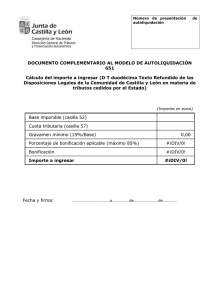
tutorial en pdf - AndroidConnect
Anuncio

Parsear HTML con htmlparser para Android
Guillem Pérez
He escogido esta librería(http://htmlparser.sourceforge.net/) aunque no había muchos ejemplos
porque la he visto realmente ligera y esta en java hay otra librería como la mozilla-parser pero pesa
bastante más que esta.
Primero de todo hemos de saber cual es la estructura de la pagina web. Como podemos ver en
nuestro ejemplo la pagina de cuantarazon.com tiene una estructura prefijada:
<div class="box story">
<a class="tag" href="http://www.cuantarazon.com/368724/bikini-soluble#comments_title"
title="34 comentarios">34</a>
<h2><a href="http://www.cuantarazon.com/368724/bikini-soluble">BIKINI
SOLUBLE</a></h2>
<p class="story_content">
<a href="http://www.cuantarazon.com/368724/bikini-soluble" class="crlink"><img
src="http://images8.cuantarazon.com/crs/2011/10/CR_368724_bikini_soluble.jpg" alt="BIKINI
SOLUBLE - No sé si será útil para las tías, pero los tíos seguro que disfrutaremos"/></a>
</p>
<div class="source">
Fuente: <a href="http://www.quo.es/sexo/curiosidades/el_primer_bikini_soluble"
rel="external">http://www.quo.es/sexo/curiosidades/el_primer_bikini_soluble</a>
</div>
</div>
<div class="box story">
<a class="tag" href="http://www.cuantarazon.com/368648/superheroes#comments_title"
title="10 comentarios">10</a>
<h2><a
href="http://www.cuantarazon.com/368648/superheroes">SUPERHÉROES</a></h2>
<p class="story_content">
<a href="http://www.cuantarazon.com/368648/superheroes" class="crlink"><img
src="http://images8.cuantarazon.com/crs/2011/10/CR_368648_superheroes.jpg"
alt="SUPERHÉROES - que ayudan a entender la fisica clásica"/></a>
</p>
<div class="source">
Fuente: <a href="http://www.taringa.net/posts/imagenes/12747644/Las-ImagenesFrikis-Del-Dia-061011-_93-Pics_.html"
rel="external">http://www.taringa.net/posts/imagenes/12747644/Las-Imagenes-Frikis-Del-Dia061011-_93-Pics_.html</a>
</div>
</div>
He borrado algún div entremedio para simplificar la lectura del html. De esta manera podemos ver
que en cada div con la clase box story empieza una entrada en este caso una divertida fotografiá que
queremos recoger y mostrar en nuestro dispositivo android.
Lo que debemos hacer es recoger cada div box story esto lo logramos con el siguiente código java:
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("DIV");
HasAttributeFilter filter1 = new HasAttributeFilter();
filter1.setAttributeName("class");
filter1.setAttributeValue("box story");
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter1;
AndFilter filter2 = new AndFilter ();
filter2.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter2;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
bean.setURL (url);
bean.getNodes();
Este código esta en uno de los ejemplos de la librería lo único que he implementado es cambiar la
etiqueta de los miembros que queremos leer: en setName, en lugar de DIV también podríamos leer
todos los links de la pagina poniendo A o todas las imágenes poniendo en su lugar la etiqueta IMG.
Podemos parsear cualquier elemento html poniendo su etiqueta en mayúsculas.
Otra de las características fundamentales es la clase HasAttributeFilter, donde podremos ir creando
las instancias necesarias según el numero de atributos que queramos filtrar, normalmente con uno o
como mucho dos atributos ya es más que suficiente. Como podemos ver en el ejemplo del código
para poner un atributo debemos poner el nombre de este y luego su valor, en este caso box story. Si
hubiéramos querido coger el link de fuente en su lugar tendríamos que poner el valor source en su
lugar de esta forma recogeríamos los dos div=”source” que hay en el html.
Por último añadimos los filtros en el FilterBean que estará encargada del parseo, por eso es muy
importante ponerle el link que queremos usar, sea el correcto y sin acortar en este caso
http://www.cuantarazon.com y después podremos recoger estos nodos con bean.getNodes(),
obteniendo la lista de nodos, partes del html, un ejemplo muy sencillo para probar si hemos hecho
bien el parser es:
NodeList nodelist = bean.getNodes();
for(int m=0;m<list.size();m++){
Node temp = list.elementAt(m);
System.out.println ("Node " + m "\n" + temp.toHtml());
}
Debería devolver por pantalla la parte del html que queremos parsear, a partir de este punto
teniendo en cuenta que es satisfactorio el parser queremos recoger el link de la imagen lo haremos
recogiendo los elementos del parser que sean una instancia de ImageTag si quisiéramos recoger
links podríamos hacer lo mismo pero con LinkTag .
