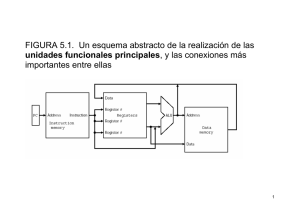
herramientas de apoyo para la enseñanza de
Anuncio

UNIVERSIDAD SIMÓN BOLÍVAR Ingeniería de la Computación HERRAMIENTAS DE APOYO PARA LA ENSEÑANZA DE ORGANIZACIÓN DEL COMPUTADOR por Pablo Daniel Reina Janowska Proyecto de Grado Presentado ante la Ilustre Universidad Simón Bolívar como Requisito Parcial para Optar al Título de Ingeniero en Computación Sartenejas, Julio del 2007 UNIVERSIDAD SIMÓN BOLÍVAR DECANATO DE ESTUDIOS PROFESIONALES COORDINACION DE INGENIERIA DE COMPUTACION ACTA FINAL DE PROYECTO DE GRADO HERRAMIENTAS DE APOYO PARA LA ENSEÑANZA DE ORGANIZACIÓN DEL COMPUTADOR Presentado por Pablo Daniel Reina Janowska Este proyecto de grado ha sido aprobado en nombre de la Universidad Simón Bolívar por el siguiente jurado examinador: _______________________________________________ Prof. Ricardo González Jurado _______________________________________________ Prof. Rodolfo Sumoza Jurado _______________________________________________ Prof. Angela DiSerio (Tutor Académico) _______________________________________________ Prof. Eduardo Blanco (Profesor Guía) Sartenejas, Julio 2007 HERRAMIENTAS DE APOYO PARA LA ENSEÑANZA DE ORGANIZACIÓN DEL COMPUTADOR por Pablo Daniel Reina Janowska RESUMEN El objetivo del presente trabajo es el desarrollo e implementación de una herramienta que permita la definición de distintas arquitecturas de computadores y la ejecución de programas para dichas arquitecturas. Esta herramienta fue concebida para facilitar el aprendizaje en el curso de Organización del Computador, y fue desarrollada en Java para permitir su portabilidad a cualquier tipo de sistema operativo. La herramienta cuenta con una interfaz gráfica sencilla y funcional para el usuario, permitiéndole así un aprendizaje rápido de la misma. Se estudiaron varias arquitecturas de computadoras para resumir un conjunto de parámetros que permiten representar un modelo genérico de las mismas, y sobre el cual basar una simulación de la máquina para ejecutar programas en ella. El resultado de este proyecto son las herramientas SimUSB Designer y SimUSB Runner. Con la primera el estudiante puede diseñar una arquitectura basada en parámetros flexibles, que logran ofrecer una gran gama de diseños posibles. La segunda herramienta permite probar el funcionamiento de las arquitecturas diseñadas con el SimUSB Designer. La estructura de clases utilizada para la simulación de una arquitectura, permite separar en componentes la misma, siguiendo el esquema de diseño en módulos para la representación genérica de arquitecturas de computadores. Finalmente se logró una herramienta que permite la simulación de varias arquitecturas, así como el estudio y creación del conjunto de instrucciones para dichas arquitecturas, consiguiéndose un apoyo más completo en la enseñanza en el curso de Organización del Computador, que con la herramienta actualmente utilizada. INDICE GENERAL RESUMEN ............................................................................................................................... iii GLOSARIO.............................................................................................................................. iv INDICE DE FIGURAS ........................................................................................................... ix REFERENCIAS ....................................................................................................................... x 1. INTRODUCCION ................................................................................................................ 1 2. MARCO TEÓRICO ............................................................................................................. 4 2.1 Arquitecturas ..................................................................................................................... 4 2.1.1 Arquitectura CISC ...................................................................................................... 4 2.1.2 Arquitectura RISC ...................................................................................................... 5 2.2 Máquina MIPS .................................................................................................................. 6 2.3 Lenguaje Ensamblador...................................................................................................... 6 2.4 Simuladores de Arquitectura............................................................................................. 8 2.4.1 CPUSim (versión CPUSim 3.3.1) .............................................................................. 9 2.4.2 SPIM ........................................................................................................................ 10 2.4.3 COVI ........................................................................................................................ 11 2.5 Marco Tecnológico ......................................................................................................... 12 2.5.1 JAVA ....................................................................................................................... 12 2.5.1.1 Ventajas de JAVA ........................................................................................... 12 2.5.2 NetBeans .................................................................................................................. 13 2.5.2.1 Ventajas de NetBeans ..................................................................................... 14 2.5.3 XML ......................................................................................................................... 15 2.5.4 Nano XML ............................................................................................................... 15 3. PLANTEAMIENTO DEL PROBLEMA ......................................................................... 17 3.1 Objetivos específicos ...................................................................................................... 17 3.2 Importancia ..................................................................................................................... 18 4. ANALISIS DE REQUERIMIENTOS .............................................................................. 19 4.1 Requerimientos de la nueva herramienta ........................................................................ 21 5. DISEÑO ............................................................................................................................... 22 5.1 Módulos y clases ............................................................................................................. 22 5.2 Interfaces de la aplicación ............................................................................................... 32 5.2.1 Interfaz para definir la arquitectura .......................................................................... 32 5.2.2 Interfaz para definir las instrucciones ...................................................................... 32 5.2.3 Interfaz de ejecución ................................................................................................ 32 5.3 XML Parser ..................................................................................................................... 33 6. DESARROLLO .................................................................................................................. 34 6.1 Módulos y funciones ....................................................................................................... 34 6.2 Interfaces de la aplicación ............................................................................................... 40 6.2.1 Interfaz para definir la arquitectura .......................................................................... 41 6.2.2 Interfaz para definir las instrucciones ...................................................................... 42 6.2.3 Interfaz de ejecución ................................................................................................ 43 6.3 Archivos XML ................................................................................................................ 44 6.3.1 Archivo XML de arquitectura .................................................................................. 44 6.3.2 Archivo XML de configuración ............................................................................... 46 6.4 Estilo de código y documentación .................................................................................. 46 6.5 Problemas encontrados ................................................................................................... 46 6.6 Estado del proyecto al entregar ....................................................................................... 47 7. CONCLUSIONES Y RECOMENDACIONES ............................................................... 48 BIBLIOGRAFÍA Y REFERENCIAS ................................................................................... 50 APÉNDICES ........................................................................................................................... 52 Apéndice A – Código fuente SimUSB Designer .................................................................. 53 Apéndice B – Código fuente SimUSB Runner ..................................................................... 91 Apéndice C – Arquitectura MIPS en SimUSB ................................................................... 158 Apéndice D – SimUSB Designer Manual .......................................................................... 170 Apéndice E – SimUSB Runner Manual.............................................................................. 179 viii INDICE DE FIGURAS FIGURA 1 - DISEÑO DE RELACIÓN ENTRE MÓDULOS ................................................ 33 FIGURA 2 - EJECUCIÓN DE INSTRUCCIONES DEL PIPELINE ..................................... 37 FIGURA 3 - TABLA DE HASH DE INSTRUCCIONES....................................................... 38 FIGURA 4 - VENTANA MAIN DE SimUSB Designer ......................................................... 41 FIGURA 5 - VENTANA INSTRUCTIONS DE SimUSB Designer ....................................... 42 FIGURA 6 - VENTANA DE SimUSB Runner ....................................................................... 43 FIGURA 7 - ARCHIVO XML DE ARQUITECTURA DISEÑADA ..................................... 45 FIGURA 8 - ARCHIVO XML DE CONFIGURACIÓN ........................................................ 46 ix GLOSARIO ALU: la Unidad Lógica Aritmética Lógica (ULA), o Arithmetic Logic Unit (ALU), es un circuito digital que calcula operaciones aritméticas (como adición, substracción, etc.) y operaciones lógicas (como OR, NOT, XOR, etc.), entre dos números. API: (del inglés Application Programming Interface - Interfaz de Programación de Aplicaciones) es el conjunto de funciones y procedimientos (o métodos si se refiere a programación orientada a objetos) que ofrece cierta biblioteca para ser utilizado por otro software como una capa de abstracción. Biestable: también llamado báscula (flip-flop en inglés), es un multivibrador capaz de permanecer en un estado determinado o en el contrario durante un tiempo indefinido. Esta característica es ampliamente utilizada en electrónica digital para memorizar información. El paso de un estado a otro se realiza variando sus entradas. CPU: la unidad central de proceso (CPU), o algunas veces simplemente procesador, es el componente en un computador digital que interpreta las instrucciones y procesa los datos contenidos en los programas de computador. DLX: es un microprocesador RISC, básicamente un MIPS revisado y simplificado con una arquitectura simple de carga/descarga de 32 bits. Pensado principalmente para propósitos educativos, se utiliza ampliamente en cursos de nivel universitario sobre arquitectura de computadores HTML: es el acrónimo inglés de HyperText Markup Language, que se traduce al español como Lenguaje de Marcas Hipertextuales. Es un lenguaje de marcación diseñado para estructurar textos y presentarlos en forma de hipertexto, que es el formato estándar de las páginas web. iv Instrucción: son un conjunto de datos insertados en una secuencia estructurada o específica que el procesador interpreta y ejecuta. En Informática, una instrucción normalmente se refiere a una operación simple que se le da a un procesador y que este llevará a