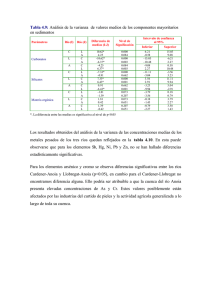
Notas de clase
Anuncio

AGRO 5005 BIOMETRÍA Notas de clase 2016 Raúl E. Macchiavelli, Ph.D. Linda Wessel-Beaver, Ph.D. Estas notas complementan el material presentado en el libro de texto del curso 1 Contenidos 1. Introducción .................................................................................................................... 3 2. Recolectando datos ......................................................................................................... 4 3. Organización y resumen de datos: métodos gráficos ...................................................... 6 4. Medidas numéricas de resumen: tendencia central ....................................................... 13 5. Medidas numéricas de resumen: variabilidad o dispersión .......................................... 15 6. Introducción a probabilidad .......................................................................................... 18 7. Distribución normal ...................................................................................................... 21 8. Muestreo aleatorio. Distribución muestral. ................................................................... 26 9. Estimación de parámetros ............................................................................................. 29 10. Pruebas estadísticas ..................................................................................................... 31 11. Pruebas t para dos muestras independientes ............................................................... 35 12. Pruebas t para datos pareados ..................................................................................... 39 13. Introducción al análisis de la varianza ........................................................................ 43 14. Comparaciones múltiples en ANOVA........................................................................ 47 15. Tablas de contingencia ................................................................................................ 51 16. Regresión lineal simple ............................................................................................... 53 17. Diseño en bloques completos al azar .......................................................................... 59 18. Introducción a los diseños experimentales ................................................................. 63 19. Documentación y comunicación de resultados ........................................................... 65 2 1. Introducción ¿Qué es la Biometría? ¿Cómo? Es la disciplina que se encarga de obtener información a partir de datos biológicos. Mediante gráficos, medidas numéricas de resumen (ej., promedio), comparaciones, predicciones, etc. Etapas que debemos seguir para obtener información “buena” a partir de los datos: 1. 2. 3. 4. Recolectar los datos Resumir los datos Analizar los datos Comunicar los resultados Ejemplo Queremos conocer el efecto de un nuevo insecticida sobre la población de un cierto insecto. Para ello el investigador selecciona cinco fincas en la región de interés y aplica el insecticida a la mitad del área sembrada en cada finca. La otra mitad del área en cada finca queda como “testigo” o “control”. Nos interesa conocer el número promedio de insectos por planta luego de aplicar el insecticida, y compararlo con el número promedio de insectos por planta en el área testigo. Población(es) de interés: Todas las plantas de ese cultivo a las que podríamos aplicar el insecticida (o todos los recuentos de insectos en todas las plantas de ese cultivo a las que podríamos aplicar el insecticida). Muestra(s): Las plantas tratadas en las cinco fincas que se usaron en el experimento (o los recuentos en las plantas usadas en el experimento). La forma más común para obtener información de los datos es realizar una INFERENCIA acerca de una población de interés con la información disponible en una muestra de esa población. Población (conjunto de todas las medidas) Muestra (subconjunto de la población) 3 2. Recolectando datos a. Muestreos b. Experimentos c. Estudios observacionales Antes de comenzar a recolectar los datos debemos especificar claramente para qué recolectamos los datos (OBJETIVOS), identificar la(s) medición(es) de interés (OBSERVACIONES) y seleccionar un diseño o plan apropiado. Estas tres etapas preliminares se pueden pensar como tres preguntas: ¿PARA QUÉ?, ¿QUÉ?, ¿CÓMO? Muestreos Planes de muestreo más comunes: 1. muestreo aleatorio simple 2. muestreo aleatorio estratificado 3. muestreo por conglomerados (de dos o más etapas) 4. muestreo sistemático En el muestreo aleatorio simple todas las posibles muestras tienen la misma probabilidad de ser elegidas. En el muestreo aleatorio estratificado la población es heterogénea, y entonces de divide en estratos más homogéneos. En cada uno de estos estratos se obtiene una muestra aleatoria simple. Por ejemplo, se muestrean aleatoriamente 15 fincas de plátano en la región central de la isla, 15 fincas en la región sur y 15 fincas en la región norte. En este ejemplo los estratos son las regiones. En el muestreo por conglomerados la población es homogénea, pero por cuestiones prácticas se muestrea en dos etapas: primero se muestrean grupos de unidades (aleatoriamente) y luego se muestrean unidades (aleatoriamente) solo en los grupos o conglomerados seleccionados en la primera etapa. Por ejemplo, muestreamos aleatoriamente 10 vaquerías, y en cada vaquería seleccionada muestreamos (aleatoriamente) la leche de 15 vacas. El conglomerado es la vaquería, y la unidad es la vaca. En el muestreo sistemático se comienza en un punto aleatorio (por ejemplo la séptima planta de la primera fila de un cultivo), y luego muestreamos cada 10 plantas. Métodos de recolección más comunes: 1. entrevistas (personales, telefónicas) 2. cuestionarios (encuestas) 3. observación directa 4. trampas (insectos) 5. muestreo de suelos 6. transectas 7. cuadrículas 4 Experimentos Diseños más comunes: 1. diseño completamente aleatorizado (DCA) 2. diseño en bloques completos aleatorizados (DBCA) 3. otros diseños y experimentos factoriales Estudios observacionales Similares a experimentos pero no hay control sobre las unidades del estudio (ya vienen con su “tratamiento” asignado). El tipo de inferencia que podemos hacer no es tan general como en los experimentos. Manejo de datos 1. Recibir los datos originales (encuestas, libro de campo, cuaderno de laboratorio, etc.) 2. Crear la base de datos en la computadora. 3. Editar la base de datos (verificar errores, pruebas lógicas, etc.) 4. Corregir y clarificar los datos. 5. Documentar la base de datos. 6. Almacenar (tanto en forma digital como en papel) los archivos originales 7. Obtener los archivos de trabajo (a partir de los originales) para pasar a las siguientes etapas. 5 3. Organización y resumen de datos: métodos gráficos 1. 2. 3. 4. ¿Qué es lo que se desea informar al lector del gráfico? Elegir cuidadosamente los títulos, ejes, colores, rayas, etc. No sobrecargar de información al gráfico. Practicar mucho! Gráficos para una variable: Gráfico de sectores (“pie chart”, gráfico de torta) Gráfico de barras (verticales, horizontales) Diagrama de tallo y hojas Histogramas de frecuencias (absolutas, relativas) Polígonos de frecuencias acumuladas (ojivas) Gráficos para dos variables: Gráfico x-y (diagrama de dispersión o “scattergram”) Series de tiempo Gráfico de sectores (“pie chart”): Se usa para representar partes de un todo (por ejemplo, porcentajes). Deben usarse para pocas categorías, y si es posible, ordenarse en forma ascendente o descendente. Variedad Cuerdas A 3500 B 1200 C 700 D 300 D (5% ) C (12% ) B (21% ) A (61% ) Gráfico de barras: similar al de sectores, excepto que la altura de la barra es la frecuencia o porcentaje que se quiere presentar. También se usa para representar totales, promedios, sumas u otras cantidades en el eje vertical. 6 Se deben dejar espacios entre las categorías discretas. Los rectángulos deben ser todos del mismo ancho. Usar barras horizontales si el número de categorías es muy alto. 3700 Cuerdas 2960 2220 1480 740 0 A B C D Variedad Gráfico x-y (diagrama de dispersión o “scattergram”): En el eje horizontal (x) se ubica la variable independiente (“explicativa”) y en el eje vertical (y) la variable dependiente (“respuesta”). 100 % Germinación 75 50 25 0 0.0025 0.0035 0.0045 Peso Seco 7 0.0055 Series de tiempo: gráfico x-y en el que el eje horizontal es el tiempo. Debe haber al menos 4-5 puntos en el eje horizontal para poder observar alguna tendencia. Diagrama de dispersión del precio de la carne de res y de cerdo entre 1925 y1941 84.0 Precio carne (cents/lbs) 74.8 65.6 56.4 47.2 38.0 1924 1927 1930 1933 1936 1939 Año Carne res Carne cerdo Otros gráficos relacionados Ganancias netas discriminadas por año de las contribuciones de la casa matriz y cuatro sucursales de una empresa agropecuaria Ganancias netas (miles de dólares) 600 500 400 300 200 100 0 1991 1992 1993 1994 1995 1996 1997 1998 1999 Año CM SUC1 SUC2 8 SUC3 SUC4 2000 2001 1942 % Germinación 100 75 50 25 0 chicas medianas grandes Tam año PG-claro PG-rojizo PG-oscuro Salto en alto en olimpiadas 95 90 altura 85 80 75 70 1896 1900 1904 1908 1912 1916 1920 1924 1928 1932 1936 1940 1944 1948 1952 1956 1960 1964 1968 1972 año Principales problemas en la construcción, presentación e interpretación de gráficos Ejes no indican claramente qué se está midiendo Escalas no apropiadas exageran u ocultan diferencias Sobrecarga de información no relevante (por ejemplo, palabras muy largas, letras muy pequeñas, 23 barras adyacentes en cada una de 5 categorías, etc.) Falta de información relevante (por ejemplo, observaciones individuales atípicas, desviaciones estándar, etc.) Demasiados detalles que distraen la atención (por ejemplo, exceso de adornos, sombras, dimensiones innecesarias, colores que no se aprecian, etc.) Énfasis en la forma y no en el contenido (estamos enseñando a estudiantes universitarios, no a alumnos de kinder!) 9 Un sitio muy interesante con ejemplos históricos de buenos y malos gráficos estadísticos que pueden visitar es http://www.math.yorku.ca/SCS/Gallery/ Diagrama de tallo y hoja: Para resumir muchos datos sin perder demasiada información. 1. Dividir cada observación en dos conjuntos de dígitos: el primero es el tallo y el segundo es la hoja. 2. Hacer una lista vertical con los tallos. 3. Para cada tallo, anotar las hojas. 4. Si quedan muy pocos tallos con muchas hojas cada uno, usar los dígitos 0-4 como hojas de un primer tallo y los dígitos 5-9 como hojas de un segundo tallo. 5. Si cada hoja tiene demasiados dígitos, redondear. Ejemplo: los siguientes son recuentos de insectos por planta en 40 plantas escogidas aleatoriamente. (Los datos ya están ordenados.) 