ANÁLISIS DE SUPERVIVIENCIA El análisis de supervivencia
Anuncio

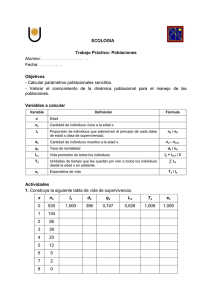
“ANÁLISIS DE SUPERVIVIENCIA El análisis de supervivencia se utiliza cuando la variable dependiente representa un periodo de tiempo entre un suceso inicial y el evento final. El análisis de supervivencia (survival análysis) tiene por objeto conocer el efecto de una variable independiente cuando la variable dependiente puede expresarse en términos de tiempo hasta que se 'dá determinado suceso'. Es decir, dada una variable cuyos valores corresponden al tiempo que transcurre hasta que ocurre un determinado suceso final, el objetivo del análisis es estimar, en función del tiempo, la probabilidad de que ocurra dicho suceso. Origen y breve historia El análisis de supervivencia originalmente se aplicó en Medicina con tablas de mortalidad, de ahí proviene la denominación y terminología que vamos a utilizar. Posteriormente se aplicó al estudio de la resistencia de materiales de ingeniería militar. Otros ejemplos de aplicación pueden ser el estudio del tiempo que se permanece empleado en la misma empresa, el tiempo de permanencia en la Universidad, el tiempo desde la boda al primer hijo, etc. Conceptos fundamentales Para poder realizar un análisis de supervivencia es encesario: 1.- Que se dé un evento inicial (origen) 2.- Que el evento final ocurra después del inicial 3.- Que el evento final sólo pueda ocurrir una vez Uno de los problemas del análisis de supervivencia es que las observaciones pueden no comenzar en el mismo momento para todas las unidades de análisis y así mismo puede que el final del periodo de observación no se disponga tampoco, de información completa de otras por abandonos, etc... De este modo el análisis de supervivencia debe de trabajar con datos incompletos, esto da lugar a que en un mismo análisis encontremos diferentes tipos de observaciones 1.- Datos censados (censored observations) son aquellos en los que se ha producido el suceso inicial 1.1.- Supervivientes el evento final no se ha dado mientras ha durado la observación 1.2.- Abandonos (withdrawn) o mortalidad experimental, producida por causas ajenas a la investigación (cambio de domicilio o hospital, fallecimiento accidental, pérdida de contacto, etc. 2.- Fallecimiento (death) evento final Así el Análisis de Supervivencia se estructura en tres periodos: 1.- Origen: momento en que un individuo es incluido en el análisis 2.- Última observación: momento en que un individuo abandona, o se pierde su pista por causas ajenas a la investigación 3.- Evento final: fallecimiento 4.- Cierre del estudio: momento en que finaliza el periodo de observación para proceder al análisis de datos 5.- Tiempo de participación: intervalo comprendido entre desde el origen hasta la última observación Fases en el Análisis de Supervivencia 1.- Construcción y análisis de la Tabla de Supervivencia En esta tabla se exponen diversas informaciones descriptivas sobre la evolución de las observaciones 1.- Tiempo inicial de cada intervalo: aparece el límite inferior de cada intervalo de tiempo 2.- Número de entradas en cada intervalo: cantidad de observaciones en cada intervalo 3.- Abandonos: casos que no han llegado al final del periodo debido al abandono (mortalidad experimental) y no a causa de producirse el evento terminal (fallecimiento) 4.- Número de observaciones expuestas a riesgo: número de entradas menos la mitad de abandonos 5.- Número de eventos terminales: es decir, fallecimientos 6.- Proporción de eventos terminales: proporción de supervivencia 7.- Proporción de supervivencia 8.- Funciones de supervivencia y sus errores típicos 9.- Mediana del tiempo de supervivencia Funciones de supervivencia 1.- Proporción de supervivencia acumulada al final del intervalo: ésta se obtiene al multiplicar la proporción de supervivencia del intervalo anterior por la proporción terminal del intervalo en cuestión 2.- Probabilidad de densidad: es la probabilidad estimada por unidad de tiempo del evento terminal que ocurre en el intervalo 3.- Proporción de azares la estimación de la probabilidad por unidad de tiempo de que los casos que entran en el intervalo experimentarán el evento terminal en este intervalo Existen fundamentalmente dos técnicas para el cálculo de las funciones de supervivencia 1.- Método actuarial de Berkson y Gage éste es más adecuado cuando el número de observaciones es grande ya que la función de supervivencia se estima dividiendo el rango del tiempo de observación en intervalos. Si el número de observaciones fuera pequeño, al agrupar los teimpos de observación en intervalos, algunos de ellos podrían quedar vacíos; en dicho caso el método adecuado sería el de Kaplan y Maier, que estima la función de supervivencia para cada uno de los tiempos de observación 2.- Método del producto de Kaplan y Meyer Puntuación de supervivencia La puntuación de supervivencia (survival score) se calcula para cada individuo comparando su tiempo de supervivencia con todas las demás observaciones. La puntuación se inicia con el cero y se incrementa en uno para cada observación cuyo tiempo de supervivencia es inferior; y se disminuye en uno para cada observación cuyo tiempo sea superior. Los abandonos se consideran superiores. Las observaciones con el mismo tiempo de supervivencia no producen cambio en la puntuación. Las puntuaciones de supervivencia se utilizan en comparaciones para determinar si existen diferencias significativas entre grupos en términos de supervivencia. En el siguiente apartado se expone un ejemplo de comparación de grupos en base a la puntuación de supervivencia Comparación de grupos A veces interesa comparar el índice de supervivencia de los diferentes grupos que pueden formarse al estar las unidades de análisis sujetas a diferentes circunstancias, (ej. diferentes tipos de tratamiento de pacientes de una determinada enfermedad, etc...) La prueba de significación que se utiliza en este caso se utiliza el estadístico D, que se calcula a partir de las puntuaciones de supervivencia utilizando el algoritmo de Lee y Desu (1972). La D se distribuye asintóticamente como una ji-cuadrado con K-1 grados de libertad, siendo k el número de grupos. La hipótesis nula sostiene que los grupos proceden de la misma población. Si la jicuadrado, derivada de la D, supera el intervalo de confianza se rechaza la hipótesis nula, con un grado de significación p. Un ejemplo mediante el procedimiento actuarial y Kaplan-Meier Formulación del problema Dada una muestra de N individuos se conoce: 1.