscitaban la relación entre la econometría y la teoría económica podemos citar a Morgan (1990, Pág. 264), quien afirma que la consecución de ”la unión de las matemáticas, la estadística y la economía en una verdadera síntesis económica”, que en los años 50 era uno “de los ideales de la econometría”, “ha fracasado". En este sentido, Maravall (1990, Pág. 155) afirma que “la econometría aún se encuentra lejos de poder ofrecer una base empírica sólida a la teoría -Pág. 25- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña económica” , y apunta (Págs. 158-159) entre las causas obvias de la crisis de la econometría las siguientes: -”Los problemas de agregación” tanto entre agentes económicos como entre datos temporales. -“La insuficiencia teórica para determinar la dinámica en los modelos económicos y econométricos” -“Los errores en las variables (o en los datos)”, tanto desde la perspectiva conceptual como del proceso de medición. Recientemente se ha mostrado (Hansen y Sargent (1991)) que los modelos VAR no son inherentemente ateóricos19. Además, en los últimos años el enfoque VAR se ha refundido con el enfoque de modelos dinámicos con mecanismos de corrección de error en el ámbito de la teoría de cointegración, dando lugar a los modelos VAR con mecanismos de corrección de error [ver Engle y Granger (1991) o Johansen (1991)]. Sin embargo, y aunque este enfoque va más allá del puro análisis de series temporales, considerando relaciones obtenidas a través de la teoría económica, los teóricos de la economía siguen viendo este enfoque como falto de un vínculo consistente con la teoría económica debido a que sólo la utiliza para especificar las relaciones a largo plazo entre las variables observables. Por su parte, Darnell (1994, Pág. xvii), sostiene que "La advertencia de Haavelmo de que la econometría no puede descubrir leyes ocultas porque no existen (leyes) para ser descubiertas (mejor dicho, son construcciones nuestras) no ha sido tenida en cuenta suficientemente, y el consecuente desengaño en los logros de la econometría se puede ver como un estímulo para la reexaminación de la naturaleza, papel y métodos de la econometría y la reevaluación de su relación con la teoría económica que ha surgido en los últimos veinte años." 19 Puesto que la hipótesis de expectativas racionales en un contexto de optimización dinámica puede imponer restricciones cruzadas sobre las ecuaciones VAR haciendo que los modelos estimados (VAR restringidos) puedan usarse para hacer inferencias acerca de los parámetros estructurales. -Pág. 26- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas I.1.7.2. ESTRATEGIAS MODELIZADORAS. En los años 70, y desde el punto de vista predictivo, con el análisis de series temporales se obtuvieron, en general, mejores resultados a corto plazo que con los modelos estructurales. Este hecho repercutió negativamente en la fiabilidad de los modelos econométricos. No obstante, a medio plazo los mejores resultados correspondían generalmente a los modelos estructurales. Como ejemplo del afianzamiento y desarrollo logrado por el análisis de series temporales en la década de los 70, en esta época, la Organización para la Cooperación y el Desarrollo Económico (OCDE) inicia unos trabajos cuyas investigaciones van dirigidas a la consecución de un sistema de indicadores cíclicos para la industria manufacturera, y que desembocarán en la publicación mensual “Principales indicadores económicos” (“Main Economic Indicators”). Los esfuerzos que se realizaron posteriormente en esta línea de trabajo también posibilitaron la consecución del sistema de indicadores cíclicos de la OCDE que divulga la antes mencionada publicación mensual. En la década siguiente (años 80), se produce una convivencia de los métodos que no están basados en teorías con los modelos econométricos estructurales. Cuando se habla de convivencia entre los análisis de series temporales y los modelos econométricos, hay que entenderlo tanto en la acepción de complementariedad como en la de coadyuvante, puesto que los primeros dan a los datos de los que se alimentan los segundos un tratamiento previo a su utilización. En este sentido, Otero (1993, Pág. 323) escribe que “el análisis de series temporales es una herramienta básica de la econometría, aunque la econometría de las series temporales es algo más que el análisis de series temporales”. En la actualidad, y como afirma Raymond (1993, Pág. 101) en lo referente al análisis del ciclo económico, los economistas responden tratando "de diseñar modelos para la predicción y control de las principales variables económicas", de forma que se pueden "dibujar dos posiciones extremas: a) la que cabría denominar <<postura estadística>>; y b) la que cabría denominar <<postura estructural>>." La primera tiene una fuerte base empírica y Según Raymond (1993, Pág. 102) "...el elemento común, y aún a riesgo de simplificar en exceso, podría ser anteponer los datos a la teoría, utilizando métodos exploratorios más o menos sofisticados, y buscar una justificación <<ex post>> de las relaciones halladas". Por otra parte, la postura estructural trata "de abordar el problema de la predicción y el análisis coyuntural de forma no desligada del proceso de causación económica.(...) Naturalmente, detrás de este enfoque se halla un modelo econométrico explicativo de las distintas variables económicas, que se supone especificado de acuerdo con un proceso causal postulado <<a priori>> por la teoría económica" (Raymond (1993, Pág. 102). -Pág. 27- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña En consecuencia, el hecho más destacable es que los modelos econométricos ya no generan las grandes perspectivas de los años 60, pero siguen siendo utilizados, ya que se trata de un instrumento disponible (y no existe una alternativa mejor) para estimar y contrastar las relaciones que sugiere la teoría económica: “el análisis de series temporales, con una fundamentación metodológica quizás más satisfactoria (que en el campo econométrico), no puede pretender contestar a los problemas de más relevancia que surgen en el análisis económico” (Maravall (1990, Pág. 155)) . Así, Bodkin et. al (1991, Pág. 555)20 vaticinan: "...nosotros vemos una continuación del crecimiento, al menos para la próxima década o más, en la industria de la modelización macroeconométrica." En lo que respecta a la percepción acerca del desarrollo futuro de los modelos econométricos, Bodkin et. al (1991) recogen una serie de tendencias para la modelización macroeconométrica de finales de este siglo (e incluso para "el siguiente" (Pág. 536)). Estos autores proponen (enlazando con el hilo conductor que mueve la realización de esta revisión histórica) un progreso de los modelos econométricos y del análisis de series temporales que confluya en una integración plena de ambas metodologías, de manera que el modelo econométrico proporcione la mayor fiabilidad posible en las predicciones a medio y largo plazo, y el análisis de series temporales (con unos requisitos informativos mucho más reducidos) sea el que de las predicciones a corto plazo. Podemos concluir afirmando que las dos posiciones "extremas" que Raymond(1993) plantea son, precisamente, las dos perspectivas con las que perseguimos hacer posible en este trabajo el estudio de una economía regional, ya que consideramos que los componentes e información inherentes a cada una de estas posturas se enriquecen y/o complementan. En definitiva, en este trabajo pretendemos recoger el testigo de la propuesta de integración (en términos predictivos) del enfoque estadístico y el enfoque estructural que Bodkin et al. (1991) propugnan para aplicarlo a la modelización regional. I.1.8. ECONOMÍA REGIONAL Y MODELIZACIÓN. Puesto que el campo de análisis de esta tesis es el de la economía regional, es necesario un acercamiento a este marco de análisis que también se ve afectado por la evolución histórica de la cuantificación en la economía. En primer lugar, debemos resaltar el carácter relativamente reciente de dicha materia: “…, el despegue real de la economía regional como una disciplina independiente no tiene lugar antes de la 2ª Guerra Mundial…. Desde entonces, 20 Bodkin, R. G., Klein, L. R., y Marwah, K. (1991): “A History of Macroeconometric Model-Building”, Edward Elgar Publishing Company. Chapter 17: “Prospects for macroeconometric modelling”. -Pág. 28- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas la economía regional ha verificado un magnífico avance en la mayor comprensión de la estructura y evolución de los sistemas económicos espaciales.” Nijkamp, P., Mills, E. S. (1986, Pág. 1). Por otra parte, nos situamos en cuanto al área de la economía regional que queremos abordar. Nijkamp, P., Mills, E. S. (1986, Pág. 2) nos emplazan de manera adecuada en las posibles orientaciones a adoptar en el análisis: “Una visión más próxima de la historia y de los logros actuales de la economía regional nos enseña que, a pesar del gran número de contribuciones diferentes en este área, podemos identificar tres campos principales en los cuales la economía regional ha generado una contribución real a la teoría y análisis económico: (1) teoría de la localización (para industrias y hogares) (2) modelización económica regional y análisis de interacción espacial (3) desarrollo y política económica regional.” Es en el segundo campo ((2) modelización económica regional y análisis de interacción espacial) en el que se alinea nuestro análisis. En este contexto, el concepto de modelo se convierte para nosotros en un elemento clave, y las orientaciones estadísticas (“no estructurales”) y estructurales (causales) que han presidido la evolución cuantitativa económica también se acomodan en el ámbito de la modelización regional. A continuación exponemos el concepto de modelo, y para ello vamos a seguir y parafrasear la línea argumental que Pulido (1987) presenta.21 Pulido (1987, Pág. 29) afirma que se debe entender por modelo la “representación, necesariamente simplificada, de cualquier fenómeno, proceso, institución y -en general- de cualquier sistema”. Según este autor, cualquier modelo pretende representar a un sistema, entendiendo por tal a “todo conjunto de elementos o componentes vinculados entre sí por ciertas relaciones” (Pág. 29). Por lo tanto, un modelo regional es una representación simplificada de un sistema que en este caso es una región22. Pero la complejidad inherente a muchos sistemas hace que no sea factible lograr recoger mediante un modelo todos sus elementos y relaciones, razón por la cual el constructor del modelo debe decidir acerca “de los elementos que 21 Para una mayor profundidad en el tema, recomendamos la lectura del Capítulo 1 de Pulido(1987). 22 Como comentaremos en el capítulo segundo, en la Nomenclatura de Unidades Estadísticas Territoriales (NUTS) existen tres niveles o tipos de regiones, y nosotros vamos a centrarnos en las regiones de nivel II o "unidades administrativas de base", que es donde se encuadran las comunidades autónomas españolas. Por lo tanto, el concepto de región que nosotros vamos a utilizar queda delimitado por consideraciones histórico-políticas, de manera que la disponibilidad de datos también viene condicionada, en general, por las divisiones del territorio nacional que han dado lugar a las Comunidades Autónomas. -Pág. 29- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña considera básicos y de las relaciones que estima como más significativas” (Pág.31) dentro del grado de detalle con el que desea trabajar. A su vez, existen distintos “niveles de formalización para un mismo sistema y un mismo <<modelista>> que van desde el mero modelo mental (…) hasta el modelo verbal (…), el físico(…) y el modelo matemático” (Pág. 31). Según Pulido (1987, Pág. 33) “los modelos matemáticos constituyen la forma más estricta de conocimiento científico de una realidad, sin que ello deba suponer el que su utilización indiscriminada asfixie toda elaboración teórica no directamente <<matematizable>> o -lo que es al menos tan perjudicial- encubra bajo su halo protector un conocimiento falso de la realidad aunque estrictamente planteado”. El hecho de adoptar un modelo matemático puede conectar con distintos grados de requerimientos teóricos, de manera que en el modelo puede subyacer una teoría económica tan débil que no dificulta la modelización (“enfoque ateórico”) o por el contrario, que se requiera como soporte una teoría que “complique” los esfuerzos modelizadores (“modelización con teoría”). Podemos afirmar que la modelización ateórica, por su naturaleza, no necesitó de aclaraciones y pesquisas especiales. No así la modelización con base fundamental en la teoría económica; como muestra de los requirimientos especiales de este tipo de modelización, sirven las palabras de Hendry y Morgan (1995, Págs. 67 - 68): “Haavelmo23(…) clarifica los conceptos de modelos y variables así como la relación entre teoría y datos. El concepto de modelo puede parecer en sí mismo evidente, pero no era suficientemente conocido en economía. La concepción práctica de un modelo surgió y se desarrolló en el trabajo de Tinbergen, y Hicks (1937) hizo la distinción entre teoría general de Keynes (1936) y su propio modelo (denominado ‘construcción’ o ‘aparato’) de aquella teoría. (…) Haavelmo ve un modelo teórico como un sistema de reglas sobre un conjunto de variables reales que conduce primeramente el análisis clarificando la distinción entre tipos de relaciones, variables y parámetros.“ Una vez sentadas estas premisas, vamos a exponer la relación entre modelos y teorías dentro del contexto del conocimiento científico. La relación modelos-teorías se inserta de una manera clara en la orientación modelizadora que se apoya de modo fundamental en el uso de la teoría. Pulido (1987, Pág. 33) escribe: “El proceso científico parte de unos axiomas o <<hipótesis>> científicas que, cuando son confirmadas y se supone que reflejan un esquema objetivo, pasan a la categoría de <<leyes>> y éstas se unifican y sistematizan en teorías”. En muchas ocasiones se identifican los conceptos de modelo y teoría. Sin embargo, hay que dejar claro que “Una teoría sobre el funcionamiento de un sistema, lleva estrechamente conectados uno o varios modelos que intenten reflejar las principales relaciones del sistema que se consideran relevantes en el contexto de esa teoría” (Pág. 34); es decir, que una teoría puede estar representada por uno o más modelos. 23 Haavelmo(1944). -Pág. 30- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas Si nos situamos dentro de la ciencia económica, existen unas teorías que se han intentado reflejar utilizando modelos formalizados matemáticamente: los modelos económicos. Pulido (1987) delimita a los modelos económicos como aquellos modelos genéricos expuestos en forma matemática y que son aplicables con validez general a diversos sistemas concretos. Sin embargo, esa generalidad que caracteriza a los modelos económicos, junto con su necesaria simplificación, les invalida para representar adecuadamente a los sistemas particulares. Es decir, que la generalidad de los modelos económicos ha hecho que los sistemas reales concretos se representen utilizando enfoques que sí recogen los elementos particulares del sistema económico en estudio. En resumen, se trata de que los modelos económicos sean útiles y operativos, y lógicamente, ésto tiene su reflejo en la elaboración de los modelos económicos a nivel regional. Nijkamp, Rietveld y Snickars (1986, Pág. 258) nos ilustran sobre los requisitos que deben cumplir: “Para que los modelos económicos regionales sean útiles deben verificar unos contrastes de pertinencia y de validez. El contraste de pertinencia aborda el problema de modelizar adaptándose a las situaciones específicas o modelizar ciñéndose al rigor teórico.(…) Los desarrollos recientes han demostrado (…) que en el estadio actual de modelización aplicada, la teoría y la práctica no son substitutivos. El contraste de validez se refiere al papel de la información regional en la construcción de modelos económicos. Está claro que a menudo se tienen que hacer concesiones en el rigor teórico para que se puedan construir modelos computables y operativos”. El contraste de pertinencia al que se refieren Nijkamp et al. (1986) implica que dentro del enfoque adoptado para la modelización económica a realizar, es habitual renunciar a aseveraciones teóricas debido a la falta de correspondencia exacta entre la perspectiva teórica general y la particular del sistema concreto en estudio. El contraste de validez conecta con un problema que nosotros consideramos de una importancia fundamental: la información regional24, cuya disponibilidad actúa de forma determinante a la hora de elegir el enfoque que presidirá la modelización a realizar. A pesar de la juventud relativa de la economía regional, existen una diversidad de técnicas y enfoques posibles para construir un modelo en este campo. Las primeras modelizaciones a nivel regional fueron extensiones simples de las experiencias modelizadoras a nivel nacional. En la actualidad, la variedad de posibles técnicas a aplicar para realizar el estudio de una economía regional es muy amplia. Así, puede servir como muestra, la estructura que Ramírez Sobrino (1992, Págs. 17-184) distingue para los métodos de análisis regional: 24 La importancia que concedemos a este tema es tal, que dedicamos el segundo capítulo de esta tesis a la información estadística económica regional. -Pág. 31- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña 1. Contabilidad social. 1.1.Matrices de contabilidad social. 2. Otras técnicas de análisis regional. 2.1.Indicadores regionales. 2.2.Modelos de interacción espacial. 2.3.Análisis “shift-share”. 2.4.Técnicas multivariantes aplicadas al análisis regional . 3. Modelos económicos regionales de aplicación normativa 3.1.Modelos de simulación 3.1.1.Modelo “input-output” 3.1.2.Modelos de base económica. 3.1.3.Modelos econométricos 3.2.Modelos de optimización 3.2.1.Modelos de programación lineal 4. Otros métodos 4.1.Modelos lineales generalizados 4.2. Estudios de prospectiva a nivel regional 4.3.Análisis multicriterio con datos mixtos cuantitativos-cualitativos 4.4. Un modelo de Markov Otro autor, Treyz (1994, Pág. 7) hace la siguiente división de los modelos regionales en función de las técnicas que utilizan: -Modelos no estructurales. “Su uso abarca predicciones basadas en tendencias pasadas, análisis de cambios regionales basados en cambios de la industria nacional, y cambios en la parte local de estas industrias nacionales. Este grupo también puede emplear métodos estadísticos, los cuales buscan regularidades pasadas en los datos regionales”. -Modelos estructurales. Llamados así “porque estos modelos incluyen las relaciones causa y efecto de una economía regional. Las relaciones que explican cómo los participantes en la economía responden ante los cambios que les afectan, tales como qué ocurriría en el consumo si la renta cambia, se denominan ‘relaciones de comportamiento’. Otro tipo de relaciones en un modelo estructural incluiría ‘relaciones definitorias’ y ‘técnicas’”. Podemos apreciar cómo en la división que Treyz presenta se distinguen de nuevo los dos enfoques que han presidido la evolución de la cuantificación económica y que nosotros vamos a llevar a la práctica en este trabajo; el enfoque que identificamos con los modelos no estructurales que emplean métodos estadísticos (no causal y con una base teórica más débil) y el que recogen los modelos estructurales (teórico). -Pág. 32- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas I.2. EL ESTUDIO DEL CICLO ECONÓMICO. Los estudios de los ciclos económicos han sido uno de los aspectos determinantes y aceleradores de la evolución de la cuantificación económica. El interés por el análisis cíclico implica un gran respaldo teórico que necesita cuantificaciones para detectar las fluctuaciones económicas. A partir de estas cuantificaciones se pueden llevar a cabo estudios que contrasten la aceptación de cada una de las hipótesis distintas acerca de las causas de los ciclos económicos. Consideramos necesario plantear el marco teórico del ciclo económico porque la búsqueda de explicaciones admisibles de las fluctuaciones en el nivel de actividad económica de una economía, debe partir de la existencia de procedimientos que detecten los cambios que se producen en la evolución de las variables macroeconómicas más relevantes. De esta manera, e igual que presentamos un método coherente para determinar las fluctuaciones económicas, también es obligado reseñar el marco teórico a partir del cual se puede explicar la evolución de las variables macroeconómicas25. Por todo lo comentado, el lector no debe aguardar la aportación de una nueva perspectiva o el planteamiento de una nueva teoría relativa al ciclo económico, sino un resumen-esquema de la literatura más básica. I.2.1. CONCEPTOS BÁSICOS. Realizamos una aproximación a las ideas fundamentales en las que se sustenta el concepto de ciclo económico. Los conocimientos que exponemos en los siguientes párrafos son ya clásicos dentro de las lecturas de introducción al ciclo económico, de manera que no nos ha parecido correcto prescindir de ellos en estos comentarios preliminares. El concepto más extendido y clásico de ciclo económico es el de Burns y Mitchell(1946)26: "Un ciclo consiste en expansiones que tienen lugar al mismo tiempo en muchas actividades económicas, seguidas por recesiones, contracciones y recuperaciones, también de carácter generalizado. Esta secuencia de cambios es recurrente pero no periódica; la duración del ciclo varía desde algo más de un año a diez o doce, y los ciclos no son divisibles en ciclos más cortos de similares características". Por lo tanto, la evolución a largo plazo de la actividad económica sufre un tipo de fluctuaciones recurrentes más o menos pronunciadas en torno a ella que reciben el nombre de ciclos económicos. De esta forma, un ciclo económico consiste en expansiones que ocurren más o menos al mismo tiempo en diversas actividades económicas, seguidas de recesiones similarmente generales que culminan en contracciones y revitalizaciones que se mezclan en la fase de expansión del ciclo siguiente. 25 Aunque no sea esta la orientación de este trabajo. Burns, A.F. y Mitchell, W.C. (1946): "Measuring Business Cycles".NBER. 26 -Pág. 33- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña Es evidente que la concepción de ciclo económico ha sufrido una evolución a lo largo del tiempo27: -El concepto clásico de ciclo económico responde a la observación del nivel de la actividad económica, entendiéndose las recesiones como una caída sostenida y absoluta en la actividad económica. -La aparición a partir de los años 70 de una fuerte tendencia en el perfil de la mayor parte de las series económicas, obliga a utilizar un nuevo concepto de ciclo económico: las fases depresivas se caracterizan como períodos en los que el ritmo de crecimiento es relativamente bajo, mientras que las fases expansivas se caracterizan por un ritmo de crecimiento relativamente alto. Aquí se habla de recesiones y de expansiones en un sentido relativo; es el llamado ciclo de crecimiento. Un criterio dentro del ciclo de crecimiento consiste en considerar el ritmo de crecimiento como relativamente bajo (alto) si es inferior (superior) al de la evolución a largo plazo de la actividad económica. De esta forma, se suele extraer la evolución global de las series, analizando sus desviaciones respecto a dicha evolución. Este se conoce como ciclo de desviaciones. Obviamente, los ciclos obtenidos van a depender del método empleado para la extracción de dicha evolución, por lo que aparece el ciclo de tasas, que sustituye el estudio de los niveles de las series por el análisis de las tasas de crecimiento. Según esta concepción del ciclo, si existe una caída en las tasas de crecimiento, se estará en recesión, y si existe una aceleración del ritmo de crecimiento se tratará de una fase expansiva. La concepción de ciclo más utilizada en la actualidad es la del ciclo de tasas. Una ventaja que tiene esta concepción con respecto a las otras es que adelantan los puntos de giro, “siendo los adelantos mayores en los inicios de recesión que en los inicios de recuperaciones” (Fernández (1991, Pág. 128)). Según Dornbusch y Fischer (1989, Pág.10): "El ciclo económico es el perfil más o menos regular de expansión (recuperación) y contracción (recesión) de la actividad económica en torno a la senda de crecimiento tendencial. En una cima cíclica, la actividad económica es elevada en relación a la tendencia y en un fondo cíclico se alcanza el punto más bajo de la actividad económica." En definitiva, podemos asentir que el ciclo refleja fluctuaciones en la actividad económica, con etapas de expansión seguidas de contracciones y reactivaciones que habitualmente oscilan entre 1 y 12 años (los movimientos cíclicos no son regulares en el tiempo). En lo referente a las posibles dudas en cuanto a la existencia de los ciclos económicos, parece estar claro que su 27 Nosotros hemos tomado como referencia de estas diferentes concepciones la síntesis que Fernández (1991, Págs. 127-128) realiza. -Pág. 34- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas contrastación empírica, entendidos como desviaciones que se producen con respecto a un crecimiento medio, es irrefutable. A continuación vamos a señalar los diferentes elementos integrantes de un ciclo económico. Los puntos críticos o puntos de giro ("turning-points") son aquellos en los cuales se pasa de una fase de expansión o aceleración a otra de contracción o desaceleración (recibiendo en este caso el nombre de máximo cíclico o pico ("peak"), por ser un máximo local), o viceversa, es decir se pasa de una fase de desaceleración a otra de aceleración (denominándoseles entonces mínimo cíclico o valle ("trough"), por ser un mínimo local). Por fase de un ciclo económico se debe entender el período de tiempo transcurrido entre dos puntos críticos o puntos de giro distintos (entre un máximo y un mínimo o entre un mínimo y un máximo). En cada fase cíclica podemos distinguir la duración y la amplitud. La duración es el período temporal existente entre la observación en que se encuentra el punto de giro analizado y la correspondiente al punto de giro inmediatamente precedente con un calificativo (máximo o mínimo cíclico) similar al que sirve de referencia. La amplitud de una fase cíclica se define como la diferencia, dada en valor absoluto, entre el valor de la tasa de crecimiento correspondiente al punto de giro analizado y el del punto de giro inmediatamente precedente con calificativo contrario. El conocimiento de la fase del ciclo económico en la que se encuentra una economía puede proporcionar un importante elemento de apoyo para tomar decisiones adecuadas en términos de política económica que contribuyan a amplificar o reducir sus etapas de crisis o expansión. El que la economía pase de un período expansivo a otro recesivo o viceversa es un hecho de gran significado económico y social, razón por la cual estos giros deben ser predichos, debiéndose estimar también su duración. El análisis de ciclos muestra que su diversidad en duración y amplitud hace que la determinación de los puntos de giro sea incierta; no es fácil distinguir inmediatamente entre lo que pueden ser pausas cortas en la expansión o en la recesión y los giros definitivos en estas fases. Resumiendo, se puede decir que el objetivo global del análisis cíclico es el conocimiento de la situación económica y su previsión a corto plazo. Los medios disponibles a aprtir de los cuales se suele intentar conseguir este objetivo son las series económicas denominadas indicadores cíclicos. Estos indicadores, debido a que miden aspectos significativos de la actividad económica y a que son sensibles a cambios en la situación económica, son de una gran utilidad para medir, interpretar y prever cambios a corto plazo en la actividad económica agregada. -Pág. 35- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña I.2.2. TEORÍAS DE LOS CICLOS. En los párrafos siguientes se pretende dar una visión muy global de lo que han sido la teorías explicativas de los ciclos a lo largo de la historia28. Estas teorías han pretendido proporcionar una explicación plausible de las fluctuaciones económicas; de esta forma, los instrumentos que posibilitan la cuantificación y detección de tales fluctuaciones se convierten en un elemento imprescindible para la contrastación empírica de dichas teorías. Gapinski (1982), siguiendo a Schumpeter (1939), distingue tres tipos de ciclos, ciclos largos, medios y cortos. A cada uno de estos tipos los denomina atendiendo al nombre de sus principales investigadores; así, a los ciclos largos los denomina de Kondratieff; a los medios, de Juglar, y a los cortos, de Kitchin. Niemira y Klein (1994, Pág. 19) enumeran cinco tipos de ciclos para cinco aspectos diversos de la actividad económica. Pons (1996, Págs. 30-32), tomando como estructura el estudio de Niemira y Klein (1994) presenta los tipos de ciclos económicos que más se han analizado en los trabajos existentes sobre los ciclos económicos. En el siguiente cuadro se recoge un esquema que plasma de manera muy sintética su trabajo: Cuadro nº 2. Principales tipos de ciclos económicos. TIPOS DE CICLOS AGRARIOS DE KITCHIN O INVENTARIOS. DE DURACIÓN H. S. Jevons (1878): 10,44 años; H.S. Jevons (1910): 3 años y medio. H. L. Moore(1914 y 1923): 8 años y medio. LOS Entre 3 y 4 años JUGLAR O DE LA INVERSIÓN Entre 6 y 12 años FIJA KUZNETS O DE LA Entre 15 y 20 años CONSTRUCCIÓN KONDRATIEFF O DE ONDA Entre 40 y 60 años LARGA CAUSAS QUE LOS ORIGINAN Cambios en la agricultura. (Modelo de la Telaraña de Ezekiel (1938): Demanda inelástica y desfase entre el momento de decidir qué se produce y el momento en el que la producción aparece en el mercado). Variaciones en el mercado a corto término, movimientos de los inventarios (“stocks”) y expectativas de los inversores. Problemas de financiación y de comercialización de las actividades nuevas. Fluctuaciones que aparecen por la inversión residencial. Desarrollo y difusión de las grandes innovaciones (por ejemplo la electricidad). Fuente: Elaboración propia a partir de Niemira y Klein (1994) y Pons(1996). Niemira y Klein (1994, Capítulo 2), recogen una evolución histórica del ciclo económico enfocada desde la perspectiva de las teorías que surgieron para 28 Hemos evitado entrar en la enumeración y descripción detallada de cada una de las teorías y modelos que las representan porque, como se ha insistido con anterioridad, no es ese el objetivo de este trabajo. Además, una exposición evolutiva, sistemática y analítica de tales teorías (tanto de las pasadas como de las más actuales) bien requeriría la realización de un esfuerzo de recopilación, estudio y meditación que de por sí sería un trabajo de investigación con una entidad propia y metas diferentes de las nuestras. -Pág. 36- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas explicar las causas de dichos ciclos. Dados los objetivos eminentemente empíricos que se persiguen en este trabajo, nos vamos a limitar a situar de una forma general al lector acerca de las teorías referentes a los ciclos económicos. Esto no quiere decir que no les consideremos importantes desde la perspectiva cognoscitiva; es más, de su estudio deben surgir futuros trabajos empíricos sobre los ciclos. En este sentido, nos adscribimos a las palabras de Pons(1996, Pág. 56) “el papel de la Teoría Económica ha de ser considerado, como mínimo, al mismo nivel que las técnicas de tratamiento de series y de extracción de señales o que los métodos de agregación de series individuales para la elaboración de indicadores cíclicos y para el análisis de la coyuntura económica”. Desde la perspectiva histórica, el interés por el análisis de las causas de los ciclos económicos no surge hasta el siglo XIX, ya que en el S.XVIII se pensaba que las crisis eran debidas a actuaciones erróneas de los agentes económicos o simplemente al azar. Es de subrayar que los fundadores de la Economía no se ocuparon en sus obras del estudio de los ciclos. Así, Adam Smith no hace referencia a la existencia de perturbaciones en el sistema económico y Ricardo consideraba a los ciclos como algo extraño para los propósitos de la Economía. Según Beltrán (1993, Pág. 276): “Los primeros economistas que se ocuparon del problema de las crisis fueron Malthus y Sismondi. La crisis económica de 1815 y la depresión que lo siguió lo plantearon. (…) Pero los ensayos de Sismondi y de Malthus no encontraron continuadores durante más de medio siglo, a pesar de que las crisis económicas y las consiguientes depresiones se fueron sucediendo…” Tal diferimiento en la entrada de la teoría de los ciclos en la Economía se puede explicar porque en las escuelas de pensamiento Clásica y Neoclásica no tenían cabida las fluctuaciones económicas, debido a que uno de sus principios básicos era que el sistema económico se ajustaba automáticamente a sí mismo. Lo más destacable del período clásico es que aparecieron los primeros análisis de los ciclos económicos, abordándose el estudio de las crisis desde el punto de vista estadístico, con lo cual, la teoría económica quedaba al margen. En lo que respecta a los economistas neoclásicos, existían teorías que, como afirma Pons (1996, Pág. 35) “encuentran las explicaciones del ciclo dentro del propio sistema económico. De esta manera, los factores exógenos tienen un papel secundario en la explicación de las fluctuaciones económicas…”. Recapitulando, podemos decir que aunque ya en los siglos XVIII y XIX existía evidencia de la existencia de los ciclos económicos, incluso ya bien entrados en el siglo XX la existencia de los ciclos económicos no era reconocida por todos los investigadores; por ejemplo, Fisher (1925) negaba su existencia y en consecuencia argüía que no se podían predecir. -Pág. 37- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña En los albores de la econometría se dotaba a las teorías de los ciclos económicos de una importancia que pasó por distintos “ciclos” en lo que respecta al reconocimiento de su entidad dentro del campo económico. Frisch (1933) en la primera declaración editorial de "Econometrica", declaraba que cada año se publicaría una revisión de los desarrollos más importantes que se produjesen dentro de los campos de interés principales para los econometras. Los campos que Frisch señalaba como los más relevantes eran cuatro: -teoría económica general (que incluía la economía pura) -teoría del ciclo económico -técnica estadística e -información estadística. Dentro de los preliminares de las teorías de los ciclos económicos, Kydland (1995) destaca la aportación de Frisch. Frisch (1933) distinguía entre los “shocks” aleatorios (impulsos) y la propagación en el tiempo de dichos “shocks”. La importancia para el modelo del ciclo económico de Frisch estaba en los “shocks” aleatorios (lo cual no ocurre en el ámbito actual de la teoría de los ciclos económicos). En lo que respecta al mecanismo de propagación, Frisch decía que estaba constituido por el capital inicial y las actividades que conducían a la construcción de capital. De esta forma, Frisch (1933) hacía que la “tecnología productiva, incluyendo la acumulación de capital, uno de los elementos centrales de la teoría, tenga su análoga en la teoría moderna de crecimiento y fluctuaciones” Kydland (1995, Pág. ix). No obstante, y a pesar de que ya desde los inicios de la Sociedad Econométrica -y estimulados por la crisis de los años 30- los ciclos económicos fueron considerados un campo de mucho interés, la teoría del ciclo económico pasó por una etapa de letargo durante la década de los 50 y de los 60. Inicialmente, la teoría del ciclo no recibió la atención suficiente debido a la falta de herramientas de análisis cuantitativo y al estado deficiente de desarrollo en el que se encontraba la disponibilidad (tanto en lo referente a su calidad, como a su periodicidad (datos trimestrales)) de datos que contabilizaran la renta y la producción. Sin embargo, estos inconvenientes se fueron puliendo con el tiempo, facilitando su desarrollo. En los preámbulos de las teorías actuales del ciclo económico destaca la aportación de Solow (1957). Solow quiere medir la contribución al crecimiento del nivel tecnológico, y para ello trata al nivel tecnológico como un residuo procedente del diferencial existente entre la producción agregada y las contribuciones de las participaciones (“inputs”) de trabajo y capital. Su idea se utilizará posteriormente (Prescott (1986)) como soporte para estimar, y de esta forma estudiar, las propiedades cíclicas del nivel tecnológico como fuente potencial de impulso. -Pág. 38- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas Es entre los años 70 y 80 cuando el interés por la teoría del ciclo económico reaparece. Lucas (1977, Pág. 9) definió el ciclo económico e hizo una revisión de sus “principales características cualitativas”: “Técnicamente, movimientos alrededor de la tendencia en el producto nacional bruto en cualquier país (…) Estos movimientos no presentan uniformidades de período ni de amplitud, es decir, ellos no se parecen a los movimientos determinísticos de las ondas que en ocasiones surgen en las ciencias naturales. Estas regularidades que son observadas están en los movimientos conjuntos (“co-movimientos”) de diferentes agregados macroeconómicos.” Este artículo de Lucas sentó una base teórica que alentó a otros autores a intentar hacerla operativa29. Lo que sí es evidente es el resurgir de las teorías del ciclo económico en los últimos veinte años. Niemira y Klein (1994, Capítulo 2) presentan una clasificación de las teorías principales relativas a los ciclos económicos y los autores que se relacionan con cada una de ellas. Según estos autores (Pág. 44): “excepto algunas (…) (como la teoría de las manchas solares), todas estas teorías pueden ser potencialmente instructivas en la comprensión de las causas actuales de inestabilidad”. Pons (1996, Págs. 36-49) realiza una presentación de estas teorías desarrolladas a lo largo de la historia, y para ello toma como marco de referencia el trabajo de Niemira y Klein (1994). En el Cuadro nº 3, parafraseando a Pons (1996, Capítulo 2), exponemos un cuadro resumen del trabajo de este autor insertado dentro del esquema (en negrita) de Niemira y Klein (1994, Pág. 43). 29 Por ejemplo, Kydland y Prescott (1990). -Pág. 39- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña Cuadro nº 3. Clasificación de teorías sobre los ciclos económicos. I. TEORÍAS UNICAUSALES RELATIVAMENTE SIMPLES. A) Agrícolas (W.S. Jevons, H.S. Jevons, H.L.Moore). Las teorías que se basan en los cambios en la producción agraria fueron de las primeras en aparecer, dada la importancia de este sector dentro de la estructura productiva en los inicios del siglo XX. Pons (1996), siguiendo a Haberler (1937) subdivide a estas teorías en tres grupos: 1º Los que sostenían que los ciclos económicos eran producidos por los cambios en la actividad agraria, siendo los autores más representativos W.S. Jevons, H.S. Jevons y H.L.Moore. 2º Teorías que afirmaban que los ciclos de las cosechas en ocasiones actuaban como un factor exógeno que desencadenaba las fluctuaciones en la actividad económica. Los autores que se integran dentro de este grupo son A.C. Pigou (1927) y D.Robertson (1915). 3º Teorías que consideran a la agricultura como un elemento pasivo en la determinación de los ciclos económicos. Entre estos autores están A. Hansen y J.M. Clark. Dentro de las teorías agrícolas para explicar las fluctuaciones cíclicas se encuentra el llamado modelo de la telaraña, de Ezekial (1938), que tiene dos fundamentos principales: que la demanda de productos agrarios es ineslástica y que existe un desfase entre el momento de decidir qué se produce y el momento en el que la producción aparece en el mercado. B) Psicológicas (Pigou). Las teorías que se basan en los aspectos psicológicos sostienen que cuando se está en una etapa de expansión, aparece un optimismo que hace que se acrecienten las inversiones y, por el contrario, cuando se está en una etapa de recesión, aparece un pesimismo que agrava todavía más la situación económica. Se puede destacar la obra de Pigou (1927). C) Monetaristas (Hawtrey). Esta teoría sostiene que son los factores únicamente monetarios (las influencias que el crédito y las restricciones monetarias tienen sobre las decisiones de consumo e inversión) los que explican el ciclo económico. Se basa en los trabajos de Hawtrey (1913). En síntesis, este autor decía que el nivel de producción de un país se determina mediante la modificación de la oferta monetaria (que se modificaba mediante la variación del tipo de interés). Para ello consideraba la ecuación de Cambridge M = k Y donde M es el “stock” de dinero (variable exógena para Hawtrey), k indica la fracción de la renta que se intenta mantener en saldos en efectivo e Y es la renta total. -Pág. 40- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas Cuadro nº 3. (Continuación I) II. TEORÍAS DE ECONOMÍA EMPRESARIAL. A) Relaciones precios-costes y márgenes de beneficios (Mitchell y Lescure). Estas teorías se fundamentan en los precios, los costes, y los márgenes de beneficios para describir las causas de los ciclos económicos. Entre los autores más importantes de esta línea de trabajo están Lescure (1923) y, principalmente, Mitchell (1913, 1927 y 1959); posteriormente, también aparecen Fabricant (1959), Hultgren (1965) y Zarnowitz (1973). Para Mitchell, eran los márgenes de beneficios, y por lo tanto los precios y los costes los determinantes de las fluctuaciones económicas. Mitchell argumentaba que si la economía está en una fase de expansión económica, las expectativas de incremento de beneficios aumentan, con lo cual incrementa la demanda desembocando en una escasez de bienes. De esta forma aparecen nuevas empresas con altas expectativas de beneficios, lo cual da lugar a un incremento de los costes y consecuentemente a una reducción de los beneficios. De esta forma, se pasaba de un período de expansión a uno de recesión. B) Ciclos de inventarios (Metzler, Abramovitz y Stanback). Su fundamentación es el hecho de que las empresas mantienen el ratio inventario/ventas constante a lo largo del tiempo. Si la economía está en una fase de expansión, incrementa la demanda y disminuyen los inventarios; de esta forma, para restablecer el ratio inventario/ventas se demanda más producción, de manera que incrementa la ocupación y la renta. Si la economía está en una fase de recesión, disminuye la demanda y aumentan los inventarios; para restablecer el ratio inventario/ventas no se dan nuevas órdenes de producción, de manera que disminuye la ocupación y la renta. Entre los estudiosos de esta teoría están Metzler (1941), Abramovitz (1950), Stanback (1962), Mack (1967) y Zarnowitz (1973). -Pág. 41- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña Cuadro nº 3. (Continuación II) III. TEORÍAS QUE ENFATIZAN EL PROCESO AHORRO-INVERSIÓN. A) Prekeynesianas. 1. Sobreinversión. En estas teorías se considera que si se está en la fase de expansión y se acelera de manera excesiva la producción de bienes de capital, aparece un exceso de capacidad productiva que desemboca en una reducción de la inversión que empuja a la crisis. a) Teorías monetarias (Wicksell, Hayek, Mises, Machlup, Robbins, Ropke y Strigel). Uno de los autores más importantes es Knut Wicksell (1935 y 1936), destacando también Hayek (1933) y Mises (1934). Otros autores con aportaciones destacables son Machlup, Robbins, Ropke y Strigel. Wicksell da una explicación monetaria de las fluctuaciones económicas. Wicksell, dentro del contexto del pensamiento económico clásico, distingue entre el tipo de interés natural, que es el que se da en una situación de equilibrio, y el tipo de interés de mercado, que es el que se manifiesta de acuerdo con las leyes de oferta y demanda. Si los bancos tienen una alta liquidez en un momento dado, aumentarán los créditos concedidos, de manera que los tipos de interés de mercado se sitúan por debajo del tipo de interés natural. Frente a esta disminución del coste del dinero, se produce un incremento de la inversión en bienes de equipo. La disminución del tipo de interés provoca por una parte un proceso inflacionario, y por otra un aumento de la producción. El elemento que restaura el equilibrio es el aumento general de precios. Los bancos experimentan una pérdida excesiva en el nivel de sus reservas, de manera que para mantenerlas aumentan los tipos de interés. Así, se inicia un proceso de contracción que finaliza una vez que se ha restablecido la igualdad entre el tipo de interés natural y el de mercado. b) No monetarias. B1. Escasez de capital (Tugan-Baranowsky, Spiethoff y Cassel). Los autores con los que se asocia esta teoría son Tugan-Baranowsky, Spiethoff y Cassel. Estos autores dicen que las recesiones económicas surgen independientemente del sistema financiero, aunque reconocen que dicho sistema juega un papel muy importante en el proceso de inversión. B2. Innovaciones (Schumpeter). Schumpeter (1939 y 1954) consideraba que eran los progresos tecnológicos y la aparición de innovaciones en los procesos productivos los que tenían su reflejo en los procesos cíclicos. 2. Infraconsumo (Maitland, Malthus, Douglas, Sismondi, Foster, Catchings, Lederer y Hobson). En estas teorías la causa principal de la crisis era la incapacidad de la economía para consumir lo que se producía en etapas de expansión económica o la falta de medios fundamentales de subsistencia. Entre los autores que defienden estas teorías se encuentran Maitland, Malthus, Douglas, Sismondi, Foster, Catchings, Lederer y Hobson. Según Malthus, la incapacidad de la economía para producir los alimentos suficientes provocaba crisis recurrentes en la evolución de la actividad económica. -Pág. 42- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas Cuadro nº 3. (Continuación III). 3. Marxistas. Estas teorías explican los ciclos económicos con el gasto en inversión. Según Marx, la miseria creciente se relaciona con la desocupación que, a su vez, es una consecuencia de los esfuerzos capitalistas para acumular capital. Esta tendencia a la acumulación es contradictoria y es una causa importante de las crisis económicas ya que provoca un exceso de producción del capital que también conlleva una tasa media de ganancia decreciente y que señala la inminencia de la crisis. B) Keynesianas. Keynes no tiene un apartado concreto en su obra “The General Theory of Employment, Interest and Money” (1936) que trate específicamente el tema de las fluctuaciones económicas, aunque sí tiene muchos elementos que pueden relacionarse con una explicación de los ciclos económicos. Desde la perspectiva keynesiana, se pueden explicar las fases de crisis por una insuficiencia de la demanda agregada. Keynes fundamentaba su explicación de los ciclos económicos en la volatilidad de la inversión. Esta volatilidad de la inversión se debe a que la inversión está más afectada por los cambios en las expectativas de los diferentes agentes económicos. C) Postkeynesianas. 1. Modelos dinámicos. El único elemento dinámico en la teoría keynesiana es el multiplicador a) Interacción entre multiplicador y acelerador (Samuelson, J.M. Clark, Aftalion y Fellner). Aftalion (1913) y Clark (1917) introducen el concepto de acelerador. Samuelson (1939) contempla el efecto multiplicador y el efecto acelerador; sostenía que un cambio en la inversión provocaba, vía el efecto multiplicador, una variación en el nivel de producción que, a la vez, motivaba un aumento del consumo determinado por la propensión marginal a consumir. Este incremento del consumo ponía en marcha el efecto acelerador que, simultáneamente, daba lugar a un incremento de la inversión. La interacción entre multiplicador y acelerador ayudaba a comprender que las expansiones y las recesiones de la economía podían afectar de manera importante a la actividad productiva, ya que no representaban un episodio ocasional en la actividad económica. Otro autor que trabajó en esta línea de consideración simultánea de multiplicador y acelerador fue Fellner (1951). b) Ciclo de crecimiento (Harrod, Hicks, Domar, Lundberg, Kalecki, Kaldor y Goodwin). En los años cuarenta y cincuenta Kalecki, Harrod, Kaldor, Domar, Hicks, y Goodwin estudian los modelos del ciclo de crecimiento, en los que la inversión neta el función de los cambios en la producción, lo cual implica que las fluctuaciones en el consumo se transmiten con una amplitud incrementada a la demanda de los bienes intermedios y de producción. c) Neomarxistas (Sherman y Evans) d) Caos (Baumol, Quandt, Brock y Sayers). Los trabajos de Baumol, Quandt, Brock y Sayers son lo más relevantes. Estos modelos pretenden explicar las etapas de expansión y de recesión a partir de los cambios técnicos que se producen en la economía. -Pág. 43- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña Cuadro nº 3 (Continuación IV) IV. NUEVAS TEORÍAS CLÁSICAS. A) Monetarista (Friedman, Brunner, Meltzer, Schwartz y Cagan). El enfoque monetarista viene representado por autores como Friedman (1956 y 1959), Cagan (1958 y 1965), Friedman y Schwartz (1963 y 1982) y Brunner y Meltzer (1989). En el enfoque monetarista, las fluctuaciones cíclicas vienen motivadas por variaciones exógenas en la cantidad de dinero que en principio afectan a variables reales, pero que con el tiempo tan sólo se reflejan en variaciones de la inflación. B) Modelos de ciclo económico “real” (King, Kydland, Nelson, Plosser y Prescott). Considera que la causa fundamental de las fluctuaciones económicas son los “shocks” reales que se producen en la economía. C) Oferta (Laffer y Craig). Los economistas de oferta investigan los factores que influyen en los incentivos para ahorrar, invertir y adquirir capital. Destaca Laffer (1982) que explica los ciclos basándose en la evolución de los tipos impositivos que afectan a la inversión (que es el principal motor de la economía). D) Ciclos políticos (Kalecki, Nordhaus, MacRae y Meiselman). Los autores más importantes son Kalecki, Akerman, Downs, Boddy, Crotty, Nordhaus, MacRae, McCallum y Meiselman. La base de esta teoría es que el gobierno adapta su política económica para maximizar las probabilidades de volver a ganar las elecciones, de manera que cuando se acercan las eleccioens el gobierno está interesado en reactivar la economía. Estas actuaciones económicas bajo la restricción de la reelección pueden ocasionar oscilaciones en la inflación, renta y ocupación. E) Expectativas racionales (Muth, Lucas, Sargent, Wallace y Barro). Los autores más importantes son Muth (1961), Sargent y Wallace (1975), Barro (1976) y Lucas (1977). Los ciclos económicos se ven como una manifestación normal de la actividad económica que se ajusta a los diferentes cambios experimentados a los largo del tiempo: los participantes en el mercado anticipan racionalmente los efectos de las políticas gubernamentales y reaccionan de acuerdo a las expectativas que se han formado. Fuente: Niemira y Klein (1994), Pons (1996) y elaboración propia. Niemira y Klein (1994, Pág. 80) concluyen el capítulo de su libro manifestando: “Si los economistas neoclásicos arguyen que los ciclos económicos son debidos a falta de percepción, información imperfecta o “shocks” aleatorios, otros estudiosos del ciclo que perseveran en la tradición de Keynes y Mitchell, arguyen que los ciclos modernos no se explican de manera unicausal sino que son el resultado de una interacción compleja entre variables reales y nominales que constituyen la razón, en parte endógena y en parte exógena, para la inestabilidad; y en cualquier caso, no unicausal, sino compleja. De esta forma, la agenda investigadora para el futuro inmediato está verdaderamente llena”. Además de las referencias señaladas, se puede profundizar en el estudio del ciclo económico desde su conexión con la teoría económica con los siguientes libros: Zarnowitz (1985 y 1992), Mullineux et al. (1993), y Kydland (1995). -Pág. 44- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas Desde otra perspectiva, Fontela (1997) adopta una tipología de las fluctuaciones económicas que se basa en su amplitud temporal, distinguiendo entre: -Ciclos de corto plazo, con una duración generalmente inferior a una década. Estos ciclos suelen ser aceptados en la actualidad por la mayoría de los economistas, y en ellos se concentran los estudios y análisis de las escuelas de pensamiento que hoy en día predominan (neoclásicos monetaristas o keynesianos en sus diversas variedades). Estos economistas tratan “de explicar mecanismos y procesos que regulan operaciones relacionadas con la producción, el consumo y la acumulación de bienes y servicios de mercado o de no-mercado” Fontela (1997, Pág. 48) y “buscan un conocimiento que sea, en gran medida, independiente del tiempo y del espacio” (Pág. 48-49). Por consiguiente, estos economistas investigan acerca de causas endógenas. -Ciclos de largo plazo, con una duración de veinte a cincuenta o más años. Este tipo de ciclos son aceptados por un número muy reducido de economistas. Fontela (1997) manifiesta que las escuelas de pensamiento que más estudian “los fenómenos estructurales que intervienen en el largo plazo” son “hoy minoritarias, con ramificaciones evolucionistas, institucionalistas o historicistas” (Pág. 48). Además, consideran que el conocimiento debe ser dependiente del tiempo y del espacio, razón por la cual buscarán fundamentalmente causas exógenas que expliquen los ciclos económicos. Fontela (1997, Pág. 49) también sintetiza los resultados de los estudios de los ciclos económicos: “es posible identificar algunas causas endógenas para los ciclos a corto plazo (en general en torno al proceso de inversión y de acumulación del capital), aunque también pueden intervenir causas exógenas (especialmente en un contexto de economía abierta, por acontecimientos que intervienen en el exterior de las fronteras de la nación); por el contrario, no se han podido identificar causas endógenas para las grandes olas cíclicas que, si existen obedecen a procesos que encuentran su origen fuera de los ámbitos estrictos de la economía (por ejemplo, en el de la ciencia y de la tecnología).” En la actualidad, se puede afirmar que las explicaciones teóricas de los ciclos económicos de corto plazo se dividen en dos grandes escuelas de pensamiento (Fontela (1997)): -La que busca la explicación en las fluctuaciones de la demanda (ya sea por cuestiones monetarias o por cuestiones no monetarias). -La que lo explica desde el lado de la oferta, defendiendo que las crisis aparecen por causas exógenas al sistema económico (impactos externos) que obligan a la economía a buscar el equilibrio. Son las llamadas teorías de los ciclos reales. -Pág. 45- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña Por otra parte, Kydland (1995) hace una división de las fluctuaciones30 en: -Principalmente nominales o monetarias , que intentan explicarlos mediante teorías del ciclo económico que se basan en los mecanismos de intermediación financiera o de crédito. La cuestión a resolver sería ¿cómo se propagan los impulsos monetarios para causar ciclos económicos? Es decir, las líneas de investigación buscan mecanismos de transmisión que posibiliten que el dinero pueda tener efectos reales. -Principalmente reales, que suelen afectar a la tecnología disponible o a las restricciones de la gente. Se explican mediante impulsos reales, ya sean en los agregados productivos o procedentes de la política fiscal. De lo que no cabe duda es de que hoy en día existe consenso para afirmar que las causas de los ciclos económicos son múltiples y sus duraciones cambiantes. Pulido (1995, Pág. 191), en línea con lo que dice Makridakis (1993), considera que la posibilidad de predecir los ciclos de forma concreta y con precisión temporal es nula; sin embargo, sostiene que la predicción debe servir para avisar y prevenir una vez que la recesión se ha iniciado. Este mismo autor (Págs. 191-192) indica que las fases de depresión cíclica se inician como consecuencia, principalmente, de la aparición de una de las cuatro siguientes causas: 1. “Un acontecimiento excepcional y frecuentemente imprevisible a priori, al menos en sus aspectos concretos y en el momento preciso: choques del petróleo, crisis bursátil… 2. Un aumento continuado de algunos desequilibrios básicos de la economía de un país (principalmente inflación, déficit público o déficit exterior) que terminan llevando, no se sabe bien cuándo ni a qué nivel, hacia una política económica diferente (una política monetaria, fiscal, de rentas o una combinación variable de ellas). 3. Un brusco cambio de expectativas originado en forma externa y que provoca reacciones en cadena de los agentes económicos: aumento en el riesgo político, anuncio de políticas económicas depresivas o poco creíbles, planes de actuación a corto, medio y largo plazo que conlleven políticas aún no anunciadas de tipo restrictivo (por ejemplo Plan de Convergencia con Maastricht). 4. Efecto contagio de un ciclo económico iniciado en las economías líderes del mundo, como consecuencia de los diferentes aspectos anteriores.” Dentro de las líneas de investigación abiertas en la actualidad, además del estudio de las teorías para explicar el ciclo económico, Kydland (1995)31 destaca 30 En Kydland(1995) se presentan una serie de lecturas que tienen relación con el marco general que proporciona la división que él presenta de las fluctuaciones y que están dentro de las investigaciones cuantitativas del ciclo de negocio dentro del modelo de equilibrio general. 31 Kydland remite a la publicación: Backus, D.K., Kehoe, P.J., Kydland, F.E. (1995): “International Business Cycles: Theory and Evidence”, en Cooley T.F.(Ed.) (1995): “Frontiers of Business Cycle Research”, Princeton University Press, 331-56. -Pág. 46- Capítulo I. Consideraciones en torno a las Modelizaciones Estadísticas y Econométricas el estudio de los ciclos económicos internacionales, señalando cuestiones tales como las interdependencias de los ciclos económicos de las naciones y la influencia de los ciclos económicos en el comercio internacional. I.2.3. CUANTIFICACIÓN CÍCLICA Y POLÍTICA ECONÓMICA. Cuando se diseñan políticas económicas se debe tener en cuenta que uno de los objetivos que se debe perseguir es el de evitar o atenuar los aspectos negativos de los ciclos económicos. Sin embargo, uno de los problemas fundamentales que afectan a la adecuada adopción de medidas de política económica adecuadas es la falta de una información adecuada que proporcione una cuantificación: “para mejorar el arte de la política anticíclica es indispensable anticipar acontecimientos y estimar las posibles consecuencias de acciones correctoras. La observación estadística y la simulación cuantificada constituyen las únicas vías de mejora para una política anticíclica que la teoría ya ha explorado de manera casi exhaustiva”. Fontela (1997, Pág. 51). Este párrafo del Profesor Fontela justifica nuestro trabajo desde otra perspectiva, ya que se aportan herramientas que posibilitan la observación estadística, el diagnóstico, la simulación, y la anticipación, de manera que la política económica se puede fundamentar en datos objetivos que redunden en unas decisiones más eficientes. Para los ciclos económicos de corto plazo, los gobiernos nacionales tienen los clásicos instrumentos fiscales (ya sea vía impuestos o gasto público) y monetarios (tipo de interés, oferta monetaria…) que actúan desde el lado de la demanda. Así, desde el punto de vista teórico, lo lógico es adoptar políticas económicas expansivas (tanto fiscales como monetarias) si se prevé que se va a entrar en una fase de recesión. No obstante, en la práctica se puede apreciar cómo la aplicación de políticas anticíclicas es complicado debido a que la realidad no es tan simple; así, una mirada a la historia económica reciente nos permite observar que en una fase de recesión se evita aplicar políticas monetarias expansivas (porque se buscan unos precios estables) y unas políticas fiscales expansivas realizadas de forma sistemática a lo largo de importantes períodos de tiempo, de manera que el importante volumen de déficit público puede entrar a formar parte, en ocasiones, de las causas que generan una recesión. Si a estos inconvenientes les añadimos los que se derivan de la interconexión existente hoy en día entre las economías, que hace que las políticas que se aplican en un país no sean independientes del contexto mundial, las perspectivas de lucha anticíclica pueden verse menguadas. Sin embargo, y a pesar de algunas complicaciones como las señaladas, es evidente que el estudio y anticipación de los ciclos económicos puede alertar de -Pág. 47- Modelización Estadístico-Econométrica Regional: El Caso de la Economía Extremeña situaciones muy negativas, siendo siempre preferible actuar con anterioridad a la crisis intentando evitarla o amortiguarla (con los instrumentos de política económica disponible y que se consideren más adecuados para el momento económico del que se trate), a que la crisis nos sorprenda y nos lleve hasta el valle del ciclo con consecuencias ya inevitables. En lo que respecta a los ciclos económicos a largo plazo, Fontela (1997) establece dos tipos de políticas fundamentales a realizar para lograr el crecimiento equilibrado de la economía (sin fases de recesión). El fin último de ambas políticas es la obtención de un ritmo constante de crecimiento económico elevado. Estas políticas son: 1ª Las políticas tecnológicas, que incluyen: -“la elaboración de planes para el desarrollo y la eficiencia de una actividad de I+D en ciencia y tecnología; -el fomento de actividades de transferencia de conocimientos entre la I+D y el mundo empresarial; - y en general, la adopción de medidas que favorezcan el desarrollo tecnológico (compras públicas, proyectos públicos con elevado contenido tecnológico, etc)” Fontela (1997, Págs. 43 - 44). 2ª Las políticas de innovación, en las que “se trata de establecer instituciones que estimulen la cultura de la innovación, o como mínimo, de eliminar los frenos institucionales que pueden en alguna circunstancia paralizar el proceso innovador” Fontela (1997, Pág. 44). Es decir, se trata de que las instituciones favorezcan, o no entorpezcan, el desarrollo competitivo empresarial, lo cual pasa por una menor intervención estatal en los mercados y la desaparición de situaciones de privilegio (por ejemplo monopolios). -Pág. 48- Capítulo II. La Información Estadística Económica Regional CAPÍTULO II: LA INFORMACIÓN ESTADÍSTICA ECONÓMICA REGIONAL. II.1. INTRODUCCIÓN. En este capítulo vamos a realizar una serie de comentarios y consideraciones sobre la información estadística económica que hoy en día está disponible a nivel regional. El contenido del capítulo se justifica por el hecho de que tal información es un requisito fundamental para la medida y análisis de la estructura y la evolución de cualquier economía y, consecuentemente, también de una economía regional. Por lo tanto, todo estudio que persiga el análisis eficiente y objetivo de una economía regional debe tener como punto de partida la disposición de una información estadística fiable. La información económica regional de las comunidades autónomas españolas cuenta con una fuente oficial (en la que nos centraremos) que es la Contabilidad Regional, elaborada y publicada por el Instituto Nacional de Estadística32. Para lograr situar a la información estadística regional en su verdadero contexto, vamos a realizar un acercamiento a la Contabilidad Nacional, presentando de forma esquemática las fuentes fundamentales de la producción estadística nacional, para pasar a continuación a comentar las principales características de la Contabilidad Regional de España. También haremos referencia a la problemática de los deflactores disponibles hoy en día para calcular las cifras macroeconómicas regionales en pesetas constantes. Para finalizar el capítulo, mencionaremos a otro tipo de información: los indicadores económicos parciales; concretando su disponibilidad en la Comunidad Autónoma de Extremadura, y haciendo especial mención a sus fuentes, periodicidad y longitud de las series. II.2. CONTABILIDAD NACIONAL ANUAL, CONTABILIDAD NACIONAL TRIMESTRAL E INDICADORES ECONOMICOS. Según el INE (1993, Pág. 6): "La Contabilidad Nacional [CN] es un conjunto de definiciones, convenios y formas de representar la actividad económica caracterizados por su completitud, rigor y extensión". La CN permite el seguimiento a corto, medio o largo plazo de la evolución de una economía. De 32 Fuentes no oficiales son, por ejemplo, el Proyecto Hispalink, el Servicio de Estudios del Banco Bilbao Vizcaya, o la FIES. -Pág. 49- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña esta forma la CN proporciona un marco conceptual contable inteligible y adaptado a las necesidades del análisis, previsión y política económica. Dicho análisis económico facilita por un lado una valoración de las políticas económicas instrumentadas, y por otro lado la formulación de un diagnóstico de la situación económica presente y futura con el objeto de diseñar medidas económicas orientadas a alcanzar unos objetivos fijados con anterioridad. Los documentos que posibilitan la realización de estos análisis son la tabla entradasalida ("input-output") (TIO), la contabilidad nacional anual (CNA) y la contabilidad nacional trimestral de España (CNT). No es el objetivo de este capítulo analizar en profundidad cada uno de estos documentos periódicos publicados por el INE, sino que lo que pretendemos es hacer unos breves comentarios sobre ellos para lograr aportar un esquema de las tres operaciones fundamentales que realiza la Contabilidad Nacional. La tabla "input-output" parte de la agrupación de las actividades económicas por ramas de actividad para después proceder a cuantificar: -los flujos y transacciones de las ramas entre sí (éstos son los llamados consumos intermedios ) -la producción que cada rama destina a la demanda final o empleos finales (ya sea consumo, formación bruta de capital o exportaciones) -y los factores utilizados por cada rama; es decir, los inputs primarios y recursos (ya sean trabajo y/o capital). La interdependencia entre los sectores productivos que realiza la TIO presenta mayor retraso que el cuadro macroeconómico de la CNA. A pesar de ésto la TIO es un instrumento que se puede aplicar a la realización de análisis estructural, de simulaciones, y por otra parte "garantiza la coherencia estadística de los datos del cuadro macroeconómico de la propia Contabilidad Nacional" (Alcaide, 1995c, Pág. 76). Según las notas metodológicas que el INE presenta en sus diferentes publicaciones, la Contabilidad Nacional Anual (CNA) surge debido a la necesidad de integrar las macromagnitudes económicas con los diferentes agentes y actividades productivas que las generan, viniendo a establecer la relación entre los agregados teóricos y las partidas conocidas y observables que las constituyen para el conjunto nacional. La CNA proporciona una visión relativamente completa y sistemática de la actividad económica y, como el INE afirma, del proceso de generación de rentas, gasto y producción. Esta visión va a posibilitar realizar confrontaciones temporales (posibilita realizar análisis comparativos de la coyuntura económica que ha habido en distintos períodos de tiempo) y espaciales (por ejemplo facilita realizar comparaciones internacionales). Pero además, desde el esquema sistemático, global y coherente -Pág. 50- Capítulo II. La Información Estadística Económica Regional que ofrece la CNA se facilita la posibilidad tanto de corroborar y/o contrastar teorías económicas, como de apoyar debates referentes a cuestiones macroeconómicas. La CN se elaboró de forma anual hasta julio de 1992, momento desde el que también está disponible de forma trimestral. La CNT viene a suponer una gran mejora en cuanto a la disponibilidad con respecto a la CNA, ya que se reduce el tiempo del año al trimestre. No obstante, incurre en una pérdida de rigor y exhaustividad con respecto a la CNA: -La CNA tiene un mayor grado de consolidación que la CNT. -La CNA tiene un mayor detalle que la CNT. La explicación hay que buscarla en que el proceso de elaboración de la CNA es más amplio y dispone de una mayor desagregación que el de la CNT. En este momento es necesario poner de relieve que siempre es útil disponer de una breve descripción de una economía a nivel agregado que resuma su funcionamiento para un determinado período de tiempo, y tanto desde el lado de la oferta como de la demanda. Un cuadro macroeconómico viene a ser, en cierta medida, esa especie de resumen o síntesis. Según Alcaide (1995c, Pág. 76): "Un cuadro macroeconómico es una tabla estadística de síntesis en la que figuran los datos de los agregados macroeconómicos básicos contenidos en la Contabilidad Nacional, y necesarios para evaluar el producto interior bruto calculado desde la óptica de la demanda y desde la producción." Pues bien, tanto la CN como la CNT presentan los cuadros macroeconómicos para el período que analizan; pero lógicamente, a los cuadros macroeconómicos de la CNT les afecta directamente la pérdida de rigor y exhauxtividad antes mencionados. En el Cuadro I, y a modo de recordatorio, se recoge un esquema de las variables explicativas de un cuadro macroeconómico, que lo que hace es mostrar de una forma sintética las variables a través de las cuales se puede calcular el producto interior bruto (PIB) desde dos vertientes distintas, la producción interna y el gasto interior. Desde el lado de la oferta se obtiene El PIB a precios de mercado como suma del valor añadido bruto calculado a coste de los factores33 de cada una de las grandes ramas productivas. A esta suma hay que agregar el impuesto sobre el valor añadido (IVA) que grava a los productos y los impuestos 33 Los valores añadidos de las distintas ramas vienen calculados a coste de los factores, es decir, incluyendo los impuestos ligados a la producción (exceptuando el IVA) netos de subvenciones. -Pág. 51- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña netos aplicados a los productos importados. Desde la óptica de la demanda, en primer lugar se presentan las variables componentes de la demanda interna, es decir, el consumo privado nacional, el consumo público, la formación bruta de capital fijo y la variación de existencias. Si a la demanda interna, que recoge el consumo y la inversión, se le suman las exportaciones de bienes y servicios, y también se le restan las importaciones de bienes y servicios34, se obtiene el producto interior bruto a precios de mercado. Cuadro nº 4. Variables explicativas de un cuadro macroeconómico. PRODUCCIÓN INTERNA ÓPTICA DE LA OFERTA: PIB COMO SUMA DE VALORES AÑADIDOS. DEMANDA AGREGADA ÓPTICA DE LA DEMANDA: PIB COMO SUMA DE GASTOS. Valor añadido bruto de las ramas Consumo privado nacional. agraria y pesquera. Valor añadido bruto de las ramas Consumo público. industriales. Valor añadido bruto de la rama de la Formación bruta de capital fijo. costrucción. Valor añadido bruto de las ramas de los Variación de existencias. servicios destinados a la venta. Valor añadido bruto de las ramas de los servicios no destinados a la venta. IVA que grava a los productos. Impuestos netos importación. ligados DEMANDA INTERNA Exportación de bienes y servicios. a la Importación de bienes y servicios (-). PRODUCTO INTERIOR BRUTO a precios de mercado PRODUCTO INTERIOR BRUTO a precios de mercado Fuente: Elaboración propia a partir de la Contabilidad Nacional. La CNA tiene un largo proceso de elaboración que, de forma muy resumida, se puede condensar en el esquema recogido en el Cuadro nº 5: 34 Las importaciones de bienes y servicios ya están recogidas en las partidas de la demanda interna, puesto que en dichas partidas están incluidas la demanda de bienes y servicios de producción nacional e importados. -Pág. 52- Capítulo II. La Información Estadística Económica Regional Cuadro nº 5. Elaboración de la CNA. ESTIMACIONES DEL AÑO T FECHA DE DISPONIBILIDAD PRIMERA ESTIMACIÓN TRIMESTRE 1º DEL AÑO T+1 (CUADRO MACROECONÓMICO) ESTIMACIÓN DEFINITIVA AÑO T+4 Fuente: Elaboración propia a partir de notas metodológicas del INE. Como se puede apreciar en el anterior esquema, en el primer trimestre del año T+1 se estima un cuadro macroeconómico con una elevada agregación para las cuentas del año T, y la estimación definitiva, no está disponible hasta el año T+4. Según Cristóbal y Martín (1992, Pág. 41): "Esta perspectiva es la que permite entender mejor la relación entre la CNA y la CNT: como la elaboración de un Cuadro Macroeconómico cuatro veces al año en lugar de una." Con todo lo comentado, la CNT se convierte en un instrumento de una significativa relevancia debido a que la frecuencia de la información que suministra se aproxima a la frecuencia informativa que los analistas demandan. Sin embargo, la CNT debe ser avanzada con la información que los indicadores económicos suministran debido a que, en muchas ocasiones, la frecuencia de la información demandada por los analistas es mayor que la de la CNT. La imposibilidad de disponer de las Cuentas Nacionales de periodicidad Anual con la frecuencia y actualidad que los analistas desearían, supone una gran limitación en su utilización. Este retraso en la publicación de los datos de la CNA, hace que éstos necesiten completarse y actualizarse a través de un conjunto de indicadores económicos con periodicidad mensual o trimestral, que tras la elaboración de un esquema de funcionamiento de los mismos, puedan adelantar el comportamiento de las magnitudes económicas recogidas en las Cuentas Nacionales. Además, la información que aporten los distintos indicadores económicos (a medida que se vayan recibiendo nuevos datos) será valorada de una forma adecuada a través del análisis de coyuntura, permitiendo un análisis más frecuente y ágil en la toma de decisiones. La laguna existente en términos de periodicidad entre los indicadores económicos mensuales y la CNA es cubierta por la Contabilidad Nacional Trimestral (CNT). En lo relativo a los indicadores económicos coyunturales, la CNT supone la composición de un marco de datos trimestrales que no se podría obtener por la mera agrupación de los indicadores económicos, ya que los datos que la CNT recoge de las distintas variables macroeconómicas están sujetos al cumplimiento de las restricciones propias de las identidades contables, puesto que deben -Pág. 53- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña conciliar las estimaciones realizadas desde la óptica del gasto y de la producción. Sin embargo, la CNT no goza de la rapidez en la disponibilidad que tienen los indicadores económicos coyunturales. Se puede concluir que es práctica habitual la estimación de un cuadro macroeconómico que supla los retrasos informativos en los que incurre la fuente fundamental: la CN. Para ello, se parte de los últimos datos disponibles de la CNA o de la CNT para el último período disponible, y en base a la información suministrada por los indicadores estadísticos disponibles, el elaborador del cuadro debe ser capaz de estimar las variables que lo integran. No queremos dejar de hacer una breve referencia a la metodología SEC95, aprobado dentro de un marco legal como es el Reglamento del Consejo de la Unión Europea, lo cual le confiere un carácter jurídico oficial. Con ello se pretende facilitar la comparación y análisis de la estructura y relaciones de las distintas economías nacionales y/o europeas, así como su evolución en el tiempo. Como el objetivo es que las cuentas nacionales y regionales de los países miembros sean rigurosos, armonizados y comparables, la UE garantiza dicha objetivo mediante la obligación (vía Reglamento) de que dichas cuentas se elaboren aplicando las mismas definiciones, clasificaciones y reglas contables. II.3. LA CONTABILIDAD REGIONAL DE ESPAÑA Tras exponer muy someramente las fuentes de información estadística fundamentales existentes a nivel nacional, nos vamos a centrar en el ámbito que verdaderamente interesa en este trabajo: el regional. La fuente fundamental de la información económica de las comunidades autónomas españolas es la Contabilidad Regional, elaborada y publicada por el INE. La base metodológica de la Contabilidad Regional de España35 (CRE) está constituida por el Sistema Europeo de Cuentas Regionales (SECR), que se integra a su vez dentro de un marco más general que es el Sistema Europeo de Cuentas Económicas Integradas (SEC)36 . El SECR es una derivación del SEC70 (que no hacía referencia a las cuentas regionales) que Eurostat estableció a principios de los años setenta. 35 Para encontrar las referencias metodológicas y aplicaciones prácticas de la Contabilidad Regional de España, sería conveniente consultar las publicaciones “Contabilidad Regional de España. Serie 1980-87, Base 1980, INE 1990”, y “Contabilidad Regional de España 1985-88, Base 1985, INE 1991”. 36 La redacción y aprobación del nuevo SEC (SEC 95; ver Eurostat(1996a)) ya se ha completado, y en él se aplican las nuevas definiciones del Sistema de Cuentas Nacionales 1993 de Naciones Unidas. -Pág. 54- Capítulo II. La Información Estadística Económica Regional El SECR es un modelo interregional que pretende realizar una desagregación de las operaciones y agregados nacionales con respecto a las regiones componentes del país correspondiente para ver el comportamiento del conjunto nacional dentro de su espacio total. Sin embargo, termina siendo una simplificación del modelo de Cuentas Nacionales debido a la carencia de información estadística a nivel regional y a la aparición de diversos problemas metodológicos en este nivel. El SECR no ofrece un sistema integrado y completo de cuentas de operaciones y agentes similar al de las Cuentas Nacionales; se centra principalmente en establecer cuentas por ramas de actividad, es decir, da prioridad a la óptica funcional o de unidades de producción homogéneas; y para la óptica institucional únicamente establece operaciones para los agentes con localización geográfica clara (Hogares y Administraciones Públicas Locales). Parte de las estimaciones nacionales para realizar el reparto regional sirviéndose para ello de la información suministrada por el cálculo de indicadores económicos regionales, de manera que si se agregan las estimaciones regionales van a dar como resultado las operaciones estimadas a nivel nacional. Dichos indicadores deben ser homogéneos en un doble sentido: tanto en la utilización de una metodología común para la construcción de los indicadores, como en el uso de una información estadística de base similar. Esta homogeneización va a permitir la comparabilidad interregional (tanto a nivel nacional como comunitario) así como la comparación de cada una de las regiones con el total nacional. La dependencia del SECR con respecto al Sistema de Cuentas Nacionales va a condicionar las estimaciones a nivel regional, de manera que los cambios de base de las Cuentas nacionales implicarán un cambio de base en las Cuentas Regionales. Estas últimas también se verán influenciadas por las modificaciones que el mismo cambio de base regional puede suponer para la mejora del método de reparto y para la mejor estimación de los Indicadores Regionales. Según Martínez López37: "El SECR se constituye en un modelo abierto y a la vez dinámico de Contabilidad. Es abierto en la medida en que no se presenta el equilibrio macroeconómico oferta, demanda y rentas como lo hace el sistema nacional. De estas tres ópticas, elige las operaciones, bien sean sobre bienes y servicios y bien sean sobre la renta, que sean susceptibles de estimación regional, renunciando a todas aquellas operaciones cuya relevancia a nivel regional sea insignificante o, aunque siéndolo, existan dificultades estadísticas que impidan su estimación; el sistema es dinámico en la medida que su metodología se va ampliando en el 37 Martínez López, A., (1992): “Contabilidad Regional de España: Metodología y Datos Disponibles”. Datos, Técnicas y Resultados del Moderno Análisis Económico Regional. Ediciones Mundi-Prensa. 1994. -Pág. 55- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña tiempo como fruto de los intercambios y experiencias de los diferentes países miembros, contactos que se producen en el seno del grupo de trabajo de Cuentas Regionales y Estadísticas Regionales que la Oficina Estadística de las Comunidades Europeas (EUROSTAT) creó con tal finalidad." Por otro lado, la delimitación regional en la Comunidad Económica Europea viene recogida en la Nomenclatura de Unidades Estadísticas Territoriales (NUTS). Actualmente esta Nomenclatura establece tres niveles o tipos de regiones: -Regiones de nivel I o "regiones comunitarias europeas" que vendrían a ser las "grandes regiones socioeconómicas" de la Comunidad. -Regiones de nivel II o "unidades administrativas de base". Aquí se encuadran las comunidades autónomas españolas. -Regiones de nivel III o "subdivisiones de las unidades administrativas de base". Estas regiones se corresponderían con las provincias españolas. Para uno de estos niveles o regiones, el SECR recomienda la estimación de distintos agregados y operaciones. Con respecto a la información que EUROSTAT solicita al nivel II de la NUTS (nivel en el que se centra este trabajo), las carencias de la Contabilidad Regional española se limitan a la no disponibilidad de la Formación Bruta de Capital fijo por rama productora y adquirente . En la actualidad, la información que presenta la Contabilidad Regional de España para las distintas Comunidades Autónomas es la que se recoge en el Cuadro nº 6. -Pág. 56- Capítulo II. La Información Estadística Económica Regional Cuadro nº 6. Información de la CRE. DATOS DEMOGRÁFICOS, OPERACIONES Y AGREGADOS *1 REGIONALES DE OFERTA (Valorados a precios corrientes). -Valor añadido bruto a precios de mercado. -Valor añadido bruto al coste de los factores. -Impuestos sobre la producción. -Subvenciones de explotación. -Remuneración de asalariados. -Excedente bruto de explotación. -Población de derecho. *2 -Empleo total.*2 -Empleo asalariado. *2 -Paro. *2 *1 Las estimaciones se presentan con una desagregación por rama de actividad al nivel R-17 de la NACE-CLIO. *2 Medidas en número de personas. OPERACIONES DE DEMANDA (Valoradas a precios corrientes). -Consumo privado final de los hogares residentes, desagregado en dos grandes funciones de consumo: alimentación, bebidas y tabaco, y resto. -Consumo final de la familias sobre el territorio económico. ÓPTICA INSTITUCIONAL.*3 -Cuenta de los hogares. Se estiman todas las operaciones que la componen, tanto los recursos como los empleos. -Cuenta de las administraciones públicas territoriales (comunidades autónomas y corporaciones locales). Se elabora una cuenta de ingresos y gastos efectivos (corrientes y de capital). *3 “La unidad institucional es un centro elemental de decisión económica caracterizado por una uniformidad de comportamiento y una autonomía de decisión en el ejercicio de su función principal (las empresas, constituidas o no en sociedad, los hogares, etc., son ejemplos típicos de unidades institucionales” (Alonso Luengo, F.y Gómez del Moral, M.,1996, Pág. 58). SERIE HOMOGÉNEA. -Existe una serie homogénea (Ver INE (1993b)) en la cual los agregados que se estimaron fueron el valor añadido bruto a precios de mercado y el empleo total desglosados según la clasificación R-6 de la NACE-CLIO. Fuente: Alonso Luengo, F.y Gómez del Moral, M.(1996), y elaboración propia. La información estructural que proporciona la Contabilidad Regional de España es un instrumento fundamental para plantear las coordenadas en las que se implementará la política regional tanto por parte de la Administración Central como por parte de la Comunidad Europea. Por ejemplo, las estadísticas de la CRE se pueden utilizar para analizar en el tiempo las consecuencias de la aplicación de determinadas políticas regionales, o para realizar estudios comparativos entre las distintas comunidades autónomas. ALONSO y GÓMEZ -Pág. 57- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña (1996, Pág. 54) resumen los usos que se pueden hacer con la información que proporcionan las cuentas regionales en uno: "servir de soporte informativo en la concepción, ejecución y evaluación de las políticas regionales que los estados establecen, sea de manera autónoma, sea conjuntamente a través de organismos e instituciones supranacionales". Estos mismos autores (Pág. 55) también plantean algunos ejemplos de usos de las estimaciones regionales, como la cuantificación y descripción de las disparidades regionales (posibilitándose también la realización de estudios estructurales y la comparación interregional ), servir de criterio en la determinación de las prioridades de desarrollo y/o en la determinación de las ayudas que tienen como objetivo la redistribución de la renta y de la riqueza nacional. Las carencias o faltas más destacables que tiene la CRE son: 1ª) No proporciona unos datos estimados de agregados macroeconómicos en pesetas constantes38, de manera que en los análisis que se realizan a nivel regional se debe pasar por la utilización de deflactores regionales “no estimados por el INE” que permitan la obtención del Valor Añadido Bruto a precios de mercado en pesetas constantes. En la actualidad, las series del VABpm en pesetas constantes que más garantías nos ofrecen para el análisis de la economía Extremeña son las estimadas por Cordero y Gayoso (1996 y 97), de forma que estas son las series de VABpm con las que trabajaremos39. 2ª) No presenta un cuadro macroeconómico regional completo. -No da información sobre consumo público, formación bruta de capital, ni sobre las operaciones externas en bienes y servicios. -Desde el punto de vista institucional no da información sobre las sociedades y las empresas (aunque sí da información de la renta familiar bruta disponible y del consumo privado de los hogares). 3ª) La información se publica con un retraso excesivo. Aunque el primer avance se presenta con un retraso de dos años con respecto al año de referencia, la definitiva se demora aún más, estando disponible la publicación a los cinco años del citado año de referencia. 4ª) No existe una Contabilidad Regional Trimestral (CRT), en línea con las aportaciones que realiza la CNT a nivel nacional. Dicha CRT posibilitaría, en primer lugar, la provisión de series históricas de los principales agregados macroeconómicos regionales que facilitarían (mediante la utilización de las técnicas estadísticas y econométricas adecuadas) la previsión y el análisis de políticas económicas . En segundo lugar, mejorarían las investigaciones y estudios macroeconómicos regionales como consecuencia del incremento de la 38 En la actualidad está disponible el PIBpm en pesetas constantes de 1986 para todas las regiones extremeñas, serie 1980-1995 (1993 y 1994 provisional y 1995 avance) pero la carencia de una desagregación mayor aborta su utilización para estudios sectoriales. 39 A continuación planteamos de una manera más rigurosa la problemática actual referida a los datos de Contabilidad Regional de España en pesetas constantes. -Pág. 58- Capítulo II. La Información Estadística Económica Regional calidad del sistema estadístico coyuntural regional. En este punto es necesario resaltar el hecho de que el SEC-95 dedica el Capítulo 12 a las cuentas trimestrales anuales, destacando la importancia de estas cuentas, pero sin hacer mención expresa a las cuentas regionales trimestrales. Estas carencias hacen que el INE suministre una información regional que no llega a cubrir las demandas de información que en la actualidad existen, ya sea debido a retrasos en la aparición de las cifras y/o debido a que no proporciona (dentro del esquema de cuentas presentado) un desarrollo de determinados ámbitos de las cuentas regionales (por ejemplo las tablas "inputoutput"). Por ello, la información "oficial" se ha visto complementada en ocasiones por trabajos realizados por diversas instituciones, por ejemplo universidades y fundaciones. La nueva metodología del SEC-95, en el cual existe un capítulo (Capítulo 13) destinado a la metodología del SEC regional, gira en torno a la estimación del PIB a precios de mercado y al coste de los factores, estima también la renta bruta disponible de las familias y la formación bruta de capital. Sin embargo, no plantea la estimación del consumo público ni de las operaciones externas en bienes y servicios. Por lo tanto, si el INE se limita a seguir la línea marcada por el SEC-95, sólo aportará a la información que actualmente suministra, la relativa a la formación bruta de capital. Por lo tanto, sería conveniente complementar esta información estructural con la estimación que proporcionaría la elaboración de algún tipo de indicador sintético que permita el seguimiento de las macromagnitudes que integran el cuadro macroeconómico, posibilitando el estudio de la evolución de la coyuntura económica a nivel regional. Con esto se paliaría la existencia de lagunas informativas desde el año de referencia y la publicación de la estimación de dicho año. Además, el seguimiento a corto plazo de la situación económica regional permitiría captar antes las desviaciones con respecto a los objetivos de política económica fijados. Por último, dicho indicador proporcionaría una herramienta muy interesante desde el punto de vista metodológico para la trimestralización de las cuentas regionales. Es en esta línea de investigación de facilitar el seguimiento, análisis coyuntural y trimestralización futura de las cuentas regionales donde se encuadra la segunda parte de esta tesis. -Pág. 59- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña II.4. LA PROBLEMÁTICA DE LOS DEFLACTORES REGIONALES. En este apartado planteamos el problema importante de los deflactores regionales como condicionantes fundamentales de los resultados a obtener en las modelizaciones estadísticas y econométricas. También se intenta justificar la elección de los deflactores a aplicar a las cifras de CRE del INE para una clasificación a seis ramas productivas (R-6) 40 en el período 1980-1995. Con estas notas pretendemos poner de manifiesto las principales discrepancias existentes para Extremadura entre los datos de Contabilidad Regional en pesetas de 1986 proporcionados por la Subdirección General de Planificación regional (Ver Cordero y Gayoso (1997)) y la base de datos Hispadat (ver Hispalink (1997))41. No vamos a entrar a comentar las diferentes opciones alternativas en lo que a deflactores regionales se refiere; una introducción a la cuestión podría ser Pena (1994), López y Pérez (1994) y Pulido (1997). La base Hispadat utiliza los deflactores nacionales con una desagregación a 17 ramas productivas (R-17), de manera que supone implícitamente que la composición de las ramas R-17 regionales es similar; dicho de otra forma, utiliza los deflactores nacionales sectoriales a R-17 como deflactores regionales sectoriales. Por su parte, el trabajo de Cordero y Gayoso (1997) ha conseguido unos deflactores específicos para determinadas ramas de cada una de las regiones españolas. La discrepacia existente entre ambos se muestra en el Cuadro nº 8. 40 Ver Cuadro nº 7 para apreciar las agrupaciones sectoriales distintas a las que nos referimos en esta tesis. 41 Los deflactores regionales que subyacen en ambas fuentes nos han parecido los más “razonables” dentro del panorama de la información estadística regional. -Pág. 60- Capítulo II. La Información Estadística Económica Regional Cuadro nº 7: Clasificaciones sectoriales. R-6 A E R-7 A E I I B S G R-9 A Agricultura E Energía Q Ind. Bienes Intermedios SECTORES NACE-CLIO R17 01 PRODUCTOS DE LA AGRICULTURA, SILVICULTURA Y PESCA 06 PRODUCTOS ENERGÉTICOS Incluye extracción y refino de petroleo, producción, transporte y distribución de energía eléctrica, gas y agua. 13 MINERALES Y METALES FERREOS Y NO FERREOS 15 MINERALES Y PRODUCTOS A BASE DE MINERALES NO METÁLICOS. Incluye extracción de materiales de construcción (arcillas, rocas, picón, etc.), y fabricación de productos de tierras cocidas para construcción y de cemento. Industria del vidrio y cerámica. 17 PRODUCTOS QUIMICOS Incluye fabricación de plásticos, abonos, plaguicidas, pinturas y barnices. K Ind. Bienes de Equipo 24 PRODUCTOS METALICOS: MAQUINAS; MATERIAL Y ACCESORIOS ELECTRICOS Incluye carpintería metálica y fabricación de estructuras metálicas; talleres mecánicos independientes. Construcción de maquinaria y equipo mecánico. Instalación de máquinas de oficinas y ordenadores. Construcción de componentes eléctricos, e instalaciones eléctricas. Grabación de discos y cintas magnéticas. Fabricación de instrumentos de precisión y óptica, prótesis, ortopedia. 28 MATERIAL DE TRANSPORTE Incluye construcción naval, reparación y mantenimiento de buques, y construcción de otro material de transpote y piezas. C Ind. Bienes de Consumo 36 42 47 50 B Z B Construcción Z Transportes y Comunicaciones L L Servicios Destinados a la Venta. G G PRODUCTOS ALIMENTICIOS, BEBIDAS Y TABACOS PRODUCTOS TEXTILES, CUERO Y CALZADO, VESTIDOS PAPEL, ARTICULOS DE PAPEL, IMPRESION PRODUCTOS DEL IND. DIVERSAS Incluye industria de madera y corcho, fab. De muebles de madera; transformación del caucho y materias plásticas; laboratorios fotográficos y otros. 53 CONTRUCCIÓN Y OBRAS DE INGENIERIA CIVIL 60 SERVICIOS DE TRANSPORTES Y COMUNICACIONES Incluye transporte interior, transporte marítimo y aereo, servicios anexos al transporte y de comunicación. 58 RECUPERACIÓN Y REPARACIÓN. SERVICIOS DE COMERCIO, HOSTELERIA Y RESTAURANTES. 69 SERVICIOS DE INSTITUCIONES DE CREDITO Y SEGURO; INMOBILIARIAS. 74 OTROS SERVICIOS DESTINADOS A LA VENTA. Incluye servicios prestados a las empresas, alquiler de bienes muebles e inmuebles, servicios recreativos y culturales; servicios personales. 86 SERVICIOS NO DESTINADOS A LA VENTA Incluye servicios de administracción general, de enseñanza e investigación, servicios de sanidad no destinados a la venta; servicio doméstico. Fuente: Elaboración propia. Es evidente que el origen de las discrepancias existentes entre ambas bases hay que buscarlo en la utilización de deflactores que difieren en el sentido recogido en el Cuadro nº 8. -Pág. 61- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 8: Discrepancias entre los deflactores. AÑO 1987 1988 1989 1990 1991 1992 A01 -2,282 1,061 -4,211 -2,021 2,408 1,312 B53 0,716 0,779 7,332 18,142 18,248 15,330 L58 -1,169 -2,027 -2,448 -3,736 -5,947 -6,632 Z60 0,099 1,941 2,044 1,317 2,137 2,127 L74 -0,599 -3,032 -5,094 -7,424 -8,221 -8,292 Notas: -Para la clasificación R-17, se han restado a los deflactores de Cordero y Gayoso(1997) los deflactores Hispadat -A01: Productos de la agricultura, de la silvicultura y de la pesca. -B53: Construcción y obras de ingeniería civil. -L58: Recuperación y reparación. Servicios de comercio, hostelería y restaurantes. -Z60: Servicios de transportes y comunicaciones. -L74: Otros servicios destinados a la venta. Lógicamente, dichas discrepancias a una desagregación R-17 se traducen en diferencias en las tasas de crecimiento de las ramas cuando se trabaja a una agregación mayor (a nueve ramas (R-9), R-6 ó Total). Teniendo en cuenta el cuadro de equivalencias entre las clasificaciones sectoriales R-17, R-9 y R-6, es inmediato señalar los sectores en los que se van a encontrar discrepancias: Cuadro nº 9: Ramas sectoriales en las que existe discrepancia. SECTORES EN LOS QUE REPERCUTEN LAS DISCREPANCIAS EXISTENTES EN LA DESAGREGACIÓN R-17 1. Ramas R-17 en las que se ha encontrado discrepancia: A01 B53 L58 Z60 L74 2. Ramas R-9 en las que inciden las discrepancias R-17: A01 B L L L 3. Ramas R-6 en las que inciden las discrepancias R-17: A01 B SV SV SV Notas: -Siendo: B = Construcción; L = Servicios destinados a la venta (excluidos transportes y comunicaciones); SV = Servicios destinados a la venta A continuación, pasamos a hacer algunos comentarios para las ramas recogidas en el cuadro anterior. -Pág. 62- Capítulo II. La Información Estadística Económica Regional II.4. 1. RAMA DE LA AGRICULTURA (RAMA A01). En el Gráfico nº 1 hemos representado los deflactores de la base Hispadat (A01H, 1986=100), y el de la base del Ministerio de Economía y Hacienda42 (A01M, 1986=100), para las cifras definitivas de la CRE, es decir, cifras sin considerar los datos provisionales y de avance (años 1993, 1994, 1995). Se puede apreciar que las discrepancias entre ambos no siguen una sistemática determinada: Gráfico nº 1. Deflactores agrarios. 130 125 120 115 110 105 100 95 90 85 80 75 70 65 60 1986 A01M A01H 1987 1988 1989 1990 1991 1992 Notas: Siendo: A01M el deflactor agrario de Cordero y Gayoso y A01H el deflactor agrario de Hispadat. La hipótesis que utiliza Hispadat de constancia de los precios para todas las Comunidades Autónomas dentro de la clasificación R-17 es, en nuestra opinión, “demasiado fuerte” dada la distinta estructura productiva agraria existente en las regiones españolas y el elenco de precios para las producciones que pueden aparecer dentro del territorio nacional. Por otra parte, es de destacar el esfuerzo de Cordero y Gayoso (1997) en la elaboración de los deflactores regionales para este sector. No obstante, su hipótesis de partida de que “la variación de los precios de los consumos intermedios y de la producción en la agricultura no puede ser muy diferente...” (Cordero y Gayoso (1997), Pág.102) que les conduce a elaborar un índice de precios sólo para la producción final agraria, también puede estar introduciendo sesgos procedentes de las distorsiones que pueden inducir en los <<gastos fuera del sector>> la diferente composición del consumo intermedio de cada Comunidad Autónoma43. 42 Cordero y Gayoso (1997). La discrepancias principales a nivel regional no aparecen como consecuencia de que los precios de los inputs agrarios sean muy diferentes, dada la semejanza existente de dichos precios a nivel interregional. 43 -Pág. 63- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Por lo tanto, consideramos que el deflactor del Ministerio es más acertado que el utilizado por Hispadat. No obstante, nuestro objetivo va a ser abundar en el análisis para conseguir un deflactor que siguiendo la línea marcada por el Ministerio de Economía para la producción, no se olvide de la obtención de un índice de precios aplicable a los gastos fuera del sector. Bajo estas condiciones, y como marco general de actuación, nuestra primera preocupación ha sido conseguir las macromagnitudes del sector agrario extremeño que nos posibiliten la obtención del deflactor implícito del VABpm agrario extremeño. Para esto, hemos partido de dos de sus componentes: producción final agraria (PF) y gastos fuera del sector (GFS). Recordemos que la diferencia entre el primer y segundo componente nos permite calcular el VABpm regional (VABpm = PF - GFS). Una vez obtenidos dichos componentes en pesetas corrientes, hemos intentado deflactarlos utilizando para ello los índices que a continuación se detallan. Nuestra intención no es otra que la de aportar una perspectiva distinta de los deflactores agrarios para su posterior discusión. En nuestro trabajo, hemos conseguido datos desagregados para las diferentes partidas de la producción final y de los gastos fuera del sector agrario para Extremadura. Una posible forma de trabajar sería proceder a su deflactación utilizando los índices de precios percibidos por los agricultores a nivel nacional para cada uno de los productos o grupos de productos (IPPRNS) y los índices de precios pagados por los agricultores a nivel nacional para los principales consumos (IPPGNS) respectivamente. De esta forma, hemos trabajado con datos de PF y de GFS en pts corrientes procedentes del Ministerio de Agricultura, pesca y Alimentación y de la Consejería de Agricultura y Comercio de la Junta de Extremadura. Se ha obtenido el VABpm en pesetas constantes como diferencia de la PF en pts constantes (transformada a pts constantes utilizando los índices de precios percibidos por los agricultores a nivel nacional para cada uno de los productos o grupos de productos (IPPRNS)) , y los GFS en pts constantes (deflactados utilizando los índices de precios pagados por los agricultores a nivel nacional para los principales consumos (IPPGNS)). De la diferencia entre la PF en pts constantes de 1986 y los GFS en pts constantes de 1986, se obtiene el VABPM en pts constantes de 1986. De esta forma, es inmediato el cálculo del deflactor implícito del VABPM para la rama de la agricultura en Extremadura, que vamos a llamar A01PROPIO. El Gráfico nº 2 es suficientemente explicativo de las diferencias existentes entre los tres deflactores considerados, y del sesgo que pueden encerrar los trabajos realizados con cada uno de estos deflactores. -Pág. 64- Capítulo II. La Información Estadística Económica Regional Gráfico nº 2. Deflactor Agrario. 125 120 115 110 105 100 95 90 1986 1987 1988 A01H 1989 A01M 1990 1991 1992 A01PROPIO Notas: Siendo: A01M el deflactor agrario de Cordero y Gayoso (1997); A01H el deflactor agrario de Hispadat y A01PROPIO nuestro propio deflactor agrario. En consecuencia, nos decantamos por el deflactor de Cordero y Gayoso(1997), ya que es el que tiene un comportamiento más acorde con el elaborado para este trabajo. El hecho de no trabajar con nuestro propio deflactor se deriva de la dificultad de elaboración de un deflactor para el período a estudiar, lo cual se deriva de la falta de datos enlazados y de las hipótesis “fuertes” a realizar en algunos casos que no nos permiten trabajar con la suficiente garantía44. No queremos terminar esta discusión sin alertar acerca del tratamiento incorrecto que se suele realizar al trabajar con las cifras agrarias, ya que una práctica bastante extendida (a la vista de la literatura que hemos consultado) es la aplicación del índice conjunto de precios percibidos por los agricultores a nivel nacional como deflactor de la PF y del índice conjunto de precios pagados por los agricultores a nivel nacional como deflactor de la partida GFS, lo cual supone un importante sesgo a la hora de extraer conclusiones fieles al comportamiento real de las macromagnitudes que se derivan de tales partidas (fundamentalmente la renta agraria). 44 De hecho, y dentro de las pruebas realizadas en el campo del deflactor agrario extremeño, tenemos elaborado un deflactor para el período 1970-1995 basándonos en la metodología y resultados del libro Colino et al. (1990). Tal deflactor se ha construido con el objetivo de corroborar la bondad del deflactor utilizado en la modelización econométrica del sector agrario extremeño, siendo los resultados satisfactorios. -Pág. 65- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña II.4.2. CONSTRUCCIÓN (RAMA B53). En el Gráfico nº 3 hemos representado los deflactores utilizados para la rama de la construcción por el Ministerio y por Hispadadat, destacándose no sólo la cuantía de la discrepancia, sino también la sistemática existente: el deflactor utilizado por Hispadat es inferior al deflactor del Ministerio, lo cual se traduciría en una sobrevaloración del VABpm de la rama de la construcción de Extremadura en pts constantes por parte de Hispadat con respecto a la misma variable proporcionada por el Ministerio. Gráfico nº 3. Deflactores para el VAB de la construcción. 200 180 160 140 120 100 80 60 40 20 0 1987 DEFLACTORES DE LA RAMA DE LA CONSTRUCCIÓN B53M B53H 1988 1989 1990 1991 1992 Notas: -Siendo: B53M el deflactor utilizado para la rama de la construcción por Cordero y Gayoso (1997) y B53H el de Hispadat. En el Gráfico nº 4 está representada la discrepancia existente para la rama B53 entre el deflactor del Ministerio (1986=100) y el de Hispadat (1986=100). Gráfico nº 4. Discrepacia entre deflactores de la construcción. 