cabo. Javadoc: es una utilidad de Sun Microsystems para generar APIs en formato HTML de un documento de código fuente Java. Javadoc es un standard industrial para documentar clases de Java. Lenguaje ensamblador: es un tipo de lenguaje de bajo nivel utilizado para escribir programas de computadora, y constituye la representación más directa del código máquina específico para cada arquitectura de computadoras legible por un programador. Máscara: (bitmask, en inglés), extrae ciertos bits particulares de una cadena binaria, con el fin de conservar los valores de estos, cuya situación nos interesa. Memoria: en la actualidad, memoria suele referirse a una forma de almacenamiento de estado sólido conocido como memoria de acceso aleatorio (RAM por sus siglas en inglés) y otras veces se refiere a otras formas de almacenamiento rápido pero temporal. Microinstrucción: son las instrucciones más básicas que tiene un CPU, puede ser operaciones entre los registros, con la memoria, en la ALU. Son usadas para definir las instrucciones del conjunto de instrucciones. Por ejemplo, la instrucción SUMA usaría normalmente varias microinstrucciones, para colocar los valores de los operándoos a la ALU, ejecutar la suma en la ALU y finalmente devolver el valor resultado de la ALU al registro de salida. RAM: es el acrónimo inglés de Random Access Memory (memoria de acceso aleatorio ó memoria de acceso directo). Parser: un analizador sintáctico (parser) en informática y lingüística es un proceso que analiza secuencias de tokens para determinar su estructura gramatical respecto a una gramática formal dada. Un parser es así mismo un programa que reconoce si una o v varias cadenas de caracteres forman parte de un determinado lenguaje, es utilizado por ejemplo en compiladores. Pipeline: la segmentación (en inglés pipeline, literalmente tuberia) es un método por el cual se consigue aumentar el rendimiento de algunos sistemas electrónicos digitales. Es aplicado, sobre todo, en microprocesadores. Consiste en descomponer la ejecución de cada instrucción en varias etapas para poder empezar a procesar una instrucción diferente en cada una de ellas y trabajar con varias a la vez. Registro: es una memoria de alta velocidad y poca capacidad, integrada en el microprocesador que permite guardar y acceder a valores muy usados, generalmente en operaciones matemáticas. RTL: Acrónimo inglés para Register Transfer Language: "Lenguaje de Transferencia entre Registros". vi CAPITULO 1 - INTRODUCCIÓN En la construcción de un computador se toman en cuenta varios aspectos, tanto económicos como funcionales. Estas funciones se ven determinadas por el diseño de la arquitectura de la máquina, sus componentes y la forma en que éstos interactúan entre si. El estudio de distintos tipos de arquitectura de computador nos permite conocer y aprovechar mejor las cualidades y funciones con las que cuenta cada computador, saber si una máquina es mejor para realizar cálculos numéricos o para lograr menores tiempos de acceso a datos almacenadas. Una modificación en el diseño arquitectónico de un computador puede cambiar radicalmente su comportamiento. El estudio de las arquitecturas de computadores es el objetivo principal del curso "Organización del Computador" (CI-3815) dictado en la Universidad Simón Bolívar. El curso cuenta con una parte teórica y otra práctica, donde los estudiantes comprueban el funcionamiento de un computador a nivel de la interacción entre los diferentes componentes de una arquitectura. Hoy en día en las universidades se hace uso de simuladores de arquitecturas, que son herramientas con las cuales se puede simular el comportamiento de una o varias arquitecturas. Estas herramientas permiten hacer cambios, pruebas y ejecución de programas sin el temor de dañar ningún componente o por falta de la máquina. Actualmente el curso de Organización del Computador utiliza en la práctica la herramienta Spim, la cual simula una arquitectura en específico, MIPS. A pesar de ser una herramienta robusta, se limita a sólo un tipo de arquitectura, con lo cual el estudiantado sólo tiene esa experiencia entre la interacción de sus componentes. Además Spim no cubre varias áreas del aprendizaje sobre las arquitecturas de computador. 1 El objetivo de este proyecto es el desarrollo e implementación de una herramienta que permita el diseño de distintos tipos de arquitecturas, basándose en sus componentes básicos y sus funcionalidades; y su posterior puesta en funcionamiento ejecutando algún programa elaborado por el usuario. Esta herramienta estará dirigida al uso didáctico del curso, para reflejar un mayor número de los objetivos que contempla el curso y dar una mejor visión del comportamiento de los componentes de la arquitectura que se diseñe. Las herramientas serán desarrolladas y diseñadas contemplando varias mejoras con respecto a la herramienta que actualmente se usa (Spim), y basados en recomendaciones de estudiantes que han visto con anterioridad el curso. Estas mejoras no sólo son funcionales, sino a nivel de interfaz y portabilidad, ya que el objetivo es lograr que el usuario adquiera rápidamente las destrezas necesarias para manejar la herramienta con comodidad sin importar el sistema operativo que use. Una simulación necesita parámetros en los cuales basar su comportamiento y mientras más parámetros se tengan, la simulación pudiera ser más realista. Como la intención de este proyecto es abarcar una gran gama de arquitecturas posibles a simular, debemos tener en cuenta parámetros comunes entre ellas. Por el tiempo estipulado del proyecto, tomaremos un conjunto básico de parámetros, los cuales han sido estudiados y probados en pequeñas simulaciones para comprobar si son suficientes. Una vez definidos los parámetros, es necesario contar con estructuras de datos con las cuales estos puedan ser manejados libremente, y un modelo de componentes que sea capaz de mantenerse genérico y a su vez completo. Para ello se utiliza Java, que al ser un lenguaje orientado a objetos, nos permite crear cada módulo en clases distintas, y separar las funciones de cada uno. El archivo con el diseño final de la arquitectura deseada será guardado con formato XML por su facilidad para almacenar y recorrer una estructura de datos. 2 La elaboración del diseño y la simulación de éste están apoyadas por una interfaz grafica creada para ofrecer un ambiente de trabajo agradable, que permitan reducir su curva de aprendizaje. Las aplicaciones vienen acompañadas con una documentación que incluye manuales para cada aplicación, que explican la función de cada componente, y un API de las clases involucradas, en formato javadoc. El paquete contiene además el código fuente y los ejecutables (.jar) de cada una. Toda la documentación ha sido incluida en los apéndices. El capítulo dos presenta el marco teórico. En el capítulo tres se encuentra el planteamiento del problema a solucionar. Dentro del capítulo cuatro se muestra el análisis de los requerimientos contemplados. El capítulo cinco muestra el diseño de las dos aplicaciones: SimUSB Designner y SimUSB Runner. En el capítulo seis se describe el desarrollo de la implementación. Finalmente el capítulo siete contiene las conclusiones del proyecto. 3 CAPITULO 2 – MARCO TEÓRICO 2.1 Arquitecturas La arquitectura del computador se puede definir como el conjunto de las características visibles para el usuario de una computadora, relativas a las funcionalidades o prestaciones que una determinada configuración, organización o estructura puede brindar. Estas características pueden estar relacionadas con aspectos como: el formato de instrucción, los modos de direccionamiento de la memoria, el conjunto de instrucciones, entre otros. Uno de los primeros aspectos a considerar a la hora de diseñar un procesador es decidir cuál será su repertorio de instrucciones, que es el conjunto de operaciones que realmente entiende el procesador, y que constituye lo que se conoce como lenguaje de máquina. Los programadores, usualmente trabajan con una abstracción conocida como lenguaje ensamblador que le permite al programador elaborar sus códigos en un lenguaje más cercano al lenguaje natural que el formato que se emplea dentro de la arquitectura del computador. Esta decisión es importante, por dos razones: Primero, el conjunto de instrucciones decide el diseño físico del procesador ya que es necesario implementar el circuito necesario para ejecutar dichas instrucciones; Segundo, cualquier operación que deba ejecutarse en el procesador deberá poder ser descrita en términos de este lenguaje elemental. Tomando en cuenta este aspecto en los computadores podemos afirmar que existen dos filosofías de diseño. La primera conduce a máquinas denominadas CISC ("Complex Instruction Set Computer") y la segunda tiene que ver con máquinas tipo RISC ("Reduced Instruction Set Computer"). 2.1.1 Arquitectura CISC Se trata de procesadores con un conjunto de instrucciones complejas, con las cuales se pueden realizar tareas más elaboradas en lugar de sólo efectuar acciones simples como las operaciones aritméticas, desplazamientos y movimientos de datos entre registros [CR1]. Algunas de sus características son: 4 • Contiene un amplio surtido de instrucciones que sirven para distintas funciones específicas. • Son instrucciones complejas, por tanto de ejecución lenta. • Para un trabajo específico se requieren pocas instrucciones, ya que es posible que exista una instrucción que realice varias de las subtareas que se desea ejecutar. Por lo tanto, máquinas que se basen en una arquitectura CISC normalmente sus programas contienen menos líneas de código, especialmente cuando es posible utilizar sus instrucciones especializadas. Algunos procesadores Intel [línea 8086, 8088, 80286, 80386, 80486] y Motorola [línea 68000, 68010, 68020, 68030, 6840] tienen arquitectura CISC. 2.1.2 Arquitectura RISC Las arquitecturas RISC se caracterizan por tener un conjunto de instrucciones reducido (de ahí las siglas en ingles Reduced Instruction Set Computer) [CR1], los procesadores basados en este tipo de arquitectura presenta las siguientes características: • El procesador contiene un conjunto reducido de instrucciones. El cual incluye actividades sencillas como las operaciones aritméticas, las de desplazamiento, las de movimiento entre registros y las de saltos. • Las instrucciones son muy simples, por tanto de ejecución rápida. Esta simplicidad permite que la mayoría de las instrucciones se ejecuten en un ciclo de reloj. Los procesadores PowerPC, DEC Alpha, MIPS, ARM, son ejemplos de máquinas RISC, utilizados por compañías como Apple, Intel, para sus computadores. 5 2.2 Máquina MIPS MIPS, acrónimo de Microprocessor without Interlocked Pipeline Stages (microprocesador sin estados de pipeline interconectados), es una arquitectura de procesadores tipo RISC desarrollada por MIPS Computer Systems Inc. Este procesador cuenta con 32 registros, con un sencillo pero completo conjunto de instrucciones y otras características que permiten a este tipo de procesador tener una excelente base para ofrecer hoy en día máquinas rápidas. [MP1] Como los diseñadores crearon un conjunto de instrucciones muy sencillo de entender, muchos cursos sobre arquitectura de computadores en las universidades suelen basarse en la arquitectura MIPS [CS1, CC1]. Anteriormente se impartían estos cursos usando microprocesadores reales, lo cual implica que cualquier error o problema requería reiniciar la máquina. Hoy en día se usan simuladores los cuales permiten implementar diferentes arquitecturas sin importar cual sea el tipo de equipo con el que se cuente. 2.3 Lenguaje Ensamblador Al desarrollarse las primeras computadoras electrónicas, se vio la necesidad de programarlas, es decir, establecer las tareas que iban a ejecutar en el lenguaje que entendiera la computadora. Las primeras se usaban como calculadoras simples; se les indicaban los pasos de cálculo, uno por uno. John Von Neumann desarrolló un modelo, en el cual se tiene una abstracción de la memoria como un conjunto de celdas que almacenan simplemente números. Estos números pueden representar dos cosas: los datos, sobre los que va a trabajar el programa; o bien, el programa, que específica cuales serán los cálculos a realizar sobre los datos. Inicialmente se tenía el problema de representar las acciones que iba a realizar la computadora, y que la memoria, al estar compuesta por biestables, solamente permitía almacenar números binarios. 