0 30 47 1 33 49 2 34 52 4 36 55 6 36 55 8 37 56 10 38 56 11 40 57 11 42 58 15 42 58 16 45 59 19 45 59 29 46 29 46 Histograma de frecuencias (absolutas o relativas): Se usa para datos cuantitativos. (Si los datos son cualitativos, el gráfico análogo es el de barras). Primero construimos una tabla de frecuencias. Dividimos los datos en intervalos de clase. Cada dato va a pertenecer a exactamente un intervalo. Para definir estos intervalos definimos el recorrido = valor máximo – valor mínimo. Dividimos el recorrido entre la cantidad de intervalos deseados (entre 5 y 20, según el número de observaciones). Ejemplo: los siguientes son recuentos de insectos por plantas en 40 plantas escogidas aleatoriamente. (Los datos ya están ordenados.) ω=59-0=59 Recorrido: 10 Si deseamos usar 6 clases, el ancho de cada intervalo debe ser mayor de 9.8 (para cubrir todas las observaciones). Por lo tanto usaremos un ancho de cada intervalo de 10. Para evitar ambigüedades, usaremos los límites de clase con un lugar decimal más que las observaciones (de esta forma ninguna observación caerá en el límite). Intervalo -0.5 – 9.5 9.5 – 19.5 19.5 – 29.5 29.5 – 39.5 39.5 – 49.5 49.5 – 59.5 Marca de clase 4.5 14.5 24.5 34.5 44.5 54.5 Frecuencia 6 6 2 7 9 10 Frecuencia Acumulada 6 12 14 21 30 40 Frecuencia Relativa .15 .15 .05 .175 .225 .25 Frec.Relativa Acumulada .15 .30 .35 .525 .75 1.00 Histograma: 15 frecuencia absoluta 12 9 6 3 0 -0.5 9.5 19.5 29.5 39.5 Ins ectos por planta 11 49.5 59.5 Polígono de frecuencias acumuladas: 1.00 frec. rel. acumulada 0.80 0.60 0.40 0.20 0.00 -0.5 9.5 19.5 29.5 39.5 49.5 59.5 Ins ectos por planta Las frecuencias relativas siempre tienen una interpretación de probabilidad. Por ejemplo, si seleccionamos una planta al azar, ¿cuál es la probabilidad de encontrar entre 10 y 19 insectos?, ¿cuál es la probabilidad de encontrar menos de 30 insectos? 12 4. Medidas numéricas de resumen: tendencia central Las medidas numéricas de resumen son más simples que los gráficos y es más sencillo hacer inferencias sobre ellas que sobre gráficos. Podemos calcular medidas numéricas sobre todas las mediciones en una población (medidas poblacionales o parámetros), o sobre las observaciones en una muestra (medidas muestrales o estadísticos). En la práctica los estadísticos pueden usarse como estimadores de los parámetros. 1. Medidas de tendencia central 1a. Modo (moda): medición más frecuente (con la mayor frecuencia). Ejemplo: 3, 5, 7, 9, 7, 8, 5, 7, 1 Modo= Mo = 7 Para datos agrupados en tablas de frecuencia, es el centro del intervalo modal (el más “alto” en el histograma). Puede usarse para datos cualitativos o cuantitativos. Puede haber más de un modo en la distribución (bimodal, trimodal, etc.) 1b. Mediana: valor central de las observaciones cuando éstas están ordenadas de menor a mayor. n 1 . 2 n n Si n es par, la mediana es el promedio de la observaciones en posiciones y 1. 2 2 Si hacemos la convención que una posición fraccional (ej. 5.5) es el promedio de las n 1 posiciones correspondientes, entonces siempre podemos usar la fórmula para la 2 posición de la mediana. Si hay un número impar de observaciones (n), la posición de la mediana es Ejemplos: 7, 9, 11, 11, 13; n=5, posición=3, Mediana=Md=11 1, 5, 6, 7, 8, 10, 10, 11; n=8, posición= 4.5, Md= (7+8)/2=7.5 Si los datos están agrupados el libro presenta una fórmulas que no vamos a usar, pero son equivalentes a interpolar a partir de la ojiva. Nosotros podemos leerla directamente desde este gráfico, como el valor sobre el eje horizontal que acumula el 50% de la frecuencia total. Para los datos de insectos por planta, 13 Frec. Relativa Acum. Ojiva 1 0.5 0 0 5 10 15 20 25 30 35 40 45 50 55 60 Insectos En este caso la mediana es aproximadamente 38. 1c. Media (promedio o media aritmética). Según sea poblacional o muestral, la denotaremos como o Y , respectivamente. 1 n Y Yi n i 1 1 k Si los datos son agrupados en intervalos, Y f iYi , donde Yi es el centro de cada n i 1 intervalo y fi es la frecuencia de cada uno de los k intervalos. Es la medida más usada, la más simple de interpretar, pero puede estar muy afectada por valores extremos. Por ejemplo, 1, 3, 5, 7 y 9 tienen Y 5 y Md=5; pero 1, 3, 5, 7, 90 tienen la misma mediana y Y 21.2 . 1d. Media “recortada” (trimmed mean). La media recortada al 10% ( Yr10% ) se calcula eliminando el 10% superior y el 10% inferior de los datos y calculando el promedio del resto. ¿Cómo se comparan Mo, Md, Y y Yr ? Si los datos tienen una distribución simétrica con un único pico central, todas son aproximadamente iguales. Si la distribución es asimétrica o “sesgada” (tiene una “cola” más larga que la otra), la media tiende hacia la cola y el modo hacia el otro extremo. Modo No único No influido por extremos No puede combinarse Datos cualitativos o cuantitativos Mediana Único No influido por extremos No puede combinarse Datos cuantitativos (al menos ordinales) 14 Media Único Influido por extremos Puede combinarse Datos cuantitativos 5. Medidas numéricas de resumen: variabilidad o dispersión 2a. Recorrido (amplitud): ω=máximo-mínimo ω=9-1=8 Ejemplo: 3, 5, 7, 9, 7, 8, 5, 7, 1, 2 Para datos agrupados en tablas de frecuencia, es la diferencia entre el límite superior del último intervalo y el límite inferior del primero. 2b. Recorrido intercuartílico (IQR): para definirlo necesitamos presentar otras medidas de posición: los percentiles. El percentil 60 ( P60 ), por ejemplo, es un valor de las observaciones que tiene el 60% de las observaciones por debajo de él, y un 40% de las observaciones por encima. La mediana, usando esta notación es P50 . Los cuartiles son percentiles que dividen el 25%, 50% y 75% de las observaciones: Q1 P25 , Q2 Md, Q3 P75 Para el cálculo de percentiles y cuartiles de datos agrupados, se usa la ojiva (de la misma manera que se usa para el cálculo de la mediana). Para datos no agrupados debemos tener los datos ordenados (por ejemplo en un diagrama n 1 de tallo y hoja). Recordemos que la posición de la mediana es . La posición de los 2 cuartiles es posición de la mediana (truncada)+1 . 2 Si estamos calculando el primer cuartil, comenzamos a contar desde el mínimo, y si estamos calculando el tercer cuartil, comenzamos a contar desde el máximo. n 10 Ejemplo: 3, 5, 7, 9, 7, 8, 5, 7, 1, 2 posición de la mediana=5.5 posición de los cuartiles = (5+1)/2=3 Q1 3, Md=6, Q3 7. El recorrido intercuartílico es la diferencia entre los cuartiles: IQR Q3 Q1 . Se debe hacer notar que hay formas alternativas de calcular percentiles y cuartiles para datos no agrupados, y es posible que InfoStat o Excel den resultados levemente diferentes cuando la cantidad de datos es pequeña. 15 2c. Varianza. Según sea poblacional o muestral, la denotaremos como 2 o s2 , respectivamente. n s 2 (Y Y ) 2 i i 1 n 1 Es la medida más usada, aunque para expresarla en las mismas unidades de las observaciones se prefiere la: 2d. Desviación estándar: s s 2 . Fórmula de cálculo para varianza y desviación estándar: 2 n Yi 1 1 n 2 i 1 2 s SS Yi n n 1 n 1 i 1 Fórmula de cálculo para datos agrupados: 2 k fiYi 1 k 2 2 s fiYi i1 n n 1 i 1 2e. Coeficiente de variación: CV= s 100 Y Esta medida puede usarse para comparar variabilidad de conjuntos de datos diferentes. Regla empírica: Si los datos tienen un histograma (distribución) en forma de montaña, el 68% de las observaciones estarán en el intervalo Y s , el 95% en el intervalo Y 2s y prácticamente el 100% en el intervalo Y 3s. Esta regla nos permite aproximar el valor de la desviación estándar usando el recorrido: s , o podemos usar s , aunque este valor seguramente subestima s. 4 6 16 Gráfico de caja (“box plot”) Este gráfico permite representar las medidas de tendencia central y variabilidad de un conjunto de datos y nos da al mismo tiempo una idea de la forma de la distribución. Aquí representamos los cuartiles Q1 y Q3 como los bordes de una caja (es decir, adentro de la caja quedará el 75%-25%=50% central de los datos). El recorrido intercuartílico es la longitud de la caja. Además marcamos la mediana como una línea en la caja. InfoStat indica la media con un punto dentro de la caja. De cada borde de la caja (cuartil inferior o superior), se dibujan líneas (“bigotes”) que se extienden hasta la última observación que no es atípica (ver más abajo). En InfoStat, las líneas se extienden hasta el valor mínimo y máximo, si no hay valores atípicos. Otros autores o programas estadísticas dibujen estas líneas hasta el percentil 5 o 95 respectivamente. Cualquier valor que esté “lejos” del centro (recordemos que la caja representa el 50% central de los datos), va a ser considerado un valor atípico. El libro de texto y InfoStat consideran valores atípicos todos los que se encuentran a una distancia mayor de 1.5 IQR del borde de la caja (es decir, 1.5 IQR de Q1 si consideramos los extremos inferiores, o 1.5 IQR de Q3 si consideramos los valores superiores). InfoStat llama el 1.5IQR el semi recorrido intercuartílico (“SRIC”). El mismo libro de texto y InfoStat consideran valores atípicos extremos aquellas observaciones a más de 3 veces el IQR del borde de la caja. Otros textos consideran valores atípicos a las observaciones que están a una distancia mayor de 3 IQR de la mediana. En este gráfico las observaciones atípicas se representan por puntos, estrellas, etc. InfoStat utiliza un punto para valores atípicos y un círculo para valores atípicos extremos. En el gráfico abajo podemos observar la tendencia central de los datos (mediana, y la media), la forma de la distribución (simétrica, asimétrica, etc.), los extremos, etc. Título Perímetro de fruto (cm) 25 Recorrido Intercuartílico (IQR – “intercuartil range” ) (50% de las observaciones Q3 20 Q2 15 Q1 10 Valores atípicos (que se encuentran a una distancia mayor de 1.5 IQR del borde de la caja) 5 1998 1999 Año 17 6. Introducción a probabilidad (El material del capítulo 4 del texto que cubriremos en el curso está en las secciones 1, 2, 3, 6, 7, 8, 9, 10, 11, 12) ¿Para qué sirve conocer probabilidad? Definiciones: Experimento aleatorio: acción cuyo resultado no podemos predecir exactamente (sólo podemos conocer los posibles resultados) Evento: conjunto de resultados de un experimento aleatorio. Conceptos de probabilidad: A. Clásica: Ne N Determinando la probabilidad de un evento 1. Listamos todos los resultados igualmente probables (N) 2. Contamos los resultados que son favorables al evento ( N e ) 3. Calculamos la probabilidad: Ne N Ejemplo: la probabilidad de seleccionar ace: N=52; Ne = 4 (número de resultados “favorables”; P = 4/52 *Solamente funciona en el caso donde los resultados son igualmente probables n B. Frecuencia relativa: e n en muchas repeticiones. Interpretación práctica. Se halla la probablidad por medio de experimentación. La probabilidad es la frecuencia relativa. n = número de veces que se realiza el experimento; ne = número de veces que evento E ocurre C. Subjetiva: “Hay un 60% de probabilidad que llueva mañana”. Propiedad 1: 0 P( A) 1 Eventos mutuamente excluyentes: A y B son mutuamente excluyentes si cuando ocurre uno el otro no puede ocurrir. Ejemplo: supongamos que el experimento sea tirar un dado, el evento A sea que salga un número menor que 3, y el evento B sea que salga un número mayor que 5. Propiedad 2: P( A o B) P( A) P( B) para eventos mutuamente excluyentes Complemento de un evento A es el evento que A no ocurra ( A ). 18 Propiedad 3: P( A) 1 P( A) Unión de dos eventos: A B es el evento que A ocurra o que B ocurra. Intersección de dos eventos: A B es el evento que A ocurra y que B ocurra. Propiedad 4: P( A B) P( A) P( B) P( A B) Variable aleatoria: Es una variable cuyo valor no conocemos de antemano. El valor se determina mediante un experimento aleatorio. Sólo sabemos cuáles son sus valores posibles, y conocemos la probabilidad que cada uno de ellos ocurra. Ejemplo: Definamos la variable aleatoria S, la suma de los resultados obtenidos al arrojar dos dados. Sus valores posibles son 2, 3, ..., 12. Según lo discutido en clase, conocemos la probabilidad de que cada uno de los valores ocurra: P(S=2)=1/36, P(S=3)=2/36, P(S=4)=3/36, P(S=5)=4/36, P(S=6)=5/36, P(S=7)=6/36, P(S=8)=5/36, P(S=9)=4/36, P(S=10)=3/36, P(S=11)=2/36, P(S=12)=1/36 Las variables aleatorias (al igual que todas las variables) se clasifican en cualitativas y cuantitativas. En general trabajaremos con variables cuantitativas (numéricas). Éstas a su vez se clasifican en discretas y continuas. Ejemplos de variables discretas (típicamente recuentos) la variable S del ejemplo anterior cantidad de árboles enfermos en una muestra de 10 árboles cantidad de hembras en una camada de cerdos cantidad de días sin lluvia desde la siembra Ejemplos de variables continuas (típicamente medidas) peso altura concentración de Mn pH del suelo Distribución de probabilidad de una variable aleatoria (discreta): es una función que asocia a cada valor de la variable aleatoria su probabilidad. 