20 18 16 14 12 10 B53 8 6 4 2 0 1987 1988 1989 1990 1991 1992 Notas: -B53 representa la diferencia entre el deflactor del VABpm de la construcción de Cordero y Gayoso (1997) y el homólogo de Hispadat. -Pág. 66- Capítulo II. La Información Estadística Económica Regional La forma de trabajar de Gayoso y Cordero (1997) nos parece más adecuada que la de Hispadat, en el sentido de que afina más que Hispadat, ya que se centra en los componentes del VABPM “remuneración de asalariados” y “excedente bruto de explotación” para posteriormente deflactarlos utilizando el índice de remuneración por asalariado y el deflactor nacional del excedente bruto de explotación. No obstante, la mejora a introducir sería trabajar en la obtención de un índice de remuneración por asalariado para Extremadura utilizando los datos proporcionados por el MOPTMA, ya que el índice utilizado en Gayoso y Cordero puede estar introduciendo sesgos procedentes de las disparidades que pueden existir entre las distintas regiones en la remuneración por asalariados en la construcción. II.4.3. SERVICIOS DESTINADOS A LA VENTA. II.4.3.1. RAMA DE LA RECUPERACIÓN Y REPARACIÓN. SERVICIOS DE COMERCIO, HOSTELERÍA Y RESTAURANTE (RAMA L58). En el Gráfico nº 5 podemos apreciar la evolución de la discrepancia existente en esta rama entre ambos deflactores, siendo inmediato afirmar que el deflactor Hispadat excede al de Cordero y Gayoso (1997), lo cual implica que los datos de Hispadat del VABpm para la rama L58 de Extremadura en pts constantes de 1986 con respecto a los mismos datos aportados por el Ministerio están infravalorados. Gráfico nº 5. Discrepacia deflactores rama L58. 1987 0 1988 1989 1990 1991 1992 -1 -2 -3 -4 L58 -5 -6 -7 Notas: -L58 representa la diferencia entre el deflactor del vabpm de la rama de la recuperación y reparación, servicios de comercio, hostelería y restaurante de Cordero y Gayoso (1997) y el homólogo de Hispadat. -Pág. 67- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cordero y Gayoso (1997) utilizan como deflactor la suma ponderada de aquellos grupos de índices de precios al consumo que estén relacionados con esta rama. Tal forma de operar aparece por la imposibilidad de conseguir cuantificaciones de volumen. II.4.3.2. SERVICIOS DE TRANSPORTES Y COMUNICACIONES (RAMA Z60) El Gráfico nº 6 recoge la evolución de la discrepancia existente en la rama Z60 entre los deflactores del Ministerio y Hispadat. El deflactor del Ministerio es superior al de Hispadat, lo cual implica que los datos de Hispadat del VABpm para la rama Z60 de Extremadura en pts constantes de 1986 con respecto a los mismos datos aportados por el Ministerio están sobrevalorados. Gráfico nº 6. Discrepancia entre deflactores de la rama Z60. 2,5 2 1,5 Z60 1 0,5 0 1987 1988 1989 1990 1991 1992 Notas: -Z60 representa la diferencia entre el deflactor del vabpm de la rama de servicios de transportes y comunicaciones de Cordero y Gayoso (1997) y el homólogo de Hispadat. El deflactor de Cordero y Gayoso (1997) fue el del grupo de transportes y comunicaciones del IPC de cada Comunidad Autónoma, para posteriormente ajustar el resultado final al total nacional. II.4.3.3. RAMA DE OTROS SERVICIOS DESTINADOS A LA VENTA (RAMA L74) Del Gráfico VII, que muestra la evolución de la discrepancia entre ambos deflactores para esta rama, se puede concluir que el deflactor Hispadat es mayor en valor que el del Ministerio, lo cual se traduce en una infravaloración de los datos de Hispadat referentes al VABpm para la rama L74 de Extremadura en pts constantes de 1986 con respecto a los mismos datos aportados por el Ministerio. -Pág. 68- Capítulo II. La Información Estadística Económica Regional Gráfico nº 7. Discrepancia entre deflactores de la rama L74. 1987 0 1988 1989 1990 1991 1992 -1 -2 -3 -4 -5 L74 -6 -7 -8 -9 Notas: -L74 representa la diferencia entre el deflactor del vabpm de la rama de otros servicios destinados a la venta de Cordero y Gayoso (1997) y el homólogo de Hispadat. Para las ramas de los servicios Cordero y Gayoso (1997) procedieron, en general, mediante la consideración del deflactor nacional de las ramas de “crédito” y de “producción imputada a los servicios bancarios” (PISB), a la vez que para deflactar el VAB de la rama de otros servicios destinados a la venta de las distintas Comunidades Autónomas, se utilizó una medida ponderada de los IPCs de grupos distintos. Las cifras en pesetas constantes así obtenidas se ajustaron al total nacional. En resumen, podemos concluir este apartado señalando las importantes implicaciones que puede introducir la elección que se realice acerca de los deflactores regionales a utilizar. Los deflactores de Cordero y Gayoso (1997) para la rama agraria nos parecen los más adecuados de las opciones contempladas. En el resto de ramas, habría que hacer un estudio más riguroso que la mera exposición descriptiva de discrepancias que nosotros hemos expuesto aquí. En este trabajo optamos por los deflactores de dichos autores porque parecen ser los que más pueden estar aproximando las cifras reales de Contabilidad Regional de España. -Pág. 69- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña II.5. INDICADORES DISPONIBLES PARA EXTREMADURA. De una manera simple, podemos decir que un indicador económico (o indicador económico parcial) es un dato que nos acerca al valor de una realidad económica en un momento de tiempo determinado. Si disponemos de un indicador económico a lo largo del tiempo, podremos realizar un análisis de la evolución de la realidad económica a la que nos aproxime. Desde la perspectiva cíclica, los indicadores económicos son series de datos que siguen de una manera regular determinadas pautas de comportamiento con respecto a un fenómeno económico de referencia, pudiéndose establecer una asociación entre dichas pautas de comportamiento y la evolución del citado fenómeno. Los problemas fundamentales que acompañan a los indicadores económicos son de dos tipos: a) De representación, en el sentido de que normalmente no son totalmente representativos del fenómeno económico en estudio. Un ejemplo clásico de representación global es el que se da entre el indicador económico “saldo neto exterior” (exportaciones menos importaciones) y el sector exterior. Por el contrario, un ejemplo de representación parcial es el que se da entre el indicador “consumo de energía eléctrica para usos domésticos” y la demanda de consumo. b) De retraso, ya que su disponibilidad, en ocasiones, es bastante posterior al momento temporal al que se refieren. A la hora de trabajar con los indicadores económicos es habitual su agrupación en distintos bloques relativos a aspectos diferentes de una economía. Ya escribimos en el Capítulo IV que una de las etapas en la elaboración de un informe típico de coyuntura regional es centrarse en el análisis del cuadro macroeconómico regional, el cual debe proporcionar la estimación de los componentes de la demanda agregada regional y de la produción interna regional para pasar a continuación a analizar el mercado de trabajo, el sector público y el sistema financiero. La información que proporcionan los indicadores económicos es muy variada, así, pueden referirse a aspectos concretos como la inversión; por ejemplo, Tainer (1993) nos dice, fundamentalmente, cómo utilizar los indicadores económicos de una manera bastante simple para mejorar los análisis de inversión. The Economist (1992) proporciona una guía muy sencilla para interpretar y realizar un análisis de los principales indicadores económicos; para ello divide a los indicadores económicos en 11 grupos que no son mutuamente excluyentes: -Pág. 70- Capítulo II. La Información Estadística Económica Regional 1º Indicadores de actividad económica. 2º Indicadores de crecimiento (tendencias y ciclos) 3º Indicadores de población, empleo y paro. 4º Indicadores de políticas fiscales del gobierno. 5º Indicadores de consumo. 6º Indicadores de inversión y ahorro. 7º Indicadores de industria y comercio. 8º Indicadores de comercio exterior. 9º Indicadores de tipos de cambio 10º Indicadores de dinero y mercados financieros. 11º Indicadores de precios y salarios. Por otra parte, y de una forma general, los bloques en los que suelen agruparse los indicadores económicos regionales son: 1.Producción o actividad económica regional. Se trata de indicadores que nos proporcionan información que se refiere a la situación de la economía desde la perspectiva de la oferta. Estos indicadores a su vez se subdividen atendiendo a la rama productiva regional con la que se identifiquen. 2.Empleo regional. Este bloque lo integran variables que permiten analizar la evolución de la población activa, del empleo y del paro. 3.Precios, salarios. Indicadores económicos que recogen la evolución de los costes (incluidos los salarios) y de los precios de venta para los distintos sectores productivos. 4.Demanda interna. Los indicadores económicos de demanda nos acercan al consumo e inversión que se realiza en la región (demanda interna) 5.Comercio exterior. Los indicadores económicos de importaciones y de exportaciones posibilitan obtener el saldo comercial, de manera que se logra situar a la economía regional con respecto al resto de economías y determinar la demanda externa. 6.Sector monetario y financiero. Indicadores económicos que nos aproximan a la realidad financiera de la región. 7.Sector público regional. Son indicadores económicos que muestran el movimiento que siguen los ingresos y gastos gestionados por las autoridades públicas. En el Anexo 1 se presentan los indicadores con los que hemos trabajado en esta tesis, detallando las características más relevantes de cada uno de ellos. El proceso de construcción y actualización de esta base ha sido de realización propia. Llegados a este punto, queremos resaltar lo laborioso y dificultoso de la construcción y actualización de una base de datos de este tipo. En el año 1996, y bajo la forma de un Convenio de Colaboración con la -Pág. 71- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Consejería de Economía de la Junta de Extremadura, trasvasamos la base de datos disponible al Servicio de estadística de la Junta de Extremadura, que en la actualidad se encarga de actualizarla. Sin embargo, algunos de los indicadores económicos que se describen en el anexo no están en la base de la Junta de Extremadura, porque son de incorporación posterior a la firma de dicho convenio o de “elaboración propia”. Entre los indicadores más relevantes incorporados a esta base de datos se encuentran los índices de producción industrial (IPI) de Extremadura, tanto el general, como los relativos a las divisiones por destino económico de “bienes de consumo”, “bienes intermedios” y “bienes de capital”. El proceso de elaboración de estos indicadores se detalla de manera resumida en el siguiente subapartado. Otro indicador novedoso ha sido la serie que recoge la producción bruta de la Central Nuclear de Almaraz, con periodicidad mensual; este indicador proporciona información muy valiosa para el sector energético de Extremadura. II.5.1. ELABORACIÓN DE ÍNDICES DE PRODUCCIÓN INDUSTRIALES PARA EXTREMADURA. La no existencia para Extremadura de aproximaciones cuantitativas (con una longitud mínima adecuada) a la evolución de su producción industrial manufacturera, nos ha obligado a elaborar nuestros propios índices de producción mensual. La publicación semestral “Coyuntura Económica de Extremadura”, editada por la Junta de Extremadura, ha suministrado hasta la fecha ocho datos del IPI trimestral extremeño. Este trabajo, realizado por la Dirección General de Planificación y Presupuestos de la Consejería de Economía, Industria y Hacienda, se elabora por métodos directos; sin embargo, sólo se dispone de datos desde el primer trimestre de 1996 hasta el último de 199745. De esta forma, la longitud tan corta del IPI general y por divisiones (4 divisiones) que la Junta de Extremadura proporciona, así como el retraso en su disponibilidad, invalida de momento su utilización con los fines perseguidos en este trabajo. De igual forma, el INE ha puesto recientemente a disposición del público índices de producción industrial generales para cada una de las 17 comunidades autónomas. Los problemas que tiene esta serie general para Extremadura son: -que incluye la rama energética46, y -que la serie tiene una longitud “corta”. Dentro de las posibles tipologías de indicadores para el seguimiento de la actividad industrial, nosotros hemos utilizado un método indirecto que, mediante un cálculo de la estructura de ponderaciones en la Comunidad de 45 La última publicación disponible es la de Junio de 1998. De manera que el índice general para la industria enmascarará la producción de la industria manufacturera. 46 -Pág. 72- Capítulo II. La Información Estadística Económica Regional Extremadura y la posterior aplicación de estos pesos a los índices de producción de las diferentes actividades industriales, obtiene un índice para el total de la industria manufacturera, así como los índices según el destino económico de los bienes: de bienes de consumo, equipo e intermedios. La idea de partida es muy intuitiva; el IPI general para España viene dado por la expresión: n IPI Nacional Total = ∑ IPI i Nacional i =1 VABiNacional Nacional , VABTotal donde i=1,...,n denota a cada una de las subramas nacionales que componen a la industria manufacturera. De igual forma, el IPI general para Extremadura es: n Extremadura IPI Total = ∑ IPI iExtremadura i =1 VABiExtremadura Extremadura VABTotal El problema para aplicar la expresión anterior es que cada IPI iExtremadura es desconocido. En nuestro caso, hemos optado por aproximar el índice i-ésimo regional ( IPI iExtremadura ) mediante el correspondiente índice nacional ( IPI iNacional ); ya que nos parece una hipótesis razonable el suponer que, trabajando al máximo nivel de desagregación sectorial, la evolución del volumen de la producción nacional marcará unos movimientos similares al regional. De esta manera, obtenemos: n IPI Extremadura Total ≈ ∑ IPI i Nacional i =1 VABiExtremadura Extremadura VABTotal Para calcular la expresión anterior, hemos partido de los datos del INE referentes a los índices de producción industrial47 (IPI) Base 1990, con una desagregación a nivel de subgrupo (3 dígitos). En definitiva, se trata de 75 series de IPIs nacionales para las ramas especificadas en el cuadro siguiente. Las observaciones disponibles parten, en general, de Enero de 1975 y se extienden hasta mayo de 1997. Esta regla se incumple en el caso de determinados subgrupos que parten del año 1992. 47 Una publicación específica es INE (1982). -Pág. 73- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 9. IPIs Nacionales para CNAE-74 (Base 90). 4-112Z 4-113Z 4-231Z 4-233Z 4-239Z 5-130Z 5-152Z 6-151Z 8-221Z 8-222Z 8-223Z 8-224Z 9-241Z 9-242Z 9-243Z 9-244Z 9-245Z 9-247Z 12-246Z 20-411Z 29-429Z 12-249Z 20-412Z 30-43ZZ 13-251Z 21-413Z 31-441Z 13-252Z 22-414Z 31-442Z 13-253Z 23-415Z 31-451Z 13-254Z 24-417Z 32-453Z 13-255Z 24-418Z 32-455Z 15-314Z 25-419Z 33-461Z 15-315Z 26-422Z 33-462Z 16-316Z 27-416Z 33-463Z 17-32ZZ 27-420Z 33-464Z 18-34ZZ 27-421Z 33-465Z 18-35ZZ 27-423Z 33-467Z 18-391Z 28-424Z 34-466Z 18-392Z 28-426Z 35-468Z 18-393Z 28-427Z 36-47ZZ 19-361Z 28-428Z 37-481Z 19-362Z 37-482Z 19-363Z 38-49ZZ 19-383Z 19-389Z Notas: El número antes del guión indica la correspondencia de las ramas TIOEX-90 con la CNAE-74. El siguiente paso ha sido agrupar los subgrupos (convenientemente ponderados) para lograr darles una estructura similar a la que nos proporciona la tabla “input-output” de Extremadura de 1990 (TIOEX-90): -Pág. 74- Capítulo II. La Información Estadística Económica Regional Cuadro nº 10. Ramas de la TIOEX-90. CÓDIGO 4 8 9 12 13 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 RAMAS TIOEX-90 MINAS Y CANTERAS PRODUCCIÓN Y 1ª TRANSF. METALES T. COCIDA Y PRODUCTOS CERÁMICOS INDUSTRIA DEL VIDRIO Y OTROS MIN. INDUSTRIA QUÍMICA CONSTRUCCIÓN METÁLICA FABRICACIÓN DE HERRAMIENTAS MÁQUINAS AGRÍCOLAS MÁQUINAS DE OFICINAS CONSTRUCCIÓN DE VEHÍCULOS ACEITES Y GRASAS INDUSTRIA CÁRNICA INDUSTRIA LÁCTEA FABRICACIÓN DE JUGOS PRODUCTOS DE MOLINERÍA PANADERÍA, PASTELERÍA ALIMENTACIÓN ANIMAL OTRAS ALIMENTARIAS INDUSTRIAS VINÍCOLAS INDUSTRIA DEL TABACO INDUSTRIA TEXTIL INDUSTRIA DEL CUERO INDUSTRIA DE LA CONFECCIÓN INDUSTRIA DE LA MADERA PRODUCTOS DEL CORCHO INDUSTRIA DEL MUEBLE INDUSTRIA DEL PAPEL, CARTÓN PRODUCTOS DE CAUCHO OTRAS MANUFACTURAS Para conseguir dicha estructura, hemos utilizado los pesos implícitos referentes a la estructura productiva que facilita la encuesta industrial de 1990 para Extremadura. Por último, se ha ponderado cada grupo obtenido en el paso anterior utilizando el coeficiente de participación de cada rama en la estructura productiva de Extremadura según la TIOEX-90. Los resultados obtenidos han sido: -un índice de producción industrial para el sector de bienes intermedios de Extremadura (IPIQ), -un índice de producción industrial para el sector de bienes de capital de Extremadura (IPIK), -Pág. 75- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña -un índice de producción industrial para el sector de bienes de consumo de Extremadura (IPIC) y -un índice de producción industrial para el sector industrial manufacturero de Extremadura (IPIG). En la Gráfica Diciembre de 1997. se recoge la representación de dichos índices hasta Gráfico nº 8. Índices de Producción Industrial para Extremadura. 120 140 110 120 100 100 90 80 80 60 70 40 60 20 76 78 80 82 84 86 88 90 92 94 96 76 78 80 82 84 IPIQ 86 88 90 92 94 96 88 90 92 94 96 IPIK 140 140 120 120 100 100 80 80 60 60 40 40 76 78 80 82 84 86 88 90 92 94 96 IPIC 76 78 80 82 84 86 IPIG Hemos comparado gráficamente nuestros resultados para el IPI general (IPIG_UEX) y sus tasas de crecimiento (TIPIGUEX) con los del INE (niveles (IPIG_INE) y tasas de crecimiento (TIPIGINE); las comparaciones gráficas se ha realizado tanto con periodicidad mensual (Gráfico nº 9.), como trimestral (Gráfico nº 10) y anual (Gráfico nº 10). -Pág. 76- Capítulo II. La Información Estadística Económica Regional Gráfico nº 9. IPIs mensuales para Extremadura. 130 20 120 10 110 100 0 90 80 -10 70 60 1992 1993 1994 IPIG_INE 1995 1996 -20 1997 1993 1994 IPIG_UEX 1995 TIPIGINE 1996 1997 TIPIGUEX Gráfico nº 10. IPIs trimestrales para Extremadura. 115 15 110 10 105 5 100 0 95 -5 90 -10 85 80 1992 1993 1994 IPIG_INE 1995 1996 1997 -15 93:1 93:3 94:1 94:3 95:1 95:3 96:1 96:3 97:1 97:3 IPIG_UEX TIPIGINE TIPIGUEX Gráfico nº 11. IPIs anuales para Extremadura. 110 10 8 105 6 4 100 2 0 95 -2 90 1992 1993 1994 IPIG_INE 1995 1996 1997 -4 1993 IPIG_UEX 1994 1995 TIPIGINE 1996 1997 TIPIGUEX En el Gráfico nº 12 se aprecian las similitudes y diferencias existentes entre el IPI general trimestral para Extremadura obtenido de manera directa por la Junta de Extremadura (IPIG_JE en niveles, TIPIG_JE en tasas interanuales), el del INE y el que hemos elaborado nosotros. -Pág. 77- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 12. IPIs trimestrales. 160 140 120 100 80 96:1 96:2 96:3 96:4 IPIG_JE 97:1 97:2 IPIG_INE 97:3 97:4 IPIG_UEX Por último, en el Gráfico nº 13. se presentan las variaciones de los distintos índices anuales. Gráfico nº 13. IPIs anuales. 14 12 10 8 6 4 2 0 1997:1 1997:2 TIPIG_JE 1997:3 TIPIGINE 1997:4 TIPIGUEX A pesar de los pocos datos disponibles, podemos indicar que el índice elaborado por nosotros es el que más se asemeja, tanto en niveles como en crecimientos interanuales al realizado por la Junta de Extremadura (que es el único obtenido mediante métodos directos). Sin embargo, no se puede cuestionar la validez del IPI del INE, ya que incluye la rama energética que, como veremos en el próximo Capítulo, es de una gran importancia dentro del panorama industrial extremeño. Podemos concluir señalando que lo más relevante es la elaboración de unos índices cuantitativos que contribuyen de manera significativa al análisis coyuntural de la industria manufacturera extremeña, aportando actualidad con unos costes bajos. -Pág. 78- Capítulo III. Evolución Reciente de la Economía Extremeña CAPÍTULO III. EVOLUCIÓN RECIENTE DE LA ECONOMÍA EXTREMEÑA. III.1. INTRODUCCIÓN. La modelización estadístico-econométrica que pretendemos realizar para la economía extremeña requiere, en primer lugar, un acercamiento a las líneas primordiales de comportamiento de dicha economía, tanto en el pasado reciente como en la actualidad, al objeto de favorecer, comprender e interpretar la representación simplificada de las relaciones fundamentales que consideremos. De esta forma, y para dar una idea adecuada de la situación económica de la Comunidad Autónoma de Extremadura, hemos concretado un análisis descriptivo que no persigue buscar las causas últimas de las bonanzas y problemas que acompañan a la economía extremeña, sino dar unas pinceladas acerca de la trayectoria que ha seguido esta economía en el período 1980-1995. Para hacer este estudio hemos tenido en cuenta determinados aspectos estructurales: a) Datos básicos del conjunto de la economía regional. b) Datos básicos referidos a la economía nacional, como marco en el que se integra la regional, y que ponen de manifiesto las relaciones entre una y otra economía. En este sentido, queremos comparar la estructura y evolución temporal de la economía extremeña con la economía española durante el período 19801995 apoyándonos en los datos suministrados por la Contabilidad Regional de España. La forma de analizar la información, pasa por un estudio comparado entre los datos agregados de la Comunidad y el conjunto nacional desde la óptica de la oferta. El INE ha puesto a disposición de los usuarios series estimadas del Producto Interior Bruto (PIB) a precios de mercado (pm) de las diferentes Comunidades Autónomas para el período 1980-1995, tanto en pesetas corrientes como constantes. Sin embargo, la dificultad que supone la asignación del impuesto sobre el valor añadido (IVA) que grava a los productos y de los impuestos netos ligados a la importación ha supuesto un obstáculo muy importante para la existencia de datos (publicados por el INE) del PIB desagregados sectorialmente a nivel regional. En definitiva, la no disposición de series desagregadas del PIBpm extremeño estimadas por el INE para la clasificación R-6 de la NACE-CLIO, nos conduce a realizar el estudio apoyándonos primordialmente en los agregados referentes al valor añadido bruto a precios de mercado (VABpm). -Pág. 79- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña La pieza clave para desarrollar la exposición es el VABpm en pesetas constantes de 1986. Las series de VABpm en pesetas constantes de 1986 con una desagregación a seis ramas (clasificación R-6: agraria, energética, industrial, construcción, servicios destinados a la venta y servicios no destinados a la venta) son las estimadas por la Subdirección General de Análisis y Programación Regional y Sectorial del Ministerio de Economía y Hacienda. Estas series son el resultado de aplicar deflactores elaborados para cada una de las ramas (Ver Cordero y Gayoso (1997)) a los datos corrientes de la Contabilidad Regional que el INE publica. Por consiguiente, el año de partida es 1980 y el último dato es el correspondiente a 1995 (último dato oficial existente en Contabilidad Regional, siendo 1993 y 1994 provisional, y 1995 avance). En este Capítulo trabajamos con el mencionado agregado tanto en niveles como en tasas de variación anual, realizando algunos análisis que hemos considerado relevantes desde la perspectiva descriptiva y cíclica. En ocasiones, los resultados obtenidos en cada uno de los apartados se presentan en gráficos suficientemente ilustrativos. Estudiamos la evolución de los coeficientes de distribución regional correspondientes al VABpm en pesetas constantes de 1986 de Extremadura para la clasificación sectorial R-6. Hemos calculado las participaciones sectoriales en el VABpm de Extremadura y en el VABpm nacional en un intento de sopesar las diferencias básicas entre ellas. También calculamos y comparamos las contribuciones al crecimiento, tanto desde la perspectiva nacional como extremeña. Las productividades medias españolas y extremeñas (medidas aproximadamente) son parangonadas, y terminamos el desarrollo analítico del capítulo detectando la convergencia o divergencia en el crecimiento regional extremeño con respecto al nacional, (señalando las ramas que determinan tales hechos). Concluimos el capítulo con un sumario de las conclusiones obtenidas. III.2. ESTRUCTURA PRODUCTIVA Y CRECIMIENTO DE LA ECONOMÍA El PIBpm de una economía regional es una macromagnitud que representa una síntesis de la actividad económica desarrollada en un año. Aprovechando la presentación por parte del INE de una estimación del PIBpm regional extremeño en pesetas constantes, hemos realizado el siguiente gráfico, en el que se representa la participación porcentual del PIBpm de Extremadura en pesetas constantes de 1986 dentro del PIBpm de España en pesetas constantes de 1986. -Pág. 80- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico nº 14. Participación porcentual del PIBpm de Extremadura en pesetas constantes de 1986 en el PIBpm de España en pesetas constantes de 1986 (PIBEXES). 2.0 1.9 1.8 1.7 1.6 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 PIBEXES Este gráfico nos muestra cómo el PIB de Extremadura constituye en la actualidad en torno a un 1,9% del PIB nacional48. Si representamos conjuntamente la tasa de variación del PIBpm de Extremadura en pesetas constantes de 1986 y la tasa de variación del PIBpm de España en pesetas constantes de 1986 (Gráfico nº 15), podemos apreciar cómo el ciclo económico extremeño y el nacional muestran comportamientos que, para determinados años, son muy diferentes. Por lo tanto, uno de los objetivos de este estudio es la identificación de los sectores que distorsionan el comportamiento del ciclo económico extremeño con respecto al nacional. Gráfico nº 15. Tasa de variación del PIBpm de Extremadura en pesetas constantes de 1986 (TPISBEXCT) y tasa de variación del PIBpm de España en pesetas constantes de 1986 (TPISBESCT). 20 15 10 5 0 -5 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TPIBESCT TPIBEXCT 48 Como posteriormente se mostrará, la explicación del “salto” para el año 1984 en la evolución de la participación en el PIB nacional se documenta con el crecimiento del sector energético extremeño en dicho año. -Pág. 81- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Por otro lado, el territorio extremeño (41.634 km2), que constituye un 8,228% del territorio nacional (505.990 Km2), se encuentra con unos ratios de densidad de población bastante bajos con respecto a la densidad media para el total nacional. Para reflejarlo gráficamente, hemos representado la densidad de población para España y para Extremadura en el Gráfico nº 16. Gráfico nº 16. Densidad de población: España y Extremadura. 0.078 0.0259 0.077 0.0258 0.076 0.0257 0.075 0.0256 0.0255 0.074 80 82 84 86 88 90 92 94 80 POBKM2ES 82 84 86 88 90 92 94 POBKM2EX Poblacion de derecho en España (en miles de POBKM 2 ES = 505.990 Km 2 personas) ; Poblacion de derecho en Extremadura ( en miles de personas) POBKM 2 EX = 41634 . Km 2 En lo que respecta a la población de derecho de Extremadura49, a lo largo del período en estudio Extremadura ha perdido participación dentro del conjunto de la población nacional. El siguiente gráfico, es una prueba buena de la pérdida de participación porcentual de la población extremeña dentro de la población total. 49 Población de derecho a 1 de Julio de cada año; es dato de Contabilidad Regional de España. -Pág. 82- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico nº 17. Población de derecho de Extremadura: participación dentro del total nacional. 2.84 2.82 2.80 2.78 2.76 2.74 2.72 80 82 84 86 88 90 92 94 PPOBEXES Total POBLACION DERECHOExtremadura *100 PPOBEXES = Total POBLACION DERECHOEspaña También se puede apreciar en el Gráfico nº 18 cómo el crecimiento de la población en Extremadura ha estado, en la mayor parte del período de análisis, por debajo del crecimiento medio nacional, incluso con tasas de crecimiento nulas o negativas para el período 1987-1991. De cualquier forma, para los tres últimos años, la población extremeña crece a un ritmo mayor que la media nacional. Gráfico nº 18. Crecimiento de la población en Extremadura ( TPOBDEX ) y crecimiento medio de la población nacional ( TPOBDEX ). 0.8 0.6 0.4 0.2 0.0 -0.2 -0.4 -0.6 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TPOBDES TPOBDEX A continuación realizamos un análisis más detallado de las características globales y sectoriales de la economía extremeña, de manera que sus rasgos fundamentales queden suficientemente claros antes de proceder a la creación de modelos estadísticos-econométricos económicos para Extremadura. Por las razones antes argumentadas, procedemos a sustituir el PIBpm nacional y de Extremadura como macromagnitudes de referencia para -Pág. 83- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña nuestro estudio, por el VABpm en pesetas constantes de 1986 para Extremadura y España. III.2.1. ESTRUCTURAS NACIONAL. PORCENTUALES SOBRE EL TOTAL Como puede apreciarse en el Gráfico nº 19, la estructura porcentual de la producción de la región extremeña sobre el VABpm total nacional, ha pasado de valores en torno al 1.7% en los primeros años a valores algo superiores al 1.8% en los últimos. Es decir, en la estructura productiva nacional, Extremadura representa en la actualidad aproximadamente algo más del 1.8%. Gráfico nº 19. Estructura porcentual sobre el total nacional. 1.95 1.90 1.85 1.80 1.75 1.70 1.65 80 82 84 86 88 90 92 94 EPEXES Total VABpmExtremadura *100 EPEXES = Total VABpm España Observando los coeficientes de participación del VABpm de cada rama de actividad50 de Extremadura en el VABpm de cada rama respectiva a nivel VABpm / Rama i − e sima R − 6 de Extremadura nacional, es decir, , se podrían ordenar las VABpm / Rama i − e sima R − 6 de España distintas ramas extremeñas de mayor a menor participación de la siguiente forma51: 1º Agricultura. 2º Energía. 3º Servicios no destinados a la venta. 4º Construcción. 5º Servicios destinados a la venta. 50 Ramas de actividad de la clasificación R-6 de la NACE-CLIO. 51 En esta clasificación se da prioridad a los valores obtenidos en los últimos años. -Pág. 84- Capítulo III. Evolución Reciente de la Economía Extremeña 6º Productos industriales. No obstante, en la anterior ordenación habría que hacer una serie de matizaciones: 1ª En lo referente a la agricultura, la agricultura extremeña está muy sometida a los factores climáticos, lo cual explica su inestable participación en el VABpm agrario nacional (Gráfico nº 20). Gráfico nº 20. Agricultura: Estructura porcentual sobre el sector nacional. 5.5 5.0 4.5 4.0 3.5 3.0 80 82 84 86 88 90 92 94 EPAEXES A gra rio VABpmExtremadura EPAEXES = A gra rio *100 VABpmEspaña 2ª En la rama energética se pasa de valores próximos al 1% en 1980 a valores superiores al 4,5% para 1985 (Gráfico nº 21). La causa de este espectacular aumento es la puesta en funcionamiento de la Central Nuclear de Almaraz. Gráfico nº 21. Energía: Estructura porcentual sobre el sector nacional. 5 4 3 2 1 0 80 82 84 86 88 90 92 94 EPEEXES Energetico VABpmExtremadura EPEEXES = Energetico *100 VABpmEspaña -Pág. 85- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña 3ª La situación de la rama de servicios no destinados a la venta ha ido ganando terreno dentro de la estructura porcentual de esta rama a nivel nacional hasta estabilizarse en torno al 2,8%; (Gráfico nº 22). Gráfico nº 22. Servicios no destinados a la venta: Estructura porcentual sobre el sector nacional. 2.9 2.8 2.7 2.6 2.5 80 82 84 86 88 90 92 94 EPGEXES Servicios no VABpmExtremadura EPGEXES = Servicios no VABpmEspaña venta *100 venta 4ª La rama de la construcción ganó terreno a nivel nacional por las obras de infraestructuras realizadas en los años 80. De cualquier forma, se consolida como el cuarto sector dentro de Extremadura en lo que se refiere a su importancia dentro de la estructura productiva nacional. (Gráfico nº 23). Gráfico nº 23. Construcción: Estructura porcentual sobre el sector nacional. 3.4 3.2 3.0 2.8 2.6 2.4 2.2 2.0 80 82 84 86 88 90 92 94 EPBEXES Construccion VABpmExtremadura EPBEXES = Construccion *100 VABpmEspaña 5º En los servicios destinados a la venta (Gráfico nº 24) hay dos etapas diferentes: - desde 1980 hasta 1985, con clara tendencia decreciente en los valores de la estructura porcentual, y -Pág. 86- Capítulo III. Evolución Reciente de la Economía Extremeña - desde 1986 hasta 1995, con ganancia en el coeficiente de participación. Gráfico nº 24. Servicios venta: Estructura porcentual sobre el sector nacional. 1.8 1.7 1.6 1.5 1.4 1.3 80 82 84 86 88 90 92 94 EPSEXES Servicios venta VABpmExtremadura EPSEXES = Servicios venta *100 VABpmEspaña 6º En la rama de productos industriales (Gráfico nº 25), es de destacar los valores tan bajos que esta rama extremeña supone con respecto a la rama nacional (valores en torno al 0.6%) y la presencia de una tendencia que indica que se pierde participación a nivel nacional. Gráfico nº 25. Industria manufacturera: Estructura porcentual sobre el sector nacional. 0.80 0.75 0.70 0.65 0.60 0.55 80 82 84 86 88 90 92 94 EPIEXES Industria VABpmExtremadura EPIEXES = Industria *100 VABpmEspaña -Pág. 87- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña III.2.2. TASAS DE VARIACION DEL VAB. Las tasas de variación (o tasas de crecimiento) calculadas como VABpmt − VABpmt −1 * 100 representan el crecimiento Tasa de var iaciont = VABpmt −1 en tantos por ciento sobre el valor precedente. III.2.2.1. INFLUENCIAS DEL CRECIMIENTO NACIONAL. Se pretende describir las influencias de cada rama (R-6) nacional en las homólogas ramas extremeñas. Si se observan las tasas de crecimiento anuales del VABpm para España y Extremadura conjuntamente (Gráfico BI), lo recalcable es la mayor suavidad de los crecimientos nacionales, el espectacular crecimiento en el año 1984 del VABpm TOTAL extremeño52, y desde el año 1990, la afinidad existente en los ritmos de crecimiento nacional y regional para marcar unas tendencias similares. Gráfico nº 26. Tasas de crecimiento anuales del VABpm para España (TVABEST) y Extremadura (TVABEXT). 20 15 10 5 0 -5 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TVABEST TVABEXT Los crecimientos nacionales explican la evolución de los crecimientos regionales, como confirma la siguiente regresión. 52 Este gran crecimiento es debido a su vez al ya mencionado crecimiento del VABPM en la rama de productos energéticos como consecuencia de la puesta en funcionamiento de la central nuclear de Almaraz. -Pág. 88- Capítulo III. Evolución Reciente de la Economía Extremeña Cuadro nº 11. Regresión entre el crecimiento del VAB español (TVABEST) y el extremeño (TVABEXT). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TVABEXT Muestra: 1981-1995 Regresores Parámetros Estimados Estadístico t-Student TVABEST 0,753 2,119 Ficticia año 84 14,681 6,393 Ficticia año 86 -5,775 -2,508 Ficticia año 88 5,816 2,348 Término independiente 0,100 0,099 2 Coeficiente de determinación (R ): 0,856; Coeficiente de determinación corregido: 0,799; Estadístico F-Snedecor: 14,979; Prob(estadístico F): 0,000; Durbin-Watson: 1,907 Según los resultados obtenidos, un incremento de un 1% en la tasa de crecimiento media del VABpm nacional supone un incremento de 0,75% en la tasa de crecimiento de la economía extremeña. Las variables ficticias recogen años atípicos, años para los que han acaecido circunstancias especiales dentro de la economía extremeña que han tenido como consecuencia que el crecimiento regional difiera de manera importante del crecimiento nacional. Pero lo que se puede afirmar de una manera general es que, exceptuando ciertos años excepcionales, el ritmo de crecimiento nacional marca las pautas de comportamiento del crecimiento de la Comunidad Autónoma de Extremadura. Por otra parte, si desagregamos los crecimientos de las diferentes ramas (clasificación R-6), se observa que en la rama agraria (gráfico BII) se advierte el lógico suavizado de los crecimientos sectoriales a nivel nacional (TA01ESM) con respecto al regional53 (TA01EXM). Para el caso de la agricultura y ganadería, la dependencia de esta rama extremeña de los factores climáticos hace que las épocas de expansión y de crisis se acentúen con respecto a la media nacional. 53 Como también comprobaremos después para el resto de las ramas R-6. -Pág. 89- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 27. Crecimiento de la rama agraria a nivel nacional (TA01ESM) y de la rama agraria extremeña (TA01EXM). 60 40 20 0 -20 -40 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TA01ESM TA01EXM En la siguiente regresión se resuelve la cuestión relativa a si la tasa de crecimiento de la rama agraria nacional influye de manera significativa en el crecimiento de la rama agraria extremeña: Cuadro nº 12. Regresión entre el crecimiento del VAB español (TA01ESM) y el extremeño (TA01EXM). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TA01EXM Muestra: 1981 - 1995 Regresores Parámetros Estimados Estadístico t-Student TA01ESM 1,464 3,538 Ficticia año 83 -33,280 -3,202 Ficticia año 84 46,875 4,362 Ficticia año 94 28,924 2,770 Término independiente -0,722 -0,255 Coeficiente de determinación (R2): 0,859 ; Coeficiente de determinación corregido:0,803 ; Estadístico F-Snedecor:15,342 ; Prob (estadístico F):0,000 ; Durbin-Watson:2,080 Podemos significar que cuando la rama agraria nacional crece un 1%, la rama agraria extremeña crece un 1,46%. Los resultados evidencian la volatilidad de la rama agraria extremeña con respecto a su homóloga nacional. A la vista de estos resultados se puede aceptar la hipótesis de seguimiento de las líneas generales de comportamiento de la rama agraria nacional, exceptuando aquellos años puntuales y atípicos para los que el comportamiento regional difiere de manera importante de lo que es la media nacional. En el Gráfico nº 28, se aprecia que el ritmo de crecimiento de la rama energética extremeña tiende a converger al crecimiento medio de dicha rama a nivel nacional. -Pág. 90- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico 28. Crecimiento de la rama energética nacional (TE06ESM) y de la rama energética extremeña (TE06EXM). 160 120 80 40 0 -40 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TE06ESM TE06EXM En este caso, las regresiones que se estimaron relacionando los crecimientos regionales con los nacionales confirman lo que se puede observar en la gráfica: los crecimientos de la rama energética extremeña convergen de una manera cada vez más acusada a los crecimientos medios nacionales. La evidencia práctica sería la inexistencia de influencias de los crecimientos nacionales en el regional hasta el año 88, momento en el que los crecimientos de la rama energética nacional explican de manera significativa los crecimientos de la rama energética extremeña: Cuadro nº 13. Regresión entre el crecimiento del VAB español (TE06ESM) y el extremeño (TE06EXM). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TE06EXM Muestra: 1988 - 1995 Regresores Parámetros Estimados Estadístico t-Student TE06ESM 1,792 3,169 Ficticia año 90 -17,951 -3,366 Coeficiente de determinación (R2):0,767; Coeficiente de determinación corregido:0,728; Estadístico F-Snedecor:19,783; Prob (estadístico F):0,004 ; Durbin-Watson:1,529 En otro ámbito, el Gráfico nº 29 es una representación de los crecimientos de las ramas industriales nacional y extremeña. Se puede observar cómo el crecimiento de la industria extremeña parece no explicarse mediante el crecimiento de la industria nacional, como así corroboran las pruebas realizadas vía regresiones. -Pág. 91- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 29. Crecimiento de la rama industrial manufacturera nacional (TI30ESM) y extremeña (TI30EXM). 30 20 10 0 -10 -20 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TI30ESM TI30EXM A continuación se analizan las relaciones entre los crecimientos de la rama industrial desagregada atendiendo a la clasificación R-9 (subramas de bienes de intermedios (TQ), bienes de capital (TK) y bienes de consumo(TC)): a) La gráfica de los crecimientos de la subrama de bienes intermedios extremeña y de su equivalente nacional es la del Gráfico nº 30. Gráfico nº 30. Crecimiento de la subrama de bienes intermedios extremeña (TQEX) y su equivalente nacional (TQES). 20 10 0 -10 -20 -30 81 82 83 84 85 86 87 88 89 90 91 92 93 94 TQES TQEX La regresión que relaciona TQEX con TQES nos confirmó que los crecimientos de la subrama nacional no explican de manera significativa los crecimientos de la subrama regional. b) Los crecimientos de la subrama de bienes de capital para Extremadura (TKEX) y su equivalente nacional (TKES) los recogemos en la siguiente gráfica. -Pág. 92- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico nº 31. Crecimiento de la subrama de bienes de capital para Extremadura (TKEX) y para España (TKES). 40 30 20 10 0 -10 -20 -30 81 82 83 84 85 86 87 88 89 90 91 92 93 94 TKES TKEX La regresión que relaciona TKEX con TKES viene dada por el Cuadro nº 14. Cuadro nº 14. Regresión entre el crecimiento del VAB español (TKES) y el extremeño (TKEX). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TKEX Muestra: 1981 - 1994 Regresores Parámetros Estimados Estadístico t-Student TKES 0,856 1,969 Ficticia año 88 37,245 3,356 Ficticia año 90 24,615 2,242 Término independiente -5,103 0,138 Coeficiente de determinación (R2): 0,687 ; Coeficiente de determinación corregido: 0,593 ; Estadístico F-Snedecor: 7,332 ; Prob (estadístico F): 0,006 ; Durbin-Watson: 1,834 c) Los crecimientos nacionales y regionales para la subrama de bienes de consumo, se representan a en el Gráfico nº 32. -Pág. 93- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 32. Crecimiento de la subrama de bienes de consumo nacional (TCES) y extremeña (TCEX). 30 20 10 0 -10 -20 81 82 83 84 85 86 87 88 89 90 91 92 93 94 TCES TCEX La regresión correspondiente a esta subrama es la del Cuadro nº 15. Cuadro nº 15. Regresión entre el crecimiento del VAB español (TCES) y el extremeño (TCEX). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TCEX Muestra: 1981 - 1994 Regresores Parámetros Estimados Estadístico t-Student TCES 1,821 2,388 Ficticia año 85 25,595 4,327 Ficticia año 86 17,422 -2,840 Término independiente -2,922 -1,472 2 Coeficiente de determinación (R ): 0,762 ; Coeficiente de determinación corregido: 0,691; Estadístico F-Snedecor: 10,709 ; Prob (estadístico F): 0,001 ; Durbin-Watson: 2,656 Podemos concluir que los crecimientos de las subramas nacionales marcan los crecimientos de las respectivas subramas a nivel regional, excepto para el caso de los bienes intermedios. En consecuencia, al agregar las tres subramas para obtener la rama industrial total extremeña, el resultado es un crecimiento industrial extremeño que no se explica atendiendo a las pautas del crecimiento industrial medio nacional. En resumen, las causas que explican la falta de influencia significativa del crecimiento de la rama industrial nacional (clasificación R-6) en el homólogo crecimiento regional son: -la distorsión que produce la subrama de bienes intermedios por la razón antes comentada y -la peculiar composición de la estructura de la rama industrial en Extremadura54, que pondera de manera distinta a como lo hacen las ponderaciones que operan a nivel medio nacional, de manera que el resultado de la producción total puede señalar un crecimiento diferente del nacional. 54 Como comprobaremos posteriormente. -Pág. 94- Capítulo III. Evolución Reciente de la Economía Extremeña Para la rama de la construcción (Gráfico nº 33), las tasas de variación de la construcción para Extremadura han evolucionado de manera distinta a las nacionales hasta el año 90, año a partir del cual la construcción extremeña recoge de manera significativa el crecimiento nacional con un cierto retraso. Gráfico nº 33. Crecimiento de la construcción para Extremadura (TB53EXM) y para España (TB53ESM). 20 10 0 -10 -20 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TB53ESM TB53EXM La siguiente regresión ratifica los comentarios realizados: Cuadro nº 16. Regresión entre el crecimiento del VAB español (TB53ESM) y el extremeño (TB53EXM). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TB53EXM Muestra: 1990 - 1995 Regresores Parámetros Estimados Estadístico t-Student TB53ESM(-1) 0,654 10,502 Término independiente 2,072 0,012 2 Coeficiente de determinación (R ): 0,965 ; Coeficiente de determinación corregido: 0,956 ; Estadístico F-Snedecor: 110,295 ; Prob (estadístico F): 0,000 ; Durbin-Watson: 2,694 En lo concerniente a los crecimientos de las ramas de servicios destinados a la venta para Extremadura y para España, la evolución general que presentan es bastante similar, sobre todo a partir de 1986. En la gráfica se aprecia un cambio estructural a partir del año 1984, momento en el que las tasas de crecimiento de la rama extremeña en estudio se sitúa a niveles generalmente similares o superiores a las tasas de crecimiento de la rama de servicios destinados a la venta en España. -Pág. 95- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 34. Crecimiento de la rama de servicios destinados a la venta para Extremadura (TS68EXM) y para España (TS68EXM). 12 8 4 0 -4 -8 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TS68EXM TS68ESM Según se puede advertir en la gráfica anterior, y como corroboran las estimaciones del Cuadro nº 17, los crecimientos de esta rama regional se explican de manera significativa por los crecimientos medios de la misma rama a nivel nacional. Cuadro nº 17. Regresión entre el crecimiento del VAB español (TS68ESM) y el extremeño (TS68EXM). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TS68EXM Muestra: 1981 - 1995 Regresores Parámetros Estimados Estadístico t-Student TS68ESM 1,458 2,449 Ficticia años 81-84 -6,237 -4,341 Ficticia año 87 -5,454 -2,185 Término independiente 1,127 0,598 Coeficiente de determinación (R2): 0,810 ; Coeficiente de determinación corregido: 0,758; Estadístico F-Snedecor: 15,691 ; Prob (estadístico F): 0,000 ; Durbin-Watson: 2,045 Notas: -Ficticia8184 es una variable ficticia que recoge el cambio estructural que se produce a partir del año 1985, y que toma el valor 0 para todo el período excepto para los años 1981, 1982 , 1983 y 1984 en los que toma el valor 1. Para finalizar este análisis de las tasas de variación de las ramas extremeñas en comparación con las nacionales, estudiamos los servicios no destinados a la venta. La gráfica siguiente es lo suficientemente aclaratoria para afirmar que los crecimientos de la región muestran un comportamiento en el crecimiento bastante similar al nacional, aunque con las oscilaciones características de los agregados regionales con respecto a los totales nacionales. -Pág. 96- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico nº 35. Crecimiento de la rama de servicios no destinados a la venta nacional (TG86ESM) y extremeña (TG86EXM). 16 12 8 4 0 -4 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TG86EXM TG86ESM Sirva como prueba de la existencia de una dependencia de lo que acontece a nivel regional en esta rama con respecto a lo que ocurre en el crecimiento medio nacional la siguiente regresión, donde se recogen con variables ficticias aquellos años para los cuales esta rama productiva extremeña tuvo un crecimiento superior al que hubo en la media nacional. Cuadro nº 18. Regresión entre el crecimiento del VAB español (TG86ESM) y el extremeño (TG86EXM ). Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TS68EXM Muestra: 1981 - 1995 Regresores Parámetros Estimados Estadístico t-Student TG86ESM 1,198 5,567 Ficticia año 83 6,395 3,903 Ficticia año 85 7,936 4,798 Ficticia año 92 3,815 2,313 Término independiente 1,127 -1,322 Coeficiente de determinación (R2): 0,881 ; Coeficiente de determinación corregido: 0,834; Estadístico F-Snedecor: 18,632 ; Prob (estadístico F): 0,000; Durbin-Watson: 2,199. III.2.2.2. CONTRASTE DE EXISTENCIA DE CICLO COMÚN. En el subapartado anterior hemos podido constatar, de manera general, la existencia de influencias significativas de los crecimientos de las ramas R-6 nacionales (o subramas R-9 para el caso industrial) en los crecimientos de las respectivas ramas R-6 extremeñas. Ahora, nuestro objetivo es tratar de comprobar la existencia de ciclos comunes entre la economía nacional y la economía extremeña aplicando el contraste definido en Engle y Kozicki (1993). La aproximación a la medición del ciclo que vamos a utilizar viene -Pág. 97- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña referida a las tasas de crecimiento del VABpm en pesetas constantes de 1986; siendo la misma herramienta que utilizan Engle y Kozicki (1993) en su trabajo. La siguiente cita recoge la idea central del artículo de dichos autores: “El problema central es comprobar si las características que se detectan en series de datos individuales tienen en realidad partes en común. Más específicamente, una característica se dirá que es común si una combinación lineal de las series logra tener la característica aunque cada una de las series posea la característica de manera individual. Se introducirá un contraste para determinar la existencia de características comunes.” Engle y Kozicki (1993, Pág. 369). La característica de partida en nuestro caso es la existencia de ciclos comunes. Para ello, comprobamos la existencia de dicha característica en ambas economías. A la vista de los siguientes resultados, afirmamos que la economía española es cíclica, mientras que la extremeña no presenta en su conjunto dicha característica.. Cuadro nº 19. Presencia de ciclo en la economía española: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TVABEST Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TVABEST(-1) 0,620 3,163 Término independiente 1,121 1,911 Coeficiente de determinación (R2): 0,454 ; Coeficiente de determinación corregido: ;Estadístico F-Snedecor: 10,009 ; Prob (estadístico F): 0,008; 0,409 Durbin-Watson: 1,494 Cuadro nº 20. Presencia de ciclo en la economía extemeña: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TVABEXT Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TVABEXT(-1) -0,119 -0,418 Término independiente 3,391 2,075 2 Coeficiente de determinación (R ): 0,014; Coeficiente de determinación corregido: 0,067; Estadístico F-Snedecor: 0,175 ; Prob (estadístico F): 0,682; Durbin-Watson: 2,107 En consecuencia, vamos a deslindar cuáles son las ramas cíclicas, tanto a nivel nacional como exremeño. -Pág. 98- Capítulo III. Evolución Reciente de la Economía Extremeña Cuadro nº 21. Presencia de ciclo en la industria manufacturera española: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TI30ESM Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TI30ESM(-1) 0,600 2,667 Ficticia año 94 5,610 2,319 Ficticia año 93 -4,635 -2,198 Término independiente 1,218 1,592 Coeficiente de determinación (R2): 0,639; Coeficiente de determinación corregido: 0,531 ; Estadístico F-Snedecor: 5,923 ; Prob (estadístico F): 0,013; Durbin-Watson: 2,009 Cuadro nº 22. Presencia de ciclo en la industria manufacturera extremeña: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TI30EXM Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TI30EXM(-1) -0,386 -2,354 Ficticia año 85 19,462 3,607 Término independiente 0,076 0,052 2 Coeficiente de determinación (R ): 0,642; Coeficiente de determinación corregido: 0,577; Estadístico F-Snedecor: 9,886 ; Prob (estadístico F): 0,003; Durbin-Watson: 2,115 Cuadro nº 23. Presencia de ciclo en los servicios destinados a la venta para España: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TS68ESM Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TS68ESM(-1) 0,454 1,991 Término independiente 1,559 2,383 Coeficiente de determinación (R2): 0,248; Coeficiente de determinación corregido: 0,185 ; Estadístico F-Snedecor: 3,965 ; Prob (estadístico F): 0,069; Durbin-Watson: 1,877 -Pág. 99- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 24. Presencia de ciclo en los servicios destinados a la venta para Extremadura: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TS68EXM Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TS68EXM(-1) 0,590 3,264 Ficticia año 86 9,364 2,962 Ficticia año 88 8,892 2,945 Término independiente 0,150 0,154 Coeficiente de determinación (R2): 0,687; Coeficiente de determinación corregido: 0,593 ; Estadístico F-Snedecor: 7,320 ; Prob (estadístico F): 0,006; Durbin-Watson: 2,047 Las ramas cíclicas (ramas en las que existe la característica común) son las siguientes: 1ª Industria (R-6). 2ª Servicios destinados a la venta (R-6). Si contemplamos a ambas economías en su conjunto, el hecho de eliminar la rama agraria no nos permite constatar la existencia de ciclo en la economía extremeña. Tras las pruebas realizadas, hemos verificado que solamente en el caso de prescindir conjuntamente de las ramas agrarias y energéticas podemos acreditar la existencia de ciclo en Extremadura. En este caso, la macromagnitud observada es el valor añadido bruto no agrario y no energético a precios de mercado en pesetas constantes de 1986; de manera que la notación utilizada para las tasas de crecimiento de dichas macromagnitudes será TVABNES (para el caso nacional) y TVABNEX (para Extremadura). En consecuencia, y atendiendo a las siguientes regresiones, se puede afirmar la presencia de la característica de ciclo para ambas economías (no agrarias y no energéticas). Cuadro nº 25. Presencia de ciclo en la economía no agraria y no energética de España: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TVABNES Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TVABNES(-1) 0,.610 2,935 Término independiente 1,276 1,917 Coeficiente de determinación (R2): 0,417; Coeficiente de determinación corregido: 0,369; Estadístico F-Snedecor: 8,614; Prob (estadístico F): 0,012; Durbin-Watson: 1,353 -Pág. 100- Capítulo III. Evolución Reciente de la Economía Extremeña Cuadro nº 26. Presencia de ciclo en la economía no agraria y no energética de Extremadura: Existencia de proceso autorregresivo de orden 1 en la especificación de sus tasas de crecimiento. Método de estimación: mínimos cuadrados ordinarios Variable dependiente: TVABNEX Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TVABNEX(-1) 0,617 3,112 Término independiente 1,371 1,906 Coeficiente de determinación (R2): 0,446; Coeficiente de determinación corregido: 0,400; Estadístico F-Snedecor: 9,689; Prob (estadístico F): 0,008; Durbin-Watson: 1,380 A modo de recapitulación de los resultados obtenidos, podemos manifestar: -En la rama agraria y energética no se presenta la característica cíclica ni a nivel nacional ni regional. -Tanto en la rama de la construcción como de servicios no destinados a la venta, la evidencia empírica muestra la existencia de ciclo a nivel nacional, pero no a nivel regional. -Las ramas de servicios destinados a la venta y de la industria presentan la característica cíclica en las dos economías. -Tanto la economía nacional como la extremeña son cíclicas si se prescinde para las dos de las ramas agraria y energética. Por lo tanto, éstas son las ramas que impiden realmente, de manera agregada, que la economía extremeña sea cíclica. A la vista del anterior sumario vamos a contrastar la existencia de ciclo común entre ambas economías, tanto de manera sectorial como agregada55. Los pasos realizados para la aplicación del contraste los hemos señalado convenientemente, y se corresponden con la ordenación práctica que recogemos en el Anexo 2. 55 Como ya hemos argumentado, sin considerar a las ramas agraria y energética. -Pág. 101- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 27. Existencia de ciclo común en la rama de la industria manufacturera española y extremeña. Regresiones auxiliares. A) PRIMERA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados en dos etapas Variable dependiente: TI30EXM Instrumentos: TI30EXM(-1) TI30ESM(-1) Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TI30ESM -0,585 -0,331 Término independiente 2.735 0,.585 Coeficiente de determinación (R2): -0,050; Coeficiente de determinación corregido: -0,137; Estadístico F-Snedecor: 0,110; Prob (estadístico F): 0,745; Durbin-Watson: 2,861 A los residuos bietápicos de esta regresión les llamamos RI. B) SEGUNDA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados ordinarios Variable dependiente: RI Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TI30EXM(-1) -0,417 -1,686 TI30ESM(-1) 0,804 1,077 Término independiente -1,280 -0,527 Coeficiente de determinación (R2): 0,241; Coeficiente de determinación corregido: 0,103; Estadístico F-Snedecor: 1,752; Prob (estadístico F): 0,218; Durbin-Watson: 2,641 En el caso de la rama industrial, y bajo la hipótesis nula de existencia de ciclos comunes (los errores estimados R1I son independientes de los valores desfasados de TI30EXM y de TI30ESM), el estadístico TR 2 se distribuye según una χ12 . Aplicando este contraste en función de los resultados obtenidos de las regresiones auxiliares (Cuadro ) para un valor crítico del 5%, obtenemos evidencia para no poder rechazar la existencia de ciclo común entre la industria extremeña y la nacional. ( TR 2 = 3,383 y χ12 (5% ) = 3,841 ). -Pág. 102- Capítulo III. Evolución Reciente de la Economía Extremeña Cuadro nº 28. Existencia de ciclo común en la rama de servicios destinados a la venta española y extremeña. Regresiones auxiliares. A) PRIMERA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados en dos etapas Variable dependiente: TS68EXM Instrumentos: TS68EXM(-1) TS68ESM(-1) Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TS68ESM 3,585 1,877 Término independiente -0.996 -1,311 Coeficiente de determinación (R2): 0,238; Coeficiente de determinación corregido: 0,174; Estadístico F-Snedecor: 3,524; Prob (estadístico F): 0,084; Durbin-Watson: 1,646 A los residuos bietápicos de esta regresión les llamamos RS. B) SEGUNDA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados ordinarios Variable dependiente: RS Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TS68EXM(-1) 0,125 0,380 TS68ESM(-1) -0,356 -0,300 Término independiente 0,634 0,219 Coeficiente de determinación (R2): 0,013; Coeficiente de determinación corregido: 0,165; Estadístico F-Snedecor: 0,075; Prob (estadístico F): 0,927; Durbin-Watson: 1,918 De manera similar al caso de la industria, obtenemos evidencia para no poder rechazar la existencia de ciclo común entre los servicios destinados a la venta de Extremadura y de España. ( TR 2 = 0,189 y χ12 (5% ) = 3,841 ). -Pág. 103- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 29. Existencia de ciclo común entre la economía extremeña (no agraria y no energética) y la economía nacional (no agraria y no energética). Regresiones auxiliares. A) PRIMERA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados en dos etapas Variable dependiente: TVABNEX Instrumentos: TVABNEX (-1) TVABNES(-1) Muestra: 1982 – 1995 Regresores Parámetros Estimados Estadístico t-Student TVABNES 1,125 2,903 Término independiente -0.078 -0,064 Coeficiente de determinación (R2): 0,305; Coeficiente de determinación corregido: 0,247; Estadístico F-Snedecor: 8,432; Prob (estadístico F): 0,013; Durbin-Watson: 1,200 A los residuos bietápicos de esta regresión les llamamos RN. B) SEGUNDA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados ordinarios Variable dependiente: RN Muestra: 1982 – 1995 Regresores Parámetros Estimados Estadístico t-Student TVABNEX(-1) 0,546 2,059 TVABNES(-1) -0,224 -0,718 Término independiente -0,970 -1,296 Coeficiente de determinación (R2): 0,321; Coeficiente de determinación corregido: 0,197; Estadístico F-Snedecor: 2,602; Prob (estadístico F): 0,118; Durbin-Watson: 1,858 En función de los resultados del cuadro anterior, rechazamos la existencia de ciclo común entre la economía extremeña (no agraria y no energética) y la economía nacional (no agraria y no energética). ( TR 2 = 4,496 y χ12 (5% ) = 3,841 ). Por otra parte, nos ha parecido interesante comprobar la existencia de ciclo común entre el VABpm no agrario y no energético de Extremadura y el VABpm total nacional. -Pág. 104- Capítulo III. Evolución Reciente de la Economía Extremeña Cuadro nº 30. Existencia de ciclo común entre la economía no agraria y no energética de Extremadura y la economía nacional. Regresiones auxiliares. A) PRIMERA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados en dos etapas Variable dependiente: TVABNEX Instrumentos: TVABNEX (-1) TVABEST(-1) Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TVABEST 1,216 2,877 Término independiente -0.033 -0,027 Coeficiente de determinación (R2): 0,272; Coeficiente de determinación corregido: 0,211; Estadístico F-Snedecor: 8,278; Prob (estadístico F): 0,013; Durbin-Watson: 1,252 A los residuos bietápicos de esta regresión les llamamos R. B) SEGUNDA REGRESIÓN AUXILIAR Método de estimación: mínimos cuadrados ordinarios Variable dependiente: RN Muestra: 1982 - 1995 Regresores Parámetros Estimados Estadístico t-Student TVABNEX(-1) 0,519 1,869 TVABNEST(-1) -0,250 -0,725 Término independiente -0,876 -1,111 Coeficiente de determinación (R2): 0,269; Coeficiente de determinación corregido: 0,137; Estadístico F-Snedecor: 2,032; Prob (estadístico F): 0,177; Durbin-Watson: 1,902 A la vista de los resultados obtenidos en el Cuadro nº 30, no rechazamos la existencia de ciclo común entre la economía extremeña (no agraria y no energética) y la economía nacional. ( TR 2 = 3,777 y χ12 (5% ) = 3,841 ). En definitiva, la economía extremeña (excluyendo las ramas agraria y no energética) es cíclica en el sentido que hemos adoptado, pero no tiene un ciclo común a la economía nacional no agraria y no energética. Sin embargo, sí existe un ciclo común entre la economía extremeña no agraria y no energética y la economía nacional total. Con una desagregación R-6, las ramas extremeñas en las que existe ciclo (industria y servicios destinados a la venta) tienen un ciclo común con las ramas nacionales homólogas. -Pág. 105- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña III.2.3. ESTRUCTURA PORCENTUAL INTERNA. En este subapartado se presenta la importancia relativa de las distintas ramas productivas extremeñas (y su evolución a lo largo de los años estudiados) utilizando la composición porcentual de su VABpm. Los cálculos realizados a nivel regional se pondrán en comparación con los homólogos datos nacionales. La estructura porcentual interna se ha calculado como el porcentaje que supone el VABpm de cada rama regional (nacional) sobre el VABpm total regional (nacional). El Gráfico nº 36 evidencia el gran diferencial existente entre Extremadura y España en lo que respecta a la importancia de la rama agraria dentro de la estructura porcentual interna. Gráfico nº 36. Agricultura: Estructura porcentual interna. 18 16 14 12 10 8 6 4 2 80 82 84 86 88 EPIAES EPIAESM EPIAEX = 90 92 94 EPIAEX EPIAEXM A gra rio VABExtremadura *100 ; EPIAEXM = media de EPIAEX; Total VABExtremadura EPIAES = A gra rio VABEspaña Total VABEspaña *100 ; EPIAESM = media de EPIAES Así, mientras que en el período en estudio la rama agraria extremeña representa una media del 14% del VABpm extremeño, para España esa media de participación del sector agrario es del 5.9%. Al observar el Gráfico nº 36., se podría llegar a pensar que en Extremadura existe una tendencia clara a la pérdida de importancia relativa del sector agrario, ya que los valores de participación en el VABpm de los últimos años denotan un intento de aproximación a los valores nacionales. No obstante, es conveniente señalar que la evolución de la producción agraria extremeña está sometida a una mayor -Pág. 106- Capítulo III. Evolución Reciente de la Economía Extremeña dependencia y condicionamiento de la climatología que la media a nivel nacional. La causa de ésto es la falta de modernización de su agricultura, donde cerca de un 50% de su producción se corresponde con agricultura de secano y ganadería extensiva. Además, las reservas de agua que abastecen a los regadíos se vieron muy disminuidas en los últimos años del período en estudio como consecuencia de la falta de lluvias, lo cual repercute negativamente en el mantenimiento de la producción de regadío en sus niveles óptimos. En resumen, el hecho de que la rama agraria pierda fuerza dentro de la estructura porcentual del VABpm se debe a la sequía de la última etapa del período analizado, siendo esta pérdida mucho más evidente en el caso extremeño por las razones señaladas; por lo tanto, puede ser lógico aventurarse a decir que una vez que se recuperen los niveles de pluviosidad y manteniéndose constante los niveles de crecimiento del resto de las ramas productivas extremeñas, la rama agraria volverá a tener un peso dentro de la estructura porcentual de Extremadura bastante similar a la que tenía al final de los años 80 y que ha sido la media del período observado (en torno al 14%)56. 56 Las estimaciones realizadas por parte de la Consejería de Agricultura y Comercio de la Junta de Extremadura y del equipo Hispalink de Extremadura para el año 1996 así lo confirman. -Pág. 107- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Pasando a analizar la rama de productos energéticos (Gráfico nº 37.), es de destacar que hasta el año 1982 Extremadura tuvo una estructura porcentual interna con un sector energético con valores inferiores a la media nacional; pero a partir del año 1983 Extremadura pasó a tener valores para la participación del sector energético en la estructura del VABpm regional varios puntos por encima de la media nacional57. Es decir, el sector energético tiene una importancia relativa muy importante en Extremadura si se compara con los datos nacionales. La tendencia decreciente que se aprecia para los últimos años en la participación en la estructura porcentual de la rama energética extremeña (que contrasta con la ganancia de peso específico de la rama energética en la estructura productiva nacional), es debida a la falta de precipitaciones, la cual repercute negativamente en la producción hidroeléctrica extremeña. Gráfico nº 37. Energía: Estructura porcentual interna. 16 14 12 10 8 6 4 2 80 82 84 86 EPIEES EPIEESM 88 90 92 94 EPIEEX EPIEEXM Energia VABExtremadura *100 ; EPIEEXM = la media de EPIEEX ; EPIEEX = Total VABExtremadura EPIEES = Energia VAB España Total VAB España *100 y EPIEESM = la media de EPIEES. 57 Ya se ha comentado que la causa de ésto hay que buscarla en la puesta a pleno funcionamiento de la Central Nuclear de Almaraz. -Pág. 108- Capítulo III. Evolución Reciente de la Economía Extremeña Dentro de la estructura porcentual interna del VABpm de Extremadura, la rama de actividad de productos industriales manufactureros (Gráfico nº 38.) está reducida a la mínima expresión en comparación con la media nacional. La diferencia es abismal; sirva como dato de referencia la media que representa la rama industrial para el periodo 1980-1995 dentro de la estructura productiva para Extremadura (8,5%) y para España (24,2%). Lo más preocupante de este sector extremeño es que no se aprecia signo alguno que evidencie una potenciación de esta rama regional de manera que su peso relativo en la economía se aproxime a lo que es el coeficiente de participación de la rama energética dentro de la estructura productiva española. Gráfico nº 38. Industria manufacturera: Estructura porcentual interna. 30 25 20 15 10 5 80 82 84 86 EPIIES EPIIESM 88 90 92 94 EPIIEX EPIIEXM Industria VAB Extremadura *100 ; EPIIEXM = media EPIIEX; siendo EPIIEX = Total VAB Extremadura EPIIES = Industria VAB España Total VAB España *100 y EPIIESM = media de EPIIES -Pág. 109- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña La composición interna de la rama de la industria manufacturera extremeña está claramente alejada de lo que es la estructura interna sectorial nacional. En el gráfico siguiente se puede apreciar cómo la industria de bienes de consumo domina el panorama industrial manufacturero extremeño, quedando relegadas a la mínima expresión las subramas de bienes de equipo y de bienes intermedios. Gráfico nº 39. Subramas industrales: Estructura porcentual interna. 50 100 45 80 40 60 35 40 30 20 25 0 20 80 82 84 EPIQES EPIQES = EPICES = EPIKEX = 86 88 90 EPIKES 92 Industria bienes consumo VABEspaña Industria VABEspaña 80 82 EPICES Industria bienes int ermedios VAB España Industria VABEspaña 94 EPIQEX *100 ; EPIKES = *100 ; EPIQEX = 84 86 88 90 EPIKEX Industria bienes equipo VABEspaña Industria VABEspaña 92 EPICEX *100 ; Industria bienes int ermedios VABExtremadura *100 , Industria VABExtremadura Industria bienes equipo Industria bienes consumo VAB Extremadura VABExtremadura *100 *100 EPICEX ; = Industria Industria VAB Extremadura VABExtremadura -Pág. 110- 94 Capítulo III. Evolución Reciente de la Economía Extremeña En la rama de la construcción (Gráfico nº 40), se distingue un claro distanciamiento de los valores porcentuales dentro de la estructura productiva interna de este sector en Extremadura con respecto a las cifras medias nacionales. No cabe duda de que la importancia relativa de esta rama en la economía extremeña es bastante superior a lo que dicha rama representa en la economía nacional, moviéndose la media de los datos de la construcción dentro de la estructura porcentual interna nacional en torno al 7,5%, mientras que para el caso extremeño se sitúa en valores próximos al 11%. Se observa que la tendencia nacional es la ganancia de porcentaje de participación para la rama de la construcción, y parece que la economía extremeña sigue en los últimos años la pauta nacional. Gráfico nº 40. Construcción: Estructura porcentual interna. 13 12 11 10 9 8 7 6 80 82 84 86 EPIBES EPIBESM EPIBEX = EPIBES = 88 90 92 94 EPIBEX EPIBEXM Construccion VAB Extremadura *100 ; EPIBEXM = media de EPIBEX; Total VAB Extremadura Construccion VAB España Total VAB España *100 y EPIBESM = media de EPIBES. -Pág. 111- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Por el contrario, los servicios destinados a la venta se sitúan en términos de media del coeficiente de participación regional algo más de 6 puntos por debajo de la media nacional en el periodo analizado (Gráfico nº 41). En esta rama se observan síntomas de que la economía extremeña se esté aproximando al porcentaje de participación de los servicios destinados a la venta en el VABpm nacional, mostrando una clara tendencia creciente desde el año 1985 de acercamiento a la cifra nacional. Gráfico nº 41. Servicios destinados a la venta: Estructura porcentual interna. 44 42 40 38 36 34 32 30 80 82 84 86 EPISES EPISESM 88 90 92 94 EPISEX EPISEXM Servicios venta VAB Extremadura *100 ; EPISEXM = media de EPISEX, EPISEX = Total VAB Extremadura EPISES = Servicios VAB España venta Total VAB España *100 ; y EPISESM es la media de EPISES. -Pág. 112- Capítulo III. Evolución Reciente de la Economía Extremeña Si desagregamos la rama de servicios destinados a la venta en dos subramas (servicios destinados a la venta (excluidos transportes y comunicaciones) y transportes y comunicaciones) lo más destacable es la mayor importancia de la subrama de transportes y comunicaciones a nivel nacional. Gráfico nº 42. Subramas de servicios venta: Estructura porcentual interna. 100 100 80 80 60 60 40 40 20 20 0 0 80 82 84 86 88 EPSZES EPSZES = 90 94 80 82 84 EPSLES 88 90 EPSLEX venta ( excluidos transportes y comunicaciones ) Servicios VABEspaña EPILEX = 86 EPSZEX Servicios VABEspaña EPSLES = EPSZEX = 92 Transportes y comunicaciones VABEspaña Servicios VAB España *100 ; venta venta *100 ; Transportes y comunicaciones VAB Extremadura *100 ; Servicios venta VABExtremadura Servicios venta ( excluidos transportes y comunicaciones ) VABExtremadura *100 Servicios venta VABExtremadura -Pág. 113- 92 94 Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña El Gráfico nº 43 muestra el elevado peso que tienen los servicios públicos en Extremadura. Así, los servicios no destinados a la venta tienen un coeficiente de participación medio en el VABpm extremeño del próximo al 20%, valor que se sitúa en torno a 7 puntos porcentuales por encima de la media nacional. Una lectura inmediata de las tendencias crecientes que se advierten para las cifras correspondientes a EPIGEX y EPIGES es que aunque a nivel nacional tendencia es a aumentar el peso del sector público, las cifras nacionales y regionales no se aproximan porque el sector público extremeño sigue ganando terreno. Gráfico nº 43. Servicios no destinados a la venta: Estructura porcentual interna. 24 22 20 18 16 14 12 10 80 82 84 86 EPIGES EPIGESM 88 90 92 94 EPIGEX EPIGEXM Servicios no venta VAB Extremadura *100 ; EPIGEXM = media de EPIGEX, EPIGEX = Total VAB Extremadura EPIGES = Servicios VAB España no venta Total VAB España *100 y EPIGESM = media de EPIGES. -Pág. 114- Capítulo III. Evolución Reciente de la Economía Extremeña En el Cuadro nº 31, el diferencial (calculado para cada rama de actividad como la diferencia entre la estructura porcentual interna en Extremadura y la correspondiente estructura porcentual interna media en España) indica cómo las ramas industrial y de servicios destinados a la venta son las que obtienen valores negativos, que tomados en valor absoluto indican un alejamiento de la presencia de estas ramas en comparación con lo que acontece a nivel nacional. Cuadro nº 31. Estructura porcentual interna de las economías extremeña y nacional. RAMAS DE ACTIVIDAD AGRARIA ENERGÉTICA INDUSTRIA CONSTRUCCIÓN SERVICIOS VENTA SERVICIOS NO VENTA MEDIA PARA LOS PERÍODOS 1980-1985 1986-1990 1991-1995 1980-1985 1986-1990 1991-1995 1980-1985 1986-1990 1991-1995 1980-1985 1986-1990 1991-1995 1980-1985 1986-1990 1991-1995 1980-1985 1986-1990 1991-1995 EXTREMADURA ESPAÑA DIFERENCIAL 15,5 14,7 10,5 8,2 12,8 10,5 9,5 8 7,6 10,8 10,8 11,4 37,8 33,7 37,9 18,2 20 22 6,5 5,9 4,9 6,2 6 5,9 24,7 24,4 23,5 7,1 7,6 8 43,2 42,8 43,3 12,2 13,2 14,4 9 8,8 5,6 2 6,8 4,6 -15,2 -16,4 -15,9 3,7 3,2 3,4 -5,4 -9,1 -5,4 6 6,8 7.6 De todo lo comentado en este subapartado , junto con el cuadro que se muestra a continuación, se puede concluir que se evidencia una clara discrepancia entre la estructura productiva interna de Extremadura y la nacional. El anterior testimonio señala el verdadero problema en cuanto a la estructura productiva de Extremadura: la carencia de una rama de productos industriales y de servicios a la venta suficientemente desarrolladas. -Pág. 115- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña III.2.4. CONTRIBUCIÓN AL CRECIMIENTO. En este apartado vamos a comentar las contribuciones al crecimiento de las ramas R-6 extremeñas al crecimiento de la rama nacional. Definimos la contribución al crecimiento de la rama i en el año t (CON ti ) de la siguiente forma: Porcentaje de participacion delVABti−1 regional en elVABti−1 nacional CON ti = . Tasa de crecimiento delVABti regional En primer lugar hemos representado el crecimiento de la economía nacional junto con la contribución al crecimiento de la economía extremeña58. Gráfico nº 44. Crecimiento de la economía nacional ( TVABEST ) y contribución al crecimiento de la economía extremeña ( CONEX ) . 6 0.3 4 0.2 2 0.1 0 0.0 -2 -0.1 82 84 86 88 90 92 94 82 84 86 88 90 92 94 CONEX TVABEST Es inmediato apreciar que las contribuciones al crecimiento de la economía extremeña han sido contrarias al crecimiento medio nacional para los años 1981, 1983 y 1986. Así, en el año 1981 el crecimiento nacional era negativo, mientras que la contribución al crecimiento en 1981 de Extremadura fue positivo. Por el contrario, las contribuciones al crecimiento en 1983 y 1986 para Extremadura fueron negativas, contradiciendo el crecimiento positivo ocurrido a nivel medio nacional. En lo que respecta a la magnitud de las cuantificaciones de las contribuciones al crecimiento, podemos afirmar que, en general, se trata de valores que han tenido muy poco impacto a nivel nacional, exceptuando el año 1984, en el cual la contribución al crecimiento de Extremadura supuso aproximadamente un 20% de la tasa de crecimiento nacional. 58 Es conveniente recordar que la suma de las contribuciones al crecimiento de todas las regiones españolas es igual al crecimiento nacional. -Pág. 116- Capítulo III. Evolución Reciente de la Economía Extremeña En el siguiente gráfico se representan las tasas de crecimiento de las ramas R-6 nacionales junto con las contribuciones al crecimiento por parte de Extremadura para cada una de las ramas. El objetivo que perseguimos es mostrar gráficamente cómo las ramas extremeñas que contribuyen de una manera relevante al acontecer económico sectorial nacional durante el período en estudio son la agraria y la energética. En consecuencia, para el resto de las ramas extremeñas (construcción, industria, servicios venta y servicios no venta) la incidencia de la contribución al crecimiento sectorial nacional es, en general, mínima. Gráfico nº 45. Tasas de crecimiento de las ramas R-6 nacionales y contribuciones al crecimiento para cada una de las ramas extremeñas. 15 8 10 6 5 4 0 2 -5 0 -10 -2 -15 -4 82 84 86 88 TA01ESM 90 92 94 82 84 CONAEX 86 88 TE06ESM 8 90 92 94 CONEEX 15 6 10 4 5 2 0 0 -5 -2 -4 -10 82 84 86 88 TI30ESM 90 92 94 82 84 CONIEX 86 88 TB53ESM 5 90 92 94 CONBEX 8 4 6 3 4 2 2 1 0 0 -1 -2 82 84 86 88 TS68ESM 90 92 94 82 CONSEX 84 86 88 TG86ESM -Pág. 117- 90 92 CONGEX 94 Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En resumen, la economía extremeña no contribuye generalmente de una manera significativa al crecimiento de la economía nacional, exceptuando algunos años en los que el buen comportamiento de las ramas agrarias o energética inciden, de forma relevante, tanto en el crecimiento de la rama nacional correspondiente como en la rama general. III.2.5. COMPARACIÓN DE PRODUCTIVIDADES. Se han calculado los valores del VABpm (pesetas constantes de 1986) por habitante59 (Gráfico nº 46). Se puede observar que a lo largo de todo el período el enorme diferencial existente entre los datos nacionales y los extremeños no mengua, de manera que el valor añadido bruto a precios de mercado por habitante para el conjunto de España es muy superior a la de Extremadura. Gráfico nº 46. Productividades por habitante. 1100 1000 900 800 700 600 500 400 80 82 84 86 VABESHAB VABESHAB = Total VAB España 59 90 92 94 VABEXHAB (en millones de pts) Poblacion de derecho de España (en miles de y VABEXHAB = 88 Total VABExtremadura (en millones de personas) pts) Poblacion de derecho de Extremadura (en miles de personas) Considerando como habitantes a la población de derecho a 1 de Julio de cada año. -Pág. 118- Capítulo III. Evolución Reciente de la Economía Extremeña Si se toma como medida de productividad el VABpm en pesetas constantes de 1986 por persona ocupada, se puede obtener el Gráfico nº 47. Esta gráfica pone de manifiesto la baja productividad, en términos globales, de la región extremeña con respecto a la media nacional. Tampoco se aprecian en dicho gráfico signos evidentes de acercamiento a los niveles medios nacionales de productividad. Gráfico nº 47. Productividades por persona ocupada. 3200 2800 2400 2000 1600 80 82 84 86 88 VABTPEES VABTPEES = VABTPEEX = Total VABEspaña 90 92 94 VABTPEEX (en millones de pts) Empleo total de España (en miles de Total VABExtremadura (en millones de personas) pts) Empleo total de Extremadura (en miles de y personas) Si se utiliza: a) VABpm(pts constantes)Rama R.6 de Extremadura / OCUPADOSRama R.6 de Extremadura b) VABpm(pts constantes)Rama R.6 de España / OCUPADOSRama R.6 de España se obtendrán unas medidas de la productividad de cada una de las 6 ramas productivas regionales y nacionales, que permitirá su comparación. -Pág. 119- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Aplicando esta medida a la rama agraria se obtiene el Gráfico nº 48, del cual se extrae como descripción general que la productividad por ocupado en términos de valor añadido agrario para Extremadura toma, a lo largo del período expuesto, valores inferiores o similares a los nacionales (excepto para el año 1988, en el que la productividad regional supera a la nacional). Gráfico nº 48. Productividades por persona ocupada: Agricultura 1800 1600 1400 1200 1000 800 600 80 82 84 86 88 90 VABAPEES VABAPEES = VABAPEEX = A gra rio VABEspaña 92 94 VABAPEEX (en millones de pts) Empleo a gra rio de España (en miles de A gra rio VABExtremadura (en millones de personas) pts) Empleo a gra rio de Extremadura (en miles de . -Pág. 120- y personas) Capítulo III. Evolución Reciente de la Economía Extremeña Por otra parte, la productividad por empleado para la rama energética es muy superior a la media nacional, como se aprecia en el Gráfico nº 49. Gráfico nº 49. Productividades por persona ocupada. Energía. 50000 40000 30000 20000 10000 0 80 82 84 86 88 VABEPEES VABEPEES = VABEPEEX = Energia VABEspaña 90 92 94 VABEPEEX (en millones de pts) Empleo energia de España (en miles de Energia VABExtremadura (en millones de personas) pts) Empleo energia de Extremadura (en miles de . -Pág. 121- y personas) Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En lo que atañe a la rama industrial extremeña, su productividad por empleado está muy alejada de la media nacional, según se evidencia en el Gráfico nº 50, donde se representan las siguientes variables: Gráfico nº 50. Productividades por persona ocupada: Industria. 4000 3500 3000 2500 2000 1500 80 82 84 86 88 90 VABIPEES VABIPEES = VABIPEEX = Industria VAB España 92 94 VABIPEEX (en millones de pts) Empleo industria de España (en miles de Industria VAB Extremadura (en millones de personas) pts) Empleo industria de Extremadura (en miles de . -Pág. 122- y personas) Capítulo III. Evolución Reciente de la Economía Extremeña En la rama de la construcción (Gráfico nº 51) se pueden apreciar dos etapas muy diferentes en lo que toca a la relación que se establece entre la productividad por empleado para Extremadura y de España, estableciéndose un antes y un después del año 1987. Para el período de tiempo comprendido entre 1980 y 1987, en líneas generales la productividad ha sido superior para Extremadura; pero durante los años 1988 y 1989 la productividad por empleado ha caído en Extremadura muy por debajo de la media del conjunto nacional, aunque parece apreciarse una tentativa de convergencia de los valores de productividad regionales a los nacionales. Gráfico nº 51. Productividades por persona ocupada: Construcción. 2800 2600 2400 2200 2000 1800 80 82 84 86 VABBPEES VABBPEES = VABBPEEX = Constuccion VAB España 88 90 92 94 VABBPEEX (en millones de pts) Empleo construccion de España (en miles de y Construccion VABExtremadura (en millones de pts) Empleo construccion de Extremadura (en miles de . -Pág. 123- personas) personas) Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En la rama de los servicios destinados a la venta (Gráfico nº 52) también se aprecia una separación bastante grande entre los niveles de productividad de Extremadura y del todo nacional, como así evidencian las variables representadas. Lo más reseñable de la evolución de la productividad por empleado de la rama de servicios destinados a la venta en este período es la existencia de dos etapas claramente diferenciadas; una primera que abarca desde 1980 hasta 1987, con tendencia decreciente, y otra posterior desde 1988 hasta 1995, con tendencia creciente en lo que a productividad se refiere, y con un crecimiento en la productividad superior al que acompaña a la rama nacional. Gráfico nº 52. Productividades por persona ocupada: Servicios venta. 3400 3200 3000 2800 2600 2400 2200 2000 80 82 84 86 88 VABSPEES 90 92 94 VABSPEEX (en millones de pts) y Empleo servicios venta de España (en miles de personas) VAB (en millones de pts) VABSPEEX = Empleo servicios venta de Extremadura (en miles de personas) VABSPEES = Servicios venta VABEspaña Servicios venta Extremadura -Pág. 124- Capítulo III. Evolución Reciente de la Economía Extremeña El Gráfico nº 53 compara las cifras (nacionales y regionales) de productividad por empleado para la rama de servicios no destinados a la venta. En este caso, los niveles de las productividades regional y nacional toman, en términos medios, valores bastante similares; y en lo que respecta a sus tendencias, ambas son crecientes. Se puede terminar declarando la similitud en términos generales (lógicamente no hay que olvidar el matiz ya expuesto con anterioridad de que las series regionales tienen un comportamiento más errático que las nacionales) de las productividades para ambas ramas de las dos economías. Gráfico nº 53. Productividades por persona ocupada: Servicios no venta. 2300 2200 2100 2000 1900 1800 80 82 84 86 88 90 VABGPEES VABGPEES = VABGPEEX = Serviciosnoventa VAB España 92 94 VABGPEEX (en millones de pts) Empleo servicios no venta de España (en miles de personas) y (en millones de pts) . Empleo servicios no venta de Extremadura (en miles de personas) Serviciosnoventa VABExtremadura -Pág. 125- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña III.2.6. ESTUDIO DE LA PRODUCCIÓN EN EXTREMADURA. Como complemento al estudio económico regional que se está realizando, en este subapartado se analiza si los niveles de crecimiento de la economía extremeña convergen o divergen de los niveles medios de crecimiento nacional. El objetivo de este subapartado es señalar las diferencias habidas en el período 1980-1995 entre el ritmo de crecimiento económico extremeño y el crecimiento medio nacional. El elevado “cambio diferencial” que se ha producido en Extremadura durante ese período de tiempo ha sido debido, básicamente, al desigual comportamiento de las ramas agrícola y energética extremeñas con respecto a las análogas ramas a nivel nacional. Este hecho justificará en buena medida, desde nuestro punto de vista, que la “economía base” sobre la que se basará el análisis coyuntural que se realizará posteriormente quede circunscrito a los sectores manufacturero, de la construcción, servicios destinados a la venta y servicios no destinados a la venta, quedando excluidos, por tanto, los sectores agrícola y energético. En el análisis que se realiza estamos interesados únicamente en la producción (y no en el empleo o en la productividad, que bien merecen un análisis propio que se aleja de nuestros objetivos); en consecuencia, la información que utilizaremos será la misma con la que hemos venido trabajando en esta capítulo: el valor añadido bruto a precios de mercado (VABpm) en pesetas constantes de 1986. En la gráfica siguiente se representa la evolución de la tasa de crecimiento del VABpm total de la economía extremeña en pesetas de 1986 ( TVABEXT ) y la tasa de crecimiento del VAB obtenido como suma del VAB en pesetas constantes de 1986 de las ramas extremeñas correspondientes a la industria manufacturera, la construcción, los servicios destinados a la venta y los servicios no destinados a la venta ( TVABNEX ). Aunque en los próximos párrafos (y a través del análisis “shift-share”) se abundará en esta cuestión, se puede apreciar a partir de esta gráfica que los cambios más importantes producidos en el ritmo de crecimiento de la región Extremeña (“shocks”) para el período analizado han sido originados por las oscilaciones de las ramas agrícola y energética. De igual forma, se han representado los homólogos datos nacionales, siendo TVABEST la tasa de crecimiento del VAB total de la economía nacional en pesetas de 1986 y TVABNES la tasa de crecimiento del VABpm nacional no agrario y no energético obtenido como suma del VAB en pesetas constantes de 1986 de las ramas nacionales correspondientes a la industria manufacturera, la construcción, los servicios destinados a la venta y los servicios no destinados a la venta. Una lectura de ambos gráficos nos exhorta a destacar el componente errático que las ramas agrícola y energética introducen en la evolución de la economía extremeña, no ocurriendo los mismo para el caso nacional. -Pág. 126- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico nº 54. Crecimientos globales. 20 6 15 4 10 2 5 0 0 -5 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TVABEXT -2 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 TVABNEX TVABEST TVABNES Tasa de crecimiento del VABpm total de la economía extremeña ( TVABEXT ), tasa de crecimiento del VAB no agrario y no energético extremeño ( TVABNEX ), tasa de crecimiento del VAB total de la economía nacional ( TVABEST ) y tasa de crecimiento del VABpm nacional no agrario y no energético ( TVABNES ) Notas. Todas las variables están medidas en pesetas de 1986 Como ya se ha comprobado, el sector agrario representa un porcentaje muy importante de la producción global en Extremadura. Por otra parte, también ha quedado patente la descompensada estructura industrial en Extremadura, donde la industria energética supone una parte muy importante del total industrial, estando además muy concentrada tal actividad en una sola empresa, la Central Nuclear de Almaraz. En ambos casos, aunque por razones diferentes, estas ramas productivas tienen un comportamiento escasamente “controlable” desde nuestra Comunidad Autónoma. En el primer caso, por la volatilidad inherente al comportamiento del sector, que está fuertemente condicionado por las circunstancias climatológicas que caractericen el “año agrícola”. En el segundo, porque la puesta a punto del funcionamiento de la Central Nuclear de Almaraz ha necesitado pasar por unas etapas de ajuste hasta llegar a un nivel de producción estable; además, el nivel de actividad de dicha Central está más ligado al ciclo económico nacional que al regional, y la mayor parte del VAB generado por el mismo repercute fuera de nuestra región. A continuación utilizaremos la técnica “shift-share” para analizar si los niveles de crecimiento de la economía extremeña han convergido o divergido, en el período 1980-95, de los niveles medios de crecimiento de España. Este método de análisis nos permite desagregar la variación que ha habido en el VAB extremeño en distintos componentes, ayudando a explicar las condiciones bajo las que se han producido los cambios en la producción. La técnica “shift-share” “se basa en la descomposición en varias partes (“shares”) de las variaciones o desplazamientos (“shifts”) que experimenta un determinado sector productivo o conjunto de sectores cuando se analiza una -Pág. 127- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña realidad económica susceptible de dividirse en varias unidades regionales" (Martín-Guzmán y Martín Pliego (1989, p. 366)). En definitiva, lo que se pretende es dividir el cambio neto (diferencia del crecimiento regional extremeño con respecto al crecimiento medio nacional) en dos componentes: un cambio estructural o proporcional (que recoge aquella parte del cambio neto atribuible a la característica configuración productiva de la región) y un cambio diferencial (que expresa la parte del cambio neto que aparece como consecuencia de que el crecimiento de todos y cada uno de los sectores ha sido distinto a nivel regional y a nivel nacional). De esta forma, se define el cambio neto como CN=rex-rn donde rex representa la tasa de crecimiento (en tanto por ciento) de la economía extremeña y rn la tasa análoga (en tanto por ciento) a nivel nacional. En el Cuadro se muestran los valores del cambio neto y el cambio neto por ramas producido en la economía extremeña con respecto a la economía nacional durante los años que marcan el período de estudio, 1980 y 1995. Cuadro nº 32. Cambio neto en extremadura para el período 1980-1995. RAMAS PRODUCTIVAS EXTREMEÑAS Agraria Energética Industrial Construcción Servicios no venta Servicios venta Total 0,003% 388,738% -31,905% 27,613% 17,977% -4,437% 8,577% Fuente: Elaboración propia a partir de datos de Cordero y Gayoso (1997). Como se puede apreciar, el cambio neto total es favorable para la economía extremeña. Si desagregamos por ramas productivas, tienen cambio neto positivo todas las ramas productivas excepto las ramas de la industria y de los servicios destinados a la venta, las cuales han tenido un crecimiento menor que el acontecido en la media nacional. Sin embargo, el simple cálculo del CN utilizando las tasas de crecimiento del año 95 sobre el año 80 de la economía extremeña y nacional es demasiado básico, ya que podría inducir a elaborar conclusiones sesgadas en lo que respecta a la evolución a lo largo de todo el período. Por esta razón, el siguiente paso es presentar la evolución del cambio neto habido en cada uno de los años del tramo 1981-95 con respecto al año anterior. Además, descomponemos el CN en la parte correspondiente al cambio estructural (CE) y al cambio diferencial (CD), según la expresión: -Pág. 128- Capítulo III. Evolución Reciente de la Economía Extremeña 6 CN t = VABi,ex,t -1 ∑ VAB i=1 ex,t -1 - VABi,n,t -1 r i,n + VABn,t -1 VABi,ex,t -1 ( r i,ex - r i,n ) ex,t -1 i=1 6 ∑ VAB = CE t + CDt donde VABi ,ex ,t −1 el valor añadido bruto del sector i-ésimo de Extremadura en el año t − 1 , VABex ,t −1 es el valor añadido bruto de Extremadura en el año t − 1 , VABi ,n,t −1 es el valor añadido bruto del sector i-ésimo de España en el año t − 1 , VABn ,t −1 es el valor añadido bruto nacional en el año t − 1 , ri ,ex es la tasa de crecimiento en términos porcentuales del sector i-ésimo de Extremadura en el año t , y ri ,n es la tasa de crecimiento en términos porcentuales del sector iésimo a nivel nacional en el año t . El Cuadro recoge los valores correspondientes al cambio neto porcentual (CN), al cambio estructural (CE) y al cambio diferencial (CD) para la economía extremeña durante el período 1980-1995: Cuadro nº 33. Descomposición del CN. AÑOS CN CE CD 1981 1,167 -0,679 1,847 1982 -0,051 0,367 -0,419 1983 -4,412 0,337 -4,749 1984 14,457 0,355 14,101 1985 1,980 0,631 1,348 1986 -6,471 -1,363 -5,107 1987 2,439 0,410 2,029 1988 4,689 0,567 4,122 1989 -4,077 -0,835 -3,241 1990 -1,230 0,312 -1,543 1991 0,271 0,243 0,027 1992 0,534 -0,087 0,622 1993(P) 0,428 0,280 0,148 1994(P) -0,920 -1,054 0,134 1995(A) -1,477 -1,551 0,073 Fuente: Elaboración propia a partir de datos del INE y del Ministerio de Economía y Hacienda. Como se puede apreciar en el Gráfico nº 55, la evolución del CN demuestra que la diferencia del crecimiento en Extremadura con respecto al crecimiento nacional no ha mantenido una tendencia constante de acercamiento o distanciamiento a los parámetros medios nacionales (salvo en los años correspondientes a la década de los noventa), existiendo algunos años -Pág. 129- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña para los cuales el CN mostró valores positivos o negativos especialmente altos. A partir del año 1990, se descubre una amortiguación de los valores del cambio neto, aproximándose el crecimiento regional al nacional. En consecuencia, no son los años finales (1990-1995) los que deben centrar nuestra atención, sino aquellos años en los que las discrepancias en el crecimiento fueron significativas. Como ya pudimos comprobar en la regresión que relacionaba el crecimiento anual del VABpm extremeño con el crecimiento anual del VABpm nacional, es en los años 1984, 1986 y 1988 donde se producen mayores desproporciones entre el crecimiento regional extremeño y el crecimiento medio nacional. Gráfico nº 55. Cambio neto porcentual (CN) de la economía extremeña con respecto a la nacional. 15 10 5 0 -5 -10 82 84 86 88 90 92 94 CN En la Gráfica siguiente se observa cómo la explicación de estos valores “atípicos” en el CN (cifras de CN comprendidas dentro del período 1980-1990) es principalmente atribuible al CD, ya que las gráficas conjuntas del CN y del CD siguen unas pautas de comportamiento muy similares. Por el contrario, las gráficas conjuntas del CN y del CE no tienen ninguna sistemática común (excepto para la etapa 1990-1995, en la que el CN disminuye. -Pág. 130- Capítulo III. Evolución Reciente de la Economía Extremeña Gráfico nº 56. Cambio neto porcentual (CN), cambio estructural (CE) y cambio diferencial (CD) para la economía extremeña. 15 15 10 10 5 5 0 0 -5 -5 -10 -10 82 84 86 88 90 CN 92 94 82 84 86 CD 88 CN 90 92 94 CE De forma más general, y a la vista de las cifras del Gráfico nº 57, se puede decir que el desplazamiento total (favorable o desfavorable) habido en Extremadura durante el período 1980-95 se ha debido en su mayor parte a las diferencias sectoriales de crecimiento entre la región y la nación (etapa 19811990), y ha influido en una menor cuantía la particular estructura productiva de nuestra comunidad autónoma (etapa 1991-1995). Gráfico nº 57. Porcentaje de participación del cambio estructural (CE) y del cambio diferencial (CD), en el cambio neto total (CN). 100 80 60 40 20 0 82 84 86 88 CEVSC 90 92 94 CDVSC CE CD *100 ; CDVSC = *100 ; CE + CD CE + CD CE = valor absoluto del cambio estructural y CD = valor absoluto del cambio diferencial. CEVSC = La gráfica anterior muestra de una manera clara cómo el CD supone un porcentaje mayor de participación en el CN para aquellos años en los que el CN, obtiene unos valores mayores. Por el contrario, para aquellos años en los que el CN obtiene unos valores menores es el CE el que obtiene una mayor relevancia. Por otra parte, la representación del CE (Gráfico nº 58) no da de manera absoluta la característica general de las ramas productivas extremeñas en lo que a la composición de su estructura productiva se refiere; sólo podemos -Pág. 131- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña afirmar que en diez de los quince años analizados el CE (la estructuración por ramas productivas) ha influido de manera positiva en el cambio neto. Gráfico nº 58. Cambio estructural (CE). 1.0 0.5 0.0 -0.5 -1.0 -1.5 -2.0 82 84 86 88 90 92 94 CE A pesar de que el CE como explicación del cambio neto sólo adquiere importancia para aquellos años en los que el CN es menor, nos ha parecido interesante representar el CE correspondiente a todas las ramas productivas extremeñas para conseguir de esta forma identificar a las que toman valores de su CE positivos o negativos a lo largo de todo el período. Así, se ha representado el cambio estructural para cada una de las ramas agraria, energética, industrial, construcción, servicios destinados a la venta y servicios no destinados a la venta. Gráfico nº 59. Cambio estructural para las ramas extremeñas. 1.0 0.6 0.5 0.4 0.0 0.2 -0.5 0.0 -1.0 -0.2 -1.5 -0.4 82 84 86 88 90 92 94 82 84 86 CEA 88 90 92 94 90 92 94 90 92 94 CEE 0.8 0.6 0.4 0.4 0.0 0.2 -0.4 0.0 -0.8 -0.2 -1.2 -0.4 82 84 86 88 90 92 94 82 84 86 CEI 88 CEB 0.0 0.5 -0.1 0.4 -0.2 0.3 -0.3 0.2 -0.4 0.1 -0.5 0.0 82 84 86 88 90 92 94 82 CES 84 86 88 CEG Agraria (CEA), energética (CEE), industrial (CEI), construcción (CEB), servicios destinados a la venta (CES) y servicios no destinados a la venta (CEG) . -Pág. 132- Capítulo III. Evolución Reciente de la Economía Extremeña A la vista de los anteriores gráficos podríamos señalar a las ramas energética y de servicios no destinados a la venta como aquellas en las que su porcentaje de participación en el VAB regional dota a la economía extremeña de un crecimiento superior al que se logra a nivel nacional por ese mismo concepto. Por el contrario, el porcentaje de participación en el VAB regional de la rama de la industria y de la rama de servicios destinados a la venta penalizan a la economía extremeña con un crecimiento menor que el que contribuye a aportar dicha rama a nivel nacional. Aunque ya es manifiesta la relación que ha existido entre una mayor disparidad de crecimiento de Extremadura con respecto a la media nacional y la existencia de un mayor cambio diferencial, si desagregamos el CD de cada año para las seis ramas productivas con las que se está trabajando, se puede apreciar cómo las ramas agraria y energética (con sus cambios diferenciales) son las que determinan fundamentalmente el hecho de que la tasa de crecimiento de Extremadura se aleje de una manera más drástica del crecimiento medio que se produce a nivel nacional. Para ver si verdaderamente se verifica ésto, nos hemos centrado en aquellos años para los cuales el cambio neto de Extremadura es superior al 2%, es decir, los años 1983 (CN=-4,41%), 1984 (CN=14,45%), 1986 (CN=-6,47%), 1987 (CN=2,43%), 1988 (CN=4,68%) y 1989 (CN=-4,07%). En la gráfica siguiente se representa el cambio diferencial total para cada uno de dichos años (CD), junto con el cambio diferencial para cada una de las ramas productivas. En esta gráfica se recoge la importancia de las ramas agraria y energética como “desestabilizadoras” del crecimiento regional con respecto al crecimiento medio nacional. -Pág. 133- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 60. Cambio diferencial (CD). 2 15 1 10 0 -1 5 -2 -3 0 -4 -5 -5 1983 CD CDA CDB 1984 CDE CDG CDI CDS 2 CD CDA CDB CDE CDG CDI CDS CDE CDG CDI CDS CDE CDG CDI CDS 2.5 2.0 0 1.5 1.0 -2 0.5 0.0 -4 -0.5 -1.0 -6 1986 CD CDA CDB 1987 CDE CDG CDI CDS 6 CD CDA CDB 2 1 4 0 2 -1 0 -2 -2 -3 -4 -4 1988 CD CDA CDB 1989 CDE CDG CDI CDS CD CDA CDB Notas: Cambio diferencial total (CD), cambio diferencial agrario (CDA), energético (CDE), industrial (CDI), construcción (CDB), servicios destinados a la venta (CDS) y servicios no destinados a la venta (CDG). Si planteamos la descomposición del cambio diferencial mediante el porcentaje que supone el cambio diferencial de cada rama con respecto al cambio diferencial total, podemos elaborar el siguiente cuadro. -Pág. 134- Capítulo III. Evolución Reciente de la Economía Extremeña Cuadro nº 34. Porcentaje de CD correspondiente a cada rama y año. AÑOS CDAVSCD CDEVSCD CDBVSCD CDGVSCD CDIVSCD CDSVSCD 1983 7.877 8.518 10.288 7.629 19.137 46.548 1984 10.576 1.611 0.694 13.230 28.701 45.184 1986 13.620 9.850 4.658 4.116 13.853 43.900 1987 20.545 10.672 2.829 3.627 20.531 41.793 1988 16.268 4.749 4.461 18.593 26.255 29.670 1989 0.800 16.613 4.024 18.974 20.866 38.720 Notas: CDA *100 , CDA + CDE + CDI + CDB + CDS + CDG CDE *100 , CDEVSCD = CDA + CDE + CDI + CDB + CDS + CDG CDB *100 , CDBVSCD = CDA + CDE + CDI + CDB + CDS + CDG CDG *100 , CDGVSCD = CDA + CDE + CDI + CDB + CDS + CDG CDI *100 , CDIVSCD = CDA + CDE + CDI + CDB + CDS + CDG CDS *100 . CDSVSCD = CDA + CDE + CDI + CDB + CDS + CDG CDAVSCD = CDi = valor absoluto del cambio diferencial para la rama R-6 i-ésima. Los porcentajes del cuadro anterior evidencian el desajuste que las ramas agraria y energética han introducido en el cambio diferencial, influyendo en última instancia en el cambio neto total regional. Se puede concluir que la peculiar composición de la estructura productiva de Extremadura (CE) no es la que explica el hecho de que, para determinados años, los valores del cambio neto reflejen un comportamiento de la tasa de crecimiento a nivel regional extremeño muy alejado del crecimiento medio producido a nivel nacional. Dicha explicación hay que buscarla en el componente dinámico (cambio diferencial), que conglutina fundamentalmente el diferente comportamiento dentro de la economía extremeña de los sectores agrícola y energético con respecto a lo acontecido en el ritmo de crecimiento de esos mismos sectores a nivel nacional. -Pág. 135- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña III.3. RECAPITULACIÓN Y CONCLUSIONES. 1) Los rasgos fundamentales de la evolución de la economía extremeña en relación a la nacional durante el período 1980-1993, muestran el mantenimiento, en líneas generales, en torno a valores superiores al 1.8% de su coeficiente de participación en la estructura productiva española. 2) En lo que respecta a la estructura porcentual del VABpm de cada rama de actividad extremeña sobre el VABpm de cada rama respectiva a nivel nacional, la ordenación de mayor a menor presencia a nivel nacional es: rama agraria, energética, servicios no destinados a la venta, construcción, servicios destinados a la venta y productos industriales (con una mínima representación). 3) En lo que se refiere a la estructura porcentual interna de la economía extremeña (en comparación con las respectivas medias nacionales), hemos confirmado una evidente discrepancia entre la estructura productiva interna de Extremadura y la estructura productiva interna media nacional. El verdadero problema en cuanto a la ordenación productiva estructural de Extremadura es la carencia de una rama de productos industriales y de servicios destinados a la venta lo suficientemente desarrolladas. El sector agrario cuenta con un notable peso en el ámbito regional extremeño, a pesar de haber sufrido un retroceso productivo en los últimos años debido al ciclo de sequía padecida desde la campaña de 1991. Sin embargo, la participación sectorial de la rama agraria extremeña en el VABpm total extremeño sigue suponiendo más del doble de la participación equivalente de la rama nacional. Sobresale el incremento experimentado en la participación del sector energético debido a la puesta en marcha de los dos reactores en la central nuclear de Almaraz. Últimamente, la producción hidroeléctrica se ha visto afectada por la ausencia de lluvias, pero lo más destacado es la gran importancia de esta rama en la estructura productiva extremeña en relación con la nacional. En la rama de la construcción se observa una mayor importancia relativa en la actividad económica de la Comunidad Autónoma de Extremadura. Es decir existe una elevada presencia de esta rama en la estructura productiva regional. Las magnitudes de la rama de productos industriales ofrece una realidad industrial muy escasa siendo la diferencia, en comparación con la media nacional, abismal. -Pág. 136- Capítulo III. Evolución Reciente de la Economía Extremeña Los servicios destinados a la venta están realizando un importante esfuerzo de acercamiento al coeficiente de participación nacional, pero aún se encuentra alejado de dicho valor. Por el contrario, los servicios no destinados a la venta participan de manera relevante en el VABpm extremeño, y mantienen una tendencia estable respecto a la participación media nacional. 