6 La solución adoptada fue la siguiente: a cada acción que pueda realizar la computadora, se le asocia un número, que será su código de operación (opcode). Por ejemplo, una calculadora programable simple podría asignar los códigos de operación: 1 = SUMA, 2 = RESTA, 3 = MULTIPLICA, 4 = DIVIDE. La descripción y uso de los opcodes y de los operandos sobre los cuales van a trabajar, es lo que se conoce como lenguaje de máquina, es decir, la lista de códigos que la máquina va a interpretar como instrucciones. Éste el lenguaje más primitivo, que depende directamente del hardware, y requiere que el programador conozca el funcionamiento de la máquina al más bajo nivel. Al sustituir los códigos de operación por una palabra que sea una clave de su significado, a la cual comúnmente se le conoce como mnemónico, se tiene el concepto de Lenguaje Ensamblador. Así, se puede definir al Lenguaje Ensamblador de la siguiente forma: Es una primera abstracción del lenguaje de máquina, que consiste en asociar a los códigos de operación, palabras clave que faciliten su uso por parte de los programadores. Como se puede ver, el lenguaje ensamblador es casi directamente traducible al lenguaje de máquina, y viceversa; simplemente, es una abstracción que facilita su uso para los programadores. Por otro lado, la computadora no entiende directamente al lenguaje ensamblador, y por consiguiente es necesario traducir los programas a lenguaje de máquina. Originalmente, este proceso se realiza manualmente, usando para ello hojas donde se escribían tablas de programa. Pero, al ser tan directa la traducción, a partir de 1952 aparecieron los programas ensambladores, que son traductores que convierten el código fuente (en lenguaje ensamblador) a código objeto (es decir, a lenguaje de máquina). [WP11] Una característica que es importante resaltar, es que generalmente al depender estos lenguajes del hardware, hay un Lenguaje de Máquina distinto (y, por consiguiente, un Lenguaje Ensamblador distinto) para cada tipo CPU. Por ejemplo, se pueden mencionar tres lenguajes completamente diferentes, que sin embargo vienen de la aplicación de los conceptos anteriores: 1. Lenguaje ensamblador de la familia Intel 80x86 2. Lenguaje ensamblador de la familia Motorola 68000 7 3. Lenguaje ensamblador del procesador POWER, desarrollado entre IBM y Motorola. Se tienen tres fabricantes distintos (anteriormente mencionados), compitiendo entre sí y cada uno aplicando conceptos distintos en la manufactura de sus procesadores, su arquitectura y programación; todos estos aspectos, influyen para que el lenguaje de máquina y ensamblador sean diferentes. 2.4 Simuladores de Arquitecturas Un simulador de arquitectura es una aplicación en la cual establecemos el comportamiento de una circuitería dada, para reproducir el funcionamiento de una máquina, y su manera de ejecutar instrucciones. La pregunta obvia en estos casos es por qué utilizar un simulador y no una máquina real. Las razones son diversas: entre ellas cabe destacar la facilidad de poder trabajar con una versión simplificada del procesador real. [ULPIT] Actualmente encontramos muchas aplicaciones que simulan procesadores y hasta sistemas completos como son SPIM y COVI. Varias de estas aplicaciones se centran sólo en arquitecturas específicas, como SPIM con MIPS, logrando de esta forma simulaciones mucho más detalladas y realistas de dicha arquitectura. Además de lograr una aplicación con muchas más opciones específicas para la arquitectura dada, a diferencia de los simuladores de máquinas genéricas, los cuales no pueden llegar a ese nivel de especificidad. Algunos de estos simuladores son desarrollados en universidades por grupos que buscan compartir sus aplicaciones y apoyar el estudio de sus materias con dichos simuladores. Por esta razón varias de estas aplicaciones se pueden conseguir en Internet y son de uso libre (aunque muchas veces no se proporciona el código fuente, siendo PCSPIM, CPUSim, COVI simuladores de este tipo). En otros casos los simuladores son desarrollados por compañías para uso interno en pruebas de productos. 8 2.4.1 CPUSim (versión CPUSim 3.3.1) Este simulador fue desarrollado en Java, lo que permite que sea ejecutado en cualquier arquitectura que soporte este lenguaje. Esta aplicación le permite a los usuarios diseñar un CPU simple de computadora a nivel del micro código (instrucciones atómicas que tienen los CPU). CPUSim permite mediante una simulación, correr programas en lenguaje de máquina o lenguaje ensamblador en los CPUs que son diseñados con la misma aplicación. A través de esta aplicación se puede simular una gran variedad de arquitecturas, incluyendo arquitecturas basadas en un acumulador, las tipo RISC, o las basadas en pila, como la Máquina Virtual de Java. [DSCC] La aplicación se caracteriza por ser una herramienta didáctica, ya que da oportunidad a los profesores de mostrar a los estudiantes una variedad de arquitecturas, además de proporcionarles la oportunidad de crear sus propias arquitecturas y escribir programas en lenguaje de máquina o de ensamblador para sus propias arquitecturas. El uso de CPUSim está diseñado con una cómoda interfaz para el desarrollo de arquitecturas e incluye las siguientes características: • Herramientas para diseñar un CPU a nivel de transferencia entre registros: o Diálogos para especificar el número y el tamaño de los registros, arreglos de registros, y RAMs. o Diálogos para especificar las microinstrucciones (ej. transferencias de bits entre los registros) que se utilizan para implementar las instrucciones de máquina. o Diálogo para especificar las instrucciones de máquina, incluyendo: el número de bits en cada instrucción. el valor del código de operación (COOP) y el número de bits que el COOP ocupa. el número de los operandos y el número de bits de cada operando. la semántica de cada instrucción (especificada por una secuencia de microinstrucciones). 9 • Un editor de texto para escribir los programas. • Un ensamblador para los programas que convierte el código para el CPU del usuario. • Una herramienta para hacer depuración durante la corrida de un programa, opcionalmente cambiando el estado de la máquina en cada paso. El manual de usuario está disponible en Formato de Documento Portable (PDF) y ofrece ayuda en línea desde el menú principal y otras áreas internas de CPUSim. 2.4.2 SPIM SPIM (MIPS escrito al revés) es un simulador que ejecuta programas en lenguaje ensamblador para los computadores basados en los procesadores MIPS R2000/R30001. La arquitectura de este tipo de procesadores es RISC, por lo tanto es simple y regular, y en consecuencia fácil de aprender y entender. SPIM también proporciona una herramienta de depuración simple, y un conjunto mínimo de servicios del sistema operativo. El SPIM no ejecuta programas escritos en código binario. Versiones anteriores del SPIM (antes de 7.0) incorporaron el sistema de instrucción en ejecución de MIPS-I usado en las computadoras de las MIPS R2000/R3000. Esta arquitectura es obsoleta aunque, es una arquitectura reconocida por su simplicidad y elegancia. SPIM (actualmente versión 7.31) implementa el soporte a una arquitectura más moderna MIPS32, que es el sistema de instrucción de MIPS-I aumentado con una gran cantidad de instrucciones extras. Los códigos MIPS de anteriores versiones de SPIM deben funcionar sin cambios, excepto para manejo de las excepciones y las interrupciones. SPIM viene con su código fuente y documentación completa. Tiene interfaz por terminal y por ventana. En Unix, Linux, y OS X de Mac el programa SPIM proporciona una interfaz de terminal simple y el programa del xspim proporciona una interfaz de ventanas. En Microsoft 1 R2000 y R3000 son distintos modelos comerciales de MIPS, datan de 1985 y 1988 respectivamente. 10 Windows, el programa spim proporciona una interfaz por la consola y PCSpim proporciona un interfaz de ventanas. 2.4.3 COVI COVI es una herramienta de apoyo a la docencia en las materias de organización y arquitectura de computadores desarrollado por el Departamento de Informática e Ingeniería de Sistemas de la Universidad de Zaragoza. [GACUZ] Simula el funcionamiento de diferentes procesadores, abarcando desde el nivel RTL hasta la programación de periféricos. Esta simulación se realiza mediante la ejecución controlada (ciclo a ciclo en su nivel más bajo) de programas en ensamblador basados en la arquitectura DLX2. Dicha arquitectura es de tipo RISC. COVI simula el comportamiento de los principales componentes de un computador real, desde el procesador y sus memorias hasta los periféricos más comunes: teclado, pantalla y disco duro. El objetivo de COVI es ayudar a la comprensión y la relación del computador con el exterior (periféricos) y su funcionamiento interno (jerarquía de memoria, interrupciones hardware y software, control de cache, etc.). El entorno COVI tan sólo presupone en sus usuarios conocimientos básicos de circuitos digitales: circuitos y bloques combinacionales (ALU, multiplexores...), circuitos y bloques secuenciales síncronos (autómatas, registros, memorias...). Por lo tanto, es de aplicación en Ingenierías Técnicas o en los primeros ciclos de Ingenierías de estudios Superiores. El manual de usuario incluye información detallada en cuanto a los bloques combinacionales y secuenciales que forman parte de las rutas de datos y la estructura de las unidades de control. 2 El DLX es un microprocesador RISC, básicamente un MIPS revisado y simplificado con una arquitectura simple de carga/descarga de 32 bits. Pensado principalmente para propósitos educativos, se utiliza ampliamente en cursos de nivel universitario sobre arquitectura de computadores. 11 2.5 Marco Tecnológico 2.5.1 JAVA JAVA es un lenguaje de programación de propósito general, orientado a objetos, el cual fue introducido por Sun Microsystems en 1995, y diseñado en principio para el ambiente distribuido de Internet. [SDNJS] Lo que hace de JAVA un concepto diferente es que, en un segundo nivel, es también un entorno para la ejecución de programas, englobado en la llamada máquina virtual de Java. Este entorno es un software que permite que las aplicaciones escritas en JAVA se ejecuten en cualquier ordenador, independientemente del sistema operativo y de la configuración de hardware utilizados. 2.5.1.1 Ventajas de JAVA 1.- Universalidad: con este término se hace referencia a la universalidad de Java con términos equivalentes como transportabilidad, o independencia de plataforma, pues para ejecutar un programa basta compilarlo una sola vez. A partir de ese momento, se puede ejecutar dicho programa en cualquier máquina que tenga implementado un intérprete de Java. [SDNJS] 2.- Sencillez: Java es un lenguaje de gran facilidad de aprendizaje, pues en su concepción se eliminaron todos aquellos elementos que no se consideraron absolutamente necesarios. Por ejemplo, en comparación con otros lenguajes como C ó C++, es notable la ausencia de apuntadores, o lo que es lo mismo, es imposible hacer referencia de forma explícita a una posición de memoria. Ello ahorra gran cantidad de tiempo a los programadores, dado que el comportamiento imprevisto de los apuntadores es una de las principales fuentes de errores en la ejecución de un programa. Por otra parte, el código escrito en Java es por lo general mucho más legible que el escrito en C ó C++. 12 3.- Orientación a objetos: Para entender qué es la orientación a objetos, recordemos que los lenguajes tradicionales no orientados a objetos, como Pascal ó C, están pensados para trabajar de forma secuencial, y basan su funcionamiento en el concepto de procedimiento o función. La tarea principal del programa se divide en funciones o tareas más pequeñas, a menudo muy interrelacionadas, por lo que es difícil modificar una función sin tener que revisar el resto del programa. Por lo tanto, también es difícil reutilizar o actualizar los programas ya escritos. En el caso de los lenguajes orientados a objetos, el concepto clave no es el de función, sino el de objeto. Un objeto es un elemento de programación, autocontenido y reutilizable, y que podríamos definir como la representación en un programa de un concepto, representación que está formada por un conjunto de variables (los datos) y un conjunto de métodos (o instrucciones para manejar los datos). 4.