19 Ejemplo: Y=cantidad de caras al arrojar dos monedas. 0 1 2 Suma Y 1 P(Y) .25 .5 .25 0.6 0.5 P(Y) 0.4 0.3 0.2 0.1 0.0 0 1 2 Y Variable binomial Tenemos n ensayos idénticos Cada ensayo puede resultar en “éxito” o “fracaso” P(éxito en un ensayo)=π es siempre la misma para todos los ensayos Los ensayos son independientes (el resultado de uno no afecta al resultado de otro) La variable Y es el número de éxitos en los n ensayos. Ejemplos: 1. Entrevistamos 40 vecinos y le preguntamos a cada uno cuál es su opinión sobre el nuevo vertedero (favorable/desfavorable) 2. Arrojamos una moneda 6 veces y contamos el número de caras obtenidas. 3. En una finca que tiene un 70% de las plantas de plátano con sigatoka (una enfermedad), muestreamos 50 plantas aleatoriamente y a cada planta la evaluamos para ver si tiene o no la enfermedad. La distribución de probabilidad de Y se llama la distribución binomial: n! P( y ) y (1 ) n y y !(n y )! La media y la varianza de Y son respectivamente, n y 2 n (1 ) . Ejemplo: Para el ejemplo 2, ¿cuál sería la probabilidad de observar 0 caras? ¿y 3 caras? 20 7. Distribución normal Variable aleatoria continua: ejemplos de variables continuas (típicamente medidas) peso altura concentración de Mn pH del suelo Para variables continuas nos interesa la probabilidad de encontrar observaciones en un intervalo, P(a Y b) , y no en un valor especifico, ya que P(Y a) 0 .La distribución de probabilidad se denomina f ( x) y es en general una curva suave. El área bajo esta curva es 1, y la probabilidades se calculan como áreas bajo la curva entre los valores de interés. Función de densidad 0.18 f(x) 0.14 0.09 0.05 P(3<x<9) 0.00 0 3 6 9 12 15 18 x La distribución normal es la más comúnmente usada para variables continuas. Está caracterizada por dos parámetros: y (la media y la desviación estándar respectivamente). La variable aleatoria Y puede tomar cualquier valor real. 1 Y 2 1 f (Y ) exp , 2 2 2 Y . Hay infinitas curvas normales, una para cada combinación de y . 21 1. 1 2 1 2 1.0 0.8 Curva 1 y=f(x) 0.6 0.4 Curva 2 0.2 0.0 0 1 2 3 4 X 2. 1 2 1 2 1.0 0.8 Curva 1 Curva 2 y=f(x) 0.6 0.4 0.2 0.0 0 1 2 3 4 X Para calcular probabilidades podemos usar la Tabla 1, que indica probabilidades asociadas con Z, que es una variable que tiene una distribución normal “estandarizada” ( 0, 1 ). Se debe notar que esta distribución es siempre simétrica alrededor de . Ejemplo 1 P(Z P(Z P(Z P(Z 1) ? 1.63) ? 0.5) ? 1) ? Para otros valores de ( , ) también podemos usar la tabla 1, notando que en esta tabla tenemos áreas desde menos infinito hasta Z desviaciones estándar a la derecha. Para usar Y esta tabla debemos calcular primero el valor Z . 22 Ejemplo 2, 100, 10. Calculemos P (Y 120) ? P (Y 90) ? P (95 Y 110) ? P (110 Y 120) ? El problema inverso también se puede se puede resolver con la tabla 1: Dada un área o probabilidad, calcular el valor de Z o Y asociado. Debemos recordar que las áreas que presenta la tabla 1 son áreas a la izquierda del valor. Por lo tanto siempre debemos expresarla de esta forma Ejemplo 3, calcular el valor de a tal que: P( Z P( Z P( Z P( Z a ) .75 a ) .10 P( Z a ) 0.90 a ) .3212 a ) .9599 P( Z a ) .0401 Ejemplo 4, con 100, 10, calcular el valor de a tal que: P (Y a ) .60 P (Y a ) .1515 P (Y a ) .33 P (Y a ) .67 P (Y a ) .7157 P (Y a ) .2843 Los mismos cálculos se pueden realizar en InfoStat usando el menú Estadísticas > Probabilidades y Cuantiles. Allí podemos seleccionar la distribución normal, su media y su varianza, y el dato que disponemos. Por ejemplo, para el ejemplo 1b, podemos hacer 23 Para el ejemplo 4b, Para ver gráficamente las áreas y poder variar los parámetros de la distribución normal podemos usar el menú Aplicaciones > Didácticas > Gráficos de funciones de densidad continuas, y elegir la normal, con los parámetros de interés. Por ejemplo, para visualizar el ejemplo 2d, 24 Función de densidad 0.04 Normal(100,100): p(evento)=0.1359 Densidad 0.03 0.02 0.02 0.01 0.00 50 70 90 110 Variable 25 130 150 8. Muestreo aleatorio. Distribución muestral. Recordemos que el muestreo aleatorio nos permite evitar tendencias sistemáticas (sesgos) en nuestra inferencia, ya que antes de hacer el muestreo no sabemos qué elementos de la población van a ser incluidos en la muestra. Muestra aleatoria simple: cada posible muestra de tamaño n tiene la misma probabilidad de ser elegida. Existen muestras aleatorias simples con y sin reemplazo, pero para poblaciones grandes no hay mucha diferencia. ¿Cómo obtenemos una muestra aleatoria simple? Mediante una tabla de números aleatorios, un generador de números aleatorios en la calculadora, u otro mecanismo físico que nos permita asegurar igual probabilidad a todas las muestras. Población de todas las muestras de tamaño n. Dada una población cualquiera, podemos generar una nueva población cuyos elementos son cada una de las muestras posibles de un cierto tamaño n. Es una población teórica que nos sirve para estudiar las propiedades de los estadísticos (medidas de resumen calculadas con la muestra). Ejemplo: Consideremos una población formada por los números 1, 2, 3, 4, 5. Todas las muestras posibles de tamaño n=2 (sin reemplazo). Es decir nuestra población de muestras de tamaño 2 está formada por los siguientes elementos: (1,2); (1,3); (1,4); (1,5); (2,3); (2,4); (2,5); (3,4); (3,5); (4,5) Ahora supongamos que calculamos Y , la media muestral a cada una de las muestras. Lo que tenemos ahora es una media muestral asociada a cada elemento de nuestra nueva población: 1.5; 2; 2.5; 3; 2.5; 3; 3.5; 3.5; 4; 4.5 Como ésta es una población de medias muestrales, podemos calcular su media Y , su desviación estándar Y , etc. También podemos considerar la distribución de probabilidad del estadístico Y . Esta distribución se llama la distribución muestral de Y . En este caso sería: Y f (Y ) 1.5 0.1 2.0 0.1 2.5 0.2 3.0 0.2 26 3.5 0.2 4.0 0.1 4.5 0.1 Los pasos a seguir cuando construímos la distribución muestral de un estadístico son: 1. Obtenemos todas las muestras posibles del tamaño deseado (o tomamos muchas muestras del tamaño deseado). 2. Para cada muestra calculamos el valor del estadístico. 3. Calculamos la probabilidad asociada con cada uno de los valores calculados en 2. Esto es una construcción teórica para estudiar las propiedades del estadístico. En la práctica no hacemos esto sino que obtenemos una muestra, y calculamos el valor de la media (u otro estadístico). Con las propiedades que conocemos usamos este valor de Y para hacer inferencias acerca de , la media poblacional de interés. Para la media muestral, y considerando muestreo con reemplazo, tenemos las siguientes propiedades: Y ; Y n ; 2 Y 2 n Si la población original es normal, la distribución de Y también es normal. Si n es grande, la distribución de Y es aproximadamente normal aunque la población original no lo sea. Este resultado se denomina “teorema central del límite”. ¿Cuán grande tiene que ser la muestra para que esta propiedad se cumpla? Depende de la forma de la distribución de la población original. En la práctica se considera que n 30 ya es suficientemente grande para la mayoría de las aplicaciones reales (esto depende de la simetría de la población original). El mismo ejemplo en Infostat. Para generar todas las muestras posibles, ponemos los datos en una columna, seleccionamos Aplicaciones > Didácticas > Todas las muestras posibles. 27 Los valores generados aparecerán en una nueva hoja de datos, y entonces podemos construir una tabla de frecuencias, o un histograma para observar la distribución muestral, o calcular medidas numéricas de resumen. Distribución muestral (n=2) frecuencia relativa 0.25 0.20 0.15 0.10 0.05 0.00 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Valores de media muestral 28 9. Estimación de parámetros El problema central que la estadística trata de resolver es cómo hacer inferencias confiables. Es decir, tratamos de decir “algo” acerca de la población usando la información disponible en una muestra. Ese “algo” que nos interesa de la población es típicamente un parámetro como la media o la varianza (en otros casos el “algo” puede ser la distribución poblacional completa, no solamente la media y la varianza de la distribución). Existen dos formas principales de hacer inferencia estadística: la estimación y la prueba de hipótesis. En la estimación nos interesa dar un valor (o un conjunto de valores) aproximado al parámetro de interés, mientras que en la segunda tratamos de ver si un valor postulado del parámetro es razonable a la luz de la evidencia en la muestra. La forma más obvia de realizar estimación es la estimación puntual: usamos el esta-dístico como un estimador del parámetro. Por ejemplo, para estimar la media poblacional podemos usar la media muestral Y . Decimos entonces que Y es un estimador puntual de , y podemos indicarlo poniendo un “sombrerito” a : ˆ Y Ya sabemos de la clase anterior que usar Y como estimador de es razonable, ya que Y (es decir, el promedio de todos los valores posibles de Y es el parámetro de interés). Otro ejemplo es ˆ 2 s 2 . Podemos verificar que s 2 2 . El principal problema con la estimación puntual es que en la práctica no es muy realista. Es mejor dar un intervalo de posibles valores del parámetro. Esta forma de estimación se llama estimación por intervalos de confianza. Para construir el intervalo, recordemos el “teorema central del límite”: si n es grande, Y ~ N , . Esto significa que el 95% de n , 1.96 los valores de Y van a estar en el intervalo 1.96 . Pero cada n n vez que Y está en este intervalo, estará en el intervalo Y 1.96 , Y 1.96 . n n Esto significa que si obtuviéramos muchas muestras aleatorias de la misma población, el 95% de las veces obtendremos valores de Y con los que podemos construir intervalos que cubrirán a . 29 Podemos pensar este proceso de la siguiente manera: 1. Obtenemos una muestra, calculamos Y y el intervalo Y 1.96 , Y 1.96 n n 2. Verificamos si este intervalo cubre a . Si lo cubre, será un intervalo “bueno”, y si no lo cubre será un intervalo “malo”. 3. Repetimos los pasos 1 y 2 muchas veces. El 95% de las veces tendremos intervalos “buenos”, y el 5% de las veces intervalos “malos”. En la práctica nosotros sólo obtenemos un intervalo, y no sabemos si es “bueno” o “malo”. Pero como sabemos que la mayoría de los intervalos son “buenos”, decimos que tenemos una “confianza” del 95% que nuestro intervalo sea “bueno”. En general, para cualquier nivel de confianza 1 100%, el intervalo de confianza será donde z Y z , , Y z 2 2 n n es un valor de la tabla normal que deja un área de 2 2 a su derecha. Si la desviación estándar poblacional no se conoce y n 30, podemos usar s, la desviación estándar muestral. Si n 30 veremos más adelante qué hacer. Tamaño muestral para estimar : Para estimar con un intervalo de confianza de un ancho no mayor de W (o lo que es lo mismo, para estimar de manera que quede a una distancia no mayor de E W de la 2 media muestral Y ) podemos usar la siguiente fórmula, que se obtiene a partir del intervalo presentado antes: n 2 z 2 E2 2 . Siempre debemos redondear el resultado hacia arriba, para asegurarnos que nuestro tamaño muestral sea suficiente para lograr la precisión deseada. Si no conocemos 2 , podemos usar información de estudios previos, estudios preliminares o usar la aproximación , que presentamos junto a la regla empírica. 