Sobre la distribución Normal y pruebas de diferencias
Anuncio

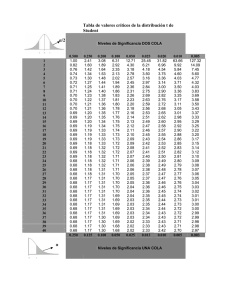
La distribución “t de student” O lo que es lo mismo: La relación entre la cerveza y los estudios de estadística La distribución t de student fue descubierta por William S. Gosset en 1908. Gosset era un estadístico empleado por la compañía de cerveza Guinness con quien tenía un contrato que estipulaba que no podía usar su nombre en sus publicaciones. Él recurrió al sobrenombre de “Student” que es como ahora conocemos el tipo de estadística que desarrolló. Lo interesante del caso es que su trabajo estaba enfocado al control de calidad de la cerveza. En el pasado otros investigadores de la compañía Guinness habían publicado artículos en los que se divulgaban secretos o información confidencial sobre el proceso de la cerveza y por eso se obligó a Gosset a aceptar la cláusula. De acuerdo al Teorema del Límite Central, la distribución muestral de una estadística (como la media de la muestra) seguirá una distribución normal, siempre y cuando el tamaño de la muestra sea suficientemente grande. grande Entonces cuando conocemos la desviación estándar de la población podemos calcular un valor o calificación z y emplear la distribución normal para evaluar probabilidades sobre la media de la muestra. Sin embargo, muchas veces los tamaños de las muestras son muy pequeños, y frecuentemente no conocemos la desviación estándar de la población. Cuando estos problemas ocurren, en estadística se recurre a una distribución conocida como la “t de student” cuyos valores están dados por: t= x−μ s n Diferencia a probar Desviación estándar de la diferencia o Error Estándar Podemos ver que la ecuación es prácticamente igual a la utilizada para la distribución muestral de medias, pero reemplazando la desviación estándar de la población por la desviación estándar de la muestra. muestra De manera similar al caso de la distribución muestral de medias para el caso de que n > 30, en donde usamos la distribución normal, podemos encontrar la distribución de los valores t de student para aquellos casos cuando n < 30. 30 T de Student df 2 5 10 15 20 25 30 50 100 0.4 0.3 Densidad Sin embargo, otra diferencia en su uso es el empleo de una o más tablas de valores t en lugar de la tabla para valor Z. Curva de Distribución 0.2 0.1 0.0 -3 -2 -1 0 X 1 2 3 Para derivar la ecuación de esta distribución, Gosset supuso que las muestras se seleccionan de una población normal. Aunque esto parecería una suposición muy restrictiva, se puede mostrar que las poblaciones no normales que poseen distribuciones en forma casi de campana también proporcionan valores de t que se aproximan muy de cerca a esta distribución. La distribución t difiere de la de Z en que la varianza de t no es igual a 1 como en la de Z, Z sino que depende del tamaño de la muestra y siempre es mayor a uno. Unicamente cuando el tamaño de la muestra tiende a infinito las dos distribuciones serán las mismas. Curva de Distribución T de Student df 2 5 10 15 20 25 30 50 100 0.4 Densidad 0.3 0.2 0.1 0.0 -3 -2 -1 0 X 1 2 3 Otra diferencia con la distribución normal, es que la forma de la distribución t de student depende de un parámetro llamado el número de grados de libertad. libertad El número de grados de libertad es igual al tamaño de la muestra (número de observaciones independientes) menos 1. gl = df= n – 1 Nota: cuando usemos software es posible que el número de grados de libertad se denomine como df o DF (“degrees of freedom”). Distribución Normal Curva de Distribución Normal, Media=0, DesvEst=1 T de Student Densidad 0.3 0.2 0.1 0.0 0.4 0.3 Densidad df 2 5 10 15 20 25 30 50 100 0.4 0.2 0.1 -6 -4 -2 0 X 2 4 6 0.0 -6 -4 -2 0 X 2 4 6 Las curvas muestran la