4) Hemos constatado el suavizado de los crecimientos sectoriales a nivel nacional con respecto a los crecimientos sectoriales regionales. De igual manera, hemos advertido que el crecimiento de la economía nacional explica la evolución del crecimiento de la economía extremeña. Para una desagregación R-6, los crecimientos en las ramas extremeñas agraria, energética, servicios destinados a la venta y servicios no destinados a la venta se explican60 por los crecimientos en sus respectivas ramas nacionales homólogas. La construcción extremeña crece, a partir de 1990 con un retraso de un año con respecto al crecimiento de la construcción española. El crecimiento de la industria extremeña no se explica mediante el crecimiento de la industria nacional; sin embargo, si atendemos a la clasificación R-9, los crecimientos de las subramas nacionales de bienes de equipo y bienes de consumo marcan los crecimientos de las respectivas subramas a nivel regional; excepto para el caso de los bienes intermedios, cuyos crecimientos no explican las variaciones de la homóloga rama regional. 5) En lo referente a la existencia de ciclo en la economía extremeña, ésta sólo es cíclica si se prescinde para el conjunto de la economía de las ramas agraria y energética. El ciclo de la economía no agraria no energética de Extremadura no es común al de la economía no agraria no energética de España; no obstante, la característica cíclica de la economía no agraria no energética de Extremadura es común al de la economía nacional total. Para la clasificación R-6, las ramas extremeñas de servicios destinados a la venta y de la industria son las únicas que presentan la característica cíclica, y además tienen un ciclo común al nacional. 6) En el tema relativo a la contribución al crecimiento nacional, podemos decir que, de manera general, la economía extremeña no contribuye de manera significativa al crecimiento de la economía nacional. La excepción a esta pauta viene recogida por algunos años en los que el buen comportamiento de las ramas agrarias o energética inciden, de forma relevante, tanto en el 60 Hay que recordar que la mayor inestabilidad de la economía regional se recoge utilizando ficticias para algunos años especiales. -Pág. 137- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña crecimiento de la rama nacional correspondiente como en la rama general. 7) Los niveles de productividad en Extremadura alcanzan valores inferiores a los que se aprecian en España, salvo en la rama de productos energéticos (debido a la poca población ocupada que requieren las centrales hidroeléctricas y nuclear instaladas en territorio extremeño), y en el sector de la construcción, que tiende a una progresiva convergencia en los ámbitos regional y nacional. El valor añadido bruto a precios de mercado por habitante para el conjunto de España es muy superior al de Extremadura. El VABpm en pesetas constantes de 1986 por persona ocupada pone de manifiesto la baja productividad, en términos globales, de la región extremeña con respecto a la media nacional, sin que apreciemos signos de acercamiento a los niveles medios nacionales de productividad. La productividad por ocupado en términos de valor añadido agrario para Extremadura toma de manera general valores inferiores o similares a los nacionales. La productividad por empleado para la rama energética es muy superior a la media nacional. En lo que concierne a la rama industrial extremeña, su productividad por empleado está muy alejada de la media nacional Para la construcción, la productividad por empleado ha caído en Extremadura muy por debajo de la media del conjunto nacional, aunque parece apreciarse una tentativa de convergencia de los valores de productividad regionales a los nacionales. En los servicios destinados a la venta también se aprecia una separación bastante grande entre los niveles de productividad de Extremadura y de la media nacional. Los servicios no destinados a la venta presentan, en líneas generales, niveles para las productividades regional y nacional bastante similares 8) El diferencial existente en el crecimiento en Extremadura con respecto al crecimiento nacional (CN) no ha mantenido una estructura estable de reducción o aumento. A partir del año 1990, se descubre una amortiguación de los valores del cambio neto, aproximándose el crecimiento regional al nacional. La causa se debe buscar en la pérdida transitoria de importancia del -Pág. 138- Capítulo III. Evolución Reciente de la Economía Extremeña sector agrario y en la estabilización de la producción en el sector energético. El cambio diferencial (CD) supone un porcentaje mayor de participación en el CN para aquellos años en los que dicho CN obtiene unos valores mayores. Por el contrario, para aquellos años en los que el CN obtiene unos valores menores es el cambio estructural (CE) el que tiene una mayor importancia. El CN ocurrido en Extremadura durante el período 1980-95 se explica fundamentalmente como consecuencia de las diferencias de crecimiento entre los sectores de la región y sus análogos nacionales (etapa 1981-1990). Para la etapa 1991-1995, el CN hay que explicarlo primordialmente en función de la particular estructura productiva de nuestra comunidad autónoma. Hemos comprobado la relación existente entre una mayor disparidad de crecimiento de Extremadura con respecto a la media nacional y la existencia de un mayor cambio diferencial (CD). La desagregación del CD de cada año para la clasificación R-6 señala a ramas agraria y energética (sus cambios diferenciales) como las determinantes esenciales del hecho de que la tasa de crecimiento de Extremadura se aleje de una manera más drástica del crecimiento medio que se produce a nivel nacional. Las ramas energética y servicios no destinados a la venta son las que consiguen (mediante unos porcentajes de participación sectorial en el VAB regional mayores que los respectivos porcentajes de participación sectorial en el VABpm nacional) dotar a la economía extremeña de un crecimiento superior al que se logra a nivel nacional. Por el contrario, el especial porcentaje de participación sectorial en el VABpm regional tanto de la rama de la industria como de la rama de servicios destinados a la venta, penaliza a la economía extremeña con un crecimiento menor que el que contribuye a aportar dicha rama a nivel nacional. Los valores del cambio neto que reflejan un comportamiento de la tasa de crecimiento a nivel regional extremeño muy alejado del crecimiento medio producido a nivel nacional se explican por el componente dinámico (cambio diferencial), que conglutina fundamentalmente el diferente comportamiento dentro de la economía extremeña de los sectores agrícola y energético con respecto a lo acontecido en el ritmo de crecimiento de esos mismos sectores a nivel nacional. Por lo tanto, la peculiar composición de la estructura productiva de Extremadura (CE) no es la causante de sus distorsiones con respecto al crecimiento medio nacional. -Pág. 139- PARTE SEGUNDA. MODELIZACIÓN ESTADÍSTICA. Capítulo IV. Marco Metodológico CAPÍTULO IV. MARCO METODOLÓGICO. IV.1. EL ANÁLISIS DE LA COYUNTURA ECONÓMICA. IV.1.1. CONCEPTO. En la actualidad, son numerosos los estudios que tienen como objetivo fundamental el análisis del discurrir de una economía, tratando de explicar el momento económico presente, su pasado más reciente y sus futuras líneas de comportamiento. A dichos estudios se les denomina análisis de coyuntura económica. En el Capítulo I se ha situado el nacimiento de los análisis de coyuntura. Este tipo de estudios se vió muy impulsado por las crisis de 1921 y de 1929; y a lo largo de la evolución de la cuantificación económica, los progresos en los modelos y métodos les han dotado de un mayor rigor así como de diagnósticos y predicciones mejores. En este apartado damos el concepto y exponemos las características de los análisis de coyuntura. Nuestro interés por este tipo de estudios se justifica porque las herramientas que aportamos en esta obra juegan un papel importante en el análisis de la coyuntura económica de la región extremeña. Por análisis de coyuntura, según Espasa61 se debe entender un "término que engloba a un tipo de estudios, que en el campo de la Economía Aplicada, pretende analizar la situación presente de la realidad económica referida a un país, región, empresa, institución , sector, etc., realizando una proyección hacia el futuro más inmediato y dando un diagnóstico de las implicaciones de dicha proyección". Es decir, se aspira a clarificar lo que sucede en cada momento en una economía, explicando su evolución pasada (de dónde viene) y perspectivas futuras (a dónde va). En consecuencia, y debido a que el acontecer de las economías es un tema de interés relevante en nuestra sociedad, existen (y han existido) motivaciones de índole tanto público como privado para llevar a cabo estos estudios. En los últimos años estamos asistiendo a un creciente interés por los estudios relativos al ámbito regional, lo cual repercute favorablemente en el incremento de los análisis de coyuntura que tienen como campo de aplicación el ámbito regional. En los análisis de coyuntura se pueden apreciar las siguientes características fundamentales: 61 Espasa, y Cancelo (Eds.) (1993): “Métodos Cuantitativos para el Análisis de la Coyuntura Económica”, Cap. 1, Pág. 23. -Pág. 143- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña a) Se debe disponer de una información suficiente. Los datos son un elemento básico en los estudios de coyuntura, ya que el acercamiento a lo que realmente ocurre en la economía se debe realizar a través de ellos. La base de información debe de ser amplia y fiable para que puedan aportar la evidencia empírica del análisis. b) Todo análisis de coyuntura requiere un esquema metodológico que facilite la interpretación de la realidad económica. Es necesario un esquema interpretativo con base en la Teoría Económica, de manera que se disponga de un marco teórico que nos de las relaciones entre las variables económicas. c) También es necesario un marco técnico que cubra las necesidades de medida y estimación. Hoy en día existe consenso en afirmar que los estudios de coyuntura requieren una base cuantitativa que deben proporcionar tanto el análisis de series temporales como la modelización econométrica. d) Los estudios de coyuntura deben señalar la fase del ciclo en el que se encuentra la economía en estudio; ésto implica identificar el pasado reciente del momento económico y marcar su trayectoria futura prevista. e) Los análisis de coyuntura no sólo deben señalar los principales problemas que afectan a una economía, sino que también deben mostrar posibles vías de solución para dichos problemas. A las tres primeras características se les suele señalar como los pilares básicos del análisis de coyuntura; sin embargo, a éstas hay que añadirles la experiencia personal en lo referente al conocimiento de algunas relaciones globales o básicas y permanentes "..., que permite dotar a los análisis coyunturales de ciertos elementos diferenciales conforme a las personales vivencias y percepciones de los diferentes analistas." (Valle(1995, Pág.55)). Un informe típico de coyuntura regional debería presentar62 en primer lugar unas referencias breves a la coyuntura nacional e internacional, para después pasar a analizar el marco global y comentar concisamente las perspectivas futuras de la economía regional. Esta etapa primera que sitúa a la economía regional dentro de la nacional, y a ésta a su vez dentro de la evolución de la economía internacional es importante, ya que el grado de apertura y la globalización de las economías en la actualidad es cada vez mayor. El siguiente paso sería centrarse en el análisis del cuadro macroeconómico regional, el cual debe proporcionar la estimación de los componentes de la demanda agregada regional y de la producción interna regional. A continuación se debería analizar el mercado de trabajo, el sector público y el sistema financiero. 62 Estas notas están escritas según la estructura de un informe de coyuntura de carácter regional que exponen Mochón y Ávila (1988). -Pág. 144- Capítulo IV. Marco Metodológico En definitiva, un informe de coyuntura debe dar un diagnóstico sobre la situación que atraviesa cada uno de los fenómenos económicos analizados63 y sus perspectivas futuras, y en este trabajo proporcionamos herramientas que posibilitan la realización de un análisis de una economía regional. VI.1.2. HERRAMIENTAS DE ANÁLISIS. La metodología para el análisis económico debe apoyarse64, en principio, en modelos econométricos que incrementen las garantías de objetividad de los análisis y que aporten información relevante acerca de los parámetros que caracterizan la relación entre variables económicas. Sin embargo, la puesta en práctica de este ideal multiecuacional es difícil (y en consecuencia poco habitual), debido a causas como las siguientes: -La dificultad que conlleva la elaboración y uso de modelos econométricos globales para una economía. Como consecuencia de ésto, la disponibilidad de este tipo de modelos está al alcance de muy pocas instituciones. -La difícil observación y comprensión de las relaciones causales que en ocasiones proporcionan sus resultados, lo cual se traduce en unos problemas a la hora de comprender el modelo. -Si se particulariza para el caso de modelos globales macroeconómicos, la no disponibilidad de observaciones -al menos en el caso de las Comunidades Autónomas- de las magnitudes a nivel mensual (trimestral) trae consigo una dificultad añadida en el uso de la información suministrada por los datos de algunas variables cuya disponibilidad es mensual (trimestral), suponiendo todo ésto una pérdida en la eficiencia del estudio de la realidad económica a corto plazo. De todo lo comentado hasta ahora podemos colegir que es muy cuestionable la utilidad de los modelos econométricos multiecuacionales de una economía cuando lo que se persigue es la obtención de la información necesaria para alimentar a un informe de coyuntura; todo ésto, sin dudar de las ventajas de su utilización con otros objetivos como puede ser la simulación de distintos escenarios económicos. Es decir, estamos conviniendo que deben ser métodos con una base fundamental en el análisis de series temporales los que recojan el comportamiento de una variable económica determinada (dadas las barreras que en la actualidad aparecen en la construcción de un modelo econométrico con datos de alta frecuencia). Entre estos métodos se encuentran los que se basan en 63 Espasa y Cancelo (Eds.) (1993) en el Capítulo 6 realizan una “propuesta del esquema metodológico a seguir en la elaboración y explotación de dicho núcleo cuantitativo [constituido por un conjunto de resultados cuantitativos suficientemente contrastados] en un análisis de coyuntura”. (op. cit. Pág. 401). 64 Ver Espasa y Cancelo (Eds.) (1993). -Pág. 145- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña el tratamiento conjunto de indicadores parciales65 que terminan con la obtención de señales que nos aproximan al comportamiento de un fenómeno en estudio. En lo que respecta a la relación existente entre los modelos econométricos y los métodos que se basan en el tratamiento conjunto de indicadores parciales, en la actualidad podemos afirmar que debe ser de complementación con respecto a la previsión, y análisis macroeconómico a corto plazo. La razón de ésto es el amplio abanico de posibilidades de diagnóstico cualitativo y cuantitativo que dichos métodos ofrecen. Así por ejemplo, no sólo podrán posibilitar la captación de cambios en el acontecer económico, sino que también se pueden utilizar para arrojar luces sobre cuestiones relacionadas con la evolución de la economía a corto plazo (como puede ser la predicción del comportamiento futuro de macromagnitudes). En el caso de España, el uso de métodos basados en indicadores se debe situar en una esfera relevante, ya que la carencia de estadísticas estructurales con una periodicidad adecuada y la menor cantidad de estadísticas con respecto a lo que sería la situación deseable, suponen un gran obstáculo para la realización de análisis a corto plazo basados en modelos econométricos. A nivel regional, nuestros razonamientos se ven reforzados por el evidente deterioro en la disponibilidad de información estadística con respecto a la situación nacional. En consecuencia, se puede afirmar que en la actualidad, la obtención de base cuantitativa para el seguimiento de la coyuntura económica se debe asentar fundamentalmente en métodos basados en el análisis de series temporales. Esta conclusión se expone sin descartar que estos métodos pueden y deben proporcionar herramientas -como por ejemplo indicadores sintéticos de actividad económica- que consigan facilitar la trimestralización (mensualización) de las principales macromagnitudes regionales, de manera que se pueda disponer de una base estadística para las mencionadas macromagnitudes con periodicidad trimestral (mensual). Bajo estas condiciones informativas, el paso a la obtención de modelos econométricos regionales con datos de alta frecuencia sería una etapa posterior, redundando en un enriquecimiento de los estudios coyunturales. Como conclusión, sirvan estas palabras de Niemira y Klein (1994, Pág. 180): “ellos [los indicadores compuestos y los modelos econométricos] deberían ser vistos como complemetarios, y no como competitivos. Cada técnica tiene sus ventajas y sus debilidades, pero cuando se trata de predecir y seguir la economía, la diversidad de técnicas simplemente añadiría comprensión.” 65 Por indicadores parciales debemos entender cualquiera de los innumerables datos económicos publicados o puestos a disposición de los usuarios de dicha información. -Pág. 146- Capítulo IV. Marco Metodológico IV.2. CUESTIONES PRELIMINARES. En el resto de este Capítulo planteamos el marco metodológico bajo el que modelizamos estadísticamente a la economía extremeña en el Capítulo V. La consumación de tal modelización no estructural, y en función del objetivo planteado (suministrar información sobre la evolución de las magnitudes económicas de una región en base a la búsqueda de regularidades estadísticas pasadas en los indicadores económicos regionales), pasa por la construcción de indicadores sintéticos de aceleraciones y desaceleraciones de la actividad económica. IV.2.1. IDEAS GENERALES. Exponemos a continuación las premisas y el contexto general en el que se encuadra este Capítulo. Un indicador económico es una variable que, en ocasiones, y aunque es portadora de contenido informativo, no llega a proporcionar una información determinante y absoluta en lo relativo a un aspecto considerado relevante de una magnitud económica a la que se pretende estudiar (y de la que no se dispone de una información directa). En consecuencia, es habitual la utilización de indicadores económicos multidimensionales para inferir el resultado del fenómeno económico a seguir. Las macromagnitudes económicas (ya sean componentes o agregados) suelen estar relacionadas con varios indicadores económicos, de manera que es un objetivo interesante la agregación de la información substancial que contienen dichos indicadores para obtener una aproximación a la evolución de la macromagnitud en cuestión como el resultado de los estados de diferentes indicadores parciales. En consecuencia, se debe someter a los indicadores económicos a un tratamiento estadístico que desemboque en la obtención de un indicador sintético o indicador compuesto66. Un indicador sintético debe resumir el comportamiento de la economía en general de un país o región, de un sector o actividad de una economía determinada, o de una magnitud económica, logrando dar una idea de su evolución desde una óptica cualitativa67 y/o cuantitativa. En este trabajo, el índice sintético proporciona un instrumento que puede posibilitar no sólo la medida, sino también la interpolación y predicción de macromagnitudes68. Generalmente, la relación que deben verificar los indicadores económicos con respecto a una macromagnitud -véase Fernández (1991)- es de correlación muestral y de cierta regularidad en el seguimiento de una evolución 66 Sin que ello implique que el indicador sintético obtenido recoja información de manera absoluta de la magnitud económica de referencia, sino que sólo pretende ser una aproximación razonable. 67 En Ramajo y Márquez (1996) se elaboran indicadores sintéticos con fines cualitativos para Extremadura. 68 En este sentido, es preciso poner de relieve que se pueden desarrollar indicadores sintéticos desde la óptica de la oferta y/o desde la óptica de la demanda. -Pág. 147- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña cíclica similar. En el Capítulo I ya advertimos de que el conocimiento de la fase del ciclo económico en la que se encuentra una economía puede proporcionar un importante elemento de apoyo para tomar decisiones adecuadas en términos de política económica, de manera que se contribuya a amplificar o reducir las etapas de crisis o expansión. Pues bien, el análisis cíclico, como herramienta para determinar la fase cíclica en la que se encuentra una economía, tiene como punto de partida fundamental a los indicadores cíclicos. Según Fernández (1991, Pág. 126): “Los indicadores cíclicos son series de datos que, midiendo aspectos significativos de la actividad económica, responden sensiblemente a cambios en el clima económico. Su función es el de ser de utilidad para prever, medir e interpretar cambios a corto plazo en la actividad económica agregada”. A lo largo de la historia económica se han utilizado a nivel internacional metodologías que tienen como meta principal recoger el estado cíclico de la economía, determinando los puntos de giro y prediciendo las tendencias económicas. Esta metodología se desarrolló en los años 30 y 40 en el seno del National Bureau of Economic Research (NBER)69. Se basan en el estudio de las regularidades estadísticas que se pueden observar en los ciclos económicos. La señal cíclica que pretenden recoger con el estudio de los indicadores sintéticos es el componente cíclico correspondiente a períodos de tiempo superiores al año. Estas metodologías se apoyan manifiestamente en la evidencia del ciclo económico (con la implicación de la existencia de un ciclo de referencia) para la construcción de un indicador sintético que anticipe dicho ciclo económico, y asumen el concepto de puntos de cambio o de giro ("turning-points") como un elemento absolutamente fundamental de sus teorías. En definitiva, se trata de combinar indicadores económicos cíclicos para formar indicadores cíclicos compuestos. Mitchel y Burns70 realizaron en 1938 un estudio en el NBER, elaborando la primera lista de indicadores del ciclo económico. Para ello, seleccionaron aquellas series de datos mensuales o trimestrales que parecían cumplir las condiciones necesarias para ser indicadores ciertos de recuperación económica. Mitchel y Burns también indican en dicho estudio las características que un indicador ideal de recuperaciones y recesiones cíclicas debería cumplir. Así, las características exigibles a un indicador de este tipo 69 Para el caso de Estados Unidos, en la actualidad el United States Department of Commerce mantiene operativo el sistema de indicadores sintéticos basados en la metodología NBER. La Organización para la Cooperación y el Desarrollo Económico (OCDE) publica indicadores adelantados mensuales (OCDE (1987)). 70 Burns, A.F. y Mitchell, W.C., (1938): "Estatistical Indicators of Cyclical Revivals". NBER. Este trabajo fue un estudio novedoso en el campo de los indicadores de ciclo económico, razón por la cual en los escritos relativos a dichos indicadores se suelen recoger sus principales aportaciones como una referencia obligada. -Pág. 148- Capítulo IV. Marco Metodológico son las siguientes71: 1.Longitud, esto es, que en la serie se puedan observar varios ciclos. 2.Significación económica, es decir, que sea explicable su comportamiento con respecto al ciclo. 3.Calidad estadística, que garantice la continuidad en la manera de medición de la parcela o ámbito económico que el indicador represente. 4.Correspondencia con las fluctuaciones cíclicas pasadas. 5.Consistencia cronológica, de manera que sus retrasos o adelantos con respecto a recesiones y recuperaciones sean constantes. 6.Perfil suave, que la componente irregular tenga una relevancia poco importante, posibilitando la rápida detección de cambios en la componente cíclica. 7.Frecuencia mensual72. 8.Prontitud en la disposición de sus datos, ya que un retraso importante en su obtención puede disminuir sustancialmente su utilidad como indicador cíclico. Como ya se ha dicho, una de las mayores aplicaciones de los indicadores económicos está en la identificación de las pautas periódicas y de los cambios que marcan las subidas y bajadas de las situaciones y perspectivas de la actividad económica. El punto de partida es establecer un ciclo de referencia que tiene como función registrar los movimientos del nivel general de actividad económica. Para ésto se elige una serie de referencia cíclica que se comparará con las series individuales para clasificarlas en adelantadas, coincidentes o retrasadas atendiendo al desfase existente entre sus puntos de giro y los de la serie de referencia cíclica. La clasificación de las series en adelantadas, coincidentes o retrasadas va a permitir la construcción de tres índices distintos o indicadores sintéticos de actividad económica. Cada uno de estos tres índices aglutinará un grupo más o menos numeroso de series (respectivamente adelantadas, coincidentes y retrasadas) en una única serie compuesta que va a dar un perfil general de los movimientos en la actividad económica adelantando, coincidiendo o retrasando la evolución de la serie de referencia cíclica. Al ser índices compuestos, se cubren mayores aspectos de la actividad que aproximan, y disminuye el riesgo de fallos en la relación existente entre un indicador (integrante del sintético) y el ciclo de referencia. Las características básicas de los índices compuestos que se obtienen son las siguientes: - El indicador sintético adelantado tendrá un fin predictivo, anticipando el inicio de las fases de aceleración y desaceleración; es decir, anticipará los puntos críticos en la actividad económica. - El indicador sintético coincidente proporciona información sobre la situación 71 72 Estas características están recogidas de Fernández (1991, Pág 126). En nuestra aplicación exigiremos frecuencia trimestral. -Pág. 149- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña actual de la evolución de la economía, ya que se construyen con series que muestran movimientos generales similares a los del ciclo de referencia. Su ventaja respecto al ciclo de referencia es que se publica con mayor frecuencia y menos retraso. Dentro del sistema que integra junto al indicador retrasado y adelantado, sirve para confirmar las predicciones cíclicas del último. - Los indicadores sintéticos retrasados tienen un carácter confirmatorio con respecto al diagnóstico proporcionado por los otros dos indicadores. Uno de los ejes fundamentales para la obtención de un conjunto satisfactorio de indicadores sintéticos es la elección de una serie de referencia del ciclo de la actividad económica del campo de aplicación. La serie estadística buscada debe tener periodicidad mensual (o incluso trimestral) y ser capaz de proporcionar una visión de la economía en su conjunto. La serie ideal sería el PIB (o una serie próxima a él) limado de algunos elementos integrantes cuyos ciclos no se relacionan con las fluctuaciones económicas (el ciclo del sector agrícola tiene una explicación climatológica, y el del sector de servicios no destinados a la venta tampoco viene inducido por las fluctuaciones económicas sino por razones más bien sociales)73. Hemos señalado muy brevemente las principios fundamentales en base a los cuales se han construido indicadores sintéticos en todo el mundo bajo el enfoque de los indicadores adelantados, coincidentes y retrasados, obteniéndose instrumentos muy útiles para el análisis coyuntural. Sin embargo, como Lahiri y Moore (1991, Págs. 1-2) destacan: ”el enfoque del indicador adelantado hace hincapié en predicciones para períodos de tiempo algo indefinidos en vez de, por ejemplo, trimestres individuales. Esta distinción es, de cualquier modo, una materia de énfasis. Los indicadores adelantados pueden ser y están siendo usados para predecir sobre unidades temporales uniformes del calendario, y no solamente alrededor de los puntos de giro. De cualquier manera, es el énfasis de los indicadores económicos adelantados sobre los ciclos lo que ha contribuido a su longevidad y ha ayudado a extenderlo por todo el mundo.” Del párrafo anterior extraemos la idea de que históricamente no se han utilizado los sistemas de indicadores cíclicos para realizar predicciones de las 73 Sin embargo, en el plano regional la no disponibilidad del PIB regional (en nuestro caso el extremeño) con periodicidad mensual o trimestral (o de una serie afín al PIB) va a ser un obstáculo que se deberá solventar. Una solución sería la construcción de un indicador sintético de referencia (con la periodicidad deseada) que recoja las fases expansivas y depresivas de la evolución cíclica de la actividad económica extremeña, o bien por la trimestralización (mensualización) de los datos anuales de contabilidad regional. -Pág. 150- Capítulo IV. Marco Metodológico fluctuaciones en la actividad económica para períodos de tiempo determinados, sino que se han empleado para obtener indicaciones de la probable evolución en términos cíclicos de la economía en el corto plazo. En definitiva, adoptan un enfoque cualitativo en vez de cuantitativo. IV.2.2. OBJETIVOS. En la segunda parte de nuestro trabajo pretendemos describir y cuantificar las fluctuaciones en el crecimiento de la actividad económica trimestral de una región española. Nuestro interés en la aproximación al crecimiento se centra, en primer lugar, en el crecimiento en sí, y en segundo lugar (pero no por ello menos importante) como medida del ciclo económico. Es decir, aquí pretendemos generar indicadores sintéticos representativos del crecimiento de macromagnitudes básicas para una economía regional desde la óptica de la oferta, de manera que es factible obtener, a partir del indicador sintético correspondiente, el estado cíclico de dicha economía. Conceptualmente, nuestra orientación es similar a la de los índices coincidentes que resumen las condiciones económicas de una economía o sector regional. Ya hemos justificado la modelización estadística como complemento de la econométrica, dando validez a los indicadores sintéticos junto a los modelos de regresión. De cualquier forma, todavía se puede plantear la siguiente cuestión: ¿por qué utilizar modelos no estructurales74 en vez de modelos estructurales para cubrir los objetivos perseguidos con la modelización estadística? La respuesta a esta cuestión (desde otra perspectiva distinta a la que hemos ofrecido anteriormente) la proporcionan Niemira y Klein (1994, Pág. 180) a través de las diferencias existentes entre ambos enfoques: 1ª “Un indicador sintético es frecuentemente un indicador de punto de giro que no tiene una verdadera variable dependiente. Esto, de cualquier modo, ha sido el origen de la crítica de este enfoque; a saber, ¿Qué se supone que mide? En el otro lado, los partidarios de este enfoque advierten de que esto sería en realidad una ventaja, por cuanto el ciclo económico no es sólamente la fluctuación de un indicador, por muy amplia que sea la base sobre la que esté elaborado”. 2ª “Un modelo de regresión normalmente asumiría una relación fija a lo largo del tiempo entre una variable dependiente y una variable independiente. No obstante, el enfoque de los indicadores sintéticos acepta, a efectos de predicción, que la relación temporal entre los indicadores y entre los ciclos económicos cambia a lo largo del tiempo.” 74 Que en este trabajo identificamos con modelización estadística para la obtención de indicadores sintéticos. -Pág. 151- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En este trabajo, y en contradicción con la práctica históricamente más habitual en los indicadores cíclicos, sí asumimos la existencia de una variable dependiente (la macromagnitud VABpm para Extremadura en pts. constantes de 1986) que condiciona el proceso de elaboración de los indicadores sintéticos. Con la consideración práctica de tal macromagnitud pretendemos cumplir tres funciones básicas: a) garantizar resultados coherentes con las cifras oficiales de Contabilidad Regional de España, b) facilitar la selección de los indicadores componentes del índice sintético mediante la caracterización del comportamiento económico regional, y c) proporcionar predicciones a corto plazo que se integren (en el sentido de Bodkin et. al (1991)) con las predicciones a medio y largo plazo -más fiables- del modelo econométrico. Por lo tanto, perseguimos la elaboración de indicadores sintéticos representativos del crecimiento de macromagnitudes básicas para la economía de la Comunidad de Extremadura desde la óptica de la oferta. También se podría desarrollar el análisis desde el lado de la demanda y de la oferta como Del Sur (1994, Pág. 269) plantea aportando un esquema metodológico semejante al de Klein y Sojo (1986): 1º “Selección inicial de indicadores (periodicidad mensual y/o trimestral) para cada macromagnitud. 2º Elaboración de indicadores sintéticos para cada macromagnitud a partir de indicadores iniciales, en dos líneas básicas: a) Ponderaciones <<a priori>>, según la desagregación de la macromagnitud y su participación en el total. b) Cálculo de la ponderación en base a los coeficientes de correlación entre las macromagnitudes y sus indicadores básicos. 3º Análisis de congruencia indicador sintético-macromagnitud. 4º Predicción de indicadores básicos por métodos de tratamiento de series temporales (ARIMA). 5º Predicciones de macromagnitudes a nivel trimestral. 6º Reconsideración de predicciones en base a un análisis de congruencia del cómputo de macromagnitudes agregadas por caminos alternativos (en particular PIB por el lado de la demanda y de la oferta). 7º Cada macromagnitud se estimará en volumen (o valor) y su deflactor correspondiente, calculándose el valor corriente a partir de los anteriores.” La aplicación de metodologías en línea con la anterior queda postergada para estados futuros de la línea de investigación en la que se encuadra esta tesis, ya que el objetivo a largo plazo será la obtención del “cierre” del cuadro macroeconómico, permitiendo un seguimiento de sus componentes tanto desde el lado de la oferta como desde el lado de la demanda. -Pág. 152- Capítulo IV. Marco Metodológico También es conveniente señalar que la disposición de dichos indicadores sintéticos trimestrales brinda la posibilidad de aplicar metodologías de interpolación (basadas en indicadores) que permitan la obtención de una serie trimestral de la macromagnitud regional que represente la actividad económica. En síntesis, en este capítulo presentamos la metodología utilizada para la construcción de indicadores sintéticos que recojan el crecimiento trimestral de la Economía Extremeña, que posibiliten el análisis cíclico, y que en una etapa posterior posibiliten la interpolación de las macromagnitudes anuales extremeñas. IV.3. EXPERIENCIAS PREVIAS. En este apartado haremos algunos comentarios relativos a las experiencias anteriores en el contexto del análisis cíclico. Pons (1996) recoge una revisión de las experiencias internacionales y nacionales; en el caso español, recoge trabajos realizados para la economía en su conjunto, así como las aportaciones fundamentales en este campo. En base a los numerosos trabajos que hemos revisado, opinamos que es difícil que muchos de ellos puedan tener, en la actualidad, su traslación directa al ámbito regional español con suficientes garantías de éxito. La razón fundamental es que, o bien se refieren a países, o bien asimilan la noción de región a espacios geográficos que poseen unas bases de información mucho más ricas que las disponibles en las regiones españolas. Por consiguiente, sólo aportamos una panorámica muy general de los estudios empíricos en el campo del análisis cíclico, haciendo especial hincapié en los trabajos más recientes a nivel regional en España, ya que éstos son los que se enfrentan a problemáticas similares a las nuestras. Las pautas en las experiencias de análisis cíclico vienen establecidas por los métodos propugnados por el NBER, los cuales han sido utilizados a lo largo de más de medio siglo, y bajo cuya orientación metodológica se encuadran los trabajos realizados por las oficinas de estadística de los principales países desarrollados. En lo concerniente a experiencias nacionales (consideradas individualmente), muchos países publican hoy en día indicadores adelantados, coincidentes y retrasados. La experiencia española más actual viene determinada por la metodología expuesta en el "Sistema de Indicadores Cíclicos de la Economía Española" del Instituto Nacional de Estadística (1994). Con este sistema de indicadores, el INE aporta información referente al momento económico de la economía española mediante su publicación en el Boletín trimestral de Coyuntura. Una revisión de las aportaciones al análisis cíclico y a la -Pág. 153- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña previsión económica a nivel nacional en el corto plazo se puede encontrar en Pons (1996, Págs. 88-96). Para la experiencia internacional (considerando varios países globalmente), Moore (1991) indica la posible utilización de indicadores adelantados para medir aspectos referentes a diversos países integrantes de un área económica75. En Lahiri y Moore (1991) se pueden obtener algunas ideas actuales referentes a tendencias, desarrollos nuevos y cuestiones de interés, en lo concerniente al análisis cíclico mediante la utilización de indicadores económicos. La investigación de hoy en día se orienta a la caracterización y modelización de la dinámica de los ciclos económicos, así como a la estimación e inferencia de modelos de vectores autorregresivos. Por ejemplo, en la Universidad de Iowa en los Estados Unidos de América, Charles F. Whiteman investiga en un modelo factorial dinámico de actividad macroeconómica para extraer un índice sintético adelantado76. Vamos a centrarnos en la experiencia modelizadora regional, ya que éste es nuestro ámbito de interés, a pesar de que las experiencias nacionales han sido la base para las regionales77. La no aplicación directa de las metodologías nacionales se justifica porque el ámbito regional posee unas características particulares que matizan y condicionan a las metodologías que se aplican a nivel nacional: a) La disposición de un menor número de indicadores económicos que a nivel nacional. b) La longitud de los indicadores es, generalmente, corta, haciendo difícil una posible clasificación dinámica con respecto a una serie de referencia. c) No se dispone de una serie de referencia de alta frecuencia (por ejemplo, el PIB trimestral o mensual). 75 Moore pone como ejemplo los estudios del Center for International Business Cycle Research (CICBR) en la Columbia University Business School de Nueva York, que muestran cómo un indicador adelantado para el Reino Unido, Alemania, Francia e Italia proporciona predicciones útiles de las exportaciones de los Estados Unidos de América a Europa. 76 Son numerosos los autores que siguen “produciendo” en el campo de la dinámica de los ciclos económicos; por ejemplo Edward B. Montgomery (NBER y Universidad de Maryland), Victor Zarnwitz (NBER y Universidad de Chicago), Allan Timmermann (Universidad de California), etc. 77 Como se refleja en del Sur (1994). -Pág. 154- Capítulo IV. Marco Metodológico En Phillips (1994), se presentan diversos trabajos regionales de análisis cíclico realizados en Estados Unidos adoptando el enfoque de los indicadores adelantados. Como Artís et al. (1997) indican: “A nivel regional, en nuestro país los trabajos sobre el análisis cíclico y la construcción de índices de actividad con una periodicidad inferior a la anual se encuentran en una fase comparativamente poco desarrollada respecto a otros países de nuestro entorno, ya que prácticamente no se han realizado aportaciones sistemáticas en este campo”. Sin embargo, recientemente parece haber un aumento de las aplicaciones a nivel regional; sirva como muestra de ello que los equipos Hispalink de Andalucía, Asturias, Canarias, Cataluña, Galicia, Madrid y Valencia disponen de un índice sintético agregado (operativo en la actualidad) para cada una de sus economías regionales, así como de indicadores sintéticos por sectores (excepto Asturias y Madrid). Ya hemos destacado el trabajo de Fernández (1991) como una de las referencias fundamentales en lo concerniente a la elaboración de indicadores sintéticos de aceleraciones y desaceleraciones en la actividad económica. Este autor sigue aplicando esta metodología en el “Boletín de Previsión y Coyuntura Económica de Cantabria”, publicación de carácter trimestral78 que es elaborada por Rodríguez Poo, J. M. (Coord.). Además, es necesario resaltar que existen muchas experiencias aplicadas a nivel regional que adoptan como base el procedimiento indicado en este trabajo, por ejemplo: -Morales, Espasa, Font, e Izquierdo (1994) y Morales, Espasa, Parra, García, Henangomez, y Beltran (1994), -Parra (1993, 1995), -Trujillo, Benítez y López (1996). La metodología de Fernández (1991), también ha servido de base para elaborar indicadores sintéticos para la Economía Extremeña79. Por otra parte, Pons (1996) es una publicación a destacar en nuestro país a la hora de abordar la descripción y medida del ciclo económico regional, ya que presenta el marco teórico esencial de los indicadores cíclicos para, a continuación, elaborar un sistema de indicadores cíclicos para la economía catalana. Como lo verdaderamente importante para la buena consumación de este trabajo es plantear una metodología rigurosa, con origen en experiencias contrastadas realizadas previamente y que logre satisfacer los objetivos planteados, en el apartado siguiente pasamos a exponer una metodología que es 78 79 El último Boletín disponible es el de Julio de 1998. Ver Ramajo y Márquez (1996) y Márquez y Ramajo (1996). -Pág. 155- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña el fruto del estudio, síntesis y aplicación de algunos de los métodos utilizados en la práctica coyuntural para la construcción de un indicador sintético coincidente. Dicha metodología consigue, en nuestra opinión, optimizar los recursos informativos de los que disponemos para poder modelizar estadísticamente a la economía extremeña. IV.4. METODOLOGÍA ESTADÍSTICA. En este apartado exponemos una visión de conjunto del proceso seguido para la elaboración de indicadores sintéticos de aceleraciones y desaceleraciones de la actividad económica en una región, que permitan la realización de un seguimiento a corto plazo del ritmo de la actividad económica total o sectorial, y que recojan su evolución cíclica. La actividad económica la vamos a aproximar a través de la macromagnitud valor añadido bruto, de manera que el cálculo de los indicadores compuestos lo vamos a realizar desde el lado de la oferta. La aproximación al ciclo económico se realiza desde la perspectiva del crecimiento de la actividad y no de sus niveles; la razón estriba en que el objetivo propuesto es la caracterización y seguimiento del ciclo de crecimiento de la economía extremeña, por lo que tiene más sentido utilizar las tasas de crecimiento que los niveles en las series80 (máxime cuando, como ocurre generalmente, la mayor parte de los indicadores utilizados en este trabajo muestran una marcada evolución tendencial). Las tasas de crecimiento que se consideran son tasas interanuales de los indicadores trimestrales ( x t ) del tipo T14 = xt − xt −4 , xt −4 y por tanto, los puntos críticos (picos y valles) se situarán en los máximos y mínimos locales de los indicadores trimestrales construidos. El cuadro que se presenta a continuación puede resultar útil para establecer y mostrar de forma bastante esquemática las etapas de las que consta el procedimiento propuesto. 80 De esta forma, y según las distintas concepciones de ciclo económico visto en el Capítulo I, nos decantamos por la utilización del ciclo de tasas. -Pág. 156- Capítulo IV. Marco Metodológico Cuadro nº 35. Esquema de la metodología aplicada para elaborar índices sintéticos. METODOLOGÍA ESTADÍSTICA APLICADA 1ª ETAPA DEFINICIÓN DEL PERÍODO TEMPORAL, RECOGIDA Y ESTUDIO DE LOS INDICADORES DISPONIBLES PRESELECCIONADOS. 2ª ETAPA MODELIZACIÓN UNIVARIANTE DE LOS INDICADORES PARCIALES PRESELECCIONADOS. 3ª ETAPA EXTRACCIÓN DE LA “SEÑAL” DE CICLO-TENDENCIA DE CADA INDICADOR PARCIAL . 4ª ETAPA SELECCIÓN DE LAS SEÑALES EXTRAÍDAS DE LOS INDICADORES PARCIALES. 5ª ETAPA AGREGACIÓN DE LAS “SEÑALES” SELECCIONADAS PARA OBTENER EL INDICADOR SINTÉTICO. 6ª ETAPA VALIDACIÓN DEL INDICADOR SINTÉTICO. Las etapas quinta y sexta son iterativas; se trata de realizar en la quinta etapa todas las agregaciones posibles a partir de los señales seleccionadas en la etapa cuarta para validar en la etapa sexta el índice compuesto. Lógicamente, el indicador sintético seleccionado será el que aporte una mejor validación. Podemos decir que las etapas mencionadas son de aplicación estándar en el conjunto de trabajos existentes, diferenciándose por cuestiones como la utilización de tasas de variación distintas, el empleo de métodos de extracción de señal diferentes, la agregación de señales con métodos distintos y/o la consideración o no de la trimestralización de macromagnitudes como parte integrante del método de selección de los mejores indicadores parciales. En los subapartados siguientes se explican y desarrollan cada una de las etapas enunciadas en el cuadro anterior. -Pág. 157- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña IV.4.1. ETAPA PRIMERA. DEFINICIÓN DEL PERÍODO TEMPORAL, RECOGIDA Y ESTUDIO DE LOS INDICADORES DISPONIBLES PRESELECCIONADOS. El punto de partida para conseguir una base de datos que recoja una batería de indicadores sobre los que trabajar, es tener en cuenta la información disponible en el ámbito espacial o institucional de realización del estudio. El conjunto de series de variables preseleccionadas o indicadores parciales iniciales, que proporcionarán la información de base necesaria para la elaboración de indicadores sintéticos, deberán verse obligados al cumplimiento de una serie de requisitos o criterios, los cuales servirán para efectuar una criba sobre el conjunto de series inicialmente disponibles81: a) Se debe perseguir que los indicadores parciales sean operativos, que sean viables; por consiguiente se valorarán los costes y las posibilidades de elaboración en su selección. Estadísticamente serán fiables, sin que presenten rupturas o cambios metodológicos debidos a cambios metodológicos. b) Deberán ser de fácil y rápida obtención para posibilitar una pronta disponibilidad de la información, de manera que sea factible un eficaz contacto con la situación económica en cada momento. c)Los indicadores seleccionados deberán tener capacidad de compendio, es decir, que con el menor número de indicadores se recoja la mayor cantidad de información posible, sin que falte la información básica referente al objetivo (macromagnitud) a medir: deben representar en conjunto a sus principales sectores (si los posee) y/o procesos económicos. d) Los indicadores parciales proporcionarán medidas referentes a la magnitud a la que se pretenda aproximar, es decir, las series elegidas tendrán una clara significación económica. Las series deberán reproducir con regularidad la evolución de la magnitud objetivo, careciendo a la vez de irregularidades y de ciclos suplementarios. e) Es deseable que el conjunto de indicadores seleccionados se formule dentro de un marco estructurado coherentemente, coordinado e interrelacionado. Este marco lo deben proporcionar el desarrollo de las estadísticas básicas y facilitará la interpretación del indicador sintético. La selección de los indicadores dentro de las series disponibles se realiza buscando que la elección implique una representación con la mayor amplitud posible de la macromagnitud objetivo. También se tendrá en cuenta la experiencia de los investigadores acerca de la significatividad de cada indicador parcial sobre la macromagnitud. La forma de acceder a esa experiencia es a través de una revisión del conjunto de 81 Criterios como los aquí recogidos se encuentran en De Góngora et al. (1989). -Pág. 158- Capítulo IV. Marco Metodológico trabajos de coyuntura fruto del estudio de diversos autores y a través de la propia experiencia modelizadora. Asimismo, toma una dimensión muy importante la definición del período temporal en el que se va a trabajar, puesto que los indicadores parciales disponibles tienen distinto número de observaciones. De esta forma, se debe definir el período temporal una vez calibrada la importancia de los indicadores parciales, pero inicialmente ya debemos considerar unas exigencias mínimas previas a la definición temporal definitiva. IV.4.2. ETAPA SEGUNDA. MODELIZACIÓN UNIVARIANTE DE LOS INDICADORES PARCIALES SELECCIONADOS. Una vez recogida la información referente a los indicadores económicos parciales disponibles, el siguiente paso es proceder a su modelización univariante. El tratamiento univariante de las series elementales es necesario para elaborar predicciones de las mismas y para corregir los efectos y acontecimientos especiales que pudiesen alterar la posterior labor de extracción de la “señal” considerada como relevante. Además, y dado que para la obtención del componente no observable relevante de cada indicador parcial vamos a utilizar los métodos basados en modelos de forma reducida, va a ser requisito necesario partir de un modelo ARIMA “que posteriormente sirve para asignar las distintas raíces de los polinomios de las medias móviles y autorregresivos a los componentes no observables” (De los Llanos et al. (1994, Pág.13). La metodología utilizada ha sido la de Box y Jenkins (1976) (modelización ARIMA) ampliada con análisis de intervención (Box y Tiao, 1975) y tratamiento de efectos calendario (Bell, Hillmer y tiao, 1983). Todos los cálculos de esta fase se realizaron con el programa TRAMO, cuyo nombre corresponde a las iniciales en lengua inglesa de ‘regresión de serie de tiempo con ruido ARIMA, observaciones perdidas y atípicas’ (“Time Series Regression with ARIMA Noise, Missing Observations and Outliers”) desarrollado por Gómez y Maravall(1997)82. Estos modelos univariantes para cada indicador parcial permitieron no sólo elaborar proyecciones futuras de cada uno de ellos, sino ‘limpiar’ las series de efectos determinísticos (que posteriormente se vuelven a añadir al componente correspondiente) que pudiesen afectar a la labor de estimación de la tendencia en la siguiente fase. 82 Ver Anexo 3. -Pág. 159- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña IV.4.3. ETAPA TERCERA. EXTRACCIÓN DE LA SEÑAL DE CADA INDICADOR PARCIAL SELECCIONADO. Una vez modelizados los indicadores parciales en niveles, el siguiente paso consistió en extraer el componente de ciclo-tendencia estocástico de cada uno de ello. La señal cíclica intenta captar las fluctuaciones de periodicidad superior al año (comportamiento a largo plazo), por lo que debe encontrarse la componente de las series seleccionadas que recoja tal información de baja frecuencia. Para ello, se supone que cada serie integrante del indicador puede descomponerse en sus componentes no observables: ciclo-tendencia, componente estacional y componente irregular. De entre el conjunto de técnicas que permiten estimar las distintas componentes de una serie, en este trabajo se ha utilizado el método basado en modelos, y más específicamente, el procedimiento basado en el modelo ARIMA de cada serie (método de forma reducida). En el Anexo 3 se hace una revisión de los métodos de extracción de señal, argumentado la elección. Los cálculos se han realizado con el programa SEATS, desarrollado por Gómez y Maravall (1997)83. Una vez aplicado dicho procedimiento a cada uno de los indicadores parciales seleccionados, se obtuvo una estimación de las series de tendencias de cada indicador parcial. Finalmente, se procedió al cálculo de las tendencias finales combinando las tendencias estocásticas recién obtenidas con los factores tendenciales deterministas que se estimaron en el modelo ARIMA de la fase anterior. Así, la forma de proceder en las tres primeras etapas es la que se recoge en el esquema siguiente: 83 Ver Anexo 3. -Pág. 160- Capítulo IV. Marco Metodológico Cuadro nº 36. Esquema del procedimiento en etapas 1ª a 3ª. “1ª ETAPA” SERIES PRESELECCIONADAS ⇓ “2ª ETAPA” PROGRAMA TRAMO ( 1 ) ARIMA + ANÁLISIS DE INTERVENCIÓN + TRATAMIENTO DE EFECTOS CALENDARIO ⇓ “3ª ETAPA” PROGRAMA SEATS ( 2 ) ESTIMACIÓN DE LAS SERIES DE TENDENCIA DE CADA INDICADOR PARCIAL ⇓ FACTORES TENDENCIALES DETERMINISTAS [DE ( 1 )] + TENDENCIAS ESTOCÁSTICAS [DE ( 2 )] = TENDENCIAS FINALES ESTIMADAS IV.4.4. ETAPA CUARTA. SELECCIÓN DE LAS SEÑALES EXTRAÍDAS DE LOS INDICADORES PARCIALES. Del Sur (1994, Pág. 267) recoge los requisitos o condiciones que deben cumplir los indicadores que finalmente se seleccionen para la generación de indicadores sintéticos de actividad: 1)”Los indicadores seleccionados deben proporcionar medidas sobre los niveles o tendencias del crecimiento global. 2)A fin de poder facilitar la interpretación del indicador sintético, los indicadores parciales deben formularse dentro de un cuadro estructurado de acuerdo con el desarrollo de las estadísticas básicas. 3)El indicador debe proporcionar un alto grado de aproximación al crecimiento. 4)Deben estar disponibles en tiempo real, a fin de asegurar una eficaz toma de contacto con la situación económica real. 5)Los indicadores parciales deben ser operativos; por ello, deben valorarse los coste y posibilidades de elaboración de los mismos.” A efectos operativos, el proceso de selección se realiza mediante regresiones (y comparaciones gráficas) entre las tasas de crecimiento anual de la macromagnitud y las de cada una de las señales de tendencia-ciclo. La tasa -Pág. 161- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña de crecimiento anual de la macromagnitud (con periodicidad anual) se calcula de manera inmediata. Para obtener la tasa equivalente para cada una de las señales de tendencia-ciclo (que tienen periodicidad trimestral) hay que calcular el crecimiento de la media de cuatro meses sobre la media de los cuatro meses inmediatamente anteriores y centrarla adecuadamente, es decir, que es necesario calcular: 3 T = 4 4 ∑x t+ j ∑x t −r j =0 4 r =1 −1 En el proceso de selección hay que atender a dos criterios fundamentales: económico y estadístico. El primer criterio implica que todas las ramas económicas que representa la macromagnitud de referencia deben quedar representadas. El segundo criterio supone la selección de aquellas señales cuyos crecimientos anuales presenten las correlaciones más elevadas con los crecimientos anuales de la macromagnitud de referencia. De cualquier forma, la selección de indicadores parciales que se realiza en esta etapa estará sujeta al filtro selector de las validaciones de la etapa sexta. IV.4.5. ETAPA QUINTA. AGREGACIÓN DE LAS “SEÑALES” DE LOS INDICADORES SELECCIONADOS PARA OBTENER EL INDICADOR SINTÉTICO. En esta etapa, la meta a alcanzar es la agregación de las señales de tendencia-ciclo que se han seleccionado en la etapa anterior al considerarse relevantes84. Vamos a reflejar esta idea utilizando la notación matricial. Sea X ti el valor que toma en el momento de tiempo t la señal de tendencia-ciclo extraída del indicador parcial i, de manera que i = 1,..., n es el número de indicadores parciales cuya señal ha sido seleccionada porque se considera que deben contribuir a la obtención del indicador sintético, y t = 1,... T es cada uno de los períodos temporales para los que se pretende realizar la agregación de la información. I t es el valor que toma el indicador sintético o compuesto que se obtiene en el momento de tiempo t mediante la síntesis de la información contenida en las señales extraídas de diversos indicadores parciales. Por lo tanto, se dispone de una matriz Χ definida como: 84 En esta etapa identificaremos por indicadores parciales a los indicadores parciales seleccionados en la etapa cuarta, y por “señales” las señales de ciclo-tendencia extraídas de los indicadores parciales seleccionados. -Pág. 162- Capítulo IV. Marco Metodológico x11 x12 . . . x1n x 21 x 22 . . . x 2 n . . . ; . . . X X X Χ = ( t1 t2 tn ) = . . . . . . x T 1 x T 2 . . . x Tn y se pretende obtener un vector columna (indicador sintético) del tipo I1 I2 . Ι = . Es decir, se trata de reducir la matriz Χ de dimensión (T x n) a la . . IT matriz Ι de dimensión (T x 1) . En definitiva, se busca condensar la información que contienen las n señales seleccionadas a lo largo del tiempo en una sola señal. Las dificultades que aparecen en este momento son: a) “La heterogeneidad de los indicadores en lo que se refiere a sus unidades de medida, y como consecuencia b) La ponderación y adición de los mismos. Puesto que no todos los indicadores parciales tienen igual importancia y además con unidades de medida diferente no son fácilmente agregables.” del Sur (1994, Pág. 267). En este sentido, Pena (1977) apunta entre los problemas para la elaboración de un indicador sintético los siguientes: 1º Los indicadores sintéticos sólo posibilitan una aproximación al fenómeno en estudio. 2º Las distintas unidades de medida de los indicadores parciales hace difícil su aditividad. 3º Al problema de la aditividad hay que añadirle el de la importancia que se debe dar a cada uno de los indicadores, lo cual nos lleva al ámbito de la ponderación de los indicadores. Lógicamente, la forma de abordar esta problemática es muy amplia, y se puede optar por métodos muy dispares; sería difícil recoger todos los posibles indicadores sintéticos. Según Ávila et al. (1996)85, se pueden distinguir dos grandes tipos de ponderaciones para conseguir la síntesis de la información: las ponderaciones endógenas (que se originan en el interior del propio modelo de ponderación teniendo en cuenta la dimensión temporal de los 85 El esquema general seguido es el de Ávila et al. (1996), pero vamos a ser más explícitos que esto autores, enriqueciendo la clasificación. Pons (1996) distingue cinco categorías dentro de los principales métodos para la composición de indicadores. -Pág. 163- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña indicadores parciales) y las exógenas (originadas fuera del modelo sin que la ponderación tenga en cuenta la dimensión temporal presente en los indicadores parciales). IV.3.5.1. PONDERACIONES EXÓGENAS. Ya podemos decir que la atemporalidad de las ponderaciones exógenas es una crítica importante a estos métodos. A los procedimientos exógenos Ávila et al (1996) los dividen en objetivos y subjetivos. Objetivos, en los cuales las ponderaciones son el fruto de estudios, análisis o encuestas que ayudan a un conocimiento mejor del fenómeno en estudio. En los procedimientos exógenos objetivos se pueden destacar los que logran ponderar los indicadores parciales en función de la información suministrada por las tablas “input-output” o por la Contabilidad Regional. Las críticas más importantes a estos métodos son dos; en primer lugar, que habitualmente no se dispone de dichos estudios, análisis o encuestas con la periodicidad deseada, lo cual repercute en una cierta fijeza en las ponderaciones, y en segundo lugar, que las ponderaciones tienen su origen en períodos temporales anteriores al momento tratado, razón por la cual se condiciona a un momento determinado a adoptar una ponderación que ya puede haber quedado obsoleta en el tiempo. Para los subjetivos no se obtiene la ponderación de fuentes de análisis objetivas. En estos procedimientos es el propio analista el que obtiene la ponderación utilizando una fórmula predeterminada para todas las señales en el mismo momento de tiempo; es decir, se prescinde del análisis teniendo en cuenta toda la información disponible a lo largo de todo el período temporal. Así, se pondera en base a una determinada medida de posición86 que él (el analista) considera adecuada, o puede otorgar a todos los indicadores el mismo peso, o un peso distinto a cada uno según su propio criterio. De cualquier forma, la crítica más importante a estos métodos es la falta de unicidad en los resultados, de forma que sería improbable que dos mismos analistas obtuviesen el mismo resultado disponiendo de la misma información. IV.3.5.2. PONDERACIONES ENDÓGENAS. También se pueden distinguir un gran número de ponderaciones endógenas; nosotros vamos a referirnos sólo a algunos, y en concreto consideramos a los procedimientos: - con base en el análisis de correlación, - basados en el análisis de regresión, - de selección automática, 86 Por ejemplo, se pueden utilizar medidas de posición como la media aritmética, la media geométrica, la mediana o la moda. -Pág. 164- Capítulo IV. Marco Metodológico - basados en el análisis de componentes principales, - Niemira y Klein (1994), - utilizados por el NBER y por el BEA, y - basados en el concepto de distancia. En el Anexo 4 explicamos cada uno de estos métodos de agregación endógenos; el método de agregación por el que nos hemos decantado, que es un método basado en el concepto de distancia, lo exponemos de forma resumida a continuación. IV.4.6. PROCEDIMIENTOS DISTANCIA. BASADOS EN EL CONCEPTO DE IV.4.6.1. INTRODUCCIÓN. Estos métodos, utilizando un concepto de distancia determinado87, sintetizan la información de los diferentes indicadores parciales a través del cálculo de las distancias de los valores de cada uno de ellos a unos valores considerados de referencia. Nosotros vamos a centrarnos en un tipo de distancia definida como Distancia P2 con la cual Zarzosa (1992)88 pretende aproximarse a la medición del bienestar social mediante la síntesis de la información que proporcionan las medidas de los estados de sus componentes89. Aunque la aplicación original del indicador con base en la Distancia P2 va dirigida al campo de la medición del bienestar social, hemos considerado adecuado emplear este procedimiento en el campo de la agregación de los indicadores económicos por las siguientes razones: 1º En este procedimiento se parte de unas características o propiedades que debe verificar un buen indicador sintético (perfectamente exportables a nuestro campo de estudio) y en base a dichas propiedades, se ha comprobado que este 87 Pena (1977) recoge algunos métodos basados en el concepto de distancia, como los que toman como base la distancia CRL de Pearson, la distancia de Frechet, la distancia generalizada de Mahalanobis, la distancia de Stone y la distancia I de Ivanovic. Como un ejemplo de síntesis de información basándose en el desarrollo del caso de la distancia euclídea, podemos citar a la recopilación que realizaron Hwang y Yoon (1981). 88 La base fundamental de la tesis de Pilar Zarzosa es un trabajo publicado en el año 1977 y escrito por el director de su tesis, el Profesor Pena Trapero. En dicho trabajo se presentaba y aplicaba la distancia DP2. 89 Pena (1977, Pág. 50) define como “componente” de un indicador sintético a “aquella propiedad que aporta alguna información medible y cuantificable con independencia de la apreciación subjetiva acerca del objetivo buscado con el indicador sintético”. En este trabajo, el concepto de componente lo vamos a identificar con el de indicador parcial, es decir, vamos a utilizar indistintamente ambos conceptos para referirnos a los indicadores parciales. Ésto supone una simplificación conceptual que redunda en una operatividad inmediata (una vez se disponga de los indicadores seleccionados). -Pág. 165- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña procedimiento genera un indicador sintético que las verifica de una manera óptima. 2º Facilidad de cálculo. Aunque el procedimiento en sí puede ser difícil de llevar a la práctica, los “constructores” de este procedimiento proporcionan un programa90 que permite explotar el indicador sintético de distancia basado en la distancia P2; la ventaja de este programa es que hace más sencillo el cálculo del indicador sintético, otorgando operatividad al procedimiento. Zarzosa (1992, Pág. 159) define como “indicador parcial o simple”“a la expresión matemática que da una medida del estado en que se encuentra un componente en relación con el objetivo buscado”. Esta autora también define como “indicador sintético o global” (nosotros también lo llamamos indicador compuesto) a “una función matemática de los indicadores parciales que cumple un conjunto de condiciones necesarias para dar una buena medida del objetivo buscado”. Las propiedades exigibles se recogen en el Anexo 4. Vamos a explicar los principales contenidos de la investigación de Pena Trapero (1977) y de Zarzosa (1992) para adaptarlo a nuestro campo de estudio. Ya hemos mencionado antes las dificultades con las que nos encontramos para la elaboración de indicadores sintéticos: heterogeneidad de las medidas y el problema de las ponderación. Los autores antes mencionados, dentro del estudio del bienestar, se inclinan por la utilización de los indicadores sintéticos basados en el concepto de distancia para la medición del bienestar social; apoyándonos en las definiciones que estos autores exponen en sus trabajos respectivos, vamos a presentar el concepto de distancia en nuestro ámbito de investigación para llegar al indicador sintético de distancia P2, que es el que utilizaremos. Sea X j el vector de estados de los indicadores parciales en el momento ( ) de tiempo j : X j = x j1 x j 2 ... x ji ... x jn , donde x ji es el valor que toma la tasa de crecimiento interanual ( T14 ) de la señal de ciclo-tendencia del indicador parcial i en el momento de tiempo j . Este vector de estados lo queremos comparar con un vector de referencia. Sea X • el vector “base de referencia”, donde X • = ( x•1 x•2 ... x•i ... x•n ) . De esta forma, x•i es el estado “base de referencia” del indicador parcial i , un estado “ideal” de dicho indicador parcial que a efectos prácticos puede ser un período con respecto al cual se realiza la comparación. 90 En la Tesis de Zarzosa (1992) se presenta el programa “FELIZ.FOR”, realizado por Félix Zarzosa en Fortran y con un diseño acorde al esquema de cálculo de la distancia DP2. -Pág. 166- Capítulo IV. Marco Metodológico del Zarzosa (1992, Pág. 167) define la Distancia General P-Métrica ( D p ) vector de estados X j al vector base de referencia X • n como: D p = ∑ x ji − x•i i =1 ( ) p 1/ p . En el caso de que p = 1 , la expresión para D1 1/ 2 2 n es D1 = ∑ x ji − x•i . En el caso de que p = 2 , D2 = ∑ x ji − x•i i =1 i =1 conociéndose a D2 como la “Distancia Cuadrática o Euclídea”. Tomando como base a D1 o D2 , se podrían definir sendos indicadores sintéticos de distancia que no solucionarían el problema de la heterogeneidad de las unidades de medida de los indicadores parciales. ( n ) IV.4.6.2. EL INDICADOR SINTÉTICO DE DISTANCIA DP2 . Una vez planteadas las propiedades exigibles a la función matemática que genera al indicador sintético y las hipótesis que garantizan que el indicador sintético va a ser operativo para el objetivo que persigue (ver Anexo 4), vamos a definir un indicador basado en el concepto de distancia en el que p = 1 y que verifica las propiedades enunciadas en el Anexo 4. Este indicador se conoce como Distancia-P2 ( DP2 ) y fue Pena trapero (1977) quien elaboró dicho indicador, que se define como sigue91: n di (1 − Ri2•i −1,i − 2 ,...,1 ) σ i =1 i DP2 = ∑ donde R12 = 0 , y siendo: d i = d i (r , k ) = xri − x ki si el indicador se aplica a la comparación de dos economías, o d i = d i (r ,•) = xri − x•i si se compara la economía r con respecto a la base de referencia X • (esta segunda opción es la que utilizaremos en este trabajo), σ i es la desviación típica de los valores que tome el indicador parcial i , y Ri2•i −1,i − 2 ,...1 es el coeficiente de determinación del indicador parcial X i sobre los indicadores parciales X i −1 , X i − 2 , ... , X 1 . Recoge la parte de la varianza de X i que viene explicada por la combinación lineal de los indicadores parciales ya introducidos en el indicador sintético; en definitiva, mide la información común entre el indicador parcial a introducir y los ya incorporados al indicador compuesto. 91 La definición de la DP2 está tomada de Zarzosa (1992, Págs. 188-191). La definición original se encuentra en Pena (1977, Pág. 114). -Pág. 167- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En la expresión de la DP2 se pueden distinguir, para cada sumando, dos componentes: d 1º) i Este componente es la distancia definida para el indicador parcial i σi dividida por la desviación típica de dicho indicador parcial, y tiene dos funciones: a) Expresar el indicador parcial en unidades abstractas, posibilitando la aditividad (hay que apreciar que el numerador y denominador están medidas en las mismas unidades) , y b) ponderar en menor grado a aquellas distancias que tienen una mayor desviación típica (aumenta la dispersión respecto a la media e interesa restarle importancia a los indicadores que presenten mayor desviación típica). 2º) (1 − Ri2•i −1,i − 2 ,...,1 ) Este segundo componente impide que la información contenida en un indicador parcial y que es común a la que posee otro u otros indicadores parciales (que viene recogida por Ri2•i −1,i − 2 ,...,1 ) se repita. Es inmediato observar que si al valor 1 se le resta la información común ( Ri2•i −1,i − 2 ,...,1 ) sólo se introducirá en el indicador sintético la información no repetida. Del análisis de este segundo componente se puede advertir el hecho de que los coeficientes de determinación variarán en función de cuál sea la variable dependiente y cuáles las explicativas que intervengan en la regresión. Por lo tanto, una cuestión importante que hay que tener en cuenta es que “el resultado de la DP2 depende del orden de entrada de los indicadores parciales” (Zarzosa (1992, Pág. 192)); en este sentido, Pena (1977, Pág. 117) afirma que para el cumplimiento de la propiedad de unicidad se requiere “fijar una jerarquización de los componentes, antes de proceder al cálculo del indicador”. Pena (1977, Pág. 96) expone un método de jerarquización para las variables que Zarzosa (1992, Pág. 195) también explica. Nosotros vamos a presentarlo aquí aplicado a nuestro ámbito: 1º Partimos de la matriz de datos que contiene las señales extraídas de los indicadores parciales. Si se trabaja con los datos en niveles, hay que cambiar el signo de las señales extraídas de indicadores que cuando aumentan su valor suponen un empeoramiento de las condiciones económicas de una economía. Por otra parte, y dado que no vamos a trabajar con los datos en niveles porque pretendemos sintetizar el ritmo de crecimiento interanual de las señales extraídas de los indicadores parciales, en primer lugar calculamos las tasas de crecimiento interanuales de las señales ( T14 ) de la señal de ciclo-tendencia del -Pág. 168- Capítulo IV. Marco Metodológico indicador parcial i en el momento de tiempo j . A continuación, le sumamos un valor (por ejemplo 100) a todas las tasas para que todas tengan el mismo signo. Por último, cambiamos de signo a las tasas (con el cambio de origen ya realizado) que se correspondan con las señales extraídas de indicadores parciales que recogen aspectos negativos de las condiciones económicas de una economía (por ejemplo el paro registrado). 2º Elegimos la base de referencia. Como justificaremos más adelante, el vector de referencia debe ser el mismo para las economías en estudio, y “la base debe ser, para cada componente, mayor o igual, o menor o igual, que los valores máximos o mínimos repectivamente de la sucesión de valores observados de tal componente” Zarzosa (1992, Págs. 195-196). 3º Calculamos la distancia de Frechet para cada uno de los momentos de tiempo j de nuestro estudio (ya sea año, o mes, o trimestre, u otra medida temporal). n x − x di •j ji ; siendo j = 1,2,..., t Fj = ∑ =∑ σi i =1 σ i i =1 n de manera que F ' = ( F1 ... Ft ) 4º Calculamos los valores absolutos de los coeficientes de correlación simple entre cada indicador parcial y la distancia F: rX 1 , F , rX 2 , F ,..., rX i , F ,..., rX n , F , y los ordenamos de mayor a menor valor. 5º Calculamos la DP2 para cada uno de los momentos de tiempo j de nuestro estudio según el orden de entrada de los indicadores parciales que hemos obtenido en el paso 4º. Al vector de distancias obtenidas les llamamos DP2(1) . 6º Calculamos los valores absolutos de los coeficientes de correlación simple entre cada indicador parcial y la DP2(1) , ordenándolos de mayor a menor. 7º Recalculamos la DP2 para cada momento del tiempo, haciendo entrar los indicadores parciales según el orden jerárquico obtenido en el paso 6º; al vector de distancias obtenido le llamamos DP2( 2 ) . 8º Se repite el proceso que hemos expuesto en los pasos 6º y 7º hasta que “la DP2 se estabiliza. Si no logra la convergencia, de forma que los resultados de -Pág. 169- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña DP2 no se estabilizan, se puede elegir la primera DP2 obtenida ( DP2(1) ), o la media de las DP2 calculadas en varias iteraciones” Zarzosa (1992, Pág. 197). IV.4.6.3. CÁLCULO DEL INDICADOR SINTÉTICO DE DISTANCIA DP2 . El cálculo del indicador sintético de distancia DP2 se ha realizado utilizando el programa Feliz.for. Zarzosa (1992, Págs. 491-493) nos expone el esquema de cálculo de la DP2 según el cual se ha diseñado dicho programa, y que nosotros transcribimos adecuándolo a nuestro campo de aplicación y según nuestra notación: { } 1º Introducción de la matriz X = x ji txn , donde x ji es el valor de la variable i-ésima en el momento de tiempo j. Es una matriz de t filas (momentos de tiempo) por n columas (variables). Las variables cuyo aumento supone un empeoramiento en las condiciones económicas llevan signo contrario. 2º Elección del vector base de referencia X • . Se puede elegir el de valores mínimos, el de máximos o introducir cualquier otro. Si se elige el de { } mínimos X • = x• j (ya tx 1 ( ) , donde cada x• j = min j x ji . 3º Cálculo de la matriz D de distancias entre cada momento de tiempo sea año, mes, trimestre,…) y la base de referencia: { } D = d ji txn ; d ji = x ji − x• j . 4º Cálculo de las desviaciones típica de las variables, σ i . 5º Obtención de la matriz de I de indicadores parciales: d ji ; I ji = I = I ji . txn σi 6º Obtención del vector F de indicadores de distancia de Frechet: { } { } F = Fj n tx 1 ; F j = ∑ I ji . i =1 7º Coeficientes de correlación entre las variables y F , r(F , X i ) = r(F , I i ) . 8º Valores absolutos de los coeficientes anteriores. 9º Obtención de X 0 , matriz X tipificada. 10º Obtención de X 0(1) , que es la matriz X 0 reordenada, según la ordenación que determinan los resultados de 8º. La primera columna de la matriz X 0(1) recogerá la variable (tipificada) a la que le corresponda el mayor valor de los obtenidos en 8º, y así sucesivamente. 11º Obtención de R (1) , matriz de correlación entre las variables 1 ' reordenadas según 8º: R (1) = ( X 0(1) ) X 0(1) t 12º Cálculo de los menores principales de R (1) . -Pág. 170- Capítulo IV. Marco Metodológico Obtención del vector de 13º 2 (1 − R ) = 1 − Ri•1,2,...,i −1 nx1 . Los factores correctores 2 { } factores correctores 2 1 − Ri •1,2 ,...,i −1 , se hallan ( ) dividiendo cada menor principal obtenido en 12º por el inmediatamente anterior. Por definición, R12 = 0 . 14º Obtención de I (1) , matriz de indicadores reordenada según 8º. 15º Cálculo del vector de indicadores sintéticos DP2 obtenido en la 1ª iteración, DP2(1) = DP2((1j)) } Tx1 : DP2(1) = I (1) (1 − R 2 ) . La primera iteración habría terminado. Comenzaría la segunda. 16º Repetición de las etapas, a partir de la 6ª, sustituyendo el vector de Frechet por el de Pena obtenido en la 1ª iteración, DP2(1) . El programa debe continuar hasta lograr la convergencia o la estabilidad total de DP2 ; en definitiva, cuando en dos iteraciones sucesivas se obtiene el mismo vector DP2 , ése es el resultado definitivo. IV.4.7. ETAPA SEXTA. VALIDACIÓN DEL INDICADOR SINTÉTICO. La validación se puede hacer desde la perspectiva gráfica o estadística. Un buen indicador sintético de actividad económica debe recoger no sólo el ciclo de la variable de referencia, sino que debe mantener una relación estadístico-econométrica satisfactoria. En cualquier caso, los indicadores sintéticos obtenidos deben ser anualizados para poderlos comparar con la macromagnitud de referencia. En este sentido, los indicadores obtenidos nos aproximan a la tasa de crecimiento de una macromagnitud de referencia en un trimestre con respecto al mismo trimestre del año anterior, V − Vt − 4 T14 = t Vt − 4 donde Vt denota el nivel de la macromagnitud en el trimestre t. El problema es que Vt es desconocido, de manera que la solución a este problema es validar con los crecimientos de la macromagnitud anual, ya que es la única que conocemos. Ahora el problema es convertir el indicador sintético trimestral ( T14 ) en anual ( T44 ). Para ello, hay que tener en cuenta que se verifica: 1 3 T44 (t ) ≈ ∑ T14 (t − 2 + j ) 4 j =0 es decir, que la tasa de crecimiento de la media de cuatro trimestres sobre la media de los cuatro trimestres precedentes ( T44 (t ) ) se puede aproximar como el promedio de las T14 convenientemente centradas92. De esta forma se puede aproximar el crecimiento interanual que recoge el indicador en cada uno de los años mediante la T44 (de cada uno de los trimestres primeros de cada año) calculada de la forma que hemos indicado. 92 Ver Espasa y Cancelo (Eds.) (1993) -Pág. 171- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Una vez que se tiene la información referente a las validaciones de todos los indicadores sintéticos construidos (resultado de las combinaciones posibles -y con sentido económico- de los crecimientos interanuales de las ciclo-tendencias trimestrales seleccionadas), el indicador elegido será aquel cuyas validaciones sean más satisfactorias. -Pág. 172- Capítulo IV. Marco Metodológico IV.5. RECAPITULACIÓN. En síntesis, la metodología estadística con la que se pretende llegar a elaborar indicadores sintéticos de actividad económica se recoge en el siguiente esquema. Cuadro nº 37. Esquema del procedimiento. “1ª ETAPA” SERIES PRESELECCIONADAS ⇓ “2ª ETAPA” PROGRAMA TRAMO ( 1 ) ARIMA + ANÁLISIS DE INTERVENCIÓN + TRATAMIENTO DE EFECTOS CALENDARIO ⇓ “3ª ETAPA” PROGRAMA SEATS ( 2 ) ESTIMACIÓN DE LAS SERIES DE TENDENCIA DE CADA INDICADOR PARCIAL ⇓ FACTORES TENDENCIALES DETERMINISTAS [DE ( 1 )] + TENDENCIAS ESTOCÁSTICAS [DE ( 2 )] = TENDENCIAS FINALES ESTIMADAS ⇓ “4ª ETAPA” SELECCIÓN (ESTADÍSTICA Y ECONÓMICA) DE LAS TENDENCIAS FINALES ESTIMADAS ⇓ “5ª ETAPA” AGREGACIÓN DE LOS CRECIMIENTOS INTERANUALES (DE LAS CICLOTENDENCIAS TRIMESTRALES ESTIMADAS) MEDIANTE LA DP2 = INDICADOR SINTÉTICO ⇓ “6ª ETAPA” VALIDACIÓN DEL INDICADOR SINTÉTICO Y SELECCIÓN DEL MEJOR -Pág. 173- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura CAPÍTULO V. CONSTRUCCIÓN DE INDICADORES SINTÉTICOS PARA EXTREMADURA. V.1. INTRODUCCIÓN. En este capítulo se aplica la metodología expuesta en el capítulo anterior, presentándose un conjunto de índices sintéticos de actividad económica para Extremadura que resumen de una forma coherente la información dispersa que suministran una batería de indicadores económicos de alta frecuencia (mensuales y/o trimestrales). Por consiguiente, se modeliza estadísticamente a la economía extremeña. En primer lugar se presenta la elaboración de un indicador sintético trimestral representativo de una macromagnitud básica para la economía de la Comunidad de Extremadura desde la óptica de la oferta (el Valor Añadido Bruto excluyendo las ramas agrarias y energética a precios de mercado: VABNANE). La elección de tal macromagnitud ha quedado justificada en el Capítulo III desde dos perspectivas distintas: en el análisis “shift-share” y en el contexto de los contrastes de ciclo común entre la economía extremeña y la nacional. Además, se obtienen indicadores sintéticos de actividad que describirán la evolución de cada uno de los sectores productivos extremeños con una desagregación a R-6: agrario (A), energético (E), industria manufacturera (I), construcción (B), servicios destinados a la venta (SV) y servicios no destinados a la venta (G). Los indicadores sintéticos tendrán una importante repercusión en el análisis de la coyuntura económica, y permitirán tanto la cuantificación de la evolución de una economía (o de un sector económico) como la determinación de la fase del ciclo económico en la que se encuentre. También se hace un análisis de la evolución cíclica de cada uno de los sectores extremeños en relación a sus homólogos nacionales. La estructura del Capítulo es la siguiente: en el segundo apartado se comentan los datos regionales que se han empleado para realizar este tipo de análisis. En el tercer apartado se exponen los resultados de aplicar la metodología estadística. En el cuarto apartado, se hace un ejercicio de comparación cíclica de las ramas (R-6) extremeñas respecto a las ramas nacionales. Para finalizar, se comentan los resultados obtenidos. -Pág. 175- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña V. 2. DATOS ESTADÍSTICOS. La meta a alcanzar es recoger el crecimiento a corto plazo y en términos reales del agregado VABNANE y de las ramas R-6 de la economía extremeña. Ya se ha explicado en el Capítulo II que la información económica regional de las comunidades autónomas españolas cuenta con una fuente oficial que es la Contabilidad Regional de España, elaborada y publicada por el Instituto Nacional de Estadística (INE); sin embargo, en las estimaciones que proporciona el INE no existen datos referentes a los agregados macroeconómicos en pesetas constantes, lo cual obliga en primer lugar a trabajar para la consecución de unos datos regionales en términos reales. La solución adoptada en este estudio ha pasado por la utilización del los deflactores sectoriales implícitos que se derivan del trabajo de Cordero y Gayoso (1997) para aplicarlos a las estimaciones sectoriales del Valor Añadido Bruto de la Contabilidad Regional Anual93. En lo referente a los indicadores económicos, la batería de variables con las que hemos trabajado la constituyen las series recogidas y descritas en el Anexo 1, 62 series mensuales y 36 trimestrales (98 series). Tales series tienen distinto número de observaciones y poseen periodicidad mensual o trimestral. Estos indicadores parciales disponibles son representativos de aspectos relativos a la actividad económica o a los sectores productivos. Todas las series están actualizadas, al menos, hasta Diciembre de 1996. V.3. APLICACIÓN DE LA METODOLOGÍA ESTADÍSTICA. En este apartado se expone de forma concisa la forma en la que se ha aplicado la metodología estadística (expuesta en el Capítulo anterior) para la elaboración, desde la óptica de la oferta, de indicadores sintéticos trimestrales de actividad económica. Además, se presentan los resultados de la aplicación. V.3.1. ETAPA PRIMERA. DEFINICIÓN DEL PERÍODO TEMPORAL, RECOGIDA Y ESTUDIO DE LOS INDICADORES DISPONIBLES PRESELECCIONADOS. Disponemos de 98 indicadores parciales con periodicidad mensual o trimestral, a partir de los cuales se deben preseleccionar aquellos con los que se obtebga una representación con la mayor amplitud posible de la macromagnitud objetivo. Otro aspecto a considerar, dadas sus implicaciones importantes, es la definición del período temporal, ya que los indicadores tienen distinto número de observaciones. Los datos se han homogeneizado para el seguimiento del VABNANE; es decir, el período común abarca desde el primer trimestre de 1987 hasta el cuarto trimestre de 1996, de forma que se dispone de información de todos los indicadores para esos 40 trimestres. 93 Ver Capítulo II. -Pág. 176- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura En el caso de la modelización estadística sectorial, el año de inicio de las series es común para series seleccionadas para un mismo sector, pero es diferente entre los distintos sectores, ya que de unos se dispone de series más largas que de otros. V.3.2. ETAPA SEGUNDA. MODELIZACIÓN UNIVARIANTE DE LOS INDICADORES PARCIALES PRESELECCIONADOS. Una vez recogida la información referente a los indicadores económicos parciales disponibles, el siguiente paso es proceder a su modelización univariante. Todos los cálculos de esta fase se realizaron con el programa TRAMO, desarrollado por Gómez y Maravall (1997). V.3.3. ETAPA TERCERA. EXTRACCIÓN DE LA “SEÑAL” DE CICLOTENDENCIA DE CADA INDICADOR PARCIAL En esta etapa entenderemos por señal como el componente de ciclotendencia estocástico de cada indicador parcial. Como ya hemos comentado, para estimar las señales de cada serie se ha utilizado el enfoque basado en modelos, y en concreto, el procedimiento basado en el modelo ARIMA de cada serie (método de forma reducida). Los cálculos se han realizado con el programa SEATS, desarrollado por Gómez y Maravall (1997). Una vez aplicado dicho procedimiento a cada uno de los indicadores parciales seleccionados, se obtuvo una estimación de las series de ciclo-tendencias de cada indicador parcial. De esta forma, ya se dispone de las señales de los distintos indicadores parciales, siendo este el elemento sobre el que se trabaja en la etapa siguiente. V.3.4. ETAPA CUARTA. SELECCIÓN DE LAS SEÑALES EXTRAÍDAS DE LOS INDICADORES PARCIALES. Niemira y Klein (1994, Pág. 169), afirman que “la selección de indicadores cíclicos tiende a ser una cuestión empírica (...)”; también indican que la selección es buena si predice bien el futuro. El carácter empírico de la selección es más evidente en economías del tipo regional donde los resultados obtenidos en las regresiones entre el VAB y cada uno de los indicadores parciales son, en ocasiones, menos satisfactorias de lo esperado. Además, en el caso extremeño, al problema de la disposición de series cortas se le añade la irregularidad de sus crecimientos sectoriales, de manera que la realización de una clasificación94 fiable de los indicadores con respecto a una serie de referencia queda pospuesta para etapas posteriores de la investigación. Los indicadores seleccionados -expuestos en este subapartado- son los que han proporcionado los resultados más satisfactorios en términos de validación, de todas las pruebas (numerosísimas) que ha sido necesario realizar. Lógicamente, 94 En coincidente, adelantado o retrasado. -Pág. 177- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña la obtención de nuevas cifras macroeconómicas y de indicadores, posibilitará una revisión de los resultados aquí presentados. En esta etapa se distinguen dos casos, un primero para el valor añadido bruto no agrario y no energético (VABNANE) y otro para el caso de los VAB sectoriales. En el primero, como se pretende conseguir una aproximación al crecimiento del VABNANE , se han calculado las tasas de crecimiento anuales de los ciclo-tendencias extraídos en la etapa anterior (anualizadas). En síntesis, el proceso de selección se ha realizado trabajando con la tasa de crecimiento del VABNANE y de las señales (en tasa de crecimiento anual) atendiendo a dos criterios fundamentales: económico y estadístico. El primer criterio implica que todos los sectores económicos que integran el VABNANE deben quedar representados. El segundo criterio supone la selección de aquellas señales cuyos crecimientos anuales presenten las correlaciones más elevadas con los crecimientos anuales del VABNANE. Los indicadores finalmente seleccionados (sus ciclo-tendencias) han sido catorce; ocho con periodicidad mensual y seis con periodicidad trimestral. En las siguientes tablas se presentan los indicadores mensuales y trimestrales, así como sus correlaciones muestrales con el crecimiento del VABNANE (TVABNANE). Cuadro nº 38. Indicadores mensuales para TVABNANE. Indicadores Notación (en crecimientos) Correlación Consumo de cemento TCEMCON 0.575 Paro registrado en la construcción TPARREGC -0.558 Licitación oficial total TLIOFTO 0.509 Matriculación de turismos TMATTUR 0.467 Matriculación vehículos de carga TMATVCAR 0.621 Consumo de energía eléctrica en industria y TCOELEIS 0.535 servicios Consumo de energía eléctrica para usos TCOELEU 0.406 domésticos Número de viajeros españoles TVIAESP 0.302 Nota: la correlación se calcula para los crecimientos anuales. -Pág. 178- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Cuadro nº 39. Indicadores trimestrales para TVABNANE. Indicadores Notación (en crecimientos) Correlación Ocupados en bienes de equipo TOCUK 0.270 Ocupados en bienes intermedios TOCUQ 0.601 Ocupados en servicios destinados a la venta TOCUSV 0.765 Ocupados en servicios no destinados a la TOCUG 0.534 venta Tasa de ocupación 0.774 TTASAOCU∗ Crédito de las entidades de depósito al TCTOSPR 0.401 sector privado. Notas: la correlación se calcula para los crecimientos anuales. En el caso de los VAB sectoriales se persigue la descripción de la evolución del crecimiento intertrimestral, y en términos reales, de los sectores productivos extremeños. Para el sector agrario, los indicadores seleccionados han sido tres; inscripción de maquinaria agrícola, población asalariada en agricultura y el índice de producción para la industria de bienes de consumo de Extremadura (indicador de elaboración propia). Es necesario destacar las dificultades que se ha encontrado dentro de este sector para encontrar indicadores parciales representativos de la producción agraria extremeña, razón por la cual se ha considerado necesario utilizar como variable aproximada (“proxy”) de dicha producción el mencionado índice de producción industrial. En principio, puede resultar llamativa la utilización de esta “proxy”, pero, si se tiene en cuenta la gran dependencia del subsector de bienes de consumo de la producción agraria extremeña, se disipan las dudas -a falta de otras variables- sobre la utilización de dicho índice. Cuadro nº 40. Indicadores seleccionados para el crecimiento del VAB agrario. Indicadores Notación (en crecimientos) Correlación Inscripción de maquinaria agrícola TINSMAQ 0.302 (Mensual). Población asalariada en agricultura TPOBASA 0.642 (Trimestral) Índice de producción industria bienes TIPIC 0.603 consumo de Extremadura (Mensual). Nota: la correlación se calcula para los crecimientos anuales. Para el sector energético se ha seleccionado la suma de las señales de tres indicadores parciales mensuales; energía bruta producida por la central nuclear de Almaraz, producción total de energía hidroeléctrica de Saltos del Guadiana en Extremadura, y producción total de energía hidroeléctrica de Iberdrola en Extremadura. El hecho de utilizar sólo indicadores de producción se justifica porque la partida “remuneración de asalariados” -como componente -Pág. 179- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña del VABpm energético extremeño- es muy reducida debido al número relativamente bajo de empleados que ocupa este sector en Extremadura. Cuadro nº 41. Indicadores seleccionados para el crecimiento del VAB energético. Indicadores Notación (en crecimientos) Correlación Producción bruta de energía eléctrica TENERG 0.945 (Mensual). Nota: la correlación se calcula para los crecimientos anuales. En lo que respecta al sector industrial manufacturero, los indicadores parciales seleccionados son: ocupados en la industria manufacturera en Extremadura, índice de producción general para la industria manufacturera de Extremadura (indicador de elaboración propia) y matriculación de vehículos de carga. Cuadro nº 42. Indicadores para el crecimiento del VAB industrial. Indicadores Notación (en crecimientos) Correlación Ocupados en la industria manufacturera en TOCUI 0.233 Extremadura (Trimestral). Índice de producción industrial general TIPIG 0.242 para Extremadura (Mensual). Matriculación de vehículos de carga TMATVCAR 0.201 (Mensual) Nota: la correlación se calcula para los crecimientos anuales. Para el sector de la construcción, los indicadores parciales finalmente seleccionados han sido: ocupados en el sector de la construcción extremeño, proyectos visados totales y consumo de cemento. Cuadro nº 43. Indicadores para el crecimiento del VAB de la construcción. Indicadores Notación (en crecimientos) Correlación Ocupados en el sector de la construcción TOCUB 0.133 (Trimestral). Proyectos visados totales (Mensual). TPROVIT 0.192 Consumo de cemento (Mensual). TCEMCON 0.399 Nota: la correlación se calcula para los crecimientos anuales. En cuanto al sector de servicios destinados a la venta, los indicadores componentes del índice sintético son: ocupados en servicios destinados a la venta, consumo de energía eléctrica en industria y servicios de Extremadura, consumo de energía eléctrica para usos domésticos, créditos concedidos al sector privado y matriculación de turismos. -Pág. 180- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Cuadro nº 44. Indicadores para el crecimiento del VAB de servicios venta. Indicadores Notación (en crecimientos) Correlación Ocupados en servicios destinados a la venta TOCUSV 0.389 (Trimestral). Consumo de energía eléctrica en industria y TCOELEIS 0.266 servicios de Extremadura (Mensual). Consumo de energía eléctrica para usos TCOELEU 0.312 domésticos (Mensual). Créditos concedidos al sector privado TCTOSPR 0.489 (Trimestral). Matriculación de turismos (Mensual). TMATTUR 0.507 Nota: la correlación se calcula para los crecimientos anuales. Por último, el indicador sintético para el sector de servicios no destinados a la venta extremeño está compuesto por: ocupados en servicios no destinados a la venta, créditos concedidos al sector público y matriculación de turismos. Cuadro nº 45. Indicadores para el crecimiento del VAB de servicios no venta. Indicadores Notación (en crecimientos) Correlación TOCUG 0.228 Ocupados en servicios no destinados a la venta (Trimestral). Créditos concedidos al sector público (Trimestral). Matriculación de turismos (Mensual). TCTOSPU 0.181 TMATTUR 0.554 Nota: la correlación se calcula para los crecimientos anuales. V.3.5. ETAPA QUINTA. AGREGACIÓN DE LAS “SEÑALES” SELECCIONADAS PARA OBTENER EL INDICADOR SINTÉTICO. Antes de proceder a la agregación de los ciclo-tendencias de los indicadores seleccionados, se deben trimestralizar aquellas señales que tengan periodicidad mensual. Además, hemos calculado el crecimiento interanual ( T 14 ) de las ciclo-tendencias. La forma de abordar la problemática concerniente a la composición de las señales seleccionadas es muy amplia (tal y como se expuso en el capítulo IV), pudiéndose optar por métodos tan dispares que sería difícil recoger todos los posibles indicadores sintéticos. Todos los procedimientos de agregación de las señales para generar los indicadores sintéticos trimestrales recogidos en el Anexo 4 se han probado con el objetivo de verificar la bondad de cada uno de ellos a la hora de construir indicadores sintéticos de actividad económica. No obstante, en la etapa de validación los resultados apuntan a elegir el índice sintético basado en la DP2 (excepto en el caso de el sector energético, en el que no se ha optado por ninguno de los procedimientos expuestos). -Pág. 181- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña La rama energética tiene como elemento distintivo que el método de agregación utilizado para la obtención de su indicador sintético es la tasa de ( ) crecimiento interanual T 14 de la señal extraída de la suma aritmética de los indicadores parciales. El cálculo del indicador sintético de distancia DP2 se ha realizado utilizando el programa Feliz.for, lo cual hace operativo un procedimiento que en otro caso resultaría difícil de realizar95. El programa ha llevado a cabo las operaciones a través de la matriz de diferencias que utiliza el vector mínimo. En este momento queremos poner de relieve que la elección del índice sintético basado en la DP2, no significa que estemos indicando la necesidad de rehusar la utilización de procedimientos como el elaborado por el NBER (que está ampliamente contrastado y con el que también hemos obtenido buenos resultados). En este trabajo simplemente advertimos del hecho de que con la utilización de la DP2 como método de agregación hemos obtenido resultados más satisfactorios en la etapa de validación del indicador que con el resto de procedimientos. La ventaja podría explicarse por la combinación de dos factores96: -Al ser un indicador de distancia, se ha operado comparando a todos los indicadores parciales con un mismo vector de referencia en un momento de tiempo. Tomando como base a Pena (1977, Pág. 77), se puede afirmar que los indicadores de distancia comparan la posición relativa de los distintos indicadores parciales (es decir que “operan” por filas). Esta peculiaridad separa a la DP2 de métodos como el análisis factorial que extrae los factores comunes que contienen los indicadores parciales (las columnas). Por todo ésto, una propuesta en línea con la que Zarzosa (1992, Pág. 186) realiza es la de utilizar el análisis factorial y los indicadores de distancia como complementarios, de manera que el primero resuma la información y el segundo la agregue97. -Al evitar la repetición de información de los indicadores parciales, impide la amplificación ostensible de las oscilaciones cíclicas de los indicadores que se produce con otros métodos. 95 En la Tesis de Pilar Zarzosa, se presenta el programa “Feliz.for”, realizado por Félix Zarzosa en Fortran y con un diseño acorde al esquema de cálculo de la distancia DP2. En este momento queremos mostrar nuestro agradecimiento al Profesor Bernardo Pena, que nos proporcionó dicho programa. 96 La comparación teórica de todos los métodos de composición de indicadores respondería a esta cuestión; sin embargo, no abordamos este tema por no ser el objetivo de este trabajo. 97 En Márquez y Ramajo (1997) se hizo un ejercicio de este tipo, siendo los resultados satisfactorios, pero el indicador sintético obtenido era más errático (exigiendo un suavizado posterior) que el que se obtenía aplicando la DP2 a las señales originales (sin componentes principales). -Pág. 182- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura V.3.6. ETAPA SEXTA. VALIDACIÓN DEL INDICADOR SINTÉTICO. Los indicadores sintéticos se validarán según la forma expuesta en el Capítulo IV. De todas las posibles opciones, el indicador sintético trimestral que recoge, en general, de manera más robusta el crecimiento de los VABpm (tanto del agregado como de los sectoriales) para Extremadura en un trimestre con respecto al mismo trimestre del año anterior es el que agrega los crecimientos T14 de las señales seleccionadas utilizando el indicador sintético de distancia DP2 . En el Cuadro nº 46 se muestran los resultados de la regresión realizada entre la tasa de crecimiento anual del VABNANE (TVABNANE) y la tasa de crecimiento anual del indicador sintético obtenido con la DP2 para las 14 señales seleccionadas (ISDp2_14). Cuadro nº 46. Validación TVABNANE = −0.020384 + 0.005177 * ISDP2 _14 R 2 = 0.962 ( −3.987) (11374 . ) Nota: entre paréntesis, estadístico t. El Gráfico nº 61 muestra el buen seguimiento que el indicador construido realiza de la economía no agraria y no energética de Extremadura. Gráfico nº 61: TVABNANE vs ISDP2_14 0 .0 6 16 0 .0 5 14 0 .0 4 12 0 .0 3 10 0 .0 2 8 0 .0 1 6 0 .0 0 4 89 90 91 92 93 TVABNANE 94 95 96 IS D P 2 _ 1 4 En el Gráfico siguiente se puede apreciar la evolución del indicador sintético de actividad económica para Extremadura, y podemos establecer el perfil de crecimiento de la economía extremeña (no agraria no energética) a nivel trimestral. -Pág. 183- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 62: Evolución trimestral del índice sintético. 16 14 12 10 8 6 4 2 88 89 90 91 92 93 94 95 96 97 IS_DP214 Por otra parte, los indicadores sintéticos sectoriales también se validan mediante regresiones que relacionan a las tasas de crecimiento del VABpm de un sector extremeño con el indicador sintético sectorial correspondiente anualizado (Cuadro nº 47). Cuadro nº 47. Regresiones entre los indicadores sintéticos anualizados y los crecimientos del vabpm sectorial extremeño. Sectores Muestra a b Estadístico t (Coeficiente b) 9,471 10,961 4,512 4,616 3,264 3,523 Intervenciones R2 A 1988-1995 -0,204 0,080 1989; 1991; 1995 0,982 E 1984-1995 0,019 1,142 1990 0,933 I 1988-1995 0,635 0,020 1989 0,893 B 1989-1995 -0,142 0,042 1989 0,841 S 1988-1995 -0,020 0,010 1990 0,733 G 1988-1995 -0,049 0,012 1988-1992 0,991 Nota: La relación ajustada es de la forma Vt = a + bI t + c1 F 1+...+ c p Fp + et ; en donde Vt es el crecimiento anual del VABpm sectorial; I t es el indicador sintético sectorial anualizado, y F 1,..., Fp son las variables de intervención, las cuales representan a las variables de impulso o de escalón. Otra forma de validación es observar gráficamente si el índice sintético anualizado sigue la evolución interanual del VABpm sectorial (Gráfico nº 63). -Pág. 184- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Gráfico nº 63. Crecimiento del VAB sectorial vs indicador sintético anualizado. 0.3 5 1.6 1.2 1.0 0.2 4 0.1 1.2 0.8 0.8 0.6 3 0.0 0.4 0.4 2 -0.1 0.2 0.0 0.0 -0.2 1 87 88 89 90 91 92 AGRARIO 93 94 -0.2 -0.4 95 84 85 86 87 INDICE 88 89 90 ENERGIA 0.15 8 7 0.10 91 92 93 94 95 INDICE 0.12 7 0.10 6 0.08 6 0.05 5 0.00 4 0.06 5 0.04 4 0.02 0.00 -0.05 3 -0.10 2 88 89 90 91 92 INDUSTRIA 93 94 3 -0.02 2 -0.04 95 89 90 INDICE 91 92 93 CONSTRUCCION 0.12 10 94 95 INDICE 0.10 7 0.08 0.10 8 0.08 6 0.06 5 0.04 0.06 6 0.02 0.04 4 0.02 4 0.00 3 -0.02 2 0.00 88 89 90 91 SER_VENTA 92 93 94 95 2 -0.04 88 INDICE 89 90 91 SERV_NOVENTA 92 93 94 95 INDICE En líneas generales, se puede afirmar que los índices sintéticos recogen de una manera aceptable la evolución sectorial de la economía extremeña. Los resultados peores se obtienen para el sector de servicios no destinados a la venta (en cuya regresión del cuadro 2 existe una variable de escalón que enmascara a los verdaderos resultados). El diagnóstico para este sector es que el indicador sintético no contiene información suficiente (le falta algún indicador parcial relevante) para recoger de manera adecuada la evolución del crecimiento sectorial. No obstante, la no disposición de otra información coyuntural para dicho sector imposibilita, de momento, la mejora de los resultados. En el Gráfico nº 64 se presentan los índices sintéticos (original y suavizado) para cada uno de los seis sectores productivos de Extremadura. Los -Pág. 185- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña índices se han suavizado utilizando un filtro recursivo de paso bajo98 definido en Cristóbal y Quilis (1994) que permite anular prácticamente las oscilaciones irregulares a la vez que conserva la señal cíclica99. Gráfico nº 64. Índices sintéticos sectoriales para Extremadura. 8 15 10 6 5 4 0 2 -5 0 -10 88 89 90 91 92 93 AGRARIO 94 95 96 86 87 88 89 TASA 90 91 92 ENERGIA 10 10 8 8 6 6 4 4 2 2 93 94 95 96 TASE 0 0 87 88 89 90 91 92 93 INDUSTRIA 94 95 96 89 90 TASI 91 92 93 94 CONSTRUCCION 12 7 10 6 8 5 6 4 4 3 2 2 95 96 TASB 1 0 87 88 89 90 91 S_VENTA 92 93 94 95 96 88 89 TASSV 90 91 92 S_NOVENTA 93 94 95 96 TASG Fuente: Elaboración propia. 