4 30 10. Pruebas estadísticas Esta es una forma de inferencia muy comúnmente usada: establecemos una hipótesis científica y tratamos de comprobarla (o no) mediante datos observados. Las etapas en la realización de pruebas estadísticas son las siguientes: 1. Formulación de las hipótesis. La hipótesis alternativa, H a , es la hipótesis de investigación (es decir, la que formulamos para ver si los datos la verifican). La hipótesis nula, H 0 , es la que mantendremos si no hay evidencia suficiente a favor de la alternativa. 2. Definición del estadístico de la prueba. 3. Construcción de la región de rechazo (valores del estadístico que me van a hacer rechazar H 0 ). 4. Conclusiones (aceptación o rechazo de H 0 ). Ejemplo: Queremos probar que el diámetro promedio del tronco de árboles de una cierta variedad de mango es mayor que 25 cm a los 5 años de injertado. Las hipótesis pueden formularse así: H 0 : 25 H a : 25 En la práctica, la hipótesis nula se plantea como el valor más cercano a la alternativa. En este caso sería H0 : 25 . Para probar estas hipótesis, obtenemos una muestra aleatoria de 15 árboles y medimos sus diámetros. Supongamos por el momento que conocemos que la distribución de los 10 diámetros es N ( ,10) . Entonces podemos afirmar que Y ~ N , . 15 Con esta información podemos definir nuestra región de rechazo, que estará formada por valores de Y que sean contradictorios a H 0 . En este caso podemos pensar en un conjunto de valores de Y mayores a una cierta constante Yc , ya que éstos serían los valores contradictorios a la hipótesis nula. 31 Gráficamente, si H 0 es verdadera, 0.2 f(y) 0.1 0.1 0.0 0.0 12.1 25.0 18.5 Yc 37.9 31.5 Diámetro Al tomar una decisión podemos estar cometiendo uno de los dos errores siguientes: 1. Rechazar H 0 cuando ésta es verdadera (error de tipo I). 2. Aceptar H 0 cuando ésta es falsa (error de tipo II). El criterio para definir la región de rechazo es fijar la probabilidad de cometer un error de tipo I ( ) y definir en base de este valor la región de rechazo. Debemos observar que este error de tipo I se puede cometer cuando H 0 es verdadera, y en ese caso nosotros conocemos exactamente la distribución de Y : 10 Y ~ N 25, . 15 Supongamos que fijamos 0.05 . Entonces la región de rechazo estará formada por los 10 29.25 valores de Y 25 1.645 15 Ahora supongamos que en nuestra muestra, Y 30. Como 30 está en la región de rechazo, la conclusión es que rechazamos H 0 , y por lo tanto afirmamos que el diámetro promedio es mayor que 25. Otra manera de alcanzar la misma conclusión es definir nuestro estadístico de la prueba como Z Y 0 n y calcular la región de rechazo en función de Z. En este caso sería Z 1.645. Como el 30 25 valor observado de Z 1.936 está en la región de rechazo, entonces 10 15 rechazamos H 0 . 32 Las etapas en la realización de pruebas estadísticas son las siguientes: 1. Formulación de las hipótesis nula y alternativa ( H 0 y H a ). Existen tres tipos de hipótesis alternativas, según cuál sea la hipótesis científica de interés: Ha : 0 , Ha : 0 , Ha : 0 . Las dos primeras son hipótesis unilaterales (o “de una cola”), mientras que la tercera es bilateral (“de dos colas”). 2. Definición del estadístico de la prueba: Y 0 Z . n 3. Construcción de la región de rechazo (R.R.), que son los valores del estadístico que me van a hacer rechazar H 0 . Ésta dependerá de la hipótesis alternativa: Para H a : 0 , la R.R. es Z Z , para H a : 0 , la R.R. es Z Z y para H a : 0 , la R.R. es Z Z 2 . 4. Conclusiones (aceptación o rechazo de H 0 ). Otra manera de definir nuestra región de rechazo es mediante el “valor p” o “nivel de significancia observado”. Este método consiste en calcular el área hacia los valores más extremos que el valor observado de Z y comparar esta área con . En este caso la regla de decisión es muy simple: Si p , rechazamos H 0 , y si p , no rechazamos H 0 . El cálculo de p depende de la hipótesis alternativa: Para H a : 0 , p Pr( Z Z observado ), para H a : 0 , p Pr( Z Z observado ), y para H a : 0 , p 2 Pr Z Z observado . Ejemplo: Para el ejemplo de la clase anterior, recordemos que para probar H0 : 25, Ha : 25 teníamos Y 30, 10, n 15 y Z 1.936. El valor p es el área a la derecha del valor observado de Z (1.94): p Pr(Z 1.94) 1 .9738 .0262 33 ¿Qué hacemos cuando es desconocido? Podemos estimarlo con s (la desviación estándar muestral). Si el tamaño de muestra es grande (n>30) entonces podemos sustituir por su estimador y usar el mismo estadístico que usábamos antes. En caso contrario tenemos que usar otro estadístico: la t de Student. Y 0 t . s n Los valores críticos para definir la región de rechazo son diferentes y deben buscarse en otra tabla. Para usar esta tabla necesitamos conocer los “grados de libertad”, que son el denominador del estimador de desviación estándar que estemos utilizando (en este caso recordemos que s tiene como denominador a n 1 , y por lo tanto tenemos n 1 grados de libertad). Si los grados de libertad son , entonces la distribución es la normal estándar. Resumen Hipótesis H0 : 0 Ha : 0 , Ha : 0 , Ha : 0 . Y 0 Estadístico de la prueba: t . s n Región de rechazo: t t , t t , t t 2 . Conclusiones (aceptación o rechazo de H 0 ). Para usar esta prueba, los datos deben ser normales (o por lo menos, en forma de montaña). Un intervalo de confianza para basado en el estadístico t es Y t 2 s 34 n . 11. Pruebas t para dos muestras independientes Consideremos la siguiente situación: queremos estudiar el efecto de una droga sobre la cantidad de parásitos en corderos. Para este estudio se eligieron 14 corderitos similares, todos infectados con el parásito. A 7 de ellos (elegidos aleatoriamente) se los trató con la droga, y los otros 7 se dejaron sin tratar. Al cabo de 6 meses se contó el número de gusanos presentes en los intestinos de cada uno de los corderos. Tratados 14 43 28 50 16 32 13 𝑌̅1=28.00 s22=215.00 Control 54 26 63 21 37 39 Y2 40.00 s22 215.33 40 ¿Cuáles serían las hipótesis de interés? H0 : 1 2 Ha : 1 2 (Las siguientes hipótesis son idénticas: Ha: tratados < control; Ha: control > tratados) Para poder probar estas hipótesis debemos conocer la distribución muestral de Y1 Y2 . Sabemos que Y1 ~ N 1 , 1 y que Y2 ~ N 2 , 2 . Además, ambas medias son n1 n2 independientes (por la forma en que diseñamos nuestro experimento). Entonces, 2 2 Y1 Y2 ~ N 1 2 , 1 2 n1 n2 Si suponemos que 12 22 , el error estándar de la diferencia se simplifica a 1 1 . n1 n2 El estimador de la varianza común se denomina s 2p y se calcula como un promedio ponderado de las dos varianzas: s 2 p n1 1 s12 n2 1 s22 n1 n2 2 s12 s22 . 2 estimador valor hipotético Ahora recordemos la estructura del estadístico t . Para error estándar del estim. probar las hipótesis de interés podemos usar también un estadístico t con la misma estructura. Este estimador tiene n1 n2 2 grados de libertad. Si n1 n2 , entonces s 2p 35 H 0 : 1 2 D0 H a : 1 2 D0 H a : 1 2 D0 1. Hipótesis: H a : 1 2 D0 t 2. Estadístico: 3. Región de rechazo: Y1 Y2 D0 1 1 sp n1 n2 t t , t t o t t 2 (los grados de libertad son n1 n2 2 ) 4. Conclusiones. También podemos calcular un intervalo de confianza para 1 2 basado en el estadístico t: 1 1 Y1 Y2 t 2 s p . n1 n2 Para que la prueba y el intervalo sean válidos, necesitamos realizar tres supuestos: 1. Poblaciones normales 2. Varianzas iguales 3. Muestras independientes Ejemplo (continuación). Para el ejemplo presentado antes, sp = 14.67 y t = -1.53 (t “observado”) Para .05 la región de rechazo son los valores de t 1.782 (observar que tenemos 12 g.l.). Por lo tanto la conclusión es que aceptamos H 0 : no hay evidencias para decir que el tratamiento con droga es mejor que el control sin droga. [si usamos Ha: control > tratado, entonces t = +1.53, la región de rechazo son los valores de t > +1.782, y la conclusión es la misma). Muestras con Varianzas no iguales ¿Cómo sabemos si las varianzas poblacionales son iguales? Existen distintas pruebas para ello. Infostat calcula una prueba F que la estudiaremos en el laboratorio correspondiente. Si los tamaños de muestra son iguales, podemos usar el cociente entre las varianzas muestrales como criterio aproximado: si la varianza mayor dividida la menor nos da un cociente menor a 3, entonces el supuesto de varianzas poblacionales iguales es aceptable. ¿Qué hacemos si el supuesto de varianzas iguales no se cumple? Existe una prueba aproximada, llamada la prueba t de varianzas separadas. El estadístico de esta prueba es t' Y1 Y2 D0 s12 s22 n1 n2 , y los grados de libertad se calculan como: 36 gl n1 1 n2 1 , donde c n2 1 c2 n1 1 (1 c)2 s12 n1 . s s22 n1 n2 2 1 Ejemplo en InfoStat: Cada dato se clasifica de una sola manera: por su tratamiento (tratado o control). (“tratamiento” es el “criterio de clasificación” 37 Infostat entran los nombres de grupos en orden alfabético. Para este ejemplo, grupo 1 es CONTROL y grupo 2 es TRATADOS. La Ha es: control > tratados, una prueba unilateral DERECHA ` Resultado de la prueba F de homogenidad de varianzas. Como 0.9985 > 0.05, concluimos que el supuesto de varianzas poblacionales iguales es aceptable. Dos maneras de interpretar los resultados: t “observado” (1.53) es menor que t “crítico” o “tabular” (1.782). Está en la región de aceptación. Aceptamos Ho: no hay evidencia para decir que el uso de la droga fue mejor que no usarla (control) El p-valor es mayor que alpha (0.0759 > 0.05). Aceptamos Ho: no hay evidencia para decir que el uso de la droga fue mejor que no usarla (control) 38 12. Pruebas t para datos pareados Consideremos la siguiente situación: queremos comparar dos laboratorios en cuanto a su confiabilidad para determinar residuos de plomo en muestras de suelo. Para ello escogemos aleatoriamente 7 muestras de suelo. A cada muestra la dividimos por la mitad, y enviamos una mitad al laboratorio 1 y la otra al laboratorio 2. Laboratorio1 7.6 10.1 9.5 1.3 3.0 5.4 6.2 Y1 6.1571 s12 10.4895 Laboratorio2 7.3 9.1 1.5 2.7 4.8 5.4 Y2 5.6000 s22 8.1467 8.4 ¿Cuáles serían las hipótesis de interés? H0 : 1 2 El estadístico de la prueba es t Ha : 1 2 6.1571 5.6 0.343 , y el valor crítico para .05 es 3.0525 17 17 t12;.025 2.179. Por lo tanto la conclusión sería que aceptamos H 0 . Si observamos los datos cuidadosamente podemos ver que casi siempre el laboratorio 1 presenta resultados más altos que el laboratorio 2. El problema es que la prueba t realizada supone que los datos son independientes, mientras que claramente los datos son “pareados” por lo que la prueba realizada es inválida. Para situaciones como esta existe una prueba que es apropiada: en vez de considerar los datos separadamente podríamos considerar las diferencias entre los datos de cada par. De esta manera eliminamos las diferencias entre pares (que no nos interesan) y nos concentramos en las diferencias dentro de cada par (que es lo que realmente nos interesa). En nuestro ejemplo nos interesa saber si, para una muestra de suelo dada, hay diferencias entre los dos laboratorios, pero no nos interesa que haya o no diferencias entre muestras diferentes (en realidad, es mejor que haya muchas diferencias entre los diferentes pares, así nuestra inferencia es más general). En resumen, lo único que necesitamos hacer es crear una nueva variable di Y1i Y2i , y realizar una prueba t para una muestra. Es decir, hemos reducido nuestro problema a tener una muestra aleatoria de diferencias, y ya sabemos que tenemos la prueba t disponible para esta situación. 