Z - Centro de Geociencias ::.. UNAM
Anuncio

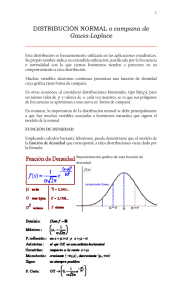
La Distribución Normal y su uso en la Inferencia Estadística Los conceptos básicos de Probabilidad y de Distribuciones Muestrales sirven como introducción al método de Inferencia Estadística; esta se compone en dos áreas: • Estimación • Pruebas de Hipótesis La estimación busca evaluar los valores de los parámetros de la población (por ejemplo la media y la desviación estándar) basados en una muestra. Las pruebas de Hipótesis constituyen un proceso relacionado con aceptar o rechazar alguna afirmación acerca de los parámetros de la población. Ejemplo. Supóngase que un fabricante de lápices compra a un proveedor borradores para pegarlos a los lápices. El fabricante tiene que decidir si cada lote de borradores del proveedor es de calidad aceptable. Para ello necesita que contenga el 15% o menos de borradores defectuosos. Desde luego, no puede inspeccionar cada borrador del lote. Debido a esto, obtiene una muestra de 20 borradores de cada lote y la inspecciona. Decide que si hay 3 o menos borradores defectuosos en la muestra, aceptará un lote; si hay más de 3 defectuoso rechazará el lote y lo de volverá al proveedor. Sin embargo, si acepta un lote cuando éste contiene más del 15% de borradores defectuosos, ha cometido un error. Por otra parte si rechaza un lote cuando contiene menos del 15% de borradores defectuosos, también ha cometido un error. Con base en la evidencia proporcionada por la muestra, el fabricante ha tratado de responder a la pregunta ¿tiene el lote una proporción de lápices defectuoso tan grande que sea necesario rechazarlo? Al responder a lo anterior, el fabricante de lápices ha tomado una decisión acerca de la proporción de defectos en la población general, ya que la proporción en la población es un parámetro de la población y las decisiones acerca de los parámetros de la población constituyen el proceso de pruebas de hipótesis, en realidad el fabricante ha realizado la tarea de probar una hipótesis. tesis Si el fabricante está interesado en estimar la verdadera proporción de defectos con base a su información muestral, tendrá que intentar responder a la pregunta Con base en la muestra ¿Qué afirmación puedo hacer acerca de la proporción de la población que es defectuosa ? Esta pregunta corresponde a lo que se llama Estimación. ¿Porqué es normal la distribución Normal? Al hacer mediciones de cualquier tipo y distribuir nuestros resultados bajo algún criterio, es muy común encontrar que los datos se agrupen de manera muy característica. En muchos de estos casos veremos que dichas distribuciones siguen una forma muy particular en la que tenemos un mayor número de observaciones para cierto valor, disminuyendo la cantidad de observaciones a ambos lados de la observación más frecuente. Un ejemplo es al dejar caer canicas por entre una serie clavos como lo muestra la figura, al final del experimento con muchas canicas tendremos que las canicas se han agrupado como se ve en la figura. Ejercicio interactivo: Máquina de Galton A este tipo de distribución se le conoce como Distribución Gaussiana, ya que el matemático alemán Karl F. Gauss (1799-1830) fue quien la describió de manera analítica. La forma de ésta función es parecida a la de una campana, por eso también se conoce como “campana de Gauss”. Distribución Normal 0.999 0.4 Densidad 0.3 0.2 0.1 0.0 -3.09 0 X Es tan común encontrar esta distribución en tan diversas ramas del