98 Se entiende por filtro de paso bajo aquel que atenúa las altas frecuencias y amplifica las bajas, por eso también se dice que su banda de paso está constituida por las bajas frecuencias. 99 Según Cristóbal y Quilis (1994), dicho filtro recursivo de paso bajo es un AR(2) con ganancia 0,5 en 8 trimestres y unitaria en la frecuencia cero; es decir, que la amplitud (el módulo de la función de respuesta de frecuencia o ganancia) de un componente cíclico de frecuencia 2π 8 es 0,5 y para los de frecuencia 0 es 1. En nuestro caso se calcula: TAS _ IS = 0.3368 IS , 1 − 0.99377 L + 0.33057 L2 siendo L el operador retardo e IS el indicador sintético. -Pág. 186- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura El índice sectorial energético adopta esa representación como consecuencia de la enorme dependencia que este sector extremeño tiene de la Central Nuclear de Almaraz, de manera que los ciclos productivos por los que pasan este tipo de centrales eléctricas tienen su fiel reflejo en la evolución del VABpm sectorial. Llama la atención la representación del indicador de servicios no venta, que en el año 1994 obtiene unos valores “extraños”. V.4. INFLUENCIAS DEL CRECIMIENTO NACIONAL. A continuación se pretende comprobar la existencia de influencias de los crecimientos nacionales en los extremeños a nivel trimestral. Para ello, en primer lugar se comparan en el Gráfico nº 65 los índices sectoriales extremeños suavizados (utilizando la tasa anual suavizada de Cristóbal y Quilis (1994)) con el crecimiento interanual de los datos sectoriales trimestrales de la Contabilidad Nacional Trimestral de España (CNTR). Suavizamos nuestro índice sintético para que presente características similares a los índices de CNTR. -Pág. 187- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 65. Comparación datos interanuales de Contabilidad Nacional Trimestral e índices sintéticos sectoriales suavizados para Extremadura. 30 AGRARIO 20 6 8 5 6 4 10 10 INDUSTRIA 8 4 6 2 3 0 0 2 -10 -20 88 89 90 91 92 CNTR 15 93 94 95 4 -2 2 1 -4 0 -6 96 0 88 89 INDICE SUAVIZADO 90 91 92 CNTR 8 CONSTRUCCION 93 94 95 96 INDICE SUAVIZADO 6 12 SERVICIOS VENTA 10 5 10 4 8 3 6 2 4 1 2 6 5 4 0 2 -5 -10 0 89 90 91 92 CNTR 93 94 95 96 0 0 89 INDICE SUAVIZADO 8 90 91 CNTR 92 93 94 95 96 INDICE SUAVIZADO 6 SERVICIOS NO VENTA 6 5 4 4 2 3 0 -2 2 88 89 90 CNTR 91 92 93 94 95 96 INDICE SUAVIZADO Nota: La industria de la CNTR contiene a los sectores industriales manufactureros y energéticos, de forma que al no disponerse de cifras desagregadas, se ha considerado apropiado comparar la rama industrial de la CNTR con el índice de la industria manufacturera extremeña. El Cuadro nº 48 indica que los crecimientos interanuales ( T14 ) de los sectores extremeños agrario, de la industria manufacturera, construcción y de servicios destinados a la venta están asociados de manera significativa a los crecimientos de sus homólogos nacionales. En las regresiones para la rama agraria, que es la única en la que se han introducido intervenciones, se puede apreciar cómo la inclusión en el período muestral de los trimestres en los que la sequía empezó a notarse, hace que desaparezcan las asociaciones al crecimiento nacional. De igual forma, de dicho cuadro se extrae la conclusión de que el comportamiento coyuntural del sector público extremeño difiere significativamente del análogo nacional100. 100 Insistimos en el hecho de que este resultado viene, en nuestra opinión, inducido por la mala representación que los indicadores parciales seleccionados para componer el indicador sintético hacen de esta rama. -Pág. 188- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Cuadro nº 48. Regresiones entre los índices sintéticos suavizados y los crecimientos sectoriales del VABpm nacional. Estadístico t R2 (Coeficiente b) Agrario 1988.1-1996.4 4.649 -0.019 -0.577 0.009 Agrario 1988.1-1992.2 4.967 0.138 2.585 0.295 1988.1-1996.4 4,481 0,033 1,993 0,848 Agrario (int.) Industria 1988.1-1996.4 4,395 0,508 6,506 0,554 Construcción 1988.1-1996.4 3,663 0,180 6,217 0,563 Servicios Venta 1988.1-1996.4 3,512 1,365 7,787 0,640 Servicios no venta 1988.1-1996.4 3,818 0,001 0,026 0,000 Nota: La relación ajustada es de la forma I t = a + bVt + et ; en donde I t es el indicador Sectores Muestra a b sintético sectorial extremeño y Vt es la T14 del VABpm sectorial de la CNTR. En la regresión del sector agrario denotada como (int.) se han introducido intervenciones para recoger la mayor incidencia del período de sequía en Extremadura. V. 5. ANÁLISIS CÍCLICO DE LAS RAMAS PRODUCTIVAS. En este apartado se pretende realizar una explotación de los indicadores sintéticos con fines de análisis cíclico. Una tarea importante a realizar es la detección de los puntos de giro (transición de una fase de expansión a una fase de desaceleración o viceversa) de los indicadores sintéticos construidos para posibilitar su clasificación cíclica con respecto a la serie nacional tomada como referencia. Para llevar a cabo el fechado se ha utilizado el programa <F> de detección de puntos de giro101 detallado en Abad y Quilis (1994, 1996), que sólo es aplicable a datos mensuales. En el fechado cíclico que realiza el programa <F> se entiende por puntos de giro (máximos y mínimos): “aquellos valores de tangente nula en la serie de tasas suavizadas que distan entre sí al menos quince meses (si son del mismo signo) y cuyas fases (número de meses entre dos puntos de giro de signo contrario) no sean inferiores a cinco meses” (Abad y Quilis (1996, Pág.72)). Previamente a la ejecución del fechado, ha sido necesario interpolar las señales cíclicas trimestrales de las cifras de CNTR y de los indicadores cíclicos sectoriales. El programa de interpolación utilizado ha sido el creado por Quilis y Abad(1997), tomando como base teórica los trabajos de Melis (1992) y Abad y Quilis (1996). No pretendemos abundar más de lo necesario en esta cuestión, ya que la interpolación la utilizamos en este caso como una simple herramienta descriptiva. En consecuencia, sólo vamos a comentar que se trata de transformar cada uno de los indicadores, formados por observaciones equidistantes y que están separados por un trimestre, en otra equivalente de valores separados por meses. La interpolación del programa es una aplicación 101 Trabajamos con programas con el objetivo de imponer objetividad en los análisis a realizar. -Pág. 189- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña directa del teorema del muestreo uniforme en el dominio del tiempo102, que sostiene que “un proceso continuo puede representarse correctamente por muestras separadas por s unidades de tiempo si, y sólo si, el proceso no contiene oscilaciones de período inferior a 2s unidades de tiempo” Melis (1992, Pág. 310), siendo s en nuestro caso igual a cuatro. Por lo tanto, la condición de aplicación es que nuestro indicador no contenga componentes de frecuencias superiores a Wc =1/ (2s)= 1/ 8 oscilaciones por unidad de tiempo, o lo que es lo mismo, que sea de banda limitada al intervalo (0, Wc). Esto ya lo hemos logrado en el caso de los indicadores sintéticos con la tasa anual suavizada. En lo que se refiere a las cifras de CNTR, ya verifican esta condición por la forma de elaborarlas. Según Melis (1992, Pág. 321), la interpolación de paso bajo consta de las siguientes etapas: a) “Intercalar s-1 ceros entre los valores de la serie original multiplicados por s.” De esta forma, para obtener una serie mensual a partir de otra trimestral hay que intercalar tres ceros entre los valores de la serie trimestral multiplicada por cuatro. b) “Someter la serie intercalada a un filtro de paso bajo (...). La salida del filtro es la serie interpolada.” El filtro de paso bajo que aplica el programa es el autorregresivo de orden 5 definido en Abad y Quilis (1996), y que viene dado por: φ 5 ( L) = 0.0018 1 − 3.9923 L + 6.4582 L − 5.2806 L3 + 2.1793 L4 + 0.3627 L5 2 Una vez aplicado el mencionado método de interpolación de paso bajo, se puede realizar el fechado con el programa <F>. La cuestión previa que hay que considerar a la hora de extraer conclusiones es que el estudio realizado en este caso adolece de unas limitaciones considerables provenientes del período temporal corto sobre el que se ha realizado el análisis. Hecha esta salvedad importante, los resultados del fechado se representan en el Gráfico nº 66. 102 Ver Melis (1992). -Pág. 190- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Gráfico nº 66. Fechado de los índices sintéticos extremeños y de las tasas de variación sectoriales interpoladas de la CNTR. AGRARIO INDUSTRIA CONSTRUCCION 20 1.5 6 ESPAÑA 1.5 15 ESPAÑA 1.5 ESPAÑA 1.0 4 1.0 0.5 2 0.5 10 1.0 10 0.5 5 0 0.0 0 0.0 0.0 0 -0.5 -2 -0.5 -10 -20 89 90 91 92 93 CNTR 94 95 -1.0 -4 -1.5 96 -6 -1.0 88 89 90 FECHADO 91 92 CNTR 10 EXTREMADURA 1.5 1.0 8 93 94 95 -1.0 -1.5 -10 96 90 -1.5 91 FECHADO 92 93 CNTR 10 EXTREMADURA 1.5 95 96 FECHADO 7 1.5 8 1.0 6 1.0 0.5 5 0.5 0.0 4 0.0 -0.5 3 -0.5 -1.0 2 -1.0 -1.5 96 1 6 0.0 4 4 -0.5 2 -1.0 0 89 90 91 92 93 INDICE 94 95 -1.5 96 2 0 88 89 90 FECHADO 91 92 INDICE 93 94 95 FECHADO -1.5 90 91 92 93 INDICE SERVICIOS VENTA SERVICIOS NO VENTA 5 94 EXTREMADURA 0.5 6 -0.5 -5 1.5 ESPAÑA 8 1.5 ESPAÑA 1.0 4 1.0 6 0.5 3 0.5 4 0.0 2 0.0 2 -0.5 1 -1.0 0 88 89 90 91 92 CNTR 93 94 95 -1.5 96 -0.5 0 -1.0 -2 88 89 90 FECHADO 91 92 CNTR 12 EXTREMADURA 1.5 93 94 95 -1.5 96 FECHADO 6 1.5 EXTREMADURA 1.0 10 1.0 5 0.5 0.5 8 0.0 4 0.0 6 -0.5 -0.5 3 4 -1.0 2 88 89 90 91 92 INDICE 93 94 FECHADO 95 -1.5 96 -1.0 2 88 89 90 91 92 INDICE 93 94 95 -1.5 96 FECHADO Fuente: Elaboración propia a partir del fechado del programa <F>. -Pág. 191- 94 95 FECHADO 96 Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña El Cuadro nº 49 recoge los detalles técnicos sobre las características básicas recogidas en los gráficos anteriores: Cuadro nº 49. Número de máximos y mínimos fechados. España Número de Extremadura Máx. Mín. Máx. Mín. observaciones 1989.01-1996.04 Agrario 88 2 2 2 3 1988.01-1996.04 Industria 100 3 4 3 3 1990.01-1996.04 Construcción 76 2 2 1 1 1988.01-1996.04 Servicios venta 100 3 4 3 4 Servicios no venta 1988.01-1996.04 100 3 4 2 2 Notas: Máx. y Mín. indican, respectivamente, el número de máximos y de mínimos detectados. Sectores Período analizado Para abundar en el análisis cíclico, se ha utilizado la técnica de clasificación cíclica que realiza el programa <G> definido en Abad y Quilis (1994, 1996), el cual permite clasificar a cada uno de los índices sintéticos sectoriales mensuales en adelantado, retrasado, coincidente o inclasificable en función del desfase que su señal cíclica tome con respecto a las cifras homólogas de CNTR. La clasificación que establece este programa es: -Adelantado: si tiene un desfase (distancia en meses entre los puntos de giro del mismo signo para el indicador y la serie de referencia) mediano negativo y superior a tres meses en valor absoluto. -Coincidente: si tiene un desfase inferior a tres meses en valor absoluto. -Retrasado: si posee un desfase mediano positivo y superior a tres meses en valor absoluto. -Inclasificable o acíclico: si el número de puntos de giro del mismo signo del indicador y de su serie de referencia que quedan emparejados es muy pequeño con respecto al número total de puntos de giro. En el cuadro siguiente se resume la información fundamental que proporcionó dicho programa al aplicárselo a nuestras series: -Pág. 192- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Cuadro nº 50. Resultados de la clasificación índices sintéticos vs tasas de CNTR sectoriales. Indicadores Clasificación Ry Rx DMG IC Signo sintéticos (Respecto a CNTR) Agrario Coincidente 0.8 1 0 -0.113 + Industria Coincidente 1 0.857 1 0.6 + Construcción Inclasificable 1 0.5 4 0.368 + Servicios venta Coincidente 1 1 -1 0.56 + Servicios no venta Inclasificable 1 0.571 0.5 0.18 + Nota: Sean nd = el número de puntos de giro con relaciones dobles (que es el mismo para ambas series); CCNTR = el conjunto de puntos de giro de la serie de referencia; CIS = el conjunto de puntos de giro de la serie a clasificar; ni = el cardinal de Ci , para i = CNTR, IS. Ry = nd//nCNTR es el porcentaje de puntos de giro que se clasifican para cada serie de referencia (datos interpolados de CNTR); Rx = nd//nIS es el porcentaje de puntos de giro que se clasifican para cada indicador sintético; si Ry y Rx son > 0,7, diremos que IS y CNTR están fuertemente relacionados, si Ry o Rx son < 0,5, diremos que no existe relación cíclica entre IS y CNTR; para el resto de casos posibles, diremos que están débilmente relacionados. DMG es la mediana de los desfases de todos los puntos de giro. Si DMG está en (-1 , 1), el ciclo regional está en fase con el español, si DMG ≥ 1, el ciclo español adelanta al extremeño (la región irá retardada), si DMG ≤ 1, la serie extremeña adelanta a la española. Signo indica el carácter procíclico (+) o anticíclico (-) de cada indicador sintético con respecto al ciclo definido por las tasas de CNTR interpoladas. ICCNTR,IS = n −1 ( FechadoCNTR × Fechado IS ) , donde Fechadoi = 1 en las etapas de ∑ t =1,...,T aceleración, y Fechadoi = −1 en las etapas de desaceleración, para i = CNTR , IS . Así, IC es un índice (comprendido entre -1 y 1) de coincidencia-conformidad global, de manera que si IC está próximo a 1, las fases de aceleración-desaceleración del indicador sintético evolucionan sincrónicamente con la serie de referencia de CNTR, si IC está próximo a -1 la sincronía existente es de tipo inverso, y si IC está próximo a 0 existe poca coincidencia entre las fases de ambas series. Por lo tanto, según los resultados del Cuadro nº 50, todos los sectores extremeños son procíclicos, es decir, que en ningún caso se les puede calificar de anticíclicos. Se aprecia que las ramas agraria, industrial y de servicios venta están fuertemente relacionados (Ry y Rx son > 0,7), mientras que el sector de la construcción y de servicios no destinados a la venta están débilmente relacionados. -Pág. 193- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña El ciclo de las ramas nacionales de la industria y de la construcción adelanta al ciclo de estas ramas extremeñas (DMG ≥ 1), mientras que los servicios venta regionales adelantan a los nacionales (los puntos de giro se han observado después en la serie de referencia). La rama agraria y de servicios no venta están en fase. A la vista del IC, las ramas que pasan por fases de aceleración y desaceleración en sincronía con las equivalentes nacionales son los servicios venta y la industria. Por el contrario, las ramas agraria, de la construcción y de servicios no destinados a la venta tienen poca coincidencia. El diagnóstico del programa es el de calificar a los sectores extremeños agrario, industrial y de servicios destinados a la venta de coincidentes, es decir, que en líneas generales llegan a los puntos de giro cíclicos con un desfase inferior a los tres meses. No obstante, para el caso del sector agrario, la medida de coincidenciaconformidad (IC = -0,1136) indica la existencia de poca coincidencia entre las fases del indicador sintético agrario y el ciclo agrario nacional. En este sentido, el análisis detallado del gráfico de fechado que proporciona el programa <F> puede posibilitar la interpretación de los resultados del programa <G>, en el sentido de que se aprecian dos etapas claramente distintas; una primera en la que se evidencia la existencia de coincidencia cíclica entre ambas series, y una segunda en la que el ciclo extremeño transcurre de manera distinta al nacional. En consecuencia, un examen más minucioso de los desfases respecto a los mínimos y máximos de los datos homólogos de CNTR junto con un conocimiento de las peculiares características del sector agrario extremeño permiten afirmar que en la fase de desaceleración (período de sequía) la economía extremeña tocó fondo antes de que lo hiciera el sector a escala nacional; de igual manera, la fase de aceleración posterior se produjo con anterioridad en la Comunidad extremeña. Estas reacciones cíclicas se explican por la especial estructura productiva del sector agrario extremeño, con una gran dependencia de los factores climáticos, de manera que el diagnóstico general sería que en períodos temporales “normales” existe coincidencia cíclica, mientras que en las etapas de inclemencias climáticas, puede haber discrepancias en el comportamiento cíclico nacional y regional. Para los sectores de la construcción y de servicios no destinados a la venta el programa no dispone de suficientes puntos de giro emparejados, razón por la cual los ha clasificado como acíclicos o inclasificables. La longitud corta de los indicadores sintéticos sectoriales no permite la realización de un diagnóstico definitivo de ambos sectores. -Pág. 194- Capítulo V. Construcción de Indicadores Sintéticos para Extremadura Para concluir, en lo que respecta a la clasificación cíclica de los sectores extremeños con respecto a los sectores nacionales, la evidencia empírica muestra que todos los sectores extremeños son procíclicos, teniendo los sectores industrial y de servicios destinados a la venta (y también, aunque con matices el sector agrario) el carácter de coincidentes con respecto a las series de referencias nacionales. Los sectores de la construcción y de servicios no destinados a la venta aparecen como acíclicos o inclasificables; sin embargo, desde nuestro punto de vista, el diagnóstico no es definitivo, habida cuenta de las dificultades encontradas a la hora de construir los indicadores sintéticos para estos sectores y del reducido espacio de tiempo utilizado para el análisis. -Pág. 195- PARTE TERCERA. MODELIZACIÓN ECONOMÉTRICA. Capítulo VI. Alternativas Modelizadoras y Conceptos CAPÍTULO VI. ALTERNATIVAS MODELIZADORAS Y CONCEPTOS. VI.1. LOS MODELOS ECONÓMICOS REGIONALES. Un objetivo importante a conseguir es la exposición del comportamiento económico regional (para las principales macromagnitudes económicas) con fines descriptivos, explicativos, predictivos y/o de simulación (simulación de políticas o planteamientos de escenarios). La perspectiva predictiva es la que obtiene una posición prioritaria en nuestro modelo, constituyendo el propósito fundamental a alcanzar; de tal forma que condiciona, de manera absoluta, en un primera etapa a la elección del enfoque modelizador a aplicar, y en una segunda etapa a la especificación final del modelo. Desde la perspectiva predictiva, parece clara la necesidad de trabajar con modelos como forma de garantizarse la objetividad de los resultados103. Nuestro interés se centra en el estudio de la evolución de un número determinado de variables, de manera que los enfoques que podemos adoptar son muy diversos. En esta parte proponemos el enfoque basado en relaciones entre variables, optando por la orientación causal que logre explicar la generación de las macromagnitudes económicas regionales. En lo referente a la técnica de predicción a utilizar en nuestro análisis regional, la elección final van a ser los modelos econométricos. La elaboración de un modelo econométrico para Extremadura requiere el conocimiento previo del estado presente de la modelización económica (y econométrica) regional. Por ello, vamos a ubicar el trabajo dentro del tejido teórico adecuado, partiendo de una visión general y terminando con la concreción de los temas de mayor relevancia en el ensayo a realizar. 103 En Espasa y Cancelo (Eds.) (1993) se argumenta esta idea. -Pág. 199- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VI.2. MODELOS REGIONALES Y MODELOS ECONOMÉTRICOS. Los modelos regionales “predicen la actividad económica, así como los efectos de las políticas y de cambios externos. Comprenden modelos de una sola región, los cuales representan una área subnacional, y modelos multiregionales, que muestran las interacciones entre dos o más áreas subnacionales. Ayudan en la elección de la política nacional que facilita los ajustes regionales ante los cambios nacionales e internacionales.” Treyz (1994, Pág. 1). Este párrafo sintetiza algunas de las ideas en torno a las que planteamos el contenido de este apartado. Los modelos regionales pueden tener dos encauzamientos, como aquellos que se orientan a un espacio componente de una nación (en el caso español sería una Comunidad Autónoma o un conjunto de éstas), o como aquellos que intentan representar una actividad o fenómeno económico que ocupa una determinada distribución espacial Por ejemplo, en España son aquellos modelos en los que la actividad en estudio implica un posicionamiento espacial que en principio no tiene porqué tener una identificación con una (o varias) Comunidad(es) Autónoma(s). Desde el punto de vista de esta tesis, es el primer enfoque el que vamos a adoptar; en concreto, nos centraremos en la Comunidad Autónoma de Extremadura como uno de los espacios regionales que componen la nación española. Las características de la economía regional deben venir recogidas por una base teórica en la que se sustente el modelo regional. Treyz (1994) nos ilustra acerca de los modelos regionales, distinguiendo entre modelos uniregionales y multiregionales. Suriñach (1987, Pág. 79) da una regla para saber cuándo se puede considerar a un modelo como uniregional: cuando trabaja con un espacio geográfico que es un todo y que no tiene desagregaciones. Aznar (1978) dice que los modelos uniregionales estudian una región completa y utilizan dentro de su especificación a las variables nacionales como exógenas; es decir, llevan implícita la aproximación llamada “descendente” (“top down”). En otro sentido, Suriñach (1987, Pág. 79) dice que un modelo multirregional es aquél que realiza el análisis de un espacio geográfico mediante la construcción de un modelo regional para cada una de sus distintas áreas, de manera que puede explicitar las interdependencias económicas para cada área. Courbis (1979b) también denomina a los modelos multiregionales como regionales-nacionales (“que estudian de manera exhaustiva e interdependiente el conjunto de las grandes regiones de una misma economía regional.” (Pág. 22)). -Pág. 200- Capítulo VI. Alternativas Modelizadoras y Conceptos Los modelos uniregionales han sido bastante criticados; así, Nijkamp, P., Rietveld, P. y Snickars, F. (1986, Pág. 259) señalan como imperfecciones de estos modelos: (i)La falta de consideración de efectos de difusión y de retroalimentación horizontal (multirregional e interregional). Especialmente en un sistema espacial dinámico caracterizado por fuerte competencia interregional, donde las predicciones uniregionales tienden a ser poco fiables. (ii)La falta de bases teóricas satisfactorias para incluir efectos de oferta en la forma de componentes específicos de localización o infraestructurales de una región. (iii)La falta de consistencia de los modelos uniregionales separados con respecto al sistema nacional total (en ocasiones conocida como la condición de aditividad). (iv)La falta de mecanismos de retroalimentación verticales entre la economía nacional y la regional (estructuras de arriba a abajo (“top-bottom”) y de abajo hacia arriba (“bottom-up”). (v)La falta de orientación específica hacia cuestiones de política local, regional o nacional en campos diversos (empleo, viveinda, tranasporte, enefgía, medio ambiente, etc.). (vi)La falta de información veraz y/o de sistemas de información accesibles que puedan servir para proporcionar los ingredientes necesarios para construir tales modelos. Estos mismos autores indican que todos estos problemas “han conducido a la aparición de varias direcciones nuevas en la construcción de modelos económicos regionales, originados desde finales de los sesenta hacia adelante.” (Pág. 259). En el cuadro siguiente presentamos de manera sinóptica las grandes tendencias en la construcción de modelos económicos regionales: -Pág. 201- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 51. Tendencias en los modelos económicos regionales. TENDENCIA PRIMERA: “puede ser caracterizada por Fechado: Desde finales de una búsqueda sistemática de representaciones cuantitativas los sesenta hasta inicios de de los sistemas económicos espaciales.” Además, ”se le los setenta. otorgó mucha importancia a la definición y especificación de los componentes e interacciones de estos sistemas.” (Nijkamp, Rietveld y Snickars (1986, Pág. 259)). Subetapas: 1ª Utilización de la metodología “input-output”. 2ª Desarrollo de modelos basados en conceptos de optimización. 3ª Fuerte tendencia hacia la especificación econométrica. 4ª Modelos basados en hipótesis de recursos infinitos. TENDENCIA SEGUNDA: “nueva dirección en la Fechado: A lo largo de los construcción de modelos regionales en los que el impacto de años setenta. restricciones diversas y los límites al crecimiento han jugado un papel esencial” (Nijkamp, Rietveld y Snickars (1986, Pág. 260)). TENDENCIA TERCERA: “se han hecho esfuerzos para Fechado:Desde mediados diseñar modelos económicos espaciales integrados que estén de los años setenta en disponibles para una evaluación de las tendencias adelante. regionales reales por medio de un amplio espectro de objetivos regionales (en ocasiones contradictorios) y/o condiciones adicionales”. (Nijkamp, Rietveld y Snickars (1986, Pág. 260). Características más destacables: -Algunos modelos son multidisplinarios (incorporan variables de distinta naturaleza: demográficas, medio ambientales, energéticas y sociales). -Tienen una mayor orientación multirregional, de manera que aparecen problemas relativos a la captación de las interacciones existentes entre las economías regionales y la nación. TENDENCIA CUARTA: Que se puede separar en dos Fechado: Desde el inicio de los años ochenta. (Weber (1986, Pág. 18)): (1) desarrollo en las técnicas modelizadoras (nuevos métodos de estimación de parámetros, desarrollo de modelos trimestrales, inclusión de subsectores) y (2) tendencia importante a la ampliación de los modelos (se plantean modelos multidisciplinares y/o interregionales) TENDENCIA ACTUAL: Se diseñan modelos con el Fechado: Desde el inicio objetivo de responder a problemas específicos planteados de los años noventa. sobre cuestiones concretas. Dentro de esta tendencia parece existir una renuncia a la búsqueda de modelos globales y/o multidisciplinares. Fuente: Nijkamp, Rietveld y Snickars (1986, Págs. 259-261), Weber (1986, Pág. 18) y elaboración propia. Hemos señalado estas tendencias con el ánimo de indicar las principales líneas modelizadoras; es decir, no hemos querido inducir a pensar que se trata de corrientes excluyentes, sino que son las preponderantes en un momento de tiempo. -Pág. 202- Capítulo VI. Alternativas Modelizadoras y Conceptos En líneas generales, y sin entrar a valorar los condicionantes que surgen en el terreno aplicado, es preferible un modelo multirregional a uno regional, porque refleja la retroalimentación (“feedback”) existente de la región a las otras regiones o a la nación (si se considera al resto de regiones como un conjunto exterior). Sin embargo, pasando al plano empírico, es más factible la ejecución de un modelo uniregional. Las razones que se suelen argumentar para defender la construcción de un modelo uniregional frente a uno multirregional suelen ser: - La obtención de datos que reflejen las relaciones entre las distintas regiones en un modelo multirregional puede ser una tarea ardua y, en la mayoría de los casos, irrealizable. Si pensamos en los datos del comercio interregional, tendremos una prueba evidente de la dificultad añadida que implican -en lo concerniente a la obtención de datos- estos tipos de modelos. - La causalidad en el sentido región-nación puede ser obviada para el caso general de regiones con economías abiertas y tamaño tan pequeño que no pueden provocar impactos importantes en la economía nacional. Dentro de los modelos multirregionales Suriñach (1987), siguiendo a Courbis (1979a), distingue cuatro aproximaciones para estudiar las interacciones existentes entre una región (en la que se centra el interés del análisis) y el resto de regiones (que incluso puede ser considerado como un sistema exterior a ella identificado con la nación): -Descendente (“Top-Down”). El sentido de la causalidad económica es desde la nación a la región, con ausencia de retroalimentación (“feedback”). -Ascendente (“Bottom-up”). El sentido de la causalidad económica es desde las regiones a la nación, de manera que las variables nacionales se obtienen por agregación de las regionales. -Interregionales. Son los que determinan conjuntamente variables de diferentes regiones, recogiendo las posibles orientaciones en la causalidad existente entre dichas regiones. -Regionales-nacionales. Son los que determinan conjuntamente las variables nacionales y regionales, recogiendo las dos posibles orientaciones en la causalidad existente entre las regiones y la nación. Suriñach (1987) subraya el hecho de que las dos primeras aproximaciones han sido desarrolladas utilizando básicamente técnicas econométricas (debido a que esta es la técnica fundamentalmente utilizada en los Estados Unidos de América, que es el país en el que mayor arraigo tienen estas aproximaciones), de igual forma que en las dos últimas aproximaciones los modelos económicos deterministas han sido los más empleados (como corresponde a la mayor implantación de estas técnicas en Europa, que es donde más se han utilizado las aproximaciones interregionales y regionales-nacionales). -Pág. 203- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña De cualquier forma, las técnicas de medición y de estimación de los modelos regionales104 son muy diversas, de manera que nos ha parecido oportuno recoger sólo aquellas que han tenido, de una manera general, una mayor implantación e importancia dentro de los estudios regionales. Algunas referencias -ya clásicas- para estudiar los modelos regionales y sus enfoques se pueden encontrar en Courbis(1980), Issaev et al. (1982), Bolton (1985), Burress et al. (1988) y Sivitanidou et al. (1988). El campo de posibles modelizaciones regionales que se podrían comentar es muy amplio y heterogéneo; la orientación estadística expuesta en la parte segunda de esta tesis la abandonamos en este parte tercera en beneficio de un enfoque causal que se sostiene de manera explícita en la teoría económica. Bajo estas premisas, Aznar (1978) divide a los modelos regionales en dos categorías: de simulación o explicativos (también llamados de comportamiento) y de optimización. El elemento en común entre estos dos grandes tipos de modelos es que tratan de explicar las relaciones entre las variables económicas, siendo el elemento distintivo que los segundos incorporan una función objetivo para maximizar o minimizar. Ramírez Sobrino (1992) agrupa a la división anterior de Aznar (1978) dentro de los modelos económicos regionales de aplicación normativa; para ello, argumenta que se trata de modelos regionales porque acotan “el ámbito espacial a la realidad regional”, y son de aplicación normativa porque “en el modelo se incluirán variables que puedan considerarse como instrumentos u objetivos de política económica” Ramírez Sobrino (1992, Pág. 124). Los modelos regionales de optimización incluyen una función objetivo, la cual recoge una medida a maximizar referente a la producción obtenida, o bien una medida de los costes de producción a minimizar sujeta a una serie de restricciones. La técnica optimizadora más utilizada ha sido los modelos de programación lineal, en los que la función objetivo a maximizar o minimizar es una función lineal sujeta a restricciones que se suelen expresar como desigualdades lineales. Por ejemplo, Richardson (1975) dice que se podría intentar maximizar la renta nacional bajo restricciones de equidad regional. El mismo autor subraya que esta técnica tiene grandes limitaciones a la hora de aplicarlas al análisis regional (Pág. 149): “El supuesto de las relaciones lineales (sobre todo las funciones lineales de producción) están en pugna con las economías de escala, las externalidades y otros factores de aglomeración que dominan en el montaje de la actividad económica en ciertas zonas.” Los modelos regionales de simulación tienen como objetivo fundamental la descripción del funcionamiento del sistema económico regional, lo cual puede posibilitar y facilitar la tarea de planificación. Los modelos regionales de 104 Volvemos a insistir en que hemos adoptado el enfoque de modelo regional desde la perspectiva de un espacio componente o integrado en un estado nacional. -Pág. 204- Capítulo VI. Alternativas Modelizadoras y Conceptos simulación que se suelen señalar en la literatura105 como técnicas fundamentales son los de entrada-salida (“input-output”), los de base económica y los econométricos. Lo que sí se puede afirmar con firmeza es que a lo largo de la historia de la modelización regional han existido unos enfoques que han sido más utilizados que otros. Por ejemplo, y sin ánimo ser exhaustivos, podemos señalar las siguientes106: -modelos gravitatorios, -análisis “shift-share”, -modelos de programación, -análisis “input-output”, -modelos de base económica y -modelos econométricos. A continuación, damos unas nociones elementales de los enfoques utilizados en este trabajo de una forma directa o indirecta; posteriormente nos centraremos de manera especial en el tipo de modelo que marca la línea de trabajo de esta parte de la tesis: el modelo econométrico regional. 105 Ver Suriñach i Caralt, J. (1987), Escolano Asensi, C. (1993), o Aguayo, E., Guisan, M.A., Rodríguez, X.A.(1997). 106 Estos ejemplos están tomados de Nijkamp, P., Rietveld, P. y Snickars, F. (1986). -Pág. 205- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VI.2.1. ANÁLISIS “SHIFT-SHARE”. Esta técnica ya la hemos utilizado en el Capítulo III, de manera que no insistiremos más en la descripción de este enfoque, aunque sí vamos a recalcar cuestiones relativas tanto a sus usos como a las críticas que recibe. En lo concerniente a su uso, descolla su utilización para satisfacer objetivos de índole descriptivo; es decir, que no es una herramienta orientada a aplicaciones con fines predictivos. En lo relativo a las críticas vertidas sobre este enfoque, queremos significar que éstas han sido muy numerosas; sirva como síntesis el siguiente texto de Nijkamp, P., Rietveld, P. y Snickars, F. (1986, Pág. 266): “El análisis “shift-share” ha sido objeto de innumerables críticas. Los resultados son sensibles al grado de detalle que se utiliza en la clasificación sectorial. Los cambios diferenciales a menudo parecen ser inestables en el tiempo, por lo que no son útiles para propósitos predictivos. Además, el análisis “shift-share” es un método esencialmente descriptivo. No explica porqué ciertas regiones tienen ventajas de localización. Por lo tanto, el uso de métodos “shiftshare” para predicciones económicas a largo plazo debe tratarse con precaución”. En definitiva, la técnica queda invalidada cuando se utiliza para predecir el crecimiento económico regional o para efectuar un análisis causal (por ejemplo, como una teoría sobre crecimiento económico) En nuestra opinión, el siguiente párrafo de Ramírez Sobrino (1992, Pág. 95-96) resume muy bien la consideración que debe prevalecer acerca de este tipo de enfoque: “Aún reconociendo sus graves inconvenientes (gran sensibilidad al nivel de desagregación sectorial, hipótesis de dudosa validez como la estabilidad de la participación sectorial en la estructura productiva, o la ausencia de poder explicativo del método) consideramos que es un instrumento útil cuando se utiliza con precaución (para períodos de tiempo no excesivamente dilatados, con fines descriptivos y no prospectivos, etc.), presentando la ventaja de requerir una información estadística que generalmente suele estar disponible.” En el capítulo siguiente especificamos un modelo econométrico de tipo descendente (“top-down”) para Extremadura, lo cual no ha sido óbice para que hayamos aplicado la técnica “shift-share” en el Capítulo III. Más aún, la utilización de este enfoque ha arrojado luz (desde la perspectiva descriptiva) sobre el estudio del crecimiento regional extremeño, de manera que el modelo econométrico se ve enriquecido en lo relativo al conocimiento de la economía extremeña por la utilización de este método. Este hecho enlaza con las palabras de Nijkamp, P., Rietveld, P. y Snickars, F. (1986, Pág. 266): “Una característica esencial y sobresaliente del análisis “shift-share” es la -Pág. 206- Capítulo VI. Alternativas Modelizadoras y Conceptos consideración del ámbito nacional como marco de referencia para el desarrollo regional. Esto también acontece en los modelos “top-down”(…). Por lo tanto, no debe sorprender que algunos modelos “top-down” estén directamente enlazados con el análisis “shift-share”(…)”. En nuestro caso, la aportación del análisis “shift-share” es la caracterización del crecimiento de la región extremeña respecto al crecimiento medio regional. -Pág. 207- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VI.2.2. MODELOS “INPUTS-OUTPUTS”. El modelo de entrada-salida (“input-output”) es un instrumento que posibilita la formalización matemática de las relaciones intersectoriales107 que se dan en la economía de una región. Pulido y Fontela (1993, Pág. 15) apuntan que en 1936 Wassily Leontief publicó en “<<The Review of Economic and Statistics>> sus primeros trabajos cuantificados sobre las relaciones productivas intersectoriales en Estados Unidos, siguiendo una metodología <<input-output>>”. Leontief pretendía hacer un modelo de equilibrio general estático, y los resultados obtenidos han sido la obtención de un método de equilibrio general desde la perspectiva de la producción predominantemente empírico. Los modelos “input-output” permiten explicitar las identidades contables que integran las llamadas tablas “input-output” mediante la realización de unos supuestos referentes a la forma de la función de producción (que se considera constante) y a la determinación del tipo (endógena o exógena) y número de variables que componen el modelo. Por consiguiente, los modelos “input-output” se sustentan en un armazón contable que le proporcionan las tablas “input-output” (TIO). Vamos a ver someramente108 las ideas fundamentales en las que se apoya una TIO, ya que no es este modelo, por las razones que posteriormente expondremos, el que configura la base fundamental para realizar la modelización perseguida109. La representación simplificada de una TIO viene dada por el gráfico siguiente, en el que se presenta la descomposición de una TIO en las subtablas que la integran. 107 En la nomenclatura de las tablas “input-output”, a las ramas de la contabilidad nacional -o regional- se les denomina sectores; en este trabajo se utilizan ambos términos indistintamente. 108 Como referencias básicas podemos citar a Miller y Blair (1985) y Pulido y Fontela (1993). 109 Aunque sí es un instrumento que explotaremos para enriquecer y argumentar algunos de nuestros análisis y conclusiones. -Pág. 208- Capítulo VI. Alternativas Modelizadoras y Conceptos Gráfico nº 67. Representación simplificada de una TIO. Salidas o empleos (“outputs”) Entradas o recursos (“inputs”) TABLA DE DEMANDA INTERMEDIA O CONSUMOS INTERMEDIOS TABLA DE DEMANDA FINAL O EMPLEOS FINALES TABLA DE “INPUTS” PRIMARIOS Y RECURSOS En el anterior cuadro aparece la subtabla de demanda intermedia, que representa las interrelaciones (compras y ventas) que se dan entre los sectores; la tabla de demanda final o empleos finales recoge los valores (para cada uno de los sectores) de los diferentes elementos integrantes de la demanda (consumo, inversión, gasto público y exportaciones); y la tabla de “inputs” primarios y recursos recoge los valores (para cada uno de los sectores) de los elementos integrantes de las entradas (“inputs”) y recursos utilizados en la producción. Según este esquema, los empleos de una TIO se reflejarían en sus filas, mientras que los recursos se recogen en las columnas. Las identidades contables que recogen el funcionamiento de una TIO giran en torno a X i (que es el valor de la producción de cada uno de los i sectores), y son las siguientes: 1ª) X i = X i1 + X i 2 +...+ X in + Ci + I i + Gi + Exi , que recogería el valor de la producción en el sector i-ésimo desde la óptica de los empleos; 2ª) X i = X 1i + X 2i +...+ X ni + Ki + Bi + Ai + (Ti − Subvi ) + Im i , que recogería el valor de la producción en el sector i-ésimo desde la óptica de los recursos. La primera identidad está orientada desde la perspectiva del destino que se le da a dicha producción, y por lo tanto agrupa a las ventas que realiza a otros sectores y a los componentes de la tabla de demanda final. En la notación utilizada antes, y siendo i , j = 1,2,..., n los sectores productivos: X ij es el valor de la producción que el sector i-ésimo vende al j-ésimo, o lo que es igual, el valor de la producción que el sector j-ésimo compra al i-ésimo. -Pág. 209- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Ci es el valor del consumo de los residentes que ha sido vendida el sector iésimo. I i es la valor de la inversión realizada por los empresarios residentes que ha sido vendida por el sector i-ésimo Gi es el valor de la producción del sector i-ésimo que ha sido comprada por el sector público Exi es el valor de la producción del sector i-ésimo que se vende fuera de la región económica que representa el modelo. La segunda identidad está enfocada desde la perspectiva de los empleos del valor de la producción, agrupando a las compras que realiza a otros sectores y a los componentes de la tabla de “inputs” primarios, es decir, que nos aproxima a la estructura de coste del sector. Según la notación utilizada: X ji es el valor de la producción que el sector i-ésimo compra al sector j-ésimo, o lo que es igual, el valor de la producción que el sector j-ésimo vende al sector iésimo Ki es el coste que ha tenido el sector i en sueldos y salarios y Seguridad Social, Bi son los beneficios del sector i-ésimo, Ai son las amortizaciones del sector i-ésimo, Ti son los impuestos soportados por el sector i-ésimo Subvi son las subvenciones recibidas por el sector i-ésimo Imi es el valor de la producción que el sector i-ésimo compra fuera de la región económica que representa el modelo. Una macromagnitud como el VAB del sector i-ésimo se obtendría como: VABi = Ki + Bi + Ai + (Ti − Subvi ) , o lo que es lo mismo: n VABi = X i − ∑ X ji − Im i . j =1 Todos los comentarios realizados hasta ahora se han hecho desde la dimensión contable; sin embargo, y como explican Aznar y Trívez (1993a, Pág. 64) “una identidad contable no es un modelo explicativo, sino una descripción <<ex post>> del funcionamiento de una economía. Para convertir una identidad contable en un modelo explicativo es preciso dar entrada a ciertos supuestos que nos señalan cuál es el comportamiento de los agentes en la economía que se pretende estudiar”. Estos mismos autores dicen que dichos supuestos hacen referencia al tipo de función de producción y a la exogeneidad de las variables del modelo. -Pág. 210- Capítulo VI. Alternativas Modelizadoras y Conceptos Para explicar estos supuestos vamos a partir del esquema básico que nos proporcionan las identidades planteadas anteriormente, desde las cuales se pueden obtener unos coeficientes denominados coeficientes técnicos que son de gran importancia para acercarse al conocimiento de la economía regional que se esté analizando. X ijt t t , donde X ijt es El coeficiente técnico total ( aij ) se define como aij = Xj el flujo de bienes y servicios interior e importado del sector i-ésimo que ha utilizado el sector j-ésimo para su producción, y X j es el valor de la producción total del sector j-ésimo. Es inmediato apreciar que los coeficientes técnicos totales nos presentan la proporción de “inputs” intermedios totales que proceden del sector i-ésimo y que se utilizan para la producción de una unidad del sector jésimo. X iji i i , Los coeficientes técnicos interiores ( aij ) se definen como aij = Xj donde X iji es el flujo de bienes y servicios interior del sector i-ésimo que ha utilizado el sector j-ésimo para su producción. Los coeficientes técnicos interiores indican la proporción de “inputs” intermedios interiores que proceden del sector i-ésimo y que se utilizan para la producción de una unidad del sector jésimo. Se puede observar que en estas definiciones existe un supuesto referente a la forma de la función de producción, ya que se está considerando que es constante110. La identidad X i = X i1 + X i 2 +...+ X in + Ci + I i + Gi + Exi se puede reescribir teniendo en cuenta las definiciones de coeficientes técnicos totales ( aijt ), de manera que X ijt = aijt X j . También se podría reescribir considerando a los coeficientes técnicos interiores ( aiji ), de forma que X iji = aiji X j , quedando la anterior identidad de la siguiente forma: X i = a11 X 1 + a12 X 2 +...+ a1n X n + Ci + I i + Gi + Exi Utilizando la notación matricial, se puede expresar la expresión anterior para todos los sectores como X = AX + D , siendo X el vector de valores de las 110 Por lo tanto, la productividad media será igual a la productividad marginal, y los rendimientos serán constantes. -Pág. 211- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña producciones sectoriales, A la matriz de coeficientes técnicos , y D el vector de demanda final que exponemos a continuación: X1 a11 X2 a 21 . . X = , A = . . . . . Xn a n1 a12 a 22 . . . . . . an2 . . . . . . . . . a1n C1 + I 1 a2n C2 + I 2 . , D= . . a nn Cn + I n + G1 + Ex1 D1 + G2 + Ex 2 D2 . . = . . . . + Gn + Ex n Dn De la expresión X = AX + D es inmediato derivar X = ( I − A) D = BD , −1 que expresa los valores de las producciones sectoriales en función de los componentes de demanda final, siendo b11 b12 b21 b22 . . B= . . . . bn1 bn 2 . . . . . . . . . b1n . b2 n . . . . . bnn la llamada matriz inversa de Leontief111. En el caso de los coeficientes técnicos interiores, cada bij representa el volumen de producción de la rama interior iésima, que es directa e indirectamente necesario para que la rama interior j-ésima pueda proporcionar una unidad del valor de la producción a la demanda final. Se ha llegado a la expresión X = BD , pero en esta expresión está implicita una hipótesis referente a las variables del modelo, de manera que la matriz X recoge a las variables endógenas, y la matriz D a las exógenas. En este caso la hipótesis realizada ha sido considerar como exógenas a las variables de consumo, inversión, gasto público y exportaciones. También se podrían haber hecho otras hipótesis, como por ejemplo considerar a las variables Ci como endógenas. Hasta ahora sólo nos hemos referido al modelo de demanda de Leontief, sin embargo, también podríamos enfocar el análisis desde la perspectiva del 111 En la actualidad se conoce como matriz inversa de Leontief a cualquiera de las matrices inversas obtenidas de las diferentes versiones que existen del modelo “inputoutput” de Leontief. A cada uno de los elementos de estas matrices inversas se les da habitualmente el nombre de multiplicador. -Pág. 212- Capítulo VI. Alternativas Modelizadoras y Conceptos modelo de oferta de Leontief o modelo de Gosh (ver Pulido y Fontela (1993)). X iji i i En este caso, se definen los coeficientes de distribución ( d ij ) como d ij = , Xi i donde X ij es el flujo de bienes y servicios interior del sector i-ésimo que ha utilizado el sector j-ésimo para su producción. Los coeficientes de distribución indican la proporción de “outputs” intermedios que proceden del sector i-ésimo y que se utilizan para la producción de una unidad del sector j-ésimo. De esta forma, podemos escribir: d 11 d 21 . D = . . . d n1 d 12 d 22 . . . . . . d n2 . . . . . . . . . d 1n d 2n . , . . d nn y definiendo VAB como un vector columna de valor añadido bruto por sectores, podemos plantear la expresión matricial: X ' = X ' D + VAB . Los modelos “input-output” regionales analizan las interdependencias sectoriales dentro del sistema económico regional. En este caso, no existen diferencias conceptuales entre un modelo “input-output” regional y uno nacional, ya que ambos se centran en un único espacio económico. Sin embargo, sí pueden existir diferencias en los asuntos considerados primordiales para un caso y otro; así: “El núcleo de los modelos nacionales “input-output” es la tabla de flujos intersectoriales. Las transacciones intersectoriales de los elementos de la demanda final normalmente no se consideran centrales en este ámbito. De cualquier modo, (…) se le ha dado alguna importancia a los enlaces intersectoriales de las inversiones.” Nijkamp, P., Rietveld, P. y Snickars, F. (1986, Pág. 263). Por otra parte, “Las cuestiones centrales en la modelización “input-output” regional, guardan relación con las teorías del comercio interregional y la movilidad de factores así como con las teorías regionales sobre elección tecnológica.” (Pág. 263). Cuando se pretenden analizar interdependencias sectoriales entre diversas regiones, nos encontramos con los modelos “input-output” interregionales, los cuales tienen el inconveniente de que la demanda de información es mayor. Vamos a expresar un modelo interregional de forma matricial particionada112; la obtención de dicho modelo pasa por hacinar las expresiones X = AX + D 112 Rodríguez Sáiz et al. (1986) expresan en forma particionada las relaciones entre dos regiones i y j (págs. 112 y 113). Nosotros, utilizando nuestra notación, hemos generalizado para el caso de j regiones. -Pág. 213- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña comentada para el caso uniregional, y además, considerar las interrelaciones sectoriales de todas las regiones: A11 X1 A21 X2 A . 31 = . . . . . X j A j1 A12 A22 A32 . . . A13 A23 A33 . . . . . . . Aj2 Aj3 . . . . . . . . . . . . . A1 j X 1 D1 A2 j X2 D2 A3 j . . . + , . . . . . . X j Dj A jj siendo X i , i = 1,..., j el vector de valores de las producciones sectoriales de la región i ; Akl , donde k = 1,... j y l = i ,..., j la matriz que recoge la proporción de “inputs” intermedios que proceden de un sector de la región késima y que se utilizan para la producción de una unidad de un sector de la región l-ésima; y Di , i = 1,..., j el vector de demanda final de cada una de las regiones. A partir de la anterior expresión, es inmediato llegar al siguiente resultado: I O O X 1 O I O X 2 O O I . = . . . . . . . . . . . X j O O O . . . . . . . . . . . . . . . . . O A11 O A21 O A31 . − . . . . . I A j1 A12 A22 A32 . . . A13 A23 A33 . . . . . . . Aj2 Aj3 . . . . . . . . . . . . . A1 j A2 j A3 j . . . A jj −1 D1 D2 . . . Dj Las interrelaciones sectoriales de una economía se pueden estudiar mediante el análisis “input-output”; para esto se pueden utilizar distintos procedimientos que tienen en común el análisis de la matriz inversa de Leontief y de la matriz de consumos intermedios; en esta línea destacan los trabajos de Hirschman (1958), Chenery-Watanabe (1958), Streit (1969) Rasmussen (1963) y Miernyck (1965)). Para un esquema de los coeficientes de relaciones interindustriales puede verse Muñoz (1988). Vamos a finalizar esta síntesis de los rasgos principales de los modelos IO mencionando tanto sus principales aplicaciones como las limitaciones que le acompañan. -Pág. 214- Capítulo VI. Alternativas Modelizadoras y Conceptos Las aplicaciones más importantes de los modelos IO son: -Los análisis de impacto económico regional (también se pueden analizar los impactos medioambientales de la contaminación) y determinación de los efectos multiplicadores de un cambio en la demanda, que hacen una evaluación de las repercusiones que las variaciones exógenas de la demanda final tienen sobre la producción, la renta y el empleo regional. -La evaluación de las consecuencias que las variaciones en los precios de los “inputs” tienen en los precios de producción y de demanda final. -La predicción de las producciones sectoriales regionales, para lo cual es necesario conocer los valores de las variables exógenas. Dentro de las limitaciones de este modelo podemos destacar: -La consideración de una función de producción constante, que implica que los coeficientes de producción también sean constantes. -La realización de predicciones con este modelo supone el conocimiento de los cambios en las variables exógenas, debiéndose utilizar otras técnicas de predicción. -Sus requisitos estadísticos hacen que los costes de elaboración de estos modelos sean muy elevados. Esta es la limitación más importante y la que invalida su aplicación con unos costes similares a los que tiene la elaboración de un modelo econométrico. Su costes elevados han hecho que estos modelos se apliquen de forma regional con muy poca frecuencia; así para Extremadura, en la actualidad disponemos de las tablas “input-output” para 1978 y 1990. -Pág. 215- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VI.2.3. MODELOS DE BASE ECONÓMICA. VI.2.3.1. PRESENTACIÓN Y SUPUESTOS BÁSICOS. Otro de los métodos causales de mayor importancia son los llamados modelos de base económica. Isard (1973, Pág. 181) identifica por base económica la relación entre las actividades básicas y no básicas de una economía. Según Richardson (1978, Pág. 162), se debe entender por modelos de base económica a aquellos que se basan en la división de una economía en sectores exógenos y endógenos. Este tipo de modelos se encuadra a su vez dentro de los modelos macroeconómicos de demanda a corto plazo. Nijkamp, Rietveld y Snickars (1986, Pág. 261) escriben: “Tiebout (1962) ha situado el análisis de base económica en la corriente principal de la teoría económica, fundamentándolo a partir del análisis macroeconómico keynesiano y del multiplicador del comercio exterior de la teoría del comercio internacional. (...) La teoría de base económica se puede considerar un predecesor de la más elaborada teoría de las relaciones interregionales e intersectoriales del análisis ‘input-output’.” Para presentar de la manera más simple un modelo de base económica, vamos a seguir en líneas generales a Treyz (1993, Pág. 11 y ss.), quien pretende construir un modelo (con fines de simulación y de predicción) para una economía abierta desde el lado de la demanda. Si se denota113 a la producción regional como Y R , descomponiéndola en consumo regional ( C R ) -tanto público como privado-, inversión regional ( I R ), exportaciones regionales ( X R ) e importaciones regionales ( M R ), podemos escribir: Y R = CR + I R + X R − M R Si se supone que las importaciones son una proporción m R de las partidas C R , I R y X R , se obtiene: Y R = C R + I R + X R − m R (C R + I R + X R ) = (1 − m R ) C R + (1 − m R ) I R + (1 − m R ) X R = rR CR + rR I R + rR X R donde r R es la proporción de las compras que se realizan dentro de la región. 113 La notación utilizada será distinta de la de Treyz (1993); en concreto, vamos a seguir la notación que Pulido (1994, Pág. 213 y ss.) utiliza para plantear este mismo modelo. -Pág. 216- Capítulo VI. Alternativas Modelizadoras y Conceptos Dentro de la expresión Y R = r R C R + r R I R + r R X R se denomina base económica neta regional ( BEN R ) a la constituida por la proporción de las compras que se realizan dentro de la región para atender la inversión y las exportaciones regionales: BEN R = r R I R + r R X R = r R ( I R + X R ) = r R BEB R denotando BEB R la base económica bruta exógena de la región. De esta forma, se puede escribir: Y R = r R C R + BEN R Además, Treyz (1993) asume que el consumo público y privado es una proporción c R de la renta regional: CR = cR Y R En resumen, las expresiones que constituyen la forma estructural del modelo son: BEN R = r R BEB R CR = cR Y R Y R = r R C R + BEN R Treyz (1993, Pág. 31) ilustra gráficamente las relaciones estructurales que se establecen entre las variables, recogiendo el sentido causal mediante flechas (Ver Gráfico nº 68). -Pág. 217- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Gráfico nº 68. Relaciones estructurales. C BEB Y BEN Denota variable endógena Denota variable exógena Fuente: Treyz (1993). El modelo expuesto en forma estructural, también puede ser planteado en forma reducida realizando las transformaciones oportunas, de manera que se obtiene: rR BEB R Y R = 1− r R cR cRr R R C = R R BEB 1− r c R r R (c R − 1) BEB R M R = 1 + 1− r R cR Si se derivan cada una de las ecuaciones reducidas con respecto a BEB R se obtienen los multiplicadores correspondientes, que proporcionan en cada caso el cambio que se da en cada una de las variables regionales que se han considerado endógenas ( Y R , C R y M R ) cuando cambian las exportaciones o la inversión regional (variables exógenas que determinan la base económica bruta). ∂ YR rR = ∂ BEB R 1 − r R c R ∂ ∂ CR cRr R = BEB R 1 − r R c R ∂ MR r R (c R − 1) = 1+ ∂ BEB R 1− r R cR -Pág. 218- Capítulo VI. Alternativas Modelizadoras y Conceptos De igual modo, se pueden examinar los efectos que tendrían sobre las variables endógenas los cambios que se produjeran en los parámetros c R y r R . De cualquier forma, se puede constatar la importancia otorgada tanto a la inversión como a las exportaciones en el modelo expuesto, ya que constituyen la base económica de la región. Sin embargo, el caso más frecuente ha sido considerar sólo a las exportaciones como la base económica de la región, siendo habitual la identificación de la base económica de una región con la capacidad de venta hacia el exterior de dicha región (exportación, al resto del país o hacia el exterior); en este caso, nos encontramos con los modelos de base exportación114. Bajo este supuesto, la idea que sostiene el modelo de base económica es que las actividades básicas (en las que el papel exportador ocupa un lugar importante) son aquellas que actúan como motores del desarrollo regional, influyendo de manera positiva en las actividades no básicas (aquellas en las que la exportación no tiene un papel significativo, de manera que están orientadas fundamentalmente al mercado local)115. Suriñach (1987, Págs. 14 y 15) desglosa los supuestos principales de este tipo de enfoque: “1.-El crecimiento regional está íntimamente ligado al crecimiento del sector básico o exportador.(…) 2.-La expansión del sector básico trae consigo un aumento de producción en el sector servicios, al que se considera como punto de apoyo del primero. 3.-Existe una relación estable entre el sector básico y el de servicios”. 114 Esta es la causa por la que habitualmente se suele hablar indistintamente de modelo de base económica o de modelo de base exportación. 115 Richardson (1986, Pág. 67 y ss.) -Pág. 219- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VI.2.3.2. ENFOQUE ECONOMÉTRICOS. DE BASE ECONÓMICA Y MODELOS En este subapartado vamos a proponer la especificación para el enfoque de base económica en otros términos. Para una determinada región, y supuesta la existencia de unos sectores considerados como básicos (son los que tienen relaciones con otras regiones nacionales y/o internacionales- y se denotan con el subíndice b) y otros considerados como no básicos o de servicios (sin conexiones con otras regiones, denotados con el subíndice n), podemos especificar116, desde la perspectiva de la demanda: xb = Abb xb + Abn xn + db x n = Anb xb + Ann x n + dn siendo: xb el vector de valores de las producciones de los sectores básicos; x n el vector de valores de las producciones de los sectores no básicos; A es la matriz de coeficientes técnicos, que aparece particionada en sus submatrices componentes: Abb es la matriz de coeficientes técnicos interiores cuyos elementos recogen la proporción de “inputs” intermedios interiores que proceden del sector básico y que se utilizan para la producción de una unidad del sector básico, Abn es la matriz de coeficientes técnicos interiores cuyos elementos recogen la proporción de “inputs” intermedios interiores que proceden del sector no básico y que se utilizan para la producción de una unidad del sector básico, Anb es la matriz de coeficientes técnicos interiores cuyos elementos recogen la proporción de “inputs” intermedios interiores que proceden del sector básico y que se utilizan para la producción de una unidad del sector no básico, y Ann es la matriz de coeficientes técnicos interiores cuyos elementos recogen la proporción de “inputs” intermedios interiores que proceden del sector no básico y que se utilizan para la producción de una unidad del sector no básico; db es el vector de demanda final para los sectores básicos; y dn es el vector de demanda final para los sectores no básicos. 116 Nos ha parecido interesante exponer el modelo en la forma escrita en Nijkamp, Rietveld y Snickars (1986, Pág. 262), ya que permite apreciar de forma clara la relación que se establece entre los sectores básicos y los sectores no básicos. -Pág. 220- Capítulo VI. Alternativas Modelizadoras y Conceptos Está claro que el planteamiento presentado es muy simple, y enfocado a las relaciones internas de una economía regional. De acuerdo con la teoría de base económica, sería sostenible la hipótesis que establece que Abn ⟨⟨1; es decir, que el determinante de la matriz Abn está próximo a cero117, de manera que es inmediato reescribir el sistema como: xb = ( I − Abb ) −1 db x n = ( I − Ann ) −1 ( Anb xb + dn ) En la expresión anterior se observa cómo el vector de valores de las producciones de los sectores básicos es independiente del vector de valores de las producciones de los sectores no básicos. Por otra parte, las producciones de los sectores no básicos dependen tanto de la demanda final para los sectores no básicos (producciones orientadas a uso final) como de la producción de los sectores básicos (producciones destinadas al sistema de producción básico). La expresión escrita tiene la ventaja de deslindar las relaciones que se establecen entre los sectores básicos y no básicos. Sin embargo, muchos modelos regionales se explican desagregando la producción sectorial, como consecuencia de la carencia de datos estadísticos desde el enfoque de la demanda. De esta forma, desde la perspectiva de la oferta118, podemos escribir: xb ' = xb ' Dbb + x n ' Dbn + VABb ' x n ' = x n ' Dnn + xb ' Dnb + VABn ' siendo D la matriz de coeficientes de distribución, que aparece particionada en sus submatrices componentes: Dbb es la matriz de coeficientes de distribución interiores cuyos elementos recogen la proporción de “outputs” intermedios interiores que proceden del sector básico y que se utilizan para la producción de una unidad del sector básico, Dbn es la matriz de coeficientes de distribución interiores cuyos elementos recogen la proporción de “outputs” intermedios interiores que proceden del sector básico y que se utilizan para la producción de una unidad del sector no básico, Dnb es la matriz de coeficientes de distribución interiores cuyos elementos recogen la proporción de “outputs” intermedios 117 Se supone que el sector básico utiliza para su producción proporciones muy pequeñas de inputs procedentes de los sectores no básicos. 118 Desde el enfoque “input-output” sería el llamado modelo de oferta de Leontief o modelo de Ghosh (Ver Pulido y Fontela (1993)). -Pág. 221- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña interiores que proceden del sector no básico y que se utilizan para la producción de una unidad del sector básico, y Dnn es la matriz de coeficientes de distribución interiores cuyos elementos recogen la proporción de “outputs” intermedios interiores que proceden del sector no básico y que se utilizan para la producción de una unidad del sector no básico; VABb es el vector de valor añadido bruto para los sectores básicos; y VABn es el vector de valor añadido bruto para los sectores no básicos. En la anterior expresión también podemos suponer que se verifica que Dbn ⟨⟨1 ; es decir, que el determinante de la matriz Dbn está próximo a cero119, de manera que es inmediato reescribir el sistema como: xb ' = ( I − Dbb ) VABb ' −1 x n ' = ( I − Dnn ) −1 (x ' b Dnb + VABn ' ) Las conclusiones son las siguientes: 1) El vector de valores de las producciones de los sectores básicos es independiente del vector de valores de las producciones de los sectores no básicos. 2) Las producciones de los sectores no básicos dependen: a) del valor añadido bruto de su sector, y b) de la producción de los sectores básicos, vía las producciones (“outputs”) del sector no básico que se destinan al sistema de producción básico. La anterior expresión ocupa un lugar fundamental en la práctica econométrica regional vigente en la actualidad en España, ya que en ella se justifican las relaciones que se establecen entre los sectores básicos y no básicos de una economía regional. Dicha práctica pasa por aproximar las producciones sectoriales mediante el valor añadido regional, de manera que una especificación econométrica muy simple, pero a la vez tremendamente operativa, viene dada por: k VABt = a 0 + a1 ∑ FBti + ut b i =1 h VABt = b0 + b1 ∑ FNBth + b2VABtb + wt n i =1 119 El sector no básico utiliza para su producción proporciones muy pequeñas de “inputs” procedentes de los sectores básicos. -Pág. 222- Capítulo VI. Alternativas Modelizadoras y Conceptos donde xb se aproxima y dinamiza mediante el vector del valor añadido bruto básico a lo largo del tiempo ( VABt b ), y se hace depender de k factores que condicionan la evolución del sector básico ( FBti ). Dentro de estos factores se encuentran, esencialmente, variables nacionales que recojan la demanda de la producción básica fuera de la región. En lo que respecta a la producción sectorial no básica ( x n ), también se aproxima y dinamiza mediante el valor añadido bruto no básico ( VABt n ), el cual se especifica en función de una serie de h variables ( FNBth ) que recogen la demanda interna total de la región, y del VABt b . Sin embargo, en la realidad puede que no podamos caracterizar exclusivamente a un mercado como nacional o regional, de manera que en ocasiones hay que considerar la existencia de sectores mixtos (vinculados tanto al mercado nacional como regional). VI.2.3.3. LIMITACIONES. Las limitaciones de este tipo de modelos han sido comentadas desde diferentes perspectivas. Glickman (1977) muestra como restricciones importantes el hecho de que se requiera la constancia del ratio sectores básicos y no básicos, así como la dificultad de asignación de los sectores en básicos o no básicos (identificación). La hipótesis de constancia del ratio que se establezca entre los sectores básicos y no básicos limita la utilización de este tipo de modelos a efectos predictivos120. Es más acertado considerar a dicho ratio cambiante debido a: -las transformaciones en factores locacionales o tecnológicos que afectan a una región, y/o -como consecuencia de la existencia de retardos (incorporación de cambios pasados) a la hora de ajustarse los cambios que se producen en los sectores no básicos coligados a cambios en los sectores básicos. El problema de la determinación de los sectores básicos y no básicos se ha intentado tratar desde distintas direcciones; así, siguiendo a Suriñach (1987, Págs.20-23) y Escolano (1993, Págs. 21-27) destacamos: 1. Identificación de los sectores en función de los mercados relevantes, suponiendo que las manufacturas, minería y agricultura son sectores básicos, y los servicios son sectores no básicos. Es un criterio poco objetivo. 2. Cálculo del coeficiente de especialización o cociente de localización ( Ci ); definido como: 120 Aunque siguen siendo válidos a efectos descripticos y no dinámicos. -Pág. 223- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña E Re gi E Re g Ci = ENaci ENac donde E Re gi es el número de ocupados en el sector i de la región, E Re g es el número de ocupados en la región, E Naci es el número de ocupados en el sector i de la nación, y E Nac es el número de ocupados en la nación. Si este cociente es mayor que 1, el empleo en el sector regional i es proporcionalmente mayor que en el sector nacional i, de manera que se considera que el sector es básico, puesto que este exceso lo puede destinar a la exportación. Las deficiencias de este método son (Suriñach (1987, Pág.22)): a)”Supone una uniformidad en el consumo y producción a lo largo de todo el territorio. b)Supone niveles de productividad iguales para todo el país. c)No considera las exportaciones e importaciones internacionales. d)Supone que toda la demanda local queda cubierta por producción local. Se subestima el tamaño de la base exportadora.” Sus ventaja fundamental es que es un método fácil de aplicar. 3. Método de los “mínimos requerimientos técnicos”, que se aplicó inicialmente a estudios de base económica urbanos. Consiste en seleccionar ciudades (o regiones) representativas de la nación y calcular el porcentaje de empleo local en cada ciudad, de manera que se supone que el porcentaje mínimo de empleo que existe para cada sector es el porcentaje mínimo necesario para la subsistencia de la ciudad. Así, el excedente de empleo sobre el porcentaje mínimo se considera empleo básico, y en consecuencia, sector básico. Las críticas fundamentales vienen por: a) “suposición de uniformidad interregional de consumo y productividad, b) suposición de que la ciudad no realiza importaciones121.” (Suriñach (1987, Pág. 23). 4. Utilización del análisis de regresión, en el cual se supone que el empleo regional en el momento actual ( E tr ) es una función lineal de sus propios valores 121 Puesto que se supone que el mínimo absoluto satisface las necesidades de una ciudad con respecto a un sector, de manera que la ciudad no puede importar (aunque sí exportar). -Pág. 224- Capítulo VI. Alternativas Modelizadoras y Conceptos retardados ( E tr−1 , E tr− 2 , E tr− 3 ) y del empleo básico ( E br ), que se determina exógenamente122: E tr = a 0 + a1 E tr−1 + a 2 E tr− 2 + a 3 E tr− 3 + a 4 E br + ut siendo ut una perturbación aleatoria. Si a 4 es significativo, la determinación que se ha realizado exógenamente del empleo básico es correcta. 5. El último método que comentamos es el más costoso, puesto que se realizan encuestas a las empresas con el fin de estimar el porcentaje de sus ventas fuera de la región. Los resultados se extrapolan sectorialmente123. Los costes y trabajos en los que se incurren son normalmente elevados. Además, pueden aparecer dificultades añadidas por la existencia de interdependencias dentro de los procesos de producción. Por ejemplo, pueden existir sectores especializados que fabriquen productos intermedios que se destinen de manera casi exclusiva a otro sector regional exportador (que lo utiliza como “input” en su proceso productivo). Un tratamiento no adecuado de la información podría calificar a dicho sector como no básico. Por otra parte, Richardson (1986) argumenta que este tipo de modelo ha entrado en desuso en el estudio de las economías regionales con fines de planificación debido a que se trata de los mismos modelos macroeconómicos que se utilizan para el estudio de las economías nacionales pero modificados para recoger la mayor importancia de los flujos externos en una economía regional. Este autor sostiene que ese intento de asemejar a las economías regionales con las nacionales, cuando los instrumentos de política económica de los que se dispone en ambos difieren, son la causa de su inutilidad en la planificación económica regional. Bajo nuestro punto de vista, y en la situación particular de la Comunidad Autónoma de Extremadura, a esta crítica de Richardson hay que añadir el hecho de que la concreción de un modelo macroeconómico de demanda implica la disponibilidad de unas estadísticas de las cuales, hoy en día, se carece en Extremadura; por consiguiente, la construcción de un modelo de este tipo entrañará una serie de dificultades que no se pueden superar en la actualidad de una manera razonable. En definitiva, nosotros no llevamos a cabo la especificación de un modelo de base económica a efectos predictivos124 por las razones argumentadas en este 122 Este método -además de poderse criticar por el número de retardos incluidos en la especificación- en la actualidad queda invalidado bajo la perspectiva de la teoría la cointegración por las implicaciones negativas que tal especificación conlleva. 123 Este es el método que se utiliza en este trabajo para identificar a los sectores básicos y no básicos, pero con matices, ya que nuestra fuente será la TIO de Extremadura para el año 1990. 124 Que es el objetivo principal perseguido con la modelización a realizar. -Pág. 225- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña apartado. Sin embargo, sí utilizamos el enfoque de base económica, y en concreto algunas de sus hipótesis, como soporte de la especificación econométrica125 del Capítulo VII. 125 Pulido (1994) da una visión de las principales alternativas en el campo de la modelización econométrica regional, y afirma “consideramos el enfoque de base económica como el criterio orientador de los modelos econométricos más básicos o elementales, incluso aunque incorporen una cierta desagregación temporal.”(Pág. 18). -Pág. 226- Capítulo VI. Alternativas Modelizadoras y Conceptos VI.2.4. MODELOS ECONOMÉTRICOS REGIONALES. Los modelos econométricos son otro tipo de modelos muy utilizados en el momento actual en el análisis económico regional. En este apartado damos una visión general de los aspectos más relevantes de este tipo de modelos en el campo regional. VI.2.4.1. INTRODUCCIÓN. En el Capítulo I expusimos una evolución de los modelos econométricos; lo que sí se puede afirmar es que los antecedentes más importantes de los modelos econométricos (Bodkin, Klein y Marwah (1991, Pág. 3)) se pueden encontrar hace ya mucho tiempo: 1º el conjunto de modelos de equilibrio general, que Leon Walras desarrolló como un sistema abstracto y Vilfredo Pareto logró extender de manera que hizo factible su estimación empírica; 2º dos modelos matemáticos de los ciclos económicos que anticipaban el enfoque econométrico, desarrollados por Ragnar Frisch y Michal Kalecki en los años 30, 3º la Teoría General de Keynes y sus desarrollos posteriores, que se utilizó de forma generalizada como base para el diseño de modelos macroeconómicos; 4º la literatura empírica sobre conceptos keynesianos macroeconómicos, y en concreto sobre la función de consumo que aparecieron entre la publicación de la “Teoría General” y “Los Ciclos Económicos en los Estados Unidos” de Tinbergen, es decir, aproximadamente desde 1937 hasta mediados de 1939. Su utilización a partir de estos antecedentes ha pasado por diferentes etapas. Sin embargo, la modelización econométrica regional tuvo que esperar a la década de los setenta (como ya manifestamos en el Capítulo I) para gozar, en términos generales, de un importante desarrollo. Posteriormente se pasó a una etapa de decadencia en lo que se refiere a la construcción de dichos modelos. Sin embargo, en el caso de España no ha habido un abandono de la modelización econométrica regional; todo lo contrario. Las circunstancias políticas particulares (y sus implicaciones económicas) que han rodeado a la evolución de España en los últimos años han significado un fertilizante generoso que ha contribuido de manera enérgica al dinamismo de la modelización económica regional en España. El objetivo es beneficiarse de las ventajas de utilización de los modelos macroeconométricos que Suriñach (1987, Pág. 11) apunta: -el conocimiento cuantitativo de la realidad económica (sea regional, nacional o sectorial), -posibilitan una política económica más coherente al poder conocer los efectos que tendrán las medidas que adopten las autoridades públicas sobre variables -Pág. 227- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña macroeconómicas. Posibilidad de realizar simulaciones de políticas alternativas, -cálculo de predicciones, -detección de las necesidades de información estadística. VI.2.4.2. ENFOQUES. Siguiendo a Weber (1986, Pág. 15), los enfoques existentes para la construcción de modelos regionales126 son los siguientes: (1)Uniregionales satélites127. En el que “las variables endógenas son determinadas como funciones de otras (endógenas) y por un número de variables exógenas regionales, mientras que el sistema en conjunto es dirigido por variables exógenas nacionales.” (Weber (1986, Pág.16.)). Para este tipo de modelos, se ignora la posible causalidad de los cambios en la región sobre las variables nacionales. (2)Uniregionales descendentes. Para este enfoque, “la actividad económica regional es determinada por variables exógenas nacionales y el resultado se distribuye para áreas locales dentro de la región” Weber (1986, Pág.15.). En la práctica, son modelos en los que las variables endógenas regionales son explicadas por variables nacionales. (3)Multiregionales descendentes. La “actividad económica [regional] es determinada a nivel nacional, y entonces se distribuye entre las regiones con la restricción de que la suma de las participaciones de todas las regiones sea 1.” Weber (1986, Pág.15.). Otra opción que expone este autor es estimar la actividad a nivel regional, de manera que se debe verificar que la suma de las estimaciones regionales sea igual a la nacional; en caso contrario, se modificarían los valores regionales estimados. (4)Multiregionales ascendentes. Los cuales “eliminan el modelo nacional y simplemente utilizan los valores regionales combinados como estimaciones nacionales, sin ajustar.” Weber (1986, Pág.15.). (5)Multiregionales híbridos. En el cual “algunas variables [nacionales] son designadas como determinantes de la actividad regional y otras son agregadas, sin ajustar, para dar el total nacional.” (Weber (1986, Pág.15.)). En definitiva, unas variables se obtienen por el enfoque descendente, y otras por el ascendente. A la vista de la anterior clasificación, y de manera sintética, podemos recoger una tipología de experiencias modelizadoras en el cuadro siguiente. 126 Y consecuentemente, para la construcción de modelos econométricos regionales. Este tipo de modelo fue propuesto en Klein (1969), quien le otorgó características teóricas que sirvieron de norma para la construcción de un modelo econométrico regional. 127 -Pág. 228- Capítulo VI. Alternativas Modelizadoras y Conceptos Cuadro nº 52. Enfoques modelizadores. Uniregional Descendente (“Top-down”) (2)Uniregionales descendentes Ascendente (“Bottom-up”) Multiregional (3)Multiregionales descendentes (4)Multiregionales ascendentes (1)Uniregionales satélites (5)Multiregionales Híbrido híbridos -abiertos -cerrados Fuente: Elaboración propia a partir de Weber (1986) y Courbis (1992). La consideración de híbridos se realiza en el sentido de que se combinan los enfoques ascendentes y descendentes, recogiendo en su especificación variables exógenas nacionales y regionales. Dentro de esta opción híbrida, y para el caso multiregional, se pueden considerar dos tipos de estructuras distintas, dando lugar a los modelos: a) cerrados o integrados, “si las variables nacionales obtenidas por agregación de variables regionales retroactúan (...) sobre las variables nacionales de las cuales dependen las variables regionales”, Courbis (1992, Pág. 146); o b) abiertos, si no se consideran las retroalimentaciones de los resultados regionales hacia la economía nacional. El Cuadro nº 52 podría enriquecerse introduciendo las aproximaciones existentes dentro de los modelos multirregionales para estudiar las interacciones entre una región y el resto de regiones. En este sentido, y considerando la causalidad multirregional, los modelos usuales vendrían recogidos en el esquema del Cuadro nº 53. Cuadro nº 53. Tipos de modelos econométricos multirregionales en función de la causalidad. Causa(fila)\Efecto(columna) Nación Regiones Nación y regiones Nación Ascendentes Regiones Descendentes Interregionales Nación y regiones Regionales-nacionales Fuente: Elaboración propia en función de la clasificación de Courbis (1979a). En este momento ya podemos afirmar que el modelo que pretendemos especificar y estimar para Extremadura es del tipo uniregional, desechando en este trabajo -por motivos obvios- el estudio de los multirregionales128. También sabemos que, en líneas generales, los modelos econométricos pueden 128 Para situarse en el campo de la modelización multirregional consúltese Courbis (1992). -Pág. 229- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña caracterizarse como descendentes (“Top-Down”) o ascendentes (“Bottomup”). En el caso descendente, es la evolución económica nacional la que “causa” o determina la actividad económica de la región. En el caso de Extremadura, es lógico pensar que ésto ocurra así, puesto que se trata de una economía abierta que, al mismo tiempo, tiene una estructura productiva que en términos porcentuales sobre el total nacional representa un tamaño lo suficientemente reducido como para que no se esperen efectos de causalidad con el sentido Extremadura-España. Además, los responsables políticos de la región no tienen como instrumentos de política económica las decisiones monetarias y fiscales que sí tienen sus homólogos nacionales, por lo que van a influir en el sistema económico regional fuerzas externas sobre las cuales no se podrá ejercer ningún tipo de control. Sin embargo, ésto no es óbice para que esta región pueda tener una evolución económica que difiera de la que se produce a nivel medio nacional, ya sea por razones de comportamiento económico de las ramas productivas diferente al que se da a nivel nacional, por una diferente estructura productiva o porque el gobierno regional tenga la posibilidad de gestionar un volumen muy importante de recursos que pueda decantar (a medio o largo plazo) los resultados económicos de una región por encima o por debajo de los que se producen a nivel medio nacional. En al apartado segundo de este Capítulo argüimos que en el plano empírico es preferible la ejecución de un modelo regional descendente, tanto por los requerimientos menores de datos, como por la posibilidad de obviar la causalidad región-nación en el caso de regiones con economías abiertas y tamaño pequeño. Con todas las premisas ya comentadas, podemos concretar que en este trabajo se persigue la elaboración de un modelo regional, identificando el concepto de región con el de Comunidad Autónoma, y alimentando a dicho modelo con datos referidos al entorno nacional y a la propia Comunidad Autónoma en estudio. Además, del elenco de modelos posibles nos decantamos por la construcción (en el Capítulo VII) de un modelo econométrico uniregional satélite. Los resultados de nuestro modelo no están sometidos a ningún tipo de congruencia (no forma parte de un esquema integrado de modelización para homogeneizar los resultados), aunque sí hay que matizar el hecho de que nuestra modelización econométrica regional viene condicionada por un equipo central129 que nos proporciona las estimaciones que sirven como variables exógenas a nuestro modelo regional. En este sentido, nuestro modelo está impregnado de la característica descendente vía variables exógenas nacionales. 129 Equipo que modeliza a la economía española en su conjunto. En nuestro caso es el Equipo Central Hispalink (“Instituto L. R. Klein). -Pág. 230- Capítulo VI. Alternativas Modelizadoras y Conceptos VI.2.4.3. SUSTENTO TEÓRICO . En lo que concierne a la base teórica sobre la que se construyen los modelos econométricos regionales, Weber (1986, Pág. 16) expone el asunto en nuestra opinión- de una forma bastante clara: “...los constructores de modelos regionales no tienen el lujo de trabajar con una teoría económica completa en el desarrollo de sus modelos. El concepto de modelización estructural es que las variables endógenas están relacionadas con otras [endógenas] y con un conjunto de variables exógenas. (...) El constructor de un modelo regional está obligado a depender de la teoría económica para el diseño básico, pero debe modificar este diseño debido a las imposiciones de las realidades con las que se encuentra, sistemas abiertos130 y limitaciones de datos131.” Pulido (1994, Pág. 211, 212) propone partir del modelo “básico regional” para presentar una panorámica de las principales alternativas dentro de la modelización econométrica regional que se lleva a cabo en el proyecto Hispalink132. El modelo “básico regional” es aquel que adopta la orientación de base económica133. El desarrollo de tales modelos -como señala Pulido- se realiza desde el lado de la oferta “principalmente por razón de limitaciones estadísticas” (Pág. 215). La especificación de los modelos econométricos de base económica desde la perspectiva de la oferta se encuentra con graves problemas que aparecen como consecuencia de una fundamentación teórica exigua. 130 De manera que no es factible la construcción de un sistema de ecuaciones simultáneo en sentido estricto, ya que la actividad económica regional está vinculada a la de la economía nacional y a la economía de regiones próximas. 131 Que puede hacer que especificaciones de modelos desde la perspectiva teórica no se puedan estimar por carencia de datos. 132 El Grupo Hispalink es una “línea de investigación en economía aplicada de un conjunto de universidades españolas. Su objetivo es la revisión y mejora permanente del análisis de la situación y perspectivas económicas de las regiones españolas. Para alcanzar tales objetivos, cada equipo ha desarrollado un modelo econométrico que trata de describir con suficiente aproximación el comportamiento de la región correspondiente. El conjunto de equipos dispone de una base de datos común que se elabora a partir de la información de la Contabilidad Regional de Eespaña (Hispadat), utiliza las mismas predicciones iniciales para el conjunto de la economía española y coordina las predicciones regionales a través de un modelo de congruencia” Hispalink (1998): Informe Semestral sobre la “Situación Actual y Perspectivas de las Regiones de España”, Junio 1998, Instituto L. R. Klein y Consejo Superior de Cámaras de Comercio, Industria y Navegación de España. Dado que esta tesis se centra en un modelo uniregional, por razones de espacio, no vamos a realizar ningún comentario relativo a la modelización integrada. 133 La relación entre el enfoque de base económica y los modelos econométricos regionales se expuso en el Capítulo VI. -Pág. 231- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña De cualquier modo, la teoría económica siempre es utilizada para la selección de las variables a introducir en el modelo, a pesar de que en la práctica econométrica es habitual encontrar especificaciones con variables endógenas retrasadas sin ningún justificante teórico. En este momento, y como mostraremos en el Capítulo VII, la teoría de la cointegración ocupa un lugar fundamental a la hora de corroborar las relaciones a largo plazo que se especifican entre variables seleccionadas bajo el filtro director de la teoría económica. VI.2.4.4. ALGUNAS EXPERIENCIAS RECIENTES EN ESPAÑA. En este trabajo no vamos a exponer ninguna revisión histórica de los modelos econométricos regionales a lo largo de la historia134, ya que nos ha parecido más interesante y enriquecedor para el trabajo centrarnos en el estado de la modelización reciente de otras regiones españolas que se han enfrentado (y se enfrentan) a problemáticas similares a las nuestras. Así, en el cuadro siguiente mostramos algunas perspectivas que podemos encontrar dentro de los modelos unirregionales integrantes del Proyecto Hispalink. No pretendemos ser exhaustivos, sólo destacar cómo equipos con una experiencia predictiva importante muestran una tendencia clara a la formulación de modelos sencillos. 134 En Bolton (1985) o Courbis (1994) se pueden encontrar exploraciones de experiencias econométricas previas. En España, Suriñach (1987), Escolano (1993) y Aguayo et al. (1997) realizan diferentes revisiones que incluyen modelos econométricos regionales americanos, europeos y españoles. -Pág. 232- Capítulo VI. Alternativas Modelizadoras y Conceptos Cuadro nº 54. Experiencias Hispalink de predicción del VAB regional. EQUIPOS Universidad de Zaragoza Modelo para Aragón. (Trívez y Mur (1994)). Universidad de Oviedo Modelo para Asturias. (Pérez et al. (1994)). Universidad de Las Palmas de Gran Canaria Modelo para Canarias. (González et al. (1994)). Universidad de Valladolid Modelo para Castilla-León. (Cavero et al. (1994)). Universidad Autónoma de Madrid Modelo para Comunidad de Madrid. (Aneiros (1994)). Universidad de Valencia Modelo para Comunidad de Valencia. (Badillo et al. (1998)). EXPERIENCIAS: ESTRUCTURAS DE LOS MODELOS Se configura en dos bloques, empleo y producción. Existen nueve ecuaciones para el bloque de producción, una para cada rama productiva: agricultura (A), energía (E), bienes intermedios (Q), bienes de equipo (K), bienes de consumo (C), construcción (B), servicios destinados a la venta (excepto transportes y comunicaciones) (L), transportes y comunicaciones (Z) y servicios no destinados a la venta (G). Inicialmente era un modelo recursivo; en el segundo bloque (Empleo) se utilizaban las variables endógenas estimadas en el primero (VAB real a 9 sectores). La estimación de las ecuaciones para cada sector dentro de cada bloque se llevaba a cabo de forma independiente. En la actualidad presenta 3 bloques (oferta, demanda y trabajo), estando solamente consolidado el de oferta. Consta de un bloque de ecuaciones en el que se modelizan los componentes de la demanda regional y sector exterior, y de un bloque de producción regional (variables endógenas son el VAB real a 9 ramas). Modelo con un bloque de producción desagregado a nueve ramas (A, E, Q, K, C, B, Z, L, G). Es un modelo trimestral. Se trata de un modelo con un solo bloque de producción simultáneo, trabajando con una desagregación a nueve ramas (A, E, Q, K, C, B, Z, L, G). Consta de cinco bloques de ecuaciones interrelacionadas: *Bloque de producción: 4 ramas (Industria, Construcción, Servicios destinados a la venta y servicios no destinados a la venta). Se renuncia a modeliza la rama agraria, limitándose a hacer hipótesis sobre el comportamiento futuro de la serie. *Bloque de mercado de trabajo Hace depender el empleo total del nivel de producción de la Comunidad Valenciana (variable tipo “proxy”: VAB total valenciano) y de la evolución del empleo nacional. *Bloque de salarios. *Bloque de precios. *Bloque de sector exterior. Universidad de Málaga Consta de un submodelo demográfico, un bloque de ecuaciones Modelo para Andalucía. de valores añadidos sectoriales a 8 ramas (A, E, Q, K, C, B, Z, (Otero et al. (1991)). L+G), un bloque de empleos sectoriales y un bloque de ecuaciones de mercado de trabajo. Universidad de Barcelona Bloque de producción; explica el valor añadido a cuatro ramas: Modelo para Cataluña. Agricultura, Industria, Construcción y Servicios. Obtiene el (Lobo et al. (1997)). VAB total como suma del VAB de las cuatro ramas. Enfoque de base económica. -Pág. 233- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña A la vista de los modelos recogidos en el Cuadro nº 54, se constata -en línea con lo comentado en apartados anteriores- la preponderancia del enfoque de oferta en el caso regional. En función de nuestros objetivos, haremos un énfasis especial en las variables utilizadas para cada rama dentro del bloque de producción, de manera que prescindimos de comentar aspectos relativos a bloques diferentes. Cuadro nº 55. Variables explicativas del VAB Agrario. EQUIPOS Universidad de Zaragoza (Trívez y Mur (1994)). Universidad de Oviedo (Pérez et al. (1994)). EXPERIENCIAS: AGRICULTURA El VAB se explica en función del empleo del sector regional y del VAB agrario nacional. Determina el VAB en función del índice de precios percibidos por los agricultures en España, de la producción de leche de vaca en Asturias, y de carne total sacrificada en los mataderos de Asturias en el año anterior. Universidad de Las Como explicativa de la producción agrícola actúan tanto el Palmas de Gran Canaria empleo sectorial canario como los precios de exportación de (González et al. (1994)). los productos (que actúan como variable aproximativa de los precios regionales) Universidad de Valladolid Trimestralizan el v.a.b.p.m. regional de la rama agraria. Según (Cavero et al. (1994)). estos autores, la agricultura posee un comportamiento que dificulta su modelización, por lo que el análisis debe realizarse por métodos directos, ligados a las estimaciones de avance sobre superficies sembradas, precios y producción; además, el carácter pluritrimestral de muchos productos es una dificultad añadida. Universidad Autónoma de El VAB agrario es una función de la proporción del VAB Madrid agrícola de Madrid sobre el VAB agrícola nacional y del (Aneiros (1994)). VAB agrícola de España. Universidad de Valencia No lo modelizan. (Badillo et al. (1998)). Universidad de Málaga Explican el VAB agrario en función del VAB nacional del (Otero et al. (1991)). sector y del VAB agrario regional retardado un período. Universidad de Barcelona Modeliza el VAB en función del VAB total catalán (para (Lobo et al. (1997)). aproximar la demanda interna), del nivel de precios agrario y del nivel anual de precipitaciones de Cataluña. No existe una constante a la hora de determinar las variables que explican la evolución del VAB agrario (Cuadro nº 55); la orientación es diversa, algunos prescinden de su modelización, otros toman como exógena la evolución de la rama nacional y también nos encontramos con modelos que sólo consideran indicadores regionales. -Pág. 234- Capítulo VI. Alternativas Modelizadoras y Conceptos Cuadro nº 56. Variables explicativas del VAB Industrial. EQUIPOS Universidad de Zaragoza (Trívez y Mur (1994)). EXPERIENCIAS: INDUSTRIA Desagrega en 4 ramas: Energía (E), Bienes Intermedios (Q), Bienes de Capital (K) y Bienes de Consumo (C). -E: La explica en función del VAB energético de España, del empleo en la rama regional y de una variable que es la suma de: el VAB de bienes intermedios de España, del VAB de bienes de equipo nacional y del VAB de bienes de consumo nacional. -Q: Especificada como una función del VAB de bienes intermedios español. -K: es una función del VAB de bienes de equipo de España, del empleo en la rama regional y de las exportaciones de la economía nacional. -C: es una función del VAB de bienes de consumo de España, del empleo de la rama regional y de la renta familiar disponible para el conjunto nacional. Universidad de Oviedo Desagrega en 4 ramas: Energía (E), Bienes Intermedios (Q), (Pérez et al. (1994)). Bienes de Capital (K) y Bienes de Consumo (C). -E: La explica en función del VAB industrial de España, de la producción de hulla en Asturias, de la producción de antracita en Asturias, y de la producción total de energía eléctrica en Asturias. -Q: Especificada como una función del VAB industrial de España, y de la producción de acero en Asturias. -K: es una función del VAB de bienes de equipo de España. -C: es una función de la Renta real bruta disponible en las familias en España y de la leche comercializada en Asturias. Universidad de Las Palmas Desagrega en 4 ramas: Energía (E), Bienes Intermedios (Q), de Gran Canaria Bienes de Capital (K) y Bienes de Consumo (C). (González et al. (1994)). -E: Especificada como una función de los precios de importación de los productos energéticos, del tipo de cambio de la peseta y de la producción total (que mide la actividad económica general). -Q: La explica en función del índice de precios relativos de la industria de consumo, de las importaciones totales y de la endógena retardada un período. -K: es una función del índice de precios de bienes intermedios, del VAB del resto de la industria y de la inversión en construcción (es una endógena del modelo). -C: es una función del VAB nacional del sector y de la inversión privada (es una endógena del modelo). -Pág. 235- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 56. (Continuación). Universidad de Valladolid (Cavero et al. (1994)). Desagrega en 4 ramas: E, Q, K, C. -E: Trimestralización del VAB regional energético. Se especifica en función del IPI nacional, de la Producción interior bruta regional de carbón (Tm), de la producción disponible regional de electricidad (Mwh) y del empleo regional en la rama. -Q: Trimestralización del VAB regional de productos manufacturados intermedios. Se explica en función IPI nacional de bienes de equipo, producción regional de cemento (Tm), del IPI nacional de materiales de construcción, del IPI nacional de la industria química y del empleo regional en Q. -K: Trimestralización del VAB regional de productos manufacturados de equipo. Se explica en función del IPI nacional de bienes de capital, del número de vehículos fabricados en Castilla y León, del IPI nacional de material de transporte privado, y del empleo regional en K. -C: Trimestralización del VAB regional de productos manufacturados de consumo. Se especifica en función del IPI nacional de bienes de consumo, del IPI nacional de alimentos, bebidad y tabaco y del empleo regional en el sector. Universidad Autónoma de Desagrega en 4 ramas: Energía (E), Bienes Intermedios (Q), Madrid (Aneiros (1994)). Bienes de Capital (K) y Bienes de Consumo (C). -E: La explica en función del VAB energético de España. -Q: Especificada como una función de la participación del VAB de bienes intermedios de Madrid en el homólogo nacional y del empleo en el sector regional. -K: es una función del VAB de bienes de equipo de España y del VAB de la industria total de la región. -C: es una función del VAB de bienes de consumo de España. Universidad de Valencia Depende del VAB industrial nacional u del nivel de (Badillo et al. (1998)). exportaciones industriales valencianas. Universidad de Málaga Desagrega en 4 ramas: Energía (E), Bienes Intermedios (Q), (Otero et al. (1991)). Bienes de Capital (K) y Bienes de Consumo (C). -E: La explica en función del VAB nacional en el sector, de los precios industriales nacionales del sector energético y del valor añadido de un conjunto de sectores (Q+C+Z). -Q: Especificada como una función del VAB nacional del sector y de las importaciones reales nacionales de bienes intermedios. -K: es una función de la variable endógena retardada un período, de la inversión real nacional en bienes de equipo, y de los precios industriales nacionales del sector de bienes de capital. -C: es una función del VAB de bienes de consumo en Andalucí retardada un período, de las importaciones reales nacionales de bienes de consumo, y del VAB total andaluz. Universidad de Barcelona Determina el VAB industrial mediante el VAB total español (Lobo et al. (1997)). (que aproxima la demanda del resto de la nación y del resto del mundo) y la productividad aparente de la industria española (como indicador de la competividad de la industria española). -Pág. 236- Capítulo VI. Alternativas Modelizadoras y Conceptos El Cuadro nº 56 parece indicar el predominio en la utilización de variables nacionales para aproximar el VAB industrial. La justificación puede ser el carácter cíclico que caracteriza a este sector. Cuadro nº 57. Variables explicativas del VAB de la Construcción. EQUIPOS Universidad de Zaragoza (Trívez y Mur (1994)). EXPERIENCIAS: CONSTRUCCIÓN Especifica el VAB en función del VAB de la rama nacional, del empleo en la rama regional, de la inversión pública total nacional y de la suma de las poblaciones de las capitales de provincia de Aragón. Universidad de Oviedo Especifica en función de la inversión real en construcción a (Pérez et al. (1994)). nivel nacional. Universidad de Las Es una función del empleo sectorial y de la inversión en Palmas de Gran Canaria construcción (que es una endógena del modelo). (González et al. (1994)). Universidad de Valladolid Trimestralización del VAB regional de la construcción. Se (Cavero et al. (1994)). explica en función de las ventas de cemento (retardadas un trimestre, ya que se considera un indicador adelantado), de la licitación oficial, del empleo regional en la construcción y de un indicador construido como [(0.2 × viviendas iniciadas) + (0.8 × viviendas terminadas)]. Universidad Autónoma de Se explica con el empleo del sector regional. Madrid (Aneiros (1994)). Universidad de Valencia Se explica con el empleo del sector regional y el VAB del (Badillo et al. (1998)). sector nacional. Universidad de Málaga Es una función del VAB del sector nacional y del VAB total (Otero et al. (1991)). andaluz. . Universidad de Barcelona Especifica el VAB en función del VAB total catalán, del (Lobo et al. (1997)). número de viviendas finalizadas y de las nuevas inversiones y ampliaciones industriales realizadas. A la vista del Cuadro nº 57, no apreciamos una sistemática común a la hora de modelizar esta rama. -Pág. 237- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 58. Variables explicativas del VAB de Servicios. EQUIPOS Universidad de Zaragoza (Trívez y Mur (1994)). EXPERIENCIAS: SERVICIOS Desagrega en transportes y comunicaciones (Z), servicios destinados a la venta (L), y servicios no destinados a la venta (G). -Z: Es una función del VAB de transportes y comunicaciones español, del empleo de la rama regional y de la inversión pública total nacional. -L: Es una función del VAB de servicios destinados a la venta en España, del empleo de la rama regional y de la suma de poblaciones de las capitales de provincia de Aragón. -G: Es una función del VAB de servicios no destinados a la venta en España y del empleo de la rama regional. Universidad de Oviedo Desagrega en transportes y comunicaciones (Z), destinados a la (Pérez et al. (1994)). venta (L), y no destinados a la venta (G). Z: Es una función del VAB de transportes y comunicaciones español y de la producción de laminados en la empresa ENSIDESA. L: Es una función del VAB de servicios destinados a la venta en España en el año anterior. G: Es una función del VAB total de España, de la productividad real del sector servicios no destinados a la venta en España y del empleo en el sector de servicios destinados a la venta en España. Universidad de Las Palmas Desagrega en transportes y comunicaciones (Z), destinados a la de Gran Canaria venta (L), y no destinados a la venta (G). (González et al. (1994)). Z: Es una función del VAB nacional del sector, del índice de precios de transportes y comunicaciones y de la entrada de turistas. L: Es una función del consumo privado interior y del empleo en servicios. G: Es una función del VAB nacional del sector, del gasto público en la Comunidad Canaria, y de la endógena retardada. Universidad de Valladolid Desagrega en transportes y comunicaciones (Z) servicios (Cavero et al. (1994)). destinados a la venta (L) y no destinados a la venta (G). -Trimestralizan el VAB regional de transportes y comunicaciones Se explica el VAB de la rama en función del movimiento de viajeros y del empleo en la rama regional. -Trimestralizan el VAB regional de servicios destinados a la venta. Se explica el VAB en función de las pernoctaciones de viajeros y del empleo en la rama regional. -Trimestralizan el VAB regional de servicios no destinados a la venta. La subrama G se explica con el empleo del sector regional. -Pág. 238- Capítulo VI. Alternativas Modelizadoras y Conceptos Cuadro nº 58. (Continuación). Universidad Autónoma de Desagrega en transportes y comunicaciones (Z), servicios Madrid (Aneiros (1994)). destinados a la venta (L), y servicios no destinados a la venta (G). Z: Es una función del VAB de transportes y comunicaciones español. L: Es una función del VAB de servicios destinados a la venta en España y del PIB total de la Comunidad Autónoma de Madrid. G: Es una función del VAB total de España. Universidad de Valencia Desagrega en servicios destinados a la venta y no destinados a (Badillo et al. (1998)). la venta (G). La primera subrama se explica con el empleo del sector regional y el VAB del sector nacional. Los servicios no destinados a la venta se especifican como una función del VAB del sector nacional. Universidad de Málaga Desagrega en transportes y comunicaciones (Z) y resto de (Otero et al. (1991)). servicios (L+G). Z: Especificada como una función de los precios industriales nacionales del sector, de la endógena retardada y del VAB total de Andalucía. RESTO DE SERVICIOS: es una función de las exportaciones reales nacionales de turismo, del VAB nacional en el sector de resto de servicios y de la endógena retardada. Universidad de Barcelona No desagrega. Explica el VAB de Servicios en función del (Lobo et al. (1997)). VAB total catalán y de las pernoctaciones hoteleras efectuadas en Cataluña. En función del esquema del Cuadro nº 58, si tenemos que destacar alguna sistemática en la rama de servicios, puede ser la consideración de la evolución de la rama nacional a la hora de explicar a la regional. En definitiva, de las características de los modelos econométricos que hemos recogido como muestra parcial de los que en la actualidad operan en España135, podemos extraer algunas características y extrapolar el estado de la situación general: 1. Entre sus variables explicativas se encuentran variables nacionales. 