39 1. H 0 : 1 2 0 H a : d 0 ( d 0) H a : d 0 Hipótesis: H a : d 0 t 2. Definición del estadístico: 3. Definición de la región de rechazo: (los grados de libertad son 4. d 0 sd n t t , t t o t t n 1 , donde n es el número de pares) 2 Conclusiones. También podemos calcular un intervalo de confianza para 1 2 basado en el estadístico t: s d t 2 d . n Para que la prueba y el intervalo sean válidos, sólo necesitamos suponer poblaciones normales (y tener el estudio diseñado como observaciones pareadas). Para hacer los cálculos en Infostat, los datos deben disponerse en columnas separadas, y cada fila representará un par. El menú Estadísticas>Inferencias para dos muestras> Prueba t apareada nos permite realizar la prueba. Los resultados para la prueba bilateral y para el intervalo de confianza del 95% son: Prueba T (muestras apareadas) 40 Obs(1) Lab. 1 Obs(2) Lab. 2 N 7 media(dif) 0.56 DE(dif) 0.46 T 3.22 p Bilat_ 0.0181 Usando un nivel de significancia del 5%, podemos ver que rechazamos la hipótesis nula, ya que el valor p es menor que α. Usando la tabla, el valor crítico correspondiente a 6 grados de libertad y 0.025 (α/2, ya que es una prueba a dos colas), es 2.447, por lo que la conclusión es también rechazar H0. Los mismos resultados se obtienen si creamos una variable diferencia=lab1-lab2 (usando el menú Datos>Fórmulas), y realizamos una prueba t de una muestra: 41 Si hubiésemos usado (en este caso) erróneamente la prueba t para muestras independientes, los datos se deberían haber arreglado de otra manera, 42 13. Introducción al análisis de la varianza En esta clase vamos a generalizar la idea de comparar dos medias independientes. Mediante el análisis de la varianza se puede probar la igualdad de t medias H 0 : 1 2 ... t . Consideremos los siguientes ejemplos. Los datos son diámetros de aguacates de 3 variedades (5 frutos de cada variedad). CASO A 6.00 5.95 5.90 5.85 5.80 Y 5.90 5.59 5.54 5.50 5.46 5.41 Y 5.50 CASO B 5.90 4.42 7.51 7.89 3.78 Y 5.90 5.10 5.05 5.00 4.95 4.90 Y 5.00 6.31 3.54 4.73 7.20 5.72 Y 5.50 4.52 6.93 4.48 5.55 3.52 Y 5.00 Caso B Caso A 8.30 7.30 7.30 6.30 6.30 Y Y 8.30 5.30 5.30 4.30 4.30 3.30 3.30 Var 1 Var 2 Var 1 Var 3 Var 2 Var 3 Variedad Variedad Aquí podemos ver que en ambos casos las medias muestrales son las mismas, pero nosotros estaríamos más convencidos que las medias poblacionales serían diferentes en el caso A, mientras que en el caso B no estaríamos tan seguros. Esto se debe a que los datos en A son menos variables dentro de cada muestra. Podemos particionar la variabilidad de las 15 observaciones en dos: la variabilidad dentro de cada muestra (grupo) y la variabilidad entre muestras (grupos). Si la variabilidad entre muestras es grande con respecto a la variabilidad dentro de muestras (Caso A), entonces vamos a pensar que los grupos tienen medias poblacionales distintas. Por otra parte, si la variabilidad entre grupos es más o menos comparable a la variabilidad dentro de grupos, entonces no habría evidencias para concluir que las medias poblacionales son diferentes. 43 Cuando pensamos en la variabilidad de las Yij podemos ver que éstas varían debido a dos causas: una es que pertenecen a distintos grupos (las “i” son diferentes) y la otra es la variabilidad aleatoria dentro de cada grupo (las desviaciones que existen entre cada Yij y su promedio i ): Variabilidad total = Variabilidad entre grupos + Variabilidad dentro de grupos Si sólo tuviéramos dos grupos (tratamientos) entonces usaríamos el estadístico t para dos muestras independientes Y Y t 1 2 s p n11 n12 Aquí también estamos comparando la variabilidad “entre” (en el numerador) con la variabilidad “dentro” (en el denominador). Si tenemos más de dos grupos podríamos comparar de a pares (por ejemplo, probar 1 2 , 1 3 , 2 3 ), pero tenemos el problema que los errores de tipo I pueden acumularse, y entonces las pruebas no ser válidas. La idea es entonces lograr una prueba para probar simultáneamente todas las medias. Esta prueba se basa en el estadístico F obtenido de la tabla de ANOVA para la partición de la variabilidad total en variabilidad “entre” y “dentro”. La notación que usaremos será la siguiente: tenemos t tratamientos, cada uno con ni repeticiones. Yij denota la j ésima observación del i ésimo tratamiento . ni Yi Yij , es la suma de todas las observaciones del tratamiento i. j 1 t ni t Y Yij Yi , es la suma de todas las observaciones. i 1 j 1 i 1 Yi es la media de las observaciones del tratamiento i. Y es la media de todas las observaciones (media general). n ni es la cantidad total de observaciones (nt si hay n observaciones en cada tratamiento). i 44 Las sumas de cuadrados se calculan de la siguiente manera: SCTotal=SCTot Yij Y Yij2 Y 2 2 i, j i, j n SCEntre=SCTratamientos=SCTrat ni Yi Y 2 i i Yi2 Y2 ni n SCDentro=SCResidual=SCError=SCRes Yij Yi SCTot-SCTrat 2 i, j La siguiente es la tabla de ANOVA: Fuente de Variación Tratamiento Residual (Error) Total Suma de Cuadrados SCTrat SCRes=SCE SCTot grados de libertad t 1 n t n 1 Cuadrado Medio CMTrat CMRes=CME F F=CMTrat/CME H 0 : 1 2 ... t H a : al menos una i es diferente Estadístico de la prueba: F CMTrat CME Región de rechazo: F F (g.l.: t 1, n t ) Vamos a aplicar estas ideas a un ejemplo: consideremos los siguientes datos de contenido de almidón en tallos de tomate bajo 3 regímenes diferentes de fertilización: A 22 20 21 18 16 B 12 14 15 10 9 C 7 9 7 6 2 SCTot Yij2 Y i, j n 3062 200 2 15 14 Y1 111 Y1 18.5 Y2 60 Y2 12.0 Y3 7.25 Y3 29 395.3333 Yi2 Y2 1112 602 292 2002 SCTrat 317.0833 n 6 5 4 15 i ni SCRes SCTot-SCTrat=78.2500 45 Fuente de Variación Suma de Cuadrados grados de libertad Cuadrado Medio F Tratamiento Residual (Error) Total 317.0833 78.2500 395.3333 2 12 14 158.5417 6.5208 24.313 H 0 : 1 2 ... t H a : al menos una i es diferente Estadístico de la prueba: F CMTrat CME Región de rechazo (α=.05): F 3.89 Cálculo del estadístico de la prueba: F 24.313 Conclusión: Rechazamos H 0 , al menos uno de los tratamientos es diferente. Otra manera de pensar este análisis es mediante un modelo para explicar cada observación: Yij i ij Vemos que cada tratamiento tiene su propia media. Los supuestos que hacemos para que nuestra prueba sea válida son los siguientes: vamos a asumir que los 11 ,..., tnt son independientes y tienen distribución normal con media 0 y varianza constante: ij ~ N 0, Otra manera de escribir este mismo modelo es pensando que cada media i se puede descomponer en una media general y una desviación de esa media i , que llamaremos el “efecto” del tratamiento i i i . Esta formulación nos permitirá extender el modelo a otras situaciones y diseños experimentales. Yij i ij i ij Las hipótesis que estamos probando pueden escribirse en término de cualquiera de las dos formulaciones del modelo: H 0 : 1 2 ... t 0 H 0 : 1 2 ... t H : al menos un es diferente de 0 a H a : al menos una i es diferente 46 i 14. Comparaciones múltiples en ANOVA Cuando rechazamos la hipótesis nula de igualdad de medias de tratamiento (o ausencia de efectos de tratamiento), concluimos que al menos una de las medias es diferente. La pregunta que nos hacemos inmediatamente es ¿cuál es/son la(s) media(s) diferente(s)? Una manera de responder a esta pregunta es a través de la comparación de cada media con todas las restantes, usando uno de los procedimientos de comparaciones múltiples. Éstos consisten en probar las siguientes t(t-1)/2 hipótesis: 1 2 ; 1 3 ; ...; t 1 t . Si tuviésemos una sola de estas hipótesis que probar, podríamos usar el estadístico t para dos muestras independientes. Como aquí tenemos más de una hipótesis, el uso de t para cada una podría ocasionar una acumulación de los errores, por lo que sólo se aconseja hacer esta prueba luego de encontrar mediante la prueba F que hay diferencias entre al menos una de las medias. Bajo el supuesto que las varianzas son iguales, el mejor estimador de la desviación estándar común es sw CME . Entonces podemos construir cada uno de los estadísticos t como, por ejemplo, Y1 Y3 t CME n11 n13 Supongamos que la cantidad de repeticiones en cada tratamiento es la misma (n). Entonces, Y1 Y3 . t CME n2 ¿Cuándo vamos a rechazar la hipótesis nula y quedarnos con la alternativa (de dos colas)? Cuando el valor del estadístico t sea mayor (en valor absoluto) que t 2 . Es decir, vamos a concluir que las medias i y j son diferentes cuando t Y1 Y3 CME 2 n t . Equivalentemente, vamos a concluir que las medias i y j son diferentes cuando 2 2CME Yi Y j t sw t =DMS. 2 2 n n Debemos notar que la cantidad a la derecha no depende de i o j (siempre que los n sean iguales) y se llama DMS “diferencia mínima significativa” porque es la diferencia más pequeña que va a hacer que dos medias sean consideradas diferentes. Si los tamaños muestrales fueran diferentes, entonces el DMS dependerá de los ni , n j . 47 2 Ejemplo Vamos a considerar un ejemplo en el que tenemos 6 tratamientos, cuyas medias aparecen en orden descendente a continuación. El valor de la diferencia mínima significativa es DMS=2.2. Tratamiento Trat. 3 Trat. 1 Trat. 5 Trat. 4 Trat. 2 Trat. 6 Y 35.7 34.0 33.9 25.1 24.7 22.8 a. El primer paso va a ser comparar la media del tratamiento 3 con todas las que le siguen (es decir, Y3 con Y1 , Y3 con Y5 , Y3 con Y4 , Y3 con Y2 , Y3 con Y6 ). Vamos a conectar con una línea las medias que no son significativamente diferentes (es decir, aquéllas cuya diferencia sea menor que DMS) Tratamiento Trat. 3 Trat. 1 Trat. 5 Trat. 4 Trat. 2 Trat. 6 Y 35.7 34.0 33.9 25.1 24.7 22.8 b. Ahora compararemos Y1 con todas las medias que le siguen, y conectaremos con líneas las medias que no son significativamente diferentes de Y1 : Tratamiento Trat. 3 Trat. 1 Trat. 5 Trat. 4 Trat. 2 Trat. 6 Y 35.7 34.0 33.9 25.1 24.7 22.8 c. Cuando seguimos el proceso para Y5 , observamos que la media que le sigue, Y4 , tiene una diferencia mayor que DMS, y por lo tanto no podemos poner una línea que una Y5 con una media que está más abajo. 