forma que puede tomar la distribución t de student la cual depende del número de grados de libertad. libertad Como se puede apreciar se parece mucho a la distribución normal. Incluso, para un número grande de grados de libertad (es decir de número de datos en la muestra) las dos distribuciones son iguales. iguales Curva de Distribución T de Student df 2 5 10 15 20 25 30 50 100 0.4 Densidad 0.3 0.2 100 grados de libertad 2 grados de libertad 0.1 0.0 -3 -2 -1 0 X 1 2 3 Aunque parece una distribución normal, la distribución t tiene un poco más de área en los extremos y menos en el centro cuando los grados de libertad son pocos. Otro punto a notar es que la distribución t es más bien una colección de distribuciones, una para cada número de grados de libertad. libertad El concepto de grados de libertad se puede visualizar haciendo referencia a la varianza muestral que es igual a: s 2 ∑ = n ( xi − x ) 2 n −1 Esta fórmula puede verse como un promedio de las distancias a la media sobre n-1 datos . La terminología de grados de libertad resulta del hecho de que si bien s2 considera n cantidades, sólo n – 1 de ellas pueden determinarse libremente. Por ejemplo, si tenemos 4 datos (n = 4) entonces tenemos cuatro diferencias: xi − x Pero sabemos que la suma de ellas es = 0, por lo que si conocemos, por ejemplo: x1 − x = 4, x2 − x = −2, x4 − x = 3 4-2+ 3 = 5 entonces, la última diferencia queda definida porque 5−5 = 0 por lo tanto x3 − x = −5 Lo que indica que sólo 3 de las diferencias (n – 1= 4 – 1 = 3) son “libres” y la otra queda definida por las demás. La distribución t de student tiene las siguientes propiedades: •La media de la distribución es igual a 0 df •La varianza es igual a donde df (se usa también ν) es el número df − 2 de grados de libertad •La varianza es siempre mayor que 1, aunque es muy cercana a 1 cuando se tiene un número de grados de libertad grande. •Con infinitos grados de libertad la distribución t es igual a la normal. Curva de Distribución T de Student df 2 5 10 15 20 25 30 50 100 0.4 Densidad 0.3 s= df df − 2 0.2 0.1 0.0 -2 -1 0 X 1 2 La distribución t de student se puede usar cuando cualquiera de las siguientes condiciones se cumplen: •La distribución de la población es normal •La distribución de la muestra es simétrica, unimodal, sin puntos dispersos y alejados (outliers) y el tamaño de la muestra es de 15 o menos •La distribución de la muestra es moderadamente asimétrica, unimodal, sin puntos dispersos (outliers) y el tamaño de la muestra está entre 16 y 30 •El tamaño de la muestra es mayor de 30, sin puntos dispersos (aunque en este caso también se puede usar la distribución normal). Cuando se extrae una muestra de una población con distribución normal (o casi normal), la media de la muestra puede compararse con la media de la población usando una valor t calculado por medio de la ecuación anterior. El valor t puede entonces asociarse con una probabilidad acumulada única que representa la posibilidad de que, dada una muestra aleatoriamente extraída de la población de tamaño n, la media de la muestra sea IGUAL, MENOR o MAYOR a la media de la población, La probabilidad acumulada para una calificación t se puede calcular en la siguiente liga: http://stattrek.com/Tables/T.aspx Ejemplo 1 La compañía USALUZ produce focos. El presidente de la Cía. dice que sus focos duran 300 días. Entonces la competencia va a varios (nótese) supermercados y compra 15 focos para probar esa afirmación. Los focos de la muestra duran en promedio 290 días con una desviación estándar de 50 días. Entonces, si quieren desmentir al presidente de USALUZ necesita saber cúál es la probabilidad de que 15 focos seleccionados al azar tengan una vida promedio no mayor de 290 días. as La solución