2. Las especificaciones de los modelos regionales son diferentes entre sí debido a que los autores los adaptan a las características particulares de sus regiones. 3. Es de destacar la limitación que supone la falta de datos, impidiendo trabajar con variables consideradas relevantes y condicionando el enfoque adoptado (que en la mayor parte de los modelos son de oferta). Es decir, la especificación se ve claramente condicionada por la disponibilidad de datos, influyendo claramente en la orientación que adopta la investigación. Así, 135 Dentro de la experiencia Hispalink. -Pág. 239- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña 4. 5. 6. 7. variables como los VAB sectoriales regionales se convierten en elementos claves. La anterior característica implica la necesidad de trabajar con relaciones simples y modelos de tamaño reducido. No obstante, esta característica no tiene porqué implicar solamente inconvenientes; así, Suriñach (1987, Pág. 48) señala como ventajas derivadas del tamaño reducido de los modelos: “comprensión fácil de sus mecanismos teóricos, obtención y análisis rápido de los resultados y simulaciones y gran facilidad de utilización técnica”. El enfoque de base económica suele orientar a la especificación econométrica, ya que proporciona simplificaciones que pueden hacer factible la construcción de modelos en España en el marco de restricciones fundamentalmente estadísticas- con las que las regiones españolas se encuentran en la actualidad. El método de estimación más utilizado en la actualidad en los modelos econométricos regionales son los mínimos cuadrados ordinarios. En general, la aplicación básica de estos modelos es la predicción y descripción de una economía regional. Pulido (1994, Pág. 221) da su opinión en lo que se refiere a las grandes líneas de perfeccionamiento de los modelos regionales de base económica: 1º “Ampliación de las variables incluidas, recogiendo aspectos no considerados hasta el momento (renta disponible, empleo, precios y salarios, etc.)”. 2º “Inclusión explícita de las relaciones intersectoriales dentro de la región y sus efectos sobre el comercio exterior con el resto de las regiones”. La característica fundamental que decanta la elección del tipo de modelo a aplicar hacia el modelo econométrico es que éste no requiere la cantidad de información que los “input-output”, pero puede proporcionar información más precisa que los de base económica. En lo referente a las limitaciones de los modelos macroeconométricos regionales, destacan: -El problema de los datos. Este es un problema que ya comentamos en el Capítulo II, pero las limitaciones aparecen por la no disponibilidad de las cifras, (tanto por retrasos en su publicación como por la falta de acceso a dichos datos), por la ruptura de las series, por el difícil acceso (o la no existencia de series largas con cierta garantía) a macromagnitudes regionales desde la perspectiva de la demanda, etc. -El anterior problema tiene incidencias econométricas, como pueden ser la especificación de relaciones simples o la omisión de variables relevantes. -Por último, una limitación importante viene por el hecho de que son frecuentes los cambios estructurales en economías “pequeñas” y en ocasiones -Pág. 240- Capítulo VI. Alternativas Modelizadoras y Conceptos inestables como las regionales, de manera que hay que tratar de la manera más eficiente posible este problema. Podemos concluir el Capítulo avanzando que en nuestro trabajo aplicado del Capítulo VII presentamos un modelo econométrico regional que no excluye a otras opciones modelizadoras, ya que se complementa y enriquece136 de las aportaciones del enfoque de base económica y del “inputoutput”. 136 Como se reflejará en el capítulo siguiente. -Pág. 241- Capítulo VII. Un Modelo Econométrico para Extremadura CAPÍTULO VII: UN MODELO ECONOMÉTRICO PARA EXTREMADURA. VII.1. INTRODUCCIÓN. En este capítulo, y atendiendo a la clasificación de Weber (1986), se presenta el bloque de producción que constituye la estructura de un modelo econométrico uniregional satélite para Extremadura. El hecho de caracterizarlo de esta forma se justifica porque las variables endógenas están en función de variables endógenas regionales, exógenas regionales, y exógenas nacionales (que ocupan un lugar muy importante en la dirección del sistema en general). Además, se ignora la posible causalidad de los cambios en la región sobre las variables nacionales. En definitiva, se trata de un modelo uniregional (porque no consideramos las interrelaciones con otras regiones), descendente (“topdown”, en el sentido de que las variables nacionales tienen un papel director importante), y en el que no se tienen en cuenta las posibles retroalimentaciones (“feed-back”) de la economía regional extremeña en la nacional (por lo que en términos de la tipología descrita en Courbis (1992) se trataría de un modelo abierto). En el Capítulo III se ha podido constatar el reducido peso de la economía extremeña respecto al total nacional; además, en dicho capítulo se ha verificado cómo el crecimiento de la economía extremeña está muy asociado al crecimiento nacional (este resultado se corrobora en el análisis cíclico del capítulo V y en este capítulo, bajo otra perspectiva, mediante la aplicación de la teoría de la cointegración). Por todo ésto, se ha considerado necesario adoptar un enfoque de tipo descendente (“top-down”), en los que se trabaja tanto con variables nacionales (que se consideran exógenas) como con variables regionales, ya sean endógenas y/o exógenas. La orientación causal descendente es matizada, en función de los principios propugnados por el enfoque de base económica, para aquellos sectores no básicos en los que su senda de crecimiento viene determinada por el nivel de actividad económica regional. Las herramientas tradicionales de análisis econométrico se fundamentan generalmente en el supuesto de que la estructura del sistema económico bajo estudio es estable. Sin embargo, esta hipótesis es muy restrictiva en el caso de modelizar economías regionales, puesto que es difícil asumir que el comportamiento futuro será similar al observado en el pasado. Así, como se muestra en el Capítulo III, Extremadura ha sufrido grandes cambios a lo largo de las últimas décadas, apareciendo el problema de la no existencia de una estructura estable para todo el período en estudio. -Pág. 243- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En consecuencia, desde la perspectiva metodológica, en este Capítulo ocupa un lugar muy importante la investigación de los efectos que produce la presencia de cambio estructural sobre el proceso de elaboración de modelos econométricos regionales, ya que ésta ha sido la dificultad principal a la que hemos tenido que hacer frente. La especificación y estimación de un modelo econométrico para Extremadura ha supuesto proponer un procedimiento (que se aparta de la práctica econométrica estándar) para aplicar cuando las relaciones estructurales no son constantes. La construcción de un modelo econométrico a escala regional tiene como objetivo típico la obtención de inferencias acerca del presente o futuro de la región analizada a partir de los datos históricos sobre la misma. En muchos casos estas inferencias conciernen al funcionamiento interno de la economía (relaciones intersectoriales, dependencia del exterior, eficiencia, etc.) o al análisis del impacto de determinadas políticas económicas (precios, subvenciones, políticas de empleo, etc.), mientras que en otras ocasiones la meta consiste en obtener predicciones de alguna variable de interés (producción, empleo, inversión, etc.). En ambos casos, para que las inferencias sean válidas se requiere que los modelos construidos sean “estables”, en el sentido de que se supone que el futuro será similar al pasado, implicando este hecho que los parámetros del modelo econométrico han de ser constantes. Si la hipótesis de constancia de los parámetros no se verifica en la práctica, cualquier inferencia que se obtenga a partir de los mismos, así como cualquier implicación de política económica que se derive del modelo, estarán sesgadas. En particular, se verán muy afectadas las simulaciones y predicciones postmuestrales que se realicen, con lo que quedará en entredicho la utilización del modelo como instrumento válido sobre el que apoyar decisiones de política económica. En el caso de las economías regionales, el problema de la inestabilidad se ve aún más agudizado que en el caso de economías nacionales, puesto que a ese nivel el impacto de “shocks” externos o internos es mucho mayor que para el total del país. Así, por ejemplo, el sector agrícola (por razones climatológicas) o el sector industrial (por razones de política de localización o de producción de las grandes empresas industriales) son prototipos de actividades económicas en cuya modelización econométrica es difícil asumir que la estructura del sistema que las caracteriza será estable en el futuro. En este contexto, las causas que pueden provocar que los parámetros de un modelo econométrico regional no sean constantes en el tiempo son las siguientes: -Pág. 244- Capítulo VII. Un Modelo Econométrico para Extremadura 1. Causas referentes a las condiciones de la economía. a) Existencia de cambios en la estructura de la economía. b) Existencia de cambios en las condiciones tecnológicas c) Comportamientos y actitudes de personas o grupos que puedan incidir en la economía regional, ya sea por decisiones políticas o por decisiones de inversión. d) Cambios en las condiciones climáticas. 2. Causas referentes a la mala especificación del modelo. a) Variables omitidas. b) Errores de medida en las variables. c) Utilización de variables aproximadas (“proxy”). Nuestro objetivo consiste en construir un modelo econométrico con fines fundamentalmente predictivos para Extremadura, para lo cual es obligado analizar cómo afecta la presencia de cambio estructural al proceso de elaboración de modelos econométricos a escala regional. El marco estadístico de partida es la teoría de la cointegración (Engle y Granger, 1987), la cual combina en su especificación econométrica básica las relaciones de equilibrio a largo plazo sugeridas por la teoría económica con el proceso de ajuste al equilibrio (en el corto plazo) de dichas relaciones a través de los mecanismos de corrección de error. En el largo plazo, y dada la interpretación de las relaciones de cointegración, es previsible la presencia de un número muy reducido de puntos de ruptura, por lo que la hipótesis que se utiliza es que pueden modelizarse dichos cambios a través de la introducción de variables ficticias137. En el corto plazo esta hipótesis se reemplaza por otra más general, en la que los parámetros del modelo pueden variar de forma continua a lo largo del tiempo. La hipótesis alternativa a la constancia es que los parámetros son estocásticos138 y varían según un modelo tipo ‘paseo aleatorio’ (multivariante), por lo que el modelo resultante puede acomodar cambios estructurales de todo tipo (bruscos o suaves) que hayan tenido lugar durante el período muestral. 137 En Canarella et al. (1990) la presencia de inestabilidad estructural en el largo plazo se modeliza usando un enfoque de parámetros variables en el tiempo. Sin embargo, tal y como señala Hall (1994), sería difícil dar una interpretación económica al modelo de largo plazo resultante de tal enfoque. 138 La modelización mediante variables ficticias implica que la alternativa a la hipótesis de constancia es un cambio determinista de los parámetros en el tiempo. Aparte de esta diferencia, el enfoque estocástico propuesto asume que el cambio en los parámetros es “suave”, frente a la hipótesis de cambio discreto (y por tanto brusco) del enfoque de variables ficticias. -Pág. 245- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña La organización del capítulo es como sigue. En el apartado dos se detallan los resultados básicos concernientes a la especificación estructural que sirve de soporte para el análisis empírico posterior. La especificación del modelo econométrico para la región de Extremadura está condicionada tanto por las limitaciones sobre la información estadística disponible a nivel regional en España como por el fin último del modelo, básicamente predictivo. En el apartado tres se discute la metodología utilizada, así como el modelo estadístico común para todas las ecuaciones del modelo econométrico, el cual se construye en el apartado cuatro. En esta última sección se procede en primer lugar al análisis de las propiedades estocásticas de las series utilizadas. Posteriormente, se pasa a la especificación de las ecuaciones a largo plazo de los siete sectores económicos considerados, analizando en cada caso la estabilidad de la relación estimada. Una vez reestimada ésta (si se hace necesario, a la vista de los resultados de los contrastes de estabilidad), se modelizan los mecanismos de corrección de error para el corto plazo, investigando de nuevo la verificación de la hipótesis de estabilidad paramétrica y reespecificando cada ecuación, si ello es preciso, siguiendo los dos enfoques metodológicos considerados en el apartado tres. En el apartado último se ofrecen las conclusiones más importantes que pueden obtenerse del trabajo realizado. -Pág. 246- Capítulo VII. Un Modelo Econométrico para Extremadura VII.2. EL MODELO ESTRUCTURAL BÁSICO El modelo econométrico está basado en las ideas fundamentales de los modelos de “base económica”. La razón fundamental que argumenta este enfoque es la simplicidad que entraña en términos de especificación, de manera que la exigencia de variables regionales que no están disponibles o a las que se tiene un acceso difícil 139 se ve minimizada. Otro tema relevante es la consideración de la hipótesis de base económica en el corto o en el largo plazo. En esta cuestión, Trívez y Mur (1994, Pág. 235) nos ilustran: “..., debemos tener presente que con esa hipótesis se está describiendo un proceso de equilibrio entre unos agregados económicos, lo que nos conduce, como hacen Brown, Coulson y Engle (1992) entre otros, a su consideración como mecanismo a largo plazo. Esta observación tiene implicaciones importantes porque significa que la resolución del modelo deberá llevarse a cabo en el contexto de la teoría de la cointegración”. Por razones estadísticas (ausencia en España de series temporales a nivel regional suficientemente largas140 desagregadas desde la perspectiva de la demanda), el modelo económico propuesto realiza una desagregación sectorial por el lado de la oferta. En concreto, se divide la producción regional en siete sectores económicos: -agricultura, -energía, -industria manufacturera, -construcción, -servicios destinados a la venta (excepto transportes y comunicaciones), -transportes y comunicaciones, y -servicios no destinados a la venta. Las variables endógenas a explicar (y predecir) vienen dadas por la producción de cada uno de esos sectores, medida a través del valor añadido bruto a precios de mercado en pesetas constantes de 1986 (que representaremos como W). 139 Por ejemplo variables de demanda. Las bases de datos HISPALINK e HISPADAT sólo contienen series de demanda final regionales para el período 1986-1993. De la primera se han extraído algunas de las macromagnitudes usadas en el trabajo. 140 -Pág. 247- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Siguiendo la línea argumental de los modelos de base económica (expuestos en el Capítulo anterior) pueden distinguirse los sectores básicos, cuya producción sirve para abastecer el mercado nacional o supranacional y los sectores no básicos o locales, los cuales venden la mayor parte de su producción en el mercado regional. Para los primeros, el nivel de actividad viene determinado fundamentalmente por factores externos, por lo que la especificación tipo es de la forma: nb E[W b |IE b ,IRb1 ,IRb2 ,... ] = α b + β b 0 IE b + ∑ β b i IR bi (VII.1) i=1 donde E[.|.] representa el valor esperado condicional, el superíndice hace referencia al sector básico b, IE es un indicador externo que mide la evolución del ciclo del mercado nacional del sector b141, e IR son indicadores regionales que complementan la especificación básica (entre los que pueden encontrarse variables que midan las ventajas de localización del sector b en la región, así como otras que expliquen las relaciones intersectoriales dentro del entorno regional). Para los sectores locales, la ecuación tipo viene dada por nl E[W |IR,IR , IR ,... ] = α l + β l 0 IR + ∑ β l i IRil l l 1 l 2 (VII.2) i=1 donde ahora IR es un indicador del nivel de demanda interna total en la región142 e IRl son indicadores regionales que complementan la relación básica (entre ellos pueden estar algunas variables que capten la relación del sector local con actividades básicas de la región). Sin embargo, como en la práctica no existen mercados exclusivamente nacionales o regionales, los sectores productivos son habitualmente mixtos, en el sentido de que parte de su actividad se determina por factores exógenos a la región y parte por circunstancias endógenas143. Este hecho implica que las relaciones que se especifican para los distintos sectores pueden ser una mezcla de las ecuaciones (VII.1) y (VII.2). 141 El coeficiente βb0 medirá entonces la sensibilidad de la producción regional del sector ante variaciones en el valor añadido del mismo a escala nacional. 142 En este caso, el coeficiente βl0 medirá la sensibilidad del sector ante cambios en la renta regional. 143 Lo cual no es óbice para que en cada sector en particular prevalezca la característica básica o local. -Pág. 248- Capítulo VII. Un Modelo Econométrico para Extremadura VII.2.1. DETERMINACIÓN DE LOS SECTORES BÁSICOS Y NO BÁSICOS. El cálculo del coeficiente de especialización o cociente de localización ( Ci ); definido en el Capítulo VI como: E Re gi E Re g Ci = ENaci ENac lo hemos calculado para las ramas de la Comunidad de Extremadura ( i = A, E , I , B, S , G ) en cada uno de los años del período 1980-1995, de manera que los resultados obtenidos son los que se muestran en el cuadro siguiente: Cuadro nº 59. Coeficientes de localización a R-6. AÑO CA CE CI CB CS 1980 2,006 0,392 0,446 0,826 0,867 1981 2,032 0,507 0,462 0,882 0,846 1982 2,027 0,572 0,475 0,927 0,829 1983 1,860 0,530 0,445 1,181 0,847 1984 1,855 0,582 0,423 1,219 0,852 1985 1,980 0,572 0,422 1,194 0,808 1986 1,863 0,540 0,436 1,272 0,823 1987 2,000 0,633 0,398 1,240 0,870 1988 2,036 0,632 0,408 1,226 0,857 1989 2,090 0,592 0,381 1,287 0,862 1990 2,187 0,590 0,379 1,302 0,854 1991 2,077 0,622 0,376 1,366 0,884 1992 2,041 0,627 0,370 1,410 0,901 1993 1,961 0,753 0,392 1,484 0,895 1994 1,926 0,751 0,395 1,423 0,903 1995 1,929 0,778 0,428 1,364 0,886 Fuente: Elaboración propia. -Pág. 249- CG 1,117 1,082 1,074 1,120 1,133 1,176 1,300 1,177 1,184 1,202 1,189 1,205 1,197 1,188 1,223 1,261 Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Tenemos que significar el hecho de que los coeficientes de localización también los hemos calculado con una desagregación R-9, siendo los resultados iguales que con R-6. Los coeficientes correspondientes a las ramas de actividad A, B y G son los únicos que superan la unidad, y según este criterio son los sectores básicos. No obstante, tomando como base el conocimiento de la economía extremeña y las características implícitas de los sectores de la construcción (B) y de servicios no destinados a la venta (G), podemos afirmar que señalar a tales sectores como aquellos que aportan la base económica de la región extremeña es un error importante que se puede derivar de alguna de las deficiencias (ya señaladas en el Capítulo VI) que presenta este criterio. Abandonando el criterio del coeficiente de localización, y en línea con Exportaciones a lo propugnado en el Capítulo VI, el cálculo del ratio Pr oduccion Efectiva partir de la Tabla “input-output” de 1990 para Extremadura con una desagregación a 9 ramas, permite detectar aquellas ramas productivas que más exportan con respecto al valor de los bienes y servicios producidos. En este sentido, y a la vista de las cifras del cuadro siguiente, es fácil señalar a los sectores agrarios (A), energéticos (E) e industria de bienes de consumo (C), como aquellos que más exportan en relación con su producción efectiva. Cuadro nº 60. Ratios de dependencia exterior sobre la producción. R-9 A E Q K C B L RATIO 0,457 0,732 0,178 0,296 0,551 0 0,016 Fuente: Elaboración propia a partir de De la Macorra (Dir.) (1995, Vol. I). Z 0,062 G 0 / Exportaci o n Sectorial Notas: RATIO = / Pr oducci o n Efectiva Sectorial Otra forma de aproximarnos a la realidad exportadora extremeña es la que se muestra en el Cuadro nº 61, en el que se pueden destacar, con una desagregación R-6, a las ramas A, E e I como las “dominantes” dentro del panorama exportador total. Si se analizan los resultados a una desagregación R-9, los resultados señalan a las ramas A, E y C como las principales ramas exportadoras de Extremadura, con más de un 92% de las exportaciones que se realizaron en nuestra Comunidad en el año 1990. -Pág. 250- Capítulo VII. Un Modelo Econométrico para Extremadura Cuadro nº 61. Ratios de dependencia exterior. R-6 A E I B SV RATIO 0,313 0,324 0.328 0 0.033 R-9 A E Q K C B L Z RATIO 0,313 0,324 0,014 0,028 0,285 0 0,023 0,009 Fuente: Elaboración propia a partir de De la Macorra (Dir.) (1995, Vol. I). G 0 G 0 Exportaci o/ n sec torial Notas: RATIO = Exportaciones Totales Por lo tanto, el diagnóstico es coincidente a la hora de señalar a las ramas A, E y C como las constituyentes de la base económica exógena de la región; es decir, que adoptando el enfoque de base económica, son estos sectores los que dependen en mayor medida de las variables de las economías externas a la región, ya que son los que dedican una mayor parte de su producción a la exportación, y además son los que, en términos absolutos, dominan las cifras exportadoras extremeñas. En consecuencia, y a R-6, los sectores de la construcción , de servicios destinados a la venta y de servicios no destinados a la venta serían los sectores no básicos (subsidiarios) de la economía extremeña. -Pág. 251- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VII.2.2. RELACIONES INTERSECTORIALES. Para aportar evidencia empírica acerca de las relaciones intersectoriales que se dan dentro de la economía extremeña, hemos optado por utilizar los coeficientes y multiplicadores que se obtienen a partir del modelo de demanda de Leontief144, el cual está “específicamente concebido para analizar los efectos que una alteración en la demanda final de uno o varios sectores, tiene sobre su producción” (Pulido y Fontela(1993, Pág. 78). Así, hemos calculado los coeficientes técnicos a partir de la Tabla “input-output” de Extremadura de 1990145 con una desagregación a 9 ramas (Ver Cuadro nº 62). Cuadro nº 62. Coeficientes técnicos. COEFICIENTES TÉCNICOS A E Q K C B Z L G 0,487 0,267 0,500 0,548 0,668 0,431 0,328 0,303 0,217 TOTALES (SUMA POR COLUMNAS) 0,143 0,192 0,274 0,385 0,223 0,174 0,153 0,068 0,065 DE IMPORTACIÓN (SUMA POR COLUMNAS) 0,345 0,075 0,226 0,163 0,445 0,258 0,175 0,235 0,151 INTERIORES (SUMA POR COLUMNAS) Fuente: Elaboración propia a partir de De la Macorra (Dir.) (1995). A la vista de los resultados anteriores es fácil apreciar que el peso de los consumos intermedios sobre la producción efectiva (suma por columnas de los coeficientes técnicos totales) se hace más importante para A, Q, K y C (ramas agraria e industriales). Dentro de estas cuatro ramas, son las ramas agrarias (A) y de industria de bienes de consumo (C) las que utilizan en mayor medida los consumos intermedios que suministran los agentes económicos de la región, según se observa en la suma por columnas de los coeficientes técnicos interiores. En consecuencia, las ramas A y C extremeñas son las más interrelacionadas en términos absolutos con el resto de ramas extremeñas a través de la adquisición de consumos intermedios. 144 El modelo de Leontief introduce la hipótesis de que la proporción de factores productivos que utilizan cada uno de los sectores es fija. De esta forma, las proporciones de ”inputs” primarios y de productos intermedios suministrados por otros sectores son fijos. 145 Los resultados que aportamos en este capítulo son los relativos a la Tabla “InputOutput” de Extremadura referidos al año 1990; no obstante, también hemos realizado los mismos cálculos con los datos de las Tablas “Input-Output” de Extremadura en el año 1978. Como las discrepancias que se extraen de ambos resultados no son signifiactivos, aportamos sólo los del año 1990. -Pág. 252- Capítulo VII. Un Modelo Econométrico para Extremadura Al estandarizar los coeficientes técnicos interiores, podemos advertir el hecho de que la rama C realiza sus compras de consumos intermedios procedentes de las ramas regionales, fundamentalmente dentro de la rama agraria (69,6%). Otro dato a destacar es que la rama Z realiza sus compras de primordialmente dentro de la rama de servicios destinados a la venta (59,8%). Cuadro nº 63. Coeficientes técnicos interiores estandarizados. A E Q K C B Z 0,565 0,000 0,059 0,000 0,696 0,001 0,000 A 0,052 0,508 0,161 0,075 0,030 0,014 0,077 E 0,003 0,010 0,263 0,072 0,002 0,289 0,002 Q 0,027 0,079 0,044 0,197 0,007 0,139 0,060 K 0,139 0,003 0,028 0,036 0,089 0,058 0,069 C 0,015 0,035 0,009 0,082 0,004 0,000 0,045 B 0,064 0,095 0,122 0,161 0,043 0,159 0,148 Z 0,137 0,270 0,315 0,378 0,129 0,340 0,598 L 0,000 0,000 0,000 0,000 0,000 0,000 0,000 G 1 1 1 1 1 1 1 TOTAL Fuente: Elaboración propia a partir de De la Macorra (Dir.)(1995). L 0,013 0,068 0,006 0,006 0,119 0,032 0,073 0,682 0,000 1 G 0,014 0,106 0,007 0,087 0,122 0,070 0,158 0,435 0,000 1 Como nuestro interés se centra en evidenciar las relaciones directas e indirectas de carácter interior, vamos a calcular a partir de cada uno de los elementos de la matriz inversa de Leontief (Ajk) la variación de la rama j (en fila) cuando la demanda final de la rama k (en columna) varía. -Pág. 253- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 64. Matriz inversa de coeficientes técnicos interiores. A E Q K C B Z L G TOTAL A 1,267 0,001 0,022 0,004 0,409 0,010 0,007 0,019 0,012 1,752 0,027 1,040 0,043 0,016 0,025 0,010 0,017 0,021 0,019 1,219 E 0,002 0,001 1,064 0,014 0,002 0,080 0,002 0,003 0,002 1,170 Q 0,013 0,007 0,012 1,034 0,008 0,039 0,012 0,003 0,015 1,143 K 0,066 0,001 0,012 0,010 1,065 0,021 0,017 0,036 0,023 1,252 C 0,008 0,003 0,003 0,015 0,005 1,002 0,009 0,009 0,012 1,067 B 0,032 0,008 0,033 0,031 0,033 0,048 1,030 0,023 0,028 1,268 Z 0,082 0,027 0,099 0,084 0,102 0,122 0,132 1,199 0,087 1,934 L 0,000 0,000 0,000 0,000 0,000 0,000 0,000 0,000 1,000 1,000 G TOTAL 1,498 1,089 1,288 1,208 1,649 1,333 1,228 1,313 1,198 Fuente: Elaboración propia a partir de De la Macorra (Dir.)(1995, Vol. I). Las interpretaciones de los elementos de la matriz inversa de coeficientes técnicos internos que resultan más relevantes son las siguientes: -Si la rama de bienes de consumo ( C ) incrementa su demanda final en una unidad, la rama agraria ( A ) deberá variar su producción en 0,409. -Si la rama de bienes de consumo ( C ) incrementa su demanda final en una unidad, la rama de servicios destinados a la venta ( L ) deberá variar su producción en 0,102. -Si la rama de la construcción ( B ) incrementa su demanda final en una unidad, la rama de servicios destinados a la venta ( L ) deberá variar su producción en 0,122. -Si la rama de transportes y comunicaciones ( Z ) incrementa su demanda final en una unidad, la rama de servicios destinados a la venta ( L ) deberá variar su producción en 0,132. Gráficamente, las interrelaciones que se deducen de la matriz inversa de Leontief son las del gráfico siguiente. Gráfico nº 69: Relaciones intersectoriales: modelo de demanda. 0,409 C 0,102 L A 0,132 Z Fuente: Elaboración propia. -Pág. 254- 0,122 B Capítulo VII. Un Modelo Econométrico para Extremadura En otro sentido, la matriz inversa de Leontief regional, Am( I − Ad ) −1 (donde Am es la matriz de coeficientes técnicos de importación, y Ad es la matriz de coeficientes técnicos interiores), es la matriz clave para interpretar las relaciones entre las demandas de inputs intermedios de cada sector regional a los sectores exteriores. Cuadro nº 65. Matriz inversa de Leontief regional. A A 0,033 E 0,031 Q 0,062 K 0,038 C 0,035 B 0,000 Z 0,004 L 0,016 G 0,000 TOTAL 0,218 E 0,000 0,017 0,090 0,047 0,003 0,000 0,007 0,041 0,000 0,207 Q 0,005 0,054 0,205 0,014 0,014 0,000 0,009 0,023 0,000 0,323 K 0,002 0,010 0,202 0,156 0,009 0,000 0,006 0,037 0,000 0,421 C 0,079 0,021 0,044 0,024 0,117 0,000 0,011 0,022 0,000 0,317 B 0,003 0,028 0,117 0,049 0,016 0,000 0,008 0,014 0,000 0,235 Z 0,002 0,104 0,007 0,027 0,021 0,000 0,003 0,019 0,000 0,182 L 0,012 0,011 0,011 0,011 0,051 0,000 0,002 0,006 0,000 0,104 G 0,002 0,009 0,018 0,040 0,012 0,000 0,003 0,010 0,000 0,094 TOTAL 0,138 0,283 0,756 0,407 0,278 0,000 0,052 0,187 0,000 Media Total 0,233 Fuente: Elaboración propia a partir de De la Macorra (Dir.)(1995). De esta forma, las ramas que se pueden calificar como de “demandadas desde el exterior” son aquellas que tienen una suma por filas en la matriz Am( I − Ad ) −1 que son superiores al promedio (0,233). En consecuencia, las ramas demandadas desde el exterior son E, Q, K y C. En otra vertiente se encuentran las ramas demandantes desde el interior (aquellas cuya suma por columnas superan el valor promedio de 0,233) que son Q, K y C. En resumen, se puede afirmar: a) Los sectores A, E y C son aquellos que constituyen la base económica exógena de la región. b) Dentro de las interrelaciones sectoriales dentro de Extremadura destacan las compras del sector de bienes de consumo al agrario y del sector de transportes y comunicaciones al sector de servicios destinados a la venta. c) Las ramas más demandadas desde el exterior son E, Q, K y C. En otra vertiente, las ramas demandantes desde el interior son Q, K y C. -Pág. 255- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Hasta este momento sólo nos hemos referido al modelo de demanda de Leontief, sin embargo, ahora enfocamos el análisis desde la perspectiva del modelo de oferta de Leontief o modelo de Gosh. Nuestro interés por este modelo se justifica porque en nuestra especificación econométrica el enfoque adoptado será el de oferta, jugando un papel fundamental la variable valor añadido bruto. El cuadro siguiente señala que el peso de la distribución sobre la producción efectiva (suma por filas de los coeficientes de mercado calculados en la matriz de coeficientes de distribución) es más importante en el caso de Q y de K. Para estas ramas es mucho más importante la distribución externa a la región que la interna. Por el contrario, la rama A distribuye los consumos intermedios fundamentalmente al interior. Cuadro nº 66. Coeficientes de distribución. COEFICIENTES DE DISTRIBUCIÓN TOTALES (Suma por filas) DE EXPORTACIÓN (Suma por filas) 0,524 0,086 A 0,324 0,151 E 3,024 2,294 Q 1,708 1,200 K 0,481 0,255 C 0,038 0 B 0,757 0,113 Z 0,333 0,037 L 0,00001 0 G Fuente: Elaboración propia a partir de De la Macorra (Dir.)(1995). INTERIORES (Suma por filas) 0,437 0,173 0,729 0,508 0,226 0,038 0,643 0,295 0,00001 Al estandarizar los coeficientes de mercado interiores (Cuadro nº 67), podemos advertir el hecho de que la rama A vende, además de a sí misma el autoconsumo, a la rama C. Otro resultado a destacar es el autoconsumo de L. -Pág. 256- Capítulo VII. Un Modelo Econométrico para Extremadura Cuadro nº 67. Coeficientes de distribución totales estandarizados. A E Q K C B Z L G A 0,413 0,000 0,004 0,000 0,537 0,000 0,000 0,043 0,003 E 0,183 0,164 0,046 0,011 0,073 0,096 0,125 0,218 0,084 Q 0,124 0,156 0,081 0,080 0,045 0,450 0,001 0,035 0,028 K 0,143 0,134 0,008 0,105 0,040 0,300 0,031 0,070 0,167 C 0,186 0,003 0,005 0,004 0,285 0,059 0,016 0,387 0,055 B 0,138 0,047 0,006 0,052 0,037 0,000 0,051 0,426 0,244 Z 0,141 0,052 0,023 0,025 0,118 0,258 0,037 0,222 0,124 L 0,082 0,055 0,015 0,019 0,079 0,132 0,040 0,490 0,088 G 0,000 0,000 0,000 0,000 0,000 0,000 0,000 0,000 1,000 Fuente: Elaboración propia a partir de De la Macorra (Dir.)(1995). TOTAL 1 1 1 1 1 1 1 1 1 El multiplicador de oferta o de inputs es el sumatorio de los elementos de la fila correspondiente de la matriz inversa de los coeficientes internos de distribución (Cuadro nº 68); y se interpreta: si incrementa en una unidad el VAB del sector situado en la fila i correspondiente, incrementarán todos los sectores su producción en la suma (efecto final sobre todos los sectores). Destacan los multiplicadores de oferta para las ramas A, Q, K y Z. El multiplicador de una expansión uniforme de los inputs primarios es la suma de los coeficientes en columnas, de manera que la interpretación a realizar es que si existe un cambio de una unidad en la oferta de inputs primarios en todos y cada uno de los sectores de la economía, la producción en el sector columna (sector j) se verá afectada en dicha suma. Destacan los multiplicadores de las ramas B, C y L. Este resultado legitima la introducción en la especificación a corto plazo del modelo econométrico (para las ramas de la construcción, industria manufacturera y servicios destinados a la venta) de variables relativas a la actividad económica global de Extremadura. Los elementos δij de la matriz inversa de los outputs ( I − D) −1 , donde D es la matriz de coeficientes de distribución, indica que un incremento en una unidad del VAB del sector i, provocará un aumento en la producción del sector j en δij unidades. -Pág. 257- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 68. Matriz inversa de los coeficientes internos de distribución. A E Q K C B Z L G A 1,267 0,000 0,003 0,001 0,308 0,010 0,002 0,039 0,010 E 0,041 1,040 0,008 0,003 0,029 0,015 0,006 0,069 0,025 Q 0,019 0,007 1,064 0,017 0,014 0,651 0,003 0,045 0,018 K 0,093 0,030 0,010 1,034 0,044 0,262 0,020 0,043 0,088 C 0,088 0,001 0,002 0,002 1,065 0,027 0,005 0,101 0,026 B 0,008 0,002 0,000 0,002 0,004 1,002 0,002 0,021 0,010 Z 0,140 0,024 0,017 0,019 0,106 0,199 1,030 0,208 0,101 L 0,039 0,008 0,006 0,006 0,037 0,056 0,015 1,199 0,035 G 0,000 0,000 0,000 0,000 0,000 0,000 0,000 0,000 1,000 TOTAL 1,696 1,113 1,109 1,084 1,607 2,221 1,084 1,725 1,313 Fuente: Elaboración propia a partir de De la Macorra (Dir.)(1995). TOTAL 1,639 1,237 1,837 1,625 1,316 1,052 1,844 1,400 1,000 La siguiente gráfica posibilita la interpretación esquemática de los elementos de la matriz inversa de coeficientes de mercado internos: Gráfico nº 70: Relaciones intersectoriales de Oferta. 0,208 L Z 0,199 B 0,140 0,262 0,651 A K Q 0.308 C Fuente: Elaboración propia. De la anterior gráfica vamos a destacar las relaciones que se producen entre la rama agraria y de la industria manufacturera de bienes de consumo, así como entre la rama de servicios destinados a la venta y transportes y comunicaciones. Estas relaciones se consideran posteriormente en la especificación de las relaciones a corto plazo del modelo econométrico. -Pág. 258- Capítulo VII. Un Modelo Econométrico para Extremadura VII.3. METODOLOGÍA VII.3.1. ESTRUCTURA ECONOMÉTRICA La estructura del modelo econométrico regional debe cumplir unos requisitos, tanto desde la perspectiva teórica como estocástica. La perspectiva teórica ya la hemos desarrollado, describiendo a la economía extremeña y adoptando el enfoque modelizador más adecuado para llegar a la utilización más eficiente de la información estadística disponible. Sin embargo, también se deben verificar unas propiedades estocásticas; en este sentido, la estructura funcional de las ecuaciones que componen el modelo econométrico regional está basada en la moderna teoría de la cointegración (Engle y Granger, 1987), la cual ha demostrado ser una herramienta muy útil para los especialistas en economía regional por sus posibilidades de aplicación en diferentes ámbitos de la modelización econométrica. En concreto, se proponen ecuaciones “tipo” en forma de mecanismo de corrección de error (MCE), en el que se plantea una relación de equilibrio a largo plazo entre las variables explicativas (no necesariamente exógenas) y la explicada (endógena), a la vez que se permite la existencia de desajustes en el corto plazo respecto a esa situación de equilibrio a través de la introducción de términos dinámicos146. La estructura básica que proponemos para las ecuaciones del modelo es una variante de los mecanismos de corrección de error tradicionales, viniendo dada por la expresión: p q i =1 i =0 ∆Wt s = γ 0 + ∑ γ 1i ∆Wt s−i + ∑ γ 2i ∆Z ts−i − α (Wt s−1 − β / X ts−1 ) + uts (VII. 3) donde: W s representa el valor añadido bruto del sector s (en logaritmos), X s es un vector de variables explicativas (en general también en logaritmos) que cointegran con la variable dependiente W s 147 y Z s es un vector de variables que explica (junto con los valores retrasados de la variable dependiente) las desviaciones en el corto plazo de la situación de equilibrio (entre las componentes de Z s se pueden encontrar algunas de las variables del vector X s)148. 146 Ver Anexo 5. Ws=βXs será entonces la relación de equilibrio a largo plazo, y Wts-βXts medirá las desviaciones del equilibrio en cada instante t. 148 La especificación propuesta supone que todas las variables que aparecen (en niveles) en [3] son I(1). 147 -Pág. 259- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VII.3.2. EL MODELO ESTADÍSTICO En la especificación (VII. 3) hemos supuesto que los parámetros son fijos, es decir, que las relaciones estructurales a largo y corto plazo son estables. Para relajar esta hipótesis distinguiremos dos casos, según que se presente inestabilidad estructural en el largo o en el corto plazo. La ecuación (VII. 3) supone que la combinación lineal Wts-β βXts de las variables integradas tiene una distribución estacionaria. Sin embargo, existe la posibilidad de un tipo más general de cointegración permitiendo que el vector de cointegración β cambie en algún punto del período muestral149. La hipótesis nula de cointegración estándar implica el modelo W ts = β 0 + β 1 X st + e ts / (VII. 4) donde W t s y X ts son I(1) y est es I(0). Si la relación (VII. 4) es estable, los parámetros β0 y β1 deben ser constantes (invariantes en el tiempo), pero si existe inestabilidad estructural dichos parámetros permanecerán constantes durante algún período de tiempo, para posteriormente cambiar (β0 o alguna componente del vector β1) hacia un nuevo nivel, obteniéndose otra relación de equilibrio con distintos valores para las pendientes o la ordenada en el origen; el cambio producido puede ser definitivo, pero también puede ocurrir que se vuelva a la situación original transcurrido un cierto período de tiempo o que se pase a otro estado de equilibrio caracterizado por un nuevo conjunto de coeficientes. Ante la presencia de cambio estructural, y teniendo como objetivo la predicción, la forma de actuar según Pérez (1995, Pág. 92) es la siguiente: -en el caso de que se identifiquen los cambios: estimación con parámetros cambiantes (PVT) o elección de la estructura más adecuada. -en el caso de que exista cambio evolutivo: estimación con parámetros cambiantes o trabajar con la estructura última. Por estimación con parámetros cambiantes vamos a entender, de acuerdo con Pérez (1995, Pág. 93), “un conjunto de alternativas de estimación aplicables en situaciones de cambio estructural”. Una posible clasificación de los métodos principales de estimación con parámetros cambiantes es la que se muestra en el cuadro siguiente, en el cual se opta por clasificar atendiendo al carácter estocástico o determinista de la estructura que siguen los parámetros cambiantes en su evolución, y al carácter estacionario o tendencial de dichos parámetros. 149 Por simplicidad en la exposición, suponemos que existe un único punto de ruptura. -Pág. 260- Capítulo VII. Un Modelo Econométrico para Extremadura Cuadro nº 69. Principales modelos con parámetros cambiantes. TIPOLOGÍA Por la naturaleza de la evolución. ESTACIONARIOS TENDENCIALES Por el tipo de evolución. DETERMINISTAS -Variación sistemática. -Regresiones cambiantes -Regresiones cambiantes. (Switching Regression): (Switching Regression) Variables ficticias con tendencia Modelos de transición Poirier ESTOCÁSTICOS -Hildretd Houck -Cooley Prescott -Swamy -Rosenberg -Hsiao -Filtro de Kalman. Fuente: Pérez (1995, Pág. 95). La clasificación realizada en el Cuadro nº 69 se ha enriquecido con alguna información adicional en el Cuadro nº 70 con el fin de proporcionar una vista panorámica más detallada de algunos de los posibles modelos de parámetros cambiantes utilizados en la práctica econométrica150. Cuadro nº 70. Modelos con parámetros cambiantes: visión de conjunto. Modelos Deterministas Estacionarios -Modelos de variación sistemática determinista. Este tipo de modelos presentan una formulación tan general que podrían encuadrarse dentro de otros tipos de modelos. La idea es la siguiente: Dentro de un modelo de regresión lineal general, y para un vector de parámetros β it de dimensión k × 1 , “Belstey (1973) propone introducir la información extramuestral necesaria mediante un conjunto de M relaciones lineales, en principio no estocásticas, del tipo β it = Z it γ , donde Z it es una matriz de k × M elementos, siendo M el número de variables que explican la variación de los parámetros a lo largo de las observaciones, y γ es un vector M × 1 de coeficientes asociados a dicha variables. (...) si consideramos a la matriz Zit como conocida y no estocástica, podríamos replantear el modelo” (Pérez (1995, Págs. 97-98)). -Modelo de regresiones cambiantes (“Switching Regression”). a) Modelos de variables ficticias b) Modelos estacionales c) Modelos de regresiones partidas (“piecewise regression”). c1) de punto de cambio conocido c2) de punto de cambio desconocido. c21) deterministas c211) Basados en el tiempo (*) c212) Basados en otras variables (*) c22) aleatorios (*) Los modelos de selección del punto de ruptura se generalizan mediante las regresiones con funciones de transición regular (“Smooth Transition Regression” de Lin y Teräsvirta (1994)). 150 Para desarrollar más este esquema ver, por ejemplo, el Capítulo 19 de Judge et al. (1985). -Pág. 261- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 70. (Continuación). Modelos Determinísticos con Evolución Tendencial -Regresiones cambiantes (“Switching Regression”): a) Variables ficticias con tendencia. b) Modelos de transición Poirier (1976). Plantea estimaciones partidas utilizando funciones cúbicas segmentadas (“Cubic Splines Functions”). Modelos Estocásticos Estacionarios “...desarrollados, en general, dentro del contexto de los modelos de datos espaciotemporales” (Pérez (1995, Pág. 115)). “...su aplicabilidad a datos puramente temporales está bastante limitada y no ofrece ventajas especiales con respecto a los (...) [otros] procedimientos...” (Pérez (1995, Pág. 116)). -Modelo de coeficientes aleatorios de Hildretd Houck (1968). Generalización en Harvey y Phillips (1982): Modelo de retorno a la normalidad (“Return-to-normality Model”). - Modelo de coeficientes aleatorios de Swamy (1970, 1971). “Este autor asume que los vectores de parámetros β m que afectan al conjunto de observaciones emporales de cada individuo, provienen de una misma distribución con media β , y matriz de varianzas y covarianzas ∆ .” (Pérez (1995, Pág. 120)). - Modelo de coeficientes aleatorios de Hsiao (1974, 1975). “Sobre la misma base del modelo de Swami, Hsiao (1974, 1975) plantea (...) que los parámetros, además de variar entre los distintos individuos, varían también a lo largo del tiempo”. (Pérez (1995, Pág. 125)). Modelos Estocásticos Tendenciales - Modelo de Cooley Prescott (1973). / “Sobre un modelo clásico de regresión del tipo y t = x t β t , los citados autores proponen una nueva especificación en la que los parámetros tienen dos componentes de variación, denominados por ellos mismos como “permanentes” y “transitorios”, pudiendo expresar, entonces, el vector de k parámetros en un momento del tiempo t según β t = β t p + ut p la siguiente formulación: p donde β t representaría el componente p β t = β t −1 + v t permanente del vector de parámetros. Los componentes aleatorios se distribuirían respectivamente como variables normales de media 0 y matriz de varianzas y Cov(ut ut/ ) = (1 − γ )σ 2 Σ u covarianzas: , donde Σ u y Σ v se asumen como conocidas 2 / Cov(v t v t ) = γ σ Σ v y normalizadas generalmente con valor 1 para el término constante.” (Pérez (1995, Pág. 130)). “El problema fundamental que plantea la aplicación práctica de este tipo de modelos es la necesidad de conocer a priori los valores de las matrices Σ u y Σ v , ya que la estimación del modelo considerándolas como desconocida, no sería factible.” (Pérez (1995, Pág. 133)). - Modelo de parámetros convergentes de Rosenberg (1973). “Está diseñado para aplicaciones de datos espacio-temporales.” (Pérez (1995, Pág. 129)). -Pág. 262- Capítulo VII. Un Modelo Econométrico para Extremadura - Modelo basado en el Filtro de Kalman (Kalman y Bucy (1961)). El sistema se debe representar en el espacio de los estados, para posteriormente utilizar el filtro de Kalman en la estimación de los parámetros cambiantes en el tiempo: “en esencia, consiste en la corrección sistemática de los valores de los parámetros en función del error de predicción cometido en el período inmediatamente anterior ponderado en función de la varianza del mismo.” (Pérez (1995, Pág. 141)). Nota: (*) indica que el método no pertenece de manera precisa a la categoría en la que está incluida. Fuente: Elaborado a partir del Cuadro impreso en Pérez (1995, Pág. 273) y de los comentarios de este mismo autor en Págs. 95-142. Si suponemos que el cambio en los parámetros es discreto, entonces se puede modelizar el cambio estructural introduciendo una variable ficticia del tipo ϕ t ,t (t) = [ 0 1] 0 si t < t 0 1 si t 0 ≤ t ≤ t 1 0 si t > t 1 (VII. 5) donde t0 denota el punto de ruptura de la relación de cointegración y t1 el punto de vuelta a la situación inicial, con 1 < t 0 ≤ t 1 ≤ T . En el caso más general donde el cambio estructural implica una modificación tanto de la ordenada en el origen como en las pendientes, la relación de cointegración con cambio estructural viene dada por W ts = β 01 + β 02 ϕ [t 0 ,t 1 ] (t)+ β 11/ Xts + β 12/ Xts ϕ [t 0 ,t 1 ] (t)+ ets (VII. 6) donde β 01 y β 02 representan, respectivamente, las ordenadas en el origen antes y después del cambio estructural, y β 11 y β 12 son los coeficientes de las pendientes en la relación de cointegración antes y después del cambio de régimen. El modelo anterior se puede generalizar para permitir más de un punto de ruptura simplemente introduciendo variables ficticias adicionales. En cualquier caso, el cambio de régimen que se está suponiendo es completamente discreto. La ventaja que tiene este tipo de cambio es la sencillez de aplicación y la inmediata e intuitiva interpretación del cambio. Podría relajarse la hipótesis de cambio de régimen discreto a través de dos mecanismos distintos. Uno de ellos consiste en modelizar el cambio estructural de una forma paramétrica, permitiendo que los parámetros cambien de forma gradual de un sistema estable a otro a través de alguna función Λ; este el modelo propuesto por Lin y Teräsvirta (1994), quienes consideran una -Pág. 263- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña especificación del tipo151 W ts = β ( donde Λ Z t , θ / 1 ( ) / Xts + β 2 Xts Λ Z t , θ + ets (VII. 7) ) es una función de transición que permite al modelo cambiar del estado E[Wt s X ts ] = β 1/ X ts a E[Wt s X ts ] = ( β 1 + β 2 ) / X ts a través de las variables Z t . Si Z t = t y Λ = ϕ t ,t obtenemos el caso de cambio discreto, [ 0 1 ] pero otro tipo de funciones flexibilizará el modelo de cambio de un régimen a otro (ver Lin y Teräsvirta (1994) para un análisis de diferentes elecciones). La otra alternativa (que utilizamos en este trabajo para el caso de la modelización de las relaciones de corto plazo) consiste en permitir que los coeficientes de la ecuación (VII. 4) sigan un proceso estocástico del tipo β t = Ψβ t −1 + ξ t , de forma tal que los parámetros cambien de forma continua a lo largo de todo el período muestral152. En lo que respecta a los parámetros del mecanismo de corrección del error , y en previsión de que en el corto plazo puedan existir inestabilidades importantes, formulamos un modelo que permite adaptarse a cualquier tipo de cambio (brusco o suave) que pueda producirse. En este sentido, el modelo determinista de variables ficticias resulta a priori demasiado rígido, siendo más conveniente un modelo estocástico154 que permita mayor flexibilidad en la evolución temporal de los parámetros. Reespecificando el modelo (VII. 3) de tal forma que en el vector α aparezcan todos los parámetros 153 151 A la que Lin y Teräsvirta denominan modelo de transición suave (STR). El modelo (VII. 7) también supone que existe únicamente un punto de ruptura en la relación a largo plazo, pero fácilmente puede generalizarse al caso de más de un cambio estructural. 152 Si Ψ=I tendremos un modelo de “paseo aleatorio” y si Ψ=B=diag{b1, b2,..., bK} se tendrá el modelo de “vuelta a la normalidad”. Al menos bajo la perspectiva del largo plazo, ambos modelos -considerados globalmente- son “excesivamente” generales, en el sentido de que suponen un cambio estructural continuo (de período a período cambian todos los coeficientes); en este sentido, al menos en el modelo de vuelta a la normalidad los coeficientes convergen (si los parámetros bi cumplen la restricción de ser menores que uno en valor absoluto) a un estado estacionario, β*, que sería el que tendría la interpretación como vector de cointegración. 153 En el trabajo seguiremos una estrategia de estimación bietápica (Engle y Granger, 1987) en la que en la primera etapa se estima la relación de cointegración, y posteriormente se estima el mecanismo de corrección de error introduciendo los residuos (retrasados) de la relación a largo plazo estimada en el primer paso. 154 También podría utilizarse un modelo del tipo STR tal como se hace en Wolters et al. (1996). -Pág. 264- Capítulo VII. Un Modelo Econométrico para Extremadura (γ0,γ11,...,γ1p,γ20,..,γ2q,- α ) y en el vector Hs todas las variables explicativas155 del mismo, la estructura de las ecuaciones del modelo que se propone son del tipo156 ∆ W ts = α t/ H ts + u ts α t = α t -1 + η t (VII. 8) donde suponemos que los errores u ts se distribuyen normalmente con media cero y varianza constante σ2 y son independientes entre sí, y que η t es un vector de variables aleatorias normales con media cero y matriz de covarianzas σ2P=Q, cuya distribución es independiente de la de los errores u ts y de la correspondiente al vector α 0 . La primera ecuación del sistema (VII. 8) se conoce como ecuación de medida y la segunda como ecuación de transición, la cual describe la evolución temporal del vector parámetros de interés, α t , que ahora se denomina vector de estados (y a sus componentes variables de estado). En nuestra aplicación supondremos que la matriz Q (conocida como matriz de dispersión) es diagonal, es decir, no se permite a las variables de estado interactuar entre sí, para lo cual deberían aparecer elementos no nulos fuera de la diagonal. Lógicamente, en el caso en que Q=0 se obtiene el modelo (VII. 3) de parámetros constantes. La especificación (VII. 8) supone que el vector de parámetros α t sigue una distribución multivariante tipo paseo aleatorio (sin deriva) y, al ser no estacionario, evoluciona en el tiempo de forma tal que puede acomodar todos los cambios estructurales que hayan tenido lugar durante el período muestral. Obviamente, pueden proponerse otros modelos estocásticos para αt dependiendo del nivel de información a priori que se posea sobre la forma, fechado y velocidad del cambio estructural157. En nuestro caso, dada la carencia de dicha información158, hemos preferido utilizar como hipótesis alternativa (por otro lado habitual) un modelo de paseo aleatorio. La elección de α t = α t -1 + η t como hipótesis de evolución de los coeficientes aleatorios tiene como ventaja fundamental su mayor flexibilidad frente a otras para recoger un espectro más amplio de cambios posibles, e implica suponer que los cambios en dichos coeficientes continuarán indefinidamente. 155 Substituyendo el vector de cointegración Wst-1-βXst-1 por el valor de los residuos estimados. 156 Ver Anexo 8 para una exposición más detallada de los modelos en el espacio de los estados. 157 Ver al respecto el apartado 4 de Hall (1994). 158 Y el reducido número de observaciones, que limita cualquier tipo de generalización. -Pág. 265- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Otras opciones para la estructura de la ecuación de estado son suponer un proceso autorregresivo de orden uno con deriva ( α t = ρ α t -1 + µ + η t ; siendo ρ el coeficiente autorregresivo y µ la media) o una media constante ( α t = α t + η t ). En el caso primero estaríamos bajo la hipótesis de que los cambios en los coeficientes aleatorios tienen alguna persistencia en el tiempo, aunque los coeficientes retornan a un valor medio pasado algún tiempo. En el caso segundo se estaría suponiendo que los cambios que se producen en los coeficientes no persisten en el tiempo. El caso de persistencia con memoria de un período para retornar a un valor medio lo abandonamos en este trabajo por parecernos una opción menos flexible que el paseo aleatorio ( que es más general, y permite considerar un abanico más amplio de opciones dentro de los cambios posibles en los parámetros). El caso de la no existencia de persistencia, lo rechazamos porque se producen cambios en los parámetros que sí tendrán un efecto persistente en el futuro. -Pág. 266- Capítulo VII. Un Modelo Econométrico para Extremadura VII.4. RESULTADOS EMPÍRICOS VII.4.1. FUENTES ESTADÍSTICAS. La mayor parte de las variables utilizadas en el trabajo se han obtenido de las bases de datos HISPALINK y Cordero y Gayoso (1997). En concreto, todas las variables referentes al valor añadido bruto (por sectores y a nivel regional y nacional) se han obtenido de dichas bases. La primera es una base histórica que recoge datos para el período 1970-1985 (ver Hispalink (1993)) mientras que la segunda abarca desde 1980 hasta 1995 con datos oficiales del Instituto Nacional de Estadística y utilización de deflactores propios. La serie homogénea para el período 1970-1995 la hemos obtenido de la siguiente forma: a las variables de Cordero y Gayoso (1980-1995) a R-9 se les ha aplicado “hacia atrás” la tasa de crecimiento anual de las mismas variables contenidas en la base HISPALINK para el período 1970-1980. El resto de variables (no referentes al valor añadido bruto) proviene de fuentes distintas de información estadística regionales o nacionales. Así, el volumen de agua embalsada al final de cada año en Extremadura (VOLAG) y el volumen medio de precipitaciones recogidas en Extremadura (PRECIP) se han obtenido del INE. La producción bruta de energía eléctrica en Extremadura (ENERG) es de elaboración propia (Consultar Anexo 1). Los datos utilizados comprenden, en general, desde 1970 hasta 1995 (último año para el que se poseen cifras oficiales), aunque en algunos sectores la longitud es más reducida debido a la inexistencia de series desagregadas para varios años al principio del período considerado. Uno de los objetivos del trabajo consiste en analizar el funcionamiento predictivo post-muestral del modelo, por lo que hemos reservado las dos últimas observaciones de las series (los años 1994-1995) y así poder hacer predicciones ex-post para dichos años. Por lo tanto, el período muestral que se utiliza en la estimación de los epígrafes siguientes es el comprendido, en general, entre 1970 y 1993. -Pág. 267- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VII.4.2. ESPECIFICACIÓN DEL MODELO. Como ya hemos expuesto, nuestra modelización es del tipo descendente. Sin embargo, adoptando el enfoque de base económica en la medida que sea posible y para los sectores que sea necesario, modificamos la causalidad en el sentido nación-región (que mantienen los sectores básicos) para conferirles una causalidad más acorde con las relaciones fundamentales que determinan la actividad en los sectores no básicos. En el Cuadro nº 71 aparecen las ramas identificadas como básicas para la región extremeña, así como las variables que van a formar parte de las ecuaciones construidas para cada rama según la estructura funcional de (VII.3), pero teniendo en cuenta la dirección teórica que sustenta a (VII.1). Cuadro nº 71. Ramas extremeñas básicas y variables consideradas. AGRICULTURA. Variable dependiente. -Valor añadido bruto agrario de Extremadura: VAEX. Variables que explican el equilibrio a largo plazo. -Valor añadido bruto agrario de España: VAES. Variables que explican las desviaciones a corto plazo. -Valor añadido bruto agrario de España: VAES. -Volumen de agua embalsada al final de cada año en Extremadura: VOLAGt-1. ENERGÍA. Variable dependiente. Valor añadido bruto energético de Extremadura: VEEX. Variables que explican el equilibrio a largo plazo. Valor añadido bruto energético de España: VEES. Variables que explican las desviaciones en el crecimiento a corto plazo. -Valor añadido bruto energético de España: VEES. -Volumen medio de precipitaciones recogidas en Extremadura: PRECIP. -Producción bruta de energía eléctrica en Extremadura: ENERG. INDUSTRIA MANUFACTURERA. Variable dependiente. Valor añadido bruto de la industria manufacturera de Extremadura: VIEX. Variables que explican el equilibrio a largo plazo. Valor añadido bruto de la industria manufacturera de España: VIES. Variables que explican las desviaciones en el crecimiento a corto plazo. Valor añadido bruto de la industria manufacturera de Extremadura en el año anterior: VIEXt-1. Valor añadido bruto total no agrario y no energético de Extremadura: VNOAEEX. Valor añadido bruto total agrario de Extremadura: VAEX. En el cuadro anterior se puede apreciar cómo, de acuerdo con lo propugnado con la teoría de base económica, las relaciones de equilibrio a largo plazo (relaciones de cointegración) para los sectores básicos extremeños vienen determinadas por variables externas a la región. Veamos con más -Pág. 268- Capítulo VII. Un Modelo Econométrico para Extremadura detalle cada una de las ramas básicas. Para la rama agraria extremeña, y debido a que su producción va orientada hacia el mercado externo o hacia un mercado interno que utiliza estos “inputs”agrarios para su transformación industrial y posterior venta fundamentalmente al mercado externo, su relación de equilibrio a largo plazo se plantea mediante la aproximación de la demanda externa a través del valor añadido bruto agrario de España. Además, es razonable considerar que la evolución de la agricultura extremeña siga las pautas generales que marca la rama nacional. Las desviaciones en el corto plazo de la situación de equilibrio se explican a través del valor añadido bruto agrario de España y del volumen de agua embalsada al final de cada año en Extremadura. Esta última variable tiene una doble misión. En primer lugar, acerca la situación de la campaña de riego en los cultivos de regadío; en segundo lugar es un buen indicador del ciclo climático en el que se encuentra la Comunidad Extremeña, recogiendo las perspectivas para los cultivos de secano. En el caso de la rama energética, se establece una relación a largo plazo con el valor añadido bruto energético de España, como forma de explicar la evolución del mercado externo. Las desviaciones en el corto plazo se explican por tres variables: el valor añadido bruto energético de España, el volumen medio de precipitaciones recogidas en Extremadura (dada la importancia de la producción hidroeléctrica en Extremadura) y la producción bruta de energía eléctrica en Extremadura. En lo que se refiere a la rama de la industria manufacturera, la demanda de la producción básica de este sector se describe a través del valor añadido bruto de la industria manufacturera de España. Los ajustes a corto plazo los explicamos a través del valor añadido bruto de la industria manufacturera de Extremadura en el año anterior, del valor añadido bruto total no agrario y no energético de Extremadura, y del valor añadido bruto total agrario de Extremadura. Como se demostró en el Capítulo III, la rama de la industria manufacturera extremeña tiene ciclo, de manera que se justifica la introducción del valor añadido bruto de la industria manufacturera de Extremadura en el año anterior. La introducción de la variable valor añadido bruto total no agrario y no energético de Extremadura como explicativa de la industria manufacturera, tiene como objetivo explicar que a corto plazo haya desviaciones de la situación de equilibrio a largo plazo, como consecuencia de la evolución de la actividad económica regional159. Por último, la introducción del valor añadido bruto agrario de Extremadura para explicar el VAB industrial manufacturero puede resultar en principio llamativo, pero existen razones que nos han inducido a trabajar en esta línea: 159 Ver Apartado VII.2.2. -Pág. 269- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña a) La gran importancia de la rama de bienes de consumo (con una desagregación a R-9) en la rama industrial manufacturera de Extremadura. Dentro de dicha rama R-9 destacamos la importancia de los alimentos (ver De la Macorra (Dir.) (1995, Vol II)). b) Las relaciones que se producen entre estos dos sectores extremeños (el sector agrario suministra “inputs” al sector industrial manufacturero) y que hemos corroborado mediante técnicas de análisis de las relaciones intersectoriales en el apartado VII.2.2. Cuadro nº 72. Ramas extremeñas no básicas y variables consideradas. CONSTRUCCIÓN. Variable dependiente. -Valor añadido bruto de la construcción de Extremadura: VBEX. Variables que explican el equilibrio a largo plazo. -Valor añadido bruto total de Extremadura: VABEX. Variables que explican las desviaciones en el crecimiento a corto plazo. -Valor añadido bruto total de Extremadura: VABEX. -Valor añadido bruto de la construcción de Extremadura en el período anterior: VBEXt1. -Valor añadido bruto de España: VABES. SERVICIOS DESTINADOS A LA VENTA. Variable dependiente. -Valor añadido bruto de servicios destinados a la venta de España: VLEX. Variables que explican el equilibrio a largo plazo. -Valor añadido bruto de servicios destinados a la venta de España: VLES. Variables que explican las desviaciones en el crecimiento a corto plazo. -Valor añadido bruto de servicios destinados a la venta de España: VLES. -Valor añadido bruto no agrario y no energético de Extremadura: VNOAEEX. TRANSPORTES Y COMUNICACIONES. Variable dependiente. -Valor añadido de transportes y comunicaciones de Extremadura: VZEX. Variables que explican el equilibrio a largo plazo. -Valor añadido de transportes y comunicaciones de España: VZES. -Valor añadido de servicios destinados a la venta de Extremadura: VLEX. Variables que explican las desviaciones en el crecimiento a corto plazo. -Valor añadido de transportes y comunicaciones de España: VZES. -Valor añadido de servicios destinados a la venta de Extremadura: VLEX. -Valor añadido de transportes y comunicaciones de Extremadura en el período anterior: VZEXt-1. SERVICIOS NO DESTINADOS A LA VENTA. Variable dependiente. -Valor añadido bruto de servicios no destinados a la venta de Extremadura: VGEX. Variables que explican el equilibrio a largo plazo. -Valor añadido bruto de servicios no destinados a la venta de España: VGES. Variables que explican las desviaciones en el crecimiento a corto plazo. -Valor añadido bruto de servicios no destinados a la venta de Extremadura: VGES. -Pág. 270- Capítulo VII. Un Modelo Econométrico para Extremadura En el Cuadro nº 72 se muestran los sectores no básicos (subsidiarios) de la economía extremeña, para los cuales, desde el punto de vista de la teoría de base económica, las relaciones de equilibrio a largo plazo deben venir especificadas en función de variables de la propia economía regional. En nuestro caso, el paradigma de sector subsidiario es la rama de la construcción extremeña, para la cual se establece una relación de equilibrio a largo plazo con el valor añadido bruto total de Extremadura (como aproximación a la demanda regional). Las variables que explican las desviaciones de la relación de equilibrio en el corto plazo son el VAB total de Extremadura160, el VAB de la construcción de Extremadura en el período anterior y el VAB de España. Para las otras tres ramas determinadas como no básicas, tenemos que distinguir dos casos diferentes. En el primero, que concierne a las ramas de servicios destinados a la venta (excluidos transportes y comunicaciones) y de servicios no destinados a la venta, hemos optado por dar prioridad al enfoque descendente dentro de las relaciones de equilibrio a largo plazo. En la rama de servicios destinados a la venta, aunque en teoría no aporta base económica a la región (y en consecuencia depende de variables de demanda interna), no hemos podido aportar evidencia empírica de relaciones con otros sectores básicos, u otras variables regionales. De esta forma, se relaciona a largo plazo el VAB de servicios destinados a la venta extremeño con el valor añadido bruto de servicios destinados a la venta de España. Los ajustes de los desequilibrios a largo plazo se recogen mediante las variables VAB de servicios destinados a la venta de España y VAB no agrario y no energético de Extremadura. Por otra parte, en el sector de servicios no destinados a la venta, es difícil mantener el enfoque de base económica tal y como lo hemos planteado, siendo más lógico pensar que las directrices nacionales marcan la evolución a largo plazo de esta rama. Por esta razón, se hace depender el VAB de este sector con el VAB de dicho sector a nivel nacional. En los ajustes a corto plazo, hemos considerado a la misma variable nacional. 160 Ver Apartado VII.2.2. -Pág. 271- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña El segundo caso es la rama de transportes y comunicaciones, para la cual se ha utilizado una variable regional que aproxima el estado de la demanda interna, y una variable nacional, fundamentada tanto por el enfoque descendente como por las especiales características de esta rama (que tiene unas claras vinculaciones con la actividad exterior). En definitiva, se trata de especificar una relación a largo plazo de tipo “mixto” para este sector, de manera que su VAB sectorial regional se pone en función tanto del VAB de transportes y comunicaciones de España como del VAB de servicios destinados a la venta de Extremadura. En las variables que explican las desviaciones en el crecimiento a corto plazo, además de las variables especificadas para la relación de cointegración, se considera el VAB de transportes y comunicaciones de Extremadura para el período anterior. -Pág. 272- Capítulo VII. Un Modelo Econométrico para Extremadura VII.4.3. PROPIEDADES ESTOCÁSTICAS DE LOS DATOS Una vez descritas las fuentes estadísticas, y planteadas las variables que formarán parte de las relaciones especificadas, como paso previo a la estimación de la ecuaciones del modelo, necesitamos analizar el orden de integrabilidad (d) de todas las variables endógenas y exógenas que aparecerán en el modelo. La literatura existente acerca de los contrastes de raíces unitarias es muy amplia, pudiéndose consultar Suriñach et al. (1995) o Reinsel (1997). En este trabajo hemos utilizado los dos contrastes de raíces unitarias ya “clásicos”, el test de Dickey-Fuller aumentado (DFA) (Dickey y Fuller (1981)) y el test de Philipps-Perron (PP) (Philipps y Perron (1988)), los cuales son correcciones del contraste de Dickey y Fuller (1979). En ambos casos, la hipótesis nula es H0:{xt~I(d)} y la alternativa H1:{xt~I(d-1)}. No obstante, y teniendo en cuenta experiencias previas sobre el estudio de las propiedades estocásticas de las series macroeconómicas españolas (Andrés et al. (1990); Molinas et al. (1991)), así como la propia naturaleza de las series regionales (con frecuentes puntos de ruptura161), se ha considerado también la versión más general del test DFA para tener en cuenta la posibilidad de existencia de tendencias determinísticas segmentadas en la media (Rappoport y Reichlin (1989)). 161 Debidos no sólo a cambios estructurales como los analizados en este trabajo, sino también a problemas “en origen” tales como cambios de base, redefiniciones de variables, errores de medida causados por la aplicación de métodos de reparto, utilización de deflactores aproximados, etc. -Pág. 273- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Los resultados de aplicar los contrastes señalados (ver Anexo 5) a las variables objeto de estudio se muestran en el Cuadro nº 73, donde también se presenta un breve resumen estadístico de las mismas. La estrategia seguida ha sido el procedimiento de contraste secuencial propuesto en Dickey y Pantula (1987), con el que parece existir consenso a la hora de ser señalado como el método más adecuado cuando se contrasta el número de raíces unitarias de series sin estacionalidad (como es nuestro caso). Se trata de partir de especificaciones generales y llegar a especificaciones específicas, mediante la realización de contrastes iterativos que intervienen de forma escalonada. De esta forma, hemos iniciado el contraste con la hipótesis nula de d raíces unitarias (siendo d el mayor valor de diferenciación planteado) y con la alternativa de d-1 raíces unitarias. En el contraste secuencial, cada vez que la hipótesis nula era rechazada, hemos trabajado con d-1 raíces unitarias como hipótesis nula. La conclusión a la que se llega es que todas las series pueden considerarse como variables I(1) (exceptuando LPRECIP que es I(0)), algunas de ellas con una única tendencia determinística y el resto de variables con varias tendencias segmentadas en la media. -Pág. 274- Capítulo VII. Un Modelo Econométrico para Extremadura Cuadro nº 73. Resultados de los contrastes de raíces unitarias. CONTRASTES DE RAÍCES UNITARIAS H 0 : {I (2)} frente a H1 : {I (1)} DFA VARIABLE LVAES LVAEX LVOLAG LVEES LVEEX LPRECIP LENERG LVBEX LVABES LVABEX LVIEX LVIES LVNOAE LVLEX LVLES LVZEX LVZES LVGEX LVGES H 0 : {I (1)} frente a H1: {I (0)} PP DFA PP PGD CT,0 N,1 t -5,49 -5,58 VC -3,61 -1,95 PGD CT,2 N,2 t -5,70 -12,59 VC -3,61 -1,95 PGD C,0 C,0 t -2,46 -3,08 VC -2,98 -3,73* PGD C,2 C,2 t -2,43 -2,93 N,0 CT,0 N,0 N,2 RR,2 C,0 C,1 C,0 N,0 N,0 C,0 N,1 RR,2 N,0 RR,2 RR,2 RR,2 -5,95 -5,21 -6,17 -4,58 -6,58 -5,59 -3,09 -5,17 -5,21 -3,20 -5,07 -2,35 -4,14 -3,11 -4,39 -7,55 -4,16 -1.95 -3,61 -1,95 -1,95 -4,08 -2,99 -2,99 -3,00 -1,95 -1,95 -3,00 -1,95 -4,08 -1,95 -4,08 -4,08 -4,08 N,2 CT,2 N,2 N,2 C,2 C,2 C,2 N,2 N,2 C,2 N,2 N,2 - -5,95 -5,37 -6,20 -8,58 -6,83 -2,09 -8,96 -5,27 -3,42 -5,02 -4,07 -3,10 - -1,95 -3,61 -1,95 -1,95 -2,99 -2,99 -3,00 -1,95 -1,95 -3,00 -1,95 -1,95 - CT,0 C,0 CT,0 C,0 RR,2 CT,0 CT,1 CT,0 C,0 CT,1 CT,0 RR,3 CT,1 CT,1 CT,1 RR,2 CT,1 -2,52 -2,69 -2,44 -4,20 -2,48 -2,72 -3,93 -2,40 -2,42 -2,77 -1,95 -4,26 -2,85 -2,28 -3,33 -3,72 -2,86 -3,60 -2,98 -3,60 -2,98 -4,08 -3,60 CT,2 C,2 CT,2 C,2 CT,2 CT,2 CT,2 C,2 CT,2 CT,2 CT,2 CT,2 CT,2 CT,2 -2,63 -3,60 -3,46 -3,72* -2,47 -3,60 -4,27 -2,98 -2,48 -3,60 -2,79 -3,61 -2,09 -3,62 -3,56 -3,72* -2,66 -3,60 -2,39 -3,62 -2,21 -3,62 -2,19 -3,61 -3,16 -3,61 -1,46 -3,60 -4,39* -3,62 -2,98 -3,62 -3,62 -4,76 -3,62 -3,62 -3,62 -4,08 -3,61 VC -2,98 -2,99 Resultado I(1) I(1) I(1) I(1) I(1) I(0) I(1) I(1) I(1) I(1) I(1) I(1) I(1) I(1) I(1) I(1) I(1) I(1) I(1) Notas: -La notación utilizada para representar a las variables es: L indica que la variable está en logaritmos, V denota el valor añadido bruto en pesetas constantes de 1986. V se acompaña de una sola letra para indicar el sector al que hace referencia (VA: agrario, VE: energía, VB: construcción, VI: industria manufacturera, VL: servicios destinados a la venta (excluido transportes y comunicaciones), VZ: transportes y comunicaciones y VG: servicios no destinados a la venta); o de varias letras para cada una de las agrupaciones sectoriales consideradas (VAB: valor añadido bruto total, VNOAE: valor añadido bruto total no agrario y no energético). La terminación final para cada variable, especifica si se trata de una variable nacional (ES) o extremeña (EX). VOLAG es el volumen de agua embalsada al final de cada año en Extremadura. PRECIP es el volumen medio de precipitaciones recogidas en Extremadura. ENERG es la producción bruta de energía eléctrica en Extremadura. -La columna PGD especifica el proceso generador de datos que se ha considerado para la variable en estudio; de esta forma, la letra N indica que la regresión auxiliar estimada no incorpora ninguna componente determinística, C señala la admisión de un término constante y CT denota la presencia de una tendencia lineal determinística. El número a continuación de estas letras (separado por coma) señala el número de retardos introducidos en el contraste DFA o el número de períodos de correlación serial a incluir (retardos de truncamiento) en el procedimiento de Newey-West para ajustar los errores estándar (en el contraste PP). En el caso de que aparezcan las letras RR, se advierte de la consideración de tendencias determinísticas segmentadas en la media para el contraste DFA (tantos segmentos como se indique en la cifra). -En la columna siguiente, t es el estadístico de prueba utilizado en cada uno de los contrastes. -VC es el valor crítico tabulado a un nivel de significación del 5% para cada uno de los contrastes obtenidos de MacKinnon (1991) o de Rappoport y Reichlin (1989). En el caso de trabajar al 1% se utiliza * al lado de la cifra correspondiente. -Pág. 275- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VII.4.4. ESTIMACIÓN DEL MODELO Siguiendo las líneas marcadas por el método bietápico propuesto por Engle y Granger (1987), nuestro esquema general de actuación queda recogido en el esquema del cuadro siguiente. Cuadro nº 74. Esquema general de estimación. Relaciones a largo plazo teóricas Estimación Contrastes de estabilidad PVT Reespecificación Ho ≡ {Estabilidad} H1 ≡ {Existe algún punto de ruptura} Rechazar Ho No Rechazar Ho Especificación modelo a corto plazo (ECM) Estimación Contrastes de estabilidad PVT Reespecificación Ho ≡ {Estabilidad} H1 ≡ {Existe algún punto de ruptura} Rechazar Ho -Pág. 276- No Rechazar Ho Capítulo VII. Un Modelo Econométrico para Extremadura VII. 4.4.1. ESTIMACIÓN DE LAS RELACIONES A LARGO PLAZO. Según el esquema que hemos elaborado y plasmado en el Cuadro nº 74, los resultados que se han obtenido dentro de cada una de las etapas se encuentran en el Anexo 7. En primer lugar se han estimado las relaciones a largo plazo del tipo (VII.4) utilizando los argumentos teóricos del apartado dos. En todos los casos se efectuó el contraste de cointegración de Engle y Granger aumentado (que emplea el test de raíces unitarias de Dickey y Fuller (1981) para determinar si las variables implicadas en la regresión estaban cointegradas. Los valores críticos para este contraste son los publicados en Davidson y MacKinnon (1993). El resultado fue que en la mayor parte de los tests no se rechazaba la hipótesis nula de existencia de una raíz unitaria en los residuos estimados (es decir, de ausencia de cointegración). Ante esta evidencia, y teniendo en cuenta los resultados de Campos et al. (1996) (los cuales ponen de manifiesto no sólo que la presencia de cambio estructural en series estacionarias puede inducir raíces unitarias espúreas162, sino que tales rupturas afectan de forma considerable a la potencia de los contrastes de cointegración en general, y en particular al procedimiento bietápico de Engle y Granger163) se procedió a aplicar una serie de contrastes de estabilidad paramétrica para detectar la presencia de puntos de ruptura en cada una de las ecuaciones de comportamiento a largo plazo164. Los contrastes utilizados se describen en el Anexo 6, y se basan en los siguientes estadísticos: a) El estadístico de razón de verosimilitud propuesto por Quandt (1960): supr SupFT = FT (δ ) δ ∈ [ δ 1 ,δ 2 ] 162 Resultado que ya fue demostrado analíticamente por Perron (1989) y evidenciado empíricamente por Hendry y Neale (1991). 163 Hay que tener en cuenta que los contrastes estándar de cointegración asumen que el vector de cointegración es invariante en el tiempo bajo la hipótesis alternativa. 164 De hecho, al aplicar los contrastes de cointegración propuestos por Gregory y Hansen (1996), los cuales permiten la posibilidad de cambios de régimen, el resultado fue que en todos los casos se rechazó la hipótesis nula de no cointegración (en este caso frente a la alternativa de cointegración en presencia de un posible punto de ruptura). No obstante, puesto que los contrastes de Gregory y Hansen sólo permiten un punto de ruptura (el procedimiento que utilizan permite además identificar tal punto), y ante la posibilidad de que exista un número mayor en nuestro caso, se ha continuado el proceso de modelización del cambio estructural. -Pág. 277- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña b) El estadístico promedio propuesto por Andrews y Ploberger (1994) y Hansen (1992): MediaF = ∫ δ2 δ1 F t (δ ) dδ c) El estadístico promedio exponencial propuesto por Andrews y Ploberger (1994): δ2 1 ExpF = ln∫ exp Ft (δ ) dδ 2 δ1 Al aplicar los tres contrastes indicados a las ecuaciones a largo plazo del modelo, en todos los casos, salvo en uno165, los valores de dichos estadísticos sobrepasaron los valores críticos correspondientes a un nivel de significación del 1% (el único caso donde no se superaron dichos valores, se rechazó la hipótesis nula al nivel del 5%). El siguiente paso consistió en introducir las variables ficticias necesarias para aproximar los cambios estructurales detectados a través de la aplicación secuencial de los estadísticos de Wald166, es decir, se estimaron relaciones de cointegración del tipo (VII.6), con tantas funciones φ[to,t1] como puntos de ruptura detectados. Los resultados obtenidos para cada uno de los sectores considerados se presentan en el Cuadro nº 75. Es necesario aclarar que se opta por estimar las relaciones de cointegración mediante mínimos cuadrados ordinarios (MCO) a la vista de que los resultados que se obtienen con el estimador (asintóticamente eficiente) modificado completamente de Phillips y Hansen (1990)167 son muy similares, tanto en las elasticidades como en los contrastes de bondad del ajuste168. 165 En concreto el contraste SupF de la agricultura (Ver Anexo 7). Somos conscientes de algunos de los problemas que este enfoque puede plantear. En primer lugar, la estimación por MCO no es eficiente y los contrastes de significación no tienen las distribuciones asintóticas estándar bajo la hipótesis de cointegración con cambios de régimen. En segundo lugar, bajo la hipótesis nula de estabilidad en los parámetros, y puesto que los puntos de ruptura son desconocidos a priori, los estadísticos de Wald construidos tienen también distribuciones no estándar. Los resultados de Hansen (1992) y Quintos y Phillips (1993) podrían ser de utilidad en la resolución de estos problemas. 167 Para consultar las características básicas de este estimador, ver el Anexo 5. 168 Es bien conocido (véase por ejemplo Stock (1987)) que la estimación mediante mínimos cuadrados ordinarios de la relación de cointegración introduce un sesgo que es bastante importante para muestras pequeñas. 166 -Pág. 278- Capítulo VII. Un Modelo Econométrico para Extremadura Cuadro nº 75. Estimación de las relaciones de cointegración. AGRICULTURA ECUACIÓN ESTIMADA; Método: MCO con variables ficticias. (t = 1971,...,1993) LVAEX t = -2,431 + 0,951 LVAES t + 0,231 D7175 t (-0,422) (2,388) (2,685) CONTRASTES DE VALIDACIÓN R2=0,279; Durbin-Watson=1,457; DFA = -3,191*; SupF = 7,784; MediaF = 2,041; ExpF = 1,797 ENERGIA ECUACIÓN ESTIMADA; Método: MCO con variables ficticias. (t = 1970,...,1993) LVEEX t = -5,070 + 1,050 LVEES t + 0,561 D7073 t + 1,087D8493 t (-0,743) (2,193) (2,652) (6,014) CONTRASTES DE VALIDACIÓN R2=0,899;Durbin-Watson =2,153;DFA= -4,747***;SupF = 7,090;MediaF = 2,326; ExpF = 1,767 CONSTRUCCIÓN ECUACIÓN ESTIMADA; Método: MCO con variables ficticias. (t = 1972,...,1993) LVBEX t = -2,366 + 1,011 LVABEX t - 19,077 D7079 t + 1,446 D7079*LVABEX t (-1,154) (6,547) (-2,545) (2,511) CONTRASTES DE VALIDACIÓN R2=0,941;Durbin-Watson=1,829;DFA = -4,046***;SupF= 7,948; MediaF = 1,745; ExpF = 1,618 INDUSTRIA MANUFACTURERA ECUACIÓN ESTIMADA ; Método: MCO con variables ficticias. (t = 1970,...,1993) LVIEX t = -7,994 + 1,182 LVIES t + 0,206 F78 t + 0,223 F80 t + 0,104 D8285 t (-5,158) (12,039) (2,551) (2,767) (2,400) CONTRASTES DE VALIDACIÓN R2=0,894; Durbin-Watson=1,995;DFA = -4,476***;SupF= 5,472; MediaF= 3,612; ExpF = 1,937 SERVICIOS DESTINADOS A LA VENTA ECUACIÓN ESTIMADA ; Método: MCO con variables ficticias. (t = 1972,...,1993) LVLEX t = -5,366 + 1,083 LVLES t + 43,937 D8185 t - 2,724 D8185*LVLES t - 11,327 D8693 t (-2,016) (6,556) (5,657) (-5,673) (-3,192) + 0,682 D8695*LVLES t (3,118) CONTRASTES DE VALIDACIÓN R2=0,962;Durbin-Watson=2,351;DFA= -5,586***;SupF= 9,726*; MediaF= 2,983; ExpF = 2,464 TRANSPORTES Y COMUNICACIONES ECUACIÓN ESTIMADA; Método: MCO con variables ficticias. (t = 1972,...,1993) LVZEX t = -5,269 + 0,722 LVZES t + 0,399 LVLEX t + 0,257 F72 t + 17,686 D8084 t (-6,491) (16,269) (4,422) (7,038) (2,505) - 1,232 D8084*LVZES t - 0,131 D8889 t (-2,493) (-5,414) CONTRASTES DE VALIDACIÓN R2=0,980;Durbin-Watson= 1,988; DFA = -4,335***; SupF=7,559; MediaF= 3,168; ExpF= 2,224 SERVICIOS NO DESTINADOS A LAVENTA ECUACIÓN ESTIMADA; Método: MCO con variables ficticias. (t = 1971,...,1993) LVGEX t = -3,636 + 1,004 LVGES t + 3,645 D7078 t - 0,257 D7078*LVGES t - 10,452 D7985 t (-4,066) (17,219) (3,447) (-3,683) (-7,288) + 0,689 D7985*LVGES t + 0,024 D9293 t (7,289) (2,225) CONTRASTES DE VALIDACIÓN R2=0,998;Durbin-Watson=2,682; DFA = -6,395***; SupF= 2,603; MediaF= 0,513; ExpF= 0,340 Notas: a)Debajo de los coeficientes estimados aparecen, entre paréntesis (y sólo como medidas descriptivas), los estadísticos t. b)* denota el rechazo de la hipótesis nula al 10%, ** al 5% y *** al 1%. c)D7175 t denota a una variable ficticia que toma el valor 1 en los años 1971-1975, y 0 en el resto; y F78 t toma 1 en 1978 y 0 en el resto. -Pág. 279- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Haremos algunos comentarios al respecto de los resultados obtenidos en las ecuaciones con variables ficticias (Cuadro nº 75): a) En primer lugar, para cada una de las ecuaciones estimadas se aplicaron de nuevo los contrastes de estabilidad SupF, MediaF y ExpF y el resultado fue que en ningún caso se rechazó la hipótesis nula de estabilidad de los parámetros estimados. b) En segundo lugar, tal y como puede comprobarse en la tabla, el estadístico DFA rechaza en todos los casos la presencia de una raíz unitaria en los errores estimados de cada ecuación; es decir, las combinaciones lineales de las variables de cada modelo son estacionarias y, por tanto, se pueden interpretar dichas relaciones como ecuaciones de cointegración o equilibrio a largo plazo con cambios de régimen. c) En tercer lugar, se observa que el número de puntos de ruptura es reducido169, con a lo sumo tres cambios estructurales por ecuación (en el caso de los sectores industrial, de transportes y comunicaciones y de servicios no destinados a la venta). Por otro lado, en varios casos se presentan simultáneamente cambios en el nivel y en las pendientes del modelo, con dos sectores (los de servicios destinados y no destinados a la venta) en los que se detectaron regímenes distintos, con dos puntos de corte con cambio tanto en la pendiente como en la ordenada en el origen. En lo que respecta a los resultados económicos de las relaciones de equilibrio a largo plazo (VII.6), vamos a subrayar algunos para cada uno de los siete sectores: a) Para los tres sectores básicos (agricultura, energía e industria manufacturera) se han obtenido elasticidades próximas a la unidad (como era de esperar), excepto para aquellos años en los que dicha elasticidad se ha visto modificada por la presencia de cambio estructural. En todos los casos, el cambio estructural ha implicado sólo una modificación de la ordenada en el origen. b) Dentro de los sectores subsidiarios, también se han obtenido elasticidades cercanas a la unidad -exceptuando aquellos años en los que se ha modelizado el cambio estructural- para aquellos sectores en los que la especificación descendente prevalece sobre la teoría de base económica 169 Lo que en cierto modo justifica el enfoque de variables ficticias, por su fácil aplicación frente a otras alternativas más elaboradas. -Pág. 280- Capítulo VII. Un Modelo Econométrico para Extremadura (servicios destinados a la venta y servicios no destinados a la venta). Para el sector de la construcción (especificado sólo en función del VAB total de Extremadura) la elasticidad es unitaria, excepto para los años en los que la relación de cointegración cambia. Por último, la rama de los transportes y comunicaciones es el ejemplo de rama “mixta”, en la que un crecimiento de un 1% en el VAB de esta rama a nivel nacional implica un crecimiento de sólo un 0.722% a nivel regional (en los años en los que no existe cambio estructural y manteniéndose constante el resto de variables), mientras que un crecimiento de un 1% en el VAB de servicios destinados a la venta extremeño implica un crecimiento del 0.399% en el VAB de transportes y comunicaciones (“ceteris paribus”). VII.4.4.2. ESTIMACIÓN DE LAS RELACIONES A CORTO PLAZO. Una vez estimadas las relaciones a largo plazo, el segundo paso del procedimiento de Engle y Granger (1987) consiste en estimar las ecuaciones a corto plazo, que vienen dadas por (VII.3), con la expresión entre paréntesis (que ahora sería del tipo (VII.6) con varias funciones φ[to,t1]) substituida por lo errores estimados que se derivan del Cuadro nº 75. Igual que para el modelo a largo plazo, en primer lugar se estimaron las ecuaciones individuales sin incluir variables ficticias y, a continuación, se llevaron a cabo los contrastes de estabilidad SupF, MediaF y ExpF. Excepto en el caso del sector de transportes y comunicaciones, en el resto de sectores los tres estadísticos utilizados rechazaron de forma simultánea la hipótesis nula de estabilidad de los parámetros de los mecanismos de corrección de error. Para tener en cuenta la presencia de cambio estructural se consideraron dos opciones. Una de ellas fue utilizar, igual que en largo plazo, variables ficticias para recoger el efecto de dichos cambios estructurales. La otra consistió en modelizar la ruptura estructural proponiendo como alternativa un modelo adaptativo como el representado por las ecuaciones (VII.8). Ambas opciones son desarrolladas a continuación. VII.4.4.2.1. PARÁMETROS CAMBIANTES: MODELO DE VARIABLES FICTICIAS. La información proporcionada por los estadísticos de Wald utilizados en los contrastes de estabilidad (complementada con un análisis gráfico de cada variable dependiente y de los residuos estimados del modelo inicial) ayudó a identificar las variables ficticias a introducir en cada una de las ecuaciones de comportamiento a corto plazo. El resultado final son las regresiones que se presentan en el Cuadro nº 76. -Pág. 281- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Cuadro nº 76. Estimación de los modelos de corrección de error (MCO con variables ficticias). AGRICULTURA ECUACIÓN ESTIMADA (t = 1972,...,1993) ∧ DLVAEX t = 0,053 - 0,923 u t-1 + 1,005 DLVAES t + 0,171 DLVOLAG t-1 + 0,214 DD7175 t (4,358) (-8,426) (4,908) (3,337) (4,498) - 0,130 D7375 t - 0,400 F83 t - 0,197 D9293 t (-4,386) (-8,353) (-5,057) CONTRASTES DE VALIDACIÓN R2 = 0,998; R2 ajustado = 0,922; Durbin-Watson: DW = 2,214; Jarque-Bera: P-val. = 0,361; Breusch-Godfrey: a) [AR(1)] P-val: 0,221; b) [AR(2)] P-val: 0,356; Ljung-Box (p=6): P-val.= 0,829; ARCH: a) [ARCH(1)] P-val: 0,201; a) [ARCH(2)] P-val: 0,600; White: P-val. = 0,761; SupF = 7,279; MediaF = 3,918; ExpF = 2,350. ENERGIA ECUACIÓN ESTIMADA (t = 1972,...,1993) ∧ DLVEEX t = -0,142 - 0,771 u t-1 + 2,574 DLVEES t + 0,407 DLPRECIP t + 1,089 DLENERG t (-2,623)(-6,024) (2,876) (5,751) (10,128) - 0,307 D7476 t + 0,590 F77 t + 0,526 F82 t + 0,171 D8892 t (-3,954) (4,343) (3,814) (2,697) CONTRASTES DE VALIDACIÓN R2 = 0,951; R2 ajustado = 0,922; Durbin-Watson: DW = 2,384; Jarque-Bera: P-val. = 0,874; Breusch-Godfrey: a) [AR(1)] P-val: 0,083; b) [AR(2)] P-val: 0,073; Ljung-Box (p=6): P-val.= 0,065; ARCH: a) [ARCH(1)] P-val: 0,118; a) [ARCH(2)] P-val: 0,264; White: P-val. = 0,304; SupF = 10,621; MediaF = 5,270; ExpF = 3,757. CONSTRUCCIÓN ECUACIÓN ESTIMADA (t = 1973,...,1993) ∧ DLVBEX t = 0,012 - 0,448 u t-1 + 0,892 DLVABEX t + 0,661 DLVABES t + 0,143 DLVBEX t-1 (2,559)(-7,792) (9,230) (4,604) (3,398) - 0,083 D7475 t + 0,066 D7677 t + 0,033 F81 t + 0,068 F83 t - 0,183 F85 t + 0,113 F86 t (-9,965) (8,060) (2,333) (5,744) (-16,459) (8,532) - 0,250 F88 t - 0,050 F89 t (-21,128) (-3,298) CONTRASTES DE VALIDACIÓN R2 = 0,994; R2 ajustado = 0,985; Durbin-Watson: DW = 2,305; Jarque-Bera: P-val. = 0,746; Breusch-Godfrey: a) [AR(1)] P-val: 0,304; b) [AR(2)] P-val: 0,159; Ljung-Box (p=6): P-val.= 0,331; ARCH: a) [ARCH(1)] P-val: 0,629; a) [ARCH(2)] P-val: 0,253; White: P-val. = 0,521; SupF = 14,859; MediaF = 7,278; ExpF = 5,183. INDUSTRIA MANUFACTURERA ECUACIÓN ESTIMADA (t = 1973,...,1993) ∧ DLVIEX t = -0,061 - 0,555 u t-1 + 2,262 DLVNOAEEX t + 0,231 DLVIEX t-1 + 0,171DLVAEX t (-2,830)(-2,337) (5,103) (1,968) (2,107) + 0,111 DF80 t + 0,128 DD8285 t + 0,142 F77 t + 0,152 F85 t (2,352) (2,857) (2,084) (2,452) CONTRASTES DE VALIDACIÓN R2 = 0,873; R2 ajustado = 0,788; Durbin-Watson: DW = 2,051; Jarque-Bera: P-val. = 0,564; Breusch-Godfrey: a) [AR(1)] P-val: 0,506; b) [AR(2)] P-val: 0,799; Ljung-Box (p=6): P-val.= 0,942; ARCH: a) [ARCH(1)] P-val: 0,308; a) [ARCH(2)] P-val: 0,446; White: P-val. = 0,611; SupF = 14,247; MediaF = 8,141*; ExpF = 5,723*. -Pág. 282- Capítulo VII. Un Modelo Econométrico para Extremadura SERVICIOS DESTINADOS A LA VENTA ECUACIÓN ESTIMADA (t = 1973,...,1993) ∧ DLVLEX t = 0,006 - 0,836 u t-1 + 0,420 DLVNOAEEX t + 0,924 DLVLES t - 0,059 F77 t (0,815)(-3,801) (2,253) (3,617) (-3,440) - 0,054 D8085 t - 0,036 F90 t (-5,665) (-2,134) CONTRASTES DE VALIDACIÓN R2 = 0,938; R2 ajustado = 0,911; Durbin-Watson: DW = 2,365; Jarque-Bera: P-val. = 0,542; Breusch-Godfrey: a) [AR(1)] P-val: 0,166; b) [AR(2)] P-val: 0,015; Ljung-Box (p=6): P-val.= 0,324; ARCH: a) [ARCH(1)] P-val: 0,957; a) [ARCH(2)] P-val: 0,166; White: P-val. = 0,157; SupF = 3,350; MediaF = 2,059; ExpF = 1,132. TRANSPORTES Y COMUNICACIONES ECUACIÓN ESTIMADA (t = 1974,...,1993) ∧ DLVZEX t = 0,008 - 0,690 u t-1 + 0,222 DLVLEX t + 0,348 DLVZES t + 0,245 DLVZEX t-1 (1,123)(-4,123) (3,054) (1,967) (3,142) +20,551 DD8084 t - 0,082 DD8889 t - 1,435 D(D8084LVZES)t (7,676) (-7,614) (-7,658) CONTRASTES DE VALIDACIÓN R2 = 0,944; R2 ajustado = 0,912; Durbin-Watson: DW = 1,756; Jarque-Bera: P-val. = 0,865; Breusch-Godfrey: a) [AR(1)] P-val: 0,741; b) [AR(2)] P-val: 0,184; Ljung-Box (p=6): P-val.= 0,781; ARCH: a) [ARCH(1)] P-val: 0,147; a) [ARCH(2)] P-val: 0,159; White: P-val. = 0,540; SupF = 5,486; MediaF = 2,539; ExpF = 1,580. SERVICIOS NO DESTINADOS A LAVENTA ECUACIÓN ESTIMADA (t = 1972,...,1993) ∧ DLVGEX t = -0,001 -0,701 u t-1 + 0,974 DLVGES t + 2,796 DD7078 t - 0,205 D(D7078LVGES) t (-0.194)(-7,689) (13,952) (4,335) (-4,797) - 17,353 DD7985 t +1,141 D(D7985LVGES) t +0,027 DD9293 t +0,015 F80 t - 0,040 F82 t (-17,291) (14,593) (6,191) (3,112) (-7,621) - 0,041 F84 t + 0,021 F88 t (-8,694) (4,808) CONTRASTES DE VALIDACIÓN R2 = 0,991; R2 ajustado = 0,982; Durbin-Watson: DW = 2,345; Jarque-Bera: P-val. = 0,645; Breusch-Godfrey: a) [AR(1)] P-val: 0,191; b) [AR(2)] P-val: 0,012; Ljung-Box (p=6): P-val.= 0,209; ARCH: a) [ARCH(1)] P-val: 0,076; a) [ARCH(2)] P-val: 0,167; White: P-val. = 0,154; SupF = 6,164; MediaF = 3,407; ExpF = 2,025. Notas: -Debajo de los coeficientes estimados aparecen, entre paréntesis, los estadísticos t correspondientes. -* denota el rechazo de la hipótesis nula al 10%, ** al 5% y *** al 1%. ∧ - u t-1 son los residuos (retrasados) de la rlación a largo plazo estimada en cada una de las ecuaciones del Cuadro nº 75. -F83 t es una variable ficticia que toma 1 en 1983 y 0 en el resto. -D seguido de valores numéricos, por ejemplo D7375 t, denota a una variable ficticia que toma el valor 1 en los años 1973-1975, y 0 en el resto. -D seguido de una variable, denota la primera diferencia de una variable, ya sea una fictica (DD7175), una variable en logaritmos (DLVOLAG), o el producto de dos variables (D(D7078LVGES)). -Pág. 283- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En lo referente al número de variables ficticias introducidas, cabe hacer dos anotaciones. En primer lugar, el número de variables ficticias de cada ecuación viene determinado por los valores de los contrastes de estabilidad; con las variables introducidas (y sólo con esas) se consigue que los mecanismos de corrección sean estables, en el sentido de que ningún estadístico de los tres propuestos supera el nivel crítico correspondiente. En segundo lugar, y como cabía esperar, el número de puntos de ruptura que aparece es mucho más elevado que en las relaciones a largo plazo, señalando la presencia de mayor inestabilidad en las relaciones de corto plazo que en la ecuaciones de equilibrio. -Pág. 284- Capítulo VII. Un Modelo Econométrico para Extremadura VII.4.4.2.2. PARÁMETROS CAMBIANTES: FILTRO DE KALMAN. Por lo que respecta a la estimación de las ecuaciones (VII.8) para cada uno de los siete sectores considerados170, la técnica de estimación que se ha utilizado está basada en la aplicación recursiva del filtro de Kalman (Kalman (1960))171. En cada instante t de tiempo, y dadas las observaciones ΔW1s,...,∆Wts, el interés se centra en estimar el vector αt usando las ecuaciones del modelo (VII.8). Bajo las hipótesis de normalidad establecidas para los errores del modelo (y para el vector de estado inicial α 0 ), y suponiéndose conocidos σ2, P (o Q) y la media y matriz de covarianzas de α 0 172, el estimador óptimo de α t usando la información Is disponible hasta el instante s, viene dado por la esperanza condicional de α t supuesto conocido Is, a la que denotaremos por E[ α t | Is]=at|s173; y el estimador óptimo para la matriz de covarianzas de α t usando la información disponible Is vendrá dado por Cov[ α t | Is]=Σt|s. Las recursiones del filtro de Kalman, para t=0,1,2,..., vienen dadas por las siguientes ecuaciones ( ver, por ejemplo, Lühtkepohl, (1993)): a t+1|t = a t|t Σ t+1|t = Σ t|t +Q / s s - α t +1 t H t+1 ] a t+1|t+1 = a t+1|t + k t+1 [ ∆ W t+1 (VII.9) s Σ t+1|t+1 = Σ t+1|t - k t+1 H t+1 Σ t+1|t donde k t+1 = [ H s t +1 Σ t+1|t H / t +1 + σ 2 ] -1 Σ t+1|t H /t +1 (VII.10) Y entonces la predicción n-períodos hacia adelante de ΔWt+ns, ΔWt+n|ts vendrá dada por s s = α t ′|t H t+n ∆ W t+n|t 170 (VII.11) Aunque en principio no era necesario reestimar el modelo correspondiente al sector de transportes y comunicaciones, por ser estable en el corto plazo, también se incluyó en esta fase al objeto de comparar los resultados entre el modelo con parámetros fijos y el de parámetros variables. 171 En el Anexo 8 presentamos una lectura introductoria al filtro de Kalman. 172 A las que denotaremos por a0|0 y ∑0|0, respectivamente. 173 Cuando s=t la evaluación de at|t se conoce como filtrado, y cuando s>t se conoce como suavizado. -Pág. 285- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña En la aplicación de las fórmulas anteriores existen varios problemas que es necesario explicitar y que hacen referencia al conjunto de parámetros que se asume son conocidos a priori. En concreto, puesto que se ha especificado un modelo de variación paramétrica tipo “paseo aleatorio” para αt, no existen valores automáticos (como la media o matriz de covarianzas incondicionales) para los valores a0|0 y Σ0|0. Por otro lado, tampoco se conocen ni los elementos de la matriz Q ni el parámetro σ2. Este último es el menos problemático puesto que no existen inconvenientes para estimarlo por máxima verosimilitud aislándolo del resto de parámetros (Chow (1984, Pág. 1222)). Con respecto a los valores de inicialización del filtro de Kalman se pueden emplear las primeras K observaciones -siendo K la dimensión del vector de estado- (Harvey (1981,1989)), un valor a priori “difuso” (Ansley y Kohn (1983)) o se pueden estimar por máxima verosimilitud junto con el resto de parámetros del modelo (Chow (1984)). En nuestro caso hemos utilizado otra alternativa, fijando (tal como se hace en Hackl y Westlund (1996)) los elementos a0|0 y Σ0|0 en los valores MCO obtenidos estimando el modelo con parámetros constantes (y sin variables ficticias) sobre el período muestral completo174. Con respecto a los elementos de la matriz Q (conocidos como hiperparámetros) se pueden seguir dos vías. Estimarlos por el método de máxima verosimilitud (Chow (1984)), o fijarlos de antemano tal como proponen, de nuevo, Hackl y Westlund (1996), para evitar problemas de falta de identificación y grandes oscilaciones en las estimaciones de los parámetros de las variables de estado. En esta aplicación, hemos seguido las dos opciones: estimar los elementos qii de la matriz Q por máxima verosimilitud; y fijar de antemano su valores, en nuestro caso tomando Q=I175. 174 Reconocemos que, supuesto que se decide fijar los valores iniciales en lugar de estimarlos, cualquiera de los otros dos métodos de inicialización considerados es más ortodoxo y correcto que el utilizado por nosotros. En uno de los casos, el reducido tamaño de la muestra nos ha impedido prescindir de algunas observaciones al inicio del período muestral. En el segundo, creímos conveniente dar un valor inicial incorporando información a priori debido a que con tan pocas observaciones un valor de inicialización difuso podría originar trayectorias con grandes fluctuaciones de período a período originadas por una mala elección del punto inicial. 175 Wolff (1987) considera un rango de matrices del tipo Q=γΣ0|0 para γ=0.0, 0.01, 0.05, 0.10 y 0.25 permitiendo mayor (γ=0.25) o menor (γ=0.0) variabilidad en las variables de estado e interacción entre las mismas. -Pág. 286- Capítulo VII. Un Modelo Econométrico para Extremadura VII.4.5. ANÁLISIS PREDICTIVO EX-POST. En este epígrafe comparamos el funcionamiento predictivo postmuestral de los modelos a corto plazo estimados en el apartado anterior. Tal y como se apuntó anteriormente, todos los modelos fueron estimados (en general) para el período 1970-1993, dejando los años 1994 y 1995 como período de prueba para la realización de un experimento de predicción ex-post. Por tanto, las predicciones realizadas con los modelos estructurales están basadas en valores reales de las variables explicativas, y se comparan dichas predicciones con los valores observados de las variables endógenas para los años considerados. Para medir el grado de bondad de las predicciones utilizamos cuatro conocidos estadísticos, todos ellos basados en funciones de pérdida simétricas. Supongamos que t = s, s + 1,..., s + n es el período de predicción, y t los valores ∧ observados y y t los valores de predicción, de manera que los estadísticos que utilizamos se calculan atendiendo a las expresiones siguientes: error medio (ME), !" 1 s+ n ∧ y t − y t ME = ∑ n + 1 t=s error absoluto medio (MAE), !" MAE = 1 s+n ∧ ∑ y − yt n + 1 t =s t error cuadrático medio (RMSE) !" RMSE = 2 1 s+n ∧ , y y y − ∑ t n + 1 t=s t el coeficiente de desigualdad (U) de Theil (1966). !" s+ n U= ∑ (CRP t=s t +1 − CRRt +1 ) s+n ∑ (CRR ) t =s -Pág. 287- t +1 2 2 ( n) ( n) Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña donde ∧ CRPt +1 = CRRt +1 = y t +1 − y t yt y t +1 − y t yt , es el cambio relativo predicho, y , es el cambio relativo real. De esta manera, se obtiene: ∧ y t +1 − y t +1 ∑ t =s yt 2 s+n U= y t +1 − y t ∑ t =s yt 2 s+n En la expresión anterior, el numerador es el error porcentual absoluto medio del método de predicción utilizado; mientras que el denominador es el error porcentual absoluto medio de un método de predicción ingenuo, en el que los valores reales más recientes se utilizan como la predicción para el próximo período. De esta forma, el estadístico U utilizado es el ratio de los RMSE de las predicciones obtenidas con el modelo estimado y con el modelo (ingenuo) de paseo aleatorio. Este estadístico tiene una fácil interpretación: a) si U<1 las predicciones del modelo son mejores que las predicciones “ingenuas” y, b) si U>1 el modelo de paseo aleatorio funciona mejor que el propuesto. Los resultados de la simulación ex-post realizada con los tres tipos de modelos utilizados (Q=0, es decir, el modelo con parámetros fijos y variables ficticias; Q=I, es decir, fijando de antemano los hiperparámetros; y, Q=diag{q11,q22,...,qKK}, es decir, estimando -por máxima verosimilitud- los elementos de la diagonal pero restringiendo el resto a cero) se presentan en la Cuadro nº 77. -Pág. 288- Capítulo VII. Un Modelo Econométrico para Extremadura Cuadro nº 77. Estadísticos sobre el funcionamiento predictivo de los modelos de simulación “ex-post” 1994-1995. MODELO Q=0 Q=I Q diag. estimada Q=0 Q=I Q diag. estimada Q=0 Q=I Q diag. estimada Q=0 Q=I Q diag. estimada Q=0 Q=I Q diag. estimada Q=0 Q=I Q diag. estimada Q=0 Q=I Q diag. estimada ME MAE RMSE Agricultura 0,075 -0,065 0,065 0,063 0,063 0,085 -0,060 0,066 0,089 Energía 0,010 0,042 0,043 -0,026 0,045 0,052 -0,084 0,084 0,109 Construcción -0,016 0,016 0,017 -0,021 0,021 0,021 0,012 0,013 0,014 Industria Manufacturera 0,026 0,026 0,028 0,012 0,024 0,027 0,009 0,009 0,013 Servicios destinados a la venta 0,011 0,011 0,013 0,016 0,016 0,017 0,041 0,041 0,042 Transportes y comunicaciones 0,006 0,017 0,018 -0,002 0,017 0,017 -0,040 0,040 0,048 Servicios no destinados a la venta -0,001 0,003 0,003 -0,003 0,003 0,004 -0,021 0,021 0,026 U 0,587 0,667 0,698 3,165 3,800 7,932 0,898 1,128 0,723 1,075 1,012 0,494 0,664 0,874 2,152 0,569 0,549 1,547 0,135 0,172 1,127 Nota: ME = error medio; MAE = error absoluto medio; RMSE = error cuadrático medio; U= coeficiente de desigualdad de Theil (1966); en negrita, los resultados mejores. Vamos a destacar algunos comentarios acerca de las cifras que aparecen en el cuadro anterior: 1º) De la comparación de los valores de los estadísticos se observa que no existe un claro dominio de los modelos con parámetros variables estocásticos sobre el modelo con parámetros fijos y variables ficticias, mejorando los resultados respecto a este último en tres de los siete sectores considerados y produciendo resultados similares en otros dos casos. 