conocimiento, que también se le da el nombre de Distribución Normal. La aportación de Gauss se honraba en los billetes de los marcos alemanes (antes de los Euros) como uno de sus descubrimientos más trascendentales. La distribución Gaussiana se aplica a una gran gama de observaciones en ramas como la biología, la geografía, la astronomía y por supuesto la economía. Muchos ejemplos de la naturaleza se pueden aproximar con una distribución normal. En general esto se puede pensar como resultado de la interacción de muchos (o un gran número) efectos aleatorios en la variable que se estudia. Por ejemplo, si medimos el tamaño de las hojas de un árbol, veremos que tienden a distribuirse en forma gaussiana. Ejercicio interactivo: Jugando con la distribución normal Pero ¿a qué se debe esta aparentemente sorprendente resultado? Estas distribuciones son el resultado del agregado de muchos procesos azarosos o fortuitos que podrían no ser observables individualmente. Matemáticamente esta distribución obedece a lo que se conoce como el Teorema del Límite Central. Este teorema estipula que si tomamos muestras de una población que tenga cualquier tipo de distribución, pero una media y varianza finitas, entonces, la distribución de las medias tiende a la distribución normal. Entre mayor sea el número de muestras mejor será la aproximación a una distribución normal. Por ejemplo, si nos tiramos un dado la probabilidad de que caiga cualquier número es 1/6. Esto implica una distribución de posibilidades de la siguiente forma (x es el número o cara): P 1/6 1 2 3 4 5 6 x Esta es una Distribución de Probabilidad Uniforme que, como se ve, es la misma probabilidad para todos los valores que toma la variable Ahora imaginemos que tiramos un dado 500 veces y tomamos el número total de puntos de cada tirada, entonces decimos que N = 1, y las sumas de cada tirada las distribuimos como en la figura. Ahora lo hacemos con 4 dados (N = 4), y luego con 7 y con 10. Al final tendremos las siguientes distribuciones: Notemos que conforme vamos aumentando el número de muestras la distribución se acerca más a una distribución normal. Ejemplo interactivo: distribución muestral Otro motivo por el cual as distribuciones normales son muy utilizadas es que tienen muchas propiedades muy convenientes. Por eso, si las variables aleatorias que nos interesan tienen distribuciones desconocidas, podemos hacer inferencias iniciales suponiendo distribuciones normales. Entre las propiedades agradables de la distribución normal, está el hecho de que • La distribución normal de una suma o diferencia (que en general es lo mismo) de distribuciones normales es también normal. Si tenemos que: y Y la correlación entre x1 y x2 es ρ, entonces: Y también: Debido a todo lo anterior esta distribución es muchas veces el modelo de partida de los análisis de los datos. Aunque cuando no podemos generalizar, muchas veces la podremos utilizar como una buena aproximación a la realidad. Distribución Normal Estándar o tipificada. Calificación Z. Una de las consecuencias del Teorema del Límite Central es que dada una población con media m y para n lo bastante grande, la distribución de la variable i x −x Z= s es una distribución normal. donde: xi es la observación que estamos queriendo analizar x es el valor de la media de la muestra s es el valor de la desviación estándar de la muestra Si nos fijamos en la fórmula el valor de Z es la distancia de la observación a la media en unidades de desviación