48 d. Repetimos el proceso para Y4 y Y2 : Tratamiento Trat. 3 Trat. 1 Trat. 5 Trat. 4 Trat. 2 Trat. 6 Y 35.7 34.0 33.9 25.1 24.7 22.8 e. Observar que hay una línea (uniendo las medias 1 y 5) que está de más, ya que las medias 1 y 5 ya aparecen unidas por la línea que va desde la media 3 hasta la media 5. Por lo tanto, eliminamos la línea redundante. Tratamiento Trat. 3 Trat. 1 Trat. 5 Trat. 4 Trat. 2 Trat. 6 Y 35.7 34.0 33.9 25.1 24.7 22.8 f. Ahora podemos dejar las líneas, o cambiar las líneas por letras iguales: Tratamiento Trat. 3 Trat. 1 Trat. 5 Trat. 4 Trat. 2 Trat. 6 Y 35.7 34.0 33.9 25.1 24.7 22.8 a a a b bc c g. Se debe observar que las medias que no están unidas por líneas verticales (o la misma letra) son significativamente diferentes entre sí. 49 Intervalos de confianza para medias y diferencias de medias en ANOVA Para reportar las medias luego de realizar un ANOVA podemos usar un gráfico de barras (que se genera opcionalmente en InfoStat), e incluir límites de confianza para las medias (o errores estándar para las medias). Las fórmulas estudiadas anteriormente usando la tabla t se podrían aplicar aquí: Y t 2 s . n s n como Si usamos una salida de InfoStat, podemos leer directamente la cantidad E.E. (error estándar) en la salida “Medias ajustadas, error estándar y número de observaciones”. Como hemos hecho para el cálculo del DMS, el mejor estimador que tenemos de la desviación estándar poblacional es (bajo el supuesto que las varianzas son iguales), CME Este estimador tiene los grados de libertad del error. Por lo tanto, el intervalo de confianza para una media de tratamiento es CME Y t 2 n Recordar que en esta fórmula n representa la cantidad de observaciones en la media específica (cantidad de repeticiones), y no la cantidad total de observaciones en todo el experimento. Los grados de libertad para el valor tabular de t son los grados de libertad del error. Similarmente podemos calcular un intervalo de confianza para la diferencia de dos medias. Suponiendo igual número de repeticiones n: 2CME n Observar que el término que se suma y resta en esta fórmula es DMS, por lo que el intervalo de confianza para la diferencia de dos medias es: Yi Y j t /2 Yi Y j DMS Si este intervalo incluye el valor de cero, las dos medias correspondientes no son significativamente diferentes. Esto es lo que hemos usado cuando estudiamos la prueba de DMS: si la diferencia de dos medias es menor que DMS, esas medias no son significativamente diferentes. El intervalo va a incluir 0 si y solo si la diferencia de las dos medias es menor que DMS. 50 15. Tablas de contingencia Este tipo de análisis se usa también para estudiar el efecto de una variable (como en regresión, que estudiaremos en las próximas conferencias) o de un tratamiento (como en ANOVA). A diferencia de ANOVA, la variable dependiente en tablas de contingencia es categórica. Por ejemplo, podemos comparar la susceptibilidad de 4 cultivares de habichuela al tizón bacteriano. Se escogen 30 plántulas al azar de cada cultivar, y se clasifica cada plántula en dos categorías: con síntomas y sin síntomas de la enfermedad. Los datos se presentan a continuación. Cultivar Bac-6 V PC GNT Con síntomas 2 16 13 7 Sin síntomas 28 14 17 23 30 30 30 30 Debemos observar que la respuesta aquí es una variable con dos posibles categorías: con o sin síntomas. Nos interesa ver si la presencia de síntomas es independiente del cultivar (es decir, si la proporción de plantas con síntomas es la misma en cada cultivar). Recordando la variable binomial (SÍ / NO), la proporción de “éxitos” la denotábamos con , en este caso denotaremos con i a la verdadera proporción de éxitos en el grupo (tratamiento) i. Entonces la hipótesis que nos interesa probar es H 0 : 1 2 3 4 Usando una notación análoga a ANOVA, la cantidad de plántulas observada en cada celda se denotará como nij : Cultivar Bac-6 Con síntomas n11 =2 Sin síntomas PC n21 =16 n31 =13 n12 =28 n22 =14 n32 =17 GNT n41 =7 n42 =23 V Si todas las variedades tuvieran la misma proporción de enfermas en la población (es decir, la hipótesis nula fuese cierta), las cantidades esperadas de plántulas en cada celda se podrían calcular como ni n j (total fila i )(total columna j ) Eij n total general 51 La tabla de valores esperados sería Con síntomas Sin síntomas PC E11 9.5 E21 9.5 E31 9.5 E12 20.5 E22 20.5 E32 20.5 GNT E41 9.5 E42 20.5 Cultivar Bac-6 V ¿Cómo sabemos que lo que nosotros estamos observando nij está lo suficientemente cerca de lo que nosotros esperamos si la hipótesis nula fuese cierta Eij ? Una forma es comparando cada valor observado con cada valor esperado: n 2 ij Eij 2 Eij Éste será el estadístico de la prueba (chi-cuadrado). Debemos notar que si lo que observamos es exactamente igual a lo que esperamos, entonces 2 0 . Si lo que observamos está muy “lejos” de lo que esperamos entonces el estadístico será muy grande. Por lo tanto, una región de rechazo razonable para esta prueba rechazará cuando el estadístico tenga valores muy grandes. Para encontrar el valor crítico debemos usar la tabla de una distribución nueva: la distribución chi-cuadrado. Para usar esta tabla debemos conocer los grados de libertad, que en el caso de tablas de contingencia siempre serán r 1 c 1 , donde r es la cantidad de filas y c la cantidad de columnas. Para que esta aproximación funcione bien necesitamos que todos lo valores esperados sean mayores o iguales a 5. En el ejemplo que estamos revisando, 2 9.5 2 9.5 2 16 9.5 9.5 2 23 20.5 20.5 2 18.023 La región de rechazo, para 0.05 y 3 grados de libertad según la tabla 7 (páginas 11001101) es 2 2 7.815 . Por lo tanto rechazamos H 0 y concluimos que al menos una de las variedades tiene una susceptibilidad diferente. Otra aplicación de esta prueba es para probar que hay independencia entre dos variables categóricas observadas conjuntamente. Por ejemplo, nos puede interesar saber si el color de flor (azul/amarillo) y el tamaño de la semilla (pequeña/mediana/grande) son caracteres independientes. Las fórmulas para el estadístico de la prueba son las mismas que las que hemos presentado para probar la igualdad de proporciones. Es importante destacar que estamos siempre probando hipótesis acerca de relaciones entre proporciones (no frecuencias absolutas) y por lo tanto cualquier gráfico de resumen que construyamos debe hacerse con proporciones. 52 16. Regresión lineal simple Hasta ahora hemos estudiado la relación entre una variable dependiente (Y) y dos o más “tratamientos” (por ejemplo: tratado / control, variedades 1-4, etc.). Ahora vamos a estudiar la relación que existe entre dos variables: una independiente y otra dependiente. Por ejemplo la cantidad de proteína en la dieta y el aumento de peso. La variable que nosotros variamos a voluntad es la “variable independiente”, y sobre la que nos interesa estudiar el efecto es la “variable dependiente”. Por ejemplo, queremos ver cuál es el promedio de ganancia de peso cuando agregamos 10%, 15%, 20% y 25% de proteína a la dieta. La relación más simple es la de una línea recta Y 0 1 x , donde Y es el aumento de peso, x es el porcentaje de proteína en la dieta, 0 es el intercepto (valor de Y cuando x=0) y 1 es la pendiente (cambio en Y cuando x aumenta en una unidad). La pendiente también se denomina coeficiente de regresión asociado a la variable independiente. Y Este modelo se llama modelo determinístico: conociendo el valor de x podemos predecir exactamente el valor de Y. En la práctica no es muy realista, ya que los puntos observados no van a estar exactamente sobre la línea recta. El siguiente gráfico es más realista: 10 9 8 7 6 5 4 3 2 0 2 4 6 8 10 x Un modelo más realista es pensar que la línea recta representa la relación entre la media de las Y para un valor dado de x y la variable independiente: Y 0 1 x . Otra forma de escribir este modelo es Y 0 1 x donde es el error aleatorio y representa la diferencia entre el valor de Y y su media Y (o lo que es lo mismo, entre el valor observado y la recta). La media de estos errores aleatorio para un valor dado de x es 0 (es decir, los valores positivos y negativos se “balancean”) y por lo tanto ambas formulaciones de este modelo estocástico son equivalentes. 53 Problema: los parámetros de la recta 0 , 1 son desconocidos, por lo que necesitaremos una muestra de N observaciones x1 , Y1 ,..., xN , YN para estimarlos. La recta que obtendremos será la recta estimada: Yˆ ˆ ˆ x 0 1 La diferencia entre cada valor observado Yi y el valor correspondiente sobre la recta estimada se llama “error de predicción” o residuo, y se denomina como e Y Yˆ . i i i Observar que esto no es lo mismo que el error aleatorio i , que es la diferencia entre cada valor observado y la recta verdadera (poblacional). Para estimar la recta vamos a usar el método de mínimos cuadrados, que consiste en elegir los parámetros 0 , 1 que minimicen la suma de los cuadrados de los errores de predicción: N N i 1 i 1 (Yi Yˆi )2 (Yi ˆo ˆ1 xi )2 Los estimadores son ˆ1 S xy S xx N S xx ( X i X ) X X i i 1 i 1 i 1 N N 2 ˆ0 Y ˆ1 x , 2 2 i N = suma de cuadrados de X N N N N i 1 i 1 i 1 i 1 S xy ( X i X )(Yi Y ) X iYi X i Yi N = suma de productos Peso Consumo 4.6 87.1 5.1 93.1 4.8 89.8 4.4 91.4 5.9 99.5 4.7 92.1 5.1 95.5 5.2 99.3 4.9 93.4 5.1 94.4 Consumo Ejemplo: Relación entre el peso de gallinas (lb) y el consumo de alimento durante 1 año. 102 100 98 96 94 92 90 88 86 y = 55.2633+ 7.6901x 4 4.5 5 5.5 6 Peso Para este ejemplo S xx 1.536, S yy 11.812, ˆ1 7.69, ˆ0 55.26. Ahora vamos a estudiar cómo realizar inferencias en regresión lineal (es decir, vamos a construir intervalos de confianza y a probar hipótesis acerca de los parámetros de interés). 54 Cuando pensamos en la variabilidad de las Yi podemos ver que estas Yi varían debido a dos causas fundamentales: una es la relación que existe entre Y y las x (la recta de regresión) y la otra es la variabilidad aleatoria alrededor de la recta (las desviaciones que existen entre cada Yi y su promedio Yi : Variabilidad total = Variabilidad explicada + Variabilidad no explicada Este mismo concepto se traduce en la siguiente fórmula: Y Y Yˆ Y Y Yˆ 2 2 i i i 2 i SC “Total” = SC “Regresión” + SC “Residual” Las fórmulas de cálculo para estas sumas de cuadrados son bastante sencillas: SCTotal SYY Yi 2 Y 2 i N SCRegresión ˆ1 S XY SCResidual SCTotal SCRegresión Podemos ver qué pasaría si todas las observaciones estuviesen sobre la recta (SCResidual=0), y qué pasaría si la mejor recta de ajuste fuese una línea horizontal (SCRegresión=0). Ahora estamos en condiciones de realizar inferencias. Recordemos nuestro modelo Yi 0 1 xi i . Vamos a asumir que este es el modelo correcto, que los 1 ,..., n son independientes y tienen distribución normal con media 0 y varianza constante: i ~ N 0, Si estos supuestos se cumplen, entonces tenemos las siguientes propiedades de la distribución muestral de ˆ0 y ˆ1 : ˆ 0 , ˆ 1 0 ˆ 0 1 x 2 N S xx , ˆ 1 S xx Además, ˆ0 y ˆ1 tienen distribución normal. Un estimador de se obtiene a partir de la suma de cuadrados residual (también llamada suma de cuadrados del “error”): 55 SCResidual SYY ˆ1S XY . N 2 N 2 Con esta información podemos construir intervalos de confianza y realizar pruebas de hipótesis usando el estadístico t que hemos estudiado antes. Por ejemplo, un intervalo de confianza para 0 sería: ˆ 2 s2 ˆ0 t s x 2 2 N S xx Si usamos una salida de InfoStat, podemos leer directamente las cantidades se x 2 N S xx ó se S xx como E.E. (error estándar) que acompaña a los estimadores del intercepto y pendiente respectivamente (“Est.”) en la salida “Coeficientes de regresión y estadísticos asociados”. Otro ejemplo: H 0 : 1 0, H a : 1 0 ˆ 0 t 1 , gl N 2 s S xx Esta última prueba es la más importante en regresión lineal: si no podemos rechazar H 0 entonces estamos concluyendo que no hay una relación lineal entre el promedio de las Y y las x. Otro estadístico alternativo para esta misma prueba se obtiene a partir de la tabla de “análisis de la varianza”, que refleja la partición de la variabilidad que mencionamos al comienzo de la clase. Fuente de Variación Suma de Cuadrados grados de libertad Regresión SCRegresión 1 Residual (Error) SCResidual=SCE N-2 Total SCTotal N-1 CMReg El estadístico para esta prueba es F Cuadrado Medio F CMReg=SCReg/1 F=CMReg/CME CME=SCE/(N-2) CME y debemos rechazar H 0 si F F . Para encontrar el valor tabular de F debemos buscar en la tabla correspondiente con 1 y N2 grados de libertad. Podemos verificar que tanto para el valor observado como para el tabular, F t 2 y por lo tanto ambas pruebas siempre van a conducir a las mismas conclusiones. 