NodeFilter filter = new TagNameFilter ("IMG");
NodeList list = new NodeList();
try {
for (NodeIterator e =nodelist.elements() ; e.hasMoreNodes ();)
e.nextNode ().collectInto (list, filter);
} catch (ParserException e1) {
e1.printStackTrace();
}
Con este sencillo código hemos filtrados los elementos que había dentro de un nodo, que
previamente hemos rellenado con la parte del código html que queríamos usar, obteniendo una lista
( list ) de los elementos con IMG. Por lo tanto en la list ya tendríamos el link de nuestra imagen.
Para poder manejarla más fácilmente la pasaremos a la clase ImageTag de esta forma podremos
usar los metodos extractImageLocn() donde nos devuelve la dirección de la imagen.
for(int m=0;m<list.size();m++){
Node temp = list.elementAt(m);
ImageTag link = new ImageTag();
if( temp instanceof ImageTag){
link = (ImageTag) temp;
data.add( new Imagen( link.getAttribute("ALT"),
link.extractImageLocn() ) );
}
}
Revisamos que todos los links sean una instancia de ImageTag y de esta forma podemos hacer un
casting para usar sus métodos, en este caso también he querido leer el Atributo ALT de la imagen
porque tiene una detallada información del titulo que es muy fácil leerla des del mismo sitio y luego
llamo el método ya dicho para poder recoger la localización.
He creado una clase Imagen para colocar rápidamente los datos recolectados, además da la
oportunidad de que si en un futuro queremos recoger más datos de las imágenes, como el source por
ejemplo solamente tendremos que añadir más variables para conseguirlo, la clase Imagen es la
típica de un objeto con sets y gets en este caso con el constructor ya demandamos que se
introduzcan los datos.
Ahora ya deberíamos tener funcionando el parser, con un sencillo main en java llamando a la
función podríamos ver que las salidas son las correctas, antes de pasarlo a la gui de android, dando
más agilidad al testeo.
En esta parte usaremos la gui de Android para mostrar los resultados, usare un ArrayAdapter para
hacer la lista, sigue el mismo patron que en la pagina de sgoliver y para no repetir lo podeis
encontrar como hacerlo aquí: http://www.sgoliver.net/blog/?p=1431
Muy importante usar la AsyncTask, al descargar los datos tardamos más del tiempo en que el
android detecta que la aplicación no responde y entonces cerraría la app, también hay que remarcar
que el update de la información se ha de hacer desde la aplicación principal y no des de la
AsyncTask porque entonces tendríamos un error al no ser el propio hilo de la app que intenta
actualizarse, de esta forma tenemos una AsyncTask, con entrada de un string ( la url de
cuantocabron que queremos parsear ) y se ve de esta forma:
private class Task_DownImagenes_CuantoCabron extends AsyncTask<String, Void,
Void> {
private List<Imagen> imagenes = new ArrayList<Imagen>();
private final ProgressDialog dialog = new ProgressDialog(
CuantoCabronActivity.this);
private String URL;
// can use UI thread here
protected void onPreExecute() {
this.dialog.setMessage("Descargando\n nuevas imagens...");
this.dialog.setCancelable(false);
this.dialog.show();
}
protected Void doInBackground(String... url) {
try {
this.URL = url[0];
ParserCuantoCabron parser = new ParserCuantoCabron(url[0]);
this.imagenes = parser.run();
} catch (Exception e) {
}
return null;
}
@Override
protected void onPostExecute(Void result) {
if (this.dialog.isShowing()) {
this.dialog.dismiss();
}
if(this.imagenes !=null )
updateViewImagenes(imagenes);
}
}
Como podéis ver a parte tenemos un dialog para mostrar que la aplicación esta ocupada que cuando
llega el momento se cierra, en la parte onPostExecute ya tenemos los datos recogidos y procedemos
ha hacer un update para ver los resultados.
Llamamos updateViewImagenes que esta contenida en la activity, que consiste en el inflate del xml
listview con el arrayadapter.
En el momento de ejecutarlo podremos ver el siguiente resultado:
Esta app pretende ser un ejemplo como parsear el html por lo que no explicare como descargar
imágenes de servidores para no desviarnos del tema principal.
Como habéis poder ver gracias a la librería htmlparser recolectar datos de las paginas html es
bastante fácil de conseguir siempre que estructuremos lo que queremos parsear, pasando cada
objeto des del bloque más grande posible a bloques más pequeños donde se pueda coger los datos
para montar nuestro objeto virtual que después usaremos para inflar el xml.
Si quieres ver más cosas como este tutorial recuerda en visitar: www.androidconnect.org