estándar, ndar es decir, a cuántas desviaciones estándar está alejada nuestra observación de la media. Veamos qué significa esto en una gráfica: Normal estándar Media=0, Desv Est=1 0.4 Densidad 0.3 Dos desviaciones estándar 0.2 Una desviación estándar 0.1 0.0 -3 -2 -1 0 Z 1 2 3 Actividad 1 Si nos dicen que una población tiene una media de 23 y una desviación estándar de 3.5, encontrar la calificación Z de a)26.6, b) 16, a) 26.6 − 23 = 1.03 3.5 Z= c)19.5 d) 29: lo que significa que 26.6 está a 1.03 desviaciones estándar a la derecha de la media (porque es positivo). b) Z= 16 - 23 = -2 3.5 lo que significa que la observación está a 2 desviaciones estándar a la izquierda de la media (porque es negativo). c) Z= 19.5 - 23 = -1 3.5 ¿Qué significa este resultado? d) Z= 29 − 23 = 1.72 3 .5 ¿Qué significa este resultado? Si cambiamos todos los valores observados a calificaciones Z, entonces podemos crear una distribución normal genérica llamada distribución normal estándar o tipificada en donde • la media, que está en el centro de la curva, nos queda en el valor 0 • la desviación estándar es ahora igual a 1 y • el área bajo la curva también es igual a la unidad lo que equivale al total de los casos de la población estudiada, es decir, El área total = 1 corresponde al 100% de los casos, y porciones del área son proporcionales a porcentajes parciales de la muestra. De este modo, la porción de área bajo la curva, limitada por dos ordenadas o perpendiculares levantadas en puntos del eje X, expresan el porcentaje de casos que quedan comprendidos entre las calificaciones Z correspondientes a los puntos sobre los que se trazan las ordenadas. Veámoslo en el siguiente diagrama. La Regla del 68 – 95 - 99.7% Todas las curvas o distribuciones de densidad normal satisfacen la siguiente propiedad a la cual comúnmente se le refiere como la Regla Empírica. 68% de las observaciones caen dentro de 1 desviación estándar de la media, media o sea, entre μ - σ y μ + σ . 95% de las observaciones caen dentro de 2 desviaciones estándar de la media, media o sea, entre μ - 2σ y μ + 2σ . 99.7% de las observaciones caen dentro de 3 desviaciones estándar de la media, media o sea, entre μ - 3σ y μ + 3σ . Podemos ver que casi todas las observaciones caen dentro de 3 desviaciones estándar de la media y más del 95% caerían a 2 desviaciones estándar de la media Porcentajes del Área total o porcentajes de la población o probabilidad 2.15% 13.59% 34.13% -3 -2 -1 Valores o calificaciones z 0 34.13% 13.59% 2.15% 1 2 3 El área correspondiente a una distancia de 1 desviación estándar de la media (a ambos lados) es de aproximadamente 68% De acuerdo a lo especificado anteriormente entonces entre 0 y 1 se encuentra el 34.13% de los casos, es decir que el área bajo la curva es 0.3413, o lo que significa que el 68.26% de la población está alejada de la media a lo más una desviación estándar. O que solamente el 4.30% de los casos están más allá de dos desviaciones estándar de la media. Existen tablas que nos ayudan a obtener los porcentajes de casos entre diferentes calificaciones Z y la media. Sin embargo se debe tener mucho cuidado de ver cuál es el área bajo la curva que nos dan, porque se tabula de forma diferente en los libros, ∞. R e g l a e m p ír i c a f(z) algunos la dan a partir de 0 y otros a partir de - -4 Ejemplos: -3 -2 -1 0 1 2 3 4 z 1.Si queremos encontrar el área bajo la curva comprendida entre las calificaciones estándar de los incisos a) y d) anteriores, buscamos