2º) El modelo en que se estiman los hiperparámetros (Q diagonal) produce en general peores resultados que el modelo donde éstos se fijan de antemano. Ello puede deberse a los problemas de identificación de tales parámetros ocasionado por el reducido tamaño de la muestra. -Pág. 289- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña 3º) Con respecto al estadístico U de Theil (1966), sólo en el caso del sector de la energía los tres modelos predicen sistemáticamente peor que el modelo “ingenuo” de paseo aleatorio. En el resto de sectores los modelos estimados funcionan en general mejor que dicho modelo ingenuo aunque, de nuevo, se observa que el modelo de parámetros variables donde se estiman los elementos qii de la diagonal de la matriz de dispersión Q produce peores resultados que los otros dos modelos propuestos. -Pág. 290- Capítulo VII. Un Modelo Econométrico para Extremadura VII.5. CONCLUSIONES La estabilidad de un modelo econométrico es un requisito básico para que éste pueda utilizarse con fines predictivos o inferenciales. A escala regional, sin embargo, la inestabilidad paramétrica de los modelos estimados con datos históricos suele ser bastante común, debido a que a ese nivel son frecuentes los “cambios de régimen”. Por este motivo, los experimentos predictivos que se realicen para simular el impacto de diferentes políticas económicas tendrán sentido únicamente si se cumple la condición (necesaria) de estabilidad. Existe una literatura bastante amplia sobre el tema de la contrastación de la hipótesis de estabilidad paramétrica (ver, por ejemplo, Stock y Watson (1996) y las referencias allí contenidas), pero las aportaciones son mucho más escasas sobre la cuestión de cómo modelizar el cambio estructural una vez que éste es detectado. Con frecuencia, un contraste de estabilidad significativo indica algún tipo de mala especificación, por lo que se procede a probar con especificaciones alternativas. En otros casos, se permite a los parámetros variar a lo largo de la muestra, siendo el método utilizado más común la introducción de variables ficticias que interaccionan con las variables originales para permitir cambios en las pendientes y/o en la ordenada en el origen. Como alternativa, también se puede dejar variar aleatoriamente a los coeficientes de regresión, dotando al modelo resultante de un mayor nivel de flexibilidad frente al caso de las variables ficticias. En este trabajo hemos utilizado ambos enfoques para construir un modelo econométrico para una región española, Extremadura, la cual ha experimentado profundos cambios en su estructura económica desde comienzos de los años ochenta. El marco econométrico de partida ha sido la teoría de la cointegración, que distingue las relaciones económicas en el largo plazo de la dinámica a corto plazo mediante la introducción de modelos de corrección de error, que son la base analítica del modelo econométrico construido en este trabajo. -Pág. 291- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Los resultados obtenidos muestran, en primer lugar, que en el caso de Extremadura existe inestabilidad estructural tanto en el largo como en el corto plazo, por lo que la metodología econométrica estándar resulta inaplicable en nuestro caso. En el largo plazo, la introducción de variables ficticias es suficiente para recoger los cambios de régimen habidos durante el período muestral, pero en el corto plazo la inestabilidad es mucho mayor por lo que parece más razonable flexibilizar el modelo de cambio permitiendo a los parámetros variar de forma aleatoria. En el análisis realizado, el modelo de parámetros variables proporciona resultados similares a los del modelo con parámetros fijos y variables ficticias, pero consideramos que el primero posee la ventaja de incorporar en las predicciones la incertidumbre futura sobre los valores de los parámetros, cosa que no ocurre con el modelo con variables ficticias. De los resultados económicos vamos a destacar la distinción que se realiza entre sectores que mantienen una relación a largo plazo con los respectivos sectores nacionales (agricultura, energía, industria manufacturera, servicios destinados a la venta y servicios no deesinados a la venta) y aquellos cuyo comportamiento a largo plazo está asociado sólo a variables regionales (construcción) o a variables regionales y nacionales (transportes y comunicaciones). -Pág. 292- PARTE CUARTA. RECAPITULACIÓN Y CONCLUSIONES. Capítulo VIII. Recapitulación, Conclusiones y Consideraciones Finales CAPÍTULO VIII: RECAPITULACIÓN, CONCLUSIONES Y CONSIDERACIONES FINALES. VIII.1. INTRODUCCIÓN. A raíz del trabajo realizado por Mitchell (1913), el estudio del ciclo económico desde una perspectiva estadística (no estructural) ha sido utilizado como una herramienta que se ha mostrado útil para el análisis coyuntural. Por otro lado Tinbergen (1937) inició el enfoque estructural del análisis del ciclo económico, el cual incorpora mecanismos causales así como la posibilidad de simular el efecto de distintas políticas económicas. Como idea global se puede colegir que en líneas generales ha existido un doble enfoque a la hora de abordar la cuantificación económica: a) Un enfoque estadístico, que es un procedimiento que persigue la medición buscando regularidades en datos pasados y sin establecer relaciones causales explícitas entre variables económicas con base en la teoría económica. Los exponente iniciales más representativos de esta tendencia son Mitchell (1913), cuya labor se vió continuada por el NBER y Schumpeter (1939). b) Un enfoque estructural, causal y que se sustenta explícitamente en la teoría económica. Su referencia inicial más importante es Tinbergen (1937), quien se vió respaldado por Haavelmo (1944), que aportó la base matemática necesaria para el entendimiento del modelo de probabilidad que se utiliza en la econometría. A lo largo de la historia de la cuantificación económica nos encontramos con defensores y detractores de las estas dos posturas generales, viéndose ambas sometidas a críticas diversas. La crítica más importante a la modelización estadística aparece por la no consideración explícita de la teoría económica. En la modelización econométrica, las críticas han venido motivadas tanto desde consideraciones teóricas como empíricas, siendo estas últimas la consecuencia de la obtención de resultados no satisfactorios. -Pág. 295- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Desde que ambas posturas existen, el predominio de un tipo de modelización sobre la otra nunca ha sido absoluto, pero sí ha habido etapas en las que el dominio de una sobre la otra ha sido más evidente. Un esbozo excesivamente simplificado, y que muestra las tendencias dentro de dichas etapas globales, podría ser el que se muestra a continuación. En primer lugar se utilizó la modelización estadística, ya que no requería de un soporte teórico tan potente como la econometría. El surgimiento de la econometría hizo que se formaran unas expectativas grandes en torno a ella que dejaron en un segundo plano al enfoque estadístico. En este sentido, hay que recordar que el método econométrico, a diferencia del estadístico, permitía la consideración explícita de la teoría económica en los modelos. Posteriormente, los malos resultados obtenidos por la segunda supusieron un nuevo empuje para la primera. La aparición de nuevos enfoques en la modelización econométrica ha posibilitado el retorno a la consideración del método econométrico como un método válido. En la actualidad, y desde la perspectiva predictiva, parece existir consenso a la hora de considerar a los enfoques estadísticos y econométricos como complementarios, de manera que el modelo estadístico proporciona unos resultados más rápidos (en el sentido de actualidad) y a menor coste para las predicciones a corto plazo, mientras que el modelo econométrico aporta una mayor fiabilidad en las predicciones a medio y largo plazo. A nivel regional, los métodos de cuantificación económica en el contexto del ciclo económico son herederos de las experiencias nacionales, y el debate estadístico-econométrico también se resuelve mediante la asignación de funciones complementarias para unos y otros; los primeros determinan la morfología y fases del ciclo a la vez que proporcionan las predicciones a corto plazo, mientras que los segundos dan las predicciones a medio plazo y posibilitan la realización de simulaciones. Por lo tanto, los dos tipos de modelización también tienen su reflejo en el ámbito regional, donde consideramos que existe una relación de complementariedad, de forma que ambos se enriquecen mutuamente. En consecuencia, y en línea con las propuestas de otros autores, proponemos a ambos tipos de modelizaciones para ser aplicados al campo de la economía regional. En la modelización económica regional, la frontera entre modelización teórica y sin teoría se vuelve más difusa como consecuencia de las concesiones teóricas que se deben hacer para construir modelos operativos que se adapten tanto a la situación particular de la región como a sus disponibilidades de datos. Todo esto condiciona la traslación empírica de las hipótesis teóricas que existen acerca del comportamiento económico regional. -Pág. 296- Capítulo VIII. Recapitulación, Conclusiones y Consideraciones Finales VIII.2. OBJETIVOS. Los propósitos fundamentales de este trabajo han estado encaminados a: a) La obtención de un conjunto de indicadores sintéticos de aceleraciones y desaceleraciones de la actividad económica, desde la perspectiva de la oferta, para Extremadura. b) La especificación, estimación y validación de un modelo econométrico que tenga como fin primordial la predicción del crecimiento de las cifras de VABpm en pesetas constantes para Extremadura. El primero se basa en la búsqueda de regularidades pasadas en las cifras macroeconómicas de Extremadura, y el enfoque adoptado se corresponde con el denominado no estructural o modelización estadística. En el segundo se trata de la modelización econométrica (enfoque causal o explicativo) de las magnitudes económicas fundamentales de Extremadura con un fin esencialmente predictivo de los agregados sectoriales. VIII.3. RECAPITULACIÓN. En función de los objetivos señalados, los contenidos de este trabajo están concebidos para conseguir un uso eficiente y óptimo de los recursos metodológicos y estadísticos (datos) disponibles en la actualidad. De esta manera, y partiendo de un marco teórico general común (Capítulo I), se plantean metodologías que proporcionen un soporte coherente (Capítulos IV y VI) a las aplicaciones empíricas (Capítulos V y VII) para Extremadura. Los ingredientes que permiten el engarce entre teoría y práctica son el conocimiento de la Economía objeto de estudio (Capítulo III) y el análisis de las fuentes estadísticas a fin de lograr el acceso al mayor número posible de datos fiables (Capítulo II). Los contenidos del Capítulo I se deslindan en dos partes, la primera se inicia con una revisión histórica de algunos de los acontecimientos más relevantes de la evolución histórica de la modelización estadística y econométrica, para terminar insertando, en el contexto de la economía regional, las derivaciones de tal evolución. Este capítulo concluye con la exposición de las ideas fundamentales en las que se sustenta el concepto de ciclo económico. Se comentan los distintos tipos de ciclos económicos y se presenta una clasificación de las teorías sobre los ciclos económicos. Para concluir, se argumenta la idea de que la política -Pág. 297- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña económica se debe fundamentar en datos objetivos que redunden en la mejora de las decisiones adoptadas. El Capítulo II muestra la información estadística disponible en la actualidad sobre Extremadura. Se señalan las carencias o faltas más destacables de la Contabilidad Regional de España indicando las lagunas informativas sobre las que nuestro trabajo pretende hacer una aportación. Dichas faltas o carencias son: a) No proporciona unos datos estimados de agregados macroeconómicos en pesetas constantes, de manera que en los análisis que se realizan a nivel regional se debe pasar por la utilización de deflactores regionales no calculados por métodos directos. b) No presenta un cuadro macroeconómico regional completo. c) La información se publica con un retraso excesivo. d) No existe una Contabilidad Regional Trimestral (CRT), en línea con las aportaciones que realiza la CNT a nivel nacional. Esto repercute negativamente en la inexistencia de series históricas de los principales agregados macroeconómicos regionales que facilitarían (mediante la utilización de las técnicas estadísticas y econométricas adecuadas): -la previsión y el análisis de políticas económicas . -la mejora de las investigaciones y estudios macroeconómicos regionales como consecuencia del incremento de la calidad del sistema estadístico coyuntural regional. En el Capítulo III se hace un estudio de la economía objeto de las modelizaciones a realizar. Este estudio es obligado, ya que es requisito indispensable para llevar a buen fin las modelizaciones. El Capítulo IV revisa el análisis de la coyuntura como un tipo de estudio de gran interés en una economía. Se relaciona este tipo de estudios con los enfoques estadísticos y econométricos. A continuación se extractan las condiciones de partida y los métodos adoptados por algunos trabajos existentes en la literatura a la hora de llevar a cabo la elaboración de índices sintéticos de actividad económica. El reflejo de este extracto es la presentación ordenada y sistemática de la metodología estadística a aplicar para la elaboración de los indicadores sintéticos para Extremadura. -Pág. 298- Capítulo VIII. Recapitulación, Conclusiones y Consideraciones Finales En el Capítulo V se aplica la metodología con las que se han logrado unas validaciones más favorables de todo el conjunto de procedimientos que se han considerado. El resultado es la obtención de indicadores sintéticos de actividad económica para la economía extremeña. Como explotación de estos indicadores, se presenta un análisis cíclico de las ramas productivas extremeñas con respecto a las nacionales. En el Capítulo VI se exponen los conceptos y enfoques causales más utilizados en la modelización económica regional. Nos centramos en el análisis “shift-share”, en los modelos de base económica y en los modelos “inputoutput” porque se explotan en este trabajo de manera complementaria a la modelización econométrica (y estadística) que se realiza para Extremadura. Se justifica la elección de los modelos econométricos dentro del panorama modelizador regional y se extraen las principales características de los modelos econométricos regionales existentes actualmente en nuestro país. En el Capítulo VII, se presenta el bloque de producción de un modelo econométrico uniregional (porque no consideramos las interrelaciones con otras regiones), descendente (“top-down”), abierto (no se tienen en cuenta las posibles retroalimentaciones (“feed-back”) de la economía regional en la nacional) y de base económica dinámica (porque la especificación dinámica parte de la consideración de la existencia de sectores básicos y no básicos en la economía) para Extremadura. El enfoque de base económica dinámica nos aporta la perspectiva teórica que preside el modelo econométrico, explotándose la tabla “inputoutput” de Extremadura para el año 90 con el objeto de justificar la clasificación de los sectores en básicos y no básicos, así como para corroborar algunas relaciones intersectoriales especialmente particulares. Se proponen ecuaciones “tipo” en forma de mecanismo de corrección de error (MCE), en el que se plantea una relación de equilibrio a largo plazo entre las variables explicativas (no necesariamente exógenas) y la explicada (endógena) en función del tipo de sector (básico o no básico) de que se trate, a la vez que se permite la existencia de desajustes en el corto plazo respecto a esa situación de equilibrio a través de la introducción de términos dinámicos. Previamente a la estimación del modelo, se analizan las propiedades estocásticas de los datos (contrastes de raíces unitarias), validándose mediante la teoría de la cointegración las relaciones a largo plazo especificadas. -Pág. 299- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña Metodológicamente, se aborda el problema de la elaboración de modelos econométricos regionales cuando las relaciones estructurales no son constantes, ilustrando la metodología propuesta mediante la estimación del modelo econométrico planteado para Extremadura. VIII.4. CONCLUSIONES. Del estudio y aplicación de la modelización estadístico-econométrica para la economía extremeña, se derivan conclusiones que se pueden clasificar en dos grupos: - las referentes a los aspectos principales de los análisis teóricos. - las que se extraen de los análisis empíricos. Aunque las conclusiones principales del trabajo se refieren a los aspectos y aplicaciones empíricas, no vamos a prescindir de comentar aquellas conclusiones metodológicas que han sido relevantes a la hora de encauzar y marcar la trayectoria empírica. A continuación recogemos las conclusiones más importantes. PRIMERA. La elección de los deflactores del VABpm regional puede suponer la obtención de cifras en términos constantes tan diferentes que condicionen los resultados de cualquier tipo de modelización. SEGUNDA. En el contexto de la problemática de los deflactores regionales, se alerta a los estudiosos de la evolución de la renta agraria extremeña de que pueden estar introduciendo sesgos importantes en sus análisis como consecuencia de la utilización de deflactores inadecuados. TERCERA. El análisis de la evolución de la economía extremeña en el período 1980-1995 indica que el panorama productivo regional revela un distanciamiento bastante significativo de los parámetros medios nacionales considerados. Dentro de la rama nacional, la rama industrial tiene una representación mínima. En este sentido, la estructura productiva extremeña está muy descompensada, careciendo prácticamente de la rama industrial y mostrando un sector de servicios destinados a la venta poco desarrollado. CUARTA. Aunque los resultados vienen condicionados por el corto período temporal utilizado, con datos de baja frecuencia (anuales, 1980-1995): a) Los crecimientos en los sectores extremeños (a seis ramas) están asociados a crecimientos en los sectores equivalentes nacionales (excepto para la industria manufacturera). -Pág. 300- Capítulo VIII. Recapitulación, Conclusiones y Consideraciones Finales b) Existe ciclo común entre: -el VAB no agrario y no energético de Extremadura y el VABpm nacional -las ramas de los servicios destinados a la venta nacional -las ramas de las industrias manufactureras de ambas economías. QUINTA. La región extremeña presenta una productividad muy baja con respecto a la media nacional, sin que se aprecien signos de acercamiento a los niveles medios nacionales de productividad. La única rama regional que tiene una productividad por empleado superior a la media del sector nacional respectivo es la energética. SEXTA. La diferencia que existe entre el crecimiento medio en Extremadura y el nacional (CN) no ha mantenido una estructura estable de reducción o aumento. La causa de las grandes diferencias en el CN hay que buscarlas en el diferente comportamiento de los sectores agrícola y energético de Extremadura con respecto al crecimiento de esos sectores a nivel nacional. En el último tercio del período en estudio se descubre una amortiguación de los valores del cambio neto, aproximándose el crecimiento regional al nacional. Por lo tanto, es de esperar que el crecimiento extremeño se mueva de manera parecida a la media nacional, viéndose esta pauta incumplida para aquellos años en los que el sector agrario176 presente resultados excelentes o pésimos. SÉPTIMA. Es factible aproximar el crecimiento interanual del VABpm no agrario y no energético trimestral de la economía extremeña mediante un índice sintético trimestral. De igual manera, también se puede realizar un seguimiento de la evolución del crecimiento interanual del VABpm en pts constantes de 1986 de cada una de las ramas productivas de Estremadura a nivel trimestral (desagregación R-6) mediante seis indicadores sintéticos construidos a tal efecto. OCTAVA. De la explotación de los índices sintéticos sectoriales para comparar la evolución trimestral de las ramas extremeñas con respecto a las nacionales, se concluye que: a) Las ramas extremeñas de la industria manufacturera y de servicios destinados a la venta son coincidentes con respecto a sus respectivas ramas nacionales. 176 A futuro no consideramos la rama energética como desestabilizadora del crecimiento regional porque ya hemos comentado que la Central Nuclear de Almaraz ya ha conseguido alcanzar niveles de producción estables. -Pág. 301- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña b) Para períodos de incidencia climática “normales” la rama agraria es coincidente. Sin embargo, cuando se inicia un período de sequía desacelera antes, de igual forma que reacciona con más rapidez para salir del “valle”. Tales resultados se explican por la gran dependencia de la rama agraria extremeña del clima. c) Las ramas de la construcción y de servicios no destinados a la venta son acíclicos o inclasificables. NOVENA. Del análisis de los índices sintéticos sectoriales se puede inferir que los crecimientos en los sectores extremeños están asociados a los crecimientos en los sectores equivalentes nacionales (excepto para la rama de servicios no destinados a la venta). DÉCIMA. El problema más importante para llevar a cabo la modelización de la economía extremeña es el cambio estructural. DÉCIMO PRIMERA. A través del análisis de cointegración se ha contrastado la existencia de sectores básicos y no básicos. La hipótesis de partida y la clasificación final se recoge en el cuadro siguiente: Cuadro nº 78. Sectores básicos y no básicos extremeños. HIPÓTESIS DE PARTIDA CLASIFICACIÓN FINAL SECTORES BÁSICOS Agricultura SECTORES NO BÁSICOS Construcción, “SECTORES BÁSICOS” Agricultura Energía Transportes y comunicaciones, Servicios destinados a la venta Servicios no destinados a la venta Energía Industria SECTORES NO BÁSICOS Construcción SECTORES MIXTOS Transportes y comunicaciones Industria Servicios destinados a la venta Servicios no destinados a la venta Nota: En la clasificación final, por “SECTORES BÁSICOS” se entiende aquellos que mantienen una relación a largo plazo con los sectores nacionales. Fuente: Elaboración propia. -Pág. 302- Capítulo VIII. Recapitulación, Conclusiones y Consideraciones Finales DÉCIMO SEGUNDA. En Extremadura existe inestabilidad estructural tanto en el largo como en el corto plazo, por lo que la metodología econométrica estándar resulta inaplicable en nuestro caso. DÉCIMO TERCERA. En el largo plazo, la introducción de variables ficticias es suficiente para recoger los cambios de régimen que han existido durante el período muestral, pero en el corto plazo la inestabilidad es mucho mayor por lo que parece más razonable flexibilizar el modelo de cambio permitiendo a los parámetros variar de forma aleatoria. DÉCIMO CUARTA. El modelo de parámetros variables proporciona resultados similares a los del modelo con parámetros fijos y variables ficticias, pero el primero posee la ventaja de incorporar en las predicciones la incertidumbre futura sobre los valores de los parámetros, cosa que no ocurre con el modelo con variables ficticias. En consecuencia, las soluciones arbitradas para el tratamiento del problema del cambio estructural en Extremadura pasan por la estimación del modelo mediante la utilización de la representación en el espacio de los estados. -Pág. 303- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VIII.5. APORTACIONES ORIGINALES. Las aportaciones originales de este trabajo se pueden clasificar en directas e indirectas. Las directas son la consecución de los objetivos marcados: la elaboración de indicadores sintéticos de actividad económica y la construcción de un modelo econométrico para Extremadura. Además, otra aportación directa adicional es la creación y actualización propia de una base constituida por series históricas de indicadores económicos parciales para Extremadura. Las indirectas son las que se derivan de la explotación de las herramientas conseguidas: 1º La elaboración de indicadores sintéticos de actividad económica permiten la puesta en práctica de estrategias para el seguimiento de la coyuntura económica de Extremadura distintas de la descripción simple de múltiples indicadores económicos parciales. 2º La construcción del modelo econométrico para la economía extremeña proporciona fundamentalmente predicciones que incorporan las técnicas econométricas más rigurosas, novedosas y adecuadas a las características de la economía de que se trata. Como consecuencia de las aportaciones de esta tesis, la situación en lo que se refiere al seguimiento de la coyuntura económica de Extremadura se ha modificado substancialmente, como se aprecia en el Cuadro nº 79177. Cuadro nº 79. Estrategias utilizadas para el seguimiento de la coyuntura económica de Extremadura. Estrategias Indicadores múltiples posibles Indicador sintético agregado. SI Indicadores sintéticos sectoriales. SI Contabilidad regional trimestral. NO♣ Modelo econométrico trimestral. NO♣ SI Estrategias existentes∗ Notas: ∗ Después de los resultados obtenidos en esta tesis. ♣Aunque no existen como tales, sí que se han visto muy potenciadas. Fuente: Elaboración propia a partir del esquema planteado en Pulido (1997). 177 Comparar con el Cuadro nº 1. -Pág. 304- Capítulo VIII. Recapitulación, Conclusiones y Consideraciones Finales Es decir, el diagnóstico coyuntural se ha visto enriquecido por la aparición de un conjunto de indicadores sintéticos. Además, se brinda la posibilidad de realizar análisis hasta ahora irrealizables. Así, se ha realizado un análisis de cada una de las seis ramas productivas de la economía regional en relación a las nacionales, clasificándolas cíclicamente. Además, los indicadores sectoriales están posibilitando la trimestralización de los VABpm (R-6) en pesetas constantes de 1986178, cubriendo parte de una parcela que, aunque debería ser subsanada por una contabilidad regional trimestral, en la actualidad está fuera de los planes a medio plazo del INE. También se están dando los primeros pasos para la futura construcción de un modelo econométrico trimestral para Extremadura. En otra línea, la obtención de predicciones objetivas y lo más precisas posibles a corto y medio plazo del comportamiento de la economía extremeña ya se puede realizar mediante la utilización de un modelo econométrico no clásico. El cuadro siguiente muestra cómo ha cambiado la situación de partida. Cuadro nº 80. Modelos econométricos para la economía extremeña. ANTES DE ESTE TRABAJO Modelo econométrico “clásico” Ramajo(1990). DESPUES DE ESTE TRABAJO Modelo econométrico “moderno” (teoría de la cointegración) y “novedoso” (incorporación del tratamiento del cambio estructural). Fuente: Elaboración propia. 178 A través de un Proyecto de análisis de coyuntura regional en el que participan varios equipos del Proyecto Hispalink. -Pág. 305- Modelización Estadístico-Econométrica Regional: el Caso de la Economía Extremeña VIII.6. CONSIDERACIONES FINALES. Queremos finalizar haciendo algunos comentarios concernientes a investigaciones futuras que permitan la obtención de modelizaciones que aporten elementos de relevancia a este trabajo. Es obligado señalar que la modelización estadístico-econométrica obtenida tiene un carácter de provisionalidad, impuesto por el hecho de que la investigación económica que desarrollamos lleva implícita los rasgos de continuidad y mejora. Continuidad porque el proceso de modelización es persistente a lo largo del tiempo; y mejora porque tanto la refinación de las bases estadísticas existentes, como la incorporación de novedades metodológicas, repercuten en una representación mejor de la economía extremeña. Por lo tanto, el trabajo aquí realizado es una base sobre la cual se desarrollarán otras versiones para la modelización estadístico-econométrica de la economía Extremeña. También queda abierta la posibilidad de construir un modelo econométrico trimestral para la economía extremeña. Como ya se ha comentado, en esta línea de investigación ya estamos dando los primeros pasos, vía la trimestralización de los VABpm (R-6) extremeños. -Pág. 306- ANEXOS. Contenido de los Anexos CONTENIDO DE LOS ANEXOS ANEXO 1: INDICADORES DISPONIBLES MENSUALES Y TRIMESTRALES........................313 1.1. MENSUALES. ............................................................................................................................313 1.1.1. INDUSTRIA....................................................................................................................313 1.1.4. COMERCIO EXTERIOR. ..............................................................................................321 1.1.5. DEMANDA.....................................................................................................................323 1.1. TRIMESTRALES. ......................................................................................................................329 1.1.1. INDUSTRIA....................................................................................................................329 1.1.2. MONETARIOS. ..............................................................................................................330 1.1.3. MERCADO DE TRABAJO. ...........................................................................................332 1.1.3.1. PARADOS. ...........................................................................................................332 1.1.3.2. ACTIVOS..............................................................................................................333 1.1.3.3. TASAS. .................................................................................................................334 1.1.3.4. OCUPADOS. ........................................................................................................335 1.1.3.5. ASALARIADOS...................................................................................................338 ANEXO 2: CONTRASTE DE EXISTENCIA DE CICLOS COMUNES.........................................339 2.1. INTRODUCCIÓN.......................................................................................................................339 2.2. CONTRASTE DE EXISTENCIA DE CICLO COMÚN............................................................339 2.2.1. PERSPECTIVA TEÓRICA.............................................................................................339 2.2.3. APLICACIÓN. ................................................................................................................343 ANEXO 3. MODELIZACIÓN UNIVARIANTE Y EXTRACCIÓN DE SEÑALES DE VARIABLES ECONÓMICAS. ............................................................................................................345 3.1. INTRODUCCIÓN.......................................................................................................................345 3.2. MODELIZACIÓN UNIVARIANTE. .........................................................................................345 3.3. LA EXTRACCIÓN DE SEÑALES. ...........................................................................................359 3.3.1. INTRODUCCIÓN...........................................................................................................359 3.3.2. COMPONENTES INOBSERVADOS Y SEÑAL RELEVANTE. .................................359 3.3.4. MÉTODOS DE EXTRACCIÓN DE LA SEÑAL RELEVANTE. .................................362 3.3.4.1. ELECCIÓN DEL MÉTODO DE EXTRACCIÓN DE SEÑAL............................369 3.3.5. EXTRACCIÓN DE LA SEÑAL RELEVANTE CON SEATS. .....................................371 ANEXO 4: PROCEDIMIENTOS PARA LA OBTENCIÓN DE INDICADORES COMPUESTOS. ....................................................................................................................................375 4.1. INTRODUCCIÓN.......................................................................................................................375 4.2. PROCEDIMIENTOS ..................................................................................................................375 4.2.1. PROCEDIMIENTOS CON BASE EN EL ANÁLISIS DE CORRELACIÓN. ..............376 4.2.2. PROCEDIMIENTOS BASADOS EN EL ANÁLISIS DE REGRESIÓN. .....................376 4.2.3. PROCEDIMIENTOS DE SELECCIÓN AUTOMÁTICA..............................................377 4.2.4. PROCEDIMIENTOS BASADOS EN EL ANÁLISIS DE COMPONENTES PRINCIPALES..........................................................................................................................379 4.2.5. PROCEDIMIENTO SIMPLE DE NIEMIRA Y KLEIN (1994).....................................380 4.2.6. PROCEDIMIENTOS UTILIZADOS POR EL NATIONAL BUREAU OF ECONOMIC RESEARCH (NBER) Y POR EL BUREAU OF ECONOMIC ANALYSIS (BEA). .......................................................................................................................................381 4.2.7. PROCEDIMIENTO BASADO EN FERNÁNDEZ (1991).............................................383 4.2.8. PROCEDIMIENTOS BASADOS EN EL CONCEPTO DE DISTANCIA. ...................384 4.2.8.1. PROPIEDADES EXIGIBLES. .............................................................................384 4.2.8.2. VERIFICACIÓN DE LAS PROPIEDADES. .......................................................387 Anexos ANEXO 5: INTEGRABILIDAD, COINTEGRACIÓN Y MODELOS DE CORRECCIÓN DE ERROR...................................................................................................................................................395 5.1. INTRODUCCIÓN.......................................................................................................................395 5.2. ANÁLISIS DE LAS PROPIEDADES DE LOS DATOS. ..........................................................395 5.3. VARIABLES COINTEGRADAS Y MODELOS DE CORRECIÓN DE ERROR. ...................398 5.4. EL ESTIMADOR MODIFICADO COMPLETAMENTE DE PHILLIPS-HANSEN................401 ANEXO 6. CONTRASTES DE CAMBIO ESTRUCTURAL............................................................407 ANEXO 7. ESTIMACIÓN DEL MODELO ECONOMÉTRICO.....................................................411 7.1. AGRICULTURA ........................................................................................................................411 7.1.a. Estimación de la relación de cointegración......................................................................411 7.1.a.1. Estimación de la relación a largo plazo teórica. ......................................................411 7.1.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....411 7.1.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................412 7.1.a.4. Contraste de cointegración. .....................................................................................412 7.1.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................413 7.1.b. Estimación del modelo de corrección de error. ...............................................................414 7.1.b.1. Estimación de la relación a corto plazo teórica. ......................................................414 7.1.b.2. Estimación de la relación a corto plazo con intervenciones. ...................................414 7.1.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. .....................................................................................................................415 7.2. ENERGÍA. ..................................................................................................................................416 7.2.a. Estimación de la relación de cointegración......................................................................416 7.2.a.1. Estimación de la relación a largo plazo teórica. ......................................................416 7.2.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....416 7.2.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................417 7.2.a.4. Contraste de cointegración. .....................................................................................417 7.2.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................418 7.2.b. Estimación del modelo de correción de error. .................................................................419 7.2.b.1. Estimación de la relación a corto plazo teórica. ......................................................419 7.2.b.2. Estimación de la relación a corto plazo con intervenciones. ...................................419 7.2.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. .....................................................................................................................420 7.3. CONSTRUCCIÓN. .....................................................................................................................421 7.3.a. Estimación de la relación de cointegración......................................................................421 7.3.a.1. Estimación de la relación a largo plazo teórica. ......................................................421 7.3.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....421 7.3.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................422 7.3.a.4. Contraste de cointegración. .....................................................................................422 7.3.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................423 7.3.b. Estimación del modelo de correción de error. .................................................................424 7.3.b.1. Estimación de la relación a corto plazo teórica. ......................................................424 7.3.b.2. Estimación de la relación a corto plazo con intervenciones. ...................................424 7.3.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. .....................................................................................................................425 Contenido de los Anexos 7.4. INDUSTRIA MANUFACTURERA...........................................................................................426 7.4.a. Estimación de la relación de cointegración......................................................................426 7.4.a.1. Estimación de la relación a largo plazo teórica. ......................................................426 7.4.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....426 7.4.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................427 7.4.a.4. Contraste de cointegración. .....................................................................................427 7.4.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................428 7.4.b. Estimación del modelo de correción de error. .................................................................429 7.4.b.1. Estimación de la relación a corto plazo teórica. ......................................................429 7.4.b.2. Estimación de la relación a corto plazo con intervenciones. ...................................429 7.4.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. .....................................................................................................................430 7.5. SERVICIOS DESTINADOS A LA VENTA..............................................................................431 7.5.a. Estimación de la relación de cointegración......................................................................431 7.5.a.1. Estimación de la relación a largo plazo teórica. ......................................................431 7.5.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....431 7.5.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................432 7.5.a.4. Contraste de cointegración. .....................................................................................432 7.5.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................433 7.5.b. Estimación del modelo de correción de error. .................................................................434 7.5.b.1. Estimación de la relación a corto plazo teórica. ......................................................434 7.5.b.2. Estimación de la relación a corto plazo con intervenciones. ...................................434 7.5.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. .....................................................................................................................435 7.6. TRANSPORTES Y COMUNICACIONES. ...............................................................................436 7.6.a. Estimación de la relación de cointegración......................................................................436 7.6.a.1. Estimación de la relación a largo plazo teórica. ......................................................436 7.6.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....436 7.6.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................437 7.6.a.4. Contraste de cointegración. .....................................................................................437 7.6.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................438 7.6.b. Estimación del modelo de correción de error. .................................................................439 7.6.b.1. Estimación de la relación a corto plazo teórica. ......................................................439 7.6.b.2. Contrastes de Chow secuenciales aplicados a la relación a corto plazo..................439 7.7. SERVICIOS NO DESTINADOS A LA VENTA. ......................................................................441 7.7.a. Estimación de la relación de cointegración......................................................................441 7.7.a.1. Estimación de la relación a largo plazo teórica. ......................................................441 7.7.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. .....441 7.7.a.3. Estimación de la relación a largo plazo teórica con intervenciones. .......................442 7.7.a.4. Contraste de cointegración. .....................................................................................442 7.7.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones................................................................................................................443 7.7.b. Estimación del modelo de correción de error. .................................................................444 7.7.b.1. Estimación de la relación a corto plazo teórica. ......................................................444 7.7.b.2. Estimación de la relación a corto plazo con intervenciones. ...................................444 7.7.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. .....................................................................................................................445 Anexos ANEXO 8: EL FILTRO DE KALMAN COMO HERRAMIENTA PARA ESTIMAR PARÁMETROS CAMBIANTES EN EL TIEMPO. ..........................................................................447 8.1. INTRODUCCIÓN.......................................................................................................................447 8.2. MODELOS EN EL ESPACIO DE LOS ESTADOS LINEALES. .............................................447 8.3. EL FILTRO DE KALMAN. .......................................................................................................450 8.4. ESTIMACIÓN DE LOS HIPERPARÁMETROS. .....................................................................452 Anexo 1 ANEXO 1: INDICADORES DISPONIBLES MENSUALES Y TRIMESTRALES. 1.1. MENSUALES. 1.1.1. INDUSTRIA. INDICADOR: NIVEL DE STOCKS (PROSTO) FUENTE: Ministerio de Industria y Energía. PERIODICIDAD: Mensual UNIDADES: Saldo de respuestas. OBSERVACIONES: 1987.01-1997.04 NOTAS: Opiniones empresariales. INDICADOR: TENDENCIA DE LA PRODUCCIÓN (PROTEN) FUENTE: Ministerio de Industria y Energía. PERIODICIDAD: Mensual UNIDADES: Saldo de respuestas. OBSERVACIONES: 1987.01-1997.04 NOTAS: Opiniones empresariales. INDICADOR: NIVEL DE LA CARTERA DE PEDIDOS (PRONIV) FUENTE: Ministerio de Industria y Energía. PERIODICIDAD: Mensual UNIDADES: Saldo de respuestas. OBSERVACIONES: 1987.01-1997.04 NOTAS: Opiniones empresariales. INDICADOR: INDICADOR DE CLIMA INDUSTRIAL (ICIBAS) FUENTE: Elaboración propia. PERIODICIDAD: Mensual. UNIDADES: Saldo de respuestas. OBSERVACIONES: 1987.01-1997.04 NOTAS: Es la media de PROTEN, PRONIV y PROSTO (PROSTO con el signo cambiado). INDICADOR: CONSUMO DE ENERGÍA ELÉCTRICA TOTAL (COELET) FUENTE: IBERDROLA Y SEVILLANA DE ELECTRICIDAD. PERIODICIDAD: Mensual. UNIDADES: Mw/h OBSERVACIONES: 1986.01-1996.12 NOTAS: Es la suma de energía facturada total por Sevillana en Badajoz y la energía facturada total por Iberdrola en Extremadura. -Pág. 313- Anexos INDICADOR: CONSUMO DE ENERGÍA ELÉCTRICA USOS DOMÉSTICOS (COELEU) FUENTE: IBERDROLA Y SEVILLANA DE ELECTRICIDAD. PERIODICIDAD: Mensual. UNIDADES: Mw/h OBSERVACIONES: 1986.01-1996.12 NOTAS: Es la suma de energía facturada para usos domésticos por Sevillana en Badajoz y por Iberdrola en Extremadura. INDICADOR: CONSUMO DE ENERGÍA ELÉCTRICA INDUSTRIA Y SERVICIOS (COELEIS) FUENTE: IBERDROLA Y SEVILLANA DE ELECTRICIDAD. PERIODICIDAD: Mensual. UNIDADES: Mw/h OBSERVACIONES: 1986.01-1996.12 NOTAS: Es la suma de energía facturada para industria y servicios por Sevillana en Badajoz (no facilita el dato agregado, sino que hay que sumar diferentes sectores) y por Iberdrola en Extremadura. INDICADOR: ÍNDICE DE PRODUCCIÓN INDUSTRIAL DE BIENES INTERMEDIOS PARA EXTREMADURA (IPIQ) FUENTE: Elaboración propia. PERIODICIDAD: Mensual. UNIDADES: Base 1990. OBSERVACIONES: 1975.01-1997.05 NOTAS: Obtenido aplicando la estructura de ponderaciones de Extremadura a los distintos índices nacionales clasificados según las actividades industriales de la CNAE. INDICADOR: ÍNDICE DE PRODUCCIÓN INDUSTRIAL DE BIENES DE CAPITAL PARA EXTREMADURA (IPIK) FUENTE: Elaboración propia. PERIODICIDAD: Mensual. UNIDADES: Base 1990. OBSERVACIONES: 1975.01-1997.05 NOTAS: Obtenido aplicando la estructura de ponderaciones de Extremadura a los distintos índices nacionales clasificados según las actividades industriales de la CNAE. INDICADOR: ÍNDICE DE PRODUCCIÓN INDUSTRIAL DE BIENES DE CONSUMO PARA EXTREMADURA (IPIC) FUENTE: Elaboración propia. PERIODICIDAD: Mensual. UNIDADES: Base 1990. OBSERVACIONES: 1975.01-1997.05 NOTAS: Obtenido aplicando la estructura de ponderaciones de Extremadura a los distintos índices nacionales clasificados según las actividades industriales de la CNAE. -Pág. 314- Anexo 1 INDICADOR: ÍNDICE DE PRODUCCIÓN INDUSTRIAL GENERAL PARA EXTREMADURA (IPIG) FUENTE: Elaboración propia. PERIODICIDAD: Mensual. UNIDADES: Base 1990. OBSERVACIONES: 1975.01-1997.05 NOTAS: Obtenido aplicando la estructura de ponderaciones de Extremadura a los distintos índices nacionales clasificados según las actividades industriales de la CNAE. -Pág. 315- Anexos 1.1.2. CONSTRUCCIÓN INDICADOR: VENTAS DE CEMENTO (CEMCON) FUENTE: Agrupación de Fabricantes de Cemento de España (OFICEMEN) PERIODICIDAD: Mensual. UNIDADES: Miles de Tm. OBSERVACIONES: 1987.01-1997.01 NOTAS: INDICADOR: LICITACIÓN OFICIAL TOTAL (LIOFTO) FUENTE: Asociación de Empresas Constructoras de Ámbito Nacional (SEOPAN). PERIODICIDAD: Mensual. UNIDADES: Millones de pesetas OBSERVACIONES: 1985.01-1996.12. NOTAS: Puesto en pts constantes con el deflactor de los costes de la construcción publicado por el INE en su Boletín Mensual de Estadística. INDICADOR: VIVIENDAS INICIADAS TOTAL (VIITO) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: Se desglosa en VIIVPO y VILIB. INDICADOR: VIVIENDAS INICIADAS (VIVIENDAS DE PROTECCIÓN OFICIAL) (VIIVPO) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: INDICADOR: VIVIENDAS INICIADAS LIBRES (VILIB) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: -Pág. 316- Anexo 1 INDICADOR: VIVIENDAS TERMINADAS TOTAL (VITETO) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: Se desglosa en VITEVPO y VITELI. INDICADOR: VIVIENDAS TERMINADAS LIBRES (VITELI) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: INDICADOR: VIVIENDAS TERMINADAS TOTAL (VIVIENDAS DE PROTECCIÓN OFICIAL) (VITEVPO) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: INDICADOR: PROYECTOS VISADOS POR EL COLEGIO DE ARQUITECTOS (PROVIT) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas OBSERVACIONES:1979.12-1996.12 NOTAS: INDICADOR: VIVIENDAS TOTALES (VIVIENDAS INICIADAS Y TERMINADAS) (VIVI) FUENTE: Ministerio de Fomento (Dirección General de la Vivienda, Arquitectura y Urbanismo) PERIODICIDAD: Mensual. UNIDADES: Viviendas iniciadas y terminadas. OBSERVACIONES:1979.12-1996.12 NOTAS: Es la suma de las viviendas iniciadas totales y las viviendas terminadas totales. -Pág. 317- Anexos 1.1.3. SERVICIOS. INDICADOR: GRADO DE OCUPACIÓN HOTELERA (GRAOCU) FUENTE: Instituto Nacional de Estadística (INE). PERIODICIDAD: Mensual. UNIDADES: Porcentaje. OBSERVACIONES: 1984.01-1997.01 NOTAS: Es la relación, en porcentaje, entre el total de las pernoctaciones y el producto de las plazas por los días del mes a que se refieren las pernoctaciones. INDICADOR: TRANSPORTE AÉREO DE PASAJEROS TOTAL (TRAAERE) FUENTE: Ministerio de Fomento (Dirección General de Aviación Civil) PERIODICIDAD: Mensual. UNIDADES: Número de Pasajeros. OBSERVACIONES: 1980.01-1997.04 NOTAS: INDICADOR: TRANSPORTE AÉREO DE PASAJEROS INTERIOR (TRAAEIN) FUENTE: Ministerio de Fomento (Dirección General de Aviación Civil) PERIODICIDAD: Mensual. UNIDADES: Número de Pasajeros. OBSERVACIONES: 1980.01-1997.04 NOTAS: INDICADOR: TRANSPORTE AÉREO DE PASAJEROS INTERNACIONAL (TRAAEIL) FUENTE: Ministerio de Fomento (Dirección General de Aviación Civil) PERIODICIDAD: Mensual. UNIDADES: Número de Pasajeros. OBSERVACIONES: 1980.01-1997.04 NOTAS: INDICADOR: NÚMERO DE VIAJEROS ESPAÑOLES (VIAESP) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Viajeros. OBSERVACIONES: 1984.01-1997.01 NOTAS: Viajero es toda persona que realiza una o más pernoctaciones seguidas en el mismo alojamiento hotelero. -Pág. 318- Anexo 1 INDICADOR: NÚMERO DE VIAJEROS EXTRANJEROS (VIAEXT) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Viajeros. OBSERVACIONES: 1984.01-1997.01 NOTAS: Viajero es toda persona que realiza una o más pernoctaciones seguidas en el mismo alojamiento hotelero. INDICADOR: NÚMERO DE VIAJEROS (TOTAL) (VIATOT) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Viajeros. OBSERVACIONES: 1984.01-1997.01 NOTAS: Viajero es toda persona que realiza una o más pernoctaciones seguidas en el mismo alojamiento hotelero. Se desglosa en VIAEXT y VIAESP. INDICADOR: PERNOCTACIONES (TOTAL) (VIAPERN) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Pernoctaciones. OBSERVACIONES: 1984.01-1997.01 NOTAS: Es la ocupación por una persona de una o más plazas o de una cama supletoria dentro de una jornada hotelera y en un mismo establecimiento. Se desglosa en PERNESP y PERNEXT. INDICADOR: PERNOCTACIONES (DE ESPAÑOLES) (PERNESP) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Pernoctaciones. OBSERVACIONES: 1984.01-1997.01 NOTAS: Es la ocupación por una persona de una o más plazas o de una cama supletoria dentro de una jornada hotelera y en un mismo establecimiento. INDICADOR: PERNOCTACIONES (DE EXTRANJEROS) (PERNEXT) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Pernoctaciones. OBSERVACIONES: 1984.01-1997.01 NOTAS: Es la ocupación por una persona de una o más plazas o de una cama supletoria dentro de una jornada hotelera y en un mismo establecimiento. -Pág. 319- Anexos INDICADOR: TRANSPORTE URBANO COLECTIVO (TRANURB) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Miles de viajeros. OBSERVACIONES: 1989.01-1996.12 NOTAS: Mensualmente se realiza una encuesta para conocer el volumen del transporte urbano. Se trata de una estadística de carácter exhaustivo, que recoge información sobre el número de viajeros transportados por las empresas metropolitanas y las dedicadas al transporte urbano de viajeros en autobús en Extremadura. Publicación: Monografía de la Estadística de Transportes. -Pág. 320- Anexo 1 1.1.4. COMERCIO EXTERIOR. INDICADOR: IMPORTACIONES TOTALES (IMPOR) FUENTE: Elaboración propia. PERIODICIDAD: Mensual. UNIDADES: Miles de pts. OBSERVACIONES: 1988.01-1997.03 NOTAS: Es la suma de IMPOQ, IMPOK e IMPOC deflactados. INDICADOR: EXPORTACIONES TOTALES (EXPOR) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Millones de pts. OBSERVACIONES: 1988.01-1997.03 NOTAS: Es la suma de EXPOQ, EXPOK y EXPOC deflactados. INDICADOR: SALDO COMERCIAL (SALCOM) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Millones de pts. OBSERVACIONES: 1988.01-1997.03 NOTAS: Exportaciones deflactadas (EXPOR) menos importaciones deflactadas (IMPOR). INDICADOR: IMPORTACIONES BIENES DE CONSUMO (IMPOC) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Miles de pts. OBSERVACIONES: 1988.01-1997.03. NOTAS: Deflactado con índice de precios de las importaciones de consumo totales. INDICADOR: IMPORTACIONES BIENES DE CAPITAL (IMPOK) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Miles de pts. OBSERVACIONES: 1988.01-1997.03. NOTAS: Deflactado con índice de precios de las importaciones de capital totales. -Pág. 321- Anexos INDICADOR: IMPORTACIONES BIENES INTERMEDIOS (IMPOQ) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Miles de pts. OBSERVACIONES: 1988.01-1997.03. NOTAS: Deflactado con índice de precios de las importaciones de bienes intermedios totales. INDICADOR: EXPORTACIONES BIENES DE CONSUMO (EXPOC) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Millones de pts. OBSERVACIONES: 1992.01-1996.12 NOTAS: Deflactado con índice de precios de las exportaciones de bienes. INDICADOR: EXPORTACIONES BIENES DE CAPITAL (EXPOK) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Millones de pts. OBSERVACIONES: 1992.01-1996.12 NOTAS: Deflactado con índice de precios de las exportaciones de equipo. INDICADOR: EXPORTACIONES BIENES INTERMEDIOS (EXPOQ) FUENTE: Ministerio de Economía y Hacienda. Agencia Estatal de Administración Tributaria. Departamento de Aduanas e II.EE. PERIODICIDAD: Mensual. UNIDADES: Millones de pts. OBSERVACIONES: 1992.01-1996.12 NOTAS: Deflactado con índice de precios de las exportaciones de bienes intermedios. -Pág. 322- Anexo 1 1.1.5. DEMANDA. INDICADOR: INSCRIPCIÓN DE MAQUINARIA AGRÍCOLA (INSMAQ) FUENTE: Ministerio de Agricultura, Pesca y alimentación. PERIODICIDAD: Mensual. UNIDADES: Unidades inscritas. OBSERVACIONES: 1985.01-1997.03 NOTAS: Incluye: Tractores [los de ruedas (tracción simple y tracción doble), es decir que prescinde de los de cadenas], motocultores, cosechadoras automotrices [el total (cereales, forraje, hortalizas, algodón y otras)] y recogedoras empacadoras [el total (de pistón, rotativas y otras)]. INDICADOR: INVERSIÓN EXTRANJERA DIRECTA (INVEXT) FUENTE: Dirección General de Transacciones Exteriores del Ministerio de Economía y Hacienda. PERIODICIDAD: Mensual. UNIDADES: Millones de Pts. OBSERVACIONES: 1986.07-1996.12 NOTAS: Se trata de una serie bastante “irregular”. Deflactada con el índice de precios general de Extremadura. INDICADOR: MATRICULACIÓN DE TURISMOS (MATTUR) FUENTE: Ministerio de Interior. Dirección General de Tráfico. PERIODICIDAD: Mensual. UNIDADES: Turismos matriculados. OBSERVACIONES: 1983.01-1996.12 NOTAS: INDICADOR: MATRICULACIÓN DE VEHÍCULOS DE CARGA (MATVCAR) FUENTE: Ministerio de Agricultura, Pesca y Alimentación. PERIODICIDAD: Mensual. UNIDADES: Matriculaciones. OBSERVACIONES: 1983.01-1996.12 NOTAS: Incluye camiones, furgonetas y tractores industriales matriculados. -Pág. 323- Anexos 1.1.6. PRECIOS. INDICADOR: IPC GENERAL DE EXTREMADURA (IPCGEX) FUENTE: INE PERIODICIDAD: Mensual. UNIDADES: Base 1992=100. OBSERVACIONES: 1979.12-1997.04 NOTAS: -Pág. 324- Anexo 1 1.1.7. MERCADO DE TRABAJO. INDICADOR: PARO REGISTRADO TOTAL (PAROREGT) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1982.01-1997.04 NOTAS: INDICADOR: PARO REGISTRADO EN AGRICULTURA (PARREGA) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1982.01-1997.04 NOTAS: INDICADOR: PARO REGISTRADO EN INDUSTRIA (PARREGI) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1980.01-1997.04 NOTAS: INDICADOR: PARO REGISTRADO EN CONSTRUCCIÓN (PARREGC) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1980.01-1997.04 NOTAS: INDICADOR: PARO REGISTRADO EN SERVICIOS (PARREGS) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1980.01-1997.04 NOTAS: -Pág. 325- Anexos INDICADOR: PARO REGISTRADO SIN EMPLEO ANTERIOR (PARRESE) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1980.01-1997.04 NOTAS: INDICADOR: PARO REGISTRADO MUJERES (PARREGM) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Miles de personas. OBSERVACIONES: 1980.01-1996.12 NOTAS: INDICADOR: COLOCACIONES TOTALES (COLOCA) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Número de colocaciones OBSERVACIONES: 1982.01-1997.04 NOTAS: INDICADOR: COLOCACIONES INDUSTRIA (COLOCI) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Número de colocaciones OBSERVACIONES: 1982.01-1996.12 NOTAS: INDICADOR: COLOCACIONES CONSTRUCCIÓN (COLOCC) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Número de colocaciones OBSERVACIONES: 1982.01-1996.12 NOTAS: -Pág. 326- Anexo 1 INDICADOR: COLOCACIONES SERVICIOS (COLOCS) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Número de colocaciones OBSERVACIONES: 1982.01-1996.12 NOTAS: INDICADOR: DEMANDAS DE EMPLEO (EMDEM) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Número de demandas. OBSERVACIONES: 1982.01-1996.12 NOTAS: INDICADOR: OFERTAS DE EMPLEO (EMOFE) FUENTE: Instituto Nacional de Empleo (INEM) PERIODICIDAD: Mensual. UNIDADES: Número de ofertas. OBSERVACIONES: 1982.01-1996.12 NOTAS: -Pág. 327- Anexos 1.1.8. ENERGÍA. INDICADOR: IBERDROLA, HIDROELÉCTRICA (ENEIBE) FUENTE: IBERDROLA PERIODICIDAD: Mensual. UNIDADES: Mwh OBSERVACIONES: 1980.01-1996.12 NOTAS: PRODUCCIÓN TOTAL ENERGÍA INDICADOR: SALTOS DEL GUADIANA, PRODUCCIÓN TOTAL ENERGÍA HIDROELÉCTRICA (ENESAL) FUENTE: SALTOS DEL GUADIANA PERIODICIDAD: Mensual. UNIDADES: Mwh OBSERVACIONES: 1980.01-1996.12 NOTAS: Datos proporcionados en Gwh de manera que Mwh=Gwh*1000. INDICADOR: ALMARAZ, ENERGÍA BRUTA PRODUCIDA (ENEALM) FUENTE: CENTRAL NUCLEAR ALMARAZ PERIODICIDAD: Mensual. UNIDADES: Mwh OBSERVACIONES: 1983.01-1997.06 NOTAS: Datos proporcionados en Millones de Kwh, de manera que Mwh=Mill. Kwh*1000. INDICADOR: ENERGÍA BRUTA PRODUCIDA TOTAL (ENERG) FUENTE: Elaboración propia, como suma de ENEALM, ENESAL y ENEIBE PERIODICIDAD: Mensual. UNIDADES: Mwh OBSERVACIONES: 1983.01-1997.06 NOTAS: -Pág. 328- Anexo 1 1.1. TRIMESTRALES. 1.1.1. INDUSTRIA. INDICADOR: UTILIZACIÓN DE LA CAPACIDAD PRODUCTIVA (UTICAP) FUENTE: Ministerio de Industria y Energía. PERIODICIDAD: Trimestral. UNIDADES: Porcentaje. OBSERVACIONES: 1987.1-1996.4 NOTAS: Pertenece a las encuestas de “opiniones empresariales”. -Pág. 329- Anexos 1.1.2. MONETARIOS. INDICADOR: CRÉDITOS DE LAS ENTIDADES DE DEPÓSITO (CTOS) FUENTE: Banco de España. PERIODICIDAD: Trimestral. UNIDADES: Miles de Millones de pts. OBSERVACIONES: 1983.1-1996.4 NOTAS: Es la suma de créditos de las entidades de depósito al sector privado (CTOSPR) y créditos de las entidades de depósito público (CTOSPU). INDICADOR: CRÉDITOS DE LAS ENTIDADES DE DEPÓSITO AL SECTOR PRIVADO (CTOSPR) FUENTE: Banco de España. PERIODICIDAD: Trimestral. UNIDADES: Miles de Millones de pts. OBSERVACIONES: 1983.1-1996.4 NOTAS: Deflactado con el IPC general de Extremadura. INDICADOR: CRÉDITOS DE LAS ENTIDADES DE DEPÓSITO PÚBLICO (CTOSPU) FUENTE: Banco de España. PERIODICIDAD: Trimestral. UNIDADES: Miles de Millones de pts. OBSERVACIONES: 1983.1-1996.4 NOTAS: Deflactado con el IPC general de Extremadura. INDICADOR: DEPÓSITOS DEL SISTEMA BANCARIO (DEPS) FUENTE: Banco de España. PERIODICIDAD: Trimestral. UNIDADES:Miles de Millones de pts. OBSERVACIONES: 1983.2-1996.4 NOTAS: Es la suma de depósitos del sector privado en el sistema bancario (DEPSPR) y depósitos del sector público en el sistema bancario (DEPSPU). INDICADOR: DEPÓSITOS DEL SECTOR PRIVADO EN EL SISTEMA BANCARIO (DEPSPR) FUENTE: Banco de España. PERIODICIDAD: Trimestral. UNIDADES: Miles de Millones de pts. OBSERVACIONES: 1970.1-1996.4 NOTAS: Deflactado con el IPC general de Extremadura. -Pág. 330- Anexo 1 INDICADOR: DEPÓSITOS DEL SECTOR PÚBLICO EN EL SISTEMA BANCARIO (DEPSPU) FUENTE: Banco de España. PERIODICIDAD: Trimestral. UNIDADES: Miles de Millones de pts. OBSERVACIONES: 1981.4-1996.4 NOTAS: Esta serie incluye sólo cajas para los años 81 y 82, cajas y bancos hasta el segundo trimestre del 86 y a partir de esa fecha también las cooperativas. Deflactado con el IPC general de Extremadura. -Pág. 331- Anexos 1.1.3. MERCADO DE TRABAJO. 1.1.3.1. PARADOS. INDICADOR: PARADOS TOTALES (PARAT) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1997.1 NOTAS: INDICADOR: PARADOS TOTALES (PARAI) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: INDICADOR: PARADOS TOTALES (PARAB) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: INDICADOR: PARADOS TOTALES (PARAS) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: INDICADOR: PARADOS TOTALES (PARASE) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: -Pág. 332- Anexo 1 1.1.3.2. ACTIVOS. INDICADOR: POBLACIÓN ACTIVA TOTAL (POBAT) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: INDICADOR: POBLACIÓN ACTIVA MUJERES (POBAM) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: INDICADOR: POBLACIÓN ACTIVA VARONES (POBAV) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1996.4 NOTAS: -Pág. 333- Anexos 1.1.3.3. TASAS. INDICADOR: TASA DE PARO TOTAL (TASPATOT) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Porcentaje. OBSERVACIONES: 1980.1-1996.4 NOTAS: INDICADOR: TASA DE OCUPADOS (TASAOCU) FUENTE: Elaboración propia a partir de datos de EPA. PERIODICIDAD: Trimestral. UNIDADES: Porcentaje. OBSERVACIONES: 1980.1-1996.4 NOTAS: TASAOCU = OCUPADOS TOTALES /POBLACIÓN ACTIVA TOTAL INDICADOR: TASA DE ACTIVIDAD TOTAL (TASACTT) FUENTE: Encuesta de población activa (EPA). PERIODICIDAD: Trimestral. UNIDADES: Porcentaje. OBSERVACIONES: 1980.1-1996.4 NOTAS: -Pág. 334- Anexo 1 1.1.3.4. OCUPADOS. INDICADOR: OCUPADOS EN AGRICULTURA (OCUA). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1997.1 NOTAS: INDICADOR: OCUPADOS EN ENERGÍA (OCUE). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: INDICADOR: OCUPADOS EN BIENES INTERMEDIOS (OCUQ). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: INDICADOR: OCUPADOS EN BIENES DE CAPITAL (OCUK). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: INDICADOR: OCUPADOS EN BIENES DE CONSUMO (OCUC). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: -Pág. 335- Anexos INDICADOR: OCUPADOS EN CONSTRUCCIÓN (OCUB). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1997.1 NOTAS: INDICADOR: OCUPADOS EN TRANSPORTES Y COMUNICACIONES (OCUZ). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: INDICADOR: OCUPADOS EN OTROS SERVICIOS DESTINADOS A LA VENTA (OCUL). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: INDICADOR: OCUPADOS EN SERVICIOS DESTINADOS A LA VENTA (OCUSV). FUENTE: EPA PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: Es la suma de OCUZ y OCUL. INDICADOR: OCUPADOS EN SERVICIOS NO DESTINADOS A LA VENTA (OCUG). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1996.4 NOTAS: -Pág. 336- Anexo 1 INDICADOR: OCUPADOS TOTALES (OCUT). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1997.1 NOTAS: INDICADOR: OCUPADOS EN INDUSTRIA (INDUSTRIA MANUFACTURERA Y ENERGÍA) (OCU6I). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1997.1 NOTAS: INDICADOR: OCUPADOS EN SERVICIOS (OCU4S). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1976.3-1997.1 NOTAS: -Pág. 337- Anexos 1.1.3.5. ASALARIADOS. INDICADOR: POBLACIÓN ASALARIADA TOTAL (POBAST). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1997.1 NOTAS: INDICADOR: POBLACIÓN ASALARIADA EN AGRICULTURA (POBASA). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1997.1 NOTAS: INDICADOR: POBLACIÓN ASALARIADA EN INDUSTRIA (POBASI). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1997.1 NOTAS: INDICADOR: POBLACIÓN ASALARIADA EN CONSTRUCCIÓN (POBASC). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1997.1 NOTAS: INDICADOR: POBLACIÓN ASALARIADA EN SERVICIOS (POBASS). FUENTE: EPA. PERIODICIDAD: Trimestral. UNIDADES: Miles de personas. OBSERVACIONES: 1980.1-1997.1 NOTAS: -Pág. 338- Anexo 2 ANEXO 2: CONTRASTE DE EXISTENCIA DE CICLOS COMUNES. 2.1. INTRODUCCIÓN. La idea intuitiva que subyace en el contraste de existencia de ciclo económico común es la siguiente: si se puede construir una combinación lineal entre la tasa de crecimiento de la economía extremeña y la tasa de crecimiento media nacional que sea un ruido blanco e independiente de dichas tasas de crecimientos retrasadas un período, existe ciclo común. En consecuencia, se afirma que si la combinación lineal resultante es ruido blanco (independiente de los valores retrasados de los crecimientos), se constata que se ha eliminado una parte común a ambas tasas de crecimiento, con lo cual es inmediato afirmar que el ciclo era similar. Por el contrario, si la combinación lineal no es ruido blanco, de manera que no existe independencia de los valores retrasados de los crecimientos, se estaría evidenciando que parte de la combinación lineal resultante se puede explicar a través de algunos de dichos crecimientos retrasados, con lo cual existe un componente cíclico no común a ambas economías. 2.2. CONTRASTE DE EXISTENCIA DE CICLO COMÚN. En este apartado se desarrolla de manera formal la idea anterior siguiendo y parafraseando a Engle y Kozicki (1993), quienes parten de un contraste para la detección de una característica en una variable y llegan a un contraste acerca de la presencia de características comunes en distintas variables. 2.2.1. PERSPECTIVA TEÓRICA. En primer lugar, se concreta lo que se entiende por característica común: “Definición: Una característica que está presente en todas y cada una de las series de un grupo se dice que es común a estas series si existe una combinación lineal de las series distinta de cero que no tiene la característica”. Engle y Kozicki (1993, pág. 370). Para nosotros las series serán las tasas de crecimiento anuales del VABpm en pesetas constantes para España y las tasas de crecimiento anuales del VABpm en pesetas constantes para Extremadura. Para presentar el contraste de Engle y Kozicki (1993) vamos a tomar las tasas de crecimiento anuales del VABpm en pesetas constantes para el total nacional (TVABEST) y -Pág. 339- Anexos las tasas de crecimiento anuales del VABpm en pesetas constantes para el total extremeño (TVABEXT)1. Las características que Engle y Kozicki (1993, pág. 370) consideran en su estudio deben cumplir los siguientes axiomas (que imputamos a nuestras series en estudio): 1.”Si TVABEST tiene (no tiene) la característica, entonces λ TVABEST tendrá (no tendrá) la característica para cualquier λ ≠ 0. 2. Si TVABEST no tiene la característica y TVABEXT no tiene la característica, entonces T=TVABEST+TVABEXT no tendrá la característica. 3. Si TVABEST no tiene la característica pero TVABEXT tiene la característica, entonces T=TVABEST+TVABEXT tendrá la característica.” La presencia de la característica cíclica para ambas economías implica que se verifiquen2 las ecuaciones: TVABESTt = β 0 + β 1TVABESTt −1 + ε ES ,t TVABEXTt = α 0 + α 1TVABEXTt −1 + ε EX ,t (A1.1) (A1.2) en las cuales ε ES ,t y ε EX ,t son ruidos blancos. Por lo tanto, y siguiendo a Engle y Kozicki (1993), vamos a identificar la presencia de ciclo en una economía con la existencia de un proceso autorregresivo de orden uno en la especificación de sus tasas de crecimiento. El hecho de que utilicemos las tasas de crecimiento del VABpm de Extremadura (España) como aproximación al ciclo económico extremeño (nacional) lleva implícito la admisión de existencia de raíces unitarias en los niveles del VABpm para Extremadura (España). La detección de la característica cíclica se realiza con los contrastes estadísticos s(TVABEST ) y s(TVABEXT ) , los cuales definen, bajo las respectivas H 0 : {No existe ciclo} y H1 : {Existe ciclo}, el conjunto de probabilidad medida de manera que para un nivel de significación α (α=0,05) se rechazan las H 0 de no existencia de ciclo (de manera individual) para TVABEST y TVABEXT si s(TVABEST ) > c y s(TVABEXT ) > c ; donde c se define como: PH0 [ s(TVABEST ) > c] ≤ 0,05 PH0 [ s(TVABEXT ) > c] ≤ 0,05 1 (A1.3) (A1.4) Tomamos estas series a efectos, pero en la práctica lo aplicaremos a distintas series del VABpm en pesetas constantes. 2 Entendiendo por tal el rechazo, para cada ecuación individual, de las hipótesis nulas de no significatividad de los parámetros β 1 y α 1 . -Pág. 340- Anexo 2 Además, Engle y Kozicki (1993) también suponen la consistencia del contraste, de forma que: lim PH1 [s (TVABEST ) > c ] = 1 T →∞ y, lim PH1 [s (TVABEXT ) > c ] = 1 T →∞ (A1.5) (A1.6) Por otra parte, el modelo estadístico que justifica la contrastación de existencia de ciclo común es: ε ES ,t TVABESTt λ = ωt + TVABEXTt 1 ε EX ,t ( A1.7) donde ε ES ,t y ε EX ,t son ruidos blancos incorrelacionados contemporáneamente, λ es el coeficiente de TVABEST (el coeficiente de TVABEXT se ha normalizado para que tome el valor 1) y ω t se puede interpretar como el componente que recoge el ciclo común de ambas economías. La consecuencia que se extrae de este modelo es que, si ambas economías en su conjunto tienen ciclo común, la combinación lineal TVABESTt − λTVABEXTt debe ser un ruido blanco independiente de TVABESTt −1 y de TVABEXTt −1 . Por lo tanto, el contraste para la hipótesis nula de existencia de ciclo común, y la hipótesis alternativa de no existencia de ciclo común, se desarrolla aplicando un contraste de existencia de característica (ciclo) a la variable u = TVABESTt − λTVABEXTt . De todo lo anterior se deduce que se puede aplicar un contraste para determinar la existencia de ciclo común que es equivalente a aplicar el contraste para la detección de la característica cíclica (antes comentado) a la variable u = TVABESTt − λTVABEXTt , siendo H 0 : {No existe ciclo común} y H1 : {Existe ciclo común}. De esta forma, considerando que los axiomas anteriormente expuestos se cumplen, la distribución de s(u) en el caso de que tomemos un valor de λ que minimice s(u) verifica la siguiente expresión: ∧ ∧ min s TVABESTt − λ TVABEXTt ≡ s TVABESTt − λ TVABEXTt ≡ s (u ) λ (A1.8) ≤ s TVABESTt − λ TVABEXTt = s ε ES ,t − λ ε EX ,t Por lo tanto, y teniendo en cuenta (A1.3) y (A1.4): -Pág. 341- Anexos [( ) ] ∧ PH0 s u > c ≤ P s ε ES ,t − λε EX ,t > c ≤ 0,05 (A1.9) No obstante, “no es posible establecer que esta clase de contraste es óptima en algún sentido” Engle y Kozicki (1993, pág. 370). Estos autores argumentan la poca potencia de este contraste así como el hecho de que generalmente es ineficiente (aunque es consistente), de manera que abandonan este enfoque simple para contrastar características comunes y adoptan el que toma como base del contraste la regresión. En esta nueva perspectiva, supongamos ahora las siguientes ecuaciones: TVABESTt = x t β1 + z t γ 1 + ε ES ,t (A1.10) (A1.11) TVABEXTt = x t β 2 + z t γ 2 + ε EX ,t donde x {x t ;t = 1,..., T } y z {zt ;t = 1,..., T } representan conjuntos de datos referidas a dos variables que aparecen dentro de las especificaciones de las dos ecuaciones. Para contrastar si la característica cíclica es común a las variables TVABESTt y TVABEXTt se puede contrastar si existe un valor λ tal que la combinación lineal u = TVABESTt − λ TVABEXTt no tenga la característica cíclica. El contraste estadístico s(u) minimizado con respecto a λ toma ahora la forma de: ∧' ∧ ( s (u ) = min s (TVABESTt − λTVABEXTt ) = u M x z z ' M x z λ ) −1 ∧ z'M x u ∧ 2 σu (A1.12) ∧ ∧ donde u t = TVABESTt − λ TVABEXTt ; M x = I − x( x ' x ) x ' es la matriz de ∧ 2 proyección; σ u = ∧' −1 ∧ u Mx u T (A1.13) es una estimación consistente de la ∧ 2 varianza residual para un contraste del tipo LM; y σ u = ( ∧' ∧ u M zx u ) T (A1.14) para un contraste tipo Wald (siendo M zx = M x I − z(z ' M x z ) z ' M x ). −1 Un estimador para λ vendría dado por un procedimiento iterativo para resolver (A1.12), ya que λ aparece tanto en el numerador como en el denominador. Sin embargo, y según Engle y Kozicki (1993), un estimador que sería equivalente asintóticamente al que obtendríamos con un proceso iterativo y que incluso en algunas ocasiones sería más conveniente, se puede obtener sólo minimizando el numerador de (A1.12). La solución en este caso sería: -Pág. 342- Anexo 2 [ λ n = TVABEXT ' M x z( z ' M x z ) z ' M x TVABEXT ∧ −1 × TVABEXT M x z( z M x z ) z M x TVABEST ' ' −1 ] −1 (A1.15) ' La expresión (A1.15) se corresponde con el estimador de mínimos cuadrados en dos etapas de λ en el modelo TVABESTt = λ TVABEXTt + x t β + ε t (A1.16) siendo los instrumentos utilizados las variables x y z . El contraste estadístico es de la misma forma que (A1.12): s( u n ) = u n M x z ( z ' M x z ) z ' M x u n ∧ ∧ ∧' ∧ −1 ∧ 2 ∧ donde u tn = TVABESTt − λ n TVABEXTt ; y σ un = ∧ 2 σ un = ∧' ∧2 σ un ∧' (A1.17) ∧ u n M x un T (A1.18) y ∧ u n M zx u n T ( A1.19) equivalen respectivamente a las expresiones (A1.13) y (A1.14). El contraste estadístico (A1.17) para la expresión (A1.18) se puede expresar como: ∧ s(u n ) = TR 2 (A1.20) donde R 2 es el coeficiente de determinación en la regresión que relaciona los residuos de mínimos cuadrados en dos etapas (MC2E) de (A1.16) utilizando como instrumentos x y z . Bajo la hipótesis nula de que la correlación serial es común para España y Extremadura, el estadístico TR 2 se distribuye como una χ 2 con tantos grados de libertad como regresores nuevos se introduzcan en la regresión que estima los residuos de mínimos cuadrados en dos etapas de (A1.16). En definitiva, se trata del grado de sobreidentificación3 que denotamos por q de dicha regresión MC2E. En resumen, bajo la H 0 : {Existe ciclo común} TR 2 ∼> χ q2 . 2.2.3. APLICACIÓN. Ya se ha expuesto el contraste de forma teórica. A efectos operativos el primer paso es comprobar la existencia de la característica cíclica, es decir, que 3 Diferencia entre el número de instrumentos utilizados y el número de coeficientes que se estiman. -Pág. 343- Anexos se verifican las ecuaciones (A1.1) y (A1.2) en el sentido comentado, ya que es requisito necesario la existencia de ciclo para cada una de las economías. A continuación, se procede de la siguiente forma: a) Estimar la ecuación: TVABEXTt = β0 + β1TVABESTt + et mediante MC2E, utilizando como instrumentos TVABEXTt −1 y TVABESTt −1 . b)Estimar mediante mínimos cuadrados la regresión: ∧ e t = α 0 + α1TVABESTt −1 + α 2 TVABEXTt −1 + v t ∧ siendo e t los residuos bietápicos estimados en el paso a). c) Tomar el R 2 de la ecuación del paso b), de manera que bajo la H 0 de existencia de ciclo común entre la economía extremeña y la española el estadístico TR 2 sigue una distribución χ 12 . -Pág. 344- Anexo 3 ANEXO 3. MODELIZACIÓN UNIVARIANTE Y EXTRACCIÓN DE SEÑALES DE VARIABLES ECONÓMICAS. 3.1. INTRODUCCIÓN. En este anexo desarrollamos algunas cuestiones relativas a la metodología expuesta en el Capítulo IV. En concreto, tratamos de una manera ordenada y aclaratoria los asuntos concernientes a la modelización univariante y a la extracción de señal de series de variables económicas. Estas dos materias se exponen con el fin de aclarar las ideas y elementos fundamentales que han guiado nuestra forma de proceder. 3.2. MODELIZACIÓN UNIVARIANTE. Los elementos de partida, los indicadores económicos parciales, con los que se alimentan nuestros métodos de análisis coyuntural, son un conjunto de observaciones (lo cual le confiere un carácter discreto) que se han generado a lo largo del tiempo de manera ordenada, y para períodos de tiempo con la misma amplitud. De esta forma, se considera a un indicador económico como una serie temporal; es decir, se trata de una realización particular de un proceso estocástico, puesto que es un conjunto de variables aleatorias que depende del tiempo. Aznar y Trívez (1993b, Pág. 1) dan una definición de proceso estocástico referida al análisis de series temporales: “Familia de variables aleatorias {yt} (donde t = -∞…∞ señala el tiempo) tal que para cada serie finita de elecciones de t, esto es, t1, t2, …,tn se define una distribución de probabilidad conjunta para las correspondientes variables aleatorias yt1, yt2, …,ytn.”. No vamos a entrar en las propiedades probabilísticas de un proceso estocástico (definidas por su función de distribución conjunta), ni en sus características, ni en sus tipos, etc. En nuestro hilo argumental sólo nos interesa subrayar que la modelización de una serie temporal observada (de un indicador económico) es la especificación de un modelo teórico que suponemos que puede generar a la serie observada. La modelización de un indicador económico es importante tanto para corregir los efectos y acontecimientos especiales que pudiesen alterar la posterior labor de extracción de la “señal” inobservada del indicador económico que se considera relevante, como para elaborar predicciones de los mismos. -Pág. 345- Anexos Dado el gran número de indicadores parciales de los que disponemos, y la prontitud con la que necesitamos disponer de las modelizaciones univariantes para agilizar el análisis coyuntural4, hemos optado por trabajar con un programa que nos permita aplicar la metodología de Box y Jenkins (1976) (modelización ARIMA) ampliada con análisis de intervención (Box y Tiao, 1975) y tratamiento de efectos calendario (Bell, Hillmer y Tiao, 1983) con cierto apremio. El programa elegido es el TRAMO, cuyo nombre corresponde a las iniciales en lengua inglesa de ‘regresión de series temporales con ruidos ARIMA, observaciones perdidas y atípicas’ (“Time Series Regression with ARIMA Noise, Missing Observations and Outliers”), desarrollado por Gómez y Maravall (1997). La utilización que hacemos de este programa es en su opción de uso personalizado; es decir, aunque el programa tiene una opción completamente automática, consideramos que el seguimiento y control por parte del analista del proceso de identificación y estimación del modelo en función de las características de la serie en estudio es un elemento clave, de manera que el procedimiento no se debe convertir en una “caja negra”. Como es importante conocer el funcionamiento del programa, vamos a exponer su forma de operar. Según Maravall y Gómez (1997, Pág. i): “TRAMO es un programa para la estimación y predicción de modelos de regresión con errores posiblemente no estacionarios (ARIMA) y con alguna sucesión de valores perdidos. El programa interpola estos valores, identifica y corrige algunos tipos de datos atípicos, y estima efectos especiales tales como el efecto calendario y pascua y, en general, efectos del tipo de variables de intervención. Proporciona procedimientos totalmente automáticos de identificación de modelos y de corrección de datos atípicos.” Las utilidades que proporciona el programa TRAMO (Maravall y Gómez (1997, Pág. 2)) son: 1)”estima por máxima verosimilitud exacta (o mínimos cuadrados incondicionales/condicionales) los parámetros (en A3.2. y A3.3.); 2)detecta y corrige varios tipos de datos atípicos; 3)calcula predicciones óptimas para las series, junto con sus MSE5; 4)proporciona interpolaciones óptimas para las observaciones perdidas y sus MSE asociados; y 5)contiene una opción para identificación automática de modelos y tratamiento automático de datos atípicos.” 4 Gómez y Maravall (1998b, Pág. 12) opinan que hay dos razones básicas para intentar identificar automáticamente a los modelos ARIMA; la primera es el aumento de la productividad como consecuencia de la eliminación de tareas mecánicas que puede realizar el ordenador, la segunda es que se dota a la identificación de una objetividad que en otro caso (métodos heurísticos y procedimientos “ad-hoc”) puede no existir. 5 Iniciales en inglés de errores cuadrados medios (“Mean Squared Error”). -Pág. 346- Anexo 3 A continuación recogemos las ideas fundamentales respecto a las operaciones que vamos a realizar con el programa TRAMO, de manera que extendemos la exposición breve de su manual (Maravall y Gómez (1997)) con el objetivo de presentar de la forma más escueta posible las operaciones que hemos realizado con este programa6. Como es sabido, los modelos ARIMA pueden ser representados y estimados como un caso especial de la representación en el espacio de los estados. De esta forma, se puede utilizar el filtro de Kalman como un algoritmo que permite calcular la función de verosimilitud de un proceso ARMA estacionario y gaussiano. Sin embargo, cuando este filtro se pretende aplicar a un proceso autorregresivo integrado de medias móviles no estacionario, surgen dificultades a la hora de definir en la forma habitual la verosimilitud, ya que la distribución del vector de estado inicial no estaría definida correctamente. El problema es más evidente en el caso de que la serie sea no estacionaria y tenga observaciones perdidas. Gómez y Maravall (1994, Pág.611) muestran: “cómo una definición alternativa de la verosimilitud, basada en la hipótesis que se hace usualmente en estimación (Box y Jenkins 1976) y en la predicción (Brockewell y Davis 1987) de los modelos ARIMA, permite una representación estándar en el espacio de los estados de las series no estacionarias, fácil de programar, que no requiere ninguna transformación de los datos y proporciona una conveniente interpretación estructural de la variable estado. Como consecuencia, el filtro de Kalman ordinario y los algoritmos de alisado de puntos fijos pueden ser utilizados eficientemente sin modificación para la estimación, predicción e interpolación. En este sentido, el problema de las observaciones perdidas en series no estacionarias puede ser simplificado considerablemente. Los resultados son extendidos a modelos de regresión con errores ARIMA.” De esta forma, el filtro de Kalman se convierte en una pieza clave en el funcionamiento del programa, pudiendo proporcionar estimaciones de los parámetros de regresión (incluyendo los coeficientes de las variables de intervención y de los datos atípicos). Un esquema del funcionamiento del programa para la identificación automática de modelos cuando las series tienen datos atípicos es el siguiente: 6 Otras referencias fundamentales para el análisis del funcionamiento del programa TRAMO son: Gómez, V.(1994), Gómez y Maravall (1993, 1994, 1998a y 1998b). -Pág. 347- Anexos Cuadro A3.1. Esquema de identificación automática de modelos con datos atípicos. “CONTRASTES PRELIMINARES” Log-nivel. Efecto calendario. Efecto Pascua. “INICIALIZACIÓN” Corregir de datos atípicos No corregir de datos atípicos. “Paso 3” “Paso 1” *Modelo conocido: detección y corrección automática de datos atípicos, siendo el valor crítico de selección de datos atípicos (C) -entrado por el usuario o -especificado por el programa en función de la longitud de la serie. *Si no se satisface condición de “stop”, puede disminuir el valor de C, yendo al Paso 1. a) Si el usuario especifica el orden de diferenciación y el modelo tiene media, ir al Paso 2. b) En caso distinto a a): - Se corrige la serie de efectos de regresión. - Se obtiene el orden de diferenciación del modelo ARIMA. - Se decide acerca de la especificación de media en el modelo. - Ir al Paso 2. “Paso 2” a) Identificación automática de ARMA (p,q) para la serie diferenciada y corregida de datos atípicos y efectos de regresión. b) Se puede contrastar si los efectos Pascua y calendario son significativos para el modelo nuevo. c) Si se quiere corregir la serie de datos atípicos, ir al Paso 3; sino “stop”. Fuente: Elaboración propia a partir de Gómez y Maravall (1998b). -Pág. 348- Anexo 3 Supongamos que y representa una serie de observaciones para un indicador económico {y t ; t = 1,..., T } , de manera que y = ( y1 ,..., y T )' (A3.1) sería la representación vectorial del indicador económico que pretendemos modelizar. El número de observaciones que tenemos para cada año del indicador económico y es s . El modelo de regresión que pretendemos estimar para la observación t-ésima (t = 1,…,T) de y lo especificamos como: y t = x t/ β + v t donde ( β = ( β 1 ,..., β k ) / x t/ = x1t x 2 t ... x kt ) (A3.2) es un vector de coeficientes de respuesta, representa un conjunto de k regresores en el momento t. Estas variables de regresión las genera el programa para recoger la presencia de efecto calendario, la presencia de efecto Pascua o la presencia de otros tipos de variables de intervención7. En lo que respecta a v t de (A3.2) se trata de un proceso que se puede modelizar como un modelo estocástico lineal estacional, multiplicativo y general (modelo estacional multiplicativo ARIMA(p,d,q)× ARIMA(P,D,Q)) del tipo: φ ( B)δ ( B)v t = θ ( B)a t (A3.3) donde φ ( B) , δ ( B) y θ ( B) son polinomios finitos en B (B es el operador retardo), y a t se supone que es una perturbación tipo ruido blanco que se distribuye normal, idéntica e independientemente con media 0 y varianza σ2. En cuanto a los mencionados polinomios finitos en B, δ ( B) = (1 − B) d (1 − B s ) D es el polinomio que contiene las raíces unitarias asociadas con la diferenciación regular (d) y con la diferenciación estacional (D), p s s× P φ ( B) = (1 + φ1 B +...+φ p B )(1 + Φ 1 B +...+ Φ P B ) es el polinomio que presenta raíces autorregresivas estacionarias y que también puede presentar raíz unitaria compleja, y θ ( B) = (1 + θ1 B +...+θq B q )(1 + Θ 1 B s +...+Θ Q B s× Q ), es el polinomio invertible de medias móviles. En la expresión (A3.3) no se ha incluido término constante en el modelo, lo cual significa que la media de la 7 La detección y eliminación de los efectos de las intervenciones (que se reflejan en forma de datos atípicos o cambios estructurales) es muy importante, ya que su presencia puede invalidar los resultados acerca de la inferencia de la estructura probabilística subyacente en una serie temporal (indicador económico). -Pág. 349- Anexos serie diferenciada δ ( B) yt es cero. Si la media de la serie diferenciada es distinta de cero, debemos incluir en el modelo el parámetro µ: φ ( B)δ ( B)(v t − µ ) = θ ( B)a t (A3.4) Este término constante se estima como un coeficiente del modelo (A3.2). Ahora comentamos de manera sucinta8 cómo se lleva a cabo con el programa TRAMO la identificación y estimación del modelo. Para ello, vamos a suponer en primer lugar (hasta que se introduzcan explícitamente) que no existen variables de regresión en (A3.2), de manera que se verifica que y t = v t . Los contrastes preliminares tienen como meta la especificación de un modelo robusto para la serie; siendo el modelo por defecto el de líneas aéreas. La selección de la especificación en logaritmos o en niveles para la serie observada yt se integra dentro de esta etapa. El programa proporciona dos contrastes (Gómez y Maravall (1998b, págs. 22 -23): 1º) Parte de la especificación y estimación del modelo9 (0,1,1) × (0,1,1)s para la serie temporal yt a la que se le ha aplicado la transformada Box-Cox para sus valores más habituales (λ=0 y λ=1), de manera que: y y t( λ ) = t ln y t para λ = 1 ( serie en niveles) para λ = 0 ( serie en log aritmos) La estimación por máxima verosimilitud de ambos modelos (en niveles y en logaritmos) permite al contraste realizado por el programa elegir la especificación más adecuada. De esta forma, el modelo a especificar estará en niveles (en logaritmos) si la suma de cuadrados de los errores del modelo en niveles es menor (mayor) que el valor obtenido de la suma de cuadrados de los errores del modelo en logaritmos multiplicado por el cuadrado de la media geométrica del jacobiano de la transformación10. 2º) Se basa en una regresión rango-media realizada en los siguientes términos (Gómez y Maravall (1998b, Pág. 23): 8 La forma de operar del programa es bastante más compleja de lo que aquí exponemos, ya que dispone de algoritmos e iteraciones que no vamos a explicar. Simplemente pretendemos mostrar las líneas básicas de actuación del programa en el proceso de identificación y estimación de un modelo. 9 La elección de la especificación del modelo de líneas aéreas de Box y Jenkins (1976) se argumenta por Gómez y Maravall (1998b) por el hecho de que es un modelo muy frecuente en la práctica. 10 Para una exposición más detallada véase Gómez y Maravall (1998b, págs. 22-23). -Pág. 350- Anexo 3 a) “Se dividen los datos en grupos de observaciones sucesivas de longitud ‘l’ igual a un múltiplo del número de observaciones por año ‘s’. Es decir, el primer grupo está formado por con las primeras ‘l’ observaciones, el segundo grupo, con las observaciones ‘l+1’ hasta ‘2l’, etc.” b) “Para cada grupo, las observaciones se clasifican y se excluyen las observaciones más pequeñas y más grandes. Esto se hace como protección contra datos atípicos.” c) “Con las otras observaciones, se calculan la media y el rango11”. d) “Se estima una regresión rango-media del tipo rt = α + β m t + µ t .” e) “El criterio es la pendiente β. Si β es mayor que un valor especificado, se toman logaritmos.” Otro objetivo de los contrastes preliminares es la modelización de algunos tipos de efectos de regresión (efecto calendario y efecto Pascua). A la hora de plantear un modelo univariante hay que tener en cuenta ciertos efectos deterministas que se manifiestan de manera recurrente y que se modelizan mediante variables artificiales. Entre estos efectos se encuentran12 el efecto calendario, el efecto Semana Santa o Pascua y el efecto de los festivos intrasemanales. El efecto calendario (un valor mensual que se obtiene como agregación de valores diarios depende de la composición de dicho mes) fue tratado de manera rigurosa en los trabajos de Eisenpress (1956), Young (1965), Liu (1980) Cleveland y Grupe (1982) , Bell y Hillmer (1983) y Hillmer et al. (1983). El efecto Pascua (la movilidad del Viernes Santo produce distorsiones sobre la actividad económica, y por lo tanto, sobre las series temporales económicas) se aborda mediante la construcción de variables artificiales que conducen a problemáticas de estimación similares a las que se dan en los efectos calendarios. Por último, los festivos intrasemanales (la agregación de los datos diarios para obtener datos mensuales puede inducir efectos importantes en ciertas variables económicas) también debe ser tratado adecuadamente y los problemas de estimación son similares a los que se dan en los dos anteriores tipos de efectos. El efecto calendario (“trading day”) y efecto Pascua (“Easter effects”) se modelizan utilizando las variables de regresión correspondientes en cada caso. Partiendo del modelo (A3.2), donde β incluye los parámetros que recogen el efecto calendario y el efecto Pascua, se diferencian (el grado de 11 Por rango se entiende una medida de dispersión que suele ser la diferencia entre el valor mayor y menor de las observaciones (recorrido). 12 Ver Espasa y Cancelo (1993). -Pág. 351- Anexos diferenciación es d) y t , x t y v t , de manera que se obtiene la siguiente expresión (en forma matricial): z = H β +w (A3.5) donde z = ( zd +1 ,..., z T ) / , H representa una matriz de dimensión (T-d) x k, y w es un proceso ARMA φ ( B) wt = θ ( B)a t . La Var( w t ) = σ2Ω; además, la matriz de covarianza de los errores (Ω) se puede escribir como Ω=LL/ utilizando la descomposición de Cholesky. De esta forma, podemos premultiplicar la ecuación (V) por L-1, de manera que se obtiene el modelo: L −1 z t = L −1 β h t + L −1 w t (A3.6) El cálculo de las variables del modelo (A3.6) se realiza mediante el filtro de Kalman, de esta forma nos encontramos con un problema de estimación mediante mínimos cuadrados ordinarios de β13. Una vez que se ha estimado β, se utiliza un “test” F para contrastar la hipótesis nula de que hay ausencia de ciclo semanal (no existe efecto calendario). Por otra parte, se utiliza un contraste t para contrastar la hipótesis nula de ausencia de efecto Pascua. También existen ocasiones en las que es necesario llevar a cabo un estudio de algunos efectos especiales. Box y Tiao (1975) denominaron intervenciones a ciertos sucesos externos que frecuentemente influyen en las series temporales. Según Aznar y Trívez (1993b, Pág. 311) “la técnica del análisis de intervención consiste en evaluar el efecto de las intervenciones en el proceso de comportamiento de una serie temporal”, y para aplicarla hay que “identificar dos características de los modelos de intervención: a) El período de comienzo ( de dichos sucesos externos o intervención) y b) la forma general del impacto de dichas intervenciones”. La existencia de tales sucesos se manifiesta mediante la observación de ciertos datos atípicos (”outliers”). Puede ocurrir que tanto el tiempo como la causa de ocurrencia de los sucesos externos sean desconocidos, y a esta circunstancia se le suele llamar análisis de datos atípicos (“outliers”) de series temporales. Como afirman Aznar y Trívez (1993b), hay que detectar y eliminar los efectos de los datos atípicos (”outliers”), ya que hacen que los resultados de la inferencia no sean muy fiables o que resulten totalmente inválidos. 13 Que se resuelve de manera eficiente aplicando el algoritmo QR (ver Gómez y Maravall (1998b, Pág. 42). Este procedimiento calcula (evitando la inversión de la matriz) de manera estable y eficiente el estimador de mínimos cuadrados generalizados de los parámetros de la regresión. -Pág. 352- Anexo 3 Los datos atípicos pueden afectar de manera importante a la identificación y estimación del modelo, repercutiendo este hecho en que la estructura de la serie temporal no queda recogida de manera satisfactoria. Por lo tanto, se trata de tener en cuenta la posible presencia de datos atípicos mediante su detección y corrección en la serie en estudio. Las variables de intervención14 que permite generar el programa TRAMO de manera automática son las que posibilitan aproximar datos atípicos, pudiéndose combinar estos tipos de variables para modelizar otros tipos de sucesos externos (intervenciones). Para exponer dichas variables, empezamos definiendo el modelo y t = ω Vt + v t en el que se descompone la serie original, siendo v t la serie libre de intervenciones, ω un coeficiente desconocido a estimar, y V t una variable de intervención que puede combinar algunas de las que exponemos a continuación15: a) Variables que afectan a la serie en un solo período temporal (t = ti), de manera que un ejemplo de modelo de regresión con análisis de intervención para de este tipo es: y t = ω I tti + v t 1 si t = t i donde I tti = es una variable ficticia (“dummy”) que toma la forma 0 si t ≠ t i de variable impulso (“pulse variable”) que aparece en los puntos atípicos del tipo aditivos (“additive outlier”), y ω es un coeficiente desconocido. b)Variables que toman la forma de una serie de unos y ceros en la forma de variables de escalón (“step variable”) y que también aparecen en las observaciones atípicas de tipo aditivo. Un ejemplo sería la variable I tti , que entra como un regresor dentro del modelo especificado con análisis de intervención para y t : y t = ω I tti + v t 1 si t i ≥ t h . donde I tti = 0 si t i < t h 14 Justificadas tanto por sucesos con causa y período de ocurrencia conocidos (análisis de intervención) o desconocidos (análisis de datos atípicos); ver Aznar y Trívez (1993b, Cáp. 12). Aunque en la definición de Box y Tiao (1975) de análisis de intervención los sucesos con causa y período de ocurrencia conocidos no venían recogidos explícitamente, el hecho de que se modelicen de manera determinista ha implicado que también se engloben dentro de dicha denominación. 15 Para una exposición más extensa, ver Aznar y Trívez (1993b, Cáp. 12). -Pág. 353- Anexos Tanto las variables de escalón como las variables de impulso (que denotaremos I tti ) se combinan de manera habitual con el resto de variables de intervención. c) Variables que afectan a la serie en un momento determinado de tiempo y cuyo efecto inicial decae de una manera exponencial que viene recogida por el coeficiente δ . Dan lugar a un tipo de dato atípico (“outlier”) conocido como cambio temporal16. Un ejemplo de especificación de un modelo de regresión para el indicador económico y t que recoge una variable de este tipo es yt = vt + 1 ω I tti (1 − δ B) 0<δ ≤1 d)Variables que afectan a la serie en un momento de tiempo y que se presentan estacionalmente, de manera que su efecto inicial decae de una manera exponencial que viene recogida por el coeficiente δ . Un ejemplo de especificación del modelo para un indicador económico y t es: yt = vt + 1 ω I tti s (1 − δs B ) 0 < δs ≤ 1 e) Variables que afectan de una manera permanente a una serie en un momento de tiempo. Un ejemplo de este tipo de variables que se corresponden con un tipo de datos atípicos conocidos como cambio de nivel17 es: yt = vt + 1 ti s ω It (1 − B)(1 − B ) f) Variables que afectan a los valores observados después de producirse el suceso de acuerdo con un proceso ARIMA. Una expresión a modo de ejemplo para este tipo de variables que recogen un tipo de dato atípico conocido cono innovacional (“innovational outlier”) es: yt = vt + 16 17 θ ( B) ω I tti δ ( B)φ ( B) Conocido en terminología anglosajona como “temporary change”. Conocido como “level shift” en lengua inglesa. -Pág. 354- Anexo 3 En definitiva, el programa TRAMO permite detectar y corregir modelos de intervención con diferentes variables de intervención. La forma de detectar los datos atípicos empieza por la estimación del modelo especificado por el usuario o, en otro caso, del modelo de líneas aéreas (opción por defecto). Una vez detectados, corrige la serie e identifica el modelo de nuevo. Con el modelo nuevo, detecta (con un valor crítico más bajo, ya que inicialmente sólo se pretendía detectar los datos “más atípicos”) y corrige los datos atípicos. De esta forma, el proceso se repite. -Pág. 355- Anexos Cuadro A3.2. Esquema de detección y corrección de datos atípicos. “INICIALIZACIÓN” ¿Tiene el modelo variables de regresión o media? SÍ Estimar por MCO y corregir. “ETAPA I: Los datos atípicos se detectan y estiman uno a uno” I.1. -Estimación ARIMA (mediante el método de Hannan-Rissanen (HR)) I.2. - Se consideran fijos los parámetros estimados en I.1. y se estiman los coeficientes de regresión por MCO, obteniéndose nuevos residuos. -Se calculan los estadísticos “t”. ∧ I.3. -Se calcula el estimador MAD ( σ ) de la desviación estándar de los { ∧ residuos ( rt* ) como σ } = 1,483 × mediana rt* − rm* , siendo rm* la mediana de los residuos estimados. I.4. ∧ -Utilizando los residuos de I.2. y σ de I.3., se calculan los estadísticos ∧ τ estimados ( τ ) para contrastar la hipótesis nula de que no existe un dato atípico en el momento t. -Para cada una de las observaciones se toma ∧ ∧ ∧ ∧ λ t = max τ IO ,t , τ AO ,t , τ TC ,t , τ LS ,t , denotando IO, AO, TC, LS datos atípicos del tipo innovacional, aditivo, cambio temporal y cambio de nivel respectivamente. !"Si λ = max t λ t = ∧ τ j ,t > C , siendo C un valor crítico, existe un dato atípico del tipo i-ésimo (i= IO, AO, TC o LS). !"Si no se encuentran datos atípicos en la primera iteración, el diagnóstico es que la serie está “limpia”, y el algoritmo para. !"Si no se encuentran datos atípicos, pero no es la primera iteración, hay que ir a la Etapa II. !"Si se encuentra algún dato atípico, se corrige a la serie de todos los efectos de regresión y vuelve a I.1. para iterar. “ETAPA II: Estimación de la regresión múltiple” -Utilizando los resultados de I.1., se contrasta si existe un dato atípico con un estadístico “t” menor que C (valor crítico de I.4.): !"si no hay ninguno, el algoritmo para. !"si hay alguno, se elimina y el algoritmo vuelve a I.2. para iterar. Fuente: Elaboración propia a partir del algoritmo detallado en Gómez y Maravall (1998b). -Pág. 356- Anexo 3 El esquema del método para la detección y corrección de datos atípicos es el recogido18 en el Cuadro A3.2. El algoritmo realiza estos contrastes preliminares a lo largo del proceso de identificación del modelo siempre que haya modificaciones en su especificación. Una vez corregidos los efectos especiales de la regresión, el paso siguiente consiste en obtener el orden de diferenciación de yt . El resumen del algoritmo que se aplica en el programa consta de los siguientes pasos (ver Gómez y Maravall (1998b)): Cuadro A3.3. Algoritmo para obtener el orden de diferenciación. PASO I. -Si el proceso es regular, se especifica: (1 + φ 1 B + φ 2 B 2 )(v t − µ ) = a t -Si el proceso es multiplicativo estacional, se especifica: (1 + φ 1 B + φ 2 B 2 )(1 + Φ 1 B s )(v t − µ ) = a t -El proceso especificado se estima con el método de Hannan y Rissanen o con mínimos cuadrados no condicionales (en función de la elección del usuario). -Una raíz se considera unitaria cuando su módulo es mayor que un valor especificado (0,97 por defecto). De esta forma, se identifica el grado de diferenciación. -A continuación se va al paso II. PASO II. -Si el proceso es regular, se especifica (1 + φ 1 B)( z t − µ ) = (1 + θ B)a t , donde z t es la serie diferenciada utilizando el orden de diferenciación dado por lass raíces unitarias obtenidas en el PASO I -Si el proceso es estacional, se especifica (1 + φ 1 B)(1 + Φ 1 B s )( zt − µ ) = (1 + θ B)(1 + Θ B s )a t . -El proceso especificado se estima con el método de Hannan y Rissanen o por máxima verosimilitud exacta, en función de la elección del usuario. -Si alguno de los parámetros autorregresivos estimados está próximo a uno, se incrementa el grado de diferenciación. -Si la serie ha aumentado su orden de diferenciación en este paso, hay que repetir el PASO II. -Por el contrario, si ninguno de los parámetros autorregresivos ha estado próximo a uno, se inicia el PASO III. PASO III -En función de la media de los residuos estimados en el PASO II, se decide acerca de la especificación o no de media en el modelo. -El algoritmo para. Fuente: Elaboración propia a partir del algoritmo detallado en Gómez y Maravall (1998b). 18 Para un desarrollo más extenso, ver Gómez y Maravall (1998b). -Pág. 357- Anexos El último paso consiste en la identificación automática del modelo ARMA estacionario que ya está corregido de datos atípicos y de otros efectos de regresión. Para ello: “sigue el procedimiento de Hannan-Rissanen, con una mejora que consiste en utilizar el filtro de Kalman en lugar de ceros para calcular los primeros residuos en el cálculo del estimador de la varianza de la innovación del modelo φ ( B)δ ( B)v t = θ ( B)a t . Para el modelo general multiplicativo: φ p ( B) Φ P ( B s ) zt = θq ( B)Θ Q ( B s )a t , la búsqueda se realiza sobre el rango 0 ≤ (p,q) ≤3, 0 ≤ (P,Q) ≤2. Esto se hace secuencialmente (...), y los órdenes finales de los polinomios son elegidos de acuerdo al criterio BIC19, con algunas posibles restricciones propuestas para incrementar la parsimonia, y favorecer modelos “equilibrados” (órdenes similares de AR y MA). Finalmente, el programa combina la facilidad para detección automática y corrección de outliers y la identificación automática de modelo ARIMA en una dirección eficiente, de manera que tiene una opción para identificación automática de modelo de una serie no estacionaria en la presencia de outliers.” (Gómez y Maravall (1997, Pág.5)). Para la predicción se pueden aplicar dos algoritmos a la serie original: el filtro de Kalman ordinario o la raíz cuadrada del filtro20. En definitiva, en esta parte del Anexo 3 hemos pretendido aportar unas ideas básicas acerca de la herramienta que vamos a utilizar para modelizar y predecir a los indicadores económicos. 19 20 Criterio de Información Bayesiano. Para un desarrollo en profundidad de esta cuestión ver Gómez y Maravall (1993). -Pág. 358- Anexo 3 3.3. LA EXTRACCIÓN DE SEÑALES. 3.3.1. INTRODUCCIÓN. Ya hemos expuesto cómo se modelizan y se realizan predicciones para los indicadores económicos parciales disponibles. Con la modelización de una serie se limpia a ésta de datos atípicos y de otros efectos que pueden estar distorsionando a la evolución de la variable observada. Sin embargo, el análisis económico a corto plazo (y en consecuencia los instrumentos que deben sintetizar la información para realizar los estudios coyunturales) debe basarse en información relevante, para lo cual es necesario extraer la señal de interés incluida en la variable observada. La extracción de señal consiste en recuperar la información esencial que contiene un fenómeno económico; así se busca facilitar su interpretación y significado estadístico de manera que los resultados que se deriven del estudio de dicha señal no estén contaminados. Esta información esencial se obtiene limpiando la información disponible hasta que se obtenga la señal que contiene; es decir, a los datos originales se les debe extraer aquella otra información (oscilaciones) que dificulta el seguimiento del fenómeno económico en cuestión. 