- Rapidez de desarrollo y mejora del software. El hecho de que Java sea un lenguaje orientado a objetos desde su concepción tiene, entre otras muchas ventajas, la de que es fácil reutilizar el código de programación, y por tanto los desarrollos de una aplicación serán más rápidos, pues es más sencillo reutilizar objetos y sus componentes que reescribir el código desde el principio. Además, una vez que el código de un objeto es estable, la reutilización de ese objeto replica ese código fiable en toda la aplicación, lo que reduce el proceso de depuración. La versión utilizada en la elaboración de la aplicación es la JDK 6, la cual tiene un rendimiento mayor, en cuanto al uso de memoria, con respecto versiones anteriores. Además provee mejor desarrollo de aplicaciones gráficas. 2.5.2 - NetBeans NetBeans se refiere a una plataforma para el desarrollo de aplicaciones de escritorio usando Java y a un entorno integrado de desarrollo (IDE). [NBNB] La plataforma NetBeans permite que las aplicaciones sean desarrolladas a partir de un conjunto de componentes de software llamados módulos. Un módulo es un archivo Java que contiene clases de java escritas para interactuar con las APIs de NetBeans y un archivo especial 13 (manifest file) que lo identifica como módulo. Las aplicaciones construidas a partir de módulos pueden ser extendidas agregándole nuevos módulos. Debido a que los módulos pueden ser desarrollados independientemente, las aplicaciones basadas en la plataforma NetBeans pueden ser extendidas fácilmente por otros desarrolladores de software. NetBeans se caracteriza por ser un proyecto de código abierto de gran éxito con una gran base de usuarios, una comunidad en constante crecimiento, y con cerca de 100 socios en todo el mundo. Sun MicroSystems fundó el proyecto de código abierto NetBeans en junio 2000, y continúa siendo el patrocinador principal de los proyectos. 2.5.2.1 Ventajas de NetBeans La Plataforma NetBeans es una base modular y extensible usada como una estructura de integración para crear aplicaciones de escritorio grandes. Empresas independientes, especializadas en desarrollo de software, proporcionan extensiones adicionales que se integran fácilmente en la plataforma y que pueden también utilizarse para desarrollar otras herramientas y soluciones. [NB1] La plataforma ofrece servicios comunes a las aplicaciones de escritorio, permitiéndole al desarrollador enfocarse en la lógica específica de su aplicación. Entre las características de la plataforma están: • Administración de las interfaces de usuario (ej. menús y barras de herramientas). • Administración de las configuraciones de los usuarios. • Administración del almacenamiento (guardando y cargando cualquier tipo de dato). • Administración de ventanas. • Framework basado en asistentes (diálogos paso a paso). 14 2.5.3 – XML XML es un Lenguaje de Etiquetado Extensible desarrollado por el World Wide Web Consortium (W3C). Es muy simple, pero estricto, y está jugando un papel fundamental en el intercambio de una gran variedad de datos. Es un lenguaje muy similar a HTML pero su función principal es describir datos y no mostrarlos, como es el caso de HTML. XML es un formato que facilita la comunicación de datos a través de diferentes aplicaciones. XML sirve para estructurar, almacenar e intercambiar información. A continuación se presenta un ejemplo de un documento escrito en XML. <?xml version="1.0" encoding="ISO-8859-1"?> <libro> <titulo>DON QUIJOTE DE LA MANCHA</titulo> <capitulo numero=”1”> <titulo> Que trata de la condición y ejercicio del famoso hidalgo </titulo> </capitulo> </libro> JAVA cuenta con varias herramientas que ayudan de manera cómoda al manejo de los datos del archivo que usa un formato XML. 2.5.4 - Nano XML NanoXML es una herramienta utilizada para procesar cualquier documento, estructura o fragmento en XML. Se encarga de: • Detectar principio y fin de un elemento • Gestionar espacios de nombres • Comprobar que el documento esté bien formado 15 De forma más específica se define NanoXML como un pequeño analizador sintáctico de XML para Java, su aparición ocurre en Abril del 2000 y surge con el objetivo de: “Ser un pequeño parser fácil de usar” [NXML] 16 CAPITULO 3 – PLANTEAMIENTO DEL PROBLEMA 3.1 Objetivo general El objetivo de este proyecto es diseñar y desarrollar una herramienta que cubra las necesidades didácticas de la asignatura de Organización del Computador dictado en la Universidad Simón Bolívar. Centrándose en puntos claves presentados en el curso, para así lograr un mejor entendimiento de los conceptos que lo componen y lograr aplicar esos conceptos en la práctica de forma más completa. La herramienta diseñada podrá ser utilizada por otras universidades como complemento didáctico en sus cursos o por personas que deseen participar en la evolución del proyecto. Dicha herramienta deberá estar orientada al uso didáctico del curso por alumnos, los cuales no tendrán nociones previas sobre su uso. Por lo que tiene que ser de rápido aprendizaje para que el alumno aproveche su tiempo para poner en práctica los conceptos estudiados en la teoría de la asignatura. 3.1.1 Objetivos específicos • Establecer los parámetros básicos con los cuales se pueda definir una gran gama de arquitecturas. • Crear una aplicación que permita el diseño parametrizado de los componentes de un computador genérico. • Crear un simulador en el cual se puedan ejecutar programas de bajo nivel para el diseño parametrizado de un computador genérico. • Brindar una interfaz sencilla e intuitiva para los usuarios de la aplicación, para así evitar confusión durante el proceso de aprendizaje. 17 3.1.2 Importancia Es necesario estudiar distintas arquitecturas para así lograr condensar, en un número reducido de parámetros, la representación de las características principales de dichas arquitecturas, y obtener una vista en general que permita crear un diseño de arquitectura capaz de soportar distintos modelos, con lo cual se obtiene un mayor rango de posibles diseños de arquitecturas. Este conjunto de parámetros deberá ser establecido mediante el uso de una herramienta, la cual permitirá, basándose en esos parámetros, diseñar una arquitectura completa en términos básicos de estructura. Una vez obtenido un diseño parametrizado genérico de la arquitectura de un computador, se creó una aplicación que pueda soportar dicho diseño, y mostrar el comportamiento de la arquitectura escogida, además de permitir la ejecución de programas en dicha arquitectura, con lo cual se puede estudiar su comportamiento. El último de los objetivos específicos tiene gran peso en el proyecto y se aplica a las dos herramientas creadas. Tanto la aplicación donde se diseñe la arquitectura, como la aplicación donde se importa una arquitectura previamente diseñada, deben tener una interfaz sencilla para no enlentecer el aprendizaje de la herramienta, y brindar mayor tiempo al usuario para comprender el funcionamiento a bajo nivel de su arquitectura, y las respuestas que obtiene de sus programas según el diseño de la maquina. 18 CAPÍTULO 4 – ANÁLISIS DE REQUERIMIENTOS Para la asignatura de Organización del Computador dictada en la Universidad Simón Bolívar se desea contar con una aplicación que abarque los temas dictados y los relacione con la práctica del curso. Por ser la universidad Simón Bolívar una casa de estudios de carácter público, la mayoría de sus laboratorios están dotados con máquina configuradas con plataformas de software libre (Linux, en varias distribuciones) para el uso estudiantil. Actualmente dicho curso utiliza la herramienta SPIM, la cual como se mencionó en el capítulo anterior, es un simulador basado en la arquitectura RISC. Esta herramienta cuenta con una curva de aprendizaje algo difícil para los principiantes, pero una gran funcionalidad para usuarios de nivel avanzado. Es una herramienta especializada en dicha arquitectura que posee grandes ventajas para quien necesite hacer simulaciones complejas. Varias debilidades de SPIM para el uso didáctico en el curso: o Su interfaz es poco amigable para el usuario (mucha información en una sola pantalla) y varía según la plataforma que se use (Linux o Windows). Además también se han observado en ocasiones, comportamientos irregulares entre plataformas usando el mismo código (accesos a la memoria de forma distinta según la plataforma (Unix, etc). o Sólo maneja un tipo de arquitectura, restringiendo la práctica del curso a sólo ese tipo de arquitectura. Los componentes que refleja la aplicación (área de registros, área de memoria, etc.) son de difícil interpretación para los principiantes, aunque una familiarizado con la herramienta, exponen adecuadamente su contenido. No muestra el pipeline durante la ejecución de un programa. o Maneja un único conjunto de instrucciones no modificables, obligando a los docentes a ofrecer prácticas basadas en la programación a bajo nivel y no en la comprensión sobre el funcionamiento de las instrucciones sobre arquitectura. 19 la También se estudió el impacto de la herramienta SPIM sobre la población estudiantil y presentaron los siguientes resultados: * El primer encuentro con la herramienta SPIM es problemático para la mayoría de los estudiantes. Presenta una interfaz rica en componentes para el usuario avanzado, pero para los principiantes es muy confusa. No se aprecia relación entre la teoría y la práctica en el laboratorio. * A medida que avanza el curso el estudiante logra una mejor comprensión y manejo de la herramienta, logrando sólo enfocarse por la programación a bajo nivel, dado que la complejidad de los proyectos aumenta. En este punto se puede apreciar un poco de relación entre el curso (la parte arquitectónica) y los componentes que presenta SPIM. * Al final del curso la herramienta termina siendo bien utilizada y comprendida, solamente en las funciones básicas requeridas en el curso, no de forma profesional. Muchas nociones vistas en la teoría del curso no son cubiertas por SPIM. Se realizaron sesiones “focus group” con estudiantes de la Universidad pertenecientes al curso de Organización del Computador y a sus profesores, para analizar la herramienta PCSPIM utilizada en la práctica del curso y así saber de sus ventajas y desventajas desde su punto de vista del estudiante. En el “focus group” (sesiones de grupo) se reúne a un grupo de personas para indagar acerca de actitudes y reacciones frente a un Producto, Servicio, concepto, Publicidad, idea o Empaque y donde las preguntas son respondidas por la interacción del grupo en una dinámica donde los participantes se sienten cómodos y libres de hablar y comentar sus opiniones. El focus group realizado dejó en evidencia la dificultad en el aprendizaje de la herramienta PCSPIM y la desviación que los estudiantes notaron entre el contenido del curso y las prácticas impartidas apoyadas en PCSPIM, además de lo anteriormente expuesto sobre las debilidades de PCSPIM. 20 4.1 Requerimientos de la nueva herramienta La herramienta debe ser capaz de ser ejecutada en cualquier plataforma, para que pueda ser usada tanto en máquinas con Linux como con Windows y debe mantener la misma interfaz sin importar la plataforma utilizada. La interfaz con el usuario debe ser intuitiva y clara, fácil para el principiante y rica en opciones para aquel que alcance un nivel de uso más complejo de la herramienta. Debe tener relacionarse claramente con la teoría dictada en el curso, presentar herramientas que permitan un mejor entendimiento y que permita llevar a la práctica de los conceptos impartidos en clase. Permitir modificar y agrandar su funcionalidad y estructura, para abarcar luego distintos dispositivos y cualquier variación que se le quiera realizar a la aplicación. Para esto debe contar con una estructura sencilla de código pero bien diseñada. Se requerirá dejar una documentación en regla sobre la elaboración de la aplicación y su ejecución. Contará con un API para las clases desarrolladas, lo cual brindará suporte en futuros cambios en la aplicación. También es necesario contar con un ejemplo concreto para utilizarlo en la práctica, éste debe ser correcto y basarse en la arquitectura MIPS. De esta forma se contará con lo suficiente para utilizar la herramienta en el curso. 