56 Correlación lineal Un concepto relacionado con el de regresión es el de correlación. Cuando hablamos de correlación pensamos en la relación que existe entre dos variables, sin distinguir cuál es la dependiente y cuál la independiente. Para medir correlación se usa el coeficiente de S XY correlación lineal: r . Este coeficiente puede tomar valores entre –1 y 1, y mide S XX SYY la fuerza de la asociación lineal entre ambas variables. Observar que no importa cuál es la x y cuál es la y, el coeficiente es simétrico. 2500 40 1913 36 Salinidad Biomasa Ejemplos de correlación: 1325 738 32 28 150 24 3.00 4.25 5.50 6.75 8.00 0 7 14 21 28 35 Zinc 2500 3.28 1913 3.14 PB Biomasa pH 1325 738 3.00 2.85 150 2.71 23 27 31 35 39 1.65 Salinidad 1.77 1.90 2.03 2.15 CO Otra forma de pensar en correlación es considerar el coeficiente de determinación, que es la proporción de la variabilidad total explicada por la regresión: 57 R2 SCRegresión SCTotal Este coeficiente siempre está entre 0 y 1, y cuanto más cerca de 1 está mejor será el ajuste. Si tuviésemos una regresión lineal simple, R 2 es simplemente el cuadrado del coeficiente de correlación lineal r. 58 17. Diseño en bloques completos al azar Recordemos el diseño completamente aleatorizado. Un supuesto fundamental era que las unidades experimentales debían ser homogéneas. Cuando las unidades no son homogéneas pero pueden agruparse en grupos de unidades homogéneas existe otro diseño, que es la generalización del diseño pareado para comparar dos grupos: el diseño en bloques completos aleatorizados (DBCA). Un “bloque” es un conjunto de unidades experimentales homogéneas (es decir, parecidas entre sí). Este diseño consiste en asignar los tratamientos aleatoriamente dentro de cada bloque de manera tal que cada tratamiento que representado una vez en cada bloque. De esta manera garantizamos que todos los tratamientos estarán representados en todos los bloques, y que las comparaciones estarán libres de las diferencias entre bloques (el mismo efecto que lográbamos con el diseño pareado). Para que este efecto del DBCA sea útil en reducir la variabilidad necesitamos que haya diferencias entre los bloques y dentro de cada bloque las unidades sean homogéneas. La notación que usaremos será la misma que para el DCA: tenemos t tratamientos, cada uno con n repeticiones (=bloques). Yij denota la observación del i ésimo tratamiento en el bloque j. . Ahora tendremos una fuente adicional de variabilidad: los bloques. Las sumas de cuadrados se calculan de la siguiente manera: SCTotal=SCTot Yij Y Yij2 Y 2 2 i, j i, j nt SCTratamientos=SCTrat n Yi Y 2 i i SCBloques=SCBl t Y j Y 2 j j 2 j Y t Yi2 Y2 n nt Y2 nt SCResidual=SCError=SCRes Yij Yi Y j Y SCTot-SCTrat-SCBl 2 i, j La siguiente es la tabla de ANOVA: Fuente de Variación Tratamiento Bloque Residual (Error) Suma de Cuadrados SCTrat SCBl SCRes=SCE Total SCTot grados de libertad t 1 n 1 n 1 t 1 Cuadrado Medio CMTrat CMBl CMRes=CME F F=CMTrat/CME F=CMBl/CME nt 1 El modelo que describe los datos provenientes de este diseño es el siguiente: 59 Yij i j ij Los supuestos que necesitamos hacer son los mismos que para el DCA (los ij son independientes, tienen distribución normal y varianza constante) y además necesitamos asumir que los efectos de los tratamientos son iguales en todos los bloques. La hipótesis de interés es, como siempre, acerca de los efectos de tratamiento: H 0 : 1 2 ... t H a : al menos una i es diferente de 0. Estadístico de la prueba: F CMTrat CME Región de rechazo: F F g.l.: t 1, (n 1)(t 1) También podemos probar la hipótesis de que no existen diferencias entre bloques: H 0 : 1 2 ... t H a : al menos una i es diferente de 0. Estadístico de la prueba: F CM Bl CME Región de rechazo: F F g.l.: n 1, (n 1)(t 1) Ejemplo de bloque analizado en Infostat Estos datos aparecen en el archivo Bloque.idb en Infostat, y representan rendimientos de un ensayo con 5 tratamientos arreglados en un DBCA con 4 repeticiones (=bloques). Para hacer el análisis en Infostat usamos el menú Estadísticas>Análisis de la Varianza. Usamos bloque y tratamiento como variables de clasificación y rendimiento como variable dependiente. 60 61 Análisis de la varianza Variable N R² R² Aj CV Rendimiento 20 0.94 0.90 5.83 Cuadro de Análisis de la Varianza (SC tipo III) F.V. SC gl CM F p-valor Modelo 4494763.30 7 642109.04 24.88 <0.0001 Bloque 203319.00 3 67773.00 2.63 0.0983 Tratamiento 4291444.30 4 1072861.08 41.57 <0.0001 Error 309716.50 12 25809.71 Total 4804479.80 19 Test:LSD Fisher Alfa:=0.05 DMS:=247.51210 Error: 25809.7083 gl: 12 Tratamiento Medias n 0 1972.75 4 A 75 2498.50 4 B 150 2973.00 4 C 225 3093.50 4 C D 300 3237.75 4 D Letras distintas indican diferencias significativas(p<= 0.05) 62 18. Introducción a los diseños experimentales Hasta este momento hemos discutido dos diseños diferentes: el diseño completamente aleatorizado (DCA) y el diseño en bloques completos aleatorizados (DBCA). En el primer caso se requiere independencia entre todas las observaciones. En un experimento, esto se logra realizando una aleatorización completa de los tratamientos a las unidades experimentales (es decir, cada unidad experimental tiene la misma probabilidad de recibir cualquiera de los tratamientos, independientemente del tratamiento asignado a unidades vecinas). Ventajas del DCA: Simple para construir Simple para analizar, aun cuando el número de repeticiones no es constante. Sirve para cualquier número de tratamientos. Desventajas del DCA: Requiere que todas las unidades experimentales sean homogéneas. Fuentes de variación no consideradas inflarán el error experimental. Cuando las unidades no son homogéneas pero pueden agruparse en grupos de unidades homogéneas existe el diseño en bloques completos aleatorizados (DBCA). Un “bloque” es un conjunto de unidades experimentales homogéneas (es decir, parecidas entre sí). Este diseño consiste en asignar los tratamientos aleatoriamente dentro de cada bloque de manera tal que cada tratamiento que representado una vez en cada bloque. De esta manera garantizamos que todos los tratamientos estarán representados en todos los bloques, y que las comparaciones estarán libres de las diferencias entre bloques (el mismo efecto que lográbamos con el diseño pareado). Para que este efecto del DBCA sea útil en reducir la variabilidad necesitamos que haya diferencias entre los bloques y dentro de cada bloque las unidades sean homogéneas. Ventajas del DBCA: Útil para comparar tratamientos en presencia de una fuente externa de variabilidad. Simple para construir y analizar (siempre que el número de repeticiones sea constante). Desventajas del DBCA: Práctico para pocos tratamientos, para que las unidades de un bloque sean realmente homogéneas. Controla una sola fuente de variabilidad externa. El efecto del tratamiento debe ser el mismo en cada bloque. Luego de haber estudiado dos diseños, podemos volver a preguntarnos: ¿qué es diseñar un estudio científico? 63 El diseño es el proceso de establecer un marco para que se puedan comparar tratamientos, grupos o condiciones. Ya hemos discutido anteriormente los tipos de estudios más comunes: experimentos y estudios observacionales. En un estudio observacional se obtiene información bajo condiciones “no perturbadas”, es decir, condiciones naturales, y se comparan las diferentes condiciones o grupos. Por el contrario, en un experimento, el investigador controla las condiciones y decide qué tratamiento recibe cada unidad. Este control permite que en un experimento se pueda atribuir al efecto observado (por ejemplo que la condición A es más efectiva que la condición B) a que las unidades fueron tratadas con dos tratamientos diferentes. En el caso de un estudio observacional, se podría argumentar que, como el investigador no tuvo control sobre las unidades antes de asignarles la condición a la que se verían expuestas, la causa de las diferencias podría ser otra. Existen situaciones prácticas, éticas, o de la naturaleza del estudio, que hacen que se tengan que hacer estudios observacionales. Si podemos escoger, el experimento nos va a brindar conclusiones más “sólidas”. Cuando hablamos de controlar las condiciones a las que exponemos a las distintas unidades en un experimento, también debemos considerar todo el desarrollo del experimento. Es decir, debemos seguir un plan (protocolo) sistemático durante todo el experimento, y cualquier situación que pudiera presentarse debería considerarse en este plan. Algunos aspectos que deberían incluirse en este plan son: 1. Los objetivos de investigación 2. La selección de los factores (condiciones) que se van a variar (“tratamientos”) 3. La identificación de otros factores de variación que puedan estar presentes (por ej., factores de bloqueo) 4. Las características a medir en las unidades experimentales (las variables de respuesta) 5. El método de aleatorización 6. Los procedimientos para registrar los datos 7. La determinación del número de repeticiones según la precisión deseada 64 19. Documentación y comunicación de resultados Esto es lo que presentamos en la primera clase de AGRO 5005: ¿Qué es la Biometría? ¿Cómo? Es la disciplina que se encarga de obtener información a partir de datos biológicos. Mediante gráficos, medidas numéricas de resumen (ej., promedio), comparaciones, predicciones, etc. Etapas que debemos seguir para obtener información “buena” a partir de los datos: 5. 6. 7. 8. Recolectar los datos Resumir los datos Analizar los datos Comunicar los resultados En esta conferencia vamos a tratar de discutir algunas ideas que permitan lograr eficazmente la etapa 4, “comunicar los resultados”. La comunicación puede ser verbal o escrita. La comunicación verbal puede ser desde una comunicación informal hasta una presentación formal. La comunicación escrita también varía desde memorandos e informes de proyecto dentro de la misma organización (interna) hasta cartas, folletos de divulgación, artículos científicos y libros (externa). En todos los casos tenemos que tener en cuenta la audiencia (hacia quién nos estamos comunicando). Los principales problemas que se pueden encontrar al comunicar resultados estadísticos son los siguientes: Distorsiones gráficas: recordemos lo que habíamos discutido antes 5. ¿Qué es lo que se desea informar al lector del grafico? 6. Elegir cuidadosamente los títulos, ejes, colores, rayas, etc. 7. No sobrecargar de información al gráfico. 8. Practicar mucho! Muestras sesgadas: éste es posiblemente uno de los problemas centrales que nos encontramos. Las conclusiones pueden ser correctas pero se refieren a la “población” equivocada. Recordemos que si no existe la aleatorización no podemos realizar la inferencia estadística correctamente. Se requiere de una planificación adecuada del estudio. Tamaño muestral inadecuado: los resultados de un experimento pueden llevar a una conclusión equivocada porque no había suficientes observaciones como para que el error de tipo II (aceptar una hipótesis nula falsa) fuese suficientemente pequeño. Se requiere de una planificación adecuada para que la cantidad de repeticiones sea suficiente como para detectar con una probabilidad alta una diferencia que exista en la población y que sea de interés para el investigador. 