3.3.2. COMPONENTES INOBSERVADOS Y SEÑAL RELEVANTE. Aunque es importante limpiar la serie económica original para realizar así una lectura mejor, no se debe olvidar que no es posible llevar a cabo la observación de la señal pura (entendiendo por tal la señal libre de todo tipo de componentes que no transmitan información esencial y que por lo tanto "contaminan"). La imposibilidad de conocer la señal pura va a obligar a trabajar con estimadores de dicha señal, llevando esto implícito el coste de incurrir en unos errores de estimación. Los procedimientos de estimación dentro del análisis de la coyuntura habitualmente pueden ir dirigidos a la obtención: -Del nivel; en este caso se estimaría la tendencia o componente ciclotendencia, y esta estimación se obtendría desestacionalizando y suavizando la serie original; -Del componente cíclico; en esta estimación, y según escribe Espasa21 "Cuando el componente tendencial es muy estable y las oscilaciones cíclicas son regulares y homogéneas, usar el crecimiento como aproximación del perfil cíclico resulta atractivo(...). Sin embargo, cuando la tendencia de un fenómeno económico es menos estable o las oscilaciones cíclicas son bastante irregulares, separar aquella de los posibles ciclos de actividad no resulta sencillo, y el interés se sitúa entonces en perfilar las características de crecimiento del componente mixto tendencia-ciclo. Este es el caso de muchos 21 Espasa y Cancelo (Eds.) (1993, Cap. 5, Pág. 326). -Pág. 359- Anexos fenómenos económicos,(...)". De cualquier forma, y dada la complejidad de su estimación, el componente cíclico se suele aproximar mediante tasas de crecimiento. -Del ritmo; aquí se estimaría el crecimiento, velocidad o ritmo de variación de la variable (o de una señal extraída de la serie), y se obtendría filtrando22 la serie original23 (o en su caso la señal extraída). Es importante señalar que el crecimiento de una variable no es importante sólo porque sirve para estimar el componente cíclico, sino que “el cálculo de la serie de crecimiento resulta imprescindible para evaluar la situación que atraviese el fenómeno económico” (Espasa y Cancelo (Eds.) (1993, Cap. 5, Pág. 326)). Es evidente la conexión que existe entre la estimación del nivel o del componente cíclico de una variable y los procesos de estimación de componentes inobservados de una serie temporal. Al mismo tiempo, también está relacionada la estimación del componente cíclico con la estimación del ritmo, de manera que “se demuestra que toda estimación fiable y robusta de la variación en variables económicas proporciona una anticipación de las oscilaciones cíclicas de dichas variables.” (Melis (1991, Pág. 10)). En definitiva, la extracción de señal parte de la hipótesis de que las series temporales referentes a fenómenos socio-económicos (Xt) tienen una estructura típica consistente en unos componentes no observables24. Estos componentes típicos o subyacentes son: - Tendencia o componente tendencial (Tt): que tiene una vinculación con los factores de largo plazo. Desde la perspectiva económica, se relaciona al componente tendencial con aquellos factores que determinan el crecimiento económico. - Estacionalidad o componente estacional (Et): que son fluctuaciones periódicas o cuasi periódicas (estacionales) de las que se destacan aquellas que tienen periodicidad igual o inferior al año. En economía, se relaciona a este componente con factores de distinta naturaleza (climática, institucional y técnica). - Ciclo o componente cíclico (Ct): refleja las fluctuaciones en la actividad económica25. Estas fluctuaciones tienen una frecuencia y sistematización 22 "En general se entiende por filtro cualquier transformación o sucesión de operaciones aritméticas que se aplique a una serie temporal" (Espasa y Cancelo (1994). Según Melis (1991, Pág. 23): “ …,filtrar es seleccionar o extraer parte de la información transportada por la señal”. 23 Una forma muy habitual de estimación del ritmo es la utilización de tasas de crecimiento. 24 Una referencia clásica del desarrollo a lo largo de la Historia de los componentes no observables es Nerlove et al. (1979, Cap.1). 25 En el Capítulo I se presenta una clasificación de las teorías principales relativas a los ciclos económicos. -Pág. 360- Anexo 3 menor que el componente estacional. - Componente irregular (It): refleja la variación no sistemática de la serie, estando impregnado normalmente de una estructura aleatoria. Atendiendo a esta descomposición, una serie temporal socio-económica típica vendría dada por26: X t = T t + Et + Ct + I t Generalmente, la tendencia se suele asociar con movimientos de larga duración, entendiendo por tal aquella con período superior a 60 meses27 (5 años), aunque para aquellas oscilaciones con período comprendido entre 5 y 10 años, existe cierta dificultad a la hora de asignarla a la tendencia o al ciclo. Por consiguiente, y debido a que en muchas ocasiones es muy difícil reconocer lo que es componente tendencial y lo que es ciclo, se suelen agrupar estos componentes en otro llamado componente ciclo-tendencia (CTt): Y t = CT t + E t + I t Es importante tener claro cuál es el aspecto esencial de un fenómeno económico (nivel, componente cíclico o ritmo) que se quiere recoger cuando se elabora un indicador sintético, ya que dependiendo de cuál sea la finalidad perseguida, puede variar la extracción de señal a realizar (y por lo tanto, el método de construcción)28. La primera duda con la que nos encontramos es, ¿cuál es la señal relevante sobre la que debemos centrar nuestro estudio?; o en términos de componentes inobservados, ¿cuál es el componente que debemos estimar? Para contestar a cuestiones referentes a la situación en la que se encuentra en un momento dado un fenómeno económico, en la práctica se ha optado frecuentemente por eliminar de los datos observados para el indicador 26 Aquí se está suponiendo que la serie observada sigue el esquema aditivo, pero también se puede considerar la hipótesis de que los componentes siguen un esquema multiplicativo del tipo: X t = e Tt e Et e Ct e I t . Como para este último caso, su transformación logarítmica seguiría un esquema aditivo, en este trabajo se va a utilizar con carácter general la hipótesis aditiva, suponiéndose que si se tratara de un esquema multiplicativo, estaría realizada la transformación logarítmica. En términos frecuenciales equivale al intervalo (0 , 2π / 60) , donde período = 60 meses. 28 En lo que se refiere al quehacer diario del campo coyuntural, existe cierto consenso entre los estudiosos del tema en dirigir sus investigaciones a la estimación del ritmo. 27 -Pág. 361- Anexos económico las variaciones estacionales y también, en otras ocasiones, las variaciones transitorias; es decir, se suele utilizar o bien la estimación del componente ciclo-tendencial, o bien el ajuste estacional del indicador económico en cuestión. Espasa y Cancelo (1993, Pág. 304) entienden por nivel o evolución subyacente29 “la trayectoria de avance firme y suave de una serie, una vez que a los datos originales se les ha extraído aquellas oscilaciones que dificultan el seguimiento del fenómeno de interés”; y proponen30 que “en general, el análisis de la evolución a corto plazo de los fenómenos económicos debe basarse en su tendencia, que es el componente no observable que mejor suele aproximar el nivel subyacente de la serie observada” (op. cit. Pág. 308). Estos autores se han decantado por la utilización de la tendencia frente a la serie desestacionalizada, porque la evolución de la segunda es más errática que la primera. En lo que se refiere a la representación de las tendencias a lo largo de la historia, ha habido distintas aproximaciones; así: “La tendencia se ha modelizado como funciones determinísticas del tiempo (ver, por ejemplo, Fellner(1956)), como procesos puramente estocásticos (en economía, una referencia estándar es Nelson y Plosser (1982)), o como una mezcla de las dos (Pierce (1978))” Maravall (1993, Pág. 5). En la actualidad se suele trabajar con tendencias estocásticas y sus procesos generadores se suponen generalmente lineales31. Nosotros, también optamos por la utilización de la tendencia como la señal relevante en este trabajo, aunque dada la dificultad para extraer la señal pura, trabajaremos con el ciclo-tendencia. 3.3.4. MÉTODOS DE EXTRACCIÓN DE LA SEÑAL RELEVANTE. La hipótesis de los componentes inobservados conlleva el problema de la estimación de tales componentes, la cual viene a su vez determinada por el tipo de representación adoptado. La representación de los componentes inobservados se puede realizar mediante especificaciones paramétricas y no paramétricas. La primera se basa fundamentalmente en la utilización de modelos lineales dinámicos, y la segunda en la consideración de propiedades relativas a la representación espectral. Según Espasa y Cancelo (1993, Pág. 269): “En la actualidad toda extracción de señales de una serie temporal, y en particular su descomposición en tendencia, estacionalidad e irregular, se basa en: 1) definir la media móvil 29 En definitiva, la señal relevante. Para ver las razones argumentadas, ver Espasa y Cancelo (Eds.) (1993, Págs. 305-309). 31 También existe la consideración de tendencias con procesos generadores de datos no lineales, como en Hamilton (1989). 30 -Pág. 362- Anexo 3 -el filtro- adecuado para resaltar ese componente (la señal), y 2) aplicar dicho filtro a la serie observada.” De esta manera, la problemática de la extracción de señal se puede plantear como un problema de filtrado lineal del tipo32: y t = H[ B , Ψ ( M )]x t (ς , M ) donde x t es la serie original, y t es la señal extraída, H[.,.] es un filtro lineal definido en el operador de retardos ( B ), Ψ(.) es un vector que recoge a otros parámetros que pueden servir para especificar el filtro, ς es un vector de parámetros que recogen características de los componentes de la serie y M es otro vector que recoge propiedades de las series sin considerar una representación explícita de las componentes (es decir, sin tener en cuenta a ς ). En este apartado se introducen algunos elementos de relevancia en lo que se refiere a los métodos de extracción de señales más utilizados para la estimación de los componentes subyacentes de una serie temporal. Como no es el objetivo fundamental de esta tesis el análisis exhaustivo de los procedimientos de extracción de señal, nos vamos a limitar a mencionar algunas de sus características más relevantes y a explicar de la manera más concisa posible el método elegido. En el cuadro siguiente33 se recoge una clasificación de los métodos más usuales: Cuadro A3.4. Métodos de Extracción de Señal. Pr oce dim ientos no Empiricistas / basados en mod elos Frecuenciales Extracci o n de señales Pr oce dim ientos En forma estructural basados en mod elos En forma reducida Nota: Los procedimientos frecuenciales se han identificado con los no basados en modelos, pero como se verá posteriormente, su enfoque se puede aplicar a los demás. Fuente: Martín (1996). A continuación, se exponen algunas características generales de estos métodos para proporcionar una visión de conjunta adecuada y fundamentar la elección del método de extracción de señal aplicado en el Capítulo V. Los procedimientos empíricos se caracterizan por no “hacer referencia explícita a ningún tipo de modelo teórico de generación de los 32 Ver Cristóbal y Martín (1994) y Martín (1996). La base esencial de la clasificación de los métodos de extracción de señal que aquí se presenta se encuentra en el capítulo cuarto de Espasa y Cancelo (1993), y en Martín (1996). En ambos textos se estudian los principales métodos empleados para la extracción de señal. Del Barrio (1997) hace una revisión de las bases, virtudes y deficiencias de los métodos de ajuste estacional. 33 -Pág. 363- Anexos datos” Espasa y cancelo (1993, Pág. 269). Estas han logrado un uso muy extenso gracias a la automatización que caracteriza a las técnicas conocidas como X11 y X11 ARIMA. Las dos tienen como característica común la aplicación de medias móviles en un procedimiento iterativo. La segunda se diferencia de la primera en que tiene en cuenta las características de la serie a la hora de elegir la longitud de las medias móviles aplicadas y en que hace una predicción de los valores necesarios para aplicar el filtrado. En la expresión general y t = H[ B , Ψ ( M )]x t (ς , M ) , la característica más relevante de este tipo de filtrado es la adaptación de las series a través de M , pero no a través de los parámetros ς asociados a las componentes. Aunque el X11 ARIMA es más flexible que el X11, no llega a actuar de manera completamente eficiente, ya que no tiene en cuenta información que el modelo de la serie original suministraría para la estimación de los componentes. Estos métodos empiricistas empezaron a ser criticados de manera importante cuando se constató que eran óptimos para el tipo de modelo denominado de líneas aéreas34. Los procedimientos frecuenciales se basan en el análisis del efecto del filtro en el dominio de la frecuencia35. Este enfoque implica la consideración de las series temporales como combinación de funciones trigonométricas. Siguiendo a Harvey (1993), recordemos que el poder espectral de cualquier ∞ proceso indeterminístico de la forma x t = ∑ ψ j ε t − j (donde ε t es una secuencia j =0 de variables aleatorias con media cero y varianza constante, y ψ 0 ,ψ 1 ,...,ψ ∞ son parámetros) se define por la función continua: ∞ f ( λ ) = (2π ) −1 [γ (0) + 2 ∑ γ (τ ) cos λτ ] τ =1 donde γ (0) es la variaza, γ (τ ) es la autocovarianza de orden τ , y λ es la frecuencia en radianes36 (puede tomar valores dentro del rango [-π,π]). Como f ( λ ) es simétrica con respecto a cero, toda la información del poder espectral está comprendida dentro del rango [0,π]. El área bajo el poder espectral para el rango [-π,π] es igual a la varianza σ2: ∫ π −π f ( λ )dλ = γ (0) = σ 2 . Es decir, que el poder espectral de un proceso lineal puede ser visto como una descomposición de la varianza del proceso en términos de frecuencia. 34 Esta puede ser la razón por la que el nuevo programa X12 del US Bureau of the Census incorpora características del enfoque AMB que comentaremos luego (Ver Bureau of the Census (1995) o Findley y Monsell (1995)). 35 Para ilustrar esta cuestión, nos remitimos al capítulo 6 de Harvey (1993), donde se recoge de manera más extensa y elaborada el extracto que aquí aportamos. 36 La relación que se establece entre frecuencia y período ( p) es λ = 2π / p . -Pág. 364- Anexo 3 Siguiendo a Harvey (1993, Pág. 190), el espectro de y t está relacionado con el de x t mediante la expresión: 2 f y ( λ ) = W ( e − iλ ) f x ( λ ) donde i = − 1 , y al término W (e −iλ ) = s ∑w e j =− r j − iλj se le conoce como la función de respuesta de frecuencia, y es el que proporciona la base para el análisis en el dominio de la frecuencia. Los efectos de un filtro lineal sobre una serie son: 1º. Cambia la importancia relativa de los diversos componentes cíclicos. El 2 cambio es capturado por el término W (e −iλ ) , que se conoce como la función de transferencia de poder. El factor por el cual la amplitud de un componente cíclico incrementa o disminuye viene dado por el módulo de la función de respuesta de frecuencia W (e −iλ ) , y la cantidad resultante se llama ganancia. El cambio en la importancia relativa de los diversos componentes cíclicos se refleja en el espectro del proceso antes y después de aplicar el filtro. Como el componente de interés para este trabajo es la tendencia (o ciclo-tendencia a efectos prácticos), en el dominio de la frecuencia, esa evolución a largo plazo de la tendencia se asocia con las frecuencias bajas del espectro. Si la frecuencia se mide en radianes; la frecuencia cero es parte de la tendencia, ya que tiene un ciclo de longitud infinita. Si λ incrementa (y en consecuencia el período decrece), llegará a un valor que no se debe incluir en la tendencia. De esta forma, una tendencia se puede definir por el pico espectral en las bajas frecuencias. En este contexto, se pueden construir filtros con una ganancia cercana a uno en el intervalo de frecuencia en el que la tendencia represente la mayor parte de variación (por ejemplo (0, λ 0 ) , con λ 0 pequeño), y una ganancia cercana a cero para otras frecuencias. 2º. Otro efecto de los filtros es que induce un cambio en la serie con respecto a su posición en el tiempo (cambio de fase). Un filtro que es simétrico no presenta un cambio de fase. De todo lo comentado, se deduce que la extracción de señal en los procedimientos frecuenciales pretende elaborar filtros que tengan ganancia unitaria en la banda de paso relevante y nula en el resto. La conclusión es que estos tipos de filtros son adecuados para el tratamiento masivo de series, pero llevan implícito la no consideración de las peculiaridades de la serie en estudio. Los procedimientos frecuenciales pueden dar lugar a la construcción de tres tipos de filtros37: 37 Ver Martín (1996) -Pág. 365- Anexos a) fijos, que adoptan el mismo diseño para todas las series; b) adaptables, que se diseñan considerando la dependencia de los parámetros de las características de las series; y c) mixtos, que combinan los procedimientos basados en modelos con el diseño de filtros fijos. Los métodos basados en modelos expresados en forma estructural38 representan en el espacio de los estados39 a los componentes subyacentes de las series temporales para posteriormente estimarlos mediante el filtro de kalman. Así, Harvey (1993, Pág. 120-121) afirma que “Los modelos estructurales de series temporales no son nada más que modelos de regresión en los cuales las variables explicativas son funciones del tiempo y los parámetros son variables en el tiempo.(...) La llave para el manejo de modelos estructurales de series temporales es la forma en el espacio de estados, con el estado del sistema representando los diversos componentes inobservables tales como la tendencia y la estacionalidad.” Los modelos estructurales, tienen como referencias básicas a Engle(1978), Harvey y Todd(1983), Gersch y Kitagawa(1983) y Harvey(1989). Para ilustrar este tipo de procedimientos adaptándonos al párrafo anterior, planteamos un ejemplo simple. Un modelo estructural de series temporales para observaciones trimestrales puede consistir en la descomposición en los componentes subyacentes, tendencia ( Tt ), ciclo ( Ct ), estacionalidad ( S t ), y componente irregular ( I t ); de manera que: x t = Tt + Ct + S t + I t Tales componentes son estocásticos, viniendo caracterizado cada uno de ellos en nuestro ejemplo por las siguientes expresiones: Tt = Tt −1 + uT , t Ct = φ Ct −1 + uC , t S t + S t −1 + S t − 2 + S t −3 = u S ,t It = uI , t Los términos de error configuran un vector de ruidos blancos normales idéntica e independientemente distribuidos (N.i.i.d) entre sí y con cualquier otro término de error del modelo: 38 Ver Harvey (1993) para un desarrollo completo de estos modelos. En el Anexo 8 exponemos las ideas básicas de la representación en el espacio de los estados y el filtro de Kalman. 39 -Pág. 366- Anexo 3 uT u C = N . i. i. d . uS uI 0 VT 0 0 , 0 0 0 0 0 0 0 VC 0 VS 0 0 0 0 0 VI Ahora, la ecuación de transición α t = Ft α t -1 + η t , t = 1 ,...,T es: Tt 1 C 0 t S t = 0 S t −1 0 S t − 2 0 5×1 0 0 0 Tt −1 uT , t u 0 0 C φ 0 t −1 C, t 0 − 1 − 1 − 1 S t −1 + u S , t 0 1 0 0 S t −2 0 0 0 1 0 5×5 S t − 3 5×1 0 0 y la ecuación de medida xt = Z t α t + u I ,t , t = 1, ... ,T : [ ] X t = 1 1 1 0 0 1×5 Tt C t S t + a I ,t S t −1 S t − 2 5×1 A partir de las ecuaciones de transición y de medida se obtienen las estimaciones de los componentes y sus predicciones post-muestrales. Según Espasa et al. (1993, Pág. 296) el principal inconveniente de este tipo de modelos es la imposición a priori de patrones de comportamiento para los componentes, que conduce a “que su forma reducida restringida sea muy parecida al modelo de las líneas aéreas”. Los procedimientos basados en modelos expresados en forma reducida40 se basan en el modelo ARIMA de la serie observada: φ (B)x t = θ (B)a t . A continuación, realizan una serie de supuestos; así, una primera hipótesis es que los componentes inobservables ciclo-tendencia (CT) , estacionalidad (S) e irregular(I), que se suponen ortogonales, se modelizan como procesos ARIMA del tipo: 40 Las referencias básicas son Burman (1980), Hillmer y Tiao (1982), Bell y Hillmer (1984) y Maravall y Pierce (1987). -Pág. 367- Anexos φ CT (B)CTt = θCT (B)b t φ S (B)S t = θS (B)c t φ I (B)I t = θI (B)d t La relación establecida para los polinomios autorregresivos es: φ (B) = φ CT (B)φ S (B)φ I (B) de forma que cada una de las raíces de φ (B) se asignan sólo a cada uno de los componentes (no existen raíces comunes). Otras restricciones son referentes al orden máximo41: el orden de φ CT (B) no ha de superar al de θCT (B) y el orden de φCS (B) no puede superar al de θ S (B) . Para llegar a una identificación de la descomposición, es necesario establecer un requisito conocido como requisito canónico, que consiste en maximizar la varianza de la innovación del componente itrregular. Las estimaciones de los componentes para la tendencia, la estacionalidad y la componente irregular son, respectivamente, las obtenidas mediante la aplicación de los siguientes filtros: a) para el componente de ciclo tendencia, σ b2 θ CT ( B)θ CT ( F )φ S ( B)φ S ( F )φ I ( B)φ I ( F ) σ a2 θ ( B )θ ( F ) b) para el componente estacional, σ c2 θ S ( B)θ S ( F )φC T ( B )φ CT ( F )φ I ( B)φ I ( F ) σ a2 θ ( B )θ ( F ) ,y c) para el componente irregular, σ d2 θ I ( B )θ I ( F )φC T ( B )φ CT ( F )φ S ( B)φ S ( F ) σ a2 θ ( B )θ ( F ) donde σ a , σ b , σ c y σ d son las desviaciones típicas respectivas de a t , b t , c t y d t , y F es el operador de adelantos, es decir F = B −1 . 41 Su objetivo es lograr que la especificación de los modelos sea sencilla. -Pág. 368- Anexo 3 El principal inconveniente de este tipo de procedimientos es que existen modelos para los que no está garantizado que se pueda obtener la descomposición de la serie42; además, es importante validar el modelo especificado para que los resultados obtenidos no estén modificados. 3.3.4.1. ELECCIÓN DEL MÉTODO DE EXTRACCIÓN DE SEÑAL. En cuanto a la elección entre filtros basados en modelos y filtros no basados en modelos, nos decantamos por los primeros ya que tienen como ventaja fundamental el considerar las características peculiares de la serie en estudio, proporcionando una base adecuada para hacer un análisis estadístico directo. Así, la utilización de filtros fijos no permite hacer inferencia. Sin embargo, los métodos basados en modelos llevan consigo el inconveniente de incurrir en un elevado coste de utilización cuando se trabaja con un número elevado de series. Se ha puesto de manifiesto con anterioridad que el enfoque basado en modelos mezcla el uso de modelos ARIMA con las técnicas de extracción de señal. La principal ventaja de los métodos basados en modelos es la consideración de la singularidad de cada serie gracias a la información suministrada por el proceso generador de datos de la serie original o de los componentes. En la actualidad, tienen dos orientaciones diferentes que están muy relacionadas entre sí: -la metodología de las series temporales estructurales (ST), y -la metodología basada en los modelos ARIMA (MBA), o modelos en forma reducida. Las dos metodologías comparten el supuesto básico de que la serie observada x t = x1 ,..., x T se puede escribir como la suma de unos componentes ortogonales distintos x t = ∑ xit , siendo xit cada uno de los componentes i (ciclo-tendencia, estacional e irregular). Además, cada uno de dichos componentes se puede escribir como un proceso ARIMA, de manera que las dos metodologías tienen en común “…la consideración explícita de los procesos generadores de los componentes” (Espasa y Cancelo (1993, Pág. 288). Los componentes ciclo-tendencia y estacional pueden tener raíces unitarias (normalmente son no estacionarios) y el componente irregular es un ruido-blanco. De esta forma se podría obtener un modelo ARIMA para la serie observada del tipo φ ( B) x t = θ ( B)a t , mediante la suma de los modelos ARIMA para cada uno de los componentes. En el modelo ARIMA anterior, φ ( B) contendría las raíces autorregresivas estacionarias y no estacionarias, y a t es un ruido-blanco. 42 Ver Espasa y Cancelo (1993). -Pág. 369- Anexos El estimador utilizado para estimar los componentes es el de mínimo error cuadrático medio (MECM): ∧ [ ] xit = E ( xit x t ) Maravall(1996a, Pág. 11) indica que “…esta esperanza condicionada se calcula con técnicas de extracción de señal” siendo el estimador de mínimo error cuadrático medio “un filtro lineal, simétrico, centrado, y convergente en las direcciones del pasado y del futuro” (Pág. 11), por lo que se deben realizar predicciones que extiendan los datos observados. En los dos casos, la estimación se realiza por máxima verosimilitud. “La descomposición de x t en componentes inobservables presenta un problema básico de identificación” (Pág. 12), el cual se resuelve realizando hipótesis (fundamentalmente relativas a la cantidad de varianza asignada al componente irregular) que son diferentes para el enfoque MBA y ST; así, el método MBA maximiza la varianza del componente irregular para lograr maximizar “la estabilidad de los componentes tendenciales y estacionales”. De esta forma, existe diferencia en la especificación de los modelos de los componentes. Una diferencia muy importante entre ambos métodos es que: -El ST especifica directamente los modelos para los componentes, sin conocer previamente el modelo ARIMA de la serie observada; calculando la esperanza condicionada mediante el filtro de Kalman. Maravall (1996a, Pág. 13) destaca la ventaja que supone para el ST la utilización del filtro de Kalman a efectos de simplicidad y flexibilidad en la programación y en el cálculo. -El MBA parte de la especificación del modelo ARIMA (siguiendo la metodología de Box y Jenkins (1970)) para la serie observada, derivando posteriormente los modelos para los componentes del modelo total. El cálculo de la esperanza condicionada se realiza utilizando el filtro de WienerKolmogorov (Referencias básicas: Whittle (1963) y Bell (1984)), que a efectos de análisis proporciona una información bastante clara. Maravall (1996a, Pág. 13) presenta una serie de ventajas del enfoque MBA respecto al enfoque ST: -El enfoque MBA es menos propenso a errores de especificación. “Un problema potencial del ST es que, dado que no incluye una etapa previa de identificación, el modelo especificado puede ser inapropiado” Maravall(1996a, Pág. 12). Este no es el caso del enfoque MBA, que parte de la identificación del modelo del agregado para posteriormente obtener (mediante la imposición de un conjunto de restricciones) los modelos de los componentes. -Pág. 370- Anexo 3 -Encuentra razonable “…ante la ausencia de información adicional, proporcionar componentes tendenciales y estacionales tan alisados como sea posible, dentro de los límites del comportamiento estocástico total de la serie observada.” Maravall(1996a, Pág. 13) -“El método MBA típicamente implica la estimación directa de menos parámetros, y proporciona resultados que son bastante robustos y numéricamente estables” Maravall(1996a, Pág. 13). En este trabajo nos decantamos por la utilización del enfoque basado en modelos ARIMA. Por otra parte, la Agencia Europea de Estadística (Eurostat) utiliza y recomienda el uso del método AMB y lo aplica con el programa SEATS (Ver por ejemplo Eurostat (1994) o Eurostat (1996b). 3.3.5. EXTRACCIÓN DE LA SEÑAL RELEVANTE CON SEATS. Por todo lo comentado antes, nos basaremos en el enfoque basado en modelos ARIMA. Para la extracción de señal utilizaremos el programa SEATS (Maravall y Gómez (1997)). El nombre de este programa se corresponde con las letras iniciales de la traducción al inglés de ‘extracción de señal en series de tiempo ARIMA’ (“Signal Extraction in ARIMA Time Series”). Vamos a describir de manera breve las utilidades que proporciona este programa con el objeto de explicar qué hace el programa. Para ello, aportamos unos extractos de la descripción del programa que Gómez y Maravall (1997) hacen43: “SEATS es un programa para la identificación de componentes inobservados en series temporales siguiendo el enfoque llamado ‘basado en modelos ARIMA’. Los componentes tendenciales, estacionales, irregulares, y cíclicos son estimados y predichos con técnicas de extracción de señal aplicadas a los modelos ARIMA. Son obtenidos los errores estándar de las estimaciones y predicciones y la estructura basada en modelo se explota para contestar a cuestiones de interés en el análisis en el corto plazo de los datos. (…) Cuando se usan [los programas TRAMO y SEATS] para ajuste estacional, TRAMO previamente adapta la serie que va a ser ajustada por SEATS.” (Maravall y Gómez (1997) Pág. i). “El programa comienza estimando un modelo ARIMA de la serie. Supongamos que x t denota la serie original, (o su transformación logarítmica), y supongamos zt = δ ( B) xt representa la serie diferenciada , donde B es el operador retardo, y δ ( B) denota las diferencias tomadas sobre x t para lograr (presumiblemente) la estacionariedad. En SEATS, 43 Una exposición adecuada requiere la lectura íntegra de dicha referencia y otras que allí se indican. -Pág. 371- Anexos δ ( B ) = ∇ d ∇ sD donde ∇ = 1 − B , y ∇ sD = (1 − B s ) D representa la diferenciación estacional de período s. El modelo para la serie diferenciada zt puede ser expresado como: − φ ( B)( z t − z ) = θ ( B)a t _ donde z es la media de zt , a t es una serie ruido-blanco de innovaciones, normalmente distribuida con media cero y varianza σ a2 , φ ( B) y θ ( B) son polinomios en B autorregresivos (AR) y medias móviles (MA), respectivamente, los cuales pueden ser expresados en forma multiplicativa como el producto de un polinomio regular en B y un polinomio estacional en Bs, como en φ ( B) = φT ( B)φs ( B s ) θ ( B) = θT ( B)θs ( Bs ) (...) el modelo completo se puede escribir en forma detallada como: φT ( B)φs ( B s )∇ d ∇ sD x t = θT ( B)θs ( B s )a t + c y, en forma concisa, como Φ( B) x t = θ ( B)a t + c donde Φ( B) = φ ( B)δ ( B) representa el polinomio autorregresivo completo, incluyendo todas las raíces unitarias. Nótese que, si p denota el orden de φ ( B) y q denota el orden de θ ( B) , entonces, el orden de Φ( B) es P = p + d + D × s .” (Gómez y Maravall (1997), págs. 56-57). “(...)El programa descompone una serie que sigue el modelo (7) en varios componentes. La descomposición puede ser aditiva o multiplicativa. Como la primera viene a ser la segunda tomando logaritmos, utilizaremos en la discusión un modelo aditivo, tal como x t = ∑ xit i donde xit representa un componente. Los componentes que SEATS considera son: x pt = el componente de tendencia -Pág. 372- Anexo 3 x st = el componente estacional x ct = el componente cíclico x ut = el componente irregular. “(...)Los componentes son determinados y derivados completamente desde la estructura del modelo ARIMA (agregado) para la serie observada, la cual puede ser directamente identificada desde los datos. El programa en su mayor parte está enfocado mensualmente o datos de frecuencia más baja, y el número máximo de observaciones es de 600.” (Gómez y Maravall (1997), p.57). “La descomposición asume componentes ortogonales, y por lo tanto cada uno tendrá una expresión ARIMA. A fin de identificar estos componentes, requeriremos que estén limpios de ruidos (excepto para el irregular). Esta es la llamada propiedad “canónica”, e implica que el ruido blanco no aditivo pueda ser extraído de un componente que no es irregular. La varianza de este último es, en este sentido, maximizada, y por el contrario, la tendencia, estacionalidad y ciclo son tan estable como sea posible (compatible con la naturaleza estocástica del modelo (7)). Aunque un supuesto arbitrario, como cualquier otro componente admisible puede ser expresado como el canónico más un ruido blanco independiente, parece sensato evitar contaminaciones de los componentes por el ruido, a menos que haya una razón a priori para hacer ésto”. (Gómez y Maravall (1997), págs.57-58). “En el caso estándar en el que SEATS y TRAMO se utilizan conjuntamente, SEATS hace el control de las raíces AR y MA mencionadas anteriormente, utilizando el modelo ARIMA para filtrar la serie linealizada, obteniendo de esta forma residuos nuevos, y produciendo un diagnóstico detallado de ellos. El programa procede después a descomponer el modelo ARIMA. Esto se hace en el dominio de la frecuencia. El espectro (o pseudo espectro) se divide en espectros aditivos, asociados con los diferentes componentes. (Estos están determinados, en su mayor parte, desde las raíces AR del modelo). La condición canónica sobre los componentes tendencial, estacional y cíclico identifica una única descomposición, desde la cual se obtienen los modelos ARIMA para los componentes (incluyendo la varianza del componente de innovación. Para una realización particular [ x1 , x 2 ,..., x T ] , el programa da el estimador de mínimo error cuadrado medio (MMSE) de los componentes, calculado con un filtro del tipo Wiener-Kolmogorov aplicado a la serie finita que se extiende con predicciones y “backcasts” (ver Burman, 1980). Para ∧ i=1,…,T, la estimación x it T , igual a la esperanza condicional E ( xit x1 ,..., x T ) , se obtiene para todos los componentes.” ((Gómez y Maravall (1997), págs. 5859). -Pág. 373- Anexos “El modelo por defecto en SEATS es el llamado Modelo de líneas aéreas, analizados en Box y Jenkins (1970). El modelo de líneas aéreas se encuentra a menudo apropiado para series reales, y proporciona filtros de estimación con comportamientos muy buenos para los componentes. Viene dado por la ecuación: ∇∇ 12 x t = (1 + θ1 B)(1 + θ12 B 12 )a t + c con − 1 < θ1 < 1 y − 1 < θ12 ≤ 0 , y x t es el logaritmo de la serie. Los componentes implícitos tienen modelos del tipo ∇ 2 x pt = θ p ( B)a pt , Sx st = θs ( B)a st , donde S = 1 + B +...+ B 11 , y θ p ( B) y θs ( B) son de orden 2 y 11 respectivamente. Comparado con otros filtros fijos, el modelo por defecto para la serie observada estima 3 parámetros: θ1 , relacionado con la estabilidad del componente de tendencia; θ12 , relacionado con la estabilidad del componente estacional; y σ a2 , una medida de carácter total de la serie. Así, en cierto grado, aún en este modelo de aplicación fija simple, el filtro para los estimadores componentes se adapta a la estructura específica de cada serie.” (Gómez y Maravall (1997, Pág. 60)). -Pág. 374- Anexo 4 ANEXO 4: PROCEDIMIENTOS PARA LA OBTENCIÓN DE INDICADORES COMPUESTOS. 4.1. INTRODUCCIÓN En este anexo se presentan otros procedimientos para la agregación de indicadores económicos que también han sido considerados en la elección del método de agregación. Los resultados obtenidos de su aplicación no los presentamos por no constituir nuestra elección final. Por otra parte, se profundiza en las características del indicador sintético DP2 . 4.2. PROCEDIMIENTOS Según la notación empleada en el Capítulo IV, sea X ti el valor que toma en el momento de tiempo t la señal de ciclo-tendencia extraída del indicador parcial i, ( i = 1,..., n ) y t = 1,... T cada uno de los períodos temporales para los que se pretende realizar la agregación de la información. I t es el valor que toma el indicador sintético o compuesto que se obtiene en el momento de tiempo t mediante la síntesis de la información contenida en las señales extraídas de diversos indicadores parciales. Por lo tanto, la matriz Χ se define como: Χ = ( X t1 X t2 . . . x11 x 21 . X tn ) = . . xT 1 y la matriz que recoge el indicador sintético es I1 I2 . Ι= . . . IT -Pág. 375- x12 x 22 . . . . . . . . xT 2 . . . . x1n x2n . ; . . x Tn Anexos 4.2.1. PROCEDIMIENTOS CORRELACIÓN. CON BASE EN EL ANÁLISIS DE Este método constaría de los siguiente pasos: 1º) Obtención del coeficiente de correlación ( ri ) entre la señal extraída del indicador parcial seleccionado y la magnitud de referencia (lógicamente, deben tener la misma frecuencia: mensual, trimestral o anual). 2º) Obtención de las ponderaciones para cada uno de los indicadores como: wi = ri n ∑r i =1 . i 3º) Obtención de los valores del indicador sintético en cada momento de tiempo t: n I t = ∑ wi x ti . i =1 4.2.2. PROCEDIMIENTOS REGRESIÓN. BASADOS EN EL ANÁLISIS DE Si M es la magnitud que pretendemos analizar mediante el indicador sintético y tiene una frecuencia de observación menor que las señales extraídas, las fases a seguir serán las siguientes: 1º) Si M tiene, por ejemplo, periodicidad anual, se deben anualizar las señales, de manera que se pueda realizar la siguiente relación regresión con datos anuales ( m son años): M m = α 0 + α1 x m1 + α 2 x m2 +...+α n x mn + em , donde se supone que em ∼ N (0, σ 2 ) , es decir, que los errores se distribuyen normal e idénticamente con media cero y varianza constante σ 2 . 2º) Suponiendo que la relación estimada en el paso 1 se mantiene para una frecuencia temporal mayor (mensual y/o trimestral), con los estimadores de la ∧ fase 1º se puede calcular M , que sería el valor que tomaría el indicador sintético para una periodicidad similar a la de los indicadores parciales: ∧ ∧ ∧ ∧ ∧ M t = I t = α 0 + α1 x t 1 + α 2 x t 2 +...+ α n x tn -Pág. 376- Anexo 4 Este procedimiento es lo que se conoce como combinación de datos de alta y baja frecuencia44. El inconveniente de este método aparece por la habitual existencia de multicolinealidad en la regresión anual, introduciendo elementos de duda en la influencia de cada una de las señales anualizadas (estadísticos t no significativos), que aunque en teoría no invalidan el modelo a efectos predictivos, en la práctica sí es necesario rechazar el modelo por la habitual presencia de signos equivocados o valores poco probables en los coeficientes. Además, la consecución de nuevos datos suele provocar grandes oscilaciones en la estimación de los parámetros. 4.2.3. PROCEDIMIENTOS DE SELECCIÓN AUTOMÁTICA. Este método se encuadra dentro del anterior, ya que el resultado obtenido también es de la forma: ∧ ∧ ∧ ∧ ∧ M t = I t = α 0 + α1 x t 1 + α 2 x t 2 +...+ α n x tn , pero con la peculiaridad de que obtiene una ecuación sólo con algunas de las señales de los indicadores seleccionadas (no todas las señales, solamente algunas) de una forma automática45. Así, este método sirve para seleccionar los regresores de una forma automática, y podría utilizarse como una referencia en la etapa de selección de indicadores parciales. La problemática es similar al caso anterior: se dispone de las señales como variables independientes y una macromagnitud como variable dependiente. No obstante, ahora se trata de elegir la mejor regresión que se pueda realizar utilizando algunas de las señales como variables independientes (aquellas que manifiestan una influencia significativa sobre el regresando y que son seleccionadas por el proceso). El uso de este tipo de procedimientos tiene la ventaja de no tener que estimar todas las ecuaciones posibles para posteriormente elegir la que consideremos mejor, ya que él nos da la que considera la mejor regresión; por otro lado proporcionan un instrumento que es un buen predictor de una variable dependiente. A los inconvenientes comentados en el método anterior, hay que añadir los asociados a la utilización de esta técnica, derivados del hecho de que para la selección de indicadores se recurre a la práctica conocida en la literatura como el “minado de datos” (“data mining”), de manera que la obtención del indicador sintético se realizará sin ningún tipo de criterio económico y atendiendo exclusivamente a razones estadístico-econométricas. En la práctica, 44 45 Ver Martínez Aguado (1992). Siempre que se disponga del equipo y programas informáticos adecuados. -Pág. 377- Anexos es poco probable que el resultado proporcionado por el procedimiento de selección automática se utilice como método de composición sin ningún tratamiento por parte del modelizador46. Entre los procedimientos automáticos de selección de variables se encuentran: -el método de selección hacia delante (“forward selection”), -el método de eliminación hacia atrás (“Backward Elimination”) -y el método de selección paso a paso (“stepwise”). Los resultados que se obtienen para cada uno de esos métodos (la selección de variables independientes) no tiene porqué coincidir; además, no se puede decir que uno sea mejor que otro de una manera absoluta47. Si los resultados obtenidos coinciden, simplemente se debe entender que la orientación que estamos dando a nuestra investigación es adecuada. A continuación vamos a exponer los pasos que se siguen en estos método para llegar a la regresión que contiene a las señales de los indicadores parciales que formarán parte del indicador sintético. a) Selección hacia adelante o progresiva (“forward selection”). Las señales de ciclo tendencia se seleccionan y se introducen de una manera progresiva atendiendo a unos criterios de entrada. La señal que entrará en primer lugar a formar parte de la ecuación es la que tenga la mayor correlación positiva o negativa con la variable dependiente, contrastándose a continuación la hipótesis nula de que el coeficiente de esa variable es igual a cero mediante el estadístico “t”. Si no se rechaza la hipótesis nula, es necesario desechar esa señal e introducir otra que ejerza una mayor influencia en la variable dependiente. Por el contrario, si se rechaza la hipótesis nula, esa señal primera entra a formar parte de la regresión. Aquí aparece un primer problema, ya que cuando se tiene una variable en la regresión, el siguiente paso es introducir la señal que tenga la mayor correlación parcial con la variable dependiente. Hay que comprobar si tiene un efecto significativo en la variable dependiente, lo cual se traduce en establecer un criterio de entrada. Este criterio es el rechazo o no rechazo de la hipótesis nula de no significación del coeficiente estimado para la nueva señal. En la práctica se suelen considerar dos criterios de entrada que no tienen por qué coincidir en la selección que proporcionan48: 46 El “constructor” del indicador sintético validará las variables seleccionadas atendiendo a razones fundamentadas en la teoría económica. 47 Se puede afirmar que, probablemente, el procedimiento más utilizado en la actualidad es el método paso a paso (“stepwise”). 48 Cuando se van añadiendo regresores, los grados de libertad asociados a la F cambian, de manera que un valor concreto de F tiene distintos niveles de significación en función del número de variables independientes. -Pág. 378- Anexo 4 -el primero sería elegir el valor mínimo del estadístico F que se debe obtener para que la señal entre a formar parte de la regresión, y -el segundo puede ser la determinación del valor máximo de la probabilidad asociada al estadístico F (probabilidad de significación del coeficiente de la señal) que se puede obtener, de manera que rebasar esa probabilidad implicaría no rechazar la hipótesis nula. Si se procede a verificar el cumplimiento del criterio establecido para que la señal pase a formar parte de la regresión y no lo verifica, la señal correspondiente no se selecciona como variable independiente, y se vuelve a repetir el proceso con el resto de señales no analizadas todavía hasta que ninguna de las que no están introducidas en la ecuación cumplan el criterio de entrada. b) El método de eliminación hacia atrás (“Backward Elimination”). Parte de la ecuación especificada con todas las variables independientes (señales de ciclo-tendencia) dentro de la ecuación, para posteriormente ir eliminando las que no verifiquen unos determinados criterios. Ahora, los criterios de eliminación se aplican mediante la detección de las señales que menos contribuyen a la reducción de la suma cuadrática residual . Los criterios más utilizados son: -La especificación del valor mínimo del estadístico F que el coeficiente de cualquier señal debe tener para permanecer en la regresión; -La determinación del valor máximo de la probabilidad asociada al estadístico F (probabilidad de significación del coeficiente de la señal) que se puede obtener, de manera que rebasar esa probabilidad implica no rechazar la hipótesis nula y el regresor se eliminaría de la ecuación. c) Selección paso a paso (“stepwise”). Este procedimiento realiza una fusión de los dos métodos anteriores, de manera que hasta que entra la primera variable, los pasos que sigue son similares a la selección hacia delante; pero una vez entrada la primera variable es cuando el método examina (aplicando el criterio de la selección hacia atrás) si la variable debe salir. El método termina cuando no hay variables que verifican ni los criterios de entrada ni los de salida. El problema fundamental que puede aquejar a este tipo de agregación de indicadores es similar al caso anterior, siendo la posible existencia de un elevado grado de multicolinealidad el problema más importante. 4.2.4. PROCEDIMIENTOS BASADOS COMPONENTES PRINCIPALES. EN EL ANÁLISIS DE La opción más simple es aplicar la técnica de los componentes principales a los crecimientos interanuales tipificados ( T14 ) de las señales. De -Pág. 379- Anexos este análisis se derivarán unos componentes, seleccionándose, en principio, aquellas componentes cuya raíz característica ( λh ) sea mayor que 1. Las componentes se ponderarán en función del porcentaje de varianza que expliquen. Existen procedimientos más elaborados que utilizan esta técnica, un ejemplo puede ser el aplicado en Pons (1996). 4.2.5. PROCEDIMIENTO SIMPLE DE NIEMIRA Y KLEIN (1994). El índice sintético ( IS ) se obtiene como la suma de los crecimientos de la señal de cada indicador parcial, pero teniendo en cuenta la importancia y volatilidad de cada uno de esos indicadores. En definitiva, se trata de aplicar la fórmula n IS = ∑ wi si Ti i donde: Ti denota la tasa de crecimiento en tantos porcentuales para el indicador iésimo, siendo i = 1,..., n el número de indicadores parciales, wi es el peso o ponderación (en definitiva, la importancia relativa) que se aplica al indicador parcial, si es el elemento de ajuste de la volatilidad del indicador parcial, una amplitud estandarizada para todos los indicadores parciales con el fin de minimizar la influencia de un indicador individual muy volátil sobre el indicador sintético. El indicador se elabora del siguiente modo49: 1. Determinación de las ponderaciones. a) Esto se puede hacer de manera objetiva o subjetiva. La suma de los pesos debe ser igual el número de indicadores parciales. Por ejemplo, el Departamento de comercio de EEUU da el valor wi = 1 . b) A continuación se relativiza (estandariza) la importancia (en porcentaje) de cada indicador parcial dividiendo cada peso asignado por el número de indicadores parciales. 2. Determinación de la volatilidad. a) Se puede calcular la desviación absoluta media con respecto al crecimiento medio de cada indicador. b) A continuación se relativiza (estandariza) la volatilidad de cada indicador parcial dividiendo cada desviación absoluta media por la suma de las desviaciones absolutas medias. Se toma en porcentaje. c) Se halla la inversa de la volatilidad estandarizada de cada indicador. 3. Determinación del peso de los indicadores parciales. 49 Para un ejemplo numérico ver Niemira y Klein (1994, págs. 171-172). -Pág. 380- Anexo 4 a) Se realiza el producto de el peso estandarizado y la inversa de la volatilidad estandarizada de cada uno de los indicadores. Esto determina los pesos finales (pi). 4. Cálculo del índice compuesto. El índice compuesto se calcula usando los pesos finales determinados en el paso anterior aplicados según indica la expresión: n IS = ∑ pi Indicadori i =1 4.2.6. PROCEDIMIENTOS UTILIZADOS POR EL NATIONAL BUREAU OF ECONOMIC RESEARCH (NBER) Y POR EL BUREAU OF ECONOMIC ANALYSIS (BEA). La metodología utilizada por ambos instituciones es similar y se desagrega en las siguientes fases50: 1) Cálculo del cambio porcentual simétrico: ct ,i = 200 x t ,i − x t −1,i x t ,i + x t −1,i Donde x t ,i es el valor del índice parcial i ( i = 1,..., n ) en el momento de tiempo t ( t = 1,..., T ). En línea con lo propugnado en este trabajo, x t ,i puede ser la señal de ciclo-tendencia del indicador parcial i . 2) Estandarización de las series obtenidas en la etapa anterior para impedir que las oscilaciones de un indicador parcial domine a las oscilaciones de los demás: ct ,i S t ,i = T c t ,i ∑ T −1 t =2 3) Ponderación de cada uno de los cambios porcentuales simétricos estandarizados. Niemira y Klein (1994, pág. 174), siguiendo a Moore y shiskin (1967), plantean la obtención de ponderaciones para cada uno de los indicadores parciales ( Wi ) en base a “su significación económica (...), adecuación estadística (...), conformidad con el ciclo económico, consistencia temporal en su relación con el ciclo de negocios, la prontitud en la obtención de los datos y la regularidad de la serie”. Se debe verificar: 50 Este procedimiento está recogido de Niemira y Klein (1994, págs. 173-175). Estos autores lo exponen en base a los trabajos de Shiskin (1961) y Moore y Shiskin (1967). -Pág. 381- Anexos n rt = ∑S i =1 t ,i Wi n ∑W i i =1 4) Se calcula el índice sintético coincidente como: (200 + rt ) I t = I t −1 (200 − rt ) donde a I se le suele asignar un valor inicial de 100. Como hemos comprobado, para las ponderaciones del paso 3) no se ha expresado la forma de cuantificación. Pons (1996, págs. 64-65) presenta la descripción, a partir del trabajo de Green y Beckman (1992), de una técnica de asignación de ponderaciones utilizada por el NBER y el BEA. Por tanto, vamos a retomar la etapa 2) para concluir con la elaboración del índice sintético: 2’) Cálculo de la media absoluta de los cambios porcentuales: c t ,i T Si = ∑ t =2 T −1 3’) Asignación de las ponderaciones. La ponderación que posee cada uno de los componentes en el índice es : βi = n y si se desea que se cumpla ∑β i =1 i 1 , n Si = 1 , se pueden obtener las ponderaciones como: β i∗ = βi n ∑β i =1 i 4’) Ajuste tendencial El porcentaje de cambio trimestral del índice sintético durante el período t ( Rt ) se calcula: -Pág. 382- Anexo 4 n n n i =1 i =1 i =1 Rt = ∑ β i ct ,i + TADJ = ∑ β i ct ,i + uVAB − ∑ β i ui En la anterior expresión, TADJ pretende actuar como un factor de ajuste tendencial, siendo u la media (tendencia) del VAB y ui es la media (tendencia) del indicador parcial (componente) i . En línea con Pons (1996, pág. 65), el TADJ se define como la diferencia entre la tendencia en el VAB y la tendencia del índice sintético coincidente calculado sin tener en cuenta el factor de ajuste, de manera que “asegura que la tendencia en el índice es igual a la tendencia del VAB. 5’) Obtención del índice sintético. Se compone de igual forma que en la etapa 4) comentada anteriormente: (200 + Rt ) I t = I t −1 (200 − Rt ) donde a I 0 = 100 . Los resultados que muestran unos indicadores sintéticos elaborados siguiendo la metodología del NBER presentan una doble ventaja frente a los construidos a partir de análisis de regresión: no necesitan una variable independiente y, además, subrayan la aparición de un punto de giro en el ritmo de actividad económica. Su principal defecto radica en el hecho de que puede haber dudas acerca de qué es lo que se está midiendo; es decir, no es un buen método para elaborar indicadores sintéticos de actividad económica, pero sí para realizar indicadores sintéticos cíclicos. 4.2.7. PROCEDIMIENTO BASADO EN FERNÁNDEZ (1991). Este procedimiento es una adaptación del esquema de agregación seguido por el (NBER). A continuación explicamos este procedimiento atendiendo a la exposición recogida en Fernández (1991, págs. 153-154): a) Se estandarizan las tasas de crecimiento de las señales de ciclo-tendencia para que tengan una amplitud común. Esto se hace dividiendo cada una de ellas entre la media aritmética de sus valores absolutos: X it 1 T ; t = 1,..., T , donde X i = ∑ X it , ∀i vit = T t =1 Xi b) Se obtiene la serie suma de las series estandarizadas: -Pág. 383- Anexos n wt = ∑ vit i =1 c) Se estandariza la serie wt : zt = wt 1 T ; t = 1,..., T donde w = ∑ wt T t =1 w d) Se obtiene un índice logarítmico mediante la acumulación de las tasas zt : L0 = log(100) Lt = Lt −1 + ( z t / 100), t = 1,..., T e) Se obtiene el índice sintético exponenciando el anterior índice logarítmico: I t = exp( Lt ), t = 0,..., T Fernández (1991, pág. 154) afirma: “Por construcción, el índice de amplitud ajustada I tiene como origen el valor 100 y una variación absoluta media igual al 1%. Así, por ejemplo, si el índice muestra un crecimiento del 2% en el último mes, significa que está creciendo el doble de rápido que en los meses pasados, y si es el crecimiento es del 0,5% entonces crece sólo la mitad de rápido que su promedio histórico”. 4.2.8. PROCEDIMIENTOS DISTANCIA. BASADOS EN EL CONCEPTO DE Nos hemos decantado por la utilización del indicador sintético de distancia DP2 , que se basa en el concepto de distancia. Este procedimiento se comenta en el Capítulo IV. En este apartado nos limitamos a recoger las propiedades que se le ha exigido al indicador sintético de distancia DP2 para su construcción, así como el cumplimiento que hace de tales propiedades. 4.2.8.1. PROPIEDADES EXIGIBLES. Las condiciones o propiedades exigibles por la función matemática que genera al indicador sintético son las siguientes51: I)Existencia y determinación. La función matemática que defina al indicador sintético debe ser tal que éste exista y no sea indeterminado para todo sistema de valores de I t , para t = 1,... T . (…) 51 Estas condiciones o propiedades están tomadas de Zarzosa (1992, Págs. 162-166), y se han adaptado a la notación que hemos empleado en el Capítulo IV. -Pág. 384- Anexo 4 II)Monotonía. El indicador sintético debe responder positivamente a una modificación positiva de los componentes y negativamente a una modificación negativa. III)Unicidad. Para una situación dada, el indicador sintético debe dar un único valor. IV)Invariancia. El indicador sintético debe ser invariante respecto a un cambio de origen y/o escala en las unidades en que vengan expresados los estados de los componentes. Esta propiedad es consecuencia de la anterior. V)Homogeneidad. La función matemática que defina al indicador I t = f ( X t 1 , X t 2 ,..., X tn ) debe ser homogénea de grado uno: sintético, f (CX t 1 , CX t 2 ,..., CX tn ) = Cf ( X t 1 , X t 2 ,..., X tn ) Así, si todos los indicadores parciales aumentan o disminuyen en la misma proporción, el indicador sintético aumentará o disminuirá en la misma proporción. VI)Transitividad. Si a , b y c son tres situaciones distintas del objetivo medible por el indicador sintético, e I (a ) , I (b) , I (c) son los valores que toma el indicador sintético para esas tres situaciones, entonces debe verificarse que: I (a ) > I (b) ⇒ I ( a ) > I ( c) I (b) > I (c) (…) VII)Exhaustividad. Pena (1977, Pág. 53) afirma que “el indicador sintético debe ser tal que aproveche al máximo y de forma útil la información suministrada por los indicadores simples” Pena (1977, Pág. 53). Según Zarzosa (1992, Pág. 164) “se entiende por <<información útil>> aquélla que no es falsa ni duplicada y puede ser interpretada según las escalas ordinales, o mejor aún, cardinales. Un indicador sintético es mejor que otro si aporta más información útil sobre el objetivo buscado. Según esta propiedad, el indicador sintético debe hacer una buena utilización de la información contenida en los indicadores parciales y eliminar la duplicación de ésta cuando sea necesario. (…)” Para dar validez a los indicadores sintéticos de distancia, Zarzosa (1992) exige que se verifiquen dos nuevas propiedades que habría que añadir a -Pág. 385- Anexos las 7 propuestas antes. El objetivo que se persigue exigiendo el cumplimiento de estas dos nuevas propiedades es posibilitar la comparación entre los indicadores sintéticos que se obtengan; por ejemplo, y aplicado al contexto del análisis económico regional, si se obtienen dos indicadores sintéticos para el sector industrial de sendas economías regionales, deberá ser posible comparar los resultados que se obtengan a partir de ambos indicadores sintéticos de industria52. Vamos a exponer estas dos propiedades adaptándolas a nuestra esfera de trabajo: VIII)Aditividad. Sean D(r ) y D( k ) los indicadores sintéticos de dos economías r y k respectivamente; el cumplimiento de la propiedad de aditividad exigiría que se verifique la siguiente igualdad: D(r ) − D( k ) = D(r , k ) ; siendo D(r ) el indicador sintético de distancia para la economía r con respecto a la base de referencia X • , D( k ) el indicador sintético de distancia para la economía k con respecto a la misma base de referencia X • y D(r , k ) el indicador sintético de distancia definido para la comparación entre ambas economías53. Zarzosa (1992, Págs. 176-180) demuestra que en el caso de que p = 1 y p = 2 , no se verifica la propiedad de aditividad, pero sí se cumple que D(r , k ) queda acotado de la siguiente forma54: D(r ) − D( k ) ≤ D(r , k ) ≤ D(r ) + D( k ) . IX)Invarianza respecto a la base de referencia. Esta propiedad se exige para que el indicador sintético de distancia para comparar dos economías cumpla la propiedad antes expuesta como III)Unicidad. Zarzosa (1992, Pág. 181) la expresa así: “El indicador sintético definido para la comparación entre dos países (economías) ha de ser 52 Para poder comparar dos economías utilizando indicadores sintéticos, es requisito necesario que los indicadores parciales utilizados sean los mismos, lo cual exige a su vez los mismos resultados en la selección de los indicadores parciales; por lo tanto, es lógico pensar que una misma selección sólo se obtendrá en el caso de trabajar con economías con estructuras productivas muy similares o en el caso de estudios enfocados a ramas productivas análogas y pertenecientes a distintas economías. 53 La definición de un indicador sintético de distancia para la comparación de dos economías tiene la misma expresión que en el caso de una única economía, simplemente cambiará la utilización como base de referencia de los valores correspondientes de los componentes del otro país. Por ejemplo, si se pretende construir un indicador sintético de distancia para la comparación de las economías r y k utilizando la Distancia General PMétrica ( D p ) del vector de estados de la economía r ( X r ) con respecto al vector de estados de la economía k ( X k ) (que actuaría de vector base de referencia) la expresión sería: 54 p n D p = ∑ ( xri − x ki ) i =1 Ver Zarzosa (1992, Págs. 180 y 181). -Pág. 386- 1/ p . Anexo 4 invariante respecto a la base de referencia que se toma para cada país (economía)”. Esta propiedad se verifica siempre que la base de referencia sea la misma para los dos países. Por otra parte, Zarzosa (1992, Pág. 161) argumenta la necesidad de plantear las siguientes hipótesis: 1ª Completitud. “El número de los componentes es tal que todas las propiedades relacionadas con el objetivo buscado por el indicador global están representadas a través de los componentes.” Zarzosa (1992, Pág. 162) Aplicado a nuestro contexto equivale a exigir que los indicadores parciales seleccionados sean representativos de la macromagnitud que pretendemos seguir. 2ªBondad de los indicadores simples.”Los indicadores parciales son buenos, es decir, miden bien los estados en que se encuentran los componentes en el momento temporal a que se refieren” Zarzosa (1992, Pág. 162). Esta hipótesis garantiza que los indicadores parciales recojan de manera adecuada tanto los cambios que se produzcan en la macromagnitud en estudio como las etapas por las que pase en su evolución. 3ª Objetividad. ”La finalidad buscada por el indicador sintético es debidamente alcanzada mediante indicadores parciales objetivos” Zarzosa (1992, Pág. 162) 4ª Comparabilidad. “En orden al objetivo medido por el indicador sintético, en nuestro caso el nivel de bienestar, se admite que dos países o dos regiones son comparables” Zarzosa (1992, Pág. 173). Para nosotros el objetivo va a ser una macromagnitud económica, de manera que también podemos admitir que dos economías son comparables. 5ª Linealidad. “Se acepta que la dependencia existente entre los valores que toman los distintos componentes es lineal.” Zarzosa (1992, Pág. 188). Zarzosa nos remite a Pena Trapero (1977, págs.104 y 105) para encontrar las razones que justifican el hecho de que esta hipótesis pueda ser asumida. De cualquier manera, es habitual el cambio de relaciones no lineales en lineales utilizando la transformación adecuada en cada caso. 4.2.8.2. DP2 : VERIFICACIÓN DE LAS PROPIEDADES. Antes hemos expuesto una serie de propiedades deseables para que un indicador sintético se pueda considerar como bueno. A continuación, comprobaremos que el indicador sintético de distancia DP2 verifica dichas propiedades: -Pág. 387- Anexos I)Existencia y determinación. El indicador sintético de distancia DP2 existe y toma un valor determinado siempre que la desviación típica de todos y cada uno de los indicadores parciales exista y sea finita y distinta de cero; es decir, siempre que se cumpla que ∀i = 1,..., n; ∃ σ i αi ≠ ∞ y αi ≠ 0 . Como afirma Pena (1977, Págs. 97-98) en lo referente a la propiedad de existencia y determinación: “en la práctica, las distribuciones con que se suele trabajar no ofrecen dificultades del tipo señalado, por lo que se puede afirmar que en condiciones muy generales se verifica” . II)Monotonía. Pena (1977, Pág. 80) demuestra esta propiedad bajo “la hipótesis de que la alteración del valor de un componente no modifique los valores de σ i y de (1 − Ri2•i −1,i − 2 ,...,1 ) ”, ya que en otro caso “habría que tener en cuenta los efectos de la alteración de dichos elementos”. Bajo dicha hipótesis, presentamos a continuación un esquema de respuesta del indicador sintético DP2 ante modificaciones en el valor del indicador parcial i-ésimo, donde δ denota “disminuye” y ∆ denota “incrementa”: a ) La base de ∆ la distancia referencia son valores ⇒ ∆ d i a la situacion ' ' deseable( ma ximo) ma ximos EMPEORA(δ su valor ) b) La base de δ la distancia referencia a la situacion ⇒ δ di son valores considerada peor ( minimo) minimos SITUACION c) La base de δ la distancia referencia son valores ⇒ δ d i a la situacion ' ' ( deseable ma ximo) ma ximos ( ) MEJORA su valor ∆ d ) La base de ∆ la distancia a la situacion referencia ⇒ ∆ di son valores considerada peor ( minimo) minimos Las implicación que se deriva de la situación a) es equivalente a la b) , y la que se deriva de c) es equivalente a la d) . La conclusión es que el indicador sintético de distancia DP2 verifica la propiedad de monotonía, ya -Pág. 388- Anexo 4 que si se modifica un indicador parcial en sentido negativo, el indicador sintético responde de forma negativa, y si la modificación es en sentido positivo, el indicador sintético responde en forma positiva; todo ésto, siempre que se mantengan el resto de indicadores parciales constantes. III)Unicidad. Según Pena (1977, Pág. 98), en el indicador sintético DP2 “la función matemática utilizada proporciona solución única para un mismo conjunto de datos a condición de que quede definida de forma única el orden de entrada de cada componente”. Como exponemos después, el orden de entrada queda definido en función del criterio de jerarquización con base en la distancia de Frechet, de manera que esta propiedad también se cumple. IV)Invarianza. Zarzosa (1992, Págs. 200-202) demuestra esta propiedad, y nosotros vamos a exponerla brevemente: si transformamos al indicador parcial i-ésimo ( X i ) de manera que le sometemos a un cambio de escala y de origen del tipo X i' = a + bX i , donde b es un número real positivo y a es un número real, el sumando i-ésimo del indicador sintético DP2 para el momento de tiempo j será ahora: d i' (1 − Ri2•i −1,...,1 ) , σ i' donde d i' = x 'ji − x•i = a + bxi − (a + bx •i ) = b xi − x •i y σ i' = bσ i , de manera que: b xi − x•i d i' d i' d i' 2 2 2 ( 1 ) ( 1 ) R R x x − = − = − •i i •i −1,...,1 i •i −1,...,1 i ' ' ' (1 − Ri •i −1,...,1 ) . bσ i σi σi σi En consecuencia, se deduce que no se altera el sumando al realizar un cambio de origen y/o escala en la variable X i , razón por la cual se verifica la propiedad de invarianza. V)Homogeneidad. Esta propiedad también la verifica el indicador sintético de distancia DP2 , como demuestra Zarzosa (1992, Págs. 202-203): si a todos los sumandos de la DP2 “se les multiplica por una misma constante, el indicador sintético DP2 queda multiplicado por dicha constante”: -Pág. 389- Anexos n DP2' = ∑ C i =1 n di d (1 − Ri2•i −1,...,1 ) = C ∑ i (1 − Ri2•i −1,...,1 ) =C DP2 σi i =1 σ i VI)Transitividad. El indicador sintético de distancia DP2 verifica la propiedad de transitividad, “ya que se trata de un valor numérico que se basa en sumas de distancias métricas que verifican la transitividad, siempre, claro está, que se tome la misma base de referencia” (pena (1977, Pág. 100). VII)Exhaustividad. El indicador sintético de distancia DP2 verifica la propiedad de exhaustividad “si cumple las condiciones de independencia, dependencia funcional, dependencia parcial y partición” Zarzosa (1992, Pág. 203). Veamos si el indicador sintético de distancia DP2 cumple cada una de estas condiciones. Condición de independencia. Esta condición se define así: “Si todos los indicadores simples son mutuamente independientes, el indicador sintético de distancia es la suma de los indicadores simples” Pena (1977, Pág. 57). Pena demostró que si todos los indicadores parciales son independientes, el indicador sintético de distancia DP2 es la distancia de Frechet: n di = F, i =1 σ i DP2 = ∑ de manera que se verifica esta condición. Condición de dependencia funcional. “Si entre los indicadores simples existe una relación funcional exacta, de forma que uno de ellos es función de otro u otros, entonces el indicador dependiente recoge la información contenida en los independientes y éstos pueden ser eliminados” Pena (1992, Págs. 57 y 58). Recogiendo la línea argumental de Pena (1977, Pág. 100), la condición de dependencia funcional se verifica, ya que los coeficientes de determinación serían igual a uno, con lo cual se eliminan todos los componentes dentro de los que exista una relación funcional exacta entre los indicadores parciales. En el caso límite, si un indicador parcial i se puede expresar como una combinación lineal del resto de indicadores parciales, la DP2 es igual a la siguiente d expresión: DP2 = i , con lo cual se puede prescindir del resto de indicadores σi parciales. Condición de dependencia parcial. -Pág. 390- Anexo 4 “Si los indicadores simples contienen información parcial de otros, el indicador sintético de distancia deberá ser modificado para eliminar la información que no es propia” Pena (1992, Págs. 57-58). Esta condición se verifica, ya que, como hemos comentado anteriormente, en la expresión de la DP2 el componente (1 − Ri2•i −1,i − 2 ,...,1 ) elimina la aprte de información recogida por los indicadores parciales que ya se ha procesado en la DP2 . Condición de partición. Si los indicadores parciales se pueden agrupar en conjuntos ortogonales entre sí, el indicador sintético de distancia DP2 se puede calcular como la suma de las DP2 de cada conjunto de indicadores parciales55. Esta propiedad se verifica para la DP2 , ya que si tenemos los indicadores parciales agrupados en conjuntos ortogonales entre sí, los coeficientes de determinación de la regresión de cualquier indicador parcial sobre otro perteneciente a otro conjunto distinto al suyo será igual a cero, de manera que el indicador sintético de distancia DP2 se podría calcular como la suma de los indicadores sintéticos de distancia DP2 calculados independientemente para cada uno de los conjuntos: DP2 = DP2(1) + DP2( 2 ) +...+ DP2( k ) siendo k el número de conjuntos de indicadores parciales que son ortogonales entre sí. Esta es la llamada “ DP2 por etapas”, que en nuestro caso tendrá pocas oportunidades de aplicarse. Como el indicador sintético de distancia DP2 verifica las cuatro anteriores condiciones, concluimos que verifica la propiedad de exhaustividad. VIII)Aditividad. Puesto que esta propiedad y la siguiente se exigen para la comparabilidad entre dos economías, es necesario exigir para que se puedan verificar ambas propiedades el hecho de que el vector de referencia es el mismo para cada economía, y además, el vector base de referencia debe ser para todos los indicadores parciales “el valor máximo o superior a éste o el valor mínimo o inferior a éste de la serie, de forma que las diferencias ( x ji − x•i ) sean todas positivas o todas negativas, cualquiera que sea el x•i ” Pena (1977, Pág. 101). Se pretende comprobar si la DP2 verifica la siguiente igualdad56: DP2 (r ) − DP2 ( k ) = DP2 (r , k ) ; siendo DP2 (r ) el indicador sintético 55 Ver Pena (1977, Pág. 58) y Zarzosa (1992, Págs. 204-205). Zarzosa (1992, Págs. 205-208) examina el cumplimiento por parte de la DP2 de la propiedad de aditividad, aquí nosotros presentamos un resumen del trabajo de esta autora. 56 -Pág. 391- Anexos de distancia DP2 para la economía r con respecto a la base de referencia X • , DP2 ( k ) el indicador sintético de distancia DP2 para la economía k con respecto a la misma base de referencia X • y DP2 (r , k ) el indicador sintético de distancia DP2 definido para la comparación entre ambas economías. Aplicando la definición de indicador sintético de distancia DP2 , es inmediato obtener que: n DP2 (r ) − DP2 ( k ) = ∑ i =1 n =∑ i =1 d i (r ,•) − d i ( k ,•) (1 − Ri2•i −1,...,1 ) = σi xri − x•i − x ki − x•i σi n DP2 (r , k ) = ∑ i =1 (1 − Ri2•i −1,...,1 ) , y xri − x ki σi (1 − Ri2•i −1,...,1 ) De las dos anteriores igualdades se concluye que, “en general, no se cumple la igualdad: DP2 (r ) − DP2 ( k ) = DP2 (r , k ) ”. Zarzosa (1992, Pág. 206). Sin embargo, según demuestra Zarzosa (1992, Págs. 206-208), el indicador sintético de distancia DP2 verifica la propidad de aditividad de forma restringida, ya que verifica DP2 (r ) − DP2 ( k ) ≤ DP2 (r , k ) ; y además, aplicando la propiedad triangular57 en la anterior igualdad, logra acotar a DP2 (r , k ) de la siguiente manera: DP2 (r ) − DP2 ( k ) ≤ DP2 (r , k ) ≤ DP2 (r ) + DP2 ( k ) . IX)Invarianza respecto a la base de referencia. Como ya hemos dicho, esta propiedad se verifica siempre que la base de referencia sea la misma para los dos países y se verifique también que el vector base de referencia para todos los indicadores parciales cumpla la condición expresada en la anterior propiedad. Zarzosa (1992, Págs. 209-210) demuestra que el indicador sintético de distancia DP2 verifica esta propiedad: -la DP2 (r , k ) ”es invariante respecto a la base de referencia puesto que ésta no interviene en su cálculo”, y 57 Desigualdad triangular: Si sumamos la distancia existente desde el vector X ri con respecto al vector X •i y la distancia existente desde el vector X ki con respecto al vector X •i , la suma resultante es mayor o igual que la distancia existente entre los vectores X ri y X ki ; es decir, que en el contexto de la distancia DP2 se verifica que: DP2 (r , k ) ≤ DP2 (r ) + DP2 ( k ) . -Pág. 392- Anexo 4 -“la distancia calculada de la forma DP2 (r ) − DP2 ( k ) , o bien DP2 (r ) − DP2 ( k ) , es invariante respecto a la base de referencia siempre que ésta sea la misma para los dos países58 (…) y, para cada componente, tome el valor máximo , o uno superior a éste, o el valor mínimo, o uno inferior a éste, de la serie de valores de dicho componente59”. En consecuencia, y dado que la base de referencia es la misma para las dos economías, y dado que las diferencias ( xri − x•i ) y ( x ki − x•i ) son todas positivas o todas negativas, la expresión: n DP2 ( r ) − DP2 ( k ) = ∑ xri − x•i − x ki − x•i i =1 σi (1 − Ri2•i −1,...,1 ) se simplifica de la siguiente forma: n DP2 ( r ) − DP2 ( k ) = ∑ i =1 58 59 xri − x•i − x ki − x•i σi n (1 − Ri2•i −1,...,1 ) = ∑ i =1 ( xri − x ki ) (1 − Ri2•i −1,...,1 ) . σi En nuestro ámbito de trabajo debemos decir “para las dos economías”. Zarzosa expresa formalmente este requisito como: X •i ≤ X ri X •i ≥ X ri ∀i; o bien ∀i . X •i ≤ X ki X •i ≥ X ki -Pág. 393- Anexo 5 ANEXO 5: INTEGRABILIDAD, COINTEGRACIÓN Y MODELOS DE CORRECCIÓN DE ERROR. 5.1. INTRODUCCIÓN. En este anexo se hace una mención superficial de algunos de los conceptos más importantes en lo que se refiere al análisis de cointegración60. No se pretende una presentación sistemática y con un contenido amplio, sino que buscamos enlazar y explicar someramente las bases teóricas que fundamentan algunas de las aplicaciones del Capítulo VIII. El interés por la teoría de la cointegración enlaza con la distinción que se realiza en el campo del análisis económico entre la información sobre el largo plazo y los de corto plazo. 5.2. ANÁLISIS DE LAS PROPIEDADES DE LOS DATOS. Está demostrado que si alguna de las variables que intervienen en la especificación de una ecuación posee un proceso generador de datos no estacionario, no es aplicable la teoría asintótica “estándar”. En la práctica econométrica tradicional, se solucionó inicialmente el problema a través de la transformación de los datos, de manera que así se evitaban situaciones del tipo de la “regresión espúrea”61. En este contexto, los contrastes de raíces unitarias son un elemento clave a la hora de determinar el orden de integrabilidad de las series económicas. El surgimiento de la teoría de la cointegración consigue aglutinar, mediante la utilización de modelos dinámicos, los conceptos de estacionariedad, orden de integración y relaciones de equilibrio propugnadas por la teoría económica. Las aportaciones de Dickey (1976), Fuller (1976) y Dickey y Fuller (1979, 1981) supusieron la base inicial a partir de la cual se han desarrollado los numerosos estudios que existen sobre contrastes del orden de integrabilidad de las series temporales. Está comprobado que los contrastes de raíces unitarias tienen escasa potencia (aún cuando se tengan observaciones en un número próximo a 100); en consecuencia, hay que ser muy cuidadosos a la hora de trabajar con este tipo de contrastes, ya que el reducido número de observaciones de las que disponemos brinda el escenario ideal para que la probabilidad de encontrar series estacionarias sea muy pequeña. En este trabajo, vamos a utilizar contrastes distintos62 con el objetivo de corroborar de manera más fehaciente el diagnóstico final en lo referente al orden de 60 Como muchas de las cuestiones relacionadas con la cointegración están incorporadas a los manuales básicos de la literatura econométrica, sólo exponemos una síntesis breve. Una referencia básica puede ser Suriñach et al. (1995). 61 Este fenómeno fue descubierto por Granger y Newbold (1974) mediante experimentos de Montecarlo. Phillips (1986) lo explicó teóricamente. 62 Como advierte Gregory (1994), del conjunto de contrastes existentes hasta la fecha, ninguno domina a los demás de manera absoluta en lo referente al tamaño y la potencia. -Pág. 395- Anexos integrabilidad (d) de cada una de las variables endógenas y exógenas que aparecen en el modelo. Dentro de este panorama, nos decantamos por la utilización de algunos de los contrastes más habituales en la actualidad63; en concreto, Dickey y Fuller aumentado64 (DFA), Philipps y Perron65 (PP) y Rappoport y Reichlin66 (RR). Supongamos que se desea contrastar la hipótesis de que una variable económica anual x t es integrada de orden uno, I(1); de esta forma, un posible proceso generador de datos (PGD) viene dado por: x t = ρ x t −1 + ε t ; t = 1,2,..., T ; ε t ~ i. i. d . N (0, σ 2 ) . En este contexto, la hipótesis nula es ρ = 1 (existencia de una raíz unitaria), o lo que es lo mismo, que x es I(1). La hipótesis alternativa es que la variable x es integrada de orden cero (I(0) o estacionaria). En la ecuación autorregresiva planteada, la estimación de ρ por mínimos cuadrados ordinarios puede ser sesgada, y además, no se conoce la distribución del estadístico t de Student cuando la variable es no estacionaria. Por todo ésto, Dickey y Fuller (1979, 1981) propusieron el contraste DF. La realización de este contraste pasa por la estimación mediante mínimos cuadrados ordinarios de distintas regresiones auxiliares (RA) que tienen en cuenta el posible PGD de la variable en estudio. La reparametrización que dichos autores realizan para plantear su contraste es α = ρ − 1, de manera que ahora H 0 : {I (1)} ≡ {α = 0} frente a H1 : {I (0)} ≡ {α < 0} . En la práctica, se consideran de forma separada las regresiones auxiliares siguientes: a) ∆x t = α 1 x t −1 + e t ; donde ∆ = 1 − L , siendo L el operador retardo. b) ∆x t = α 0 + α x 1 t −1 +et c) ∆x t = α 0 + α 1 x t −1 + α 3 t + e t ; donde t es una tendencia lineal determinística. En definitiva, se contrasta que el PGD es AR(1) mediante una regresión auxiliar que puede incorporar un término constante y una tendencia lineal determinística. Los ratios ”t” asociados a cada α 1 no siguen la habitual distribución t-Student; por esta razón para contrastar H 0 : {I (1)} frente a H1: {I (0)} se utilizan tablas obtenidas mediante simulaciones (no derivadas analíticamente)67. 63 Es necesario destacar que el rango de contrastes que se pueden aplicar a los estudios empíricos no se limita, en absoluto, a los que vamos a usar aquí (ver por ejemplo, Stock y Watson (1988), Sargan y Bhargava (1983), Phillips y Ouliaris (1990)). 64 Dickey y Fuller (1981). 65 Phillips y Perron (1988). 66 Rappoport y Reichlin (1989). 67 La distribución asintótica y para distintos tamaños muestrales de cada uno de los ratios “t” correspondientes a los coeficientes α1 de cada una de las regresiones auxiliares fueron presentadas por Fuller (1976). Posteriormente, en MacKinnon (1991) se posibilita el cálculo de los valores críticos del contraste DFA para cualquier tamaño muestral y cualquier especificación de la regresión auxiliar del contraste DFA. -Pág. 396- Anexo 5 El contraste DFA se basa en las ecuaciones de regresión siguientes: p ∆ x t = α 0 +α 1∆ d d -1 x t -1 + ∑ γ j ∆ d x t - j + ε t j=1 p ∆ x t = α +α ∆ d * 0 * 1 d -1 * x t -1 + α ∆ t + ∑ γ j ∆ d x t - j + ε *t * 2 d -1 j=1 donde se supone que los errores son perturbaciones Gaussianas tipo “ruido blanco”. Los estadísticos t de α1 o α1* son los valores usados para contrastar la hipótesis de que este coeficiente es igual a cero o significativamente distinto de él. El contraste de Phillips y Perron (PP) es una correción no paramétrica del contraste Dickey-Fuller (DF) que atenúa los efectos de la autocorrelación del término de perturbación de la regresión auxiliar (ver Philipps y Perron (1988)). La versión más general del test DFA para tener en cuenta la posibilidad de existencia de tendencias determinísticas segmentadas en la media (Rappoport y Reichlin, 1989). En este caso la media se puede escribir como c1 + b1 t para t ≤t 1* * * c2 + b2 t para t 1 ≤ t ≤t 2 µt= ... * cn + bn t para t ≥t n-1 donde ti* son los instantes en los que se produce ruptura en la tendencia. El test DFA toma entonces la forma ∆ d x t = α 1 ∆ d -1 x t -1 - α 1 ∆ d -1 µ t -1 + a ** (L) ∆ d x t -1 + a * (L) ∆ d µ t + ε t donde los polinomios de retardos a*(L) y a**(L) están relacionados (imponiendo la restricción de normalización a*(0)=1) a través de la ecuación a*(L)=1+a**(L)L. La regresión (11) se hace operativa substituyendo µ t por la expresión n n µ t = c1 + b1 t + ∑ ( ci - ci-1 ) Di-1,t + ∑ (bi - bi-1 ) Di-1,t t i=2 i=2 donde la variable ficticia Di,t toma valor unitario a partir del instante ti*. Una vez determinado el orden de integrabilidad de las series, la diferenciación de las mismas para convertirlas en estacionarias, hace que se pierda información relativa a las relaciones a largo plazo entre las variables, eliminando la posibilidad de estimar las relaciones existentes entre los niveles de las variables. Por consiguiente, un objetivo a conseguir es el mantenimiento de dicha información de largo plazo en la modelización que se realiza. De esta -Pág. 397- Anexos forma, el primer paso es el análisis de las relaciones de equilibrio a largo plazo que se dan entre las variables para, posteriormente, plantear un modelo que sea consistente con las relaciones a largo plazo. A dichas relaciones se les conoce como relaciones de cointegración y al tipo de modelización que se suele utilizar en la práctica econométrica para mantener la información a largo plazo se le denomina de corrección de error (MCE). 5.3. VARIABLES COINTEGRADAS Y MODELOS DE CORRECIÓN DE ERROR. La búsqueda de relaciones de cointegración pretende encontrar68 relaciones estacionarias entre un conjunto de variables no estacionarias. En otras palabras, se trata de hallar una relación lineal para un período de tiempo largo (es decir, un equilibrio) entre un conjunto de variables integradas. Sin embargo, el hecho de que dos o más series verifiquen un equilibrio en el largo plazo (que estén cointegradas), no implica que en el corto plazo no puedan separarse de manera importante de dicho equilibrio. Harvey (1993, pág. 257) expone de manera clara el concepto de cointegración: “si dos series y1t e y2t, son ambas I(d), será normal que cualquier combinación lineal sea también I(d). De cualquier modo, es posible que exista una combinación lineal de las dos series para las que el orden de integración sea más pequeño que d. En este caso se dice que las series son cointegradas. Más generalmente, tenemos la siguiente definición. Los componentes del vector yt se dice que están cointegrados de orden d, b si (a) todos los componentes de yt son I(d); y (b) existe un vector no nulo, α, tal que α’ yt es I(d-b) con b>0. Esto se puede expresar como yt ∼CI(d,b). El vector α es conocido como el vector de cointegración.” Las cuestiones que se plantean son cómo estimar el vector de cointegración y cómo contrastar si dos o más variables están cointegradas. La primera cuestión se resuelve mediante la estimación por mínimos cuadrados ordinarios de la relación de equilibrio a largo plazo entre las variables en niveles, por ejemplo: y1, t = β 68 0 +β 1 y 2 , t + ut Normalmente bajo las indicaciones de la teoría económica. -Pág. 398- Anexo 5 Sin embargo, esta manera de proceder puede provocar sesgo y pérdida de eficiencia para muestras pequeñas. En la literatura aparecen autores que proponen enfoques para obtener estimaciones mejores69. En lo que se refiere al contraste de cointegración, se puede contrastar la hipótesis nula de no cointegración contra la alternativa de cointegración, aplicando contrastes de raíces unitarias a los residuos de la regresión de largo plazo70. Nosotros utilizaremos el contraste de Engle y Granger aumentado (1987). Este contraste parte de la estimación de la relación de cointegración y, posteriormente, utiliza los errores estimados en esta regresión para realizar el contraste de DFA. Los valores críticos para este contraste dependen del número de variables I(1) que aparecen como explicativas en la relación de equilibrio. Una vez que se tiene un conjunto de variables cointegradas, el interés se centra en combinar la información de largo y corto plazo. Un modelo de corrección del error es un modelo dinámico71 que mantiene la información sobre el largo plazo a la vez que incorpora la desviación respecto a la situación de equilibrio del período anterior. Engle y Granger (1987, pág. 254) dan la siguiente definición: “Un vector de series temporales x t tiene una representación de corrección de error si puede ser expresada como: A( B)(1 − B) x t = −γ z t −1 + ut donde ut es una perturbación multivariante estacionaria, con A(0) = I , A(1) tiene todos los elementos finitos, zt = α / x t , y γ ≠ 0 ”. En la anterior definición, B denota el operador de retardos, y A( B) es un polinomio de retardos de orden finito del tipo A( B) = I N + Γ1 B + Γ2 B 2 +...+ Γ p B p . Un ejemplo de modelo representado en forma de corrección de error en el contexto del ejemplo que estamos poniendo es el siguiente: ∆ y1,t =γ p 0 +∑ i =1 γ m 1i ∆ y1,t −1 + ∑ λ j =1 1j ∆ y 2 ,t − α ( y1,t −1 − β 0 −β donde ∆ es el operador de primeras diferencias y ut ∼ i.i. d . (0, σ 69 1 2 − y 2 , t −1 ) + u t ). Phillips y Loretan (1991) realizan una revisión de los métodos de estimación de los equilibrios económicos en el largo plazo. 70 Intuitivamente, la idea básica es que si dos variables están cointegradas, el término de error que se deriva de su relación de equilibrio a largo plazo debe ser I(0). 71 Un modelo en el que la función de regresión depende de valores retardados de una o más variables dependientes. -Pág. 399- Anexos En este modelo, se supone que las variables y1,t e y 2,t son integradas de orden uno y están cointegradas, de manera que ( y1,t −1 − β 0 − β 1 − y 2 ,t −1 ) , que se conoce como error de cointegración, es I(0) y mide la distancia que separa a la relación entre y1,t e y 2,t del equilibrio a largo plazo. En consecuencia, α se puede interpretar como la proporción del desequilibrio que se recoge en la variación de y1,t en un período o como la velocidad de ajuste de ∆ y1,t en relación a desviaciones del equilibrio a largo plazo. Este modelo también puede incorporar variables (del tipo ∆ x jt ) que deben ser no estocásticas o I(0). En el contexto de los MCE, el primer asunto que nos podemos plantear es la posibilidad de utilizar la parametrización que estos modelos presentan para el caso de variables cointegradas. En este sentido, el teorema de representación de Granger72 garantiza la existencia de un modelo de corrección de error para dos o más variables que están cointegradas. A continuación exponemos de manera muy resumida este teorema: Si el vector de variables económicas x t , de dimensión N × 1 y que se puede representar como (1 − B) x t = C ( B)ε t es cointegrado con d=1, b=1 y con rango de cointegración r , existe una representación de corrección de error en función del vector zt = α / xt que tiene dimensión r × 1 y está constituido por variables aleatorias estacionarias: A ∗ ( B)(1 − B) x t = −γ z t −1 + d ( B)ε t con A ∗ (0) = I N y A ∗ ( B) = I N + Γ1 B + Γ2 B 2 +...+ Γ p B p . En lo que respecta a la estimación del MCE, como β 0 y β 1 son desconocidos hay que estimarlos, y existen varios procedimientos alternativos. El más simple es el método de dos etapas de Engle y Granger. En la primera etapa los parámetros del vector de cointegración son estimados a partir de la regresión estática de las variables en niveles (regresión de cointegración). La segunda etapa utiliza en la forma de corrección de error los parámetros estimados en la primera. La estimación de la primera etapa mediante mínimos cuadrados ordinarios lleva a estimaciones superconsistentes73. Sin embargo, la superconsistencia no implica que se verifiquen las propiedades deseables para muestras finitas74, pudiendo aparecer en la práctica sesgo y pérdida de eficiencia. En consecuencia, una de las razones principales para utilizar 72 Ver Engle y Granger (1987, págs. 255 y 256). Es decir, que el estimador mínimo cuadrático de un conjunto de variables cointegradas de orden CI(1,1) converge más rápidamente que en el caso de estimadores mínimo cuadráticos obtenidos para una regresión que cumple los supuestos clásicos (Ver Banerjee, Dolado, Hendry y Smith (1986) y Stock (1987)). 74 Ver Banerjee, Dolado, Hendry y Smith (1986) y Stock (1987). 73 -Pág. 400- Anexo 5 estrategias de estimación diferentes para las regresiones estáticas es que el sesgo que puede surgir en las estimaciones mediante mínimos cuadrados ordinarios es grande. 5.4. EL ESTIMADOR PHILLIPS-HANSEN. MODIFICADO COMPLETAMENTE DE Vamos a considerar el estimador de Phillips y Hansen (1990), que es un estimador asintóticamente eficiente cuando tenemos un conjunto de variables I(1) y se da una única relación de cointegración entre ellas75. Este estimador se lleva a cabo en dos etapas, según la pauta establecida por Engle y Granger (1987). Así, en la primera etapa estima mediante el estimador de mínimos cuadrados en dos etapas modificado completamente la ecuación de cointegración para, a continuación, tomar los residuos estimados en esta etapa y utilizarlos en el MCE. A su vez, el cálculo del estimador de Phillips y Hansen (1990) para los parámetros de la relación a largo plazo se lleva a cabo en dos pasos. El primero corrige a la variable dependiente (en la ecuación a largo plazo) de la interrelación existente entre los residuos mínimo cuadráticos de la regresión de cointegración y las variables que, en primeras diferencias, explican las desviaciones en el MCE. El segundo calcula el estimador y su matriz de covarianzas. Para ilustrar ambos pasos, vamos a partir del modelo: yt = β 0 +β / 1 xt + vt , t = 1,2,..., T donde x t es un vector k × 1 de regresores I(1), de manera que la primera diferencia: ∆ xt = µ + ut , t = 2,3,..., T es un proceso estacionario en el que µ es un vector k × 1 de parámetros de deriva y ut es un vector de variables estacionarias (I(0)). Se supone, además, que los regresores no pueden estar cointegrados entre ellos. También se supone que ζ t = (v t , ut/ ) / tiene media cero y una matriz de covarianzas Σ , que es definida positiva finita, y que además es estacionario. 75 Esta es la razón que hace que nos decantemos por este método. Vamos a tomar como referencia fundamental para explicar este método a Hansen (1992), ya que las estimaciones que realizamos en el Capítulo VIII son las que expone este autor. En este apartado sólo pretendemos describir de la manera más clara posible los estimadores con los que hemos comparado las estimaciones mínimo cuadráticas de las ecuaciones con mecanismos de corrección de error del modelo econométrico para Extremadura. -Pág. 401- Anexos La estimación del modelo en niveles permite obtener el vector de ∧ residuos mínimo cuadráticos v t , de manera que se puede obtener: ∧ ζ t v∧ = ∧ t , ut ∧ ∧ t = 2,3,..., T ∧ siendo u t = ∆ x t − µ , t = 2,3,..., T y µ = (T − 1) −1 T ∑∆ x t =2 t . Se puede conseguir un estimador consistente para la varianza de largo plazo de ζ ∧ ζ t ∧ t ( Ω ) mediante un estimador tipo kernel con base en los residuos . La estimación de la matriz de covarianzas tiene la forma siguiente: ∧ ∧ Ω Ω 11 12 ∧ ∧ ∧ ∧ / 1 × 1 1 × k Ω = Σ+ Λ+ Λ = ∧ ∧ . Ω Ω 21 22 k × 1 k × k En consecuencia, el problema para calcular el estimador de mínimos cuadrados ordinarios modificado completamente es la estimación de las matrices Σ y Γ . La descomposición Ω = Σ + Λ + Λ/ es importante a la hora de entender la estructura de Ω ; así si ζ t está incorrelacionado serialmente y es estacionario, la matriz Ω es una matriz de covarianza con las características habituales. Sin embargo, en muchas aplicaciones los residuos de cointegración ∧ v t están correlacionados, de forma que la estimación kernel incorporará un importante sesgo a no ser que se utilice un parámetro de amplitud elevada que consiga incrementar la varianza del estimador. La conclusión es que un estimador prefiltrado es preferible para muestras de tamaño pequeño. Hansen (1992, pág. 323) propone la utilización de un modelo vectorial autorregresivo ∧ (VAR) de primer orden del tipo ζ ∧ t ∧ =φ ζ ∧ + e t ; de manera que una vez que t −1 ∧ se dispone de los residuos e t filtrados, se puede aplicar un estimador de la clase de los estimadores kernel de la matriz de densidad espectral76 que proporciona estimaciones semidefinidas positivas del tipo: 76 Estos estimadores son los que considera Andrews (1991), y se corresponden con la clase de estimadores estudiados por Parzen (1957). -Pág. 402- Anexo 5 1 T ∧ ∧/ Λ e = ∑ w( j , m) ∑ e t − j e t , T t = j +1 j =0 T ∧ para j ≥ 0, y donde w( j , m) es la función de ponderación, siendo m el parámetro de amplitud. ∧ Una vez conocido Λ e , se pueden estimar los parámetros de la matriz de ∧ la matriz Γ : ∧ ∧ ∧ ∧/ ∧ ∧ ∧ Γ = ( I − φ ) −1 Γ e ( I − φ ) −1 − ( I − φ ) −1 φ Σ ∧ 1 T ∧ ∧/ donde Σ = ∑ ζ t − j ζ t . T i =1 La dificultad se encuentra en la elección del núcleo (puede ser cualquiera que dé una estimación semidefinida positiva) y del parámetro de amplitud. En lo que se refiere a la elección del núcleo, Hansen (1992) recoge la recomendación de Andrews (1991), el núcleo espectral cuadrático (QS), que se define como: w( x ) = 25 sen(6π x / 5) − cos(6π x / 5) , ∀x ∈ R . 2 2 12π x 6π x / 5 Otras opciones consideradas por Andrews (1991) pueden ser los núcleos de Bartlett: w( j , m) = 1 − s , 0 ≤ j ≤ m ; y de m m 2 3 1 − 6( j / m) + 6( j / m) , 0 ≤ j ≤ 2 , Parzen: w( j , m) = . 2(1 − j / m) 3 , m < j ≤ m 2 ∧ Ahora hay que obtener un estimador para la amplitud óptima (m) ; Andrews (1991) recomienda adoptar un método del tipo predeterminado (“plug-in”) “caracterizado por el uso de una fórmula asintótica para un parámetro de amplitud óptima (...) en la cual las estimaciones ‘predeterminadas’ se sitúan en lugar de varios parámetros desconocidos en la fórmula” (pág. 832). Las elecciones predeterminadas de Andrews (1991, pág. 830) son: -Pág. 403- Anexos ∧ ∧ , (α (1)T ) 1/ 3 QS: m = 11147 ∧ ∧ Bartlett: m = 2,6614(α (2)T ) 1/5 ∧ ∧ Parzen: m = 1,3221(α (2)T ) 1/5 En las expresiones anteriores, Andrews (1991) propone la utilización de ∧ ∧ estimaciones paramétricas para α (1) y α (2) : ∧2 ∧ 2 ∑ ∧ a =1 α (1) = ∧2 ∧2 4 ρa σ a p ∧ ∧ (1 − ρ a ) (1 + ρ a ) 6 ∧2 p σa a =1 (1 − ρ a ) 4 ∑ p 4 ρa σ a a =1 (1 − ρ a ) 8 ∑ 2 ∧ ; y α ( 2) = ∧2 p σa a =1 (1 − ρ a ) 4 ∑ ∧ ∧ . ∧ ∧2 ∧ donde ρ a es la estimación autorregresiva para el elemento a-ésimo y σ a la estimación de la varianza para el elemento a-ésimo. Tales estimaciones ∧ provienen de un modelo autorregresivo de orden uno para cada elemento e at ∧ ( a = 1, ..., k + 1 ) de e t . Según Andrews (1991, pág. 834)77: “La aproximación mediante el empleo de k + 1 modelos paramétricos univariantes tiene las ventajas de la simplicidad y parsimonia sobre el uso de un único modelo univariante”. Ahora, a partir de: ∆∧ 11 ∆ = Σ + Γ = ∧ ∆ 21 ∧ ∧ ∧ ∧ ∆ 12 ∧ , ∆ 22 se construyen los elementos ∧ ∧ ∧ ∧ ∧ Z = ∆ 21 − ∆ 22 Ω 22 −1 Ω 21 , ∧∗ ∧ ∧ ∧ y t = y t − Ω 12 Ω 22 −1 u t ; y 77 Y adaptádolo a nuestra notación. -Pág. 404- Anexo 5 Ο 1 × k D = ( k + 1) × k I k k × k de manera que el estimador de mínimos cuadrados ordinarios modificado completamente viene dado por: ∧∗ ∧∗ ∧ β = (W /W ) −1 (W / y − TD Z ) , ∧∗ ∧∗ ∧∗ ∧∗ siendo y = ( y 1 , y 2 ,..., y T ) / , W = (τ ∧∗ T , X) , y τ T , ,...,1) / y = (11 ∧ Var ( β ) = w 11.2 (W / W ) −1 ∧ ∧ ∧ ∧ ∧ donde w11.2 = Ω 11 − Ω 12 Ω 22 −1 Ω 21 Según Banerjee et al. (1993, pág. 240), la modificación total que lleva ∧∗ β logra dos objetivos: “Primero, teniendo en cuenta cualquier correlación ∧ serial en los residuos, el término de corrección del sesgo D Z mitiga los efectos del sesgo de segundo orden78. Segundo, la corrección para la ∧∗ simultaneidad de largo plazo en el sistema realizada utilizando y (en lugar ∧ de y ) permite el uso de los procedimientos para inferencia convencionales (asintóticos).” 78 Se refiere al sesgo debido a la endogeneidad de los regresores. -Pág. 405- Anexo 6 ANEXO 6. CONTRASTES DE CAMBIO ESTRUCTURAL. Nuestro punto de partida es la existencia (para cada una de las ecuaciones) de cambio estructural en la fracción δ0=t0/T de la muestra, siendo T el tamaño muestral y t0 la observación desconocida en la que se produce el punto de ruptura, de forma que δ0∈(0,1). En consecuencia, el punto de ruptura viene dado por t0= δ0 T. Nuestro interés se centra en contrastar el cambio estructural para un vector de parámetros β de dimensión h×1 que toma el valor β1 para t=1,..., δ0 T y el valor β2 para t=δ0 T+1,...,T. A efectos de contraste de estabilidad paramétrica, la hipótesis nula es H0: {β1=β2 ∀ t=1,...,T}, y la alternativa H1: {β1(δ0) para t=1,..., δ0 T y β2(δ0) para t=δ0 T+1,...,T}. Lo determinante en este caso es el desconocimiento a priori de la localización exacta del posible punto de corte, de manera que el parámetro δ0 no aparece bajo la hipótesis nula (sólo aparece bajo la hipótesis alternativa). Ante esta situación, los contrastes habituales de cambio estructural (contraste de Wald, del ratio de verosimilitud (LR) y del multiplicador de Lagrange (LM)), que se construirían tomando a δ0 como un parámetro, no poseen sus distribuciones asintóticas estándar. La forma de enfrentarse a esta problemática pasa por la aplicación de contrastes de cambio estructural basados en el cálculo de estadísticos de Wald, LR o LM secuenciales, FT(δ), los cuales contrastan la hipótesis nula de estabilidad frente a la alternativa de existencia de algún punto de ruptura en la observación t0 (más concretamente, en la fracción δ0=t0/T de la muestra). La localización exacta de los posibles puntos de corte no es conocida a priori, de manera que se calculan los estadísticos FT(t/T) para todos los puntos de la muestra y a continuación se construye algún funcional de los mismos. es79: Así, en la forma de Wald, el contraste para cambio estructural en t/T FT (t / T ) = ( SCR1,T − SCR1,t + SCRt +1,T (SCR 1,r + SCRt +1,T ) ) (T − 2 k ) En la expresión anterior, k es el número de parámetros a estimar en la ecuación del tipo VII.4 (del Capítulo VII), SCR1,T es la suma de cuadrados de los errores obtenidos en la estimación de la ecuación del tipo VII.4 para las 79 Tal como señala Andrews (1993), no se pueden utilizar todos los puntos t/TЄ[0,1], puesto que en ese caso los contrastes divergerán hacia infinito, por lo que propone utilizar la región =[δ1,δ2]=[0.15,0.85] (un subconjunto compacto del intervalo (0,1)). -Pág. 407- Anexos observaciones 1,...,T , etc. A continuación, y como revisión breve, describimos los tres funcionales considerados80 en nuestro trabajo: a) El estadístico de razón de verosimilitud propuesto por Quandt (1960): SupFT = supr FT (δ ) δ ∈ [ δ 1 ,δ 2 ] Bajo la hipótesis nula de no existencia de cambio estructural, Andrews (1993) y Andrews y Ploberger (1994) muestran que: ( ) SupFT → d SupF δ 0 = sup τ ∈ [ δ 1 ,δ 2 ] F (τ ) donde → d denota “converge en distribución”, W(τ ) representa a un vector de movimientos brownianos de dimensión h×1 de manera que (W (τ ) − τ W (τ )) (W (τ ) − τ W (1)) , δ / F (τ ) = Además, δ 0 = τ (1 − τ ) 1 1+ λ , siendo λ = 1 = t1 t y δ2 = 2 . T T ( ). δ (1 − δ ) δ 2 1− δ 1 1 2 b) El estadístico promedio propuesto por Andrews y Ploberger (1994) y Hansen (1992): MediaF = ∫ δ2 δ1 F t (δ ) dδ que tiene como distribución asintótica nula: MediaFT → d MediaF (δ0 ) = 1 δ2 −δ1 80 ∫ δ2 δ1 F (τ ) dτ Las distribuciones asintóticas de los mismos se discuten en Andrews (1993) y Andrews y Ploberger (1994), siendo en todos los casos no estándar (funcionales de movimientos Brownianos multidimensionales). -Pág. 408- Anexo 6 c) El estadístico promedio exponencial propuesto por Andrews y Ploberger (1994): δ2 1 ExpF = ln∫ exp Ft (δ ) dδ δ1 2 donde: 1 ExpFT → d ExpF δ 0 = ln δ 2 − δ 1 ( ) ∫ δ2 δ1 1 exp Ft (τ ) dτ 2 Como ya hemos señalado, la principal dificultad para trabajar con estos estadísticos reside en la naturaleza no estándar de sus distribuciones. Sus distribuciones asintóticas dependen del número de coeficientes de la ecuación (h) y del rango muestral sobre el que se contrasta el cambio estructural (parámetro λ ). Todos los contrastes considerados poseen la misma hipótesis nula, pero difieren en la elección de su hipótesis alternativa, de manera que tendrán más potencia contra unas alternativas que contra otras. Hansen (1992) señala que si nuestro interés se centra en descubrir la presencia de un cambio de régimen rápido, el contraste más adecuado es el SupF (potencia frente a cambios estructurales en fecha desconocida), mientras que si el cambio del modelo es gradual, el MediaF es el adecuado (potencia frente a cambios continuos o inestabilidad paramétrica). Según Andrew y Ploberger (1994), el ExpF tiene como ventaja principal haber sido generado para verificar ciertas propiedades de optimalidad. Fair (1994), sugiere la utilización del ExpF para posteriormente centrarse en el SupF. Por todo lo comentado, parece ser que la opción más razonable es el cálculo de los tres estadísticos, puesto que las orientaciones diferentes que adoptan pueden aportar evidencias distintas acerca del rechazo de la hipótesis de estabilidad en las ecuaciones del largo o del corto plazo. -Pág. 409- Anexo 7 ANEXO 7. ESTIMACIÓN DEL MODELO ECONOMÉTRICO. 7.1. AGRICULTURA 7.1.a. Estimación de la relación de cointegración. 7.1.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la regresión estimada. Cuadro A7.1. Agricultura, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVAEX Sample: 1971 1993 Included observations: 23 Variable C LVAES Coefficient 8.333572 0.208061 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 4.701270 0.326200 0.019005 -0.027709 0.139727 0.409995 13.67610 1.275684 t-Statistic 1.772621 0.637833 Prob. 0.0908 0.5305 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 11.33214 0.137830 -3.853190 -3.754452 0.406831 0.530477 7.1.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la gráfica siguiente: Gráfico A7.1. Estadísticos Wald Secuenciales en Agricultura. 16 14 12 10 8 6 4 2 74 76 78 80 82 84 WALD_A -Pág. 411- 86 88 90 Anexos En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del Cuadro A7.2.: Cuadro A7.2. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 14,680(**) 8,480(***) 5,767(***) Valor crítico al 5% Valor crítico al 1% Valor crítico al 1% 11,280 3,670 2,569 Nota: (**) denota el rechazo de la hipótesis nula al 5% y (***) al 1%. 7.1.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de los resultados del Cuadro A7.2. y de la representación gráfica de la estimación del cuadro A7.1., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.3.). Cuadro A7.3. Agricultura: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVAEX Sample: 1971 1993 Included observations: 23 Variable C LVAES D7175 Coefficient -2.431953 0.951550 0.231711 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 5.755412 0.398440 0.086278 0.279013 0.206915 0.122745 0.301328 17.21750 1.457128 t-Statistic -0.422551 2.388190 2.685625 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.6771 0.0269 0.0142 11.33214 0.137830 -4.074181 -3.926073 3.869884 0.037955 7.1.a.4. Contraste de cointegración. El contraste del Cuadro A7.4. nos permite aceptar la relación estimada en el Cuadro A7.3. como la relación de equilibrio a largo plazo (cointegración). Es necesario aclarar que en todos los contrastes de cointegración que aparecen en este Anexo 7, se presentan las salidas originales del programa “Eviews”, sin embargo, los valores críticos se han obtenido de la Tabla 20.2 de Davidson, R. y McKinnon, J. G. (1993): “Estimation and Inference in Econometrics”, Oxford University Press. -Pág. 412- Anexo 7 Cuadro A7.4. Agricultura: contraste de cointegración. ADF Test Statistic -3.191008 1% Critical Value* 5% Critical Value 10% Critical Value -3.7667 -3.0038 -2.6417 *MacKinnon critical values for rejection of hypothesis of a unit root. Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_CA93) Sample(adjusted): 1972 1993 Included observations: 22 after adjusting endpoints Variable Coefficient Std. Error t-Statistic Prob. EQ_CA93(-1) C -0.782542 -0.004042 0.245234 0.025753 -3.191008 -0.156952 0.0046 0.8769 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.337365 0.304233 0.120127 0.288609 16.45434 1.768902 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -0.012661 0.144015 -4.151908 -4.052723 10.18253 0.004589 7.1.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el gráfico A7.2. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.5. se comprueba la inexistencia de cambio estructural. Gráfico A7.2. Estadísticos Wald Secuenciales en Agricultura con ficticias. 8 6 4 2 0 74 76 78 80 82 84 86 88 90 WALD_A_D Cuadro A7.5. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 7,784(NS) 2,041(NS) 1,797(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 11,280 4,414 3,195 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 413- Anexos 7.1.b. Estimación del modelo de correción de error. 7.1.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.6.: Relación a corto plazo. LS // Dependent Variable is DLVAEX Sample: 1972 1993 Included observations: 22 Variable C DLVAES DLVOLAG1 RES_ALP1 DD7175 Coefficient -0.001534 0.740080 0.219482 -0.760808 0.140750 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.026968 0.512868 0.123285 0.261790 0.121897 0.576606 0.476984 0.117824 0.236003 18.66785 2.093155 t-Statistic -0.056889 1.443022 1.780274 -2.906177 1.154661 Prob. 0.9553 0.1672 0.0929 0.0098 0.2642 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -0.012490 0.162921 -4.080408 -3.832444 5.787931 0.003965 7.1.b.2. Estimación de la relación a corto plazo con intervenciones. En el cuadro siguiente se muestra la estimación del modelo de corrección de error con el que se logra el no rechazo de la hipótesis de estabilidad. Cuadro A7.7. Relación a corto plazo con intervenciones. LS // Dependent Variable is DLVAEX Sample: 1972 1993 Included observations: 22 Variable C DLVAES DLVOLAG1 RES_ALP1 DD7175 D7375 F83 D9293 Coefficient 0.053763 1.005560 0.171363 -0.923948 0.214006 -0.130044 -0.400304 -0.197317 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.012335 0.204873 0.051346 0.109643 0.047569 0.029647 0.047923 0.039016 0.948472 0.922708 0.045294 0.028722 41.83582 2.214794 t-Statistic 4.358487 4.908217 3.337445 -8.426906 4.498844 -4.386495 -8.353035 -5.057343 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -Pág. 414- Prob. 0.0007 0.0002 0.0049 0.0000 0.0005 0.0006 0.0000 0.0002 -0.012490 0.162921 -5.913861 -5.517118 36.81391 0.000000 Anexo 7 7.1.