21 CAPITULO 5 - DISEÑO La aplicación a desarrollar se separó en dos componentes iniciales, el USBDesigner y el USBRunner. El USBDesigner permite el diseño de la arquitectura que se desea modelar con la aplicación. Permite definir las características de dicha arquitectura indicando el número de los registros, el tamaño en bits, el formato de las instrucciones, el conjunto de instrucciones, entre otros. En cambio, el USBRunner permite la ejecución de un programa y una aplicación para la corrida de instrucciones en una arquitectura diseñada previamente. Únicamente USBRunner utilizará los módulos creados y las clases, dado que el USBDesigner sólo necesita guardar los parámetros de las instrucciones y la parte principal que es la interfaz para la selección de parámetros de la arquitectura a diseñar. 5.1.- Módulos y clases La aplicación está conformada por simplificada varios módulos que modelan de forma algunas funcionalidades y componentes de una arquitectura genérica. Esta modularización de componentes facilita la integración entre partes al especializar las funcionalidades de cada componente por módulo, así, si se necesita modificar la forma en la que un componente actúa, sólo debe cambiarse dicho módulo sin afectar al resto. - Módulo Registro: Es esencialmente una clase contenedora (guarda valores). El módulo para registro, tendrá funcionalidades de escritura y lectura, con una capacidad medida en bytes. Las variables y métodos de la clase Register son: - Entero “size”: define el tamaño del arreglo de bytes que representara el tamaño del registro. - Arreglo de bytes “valué”: almacena los bytes de datos del registro. - Cadena de caracteres “name”: tiene el nombre del registro. - Método getSize(): devuelve un entero con el tamaño del registro. - Método setValue(byte[] val): con parámetro de entrada el arreglo de bytes que será almacenado en el registro. Sólo guarda el arreglo si es del mismo tamaño que 22 “size”. Este método hará uso de la clase Shouts asignada para reflejar el cambio sucedido. - Método getValue(): devuelve el arreglo de bytes que almacena el registro. - Método setIntValue(int val): guarda en el arreglo de bytes la representación del entero de entrada (representación conseguida con 4 bytes). También llama a la clase “Shouts” para reflejar el cambio. - getIntValue(): devuelve el valor del contenido del arreglo de bytes en su representación como número entero. - Método reset(): reinicia al registro, dejándolo en el estado de inicialización. - Register(String name, int siz, CPU core): método de creación del objeto registro, debiéndole dar un nombre (“name”), su tamaño (“siz”) y el CPU al cual estát ligado (“core”) - Módulo ALU: Es utilizada tanto por el módulo Microinstruccion y CPU. Se encarga de realizar las operaciones lógico – aritméticas usando los registros de entrada y dejando el resultado en dos registros de salida. La ejecución de la ALU modifica el registro STATUS si ocurre una excepción. Está constituido por 4 registros de uso interno, 2 para operandos y 2 para el almacenar resultado (por ejemplo la división da un resto y un cociente). De ocurrir una división entre cero o un desborde en las operaciones. Variables y métodos de la clase ALU: - Entero “maskOverflow”: almacena el valor de la máscara para el desborde. Con las máscaras se modifica el registro de estado dependiendo de la situación presentada. - Entero “maskDivByZero”: almacena el valor de la máscara para la división entre cero. - Cadena de caracteres “STATUSREG”: para el nombre que se le dio al registro de estado (STATUS). - Registros “ALU_A” y “ALU_B”: son los registros operandos (A+B). - Registros “ALU_ZHi” y “ALU_ZLo”: son los registros resultado, en operaciones donde hay más de un resultado por ejemplo en la división se almacena el cociente en “ALU_ZLo” y el resto en “ALU_ZHi”, en la multiplicación si el valor resultado puede ser almacenado en un sólo registro será en “ALU_ZLo”, de lo contrario el 23 resultado será almacenado en los dos registros resultado, separando los 32 bits más significativos en el registro “ALU_ZHi” y los otros en “ALU_ZLo”. - Método setRegisterData(String RegName, byte[] value): dado un nombre de registro (entre ALU_A, ALU_B, ALU_ZHi y ALU_ZLo) guarda el arreglo de bytes value en dicho registro. - Método setRegisterDataInt(String RegName, int value): dado un nombre de registro (entre ALU_A, ALUB, ALU_ZHi y ALU_ZLo) guarda el entero value en dicho registro. - Método getRegisterData(String RegName): dado un nombre de registro (entre ALU_A, ALUB, ALU_ZHi y ALU_ZLo) devuelve el arreglo de bytes de dicho registro. - Método getRegisterDataInt(String RegName): dado un nombre de registro (entre ALU_A, ALUB, ALU_ZHi y ALU_ZLo) devuelve el valor entero de dicho registro. - Método excecute(String Operation): dependiendo de la cadena de caracteres Operation (entre “and”, “bitwise1Complement”, “div”, “leftShift”, “minus”, “minusU”, “mult”, “negation2Complement”, “or”, “rightShift”, “rotateLeft”, “rotateRigth”, “sum”, “sumU”, “unsignRightShift”, “xor”) ejecutará el método asociado (el nombre del método y la palabra clave corresponden). - Métodos de operación: realizarán la operación correspondiente a su nombre, entre los registros operando, dejando el resultado en los registros resultado. Los metodos implementados son : and(), bitwise1Complement(), div(), leftShift(), minus(), minusU(), mult(), negation2Complement(), or(), rightShift(), rotateLeft(), rotateRigth(), sum(), sumU(), unsignRightShift(), xor(). - Método reset(): reinicia el objeto ALU a sus parámetros iniciales. - ALU(CPU cor, String statusReg, String maskOverf, String maskDivByZ): crea el objeto ALU, ligado al CPU cor, con el nombre del registro STATUS statusReg, y la representación en caracteres de las máscaras para el desborde y la división entre cero. 24 - Módulo Microinstrucción: este módulo tendrá la función de ejecutar una microinstrucción dada del repertorio ofrecido, además ejecutará las operaciones de la ALU tomándolas como otra microinstrucción. Las microinstrucciones ofrecidas son: - InmInttoR: Colocar en un registro dado el valor de un entero. - RtoMem: Colocar un valor en memoria a partir de un registro dado. - RtoOnes: Colocar 1 en todos los bits de un registro. - RtoZero: Colocar 0 en todos los bits de un registro. - RtoR: Copiar el valor de un registro a otro. - inmOpertoR: Realizar una operación inmediata tomando el valor de un registro (por ejemplo, sumarle 4 a un registro). - Branchs: Realizar comparaciones registro contra registro, registro contra un valor inmediato o un valor inmediato contra otro, dando como resultado de ser positiva la comparación un número dado o 0 (cero) de lo contrario. - NOP: no realiza nada. - HALT: detiene la ejecución colocando en el registro STATUS la máscara correspondiente. - AluOperation: Todas las operaciones de la ALU. Variables y métodos de la clase Microinstructions: - Método execute(String mi, Vector<String> args): ejecuta una microinstrucción (entre BranchInmtoInm, BranchRtoInm, BranchRtoR, InmInttoR, MemBytetoIO, IOtoR, MemtoR, RtoIO, RtoMem, RtoOnes, RtoR, RtoZero, halt, inmOpertoR, nop), llamando al método asociado, con los argumentos de entrada según el método. - Métodos para las microinstrucciones: el nombre de cada microinstrucción (en ingles) simboliza la función del mismo. Las microinstrucciones implementadas son: InmInttoR(int value, String Destiny), InmtoR(byte[] data, String Destiny), RtoR(String Origin, String Destiny), MemtoR(String memAdrReg, String Destiny), RtoMem(String memAdrReg, String Origin), RtoZero(String Destiny), RtoOnes(String Destiny), RtoIO(String Origin), ALUOperation(String oper), 25 BranchRtoR(String left, String rigth, String cond, int jump), BranchRtoInm(String left, int rigth, String cond, int jump), BranchInmtoInm(int left, int right, String cond, int jump), inmOpertoR(String reg, String oper, String inm), halt(), nop(). Los métodos BranchX devuelven un entero, el cual es el número de líneas de salto si se cumple la condición, 0 (sin salto) si no se cumple. - Microinstructions(CPU newCore): crea el objeto microinstrucción ligado al CPU newCore. - Módulo Memoria: este módulo representa la memoria del computador, asignándole un tamaño en bytes permitiendo operaciones de lectura y escritura direccionando, ya sea por bytes o por palabras. Variables y métodos de la clase Memory: - Entero “memSize”: el tamaño en cantidad de bytes de la memoria. - Arreglo de bytes “memData”: la estructura de memoria en sí, donde se guardan los datos. - Booleano “bigEndian”: específica cómo se debe leer la memoria. - Booleano “readByByte”: especifica la forma de acceder a las posiciones de memoria. - Arreglo de arreglo de caracteres “sectionNames”, un arreglo con los nombres de cada sección de la memoria. - Arreglo de enteros “sectionAddrs”: un arreglo de enteros con la dirección de memoria para cada sección. - Entero “wordSize”: tamaño en bytes de una palabra. - Métodos Getters y Setters: cada variable tiene un get y un set (obtener e insertar). - Método setDataByte(byte dat, int addrs): guarda el byte “dat” en la dirección de memoria “addrs”. - Método setDataByteArray(byte[] dat, int addrs): guarda un arreglo de bytes “dat” desde la dirección de memoria “addrs”. - Método setDataInt(int value, int addrs): guarda la representación en bytes de el entero “value” (en 4 bytes continuos) desde la dirección “addrs”. - Método getDataByte(int addrs): devuelve el byte ubicado en la dirección de memoria “addrs”. 26 - Método getDataByteArray(int addrs, int length): devuelve los “length” bytes seguidos ubicados desde la dirección de memoria “addrs”. - Método getDataInt(int addrs): devuelve el entero ubicado en la dirección de memoria “addrs” (los 4 bytes continuos). - Método reset(): vacía los datos de la memoria. - Memory(int siz, int numSections, CPU core): crea un nuevo objeto Memory ligado al CPU “core”, con el tamaño de memoria “siz” y el número de secciones “numSections”. - Módulo Pipeline: el módulo pipeline permite especificar las etapas que conforman un procesador segmentado y las tareas que se efectúan en cada una ellas. Variables y métodos de la clase Pipeline: - Instrucciones “preMI” y “postMI”: son el conjunto de microinstrucciones a realizar en cada estado del pipeline, antes y después de ejecutar un estado de la instrucción alojada en el pipeline. Estas siempre se ejecutarán (aunque pueden ser vacías en algún estado). - Entero “numStages”: la cantidad de estados que contendrá el pipeline. - Enteros “firstAddress”, “currentAddress”: la dirección de memoria donde se encuentra la primera instrucción a ejecutar y la actual. - Arreglo de instrucciones “instPipe”: arreglo del tamaño de la cantidad de estados, para guardar cada instrucción que se encuentra en ejecución. - Método setInitialPCData(): coloca en el registro PC la dirección de memoria de la primera instrucción a ejecutar. - Método runBySteps(int steps): ejecuta “steps” iteraciones del pipeline, deteniéndose sólo de haberse terminado las direcciones de memoria, o si el registro STATUS tiene los bits de parada. - Método statusCheck(): verifica el estado del registro STATUS. - Método reset(): reinicia el pipeline en su estado inicial. - Pipeline(CPU core, String PC, String IR, String STATUS, int firstAddrss, int numStages, Instruction preMI, Instruction postMI): crea un objeto Pipeline, con la dirección de memoria donde se ubica la primera instrucción a ejecutar “firstAddrss”, el número de estados del pipeline y las pre y post instrucciones. 27 - Módulo Instrucción Manager e Instrucción: éste deberá poseer una estructura genérica lo suficientemente flexible para poder crear varios formatos de instrucción. Estas instrucciones deberán señalar en cada estado del pipeline el conjunto de microinstrucciones a ejecutarse (deben corresponder al CPU a diseñar). La funcionalidad que tendrá una instrucción será la de ejecutarse, extraer los datos de la operación de cada campo especificado en el diseño de la misma instrucción para poder usarlos como parámetros en su ejecución. Variables y métodos de la clase Instruction_Manager: - Tabla de Hash “coopsInst”: enlaza un objeto instrucción con su código de operación. - Vector de cadenas de caracteres “coopExt”, almacena los códigos de operación de extensión de las instrucciones. - Arreglo de enteros “coopMaskBounds”: dos enteros que definen el campo donde se ubica el código de operación dentro del arreglo de bits que simboliza la instrucción. Uno para el comienzo y otro para el final del campo. - Vector de arreglos de enteros: dos enteros que definen el campo donde se ubica el código de operación extendido para cada código de operación extendido que se use. - Método getInstruction(byte[] inst): dada una instrucción inst, se obtiene su código de operación y se devuelve la instrucción a la cual pertenece ese código para así tener su estructura de ejecución (microinstrucciones por estado). - Método addInstruction(String coop, Instruction ins): agrega una instrucción ins con el código de operación coop correspondiente a la Tabla de Hash. - Método addInstructionExt(String coop, String ext, Instruction ins): agrega una instrucción “ins” con el código de operación “coop” correspondiente y su extensión. - Instruction_Manager(CPU core, int[] coopMsk, Vector<String> coopExtend, Vector<int[]> coopExtMsk): crea un objeto Instruction_Manager ligado al CPU “core”, con la ubicación de código de operación “coopMsk” y los datos para las extensiones de código con sus ubicaciones. 