en la tabla los valores que corresponden: para Z = 1.03 el área bajo la curva es 0.8485 para Z = 1.72 el área bajo la curva es 0.9564 lo que nos da un área de 0.9564-0.8485 = 0.1079 Esto quiere decir que el 10.79% está entre los valores 26.6 y 29 (recordar que el área total =1 equivale al 100% de los casos). z Que porcentaje de datos podríamos esperar con valores mayores a 29? para Z = 1.72 el área bajo la curva es 0.9564 lo que nos da 1 – 0.9564 = 0.0436 o sea 4.36% 10.79% 95.64% z 2. Encontrar el área bajo la curva entre las calificaciones Z = -2 y Z = -1 Como en unas tablas no nos dan el área del lado izquierdo podemos usar los valores del lado derecho y el área es la misma porque la curva es simétrica. Para Z = 2 el área bajo la curva es 0.9772 para Z = 1 el área bajo la curva es 0.8413 lo que nos da un área entre medio de ellas de 0.9772-0.8413 = 0.1359 z Cálculo de Probabilidades Antes de pasar a usar los conceptos anteriores tenemos que definir qué es la probabilidad. Podemos pensar en este concepto de dos maneras: 1. Si conocemos todos los resultados posibles de un experimento u observación, y queremos saber el porcentaje de que ocurra un cierto tipo de resultado, entonces llamamos probabilidad a: P( A) = Número ⋅ de ⋅ resultados ⋅ de ⋅ un ⋅ cierto ⋅ tipo n = Número ⋅ de ⋅ resultados ⋅ totales N Actividad No. 1: Al tirar dos dados queremos ver la probabilidad de que salga el número 4 al sumar los puntos. En este caso el número total de resultados es 36, por lo tanto N=36 El número de resultados que cumplen el criterio es 1+3, 2+2, 3+1, n=3 n 3 1 P( A) = = = N 36 12 Es la probabilidad de que la suma de los puntos de dos dados sea = 4 Si embargo, algunas de estas sumas se repiten, por lo que podemos hacer una tabla como la siguiente Valores de la suma (x) Número de casos Probabilidad P(x) 2 1 1/36 3 2 2/36 4 3 3/36 5 4 4/36 6 5 5/36 7 6 6/36 8 5 5/36 9 4 4/36 10 3 3/36 11 2 2/36 12 1 1/26 Total 36 1.0 Si ahora hacemos un histograma con los valores de las sumas y sus probabilidades, tendremos lo siguiente Esto es lo que llamaríamos a una distribución de probabilidad para la suma de dos dados. La cual, por cierto, en este caso se aproxima a una distribución normal. 2. La otra manera de pensar en el concepto de probabilidad es por medio de la idea de frecuencia. Si realizamos un experimento muchas veces (tantas como sea posible) entonces P( A) = Número ⋅ de ⋅ resultados ⋅ de ⋅ un ⋅ cierto ⋅ tipo n = Número ⋅ de ⋅ resultados ⋅ totales N La diferencia con la forma anterior es que ahora no conocemos todos los posibles casos, sino que los “medimos” con base en una serie de experimentos. Como puede pensarse, en esta situación tendremos una “aproximación” a la probabilidad buscada, la cual es mejor mientras mayor sea el número de experimentos. Actividad 1. Si se tiene una media de 156 y una desviación estándar de 15, encontrar las calificaciones Z para: a) 144 b) 167 c) 173 d) 136 Encontrar el área bajo la curva entre las calificaciones Z de: a) y b) b) y c) b) y d) Nota: se puede consultar cualquier tabla de calificaciones Z en un libro de estadística pero hay que fijarse si se tabula la curva completa o sólo la mitad. El concepto de calificación Z estudiado nos va a ayudar para calcular probabilidades de que ocurra un cierto caso referido a la media de la población, como veremos a continuación. Actividad 2. Resolver los siguientes problemas El promedio de estudiantes inscritos en jardines de niños es de 500 