- Si se ha producido o no un suceso final en un periodo de tiempo 2.- objetivo del análisis: obtener una función de t cuyos valores proporcionen la probabilidad de que el suceso final no ocurra hasta un periodo de tiempo superior o igual a t o, equivalente, si denominamos fallecer a la ocurrencia del suceso final y sobrevivir a la no ocurrencia, se trata de obtener una función cuyos valores proporcionen la probabilidad de sobrevivir, el menos, hasta el instante t. 3.- Variables: • T Tiempo de observación • Z variable dicotómica cuyos valores indican ocurrencia o no del suceso final • REAPARICI: Reaparición de la sintomatología ulcerosa. Valores: Si y No codificados numéricamente como 1 y 2, respectivamente • RESPUEST: Tiempo de respuesta al tratamiento de la sintomatología ulcerosa • TABACO: El paciente ha dejado de fumar. Valores Si y No, codificados respectivamente, como 1 y 2. • TIEMPO: Tiempo transcurrido desde la respuesta al tratamiento y la última revisión antes del cierre del estudio ( en semanas, con el método Actuarial, y en días, con el Kaplan-Meier) Las diferentes situaciones con las que podemos encontrarnos: • Que en la última sesión antes del cierre del estudio la sintomatología ulcerosa hubiera aparecido, siendo el tiempo transcurrido desde la respuesta al tratamiento yla reaparición igual a ti. En dicho caso, el valor de Reaparic sería = 1y el tiempo de observación coincidiría con el tiempo de reaparición TIEMPO =t. • Que en la última revisión antes del cierre del estudio la sintomatología ulcerosa no hubiera a parecido, siendo el tiempo observacional = t. En dicho caso el valor REAPARIC será igual a 2 y el de TIEMPO igual a t. En esta situación, se desconoce si la sintomatología habría reaparecido con el supuesto caso de que el tiempo de observación hubiera sido mayor A partir de esta información, el objeto es estimar, para cada uno de los distintos tiempos de observación t y en cada uno de los ocho grupos, la probabilidad de que la sintomatología ulcerosa no aparezca hasta transcurrido un periodo de tiempo como mínimo igual a t desde la respuesta al tratamiento. Método actuarial Al solicitar el análisis y dado que existen dos variables independientes las posibles combinaciones de sus respectivas categorías dan como resultado ocho tablas. El tiempo de observación se encuentra dividido en 8 intervalos de 8 semanas días Interpretación (Tabla primera tiempo de respuesta 4 a 8 semanas y no ha dejado de fumar): Obsérvese que en esta tabla, correspondiente al conjunto de pacientes que han dejado de fumar y cuyo tiempo de respuesta al argumento coincide con el mínimo obtenido, la probabilidad estimada de que la sintomatología ulcerosa no reaparezca hasta pasadas, al menos, 40 semanas desde la respuesta al tratamiento es igual a 1. A partir de las 48 semanas dicha probabilidad se reduce prácticamente a la mitad. Sin embargo, en la última tabla correspondiente al conjunto de pacientes que no han dejado de fumar y cuyo tiempo de respuesta coincide con el máximo obtenido, aunque la probabilidad estimada de la sintomatología ulcerosa no aparezca, hasta al menos, 16 semanas es alta, a partir de las 24 semanas dicha probabilidad disminuye significativamente. Además la mediana del tiempo de reaparición de la sintomatología, es decir, del tiempo en el que se espera que la sintomatología haya reaparecido al menos para la mitad de los pacientes es igual a 49,5 y a 19,47 semanas, en el primer y en el segundo grupo de pacientes, respectivamente. Luego parece que, tal y como se sospecha, el tiempo de respuesta al tratamiento y el abandono o no del hábito de fumar influyen en el tiempo de reaparición de la sintomatología ulcerosa. Junto con la función de supervivencia, la tabla de cálculo proporciona dos funciones más: la función de densidad de probabilidad y la función de riesgo. Las tres funciones son matemáticamente equivalentes, en el sentido de que, conocido el valor de una cualquiera de las tres, el de las dos restantes puede ser calculado mediante una expresión matemática. Los errores estándar de los valores estimados se disponen a continuación de la mediana, si consideramos que éstos son una medida del error cometido en la estimación, cuanto menor sea su valor más precisa será la estimación del valor de la función correspondiente. Concretamente, dado que el error estándar de los valores estimados de la función de supervivencia son pequeños, podemos concluir que las estimaciones son bastante precisas. Comparación de la supervivencia en distintos grupos de individuos Interpretación Representación gráfica” Este tema corresponde al capítulo del mismo título que encontrareis en el texto de FERRÁN ARANAZ MAGDALENA SPSS para Windows Programación y Análisis Estadístico McGraw-Hill Madrid 1996 También podiís completarlo con R. BISQUERRA ALZINA Introducción Conceptual al Análisis Conceptual Multivariable. Un enfoque informático con los paquetes SPSS_X, BMDP, LISREL, y SPAD. Vol II. Barcelona, 1989