28 Variables y métodos de la clase Instruction: - Entero “coop”: el valor del código de operación asignado a la instrucción. - Arreglo de cadenas de caracteres “params”: los nombres de los parámetros de la instrucción. - Vector de cadenas de caracteres “paramsNames”: otra representación de los nombres de los parámetros de la instrucción. - Vector de arreglo de enteros “paramsBounds”: las ubicaciones dentro del arreglo de bits de la instrucción donde se encuentran los parámetros. - Vector de vector de vector de cadena de caracteres “stages”: o vector de estados (correspondientes al pipeline) con las microinstrucciones para dicho estado. - Arreglo de bytes “instruction”: la instrucción en su representación por bytes. - Cadena de caracteres “name”: nombre de la instrucción. - Métodos Getters y Setters: cada variable tiene un get y un set (obtener e insertar). - Método toString(): la representación en caracteres de la instrucción con su nombre, contenido y parámetros. - Método cloneInstruction(): devuelve un duplicado de la estructura de la instrucción actual, es para evitar usar el mismo apuntador al objeto cuando se requiere es la estructura. - Método execute(CPU core, int stageIndex): ejecuta las acciones del estado “stageIndex” de la instrucción en el CPU “core”. - Método putParameters(Vector<String> micro): devuelve los parámetros de la instrucción según la ubicación definida para cada uno de ellos. - Módulo CPU: La función de este módulo será contener a los demás módulos y permitir la llamada y ejecución de cada función de los componentes, será el ente central de la aplicación. Variables y métodos de la clase CPU: - Cadena de caracteres “cpuName”: nombre de la arquitectura. - Arreglo de Register “CPURegs”: los registros del cpu. - Entero “sizeOfRegisters”: tamaño de los registros en bytes. - Entero “sizeOfInstructions”: tamaño de las palabras en bytes. 29 - Arreglo de Register “GenRegs”: los registros de uso general del cpu. - Memory “memory”: memoria de la arquitectura. - Microinstructions “microInstrs”: las microinstrucciones del cpu. - ALU “alu”: la ALU del cpu. - Instruction_Manager “instManager”: el manejador de las instrucciones del cpu. - Tabla de hash “StatusMasks”: las máscaras para el registro STATUS. - Pipeline “pipe”: el pipeline del cpu. - ShoutsInterface “SInterf: la interfaz de salida de los sucesos e información del cpu. - Método setCpuName(String name): asigna “name” como nombre del cpu. - Método setMemory(int siz, int numSections, String[] secNames, int[] secAddrs, int wordSize, boolean bigEnd, boolean byteRead): inicializa la memoria de la arquitectura con “siz” como tamaño, la cantidad de secciones, dirección y nombres de cada sección en “numSections”, “secAddrs” y “secNames” respectivamente, el tamaño de la palabra “wordSize” y “bigEnd”, “byteRead” para definir el tipo de endian y la forma de acceso a memoria. - Método setPipeline(String PC, String IR, String STATUS, int firstAdress, int numStages, Instruction preMI, Instruction postMI): inicializa el pipeline con “PC”, “IR”, “STATUS” para definir los nombres de dichos registros, “firstAdress” indica la primera dirección de memoria en donde se encuentran las instrucciones, “numStages” indica la cantidad de estados que tiene el pipeline y “preMI” y “postMI” son las pre y post instrucciones del pipeline respectivamente. - Método setInstructionManager(CPU core, int[] coopMsk, Vector<String> coopExtend, Vector<int[]> coopExtMsk): inicializa el manejador de instrucciones con “core” como el cpu ligado al manejador, “coopMsk” señala la ubicación del código de operación, “coopExtend”, “coopExtMsk” son la información sobre los códigos de operación extendidos. - Método addInstruction(String coop, Instruction ins): agrega una instrucción al conjunto de instrucciones, indicando el código de operación de la instrucción a agregar. - Método addInstructionExt(String coop, String ext, Instruction ins): agrega una instrucción al conjunto de instrucciones, indicando el código de operación de la instrucción a agregar. Esta instrucción tiene código de operación extendido. 30 - Método getRegisterData(String name): devuelve el valor que contiene el registro “name”. - Método getRegisterDataInt(String name): devuelve el valor entero que contiene el registro “name”. - Método setRegisterData(String name, byte[] data): asigna los bytes “data” al registro “name”. - Método setRegisterDataInt(String name, int data): asigna el valor “data” al registro “name”. - Método setCPURegisterData(int index, byte[] data): asigna los bytes “data” al registro especial del cpu “index”. - Método setGenRegisterData(int index, byte[] data): asigna los bytes “data” al registro general “name”. - Método getSizeOfRegisters(): devuelve el tamaño de los registros. - Método getInstruction(byte[] code): devuelve la instrucción que tiene el mismo código de operación encontrado en “code”. - Método start(int steps): ejecuta las instrucciones cargadas en memoria, con “steps” pasos. - Método halt(): detiene la ejecución de las instrucciones. - Método reset(): reinicializa el cpu. - Método showShouts(String witch, boolean show): activa la salida de los mensajes del cpu, indicando cual componente se desea mostrar. - Método loadROM(String file, int address, String type): carga un archivo “file” con las instrucciones en el área de la memoria “address”, indicando el tipo de lectura para el archivo (binario, hexadecimal o decimal) con “type”. - Método getGenRegsCount(): devuelve la cantidad de registros generales. - Método getName(): devuelve el nombre del cpu. - Método getFirstInstructionAddress(): devuelve la dirección de memoria donde se encuentra la primera instrucción a ejecutar. - Método setInitialPCData(): asigna el valor al registro PC de la primera dirección de memoria donde se encuentran las instrucciones. - Método CPU(int regsSize, int numGenRegs, Hashtable bitStatusMasks, int instSize, ShoutsInterface SsI): inicializa el cpu indicando el tamaño de los registros, la cantidad de registros generales, las máscaras para el registro STATUS, el tamaño de las instrucciones y la interfaz de salida de información. 31 5.2.- Interfaces de la aplicación Dado que la aplicación será de uso didáctico, la interfaz deberá ser de fácil manejo e intuitiva, para motivar su uso y dar comodidad a los usuarios. Esta presenta la arquitectura diseñada y los cambios ocurridos en el contenido de cada componente durante la ejecución de un programa, y así tener un seguimiento a lo sucedido, con lo que se podrá tener una mayor comprensión sobre el funcionamiento de la arquitectura diseñada. La aplicación tendrá los textos en ingles, pero posee una ayuda tanto en ingles como en español que dará suficiente apoyo para entender la forma de usarla. 5.2.1.- Interfaz para definir la arquitectura Presenta todos los parámetros que contendrá nuestra arquitectura, desde la cantidad de registros a utilizar hasta cada una de las instrucciones que tendrá el procesador. En ella se hará el trabajo de diseño, para luego ejecutar programas en la arquitectura realizada. Por ello deberá ser de rápida comprensión para no perder el tiempo entendiendo la aplicación y no diseñando la arquitectura. 5.2.2.- Interfaz para definir las instrucciones Dado que normalmente el conjunto de instrucciones es extenso, deberá poseer ventajas que permitan crear varias instrucciones distintas, de forma rápida y para las instrucciones que compartan una construcción similar (por ejemplo la suma y la resta sólo difieren en mandar a la unidad aritmética a sumar o a restar, lo demás tiende a ser igual entre ambas). 5.2.3.- Interfaz de ejecución Dado que luego de tener una arquitectura completamente diseñada, la ejecución de un programa en dicha arquitectura será la parte crucial de la aplicación. En la ejecución se muestran información y cambios en los componentes, ocurridos durante la ejecución de un programa. 32 Esta interfaz debe dar toda la información posible sobre la ejecución, los cambios dentro de los componentes de la arquitectura, sin ser superfluos ni ahogar al usuario con demasiados datos a la vez. Por esto debe tener una separación clara de cada módulo que presente y debe darle al usuario la posibilidad de modificar la ubicación de los componentes a su antojo. 5.3.- XML Parser El diseño de la arquitectura será guardado en un archivo con formato XML. El manejo del archivo XML lo hará el XML Parser, al cual podemos darle los datos a almacenar y también podemos obtener a través de él, los valores presentes en los campos del XML. La relación entre los módulos queda representada en la Figura 1. FIGURA 1 – DISEÑO DE RELACIÓN ENTRE MÓDULOS 33 CAPITULO 6 – DESARROLLO 6.1.- Módulos y funciones La herramienta desarrollada se realizó utilizando el lenguaje de programación Java, versión 1.6 que contiene mejoras en las librerías de componentes gráficos con respecto a versiones anteriores. Se contempla que casi todo módulo deberá reflejar la acción que realiza y el cambio de su contenido, para ello se construyó una clase abstracta ShoutsInterface (shout del ingles gritar, para que cada módulo “exprese” el cambio que sufrió) con métodos que serán invocados cada vez que esto ocurra. Dos clases que extienden la clase ShoutsInterface: ShoutsConsole y ShoutsGUI, se utilizan para realizar la salida de información a la consola del Terminal o a la interfaz gráfica, según sea el caso. Métodos de la clase abstracta ShoutsInterface: - regShout(String regName, String oldValue, String newValue): será llamado cada vez que un registro cambie su contenido, teniendo como parámetros el nombre del registro que fue modificado, el valor anterior al cambio y el nuevo valor. - memShout(String addr, String oldValue, String newValue): se ejecuta cuando una dirección de memoria cambia su contenido, los parámetros son la dirección de memoria a cambiar, el contenido anterior y el nuevo. - pipeShout(int stage, String inst, Vector<Vector<String>> micInst): en cada iteración del pipeline se llamará este método para reflejar lo sucedido, los parámetros son el número de estado en que se encuentra, la instrucción que está siendo ejecutada con la lista de microinstrucciones que deberá realizar. - lastShout(int condition): será llamado cuando se ejecute la última iteración y tendrá como parámetro la acción que causo el término de la ejecución. 34 Las características más resaltantes en cada clase son: Registro: implementado en la clase Register.java, y es utilizada en otras clases. Esta clase es básicamente un repositorio de datos. Los datos están guardados en un arreglo de bytes de tamaño 4 (para representar palabras de hasta 32 bits). Dentro de la estructura de la clase CPU, tenemos varios registros de importancia: PC: almacena la dirección de la próxima instrucción a ser ejecutada . STATUS: el cual será revisado constantemente por el pipeline para determinar si se ha de detener la ejecución de un programa. La ALU modifica el valor del registro STATUS si ocurre un desborde en alguna operación aritmética, o una división entre cero (con las máscaras designadas). ALU: implementado en la clase ALU.java. Lo más interesante de la clase es el método execute donde dependiendo de una palabra clave de operación, llama a otro método interno que realizará la operación solicitada. En esta clase es donde se realiza la suma, resta, etc. entre los registros internos de la clase. Microinstrucción: implementada en la clase Microinstructions.java, la cual se encarga de ejecutar el conjunto de instrucciones básicas de las que estará provisto todo CPU. Esta clase es similar a la clase ALU, realiza asignación de datos entre registros. También llama a la clase ALU para que realice algunas de las operaciones lógicas o aritméticas. La particularidad de esta clase está en los métodos Branch (salto), los cuales devuelven un entero como resultado de la operación, para así definir el número de microinstrucciones que la instrucción, al ser aceptada la condición de salto, debe omitir. La microinstrucción que detiene la ejecución de la aplicación, llamada Halt, cambia el registro STATUS para indicar que el programa debe ser detenido (es en el pipeline donde se revisa el registro STATUS para ejecutar esta indicación). 