con una desviación estándar de 100. El número de alumnos tiene una distribución aproximadamente normal. ¿Cuál es la probabilidad de que el número de alumnos inscritos en una escuela elegida al azar esté: a) entre 450 y 500 b) entre 400 y 640 μ = 500, σ = 100 Distribution Plot Normal, Mean=0, StDev=1 0.4 a) 0.191 Área = 0.1915 450 − 500 z1 = = −0.5 100 z2 = 0 Density 0.3 0.2 0.1 0.0 P(450 < x < 500 ) = [φ(0.5)]- [φ(0)] = 0.6915-0.5 = 0.1915 -0.5 0 X Respuesta: la probabilidad es de 19.15% b) entre 400 y 640 μ = 500, σ = 100 Área = 0.7605 b) 400 − 500 = −1 100 z2 = 640 − 500 = 1. 4 100 P(400 < x < 640 ) = φ(1)- [1-φ(1.4)] = 0.8413-(1-.9192) = 0.8413-0.0808 = 0.7605 0.761 0.4 0.3 Density z1 = Distribution Plot Normal, Mean=0, StDev=1 0.2 0.1 0.0 -1 0 X 1.4 Respuesta: la probabilidad es de 76.05% Se ha determinado que la vida útil de cierta marca de llantas radiales tienen una distribución normal con un promedio de 38,000 kilómetros y desviación estándar de 3,000 kilómetros a)¿Cuál es la probabilidad de que una llanta elegida al azar tenga una vida útil de cuando menos 30,000 kilómetros? b)¿Cuál es la probabilidad de que dure 40,000 kilómetros o más? μ = 38,000 , σ = 3000 Distribution Plot Normal, Mean=0, StDev=1 0.996 0.4 a) Área = 0.9962 z1 = 30000 − 38000 = −2.666 3000 Density 0.3 0.2 0.1 P(x > 30,000 ) = φ(2.67) = 0.9962 0.0 -2.666 0 X Respuesta: la probabilidad es de 99.62% b)¿Cuál es la probabilidad de que dure 40,000 kilómetros o más? b) Distribution Plot Normal, Mean=0, StDev=1 40000 − 38000 z1 = = 0.666 3000 0.4 Density 0.3 P(x > 40,000 ) = 1- φ(0.67) = 1-0.7486 = 0.2514 Área = 0.2514 0.2 0.1 0.0 0.253 0 X 0.666 Respuesta: la probabilidad es de 25.14% Un distribuidor hace un pedido de 500 de las llantas especificadas en el problema anterior. Aproximadamente cuántas llantas durarán a) entre 30,000 y 40,000 kilómetros b) 38,000 kilómetros o más a) 30000 − 38000 z1 = = −2.666 3000 40000 − 38000 z2 = = 0.666 3000 Distribution Plot Normal, Mean=0, StDev=1 P(30000 < x < 40000) = φ(0.67) –[1- φ(2.67)] Área = 0.7486 0.3 Density = 0.7486 – (1 – 0.9962) = 0.7486 0.4 0.743 0.2 0.1 0.0 74.86% de 500, 0.7486x500 = 374.3 -2.666 0 X 0.666 Actividad 3. El tiempo promedio que tarda un paciente en llevar a cabo un test psicológico es de 12 min con una desviación estándar (o típica) de 2 min. Se considera que tiene una distribución normal. a) Si se selecciona al azar un estudiante ¿ Cuál es la probabilidad de tarde 15 min o más? Distribution Plot Normal, Mean=0, StDev=1 8. μ = 12, σ = 2 a) P (15 ≤ x ) P (15 ≤ x ) = 1 − ϕ (1.5) = 1 − 0.9332 = 0.0668 La probabilidad es del 6.68% 0.3 Density 15 − 12 3 Z= = = 1 .5 2 2 0.4 Área = 0.0668 0.2 0.1 0.0668 0.0 0 X 1.5 b) Si en una universidad hay 10000 estudiantes ¿Cuántos tardarán más de 11 min? Distribution Plot Normal, Mean=0, StDev=1 b) P (11 ≤ x ) 11 − 12 1 = − = − 0 .5 2 2 P (11 ≤ x ) = 0.6915 0.6915 × 10,000 = 6,915 0.3 Density Z= 0.4 Área = 0.6915 0.2 0.691 0.1 0.0 -0.5 0 X El número estimado de estudiantes que tardarán más de 11 min. en resolver el test es de 6,915 TAREA 3 Supóngase que la duración promedio de las estancias de los pacientes en un hospital es de 10 días con una desviación estándar de 2 días. Considérese que la distribución de las duraciones está normalmente distribuida. a) ¿Cuál es la probabilidad de que el próximo paciente que se reciba permanezca más de 11 días? b) Si el día de hoy se admitieran 200 pacientes ¿Cuántos continuarán en el hospital después de 2 semanas?