65 Al informar las conclusiones debemos especificar claramente cómo se obtuvieron las observaciones, qué diseño se usó (=cómo se aleatorizó) y cuántas observaciones (=repeticiones) se realizaron. Si es posible, se debería incluir un estudio de la potencia de las pruebas para evidenciar que el tamaño muestral fue adecuado para detectar las diferencias de interés. Preparación de los datos para el análisis 1. Generar (recibir) los datos originales 2. Crear la base de datos a partir de los datos originales 3. Editar la base de datos 4. Corregir y clarificar la base de datos comparándola con los datos originales 5. Finalizar la base de datos, archivarla y crear copias (en varios medios, como USB, DVD, papel, etc.) 6. Crear archivos de datos para los análisis Es muy importante (y en algunas áreas obligatorio) llevar un registro detallado de todo el proceso para, de ser necesario, rehacer nuevamente las distintas etapas por las que los datos han pasado. Una forma común de documentar esto es mediante un registro del estudio (cuaderno de bitácora o “study log”). Éste debería incluir: a. datos recibidos, y de quién b. investigador a cargo del estudio c. estadístico y otro personal asignado d. descripción breve del estudio e. tratamientos usados f. diseño experimental usado g. mapa de campo con tratamientos y aleatorizaciones h. fuente de los datos originales i. variables dependientes medidas (“respuestas”) j. fechas de toma de datos, análisis, etc. k. irregularidades en la toma de datos, registro, etc. l. otra información relacionada Guías para el análisis e informe estadísticos Los análisis preliminares, a menudo descriptivos o gráficos, permiten familiarizarse con los datos, observar algunas relaciones, detectar problemas, etc. Los análisis primarios se hacen para responder las preguntas de investigación que se indicaron en los objetivos del estudio. Los análisis secundarios (o de apoyo) incluyen métodos alternativos de observar los datos, uso de métodos poco comunes en el área de aplicación, exploración de hipótesis sugeridas por los resultados del experimento, etc. Informe estadístico 66 a. b. c. d. e. f. g. h. Resumen Introducción Diseño experimental y procedimientos del estudio Estadísticos descriptivos Metodología estadística Resultados y conclusiones Discusión Lista de datos y salidas de computación relevantes Documentación y almacenamiento de resultados La idea fundamental es que podamos tener la documentación y los datos almacenados de forma tal que en el futuro nosotros (o algúna otra persona) pueda rehacer los análisis, obtener nuevos resultados (o confirmar los obtenidos) y alcanzar nuevas conclusiones sin mayores dificultades. En algunas áreas de investigación esto es necesario para poder evaluar la calidad de las conclusiones obtenidas, y en todos los casos es una práctica muy importante. 67 Biometría AGRO 5005 Número de horas crédito: 3 (tres). Se realizarán dos horas de conferencia semanales y un laboratorio semanal de 3 horas. Prerrequisitos, correquisitos y otros conocimientos: se espera que los estudiantes posean destrezas básicas en el uso de computadoras personales. Descripción: Conceptos básicos del razonamiento estadístico aplicado a problemas en las ciencias agrícolas, biológicas y ambientales. Recolección, descripción gráfica y resumen numérico de los datos. Conceptos de probabilidad y muestreo. Estimación y prueba de hipótesis, análisis de la varianza, correlación y regresión lineal. Los estudiantes describen y analizan conjuntos de datos reales y usan programas estadísticos de computación. Propósito del curso: Este curso permite a los estudiantes graduados y subgraduados avanzados aprender un aspecto crucial para su futura actividad de investigación: la metodología a seguir para obtener conclusiones válidas a partir de estudios experimentales. Este curso sirve como base de programas graduados en ciencias agrícolas, biología, ciencias marinas y kinesiología, y se complementa con el curso de biometría avanzada (AGRO 6600). Objetivos: Se espera que al finalizar el curso el estudiante conozca los principales métodos de análisis de datos experimentales. pueda construir gráficos y medidas que representen y resuman adecuadamente los datos disponibles. pueda analizar experimentos simples, obteniendo conclusiones válidas. conozca y aplique regresión y correlación lineal. use el programa estadístico Infostat, obteniendo conclusiones válidas a partir de las salidas de computación. Conferencias: Martes y Jueves 9:30-10:20 am, P 213 (sección 036) Laboratorios: Lunes 1:30-4:20 pm, AP203 (sección 071L) Lunes 4:30-7:20 pm, AP203 (sección 100L) Martes 1:30-4:20 pm, AP203 (sección 076L) Miércoles 1:30-4:20 pm, AP203 (sección 070L) Miércoles 4:30-7:30 pm, AP203 (sección 101L) Jueves 1:30-4:20 pm, AP203 (sección 077L) Profesores: Dr. Raúl E. Macchiavelli (conferencias) Oficina: P217A, Decanato AP200 Teléfono: 787-832-4040 ext.3020 (oficina) o 5975 (decanato) e-mail: [email protected] Horas de oficina: Martes y Jueves 8 a 9 am 68 Dra. Linda Wessel Beaver (conferencias; coordinadora de laboratorios) Oficina: P-110, Laboratorio P 111, Teléfono: 787-832-4040 ext. 6334 e-mail: [email protected] Horas de oficina: Instructores de laboratorio: Sra. Rocío Suárez (laboratorio de miércoles 4:30-7:30) Oficina: P-218A Teléfono: 787-832-4040 ext. 3851 o 2313 e-mail: [email protected] Horas de oficina: martes y jueves 4:30 – 5:15 pm o por acuerdo Estrategias instruccionales: Conferencia: dos conferencias semanales de asistencia obligatoria. El material a discutir en las conferencias se encuentra en el texto del curso, y un resumen del mismo está disponible en las notas de clase (ver la página web del curso). Laboratorio: un laboratorio semanal de asistencia obligatoria. Durante el mismo se discutirán temas y analizarán datos usando computadoras. El material y los datos de cada laboratorio estarán disponibles en la página web del curso. Los estudiantes deben llevar al laboratorio calculadora con funciones estadísticas, el texto (incluyendo las tablas estadísticas a usarse) y dispositivo de memoria. (Para no interrumpir las conferencias o laboratorios, está prohibido el uso de teléfonos celulares. Favor ponerlos en modo silencioso durante las clases y los exámenes.) Recursos de aprendizaje: Los laboratorios se realizarán en el laboratorio de computadoras de Biometría, donde hay disponibles 17 computadoras personales, además de un servidor, impresora y pantalla inteligente. Los estudiantes deberán traer a los laboratorios sus calculadoras, las que deben tener funciones estadísticas disponibles. El material de conferencias y laboratorios, así como los datos a analizar estarán disponibles en la página del curso http://academic.uprm.edu/rmacchia/agro5005 Estrategias de evaluación / Herramientas de avalúo Pruebas cortas (quizes): cinco quizes durante los laboratorios. Estos quizes no se anunciarán. La nota final solamente incluirá el promedio de los 4 mejores quizes. Exámenes parciales: dos exámenes parciales, tentativamente los días 13 de octubre y 10 de noviembre en P213 (7:30 pm a 9 pm). Durante los exámenes se proveerán las tablas y fórmulas necesarias, y los estudiantes podrán usar calculadora y el libro (no se permiten notas de clase ni fotocopias). Los exámenes de años anteriores estarán disponibles en la página web del curso. Los teléfonos celulares no se permiten durante el examen: los teléfonos celulares, tabletas y otros aparatos electrónicos deberán permanecer en las 69 carteras o bultos. La posesión de un teléfono celular fuera de una cartera o bulto durante el examen se considerará como intento de plagio. Examen Final: el examen final será un trabajo integrador del material estudiado durante el curso. Durante los exámenes se proveerán las tablas y fórmulas necesarias, y los estudiantes podrán usar calculadora y el libro (no se permiten notas de clase ni fotocopias). Los exámenes de años anteriores estarán disponibles en la página web del curso. Asistencia y participación en clase y laboratorios: para evaluar la participación de estudiantes en laboratorios cada estudiante deberá presentar un informe del mismo la semana siguiente a la realización del laboratorio correspondiente. La calificación final se basará en un promedio ponderado de las notas de Asistencia y participación (10%) Quizes (20%) Exámenes parciales (22% cada uno) Examen final (26%) Sistema de calificación: La nota final se basará en la calificación final de acuerdo a la siguiente equivalencia A: 90 o más B: 80 o más pero menos de 90 C: 70 o más pero menos de 80 D: 60 o más pero menos de 70 F: menos de 60 Bosquejo del curso Conferencias Fecha Aprox. 1. Introducción. Conceptos, usos y aplicaciones. 2. Estudios observacionales y experimentales. Muestreo. Manejo de datos. 3. Descripción de datos. Métodos gráficos. 4. Descripción de datos. Medidas de tendencia central y variabilidad. 5. Elementos de probabilidad. Distribución binomial. 6. Distribución normal. 16 agosto Sección del texto Sección del texto Sección del texto (sexta ed.) (quinta ed.) (cuarta ed.) Capítulo 1 Capítulo 1 Capítulo 1 18, 23 agosto Capítulo 2 Capítulo 2 Capítulo 2 25, 30 agosto 3.1-3.3, 3.7 3.1-3.3, 3.7 3.1-3.3, 3.7 1, 6 septiembre 3.4-3.6 3.4-3.6 3.4-3.6 8, 13, 15 septiembre 20, 27 septiembre 29 septiembre 4.2-4.3, 4.6-4.8 4.1-4.3, 4.6-4.8 4.1-4.3, 4.6-4.8 4.10 4.9, 4.10 4.9, 4.10 4.11-4.12 4.12 4.12 7. Distribuciones muestrales. 70 8. Estimación y pruebas de hipótesis para medias. PRIMER EXAMEN PARCIAL 4, 6, 11, 13 5.2-5.4, 5.6-5.7 octubre 13 octubre, 7:30 pm 9. Inferencias para dos medias. 18, 25, 27 6.2, 6.4 octubre 10. Análisis de la varianza. DCA. 1, 3 noviembre 8.1-8.3, 9.3 11. Pruebas de chi-cuadrado. 10 noviembre SEGUNDO EXAMEN PARCIAL 10 noviembre, 7:30 pm 12. Regresión y correlación 15, 17, 22 lineal. noviembre 13. Introducción al diseño de 29 noviembre, 1 experimentos. DCA y DBCA. diciembre 14. Comunicación de resultados 6, 8 diciembre EXAMEN FINAL 10.5-10.6 5.1-5.4, 5.6-5.7 5.1-5.3, 5.5-5.8 Temas 1-6; Labs 1-6 6.1-6.2, 6.4 6.1-6.2, 6.5 8.1-8.4, 9.1, 9.4 13.1-13.4, 14.4, 15.1-2 10.4, 10.6 8.1, 8.7 Temas 7-9; Labs 7-10 11.1-11.3, 11.7 11.1-11.3, 11.7 9.1-2, 9.5, 10.1-2 14.1-14.2, 15.115.2 14.1,14.2, 15.3 15.1-15.3 20.1-20.5 Laboratorio LAB 1 LAB 2 LAB 3 LAB 4 LAB 5 Fecha (Lu, Ma, Mi, Ju) 22, 23, 24, 25 agosto 29, 30, 31 agosto, 1 sept. 12, 6, 7, 8 septiembre 19, 13, 14, 15 septiembre 26, 27, 21, 20 septiembre Tema Introducción. Infostat. Manejo de datos. Gráficos I Resumen gráfico de la información II Estadísticos descriptivos. Probabilidad y distribución binomial. LAB 6 3, 4 octubre, 28, 29 sept. Distribución normal. LAB 7 LAB 8 LAB 9 12, 11, 5, 6 octubre 17, 18, 19, 13 octubre 24, 25, 26, 27 octubre Distribución muestral. Estimación y prueba de hipótesis. Pruebas t para una media y para dos medias independientes. LAB 10 LAB 11 LAB 12 LAB 13 LAB 14 31 oct., 1, 2, 3 noviembre 9, 10, 11, 5 noviembre 16, 17, 18, 12 noviembre 28, 29, 30 noviembre, 1 dic. 5, 6, 7, 8 diciembre Pruebas para datos pareados. Análisis de la varianza. Pruebas de chi cuadrado. Regresión y correlación lineal. Diseño en bloques completos aleatorizados Bibliografía: Ott, R.L. y M. Longnecker (2010). An Introduction to Statistical Methods and Data Analysis. 6ta. ed. Pacific Grove (CA): Duxbury (también la cuarta, la quinta y la séptima edición son recomendadas) Macchiavelli, R. y Wessel Beaver, Linda (2016). Notas de Clase de Biometría (disponible en la página web del curso). InfoStat (2015). InfoStat versión 2015. Grupo InfoStat, Facultad de Ciencias Agropecuarias, Universidad Nacional de Córdoba, Argentina (descargar gratuitamente de http://www.infostat.com.ar ) 71