35 Memoria: implementada en la clase llamada Memory.java, se encarga de almacenar los “bytes” de datos. Así como la clase Registro, es un repositorio con la particularidad que posiciona los datos a guardar en el arreglo de bytes. Las opciones de ordenamiento de bytes en una palabra Big Endian/Little Endian y el cambio en la forma de direccionamiento por byte o por palabra están presentadas en la interfaz gráfica, no obstante, solo esta implementada la lectura direccionada por byte y el ordenamiento de bytes Little Endian. Pipeline: implementado en la clase llamada Pipeline.java se encarga de la ejecución iterativa de las instrucciones que se encuentran en el área de la memoria. El pipeline cuenta con dos instrucciones propias (pre y post instrucciones), las cuales se ejecutarán antes y después de cualquier instrucción que entre en el pipeline. Estas instrucciones (configuradas en el diseño de la arquitectura) ahorran tiempo en el diseño, para realizar procedimientos que sean necesarios en cada ejecución (por ejemplo la actualización del registro PC). Por cada estado del pipeline se tiene una instrucción. Estas instrucciones se actualizan al entrar una nueva en el primer estado del pipeline y las siguientes cambian a la posición i+1, del arreglo de instrucciones (arreglo de tamaño igual a la cantidad de estados). El procedimiento para la ejecución de las instrucciones es el siguiente: Cuando el ciclo de ejecución inicia, se comprueba la dirección de memoria contenida en el registro PC, si ésta es válida se toma la instrucción localizada en dicha dirección y pasa a ser la primera en el arreglo de instrucciones. Se ejecutan el conjunto de acciones del primer estado de la pre-instrucción, seguido el conjunto de acciones del primer estado de la primera instrucción del arreglo y finalmente el conjunto de instrucciones del primer estado de la postinstrucción. Así mismo se ejecutarán en secuencia las acciones del estado i de la preinstrucción, secuencia de acciones del estado i de la instrucción i del arreglo y por último la secuencia de acciones del estado i de la post-instrucción. Al finalizar la ejecución de las n instrucciones (estados), se revisa si el registro STATUS ha cambiado para detener la ejecución del programa o si se continúan tomando instrucciones. 36 La Figura 2 muestra el ciclo de ejecución. Ciclo de ejecución de instrucciones en el pipeline Inicio PC.value < MEM.size S Se tomó una instrucción de MEM[PC] y se coloca en instrucciones[0] De instrucciones[i] a instrucciones[i+1] Punto de diferencia NO Fin Ejecución en todos los estados (solo hay una instrucción “0”) NO S STATUS.halt 1 PRE.estado(0); instrucciones[0].estado(0); POST.estado(0); 2 PRE.estado(1); 3 PRE.estado(2); POST.estado(1); POST.estado(2); Ejecución en todos los estados (instrucción “0”->“1”, nueva “0”) Segunda iteración 1 PRE.estado(0); instrucciones[0].estado(0); POST.estado(0); 2 PRE.estado(1); instrucciones[1].estado(1); POST.estado(1); 3 PRE.estado(2); POST.estado(2); Ejecución en todos los estados (instrucción “0”->“1”, “1”->“2”, nueva “0”) Tercera iteración 1 PRE.estado(0); instrucciones[0].estado(0); POST.estado(0); 2 PRE.estado(1); instrucciones[1].estado(1); POST.estado(1); 3 PRE.estado(2); instrucciones[0].estado(2); POST.estado(2); Ejemplo con 3 estados en el pipeline. Tres iteraciones con tres instrucciones FIGURA 2 – EJECUCIÓN DE INSTRUCCIONES DEL PIPELINE Instruction Manager e Instruction: implementado en dos clases: - Instruction_Manager.java se encarga del manejo de las instrucciones. 37 Almacena en una tabla de Hash las instrucciones, usando sus códigos de operación como claves. En caso de que la instrucción posea un código extendido, la clave será COOP+EXT, ambos valores en representación binaria. La Figura 3 ejemplifica ambos casos. 000000+01111 Instrucción 010000 Instrucción Objeto instrucción correspondiente al código de operación 000000 con condigo extendido 01111 Objeto instrucción correspondiente al código de operación 010000 FIGURA 3 – TABLA DE HASH DE INSTRUCCIONES (ejemplo) - Instruction.java, esta es una de las clases esenciales para la ejecución de programas, ya que es capaz de llamar a las acciones que debe realizar en cualquier estado del pipeline. Su método toString() permite obtener una representación de la instrucción, código de operación, parámetros y acciones a ejecutar por estado. Se utiliza para realizar pruebas durante la elaboración de la aplicación. Se necesitó implementar un método cloneInstruction() que devuelve una copia de la instrucción para cuando sea usada por el manejador de instrucciones, no se vea afectado ninguno de los valores originalmente presentes en la instrucción. Esto solventa problemas con apuntadores y nos permite conservar intactos los parámetros de la instrucción. Para clonar un objeto complejo como éste, se debe recorrer cada componente que sea un apuntador hasta obtener su valor concreto y asignarlo a una instrucción nueva que será devuelta al final del recorrido. Un estado en la instrucción se ejecuta al accionar cada una de las microinstrucciones que componen al mismo; estas al ser ejecutadas, devuelven un valor entero, el cual indica cuantas microinstrucciones deben ser saltadas. Estos saltos sólo ocurren en microinstrucciones tipo Branch, que de cumplirse una condición especifica, devuelven el valor numérico que se les indico, en lugar de devolver 0 (cero) como todas las demás microinstrucciones. 38 La mayoría de las instrucciones que comúnmente usamos, tienen varios parámetros. La clase Instruction.java los guarda en un listado con los nombres establecidos en el diseño de la arquitectura. Para la ejecución de una instrucción es necesario obtener el valor del campo del parámetro (si fuera un parámetro inmediato por ejemplo) o dejar la referencia del campo (referencia a un registro). El método putParameters devuelve los valores a ejecutar por la microinstrucción. Adicionalmente se creó una clase BoneInstruction.java la cual es una versión de repositorio para los parámetros de la instrucción. Esta clase es usada en la aplicación de diseño y ayuda en el ahorro de memoria del sistema operativo donde se ejecuta la aplicación, ya que constituye un objeto de menor tamaño (en bits) que la instrucción normal y para la aplicación de diseño no son necesarios los métodos de ejecución, etc. de la clase instruction.java CPU: módulo implementado en la clase llamada CPU.java. Es la clase principal en donde se contienen e inicializan todas las clases que modelan la arquitectura genérica. Por medio de esta clase se comunican e interactúan las demás clases entre sí. El método más resaltante es el que carga el conjunto de instrucciones programadas por el usuario desde un archivo a la memoria del computador simulado. Puede leer cada línea del archivo (código del programa a ejecutar) en formato binario, hexadecimal y decimal, lo cual es una gran herramienta para probar a los estudiantes sus conocimientos sobre los cambios de base numérica para obtener las distintas formas de entrada. Cada línea del programa es convertida en un arreglo de 4 bytes y se colocan continuos en la memoria desde una posición de memoria inicial dada. Clases principales (main) de las aplicaciones USB Designer y USB Runner: La clase SimUSBDesigner.java es la que contiene la interfaz para el uso de la herramienta de diseño. Inicia la aplicación y la mayoría de los métodos que contiene son usados para dar respuesta de los componentes gráficos (accionar de botones, listas, etc.) y algunas acciones extras para el procesamiento de los datos (verificación de parámetros, etc.). 39 Tiene una estructura de datos que corresponde al esqueleto de una arquitectura genérica, para poder contener todos los parámetros que se usan al definir una arquitectura. El diseño se guarda en XML, pero también tiene métodos que imprimen un archivo de texto o un documento HTML, con los cuales se puede visualizar el diseño creado. USB Runner cuenta con la clase MAIN.java para iniciar la herramienta. Así como SIMUSBDesigner.java, cuenta con una estructura que corresponde al esqueleto de una arquitectura genérica, la cual se carga con los valores tomados de un archivo XML de diseño previamente creado. Al principio se inicializa todos los parámetros y módulos básicos (registros, memoria, etc.) en valores nulos o neutros (ceros). USB Runner también cuenta con métodos que atienden los cambios ocurridos en los componentes al ejecutar algún programa y reflejan dichos cambios en la interfaz. La aplicación puede ser ejecutada en modo consola o en modo de ventanas. Esta opción se establece en el método main(), si se tienen parámetros al ejecutar la aplicación (archivo del cpu diseñado, archivo de instrucciones, dirección de inicio en memoria y modo de reflejar los cambios) se ejecutará en consola. Sin parámetros, ejecuta la versión con interfaz de ventanas. 6.2.- Interfaces de la aplicación Ofrece componentes adecuados para cada parámetro en el diseño de la arquitectura (cuadros de caja para opciones reducidas, cuadros de texto para entrada de valores, etc.). Sus menues son sencillos y responden a atajos de teclas para las acciones más comunes (abrir, guardar, etc.). Además cuenta con el uso del botón derecho para permitir más opciones en ciertas áreas de la aplicación (como en las tablas). Las interfaces están en inglés, aunque los botones y menues son de fácil entendimiento. Cada aplicación cuenta con una ayuda que muestra una descripción de los componentes y se encuentra tanto en inglés como en español, ya que los usuarios a quien va dirigida principalmente la aplicación son de habla hispana. 40 Al estar desarrollada en java, permite mantener el mismo aspecto general (con excepción de algunos detalles de componentes) sin importar la plataforma en la que se ejecute. 6.2.1.- Interfaz para definir la arquitectura Para poder establecer todos los parámetros que comprende el diseño de una arquitectura en nuestro modelo genérico, dividimos el área de trabajo en dos áreas; el área principal y el área de instrucciones. Esta división se logra usando pestañas. FIGURA 4 – VENTANA MAIN DE SimUSB Designer Como se aprecia en la FIGURA 4, el área principal contiene los campos para el nombre del diseño, opciones en los registros, el área de la memoria, las máscaras del registro STATUS y el área del pipeline. 41 Varios campos sólo aceptan valores numéricos y para mantener esta especificación se usaron componentes JFormattedTextField que ayudan a facilitar la revisión en la entrada de datos. En general se usaron cuadros de combo (combobox) para los parámetros en los cuales sólo se permite un valor dado entre una lista de opciones. Dado que para algunas áreas es necesario tener un parámetro en específico (por ejemplo, definir la cantidad de estados del pipeline para que los muestre el cuadro de combo), se usan botones con la etiqueta “SET” para confirmar los cambios y que éstos se reflejen en los demás componentes. 6.2.2.- Interfaz para definir las instrucciones En el área de instrucciones tenemos un listado de las instrucciones que se estén creando, un área para establecer los códigos de operación extendidos y su localización en la instrucción y un área para crear una instrucción. FIGURA 5 – VENTANA INSTRUCTIONS DE SimUSB Designer 42 Muchas instrucciones tienen un comportamiento similar salvo en algún punto clave, como sucede con las instrucciones aritméticas en donde sólo cambia la operación a realizar, pero los demás pasos (copia de parámetros a los registros, etc.) son idénticos. Para estos casos se puede seleccionar una instrucción previamente creada y al guardarla con otro nombre automáticamente guarda una nueva instrucción en la lista. 6.2.3.- Interfaz de ejecución FIGURA 6 – VENTANA DE SimUSB Runner Es necesario presentar todos los componentes simulados y reflejar los cambios y acciones que ocurran. Para esto se utiliza un sistema de ventanas que facilitan la visión de cada área, permitiendo modificar el tamaño y posición de cada ventana (incluso se pueden ocultar). 