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. En el Gráfico A7.3. se representan los estadísticos Wald secuenciales para el modelo de corrección de error con variables ficticias. Gráfico A7.3. Estadísticos Wald Secuenciales en Agricultura con ficticias. 8000 6000 4000 2000 0 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 WALD_A_CP En el cuadro siguiente se comprueba el no rechazo de la hipótesis nula de estabilidad para el modelo con ficticias. Cuadro A7.8. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 7,279(NS) 3,918(NS) 2,350(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 15,936 7,292 5,171 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 415- Anexos 7.2. ENERGÍA. 7.2.a. Estimación de la relación de cointegración. 7.2.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la relación estimada. Cuadro A7.9. Energía, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVEEX Sample: 1970 1993 Included observations: 24 Variable C LVEES Coefficient -20.14173 2.142476 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 5.886812 0.411568 0.551924 0.531557 0.492899 5.344882 -16.03155 0.598043 t-Statistic -3.421500 5.205649 Prob. 0.0024 0.0000 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 10.49848 0.720160 -1.335248 -1.237077 27.09879 0.000032 7.2.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la siguiente gráfica: Gráfico A7.4. Estadísticos Wald Secuenciales en Energía. 50 40 30 20 10 0 74 76 78 80 82 84 WALD_E -Pág. 416- 86 88 90 Anexo 7 En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del cuadro siguiente: Cuadro A7.10. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 48,986(***) 12,712(***) 21,451(***) Valor crítico al 1% Valor crítico al 1% Valor crítico al 1% 9,681 3,670 2,569 Nota: (***) denota el rechazo de la hipótesis nula al 1%. 7.2.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de los resultados del Cuadro A7.10. y de la representación gráfica de la estimación del cuadro A7.9., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.11.). Cuadro A7.11. Energía: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVEEX Sample: 1970 1993 Included observations: 24 Variable C LVEES D7073 D8495 Coefficient -5.070817 1.050640 0.561538 1.080435 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 6.816566 0.478952 0.211695 0.179637 0.898019 0.882722 0.246626 1.216483 1.730551 2.153197 t-Statistic -0.743896 2.193624 2.652581 6.014553 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.4656 0.0402 0.0153 0.0000 10.49848 0.720160 -2.648756 -2.452414 58.70488 0.000000 7.2.a.4. Contraste de cointegración. El contraste del Cuadro A7.12. nos permite aceptar la relación estimada en el Cuadro A7.3. como la relación de equilibrio a largo plazo (cointegración). -Pág. 417- Anexos Cuadro A7.12. Energía: contraste de cointegración. ADF Test Statistic -4.747923 1% Critical Value* 5% Critical Value 10% Critical Value -3.7856 -3.0114 -2.6457 *MacKinnon critical values for rejection of hypothesis of a unit root. Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_CE93) Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable EQ_CE93(-1) C Coefficient -1.093537 -0.008108 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.230319 0.054453 t-Statistic -4.747923 -0.148896 0.542640 0.518569 0.249524 1.182985 0.405349 1.948236 Prob. 0.0001 0.8832 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -0.010627 0.359621 -2.686005 -2.586527 22.54278 0.000140 7.2.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el gráfico A7.2. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.5. se comprueba la inexistencia de cambio estructural. Gráfico A7.5. Estadísticos Wald Secuenciales en Energía con ficticias. 8 6 4 2 0 74 76 78 80 82 84 86 88 90 WALD_E_D Cuadro A7.13. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 7,090(NS) 2.326(NS) 1,767(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 11,280 4,414 3,195 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 418- Anexo 7 7.2.b. Estimación del modelo de correción de error. 7.2.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.14. Relación a corto plazo. LS // Dependent Variable is DLVEEX Sample: 1972 1993 Included observations: 22 Variable C DLVEES DLPRECIP DLENERG EQ_CER1 Coefficient -0.089562 2.555301 0.273434 1.059819 -0.933445 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.080805 1.609713 0.156125 0.224651 0.260584 0.667879 0.589732 0.253816 1.095186 1.784656 1.928604 t-Statistic -1.108363 1.587426 1.751382 4.717636 -3.582130 Prob. 0.2831 0.1308 0.0979 0.0002 0.0023 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.052827 0.396265 -2.545573 -2.297609 8.546525 0.000570 7.2.b.2. Estimación de la relación a corto plazo con intervenciones. Cuadro A7.15. Relación a corto plazo con intervenciones. LS // Dependent Variable is DLVEEX Sample: 1972 1993 Included observations: 22 Variable C DLVEES DLPRECIP DLENERG EQ_CER1 D7476 F77 F82 D8892 Coefficient -0.142283 2.574246 0.407476 1.089246 -0.771563 -0.307917 0.590313 0.526392 0.171358 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.054225 0.894879 0.070847 0.107543 0.128065 0.077869 0.135897 0.138014 0.063526 0.951926 0.922343 0.110427 0.158525 23.04510 2.384082 t-Statistic -2.623954 2.876640 5.751504 10.12845 -6.024778 -3.954310 4.343815 3.814050 2.697453 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -Pág. 419- Prob. 0.0210 0.0130 0.0001 0.0000 0.0000 0.0016 0.0008 0.0021 0.0183 0.052827 0.396265 -4.114704 -3.668369 32.17734 0.000000 Anexos 7.2.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. En el Gráfico A7.6. se representan los estadísticos Wald secuenciales para el modelo de corrección de error con variables ficticias. Gráfico A7.6. Estadísticos Wald Secuenciales en Energía con ficticias. 12 10 8 6 4 2 0 77 78 79 80 81 82 83 84 85 86 87 88 89 WALD_E_CP A la vista del cuadro siguiente se constata la inexistencia de cambio estructural en la relación estimada. Cuadro A7.16 Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 10,621(NS) 5,270(NS) 3,757(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 17,928 8,715 6,101 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 420- Anexo 7 7.3. CONSTRUCCIÓN. 7.3.a. Estimación de la relación de cointegración. 7.3.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la relación estimada. Cuadro A7.17. Construcción, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVBEX Sample: 1972 1993 Included observations: 22 Variable C LVABEX Coefficient -10.32152 1.607166 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 1.944483 0.147605 0.855653 0.848436 0.128345 0.329451 14.99841 0.770082 t-Statistic -5.308107 10.88829 Prob. 0.0000 0.0000 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 10.84848 0.329672 -4.019551 -3.920365 118.5549 0.000000 7.3.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la gráfica siguiente: Gráfico A7.7. Estadísticos Wald Secuenciales en Construcción. 50 40 30 20 10 0 76 78 80 82 84 WALD_B -Pág. 421- 86 88 90 Anexos En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del Cuadro: Cuadro A7.18. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 39,806(***) 15,788(***) 17,320(***) Valor crítico al 1% Valor crítico al 1% Valor crítico al 1% 9,681 3,670 2,569 Nota: (***) denota el rechazo de la hipótesis nula al 1%. 7.3.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de los resultados del Cuadro A7.18. y de la representación gráfica de la estimación recogida en el Cuadro A7.17., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.19.). Cuadro A7.19. Construcción: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVBEX Sample: 1972 1993 Included observations: 22 Variable C LVABEX D7079 D7079*LVABEX Coefficient -2.366949 1.011137 -19.07747 1.446728 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 2.050389 0.154428 7.494921 0.576053 0.941051 0.931226 0.086456 0.134544 24.84936 1.829589 t-Statistic -1.154390 6.547645 -2.545387 2.511448 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.2634 0.0000 0.0203 0.0218 10.84848 0.329672 -4.733273 -4.534902 95.78210 0.000000 7.3.a.4. Contraste de cointegración. El contraste del Cuadro A7.20. nos permite aceptar la relación estimada en el Cuadro A7.19. como la relación de equilibrio a largo plazo (cointegración). -Pág. 422- Anexo 7 Cuadro A7.20. Construcción: contraste de cointegración. ADF Test Statistic -4.046424 1% Critical Value* 5% Critical Value 10% Critical Value -3.7856 -3.0114 -2.6457 *MacKinnon critical values for rejection of hypothesis of a unit root. Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_LP_BR) Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable EQ_LP_BR(-1) C Coefficient -0.926957 -0.001722 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.229081 0.018210 0.462875 0.434606 0.083420 0.132218 23.41447 1.936693 t-Statistic -4.046424 -0.094558 Prob. 0.0007 0.9257 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.000177 0.110941 -4.877350 -4.777872 16.37355 0.000689 7.3.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el Gráfico A7.8. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.21. se contrasta la inexistencia de cambio estructural. Gráfico A7.8. Estadísticos Wald Secuenciales en Construcción con ficticias. 10 8 6 4 2 0 76 78 80 82 84 86 88 90 WALD_B_D Cuadro A7.21. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 7,948(NS) 1,745(NS) 1,618(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 11,280 4,414 3,195 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 423- Anexos 7.3.b. Estimación del modelo de correción de error. 7.3.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.22. Relación a corto plazo. LS // Dependent Variable is DLVBEX Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable C RES_BLP(-1) D(LVABEX) DLVBEX(-1) DLVABES Coefficient 0.024585 -0.621474 0.589490 0.051529 0.038243 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.035832 0.326485 0.625260 0.286175 1.063635 0.200906 0.001132 0.084023 0.112957 25.06760 2.096798 t-Statistic 0.686129 -1.903529 0.942792 0.180060 0.035955 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.5025 0.0751 0.3598 0.8594 0.9718 0.045308 0.084070 -4.749077 -4.500381 1.005668 0.433477 7.3.b.2. Estimación de la relación a corto plazo con intervenciones. Cuadro A7.23. Relación a corto plazo con intervenciones. LS // Dependent Variable is DLVBEX Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable C RES_BLP(-1) D(LVABEX) DLVBEX(-1) DLVABES D7475 D7677 F81 F83 F85 F86 F88 F89 Coefficient 0.012835 -0.448358 0.892180 0.143920 0.661423 -0.083255 0.066732 0.033046 0.068160 -0.183659 0.113674 -0.250447 -0.050913 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.005015 0.057534 0.096653 0.042348 0.143654 0.008354 0.008279 0.014160 0.011866 0.011158 0.013323 0.011854 0.015435 0.994119 0.985298 0.010194 0.000831 76.64101 2.305159 t-Statistic 2.559367 -7.792871 9.230757 3.398503 4.604275 -9.965305 8.060121 2.333777 5.744319 -16.45917 8.532414 -21.12842 -3.298626 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -Pág. 424- Prob. 0.0337 0.0001 0.0000 0.0094 0.0017 0.0000 0.0000 0.0479 0.0004 0.0000 0.0000 0.0000 0.0109 0.045308 0.084070 -8.898926 -8.252317 112.6929 0.000000 Anexo 7 7.3.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. En el Gráfico A7.9. se representan los estadísticos Wald secuenciales para el modelo de corrección de error con variables ficticias. Gráfico A7.9. Estadísticos Wald Secuenciales en Construcción con ficticias. 9 8 7 6 5 4 3 78 79 80 81 82 83 84 85 86 87 88 89 WALD_B_CP El cuadro siguiente nos indica la inesxistencia de cambio estructural en la ecuación con mecanismo de corrección de error y variables ficticias. Cuadro A7.24. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 8,756(NS) 6,443(NS) 5,183(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 17,928 8,715 6,101 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 425- Anexos 7.4. INDUSTRIA MANUFACTURERA. 7.4.a. Estimación de la relación de cointegración. 7.4.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la relación estimada. Cuadro A7.25. Industria manufacturera, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVIEX Sample: 1970 1993 Included observations: 24 Variable C LVIES Coefficient -7.899405 1.178867 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 1.985007 0.125843 0.799554 0.790443 0.100856 0.223783 22.04707 1.170149 t-Statistic -3.979536 9.367777 Prob. 0.0006 0.0000 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 10.69469 0.220318 -4.508466 -4.410295 87.75524 0.000000 7.4.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la siguiente gráfica: Gráfico A7.10. Estadísticos Wald Secuenciales en Industria. 35 30 25 20 15 10 5 0 74 76 78 80 82 84 WALD_I -Pág. 426- 86 88 90 Anexo 7 En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del Cuadro: Cuadro A7.26. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 30,133(***) 12,384(***) 12,083(***) Valor crítico al 1% Valor crítico al 1% Valor crítico al 1% 9,681 3,670 2,569 Nota: (***) denota el rechazo de la hipótesis nula al 1%. 7.4.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de los resultados del Cuadro A7.26. y de la representación gráfica de la estimación realizada en A7.25., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.27.). Cuadro A7.27. Industria: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVIEX Sample: 1970 1993 Included observations: 24 Variable C LVIES F78 F80 D8285 Coefficient -7.994749 1.182673 0.206234 0.223657 0.104423 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 1.549690 0.098230 0.080824 0.080813 0.043508 0.894705 0.872538 0.078658 0.117554 29.77244 1.995065 t-Statistic -5.158934 12.03985 2.551630 2.767571 2.400073 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0001 0.0000 0.0195 0.0123 0.0268 10.69469 0.220318 -4.902247 -4.656819 40.36141 0.000000 7.4.a.4. Contraste de cointegración. El contraste del Cuadro A7.28. nos permite aceptar la relación estimada en el Cuadro A7.27. como la relación de equilibrio a largo plazo (cointegración). -Pág. 427- Anexos Cuadro A7.28. Industria: contraste de cointegración. ADF Test Statistic -4.476101 1% Critical Value* 5% Critical Value 10% Critical Value -3.7667 -3.0038 -2.6417 *MacKinnon critical values for rejection of hypothesis of a unit root. Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_LP_IR) Sample(adjusted): 1972 1993 Included observations: 22 after adjusting endpoints Variable Coefficient Std. Error t-Statistic Prob. EQ_LP_IR(-1) C -0.976986 0.001358 0.218267 0.015817 -4.476101 0.085826 0.0002 0.9325 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.500443 0.475465 0.074158 0.109988 27.06601 2.043823 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.003389 0.102393 -5.116606 -5.017420 20.03548 0.000231 7.4.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el Gráfico A7.11. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.29. se comprueba el no rechazo de la hipótesis de cambio estructural. Gráfico A7.11. Estadísticos Wald Secuenciales en Industria con ficticias. 6 5 4 3 2 74 76 78 80 82 84 86 88 90 WALD_I_D Cuadro A7.29. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 5,472(NS) 3,612(NS) 1,937(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 11,280 4,414 3,195 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 428- Anexo 7 7.4.b. Estimación del modelo de correción de error. 7.4.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.30. Relación a corto plazo. LS // Dependent Variable is DLVIEX Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable C RES_LPI1 DLVIEX1 DLVNOAE DLVAEX DF80 DD8285 Coefficient -0.031222 -0.909144 0.195693 1.858739 0.140317 0.144224 0.123617 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.023110 0.242248 0.141606 0.508303 0.095889 0.055755 0.054345 0.783078 0.690111 0.068303 0.065314 30.81954 2.053938 t-Statistic -1.351028 -3.752956 1.381951 3.656757 1.463331 2.586743 2.274681 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.1981 0.0021 0.1886 0.0026 0.1655 0.0215 0.0392 0.026715 0.122698 -5.106405 -4.758231 8.423218 0.000535 7.4.b.2. Estimación de la relación a corto plazo con intervenciones. En el cuadro siguiente se muestra la estimación del modelo de corrección de error con el que se logra el no rechazo de la hipótesis de estabilidad. Cuadro A7.31. Relación a corto plazo con intervenciones. LS // Dependent Variable is DLVIEX Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable C RES_LPI1 DLVIEX1 DLVNOAE DLVAEX DF80 DD8285 F77 F85 Coefficient -0.061989 -0.555679 0.231764 2.262131 0.171517 0.111754 0.128267 0.142805 0.152279 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.021897 0.237696 0.117747 0.443225 0.081380 0.047499 0.044884 0.068507 0.062094 0.873332 0.788886 0.056376 0.038139 36.46820 2.051636 t-Statistic -2.830886 -2.337775 1.968316 5.103797 2.107602 2.352777 2.857775 2.084531 2.452398 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -Pág. 429- Prob. 0.0152 0.0375 0.0726 0.0003 0.0568 0.0365 0.0144 0.0591 0.0305 0.026715 0.122698 -5.453896 -5.006243 10.34196 0.000246 Anexos 7.4.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. En el Gráfico A7.12. se representan los estadísticos Wald secuenciales para el modelo de corrección de error con variables ficticias. Gráfico A7.12. Estadísticos Wald Secuenciales en Industria con ficticias. 16 14 12 10 8 6 4 2 78 79 80 81 82 83 84 85 86 87 88 89 WALD_I_CP En el cuadro siguiente se comprueba el no rechazo de la hipótesis de estabilidad. Cuadro A7.32. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 14,247(NS) 8,141(NS) 5,723(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 17,928 8,715 6,101 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 430- Anexo 7 7.5. SERVICIOS DESTINADOS A LA VENTA. 7.5.a. Estimación de la relación de cointegración. 7.5.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la relación estimada. Cuadro A7.33. Servicios destinados a la venta, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVLEX Sample: 1972 1993 Included observations: 22 Variable C LVLES Coefficient 0.792996 0.698344 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 2.003520 0.123516 0.615134 0.595891 0.078015 0.121726 25.95067 0.366026 t-Statistic 0.395801 5.653866 Prob. 0.6964 0.0000 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 12.12024 0.122723 -5.015211 -4.916025 31.96620 0.000016 7.5.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la siguiente gráfica: Gráfico A7.13. Estadísticos Wald Secuenciales en Servicios destinados a la venta. 70 60 50 40 30 20 10 0 76 78 80 82 84 WALD_L -Pág. 431- 86 88 90 Anexos En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del Cuadro: Cuadro A7.34. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 60,229(***) 19,928(***) 27,842(***) Valor crítico al 1% Valor crítico al 1% Valor crítico al 1% 9,681 3,670 2,569 Nota: (***) denota el rechazo de la hipótesis nula al 1%. 7.5.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de las estimación que muestra el Cuadro A7.34. y de la representación gráfica de la estimación del Cuadro A7.34., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.35.). Cuadro A7.35. Servicios destinados a la venta: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVLEX Sample: 1972 1993 Included observations: 22 Variable C LVLES D8185 D8185*LVLES D8693 D8693*LVLES Coefficient -5.366091 1.083666 43.93700 -2.724110 -11.32763 0.682184 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 2.661011 0.165276 7.766833 0.480188 3.548128 0.218752 0.962932 0.951348 0.027069 0.011724 51.69227 2.351518 t-Statistic -2.016561 6.556721 5.657004 -5.673010 -3.192565 3.118523 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0608 0.0000 0.0000 0.0000 0.0057 0.0066 12.12024 0.122723 -6.991719 -6.694162 83.12826 0.000000 7.5.a.4. Contraste de cointegración. El contraste del Cuadro A7.36. nos permite no rechazar la relación estimada en el Cuadro A7.35. como la relación de equilibrio a largo plazo (cointegración). -Pág. 432- Anexo 7 Cuadro A7.36. Servicios destinados a la venta: contraste de cointegración. ADF Test Statistic -5.586128 1% Critical Value* 5% Critical Value 10% Critical Value *MacKinnon critical values for rejection of hypothesis of a unit root. -3.7856 -3.0114 -2.6457 Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_LP_LR) Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable EQ_LP_LR(-1) C Coefficient -1.224855 0.001082 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.219267 0.005108 0.621550 0.601632 0.023393 0.010397 50.11511 1.982005 t-Statistic -5.586128 0.211756 Prob. 0.0000 0.8346 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.002135 0.037063 -7.420269 -7.320790 31.20483 0.000022 7.5.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el Gráfico A7.14. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.37. se comprueba la inexistencia de cambio estructural. Gráfico A7.14. Estadísticos Wald Secuenciales en Servicios destinados a la venta con ficticias. 10 8 6 4 2 0 76 78 80 82 84 86 88 90 WALD_L_D Cuadro A7.37. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 9,726(NS) 2,983(NS) 2,464(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 11,280 4,414 3,195 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 433- Anexos 7.5.b. Estimación del modelo de correción de error. 7.5.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.38. Relación a corto plazo. LS // Dependent Variable is DLVLEX Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable C RES_LLP1 DLVNOAE DLVLES Coefficient -0.027686 -0.553851 0.808470 0.997235 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.011108 0.343031 0.297912 0.476466 0.736787 0.690338 0.029809 0.015106 46.19296 1.829170 t-Statistic -2.492420 -1.614582 2.713791 2.092983 Prob. 0.0233 0.1248 0.0147 0.0517 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.021362 0.053568 -6.856255 -6.657298 15.86218 0.000035 7.5.b.2. Estimación de la relación a corto plazo con intervenciones. Cuadro A7.39. Relación a corto plazo con intervenciones. LS // Dependent Variable is DLVLEX Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints Variable C RES_LLP1 DLVNOAE DLVLES F77 D8085 F90 Coefficient 0.006765 -0.836192 0.420453 0.924022 -0.059502 -0.054909 -0.036131 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.008301 0.219977 0.186561 0.255448 0.017296 0.009692 0.016930 0.938027 0.911467 0.015939 0.003557 61.37868 2.365906 t-Statistic 0.815024 -3.801270 2.253700 3.617265 -3.440294 -5.665636 -2.134111 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -Pág. 434- Prob. 0.4287 0.0019 0.0408 0.0028 0.0040 0.0001 0.0510 0.021362 0.053568 -8.016799 -7.668625 35.31729 0.000000 Anexo 7 7.5.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. En el Gráfico A7.15. se representan los estadísticos Wald secuenciales para el modelo de corrección de error con variables ficticias. Gráfico A7.15. Estadísticos Wald Secuenciales en Servicios destinados a la venta con ficticias. 3.5 3.0 2.5 2.0 1.5 1.0 0.5 0.0 77 78 79 80 81 82 83 84 85 86 87 88 89 90 WALD_L_CP Los resultados del Cuadro A7.40. nos permiten quedarnos con la regresión estimada en A7.39. Cuadro A7.40. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 3,350(NS) 2,023(NS) 1,132(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 15,936 7,292 5,171 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 435- Anexos 7.6. TRANSPORTES Y COMUNICACIONES. 7.6.a. Estimación de la relación de cointegración. 7.6.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la relación estimada. Cuadro A7.41. Energía, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVZEX Sample: 1972 1993 Included observations: 22 Variable C LVZES LVLEX Coefficient -1.846341 0.632320 0.224539 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 1.676239 0.095299 0.190138 0.851095 0.835421 0.076989 0.112619 26.80602 0.648879 t-Statistic -1.101478 6.635091 1.180926 Prob. 0.2844 0.0000 0.2522 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 9.909633 0.189776 -5.002060 -4.853282 54.29899 0.000000 7.6.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la siguiente gráfica: Gráfico A7.16. Estadísticos Wald Secuenciales en Transportes y comunicaciones. 35 30 25 20 15 10 5 76 78 80 82 84 86 WALD_Z -Pág. 436- 88 90 Anexo 7 En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del Cuadro: Cuadro A7.42. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 33,947(***) 15,078(***) 14,088(***) Valor crítico al 1% Valor crítico al 1% Valor crítico al 1% 11,909 5,064 3,518 Nota: (***) denota el rechazo de la hipótesis nula al 1%. 7.6.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de la regresión del Cuadro A7.42. y de la representación gráfica de la regresión del Cuadro A7.41., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.43.). Cuadro A7.43. Transportes y comunicaciones: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVZEX Sample: 1972 1993 Included observations: 22 Variable C LVZES LVLEX F72 D8084 D8084*LVZES D8889 Coefficient -5.269054 0.722161 0.399566 0.257349 17.68667 -1.232400 -0.131521 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.811626 0.044386 0.090351 0.036561 7.058870 0.494242 0.024290 0.980880 0.973232 0.031049 0.014461 49.38418 1.988887 t-Statistic -6.491975 16.26991 4.422368 7.038798 2.505595 -2.493514 -5.414604 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0000 0.0000 0.0005 0.0000 0.0242 0.0248 0.0001 9.909633 0.189776 -6.690984 -6.343834 128.2512 0.000000 7.6.a.4. Contraste de cointegración. El contraste del Cuadro A7.44. nos permite aceptar la relación estimada en el Cuadro A7.43. como la relación de equilibrio a largo plazo (cointegración). -Pág. 437- Anexos Cuadro A7.4. Transportes y comunicaciones: contraste de cointegración. ADF Test Statistic -4.335614 1% Critical Value* 5% Critical Value 10% Critical Value *MacKinnon critical values for rejection of hypothesis of a unit root. Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_LP_ZR) Sample(adjusted): 1973 1993 Included observations: 21 after adjusting endpoints -3.7856 -3.0114 -2.6457 Variable EQ_LP_ZR(-1) C Prob. 0.0004 0.9855 Coefficient -1.057634 -0.000111 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.243941 0.006030 0.497322 0.470865 0.027548 0.014419 46.68179 1.720030 t-Statistic -4.335614 -0.018380 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.001923 0.037870 -7.093285 -6.993807 18.79755 0.000356 7.6.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el Gráfico A7.17. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.45. se comprueba la inexistencia de cambio estructural. Gráfico A7.17. Estadísticos Wald Secuenciales en Transportes y comunicaciones con ficticias. 8 6 4 2 0 76 78 80 82 84 86 88 90 WALD_Z_D Cuadro A7.45. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 7,559(NS) 3,065(NS) 2,224(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 13,677 5,931 4,215 Nota: (*) denota el rechazo de la hipótesis nula al 10%, (**) al 5% y (***) al 1%. (NS) denota el no rechazo de la hipótesis nula. -Pág. 438- Anexo 7 7.6.b. Estimación del modelo de correción de error. 7.6.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.46. Relación a corto plazo. LS // Dependent Variable is DLVZEX Sample: 1974 1993 Included observations: 20 Variable C RES_ZLP1 DLVLEX DLVZES DLVZEX1 DD8084 DD8889 DD8084LVZES Coefficient 0.008772 -0.690211 0.222499 0.348728 0.245171 20.55166 -0.082167 -1.435019 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.007807 0.167375 0.072848 0.177285 0.078012 2.677319 0.010791 0.187369 0.944512 0.912144 0.013866 0.002307 62.29549 1.756502 t-Statistic 1.123697 -4.123745 3.054280 1.967052 3.142719 7.676210 -7.614358 -7.658782 Prob. 0.2831 0.0014 0.0100 0.0727 0.0085 0.0000 0.0000 0.0000 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.034817 0.046781 -8.267426 -7.869133 29.18056 0.000001 7.6.b.2. Contrastes de Chow secuenciales aplicados a la relación a corto plazo. En esta ecuación, como se puede comprobar en el Cuadro A7.47., la relación es estable, de manera que no ha sido necesario introducir variables ficticias. Gráfico A7.18. Estadísticos Wald Secuenciales en Transportes y comunicaciones. 6 5 4 3 2 1 79 80 81 82 83 84 85 WALD_Z_CP -Pág. 439- 86 87 88 89 Anexos Cuadro A7.47. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 4,984(NS) 2,271(NS) 1,580(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 15,936 7,292 5,171 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 440- Anexo 7 7.7. SERVICIOS NO DESTINADOS A LA VENTA. 7.7.a. Estimación de la relación de cointegración. 7.7.a.1. Estimación de la relación a largo plazo teórica. En el cuadro siguiente se muestra la relación estimada. Cuadro A7.48. Servicios no destinados a la venta, estimación de la relación a largo plazo teórica. LS // Dependent Variable is LVGEX Sample: 1971 1993 Included observations: 23 Variable C LVGES Coefficient -6.268036 1.174640 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.469943 0.031250 0.985355 0.984657 0.046583 0.045570 38.94054 0.421087 t-Statistic -13.33786 37.58846 Prob. 0.0000 0.0000 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 11.39263 0.376075 -6.050098 -5.951359 1412.892 0.000000 7.7.a.2. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica. Los estadísticos de Wald secuenciales para este sector son los que aparecen en la siguiente gráfica: Gráfico A7.19. Estadísticos Wald Secuenciales en Servicios no destinados a la venta. 80 60 40 20 0 74 76 78 80 82 84 WALD_G -Pág. 441- 86 88 90 Anexos En base a dichos estadísticos se han calculado los estadísticos para llevar a cabo los contrastes de estabilidad -SupF, MediaF y ExpF-, siendo los resultados obtenidos los del Cuadro: Cuadro A7.49. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 72,483(***) 16,369(***) 33,246(***) Valor crítico al 1% Valor crítico al 1% Valor crítico al 1% 9,681 3,670 2,569 Nota: (***) denota el rechazo de la hipótesis nula al 1%. 7.7.a.3. Estimación de la relación a largo plazo teórica con intervenciones. En función de los resultados del Cuadro A7.49. y de la representación gráfica de la estimación recogida en el cuadro A7.48., se han introducido variables ficticias para aproximar el cambio estructural (Ver Cuadro A7.50.). Cuadro A7.50. Servicios no destinados a la venta: estimación de la relación a largo plazo teórica con intervenciones. LS // Dependent Variable is LVGEX Sample: 1971 1993 Included observations: 23 Variable LVGES C D7078 D7078*LVGES D7985 D7985*LVGES D9293 Coefficient 1.004087 -3.636357 3.645946 -0.257244 -10.45291 0.689951 0.024454 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.058312 0.894278 1.057465 0.069834 1.434189 0.094654 0.015924 0.998883 0.998464 0.014737 0.003475 68.53737 2.682593 t-Statistic 17.21919 -4.066251 3.447817 -3.683668 -7.288378 7.289181 1.535688 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.0000 0.0009 0.0033 0.0020 0.0000 0.0000 0.1442 11.39263 0.376075 -8.188952 -7.843367 2385.048 0.000000 7.7.a.4. Contraste de cointegración. El contraste del Cuadro A7.51. nos permite aceptar la relación estimada en el Cuadro A7.50. como la relación de equilibrio a largo plazo (cointegración). -Pág. 442- Anexo 7 Cuadro A7.51. Servicios no destinados a la venta: contraste de cointegración. ADF Test Statistic -6.395073 1% Critical Value* 5% Critical Value 10% Critical Value *MacKinnon critical values for rejection of hypothesis of a unit root. -3.7667 -3.0038 -2.6417 Augmented Dickey-Fuller Test Equation LS // Dependent Variable is D(EQ_LP_GR) Sample(adjusted): 1972 1993 Included observations: 22 after adjusting endpoints Variable EQ_LP_GR(-1) C Coefficient -1.342910 7.47E-05 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.209991 0.002638 0.671576 0.655155 0.012372 0.003061 66.46280 2.188076 t-Statistic -6.395073 0.028314 Prob. 0.0000 0.9777 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.000192 0.021068 -8.698132 -8.598946 40.89695 0.000003 7.7.a.5. Contrastes de Chow secuenciales aplicados a la relación a largo plazo teórica con intervenciones. En el Gráfico A7.20. se muestra la evolución de los estadísticos de Wald calculados secuencialmente, mientras que en el Cuadro A7.52. se comprueba la inexistencia de cambio estructural. Gráfico A7.20. Estadísticos Wald Secuenciales en Servicios no destinados a la venta con ficticias. 3.0 2.5 2.0 1.5 1.0 0.5 0.0 74 76 78 80 82 84 86 88 90 WALD_G_D Cuadro A7.52. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 2,603(NS) 0,556(NS) 0,340(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 11,280 4,414 3,195 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 443- Anexos 7.7.b. Estimación del modelo de correción de error. 7.7.b.1. Estimación de la relación a corto plazo teórica. En el cuadro siguiente se muestra la estimación del modelo de corrección de error que se deriva de las relaciones especificadas a largo plazo. Cuadro A7.53. Relación a corto plazo. LS // Dependent Variable is DLVGEX Sample: 1972 1993 Included observations: 22 Variable C RES_GLP1 DLVGES DD7078 DD7078LVGES DD7985 DD7985LVGES DD9293 Coefficient -0.004644 -1.328417 1.142309 4.323270 -0.301690 -11.44568 0.755845 0.023641 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.011114 0.224491 0.212260 1.899407 0.126119 2.908605 0.191691 0.014175 0.881083 0.821624 0.012642 0.002237 69.91120 2.127371 t-Statistic -0.417870 -5.917474 5.381638 2.276116 -2.392112 -3.935111 3.943043 1.667759 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Prob. 0.6824 0.0000 0.0001 0.0391 0.0313 0.0015 0.0015 0.1176 0.052089 0.029933 -8.466168 -8.069425 14.81839 0.000017 7.7.b.2. Estimación de la relación a corto plazo con intervenciones. Cuadro A7.54. Relación a corto plazo con intervenciones. LS // Dependent Variable is DLVGEX Sample: 1972 1993 Included observations: 22 Variable C RES_GLP1 DLVGES DD7078 DD7078LVGES DD7985 DD7985LVGES DD9293 F80 F82 F84 F88 Coefficient -0.000694 -0.701559 0.974421 2.796387 -0.205018 -17.29106 1.141906 0.027924 0.015005 -0.040791 -0.041269 0.021747 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Std. Error 0.003561 0.091231 0.069836 0.644955 0.042734 1.186592 0.078248 0.004510 0.004821 0.005352 0.004747 0.004523 0.991608 0.982377 0.003974 0.000158 99.07421 2.345349 t-Statistic -0.194833 -7.689954 13.95294 4.335786 -4.797568 -14.57204 14.59344 6.191714 3.112750 -7.621804 -8.694258 4.808451 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -Pág. 444- Prob. 0.8494 0.0000 0.0000 0.0015 0.0007 0.0000 0.0000 0.0001 0.0110 0.0000 0.0000 0.0007 0.052089 0.029933 -10.75371 -10.15860 107.4226 0.000000 Anexo 7 7.7.b.3. Contrastes de Chow secuenciales aplicados a la relación a corto plazo con intervenciones. En el Gráfico A7.21. se representan los estadísticos Wald secuenciales para el modelo de corrección de error con variables ficticias. Gráfico A7.21. Estadísticos Wald Secuenciales en Servicios no destinados a la venta con ficticias. 7 6 5 4 3 2 1 76 78 80 82 84 86 88 90 WALD_G_CP Como se puede comprobar en el Cuadro A7.55., la especificación proporcionada a la ecuación es estable. Cuadro A7.55. Contrastes de estabilidad. Sup(F) Media(F) Exp(F) 6,164(NS) 3,232(NS) 2,025(NS) Valor crítico al 5% Valor crítico al 5% Valor crítico al 5% 13,677 5,931 4,215 Nota: (NS) denota el no rechazo de la hipótesis nula. -Pág. 445- Anexo 8 ANEXO 8: EL FILTRO DE KALMAN COMO HERRAMIENTA PARA ESTIMAR PARÁMETROS CAMBIANTES EN EL TIEMPO. 8.1. INTRODUCCIÓN. Dentro de los modelos con parámetros cambiantes estocásticostendenciales hemos destacado a un grupo que tiene como rasgo en común partir de la representación formal de un fenómeno en la forma de espacio de los estados, para posteriormente utilizar el denominado filtro de Kalman como técnica de estimación lineal. El filtro de Kalman es una técnica que proporciona el estimador lineal óptimo de mínima varianza mediante la minimización del error cuadrático medio. Este Anexo expone las ideas esenciales en las que se apoya dicha técnica en lo referente a la utilización que le damos en el Capítulo VII. Las referencias fundamentales, con los resultados que aquí se exponen desarrollados de manera amplia, se pueden encontrar en Harvey (1993, Capítulo 4), Hamilton (1994, Capítulo 13) y Lütkepohl (1993, Capítulo 13). 8.2. MODELOS EN EL ESPACIO DE LOS ESTADOS LINEALES. Los modelos en el espacio de los estados lineales relacionan las observaciones de series temporales ( y t , donde t = 1,..., T ) con “estados” inobservados ( α t ) mediante la llamada ecuación lineal de medida: yt = Z t α t + ε t siendo Z t la conocida como matriz de observación, y ε t un vector de ( ) perturbaciones incorrelacionados serialmente con media cero [ E ε t = 0 ] y ( ) matriz de covarianza Σ t [ Cov ε t = Σ t ]. Vamos a suponer que Σ t es diagonal, es decir, que los elementos de fuera de la diagonal principal toman el valor cero, de manera que las perturbaciones están incorrelacionadas entre sí. En el cuadro siguiente se recoge la especificación de la ecuación de medida. -Pág. 447- Anexos Cuadro A8.1. Ecuación de medida. y t = Z t α t + ε t , t = 1, ... , T donde: y t : vector Tx1 Z t : matriz Txm α t : vector mx1 ε t : vector T × 1 de perturbaciones incorrelacionadas serialmente, con media cero y matriz de covarianza Σ t diagonal; es decir: E( ε t ) = 0 y Var( ε t ) = Σ t = σ t2 I t Además, se supone que los estados ( α t ) siguen un modelo de transición estocástico que viene dado por la llamada ecuación lineal de transición: α t = Ft α t -1 + η t donde Ft es la matriz de transición y η t es un vector de variables aleatorias ( ) normales con media cero y Cov η t = Qt . También vamos a suponer que la matriz Qt es diagonal, es decir, que no vamos a permitir a las variables de estado interactuar entre sí, y los elementos de fuera de la diagonal principal toman el valor cero. Se puede constatar que la ecuación [1] es un modelo de regresión lineal con parámetros ( α t , llamado vector de estado) que varían en el tiempo en la forma especificada por [2]. A las componentes del vector de estado se les conoce como variables de estado. Así, denotamos al estado inicial ( ) ( ) como α 0 , verificándose que E α 0 = a 0 y Cov α 0 = Q 0 . La especificación de la ecuación de transición la recogemos en el Cuadro AV.2. Cuadro A8.2. Ecuación de transición. α t = Ft α t -1 + ηt , t = 1 ,..., T Esta es la llamada ecuación de transición, en la cual: F t : matriz m × m ηt : vector mx1 de perturbaciones incorrelacionadas serialmente, con media cero y matriz de covarianza Qt ,es decir, E( ηt ) = 0 y Var( ηt ) = Qt -Pág. 448- Anexo 8 Otras hipótesis a considerar son que la distribución de η t es independiente de la de los errores ε t . Además, también se supone que dichas distribuciones están incorrelacionadas con la correspondiente al vector de estado inicial α 0 . En nuestro contexto, la modelización en el estado de los espacios se realiza para analizar datos aproximadamente normales, de manera que vamos a suponer normalidad conjunta para ε t , η t y α 0 . Las hipótesis que hemos supuesto para complementar la especificación del modelo en el espacio de los estados son las que aparecen en el cuadro AV.8. Cuadro A8.3. Hipótesis adicionales. a ) E ( α 0 ) = a 0 y Var ( α 0 ) = Q0 b) E ( ε t η s/ ) = 0 para todo s, t = 1,..., T ; y E ( ε t α /0 ) = 0 , E ( ηt α /0 ) = 0 , para t = 1,...,T c) ε t → d N (0, Σ t ), ηt → d N (0, Qt ), α 0 → d N (a 0 , Q0 ). Dentro del modelo de parámetros variables representado en el espacio de los estados, y dado un conjunto de observaciones para {y t } y {Z t } , el { } propósito a lograr en primer lugar es la estimación de los estados α t . En función del instante en el que se desea hacer la estimación, se pueden distinguir tres problemas distintos: a) el problema del alisado, si t < T ; b) el problema del filtrado, si t = T ; y c) el problema de la predicción, si t > T . En este trabajo nos interesan fundamentalmente los problemas del filtrado y de la predicción, aunque haremos alguna mención al problema del alisado. Estos problemas se enfrentan habitualmente con la dificultad que conlleva el hecho de que las matrices de covarianzas Σ t , Qt y los valores iniciales a 0 y Q 0 son desconocidos. De manera general podemos afirmar que dependen de parámetros desconocidos a los que se les denomina hiperparámetros, y que vamos a recoger mediante el vector de parámetros Θ : Σ t = Σ t (Θ) , Qt = Qt (Θ) , a 0 = a 0 (Θ) y Q 0 = Q 0 (Θ) . Para la matriz de covarianza Σ t , vamos a suponer que tiene un comportamiento homocedástico: ( ) Cov ε t = Σ t = σ 2ε I t ; siendo σ 2ε = constante -Pág. 449- Anexos En la estructura que hemos elegido en el Capítulo VII para nuestra ecuación de transición, hemos adoptado el supuesto de que los parámetros de cada una de las ecuaciones del modelo econométrico regional siguen un paseo aleatorio sin deriva del tipo α t = α t -1 + η t , donde E( ηt ) = 0 y Var( ηt ) = Qt . Hemos optado por desechar la posibilidad de cambios en los niveles de los parámetros α t a través de Ft porque no disponemos de información acerca de la estructura de evolución de dichos parámetros en el tiempo. En definitiva, se trata de suponer un comportamiento estacionario para los parámetros: Ft = I t donde I t denota a la matriz identidad. Por otra parte, es necesario destacar el hecho de que si admitimos a Qt como singular, abandonamos de hecho la hipótesis de parámetros variables para pasar a los parámetros fijos. 8.3. EL FILTRO DE KALMAN. El filtro de Kalman es una técnica de estimación que se formula tomando como base los modelos representados en el espacio de los estados. Cuando el filtro de Kalman se aplica con el objetivo de reducir la influencia perturbadora a la que están sometidas las observaciones para, de esta forma, poder realizar una estimación lo más adecuada posible del fenómeno en estudio, se dice que está operando como una técnica de filtrado estocástico. En el caso del filtrado, la esperanza condicional de α t viene dada por: ( ) E α t y1 ,..., y t , z1 ,..., zt = a t t , definiéndose la matriz de varianzas y covarianzas del error de estimación como: ( )( ) / E α t − a t t α t − a t t = Vt t ( ) En consecuencia, α t y1 ,..., y t , z1 ,..., zt ∼ N a t t ,Vt t , ya que el modelo es lineal y hemos supuesto normalidad. De igual manera, en el caso de la predicción, el mejor predictor un período hacia adelante viene determinado por: ( ) E α t y1 ,..., y t −1 , z1 ,..., z t −1 = a t t −1 -Pág. 450- Anexo 8 siendo la matriz de varianzas y covarianzas del error de predicción / E α t − a t t −1 α t − a t t −1 = Vt t −1 ( )( ) En resumen, y dado que se ha supuesto normalidad, ( α t y1 ,..., y t −1 , z1 ,..., zt −1 ∼ N a t t −1 ,Vt t −1 ) Ya tenemos planteadas las expresiones de las esperanzas y las covarianzas y el interés se centra ahora en calcular dichas matrices. Aquí es donde opera el filtro de Kalman, que es un algoritmo recurrente que calcula el estimador lineal óptimo de mínima varianza. Las ecuaciones del filtro están constituidas por las siguientes expresiones: a) Inicialización: a 0 0 = a 0 y V0 0 = Q 0 . b) Procedimiento recursivo para t = 1,..., T : b1) Predicción. b11) Estimación de la predicción un período hacia adelante a t t −1 = a t −1 t −1 b12) Estimación de la matriz de varianzas y covarianzas del error de predicción un período hacia adelante. Vt t −1 = Vt −1 t −1 + Qt b2) Cálculo de la matriz de ganancia [ K t = Vt t −1 Z t/ Z tVt t −1 Z t/ + Σ t ] −1 b3) Estimación de la innovación: Γt = y t − Z t a t t −1 b4) Corrección b41) Corrección del estimador (filtrado): a t t = a t t −1 + Kt Γt b42) Corrección de la covarianza del error de estimación: Vt t = Vt t −1 − K t Z tVt t −1 El procedimiento recursivo se inicia con la observación primera ( t = 1 ) y se continúa ejecutando hasta t = T . Una vez desarrollado el proceso anterior, se está en condiciones de proceder al cálculo de la predicción para t > T : c1) Predicción de las variables de estado y de su matriz de varianzas y covarianzas: a T +1 T = a T T -Pág. 451- Anexos ( ) ( ) Cov a T +1 T = Cov a T T + Qt c2) Predicción de las variables endógenas y de su matriz de varianzas y covarianzas y T +1 T = Z T +1 a ( T +1 T ) Cov ( y T ) = Z T +1Cov a T +1 T Z T/ +1 + Σ ε Para concluir este apartado vamos a hacer algún comentario acerca del problema del alisado, en el cual, la esperanza condicional de α t viene dada por ( ) E α t y1 ,..., y T , z1 ,..., z T = a t T , definiéndose la matriz de varianzas y covarianzas del error de estimación como: ( )( ) / E α t − a t T α t − a t T = Vt T , ( ) de forma que α t y1 ,..., y T , z1 ,..., zT ∼ N a t T ,Vt T , puesto que para el modelo lineal hemos supuesto normalidad. Existen distintos tipos de algoritmos básicos de alisado para un modelo lineal, siendo el llamado alisado de intervalo fijo la forma más usual en economía (otros son el alisado de punto fijo y de retardo fijo). El alisado de intervalo fijo se realiza mediante procesos iterativos funcionando hacia atrás para t = T ,...,1 , estimándose el alisador: ( a t −1 T = a t −1 t −1 + Vt −1 t −1 Vt −1 t −1 ) (a −1 tT − a t t −1 ) y la estimación de la matriz de varianzas y covarianzas del error de alisado: ( Vt −1 T = Vt −1 t −1 + Vt −1 t −1 Vt −1 t −1 ) (V −1 tT ) ( − Vt t −1 Vt −1 t −1 Vt −1 t −1 ) −1 / 8.4. ESTIMACIÓN DE LOS HIPERPARÁMETROS. El problema para aplicar las reiteraciones del filtro de Kalman es que debemos obtener estimaciones de los hiperparámetros Θ (vector de parámetros desconocidos). Θ está formado por los valores iniciales a 0 , Q0 , y -Pág. 452- Anexo 8 por los elementos desconocidos de Σ t (en nuestro caso σ ε2 ) y de Qt . Vamos a considerar a los parámetros Θ constantes. Bajo las condiciones anteriores, partimos de la función de densidad de probabilidad conjunta normal de las observaciones muestrales en función del conjunto de parámetros desconocidos: L(Θ) = p( y1 ,..., y T ; Θ) El objetivo es maximizar L(Θ) , y nos encontramos con dos maneras habituales de abordar el problema: 1ª) Maximización de manera directa Se trata de descomponer factorialmente la función de verosimilitud mediante la llamada descomposición por el error de predicción. El resultado es el producto de funciones de densidad condicionales ( ) del tipo p y1 ,..., y t y1 ,..., y t −1 ; Θ : ( T ) L( y1 ,..., y T ; Θ) = ∏ p y1 ,..., y t y1 ,..., y t −1 ; Θ . t =1 ) ( ( )) ( Teniendo en cuenta que y t y1 ,..., y t −1 ∼ N y t t −1 , Cov y t t −1 , el logaritmo de la función de verosimilitud se puede expresar como: ln L( y1 ,..., y T ; Θ) = − − ( 1 T ∑ y − y t t −1 2 t =1 t ( 1 T T ln(2π ) − ∑ ln Cov y t t −1 2 2 t =1 )( ( / Cov y t t −1 )) ( y −1 t − y t t −1 ) ) Ahora se maximiza la función de verosimilitud mediante algoritmos numéricos que calculan la verosimilitud para cualquier valor fijado de Θ . La principal dificultad que conlleva la utilización de este método es que las estimaciones que se obtienen para los hiperparámetros pueden variar de manera importante en función del período muestral y/o del procedimiento de optimización numérica utilizados. 2ª) Maximización de manera indirecta, que utiliza el algoritmo EM (iniciales de etapa de esperanza -etapa de maximización: “expectation stepmaximization step”) de Dempster, Laird y Rubin (1977). Este algoritmo se aplicó con éxito al campo de la modelización en el espacio de los estados (ver Watson y Engle (1983)). Parte del logaritmo de verosimilitud de la muestra completa: -Pág. 453- Anexos ( ) ln L y1 ,..., y T , α 0 ,..., α T ,; Θ = − T T ( 1 T ln σ ε2 − 2 2σ ε2 ( ) ∑ (y ) ) ( − / 1 T ln(det Q) − ∑ α t − α t −1 Q −1 α t − α t −1 ∑ 2 t =1 2 t =1 − / 1 T 1 ln(det Q0 ) − α 0 − a 0 Q0−1 α 0 − a 0 ∑ 2 t =1 2 ( ) ( T t =1 t − z t/ α t ) 2 ) Para cada una de las iteraciones del algoritmo, se establecen dos etapas: 1ª) En la etapa de esperanza, calcula la esperanza condicional del logaritmo de verosimilitud dadas las observaciones y los parámetros obtenidos en la etapa iésima: ( ) [ ( ) M Θ Θ ( i ) = E ln L y1 ,..., y T , α 0 ,..., α T ,; Θ y1 ,..., y T , Θ ( (i) ] ) 2ª) En la etapa de maximización, se maximiza M Θ Θ ( i ) con respecto a Θ . El algoritmo que se aplica para estimar conjuntamente a t T , Vt T y Θ pasa por la aplicación del filtro y alisado de Kalman en Θ (i ) y la resolución de manera analítica del problema de maximización. El algoritmo iterativo resultante es el siguiente: a)Etapa de elección de los valores iniciales: a 0(0) , Q0(0) , σ (0) y Q (0) . 2 b)Etapa de alisado, que partiendo de los valores estimados a 0( i ) , Q0(i ) , σ (i ) y 2 Q (i ) (donde i = 0,1,2,... , son las iteraciones que paran cuando Θ (i ) es más pequeño que algún criterio de convergencia determinado) aplica el filtrado y alisado lineal de Kalman para obtener a t(iT) , Vt (Ti) . c)Se calcula la esperanza condicional del logaritmo de verosimilitud dadas las [ ( )] observaciones y los parámetros obtenidos en la etapa i-ésima M Θ Θ (i ) , para ( ) a continuación maximizar M Θ Θ (i ) respecto a los parámetros desconocidos a 0( i ) , Q0(i ) , σ 2 (i ) y Q (i ) . El cálculo de dichos parámetros viene dado por: -Pág. 454- Anexo 8 a 0(i +1) = a 0(i ) Q0(i +1) = Q0(i ) 1 T Q ( i +1) = ∑ a t(iT) − a t(−i )1 T a t(iT) − a t(−i )1 T T t =1 ( )( ( ) − Vt (Ti)/ Vt (−i1) t −1 Vt (ti−) 1 σ ( i +1) = 2 ( 1 T (i ) y t − z t/ α t T ∑ T 1 ) −1 2 ) / ( ) + Vt (Ti) − Vt (−i1) t −1 Vt (ti−) 1 −1 Vt (Ti) / + V (i ) t −1 T (i ) + z t/V t T z t La ventaja de este método indirecto con respecto al directo es que las iteraciones se calculan más fácilmente, sin embargo, su convergencia es más lenta. -Pág. 455- REFERENCIAS BIBLIOGRÁFICAS . Referencias REFERENCIAS BIBLIOGRÁFICAS. ABAD, A. M. y QUILIS, E. M. (1994): “A Technique for Cyclical Analysis”, Eurostat-INSEE Workshop on Short Term Indicators, París, Francia. ABAD, A. M. y QUILIS, E. M. (1996), “<F> y <G>: “Dos Programas para el Análisis Cíclico. Aplicación a los agregados monetarios”, Boletín Trimestral de Coyuntura, Vol. 62, Instituto Nacional de Estadística, Madrid. ADAMS, F. G. y GLICKMAN N. J. (Eds.) (1980): “Modelling the Multirregional Economic System”, Lexington, Mass.: D. C. Heath. AGUAYO, E., GUISAN, M. A., y RODRÍGUEZ, X. A. (1997): “Modelización Regional: Técnicas y Tipos de Modelos”, Documentos de Econometría Aplicada y Estudios Cuantitativos, Número 8, Universidade de Santiago de Compostela. ALCAIDE, J. (1995a): “Fuentes de Información para el Seguimiento de la Coyuntura Económica Española”, Papeles de Economía Española, nº 62, Págs. 59-66. ALCAIDE, J. (1995b): “Las Estadísticas Financieras Españolas: Ámbito y Fuentes.” Papeles de Economía Española, nº 62, Págs. 67-75. ALCAIDE, J. (1995c): “¿Cómo se Elabora un Cuadro Macroeconómico?”, Papeles de Economía Española, nº 62, Págs. 76-82. ALCAIDE, J. (1996): “Contabilidad Regional de la Autonomías Españolas: un Modelo Simplificado”, Papeles de Economía Española, nº 67, Págs. 2-45. ALONSO, F., y GÓMEZ, M. (1996): “El Conocimiento de la Economía Regional a través de la Contabilidad Regional”, Papeles de Economía Española, nº 67, Págs. 46-62. ANDRÉS, J. A., ESCRIBANO, C., MOLINAS, C. y TAGUAS, D. (1990): “La inversión en España: Modelización con Restricciones de Equilibrio“ (Barcelona-Madrid: Antoni Bosch, ed., e Instituto de Estudios Fiscales). -Pág. 459- Referencias ANDREWS, D. y PLOBERGER, W. (1994): “Optimal Tests When a Nuisance Parameter Is Present Only Under the Alternative”, Econometrica, 62, 1383-1414. ANDREWS, D. (1991): “Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation”, Econometrica, 59, 817-858. ANDREWS, D. (1993): “Tests for Parameter Instability and Structural Change With Unknown Change Point”, Econometrica, 61, 821-856. ANEIROS, J. (1994): “Modelización Econométrica Regional: una Aplicación para la Comunidad Autónoma de Madrid”, Universidad Autónoma de Madrid (UAM), Instituto L. R. Klein, Junio de 1994. (Trabajo de PreTesis). ANSLEY, C. y KOHN, R. (1983): “State Space Models and Diffuse Initial Conditions, I: Filtering and Likelihood”, Technical Report 13, University of Chicago, Statistics Research Center, Graduate School of Business. ARTÍS, M., CLAR, M., DEL BARRIO, T., LÓPEZ-BAZO, E. y SURIÑACH, J. (1996): “Teoría de la Cointegración y su aplicación al Análisis de las magnitudes de la Economía Andaluza”, Boletín Económico de Andalucía, Junta de Andalucía, Nº 21, Págs. 139-158. ARTÍS, M., PONS, J., SIERRA, M. y SURIÑACH, J. (1997): “Nivel de Actividad mediante Indicadores de Coyuntura”, Revista de Economía Aplicada, Nº 13 (Vol. V), 1997, Págs. 129 a 147. ARTÍS, M. y SURIÑACH, J. (1993): “Modelització Economètrica Regional. El Model Hispalink-Catalunya per a la Previsió i simulació de l’Economia Catalana”, Generalitat de Catalunya, Institut d’Estadística de Catalunya, Barcelona. ÁVILA, A. J., AVILÉS, C. A., LOZANO, A.V., TORRES, J. L. y VILLALBA, F. (1996): “Análisis de Coyuntura, Cuadros Macroeconómicos, Previsiones y Estimación del Crecimiento Regional”. Boletín Económico de Andalucía. Nº 21, págs 77-99. AZNAR, A. (1978): “Planificación y Modelos Econométricos” Editorial Pirámide. Colección Quantum AZNAR, A. y TRÍVEZ, F. J. (1993a): “Métodos de Predicción en Economía (I): Fundamentos, Input-Output, Modelos Econométricos y Métodos no Paramétricos de Series Temporales”. Editorial Ariel, Barcelona. AZNAR, A. y TRÍVEZ, F. J. (1993b): “Métodos de Predicción en Economía (II): Análisis de Series Temporales”. Editorial Ariel, Barcelona. -Pág. 460- Referencias BADILLO, R., CABRER, B., y VILA, L. E. (1998): “Pred icción Dinámica del VAB Regional a través de Mecanismos de correción de Error”, Comunicación presentada en la XII Reunión Asepelt de España, Córdoba, 1998. BANERJEE, A., DOLADO, J., GALBRAITH, J. W. y HENDRY, D.F. (1993): “Co-integretation, Error-correction, and the Econometric Analysis of Non-stationary Data”, Advanced Texts in Econometrics, Oxford University Press. BANERJEE, A., DOLADO, J., HENDRY, D. y SMITH (1986): “Exploring Equilibrium Relationships in Econometrics Through Static Models: some Monte Carlo Evidence”, Oxford Bulletin of Economics and Statistics, 48, Págs. 253-278. BASSMAN, R. L. (1972): “The Brookings Quaterly Econometric Model: Science o Number Mysticism”, en BRUNNER, K. (Ed.) (1972): “Problems and Issues in Current Econometric Practice”, Columbus: Ohio State University. BELL, W. R., y HILLMER, S. C. (1983): “Modelling Time Series with Calendar Variation”, Journal of the American Statistical Association, 78, Nº 383, September, 526-34. BELL, W. R., y HILLMER, S. C. (1984): “Issues Involved with the Seasonal Ajustment of Economic Time Series (con discusión)”, Journal of Business and Economic Statistics, Vol. 2, 291-349. BELL, W. R. (1984): “Signal Extraction for Nonstationary Time Series”. The Annal of Statistics. BELL, W. R. y HILLMER, S. C. (1984): “Issues Involved with the Seasonal Adjustment of Economic Time Series”, Journal of Business and Economic Statistics 2, 291-320. BELL, W. R., HILLMER, S. C. y TIAO, G. C. (1984): “Modelling Considerations in the Seasonal Adjustment of Economic Time Series”, en Zellner, A. (Ed.) (1983): “Applied Time Series Analysis of Economic Data”, U. S. Department of Commerce, Bureau of the Census, Washington, U.S.A. BELSLEY, D. A. (1973): “The Applicability of the Kalman Filter in the Determination of Systematic Parameter Variation”, Annals of Economics and social Measurement, Vol. 2, nº 4, Págs. 531-533. -Pág. 461- Referencias BELTRÁN L. (1993): “Historia de las Doctrinas Económicas”, Editorial Teide, Barcelona, Quinta Edición. BENNETT, R. J. y HORDICJK, L. (1986): “Regional Econometric and Dinamic Models”, en NIJKAMP, P. (Eds.) (1986), Chapter 10, Págs. 407 - 441. BODKIN, R. G., KLEIN, L. R. y MARWAH, K. (Ed.) (1991): “A History of Macroeconometric Model-Building”, Edward Elgar Publishing Company. BOLLERSLEV, T. (1986): “Generalized Autoregressive Conditional Heteroskedasticity”, Journal of Econometrics, 31, April, 307-27. BOLTON, R. (1985): “Regional Econometric Models”, Journal of Regional Science, Vol. 25 Nº 4, Págs. 495-520. Recogido en BODKIN, R. G., KLEIN, L.R., MARWAH, K. (Ed.) (1991): “A History of Macroeconometric Model-Building”, Edward Elgar Publishing Company, Cap. 13, Págs. 451-479. BOX, G. E. P., HILLMER, S., y TIAO, G. C. (1978): “Analysis and Modelling of Seasonal Time Series” (con discusión), en ZELLNER, A. (Ed.) (1978) 309-344. BOX, G. E. P., TIAO, G. C. (1975): “Intervention Analysis with Applications to Economic and Environmental Problems”, Journal of the American Statistical Association, 70 , number 349, March, 70-79. BOX, G. E. P. y JENKINS, G. M. (1970): “Time Series Analysis: Forecasting and Control”, San Francisco, Holden Day. BOX, G. E. P. y JENKINS, G. M. (1976): “Time Series Analysis: Forecasting and Control”, 2ª ed., San Francisco, Holden Day. BOX, G. E. P., HILLMER, S. C. y TIAO, G. C. (1978): “Analysis and Modeling of Seasonal Time Series”, en Zellner, A. (Ed.), Seasonal Analysis of Economic Time Series, Washington, D.C.: U.S.Dept. of Commerce - Bureau of the Census, 309-334. BROCKEWELL, P. y DAVIS, R. (1987): “Time Series: Theory and Methods”, Berlin: Springer-Verlag. BROWN, S. J., COULSON, N. E. y ENGLE, R. F. (1992): “On the Determination of Regional Base and Regional Base Multipliers”, Regional Science and Urban Economics, nº22, Págs. 619-635. -Pág. 462- Referencias BRUNNER, K. y MELTZER, A. (Eds.) (1983): “Theory, Policy, Institutions: Papers from the Carnegie-Rochester Conference Series on Public Policy.”, Elsevier Science Publishers B. V. North-Holland. BUREAU OF THE CENSUS (1995): “X-12-ARIMA Reference Manual” Washington, D.C.: U.S. Bureau of the Census, April 1995. BURMAN, J. P. (1980): “Seasonal Adjustment by Signal Extraction”, Journal of the Royal Statistical Society, Series A, Vol. 143, 321-337. BURNS, A. F. y MITCHELL, W. C. (1946): “Measuring Business Cycles”, National Bureau of Economic Research, Columbia University Press. BURRESS, D., EGLINSKY, M., y OSLUND, P. (1988): “A Survey of Static and Dinamic State-Level Input-Output Models”. Institute for Public Policy and Business Research, University of Kansas Research Discussion Paper. CABRER, B. (1997): “Métodos de Análisis Regional: Perspectivas de Futuro” (Págs. 283-308) Revista Valenciana d’Estudis Autonòmics, Nº 21 (Nº Extraordinario) Generalitat Valenciana. Valencia. CABRER, B. (Coord.) (1995): “La Integración Económica Regional en España. La Comunidad Valenciana”. Ediciones Mundi-Prensa. Madrid. CAMPOS, J., ERICSSON, N. y HENDRY, D. F. (1996): “Cointegration test in the presence of structural breaks, Journal of Econometrics”, 70, 187220. CANARELLA, G., POLLARD, S. y LAI, K.(1990): Cointegration between exchange rates and relative price: another view, European Economic Review, 34, 1303-1322. CAVERO, J., FERNÁNDEZ-ABASCAL, H., GÓMEZ, I., LORENZO, C., RODRÍGUEZ, B. ROJO, J. L. y SANZ, J. A. (1994): “Hacia un Modelo Trimestral de Predicción de la Economía Castellano-Leonesa. El modelo Hispalink C y L”, en TRÍVEZ, F. J. (Coordinador) (1994). CHAREMZA, W., y DEADMAN (1992): “New Directions in Econometric Practice: General to Specific Modeling”, Cointegration, and Vector Autoregression”, Edwar Elgar Publishing Ltd, UK. CHOW, G. (1984): “Random and Changing Coefficient Models”, en Z. Griliches, Z. y Intriligator, M., (Eds.) (1984): “Handbook of Econometrics”, Vol. II, Amsterdam: North-Holland, 1213-1245. CHRIST, C. (1994): “The Cowles Comission’s Contributions to Econometrics at Chicago, 1939-1955”, Journal of Economic Literature, Vol. 32, Págs. 30-59. -Pág. 463- Referencias CLEVELAND, W. P., y GRUPE, M. R. (1982): “Modeling Time Series when Calendar Effects are Present (con discusión)”, en A. Zellner (Ed.) (1982), 57-73. CLEVELAND, W. P. y TIAO, G. C. (1976): “Decomposition of Seasonal Time Series: A Model for the X-11 Program”, Journal of the American Statistical Association, Vol. 71, 581-587. COLINO SUEIRAS, J.(DIR.), BELLO FERNÁNDEZ, E., CARREÑO SANDOVAL, F., LÓPEZ MARTÍNEZ, M., NOGUERA MÉNDEZ, P., RIQUELME PEREA, F. (1990): “Precios, Productividad y Renta en las Agriculturas Españolas”. Coedición: Ediciones Mundi Prensa y Unión de Pequeños Agricultores. COOLEY, T. y LEROY, S. (1985): “Atheoretical Macroeconometrics: a Critique”, Journal of Monetary Economics, 16, 283-368. CORDERO, G., GAYOSO, A. (1997): “Evolución de las Economías Regionales en los Primeros 90”, Ministerio de Economía y Hacienda. Secretaría de Estado de Presupuestos y Gastos. Dirección General de Análisis y Programación Presupuestaria. Noviembre de 1997. COURBIS, R. (1979a): “Multiregional Modelling and the Interaction between Regional and National Development: a General Theoretical Framework”, en ADAMS, F. G. y GLICKMAN N. J. (Eds.) (1980): “Modelling the Multirregional Economic System”, Lexington, Mass.: D. C. Heath. COURBIS, R. (Eds.) (1979b): “Modèles Régionaux et Modèles RegionauxNationaux”. Actes du Deuxième Colloque International d'Econométrie Appliquée. Éditions Cujas Paris. COURBIS, R. (1980): “Multiregional Modeling and the Interaction between Regional and National Development”, in ADAMS, F. G. y GLICKMAN N. J. (Eds.) (1980): “Modelling the Multirregional Economic System”, Lexington, Mass.: D. C. Heath, Págs. 107-130. COURBIS, R. (1994): “La Modelización Multiregional en Europa Occidental: Balance y Perspectivas”, en PULIDO, A., CABRER, B. (Coords.) (1994): “Datos, Técnicas y Resultados del Moderno Análisis Económico Regional”, Ediciones Mundi-Prensa.Págs. 145-181. CRISTÓBAL, A. y MARTÍN, E. (1995): “Señal de Ciclo-Tendencia frente al Ajuste Estacional en la Contabilidad Nacional Trimestral”, Boletín Trimestral de Coyuntura, 55, Instituto Nacional de Estadística, pp 70102. -Pág. 464- Referencias CRISTÓBAL, A. y MARTÍN, E. (1992): “Contabilidad Nacional Trimestral de España”. Situación. Monográfico: La Estadística en España Hoy. Varios Autores, Nº 3, Págs. 39-43. CRISTÓBAL, A. y MARTÍN, E. (1994): “Tasas de Variación, Filtros y Análisis de la Coyuntura”, Boletín Trimestral de Coyuntura, 52, Junio 1994, INE. DAGUM, E. B. (1980): “The X11ARIMA Seasonal Adjustment Method”, Statistics Canada, Ottawa. DAGUM, E. B. (1988): “The X11ARIMA/88 Seasonal Adjustment Method”, Statistics Canada, Ottawa. DAGUM, E. B. (1990): “The X11ARIMA/88 Seasonal Adjustment Method”, Seminario Internacional de Estadistica en Euskadi,21, Instituto Vasco de Estadística. DARNELL, A. C. (Ed.) (1994): “The History of Econometrics”, (Volumes I and II). Cambridge. University Press. The international Library of Critical Writings en economics, Edward Elgar Publishing Limited. DAVIDSON, J. E. H., HENDRY, D. F., SRBA, F. y YEO, S. (1978): “Econometric Modelling of the Aggregate Time-Series Relationship Between Consumers” Expenditure and Income in the United Kingdom”, The Economic Journal, 88, December, 661-92. DAVIDSON, R. y MCKINNON, J. G. (1993): “Estimation and Inference in Econometrics”, Oxford University Press. DE GÓNGORA, C., PULIDO MARTÍNEZ, A., MARTÍN, E., DEL SUR, A. y PULIDO, A. (1989): “Indicadores de Alerta”, CEPREDE, Mayo de 1989. DE LA MACORRA, L. F. (Dir.) (1995): “Tablas Input-Output y Contabilidad Regional en Extremadura. 1990”. Vol. I. y II. Junta de Extremadura, Consejería de Economía y Hacienda. DE LOS LLANOS, M. y VALENTINA, A. (1994): “Métodos para la Extracción de Señales y para la Trimestralización”. Documento de trabajo nº 9415 Banco de España - Servicios de Estudios. DE MARCHI, N. y GILBERT, C. (1990): “History and Methodology of Econometrics”, Oxford Economic Papers, Volume 41, number 1 -Pág. 465- Referencias DEL BARRIO, T., CLAR, M. y PONS, E. (1996): “El Filtro de Líneas Aéreas Modificadas, Integrabilidad y Cointegración”, Documents de Treball de la Divisió de Ciències Jurídiques, Economiques i Socials, Universitat de Barcelona. DEL SUR MORA, A. (1994): “Generación de Indicadores Compuestos sobre Actividad económica Nacional y Regional a Corto Plazo”, en PULIDO, A., CABRER, B. (Coords.) (1994): “Datos, Técnicas y Resultados del Moderno Análisis Económico Regional”, Ediciones Mundi-Prensa, Págs. 265-284. DELRIEU, J.C. y ESPASA, A. (1994): “Consideraciones sobre las Fuentes Estadísticas Macroeconómicas en España: Innovaciones Recientes y Procedimientos para el Análisis de los Datos”. Economistas, nº59, págs 42-56. DEMPSTER, A. P., LAIRD, N. M. y RUBIN, D. B. (1977): “MaximumLikelihood From Incomplete Data Via the EM-Algorithm”, Journal of the Royal Statistical Society, B39, Págs. 1-38 DICKEY, D. A. y FULLER, W. A. (1979): “Distribution of the Estimators for Autoregressive Time Series with a Unit Root”, Journal of the American Statistical Association, 74, June, Págs. 427-431. DICKEY, D. A. y PANTULA, S. G. (1987): “Determining the Order of Differencing in Autoregressive Processes.”, Journal of Business & Economic Statistics, October 1987, Vol. 5, Nº 4, Págs. 455-461. DICKEY, D. A. y FULLER, W. A. (1981): “Likelihood Ratio Statistics for Autoregressive Time Series with a Unit Root”, Econometrica, 49, Págs. 1057-1072. DORNBUSCH, R. y FISCHER, S. (1989): “Macroeconomía”. 4ª Ed. McgrawHill. EISENPRESS, H. (1956): “Regression Techniques Applied to Seasonal Corrections and Adjustments for Calendar Shifts”, Journal of the American Statistical Association, Vol. 51, 615-620. ENGLE, R. y GRANGER, C. (Eds.) (1991): “Long-run Economic Relationships”, New York: Oxford University Press. ENGLE R. y GRANGER, C. (1987): “Co-integration and Error Correction: Representation, Estimation and Testing”, Econometrica, 55, 251-276. -Pág. 466- Referencias ENGLE, R. F. (1978): “Estimating Structural Models of Seasonality”; en Zellner, A. (ed.) (1978): “Seasonal Analysis of Economic Time Series “, Washington DC: Bureau of the Census, 281-308. ENGLE, R. F. (1982): “Autoregresive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflations”, Econometrica, 50, 987-1008. ENGLE, R. F. (1983): “Estimates of the Variance of U. S. Inflation Based on the ARCH Model”, Journal of Money, Credit, and Banking, 15, 286-301. ENGLE, R. F., HENDRY, D. F., RICHARD, J. F. (1983): “Exogeneity”, Econometrica, 51, Nº 2, March, 277-304. ENGLE, R. F. y KOZICKI, S. (1993): “Testing for Common Features”, Journal of Business & Economic Statistics, Octubre 1993, Vol. 11, Nº 4, Págs. 369-395. ENGLE, R. F. (1978): “Estimating Structural Models of Seasonality”, in A. Zellner (ed.), Seasonal Analysis of Economic Time Series, Washington, D.C.: U.S. Dept. Of Commerce - Bureau of the Census, 281-297. EPSTEIN, R. J. (1987): “A History of Econometrics”. North Holland. ERICSSON, N. R. (1992): “Cointegration, Exogeneity and Policy Analysis; an Overview”, Journal of Policy Modelling, Vol. 14, 251-280. ESCOLANO, C. (1993): “Modelización Econométrica Regional: Una Aplicación para la Comunidad Valenciana”, Tesis Doctoral, Universidad de Alicante. ESCUDER, R (1986): Métodos Estadísticos Aplicados a la Economía, Ed. Ariel, Barcelona. ESPASA, A. y CANCELO, J. R. (1994): “El Cálculo del Crecimiento de Variables Económicas a partir de Modelos Cuantitativos”, Boletín Trimestral de Coyuntura, INE, nº 52. ESPASA, A. y CANCELO, J. R. (Eds.) (1993): “Métodos Cuantitativos para el Análisis de la Coyuntura Económica”, Alianza Editorial, Madrid. EUROSTAT (1994): “Methodology of Industrial Short Term Indicators; Rules and Recommendations”. Luxembourg: Eurostat, September 1994. EUROSTAT (1996a): “Système Européen des Comptes. SEC 1995”. Luxembourg. -Pág. 467- Referencias EUROSTAT (1996b): “Industrial Trends”, Monthly Statistics. EZEQUIEL, M. (1938): “The Cobweb Effect”, Quaterly Journal of Economics, 52, 255-280. FAIR, R. C. (1994): “Testing Macroeconometric Models”, Harvad University Press. Cambridge, Massachusetts. FERNÁNDEZ MACHO, F. J. (1991): “Indicadores Sintéticos de Aceleraciones y Desaceleracioens en la Actividad Económica”, Revista Española de Economía, Vol 8, Nº 1, Págs. 125-156. FINDLEY, D. F., MONSELL, B., OTTO, M., BELL, W. and PUGH, M. (1992): “Towards X-12 ARIMA”, Mimeo, Bureau of Census. FINDLEY, D. F., MONSELL, B. C. (1995): “New Features of the X-12ARIMA Seasonal Adjustment Package”, Washington, D.C.: Statistical Research Division. U.S. Bureau of the Census. FISHER, I. (1925): “Our Unstable Dollar and the so-Called Business Cycle”. Journal of the American Statistical Association, Vol. 20, 179-202; (págs 181-191,194-198) en HENDRY, D.F, AND MORGAN, M.S. (Eds.) (1995). FISHER, B. (1995): “Decomposition of Time Series: Comparing Different Methods in Theory and Practice”, Version 2.1, Luxembourg: Eurostat, April 1995. FONTELA MONTES, E. (1997): “Los Ciclos Económicos en la Economía Moderna”. Fundación Argentaria. Madrid. FRISCH, R. (1933a): “Editorial”, Econometrica, 1, 1- 4. FRISH, R. (1933b): “Propagation Problems and Impulse Problems in Dinamic Economics”, en Economic Essays in Honour of Gustav Cassel, London: Allen and Unwin, 171-205. Reeditado en KYDLAND, F. E. (Ed.) (1995): “Business Cycle Theory”. Cap. 1. The international Library of Critical Writings en economics, Nº 58. Edward Elgar Publishing Limited. FULLER, W. A. (1976): “Introduction to Statistical Time Series, New York, John Wiley and Sons. GAPINSKI, J. H. (1982): “Macroeconomics Theory Statistics. Dinamics and Policy”, McGraw-Hill. -Pág. 468- Referencias GERSCH, W. y KITAGAWA, G. (1983): “The Prediction of Time Series with Trends and Seasonalities”, Journal of Business and Economic Statistics 1, 253-264. GEWEKE, J., MEESE, R. y DENT, W. (1983): “Comparing Alternative Tests of Causality in Temporal Systems”, Journal of Econometrics, Vol. 21, 161194. GLICKMAN, J. (1977): “Econometric Analysis of Regional System”, Nueva York: Academic Press. GÓMEZ, V. y MARAVALL, A. (1992): “Time Series Regression with Arima Noise and Missing Observations - Program TRAM”, EUI Working Paper Eco No. 92/81, Department of Economics, European University Institute. GÓMEZ, V. y MARAVALL, A. (1993): “Inizializing the Kalman Filter with Incompletely Specified Initial Conditions”, en CHEN, G. R. (Ed.): “Approximate Kalman Filtering (Series on Approximation and Decomposition)”, London: World Scientific Publ. Co. GÓMEZ, V. y MARAVALL, A. (1994): “Estimation, Prediction and Interpolation for Nonstationary Series with the Kalman Filter”, Journal of the American Statistical Association. Vol 89, June 1994. (611-624). GÓMEZ, V. y MARAVALL, A. (1997): “Programs TRAMO (Times Series Regression with ARIMA Noise, Missing Observations, and Outliers) and SEATS (Signal Extraction in ARIMA Time Series). Instructions for the User.” Beta Version: January 1997. GÓMEZ, V. y MARAVALL A. (1998a): “Guide for Usig the Programs TRAMO and SEATS”. Beta Version: December 1997. Banco de España. Servicio de Estudios. Documento de Trabajo nº 9805. GÓMEZ, V. y MARAVALL, A. (1998b): “Automatic Modeling Methods for Univariate Series”. Banco de España. Servicio de Estudios. Documento de Trabajo nº 9808. GÓMEZ, V. (1994): “Especificación Automática de Modelos Arima en Presencia de Observaciones Atípicas”, Mimeo, Departamento de Estadística e I.O., Universidad Complutense de Madrid, Junio 1994. -Pág. 469- Referencias GONZÁLEZ, B. y BOZA, J. (1994): “Un Modelo Regional-Tipo. El Modelo Mecalink de la Economía Canaria”, en PULIDO, A., CABRER, B. (Coords.) (1994): “Datos, Técnicas y Resultados del Moderno Análisis Económico Regional”, Ediciones Mundi-Prensa, Págs. 183-209. GRANGER, C. W. J. (1969): “Investigating Causal Relations by Econometric Models and Cross-Spectral Methods”, Econometrica, 37, Nº 3, July, 42438. GRANGER, C. W. J. y NEWBOLD, P. (1974): “Spurious Regressions in Econometrics”, Journal of Econometrics, 2, Págs. 111-120. GRANGER, C. W. J. y NEWBOLD, P. (1977): “Forecasting Economic Time Series”, New york, Academic Press. GREEN, G. R. y BECKMAN, B. A. (1992): “The Composite Index of Coincident Indicators and Alternative Coincident Indexes”, Survey of Current Business, 72, 42-45. GREGORY, A. y HANSEN, B. (1996): “Residual-based tests for cointegration in models with regime shifts”, Journal of Econometrics, 70, 99-126. HAAVELMO, T. (1943): “Statistical Testing of Business Cycle Theories”. Review of Economic Statistics, 25, 13-18. HAAVELMO, T. (1944): “The Probability Approach in Econometrics”. Supplement to Econometrica, vol. 12, en HENDRY, D.F, AND MORGAN, M.S. (Eds.) (1995). HACKL, P. y WESTLUND, A. (1996): “Demand for international telecommunication. Time-varying price elasticity”, Journal of Econometrics, 70, 243-260. HALL, S. (1994): “Modelling economies in transition”, Centre for Economic Forecasting, London Business School. HAMILTON, J. D. (1989): “A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle”, Econometrica, 57, 357-384. HAMILTON, J. D. (1994): “Time Series Analysis”, Princeton University Press, Prnceton, New Jersey. HANSEN, B. (1992): “Tests for Parameter Instability in regressions with I(1) Processes”, Journal of Business and Economic Statistics, 10, 321-336. -Pág. 470- Referencias HANSEN, L. y SARGENT, T. (1991): “Rational Expectations Econometrics”, Westfield Press, Boulder, CO. HARVEY, A. (1981): “The Econometric Analysis of Time Series”(Oxford: Philip Allan Publishers Limited). HARVEY, A. C. (1989): “Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge: Cambridge University Press. HARVEY, A. (1995): “Introduction” dentro de HARVEY, A. (Ed.)(1995): “Time Series” The international Library of Critical Writings en economics, Nº 5. Edward Elgar Publishing Limited. HARVEY, A. C. y KOOPMAN, S. J. (1992): “Diagnostic Checking of Unobserved-Components Time Series Models”. Journal of Business & Economic Statistics, October 1992, Vol. 10, Nº 4. HARVEY, A. C. (1993): “Time Series Models”, Second Edition, Harvester Wheatsheaf, London. HARVEY, A. C. y TODD, P. H. J. (1983): “Forecasting Economic Time Series With Structural and Box-Jenkins Models: A Case Study”. Journal of Business & Economic Statistics, Vol. 1, Nº 4, October 1983, 299306. HENDRY, D. F. (1979): “Predictive Failure and Econometric Modelling in Macroeconometrics: the Transactions Demand for Money”, en ORMEROD, P. (Ed.) (1979): “Economic Modelling”, Heinemann, London. HENDRY, D. F, y MORGAN, M. S. (Eds.) (1995): “The Foundations of Econometric Analysis”. Cambridge University Press. HENDRY, D. F. y NEALE, A. (1991): “A Monte Carlo study of the effects of structural breaks on tests for unit roots”, en HACKL, P. y WESTLUND, A. (Eds.): “Economic structural change: analysis and forecasting”, Berlin: Springer-Verlag, 95-119. HEWINGS, G. J. D. y JENSEN, R. C. (1986): “Regional, Interregional and Multiregional Input-Output Analysis”, in NIJKAMP, P. (Eds.) (1986), Chapter 8, págs 295 - 356. HICKS, J. R. (1937): “Mr Keynes and the ‘Classics’: a Suggested Interpretation”, Econometrica, Vol 5, págs 147 - 159. -Pág. 471- Referencias HILLMER, S. C. y TIAO, G. C. (1982): “An ARIMA -Model-Based Approach to Seasonal Adjustment”, Journal of the American Statistical Association, 77, March, 63-70. HILLMER, S. C., BELL, W. R., y TIAO, G. C. (1983): “Modelling Considerations in the Seasonal Adjustment of Economic Time Series (con discusión)”, en A. Zellner (Ed.) (1983), 74-124. HILLMER, S. C. y TIAO, G. C. (1982): “An ARIMA-Model Based Approach to Seasonal Adjustment”, Journal of the American Stadistical Association, 8, pp. 231-47. HISPALINK (1993): “Banco de datos multirregional HISPALINK” (Madrid: Consejo Superior de Cámaras de Comercio, Industria y Navegación de España). HISPALINK (1997): “HISPADAT. Banco de datos” (Madrid: Instituto L.R. Klein y Consejo Superior de Cámaras de Comercio, Industria y Navegación de España). HOLT, C. C. (1957): “Forecasting Seasonals and Trends by Exponentially Weighted Moving Averages”, ONR Research Memorandum Nº 52, Carnegie Institute of Technology, Pittsburgh, Pennsylvania. HOOD, W. C. y KOOPMANS, T. C. (Eds.) (1953): “Studies in Econometric Method”, Monografía 14 de la Cowles Commision, Wiley. HWANG, C. y YOON, K.: “Multiple Attribute Dicision Making. Methods and Applications”. Springer Verlag. New York. INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1982): “Números Índices de la Producción Industrial. Base 100 en 1972. Monografía Técnica”. INE 1982. INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1988): “Características Generales de la Metodología Aplicada en las Distintas Estimaciones de la Contabilidad Nacional”. Enero-1988. INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1990): “Contabilidad Regional de España. Serie 1980-87, Base 1980”, INE 1990. INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1991): “Contabilidad Regional de España 1985-88, Base 1985”, INE 1991. INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1993a): “Contabilidad Nacional Trimestral de España. Metodología y Serie Trimestral 19701992”. INE. Madrid. -Pág. 472- Referencias INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1993b): “Contabilidad Regional de España. Base 1986. Serie Homogénea 1980-1989”. INE. Madrid. INSTITUTO NACIONAL DE ESTADÍSTICA (INE) (1994): “Sistema de Indicadores Cíclicos de la Economía Española. Metodología e Índices Sintéticos de Adelanto, Coincidencia y Retraso”. INE. Madrid. ISARD, W. (1973): “Métodos de Análisis Regional”, Editorial Ariel. Esplugues de Llobregat (Barcelona). ISSAEV, B., NIJKAMP, P., RIETVELD, P. y SNICKARS, F. (Eds.) (1982): “Multiregional Economic Modeling: Practice and Prospect”, Amsterdam: North-Holland Publ. Co. JORGENSON, D. W. (1966): “Rational Distributed Lag Functions”, Econometrica, 34. JUDGE, G.G., GRIFFITHS, W.E., CARTER H. R., HELMUT LÜTKEPOHL, TSOUNG-CHAO LEE (1985): “The Theory and Practice of Econometrics“ Second Edition, Wiley International Edition. KALMAN, R. E. (1960): “A New Approach to Linear Filtering and Prediction Problems”, Journal of Basic Engineering, Transactions of the ASME, Series D, 82, March, 35-45. KALMAN, R. E. (1963): “New Methods in Wiener Filtering Theory”, dentro de John L.Bogdanoff y Frank Kozin, (Eds.) (1963): “Proceedings of the First Symposium of Engineering Applications of Random Function Theory and Probability”, 270-388, New York: Wiley. KENDALL, M. G. (1968): “The History of statsitical Methods”, in International Encyclopedia of the Social Sciences, de. D. L. sills, Vol. 15, New York: Macmillan and The Free Press, 224-232. KEYNES, J. M. (1939): “Professor Tinbergen’s Method”. Economic Journal, 49, Págs. 558-568. KEYNES, J. N. (1890): “The Scope and Method of Political Economy”, Macmillan, London, 1891, in HENDRY, D.F, AND MORGAN, M.S. (Eds.) (1995). KITAGAWA, G. (1987): “Non-Gaussian State-Space Modeling of Nonstationary Time Series”, Journal of the American Statistical Association, 82, December, 1032-41. KITAGAWA, G. y GERSCH, W. (1984): “A Smoothness Priors-State Space Modeling of Time Series with Trend and Seasonality”, Journal of the American Statistical Association, 79, June, 378-89. -Pág. 473- Referencias KLEIN, L. R. (Ed.) (1950): “Economic Fluctuations in the United States, 19211941”, Monografía 11 de la Cowles Commision, Wiley. KLEIN, L. R. y SOJO, E. (1986): “Combinations of High and Low Frecuency Data in Macroeconometrics Models”. KLEIN, L. R. y YOUNG, R. M. (1980): “An Introduction to Econometric Forecasting and Forecasting Models”, Fourth Printing, March 1982, Lexington Books. KOOPMANS, T. C. (Ed.) (1950): “Statistical Inference in Dynamic Economic Models”, Monografía 10 de la Cowles Commision, Wiley. KYDLAND, F. E. y PRESCOTT, E. C. (1982): “Time to Build and Aggregate Fluctuations”, Econometrica, Vol. 50, Págs. 1345-1370. KYDLAND, F. E. y PRESCOTT, E. C. (1990): “Business Cycles: Real Facts and a Monetary Myth”, Federal Reserve Bank of Minneapolis Quaterly Review, 14 (2), Spring, 3-18. Reeditado en KYDLAND, F. E. (Ed.)(1995): “Business Cycle Theory”. Cap. 4. The international Library of Critical Writings en economics, Nº 58. Edward Elgar Publishing Limited. KYDLAND, F. E. (1995): “Introduction” en KYDLAND, F. E. (Ed.) (1995). Págs. ix a xvi. KYDLAND, F. E. (Ed.) (1995): “Business Cycle Theory”. The international Library of Critical Writings en economics, Nº 58. Edward Elgar Publishing Limited. LAHIRI, K. y MOORE, G. H. (Eds.) (1991): “Leading Economic Indicators: New Approaches and Forecasting Records”. Cambridge. University Press. LEONTIEF, W. (1936): “Cuantitative Input-Output Relations in the Economic System of the United States”, Review of Economics and Statistics. Vol. 18, Nº 3, Págs. 105-125. LIN, C-F. y TERÄSVIRTA, T. (1994): Testing the constancy of regression parameters against continuous structural change, Journal of Econometrics, 62, 211-228. LIU, L. M. (1980): “Analysis of Time Series with Calendar Effects”, Management Science, Vol. 26, 106-112. -Pág. 474- Referencias LLANOS, M. y VALENTINA, A. (1994): “Métodos para la Extracción de Señales y para la Trimestralización. Una Aplicación: Trimestralización del Deflactor del Consumo Privado Nacional”, Banco de España, Documento de Trabajo nº 9415. LOBO, R. y CLAR, M. (1997): “Un Modelo Econométrico Regional con Base Económica para Cataluña”, Comunicaciones de la XXIII Reunión de Estudios Regionales, Valencia, 18, 19, 20 y 21 de Noviembre de 1997, Vol. II, Págs. 497-502. LÓPEZ, A. J. y PÉREZ, R. (1994): “Deflactores Sectoriales Regionales. Una Propuesta para Asturias”, Ponencia Presentada en la XI Jornadas Hispalink, Oviedo, Marzo 1994, Hispalink, Págs. 26-47. LUCAS, R.E. (1976): “Econometric Policy Evaluation: A Critique”, en BRUNNER, K. y MELTZER, A. (Eds.) (1983), Págs. 257-284. Reproducido de The Phillips Curve and Labor Markets, CarnegieRochester Conference Series on Public Policy, Vol. 1, Págs. 19-46. LUCAS, R. E. (1977): “Understanding Business Cycles”, en Karl Brunner y Allan H. Meltzer (Eds.), Stabilization of the Domestic and International Economy, Carnegie-Rochester Conference Series on Public Policy, 5, 729. Reeditado en KYDLAND, F. E. (Ed.) (1995): “Business Cycle Theory”. Cap. 5. The international Library of Critical Writings en economics, Nº 58. Edward Elgar Publishing Limited. LUCAS, R. E. y SARGENT, T.J. (1978): “After Keynesian Macroeconomics”, en After the Phillips Curve: Persistence of High Inflation and High Unemployment, Conference Series Nº 19, Federal Reserve Bank of Boston. LÜTKEPOHL, H. (1993): “Introduction to Multiple Time Series Analysis”, Springer-Verlag. New York. MAKRIDAKIS, S.G. (1993): “Pronósticos. Estrategia y Planificación para el Siglo XXI”. Díaz de Santos. MARAVALL, A. (1985): “On Structural Time Series Model and the Characterization of Components”, Journal of Business and Economic Statistics, 3, pp. 350-5. MARAVALL, A. (1986): “An Application of Model-Based Estimation of Unobserved Components”, International of Forecasting, 2,pp. 305-18. -Pág. 475- Referencias MARAVALL, A. (1987): “Descomposición de Series Temporales: Especificación, Estimación e Inferencia (con discusión)”, Estadística Española, Nº 114, 11-106. MARAVALL, A. (1989): “La Extracción de Señales y el Análisis de la Coyuntura”, Revista Española de Economía, vol. 6, nº 1 y 2, Págs. 109130. MARAVALL, A. (1990): “Algunas Reflexiones sobre la Utilización del Análisis de Series Temporales en Economía”, Revista Española de Economía, Vol. 7, Nº 2, (1990). MARAVALL, A. (1993): “Stochastic Linear Trends. Models and estimators”. Journal of Econometrics, 56, pp. 5-37. MARAVALL, A. (1996): “Short-Term Analysis of Macroeconomic Time Series”. Banco de España. Servicio de estudios. Documento de Trabajo nº 9607. MARAVALL, A. y PIERCE, D. A. (1987): “A Prototypical Seasonal Adjustment Model”, Journal of Time Series Analysis 8, 177-193. MARAVALL, A. y PEÑA, D. (1996): “Missing Observations and Additive Outliers in Time Series Models”, Banco de España, Servicio de Estudios, Documento de Trabajo nº 9612. MARAVALL, A. y PLANAS, C. (1996): “Estimation Error and the Specification of Unobserved Component Models.” Banco de España. Servicio de estudios. Documento de Trabajo nº 9608. MÁRQUEZ, M. A. y RAMAJO, J. (1996): “Elaboración de Indicadores sintéticos para el Seguimiento a Corto Plazo de la Economía Extremeña”, Comunicación presentada en la X Reunión Asepelt España, Albacete, 20 y 21 de Junio de 1996. MARTÍN ACEÑA, P. (1990): “Antecedentes Históricos del Análisis de Coyuntura en España”. Revista de economía, nº 6, 82-86. MARTÍN QUILIS, E. (1996): “Apuntes de Extracción de la Señal en Series Económicas”. Subdirección General de Cuentas Nacionales, Instituto Nacional de Estadística. -Pág. 476- Referencias MARTÍNEZ AGUADO, T. (1992): “Combinación de Datos de Alta y Baja Frecuencia. Aplicación al Análisis de la Coyuntura”, en PULIDO, A., CABRER, B. (Coords.) (1994): “Datos, Técnicas y Resultados del Moderno Análisis Económico Regional”, Ediciones Mundi-Prensa. MARTÍNEZ LÓPEZ, A. (1992): “Contabilidad Regional de España: Metodología y datos disponibles”. Datos, Técnicas y Resultados del Moderno Análisis Económico Regional. Ediciones Mundi-Prensa, 1994, 23-40. MARTÍNEZ LÓPEZ, A. (1996): “La Metodología Utilizada para la Elaboración de la Contabilidad Regional de España”. Boletín Económico de Andalucía. Nº21, págs 37-48. MCKINNON, J. (1991): “Critical values for cointegration tests in long-run economic relationships”, en ENGLE R. y GRANGER, C. (Eds.) (1991), Págs. 267-276. MELIS, F. (1991): “La Estimación del Ritmo de Variación en Series Económicas”, Estadística Española, Vol. 33, Núm. 126, 1991, Págs. 756. MELIS, F. (1992), “Agregación Temporal y Solapamiento o Aliasing”, Estadística Española, Vol. 34, Núm. 130, Págs. 309-346. MILLER, R. E. y BLAIR, P. D. (1985): “Input-Output Analysis: Foundations and Extensions”, Prentice-Hall, Inc., Englewood Clifs, New Jersey. MITCHELL, W. C. (1913): “Business Cycles and their Causes”. California University Memoirs. Volume III, reeditado en MITCHELL, W. C.(1959): “Business Cycles and their Causes”. Berkeley. University of California Press. MOCHÓN, F. y ANCOCHEA, G. (1981): “El Análisis de la Coyuntura. Una Metodología”. Pirámide. Madrid. MOCHÓN, F. y ÁVILA, A. J. (1988): “Análisis de Coyuntura Regional: Elaboración de Cuadros Macroeconómicos a partir de Datos Coyunturales.” Ekonomiaz, nº 11, 1988. MOLINAS, C., SEBASTIÁN, M. y ZABALZA, A. (1991): “La Economía Española: una Perspectiva Macroeconómica” (Barcelona-Madrid: Antoni Bosch, ed., e Instituto de Estudios Fiscales). -Pág. 477- Referencias MOORE, G. H. (1991): “New Developments en Leading Indicators”, en LAHIRI, K. Y MOORE, G. H. (Eds.) (1991): “Leading Economic Indicators: New Approaches and Forecasting Records”. Cambridge. University Press, Págs. 141-147. MOORE, G. H. y SHISKIN, J. (1967): “Indicators of Business expansions and Contractions”, National Bureau of Economic Research, New York. MORAL, A. y TITOS, A. (Dir.) (1981): “Tablas Input-Output Cuentas Regionales y Balanza Comercial de Extremadura. Año 1978”. Volumen I y II, Banco de Bilbao. MORALES, E. ESPASA, A. FONT, A. e IZQUIERDO, J. F. (1994): “Estimación del Crecimiento del V.A.B. no Agrario de Baleares a partir de un Indicador Sintético”, en ESPASA, A. (1994): “Métodos Estadísticos-Econométricos para el Análisis de la Coyuntura Económica”, Eustat, Págs. 197-210. MORALES, E., ESPASA, A., PARRA, F. J., GARCÍA, M. J., HENÁNGÓMEZ, M. y BELTRÁN, M. (1994): “Estimación del Crecimiento del V.A.B. de Castilla y León a partir de un Indicador Sintético y su Utilización con Fines de Análisis Coyuntural”, Comunicación publicada en las Actas del IV Congreso de Economía Regional de Castilla y León; Burgos, 24, 25 y 26 de Noviembre de 1994, Págs. 1534-1548. MORGAN, M.S. (1990): “The History of Econometric Ideas”. Cambridge. University Press. MULLINEUX, A. W., DICKINSON, D. G. y PENG, W. (1993): “Business Cycles”, Basil Blackwell, Oxford. MUÑOZ, C. (1988): “Elaboración y Utilización de las Tablas Input-Output Regionales”, Papeles de Economía Española, nº 35, Págs. 457-469. MUTH, J. F. (1960): “Optimal Properties of Exponentially Weighted Forecasts”, Journal of the American Statistical Association, 55, June, 299-306. NELSON, C. R. y PLOSSER, C. I. (1982): “Trends and Random Walks in Macroeconomic Times Series: Some Evidence and Implications”, Journal of Monetary Economics, 10, September, 139-162. NERLOVE, M. y WAGE, S. (1964): “On the Optimality of Adaptative Forecasting”, Management Science, 10, 207-29. NERVOLE, M., GRETHER D, y CARVALHO, J. L. (1979): “Analysis of Economic Time Series: a Synthesis”, Academic Press, New York, USA. -Pág. 478- Referencias NIEMIRA, M. P. y KLEIN, P. A. (1994): “Forecasting Financial and Economic Cycles”. John Wiley & Sons. New York. NIJKAMP, P. (Eds.) (1986): “Handbook of Regional and Urban Economics”, Volume I, Regional Economics, North-Holland. NIJKAMP, P. y MILLS, E. S. (1986): “Advances in Regional Economics”, in NIJKAMP, P. (Eds.) (1986), Chapter 1, págs 1-17. NIJKAMP, P., RIETVELD, P. y SNICKARS, F. (1986): “Regional and Multiregional Economic Models: a Survey”, en NIJKAMP, P. (Eds.) (1986), Chapter 7, págs 257 - 293. OCDE (1987): “OECD Leading Indicators and Bussiness Cycles in Member Countries. 1960-1985”, OCDE, París. OTERO, J. M., ISLA, F., TRUJILLO, F., FERNÁNDEZ, A. y LÓPEZ, P. (1996): “Modelización económica regional: el proyecto HispalinkAndalucía”, Boletín Económico de Andalucía, 21, Págs. 49-66, Consejería de Economía y Hacienda, Junta de Andalucía, Sevilla. OTERO, J. M., MARTÍN, G., TRUJILLO, F. y FERNÁNDEZ, A. (1991): “Predicciones de Población Activa, Producción, Empleo y Paro en Andalucía”, Boletín Económico de Andalucía, 12, Consejería de Economía y Hacienda, Junta de Andalucía, Sevilla. OTERO, J. M. (1993): “Econometría. Series Temporales y Predicción”. Editorial AC. PAGAN, A. R. (1975): “A Note on the Extraction of Components from Time Series”, Econometrica, 43, 163-8. PARRA RODRÍGUEZ, F. J. (1993): “Aproximación al Ciclo Económico de Castilla y León. Comparación con los Ciclos Español y Europeo”, Revista de Estudios Europeos, 5, 1993, Págs. 95-107. PARZEN, E. (1957): “On Consistent Estimates of the Spectrum of a Stationary Time Series”, Annals of Mathematical Statistics, 28, Págs. 329-348. PENA TRAPERO, J. B. (1977): “Problemas de la medición del bienestar y Conceptos Afines (Una Aplicación al caso Español)”. INE, Madrid. PENA TRAPERO, J. B. (1994): “Nota Sobre la Deflación de los Valores Añadidos Regionales”, Ponencia Presentada en la XI Jornadas Hispalink, Oviedo, Marzo 1994, Hispalink, Págs. 2-8. -Pág. 479- Referencias PÉREZ GARCÍA, J. (1995): “Tratamiento Econométrico del Cambio Estructural: El Método de Estimación Paramétrica Ponderada”, Tesis Doctoral, Instituto L. R. Klein, Dpto. de Economía Aplicada, Universidad Autónoma de Madrid. PÉREZ, R., LÓPEZ, A. J., CASO, C., RÍO, M. J. y HERNÁNDEZ, M. (1994): “Mecastur: Modelo Econométrico para Asturias”, en TRÍVEZ, F. J. (Coordinador) (1994), Págs. 273-292. PERRON, P. (1989): The great crash, the oil price shock, and the unit root hypothesis, Econometrica, 57, 1361-1401. PERRYMAN, M. R. y PERRYMAN, N. S. (1986): “The Regional Business Cycle: a Theoretical Exposition with Time Series, Cross Sectional, and Predictive Applications”, en PERRYMAN, M.R. y SCHMIDT, J. R. (Ed.) (1986), Págs. 125-158. PERRYMAN, M. R. y SCHMIDT, J. R. (Ed.) (1986): “Regional Econometric Modeling”, Boston: Kluwer•Nijhoff Publishing. PERSONS, W. M. (1919): “Indices of Bussiness Conditions”. Review of Economics and Statistics, 1, págs 5-110. PERSONS, W. M. (1924): “The Problem of Business forecasting” en “The Problem of Business Forecasting”, Pollak Foundation for Economic Research Publications, No. 6, London: Pitman. PESARAN, M. H. (1990): “Econometrics”, dentro de “The New Palgrave: Econometrics”. Edited by J. Eatwell, M. Milgte and P. Newman. Mac Millan Press. PHILIPS, P. C. B. (1986): “Understanding Spurious Regressions in Econometrics”, Journal of Econometrics, 33, Págs. 311-340. PHILIPS, P. C. B. y LORETAN, M. (1991): “Estimating Long-run Economic Equilibria”, Review of Economic Studies, 58, Págs. 407-436. PHILLIPS, K. R. (1994): “Regional Indexes of Leading economic Indicators”, en NIEMIRA, M.P., KLEIN, P.A. (1994): “Forecasting Financial and Economic Cycles”. John Wiley & Sons. New York, Págs. 347-361. PHILLIPS, P. (1991): “Optimal Inference in Cointegrated Systems”, Econometrica, Vol. 59, Págs. 283-306. PHILLIPS, P. C. B. y HANSEN, B. E. (1990): “Statistical Inference in Instrumental Variables Regression whith I(1) Process”, Review of Economic Studies, 57, Págs. 99-125. -Pág. 480- Referencias PHILLIPS, P.C.B. y PERRON, P. (1988): “Testing for Unit Roots in Time Series”, Biometrica, 75, Págs. 235-346. PONS NOVELL, J. (1996): “Un Sistema d’Indicadors cíclics per a l’Economia Catalana”. Edicions de la Universitat de Barcelona. PONS NOVELL, J. y SURIÑACH CARALT, J. (1995): “Un Indicador Cíclico para la Economía Catalana” Actas de la IX REUNIÓN ASEPELT ESPAÑA, Vol. I, Págs. 383-395. POPPER, K. (1980): “La Lógica de la Investigación Científica”. Tecnos. Madrid. PULIDO, A. (1985): “Experiencias con modelos macroeconométricos: Luces y Sombras keynesianas”. Documento metodológico. Enero. CEPREDE. PULIDO, A. (1987): “Modelos Econométricos”, Segunda Edición, Ediciones Pirámide, Madrid. PULIDO, A. (1989): “Predicción Económica y Empresarial”. Ediciones Pirámide. Madrid. PULIDO, A. (1992): “25 Años de Experiencia en Econometría Aplicada”, Centro L. R. Klein, Universidad Autónoma de Madrid. PULIDO, A. (1994): “Panorámica de la modelización Econométrica Regional”, Cuadernos Aragoneses de Economía, 2ª Época, Volumen 4, Número 2, Págs. 211-229. PULIDO, A. (1995): “Economía para Entender”. Ediciones Pirámide. Madrid. PULIDO, A. (1995): “Integración Económica Regional”, en CABRER, B. (Coord.) (1995): “La Integración Económica Regional en España. La Comunidad Valenciana”, Ediciones Mundi-Prensa. PULIDO, A. (1997): “Previsiones Regionales: el Caso del Modelo Hispalink”, Curso impartido en la Universidad Internacional Menéndez Pelayo, Santander, 14-18 de Julio. PULIDO, A. y FONTELA E. (1993): “Análisis Input-Output: Teorías, Datos, Programas y Aplicaciones”. Ediciones Pirámide, Madrid. QUANDT, R. (1960): Tests of the Hypothesis That a Linear Regression System Obeys Two Separate Regimes, Journal of the American Statistical Association, 55, 324-330. -Pág. 481- Referencias QUINTOS, C. y PHILLIPS, P. (1993): “Parameter constancy in cointegrating regresssions”, Empirical Economics, 18, 675-703. RAMAJO, J. y MÁRQUEZ, M A. (1996): “Elaboración de indicadores sintéticos para el seguimiento de la coyuntura económica de Extremadura”, Monográfico de la Consejería de Economía, Industria y Hacienda, Junta de Extremadura. RAMAJO, J. (1990): “Tendencias Sectoriales en Extremadura: Modelización Econométrica de los Valores Añadidos”, Consejería de Economía y Hacienda, Junta de Extremadura. RAMÍREZ SOBRINO, J. N. (1992): “El Análisis Cuantitativo de la Economía Regional: los Modelos Econométricos Regionales”, Publicaciones ETEA, Colección Tesis Doctorales. RAPPOPORT, P. y REICHLIN, L. (1989): “Segmented trends and nonstationary time series”, The Economic Journal, 99, 168-177. RAYMOND, J. L. (1993): “Análisis Coyuntural y Modelos Macroeconómicos”. Revista de Economía. Número 713. RAYMOND, J. L. (1994): “Condicionantes Externos de la Evolución de la Economía Española”, Documentos de trabajo, Número 104/1994, Fundación Fondo para la Investigación Económica y Social.¡Error! Marcador no definido. REINSEL, G. C. (1997): “Elements of Multivariate Time Series Analysis.” Second edition. Springer Verlag. New york. RICHARDSON, H. W. (1975): “Elementos de Economía Regional”, Alianza Universidad, Madrid, (Versión española de Fernando Escribano de “Elements of Regional Economics”, 1969) RICHARDSON, H. W. (1978): “El Estado de la Economía Regional: un Artículo de Síntesis”, Revista de Estudios Regionales, Nº 3, 147-217. RICHARDSON, H. W. (1986): “Economía Regional y Urbana”, Alianza Universidad Textos, Madrid. (Versión española de Marta Casares de “Regional and Urban Economics”, 1978). ROBBINS, L. (1932): “An Essay on the Nature and Significance of Economic Science”. Macmillan, London, 1932, págs 98-105, in HENDRY, D.F, AND MORGAN, M.S. (Eds.) (1995, Págs. 98 - 102). RODRÍGUEZ POO, J. M. (Coord.) (1998): “Boletín de Previsión y Coyuntura Económica de Cantabria”, Boletín de carácter trimestral, Gobierno de Cantabria, Consejería de Economía y Hacienda. -Pág. 482- Referencias RODRÍGUEZ SÁIZ, L., MARTÍN PLIEGO, J., PAREJO GÁMIR, J. A. y ALMOGERA GÓMEZ, A. (1986): “Política Económica Regional”, Alianza Editorial, Madrid. RODRÍGUEZ, S., DÁVILA, D. y GONZÁLEZ, B. (1994): “El modelo Econométrico y de Indicadores de la Economía Canaria Mecalink”, en TRÍVEZ, F. J. (Coordinador) (1994), Págs. 293-316. SARRIS, A. H. (1973): “Kalman Filter Models. A Bayesian Approach to Estimation of Time-Varying Regression Coefficients”, Annals of Economics and Social Measurement, Vol. 2, nº4, Págs. 501-523. SCHULZ, M. (1938): “The Theory and Measurement of Demand”, University of Chicago Press. SCHUMPETER, J. A. (1939): “Business Cycles”. Nueva York. SCHWEPPE, F. C. (1965): “Evaluation of Likelihood Functions for Gaussian Signals”, IEEE Transactions on Information Theory, 11, January, 61-70. SERRANO, G. y CABRER, B. (1995): “Una Visión Agregada de la Economía Valenciana”, en CABRER BORRÁS, B. (Coordinador) (1995), Págs. 47-67. SHISKIN, J. (1961): “Signals of Recession and Recovery”, National Bureau of Economic Research, New York. SHISKIN, J., YOUNG, A. y MUSGRAVE, J. C. (1967): “The X11 Variant of the Census Method II Seasonal Adjustment Program”, Bureau of Census, Technical Paper 15, Washington. SHISKIN, J., YOUNG, A. y MUSGRAVE, J. C. (1967): “The X-11 Variant of the Census Method II Seasonal Adjustment Program, Technical Paper 15, Bureau of the Census, Washington. SIMS, C. A. (1972): “Money, Income, and Causality”, American Economic Review, LXII, September, 540-552. SIMS, C. A. (1980): “Macroeconometrics and Reality”, Econometrica, vol. 48, nº 1 (January) Págs. 1 - 48. SIVITANIDOU, R. M. y POLENSKE, K. R. (1988): “Assessing Regional Economic Impacts with Microcomputers”. American Planning Association Journal, 101-106. -Pág. 483- Referencias SLUTSKY, E. (1927): “The Summation of Random Causes as the Source of Cyclic Processes”, en Problems of Economic Conditions, Volumen III, Moscú. Traducción al inglés en Econometrica, 5, año 1937, Págs. 105146. SOLOW, R. M. (1957): “Technical Change and the Aggregate Production Function”. Review of Economics and Statistics, XXXIX (3) August, 312-20. Reeditado en KYDLAND, F. E. (Ed.) (1995): “Business Cycle Theory”. Cap. 2. The international Library of Critical Writings en economics, Nº 58. Edward Elgar Publishing Limited. STIGLER, G. J. (1954): “The Early History of Empirical Studies of Consumer Behaviour”, Journal of Political Economy, 62, págs 95-113. STIGLER, S. M. (1978): “Francis Ysidro Edgeworth, Statistician” (Con discusión), Journal of the Royal Statistical Society Series A, 141, 287322. STOCK, J. H. (1987): “Asymptotic Properties of Least Squares Estimators of Cointegrating Vectors”, Econometrica, 55, Nº 5, 1035-56. STOCK, J. y WATSON, M. (1996): “Evidence on structural instability in macroeconomic time series relations”, Journal of Business and Economic Statistics, 14, 11-30. SURIÑACH, J. (1987): “Un Modelo Econométrico Regional para Cataluña”, Tesis Doctoral, Universidad de Barcelona, Departamento de Econometría, Estadística y Economía Española. SURIÑACH, J., ARTÍS, M., LÓPEZ-BAZO, E. y SANSÓ, A. (1995): “Análisis Económico Regional: Nociones Básicas de la Teoría de la Cointegración”, Antoni Bosch Editor. Barcelona. THE ECONOMIST (1993): “Guía de los Indicadores Económicos”, Ediciones del Prado, Madrid. THEIL, H. (1966): “Applied Economic Forecasting” , Amsterdam: NorthHolland. THEIL, H. y WAGE, S. (1964): “Some Observations on Adaptative Forecasting”, Management Science, 10, 198-206. TIAO, G. C. y BOX, G. E. P. (1981): “Modeling Multiple Time Series with Applications”, Journal of the American Statistical Association, 76, Nº 376, December, 802-16. -Pág. 484- Referencias TIEBOUT, C. M. (1962): “The Community Economic Base Study”, Supplementary Paper Nº 16, Commitee for Economic Development, Washington. TINBERGEN, J. (1937): “An Econometric Approach to Business Cycle Problems, Hermann and Cie. TINBERGEN, J. (1939): “Statistical Testing of Business Cycle Theories. Vol I: A Method and its Application to Investment Activity; Vol II: Business Cycles in the United States of America, 1919-1932. Geneva: League of Nations. TREYZ, G. (1993): “Regional economic modeling. A Systematic Approach to Economic Forecasting and Policy”, Boston: Kluwer Academic Publishers. TREYZ, G. (1994): “Regional Economic Modeling: A Systematic Approach to Economic Forecasting and Policy Analysis”, Second printing, Kluwer Academic Publishers, Massachusetts. TRÍVEZ, F. J. (Coord.) (1994): “Modelos Econométricos Regionales”, Cuadernos Aragoneses de Economía, 2ª Época, Volumen 4, Número 2. TRÍVEZ, F. J. y MUR, J. (1994): “El Modelo Econométrico Regional Sectorial Hispalink Aragón”, en TRÍVEZ, F. J. (Coordinador) (1994), Págs. 231272. TRUJILLO, F., BENÍTEZ, M. D. y LÓPEZ, P. (1996): “ISTAN: Un Indicador Sintético Trimestral de la Actividad Económica no Agraria de Andalucía”, Comunicación presentada en la X Reunión ASEPELTEspaña, Albacete, Junio 21-22 de 1996. VALLE, V. (1995): “Algunas Cuestiones Básicas en el Análisis de la Coyuntura Económica”. Papeles de Economía Española, nº 62, 1995. VINING, R. (1949): “Koopmans on the Choice of Variables to be Studied and of Methods of Measurement”. Review of Economics and Statistics, 31, 7786. WALLIS, K. F. (1980): “Econometric Implications of the Rational Expectations Hypothesis”, Econometrica, Vol. 48, Nº 1, January, 49-73. WATSON, M. W. y ENGLE, R. F. (1983): “Alternative Algorithms for the Estimation of Dynamic Factor, MIMIC, and Varying Coefficient Regression Models”, Journal of Econometrics, 23, Págs. 385-400. -Pág. 485- Referencias WEBER, R. E. (1986): “Regional Econometric Modelling and the New Jersey State Model”, en PERRYMAN, M.R. y SCHMIDT, J. R. (Ed.) (1986): “Regional Econometric Modeling”, Boston: Kluwer•Nijhoff Publishing, Págs. 13-39. WHITTLE, P. (1963): “Prediction and Regulation by Linear Least-Square Methods”, London: English Universities Press. WINTERS, P.R. (1960): “Forecasting Sales by Exponentially Weighted Moving Averages”, Management Science, 6, April, 324-42. WOLF, C. (1987): “Time-Varying Parameters and the Out-of-Sample Forecasting Performance of Structural Exchange Rate Models”, Journal of Business and Economic Statistics, 5, 87-97. WOLTERS, J., TERÄSVIRTA, T. y LÜHTKEPOHL, H. (1996): “Modelling the Demand for M3 in the Unified Germany”, Discussion Paper 23, Humboldt Universität zu Berlin. WORKING, E. J. (1927): “What do Statistical 'Demand Curves' show?”, Quaterly Journal of Economics, 41, 212-35. YOUNG, A. H. (1965): “Estimating Trading-Day Variation in Monthly Economic Time Series”, Technical Paper 12, Bureau of the Census, Washington. YULE, C.U. (1926): “Why do we sometimes get nonsense correlations between time-series? A Study in Sampling and the Nature of Time Series”. Journal of the Royal Statistical Society. 89. Págs. 1-64. ZARNOWITZ, V. (1985): “Recent Work on Business Cycles in Historical Perspective: a Review of Theories and Evidence”, Journal of Economic Research, New York. ZARNOWITZ, V. (1992): “Business Cycles. Theory, History, Indicators and Forecasting.”, National Bureau of economic Research, Studies in Business Cycles, Volume 27, The University of Chicago Press. ZARZOSA, P. (1992): “Aproximación a la Medición del Bienestar Social: Estudio de la Idoneidad del Indicador Sintético <<DISTANCIA P2>>“, Tesis Doctoral, Universidad de Valladolid, Facultad de Ciencias Económicas y Empresariales. ZELLNER, A. (1979): “Causality and Econometrics”, dentro de Karl Brunner and Allan H. Meltzer (Eds.): “Three Aspects of Policy and Policymaking: Knowledge, Data and Institutions”, Carnegie-Rochester Conference Series on Public Policy, Volume 10, Elsevier, 1979, 9-54. -Pág. 486- Referencias ZELLNER, A. (Ed.) (1978): “Seasonal Analysis of Econometric Models” (con discusión), Journal of the Census, Washington. ZELLNER, A. (Ed.) (1983): “Applied Time Series Analysis of Economic Data”, U. S. Department of Comerce, Bureau of the Census. -Pág. 487-