de este tipo de problemas requiere calcular el valor t basado en los datos y después usar una tabla de distribución t para encontrar la probabilidad de forma similar a lo que hicimos con la distribución normal. Existe sin embargo software con el que podemos evitar el uso de tablas. Solución Primero necesitamos calcular el valor t usando nuestra fórmula 290 − 300 − 10 = = −0.7746 50 12.91 15 Donde x es la media de la muestra, μ la media de la población, s es la desviación t= estándar de la muestra y n el tamaño de la muestra. OK ¿qué nos dice este valor? Ahora podemos usar una tabla o software como la T Distribution Calculator (http://stattrek.com/Tables/T.aspx) o minitab. Usando ésta última seleccionamos "T score" del menú de “random variable” e introducimos los datos: * Grados de libertad (ν): 15 - 1 = 14. * El valor t que obtuvimos = - 0.7745966. El resultado nos da: 0.2257. Esto significa que si la verdadera vida de un foco es de 300 días, hay una probabilidad de 22.6% de que la vida promedio de 15 focos seleccionados al azar sea menor o igual a 290 días y nosotros ha sabríamos a qué atenernos si queremos poner en ridículo al Presidente o Jefe. Nota: ¿Piensas que 22% de probabilidades de que pase algo es mucho o poco? Veamos el resultado gráficamente Distribución t 14 grados de libertad 0.4 Densidad 0.3 0.2 0.1 0.226 0.0 -0.7746 0 X Ejemplo 2 Supongamos que las calificaciones de una prueba están distribuídos normalmente con una media de 100. Ahora supongamos que seleccionamos 20 estudiantes y les hacemos un exámen. La desviación estándar de la muestra es de 15. ¿Cuál es la probabilidad de que el promedio en el grupo de muestra sea cuando más 110? ¿Cuál es la probabilidad de que el promedio en el grupo de muestra sea más 110? Solución: Primero calculamos el valor t como en el caso anterior ya sea en tablas o con ayuda de herramientas tipo Minitab, Excel, etc. Nuestros datos son: Número de grados de libertad: n-1 = 20 -1 = 19 La media de la población es igual a 100 La media de la muestra es igual a 110 La desviación estándar de la muestra es igual a 15 El valor t es t= 110 − 100 = 2.9814 15 20 Usando estos valores nos da un resultado de probabilidad acumulada de 0.00496. Esto implica que hay una probabilidad de 0.45% de que el promedio en una muestra sea mayor de 110. Veamos el resultado gráficamente Distribución t 14 grados de libertad 0.4 Densidad 0.3 0.2 0.1 0.0 0.00496 0 X 2.9814 Ejemplo 3: Un ingeniero químico afirma que el rendimiento medio de cierto proceso en lotes es 500 gramos por milímetro de materia prima. Para verificar esta afirmación toma una muestra de 25 lotes cada mes. Si el valor de t calculado cae entre –t0.05 y t0.05, aceptaría su afirmación (con 90% de confianza). ¿Qué conclusión extraería de una muestra que tiene una media de 518 gramos por milímetro y una desviación estándar de 40 gramos? Suponga que la distribución de rendimientos es aproximadamente normal. Solución: De la tabla encontramos que t±0.05 para 24 grados de libertad es ±1.711. Por tanto, el fabricante queda satisfecho con esta afirmación si una muestra de 25 lotes rinde un valor t entre –1.711 y 1.711. 518 − 500 Se procede a calcular el valor de t: t= = 2.25 40 25 Este es un valor muy por arriba de 1.711, por lo que el fabricante diría que no es cierta la afirmación. Sin embargo, si se encuentra la probabilidad de obtener un valor de t con 24 grados de libertad igual o mayor a 2.25 se busca en la tabla y es aproximadamente de 0.02. De aquí que es probable que el fabricante concluya que el proceso produce un mejor rendimiento de producto que el que suponía. Distribución de probabilidad para t de student 90% del área -1.711 1.711 El valor de t = 2.25 cae en esta zona de la distribución