43 Tenemos tablas para presentar el contenido de los registros y del área de la memoria, contando con la opción de ver el valor de su contenido en diferentes formatos (binario, decimal, hexadecimal). La ventana que muestra los estados del pipeline incluye una tabla la cual se ajustará a la cantidad de estados y presenta las instrucciones que se ejecutan en cada uno. En la ventana de consola tenemos reflejado cada cambio ocurrido en los componentes que queramos ver (usando un cuadro de selección) y se puede guardar en un archivo de texto todos los sucesos. Esto permite hacer un seguimiento de la ejecución en cualquier otro momento. 6.3.- Archivos XML Para guardar el diseño de la arquitectura utilizamos un archivo con formato XML. Además guardamos la configuración de ventanas de la herramienta USB Runner en otro archivo con formato XML. 6.3.1.- Archivo XML de arquitectura El diseño de este archivo fue una parte crucial en todo el proyecto, dado que se debía mantener la estructura de una arquitectura junto a los parámetros e instrucciones de la misma. La utilización del formato XML nos permitió separar de forma ordenada cada componente de la arquitectura y gracias a librerías de uso libre para procesar archivos XML, podemos acceder a cada campo de forma rápida y sencilla. Además el formato del archivo permite al usuario ver directamente su contenido y entender cada campo, lo cual da la facilidad de estudiarlo sin tener que hacer uso de la aplicación de diseño. Incluso es sencillo modificar el archivo sin tener que hacer uso de la herramienta, siempre y cuando se tenga cuidado en respetar las etiquetas del XML. 44 Este archivo se puede separar en dos secciones, la estructura los módulos de la máquina y el conjunto de instrucciones. <CPU name="PseudoMIPS" registerSize="4" numRegs="32" instructionSize="32"> <Masks> <Mask name="overflow" value="10"/> <Mask name="divbyzero" value="11"/> <Mask name="haltBit" value="1"/> </Masks> <Memory size="1024" numSections="1" wordSize="4" bigEndian="true" readByByte="true"> <MemLabel name="Main" address="0"/> </Memory> <Pipeline firstAddress="0" numStages="3"> <PreCode> <Stages> <Stage name="fetch"> <Microinstruction code="MemtoR" param1="PC" param2="IR"/> <Microinstruction code="inmOpertoR" param1="PC" param2="+" param3="4"/> </Stage> </Stages> </PreCode> </Pipeline> <Coops> <GlobalCoop upperBound="31" bottomBound="26"/> <ExtendedCoops> <ExtCoop coop="000000" extUpperBound="5" extBottomBound="0"/> </ExtendedCoops> </Coops> <Instructions> <Instruction name="ADD" coop="000000" extcoop="100000"> <Parameters> <Parameter name="coop" upperBound="31" bottomBound="26"/> <Parameter name="rs" upperBound="25" bottomBound="21"/> <Parameter name="rt" upperBound="20" bottomBound="16"/> <Parameter name="rd" upperBound="15" bottomBound="11"/> <Parameter name="extcoop" upperBound="5" bottomBound="0"/> </Parameters> <Stages> <Stage name="execute"> <Microinstruction code="RtoR" param1="rs" param2="ALU-A"/> <Microinstruction code="RtoR" param1="rt" param2="ALU-B"/> <Microinstruction code="ALU-sum"/> <Microinstruction code="RtoR" param1="ALU-ZLo" param2="rd"/> </Stage> <Stage name="read"/> <Stage name="write"/> </Stages> </Instruction> : : </Instructions> </CPU> FIGURA 7 – ARCHIVO XML DE ARQUITECTURA DISEÑADA 45 6.3.2.- Archivo XML de configuración Es utilizado para mantener los valores en la posición de las ventanas de la aplicación. <config> <cpuSteps number="3"/> <windows> <main width="800" height="600"/> <pipeline width="470" height="330" x="0" y="0"/> <registers width="320" height="250" x="470" y="0"/> <console width="470" height="210" x="0" y="330"/> <memory width="320" height="290" x="470" y="250"/> </windows> </config> FIGURA 8 – ARCHIVO XML DE CONFIGURACIÓN 6.4.- Estilo de código y documentación El estilo del código se considera limpio por tener comentarios sólo en los lugares adecuados y las líneas de código separadas .Con variables y métodos mnemónicos lo cual ayuda a su lectura y comprensión. La documentación está basada en JavaDoc el cual permite crear un API en HTML de las clases y métodos utilizados. Esta documentación se entrega junto a la aplicación, para que cualquier interesado en modificar la aplicación tenga todo lo necesario para entender el código. 6.5.- Problemas encontrados El primer problema fue poder reflejar toda la estructura de una arquitectura genérica, tratando de no colocar muchos parámetros estáticos para así no afectar el número de arquitecturas que se pueden diseñar. Esto se solventó parametrizando varias arquitecturas y encontrando patrones comunes con los cuales ofrecer muchas posibilidades de combinación que logran cubrir gran cantidad de arquitecturas. 46 Lo siguiente era agrupar los conceptos que se dictan en la teoría de la materia y plasmarlos en la aplicación, para de esta forma lograr que el usuario principiante aprenda los conceptos y que el usuario experimentado logre explotarlos. Al analizar objetivos del curso, se pudo seguir el avance en el aprendizaje y de esta forma el usuario va desde crear la arquitectura centrándose en los componentes que utilizarán, la creación de las instrucciones teniendo en cuenta todos los componentes que tiene a su alcance, hasta la elaboración de programas que usen de forma correcta la arquitectura que se diseñó. Otro problema fue crear una interfaz amigable ya que durante la recopilación de información en un Focus group, se puso en evidencia que muchas de las herramientas que se ofrecen son de uso profesional, dejando a los usuarios principiantes con dificultades para el aprendizaje del mismo. Tomando nota de varias funcionalidades requeridas por la mayoría de los usuarios de este tipo de aplicaciones, el diseño de la interfaz es sencillo y permite tanto a un usuario principiante aprender rápidamente el uso de la herramienta y como a un usuario experimentado aprovecha al máximo sus funciones. 6.6.- Estado del proyecto al entregar La herramienta cuenta con un diseñador y un simulador de arquitecturas funcional y completo hasta el alcance esperado (diseño y simulación de una arquitectura genérica). También cuenta con una estructura de datos y de código sencillo que permitirá a futuras ampliaciones conectarse con el código principal sin complicaciones. También deja espacio a mejoras en el diseño por tratarse de una primera versión de la aplicación con alcance mínimo en sus capacidades (sólo hace uso de registros y un área de memoria) pero está completamente funcional para la realización de muchos proyectos tanto para aquellos basados en la creación de arquitecturas, conjuntos de instrucciones como para la ejecución de programas que corran en una arquitectura dada. Varios proyectos de ampliación discutidos fueron contemplados y se creó una estructura jerárquica capaz de soportar grandes cambios en el futuro con un mínimo de modificaciones internas. 47 CAPITULO 7 - CONCLUSIONES Y RECOMENDACIONES Este proyecto es sólo un pequeño aporte para proveer a estudiantes de una herramienta que les facilite la comprensión del funcionamiento y diseño de una arquitectura del computador. Se crearon dos aplicaciones que permiten el modelado de una arquitectura genérica parametrizada y la ejecución de programas sobre dicha arquitectura, para así poder estudiar su comportamiento y funcionalidad. Durante el desarrollo de este trabajo se pudo apreciar los niveles de complejidad que pueden alcanzarse en la simulación de computadores ya que la interacción de sus componentes se ve afectada por muchos factores que para fines didácticos pueden ser omitidos. Las herramientas creadas en este proyecto permiten describir a las arquitecturas en componentes tales como los registros, la memoria, la ALU, entre otros, sólo representando sus funcionalidades más básicas. Para hacer más fácil su comprensión por parte de los estudiantes del curso de Organización del Computador. Aunque la aplicación sólo contempla pocos componentes del computador (buscando reflejar sólo lo necesario para poder ser probada), existen multitud de componentes que pueden ser agregados a la simulación, añadiendo muchas más variantes y opciones a la funcionalidad de la aplicación. Con estos componentes añadidos la herramienta podría crecer para ser un simulador mucho más completo y poderoso, con lo que podría ser utilizada para hacer probar arquitecturas más complejas. La forma en que se desarrolló la aplicación permite fácilmente incorporar nuevas características dentro de su código, que logren cada vez acercar más todos los objetivos que contempla el curso de Organización del Computador a la práctica. Su implementación en Java permite compartir la herramienta no sólo a nivel de uso, sino a nivel de programación, otorgándole la oportunidad a cualquier programador de ampliar las funcionalidades de la misma. 48 La herramienta desarrollada permite que el estudiante empiece con la creación de una arquitectura, teniendo en cuenta sus componentes ya parametrizados y su conjunto de instrucciones, que posee bastantes variantes para poder cubrir cualquier necesidad de diseño. El usuario de la herramienta podrá, luego de tener una arquitectura diseñada, importarla para su prueba, ejecutando programas desarrollados específicamente para dicha arquitectura. De esta forma podrá probar el comportamiento de su arquitectura con distintos programas, y así analizar y comparar diferentes tipos de arquitecturas. Para la ejecución de un programa el usuario deberá "traducir" su programa al código de máquina definido en la arquitectura que desee usar. Una herramienta que se podría desarrollar en el futuro puede ser un traductor de lenguaje ensamblador al lenguaje de máquina de un diseño de arquitectura. 49 Bibliografía Quark. "Introduccion al XML". Disponible en: http://quark.fe.up.pt/cursoxml/curso.pdf. Ultimo acceso: Julio 2007 SlashDat!: Angel Barbero. "Tutorial de XML". Disponible en: http://www.dat.etsit.upm.es/~abarbero/curso/xml/xmltutorial.html. Ultimo acceso: Julio 2007 NanoXML. "Documentation". Disponible en: http://nanoxml.cyberelf.be/. Ultimo acceso: Julio 2007 Wikipedia La enciclopedia libre. Ultimo acceso: Julio 2007 Enlaces: http://en.wikipedia.org/wiki/Instruction_set_architecture http://en.wikipedia.org/wiki/Microcode http://en.wikipedia.org/wiki/Assembly_language http://en.wikipedia.org/wiki/ALU http://en.wikipedia.org/wiki/Instruction_pipeline http://en.wikipedia.org/wiki/Classic_RISC_pipeline http://en.wikipedia.org/wiki/Addressing_mode http://en.wikipedia.org/wiki/Two%27s_complement http://en.wikipedia.org/wiki/Bitwise_operation http://en.wikipedia.org/wiki/MIPS_architecture http://es.wikipedia.org/wiki/Compilador Fundamentos de Computadores II. "Prácticas de Fundamentos de Computadores II". Disponible en: http://www2.dis.ulpgc.es/~itig-fc2/web-practicas/. Ultimo acceso: Julio 2007 Clayton School of Information Technology. "J-MIPS - The Java MIPS simulator". Disponible en: http://www.csse.monash.edu.au/packages/jmips/. Ultimo acceso: Julio 2007 50 Willkommen bei SIMPLE. Disponible en: http://sourceforge.net/projects/jmvm. Ultimo acceso: Julio 2007 Colby College Computer Science Department. "CPU Sim". Disponible en: http://www.cs.colby.edu/~djskrien/CPUSim/. Ultimo acceso: Julio 2007 The University of Wisconsin. “SPIM A MIPS32 Simulator”. Disponible en: http://pages.cs.wisc.edu/~larus/spim.html. Ultimo acceso: Julio 2007 Grupo de Arquitectura de Computadores de la Universidad de Zaragoza. "Simuladores para docencia". Disponible en: http://webdiis.unizar.es/gaz/docencia/simula.html. Ultimo acceso: Julio 2007 Site de Sistemas Operativos de la Universidad de Buenos Aires. “Apuntes”. Disponible en: http://www-2.dc.uba.ar/materias/so/datos/cap08.pdf Ultimo acceso: Julio 2007 Sun Developer Network. Disponible en: http://java.sun.com/. Ultimo acceso: Julio 2007 Net Beans. Disponible en: http://www.netbeans.org/index.html Ultimo acceso: Julio 2007 J. Alastruey, O. Blasco, A. Hurtado, P. Ibáñez y V. Viñals "COVI: Computador Virtual". XIII Jornadas de Paralelismo, Lérida (España). 9-11 Sept. 2002. J. A. Ortega, N. Ayuso y L. M. Ramos. "Simulador de Máquina Sencilla". XVI Jornadas de Paralelismo, Granada (España). Sept. 2005. 51 The real world Felipe Faesch Gutierrez. "Entorno de Simulación del Microprocesador Motorola MC68000". Disponible en: http://weblogs.udp.cl/felipe.faesch/archivos/(1545)ManualdeUsuario.pdf. Ultimo acceso: Julio 2007 MIPS Technologies. Disponible en: http://www.mips.com. Ultimo acceso: Julio 2007 52